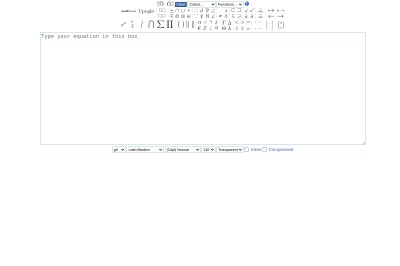
本篇博文主要展示每日从Arxiv论文网站获取的最新论文列表,以计算机视觉、自然语言处理、机器学习、人工智能等大方向进行划分。
+统计
+今日共更新452篇论文,其中:
+
+计算机视觉
+
+ 1. 标题:AutoAD II: The Sequel -- Who, When, and What in Movie Audio Description
+ 编号:[2]
+ 链接:https://arxiv.org/abs/2310.06838
+ 作者:Tengda Han, Max Bain, Arsha Nagrani, Gül Varol, Weidi Xie, Andrew Zisserman
+ 备注:ICCV2023. Project page: this https URL
+ 关键词:visually impaired audiences, suitable time intervals, Audio Description, CLIP visual features, impaired audiences
+
+ 点击查看摘要
+ Audio Description (AD) is the task of generating descriptions of visual content, at suitable time intervals, for the benefit of visually impaired audiences. For movies, this presents notable challenges -- AD must occur only during existing pauses in dialogue, should refer to characters by name, and ought to aid understanding of the storyline as a whole. To this end, we develop a new model for automatically generating movie AD, given CLIP visual features of the frames, the cast list, and the temporal locations of the speech; addressing all three of the 'who', 'when', and 'what' questions: (i) who -- we introduce a character bank consisting of the character's name, the actor that played the part, and a CLIP feature of their face, for the principal cast of each movie, and demonstrate how this can be used to improve naming in the generated AD; (ii) when -- we investigate several models for determining whether an AD should be generated for a time interval or not, based on the visual content of the interval and its neighbours; and (iii) what -- we implement a new vision-language model for this task, that can ingest the proposals from the character bank, whilst conditioning on the visual features using cross-attention, and demonstrate how this improves over previous architectures for AD text generation in an apples-to-apples comparison.
+
+
+
+ 2. 标题:What Does Stable Diffusion Know about the 3D Scene?
+ 编号:[4]
+ 链接:https://arxiv.org/abs/2310.06836
+ 作者:Guanqi Zhan, Chuanxia Zheng, Weidi Xie, Andrew Zisserman
+ 备注:
+ 关键词:highly photo-realistic images, Stable Diffusion enable, Stable Diffusion, Recent advances, advances in generative
+
+ 点击查看摘要
+ Recent advances in generative models like Stable Diffusion enable the generation of highly photo-realistic images. Our objective in this paper is to probe the diffusion network to determine to what extent it 'understands' different properties of the 3D scene depicted in an image. To this end, we make the following contributions: (i) We introduce a protocol to evaluate whether a network models a number of physical 'properties' of the 3D scene by probing for explicit features that represent these properties. The probes are applied on datasets of real images with annotations for the property. (ii) We apply this protocol to properties covering scene geometry, scene material, support relations, lighting, and view dependent measures. (iii) We find that Stable Diffusion is good at a number of properties including scene geometry, support relations, shadows and depth, but less performant for occlusion. (iv) We also apply the probes to other models trained at large-scale, including DINO and CLIP, and find their performance inferior to that of Stable Diffusion.
+
+
+
+ 3. 标题:Neural Bounding
+ 编号:[11]
+ 链接:https://arxiv.org/abs/2310.06822
+ 作者:Wenxin Liu, Michael Fischer, Paul D. Yoo, Tobias Ritschel
+ 备注:
+ 关键词:early inception, established concept, concept in computer, computer graphics, graphics and vision
+
+ 点击查看摘要
+ Bounding volumes are an established concept in computer graphics and vision tasks but have seen little change since their early inception. In this work, we study the use of neural networks as bounding volumes. Our key observation is that bounding, which so far has primarily been considered a problem of computational geometry, can be redefined as a problem of learning to classify space into free and empty. This learning-based approach is particularly advantageous in high-dimensional spaces, such as animated scenes with complex queries, where neural networks are known to excel. However, unlocking neural bounding requires a twist: allowing -- but also limiting -- false positives, while ensuring that the number of false negatives is strictly zero. We enable such tight and conservative results using a dynamically-weighted asymmetric loss function. Our results show that our neural bounding produces up to an order of magnitude fewer false positives than traditional methods.
+
+
+
+ 4. 标题:Uni3D: Exploring Unified 3D Representation at Scale
+ 编号:[24]
+ 链接:https://arxiv.org/abs/2310.06773
+ 作者:Junsheng Zhou, Jinsheng Wang, Baorui Ma, Yu-Shen Liu, Tiejun Huang, Xinlong Wang
+ 备注:Code and Demo: this https URL
+ 关键词:vision and language, images or text, extensively investigated, past few years, led to revolutions
+
+ 点击查看摘要
+ Scaling up representations for images or text has been extensively investigated in the past few years and has led to revolutions in learning vision and language. However, scalable representation for 3D objects and scenes is relatively unexplored. In this work, we present Uni3D, a 3D foundation model to explore the unified 3D representation at scale. Uni3D uses a 2D initialized ViT end-to-end pretrained to align the 3D point cloud features with the image-text aligned features. Via the simple architecture and pretext task, Uni3D can leverage abundant 2D pretrained models as initialization and image-text aligned models as the target, unlocking the great potential of 2D models and scaling-up strategies to the 3D world. We efficiently scale up Uni3D to one billion parameters, and set new records on a broad range of 3D tasks, such as zero-shot classification, few-shot classification, open-world understanding and part segmentation. We show that the strong Uni3D representation also enables applications such as 3D painting and retrieval in the wild. We believe that Uni3D provides a new direction for exploring both scaling up and efficiency of the representation in 3D domain.
+
+
+
+ 5. 标题:TopoMLP: An Simple yet Strong Pipeline for Driving Topology Reasoning
+ 编号:[34]
+ 链接:https://arxiv.org/abs/2310.06753
+ 作者:Dongming Wu, Jiahao Chang, Fan Jia, Yingfei Liu, Tiancai Wang, Jianbing Shen
+ 备注:The 1st solution for 1st OpenLane Topology in Autonomous Driving Challenge. Code is at this https URL
+ 关键词:comprehensively understand road, understand road scenes, present drivable routes, Topology, aims to comprehensively
+
+ 点击查看摘要
+ Topology reasoning aims to comprehensively understand road scenes and present drivable routes in autonomous driving. It requires detecting road centerlines (lane) and traffic elements, further reasoning their topology relationship, i.e., lane-lane topology, and lane-traffic topology. In this work, we first present that the topology score relies heavily on detection performance on lane and traffic elements. Therefore, we introduce a powerful 3D lane detector and an improved 2D traffic element detector to extend the upper limit of topology performance. Further, we propose TopoMLP, a simple yet high-performance pipeline for driving topology reasoning. Based on the impressive detection performance, we develop two simple MLP-based heads for topology generation. TopoMLP achieves state-of-the-art performance on OpenLane-V2 benchmark, i.e., 41.2% OLS with ResNet-50 backbone. It is also the 1st solution for 1st OpenLane Topology in Autonomous Driving Challenge. We hope such simple and strong pipeline can provide some new insights to the community. Code is at this https URL.
+
+
+
+ 6. 标题:HiFi-123: Towards High-fidelity One Image to 3D Content Generation
+ 编号:[38]
+ 链接:https://arxiv.org/abs/2310.06744
+ 作者:Wangbo Yu, Li Yuan, Yan-Pei Cao, Xiangjun Gao, Xiaoyu Li, Long Quan, Ying Shan, Yonghong Tian
+ 备注:
+ 关键词:Recent advances, diffusion models, models have enabled, single image, image
+
+ 点击查看摘要
+ Recent advances in text-to-image diffusion models have enabled 3D generation from a single image. However, current image-to-3D methods often produce suboptimal results for novel views, with blurred textures and deviations from the reference image, limiting their practical applications. In this paper, we introduce HiFi-123, a method designed for high-fidelity and multi-view consistent 3D generation. Our contributions are twofold: First, we propose a reference-guided novel view enhancement technique that substantially reduces the quality gap between synthesized and reference views. Second, capitalizing on the novel view enhancement, we present a novel reference-guided state distillation loss. When incorporated into the optimization-based image-to-3D pipeline, our method significantly improves 3D generation quality, achieving state-of-the-art performance. Comprehensive evaluations demonstrate the effectiveness of our approach over existing methods, both qualitatively and quantitatively.
+
+
+
+ 7. 标题:Domain Generalization by Rejecting Extreme Augmentations
+ 编号:[64]
+ 链接:https://arxiv.org/abs/2310.06670
+ 作者:Masih Aminbeidokhti, Fidel A. Guerrero Peña, Heitor Rapela Medeiros, Thomas Dubail, Eric Granger, Marco Pedersoli
+ 备注:
+ 关键词:regularizing deep learning, deep learning models, Data augmentation, test data follow, effective techniques
+
+ 点击查看摘要
+ Data augmentation is one of the most effective techniques for regularizing deep learning models and improving their recognition performance in a variety of tasks and domains. However, this holds for standard in-domain settings, in which the training and test data follow the same distribution. For the out-of-domain case, where the test data follow a different and unknown distribution, the best recipe for data augmentation is unclear. In this paper, we show that for out-of-domain and domain generalization settings, data augmentation can provide a conspicuous and robust improvement in performance. To do that, we propose a simple training procedure: (i) use uniform sampling on standard data augmentation transformations; (ii) increase the strength transformations to account for the higher data variance expected when working out-of-domain, and (iii) devise a new reward function to reject extreme transformations that can harm the training. With this procedure, our data augmentation scheme achieves a level of accuracy that is comparable to or better than state-of-the-art methods on benchmark domain generalization datasets. Code: \url{this https URL}
+
+
+
+ 8. 标题:Latent Diffusion Counterfactual Explanations
+ 编号:[65]
+ 链接:https://arxiv.org/abs/2310.06668
+ 作者:Karim Farid, Simon Schrodi, Max Argus, Thomas Brox
+ 备注:
+ 关键词:counterfactual generation, promising method, method for elucidating, Diffusion Counterfactual Explanations, Counterfactual explanations
+
+ 点击查看摘要
+ Counterfactual explanations have emerged as a promising method for elucidating the behavior of opaque black-box models. Recently, several works leveraged pixel-space diffusion models for counterfactual generation. To handle noisy, adversarial gradients during counterfactual generation -- causing unrealistic artifacts or mere adversarial perturbations -- they required either auxiliary adversarially robust models or computationally intensive guidance schemes. However, such requirements limit their applicability, e.g., in scenarios with restricted access to the model's training data. To address these limitations, we introduce Latent Diffusion Counterfactual Explanations (LDCE). LDCE harnesses the capabilities of recent class- or text-conditional foundation latent diffusion models to expedite counterfactual generation and focus on the important, semantic parts of the data. Furthermore, we propose a novel consensus guidance mechanism to filter out noisy, adversarial gradients that are misaligned with the diffusion model's implicit classifier. We demonstrate the versatility of LDCE across a wide spectrum of models trained on diverse datasets with different learning paradigms. Finally, we showcase how LDCE can provide insights into model errors, enhancing our understanding of black-box model behavior.
+
+
+
+ 9. 标题:SC2GAN: Rethinking Entanglement by Self-correcting Correlated GAN Space
+ 编号:[66]
+ 链接:https://arxiv.org/abs/2310.06667
+ 作者:Zikun Chen, Han Zhao, Parham Aarabi, Ruowei Jiang
+ 备注:Accepted to the Out Of Distribution Generalization in Computer Vision workshop at ICCV2023
+ 关键词:Generative Adversarial Networks, Adversarial Networks, learned latent space, Generative Adversarial, latent space
+
+ 点击查看摘要
+ Generative Adversarial Networks (GANs) can synthesize realistic images, with the learned latent space shown to encode rich semantic information with various interpretable directions. However, due to the unstructured nature of the learned latent space, it inherits the bias from the training data where specific groups of visual attributes that are not causally related tend to appear together, a phenomenon also known as spurious correlations, e.g., age and eyeglasses or women and lipsticks. Consequently, the learned distribution often lacks the proper modelling of the missing examples. The interpolation following editing directions for one attribute could result in entangled changes with other attributes. To address this problem, previous works typically adjust the learned directions to minimize the changes in other attributes, yet they still fail on strongly correlated features. In this work, we study the entanglement issue in both the training data and the learned latent space for the StyleGAN2-FFHQ model. We propose a novel framework SC$^2$GAN that achieves disentanglement by re-projecting low-density latent code samples in the original latent space and correcting the editing directions based on both the high-density and low-density regions. By leveraging the original meaningful directions and semantic region-specific layers, our framework interpolates the original latent codes to generate images with attribute combination that appears infrequently, then inverts these samples back to the original latent space. We apply our framework to pre-existing methods that learn meaningful latent directions and showcase its strong capability to disentangle the attributes with small amounts of low-density region samples added.
+
+
+
+ 10. 标题:Evaluating Explanation Methods for Vision-and-Language Navigation
+ 编号:[71]
+ 链接:https://arxiv.org/abs/2310.06654
+ 作者:Guanqi Chen, Lei Yang, Guanhua Chen, Jia Pan
+ 备注:Accepted by ECAI 2023
+ 关键词:embodied artificial intelligence, natural language instructions, achieving embodied artificial, deep neural models, deep neural
+
+ 点击查看摘要
+ The ability to navigate robots with natural language instructions in an unknown environment is a crucial step for achieving embodied artificial intelligence (AI). With the improving performance of deep neural models proposed in the field of vision-and-language navigation (VLN), it is equally interesting to know what information the models utilize for their decision-making in the navigation tasks. To understand the inner workings of deep neural models, various explanation methods have been developed for promoting explainable AI (XAI). But they are mostly applied to deep neural models for image or text classification tasks and little work has been done in explaining deep neural models for VLN tasks. In this paper, we address these problems by building quantitative benchmarks to evaluate explanation methods for VLN models in terms of faithfulness. We propose a new erasure-based evaluation pipeline to measure the step-wise textual explanation in the sequential decision-making setting. We evaluate several explanation methods for two representative VLN models on two popular VLN datasets and reveal valuable findings through our experiments.
+
+
+
+ 11. 标题:How (not) to ensemble LVLMs for VQA
+ 编号:[78]
+ 链接:https://arxiv.org/abs/2310.06641
+ 作者:Lisa Alazraki, Lluis Castrejon, Mostafa Dehghani, Fantine Huot, Jasper Uijlings, Thomas Mensink
+ 备注:Under submission
+ 关键词:Large Vision-Language Models, era of Large, Large Vision-Language, paper studies ensembling, paper studies
+
+ 点击查看摘要
+ This paper studies ensembling in the era of Large Vision-Language Models (LVLMs). Ensembling is a classical method to combine different models to get increased performance. In the recent work on Encyclopedic-VQA the authors examine a wide variety of models to solve their task: from vanilla LVLMs, to models including the caption as extra context, to models augmented with Lens-based retrieval of Wikipedia pages. Intuitively these models are highly complementary, which should make them ideal for ensembling. Indeed, an oracle experiment shows potential gains from 48.8% accuracy (the best single model) all the way up to 67% (best possible ensemble). So it is a trivial exercise to create an ensemble with substantial real gains. Or is it?
+
+
+
+ 12. 标题:Blind Dates: Examining the Expression of Temporality in Historical Photographs
+ 编号:[80]
+ 链接:https://arxiv.org/abs/2310.06633
+ 作者:Alexandra Barancová, Melvin Wevers, Nanne van Noord
+ 备注:
+ 关键词:computer vision models, discern temporal information, focusing specifically, capacity of computer, Boer Scene Detection
+
+ 点击查看摘要
+ This paper explores the capacity of computer vision models to discern temporal information in visual content, focusing specifically on historical photographs. We investigate the dating of images using OpenCLIP, an open-source implementation of CLIP, a multi-modal language and vision model. Our experiment consists of three steps: zero-shot classification, fine-tuning, and analysis of visual content. We use the \textit{De Boer Scene Detection} dataset, containing 39,866 gray-scale historical press photographs from 1950 to 1999. The results show that zero-shot classification is relatively ineffective for image dating, with a bias towards predicting dates in the past. Fine-tuning OpenCLIP with a logistic classifier improves performance and eliminates the bias. Additionally, our analysis reveals that images featuring buses, cars, cats, dogs, and people are more accurately dated, suggesting the presence of temporal markers. The study highlights the potential of machine learning models like OpenCLIP in dating images and emphasizes the importance of fine-tuning for accurate temporal analysis. Future research should explore the application of these findings to color photographs and diverse datasets.
+
+
+
+ 13. 标题:EViT: An Eagle Vision Transformer with Bi-Fovea Self-Attention
+ 编号:[82]
+ 链接:https://arxiv.org/abs/2310.06629
+ 作者:Yulong Shi, Mingwei Sun, Yongshuai Wang, Rui Wang, Hui Sun, Zengqiang Chen
+ 备注:11 pages, 4 figures
+ 关键词:demonstrated competitive performance, vision transformer, vision, eagle vision, Eagle Vision Transformers
+
+ 点击查看摘要
+ Because of the advancement of deep learning technology, vision transformer has demonstrated competitive performance in various computer vision tasks. Unfortunately, vision transformer still faces some challenges such as high computational complexity and absence of desirable inductive bias. To alleviate these problems, this study proposes a novel Bi-Fovea Self-Attention (BFSA) inspired by the physiological structure and characteristics of bi-fovea vision in eagle eyes. This BFSA can simulate the shallow fovea and deep fovea functions of eagle vision, enabling the network to extract feature representations of targets from coarse to fine, facilitating the interaction of multi-scale feature representations. Additionally, this study designs a Bionic Eagle Vision (BEV) block based on BFSA and CNN. It combines CNN and Vision Transformer, to enhance the network's local and global representation ability for targets. Furthermore, this study develops a unified and efficient general pyramid backbone network family, named Eagle Vision Transformers (EViTs) by stacking the BEV blocks. Experimental results on various computer vision tasks including image classification, object detection, instance segmentation and other transfer learning tasks show that the proposed EViTs perform significantly better than the baselines under similar model sizes, which exhibits faster speed on graphics processing unit compared to other models. Code will be released at this https URL.
