本篇博文主要展示每日从Arxiv论文网站获取的最新论文列表,以自然语言处理、信息检索、计算机视觉等类目进行划分。
+统计
+今日共更新975篇论文,其中:
+
+- 自然语言处理166篇
+- 信息检索35篇
+- 计算机视觉300篇
+
+自然语言处理
+
+ 1. 【2412.12094】SepLLM: Accelerate Large Language Models by Compressing One Segment into One Separator
+ 链接:https://arxiv.org/abs/2412.12094
+ 作者:Guoxuan Chen,Han Shi,Jiawei Li,Yihang Gao,Xiaozhe Ren,Yimeng Chen,Xin Jiang,Zhenguo Li,Weiyang Liu,Chao Huang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Large Language Models, language processing tasks, natural language processing, exhibited exceptional performance, Large Language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have exhibited exceptional performance across a spectrum of natural language processing tasks. However, their substantial sizes pose considerable challenges, particularly in computational demands and inference speed, due to their quadratic complexity. In this work, we have identified a key pattern: certain seemingly meaningless special tokens (i.e., separators) contribute disproportionately to attention scores compared to semantically meaningful tokens. This observation suggests that information of the segments between these separator tokens can be effectively condensed into the separator tokens themselves without significant information loss. Guided by this insight, we introduce SepLLM, a plug-and-play framework that accelerates inference by compressing these segments and eliminating redundant tokens. Additionally, we implement efficient kernels for training acceleration. Experimental results across training-free, training-from-scratch, and post-training settings demonstrate SepLLM's effectiveness. Notably, using the Llama-3-8B backbone, SepLLM achieves over 50% reduction in KV cache on the GSM8K-CoT benchmark while maintaining comparable performance. Furthermore, in streaming settings, SepLLM effectively processes sequences of up to 4 million tokens or more while maintaining consistent language modeling capabilities.
+
+
+
+ 2. 【2412.12072】Making FETCH! Happen: Finding Emergent Dog Whistles Through Common Habitats
+ 链接:https://arxiv.org/abs/2412.12072
+ 作者:Kuleen Sasse,Carlos Aguirre,Isabel Cachola,Sharon Levy,Mark Dredze
+ 类目:Computation and Language (cs.CL)
+ 关键词:upsetting or offensive, WARNING, Dog whistles, Large Language Models, Dog
+ 备注:
+
+ 点击查看摘要
+ Abstract:WARNING: This paper contains content that maybe upsetting or offensive to some readers. Dog whistles are coded expressions with dual meanings: one intended for the general public (outgroup) and another that conveys a specific message to an intended audience (ingroup). Often, these expressions are used to convey controversial political opinions while maintaining plausible deniability and slip by content moderation filters. Identification of dog whistles relies on curated lexicons, which have trouble keeping up to date. We introduce \textbf{FETCH!}, a task for finding novel dog whistles in massive social media corpora. We find that state-of-the-art systems fail to achieve meaningful results across three distinct social media case studies. We present \textbf{EarShot}, a novel system that combines the strengths of vector databases and Large Language Models (LLMs) to efficiently and effectively identify new dog whistles.
+
+
+
+ 3. 【2412.12062】Semi-automated analysis of audio-recorded lessons: The case of teachers' engaging messages
+ 链接:https://arxiv.org/abs/2412.12062
+ 作者:Samuel Falcon,Carmen Alvarez-Alvarez,Jaime Leon
+ 类目:Computation and Language (cs.CL); Computers and Society (cs.CY)
+ 关键词:influences student outcomes, student outcomes, Engaging messages delivered, Engaging messages, key aspect
+ 备注:
+
+ 点击查看摘要
+ Abstract:Engaging messages delivered by teachers are a key aspect of the classroom discourse that influences student outcomes. However, improving this communication is challenging due to difficulties in obtaining observations. This study presents a methodology for efficiently extracting actual observations of engaging messages from audio-recorded lessons. We collected 2,477 audio-recorded lessons from 75 teachers over two academic years. Using automatic transcription and keyword-based filtering analysis, we identified and classified engaging messages. This method reduced the information to be analysed by 90%, optimising the time and resources required compared to traditional manual coding. Subsequent descriptive analysis revealed that the most used messages emphasised the future benefits of participating in school activities. In addition, the use of engaging messages decreased as the academic year progressed. This study offers insights for researchers seeking to extract information from teachers' discourse in naturalistic settings and provides useful information for designing interventions to improve teachers' communication strategies.
+
+
+
+ 4. 【2412.12061】Virtual Agent-Based Communication Skills Training to Facilitate Health Persuasion Among Peers
+ 链接:https://arxiv.org/abs/2412.12061
+ 作者:Farnaz Nouraei,Keith Rebello,Mina Fallah,Prasanth Murali,Haley Matuszak,Valerie Jap,Andrea Parker,Michael Paasche-Orlow,Timothy Bickmore
+ 类目:Human-Computer Interaction (cs.HC); Computation and Language (cs.CL); Computers and Society (cs.CY)
+ 关键词:health behavior, stigmatizing or controversial, laypeople are motivated, motivated to improve, family or friends
+ 备注: Accepted at CSCW '24
+
+ 点击查看摘要
+ Abstract:Many laypeople are motivated to improve the health behavior of their family or friends but do not know where to start, especially if the health behavior is potentially stigmatizing or controversial. We present an approach that uses virtual agents to coach community-based volunteers in health counseling techniques, such as motivational interviewing, and allows them to practice these skills in role-playing scenarios. We use this approach in a virtual agent-based system to increase COVID-19 vaccination by empowering users to influence their social network. In a between-subjects comparative design study, we test the effects of agent system interactivity and role-playing functionality on counseling outcomes, with participants evaluated by standardized patients and objective judges. We find that all versions are effective at producing peer counselors who score adequately on a standardized measure of counseling competence, and that participants were significantly more satisfied with interactive virtual agents compared to passive viewing of the training material. We discuss design implications for interpersonal skills training systems based on our findings.
+
+
+
+ 5. 【2412.12040】How Private are Language Models in Abstractive Summarization?
+ 链接:https://arxiv.org/abs/2412.12040
+ 作者:Anthony Hughes,Nikolaos Aletras,Ning Ma
+ 类目:Computation and Language (cs.CL)
+ 关键词:shown outstanding performance, Language models, medicine and law, shown outstanding, outstanding performance
+ 备注:
+
+ 点击查看摘要
+ Abstract:Language models (LMs) have shown outstanding performance in text summarization including sensitive domains such as medicine and law. In these settings, it is important that personally identifying information (PII) included in the source document should not leak in the summary. Prior efforts have mostly focused on studying how LMs may inadvertently elicit PII from training data. However, to what extent LMs can provide privacy-preserving summaries given a non-private source document remains under-explored. In this paper, we perform a comprehensive study across two closed- and three open-weight LMs of different sizes and families. We experiment with prompting and fine-tuning strategies for privacy-preservation across a range of summarization datasets across three domains. Our extensive quantitative and qualitative analysis including human evaluation shows that LMs often cannot prevent PII leakage on their summaries and that current widely-used metrics cannot capture context dependent privacy risks.
+
+
+
+ 6. 【2412.12039】Can LLM Prompting Serve as a Proxy for Static Analysis in Vulnerability Detection
+ 链接:https://arxiv.org/abs/2412.12039
+ 作者:Ira Ceka,Feitong Qiao,Anik Dey,Aastha Valechia,Gail Kaiser,Baishakhi Ray
+ 类目:Cryptography and Security (cs.CR); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Software Engineering (cs.SE)
+ 关键词:large language models, shown limited ability, remarkable success, vulnerability detection, shown limited
+ 备注:
+
+ 点击查看摘要
+ Abstract:Despite their remarkable success, large language models (LLMs) have shown limited ability on applied tasks such as vulnerability detection. We investigate various prompting strategies for vulnerability detection and, as part of this exploration, propose a prompting strategy that integrates natural language descriptions of vulnerabilities with a contrastive chain-of-thought reasoning approach, augmented using contrastive samples from a synthetic dataset. Our study highlights the potential of LLMs to detect vulnerabilities by integrating natural language descriptions, contrastive reasoning, and synthetic examples into a comprehensive prompting framework. Our results show that this approach can enhance LLM understanding of vulnerabilities. On a high-quality vulnerability detection dataset such as SVEN, our prompting strategies can improve accuracies, F1-scores, and pairwise accuracies by 23%, 11%, and 14%, respectively.
+
+
+
+ 7. 【2412.12004】he Open Source Advantage in Large Language Models (LLMs)
+ 链接:https://arxiv.org/abs/2412.12004
+ 作者:Jiya Manchanda,Laura Boettcher,Matheus Westphalen,Jasser Jasser
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:advanced text generation, Large language models, natural language processing, Large language, mark a key
+ 备注: 7 pages, 0 figures
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) mark a key shift in natural language processing (NLP), having advanced text generation, translation, and domain-specific reasoning. Closed-source models like GPT-4, powered by proprietary datasets and extensive computational resources, lead with state-of-the-art performance today. However, they face criticism for their "black box" nature and for limiting accessibility in a manner that hinders reproducibility and equitable AI development. By contrast, open-source initiatives like LLaMA and BLOOM prioritize democratization through community-driven development and computational efficiency. These models have significantly reduced performance gaps, particularly in linguistic diversity and domain-specific applications, while providing accessible tools for global researchers and developers. Notably, both paradigms rely on foundational architectural innovations, such as the Transformer framework by Vaswani et al. (2017). Closed-source models excel by scaling effectively, while open-source models adapt to real-world applications in underrepresented languages and domains. Techniques like Low-Rank Adaptation (LoRA) and instruction-tuning datasets enable open-source models to achieve competitive results despite limited resources. To be sure, the tension between closed-source and open-source approaches underscores a broader debate on transparency versus proprietary control in AI. Ethical considerations further highlight this divide. Closed-source systems restrict external scrutiny, while open-source models promote reproducibility and collaboration but lack standardized auditing documentation frameworks to mitigate biases. Hybrid approaches that leverage the strengths of both paradigms are likely to shape the future of LLM innovation, ensuring accessibility, competitive technical performance, and ethical deployment.
+
+
+
+ 8. 【2412.12001】LLM-RG4: Flexible and Factual Radiology Report Generation across Diverse Input Contexts
+ 链接:https://arxiv.org/abs/2412.12001
+ 作者:Zhuhao Wang,Yihua Sun,Zihan Li,Xuan Yang,Fang Chen,Hongen Liao
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:radiologists tail content, complex task requiring, radiology report drafting, Drafting radiology reports, task requiring flexibility
+ 备注:
+
+ 点击查看摘要
+ Abstract:Drafting radiology reports is a complex task requiring flexibility, where radiologists tail content to available information and particular clinical demands. However, most current radiology report generation (RRG) models are constrained to a fixed task paradigm, such as predicting the full ``finding'' section from a single image, inherently involving a mismatch between inputs and outputs. The trained models lack the flexibility for diverse inputs and could generate harmful, input-agnostic hallucinations. To bridge the gap between current RRG models and the clinical demands in practice, we first develop a data generation pipeline to create a new MIMIC-RG4 dataset, which considers four common radiology report drafting scenarios and has perfectly corresponded input and output. Secondly, we propose a novel large language model (LLM) based RRG framework, namely LLM-RG4, which utilizes LLM's flexible instruction-following capabilities and extensive general knowledge. We further develop an adaptive token fusion module that offers flexibility to handle diverse scenarios with different input combinations, while minimizing the additional computational burden associated with increased input volumes. Besides, we propose a token-level loss weighting strategy to direct the model's attention towards positive and uncertain descriptions. Experimental results demonstrate that LLM-RG4 achieves state-of-the-art performance in both clinical efficiency and natural language generation on the MIMIC-RG4 and MIMIC-CXR datasets. We quantitatively demonstrate that our model has minimal input-agnostic hallucinations, whereas current open-source models commonly suffer from this problem.
+
+
+
+ 9. 【2412.11990】ExecRepoBench: Multi-level Executable Code Completion Evaluation
+ 链接:https://arxiv.org/abs/2412.11990
+ 作者:Jian Yang,Jiajun Zhang,Jiaxi Yang,Ke Jin,Lei Zhang,Qiyao Peng,Ken Deng,Yibo Miao,Tianyu Liu,Zeyu Cui,Binyuan Hui,Junyang Lin
+ 类目:Computation and Language (cs.CL)
+ 关键词:daily software development, essential tool, tool for daily, Code completion, daily software
+ 备注:
+
+ 点击查看摘要
+ Abstract:Code completion has become an essential tool for daily software development. Existing evaluation benchmarks often employ static methods that do not fully capture the dynamic nature of real-world coding environments and face significant challenges, including limited context length, reliance on superficial evaluation metrics, and potential overfitting to training datasets. In this work, we introduce a novel framework for enhancing code completion in software development through the creation of a repository-level benchmark ExecRepoBench and the instruction corpora Repo-Instruct, aim at improving the functionality of open-source large language models (LLMs) in real-world coding scenarios that involve complex interdependencies across multiple files. ExecRepoBench includes 1.2K samples from active Python repositories. Plus, we present a multi-level grammar-based completion methodology conditioned on the abstract syntax tree to mask code fragments at various logical units (e.g. statements, expressions, and functions). Then, we fine-tune the open-source LLM with 7B parameters on Repo-Instruct to produce a strong code completion baseline model Qwen2.5-Coder-Instruct-C based on the open-source model. Qwen2.5-Coder-Instruct-C is rigorously evaluated against existing benchmarks, including MultiPL-E and ExecRepoBench, which consistently outperforms prior baselines across all programming languages. The deployment of \ourmethod{} can be used as a high-performance, local service for programming development\footnote{\url{this https URL}}.
+
+
+
+ 10. 【2412.11988】SciFaultyQA: Benchmarking LLMs on Faulty Science Question Detection with a GAN-Inspired Approach to Synthetic Dataset Generation
+ 链接:https://arxiv.org/abs/2412.11988
+ 作者:Debarshi Kundu
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Gemini Flash frequently, Gemini Flash, woman can produce, Flash frequently answer, woman
+ 备注:
+
+ 点击查看摘要
+ Abstract:Consider the problem: ``If one man and one woman can produce one child in one year, how many children will be produced by one woman and three men in 0.5 years?" Current large language models (LLMs) such as GPT-4o, GPT-o1-preview, and Gemini Flash frequently answer "0.5," which does not make sense. While these models sometimes acknowledge the unrealistic nature of the question, in many cases (8 out of 10 trials), they provide the nonsensical answer of "0.5 child." Additionally, temporal variation has been observed: if an LLM answers correctly once (by recognizing the faulty nature of the question), subsequent responses are more likely to also reflect this understanding. However, this is inconsistent.
+These types of questions have motivated us to develop a dataset of science questions, SciFaultyQA, where the questions themselves are intentionally faulty. We observed that LLMs often proceed to answer these flawed questions without recognizing their inherent issues, producing results that are logically or scientifically invalid. By analyzing such patterns, we developed a novel method for generating synthetic datasets to evaluate and benchmark the performance of various LLMs in identifying these flawed questions. We have also developed novel approaches to reduce the errors.
+
Subjects:
+Computation and Language (cs.CL); Machine Learning (cs.LG)
+Cite as:
+arXiv:2412.11988 [cs.CL]
+(or
+arXiv:2412.11988v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2412.11988
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 11. 【2412.11986】Speak Improve Corpus 2025: an L2 English Speech Corpus for Language Assessment and Feedback
+ 链接:https://arxiv.org/abs/2412.11986
+ 作者:Kate Knill,Diane Nicholls,Mark J.F. Gales,Mengjie Qian,Pawel Stroinski
+ 类目:Computation and Language (cs.CL)
+ 关键词:Improve learning platform, language processing systems, introduce the Speak, Improve learning, https URL
+ 备注:
+
+ 点击查看摘要
+ Abstract:We introduce the Speak \ Improve Corpus 2025, a dataset of L2 learner English data with holistic scores and language error annotation, collected from open (spontaneous) speaking tests on the Speak \ Improve learning platform this https URL . The aim of the corpus release is to address a major challenge to developing L2 spoken language processing systems, the lack of publicly available data with high-quality annotations. It is being made available for non-commercial use on the ELiT website. In designing this corpus we have sought to make it cover a wide-range of speaker attributes, from their L1 to their speaking ability, as well as providing manual annotations. This enables a range of language-learning tasks to be examined, such as assessing speaking proficiency or providing feedback on grammatical errors in a learner's speech. Additionally, the data supports research into the underlying technology required for these tasks including automatic speech recognition (ASR) of low resource L2 learner English, disfluency detection or spoken grammatical error correction (GEC). The corpus consists of around 340 hours of L2 English learners audio with holistic scores, and a subset of audio annotated with transcriptions and error labels.
+
+
+
+ 12. 【2412.11985】Speak Improve Challenge 2025: Tasks and Baseline Systems
+ 链接:https://arxiv.org/abs/2412.11985
+ 作者:Mengjie Qian,Kate Knill,Stefano Banno,Siyuan Tang,Penny Karanasou,Mark J.F. Gales,Diane Nicholls
+ 类目:Computation and Language (cs.CL)
+ 关键词:Spoken Language Assessment, Speak Improve Challenge, Speak Improve, Spoken Grammatical Error, Speak Improve learning
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper presents the "Speak Improve Challenge 2025: Spoken Language Assessment and Feedback" -- a challenge associated with the ISCA SLaTE 2025 Workshop. The goal of the challenge is to advance research on spoken language assessment and feedback, with tasks associated with both the underlying technology and language learning feedback. Linked with the challenge, the Speak Improve (SI) Corpus 2025 is being pre-released, a dataset of L2 learner English data with holistic scores and language error annotation, collected from open (spontaneous) speaking tests on the Speak Improve learning platform. The corpus consists of 340 hours of audio data from second language English learners with holistic scores, and a 60-hour subset with manual transcriptions and error labels. The Challenge has four shared tasks: Automatic Speech Recognition (ASR), Spoken Language Assessment (SLA), Spoken Grammatical Error Correction (SGEC), and Spoken Grammatical Error Correction Feedback (SGECF). Each of these tasks has a closed track where a predetermined set of models and data sources are allowed to be used, and an open track where any public resource may be used. Challenge participants may do one or more of the tasks. This paper describes the challenge, the SI Corpus 2025, and the baseline systems released for the Challenge.
+
+
+
+ 13. 【2412.11978】Speech Foundation Models and Crowdsourcing for Efficient, High-Quality Data Collection
+ 链接:https://arxiv.org/abs/2412.11978
+ 作者:Beomseok Lee,Marco Gaido,Ioan Calapodescu,Laurent Besacier,Matteo Negri
+ 类目:Computation and Language (cs.CL); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:non-experts necessitates protocols, Speech Foundation Models, final data quality, ensure final data, speech data acquisition
+ 备注: Accepted at COLING 2025 main conference
+
+ 点击查看摘要
+ Abstract:While crowdsourcing is an established solution for facilitating and scaling the collection of speech data, the involvement of non-experts necessitates protocols to ensure final data quality. To reduce the costs of these essential controls, this paper investigates the use of Speech Foundation Models (SFMs) to automate the validation process, examining for the first time the cost/quality trade-off in data acquisition. Experiments conducted on French, German, and Korean data demonstrate that SFM-based validation has the potential to reduce reliance on human validation, resulting in an estimated cost saving of over 40.0% without degrading final data quality. These findings open new opportunities for more efficient, cost-effective, and scalable speech data acquisition.
+
+
+
+ 14. 【2412.11974】Emma-X: An Embodied Multimodal Action Model with Grounded Chain of Thought and Look-ahead Spatial Reasoning
+ 链接:https://arxiv.org/abs/2412.11974
+ 作者:Qi Sun,Pengfei Hong,Tej Deep Pala,Vernon Toh,U-Xuan Tan,Deepanway Ghosal,Soujanya Poria
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Traditional reinforcement learning-based, Traditional reinforcement, reinforcement learning-based robotic, learning-based robotic control, robotic control methods
+ 备注: [this https URL](https://github.com/declare-lab/Emma-X) , [this https URL](https://huggingface.co/declare-lab/Emma-X)
+
+ 点击查看摘要
+ Abstract:Traditional reinforcement learning-based robotic control methods are often task-specific and fail to generalize across diverse environments or unseen objects and instructions. Visual Language Models (VLMs) demonstrate strong scene understanding and planning capabilities but lack the ability to generate actionable policies tailored to specific robotic embodiments. To address this, Visual-Language-Action (VLA) models have emerged, yet they face challenges in long-horizon spatial reasoning and grounded task planning. In this work, we propose the Embodied Multimodal Action Model with Grounded Chain of Thought and Look-ahead Spatial Reasoning, Emma-X. Emma-X leverages our constructed hierarchical embodiment dataset based on BridgeV2, containing 60,000 robot manipulation trajectories auto-annotated with grounded task reasoning and spatial guidance. Additionally, we introduce a trajectory segmentation strategy based on gripper states and motion trajectories, which can help mitigate hallucination in grounding subtask reasoning generation. Experimental results demonstrate that Emma-X achieves superior performance over competitive baselines, particularly in real-world robotic tasks requiring spatial reasoning.
+
+
+
+ 15. 【2412.11970】DARWIN 1.5: Large Language Models as Materials Science Adapted Learners
+ 链接:https://arxiv.org/abs/2412.11970
+ 作者:Tong Xie,Yuwei Wan,Yixuan Liu,Yuchen Zeng,Wenjie Zhang,Chunyu Kit,Dongzhan Zhou,Bram Hoex
+ 类目:Computation and Language (cs.CL)
+ 关键词:diverse search spaces, search spaces, aim to find, find components, components and structures
+ 备注:
+
+ 点击查看摘要
+ Abstract:Materials discovery and design aim to find components and structures with desirable properties over highly complex and diverse search spaces. Traditional solutions, such as high-throughput simulations and machine learning (ML), often rely on complex descriptors, which hinder generalizability and transferability across tasks. Moreover, these descriptors may deviate from experimental data due to inevitable defects and purity issues in the real world, which may reduce their effectiveness in practical applications. To address these challenges, we propose Darwin 1.5, an open-source large language model (LLM) tailored for materials science. By leveraging natural language as input, Darwin eliminates the need for task-specific descriptors and enables a flexible, unified approach to material property prediction and discovery. We employ a two-stage training strategy combining question-answering (QA) fine-tuning with multi-task learning (MTL) to inject domain-specific knowledge in various modalities and facilitate cross-task knowledge transfer. Through our strategic approach, we achieved a significant enhancement in the prediction accuracy of LLMs, with a maximum improvement of 60\% compared to LLaMA-7B base models. It further outperforms traditional machine learning models on various tasks in material science, showcasing the potential of LLMs to provide a more versatile and scalable foundation model for materials discovery and design.
+
+
+
+ 16. 【2412.11965】Inferring Functionality of Attention Heads from their Parameters
+ 链接:https://arxiv.org/abs/2412.11965
+ 作者:Amit Elhelo,Mor Geva
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language models, building blocks, blocks of large, large language, Attention
+ 备注:
+
+ 点击查看摘要
+ Abstract:Attention heads are one of the building blocks of large language models (LLMs). Prior work on investigating their operation mostly focused on analyzing their behavior during inference for specific circuits or tasks. In this work, we seek a comprehensive mapping of the operations they implement in a model. We propose MAPS (Mapping Attention head ParameterS), an efficient framework that infers the functionality of attention heads from their parameters, without any model training or inference. We showcase the utility of MAPS for answering two types of questions: (a) given a predefined operation, mapping how strongly heads across the model implement it, and (b) given an attention head, inferring its salient functionality. Evaluating MAPS on 20 operations across 6 popular LLMs shows its estimations correlate with the head's outputs during inference and are causally linked to the model's predictions. Moreover, its mappings reveal attention heads of certain operations that were overlooked in previous studies, and valuable insights on function universality and architecture biases in LLMs. Next, we present an automatic pipeline and analysis that leverage MAPS to characterize the salient operations of a given head. Our pipeline produces plausible operation descriptions for most heads, as assessed by human judgment, while revealing diverse operations.
+
+
+
+ 17. 【2412.11940】he Impact of Token Granularity on the Predictive Power of Language Model Surprisal
+ 链接:https://arxiv.org/abs/2412.11940
+ 作者:Byung-Doh Oh,William Schuler
+ 类目:Computation and Language (cs.CL)
+ 关键词:human readers, raises questions, token granularity, surprisal, language modeling influence
+ 备注:
+
+ 点击查看摘要
+ Abstract:Word-by-word language model surprisal is often used to model the incremental processing of human readers, which raises questions about how various choices in language modeling influence its predictive power. One factor that has been overlooked in cognitive modeling is the granularity of subword tokens, which explicitly encodes information about word length and frequency, and ultimately influences the quality of vector representations that are learned. This paper presents experiments that manipulate the token granularity and evaluate its impact on the ability of surprisal to account for processing difficulty of naturalistic text and garden-path constructions. Experiments with naturalistic reading times reveal a substantial influence of token granularity on surprisal, with tokens defined by a vocabulary size of 8,000 resulting in surprisal that is most predictive. In contrast, on garden-path constructions, language models trained on coarser-grained tokens generally assigned higher surprisal to critical regions, suggesting their increased sensitivity to syntax. Taken together, these results suggest a large role of token granularity on the quality of language model surprisal for cognitive modeling.
+
+
+
+ 18. 【2412.11939】SEAGraph: Unveiling the Whole Story of Paper Review Comments
+ 链接:https://arxiv.org/abs/2412.11939
+ 作者:Jianxiang Yu,Jiaqi Tan,Zichen Ding,Jiapeng Zhu,Jiahao Li,Yao Cheng,Qier Cui,Yunshi Lan,Xiang Li
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Peer review, peer review process, ensures the integrity, traditional peer review, cornerstone of scientific
+ 备注:
+
+ 点击查看摘要
+ Abstract:Peer review, as a cornerstone of scientific research, ensures the integrity and quality of scholarly work by providing authors with objective feedback for refinement. However, in the traditional peer review process, authors often receive vague or insufficiently detailed feedback, which provides limited assistance and leads to a more time-consuming review cycle. If authors can identify some specific weaknesses in their paper, they can not only address the reviewer's concerns but also improve their work. This raises the critical question of how to enhance authors' comprehension of review comments. In this paper, we present SEAGraph, a novel framework developed to clarify review comments by uncovering the underlying intentions behind them. We construct two types of graphs for each paper: the semantic mind graph, which captures the author's thought process, and the hierarchical background graph, which delineates the research domains related to the paper. A retrieval method is then designed to extract relevant content from both graphs, facilitating coherent explanations for the review comments. Extensive experiments show that SEAGraph excels in review comment understanding tasks, offering significant benefits to authors.
+
+
+
+ 19. 【2412.11937】Precise Length Control in Large Language Models
+ 链接:https://arxiv.org/abs/2412.11937
+ 作者:Bradley Butcher,Michael O'Keefe,James Titchener
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, Language Models, production systems, powering applications
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) are increasingly used in production systems, powering applications such as chatbots, summarization, and question answering. Despite their success, controlling the length of their response remains a significant challenge, particularly for tasks requiring structured outputs or specific levels of detail. In this work, we propose a method to adapt pre-trained decoder-only LLMs for precise control of response length. Our approach incorporates a secondary length-difference positional encoding (LDPE) into the input embeddings, which counts down to a user-set response termination length. Fine-tuning with LDPE allows the model to learn to terminate responses coherently at the desired length, achieving mean token errors of less than 3 tokens. We also introduce Max New Tokens++, an extension that enables flexible upper-bound length control, rather than an exact target. Experimental results on tasks such as question answering and document summarization demonstrate that our method enables precise length control without compromising response quality.
+
+
+
+ 20. 【2412.11936】A Survey of Mathematical Reasoning in the Era of Multimodal Large Language Model: Benchmark, Method Challenges
+ 链接:https://arxiv.org/abs/2412.11936
+ 作者:Yibo Yan,Jiamin Su,Jianxiang He,Fangteng Fu,Xu Zheng,Yuanhuiyi Lyu,Kun Wang,Shen Wang,Qingsong Wen,Xuming Hu
+ 类目:Computation and Language (cs.CL)
+ 关键词:Mathematical reasoning, large language models, human cognition, scientific advancements, core aspect
+ 备注:
+
+ 点击查看摘要
+ Abstract:Mathematical reasoning, a core aspect of human cognition, is vital across many domains, from educational problem-solving to scientific advancements. As artificial general intelligence (AGI) progresses, integrating large language models (LLMs) with mathematical reasoning tasks is becoming increasingly significant. This survey provides the first comprehensive analysis of mathematical reasoning in the era of multimodal large language models (MLLMs). We review over 200 studies published since 2021, and examine the state-of-the-art developments in Math-LLMs, with a focus on multimodal settings. We categorize the field into three dimensions: benchmarks, methodologies, and challenges. In particular, we explore multimodal mathematical reasoning pipeline, as well as the role of (M)LLMs and the associated methodologies. Finally, we identify five major challenges hindering the realization of AGI in this domain, offering insights into the future direction for enhancing multimodal reasoning capabilities. This survey serves as a critical resource for the research community in advancing the capabilities of LLMs to tackle complex multimodal reasoning tasks.
+
+
+
+ 21. 【2412.11927】Explainable Procedural Mistake Detection
+ 链接:https://arxiv.org/abs/2412.11927
+ 作者:Shane Storks,Itamar Bar-Yossef,Yayuan Li,Zheyuan Zhang,Jason J. Corso,Joyce Chai
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:recently attracted attention, research community, Automated task guidance, guidance has recently, recently attracted
+ 备注:
+
+ 点击查看摘要
+ Abstract:Automated task guidance has recently attracted attention from the AI research community. Procedural mistake detection (PMD) is a challenging sub-problem of classifying whether a human user (observed through egocentric video) has successfully executed the task at hand (specified by a procedural text). Despite significant efforts in building resources and models for PMD, machine performance remains nonviable, and the reasoning processes underlying this performance are opaque. As such, we recast PMD to an explanatory self-dialog of questions and answers, which serve as evidence for a decision. As this reformulation enables an unprecedented transparency, we leverage a fine-tuned natural language inference (NLI) model to formulate two automated coherence metrics for generated explanations. Our results show that while open-source VLMs struggle with this task off-the-shelf, their accuracy, coherence, and dialog efficiency can be vastly improved by incorporating these coherence metrics into common inference and fine-tuning methods. Furthermore, our multi-faceted metrics can visualize common outcomes at a glance, highlighting areas for improvement.
+
+
+
+ 22. 【2412.11923】PICLe: Pseudo-Annotations for In-Context Learning in Low-Resource Named Entity Detection
+ 链接:https://arxiv.org/abs/2412.11923
+ 作者:Sepideh Mamooler,Syrielle Montariol,Alexander Mathis,Antoine Bosselut
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, enables Large Language, Language Models, Large Language, enables Large
+ 备注: Preprint
+
+ 点击查看摘要
+ Abstract:In-context learning (ICL) enables Large Language Models (LLMs) to perform tasks using few demonstrations, facilitating task adaptation when labeled examples are hard to obtain. However, ICL is sensitive to the choice of demonstrations, and it remains unclear which demonstration attributes enable in-context generalization. In this work, we conduct a perturbation study of in-context demonstrations for low-resource Named Entity Detection (NED). Our surprising finding is that in-context demonstrations with partially correct annotated entity mentions can be as effective for task transfer as fully correct demonstrations. Based off our findings, we propose Pseudo-annotated In-Context Learning (PICLe), a framework for in-context learning with noisy, pseudo-annotated demonstrations. PICLe leverages LLMs to annotate many demonstrations in a zero-shot first pass. We then cluster these synthetic demonstrations, sample specific sets of in-context demonstrations from each cluster, and predict entity mentions using each set independently. Finally, we use self-verification to select the final set of entity mentions. We evaluate PICLe on five biomedical NED datasets and show that, with zero human annotation, PICLe outperforms ICL in low-resource settings where limited gold examples can be used as in-context demonstrations.
+
+
+
+ 23. 【2412.11919】RetroLLM: Empowering Large Language Models to Retrieve Fine-grained Evidence within Generation
+ 链接:https://arxiv.org/abs/2412.11919
+ 作者:Xiaoxi Li,Jiajie Jin,Yujia Zhou,Yongkang Wu,Zhonghua Li,Qi Ye,Zhicheng Dou
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:Large language models, exhibit remarkable generative, remarkable generative capabilities, Large language, language models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) exhibit remarkable generative capabilities but often suffer from hallucinations. Retrieval-augmented generation (RAG) offers an effective solution by incorporating external knowledge, but existing methods still face several limitations: additional deployment costs of separate retrievers, redundant input tokens from retrieved text chunks, and the lack of joint optimization of retrieval and generation. To address these issues, we propose \textbf{RetroLLM}, a unified framework that integrates retrieval and generation into a single, cohesive process, enabling LLMs to directly generate fine-grained evidence from the corpus with constrained decoding. Moreover, to mitigate false pruning in the process of constrained evidence generation, we introduce (1) hierarchical FM-Index constraints, which generate corpus-constrained clues to identify a subset of relevant documents before evidence generation, reducing irrelevant decoding space; and (2) a forward-looking constrained decoding strategy, which considers the relevance of future sequences to improve evidence accuracy. Extensive experiments on five open-domain QA datasets demonstrate RetroLLM's superior performance across both in-domain and out-of-domain tasks. The code is available at \url{this https URL}.
+
+
+
+ 24. 【2412.11912】CharacterBench: Benchmarking Character Customization of Large Language Models
+ 链接:https://arxiv.org/abs/2412.11912
+ 作者:Jinfeng Zhou,Yongkang Huang,Bosi Wen,Guanqun Bi,Yuxuan Chen,Pei Ke,Zhuang Chen,Xiyao Xiao,Libiao Peng,Kuntian Tang,Rongsheng Zhang,Le Zhang,Tangjie Lv,Zhipeng Hu,Hongning Wang,Minlie Huang
+ 类目:Computation and Language (cs.CL)
+ 关键词:Character-based dialogue, freely customize characters, aka role-playing, relies on LLMs, users to freely
+ 备注: AAAI 2025
+
+ 点击查看摘要
+ Abstract:Character-based dialogue (aka role-playing) enables users to freely customize characters for interaction, which often relies on LLMs, raising the need to evaluate LLMs' character customization capability. However, existing benchmarks fail to ensure a robust evaluation as they often only involve a single character category or evaluate limited dimensions. Moreover, the sparsity of character features in responses makes feature-focused generative evaluation both ineffective and inefficient. To address these issues, we propose CharacterBench, the largest bilingual generative benchmark, with 22,859 human-annotated samples covering 3,956 characters from 25 detailed character categories. We define 11 dimensions of 6 aspects, classified as sparse and dense dimensions based on whether character features evaluated by specific dimensions manifest in each response. We enable effective and efficient evaluation by crafting tailored queries for each dimension to induce characters' responses related to specific dimensions. Further, we develop CharacterJudge model for cost-effective and stable evaluations. Experiments show its superiority over SOTA automatic judges (e.g., GPT-4) and our benchmark's potential to optimize LLMs' character customization. Our repository is at this https URL.
+
+
+
+ 25. 【2412.11908】Can Language Models Rival Mathematics Students? Evaluating Mathematical Reasoning through Textual Manipulation and Human Experiments
+ 链接:https://arxiv.org/abs/2412.11908
+ 作者:Andrii Nikolaiev,Yiannos Stathopoulos,Simone Teufel
+ 类目:Computation and Language (cs.CL)
+ 关键词:recent large language, large language models, ability of recent, recent large, large language
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this paper we look at the ability of recent large language models (LLMs) at solving mathematical problems in combinatorics. We compare models LLaMA-2, LLaMA-3.1, GPT-4, and Mixtral against each other and against human pupils and undergraduates with prior experience in mathematical olympiads. To facilitate these comparisons we introduce the Combi-Puzzles dataset, which contains 125 problem variants based on 25 combinatorial reasoning problems. Each problem is presented in one of five distinct forms, created by systematically manipulating the problem statements through adversarial additions, numeric parameter changes, and linguistic obfuscation. Our variations preserve the mathematical core and are designed to measure the generalisability of LLM problem-solving abilities, while also increasing confidence that problems are submitted to LLMs in forms that have not been seen as training instances. We found that a model based on GPT-4 outperformed all other models in producing correct responses, and performed significantly better in the mathematical variation of the problems than humans. We also found that modifications to problem statements significantly impact the LLM's performance, while human performance remains unaffected.
+
+
+
+ 26. 【2412.11896】Classification of Spontaneous and Scripted Speech for Multilingual Audio
+ 链接:https://arxiv.org/abs/2412.11896
+ 作者:Shahar Elisha,Andrew McDowell,Mariano Beguerisse-Díaz,Emmanouil Benetos
+ 类目:Computation and Language (cs.CL); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:speech processing research, speech styles influence, styles influence speech, influence speech processing, processing research
+ 备注: Accepted to IEEE Spoken Language Technology Workshop 2024
+
+ 点击查看摘要
+ Abstract:Distinguishing scripted from spontaneous speech is an essential tool for better understanding how speech styles influence speech processing research. It can also improve recommendation systems and discovery experiences for media users through better segmentation of large recorded speech catalogues. This paper addresses the challenge of building a classifier that generalises well across different formats and languages. We systematically evaluate models ranging from traditional, handcrafted acoustic and prosodic features to advanced audio transformers, utilising a large, multilingual proprietary podcast dataset for training and validation. We break down the performance of each model across 11 language groups to evaluate cross-lingual biases. Our experimental analysis extends to publicly available datasets to assess the models' generalisability to non-podcast domains. Our results indicate that transformer-based models consistently outperform traditional feature-based techniques, achieving state-of-the-art performance in distinguishing between scripted and spontaneous speech across various languages.
+
+
+
+ 27. 【2412.11878】Using Instruction-Tuned Large Language Models to Identify Indicators of Vulnerability in Police Incident Narratives
+ 链接:https://arxiv.org/abs/2412.11878
+ 作者:Sam Relins,Daniel Birks,Charlie Lloyd
+ 类目:Computation and Language (cs.CL)
+ 关键词:routinely collected unstructured, describes police-public interactions, instruction tuned large, tuned large language, Boston Police Department
+ 备注: 33 pages, 6 figures Submitted to Journal of Quantitative Criminology
+
+ 点击查看摘要
+ Abstract:Objectives: Compare qualitative coding of instruction tuned large language models (IT-LLMs) against human coders in classifying the presence or absence of vulnerability in routinely collected unstructured text that describes police-public interactions. Evaluate potential bias in IT-LLM codings. Methods: Analyzing publicly available text narratives of police-public interactions recorded by Boston Police Department, we provide humans and IT-LLMs with qualitative labelling codebooks and compare labels generated by both, seeking to identify situations associated with (i) mental ill health; (ii) substance misuse; (iii) alcohol dependence; and (iv) homelessness. We explore multiple prompting strategies and model sizes, and the variability of labels generated by repeated prompts. Additionally, to explore model bias, we utilize counterfactual methods to assess the impact of two protected characteristics - race and gender - on IT-LLM classification. Results: Results demonstrate that IT-LLMs can effectively support human qualitative coding of police incident narratives. While there is some disagreement between LLM and human generated labels, IT-LLMs are highly effective at screening narratives where no vulnerabilities are present, potentially vastly reducing the requirement for human coding. Counterfactual analyses demonstrate that manipulations to both gender and race of individuals described in narratives have very limited effects on IT-LLM classifications beyond those expected by chance. Conclusions: IT-LLMs offer effective means to augment human qualitative coding in a way that requires much lower levels of resource to analyze large unstructured datasets. Moreover, they encourage specificity in qualitative coding, promote transparency, and provide the opportunity for more standardized, replicable approaches to analyzing large free-text police data sources.
+
+
+
+ 28. 【2412.11863】GeoX: Geometric Problem Solving Through Unified Formalized Vision-Language Pre-training
+ 链接:https://arxiv.org/abs/2412.11863
+ 作者:Renqiu Xia,Mingsheng Li,Hancheng Ye,Wenjie Wu,Hongbin Zhou,Jiakang Yuan,Tianshuo Peng,Xinyu Cai,Xiangchao Yan,Bin Wang,Conghui He,Botian Shi,Tao Chen,Junchi Yan,Bo Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Geometry Problem Solving, automatic Geometry Problem, Multi-modal Large Language, Large Language Models, automatic Geometry
+ 备注: Our code is available at [this https URL](https://github.com/UniModal4Reasoning/GeoX)
+
+ 点击查看摘要
+ Abstract:Despite their proficiency in general tasks, Multi-modal Large Language Models (MLLMs) struggle with automatic Geometry Problem Solving (GPS), which demands understanding diagrams, interpreting symbols, and performing complex reasoning. This limitation arises from their pre-training on natural images and texts, along with the lack of automated verification in the problem-solving process. Besides, current geometric specialists are limited by their task-specific designs, making them less effective for broader geometric problems. To this end, we present GeoX, a multi-modal large model focusing on geometric understanding and reasoning tasks. Given the significant differences between geometric diagram-symbol and natural image-text, we introduce unimodal pre-training to develop a diagram encoder and symbol decoder, enhancing the understanding of geometric images and corpora. Furthermore, we introduce geometry-language alignment, an effective pre-training paradigm that bridges the modality gap between unimodal geometric experts. We propose a Generator-And-Sampler Transformer (GS-Former) to generate discriminative queries and eliminate uninformative representations from unevenly distributed geometric signals. Finally, GeoX benefits from visual instruction tuning, empowering it to take geometric images and questions as input and generate verifiable solutions. Experiments show that GeoX outperforms both generalists and geometric specialists on publicly recognized benchmarks, such as GeoQA, UniGeo, Geometry3K, and PGPS9k.
+
+
+
+ 29. 【2412.11851】A Benchmark and Robustness Study of In-Context-Learning with Large Language Models in Music Entity Detection
+ 链接:https://arxiv.org/abs/2412.11851
+ 作者:Simon Hachmeier,Robert Jäschke
+ 类目:Computation and Language (cs.CL); Multimedia (cs.MM)
+ 关键词:Detecting music entities, processing music search, music search queries, analyzing music consumption, Detecting music
+ 备注:
+
+ 点击查看摘要
+ Abstract:Detecting music entities such as song titles or artist names is a useful application to help use cases like processing music search queries or analyzing music consumption on the web. Recent approaches incorporate smaller language models (SLMs) like BERT and achieve high results. However, further research indicates a high influence of entity exposure during pre-training on the performance of the models. With the advent of large language models (LLMs), these outperform SLMs in a variety of downstream tasks. However, researchers are still divided if this is applicable to tasks like entity detection in texts due to issues like hallucination. In this paper, we provide a novel dataset of user-generated metadata and conduct a benchmark and a robustness study using recent LLMs with in-context-learning (ICL). Our results indicate that LLMs in the ICL setting yield higher performance than SLMs. We further uncover the large impact of entity exposure on the best performing LLM in our study.
+
+
+
+ 30. 【2412.11835】Improved Models for Media Bias Detection and Subcategorization
+ 链接:https://arxiv.org/abs/2412.11835
+ 作者:Tim Menzner,Jochen L. Leidner
+ 类目:Computation and Language (cs.CL)
+ 关键词:present improved models, English news articles, bias in English, present improved, granular detection
+ 备注:
+
+ 点击查看摘要
+ Abstract:We present improved models for the granular detection and sub-classification news media bias in English news articles. We compare the performance of zero-shot versus fine-tuned large pre-trained neural transformer language models, explore how the level of detail of the classes affects performance on a novel taxonomy of 27 news bias-types, and demonstrate how using synthetically generated example data can be used to improve quality
+
+
+
+ 31. 【2412.11834】Wonderful Matrices: Combining for a More Efficient and Effective Foundation Model Architecture
+ 链接:https://arxiv.org/abs/2412.11834
+ 作者:Jingze Shi,Bingheng Wu
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:combining sequence transformation, state space duality, combining sequence, combining state transformation, sequence transformation
+ 备注: The code is open-sourced at [this https URL](https://github.com/LoserCheems/Doge)
+
+ 点击查看摘要
+ Abstract:In order to make the foundation model more efficient and effective, our idea is combining sequence transformation and state transformation. First, we prove the availability of rotary position embedding in the state space duality algorithm, which reduces the perplexity of the hybrid quadratic causal self-attention and state space duality by more than 4%, to ensure that the combining sequence transformation unifies position encoding. Second, we propose dynamic mask attention, which maintains 100% accuracy in the more challenging multi-query associative recall task, improving by more than 150% compared to quadratic causal self-attention and state space duality, to ensure that the combining sequence transformation selectively filters relevant information. Third, we design cross domain mixture of experts, which makes the computational speed of expert retrieval with more than 1024 experts 8 to 10 times faster than the mixture of experts, to ensure that the combining state transformation quickly retrieval mixture. Finally, we summarize these matrix algorithms that can form the foundation model: Wonderful Matrices, which can be a competitor to popular model architectures.
+
+
+
+ 32. 【2412.11831】Are You Doubtful? Oh, It Might Be Difficult Then! Exploring the Use of Model Uncertainty for Question Difficulty Estimation
+ 链接:https://arxiv.org/abs/2412.11831
+ 作者:Leonidas Zotos,Hedderik van Rijn,Malvina Nissim
+ 类目:Computation and Language (cs.CL)
+ 关键词:assess learning progress, educational setting, learning progress, commonly used strategy, strategy to assess
+ 备注: 14 pages,7 figures
+
+ 点击查看摘要
+ Abstract:In an educational setting, an estimate of the difficulty of multiple-choice questions (MCQs), a commonly used strategy to assess learning progress, constitutes very useful information for both teachers and students. Since human assessment is costly from multiple points of view, automatic approaches to MCQ item difficulty estimation are investigated, yielding however mixed success until now. Our approach to this problem takes a different angle from previous work: asking various Large Language Models to tackle the questions included in two different MCQ datasets, we leverage model uncertainty to estimate item difficulty. By using both model uncertainty features as well as textual features in a Random Forest regressor, we show that uncertainty features contribute substantially to difficulty prediction, where difficulty is inversely proportional to the number of students who can correctly answer a question. In addition to showing the value of our approach, we also observe that our model achieves state-of-the-art results on the BEA publicly available dataset.
+
+
+
+ 33. 【2412.11823】Advancements and Challenges in Bangla Question Answering Models: A Comprehensive Review
+ 链接:https://arxiv.org/abs/2412.11823
+ 作者:Md Iftekhar Islam Tashik,Abdullah Khondoker,Enam Ahmed Taufik,Antara Firoz Parsa,S M Ishtiak Mahmud
+ 类目:Computation and Language (cs.CL)
+ 关键词:Bangla Question Answering, Natural Language Processing, Question Answering, experienced notable progress, Language Processing
+ 备注:
+
+ 点击查看摘要
+ Abstract:The domain of Natural Language Processing (NLP) has experienced notable progress in the evolution of Bangla Question Answering (QA) systems. This paper presents a comprehensive review of seven research articles that contribute to the progress in this domain. These research studies explore different aspects of creating question-answering systems for the Bangla language. They cover areas like collecting data, preparing it for analysis, designing models, conducting experiments, and interpreting results. The papers introduce innovative methods like using LSTM-based models with attention mechanisms, context-based QA systems, and deep learning techniques based on prior knowledge. However, despite the progress made, several challenges remain, including the lack of well-annotated data, the absence of high-quality reading comprehension datasets, and difficulties in understanding the meaning of words in context. Bangla QA models' precision and applicability are constrained by these challenges. This review emphasizes the significance of these research contributions by highlighting the developments achieved in creating Bangla QA systems as well as the ongoing effort required to get past roadblocks and improve the performance of these systems for actual language comprehension tasks.
+
+
+
+ 34. 【2412.11814】EventSum: A Large-Scale Event-Centric Summarization Dataset for Chinese Multi-News Documents
+ 链接:https://arxiv.org/abs/2412.11814
+ 作者:Mengna Zhu,Kaisheng Zeng,Mao Wang,Kaiming Xiao,Lei Hou,Hongbin Huang,Juanzi Li
+ 类目:Computation and Language (cs.CL)
+ 关键词:large-scale sports events, real life, evolve continuously, continuously over time, major disasters
+ 备注: Extended version for paper accepted to AAAI 2025
+
+ 点击查看摘要
+ Abstract:In real life, many dynamic events, such as major disasters and large-scale sports events, evolve continuously over time. Obtaining an overview of these events can help people quickly understand the situation and respond more effectively. This is challenging because the key information of the event is often scattered across multiple documents, involving complex event knowledge understanding and reasoning, which is under-explored in previous work. Therefore, we proposed the Event-Centric Multi-Document Summarization (ECS) task, which aims to generate concise and comprehensive summaries of a given event based on multiple related news documents. Based on this, we constructed the EventSum dataset, which was constructed using Baidu Baike entries and underwent extensive human annotation, to facilitate relevant research. It is the first large scale Chinese multi-document summarization dataset, containing 5,100 events and a total of 57,984 news documents, with an average of 11.4 input news documents and 13,471 characters per event. To ensure data quality and mitigate potential data leakage, we adopted a multi-stage annotation approach for manually labeling the test set. Given the complexity of event-related information, existing metrics struggle to comprehensively assess the quality of generated summaries. We designed specific metrics including Event Recall, Argument Recall, Causal Recall, and Temporal Recall along with corresponding calculation methods for evaluation. We conducted comprehensive experiments on EventSum to evaluate the performance of advanced long-context Large Language Models (LLMs) on this task. Our experimental results indicate that: 1) The event-centric multi-document summarization task remains challenging for existing long-context LLMs; 2) The recall metrics we designed are crucial for evaluating the comprehensiveness of the summary information.
+
+
+
+ 35. 【2412.11803】UAlign: Leveraging Uncertainty Estimations for Factuality Alignment on Large Language Models
+ 链接:https://arxiv.org/abs/2412.11803
+ 作者:Boyang Xue,Fei Mi,Qi Zhu,Hongru Wang,Rui Wang,Sheng Wang,Erxin Yu,Xuming Hu,Kam-Fai Wong
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, demonstrating impressive capabilities, Language Models, knowledge boundaries
+ 备注:
+
+ 点击查看摘要
+ Abstract:Despite demonstrating impressive capabilities, Large Language Models (LLMs) still often struggle to accurately express the factual knowledge they possess, especially in cases where the LLMs' knowledge boundaries are ambiguous. To improve LLMs' factual expressions, we propose the UAlign framework, which leverages Uncertainty estimations to represent knowledge boundaries, and then explicitly incorporates these representations as input features into prompts for LLMs to Align with factual knowledge. First, we prepare the dataset on knowledge question-answering (QA) samples by calculating two uncertainty estimations, including confidence score and semantic entropy, to represent the knowledge boundaries for LLMs. Subsequently, using the prepared dataset, we train a reward model that incorporates uncertainty estimations and then employ the Proximal Policy Optimization (PPO) algorithm for factuality alignment on LLMs. Experimental results indicate that, by integrating uncertainty representations in LLM alignment, the proposed UAlign can significantly enhance the LLMs' capacities to confidently answer known questions and refuse unknown questions on both in-domain and out-of-domain tasks, showing reliability improvements and good generalizability over various prompt- and training-based baselines.
+
+
+
+ 36. 【2412.11795】ProsodyFM: Unsupervised Phrasing and Intonation Control for Intelligible Speech Synthesis
+ 链接:https://arxiv.org/abs/2412.11795
+ 作者:Xiangheng He,Junjie Chen,Zixing Zhang,Björn W. Schuller
+ 类目:Computation and Language (cs.CL); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:meaning of words, intonation, rich information, literal meaning, Terminal Intonation Encoder
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Prosody contains rich information beyond the literal meaning of words, which is crucial for the intelligibility of speech. Current models still fall short in phrasing and intonation; they not only miss or misplace breaks when synthesizing long sentences with complex structures but also produce unnatural intonation. We propose ProsodyFM, a prosody-aware text-to-speech synthesis (TTS) model with a flow-matching (FM) backbone that aims to enhance the phrasing and intonation aspects of prosody. ProsodyFM introduces two key components: a Phrase Break Encoder to capture initial phrase break locations, followed by a Duration Predictor for the flexible adjustment of break durations; and a Terminal Intonation Encoder which integrates a set of intonation shape tokens combined with a novel Pitch Processor for more robust modeling of human-perceived intonation change. ProsodyFM is trained with no explicit prosodic labels and yet can uncover a broad spectrum of break durations and intonation patterns. Experimental results demonstrate that ProsodyFM can effectively improve the phrasing and intonation aspects of prosody, thereby enhancing the overall intelligibility compared to four state-of-the-art (SOTA) models. Out-of-distribution experiments show that this prosody improvement can further bring ProsodyFM superior generalizability for unseen complex sentences and speakers. Our case study intuitively illustrates the powerful and fine-grained controllability of ProsodyFM over phrasing and intonation.
+
+
+
+ 37. 【2412.11787】A Method for Detecting Legal Article Competition for Korean Criminal Law Using a Case-augmented Mention Graph
+ 链接:https://arxiv.org/abs/2412.11787
+ 作者:Seonho An,Young Yik Rhim,Min-Soo Kim
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:increasingly complex, growing more intricate, making it progressively, social systems, systems become increasingly
+ 备注: under review
+
+ 点击查看摘要
+ Abstract:As social systems become increasingly complex, legal articles are also growing more intricate, making it progressively harder for humans to identify any potential competitions among them, particularly when drafting new laws or applying existing laws. Despite this challenge, no method for detecting such competitions has been proposed so far. In this paper, we propose a new legal AI task called Legal Article Competition Detection (LACD), which aims to identify competing articles within a given law. Our novel retrieval method, CAM-Re2, outperforms existing relevant methods, reducing false positives by 20.8% and false negatives by 8.3%, while achieving a 98.2% improvement in precision@5, for the LACD task. We release our codes at this https URL.
+
+
+
+ 38. 【2412.11763】QUENCH: Measuring the gap between Indic and Non-Indic Contextual General Reasoning in LLMs
+ 链接:https://arxiv.org/abs/2412.11763
+ 作者:Mohammad Aflah Khan,Neemesh Yadav,Sarah Masud,Md. Shad Akhtar
+ 类目:Computation and Language (cs.CL)
+ 关键词:English Quizzing Benchmark, large language models, advanced benchmarking systems, rise of large, large language
+ 备注: 17 Pages, 6 Figures, 8 Tables, COLING 2025
+
+ 点击查看摘要
+ Abstract:The rise of large language models (LLMs) has created a need for advanced benchmarking systems beyond traditional setups. To this end, we introduce QUENCH, a novel text-based English Quizzing Benchmark manually curated and transcribed from YouTube quiz videos. QUENCH possesses masked entities and rationales for the LLMs to predict via generation. At the intersection of geographical context and common sense reasoning, QUENCH helps assess world knowledge and deduction capabilities of LLMs via a zero-shot, open-domain quizzing setup. We perform an extensive evaluation on 7 LLMs and 4 metrics, investigating the influence of model size, prompting style, geographical context, and gold-labeled rationale generation. The benchmarking concludes with an error analysis to which the LLMs are prone.
+
+
+
+ 39. 【2412.11757】SCITAT: A Question Answering Benchmark for Scientific Tables and Text Covering Diverse Reasoning Types
+ 链接:https://arxiv.org/abs/2412.11757
+ 作者:Xuanliang Zhang,Dingzirui Wang,Baoxin Wang,Longxu Dou,Xinyuan Lu,Keyan Xu,Dayong Wu,Qingfu Zhu,Wanxiang Che
+ 类目:Computation and Language (cs.CL)
+ 关键词:important task aimed, reasoning types, Scientific question answering, tables and text, current SQA datasets
+ 备注:
+
+ 点击查看摘要
+ Abstract:Scientific question answering (SQA) is an important task aimed at answering questions based on papers. However, current SQA datasets have limited reasoning types and neglect the relevance between tables and text, creating a significant gap with real scenarios. To address these challenges, we propose a QA benchmark for scientific tables and text with diverse reasoning types (SciTaT). To cover more reasoning types, we summarize various reasoning types from real-world questions. To involve both tables and text, we require the questions to incorporate tables and text as much as possible. Based on SciTaT, we propose a strong baseline (CaR), which combines various reasoning methods to address different reasoning types and process tables and text at the same time. CaR brings average improvements of 12.9% over other baselines on SciTaT, validating its effectiveness. Error analysis reveals the challenges of SciTaT, such as complex numerical calculations and domain knowledge.
+
+
+
+ 40. 【2412.11750】Common Ground, Diverse Roots: The Difficulty of Classifying Common Examples in Spanish Varieties
+ 链接:https://arxiv.org/abs/2412.11750
+ 作者:Javier A. Lopetegui,Arij Riabi,Djamé Seddah
+ 类目:Computation and Language (cs.CL)
+ 关键词:Variations in languages, NLP systems designed, culturally sensitive tasks, hate speech detection, conversational agents
+ 备注: Accepted to VARDIAL 2025
+
+ 点击查看摘要
+ Abstract:Variations in languages across geographic regions or cultures are crucial to address to avoid biases in NLP systems designed for culturally sensitive tasks, such as hate speech detection or dialog with conversational agents. In languages such as Spanish, where varieties can significantly overlap, many examples can be valid across them, which we refer to as common examples. Ignoring these examples may cause misclassifications, reducing model accuracy and fairness. Therefore, accounting for these common examples is essential to improve the robustness and representativeness of NLP systems trained on such data. In this work, we address this problem in the context of Spanish varieties. We use training dynamics to automatically detect common examples or errors in existing Spanish datasets. We demonstrate the efficacy of using predicted label confidence for our Datamaps \cite{swayamdipta-etal-2020-dataset} implementation for the identification of hard-to-classify examples, especially common examples, enhancing model performance in variety identification tasks. Additionally, we introduce a Cuban Spanish Variety Identification dataset with common examples annotations developed to facilitate more accurate detection of Cuban and Caribbean Spanish varieties. To our knowledge, this is the first dataset focused on identifying the Cuban, or any other Caribbean, Spanish variety.
+
+
+
+ 41. 【2412.11745】Beyond Dataset Creation: Critical View of Annotation Variation and Bias Probing of a Dataset for Online Radical Content Detection
+ 链接:https://arxiv.org/abs/2412.11745
+ 作者:Arij Riabi,Virginie Mouilleron,Menel Mahamdi,Wissam Antoun,Djamé Seddah
+ 类目:Computation and Language (cs.CL)
+ 关键词:poses significant risks, including inciting violence, spreading extremist ideologies, online platforms poses, platforms poses significant
+ 备注: Accepted to COLING 2025
+
+ 点击查看摘要
+ Abstract:The proliferation of radical content on online platforms poses significant risks, including inciting violence and spreading extremist ideologies. Despite ongoing research, existing datasets and models often fail to address the complexities of multilingual and diverse data. To bridge this gap, we introduce a publicly available multilingual dataset annotated with radicalization levels, calls for action, and named entities in English, French, and Arabic. This dataset is pseudonymized to protect individual privacy while preserving contextual information. Beyond presenting our \href{this https URL}{freely available dataset}, we analyze the annotation process, highlighting biases and disagreements among annotators and their implications for model performance. Additionally, we use synthetic data to investigate the influence of socio-demographic traits on annotation patterns and model predictions. Our work offers a comprehensive examination of the challenges and opportunities in building robust datasets for radical content detection, emphasizing the importance of fairness and transparency in model development.
+
+
+
+ 42. 【2412.11741】CSR:Achieving 1 Bit Key-Value Cache via Sparse Representation
+ 链接:https://arxiv.org/abs/2412.11741
+ 作者:Hongxuan Zhang,Yao Zhao,Jiaqi Zheng,Chenyi Zhuang,Jinjie Gu,Guihai Chen
+ 类目:Computation and Language (cs.CL)
+ 关键词:significant scalability challenges, long-context text applications, text applications utilizing, applications utilizing large, utilizing large language
+ 备注:
+
+ 点击查看摘要
+ Abstract:The emergence of long-context text applications utilizing large language models (LLMs) has presented significant scalability challenges, particularly in memory footprint. The linear growth of the Key-Value (KV) cache responsible for storing attention keys and values to minimize redundant computations can lead to substantial increases in memory consumption, potentially causing models to fail to serve with limited memory resources. To address this issue, we propose a novel approach called Cache Sparse Representation (CSR), which converts the KV cache by transforming the dense Key-Value cache tensor into sparse indexes and weights, offering a more memory-efficient representation during LLM inference. Furthermore, we introduce NeuralDict, a novel neural network-based method for automatically generating the dictionary used in our sparse representation. Our extensive experiments demonstrate that CSR achieves performance comparable to state-of-the-art KV cache quantization algorithms while maintaining robust functionality in memory-constrained environments.
+
+
+
+ 43. 【2412.11736】Personalized LLM for Generating Customized Responses to the Same Query from Different Users
+ 链接:https://arxiv.org/abs/2412.11736
+ 作者:Hang Zeng,Chaoyue Niu,Fan Wu,Chengfei Lv,Guihai Chen
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language model, Existing work, questioner-aware LLM personalization, large language, assigned different responding
+ 备注: 9 pages
+
+ 点击查看摘要
+ Abstract:Existing work on large language model (LLM) personalization assigned different responding roles to LLM, but overlooked the diversity of questioners. In this work, we propose a new form of questioner-aware LLM personalization, generating different responses even for the same query from different questioners. We design a dual-tower model architecture with a cross-questioner general encoder and a questioner-specific encoder. We further apply contrastive learning with multi-view augmentation, pulling close the dialogue representations of the same questioner, while pulling apart those of different questioners. To mitigate the impact of question diversity on questioner-contrastive learning, we cluster the dialogues based on question similarity and restrict the scope of contrastive learning within each cluster. We also build a multi-questioner dataset from English and Chinese scripts and WeChat records, called MQDialog, containing 173 questioners and 12 responders. Extensive evaluation with different metrics shows a significant improvement in the quality of personalized response generation.
+
+
+
+ 44. 【2412.11732】Findings of the WMT 2024 Shared Task on Discourse-Level Literary Translation
+ 链接:https://arxiv.org/abs/2412.11732
+ 作者:Longyue Wang,Siyou Liu,Chenyang Lyu,Wenxiang Jiao,Xing Wang,Jiahao Xu,Zhaopeng Tu,Yan Gu,Weiyu Chen,Minghao Wu,Liting Zhou,Philipp Koehn,Andy Way,Yulin Yuan
+ 类目:Computation and Language (cs.CL)
+ 关键词:WMT translation shared, Discourse-Level Literary Translation, translation shared task, WMT translation, Literary Translation
+ 备注: WMT2024
+
+ 点击查看摘要
+ Abstract:Following last year, we have continued to host the WMT translation shared task this year, the second edition of the Discourse-Level Literary Translation. We focus on three language directions: Chinese-English, Chinese-German, and Chinese-Russian, with the latter two ones newly added. This year, we totally received 10 submissions from 5 academia and industry teams. We employ both automatic and human evaluations to measure the performance of the submitted systems. The official ranking of the systems is based on the overall human judgments. We release data, system outputs, and leaderboard at this https URL.
+
+
+
+ 45. 【2412.11716】LLMs Can Simulate Standardized Patients via Agent Coevolution
+ 链接:https://arxiv.org/abs/2412.11716
+ 作者:Zhuoyun Du,Lujie Zheng,Renjun Hu,Yuyang Xu,Xiawei Li,Ying Sun,Wei Chen,Jian Wu,Haolei Cai,Haohao Ying
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Human-Computer Interaction (cs.HC); Multiagent Systems (cs.MA)
+ 关键词:Large Language Model, Training medical personnel, requiring extensive domain, extensive domain expertise, remains a complex
+ 备注: Work in Progress
+
+ 点击查看摘要
+ Abstract:Training medical personnel using standardized patients (SPs) remains a complex challenge, requiring extensive domain expertise and role-specific practice. Most research on Large Language Model (LLM)-based simulated patients focuses on improving data retrieval accuracy or adjusting prompts through human feedback. However, this focus has overlooked the critical need for patient agents to learn a standardized presentation pattern that transforms data into human-like patient responses through unsupervised simulations. To address this gap, we propose EvoPatient, a novel simulated patient framework in which a patient agent and doctor agents simulate the diagnostic process through multi-turn dialogues, simultaneously gathering experience to improve the quality of both questions and answers, ultimately enabling human doctor training. Extensive experiments on various cases demonstrate that, by providing only overall SP requirements, our framework improves over existing reasoning methods by more than 10% in requirement alignment and better human preference, while achieving an optimal balance of resource consumption after evolving over 200 cases for 10 hours, with excellent generalizability. The code will be available at this https URL.
+
+
+
+ 46. 【2412.11713】Seeker: Towards Exception Safety Code Generation with Intermediate Language Agents Framework
+ 链接:https://arxiv.org/abs/2412.11713
+ 作者:Xuanming Zhang,Yuxuan Chen,Yiming Zheng,Zhexin Zhang,Yuan Yuan,Minlie Huang
+ 类目:Computation and Language (cs.CL); Software Engineering (cs.SE)
+ 关键词:exception handling, improper or missing, missing exception handling, handling, Distorted Handling Solution
+ 备注: 30 pages, 9 figures, submitted to ARR Dec
+
+ 点击查看摘要
+ Abstract:In real world software development, improper or missing exception handling can severely impact the robustness and reliability of code. Exception handling mechanisms require developers to detect, capture, and manage exceptions according to high standards, but many developers struggle with these tasks, leading to fragile code. This problem is particularly evident in open-source projects and impacts the overall quality of the software ecosystem. To address this challenge, we explore the use of large language models (LLMs) to improve exception handling in code. Through extensive analysis, we identify three key issues: Insensitive Detection of Fragile Code, Inaccurate Capture of Exception Block, and Distorted Handling Solution. These problems are widespread across real world repositories, suggesting that robust exception handling practices are often overlooked or mishandled. In response, we propose Seeker, a multi-agent framework inspired by expert developer strategies for exception handling. Seeker uses agents: Scanner, Detector, Predator, Ranker, and Handler to assist LLMs in detecting, capturing, and resolving exceptions more effectively. Our work is the first systematic study on leveraging LLMs to enhance exception handling practices in real development scenarios, providing valuable insights for future improvements in code reliability.
+
+
+
+ 47. 【2412.11711】MiMoTable: A Multi-scale Spreadsheet Benchmark with Meta Operations for Table Reasoning
+ 链接:https://arxiv.org/abs/2412.11711
+ 作者:Zheng Li,Yang Du,Mao Zheng,Mingyang Song
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Language Models, Large Language, Extensive research, capability of Large
+ 备注: Accepted by COLING 2025
+
+ 点击查看摘要
+ Abstract:Extensive research has been conducted to explore the capability of Large Language Models (LLMs) for table reasoning and has significantly improved the performance on existing benchmarks. However, tables and user questions in real-world applications are more complex and diverse, presenting an unignorable gap compared to the existing benchmarks. To fill the gap, we propose a \textbf{M}ult\textbf{i}-scale spreadsheet benchmark with \textbf{M}eta \textbf{o}perations for \textbf{Table} reasoning, named as MiMoTable. Specifically, MiMoTable incorporates two key features. First, the tables in MiMoTable are all spreadsheets used in real-world scenarios, which cover seven domains and contain different types. Second, we define a new criterion with six categories of meta operations for measuring the difficulty of each question in MiMoTable, simultaneously as a new perspective for measuring the difficulty of the existing benchmarks. Experimental results show that Claude-3.5-Sonnet achieves the best performance with 77.4\% accuracy, indicating that there is still significant room to improve for LLMs on MiMoTable. Furthermore, we grade the difficulty of existing benchmarks according to our new criteria. Experiments have shown that the performance of LLMs decreases as the difficulty of benchmarks increases, thereby proving the effectiveness of our proposed new criterion.
+
+
+
+ 48. 【2412.11707】Context Filtering with Reward Modeling in Question Answering
+ 链接:https://arxiv.org/abs/2412.11707
+ 作者:Sangryul Kim,James Thorne
+ 类目:Computation and Language (cs.CL)
+ 关键词:Question Answering, relevant context retrieved, retrieval system, finding answers, context retrieved
+ 备注: Accepted Main Conference at COLING 2025
+
+ 点击查看摘要
+ Abstract:Question Answering (QA) in NLP is the task of finding answers to a query within a relevant context retrieved by a retrieval system. Yet, the mix of relevant and irrelevant information in these contexts can hinder performance enhancements in QA tasks. To address this, we introduce a context filtering approach that removes non-essential details, summarizing crucial content through Reward Modeling. This method emphasizes keeping vital data while omitting the extraneous during summarization model training. We offer a framework for developing efficient QA models by discerning useful information from dataset pairs, bypassing the need for costly human evaluation. Furthermore, we show that our approach can significantly outperform the baseline, as evidenced by a 6.8-fold increase in the EM Per Token (EPT) metric, which we propose as a measure of token efficiency, indicating a notable token-efficiency boost for low-resource settings.
+
+
+
+ 49. 【2412.11704】Vocabulary Expansion of Chat Models with Unlabeled Target Language Data
+ 链接:https://arxiv.org/abs/2412.11704
+ 作者:Atsuki Yamaguchi,Terufumi Morishita,Aline Villavicencio,Nikolaos Aletras
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:general task-solving abilities, language models trained, models, trained solely, outperform base models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Chat models (i.e. language models trained to follow instructions through conversation with humans) outperform base models (i.e. trained solely on unlabeled data) in both conversation and general task-solving abilities. These models are generally English-centric and require further adaptation for languages that are underrepresented in or absent from their training data. A common technique for adapting base models is to extend the model's vocabulary with target language tokens, i.e. vocabulary expansion (VE), and then continually pre-train it on language-specific data. Using chat data is ideal for chat model adaptation, but often, either this does not exist or is costly to construct. Alternatively, adapting chat models with unlabeled data is a possible solution, but it could result in catastrophic forgetting. In this paper, we investigate the impact of using unlabeled target language data for VE on chat models for the first time. We first show that off-the-shelf VE generally performs well across target language tasks and models in 71% of cases, though it underperforms in scenarios where source chat models are already strong. To further improve adapted models, we propose post-hoc techniques that inject information from the source model without requiring any further training. Experiments reveal the effectiveness of our methods, helping the adapted models to achieve performance improvements in 87% of cases.
+
+
+
+ 50. 【2412.11699】CoinMath: Harnessing the Power of Coding Instruction for Math LLMs
+ 链接:https://arxiv.org/abs/2412.11699
+ 作者:Chengwei Wei,Bin Wang,Jung-jae Kim,Guimei Liu,Nancy F. Chen
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, solving mathematical problems, Language Models, shown strong performance
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have shown strong performance in solving mathematical problems, with code-based solutions proving particularly effective. However, the best practice to leverage coding instruction data to enhance mathematical reasoning remains underexplored. This study investigates three key questions: (1) How do different coding styles of mathematical code-based rationales impact LLMs' learning performance? (2) Can general-domain coding instructions improve performance? (3) How does integrating textual rationales with code-based ones during training enhance mathematical reasoning abilities? Our findings reveal that code-based rationales with concise comments, descriptive naming, and hardcoded solutions are beneficial, while improvements from general-domain coding instructions and textual rationales are relatively minor. Based on these insights, we propose CoinMath, a learning strategy designed to enhance mathematical reasoning by diversifying the coding styles of code-based rationales. CoinMath generates a variety of code-based rationales incorporating concise comments, descriptive naming conventions, and hardcoded solutions. Experimental results demonstrate that CoinMath significantly outperforms its baseline model, MAmmoTH, one of the SOTA math LLMs.
+
+
+
+ 51. 【2412.11694】From Specific-MLLM to Omni-MLLM: A Survey about the MLLMs alligned with Multi-Modality
+ 链接:https://arxiv.org/abs/2412.11694
+ 作者:Shixin Jiang,Jiafeng Liang,Ming Liu,Bing Qin
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:single-modal tasks, multimodal information, excels in single-modal, extends the range, range of general
+ 备注: 13 pages
+
+ 点击查看摘要
+ Abstract:From the Specific-MLLM, which excels in single-modal tasks, to the Omni-MLLM, which extends the range of general modalities, this evolution aims to achieve understanding and generation of multimodal information. Omni-MLLM treats the features of different modalities as different "foreign languages," enabling cross-modal interaction and understanding within a unified space. To promote the advancement of related research, we have compiled 47 relevant papers to provide the community with a comprehensive introduction to Omni-MLLM. We first explain the four core components of Omni-MLLM for unified modeling and interaction of multiple modalities. Next, we introduce the effective integration achieved through "alignment pretraining" and "instruction fine-tuning," and discuss open-source datasets and testing of interaction capabilities. Finally, we summarize the main challenges facing current Omni-MLLM and outline future directions.
+
+
+
+ 52. 【2412.11691】Multilingual and Explainable Text Detoxification with Parallel Corpora
+ 链接:https://arxiv.org/abs/2412.11691
+ 作者:Daryna Dementieva,Nikolay Babakov,Amit Ronen,Abinew Ali Ayele,Naquee Rizwan,Florian Schneider,Xintong Wang,Seid Muhie Yimam,Daniil Moskovskiy,Elisei Stakovskii,Eran Kaufman,Ashraf Elnagar,Animesh Mukherjee,Alexander Panchenko
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Government of India, European Union, European Parliament, social media platforms, digital abusive speech
+ 备注: COLING 2025, main conference, long
+
+ 点击查看摘要
+ Abstract:Even with various regulations in place across countries and social media platforms (Government of India, 2021; European Parliament and Council of the European Union, 2022, digital abusive speech remains a significant issue. One potential approach to address this challenge is automatic text detoxification, a text style transfer (TST) approach that transforms toxic language into a more neutral or non-toxic form. To date, the availability of parallel corpora for the text detoxification task (Logachevavet al., 2022; Atwell et al., 2022; Dementievavet al., 2024a) has proven to be crucial for state-of-the-art approaches. With this work, we extend parallel text detoxification corpus to new languages -- German, Chinese, Arabic, Hindi, and Amharic -- testing in the extensive multilingual setup TST baselines. Next, we conduct the first of its kind an automated, explainable analysis of the descriptive features of both toxic and non-toxic sentences, diving deeply into the nuances, similarities, and differences of toxicity and detoxification across 9 languages. Finally, based on the obtained insights, we experiment with a novel text detoxification method inspired by the Chain-of-Thoughts reasoning approach, enhancing the prompting process through clustering on relevant descriptive attributes.
+
+
+
+ 53. 【2412.11679】Bias Vector: Mitigating Biases in Language Models with Task Arithmetic Approach
+ 链接:https://arxiv.org/abs/2412.11679
+ 作者:Daiki Shirafuji,Makoto Takenaka,Shinya Taguchi
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Bias Vector method, Bias Vector, causing social problems, Vector method, Bias
+ 备注: Accepted to COLING2025
+
+ 点击查看摘要
+ Abstract:The use of language models (LMs) has increased considerably in recent years, and the biases and stereotypes in training data that are reflected in the LM outputs are causing social problems. In this paper, inspired by the task arithmetic, we propose the ``Bias Vector'' method for the mitigation of these LM biases. The Bias Vector method does not require manually created debiasing data. The three main steps of our approach involve: (1) continual training the pre-trained LMs on biased data using masked language modeling; (2) constructing the Bias Vector as the difference between the weights of the biased LMs and those of pre-trained LMs; and (3) subtracting the Bias Vector from the weights of the pre-trained LMs for debiasing. We evaluated the Bias Vector method on the SEAT across three LMs and confirmed an average improvement of 0.177 points. We demonstrated that the Bias Vector method does not degrade the LM performance on downstream tasks in the GLUE benchmark. In addition, we examined the impact of scaling factors, which control the magnitudes of Bias Vectors, with effect sizes on the SEAT and conducted a comprehensive evaluation of our debiased LMs across both the SEAT and GLUE benchmarks.
+
+
+
+ 54. 【2412.11671】BioBridge: Unified Bio-Embedding with Bridging Modality in Code-Switched EMR
+ 链接:https://arxiv.org/abs/2412.11671
+ 作者:Jangyeong Jeon,Sangyeon Cho,Dongjoon Lee,Changhee Lee,Junyeong Kim
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Pediatric Emergency Department, significant global challenge, Pediatric Emergency, Emergency Department, Natural Language Processing
+ 备注: Accepted at IEEE Access 2024
+
+ 点击查看摘要
+ Abstract:Pediatric Emergency Department (PED) overcrowding presents a significant global challenge, prompting the need for efficient solutions. This paper introduces the BioBridge framework, a novel approach that applies Natural Language Processing (NLP) to Electronic Medical Records (EMRs) in written free-text form to enhance decision-making in PED. In non-English speaking countries, such as South Korea, EMR data is often written in a Code-Switching (CS) format that mixes the native language with English, with most code-switched English words having clinical significance. The BioBridge framework consists of two core modules: "bridging modality in context" and "unified bio-embedding." The "bridging modality in context" module improves the contextual understanding of bilingual and code-switched EMRs. In the "unified bio-embedding" module, the knowledge of the model trained in the medical domain is injected into the encoder-based model to bridge the gap between the medical and general domains. Experimental results demonstrate that the proposed BioBridge significantly performance traditional machine learning and pre-trained encoder-based models on several metrics, including F1 score, area under the receiver operating characteristic curve (AUROC), area under the precision-recall curve (AUPRC), and Brier score. Specifically, BioBridge-XLM achieved enhancements of 0.85% in F1 score, 0.75% in AUROC, and 0.76% in AUPRC, along with a notable 3.04% decrease in the Brier score, demonstrating marked improvements in accuracy, reliability, and prediction calibration over the baseline XLM model. The source code will be made publicly available.
+
+
+
+ 55. 【2412.11664】C3oT: Generating Shorter Chain-of-Thought without Compromising Effectiveness
+ 链接:https://arxiv.org/abs/2412.11664
+ 作者:Yu Kang,Xianghui Sun,Liangyu Chen,Wei Zou
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:large language models, CoT, effectively improve, significantly improve, improve the accuracy
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Generating Chain-of-Thought (CoT) before deriving the answer can effectively improve the reasoning capabilities of large language models (LLMs) and significantly improve the accuracy of the generated answer. However, in most cases, the length of the generated CoT is much longer than the desired final answer, which results in additional decoding costs. Furthermore, existing research has discovered that shortening the reasoning steps in CoT, even while preserving the key information, diminishes LLMs' abilities. These phenomena make it difficult to use LLMs and CoT in many real-world applications that only require the final answer and are sensitive to latency, such as search and recommendation. To reduce the costs of model decoding and shorten the length of the generated CoT, this paper presents $\textbf{C}$onditioned $\textbf{C}$ompressed $\textbf{C}$hain-of-$\textbf{T}$hought (C3oT), a CoT compression framework that involves a compressor to compress an original longer CoT into a shorter CoT while maintaining key information and interpretability, a conditioned training method to train LLMs with both longer CoT and shorter CoT simultaneously to learn the corresponding relationships between them, and a conditioned inference method to gain the reasoning ability learned from longer CoT by generating shorter CoT. We conduct experiments over four datasets from arithmetic and commonsense scenarios, showing that the proposed method is capable of compressing the length of generated CoT by up to more than 50% without compromising its effectiveness.
+
+
+
+ 56. 【2412.11653】Self-Adaptive Paraphrasing and Preference Learning for Improved Claim Verifiability
+ 链接:https://arxiv.org/abs/2412.11653
+ 作者:Amelie Wührl,Roman Klinger
+ 类目:Computation and Language (cs.CL)
+ 关键词:predict verdicts accurately, claims critically influence, structure and phrasing, verdicts accurately, critically influence
+ 备注: Under review at ACL ARR
+
+ 点击查看摘要
+ Abstract:In fact-checking, structure and phrasing of claims critically influence a model's ability to predict verdicts accurately. Social media content in particular rarely serves as optimal input for verification systems, which necessitates pre-processing to extract the claim from noisy context before fact checking. Prior work suggests extracting a claim representation that humans find to be checkworthy and verifiable. This has two limitations: (1) the format may not be optimal for a fact-checking model, and (2), it requires annotated data to learn the extraction task from. We address both issues and propose a method to extract claims that is not reliant on labeled training data. Instead, our self-adaptive approach only requires a black-box fact checking model and a generative language model (LM). Given a tweet, we iteratively optimize the LM to generate a claim paraphrase that increases the performance of a fact checking model. By learning from preference pairs, we align the LM to the fact checker using direct preference optimization. We show that this novel setup extracts a claim paraphrase that is more verifiable than their original social media formulations, and is on par with competitive baselines. For refuted claims, our method consistently outperforms all baselines.
+
+
+
+ 57. 【2412.11652】SE-GCL: An Event-Based Simple and Effective Graph Contrastive Learning for Text Representation
+ 链接:https://arxiv.org/abs/2412.11652
+ 作者:Tao Meng,Wei Ai,Jianbin Li,Ze Wang,Yuntao Shou,Keqin Li
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:natural language processing, graph contrastive learning, Text representation learning, contrastive learning, graph contrastive
+ 备注: 19 pages, 6 tables
+
+ 点击查看摘要
+ Abstract:Text representation learning is significant as the cornerstone of natural language processing. In recent years, graph contrastive learning (GCL) has been widely used in text representation learning due to its ability to represent and capture complex text information in a self-supervised setting. However, current mainstream graph contrastive learning methods often require the incorporation of domain knowledge or cumbersome computations to guide the data augmentation process, which significantly limits the application efficiency and scope of GCL. Additionally, many methods learn text representations only by constructing word-document relationships, which overlooks the rich contextual semantic information in the text. To address these issues and exploit representative textual semantics, we present an event-based, simple, and effective graph contrastive learning (SE-GCL) for text representation. Precisely, we extract event blocks from text and construct internal relation graphs to represent inter-semantic interconnections, which can ensure that the most critical semantic information is preserved. Then, we devise a streamlined, unsupervised graph contrastive learning framework to leverage the complementary nature of the event semantic and structural information for intricate feature data capture. In particular, we introduce the concept of an event skeleton for core representation semantics and simplify the typically complex data augmentation techniques found in existing graph contrastive learning to boost algorithmic efficiency. We employ multiple loss functions to prompt diverse embeddings to converge or diverge within a confined distance in the vector space, ultimately achieving a harmonious equilibrium. We conducted experiments on the proposed SE-GCL on four standard data sets (AG News, 20NG, SougouNews, and THUCNews) to verify its effectiveness in text representation learning.
+
+
+
+ 58. 【2412.11637】On Crowdsourcing Task Design for Discourse Relation Annotation
+ 链接:https://arxiv.org/abs/2412.11637
+ 作者:Frances Yung,Vera Demberg
+ 类目:Computation and Language (cs.CL)
+ 关键词:involves complex reasoning, Interpreting implicit discourse, relations involves complex, Interpreting implicit, discourse relations involves
+ 备注: To appear in the workshop of Context and Meaning - Navigating Disagreements in NLP Annotations
+
+ 点击查看摘要
+ Abstract:Interpreting implicit discourse relations involves complex reasoning, requiring the integration of semantic cues with background knowledge, as overt connectives like because or then are absent. These relations often allow multiple interpretations, best represented as distributions. In this study, we compare two established methods that crowdsource English implicit discourse relation annotation by connective insertion: a free-choice approach, which allows annotators to select any suitable connective, and a forced-choice approach, which asks them to select among a set of predefined options. Specifically, we re-annotate the whole DiscoGeM 1.0 corpus -- initially annotated with the free-choice method -- using the forced-choice approach. The free-choice approach allows for flexible and intuitive insertion of various connectives, which are context-dependent. Comparison among over 130,000 annotations, however, shows that the free-choice strategy produces less diverse annotations, often converging on common labels. Analysis of the results reveals the interplay between task design and the annotators' abilities to interpret and produce discourse relations.
+
+
+
+ 59. 【2412.11625】Fool Me, Fool Me: User Attitudes Toward LLM Falsehoods
+ 链接:https://arxiv.org/abs/2412.11625
+ 作者:Diana Bar-Or Nirman,Ariel Weizman,Amos Azaria
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Language Models, Large Language, central tools, provide inaccurate
+ 备注: 11 pages, 5 figures, 5 tables
+
+ 点击查看摘要
+ Abstract:While Large Language Models (LLMs) have become central tools in various fields, they often provide inaccurate or false information. This study examines user preferences regarding falsehood responses from LLMs. Specifically, we evaluate preferences for LLM responses where false statements are explicitly marked versus unmarked responses and preferences for confident falsehoods compared to LLM disclaimers acknowledging a lack of knowledge. Additionally, we investigate how requiring users to assess the truthfulness of statements influences these preferences.
+Surprisingly, 61\% of users prefer unmarked falsehood responses over marked ones, and 69\% prefer confident falsehoods over LLMs admitting lack of knowledge. In all our experiments, a total of 300 users participated, contributing valuable data to our analysis and conclusions. When users are required to evaluate the truthfulness of statements, preferences for unmarked and falsehood responses decrease slightly but remain high. These findings suggest that user preferences, which influence LLM training via feedback mechanisms, may inadvertently encourage the generation of falsehoods. Future research should address the ethical and practical implications of aligning LLM behavior with such preferences.
+
Comments:
+11 pages, 5 figures, 5 tables
+Subjects:
+Computation and Language (cs.CL)
+Cite as:
+arXiv:2412.11625 [cs.CL]
+(or
+arXiv:2412.11625v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2412.11625
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 60. 【2412.11615】MT-LENS: An all-in-one Toolkit for Better Machine Translation Evaluation
+ 链接:https://arxiv.org/abs/2412.11615
+ 作者:Javier García Gilabert,Carlos Escolano,Audrey Mash,Xixian Liao,Maite Melero
+ 类目:Computation and Language (cs.CL)
+ 关键词:gender bias detection, evaluate Machine Translation, evaluate Machine, Large Language Models, added toxicity
+ 备注: 6 pages, 2 figures
+
+ 点击查看摘要
+ Abstract:We introduce MT-LENS, a framework designed to evaluate Machine Translation (MT) systems across a variety of tasks, including translation quality, gender bias detection, added toxicity, and robustness to misspellings. While several toolkits have become very popular for benchmarking the capabilities of Large Language Models (LLMs), existing evaluation tools often lack the ability to thoroughly assess the diverse aspects of MT performance. MT-LENS addresses these limitations by extending the capabilities of LM-eval-harness for MT, supporting state-of-the-art datasets and a wide range of evaluation metrics. It also offers a user-friendly platform to compare systems and analyze translations with interactive visualizations. MT-LENS aims to broaden access to evaluation strategies that go beyond traditional translation quality evaluation, enabling researchers and engineers to better understand the performance of a NMT model and also easily measure system's biases.
+
+
+
+ 61. 【2412.11605】SPaR: Self-Play with Tree-Search Refinement to Improve Instruction-Following in Large Language Models
+ 链接:https://arxiv.org/abs/2412.11605
+ 作者:Jiale Cheng,Xiao Liu,Cunxiang Wang,Xiaotao Gu,Yida Lu,Dan Zhang,Yuxiao Dong,Jie Tang,Hongning Wang,Minlie Huang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:fundamental capability, capability of language, subtle requirements, accurately reflect, Instruction-following
+ 备注:
+
+ 点击查看摘要
+ Abstract:Instruction-following is a fundamental capability of language models, requiring the model to recognize even the most subtle requirements in the instructions and accurately reflect them in its output. Such an ability is well-suited for and often optimized by preference learning. However, existing methods often directly sample multiple independent responses from the model when creating preference pairs. Such practice can introduce content variations irrelevant to whether the instruction is precisely followed (e.g., different expressions about the same semantic), interfering with the goal of teaching models to recognize the key differences that lead to improved instruction following. In light of this, we introduce SPaR, a self-play framework integrating tree-search self-refinement to yield valid and comparable preference pairs free from distractions. By playing against itself, an LLM employs a tree-search strategy to refine its previous responses with respect to the instruction while minimizing unnecessary variations. Our experiments show that a LLaMA3-8B model, trained over three iterations guided by SPaR, surpasses GPT-4-Turbo on the IFEval benchmark without losing general capabilities. Furthermore, SPaR demonstrates promising scalability and transferability, greatly enhancing models like GLM-4-9B and LLaMA3-70B. We also identify how inference scaling in tree search would impact model performance. Our code and data are publicly available at this https URL.
+
+
+
+ 62. 【2412.11567】AUEB-Archimedes at RIRAG-2025: Is obligation concatenation really all you need?
+ 链接:https://arxiv.org/abs/2412.11567
+ 作者:Ioannis Chasandras,Odysseas S. Chlapanis,Ion Androutsopoulos
+ 类目:Computation and Language (cs.CL)
+ 关键词:requires answering regulatory, answering regulatory questions, retrieving relevant passages, paper presents, shared task
+ 备注: RIRAG 2025 Shared-Task at RegNLP workshop collocated with COLING 2025
+
+ 点击查看摘要
+ Abstract:This paper presents the systems we developed for RIRAG-2025, a shared task that requires answering regulatory questions by retrieving relevant passages. The generated answers are evaluated using RePASs, a reference-free and model-based metric. Our systems use a combination of three retrieval models and a reranker. We show that by exploiting a neural component of RePASs that extracts important sentences ('obligations') from the retrieved passages, we achieve a dubiously high score (0.947), even though the answers are directly extracted from the retrieved passages and are not actually generated answers. We then show that by selecting the answer with the best RePASs among a few generated alternatives and then iteratively refining this answer by reducing contradictions and covering more obligations, we can generate readable, coherent answers that achieve a more plausible and relatively high score (0.639).
+
+
+
+ 63. 【2412.11560】he Role of Natural Language Processing Tasks in Automatic Literary Character Network Construction
+ 链接:https://arxiv.org/abs/2412.11560
+ 作者:Arthur Amalvy(LIA),Vincent Labatut(LIA),Richard Dufour(LS2N - équipe TALN)
+ 类目:Computation and Language (cs.CL)
+ 关键词:natural language processing, automatic extraction, texts is generally, generally carried, low-level NLP tasks
+ 备注:
+
+ 点击查看摘要
+ Abstract:The automatic extraction of character networks from literary texts is generally carried out using natural language processing (NLP) cascading pipelines. While this approach is widespread, no study exists on the impact of low-level NLP tasks on their performance. In this article, we conduct such a study on a literary dataset, focusing on the role of named entity recognition (NER) and coreference resolution when extracting co-occurrence networks. To highlight the impact of these tasks' performance, we start with gold-standard annotations, progressively add uniformly distributed errors, and observe their impact in terms of character network quality. We demonstrate that NER performance depends on the tested novel and strongly affects character detection. We also show that NER-detected mentions alone miss a lot of character co-occurrences, and that coreference resolution is needed to prevent this. Finally, we present comparison points with 2 methods based on large language models (LLMs), including a fully end-to-end one, and show that these models are outperformed by traditional NLP pipelines in terms of recall.
+
+
+
+ 64. 【2412.11556】oken Prepending: A Training-Free Approach for Eliciting Better Sentence Embeddings from LLMs
+ 链接:https://arxiv.org/abs/2412.11556
+ 作者:Yuchen Fu,Zifeng Cheng,Zhiwei Jiang,Zhonghui Wang,Yafeng Yin,Zhengliang Li,Qing Gu
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Extracting sentence embeddings, semantic understanding capabilities, large language models, demonstrated stronger semantic, stronger semantic understanding
+ 备注: 14 pages, 5 figures
+
+ 点击查看摘要
+ Abstract:Extracting sentence embeddings from large language models (LLMs) is a promising direction, as LLMs have demonstrated stronger semantic understanding capabilities. Previous studies typically focus on prompt engineering to elicit sentence embeddings from LLMs by prompting the model to encode sentence information into the embedding of the last token. However, LLMs are mostly decoder-only models with causal attention and the earlier tokens in the sentence cannot attend to the latter tokens, resulting in biased encoding of sentence information and cascading effects on the final decoded token. To this end, we propose a novel Token Prepending (TP) technique that prepends each layer's decoded sentence embedding to the beginning of the sentence in the next layer's input, allowing earlier tokens to attend to the complete sentence information under the causal attention mechanism. The proposed TP technique is a plug-and-play and training-free technique, which means it can be seamlessly integrated with various prompt-based sentence embedding methods and autoregressive LLMs. Extensive experiments on various Semantic Textual Similarity (STS) tasks and downstream classification tasks demonstrate that our proposed TP technique can significantly improve the performance of existing prompt-based sentence embedding methods across different LLMs, while incurring negligible additional inference cost.
+
+
+
+ 65. 【2412.11543】Error Diversity Matters: An Error-Resistant Ensemble Method for Unsupervised Dependency Parsing
+ 链接:https://arxiv.org/abs/2412.11543
+ 作者:Behzad Shayegh,Hobie H.-B. Lee,Xiaodan Zhu,Jackie Chi Kit Cheung,Lili Mou
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:dependency parse structures, address unsupervised dependency, unsupervised dependency parsing, output dependency parse, post hoc aggregation
+ 备注: Accepted by the AAAI Conference on Artificial Intelligence (AAAI) 2025
+
+ 点击查看摘要
+ Abstract:We address unsupervised dependency parsing by building an ensemble of diverse existing models through post hoc aggregation of their output dependency parse structures. We observe that these ensembles often suffer from low robustness against weak ensemble components due to error accumulation. To tackle this problem, we propose an efficient ensemble-selection approach that avoids error accumulation. Results demonstrate that our approach outperforms each individual model as well as previous ensemble techniques. Additionally, our experiments show that the proposed ensemble-selection method significantly enhances the performance and robustness of our ensemble, surpassing previously proposed strategies, which have not accounted for error diversity.
+
+
+
+ 66. 【2412.11538】owards a Speech Foundation Model for Singapore and Beyond
+ 链接:https://arxiv.org/abs/2412.11538
+ 作者:Muhammad Huzaifah,Tianchi Liu,Hardik B. Sailor,Kye Min Tan,Tarun K. Vangani,Qiongqiong Wang,Jeremy H. M. Wong,Nancy F. Chen,Ai Ti Aw
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Audio and Speech Processing (eess.AS)
+ 关键词:MERaLiON Speech Encoder, National Multimodal Large, Singapore National Multimodal, downstream speech applications, foundation model designed
+ 备注:
+
+ 点击查看摘要
+ Abstract:This technical report describes the MERaLiON Speech Encoder, a foundation model designed to support a wide range of downstream speech applications. Developed as part of Singapore's National Multimodal Large Language Model Programme, the MERaLiON Speech Encoder is tailored to address the speech processing needs in Singapore and the surrounding Southeast Asian region. The model currently supports mainly English, including the variety spoken in Singapore. We are actively expanding our datasets to gradually cover other languages in subsequent releases. The MERaLiON Speech Encoder was pre-trained from scratch on 200K hours of unlabelled speech data using a self-supervised learning approach based on masked language modelling. We describe our training procedure and hyperparameter tuning experiments in detail below. Our evaluation demonstrates improvements to spontaneous and Singapore speech benchmarks for speech recognition, while remaining competitive to other state-of-the-art speech encoders across ten other speech tasks. We commit to releasing our model, supporting broader research endeavours, both in Singapore and beyond.
+
+
+
+ 67. 【2412.11536】Let your LLM generate a few tokens and you will reduce the need for retrieval
+ 链接:https://arxiv.org/abs/2412.11536
+ 作者:Hervé Déjean
+ 类目:Computation and Language (cs.CL)
+ 关键词:efficiently large language, large language models, parametric memory, investigate how efficiently, efficiently large
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this paper, we investigate how efficiently large language models (LLM) can be trained to check whether an answer is already stored in their parametric memory. We distill an LLM-as-a-judge to compute the IK (I Know) score. We found that this method is particularly beneficial in the context of retrieval-assisted augmented generation (RAG), with a respectable accuracy of 80%. It enables a significant reduction (more than 50%) in the number of search and reranking steps required for certain data sets. We have also introduced the IK score, which serves as a useful tool for characterising datasets by facilitating the classification task. Interestingly, through the inclusion of response tokens as input, our results suggest that only about 20,000 training samples are required to achieve good performance. The central element of this work is the use of a teacher model - the LLM as a judge - to generate training data. We also assess the robustness of the IK classifier by evaluating it with various types of teachers, including both string-based methods and LLMs, with the latter providing better results.
+
+
+
+ 68. 【2412.11517】DART: An AIGT Detector using AMR of Rephrased Text
+ 链接:https://arxiv.org/abs/2412.11517
+ 作者:Hyeonchu Park,Byungjun Kim,Bugeun Kim
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:large language models, human-like texts, AI-generated texts, generate more human-like, large language
+ 备注: Under review
+
+ 点击查看摘要
+ Abstract:As large language models (LLMs) generate more human-like texts, concerns about the side effects of AI-generated texts (AIGT) have grown. So, researchers have developed methods for detecting AIGT. However, two challenges remain. First, the performance on detecting black-box LLMs is low, because existing models have focused on syntactic features. Second, most AIGT detectors have been tested on a single-candidate setting, which assumes that we know the origin of an AIGT and may deviate from the real-world scenario. To resolve these challenges, we propose DART, which consists of four steps: rephrasing, semantic parsing, scoring, and multiclass classification. We conducted several experiments to test the performance of DART by following previous work. The experimental result shows that DART can discriminate multiple black-box LLMs without using syntactic features and knowing the origin of AIGT.
+
+
+
+ 69. 【2412.11506】Glimpse: Enabling White-Box Methods to Use Proprietary Models for Zero-Shot LLM-Generated Text Detection
+ 链接:https://arxiv.org/abs/2412.11506
+ 作者:Guangsheng Bao,Yanbin Zhao,Juncai He,Yue Zhang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:LLM-generated text detection, Advanced large language, large language models, text detection, generate text
+ 备注: 10 pages, 9 figures, 10 tables
+
+ 点击查看摘要
+ Abstract:Advanced large language models (LLMs) can generate text almost indistinguishable from human-written text, highlighting the importance of LLM-generated text detection. However, current zero-shot techniques face challenges as white-box methods are restricted to use weaker open-source LLMs, and black-box methods are limited by partial observation from stronger proprietary LLMs. It seems impossible to enable white-box methods to use proprietary models because API-level access to the models neither provides full predictive distributions nor inner embeddings. To traverse the divide, we propose Glimpse, a probability distribution estimation approach, predicting the full distributions from partial observations. Despite the simplicity of Glimpse, we successfully extend white-box methods like Entropy, Rank, Log-Rank, and Fast-DetectGPT to latest proprietary models. Experiments show that Glimpse with Fast-DetectGPT and GPT-3.5 achieves an average AUROC of about 0.95 in five latest source models, improving the score by 51% relative to the remaining space of the open source baseline (Table 1). It demonstrates that the latest LLMs can effectively detect their own outputs, suggesting that advanced LLMs may be the best shield against themselves.
+
+
+
+ 70. 【2412.11500】Intention Knowledge Graph Construction for User Intention Relation Modeling
+ 链接:https://arxiv.org/abs/2412.11500
+ 作者:Jiaxin Bai,Zhaobo Wang,Junfei Cheng,Dan Yu,Zerui Huang,Weiqi Wang,Xin Liu,Chen Luo,Qi He,Yanming Zhu,Bo Li,Yangqiu Song
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Understanding user intentions, Understanding user, online platforms, challenging for online, Understanding
+ 备注:
+
+ 点击查看摘要
+ Abstract:Understanding user intentions is challenging for online platforms. Recent work on intention knowledge graphs addresses this but often lacks focus on connecting intentions, which is crucial for modeling user behavior and predicting future actions. This paper introduces a framework to automatically generate an intention knowledge graph, capturing connections between user intentions. Using the Amazon m2 dataset, we construct an intention graph with 351 million edges, demonstrating high plausibility and acceptance. Our model effectively predicts new session intentions and enhances product recommendations, outperforming previous state-of-the-art methods and showcasing the approach's practical utility.
+
+
+
+ 71. 【2412.11494】FTP: A Fine-grained Token-wise Pruner for Large Language Models via Token Routing
+ 链接:https://arxiv.org/abs/2412.11494
+ 作者:Zekai Li,Jintu Zheng,Ji Liu,Han Liu,Haowei Zhu,Zeping Li,Fuwei Yang,Haiduo Huang,Jinzhang Peng,Dong Li,Lu Tian,Emad Barsoum
+ 类目:Computation and Language (cs.CL)
+ 关键词:demonstrated superior performance, large language models, increase model size, significantly increase model, large language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recently, large language models (LLMs) have demonstrated superior performance across various tasks by adhering to scaling laws, which significantly increase model size. However, the huge computation overhead during inference hinders the deployment in industrial applications. Many works leverage traditional compression approaches to boost model inference, but these always introduce additional training costs to restore the performance and the pruning results typically show noticeable performance drops compared to the original model when aiming for a specific level of acceleration. To address these issues, we propose a fine-grained token-wise pruning approach for the LLMs, which presents a learnable router to adaptively identify the less important tokens and skip them across model blocks to reduce computational cost during inference. To construct the router efficiently, we present a search-based sparsity scheduler for pruning sparsity allocation, a trainable router combined with our proposed four low-dimensional factors as input and three proposed losses. We conduct extensive experiments across different benchmarks on different LLMs to demonstrate the superiority of our method. Our approach achieves state-of-the-art (SOTA) pruning results, surpassing other existing pruning methods. For instance, our method outperforms BlockPruner and ShortGPT by approximately 10 points on both LLaMA2-7B and Qwen1.5-7B in accuracy retention at comparable token sparsity levels.
+
+
+
+ 72. 【2412.11477】NoteContrast: Contrastive Language-Diagnostic Pretraining for Medical Text
+ 链接:https://arxiv.org/abs/2412.11477
+ 作者:Prajwal Kailas,Max Homilius,Rahul C. Deo,Calum A. MacRae
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:enhancing patient care, medical notes, Accurate diagnostic coding, medical, diagnostic coding
+ 备注:
+
+ 点击查看摘要
+ Abstract:Accurate diagnostic coding of medical notes is crucial for enhancing patient care, medical research, and error-free billing in healthcare organizations. Manual coding is a time-consuming task for providers, and diagnostic codes often exhibit low sensitivity and specificity, whereas the free text in medical notes can be a more precise description of a patients status. Thus, accurate automated diagnostic coding of medical notes has become critical for a learning healthcare system. Recent developments in long-document transformer architectures have enabled attention-based deep-learning models to adjudicate medical notes. In addition, contrastive loss functions have been used to jointly pre-train large language and image models with noisy labels. To further improve the automated adjudication of medical notes, we developed an approach based on i) models for ICD-10 diagnostic code sequences using a large real-world data set, ii) large language models for medical notes, and iii) contrastive pre-training to build an integrated model of both ICD-10 diagnostic codes and corresponding medical text. We demonstrate that a contrastive approach for pre-training improves performance over prior state-of-the-art models for the MIMIC-III-50, MIMIC-III-rare50, and MIMIC-III-full diagnostic coding tasks.
+
+
+
+ 73. 【2412.11459】Understanding Knowledge Hijack Mechanism in In-context Learning through Associative Memory
+ 链接:https://arxiv.org/abs/2412.11459
+ 作者:Shuo Wang,Issei Sato
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:enables large language, large language models, contextual information provided, enables large, large language
+ 备注:
+
+ 点击查看摘要
+ Abstract:In-context learning (ICL) enables large language models (LLMs) to adapt to new tasks without fine-tuning by leveraging contextual information provided within a prompt. However, ICL relies not only on contextual clues but also on the global knowledge acquired during pretraining for the next token prediction. Analyzing this process has been challenging due to the complex computational circuitry of LLMs. This paper investigates the balance between in-context information and pretrained bigram knowledge in token prediction, focusing on the induction head mechanism, a key component in ICL. Leveraging the fact that a two-layer transformer can implement the induction head mechanism with associative memories, we theoretically analyze the logits when a two-layer transformer is given prompts generated by a bigram model. In the experiments, we design specific prompts to evaluate whether the outputs of a two-layer transformer align with the theoretical results.
+
+
+
+ 74. 【2412.11455】owards Better Multi-task Learning: A Framework for Optimizing Dataset Combinations in Large Language Models
+ 链接:https://arxiv.org/abs/2412.11455
+ 作者:Zaifu Zhan,Rui Zhang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:enhancing multi-task learning, efficiently select optimal, large language models, select optimal dataset, multi-task learning
+ 备注: 14 pages, 5 figures, 4 tables
+
+ 点击查看摘要
+ Abstract:To efficiently select optimal dataset combinations for enhancing multi-task learning (MTL) performance in large language models, we proposed a novel framework that leverages a neural network to predict the best dataset combinations. The framework iteratively refines the selection, greatly improving efficiency, while being model-, dataset-, and domain-independent. Through experiments on 12 biomedical datasets across four tasks - named entity recognition, relation extraction, event extraction, and text classification-we demonstrate that our approach effectively identifies better combinations, even for tasks that may seem unpromising from a human perspective. This verifies that our framework provides a promising solution for maximizing MTL potential.
+
+
+
+ 75. 【2412.11453】ACE-$M^3$: Automatic Capability Evaluator for Multimodal Medical Models
+ 链接:https://arxiv.org/abs/2412.11453
+ 作者:Xiechi Zhang,Shunfan Zheng,Linlin Wang,Gerard de Melo,Zhu Cao,Xiaoling Wang,Liang He
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:multimodal large language, large language models, textbf, gain prominence, large language
+ 备注:
+
+ 点击查看摘要
+ Abstract:As multimodal large language models (MLLMs) gain prominence in the medical field, the need for precise evaluation methods to assess their effectiveness has become critical. While benchmarks provide a reliable means to evaluate the capabilities of MLLMs, traditional metrics like ROUGE and BLEU employed for open domain evaluation only focus on token overlap and may not align with human judgment. Although human evaluation is more reliable, it is labor-intensive, costly, and not scalable. LLM-based evaluation methods have proven promising, but to date, there is still an urgent need for open-source multimodal LLM-based evaluators in the medical field. To address this issue, we introduce ACE-$M^3$, an open-sourced \textbf{A}utomatic \textbf{C}apability \textbf{E}valuator for \textbf{M}ultimodal \textbf{M}edical \textbf{M}odels specifically designed to assess the question answering abilities of medical MLLMs. It first utilizes a branch-merge architecture to provide both detailed analysis and a concise final score based on standard medical evaluation criteria. Subsequently, a reward token-based direct preference optimization (RTDPO) strategy is incorporated to save training time without compromising performance of our model. Extensive experiments have demonstrated the effectiveness of our ACE-$M^3$ model\footnote{\url{this https URL}} in evaluating the capabilities of medical MLLMs.
+
+
+
+ 76. 【2412.11431】Optimized Quran Passage Retrieval Using an Expanded QA Dataset and Fine-Tuned Language Models
+ 链接:https://arxiv.org/abs/2412.11431
+ 作者:Mohamed Basem,Islam Oshallah,Baraa Hikal,Ali Hamdi,Ammar Mohamed
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:modern standard Arabic, standard Arabic, classical Arabic, Understanding the deep, Holy Qur'an
+ 备注:
+
+ 点击查看摘要
+ Abstract:Understanding the deep meanings of the Qur'an and bridging the language gap between modern standard Arabic and classical Arabic is essential to improve the question-and-answer system for the Holy Qur'an. The Qur'an QA 2023 shared task dataset had a limited number of questions with weak model retrieval. To address this challenge, this work updated the original dataset and improved the model accuracy. The original dataset, which contains 251 questions, was reviewed and expanded to 629 questions with question diversification and reformulation, leading to a comprehensive set of 1895 categorized into single-answer, multi-answer, and zero-answer types. Extensive experiments fine-tuned transformer models, including AraBERT, RoBERTa, CAMeLBERT, AraELECTRA, and BERT. The best model, AraBERT-base, achieved a MAP@10 of 0.36 and MRR of 0.59, representing improvements of 63% and 59%, respectively, compared to the baseline scores (MAP@10: 0.22, MRR: 0.37). Additionally, the dataset expansion led to improvements in handling "no answer" cases, with the proposed approach achieving a 75% success rate for such instances, compared to the baseline's 25%. These results demonstrate the effect of dataset improvement and model architecture optimization in increasing the performance of QA systems for the Holy Qur'an, with higher accuracy, recall, and precision.
+
+
+
+ 77. 【2412.11418】ConceptEdit: Conceptualization-Augmented Knowledge Editing in Large Language Models for Commonsense Reasoning
+ 链接:https://arxiv.org/abs/2412.11418
+ 作者:Liyu Zhang,Weiqi Wang,Tianqing Fang,Yangqiu Song
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Model, Large Language, Language Model, improve output consistency, adjust a Large
+ 备注:
+
+ 点击查看摘要
+ Abstract:Knowledge Editing (KE) aims to adjust a Large Language Model's (LLM) internal representations and parameters to correct inaccuracies and improve output consistency without incurring the computational expense of re-training the entire model. However, editing commonsense knowledge still faces difficulties, including limited knowledge coverage in existing resources, the infeasibility of annotating labels for an overabundance of commonsense knowledge, and the strict knowledge formats of current editing methods. In this paper, we address these challenges by presenting ConceptEdit, a framework that integrates conceptualization and instantiation into the KE pipeline for LLMs to enhance their commonsense reasoning capabilities. ConceptEdit dynamically diagnoses implausible commonsense knowledge within an LLM using another verifier LLM and augments the source knowledge to be edited with conceptualization for stronger generalizability. Experimental results demonstrate that LLMs enhanced with ConceptEdit successfully generate commonsense knowledge with improved plausibility compared to other baselines and achieve stronger performance across multiple question answering benchmarks.
+
+
+
+ 78. 【2412.11414】Biased or Flawed? Mitigating Stereotypes in Generative Language Models by Addressing Task-Specific Flaws
+ 链接:https://arxiv.org/abs/2412.11414
+ 作者:Akshita Jha,Sanchit Kabra,Chandan K. Reddy
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:amplify societal biases, Recent studies, reflect and amplify, amplify societal, societal biases
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent studies have shown that generative language models often reflect and amplify societal biases in their outputs. However, these studies frequently conflate observed biases with other task-specific shortcomings, such as comprehension failure. For example, when a model misinterprets a text and produces a response that reinforces a stereotype, it becomes difficult to determine whether the issue arises from inherent bias or from a misunderstanding of the given content. In this paper, we conduct a multi-faceted evaluation that distinctly disentangles bias from flaws within the reading comprehension task. We propose a targeted stereotype mitigation framework that implicitly mitigates observed stereotypes in generative models through instruction-tuning on general-purpose datasets. We reduce stereotypical outputs by over 60% across multiple dimensions -- including nationality, age, gender, disability, and physical appearance -- by addressing comprehension-based failures, and without relying on explicit debiasing techniques. We evaluate several state-of-the-art generative models to demonstrate the effectiveness of our approach while maintaining the overall utility. Our findings highlight the need to critically disentangle the concept of `bias' from other types of errors to build more targeted and effective mitigation strategies. CONTENT WARNING: Some examples contain offensive stereotypes.
+
+
+
+ 79. 【2412.11404】Attention with Dependency Parsing Augmentation for Fine-Grained Attribution
+ 链接:https://arxiv.org/abs/2412.11404
+ 作者:Qiang Ding,Lvzhou Luo,Yixuan Cao,Ping Luo
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:validating RAG-generated content, efficiently validating RAG-generated, fine-grained attribution mechanism, Existing fine-grained attribution, RAG-generated content
+ 备注: 16 pages, 7 figures, submitted to ACL ARR 2024 October
+
+ 点击查看摘要
+ Abstract:To assist humans in efficiently validating RAG-generated content, developing a fine-grained attribution mechanism that provides supporting evidence from retrieved documents for every answer span is essential. Existing fine-grained attribution methods rely on model-internal similarity metrics between responses and documents, such as saliency scores and hidden state similarity. However, these approaches suffer from either high computational complexity or coarse-grained representations. Additionally, a common problem shared by the previous works is their reliance on decoder-only Transformers, limiting their ability to incorporate contextual information after the target span. To address the above problems, we propose two techniques applicable to all model-internals-based methods. First, we aggregate token-wise evidence through set union operations, preserving the granularity of representations. Second, we enhance the attributor by integrating dependency parsing to enrich the semantic completeness of target spans. For practical implementation, our approach employs attention weights as the similarity metric. Experimental results demonstrate that the proposed method consistently outperforms all prior works.
+
+
+
+ 80. 【2412.11388】INTERACT: Enabling Interactive, Question-Driven Learning in Large Language Models
+ 链接:https://arxiv.org/abs/2412.11388
+ 作者:Aum Kendapadi,Kerem Zaman,Rakesh R. Menon,Shashank Srivastava
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large language models, remain passive learners, Large language, absorbing static data, Adaptive Concept Transfer
+ 备注: 30 pages, 8 figures, 14 tables
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) excel at answering questions but remain passive learners--absorbing static data without the ability to question and refine knowledge. This paper explores how LLMs can transition to interactive, question-driven learning through student-teacher dialogues. We introduce INTERACT (INTEReractive Learning for Adaptive Concept Transfer), a framework in which a "student" LLM engages a "teacher" LLM through iterative inquiries to acquire knowledge across 1,347 contexts, including song lyrics, news articles, movie plots, academic papers, and images. Our experiments show that across a wide range of scenarios and LLM architectures, interactive learning consistently enhances performance, achieving up to a 25% improvement, with 'cold-start' student models matching static learning baselines in as few as five dialogue turns. Interactive setups can also mitigate the disadvantages of weaker teachers, showcasing the robustness of question-driven learning.
+
+
+
+ 81. 【2412.11385】Why Does ChatGPT "Delve" So Much? Exploring the Sources of Lexical Overrepresentation in Large Language Models
+ 链接:https://arxiv.org/abs/2412.11385
+ 作者:Tom S. Juzek,Zina B. Ward
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:undergoing rapid change, Scientific English, years ago, undergoing rapid, rapid change
+ 备注: 15 pages, 8 figures, The 31st International Conference on Computational Linguistics (COLING 2025)
+
+ 点击查看摘要
+ Abstract:Scientific English is currently undergoing rapid change, with words like "delve," "intricate," and "underscore" appearing far more frequently than just a few years ago. It is widely assumed that scientists' use of large language models (LLMs) is responsible for such trends. We develop a formal, transferable method to characterize these linguistic changes. Application of our method yields 21 focal words whose increased occurrence in scientific abstracts is likely the result of LLM usage. We then pose "the puzzle of lexical overrepresentation": WHY are such words overused by LLMs? We fail to find evidence that lexical overrepresentation is caused by model architecture, algorithm choices, or training data. To assess whether reinforcement learning from human feedback (RLHF) contributes to the overuse of focal words, we undertake comparative model testing and conduct an exploratory online study. While the model testing is consistent with RLHF playing a role, our experimental results suggest that participants may be reacting differently to "delve" than to other focal words. With LLMs quickly becoming a driver of global language change, investigating these potential sources of lexical overrepresentation is important. We note that while insights into the workings of LLMs are within reach, a lack of transparency surrounding model development remains an obstacle to such research.
+
+
+
+ 82. 【2412.11376】ChatTime: A Unified Multimodal Time Series Foundation Model Bridging Numerical and Textual Data
+ 链接:https://arxiv.org/abs/2412.11376
+ 作者:Chengsen Wang,Qi Qi,Jingyu Wang,Haifeng Sun,Zirui Zhuang,Jinming Wu,Lei Zhang,Jianxin Liao
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Human experts typically, experts typically integrate, Human experts, typically integrate numerical, time series
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Human experts typically integrate numerical and textual multimodal information to analyze time series. However, most traditional deep learning predictors rely solely on unimodal numerical data, using a fixed-length window for training and prediction on a single dataset, and cannot adapt to different scenarios. The powered pre-trained large language model has introduced new opportunities for time series analysis. Yet, existing methods are either inefficient in training, incapable of handling textual information, or lack zero-shot forecasting capability. In this paper, we innovatively model time series as a foreign language and construct ChatTime, a unified framework for time series and text processing. As an out-of-the-box multimodal time series foundation model, ChatTime provides zero-shot forecasting capability and supports bimodal input/output for both time series and text. We design a series of experiments to verify the superior performance of ChatTime across multiple tasks and scenarios, and create four multimodal datasets to address data gaps. The experimental results demonstrate the potential and utility of ChatTime.
+
+
+
+ 83. 【2412.11373】Codenames as a Benchmark for Large Language Models
+ 链接:https://arxiv.org/abs/2412.11373
+ 作者:Matthew Stephenson,Matthew Sidji,Benoît Ronval
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, word-based board game, popular word-based board, board game Codenames
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this paper, we propose the use of the popular word-based board game Codenames as a suitable benchmark for evaluating the reasoning capabilities of Large Language Models (LLMs). Codenames presents a highly interesting challenge for achieving successful AI performance, requiring both a sophisticated understanding of language, theory of mind, and epistemic reasoning capabilities. Prior attempts to develop agents for Codenames have largely relied on word embedding techniques, which have a limited vocabulary range and perform poorly when paired with differing approaches. LLMs have demonstrated enhanced reasoning and comprehension capabilities for language-based tasks, but can still suffer in lateral thinking challenges. We evaluate the capabilities of several state-of-the-art LLMs, including GPT-4o, Gemini 1.5, Claude 3.5 Sonnet, and Llama 3.1, across a variety of board setups. Our results indicate that while certain LLMs perform better than others overall, different models exhibit varying emergent behaviours during gameplay and excel at specific roles. We also evaluate the performance of different combinations of LLMs when playing cooperatively together, demonstrating that LLM agents are more generalisable to a wider range of teammates than prior techniques.
+
+
+
+ 84. 【2412.11344】Can AI Extract Antecedent Factors of Human Trust in AI? An Application of Information Extraction for Scientific Literature in Behavioural and Computer Sciences
+ 链接:https://arxiv.org/abs/2412.11344
+ 作者:Melanie McGrath,Harrison Bailey,Necva Bölücü,Xiang Dai,Sarvnaz Karimi,Cecile Paris
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:transform unstructured knowledge, unstructured knowledge hidden, down-stream tasks, scientific literature, main techniques
+ 备注:
+
+ 点击查看摘要
+ Abstract:Information extraction from the scientific literature is one of the main techniques to transform unstructured knowledge hidden in the text into structured data which can then be used for decision-making in down-stream tasks. One such area is Trust in AI, where factors contributing to human trust in artificial intelligence applications are studied. The relationships of these factors with human trust in such applications are complex. We hence explore this space from the lens of information extraction where, with the input of domain experts, we carefully design annotation guidelines, create the first annotated English dataset in this domain, investigate an LLM-guided annotation, and benchmark it with state-of-the-art methods using large language models in named entity and relation extraction. Our results indicate that this problem requires supervised learning which may not be currently feasible with prompt-based LLMs.
+
+
+
+ 85. 【2412.11333】Segment-Level Diffusion: A Framework for Controllable Long-Form Generation with Diffusion Language Models
+ 链接:https://arxiv.org/abs/2412.11333
+ 作者:Xiaochen Zhu,Georgi Karadzhov,Chenxi Whitehouse,Andreas Vlachos
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:contextually accurate text, generating long, models have shown, shown promise, contextually accurate
+ 备注:
+
+ 点击查看摘要
+ Abstract:Diffusion models have shown promise in text generation but often struggle with generating long, coherent, and contextually accurate text. Token-level diffusion overlooks word-order dependencies and enforces short output windows, while passage-level diffusion struggles with learning robust representation for long-form text. To address these challenges, we propose Segment-Level Diffusion (SLD), a framework that enhances diffusion-based text generation through text segmentation, robust representation training with adversarial and contrastive learning, and improved latent-space guidance. By segmenting long-form outputs into separate latent representations and decoding them with an autoregressive decoder, SLD simplifies diffusion predictions and improves scalability. Experiments on XSum, ROCStories, DialogSum, and DeliData demonstrate that SLD achieves competitive or superior performance in fluency, coherence, and contextual compatibility across automatic and human evaluation metrics comparing with other diffusion and autoregressive baselines. Ablation studies further validate the effectiveness of our segmentation and representation learning strategies.
+
+
+
+ 86. 【2412.11318】Generics are puzzling. Can language models find the missing piece?
+ 链接:https://arxiv.org/abs/2412.11318
+ 作者:Gustavo Cilleruelo Calderón,Emily Allaway,Barry Haddow,Alexandra Birch
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:world without explicit, generics, explicit quantification, Abstract, naturally occurring
+ 备注: Accepted at CoLing 2025
+
+ 点击查看摘要
+ Abstract:Generic sentences express generalisations about the world without explicit quantification. Although generics are central to everyday communication, building a precise semantic framework has proven difficult, in part because speakers use generics to generalise properties with widely different statistical prevalence. In this work, we study the implicit quantification and context-sensitivity of generics by leveraging language models as models of language. We create ConGen, a dataset of 2873 naturally occurring generic and quantified sentences in context, and define p-acceptability, a metric based on surprisal that is sensitive to quantification. Our experiments show generics are more context-sensitive than determiner quantifiers and about 20% of naturally occurring generics we analyze express weak generalisations. We also explore how human biases in stereotypes can be observed in language models.
+
+
+
+ 87. 【2412.11317】RoLargeSum: A Large Dialect-Aware Romanian News Dataset for Summary, Headline, and Keyword Generation
+ 链接:https://arxiv.org/abs/2412.11317
+ 作者:Andrei-Marius Avram,Mircea Timpuriu,Andreea Iuga,Vlad-Cristian Matei,Iulian-Marius Tăiatu,Tudor Găină,Dumitru-Clementin Cercel,Florin Pop,Mihaela-Claudia Cercel
+ 类目:Computation and Language (cs.CL)
+ 关键词:supervised automatic summarisation, automatic summarisation methods, summarisation methods requires, methods requires sufficient, requires sufficient corpora
+ 备注: Accepted at COLING 2024 (long papers)
+
+ 点击查看摘要
+ Abstract:Using supervised automatic summarisation methods requires sufficient corpora that include pairs of documents and their summaries. Similarly to many tasks in natural language processing, most of the datasets available for summarization are in English, posing challenges for developing summarization models in other languages. Thus, in this work, we introduce RoLargeSum, a novel large-scale summarization dataset for the Romanian language crawled from various publicly available news websites from Romania and the Republic of Moldova that were thoroughly cleaned to ensure a high-quality standard. RoLargeSum contains more than 615K news articles, together with their summaries, as well as their headlines, keywords, dialect, and other metadata that we found on the targeted websites. We further evaluated the performance of several BART variants and open-source large language models on RoLargeSum for benchmarking purposes. We manually evaluated the results of the best-performing system to gain insight into the potential pitfalls of this data set and future development.
+
+
+
+ 88. 【2412.11314】Reliable, Reproducible, and Really Fast Leaderboards with Evalica
+ 链接:https://arxiv.org/abs/2412.11314
+ 作者:Dmitry Ustalov
+ 类目:Computation and Language (cs.CL)
+ 关键词:natural language processing, modern evaluation protocols, instruction-tuned large language, large language models, urges the development
+ 备注: accepted at COLING 2025 system demonstration track
+
+ 点击查看摘要
+ Abstract:The rapid advancement of natural language processing (NLP) technologies, such as instruction-tuned large language models (LLMs), urges the development of modern evaluation protocols with human and machine feedback. We introduce Evalica, an open-source toolkit that facilitates the creation of reliable and reproducible model leaderboards. This paper presents its design, evaluates its performance, and demonstrates its usability through its Web interface, command-line interface, and Python API.
+
+
+
+ 89. 【2412.11302】Sequence-Level Analysis of Leakage Risk of Training Data in Large Language Models
+ 链接:https://arxiv.org/abs/2412.11302
+ 作者:Trishita Tiwari,G. Edward Suh
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Large Language Models, Large Language, sequence level probabilities, Language Models, previously obtained
+ 备注:
+
+ 点击查看摘要
+ Abstract:This work advocates for the use of sequence level probabilities for quantifying the risk of extraction training data from Large Language Models (LLMs) as they provide much finer-grained information than has been previously obtained. We re-analyze the effects of decoding schemes, model-size, prefix length, partial sequence leakages, and token positions to uncover new insights that have were not possible in prior work due to their choice of metrics. We perform this study on two pre-trained models, LLaMa and OPT, trained on the Common Crawl and Pile respectively. We discover that 1) Extraction rate, the predominant metric used in prior quantification work, underestimates the threat of leakage of training data in randomized LLMs by as much as 2.14x. 2) Though, on average, larger models and longer prefixes can extract more data, this is not true with a substantial portion of individual sequences. 30.4-41.5% of our sequences are easier to extract with either shorter prefixes or smaller models. 3) Contrary to prior belief, partial leakage in the commonly used decoding schemes like top-k and top-p are not easier than leaking verbatim training data. 4) Extracting later tokens in a sequence is as much as 912% easier than extracting earlier tokens. The insights gained from our analysis show that it is important to look at leakage of training data on a per-sequence basis.
+
+
+
+ 90. 【2412.11261】CATER: Leveraging LLM to Pioneer a Multidimensional, Reference-Independent Paradigm in Translation Quality Evaluation
+ 链接:https://arxiv.org/abs/2412.11261
+ 作者:Kurando IIDA,Kenjiro MIMURA
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Comprehensive AI-assisted Translation, Translation Edit Ratio, evaluating machine translation, AI-assisted Translation Edit, introduces the Comprehensive
+ 备注: 17pages,1sample prompt
+
+ 点击查看摘要
+ Abstract:This paper introduces the Comprehensive AI-assisted Translation Edit Ratio (CATER), a novel and fully prompt-driven framework for evaluating machine translation (MT) quality. Leveraging large language models (LLMs) via a carefully designed prompt-based protocol, CATER expands beyond traditional reference-bound metrics, offering a multidimensional, reference-independent evaluation that addresses linguistic accuracy, semantic fidelity, contextual coherence, stylistic appropriateness, and information completeness. CATER's unique advantage lies in its immediate implementability: by providing the source and target texts along with a standardized prompt, an LLM can rapidly identify errors, quantify edit effort, and produce category-level and overall scores. This approach eliminates the need for pre-computed references or domain-specific resources, enabling instant adaptation to diverse languages, genres, and user priorities through adjustable weights and prompt modifications. CATER's LLM-enabled strategy supports more nuanced assessments, capturing phenomena such as subtle omissions, hallucinations, and discourse-level shifts that increasingly challenge contemporary MT systems. By uniting the conceptual rigor of frameworks like MQM and DQF with the scalability and flexibility of LLM-based evaluation, CATER emerges as a valuable tool for researchers, developers, and professional translators worldwide. The framework and example prompts are openly available, encouraging community-driven refinement and further empirical validation.
+
+
+
+ 91. 【2412.11250】Beyond Discrete Personas: Personality Modeling Through Journal Intensive Conversations
+ 链接:https://arxiv.org/abs/2412.11250
+ 作者:Sayantan Pal,Souvik Das,Rohini K. Srihari
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, Large Language, Synthetic Persona Chat, Blended Skill Talk, Persona Chat
+ 备注: Accepted in COLING 2025
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have significantly improved personalized conversational capabilities. However, existing datasets like Persona Chat, Synthetic Persona Chat, and Blended Skill Talk rely on static, predefined personas. This approach often results in dialogues that fail to capture human personalities' fluid and evolving nature. To overcome these limitations, we introduce a novel dataset with around 400,000 dialogues and a framework for generating personalized conversations using long-form journal entries from Reddit. Our approach clusters journal entries for each author and filters them by selecting the most representative cluster, ensuring that the retained entries best reflect the author's personality. We further refine the data by capturing the Big Five personality traits --openness, conscientiousness, extraversion, agreeableness, and neuroticism --ensuring that dialogues authentically reflect an individual's personality. Using Llama 3 70B, we generate high-quality, personality-rich dialogues grounded in these journal entries. Fine-tuning models on this dataset leads to an 11% improvement in capturing personality traits on average, outperforming existing approaches in generating more coherent and personality-driven dialogues.
+
+
+
+ 92. 【2412.11242】rimLLM: Progressive Layer Dropping for Domain-Specific LLMs
+ 链接:https://arxiv.org/abs/2412.11242
+ 作者:Lanxiang Hu,Tajana Rosing,Hao Zhang
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Specializing large language, Specializing large, large language models, privacy constraints, large language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Specializing large language models (LLMs) for local deployment in domain-specific use cases is necessary for strong performance while meeting latency and privacy constraints. However, conventional task-specific adaptation approaches do not show simultaneous memory saving and inference speedup at deployment time. Practical compression techniques like quantization and pruning require dedicated hardware or kernel support to achieve measured inference speedup. We develop TrimLLM based on the layer-wise specialization phenomenon we empirically observed and verified on contemporary LLMs. TrimLLM reduces the depth of LLMs via progressive layer dropping. We show it retains LLMs' capacity in specific domains and achieves inference speedup irrespective of hardware and deep learning frameworks. We evaluated TrimLLM on LLMs of various sizes for inference; models adapted on medical, legal, and financial datasets all demonstrate $2.1-5.7\times$ inference speedup on consumer GPUs and up to $3.1\times$ speedup on A100 when compared to state-of-the-art model compression algorithms, with no loss in accuracy at 50$\sim$60\% model compression ratio.
+
+
+
+ 93. 【2412.11231】Smaller Language Models Are Better Instruction Evolvers
+ 链接:https://arxiv.org/abs/2412.11231
+ 作者:Tingfeng Hui,Lulu Zhao,Guanting Dong,Yaqi Zhang,Hua Zhou,Sen Su
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language models, language models, unleash the complete, smaller language models, Instruction
+ 备注: Work in progress
+
+ 点击查看摘要
+ Abstract:Instruction tuning has been widely used to unleash the complete potential of large language models. Notably, complex and diverse instructions are of significant importance as they can effectively align models with various downstream tasks. However, current approaches to constructing large-scale instructions predominantly favour powerful models such as GPT-4 or those with over 70 billion parameters, under the empirical presumption that such larger language models (LLMs) inherently possess enhanced capabilities. In this study, we question this prevalent assumption and conduct an in-depth exploration into the potential of smaller language models (SLMs) in the context of instruction evolution. Extensive experiments across three scenarios of instruction evolution reveal that smaller language models (SLMs) can synthesize more effective instructions than LLMs. Further analysis demonstrates that SLMs possess a broader output space during instruction evolution, resulting in more complex and diverse variants. We also observe that the existing metrics fail to focus on the impact of the instructions. Thus, we propose Instruction Complex-Aware IFD (IC-IFD), which introduces instruction complexity in the original IFD score to evaluate the effectiveness of instruction data more accurately. Our source code is available at: \href{this https URL}{this https URL}
+
+
+
+ 94. 【2412.11203】ask-Oriented Dialog Systems for the Senegalese Wolof Language
+ 链接:https://arxiv.org/abs/2412.11203
+ 作者:Derguene Mbaye,Moussa Diallo
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Human-Computer Interaction (cs.HC); Information Retrieval (cs.IR)
+ 关键词:large language models, recent years, interest in conversational, conversational agents, rise of large
+ 备注: 10 pages, 3 tables, 6 figures, The 31st International Conference on Computational Linguistics (COLING 2025)
+
+ 点击查看摘要
+ Abstract:In recent years, we are seeing considerable interest in conversational agents with the rise of large language models (LLMs). Although they offer considerable advantages, LLMs also present significant risks, such as hallucination, which hinder their widespread deployment in industry. Moreover, low-resource languages such as African ones are still underrepresented in these systems limiting their performance in these languages. In this paper, we illustrate a more classical approach based on modular architectures of Task-oriented Dialog Systems (ToDS) offering better control over outputs. We propose a chatbot generation engine based on the Rasa framework and a robust methodology for projecting annotations onto the Wolof language using an in-house machine translation system. After evaluating a generated chatbot trained on the Amazon Massive dataset, our Wolof Intent Classifier performs similarly to the one obtained for French, which is a resource-rich language. We also show that this approach is extensible to other low-resource languages, thanks to the intent classifier's language-agnostic pipeline, simplifying the design of chatbots in these languages.
+
+
+
+ 95. 【2412.11196】Drawing the Line: Enhancing Trustworthiness of MLLMs Through the Power of Refusal
+ 链接:https://arxiv.org/abs/2412.11196
+ 作者:Yuhao Wang,Zhiyuan Zhu,Heyang Liu,Yusheng Liao,Hongcheng Liu,Yanfeng Wang,Yu Wang
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Multimodal large language, inaccurate responses undermines, Multimodal large, multimodal perception, large language models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multimodal large language models (MLLMs) excel at multimodal perception and understanding, yet their tendency to generate hallucinated or inaccurate responses undermines their trustworthiness. Existing methods have largely overlooked the importance of refusal responses as a means of enhancing MLLMs reliability. To bridge this gap, we present the Information Boundary-aware Learning Framework (InBoL), a novel approach that empowers MLLMs to refuse to answer user queries when encountering insufficient information. To the best of our knowledge, InBoL is the first framework that systematically defines the conditions under which refusal is appropriate for MLLMs using the concept of information boundaries proposed in our paper. This framework introduces a comprehensive data generation pipeline and tailored training strategies to improve the model's ability to deliver appropriate refusal responses. To evaluate the trustworthiness of MLLMs, we further propose a user-centric alignment goal along with corresponding metrics. Experimental results demonstrate a significant improvement in refusal accuracy without noticeably compromising the model's helpfulness, establishing InBoL as a pivotal advancement in building more trustworthy MLLMs.
+
+
+
+ 96. 【2412.11189】Leveraging Large Language Models for Active Merchant Non-player Characters
+ 链接:https://arxiv.org/abs/2412.11189
+ 作者:Byungjun Kim,Minju Kim,Dayeon Seo,Bugeun Kim
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:merchant non-player characters, current merchant non-player, significant issues leading, non-player characters, highlight two significant
+ 备注: Under review
+
+ 点击查看摘要
+ Abstract:We highlight two significant issues leading to the passivity of current merchant non-player characters (NPCs): pricing and communication. While immersive interactions have been a focus, negotiations between merchant NPCs and players on item prices have not received sufficient attention. First, we define passive pricing as the limited ability of merchants to modify predefined item prices. Second, passive communication means that merchants can only interact with players in a scripted manner. To tackle these issues and create an active merchant NPC, we propose a merchant framework based on large language models (LLMs), called MART, which consists of an appraiser module and a negotiator module. We conducted two experiments to guide game developers in selecting appropriate implementations by comparing different training methods and LLM sizes. Our findings indicate that finetuning methods, such as supervised finetuning (SFT) and knowledge distillation (KD), are effective in using smaller LLMs to implement active merchant NPCs. Additionally, we found three irregular cases arising from the responses of LLMs. We expect our findings to guide developers in using LLMs for developing active merchant NPCs.
+
+
+
+ 97. 【2412.11187】Analyzing the Attention Heads for Pronoun Disambiguation in Context-aware Machine Translation Models
+ 链接:https://arxiv.org/abs/2412.11187
+ 作者:Paweł Mąka,Yusuf Can Semerci,Jan Scholtes,Gerasimos Spanakis
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Context-aware Machine Translation, Machine Translation models, Context-aware Machine, Machine Translation, language directions
+ 备注: COLING 2025
+
+ 点击查看摘要
+ Abstract:In this paper, we investigate the role of attention heads in Context-aware Machine Translation models for pronoun disambiguation in the English-to-German and English-to-French language directions. We analyze their influence by both observing and modifying the attention scores corresponding to the plausible relations that could impact a pronoun prediction. Our findings reveal that while some heads do attend the relations of interest, not all of them influence the models' ability to disambiguate pronouns. We show that certain heads are underutilized by the models, suggesting that model performance could be improved if only the heads would attend one of the relations more strongly. Furthermore, we fine-tune the most promising heads and observe the increase in pronoun disambiguation accuracy of up to 5 percentage points which demonstrates that the improvements in performance can be solidified into the models' parameters.
+
+
+
+ 98. 【2412.11172】Unpacking the Resilience of SNLI Contradiction Examples to Attacks
+ 链接:https://arxiv.org/abs/2412.11172
+ 作者:Chetan Verma,Archit Agarwal
+ 类目:Computation and Language (cs.CL)
+ 关键词:Pre-trained models excel, understanding remains uncertain, true language understanding, language understanding remains, SNLI and MultiNLI
+ 备注:
+
+ 点击查看摘要
+ Abstract:Pre-trained models excel on NLI benchmarks like SNLI and MultiNLI, but their true language understanding remains uncertain. Models trained only on hypotheses and labels achieve high accuracy, indicating reliance on dataset biases and spurious correlations. To explore this issue, we applied the Universal Adversarial Attack to examine the model's vulnerabilities. Our analysis revealed substantial drops in accuracy for the entailment and neutral classes, whereas the contradiction class exhibited a smaller decline. Fine-tuning the model on an augmented dataset with adversarial examples restored its performance to near-baseline levels for both the standard and challenge sets. Our findings highlight the value of adversarial triggers in identifying spurious correlations and improving robustness while providing insights into the resilience of the contradiction class to adversarial attacks.
+
+
+
+ 99. 【2412.11167】Cultural Palette: Pluralising Culture Alignment via Multi-agent Palette
+ 链接:https://arxiv.org/abs/2412.11167
+ 作者:Jiahao Yuan,Zixiang Di,Shangzixin Zhao,Usman Naseem
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large language models, inherent monocultural biases, nuanced cultural semantics, Large language, capturing nuanced cultural
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) face challenges in aligning with diverse cultural values despite their remarkable performance in generation, which stems from inherent monocultural biases and difficulties in capturing nuanced cultural semantics. Existing methods lack adaptability to unkown culture after finetuning. Inspired by cultural geography across five continents, we propose Cultural Palette, a multi-agent framework for cultural alignment. We first introduce the Pentachromatic Cultural Palette Dataset synthesized using LLMs to capture diverse cultural values from social dialogues across five continents. Building on this, Cultural Palette integrates five continent-level alignment agents with a meta-agent using our superior Cultural MoErges alignment technique by dynamically activating relevant cultural expertise based on user prompts to adapting new culture, which outperforms other joint and merging alignment strategies in overall cultural value alignment. Each continent agent generates a cultural draft, which is then refined and self-regulated by the meta-agent to produce the final culturally aligned response. Experiments across various countries demonstrate that Cultural Palette surpasses existing baselines in cultural alignment.
+
+
+
+ 100. 【2412.11145】he Superalignment of Superhuman Intelligence with Large Language Models
+ 链接:https://arxiv.org/abs/2412.11145
+ 作者:Minlie Huang,Yingkang Wang,Shiyao Cui,Pei Ke,Jie Tang
+ 类目:Computation and Language (cs.CL)
+ 关键词:witnessed superhuman intelligence, large language models, multimodal language models, large language, multimodal language
+ 备注: Under review of Science China
+
+ 点击查看摘要
+ Abstract:We have witnessed superhuman intelligence thanks to the fast development of large language models and multimodal language models. As the application of such superhuman models becomes more and more common, a critical question rises here: how can we ensure superhuman models are still safe, reliable and aligned well to human values? In this position paper, we discuss the concept of superalignment from the learning perspective to answer this question by outlining the learning paradigm shift from large-scale pretraining, supervised fine-tuning, to alignment training. We define superalignment as designing effective and efficient alignment algorithms to learn from noisy-labeled data (point-wise samples or pair-wise preference data) in a scalable way when the task becomes very complex for human experts to annotate and the model is stronger than human experts. We highlight some key research problems in superalignment, namely, weak-to-strong generalization, scalable oversight, and evaluation. We then present a conceptual framework for superalignment, which consists of three modules: an attacker which generates adversary queries trying to expose the weaknesses of a learner model; a learner which will refine itself by learning from scalable feedbacks generated by a critic model along with minimal human experts; and a critic which generates critics or explanations for a given query-response pair, with a target of improving the learner by criticizing. We discuss some important research problems in each component of this framework and highlight some interesting research ideas that are closely related to our proposed framework, for instance, self-alignment, self-play, self-refinement, and more. Last, we highlight some future research directions for superalignment, including identification of new emergent risks and multi-dimensional alignment.
+
+
+
+ 101. 【2412.11142】AD-LLM: Benchmarking Large Language Models for Anomaly Detection
+ 链接:https://arxiv.org/abs/2412.11142
+ 作者:Tiankai Yang,Yi Nian,Shawn Li,Ruiyao Xu,Yuangang Li,Jiaqi Li,Zhuo Xiao,Xiyang Hu,Ryan Rossi,Kaize Ding,Xia Hu,Yue Zhao
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:important machine learning, including fraud detection, machine learning task, medical diagnosis, NLP anomaly detection
+ 备注:
+
+ 点击查看摘要
+ Abstract:Anomaly detection (AD) is an important machine learning task with many real-world uses, including fraud detection, medical diagnosis, and industrial monitoring. Within natural language processing (NLP), AD helps detect issues like spam, misinformation, and unusual user activity. Although large language models (LLMs) have had a strong impact on tasks such as text generation and summarization, their potential in AD has not been studied enough. This paper introduces AD-LLM, the first benchmark that evaluates how LLMs can help with NLP anomaly detection. We examine three key tasks: (i) zero-shot detection, using LLMs' pre-trained knowledge to perform AD without tasks-specific training; (ii) data augmentation, generating synthetic data and category descriptions to improve AD models; and (iii) model selection, using LLMs to suggest unsupervised AD models. Through experiments with different datasets, we find that LLMs can work well in zero-shot AD, that carefully designed augmentation methods are useful, and that explaining model selection for specific datasets remains challenging. Based on these results, we outline six future research directions on LLMs for AD.
+
+
+
+ 102. 【2412.11125】Feature engineering vs. deep learning for paper section identification: Toward applications in Chinese medical literature
+ 链接:https://arxiv.org/abs/2412.11125
+ 作者:Sijia Zhou,Xin Li
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Section identification, literature section identification, library science, knowledge management, Chinese literature section
+ 备注:
+
+ 点击查看摘要
+ Abstract:Section identification is an important task for library science, especially knowledge management. Identifying the sections of a paper would help filter noise in entity and relation extraction. In this research, we studied the paper section identification problem in the context of Chinese medical literature analysis, where the subjects, methods, and results are more valuable from a physician's perspective. Based on previous studies on English literature section identification, we experiment with the effective features to use with classic machine learning algorithms to tackle the problem. It is found that Conditional Random Fields, which consider sentence interdependency, is more effective in combining different feature sets, such as bag-of-words, part-of-speech, and headings, for Chinese literature section identification. Moreover, we find that classic machine learning algorithms are more effective than generic deep learning models for this problem. Based on these observations, we design a novel deep learning model, the Structural Bidirectional Long Short-Term Memory (SLSTM) model, which models word and sentence interdependency together with the contextual information. Experiments on a human-curated asthma literature dataset show that our approach outperforms the traditional machine learning methods and other deep learning methods and achieves close to 90% precision and recall in the task. The model shows good potential for use in other text mining tasks. The research has significant methodological and practical implications.
+
+
+
+ 103. 【2412.11090】Hanprome: Modified Hangeul for Expression of foreign language pronunciation
+ 链接:https://arxiv.org/abs/2412.11090
+ 作者:Wonchan Kim,Michelle Meehyun Kim
+ 类目:ound (cs.SD); Computation and Language (cs.CL); Audio and Speech Processing (eess.AS)
+ 关键词:basic form, Hangeul was created, existing alphabets, Hangeul, phonetic alphabet
+ 备注: 21 pages
+
+ 点击查看摘要
+ Abstract:Hangeul was created as a phonetic alphabet and is known to have the best 1:1 correspondence between letters and pronunciation among existing alphabets. In this paper, we examine the possibility of modifying the basic form of Hangeul and using it as a kind of phonetic symbol. The core concept of this approach is to preserve the basic form of the alphabet, modifying only the shape of a stroke rather than the letter itself. To the best of our knowledge, no previous attempts in any language have been made to express pronunciations of an alphabet different from the original simply by changing the shape of the alphabet strokes, and this paper is probably the first attempt in this direction.
+
+
+
+ 104. 【2412.11063】LAW: Legal Agentic Workflows for Custody and Fund Services Contracts
+ 链接:https://arxiv.org/abs/2412.11063
+ 作者:William Watson,Nicole Cho,Nishan Srishankar,Zhen Zeng,Lucas Cecchi,Daniel Scott,Suchetha Siddagangappa,Rachneet Kaur,Tucker Balch,Manuela Veloso
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Software Engineering (cs.SE)
+ 关键词:key provider responsibilities, Large Language Model, domain govern critical, govern critical aspects, services domain govern
+ 备注: Accepted at The 31st International Conference on Computational Linguistics (COLING 2025)
+
+ 点击查看摘要
+ Abstract:Legal contracts in the custody and fund services domain govern critical aspects such as key provider responsibilities, fee schedules, and indemnification rights. However, it is challenging for an off-the-shelf Large Language Model (LLM) to ingest these contracts due to the lengthy unstructured streams of text, limited LLM context windows, and complex legal jargon. To address these challenges, we introduce LAW (Legal Agentic Workflows for Custody and Fund Services Contracts). LAW features a modular design that responds to user queries by orchestrating a suite of domain-specific tools and text agents. Our experiments demonstrate that LAW, by integrating multiple specialized agents and tools, significantly outperforms the baseline. LAW excels particularly in complex tasks such as calculating a contract's termination date, surpassing the baseline by 92.9% points. Furthermore, LAW offers a cost-effective alternative to traditional fine-tuned legal LLMs by leveraging reusable, domain-specific tools.
+
+
+
+ 105. 【2412.11053】NITRO: LLM Inference on Intel Laptop NPUs
+ 链接:https://arxiv.org/abs/2412.11053
+ 作者:Anthony Fei,Mohamed S. Abdelfattah
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, finding large usage, natural language processing, Large Language, ChatGPT and Gemini
+ 备注: 11 pages, 7 figures
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have become essential tools in natural language processing, finding large usage in chatbots such as ChatGPT and Gemini, and are a central area of research. A particular area of interest includes designing hardware specialized for these AI applications, with one such example being the neural processing unit (NPU). In 2023, Intel released the Intel Core Ultra processor with codename Meteor Lake, featuring a CPU, GPU, and NPU system-on-chip. However, official software support for the NPU through Intel's OpenVINO framework is limited to static model inference. The dynamic nature of autoregressive token generation in LLMs is therefore not supported out of the box. To address this shortcoming, we present NITRO (NPU Inference for Transformers Optimization), a Python-based framework built on top of OpenVINO to support text and chat generation on NPUs. In this paper, we discuss in detail the key modifications made to the transformer architecture to enable inference, some performance benchmarks, and future steps towards improving the package. The code repository for NITRO can be found here: this https URL.
+
+
+
+ 106. 【2412.11041】Separate the Wheat from the Chaff: A Post-Hoc Approach to Safety Re-Alignment for Fine-Tuned Language Models
+ 链接:https://arxiv.org/abs/2412.11041
+ 作者:Di Wu,Xin Lu,Yanyan Zhao,Bing Qin
+ 类目:Computation and Language (cs.CL)
+ 关键词:achieve effective safety, effective safety alignment, large language models, achieve effective, time of release
+ 备注: 14 pages, 12 figures,
+
+ 点击查看摘要
+ Abstract:Although large language models (LLMs) achieve effective safety alignment at the time of release, they still face various safety challenges. A key issue is that fine-tuning often compromises the safety alignment of LLMs. To address this issue, we propose a method named \textbf{IRR} (\textbf{I}dentify, \textbf{R}emove, and \textbf{R}ecalibrate for Safety Realignment) that performs safety realignment for LLMs. The core of IRR is to identify and remove unsafe delta parameters from the fine-tuned models, while recalibrating the retained ones. We evaluate the effectiveness of IRR across various datasets, including both full fine-tuning and LoRA methods. Our results demonstrate that IRR significantly enhances the safety performance of fine-tuned models on safety benchmarks, such as harmful queries and jailbreak attacks, while maintaining their performance on downstream tasks. The source code is available at: \url{this https URL}.
+
+
+
+ 107. 【2412.11016】A Contextualized BERT model for Knowledge Graph Completion
+ 链接:https://arxiv.org/abs/2412.11016
+ 作者:Haji Gul,Abdul Ghani Naim,Ajaz A. Bhat
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Knowledge Graph Completion, representing structured, enabling tasks, recommendation systems, systems and inference
+ 备注: MuslML Workshop, 38th Conference on Neural Information Processing Systems (NeurIPS 2024)
+
+ 点击查看摘要
+ Abstract:Knowledge graphs (KGs) are valuable for representing structured, interconnected information across domains, enabling tasks like semantic search, recommendation systems and inference. A pertinent challenge with KGs, however, is that many entities (i.e., heads, tails) or relationships are unknown. Knowledge Graph Completion (KGC) addresses this by predicting these missing nodes or links, enhancing the graph's informational depth and utility. Traditional methods like TransE and ComplEx predict tail entities but struggle with unseen entities. Textual-based models leverage additional semantics but come with high computational costs, semantic inconsistencies, and data imbalance issues. Recent LLM-based models show improvement but overlook contextual information and rely heavily on entity descriptions. In this study, we introduce a contextualized BERT model for KGC that overcomes these limitations by utilizing the contextual information from neighbouring entities and relationships to predict tail entities. Our model eliminates the need for entity descriptions and negative triplet sampling, reducing computational demands while improving performance. Our model outperforms state-of-the-art methods on standard datasets, improving Hit@1 by 5.3% and 4.88% on FB15k-237 and WN18RR respectively, setting a new benchmark in KGC.
+
+
+
+ 108. 【2412.11009】Dual Traits in Probabilistic Reasoning of Large Language Models
+ 链接:https://arxiv.org/abs/2412.11009
+ 作者:Shenxiong Li,Huaxia Rui
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computers and Society (cs.CY)
+ 关键词:evaluate posterior probabilities, large language models, conducted three experiments, experiments to investigate, investigate how large
+ 备注:
+
+ 点击查看摘要