+
+
+
+ 14. 标题:What If the TV Was Off? Examining Counterfactual Reasoning Abilities of Multi-modal Language Models
+ 编号:[83]
+ 链接:https://arxiv.org/abs/2310.06627
+ 作者:Letian Zhang, Xiaotong Zhai, Zhongkai Zhao, Xin Wen, Yongshuo Zong, Bingchen Zhao
+ 备注:Short paper accepted at ICCV 2023 VLAR workshop
+ 关键词:Counterfactual reasoning ability, human intelligence, core abilities, abilities of human, reasoning ability
+
+ 点击查看摘要
+ Counterfactual reasoning ability is one of the core abilities of human intelligence. This reasoning process involves the processing of alternatives to observed states or past events, and this process can improve our ability for planning and decision-making. In this work, we focus on benchmarking the counterfactual reasoning ability of multi-modal large language models. We take the question and answer pairs from the VQAv2 dataset and add one counterfactual presupposition to the questions, with the answer being modified accordingly. After generating counterfactual questions and answers using ChatGPT, we manually examine all generated questions and answers to ensure correctness. Over 2k counterfactual question and answer pairs are collected this way. We evaluate recent vision language models on our newly collected test dataset and found that all models exhibit a large performance drop compared to the results tested on questions without the counterfactual presupposition. This result indicates that there still exists space for developing vision language models. Apart from the vision language models, our proposed dataset can also serves as a benchmark for evaluating the ability of code generation LLMs, results demonstrate a large gap between GPT-4 and current open-source models. Our code and dataset are available at \url{this https URL}.
+
+
+
+ 15. 标题:V2X-AHD:Vehicle-to-Everything Cooperation Perception via Asymmetric Heterogenous Distillation Network
+ 编号:[91]
+ 链接:https://arxiv.org/abs/2310.06603
+ 作者:Caizhen He, Hai Wang, Long Chen, Tong Luo, Yingfeng Cai
+ 备注:
+ 关键词:provide accurate position, accurate position information, intelligent traffic systems, vehicle-road cooperation perception, intelligent traffic
+
+ 点击查看摘要
+ Object detection is the central issue of intelligent traffic systems, and recent advancements in single-vehicle lidar-based 3D detection indicate that it can provide accurate position information for intelligent agents to make decisions and plan. Compared with single-vehicle perception, multi-view vehicle-road cooperation perception has fundamental advantages, such as the elimination of blind spots and a broader range of perception, and has become a research hotspot. However, the current perception of cooperation focuses on improving the complexity of fusion while ignoring the fundamental problems caused by the absence of single-view outlines. We propose a multi-view vehicle-road cooperation perception system, vehicle-to-everything cooperative perception (V2X-AHD), in order to enhance the identification capability, particularly for predicting the vehicle's shape. At first, we propose an asymmetric heterogeneous distillation network fed with different training data to improve the accuracy of contour recognition, with multi-view teacher features transferring to single-view student features. While the point cloud data are sparse, we propose Spara Pillar, a spare convolutional-based plug-in feature extraction backbone, to reduce the number of parameters and improve and enhance feature extraction capabilities. Moreover, we leverage the multi-head self-attention (MSA) to fuse the single-view feature, and the lightweight design makes the fusion feature a smooth expression. The results of applying our algorithm to the massive open dataset V2Xset demonstrate that our method achieves the state-of-the-art result. The V2X-AHD can effectively improve the accuracy of 3D object detection and reduce the number of network parameters, according to this study, which serves as a benchmark for cooperative perception. The code for this article is available at this https URL.
+
+
+
+ 16. 标题:Pi-DUAL: Using Privileged Information to Distinguish Clean from Noisy Labels
+ 编号:[93]
+ 链接:https://arxiv.org/abs/2310.06600
+ 作者:Ke Wang, Guillermo Ortiz-Jimenez, Rodolphe Jenatton, Mark Collier, Efi Kokiopoulou, Pascal Frossard
+ 备注:
+ 关键词:pervasive problem, problem in deep, compromises the generalization, Label noise, deep learning
+
+ 点击查看摘要
+ Label noise is a pervasive problem in deep learning that often compromises the generalization performance of trained models. Recently, leveraging privileged information (PI) -- information available only during training but not at test time -- has emerged as an effective approach to mitigate this issue. Yet, existing PI-based methods have failed to consistently outperform their no-PI counterparts in terms of preventing overfitting to label noise. To address this deficiency, we introduce Pi-DUAL, an architecture designed to harness PI to distinguish clean from wrong labels. Pi-DUAL decomposes the output logits into a prediction term, based on conventional input features, and a noise-fitting term influenced solely by PI. A gating mechanism steered by PI adaptively shifts focus between these terms, allowing the model to implicitly separate the learning paths of clean and wrong labels. Empirically, Pi-DUAL achieves significant performance improvements on key PI benchmarks (e.g., +6.8% on ImageNet-PI), establishing a new state-of-the-art test set accuracy. Additionally, Pi-DUAL is a potent method for identifying noisy samples post-training, outperforming other strong methods at this task. Overall, Pi-DUAL is a simple, scalable and practical approach for mitigating the effects of label noise in a variety of real-world scenarios with PI.
+
+
+
+ 17. 标题:REVO-LION: Evaluating and Refining Vision-Language Instruction Tuning Datasets
+ 编号:[95]
+ 链接:https://arxiv.org/abs/2310.06594
+ 作者:Ning Liao, Shaofeng Zhang, Renqiu Xia, Bo Zhang, Min Cao, Yu Qiao, Junchi Yan
+ 备注:
+ 关键词:emerging line, VLIT datasets, VLIT, all-powerful VLIT model, dataset
+
+ 点击查看摘要
+ There is an emerging line of research on multimodal instruction tuning, and a line of benchmarks have been proposed for evaluating these models recently. Instead of evaluating the models directly, in this paper we try to evaluate the Vision-Language Instruction-Tuning (VLIT) datasets themselves and further seek the way of building a dataset for developing an all-powerful VLIT model, which we believe could also be of utility for establishing a grounded protocol for benchmarking VLIT models. For effective analysis of VLIT datasets that remains an open question, we propose a tune-cross-evaluation paradigm: tuning on one dataset and evaluating on the others in turn. For each single tune-evaluation experiment set, we define the Meta Quality (MQ) as the mean score measured by a series of caption metrics including BLEU, METEOR, and ROUGE-L to quantify the quality of a certain dataset or a sample. On this basis, to evaluate the comprehensiveness of a dataset, we develop the Dataset Quality (DQ) covering all tune-evaluation sets. To lay the foundation for building a comprehensive dataset and developing an all-powerful model for practical applications, we further define the Sample Quality (SQ) to quantify the all-sided quality of each sample. Extensive experiments validate the rationality of the proposed evaluation paradigm. Based on the holistic evaluation, we build a new dataset, REVO-LION (REfining VisiOn-Language InstructiOn tuNing), by collecting samples with higher SQ from each dataset. With only half of the full data, the model trained on REVO-LION can achieve performance comparable to simply adding all VLIT datasets up. In addition to developing an all-powerful model, REVO-LION also includes an evaluation set, which is expected to serve as a convenient evaluation benchmark for future research.
+
+
+
+ 18. 标题:Hierarchical Mask2Former: Panoptic Segmentation of Crops, Weeds and Leaves
+ 编号:[99]
+ 链接:https://arxiv.org/abs/2310.06582
+ 作者:Madeleine Darbyshire, Elizabeth Sklar, Simon Parsons
+ 备注:6 pages, 5 figures, 2 tables, for code, see this https URL
+ 关键词:sectors including agriculture, enable detailed inferences, Advancements in machine, machine vision, potential to transform
+
+ 点击查看摘要
+ Advancements in machine vision that enable detailed inferences to be made from images have the potential to transform many sectors including agriculture. Precision agriculture, where data analysis enables interventions to be precisely targeted, has many possible applications. Precision spraying, for example, can limit the application of herbicide only to weeds, or limit the application of fertiliser only to undernourished crops, instead of spraying the entire field. The approach promises to maximise yields, whilst minimising resource use and harms to the surrounding environment. To this end, we propose a hierarchical panoptic segmentation method to simultaneously identify indicators of plant growth and locate weeds within an image. We adapt Mask2Former, a state-of-the-art architecture for panoptic segmentation, to predict crop, weed and leaf masks. We achieve a PQ† of 75.99. Additionally, we explore approaches to make the architecture more compact and therefore more suitable for time and compute constrained applications. With our more compact architecture, inference is up to 60% faster and the reduction in PQ† is less than 1%.
+
+
+
+ 19. 标题:Energy-Efficient Visual Search by Eye Movement and Low-Latency Spiking Neural Network
+ 编号:[101]
+ 链接:https://arxiv.org/abs/2310.06578
+ 作者:Yunhui Zhou, Dongqi Han, Yuguo Yu
+ 备注:
+ 关键词:incorporates non-uniform resolution, vision incorporates non-uniform, visual field size, non-uniform resolution retina, spiking neural network
+
+ 点击查看摘要
+ Human vision incorporates non-uniform resolution retina, efficient eye movement strategy, and spiking neural network (SNN) to balance the requirements in visual field size, visual resolution, energy cost, and inference latency. These properties have inspired interest in developing human-like computer vision. However, existing models haven't fully incorporated the three features of human vision, and their learned eye movement strategies haven't been compared with human's strategy, making the models' behavior difficult to interpret. Here, we carry out experiments to examine human visual search behaviors and establish the first SNN-based visual search model. The model combines an artificial retina with spiking feature extraction, memory, and saccade decision modules, and it employs population coding for fast and efficient saccade decisions. The model can learn either a human-like or a near-optimal fixation strategy, outperform humans in search speed and accuracy, and achieve high energy efficiency through short saccade decision latency and sparse activation. It also suggests that the human search strategy is suboptimal in terms of search speed. Our work connects modeling of vision in neuroscience and machine learning and sheds light on developing more energy-efficient computer vision algorithms.
+
+
+
+ 20. 标题:SketchBodyNet: A Sketch-Driven Multi-faceted Decoder Network for 3D Human Reconstruction
+ 编号:[102]
+ 链接:https://arxiv.org/abs/2310.06577
+ 作者:Fei Wang, Kongzhang Tang, Hefeng Wu, Baoquan Zhao, Hao Cai, Teng Zhou
+ 备注:9 pages, to appear in Pacific Graphics 2023
+ 关键词:received increasing attention, increasing attention recently, attention recently due, received increasing, recently due
+
+ 点击查看摘要
+ Reconstructing 3D human shapes from 2D images has received increasing attention recently due to its fundamental support for many high-level 3D applications. Compared with natural images, freehand sketches are much more flexible to depict various shapes, providing a high potential and valuable way for 3D human reconstruction. However, such a task is highly challenging. The sparse abstract characteristics of sketches add severe difficulties, such as arbitrariness, inaccuracy, and lacking image details, to the already badly ill-posed problem of 2D-to-3D reconstruction. Although current methods have achieved great success in reconstructing 3D human bodies from a single-view image, they do not work well on freehand sketches. In this paper, we propose a novel sketch-driven multi-faceted decoder network termed SketchBodyNet to address this task. Specifically, the network consists of a backbone and three separate attention decoder branches, where a multi-head self-attention module is exploited in each decoder to obtain enhanced features, followed by a multi-layer perceptron. The multi-faceted decoders aim to predict the camera, shape, and pose parameters, respectively, which are then associated with the SMPL model to reconstruct the corresponding 3D human mesh. In learning, existing 3D meshes are projected via the camera parameters into 2D synthetic sketches with joints, which are combined with the freehand sketches to optimize the model. To verify our method, we collect a large-scale dataset of about 26k freehand sketches and their corresponding 3D meshes containing various poses of human bodies from 14 different angles. Extensive experimental results demonstrate our SketchBodyNet achieves superior performance in reconstructing 3D human meshes from freehand sketches.
+
+
+
+ 21. 标题:Efficient Retrieval of Images with Irregular Patterns using Morphological Image Analysis: Applications to Industrial and Healthcare datasets
+ 编号:[105]
+ 链接:https://arxiv.org/abs/2310.06566
+ 作者:Jiajun Zhang, Georgina Cosma, Sarah Bugby, Jason Watkins
+ 备注:35 pages, 5 figures, 19 tables (17 tables in appendix), submitted to Special Issue: Advances and Challenges in Multimodal Machine Learning 2nd Edition, Journal of Imaging, MDPI
+ 关键词:process of searching, searching and retrieving, database based, visual content, images
+
+ 点击查看摘要
+ Image retrieval is the process of searching and retrieving images from a database based on their visual content and features. Recently, much attention has been directed towards the retrieval of irregular patterns within industrial or medical images by extracting features from the images, such as deep features, colour-based features, shape-based features and local features. This has applications across a spectrum of industries, including fault inspection, disease diagnosis, and maintenance prediction. This paper proposes an image retrieval framework to search for images containing similar irregular patterns by extracting a set of morphological features (DefChars) from images; the datasets employed in this paper contain wind turbine blade images with defects, chest computerised tomography scans with COVID-19 infection, heatsink images with defects, and lake ice images. The proposed framework was evaluated with different feature extraction methods (DefChars, resized raw image, local binary pattern, and scale-invariant feature transforms) and distance metrics to determine the most efficient parameters in terms of retrieval performance across datasets. The retrieval results show that the proposed framework using the DefChars and the Manhattan distance metric achieves a mean average precision of 80% and a low standard deviation of 0.09 across classes of irregular patterns, outperforming alternative feature-metric combinations across all datasets. Furthermore, the low standard deviation between each class highlights DefChars' capability for a reliable image retrieval task, even in the presence of class imbalances or small-sized datasets.
+
+
+
+ 22. 标题:Compositional Representation Learning for Brain Tumour Segmentation
+ 编号:[106]
+ 链接:https://arxiv.org/abs/2310.06562
+ 作者:Xiao Liu, Antanas Kascenas, Hannah Watson, Sotirios A. Tsaftaris, Alison Q. O'Neil
+ 备注:Accepted by DART workshop, MICCAI 2023
+ 关键词:achieve human expert-level, human expert-level performance, large amount, achieve human, human expert-level
+
+ 点击查看摘要
+ For brain tumour segmentation, deep learning models can achieve human expert-level performance given a large amount of data and pixel-level annotations. However, the expensive exercise of obtaining pixel-level annotations for large amounts of data is not always feasible, and performance is often heavily reduced in a low-annotated data regime. To tackle this challenge, we adapt a mixed supervision framework, vMFNet, to learn robust compositional representations using unsupervised learning and weak supervision alongside non-exhaustive pixel-level pathology labels. In particular, we use the BraTS dataset to simulate a collection of 2-point expert pathology annotations indicating the top and bottom slice of the tumour (or tumour sub-regions: peritumoural edema, GD-enhancing tumour, and the necrotic / non-enhancing tumour) in each MRI volume, from which weak image-level labels that indicate the presence or absence of the tumour (or the tumour sub-regions) in the image are constructed. Then, vMFNet models the encoded image features with von-Mises-Fisher (vMF) distributions, via learnable and compositional vMF kernels which capture information about structures in the images. We show that good tumour segmentation performance can be achieved with a large amount of weakly labelled data but only a small amount of fully-annotated data. Interestingly, emergent learning of anatomical structures occurs in the compositional representation even given only supervision relating to pathology (tumour).
+
+
+
+ 23. 标题:Be Careful What You Smooth For: Label Smoothing Can Be a Privacy Shield but Also a Catalyst for Model Inversion Attacks
+ 编号:[111]
+ 链接:https://arxiv.org/abs/2310.06549
+ 作者:Lukas Struppek, Dominik Hintersdorf, Kristian Kersting
+ 备注:23 pages, 8 tables, 8 figures
+ 关键词:showing diverse benefits, widely adopted regularization, adopted regularization method, deep learning, showing diverse
+
+ 点击查看摘要
+ Label smoothing -- using softened labels instead of hard ones -- is a widely adopted regularization method for deep learning, showing diverse benefits such as enhanced generalization and calibration. Its implications for preserving model privacy, however, have remained unexplored. To fill this gap, we investigate the impact of label smoothing on model inversion attacks (MIAs), which aim to generate class-representative samples by exploiting the knowledge encoded in a classifier, thereby inferring sensitive information about its training data. Through extensive analyses, we uncover that traditional label smoothing fosters MIAs, thereby increasing a model's privacy leakage. Even more, we reveal that smoothing with negative factors counters this trend, impeding the extraction of class-related information and leading to privacy preservation, beating state-of-the-art defenses. This establishes a practical and powerful novel way for enhancing model resilience against MIAs.
+
+
+
+ 24. 标题:Perceptual MAE for Image Manipulation Localization: A High-level Vision Learner Focusing on Low-level Features
+ 编号:[121]
+ 链接:https://arxiv.org/abs/2310.06525
+ 作者:Xiaochen Ma, Jizhe Zhou, Xiong Xu, Zhuohang Jiang, Chi-Man Pun
+ 备注:
+ 关键词:making Image Manipulation, multimedia forensics faces, multimedia generation technology, forensics faces unprecedented, faces unprecedented challenges
+
+ 点击查看摘要
+ Nowadays, multimedia forensics faces unprecedented challenges due to the rapid advancement of multimedia generation technology thereby making Image Manipulation Localization (IML) crucial in the pursuit of truth. The key to IML lies in revealing the artifacts or inconsistencies between the tampered and authentic areas, which are evident under pixel-level features. Consequently, existing studies treat IML as a low-level vision task, focusing on allocating tampered masks by crafting pixel-level features such as image RGB noises, edge signals, or high-frequency features. However, in practice, tampering commonly occurs at the object level, and different classes of objects have varying likelihoods of becoming targets of tampering. Therefore, object semantics are also vital in identifying the tampered areas in addition to pixel-level features. This necessitates IML models to carry out a semantic understanding of the entire image. In this paper, we reformulate the IML task as a high-level vision task that greatly benefits from low-level features. Based on such an interpretation, we propose a method to enhance the Masked Autoencoder (MAE) by incorporating high-resolution inputs and a perceptual loss supervision module, which is termed Perceptual MAE (PMAE). While MAE has demonstrated an impressive understanding of object semantics, PMAE can also compensate for low-level semantics with our proposed enhancements. Evidenced by extensive experiments, this paradigm effectively unites the low-level and high-level features of the IML task and outperforms state-of-the-art tampering localization methods on all five publicly available datasets.
+
+
+
+ 25. 标题:Watt For What: Rethinking Deep Learning's Energy-Performance Relationship
+ 编号:[122]
+ 链接:https://arxiv.org/abs/2310.06522
+ 作者:Shreyank N Gowda, Xinyue Hao, Gen Li, Laura Sevilla-Lara, Shashank Narayana Gowda
+ 备注:
+ 关键词:natural language processing, achieving unprecedented levels, revolutionized various fields, language processing, image recognition
+
+ 点击查看摘要
+ Deep learning models have revolutionized various fields, from image recognition to natural language processing, by achieving unprecedented levels of accuracy. However, their increasing energy consumption has raised concerns about their environmental impact, disadvantaging smaller entities in research and exacerbating global energy consumption. In this paper, we explore the trade-off between model accuracy and electricity consumption, proposing a metric that penalizes large consumption of electricity. We conduct a comprehensive study on the electricity consumption of various deep learning models across different GPUs, presenting a detailed analysis of their accuracy-efficiency trade-offs. By evaluating accuracy per unit of electricity consumed, we demonstrate how smaller, more energy-efficient models can significantly expedite research while mitigating environmental concerns. Our results highlight the potential for a more sustainable approach to deep learning, emphasizing the importance of optimizing models for efficiency. This research also contributes to a more equitable research landscape, where smaller entities can compete effectively with larger counterparts. This advocates for the adoption of efficient deep learning practices to reduce electricity consumption, safeguarding the environment for future generations whilst also helping ensure a fairer competitive landscape.
+
+
+
+ 26. 标题:Deep Learning for Automatic Detection and Facial Recognition in Japanese Macaques: Illuminating Social Networks
+ 编号:[136]
+ 链接:https://arxiv.org/abs/2310.06489
+ 作者:Julien Paulet (UJM), Axel Molina (ENS-PSL), Benjamin Beltzung (IPHC), Takafumi Suzumura, Shinya Yamamoto, Cédric Sueur (IPHC, IUF, ANTHROPO LAB)
+ 备注:
+ 关键词:social structures understanding, ecology and ethology, structures understanding, plays a pivotal, pivotal role
+
+ 点击查看摘要
+ Individual identification plays a pivotal role in ecology and ethology, notably as a tool for complex social structures understanding. However, traditional identification methods often involve invasive physical tags and can prove both disruptive for animals and time-intensive for researchers. In recent years, the integration of deep learning in research offered new methodological perspectives through automatization of complex tasks. Harnessing object detection and recognition technologies is increasingly used by researchers to achieve identification on video footage. This study represents a preliminary exploration into the development of a non-invasive tool for face detection and individual identification of Japanese macaques (Macaca fuscata) through deep learning. The ultimate goal of this research is, using identifications done on the dataset, to automatically generate a social network representation of the studied population. The current main results are promising: (i) the creation of a Japanese macaques' face detector (Faster-RCNN model), reaching a 82.2% accuracy and (ii) the creation of an individual recognizer for K{ō}jima island macaques population (YOLOv8n model), reaching a 83% accuracy. We also created a K{ō}jima population social network by traditional methods, based on co-occurrences on videos. Thus, we provide a benchmark against which the automatically generated network will be assessed for reliability. These preliminary results are a testament to the potential of this innovative approach to provide the scientific community with a tool for tracking individuals and social network studies in Japanese macaques.
+
+
+
+ 27. 标题:SpikeCLIP: A Contrastive Language-Image Pretrained Spiking Neural Network
+ 编号:[137]
+ 链接:https://arxiv.org/abs/2310.06488
+ 作者:Tianlong Li, Wenhao Liu, Changze Lv, Jianhan Xu, Cenyuan Zhang, Muling Wu, Xiaoqing Zheng, Xuanjing Huang
+ 备注:
+ 关键词:Spiking neural networks, deep neural networks, neural networks, improved energy efficiency, Spiking neural
+
+ 点击查看摘要
+ Spiking neural networks (SNNs) have demonstrated the capability to achieve comparable performance to deep neural networks (DNNs) in both visual and linguistic domains while offering the advantages of improved energy efficiency and adherence to biological plausibility. However, the extension of such single-modality SNNs into the realm of multimodal scenarios remains an unexplored territory. Drawing inspiration from the concept of contrastive language-image pre-training (CLIP), we introduce a novel framework, named SpikeCLIP, to address the gap between two modalities within the context of spike-based computing through a two-step recipe involving ``Alignment Pre-training + Dual-Loss Fine-tuning". Extensive experiments demonstrate that SNNs achieve comparable results to their DNN counterparts while significantly reducing energy consumption across a variety of datasets commonly used for multimodal model evaluation. Furthermore, SpikeCLIP maintains robust performance in image classification tasks that involve class labels not predefined within specific categories.
+
+
+
+ 28. 标题:Topological RANSAC for instance verification and retrieval without fine-tuning
+ 编号:[138]
+ 链接:https://arxiv.org/abs/2310.06486
+ 作者:Guoyuan An, Juhyung Seon, Inkyu An, Yuchi Huo, Sung-Eui Yoon
+ 备注:
+ 关键词:enhancing explainable image, explainable image retrieval, set is unavailable, paper presents, presents an innovative
+
+ 点击查看摘要
+ This paper presents an innovative approach to enhancing explainable image retrieval, particularly in situations where a fine-tuning set is unavailable. The widely-used SPatial verification (SP) method, despite its efficacy, relies on a spatial model and the hypothesis-testing strategy for instance recognition, leading to inherent limitations, including the assumption of planar structures and neglect of topological relations among features. To address these shortcomings, we introduce a pioneering technique that replaces the spatial model with a topological one within the RANSAC process. We propose bio-inspired saccade and fovea functions to verify the topological consistency among features, effectively circumventing the issues associated with SP's spatial model. Our experimental results demonstrate that our method significantly outperforms SP, achieving state-of-the-art performance in non-fine-tuning retrieval. Furthermore, our approach can enhance performance when used in conjunction with fine-tuned features. Importantly, our method retains high explainability and is lightweight, offering a practical and adaptable solution for a variety of real-world applications.
+
+
+
+ 29. 标题:Focus on Local Regions for Query-based Object Detection
+ 编号:[145]
+ 链接:https://arxiv.org/abs/2310.06470
+ 作者:Hongbin Xu, Yamei Xia, Shuai Zhao, Bo Cheng
+ 备注:
+ 关键词:garnered significant attention, advent of DETR, garnered significant, significant attention, DETR
+
+ 点击查看摘要
+ Query-based methods have garnered significant attention in object detection since the advent of DETR, the pioneering end-to-end query-based detector. However, these methods face challenges like slow convergence and suboptimal performance. Notably, self-attention in object detection often hampers convergence due to its global focus. To address these issues, we propose FoLR, a transformer-like architecture with only decoders. We enhance the self-attention mechanism by isolating connections between irrelevant objects that makes it focus on local regions but not global regions. We also design the adaptive sampling method to extract effective features based on queries' local regions from feature maps. Additionally, we employ a look-back strategy for decoders to retain prior information, followed by the Feature Mixer module to fuse features and queries. Experimental results demonstrate FoLR's state-of-the-art performance in query-based detectors, excelling in convergence speed and computational efficiency.
+
+
+
+ 30. 标题:A Geometrical Approach to Evaluate the Adversarial Robustness of Deep Neural Networks
+ 编号:[147]
+ 链接:https://arxiv.org/abs/2310.06468
+ 作者:Yang Wang, Bo Dong, Ke Xu, Haiyin Piao, Yufei Ding, Baocai Yin, Xin Yang
+ 备注:ACM Transactions on Multimedia Computing, Communications, and Applications (ACM TOMM)
+ 关键词:Deep Neural Networks, computer vision tasks, Deep Neural, Neural Networks, adversarial
+
+ 点击查看摘要
+ Deep Neural Networks (DNNs) are widely used for computer vision tasks. However, it has been shown that deep models are vulnerable to adversarial attacks, i.e., their performances drop when imperceptible perturbations are made to the original inputs, which may further degrade the following visual tasks or introduce new problems such as data and privacy security. Hence, metrics for evaluating the robustness of deep models against adversarial attacks are desired. However, previous metrics are mainly proposed for evaluating the adversarial robustness of shallow networks on the small-scale datasets. Although the Cross Lipschitz Extreme Value for nEtwork Robustness (CLEVER) metric has been proposed for large-scale datasets (e.g., the ImageNet dataset), it is computationally expensive and its performance relies on a tractable number of samples. In this paper, we propose the Adversarial Converging Time Score (ACTS), an attack-dependent metric that quantifies the adversarial robustness of a DNN on a specific input. Our key observation is that local neighborhoods on a DNN's output surface would have different shapes given different inputs. Hence, given different inputs, it requires different time for converging to an adversarial sample. Based on this geometry meaning, ACTS measures the converging time as an adversarial robustness metric. We validate the effectiveness and generalization of the proposed ACTS metric against different adversarial attacks on the large-scale ImageNet dataset using state-of-the-art deep networks. Extensive experiments show that our ACTS metric is an efficient and effective adversarial metric over the previous CLEVER metric.
+
+
+
+ 31. 标题:Solution for SMART-101 Challenge of ICCV Multi-modal Algorithmic Reasoning Task 2023
+ 编号:[158]
+ 链接:https://arxiv.org/abs/2310.06440
+ 作者:Xiangyu Wu, Yang Yang, Shengdong Xu, Yifeng Wu, Qingguo Chen, Jianfeng Lu
+ 备注:
+ 关键词:Algorithmic Reasoning Task, Multi-modal Algorithmic Reasoning, Reasoning Task, Multi-modal Algorithmic, Algorithmic Reasoning
+
+ 点击查看摘要
+ In this paper, we present our solution to a Multi-modal Algorithmic Reasoning Task: SMART-101 Challenge. Different from the traditional visual question-answering datasets, this challenge evaluates the abstraction, deduction, and generalization abilities of neural networks in solving visuolinguistic puzzles designed specifically for children in the 6-8 age group. We employed a divide-and-conquer approach. At the data level, inspired by the challenge paper, we categorized the whole questions into eight types and utilized the llama-2-chat model to directly generate the type for each question in a zero-shot manner. Additionally, we trained a yolov7 model on the icon45 dataset for object detection and combined it with the OCR method to recognize and locate objects and text within the images. At the model level, we utilized the BLIP-2 model and added eight adapters to the image encoder VIT-G to adaptively extract visual features for different question types. We fed the pre-constructed question templates as input and generated answers using the flan-t5-xxl decoder. Under the puzzle splits configuration, we achieved an accuracy score of 26.5 on the validation set and 24.30 on the private test set.
+
+
+
+ 32. 标题:Skeleton Ground Truth Extraction: Methodology, Annotation Tool and Benchmarks
+ 编号:[159]
+ 链接:https://arxiv.org/abs/2310.06437
+ 作者:Cong Yang, Bipin Indurkhya, John See, Bo Gao, Yan Ke, Zeyd Boukhers, Zhenyu Yang, Marcin Grzegorzek
+ 备注:Accepted for publication in the International Journal of Computer Vision (IJCV)
+ 关键词:Skeleton Ground Truth, Ground Truth, deep learning techniques, Convolutional Neural Networks, Skeleton Ground
+
+ 点击查看摘要
+ Skeleton Ground Truth (GT) is critical to the success of supervised skeleton extraction methods, especially with the popularity of deep learning techniques. Furthermore, we see skeleton GTs used not only for training skeleton detectors with Convolutional Neural Networks (CNN) but also for evaluating skeleton-related pruning and matching algorithms. However, most existing shape and image datasets suffer from the lack of skeleton GT and inconsistency of GT standards. As a result, it is difficult to evaluate and reproduce CNN-based skeleton detectors and algorithms on a fair basis. In this paper, we present a heuristic strategy for object skeleton GT extraction in binary shapes and natural images. Our strategy is built on an extended theory of diagnosticity hypothesis, which enables encoding human-in-the-loop GT extraction based on clues from the target's context, simplicity, and completeness. Using this strategy, we developed a tool, SkeView, to generate skeleton GT of 17 existing shape and image datasets. The GTs are then structurally evaluated with representative methods to build viable baselines for fair comparisons. Experiments demonstrate that GTs generated by our strategy yield promising quality with respect to standard consistency, and also provide a balance between simplicity and completeness.
+
+
+
+ 33. 标题:Retromorphic Testing: A New Approach to the Test Oracle Problem
+ 编号:[163]
+ 链接:https://arxiv.org/abs/2310.06433
+ 作者:Boxi Yu, Qiuyang Mang, Qingshuo Guo, Pinjia He
+ 备注:
+ 关键词:test oracle serves, testing, program, criterion or mechanism, mechanism to assess
+
+ 点击查看摘要
+ A test oracle serves as a criterion or mechanism to assess the correspondence between software output and the anticipated behavior for a given input set. In automated testing, black-box techniques, known for their non-intrusive nature in test oracle construction, are widely used, including notable methodologies like differential testing and metamorphic testing. Inspired by the mathematical concept of inverse function, we present Retromorphic Testing, a novel black-box testing methodology. It leverages an auxiliary program in conjunction with the program under test, which establishes a dual-program structure consisting of a forward program and a backward program. The input data is first processed by the forward program and then its program output is reversed to its original input format using the backward program. In particular, the auxiliary program can operate as either the forward or backward program, leading to different testing modes. The process concludes by examining the relationship between the initial input and the transformed output within the input domain. For example, to test the implementation of the sine function $\sin(x)$, we can employ its inverse function, $\arcsin(x)$, and validate the equation $x = \sin(\arcsin(x)+2k\pi), \forall k \in \mathbb{Z}$. In addition to the high-level concept of Retromorphic Testing, this paper presents its three testing modes with illustrative use cases across diverse programs, including algorithms, traditional software, and AI applications.
+
+
+
+ 34. 标题:Conformal Prediction for Deep Classifier via Label Ranking
+ 编号:[164]
+ 链接:https://arxiv.org/abs/2310.06430
+ 作者:Jianguo Huang, Huajun Xi, Linjun Zhang, Huaxiu Yao, Yue Qiu, Hongxin Wei
+ 备注:
+ 关键词:prediction sets, generates prediction sets, Sorted Adaptive prediction, Conformal prediction, statistical framework
+
+ 点击查看摘要
+ Conformal prediction is a statistical framework that generates prediction sets containing ground-truth labels with a desired coverage guarantee. The predicted probabilities produced by machine learning models are generally miscalibrated, leading to large prediction sets in conformal prediction. In this paper, we empirically and theoretically show that disregarding the probabilities' value will mitigate the undesirable effect of miscalibrated probability values. Then, we propose a novel algorithm named $\textit{Sorted Adaptive prediction sets}$ (SAPS), which discards all the probability values except for the maximum softmax probability. The key idea behind SAPS is to minimize the dependence of the non-conformity score on the probability values while retaining the uncertainty information. In this manner, SAPS can produce sets of small size and communicate instance-wise uncertainty. Theoretically, we provide a finite-sample coverage guarantee of SAPS and show that the expected value of set size from SAPS is always smaller than APS. Extensive experiments validate that SAPS not only lessens the prediction sets but also broadly enhances the conditional coverage rate and adaptation of prediction sets.
+
+
+
+ 35. 标题:AnoDODE: Anomaly Detection with Diffusion ODE
+ 编号:[170]
+ 链接:https://arxiv.org/abs/2310.06420
+ 作者:Xianyao Hu, Congming Jin
+ 备注:11 pages, 5 figures
+ 关键词:identifying atypical data, atypical data samples, process of identifying, identifying atypical, samples that significantly
+
+ 点击查看摘要
+ Anomaly detection is the process of identifying atypical data samples that significantly deviate from the majority of the dataset. In the realm of clinical screening and diagnosis, detecting abnormalities in medical images holds great importance. Typically, clinical practice provides access to a vast collection of normal images, while abnormal images are relatively scarce. We hypothesize that abnormal images and their associated features tend to manifest in low-density regions of the data distribution. Following this assumption, we turn to diffusion ODEs for unsupervised anomaly detection, given their tractability and superior performance in density estimation tasks. More precisely, we propose a new anomaly detection method based on diffusion ODEs by estimating the density of features extracted from multi-scale medical images. Our anomaly scoring mechanism depends on computing the negative log-likelihood of features extracted from medical images at different scales, quantified in bits per dimension. Furthermore, we propose a reconstruction-based anomaly localization suitable for our method. Our proposed method not only identifie anomalies but also provides interpretability at both the image and pixel levels. Through experiments on the BraTS2021 medical dataset, our proposed method outperforms existing methods. These results confirm the effectiveness and robustness of our method.
+
+
+
+ 36. 标题:Boundary Discretization and Reliable Classification Network for Temporal Action Detection
+ 编号:[177]
+ 链接:https://arxiv.org/abs/2310.06403
+ 作者:Zhenying Fang
+ 备注:12 pages
+ 关键词:Boundary Discretization, Temporal action detection, untrimmed videos, action detection aims, aims to recognize
+
+ 点击查看摘要
+ Temporal action detection aims to recognize the action category and determine the starting and ending time of each action instance in untrimmed videos. The mixed methods have achieved remarkable performance by simply merging anchor-based and anchor-free approaches. However, there are still two crucial issues in the mixed framework: (1) Brute-force merging and handcrafted anchors design affect the performance and practical application of the mixed methods. (2) A large number of false positives in action category predictions further impact the detection performance. In this paper, we propose a novel Boundary Discretization and Reliable Classification Network (BDRC-Net) that addresses the above issues by introducing boundary discretization and reliable classification modules. Specifically, the boundary discretization module (BDM) elegantly merges anchor-based and anchor-free approaches in the form of boundary discretization, avoiding the handcrafted anchors design required by traditional mixed methods. Furthermore, the reliable classification module (RCM) predicts reliable action categories to reduce false positives in action category predictions. Extensive experiments conducted on different benchmarks demonstrate that our proposed method achieves favorable performance compared with the state-of-the-art. For example, BDRC-Net hits an average mAP of 68.6% on THUMOS'14, outperforming the previous best by 1.5%. The code will be released at this https URL.
+
+
+
+ 37. 标题:Learning Stackable and Skippable LEGO Bricks for Efficient, Reconfigurable, and Variable-Resolution Diffusion Modeling
+ 编号:[184]
+ 链接:https://arxiv.org/abs/2310.06389
+ 作者:Huangjie Zheng, Zhendong Wang, Jianbo Yuan, Guanghan Ning, Pengcheng He, Quanzeng You, Hongxia Yang, Mingyuan Zhou
+ 备注:
+ 关键词:significant computational costs, generating photo-realistic images, LEGO bricks, significant computational, LEGO
+
+ 点击查看摘要
+ Diffusion models excel at generating photo-realistic images but come with significant computational costs in both training and sampling. While various techniques address these computational challenges, a less-explored issue is designing an efficient and adaptable network backbone for iterative refinement. Current options like U-Net and Vision Transformer often rely on resource-intensive deep networks and lack the flexibility needed for generating images at variable resolutions or with a smaller network than used in training. This study introduces LEGO bricks, which seamlessly integrate Local-feature Enrichment and Global-content Orchestration. These bricks can be stacked to create a test-time reconfigurable diffusion backbone, allowing selective skipping of bricks to reduce sampling costs and generate higher-resolution images than the training data. LEGO bricks enrich local regions with an MLP and transform them using a Transformer block while maintaining a consistent full-resolution image across all bricks. Experimental results demonstrate that LEGO bricks enhance training efficiency, expedite convergence, and facilitate variable-resolution image generation while maintaining strong generative performance. Moreover, LEGO significantly reduces sampling time compared to other methods, establishing it as a valuable enhancement for diffusion models.