+ Abstract:We conducted three experiments to investigate how large language models (LLMs) evaluate posterior probabilities. Our results reveal the coexistence of two modes in posterior judgment among state-of-the-art models: a normative mode, which adheres to Bayes' rule, and a representative-based mode, which relies on similarity -- paralleling human System 1 and System 2 thinking. Additionally, we observed that LLMs struggle to recall base rate information from their memory, and developing prompt engineering strategies to mitigate representative-based judgment may be challenging. We further conjecture that the dual modes of judgment may be a result of the contrastive loss function employed in reinforcement learning from human feedback. Our findings underscore the potential direction for reducing cognitive biases in LLMs and the necessity for cautious deployment of LLMs in critical areas.
+
+
+
+ 109. 【2412.11006】Entropy-Regularized Process Reward Model
+ 链接:https://arxiv.org/abs/2412.11006
+ 作者:Hanning Zhang,Pengcheng Wang,Shizhe Diao,Yong Lin,Rui Pan,Hanze Dong,Dylan Zhang,Pavlo Molchanov,Tong Zhang
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:Large language models, making systematic errors, performing complex multi-step, Large language, complex multi-step reasoning
+ 备注: Preprint
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) have shown promise in performing complex multi-step reasoning, yet they continue to struggle with mathematical reasoning, often making systematic errors. A promising solution is reinforcement learning (RL) guided by reward models, particularly those focusing on process rewards, which score each intermediate step rather than solely evaluating the final outcome. This approach is more effective at guiding policy models towards correct reasoning trajectories. In this work, we propose an entropy-regularized process reward model (ER-PRM) that integrates KL-regularized Markov Decision Processes (MDP) to balance policy optimization with the need to prevent the policy from shifting too far from its initial distribution. We derive a novel reward construction method based on the theoretical results. Our theoretical analysis shows that we could derive the optimal reward model from the initial policy sampling. Our empirical experiments on the MATH and GSM8K benchmarks demonstrate that ER-PRM consistently outperforms existing process reward models, achieving 1% improvement on GSM8K and 2-3% improvement on MATH under best-of-N evaluation, and more than 1% improvement under RLHF. These results highlight the efficacy of entropy-regularization in enhancing LLMs' reasoning capabilities.
+
+
+
+ 110. 【2412.10991】Navigating Dialectal Bias and Ethical Complexities in Levantine Arabic Hate Speech Detection
+ 链接:https://arxiv.org/abs/2412.10991
+ 作者:Ahmed Haj Ahmed,Rui-Jie Yew,Xerxes Minocher,Suresh Venkatasubramanian
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computers and Society (cs.CY)
+ 关键词:Social media platforms, Social media, hate speech, hate speech detection, Levantine Arabic
+ 备注:
+
+ 点击查看摘要
+ Abstract:Social media platforms have become central to global communication, yet they also facilitate the spread of hate speech. For underrepresented dialects like Levantine Arabic, detecting hate speech presents unique cultural, ethical, and linguistic challenges. This paper explores the complex sociopolitical and linguistic landscape of Levantine Arabic and critically examines the limitations of current datasets used in hate speech detection. We highlight the scarcity of publicly available, diverse datasets and analyze the consequences of dialectal bias within existing resources. By emphasizing the need for culturally and contextually informed natural language processing (NLP) tools, we advocate for a more nuanced and inclusive approach to hate speech detection in the Arab world.
+
+
+
+ 111. 【2412.10960】Can LLMs Help Create Grammar?: Automating Grammar Creation for Endangered Languages with In-Context Learning
+ 链接:https://arxiv.org/abs/2412.10960
+ 作者:Piyapath T Spencer,Nanthipat Kongborrirak
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, LLMs, Large Language, application of Large, endangered languages
+ 备注: Preprint manuscript. Under revision. Accepted to COLING 2025
+
+ 点击查看摘要
+ Abstract:Yes! In the present-day documenting and preserving endangered languages, the application of Large Language Models (LLMs) presents a promising approach. This paper explores how LLMs, particularly through in-context learning, can assist in generating grammatical information for low-resource languages with limited amount of data. We takes Moklen as a case study to evaluate the efficacy of LLMs in producing coherent grammatical rules and lexical entries using only bilingual dictionaries and parallel sentences of the unknown language without building the model from scratch. Our methodology involves organising the existing linguistic data and prompting to efficiently enable to generate formal XLE grammar. Our results demonstrate that LLMs can successfully capture key grammatical structures and lexical information, although challenges such as the potential for English grammatical biases remain. This study highlights the potential of LLMs to enhance language documentation efforts, providing a cost-effective solution for generating linguistic data and contributing to the preservation of endangered languages.
+
+
+
+ 112. 【2412.10939】Human-Centric NLP or AI-Centric Illusion?: A Critical Investigation
+ 链接:https://arxiv.org/abs/2412.10939
+ 作者:Piyapath T Spencer
+ 类目:Computers and Society (cs.CY); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Human-Computer Interaction (cs.HC)
+ 关键词:underlying AI-centric focus, claims to prioritise, implementations reveal, reveal an underlying, underlying AI-centric
+ 备注: Preprint to be published in Proceedings of PACLIC38
+
+ 点击查看摘要
+ Abstract:Human-Centric NLP often claims to prioritise human needs and values, yet many implementations reveal an underlying AI-centric focus. Through an analysis of case studies in language modelling, behavioural testing, and multi-modal alignment, this study identifies a significant gap between the ideas of human-centricity and actual practices. Key issues include misalignment with human-centred design principles, the reduction of human factors to mere benchmarks, and insufficient consideration of real-world impacts. The discussion explores whether Human-Centric NLP embodies true human-centred design, emphasising the need for interdisciplinary collaboration and ethical considerations. The paper advocates for a redefinition of Human-Centric NLP, urging a broader focus on real-world utility and societal implications to ensure that language technologies genuinely serve and empower users.
+
+
+
+ 113. 【2412.10933】Enhancing Discoverability in Enterprise Conversational Systems with Proactive Question Suggestions
+ 链接:https://arxiv.org/abs/2412.10933
+ 作者:Xiaobin Shen,Daniel Lee,Sumit Ranjan,Sai Sree Harsha,Pawan Sevak,Yunyao Li
+ 类目:Computation and Language (cs.CL)
+ 关键词:completing daily tasks, customer management, increasingly popular, popular to assist, completing daily
+ 备注:
+
+ 点击查看摘要
+ Abstract:Enterprise conversational AI systems are becoming increasingly popular to assist users in completing daily tasks such as those in marketing and customer management. However, new users often struggle to ask effective questions, especially in emerging systems with unfamiliar or evolving capabilities. This paper proposes a framework to enhance question suggestions in conversational enterprise AI systems by generating proactive, context-aware questions that try to address immediate user needs while improving feature discoverability. Our approach combines periodic user intent analysis at the population level with chat session-based question generation. We evaluate the framework using real-world data from the AI Assistant for Adobe Experience Platform (AEP), demonstrating the improved usefulness and system discoverability of the AI Assistant.
+
+
+
+ 114. 【2412.10924】okens, the oft-overlooked appetizer: Large language models, the distributional hypothesis, and meaning
+ 链接:https://arxiv.org/abs/2412.10924
+ 作者:Julia Witte Zimmerman,Denis Hudon,Kathryn Cramer,Alejandro J. Ruiz,Calla Beauregard,Ashley Fehr,Mikaela Irene Fudolig,Bradford Demarest,Yoshi Meke Bird,Milo Z. Trujillo,Christopher M. Danforth,Peter Sheridan Dodds
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:transformer-based large language, large language models, including the transformer-based, language models, human-like language performance
+ 备注:
+
+ 点击查看摘要
+ Abstract:Tokenization is a necessary component within the current architecture of many language models, including the transformer-based large language models (LLMs) of Generative AI, yet its impact on the model's cognition is often overlooked. We argue that LLMs demonstrate that the Distributional Hypothesis (DM) is sufficient for reasonably human-like language performance, and that the emergence of human-meaningful linguistic units among tokens motivates linguistically-informed interventions in existing, linguistically-agnostic tokenization techniques, particularly with respect to their roles as (1) semantic primitives and as (2) vehicles for conveying salient distributional patterns from human language to the model. We explore tokenizations from a BPE tokenizer; extant model vocabularies obtained from Hugging Face and tiktoken; and the information in exemplar token vectors as they move through the layers of a RoBERTa (large) model. Besides creating sub-optimal semantic building blocks and obscuring the model's access to the necessary distributional patterns, we describe how tokenization pretraining can be a backdoor for bias and other unwanted content, which current alignment practices may not remediate. Additionally, we relay evidence that the tokenization algorithm's objective function impacts the LLM's cognition, despite being meaningfully insulated from the main system intelligence.
+
+
+
+ 115. 【2412.10918】LLMs-in-the-Loop Part 2: Expert Small AI Models for Anonymization and De-identification of PHI Across Multiple Languages
+ 链接:https://arxiv.org/abs/2412.10918
+ 作者:Murat Gunay,Bunyamin Keles,Raife Hizlan
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:protected health information, effective patient data, patient data processing, health information, rise of chronic
+ 备注: 21 pages, 7 tables
+
+ 点击查看摘要
+ Abstract:The rise of chronic diseases and pandemics like COVID-19 has emphasized the need for effective patient data processing while ensuring privacy through anonymization and de-identification of protected health information (PHI). Anonymized data facilitates research without compromising patient confidentiality. This paper introduces expert small AI models developed using the LLM-in-the-loop methodology to meet the demand for domain-specific de-identification NER models. These models overcome the privacy risks associated with large language models (LLMs) used via APIs by eliminating the need to transmit or store sensitive data. More importantly, they consistently outperform LLMs in de-identification tasks, offering superior performance and reliability. Our de-identification NER models, developed in eight languages (English, German, Italian, French, Romanian, Turkish, Spanish, and Arabic) achieved f1-micro score averages of 0.966, 0.975, 0.976, 0.970, 0.964, 0.974, 0.978, and 0.953 respectively. These results establish them as the most accurate healthcare anonymization solutions, surpassing existing small models and even general-purpose LLMs such as GPT-4o. While Part-1 of this series introduced the LLM-in-the-loop methodology for bio-medical document translation, this second paper showcases its success in developing cost-effective expert small NER models in de-identification tasks. Our findings lay the groundwork for future healthcare AI innovations, including biomedical entity and relation extraction, demonstrating the value of specialized models for domain-specific challenges.
+
+
+
+ 116. 【2412.10913】Quantifying Extreme Opinions on Reddit Amidst the 2023 Israeli-Palestinian Conflict
+ 链接:https://arxiv.org/abs/2412.10913
+ 作者:Alessio Guerra,Marcello Lepre,Oktay Karakus
+ 类目:ocial and Information Networks (cs.SI); Computation and Language (cs.CL)
+ 关键词:Jabalia Refugee Camp, utilising a comprehensive, Reddit subreddits, investigates the dynamics, comprehensive dataset
+ 备注: 31 pages, 8 figures and 6 tables
+
+ 点击查看摘要
+ Abstract:This study investigates the dynamics of extreme opinions on social media during the 2023 Israeli-Palestinian conflict, utilising a comprehensive dataset of over 450,000 posts from four Reddit subreddits (r/Palestine, r/Judaism, r/IsraelPalestine, and r/worldnews). A lexicon-based, unsupervised methodology was developed to measure "extreme opinions" by considering factors such as anger, polarity, and subjectivity. The analysis identifies significant peaks in extremism scores that correspond to pivotal real-life events, such as the IDF's bombings of Al Quds Hospital and the Jabalia Refugee Camp, and the end of a ceasefire following a terrorist attack. Additionally, this study explores the distribution and correlation of these scores across different subreddits and over time, providing insights into the propagation of polarised sentiments in response to conflict events. By examining the quantitative effects of each score on extremism and analysing word cloud similarities through Jaccard indices, the research offers a nuanced understanding of the factors driving extreme online opinions. This approach underscores the potential of social media analytics in capturing the complex interplay between real-world events and online discourse, while also highlighting the limitations and challenges of measuring extremism in social media contexts.
+
+
+
+ 117. 【2412.10906】SusGen-GPT: A Data-Centric LLM for Financial NLP and Sustainability Report Generation
+ 链接:https://arxiv.org/abs/2412.10906
+ 作者:Qilong Wu,Xiaoneng Xiang,Hejia Huang,Xuan Wang,Yeo Wei Jie,Ranjan Satapathy,Ricardo Shirota Filho,Bharadwaj Veeravalli
+ 类目:Computation and Language (cs.CL); Computational Engineering, Finance, and Science (cs.CE); Machine Learning (cs.LG); Computational Finance (q-fin.CP)
+ 关键词:advanced NLP tools, focus on Environmental, ESG report generation, considerations highlight, sustainability report generation
+ 备注:
+
+ 点击查看摘要
+ Abstract:The rapid growth of the financial sector and the rising focus on Environmental, Social, and Governance (ESG) considerations highlight the need for advanced NLP tools. However, open-source LLMs proficient in both finance and ESG domains remain scarce. To address this gap, we introduce SusGen-30K, a category-balanced dataset comprising seven financial NLP tasks and ESG report generation, and propose TCFD-Bench, a benchmark for evaluating sustainability report generation. Leveraging this dataset, we developed SusGen-GPT, a suite of models achieving state-of-the-art performance across six adapted and two off-the-shelf tasks, trailing GPT-4 by only 2% despite using 7-8B parameters compared to GPT-4's 1,700B. Based on this, we propose the SusGen system, integrated with Retrieval-Augmented Generation (RAG), to assist in sustainability report generation. This work demonstrates the efficiency of our approach, advancing research in finance and ESG.
+
+
+
+ 118. 【2412.10893】BgGPT 1.0: Extending English-centric LLMs to other languages
+ 链接:https://arxiv.org/abs/2412.10893
+ 作者:Anton Alexandrov,Veselin Raychev,Dimitar I. Dimitrov,Ce Zhang,Martin Vechev,Kristina Toutanova
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Bulgarian language understanding, versions of Google, Bulgarian language tasks, Bulgarian language, continually pretrained
+ 备注:
+
+ 点击查看摘要
+ Abstract:We present BgGPT-Gemma-2-27B-Instruct and BgGPT-Gemma-2-9B-Instruct: continually pretrained and fine-tuned versions of Google's Gemma-2 models, specifically optimized for Bulgarian language understanding and generation. Leveraging Gemma-2's multilingual capabilities and over 100 billion tokens of Bulgarian and English text data, our models demonstrate strong performance in Bulgarian language tasks, setting a new standard for language-specific AI models. Our approach maintains the robust capabilities of the original Gemma-2 models, ensuring that the English language performance remains intact. To preserve the base model capabilities, we incorporate continual learning strategies based on recent Branch-and-Merge techniques as well as thorough curation and selection of training data. We provide detailed insights into our methodology, including the release of model weights with a commercial-friendly license, enabling broader adoption by researchers, companies, and hobbyists. Further, we establish a comprehensive set of benchmarks based on non-public educational data sources to evaluate models on Bulgarian language tasks as well as safety and chat capabilities. Our findings demonstrate the effectiveness of fine-tuning state-of-the-art models like Gemma 2 to enhance language-specific AI applications while maintaining cross-lingual capabilities.
+
+
+
+ 119. 【2412.10870】A Novel End-To-End Event Geolocation Method Leveraging Hyperbolic Space and Toponym Hierarchies
+ 链接:https://arxiv.org/abs/2412.10870
+ 作者:Yaqiong Qiao,Guojun Huang
+ 类目:Computation and Language (cs.CL)
+ 关键词:Timely detection, event detection, provide critical information, event detection module, event geolocation method
+ 备注:
+
+ 点击查看摘要
+ Abstract:Timely detection and geolocation of events based on social data can provide critical information for applications such as crisis response and resource allocation. However, most existing methods are greatly affected by event detection errors, leading to insufficient geolocation accuracy. To this end, this paper proposes a novel end-to-end event geolocation method (GTOP) leveraging Hyperbolic space and toponym hierarchies. Specifically, the proposed method contains one event detection module and one geolocation module. The event detection module constructs a heterogeneous information networks based on social data, and then constructs a homogeneous message graph and combines it with the text and time feature of the message to learning initial features of nodes. Node features are updated in Hyperbolic space and then fed into a classifier for event detection. To reduce the geolocation error, this paper proposes a noise toponym filtering algorithm (HIST) based on the hierarchical structure of toponyms. HIST analyzes the hierarchical structure of toponyms mentioned in the event cluster, taking the highly frequent city-level locations as the coarse-grained locations for events. By comparing the hierarchical structure of the toponyms within the cluster against those of the coarse-grained locations of events, HIST filters out noisy toponyms. To further improve the geolocation accuracy, we propose a fine-grained pseudo toponyms generation algorithm (FIT) based on the output of HIST, and combine generated pseudo toponyms with filtered toponyms to locate events based on the geographic center points of the combined toponyms. Extensive experiments are conducted on the Chinese dataset constructed in this paper and another public English dataset. The experimental results show that the proposed method is superior to the state-of-the-art baselines.
+
+
+
+ 120. 【2412.10858】CRENER: A Character Relation Enhanced Chinese NER Model
+ 链接:https://arxiv.org/abs/2412.10858
+ 作者:Yaqiong Qiao,Shixuan Peng
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:Chinese NER, Named Entity Recognition, Chinese Named Entity, Chinese NER accuracy, Chinese NER task
+ 备注:
+
+ 点击查看摘要
+ Abstract:Chinese Named Entity Recognition (NER) is an important task in information extraction, which has a significant impact on downstream applications. Due to the lack of natural separators in Chinese, previous NER methods mostly relied on external dictionaries to enrich the semantic and boundary information of Chinese words. However, such methods may introduce noise that affects the accuracy of named entity recognition. To this end, we propose a character relation enhanced Chinese NER model (CRENER). This model defines four types of tags that reflect the relationships between characters, and proposes a fine-grained modeling of the relationships between characters based on three types of relationships: adjacency relations between characters, relations between characters and tags, and relations between tags, to more accurately identify entity boundaries and improve Chinese NER accuracy. Specifically, we transform the Chinese NER task into a character-character relationship classification task, ensuring the accuracy of entity boundary recognition through joint modeling of relation tags. To enhance the model's ability to understand contextual information, WRENER further constructed an adapted transformer encoder that combines unscaled direction-aware and distance-aware masked self-attention mechanisms. Moreover, a relationship representation enhancement module was constructed to model predefined relationship tags, effectively mining the relationship representations between characters and tags. Experiments conducted on four well-known Chinese NER benchmark datasets have shown that the proposed model outperforms state-of-the-art baselines. The ablation experiment also demonstrated the effectiveness of the proposed model.
+
+
+
+ 121. 【2412.10849】Superhuman performance of a large language model on the reasoning tasks of a physician
+ 链接:https://arxiv.org/abs/2412.10849
+ 作者:Peter G. Brodeur,Thomas A. Buckley,Zahir Kanjee,Ethan Goh,Evelyn Bin Ling,Priyank Jain,Stephanie Cabral,Raja-Elie Abdulnour,Adrian Haimovich,Jason A. Freed,Andrew Olson,Daniel J. Morgan,Jason Hom,Robert Gallo,Eric Horvitz,Jonathan Chen,Arjun K. Manrai,Adam Rodman
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:multiple choice question, choice question benchmarks, large language models, large language, traditionally been evaluated
+ 备注:
+
+ 点击查看摘要
+ Abstract:Performance of large language models (LLMs) on medical tasks has traditionally been evaluated using multiple choice question benchmarks. However, such benchmarks are highly constrained, saturated with repeated impressive performance by LLMs, and have an unclear relationship to performance in real clinical scenarios. Clinical reasoning, the process by which physicians employ critical thinking to gather and synthesize clinical data to diagnose and manage medical problems, remains an attractive benchmark for model performance. Prior LLMs have shown promise in outperforming clinicians in routine and complex diagnostic scenarios. We sought to evaluate OpenAI's o1-preview model, a model developed to increase run-time via chain of thought processes prior to generating a response. We characterize the performance of o1-preview with five experiments including differential diagnosis generation, display of diagnostic reasoning, triage differential diagnosis, probabilistic reasoning, and management reasoning, adjudicated by physician experts with validated psychometrics. Our primary outcome was comparison of the o1-preview output to identical prior experiments that have historical human controls and benchmarks of previous LLMs. Significant improvements were observed with differential diagnosis generation and quality of diagnostic and management reasoning. No improvements were observed with probabilistic reasoning or triage differential diagnosis. This study highlights o1-preview's ability to perform strongly on tasks that require complex critical thinking such as diagnosis and management while its performance on probabilistic reasoning tasks was similar to past models. New robust benchmarks and scalable evaluation of LLM capabilities compared to human physicians are needed along with trials evaluating AI in real clinical settings.
+
+
+
+ 122. 【2412.10848】Large Language Models for Medical Forecasting -- Foresight 2
+ 链接:https://arxiv.org/abs/2412.10848
+ 作者:Zeljko Kraljevic,Joshua Au Yeung,Daniel Bean,James Teo,Richard J. Dobson
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:modelling patient timelines, large language model, removed for anon, large language, language model fine-tuned
+ 备注:
+
+ 点击查看摘要
+ Abstract:Foresight 2 (FS2) is a large language model fine-tuned on hospital data for modelling patient timelines (GitHub 'removed for anon'). It can understand patients' clinical notes and predict SNOMED codes for a wide range of biomedical use cases, including diagnosis suggestions, risk forecasting, and procedure and medication recommendations. FS2 is trained on the free text portion of the MIMIC-III dataset, firstly through extracting biomedical concepts and then creating contextualised patient timelines, upon which the model is then fine-tuned. The results show significant improvement over the previous state-of-the-art for the next new biomedical concept prediction (P/R - 0.73/0.66 vs 0.52/0.32) and a similar improvement specifically for the next new disorder prediction (P/R - 0.69/0.62 vs 0.46/0.25). Finally, on the task of risk forecast, we compare our model to GPT-4-turbo (and a range of open-source biomedical LLMs) and show that FS2 performs significantly better on such tasks (P@5 - 0.90 vs 0.65). This highlights the need to incorporate hospital data into LLMs and shows that small models outperform much larger ones when fine-tuned on high-quality, specialised data.
+
+
+
+ 123. 【2412.10827】Rethinking Chain-of-Thought from the Perspective of Self-Training
+ 链接:https://arxiv.org/abs/2412.10827
+ 作者:Zongqian Wu,Baoduo Xu,Ruochen Cui,Mengmeng Zhan,Xiaofeng Zhu,Lei Feng
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:large language models, activating latent capabilities, language models, effective approach, approach for activating
+ 备注: 16 pages, 12 figures
+
+ 点击查看摘要
+ Abstract:Chain-of-thought (CoT) reasoning has emerged as an effective approach for activating latent capabilities in large language models (LLMs). We observe that CoT shares significant similarities with self-training in terms of their learning processes. Motivated by these parallels, this paper explores the underlying relationship between CoT and self-training, demonstrating how insights from self-training can enhance CoT performance. Specifically, our study first reveals that CoT, like self-training, follows the principle of semantic entropy minimization. Leveraging this insight, we propose a novel CoT framework that incorporates two key components: (i) a task-specific prompt module designed to guide LLMs in generating high-quality initial reasoning processes, and (ii) an adaptive reasoning iteration module for progressively refining the reasoning process.
+
+
+
+ 124. 【2412.10823】FinGPT: Enhancing Sentiment-Based Stock Movement Prediction with Dissemination-Aware and Context-Enriched LLMs
+ 链接:https://arxiv.org/abs/2412.10823
+ 作者:Yixuan Liang,Yuncong Liu,Boyu Zhang,Christina Dan Wang,Hongyang Yang
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG); Computational Finance (q-fin.CP); Trading and Market Microstructure (q-fin.TR)
+ 关键词:Financial sentiment analysis, Financial sentiment, crucial for understanding, Financial, sentiment analysis
+ 备注: 1st Workshop on Preparing Good Data for Generative AI: Challenges and Approaches@ AAAI 2025
+
+ 点击查看摘要
+ Abstract:Financial sentiment analysis is crucial for understanding the influence of news on stock prices. Recently, large language models (LLMs) have been widely adopted for this purpose due to their advanced text analysis capabilities. However, these models often only consider the news content itself, ignoring its dissemination, which hampers accurate prediction of short-term stock movements. Additionally, current methods often lack sufficient contextual data and explicit instructions in their prompts, limiting LLMs' ability to interpret news. In this paper, we propose a data-driven approach that enhances LLM-powered sentiment-based stock movement predictions by incorporating news dissemination breadth, contextual data, and explicit instructions. We cluster recent company-related news to assess its reach and influence, enriching prompts with more specific data and precise instructions. This data is used to construct an instruction tuning dataset to fine-tune an LLM for predicting short-term stock price movements. Our experimental results show that our approach improves prediction accuracy by 8\% compared to existing methods.
+
+
+
+ 125. 【2412.10805】Are Language Models Agnostic to Linguistically Grounded Perturbations? A Case Study of Indic Languages
+ 链接:https://arxiv.org/abs/2412.10805
+ 作者:Poulami Ghosh,Raj Dabre,Pushpak Bhattacharyya
+ 类目:Computation and Language (cs.CL)
+ 关键词:Pre-trained language models, linguistically grounded attacks, Pre-trained language, linguistically grounded, input text
+ 备注: Work in Progress
+
+ 点击查看摘要
+ Abstract:Pre-trained language models (PLMs) are known to be susceptible to perturbations to the input text, but existing works do not explicitly focus on linguistically grounded attacks, which are subtle and more prevalent in nature. In this paper, we study whether PLMs are agnostic to linguistically grounded attacks or not. To this end, we offer the first study addressing this, investigating different Indic languages and various downstream tasks. Our findings reveal that although PLMs are susceptible to linguistic perturbations, when compared to non-linguistic attacks, PLMs exhibit a slightly lower susceptibility to linguistic attacks. This highlights that even constrained attacks are effective. Moreover, we investigate the implications of these outcomes across a range of languages, encompassing diverse language families and different scripts.
+
+
+
+ 126. 【2412.10742】WEPO: Web Element Preference Optimization for LLM-based Web Navigation
+ 链接:https://arxiv.org/abs/2412.10742
+ 作者:Jiarun Liu,Jia Hao,Chunhong Zhang,Zheng Hu
+ 类目:Computation and Language (cs.CL)
+ 关键词:grounding pretrained Large, pretrained Large Language, Large Language Models, pretrained Large, Large Language
+ 备注: Published at AAAI 2025
+
+ 点击查看摘要
+ Abstract:The rapid advancement of autonomous web navigation has significantly benefited from grounding pretrained Large Language Models (LLMs) as agents. However, current research has yet to fully leverage the redundancy of HTML elements for contrastive training. This paper introduces a novel approach to LLM-based web navigation tasks, called Web Element Preference Optimization (WEPO). WEPO utilizes unsupervised preference learning by sampling distance-based non-salient web elements as negative samples, optimizing maximum likelihood objective within Direct Preference Optimization (DPO). We evaluate WEPO on the Mind2Web benchmark and empirically demonstrate that WEPO aligns user high-level intent with output actions more effectively. The results show that our method achieved the state-of-the-art, with an improvement of 13.8% over WebAgent and 5.3% over the visual language model CogAgent baseline. Our findings underscore the potential of preference optimization to enhance web navigation and other web page based tasks, suggesting a promising direction for future research.
+
+
+
+ 127. 【2412.10717】HITgram: A Platform for Experimenting with n-gram Language Models
+ 链接:https://arxiv.org/abs/2412.10717
+ 作者:Shibaranjani Dasgupta,Chandan Maity,Somdip Mukherjee,Rohan Singh,Diptendu Dutta,Debasish Jana
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large language models, Large language, limiting accessibility, resource intensive, powerful but resource
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) are powerful but resource intensive, limiting accessibility. HITgram addresses this gap by offering a lightweight platform for n-gram model experimentation, ideal for resource-constrained environments. It supports unigrams to 4-grams and incorporates features like context sensitive weighting, Laplace smoothing, and dynamic corpus management to e-hance prediction accuracy, even for unseen word sequences. Experiments demonstrate HITgram's efficiency, achieving 50,000 tokens/second and generating 2-grams from a 320MB corpus in 62 seconds. HITgram scales efficiently, constructing 4-grams from a 1GB file in under 298 seconds on an 8 GB RAM system. Planned enhancements include multilingual support, advanced smoothing, parallel processing, and model saving, further broadening its utility.
+
+
+
+ 128. 【2412.10712】owards Effective, Efficient and Unsupervised Social Event Detection in the Hyperbolic Space
+ 链接:https://arxiv.org/abs/2412.10712
+ 作者:Xiaoyan Yu,Yifan Wei,Shuaishuai Zhou,Zhiwei Yang,Li Sun,Hao Peng,Liehuang Zhu,Philip S. Yu
+ 类目:Computation and Language (cs.CL)
+ 关键词:social message data, social event detection, dynamic nature, data has posed, posed challenges
+ 备注: Accepted to AAAI 2025
+
+ 点击查看摘要
+ Abstract:The vast, complex, and dynamic nature of social message data has posed challenges to social event detection (SED). Despite considerable effort, these challenges persist, often resulting in inadequately expressive message representations (ineffective) and prolonged learning durations (inefficient). In response to the challenges, this work introduces an unsupervised framework, HyperSED (Hyperbolic SED). Specifically, the proposed framework first models social messages into semantic-based message anchors, and then leverages the structure of the anchor graph and the expressiveness of the hyperbolic space to acquire structure- and geometry-aware anchor representations. Finally, HyperSED builds the partitioning tree of the anchor message graph by incorporating differentiable structural information as the reflection of the detected events. Extensive experiments on public datasets demonstrate HyperSED's competitive performance, along with a substantial improvement in efficiency compared to the current state-of-the-art unsupervised paradigm. Statistically, HyperSED boosts incremental SED by an average of 2%, 2%, and 25% in NMI, AMI, and ARI, respectively; enhancing efficiency by up to 37.41 times and at least 12.10 times, illustrating the advancement of the proposed framework. Our code is publicly available at this https URL.
+
+
+
+ 129. 【2412.10705】Efficient Adaptation of Multilingual Models for Japanese ASR
+ 链接:https://arxiv.org/abs/2412.10705
+ 作者:Mark Bajo,Haruka Fukukawa,Ryuji Morita,Yuma Ogasawara
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:Automatic Speech Recognition, Automatic Speech, Speech Recognition, specifically OpenAI Whisper-Tiny, study explores fine-tuning
+ 备注:
+
+ 点击查看摘要
+ Abstract:This study explores fine-tuning multilingual ASR (Automatic Speech Recognition) models, specifically OpenAI's Whisper-Tiny, to improve performance in Japanese. While multilingual models like Whisper offer versatility, they often lack precision in specific languages. Conversely, monolingual models like ReazonSpeech excel in language-specific tasks but are less adaptable. Using Japanese-specific datasets and Low-Rank Adaptation (LoRA) along with end-to-end (E2E) training, we fine-tuned Whisper-Tiny to bridge this gap. Our results show that fine-tuning reduced Whisper-Tiny's Character Error Rate (CER) from 32.7 to 20.8 with LoRA and to 14.7 with end-to-end fine-tuning, surpassing Whisper-Base's CER of 20.2. However, challenges with domain-specific terms remain, highlighting the need for specialized datasets. These findings demonstrate that fine-tuning multilingual models can achieve strong language-specific performance while retaining their flexibility. This approach provides a scalable solution for improving ASR in resource-constrained environments and languages with complex writing systems like Japanese.
+
+
+
+ 130. 【2412.10704】VisDoM: Multi-Document QA with Visually Rich Elements Using Multimodal Retrieval-Augmented Generation
+ 链接:https://arxiv.org/abs/2412.10704
+ 作者:Manan Suri,Puneet Mathur,Franck Dernoncourt,Kanika Goswami,Ryan A. Rossi,Dinesh Manocha
+ 类目:Computation and Language (cs.CL)
+ 关键词:document-grounded question answering, visually rich elements, question answering, Understanding information, Retrieval Augmented Generation
+ 备注:
+
+ 点击查看摘要
+ Abstract:Understanding information from a collection of multiple documents, particularly those with visually rich elements, is important for document-grounded question answering. This paper introduces VisDoMBench, the first comprehensive benchmark designed to evaluate QA systems in multi-document settings with rich multimodal content, including tables, charts, and presentation slides. We propose VisDoMRAG, a novel multimodal Retrieval Augmented Generation (RAG) approach that simultaneously utilizes visual and textual RAG, combining robust visual retrieval capabilities with sophisticated linguistic reasoning. VisDoMRAG employs a multi-step reasoning process encompassing evidence curation and chain-of-thought reasoning for concurrent textual and visual RAG pipelines. A key novelty of VisDoMRAG is its consistency-constrained modality fusion mechanism, which aligns the reasoning processes across modalities at inference time to produce a coherent final answer. This leads to enhanced accuracy in scenarios where critical information is distributed across modalities and improved answer verifiability through implicit context attribution. Through extensive experiments involving open-source and proprietary large language models, we benchmark state-of-the-art document QA methods on VisDoMBench. Extensive results show that VisDoMRAG outperforms unimodal and long-context LLM baselines for end-to-end multimodal document QA by 12-20%.
+
+
+
+ 131. 【2412.10689】Learning to Verify Summary Facts with Fine-Grained LLM Feedback
+ 链接:https://arxiv.org/abs/2412.10689
+ 作者:Jihwan Oh,Jeonghwan Choi,Nicole Hee-Yeon Kim,Taewon Yun,Hwanjun Song
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Training automatic summary, Training automatic, human-labeled data, leveraging Large Language, Large Language Model
+ 备注: Accepted at COLING 2025
+
+ 点击查看摘要
+ Abstract:Training automatic summary fact verifiers often faces the challenge of a lack of human-labeled data. In this paper, we explore alternative way of leveraging Large Language Model (LLM) generated feedback to address the inherent limitation of using human-labeled data. We introduce FineSumFact, a large-scale dataset containing fine-grained factual feedback on summaries. We employ 10 distinct LLMs for diverse summary generation and Llama-3-70B-Instruct for feedback. We utilize this dataset to fine-tune the lightweight open-source model Llama-3-8B-Instruct, optimizing resource efficiency while maintaining high performance. Our experimental results reveal that the model trained on extensive LLM-generated datasets surpasses that trained on smaller human-annotated datasets when evaluated using human-generated test sets. Fine-tuning fact verification models with LLM feedback can be more effective and cost-efficient than using human feedback. The dataset is available at this https URL.
+
+
+
+ 132. 【2412.10684】Inference Scaling for Bridging Retrieval and Augmented Generation
+ 链接:https://arxiv.org/abs/2412.10684
+ 作者:Youngwon Lee,Seung-won Hwang,Daniel Campos,Filip Graliński,Zhewei Yao,Yuxiong He
+ 类目:Computation and Language (cs.CL)
+ 关键词:Retrieval-augmented generation, large language model, incorporating retrieved contexts, popular approach, approach to steering
+ 备注:
+
+ 点击查看摘要
+ Abstract:Retrieval-augmented generation (RAG) has emerged as a popular approach to steering the output of a large language model (LLM) by incorporating retrieved contexts as inputs. However, existing work observed the generator bias, such that improving the retrieval results may negatively affect the outcome. In this work, we show such bias can be mitigated, from inference scaling, aggregating inference calls from the permuted order of retrieved contexts. The proposed Mixture-of-Intervention (MOI) explicitly models the debiased utility of each passage with multiple forward passes to construct a new ranking. We also show that MOI can leverage the retriever's prior knowledge to reduce the computational cost by minimizing the number of permutations considered and lowering the cost per LLM call. We showcase the effectiveness of MOI on diverse RAG tasks, improving ROUGE-L on MS MARCO and EM on HotpotQA benchmarks by ~7 points.
+
+
+
+ 133. 【2412.10675】Chasing Progress, Not Perfection: Revisiting Strategies for End-to-End LLM Plan Generation
+ 链接:https://arxiv.org/abs/2412.10675
+ 作者:Sukai Huang,Trevor Cohn,Nir Lipovetzky
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, Large Language, Language Models, capability of Large, topic of debate
+ 备注: 8 pages main body, 10 pages appendix, accepted by Workshop on Planning in the Era of LLMs (LM4Plan @ AAAI 2025)
+
+ 点击查看摘要
+ Abstract:The capability of Large Language Models (LLMs) to plan remains a topic of debate. Some critics argue that strategies to boost LLMs' reasoning skills are ineffective in planning tasks, while others report strong outcomes merely from training models on a planning corpus. This study reassesses recent strategies by developing an end-to-end LLM planner and employing diverse metrics for a thorough evaluation. We find that merely fine-tuning LLMs on a corpus of planning instances does not lead to robust planning skills, as indicated by poor performance on out-of-distribution test sets. At the same time, we find that various strategies, including Chain-of-Thought, do enhance the probability of a plan being executable. This indicates progress towards better plan quality, despite not directly enhancing the final validity rate. Among the strategies we evaluated, reinforcement learning with our novel `Longest Contiguous Common Subsequence' reward emerged as the most effective, contributing to both plan validity and executability. Overall, our research addresses key misconceptions in the LLM-planning literature; we validate incremental progress in plan executability, although plan validity remains a challenge. Hence, future strategies should focus on both these aspects, drawing insights from our findings.
+
+
+
+ 134. 【2412.10654】hinking with Knowledge Graphs: Enhancing LLM Reasoning Through Structured Data
+ 链接:https://arxiv.org/abs/2412.10654
+ 作者:Xue Wu,Kostas Tsioutsiouliklis
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Large Language Models, natural language understanding, demonstrated remarkable capabilities, Large Language, Language Models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have demonstrated remarkable capabilities in natural language understanding and generation. However, they often struggle with complex reasoning tasks and are prone to hallucination. Recent research has shown promising results in leveraging knowledge graphs (KGs) to enhance LLM performance. KGs provide a structured representation of entities and their relationships, offering a rich source of information that can enhance the reasoning capabilities of LLMs. For this work, we have developed different techniques that tightly integrate KG structures and semantics into LLM representations. Our results show that we are able to significantly improve the performance of LLMs in complex reasoning scenarios, and ground the reasoning process with KGs. We are the first to represent KGs with programming language and fine-tune pretrained LLMs with KGs. This integration facilitates more accurate and interpretable reasoning processes, paving the way for more advanced reasoning capabilities of LLMs.
+
+
+
+ 135. 【2412.10617】BinarySelect to Improve Accessibility of Black-Box Attack Research
+ 链接:https://arxiv.org/abs/2412.10617
+ 作者:Shatarupa Ghosh,Jonathan Rusert
+ 类目:Cryptography and Security (cs.CR); Computation and Language (cs.CL)
+ 关键词:robustness of NLP, NLP models, queries, testing the robustness, rise of transformers
+ 备注: Accepted to COLING 2025, 17 pages, 5 figures, 11 tables
+
+ 点击查看摘要
+ Abstract:Adversarial text attack research is useful for testing the robustness of NLP models, however, the rise of transformers has greatly increased the time required to test attacks. Especially when researchers do not have access to adequate resources (e.g. GPUs). This can hinder attack research, as modifying one example for an attack can require hundreds of queries to a model, especially for black-box attacks. Often these attacks remove one token at a time to find the ideal one to change, requiring $n$ queries (the length of the text) right away. We propose a more efficient selection method called BinarySelect which combines binary search and attack selection methods to greatly reduce the number of queries needed to find a token. We find that BinarySelect only needs $\text{log}_2(n) * 2$ queries to find the first token compared to $n$ queries. We also test BinarySelect in an attack setting against 5 classifiers across 3 datasets and find a viable tradeoff between number of queries saved and attack effectiveness. For example, on the Yelp dataset, the number of queries is reduced by 32% (72 less) with a drop in attack effectiveness of only 5 points. We believe that BinarySelect can help future researchers study adversarial attacks and black-box problems more efficiently and opens the door for researchers with access to less resources.
+
+
+
+ 136. 【2412.10587】Evaluation of GPT-4o GPT-4o-mini's Vision Capabilities for Salt Evaporite Identification
+ 链接:https://arxiv.org/abs/2412.10587
+ 作者:Deven B. Dangi,Beni B. Dangi,Oliver Steinbock
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:diverse practical applications, stains' has diverse, practical applications, Identifying salts, diverse practical
+ 备注: 11 pages, 7 figures
+
+ 点击查看摘要
+ Abstract:Identifying salts from images of their 'stains' has diverse practical applications. While specialized AI models are being developed, this paper explores the potential of OpenAI's state-of-the-art vision models (GPT-4o and GPT-4o-mini) as an immediate solution. Testing with 12 different types of salts, the GPT-4o model achieved 57% accuracy and a 0.52 F1 score, significantly outperforming both random chance (8%) and GPT-4o mini (11% accuracy). Results suggest that current vision models could serve as an interim solution for salt identification from stain images.
+
+
+
+ 137. 【2412.10582】WHAT-IF: Exploring Branching Narratives by Meta-Prompting Large Language Models
+ 链接:https://arxiv.org/abs/2412.10582
+ 作者:Runsheng "Anson" Huang,Lara J. Martin,Chris Callison-Burch
+ 类目:Computation and Language (cs.CL)
+ 关键词:Hero Alternate Timeline, Writing a Hero, Interactive Fiction, create branching narratives, Hero Alternate
+ 备注:
+
+ 点击查看摘要
+ Abstract:WHAT-IF -- Writing a Hero's Alternate Timeline through Interactive Fiction -- is a system that uses zero-shot meta-prompting to create branching narratives from a prewritten story. Played as an interactive fiction (IF) game, WHAT-IF lets the player choose between decisions that the large language model (LLM) GPT-4 generates as possible branches in the story. Starting with an existing linear plot as input, a branch is created at each key decision taken by the main character. By meta-prompting the LLM to consider the major plot points from the story, the system produces coherent and well-structured alternate storylines. WHAT-IF stores the branching plot tree in a graph which helps it to both keep track of the story for prompting and maintain the structure for the final IF system. A video demo of our system can be found here: this https URL.
+
+
+
+ 138. 【2412.10571】Evidence Contextualization and Counterfactual Attribution for Conversational QA over Heterogeneous Data with RAG Systems
+ 链接:https://arxiv.org/abs/2412.10571
+ 作者:Rishiraj Saha Roy,Joel Schlotthauer,Chris Hinze,Andreas Foltyn,Luzian Hahn,Fabian Kuech
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:Retrieval Augmented Generation, Retrieval Augmented, Augmented Generation, Conversational Question Answering, RAG
+ 备注: Extended version of demo paper accepted at WSDM 2025
+
+ 点击查看摘要
+ Abstract:Retrieval Augmented Generation (RAG) works as a backbone for interacting with an enterprise's own data via Conversational Question Answering (ConvQA). In a RAG system, a retriever fetches passages from a collection in response to a question, which are then included in the prompt of a large language model (LLM) for generating a natural language (NL) answer. However, several RAG systems today suffer from two shortcomings: (i) retrieved passages usually contain their raw text and lack appropriate document context, negatively impacting both retrieval and answering quality; and (ii) attribution strategies that explain answer generation usually rely only on similarity between the answer and the retrieved passages, thereby only generating plausible but not causal explanations. In this work, we demonstrate RAGONITE, a RAG system that remedies the above concerns by: (i) contextualizing evidence with source metadata and surrounding text; and (ii) computing counterfactual attribution, a causal explanation approach where the contribution of an evidence to an answer is determined by the similarity of the original response to the answer obtained by removing that evidence. To evaluate our proposals, we release a new benchmark ConfQuestions, with 300 hand-created conversational questions, each in English and German, coupled with ground truth URLs, completed questions, and answers from 215 public Confluence pages, that are typical of enterprise wiki spaces with heterogeneous elements. Experiments with RAGONITE on ConfQuestions show the viability of our ideas: contextualization improves RAG performance, and counterfactual attribution is effective at explaining RAG answers.
+
+
+
+ 139. 【2412.10558】oo Big to Fool: Resisting Deception in Language Models
+ 链接:https://arxiv.org/abs/2412.10558
+ 作者:Mohammad Reza Samsami,Mats Leon Richter,Juan Rodriguez,Megh Thakkar,Sarath Chandar,Maxime Gasse
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Large language models, generate accurate responses, Large language, accurate responses, balance their weight-encoded
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models must balance their weight-encoded knowledge with in-context information from prompts to generate accurate responses. This paper investigates this interplay by analyzing how models of varying capacities within the same family handle intentionally misleading in-context information. Our experiments demonstrate that larger models exhibit higher resilience to deceptive prompts, showcasing an advanced ability to interpret and integrate prompt information with their internal knowledge. Furthermore, we find that larger models outperform smaller ones in following legitimate instructions, indicating that their resilience is not due to disregarding in-context information. We also show that this phenomenon is likely not a result of memorization but stems from the models' ability to better leverage implicit task-relevant information from the prompt alongside their internally stored knowledge.
+
+
+
+ 140. 【2412.10543】RAGServe: Fast Quality-Aware RAG Systems with Configuration Adaptation
+ 链接:https://arxiv.org/abs/2412.10543
+ 作者:Siddhant Ray,Rui Pan,Zhuohan Gu,Kuntai Du,Ganesh Ananthanarayanan,Ravi Netravali,Junchen Jiang
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:Retrieval Augmented Generation, Retrieval Augmented, large language models, external knowledge, Augmented Generation
+ 备注: 17 pages, 18 figures
+
+ 点击查看摘要
+ Abstract:RAG (Retrieval Augmented Generation) allows LLMs (large language models) to generate better responses with external knowledge, but using more external knowledge often improves generation quality at the expense of response delay. Prior work either reduces the response delay (through better scheduling of RAG queries) or strives to maximize quality (which involves tuning the RAG workflow), but they fall short in optimizing the tradeoff between the delay and quality of RAG responses. This paper presents RAGServe, the first RAG system that jointly schedules queries and adapts the key RAG configurations of each query, such as the number of retrieved text chunks and synthesis methods, in order to balance quality optimization and response delay reduction. Using 4 popular RAG-QA datasets, we show that compared with the state-of-the-art RAG optimization schemes, RAGServe reduces the generation latency by $1.64-2.54\times$ without sacrificing generation quality.
+
+
+
+ 141. 【2412.10535】On Adversarial Robustness and Out-of-Distribution Robustness of Large Language Models
+ 链接:https://arxiv.org/abs/2412.10535
+ 作者:April Yang,Jordan Tab,Parth Shah,Paul Kotchavong
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:diverse applications necessitates, OOD robustness, robustness, increasing reliance, reliance on large
+ 备注:
+
+ 点击查看摘要
+ Abstract:The increasing reliance on large language models (LLMs) for diverse applications necessitates a thorough understanding of their robustness to adversarial perturbations and out-of-distribution (OOD) inputs. In this study, we investigate the correlation between adversarial robustness and OOD robustness in LLMs, addressing a critical gap in robustness evaluation. By applying methods originally designed to improve one robustness type across both contexts, we analyze their performance on adversarial and out-of-distribution benchmark datasets. The input of the model consists of text samples, with the output prediction evaluated in terms of accuracy, precision, recall, and F1 scores in various natural language inference tasks.
+Our findings highlight nuanced interactions between adversarial robustness and OOD robustness, with results indicating limited transferability between the two robustness types. Through targeted ablations, we evaluate how these correlations evolve with different model sizes and architectures, uncovering model-specific trends: smaller models like LLaMA2-7b exhibit neutral correlations, larger models like LLaMA2-13b show negative correlations, and Mixtral demonstrates positive correlations, potentially due to domain-specific alignment. These results underscore the importance of hybrid robustness frameworks that integrate adversarial and OOD strategies tailored to specific models and domains. Further research is needed to evaluate these interactions across larger models and varied architectures, offering a pathway to more reliable and generalizable LLMs.
+
Subjects:
+Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+Cite as:
+arXiv:2412.10535 [cs.CL]
+(or
+arXiv:2412.10535v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2412.10535
+Focus to learn more
+ arXiv-issued DOI via DataCite</p>
+
+
+
+
+ 142. 【2412.10529】Solving the Inverse Alignment Problem for Efficient RLHF
+ 链接:https://arxiv.org/abs/2412.10529
+ 作者:Shambhavi Krishna,Aishwarya Sahoo
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:Collecting high-quality preference, Collecting high-quality, resource-intensive and challenging, high-quality preference datasets, reinforcement learning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Collecting high-quality preference datasets for reinforcement learning from human feedback (RLHF) is resource-intensive and challenging. As a result, researchers often train reward models on extensive offline datasets which aggregate diverse generation sources and scoring/alignment policies. We hypothesize that this aggregation has an averaging effect on reward model scores, which limits signal and impairs the alignment process. Inspired by the field of inverse RL, we define the 'inverse alignment problem' in language model training, where our objective is to optimize the critic's reward for a fixed actor and a fixed offline preference dataset. We hypothesize that solving the inverse alignment problem will improve reward model quality by providing clearer feedback on the policy's current behavior. To that end, we investigate whether repeatedly fine-tuning a reward model on subsets of the offline preference dataset aligned with a periodically frozen policy during RLHF improves upon vanilla RLHF. Our empirical results demonstrate that this approach facilitates superior alignment and faster convergence compared to using an unaligned or out-of-distribution reward model relative to the LLM policy.
+
+
+
+ 143. 【2412.10510】DEFAME: Dynamic Evidence-based FAct-checking with Multimodal Experts
+ 链接:https://arxiv.org/abs/2412.10510
+ 作者:Tobias Braun,Mark Rothermel,Marcus Rohrbach,Anna Rohrbach
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:present Dynamic Evidence-based, Dynamic Evidence-based FAct-checking, trust and democracy, necessitating robust, scalable Fact-Checking systems
+ 备注:
+
+ 点击查看摘要
+ Abstract:The proliferation of disinformation presents a growing threat to societal trust and democracy, necessitating robust and scalable Fact-Checking systems. In this work, we present Dynamic Evidence-based FAct-checking with Multimodal Experts (DEFAME), a modular, zero-shot MLLM pipeline for open-domain, text-image claim verification. DEFAME frames the problem of fact-checking as a six-stage process, dynamically deciding about the usage of external tools for the retrieval of textual and visual evidence. In addition to the claim's veracity, DEFAME returns a justification accompanied by a comprehensive, multimodal fact-checking report. While most alternatives either focus on sub-tasks of fact-checking, lack explainability or are limited to text-only inputs, DEFAME solves the problem of fact-checking end-to-end, including claims with images or those that require visual evidence. Evaluation on the popular benchmarks VERITE, AVeriTeC, and MOCHEG shows that DEFAME surpasses all previous methods, establishing it as the new state-of-the-art fact-checking system.
+
+
+
+ 144. 【2412.10509】Do Large Language Models Show Biases in Causal Learning?
+ 链接:https://arxiv.org/abs/2412.10509
+ 作者:Maria Victoria Carro,Francisca Gauna Selasco,Denise Alejandra Mester,Margarita Gonzales,Mario A. Leiva,Maria Vanina Martinez,Gerardo I. Simari
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:developing the capability, capability of making, making causal inferences, causal inferences based, Causal
+ 备注: 15 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:Causal learning is the cognitive process of developing the capability of making causal inferences based on available information, often guided by normative principles. This process is prone to errors and biases, such as the illusion of causality, in which people perceive a causal relationship between two variables despite lacking supporting evidence. This cognitive bias has been proposed to underlie many societal problems, including social prejudice, stereotype formation, misinformation, and superstitious thinking. In this research, we investigate whether large language models (LLMs) develop causal illusions, both in real-world and controlled laboratory contexts of causal learning and inference. To this end, we built a dataset of over 2K samples including purely correlational cases, situations with null contingency, and cases where temporal information excludes the possibility of causality by placing the potential effect before the cause. We then prompted the models to make statements or answer causal questions to evaluate their tendencies to infer causation erroneously in these structured settings. Our findings show a strong presence of causal illusion bias in LLMs. Specifically, in open-ended generation tasks involving spurious correlations, the models displayed bias at levels comparable to, or even lower than, those observed in similar studies on human subjects. However, when faced with null-contingency scenarios or temporal cues that negate causal relationships, where it was required to respond on a 0-100 scale, the models exhibited significantly higher bias. These findings suggest that the models have not uniformly, consistently, or reliably internalized the normative principles essential for accurate causal learning.
+
+
+
+ 145. 【2412.10467】MGM: Global Understanding of Audience Overlap Graphs for Predicting the Factuality and the Bias of News Media
+ 链接:https://arxiv.org/abs/2412.10467
+ 作者:Muhammad Arslan Manzoor,Ruihong Zeng,Dilshod Azizov,Preslav Nakov,Shangsong Liang
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (stat.ML)
+ 关键词:growing digital data, rapidly growing digital, reliable information online, seeking reliable information, political bias
+ 备注:
+
+ 点击查看摘要
+ Abstract:In the current era of rapidly growing digital data, evaluating the political bias and factuality of news outlets has become more important for seeking reliable information online. In this work, we study the classification problem of profiling news media from the lens of political bias and factuality. Traditional profiling methods, such as Pre-trained Language Models (PLMs) and Graph Neural Networks (GNNs) have shown promising results, but they face notable challenges. PLMs focus solely on textual features, causing them to overlook the complex relationships between entities, while GNNs often struggle with media graphs containing disconnected components and insufficient labels. To address these limitations, we propose MediaGraphMind (MGM), an effective solution within a variational Expectation-Maximization (EM) framework. Instead of relying on limited neighboring nodes, MGM leverages features, structural patterns, and label information from globally similar nodes. Such a framework not only enables GNNs to capture long-range dependencies for learning expressive node representations but also enhances PLMs by integrating structural information and therefore improving the performance of both models. The extensive experiments demonstrate the effectiveness of the proposed framework and achieve new state-of-the-art results. Further, we share our repository1 which contains the dataset, code, and documentation
+
+
+
+ 146. 【2412.10434】NAT-NL2GQL: A Novel Multi-Agent Framework for Translating Natural Language to Graph Query Language
+ 链接:https://arxiv.org/abs/2412.10434
+ 作者:Yuanyuan Liang,Tingyu Xie,Gan Peng,Zihao Huang,Yunshi Lan,Weining Qian
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Databases (cs.DB)
+ 关键词:Large Language Models, emergence of Large, Language Models, Large Language, traditional natural language
+ 备注: 12 pages,6 figures
+
+ 点击查看摘要
+ Abstract:The emergence of Large Language Models (LLMs) has revolutionized many fields, not only traditional natural language processing (NLP) tasks. Recently, research on applying LLMs to the database field has been booming, and as a typical non-relational database, the use of LLMs in graph database research has naturally gained significant attention. Recent efforts have increasingly focused on leveraging LLMs to translate natural language into graph query language (NL2GQL). Although some progress has been made, these methods have clear limitations, such as their reliance on streamlined processes that often overlook the potential of LLMs to autonomously plan and collaborate with other LLMs in tackling complex NL2GQL challenges. To address this gap, we propose NAT-NL2GQL, a novel multi-agent framework for translating natural language to graph query language. Specifically, our framework consists of three synergistic agents: the Preprocessor agent, the Generator agent, and the Refiner agent. The Preprocessor agent manages data processing as context, including tasks such as name entity recognition, query rewriting, path linking, and the extraction of query-related schemas. The Generator agent is a fine-tuned LLM trained on NL-GQL data, responsible for generating corresponding GQL statements based on queries and their related schemas. The Refiner agent is tasked with refining the GQL or context using error information obtained from the GQL execution results. Given the scarcity of high-quality open-source NL2GQL datasets based on nGQL syntax, we developed StockGQL, a dataset constructed from a financial market graph database. It is available at: this https URL. Experimental results on the StockGQL and SpCQL datasets reveal that our method significantly outperforms baseline approaches, highlighting its potential for advancing NL2GQL research.
+
+
+
+ 147. 【2412.10432】Imitate Before Detect: Aligning Machine Stylistic Preference for Machine-Revised Text Detection
+ 链接:https://arxiv.org/abs/2412.10432
+ 作者:Jiaqi Chen,Xiaoye Zhu,Tianyang Liu,Ying Chen,Xinhui Chen,Yiwen Yuan,Chak Tou Leong,Zuchao Li,Tang Long,Lei Zhang,Chenyu Yan,Guanghao Mei,Jie Zhang,Lefei Zhang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Cryptography and Security (cs.CR)
+ 关键词:Large Language Models, Large Language, making detecting machine-generated, revolutionized text generation, text increasingly challenging
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have revolutionized text generation, making detecting machine-generated text increasingly challenging. Although past methods have achieved good performance on detecting pure machine-generated text, those detectors have poor performance on distinguishing machine-revised text (rewriting, expansion, and polishing), which can have only minor changes from its original human prompt. As the content of text may originate from human prompts, detecting machine-revised text often involves identifying distinctive machine styles, e.g., worded favored by LLMs. However, existing methods struggle to detect machine-style phrasing hidden within the content contributed by humans. We propose the "Imitate Before Detect" (ImBD) approach, which first imitates the machine-style token distribution, and then compares the distribution of the text to be tested with the machine-style distribution to determine whether the text has been machine-revised. To this end, we introduce style preference optimization (SPO), which aligns a scoring LLM model to the preference of text styles generated by machines. The aligned scoring model is then used to calculate the style-conditional probability curvature (Style-CPC), quantifying the log probability difference between the original and conditionally sampled texts for effective detection. We conduct extensive comparisons across various scenarios, encompassing text revisions by six LLMs, four distinct text domains, and three machine revision types. Compared to existing state-of-the-art methods, our method yields a 13% increase in AUC for detecting text revised by open-source LLMs, and improves performance by 5% and 19% for detecting GPT-3.5 and GPT-4o revised text, respectively. Notably, our method surpasses the commercially trained GPT-Zero with just $1,000$ samples and five minutes of SPO, demonstrating its efficiency and effectiveness.
+
+
+
+ 148. 【2412.10427】Identifying and Manipulating Personality Traits in LLMs Through Activation Engineering
+ 链接:https://arxiv.org/abs/2412.10427
+ 作者:Rumi A. Allbert,James K. Wiles
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:large language models, Contrastive Activation Addition, language models, recent years, field of large
+ 备注:
+
+ 点击查看摘要
+ Abstract:The field of large language models (LLMs) has grown rapidly in recent years, driven by the desire for better efficiency, interpretability, and safe use. Building on the novel approach of "activation engineering," this study explores personality modification in LLMs, drawing inspiration from research like Refusal in LLMs Is Mediated by a Single Direction (arXiv:2406.11717) and Steering Llama 2 via Contrastive Activation Addition (arXiv:2312.06681). We leverage activation engineering to develop a method for identifying and adjusting activation directions related to personality traits, which may allow for dynamic LLM personality fine-tuning. This work aims to further our understanding of LLM interpretability while examining the ethical implications of such developments.
+
+
+
+ 149. 【2412.10426】CAP: Evaluation of Persuasive and Creative Image Generation
+ 链接:https://arxiv.org/abs/2412.10426
+ 作者:Aysan Aghazadeh,Adriana Kovashka
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL); Graphics (cs.GR)
+ 关键词:CAP, advertisement image generation, Alignment, Persuasiveness, images
+ 备注:
+
+ 点击查看摘要
+ Abstract:We address the task of advertisement image generation and introduce three evaluation metrics to assess Creativity, prompt Alignment, and Persuasiveness (CAP) in generated advertisement images. Despite recent advancements in Text-to-Image (T2I) generation and their performance in generating high-quality images for explicit descriptions, evaluating these models remains challenging. Existing evaluation methods focus largely on assessing alignment with explicit, detailed descriptions, but evaluating alignment with visually implicit prompts remains an open problem. Additionally, creativity and persuasiveness are essential qualities that enhance the effectiveness of advertisement images, yet are seldom measured. To address this, we propose three novel metrics for evaluating the creativity, alignment, and persuasiveness of generated images. Our findings reveal that current T2I models struggle with creativity, persuasiveness, and alignment when the input text is implicit messages. We further introduce a simple yet effective approach to enhance T2I models' capabilities in producing images that are better aligned, more creative, and more persuasive.
+
+
+
+ 150. 【2412.10425】Active Inference for Self-Organizing Multi-LLM Systems: A Bayesian Thermodynamic Approach to Adaptation
+ 链接:https://arxiv.org/abs/2412.10425
+ 作者:Rithvik Prakki
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:paper introduces, integrating active inference, active inference, integrating active, large language models
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper introduces a novel approach to creating adaptive language agents by integrating active inference with large language models (LLMs). While LLMs demonstrate remarkable capabilities, their reliance on static prompts limits adaptation to new information and changing environments. We address this by implementing an active inference framework that acts as a cognitive layer above an LLM-based agent, dynamically adjusting prompts and search strategies through principled information-seeking behavior. Our framework models the environment using three state factors (prompt, search, and information states) with seven observation modalities capturing quality metrics. By framing the agent's learning through the free energy principle, we enable systematic exploration of prompt combinations and search strategies. Experimental results demonstrate the effectiveness of this approach, with the agent developing accurate models of environment dynamics evidenced by emergent structure in observation matrices. Action selection patterns reveal sophisticated exploration-exploitation behavior, transitioning from initial information-gathering to targeted prompt testing. The integration of thermodynamic principles with language model capabilities provides a principled framework for creating robust, adaptable agents, extending active inference beyond traditional low-dimensional control problems to high-dimensional, language-driven environments.
+
+
+
+ 151. 【2412.10424】LLM-AS-AN-INTERVIEWER: Beyond Static Testing Through Dynamic LLM Evaluation
+ 链接:https://arxiv.org/abs/2412.10424
+ 作者:Eunsu Kim,Juyoung Suk,Seungone Kim,Niklas Muennighoff,Dongkwan Kim,Alice Oh
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:large language models, language models, paradigm for large, large language, LLM
+ 备注:
+
+ 点击查看摘要
+ Abstract:We introduce a novel evaluation paradigm for large language models (LLMs), LLM-as-an-Interviewer. This approach consists of a two stage process designed to assess the true capabilities of LLMs: first, modifying benchmark datasets to generate initial queries, and second, interacting with the LLM through feedback and follow up questions. Compared to existing evaluation methods such as LLM as a Judge, our framework addresses several limitations, including data contamination, verbosity bias, and self enhancement bias. Additionally, we show that our multi turn evaluation process provides valuable insights into the LLM's performance in real-world scenarios, including its adaptability to feedback and its ability to handle follow up questions, including clarification or requests for additional knowledge. Finally, we propose the Interview Report, which offers a comprehensive reflection of an LLM's strengths and weaknesses, illustrated with specific examples from the interview process. This report delivers a snapshot of the LLM's capabilities, providing a detailed picture of its practical performance.
+
+
+
+ 152. 【2412.10423】Look Before You Leap: Enhancing Attention and Vigilance Regarding Harmful Content with GuidelineLLM
+ 链接:https://arxiv.org/abs/2412.10423
+ 作者:Shaoqing Zhang,Zhuosheng Zhang,Kehai Chen,Rongxiang Weng,Muyun Yang,Tiejun Zhao,Min Zhang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:large language models, alignment mechanisms, large language, language models, increasingly vulnerable
+ 备注:
+
+ 点击查看摘要
+ Abstract:Despite being empowered with alignment mechanisms, large language models (LLMs) are increasingly vulnerable to emerging jailbreak attacks that can compromise their alignment mechanisms. This vulnerability poses significant risks to the real-world applications. Existing work faces challenges in both training efficiency and generalization capabilities (i.e., Reinforcement Learning from Human Feedback and Red-Teaming). Developing effective strategies to enable LLMs to resist continuously evolving jailbreak attempts represents a significant challenge. To address this challenge, we propose a novel defensive paradigm called GuidelineLLM, which assists LLMs in recognizing queries that may have harmful content. Before LLMs respond to a query, GuidelineLLM first identifies potential risks associated with the query, summarizes these risks into guideline suggestions, and then feeds these guidelines to the responding LLMs. Importantly, our approach eliminates the necessity for additional safety fine-tuning of the LLMs themselves; only the GuidelineLLM requires fine-tuning. This characteristic enhances the general applicability of GuidelineLLM across various LLMs. Experimental results demonstrate that GuidelineLLM can significantly reduce the attack success rate (ASR) against the LLMs (an average reduction of 34.17\% ASR) while maintaining the helpfulness of the LLMs in handling benign queries. Code is available at this https URL.
+
+
+
+ 153. 【2412.10422】AutoPrep: Natural Language Question-Aware Data Preparation with a Multi-Agent Framework
+ 链接:https://arxiv.org/abs/2412.10422
+ 作者:Meihao Fan,Ju Fan,Nan Tang,Lei Cao,Xiaoyong Du
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Tabular Question Answering, Answering natural language, extract meaningful insights, meaningful insights quickly, Answering natural
+ 备注:
+
+ 点击查看摘要
+ Abstract:Answering natural language (NL) questions about tables, which is referred to as Tabular Question Answering (TQA), is important because it enables users to extract meaningful insights quickly and efficiently from structured data, bridging the gap between human language and machine-readable formats. Many of these tables originate from web sources or real-world scenarios, necessitating careful data preparation (or data prep for short) to ensure accurate answers. However, unlike traditional data prep, question-aware data prep introduces new requirements, which include tasks such as column augmentation and filtering for given questions, and question-aware value normalization or conversion. Because each of the above tasks is unique, a single model (or agent) may not perform effectively across all scenarios. In this paper, we propose AUTOPREP, a large language model (LLM)-based multi-agent framework that leverages the strengths of multiple agents, each specialized in a certain type of data prep, ensuring more accurate and contextually relevant responses. Given an NL question over a table, AUTOPREP performs data prep through three key components. Planner: Determines a logical plan, outlining a sequence of high-level operations. Programmer: Translates this logical plan into a physical plan by generating the corresponding low-level code. Executor: Iteratively executes and debugs the generated code to ensure correct outcomes. To support this multi-agent framework, we design a novel chain-of-thought reasoning mechanism for high-level operation suggestion, and a tool-augmented method for low-level code generation. Extensive experiments on real-world TQA datasets demonstrate that AUTOPREP can significantly improve the SOTA TQA solutions through question-aware data prep.
+
+
+
+ 154. 【2412.10419】Personalized and Sequential Text-to-Image Generation
+ 链接:https://arxiv.org/abs/2412.10419
+ 作者:Ofir Nabati,Guy Tennenholtz,ChihWei Hsu,Moonkyung Ryu,Deepak Ramachandran,Yinlam Chow,Xiang Li,Craig Boutilier
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG); Systems and Control (eess.SY)
+ 关键词:designing a reinforcement, reinforcement learning, address the problem, iteratively improves, improves a set
+ 备注: Link to PASTA dataset: [this https URL](https://www.kaggle.com/datasets/googleai/pasta-data)
+
+ 点击查看摘要
+ Abstract:We address the problem of personalized, interactive text-to-image (T2I) generation, designing a reinforcement learning (RL) agent which iteratively improves a set of generated images for a user through a sequence of prompt expansions. Using human raters, we create a novel dataset of sequential preferences, which we leverage, together with large-scale open-source (non-sequential) datasets. We construct user-preference and user-choice models using an EM strategy and identify varying user preference types. We then leverage a large multimodal language model (LMM) and a value-based RL approach to suggest a personalized and diverse slate of prompt expansions to the user. Our Personalized And Sequential Text-to-image Agent (PASTA) extends T2I models with personalized multi-turn capabilities, fostering collaborative co-creation and addressing uncertainty or underspecification in a user's intent. We evaluate PASTA using human raters, showing significant improvement compared to baseline methods. We also release our sequential rater dataset and simulated user-rater interactions to support future research in personalized, multi-turn T2I generation.
+
+
+
+ 155. 【2412.10418】Constrained Decoding with Speculative Lookaheads
+ 链接:https://arxiv.org/abs/2412.10418
+ 作者:Nishanth Nakshatri,Shamik Roy,Rajarshi Das,Suthee Chaidaroon,Leonid Boytsov,Rashmi Gangadharaiah
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:highly effective method, human preferences, aligning LLM generations, highly effective, effective method
+ 备注: Under submission
+
+ 点击查看摘要
+ Abstract:Constrained decoding with lookahead heuristics (CDLH) is a highly effective method for aligning LLM generations to human preferences. However, the extensive lookahead roll-out operations for each generated token makes CDLH prohibitively expensive, resulting in low adoption in practice. In contrast, common decoding strategies such as greedy decoding are extremely efficient, but achieve very low constraint satisfaction. We propose constrained decoding with speculative lookaheads (CDSL), a technique that significantly improves upon the inference efficiency of CDLH without experiencing the drastic performance reduction seen with greedy decoding. CDSL is motivated by the recently proposed idea of speculative decoding that uses a much smaller draft LLM for generation and a larger target LLM for verification. In CDSL, the draft model is used to generate lookaheads which is verified by a combination of target LLM and task-specific reward functions. This process accelerates decoding by reducing the computational burden while maintaining strong performance. We evaluate CDSL in two constraint decoding tasks with three LLM families and achieve 2.2x to 12.15x speedup over CDLH without significant performance reduction.
+
+
+
+ 156. 【2412.10417】Leveraging Audio and Text Modalities in Mental Health: A Study of LLMs Performance
+ 链接:https://arxiv.org/abs/2412.10417
+ 作者:Abdelrahman A. Ali,Aya E. Fouda,Radwa J. Hanafy,Mohammed E. Fouda
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:Mental health disorders, Traumatic Stress Disorder, increasingly prevalent worldwide, support early diagnosis, Post Traumatic Stress
+ 备注:
+
+ 点击查看摘要
+ Abstract:Mental health disorders are increasingly prevalent worldwide, creating an urgent need for innovative tools to support early diagnosis and intervention. This study explores the potential of Large Language Models (LLMs) in multimodal mental health diagnostics, specifically for detecting depression and Post Traumatic Stress Disorder through text and audio modalities. Using the E-DAIC dataset, we compare text and audio modalities to investigate whether LLMs can perform equally well or better with audio inputs. We further examine the integration of both modalities to determine if this can enhance diagnostic accuracy, which generally results in improved performance metrics. Our analysis specifically utilizes custom-formulated metrics; Modal Superiority Score and Disagreement Resolvement Score to evaluate how combined modalities influence model performance. The Gemini 1.5 Pro model achieves the highest scores in binary depression classification when using the combined modality, with an F1 score of 0.67 and a Balanced Accuracy (BA) of 77.4%, assessed across the full dataset. These results represent an increase of 3.1% over its performance with the text modality and 2.7% over the audio modality, highlighting the effectiveness of integrating modalities to enhance diagnostic accuracy. Notably, all results are obtained in zero-shot inferring, highlighting the robustness of the models without requiring task-specific fine-tuning. To explore the impact of different configurations on model performance, we conduct binary, severity, and multiclass tasks using both zero-shot and few-shot prompts, examining the effects of prompt variations on performance. The results reveal that models such as Gemini 1.5 Pro in text and audio modalities, and GPT-4o mini in the text modality, often surpass other models in balanced accuracy and F1 scores across multiple tasks.
+
+
+
+ 157. 【2412.10416】SUPERMERGE: An Approach For Gradient-Based Model Merging
+ 链接:https://arxiv.org/abs/2412.10416
+ 作者:Haoyu Yang,Zheng Zhang,Saket Sathe
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:simultaneously support thousands, Large language models, Large language, possess the superpower, superpower to simultaneously
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models, such as ChatGPT, Claude, or LLaMA, are gigantic, monolithic, and possess the superpower to simultaneously support thousands of tasks. However, high-throughput applications often prefer smaller task-specific models because of their lower latency and cost. One challenge of using task-specific models is the incremental need for solving newer tasks after the model is already deployed for existing tasks. A straightforward solution requires fine-tuning the model again for both existing and new tasks, which is computationally expensive and time-consuming. To address this issue, we propose a model merging based approach called SUPERMERGE. SUPERMERGE is a gradient-based method to systematically merge several fine-tuned models trained on existing and new tasks. SUPERMERGE is designed to be lightweight and fast, and the merged model achieves similar performance to fully fine-tuned models on all tasks. Furthermore, we proposed a hierarchical model merging strategy to reduce the peak space requirement without sacrificing the performance of the merged model. We experimentally demonstrate that SUPERMERGE outperforms existing model merging methods on common natural language processing and computer vision tasks.
+
+
+
+ 158. 【2412.10415】Generative Adversarial Reviews: When LLMs Become the Critic
+ 链接:https://arxiv.org/abs/2412.10415
+ 作者:Nicolas Bougie,Narimasa Watanabe
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:standards for publication, meet the quality, quality standards, scientific progress, strain traditional scientific
+ 备注:
+
+ 点击查看摘要
+ Abstract:The peer review process is fundamental to scientific progress, determining which papers meet the quality standards for publication. Yet, the rapid growth of scholarly production and increasing specialization in knowledge areas strain traditional scientific feedback mechanisms. In light of this, we introduce Generative Agent Reviewers (GAR), leveraging LLM-empowered agents to simulate faithful peer reviewers. To enable generative reviewers, we design an architecture that extends a large language model with memory capabilities and equips agents with reviewer personas derived from historical data. Central to this approach is a graph-based representation of manuscripts, condensing content and logically organizing information - linking ideas with evidence and technical details. GAR's review process leverages external knowledge to evaluate paper novelty, followed by detailed assessment using the graph representation and multi-round assessment. Finally, a meta-reviewer aggregates individual reviews to predict the acceptance decision. Our experiments demonstrate that GAR performs comparably to human reviewers in providing detailed feedback and predicting paper outcomes. Beyond mere performance comparison, we conduct insightful experiments, such as evaluating the impact of reviewer expertise and examining fairness in reviews. By offering early expert-level feedback, typically restricted to a limited group of researchers, GAR democratizes access to transparent and in-depth evaluation.
+
+
+
+ 159. 【2412.10414】Exploring Complex Mental Health Symptoms via Classifying Social Media Data with Explainable LLMs
+ 链接:https://arxiv.org/abs/2412.10414
+ 作者:Kexin Chen,Noelle Lim,Claire Lee,Michael Guerzhoy
+ 类目:Computation and Language (cs.CL)
+ 关键词:data classification tasks, challenging social media, social media text, media text data, text data classification
+ 备注: Accepted to Machine Learning for Health (ML4H) Findings 2024 (co-located with NeurIPS 2024)
+
+ 点击查看摘要
+ Abstract:We propose a pipeline for gaining insights into complex diseases by training LLMs on challenging social media text data classification tasks, obtaining explanations for the classification outputs, and performing qualitative and quantitative analysis on the explanations. We report initial results on predicting, explaining, and systematizing the explanations of predicted reports on mental health concerns in people reporting Lyme disease concerns. We report initial results on predicting future ADHD concerns for people reporting anxiety disorder concerns, and demonstrate preliminary results on visualizing the explanations for predicting that a person with anxiety concerns will in the future have ADHD concerns.
+
+
+
+ 160. 【2412.10413】Evaluating Robustness of LLMs on Crisis-Related Microblogs across Events, Information Types, and Linguistic Features
+ 链接:https://arxiv.org/abs/2412.10413
+ 作者:Muhammad Imran,Abdul Wahab Ziaullah,Kai Chen,Ferda Ofli
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Social and Information Networks (cs.SI)
+ 关键词:response authorities, governments and response, microblogging platforms, real-time information, Twitter
+ 备注: 12 pages, 10 figs, 5 tables
+
+ 点击查看摘要
+ Abstract:The widespread use of microblogging platforms like X (formerly Twitter) during disasters provides real-time information to governments and response authorities. However, the data from these platforms is often noisy, requiring automated methods to filter relevant information. Traditionally, supervised machine learning models have been used, but they lack generalizability. In contrast, Large Language Models (LLMs) show better capabilities in understanding and processing natural language out of the box. This paper provides a detailed analysis of the performance of six well-known LLMs in processing disaster-related social media data from a large-set of real-world events. Our findings indicate that while LLMs, particularly GPT-4o and GPT-4, offer better generalizability across different disasters and information types, most LLMs face challenges in processing flood-related data, show minimal improvement despite the provision of examples (i.e., shots), and struggle to identify critical information categories like urgent requests and needs. Additionally, we examine how various linguistic features affect model performance and highlight LLMs' vulnerabilities against certain features like typos. Lastly, we provide benchmarking results for all events across both zero- and few-shot settings and observe that proprietary models outperform open-source ones in all tasks.
+
+
+
+ 161. 【2412.10400】Reinforcement Learning Enhanced LLMs: A Survey
+ 链接:https://arxiv.org/abs/2412.10400
+ 作者:Shuhe Wang,Shengyu Zhang,Jie Zhang,Runyi Hu,Xiaoya Li,Tianwei Zhang,Jiwei Li,Fei Wu,Guoyin Wang,Eduard Hovy
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:enhancing large language, paper surveys research, reinforcement learning, large language models, rapidly growing research
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper surveys research in the rapidly growing field of enhancing large language models (LLMs) with reinforcement learning (RL), a technique that enables LLMs to improve their performance by receiving feedback in the form of rewards based on the quality of their outputs, allowing them to generate more accurate, coherent, and contextually appropriate responses. In this work, we make a systematic review of the most up-to-date state of knowledge on RL-enhanced LLMs, attempting to consolidate and analyze the rapidly growing research in this field, helping researchers understand the current challenges and advancements. Specifically, we (1) detail the basics of RL; (2) introduce popular RL-enhanced LLMs; (3) review researches on two widely-used reward model-based RL techniques: Reinforcement Learning from Human Feedback (RLHF) and Reinforcement Learning from AI Feedback (RLAIF); and (4) explore Direct Preference Optimization (DPO), a set of methods that bypass the reward model to directly use human preference data for aligning LLM outputs with human expectations. We will also point out current challenges and deficiencies of existing methods and suggest some avenues for further improvements.
+
+
+
+ 162. 【2412.10388】AI-assisted summary of suicide risk Formulation
+ 链接:https://arxiv.org/abs/2412.10388
+ 作者:Rajib Rana,Niall Higgins,Kazi N. Haque,John Reilly,Kylie Burke,Kathryn Turner,Anthony R. Pisani,Terry Stedman
+ 类目:Computation and Language (cs.CL); Computers and Society (cs.CY)
+ 关键词:suicide risk assessment, risk assessment, individual problems, seeks to understand, understand the idiosyncratic
+ 备注:
+
+ 点击查看摘要
+ Abstract:Background: Formulation, associated with suicide risk assessment, is an individualised process that seeks to understand the idiosyncratic nature and development of an individual's problems. Auditing clinical documentation on an electronic health record (EHR) is challenging as it requires resource-intensive manual efforts to identify keywords in relevant sections of specific forms. Furthermore, clinicians and healthcare professionals often do not use keywords; their clinical language can vary greatly and may contain various jargon and acronyms. Also, the relevant information may be recorded elsewhere. This study describes how we developed advanced Natural Language Processing (NLP) algorithms, a branch of Artificial Intelligence (AI), to analyse EHR data automatically. Method: Advanced Optical Character Recognition techniques were used to process unstructured data sets, such as portable document format (pdf) files. Free text data was cleaned and pre-processed using Normalisation of Free Text techniques. We developed algorithms and tools to unify the free text. Finally, the formulation was checked for the presence of each concept based on similarity using NLP-powered semantic matching techniques. Results: We extracted information indicative of formulation and assessed it to cover the relevant concepts. This was achieved using a Weighted Score to obtain a Confidence Level. Conclusion: The rigour to which formulation is completed is crucial to effectively using EHRs, ensuring correct and timely identification, engagement and interventions that may potentially avoid many suicide attempts and suicides.
+
+
+
+ 163. 【2412.06845】Fully Open Source Moxin-7B Technical Report
+ 链接:https://arxiv.org/abs/2412.06845
+ 作者:Pu Zhao,Xuan Shen,Zhenglun Kong,Yixin Shen,Sung-En Chang,Timothy Rupprecht,Lei Lu,Enfu Nan,Changdi Yang,Yumei He,Xingchen Xu,Yu Huang,Wei Wang,Yue Chen,Yong He,Yanzhi Wang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Large Language Models, Large Language, Language Models, significant transformation, open-source LLMs
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recently, Large Language Models (LLMs) have undergone a significant transformation, marked by a rapid rise in both their popularity and capabilities. Leading this evolution are proprietary LLMs like GPT-4 and GPT-o1, which have captured widespread attention in the AI community due to their remarkable performance and versatility. Simultaneously, open-source LLMs, such as LLaMA and Mistral, have made great contributions to the ever-increasing popularity of LLMs due to the ease to customize and deploy the models across diverse applications. Although open-source LLMs present unprecedented opportunities for innovation and research, the commercialization of LLMs has raised concerns about transparency, reproducibility, and safety. Many open-source LLMs fail to meet fundamental transparency requirements by withholding essential components like training code and data, and some use restrictive licenses whilst claiming to be "open-source," which may hinder further innovations on LLMs. To mitigate this issue, we introduce Moxin 7B, a fully open-source LLM developed in accordance with the Model Openness Framework (MOF), a ranked classification system that evaluates AI models based on model completeness and openness, adhering to principles of open science, open source, open data, and open access. Our model achieves the highest MOF classification level of "open science" through the comprehensive release of pre-training code and configurations, training and fine-tuning datasets, and intermediate and final checkpoints. Experiments show that our model achieves superior performance in zero-shot evaluation compared with popular 7B models and performs competitively in few-shot evaluation.
+
+
+
+ 164. 【2412.12009】SpeechPrune: Context-aware Token Pruning for Speech Information Retrieval
+ 链接:https://arxiv.org/abs/2412.12009
+ 作者:Yueqian Lin,Yuzhe Fu,Jingyang Zhang,Yudong Liu,Jianyi Zhang,Jingwei Sun,Hai "Helen" Li,Yiran Chen
+ 类目:Audio and Speech Processing (eess.AS); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Sound (cs.SD)
+ 关键词:Speech Information Retrieval, Speech Large Language, Large Language Models, introduce Speech Information, Information Retrieval
+ 备注: Project page and dataset is available at [this https URL](https://speechprune.github.io/)
+
+ 点击查看摘要
+ Abstract:We introduce Speech Information Retrieval (SIR), a new long-context task for Speech Large Language Models (Speech LLMs), and present SPIRAL, a 1,012-sample benchmark testing models' ability to extract critical details from approximately 90-second spoken inputs. While current Speech LLMs excel at short-form tasks, they struggle with the computational and representational demands of longer audio sequences. To address this limitation, we propose SpeechPrune, a training-free token pruning strategy that uses speech-text similarity and approximated attention scores to efficiently discard irrelevant tokens. In SPIRAL, SpeechPrune achieves accuracy improvements of 29% and up to 47% over the original model and the random pruning model at a pruning rate of 20%, respectively. SpeechPrune can maintain network performance even at a pruning level of 80%. This approach highlights the potential of token-level pruning for efficient and scalable long-form speech understanding.
+
+
+
+ 165. 【2412.11185】ransliterated Zero-Shot Domain Adaptation for Automatic Speech Recognition
+ 链接:https://arxiv.org/abs/2412.11185
+ 作者:Han Zhu,Gaofeng Cheng,Qingwei Zhao,Pengyuan Zhang
+ 类目:Audio and Speech Processing (eess.AS); Computation and Language (cs.CL); Sound (cs.SD)
+ 关键词:automatic speech recognition, target domain data, target domain, speech recognition models, Domain
+ 备注:
+
+ 点击查看摘要
+ Abstract:The performance of automatic speech recognition models often degenerates on domains not covered by the training data. Domain adaptation can address this issue, assuming the availability of the target domain data in the target language. However, such assumption does not stand in many real-world applications. To make domain adaptation more applicable, we address the problem of zero-shot domain adaptation (ZSDA), where target domain data is unavailable in the target language. Instead, we transfer the target domain knowledge from another source language where the target domain data is more accessible. To do that, we first perform cross-lingual pre-training (XLPT) to share domain knowledge across languages, then use target language fine-tuning to build the final model. One challenge in this practice is that the pre-trained knowledge can be forgotten during fine-tuning, resulting in sub-optimal adaptation performance. To address this issue, we propose transliterated ZSDA to achieve consistent pre-training and fine-tuning labels, leading to maximum preservation of the pre-trained knowledge. Experimental results show that transliterated ZSDA relatively decreases the word error rate by 9.2% compared with a wav2vec 2.0 baseline. Moreover, transliterated ZSDA consistently outperforms self-supervised ZSDA and performs on par with supervised ZSDA, proving the superiority of transliteration-based pre-training labels.
+
+
+
+ 166. 【2412.10428】Observing Micromotives and Macrobehavior of Large Language Models
+ 链接:https://arxiv.org/abs/2412.10428
+ 作者:Yuyang Cheng,Xingwei Qu,Tomas Goldsack,Chenghua Lin,Chung-Chi Chen
+ 类目:Physics and Society (physics.soc-ph); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Nobel Memorial Prize, Nobel Memorial, Economic Sciences, Memorial Prize, Prize in Economic
+ 备注:
+
+ 点击查看摘要
+ Abstract:Thomas C. Schelling, awarded the 2005 Nobel Memorial Prize in Economic Sciences, pointed out that ``individuals decisions (micromotives), while often personal and localized, can lead to societal outcomes (macrobehavior) that are far more complex and different from what the individuals intended.'' The current research related to large language models' (LLMs') micromotives, such as preferences or biases, assumes that users will make more appropriate decisions once LLMs are devoid of preferences or biases. Consequently, a series of studies has focused on removing bias from LLMs. In the NLP community, while there are many discussions on LLMs' micromotives, previous studies have seldom conducted a systematic examination of how LLMs may influence society's macrobehavior. In this paper, we follow the design of Schelling's model of segregation to observe the relationship between the micromotives and macrobehavior of LLMs. Our results indicate that, regardless of the level of bias in LLMs, a highly segregated society will emerge as more people follow LLMs' suggestions. We hope our discussion will spark further consideration of the fundamental assumption regarding the mitigation of LLMs' micromotives and encourage a reevaluation of how LLMs may influence users and society.
+
+
+信息检索
+
+ 1. 【2412.12092】No More Tuning: Prioritized Multi-Task Learning with Lagrangian Differential Multiplier Methods
+ 链接:https://arxiv.org/abs/2412.12092
+ 作者:Zhengxing Cheng,Yuheng Huang,Zhixuan Zhang,Dan Ou,Qingwen Liu
+ 类目:Machine Learning (cs.LG); Information Retrieval (cs.IR)
+ 关键词:found widespread application, diverse domains, found widespread, MTL, tasks
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Given the ubiquity of multi-task in practical systems, Multi-Task Learning (MTL) has found widespread application across diverse domains. In real-world scenarios, these tasks often have different priorities. For instance, In web search, relevance is often prioritized over other metrics, such as click-through rates or user engagement. Existing frameworks pay insufficient attention to the prioritization among different tasks, which typically adjust task-specific loss function weights to differentiate task priorities. However, this approach encounters challenges as the number of tasks grows, leading to exponential increases in hyper-parameter tuning complexity. Furthermore, the simultaneous optimization of multiple objectives can negatively impact the performance of high-priority tasks due to interference from lower-priority tasks.
+In this paper, we introduce a novel multi-task learning framework employing Lagrangian Differential Multiplier Methods for step-wise multi-task optimization. It is designed to boost the performance of high-priority tasks without interference from other tasks. Its primary advantage lies in its ability to automatically optimize multiple objectives without requiring balancing hyper-parameters for different tasks, thereby eliminating the need for manual tuning. Additionally, we provide theoretical analysis demonstrating that our method ensures optimization guarantees, enhancing the reliability of the process. We demonstrate its effectiveness through experiments on multiple public datasets and its application in Taobao search, a large-scale industrial search ranking system, resulting in significant improvements across various business metrics.
+
Comments:
+Accepted by AAAI 2025
+Subjects:
+Machine Learning (cs.LG); Information Retrieval (cs.IR)
+ACMclasses:
+I.2.6; H.3.3
+Cite as:
+arXiv:2412.12092 [cs.LG]
+(or
+arXiv:2412.12092v1 [cs.LG] for this version)
+https://doi.org/10.48550/arXiv.2412.12092
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 2. 【2412.11919】RetroLLM: Empowering Large Language Models to Retrieve Fine-grained Evidence within Generation
+ 链接:https://arxiv.org/abs/2412.11919
+ 作者:Xiaoxi Li,Jiajie Jin,Yujia Zhou,Yongkang Wu,Zhonghua Li,Qi Ye,Zhicheng Dou
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:Large language models, exhibit remarkable generative, remarkable generative capabilities, Large language, language models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) exhibit remarkable generative capabilities but often suffer from hallucinations. Retrieval-augmented generation (RAG) offers an effective solution by incorporating external knowledge, but existing methods still face several limitations: additional deployment costs of separate retrievers, redundant input tokens from retrieved text chunks, and the lack of joint optimization of retrieval and generation. To address these issues, we propose \textbf{RetroLLM}, a unified framework that integrates retrieval and generation into a single, cohesive process, enabling LLMs to directly generate fine-grained evidence from the corpus with constrained decoding. Moreover, to mitigate false pruning in the process of constrained evidence generation, we introduce (1) hierarchical FM-Index constraints, which generate corpus-constrained clues to identify a subset of relevant documents before evidence generation, reducing irrelevant decoding space; and (2) a forward-looking constrained decoding strategy, which considers the relevance of future sequences to improve evidence accuracy. Extensive experiments on five open-domain QA datasets demonstrate RetroLLM's superior performance across both in-domain and out-of-domain tasks. The code is available at \url{this https URL}.
+
+
+
+ 3. 【2412.11905】One for Dozens: Adaptive REcommendation for All Domains with Counterfactual Augmentation
+ 链接:https://arxiv.org/abs/2412.11905
+ 作者:Huishi Luo,Yiwen Chen,Yiqing Wu,Fuzhen Zhuang,Deqing Wang
+ 类目:Information Retrieval (cs.IR)
+ 关键词:enhance recommendation performance, Multi-domain recommendation, traditional MDR algorithms, aims to enhance, domains
+ 备注: Accepted at AAAI 2025
+
+ 点击查看摘要
+ Abstract:Multi-domain recommendation (MDR) aims to enhance recommendation performance across various domains. However, real-world recommender systems in online platforms often need to handle dozens or even hundreds of domains, far exceeding the capabilities of traditional MDR algorithms, which typically focus on fewer than five domains. Key challenges include a substantial increase in parameter count, high maintenance costs, and intricate knowledge transfer patterns across domains. Furthermore, minor domains often suffer from data sparsity, leading to inadequate training in classical methods. To address these issues, we propose Adaptive REcommendation for All Domains with counterfactual augmentation (AREAD). AREAD employs a hierarchical structure with a limited number of expert networks at several layers, to effectively capture domain knowledge at different granularities. To adaptively capture the knowledge transfer pattern across domains, we generate and iteratively prune a hierarchical expert network selection mask for each domain during training. Additionally, counterfactual assumptions are used to augment data in minor domains, supporting their iterative mask pruning. Our experiments on two public datasets, each encompassing over twenty domains, demonstrate AREAD's effectiveness, especially in data-sparse domains. Source code is available at this https URL.
+
+
+
+ 4. 【2412.11864】Investigating Mixture of Experts in Dense Retrieval
+ 链接:https://arxiv.org/abs/2412.11864
+ 作者:Effrosyni Sokli,Pranav Kasela,Georgios Peikos,Gabriella Pasi
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI)
+ 关键词:advanced Information Retrieval, Dense Retrieval Models, advanced Information, Dense Retrieval, Information Retrieval
+ 备注:
+
+ 点击查看摘要
+ Abstract:While Dense Retrieval Models (DRMs) have advanced Information Retrieval (IR), one limitation of these neural models is their narrow generalizability and robustness. To cope with this issue, one can leverage the Mixture-of-Experts (MoE) architecture. While previous IR studies have incorporated MoE architectures within the Transformer layers of DRMs, our work investigates an architecture that integrates a single MoE block (SB-MoE) after the output of the final Transformer layer. Our empirical evaluation investigates how SB-MoE compares, in terms of retrieval effectiveness, to standard fine-tuning. In detail, we fine-tune three DRMs (TinyBERT, BERT, and Contriever) across four benchmark collections with and without adding the MoE block. Moreover, since MoE showcases performance variations with respect to its parameters (i.e., the number of experts), we conduct additional experiments to investigate this aspect further. The findings show the effectiveness of SB-MoE especially for DRMs with a low number of parameters (i.e., TinyBERT), as it consistently outperforms the fine-tuned underlying model on all four benchmarks. For DRMs with a higher number of parameters (i.e., BERT and Contriever), SB-MoE requires larger numbers of training samples to yield better retrieval performance.
+
+
+
+ 5. 【2412.11846】SPGL: Enhancing Session-based Recommendation with Single Positive Graph Learning
+ 链接:https://arxiv.org/abs/2412.11846
+ 作者:Tiantian Liang,Zhe Yang
+ 类目:Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:Session-based recommendation seeks, Session-based recommendation, seeks to forecast, Single Positive optimization, session-based recommendation model
+ 备注: ICONIP 2024
+
+ 点击查看摘要
+ Abstract:Session-based recommendation seeks to forecast the next item a user will be interested in, based on their interaction sequences. Due to limited interaction data, session-based recommendation faces the challenge of limited data availability. Traditional methods enhance feature learning by constructing complex models to generate positive and negative samples. This paper proposes a session-based recommendation model using Single Positive optimization loss and Graph Learning (SPGL) to deal with the problem of data sparsity, high model complexity and weak transferability. SPGL utilizes graph convolutional networks to generate global item representations and batch session representations, effectively capturing intrinsic relationships between items. The use of single positive optimization loss improves uniformity of item representations, thereby enhancing recommendation accuracy. In the intent extractor, SPGL considers the hop count of the adjacency matrix when constructing the directed global graph to fully integrate spatial information. It also takes into account the reverse positional information of items when constructing session representations to incorporate temporal information. Comparative experiments across three benchmark datasets, Tmall, RetailRocket and Diginetica, demonstrate the model's effectiveness. The source code can be accessed on this https URL .
+
+
+
+ 6. 【2412.11832】A Distributed Collaborative Retrieval Framework Excelling in All Queries and Corpora based on Zero-shot Rank-Oriented Automatic Evaluation
+ 链接:https://arxiv.org/abs/2412.11832
+ 作者:Tian-Yi Che,Xian-Ling Mao,Chun Xu,Cheng-Xin Xin,Heng-Da Xu,Jin-Yu Liu,Heyan Huang
+ 类目:Information Retrieval (cs.IR)
+ 关键词:Numerous retrieval models, demonstrated remarkable performance, queries and corpora, Numerous retrieval, including sparse
+ 备注:
+
+ 点击查看摘要
+ Abstract:Numerous retrieval models, including sparse, dense and llm-based methods, have demonstrated remarkable performance in predicting the relevance between queries and corpora. However, the preliminary effectiveness analysis experiments indicate that these models fail to achieve satisfactory performance on the majority of queries and corpora, revealing their effectiveness restricted to specific scenarios. Thus, to tackle this problem, we propose a novel Distributed Collaborative Retrieval Framework (DCRF), outperforming each single model across all queries and corpora. Specifically, the framework integrates various retrieval models into a unified system and dynamically selects the optimal results for each user's query. It can easily aggregate any retrieval model and expand to any application scenarios, illustrating its flexibility and this http URL, to reduce maintenance and training costs, we design four effective prompting strategies with large language models (LLMs) to evaluate the quality of ranks without reliance of labeled data. Extensive experiments demonstrate that proposed framework, combined with 8 efficient retrieval models, can achieve performance comparable to effective listwise methods like RankGPT and ListT5, while offering superior efficiency. Besides, DCRF surpasses all selected retrieval models on the most datasets, indicating the effectiveness of our prompting strategies on rank-oriented automatic evaluation.
+
+
+
+ 7. 【2412.11818】Leveraging User-Generated Metadata of Online Videos for Cover Song Identification
+ 链接:https://arxiv.org/abs/2412.11818
+ 作者:Simon Hachmeier,Robert Jäschke
+ 类目:Multimedia (cs.MM); Information Retrieval (cs.IR)
+ 关键词:cover song identification, cover song, rich source, song identification, cover
+ 备注: accepted for presentation at NLP for Music and Audio (NLP4MusA) 2024
+
+ 点击查看摘要
+ Abstract:YouTube is a rich source of cover songs. Since the platform itself is organized in terms of videos rather than songs, the retrieval of covers is not trivial. The field of cover song identification addresses this problem and provides approaches that usually rely on audio content. However, including the user-generated video metadata available on YouTube promises improved identification results. In this paper, we propose a multi-modal approach for cover song identification on online video platforms. We combine the entity resolution models with audio-based approaches using a ranking model. Our findings implicate that leveraging user-generated metadata can stabilize cover song identification performance on YouTube.
+
+
+
+ 8. 【2412.11787】A Method for Detecting Legal Article Competition for Korean Criminal Law Using a Case-augmented Mention Graph
+ 链接:https://arxiv.org/abs/2412.11787
+ 作者:Seonho An,Young Yik Rhim,Min-Soo Kim
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:increasingly complex, growing more intricate, making it progressively, social systems, systems become increasingly
+ 备注: under review
+
+ 点击查看摘要
+ Abstract:As social systems become increasingly complex, legal articles are also growing more intricate, making it progressively harder for humans to identify any potential competitions among them, particularly when drafting new laws or applying existing laws. Despite this challenge, no method for detecting such competitions has been proposed so far. In this paper, we propose a new legal AI task called Legal Article Competition Detection (LACD), which aims to identify competing articles within a given law. Our novel retrieval method, CAM-Re2, outperforms existing relevant methods, reducing false positives by 20.8% and false negatives by 8.3%, while achieving a 98.2% improvement in precision@5, for the LACD task. We release our codes at this https URL.
+
+
+
+ 9. 【2412.11758】Establishing a Foundation for Tetun Text Ad-Hoc Retrieval: Indexing, Stemming, Retrieval, and Ranking
+ 链接:https://arxiv.org/abs/2412.11758
+ 作者:Gabriel de Jesus,Sérgio Nunes
+ 类目:Information Retrieval (cs.IR)
+ 关键词:Searching for information, requires effective retrieval, Tetun, Tetun text retrieval, internet and digital
+ 备注:
+
+ 点击查看摘要
+ Abstract:Searching for information on the internet and digital platforms to satisfy an information need requires effective retrieval solutions. However, such solutions are not yet available for Tetun, making it challenging to find relevant documents for text-based search queries in this language. To address these challenges, this study investigates Tetun text retrieval with a focus on the ad-hoc retrieval task. It begins by developing essential language resources -- including a list of stopwords, a stemmer, and a test collection -- which serve as foundational components for solutions tailored to Tetun text retrieval. Various strategies are then explored using both document titles and content to evaluate retrieval effectiveness. The results show that retrieving document titles, after removing hyphens and apostrophes without applying stemming, significantly improves retrieval performance compared to the baseline. Efficiency increases by 31.37%, while effectiveness achieves an average gain of 9.40% in MAP@10 and 30.35% in nDCG@10 with DFR BM25. Beyond the top-10 cutoff point, Hiemstra LM demonstrates strong performance across various retrieval strategies and evaluation metrics. Contributions of this work include the development of Labadain-Stopwords (a list of 160 Tetun stopwords), Labadain-Stemmer (a Tetun stemmer with three variants), and Labadain-Avaliadór (a Tetun test collection containing 59 topics, 33,550 documents, and 5,900 qrels).
+
+
+
+ 10. 【2412.11747】Beyond Graph Convolution: Multimodal Recommendation with Topology-aware MLPs
+ 链接:https://arxiv.org/abs/2412.11747
+ 作者:Junjie Huang,Jiarui Qin,Yong Yu,Weinan Zhang
+ 类目:Information Retrieval (cs.IR)
+ 关键词:richer semantic information, exploit richer semantic, Graph Convolutional Networks, multimodal recommender systems, leveraging Graph Convolutional
+ 备注: AAAI 2025. 11 pages, 9 figures
+
+ 点击查看摘要
+ Abstract:Given the large volume of side information from different modalities, multimodal recommender systems have become increasingly vital, as they exploit richer semantic information beyond user-item interactions. Recent works highlight that leveraging Graph Convolutional Networks (GCNs) to explicitly model multimodal item-item relations can significantly enhance recommendation performance. However, due to the inherent over-smoothing issue of GCNs, existing models benefit only from shallow GCNs with limited representation power. This drawback is especially pronounced when facing complex and high-dimensional patterns such as multimodal data, as it requires large-capacity models to accommodate complicated correlations. To this end, in this paper, we investigate bypassing GCNs when modeling multimodal item-item relationship. More specifically, we propose a Topology-aware Multi-Layer Perceptron (TMLP), which uses MLPs instead of GCNs to model the relationships between items. TMLP enhances MLPs with topological pruning to denoise item-item relations and intra (inter)-modality learning to integrate higher-order modality correlations. Extensive experiments on three real-world datasets verify TMLP's superiority over nine baselines. We also find that by discarding the internal message passing in GCNs, which is sensitive to node connections, TMLP achieves significant improvements in both training efficiency and robustness against existing models.
+
+
+
+ 11. 【2412.11729】STAIR: Manipulating Collaborative and Multimodal Information for E-Commerce Recommendation
+ 链接:https://arxiv.org/abs/2412.11729
+ 作者:Cong Xu,Yunhang He,Jun Wang,Wei Zhang
+ 类目:Information Retrieval (cs.IR)
+ 关键词:multimodal recommendation methods, multimodal information, Vanilla graph convolution, mining of modalities, fully utilize
+ 备注: Accepted at AAAI 2025
+
+ 点击查看摘要
+ Abstract:While the mining of modalities is the focus of most multimodal recommendation methods, we believe that how to fully utilize both collaborative and multimodal information is pivotal in e-commerce scenarios where, as clarified in this work, the user behaviors are rarely determined entirely by multimodal features. In order to combine the two distinct types of information, some additional challenges are encountered: 1) Modality erasure: Vanilla graph convolution, which proves rather useful in collaborative filtering, however erases multimodal information; 2) Modality forgetting: Multimodal information tends to be gradually forgotten as the recommendation loss essentially facilitates the learning of collaborative information. To this end, we propose a novel approach named STAIR, which employs a novel STepwise grAph convolution to enable a co-existence of collaborative and multimodal Information in e-commerce Recommendation. Besides, it starts with the raw multimodal features as an initialization, and the forgetting problem can be significantly alleviated through constrained embedding updates. As a result, STAIR achieves state-of-the-art recommendation performance on three public e-commerce datasets with minimal computational and memory costs. Our code is available at this https URL.
+
+
+
+ 12. 【2412.11589】Future Sight and Tough Fights: Revolutionizing Sequential Recommendation with FENRec
+ 链接:https://arxiv.org/abs/2412.11589
+ 作者:Yu-Hsuan Huang,Ling Lo,Hongxia Xie,Hong-Han Shuai,Wen-Huang Cheng
+ 类目:Information Retrieval (cs.IR)
+ 关键词:time-ordered interaction sequences, analyzing time-ordered interaction, systems predict user, predict user preferences, systems predict
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Sequential recommendation (SR) systems predict user preferences by analyzing time-ordered interaction sequences. A common challenge for SR is data sparsity, as users typically interact with only a limited number of items. While contrastive learning has been employed in previous approaches to address the challenges, these methods often adopt binary labels, missing finer patterns and overlooking detailed information in subsequent behaviors of users. Additionally, they rely on random sampling to select negatives in contrastive learning, which may not yield sufficiently hard negatives during later training stages. In this paper, we propose Future data utilization with Enduring Negatives for contrastive learning in sequential Recommendation (FENRec). Our approach aims to leverage future data with time-dependent soft labels and generate enduring hard negatives from existing data, thereby enhancing the effectiveness in tackling data sparsity. Experiment results demonstrate our state-of-the-art performance across four benchmark datasets, with an average improvement of 6.16\% across all metrics.
+
+
+
+ 13. 【2412.11557】Enhancing Healthcare Recommendation Systems with a Multimodal LLMs-based MOE Architecture
+ 链接:https://arxiv.org/abs/2412.11557
+ 作者:Jingyu Xu,Yang Wang
+ 类目:Information Retrieval (cs.IR); Databases (cs.DB)
+ 关键词:fields urgently require, urgently require advanced, require advanced architectures, advanced architectures capable, address specific problems
+ 备注: 10 page, accpted by Conf-SMPL conference
+
+ 点击查看摘要
+ Abstract:With the increasing availability of multimodal data, many fields urgently require advanced architectures capable of effectively integrating these diverse data sources to address specific problems. This study proposes a hybrid recommendation model that combines the Mixture of Experts (MOE) framework with large language models to enhance the performance of recommendation systems in the healthcare domain. We built a small dataset for recommending healthy food based on patient descriptions and evaluated the model's performance on several key metrics, including Precision, Recall, NDCG, and MAP@5. The experimental results show that the hybrid model outperforms the baseline models, which use MOE or large language models individually, in terms of both accuracy and personalized recommendation effectiveness. The paper finds image data provided relatively limited improvement in the performance of the personalized recommendation system, particularly in addressing the cold start problem. Then, the issue of reclassification of images also affected the recommendation results, especially when dealing with low-quality images or changes in the appearance of items, leading to suboptimal performance. The findings provide valuable insights into the development of powerful, scalable, and high-performance recommendation systems, advancing the application of personalized recommendation technologies in real-world domains such as healthcare.
+
+
+
+ 14. 【2412.11431】Optimized Quran Passage Retrieval Using an Expanded QA Dataset and Fine-Tuned Language Models
+ 链接:https://arxiv.org/abs/2412.11431
+ 作者:Mohamed Basem,Islam Oshallah,Baraa Hikal,Ali Hamdi,Ammar Mohamed
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:modern standard Arabic, standard Arabic, classical Arabic, Understanding the deep, Holy Qur'an
+ 备注:
+
+ 点击查看摘要
+ Abstract:Understanding the deep meanings of the Qur'an and bridging the language gap between modern standard Arabic and classical Arabic is essential to improve the question-and-answer system for the Holy Qur'an. The Qur'an QA 2023 shared task dataset had a limited number of questions with weak model retrieval. To address this challenge, this work updated the original dataset and improved the model accuracy. The original dataset, which contains 251 questions, was reviewed and expanded to 629 questions with question diversification and reformulation, leading to a comprehensive set of 1895 categorized into single-answer, multi-answer, and zero-answer types. Extensive experiments fine-tuned transformer models, including AraBERT, RoBERTa, CAMeLBERT, AraELECTRA, and BERT. The best model, AraBERT-base, achieved a MAP@10 of 0.36 and MRR of 0.59, representing improvements of 63% and 59%, respectively, compared to the baseline scores (MAP@10: 0.22, MRR: 0.37). Additionally, the dataset expansion led to improvements in handling "no answer" cases, with the proposed approach achieving a 75% success rate for such instances, compared to the baseline's 25%. These results demonstrate the effect of dataset improvement and model architecture optimization in increasing the performance of QA systems for the Holy Qur'an, with higher accuracy, recall, and precision.
+
+
+
+ 15. 【2412.11216】Distribution-Consistency-Guided Multi-modal Hashing
+ 链接:https://arxiv.org/abs/2412.11216
+ 作者:Jin-Yu Liu,Xian-Ling Mao,Tian-Yi Che,Rong-Cheng Tu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:low storage requirements, Multi-modal hashing methods, gained popularity due, Multi-modal hashing, noisy labels
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multi-modal hashing methods have gained popularity due to their fast speed and low storage requirements. Among them, the supervised methods demonstrate better performance by utilizing labels as supervisory signals compared with unsupervised methods. Currently, for almost all supervised multi-modal hashing methods, there is a hidden assumption that training sets have no noisy labels. However, labels are often annotated incorrectly due to manual labeling in real-world scenarios, which will greatly harm the retrieval performance. To address this issue, we first discover a significant distribution consistency pattern through experiments, i.e., the 1-0 distribution of the presence or absence of each category in the label is consistent with the high-low distribution of similarity scores of the hash codes relative to category centers. Then, inspired by this pattern, we propose a novel Distribution-Consistency-Guided Multi-modal Hashing (DCGMH), which aims to filter and reconstruct noisy labels to enhance retrieval performance. Specifically, the proposed method first randomly initializes several category centers, which are used to compute the high-low distribution of similarity scores; Noisy and clean labels are then separately filtered out via the discovered distribution consistency pattern to mitigate the impact of noisy labels; Subsequently, a correction strategy, which is indirectly designed via the distribution consistency pattern, is applied to the filtered noisy labels, correcting high-confidence ones while treating low-confidence ones as unlabeled for unsupervised learning, thereby further enhancing the model's performance. Extensive experiments on three widely used datasets demonstrate the superiority of the proposed method compared to state-of-the-art baselines in multi-modal retrieval tasks. The code is available at this https URL.
+
+
+
+ 16. 【2412.11203】ask-Oriented Dialog Systems for the Senegalese Wolof Language
+ 链接:https://arxiv.org/abs/2412.11203
+ 作者:Derguene Mbaye,Moussa Diallo
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Human-Computer Interaction (cs.HC); Information Retrieval (cs.IR)
+ 关键词:large language models, recent years, interest in conversational, conversational agents, rise of large
+ 备注: 10 pages, 3 tables, 6 figures, The 31st International Conference on Computational Linguistics (COLING 2025)
+
+ 点击查看摘要
+ Abstract:In recent years, we are seeing considerable interest in conversational agents with the rise of large language models (LLMs). Although they offer considerable advantages, LLMs also present significant risks, such as hallucination, which hinder their widespread deployment in industry. Moreover, low-resource languages such as African ones are still underrepresented in these systems limiting their performance in these languages. In this paper, we illustrate a more classical approach based on modular architectures of Task-oriented Dialog Systems (ToDS) offering better control over outputs. We propose a chatbot generation engine based on the Rasa framework and a robust methodology for projecting annotations onto the Wolof language using an in-house machine translation system. After evaluating a generated chatbot trained on the Amazon Massive dataset, our Wolof Intent Classifier performs similarly to the one obtained for French, which is a resource-rich language. We also show that this approach is extensible to other low-resource languages, thanks to the intent classifier's language-agnostic pipeline, simplifying the design of chatbots in these languages.
+
+
+
+ 17. 【2412.11127】Modeling the Heterogeneous Duration of User Interest in Time-Dependent Recommendation: A Hidden Semi-Markov Approach
+ 链接:https://arxiv.org/abs/2412.11127
+ 作者:Haidong Zhang,Wancheng Ni,Xin Li,Yiping Yang
+ 类目:Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:Recommender systems, time-dependent recommender systems, education materials, suggesting books, exploring their behaviors
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recommender systems are widely used for suggesting books, education materials, and products to users by exploring their behaviors. In reality, users' preferences often change over time, leading to studies on time-dependent recommender systems. However, most existing approaches that deal with time information remain primitive. In this paper, we extend existing methods and propose a hidden semi-Markov model to track the change of users' interests. Particularly, this model allows for capturing the different durations of user stays in a (latent) interest state, which can better model the heterogeneity of user interests and focuses. We derive an expectation maximization algorithm to estimate the parameters of the framework and predict users' actions. Experiments on three real-world datasets show that our model significantly outperforms the state-of-the-art time-dependent and static benchmark methods. Further analyses of the experiment results indicate that the performance improvement is related to the heterogeneity of state durations and the drift of user interests in the dataset.
+
+
+
+ 18. 【2412.11105】Multi-Graph Co-Training for Capturing User Intent in Session-based Recommendation
+ 链接:https://arxiv.org/abs/2412.11105
+ 作者:Zhe Yang,Tiantian Liang
+ 类目:Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:focuses on predicting, interact with based, based on sequences, sequences of anonymous, Session-based recommendation focuses
+ 备注: COLING 2025 Main Conference
+
+ 点击查看摘要
+ Abstract:Session-based recommendation focuses on predicting the next item a user will interact with based on sequences of anonymous user sessions. A significant challenge in this field is data sparsity due to the typically short-term interactions. Most existing methods rely heavily on users' current interactions, overlooking the wealth of auxiliary information available. To address this, we propose a novel model, the Multi-Graph Co-Training model (MGCOT), which leverages not only the current session graph but also similar session graphs and a global item relation graph. This approach allows for a more comprehensive exploration of intrinsic relationships and better captures user intent from multiple views, enabling session representations to complement each other. Additionally, MGCOT employs multi-head attention mechanisms to effectively capture relevant session intent and uses contrastive learning to form accurate and robust session representations. Extensive experiments on three datasets demonstrate that MGCOT significantly enhances the performance of session-based recommendations, particularly on the Diginetica dataset, achieving improvements up to 2.00% in P@20 and 10.70% in MRR@20. Resources have been made publicly available in our GitHub repository this https URL.
+
+
+
+ 19. 【2412.11087】Leveraging Large Vision-Language Model as User Intent-aware Encoder for Composed Image Retrieval
+ 链接:https://arxiv.org/abs/2412.11087
+ 作者:Zelong Sun,Dong Jing,Guoxing Yang,Nanyi Fei,Zhiwu Lu
+ 类目:Information Retrieval (cs.IR)
+ 关键词:Composed Image Retrieval, retrieve target images, Composed Image, Image Retrieval, hybrid-modality query consisting
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Composed Image Retrieval (CIR) aims to retrieve target images from candidate set using a hybrid-modality query consisting of a reference image and a relative caption that describes the user intent. Recent studies attempt to utilize Vision-Language Pre-training Models (VLPMs) with various fusion strategies for addressing the this http URL, these methods typically fail to simultaneously meet two key requirements of CIR: comprehensively extracting visual information and faithfully following the user intent. In this work, we propose CIR-LVLM, a novel framework that leverages the large vision-language model (LVLM) as the powerful user intent-aware encoder to better meet these requirements. Our motivation is to explore the advanced reasoning and instruction-following capabilities of LVLM for accurately understanding and responding the user intent. Furthermore, we design a novel hybrid intent instruction module to provide explicit intent guidance at two levels: (1) The task prompt clarifies the task requirement and assists the model in discerning user intent at the task level. (2) The instance-specific soft prompt, which is adaptively selected from the learnable prompt pool, enables the model to better comprehend the user intent at the instance level compared to a universal prompt for all instances. CIR-LVLM achieves state-of-the-art performance across three prominent benchmarks with acceptable inference efficiency. We believe this study provides fundamental insights into CIR-related fields.
+
+
+
+ 20. 【2412.11068】RecSys Arena: Pair-wise Recommender System Evaluation with Large Language Models
+ 链接:https://arxiv.org/abs/2412.11068
+ 作者:Zhuo Wu,Qinglin Jia,Chuhan Wu,Zhaocheng Du,Shuai Wang,Zan Wang,Zhenhua Dong
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI)
+ 关键词:Evaluating the quality, design and optimization, LLM Chatbot Arena, Evaluating, offline metrics
+ 备注:
+
+ 点击查看摘要
+ Abstract:Evaluating the quality of recommender systems is critical for algorithm design and optimization. Most evaluation methods are computed based on offline metrics for quick algorithm evolution, since online experiments are usually risky and time-consuming. However, offline evaluation usually cannot fully reflect users' preference for the outcome of different recommendation algorithms, and the results may not be consistent with online A/B test. Moreover, many offline metrics such as AUC do not offer sufficient information for comparing the subtle differences between two competitive recommender systems in different aspects, which may lead to substantial performance differences in long-term online serving. Fortunately, due to the strong commonsense knowledge and role-play capability of large language models (LLMs), it is possible to obtain simulated user feedback on offline recommendation results. Motivated by the idea of LLM Chatbot Arena, in this paper we present the idea of RecSys Arena, where the recommendation results given by two different recommender systems in each session are evaluated by an LLM judger to obtain fine-grained evaluation feedback. More specifically, for each sample we use LLM to generate a user profile description based on user behavior history or off-the-shelf profile features, which is used to guide LLM to play the role of this user and evaluate the relative preference for two recommendation results generated by different models. Through extensive experiments on two recommendation datasets in different scenarios, we demonstrate that many different LLMs not only provide general evaluation results that are highly consistent with canonical offline metrics, but also provide rich insight in many subjective aspects. Moreover, it can better distinguish different algorithms with comparable performance in terms of AUC and nDCG.
+
+
+
+ 21. 【2412.10858】CRENER: A Character Relation Enhanced Chinese NER Model
+ 链接:https://arxiv.org/abs/2412.10858
+ 作者:Yaqiong Qiao,Shixuan Peng
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:Chinese NER, Named Entity Recognition, Chinese Named Entity, Chinese NER accuracy, Chinese NER task
+ 备注:
+
+ 点击查看摘要
+ Abstract:Chinese Named Entity Recognition (NER) is an important task in information extraction, which has a significant impact on downstream applications. Due to the lack of natural separators in Chinese, previous NER methods mostly relied on external dictionaries to enrich the semantic and boundary information of Chinese words. However, such methods may introduce noise that affects the accuracy of named entity recognition. To this end, we propose a character relation enhanced Chinese NER model (CRENER). This model defines four types of tags that reflect the relationships between characters, and proposes a fine-grained modeling of the relationships between characters based on three types of relationships: adjacency relations between characters, relations between characters and tags, and relations between tags, to more accurately identify entity boundaries and improve Chinese NER accuracy. Specifically, we transform the Chinese NER task into a character-character relationship classification task, ensuring the accuracy of entity boundary recognition through joint modeling of relation tags. To enhance the model's ability to understand contextual information, WRENER further constructed an adapted transformer encoder that combines unscaled direction-aware and distance-aware masked self-attention mechanisms. Moreover, a relationship representation enhancement module was constructed to model predefined relationship tags, effectively mining the relationship representations between characters and tags. Experiments conducted on four well-known Chinese NER benchmark datasets have shown that the proposed model outperforms state-of-the-art baselines. The ablation experiment also demonstrated the effectiveness of the proposed model.
+
+
+
+ 22. 【2412.10787】Why Not Together? A Multiple-Round Recommender System for Queries and Items
+ 链接:https://arxiv.org/abs/2412.10787
+ 作者:Jiarui Jin,Xianyu Chen,Weinan Zhang,Yong Yu,Jun Wang
+ 类目:Information Retrieval (cs.IR)
+ 关键词:recommender systems involves, systems involves modeling, modeling user preferences, involves modeling user, fundamental technique
+ 备注: KDD 2025
+
+ 点击查看摘要
+ Abstract:A fundamental technique of recommender systems involves modeling user preferences, where queries and items are widely used as symbolic representations of user interests. Queries delineate user needs at an abstract level, providing a high-level description, whereas items operate on a more specific and concrete level, representing the granular facets of user preference. While practical, both query and item recommendations encounter the challenge of sparse user feedback. To this end, we propose a novel approach named Multiple-round Auto Guess-and-Update System (MAGUS) that capitalizes on the synergies between both types, allowing us to leverage both query and item information to form user interests. This integrated system introduces a recursive framework that could be applied to any recommendation method to exploit queries and items in historical interactions and to provide recommendations for both queries and items in each interaction round. Empirical results from testing 12 different recommendation methods demonstrate that integrating queries into item recommendations via MAGUS significantly enhances the efficiency, with which users can identify their preferred items during multiple-round interactions.
+
+
+
+ 23. 【2412.10770】Learned Data Compression: Challenges and Opportunities for the Future
+ 链接:https://arxiv.org/abs/2412.10770
+ 作者:Qiyu Liu,Siyuan Han,Jianwei Liao,Jin Li,Jingshu Peng,Jun Du,Lei Chen
+ 类目:Databases (cs.DB); Information Retrieval (cs.IR)
+ 关键词:Compressing integer keys, Compressing integer, emph, multiple communities, high-performance computing
+ 备注:
+
+ 点击查看摘要
+ Abstract:Compressing integer keys is a fundamental operation among multiple communities, such as database management (DB), information retrieval (IR), and high-performance computing (HPC). Recent advances in \emph{learned indexes} have inspired the development of \emph{learned compressors}, which leverage simple yet compact machine learning (ML) models to compress large-scale sorted keys. The core idea behind learned compressors is to \emph{losslessly} encode sorted keys by approximating them with \emph{error-bounded} ML models (e.g., piecewise linear functions) and using a \emph{residual array} to guarantee accurate key reconstruction.
+While the concept of learned compressors remains in its early stages of exploration, our benchmark results demonstrate that an SIMD-optimized learned compressor can significantly outperform state-of-the-art CPU-based compressors. Drawing on our preliminary experiments, this vision paper explores the potential of learned data compression to enhance critical areas in DBMS and related domains. Furthermore, we outline the key technical challenges that existing systems must address when integrating this emerging methodology.
+
Subjects:
+Databases (cs.DB); Information Retrieval (cs.IR)
+Cite as:
+arXiv:2412.10770 [cs.DB]
+(or
+arXiv:2412.10770v1 [cs.DB] for this version)
+https://doi.org/10.48550/arXiv.2412.10770
+Focus to learn more
+ arXiv-issued DOI via DataCite</p>
+
+
+
+
+ 24. 【2412.10745】Enhancing Event Extraction from Short Stories through Contextualized Prompts
+ 链接:https://arxiv.org/abs/2412.10745
+ 作者:Chaitanya Kirti(1),Ayon Chattopadhyay(1),Ashish Anand(1),Prithwijit Guha(1) ((1) Indian Institute of Technology Guwahati)
+ 类目:Information Retrieval (cs.IR)
+ 关键词:natural language processing, important natural language, Event extraction, language processing, natural language
+ 备注: 47 pages, 8 figures, Planning to submit in Elsevier (Computer Speech and Language Journal)
+
+ 点击查看摘要
+ Abstract:Event extraction is an important natural language processing (NLP) task of identifying events in an unstructured text. Although a plethora of works deal with event extraction from new articles, clinical text etc., only a few works focus on event extraction from literary content. Detecting events in short stories presents several challenges to current systems, encompassing a different distribution of events as compared to other domains and the portrayal of diverse emotional conditions. This paper presents \texttt{Vrittanta-EN}, a collection of 1000 English short stories annotated for real events. Exploring this field could result in the creation of techniques and resources that support literary scholars in improving their effectiveness. This could simultaneously influence the field of Natural Language Processing. Our objective is to clarify the intricate idea of events in the context of short stories. Towards the objective, we collected 1,000 short stories written mostly for children in the Indian context. Further, we present fresh guidelines for annotating event mentions and their categories, organized into \textit{seven distinct classes}. The classes are {\tt{COGNITIVE-MENTAL-STATE(CMS), COMMUNICATION(COM), CONFLICT(CON), GENERAL-ACTIVITY(GA), LIFE-EVENT(LE), MOVEMENT(MOV), and OTHERS(OTH)}}. Subsequently, we apply these guidelines to annotate the short story dataset. Later, we apply the baseline methods for automatically detecting and categorizing events. We also propose a prompt-based method for event detection and classification. The proposed method outperforms the baselines, while having significant improvement of more than 4\% for the class \texttt{CONFLICT} in event classification task.
+
+
+
+ 25. 【2412.10737】Sentiment and Hashtag-aware Attentive Deep Neural Network for Multimodal Post Popularity Prediction
+ 链接:https://arxiv.org/abs/2412.10737
+ 作者:Shubhi Bansal,Mohit Kumar,Chandravardhan Singh Raghaw,Nagendra Kumar
+ 类目:Information Retrieval (cs.IR); Social and Information Networks (cs.SI)
+ 关键词:comprising multiple modes, posts comprising multiple, media users articulate, social media platforms, Social media users
+ 备注:
+
+ 点击查看摘要
+ Abstract:Social media users articulate their opinions on a broad spectrum of subjects and share their experiences through posts comprising multiple modes of expression, leading to a notable surge in such multimodal content on social media platforms. Nonetheless, accurately forecasting the popularity of these posts presents a considerable challenge. Prevailing methodologies primarily center on the content itself, thereby overlooking the wealth of information encapsulated within alternative modalities such as visual demographics, sentiments conveyed through hashtags and adequately modeling the intricate relationships among hashtags, texts, and accompanying images. This oversight limits the ability to capture emotional connection and audience relevance, significantly influencing post popularity. To address these limitations, we propose a seNtiment and hAshtag-aware attentive deep neuRal netwoRk for multimodAl posT pOpularity pRediction, herein referred to as NARRATOR that extracts visual demographics from faces appearing in images and discerns sentiment from hashtag usage, providing a more comprehensive understanding of the factors influencing post popularity Moreover, we introduce a hashtag-guided attention mechanism that leverages hashtags as navigational cues, guiding the models focus toward the most pertinent features of textual and visual modalities, thus aligning with target audience interests and broader social media context. Experimental results demonstrate that NARRATOR outperforms existing methods by a significant margin on two real-world datasets. Furthermore, ablation studies underscore the efficacy of integrating visual demographics, sentiment analysis of hashtags, and hashtag-guided attention mechanisms in enhancing the performance of post popularity prediction, thereby facilitating increased audience relevance, emotional engagement, and aesthetic appeal.
+
+
+
+ 26. 【2412.10714】Movie Recommendation using Web Crawling
+ 链接:https://arxiv.org/abs/2412.10714
+ 作者:Pronit Raj,Chandrashekhar Kumar,Harshit Shekhar,Amit Kumar,Kritibas Paul,Debasish Jana
+ 类目:Information Retrieval (cs.IR)
+ 关键词:today digital world, streaming platforms offer, find content matching, digital world, streaming platforms
+ 备注: 12 pages, 3 figures, Accepted and to be published in Proceedings of 2025 International Conference on Applied Algorithms (ICAA), Kolkata, India, Dec 8-10, 2025
+
+ 点击查看摘要
+ Abstract:In today's digital world, streaming platforms offer a vast array of movies, making it hard for users to find content matching their preferences. This paper explores integrating real time data from popular movie websites using advanced HTML scraping techniques and APIs. It also incorporates a recommendation system trained on a static Kaggle dataset, enhancing the relevance and freshness of suggestions. By combining content based filtering, collaborative filtering, and a hybrid model, we create a system that utilizes both historical and real time data for more personalized suggestions. Our methodology shows that incorporating dynamic data not only boosts user satisfaction but also aligns recommendations with current viewing trends.
+
+
+
+ 27. 【2412.10701】Beyond Quantile Methods: Improved Top-K Threshold Estimation for Traditional and Learned Sparse Indexes
+ 链接:https://arxiv.org/abs/2412.10701
+ 作者:Jinrui Gou,Yifan Liu,Minghao Shao,Torsten Suel
+ 类目:Information Retrieval (cs.IR)
+ 关键词:k-th highest ranking, highest ranking result, common top-k query, top-k query processing, estimating the score
+ 备注:
+
+ 点击查看摘要
+ Abstract:Top-k threshold estimation is the problem of estimating the score of the k-th highest ranking result of a search query. A good estimate can be used to speed up many common top-k query processing algorithms, and thus a number of researchers have recently studied the problem. Among the various approaches that have been proposed, quantile methods appear to give the best estimates overall at modest computational costs, followed by sampling-based methods in certain cases. In this paper, we make two main contributions. First, we study how to get even better estimates than the state of the art. Starting from quantile-based methods, we propose a series of enhancements that give improved estimates in terms of the commonly used mean under-prediction fraction (MUF). Second, we study the threshold estimation problem on recently proposed learned sparse index structures, showing that our methods also work well for these cases. Our best methods substantially narrow the gap between the state of the art and the ideal MUF of 1.0, at some additional cost in time and space.
+
+
+
+ 28. 【2412.10680】UCDR-Adapter: Exploring Adaptation of Pre-Trained Vision-Language Models for Universal Cross-Domain Retrieval
+ 链接:https://arxiv.org/abs/2412.10680
+ 作者:Haoyu Jiang,Zhi-Qi Cheng,Gabriel Moreira,Jiawen Zhu,Jingdong Sun,Bukun Ren,Jun-Yan He,Qi Dai,Xian-Sheng Hua
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Information Retrieval (cs.IR); Multimedia (cs.MM)
+ 关键词:Universal Cross-Domain Retrieval, Universal Cross-Domain, retrieves relevant images, retrieves relevant, ensuring robust generalization
+ 备注: Accepted to WACV 2025. Project link: [this https URL](https://github.com/fine68/UCDR2024)
+
+ 点击查看摘要
+ Abstract:Universal Cross-Domain Retrieval (UCDR) retrieves relevant images from unseen domains and classes without semantic labels, ensuring robust generalization. Existing methods commonly employ prompt tuning with pre-trained vision-language models but are inherently limited by static prompts, reducing adaptability. We propose UCDR-Adapter, which enhances pre-trained models with adapters and dynamic prompt generation through a two-phase training strategy. First, Source Adapter Learning integrates class semantics with domain-specific visual knowledge using a Learnable Textual Semantic Template and optimizes Class and Domain Prompts via momentum updates and dual loss functions for robust alignment. Second, Target Prompt Generation creates dynamic prompts by attending to masked source prompts, enabling seamless adaptation to unseen domains and classes. Unlike prior approaches, UCDR-Adapter dynamically adapts to evolving data distributions, enhancing both flexibility and generalization. During inference, only the image branch and generated prompts are used, eliminating reliance on textual inputs for highly efficient retrieval. Extensive benchmark experiments show that UCDR-Adapter consistently outperforms ProS in most cases and other state-of-the-art methods on UCDR, U(c)CDR, and U(d)CDR settings.
+
+
+
+ 29. 【2412.10674】USM: Unbiased Survey Modeling for Limiting Negative User Experiences in Recommendation Systems
+ 链接:https://arxiv.org/abs/2412.10674
+ 作者:Chenghui Yu,Peiyi Li,Haoze Wu,Bingfeng Deng,Hongyu Xiong
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI)
+ 关键词:improve user experience, crucial to guardrail, signals, Negative feedback signals, guardrail content recommendations
+ 备注: 9 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:Negative feedback signals are crucial to guardrail content recommendations and improve user experience. When these signals are effectively integrated into recommendation systems, they play a vital role in preventing the promotion of harmful or undesirable content, thereby contributing to a healthier online environment. However, the challenges associated with negative signals are noteworthy. Due to the limited visibility of options for users to express negative feedback, these signals are often sparse compared to positive signals. This imbalance can lead to a skewed understanding of user preferences, resulting in recommendations that prioritize short-term engagement over long-term satisfaction. Moreover, an over-reliance on positive signals can create a filter bubble, where users are continuously exposed to content that aligns with their immediate preferences but may not be beneficial in the long run. This scenario can ultimately lead to user attrition as audiences become disillusioned with the quality of the content provided. Additionally, existing user signals frequently fail to meet specific customized requirements, such as understanding the underlying reasons for a user's likes or dislikes regarding a video. This lack of granularity hinders our ability to tailor content recommendations effectively, as we cannot identify the particular attributes of content that resonate with individual users.
+
+
+
+ 30. 【2412.10595】Recommendation and Temptation
+ 链接:https://arxiv.org/abs/2412.10595
+ 作者:Md Sanzeed Anwar,Paramveer S. Dhillon,Grant Schoenebeck
+ 类目:Information Retrieval (cs.IR); Computers and Society (cs.CY); Computer Science and Game Theory (cs.GT)
+ 关键词:users' dual-self nature, capture users' dual-self, Traditional recommender systems, long-term benefits, instant gratification
+ 备注:
+
+ 点击查看摘要
+ Abstract:Traditional recommender systems based on utility maximization and revealed preferences often fail to capture users' dual-self nature, where consumption choices are driven by both long-term benefits (enrichment) and desire for instant gratification (temptation). Consequently, these systems may generate recommendations that fail to provide long-lasting satisfaction to users. To address this issue, we propose a novel user model that accounts for this dual-self behavior and develop an optimal recommendation strategy to maximize enrichment from consumption. We highlight the limitations of historical consumption data in implementing this strategy and present an estimation framework that makes minimal assumptions and leverages explicit user feedback and implicit choice data to overcome these constraints. We evaluate our approach through both synthetic simulations and simulations based on real-world data from the MovieLens dataset. Results demonstrate that our proposed recommender can deliver superior enrichment compared to several competitive baseline algorithms that assume a single utility type and rely solely on revealed preferences. Our work emphasizes the critical importance of optimizing for enrichment in recommender systems, particularly in temptation-laden consumption contexts. Our findings have significant implications for content platforms, user experience design, and the development of responsible AI systems, paving the way for more nuanced and user-centric recommendation approaches.
+
+
+
+ 31. 【2412.10576】Agro-STAY : Collecte de donn\'ees et analyse des informations en agriculture alternative issues de YouTube
+ 链接:https://arxiv.org/abs/2412.10576
+ 作者:Laura Maxim,Julien Rabatel,Jean-Marc Douguet,Natalia Grabar,Roberto Interdonato,Sébastien Loustau,Mathieu Roche,Maguelonne Teisseire
+ 类目:Information Retrieval (cs.IR)
+ 关键词:combine energy sobriety, energy sobriety, self-production of food, arouses an increasing, increasing interest
+ 备注: 8 pages, in French language, 3 figures
+
+ 点击查看摘要
+ Abstract:To address the current crises (climatic, social, economic), the self-sufficiency -- a set of practices that combine energy sobriety, self-production of food and energy, and self-construction - arouses an increasing interest. The CNRS STAY project (Savoirs Techniques pour l'Auto-suffisance, sur YouTube) explores this topic by analyzing techniques shared on YouTube. We present Agro-STAY, a platform designed for the collection, processing, and visualization of data from YouTube videos and their comments. We use Natural Language Processing (NLP) techniques and language models, which enable a fine-grained analysis of alternative agricultural practice described online.
+--
+Face aux crises actuelles (climatiques, sociales, économiques), l'auto-suffisance -- ensemble de pratiques combinant sobriété énergétique, autoproduction alimentaire et énergétique et autoconstruction - suscite un intérêt croissant. Le projet CNRS STAY (Savoirs Techniques pour l'Auto-suffisance, sur YouTube) s'inscrit dans ce domaine en analysant les savoirs techniques diffusés sur YouTube. Nous présentons Agro-STAY, une plateforme dédiée à la collecte, au traitement et à la visualisation de données issues de vidéos YouTube et de leurs commentaires. En mobilisant des techniques de traitement automatique des langues (TAL) et des modèles de langues, ce travail permet une analyse fine des pratiques agricoles alternatives décrites en ligne.
+
Comments:
+8 pages, in Frnch language, 3 figures
+Subjects:
+Information Retrieval (cs.IR)
+Cite as:
+arXiv:2412.10576 [cs.IR]
+(or
+arXiv:2412.10576v1 [cs.IR] for this version)
+https://doi.org/10.48550/arXiv.2412.10576
+Focus to learn more
+ arXiv-issued DOI via DataCite</p>
+
+
+
+
+ 32. 【2412.10571】Evidence Contextualization and Counterfactual Attribution for Conversational QA over Heterogeneous Data with RAG Systems
+ 链接:https://arxiv.org/abs/2412.10571
+ 作者:Rishiraj Saha Roy,Joel Schlotthauer,Chris Hinze,Andreas Foltyn,Luzian Hahn,Fabian Kuech
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:Retrieval Augmented Generation, Retrieval Augmented, Augmented Generation, Conversational Question Answering, RAG
+ 备注: Extended version of demo paper accepted at WSDM 2025
+
+ 点击查看摘要
+ Abstract:Retrieval Augmented Generation (RAG) works as a backbone for interacting with an enterprise's own data via Conversational Question Answering (ConvQA). In a RAG system, a retriever fetches passages from a collection in response to a question, which are then included in the prompt of a large language model (LLM) for generating a natural language (NL) answer. However, several RAG systems today suffer from two shortcomings: (i) retrieved passages usually contain their raw text and lack appropriate document context, negatively impacting both retrieval and answering quality; and (ii) attribution strategies that explain answer generation usually rely only on similarity between the answer and the retrieved passages, thereby only generating plausible but not causal explanations. In this work, we demonstrate RAGONITE, a RAG system that remedies the above concerns by: (i) contextualizing evidence with source metadata and surrounding text; and (ii) computing counterfactual attribution, a causal explanation approach where the contribution of an evidence to an answer is determined by the similarity of the original response to the answer obtained by removing that evidence. To evaluate our proposals, we release a new benchmark ConfQuestions, with 300 hand-created conversational questions, each in English and German, coupled with ground truth URLs, completed questions, and answers from 215 public Confluence pages, that are typical of enterprise wiki spaces with heterogeneous elements. Experiments with RAGONITE on ConfQuestions show the viability of our ideas: contextualization improves RAG performance, and counterfactual attribution is effective at explaining RAG answers.
+
+
+
+ 33. 【2412.10543】RAGServe: Fast Quality-Aware RAG Systems with Configuration Adaptation
+ 链接:https://arxiv.org/abs/2412.10543
+ 作者:Siddhant Ray,Rui Pan,Zhuohan Gu,Kuntai Du,Ganesh Ananthanarayanan,Ravi Netravali,Junchen Jiang
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:Retrieval Augmented Generation, Retrieval Augmented, large language models, external knowledge, Augmented Generation
+ 备注: 17 pages, 18 figures
+
+ 点击查看摘要
+ Abstract:RAG (Retrieval Augmented Generation) allows LLMs (large language models) to generate better responses with external knowledge, but using more external knowledge often improves generation quality at the expense of response delay. Prior work either reduces the response delay (through better scheduling of RAG queries) or strives to maximize quality (which involves tuning the RAG workflow), but they fall short in optimizing the tradeoff between the delay and quality of RAG responses. This paper presents RAGServe, the first RAG system that jointly schedules queries and adapts the key RAG configurations of each query, such as the number of retrieved text chunks and synthesis methods, in order to balance quality optimization and response delay reduction. Using 4 popular RAG-QA datasets, we show that compared with the state-of-the-art RAG optimization schemes, RAGServe reduces the generation latency by $1.64-2.54\times$ without sacrificing generation quality.
+
+
+
+ 34. 【2412.10514】CRS Arena: Crowdsourced Benchmarking of Conversational Recommender Systems
+ 链接:https://arxiv.org/abs/2412.10514
+ 作者:Nolwenn Bernard,Hideaki Joko,Faegheh Hasibi,Krisztian Balog
+ 类目:Information Retrieval (cs.IR)
+ 关键词:Conversational Recommender Systems, Conversational Recommender, introduce CRS Arena, anonymous conversational recommender, CRS Arena
+ 备注: Proceedings of the Eighteenth ACM International Conference on Web Search and Data Mining (WSDM '25), March 10--14, 2025, Hannover, Germany
+
+ 点击查看摘要
+ Abstract:We introduce CRS Arena, a research platform for scalable benchmarking of Conversational Recommender Systems (CRS) based on human feedback. The platform displays pairwise battles between anonymous conversational recommender systems, where users interact with the systems one after the other before declaring either a winner or a draw. CRS Arena collects conversations and user feedback, providing a foundation for reliable evaluation and ranking of CRSs. We conduct experiments with CRS Arena on both open and closed crowdsourcing platforms, confirming that both setups produce highly correlated rankings of CRSs and conversations with similar characteristics. We release CRSArena-Dial, a dataset of 474 conversations and their corresponding user feedback, along with a preliminary ranking of the systems based on the Elo rating system. The platform is accessible at this https URL.
+
+
+
+ 35. 【2412.10381】Supervised Learning-enhanced Multi-Group Actor Critic for Live-stream Recommendation
+ 链接:https://arxiv.org/abs/2412.10381
+ 作者:Jingxin Liu,Xiang Gao,Yisha Li,Xin Li,Haiyang Lu,Ben Wang
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI)
+ 关键词:improving dwelling time, enhancing user retention, capture users' long-term, Reinforcement Learning, users' long-term engagement
+ 备注:
+
+ 点击查看摘要
+ Abstract:Reinforcement Learning (RL) has been widely applied in recommendation systems to capture users' long-term engagement, thereby improving dwelling time and enhancing user retention. In the context of a short video live-stream mixed recommendation scenario, the live-stream recommendation system (RS) decides whether to inject at most one live-stream into the video feed for each user request. To maximize long-term user engagement, it is crucial to determine an optimal live-stream injection policy for accurate live-stream allocation. However, traditional RL algorithms often face divergence and instability problems, and these issues are even more pronounced in our scenario. To address these challenges, we propose a novel Supervised Learning-enhanced Multi-Group Actor Critic algorithm (SL-MGAC). Specifically, we introduce a supervised learning-enhanced actor-critic framework that incorporates variance reduction techniques, where multi-task reward learning helps restrict bootstrapping error accumulation during critic learning. Additionally, we design a multi-group state decomposition module for both actor and critic networks to reduce prediction variance and improve model stability. Empirically, we evaluate the SL-MGAC algorithm using offline policy evaluation (OPE) and online A/B testing. Experimental results demonstrate that the proposed method not only outperforms baseline methods but also exhibits enhanced stability in online recommendation scenarios.
+
+
+计算机视觉
+
+ 1. 【2412.12096】PanSplat: 4K Panorama Synthesis with Feed-Forward Gaussian Splatting
+ 链接:https://arxiv.org/abs/2412.12096
+ 作者:Cheng Zhang,Haofei Xu,Qianyi Wu,Camilo Cruz Gambardella,Dinh Phung,Jianfei Cai
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:gained significant attention, virtual reality, virtual tours, advent of portable, autonomous driving
+ 备注: Project Page: [this https URL](https://chengzhag.github.io/publication/pansplat/) Code: [this https URL](https://github.com/chengzhag/PanSplat)
+
+ 点击查看摘要
+ Abstract:With the advent of portable 360° cameras, panorama has gained significant attention in applications like virtual reality (VR), virtual tours, robotics, and autonomous driving. As a result, wide-baseline panorama view synthesis has emerged as a vital task, where high resolution, fast inference, and memory efficiency are essential. Nevertheless, existing methods are typically constrained to lower resolutions (512 $\times$ 1024) due to demanding memory and computational requirements. In this paper, we present PanSplat, a generalizable, feed-forward approach that efficiently supports resolution up to 4K (2048 $\times$ 4096). Our approach features a tailored spherical 3D Gaussian pyramid with a Fibonacci lattice arrangement, enhancing image quality while reducing information redundancy. To accommodate the demands of high resolution, we propose a pipeline that integrates a hierarchical spherical cost volume and Gaussian heads with local operations, enabling two-step deferred backpropagation for memory-efficient training on a single A100 GPU. Experiments demonstrate that PanSplat achieves state-of-the-art results with superior efficiency and image quality across both synthetic and real-world datasets. Code will be available at \url{this https URL}.
+
+
+
+ 2. 【2412.12095】Causal Diffusion Transformers for Generative Modeling
+ 链接:https://arxiv.org/abs/2412.12095
+ 作者:Chaorui Deng,Deyao Zh,Kunchang Li,Shi Guan,Haoqi Fan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:introduce Causal Diffusion, introduce Causal, Causal Diffusion, Diffusion, Causal
+ 备注: 21 pages, 22 figures
+
+ 点击查看摘要
+ Abstract:We introduce Causal Diffusion as the autoregressive (AR) counterpart of Diffusion models. It is a next-token(s) forecasting framework that is friendly to both discrete and continuous modalities and compatible with existing next-token prediction models like LLaMA and GPT. While recent works attempt to combine diffusion with AR models, we show that introducing sequential factorization to a diffusion model can substantially improve its performance and enables a smooth transition between AR and diffusion generation modes. Hence, we propose CausalFusion - a decoder-only transformer that dual-factorizes data across sequential tokens and diffusion noise levels, leading to state-of-the-art results on the ImageNet generation benchmark while also enjoying the AR advantage of generating an arbitrary number of tokens for in-context reasoning. We further demonstrate CausalFusion's multimodal capabilities through a joint image generation and captioning model, and showcase CausalFusion's ability for zero-shot in-context image manipulations. We hope that this work could provide the community with a fresh perspective on training multimodal models over discrete and continuous data.
+
+
+
+ 3. 【2412.12093】CAP4D: Creating Animatable 4D Portrait Avatars with Morphable Multi-View Diffusion Models
+ 链接:https://arxiv.org/abs/2412.12093
+ 作者:Felix Taubner,Ruihang Zhang,Mathieu Tuli,David B. Lindell
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:applications including advertising, Reconstructing photorealistic, including advertising, virtual reality, avatar reconstruction
+ 备注: 23 pages, 15 figures
+
+ 点击查看摘要
+ Abstract:Reconstructing photorealistic and dynamic portrait avatars from images is essential to many applications including advertising, visual effects, and virtual reality. Depending on the application, avatar reconstruction involves different capture setups and constraints $-$ for example, visual effects studios use camera arrays to capture hundreds of reference images, while content creators may seek to animate a single portrait image downloaded from the internet. As such, there is a large and heterogeneous ecosystem of methods for avatar reconstruction. Techniques based on multi-view stereo or neural rendering achieve the highest quality results, but require hundreds of reference images. Recent generative models produce convincing avatars from a single reference image, but visual fidelity yet lags behind multi-view techniques. Here, we present CAP4D: an approach that uses a morphable multi-view diffusion model to reconstruct photoreal 4D (dynamic 3D) portrait avatars from any number of reference images (i.e., one to 100) and animate and render them in real time. Our approach demonstrates state-of-the-art performance for single-, few-, and multi-image 4D portrait avatar reconstruction, and takes steps to bridge the gap in visual fidelity between single-image and multi-view reconstruction techniques.
+
+
+
+ 4. 【2412.12091】Wonderland: Navigating 3D Scenes from a Single Image
+ 链接:https://arxiv.org/abs/2412.12091
+ 作者:Hanwen Liang,Junli Cao,Vidit Goel,Guocheng Qian,Sergei Korolev,Demetri Terzopoulos,Konstantinos N. Plataniotis,Sergey Tulyakov,Jian Ren
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:single arbitrary image, challenging question, paper addresses, addresses a challenging, single arbitrary
+ 备注: Project page: [this https URL](https://snap-research.github.io/wonderland/)
+
+ 点击查看摘要
+ Abstract:This paper addresses a challenging question: How can we efficiently create high-quality, wide-scope 3D scenes from a single arbitrary image? Existing methods face several constraints, such as requiring multi-view data, time-consuming per-scene optimization, low visual quality in backgrounds, and distorted reconstructions in unseen areas. We propose a novel pipeline to overcome these limitations. Specifically, we introduce a large-scale reconstruction model that uses latents from a video diffusion model to predict 3D Gaussian Splattings for the scenes in a feed-forward manner. The video diffusion model is designed to create videos precisely following specified camera trajectories, allowing it to generate compressed video latents that contain multi-view information while maintaining 3D consistency. We train the 3D reconstruction model to operate on the video latent space with a progressive training strategy, enabling the efficient generation of high-quality, wide-scope, and generic 3D scenes. Extensive evaluations across various datasets demonstrate that our model significantly outperforms existing methods for single-view 3D scene generation, particularly with out-of-domain images. For the first time, we demonstrate that a 3D reconstruction model can be effectively built upon the latent space of a diffusion model to realize efficient 3D scene generation.
+
+
+
+ 5. 【2412.12089】Stabilizing Reinforcement Learning in Differentiable Multiphysics Simulation
+ 链接:https://arxiv.org/abs/2412.12089
+ 作者:Eliot Xing,Vernon Luk,Jean Oh
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:deep reinforcement learning, collect large amounts, complex control policies, Recent advances, train complex control
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advances in GPU-based parallel simulation have enabled practitioners to collect large amounts of data and train complex control policies using deep reinforcement learning (RL), on commodity GPUs. However, such successes for RL in robotics have been limited to tasks sufficiently simulated by fast rigid-body dynamics. Simulation techniques for soft bodies are comparatively several orders of magnitude slower, thereby limiting the use of RL due to sample complexity requirements. To address this challenge, this paper presents both a novel RL algorithm and a simulation platform to enable scaling RL on tasks involving rigid bodies and deformables. We introduce Soft Analytic Policy Optimization (SAPO), a maximum entropy first-order model-based actor-critic RL algorithm, which uses first-order analytic gradients from differentiable simulation to train a stochastic actor to maximize expected return and entropy. Alongside our approach, we develop Rewarped, a parallel differentiable multiphysics simulation platform that supports simulating various materials beyond rigid bodies. We re-implement challenging manipulation and locomotion tasks in Rewarped, and show that SAPO outperforms baselines over a range of tasks that involve interaction between rigid bodies, articulations, and deformables.
+
+
+
+ 6. 【2412.12087】Instruction-based Image Manipulation by Watching How Things Move
+ 链接:https://arxiv.org/abs/2412.12087
+ 作者:Mingdeng Cao,Xuaner Zhang,Yinqiang Zheng,Zhihao Xia
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:multimodal large language, generate editing instructions, training instruction-based image, large language models, paper introduces
+ 备注: Project page: [this https URL](https://ljzycmd.github.io/projects/InstructMove/)
+
+ 点击查看摘要
+ Abstract:This paper introduces a novel dataset construction pipeline that samples pairs of frames from videos and uses multimodal large language models (MLLMs) to generate editing instructions for training instruction-based image manipulation models. Video frames inherently preserve the identity of subjects and scenes, ensuring consistent content preservation during editing. Additionally, video data captures diverse, natural dynamics-such as non-rigid subject motion and complex camera movements-that are difficult to model otherwise, making it an ideal source for scalable dataset construction. Using this approach, we create a new dataset to train InstructMove, a model capable of instruction-based complex manipulations that are difficult to achieve with synthetically generated datasets. Our model demonstrates state-of-the-art performance in tasks such as adjusting subject poses, rearranging elements, and altering camera perspectives.
+
+
+
+ 7. 【2412.12083】IDArb: Intrinsic Decomposition for Arbitrary Number of Input Views and Illuminations
+ 链接:https://arxiv.org/abs/2412.12083
+ 作者:Zhibing Li,Tong Wu,Jing Tan,Mengchen Zhang,Jiaqi Wang,Dahua Lin
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Capturing geometric, vision and graphics, remains a fundamental, computer vision, material information
+ 备注:
+
+ 点击查看摘要
+ Abstract:Capturing geometric and material information from images remains a fundamental challenge in computer vision and graphics. Traditional optimization-based methods often require hours of computational time to reconstruct geometry, material properties, and environmental lighting from dense multi-view inputs, while still struggling with inherent ambiguities between lighting and material. On the other hand, learning-based approaches leverage rich material priors from existing 3D object datasets but face challenges with maintaining multi-view consistency. In this paper, we introduce IDArb, a diffusion-based model designed to perform intrinsic decomposition on an arbitrary number of images under varying illuminations. Our method achieves accurate and multi-view consistent estimation on surface normals and material properties. This is made possible through a novel cross-view, cross-domain attention module and an illumination-augmented, view-adaptive training strategy. Additionally, we introduce ARB-Objaverse, a new dataset that provides large-scale multi-view intrinsic data and renderings under diverse lighting conditions, supporting robust training. Extensive experiments demonstrate that IDArb outperforms state-of-the-art methods both qualitatively and quantitatively. Moreover, our approach facilitates a range of downstream tasks, including single-image relighting, photometric stereo, and 3D reconstruction, highlighting its broad applications in realistic 3D content creation.
+
+
+
+ 8. 【2412.12079】UniLoc: Towards Universal Place Recognition Using Any Single Modality
+ 链接:https://arxiv.org/abs/2412.12079
+ 作者:Yan Xia,Zhendong Li,Yun-Jin Li,Letian Shi,Hu Cao,João F. Henriques,Daniel Cremers
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:single-modality retrieval, recognition methods focus, focus on single-modality, methods focus, place recognition
+ 备注: 14 pages, 10 figures
+
+ 点击查看摘要
+ Abstract:To date, most place recognition methods focus on single-modality retrieval. While they perform well in specific environments, cross-modal methods offer greater flexibility by allowing seamless switching between map and query sources. It also promises to reduce computation requirements by having a unified model, and achieving greater sample efficiency by sharing parameters. In this work, we develop a universal solution to place recognition, UniLoc, that works with any single query modality (natural language, image, or point cloud). UniLoc leverages recent advances in large-scale contrastive learning, and learns by matching hierarchically at two levels: instance-level matching and scene-level matching. Specifically, we propose a novel Self-Attention based Pooling (SAP) module to evaluate the importance of instance descriptors when aggregated into a place-level descriptor. Experiments on the KITTI-360 dataset demonstrate the benefits of cross-modality for place recognition, achieving superior performance in cross-modal settings and competitive results also for uni-modal scenarios. Our project page is publicly available at this https URL.