+
+
+
+ 38. 标题:3DS-SLAM: A 3D Object Detection based Semantic SLAM towards Dynamic Indoor Environments
+ 编号:[186]
+ 链接:https://arxiv.org/abs/2310.06385
+ 作者:Ghanta Sai Krishna, Kundrapu Supriya, Sabur Baidya
+ 备注:
+ 关键词:camera localization accuracy, Simultaneous Localization, Localization and Mapping, localization accuracy, camera localization
+
+ 点击查看摘要
+ The existence of variable factors within the environment can cause a decline in camera localization accuracy, as it violates the fundamental assumption of a static environment in Simultaneous Localization and Mapping (SLAM) algorithms. Recent semantic SLAM systems towards dynamic environments either rely solely on 2D semantic information, or solely on geometric information, or combine their results in a loosely integrated manner. In this research paper, we introduce 3DS-SLAM, 3D Semantic SLAM, tailored for dynamic scenes with visual 3D object detection. The 3DS-SLAM is a tightly-coupled algorithm resolving both semantic and geometric constraints sequentially. We designed a 3D part-aware hybrid transformer for point cloud-based object detection to identify dynamic objects. Subsequently, we propose a dynamic feature filter based on HDBSCAN clustering to extract objects with significant absolute depth differences. When compared against ORB-SLAM2, 3DS-SLAM exhibits an average improvement of 98.01% across the dynamic sequences of the TUM RGB-D dataset. Furthermore, it surpasses the performance of the other four leading SLAM systems designed for dynamic environments.
+
+
+
+ 39. 标题:Leveraging Diffusion-Based Image Variations for Robust Training on Poisoned Data
+ 编号:[194]
+ 链接:https://arxiv.org/abs/2310.06372
+ 作者:Lukas Struppek, Martin B. Hentschel, Clifton Poth, Dominik Hintersdorf, Kristian Kersting
+ 备注:11 pages, 3 tables, 2 figures
+ 关键词:surreptitiously introduce hidden, introduce hidden functionalities, Backdoor attacks pose, training neural networks, attacks pose
+
+ 点击查看摘要
+ Backdoor attacks pose a serious security threat for training neural networks as they surreptitiously introduce hidden functionalities into a model. Such backdoors remain silent during inference on clean inputs, evading detection due to inconspicuous behavior. However, once a specific trigger pattern appears in the input data, the backdoor activates, causing the model to execute its concealed function. Detecting such poisoned samples within vast datasets is virtually impossible through manual inspection. To address this challenge, we propose a novel approach that enables model training on potentially poisoned datasets by utilizing the power of recent diffusion models. Specifically, we create synthetic variations of all training samples, leveraging the inherent resilience of diffusion models to potential trigger patterns in the data. By combining this generative approach with knowledge distillation, we produce student models that maintain their general performance on the task while exhibiting robust resistance to backdoor triggers.
+
+
+
+ 40. 标题:Advanced Efficient Strategy for Detection of Dark Objects Based on Spiking Network with Multi-Box Detection
+ 编号:[196]
+ 链接:https://arxiv.org/abs/2310.06370
+ 作者:Munawar Ali, Baoqun Yin, Hazrat Bilal, Aakash Kumar, Ali Muhammad, Avinash Rohra
+ 备注:
+ 关键词:deep learning algorithms, shown amazing performance, recognizing darker objects, object detection tasks, largest challenge
+
+ 点击查看摘要
+ Several deep learning algorithms have shown amazing performance for existing object detection tasks, but recognizing darker objects is the largest challenge. Moreover, those techniques struggled to detect or had a slow recognition rate, resulting in significant performance losses. As a result, an improved and accurate detection approach is required to address the above difficulty. The whole study proposes a combination of spiked and normal convolution layers as an energy-efficient and reliable object detector model. The proposed model is split into two sections. The first section is developed as a feature extractor, which utilizes pre-trained VGG16, and the second section of the proposal structure is the combination of spiked and normal Convolutional layers to detect the bounding boxes of images. We drew a pre-trained model for classifying detected objects. With state of the art Python libraries, spike layers can be trained efficiently. The proposed spike convolutional object detector (SCOD) has been evaluated on VOC and Ex-Dark datasets. SCOD reached 66.01% and 41.25% mAP for detecting 20 different objects in the VOC-12 and 12 objects in the Ex-Dark dataset. SCOD uses 14 Giga FLOPS for its forward path calculations. Experimental results indicated superior performance compared to Tiny YOLO, Spike YOLO, YOLO-LITE, Tinier YOLO and Center of loc+Xception based on mAP for the VOC dataset.
+
+
+
+ 41. 标题:CoinSeg: Contrast Inter- and Intra- Class Representations for Incremental Segmentation
+ 编号:[198]
+ 链接:https://arxiv.org/abs/2310.06368
+ 作者:Zekang Zhang, Guangyu Gao, Jianbo Jiao, Chi Harold Liu, Yunchao Wei
+ 备注:Accepted by ICCV 2023
+ 关键词:semantic segmentation aims, Class incremental semantic, incremental semantic segmentation, semantic segmentation, segmentation aims
+
+ 点击查看摘要
+ Class incremental semantic segmentation aims to strike a balance between the model's stability and plasticity by maintaining old knowledge while adapting to new concepts. However, most state-of-the-art methods use the freeze strategy for stability, which compromises the model's this http URL contrast, releasing parameter training for plasticity could lead to the best performance for all categories, but this requires discriminative feature representation.Therefore, we prioritize the model's plasticity and propose the Contrast inter- and intra-class representations for Incremental Segmentation (CoinSeg), which pursues discriminative representations for flexible parameter tuning. Inspired by the Gaussian mixture model that samples from a mixture of Gaussian distributions, CoinSeg emphasizes intra-class diversity with multiple contrastive representation centroids. Specifically, we use mask proposals to identify regions with strong objectness that are likely to be diverse instances/centroids of a category. These mask proposals are then used for contrastive representations to reinforce intra-class diversity. Meanwhile, to avoid bias from intra-class diversity, we also apply category-level pseudo-labels to enhance category-level consistency and inter-category diversity. Additionally, CoinSeg ensures the model's stability and alleviates forgetting through a specific flexible tuning strategy. We validate CoinSeg on Pascal VOC 2012 and ADE20K datasets with multiple incremental scenarios and achieve superior results compared to previous state-of-the-art methods, especially in more challenging and realistic long-term scenarios. Code is available at this https URL.
+
+
+
+ 42. 标题:Fire Detection From Image and Video Using YOLOv5
+ 编号:[207]
+ 链接:https://arxiv.org/abs/2310.06351
+ 作者:Arafat Islam, Md. Imtiaz Habib
+ 备注:6 pages, 6 sections, unpublished paper
+ 关键词:detection deep learning, deep learning algorithm, detection, fire detection, fire detection deep
+
+ 点击查看摘要
+ For the detection of fire-like targets in indoor, outdoor and forest fire images, as well as fire detection under different natural lights, an improved YOLOv5 fire detection deep learning algorithm is proposed. The YOLOv5 detection model expands the feature extraction network from three dimensions, which enhances feature propagation of fire small targets identification, improves network performance, and reduces model parameters. Furthermore, through the promotion of the feature pyramid, the top-performing prediction box is obtained. Fire-YOLOv5 attains excellent results compared to state-of-the-art object detection networks, notably in the detection of small targets of fire and smoke with mAP 90.5% and f1 score 88%. Overall, the Fire-YOLOv5 detection model can effectively deal with the inspection of small fire targets, as well as fire-like and smoke-like objects with F1 score 0.88. When the input image size is 416 x 416 resolution, the average detection time is 0.12 s per frame, which can provide real-time forest fire detection. Moreover, the algorithm proposed in this paper can also be applied to small target detection under other complicated situations. The proposed system shows an improved approach in all fire detection metrics such as precision, recall, and mean average precision.
+
+
+
+ 43. 标题:JointNet: Extending Text-to-Image Diffusion for Dense Distribution Modeling
+ 编号:[209]
+ 链接:https://arxiv.org/abs/2310.06347
+ 作者:Jingyang Zhang, Shiwei Li, Yuanxun Lu, Tian Fang, David McKinnon, Yanghai Tsin, Long Quan, Yao Yao
+ 备注:
+ 关键词:neural network architecture, additional dense modality, architecture for modeling, dense modality branch, RGB branch
+
+ 点击查看摘要
+ We introduce JointNet, a novel neural network architecture for modeling the joint distribution of images and an additional dense modality (e.g., depth maps). JointNet is extended from a pre-trained text-to-image diffusion model, where a copy of the original network is created for the new dense modality branch and is densely connected with the RGB branch. The RGB branch is locked during network fine-tuning, which enables efficient learning of the new modality distribution while maintaining the strong generalization ability of the large-scale pre-trained diffusion model. We demonstrate the effectiveness of JointNet by using RGBD diffusion as an example and through extensive experiments, showcasing its applicability in a variety of applications, including joint RGBD generation, dense depth prediction, depth-conditioned image generation, and coherent tile-based 3D panorama generation.
+
+
+
+ 44. 标题:Filter Pruning For CNN With Enhanced Linear Representation Redundancy
+ 编号:[210]
+ 链接:https://arxiv.org/abs/2310.06344
+ 作者:Bojue Wang, Chunmei Ma, Bin Liu, Nianbo Liu, Jinqi Zhu
+ 备注:
+ 关键词:parallel computing techniques, thriving developed parallel, developed parallel computing, pruning excels non-structured, excels non-structured methods
+
+ 点击查看摘要
+ Structured network pruning excels non-structured methods because they can take advantage of the thriving developed parallel computing techniques. In this paper, we propose a new structured pruning method. Firstly, to create more structured redundancy, we present a data-driven loss function term calculated from the correlation coefficient matrix of different feature maps in the same layer, named CCM-loss. This loss term can encourage the neural network to learn stronger linear representation relations between feature maps during the training from the scratch so that more homogenous parts can be removed later in pruning. CCM-loss provides us with another universal transcendental mathematical tool besides L*-norm regularization, which concentrates on generating zeros, to generate more redundancy but for the different genres. Furthermore, we design a matching channel selection strategy based on principal components analysis to exploit the maximum potential ability of CCM-loss. In our new strategy, we mainly focus on the consistency and integrality of the information flow in the network. Instead of empirically hard-code the retain ratio for each layer, our channel selection strategy can dynamically adjust each layer's retain ratio according to the specific circumstance of a per-trained model to push the prune ratio to the limit. Notably, on the Cifar-10 dataset, our method brings 93.64% accuracy for pruned VGG-16 with only 1.40M parameters and 49.60M FLOPs, the pruned ratios for parameters and FLOPs are 90.6% and 84.2%, respectively. For ResNet-50 trained on the ImageNet dataset, our approach achieves 42.8% and 47.3% storage and computation reductions, respectively, with an accuracy of 76.23%. Our code is available at this https URL.
+
+
+
+ 45. 标题:Local Style Awareness of Font Images
+ 编号:[215]
+ 链接:https://arxiv.org/abs/2310.06337
+ 作者:Daichi Haraguchi, Seiichi Uchida
+ 备注:Accepted at ICDAR WML 2023
+ 关键词:local parts, serifs and curvatures, parts, local, attention
+
+ 点击查看摘要
+ When we compare fonts, we often pay attention to styles of local parts, such as serifs and curvatures. This paper proposes an attention mechanism to find important local parts. The local parts with larger attention are then considered important. The proposed mechanism can be trained in a quasi-self-supervised manner that requires no manual annotation other than knowing that a set of character images is from the same font, such as Helvetica. After confirming that the trained attention mechanism can find style-relevant local parts, we utilize the resulting attention for local style-aware font generation. Specifically, we design a new reconstruction loss function to put more weight on the local parts with larger attention for generating character images with more accurate style realization. This loss function has the merit of applicability to various font generation models. Our experimental results show that the proposed loss function improves the quality of generated character images by several few-shot font generation models.
+
+
+
+ 46. 标题:CrowdRec: 3D Crowd Reconstruction from Single Color Images
+ 编号:[218]
+ 链接:https://arxiv.org/abs/2310.06332
+ 作者:Buzhen Huang, Jingyi Ju, Yangang Wang
+ 备注:technical report
+ 关键词:GigaCrowd challenge, technical report, crowd, spatial distribution, single-person
+
+ 点击查看摘要
+ This is a technical report for the GigaCrowd challenge. Reconstructing 3D crowds from monocular images is a challenging problem due to mutual occlusions, server depth ambiguity, and complex spatial distribution. Since no large-scale 3D crowd dataset can be used to train a robust model, the current multi-person mesh recovery methods can hardly achieve satisfactory performance in crowded scenes. In this paper, we exploit the crowd features and propose a crowd-constrained optimization to improve the common single-person method on crowd images. To avoid scale variations, we first detect human bounding-boxes and 2D poses from the original images with off-the-shelf detectors. Then, we train a single-person mesh recovery network using existing in-the-wild image datasets. To promote a more reasonable spatial distribution, we further propose a crowd constraint to refine the single-person network parameters. With the optimization, we can obtain accurate body poses and shapes with reasonable absolute positions from a large-scale crowd image using a single-person backbone. The code will be publicly available at~\url{this https URL}.
+
+
+
+ 47. 标题:Precise Payload Delivery via Unmanned Aerial Vehicles: An Approach Using Object Detection Algorithms
+ 编号:[219]
+ 链接:https://arxiv.org/abs/2310.06329
+ 作者:Aditya Vadduri, Anagh Benjwal, Abhishek Pai, Elkan Quadros, Aniruddh Kammar, Prajwal Uday
+ 备注:Second International Conference on Artificial Intelligence, Computational Electronics and Communication System (AICECS 2023)
+ 关键词:unmanned aerial vehicles, autonomous payload delivery, Recent years, aerial vehicles, payload delivery
+
+ 点击查看摘要
+ Recent years have seen tremendous advancements in the area of autonomous payload delivery via unmanned aerial vehicles, or drones. However, most of these works involve delivering the payload at a predetermined location using its GPS coordinates. By relying on GPS coordinates for navigation, the precision of payload delivery is restricted to the accuracy of the GPS network and the availability and strength of the GPS connection, which may be severely restricted by the weather condition at the time and place of operation. In this work we describe the development of a micro-class UAV and propose a novel navigation method that improves the accuracy of conventional navigation methods by incorporating a deep-learning-based computer vision approach to identify and precisely align the UAV with a target marked at the payload delivery position. This proposed method achieves a 500% increase in average horizontal precision over conventional GPS-based approaches.
+
+
+
+ 48. 标题:Advancing Pose-Guided Image Synthesis with Progressive Conditional Diffusion Models
+ 编号:[225]
+ 链接:https://arxiv.org/abs/2310.06313
+ 作者:Fei Shen, Hu Ye, Jun Zhang, Cong Wang, Xiao Han, Wei Yang
+ 备注:
+ 关键词:conditional diffusion model, Conditional Diffusion, Progressive Conditional Diffusion, diffusion model, person image synthesis
+
+ 点击查看摘要
+ Recent work has showcased the significant potential of diffusion models in pose-guided person image synthesis. However, owing to the inconsistency in pose between the source and target images, synthesizing an image with a distinct pose, relying exclusively on the source image and target pose information, remains a formidable challenge. This paper presents Progressive Conditional Diffusion Models (PCDMs) that incrementally bridge the gap between person images under the target and source poses through three stages. Specifically, in the first stage, we design a simple prior conditional diffusion model that predicts the global features of the target image by mining the global alignment relationship between pose coordinates and image appearance. Then, the second stage establishes a dense correspondence between the source and target images using the global features from the previous stage, and an inpainting conditional diffusion model is proposed to further align and enhance the contextual features, generating a coarse-grained person image. In the third stage, we propose a refining conditional diffusion model to utilize the coarsely generated image from the previous stage as a condition, achieving texture restoration and enhancing fine-detail consistency. The three-stage PCDMs work progressively to generate the final high-quality and high-fidelity synthesized image. Both qualitative and quantitative results demonstrate the consistency and photorealism of our proposed PCDMs under challenging scenarios.The code and model will be available at this https URL.
+
+
+
+ 49. 标题:Improving Compositional Text-to-image Generation with Large Vision-Language Models
+ 编号:[227]
+ 链接:https://arxiv.org/abs/2310.06311
+ 作者:Song Wen, Guian Fang, Renrui Zhang, Peng Gao, Hao Dong, Dimitris Metaxas
+ 备注:
+ 关键词:shown significant promise, Recent advancements, significant promise, shown significant, input texts
+
+ 点击查看摘要
+ Recent advancements in text-to-image models, particularly diffusion models, have shown significant promise. However, compositional text-to-image models frequently encounter difficulties in generating high-quality images that accurately align with input texts describing multiple objects, variable attributes, and intricate spatial relationships. To address this limitation, we employ large vision-language models (LVLMs) for multi-dimensional assessment of the alignment between generated images and their corresponding input texts. Utilizing this assessment, we fine-tune the diffusion model to enhance its alignment capabilities. During the inference phase, an initial image is produced using the fine-tuned diffusion model. The LVLM is then employed to pinpoint areas of misalignment in the initial image, which are subsequently corrected using the image editing algorithm until no further misalignments are detected by the LVLM. The resultant image is consequently more closely aligned with the input text. Our experimental results validate that the proposed methodology significantly improves text-image alignment in compositional image generation, particularly with respect to object number, attribute binding, spatial relationships, and aesthetic quality.
+
+
+
+ 50. 标题:Towards More Efficient Depression Risk Recognition via Gait
+ 编号:[245]
+ 链接:https://arxiv.org/abs/2310.06283
+ 作者:Min Ren, Muchan Tao, Xuecai Hu, Xiaotong Liu, Qiong Li, Yongzhen Huang
+ 备注:
+ 关键词:prevalent mental illness, highly prevalent mental, depression risk, Depression, million individuals worldwide
+
+ 点击查看摘要
+ Depression, a highly prevalent mental illness, affects over 280 million individuals worldwide. Early detection and timely intervention are crucial for promoting remission, preventing relapse, and alleviating the emotional and financial burdens associated with depression. However, patients with depression often go undiagnosed in the primary care setting. Unlike many physiological illnesses, depression lacks objective indicators for recognizing depression risk, and existing methods for depression risk recognition are time-consuming and often encounter a shortage of trained medical professionals. The correlation between gait and depression risk has been empirically established. Gait can serve as a promising objective biomarker, offering the advantage of efficient and convenient data collection. However, current methods for recognizing depression risk based on gait have only been validated on small, private datasets, lacking large-scale publicly available datasets for research purposes. Additionally, these methods are primarily limited to hand-crafted approaches. Gait is a complex form of motion, and hand-crafted gait features often only capture a fraction of the intricate associations between gait and depression risk. Therefore, this study first constructs a large-scale gait database, encompassing over 1,200 individuals, 40,000 gait sequences, and covering six perspectives and three types of attire. Two commonly used psychological scales are provided as depression risk annotations. Subsequently, a deep learning-based depression risk recognition model is proposed, overcoming the limitations of hand-crafted approaches. Through experiments conducted on the constructed large-scale database, the effectiveness of the proposed method is validated, and numerous instructive insights are presented in the paper, highlighting the significant potential of gait-based depression risk recognition.