+
+
+
+ 9. 【2412.12077】CPath-Omni: A Unified Multimodal Foundation Model for Patch and Whole Slide Image Analysis in Computational Pathology
+ 链接:https://arxiv.org/abs/2412.12077
+ 作者:Yuxuan Sun,Yixuan Si,Chenglu Zhu,Xuan Gong,Kai Zhang,Pingyi Chen,Ye Zhang,Zhongyi Shui,Tao Lin,Lin Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:brought significant advancements, brought significant, significant advancements, WSI level image, large multimodal models
+ 备注: 22 pages, 13 figures
+
+ 点击查看摘要
+ Abstract:The emergence of large multimodal models (LMMs) has brought significant advancements to pathology. Previous research has primarily focused on separately training patch-level and whole-slide image (WSI)-level models, limiting the integration of learned knowledge across patches and WSIs, and resulting in redundant models. In this work, we introduce CPath-Omni, the first 15-billion-parameter LMM designed to unify both patch and WSI level image analysis, consolidating a variety of tasks at both levels, including classification, visual question answering, captioning, and visual referring prompting. Extensive experiments demonstrate that CPath-Omni achieves state-of-the-art (SOTA) performance across seven diverse tasks on 39 out of 42 datasets, outperforming or matching task-specific models trained for individual tasks. Additionally, we develop a specialized pathology CLIP-based visual processor for CPath-Omni, CPath-CLIP, which, for the first time, integrates different vision models and incorporates a large language model as a text encoder to build a more powerful CLIP model, which achieves SOTA performance on nine zero-shot and four few-shot datasets. Our findings highlight CPath-Omni's ability to unify diverse pathology tasks, demonstrating its potential to streamline and advance the field of foundation model in pathology.
+
+
+
+ 10. 【2412.12075】CG-Bench: Clue-grounded Question Answering Benchmark for Long Video Understanding
+ 链接:https://arxiv.org/abs/2412.12075
+ 作者:Guo Chen,Yicheng Liu,Yifei Huang,Yuping He,Baoqi Pei,Jilan Xu,Yali Wang,Tong Lu,Limin Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:multimodal large language, large language models, video, long video understanding, video understanding
+ 备注: 14 pages, 9 figures
+
+ 点击查看摘要
+ Abstract:Most existing video understanding benchmarks for multimodal large language models (MLLMs) focus only on short videos. The limited number of benchmarks for long video understanding often rely solely on multiple-choice questions (MCQs). However, because of the inherent limitation of MCQ-based evaluation and the increasing reasoning ability of MLLMs, models can give the current answer purely by combining short video understanding with elimination, without genuinely understanding the video content. To address this gap, we introduce CG-Bench, a novel benchmark designed for clue-grounded question answering in long videos. CG-Bench emphasizes the model's ability to retrieve relevant clues for questions, enhancing evaluation credibility. It features 1,219 manually curated videos categorized by a granular system with 14 primary categories, 171 secondary categories, and 638 tertiary categories, making it the largest benchmark for long video analysis. The benchmark includes 12,129 QA pairs in three major question types: perception, reasoning, and hallucination. Compensating the drawbacks of pure MCQ-based evaluation, we design two novel clue-based evaluation methods: clue-grounded white box and black box evaluations, to assess whether the model generates answers based on the correct understanding of the video. We evaluate multiple closed-source and open-source MLLMs on CG-Bench. Results indicate that current models significantly underperform in understanding long videos compared to short ones, and a significant gap exists between open-source and commercial models. We hope CG-Bench can advance the development of more trustworthy and capable MLLMs for long video understanding. All annotations and video data are released at this https URL.
+
+
+
+ 11. 【2412.12068】SPADE: Spectroscopic Photoacoustic Denoising using an Analytical and Data-free Enhancement Framework
+ 链接:https://arxiv.org/abs/2412.12068
+ 作者:Fangzhou Lin,Shang Gao,Yichuan Tang,Xihan Ma,Ryo Murakami,Ziming Zhang,John D. Obayemic,Winston W. Soboyejo,Haichong K. Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:optical absorption spectra, differentiate chromophores based, unique optical absorption, Spectroscopic photoacoustic, absorption spectra
+ 备注: 20 pages, 7 figures
+
+ 点击查看摘要
+ Abstract:Spectroscopic photoacoustic (sPA) imaging uses multiple wavelengths to differentiate chromophores based on their unique optical absorption spectra. This technique has been widely applied in areas such as vascular mapping, tumor detection, and therapeutic monitoring. However, sPA imaging is highly susceptible to noise, leading to poor signal-to-noise ratio (SNR) and compromised image quality. Traditional denoising techniques like frame averaging, though effective in improving SNR, can be impractical for dynamic imaging scenarios due to reduced frame rates. Advanced methods, including learning-based approaches and analytical algorithms, have demonstrated promise but often require extensive training data and parameter tuning, limiting their adaptability for real-time clinical use. In this work, we propose a sPA denoising using a tuning-free analytical and data-free enhancement (SPADE) framework for denoising sPA images. This framework integrates a data-free learning-based method with an efficient BM3D-based analytical approach while preserves spectral linearity, providing noise reduction and ensuring that functional information is maintained. The SPADE framework was validated through simulation, phantom, ex vivo, and in vivo experiments. Results demonstrated that SPADE improved SNR and preserved spectral information, outperforming conventional methods, especially in challenging imaging conditions. SPADE presents a promising solution for enhancing sPA imaging quality in clinical applications where noise reduction and spectral preservation are critical.
+
+
+
+ 12. 【2412.12050】Exploring Semantic Consistency and Style Diversity for Domain Generalized Semantic Segmentation
+ 链接:https://arxiv.org/abs/2412.12050
+ 作者:Hongwei Niu,Linhuang Xie,Jianghang Lin,Shengchuan Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Generalized Semantic Segmentation, Domain Generalized Semantic, Generalized Semantic, unknown target domains, source domain data
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Domain Generalized Semantic Segmentation (DGSS) seeks to utilize source domain data exclusively to enhance the generalization of semantic segmentation across unknown target domains. Prevailing studies predominantly concentrate on feature normalization and domain randomization, these approaches exhibit significant limitations. Feature normalization-based methods tend to confuse semantic features in the process of constraining the feature space distribution, resulting in classification misjudgment. Domain randomization-based methods frequently incorporate domain-irrelevant noise due to the uncontrollability of style transformations, resulting in segmentation ambiguity. To address these challenges, we introduce a novel framework, named SCSD for Semantic Consistency prediction and Style Diversity generalization. It comprises three pivotal components: Firstly, a Semantic Query Booster is designed to enhance the semantic awareness and discrimination capabilities of object queries in the mask decoder, enabling cross-domain semantic consistency prediction. Secondly, we develop a Text-Driven Style Transform module that utilizes domain difference text embeddings to controllably guide the style transformation of image features, thereby increasing inter-domain style diversity. Lastly, to prevent the collapse of similar domain feature spaces, we introduce a Style Synergy Optimization mechanism that fortifies the separation of inter-domain features and the aggregation of intra-domain features by synergistically weighting style contrastive loss and style aggregation loss. Extensive experiments demonstrate that the proposed SCSD significantly outperforms existing state-of-theart methods. Notably, SCSD trained on GTAV achieved an average of 49.11 mIoU on the four unseen domain datasets, surpassing the previous state-of-the-art method by +4.08 mIoU. Code is available at this https URL.
+
+
+
+ 13. 【2412.12048】A LoRA is Worth a Thousand Pictures
+ 链接:https://arxiv.org/abs/2412.12048
+ 作者:Chenxi Liu,Towaki Takikawa,Alec Jacobson
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Low Rank Adaptation, customization widely accessible, Rank Adaptation, Low Rank, Recent advances
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advances in diffusion models and parameter-efficient fine-tuning (PEFT) have made text-to-image generation and customization widely accessible, with Low Rank Adaptation (LoRA) able to replicate an artist's style or subject using minimal data and computation. In this paper, we examine the relationship between LoRA weights and artistic styles, demonstrating that LoRA weights alone can serve as an effective descriptor of style, without the need for additional image generation or knowledge of the original training set. Our findings show that LoRA weights yield better performance in clustering of artistic styles compared to traditional pre-trained features, such as CLIP and DINO, with strong structural similarities between LoRA-based and conventional image-based embeddings observed both qualitatively and quantitatively. We identify various retrieval scenarios for the growing collection of customized models and show that our approach enables more accurate retrieval in real-world settings where knowledge of the training images is unavailable and additional generation is required. We conclude with a discussion on potential future applications, such as zero-shot LoRA fine-tuning and model attribution.
+
+
+
+ 14. 【2412.12032】FSFM: A Generalizable Face Security Foundation Model via Self-Supervised Facial Representation Learning
+ 链接:https://arxiv.org/abs/2412.12032
+ 作者:Gaojian Wang,Feng Lin,Tong Wu,Zhenguang Liu,Zhongjie Ba,Kui Ren
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:unlabeled real faces, generalization performance, transferable facial representation, robust and transferable, respect to generalization
+ 备注: 21 pages, 11 figures, project page: [this https URL](https://fsfm-3c.github.io)
+
+ 点击查看摘要
+ Abstract:This work asks: with abundant, unlabeled real faces, how to learn a robust and transferable facial representation that boosts various face security tasks with respect to generalization performance? We make the first attempt and propose a self-supervised pretraining framework to learn fundamental representations of real face images, FSFM, that leverages the synergy between masked image modeling (MIM) and instance discrimination (ID). We explore various facial masking strategies for MIM and present a simple yet powerful CRFR-P masking, which explicitly forces the model to capture meaningful intra-region consistency and challenging inter-region coherency. Furthermore, we devise the ID network that naturally couples with MIM to establish underlying local-to-global correspondence via tailored self-distillation. These three learning objectives, namely 3C, empower encoding both local features and global semantics of real faces. After pretraining, a vanilla ViT serves as a universal vision foundation model for downstream face security tasks: cross-dataset deepfake detection, cross-domain face anti-spoofing, and unseen diffusion facial forgery detection. Extensive experiments on 10 public datasets demonstrate that our model transfers better than supervised pretraining, visual and facial self-supervised learning arts, and even outperforms task-specialized SOTA methods.
+
+
+
+ 15. 【2412.12031】RepFace: Refining Closed-Set Noise with Progressive Label Correction for Face Recognition
+ 链接:https://arxiv.org/abs/2412.12031
+ 作者:Jie Zhang,Xun Gong,Zhonglin Sun
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:made remarkable strides, Face recognition, face recognition performance, remarkable strides, discriminative losses
+ 备注: 11 pages, 5 figures, AAAI2025
+
+ 点击查看摘要
+ Abstract:Face recognition has made remarkable strides, driven by the expanding scale of datasets, advancements in various backbone and discriminative losses. However, face recognition performance is heavily affected by the label noise, especially closed-set noise. While numerous studies have focused on handling label noise, addressing closed-set noise still poses challenges. This paper identifies this challenge as training isn't robust to noise at the early-stage training, and necessitating an appropriate learning strategy for samples with low confidence, which are often misclassified as closed-set noise in later training phases. To address these issues, we propose a new framework to stabilize the training at early stages and split the samples into clean, ambiguous and noisy groups which are devised with separate training strategies. Initially, we employ generated auxiliary closed-set noisy samples to enable the model to identify noisy data at the early stages of training. Subsequently, we introduce how samples are split into clean, ambiguous and noisy groups by their similarity to the positive and nearest negative centers. Then we perform label fusion for ambiguous samples by incorporating accumulated model predictions. Finally, we apply label smoothing within the closed set, adjusting the label to a point between the nearest negative class and the initially assigned label. Extensive experiments validate the effectiveness of our method on mainstream face datasets, achieving state-of-the-art results. The code will be released upon acceptance.
+
+
+
+ 16. 【2412.12001】LLM-RG4: Flexible and Factual Radiology Report Generation across Diverse Input Contexts
+ 链接:https://arxiv.org/abs/2412.12001
+ 作者:Zhuhao Wang,Yihua Sun,Zihan Li,Xuan Yang,Fang Chen,Hongen Liao
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:radiologists tail content, complex task requiring, radiology report drafting, Drafting radiology reports, task requiring flexibility
+ 备注:
+
+ 点击查看摘要
+ Abstract:Drafting radiology reports is a complex task requiring flexibility, where radiologists tail content to available information and particular clinical demands. However, most current radiology report generation (RRG) models are constrained to a fixed task paradigm, such as predicting the full ``finding'' section from a single image, inherently involving a mismatch between inputs and outputs. The trained models lack the flexibility for diverse inputs and could generate harmful, input-agnostic hallucinations. To bridge the gap between current RRG models and the clinical demands in practice, we first develop a data generation pipeline to create a new MIMIC-RG4 dataset, which considers four common radiology report drafting scenarios and has perfectly corresponded input and output. Secondly, we propose a novel large language model (LLM) based RRG framework, namely LLM-RG4, which utilizes LLM's flexible instruction-following capabilities and extensive general knowledge. We further develop an adaptive token fusion module that offers flexibility to handle diverse scenarios with different input combinations, while minimizing the additional computational burden associated with increased input volumes. Besides, we propose a token-level loss weighting strategy to direct the model's attention towards positive and uncertain descriptions. Experimental results demonstrate that LLM-RG4 achieves state-of-the-art performance in both clinical efficiency and natural language generation on the MIMIC-RG4 and MIMIC-CXR datasets. We quantitatively demonstrate that our model has minimal input-agnostic hallucinations, whereas current open-source models commonly suffer from this problem.
+
+
+
+ 17. 【2412.11998】SAMIC: Segment Anything with In-Context Spatial Prompt Engineering
+ 链接:https://arxiv.org/abs/2412.11998
+ 作者:Savinay Nagendra,Kashif Rashid,Chaopeng Shen,Daniel Kifer
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:labeled reference images, identify specific types, reference images, identify specific, types of objects
+ 备注:
+
+ 点击查看摘要
+ Abstract:Few-shot segmentation is the problem of learning to identify specific types of objects (e.g., airplanes) in images from a small set of labeled reference images. The current state of the art is driven by resource-intensive construction of models for every new domain-specific application. Such models must be trained on enormous labeled datasets of unrelated objects (e.g., cars, trains, animals) so that their ``knowledge'' can be transferred to new types of objects. In this paper, we show how to leverage existing vision foundation models (VFMs) to reduce the incremental cost of creating few-shot segmentation models for new domains. Specifically, we introduce SAMIC, a small network that learns how to prompt VFMs in order to segment new types of objects in domain-specific applications. SAMIC enables any task to be approached as a few-shot learning problem. At 2.6 million parameters, it is 94% smaller than the leading models (e.g., having ResNet 101 backbone with 45+ million parameters). Even using 1/5th of the training data provided by one-shot benchmarks, SAMIC is competitive with, or sets the state of the art, on a variety of few-shot and semantic segmentation datasets including COCO-$20^i$, Pascal-$5^i$, PerSeg, FSS-1000, and NWPU VHR-10.
+
+
+
+ 18. 【2412.11974】Emma-X: An Embodied Multimodal Action Model with Grounded Chain of Thought and Look-ahead Spatial Reasoning
+ 链接:https://arxiv.org/abs/2412.11974
+ 作者:Qi Sun,Pengfei Hong,Tej Deep Pala,Vernon Toh,U-Xuan Tan,Deepanway Ghosal,Soujanya Poria
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Traditional reinforcement learning-based, Traditional reinforcement, reinforcement learning-based robotic, learning-based robotic control, robotic control methods
+ 备注: [this https URL](https://github.com/declare-lab/Emma-X) , [this https URL](https://huggingface.co/declare-lab/Emma-X)
+
+ 点击查看摘要
+ Abstract:Traditional reinforcement learning-based robotic control methods are often task-specific and fail to generalize across diverse environments or unseen objects and instructions. Visual Language Models (VLMs) demonstrate strong scene understanding and planning capabilities but lack the ability to generate actionable policies tailored to specific robotic embodiments. To address this, Visual-Language-Action (VLA) models have emerged, yet they face challenges in long-horizon spatial reasoning and grounded task planning. In this work, we propose the Embodied Multimodal Action Model with Grounded Chain of Thought and Look-ahead Spatial Reasoning, Emma-X. Emma-X leverages our constructed hierarchical embodiment dataset based on BridgeV2, containing 60,000 robot manipulation trajectories auto-annotated with grounded task reasoning and spatial guidance. Additionally, we introduce a trajectory segmentation strategy based on gripper states and motion trajectories, which can help mitigate hallucination in grounding subtask reasoning generation. Experimental results demonstrate that Emma-X achieves superior performance over competitive baselines, particularly in real-world robotic tasks requiring spatial reasoning.
+
+
+
+ 19. 【2412.11972】Controllable Shadow Generation with Single-Step Diffusion Models from Synthetic Data
+ 链接:https://arxiv.org/abs/2412.11972
+ 作者:Onur Tasar,Clément Chadebec,Benjamin Aubin
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Physics-based approaches require, Realistic shadow generation, learning-based techniques struggle, existing methods suffer, Physics-based approaches
+ 备注:
+
+ 点击查看摘要
+ Abstract:Realistic shadow generation is a critical component for high-quality image compositing and visual effects, yet existing methods suffer from certain limitations: Physics-based approaches require a 3D scene geometry, which is often unavailable, while learning-based techniques struggle with control and visual artifacts. We introduce a novel method for fast, controllable, and background-free shadow generation for 2D object images. We create a large synthetic dataset using a 3D rendering engine to train a diffusion model for controllable shadow generation, generating shadow maps for diverse light source parameters. Through extensive ablation studies, we find that rectified flow objective achieves high-quality results with just a single sampling step enabling real-time applications. Furthermore, our experiments demonstrate that the model generalizes well to real-world images. To facilitate further research in evaluating quality and controllability in shadow generation, we release a new public benchmark containing a diverse set of object images and shadow maps in various settings. The project page is available at this https URL
+
+
+
+ 20. 【2412.11959】Gramian Multimodal Representation Learning and Alignment
+ 链接:https://arxiv.org/abs/2412.11959
+ 作者:Giordano Cicchetti,Eleonora Grassucci,Luigi Sigillo,Danilo Comminiello
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Human perception integrates, perception integrates multiple, Human perception, integrates multiple modalities, multiple modalities
+ 备注:
+
+ 点击查看摘要
+ Abstract:Human perception integrates multiple modalities, such as vision, hearing, and language, into a unified understanding of the surrounding reality. While recent multimodal models have achieved significant progress by aligning pairs of modalities via contrastive learning, their solutions are unsuitable when scaling to multiple modalities. These models typically align each modality to a designated anchor without ensuring the alignment of all modalities with each other, leading to suboptimal performance in tasks requiring a joint understanding of multiple modalities. In this paper, we structurally rethink the pairwise conventional approach to multimodal learning and we present the novel Gramian Representation Alignment Measure (GRAM), which overcomes the above-mentioned limitations. GRAM learns and then aligns $n$ modalities directly in the higher-dimensional space in which modality embeddings lie by minimizing the Gramian volume of the $k$-dimensional parallelotope spanned by the modality vectors, ensuring the geometric alignment of all modalities simultaneously. GRAM can replace cosine similarity in any downstream method, holding for 2 to $n$ modality and providing more meaningful alignment with respect to previous similarity measures. The novel GRAM-based contrastive loss function enhances the alignment of multimodal models in the higher-dimensional embedding space, leading to new state-of-the-art performance in downstream tasks such as video-audio-text retrieval and audio-video classification. The project page, the code, and the pretrained models are available at this https URL.
+
+
+
+ 21. 【2412.11953】Reliable Breast Cancer Molecular Subtype Prediction based on uncertainty-aware Bayesian Deep Learning by Mammography
+ 链接:https://arxiv.org/abs/2412.11953
+ 作者:Mohaddeseh Chegini,Ali Mahloojifar
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:breast cancer molecular, Breast cancer, cancer molecular subtypes, breast cancer classification, molecular subtypes
+ 备注:
+
+ 点击查看摘要
+ Abstract:Breast cancer is a heterogeneous disease with different molecular subtypes, clinical behavior, treatment responses as well as survival outcomes. The development of a reliable, accurate, available and inexpensive method to predict the molecular subtypes using medical images plays an important role in the diagnosis and prognosis of breast cancer. Recently, deep learning methods have shown good performance in the breast cancer classification tasks using various medical images. Despite all that success, classical deep learning cannot deliver the predictive uncertainty. The uncertainty represents the validity of the this http URL, the high predicted uncertainty might cause a negative effect in the accurate diagnosis of breast cancer molecular subtypes. To overcome this, uncertainty quantification methods are used to determine the predictive uncertainty. Accordingly, in this study, we proposed an uncertainty-aware Bayesian deep learning model using the full mammogram images. In addition, to increase the performance of the multi-class molecular subtype classification task, we proposed a novel hierarchical classification strategy, named the two-stage classification strategy. The separate AUC of the proposed model for each subtype was 0.71, 0.75 and 0.86 for HER2-enriched, luminal and triple-negative classes, respectively. The proposed model not only has a comparable performance to other studies in the field of breast cancer molecular subtypes prediction, even using full mammography images, but it is also more reliable, due to quantify the predictive uncertainty.
+
+
+
+ 22. 【2412.11952】Advancing Comprehensive Aesthetic Insight with Multi-Scale Text-Guided Self-Supervised Learning
+ 链接:https://arxiv.org/abs/2412.11952
+ 作者:Yuti Liu,Shice Liu,Junyuan Gao,Pengtao Jiang,Hao Zhang,Jinwei Chen,Bo Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Image Aesthetic Assessment, Multi-modal Large Language, Aesthetic, areas for improvement, Large Language Models
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Image Aesthetic Assessment (IAA) is a vital and intricate task that entails analyzing and assessing an image's aesthetic values, and identifying its highlights and areas for improvement. Traditional methods of IAA often concentrate on a single aesthetic task and suffer from inadequate labeled datasets, thus impairing in-depth aesthetic comprehension. Despite efforts to overcome this challenge through the application of Multi-modal Large Language Models (MLLMs), such models remain underdeveloped for IAA purposes. To address this, we propose a comprehensive aesthetic MLLM capable of nuanced aesthetic insight. Central to our approach is an innovative multi-scale text-guided self-supervised learning technique. This technique features a multi-scale feature alignment module and capitalizes on a wealth of unlabeled data in a self-supervised manner to structurally and functionally enhance aesthetic ability. The empirical evidence indicates that accompanied with extensive instruct-tuning, our model sets new state-of-the-art benchmarks across multiple tasks, including aesthetic scoring, aesthetic commenting, and personalized image aesthetic assessment. Remarkably, it also demonstrates zero-shot learning capabilities in the emerging task of aesthetic suggesting. Furthermore, for personalized image aesthetic assessment, we harness the potential of in-context learning and showcase its inherent advantages.
+
+
+
+ 23. 【2412.11949】Coconut Palm Tree Counting on Drone Images with Deep Object Detection and Synthetic Training Data
+ 链接:https://arxiv.org/abs/2412.11949
+ 作者:Tobias Rohe,Barbara Böhm,Michael Kölle,Jonas Stein,Robert Müller,Claudia Linnhoff-Popien
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:including agriculture, revolutionized various domains, YOLO, Abstract, trees
+ 备注: 9 pages
+
+ 点击查看摘要
+ Abstract:Drones have revolutionized various domains, including agriculture. Recent advances in deep learning have propelled among other things object detection in computer vision. This study utilized YOLO, a real-time object detector, to identify and count coconut palm trees in Ghanaian farm drone footage. The farm presented has lost track of its trees due to different planting phases. While manual counting would be very tedious and error-prone, accurately determining the number of trees is crucial for efficient planning and management of agricultural processes, especially for optimizing yields and predicting production. We assessed YOLO for palm detection within a semi-automated framework, evaluated accuracy augmentations, and pondered its potential for farmers. Data was captured in September 2022 via drones. To optimize YOLO with scarce data, synthetic images were created for model training and validation. The YOLOv7 model, pretrained on the COCO dataset (excluding coconut palms), was adapted using tailored data. Trees from footage were repositioned on synthetic images, with testing on distinct authentic images. In our experiments, we adjusted hyperparameters, improving YOLO's mean average precision (mAP). We also tested various altitudes to determine the best drone height. From an initial mAP@.5 of $0.65$, we achieved 0.88, highlighting the value of synthetic images in agricultural scenarios.
+
+
+
+ 24. 【2412.11917】Does VLM Classification Benefit from LLM Description Semantics?
+ 链接:https://arxiv.org/abs/2412.11917
+ 作者:Pingchuan Ma,Lennart Rietdorf,Dmytro Kotovenko,Vincent Tao Hu,Björn Ommer
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Accurately describing images, Accurately describing, Large Language Models, foundation of explainable, Language Models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Accurately describing images via text is a foundation of explainable AI. Vision-Language Models (VLMs) like CLIP have recently addressed this by aligning images and texts in a shared embedding space, expressing semantic similarities between vision and language embeddings. VLM classification can be improved with descriptions generated by Large Language Models (LLMs). However, it is difficult to determine the contribution of actual description semantics, as the performance gain may also stem from a semantic-agnostic ensembling effect. Considering this, we ask how to distinguish the actual discriminative power of descriptions from performance boosts that potentially rely on an ensembling effect. To study this, we propose an alternative evaluation scenario that shows a characteristic behavior if the used descriptions have discriminative power. Furthermore, we propose a training-free method to select discriminative descriptions that work independently of classname ensembling effects. The training-free method works in the following way: A test image has a local CLIP label neighborhood, i.e., its top-$k$ label predictions. Then, w.r.t. to a small selection set, we extract descriptions that distinguish each class well in the local neighborhood. Using the selected descriptions, we demonstrate improved classification accuracy across seven datasets and provide in-depth analysis and insights into the explainability of description-based image classification by VLMs.
+
+
+
+ 25. 【2412.11906】PunchBench: Benchmarking MLLMs in Multimodal Punchline Comprehension
+ 链接:https://arxiv.org/abs/2412.11906
+ 作者:Kun Ouyang,Yuanxin Liu,Shicheng Li,Yi Liu,Hao Zhou,Fandong Meng,Jie Zhou,Xu Sun
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:online multimedia platforms, multimedia platforms, involve humor, humor or sarcasm, sarcasm conveyed
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multimodal punchlines, which involve humor or sarcasm conveyed in image-caption pairs, are a popular way of communication on online multimedia platforms. With the rapid development of multimodal large language models (MLLMs), it is essential to assess their ability to effectively comprehend these punchlines. However, existing benchmarks on punchline comprehension suffer from three major limitations: 1) language shortcuts that allow models to solely rely on text, 2) lack of question diversity, and 3) narrow focus on a specific domain of multimodal content (e.g., cartoon). To address these limitations, we introduce a multimodal \textbf{Punch}line comprehension \textbf{Bench}mark, named \textbf{PunchBench}, which is tailored for accurate and comprehensive evaluation of punchline comprehension. To enhance the evaluation accuracy, we generate synonymous and antonymous captions by modifying original captions, which mitigates the impact of shortcuts in the captions. To provide a comprehensive evaluation, PunchBench incorporates diverse question formats and image-captions from various domains. On this basis, we conduct extensive evaluations and reveal a significant gap between state-of-the-art MLLMs and humans in punchline comprehension. To improve punchline comprehension, we propose Simple-to-Complex Chain-of-Question (SC-CoQ) strategy, enabling the models to incrementally address complicated questions by first mastering simple ones. SC-CoQ effectively enhances the performance of various MLLMs on PunchBench, surpassing in-context learning and chain-of-thought.
+
+
+
+ 26. 【2412.11892】From 2D CAD Drawings to 3D Parametric Models: A Vision-Language Approach
+ 链接:https://arxiv.org/abs/2412.11892
+ 作者:Xilin Wang,Jia Zheng,Yuanchao Hu,Hao Zhu,Qian Yu,Zihan Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:CAD, parametric models, models, CAD drawings, method
+ 备注: To Appear in AAAI 2025. The project page is at [this https URL](https://manycore-research.github.io/CAD2Program)
+
+ 点击查看摘要
+ Abstract:In this paper, we present CAD2Program, a new method for reconstructing 3D parametric models from 2D CAD drawings. Our proposed method is inspired by recent successes in vision-language models (VLMs), and departs from traditional methods which rely on task-specific data representations and/or algorithms. Specifically, on the input side, we simply treat the 2D CAD drawing as a raster image, regardless of its original format, and encode the image with a standard ViT model. We show that such an encoding scheme achieves competitive performance against existing methods that operate on vector-graphics inputs, while imposing substantially fewer restrictions on the 2D drawings. On the output side, our method auto-regressively predicts a general-purpose language describing 3D parametric models in text form. Compared to other sequence modeling methods for CAD which use domain-specific sequence representations with fixed-size slots, our text-based representation is more flexible, and can be easily extended to arbitrary geometric entities and semantic or functional properties. Experimental results on a large-scale dataset of cabinet models demonstrate the effectiveness of our method.
+
+
+
+ 27. 【2412.11890】SegMAN: Omni-scale Context Modeling with State Space Models and Local Attention for Semantic Segmentation
+ 链接:https://arxiv.org/abs/2412.11890
+ 作者:Yunxiang Fu,Meng Lou,Yizhou Yu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:High-quality semantic segmentation, semantic segmentation relies, global context modeling, local detail encoding, High-quality semantic
+ 备注:
+
+ 点击查看摘要
+ Abstract:High-quality semantic segmentation relies on three key capabilities: global context modeling, local detail encoding, and multi-scale feature extraction. However, recent methods struggle to possess all these capabilities simultaneously. Hence, we aim to empower segmentation networks to simultaneously carry out efficient global context modeling, high-quality local detail encoding, and rich multi-scale feature representation for varying input resolutions. In this paper, we introduce SegMAN, a novel linear-time model comprising a hybrid feature encoder dubbed SegMAN Encoder, and a decoder based on state space models. Specifically, the SegMAN Encoder synergistically integrates sliding local attention with dynamic state space models, enabling highly efficient global context modeling while preserving fine-grained local details. Meanwhile, the MMSCopE module in our decoder enhances multi-scale context feature extraction and adaptively scales with the input resolution. We comprehensively evaluate SegMAN on three challenging datasets: ADE20K, Cityscapes, and COCO-Stuff. For instance, SegMAN-B achieves 52.6% mIoU on ADE20K, outperforming SegNeXt-L by 1.6% mIoU while reducing computational complexity by over 15% GFLOPs. On Cityscapes, SegMAN-B attains 83.8% mIoU, surpassing SegFormer-B3 by 2.1% mIoU with approximately half the GFLOPs. Similarly, SegMAN-B improves upon VWFormer-B3 by 1.6% mIoU with lower GFLOPs on the COCO-Stuff dataset. Our code is available at this https URL.
+
+
+
+ 28. 【2412.11883】owards Physically-Based Sky-Modeling
+ 链接:https://arxiv.org/abs/2412.11883
+ 作者:Ian J. Maquignaz
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:Accurate environment maps, Extended Dynamic Range, rendering photorealistic outdoor, captured HDR imagery, Accurate environment
+ 备注:
+
+ 点击查看摘要
+ Abstract:Accurate environment maps are a key component in rendering photorealistic outdoor scenes with coherent illumination. They enable captivating visual arts, immersive virtual reality and a wide range of engineering and scientific applications. Recent works have extended sky-models to be more comprehensive and inclusive of cloud formations but existing approaches fall short in faithfully recreating key-characteristics in physically captured HDRI. As we demonstrate, environment maps produced by sky-models do not relight scenes with the same tones, shadows, and illumination coherence as physically captured HDR imagery. Though the visual quality of DNN-generated LDR and HDR imagery has greatly progressed in recent years, we demonstrate this progress to be tangential to sky-modelling. Due to the Extended Dynamic Range (EDR) of 14EV required for outdoor environment maps inclusive of the sun, sky-modelling extends beyond the conventional paradigm of High Dynamic Range Imagery (HDRI). In this work, we propose an all-weather sky-model, learning weathered-skies directly from physically captured HDR imagery. Per user-controlled positioning of the sun and cloud formations, our model (AllSky) allows for emulation of physically captured environment maps with improved retention of the Extended Dynamic Range (EDR) of the sky.
+
+
+
+ 29. 【2412.11866】Event-based Motion Deblurring via Multi-Temporal Granularity Fusion
+ 链接:https://arxiv.org/abs/2412.11866
+ 作者:Xiaopeng Lin,Hongwei Ren,Yulong Huang,Zunchang Liu,Yue Zhou,Haotian Fu,Biao Pan,Bojun Cheng
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:inevitably produce blurry, produce blurry effects, blurry effects due, Conventional frame-based cameras, cameras inevitably produce
+ 备注: 12 pages, 8 figures
+
+ 点击查看摘要
+ Abstract:Conventional frame-based cameras inevitably produce blurry effects due to motion occurring during the exposure time. Event camera, a bio-inspired sensor offering continuous visual information could enhance the deblurring performance. Effectively utilizing the high-temporal-resolution event data is crucial for extracting precise motion information and enhancing deblurring performance. However, existing event-based image deblurring methods usually utilize voxel-based event representations, losing the fine-grained temporal details that are mathematically essential for fast motion deblurring. In this paper, we first introduce point cloud-based event representation into the image deblurring task and propose a Multi-Temporal Granularity Network (MTGNet). It combines the spatially dense but temporally coarse-grained voxel-based event representation and the temporally fine-grained but spatially sparse point cloud-based event. To seamlessly integrate such complementary representations, we design a Fine-grained Point Branch. An Aggregation and Mapping Module (AMM) is proposed to align the low-level point-based features with frame-based features and an Adaptive Feature Diffusion Module (AFDM) is designed to manage the resolution discrepancies between event data and image data by enriching the sparse point feature. Extensive subjective and objective evaluations demonstrate that our method outperforms current state-of-the-art approaches on both synthetic and real-world datasets.
+
+
+
+ 30. 【2412.11863】GeoX: Geometric Problem Solving Through Unified Formalized Vision-Language Pre-training
+ 链接:https://arxiv.org/abs/2412.11863
+ 作者:Renqiu Xia,Mingsheng Li,Hancheng Ye,Wenjie Wu,Hongbin Zhou,Jiakang Yuan,Tianshuo Peng,Xinyu Cai,Xiangchao Yan,Bin Wang,Conghui He,Botian Shi,Tao Chen,Junchi Yan,Bo Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Geometry Problem Solving, automatic Geometry Problem, Multi-modal Large Language, Large Language Models, automatic Geometry
+ 备注: Our code is available at [this https URL](https://github.com/UniModal4Reasoning/GeoX)
+
+ 点击查看摘要
+ Abstract:Despite their proficiency in general tasks, Multi-modal Large Language Models (MLLMs) struggle with automatic Geometry Problem Solving (GPS), which demands understanding diagrams, interpreting symbols, and performing complex reasoning. This limitation arises from their pre-training on natural images and texts, along with the lack of automated verification in the problem-solving process. Besides, current geometric specialists are limited by their task-specific designs, making them less effective for broader geometric problems. To this end, we present GeoX, a multi-modal large model focusing on geometric understanding and reasoning tasks. Given the significant differences between geometric diagram-symbol and natural image-text, we introduce unimodal pre-training to develop a diagram encoder and symbol decoder, enhancing the understanding of geometric images and corpora. Furthermore, we introduce geometry-language alignment, an effective pre-training paradigm that bridges the modality gap between unimodal geometric experts. We propose a Generator-And-Sampler Transformer (GS-Former) to generate discriminative queries and eliminate uninformative representations from unevenly distributed geometric signals. Finally, GeoX benefits from visual instruction tuning, empowering it to take geometric images and questions as input and generate verifiable solutions. Experiments show that GeoX outperforms both generalists and geometric specialists on publicly recognized benchmarks, such as GeoQA, UniGeo, Geometry3K, and PGPS9k.
+
+
+
+ 31. 【2412.11840】Sonar-based Deep Learning in Underwater Robotics: Overview, Robustness and Challenges
+ 链接:https://arxiv.org/abs/2412.11840
+ 作者:Martin Aubard,Ana Madureira,Luís Teixeira,José Pinto
+ 类目:Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV); Signal Processing (eess.SP)
+ 关键词:Autonomous Underwater Vehicles, onboard Deep Learning, Autonomous Underwater, Underwater Vehicles, exploration and monitoring
+ 备注:
+
+ 点击查看摘要
+ Abstract:With the growing interest in underwater exploration and monitoring, Autonomous Underwater Vehicles (AUVs) have become essential. The recent interest in onboard Deep Learning (DL) has advanced real-time environmental interaction capabilities relying on efficient and accurate vision-based DL models. However, the predominant use of sonar in underwater environments, characterized by limited training data and inherent noise, poses challenges to model robustness. This autonomy improvement raises safety concerns for deploying such models during underwater operations, potentially leading to hazardous situations. This paper aims to provide the first comprehensive overview of sonar-based DL under the scope of robustness. It studies sonar-based DL perception task models, such as classification, object detection, segmentation, and SLAM. Furthermore, the paper systematizes sonar-based state-of-the-art datasets, simulators, and robustness methods such as neural network verification, out-of-distribution, and adversarial attacks. This paper highlights the lack of robustness in sonar-based DL research and suggests future research pathways, notably establishing a baseline sonar-based dataset and bridging the simulation-to-reality gap.
+
+
+
+ 32. 【2412.11836】UnMA-CapSumT: Unified and Multi-Head Attention-driven Caption Summarization Transformer
+ 链接:https://arxiv.org/abs/2412.11836
+ 作者:Dhruv Sharma,Chhavi Dhiman,Dinesh Kumar
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:increased immense popularity, stylized image captioning, natural language descriptions, Image captioning, image captioning model
+ 备注:
+
+ 点击查看摘要
+ Abstract:Image captioning is the generation of natural language descriptions of images which have increased immense popularity in the recent past. With this different deep-learning techniques are devised for the development of factual and stylized image captioning models. Previous models focused more on the generation of factual and stylized captions separately providing more than one caption for a single image. The descriptions generated from these suffer from out-of-vocabulary and repetition issues. To the best of our knowledge, no such work exists that provided a description that integrates different captioning methods to describe the contents of an image with factual and stylized (romantic and humorous) elements. To overcome these limitations, this paper presents a novel Unified Attention and Multi-Head Attention-driven Caption Summarization Transformer (UnMA-CapSumT) based Captioning Framework. It utilizes both factual captions and stylized captions generated by the Modified Adaptive Attention-based factual image captioning model (MAA-FIC) and Style Factored Bi-LSTM with attention (SF-Bi-ALSTM) driven stylized image captioning model respectively. SF-Bi-ALSTM-based stylized IC model generates two prominent styles of expression- {romance, and humor}. The proposed summarizer UnMHA-ST combines both factual and stylized descriptions of an input image to generate styled rich coherent summarized captions. The proposed UnMHA-ST transformer learns and summarizes different linguistic styles efficiently by incorporating proposed word embedding fastText with Attention Word Embedding (fTA-WE) and pointer-generator network with coverage mechanism concept to solve the out-of-vocabulary issues and repetition problem. Extensive experiments are conducted on Flickr8K and a subset of FlickrStyle10K with supporting ablation studies to prove the efficiency and efficacy of the proposed framework.
+
+
+
+ 33. 【2412.11820】Spatiotemporal Blind-Spot Network with Calibrated Flow Alignment for Self-Supervised Video Denoising
+ 链接:https://arxiv.org/abs/2412.11820
+ 作者:Zikang Chen,Tao Jiang,Xiaowan Hu,Wang Zhang,Huaqiu Li,Haoqian Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:ground truth data, optical flow, recover clean frames, optical flow alignment, truth data
+ 备注:
+
+ 点击查看摘要
+ Abstract:Self-supervised video denoising aims to remove noise from videos without relying on ground truth data, leveraging the video itself to recover clean frames. Existing methods often rely on simplistic feature stacking or apply optical flow without thorough analysis. This results in suboptimal utilization of both inter-frame and intra-frame information, and it also neglects the potential of optical flow alignment under self-supervised conditions, leading to biased and insufficient denoising outcomes. To this end, we first explore the practicality of optical flow in the self-supervised setting and introduce a SpatioTemporal Blind-spot Network (STBN) for global frame feature utilization. In the temporal domain, we utilize bidirectional blind-spot feature propagation through the proposed blind-spot alignment block to ensure accurate temporal alignment and effectively capture long-range dependencies. In the spatial domain, we introduce the spatial receptive field expansion module, which enhances the receptive field and improves global perception capabilities. Additionally, to reduce the sensitivity of optical flow estimation to noise, we propose an unsupervised optical flow distillation mechanism that refines fine-grained inter-frame interactions during optical flow alignment. Our method demonstrates superior performance across both synthetic and real-world video denoising datasets. The source code is publicly available at this https URL.
+
+
+
+ 34. 【2412.11819】HiGDA: Hierarchical Graph of Nodes to Learn Local-to-Global Topology for Semi-Supervised Domain Adaptation
+ 链接:https://arxiv.org/abs/2412.11819
+ 作者:Ba Hung Ngo,Doanh C. Bui,Nhat-Tuong Do-Tran,Tae Jong Choi
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:enhanced representational power, attracted significant interest, deep learning models, recent years, enhanced representational
+ 备注: Accepted for presentation at AAAI2025
+
+ 点击查看摘要
+ Abstract:The enhanced representational power and broad applicability of deep learning models have attracted significant interest from the research community in recent years. However, these models often struggle to perform effectively under domain shift conditions, where the training data (the source domain) is related to but exhibits different distributions from the testing data (the target domain). To address this challenge, previous studies have attempted to reduce the domain gap between source and target data by incorporating a few labeled target samples during training - a technique known as semi-supervised domain adaptation (SSDA). While this strategy has demonstrated notable improvements in classification performance, the network architectures used in these approaches primarily focus on exploiting the features of individual images, leaving room for improvement in capturing rich representations. In this study, we introduce a Hierarchical Graph of Nodes designed to simultaneously present representations at both feature and category levels. At the feature level, we introduce a local graph to identify the most relevant patches within an image, facilitating adaptability to defined main object representations. At the category level, we employ a global graph to aggregate the features from samples within the same category, thereby enriching overall representations. Extensive experiments on widely used SSDA benchmark datasets, including Office-Home, DomainNet, and VisDA2017, demonstrate that both quantitative and qualitative results substantiate the effectiveness of HiGDA, establishing it as a new state-of-the-art method.
+
+
+
+ 35. 【2412.11815】ColorFlow: Retrieval-Augmented Image Sequence Colorization
+ 链接:https://arxiv.org/abs/2412.11815
+ 作者:Junhao Zhuang,Xuan Ju,Zhaoyang Zhang,Yong Liu,Shiyi Zhang,Chun Yuan,Ying Shan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:significant market demand, comic series colorization, image sequence colorization, market demand, preserving character
+ 备注: Project Page: [this https URL](https://zhuang2002.github.io/ColorFlow/)
+
+ 点击查看摘要
+ Abstract:Automatic black-and-white image sequence colorization while preserving character and object identity (ID) is a complex task with significant market demand, such as in cartoon or comic series colorization. Despite advancements in visual colorization using large-scale generative models like diffusion models, challenges with controllability and identity consistency persist, making current solutions unsuitable for industrial this http URL address this, we propose ColorFlow, a three-stage diffusion-based framework tailored for image sequence colorization in industrial applications. Unlike existing methods that require per-ID finetuning or explicit ID embedding extraction, we propose a novel robust and generalizable Retrieval Augmented Colorization pipeline for colorizing images with relevant color references. Our pipeline also features a dual-branch design: one branch for color identity extraction and the other for colorization, leveraging the strengths of diffusion models. We utilize the self-attention mechanism in diffusion models for strong in-context learning and color identity matching. To evaluate our model, we introduce ColorFlow-Bench, a comprehensive benchmark for reference-based colorization. Results show that ColorFlow outperforms existing models across multiple metrics, setting a new standard in sequential image colorization and potentially benefiting the art industry. We release our codes and models on our project page: this https URL.
+
+
+
+ 36. 【2412.11813】Designing Semi-Structured Pruning of Graph Convolutional Networks for Skeleton-based Recognition
+ 链接:https://arxiv.org/abs/2412.11813
+ 作者:Hichem Sahbi
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Deep neural networks, Deep neural, nowadays witnessing, witnessing a major, major success
+ 备注:
+
+ 点击查看摘要
+ Abstract:Deep neural networks (DNNs) are nowadays witnessing a major success in solving many pattern recognition tasks including skeleton-based classification. The deployment of DNNs on edge-devices, endowed with limited time and memory resources, requires designing lightweight and efficient variants of these networks. Pruning is one of the lightweight network design techniques that operate by removing unnecessary network parts, in a structured or an unstructured manner, including individual weights, neurons or even entire channels. Nonetheless, structured and unstructured pruning methods, when applied separately, may either be inefficient or ineffective. In this paper, we devise a novel semi-structured method that discards the downsides of structured and unstructured pruning while gathering their upsides to some extent. The proposed solution is based on a differentiable cascaded parametrization which combines (i) a band-stop mechanism that prunes weights depending on their magnitudes, (ii) a weight-sharing parametrization that prunes connections either individually or group-wise, and (iii) a gating mechanism which arbitrates between different group-wise and entry-wise pruning. All these cascaded parametrizations are built upon a common latent tensor which is trained end-to-end by minimizing a classification loss and a surrogate tensor rank regularizer. Extensive experiments, conducted on the challenging tasks of action and hand-gesture recognition, show the clear advantage of our proposed semi-structured pruning approach against both structured and unstructured pruning, when taken separately, as well as the related work.
+
+
+
+ 37. 【2412.11812】CLDA-YOLO: Visual Contrastive Learning Based Domain Adaptive YOLO Detector
+ 链接:https://arxiv.org/abs/2412.11812
+ 作者:Tianheng Qiu,Ka Lung Law,Guanghua Pan,Jufei Wang,Xin Gao,Xuan Huang,Hu Wei
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Unsupervised domain adaptive, domain adaptive YOLO, domain adaptive, adaptive YOLO detector, YOLO detector
+ 备注:
+
+ 点击查看摘要
+ Abstract:Unsupervised domain adaptive (UDA) algorithms can markedly enhance the performance of object detectors under conditions of domain shifts, thereby reducing the necessity for extensive labeling and retraining. Current domain adaptive object detection algorithms primarily cater to two-stage detectors, which tend to offer minimal improvements when directly applied to single-stage detectors such as YOLO. Intending to benefit the YOLO detector from UDA, we build a comprehensive domain adaptive architecture using a teacher-student cooperative system for the YOLO detector. In this process, we propose uncertainty learning to cope with pseudo-labeling generated by the teacher model with extreme uncertainty and leverage dynamic data augmentation to asymptotically adapt the teacher-student system to the environment. To address the inability of single-stage object detectors to align at multiple stages, we utilize a unified visual contrastive learning paradigm that aligns instance at backbone and head respectively, which steadily improves the robustness of the detectors in cross-domain tasks. In summary, we present an unsupervised domain adaptive YOLO detector based on visual contrastive learning (CLDA-YOLO), which achieves highly competitive results across multiple domain adaptive datasets without any reduction in inference speed.
+
+
+
+ 38. 【2412.11807】PhysAug: A Physical-guided and Frequency-based Data Augmentation for Single-Domain Generalized Object Detection
+ 链接:https://arxiv.org/abs/2412.11807
+ 作者:Xiaoran Xu,Jiangang Yang,Wenhui Shi,Siyuan Ding,Luqing Luo,Jian Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Generalized Object Detection, Single-Domain Generalized Object, single source domain, unseen target domains, Object Detection
+ 备注:
+
+ 点击查看摘要
+ Abstract:Single-Domain Generalized Object Detection~(S-DGOD) aims to train on a single source domain for robust performance across a variety of unseen target domains by taking advantage of an object detector. Existing S-DGOD approaches often rely on data augmentation strategies, including a composition of visual transformations, to enhance the detector's generalization ability. However, the absence of real-world prior knowledge hinders data augmentation from contributing to the diversity of training data distributions. To address this issue, we propose PhysAug, a novel physical model-based non-ideal imaging condition data augmentation method, to enhance the adaptability of the S-DGOD tasks. Drawing upon the principles of atmospheric optics, we develop a universal perturbation model that serves as the foundation for our proposed PhysAug. Given that visual perturbations typically arise from the interaction of light with atmospheric particles, the image frequency spectrum is harnessed to simulate real-world variations during training. This approach fosters the detector to learn domain-invariant representations, thereby enhancing its ability to generalize across various settings. Without altering the network architecture or loss function, our approach significantly outperforms the state-of-the-art across various S-DGOD datasets. In particular, it achieves a substantial improvement of $7.3\%$ and $7.2\%$ over the baseline on DWD and Cityscape-C, highlighting its enhanced generalizability in real-world settings.
+
+
+
+ 39. 【2412.11802】AMI-Net: Adaptive Mask Inpainting Network for Industrial Anomaly Detection and Localization
+ 链接:https://arxiv.org/abs/2412.11802
+ 作者:Wei Luo,Haiming Yao,Wenyong Yu,Zhengyong Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Unsupervised visual anomaly, enhancing industrial production, industrial production quality, visual anomaly detection, quality and efficiency
+ 备注: Accepted by IEEE Transactions on Automation Science and [this http URL](http://Engineering.Code) is available at: [this https URL](https://github.com/luow23/AMI-Net)
+
+ 点击查看摘要
+ Abstract:Unsupervised visual anomaly detection is crucial for enhancing industrial production quality and efficiency. Among unsupervised methods, reconstruction approaches are popular due to their simplicity and effectiveness. The key aspect of reconstruction methods lies in the restoration of anomalous regions, which current methods have not satisfactorily achieved. To tackle this issue, we introduce a novel \uline{A}daptive \uline{M}ask \uline{I}npainting \uline{Net}work (AMI-Net) from the perspective of adaptive mask-inpainting. In contrast to traditional reconstruction methods that treat non-semantic image pixels as targets, our method uses a pre-trained network to extract multi-scale semantic features as reconstruction targets. Given the multiscale nature of industrial defects, we incorporate a training strategy involving random positional and quantitative masking. Moreover, we propose an innovative adaptive mask generator capable of generating adaptive masks that effectively mask anomalous regions while preserving normal regions. In this manner, the model can leverage the visible normal global contextual information to restore the masked anomalous regions, thereby effectively suppressing the reconstruction of defects. Extensive experimental results on the MVTec AD and BTAD industrial datasets validate the effectiveness of the proposed method. Additionally, AMI-Net exhibits exceptional real-time performance, striking a favorable balance between detection accuracy and speed, rendering it highly suitable for industrial applications. Code is available at: this https URL
+
+
+
+ 40. 【2412.11788】Neural Collapse Inspired Knowledge Distillation
+ 链接:https://arxiv.org/abs/2412.11788
+ 作者:Shuoxi Zhang,Zijian Song,Kun He
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:demonstrated their ability, knowledge distillation, distillation, Neural Collapse, Existing knowledge distillation
+ 备注: 13 pages, 7 figures. Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Existing knowledge distillation (KD) methods have demonstrated their ability in achieving student network performance on par with their teachers. However, the knowledge gap between the teacher and student remains significant and may hinder the effectiveness of the distillation process. In this work, we introduce the structure of Neural Collapse (NC) into the KD framework. NC typically occurs in the final phase of training, resulting in a graceful geometric structure where the last-layer features form a simplex equiangular tight frame. Such phenomenon has improved the generalization of deep network training. We hypothesize that NC can also alleviate the knowledge gap in distillation, thereby enhancing student performance. This paper begins with an empirical analysis to bridge the connection between knowledge distillation and neural collapse. Through this analysis, we establish that transferring the teacher's NC structure to the student benefits the distillation process. Therefore, instead of merely transferring instance-level logits or features, as done by existing distillation methods, we encourage students to learn the teacher's NC structure. Thereby, we propose a new distillation paradigm termed Neural Collapse-inspired Knowledge Distillation (NCKD). Comprehensive experiments demonstrate that NCKD is simple yet effective, improving the generalization of all distilled student models and achieving state-of-the-art accuracy performance.
+
+
+
+ 41. 【2412.11785】InterDyn: Controllable Interactive Dynamics with Video Diffusion Models
+ 链接:https://arxiv.org/abs/2412.11785
+ 作者:Rick Akkerman,Haiwen Feng,Michael J. Black,Dimitrios Tzionas,Victoria Fernández Abrevaya
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:intelligent systems, humans and intelligent, Predicting, Predicting the dynamics, interacting objects
+ 备注:
+
+ 点击查看摘要
+ Abstract:Predicting the dynamics of interacting objects is essential for both humans and intelligent systems. However, existing approaches are limited to simplified, toy settings and lack generalizability to complex, real-world environments. Recent advances in generative models have enabled the prediction of state transitions based on interventions, but focus on generating a single future state which neglects the continuous motion and subsequent dynamics resulting from the interaction. To address this gap, we propose InterDyn, a novel framework that generates videos of interactive dynamics given an initial frame and a control signal encoding the motion of a driving object or actor. Our key insight is that large video foundation models can act as both neural renderers and implicit physics simulators by learning interactive dynamics from large-scale video data. To effectively harness this capability, we introduce an interactive control mechanism that conditions the video generation process on the motion of the driving entity. Qualitative results demonstrate that InterDyn generates plausible, temporally consistent videos of complex object interactions while generalizing to unseen objects. Quantitative evaluations show that InterDyn outperforms baselines that focus on static state transitions. This work highlights the potential of leveraging video generative models as implicit physics engines.
+
+
+
+ 42. 【2412.11779】Impact of Face Alignment on Face Image Quality
+ 链接:https://arxiv.org/abs/2412.11779
+ 作者:Eren Onaran,Erdi Sarıtaş,Hazım Kemal Ekenel
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:face image quality, Face, face image, alignment, facial analysis tasks
+ 备注: Accepted at EAI ROSENET 2024 - 8th EAI International Conference on Robotic Sensor Networks
+
+ 点击查看摘要
+ Abstract:Face alignment is a crucial step in preparing face images for feature extraction in facial analysis tasks. For applications such as face recognition, facial expression recognition, and facial attribute classification, alignment is widely utilized during both training and inference to standardize the positions of key landmarks in the face. It is well known that the application and method of face alignment significantly affect the performance of facial analysis models. However, the impact of alignment on face image quality has not been thoroughly investigated. Current FIQA studies often assume alignment as a prerequisite but do not explicitly evaluate how alignment affects quality metrics, especially with the advent of modern deep learning-based detectors that integrate detection and landmark localization. To address this need, our study examines the impact of face alignment on face image quality scores. We conducted experiments on the LFW, IJB-B, and SCFace datasets, employing MTCNN and RetinaFace models for face detection and alignment. To evaluate face image quality, we utilized several assessment methods, including SER-FIQ, FaceQAN, DifFIQA, and SDD-FIQA. Our analysis included examining quality score distributions for the LFW and IJB-B datasets and analyzing average quality scores at varying distances in the SCFace dataset. Our findings reveal that face image quality assessment methods are sensitive to alignment. Moreover, this sensitivity increases under challenging real-life conditions, highlighting the importance of evaluating alignment's role in quality assessment.
+
+
+
+ 43. 【2412.11767】IDEA-Bench: How Far are Generative Models from Professional Designing?
+ 链接:https://arxiv.org/abs/2412.11767
+ 作者:Chen Liang,Lianghua Huang,Jingwu Fang,Huanzhang Dou,Wei Wang,Zhi-Fan Wu,Yupeng Shi,Junge Zhang,Xin Zhao,Yu Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:requiring deep interpretation, Real-world design tasks, film storyboard development, picture book creation, photo retouching
+ 备注:
+
+ 点击查看摘要
+ Abstract:Real-world design tasks - such as picture book creation, film storyboard development using character sets, photo retouching, visual effects, and font transfer - are highly diverse and complex, requiring deep interpretation and extraction of various elements from instructions, descriptions, and reference images. The resulting images often implicitly capture key features from references or user inputs, making it challenging to develop models that can effectively address such varied tasks. While existing visual generative models can produce high-quality images based on prompts, they face significant limitations in professional design scenarios that involve varied forms and multiple inputs and outputs, even when enhanced with adapters like ControlNets and LoRAs. To address this, we introduce IDEA-Bench, a comprehensive benchmark encompassing 100 real-world design tasks, including rendering, visual effects, storyboarding, picture books, fonts, style-based, and identity-preserving generation, with 275 test cases to thoroughly evaluate a model's general-purpose generation capabilities. Notably, even the best-performing model only achieves 22.48 on IDEA-Bench, while the best general-purpose model only achieves 6.81. We provide a detailed analysis of these results, highlighting the inherent challenges and providing actionable directions for improvement. Additionally, we provide a subset of 18 representative tasks equipped with multimodal large language model (MLLM)-based auto-evaluation techniques to facilitate rapid model development and comparison. We releases the benchmark data, evaluation toolkits, and an online leaderboard at this https URL, aiming to drive the advancement of generative models toward more versatile and applicable intelligent design systems.
+
+
+
+ 44. 【2412.11762】GS-ProCams: Gaussian Splatting-based Projector-Camera Systems
+ 链接:https://arxiv.org/abs/2412.11762
+ 作者:Qingyue Deng,Jijiang Li,Haibin Ling,Bingyao Huang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR); Multimedia (cs.MM)
+ 关键词:Gaussian Splatting-based framework, Splatting-based framework, Gaussian Splatting-based, projector-camera systems, framework for projector-camera
+ 备注:
+
+ 点击查看摘要
+ Abstract:We present GS-ProCams, the first Gaussian Splatting-based framework for projector-camera systems (ProCams). GS-ProCams significantly enhances the efficiency of projection mapping (PM) that requires establishing geometric and radiometric mappings between the projector and the camera. Previous CNN-based ProCams are constrained to a specific viewpoint, limiting their applicability to novel perspectives. In contrast, NeRF-based ProCams support view-agnostic projection mapping, however, they require an additional colocated light source and demand significant computational and memory resources. To address this issue, we propose GS-ProCams that employs 2D Gaussian for scene representations, and enables efficient view-agnostic ProCams applications. In particular, we explicitly model the complex geometric and photometric mappings of ProCams using projector responses, the target surface's geometry and materials represented by Gaussians, and global illumination component. Then, we employ differentiable physically-based rendering to jointly estimate them from captured multi-view projections. Compared to state-of-the-art NeRF-based methods, our GS-ProCams eliminates the need for additional devices, achieving superior ProCams simulation quality. It is also 600 times faster and uses only 1/10 of the GPU memory.
+
+
+
+ 45. 【2412.11755】Generative Inbetweening through Frame-wise Conditions-Driven Video Generation
+ 链接:https://arxiv.org/abs/2412.11755
+ 作者:Tianyi Zhu,Dongwei Ren,Qilong Wang,Xiaohe Wu,Wangmeng Zuo
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Generative inbetweening aims, Generative inbetweening, intermediate frame sequences, video generation models, video generation
+ 备注:
+
+ 点击查看摘要
+ Abstract:Generative inbetweening aims to generate intermediate frame sequences by utilizing two key frames as input. Although remarkable progress has been made in video generation models, generative inbetweening still faces challenges in maintaining temporal stability due to the ambiguous interpolation path between two key frames. This issue becomes particularly severe when there is a large motion gap between input frames. In this paper, we propose a straightforward yet highly effective Frame-wise Conditions-driven Video Generation (FCVG) method that significantly enhances the temporal stability of interpolated video frames. Specifically, our FCVG provides an explicit condition for each frame, making it much easier to identify the interpolation path between two input frames and thus ensuring temporally stable production of visually plausible video frames. To achieve this, we suggest extracting matched lines from two input frames that can then be easily interpolated frame by frame, serving as frame-wise conditions seamlessly integrated into existing video generation models. In extensive evaluations covering diverse scenarios such as natural landscapes, complex human poses, camera movements and animations, existing methods often exhibit incoherent transitions across frames. In contrast, our FCVG demonstrates the capability to generate temporally stable videos using both linear and non-linear interpolation curves. Our project page and code are available at \url{this https URL}.
+
+
+
+ 46. 【2412.11753】DriveGazen: Event-Based Driving Status Recognition using Conventional Camera
+ 链接:https://arxiv.org/abs/2412.11753
+ 作者:Xiaoyin Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:real-time method robust, driving status, wearable driving status, identifying driving status, Driving State Network
+ 备注: 9 pages, 4 figures, (AAAI25)The 39th Annual AAAI Conference on Artificial Intelligence
+
+ 点击查看摘要
+ Abstract:We introduce a wearable driving status recognition device and our open-source dataset, along with a new real-time method robust to changes in lighting conditions for identifying driving status from eye observations of drivers. The core of our method is generating event frames from conventional intensity frames, and the other is a newly designed Attention Driving State Network (ADSN). Compared to event cameras, conventional cameras offer complete information and lower hardware costs, enabling captured frames to encode rich spatial information. However, these textures lack temporal information, posing challenges in effectively identifying driving status. DriveGazen addresses this issue from three perspectives. First, we utilize video frames to generate realistic synthetic dynamic vision sensor (DVS) events. Second, we adopt a spiking neural network to decode pertinent temporal information. Lastly, ADSN extracts crucial spatial cues from corresponding intensity frames and conveys spatial attention to convolutional spiking layers during both training and inference through a novel guide attention module to guide the feature learning and feature enhancement of the event frame. We specifically collected the Driving Status (DriveGaze) dataset to demonstrate the effectiveness of our approach. Additionally, we validate the superiority of the DriveGazen on the Single-eye Event-based Emotion (SEE) dataset. To the best of our knowledge, our method is the first to utilize guide attention spiking neural networks and eye-based event frames generated from conventional cameras for driving status recognition. Please refer to our project page for more details: this https URL.
+
+
+
+ 47. 【2412.11752】Deformable Radial Kernel Splatting
+ 链接:https://arxiv.org/abs/2412.11752
+ 作者:Yi-Hua Huang,Ming-Xian Lin,Yang-Tian Sun,Ziyi Yang,Xiaoyang Lyu,Yan-Pei Cao,Xiaojuan Qi
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:technique for representing, Gaussian splatting, robust technique, Gaussians' inherent radial, extends Gaussian splatting
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recently, Gaussian splatting has emerged as a robust technique for representing 3D scenes, enabling real-time rasterization and high-fidelity rendering. However, Gaussians' inherent radial symmetry and smoothness constraints limit their ability to represent complex shapes, often requiring thousands of primitives to approximate detailed geometry. We introduce Deformable Radial Kernel (DRK), which extends Gaussian splatting into a more general and flexible framework. Through learnable radial bases with adjustable angles and scales, DRK efficiently models diverse shape primitives while enabling precise control over edge sharpness and boundary curvature. iven DRK's planar nature, we further develop accurate ray-primitive intersection computation for depth sorting and introduce efficient kernel culling strategies for improved rasterization efficiency. Extensive experiments demonstrate that DRK outperforms existing methods in both representation efficiency and rendering quality, achieving state-of-the-art performance while dramatically reducing primitive count.
+
+
+
+ 48. 【2412.11735】ransferable Adversarial Face Attack with Text Controlled Attribute
+ 链接:https://arxiv.org/abs/2412.11735
+ 作者:Wenyun Li,Zheng Zhang,Xiangyuan Lan,Dongmei Jiang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:semantically meaningful perturbations, Traditional adversarial attacks, attacks typically produce, typically produce adversarial, Traditional adversarial
+ 备注:
+
+ 点击查看摘要
+ Abstract:Traditional adversarial attacks typically produce adversarial examples under norm-constrained conditions, whereas unrestricted adversarial examples are free-form with semantically meaningful perturbations. Current unrestricted adversarial impersonation attacks exhibit limited control over adversarial face attributes and often suffer from low transferability. In this paper, we propose a novel Text Controlled Attribute Attack (TCA$^2$) to generate photorealistic adversarial impersonation faces guided by natural language. Specifically, the category-level personal softmax vector is employed to precisely guide the impersonation attacks. Additionally, we propose both data and model augmentation strategies to achieve transferable attacks on unknown target models. Finally, a generative model, \textit{i.e}, Style-GAN, is utilized to synthesize impersonated faces with desired attributes. Extensive experiments on two high-resolution face recognition datasets validate that our TCA$^2$ method can generate natural text-guided adversarial impersonation faces with high transferability. We also evaluate our method on real-world face recognition systems, \textit{i.e}, Face++ and Aliyun, further demonstrating the practical potential of our approach.
+
+
+
+ 49. 【2412.11715】Discrepancy-Aware Attention Network for Enhanced Audio-Visual Zero-Shot Learning
+ 链接:https://arxiv.org/abs/2412.11715
+ 作者:RunLin Yu,Yipu Gong,Wenrui Li,Aiwen Sun,Mengren Zheng
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:Audio-visual Zero-Shot Learning, video classification tasks, Zero-Shot Learning, identify unseen classes, attracted significant attention
+ 备注:
+
+ 点击查看摘要
+ Abstract:Audio-visual Zero-Shot Learning (ZSL) has attracted significant attention for its ability to identify unseen classes and perform well in video classification tasks. However, modal imbalance in (G)ZSL leads to over-reliance on the optimal modality, reducing discriminative capabilities for unseen classes. Some studies have attempted to address this issue by modifying parameter gradients, but two challenges still remain: (a) Quality discrepancies, where modalities offer differing quantities and qualities of information for the same concept. (b) Content discrepancies, where sample contributions within a modality vary significantly. To address these challenges, we propose a Discrepancy-Aware Attention Network (DAAN) for Enhanced Audio-Visual ZSL. Our approach introduces a Quality-Discrepancy Mitigation Attention (QDMA) unit to minimize redundant information in the high-quality modality and a Contrastive Sample-level Gradient Modulation (CSGM) block to adjust gradient magnitudes and balance content discrepancies. We quantify modality contributions by integrating optimization and convergence rate for more precise gradient modulation in CSGM. Experiments demonstrates DAAN achieves state-of-the-art performance on benchmark datasets, with ablation studies validating the effectiveness of individual modules.
+
+
+
+ 50. 【2412.11710】Re-Attentional Controllable Video Diffusion Editing
+ 链接:https://arxiv.org/abs/2412.11710
+ 作者:Yuanzhi Wang,Yong Li,Mengyi Liu,Xiaoya Zhang,Xin Liu,Zhen Cui,Antoni B. Chan
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:garnered popularity due, Video Diffusion Editing, video editing, video, Editing
+ 备注: Accepted by AAAI 2025. Codes are released at: [this https URL](https://github.com/mdswyz/ReAtCo)
+
+ 点击查看摘要
+ Abstract:Editing videos with textual guidance has garnered popularity due to its streamlined process which mandates users to solely edit the text prompt corresponding to the source video. Recent studies have explored and exploited large-scale text-to-image diffusion models for text-guided video editing, resulting in remarkable video editing capabilities. However, they may still suffer from some limitations such as mislocated objects, incorrect number of objects. Therefore, the controllability of video editing remains a formidable challenge. In this paper, we aim to challenge the above limitations by proposing a Re-Attentional Controllable Video Diffusion Editing (ReAtCo) method. Specially, to align the spatial placement of the target objects with the edited text prompt in a training-free manner, we propose a Re-Attentional Diffusion (RAD) to refocus the cross-attention activation responses between the edited text prompt and the target video during the denoising stage, resulting in a spatially location-aligned and semantically high-fidelity manipulated video. In particular, to faithfully preserve the invariant region content with less border artifacts, we propose an Invariant Region-guided Joint Sampling (IRJS) strategy to mitigate the intrinsic sampling errors w.r.t the invariant regions at each denoising timestep and constrain the generated content to be harmonized with the invariant region content. Experimental results verify that ReAtCo consistently improves the controllability of video diffusion editing and achieves superior video editing performance.
+
+
+
+ 51. 【2412.11706】AsymRnR: Video Diffusion Transformers Acceleration with Asymmetric Reduction and Restoration
+ 链接:https://arxiv.org/abs/2412.11706
+ 作者:Wenhao Sun,Rong-Cheng Tu,Jingyi Liao,Zhao Jin,Dacheng Tao
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Video Diffusion Transformers, Diffusion Transformers, demonstrated significant potential, generating high-fidelity videos, computationally intensive
+ 备注: 11 pages, 7 figures
+
+ 点击查看摘要
+ Abstract:Video Diffusion Transformers (DiTs) have demonstrated significant potential for generating high-fidelity videos but are computationally intensive. Existing acceleration methods include distillation, which requires costly retraining, and feature caching, which is highly sensitive to network architecture. Recent token reduction methods are training-free and architecture-agnostic, offering greater flexibility and wider applicability. However, they enforce the same sequence length across different components, constraining their acceleration potential. We observe that intra-sequence redundancy in video DiTs varies across features, blocks, and denoising timesteps. Building on this observation, we propose Asymmetric Reduction and Restoration (AsymRnR), a training-free approach to accelerate video DiTs. It offers a flexible and adaptive strategy that reduces the number of tokens based on their redundancy to enhance both acceleration and generation quality. We further propose matching cache to facilitate faster processing. Integrated into state-of-the-art video DiTs, AsymRnR achieves a superior speedup without compromising the quality.
+
+
+
+ 52. 【2412.11702】Flex-PE: Flexible and SIMD Multi-Precision Processing Element for AI Workloads
+ 链接:https://arxiv.org/abs/2412.11702
+ 作者:Mukul Lokhande,Gopal Raut,Santosh Kumar Vishvakarma
+ 类目:Hardware Architecture (cs.AR); Computer Vision and Pattern Recognition (cs.CV); Distributed, Parallel, and Cluster Computing (cs.DC); Image and Video Processing (eess.IV)
+ 关键词:linear activation functions, deep learning inference, Vision Transformers, driven AI models, drives a strong
+ 备注: 10 pages, 5 figures, Preprint, Submitted to TVLSI Regular papers
+
+ 点击查看摘要
+ Abstract:The rapid adaptation of data driven AI models, such as deep learning inference, training, Vision Transformers (ViTs), and other HPC applications, drives a strong need for runtime precision configurable different non linear activation functions (AF) hardware support. Existing solutions support diverse precision or runtime AF reconfigurability but fail to address both simultaneously. This work proposes a flexible and SIMD multiprecision processing element (FlexPE), which supports diverse runtime configurable AFs, including sigmoid, tanh, ReLU and softmax, and MAC operation. The proposed design achieves an improved throughput of up to 16X FxP4, 8X FxP8, 4X FxP16 and 1X FxP32 in pipeline mode with 100% time multiplexed hardware. This work proposes an area efficient multiprecision iterative mode in the SIMD systolic arrays for edge AI use cases. The design delivers superior performance with up to 62X and 371X reductions in DMA reads for input feature maps and weight filters in VGG16, with an energy efficiency of 8.42 GOPS / W within the accuracy loss of 2%. The proposed architecture supports emerging 4-bit computations for DL inference while enhancing throughput in FxP8/16 modes for transformers and other HPC applications. The proposed approach enables future energy-efficient AI accelerators in edge and cloud environments.
+
+
+
+ 53. 【2412.11685】Ultra-High-Definition Dynamic Multi-Exposure Image Fusion via Infinite Pixel Learning
+ 链接:https://arxiv.org/abs/2412.11685
+ 作者:Xingchi Chen,Zhuoran Zheng,Xuerui Li,Yuying Chen,Shu Wang,Wenqi Ren
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:device imaging resolution, UHD multi-exposure dynamic, UHD dynamic multi-exposure, single consumer-grade GPU, Large Language Model
+ 备注:
+
+ 点击查看摘要
+ Abstract:With the continuous improvement of device imaging resolution, the popularity of Ultra-High-Definition (UHD) images is increasing. Unfortunately, existing methods for fusing multi-exposure images in dynamic scenes are designed for low-resolution images, which makes them inefficient for generating high-quality UHD images on a resource-constrained device. To alleviate the limitations of extremely long-sequence inputs, inspired by the Large Language Model (LLM) for processing infinitely long texts, we propose a novel learning paradigm to achieve UHD multi-exposure dynamic scene image fusion on a single consumer-grade GPU, named Infinite Pixel Learning (IPL). The design of our approach comes from three key components: The first step is to slice the input sequences to relieve the pressure generated by the model processing the data stream; Second, we develop an attention cache technique, which is similar to KV cache for infinite data stream processing; Finally, we design a method for attention cache compression to alleviate the storage burden of the cache on the device. In addition, we provide a new UHD benchmark to evaluate the effectiveness of our method. Extensive experimental results show that our method maintains high-quality visual performance while fusing UHD dynamic multi-exposure images in real-time (40fps) on a single consumer-grade GPU.
+
+
+
+ 54. 【2412.11680】EGP3D: Edge-guided Geometric Preserving 3D Point Cloud Super-resolution for RGB-D camera
+ 链接:https://arxiv.org/abs/2412.11680
+ 作者:Zheng Fang,Ke Ye,Yaofang Liu,Gongzhe Li,Xianhong Zhao,Jialong Li,Ruxin Wang,Yuchen Zhang,Xiangyang Ji,Qilin Sun
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:depth images captured, point cloud, point cloud super-resolution, reconstruction and robots, low resolution
+ 备注:
+
+ 点击查看摘要
+ Abstract:Point clouds or depth images captured by current RGB-D cameras often suffer from low resolution, rendering them insufficient for applications such as 3D reconstruction and robots. Existing point cloud super-resolution (PCSR) methods are either constrained by geometric artifacts or lack attention to edge details. To address these issues, we propose an edge-guided geometric-preserving 3D point cloud super-resolution (EGP3D) method tailored for RGB-D cameras. Our approach innovatively optimizes the point cloud with an edge constraint on a projected 2D space, thereby ensuring high-quality edge preservation in the 3D PCSR task. To tackle geometric optimization challenges in super-resolution point clouds, particularly preserving edge shapes and smoothness, we introduce a multi-faceted loss function that simultaneously optimizes the Chamfer distance, Hausdorff distance, and gradient smoothness. Existing datasets used for point cloud upsampling are predominantly synthetic and inadequately represent real-world scenarios, neglecting noise and stray light effects. To address the scarcity of realistic RGB-D data for PCSR tasks, we built a dataset that captures real-world noise and stray-light effects, offering a more accurate representation of authentic environments. Validated through simulations and real-world experiments, the proposed method exhibited superior performance in preserving edge clarity and geometric details.
+
+
+
+ 55. 【2412.11673】DINO-Foresight Looking into the Future with DINO
+ 链接:https://arxiv.org/abs/2412.11673
+ 作者:Efstathios Karypidis,Ioannis Kakogeorgiou,Spyros Gidaris,Nikos Komodakis
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Predicting future dynamics, Predicting future, Vision Foundation Models, driving and robotics, environment is key
+ 备注:
+
+ 点击查看摘要
+ Abstract:Predicting future dynamics is crucial for applications like autonomous driving and robotics, where understanding the environment is key. Existing pixel-level methods are computationally expensive and often focus on irrelevant details. To address these challenges, we introduce $\texttt{DINO-Foresight}$, a novel framework that operates in the semantic feature space of pretrained Vision Foundation Models (VFMs). Our approach trains a masked feature transformer in a self-supervised manner to predict the evolution of VFM features over time. By forecasting these features, we can apply off-the-shelf, task-specific heads for various scene understanding tasks. In this framework, VFM features are treated as a latent space, to which different heads attach to perform specific tasks for future-frame analysis. Extensive experiments show that our framework outperforms existing methods, demonstrating its robustness and scalability. Additionally, we highlight how intermediate transformer representations in $\texttt{DINO-Foresight}$ improve downstream task performance, offering a promising path for the self-supervised enhancement of VFM features. We provide the implementation code at this https URL .
+
+
+
+ 56. 【2412.11668】Online Writer Retrieval with Chinese Handwritten Phrases: A Synergistic Temporal-Frequency Representation Learning Approach
+ 链接:https://arxiv.org/abs/2412.11668
+ 作者:Peirong Zhang,Lianwen Jin
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:accurately search relevant, search relevant handwriting, relevant handwriting instances, effective retrieval systems, spurred a critical
+ 备注:
+
+ 点击查看摘要
+ Abstract:Currently, the prevalence of online handwriting has spurred a critical need for effective retrieval systems to accurately search relevant handwriting instances from specific writers, known as online writer retrieval. Despite the growing demand, this field suffers from a scarcity of well-established methodologies and public large-scale datasets. This paper tackles these challenges with a focus on Chinese handwritten phrases. First, we propose DOLPHIN, a novel retrieval model designed to enhance handwriting representations through synergistic temporal-frequency analysis. For frequency feature learning, we propose the HFGA block, which performs gated cross-attention between the vanilla temporal handwriting sequence and its high-frequency sub-bands to amplify salient writing details. For temporal feature learning, we propose the CAIR block, tailored to promote channel interaction and reduce channel redundancy. Second, to address data deficit, we introduce OLIWER, a large-scale online writer retrieval dataset encompassing over 670,000 Chinese handwritten phrases from 1,731 individuals. Through extensive evaluations, we demonstrate the superior performance of DOLPHIN over existing methods. In addition, we explore cross-domain writer retrieval and reveal the pivotal role of increasing feature alignment in bridging the distributional gap between different handwriting data. Our findings emphasize the significance of point sampling frequency and pressure features in improving handwriting representation quality and retrieval performance. Code and dataset are available at this https URL.
+
+
+
+ 57. 【2412.11663】LMM-Regularized CLIP Embeddings for Image Classification
+ 链接:https://arxiv.org/abs/2412.11663
+ 作者:Maria Tzelepi,Vasileios Mezaris
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:CLIP vision-language model, Large Multimodal Model, powerful CLIP vision-language, CLIP image encoder, CLIP image
+ 备注: Accepted for publication, 26th Int. Symp. on Multimedia (IEEE ISM 2024), Tokyo, Japan, Dec. 2024. This is the authors' "accepted version"
+
+ 点击查看摘要
+ Abstract:In this paper we deal with image classification tasks using the powerful CLIP vision-language model. Our goal is to advance the classification performance using the CLIP's image encoder, by proposing a novel Large Multimodal Model (LMM) based regularization method. The proposed method uses an LMM to extract semantic descriptions for the images of the dataset. Then, it uses the CLIP's text encoder, frozen, in order to obtain the corresponding text embeddings and compute the mean semantic class descriptions. Subsequently, we adapt the CLIP's image encoder by adding a classification head, and we train it along with the image encoder output, apart from the main classification objective, with an additional auxiliary objective. The additional objective forces the embeddings at the image encoder's output to become similar to their corresponding LMM-generated mean semantic class descriptions. In this way, it produces embeddings with enhanced discrimination ability, leading to improved classification performance. The effectiveness of the proposed regularization method is validated through extensive experiments on three image classification datasets.
+
+
+
+ 58. 【2412.11657】CNNtention: Can CNNs do better with Attention?
+ 链接:https://arxiv.org/abs/2412.11657
+ 作者:Julian Glattki,Nikhil Kapila,Tejas Rathi
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Convolutional Neural Networks, Convolutional Neural, Neural Networks, recently attention-based mechanisms, image classification tasks
+ 备注: 10 pages, 11 figures
+
+ 点击查看摘要
+ Abstract:Convolutional Neural Networks (CNNs) have been the standard for image classification tasks for a long time, but more recently attention-based mechanisms have gained traction. This project aims to compare traditional CNNs with attention-augmented CNNs across an image classification task. By evaluating and comparing their performance, accuracy and computational efficiency, the project will highlight benefits and trade-off of the localized feature extraction of traditional CNNs and the global context capture in attention-augmented CNNs. By doing this, we can reveal further insights into their respective strengths and weaknesses, guide the selection of models based on specific application needs and ultimately, enhance understanding of these architectures in the deep learning community.
+This was our final project for CS7643 Deep Learning course at Georgia Tech.
+
Comments:
+10 pages, 11 figures
+Subjects:
+Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+MSC classes:
+68T45 (Primary), 68T07 (Secondary)
+Cite as:
+arXiv:2412.11657 [cs.CV]
+(or
+arXiv:2412.11657v1 [cs.CV] for this version)
+https://doi.org/10.48550/arXiv.2412.11657
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 59. 【2412.11650】Image Gradient-Aided Photometric Stereo Network
+ 链接:https://arxiv.org/abs/2412.11650
+ 作者:Kaixuan Wang,Lin Qi,Shiyu Qin,Kai Luo,Yakun Ju,Xia Li,Junyu Dong
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:endeavors to ascertain, shading clues, photometric images, Photometric stereo, ascertain surface normals
+ 备注: 13 pages, 5 figures, published to Springer
+
+ 点击查看摘要
+ Abstract:Photometric stereo (PS) endeavors to ascertain surface normals using shading clues from photometric images under various illuminations. Recent deep learning-based PS methods often overlook the complexity of object surfaces. These neural network models, which exclusively rely on photometric images for training, often produce blurred results in high-frequency regions characterized by local discontinuities, such as wrinkles and edges with significant gradient changes. To address this, we propose the Image Gradient-Aided Photometric Stereo Network (IGA-PSN), a dual-branch framework extracting features from both photometric images and their gradients. Furthermore, we incorporate an hourglass regression network along with supervision to regularize normal regression. Experiments on DiLiGenT benchmarks show that IGA-PSN outperforms previous methods in surface normal estimation, achieving a mean angular error of 6.46 while preserving textures and geometric shapes in complex regions.
+
+
+
+ 60. 【2412.11639】High-speed and High-quality Vision Reconstruction of Spike Camera with Spike Stability Theorem
+ 链接:https://arxiv.org/abs/2412.11639
+ 作者:Wei Zhang,Weiquan Yan,Yun Zhao,Wenxiang Cheng,Gang Chen,Huihui Zhou,Yonghong Tian
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:Neuromorphic vision sensors, spike camera, dynamic vision sensor, gained increasing attention, spike
+ 备注:
+
+ 点击查看摘要
+ Abstract:Neuromorphic vision sensors, such as the dynamic vision sensor (DVS) and spike camera, have gained increasing attention in recent years. The spike camera can detect fine textures by mimicking the fovea in the human visual system, and output a high-frequency spike stream. Real-time high-quality vision reconstruction from the spike stream can build a bridge to high-level vision task applications of the spike camera. To realize high-speed and high-quality vision reconstruction of the spike camera, we propose a new spike stability theorem that reveals the relationship between spike stream characteristics and stable light intensity. Based on the spike stability theorem, two parameter-free algorithms are designed for the real-time vision reconstruction of the spike camera. To demonstrate the performances of our algorithms, two datasets (a public dataset PKU-Spike-High-Speed and a newly constructed dataset SpikeCityPCL) are used to compare the reconstruction quality and speed of various reconstruction methods. Experimental results show that, compared with the current state-of-the-art (SOTA) reconstruction methods, our reconstruction methods obtain the best tradeoff between the reconstruction quality and speed. Additionally, we design the FPGA implementation method of our algorithms to realize the real-time (running at 20,000 FPS) visual reconstruction. Our work provides new theorem and algorithm foundations for the real-time edge-end vision processing of the spike camera.
+
+
+
+ 61. 【2412.11638】IDProtector: An Adversarial Noise Encoder to Protect Against ID-Preserving Image Generation
+ 链接:https://arxiv.org/abs/2412.11638
+ 作者:Yiren Song,Pei Yang,Hai Ci,Mike Zheng Shou
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:revolutionized identity-preserving generation, identity-preserving generation, Recently, efficient identity-preserving generation, zero-shot methods
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recently, zero-shot methods like InstantID have revolutionized identity-preserving generation. Unlike multi-image finetuning approaches such as DreamBooth, these zero-shot methods leverage powerful facial encoders to extract identity information from a single portrait photo, enabling efficient identity-preserving generation through a single inference pass. However, this convenience introduces new threats to the facial identity protection. This paper aims to safeguard portrait photos from unauthorized encoder-based customization. We introduce IDProtector, an adversarial noise encoder that applies imperceptible adversarial noise to portrait photos in a single forward pass. Our approach offers universal protection for portraits against multiple state-of-the-art encoder-based methods, including InstantID, IP-Adapter, and PhotoMaker, while ensuring robustness to common image transformations such as JPEG compression, resizing, and affine transformations. Experiments across diverse portrait datasets and generative models reveal that IDProtector generalizes effectively to unseen data and even closed-source proprietary models.
+
+
+
+ 62. 【2412.11634】Predicting the Original Appearance of Damaged Historical Documents
+ 链接:https://arxiv.org/abs/2412.11634
+ 作者:Zhenhua Yang,Dezhi Peng,Yongxin Shi,Yuyi Zhang,Chongyu Liu,Lianwen Jin
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:severe damages including, Historical Document Repair, Historical documents encompass, including character missing, damages including character
+ 备注: Accepted to AAAI 2025; Github Page: [this https URL](https://github.com/yeungchenwa/HDR)
+
+ 点击查看摘要
+ Abstract:Historical documents encompass a wealth of cultural treasures but suffer from severe damages including character missing, paper damage, and ink erosion over time. However, existing document processing methods primarily focus on binarization, enhancement, etc., neglecting the repair of these damages. To this end, we present a new task, termed Historical Document Repair (HDR), which aims to predict the original appearance of damaged historical documents. To fill the gap in this field, we propose a large-scale dataset HDR28K and a diffusion-based network DiffHDR for historical document repair. Specifically, HDR28K contains 28,552 damaged-repaired image pairs with character-level annotations and multi-style degradations. Moreover, DiffHDR augments the vanilla diffusion framework with semantic and spatial information and a meticulously designed character perceptual loss for contextual and visual coherence. Experimental results demonstrate that the proposed DiffHDR trained using HDR28K significantly surpasses existing approaches and exhibits remarkable performance in handling real damaged documents. Notably, DiffHDR can also be extended to document editing and text block generation, showcasing its high flexibility and generalization capacity. We believe this study could pioneer a new direction of document processing and contribute to the inheritance of invaluable cultures and civilizations. The dataset and code is available at this https URL.
+
+
+
+ 63. 【2412.11621】VG-TVP: Multimodal Procedural Planning via Visually Grounded Text-Video Prompting
+ 链接:https://arxiv.org/abs/2412.11621
+ 作者:Muhammet Furkan Ilaslan,Ali Koksal,Kevin Qinhong Lin,Burak Satar,Mike Zheng Shou,Qianli Xu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:Large Language Model, Large Language, users remains under-explored, multimodal instructions augmented, assist users remains
+ 备注: Accepted for The 39th Annual AAAI Conference on Artificial Intelligence 2025 in Main Track, 19 pages, 24 figures
+
+ 点击查看摘要
+ Abstract:Large Language Model (LLM)-based agents have shown promise in procedural tasks, but the potential of multimodal instructions augmented by texts and videos to assist users remains under-explored. To address this gap, we propose the Visually Grounded Text-Video Prompting (VG-TVP) method which is a novel LLM-empowered Multimodal Procedural Planning (MPP) framework. It generates cohesive text and video procedural plans given a specified high-level objective. The main challenges are achieving textual and visual informativeness, temporal coherence, and accuracy in procedural plans. VG-TVP leverages the zero-shot reasoning capability of LLMs, the video-to-text generation ability of the video captioning models, and the text-to-video generation ability of diffusion models. VG-TVP improves the interaction between modalities by proposing a novel Fusion of Captioning (FoC) method and using Text-to-Video Bridge (T2V-B) and Video-to-Text Bridge (V2T-B). They allow LLMs to guide the generation of visually-grounded text plans and textual-grounded video plans. To address the scarcity of datasets suitable for MPP, we have curated a new dataset called Daily-Life Task Procedural Plans (Daily-PP). We conduct comprehensive experiments and benchmarks to evaluate human preferences (regarding textual and visual informativeness, temporal coherence, and plan accuracy). Our VG-TVP method outperforms unimodal baselines on the Daily-PP dataset.
+
+
+
+ 64. 【2412.11620】Combating Semantic Contamination in Learning with Label Noise
+ 链接:https://arxiv.org/abs/2412.11620
+ 作者:Wenxiao Fan,Kan Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:deep neural networks, Semantic Contamination, neural networks, performance of deep, deep neural
+ 备注: AAAI2025
+
+ 点击查看摘要
+ Abstract:Noisy labels can negatively impact the performance of deep neural networks. One common solution is label refurbishment, which involves reconstructing noisy labels through predictions and distributions. However, these methods may introduce problematic semantic associations, a phenomenon that we identify as Semantic Contamination. Through an analysis of Robust LR, a representative label refurbishment method, we found that utilizing the logits of views for refurbishment does not adequately balance the semantic information of individual classes. Conversely, using the logits of models fails to maintain consistent semantic relationships across models, which explains why label refurbishment methods frequently encounter issues related to Semantic Contamination. To address this issue, we propose a novel method called Collaborative Cross Learning, which utilizes semi-supervised learning on refurbished labels to extract appropriate semantic associations from embeddings across views and models. Experimental results show that our method outperforms existing approaches on both synthetic and real-world noisy datasets, effectively mitigating the impact of label noise and Semantic Contamination.
+
+
+
+ 65. 【2412.11609】CLIP-SR: Collaborative Linguistic and Image Processing for Super-Resolution
+ 链接:https://arxiv.org/abs/2412.11609
+ 作者:Bingwen Hu,Heng Liu,Zhedong Zheng,Ping Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Convolutional Neural Networks, Convolutional Neural, Neural Networks, CNN-based methods rely, methods rely solely
+ 备注: 11 pages, 10 figures
+
+ 点击查看摘要
+ Abstract:Convolutional Neural Networks (CNNs) have advanced Image Super-Resolution (SR), but most CNN-based methods rely solely on pixel-based transformations, often leading to artifacts and blurring, particularly with severe downsampling (e.g., 8x or 16x). Recent text-guided SR methods attempt to leverage textual information for enhanced detail, but they frequently struggle with effective alignment, resulting in inconsistent semantic coherence. To address these limitations, we introduce a multi-modal semantic enhancement approach that combines textual semantics with visual features, effectively tackling semantic mismatches and detail loss in highly degraded LR images. Our proposed multi-modal collaborative framework enables the production of realistic and high-quality SR images at significant up-scaling factors. The framework integrates text and image inputs, employing a prompt predictor, Text-Image Fusion Block (TIFBlock), and Iterative Refinement Module alongside CLIP (Contrastive Language-Image Pretraining) features to guide a progressive enhancement process with fine-grained alignment. This alignment produces high-resolution outputs with crisp details and semantic coherence, even at large scaling factors. Through extensive comparative experiments and ablation studies, we validate the effectiveness of our approach. Additionally, by incorporating textual semantic guidance, our technique enables a degree of super-resolution editability while maintaining semantic coherence.
+
+
+
+ 66. 【2412.11608】owards Adversarial Robustness of Model-Level Mixture-of-Experts Architectures for Semantic Segmentation
+ 链接:https://arxiv.org/abs/2412.11608
+ 作者:Svetlana Pavlitska,Enrico Eisen,J. Marius Zöllner
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:deep neural networks, well-known deficiency, deficiency of deep, deep neural, neural networks
+ 备注: Accepted for publication at ICMLA 2024
+
+ 点击查看摘要
+ Abstract:Vulnerability to adversarial attacks is a well-known deficiency of deep neural networks. Larger networks are generally more robust, and ensembling is one method to increase adversarial robustness: each model's weaknesses are compensated by the strengths of others. While an ensemble uses a deterministic rule to combine model outputs, a mixture of experts (MoE) includes an additional learnable gating component that predicts weights for the outputs of the expert models, thus determining their contributions to the final prediction. MoEs have been shown to outperform ensembles on specific tasks, yet their susceptibility to adversarial attacks has not been studied yet. In this work, we evaluate the adversarial vulnerability of MoEs for semantic segmentation of urban and highway traffic scenes. We show that MoEs are, in most cases, more robust to per-instance and universal white-box adversarial attacks and can better withstand transfer attacks. Our code is available at \url{this https URL}.
+
+
+
+ 67. 【2412.11599】3D$^2$-Actor: Learning Pose-Conditioned 3D-Aware Denoiser for Realistic Gaussian Avatar Modeling
+ 链接:https://arxiv.org/abs/2412.11599
+ 作者:Zichen Tang,Hongyu Yang,Hanchen Zhang,Jiaxin Chen,Di Huang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:sparse multi-view RGB, Advancements in neural, neural implicit representations, multi-view RGB videos, multi-view RGB
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Advancements in neural implicit representations and differentiable rendering have markedly improved the ability to learn animatable 3D avatars from sparse multi-view RGB videos. However, current methods that map observation space to canonical space often face challenges in capturing pose-dependent details and generalizing to novel poses. While diffusion models have demonstrated remarkable zero-shot capabilities in 2D image generation, their potential for creating animatable 3D avatars from 2D inputs remains underexplored. In this work, we introduce 3D$^2$-Actor, a novel approach featuring a pose-conditioned 3D-aware human modeling pipeline that integrates iterative 2D denoising and 3D rectifying steps. The 2D denoiser, guided by pose cues, generates detailed multi-view images that provide the rich feature set necessary for high-fidelity 3D reconstruction and pose rendering. Complementing this, our Gaussian-based 3D rectifier renders images with enhanced 3D consistency through a two-stage projection strategy and a novel local coordinate representation. Additionally, we propose an innovative sampling strategy to ensure smooth temporal continuity across frames in video synthesis. Our method effectively addresses the limitations of traditional numerical solutions in handling ill-posed mappings, producing realistic and animatable 3D human avatars. Experimental results demonstrate that 3D$^2$-Actor excels in high-fidelity avatar modeling and robustly generalizes to novel poses. Code is available at: this https URL.
+
+
+
+ 68. 【2412.11596】MeshArt: Generating Articulated Meshes with Structure-guided Transformers
+ 链接:https://arxiv.org/abs/2412.11596
+ 作者:Daoyi Gao,Yawar Siddiqui,Lei Li,Angela Dai
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:interactable virtual assets, creating realistic, simply static, fundamental for creating, interactable virtual
+ 备注: Project Page: [this https URL](https://daoyig.github.io/Mesh_Art/)
+
+ 点击查看摘要
+ Abstract:Articulated 3D object generation is fundamental for creating realistic, functional, and interactable virtual assets which are not simply static. We introduce MeshArt, a hierarchical transformer-based approach to generate articulated 3D meshes with clean, compact geometry, reminiscent of human-crafted 3D models. We approach articulated mesh generation in a part-by-part fashion across two stages. First, we generate a high-level articulation-aware object structure; then, based on this structural information, we synthesize each part's mesh faces. Key to our approach is modeling both articulation structures and part meshes as sequences of quantized triangle embeddings, leading to a unified hierarchical framework with transformers for autoregressive generation. Object part structures are first generated as their bounding primitives and articulation modes; a second transformer, guided by these articulation structures, then generates each part's mesh triangles. To ensure coherency among generated parts, we introduce structure-guided conditioning that also incorporates local part mesh connectivity. MeshArt shows significant improvements over state of the art, with 57.1% improvement in structure coverage and a 209-point improvement in mesh generation FID.
+
+
+
+ 69. 【2412.11594】VersaGen: Unleashing Versatile Visual Control for Text-to-Image Synthesis
+ 链接:https://arxiv.org/abs/2412.11594
+ 作者:Zhipeng Chen,Lan Yang,Yonggang Qi,Honggang Zhang,Kaiyue Pang,Ke Li,Yi-Zhe Song
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:enabling precise visual, enabling precise, significant challenge, rapid advancements, remains a significant
+ 备注: The paper has been accepted by AAAI 2025. Paper code: [this https URL](https://github.com/FelixChan9527/VersaGen_official)
+
+ 点击查看摘要
+ Abstract:Despite the rapid advancements in text-to-image (T2I) synthesis, enabling precise visual control remains a significant challenge. Existing works attempted to incorporate multi-facet controls (text and sketch), aiming to enhance the creative control over generated images. However, our pilot study reveals that the expressive power of humans far surpasses the capabilities of current methods. Users desire a more versatile approach that can accommodate their diverse creative intents, ranging from controlling individual subjects to manipulating the entire scene composition. We present VersaGen, a generative AI agent that enables versatile visual control in T2I synthesis. VersaGen admits four types of visual controls: i) single visual subject; ii) multiple visual subjects; iii) scene background; iv) any combination of the three above or merely no control at all. We train an adaptor upon a frozen T2I model to accommodate the visual information into the text-dominated diffusion process. We introduce three optimization strategies during the inference phase of VersaGen to improve generation results and enhance user experience. Comprehensive experiments on COCO and Sketchy validate the effectiveness and flexibility of VersaGen, as evidenced by both qualitative and quantitative results.
+
+
+
+ 70. 【2412.11586】StrandHead: Text to Strand-Disentangled 3D Head Avatars Using Hair Geometric Priors
+ 链接:https://arxiv.org/abs/2412.11586
+ 作者:Xiaokun Sun,Zeyu Cai,Zhenyu Zhang,Ying Tai,Jian Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:existing avatar generation, generation methods fail, avatar generation methods, practical hair due, distinct personality
+ 备注: Project page: [this https URL](https://xiaokunsun.github.io/StrandHead.github.io)
+
+ 点击查看摘要
+ Abstract:While haircut indicates distinct personality, existing avatar generation methods fail to model practical hair due to the general or entangled representation. We propose StrandHead, a novel text to 3D head avatar generation method capable of generating disentangled 3D hair with strand representation. Without using 3D data for supervision, we demonstrate that realistic hair strands can be generated from prompts by distilling 2D generative diffusion models. To this end, we propose a series of reliable priors on shape initialization, geometric primitives, and statistical haircut features, leading to a stable optimization and text-aligned performance. Extensive experiments show that StrandHead achieves the state-of-the-art reality and diversity of generated 3D head and hair. The generated 3D hair can also be easily implemented in the Unreal Engine for physical simulation and other applications. The code will be available at this https URL.
+
+
+
+ 71. 【2412.11582】Oriented Tiny Object Detection: A Dataset, Benchmark, and Dynamic Unbiased Learning
+ 链接:https://arxiv.org/abs/2412.11582
+ 作者:Chang Xu,Ruixiang Zhang,Wen Yang,Haoran Zhu,Fang Xu,Jian Ding,Gui-Song Xia
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Detecting oriented tiny, Detecting oriented, real-world applications, remains an intricate, under-explored problem
+ 备注:
+
+ 点击查看摘要
+ Abstract:Detecting oriented tiny objects, which are limited in appearance information yet prevalent in real-world applications, remains an intricate and under-explored problem. To address this, we systemically introduce a new dataset, benchmark, and a dynamic coarse-to-fine learning scheme in this study. Our proposed dataset, AI-TOD-R, features the smallest object sizes among all oriented object detection datasets. Based on AI-TOD-R, we present a benchmark spanning a broad range of detection paradigms, including both fully-supervised and label-efficient approaches. Through investigation, we identify a learning bias presents across various learning pipelines: confident objects become increasingly confident, while vulnerable oriented tiny objects are further marginalized, hindering their detection performance. To mitigate this issue, we propose a Dynamic Coarse-to-Fine Learning (DCFL) scheme to achieve unbiased learning. DCFL dynamically updates prior positions to better align with the limited areas of oriented tiny objects, and it assigns samples in a way that balances both quantity and quality across different object shapes, thus mitigating biases in prior settings and sample selection. Extensive experiments across eight challenging object detection datasets demonstrate that DCFL achieves state-of-the-art accuracy, high efficiency, and remarkable versatility. The dataset, benchmark, and code are available at this https URL.
+
+
+
+ 72. 【2412.11579】SweepEvGS: Event-Based 3D Gaussian Splatting for Macro and Micro Radiance Field Rendering from a Single Sweep
+ 链接:https://arxiv.org/abs/2412.11579
+ 作者:Jingqian Wu,Shuo Zhu,Chutian Wang,Boxin Shi,Edmund Y. Lam
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Gaussian Splatting, continuously calibrated input, Gaussian primitives, Recent advancements, calibrated input views
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advancements in 3D Gaussian Splatting (3D-GS) have demonstrated the potential of using 3D Gaussian primitives for high-speed, high-fidelity, and cost-efficient novel view synthesis from continuously calibrated input views. However, conventional methods require high-frame-rate dense and high-quality sharp images, which are time-consuming and inefficient to capture, especially in dynamic environments. Event cameras, with their high temporal resolution and ability to capture asynchronous brightness changes, offer a promising alternative for more reliable scene reconstruction without motion blur. In this paper, we propose SweepEvGS, a novel hardware-integrated method that leverages event cameras for robust and accurate novel view synthesis across various imaging settings from a single sweep. SweepEvGS utilizes the initial static frame with dense event streams captured during a single camera sweep to effectively reconstruct detailed scene views. We also introduce different real-world hardware imaging systems for real-world data collection and evaluation for future research. We validate the robustness and efficiency of SweepEvGS through experiments in three different imaging settings: synthetic objects, real-world macro-level, and real-world micro-level view synthesis. Our results demonstrate that SweepEvGS surpasses existing methods in visual rendering quality, rendering speed, and computational efficiency, highlighting its potential for dynamic practical applications.
+
+
+
+ 73. 【2412.11578】DVP-MVS: Synergize Depth-Edge and Visibility Prior for Multi-View Stereo
+ 链接:https://arxiv.org/abs/2412.11578
+ 作者:Zhenlong Yuan,Jinguo Luo,Fei Shen,Zhaoxin Li,Cong Liu,Tianlu Mao,Zhaoqi Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:recently exhibited substantial, exhibited substantial effectiveness, reconstruct textureless areas, patch deformation, visibility-aware patch deformation
+ 备注:
+
+ 点击查看摘要
+ Abstract:Patch deformation-based methods have recently exhibited substantial effectiveness in multi-view stereo, due to the incorporation of deformable and expandable perception to reconstruct textureless areas. However, such approaches typically focus on exploring correlative reliable pixels to alleviate match ambiguity during patch deformation, but ignore the deformation instability caused by mistaken edge-skipping and visibility occlusion, leading to potential estimation deviation. To remedy the above issues, we propose DVP-MVS, which innovatively synergizes depth-edge aligned and cross-view prior for robust and visibility-aware patch deformation. Specifically, to avoid unexpected edge-skipping, we first utilize Depth Anything V2 followed by the Roberts operator to initialize coarse depth and edge maps respectively, both of which are further aligned through an erosion-dilation strategy to generate fine-grained homogeneous boundaries for guiding patch deformation. In addition, we reform view selection weights as visibility maps and restore visible areas by cross-view depth reprojection, then regard them as cross-view prior to facilitate visibility-aware patch deformation. Finally, we improve propagation and refinement with multi-view geometry consistency by introducing aggregated visible hemispherical normals based on view selection and local projection depth differences based on epipolar lines, respectively. Extensive evaluations on ETH3D and Tanks Temples benchmarks demonstrate that our method can achieve state-of-the-art performance with excellent robustness and generalization.
+
+
+
+ 74. 【2412.11576】Aligning Visual and Semantic Interpretability through Visually Grounded Concept Bottleneck Models
+ 链接:https://arxiv.org/abs/2412.11576
+ 作者:Patrick Knab,Katharina Prasse,Sascha Marton,Christian Bartelt,Margret Keuper
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:networks increases steadily, neural networks increases, Concept Bottleneck Models, increases steadily, Bottleneck Models
+ 备注: *Equal contribution
+
+ 点击查看摘要
+ Abstract:The performance of neural networks increases steadily, but our understanding of their decision-making lags behind. Concept Bottleneck Models (CBMs) address this issue by incorporating human-understandable concepts into the prediction process, thereby enhancing transparency and interpretability. Since existing approaches often rely on large language models (LLMs) to infer concepts, their results may contain inaccurate or incomplete mappings, especially in complex visual domains. We introduce visually Grounded Concept Bottleneck Models (GCBM), which derive concepts on the image level using segmentation and detection foundation models. Our method generates inherently interpretable concepts, which can be grounded in the input image using attribution methods, allowing interpretations to be traced back to the image plane. We show that GCBM concepts are meaningful interpretability vehicles, which aid our understanding of model embedding spaces. GCBMs allow users to control the granularity, number, and naming of concepts, providing flexibility and are easily adaptable to new datasets without pre-training or additional data needed. Prediction accuracy is within 0.3-6% of the linear probe and GCBMs perform especially well for fine-grained classification interpretability on CUB, due to their dataset specificity. Our code is available on this https URL.
+
+
+
+ 75. 【2412.11574】PyPotteryLens: An Open-Source Deep Learning Framework for Automated Digitisation of Archaeological Pottery Documentation
+ 链接:https://arxiv.org/abs/2412.11574
+ 作者:Lorenzo Cardarelli
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:aspect of archaeology, study represents, represents a crucial, crucial but time-consuming, time-consuming aspect
+ 备注:
+
+ 点击查看摘要
+ Abstract:Archaeological pottery documentation and study represents a crucial but time-consuming aspect of archaeology. While recent years have seen advances in digital documentation methods, vast amounts of legacy data remain locked in traditional publications. This paper introduces PyPotteryLens, an open-source framework that leverages deep learning to automate the digitisation and processing of archaeological pottery drawings from published sources. The system combines state-of-the-art computer vision models (YOLO for instance segmentation and EfficientNetV2 for classification) with an intuitive user interface, making advanced digital methods accessible to archaeologists regardless of technical expertise. The framework achieves over 97\% precision and recall in pottery detection and classification tasks, while reducing processing time by up to 5x to 20x compared to manual methods. Testing across diverse archaeological contexts demonstrates robust generalisation capabilities. Also, the system's modular architecture facilitates extension to other archaeological materials, while its standardised output format ensures long-term preservation and reusability of digitised data as well as solid basis for training machine learning algorithms. The software, documentation, and examples are available on GitHub (this https URL).
+
+
+
+ 76. 【2412.11561】RADARSAT Constellation Mission Compact Polarisation SAR Data for Burned Area Mapping with Deep Learning
+ 链接:https://arxiv.org/abs/2412.11561
+ 作者:Yu Zhao,Yifang Ban
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Monitoring wildfires, increasingly critical due, burned area mapping, mapping burned areas, burned areas
+ 备注:
+
+ 点击查看摘要
+ Abstract:Monitoring wildfires has become increasingly critical due to the sharp rise in wildfire incidents in recent years. Optical satellites like Sentinel-2 and Landsat are extensively utilized for mapping burned areas. However, the effectiveness of optical sensors is compromised by clouds and smoke, which obstruct the detection of burned areas. Thus, satellites equipped with Synthetic Aperture Radar (SAR), such as dual-polarization Sentinel-1 and quad-polarization RADARSAT-1/-2 C-band SAR, which can penetrate clouds and smoke, are investigated for mapping burned areas. However, there is limited research on using compact polarisation (compact-pol) C-band RADARSAT Constellation Mission (RCM) SAR data for this purpose. This study aims to investigate the capacity of compact polarisation RCM data for burned area mapping through deep learning. Compact-pol m-chi decomposition and Compact-pol Radar Vegetation Index (CpRVI) are derived from the RCM Multi-look Complex product. A deep-learning-based processing pipeline incorporating ConvNet-based and Transformer-based models is applied for burned area mapping, with three different input settings: using only log-ratio dual-polarization intensity images images, using only compact-pol decomposition plus CpRVI, and using all three data sources. The results demonstrate that compact-pol m-chi decomposition and CpRVI images significantly complement log-ratio images for burned area mapping. The best-performing Transformer-based model, UNETR, trained with log-ratio, m-chi decomposition, and CpRVI data, achieved an F1 Score of 0.718 and an IoU Score of 0.565, showing a notable improvement compared to the same model trained using only log-ratio images.
+
+
+
+ 77. 【2412.11555】S-SatFire: A Multi-Task Satellite Image Time-Series Dataset for Wildfire Detection and Prediction
+ 链接:https://arxiv.org/abs/2412.11555
+ 作者:Yu Zhao,Sebastian Gerard,Yifang Ban
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:understanding wildfire behaviour, essential for understanding, Wildfire, Earth observation data, active fire detection
+ 备注:
+
+ 点击查看摘要
+ Abstract:Wildfire monitoring and prediction are essential for understanding wildfire behaviour. With extensive Earth observation data, these tasks can be integrated and enhanced through multi-task deep learning models. We present a comprehensive multi-temporal remote sensing dataset for active fire detection, daily wildfire monitoring, and next-day wildfire prediction. Covering wildfire events in the contiguous U.S. from January 2017 to October 2021, the dataset includes 3552 surface reflectance images and auxiliary data such as weather, topography, land cover, and fuel information, totalling 71 GB. The lifecycle of each wildfire is documented, with labels for active fires (AF) and burned areas (BA), supported by manual quality assurance of AF and BA test labels. The dataset supports three tasks: a) active fire detection, b) daily burned area mapping, and c) wildfire progression prediction. Detection tasks use pixel-wise classification of multi-spectral, multi-temporal images, while prediction tasks integrate satellite and auxiliary data to model fire dynamics. This dataset and its benchmarks provide a foundation for advancing wildfire research using deep learning.
+
+
+
+ 78. 【2412.11553】raining Strategies for Isolated Sign Language Recognition
+ 链接:https://arxiv.org/abs/2412.11553
+ 作者:Karina Kvanchiani,Roman Kraynov,Elizaveta Petrova,Petr Surovcev,Aleksandr Nagaev,Alexander Kapitanov
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Isolated Sign Language, Sign Language Recognition, Sign Language, Isolated Sign, comprehensive model training
+ 备注: sign language recognition, training strategies, computer vision
+
+ 点击查看摘要
+ Abstract:This paper introduces a comprehensive model training pipeline for Isolated Sign Language Recognition (ISLR) designed to accommodate the distinctive characteristics and constraints of the Sign Language (SL) domain. The constructed pipeline incorporates carefully selected image and video augmentations to tackle the challenges of low data quality and varying sign speeds. Including an additional regression head combined with IoU-balanced classification loss enhances the model's awareness of the gesture and simplifies capturing temporal information. Extensive experiments demonstrate that the developed training pipeline easily adapts to different datasets and architectures. Additionally, the ablation study shows that each proposed component expands the potential to consider ISLR task specifics. The presented strategies improve recognition performance on a broad set of ISLR benchmarks. Moreover, we achieved a state-of-the-art result on the WLASL and Slovo benchmarks with 1.63% and 14.12% improvements compared to the previous best solution, respectively.
+
+
+
+ 79. 【2412.11549】MPQ-DM: Mixed Precision Quantization for Extremely Low Bit Diffusion Models
+ 链接:https://arxiv.org/abs/2412.11549
+ 作者:Weilun Feng,Haotong Qin,Chuanguang Yang,Zhulin An,Libo Huang,Boyu Diao,Fei Wang,Renshuai Tao,Yongjun Xu,Michele Magno
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:received wide attention, Diffusion models, generation tasks, Diffusion, received wide
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Diffusion models have received wide attention in generation tasks. However, the expensive computation cost prevents the application of diffusion models in resource-constrained scenarios. Quantization emerges as a practical solution that significantly saves storage and computation by reducing the bit-width of parameters. However, the existing quantization methods for diffusion models still cause severe degradation in performance, especially under extremely low bit-widths (2-4 bit). The primary decrease in performance comes from the significant discretization of activation values at low bit quantization. Too few activation candidates are unfriendly for outlier significant weight channel quantization, and the discretized features prevent stable learning over different time steps of the diffusion model. This paper presents MPQ-DM, a Mixed-Precision Quantization method for Diffusion Models. The proposed MPQ-DM mainly relies on two techniques:(1) To mitigate the quantization error caused by outlier severe weight channels, we propose an Outlier-Driven Mixed Quantization (OMQ) technique that uses $Kurtosis$ to quantify outlier salient channels and apply optimized intra-layer mixed-precision bit-width allocation to recover accuracy performance within target efficiency.(2) To robustly learn representations crossing time steps, we construct a Time-Smoothed Relation Distillation (TRD) scheme between the quantized diffusion model and its full-precision counterpart, transferring discrete and continuous latent to a unified relation space to reduce the representation inconsistency. Comprehensive experiments demonstrate that MPQ-DM achieves significant accuracy gains under extremely low bit-widths compared with SOTA quantization methods. MPQ-DM achieves a 58\% FID decrease under W2A4 setting compared with baseline, while all other methods even collapse.
+
+
+
+ 80. 【2412.11542】Meta Curvature-Aware Minimization for Domain Generalization
+ 链接:https://arxiv.org/abs/2412.11542
+ 作者:Ziyang Chen,Yiwen Ye,Feilong Tang,Yongsheng Pan,Yong Xia
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:source domains, unseen domains, Domain generalization, aims to enhance, enhance the ability
+ 备注: 21 pages, 5 figures, 17 tables
+
+ 点击查看摘要
+ Abstract:Domain generalization (DG) aims to enhance the ability of models trained on source domains to generalize effectively to unseen domains. Recently, Sharpness-Aware Minimization (SAM) has shown promise in this area by reducing the sharpness of the loss landscape to obtain more generalized models. However, SAM and its variants sometimes fail to guide the model toward a flat minimum, and their training processes exhibit limitations, hindering further improvements in model generalization. In this paper, we first propose an improved model training process aimed at encouraging the model to converge to a flat minima. To achieve this, we design a curvature metric that has a minimal effect when the model is far from convergence but becomes increasingly influential in indicating the curvature of the minima as the model approaches a local minimum. Then we derive a novel algorithm from this metric, called Meta Curvature-Aware Minimization (MeCAM), to minimize the curvature around the local minima. Specifically, the optimization objective of MeCAM simultaneously minimizes the regular training loss, the surrogate gap of SAM, and the surrogate gap of meta-learning. We provide theoretical analysis on MeCAM's generalization error and convergence rate, and demonstrate its superiority over existing DG methods through extensive experiments on five benchmark DG datasets, including PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet. Code will be available on GitHub.
+
+
+
+ 81. 【2412.11540】SP$^2$T: Sparse Proxy Attention for Dual-stream Point Transformer
+ 链接:https://arxiv.org/abs/2412.11540
+ 作者:Jiaxu Wan,Hong Zhang,Ziqi He,Qishu Wang,Ding Yuan,Yifan Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:yielded significant advances, receptive field, yielded significant, significant advances, advances in broadening
+ 备注: 13 pages, 14 figures, 14 tables
+
+ 点击查看摘要
+ Abstract:In 3D understanding, point transformers have yielded significant advances in broadening the receptive field. However, further enhancement of the receptive field is hindered by the constraints of grouping attention. The proxy-based model, as a hot topic in image and language feature extraction, uses global or local proxies to expand the model's receptive field. But global proxy-based methods fail to precisely determine proxy positions and are not suited for tasks like segmentation and detection in the point cloud, and exist local proxy-based methods for image face difficulties in global-local balance, proxy sampling in various point clouds, and parallel cross-attention computation for sparse association. In this paper, we present SP$^2$T, a local proxy-based dual stream point transformer, which promotes global receptive field while maintaining a balance between local and global information. To tackle robust 3D proxy sampling, we propose a spatial-wise proxy sampling with vertex-based point proxy associations, ensuring robust point-cloud sampling in many scales of point cloud. To resolve economical association computation, we introduce sparse proxy attention combined with table-based relative bias, which enables low-cost and precise interactions between proxy and point features. Comprehensive experiments across multiple datasets reveal that our model achieves SOTA performance in downstream tasks. The code has been released in this https URL .
+
+
+
+ 82. 【2412.11535】Near Large Far Small: Relative Distance Based Partition Learning for UAV-view Geo-Localization
+ 链接:https://arxiv.org/abs/2412.11535
+ 作者:Quan Chen,Tingyu Wang,Rongfeng Lu,Bolun Zheng,Zhedong Zheng,Chenggang Yan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:presents substantial challenges, presents substantial, substantial challenges, primarily due, due to appearance
+ 备注: In Peer Review
+
+ 点击查看摘要
+ Abstract:UAV-view Geo-Localization (UVGL) presents substantial challenges, primarily due to appearance differences between drone-view and satellite-view. Existing methods develop partition learning strategies aimed at mining more comprehensive information by constructing diverse part-level feature representations, which rely on consistent cross-view scales. However, variations of UAV flight state leads to the scale mismatch of cross-views, resulting in serious performance degradation of partition-based methods. To overcome this issue, we propose a partition learning framework based on relative distance, which alleviates the dependence on scale consistency while mining fine-grained features. Specifically, we propose a distance guided dynamic partition learning strategy (DGDPL), consisting of a square partition strategy and a dynamic-guided adjustment strategy. The former is utilized to extract fine-grained features and global features in a simple manner. The latter calculates the relative distance ratio between drone- and satellite-view to adjust the partition size, thereby aligning the semantic information between partition pairs. Furthermore, we propose a saliency-guided refinement strategy to refine part-level features, so as to further improve the retrieval accuracy. Extensive experiments show that our approach achieves superior geo-localization accuracy across various scale-inconsistent scenarios, and exhibits remarkable robustness against scale variations. The code will be released.
+
+
+
+ 83. 【2412.11530】RoMeO: Robust Metric Visual Odometry
+ 链接:https://arxiv.org/abs/2412.11530
+ 作者:Junda Cheng,Zhipeng Cai,Zhaoxing Zhang,Wei Yin,Matthias Muller,Michael Paulitsch,Xin Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:fundamental building block, estimate camera poses, Metric Visual Odometry, Visual odometry, aims to estimate
+ 备注:
+
+ 点击查看摘要
+ Abstract:Visual odometry (VO) aims to estimate camera poses from visual inputs -- a fundamental building block for many applications such as VR/AR and robotics. This work focuses on monocular RGB VO where the input is a monocular RGB video without IMU or 3D sensors. Existing approaches lack robustness under this challenging scenario and fail to generalize to unseen data (especially outdoors); they also cannot recover metric-scale poses. We propose Robust Metric Visual Odometry (RoMeO), a novel method that resolves these issues leveraging priors from pre-trained depth models. RoMeO incorporates both monocular metric depth and multi-view stereo (MVS) models to recover metric-scale, simplify correspondence search, provide better initialization and regularize optimization. Effective strategies are proposed to inject noise during training and adaptively filter noisy depth priors, which ensure the robustness of RoMeO on in-the-wild data. As shown in Fig.1, RoMeO advances the state-of-the-art (SOTA) by a large margin across 6 diverse datasets covering both indoor and outdoor scenes. Compared to the current SOTA DPVO, RoMeO reduces the relative (align the trajectory scale with GT) and absolute trajectory errors both by 50%. The performance gain also transfers to the full SLAM pipeline (with global BA loop closure). Code will be released upon acceptance.
+
+
+
+ 84. 【2412.11529】Cross-View Geo-Localization with Street-View and VHR Satellite Imagery in Decentrality Settings
+ 链接:https://arxiv.org/abs/2412.11529
+ 作者:Panwang Xia,Lei Yu,Yi Wan,Qiong Wu,Peiqi Chen,Liheng Zhong,Yongxiang Yao,Dong Wei,Xinyi Liu,Lixiang Ru,Yingying Zhang,Jiangwei Lao,Jingdong Chen,Ming Yang,Yongjun Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:geo-tagged aerial-view reference, aerial-view reference images, matching street-view query, GNSS-denied environments, environments by matching
+ 备注:
+
+ 点击查看摘要
+ Abstract:Cross-View Geo-Localization tackles the problem of image geo-localization in GNSS-denied environments by matching street-view query images with geo-tagged aerial-view reference images. However, existing datasets and methods often assume center-aligned settings or only consider limited decentrality (i.e., the offset of the query image from the reference image center). This assumption overlooks the challenges present in real-world applications, where large decentrality can significantly enhance localization efficiency but simultaneously lead to a substantial degradation in localization accuracy. To address this limitation, we introduce CVSat, a novel dataset designed to evaluate cross-view geo-localization with a large geographic scope and diverse landscapes, emphasizing the decentrality issue. Meanwhile, we propose AuxGeo (Auxiliary Enhanced Geo-Localization), which leverages a multi-metric optimization strategy with two novel modules: the Bird's-eye view Intermediary Module (BIM) and the Position Constraint Module (PCM). BIM uses bird's-eye view images derived from street-view panoramas as an intermediary, simplifying the cross-view challenge with decentrality to a cross-view problem and a decentrality problem. PCM leverages position priors between cross-view images to establish multi-grained alignment constraints. These modules improve the performance of cross-view geo-localization with the decentrality problem. Extensive experiments demonstrate that AuxGeo outperforms previous methods on our proposed CVSat dataset, mitigating the issue of large decentrality, and also achieves state-of-the-art performance on existing public datasets such as CVUSA, CVACT, and VIGOR.
+
+
+
+ 85. 【2412.11525】Sequence Matters: Harnessing Video Models in Super-Resolution
+ 链接:https://arxiv.org/abs/2412.11525
+ 作者:Hyun-kyu Ko,Dongheok Park,Youngin Park,Byeonghyeon Lee,Juhee Han,Eunbyung Park
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:reconstruct high-fidelity, aims to reconstruct, models, images, multi-view images
+ 备注: Project page: [this https URL](https://ko-lani.github.io/Sequence-Matters)
+
+ 点击查看摘要
+ Abstract:3D super-resolution aims to reconstruct high-fidelity 3D models from low-resolution (LR) multi-view images. Early studies primarily focused on single-image super-resolution (SISR) models to upsample LR images into high-resolution images. However, these methods often lack view consistency because they operate independently on each image. Although various post-processing techniques have been extensively explored to mitigate these inconsistencies, they have yet to fully resolve the issues. In this paper, we perform a comprehensive study of 3D super-resolution by leveraging video super-resolution (VSR) models. By utilizing VSR models, we ensure a higher degree of spatial consistency and can reference surrounding spatial information, leading to more accurate and detailed reconstructions. Our findings reveal that VSR models can perform remarkably well even on sequences that lack precise spatial alignment. Given this observation, we propose a simple yet practical approach to align LR images without involving fine-tuning or generating 'smooth' trajectory from the trained 3D models over LR images. The experimental results show that the surprisingly simple algorithms can achieve the state-of-the-art results of 3D super-resolution tasks on standard benchmark datasets, such as the NeRF-synthetic and MipNeRF-360 datasets. Project page: this https URL
+
+
+
+ 86. 【2412.11520】EditSplat: Multi-View Fusion and Attention-Guided Optimization for View-Consistent 3D Scene Editing with 3D Gaussian Splatting
+ 链接:https://arxiv.org/abs/2412.11520
+ 作者:Dong In Lee,Hyeongcheol Park,Jiyoung Seo,Eunbyung Park,Hyunje Park,Ha Dam Baek,Shin Sangheon,Sangmin kim,Sangpil Kim
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Recent advancements, highlighted the potential, potential of text-driven, Recent, multi-view
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advancements in 3D editing have highlighted the potential of text-driven methods in real-time, user-friendly AR/VR applications. However, current methods rely on 2D diffusion models without adequately considering multi-view information, resulting in multi-view inconsistency. While 3D Gaussian Splatting (3DGS) significantly improves rendering quality and speed, its 3D editing process encounters difficulties with inefficient optimization, as pre-trained Gaussians retain excessive source information, hindering optimization. To address these limitations, we propose \textbf{EditSplat}, a novel 3D editing framework that integrates Multi-view Fusion Guidance (MFG) and Attention-Guided Trimming (AGT). Our MFG ensures multi-view consistency by incorporating essential multi-view information into the diffusion process, leveraging classifier-free guidance from the text-to-image diffusion model and the geometric properties of 3DGS. Additionally, our AGT leverages the explicit representation of 3DGS to selectively prune and optimize 3D Gaussians, enhancing optimization efficiency and enabling precise, semantically rich local edits. Through extensive qualitative and quantitative evaluations, EditSplat achieves superior multi-view consistency and editing quality over existing methods, significantly enhancing overall efficiency.
+
+
+
+ 87. 【2412.11519】LineArt: A Knowledge-guided Training-free High-quality Appearance Transfer for Design Drawing with Diffusion Model
+ 链接:https://arxiv.org/abs/2412.11519
+ 作者:Xi Wang,Hongzhen Li,Heng Fang,Yichen Peng,Haoran Xie,Xi Yang,Chuntao Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:technologies reduce costs, image generation technologies, generation technologies reduce, reduce costs, Image rendering
+ 备注: Project Page: [this https URL](https://meaoxixi.github.io/LineArt/)
+
+ 点击查看摘要
+ Abstract:Image rendering from line drawings is vital in design and image generation technologies reduce costs, yet professional line drawings demand preserving complex details. Text prompts struggle with accuracy, and image translation struggles with consistency and fine-grained control. We present LineArt, a framework that transfers complex appearance onto detailed design drawings, facilitating design and artistic creation. It generates high-fidelity appearance while preserving structural accuracy by simulating hierarchical visual cognition and integrating human artistic experience to guide the diffusion process. LineArt overcomes the limitations of current methods in terms of difficulty in fine-grained control and style degradation in design drawings. It requires no precise 3D modeling, physical property specs, or network training, making it more convenient for design tasks. LineArt consists of two stages: a multi-frequency lines fusion module to supplement the input design drawing with detailed structural information and a two-part painting process for Base Layer Shaping and Surface Layer Coloring. We also present a new design drawing dataset ProLines for evaluation. The experiments show that LineArt performs better in accuracy, realism, and material precision compared to SOTAs.
+
+
+
+ 88. 【2412.11513】IGR: Improving Diffusion Model for Garment Restoration from Person Image
+ 链接:https://arxiv.org/abs/2412.11513
+ 作者:Le Shen,Rong Huang,Zhijie Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:virtual try-on task, requiring accurate capture, try-on task, requiring accurate, inverse of virtual
+ 备注:
+
+ 点击查看摘要
+ Abstract:Garment restoration, the inverse of virtual try-on task, focuses on restoring standard garment from a person image, requiring accurate capture of garment details. However, existing methods often fail to preserve the identity of the garment or rely on complex processes. To address these limitations, we propose an improved diffusion model for restoring authentic garments. Our approach employs two garment extractors to independently capture low-level features and high-level semantics from the person image. Leveraging a pretrained latent diffusion model, these features are integrated into the denoising process through garment fusion blocks, which combine self-attention and cross-attention layers to align the restored garment with the person image. Furthermore, a coarse-to-fine training strategy is introduced to enhance the fidelity and authenticity of the generated garments. Experimental results demonstrate that our model effectively preserves garment identity and generates high-quality restorations, even in challenging scenarios such as complex garments or those with occlusions.
+
+
+
+ 89. 【2412.11512】SpatialMe: Stereo Video Conversion Using Depth-Warping and Blend-Inpainting
+ 链接:https://arxiv.org/abs/2412.11512
+ 作者:Jiale Zhang,Qianxi Jia,Yang Liu,Wei Zhang,Wei Wei,Xin Tian
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:immersive stereo format, transform monocular videos, video conversion aims, aims to transform, transform monocular
+ 备注:
+
+ 点击查看摘要
+ Abstract:Stereo video conversion aims to transform monocular videos into immersive stereo format. Despite the advancements in novel view synthesis, it still remains two major challenges: i) difficulty of achieving high-fidelity and stable results, and ii) insufficiency of high-quality stereo video data. In this paper, we introduce SpatialMe, a novel stereo video conversion framework based on depth-warping and blend-inpainting. Specifically, we propose a mask-based hierarchy feature update (MHFU) refiner, which integrate and refine the outputs from designed multi-branch inpainting module, using feature update unit (FUU) and mask mechanism. We also propose a disparity expansion strategy to address the problem of foreground bleeding. Furthermore, we conduct a high-quality real-world stereo video dataset -- StereoV1K, to alleviate the data shortage. It contains 1000 stereo videos captured in real-world at a resolution of 1180 x 1180, covering various indoor and outdoor scenes. Extensive experiments demonstrate the superiority of our approach in generating stereo videos over state-of-the-art methods.
+
+
+
+ 90. 【2412.11509】Skip Tuning: Pre-trained Vision-Language Models are Effective and Efficient Adapters Themselves
+ 链接:https://arxiv.org/abs/2412.11509
+ 作者:Shihan Wu,Ji Zhang,Pengpeng Zeng,Lianli Gao,Jingkuan Song,Heng Tao Shen
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:pre-trained vision-language models, large pre-trained vision-language, transferring large pre-trained, Prompt tuning, context vectors
+ 备注:
+
+ 点击查看摘要
+ Abstract:Prompt tuning (PT) has long been recognized as an effective and efficient paradigm for transferring large pre-trained vision-language models (VLMs) to downstream tasks by learning a tiny set of context vectors. Nevertheless, in this work, we reveal that freezing the parameters of VLMs during learning the context vectors neither facilitates the transferability of pre-trained knowledge nor improves the memory and time efficiency significantly. Upon further investigation, we find that reducing both the length and width of the feature-gradient propagation flows of the full fine-tuning (FT) baseline is key to achieving effective and efficient knowledge transfer. Motivated by this, we propose Skip Tuning, a novel paradigm for adapting VLMs to downstream tasks. Unlike existing PT or adapter-based methods, Skip Tuning applies Layer-wise Skipping (LSkip) and Class-wise Skipping (CSkip) upon the FT baseline without introducing extra context vectors or adapter modules. Extensive experiments across a wide spectrum of benchmarks demonstrate the superior effectiveness and efficiency of our Skip Tuning over both PT and adapter-based methods. Code: this https URL.
+
+
+
+ 91. 【2412.11495】Exploring More from Multiple Gait Modalities for Human Identification
+ 链接:https://arxiv.org/abs/2412.11495
+ 作者:Dongyang Jin,Chao Fan,Weihua Chen,Shiqi Yu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:distinct walking patterns, soft biometric characteristic, unrestrained human identification, exhibiting a promising, kind of soft
+ 备注:
+
+ 点击查看摘要
+ Abstract:The gait, as a kind of soft biometric characteristic, can reflect the distinct walking patterns of individuals at a distance, exhibiting a promising technique for unrestrained human identification. With largely excluding gait-unrelated cues hidden in RGB videos, the silhouette and skeleton, though visually compact, have acted as two of the most prevailing gait modalities for a long time. Recently, several attempts have been made to introduce more informative data forms like human parsing and optical flow images to capture gait characteristics, along with multi-branch architectures. However, due to the inconsistency within model designs and experiment settings, we argue that a comprehensive and fair comparative study among these popular gait modalities, involving the representational capacity and fusion strategy exploration, is still lacking. From the perspectives of fine vs. coarse-grained shape and whole vs. pixel-wise motion modeling, this work presents an in-depth investigation of three popular gait representations, i.e., silhouette, human parsing, and optical flow, with various fusion evaluations, and experimentally exposes their similarities and differences. Based on the obtained insights, we further develop a C$^2$Fusion strategy, consequently building our new framework MultiGait++. C$^2$Fusion preserves commonalities while highlighting differences to enrich the learning of gait features. To verify our findings and conclusions, extensive experiments on Gait3D, GREW, CCPG, and SUSTech1K are conducted. The code is available at this https URL.
+
+
+
+ 92. 【2412.11489】HGSFusion: Radar-Camera Fusion with Hybrid Generation and Synchronization for 3D Object Detection
+ 链接:https://arxiv.org/abs/2412.11489
+ 作者:Zijian Gu,Jianwei Ma,Yan Huang,Honghao Wei,Zhanye Chen,Hui Zhang,Wei Hong
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Robotics (cs.RO)
+ 关键词:Millimeter-wave radar plays, autonomous driving due, Millimeter-wave radar, capabilities for perception, plays a vital
+ 备注: 12 pages, 8 figures, 7 tables. Accepted by AAAI 2025 , the 39th Annual AAAI Conference on Artificial Intelligence
+
+ 点击查看摘要
+ Abstract:Millimeter-wave radar plays a vital role in 3D object detection for autonomous driving due to its all-weather and all-lighting-condition capabilities for perception. However, radar point clouds suffer from pronounced sparsity and unavoidable angle estimation errors. To address these limitations, incorporating a camera may partially help mitigate the shortcomings. Nevertheless, the direct fusion of radar and camera data can lead to negative or even opposite effects due to the lack of depth information in images and low-quality image features under adverse lighting conditions. Hence, in this paper, we present the radar-camera fusion network with Hybrid Generation and Synchronization (HGSFusion), designed to better fuse radar potentials and image features for 3D object detection. Specifically, we propose the Radar Hybrid Generation Module (RHGM), which fully considers the Direction-Of-Arrival (DOA) estimation errors in radar signal processing. This module generates denser radar points through different Probability Density Functions (PDFs) with the assistance of semantic information. Meanwhile, we introduce the Dual Sync Module (DSM), comprising spatial sync and modality sync, to enhance image features with radar positional information and facilitate the fusion of distinct characteristics in different modalities. Extensive experiments demonstrate the effectiveness of our approach, outperforming the state-of-the-art methods in the VoD and TJ4DRadSet datasets by $6.53\%$ and $2.03\%$ in RoI AP and BEV AP, respectively. The code is available at this https URL.
+
+
+
+ 93. 【2412.11484】Efficient Policy Adaptation with Contrastive Prompt Ensemble for Embodied Agents
+ 链接:https://arxiv.org/abs/2412.11484
+ 作者:Wonje Choi,Woo Kyung Kim,SeungHyun Kim,Honguk Woo
+ 类目:Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:achieving zero-shot adaptation, zero-shot adaptation capability, unseen visual observations, embodied reinforcement learning, rapid policy adaptation
+ 备注: Accepted at NeurIPS 2023
+
+ 点击查看摘要
+ Abstract:For embodied reinforcement learning (RL) agents interacting with the environment, it is desirable to have rapid policy adaptation to unseen visual observations, but achieving zero-shot adaptation capability is considered as a challenging problem in the RL context. To address the problem, we present a novel contrastive prompt ensemble (ConPE) framework which utilizes a pretrained vision-language model and a set of visual prompts, thus enabling efficient policy learning and adaptation upon a wide range of environmental and physical changes encountered by embodied agents. Specifically, we devise a guided-attention-based ensemble approach with multiple visual prompts on the vision-language model to construct robust state representations. Each prompt is contrastively learned in terms of an individual domain factor that significantly affects the agent's egocentric perception and observation. For a given task, the attention-based ensemble and policy are jointly learned so that the resulting state representations not only generalize to various domains but are also optimized for learning the task. Through experiments, we show that ConPE outperforms other state-of-the-art algorithms for several embodied agent tasks including navigation in AI2THOR, manipulation in egocentric-Metaworld, and autonomous driving in CARLA, while also improving the sample efficiency of policy learning and adaptation.
+
+
+
+ 94. 【2412.11480】Data-driven Precipitation Nowcasting Using Satellite Imagery
+ 链接:https://arxiv.org/abs/2412.11480
+ 作者:Young-Jae Park,Doyi Kim,Minseok Seo,Hae-Gon Jeon,Yeji Choi
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:Accurate precipitation forecasting, warnings of disasters, floods and landslides, Accurate precipitation, forecasting is crucial
+ 备注: Accepted by AAAI2025
+
+ 点击查看摘要
+ Abstract:Accurate precipitation forecasting is crucial for early warnings of disasters, such as floods and landslides. Traditional forecasts rely on ground-based radar systems, which are space-constrained and have high maintenance costs. Consequently, most developing countries depend on a global numerical model with low resolution, instead of operating their own radar systems. To mitigate this gap, we propose the Neural Precipitation Model (NPM), which uses global-scale geostationary satellite imagery. NPM predicts precipitation for up to six hours, with an update every hour. We take three key channels to discriminate rain clouds as input: infrared radiation (at a wavelength of 10.5 $\mu m$), upper- (6.3 $\mu m$), and lower- (7.3 $\mu m$) level water vapor channels. Additionally, NPM introduces positional encoders to capture seasonal and temporal patterns, accounting for variations in precipitation. Our experimental results demonstrate that NPM can predict rainfall in real-time with a resolution of 2 km. The code and dataset are available at this https URL.
+
+
+
+ 95. 【2412.11475】OmniVLM: A Token-Compressed, Sub-Billion-Parameter Vision-Language Model for Efficient On-Device Inference
+ 链接:https://arxiv.org/abs/2412.11475
+ 作者:Wei Chen,Zhiyuan Li,Shuo Xin
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Direct Preference Optimization, minimal-edit Direct Preference, Preference Optimization, vision-language model, Abstract
+ 备注:
+
+ 点击查看摘要
+ Abstract:We present OmniVLM, a sub-billion-parameter vision-language model for efficient on-device inference. OmniVLM introduces a token compression mechanism that reduces visual token sequence length from 729 to 81 tokens, significantly reducing computational overhead while preserving visual-semantic fidelity. Through a multi-stage training pipeline of pretraining, supervised fine-tuning, and minimal-edit Direct Preference Optimization (DPO), OmniVLM matches the performance of larger models. On multiple benchmarks including ScienceQA, POPE, and MMMU, OmniVLM outperforms existing baselines like nanoLLAVA within a 968M-parameter footprint. Empirical results on the same laptop demonstrate 9.1x faster time-to-first-token (0.75s vs 6.82s) and 1.5x higher decoding speed (29.41 vs 19.20 tokens/s) compared to nanoLLAVA, enabling efficient deployment on edge devices. The model weights can be accessed on huggingface: \url{this https URL}, and the inference examples can be find in Appendix B.
+
+
+
+ 96. 【2412.11467】Exploring Temporal Event Cues for Dense Video Captioning in Cyclic Co-learning
+ 链接:https://arxiv.org/abs/2412.11467
+ 作者:Zhuyang Xie,Yan Yang,Yankai Yu,Jie Wang,Yongquan Jiang,Xiao Wu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Dense video captioning, video captioning aims, Dense video, video captioning, video captioning network
+ 备注: Accepted at AAAI 2025
+
+ 点击查看摘要
+ Abstract:Dense video captioning aims to detect and describe all events in untrimmed videos. This paper presents a dense video captioning network called Multi-Concept Cyclic Learning (MCCL), which aims to: (1) detect multiple concepts at the frame level, using these concepts to enhance video features and provide temporal event cues; and (2) design cyclic co-learning between the generator and the localizer within the captioning network to promote semantic perception and event localization. Specifically, we perform weakly supervised concept detection for each frame, and the detected concept embeddings are integrated into the video features to provide event cues. Additionally, video-level concept contrastive learning is introduced to obtain more discriminative concept embeddings. In the captioning network, we establish a cyclic co-learning strategy where the generator guides the localizer for event localization through semantic matching, while the localizer enhances the generator's event semantic perception through location matching, making semantic perception and event localization mutually beneficial. MCCL achieves state-of-the-art performance on the ActivityNet Captions and YouCook2 datasets. Extensive experiments demonstrate its effectiveness and interpretability.
+
+
+
+ 97. 【2412.11464】MaskCLIP++: A Mask-Based CLIP Fine-tuning Framework for Open-Vocabulary Image Segmentation
+ 链接:https://arxiv.org/abs/2412.11464
+ 作者:Quan-Sheng Zeng,Yunheng Li,Daquan Zhou,Guanbin Li,Qibin Hou,Ming-Ming Cheng
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Contrastive Language-Image Pre-training, Language-Image Pre-training, models like Contrastive, Contrastive Language-Image, Open-vocabulary image segmentation
+ 备注: 20 pages, 8 figures
+
+ 点击查看摘要
+ Abstract:Open-vocabulary image segmentation has been advanced through the synergy between mask generators and vision-language models like Contrastive Language-Image Pre-training (CLIP). Previous approaches focus on generating masks while aligning mask features with text embeddings during training. In this paper, we observe that relying on generated low-quality masks can weaken the alignment of vision and language in regional representations. This motivates us to present a new fine-tuning framework, named MaskCLIP++, which uses ground-truth masks instead of generated masks to enhance the mask classification capability of CLIP. Due to the limited diversity of image segmentation datasets with mask annotations, we propose incorporating a consistency alignment constraint during fine-tuning, which alleviates categorical bias toward the fine-tuning dataset. After low-cost fine-tuning, combining with the mask generator in previous state-of-the-art mask-based open vocabulary segmentation methods, we achieve performance improvements of +1.7, +2.3, +2.1, +3.1, and +0.3 mIoU on the A-847, PC-459, A-150, PC-59, and PAS-20 datasets, respectively.
+
+
+
+ 98. 【2412.11463】FedCAR: Cross-client Adaptive Re-weighting for Generative Models in Federated Learning
+ 链接:https://arxiv.org/abs/2412.11463
+ 作者:Minjun Kim,Minjee Kim,Jinhoon Jeong
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Generative models trained, Generative models, trained on multi-institutional, provide an enriched, enriched understanding
+ 备注:
+
+ 点击查看摘要
+ Abstract:Generative models trained on multi-institutional datasets can provide an enriched understanding through diverse data distributions. However, training the models on medical images is often challenging due to hospitals' reluctance to share data for privacy reasons. Federated learning(FL) has emerged as a privacy-preserving solution for training distributed datasets across data centers by aggregating model weights from multiple clients instead of sharing raw data. Previous research has explored the adaptation of FL to generative models, yet effective aggregation algorithms specifically tailored for generative models remain unexplored. We hereby propose a novel algorithm aimed at improving the performance of generative models within FL. Our approach adaptively re-weights the contribution of each client, resulting in well-trained shared parameters. In each round, the server side measures the distribution distance between fake images generated by clients instead of directly comparing the Fréchet Inception Distance per client, thereby enhancing efficiency of the learning. Experimental results on three public chest X-ray datasets show superior performance in medical image generation, outperforming both centralized learning and conventional FL algorithms. Our code is available at this https URL.
+
+
+
+ 99. 【2412.11458】HResFormer: Hybrid Residual Transformer for Volumetric Medical Image Segmentation
+ 链接:https://arxiv.org/abs/2412.11458
+ 作者:Sucheng Ren,Xiaomeng Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:textbf, Vision Transformer shows, medical image segmentation, Vision Transformer, medical image
+ 备注: Accepted by TNNLS
+
+ 点击查看摘要
+ Abstract:Vision Transformer shows great superiority in medical image segmentation due to the ability in learning long-range dependency. For medical image segmentation from 3D data, such as computed tomography (CT), existing methods can be broadly classified into 2D-based and 3D-based methods. One key limitation in 2D-based methods is that the intra-slice information is ignored, while the limitation in 3D-based methods is the high computation cost and memory consumption, resulting in a limited feature representation for inner-slice information. During the clinical examination, radiologists primarily use the axial plane and then routinely review both axial and coronal planes to form a 3D understanding of anatomy. Motivated by this fact, our key insight is to design a hybrid model which can first learn fine-grained inner-slice information and then generate a 3D understanding of anatomy by incorporating 3D information. We present a novel \textbf{H}ybrid \textbf{Res}idual trans\textbf{Former} \textbf{(HResFormer)} for 3D medical image segmentation. Building upon standard 2D and 3D Transformer backbones, HResFormer involves two novel key designs: \textbf{(1)} a \textbf{H}ybrid \textbf{L}ocal-\textbf{G}lobal fusion \textbf{M}odule \textbf{(HLGM)} to effectively and adaptively fuse inner-slice information from 2D Transformer and intra-slice information from 3D volumes for 3D Transformer with local fine-grained and global long-range representation. \textbf{(2)} a residual learning of the hybrid model, which can effectively leverage the inner-slice and intra-slice information for better 3D understanding of anatomy. Experiments show that our HResFormer outperforms prior art on widely-used medical image segmentation benchmarks. This paper sheds light on an important but neglected way to design Transformers for 3D medical image segmentation.
+
+
+
+ 100. 【2412.11457】MOVIS: Enhancing Multi-Object Novel View Synthesis for Indoor Scenes
+ 链接:https://arxiv.org/abs/2412.11457
+ 作者:Ruijie Lu,Yixin Chen,Junfeng Ni,Baoxiong Jia,Yu Liu,Diwen Wan,Gang Zeng,Siyuan Huang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Repurposing pre-trained diffusion, Repurposing pre-trained, pre-trained diffusion models, object, Repurposing
+ 备注:
+
+ 点击查看摘要
+ Abstract:Repurposing pre-trained diffusion models has been proven to be effective for NVS. However, these methods are mostly limited to a single object; directly applying such methods to compositional multi-object scenarios yields inferior results, especially incorrect object placement and inconsistent shape and appearance under novel views. How to enhance and systematically evaluate the cross-view consistency of such models remains under-explored. To address this issue, we propose MOVIS to enhance the structural awareness of the view-conditioned diffusion model for multi-object NVS in terms of model inputs, auxiliary tasks, and training strategy. First, we inject structure-aware features, including depth and object mask, into the denoising U-Net to enhance the model's comprehension of object instances and their spatial relationships. Second, we introduce an auxiliary task requiring the model to simultaneously predict novel view object masks, further improving the model's capability in differentiating and placing objects. Finally, we conduct an in-depth analysis of the diffusion sampling process and carefully devise a structure-guided timestep sampling scheduler during training, which balances the learning of global object placement and fine-grained detail recovery. To systematically evaluate the plausibility of synthesized images, we propose to assess cross-view consistency and novel view object placement alongside existing image-level NVS metrics. Extensive experiments on challenging synthetic and realistic datasets demonstrate that our method exhibits strong generalization capabilities and produces consistent novel view synthesis, highlighting its potential to guide future 3D-aware multi-object NVS tasks.
+
+
+
+ 101. 【2412.11452】Multilabel Classification for Lung Disease Detection: Integrating Deep Learning and Natural Language Processing
+ 链接:https://arxiv.org/abs/2412.11452
+ 作者:Maria Efimovich,Jayden Lim,Vedant Mehta,Ethan Poon
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Image and Video Processing (eess.IV)
+ 关键词:Classifying chest radiographs, challenging task, experienced radiologists, Classifying chest, time-consuming and challenging
+ 备注: All authors contributed equally
+
+ 点击查看摘要
+ Abstract:Classifying chest radiographs is a time-consuming and challenging task, even for experienced radiologists. This provides an area for improvement due to the difficulty in precisely distinguishing between conditions such as pleural effusion, pneumothorax, and pneumonia. We propose a novel transfer learning model for multi-label lung disease classification, utilizing the CheXpert dataset with over 12,617 images of frontal radiographs being analyzed. By integrating RadGraph parsing for efficient annotation extraction, we enhance the model's ability to accurately classify multiple lung diseases from complex medical images. The proposed model achieved an F1 score of 0.69 and an AUROC of 0.86, demonstrating its potential for clinical applications. Also explored was the use of Natural Language Processing (NLP) to parse report metadata and address uncertainties in disease classification. By comparing uncertain reports with more certain cases, the NLP-enhanced model improves its ability to conclusively classify conditions. This research highlights the connection between deep learning and NLP, underscoring their potential to enhance radiological diagnostics and aid in the efficient analysis of chest radiographs.
+
+
+
+ 102. 【2412.11450】GroupFace: Imbalanced Age Estimation Based on Multi-hop Attention Graph Convolutional Network and Group-aware Margin Optimization
+ 链接:https://arxiv.org/abs/2412.11450
+ 作者:Yiping Zhang,Yuntao Shou,Wei Ai,Tao Meng,Keqin Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:groups, age estimation, computer vision, recent advances, advances in computer
+ 备注: 15 pages, 10 figures
+
+ 点击查看摘要
+ Abstract:With the recent advances in computer vision, age estimation has significantly improved in overall accuracy. However, owing to the most common methods do not take into account the class imbalance problem in age estimation datasets, they suffer from a large bias in recognizing long-tailed groups. To achieve high-quality imbalanced learning in long-tailed groups, the dominant solution lies in that the feature extractor learns the discriminative features of different groups and the classifier is able to provide appropriate and unbiased margins for different groups by the discriminative features. Therefore, in this novel, we propose an innovative collaborative learning framework (GroupFace) that integrates a multi-hop attention graph convolutional network and a dynamic group-aware margin strategy based on reinforcement learning. Specifically, to extract the discriminative features of different groups, we design an enhanced multi-hop attention graph convolutional network. This network is capable of capturing the interactions of neighboring nodes at different distances, fusing local and global information to model facial deep aging, and exploring diverse representations of different groups. In addition, to further address the class imbalance problem, we design a dynamic group-aware margin strategy based on reinforcement learning to provide appropriate and unbiased margins for different groups. The strategy divides the sample into four age groups and considers identifying the optimum margins for various age groups by employing a Markov decision process. Under the guidance of the agent, the feature representation bias and the classification margin deviation between different groups can be reduced simultaneously, balancing inter-class separability and intra-class proximity. After joint optimization, our architecture achieves excellent performance on several age estimation benchmark datasets.
+
+
+
+ 103. 【2412.11443】Universal Domain Adaptive Object Detection via Dual Probabilistic Alignment
+ 链接:https://arxiv.org/abs/2412.11443
+ 作者:Yuanfan Zheng,Jinlin Wu,Wuyang Li,Zhen Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Adaptive Object Detection, Domain Adaptive Object, Object Detection, Adaptive Object, labeled source domain
+ 备注: This work is accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Domain Adaptive Object Detection (DAOD) transfers knowledge from a labeled source domain to an unannotated target domain under closed-set assumption. Universal DAOD (UniDAOD) extends DAOD to handle open-set, partial-set, and closed-set domain adaptation. In this paper, we first unveil two issues: domain-private category alignment is crucial for global-level features, and the domain probability heterogeneity of features across different levels. To address these issues, we propose a novel Dual Probabilistic Alignment (DPA) framework to model domain probability as Gaussian distribution, enabling the heterogeneity domain distribution sampling and measurement. The DPA consists of three tailored modules: the Global-level Domain Private Alignment (GDPA), the Instance-level Domain Shared Alignment (IDSA), and the Private Class Constraint (PCC). GDPA utilizes the global-level sampling to mine domain-private category samples and calculate alignment weight through a cumulative distribution function to address the global-level private category alignment. IDSA utilizes instance-level sampling to mine domain-shared category samples and calculates alignment weight through Gaussian distribution to conduct the domain-shared category domain alignment to address the feature heterogeneity. The PCC aggregates domain-private category centroids between feature and probability spaces to mitigate negative transfer. Extensive experiments demonstrate that our DPA outperforms state-of-the-art UniDAOD and DAOD methods across various datasets and scenarios, including open, partial, and closed sets. Codes are available at \url{this https URL}.
+
+
+
+ 104. 【2412.11435】Learning Implicit Features with Flow Infused Attention for Realistic Virtual Try-On
+ 链接:https://arxiv.org/abs/2412.11435
+ 作者:Delong Zhang,Qiwei Huang,Yuanliu Liu,Yang Sun,Wei-Shi Zheng,Pengfei Xiong,Wei Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Image-based virtual try-on, Image-based virtual, garment image, garment image firstly, fit the garment
+ 备注:
+
+ 点击查看摘要
+ Abstract:Image-based virtual try-on is challenging since the generated image should fit the garment to model images in various poses and keep the characteristics and details of the garment simultaneously. A popular research stream warps the garment image firstly to reduce the burden of the generation stage, which relies highly on the performance of the warping module. Other methods without explicit warping often lack sufficient guidance to fit the garment to the model images. In this paper, we propose FIA-VTON, which leverages the implicit warp feature by adopting a Flow Infused Attention module on virtual try-on. The dense warp flow map is projected as indirect guidance attention to enhance the feature map warping in the generation process implicitly, which is less sensitive to the warping estimation accuracy than an explicit warp of the garment image. To further enhance implicit warp guidance, we incorporate high-level spatial attention to complement the dense warp. Experimental results on the VTON-HD and DressCode dataset significantly outperform state-of-the-art methods, demonstrating that FIA-VTON is effective and robust for virtual try-on.
+
+
+
+ 105. 【2412.11428】View Transformation Robustness for Multi-View 3D Object Reconstruction with Reconstruction Error-Guided View Selection
+ 链接:https://arxiv.org/abs/2412.11428
+ 作者:Qi Zhang,Zhouhang Luo,Tao Yu,Hui Huang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Stable Diffusion models, View transformation robustness, Stable Diffusion, view transformations, View
+ 备注: Accepted to AAAI 25
+
+ 点击查看摘要
+ Abstract:View transformation robustness (VTR) is critical for deep-learning-based multi-view 3D object reconstruction models, which indicates the methods' stability under inputs with various view transformations. However, existing research seldom focused on view transformation robustness in multi-view 3D object reconstruction. One direct way to improve the models' VTR is to produce data with more view transformations and add them to model training. Recent progress on large vision models, particularly Stable Diffusion models, has provided great potential for generating 3D models or synthesizing novel view images with only a single image input. Directly deploying these models at inference consumes heavy computation resources and their robustness to view transformations is not guaranteed either. To fully utilize the power of Stable Diffusion models without extra inference computation burdens, we propose to generate novel views with Stable Diffusion models for better view transformation robustness. Instead of synthesizing random views, we propose a reconstruction error-guided view selection method, which considers the reconstruction errors' spatial distribution of the 3D predictions and chooses the views that could cover the reconstruction errors as much as possible. The methods are trained and tested on sets with large view transformations to validate the 3D reconstruction models' robustness to view transformations. Extensive experiments demonstrate that the proposed method can outperform state-of-the-art 3D reconstruction methods and other view transformation robustness comparison methods.
+
+
+
+ 106. 【2412.11423】Nearly Zero-Cost Protection Against Mimicry by Personalized Diffusion Models
+ 链接:https://arxiv.org/abs/2412.11423
+ 作者:Namhyuk Ahn,KiYoon Yoo,Wonhyuk Ahn,Daesik Kim,Seung-Hun Nam
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:diffusion models revolutionize, Recent advancements, models revolutionize image, revolutionize image generation, risks of misuse
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advancements in diffusion models revolutionize image generation but pose risks of misuse, such as replicating artworks or generating deepfakes. Existing image protection methods, though effective, struggle to balance protection efficacy, invisibility, and latency, thus limiting practical use. We introduce perturbation pre-training to reduce latency and propose a mixture-of-perturbations approach that dynamically adapts to input images to minimize performance degradation. Our novel training strategy computes protection loss across multiple VAE feature spaces, while adaptive targeted protection at inference enhances robustness and invisibility. Experiments show comparable protection performance with improved invisibility and drastically reduced inference time. The code and demo are available at \url{this https URL}
+
+
+
+ 107. 【2412.11420】Category Level 6D Object Pose Estimation from a Single RGB Image using Diffusion
+ 链接:https://arxiv.org/abs/2412.11420
+ 作者:Adam Bethell,Ravi Garg,Ian Reid
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:computer vision, fundamental task, task in computer, Estimating, single RGB image
+ 备注:
+
+ 点击查看摘要
+ Abstract:Estimating the 6D pose and 3D size of an object from an image is a fundamental task in computer vision. Most current approaches are restricted to specific instances with known models or require ground truth depth information or point cloud captures from LIDAR. We tackle the harder problem of pose estimation for category-level objects from a single RGB image. We propose a novel solution that eliminates the need for specific object models or depth information. Our method utilises score-based diffusion models to generate object pose hypotheses to model the distribution of possible poses for the object. Unlike previous methods that rely on costly trained likelihood estimators to remove outliers before pose aggregation using mean pooling, we introduce a simpler approach using Mean Shift to estimate the mode of the distribution as the final pose estimate. Our approach outperforms the current state-of-the-art on the REAL275 dataset by a significant margin.
+
+
+
+ 108. 【2412.11412】V-MIND: Building Versatile Monocular Indoor 3D Detector with Diverse 2D Annotations
+ 链接:https://arxiv.org/abs/2412.11412
+ 作者:Jin-Cheng Jhang,Tao Tu,Fu-En Wang,Ke Zhang,Min Sun,Cheng-Hao Kuo
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:gaining significant attention, significant attention, robotic applications, gaining significant, increasing demand
+ 备注: WACV 2025
+
+ 点击查看摘要
+ Abstract:The field of indoor monocular 3D object detection is gaining significant attention, fueled by the increasing demand in VR/AR and robotic applications. However, its advancement is impeded by the limited availability and diversity of 3D training data, owing to the labor-intensive nature of 3D data collection and annotation processes. In this paper, we present V-MIND (Versatile Monocular INdoor Detector), which enhances the performance of indoor 3D detectors across a diverse set of object classes by harnessing publicly available large-scale 2D datasets. By leveraging well-established monocular depth estimation techniques and camera intrinsic predictors, we can generate 3D training data by converting large-scale 2D images into 3D point clouds and subsequently deriving pseudo 3D bounding boxes. To mitigate distance errors inherent in the converted point clouds, we introduce a novel 3D self-calibration loss for refining the pseudo 3D bounding boxes during training. Additionally, we propose a novel ambiguity loss to address the ambiguity that arises when introducing new classes from 2D datasets. Finally, through joint training with existing 3D datasets and pseudo 3D bounding boxes derived from 2D datasets, V-MIND achieves state-of-the-art object detection performance across a wide range of classes on the Omni3D indoor dataset.
+
+
+
+ 109. 【2412.11409】Multi-modal and Multi-scale Spatial Environment Understanding for Immersive Visual Text-to-Speech
+ 链接:https://arxiv.org/abs/2412.11409
+ 作者:Rui Liu,Shuwei He,Yifan Hu,Haizhou Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Multimedia (cs.MM)
+ 关键词:spatial, spatial environment, global spatial, global spatial visual, spatial visual information
+ 备注: 9 pages,2 figures, Accepted by AAAI'2025
+
+ 点击查看摘要
+ Abstract:Visual Text-to-Speech (VTTS) aims to take the environmental image as the prompt to synthesize the reverberant speech for the spoken content. The challenge of this task lies in understanding the spatial environment from the image. Many attempts have been made to extract global spatial visual information from the RGB space of an spatial image. However, local and depth image information are crucial for understanding the spatial environment, which previous works have ignored. To address the issues, we propose a novel multi-modal and multi-scale spatial environment understanding scheme to achieve immersive VTTS, termed M2SE-VTTS. The multi-modal aims to take both the RGB and Depth spaces of the spatial image to learn more comprehensive spatial information, and the multi-scale seeks to model the local and global spatial knowledge simultaneously. Specifically, we first split the RGB and Depth images into patches and adopt the Gemini-generated environment captions to guide the local spatial understanding. After that, the multi-modal and multi-scale features are integrated by the local-aware global spatial understanding. In this way, M2SE-VTTS effectively models the interactions between local and global spatial contexts in the multi-modal spatial environment. Objective and subjective evaluations suggest that our model outperforms the advanced baselines in environmental speech generation. The code and audio samples are available at: this https URL.
+
+
+
+ 110. 【2412.11407】An Enhanced Classification Method Based on Adaptive Multi-Scale Fusion for Long-tailed Multispectral Point Clouds
+ 链接:https://arxiv.org/abs/2412.11407
+ 作者:TianZhu Liu,BangYan Hu,YanFeng Gu,Xian Li,Aleksandra Pižurica
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:Multispectral point cloud, Multispectral point, observed scene, scene understanding, point cloud
+ 备注: 16 pages, 9 figures, 5 tables
+
+ 点击查看摘要
+ Abstract:Multispectral point cloud (MPC) captures 3D spatial-spectral information from the observed scene, which can be used for scene understanding and has a wide range of applications. However, most of the existing classification methods were extensively tested on indoor datasets, and when applied to outdoor datasets they still face problems including sparse labeled targets, differences in land-covers scales, and long-tailed distributions. To address the above issues, an enhanced classification method based on adaptive multi-scale fusion for MPCs with long-tailed distributions is proposed. In the training set generation stage, a grid-balanced sampling strategy is designed to reliably generate training samples from sparse labeled datasets. In the feature learning stage, a multi-scale feature fusion module is proposed to fuse shallow features of land-covers at different scales, addressing the issue of losing fine features due to scale variations in land-covers. In the classification stage, an adaptive hybrid loss module is devised to utilize multi-classification heads with adaptive weights to balance the learning ability of different classes, improving the classification performance of small classes due to various-scales and long-tailed distributions in land-covers. Experimental results on three MPC datasets demonstrate the effectiveness of the proposed method compared with the state-of-the-art methods.
+
+
+
+ 111. 【2412.11396】Leveraging Retrieval-Augmented Tags for Large Vision-Language Understanding in Complex Scenes
+ 链接:https://arxiv.org/abs/2412.11396
+ 作者:Antonio Carlos Rivera,Anthony Moore,Steven Robinson
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:tasks poses significant, poses significant challenges, Large Vision-Language Models, vision-language tasks poses, handling unseen objects
+ 备注:
+
+ 点击查看摘要
+ Abstract:Object-aware reasoning in vision-language tasks poses significant challenges for current models, particularly in handling unseen objects, reducing hallucinations, and capturing fine-grained relationships in complex visual scenes. To address these limitations, we propose the Vision-Aware Retrieval-Augmented Prompting (VRAP) framework, a generative approach that enhances Large Vision-Language Models (LVLMs) by integrating retrieval-augmented object tags into their prompts. VRAP introduces a novel pipeline where structured tags, including objects, attributes, and relationships, are extracted using pretrained visual encoders and scene graph parsers. These tags are enriched with external knowledge and incorporated into the LLM's input, enabling detailed and accurate reasoning. We evaluate VRAP across multiple vision-language benchmarks, including VQAv2, GQA, VizWiz, and COCO, achieving state-of-the-art performance in fine-grained reasoning and multimodal understanding. Additionally, our ablation studies highlight the importance of retrieval-augmented tags and contrastive learning, while human evaluations confirm VRAP's ability to generate accurate, detailed, and contextually relevant responses. Notably, VRAP achieves a 40% reduction in inference latency by eliminating runtime retrieval. These results demonstrate that VRAP is a robust and efficient framework for advancing object-aware multimodal reasoning.
+
+
+
+ 112. 【2412.11395】Depth-Centric Dehazing and Depth-Estimation from Real-World Hazy Driving Video
+ 链接:https://arxiv.org/abs/2412.11395
+ 作者:Junkai Fan,Kun Wang,Zhiqiang Yan,Xiang Chen,Shangbing Gao,Jun Li,Jian Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:depth estimation, real monocular hazy, depth, study the challenging, challenging problem
+ 备注: Accepted by AAAI 20205, Project page: [this https URL](https://fanjunkai1.github.io/projectpage/DCL/index.html)
+
+ 点击查看摘要
+ Abstract:In this paper, we study the challenging problem of simultaneously removing haze and estimating depth from real monocular hazy videos. These tasks are inherently complementary: enhanced depth estimation improves dehazing via the atmospheric scattering model (ASM), while superior dehazing contributes to more accurate depth estimation through the brightness consistency constraint (BCC). To tackle these intertwined tasks, we propose a novel depth-centric learning framework that integrates the ASM model with the BCC constraint. Our key idea is that both ASM and BCC rely on a shared depth estimation network. This network simultaneously exploits adjacent dehazed frames to enhance depth estimation via BCC and uses the refined depth cues to more effectively remove haze through ASM. Additionally, we leverage a non-aligned clear video and its estimated depth to independently regularize the dehazing and depth estimation networks. This is achieved by designing two discriminator networks: $D_{MFIR}$ enhances high-frequency details in dehazed videos, and $D_{MDR}$ reduces the occurrence of black holes in low-texture regions. Extensive experiments demonstrate that the proposed method outperforms current state-of-the-art techniques in both video dehazing and depth estimation tasks, especially in real-world hazy scenes. Project page: this https URL.
+
+
+
+ 113. 【2412.11391】mporal Contrastive Learning for Video Temporal Reasoning in Large Vision-Language Models
+ 链接:https://arxiv.org/abs/2412.11391
+ 作者:Rafael Souza,Jia-Hao Lim,Alexander Davis
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:semantic concepts consistently, align semantic concepts, Temporal Semantic Alignment, Temporal, Temporal Contrastive Loss
+ 备注:
+
+ 点击查看摘要
+ Abstract:Temporal reasoning is a critical challenge in video-language understanding, as it requires models to align semantic concepts consistently across time. While existing large vision-language models (LVLMs) and large language models (LLMs) excel at static tasks, they struggle to capture dynamic interactions and temporal dependencies in video sequences. In this work, we propose Temporal Semantic Alignment via Dynamic Prompting (TSADP), a novel framework that enhances temporal reasoning capabilities through dynamic task-specific prompts and temporal contrastive learning. TSADP leverages a Dynamic Prompt Generator (DPG) to encode fine-grained temporal relationships and a Temporal Contrastive Loss (TCL) to align visual and textual embeddings across time. We evaluate our method on the VidSitu dataset, augmented with enriched temporal annotations, and demonstrate significant improvements over state-of-the-art models in tasks such as Intra-Video Entity Association, Temporal Relationship Understanding, and Chronology Prediction. Human evaluations further confirm TSADP's ability to generate coherent and semantically accurate descriptions. Our analysis highlights the robustness, efficiency, and practical utility of TSADP, making it a step forward in the field of video-language understanding.
+
+
+
+ 114. 【2412.11381】Adapting Segment Anything Model (SAM) to Experimental Datasets via Fine-Tuning on GAN-based Simulation: A Case Study in Additive Manufacturing
+ 链接:https://arxiv.org/abs/2412.11381
+ 作者:Anika Tabassum,Amirkoushyar Ziabari
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Image and Video Processing (eess.IV)
+ 关键词:X-ray computed tomography, Industrial X-ray computed, computed tomography, XCT commonly accompanied, powerful tool
+ 备注:
+
+ 点击查看摘要
+ Abstract:Industrial X-ray computed tomography (XCT) is a powerful tool for non-destructive characterization of materials and manufactured components. XCT commonly accompanied by advanced image analysis and computer vision algorithms to extract relevant information from the images. Traditional computer vision models often struggle due to noise, resolution variability, and complex internal structures, particularly in scientific imaging applications. State-of-the-art foundational models, like the Segment Anything Model (SAM)-designed for general-purpose image segmentation-have revolutionized image segmentation across various domains, yet their application in specialized fields like materials science remains under-explored. In this work, we explore the application and limitations of SAM for industrial X-ray CT inspection of additive manufacturing components. We demonstrate that while SAM shows promise, it struggles with out-of-distribution data, multiclass segmentation, and computational efficiency during fine-tuning. To address these issues, we propose a fine-tuning strategy utilizing parameter-efficient techniques, specifically Conv-LoRa, to adapt SAM for material-specific datasets. Additionally, we leverage generative adversarial network (GAN)-generated data to enhance the training process and improve the model's segmentation performance on complex X-ray CT data. Our experimental results highlight the importance of tailored segmentation models for accurate inspection, showing that fine-tuning SAM on domain-specific scientific imaging data significantly improves performance. However, despite improvements, the model's ability to generalize across diverse datasets remains limited, highlighting the need for further research into robust, scalable solutions for domain-specific segmentation tasks.
+
+
+
+ 115. 【2412.11380】Relation-Guided Adversarial Learning for Data-free Knowledge Transfer
+ 链接:https://arxiv.org/abs/2412.11380
+ 作者:Yingping Liang,Ying Fu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:recovering training data, pre-trained model, data, diversity, samples
+ 备注:
+
+ 点击查看摘要
+ Abstract:Data-free knowledge distillation transfers knowledge by recovering training data from a pre-trained model. Despite the recent success of seeking global data diversity, the diversity within each class and the similarity among different classes are largely overlooked, resulting in data homogeneity and limited performance. In this paper, we introduce a novel Relation-Guided Adversarial Learning method with triplet losses, which solves the homogeneity problem from two aspects. To be specific, our method aims to promote both intra-class diversity and inter-class confusion of the generated samples. To this end, we design two phases, an image synthesis phase and a student training phase. In the image synthesis phase, we construct an optimization process to push away samples with the same labels and pull close samples with different labels, leading to intra-class diversity and inter-class confusion, respectively. Then, in the student training phase, we perform an opposite optimization, which adversarially attempts to reduce the distance of samples of the same classes and enlarge the distance of samples of different classes. To mitigate the conflict of seeking high global diversity and keeping inter-class confusing, we propose a focal weighted sampling strategy by selecting the negative in the triplets unevenly within a finite range of distance. RGAL shows significant improvement over previous state-of-the-art methods in accuracy and data efficiency. Besides, RGAL can be inserted into state-of-the-art methods on various data-free knowledge transfer applications. Experiments on various benchmarks demonstrate the effectiveness and generalizability of our proposed method on various tasks, specially data-free knowledge distillation, data-free quantization, and non-exemplar incremental learning. Our code is available at this https URL.
+
+
+
+ 116. 【2412.11375】xt and Image Are Mutually Beneficial: Enhancing Training-Free Few-Shot Classification with CLIP
+ 链接:https://arxiv.org/abs/2412.11375
+ 作者:Yayuan Li,Jintao Guo,Lei Qi,Wenbin Li,Yinghuan Shi
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Contrastive Language-Image Pretraining, Contrastive Language-Image, Language-Image Pretraining, vision tasks, CLIP
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Contrastive Language-Image Pretraining (CLIP) has been widely used in vision tasks. Notably, CLIP has demonstrated promising performance in few-shot learning (FSL). However, existing CLIP-based methods in training-free FSL (i.e., without the requirement of additional training) mainly learn different modalities independently, leading to two essential issues: 1) severe anomalous match in image modality; 2) varying quality of generated text prompts. To address these issues, we build a mutual guidance mechanism, that introduces an Image-Guided-Text (IGT) component to rectify varying quality of text prompts through image representations, and a Text-Guided-Image (TGI) component to mitigate the anomalous match of image modality through text representations. By integrating IGT and TGI, we adopt a perspective of Text-Image Mutual guidance Optimization, proposing TIMO. Extensive experiments show that TIMO significantly outperforms the state-of-the-art (SOTA) training-free method. Additionally, by exploring the extent of mutual guidance, we propose an enhanced variant, TIMO-S, which even surpasses the best training-required methods by 0.33% with approximately 100 times less time cost. Our code is available at this https URL.
+
+
+
+ 117. 【2412.11365】BiM-VFI: directional Motion Field-Guided Frame Interpolation for Video with Non-uniform Motions
+ 链接:https://arxiv.org/abs/2412.11365
+ 作者:Wonyong Seo,Jihyong Oh,Munchurl Kim
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Existing Video Frame, Video Frame interpolation, Existing Video, yield blurred interpolated, Content-Aware Upsampling Network
+ 备注:
+
+ 点击查看摘要
+ Abstract:Existing Video Frame interpolation (VFI) models tend to suffer from time-to-location ambiguity when trained with video of non-uniform motions, such as accelerating, decelerating, and changing directions, which often yield blurred interpolated frames. In this paper, we propose (i) a novel motion description map, Bidirectional Motion field (BiM), to effectively describe non-uniform motions; (ii) a BiM-guided Flow Net (BiMFN) with Content-Aware Upsampling Network (CAUN) for precise optical flow estimation; and (iii) Knowledge Distillation for VFI-centric Flow supervision (KDVCF) to supervise the motion estimation of VFI model with VFI-centric teacher flows. The proposed VFI is called a Bidirectional Motion field-guided VFI (BiM-VFI) model. Extensive experiments show that our BiM-VFI model significantly surpasses the recent state-of-the-art VFI methods by 26% and 45% improvements in LPIPS and STLPIPS respectively, yielding interpolated frames with much fewer blurs at arbitrary time instances.
+
+
+
+ 118. 【2412.11360】Visual IRL for Human-Like Robotic Manipulation
+ 链接:https://arxiv.org/abs/2412.11360
+ 作者:Ehsan Asali,Prashant Doshi
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:introduce Visual IRL, learn manipulation tasks, collaborative robots, human, Visual IRL
+ 备注:
+
+ 点击查看摘要
+ Abstract:We present a novel method for collaborative robots (cobots) to learn manipulation tasks and perform them in a human-like manner. Our method falls under the learn-from-observation (LfO) paradigm, where robots learn to perform tasks by observing human actions, which facilitates quicker integration into industrial settings compared to programming from scratch. We introduce Visual IRL that uses the RGB-D keypoints in each frame of the observed human task performance directly as state features, which are input to inverse reinforcement learning (IRL). The inversely learned reward function, which maps keypoints to reward values, is transferred from the human to the cobot using a novel neuro-symbolic dynamics model, which maps human kinematics to the cobot arm. This model allows similar end-effector positioning while minimizing joint adjustments, aiming to preserve the natural dynamics of human motion in robotic manipulation. In contrast with previous techniques that focus on end-effector placement only, our method maps multiple joint angles of the human arm to the corresponding cobot joints. Moreover, it uses an inverse kinematics model to then minimally adjust the joint angles, for accurate end-effector positioning. We evaluate the performance of this approach on two different realistic manipulation tasks. The first task is produce processing, which involves picking, inspecting, and placing onions based on whether they are blemished. The second task is liquid pouring, where the robot picks up bottles, pours the contents into designated containers, and disposes of the empty bottles. Our results demonstrate advances in human-like robotic manipulation, leading to more human-robot compatibility in manufacturing applications.
+
+
+
+ 119. 【2412.11342】One-Shot Multilingual Font Generation Via ViT
+ 链接:https://arxiv.org/abs/2412.11342
+ 作者:Zhiheng Wang,Jiarui Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:poses unique challenges, design poses unique, Font design poses, individually crafted, poses unique
+ 备注:
+
+ 点击查看摘要
+ Abstract:Font design poses unique challenges for logographic languages like Chinese, Japanese, and Korean (CJK), where thousands of unique characters must be individually crafted. This paper introduces a novel Vision Transformer (ViT)-based model for multi-language font generation, effectively addressing the complexities of both logographic and alphabetic scripts. By leveraging ViT and pretraining with a strong visual pretext task (Masked Autoencoding, MAE), our model eliminates the need for complex design components in prior frameworks while achieving comprehensive results with enhanced generalizability. Remarkably, it can generate high-quality fonts across multiple languages for unseen, unknown, and even user-crafted characters. Additionally, we integrate a Retrieval-Augmented Guidance (RAG) module to dynamically retrieve and adapt style references, improving scalability and real-world applicability. We evaluated our approach in various font generation tasks, demonstrating its effectiveness, adaptability, and scalability.
+
+
+
+ 120. 【2412.11337】Modality-Driven Design for Multi-Step Dexterous Manipulation: Insights from Neuroscience
+ 链接:https://arxiv.org/abs/2412.11337
+ 作者:Naoki Wake,Atsushi Kanehira,Daichi Saito,Jun Takamatsu,Kazuhiro Sasabuchi,Hideki Koike,Katsushi Ikeuchi
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Multi-step dexterous manipulation, household scenarios, fundamental skill, skill in household, remains an underexplored
+ 备注: 8 pages, 5 figures, 2 tables. Last updated on December 14th, 2024
+
+ 点击查看摘要
+ Abstract:Multi-step dexterous manipulation is a fundamental skill in household scenarios, yet remains an underexplored area in robotics. This paper proposes a modular approach, where each step of the manipulation process is addressed with dedicated policies based on effective modality input, rather than relying on a single end-to-end model. To demonstrate this, a dexterous robotic hand performs a manipulation task involving picking up and rotating a box. Guided by insights from neuroscience, the task is decomposed into three sub-skills, 1)reaching, 2)grasping and lifting, and 3)in-hand rotation, based on the dominant sensory modalities employed in the human brain. Each sub-skill is addressed using distinct methods from a practical perspective: a classical controller, a Vision-Language-Action model, and a reinforcement learning policy with force feedback, respectively. We tested the pipeline on a real robot to demonstrate the feasibility of our approach. The key contribution of this study lies in presenting a neuroscience-inspired, modality-driven methodology for multi-step dexterous manipulation.
+
+
+
+ 121. 【2412.11325】Sonicmesh: Enhancing 3D Human Mesh Reconstruction in Vision-Impaired Environments With Acoustic Signals
+ 链接:https://arxiv.org/abs/2412.11325
+ 作者:Xiaoxuan Liang,Wuyang Zhang,Hong Zhou,Zhaolong Wei,Sicheng Zhu,Yansong Li,Rui Yin,Jiantao Yuan,Jeremy Gummeson
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:Human Mesh Reconstruction, Mesh Reconstruction, acoustic signals, RGB images faces, privacy concerns
+ 备注:
+
+ 点击查看摘要
+ Abstract:3D Human Mesh Reconstruction (HMR) from 2D RGB images faces challenges in environments with poor lighting, privacy concerns, or occlusions. These weaknesses of RGB imaging can be complemented by acoustic signals, which are widely available, easy to deploy, and capable of penetrating obstacles. However, no existing methods effectively combine acoustic signals with RGB data for robust 3D HMR. The primary challenges include the low-resolution images generated by acoustic signals and the lack of dedicated processing backbones. We introduce SonicMesh, a novel approach combining acoustic signals with RGB images to reconstruct 3D human mesh. To address the challenges of low resolution and the absence of dedicated processing backbones in images generated by acoustic signals, we modify an existing method, HRNet, for effective feature extraction. We also integrate a universal feature embedding technique to enhance the precision of cross-dimensional feature alignment, enabling SonicMesh to achieve high accuracy. Experimental results demonstrate that SonicMesh accurately reconstructs 3D human mesh in challenging environments such as occlusions, non-line-of-sight scenarios, and poor lighting.
+
+
+
+ 122. 【2412.11306】Unimodal and Multimodal Static Facial Expression Recognition for Virtual Reality Users with EmoHeVRDB
+ 链接:https://arxiv.org/abs/2412.11306
+ 作者:Thorben Ortmann,Qi Wang,Larissa Putzar
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Facial Expression Activations, Pro Virtual Reality, Meta Quest Pro, Quest Pro Virtual, utilizing Facial Expression
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this study, we explored the potential of utilizing Facial Expression Activations (FEAs) captured via the Meta Quest Pro Virtual Reality (VR) headset for Facial Expression Recognition (FER) in VR settings. Leveraging the EmojiHeroVR Database (EmoHeVRDB), we compared several unimodal approaches and achieved up to 73.02% accuracy for the static FER task with seven emotion categories. Furthermore, we integrated FEA and image data in multimodal approaches, observing significant improvements in recognition accuracy. An intermediate fusion approach achieved the highest accuracy of 80.42%, significantly surpassing the baseline evaluation result of 69.84% reported for EmoHeVRDB's image data. Our study is the first to utilize EmoHeVRDB's unique FEA data for unimodal and multimodal static FER, establishing new benchmarks for FER in VR settings. Our findings highlight the potential of fusing complementary modalities to enhance FER accuracy in VR settings, where conventional image-based methods are severely limited by the occlusion caused by Head-Mounted Displays (HMDs).
+
+
+
+ 123. 【2412.11286】Detecting Daily Living Gait Amid Huntington's Disease Chorea using a Foundation Deep Learning Model
+ 链接:https://arxiv.org/abs/2412.11286
+ 作者:Dafna Schwartz,Lori Quinn,Nora E. Fritz,Lisa M. Muratori,Jeffery M. Hausdorff,Ran Gilad Bachrach
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Wearable sensors offer, collect physical activity, Wearable sensors, physical activity, key component
+ 备注:
+
+ 点击查看摘要
+ Abstract:Wearable sensors offer a non-invasive way to collect physical activity (PA) data, with walking as a key component. Existing models often struggle to detect gait bouts in individuals with neurodegenerative diseases (NDDs) involving involuntary movements. We developed J-Net, a deep learning model inspired by U-Net, which uses a pre-trained self-supervised foundation model fine-tuned with Huntington`s disease (HD) in-lab data and paired with a segmentation head for gait detection. J-Net processes wrist-worn accelerometer data to detect gait during daily living. We evaluated J-Net on in-lab and daily-living data from HD, Parkinson`s disease (PD), and controls. J-Net achieved a 10-percentage point improvement in ROC-AUC for HD over existing methods, reaching 0.97 for in-lab data. In daily-living environments, J-Net estimates showed no significant differences in median daily walking time between HD and controls (p = 0.23), in contrast to other models, which indicated counterintuitive results (p 0.005). Walking time measured by J-Net correlated with the UHDRS-TMS clinical severity score (r=-0.52; p=0.02), confirming its clinical relevance. Fine-tuning J-Net on PD data also improved gait detection over current methods. J-Net`s architecture effectively addresses the challenges of gait detection in severe chorea and offers robust performance in daily living. The dataset and J-Net model are publicly available, providing a resource for further research into NDD-related gait impairments.
+
+
+
+ 124. 【2412.11284】Learning Normal Flow Directly From Event Neighborhoods
+ 链接:https://arxiv.org/abs/2412.11284
+ 作者:Dehao Yuan,Levi Burner,Jiayi Wu,Minghui Liu,Jingxi Chen,Yiannis Aloimonos,Cornelia Fermüller
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Event-based motion field, Event-based motion, motion field estimation, normal flow, motion field
+ 备注:
+
+ 点击查看摘要
+ Abstract:Event-based motion field estimation is an important task. However, current optical flow methods face challenges: learning-based approaches, often frame-based and relying on CNNs, lack cross-domain transferability, while model-based methods, though more robust, are less accurate. To address the limitations of optical flow estimation, recent works have focused on normal flow, which can be more reliably measured in regions with limited texture or strong edges. However, existing normal flow estimators are predominantly model-based and suffer from high errors.
+In this paper, we propose a novel supervised point-based method for normal flow estimation that overcomes the limitations of existing event learning-based approaches. Using a local point cloud encoder, our method directly estimates per-event normal flow from raw events, offering multiple unique advantages: 1) It produces temporally and spatially sharp predictions. 2) It supports more diverse data augmentation, such as random rotation, to improve robustness across various domains. 3) It naturally supports uncertainty quantification via ensemble inference, which benefits downstream tasks. 4) It enables training and inference on undistorted data in normalized camera coordinates, improving transferability across cameras. Extensive experiments demonstrate our method achieves better and more consistent performance than state-of-the-art methods when transferred across different datasets. Leveraging this transferability, we train our model on the union of datasets and release it for public use. Finally, we introduce an egomotion solver based on a maximum-margin problem that uses normal flow and IMU to achieve strong performance in challenging scenarios.
+
Subjects:
+Computer Vision and Pattern Recognition (cs.CV)
+Cite as:
+arXiv:2412.11284 [cs.CV]
+(or
+arXiv:2412.11284v1 [cs.CV] for this version)
+https://doi.org/10.48550/arXiv.2412.11284
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 125. 【2412.11279】VividFace: A Diffusion-Based Hybrid Framework for High-Fidelity Video Face Swapping
+ 链接:https://arxiv.org/abs/2412.11279
+ 作者:Hao Shao,Shulun Wang,Yang Zhou,Guanglu Song,Dailan He,Shuo Qin,Zhuofan Zong,Bingqi Ma,Yu Liu,Hongsheng Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Graphics (cs.GR)
+ 关键词:Video face swapping, face swapping, Video face, methods primarily focus, complex scenarios
+ 备注: project page: [this https URL](https://hao-shao.com/projects/vividface.html)
+
+ 点击查看摘要
+ Abstract:Video face swapping is becoming increasingly popular across various applications, yet existing methods primarily focus on static images and struggle with video face swapping because of temporal consistency and complex scenarios. In this paper, we present the first diffusion-based framework specifically designed for video face swapping. Our approach introduces a novel image-video hybrid training framework that leverages both abundant static image data and temporal video sequences, addressing the inherent limitations of video-only training. The framework incorporates a specially designed diffusion model coupled with a VidFaceVAE that effectively processes both types of data to better maintain temporal coherence of the generated videos. To further disentangle identity and pose features, we construct the Attribute-Identity Disentanglement Triplet (AIDT) Dataset, where each triplet has three face images, with two images sharing the same pose and two sharing the same identity. Enhanced with a comprehensive occlusion augmentation, this dataset also improves robustness against occlusions. Additionally, we integrate 3D reconstruction techniques as input conditioning to our network for handling large pose variations. Extensive experiments demonstrate that our framework achieves superior performance in identity preservation, temporal consistency, and visual quality compared to existing methods, while requiring fewer inference steps. Our approach effectively mitigates key challenges in video face swapping, including temporal flickering, identity preservation, and robustness to occlusions and pose variations.
+
+
+
+ 126. 【2412.11258】GaussianProperty: Integrating Physical Properties to 3D Gaussians with LMMs
+ 链接:https://arxiv.org/abs/2412.11258
+ 作者:Xinli Xu,Wenhang Ge,Dicong Qiu,ZhiFei Chen,Dongyu Yan,Zhuoyun Liu,Haoyu Zhao,Hanfeng Zhao,Shunsi Zhang,Junwei Liang,Ying-Cong Chen
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Estimating physical properties, Estimating physical, physical properties, computer vision, augmented reality
+ 备注: 17 pages, 17 figures
+
+ 点击查看摘要
+ Abstract:Estimating physical properties for visual data is a crucial task in computer vision, graphics, and robotics, underpinning applications such as augmented reality, physical simulation, and robotic grasping. However, this area remains under-explored due to the inherent ambiguities in physical property estimation. To address these challenges, we introduce GaussianProperty, a training-free framework that assigns physical properties of materials to 3D Gaussians. Specifically, we integrate the segmentation capability of SAM with the recognition capability of GPT-4V(ision) to formulate a global-local physical property reasoning module for 2D images. Then we project the physical properties from multi-view 2D images to 3D Gaussians using a voting strategy. We demonstrate that 3D Gaussians with physical property annotations enable applications in physics-based dynamic simulation and robotic grasping. For physics-based dynamic simulation, we leverage the Material Point Method (MPM) for realistic dynamic simulation. For robot grasping, we develop a grasping force prediction strategy that estimates a safe force range required for object grasping based on the estimated physical properties. Extensive experiments on material segmentation, physics-based dynamic simulation, and robotic grasping validate the effectiveness of our proposed method, highlighting its crucial role in understanding physical properties from visual data. Online demo, code, more cases and annotated datasets are available on \href{this https URL}{this https URL}.
+
+
+
+ 127. 【2412.11248】Multimodal Class-aware Semantic Enhancement Network for Audio-Visual Video Parsing
+ 链接:https://arxiv.org/abs/2412.11248
+ 作者:Pengcheng Zhao,Jinxing Zhou,Dan Guo,Yang Zhao,Yanxiang Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:Parsing task aims, task aims, aims to recognize, recognize and temporally, temporally localize
+ 备注: Accepted by AAAI-2025
+
+ 点击查看摘要
+ Abstract:The Audio-Visual Video Parsing task aims to recognize and temporally localize all events occurring in either the audio or visual stream, or both. Capturing accurate event semantics for each audio/visual segment is vital. Prior works directly utilize the extracted holistic audio and visual features for intra- and cross-modal temporal interactions. However, each segment may contain multiple events, resulting in semantically mixed holistic features that can lead to semantic interference during intra- or cross-modal interactions: the event semantics of one segment may incorporate semantics of unrelated events from other segments. To address this issue, our method begins with a Class-Aware Feature Decoupling (CAFD) module, which explicitly decouples the semantically mixed features into distinct class-wise features, including multiple event-specific features and a dedicated background feature. The decoupled class-wise features enable our model to selectively aggregate useful semantics for each segment from clearly matched classes contained in other segments, preventing semantic interference from irrelevant classes. Specifically, we further design a Fine-Grained Semantic Enhancement module for encoding intra- and cross-modal relations. It comprises a Segment-wise Event Co-occurrence Modeling (SECM) block and a Local-Global Semantic Fusion (LGSF) block. The SECM exploits inter-class dependencies of concurrent events within the same timestamp with the aid of a new event co-occurrence loss. The LGSF further enhances the event semantics of each segment by incorporating relevant semantics from more informative global video features. Extensive experiments validate the effectiveness of the proposed modules and loss functions, resulting in a new state-of-the-art parsing performance.
+
+
+
+ 128. 【2412.11241】Volumetric Mapping with Panoptic Refinement via Kernel Density Estimation for Mobile Robots
+ 链接:https://arxiv.org/abs/2412.11241
+ 作者:Khang Nguyen,Tuan Dang,Manfred Huber
+ 类目:Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Reconstructing three-dimensional, robotic applications, semantic understanding, understanding is vital, Reconstructing
+ 备注:
+
+ 点击查看摘要
+ Abstract:Reconstructing three-dimensional (3D) scenes with semantic understanding is vital in many robotic applications. Robots need to identify which objects, along with their positions and shapes, to manipulate them precisely with given tasks. Mobile robots, especially, usually use lightweight networks to segment objects on RGB images and then localize them via depth maps; however, they often encounter out-of-distribution scenarios where masks over-cover the objects. In this paper, we address the problem of panoptic segmentation quality in 3D scene reconstruction by refining segmentation errors using non-parametric statistical methods. To enhance mask precision, we map the predicted masks into a depth frame to estimate their distribution via kernel densities. The outliers in depth perception are then rejected without the need for additional parameters in an adaptive manner to out-of-distribution scenarios, followed by 3D reconstruction using projective signed distance functions (SDFs). We validate our method on a synthetic dataset, which shows improvements in both quantitative and qualitative results for panoptic mapping. Through real-world testing, the results furthermore show our method's capability to be deployed on a real-robot system. Our source code is available at: this https URL panoptic mapping.
+
+
+
+ 129. 【2412.11237】On the Generalizability of Iterative Patch Selection for Memory-Efficient High-Resolution Image Classification
+ 链接:https://arxiv.org/abs/2412.11237
+ 作者:Max Riffi-Aslett,Christina Fell
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Classifying large images, Classifying large, megapixel MNIST, regions of interest, memory constraints
+ 备注: 15 pages, submitted to Springer Nature, International Journal of Computer Vision
+
+ 点击查看摘要
+ Abstract:Classifying large images with small or tiny regions of interest (ROI) is challenging due to computational and memory constraints. Weakly supervised memory-efficient patch selectors have achieved results comparable with strongly supervised methods. However, low signal-to-noise ratios and low entropy attention still cause overfitting. We explore these issues using a novel testbed on a memory-efficient cross-attention transformer with Iterative Patch Selection (IPS) as the patch selection module. Our testbed extends the megapixel MNIST benchmark to four smaller O2I (object-to-image) ratios ranging from 0.01% to 0.14% while keeping the canvas size fixed and introducing a noise generation component based on Bézier curves. Experimental results generalize the observations made on CNNs to IPS whereby the O2I threshold below which the classifier fails to generalize is affected by the training dataset size. We further observe that the magnitude of this interaction differs for each task of the Megapixel MNIST. For tasks "Maj" and "Top", the rate is at its highest, followed by tasks "Max" and "Multi" where in the latter, this rate is almost at 0. Moreover, results show that in a low data setting, tuning the patch size to be smaller relative to the ROI improves generalization, resulting in an improvement of + 15% for the megapixel MNIST and + 5% for the Swedish traffic signs dataset compared to the original object-to-patch ratios in IPS. Further outcomes indicate that the similarity between the thickness of the noise component and the digits in the megapixel MNIST gradually causes IPS to fail to generalize, contributing to previous suspicions.
+
+
+
+ 130. 【2412.11228】Uni-AdaFocus: Spatial-temporal Dynamic Computation for Video Recognition
+ 链接:https://arxiv.org/abs/2412.11228
+ 作者:Yulin Wang,Haoji Zhang,Yang Yue,Shiji Song,Chao Deng,Junlan Feng,Gao Huang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:paper presents, aim to improve, improve computational efficiency, data redundancy, video understanding
+ 备注: Accepted by IEEE TPAMI. Journal version of [arXiv:2105.03245](https://arxiv.org/abs/2105.03245) (AdaFocusV1, ICCV 2021 Oral), [arXiv:2112.14238](https://arxiv.org/abs/2112.14238) (AdaFocusV2, CVPR 2022), and [arXiv:2209.13465](https://arxiv.org/abs/2209.13465) (AdaFocusV3, ECCV 2022). Code and pre-trained models: [this https URL](https://github.com/LeapLabTHU/Uni-AdaFocus)
+
+ 点击查看摘要
+ Abstract:This paper presents a comprehensive exploration of the phenomenon of data redundancy in video understanding, with the aim to improve computational efficiency. Our investigation commences with an examination of spatial redundancy, which refers to the observation that the most informative region in each video frame usually corresponds to a small image patch, whose shape, size and location shift smoothly across frames. Motivated by this phenomenon, we formulate the patch localization problem as a dynamic decision task, and introduce a spatially adaptive video recognition approach, termed AdaFocus. In specific, a lightweight encoder is first employed to quickly process the full video sequence, whose features are then utilized by a policy network to identify the most task-relevant regions. Subsequently, the selected patches are inferred by a high-capacity deep network for the final prediction. The full model can be trained in end-to-end conveniently. Furthermore, AdaFocus can be extended by further considering temporal and sample-wise redundancies, i.e., allocating the majority of computation to the most task-relevant frames, and minimizing the computation spent on relatively "easier" videos. Our resulting approach, Uni-AdaFocus, establishes a comprehensive framework that seamlessly integrates spatial, temporal, and sample-wise dynamic computation, while it preserves the merits of AdaFocus in terms of efficient end-to-end training and hardware friendliness. In addition, Uni-AdaFocus is general and flexible as it is compatible with off-the-shelf efficient backbones (e.g., TSM and X3D), which can be readily deployed as our feature extractor, yielding a significantly improved computational efficiency. Empirically, extensive experiments based on seven benchmark datasets and three application scenarios substantiate that Uni-AdaFocus is considerably more efficient than the competitive baselines.
+
+
+
+ 131. 【2412.11224】GenLit: Reformulating Single-Image Relighting as Video Generation
+ 链接:https://arxiv.org/abs/2412.11224
+ 作者:Shrisha Bharadwaj,Haiwen Feng,Victoria Abrevaya,Michael J. Black
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:Manipulating the illumination, single image represents, represents a fundamental, fundamental challenge, challenge in computer
+ 备注:
+
+ 点击查看摘要
+ Abstract:Manipulating the illumination within a single image represents a fundamental challenge in computer vision and graphics. This problem has been traditionally addressed using inverse rendering techniques, which require explicit 3D asset reconstruction and costly ray tracing simulations. Meanwhile, recent advancements in visual foundation models suggest that a new paradigm could soon be practical and possible -- one that replaces explicit physical models with networks that are trained on massive amounts of image and video data. In this paper, we explore the potential of exploiting video diffusion models, and in particular Stable Video Diffusion (SVD), in understanding the physical world to perform relighting tasks given a single image. Specifically, we introduce GenLit, a framework that distills the ability of a graphics engine to perform light manipulation into a video generation model, enabling users to directly insert and manipulate a point light in the 3D world within a given image and generate the results directly as a video sequence. We find that a model fine-tuned on only a small synthetic dataset (270 objects) is able to generalize to real images, enabling single-image relighting with realistic ray tracing effects and cast shadows. These results reveal the ability of video foundation models to capture rich information about lighting, material, and shape. Our findings suggest that such models, with minimal training, can be used for physically-based rendering without explicit physically asset reconstruction and complex ray tracing. This further suggests the potential of such models for controllable and physically accurate image synthesis tasks.
+
+
+
+ 132. 【2412.11216】Distribution-Consistency-Guided Multi-modal Hashing
+ 链接:https://arxiv.org/abs/2412.11216
+ 作者:Jin-Yu Liu,Xian-Ling Mao,Tian-Yi Che,Rong-Cheng Tu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:low storage requirements, Multi-modal hashing methods, gained popularity due, Multi-modal hashing, noisy labels
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multi-modal hashing methods have gained popularity due to their fast speed and low storage requirements. Among them, the supervised methods demonstrate better performance by utilizing labels as supervisory signals compared with unsupervised methods. Currently, for almost all supervised multi-modal hashing methods, there is a hidden assumption that training sets have no noisy labels. However, labels are often annotated incorrectly due to manual labeling in real-world scenarios, which will greatly harm the retrieval performance. To address this issue, we first discover a significant distribution consistency pattern through experiments, i.e., the 1-0 distribution of the presence or absence of each category in the label is consistent with the high-low distribution of similarity scores of the hash codes relative to category centers. Then, inspired by this pattern, we propose a novel Distribution-Consistency-Guided Multi-modal Hashing (DCGMH), which aims to filter and reconstruct noisy labels to enhance retrieval performance. Specifically, the proposed method first randomly initializes several category centers, which are used to compute the high-low distribution of similarity scores; Noisy and clean labels are then separately filtered out via the discovered distribution consistency pattern to mitigate the impact of noisy labels; Subsequently, a correction strategy, which is indirectly designed via the distribution consistency pattern, is applied to the filtered noisy labels, correcting high-confidence ones while treating low-confidence ones as unlabeled for unsupervised learning, thereby further enhancing the model's performance. Extensive experiments on three widely used datasets demonstrate the superiority of the proposed method compared to state-of-the-art baselines in multi-modal retrieval tasks. The code is available at this https URL.
+
+
+
+ 133. 【2412.11214】Image Forgery Localization with State Space Models
+ 链接:https://arxiv.org/abs/2412.11214
+ 作者:Zijie Lou,Gang Cao
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Pixel dependency modeling, Pixel dependency, image forgery localization, Selective State Space, dependency modeling
+ 备注:
+
+ 点击查看摘要
+ Abstract:Pixel dependency modeling from tampered images is pivotal for image forgery localization. Current approaches predominantly rely on convolutional neural network (CNN) or Transformer-based models, which often either lack sufficient receptive fields or entail significant computational overheads. In this paper, we propose LoMa, a novel image forgery localization method that leverages the Selective State Space (S6) model for global pixel dependency modeling and inverted residual CNN for local pixel dependency modeling. Our method introduces the Mixed-SSM Block, which initially employs atrous selective scan to traverse the spatial domain and convert the tampered image into order patch sequences, and subsequently applies multidirectional S6 modeling. In addition, an auxiliary convolutional branch is introduced to enhance local feature extraction. This design facilitates the efficient extraction of global dependencies while upholding linear complexity. Upon modeling the pixel dependency with the SSM and CNN blocks, the pixel-wise forgery localization results are obtained by a simple MLP decoder. Extensive experimental results validate the superiority of LoMa over CNN-based and Transformer-based state-of-the-arts.
+
+
+
+ 134. 【2412.11210】ViPOcc: Leveraging Visual Priors from Vision Foundation Models for Single-View 3D Occupancy Prediction
+ 链接:https://arxiv.org/abs/2412.11210
+ 作者:Yi Feng,Yu Han,Xijing Zhang,Tanghui Li,Yanting Zhang,Rui Fan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:vision-centric autonomous driving, occupancy prediction, autonomous driving, ill-posed and challenging, challenging problem
+ 备注: accepted to AAAI25
+
+ 点击查看摘要
+ Abstract:Inferring the 3D structure of a scene from a single image is an ill-posed and challenging problem in the field of vision-centric autonomous driving. Existing methods usually employ neural radiance fields to produce voxelized 3D occupancy, lacking instance-level semantic reasoning and temporal photometric consistency. In this paper, we propose ViPOcc, which leverages the visual priors from vision foundation models (VFMs) for fine-grained 3D occupancy prediction. Unlike previous works that solely employ volume rendering for RGB and depth image reconstruction, we introduce a metric depth estimation branch, in which an inverse depth alignment module is proposed to bridge the domain gap in depth distribution between VFM predictions and the ground truth. The recovered metric depth is then utilized in temporal photometric alignment and spatial geometric alignment to ensure accurate and consistent 3D occupancy prediction. Additionally, we also propose a semantic-guided non-overlapping Gaussian mixture sampler for efficient, instance-aware ray sampling, which addresses the redundant and imbalanced sampling issue that still exists in previous state-of-the-art methods. Extensive experiments demonstrate the superior performance of ViPOcc in both 3D occupancy prediction and depth estimation tasks on the KITTI-360 and KITTI Raw datasets. Our code is available at: \url{this https URL}.
+
+
+
+ 135. 【2412.11198】GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control
+ 链接:https://arxiv.org/abs/2412.11198
+ 作者:Mariam Hassan,Sebastian Stapf,Ahmad Rahimi,Pedro M B Rezende,Yasaman Haghighi,David Brüggemann,Isinsu Katircioglu,Lin Zhang,Xiaoran Chen,Suman Saha,Marco Cannici,Elie Aljalbout,Botao Ye,Xi Wang,Aram Davtyan,Mathieu Salzmann,Davide Scaramuzza,Marc Pollefeys,Paolo Favaro,Alexandre Alahi
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Generalizable Ego-vision Multimodal, Ego-vision Multimodal world, Generalizable Ego-vision, predicts future frames, human poses
+ 备注:
+
+ 点击查看摘要
+ Abstract:We present GEM, a Generalizable Ego-vision Multimodal world model that predicts future frames using a reference frame, sparse features, human poses, and ego-trajectories. Hence, our model has precise control over object dynamics, ego-agent motion and human poses. GEM generates paired RGB and depth outputs for richer spatial understanding. We introduce autoregressive noise schedules to enable stable long-horizon generations. Our dataset is comprised of 4000+ hours of multimodal data across domains like autonomous driving, egocentric human activities, and drone flights. Pseudo-labels are used to get depth maps, ego-trajectories, and human poses. We use a comprehensive evaluation framework, including a new Control of Object Manipulation (COM) metric, to assess controllability. Experiments show GEM excels at generating diverse, controllable scenarios and temporal consistency over long generations. Code, models, and datasets are fully open-sourced.
+
+
+
+ 136. 【2412.11196】Drawing the Line: Enhancing Trustworthiness of MLLMs Through the Power of Refusal
+ 链接:https://arxiv.org/abs/2412.11196
+ 作者:Yuhao Wang,Zhiyuan Zhu,Heyang Liu,Yusheng Liao,Hongcheng Liu,Yanfeng Wang,Yu Wang
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Multimodal large language, inaccurate responses undermines, Multimodal large, multimodal perception, large language models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multimodal large language models (MLLMs) excel at multimodal perception and understanding, yet their tendency to generate hallucinated or inaccurate responses undermines their trustworthiness. Existing methods have largely overlooked the importance of refusal responses as a means of enhancing MLLMs reliability. To bridge this gap, we present the Information Boundary-aware Learning Framework (InBoL), a novel approach that empowers MLLMs to refuse to answer user queries when encountering insufficient information. To the best of our knowledge, InBoL is the first framework that systematically defines the conditions under which refusal is appropriate for MLLMs using the concept of information boundaries proposed in our paper. This framework introduces a comprehensive data generation pipeline and tailored training strategies to improve the model's ability to deliver appropriate refusal responses. To evaluate the trustworthiness of MLLMs, we further propose a user-centric alignment goal along with corresponding metrics. Experimental results demonstrate a significant improvement in refusal accuracy without noticeably compromising the model's helpfulness, establishing InBoL as a pivotal advancement in building more trustworthy MLLMs.
+
+
+
+ 137. 【2412.11193】Light-T2M: A Lightweight and Fast Model for Text-to-motion Generation
+ 链接:https://arxiv.org/abs/2412.11193
+ 作者:Ling-An Zeng,Guohong Huang,Gaojie Wu,Wei-Shi Zheng
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:high usage costs, local information modeling, current methods involve, slow inference speeds, reduce usage costs
+ 备注: Accepted to AAAI 2025
+
+ 点击查看摘要
+ Abstract:Despite the significant role text-to-motion (T2M) generation plays across various applications, current methods involve a large number of parameters and suffer from slow inference speeds, leading to high usage costs. To address this, we aim to design a lightweight model to reduce usage costs. First, unlike existing works that focus solely on global information modeling, we recognize the importance of local information modeling in the T2M task by reconsidering the intrinsic properties of human motion, leading us to propose a lightweight Local Information Modeling Module. Second, we introduce Mamba to the T2M task, reducing the number of parameters and GPU memory demands, and we have designed a novel Pseudo-bidirectional Scan to replicate the effects of a bidirectional scan without increasing parameter count. Moreover, we propose a novel Adaptive Textual Information Injector that more effectively integrates textual information into the motion during generation. By integrating the aforementioned designs, we propose a lightweight and fast model named Light-T2M. Compared to the state-of-the-art method, MoMask, our Light-T2M model features just 10\% of the parameters (4.48M vs 44.85M) and achieves a 16\% faster inference time (0.152s vs 0.180s), while surpassing MoMask with an FID of \textbf{0.040} (vs. 0.045) on HumanML3D dataset and 0.161 (vs. 0.228) on KIT-ML dataset. The code is available at this https URL.
+
+
+
+ 138. 【2412.11186】Efficient Quantization-Aware Training on Segment Anything Model in Medical Images and Its Deployment
+ 链接:https://arxiv.org/abs/2412.11186
+ 作者:Haisheng Lu,Yujie Fu,Fan Zhang,Le Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Medical image segmentation, clinical practice, advanced this field, critical component, component of clinical
+ 备注: 14 pages, 3 figures, to be published in LNCS
+
+ 点击查看摘要
+ Abstract:Medical image segmentation is a critical component of clinical practice, and the state-of-the-art MedSAM model has significantly advanced this field. Nevertheless, critiques highlight that MedSAM demands substantial computational resources during inference. To address this issue, the CVPR 2024 MedSAM on Laptop Challenge was established to find an optimal balance between accuracy and processing speed. In this paper, we introduce a quantization-aware training pipeline designed to efficiently quantize the Segment Anything Model for medical images and deploy it using the OpenVINO inference engine. This pipeline optimizes both training time and disk storage. Our experimental results confirm that this approach considerably enhances processing speed over the baseline, while still achieving an acceptable accuracy level. The training script, inference script, and quantized model are publicly accessible at this https URL.
+
+
+
+ 139. 【2412.11183】OccScene: Semantic Occupancy-based Cross-task Mutual Learning for 3D Scene Generation
+ 链接:https://arxiv.org/abs/2412.11183
+ 作者:Bohan Li,Xin Jin,Jianan Wang,Yukai Shi,Yasheng Sun,Xiaofeng Wang,Zhuang Ma,Baao Xie,Chao Ma,Xiaokang Yang,Wenjun Zeng
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Recent diffusion models, demonstrated remarkable performance, Recent diffusion, demonstrated remarkable, perception
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent diffusion models have demonstrated remarkable performance in both 3D scene generation and perception tasks. Nevertheless, existing methods typically separate these two processes, acting as a data augmenter to generate synthetic data for downstream perception tasks. In this work, we propose OccScene, a novel mutual learning paradigm that integrates fine-grained 3D perception and high-quality generation in a unified framework, achieving a cross-task win-win effect. OccScene generates new and consistent 3D realistic scenes only depending on text prompts, guided with semantic occupancy in a joint-training diffusion framework. To align the occupancy with the diffusion latent, a Mamba-based Dual Alignment module is introduced to incorporate fine-grained semantics and geometry as perception priors. Within OccScene, the perception module can be effectively improved with customized and diverse generated scenes, while the perception priors in return enhance the generation performance for mutual benefits. Extensive experiments show that OccScene achieves realistic 3D scene generation in broad indoor and outdoor scenarios, while concurrently boosting the perception models to achieve substantial performance improvements in the 3D perception task of semantic occupancy prediction.
+
+
+
+ 140. 【2412.11170】Benchmarking and Learning Multi-Dimensional Quality Evaluator for Text-to-3D Generation
+ 链接:https://arxiv.org/abs/2412.11170
+ 作者:Yujie Zhang,Bingyang Cui,Qi Yang,Zhu Li,Yiling Xu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:achieved remarkable progress, methods remains challenging, lack fine-grained evaluation, benchmarks lack fine-grained, recent years
+ 备注:
+
+ 点击查看摘要
+ Abstract:Text-to-3D generation has achieved remarkable progress in recent years, yet evaluating these methods remains challenging for two reasons: i) Existing benchmarks lack fine-grained evaluation on different prompt categories and evaluation dimensions. ii) Previous evaluation metrics only focus on a single aspect (e.g., text-3D alignment) and fail to perform multi-dimensional quality assessment. To address these problems, we first propose a comprehensive benchmark named MATE-3D. The benchmark contains eight well-designed prompt categories that cover single and multiple object generation, resulting in 1,280 generated textured meshes. We have conducted a large-scale subjective experiment from four different evaluation dimensions and collected 107,520 annotations, followed by detailed analyses of the results. Based on MATE-3D, we propose a novel quality evaluator named HyperScore. Utilizing hypernetwork to generate specified mapping functions for each evaluation dimension, our metric can effectively perform multi-dimensional quality assessment. HyperScore presents superior performance over existing metrics on MATE-3D, making it a promising metric for assessing and improving text-to-3D generation. The project is available at this https URL.
+
+
+
+ 141. 【2412.11165】OTLRM: Orthogonal Learning-based Low-Rank Metric for Multi-Dimensional Inverse Problems
+ 链接:https://arxiv.org/abs/2412.11165
+ 作者:Xiangming Wang,Haijin Zeng,Jiaoyang Chen,Sheng Liu,Yongyong Chen,Guoqing Chao
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:multi-frame videos inherently, videos inherently exhibit, inherently exhibit robust, exhibit robust low-rank, multispectral image denoising
+ 备注: AAAI 2025
+
+ 点击查看摘要
+ Abstract:In real-world scenarios, complex data such as multispectral images and multi-frame videos inherently exhibit robust low-rank property. This property is vital for multi-dimensional inverse problems, such as tensor completion, spectral imaging reconstruction, and multispectral image denoising. Existing tensor singular value decomposition (t-SVD) definitions rely on hand-designed or pre-given transforms, which lack flexibility for defining tensor nuclear norm (TNN). The TNN-regularized optimization problem is solved by the singular value thresholding (SVT) operator, which leverages the t-SVD framework to obtain the low-rank tensor. However, it is quite complicated to introduce SVT into deep neural networks due to the numerical instability problem in solving the derivatives of the eigenvectors. In this paper, we introduce a novel data-driven generative low-rank t-SVD model based on the learnable orthogonal transform, which can be naturally solved under its representation. Prompted by the linear algebra theorem of the Householder transformation, our learnable orthogonal transform is achieved by constructing an endogenously orthogonal matrix adaptable to neural networks, optimizing it as arbitrary orthogonal matrices. Additionally, we propose a low-rank solver as a generalization of SVT, which utilizes an efficient representation of generative networks to obtain low-rank structures. Extensive experiments highlight its significant restoration enhancements.
+
+
+
+ 142. 【2412.11161】Why and How: Knowledge-Guided Learning for Cross-Spectral Image Patch Matching
+ 链接:https://arxiv.org/abs/2412.11161
+ 作者:Chuang Yu,Yunpeng Liu,Jinmiao Zhao,Xiangyu Yue
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:learning, Recently, feature relation learning, learning based, metric learning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recently, cross-spectral image patch matching based on feature relation learning has attracted extensive attention. However, performance bottleneck problems have gradually emerged in existing methods. To address this challenge, we make the first attempt to explore a stable and efficient bridge between descriptor learning and metric learning, and construct a knowledge-guided learning network (KGL-Net), which achieves amazing performance improvements while abandoning complex network structures. Specifically, we find that there is feature extraction consistency between metric learning based on feature difference learning and descriptor learning based on Euclidean distance. This provides the foundation for bridge building. To ensure the stability and efficiency of the constructed bridge, on the one hand, we conduct an in-depth exploration of 20 combined network architectures. On the other hand, a feature-guided loss is constructed to achieve mutual guidance of features. In addition, unlike existing methods, we consider that the feature mapping ability of the metric branch should receive more attention. Therefore, a hard negative sample mining for metric learning (HNSM-M) strategy is constructed. To the best of our knowledge, this is the first time that hard negative sample mining for metric networks has been implemented and brings significant performance gains. Extensive experimental results show that our KGL-Net achieves SOTA performance in three different cross-spectral image patch matching scenarios. Our code are available at this https URL.
+
+
+
+ 143. 【2412.11154】From Easy to Hard: Progressive Active Learning Framework for Infrared Small Target Detection with Single Point Supervision
+ 链接:https://arxiv.org/abs/2412.11154
+ 作者:Chuang Yu,Jinmiao Zhao,Yunpeng Liu,Sicheng Zhao,Xiangyu Yue
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:single-frame infrared small, drawn wide-spread attention, single point supervision, infrared small target, Progressive Active Learning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recently, single-frame infrared small target (SIRST) detection with single point supervision has drawn wide-spread attention. However, the latest label evolution with single point supervision (LESPS) framework suffers from instability, excessive label evolution, and difficulty in exerting embedded network performance. Therefore, we construct a Progressive Active Learning (PAL) framework. Specifically, inspired by organisms gradually adapting to their environment and continuously accumulating knowledge, we propose an innovative progressive active learning idea, which emphasizes that the network progressively and actively recognizes and learns more hard samples to achieve continuous performance enhancement. Based on this, on the one hand, we propose a model pre-start concept, which focuses on selecting a portion of easy samples and can help models have basic task-specific learning capabilities. On the other hand, we propose a refined dual-update strategy, which can promote reasonable learning of harder samples and continuous refinement of pseudo-labels. In addition, to alleviate the risk of excessive label evolution, a decay factor is reasonably introduced, which helps to achieve a dynamic balance between the expansion and contraction of target annotations. Extensive experiments show that convolutional neural networks (CNNs) equipped with our PAL framework have achieved state-of-the-art (SOTA) results on multiple public datasets. Furthermore, our PAL framework can build a efficient and stable bridge between full supervision and point supervision tasks. Our code are available at this https URL.
+
+
+
+ 144. 【2412.11152】Dual-Schedule Inversion: Training- and Tuning-Free Inversion for Real Image Editing
+ 链接:https://arxiv.org/abs/2412.11152
+ 作者:Jiancheng Huang,Yi Huang,Jianzhuang Liu,Donghao Zhou,Yifan Liu,Shifeng Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:practical AIGC task, Text-conditional image editing, practical AIGC, AIGC task, DDIM Inversion
+ 备注:
+
+ 点击查看摘要
+ Abstract:Text-conditional image editing is a practical AIGC task that has recently emerged with great commercial and academic value. For real image editing, most diffusion model-based methods use DDIM Inversion as the first stage before editing. However, DDIM Inversion often results in reconstruction failure, leading to unsatisfactory performance for downstream editing. To address this problem, we first analyze why the reconstruction via DDIM Inversion fails. We then propose a new inversion and sampling method named Dual-Schedule Inversion. We also design a classifier to adaptively combine Dual-Schedule Inversion with different editing methods for user-friendly image editing. Our work can achieve superior reconstruction and editing performance with the following advantages: 1) It can reconstruct real images perfectly without fine-tuning, and its reversibility is guaranteed mathematically. 2) The edited object/scene conforms to the semantics of the text prompt. 3) The unedited parts of the object/scene retain the original identity.
+
+
+
+ 145. 【2412.11149】A Comprehensive Survey of Action Quality Assessment: Method and Benchmark
+ 链接:https://arxiv.org/abs/2412.11149
+ 作者:Kanglei Zhou,Ruizhi Cai,Liyuan Wang,Hubert P. H. Shum,Xiaohui Liang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Action Quality Assessment, Action Quality, human actions, human judgment, Quality Assessment
+ 备注:
+
+ 点击查看摘要
+ Abstract:Action Quality Assessment (AQA) quantitatively evaluates the quality of human actions, providing automated assessments that reduce biases in human judgment. Its applications span domains such as sports analysis, skill assessment, and medical care. Recent advances in AQA have introduced innovative methodologies, but similar methods often intertwine across different domains, highlighting the fragmented nature that hinders systematic reviews. In addition, the lack of a unified benchmark and limited computational comparisons hinder consistent evaluation and fair assessment of AQA approaches. In this work, we address these gaps by systematically analyzing over 150 AQA-related papers to develop a hierarchical taxonomy, construct a unified benchmark, and provide an in-depth analysis of current trends, challenges, and future directions. Our hierarchical taxonomy categorizes AQA methods based on input modalities (video, skeleton, multi-modal) and their specific characteristics, highlighting the evolution and interrelations across various approaches. To promote standardization, we present a unified benchmark, integrating diverse datasets to evaluate the assessment precision and computational efficiency. Finally, we review emerging task-specific applications and identify under-explored challenges in AQA, providing actionable insights into future research directions. This survey aims to deepen understanding of AQA progress, facilitate method comparison, and guide future innovations. The project web page can be found at this https URL.
+
+
+
+ 146. 【2412.11148】Redefining Normal: A Novel Object-Level Approach for Multi-Object Novelty Detection
+ 链接:https://arxiv.org/abs/2412.11148
+ 作者:Mohammadreza Salehi,Nikolaos Apostolikas,Efstratios Gavves,Cees G. M. Snoek,Yuki M. Asano
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:accurately identifying outliers, specific class information, class information poses, accurately identifying, significant challenge
+ 备注: Accepted at ACCV24(Oral)
+
+ 点击查看摘要
+ Abstract:In the realm of novelty detection, accurately identifying outliers in data without specific class information poses a significant challenge. While current methods excel in single-object scenarios, they struggle with multi-object situations due to their focus on individual objects. Our paper suggests a novel approach: redefining `normal' at the object level in training datasets. Rather than the usual image-level view, we consider the most dominant object in a dataset as the norm, offering a perspective that is more effective for real-world scenarios. Adapting to our object-level definition of `normal', we modify knowledge distillation frameworks, where a student network learns from a pre-trained teacher network. Our first contribution, DeFeND(Dense Feature Fine-tuning on Normal Data), integrates dense feature fine-tuning into the distillation process, allowing the teacher network to focus on object-level features with a self-supervised loss. The second is masked knowledge distillation, where the student network works with partially hidden inputs, honing its ability to deduce and generalize from incomplete data. This approach not only fares well in single-object novelty detection but also considerably surpasses existing methods in multi-object contexts. The implementation is available at: this https URL
+
+
+
+ 147. 【2412.11124】Combating Multimodal LLM Hallucination via Bottom-up Holistic Reasoning
+ 链接:https://arxiv.org/abs/2412.11124
+ 作者:Shengqiong Wu,Hao Fei,Liangming Pan,William Yang Wang,Shuicheng Yan,Tat-Seng Chua
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:large language models, multimodal large language, shown unprecedented capabilities, Recent advancements, language models
+ 备注: 16 pages, 10 figures, accepted by AAAI 25
+
+ 点击查看摘要
+ Abstract:Recent advancements in multimodal large language models (MLLMs) have shown unprecedented capabilities in advancing various vision-language tasks. However, MLLMs face significant challenges with hallucinations, and misleading outputs that do not align with the input data. While existing efforts are paid to combat MLLM hallucinations, several pivotal challenges are still unsolved. First, while current approaches aggressively focus on addressing errors at the perception level, another important type at the cognition level requiring factual commonsense can be overlooked. In addition, existing methods might fall short in finding a more effective way to represent visual input, which is yet a key bottleneck that triggers visual hallucinations. Moreover, MLLMs can frequently be misled by faulty textual inputs and cause hallucinations, while unfortunately, this type of issue has long been overlooked by existing studies. Inspired by human intuition in handling hallucinations, this paper introduces a novel bottom-up reasoning framework. Our framework systematically addresses potential issues in both visual and textual inputs by verifying and integrating perception-level information with cognition-level commonsense knowledge, ensuring more reliable outputs. Extensive experiments demonstrate significant improvements in multiple hallucination benchmarks after integrating MLLMs with the proposed framework. In-depth analyses reveal the great potential of our methods in addressing perception- and cognition-level hallucinations.
+
+
+
+ 148. 【2412.11119】Impact of Adversarial Attacks on Deep Learning Model Explainability
+ 链接:https://arxiv.org/abs/2412.11119
+ 作者:Gazi Nazia Nur,Mohammad Ahnaf Sadat
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:autonomous feature extraction, deep learning models, feature extraction, black-box nature, investigate the impact
+ 备注: 29 pages with reference included, submitted to a journal
+
+ 点击查看摘要
+ Abstract:In this paper, we investigate the impact of adversarial attacks on the explainability of deep learning models, which are commonly criticized for their black-box nature despite their capacity for autonomous feature extraction. This black-box nature can affect the perceived trustworthiness of these models. To address this, explainability techniques such as GradCAM, SmoothGrad, and LIME have been developed to clarify model decision-making processes. Our research focuses on the robustness of these explanations when models are subjected to adversarial attacks, specifically those involving subtle image perturbations that are imperceptible to humans but can significantly mislead models. For this, we utilize attack methods like the Fast Gradient Sign Method (FGSM) and the Basic Iterative Method (BIM) and observe their effects on model accuracy and explanations. The results reveal a substantial decline in model accuracy, with accuracies dropping from 89.94% to 58.73% and 45.50% under FGSM and BIM attacks, respectively. Despite these declines in accuracy, the explanation of the models measured by metrics such as Intersection over Union (IoU) and Root Mean Square Error (RMSE) shows negligible changes, suggesting that these metrics may not be sensitive enough to detect the presence of adversarial perturbations.
+
+
+
+ 149. 【2412.11102】Empowering LLMs to Understand and Generate Complex Vector Graphics
+ 链接:https://arxiv.org/abs/2412.11102
+ 作者:Ximing Xing,Juncheng Hu,Guotao Liang,Jing Zhang,Dong Xu,Qian Yu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:profoundly impacted natural, impacted natural language, natural language processing, Large Language Models, scalable vector graphics
+ 备注: Project Page: [this https URL](https://ximinng.github.io/LLM4SVGProject/)
+
+ 点击查看摘要
+ Abstract:The unprecedented advancements in Large Language Models (LLMs) have profoundly impacted natural language processing but have yet to fully embrace the realm of scalable vector graphics (SVG) generation. While LLMs encode partial knowledge of SVG data from web pages during training, recent findings suggest that semantically ambiguous and tokenized representations within LLMs may result in hallucinations in vector primitive predictions. Additionally, LLM training typically lacks modeling and understanding of the rendering sequence of vector paths, which can lead to occlusion between output vector primitives. In this paper, we present LLM4SVG, an initial yet substantial step toward bridging this gap by enabling LLMs to better understand and generate vector graphics. LLM4SVG facilitates a deeper understanding of SVG components through learnable semantic tokens, which precisely encode these tokens and their corresponding properties to generate semantically aligned SVG outputs. Using a series of learnable semantic tokens, a structured dataset for instruction following is developed to support comprehension and generation across two primary tasks. Our method introduces a modular architecture to existing large language models, integrating semantic tags, vector instruction encoders, fine-tuned commands, and powerful LLMs to tightly combine geometric, appearance, and language information. To overcome the scarcity of SVG-text instruction data, we developed an automated data generation pipeline that collected a massive dataset of more than 250k SVG data and 580k SVG-text instructions, which facilitated the adoption of the two-stage training strategy popular in LLM development. By exploring various training strategies, we developed LLM4SVG, which significantly moves beyond optimized rendering-based approaches and language-model-based baselines to achieve remarkable results in human evaluation tasks.
+
+
+
+ 150. 【2412.11100】DynamicScaler: Seamless and Scalable Video Generation for Panoramic Scenes
+ 链接:https://arxiv.org/abs/2412.11100
+ 作者:Jinxiu Liu,Shaoheng Lin,Yinxiao Li,Ming-Hsuan Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:generate high-quality scene-level, increasing demand, applications and spatial, spatial intelligence, intelligence has heightened
+ 备注:
+
+ 点击查看摘要
+ Abstract:The increasing demand for immersive AR/VR applications and spatial intelligence has heightened the need to generate high-quality scene-level and 360° panoramic video. However, most video diffusion models are constrained by limited resolution and aspect ratio, which restricts their applicability to scene-level dynamic content synthesis. In this work, we propose the DynamicScaler, addressing these challenges by enabling spatially scalable and panoramic dynamic scene synthesis that preserves coherence across panoramic scenes of arbitrary size. Specifically, we introduce a Offset Shifting Denoiser, facilitating efficient, synchronous, and coherent denoising panoramic dynamic scenes via a diffusion model with fixed resolution through a seamless rotating Window, which ensures seamless boundary transitions and consistency across the entire panoramic space, accommodating varying resolutions and aspect ratios. Additionally, we employ a Global Motion Guidance mechanism to ensure both local detail fidelity and global motion continuity. Extensive experiments demonstrate our method achieves superior content and motion quality in panoramic scene-level video generation, offering a training-free, efficient, and scalable solution for immersive dynamic scene creation with constant VRAM consumption regardless of the output video resolution. Our project page is available at \url{this https URL}.
+
+
+
+ 151. 【2412.11088】Seeing the Forest and the Trees: Solving Visual Graph and Tree Based Data Structure Problems using Large Multimodal Models
+ 链接:https://arxiv.org/abs/2412.11088
+ 作者:Sebastian Gutierrez,Irene Hou,Jihye Lee,Kenneth Angelikas,Owen Man,Sophia Mettille,James Prather,Paul Denny,Stephen MacNeil
+ 类目:Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Computers and Society (cs.CY)
+ 关键词:Recent advancements, integrity among educators, advancements in generative, generative AI systems, systems have raised
+ 备注: 14 pages, 4 figures, to be published in ACE 2025
+
+ 点击查看摘要
+ Abstract:Recent advancements in generative AI systems have raised concerns about academic integrity among educators. Beyond excelling at solving programming problems and text-based multiple-choice questions, recent research has also found that large multimodal models (LMMs) can solve Parsons problems based only on an image. However, such problems are still inherently text-based and rely on the capabilities of the models to convert the images of code blocks to their corresponding text. In this paper, we further investigate the capabilities of LMMs to solve graph and tree data structure problems based only on images. To achieve this, we computationally construct and evaluate a novel benchmark dataset comprising 9,072 samples of diverse graph and tree data structure tasks to assess the performance of the GPT-4o, GPT-4v, Gemini 1.5 Pro, Gemini 1.5 Flash, Gemini 1.0 Pro Vision, and Claude 3 model families. GPT-4o and Gemini 1.5 Flash performed best on trees and graphs respectively. GPT-4o achieved 87.6% accuracy on tree samples, while Gemini 1.5 Flash, achieved 56.2% accuracy on graph samples. Our findings highlight the influence of structural and visual variations on model performance. This research not only introduces an LMM benchmark to facilitate replication and further exploration but also underscores the potential of LMMs in solving complex computing problems, with important implications for pedagogy and assessment practices.
+
+
+
+ 152. 【2412.11080】Deep Spectral Clustering via Joint Spectral Embedding and Kmeans
+ 链接:https://arxiv.org/abs/2412.11080
+ 作者:Wengang Guo,Wei Ye
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:popular clustering method, spectral embedding space, spectral embedding, Spectral, spectral embedding module
+ 备注:
+
+ 点击查看摘要
+ Abstract:Spectral clustering is a popular clustering method. It first maps data into the spectral embedding space and then uses Kmeans to find clusters. However, the two decoupled steps prohibit joint optimization for the optimal solution. In addition, it needs to construct the similarity graph for samples, which suffers from the curse of dimensionality when the data are high-dimensional. To address these two challenges, we introduce \textbf{D}eep \textbf{S}pectral \textbf{C}lustering (\textbf{DSC}), which consists of two main modules: the spectral embedding module and the greedy Kmeans module. The former module learns to efficiently embed raw samples into the spectral embedding space using deep neural networks and power iteration. The latter module improves the cluster structures of Kmeans on the learned spectral embeddings by a greedy optimization strategy, which iteratively reveals the direction of the worst cluster structures and optimizes embeddings in this direction. To jointly optimize spectral embeddings and clustering, we seamlessly integrate the two modules and optimize them in an end-to-end manner. Experimental results on seven real-world datasets demonstrate that DSC achieves state-of-the-art clustering performance.
+
+
+
+ 153. 【2412.11077】Reason-before-Retrieve: One-Stage Reflective Chain-of-Thoughts for Training-Free Zero-Shot Composed Image Retrieval
+ 链接:https://arxiv.org/abs/2412.11077
+ 作者:Yuanmin Tang,Xiaoting Qin,Jue Zhang,Jing Yu,Gaopeng Gou,Gang Xiong,Qingwei Ling,Saravan Rajmohan,Dongmei Zhang,Qi Wu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Composed Image Retrieval, user-specified textual modifications, Large Language Models, integrating user-specified textual, Composed Image
+ 备注:
+
+ 点击查看摘要
+ Abstract:Composed Image Retrieval (CIR) aims to retrieve target images that closely resemble a reference image while integrating user-specified textual modifications, thereby capturing user intent more precisely. Existing training-free zero-shot CIR (ZS-CIR) methods often employ a two-stage process: they first generate a caption for the reference image and then use Large Language Models for reasoning to obtain a target description. However, these methods suffer from missing critical visual details and limited reasoning capabilities, leading to suboptimal retrieval performance. To address these challenges, we propose a novel, training-free one-stage method, One-Stage Reflective Chain-of-Thought Reasoning for ZS-CIR (OSrCIR), which employs Multimodal Large Language Models to retain essential visual information in a single-stage reasoning process, eliminating the information loss seen in two-stage methods. Our Reflective Chain-of-Thought framework further improves interpretative accuracy by aligning manipulation intent with contextual cues from reference images. OSrCIR achieves performance gains of 1.80% to 6.44% over existing training-free methods across multiple tasks, setting new state-of-the-art results in ZS-CIR and enhancing its utility in vision-language applications. Our code will be available at this https URL.
+
+
+
+ 154. 【2412.11076】MoRe: Class Patch Attention Needs Regularization for Weakly Supervised Semantic Segmentation
+ 链接:https://arxiv.org/abs/2412.11076
+ 作者:Zhiwei Yang,Yucong Meng,Kexue Fu,Shuo Wang,Zhijian Song
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Weakly Supervised Semantic, Supervised Semantic Segmentation, Weakly Supervised, Class Activation Maps, image-level labels typically
+ 备注: AAAI 2025
+
+ 点击查看摘要
+ Abstract:Weakly Supervised Semantic Segmentation (WSSS) with image-level labels typically uses Class Activation Maps (CAM) to achieve dense predictions. Recently, Vision Transformer (ViT) has provided an alternative to generate localization maps from class-patch attention. However, due to insufficient constraints on modeling such attention, we observe that the Localization Attention Maps (LAM) often struggle with the artifact issue, i.e., patch regions with minimal semantic relevance are falsely activated by class tokens. In this work, we propose MoRe to address this issue and further explore the potential of LAM. Our findings suggest that imposing additional regularization on class-patch attention is necessary. To this end, we first view the attention as a novel directed graph and propose the Graph Category Representation module to implicitly regularize the interaction among class-patch entities. It ensures that class tokens dynamically condense the related patch information and suppress unrelated artifacts at a graph level. Second, motivated by the observation that CAM from classification weights maintains smooth localization of objects, we devise the Localization-informed Regularization module to explicitly regularize the class-patch attention. It directly mines the token relations from CAM and further supervises the consistency between class and patch tokens in a learnable manner. Extensive experiments are conducted on PASCAL VOC and MS COCO, validating that MoRe effectively addresses the artifact issue and achieves state-of-the-art performance, surpassing recent single-stage and even multi-stage methods. Code is available at this https URL.
+
+
+
+ 155. 【2412.11074】Adapter-Enhanced Semantic Prompting for Continual Learning
+ 链接:https://arxiv.org/abs/2412.11074
+ 作者:Baocai Yin,Ji Zhao,Huajie Jiang,Ningning Hou,Yongli Hu,Amin Beheshti,Ming-Hsuan Yang,Yuankai Qi
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:evolving data streams, adapt to evolving, enables models, data streams, models to adapt
+ 备注:
+
+ 点击查看摘要
+ Abstract:Continual learning (CL) enables models to adapt to evolving data streams. A major challenge of CL is catastrophic forgetting, where new knowledge will overwrite previously acquired knowledge. Traditional methods usually retain the past data for replay or add additional branches in the model to learn new knowledge, which has high memory requirements. In this paper, we propose a novel lightweight CL framework, Adapter-Enhanced Semantic Prompting (AESP), which integrates prompt tuning and adapter techniques. Specifically, we design semantic-guided prompts to enhance the generalization ability of visual features and utilize adapters to efficiently fuse the semantic information, aiming to learn more adaptive features for the continual learning task. Furthermore, to choose the right task prompt for feature adaptation, we have developed a novel matching mechanism for prompt selection. Extensive experiments on three CL datasets demonstrate that our approach achieves favorable performance across multiple metrics, showing its potential for advancing CL.
+
+
+
+ 156. 【2412.11070】HC-LLM: Historical-Constrained Large Language Models for Radiology Report Generation
+ 链接:https://arxiv.org/abs/2412.11070
+ 作者:Tengfei Liu,Jiapu Wang,Yongli Hu,Mingjie Li,Junfei Yi,Xiaojun Chang,Junbin Gao,Baocai Yin
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Radiology report generation, models typically focus, large language models, Radiology report, individual exams
+ 备注: Accepted by AAAI2025
+
+ 点击查看摘要
+ Abstract:Radiology report generation (RRG) models typically focus on individual exams, often overlooking the integration of historical visual or textual data, which is crucial for patient follow-ups. Traditional methods usually struggle with long sequence dependencies when incorporating historical information, but large language models (LLMs) excel at in-context learning, making them well-suited for analyzing longitudinal medical data. In light of this, we propose a novel Historical-Constrained Large Language Models (HC-LLM) framework for RRG, empowering LLMs with longitudinal report generation capabilities by constraining the consistency and differences between longitudinal images and their corresponding reports. Specifically, our approach extracts both time-shared and time-specific features from longitudinal chest X-rays and diagnostic reports to capture disease progression. Then, we ensure consistent representation by applying intra-modality similarity constraints and aligning various features across modalities with multimodal contrastive and structural constraints. These combined constraints effectively guide the LLMs in generating diagnostic reports that accurately reflect the progression of the disease, achieving state-of-the-art results on the Longitudinal-MIMIC dataset. Notably, our approach performs well even without historical data during testing and can be easily adapted to other multimodal large models, enhancing its versatility.
+
+
+
+ 157. 【2412.11067】CFSynthesis: Controllable and Free-view 3D Human Video Synthesis
+ 链接:https://arxiv.org/abs/2412.11067
+ 作者:Cui Liyuan,Xu Xiaogang,Dong Wenqi,Yang Zesong,Bao Hujun,Cui Zhaopeng
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:video synthesis aims, create lifelike characters, Human video synthesis, content creation, synthesis aims
+ 备注:
+
+ 点击查看摘要
+ Abstract:Human video synthesis aims to create lifelike characters in various environments, with wide applications in VR, storytelling, and content creation. While 2D diffusion-based methods have made significant progress, they struggle to generalize to complex 3D poses and varying scene backgrounds. To address these limitations, we introduce CFSynthesis, a novel framework for generating high-quality human videos with customizable attributes, including identity, motion, and scene configurations. Our method leverages a texture-SMPL-based representation to ensure consistent and stable character appearances across free viewpoints. Additionally, we introduce a novel foreground-background separation strategy that effectively decomposes the scene as foreground and background, enabling seamless integration of user-defined backgrounds. Experimental results on multiple datasets show that CFSynthesis not only achieves state-of-the-art performance in complex human animations but also adapts effectively to 3D motions in free-view and user-specified scenarios.
+
+
+
+ 158. 【2412.11061】Classification Drives Geographic Bias in Street Scene Segmentation
+ 链接:https://arxiv.org/abs/2412.11061
+ 作者:Rahul Nair,Gabriel Tseng,Esther Rolf,Bhanu Tokas,Hannah Kerner
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computers and Society (cs.CY); Machine Learning (cs.LG)
+ 关键词:lacking geographic diversity, datasets lacking geographic, image datasets lacking, Eurocentric models, lacking geographic
+ 备注:
+
+ 点击查看摘要
+ Abstract:Previous studies showed that image datasets lacking geographic diversity can lead to biased performance in models trained on them. While earlier work studied general-purpose image datasets (e.g., ImageNet) and simple tasks like image recognition, we investigated geo-biases in real-world driving datasets on a more complex task: instance segmentation. We examined if instance segmentation models trained on European driving scenes (Eurocentric models) are geo-biased. Consistent with previous work, we found that Eurocentric models were geo-biased. Interestingly, we found that geo-biases came from classification errors rather than localization errors, with classification errors alone contributing 10-90% of the geo-biases in segmentation and 19-88% of the geo-biases in detection. This showed that while classification is geo-biased, localization (including detection and segmentation) is geographically robust. Our findings show that in region-specific models (e.g., Eurocentric models), geo-biases from classification errors can be significantly mitigated by using coarser classes (e.g., grouping car, bus, and truck as 4-wheeler).
+
+
+
+ 159. 【2412.11060】Making Bias Amplification in Balanced Datasets Directional and Interpretable
+ 链接:https://arxiv.org/abs/2412.11060
+ 作者:Bhanu Tokas,Rahul Nair,Hannah Kerner
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:amplification, bias amplification, bias, DPA, measure bias amplification
+ 备注:
+
+ 点击查看摘要
+ Abstract:Most of the ML datasets we use today are biased. When we train models on these biased datasets, they often not only learn dataset biases but can also amplify them -- a phenomenon known as bias amplification. Several co-occurrence-based metrics have been proposed to measure bias amplification between a protected attribute A (e.g., gender) and a task T (e.g., cooking). However, these metrics fail to measure biases when A is balanced with T. To measure bias amplification in balanced datasets, recent work proposed a predictability-based metric called leakage amplification. However, leakage amplification cannot identify the direction in which biases are amplified. In this work, we propose a new predictability-based metric called directional predictability amplification (DPA). DPA measures directional bias amplification, even for balanced datasets. Unlike leakage amplification, DPA is easier to interpret and less sensitive to attacker models (a hyperparameter in predictability-based metrics). Our experiments on tabular and image datasets show that DPA is an effective metric for measuring directional bias amplification. The code will be available soon.
+
+
+
+ 160. 【2412.11058】SHMT: Self-supervised Hierarchical Makeup Transfer via Latent Diffusion Models
+ 链接:https://arxiv.org/abs/2412.11058
+ 作者:Zhaoyang Sun,Shengwu Xiong,Yaxiong Chen,Fei Du,Weihua Chen,Fan Wang,Yi Rong
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:apply diverse makeup, diverse makeup styles, makeup styles precisely, facial image, Hierarchical Makeup Transfer
+ 备注: Accepted by NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:This paper studies the challenging task of makeup transfer, which aims to apply diverse makeup styles precisely and naturally to a given facial image. Due to the absence of paired data, current methods typically synthesize sub-optimal pseudo ground truths to guide the model training, resulting in low makeup fidelity. Additionally, different makeup styles generally have varying effects on the person face, but existing methods struggle to deal with this diversity. To address these issues, we propose a novel Self-supervised Hierarchical Makeup Transfer (SHMT) method via latent diffusion models. Following a "decoupling-and-reconstruction" paradigm, SHMT works in a self-supervised manner, freeing itself from the misguidance of imprecise pseudo-paired data. Furthermore, to accommodate a variety of makeup styles, hierarchical texture details are decomposed via a Laplacian pyramid and selectively introduced to the content representation. Finally, we design a novel Iterative Dual Alignment (IDA) module that dynamically adjusts the injection condition of the diffusion model, allowing the alignment errors caused by the domain gap between content and makeup representations to be corrected. Extensive quantitative and qualitative analyses demonstrate the effectiveness of our method. Our code is available at \url{this https URL}.
+
+
+
+ 161. 【2412.11056】Overview of TREC 2024 Medical Video Question Answering (MedVidQA) Track
+ 链接:https://arxiv.org/abs/2412.11056
+ 作者:Deepak Gupta,Dina Demner-Fushman
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:artificial intelligence, natural language query, key goals, goals of artificial, facilitates communication
+ 备注:
+
+ 点击查看摘要
+ Abstract:One of the key goals of artificial intelligence (AI) is the development of a multimodal system that facilitates communication with the visual world (image and video) using a natural language query. Earlier works on medical question answering primarily focused on textual and visual (image) modalities, which may be inefficient in answering questions requiring demonstration. In recent years, significant progress has been achieved due to the introduction of large-scale language-vision datasets and the development of efficient deep neural techniques that bridge the gap between language and visual understanding. Improvements have been made in numerous vision-and-language tasks, such as visual captioning visual question answering, and natural language video localization. Most of the existing work on language vision focused on creating datasets and developing solutions for open-domain applications. We believe medical videos may provide the best possible answers to many first aid, medical emergency, and medical education questions. With increasing interest in AI to support clinical decision-making and improve patient engagement, there is a need to explore such challenges and develop efficient algorithms for medical language-video understanding and generation. Toward this, we introduced new tasks to foster research toward designing systems that can understand medical videos to provide visual answers to natural language questions, and are equipped with multimodal capability to generate instruction steps from the medical video. These tasks have the potential to support the development of sophisticated downstream applications that can benefit the public and medical professionals.
+
+
+
+ 162. 【2412.11050】RAC3: Retrieval-Augmented Corner Case Comprehension for Autonomous Driving with Vision-Language Models
+ 链接:https://arxiv.org/abs/2412.11050
+ 作者:Yujin Wang,Quanfeng Liu,Jiaqi Fan,Jinlong Hong,Hongqing Chu,Mengjian Tian,Bingzhao Gao,Hong Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Understanding and addressing, autonomous driving systems, addressing corner cases, essential for ensuring, driving systems
+ 备注: 12 pages, 7 figures
+
+ 点击查看摘要
+ Abstract:Understanding and addressing corner cases is essential for ensuring the safety and reliability of autonomous driving systems. Vision-Language Models (VLMs) play a crucial role in enhancing scenario comprehension, yet they face significant challenges, such as hallucination and insufficient real-world grounding, which compromise their performance in critical driving scenarios. In this work, we propose RAC3, a novel framework designed to improve VLMs' ability to handle corner cases effectively. The framework integrates Retrieval-Augmented Generation (RAG) to mitigate hallucination by dynamically incorporating context-specific external knowledge. A cornerstone of RAC3 is its cross-modal alignment fine-tuning, which utilizes contrastive learning to embed image-text pairs into a unified semantic space, enabling robust retrieval of similar scenarios. We evaluate RAC3 through extensive experiments using a curated dataset of corner case scenarios, demonstrating its ability to enhance semantic alignment, improve hallucination mitigation, and achieve superior performance metrics, such as Cosine Similarity and ROUGE-L scores. For example, for the LLaVA-v1.6-34B VLM, the cosine similarity between the generated text and the reference text has increased by 5.22\%. The F1-score in ROUGE-L has increased by 39.91\%, the Precision has increased by 55.80\%, and the Recall has increased by 13.74\%. This work underscores the potential of retrieval-augmented VLMs to advance the robustness and safety of autonomous driving in complex environments.
+
+
+
+ 163. 【2412.11045】Facial Surgery Preview Based on the Orthognathic Treatment Prediction
+ 链接:https://arxiv.org/abs/2412.11045
+ 作者:Huijun Han,Congyi Zhang,Lifeng Zhu,Pradeep Singh,Richard Tai Chiu Hsung,Yiu Yan Leung,Taku Komura,Wenping Wang,Min Gu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Human-Computer Interaction (cs.HC)
+ 关键词:facial, Orthognathic surgery, facial appearance, Orthognathic surgery consultation, study
+ 备注: 9 pages, 5 figures
+
+ 点击查看摘要
+ Abstract:Orthognathic surgery consultation is essential to help patients understand the changes to their facial appearance after surgery. However, current visualization methods are often inefficient and inaccurate due to limited pre- and post-treatment data and the complexity of the treatment. To overcome these challenges, this study aims to develop a fully automated pipeline that generates accurate and efficient 3D previews of postsurgical facial appearances for patients with orthognathic treatment without requiring additional medical images. The study introduces novel aesthetic losses, such as mouth-convexity and asymmetry losses, to improve the accuracy of facial surgery prediction. Additionally, it proposes a specialized parametric model for 3D reconstruction of the patient, medical-related losses to guide latent code prediction network optimization, and a data augmentation scheme to address insufficient data. The study additionally employs FLAME, a parametric model, to enhance the quality of facial appearance previews by extracting facial latent codes and establishing dense correspondences between pre- and post-surgery geometries. Quantitative comparisons showed the algorithm's effectiveness, and qualitative results highlighted accurate facial contour and detail predictions. A user study confirmed that doctors and the public could not distinguish between machine learning predictions and actual postoperative results. This study aims to offer a practical, effective solution for orthognathic surgery consultations, benefiting doctors and patients.
+
+
+
+ 164. 【2412.11034】SAM-IF: Leveraging SAM for Incremental Few-Shot Instance Segmentation
+ 链接:https://arxiv.org/abs/2412.11034
+ 作者:Xudong Zhou,Wenhao He
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Segment Anything Model, leveraging the Segment, instance segmentation leveraging, Model, instance segmentation
+ 备注:
+
+ 点击查看摘要
+ Abstract:We propose SAM-IF, a novel method for incremental few-shot instance segmentation leveraging the Segment Anything Model (SAM). SAM-IF addresses the challenges of class-agnostic instance segmentation by introducing a multi-class classifier and fine-tuning SAM to focus on specific target objects. To enhance few-shot learning capabilities, SAM-IF employs a cosine-similarity-based classifier, enabling efficient adaptation to novel classes with minimal data. Additionally, SAM-IF supports incremental learning by updating classifier weights without retraining the decoder. Our method achieves competitive but more reasonable results compared to existing approaches, particularly in scenarios requiring specific object segmentation with limited labeled data.
+
+
+
+ 165. 【2412.11033】AURORA: Automated Unleash of 3D Room Outlines for VR Applications
+ 链接:https://arxiv.org/abs/2412.11033
+ 作者:Huijun Han,Yongqing Liang,Yuanlong Zhou,Wenping Wang,Edgar J. Rojas-Munoz,Xin Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:maintain spatial accuracy, provide design flexibility, accurately replicating real-world, Creating realistic, replicating real-world details
+ 备注: 8 pages, 4 figures
+
+ 点击查看摘要
+ Abstract:Creating realistic VR experiences is challenging due to the labor-intensive process of accurately replicating real-world details into virtual scenes, highlighting the need for automated methods that maintain spatial accuracy and provide design flexibility. In this paper, we propose AURORA, a novel method that leverages RGB-D images to automatically generate both purely virtual reality (VR) scenes and VR scenes combined with real-world elements. This approach can benefit designers by streamlining the process of converting real-world details into virtual scenes. AURORA integrates advanced techniques in image processing, segmentation, and 3D reconstruction to efficiently create realistic and detailed interior designs from real-world environments. The design of this integration ensures optimal performance and precision, addressing key challenges in automated indoor design generation by uniquely combining and leveraging the strengths of foundation models. We demonstrate the effectiveness of our approach through experiments, both on self-captured data and public datasets, showcasing its potential to enhance virtual reality (VR) applications by providing interior designs that conform to real-world positioning.
+
+
+
+ 166. 【2412.11026】SceneLLM: Implicit Language Reasoning in LLM for Dynamic Scene Graph Generation
+ 链接:https://arxiv.org/abs/2412.11026
+ 作者:Hang Zhang,Zhuoling Li,Jun Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:make informed decisions, autonomous driving systems, intricate spatio-temporal information, Scene Graph Generation, crucial for mobile
+ 备注: 27 pages, 4 figures
+
+ 点击查看摘要
+ Abstract:Dynamic scenes contain intricate spatio-temporal information, crucial for mobile robots, UAVs, and autonomous driving systems to make informed decisions. Parsing these scenes into semantic triplets Subject-Predicate-Object for accurate Scene Graph Generation (SGG) is highly challenging due to the fluctuating spatio-temporal complexity. Inspired by the reasoning capabilities of Large Language Models (LLMs), we propose SceneLLM, a novel framework that leverages LLMs as powerful scene analyzers for dynamic SGG. Our framework introduces a Video-to-Language (V2L) mapping module that transforms video frames into linguistic signals (scene tokens), making the input more comprehensible for LLMs. To better encode spatial information, we devise a Spatial Information Aggregation (SIA) scheme, inspired by the structure of Chinese characters, which encodes spatial data into tokens. Using Optimal Transport (OT), we generate an implicit language signal from the frame-level token sequence that captures the video's spatio-temporal information. To further improve the LLM's ability to process this implicit linguistic input, we apply Low-Rank Adaptation (LoRA) to fine-tune the model. Finally, we use a transformer-based SGG predictor to decode the LLM's reasoning and predict semantic triplets. Our method achieves state-of-the-art results on the Action Genome (AG) benchmark, and extensive experiments show the effectiveness of SceneLLM in understanding and generating accurate dynamic scene graphs.
+
+
+
+ 167. 【2412.11025】From Simple to Professional: A Combinatorial Controllable Image Captioning Agent
+ 链接:https://arxiv.org/abs/2412.11025
+ 作者:Xinran Wang,Muxi Diao,Baoteng Li,Haiwen Zhang,Kongming Liang,Zhanyu Ma
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Image Captioning Agent, Controllable Image Captioning, image captioning tasks, Controllable Image, innovative system designed
+ 备注: A technical report. Project: [this https URL](https://github.com/xin-ran-w/CapAgent)
+
+ 点击查看摘要
+ Abstract:The Controllable Image Captioning Agent (CapAgent) is an innovative system designed to bridge the gap between user simplicity and professional-level outputs in image captioning tasks. CapAgent automatically transforms user-provided simple instructions into detailed, professional instructions, enabling precise and context-aware caption generation. By leveraging multimodal large language models (MLLMs) and external tools such as object detection tool and search engines, the system ensures that captions adhere to specified guidelines, including sentiment, keywords, focus, and formatting. CapAgent transparently controls each step of the captioning process, and showcases its reasoning and tool usage at every step, fostering user trust and engagement. The project code is available at this https URL.
+
+
+
+ 168. 【2412.11024】Exploring Diffusion and Flow Matching Under Generator Matching
+ 链接:https://arxiv.org/abs/2412.11024
+ 作者:Zeeshan Patel,James DeLoye,Lance Mathias
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:flow matching, Generator Matching framework, Generator Matching, comprehensive theoretical comparison, diffusion and flow
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this paper, we present a comprehensive theoretical comparison of diffusion and flow matching under the Generator Matching framework. Despite their apparent differences, both diffusion and flow matching can be viewed under the unified framework of Generator Matching. By recasting both diffusion and flow matching under the same generative Markov framework, we provide theoretical insights into why flow matching models can be more robust empirically and how novel model classes can be constructed by mixing deterministic and stochastic components. Our analysis offers a fresh perspective on the relationships between state-of-the-art generative modeling paradigms.
+
+
+
+ 169. 【2412.11023】Exploring Enhanced Contextual Information for Video-Level Object Tracking
+ 链接:https://arxiv.org/abs/2412.11023
+ 作者:Ben Kang,Xin Chen,Simiao Lai,Yang Liu,Yi Liu,Dong Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Contextual information, visual object tracking, information, Contextual Information Fusion, increasingly crucial
+ 备注: This paper was accepted by AAAI2025
+
+ 点击查看摘要
+ Abstract:Contextual information at the video level has become increasingly crucial for visual object tracking. However, existing methods typically use only a few tokens to convey this information, which can lead to information loss and limit their ability to fully capture the context. To address this issue, we propose a new video-level visual object tracking framework called MCITrack. It leverages Mamba's hidden states to continuously record and transmit extensive contextual information throughout the video stream, resulting in more robust object tracking. The core component of MCITrack is the Contextual Information Fusion module, which consists of the mamba layer and the cross-attention layer. The mamba layer stores historical contextual information, while the cross-attention layer integrates this information into the current visual features of each backbone block. This module enhances the model's ability to capture and utilize contextual information at multiple levels through deep integration with the backbone. Experiments demonstrate that MCITrack achieves competitive performance across numerous benchmarks. For instance, it gets 76.6% AUC on LaSOT and 80.0% AO on GOT-10k, establishing a new state-of-the-art performance. Code and models are available at this https URL.
+
+
+
+ 170. 【2412.11017】On Distilling the Displacement Knowledge for Few-Shot Class-Incremental Learning
+ 链接:https://arxiv.org/abs/2412.11017
+ 作者:Pengfei Fang,Yongchun Qin,Hui Xue
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Few-shot Class-Incremental Learning, Class-Incremental Learning, evolving data distributions, knowledge distillation, addresses the challenges
+ 备注:
+
+ 点击查看摘要
+ Abstract:Few-shot Class-Incremental Learning (FSCIL) addresses the challenges of evolving data distributions and the difficulty of data acquisition in real-world scenarios. To counteract the catastrophic forgetting typically encountered in FSCIL, knowledge distillation is employed as a way to maintain the knowledge from learned data distribution. Recognizing the limitations of generating discriminative feature representations in a few-shot context, our approach incorporates structural information between samples into knowledge distillation. This structural information serves as a remedy for the low quality of features. Diverging from traditional structured distillation methods that compute sample similarity, we introduce the Displacement Knowledge Distillation (DKD) method. DKD utilizes displacement rather than similarity between samples, incorporating both distance and angular information to significantly enhance the information density retained through knowledge distillation. Observing performance disparities in feature distribution between base and novel classes, we propose the Dual Distillation Network (DDNet). This network applies traditional knowledge distillation to base classes and DKD to novel classes, challenging the conventional integration of novel classes with base classes. Additionally, we implement an instance-aware sample selector during inference to dynamically adjust dual branch weights, thereby leveraging the complementary strengths of each approach. Extensive testing on three benchmarks demonstrates that DDNet achieves state-of-the-art results. Moreover, through rigorous experimentation and comparison, we establish the robustness and general applicability of our proposed DKD method.
+
+
+
+ 171. 【2412.11008】owards Context-aware Convolutional Network for Image Restoration
+ 链接:https://arxiv.org/abs/2412.11008
+ 作者:Fangwei Hao,Ji Du,Weiyun Liang,Jing Xu,Xiaoxuan Xu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:corrupted observation, recover a high-quality, non-linear feature spaces, long-standing task, Image restoration
+ 备注:
+
+ 点击查看摘要
+ Abstract:Image restoration (IR) is a long-standing task to recover a high-quality image from its corrupted observation. Recently, transformer-based algorithms and some attention-based convolutional neural networks (CNNs) have presented promising results on several IR tasks. However, existing convolutional residual building modules for IR encounter limited ability to map inputs into high-dimensional and non-linear feature spaces, and their local receptive fields have difficulty in capturing long-range context information like Transformer. Besides, CNN-based attention modules for IR either face static abundant parameters or have limited receptive fields. To address the first issue, we propose an efficient residual star module (ERSM) that includes context-aware "star operation" (element-wise multiplication) to contextually map features into exceedingly high-dimensional and non-linear feature spaces, which greatly enhances representation learning. To further boost the extraction of contextual information, as for the second issue, we propose a large dynamic integration module (LDIM) which possesses an extremely large receptive field. Thus, LDIM can dynamically and efficiently integrate more contextual information that helps to further significantly improve the reconstruction performance. Integrating ERSM and LDIM into an U-shaped backbone, we propose a context-aware convolutional network (CCNet) with powerful learning ability for contextual high-dimensional mapping and abundant contextual information. Extensive experiments show that our CCNet with low model complexity achieves superior performance compared to other state-of-the-art IR methods on several IR tasks, including image dehazing, image motion deblurring, and image desnowing.
+
+
+
+ 172. 【2412.10995】RapidNet: Multi-Level Dilated Convolution Based Mobile Backbone
+ 链接:https://arxiv.org/abs/2412.10995
+ 作者:Mustafa Munir,Md Mostafijur Rahman,Radu Marculescu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:dominated computer vision, recent years, Multi-Level Dilated Convolutions, Vision transformers, Vision
+ 备注: Accepted in 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV 2025)
+
+ 点击查看摘要
+ Abstract:Vision transformers (ViTs) have dominated computer vision in recent years. However, ViTs are computationally expensive and not well suited for mobile devices; this led to the prevalence of convolutional neural network (CNN) and ViT-based hybrid models for mobile vision applications. Recently, Vision GNN (ViG) and CNN hybrid models have also been proposed for mobile vision tasks. However, all of these methods remain slower compared to pure CNN-based models. In this work, we propose Multi-Level Dilated Convolutions to devise a purely CNN-based mobile backbone. Using Multi-Level Dilated Convolutions allows for a larger theoretical receptive field than standard convolutions. Different levels of dilation also allow for interactions between the short-range and long-range features in an image. Experiments show that our proposed model outperforms state-of-the-art (SOTA) mobile CNN, ViT, ViG, and hybrid architectures in terms of accuracy and/or speed on image classification, object detection, instance segmentation, and semantic segmentation. Our fastest model, RapidNet-Ti, achieves 76.3\% top-1 accuracy on ImageNet-1K with 0.9 ms inference latency on an iPhone 13 mini NPU, which is faster and more accurate than MobileNetV2x1.4 (74.7\% top-1 with 1.0 ms latency). Our work shows that pure CNN architectures can beat SOTA hybrid and ViT models in terms of accuracy and speed when designed properly.
+
+
+
+ 173. 【2412.10977】Point Cloud to Mesh Reconstruction: A Focus on Key Learning-Based Paradigms
+ 链接:https://arxiv.org/abs/2412.10977
+ 作者:Fatima Zahra Iguenfer,Achraf Hsain,Hiba Amissa,Yousra Chtouki
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:Reconstructing meshes, autonomous systems, medical imaging, meshes from point, point clouds
+ 备注:
+
+ 点击查看摘要
+ Abstract:Reconstructing meshes from point clouds is an important task in fields such as robotics, autonomous systems, and medical imaging. This survey examines state-of-the-art learning-based approaches to mesh reconstruction, categorizing them into five paradigms: PointNet family, autoencoder architectures, deformation-based methods, point-move techniques, and primitive-based approaches. Each paradigm is explored in depth, detailing the primary approaches and their underlying methodologies. By comparing these techniques, our study serves as a comprehensive guide, and equips researchers and practitioners with the knowledge to navigate the landscape of learning-based mesh reconstruction techniques. The findings underscore the transformative potential of these methods, which often surpass traditional techniques in allowing detailed and efficient reconstructions.
+
+
+
+ 174. 【2412.10972】DCSEG: Decoupled 3D Open-Set Segmentation using Gaussian Splatting
+ 链接:https://arxiv.org/abs/2412.10972
+ 作者:Luis Wiedmann,Luca Wiehe,David Rozenberszki
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:virtual reality applications, multiple downstream robotics, robotics and augmented, virtual reality, reality applications
+ 备注:
+
+ 点击查看摘要
+ Abstract:Open-set 3D segmentation represents a major point of interest for multiple downstream robotics and augmented/virtual reality applications. Recent advances introduce 3D Gaussian Splatting as a computationally efficient representation of the underlying scene. They enable the rendering of novel views while achieving real-time display rates and matching the quality of computationally far more expensive methods. We present a decoupled 3D segmentation pipeline to ensure modularity and adaptability to novel 3D representations and semantic segmentation foundation models. The pipeline proposes class-agnostic masks based on a 3D reconstruction of the scene. Given the resulting class-agnostic masks, we use a class-aware 2D foundation model to add class annotations to the 3D masks. We test this pipeline with 3D Gaussian Splatting and different 2D segmentation models and achieve better performance than more tailored approaches while also significantly increasing the modularity.
+
+
+
+ 175. 【2412.10958】SoftVQ-VAE: Efficient 1-Dimensional Continuous Tokenizer
+ 链接:https://arxiv.org/abs/2412.10958
+ 作者:Hao Chen,Ze Wang,Xiang Li,Ximeng Sun,Fangyi Chen,Jiang Liu,Jindong Wang,Bhiksha Raj,Zicheng Liu,Emad Barsoum
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:high compression ratios, compression ratios remains, high compression, compression ratios, ratios remains
+ 备注: Code and model: [this https URL](https://github.com/Hhhhhhao/continuous_tokenizer)
+
+ 点击查看摘要
+ Abstract:Efficient image tokenization with high compression ratios remains a critical challenge for training generative models. We present SoftVQ-VAE, a continuous image tokenizer that leverages soft categorical posteriors to aggregate multiple codewords into each latent token, substantially increasing the representation capacity of the latent space. When applied to Transformer-based architectures, our approach compresses 256x256 and 512x512 images using as few as 32 or 64 1-dimensional tokens. Not only does SoftVQ-VAE show consistent and high-quality reconstruction, more importantly, it also achieves state-of-the-art and significantly faster image generation results across different denoising-based generative models. Remarkably, SoftVQ-VAE improves inference throughput by up to 18x for generating 256x256 images and 55x for 512x512 images while achieving competitive FID scores of 1.78 and 2.21 for SiT-XL. It also improves the training efficiency of the generative models by reducing the number of training iterations by 2.3x while maintaining comparable performance. With its fully-differentiable design and semantic-rich latent space, our experiment demonstrates that SoftVQ-VQE achieves efficient tokenization without compromising generation quality, paving the way for more efficient generative models. Code and model are released.
+
+
+
+ 176. 【2412.10955】Deep Learning-Based Noninvasive Screening of Type 2 Diabetes with Chest X-ray Images and Electronic Health Records
+ 链接:https://arxiv.org/abs/2412.10955
+ 作者:Sanjana Gundapaneni,Zhuo Zhi,Miguel Rodrigues
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:widespread global prevalence, clinical diagnostic tests, suboptimal clinical diagnostic, diabetes mellitus, global prevalence
+ 备注:
+
+ 点击查看摘要
+ Abstract:The imperative for early detection of type 2 diabetes mellitus (T2DM) is challenged by its asymptomatic onset and dependence on suboptimal clinical diagnostic tests, contributing to its widespread global prevalence. While research into noninvasive T2DM screening tools has advanced, conventional machine learning approaches remain limited to unimodal inputs due to extensive feature engineering requirements. In contrast, deep learning models can leverage multimodal data for a more holistic understanding of patients' health conditions. However, the potential of chest X-ray (CXR) imaging, one of the most commonly performed medical procedures, remains underexplored. This study evaluates the integration of CXR images with other noninvasive data sources, including electronic health records (EHRs) and electrocardiography signals, for T2DM detection. Utilising datasets meticulously compiled from the MIMIC-IV databases, we investigated two deep fusion paradigms: an early fusion-based multimodal transformer and a modular joint fusion ResNet-LSTM architecture. The end-to-end trained ResNet-LSTM model achieved an AUROC of 0.86, surpassing the CXR-only baseline by 2.3% with just 9863 training samples. These findings demonstrate the diagnostic value of CXRs within multimodal frameworks for identifying at-risk individuals early. Additionally, the dataset preprocessing pipeline has also been released to support further research in this domain.
+
+
+
+ 177. 【2412.10946】SegHeD+: Segmentation of Heterogeneous Data for Multiple Sclerosis Lesions with Anatomical Constraints and Lesion-aware Augmentation
+ 链接:https://arxiv.org/abs/2412.10946
+ 作者:Berke Doga Basaran,Paul M. Matthews,Wenjia Bai
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:brain magnetic resonance, monitoring multiple sclerosis, Assessing lesions, magnetic resonance, images is essential
+ 备注: 20 pages, 6 figures, 6 tables
+
+ 点击查看摘要
+ Abstract:Assessing lesions and tracking their progression over time in brain magnetic resonance (MR) images is essential for diagnosing and monitoring multiple sclerosis (MS). Machine learning models have shown promise in automating the segmentation of MS lesions. However, training these models typically requires large, well-annotated datasets. Unfortunately, MS imaging datasets are often limited in size, spread across multiple hospital sites, and exhibit different formats (such as cross-sectional or longitudinal) and annotation styles. This data diversity presents a significant obstacle to developing a unified model for MS lesion segmentation. To address this issue, we introduce SegHeD+, a novel segmentation model that can handle multiple datasets and tasks, accommodating heterogeneous input data and performing segmentation for all lesions, new lesions, and vanishing lesions. We integrate domain knowledge about MS lesions by incorporating longitudinal, anatomical, and volumetric constraints into the segmentation model. Additionally, we perform lesion-level data augmentation to enlarge the training set and further improve segmentation performance. SegHeD+ is evaluated on five MS datasets and demonstrates superior performance in segmenting all, new, and vanishing lesions, surpassing several state-of-the-art methods in the field.
+
+
+
+ 178. 【2412.10943】Unconstrained Salient and Camouflaged Object Detection
+ 链接:https://arxiv.org/abs/2412.10943
+ 作者:Zhangjun Zhou,Yiping Li,Chunlin Zhong,Jianuo Huang,Jialun Pei,He Tang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:camouflaged objects, Camouflaged Object Detection, Visual Salient Object, Camouflaged, salient and camouflaged
+ 备注: 24 pages, 12 figures
+
+ 点击查看摘要
+ Abstract:Visual Salient Object Detection (SOD) and Camouflaged Object Detection (COD) are two interrelated yet distinct tasks. Both tasks model the human visual system's ability to perceive the presence of objects. The traditional SOD datasets and methods are designed for scenes where only salient objects are present, similarly, COD datasets and methods are designed for scenes where only camouflaged objects are present. However, scenes where both salient and camouflaged objects coexist, or where neither is present, are not considered. This simplifies the existing research on SOD and COD. In this paper, to explore a more generalized approach to SOD and COD, we introduce a benchmark called Unconstrained Salient and Camouflaged Object Detection (USCOD), which supports the simultaneous detection of salient and camouflaged objects in unconstrained scenes, regardless of their presence. Towards this, we construct a large-scale dataset, CS12K, that encompasses a variety of scenes, including four distinct types: only salient objects, only camouflaged objects, both, and neither. In our benchmark experiments, we identify a major challenge in USCOD: distinguishing between salient and camouflaged objects within the same scene. To address this challenge, we propose USCNet, a baseline model for USCOD that decouples the learning of attribute distinction from mask reconstruction. The model incorporates an APG module, which learns both sample-generic and sample-specific features to enhance the attribute differentiation between salient and camouflaged objects. Furthermore, to evaluate models' ability to distinguish between salient and camouflaged objects, we design a metric called Camouflage-Saliency Confusion Score (CSCS). The proposed method achieves state-of-the-art performance on the newly introduced USCOD task. The code and dataset will be publicly available.
+
+
+
+ 179. 【2412.10942】Meta-evaluating stability measures: MAX-Senstivity AVG-Sensitivity
+ 链接:https://arxiv.org/abs/2412.10942
+ 作者:Miquel Miró-Nicolau,Antoni Jaume-i-Capó,Gabriel Moyà-Alcover
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:eXplainable Artificial Intelligence, Artificial Intelligence, eXplainable Artificial, systems has introduced, introduced a set
+ 备注:
+
+ 点击查看摘要
+ Abstract:The use of eXplainable Artificial Intelligence (XAI) systems has introduced a set of challenges that need resolution. The XAI robustness, or stability, has been one of the goals of the community from its beginning. Multiple authors have proposed evaluating this feature using objective evaluation measures. Nonetheless, many questions remain. With this work, we propose a novel approach to meta-evaluate these metrics, i.e. analyze the correctness of the evaluators. We propose two new tests that allowed us to evaluate two different stability measures: AVG-Sensitiviy and MAX-Senstivity. We tested their reliability in the presence of perfect and robust explanations, generated with a Decision Tree; as well as completely random explanations and prediction. The metrics results showed their incapacity of identify as erroneous the random explanations, highlighting their overall unreliability.
+
+
+
+ 180. 【2412.10935】Progressive Compression with Universally Quantized Diffusion Models
+ 链接:https://arxiv.org/abs/2412.10935
+ 作者:Yibo Yang,Justus C. Will,Stephan Mandt
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:inverse problem solving, achieved mainstream success, generative modeling tasks, problem solving, Diffusion probabilistic models
+ 备注: 20 pages, 10 figures, submitted to ICLR 2025
+
+ 点击查看摘要
+ Abstract:Diffusion probabilistic models have achieved mainstream success in many generative modeling tasks, from image generation to inverse problem solving. A distinct feature of these models is that they correspond to deep hierarchical latent variable models optimizing a variational evidence lower bound (ELBO) on the data likelihood. Drawing on a basic connection between likelihood modeling and compression, we explore the potential of diffusion models for progressive coding, resulting in a sequence of bits that can be incrementally transmitted and decoded with progressively improving reconstruction quality. Unlike prior work based on Gaussian diffusion or conditional diffusion models, we propose a new form of diffusion model with uniform noise in the forward process, whose negative ELBO corresponds to the end-to-end compression cost using universal quantization. We obtain promising first results on image compression, achieving competitive rate-distortion and rate-realism results on a wide range of bit-rates with a single model, bringing neural codecs a step closer to practical deployment.
+
+
+
+ 181. 【2412.10925】Video Representation Learning with Joint-Embedding Predictive Architectures
+ 链接:https://arxiv.org/abs/2412.10925
+ 作者:Katrina Drozdov,Ravid Shwartz-Ziv,Yann LeCun
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:increasingly important topic, machine learning research, Video representation learning, present Video JEPA, increasingly important
+ 备注:
+
+ 点击查看摘要
+ Abstract:Video representation learning is an increasingly important topic in machine learning research. We present Video JEPA with Variance-Covariance Regularization (VJ-VCR): a joint-embedding predictive architecture for self-supervised video representation learning that employs variance and covariance regularization to avoid representation collapse. We show that hidden representations from our VJ-VCR contain abstract, high-level information about the input data. Specifically, they outperform representations obtained from a generative baseline on downstream tasks that require understanding of the underlying dynamics of moving objects in the videos. Additionally, we explore different ways to incorporate latent variables into the VJ-VCR framework that capture information about uncertainty in the future in non-deterministic settings.
+
+
+
+ 182. 【2412.10908】Do large language vision models understand 3D shapes?
+ 链接:https://arxiv.org/abs/2412.10908
+ 作者:Sagi Eppel
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Large vision language, Large vision, vision language models, general visual understanding, vision language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large vision language models (LVLM) are the leading A.I approach for achieving a general visual understanding of the world. Models such as GPT, Claude, Gemini, and LLama can use images to understand and analyze complex visual scenes. 3D objects and shapes are the basic building blocks of the world, recognizing them is a fundamental part of human perception. The goal of this work is to test whether LVLMs truly understand 3D shapes by testing the models ability to identify and match objects of the exact same 3D shapes but with different orientations and materials/textures. Test images were created using CGI with a huge number of highly diverse objects, materials, and scenes. The results of this test show that the ability of such models to match 3D shapes is significantly below humans but much higher than random guesses. Suggesting that the models have gained some abstract understanding of 3D shapes but still trail far beyond humans in this task. Mainly it seems that the models can easily identify the same object with a different orientation as well as matching identical 3D shapes of the same orientation but with different material textures. However, when both the object material and orientation are changed, all models perform poorly relative to humans.
+
+
+
+ 183. 【2412.10902】Enhancing Road Crack Detection Accuracy with BsS-YOLO: Optimizing Feature Fusion and Attention Mechanisms
+ 链接:https://arxiv.org/abs/2412.10902
+ 作者:Jiaze Tang,Angzehua Feng,Vladimir Korkhov,Yuxi Pu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:offering significant economic, significant economic benefits, extending road lifespan, Path Aggregation Network, infrastructure preservation
+ 备注:
+
+ 点击查看摘要
+ Abstract:Effective road crack detection is crucial for road safety, infrastructure preservation, and extending road lifespan, offering significant economic benefits. However, existing methods struggle with varied target scales, complex backgrounds, and low adaptability to different environments. This paper presents the BsS-YOLO model, which optimizes multi-scale feature fusion through an enhanced Path Aggregation Network (PAN) and Bidirectional Feature Pyramid Network (BiFPN). The incorporation of weighted feature fusion improves feature representation, boosting detection accuracy and robustness. Furthermore, a Simple and Effective Attention Mechanism (SimAM) within the backbone enhances precision via spatial and channel-wise attention. The detection layer integrates a Shuffle Attention mechanism, which rearranges and mixes features across channels, refining key representations and further improving accuracy. Experimental results show that BsS-YOLO achieves a 2.8% increase in mean average precision (mAP) for road crack detection, supporting its applicability in diverse scenarios, including urban road maintenance and highway inspections.
+
+
+
+ 184. 【2412.10900】PEARL: Input-Agnostic Prompt Enhancement with Negative Feedback Regulation for Class-Incremental Learning
+ 链接:https://arxiv.org/abs/2412.10900
+ 作者:Yongchun Qin,Pengfei Fang,Hui Xue
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Class-incremental learning, forgetting previously learned, aims to continuously, Negative Feedback Regulation, CIL
+ 备注: Accepted by AAAI-25
+
+ 点击查看摘要
+ Abstract:Class-incremental learning (CIL) aims to continuously introduce novel categories into a classification system without forgetting previously learned ones, thus adapting to evolving data distributions. Researchers are currently focusing on leveraging the rich semantic information of pre-trained models (PTMs) in CIL tasks. Prompt learning has been adopted in CIL for its ability to adjust data distribution to better align with pre-trained knowledge. This paper critically examines the limitations of existing methods from the perspective of prompt learning, which heavily rely on input information. To address this issue, we propose a novel PTM-based CIL method called Input-Agnostic Prompt Enhancement with Negative Feedback Regulation (PEARL). In PEARL, we implement an input-agnostic global prompt coupled with an adaptive momentum update strategy to reduce the model's dependency on data distribution, thereby effectively mitigating catastrophic forgetting. Guided by negative feedback regulation, this adaptive momentum update addresses the parameter sensitivity inherent in fixed-weight momentum updates. Furthermore, it fosters the continuous enhancement of the prompt for new tasks by harnessing correlations between different tasks in CIL. Experiments on six benchmarks demonstrate that our method achieves state-of-the-art performance. The code is available at: this https URL.
+
+
+
+ 185. 【2412.10891】Zigzag Diffusion Sampling: The Path to Success Is Zigzag
+ 链接:https://arxiv.org/abs/2412.10891
+ 作者:Lichen Bai,Shitong Shao,Zikai Zhou,Zipeng Qi,Zhiqiang Xu,Haoyi Xiong,Zeke Xie
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:popular generative paradigm, Diffusion models, desired directions, popular generative, generative paradigm
+ 备注:
+
+ 点击查看摘要
+ Abstract:Diffusion models, the most popular generative paradigm so far, can inject conditional information into the generation path to guide the latent towards desired directions. However, existing text-to-image diffusion models often fail to maintain high image quality and high prompt-image alignment for those challenging prompts. To mitigate this issue and enhance existing pretrained diffusion models, we mainly made three contributions in this paper. First, we theoretically and empirically demonstrate that the conditional guidance gap between the denoising and inversion processes captures prompt-related semantic information. Second, motivated by theoretical analysis, we derive Zigzag Diffusion Sampling (Z-Sampling), a novel sampling method that leverages the guidance gap to accumulate semantic information step-by-step throughout the entire generation process, leading to improved sampling results. Moreover, as a plug-and-play method, Z-Sampling can be generally applied to various diffusion models (e.g., accelerated ones and Transformer-based ones) with very limited coding and computational costs. Third, our extensive experiments demonstrate that Z-Sampling can generally and significantly enhance generation quality across various benchmark datasets, diffusion models, and performance evaluation metrics. For example, Z-Sampling can even make DreamShaper achieve the HPSv2 winning rate higher than 94% over the original results. Moreover, Z-Sampling can further enhance existing diffusion models combined with other orthogonal methods, including Diffusion-DPO.
+
+
+
+ 186. 【2412.10861】Heterogeneous Graph Transformer for Multiple Tiny Object Tracking in RGB-T Videos
+ 链接:https://arxiv.org/abs/2412.10861
+ 作者:Qingyu Xu,Longguang Wang,Weidong Sheng,Yingqian Wang,Chao Xiao,Chao Ma,Wei An
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:highly challenging due, Heterogeneous Graph Transformer, tiny object tracking, tiny objects, Heterogeneous Graph
+ 备注: N/A
+
+ 点击查看摘要
+ Abstract:Tracking multiple tiny objects is highly challenging due to their weak appearance and limited features. Existing multi-object tracking algorithms generally focus on single-modality scenes, and overlook the complementary characteristics of tiny objects captured by multiple remote sensors. To enhance tracking performance by integrating complementary information from multiple sources, we propose a novel framework called {HGT-Track (Heterogeneous Graph Transformer based Multi-Tiny-Object Tracking)}. Specifically, we first employ a Transformer-based encoder to embed images from different modalities. Subsequently, we utilize Heterogeneous Graph Transformer to aggregate spatial and temporal information from multiple modalities to generate detection and tracking features. Additionally, we introduce a target re-detection module (ReDet) to ensure tracklet continuity by maintaining consistency across different modalities. Furthermore, this paper introduces the first benchmark VT-Tiny-MOT (Visible-Thermal Tiny Multi-Object Tracking) for RGB-T fused multiple tiny object tracking. Extensive experiments are conducted on VT-Tiny-MOT, and the results have demonstrated the effectiveness of our method. Compared to other state-of-the-art methods, our method achieves better performance in terms of MOTA (Multiple-Object Tracking Accuracy) and ID-F1 score. The code and dataset will be made available at this https URL.
+
+
+
+ 187. 【2412.10857】Robust Recognition of Persian Isolated Digits in Speech using Deep Neural Network
+ 链接:https://arxiv.org/abs/2412.10857
+ 作者:Ali Nasr-Esfahani,Mehdi Bekrani,Roozbeh Rajabi
+ 类目:ound (cs.SD); Computer Vision and Pattern Recognition (cs.CV); Audio and Speech Processing (eess.AS)
+ 关键词:speech recognition applications, artificial intelligence, recent years, advanced significantly, significantly in speech
+ 备注: 15 pages, submitted to journal
+
+ 点击查看摘要
+ Abstract:In recent years, artificial intelligence (AI) has advanced significantly in speech recognition applications. Speech-based interaction with digital systems, particularly AI-driven digit recognition, has emerged as a prominent application. However, existing neural network-based methods often neglect the impact of noise, leading to reduced accuracy in noisy environments. This study tackles the challenge of recognizing the isolated spoken Persian numbers (zero to nine), particularly distinguishing phonetically similar numbers, in noisy environments. The proposed method, which is designed for speaker-independent recognition, combines residual convolutional neural network and bidirectional gated recurrent unit in a hybrid structure for Persian number recognition. This method employs word units as input instead of phoneme units. Audio data from 51 speakers of FARSDIGIT1 database are utilized after augmentation using various noises, and the Mel-Frequency Cepstral Coefficients (MFCC) technique is employed for feature extraction. The experimental results show the proposed method efficacy with 98.53%, 96.10%, and 95.9% recognition accuracy for training, validation, and test, respectively. In the noisy environment, the proposed method exhibits an average performance improvement of 26.88% over phoneme unit-based LSTM method for Persian numbers. In addition, the accuracy of the proposed method is 7.61% better than that of the Mel-scale Two Dimension Root Cepstrum Coefficients (MTDRCC) feature extraction technique along with MLP model in the test data for the same dataset.
+
+
+
+ 188. 【2412.10853】SEW: Self-calibration Enhanced Whole Slide Pathology Image Analysis
+ 链接:https://arxiv.org/abs/2412.10853
+ 作者:Haoming Luo,Xiaotian Yu,Shengxuming Zhang,Jiabin Xia,Yang Jian,Yuning Sun,Liang Xue,Mingli Song,Jing Zhang,Xiuming Zhang,Zunlei Feng
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:providing extensive tissue, gigapixel images providing, images providing extensive, Pathology images, gold standard
+ 备注:
+
+ 点击查看摘要
+ Abstract:Pathology images are considered the "gold standard" for cancer diagnosis and treatment, with gigapixel images providing extensive tissue and cellular information. Existing methods fail to simultaneously extract global structural and local detail f
+
+
+
+ 189. 【2412.10846】Detecting Activities of Daily Living in Egocentric Video to Contextualize Hand Use at Home in Outpatient Neurorehabilitation Settings
+ 链接:https://arxiv.org/abs/2412.10846
+ 作者:Adesh Kadambi,José Zariffa
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Human-Computer Interaction (cs.HC)
+ 关键词:spinal cord injury, Wearable egocentric cameras, cord injury, Wearable egocentric, cameras and machine
+ 备注: To be submitted to IEEE Transactions on Neural Systems and Rehabilitation Engineering. 11 pages, 3 figures, 2 tables
+
+ 点击查看摘要
+ Abstract:Wearable egocentric cameras and machine learning have the potential to provide clinicians with a more nuanced understanding of patient hand use at home after stroke and spinal cord injury (SCI). However, they require detailed contextual information (i.e., activities and object interactions) to effectively interpret metrics and meaningfully guide therapy planning. We demonstrate that an object-centric approach, focusing on what objects patients interact with rather than how they move, can effectively recognize Activities of Daily Living (ADL) in real-world rehabilitation settings. We evaluated our models on a complex dataset collected in the wild comprising 2261 minutes of egocentric video from 16 participants with impaired hand function. By leveraging pre-trained object detection and hand-object interaction models, our system achieves robust performance across different impairment levels and environments, with our best model achieving a mean weighted F1-score of 0.78 +/- 0.12 and maintaining an F1-score 0.5 for all participants using leave-one-subject-out cross validation. Through qualitative analysis, we observe that this approach generates clinically interpretable information about functional object use while being robust to patient-specific movement variations, making it particularly suitable for rehabilitation contexts with prevalent upper limb impairment.
+
+
+
+ 190. 【2412.10843】Learning Semantic-Aware Representation in Visual-Language Models for Multi-Label Recognition with Partial Labels
+ 链接:https://arxiv.org/abs/2412.10843
+ 作者:Haoxian Ruan,Zhihua Xu,Zhijing Yang,Yongyi Lu,Jinghui Qin,Tianshui Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:real application scenarios, complete multi-label datasets, Multi-label recognition, complete multi-label, application scenarios
+ 备注: ACM Transactions on Multimedia Computing Communications and Applications
+
+ 点击查看摘要
+ Abstract:Multi-label recognition with partial labels (MLR-PL), in which only some labels are known while others are unknown for each image, is a practical task in computer vision, since collecting large-scale and complete multi-label datasets is difficult in real application scenarios. Recently, vision language models (e.g. CLIP) have demonstrated impressive transferability to downstream tasks in data limited or label limited settings. However, current CLIP-based methods suffer from semantic confusion in MLR task due to the lack of fine-grained information in the single global visual and textual representation for all categories. In this work, we address this problem by introducing a semantic decoupling module and a category-specific prompt optimization method in CLIP-based framework. Specifically, the semantic decoupling module following the visual encoder learns category-specific feature maps by utilizing the semantic-guided spatial attention mechanism. Moreover, the category-specific prompt optimization method is introduced to learn text representations aligned with category semantics. Therefore, the prediction of each category is independent, which alleviate the semantic confusion problem. Extensive experiments on Microsoft COCO 2014 and Pascal VOC 2007 datasets demonstrate that the proposed framework significantly outperforms current state-of-art methods with a simpler model structure. Additionally, visual analysis shows that our method effectively separates information from different categories and achieves better performance compared to CLIP-based baseline method.
+
+
+
+ 191. 【2412.10840】Attention-driven GUI Grounding: Leveraging Pretrained Multimodal Large Language Models without Fine-Tuning
+ 链接:https://arxiv.org/abs/2412.10840
+ 作者:Hai-Ming Xu,Qi Chen,Lei Wang,Lingqiao Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Large Language Models, Graphical User Interfaces, Multimodal Large Language, interpret Graphical User, Language Models
+ 备注: Accepted to AAAI 2025
+
+ 点击查看摘要
+ Abstract:Recent advancements in Multimodal Large Language Models (MLLMs) have generated significant interest in their ability to autonomously interact with and interpret Graphical User Interfaces (GUIs). A major challenge in these systems is grounding-accurately identifying critical GUI components such as text or icons based on a GUI image and a corresponding text query. Traditionally, this task has relied on fine-tuning MLLMs with specialized training data to predict component locations directly. However, in this paper, we propose a novel Tuning-free Attention-driven Grounding (TAG) method that leverages the inherent attention patterns in pretrained MLLMs to accomplish this task without the need for additional fine-tuning. Our method involves identifying and aggregating attention maps from specific tokens within a carefully constructed query prompt. Applied to MiniCPM-Llama3-V 2.5, a state-of-the-art MLLM, our tuning-free approach achieves performance comparable to tuning-based methods, with notable success in text localization. Additionally, we demonstrate that our attention map-based grounding technique significantly outperforms direct localization predictions from MiniCPM-Llama3-V 2.5, highlighting the potential of using attention maps from pretrained MLLMs and paving the way for future innovations in this domain.
+
+
+
+ 192. 【2412.10834】SegACIL: Solving the Stability-Plasticity Dilemma in Class-Incremental Semantic Segmentation
+ 链接:https://arxiv.org/abs/2412.10834
+ 作者:Jiaxu Li,Songning Lai,Rui Li,Di Fang,Kejia Fan,Jianheng Tang,Yuhan Zhao,Rongchang Zhao,Dongzhan Zhou,Yutao Yue,Huiping Zhuang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:made remarkable progress, processing continuously incoming, continuously incoming data, recent years, models continue
+ 备注:
+
+ 点击查看摘要
+ Abstract:While deep learning has made remarkable progress in recent years, models continue to struggle with catastrophic forgetting when processing continuously incoming data. This issue is particularly critical in continual learning, where the balance between retaining prior knowledge and adapting to new information-known as the stability-plasticity dilemma-remains a significant challenge. In this paper, we propose SegACIL, a novel continual learning method for semantic segmentation based on a linear closed-form solution. Unlike traditional methods that require multiple epochs for training, SegACIL only requires a single epoch, significantly reducing computational costs. Furthermore, we provide a theoretical analysis demonstrating that SegACIL achieves performance on par with joint learning, effectively retaining knowledge from previous data which makes it to keep both stability and plasticity at the same time. Extensive experiments on the Pascal VOC2012 dataset show that SegACIL achieves superior performance in the sequential, disjoint, and overlap settings, offering a robust solution to the challenges of class-incremental semantic segmentation. Code is available at this https URL.
+
+
+
+ 193. 【2412.10831】Unbiased General Annotated Dataset Generation
+ 链接:https://arxiv.org/abs/2412.10831
+ 作者:Dengyang Jiang,Haoyu Wang,Lei Zhang,Wei Wei,Guang Dai,Mengmeng Wang,Jingdong Wang,Yanning Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:comprises numerous manually, numerous manually collected, manually collected images, Pre-training backbone networks, generalization capacity
+ 备注: Preprint
+
+ 点击查看摘要
+ Abstract:Pre-training backbone networks on a general annotated dataset (e.g., ImageNet) that comprises numerous manually collected images with category annotations has proven to be indispensable for enhancing the generalization capacity of downstream visual tasks. However, those manually collected images often exhibit bias, which is non-transferable across either categories or domains, thus causing the model's generalization capacity degeneration. To mitigate this problem, we present an unbiased general annotated dataset generation framework (ubGen). Instead of expensive manual collection, we aim at directly generating unbiased images with category annotations. To achieve this goal, we propose to leverage the advantage of a multimodal foundation model (e.g., CLIP), in terms of aligning images in an unbiased semantic space defined by language. Specifically, we develop a bi-level semantic alignment loss, which not only forces all generated images to be consistent with the semantic distribution of all categories belonging to the target dataset in an adversarial learning manner, but also requires each generated image to match the semantic description of its category name. In addition, we further cast an existing image quality scoring model into a quality assurance loss to preserve the quality of the generated image. By leveraging these two loss functions, we can obtain an unbiased image generation model by simply fine-tuning a pre-trained diffusion model using only all category names in the target dataset as input. Experimental results confirm that, compared with the manually labeled dataset or other synthetic datasets, the utilization of our generated unbiased datasets leads to stable generalization capacity enhancement of different backbone networks across various tasks, especially in tasks where the manually labeled samples are scarce.
+
+
+
+ 194. 【2412.10824】Diffusion Model from Scratch
+ 链接:https://arxiv.org/abs/2412.10824
+ 作者:Wang Zhen,Dong Yunyun
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Denoising Diffusion Probability, Diffusion Probability Model, popular generative models, paper Denoising Diffusion, Diffusion generative models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Diffusion generative models are currently the most popular generative models. However, their underlying modeling process is quite complex, and starting directly with the seminal paper Denoising Diffusion Probability Model (DDPM) can be challenging. This paper aims to assist readers in building a foundational understanding of generative models by tracing the evolution from VAEs to DDPM through detailed mathematical derivations and a problem-oriented analytical approach. It also explores the core ideas and improvement strategies of current mainstream methodologies, providing guidance for undergraduate and graduate students interested in learning about diffusion models.
+
+
+
+ 195. 【2412.10817】Enhance Vision-Language Alignment with Noise
+ 链接:https://arxiv.org/abs/2412.10817
+ 作者:Sida Huang,Hongyuan Zhang,Xuelong Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:noise, pre-trained vision-language, enhancing the alignment, critical challenge, advancement of pre-trained
+ 备注:
+
+ 点击查看摘要
+ Abstract:With the advancement of pre-trained vision-language (VL) models, enhancing the alignment between visual and linguistic modalities in downstream tasks has emerged as a critical challenge. Different from existing fine-tuning methods that add extra modules to these two modalities, we investigate whether the frozen model can be fine-tuned by customized noise. Our approach is motivated by the scientific study of beneficial noise, namely Positive-incentive Noise (Pi-noise or $\pi$-noise) , which quantitatively analyzes the impact of noise. It therefore implies a new scheme to learn beneficial noise distribution that can be employed to fine-tune VL models. Focusing on few-shot classification tasks based on CLIP, we reformulate the inference process of CLIP and apply variational inference, demonstrating how to generate $\pi$-noise towards visual and linguistic modalities. Then, we propose Positive-incentive Noise Injector (PiNI), which can fine-tune CLIP via injecting noise into both visual and text encoders. Since the proposed method can learn the distribution of beneficial noise, we can obtain more diverse embeddings of vision and language to better align these two modalities for specific downstream tasks within limited computational resources. We evaluate different noise incorporation approaches and network architectures of PiNI. The evaluation across 11 datasets demonstrates its effectiveness.
+
+
+
+ 196. 【2412.10816】Hyper-Fusion Network for Semi-Automatic Segmentation of Skin Lesions
+ 链接:https://arxiv.org/abs/2412.10816
+ 作者:Lei Bi,Michael Fulham,Jinman Kim
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Automatic skin lesion, segmentation methods, semi-automatic segmentation methods, skin lesions, automatic segmentation methods
+ 备注: Accepted by the journal of medical image analysis
+
+ 点击查看摘要
+ Abstract:Automatic skin lesion segmentation methods based on fully convolutional networks (FCNs) are regarded as the state-of-the-art for accuracy. When there are, however, insufficient training data to cover all the variations in skin lesions, where lesions from different patients may have major differences in size/shape/texture, these methods failed to segment the lesions that have image characteristics, which are less common in the training datasets. FCN-based semi-automatic segmentation methods, which fuse user-inputs with high-level semantic image features derived from FCNs offer an ideal complement to overcome limitations of automatic segmentation methods. These semi-automatic methods rely on the automated state-of-the-art FCNs coupled with user-inputs for refinements, and therefore being able to tackle challenging skin lesions. However, there are a limited number of FCN-based semi-automatic segmentation methods and all these methods focused on early-fusion, where the first few convolutional layers are used to fuse image features and user-inputs and then derive fused image features for segmentation. For early-fusion based methods, because the user-input information can be lost after the first few convolutional layers, consequently, the user-input information will have limited guidance and constraint in segmenting the challenging skin lesions with inhomogeneous textures and fuzzy boundaries. Hence, in this work, we introduce a hyper-fusion network (HFN) to fuse the extracted user-inputs and image features over multiple stages. We separately extract complementary features which then allows for an iterative use of user-inputs along all the fusion stages to refine the segmentation. We evaluated our HFN on ISIC 2017, ISIC 2016 and PH2 datasets, and our results show that the HFN is more accurate and generalizable than the state-of-the-art methods.
+
+
+
+ 197. 【2412.10804】Medical Manifestation-Aware De-Identification
+ 链接:https://arxiv.org/abs/2412.10804
+ 作者:Yuan Tian,Shuo Wang,Guangtao Zhai
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:common scenes, large-scale patient face, Face de-identification, widely studied, studied for common
+ 备注: Accepted to AAAI 2025
+
+ 点击查看摘要
+ Abstract:Face de-identification (DeID) has been widely studied for common scenes, but remains under-researched for medical scenes, mostly due to the lack of large-scale patient face datasets. In this paper, we release MeMa, consisting of over 40,000 photo-realistic patient faces. MeMa is re-generated from massive real patient photos. By carefully modulating the generation and data-filtering procedures, MeMa avoids breaching real patient privacy, while ensuring rich and plausible medical manifestations. We recruit expert clinicians to annotate MeMa with both coarse- and fine-grained labels, building the first medical-scene DeID benchmark. Additionally, we propose a baseline approach for this new medical-aware DeID task, by integrating data-driven medical semantic priors into the DeID procedure. Despite its conciseness and simplicity, our approach substantially outperforms previous ones. Dataset is available at this https URL.
+
+
+
+ 198. 【2412.10795】Reliable and superior elliptic Fourier descriptor normalization and its application software ElliShape with efficient image processing
+ 链接:https://arxiv.org/abs/2412.10795
+ 作者:Hui Wu(1,2,3,4),Jia-Jie Yang(1,3,4),Chao-Qun Li(5),Jin-Hua Ran(2,4,6),Ren-Hua Peng(6,7),Xiao-Quan Wang(1,2,3,4,6) ((1) Big Data and AI Biodiversity Conservation Research Center, Institute of Botany, Chinese Academy of Sciences, Beijing, China (2) State Key Laboratory of Plant Diversity and Specialty Crops and Key Laboratory of Systematic and Evolutionary Botany, Institute of Botany, Chinese Academy of Sciences, Beijing, China (3) Plant Science Data Center, Chinese Academy of Sciences, Beijing, China (4) China National Botanical Garden, Beijing, China (5) School of Life Sciences, Qilu Normal University, Jinan, China (6) University of Chinese Academy of Sciences, Beijing, China (7) Key Laboratory of Noise and Vibration Control, Institute of Acoustics, Chinese Academy of Sciences, Beijing, China)
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Quantitative Methods (q-bio.QM)
+ 关键词:Elliptic Fourier analysis, Elliptic Fourier, elliptic Fourier descriptors, Fourier analysis, geometric morphometrics
+ 备注:
+
+ 点击查看摘要
+ Abstract:Elliptic Fourier analysis (EFA) is a powerful tool for shape analysis, which is often employed in geometric morphometrics. However, the normalization of elliptic Fourier descriptors has persistently posed challenges in obtaining unique results in basic contour transformations, requiring extensive manual alignment. Additionally, contemporary contour/outline extraction methods often struggle to handle complex digital images. Here, we reformulated the procedure of EFDs calculation to improve computational efficiency and introduced a novel approach for EFD normalization, termed true EFD normalization, which remains invariant under all basic contour transformations. These improvements are crucial for processing large sets of contour curves collected from different platforms with varying transformations. Based on these improvements, we developed ElliShape, a user-friendly software. Particularly, the improved contour/outline extraction employs an interactive approach that combines automatic contour generation for efficiency with manual correction for essential modifications and refinements. We evaluated ElliShape's stability, robustness, and ease of use by comparing it with existing software using standard datasets. ElliShape consistently produced reliable reconstructed shapes and normalized EFD values across different contours and transformations, and it demonstrated superior performance in visualization and efficient processing of various digital images for contour this http URL output annotated images and EFDs could be utilized in deep learning-based data training, thereby advancing artificial intelligence in botany and offering innovative solutions for critical challenges in biodiversity conservation, species classification, ecosystem function assessment, and related critical issues.
+
+
+
+ 199. 【2412.10786】Optimizing Few-Step Sampler for Diffusion Probabilistic Model
+ 链接:https://arxiv.org/abs/2412.10786
+ 作者:Jen-Yuan Huang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Diffusion Probabilistic Models, demonstrated exceptional capability, intensive computational cost, Ordinary Differential Equation, Diffusion Probabilistic
+ 备注:
+
+ 点击查看摘要
+ Abstract:Diffusion Probabilistic Models (DPMs) have demonstrated exceptional capability of generating high-quality and diverse images, but their practical application is hindered by the intensive computational cost during inference. The DPM generation process requires solving a Probability-Flow Ordinary Differential Equation (PF-ODE), which involves discretizing the integration domain into intervals for numerical approximation. This corresponds to the sampling schedule of a diffusion ODE solver, and we notice the solution from a first-order solver can be expressed as a convex combination of model outputs at all scheduled time-steps. We derive an upper bound for the discretization error of the sampling schedule, which can be efficiently optimized with Monte-Carlo estimation. Building on these theoretical results, we purpose a two-phase alternating optimization algorithm. In Phase-1, the sampling schedule is optimized for the pre-trained DPM; in Phase-2, the DPM further tuned on the selected time-steps. Experiments on a pre-trained DPM for ImageNet64 dataset demonstrate the purposed method consistently improves the baseline across various number of sampling steps.
+
+
+
+ 200. 【2412.10785】StyleDiT: A Unified Framework for Diverse Child and Partner Faces Synthesis with Style Latent Diffusion Transformer
+ 链接:https://arxiv.org/abs/2412.10785
+ 作者:Pin-Yen Chiu,Dai-Jie Wu,Po-Hsun Chu,Chia-Hsuan Hsu,Hsiang-Chen Chiu,Chih-Yu Wang,Jun-Cheng Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:challenging problem due, Kinship face synthesis, challenging problem, problem due, scarcity and low
+ 备注:
+
+ 点击查看摘要
+ Abstract:Kinship face synthesis is a challenging problem due to the scarcity and low quality of the available kinship data. Existing methods often struggle to generate descendants with both high diversity and fidelity while precisely controlling facial attributes such as age and gender. To address these issues, we propose the Style Latent Diffusion Transformer (StyleDiT), a novel framework that integrates the strengths of StyleGAN with the diffusion model to generate high-quality and diverse kinship faces. In this framework, the rich facial priors of StyleGAN enable fine-grained attribute control, while our conditional diffusion model is used to sample a StyleGAN latent aligned with the kinship relationship of conditioning images by utilizing the advantage of modeling complex kinship relationship distribution. StyleGAN then handles latent decoding for final face generation. Additionally, we introduce the Relational Trait Guidance (RTG) mechanism, enabling independent control of influencing conditions, such as each parent's facial image. RTG also enables a fine-grained adjustment between the diversity and fidelity in synthesized faces. Furthermore, we extend the application to an unexplored domain: predicting a partner's facial images using a child's image and one parent's image within the same framework. Extensive experiments demonstrate that our StyleDiT outperforms existing methods by striking an excellent balance between generating diverse and high-fidelity kinship faces.
+
+
+
+ 201. 【2412.10783】Video Diffusion Transformers are In-Context Learners
+ 链接:https://arxiv.org/abs/2412.10783
+ 作者:Zhengcong Fei,Di Qiu,Changqian Yu,Debang Li,Mingyuan Fan,Xiang Wen
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:minimal tuning required, enabling in-context capabilities, video diffusion transformers, diffusion transformers, required for activation
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper investigates a solution for enabling in-context capabilities of video diffusion transformers, with minimal tuning required for activation. Specifically, we propose a simple pipeline to leverage in-context generation: ($\textbf{i}$) concatenate videos along spacial or time dimension, ($\textbf{ii}$) jointly caption multi-scene video clips from one source, and ($\textbf{iii}$) apply task-specific fine-tuning using carefully curated small datasets. Through a series of diverse controllable tasks, we demonstrate qualitatively that existing advanced text-to-video models can effectively perform in-context generation. Notably, it allows for the creation of consistent multi-scene videos exceeding 30 seconds in duration, without additional computational overhead. Importantly, this method requires no modifications to the original models, results in high-fidelity video outputs that better align with prompt specifications and maintain role consistency. Our framework presents a valuable tool for the research community and offers critical insights for advancing product-level controllable video generation systems. The data, code, and model weights are publicly available at: \url{this https URL}.
+
+
+
+ 202. 【2412.10778】Sample-efficient Unsupervised Policy Cloning from Ensemble Self-supervised Labeled Videos
+ 链接:https://arxiv.org/abs/2412.10778
+ 作者:Xin Liu,Yaran Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:develop expert-level strategies, methodologies have demonstrated, demonstrated the ability, ability to develop, develop expert-level
+ 备注:
+
+ 点击查看摘要