+
+
+
+ 51. 标题:MuseChat: A Conversational Music Recommendation System for Videos
+ 编号:[246]
+ 链接:https://arxiv.org/abs/2310.06282
+ 作者:Zhikang Dong, Bin Chen, Xiulong Liu, Pawel Polak, Peng Zhang
+ 备注:
+ 关键词:innovative dialog-based music, music, innovative dialog-based, recommendation, dialog-based music recommendation
+
+ 点击查看摘要
+ We introduce MuseChat, an innovative dialog-based music recommendation system. This unique platform not only offers interactive user engagement but also suggests music tailored for input videos, so that users can refine and personalize their music selections. In contrast, previous systems predominantly emphasized content compatibility, often overlooking the nuances of users' individual preferences. For example, all the datasets only provide basic music-video pairings or such pairings with textual music descriptions. To address this gap, our research offers three contributions. First, we devise a conversation-synthesis method that simulates a two-turn interaction between a user and a recommendation system, which leverages pre-trained music tags and artist information. In this interaction, users submit a video to the system, which then suggests a suitable music piece with a rationale. Afterwards, users communicate their musical preferences, and the system presents a refined music recommendation with reasoning. Second, we introduce a multi-modal recommendation engine that matches music either by aligning it with visual cues from the video or by harmonizing visual information, feedback from previously recommended music, and the user's textual input. Third, we bridge music representations and textual data with a Large Language Model(Vicuna-7B). This alignment equips MuseChat to deliver music recommendations and their underlying reasoning in a manner resembling human communication. Our evaluations show that MuseChat surpasses existing state-of-the-art models in music retrieval tasks and pioneers the integration of the recommendation process within a natural language framework.
+
+
+
+ 52. 标题:High-Fidelity 3D Head Avatars Reconstruction through Spatially-Varying Expression Conditioned Neural Radiance Field
+ 编号:[249]
+ 链接:https://arxiv.org/abs/2310.06275
+ 作者:Minghan Qin, Yifan Liu, Yuelang Xu, Xiaochen Zhao, Yebin Liu, Haoqian Wang
+ 备注:9 pages, 5 figures
+ 关键词:head avatar reconstruction, avatar reconstruction lies, head avatar, facial expression details, head avatar methods
+
+ 点击查看摘要
+ One crucial aspect of 3D head avatar reconstruction lies in the details of facial expressions. Although recent NeRF-based photo-realistic 3D head avatar methods achieve high-quality avatar rendering, they still encounter challenges retaining intricate facial expression details because they overlook the potential of specific expression variations at different spatial positions when conditioning the radiance field. Motivated by this observation, we introduce a novel Spatially-Varying Expression (SVE) conditioning. The SVE can be obtained by a simple MLP-based generation network, encompassing both spatial positional features and global expression information. Benefiting from rich and diverse information of the SVE at different positions, the proposed SVE-conditioned neural radiance field can deal with intricate facial expressions and achieve realistic rendering and geometry details of high-fidelity 3D head avatars. Additionally, to further elevate the geometric and rendering quality, we introduce a new coarse-to-fine training strategy, including a geometry initialization strategy at the coarse stage and an adaptive importance sampling strategy at the fine stage. Extensive experiments indicate that our method outperforms other state-of-the-art (SOTA) methods in rendering and geometry quality on mobile phone-collected and public datasets.
+
+
+
+ 53. 标题:Tackling Data Bias in MUSIC-AVQA: Crafting a Balanced Dataset for Unbiased Question-Answering
+ 编号:[266]
+ 链接:https://arxiv.org/abs/2310.06238
+ 作者:Xiulong Liu, Zhikang Dong, Peng Zhang
+ 备注:
+ 关键词:recent years, intersection of audio, driving forward, multimodal research, growing emphasis
+
+ 点击查看摘要
+ In recent years, there has been a growing emphasis on the intersection of audio, vision, and text modalities, driving forward the advancements in multimodal research. However, strong bias that exists in any modality can lead to the model neglecting the others. Consequently, the model's ability to effectively reason across these diverse modalities is compromised, impeding further advancement. In this paper, we meticulously review each question type from the original dataset, selecting those with pronounced answer biases. To counter these biases, we gather complementary videos and questions, ensuring that no answers have outstanding skewed distribution. In particular, for binary questions, we strive to ensure that both answers are almost uniformly spread within each question category. As a result, we construct a new dataset, named MUSIC-AVQA v2.0, which is more challenging and we believe could better foster the progress of AVQA task. Furthermore, we present a novel baseline model that delves deeper into the audio-visual-text interrelation. On MUSIC-AVQA v2.0, this model surpasses all the existing benchmarks, improving accuracy by 2% on MUSIC-AVQA v2.0, setting a new state-of-the-art performance.
+
+
+
+ 54. 标题:Efficient Adaptation of Large Vision Transformer via Adapter Re-Composing
+ 编号:[268]
+ 链接:https://arxiv.org/abs/2310.06234
+ 作者:Wei Dong, Dawei Yan, Zhijun Lin, Peng Wang
+ 备注:Paper is accepted to NeurIPS 2023
+ 关键词:training task-specific models, high-capacity pre-trained models, pre-trained models, shifting the focus, adapting pre-trained models
+
+ 点击查看摘要
+ The advent of high-capacity pre-trained models has revolutionized problem-solving in computer vision, shifting the focus from training task-specific models to adapting pre-trained models. Consequently, effectively adapting large pre-trained models to downstream tasks in an efficient manner has become a prominent research area. Existing solutions primarily concentrate on designing lightweight adapters and their interaction with pre-trained models, with the goal of minimizing the number of parameters requiring updates. In this study, we propose a novel Adapter Re-Composing (ARC) strategy that addresses efficient pre-trained model adaptation from a fresh perspective. Our approach considers the reusability of adaptation parameters and introduces a parameter-sharing scheme. Specifically, we leverage symmetric down-/up-projections to construct bottleneck operations, which are shared across layers. By learning low-dimensional re-scaling coefficients, we can effectively re-compose layer-adaptive adapters. This parameter-sharing strategy in adapter design allows us to significantly reduce the number of new parameters while maintaining satisfactory performance, thereby offering a promising approach to compress the adaptation cost. We conduct experiments on 24 downstream image classification tasks using various Vision Transformer variants to evaluate our method. The results demonstrate that our approach achieves compelling transfer learning performance with a reduced parameter count. Our code is available at \href{this https URL}{this https URL}.
+
+
+
+ 55. 标题:Spiking PointNet: Spiking Neural Networks for Point Clouds
+ 编号:[270]
+ 链接:https://arxiv.org/abs/2310.06232
+ 作者:Dayong Ren, Zhe Ma, Yuanpei Chen, Weihang Peng, Xiaode Liu, Yuhan Zhang, Yufei Guo
+ 备注:Accepted by NeurIPS
+ 关键词:Spiking Neural Networks, enjoying extreme energy, extreme energy efficiency, shown gradually increasing, Neural Networks
+
+ 点击查看摘要
+ Recently, Spiking Neural Networks (SNNs), enjoying extreme energy efficiency, have drawn much research attention on 2D visual recognition and shown gradually increasing application potential. However, it still remains underexplored whether SNNs can be generalized to 3D recognition. To this end, we present Spiking PointNet in the paper, the first spiking neural model for efficient deep learning on point clouds. We discover that the two huge obstacles limiting the application of SNNs in point clouds are: the intrinsic optimization obstacle of SNNs that impedes the training of a big spiking model with large time steps, and the expensive memory and computation cost of PointNet that makes training a big spiking point model unrealistic. To solve the problems simultaneously, we present a trained-less but learning-more paradigm for Spiking PointNet with theoretical justifications and in-depth experimental analysis. In specific, our Spiking PointNet is trained with only a single time step but can obtain better performance with multiple time steps inference, compared to the one trained directly with multiple time steps. We conduct various experiments on ModelNet10, ModelNet40 to demonstrate the effectiveness of Spiking PointNet. Notably, our Spiking PointNet even can outperform its ANN counterpart, which is rare in the SNN field thus providing a potential research direction for the following work. Moreover, Spiking PointNet shows impressive speedup and storage saving in the training phase.
+
+
+
+ 56. 标题:CoT3DRef: Chain-of-Thoughts Data-Efficient 3D Visual Grounding
+ 编号:[282]
+ 链接:https://arxiv.org/abs/2310.06214
+ 作者:Eslam Mohamed Bakr, Mohamed Ayman, Mahmoud Ahmed, Habib Slim, Mohamed Elhoseiny
+ 备注:
+ 关键词:scenes conditioned, conditioned by utterances, visual grounding, ability to localize, referred object directly
+
+ 点击查看摘要
+ 3D visual grounding is the ability to localize objects in 3D scenes conditioned by utterances. Most existing methods devote the referring head to localize the referred object directly, causing failure in complex scenarios. In addition, it does not illustrate how and why the network reaches the final decision. In this paper, we address this question Can we design an interpretable 3D visual grounding framework that has the potential to mimic the human perception system?. To this end, we formulate the 3D visual grounding problem as a sequence-to-sequence task by first predicting a chain of anchors and then the final target. Interpretability not only improves the overall performance but also helps us identify failure cases. Following the chain of thoughts approach enables us to decompose the referring task into interpretable intermediate steps, boosting the performance and making our framework extremely data-efficient. Moreover, our proposed framework can be easily integrated into any existing architecture. We validate our approach through comprehensive experiments on the Nr3D, Sr3D, and Scanrefer benchmarks and show consistent performance gains compared to existing methods without requiring manually annotated data. Furthermore, our proposed framework, dubbed CoT3DRef, is significantly data-efficient, whereas on the Sr3D dataset, when trained only on 10% of the data, we match the SOTA performance that trained on the entire data.
+
+
+
+ 57. 标题:DiPS: Discriminative Pseudo-Label Sampling with Self-Supervised Transformers for Weakly Supervised Object Localization
+ 编号:[292]
+ 链接:https://arxiv.org/abs/2310.06196
+ 作者:Shakeeb Murtaza, Soufiane Belharbi, Marco Pedersoli, Aydin Sarraf, Eric Granger
+ 备注:
+ 关键词:shown great potential, Self-supervised vision transformers, Self-supervised vision, shown great, great potential
+
+ 点击查看摘要
+ Self-supervised vision transformers (SSTs) have shown great potential to yield rich localization maps that highlight different objects in an image. However, these maps remain class-agnostic since the model is unsupervised. They often tend to decompose the image into multiple maps containing different objects while being unable to distinguish the object of interest from background noise objects. In this paper, Discriminative Pseudo-label Sampling (DiPS) is introduced to leverage these class-agnostic maps for weakly-supervised object localization (WSOL), where only image-class labels are available. Given multiple attention maps, DiPS relies on a pre-trained classifier to identify the most discriminative regions of each attention map. This ensures that the selected ROIs cover the correct image object while discarding the background ones, and, as such, provides a rich pool of diverse and discriminative proposals to cover different parts of the object. Subsequently, these proposals are used as pseudo-labels to train our new transformer-based WSOL model designed to perform classification and localization tasks. Unlike standard WSOL methods, DiPS optimizes performance in both tasks by using a transformer encoder and a dedicated output head for each task, each trained using dedicated loss functions. To avoid overfitting a single proposal and promote better object coverage, a single proposal is randomly selected among the top ones for a training image at each training step. Experimental results on the challenging CUB, ILSVRC, OpenImages, and TelDrone datasets indicate that our architecture, in combination with our transformer-based proposals, can yield better localization performance than state-of-the-art methods.
+
+
+
+ 58. 标题:DEUX: Active Exploration for Learning Unsupervised Depth Perception
+ 编号:[308]
+ 链接:https://arxiv.org/abs/2310.06164
+ 作者:Marvin Chancán, Alex Wong, Ian Abraham
+ 备注:
+ 关键词:predefined camera trajectories, depth completion, Depth, non-interactive datasets, datasets with predefined
+
+ 点击查看摘要
+ Depth perception models are typically trained on non-interactive datasets with predefined camera trajectories. However, this often introduces systematic biases into the learning process correlated to specific camera paths chosen during data acquisition. In this paper, we investigate the role of how data is collected for learning depth completion, from a robot navigation perspective, by leveraging 3D interactive environments. First, we evaluate four depth completion models trained on data collected using conventional navigation techniques. Our key insight is that existing exploration paradigms do not necessarily provide task-specific data points to achieve competent unsupervised depth completion learning. We then find that data collected with respect to photometric reconstruction has a direct positive influence on model performance. As a result, we develop an active, task-informed, depth uncertainty-based motion planning approach for learning depth completion, which we call DEpth Uncertainty-guided eXploration (DEUX). Training with data collected by our approach improves depth completion by an average greater than 18% across four depth completion models compared to existing exploration methods on the MP3D test set. We show that our approach further improves zero-shot generalization, while offering new insights into integrating robot learning-based depth estimation.
+
+
+
+ 59. 标题:Layout Sequence Prediction From Noisy Mobile Modality
+ 编号:[321]
+ 链接:https://arxiv.org/abs/2310.06138
+ 作者:Haichao Zhang, Yi Xu, Hongsheng Lu, Takayuki Shimizu, Yun Fu
+ 备注:In Proceedings of the 31st ACM International Conference on Multimedia 2023 (MM 23)
+ 关键词:understanding pedestrian movement, driving and robotics, plays a vital, vital role, role in understanding
+
+ 点击查看摘要
+ Trajectory prediction plays a vital role in understanding pedestrian movement for applications such as autonomous driving and robotics. Current trajectory prediction models depend on long, complete, and accurately observed sequences from visual modalities. Nevertheless, real-world situations often involve obstructed cameras, missed objects, or objects out of sight due to environmental factors, leading to incomplete or noisy trajectories. To overcome these limitations, we propose LTrajDiff, a novel approach that treats objects obstructed or out of sight as equally important as those with fully visible trajectories. LTrajDiff utilizes sensor data from mobile phones to surmount out-of-sight constraints, albeit introducing new challenges such as modality fusion, noisy data, and the absence of spatial layout and object size information. We employ a denoising diffusion model to predict precise layout sequences from noisy mobile data using a coarse-to-fine diffusion strategy, incorporating the RMS, Siamese Masked Encoding Module, and MFM. Our model predicts layout sequences by implicitly inferring object size and projection status from a single reference timestamp or significantly obstructed sequences. Achieving SOTA results in randomly obstructed experiments and extremely short input experiments, our model illustrates the effectiveness of leveraging noisy mobile data. In summary, our approach offers a promising solution to the challenges faced by layout sequence and trajectory prediction models in real-world settings, paving the way for utilizing sensor data from mobile phones to accurately predict pedestrian bounding box trajectories. To the best of our knowledge, this is the first work that addresses severely obstructed and extremely short layout sequences by combining vision with noisy mobile modality, making it the pioneering work in the field of layout sequence trajectory prediction.
+
+
+
+ 60. 标题:Factorized Tensor Networks for Multi-Task and Multi-Domain Learning
+ 编号:[325]
+ 链接:https://arxiv.org/abs/2310.06124
+ 作者:Yash Garg, Nebiyou Yismaw, Rakib Hyder, Ashley Prater-Bennette, M. Salman Asif
+ 备注:
+ 关键词:learn multiple tasks, learning methods seek, single unified network, seek to learn, learn multiple
+
+ 点击查看摘要
+ Multi-task and multi-domain learning methods seek to learn multiple tasks/domains, jointly or one after another, using a single unified network. The key challenge and opportunity is to exploit shared information across tasks and domains to improve the efficiency of the unified network. The efficiency can be in terms of accuracy, storage cost, computation, or sample complexity. In this paper, we propose a factorized tensor network (FTN) that can achieve accuracy comparable to independent single-task/domain networks with a small number of additional parameters. FTN uses a frozen backbone network from a source model and incrementally adds task/domain-specific low-rank tensor factors to the shared frozen network. This approach can adapt to a large number of target domains and tasks without catastrophic forgetting. Furthermore, FTN requires a significantly smaller number of task-specific parameters compared to existing methods. We performed experiments on widely used multi-domain and multi-task datasets. We show the experiments on convolutional-based architecture with different backbones and on transformer-based architecture. We observed that FTN achieves similar accuracy as single-task/domain methods while using only a fraction of additional parameters per task.
+
+
+
+ 61. 标题:Text-driven Prompt Generation for Vision-Language Models in Federated Learning
+ 编号:[326]
+ 链接:https://arxiv.org/abs/2310.06123
+ 作者:Chen Qiu, Xingyu Li, Chaithanya Kumar Mummadi, Madan Ravi Ganesh, Zhenzhen Li, Lu Peng, Wan-Yi Lin
+ 备注:
+ 关键词:shown great success, adapting CLIP, federated learning due, vision-language models, downstream tasks
+
+ 点击查看摘要
+ Prompt learning for vision-language models, e.g., CoOp, has shown great success in adapting CLIP to different downstream tasks, making it a promising solution for federated learning due to computational reasons. Existing prompt learning techniques replace hand-crafted text prompts with learned vectors that offer improvements on seen classes, but struggle to generalize to unseen classes. Our work addresses this challenge by proposing Federated Text-driven Prompt Generation (FedTPG), which learns a unified prompt generation network across multiple remote clients in a scalable manner. The prompt generation network is conditioned on task-related text input, thus is context-aware, making it suitable to generalize for both seen and unseen classes. Our comprehensive empirical evaluations on nine diverse image classification datasets show that our method is superior to existing federated prompt learning methods, that achieve overall better generalization on both seen and unseen classes and is also generalizable to unseen datasets.
+
+
+
+ 62. 标题:QR-Tag: Angular Measurement and Tracking with a QR-Design Marker
+ 编号:[336]
+ 链接:https://arxiv.org/abs/2310.06109
+ 作者:Simeng Qiu, Hadi Amata, Wolfgang Heidrich
+ 备注:
+ 关键词:industrial computer vision, virtual and augmented, augmented reality, computer vision, applications in domains
+
+ 点击查看摘要
+ Directional information measurement has many applications in domains such as robotics, virtual and augmented reality, and industrial computer vision. Conventional methods either require pre-calibration or necessitate controlled environments. The state-of-the-art MoireTag approach exploits the Moire effect and QR-design to continuously track the angular shift precisely. However, it is still not a fully QR code design. To overcome the above challenges, we propose a novel snapshot method for discrete angular measurement and tracking with scannable QR-design patterns that are generated by binary structures printed on both sides of a glass plate. The QR codes, resulting from the parallax effect due to the geometry alignment between two layers, can be readily measured as angular information using a phone camera. The simulation results show that the proposed non-contact object tracking framework is computationally efficient with high accuracy.
+
+
+
+ 63. 标题:Developing and Refining a Multifunctional Facial Recognition System for Older Adults with Cognitive Impairments: A Journey Towards Enhanced Quality of Life
+ 编号:[337]
+ 链接:https://arxiv.org/abs/2310.06107
+ 作者:Li He
+ 备注:10 pages
+ 关键词:major health concern, aging significantly, health concern, global population, population is aging
+
+ 点击查看摘要
+ In an era where the global population is aging significantly, cognitive impairments among the elderly have become a major health concern. The need for effective assistive technologies is clear, and facial recognition systems are emerging as promising tools to address this issue. This document discusses the development and evaluation of a new Multifunctional Facial Recognition System (MFRS), designed specifically to assist older adults with cognitive impairments. The MFRS leverages face_recognition [1], a powerful open-source library capable of extracting, identifying, and manipulating facial features. Our system integrates the face recognition and retrieval capabilities of face_recognition, along with additional functionalities to capture images and record voice memos. This combination of features notably enhances the system's usability and versatility, making it a more user-friendly and universally applicable tool for end-users. The source code for this project can be accessed at this https URL.