+ Abstract:Current advanced policy learning methodologies have demonstrated the ability to develop expert-level strategies when provided enough information. However, their requirements, including task-specific rewards, expert-labeled trajectories, and huge environmental interactions, can be expensive or even unavailable in many scenarios. In contrast, humans can efficiently acquire skills within a few trials and errors by imitating easily accessible internet video, in the absence of any other supervision. In this paper, we try to let machines replicate this efficient watching-and-learning process through Unsupervised Policy from Ensemble Self-supervised labeled Videos (UPESV), a novel framework to efficiently learn policies from videos without any other expert supervision. UPESV trains a video labeling model to infer the expert actions in expert videos, through several organically combined self-supervised tasks. Each task performs its own duties, and they together enable the model to make full use of both expert videos and reward-free interactions for advanced dynamics understanding and robust prediction. Simultaneously, UPESV clones a policy from the labeled expert videos, in turn collecting environmental interactions for self-supervised tasks. After a sample-efficient and unsupervised (i.e., reward-free) training process, an advanced video-imitated policy is obtained. Extensive experiments in sixteen challenging procedurally-generated environments demonstrate that the proposed UPESV achieves state-of-the-art few-shot policy learning (outperforming five current advanced baselines on 12/16 tasks) without exposure to any other supervision except videos. Detailed analysis is also provided, verifying the necessity of each self-supervised task employed in UPESV.
+
+
+
+ 203. 【2412.10768】VinTAGe: Joint Video and Text Conditioning for Holistic Audio Generation
+ 链接:https://arxiv.org/abs/2412.10768
+ 作者:Saksham Singh Kushwaha,Yapeng Tian
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:Recent advances, audio generation, holistic audio generation, offscreen sounds, generation
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advances in audio generation have focused on text-to-audio (T2A) and video-to-audio (V2A) tasks. However, T2A or V2A methods cannot generate holistic sounds (onscreen and off-screen). This is because T2A cannot generate sounds aligning with onscreen objects, while V2A cannot generate semantically complete (offscreen sounds missing). In this work, we address the task of holistic audio generation: given a video and a text prompt, we aim to generate both onscreen and offscreen sounds that are temporally synchronized with the video and semantically aligned with text and video. Previous approaches for joint text and video-to-audio generation often suffer from modality bias, favoring one modality over the other. To overcome this limitation, we introduce VinTAGe, a flow-based transformer model that jointly considers text and video to guide audio generation. Our framework comprises two key components: a Visual-Text Encoder and a Joint VT-SiT model. To reduce modality bias and improve generation quality, we employ pretrained uni-modal text-to-audio and video-to-audio generation models for additional guidance. Due to the lack of appropriate benchmarks, we also introduce VinTAGe-Bench, a dataset of 636 video-text-audio pairs containing both onscreen and offscreen sounds. Our comprehensive experiments on VinTAGe-Bench demonstrate that joint text and visual interaction is necessary for holistic audio generation. Furthermore, VinTAGe achieves state-of-the-art results on the VGGSound benchmark. Our source code and pre-trained models will be released. Demo is available at: this https URL.
+
+
+
+ 204. 【2412.10765】Neural Network Meta Classifier: Improving the Reliability of Anomaly Segmentation
+ 链接:https://arxiv.org/abs/2412.10765
+ 作者:Jurica Runtas,Tomislav Petkovic
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:predefined closed set, Deep neural networks, Deep neural, set of classes, contemporary solution
+ 备注: Accepted to VISAPP 2025
+
+ 点击查看摘要
+ Abstract:Deep neural networks (DNNs) are a contemporary solution for semantic segmentation and are usually trained to operate on a predefined closed set of classes. In open-set environments, it is possible to encounter semantically unknown objects or anomalies. Road driving is an example of such an environment in which, from a safety standpoint, it is important to ensure that a DNN indicates it is operating outside of its learned semantic domain. One possible approach to anomaly segmentation is entropy maximization, which is paired with a logistic regression based post-processing step called meta classification, which is in turn used to improve the reliability of detection of anomalous pixels. We propose to substitute the logistic regression meta classifier with a more expressive lightweight fully connected neural network. We analyze advantages and drawbacks of the proposed neural network meta classifier and demonstrate its better performance over logistic regression. We also introduce the concept of informative out-of-distribution examples which we show to improve training results when using entropy maximization in practice. Finally, we discuss the loss of interpretability and show that the behavior of logistic regression and neural network is strongly correlated.
+
+
+
+ 205. 【2412.10761】Rebalanced Vision-Language Retrieval Considering Structure-Aware Distillation
+ 链接:https://arxiv.org/abs/2412.10761
+ 作者:Yang Yang,Wenjuan Xi,Luping Zhou,Jinhui Tang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Vision-language retrieval aims, cross-modal matching, matching, Vision-language retrieval, cross-modal
+ 备注:
+
+ 点击查看摘要
+ Abstract:Vision-language retrieval aims to search for similar instances in one modality based on queries from another modality. The primary objective is to learn cross-modal matching representations in a latent common space. Actually, the assumption underlying cross-modal matching is modal balance, where each modality contains sufficient information to represent the others. However, noise interference and modality insufficiency often lead to modal imbalance, making it a common phenomenon in practice. The impact of imbalance on retrieval performance remains an open question. In this paper, we first demonstrate that ultimate cross-modal matching is generally sub-optimal for cross-modal retrieval when imbalanced modalities exist. The structure of instances in the common space is inherently influenced when facing imbalanced modalities, posing a challenge to cross-modal similarity measurement. To address this issue, we emphasize the importance of meaningful structure-preserved matching. Accordingly, we propose a simple yet effective method to rebalance cross-modal matching by learning structure-preserved matching representations. Specifically, we design a novel multi-granularity cross-modal matching that incorporates structure-aware distillation alongside the cross-modal matching loss. While the cross-modal matching loss constraints instance-level matching, the structure-aware distillation further regularizes the geometric consistency between learned matching representations and intra-modal representations through the developed relational matching. Extensive experiments on different datasets affirm the superior cross-modal retrieval performance of our approach, simultaneously enhancing single-modal retrieval capabilities compared to the baseline models.
+
+
+
+ 206. 【2412.10758】Optimizing Vision-Language Interactions Through Decoder-Only Models
+ 链接:https://arxiv.org/abs/2412.10758
+ 作者:Kaito Tanaka,Benjamin Tan,Brian Wong
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:encoders introduces challenges, Multimodal Unified Decoder, Adaptive Input Fusion, separate visual encoders, visual encoders introduces
+ 备注:
+
+ 点击查看摘要
+ Abstract:Vision-Language Models (VLMs) have emerged as key enablers for multimodal tasks, but their reliance on separate visual encoders introduces challenges in efficiency, scalability, and modality alignment. To address these limitations, we propose MUDAIF (Multimodal Unified Decoder with Adaptive Input Fusion), a decoder-only vision-language model that seamlessly integrates visual and textual inputs through a novel Vision-Token Adapter (VTA) and adaptive co-attention mechanism. By eliminating the need for a visual encoder, MUDAIF achieves enhanced efficiency, flexibility, and cross-modal understanding. Trained on a large-scale dataset of 45M image-text pairs, MUDAIF consistently outperforms state-of-the-art methods across multiple benchmarks, including VQA, image captioning, and multimodal reasoning tasks. Extensive analyses and human evaluations demonstrate MUDAIF's robustness, generalization capabilities, and practical usability, establishing it as a new standard in encoder-free vision-language models.
+
+
+
+ 207. 【2412.10756】Damage Assessment after Natural Disasters with UAVs: Semantic Feature Extraction using Deep Learning
+ 链接:https://arxiv.org/abs/2412.10756
+ 作者:Nethmi S. Hewawiththi,M. Mahesha Viduranga,Vanodhya G. Warnasooriya,Tharindu Fernando,Himal A. Suraweera,Sridha Sridharan,Clinton Fookes
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Unmanned aerial vehicle-assisted, promoted recently due, Unmanned aerial, aerial vehicle-assisted disaster, vehicle-assisted disaster recovery
+ 备注: 11 pages, 8 figures
+
+ 点击查看摘要
+ Abstract:Unmanned aerial vehicle-assisted disaster recovery missions have been promoted recently due to their reliability and flexibility. Machine learning algorithms running onboard significantly enhance the utility of UAVs by enabling real-time data processing and efficient decision-making, despite being in a resource-constrained environment. However, the limited bandwidth and intermittent connectivity make transmitting the outputs to ground stations challenging. This paper proposes a novel semantic extractor that can be adopted into any machine learning downstream task for identifying the critical data required for decision-making. The semantic extractor can be executed onboard which results in a reduction of data that needs to be transmitted to ground stations. We test the proposed architecture together with the semantic extractor on two publicly available datasets, FloodNet and RescueNet, for two downstream tasks: visual question answering and disaster damage level classification. Our experimental results demonstrate the proposed method maintains high accuracy across different downstream tasks while significantly reducing the volume of transmitted data, highlighting the effectiveness of our semantic extractor in capturing task-specific salient information.
+
+
+
+ 208. 【2412.10749】Patch-level Sounding Object Tracking for Audio-Visual Question Answering
+ 链接:https://arxiv.org/abs/2412.10749
+ 作者:Zhangbin Li,Jinxing Zhou,Jing Zhang,Shengeng Tang,Kun Li,Dan Guo
+ 类目:Multimedia (cs.MM); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Answering questions related, AVQA task, sounding objects related, Answering questions, Patch-level Sounding Object
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Answering questions related to audio-visual scenes, i.e., the AVQA task, is becoming increasingly popular. A critical challenge is accurately identifying and tracking sounding objects related to the question along the timeline. In this paper, we present a new Patch-level Sounding Object Tracking (PSOT) method. It begins with a Motion-driven Key Patch Tracking (M-KPT) module, which relies on visual motion information to identify salient visual patches with significant movements that are more likely to relate to sounding objects and questions. We measure the patch-wise motion intensity map between neighboring video frames and utilize it to construct and guide a motion-driven graph network. Meanwhile, we design a Sound-driven KPT (S-KPT) module to explicitly track sounding patches. This module also involves a graph network, with the adjacency matrix regularized by the audio-visual correspondence map. The M-KPT and S-KPT modules are performed in parallel for each temporal segment, allowing balanced tracking of salient and sounding objects. Based on the tracked patches, we further propose a Question-driven KPT (Q-KPT) module to retain patches highly relevant to the question, ensuring the model focuses on the most informative clues. The audio-visual-question features are updated during the processing of these modules, which are then aggregated for final answer prediction. Extensive experiments on standard datasets demonstrate the effectiveness of our method, achieving competitive performance even compared to recent large-scale pretraining-based approaches.
+
+
+
+ 209. 【2412.10748】A Pioneering Neural Network Method for Efficient and Robust Fuel Sloshing Simulation in Aircraft
+ 链接:https://arxiv.org/abs/2412.10748
+ 作者:Yu Chen,Shuai Zheng,Nianyi Wang,Menglong Jin,Yan Chang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR); Machine Learning (cs.LG); Fluid Dynamics (physics.flu-dyn)
+ 关键词:aircraft safety research, Simulating fuel sloshing, safety research, Simulating fuel, aircraft
+ 备注: This paper has been accepted by AAAI Conference on Artificial Intelligence (AAAI-25)
+
+ 点击查看摘要
+ Abstract:Simulating fuel sloshing within aircraft tanks during flight is crucial for aircraft safety research. Traditional methods based on Navier-Stokes equations are computationally expensive. In this paper, we treat fluid motion as point cloud transformation and propose the first neural network method specifically designed for simulating fuel sloshing in aircraft. This model is also the deep learning model that is the first to be capable of stably modeling fluid particle dynamics in such complex scenarios. Our triangle feature fusion design achieves an optimal balance among fluid dynamics modeling, momentum conservation constraints, and global stability control. Additionally, we constructed the Fueltank dataset, the first dataset for aircraft fuel surface sloshing. It comprises 320,000 frames across four typical tank types and covers a wide range of flight maneuvers, including multi-directional rotations. We conducted comprehensive experiments on both our dataset and the take-off scenario of the aircraft. Compared to existing neural network-based fluid simulation algorithms, we significantly enhanced accuracy while maintaining high computational speed. Compared to traditional SPH methods, our speed improved approximately 10 times. Furthermore, compared to traditional fluid simulation software such as Flow3D, our computation speed increased by more than 300 times.
+
+
+
+ 210. 【2412.10741】RegMixMatch: Optimizing Mixup Utilization in Semi-Supervised Learning
+ 链接:https://arxiv.org/abs/2412.10741
+ 作者:Haorong Han,Jidong Yuan,Chixuan Wei,Zhongyang Yu
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)
+ 关键词:Consistency regularization, advanced semi-supervised learning, significantly advanced semi-supervised, SSL, significantly advanced
+ 备注:
+
+ 点击查看摘要
+ Abstract:Consistency regularization and pseudo-labeling have significantly advanced semi-supervised learning (SSL). Prior works have effectively employed Mixup for consistency regularization in SSL. However, our findings indicate that applying Mixup for consistency regularization may degrade SSL performance by compromising the purity of artificial labels. Moreover, most pseudo-labeling based methods utilize thresholding strategy to exclude low-confidence data, aiming to mitigate confirmation bias; however, this approach limits the utility of unlabeled samples. To address these challenges, we propose RegMixMatch, a novel framework that optimizes the use of Mixup with both high- and low-confidence samples in SSL. First, we introduce semi-supervised RegMixup, which effectively addresses reduced artificial labels purity by using both mixed samples and clean samples for training. Second, we develop a class-aware Mixup technique that integrates information from the top-2 predicted classes into low-confidence samples and their artificial labels, reducing the confirmation bias associated with these samples and enhancing their effective utilization. Experimental results demonstrate that RegMixMatch achieves state-of-the-art performance across various SSL benchmarks.
+
+
+
+ 211. 【2412.10739】DSRC: Learning Density-insensitive and Semantic-aware Collaborative Representation against Corruptions
+ 链接:https://arxiv.org/abs/2412.10739
+ 作者:Jingyu Zhang,Yilei Wang,Lang Qian,Peng Sun,Zengwen Li,Sudong Jiang,Maolin Liu,Liang Song
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:achieved significant success, multi-agent collaborative perception, collaborative perception, Semantic-aware collaborative Representation, collaborative perception methods
+ 备注: Accepted by AAAI2025
+
+ 点击查看摘要
+ Abstract:As a potential application of Vehicle-to-Everything (V2X) communication, multi-agent collaborative perception has achieved significant success in 3D object detection. While these methods have demonstrated impressive results on standard benchmarks, the robustness of such approaches in the face of complex real-world environments requires additional verification. To bridge this gap, we introduce the first comprehensive benchmark designed to evaluate the robustness of collaborative perception methods in the presence of natural corruptions typical of real-world environments. Furthermore, we propose DSRC, a robustness-enhanced collaborative perception method aiming to learn Density-insensitive and Semantic-aware collaborative Representation against Corruptions. DSRC consists of two key designs: i) a semantic-guided sparse-to-dense distillation framework, which constructs multi-view dense objects painted by ground truth bounding boxes to effectively learn density-insensitive and semantic-aware collaborative representation; ii) a feature-to-point cloud reconstruction approach to better fuse critical collaborative representation across agents. To thoroughly evaluate DSRC, we conduct extensive experiments on real-world and simulated datasets. The results demonstrate that our method outperforms SOTA collaborative perception methods in both clean and corrupted conditions. Code is available at this https URL.
+
+
+
+ 212. 【2412.10734】OmniHD-Scenes: A Next-Generation Multimodal Dataset for Autonomous Driving
+ 链接:https://arxiv.org/abs/2412.10734
+ 作者:Lianqing Zheng,Long Yang,Qunshu Lin,Wenjin Ai,Minghao Liu,Shouyi Lu,Jianan Liu,Hongze Ren,Jingyue Mo,Xiaokai Bai,Jie Bai,Zhixiong Ma,Xichan Zhu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:autonomous driving algorithms, autonomous driving, rapid advancement, advancement of deep, deep learning
+ 备注:
+
+ 点击查看摘要
+ Abstract:The rapid advancement of deep learning has intensified the need for comprehensive data for use by autonomous driving algorithms. High-quality datasets are crucial for the development of effective data-driven autonomous driving solutions. Next-generation autonomous driving datasets must be multimodal, incorporating data from advanced sensors that feature extensive data coverage, detailed annotations, and diverse scene representation. To address this need, we present OmniHD-Scenes, a large-scale multimodal dataset that provides comprehensive omnidirectional high-definition data. The OmniHD-Scenes dataset combines data from 128-beam LiDAR, six cameras, and six 4D imaging radar systems to achieve full environmental perception. The dataset comprises 1501 clips, each approximately 30-s long, totaling more than 450K synchronized frames and more than 5.85 million synchronized sensor data points. We also propose a novel 4D annotation pipeline. To date, we have annotated 200 clips with more than 514K precise 3D bounding boxes. These clips also include semantic segmentation annotations for static scene elements. Additionally, we introduce a novel automated pipeline for generation of the dense occupancy ground truth, which effectively leverages information from non-key frames. Alongside the proposed dataset, we establish comprehensive evaluation metrics, baseline models, and benchmarks for 3D detection and semantic occupancy prediction. These benchmarks utilize surround-view cameras and 4D imaging radar to explore cost-effective sensor solutions for autonomous driving applications. Extensive experiments demonstrate the effectiveness of our low-cost sensor configuration and its robustness under adverse conditions. Data will be released at this https URL.
+
+
+
+ 213. 【2412.10730】MAL: Cluster-Masked and Multi-Task Pretraining for Enhanced xLSTM Vision Performance
+ 链接:https://arxiv.org/abs/2412.10730
+ 作者:Wenjun Huang,Jianguo Hu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Long Short-Term Memory, traditionally faced challenges, effectively capturing complex, capturing complex dependencies, Long Short-Term
+ 备注:
+
+ 点击查看摘要
+ Abstract:The Long Short-Term Memory (LSTM) networks have traditionally faced challenges in scaling and effectively capturing complex dependencies in visual tasks. The xLSTM architecture has emerged to address these limitations, incorporating exponential gating and a parallel matrix memory structure to enhance performance and scalability. Despite these advancements, the potential of xLSTM in visual computing has not been fully realized, particularly in leveraging autoregressive techniques for improved feature extraction. In this paper, we introduce MAL (Cluster-Masked and Multi-Task Pretraining for Enhanced xLSTM Vision Performance), a novel framework that enhances xLSTM's capabilities through innovative pretraining strategies. We propose a cluster-masked masking method that significantly improves local feature capture and optimizes image scanning efficiency. Additionally, our universal encoder-decoder pretraining approach integrates multiple tasks, including image autoregression, depth estimation, and image segmentation, thereby enhancing the model's adaptability and robustness across diverse visual tasks. Our experimental results demonstrate that MAL surpasses traditional supervised models and fully leverages the scaling potential of xLSTM, setting a new benchmark in visual task performance.
+
+
+
+ 214. 【2412.10726】NoisyEQA: Benchmarking Embodied Question Answering Against Noisy Queries
+ 链接:https://arxiv.org/abs/2412.10726
+ 作者:Tao Wu,Chuhao Zhou,Yen Heng Wong,Lin Gu,Jianfei Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Robotics (cs.RO)
+ 关键词:Embodied Question Answering, enhancing agents' abilities, Vision-Language Models, development of Embodied, Question Answering
+ 备注:
+
+ 点击查看摘要
+ Abstract:The rapid advancement of Vision-Language Models (VLMs) has significantly advanced the development of Embodied Question Answering (EQA), enhancing agents' abilities in language understanding and reasoning within complex and realistic scenarios. However, EQA in real-world scenarios remains challenging, as human-posed questions often contain noise that can interfere with an agent's exploration and response, bringing challenges especially for language beginners and non-expert users. To address this, we introduce a NoisyEQA benchmark designed to evaluate an agent's ability to recognize and correct noisy questions. This benchmark introduces four common types of noise found in real-world applications: Latent Hallucination Noise, Memory Noise, Perception Noise, and Semantic Noise generated through an automated dataset creation framework. Additionally, we also propose a 'Self-Correction' prompting mechanism and a new evaluation metric to enhance and measure both noise detection capability and answer quality. Our comprehensive evaluation reveals that current EQA agents often struggle to detect noise in questions, leading to responses that frequently contain erroneous information. Through our Self-Correct Prompting mechanism, we can effectively improve the accuracy of agent answers.
+
+
+
+ 215. 【2412.10723】HEP-NAS: Towards Efficient Few-shot Neural Architecture Search via Hierarchical Edge Partitioning
+ 链接:https://arxiv.org/abs/2412.10723
+ 作者:Jianfeng Li,Jiawen Zhang,Feng Wang,Lianbo Ma
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:adopting weight-sharing strategy, reduce search costs, One-shot methods, significantly advanced, advanced the field
+ 备注:
+
+ 点击查看摘要
+ Abstract:One-shot methods have significantly advanced the field of neural architecture search (NAS) by adopting weight-sharing strategy to reduce search costs. However, the accuracy of performance estimation can be compromised by co-adaptation. Few-shot methods divide the entire supernet into individual sub-supernets by splitting edge by edge to alleviate this issue, yet neglect relationships among edges and result in performance degradation on huge search space. In this paper, we introduce HEP-NAS, a hierarchy-wise partition algorithm designed to further enhance accuracy. To begin with, HEP-NAS treats edges sharing the same end node as a hierarchy, permuting and splitting edges within the same hierarchy to directly search for the optimal operation combination for each intermediate node. This approach aligns more closely with the ultimate goal of NAS. Furthermore, HEP-NAS selects the most promising sub-supernet after each segmentation, progressively narrowing the search space in which the optimal architecture may exist. To improve performance evaluation of sub-supernets, HEP-NAS employs search space mutual distillation, stabilizing the training process and accelerating the convergence of each individual sub-supernet. Within a given budget, HEP-NAS enables the splitting of all edges and gradually searches for architectures with higher accuracy. Experimental results across various datasets and search spaces demonstrate the superiority of HEP-NAS compared to state-of-the-art methods.
+
+
+
+ 216. 【2412.10720】Bridging Vision and Language: Modeling Causality and Temporality in Video Narratives
+ 链接:https://arxiv.org/abs/2412.10720
+ 作者:Ji-jun Park,Soo-joon Choi
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:multimodal machine learning, aiming to generate, critical task, field of multimodal, multimodal machine
+ 备注:
+
+ 点击查看摘要
+ Abstract:Video captioning is a critical task in the field of multimodal machine learning, aiming to generate descriptive and coherent textual narratives for video content. While large vision-language models (LVLMs) have shown significant progress, they often struggle to capture the causal and temporal dynamics inherent in complex video sequences. To address this limitation, we propose an enhanced framework that integrates a Causal-Temporal Reasoning Module (CTRM) into state-of-the-art LVLMs. CTRM comprises two key components: the Causal Dynamics Encoder (CDE) and the Temporal Relational Learner (TRL), which collectively encode causal dependencies and temporal consistency from video frames. We further design a multi-stage learning strategy to optimize the model, combining pre-training on large-scale video-text datasets, fine-tuning on causally annotated data, and contrastive alignment for better embedding coherence. Experimental results on standard benchmarks such as MSVD and MSR-VTT demonstrate that our method outperforms existing approaches in both automatic metrics (CIDEr, BLEU-4, ROUGE-L) and human evaluations, achieving more fluent, coherent, and relevant captions. These results validate the effectiveness of our approach in generating captions with enriched causal-temporal narratives.
+
+
+
+ 217. 【2412.10719】Just a Few Glances: Open-Set Visual Perception with Image Prompt Paradigm
+ 链接:https://arxiv.org/abs/2412.10719
+ 作者:Jinrong Zhang,Penghui Wang,Chunxiao Liu,Wei Liu,Dian Jin,Qiong Zhang,Erli Meng,Zhengnan Hu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Open-Set Object Detection, Open-Set Object, Object Detection, prompt paradigm, prompt
+ 备注: Accepted by AAAI2025
+
+ 点击查看摘要
+ Abstract:To break through the limitations of pre-training models on fixed categories, Open-Set Object Detection (OSOD) and Open-Set Segmentation (OSS) have attracted a surge of interest from researchers. Inspired by large language models, mainstream OSOD and OSS methods generally utilize text as a prompt, achieving remarkable performance. Following SAM paradigm, some researchers use visual prompts, such as points, boxes, and masks that cover detection or segmentation targets. Despite these two prompt paradigms exhibit excellent performance, they also reveal inherent limitations. On the one hand, it is difficult to accurately describe characteristics of specialized category using textual description. On the other hand, existing visual prompt paradigms heavily rely on multi-round human interaction, which hinders them being applied to fully automated pipeline. To address the above issues, we propose a novel prompt paradigm in OSOD and OSS, that is, \textbf{Image Prompt Paradigm}. This brand new prompt paradigm enables to detect or segment specialized categories without multi-round human intervention. To achieve this goal, the proposed image prompt paradigm uses just a few image instances as prompts, and we propose a novel framework named \textbf{MI Grounding} for this new paradigm. In this framework, high-quality image prompts are automatically encoded, selected and fused, achieving the single-stage and non-interactive inference. We conduct extensive experiments on public datasets, showing that MI Grounding achieves competitive performance on OSOD and OSS benchmarks compared to text prompt paradigm methods and visual prompt paradigm methods. Moreover, MI Grounding can greatly outperform existing method on our constructed specialized ADR50K dataset.
+
+
+
+ 218. 【2412.10718】GRID: Visual Layout Generation
+ 链接:https://arxiv.org/abs/2412.10718
+ 作者:Cong Wan,Xiangyang Luo,Zijian Cai,Yiren Song,Yunlong Zhao,Yifan Bai,Yuhang He,Yihong Gong
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:akin to film, film strips, paradigm that reframes, reframes a broad, broad range
+ 备注: preprint, codes: [this https URL](https://github.com/Should-AI-Lab/GRID)
+
+ 点击查看摘要
+ Abstract:In this paper, we introduce GRID, a novel paradigm that reframes a broad range of visual generation tasks as the problem of arranging grids, akin to film strips. At its core, GRID transforms temporal sequences into grid layouts, enabling image generation models to process visual sequences holistically. To achieve both layout consistency and motion coherence, we develop a parallel flow-matching training strategy that combines layout matching and temporal losses, guided by a coarse-to-fine schedule that evolves from basic layouts to precise motion control. Our approach demonstrates remarkable efficiency, achieving up to 35 faster inference speeds while using 1/1000 of the computational resources compared to specialized models. Extensive experiments show that GRID exhibits exceptional versatility across diverse visual generation tasks, from Text-to-Video to 3D Editing, while maintaining its foundational image generation capabilities. This dual strength in both expanded applications and preserved core competencies establishes GRID as an efficient and versatile omni-solution for visual generation.
+
+
+
+ 219. 【2412.10710】Virtual Trial Room with Computer Vision and Machine Learning
+ 链接:https://arxiv.org/abs/2412.10710
+ 作者:Tulashi Prasasd Joshi,Amrendra Kumar Yadav,Arjun Chhetri,Suraj Agrahari,Umesh Kanta Ghimire
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Online shopping, retail industry, convenience and accessibility, shopping has revolutionized, revolutionized the retail
+ 备注:
+
+ 点击查看摘要
+ Abstract:Online shopping has revolutionized the retail industry, providing customers with convenience and accessibility. However, customers often hesitate to purchase wearable products such as watches, jewelry, glasses, shoes, and clothes due to the lack of certainty regarding fit and suitability. This leads to significant return rates, causing problems for both customers and vendors. To address this issue, a platform called the Virtual Trial Room with Computer Vision and Machine Learning is designed which enables customers to easily check whether a product will fit and suit them or not. To achieve this, an AI-generated 3D model of the human head was created from a single 2D image using the DECA model. This 3D model was then superimposed with a custom-made 3D model of glass which is based on real-world measurements and fitted over the human head. To replicate the real-world look and feel, the model was retouched with textures, lightness, and smoothness. Furthermore, a full-stack application was developed utilizing various fornt-end and back-end technologies. This application enables users to view 3D-generated results on the website, providing an immersive and interactive experience.
+
+
+
+ 220. 【2412.10707】MambaPro: Multi-Modal Object Re-Identification with Mamba Aggregation and Synergistic Prompt
+ 链接:https://arxiv.org/abs/2412.10707
+ 作者:Yuhao Wang,Xuehu Liu,Tianyu Yan,Yang Liu,Aihua Zheng,Pingping Zhang,Huchuan Lu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:utilizing complementary image, complementary image information, multi-modal object ReID, Multi-modal object, object ReID
+ 备注: This work is accepted by AAAI2025. More modifications may be performed
+
+ 点击查看摘要
+ Abstract:Multi-modal object Re-IDentification (ReID) aims to retrieve specific objects by utilizing complementary image information from different modalities. Recently, large-scale pre-trained models like CLIP have demonstrated impressive performance in traditional single-modal object ReID tasks. However, they remain unexplored for multi-modal object ReID. Furthermore, current multi-modal aggregation methods have obvious limitations in dealing with long sequences from different modalities. To address above issues, we introduce a novel framework called MambaPro for multi-modal object ReID. To be specific, we first employ a Parallel Feed-Forward Adapter (PFA) for adapting CLIP to multi-modal object ReID. Then, we propose the Synergistic Residual Prompt (SRP) to guide the joint learning of multi-modal features. Finally, leveraging Mamba's superior scalability for long sequences, we introduce Mamba Aggregation (MA) to efficiently model interactions between different modalities. As a result, MambaPro could extract more robust features with lower complexity. Extensive experiments on three multi-modal object ReID benchmarks (i.e., RGBNT201, RGBNT100 and MSVR310) validate the effectiveness of our proposed methods. The source code is available at this https URL.
+
+
+
+ 221. 【2412.10702】Memory Efficient Matting with Adaptive Token Routing
+ 链接:https://arxiv.org/abs/2412.10702
+ 作者:Yiheng Lin,Yihan Hu,Chenyi Zhang,Ting Liu,Xiaochao Qu,Luoqi Liu,Yao Zhao,Yunchao Wei
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:recently achieved outstanding, achieved outstanding performance, Transformer-based models, models have recently, recently achieved
+ 备注:
+
+ 点击查看摘要
+ Abstract:Transformer-based models have recently achieved outstanding performance in image matting. However, their application to high-resolution images remains challenging due to the quadratic complexity of global self-attention. To address this issue, we propose MEMatte, a memory-efficient matting framework for processing high-resolution images. MEMatte incorporates a router before each global attention block, directing informative tokens to the global attention while routing other tokens to a Lightweight Token Refinement Module (LTRM). Specifically, the router employs a local-global strategy to predict the routing probability of each token, and the LTRM utilizes efficient modules to simulate global attention. Additionally, we introduce a Batch-constrained Adaptive Token Routing (BATR) mechanism, which allows each router to dynamically route tokens based on image content and the stages of attention block in the network. Furthermore, we construct an ultra high-resolution image matting dataset, UHR-395, comprising 35,500 training images and 1,000 test images, with an average resolution of $4872\times6017$. This dataset is created by compositing 395 different alpha mattes across 11 categories onto various backgrounds, all with high-quality manual annotation. Extensive experiments demonstrate that MEMatte outperforms existing methods on both high-resolution and real-world datasets, significantly reducing memory usage by approximately 88% and latency by 50% on the Composition-1K benchmark.
+
+
+
+ 222. 【2412.10687】Linked Adapters: Linking Past and Future to Present for Effective Continual Learning
+ 链接:https://arxiv.org/abs/2412.10687
+ 作者:Dupati Srikar Chandra,P. K. Srijith,Dana Rezazadegan,Chris McCarthy
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:adapters, Continual learning, Linked Adapters, system to learn, acquired from previous
+ 备注: 13 Pages, 5 Figures
+
+ 点击查看摘要
+ Abstract:Continual learning allows the system to learn and adapt to new tasks while retaining the knowledge acquired from previous tasks. However, deep learning models suffer from catastrophic forgetting of knowledge learned from earlier tasks while learning a new task. Moreover, retraining large models like transformers from scratch for every new task is costly. An effective approach to address continual learning is to use a large pre-trained model with task-specific adapters to adapt to the new tasks. Though this approach can mitigate catastrophic forgetting, they fail to transfer knowledge across tasks as each task is learning adapters separately. To address this, we propose a novel approach Linked Adapters that allows knowledge transfer through a weighted attention mechanism to other task-specific adapters. Linked adapters use a multi-layer perceptron (MLP) to model the attention weights, which overcomes the challenge of backward knowledge transfer in continual learning in addition to modeling the forward knowledge transfer. During inference, our proposed approach effectively leverages knowledge transfer through MLP-based attention weights across all the lateral task adapters. Through numerous experiments conducted on diverse image classification datasets, we effectively demonstrated the improvement in performance on the continual learning tasks using Linked Adapters.
+
+
+
+ 223. 【2412.10681】One Pixel is All I Need
+ 链接:https://arxiv.org/abs/2412.10681
+ 作者:Deng Siqin,Zhou Xiaoyi
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Vision Transformers, achieved record-breaking performance, http URL, visual tasks, achieved record-breaking
+ 备注:
+
+ 点击查看摘要
+ Abstract:Vision Transformers (ViTs) have achieved record-breaking performance in various visual tasks. However, concerns about their robustness against backdoor attacks have grown. Backdoor attacks involve associating a specific trigger with a target label, causing the model to predict the attacker-specified label when the trigger is present, while correctly identifying clean this http URL found that ViTs exhibit higher attack success rates for quasi-triggers(patterns different from but similar to the original training triggers)compared to CNNs. Moreover, some backdoor features in clean samples can suppress the original trigger, making quasi-triggers more this http URL better understand and exploit these vulnerabilities, we developed a tool called the Perturbation Sensitivity Distribution Map (PSDM). PSDM computes and sums gradients over many inputs to show how sensitive the model is to small changes in the input. In ViTs, PSDM reveals a patch-like pattern where central pixels are more sensitive than edges. We use PSDM to guide the creation of this http URL on these findings, we designed "WorstVIT," a simple yet effective data poisoning backdoor for ViT models. This attack requires an extremely low poisoning rate, trains for just one epoch, and modifies a single pixel to successfully attack all validation images.
+
+
+
+ 224. 【2412.10680】UCDR-Adapter: Exploring Adaptation of Pre-Trained Vision-Language Models for Universal Cross-Domain Retrieval
+ 链接:https://arxiv.org/abs/2412.10680
+ 作者:Haoyu Jiang,Zhi-Qi Cheng,Gabriel Moreira,Jiawen Zhu,Jingdong Sun,Bukun Ren,Jun-Yan He,Qi Dai,Xian-Sheng Hua
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Information Retrieval (cs.IR); Multimedia (cs.MM)
+ 关键词:Universal Cross-Domain Retrieval, Universal Cross-Domain, retrieves relevant images, retrieves relevant, ensuring robust generalization
+ 备注: Accepted to WACV 2025. Project link: [this https URL](https://github.com/fine68/UCDR2024)
+
+ 点击查看摘要
+ Abstract:Universal Cross-Domain Retrieval (UCDR) retrieves relevant images from unseen domains and classes without semantic labels, ensuring robust generalization. Existing methods commonly employ prompt tuning with pre-trained vision-language models but are inherently limited by static prompts, reducing adaptability. We propose UCDR-Adapter, which enhances pre-trained models with adapters and dynamic prompt generation through a two-phase training strategy. First, Source Adapter Learning integrates class semantics with domain-specific visual knowledge using a Learnable Textual Semantic Template and optimizes Class and Domain Prompts via momentum updates and dual loss functions for robust alignment. Second, Target Prompt Generation creates dynamic prompts by attending to masked source prompts, enabling seamless adaptation to unseen domains and classes. Unlike prior approaches, UCDR-Adapter dynamically adapts to evolving data distributions, enhancing both flexibility and generalization. During inference, only the image branch and generated prompts are used, eliminating reliance on textual inputs for highly efficient retrieval. Extensive benchmark experiments show that UCDR-Adapter consistently outperforms ProS in most cases and other state-of-the-art methods on UCDR, U(c)CDR, and U(d)CDR settings.
+
+
+
+ 225. 【2412.10679】U-FaceBP: Uncertainty-aware Bayesian Ensemble Deep Learning for Face Video-based Blood Pressure Measurement
+ 链接:https://arxiv.org/abs/2412.10679
+ 作者:Yusuke Akamatsu,Terumi Umematsu,Hitoshi Imaoka
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:Blood pressure, plays an essential, essential role, role in assessing, daily basis
+ 备注:
+
+ 点击查看摘要
+ Abstract:Blood pressure (BP) measurement plays an essential role in assessing health on a daily basis. Remote photoplethysmography (rPPG), which extracts pulse waves from camera-captured face videos, has the potential to easily measure BP for daily health monitoring. However, there are many uncertainties in BP estimation using rPPG, resulting in limited estimation performance. In this paper, we propose U-FaceBP, an uncertainty-aware Bayesian ensemble deep learning method for face video-based BP measurement. U-FaceBP models three types of uncertainty, i.e., data, model, and ensemble uncertainties, in face video-based BP estimation with a Bayesian neural network (BNN). We also design U-FaceBP as an ensemble method, with which BP is estimated from rPPG signals, PPG signals estimated from face videos, and face images using multiple BNNs. A large-scale experiment with 786 subjects demonstrates that U-FaceBP outperforms state-of-the-art BP estimation methods. We also show that the uncertainties estimated from U-FaceBP are reasonable and useful for prediction confidence.
+
+
+
+ 226. 【2412.10663】Memory-Efficient 4-bit Preconditioned Stochastic Optimization
+ 链接:https://arxiv.org/abs/2412.10663
+ 作者:Jingyang Li,Kuangyu Ding,Kim-Chuan Toh,Pan Zhou
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Optimization and Control (math.OC)
+ 关键词:neural network training, Preconditioned stochastic optimization, large-scale neural network, demonstrated superior performance, Preconditioned stochastic
+ 备注:
+
+ 点击查看摘要
+ Abstract:Preconditioned stochastic optimization algorithms, exemplified by Shampoo, have demonstrated superior performance over first-order optimizers, providing both theoretical advantages in convergence rates and practical improvements in large-scale neural network training. However, they incur substantial memory overhead due to the storage demands of non-diagonal preconditioning matrices. To address this, we introduce 4-bit quantization for Shampoo's preconditioners. We introduced two key methods: First, we apply Cholesky decomposition followed by quantization of the Cholesky factors, reducing memory usage by leveraging their lower triangular structure while preserving symmetry and positive definiteness to minimize information loss. To our knowledge, this is the first quantization approach applied to Cholesky factors of preconditioners. Second, we incorporate error feedback in the quantization process, efficiently storing Cholesky factors and error states in the lower and upper triangular parts of the same matrix. Through extensive experiments, we demonstrate that combining Cholesky quantization with error feedback enhances memory efficiency and algorithm performance in large-scale deep-learning tasks. Theoretically, we also provide convergence proofs for quantized Shampoo under both smooth and non-smooth stochastic optimization settings.
+
+
+
+ 227. 【2412.10659】MEATRD: Multimodal Anomalous Tissue Region Detection Enhanced with Spatial Transcriptomics
+ 链接:https://arxiv.org/abs/2412.10659
+ 作者:Kaichen Xu,Qilong Wu,Yan Lu,Yinan Zheng,Wenlin Li,Xingjie Tang,Jun Wang,Xiaobo Sun
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Quantitative Methods (q-bio.QM)
+ 关键词:ATR detection, ATR detection methods, anomalous tissue regions, pathological studies, crucial in clinical
+ 备注: AAAI 2025. Code: [this https URL](https://github.com/wqlzuel/MEATRD)
+
+ 点击查看摘要
+ Abstract:The detection of anomalous tissue regions (ATRs) within affected tissues is crucial in clinical diagnosis and pathological studies. Conventional automated ATR detection methods, primarily based on histology images alone, falter in cases where ATRs and normal tissues have subtle visual differences. The recent spatial transcriptomics (ST) technology profiles gene expressions across tissue regions, offering a molecular perspective for detecting ATRs. However, there is a dearth of ATR detection methods that effectively harness complementary information from both histology images and ST. To address this gap, we propose MEATRD, a novel ATR detection method that integrates histology image and ST data. MEATRD is trained to reconstruct image patches and gene expression profiles of normal tissue spots (inliers) from their multimodal embeddings, followed by learning a one-class classification AD model based on latent multimodal reconstruction errors. This strategy harmonizes the strengths of reconstruction-based and one-class classification approaches. At the heart of MEATRD is an innovative masked graph dual-attention transformer (MGDAT) network, which not only facilitates cross-modality and cross-node information sharing but also addresses the model over-generalization issue commonly seen in reconstruction-based AD methods. Additionally, we demonstrate that modality-specific, task-relevant information is collated and condensed in multimodal bottleneck encoding generated in MGDAT, marking the first theoretical analysis of the informational properties of multimodal bottleneck encoding. Extensive evaluations across eight real ST datasets reveal MEATRD's superior performance in ATR detection, surpassing various state-of-the-art AD methods. Remarkably, MEATRD also proves adept at discerning ATRs that only show slight visual deviations from normal tissues.
+
+
+
+ 228. 【2412.10651】LAN: Learning to Adapt Noise for Image Denoising
+ 链接:https://arxiv.org/abs/2412.10651
+ 作者:Changjin Kim,Tae Hyun Kim,Sungyong Baik
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Removing noise, capturing environments, noise, challenging task, type and amount
+ 备注: CVPR2024
+
+ 点击查看摘要
+ Abstract:Removing noise from images, a.k.a image denoising, can be a very challenging task since the type and amount of noise can greatly vary for each image due to many factors including a camera model and capturing environments. While there have been striking improvements in image denoising with the emergence of advanced deep learning architectures and real-world datasets, recent denoising networks struggle to maintain performance on images with noise that has not been seen during training. One typical approach to address the challenge would be to adapt a denoising network to new noise distribution. Instead, in this work, we shift our focus to adapting the input noise itself, rather than adapting a network. Thus, we keep a pretrained network frozen, and adapt an input noise to capture the fine-grained deviations. As such, we propose a new denoising algorithm, dubbed Learning-to-Adapt-Noise (LAN), where a learnable noise offset is directly added to a given noisy image to bring a given input noise closer towards the noise distribution a denoising network is trained to handle. Consequently, the proposed framework exhibits performance improvement on images with unseen noise, displaying the potential of the proposed research direction. The code is available at this https URL
+
+
+
+ 229. 【2412.10650】DeMo: Decoupled Feature-Based Mixture of Experts for Multi-Modal Object Re-Identification
+ 链接:https://arxiv.org/abs/2412.10650
+ 作者:Yuhao Wang,Yang Liu,Aihua Zheng,Pingping Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:combining complementary information, multi-modal object ReID, Multi-modal object Re-IDentification, Multi-modal object, aims to retrieve
+ 备注: This work is accepted by AAAI2025. More motifications may be performed
+
+ 点击查看摘要
+ Abstract:Multi-modal object Re-IDentification (ReID) aims to retrieve specific objects by combining complementary information from multiple modalities. Existing multi-modal object ReID methods primarily focus on the fusion of heterogeneous features. However, they often overlook the dynamic quality changes in multi-modal imaging. In addition, the shared information between different modalities can weaken modality-specific information. To address these issues, we propose a novel feature learning framework called DeMo for multi-modal object ReID, which adaptively balances decoupled features using a mixture of experts. To be specific, we first deploy a Patch-Integrated Feature Extractor (PIFE) to extract multi-granularity and multi-modal features. Then, we introduce a Hierarchical Decoupling Module (HDM) to decouple multi-modal features into non-overlapping forms, preserving the modality uniqueness and increasing the feature diversity. Finally, we propose an Attention-Triggered Mixture of Experts (ATMoE), which replaces traditional gating with dynamic attention weights derived from decoupled features. With these modules, our DeMo can generate more robust multi-modal features. Extensive experiments on three multi-modal object ReID benchmarks fully verify the effectiveness of our methods. The source code is available at this https URL.
+
+
+
+ 230. 【2412.10647】Enhancement of text recognition for hanja handwritten documents of Ancient Korea
+ 链接:https://arxiv.org/abs/2412.10647
+ 作者:Joonmo Ahna,Taehong Jang,Quan Fengnyu,Hyungil Lee,Jaehyuk Lee,Sojung Lucia Kim
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:optical character recognition, high-performance optical character, highly variable cropping, optical character, classical Chinese characters
+ 备注:
+
+ 点击查看摘要
+ Abstract:We implemented a high-performance optical character recognition model for classical handwritten documents using data augmentation with highly variable cropping within the document region. Optical character recognition in handwritten documents, especially classical documents, has been a challenging topic in many countries and research organizations due to its difficulty. Although many researchers have conducted research on this topic, the quality of classical texts over time and the unique stylistic characteristics of various authors have made it difficult, and it is clear that the recognition of hanja handwritten documents is a meaningful and special challenge, especially since hanja, which has been developed by reflecting the vocabulary, semantic, and syntactic features of the Joseon Dynasty, is different from classical Chinese characters. To study this challenge, we used 1100 cursive documents, which are small in size, and augmented 100 documents per document by cropping a randomly sized region within each document for training, and trained them using a two-stage object detection model, High resolution neural network (HRNet), and applied the resulting model to achieve a high inference recognition rate of 90% for cursive documents. Through this study, we also confirmed that the performance of OCR is affected by the simplified characters, variants, variant characters, common characters, and alternators of Chinese characters that are difficult to see in other studies, and we propose that the results of this study can be applied to optical character recognition of modern documents in multiple languages as well as other typefaces in classical documents.
+
+
+
+ 231. 【2412.10624】CATALOG: A Camera Trap Language-guided Contrastive Learning Model
+ 链接:https://arxiv.org/abs/2412.10624
+ 作者:Julian D. Santamaria,Claudia Isaza,Jhony H. Giraldo
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:computer vision tasks, Foundation Models, object detection, computer vision, Camera Trap Language-guided
+ 备注:
+
+ 点击查看摘要
+ Abstract:Foundation Models (FMs) have been successful in various computer vision tasks like image classification, object detection and image segmentation. However, these tasks remain challenging when these models are tested on datasets with different distributions from the training dataset, a problem known as domain shift. This is especially problematic for recognizing animal species in camera-trap images where we have variability in factors like lighting, camouflage and occlusions. In this paper, we propose the Camera Trap Language-guided Contrastive Learning (CATALOG) model to address these issues. Our approach combines multiple FMs to extract visual and textual features from camera-trap data and uses a contrastive loss function to train the model. We evaluate CATALOG on two benchmark datasets and show that it outperforms previous state-of-the-art methods in camera-trap image recognition, especially when the training and testing data have different animal species or come from different geographical areas. Our approach demonstrates the potential of using FMs in combination with multi-modal fusion and contrastive learning for addressing domain shifts in camera-trap image recognition. The code of CATALOG is publicly available at this https URL.
+
+
+
+ 232. 【2412.10604】EvalGIM: A Library for Evaluating Generative Image Models
+ 链接:https://arxiv.org/abs/2412.10604
+ 作者:Melissa Hall,Oscar Mañas,Reyhane Askari,Mark Ibrahim,Candace Ross,Pietro Astolfi,Tariq Berrada Ifriqi,Marton Havasi,Yohann Benchetrit,Karen Ullrich,Carolina Braga,Abhishek Charnalia,Maeve Ryan,Mike Rabbat,Michal Drozdzal,Jakob Verbeek,Adriana Romero Soriano
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Evaluation Exercises, evaluation, adoption of automatic, automatic benchmarking methods, generative models
+ 备注: For code, see [this https URL](https://github.com/facebookresearch/EvalGIM/tree/main)
+
+ 点击查看摘要
+ Abstract:As the use of text-to-image generative models increases, so does the adoption of automatic benchmarking methods used in their evaluation. However, while metrics and datasets abound, there are few unified benchmarking libraries that provide a framework for performing evaluations across many datasets and metrics. Furthermore, the rapid introduction of increasingly robust benchmarking methods requires that evaluation libraries remain flexible to new datasets and metrics. Finally, there remains a gap in synthesizing evaluations in order to deliver actionable takeaways about model performance. To enable unified, flexible, and actionable evaluations, we introduce EvalGIM (pronounced ''EvalGym''), a library for evaluating generative image models. EvalGIM contains broad support for datasets and metrics used to measure quality, diversity, and consistency of text-to-image generative models. In addition, EvalGIM is designed with flexibility for user customization as a top priority and contains a structure that allows plug-and-play additions of new datasets and metrics. To enable actionable evaluation insights, we introduce ''Evaluation Exercises'' that highlight takeaways for specific evaluation questions. The Evaluation Exercises contain easy-to-use and reproducible implementations of two state-of-the-art evaluation methods of text-to-image generative models: consistency-diversity-realism Pareto Fronts and disaggregated measurements of performance disparities across groups. EvalGIM also contains Evaluation Exercises that introduce two new analysis methods for text-to-image generative models: robustness analyses of model rankings and balanced evaluations across different prompt styles. We encourage text-to-image model exploration with EvalGIM and invite contributions at this https URL.
+
+
+
+ 233. 【2412.10597】Err on the Side of Texture: Texture Bias on Real Data
+ 链接:https://arxiv.org/abs/2412.10597
+ 作者:Blaine Hoak,Ryan Sheatsley,Patrick McDaniel
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Cryptography and Security (cs.CR)
+ 关键词:Bias significantly undermines, machine learning models, significantly undermines, trustworthiness of machine, machine learning
+ 备注: Accepted to IEEE Secure and Trustworthy Machine Learning (SaTML)
+
+ 点击查看摘要
+ Abstract:Bias significantly undermines both the accuracy and trustworthiness of machine learning models. To date, one of the strongest biases observed in image classification models is texture bias-where models overly rely on texture information rather than shape information. Yet, existing approaches for measuring and mitigating texture bias have not been able to capture how textures impact model robustness in real-world settings. In this work, we introduce the Texture Association Value (TAV), a novel metric that quantifies how strongly models rely on the presence of specific textures when classifying objects. Leveraging TAV, we demonstrate that model accuracy and robustness are heavily influenced by texture. Our results show that texture bias explains the existence of natural adversarial examples, where over 90% of these samples contain textures that are misaligned with the learned texture of their true label, resulting in confident mispredictions.
+
+
+
+ 234. 【2412.10594】owards Unified Benchmark and Models for Multi-Modal Perceptual Metrics
+ 链接:https://arxiv.org/abs/2412.10594
+ 作者:Sara Ghazanfari,Siddharth Garg,Nicolas Flammarion,Prashanth Krishnamurthy,Farshad Khorrami,Francesco Croce
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:develop automated metrics, highly complex, making it challenging, multimodal inputs, inputs is highly
+ 备注:
+
+ 点击查看摘要
+ Abstract:Human perception of similarity across uni- and multimodal inputs is highly complex, making it challenging to develop automated metrics that accurately mimic it. General purpose vision-language models, such as CLIP and large multi-modal models (LMMs), can be applied as zero-shot perceptual metrics, and several recent works have developed models specialized in narrow perceptual tasks. However, the extent to which existing perceptual metrics align with human perception remains unclear. To investigate this question, we introduce UniSim-Bench, a benchmark encompassing 7 multi-modal perceptual similarity tasks, with a total of 25 datasets. Our evaluation reveals that while general-purpose models perform reasonably well on average, they often lag behind specialized models on individual tasks. Conversely, metrics fine-tuned for specific tasks fail to generalize well to unseen, though related, tasks. As a first step towards a unified multi-task perceptual similarity metric, we fine-tune both encoder-based and generative vision-language models on a subset of the UniSim-Bench tasks. This approach yields the highest average performance, and in some cases, even surpasses taskspecific models. Nevertheless, these models still struggle with generalization to unseen tasks, highlighting the ongoing challenge of learning a robust, unified perceptual similarity metric capable of capturing the human notion of similarity. The code and models are available at this https URL.
+
+
+
+ 235. 【2412.10589】PanSR: An Object-Centric Mask Transformer for Panoptic Segmentation
+ 链接:https://arxiv.org/abs/2412.10589
+ 作者:Lojze Žust,Matej Kristan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:autonomous vehicles, task in computer, computer vision, perception in autonomous, Panoptic segmentation
+ 备注: 8 pages, 9 figures
+
+ 点击查看摘要
+ Abstract:Panoptic segmentation is a fundamental task in computer vision and a crucial component for perception in autonomous vehicles. Recent mask-transformer-based methods achieve impressive performance on standard benchmarks but face significant challenges with small objects, crowded scenes and scenes exhibiting a wide range of object scales. We identify several fundamental shortcomings of the current approaches: (i) the query proposal generation process is biased towards larger objects, resulting in missed smaller objects, (ii) initially well-localized queries may drift to other objects, resulting in missed detections, (iii) spatially well-separated instances may be merged into a single mask causing inconsistent and false scene interpretations. To address these issues, we rethink the individual components of the network and its supervision, and propose a novel method for panoptic segmentation PanSR. PanSR effectively mitigates instance merging, enhances small-object detection and increases performance in crowded scenes, delivering a notable +3.4 PQ improvement over state-of-the-art on the challenging LaRS benchmark, while reaching state-of-the-art performance on Cityscapes. The code and models will be publicly available at this https URL.
+
+
+
+ 236. 【2412.10587】Evaluation of GPT-4o GPT-4o-mini's Vision Capabilities for Salt Evaporite Identification
+ 链接:https://arxiv.org/abs/2412.10587
+ 作者:Deven B. Dangi,Beni B. Dangi,Oliver Steinbock
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:diverse practical applications, stains' has diverse, practical applications, Identifying salts, diverse practical
+ 备注: 11 pages, 7 figures
+
+ 点击查看摘要
+ Abstract:Identifying salts from images of their 'stains' has diverse practical applications. While specialized AI models are being developed, this paper explores the potential of OpenAI's state-of-the-art vision models (GPT-4o and GPT-4o-mini) as an immediate solution. Testing with 12 different types of salts, the GPT-4o model achieved 57% accuracy and a 0.52 F1 score, significantly outperforming both random chance (8%) and GPT-4o mini (11% accuracy). Results suggest that current vision models could serve as an interim solution for salt identification from stain images.
+
+
+
+ 237. 【2412.10573】ExeChecker: Where Did I Go Wrong?
+ 链接:https://arxiv.org/abs/2412.10573
+ 作者:Yiwen Gu,Mahir Patel,Margrit Betke
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Human-Computer Interaction (cs.HC); Machine Learning (cs.LG)
+ 关键词:learning based framework, based framework, contrastive learning based, exercises, present a contrastive
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this paper, we present a contrastive learning based framework, ExeChecker, for the interpretation of rehabilitation exercises. Our work builds upon state-of-the-art advances in the area of human pose estimation, graph-attention neural networks, and transformer interpretablity. The downstream task is to assist rehabilitation by providing informative feedback to users while they are performing prescribed exercises. We utilize a contrastive learning strategy during training. Given a tuple of correctly and incorrectly executed exercises, our model is able to identify and highlight those joints that are involved in an incorrect movement and thus require the user's attention. We collected an in-house dataset, ExeCheck, with paired recordings of both correct and incorrect execution of exercises. In our experiments, we tested our method on this dataset as well as the UI-PRMD dataset and found ExeCheck outperformed the baseline method using pairwise sequence alignment in identifying joints of physical relevance in rehabilitation exercises.
+
+
+
+ 238. 【2412.10569】Learning to Merge Tokens via Decoupled Embedding for Efficient Vision Transformers
+ 链接:https://arxiv.org/abs/2412.10569
+ 作者:Dong Hoon Lee,Seunghoon Hong
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Vision Transformers, Recent token reduction, token merging, Recent token, token
+ 备注: NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:Recent token reduction methods for Vision Transformers (ViTs) incorporate token merging, which measures the similarities between token embeddings and combines the most similar pairs. However, their merging policies are directly dependent on intermediate features in ViTs, which prevents exploiting features tailored for merging and requires end-to-end training to improve token merging. In this paper, we propose Decoupled Token Embedding for Merging (DTEM) that enhances token merging through a decoupled embedding learned via a continuously relaxed token merging process. Our method introduces a lightweight embedding module decoupled from the ViT forward pass to extract dedicated features for token merging, thereby addressing the restriction from using intermediate features. The continuously relaxed token merging, applied during training, enables us to learn the decoupled embeddings in a differentiable manner. Thanks to the decoupled structure, our method can be seamlessly integrated into existing ViT backbones and trained either modularly by learning only the decoupled embeddings or end-to-end by fine-tuning. We demonstrate the applicability of DTEM on various tasks, including classification, captioning, and segmentation, with consistent improvement in token merging. Especially in the ImageNet-1k classification, DTEM achieves a 37.2% reduction in FLOPs while maintaining a top-1 accuracy of 79.85% with DeiT-small. Code is available at \href{this https URL}{link}.
+
+
+
+ 239. 【2412.10566】EVLM: Self-Reflective Multimodal Reasoning for Cross-Dimensional Visual Editing
+ 链接:https://arxiv.org/abs/2412.10566
+ 作者:Umar Khalid,Hasan Iqbal,Azib Farooq,Nazanin Rahnavard,Jing Hua,Chen Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:ambiguous instructions remains, visual content based, based on ambiguous, remains a challenging, challenging problem
+ 备注: Technical Report
+
+ 点击查看摘要
+ Abstract:Editing complex visual content based on ambiguous instructions remains a challenging problem in vision-language modeling. While existing models can contextualize content, they often struggle to grasp the underlying intent within a reference image or scene, leading to misaligned edits. We introduce the Editing Vision-Language Model (EVLM), a system designed to interpret such instructions in conjunction with reference visuals, producing precise and context-aware editing prompts. Leveraging Chain-of-Thought (CoT) reasoning and KL-Divergence Target Optimization (KTO) alignment technique, EVLM captures subjective editing preferences without requiring binary labels. Fine-tuned on a dataset of 30,000 CoT examples, with rationale paths rated by human evaluators, EVLM demonstrates substantial improvements in alignment with human intentions. Experiments across image, video, 3D, and 4D editing tasks show that EVLM generates coherent, high-quality instructions, supporting a scalable framework for complex vision-language applications.
+
+
+
+ 240. 【2412.10533】SUGAR: Subject-Driven Video Customization in a Zero-Shot Manner
+ 链接:https://arxiv.org/abs/2412.10533
+ 作者:Yufan Zhou,Ruiyi Zhang,Jiuxiang Gu,Nanxuan Zhao,Jing Shi,Tong Sun
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:subject-driven video customization, present SUGAR, SUGAR, SUGAR achieves, video customization
+ 备注: webpage [this https URL](https://drboog.github.io/SUGAR)
+
+ 点击查看摘要
+ Abstract:We present SUGAR, a zero-shot method for subject-driven video customization. Given an input image, SUGAR is capable of generating videos for the subject contained in the image and aligning the generation with arbitrary visual attributes such as style and motion specified by user-input text. Unlike previous methods, which require test-time fine-tuning or fail to generate text-aligned videos, SUGAR achieves superior results without the need for extra cost at test-time. To enable zero-shot capability, we introduce a scalable pipeline to construct synthetic dataset which is specifically designed for subject-driven customization, leading to 2.5 millions of image-video-text triplets. Additionally, we propose several methods to enhance our model, including special attention designs, improved training strategies, and a refined sampling algorithm. Extensive experiments are conducted. Compared to previous methods, SUGAR achieves state-of-the-art results in identity preservation, video dynamics, and video-text alignment for subject-driven video customization, demonstrating the effectiveness of our proposed method.
+
+
+
+ 241. 【2412.10525】RowDetr: End-to-End Row Detection Using Polynomials
+ 链接:https://arxiv.org/abs/2412.10525
+ 作者:Rahul Harsha Cheppally,Ajay Sharda
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:under-canopy agricultural settings, garnered significant interest, significant interest due, Crop row detection, GPS-denied environments
+ 备注: Code will be open sourced upon publication
+
+ 点击查看摘要
+ Abstract:Crop row detection has garnered significant interest due to its critical role in enabling navigation in GPS-denied environments, such as under-canopy agricultural settings. To address this challenge, we propose RowDetr, an end-to-end neural network that utilizes smooth polynomial functions to delineate crop boundaries in image space. A novel energy-based loss function, PolyOptLoss, is introduced to enhance learning robustness, even with noisy labels. The proposed model demonstrates a 3% improvement over Agronav in key performance metrics while being six times faster, making it well-suited for real-time applications. Additionally, metrics from lane detection studies were adapted to comprehensively evaluate the system, showcasing its accuracy and adaptability in various scenarios.
+
+
+
+ 242. 【2412.10523】he Language of Motion: Unifying Verbal and Non-verbal Language of 3D Human Motion
+ 链接:https://arxiv.org/abs/2412.10523
+ 作者:Changan Chen,Juze Zhang,Shrinidhi K. Lakshmikanth,Yusu Fang,Ruizhi Shao,Gordon Wetzstein,Li Fei-Fei,Ehsan Adeli
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:facial expressions, communication is inherently, verbal and non-verbal, Human communication, motion
+ 备注: Project page: [this http URL](http://languageofmotion.github.io)
+
+ 点击查看摘要
+ Abstract:Human communication is inherently multimodal, involving a combination of verbal and non-verbal cues such as speech, facial expressions, and body gestures. Modeling these behaviors is essential for understanding human interaction and for creating virtual characters that can communicate naturally in applications like games, films, and virtual reality. However, existing motion generation models are typically limited to specific input modalities -- either speech, text, or motion data -- and cannot fully leverage the diversity of available data. In this paper, we propose a novel framework that unifies verbal and non-verbal language using multimodal language models for human motion understanding and generation. This model is flexible in taking text, speech, and motion or any combination of them as input. Coupled with our novel pre-training strategy, our model not only achieves state-of-the-art performance on co-speech gesture generation but also requires much less data for training. Our model also unlocks an array of novel tasks such as editable gesture generation and emotion prediction from motion. We believe unifying the verbal and non-verbal language of human motion is essential for real-world applications, and language models offer a powerful approach to achieving this goal. Project page: this http URL.
+
+
+
+ 243. 【2412.10511】Automated Image Captioning with CNNs and Transformers
+ 链接:https://arxiv.org/abs/2412.10511
+ 作者:Joshua Adrian Cahyono,Jeremy Nathan Jusuf
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:natural language processing, generates natural language, natural language descriptions, natural language, language processing
+ 备注:
+
+ 点击查看摘要
+ Abstract:This project aims to create an automated image captioning system that generates natural language descriptions for input images by integrating techniques from computer vision and natural language processing. We employ various different techniques, ranging from CNN-RNN to the more advanced transformer-based techniques. Training is carried out on image datasets paired with descriptive captions, and model performance will be evaluated using established metrics such as BLEU, METEOR, and CIDEr. The project will also involve experimentation with advanced attention mechanisms, comparisons of different architectural choices, and hyperparameter optimization to refine captioning accuracy and overall system effectiveness.
+
+
+
+ 244. 【2412.10510】DEFAME: Dynamic Evidence-based FAct-checking with Multimodal Experts
+ 链接:https://arxiv.org/abs/2412.10510
+ 作者:Tobias Braun,Mark Rothermel,Marcus Rohrbach,Anna Rohrbach
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:present Dynamic Evidence-based, Dynamic Evidence-based FAct-checking, trust and democracy, necessitating robust, scalable Fact-Checking systems
+ 备注:
+
+ 点击查看摘要
+ Abstract:The proliferation of disinformation presents a growing threat to societal trust and democracy, necessitating robust and scalable Fact-Checking systems. In this work, we present Dynamic Evidence-based FAct-checking with Multimodal Experts (DEFAME), a modular, zero-shot MLLM pipeline for open-domain, text-image claim verification. DEFAME frames the problem of fact-checking as a six-stage process, dynamically deciding about the usage of external tools for the retrieval of textual and visual evidence. In addition to the claim's veracity, DEFAME returns a justification accompanied by a comprehensive, multimodal fact-checking report. While most alternatives either focus on sub-tasks of fact-checking, lack explainability or are limited to text-only inputs, DEFAME solves the problem of fact-checking end-to-end, including claims with images or those that require visual evidence. Evaluation on the popular benchmarks VERITE, AVeriTeC, and MOCHEG shows that DEFAME surpasses all previous methods, establishing it as the new state-of-the-art fact-checking system.
+
+
+
+ 245. 【2412.10494】SnapGen-V: Generating a Five-Second Video within Five Seconds on a Mobile Device
+ 链接:https://arxiv.org/abs/2412.10494
+ 作者:Yushu Wu,Zhixing Zhang,Yanyu Li,Yanwu Xu,Anil Kag,Yang Sui,Huseyin Coskun,Ke Ma,Aleksei Lebedev,Ju Hu,Dimitris Metaxas,Yanzhi Wang,Sergey Tulyakov,Jian Ren
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Performance (cs.PF)
+ 关键词:past year, diffusion-based video generation, witnessed the unprecedented, unprecedented success, success of diffusion-based
+ 备注: [this https URL](https://snap-research.github.io/snapgen-v/)
+
+ 点击查看摘要
+ Abstract:We have witnessed the unprecedented success of diffusion-based video generation over the past year. Recently proposed models from the community have wielded the power to generate cinematic and high-resolution videos with smooth motions from arbitrary input prompts. However, as a supertask of image generation, video generation models require more computation and are thus hosted mostly on cloud servers, limiting broader adoption among content creators. In this work, we propose a comprehensive acceleration framework to bring the power of the large-scale video diffusion model to the hands of edge users. From the network architecture scope, we initialize from a compact image backbone and search out the design and arrangement of temporal layers to maximize hardware efficiency. In addition, we propose a dedicated adversarial fine-tuning algorithm for our efficient model and reduce the denoising steps to 4. Our model, with only 0.6B parameters, can generate a 5-second video on an iPhone 16 PM within 5 seconds. Compared to server-side models that take minutes on powerful GPUs to generate a single video, we accelerate the generation by magnitudes while delivering on-par quality.
+
+
+
+ 246. 【2412.10493】SafetyDPO: Scalable Safety Alignment for Text-to-Image Generation
+ 链接:https://arxiv.org/abs/2412.10493
+ 作者:Runtao Liu,Chen I Chieh,Jindong Gu,Jipeng Zhang,Renjie Pi,Qifeng Chen,Philip Torr,Ashkan Khakzar,Fabio Pizzati
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:guardrails expose end, expose end users, Direct Preference Optimization, safety guardrails expose, guardrails expose
+ 备注:
+
+ 点击查看摘要
+ Abstract:Text-to-image (T2I) models have become widespread, but their limited safety guardrails expose end users to harmful content and potentially allow for model misuse. Current safety measures are typically limited to text-based filtering or concept removal strategies, able to remove just a few concepts from the model's generative capabilities. In this work, we introduce SafetyDPO, a method for safety alignment of T2I models through Direct Preference Optimization (DPO). We enable the application of DPO for safety purposes in T2I models by synthetically generating a dataset of harmful and safe image-text pairs, which we call CoProV2. Using a custom DPO strategy and this dataset, we train safety experts, in the form of low-rank adaptation (LoRA) matrices, able to guide the generation process away from specific safety-related concepts. Then, we merge the experts into a single LoRA using a novel merging strategy for optimal scaling performance. This expert-based approach enables scalability, allowing us to remove 7 times more harmful concepts from T2I models compared to baselines. SafetyDPO consistently outperforms the state-of-the-art on many benchmarks and establishes new practices for safety alignment in T2I networks. Code and data will be shared at this https URL.
+
+
+
+ 247. 【2412.10492】QSM-RimDS: A highly sensitive paramagnetic rim lesion detection and segmentation tool for multiple sclerosis lesions
+ 链接:https://arxiv.org/abs/2412.10492
+ 作者:Ha Luu,Mert Sisman,Ilhami Kovanlikaya,Tam Vu,Pascal Spincemaille,Yi Wang,Francesca Bagnato,Susan Gauthier,Thanh Nguyen
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:Paramagnetic rim lesions, innate immune response, Paramagnetic rim, QSM lesion mask, PRL detection
+ 备注: 11 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:Paramagnetic rim lesions (PRLs) are imaging biomarker of the innate immune response in MS lesions. QSM-RimNet, a state-of-the-art tool for PRLs detection on QSM, can identify PRLs but requires precise QSM lesion mask and does not provide rim segmentation. Therefore, the aims of this study are to develop QSM-RimDS algorithm to detect PRLs using the readily available FLAIR lesion mask and to provide rim segmentation for microglial quantification. QSM-RimDS, a deep-learning based tool for joint PRL rim segmentation and PRL detection has been developed. QSM-RimDS has obtained state-of-the art performance in PRL detection and therefore has the potential to be used in clinical practice as a tool to assist human readers for the time-consuming PRL detection and segmentation task. QSM-RimDS is made publicly available [this https URL]
+
+
+
+ 248. 【2412.10489】CognitionCapturer: Decoding Visual Stimuli From Human EEG Signal With Multimodal Information
+ 链接:https://arxiv.org/abs/2412.10489
+ 作者:Kaifan Zhang,Lihuo He,Xin Jiang,Wen Lu,Di Wang,Xinbo Gao
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Signal Processing (eess.SP)
+ 关键词:attracted significant attention, high temporal sensitivity, EEG, EEG signals, attracted significant
+ 备注:
+
+ 点击查看摘要
+ Abstract:Electroencephalogram (EEG) signals have attracted significant attention from researchers due to their non-invasive nature and high temporal sensitivity in decoding visual stimuli. However, most recent studies have focused solely on the relationship between EEG and image data pairs, neglecting the valuable ``beyond-image-modality" information embedded in EEG signals. This results in the loss of critical multimodal information in EEG. To address this limitation, we propose CognitionCapturer, a unified framework that fully leverages multimodal data to represent EEG signals. Specifically, CognitionCapturer trains Modality Expert Encoders for each modality to extract cross-modal information from the EEG modality. Then, it introduces a diffusion prior to map the EEG embedding space to the CLIP embedding space, followed by using a pretrained generative model, the proposed framework can reconstruct visual stimuli with high semantic and structural fidelity. Notably, the framework does not require any fine-tuning of the generative models and can be extended to incorporate more modalities. Through extensive experiments, we demonstrate that CognitionCapturer outperforms state-of-the-art methods both qualitatively and quantitatively. Code: this https URL.
+
+
+
+ 249. 【2412.10488】SVGBuilder: Component-Based Colored SVG Generation with Text-Guided Autoregressive Transformers
+ 链接:https://arxiv.org/abs/2412.10488
+ 作者:Zehao Chen,Rong Pan
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Graphics (cs.GR)
+ 关键词:Scalable Vector Graphics, Scalable Vector, offering resolution independence, essential XML-based formats, Vector Graphics
+ 备注: Project: [this https URL](https://svgbuilder.github.io)
+
+ 点击查看摘要
+ Abstract:Scalable Vector Graphics (SVG) are essential XML-based formats for versatile graphics, offering resolution independence and scalability. Unlike raster images, SVGs use geometric shapes and support interactivity, animation, and manipulation via CSS and JavaScript. Current SVG generation methods face challenges related to high computational costs and complexity. In contrast, human designers use component-based tools for efficient SVG creation. Inspired by this, SVGBuilder introduces a component-based, autoregressive model for generating high-quality colored SVGs from textual input. It significantly reduces computational overhead and improves efficiency compared to traditional methods. Our model generates SVGs up to 604 times faster than optimization-based approaches. To address the limitations of existing SVG datasets and support our research, we introduce ColorSVG-100K, the first large-scale dataset of colored SVGs, comprising 100,000 graphics. This dataset fills the gap in color information for SVG generation models and enhances diversity in model training. Evaluation against state-of-the-art models demonstrates SVGBuilder's superior performance in practical applications, highlighting its efficiency and quality in generating complex SVG graphics.
+
+
+
+ 250. 【2412.10482】Dynamic Entity-Masked Graph Diffusion Model for histopathological image Representation Learning
+ 链接:https://arxiv.org/abs/2412.10482
+ 作者:Zhenfeng Zhuang,Min Cen,Yanfeng Li,Fangyu Zhou,Lequan Yu,Baptiste Magnier,Liansheng Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Significant disparities, transfer pre-trained models, natural images, make it challenging, challenging to directly
+ 备注:
+
+ 点击查看摘要
+ Abstract:Significant disparities between the features of natural images and those inherent to histopathological images make it challenging to directly apply and transfer pre-trained models from natural images to histopathology tasks. Moreover, the frequent lack of annotations in histopathology patch images has driven researchers to explore self-supervised learning methods like mask reconstruction for learning representations from large amounts of unlabeled data. Crucially, previous mask-based efforts in self-supervised learning have often overlooked the spatial interactions among entities, which are essential for constructing accurate representations of pathological entities. To address these challenges, constructing graphs of entities is a promising approach. In addition, the diffusion reconstruction strategy has recently shown superior performance through its random intensity noise addition technique to enhance the robust learned representation. Therefore, we introduce H-MGDM, a novel self-supervised Histopathology image representation learning method through the Dynamic Entity-Masked Graph Diffusion Model. Specifically, we propose to use complementary subgraphs as latent diffusion conditions and self-supervised targets respectively during pre-training. We note that the graph can embed entities' topological relationships and enhance representation. Dynamic conditions and targets can improve pathological fine reconstruction. Our model has conducted pretraining experiments on three large histopathological datasets. The advanced predictive performance and interpretability of H-MGDM are clearly evaluated on comprehensive downstream tasks such as classification and survival analysis on six datasets. Our code will be publicly available at this https URL.
+
+
+
+ 251. 【2412.10474】CrossVIT-augmented Geospatial-Intelligence Visualization System for Tracking Economic Development Dynamics
+ 链接:https://arxiv.org/abs/2412.10474
+ 作者:Yanbing Bai,Jinhua Su,Bin Qiao,Xiaoran Ma
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Timely and accurate, accurate economic data, effective policymaking, crucial for effective, Timely
+ 备注:
+
+ 点击查看摘要
+ Abstract:Timely and accurate economic data is crucial for effective policymaking. Current challenges in data timeliness and spatial resolution can be addressed with advancements in multimodal sensing and distributed computing. We introduce Senseconomic, a scalable system for tracking economic dynamics via multimodal imagery and deep learning. Built on the Transformer framework, it integrates remote sensing and street view images using cross-attention, with nighttime light data as weak supervision. The system achieved an R-squared value of 0.8363 in county-level economic predictions and halved processing time to 23 minutes using distributed computing. Its user-friendly design includes a Vue3-based front end with Baidu maps for visualization and a Python-based back end automating tasks like image downloads and preprocessing. Senseconomic empowers policymakers and researchers with efficient tools for resource allocation and economic planning.
+
+
+
+ 252. 【2412.10471】VCA: Video Curious Agent for Long Video Understanding
+ 链接:https://arxiv.org/abs/2412.10471
+ 作者:Zeyuan Yang,Delin Chen,Xueyang Yu,Maohao Shen,Chuang Gan
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:poses unique challenges, unique challenges due, low information density, understanding poses unique, poses unique
+ 备注:
+
+ 点击查看摘要
+ Abstract:Long video understanding poses unique challenges due to their temporal complexity and low information density. Recent works address this task by sampling numerous frames or incorporating auxiliary tools using LLMs, both of which result in high computational costs. In this work, we introduce a curiosity-driven video agent with self-exploration capability, dubbed as VCA. Built upon VLMs, VCA autonomously navigates video segments and efficiently builds a comprehensive understanding of complex video sequences. Instead of directly sampling frames, VCA employs a tree-search structure to explore video segments and collect frames. Rather than relying on external feedback or reward, VCA leverages VLM's self-generated intrinsic reward to guide its exploration, enabling it to capture the most crucial information for reasoning. Experimental results on multiple long video benchmarks demonstrate our approach's superior effectiveness and efficiency.
+
+
+
+ 253. 【2412.10464】Automatic Detection, Positioning and Counting of Grape Bunches Using Robots
+ 链接:https://arxiv.org/abs/2412.10464
+ 作者:Xumin Gao
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Robotics (cs.RO)
+ 关键词:yield estimation technology, promote agricultural automatic, agricultural automatic picking, grape bunches, automatic picking
+ 备注:
+
+ 点击查看摘要
+ Abstract:In order to promote agricultural automatic picking and yield estimation technology, this project designs a set of automatic detection, positioning and counting algorithms for grape bunches, and applies it to agricultural robots. The Yolov3 detection network is used to realize the accurate detection of grape bunches, and the local tracking algorithm is added to eliminate relocation. Then it obtains the accurate 3D spatial position of the central points of grape bunches using the depth distance and the spatial restriction method. Finally, the counting of grape bunches is completed. It is verified using the agricultural robot in the simulated vineyard environment. The project code is released at: this https URL.
+
+
+
+ 254. 【2412.10460】Enriching Multimodal Sentiment Analysis through Textual Emotional Descriptions of Visual-Audio Content
+ 链接:https://arxiv.org/abs/2412.10460
+ 作者:Sheng Wu,Xiaobao Wang,Longbiao Wang,Dongxiao He,Jianwu Dang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:critical research frontier, comprehensively unravel human, unravel human emotions, research frontier, seeking to comprehensively
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multimodal Sentiment Analysis (MSA) stands as a critical research frontier, seeking to comprehensively unravel human emotions by amalgamating text, audio, and visual data. Yet, discerning subtle emotional nuances within audio and video expressions poses a formidable challenge, particularly when emotional polarities across various segments appear similar. In this paper, our objective is to spotlight emotion-relevant attributes of audio and visual modalities to facilitate multimodal fusion in the context of nuanced emotional shifts in visual-audio scenarios. To this end, we introduce DEVA, a progressive fusion framework founded on textual sentiment descriptions aimed at accentuating emotional features of visual-audio content. DEVA employs an Emotional Description Generator (EDG) to transmute raw audio and visual data into textualized sentiment descriptions, thereby amplifying their emotional characteristics. These descriptions are then integrated with the source data to yield richer, enhanced features. Furthermore, DEVA incorporates the Text-guided Progressive Fusion Module (TPF), leveraging varying levels of text as a core modality guide. This module progressively fuses visual-audio minor modalities to alleviate disparities between text and visual-audio modalities. Experimental results on widely used sentiment analysis benchmark datasets, including MOSI, MOSEI, and CH-SIMS, underscore significant enhancements compared to state-of-the-art models. Moreover, fine-grained emotion experiments corroborate the robust sensitivity of DEVA to subtle emotional variations.
+
+
+
+ 255. 【2412.10458】Motion Generation Review: Exploring Deep Learning for Lifelike Animation with Manifold
+ 链接:https://arxiv.org/abs/2412.10458
+ 作者:Jiayi Zhao,Dongdong Weng,Qiuxin Du,Zeyu Tian
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR); Human-Computer Interaction (cs.HC)
+ 关键词:involves creating natural, creating natural sequences, human body poses, generation involves creating, Human motion generation
+ 备注:
+
+ 点击查看摘要
+ Abstract:Human motion generation involves creating natural sequences of human body poses, widely used in gaming, virtual reality, and human-computer interaction. It aims to produce lifelike virtual characters with realistic movements, enhancing virtual agents and immersive experiences. While previous work has focused on motion generation based on signals like movement, music, text, or scene background, the complexity of human motion and its relationships with these signals often results in unsatisfactory outputs. Manifold learning offers a solution by reducing data dimensionality and capturing subspaces of effective motion. In this review, we present a comprehensive overview of manifold applications in human motion generation, one of the first in this domain. We explore methods for extracting manifolds from unstructured data, their application in motion generation, and discuss their advantages and future directions. This survey aims to provide a broad perspective on the field and stimulate new approaches to ongoing challenges.
+
+
+
+ 256. 【2412.10457】Explaining Model Overfitting in CNNs via GMM Clustering
+ 链接:https://arxiv.org/abs/2412.10457
+ 作者:Hui Dou,Xinyu Mu,Mengjun Yi,Feng Han,Jian Zhao,Furao Shen
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Convolutional Neural Networks, Convolutional Neural, Neural Networks, demonstrated remarkable prowess, computer vision
+ 备注:
+
+ 点击查看摘要
+ Abstract:Convolutional Neural Networks (CNNs) have demonstrated remarkable prowess in the field of computer vision. However, their opaque decision-making processes pose significant challenges for practical applications. In this study, we provide quantitative metrics for assessing CNN filters by clustering the feature maps corresponding to individual filters in the model via Gaussian Mixture Model (GMM). By analyzing the clustering results, we screen out some anomaly filters associated with outlier samples. We further analyze the relationship between the anomaly filters and model overfitting, proposing three hypotheses. This method is universally applicable across diverse CNN architectures without modifications, as evidenced by its successful application to models like AlexNet and LeNet-5. We present three meticulously designed experiments demonstrating our hypotheses from the perspectives of model behavior, dataset characteristics, and filter impacts. Through this work, we offer a novel perspective for evaluating the CNN performance and gain new insights into the operational behavior of model overfitting.
+
+
+
+ 257. 【2412.10456】FovealNet: Advancing AI-Driven Gaze Tracking Solutions for Optimized Foveated Rendering System Performance in Virtual Reality
+ 链接:https://arxiv.org/abs/2412.10456
+ 作者:Wenxuan Liu,Monde Duinkharjav,Qi Sun,Sai Qian Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Leveraging real-time eye-tracking, quality virtual reality, Leveraging real-time, optimizes hardware efficiency, enhances visual quality
+ 备注:
+
+ 点击查看摘要
+ Abstract:Leveraging real-time eye-tracking, foveated rendering optimizes hardware efficiency and enhances visual quality virtual reality (VR). This approach leverages eye-tracking techniques to determine where the user is looking, allowing the system to render high-resolution graphics only in the foveal region-the small area of the retina where visual acuity is highest, while the peripheral view is rendered at lower resolution. However, modern deep learning-based gaze-tracking solutions often exhibit a long-tail distribution of tracking errors, which can degrade user experience and reduce the benefits of foveated rendering by causing misalignment and decreased visual quality.
+This paper introduces \textit{FovealNet}, an advanced AI-driven gaze tracking framework designed to optimize system performance by strategically enhancing gaze tracking accuracy. To further reduce the implementation cost of the gaze tracking algorithm, FovealNet employs an event-based cropping method that eliminates over $64.8\%$ of irrelevant pixels from the input image. Additionally, it incorporates a simple yet effective token-pruning strategy that dynamically removes tokens on the fly without compromising tracking accuracy. Finally, to support different runtime rendering configurations, we propose a system performance-aware multi-resolution training strategy, allowing the gaze tracking DNN to adapt and optimize overall system performance more effectively. Evaluation results demonstrate that FovealNet achieves at least $1.42\times$ speed up compared to previous methods and 13\% increase in perceptual quality for foveated output.
+
Subjects:
+Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+Cite as:
+arXiv:2412.10456 [cs.CV]
+(or
+arXiv:2412.10456v1 [cs.CV] for this version)
+https://doi.org/10.48550/arXiv.2412.10456
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 258. 【2412.10455】Geo-LLaVA: A Large Multi-Modal Model for Solving Geometry Math Problems with Meta In-Context Learning
+ 链接:https://arxiv.org/abs/2412.10455
+ 作者:Shihao Xu,Yiyang Luo,Wei Shi
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computational Geometry (cs.CG)
+ 关键词:pose significant challenges, involve visual elements, mathematics problems pose, problems pose significant, Geometry mathematics problems
+ 备注:
+
+ 点击查看摘要
+ Abstract:Geometry mathematics problems pose significant challenges for large language models (LLMs) because they involve visual elements and spatial reasoning. Current methods primarily rely on symbolic character awareness to address these problems. Considering geometry problem solving is a relatively nascent field with limited suitable datasets and currently almost no work on solid geometry problem solving, we collect a geometry question-answer dataset by sourcing geometric data from Chinese high school education websites, referred to as GeoMath. It contains solid geometry questions and answers with accurate reasoning steps as compensation for existing plane geometry datasets. Additionally, we propose a Large Multi-modal Model (LMM) framework named Geo-LLaVA, which incorporates retrieval augmentation with supervised fine-tuning (SFT) in the training stage, called meta-training, and employs in-context learning (ICL) during inference to improve performance. Our fine-tuned model with ICL attains the state-of-the-art performance of 65.25% and 42.36% on selected questions of the GeoQA dataset and GeoMath dataset respectively with proper inference steps. Notably, our model initially endows the ability to solve solid geometry problems and supports the generation of reasonable solid geometry picture descriptions and problem-solving steps. Our research sets the stage for further exploration of LLMs in multi-modal math problem-solving, particularly in geometry math problems.
+
+
+
+ 259. 【2412.10453】Analysis of Object Detection Models for Tiny Object in Satellite Imagery: A Dataset-Centric Approach
+ 链接:https://arxiv.org/abs/2412.10453
+ 作者:Kailas PS,Selvakumaran R,Palani Murugan,Ramesh Kumar V,Malaya Kumar Biswal M
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:revolutionizing basic computer, computer vision tasks, basic computer vision, deep learning-based object, learning-based object detection
+ 备注: Conference Proceesings of AIAA SciTech Forum 2025 and Exposition
+
+ 点击查看摘要
+ Abstract:In recent years, significant advancements have been made in deep learning-based object detection algorithms, revolutionizing basic computer vision tasks, notably in object detection, tracking, and segmentation. This paper delves into the intricate domain of Small-Object-Detection (SOD) within satellite imagery, highlighting the unique challenges stemming from wide imaging ranges, object distribution, and their varying appearances in bird's-eye-view satellite images. Traditional object detection models face difficulties in detecting small objects due to limited contextual information and class imbalances. To address this, our research presents a meticulously curated dataset comprising 3000 images showcasing cars, ships, and airplanes in satellite imagery. Our study aims to provide valuable insights into small object detection in satellite imagery by empirically evaluating state-of-the-art models. Furthermore, we tackle the challenges of satellite video-based object tracking, employing the Byte Track algorithm on the SAT-MTB dataset. Through rigorous experimentation, we aim to offer a comprehensive understanding of the efficacy of state-of-the-art models in Small-Object-Detection for satellite applications. Our findings shed light on the effectiveness of these models and pave the way for future advancements in satellite imagery analysis.
+
+
+
+ 260. 【2412.10448】Unlocking Visual Secrets: Inverting Features with Diffusion Priors for Image Reconstruction
+ 链接:https://arxiv.org/abs/2412.10448
+ 作者:Sai Qian Zhang,Ziyun Li,Chuan Guo,Saeed Mahloujifar,Deeksha Dangwal,Edward Suh,Barbara De Salvo,Chiao Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Inverting visual representations, deep neural networks, Inverting visual, deep learning, DNN features
+ 备注:
+
+ 点击查看摘要
+ Abstract:Inverting visual representations within deep neural networks (DNNs) presents a challenging and important problem in the field of security and privacy for deep learning. The main goal is to invert the features of an unidentified target image generated by a pre-trained DNN, aiming to reconstruct the original image. Feature inversion holds particular significance in understanding the privacy leakage inherent in contemporary split DNN execution techniques, as well as in various applications based on the extracted DNN features.
+In this paper, we explore the use of diffusion models, a promising technique for image synthesis, to enhance feature inversion quality. We also investigate the potential of incorporating alternative forms of prior knowledge, such as textual prompts and cross-frame temporal correlations, to further improve the quality of inverted features. Our findings reveal that diffusion models can effectively leverage hidden information from the DNN features, resulting in superior reconstruction performance compared to previous methods. This research offers valuable insights into how diffusion models can enhance privacy and security within applications that are reliant on DNN features.
+
Subjects:
+Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+Cite as:
+arXiv:2412.10448 [cs.CV]
+(or
+arXiv:2412.10448v1 [cs.CV] for this version)
+https://doi.org/10.48550/arXiv.2412.10448
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 261. 【2412.10447】dyBot++: An Open-Source Holonomic Mobile Manipulator for Robot Learning
+ 链接:https://arxiv.org/abs/2412.10447
+ 作者:Jimmy Wu,William Chong,Robert Holmberg,Aaditya Prasad,Yihuai Gao,Oussama Khatib,Shuran Song,Szymon Rusinkiewicz,Jeannette Bohg
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Exploiting the promise, mobile manipulation tasks, manipulation tasks, human-guided demonstrations, mobile manipulation
+ 备注: Conference on Robot Learning (CoRL), 2024. Project page: [this https URL](https://tidybot2.github.io)
+
+ 点击查看摘要
+ Abstract:Exploiting the promise of recent advances in imitation learning for mobile manipulation will require the collection of large numbers of human-guided demonstrations. This paper proposes an open-source design for an inexpensive, robust, and flexible mobile manipulator that can support arbitrary arms, enabling a wide range of real-world household mobile manipulation tasks. Crucially, our design uses powered casters to enable the mobile base to be fully holonomic, able to control all planar degrees of freedom independently and simultaneously. This feature makes the base more maneuverable and simplifies many mobile manipulation tasks, eliminating the kinematic constraints that create complex and time-consuming motions in nonholonomic bases. We equip our robot with an intuitive mobile phone teleoperation interface to enable easy data acquisition for imitation learning. In our experiments, we use this interface to collect data and show that the resulting learned policies can successfully perform a variety of common household mobile manipulation tasks.
+
+
+
+ 262. 【2412.10446】Disentanglement and Compositionality of Letter Identity and Letter Position in Variational Auto-Encoder Vision Models
+ 链接:https://arxiv.org/abs/2412.10446
+ 作者:Bruno Bianchi,Aakash Agrawal,Stanislas Dehaene,Emmanuel Chemla,Yair Lakretz
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:letter, disentangle letter position, bufflo or add, accurately count, models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Human readers can accurately count how many letters are in a word (e.g., 7 in ``buffalo''), remove a letter from a given position (e.g., ``bufflo'') or add a new one. The human brain of readers must have therefore learned to disentangle information related to the position of a letter and its identity. Such disentanglement is necessary for the compositional, unbounded, ability of humans to create and parse new strings, with any combination of letters appearing in any positions. Do modern deep neural models also possess this crucial compositional ability? Here, we tested whether neural models that achieve state-of-the-art on disentanglement of features in visual input can also disentangle letter position and letter identity when trained on images of written words. Specifically, we trained beta variational autoencoder ($\beta$-VAE) to reconstruct images of letter strings and evaluated their disentanglement performance using CompOrth - a new benchmark that we created for studying compositional learning and zero-shot generalization in visual models for orthography. The benchmark suggests a set of tests, of increasing complexity, to evaluate the degree of disentanglement between orthographic features of written words in deep neural models. Using CompOrth, we conducted a set of experiments to analyze the generalization ability of these models, in particular, to unseen word length and to unseen combinations of letter identities and letter positions. We found that while models effectively disentangle surface features, such as horizontal and vertical `retinal' locations of words within an image, they dramatically fail to disentangle letter position and letter identity and lack any notion of word length. Together, this study demonstrates the shortcomings of state-of-the-art $\beta$-VAE models compared to humans and proposes a new challenge and a corresponding benchmark to evaluate neural models.
+
+
+
+ 263. 【2412.10444】Boundary Exploration of Next Best View Policy in 3D Robotic Scanning
+ 链接:https://arxiv.org/abs/2412.10444
+ 作者:Leihui Li,Xuping Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:Boundary Exploration NBV, NBV, capture and reconstruction, pivotal challenge, potential to greatly
+ 备注: Will be submitted to IROS 2025
+
+ 点击查看摘要
+ Abstract:The Next Best View (NBV) problem is a pivotal challenge in 3D robotic scanning, with the potential to greatly improve the efficiency of object capture and reconstruction. Current methods for determining the NBV often overlook view overlaps, assume a virtual origin point for the camera's focus, and rely on voxel representations of 3D data. To address these issues and improve the practicality of scanning unknown objects, we propose an NBV policy in which the next view explores the boundary of the scanned point cloud, and the overlap is intrinsically considered. The scanning distance or camera working distance is adjustable and flexible. To this end, a model-based approach is proposed where the next sensor positions are searched iteratively based on a reference model. A score is calculated by considering the overlaps between newly scanned and existing data, as well as the final convergence. Additionally, following the boundary exploration idea, a deep learning network, Boundary Exploration NBV network (BENBV-Net), is designed and proposed, which can be used to predict the NBV directly from the scanned data without requiring the reference model. It predicts the scores for given boundaries, and the boundary with the highest score is selected as the target point of the next best view. BENBV-Net improves the speed of NBV generation while maintaining the performance of the model-based approach. Our proposed methods are evaluated and compared with existing approaches on the ShapeNet, ModelNet, and 3D Repository datasets. Experimental results demonstrate that our approach outperforms others in terms of scanning efficiency and overlap, both of which are crucial for practical 3D scanning applications. The related code is released at \url{this http URL}.
+
+
+
+ 264. 【2412.10443】SweetTokenizer: Semantic-Aware Spatial-Temporal Tokenizer for Compact Visual Discretization
+ 链接:https://arxiv.org/abs/2412.10443
+ 作者:Zhentao Tan,Ben Xue,Jian Jia,Junhao Wang,Wencai Ye,Shaoyun Shi,Mingjie Sun,Wenjin Wu,Quan Chen,Peng Jiang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:textbf, effective discretization approach, vision data, paper presents, discretization approach
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper presents the \textbf{S}emantic-a\textbf{W}ar\textbf{E} spatial-t\textbf{E}mporal \textbf{T}okenizer (SweetTokenizer), a compact yet effective discretization approach for vision data. Our goal is to boost tokenizers' compression ratio while maintaining reconstruction fidelity in the VQ-VAE paradigm. Firstly, to obtain compact latent representations, we decouple images or videos into spatial-temporal dimensions, translating visual information into learnable querying spatial and temporal tokens through a \textbf{C}ross-attention \textbf{Q}uery \textbf{A}uto\textbf{E}ncoder (CQAE). Secondly, to complement visual information during compression, we quantize these tokens via a specialized codebook derived from off-the-shelf LLM embeddings to leverage the rich semantics from language modality. Finally, to enhance training stability and convergence, we also introduce a curriculum learning strategy, which proves critical for effective discrete visual representation learning. SweetTokenizer achieves comparable video reconstruction fidelity with only \textbf{25\%} of the tokens used in previous state-of-the-art video tokenizers, and boost video generation results by \textbf{32.9\%} w.r.t gFVD. When using the same token number, we significantly improves video and image reconstruction results by \textbf{57.1\%} w.r.t rFVD on UCF-101 and \textbf{37.2\%} w.r.t rFID on ImageNet-1K. Additionally, the compressed tokens are imbued with semantic information, enabling few-shot recognition capabilities powered by LLMs in downstream applications.
+
+
+
+ 265. 【2412.10441】Novel 3D Binary Indexed Tree for Volume Computation of 3D Reconstructed Models from Volumetric Data
+ 链接:https://arxiv.org/abs/2412.10441
+ 作者:Quoc-Bao Nguyen-Le,Tuan-Hy Le,Anh-Triet Do
+ 类目:Graphics (cs.GR); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:subsequent qualitative analysis, medical imaging, burgeoning field, field of medical, holds a significant
+ 备注: 8 pages, 7 figures
+
+ 点击查看摘要
+ Abstract:In the burgeoning field of medical imaging, precise computation of 3D volume holds a significant importance for subsequent qualitative analysis of 3D reconstructed objects. Combining multivariate calculus, marching cube algorithm, and binary indexed tree data structure, we developed an algorithm for efficient computation of intrinsic volume of any volumetric data recovered from computed tomography (CT) or magnetic resonance (MR). We proposed the 30 configurations of volume values based on the polygonal mesh generation method. Our algorithm processes the data in scan-line order simultaneously with reconstruction algorithm to create a Fenwick tree, ensuring query time much faster and assisting users' edition of slicing or transforming model. We tested the algorithm's accuracy on simple 3D objects (e.g., sphere, cylinder) to complicated structures (e.g., lungs, cardiac chambers). The result deviated within $\pm 0.004 \text{cm}^3$ and there is still room for further improvement.
+
+
+
+ 266. 【2412.10440】Multi-level Matching Network for Multimodal Entity Linking
+ 链接:https://arxiv.org/abs/2412.10440
+ 作者:Zhiwei Hu,Víctor Gutiérrez-Basulto,Ru Li,Jeff Z. Pan
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:link ambiguous mentions, multimodal knowledge base, Multimodal entity linking, aims to link, knowledge base
+ 备注: Accepted at KDD'25
+
+ 点击查看摘要
+ Abstract:Multimodal entity linking (MEL) aims to link ambiguous mentions within multimodal contexts to corresponding entities in a multimodal knowledge base. Most existing approaches to MEL are based on representation learning or vision-and-language pre-training mechanisms for exploring the complementary effect among multiple modalities. However, these methods suffer from two limitations. On the one hand, they overlook the possibility of considering negative samples from the same modality. On the other hand, they lack mechanisms to capture bidirectional cross-modal interaction. To address these issues, we propose a Multi-level Matching network for Multimodal Entity Linking (M3EL). Specifically, M3EL is composed of three different modules: (i) a Multimodal Feature Extraction module, which extracts modality-specific representations with a multimodal encoder and introduces an intra-modal contrastive learning sub-module to obtain better discriminative embeddings based on uni-modal differences; (ii) an Intra-modal Matching Network module, which contains two levels of matching granularity: Coarse-grained Global-to-Global and Fine-grained Global-to-Local, to achieve local and global level intra-modal interaction; (iii) a Cross-modal Matching Network module, which applies bidirectional strategies, Textual-to-Visual and Visual-to-Textual matching, to implement bidirectional cross-modal interaction. Extensive experiments conducted on WikiMEL, RichpediaMEL, and WikiDiverse datasets demonstrate the outstanding performance of M3EL when compared to the state-of-the-art baselines.
+
+
+
+ 267. 【2412.10439】CogNav: Cognitive Process Modeling for Object Goal Navigation with LLMs
+ 链接:https://arxiv.org/abs/2412.10439
+ 作者:Yihan Cao,Jiazhao Zhang,Zhinan Yu,Shuzhen Liu,Zheng Qin,Qin Zou,Bo Du,Kai Xu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:Object goal navigation, requires the agent, agent to find, find a target, cognitive
+ 备注:
+
+ 点击查看摘要
+ Abstract:Object goal navigation (ObjectNav) is a fundamental task of embodied AI that requires the agent to find a target object in unseen environments. This task is particularly challenging as it demands both perceptual and cognitive processes for effective perception and decision-making. While perception has gained significant progress powered by the rapidly developed visual foundation models, the progress on the cognitive side remains limited to either implicitly learning from massive navigation demonstrations or explicitly leveraging pre-defined heuristic rules. Inspired by neuroscientific evidence that humans consistently update their cognitive states while searching for objects in unseen environments, we present CogNav, which attempts to model this cognitive process with the help of large language models. Specifically, we model the cognitive process with a finite state machine composed of cognitive states ranging from exploration to identification. The transitions between the states are determined by a large language model based on an online built heterogeneous cognitive map containing spatial and semantic information of the scene being explored. Extensive experiments on both synthetic and real-world environments demonstrate that our cognitive modeling significantly improves ObjectNav efficiency, with human-like navigation behaviors. In an open-vocabulary and zero-shot setting, our method advances the SOTA of the HM3D benchmark from 69.3% to 87.2%. The code and data will be released.
+
+
+
+ 268. 【2412.10438】Automatic Image Annotation for Mapped Features Detection
+ 链接:https://arxiv.org/abs/2412.10438
+ 作者:Maxime Noizet(UTC, Heudiasyc),Philippe Xu(ENSTA Paris),Philippe Bonnifait(UTC, Heudiasyc)
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Detecting road features, Detecting road, key enabler, enabler for autonomous, autonomous driving
+ 备注:
+
+ 点击查看摘要
+ Abstract:Detecting road features is a key enabler for autonomous driving and localization. For instance, a reliable detection of poles which are widespread in road environments can improve localization. Modern deep learning-based perception systems need a significant amount of annotated data. Automatic annotation avoids time-consuming and costly manual annotation. Because automatic methods are prone to errors, managing annotation uncertainty is crucial to ensure a proper learning process. Fusing multiple annotation sources on the same dataset can be an efficient way to reduce the errors. This not only improves the quality of annotations, but also improves the learning of perception models. In this paper, we consider the fusion of three automatic annotation methods in images: feature projection from a high accuracy vector map combined with a lidar, image segmentation and lidar segmentation. Our experimental results demonstrate the significant benefits of multi-modal automatic annotation for pole detection through a comparative evaluation on manually annotated images. Finally, the resulting multi-modal fusion is used to fine-tune an object detection model for pole base detection using unlabeled data, showing overall improvements achieved by enhancing network specialization. The dataset is publicly available.
+
+
+
+ 269. 【2412.10437】SVGFusion: Scalable Text-to-SVG Generation via Vector Space Diffusion
+ 链接:https://arxiv.org/abs/2412.10437
+ 作者:Ximing Xing,Juncheng Hu,Jing Zhang,Dong Xu,Qian Yu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR); Machine Learning (cs.LG)
+ 关键词:scalable vector representations, Scalable Vector Graphics, Scalable Vector, intricate graphic distributions, vector representations required
+ 备注: project page: \href{ [this https URL](https://ximinng.github.io/SVGFusionProject/) }{ [this https URL](https://ximinng.github.io/SVGFusionProject/) }
+
+ 点击查看摘要
+ Abstract:The generation of Scalable Vector Graphics (SVG) assets from textual data remains a significant challenge, largely due to the scarcity of high-quality vector datasets and the limitations in scalable vector representations required for modeling intricate graphic distributions. This work introduces SVGFusion, a Text-to-SVG model capable of scaling to real-world SVG data without reliance on a text-based discrete language model or prolonged SDS optimization. The essence of SVGFusion is to learn a continuous latent space for vector graphics with a popular Text-to-Image framework. Specifically, SVGFusion consists of two modules: a Vector-Pixel Fusion Variational Autoencoder (VP-VAE) and a Vector Space Diffusion Transformer (VS-DiT). VP-VAE takes both the SVGs and corresponding rasterizations as inputs and learns a continuous latent space, whereas VS-DiT learns to generate a latent code within this space based on the text prompt. Based on VP-VAE, a novel rendering sequence modeling strategy is proposed to enable the latent space to embed the knowledge of construction logics in SVGs. This empowers the model to achieve human-like design capabilities in vector graphics, while systematically preventing occlusion in complex graphic compositions. Moreover, our SVGFusion's ability can be continuously improved by leveraging the scalability of the VS-DiT by adding more VS-DiT blocks. A large-scale SVG dataset is collected to evaluate the effectiveness of our proposed method. Extensive experimentation has confirmed the superiority of our SVGFusion over existing SVG generation methods, achieving enhanced quality and generalizability, thereby establishing a novel framework for SVG content creation. Code, model, and data will be released at: \href{this https URL}{this https URL}
+
+
+
+ 270. 【2412.10436】Benchmarking Federated Learning for Semantic Datasets: Federated Scene Graph Generation
+ 链接:https://arxiv.org/abs/2412.10436
+ 作者:SeungBum Ha,Taehwan Lee,Jiyoun Lim,Sung Whan Yoon
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:data-decentralized training framework, locally distributed samples, recently garnered attention, keeping data privacy, semantic heterogeneity
+ 备注: This work has been submitted to the IEEE for possible publication
+
+ 点击查看摘要
+ Abstract:Federated learning (FL) has recently garnered attention as a data-decentralized training framework that enables the learning of deep models from locally distributed samples while keeping data privacy. Built upon the framework, immense efforts have been made to establish FL benchmarks, which provide rigorous evaluation settings that control data heterogeneity across clients. Prior efforts have mainly focused on handling relatively simple classification tasks, where each sample is annotated with a one-hot label, such as MNIST, CIFAR, LEAF benchmark, etc. However, little attention has been paid to demonstrating an FL benchmark that handles complicated semantics, where each sample encompasses diverse semantic information from multiple labels, such as Panoptic Scene Graph Generation (PSG) with objects, subjects, and relations between them. Because the existing benchmark is designed to distribute data in a narrow view of a single semantic, e.g., a one-hot label, managing the complicated semantic heterogeneity across clients when formalizing FL benchmarks is non-trivial. In this paper, we propose a benchmark process to establish an FL benchmark with controllable semantic heterogeneity across clients: two key steps are i) data clustering with semantics and ii) data distributing via controllable semantic heterogeneity across clients. As a proof of concept, we first construct a federated PSG benchmark, demonstrating the efficacy of the existing PSG methods in an FL setting with controllable semantic heterogeneity of scene graphs. We also present the effectiveness of our benchmark by applying robust federated learning algorithms to data heterogeneity to show increased performance. Our code is available at this https URL.
+
+
+
+ 271. 【2412.10435】COEF-VQ: Cost-Efficient Video Quality Understanding through a Cascaded Multimodal LLM Framework
+ 链接:https://arxiv.org/abs/2412.10435
+ 作者:Xin Dong,Sen Jia,Hongyu Xiong
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Multimodal Large Language, recent Multimodal Large, Large Language Model, Multimodal Large, Large Language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recently, with the emergence of recent Multimodal Large Language Model (MLLM) technology, it has become possible to exploit its video understanding capability on different classification tasks. In practice, we face the difficulty of huge requirements for GPU resource if we need to deploy MLLMs online. In this paper, we propose COEF-VQ, a novel cascaded MLLM framework for better video quality understanding on TikTok. To this end, we first propose a MLLM fusing all visual, textual and audio signals, and then develop a cascade framework with a lightweight model as pre-filtering stage and MLLM as fine-consideration stage, significantly reducing the need for GPU resource, while retaining the performance demonstrated solely by MLLM. To demonstrate the effectiveness of COEF-VQ, we deployed this new framework onto the video management platform (VMP) at TikTok, and performed a series of detailed experiments on two in-house tasks related to video quality understanding. We show that COEF-VQ leads to substantial performance gains with limit resource consumption in these two tasks.
+
+
+
+ 272. 【2412.10433】Implicit Neural Compression of Point Clouds
+ 链接:https://arxiv.org/abs/2412.10433
+ 作者:Hongning Ruan,Yulin Shao,Qianqian Yang,Liang Zhao,Zhaoyang Zhang,Dusit Niyato
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Signal Processing (eess.SP)
+ 关键词:numerous applications due, point cloud, objects and scenes, Point, accurately depict
+ 备注: 16 pages, 8 figures
+
+ 点击查看摘要
+ Abstract:Point clouds have gained prominence in numerous applications due to their ability to accurately depict 3D objects and scenes. However, compressing unstructured, high-precision point cloud data effectively remains a significant challenge. In this paper, we propose NeRC$^{\textbf{3}}$, a novel point cloud compression framework leveraging implicit neural representations to handle both geometry and attributes. Our approach employs two coordinate-based neural networks to implicitly represent a voxelized point cloud: the first determines the occupancy status of a voxel, while the second predicts the attributes of occupied voxels. By feeding voxel coordinates into these networks, the receiver can efficiently reconstructs the original point cloud's geometry and attributes. The neural network parameters are quantized and compressed alongside auxiliary information required for reconstruction. Additionally, we extend our method to dynamic point cloud compression with techniques to reduce temporal redundancy, including a 4D spatial-temporal representation termed 4D-NeRC$^{\textbf{3}}$. Experimental results validate the effectiveness of our approach: for static point clouds, NeRC$^{\textbf{3}}$ outperforms octree-based methods in the latest G-PCC standard. For dynamic point clouds, 4D-NeRC$^{\textbf{3}}$ demonstrates superior geometry compression compared to state-of-the-art G-PCC and V-PCC standards and achieves competitive results for joint geometry and attribute compression.
+
+
+
+ 273. 【2412.10431】CUPS: Improving Human Pose-Shape Estimators with Conformalized Deep Uncertainty
+ 链接:https://arxiv.org/abs/2412.10431
+ 作者:Harry Zhang,Luca Carlone
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:introduce CUPS, RGB videos, uncertainty quantification, conformal prediction, integrating uncertainty quantification
+ 备注:
+
+ 点击查看摘要
+ Abstract:We introduce CUPS, a novel method for learning sequence-to-sequence 3D human shapes and poses from RGB videos with uncertainty quantification. To improve on top of prior work, we develop a method to generate and score multiple hypotheses during training, effectively integrating uncertainty quantification into the learning process. This process results in a deep uncertainty function that is trained end-to-end with the 3D pose estimator. Post-training, the learned deep uncertainty model is used as the conformity score, which can be used to calibrate a conformal predictor in order to assess the quality of the output prediction. Since the data in human pose-shape learning is not fully exchangeable, we also present two practical bounds for the coverage gap in conformal prediction, developing theoretical backing for the uncertainty bound of our model. Our results indicate that by taking advantage of deep uncertainty with conformal prediction, our method achieves state-of-the-art performance across various metrics and datasets while inheriting the probabilistic guarantees of conformal prediction.
+
+
+
+ 274. 【2412.10430】Unsupervised Cross-Domain Regression for Fine-grained 3D Game Character Reconstruction
+ 链接:https://arxiv.org/abs/2412.10430
+ 作者:Qi Wen,Xiang Wen,Hao Jiang,Siqi Yang,Bingfeng Han,Tianlei Hu,Gang Chen,Shuang Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:virtual world faithfully, world faithfully, rapid development, virtual world, game character
+ 备注: 12 pages, 10 figures
+
+ 点击查看摘要
+ Abstract:With the rise of the ``metaverse'' and the rapid development of games, it has become more and more critical to reconstruct characters in the virtual world faithfully. The immersive experience is one of the most central themes of the ``metaverse'', while the reducibility of the avatar is the crucial point. Meanwhile, the game is the carrier of the metaverse, in which players can freely edit the facial appearance of the game character. In this paper, we propose a simple but powerful cross-domain framework that can reconstruct fine-grained 3D game characters from single-view images in an end-to-end manner. Different from the previous methods, which do not resolve the cross-domain gap, we propose an effective regressor that can greatly reduce the discrepancy between the real-world domain and the game domain. To figure out the drawbacks of no ground truth, our unsupervised framework has accomplished the knowledge transfer of the target domain. Additionally, an innovative contrastive loss is proposed to solve the instance-wise disparity, which keeps the person-specific details of the reconstructed character. In contrast, an auxiliary 3D identity-aware extractor is activated to make the results of our model more impeccable. Then a large set of physically meaningful facial parameters is generated robustly and exquisitely. Experiments demonstrate that our method yields state-of-the-art performance in 3D game character reconstruction.
+
+
+
+ 275. 【2412.10429】GPTDrawer: Enhancing Visual Synthesis through ChatGPT
+ 链接:https://arxiv.org/abs/2412.10429
+ 作者:Kun Li,Xinwei Chen,Tianyou Song,Hansong Zhang,Wenzhe Zhang,Qing Shan
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:prompts remains paramount, textual prompts remains, AI-driven image generation, remains paramount, burgeoning field
+ 备注:
+
+ 点击查看摘要
+ Abstract:In the burgeoning field of AI-driven image generation, the quest for precision and relevance in response to textual prompts remains paramount. This paper introduces GPTDrawer, an innovative pipeline that leverages the generative prowess of GPT-based models to enhance the visual synthesis process. Our methodology employs a novel algorithm that iteratively refines input prompts using keyword extraction, semantic analysis, and image-text congruence evaluation. By integrating ChatGPT for natural language processing and Stable Diffusion for image generation, GPTDrawer produces a batch of images that undergo successive refinement cycles, guided by cosine similarity metrics until a threshold of semantic alignment is attained. The results demonstrate a marked improvement in the fidelity of images generated in accordance with user-defined prompts, showcasing the system's ability to interpret and visualize complex semantic constructs. The implications of this work extend to various applications, from creative arts to design automation, setting a new benchmark for AI-assisted creative processes.
+
+
+
+ 276. 【2412.10426】CAP: Evaluation of Persuasive and Creative Image Generation
+ 链接:https://arxiv.org/abs/2412.10426
+ 作者:Aysan Aghazadeh,Adriana Kovashka
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL); Graphics (cs.GR)
+ 关键词:CAP, advertisement image generation, Alignment, Persuasiveness, images
+ 备注:
+
+ 点击查看摘要
+ Abstract:We address the task of advertisement image generation and introduce three evaluation metrics to assess Creativity, prompt Alignment, and Persuasiveness (CAP) in generated advertisement images. Despite recent advancements in Text-to-Image (T2I) generation and their performance in generating high-quality images for explicit descriptions, evaluating these models remains challenging. Existing evaluation methods focus largely on assessing alignment with explicit, detailed descriptions, but evaluating alignment with visually implicit prompts remains an open problem. Additionally, creativity and persuasiveness are essential qualities that enhance the effectiveness of advertisement images, yet are seldom measured. To address this, we propose three novel metrics for evaluating the creativity, alignment, and persuasiveness of generated images. Our findings reveal that current T2I models struggle with creativity, persuasiveness, and alignment when the input text is implicit messages. We further introduce a simple yet effective approach to enhance T2I models' capabilities in producing images that are better aligned, more creative, and more persuasive.
+
+
+
+ 277. 【2412.10419】Personalized and Sequential Text-to-Image Generation
+ 链接:https://arxiv.org/abs/2412.10419
+ 作者:Ofir Nabati,Guy Tennenholtz,ChihWei Hsu,Moonkyung Ryu,Deepak Ramachandran,Yinlam Chow,Xiang Li,Craig Boutilier
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG); Systems and Control (eess.SY)
+ 关键词:designing a reinforcement, reinforcement learning, address the problem, iteratively improves, improves a set
+ 备注: Link to PASTA dataset: [this https URL](https://www.kaggle.com/datasets/googleai/pasta-data)
+
+ 点击查看摘要
+ Abstract:We address the problem of personalized, interactive text-to-image (T2I) generation, designing a reinforcement learning (RL) agent which iteratively improves a set of generated images for a user through a sequence of prompt expansions. Using human raters, we create a novel dataset of sequential preferences, which we leverage, together with large-scale open-source (non-sequential) datasets. We construct user-preference and user-choice models using an EM strategy and identify varying user preference types. We then leverage a large multimodal language model (LMM) and a value-based RL approach to suggest a personalized and diverse slate of prompt expansions to the user. Our Personalized And Sequential Text-to-image Agent (PASTA) extends T2I models with personalized multi-turn capabilities, fostering collaborative co-creation and addressing uncertainty or underspecification in a user's intent. We evaluate PASTA using human raters, showing significant improvement compared to baseline methods. We also release our sequential rater dataset and simulated user-rater interactions to support future research in personalized, multi-turn T2I generation.
+
+
+
+ 278. 【2412.11946】Physics Meets Pixels: PDE Models in Image Processing
+ 链接:https://arxiv.org/abs/2412.11946
+ 作者:Alejandro Garnung Menéndez
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Numerical Analysis (math.NA)
+ 关键词:Partial Differential Equations, Partial Differential, Differential Equations, geometric properties inherent, image processing
+ 备注: 19 pages, 15 figures, 4 tables
+
+ 点击查看摘要
+ Abstract:Partial Differential Equations (PDEs) have long been recognized as powerful tools for image processing and analysis, providing a framework to model and exploit structural and geometric properties inherent in visual data. Over the years, numerous PDE-based models have been developed and refined, inspired by natural analogies between physical phenomena and image spaces. These methods have proven highly effective in a wide range of applications, including denoising, deblurring, sharpening, inpainting, feature extraction, and others. This work provides a theoretical and computational exploration of both fundamental and innovative PDE models applied to image processing, accompanied by extensive numerical experimentation and objective and subjective analysis. Building upon well-established techniques, we introduce novel physical-based PDE models specifically designed for various image processing tasks. These models incorporate mathematical principles and approaches that, to the best of our knowledge, have not been previously applied in this domain, showcasing their potential to address challenges beyond the capabilities of traditional and existing PDE methods. By formulating and solving these mathematical models, we demonstrate their effectiveness in advancing image processing tasks while retaining a rigorous connection to their theoretical underpinnings. This work seeks to bridge foundational concepts and cutting-edge innovations, contributing to the evolution of PDE methodologies in digital image processing and related interdisciplinary fields.
+
+
+
+ 279. 【2412.11938】Are the Latent Representations of Foundation Models for Pathology Invariant to Rotation?
+ 链接:https://arxiv.org/abs/2412.11938
+ 作者:Matouš Elphick,Samra Turajlic,Guang Yang
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:digital pathology encode, pathology encode small, encode small patches, downstream tasks, digital pathology
+ 备注: Samra Turajlic and Guang Yang are joint last authors
+
+ 点击查看摘要
+ Abstract:Self-supervised foundation models for digital pathology encode small patches from H\E whole slide images into latent representations used for downstream tasks. However, the invariance of these representations to patch rotation remains unexplored. This study investigates the rotational invariance of latent representations across twelve foundation models by quantifying the alignment between non-rotated and rotated patches using mutual $k$-nearest neighbours and cosine distance. Models that incorporated rotation augmentation during self-supervised training exhibited significantly greater invariance to rotations. We hypothesise that the absence of rotational inductive bias in the transformer architecture necessitates rotation augmentation during training to achieve learned invariance. Code: this https URL.
+
+
+
+ 280. 【2412.11849】Ensemble Learning and 3D Pix2Pix for Comprehensive Brain Tumor Analysis in Multimodal MRI
+ 链接:https://arxiv.org/abs/2412.11849
+ 作者:Ramy A. Zeineldin,Franziska Mathis-Ullrich
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Generative Adversarial Network, convolutional neural networks, multi-modal magnetic resonance, Generative Adversarial, Adversarial Network
+ 备注: Accepted at the MICCAI BraTS Challenge 2023
+
+ 点击查看摘要
+ Abstract:Motivated by the need for advanced solutions in the segmentation and inpainting of glioma-affected brain regions in multi-modal magnetic resonance imaging (MRI), this study presents an integrated approach leveraging the strengths of ensemble learning with hybrid transformer models and convolutional neural networks (CNNs), alongside the innovative application of 3D Pix2Pix Generative Adversarial Network (GAN). Our methodology combines robust tumor segmentation capabilities, utilizing axial attention and transformer encoders for enhanced spatial relationship modeling, with the ability to synthesize biologically plausible brain tissue through 3D Pix2Pix GAN. This integrated approach addresses the BraTS 2023 cluster challenges by offering precise segmentation and realistic inpainting, tailored for diverse tumor types and sub-regions. The results demonstrate outstanding performance, evidenced by quantitative evaluations such as the Dice Similarity Coefficient (DSC), Hausdorff Distance (HD95) for segmentation, and Structural Similarity Index Measure (SSIM), Peak Signal-to-Noise Ratio (PSNR), and Mean-Square Error (MSE) for inpainting. Qualitative assessments further validate the high-quality, clinically relevant outputs. In conclusion, this study underscores the potential of combining advanced machine learning techniques for comprehensive brain tumor analysis, promising significant advancements in clinical decision-making and patient care within the realm of medical imaging.
+
+
+
+ 281. 【2412.11771】Point Cloud-Assisted Neural Image Compression
+ 链接:https://arxiv.org/abs/2412.11771
+ 作者:Ziqun Li,Qi Zhang,Xiaofeng Huang,Zhao Wang,Siwei Ma,Wei Yan
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:High-efficient image compression, High-efficient image, critical requirement, image compression, image compression performance
+ 备注:
+
+ 点击查看摘要
+ Abstract:High-efficient image compression is a critical requirement. In several scenarios where multiple modalities of data are captured by different sensors, the auxiliary information from other modalities are not fully leveraged by existing image-only codecs, leading to suboptimal compression efficiency. In this paper, we increase image compression performance with the assistance of point cloud, which is widely adopted in the area of autonomous driving. We first unify the data representation for both modalities to facilitate data processing. Then, we propose the point cloud-assisted neural image codec (PCA-NIC) to enhance the preservation of image texture and structure by utilizing the high-dimensional point cloud information. We further introduce a multi-modal feature fusion transform module (MMFFT) to capture more representative image features, remove redundant information between channels and modalities that are not relevant to the image content. Our work is the first to improve image compression performance using point cloud and achieves state-of-the-art performance.
+
+
+
+ 282. 【2412.11681】Fast-staged CNN Model for Accurate pulmonary diseases and Lung cancer detection
+ 链接:https://arxiv.org/abs/2412.11681
+ 作者:Abdelbaki Souid,Mohamed Hamroun,Soufiene Ben Othman,Hedi Sakli,Naceur Abdelkarim
+ 类目:Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:global health concern, significant global health, health concern, treated promptly, significant global
+ 备注: IEEE International Workshop on Mechatronic Systems Supervision 2023
+
+ 点击查看摘要
+ Abstract:Pulmonary pathologies are a significant global health concern, often leading to fatal outcomes if not diagnosed and treated promptly. Chest radiography serves as a primary diagnostic tool, but the availability of experienced radiologists remains limited. Advances in Artificial Intelligence (AI) and machine learning, particularly in computer vision, offer promising solutions to address this challenge.
+This research evaluates a deep learning model designed to detect lung cancer, specifically pulmonary nodules, along with eight other lung pathologies, using chest radiographs. The study leverages diverse datasets comprising over 135,120 frontal chest radiographs to train a Convolutional Neural Network (CNN). A two-stage classification system, utilizing ensemble methods and transfer learning, is employed to first triage images into Normal or Abnormal categories and then identify specific pathologies, including lung nodules.
+The deep learning model achieves notable results in nodule classification, with a top-performing accuracy of 77%, a sensitivity of 0.713, a specificity of 0.776 during external validation, and an AUC score of 0.888. Despite these successes, some misclassifications were observed, primarily false negatives.
+In conclusion, the model demonstrates robust potential for generalization across diverse patient populations, attributed to the geographic diversity of the training dataset. Future work could focus on integrating ETL data distribution strategies and expanding the dataset with additional nodule-type samples to further enhance diagnostic accuracy.
+
Comments:
+IEEE International Workshop on Mechatronic Systems Supervision 2023
+Subjects:
+Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+Cite as:
+arXiv:2412.11681 [eess.IV]
+(or
+arXiv:2412.11681v1 [eess.IV] for this version)
+https://doi.org/10.48550/arXiv.2412.11681
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)
+
+Submission history From: Mohamed Hamroun [view email] [v1]
+Mon, 16 Dec 2024 11:47:07 UTC (1,133 KB)
+
+
+
+ 283. 【2412.11468】Block-Based Multi-Scale Image Rescaling
+ 链接:https://arxiv.org/abs/2412.11468
+ 作者:Jian Li,Siwang Zhou
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Image rescaling, image rescaling methods, Image, Image Rescaling Framework, seeks to determine
+ 备注: This paper has been accepted by AAAI2025
+
+ 点击查看摘要
+ Abstract:Image rescaling (IR) seeks to determine the optimal low-resolution (LR) representation of a high-resolution (HR) image to reconstruct a high-quality super-resolution (SR) image. Typically, HR images with resolutions exceeding 2K possess rich information that is unevenly distributed across the image. Traditional image rescaling methods often fall short because they focus solely on the overall scaling rate, ignoring the varying amounts of information in different parts of the image. To address this limitation, we propose a Block-Based Multi-Scale Image Rescaling Framework (BBMR), tailored for IR tasks involving HR images of 2K resolution and higher. BBMR consists of two main components: the Downscaling Module and the Upscaling Module. In the Downscaling Module, the HR image is segmented into sub-blocks of equal size, with each sub-block receiving a dynamically allocated scaling rate while maintaining a constant overall scaling rate. For the Upscaling Module, we introduce the Joint Super-Resolution method (JointSR), which performs SR on these sub-blocks with varying scaling rates and effectively eliminates blocking artifacts. Experimental results demonstrate that BBMR significantly enhances the SR image quality on the of 2K and 4K test dataset compared to initial network image rescaling methods.
+
+
+
+ 284. 【2412.11379】Controllable Distortion-Perception Tradeoff Through Latent Diffusion for Neural Image Compression
+ 链接:https://arxiv.org/abs/2412.11379
+ 作者:Chuqin Zhou,Guo Lu,Jiangchuan Li,Xiangyu Chen,Zhengxue Cheng,Li Song,Wenjun Zhang
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Neural image, Neural image compression, trade-off among rate, fixed neural image, neural image codec
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Neural image compression often faces a challenging trade-off among rate, distortion and perception. While most existing methods typically focus on either achieving high pixel-level fidelity or optimizing for perceptual metrics, we propose a novel approach that simultaneously addresses both aspects for a fixed neural image codec. Specifically, we introduce a plug-and-play module at the decoder side that leverages a latent diffusion process to transform the decoded features, enhancing either low distortion or high perceptual quality without altering the original image compression codec. Our approach facilitates fusion of original and transformed features without additional training, enabling users to flexibly adjust the balance between distortion and perception during inference. Extensive experimental results demonstrate that our method significantly enhances the pretrained codecs with a wide, adjustable distortion-perception range while maintaining their original compression capabilities. For instance, we can achieve more than 150% improvement in LPIPS-BDRate without sacrificing more than 1 dB in PSNR.
+
+
+
+ 285. 【2412.11377】Improving Automatic Fetal Biometry Measurement with Swoosh Activation Function
+ 链接:https://arxiv.org/abs/2412.11377
+ 作者:Shijia Zhou,Euijoon Ahn,Hao Wang,Ann Quinton,Narelle Kennedy,Pradeeba Sridar,Ralph Nanan,Jinman Kim
+ 类目:Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:fetal thalamus diameter, abnormal fetal thalamus, fetal thalamus development, fetal head circumference, identifying abnormal fetal
+ 备注:
+
+ 点击查看摘要
+ Abstract:The measurement of fetal thalamus diameter (FTD) and fetal head circumference (FHC) are crucial in identifying abnormal fetal thalamus development as it may lead to certain neuropsychiatric disorders in later life. However, manual measurements from 2D-US images are laborious, prone to high inter-observer variability, and complicated by the high signal-to-noise ratio nature of the images. Deep learning-based landmark detection approaches have shown promise in measuring biometrics from US images, but the current state-of-the-art (SOTA) algorithm, BiometryNet, is inadequate for FTD and FHC measurement due to its inability to account for the fuzzy edges of these structures and the complex shape of the FTD structure. To address these inadequacies, we propose a novel Swoosh Activation Function (SAF) designed to enhance the regularization of heatmaps produced by landmark detection algorithms. Our SAF serves as a regularization term to enforce an optimum mean squared error (MSE) level between predicted heatmaps, reducing the dispersiveness of hotspots in predicted heatmaps. Our experimental results demonstrate that SAF significantly improves the measurement performances of FTD and FHC with higher intraclass correlation coefficient scores in FTD and lower mean difference scores in FHC measurement than those of the current SOTA algorithm BiometryNet. Moreover, our proposed SAF is highly generalizable and architecture-agnostic. The SAF's coefficients can be configured for different tasks, making it highly customizable. Our study demonstrates that the SAF activation function is a novel method that can improve measurement accuracy in fetal biometry landmark detection. This improvement has the potential to contribute to better fetal monitoring and improved neonatal outcomes.
+
+
+
+ 286. 【2412.11362】VRVVC: Variable-Rate NeRF-Based Volumetric Video Compression
+ 链接:https://arxiv.org/abs/2412.11362
+ 作者:Qiang Hu,Houqiang Zhong,Zihan Zheng,Xiaoyun Zhang,Zhengxue Cheng,Li Song,Guangtao Zhai,Yanfeng Wang
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Neural Radiance Field, Neural Radiance, Radiance Field, revolutionized visual media, delivering photorealistic Free-Viewpoint
+ 备注:
+
+ 点击查看摘要
+ Abstract:Neural Radiance Field (NeRF)-based volumetric video has revolutionized visual media by delivering photorealistic Free-Viewpoint Video (FVV) experiences that provide audiences with unprecedented immersion and interactivity. However, the substantial data volumes pose significant challenges for storage and transmission. Existing solutions typically optimize NeRF representation and compression independently or focus on a single fixed rate-distortion (RD) tradeoff. In this paper, we propose VRVVC, a novel end-to-end joint optimization variable-rate framework for volumetric video compression that achieves variable bitrates using a single model while maintaining superior RD performance. Specifically, VRVVC introduces a compact tri-plane implicit residual representation for inter-frame modeling of long-duration dynamic scenes, effectively reducing temporal redundancy. We further propose a variable-rate residual representation compression scheme that leverages a learnable quantization and a tiny MLP-based entropy model. This approach enables variable bitrates through the utilization of predefined Lagrange multipliers to manage the quantization error of all latent representations. Finally, we present an end-to-end progressive training strategy combined with a multi-rate-distortion loss function to optimize the entire framework. Extensive experiments demonstrate that VRVVC achieves a wide range of variable bitrates within a single model and surpasses the RD performance of existing methods across various datasets.
+
+
+
+ 287. 【2412.11277】Macro2Micro: Cross-modal Magnetic Resonance Imaging Synthesis Leveraging Multi-scale Brain Structures
+ 链接:https://arxiv.org/abs/2412.11277
+ 作者:Sooyoung Kim,Joonwoo Kwon,Junbeom Kwon,Sangyoon Bae,Yuewei Lin,Shinjae Yoo,Jiook Cha
+ 类目:Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Spanning multiple scales-from, multiple scales-from macroscopic, scales-from macroscopic anatomy, intricate microscopic architecture-the, microscopic architecture-the human
+ 备注: The code will be made available upon acceptance
+
+ 点击查看摘要
+ Abstract:Spanning multiple scales-from macroscopic anatomy down to intricate microscopic architecture-the human brain exemplifies a complex system that demands integrated approaches to fully understand its complexity. Yet, mapping nonlinear relationships between these scales remains challenging due to technical limitations and the high cost of multimodal Magnetic Resonance Imaging (MRI) acquisition. Here, we introduce Macro2Micro, a deep learning framework that predicts brain microstructure from macrostructure using a Generative Adversarial Network (GAN). Grounded in the scale-free, self-similar nature of brain organization-where microscale information can be inferred from macroscale patterns-Macro2Micro explicitly encodes multiscale brain representations into distinct processing branches. To further enhance image fidelity and suppress artifacts, we propose a simple yet effective auxiliary discriminator and learning objective. Our results show that Macro2Micro faithfully translates T1-weighted MRIs into corresponding Fractional Anisotropy (FA) images, achieving a 6.8% improvement in the Structural Similarity Index Measure (SSIM) compared to previous methods, while preserving the individual neurobiological characteristics.
+
+
+
+ 288. 【2412.11108】Plug-and-Play Priors as a Score-Based Method
+ 链接:https://arxiv.org/abs/2412.11108
+ 作者:Chicago Y. Park,Yuyang Hu,Michael T. McCann,Cristina Garcia-Cardona,Brendt Wohlberg,Ulugbek S. Kamilov
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:solving imaging inverse, imaging inverse problems, integrating physical measurement, physical measurement models, pre-trained deep denoisers
+ 备注:
+
+ 点击查看摘要
+ Abstract:Plug-and-play (PnP) methods are extensively used for solving imaging inverse problems by integrating physical measurement models with pre-trained deep denoisers as priors. Score-based diffusion models (SBMs) have recently emerged as a powerful framework for image generation by training deep denoisers to represent the score of the image prior. While both PnP and SBMs use deep denoisers, the score-based nature of PnP is unexplored in the literature due to its distinct origins rooted in proximal optimization. This letter introduces a novel view of PnP as a score-based method, a perspective that enables the re-use of powerful SBMs within classical PnP algorithms without retraining. We present a set of mathematical relationships for adapting popular SBMs as priors within PnP. We show that this approach enables a direct comparison between PnP and SBM-based reconstruction methods using the same neural network as the prior. Code is available at this https URL.
+
+
+
+ 289. 【2412.11106】Unpaired Multi-Domain Histopathology Virtual Staining using Dual Path Prompted Inversion
+ 链接:https://arxiv.org/abs/2412.11106
+ 作者:Bing Xiong,Yue Peng,RanRan Zhang,Fuqiang Chen,JiaYe He,Wenjian Qin
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:histochemically stained tissue, stained tissue samples, staining leverages computer-aided, Virtual staining, leverages computer-aided techniques
+ 备注:
+
+ 点击查看摘要
+ Abstract:Virtual staining leverages computer-aided techniques to transfer the style of histochemically stained tissue samples to other staining types. In virtual staining of pathological images, maintaining strict structural consistency is crucial, as these images emphasize structural integrity more than natural images. Even slight structural alterations can lead to deviations in diagnostic semantic information. Furthermore, the unpaired characteristic of virtual staining data may compromise the preservation of pathological diagnostic content. To address these challenges, we propose a dual-path inversion virtual staining method using prompt learning, which optimizes visual prompts to control content and style, while preserving complete pathological diagnostic content. Our proposed inversion technique comprises two key components: (1) Dual Path Prompted Strategy, we utilize a feature adapter function to generate reference images for inversion, providing style templates for input image inversion, called Style Target Path. We utilize the inversion of the input image as the Structural Target path, employing visual prompt images to maintain structural consistency in this path while preserving style information from the style Target path. During the deterministic sampling process, we achieve complete content-style disentanglement through a plug-and-play embedding visual prompt approach. (2) StainPrompt Optimization, where we only optimize the null visual prompt as ``operator'' for dual path inversion, rather than fine-tune pre-trained model. We optimize null visual prompt for structual and style trajectory around pivotal noise on each timestep, ensuring accurate dual-path inversion reconstruction. Extensive evaluations on publicly available multi-domain unpaired staining datasets demonstrate high structural consistency and accurate style transfer results.
+
+
+
+ 290. 【2412.11039】A Digitalized Atlas for Pulmonary Airway
+ 链接:https://arxiv.org/abs/2412.11039
+ 作者:Minghui Zhang,Chenyu Li,Hanxiao Zhang,Yaoyu Liu,Yun Gu
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:pipeline for automatic, anatomies with lobar, segmental and subsegmental, subsegmental labeling, automatic extraction
+ 备注: Under Review
+
+ 点击查看摘要
+ Abstract:In this work, we proposed AirwayAtlas, which is an end-to-end pipeline for automatic extraction of airway anatomies with lobar, segmental and subsegmental labeling. A compact representation, AirwaySign, is generated based on diverse features of airway branches. Experiments on multi-center datasets validated the effectiveness of AirwayAtlas. We also demonstrated that AirwaySign is a powerful tool for correlation analysis on pulmonary diseases.
+
+
+
+ 291. 【2412.10997】Mask Enhanced Deeply Supervised Prostate Cancer Detection on B-mode Micro-Ultrasound
+ 链接:https://arxiv.org/abs/2412.10997
+ 作者:Lichun Zhang,Steve Ran Zhou,Moon Hyung Choi,Jeong Hoon Lee,Shengtian Sang,Adam Kinnaird,Wayne G. Brisbane,Giovanni Lughezzani,Davide Maffei,Vittorio Fasulo,Patrick Albers,Sulaiman Vesal,Wei Shao,Ahmed N. El Kaffas,Richard E. Fan,Geoffrey A. Sonn,Mirabela Rusu
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Prostate cancer, deaths among men, cancer-related deaths, cancer, clinically significant cancer
+ 备注:
+
+ 点击查看摘要
+ Abstract:Prostate cancer is a leading cause of cancer-related deaths among men. The recent development of high frequency, micro-ultrasound imaging offers improved resolution compared to conventional ultrasound and potentially a better ability to differentiate clinically significant cancer from normal tissue. However, the features of prostate cancer remain subtle, with ambiguous borders with normal tissue and large variations in appearance, making it challenging for both machine learning and humans to localize it on micro-ultrasound images.
+We propose a novel Mask Enhanced Deeply-supervised Micro-US network, termed MedMusNet, to automatically and more accurately segment prostate cancer to be used as potential targets for biopsy procedures. MedMusNet leverages predicted masks of prostate cancer to enforce the learned features layer-wisely within the network, reducing the influence of noise and improving overall consistency across frames.
+MedMusNet successfully detected 76% of clinically significant cancer with a Dice Similarity Coefficient of 0.365, significantly outperforming the baseline Swin-M2F in specificity and accuracy (Wilcoxon test, Bonferroni correction, p-value0.05). While the lesion-level and patient-level analyses showed improved performance compared to human experts and different baseline, the improvements did not reach statistical significance, likely on account of the small cohort.
+We have presented a novel approach to automatically detect and segment clinically significant prostate cancer on B-mode micro-ultrasound images. Our MedMusNet model outperformed other models, surpassing even human experts. These preliminary results suggest the potential for aiding urologists in prostate cancer diagnosis via biopsy and treatment decision-making.
+
Subjects:
+Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+Cite as:
+arXiv:2412.10997 [eess.IV]
+(or
+arXiv:2412.10997v1 [eess.IV] for this version)
+https://doi.org/10.48550/arXiv.2412.10997
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)
+
+Submission history From: Mirabela Rusu [view email] [v1]
+Sat, 14 Dec 2024 23:40:53 UTC (4,740 KB)
+
+
+
+ 292. 【2412.10985】MorphiNet: A Graph Subdivision Network for Adaptive Bi-ventricle Surface Reconstruction
+ 链接:https://arxiv.org/abs/2412.10985
+ 作者:Yu Deng,Yiyang Xu,Linglong Qian,Charlene Mauger,Anastasia Nasopoulou,Steven Williams,Michelle Williams,Steven Niederer,David Newby,Andrew McCulloch,Jeff Omens,Kuberan Pushprajah,Alistair Young
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Cardiac Magnetic Resonance, Magnetic Resonance, visualize soft tissues, Cardiac Magnetic, CMR images
+ 备注:
+
+ 点击查看摘要
+ Abstract:Cardiac Magnetic Resonance (CMR) imaging is widely used for heart modelling and digital twin computational analysis due to its ability to visualize soft tissues and capture dynamic functions. However, the anisotropic nature of CMR images, characterized by large inter-slice distances and misalignments from cardiac motion, poses significant challenges to accurate model reconstruction. These limitations result in data loss and measurement inaccuracies, hindering the capture of detailed anatomical structures. This study introduces MorphiNet, a novel network that enhances heart model reconstruction by leveraging high-resolution Computer Tomography (CT) images, unpaired with CMR images, to learn heart anatomy. MorphiNet encodes anatomical structures as gradient fields, transforming template meshes into patient-specific geometries. A multi-layer graph subdivision network refines these geometries while maintaining dense point correspondence. The proposed method achieves high anatomy fidelity, demonstrating approximately 40% higher Dice scores, half the Hausdorff distance, and around 3 mm average surface error compared to state-of-the-art methods. MorphiNet delivers superior results with greater inference efficiency. This approach represents a significant advancement in addressing the challenges of CMR-based heart model reconstruction, potentially improving digital twin computational analyses of cardiac structure and functions.
+
+
+
+ 293. 【2412.10967】Biological and Radiological Dictionary of Radiomics Features: Addressing Understandable AI Issues in Personalized Prostate Cancer; Dictionary version PM1.0
+ 链接:https://arxiv.org/abs/2412.10967
+ 作者:Mohammad R. Salmanpour,Sajad Amiri,Sara Gharibi,Ahmad Shariftabrizi,Yixi Xu,William B Weeks,Arman Rahmim,Ilker Hacihaliloglu
+ 类目:Medical Physics (physics.med-ph); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:abnormal imaging findings, radiological radiomics features, visual semantic features, predict UCLA scores, moving beyond abnormal
+ 备注: 24 pages, 3 Figures, 2 Tables
+
+ 点击查看摘要
+ Abstract:This study investigates the connection between visual semantic features in PI-RADS and associated risk factors, moving beyond abnormal imaging findings by creating a standardized dictionary of biological/radiological radiomics features (RFs). Using multiparametric prostate MRI sequences (T2-weighted imaging [T2WI], diffusion-weighted imaging [DWI], and apparent diffusion coefficient [ADC]), six interpretable and seven complex classifiers, combined with nine feature selection algorithms (FSAs), were applied to segmented lesions to predict UCLA scores. Combining T2WI, DWI, and ADC with FSAs such as ANOVA F-test, Correlation Coefficient, and Fisher Score, and utilizing logistic regression, identified key features: the 90th percentile from T2WI (hypo-intensity linked to cancer risk), variance from T2WI (lesion heterogeneity), shape metrics like Least Axis Length and Surface Area to Volume ratio from ADC (lesion compactness), and Run Entropy from ADC (texture consistency). This approach achieved an average accuracy of 0.78, outperforming single-sequence methods (p 0.05). The developed dictionary provides a common language, fostering collaboration between clinical professionals and AI developers to enable trustworthy, interpretable AI for reliable clinical decisions.
+
+
+
+ 294. 【2412.10882】Integrating Generative and Physics-Based Models for Ptychographic Imaging with Uncertainty Quantification
+ 链接:https://arxiv.org/abs/2412.10882
+ 作者:Canberk Ekmekci,Tekin Bicer,Zichao Wendy Di,Junjing Deng,Mujdat Cetin
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Machine Learning (stat.ML)
+ 关键词:diffractive imaging technique, enables imaging nanometer-scale, imaging nanometer-scale features, coherent diffractive imaging, scanning coherent diffractive
+ 备注: Machine Learning and the Physical Sciences Workshop at NeurIPS 2024, 7 pages, 4 figures
+
+ 点击查看摘要
+ Abstract:Ptychography is a scanning coherent diffractive imaging technique that enables imaging nanometer-scale features in extended samples. One main challenge is that widely used iterative image reconstruction methods often require significant amount of overlap between adjacent scan locations, leading to large data volumes and prolonged acquisition times. To address this key limitation, this paper proposes a Bayesian inversion method for ptychography that performs effectively even with less overlap between neighboring scan locations. Furthermore, the proposed method can quantify the inherent uncertainty on the ptychographic object, which is created by the ill-posed nature of the ptychographic inverse problem. At a high level, the proposed method first utilizes a deep generative model to learn the prior distribution of the object and then generates samples from the posterior distribution of the object by using a Markov Chain Monte Carlo algorithm. Our results from simulated ptychography experiments show that the proposed framework can consistently outperform a widely used iterative reconstruction algorithm in cases of reduced overlap. Moreover, the proposed framework can provide uncertainty estimates that closely correlate with the true error, which is not available in practice. The project website is available here.
+
+
+
+ 295. 【2412.10826】Generative AI: A Pix2pix-GAN-Based Machine Learning Approach for Robust and Efficient Lung Segmentation
+ 链接:https://arxiv.org/abs/2412.10826
+ 作者:Sharmin Akter
+ 类目:Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:lead to misdiagnoses, Chest radiography, radiography is climacteric, climacteric in identifying, radiologist workload
+ 备注: 6 pages, 12 figures, 2 tables
+
+ 点击查看摘要
+ Abstract:Chest radiography is climacteric in identifying different pulmonary diseases, yet radiologist workload and inefficiency can lead to misdiagnoses. Automatic, accurate, and efficient segmentation of lung from X-ray images of chest is paramount for early disease detection. This study develops a deep learning framework using a Pix2pix Generative Adversarial Network (GAN) to segment pulmonary abnormalities from CXR images. This framework's image preprocessing and augmentation techniques were properly incorporated with a U-Net-inspired generator-discriminator architecture. Initially, it loaded the CXR images and manual masks from the Montgomery and Shenzhen datasets, after which preprocessing and resizing were performed. A U-Net generator is applied to the processed CXR images that yield segmented masks; then, a Discriminator Network differentiates between the generated and real masks. Montgomery dataset served as the model's training set in the study, and the Shenzhen dataset was used to test its robustness, which was used here for the first time. An adversarial loss and an L1 distance were used to optimize the model in training. All metrics, which assess precision, recall, F1 score, and Dice coefficient, prove the effectiveness of this framework in pulmonary abnormality segmentation. It, therefore, sets the basis for future studies to be performed shortly using diverse datasets that could further confirm its clinical applicability in medical imaging.
+
+
+
+ 296. 【2412.10776】Boosting ViT-based MRI Reconstruction from the Perspectives of Frequency Modulation, Spatial Purification, and Scale Diversification
+ 链接:https://arxiv.org/abs/2412.10776
+ 作者:Yucong Meng,Zhiwei Yang,Yonghong Shi,Zhijian Song
+ 类目:Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:reconstruction process presents, challenging ill-posed inverse, ill-posed inverse problem, inverse problem due, accelerated MRI reconstruction
+ 备注:
+
+ 点击查看摘要
+ Abstract:The accelerated MRI reconstruction process presents a challenging ill-posed inverse problem due to the extensive under-sampling in k-space. Recently, Vision Transformers (ViTs) have become the mainstream for this task, demonstrating substantial performance improvements. However, there are still three significant issues remain unaddressed: (1) ViTs struggle to capture high-frequency components of images, limiting their ability to detect local textures and edge information, thereby impeding MRI restoration; (2) Previous methods calculate multi-head self-attention (MSA) among both related and unrelated tokens in content, introducing noise and significantly increasing computational burden; (3) The naive feed-forward network in ViTs cannot model the multi-scale information that is important for image restoration. In this paper, we propose FPS-Former, a powerful ViT-based framework, to address these issues from the perspectives of frequency modulation, spatial purification, and scale diversification. Specifically, for issue (1), we introduce a frequency modulation attention module to enhance the self-attention map by adaptively re-calibrating the frequency information in a Laplacian pyramid. For issue (2), we customize a spatial purification attention module to capture interactions among closely related tokens, thereby reducing redundant or irrelevant feature representations. For issue (3), we propose an efficient feed-forward network based on a hybrid-scale fusion strategy. Comprehensive experiments conducted on three public datasets show that our FPS-Former outperforms state-of-the-art methods while requiring lower computational costs.
+
+
+
+ 297. 【2412.10629】Rapid Reconstruction of Extremely Accelerated Liver 4D MRI via Chained Iterative Refinement
+ 链接:https://arxiv.org/abs/2412.10629
+ 作者:Di Xu,Xin Miao,Hengjie Liu,Jessica E. Scholey,Wensha Yang,Mary Feng,Michael Ohliger,Hui Lin,Yi Lao,Yang Yang,Ke Sheng
+ 类目:Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Abstract Purpose, impractically long scanning, dense k-space signal, k-space signal acquisition, signal acquisition covering
+ 备注:
+
+ 点击查看摘要
+ Abstract:Abstract Purpose: High-quality 4D MRI requires an impractically long scanning time for dense k-space signal acquisition covering all respiratory phases. Accelerated sparse sampling followed by reconstruction enhancement is desired but often results in degraded image quality and long reconstruction time. We hereby propose the chained iterative reconstruction network (CIRNet) for efficient sparse-sampling reconstruction while maintaining clinically deployable quality. Methods: CIRNet adopts the denoising diffusion probabilistic framework to condition the image reconstruction through a stochastic iterative denoising process. During training, a forward Markovian diffusion process is designed to gradually add Gaussian noise to the densely sampled ground truth (GT), while CIRNet is optimized to iteratively reverse the Markovian process from the forward outputs. At the inference stage, CIRNet performs the reverse process solely to recover signals from noise, conditioned upon the undersampled input. CIRNet processed the 4D data (3D+t) as temporal slices (2D+t). The proposed framework is evaluated on a data cohort consisting of 48 patients (12332 temporal slices) who underwent free-breathing liver 4D MRI. 3-, 6-, 10-, 20- and 30-times acceleration were examined with a retrospective random undersampling scheme. Compressed sensing (CS) reconstruction with a spatiotemporal constraint and a recently proposed deep network, Re-Con-GAN, are selected as baselines. Results: CIRNet consistently achieved superior performance compared to CS and Re-Con-GAN. The inference time of CIRNet, CS, and Re-Con-GAN are 11s, 120s, and 0.15s. Conclusion: A novel framework, CIRNet, is presented. CIRNet maintains useable image quality for acceleration up to 30 times, significantly reducing the burden of 4DMRI.
+
+
+
+ 298. 【2412.10538】Predictive Pattern Recognition Techniques Towards Spatiotemporal Representation of Plant Growth in Simulated and Controlled Environments: A Comprehensive Review
+ 链接:https://arxiv.org/abs/2412.10538
+ 作者:Mohamed Debbagh,Shangpeng Sun,Mark Lefsrud
+ 类目:Quantitative Methods (q-bio.QM); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:plant phenomics research, Accurate predictions, plant growth patterns, phenomics research, simulated and controlled
+ 备注:
+
+ 点击查看摘要
+ Abstract:Accurate predictions and representations of plant growth patterns in simulated and controlled environments are important for addressing various challenges in plant phenomics research. This review explores various works on state-of-the-art predictive pattern recognition techniques, focusing on the spatiotemporal modeling of plant traits and the integration of dynamic environmental interactions. We provide a comprehensive examination of deterministic, probabilistic, and generative modeling approaches, emphasizing their applications in high-throughput phenotyping and simulation-based plant growth forecasting. Key topics include regressions and neural network-based representation models for the task of forecasting, limitations of existing experiment-based deterministic approaches, and the need for dynamic frameworks that incorporate uncertainty and evolving environmental feedback. This review surveys advances in 2D and 3D structured data representations through functional-structural plant models and conditional generative models. We offer a perspective on opportunities for future works, emphasizing the integration of domain-specific knowledge to data-driven methods, improvements to available datasets, and the implementation of these techniques toward real-world applications.
+
+
+
+ 299. 【2412.10452】Structurally Consistent MRI Colorization using Cross-modal Fusion Learning
+ 链接:https://arxiv.org/abs/2412.10452
+ 作者:Mayuri Mathur,Anav Chaudhary,Saurabh Kumar Gupta,Ojaswa Sharma
+ 类目:Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:underlying imaging modality, Medical image colorization, MRI, source MRI data, Medical image
+ 备注: 9 pages, 6 figures, 2 Tables
+
+ 点击查看摘要
+ Abstract:Medical image colorization can greatly enhance the interpretability of the underlying imaging modality and provide insights into human anatomy. The objective of medical image colorization is to transfer a diverse spectrum of colors distributed across human anatomy from Cryosection data to source MRI data while retaining the structures of the MRI. To achieve this, we propose a novel architecture for structurally consistent color transfer to the source MRI data. Our architecture fuses segmentation semantics of Cryosection images for stable contextual colorization of various organs in MRI images. For colorization, we neither require precise registration between MRI and Cryosection images, nor segmentation of MRI images. Additionally, our architecture incorporates a feature compression-and-activation mechanism to capture organ-level global information and suppress noise, enabling the distinction of organ-specific data in MRI scans for more accurate and realistic organ-specific colorization. Our experiments demonstrate that our architecture surpasses the existing methods and yields better quantitative and qualitative results.
+
+
+
+ 300. 【2412.10392】Computational Methods for Breast Cancer Molecular Profiling through Routine Histopathology: A Review
+ 链接:https://arxiv.org/abs/2412.10392
+ 作者:Suchithra Kunhoth,Somaya Al- Maadeed,Younes Akbari,Rafif Al Saady
+ 类目:Quantitative Methods (q-bio.QM); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Precision medicine, breast cancer management, advancing beyond conventional, individualized therapies, conventional methods
+ 备注:
+
+ 点击查看摘要
+ Abstract:Precision medicine has become a central focus in breast cancer management, advancing beyond conventional methods to deliver more precise and individualized therapies. Traditionally, histopathology images have been used primarily for diagnostic purposes; however, they are now recognized for their potential in molecular profiling, which provides deeper insights into cancer prognosis and treatment response. Recent advancements in artificial intelligence (AI) have enabled digital pathology to analyze histopathologic images for both targeted molecular and broader omic biomarkers, marking a pivotal step in personalized cancer care. These technologies offer the capability to extract various biomarkers such as genomic, transcriptomic, proteomic, and metabolomic markers directly from the routine hematoxylin and eosin (HE) stained images, which can support treatment decisions without the need for costly molecular assays. In this work, we provide a comprehensive review of AI-driven techniques for biomarker detection, with a focus on diverse omic biomarkers that allow novel biomarker discovery. Additionally, we analyze the major challenges faced in this field for robust algorithm development. These challenges highlight areas where further research is essential to bridge the gap between AI research and clinical application.
+
+
+





/Fig1_pretrain_finetune.png)
/Fig2_eda1.png)
/Fig2_eda2.png)
/Fig2_eda3.png)
/Fig3_reweight.png)
/Fig5_model1.png)
/Fig5_attention_mask.png)
/Fig4_wwm.png)
/Fig5_model2.png)
/Fig5_model3.png)
/Fig7_ensemble1.png)
/Fig6_res1.png)
/Fig6_res2.png)


%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_text_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_entity_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/model.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/dont_stop_pretraining.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/a.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/b.png)

%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/lengths_histplot.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_entity_lengths.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_label_dist.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/%E6%80%BB%E4%BD%93%E6%96%B9%E6%A1%88.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/pretrain_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/finetune_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/rdrop.png)

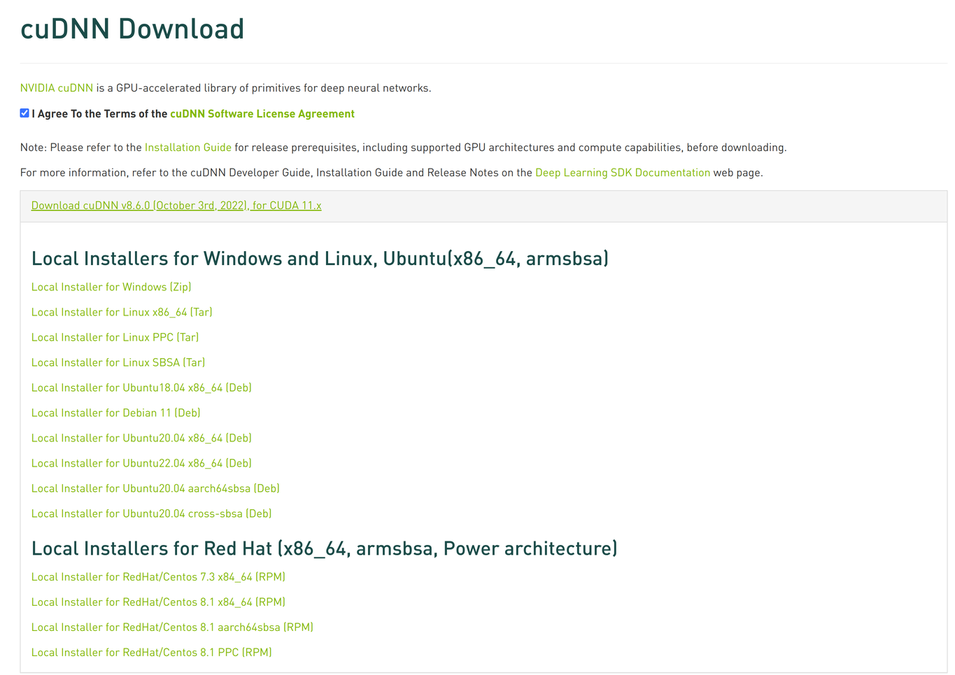
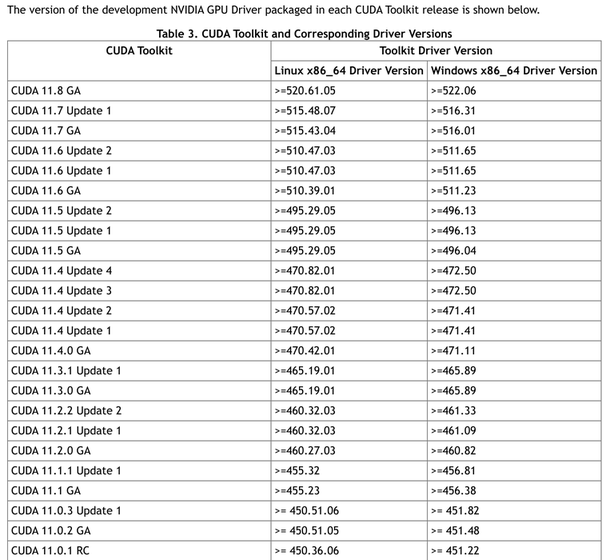