+
+
+
+ 64. 标题:Quantile-based Maximum Likelihood Training for Outlier Detection
+ 编号:[342]
+ 链接:https://arxiv.org/abs/2310.06085
+ 作者:Masoud Taghikhah, Nishant Kumar, Siniša Šegvić, Abouzar Eslami, Stefan Gumhold
+ 备注:Code available at this https URL
+ 关键词:effectively predicts true, predicts true object, true object class, learning effectively predicts, effectively predicts
+
+ 点击查看摘要
+ Discriminative learning effectively predicts true object class for image classification. However, it often results in false positives for outliers, posing critical concerns in applications like autonomous driving and video surveillance systems. Previous attempts to address this challenge involved training image classifiers through contrastive learning using actual outlier data or synthesizing outliers for self-supervised learning. Furthermore, unsupervised generative modeling of inliers in pixel space has shown limited success for outlier detection. In this work, we introduce a quantile-based maximum likelihood objective for learning the inlier distribution to improve the outlier separation during inference. Our approach fits a normalizing flow to pre-trained discriminative features and detects the outliers according to the evaluated log-likelihood. The experimental evaluation demonstrates the effectiveness of our method as it surpasses the performance of the state-of-the-art unsupervised methods for outlier detection. The results are also competitive compared with a recent self-supervised approach for outlier detection. Our work allows to reduce dependency on well-sampled negative training data, which is especially important for domains like medical diagnostics or remote sensing.
+
+
+
+ 65. 标题:Augmenting Vision-Based Human Pose Estimation with Rotation Matrix
+ 编号:[350]
+ 链接:https://arxiv.org/abs/2310.06068
+ 作者:Milad Vazan, Fatemeh Sadat Masoumi, Ruizhi Ou, Reza Rawassizadeh
+ 备注:24 pages
+ 关键词:automatically track indoor, inside the gym, track indoor activities, indoor activities inside, Fitness applications
+
+ 点击查看摘要
+ Fitness applications are commonly used to monitor activities within the gym, but they often fail to automatically track indoor activities inside the gym. This study proposes a model that utilizes pose estimation combined with a novel data augmentation method, i.e., rotation matrix. We aim to enhance the classification accuracy of activity recognition based on pose estimation data. Through our experiments, we experiment with different classification algorithms along with image augmentation approaches. Our findings demonstrate that the SVM with SGD optimization, using data augmentation with the Rotation Matrix, yields the most accurate results, achieving a 96% accuracy rate in classifying five physical activities. Conversely, without implementing the data augmentation techniques, the baseline accuracy remains at a modest 64%.
+
+
+
+ 66. 标题:DyST: Towards Dynamic Neural Scene Representations on Real-World Videos
+ 编号:[358]
+ 链接:https://arxiv.org/abs/2310.06020
+ 作者:Maximilian Seitzer, Sjoerd van Steenkiste, Thomas Kipf, Klaus Greff, Mehdi S. M. Sajjadi
+ 备注:Project website: this https URL
+ 关键词:Visual understanding, individual images, semantics and flat, monocular real-world videos, Dynamic Scene Transformer
+
+ 点击查看摘要
+ Visual understanding of the world goes beyond the semantics and flat structure of individual images. In this work, we aim to capture both the 3D structure and dynamics of real-world scenes from monocular real-world videos. Our Dynamic Scene Transformer (DyST) model leverages recent work in neural scene representation to learn a latent decomposition of monocular real-world videos into scene content, per-view scene dynamics, and camera pose. This separation is achieved through a novel co-training scheme on monocular videos and our new synthetic dataset DySO. DyST learns tangible latent representations for dynamic scenes that enable view generation with separate control over the camera and the content of the scene.
+
+
+
+ 67. 标题:CoBEVFusion: Cooperative Perception with LiDAR-Camera Bird's-Eye View Fusion
+ 编号:[360]
+ 链接:https://arxiv.org/abs/2310.06008
+ 作者:Donghao Qiao, Farhana Zulkernine
+ 备注:
+ 关键词:Connected Autonomous Vehicles, Autonomous Vehicles, Connected Autonomous, cooperative perception, Vehicles
+
+ 点击查看摘要
+ Autonomous Vehicles (AVs) use multiple sensors to gather information about their surroundings. By sharing sensor data between Connected Autonomous Vehicles (CAVs), the safety and reliability of these vehicles can be improved through a concept known as cooperative perception. However, recent approaches in cooperative perception only share single sensor information such as cameras or LiDAR. In this research, we explore the fusion of multiple sensor data sources and present a framework, called CoBEVFusion, that fuses LiDAR and camera data to create a Bird's-Eye View (BEV) representation. The CAVs process the multi-modal data locally and utilize a Dual Window-based Cross-Attention (DWCA) module to fuse the LiDAR and camera features into a unified BEV representation. The fused BEV feature maps are shared among the CAVs, and a 3D Convolutional Neural Network is applied to aggregate the features from the CAVs. Our CoBEVFusion framework was evaluated on the cooperative perception dataset OPV2V for two perception tasks: BEV semantic segmentation and 3D object detection. The results show that our DWCA LiDAR-camera fusion model outperforms perception models with single-modal data and state-of-the-art BEV fusion models. Our overall cooperative perception architecture, CoBEVFusion, also achieves comparable performance with other cooperative perception models.
+
+
+
+ 68. 标题:DynamicBEV: Leveraging Dynamic Queries and Temporal Context for 3D Object Detection
+ 编号:[370]
+ 链接:https://arxiv.org/abs/2310.05989
+ 作者:Jiawei Yao, Yingxin Lai
+ 备注:
+ 关键词:Bird Eye View, object detection, driving and robotics, crucial for applications, applications like autonomous
+
+ 点击查看摘要
+ 3D object detection is crucial for applications like autonomous driving and robotics. While query-based 3D object detection for BEV (Bird's Eye View) images has seen significant advancements, most existing methods follows the paradigm of static query. Such paradigm is incapable of adapting to complex spatial-temporal relationships in the scene. To solve this problem, we introduce a new paradigm in DynamicBEV, a novel approach that employs dynamic queries for BEV-based 3D object detection. In contrast to static queries, the proposed dynamic queries exploit K-means clustering and Top-K Attention in a creative way to aggregate information more effectively from both local and distant feature, which enable DynamicBEV to adapt iteratively to complex scenes. To further boost efficiency, DynamicBEV incorporates a Lightweight Temporal Fusion Module (LTFM), designed for efficient temporal context integration with a significant computation reduction. Additionally, a custom-designed Diversity Loss ensures a balanced feature representation across scenarios. Extensive experiments on the nuScenes dataset validate the effectiveness of DynamicBEV, establishing a new state-of-the-art and heralding a paradigm-level breakthrough in query-based BEV object detection.
+
+
+
+ 69. 标题:The Unreasonable Effectiveness of Linear Prediction as a Perceptual Metric
+ 编号:[372]
+ 链接:https://arxiv.org/abs/2310.05986
+ 作者:Daniel Severo, Lucas Theis, Johannes Ballé
+ 备注:
+ 关键词:deep neural network, neural network features, Linear Autoregressive Similarity, Autoregressive Similarity Index, visual system
+
+ 点击查看摘要
+ We show how perceptual embeddings of the visual system can be constructed at inference-time with no training data or deep neural network features. Our perceptual embeddings are solutions to a weighted least squares (WLS) problem, defined at the pixel-level, and solved at inference-time, that can capture global and local image characteristics. The distance in embedding space is used to define a perceptual similarity metric which we call LASI: Linear Autoregressive Similarity Index. Experiments on full-reference image quality assessment datasets show LASI performs competitively with learned deep feature based methods like LPIPS (Zhang et al., 2018) and PIM (Bhardwaj et al., 2020), at a similar computational cost to hand-crafted methods such as MS-SSIM (Wang et al., 2003). We found that increasing the dimensionality of the embedding space consistently reduces the WLS loss while increasing performance on perceptual tasks, at the cost of increasing the computational complexity. LASI is fully differentiable, scales cubically with the number of embedding dimensions, and can be parallelized at the pixel-level. A Maximum Differentiation (MAD) competition (Wang & Simoncelli, 2008) between LASI and LPIPS shows that both methods are capable of finding failure points for the other, suggesting these metrics can be combined.
+
+
+
+ 70. 标题:Automating global landslide detection with heterogeneous ensemble deep-learning classification
+ 编号:[381]
+ 链接:https://arxiv.org/abs/2310.05959
+ 作者:Alexandra Jarna Ganerød, Gabriele Franch, Erin Lindsay, Martina Calovi
+ 备注:Author 1 and Author 2 contributed equally to this work
+ 关键词:changing climatic conditions, extreme weather events, climatic conditions, secondary consequences, changing climatic
+
+ 点击查看摘要
+ With changing climatic conditions, we are already seeing an increase in extreme weather events and their secondary consequences, including landslides. Landslides threaten infrastructure, including roads, railways, buildings, and human life. Hazard-based spatial planning and early warning systems are cost-effective strategies to reduce the risk to society from landslides. However, these both rely on data from previous landslide events, which is often scarce. Many deep learning (DL) models have recently been applied for landside mapping using medium- to high-resolution satellite images as input. However, they often suffer from sensitivity problems, overfitting, and low mapping accuracy. This study addresses some of these limitations by using a diverse global landslide dataset, using different segmentation models, such as Unet, Linknet, PSP-Net, PAN, and DeepLab and based on their performances, building an ensemble model. The ensemble model achieved the highest F1-score (0.69) when combining both Sentinel-1 and Sentinel-2 bands, with the highest average improvement of 6.87 % when the ensemble size was 20. On the other hand, Sentinel-2 bands only performed very well, with an F1 score of 0.61 when the ensemble size is 20 with an improvement of 14.59 % when the ensemble size is 20. This result shows considerable potential in building a robust and reliable monitoring system based on changes in vegetation index dNDVI only.
+
+
+
+ 71. 标题:Reducing the False Positive Rate Using Bayesian Inference in Autonomous Driving Perception
+ 编号:[385]
+ 链接:https://arxiv.org/abs/2310.05951
+ 作者:Johann J. S. Bastos, Bruno L. S. da Silva, Tiago Zanotelli, Cristiano Premebida, Gledson Melotti
+ 备注:
+ 关键词:numerous research works, intelligent vehicles, Object recognition, crucial step, autonomous and intelligent
+
+ 点击查看摘要
+ Object recognition is a crucial step in perception systems for autonomous and intelligent vehicles, as evidenced by the numerous research works in the topic. In this paper, object recognition is explored by using multisensory and multimodality approaches, with the intention of reducing the false positive rate (FPR). The reduction of the FPR becomes increasingly important in perception systems since the misclassification of an object can potentially cause accidents. In particular, this work presents a strategy through Bayesian inference to reduce the FPR considering the likelihood function as a cumulative distribution function from Gaussian kernel density estimations, and the prior probabilities as cumulative functions of normalized histograms. The validation of the proposed methodology is performed on the KITTI dataset using deep networks (DenseNet, NasNet, and EfficientNet), and recent 3D point cloud networks (PointNet, and PintNet++), by considering three object-categories (cars, cyclists, pedestrians) and the RGB and LiDAR sensor modalities.
+
+
+
+ 72. 标题:Robust and Efficient Interference Neural Networks for Defending Against Adversarial Attacks in ImageNet
+ 编号:[386]
+ 链接:https://arxiv.org/abs/2310.05947
+ 作者:Yunuo Xiong, Shujuan Liu, Hongwei Xiong
+ 备注:11 pages, 3 figures
+ 关键词:deep learning urgently, key scientific problem, deep learning, learning urgently, affected the task
+
+ 点击查看摘要
+ The existence of adversarial images has seriously affected the task of image recognition and practical application of deep learning, it is also a key scientific problem that deep learning urgently needs to solve. By far the most effective approach is to train the neural network with a large number of adversarial examples. However, this adversarial training method requires a huge amount of computing resources when applied to ImageNet, and has not yet achieved satisfactory results for high-intensity adversarial attacks. In this paper, we construct an interference neural network by applying additional background images and corresponding labels, and use pre-trained ResNet-152 to efficiently complete the training. Compared with the state-of-the-art results under the PGD attack, it has a better defense effect with much smaller computing resources. This work provides new ideas for academic research and practical applications of effective defense against adversarial attacks.
+
+
+
+ 73. 标题:Analysis of Learned Features and Framework for Potato Disease Detection
+ 编号:[387]
+ 链接:https://arxiv.org/abs/2310.05943
+ 作者:Shikha Gupta, Soma Chakraborty, Renu Rameshan
+ 备注:15 pages, 8 figures
+ 关键词:plant disease detection, applications like plant, model is trained, trained on publicly, tested on field
+
+ 点击查看摘要
+ For applications like plant disease detection, usually, a model is trained on publicly available data and tested on field data. This means that the test data distribution is not the same as the training data distribution, which affects the classifier performance adversely. We handle this dataset shift by ensuring that the features are learned from disease spots in the leaf or healthy regions, as applicable. This is achieved using a faster Region-based convolutional neural network (RCNN) as one of the solutions and an attention-based network as the other. The average classification accuracies of these classifiers are approximately 95% while evaluated on the test set corresponding to their training dataset. These classifiers also performed equivalently, with an average score of 84% on a dataset not seen during the training phase.
+
+
+
+ 74. 标题:Component attention network for multimodal dance improvisation recognition
+ 编号:[392]
+ 链接:https://arxiv.org/abs/2310.05938
+ 作者:Jia Fu, Jiarui Tan, Wenjie Yin, Sepideh Pashami, Mårten Björkman
+ 备注:Accepted to 25th ACM International Conference on Multimodal Interaction (ICMI 2023)
+ 关键词:active research topic, active research, research topic, fusion, Dance
+
+ 点击查看摘要
+ Dance improvisation is an active research topic in the arts. Motion analysis of improvised dance can be challenging due to its unique dynamics. Data-driven dance motion analysis, including recognition and generation, is often limited to skeletal data. However, data of other modalities, such as audio, can be recorded and benefit downstream tasks. This paper explores the application and performance of multimodal fusion methods for human motion recognition in the context of dance improvisation. We propose an attention-based model, component attention network (CANet), for multimodal fusion on three levels: 1) feature fusion with CANet, 2) model fusion with CANet and graph convolutional network (GCN), and 3) late fusion with a voting strategy. We conduct thorough experiments to analyze the impact of each modality in different fusion methods and distinguish critical temporal or component features. We show that our proposed model outperforms the two baseline methods, demonstrating its potential for analyzing improvisation in dance.
+
+
+
+ 75. 标题:DF-3DFace: One-to-Many Speech Synchronized 3D Face Animation with Diffusion
+ 编号:[395]
+ 链接:https://arxiv.org/abs/2310.05934
+ 作者:Se Jin Park, Joanna Hong, Minsu Kim, Yong Man Ro
+ 备注:
+ 关键词:gained significant attention, facial, gained significant, significant attention, ability to create
+
+ 点击查看摘要
+ Speech-driven 3D facial animation has gained significant attention for its ability to create realistic and expressive facial animations in 3D space based on speech. Learning-based methods have shown promising progress in achieving accurate facial motion synchronized with speech. However, one-to-many nature of speech-to-3D facial synthesis has not been fully explored: while the lip accurately synchronizes with the speech content, other facial attributes beyond speech-related motions are variable with respect to the speech. To account for the potential variance in the facial attributes within a single speech, we propose DF-3DFace, a diffusion-driven speech-to-3D face mesh synthesis. DF-3DFace captures the complex one-to-many relationships between speech and 3D face based on diffusion. It concurrently achieves aligned lip motion by exploiting audio-mesh synchronization and masked conditioning. Furthermore, the proposed method jointly models identity and pose in addition to facial motions so that it can generate 3D face animation without requiring a reference identity mesh and produce natural head poses. We contribute a new large-scale 3D facial mesh dataset, 3D-HDTF to enable the synthesis of variations in identities, poses, and facial motions of 3D face mesh. Extensive experiments demonstrate that our method successfully generates highly variable facial shapes and motions from speech and simultaneously achieves more realistic facial animation than the state-of-the-art methods.
+
+
+
+ 76. 标题:Deep Learning based Tomato Disease Detection and Remedy Suggestions using Mobile Application
+ 编号:[398]
+ 链接:https://arxiv.org/abs/2310.05929
+ 作者:Yagya Raj Pandeya, Samin Karki, Ishan Dangol, Nitesh Rajbanshi
+ 备注:
+ 关键词:addressing crop diseases, comprehensive computer system, practice traditional farming, comprehensive computer, practice traditional
+
+ 点击查看摘要
+ We have developed a comprehensive computer system to assist farmers who practice traditional farming methods and have limited access to agricultural experts for addressing crop diseases. Our system utilizes artificial intelligence (AI) to identify and provide remedies for vegetable diseases. To ensure ease of use, we have created a mobile application that offers a user-friendly interface, allowing farmers to inquire about vegetable diseases and receive suitable solutions in their local language. The developed system can be utilized by any farmer with a basic understanding of a smartphone. Specifically, we have designed an AI-enabled mobile application for identifying and suggesting remedies for vegetable diseases, focusing on tomato diseases to benefit the local farming community in Nepal. Our system employs state-of-the-art object detection methodology, namely You Only Look Once (YOLO), to detect tomato diseases. The detected information is then relayed to the mobile application, which provides remedy suggestions guided by domain experts. In order to train our system effectively, we curated a dataset consisting of ten classes of tomato diseases. We utilized various data augmentation methods to address overfitting and trained a YOLOv5 object detector. The proposed method achieved a mean average precision of 0.76 and offers an efficient mobile interface for interacting with the AI system. While our system is currently in the development phase, we are actively working towards enhancing its robustness and real-time usability by accumulating more training samples.
+
+
+
+ 77. 标题:NECO: NEural Collapse Based Out-of-distribution detection
+ 编号:[400]
+ 链接:https://arxiv.org/abs/2310.06823
+ 作者:Mouïn Ben Ammar, Nacim Belkhir, Sebastian Popescu, Antoine Manzanera, Gianni Franchi
+ 备注:28 pages
+ 关键词:machine learning due, epistemological limits, OOD, OOD detection, critical challenge
+
+ 点击查看摘要
+ Detecting out-of-distribution (OOD) data is a critical challenge in machine learning due to model overconfidence, often without awareness of their epistemological limits. We hypothesize that ``neural collapse'', a phenomenon affecting in-distribution data for models trained beyond loss convergence, also influences OOD data. To benefit from this interplay, we introduce NECO, a novel post-hoc method for OOD detection, which leverages the geometric properties of ``neural collapse'' and of principal component spaces to identify OOD data. Our extensive experiments demonstrate that NECO achieves state-of-the-art results on both small and large-scale OOD detection tasks while exhibiting strong generalization capabilities across different network architectures. Furthermore, we provide a theoretical explanation for the effectiveness of our method in OOD detection. We plan to release the code after the anonymity period.