/autoencoder-architecture.png)
/variational-autoencoder-architecture.png)
/forward_vs_reversed_KL.png)
/vae-implement.png)
/reparam.png)
/generated_samples.png)







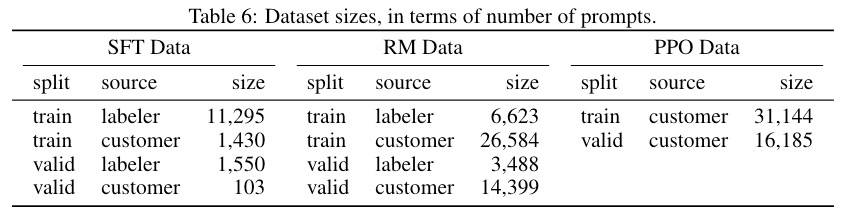
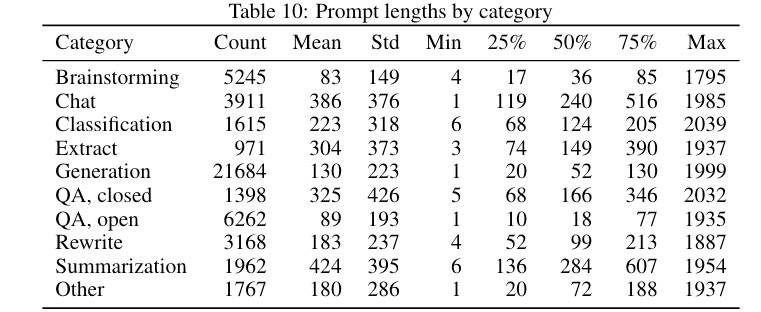
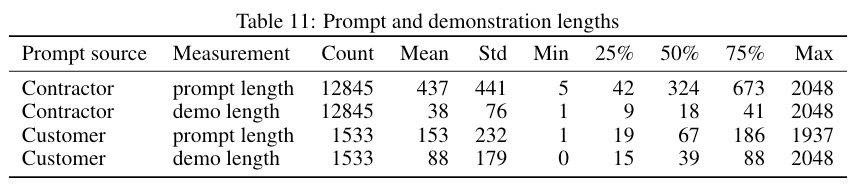

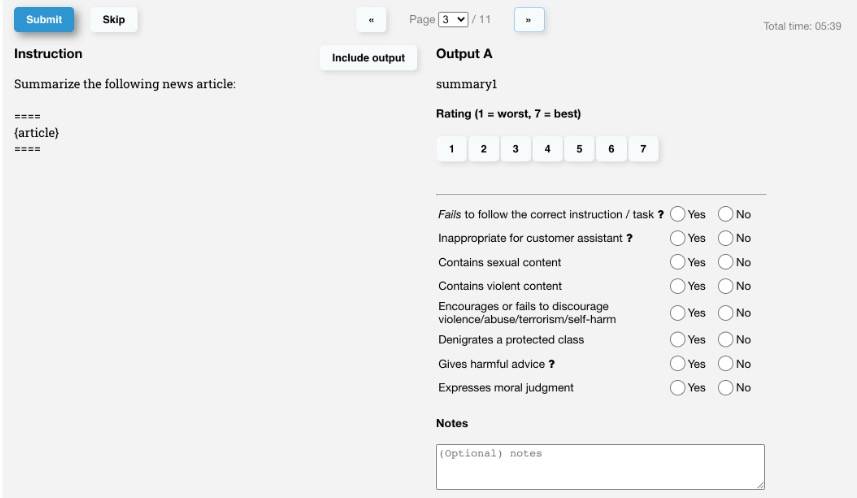
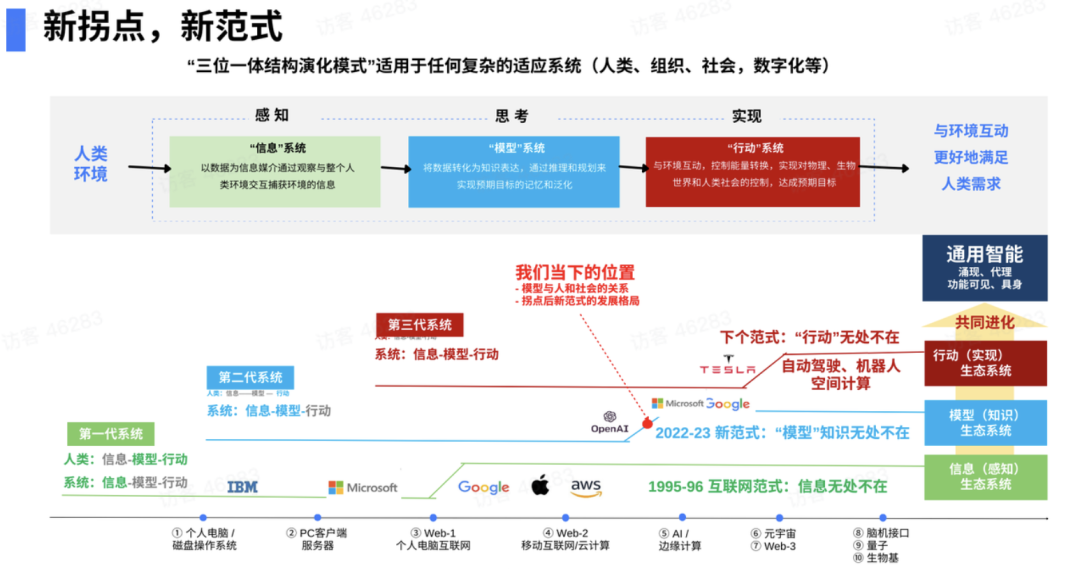
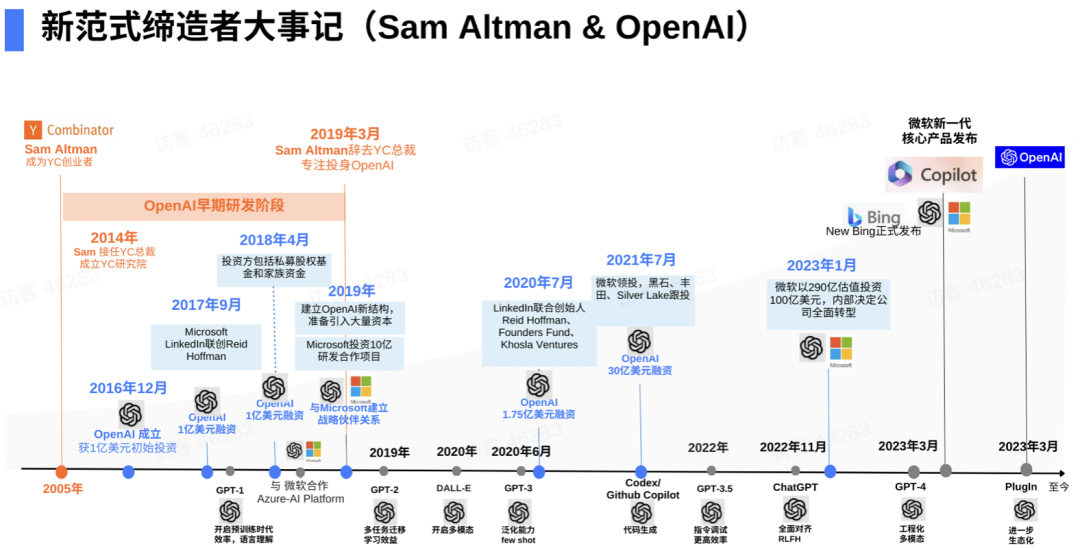
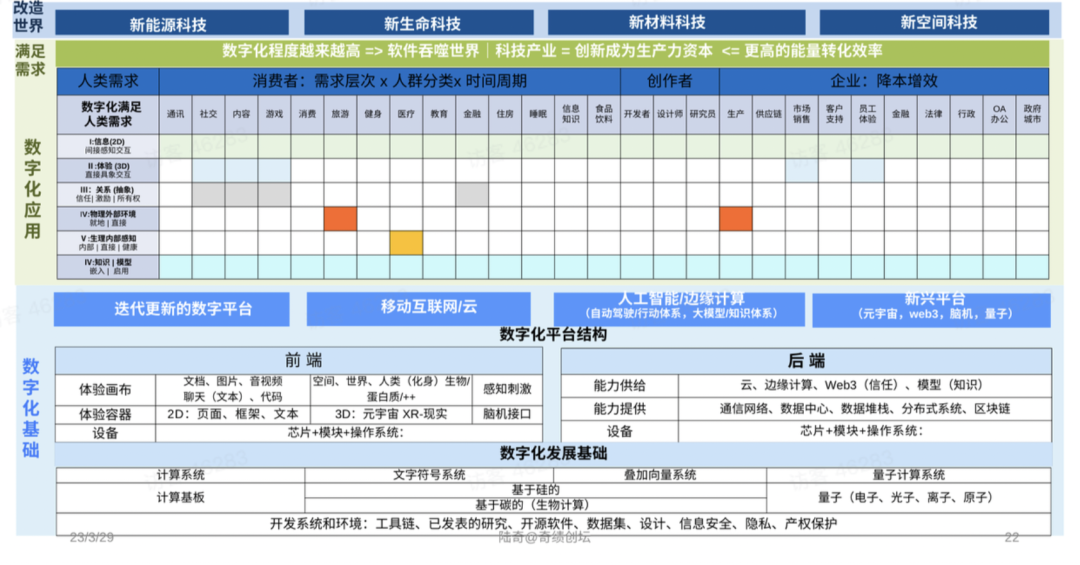
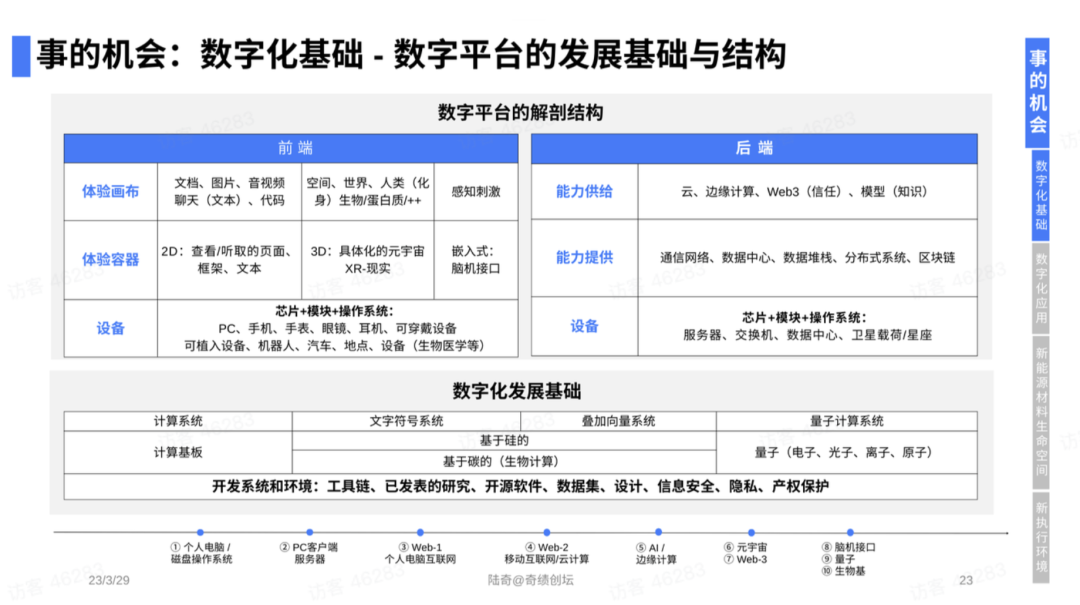
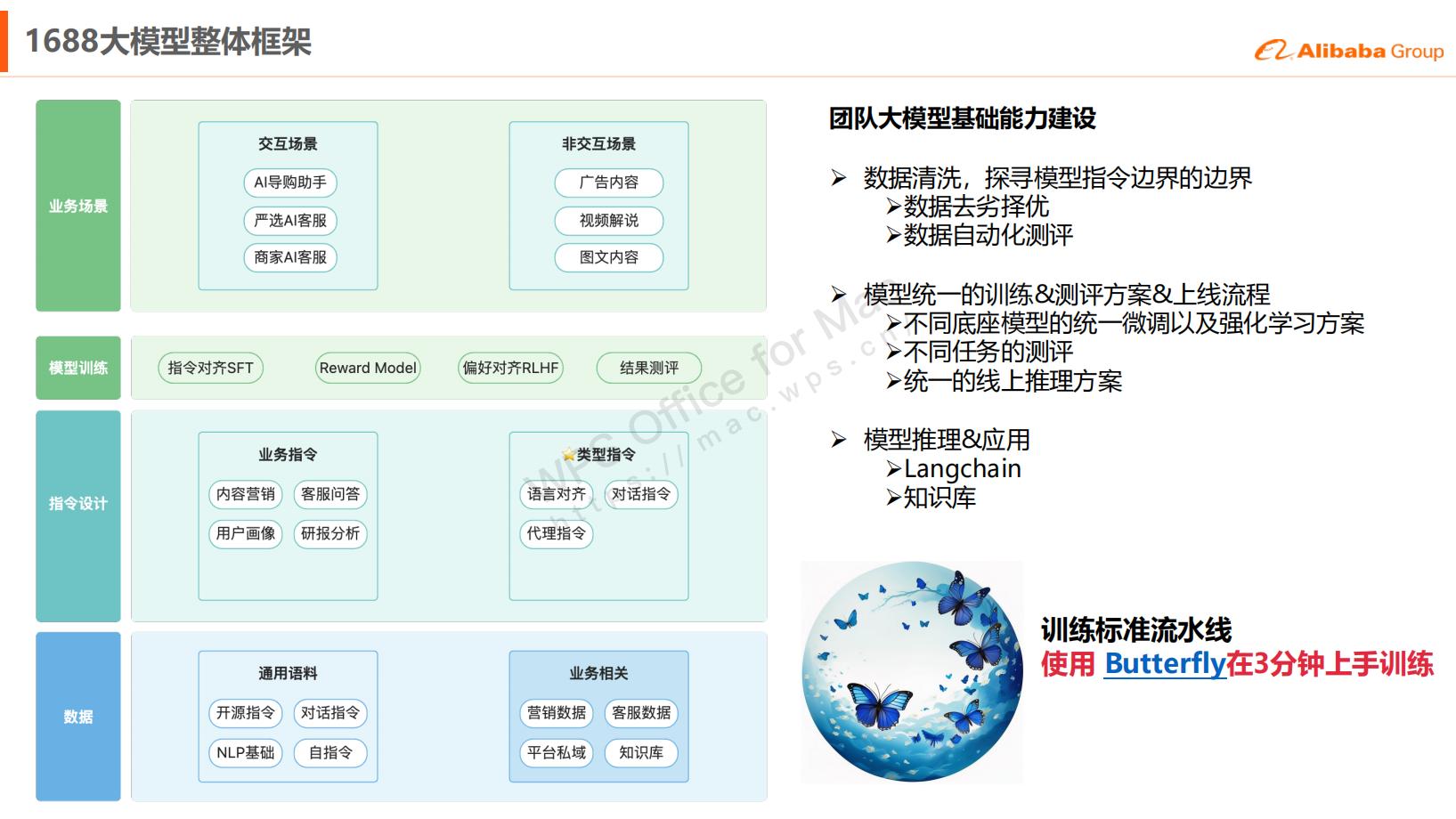
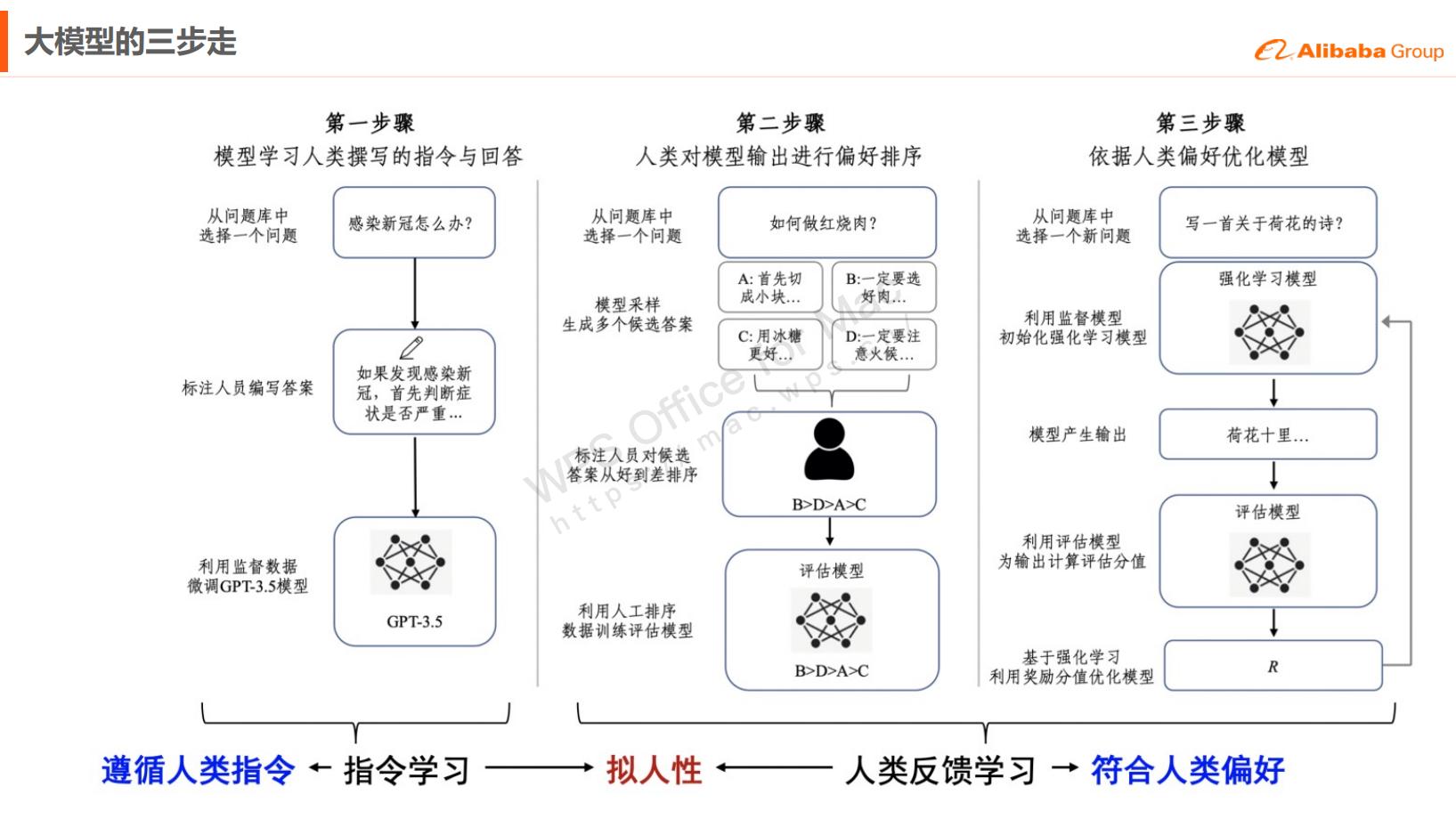
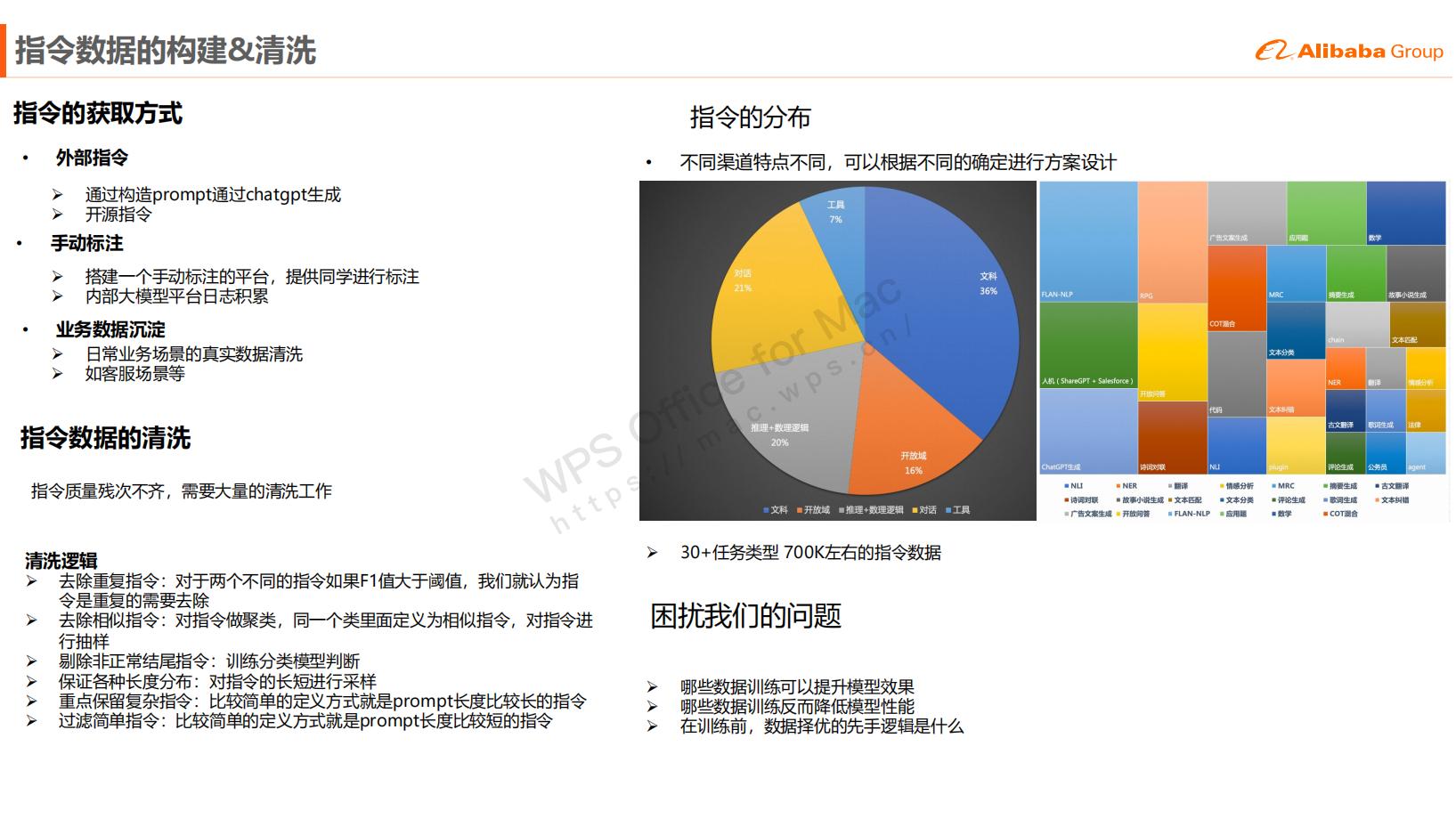

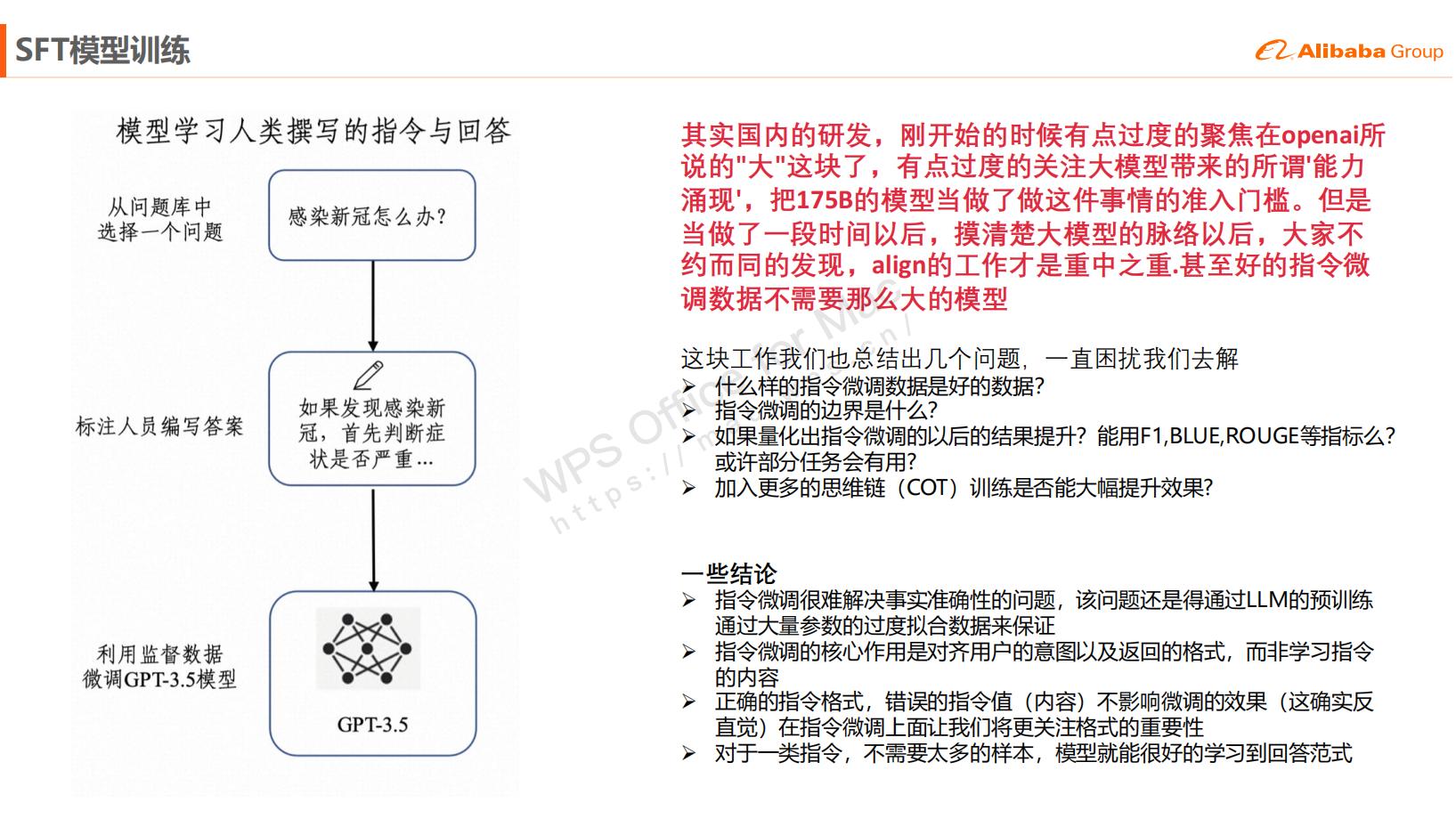

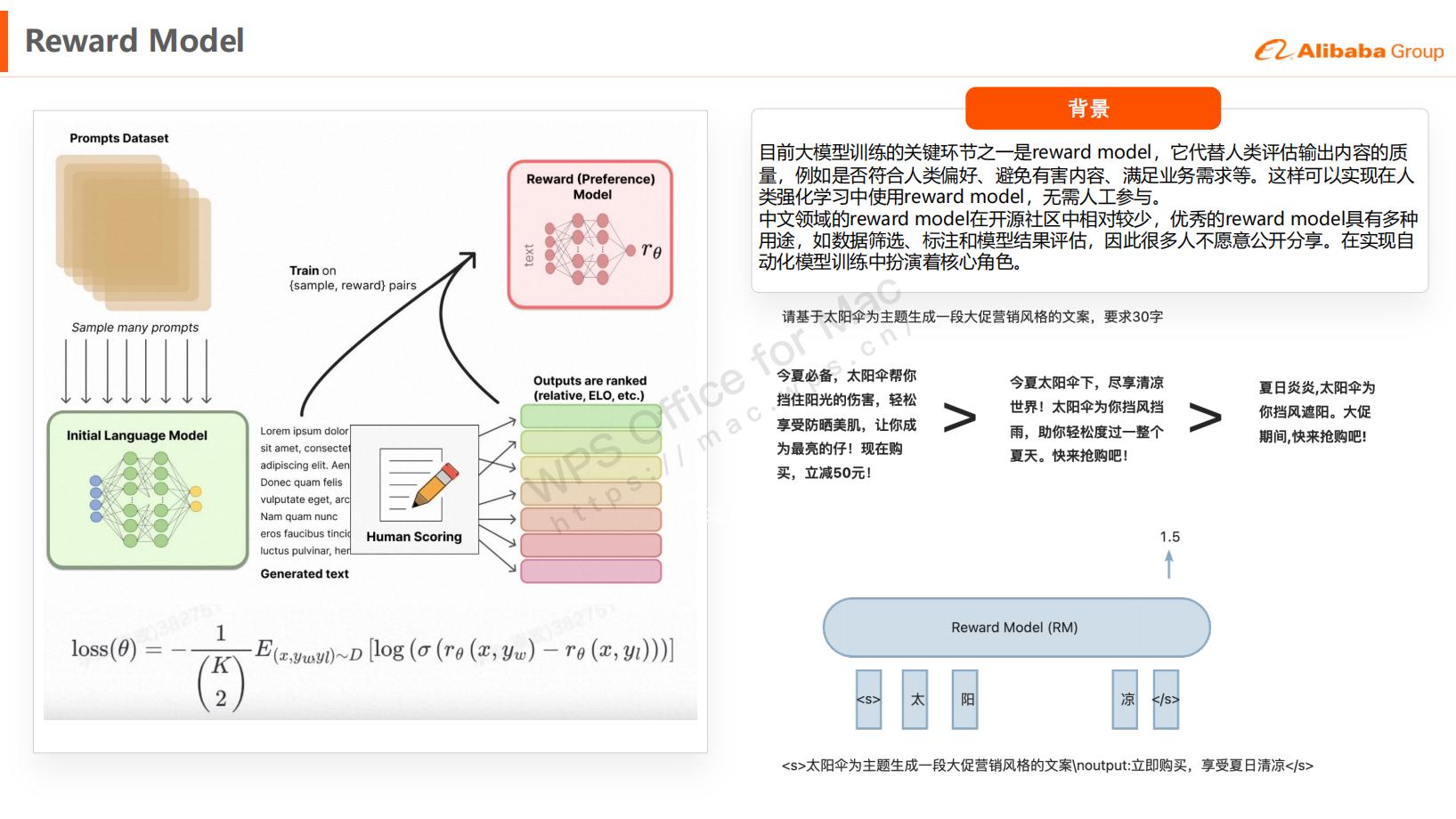




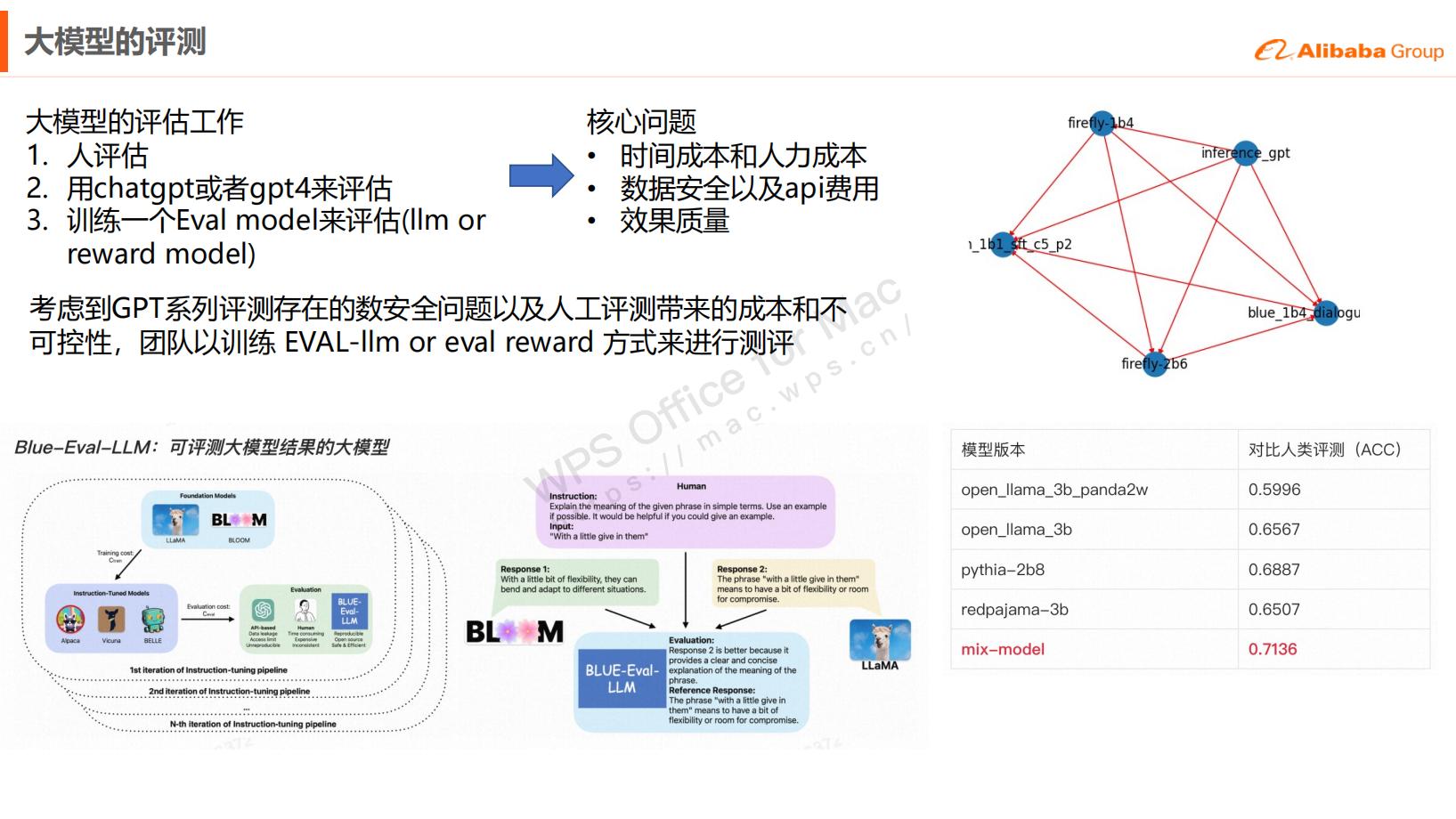
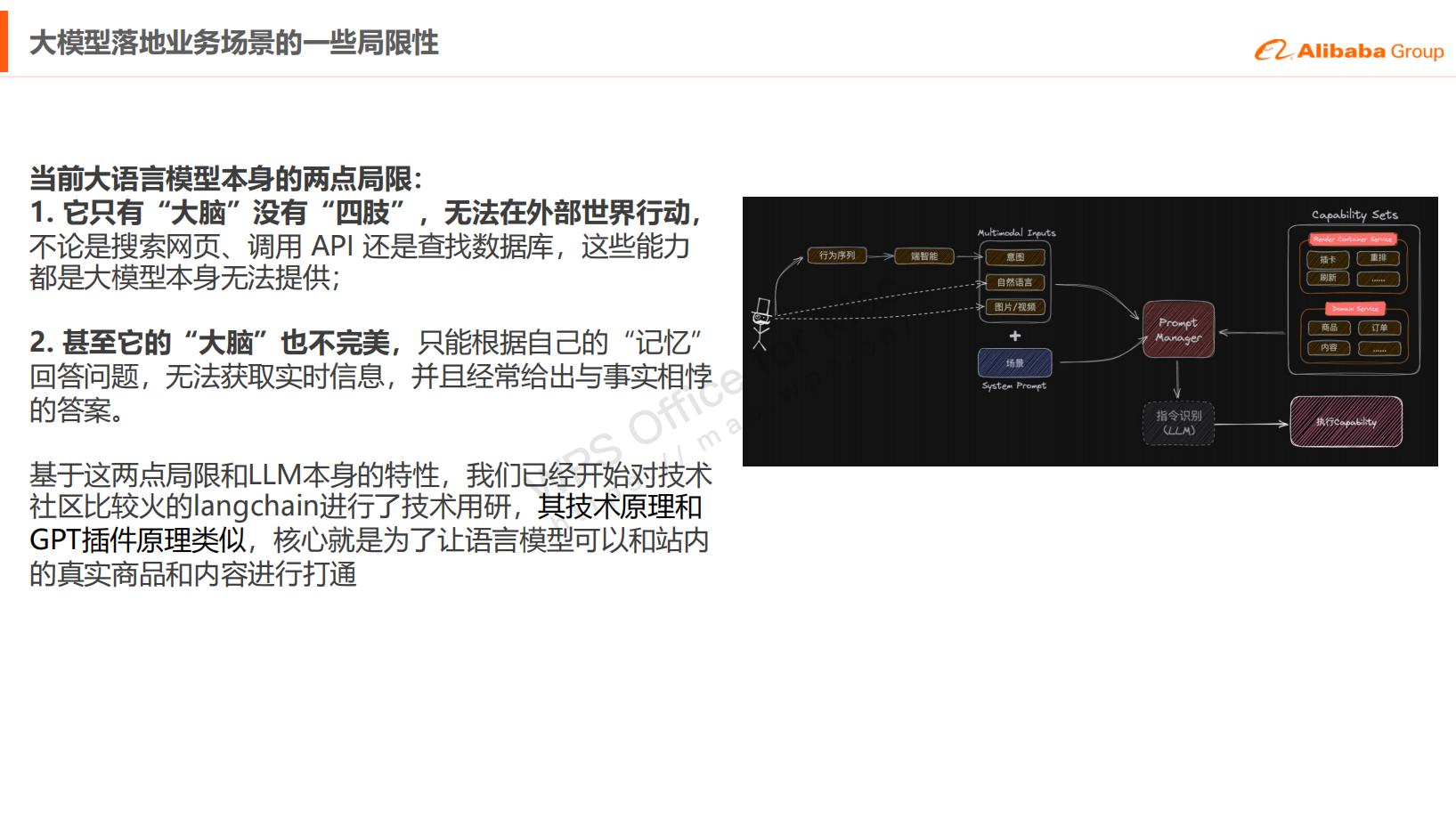





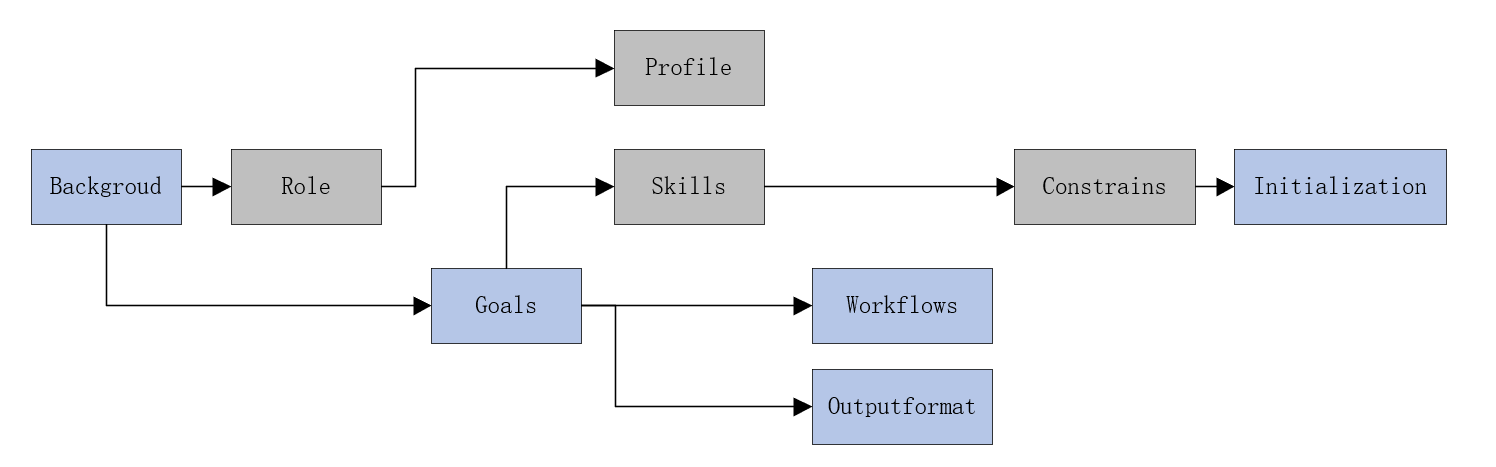

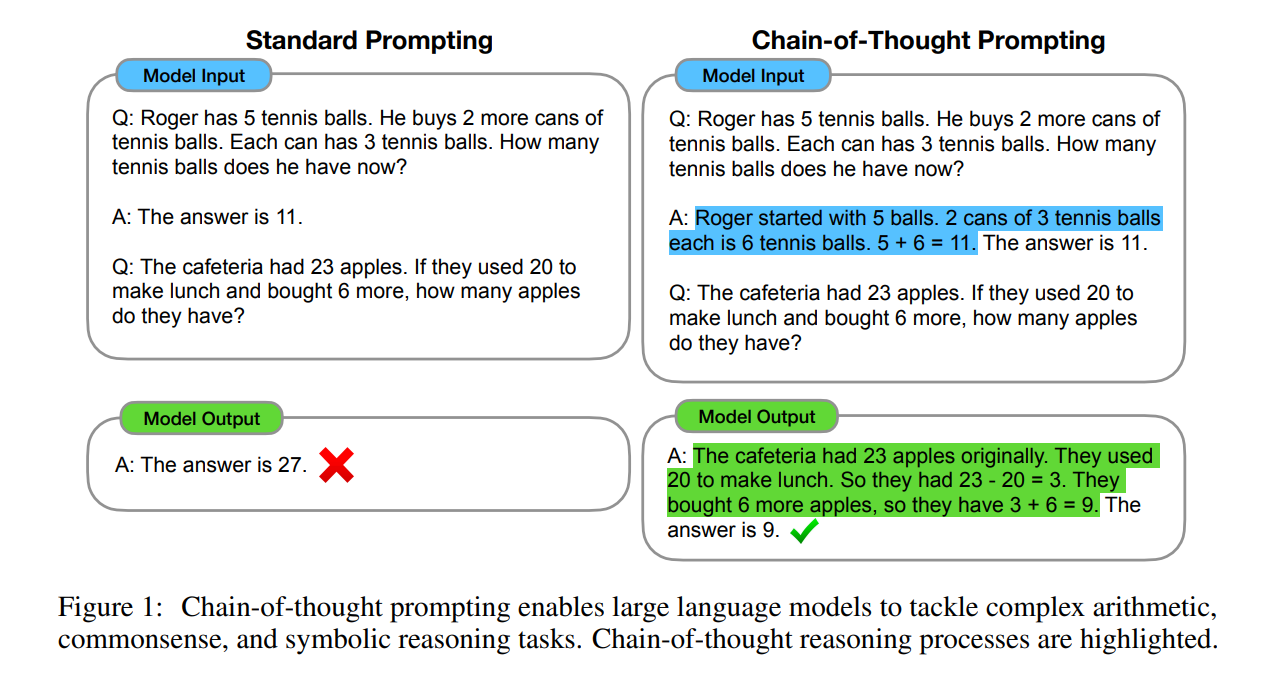

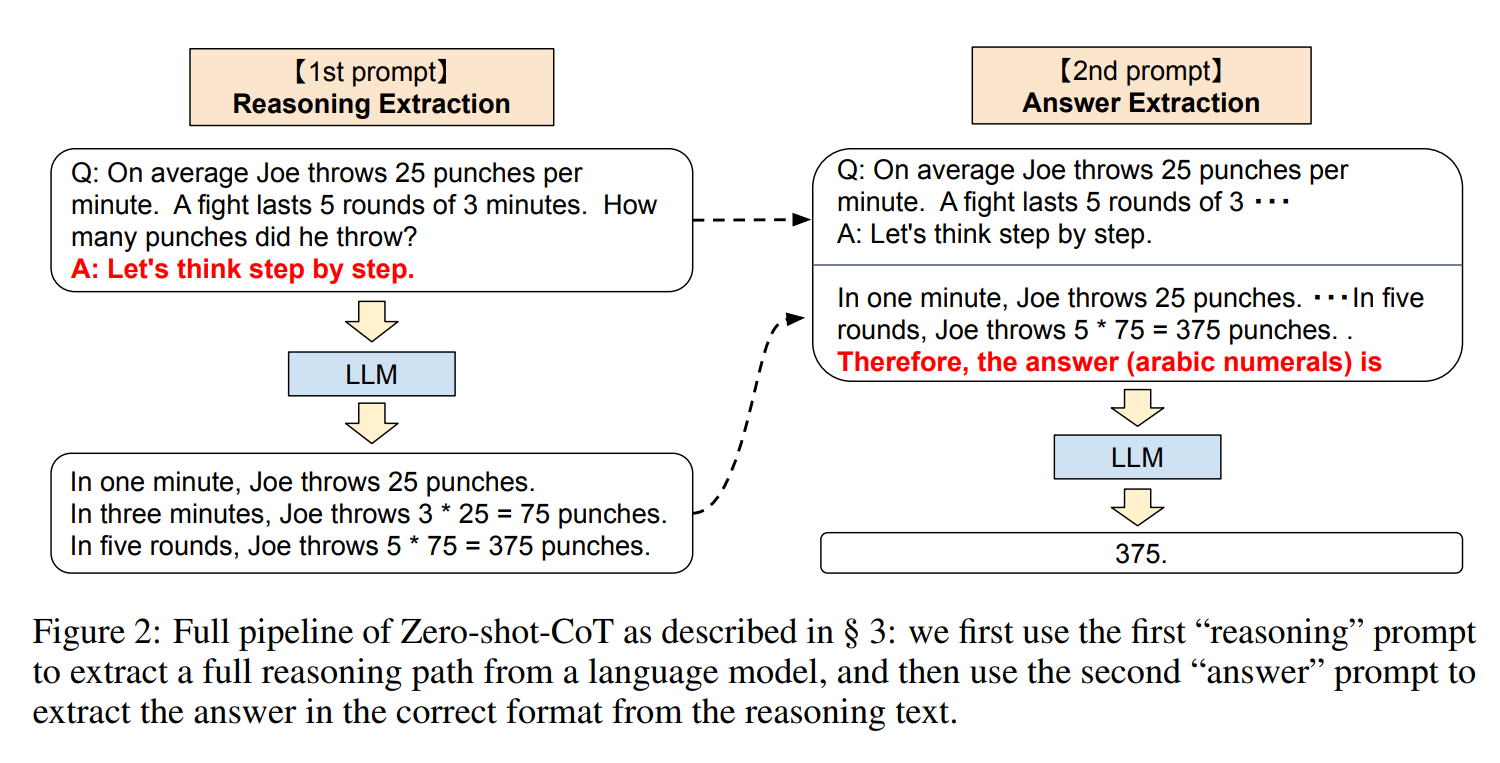
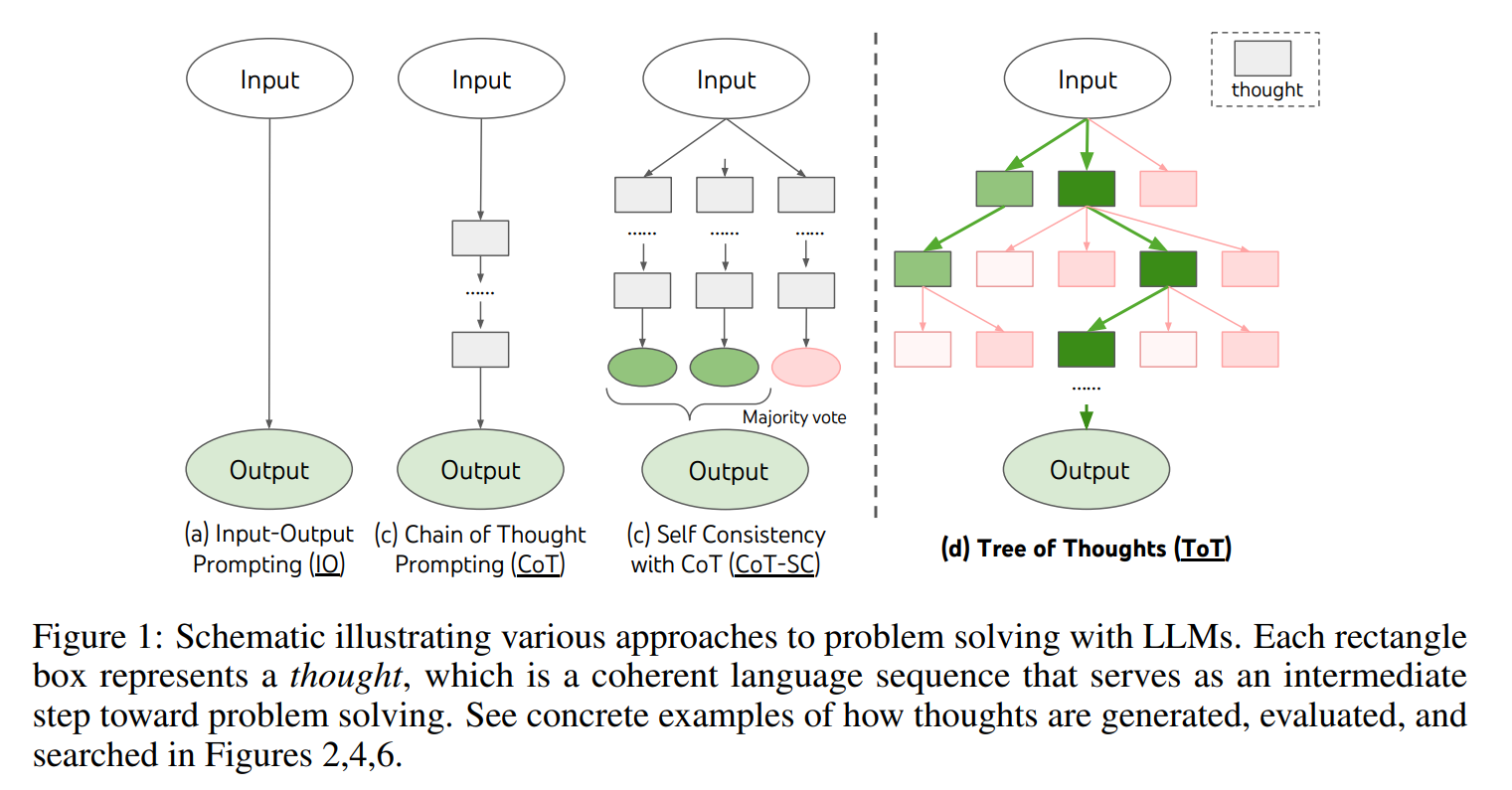


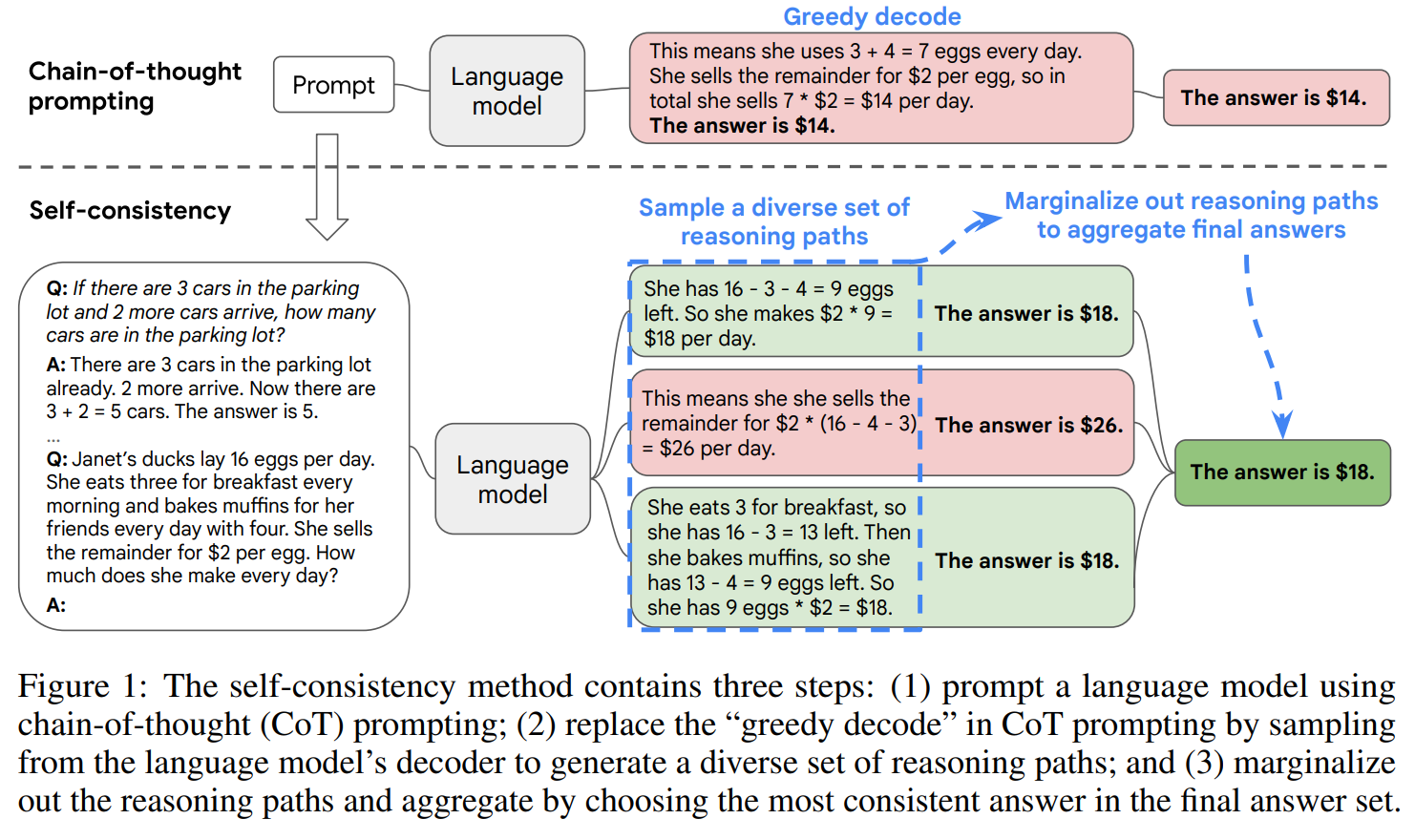
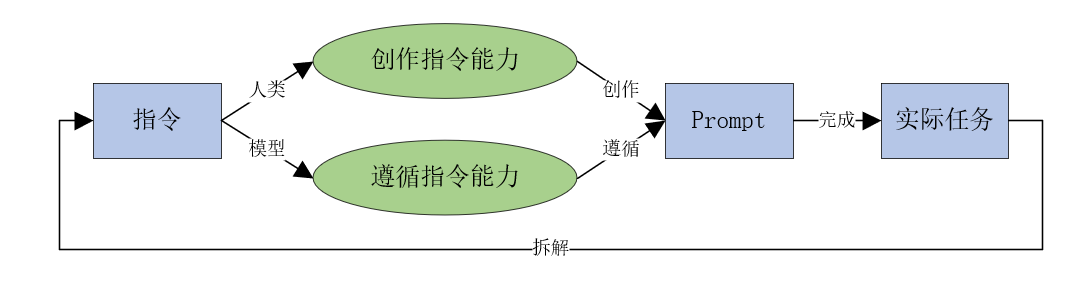



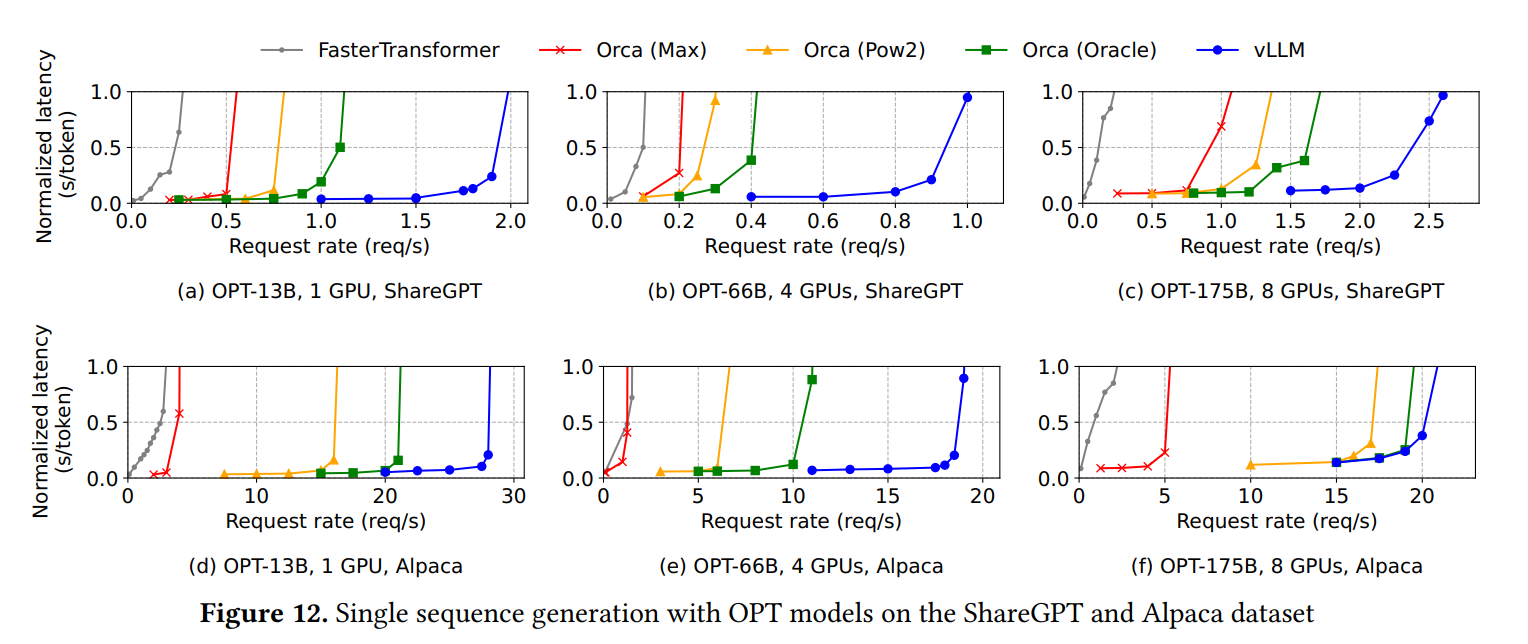
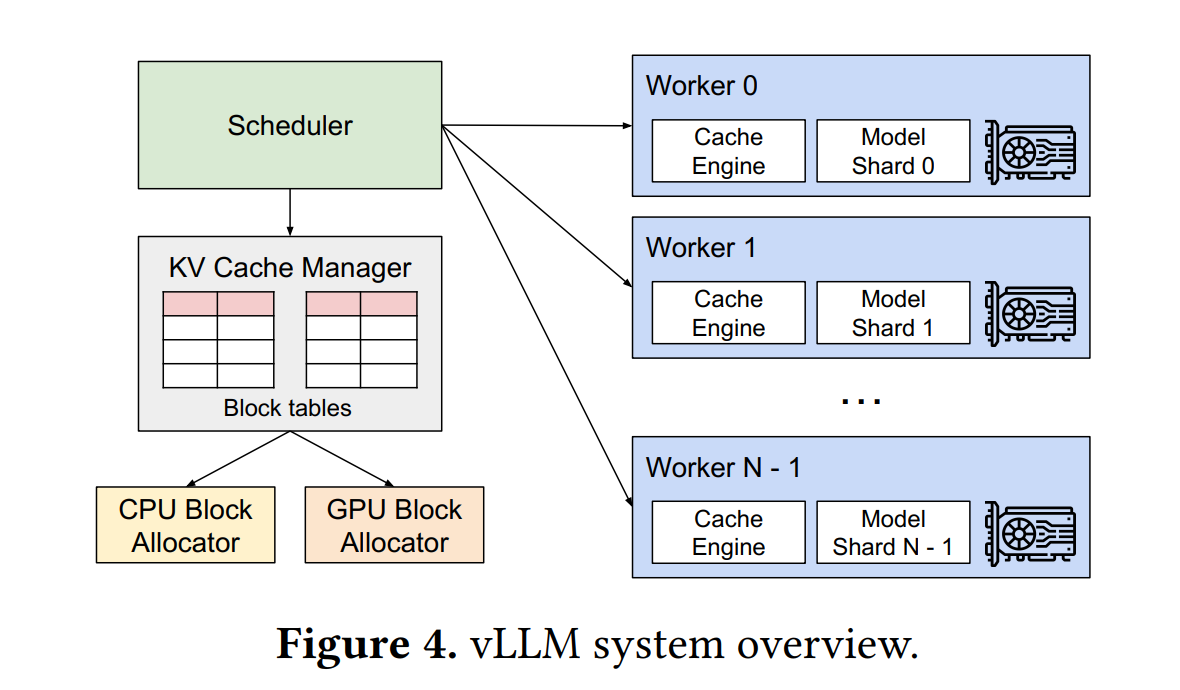
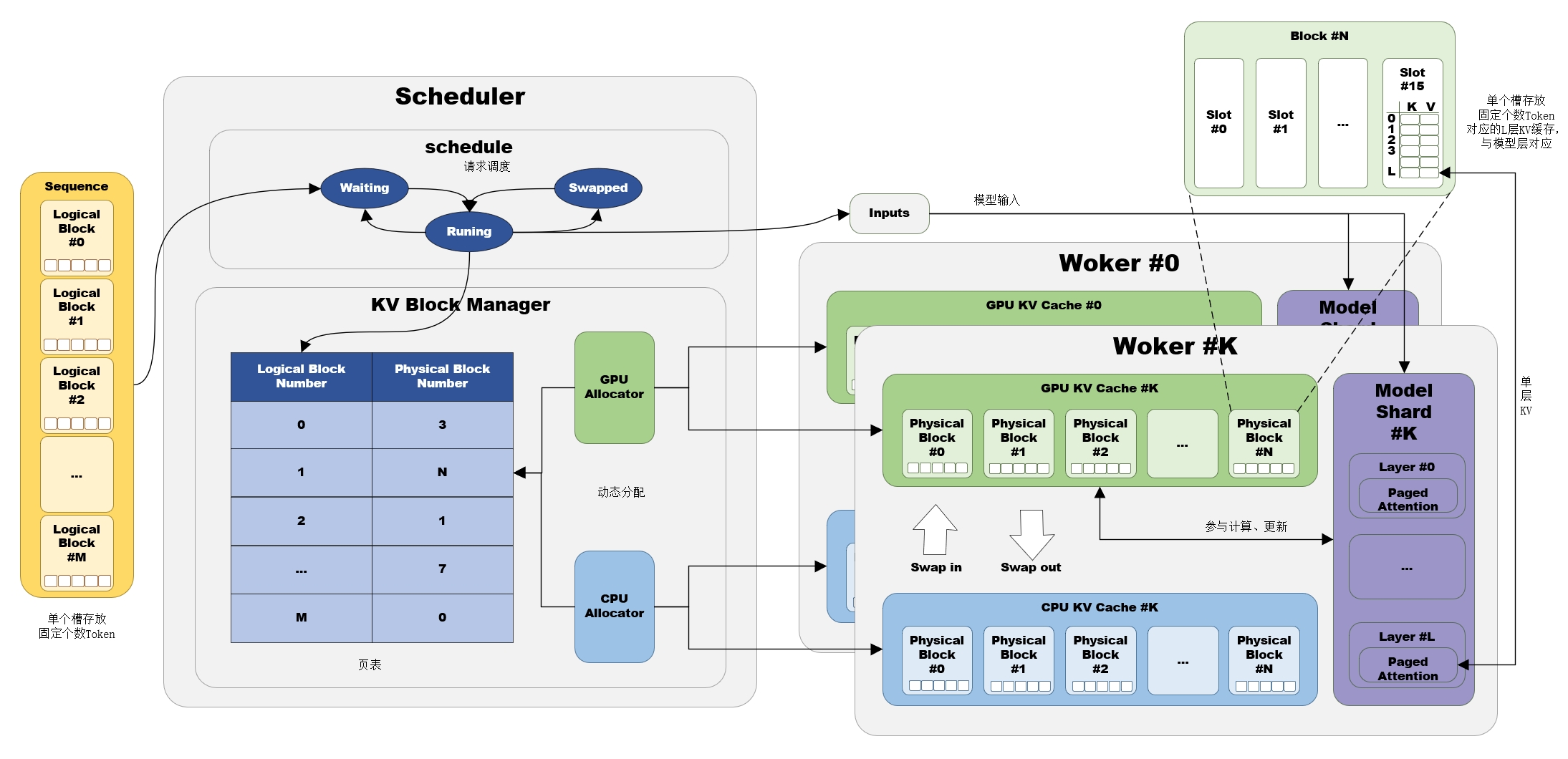
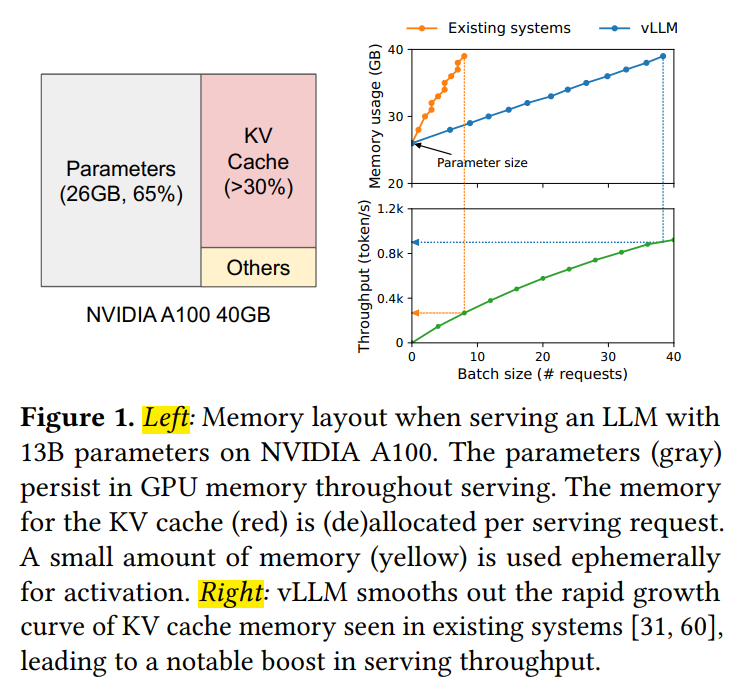
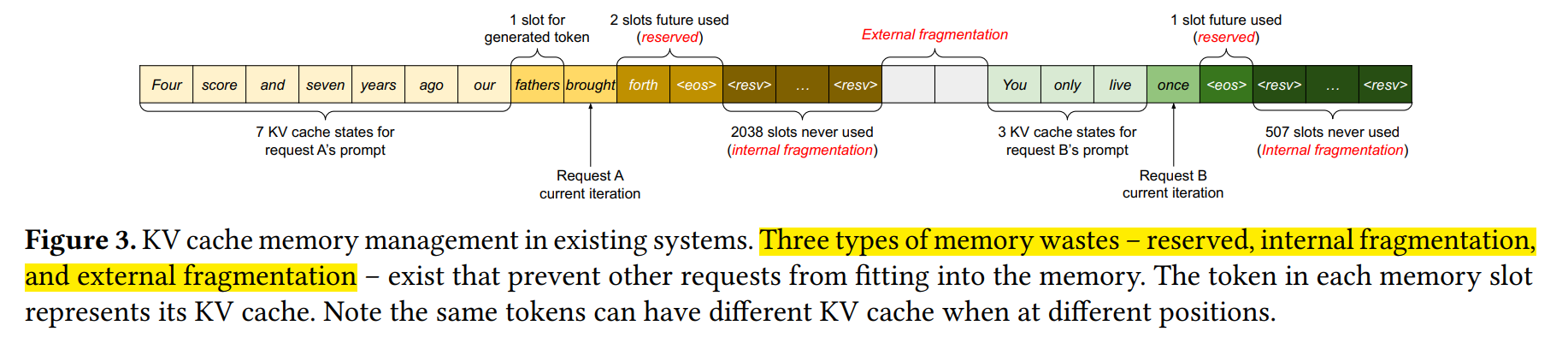
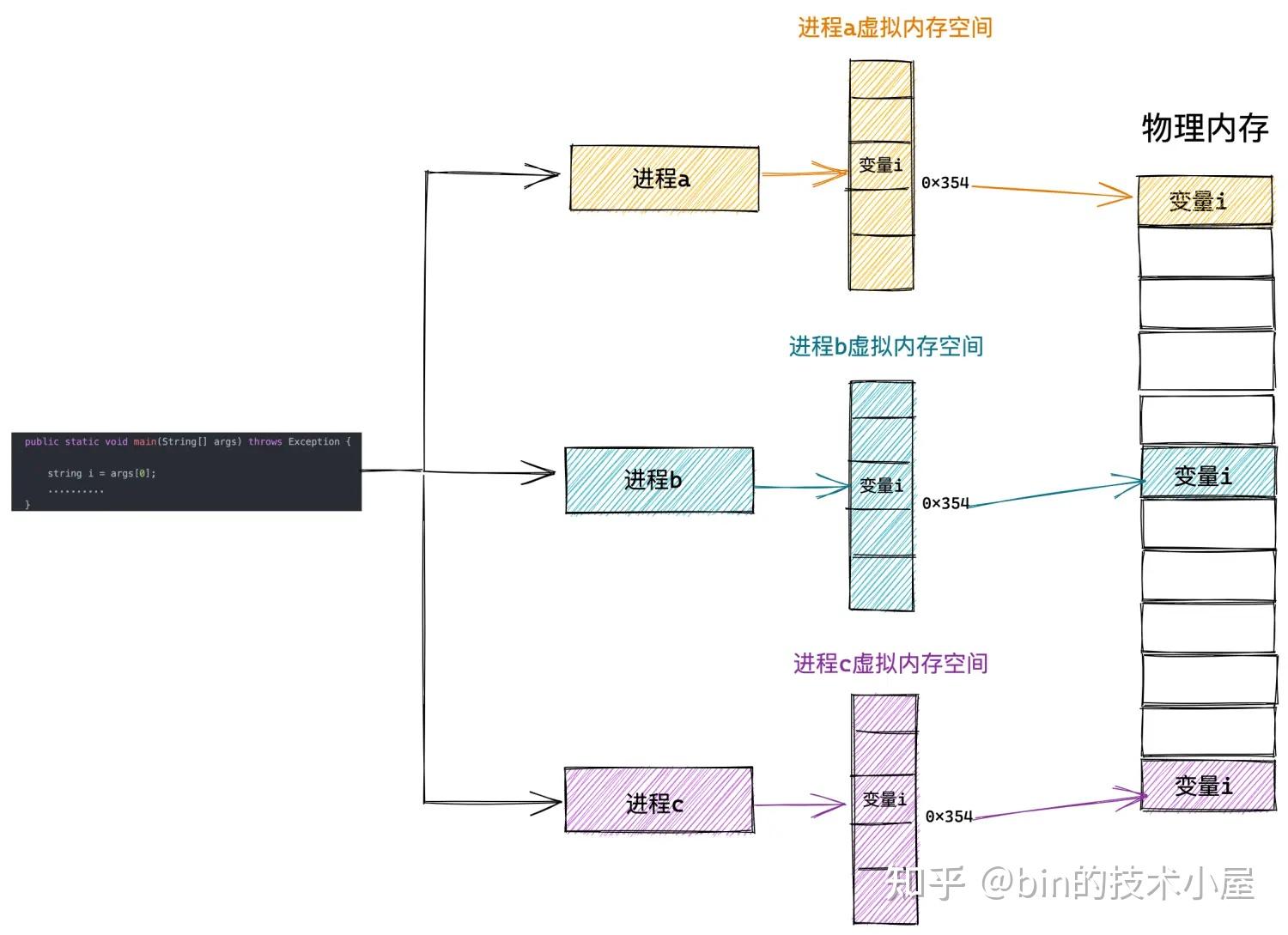
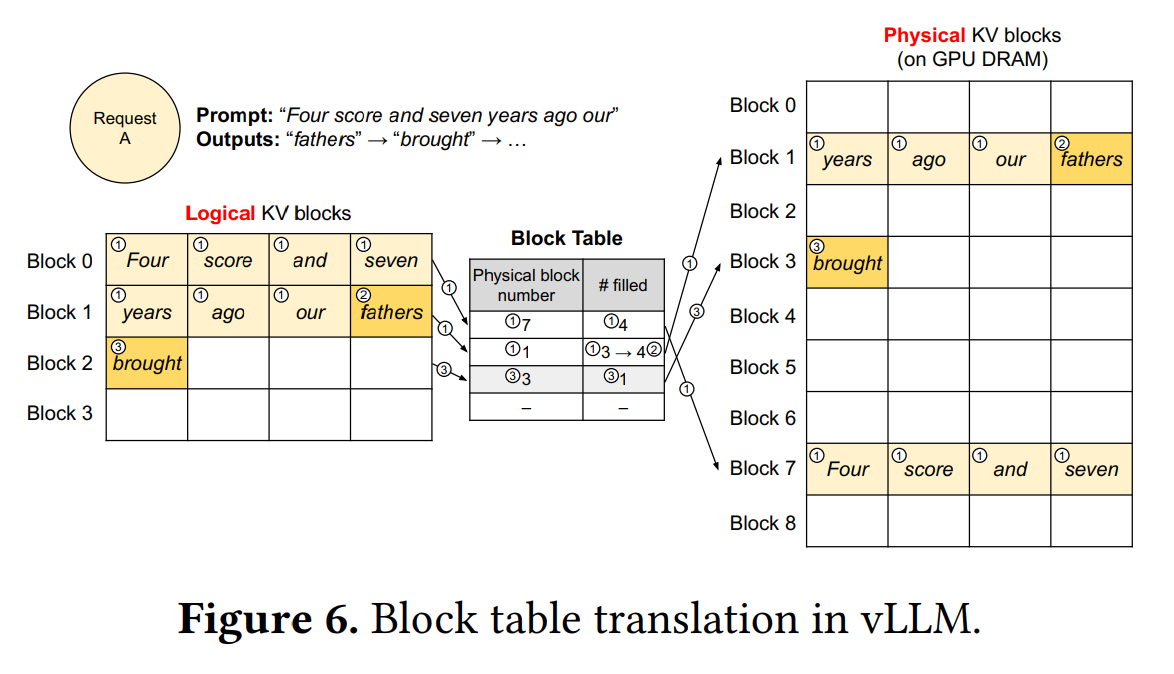
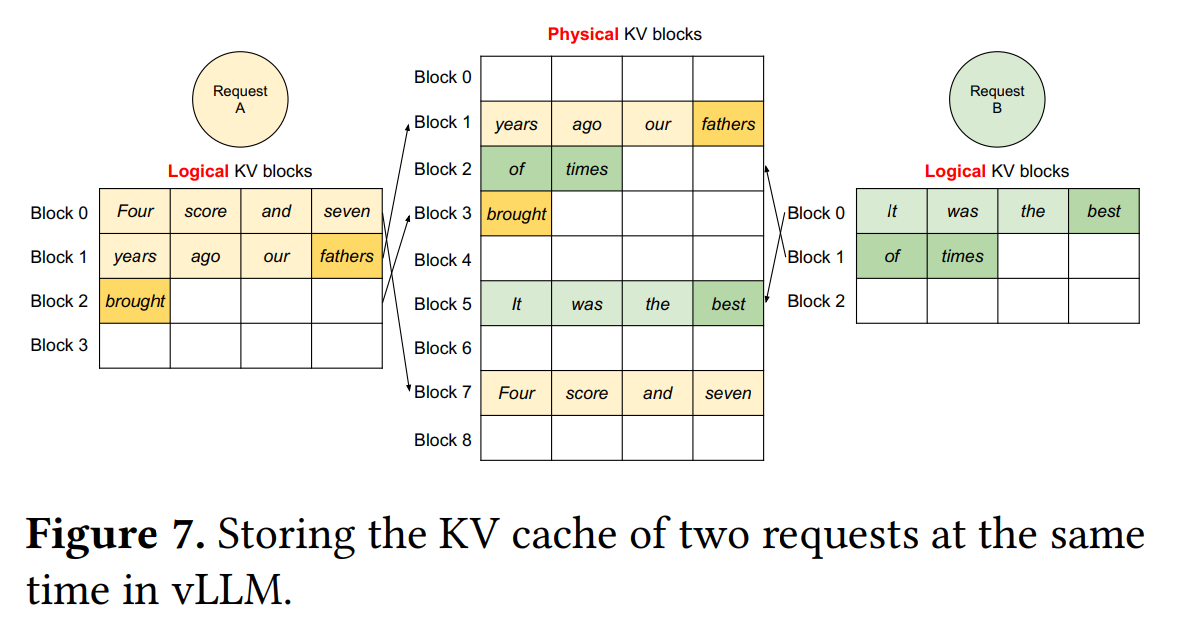
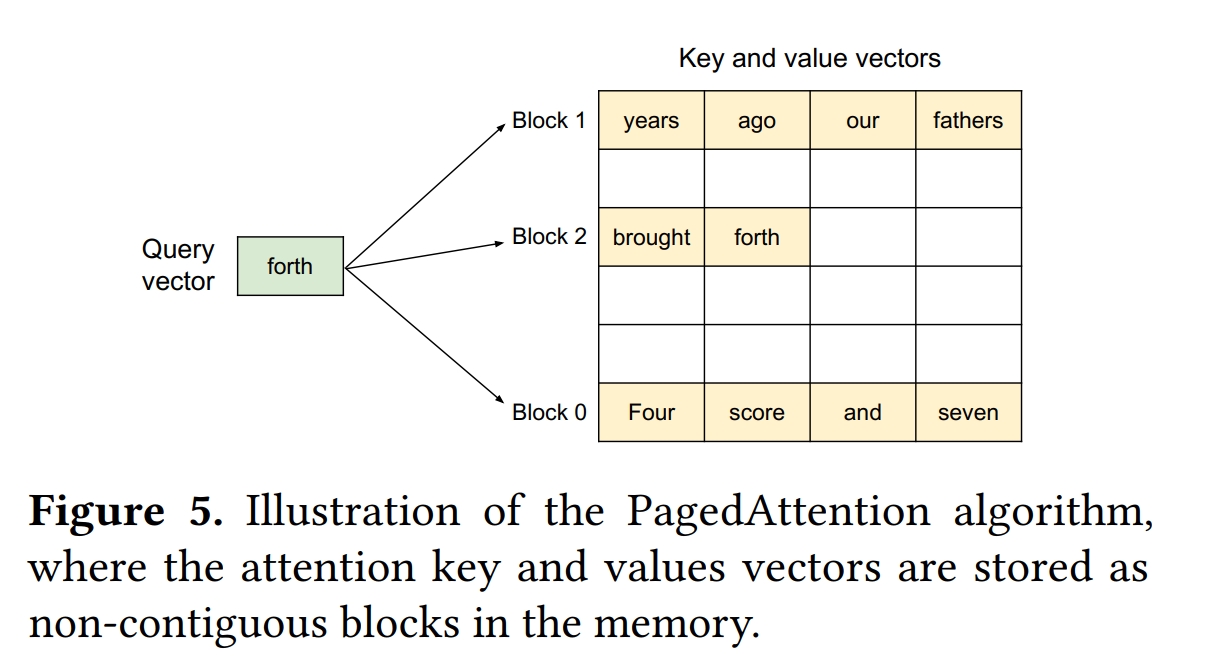
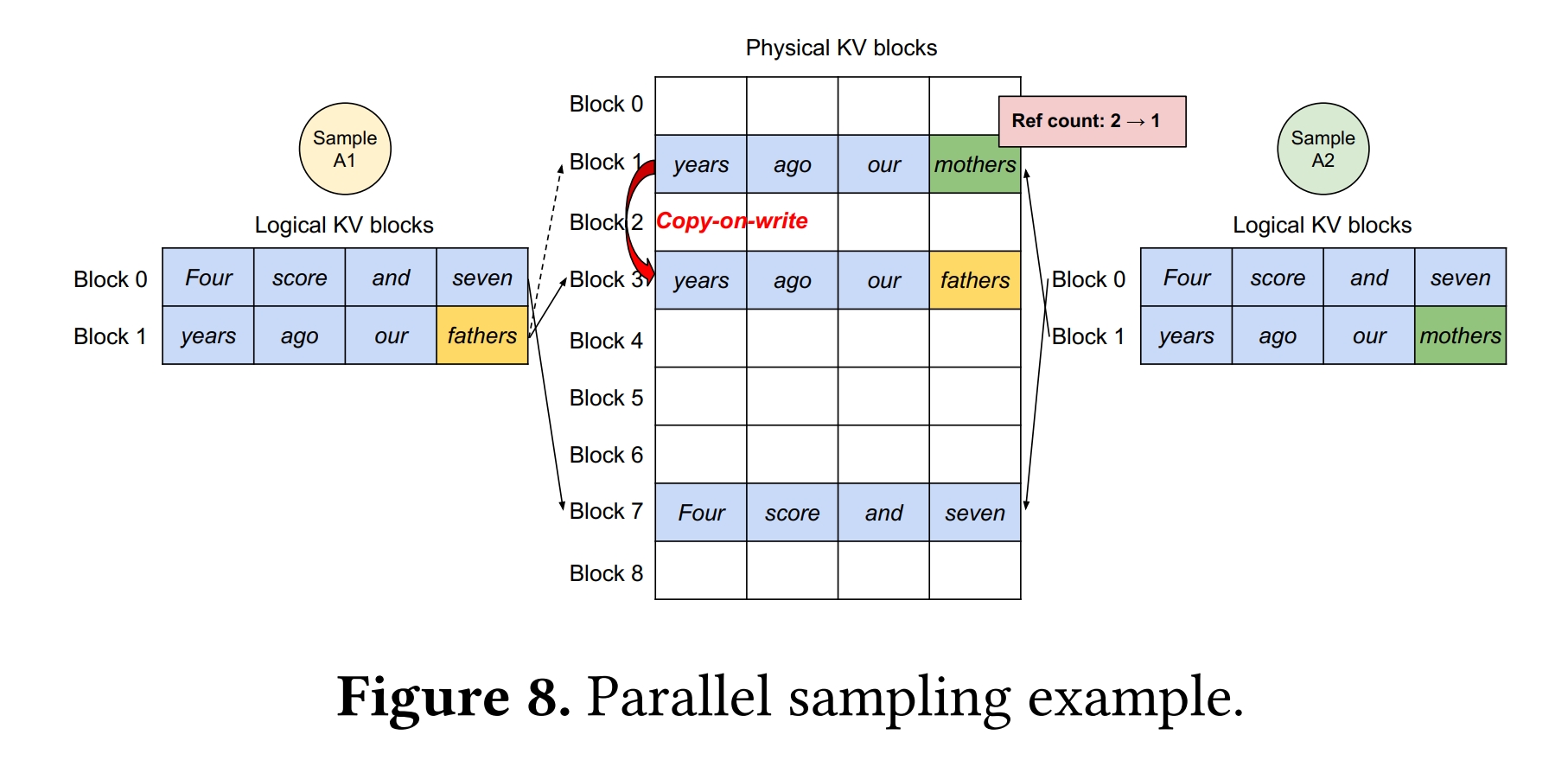
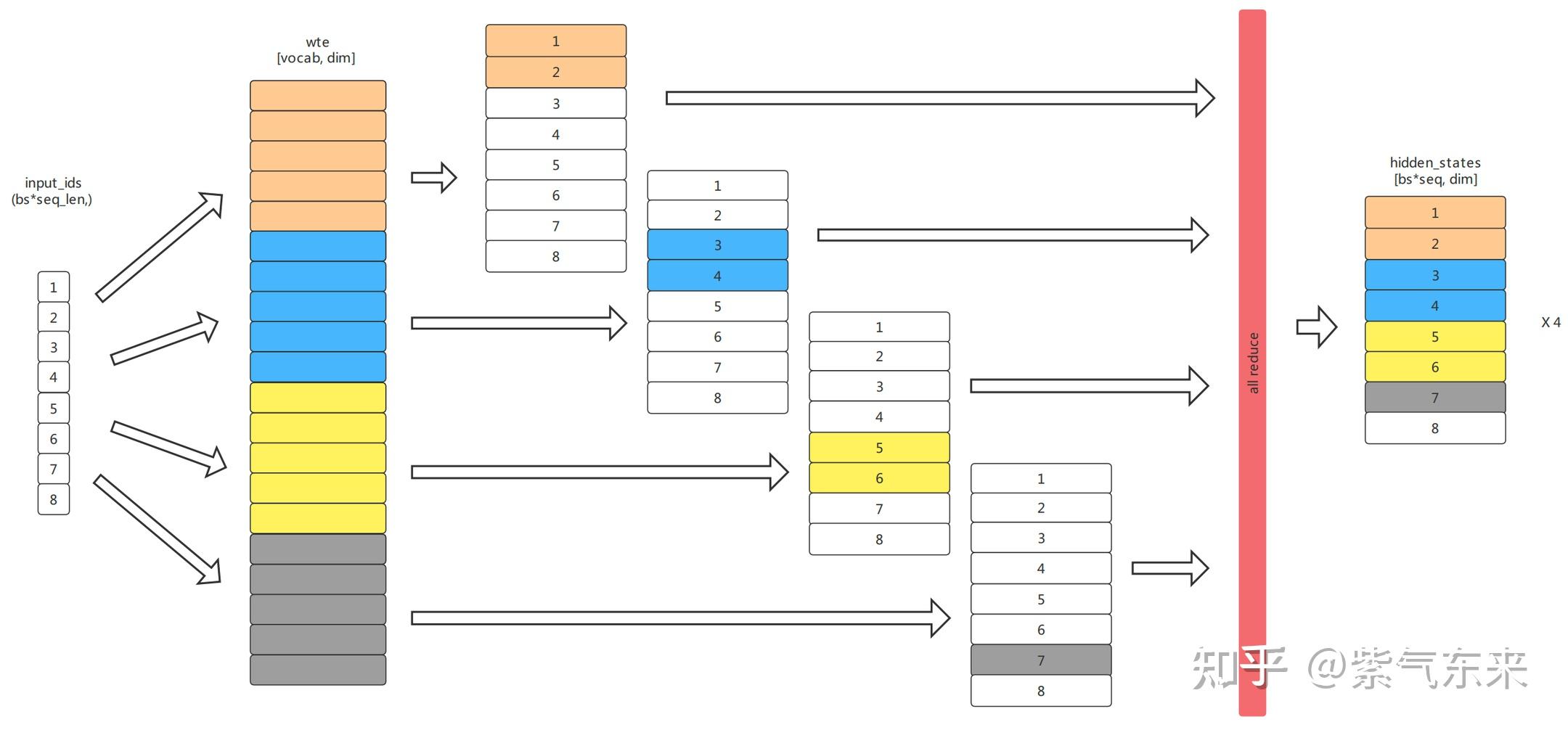
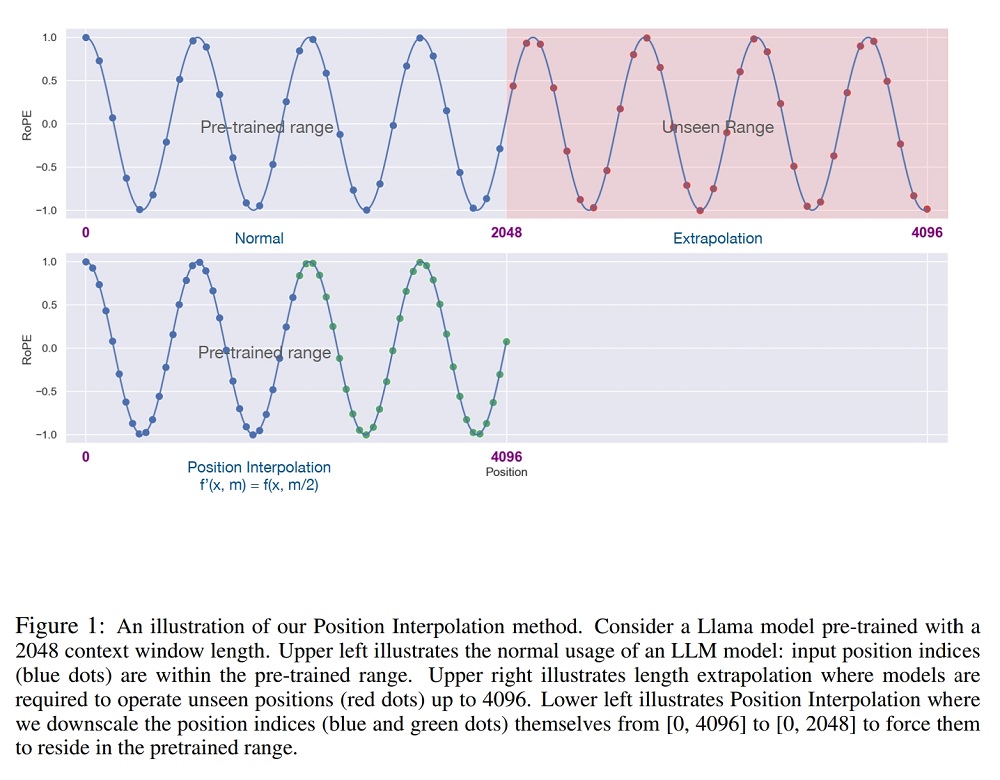
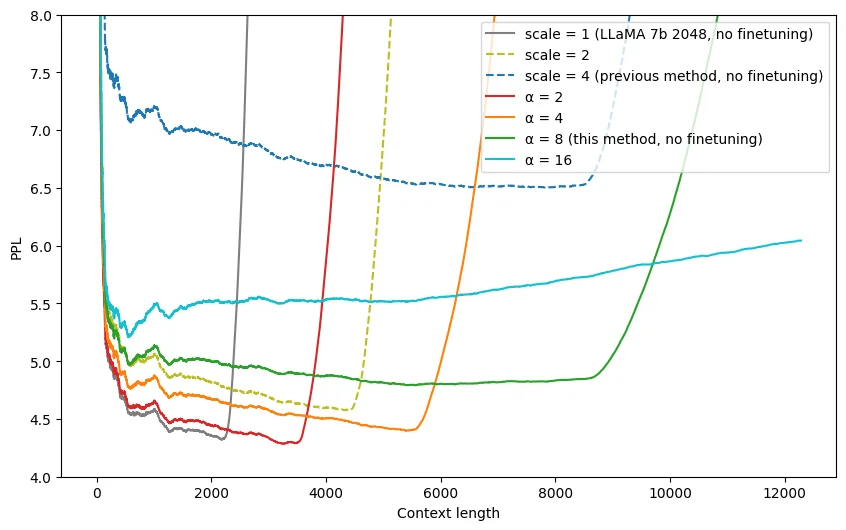
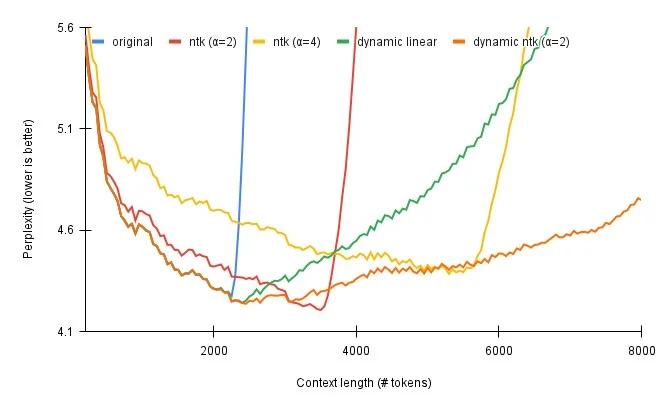
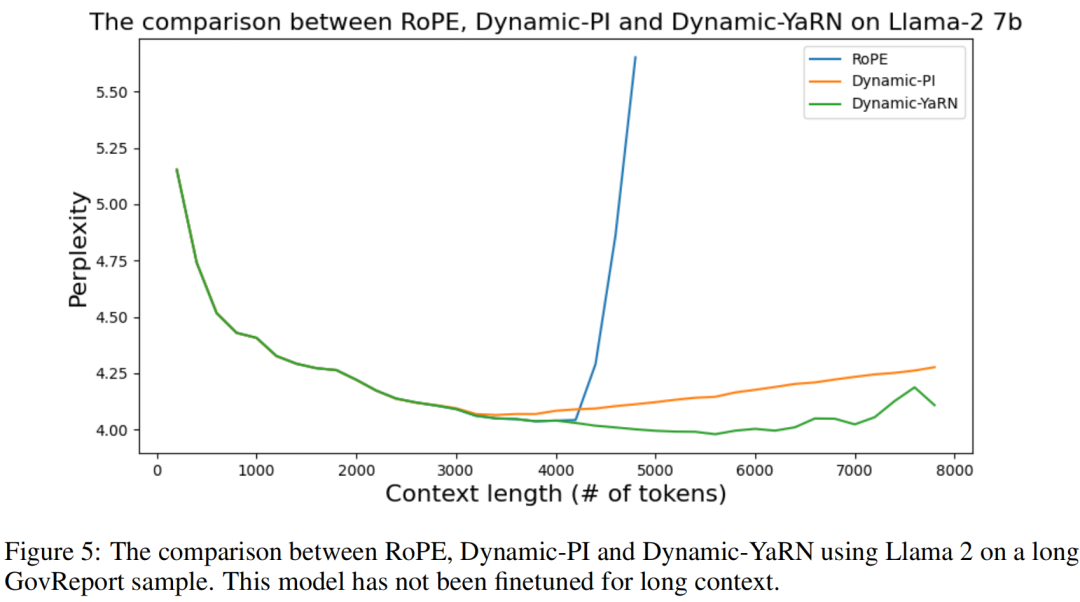










 ' +
+ '
' +
+ '