+
+
+
+ 78. 标题:Multi-domain improves out-of-distribution and data-limited scenarios for medical image analysis
+ 编号:[402]
+ 链接:https://arxiv.org/abs/2310.06737
+ 作者:Ece Ozkan, Xavier Boix
+ 备注:
+ 关键词:Current machine learning, machine learning methods, analysis primarily focus, image analysis primarily, developing models tailored
+
+ 点击查看摘要
+ Current machine learning methods for medical image analysis primarily focus on developing models tailored for their specific tasks, utilizing data within their target domain. These specialized models tend to be data-hungry and often exhibit limitations in generalizing to out-of-distribution samples. Recently, foundation models have been proposed, which combine data from various domains and demonstrate excellent generalization capabilities. Building upon this, this work introduces the incorporation of diverse medical image domains, including different imaging modalities like X-ray, MRI, CT, and ultrasound images, as well as various viewpoints such as axial, coronal, and sagittal views. We refer to this approach as multi-domain model and compare its performance to that of specialized models. Our findings underscore the superior generalization capabilities of multi-domain models, particularly in scenarios characterized by limited data availability and out-of-distribution, frequently encountered in healthcare applications. The integration of diverse data allows multi-domain models to utilize shared information across domains, enhancing the overall outcomes significantly. To illustrate, for organ recognition, multi-domain model can enhance accuracy by up to 10% compared to conventional specialized models.
+
+
+
+ 79. 标题:Deep Cardiac MRI Reconstruction with ADMM
+ 编号:[407]
+ 链接:https://arxiv.org/abs/2310.06628
+ 作者:George Yiasemis, Nikita Moriakov, Jan-Jakob Sonke, Jonas Teuwen
+ 备注:12 pages, 3 figures, 2 tables. CMRxRecon Challenge, MICCAI 2023
+ 关键词:identifying cardiovascular diseases, valuable non-invasive tool, Cardiac magnetic resonance, magnetic resonance imaging, cardiovascular diseases
+
+ 点击查看摘要
+ Cardiac magnetic resonance imaging is a valuable non-invasive tool for identifying cardiovascular diseases. For instance, Cine MRI is the benchmark modality for assessing the cardiac function and anatomy. On the other hand, multi-contrast (T1 and T2) mapping has the potential to assess pathologies and abnormalities in the myocardium and interstitium. However, voluntary breath-holding and often arrhythmia, in combination with MRI's slow imaging speed, can lead to motion artifacts, hindering real-time acquisition image quality. Although performing accelerated acquisitions can facilitate dynamic imaging, it induces aliasing, causing low reconstructed image quality in Cine MRI and inaccurate T1 and T2 mapping estimation. In this work, inspired by related work in accelerated MRI reconstruction, we present a deep learning (DL)-based method for accelerated cine and multi-contrast reconstruction in the context of dynamic cardiac imaging. We formulate the reconstruction problem as a least squares regularized optimization task, and employ vSHARP, a state-of-the-art DL-based inverse problem solver, which incorporates half-quadratic variable splitting and the alternating direction method of multipliers with neural networks. We treat the problem in two setups; a 2D reconstruction and a 2D dynamic reconstruction task, and employ 2D and 3D deep learning networks, respectively. Our method optimizes in both the image and k-space domains, allowing for high reconstruction fidelity. Although the target data is undersampled with a Cartesian equispaced scheme, we train our model using both Cartesian and simulated non-Cartesian undersampling schemes to enhance generalization of the model to unseen data. Furthermore, our model adopts a deep neural network to learn and refine the sensitivity maps of multi-coil k-space data. Lastly, our method is jointly trained on both, undersampled cine and multi-contrast data.
+
+
+
+ 80. 标题:Data efficient deep learning for medical image analysis: A survey
+ 编号:[411]
+ 链接:https://arxiv.org/abs/2310.06557
+ 作者:Suruchi Kumari, Pravendra Singh
+ 备注:Under Review
+ 关键词:medical image analysis, medical image, image analysis, deep learning, learning
+
+ 点击查看摘要
+ The rapid evolution of deep learning has significantly advanced the field of medical image analysis. However, despite these achievements, the further enhancement of deep learning models for medical image analysis faces a significant challenge due to the scarcity of large, well-annotated datasets. To address this issue, recent years have witnessed a growing emphasis on the development of data-efficient deep learning methods. This paper conducts a thorough review of data-efficient deep learning methods for medical image analysis. To this end, we categorize these methods based on the level of supervision they rely on, encompassing categories such as no supervision, inexact supervision, incomplete supervision, inaccurate supervision, and only limited supervision. We further divide these categories into finer subcategories. For example, we categorize inexact supervision into multiple instance learning and learning with weak annotations. Similarly, we categorize incomplete supervision into semi-supervised learning, active learning, and domain-adaptive learning and so on. Furthermore, we systematically summarize commonly used datasets for data efficient deep learning in medical image analysis and investigate future research directions to conclude this survey.
+
+
+
+ 81. 标题:Adversarial Masked Image Inpainting for Robust Detection of Mpox and Non-Mpox
+ 编号:[419]
+ 链接:https://arxiv.org/abs/2310.06318
+ 作者:Yubiao Yue, Zhenzhang Li
+ 备注:
+ 关键词:MIM, mpox diagnostic technology, efficient mpox diagnostic, mpox cases continue, mpox
+
+ 点击查看摘要
+ Due to the lack of efficient mpox diagnostic technology, mpox cases continue to increase. Recently, the great potential of deep learning models in detecting mpox and non-mpox has been proven. However, existing models learn image representations via image classification, which results in they may be easily susceptible to interference from real-world noise, require diverse non-mpox images, and fail to detect abnormal input. These drawbacks make classification models inapplicable in real-world settings. To address these challenges, we propose "Mask, Inpainting, and Measure" (MIM). In MIM's pipeline, a generative adversarial network only learns mpox image representations by inpainting the masked mpox images. Then, MIM determines whether the input belongs to mpox by measuring the similarity between the inpainted image and the original image. The underlying intuition is that since MIM solely models mpox images, it struggles to accurately inpaint non-mpox images in real-world settings. Without utilizing any non-mpox images, MIM cleverly detects mpox and non-mpox and can handle abnormal inputs. We used the recognized mpox dataset (MSLD) and images of eighteen non-mpox skin diseases to verify the effectiveness and robustness of MIM. Experimental results show that the average AUROC of MIM achieves 0.8237. In addition, we demonstrated the drawbacks of classification models and buttressed the potential of MIM through clinical validation. Finally, we developed an online smartphone app to provide free testing to the public in affected areas. This work first employs generative models to improve mpox detection and provides new insights into binary decision-making tasks in medical images.
+
+
+
+ 82. 标题:Three-Dimensional Medical Image Fusion with Deformable Cross-Attention
+ 编号:[420]
+ 链接:https://arxiv.org/abs/2310.06291
+ 作者:Lin Liu, Xinxin Fan, Chulong Zhang, Jingjing Dai, Yaoqin Xie, Xiaokun Liang
+ 备注:
+ 关键词:medical image processing, image fusion plays, tumor detection, plays an instrumental, instrumental role
+
+ 点击查看摘要
+ Multimodal medical image fusion plays an instrumental role in several areas of medical image processing, particularly in disease recognition and tumor detection. Traditional fusion methods tend to process each modality independently before combining the features and reconstructing the fusion image. However, this approach often neglects the fundamental commonalities and disparities between multimodal information. Furthermore, the prevailing methodologies are largely confined to fusing two-dimensional (2D) medical image slices, leading to a lack of contextual supervision in the fusion images and subsequently, a decreased information yield for physicians relative to three-dimensional (3D) images. In this study, we introduce an innovative unsupervised feature mutual learning fusion network designed to rectify these limitations. Our approach incorporates a Deformable Cross Feature Blend (DCFB) module that facilitates the dual modalities in discerning their respective similarities and differences. We have applied our model to the fusion of 3D MRI and PET images obtained from 660 patients in the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset. Through the application of the DCFB module, our network generates high-quality MRI-PET fusion images. Experimental results demonstrate that our method surpasses traditional 2D image fusion methods in performance metrics such as Peak Signal to Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM). Importantly, the capacity of our method to fuse 3D images enhances the information available to physicians and researchers, thus marking a significant step forward in the field. The code will soon be available online.
+
+
+
+ 83. 标题:HydraViT: Adaptive Multi-Branch Transformer for Multi-Label Disease Classification from Chest X-ray Images
+ 编号:[430]
+ 链接:https://arxiv.org/abs/2310.06143
+ 作者:Şaban Öztürk, M. Yiğit Turalı, Tolga Çukur
+ 备注:
+ 关键词:essential diagnostic tool, pathological abnormalities, Chest X-ray, identification of chest, essential diagnostic
+
+ 点击查看摘要
+ Chest X-ray is an essential diagnostic tool in the identification of chest diseases given its high sensitivity to pathological abnormalities in the lungs. However, image-driven diagnosis is still challenging due to heterogeneity in size and location of pathology, as well as visual similarities and co-occurrence of separate pathology. Since disease-related regions often occupy a relatively small portion of diagnostic images, classification models based on traditional convolutional neural networks (CNNs) are adversely affected given their locality bias. While CNNs were previously augmented with attention maps or spatial masks to guide focus on potentially critical regions, learning localization guidance under heterogeneity in the spatial distribution of pathology is challenging. To improve multi-label classification performance, here we propose a novel method, HydraViT, that synergistically combines a transformer backbone with a multi-branch output module with learned weighting. The transformer backbone enhances sensitivity to long-range context in X-ray images, while using the self-attention mechanism to adaptively focus on task-critical regions. The multi-branch output module dedicates an independent branch to each disease label to attain robust learning across separate disease classes, along with an aggregated branch across labels to maintain sensitivity to co-occurrence relationships among pathology. Experiments demonstrate that, on average, HydraViT outperforms competing attention-guided methods by 1.2%, region-guided methods by 1.4%, and semantic-guided methods by 1.0% in multi-label classification performance.
+
+
+
+ 84. 标题:Advancing Diagnostic Precision: Leveraging Machine Learning Techniques for Accurate Detection of Covid-19, Pneumonia, and Tuberculosis in Chest X-Ray Images
+ 编号:[434]
+ 链接:https://arxiv.org/abs/2310.06080
+ 作者:Aditya Kulkarni, Guruprasad Parasnis, Harish Balasubramanian, Vansh Jain, Anmol Chokshi, Reena Sonkusare
+ 备注:11 pages, 18 figures, Under review in Discover Artificial Intelligence Journal by Springer Nature
+ 关键词:global health concerns, people worldwide, global health, health concerns, concerns that affect
+
+ 点击查看摘要
+ Lung diseases such as COVID-19, tuberculosis (TB), and pneumonia continue to be serious global health concerns that affect millions of people worldwide. In medical practice, chest X-ray examinations have emerged as the norm for diagnosing diseases, particularly chest infections such as COVID-19. Paramedics and scientists are working intensively to create a reliable and precise approach for early-stage COVID-19 diagnosis in order to save lives. But with a variety of symptoms, medical diagnosis of these disorders poses special difficulties. It is essential to address their identification and timely diagnosis in order to successfully treat and prevent these illnesses. In this research, a multiclass classification approach using state-of-the-art methods for deep learning and image processing is proposed. This method takes into account the robustness and efficiency of the system in order to increase diagnostic precision of chest diseases. A comparison between a brand-new convolution neural network (CNN) and several transfer learning pre-trained models including VGG19, ResNet, DenseNet, EfficientNet, and InceptionNet is recommended. Publicly available and widely used research datasets like Shenzen, Montogomery, the multiclass Kaggle dataset and the NIH dataset were used to rigorously test the model. Recall, precision, F1-score, and Area Under Curve (AUC) score are used to evaluate and compare the performance of the proposed model. An AUC value of 0.95 for COVID-19, 0.99 for TB, and 0.98 for pneumonia is obtained using the proposed network. Recall and precision ratings of 0.95, 0.98, and 0.97, respectively, likewise met high standards.
+
+
+
+ 85. 标题:Data Augmentation through Pseudolabels in Automatic Region Based Coronary Artery Segmentation for Disease Diagnosis
+ 编号:[440]
+ 链接:https://arxiv.org/abs/2310.05990
+ 作者:Sandesh Pokhrel, Sanjay Bhandari, Eduard Vazquez, Yash Raj Shrestha, Binod Bhattarai
+ 备注:arXiv admin note: text overlap with arXiv:2310.04749
+ 关键词:Coronary Artery Diseases, Coronary Artery, Artery Diseases, death and disability, Artery
+
+ 点击查看摘要
+ Coronary Artery Diseases(CADs) though preventable are one of the leading causes of death and disability. Diagnosis of these diseases is often difficult and resource intensive. Segmentation of arteries in angiographic images has evolved as a tool for assistance, helping clinicians in making accurate diagnosis. However, due to the limited amount of data and the difficulty in curating a dataset, the task of segmentation has proven challenging. In this study, we introduce the idea of using pseudolabels as a data augmentation technique to improve the performance of the baseline Yolo model. This method increases the F1 score of the baseline by 9% in the validation dataset and by 3% in the test dataset.
+
+
+
+ 86. 标题:Automated Chest X-Ray Report Generator Using Multi-Model Deep Learning Approach
+ 编号:[443]
+ 链接:https://arxiv.org/abs/2310.05969
+ 作者:Arief Purnama Muharram, Hollyana Puteri Haryono, Abassi Haji Juma, Ira Puspasari, Nugraha Priya Utama
+ 备注:Presented in the 2023 IEEE International Conference on Data and Software Engineering (ICoDSE 2023)
+ 关键词:interpreting chest X-ray, chest X-ray, chest X-ray images, chest X-ray report, Reading and interpreting
+
+ 点击查看摘要
+ Reading and interpreting chest X-ray images is one of the most radiologist's routines. However, it still can be challenging, even for the most experienced ones. Therefore, we proposed a multi-model deep learning-based automated chest X-ray report generator system designed to assist radiologists in their work. The basic idea of the proposed system is by utilizing multi binary-classification models for detecting multi abnormalities, with each model responsible for detecting one abnormality, in a single image. In this study, we limited the radiology abnormalities detection to only cardiomegaly, lung effusion, and consolidation. The system generates a radiology report by performing the following three steps: image pre-processing, utilizing deep learning models to detect abnormalities, and producing a report. The aim of the image pre-processing step is to standardize the input by scaling it to 128x128 pixels and slicing it into three segments, which covers the upper, lower, and middle parts of the lung. After pre-processing, each corresponding model classifies the image, resulting in a 0 (zero) for no abnormality detected and a 1 (one) for the presence of an abnormality. The prediction outputs of each model are then concatenated to form a 'result code'. The 'result code' is used to construct a report by selecting the appropriate pre-determined sentence for each detected abnormality in the report generation step. The proposed system is expected to reduce the workload of radiologists and increase the accuracy of chest X-ray diagnosis.
+
+
+
+ 87. 标题:EndoMapper dataset of complete calibrated endoscopy procedures
+ 编号:[452]
+ 链接:https://arxiv.org/abs/2204.14240
+ 作者:Pablo Azagra, Carlos Sostres, Ángel Ferrandez, Luis Riazuelo, Clara Tomasini, Oscar León Barbed, Javier Morlana, David Recasens, Victor M. Batlle, Juan J. Gómez-Rodríguez, Richard Elvira, Julia López, Cristina Oriol, Javier Civera, Juan D. Tardós, Ana Cristina Murillo, Angel Lanas, José M.M. Montiel
+ 备注:17 pages, 14 figures, 8 tables
+ 关键词:Computer-assisted systems, Visual Simultaneous Localization, spatial Artificial Intelligence, Artificial Intelligence, Localization and Mapping
+
+ 点击查看摘要
+ Computer-assisted systems are becoming broadly used in medicine. In endoscopy, most research focuses on the automatic detection of polyps or other pathologies, but localization and navigation of the endoscope are completely performed manually by physicians. To broaden this research and bring spatial Artificial Intelligence to endoscopies, data from complete procedures is needed. This paper introduces the Endomapper dataset, the first collection of complete endoscopy sequences acquired during regular medical practice, making secondary use of medical data. Its main purpose is to facilitate the development and evaluation of Visual Simultaneous Localization and Mapping (VSLAM) methods in real endoscopy data. The dataset contains more than 24 hours of video. It is the first endoscopic dataset that includes endoscope calibration as well as the original calibration videos. Meta-data and annotations associated with the dataset vary from the anatomical landmarks, procedure labeling, segmentations, reconstructions, simulated sequences with ground truth and same patient procedures. The software used in this paper is publicly available.
+
+
+自然语言处理
+
+ 1. 标题:LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression
+ 编号:[1]
+ 链接:https://arxiv.org/abs/2310.06839
+ 作者:Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, Lili Qiu
+ 备注:
+ 关键词:large language models, long context scenarios, large language, language models, face three main
+
+ 点击查看摘要
+ In long context scenarios, large language models (LLMs) face three main challenges: higher computational/financial cost, longer latency, and inferior performance. Some studies reveal that the performance of LLMs depends on both the density and the position of the key information (question relevant) in the input prompt. Inspired by these findings, we propose LongLLMLingua for prompt compression towards improving LLMs' perception of the key information to simultaneously address the three challenges. We conduct evaluation on a wide range of long context scenarios including single-/multi-document QA, few-shot learning, summarization, synthetic tasks, and code completion. The experimental results show that LongLLMLingua compressed prompt can derive higher performance with much less cost. The latency of the end-to-end system is also reduced. For example, on NaturalQuestions benchmark, LongLLMLingua gains a performance boost of up to 17.1% over the original prompt with ~4x fewer tokens as input to GPT-3.5-Turbo. It can derive cost savings of \$28.5 and \$27.4 per 1,000 samples from the LongBench and ZeroScrolls benchmark, respectively. Additionally, when compressing prompts of ~10k tokens at a compression rate of 2x-10x, LongLLMLingua can speed up the end-to-end latency by 1.4x-3.8x. Our code is available at this https URL.
+
+
+
+ 2. 标题:Generating and Evaluating Tests for K-12 Students with Language Model Simulations: A Case Study on Sentence Reading Efficiency
+ 编号:[3]
+ 链接:https://arxiv.org/abs/2310.06837
+ 作者:Eric Zelikman, Wanjing Anya Ma, Jasmine E. Tran, Diyi Yang, Jason D. Yeatman, Nick Haber
+ 备注:Accepted to EMNLP 2023 (Main)
+ 关键词:Developing an educational, expensive and time-consuming, collecting hundreds, test, tests
+
+ 点击查看摘要
+ Developing an educational test can be expensive and time-consuming, as each item must be written by experts and then evaluated by collecting hundreds of student responses. Moreover, many tests require multiple distinct sets of questions administered throughout the school year to closely monitor students' progress, known as parallel tests. In this study, we focus on tests of silent sentence reading efficiency, used to assess students' reading ability over time. To generate high-quality parallel tests, we propose to fine-tune large language models (LLMs) to simulate how previous students would have responded to unseen items. With these simulated responses, we can estimate each item's difficulty and ambiguity. We first use GPT-4 to generate new test items following a list of expert-developed rules and then apply a fine-tuned LLM to filter the items based on criteria from psychological measurements. We also propose an optimal-transport-inspired technique for generating parallel tests and show the generated tests closely correspond to the original test's difficulty and reliability based on crowdworker responses. Our evaluation of a generated test with 234 students from grades 2 to 8 produces test scores highly correlated (r=0.93) to those of a standard test form written by human experts and evaluated across thousands of K-12 students.
+
+
+
+ 3. 标题:Lemur: Harmonizing Natural Language and Code for Language Agents
+ 编号:[6]
+ 链接:https://arxiv.org/abs/2310.06830
+ 作者:Yiheng Xu, Hongjin Su, Chen Xing, Boyu Mi, Qian Liu, Weijia Shi, Binyuan Hui, Fan Zhou, Yitao Liu, Tianbao Xie, Zhoujun Cheng, Siheng Zhao, Lingpeng Kong, Bailin Wang, Caiming Xiong, Tao Yu
+ 备注:
+ 关键词:openly accessible language, accessible language models, language models optimized, versatile language agents, openly accessible
+
+ 点击查看摘要
+ We introduce Lemur and Lemur-Chat, openly accessible language models optimized for both natural language and coding capabilities to serve as the backbone of versatile language agents. The evolution from language chat models to functional language agents demands that models not only master human interaction, reasoning, and planning but also ensure grounding in the relevant environments. This calls for a harmonious blend of language and coding capabilities in the models. Lemur and Lemur-Chat are proposed to address this necessity, demonstrating balanced proficiencies in both domains, unlike existing open-source models that tend to specialize in either. Through meticulous pre-training using a code-intensive corpus and instruction fine-tuning on text and code data, our models achieve state-of-the-art averaged performance across diverse text and coding benchmarks among open-source models. Comprehensive experiments demonstrate Lemur's superiority over existing open-source models and its proficiency across various agent tasks involving human communication, tool usage, and interaction under fully- and partially- observable environments. The harmonization between natural and programming languages enables Lemur-Chat to significantly narrow the gap with proprietary models on agent abilities, providing key insights into developing advanced open-source agents adept at reasoning, planning, and operating seamlessly across environments. this https URL
+
+
+
+ 4. 标题:Teaching Language Models to Hallucinate Less with Synthetic Tasks
+ 编号:[8]
+ 链接:https://arxiv.org/abs/2310.06827
+ 作者:Erik Jones, Hamid Palangi, Clarisse Simões, Varun Chandrasekaran, Subhabrata Mukherjee, Arindam Mitra, Ahmed Awadallah, Ece Kamar
+ 备注:
+ 关键词:clinical report generation, Large language models, Large language, document-based question-answering, report generation
+
+ 点击查看摘要
+ Large language models (LLMs) frequently hallucinate on abstractive summarization tasks such as document-based question-answering, meeting summarization, and clinical report generation, even though all necessary information is included in context. However, optimizing LLMs to hallucinate less on these tasks is challenging, as hallucination is hard to efficiently evaluate at each optimization step. In this work, we show that reducing hallucination on a synthetic task can also reduce hallucination on real-world downstream tasks. Our method, SynTra, first designs a synthetic task where hallucinations are easy to elicit and measure. It next optimizes the LLM's system message via prefix-tuning on the synthetic task, and finally transfers the system message to realistic, hard-to-optimize tasks. Across three realistic abstractive summarization tasks, SynTra reduces hallucination for two 13B-parameter LLMs using only a synthetic retrieval task for supervision. We also find that optimizing the system message rather than the model weights can be critical; fine-tuning the entire model on the synthetic task can counterintuitively increase hallucination. Overall, SynTra demonstrates that the extra flexibility of working with synthetic data can help mitigate undesired behaviors in practice.
+
+
+
+ 5. 标题:Mistral 7B
+ 编号:[9]
+ 链接:https://arxiv.org/abs/2310.06825
+ 作者:Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed
+ 备注:Models and code are available at this https URL
+ 关键词:language model engineered, performance and efficiency, introduce Mistral, engineered for superior, superior performance
+
+ 点击查看摘要
+ We introduce Mistral 7B v0.1, a 7-billion-parameter language model engineered for superior performance and efficiency. Mistral 7B outperforms Llama 2 13B across all evaluated benchmarks, and Llama 1 34B in reasoning, mathematics, and code generation. Our model leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost. We also provide a model fine-tuned to follow instructions, Mistral 7B -- Instruct, that surpasses the Llama 2 13B -- Chat model both on human and automated benchmarks. Our models are released under the Apache 2.0 license.
+
+
+
+ 6. 标题:Text Embeddings Reveal (Almost) As Much As Text
+ 编号:[12]
+ 链接:https://arxiv.org/abs/2310.06816
+ 作者:John X. Morris, Volodymyr Kuleshov, Vitaly Shmatikov, Alexander M. Rush
+ 备注:Accepted at EMNLP 2023
+ 关键词:text, text embeddings reveal, text embeddings, embeddings reveal, original text
+
+ 点击查看摘要
+ How much private information do text embeddings reveal about the original text? We investigate the problem of embedding \textit{inversion}, reconstructing the full text represented in dense text embeddings. We frame the problem as controlled generation: generating text that, when reembedded, is close to a fixed point in latent space. We find that although a naïve model conditioned on the embedding performs poorly, a multi-step method that iteratively corrects and re-embeds text is able to recover $92\%$ of $32\text{-token}$ text inputs exactly. We train our model to decode text embeddings from two state-of-the-art embedding models, and also show that our model can recover important personal information (full names) from a dataset of clinical notes. Our code is available on Github: \href{this https URL}{this http URL}.
+
+
+
+ 7. 标题:Advancing Transformer's Capabilities in Commonsense Reasoning
+ 编号:[13]
+ 链接:https://arxiv.org/abs/2310.06803
+ 作者:Yu Zhou, Yunqiu Han, Hanyu Zhou, Yulun Wu
+ 备注:
+ 关键词:shown great potential, purpose pre-trained language, Recent advances, commonsense reasoning, general purpose pre-trained
+
+ 点击查看摘要
+ Recent advances in general purpose pre-trained language models have shown great potential in commonsense reasoning. However, current works still perform poorly on standard commonsense reasoning benchmarks including the Com2Sense Dataset. We argue that this is due to a disconnect with current cutting-edge machine learning methods. In this work, we aim to bridge the gap by introducing current ML-based methods to improve general purpose pre-trained language models in the task of commonsense reasoning. Specifically, we experiment with and systematically evaluate methods including knowledge transfer, model ensemble, and introducing an additional pairwise contrastive objective. Our best model outperforms the strongest previous works by ~15\% absolute gains in Pairwise Accuracy and ~8.7\% absolute gains in Standard Accuracy.
+
+
+
+ 8. 标题:OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text
+ 编号:[19]
+ 链接:https://arxiv.org/abs/2310.06786
+ 作者:Keiran Paster, Marco Dos Santos, Zhangir Azerbayev, Jimmy Ba
+ 备注:
+ 关键词:carefully thought-out tokens, carefully thought-out, growing evidence, evidence that pretraining, pretraining on high
+
+ 点击查看摘要
+ There is growing evidence that pretraining on high quality, carefully thought-out tokens such as code or mathematics plays an important role in improving the reasoning abilities of large language models. For example, Minerva, a PaLM model finetuned on billions of tokens of mathematical documents from arXiv and the web, reported dramatically improved performance on problems that require quantitative reasoning. However, because all known open source web datasets employ preprocessing that does not faithfully preserve mathematical notation, the benefits of large scale training on quantitive web documents are unavailable to the research community. We introduce OpenWebMath, an open dataset inspired by these works containing 14.7B tokens of mathematical webpages from Common Crawl. We describe in detail our method for extracting text and LaTeX content and removing boilerplate from HTML documents, as well as our methods for quality filtering and deduplication. Additionally, we run small-scale experiments by training 1.4B parameter language models on OpenWebMath, showing that models trained on 14.7B tokens of our dataset surpass the performance of models trained on over 20x the amount of general language data. We hope that our dataset, openly released on the Hugging Face Hub, will help spur advances in the reasoning abilities of large language models.
+
+
+
+ 9. 标题:Uni3D: Exploring Unified 3D Representation at Scale
+ 编号:[24]
+ 链接:https://arxiv.org/abs/2310.06773
+ 作者:Junsheng Zhou, Jinsheng Wang, Baorui Ma, Yu-Shen Liu, Tiejun Huang, Xinlong Wang
+ 备注:Code and Demo: this https URL
+ 关键词:vision and language, images or text, extensively investigated, past few years, led to revolutions
+
+ 点击查看摘要
+ Scaling up representations for images or text has been extensively investigated in the past few years and has led to revolutions in learning vision and language. However, scalable representation for 3D objects and scenes is relatively unexplored. In this work, we present Uni3D, a 3D foundation model to explore the unified 3D representation at scale. Uni3D uses a 2D initialized ViT end-to-end pretrained to align the 3D point cloud features with the image-text aligned features. Via the simple architecture and pretext task, Uni3D can leverage abundant 2D pretrained models as initialization and image-text aligned models as the target, unlocking the great potential of 2D models and scaling-up strategies to the 3D world. We efficiently scale up Uni3D to one billion parameters, and set new records on a broad range of 3D tasks, such as zero-shot classification, few-shot classification, open-world understanding and part segmentation. We show that the strong Uni3D representation also enables applications such as 3D painting and retrieval in the wild. We believe that Uni3D provides a new direction for exploring both scaling up and efficiency of the representation in 3D domain.
+
+
+
+ 10. 标题:SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
+ 编号:[26]
+ 链接:https://arxiv.org/abs/2310.06770
+ 作者:Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, Karthik Narasimhan
+ 备注:Data, code, and leaderboard are available at this https URL
+ 关键词:evaluate them effectively, outpaced our ability, ability to evaluate, future development, essential to study
+
+ 点击查看摘要
+ Language models have outpaced our ability to evaluate them effectively, but for their future development it is essential to study the frontier of their capabilities. We consider real-world software engineering to be a rich, sustainable, and challenging testbed for evaluating the next generation of language models. We therefore introduce SWE-bench, an evaluation framework including $2,294$ software engineering problems drawn from real GitHub issues and corresponding pull requests across $12$ popular Python repositories. Given a codebase along with a description of an issue to be resolved, a language model is tasked with editing the codebase to address the issue. Resolving issues in SWE-bench frequently requires understanding and coordinating changes across multiple functions, classes, and even files simultaneously, calling for models to interact with execution environments, process extremely long contexts and perform complex reasoning that goes far beyond traditional code generation. Our evaluations show that both state-of-the-art proprietary models and our fine-tuned model SWE-Llama can resolve only the simplest issues. Claude 2 and GPT-4 solve a mere $4.8$% and $1.7$% of instances respectively, even when provided with an oracle retriever. Advances on SWE-bench represent steps towards LMs that are more practical, intelligent, and autonomous.
+
+
+
+ 11. 标题:OmniLingo: Listening- and speaking-based language learning
+ 编号:[28]
+ 链接:https://arxiv.org/abs/2310.06764
+ 作者:Francis M. Tyers, Nicholas Howell
+ 备注:
+ 关键词:speaking-based language learning, language learning applications, demonstration client built, present OmniLingo, demo paper
+
+ 点击查看摘要
+ In this demo paper we present OmniLingo, an architecture for distributing data for listening- and speaking-based language learning applications and a demonstration client built using the architecture. The architecture is based on the Interplanetary Filesystem (IPFS) and puts at the forefront user sovereignty over data.
+
+
+
+ 12. 标题:TRACE: A Comprehensive Benchmark for Continual Learning in Large Language Models
+ 编号:[30]
+ 链接:https://arxiv.org/abs/2310.06762
+ 作者:Xiao Wang, Yuansen Zhang, Tianze Chen, Songyang Gao, Senjie Jin, Xianjun Yang, Zhiheng Xi, Rui Zheng, Yicheng Zou, Tao Gui, Qi Zhang, Xuanjing Huang
+ 备注:
+ 关键词:large language models, Aligned large language, continual learning, demonstrate exceptional capabilities, language models
+
+ 点击查看摘要
+ Aligned large language models (LLMs) demonstrate exceptional capabilities in task-solving, following instructions, and ensuring safety. However, the continual learning aspect of these aligned LLMs has been largely overlooked. Existing continual learning benchmarks lack sufficient challenge for leading aligned LLMs, owing to both their simplicity and the models' potential exposure during instruction tuning. In this paper, we introduce TRACE, a novel benchmark designed to evaluate continual learning in LLMs. TRACE consists of 8 distinct datasets spanning challenging tasks including domain-specific tasks, multilingual capabilities, code generation, and mathematical reasoning. All datasets are standardized into a unified format, allowing for effortless automatic evaluation of LLMs. Our experiments show that after training on TRACE, aligned LLMs exhibit significant declines in both general ability and instruction-following capabilities. For example, the accuracy of llama2-chat 13B on gsm8k dataset declined precipitously from 28.8\% to 2\% after training on our datasets. This highlights the challenge of finding a suitable tradeoff between achieving performance on specific tasks while preserving the original prowess of LLMs. Empirical findings suggest that tasks inherently equipped with reasoning paths contribute significantly to preserving certain capabilities of LLMs against potential declines. Motivated by this, we introduce the Reasoning-augmented Continual Learning (RCL) approach. RCL integrates task-specific cues with meta-rationales, effectively reducing catastrophic forgetting in LLMs while expediting convergence on novel tasks.
+
+
+
+ 13. 标题:Exploring Memorization in Fine-tuned Language Models
+ 编号:[45]
+ 链接:https://arxiv.org/abs/2310.06714
+ 作者:Shenglai Zeng, Yaxin Li, Jie Ren, Yiding Liu, Han Xu, Pengfei He, Yue Xing, Shuaiqiang Wang, Jiliang Tang, Dawei Yin
+ 备注:
+ 关键词:shown great capabilities, raising tremendous privacy, LLMs have shown, copyright concerns, shown great
+
+ 点击查看摘要
+ LLMs have shown great capabilities in various tasks but also exhibited memorization of training data, thus raising tremendous privacy and copyright concerns. While prior work has studied memorization during pre-training, the exploration of memorization during fine-tuning is rather limited. Compared with pre-training, fine-tuning typically involves sensitive data and diverse objectives, thus may bring unique memorization behaviors and distinct privacy risks. In this work, we conduct the first comprehensive analysis to explore LMs' memorization during fine-tuning across tasks. Our studies with open-sourced and our own fine-tuned LMs across various tasks indicate that fine-tuned memorization presents a strong disparity among tasks. We provide an understanding of this task disparity via sparse coding theory and unveil a strong correlation between memorization and attention score distribution. By investigating its memorization behavior, multi-task fine-tuning paves a potential strategy to mitigate fine-tuned memorization.
+
+
+
+ 14. 标题:Quality Control at Your Fingertips: Quality-Aware Translation Models
+ 编号:[49]
+ 链接:https://arxiv.org/abs/2310.06707
+ 作者:Christian Tomani, David Vilar, Markus Freitag, Colin Cherry, Subhajit Naskar, Mara Finkelstein, Daniel Cremers
+ 备注:
+ 关键词:neural machine translation, Minimum Bayes Risk, decoding, MAP decoding, strategy for neural
+
+ 点击查看摘要
+ Maximum-a-posteriori (MAP) decoding is the most widely used decoding strategy for neural machine translation (NMT) models. The underlying assumption is that model probability correlates well with human judgment, with better translations being more likely. However, research has shown that this assumption does not always hold, and decoding strategies which directly optimize a utility function, like Minimum Bayes Risk (MBR) or Quality-Aware decoding can significantly improve translation quality over standard MAP decoding. The main disadvantage of these methods is that they require an additional model to predict the utility, and additional steps during decoding, which makes the entire process computationally demanding. In this paper, we propose to make the NMT models themselves quality-aware by training them to estimate the quality of their own output. During decoding, we can use the model's own quality estimates to guide the generation process and produce the highest-quality translations possible. We demonstrate that the model can self-evaluate its own output during translation, eliminating the need for a separate quality estimation model. Moreover, we show that using this quality signal as a prompt during MAP decoding can significantly improve translation quality. When using the internal quality estimate to prune the hypothesis space during MBR decoding, we can not only further improve translation quality, but also reduce inference speed by two orders of magnitude.
+
+
+
+ 15. 标题:Temporally Aligning Long Audio Interviews with Questions: A Case Study in Multimodal Data Integration
+ 编号:[51]
+ 链接:https://arxiv.org/abs/2310.06702
+ 作者:Piyush Singh Pasi, Karthikeya Battepati, Preethi Jyothi, Ganesh Ramakrishnan, Tanmay Mahapatra, Manoj Singh
+ 备注:Work Accepted in IJCAI-23- AI and Social Good Track
+ 关键词:supervision during training, amount of research, research using complete, complete supervision, long audio
+
+ 点击查看摘要
+ The problem of audio-to-text alignment has seen significant amount of research using complete supervision during training. However, this is typically not in the context of long audio recordings wherein the text being queried does not appear verbatim within the audio file. This work is a collaboration with a non-governmental organization called CARE India that collects long audio health surveys from young mothers residing in rural parts of Bihar, India. Given a question drawn from a questionnaire that is used to guide these surveys, we aim to locate where the question is asked within a long audio recording. This is of great value to African and Asian organizations that would otherwise have to painstakingly go through long and noisy audio recordings to locate questions (and answers) of interest. Our proposed framework, INDENT, uses a cross-attention-based model and prior information on the temporal ordering of sentences to learn speech embeddings that capture the semantics of the underlying spoken text. These learnt embeddings are used to retrieve the corresponding audio segment based on text queries at inference time. We empirically demonstrate the significant effectiveness (improvement in R-avg of about 3%) of our model over those obtained using text-based heuristics. We also show how noisy ASR, generated using state-of-the-art ASR models for Indian languages, yields better results when used in place of speech. INDENT, trained only on Hindi data is able to cater to all languages supported by the (semantically) shared text space. We illustrate this empirically on 11 Indic languages.
+
+
+
+ 16. 标题:Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning
+ 编号:[52]
+ 链接:https://arxiv.org/abs/2310.06694
+ 作者:Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, Danqi Chen
+ 备注:The code and models are available at this https URL
+ 关键词:recently emerged moderate-sized, emerged moderate-sized large, moderate-sized large language, large language models, popularity of LLaMA
+
+ 点击查看摘要
+ The popularity of LLaMA (Touvron et al., 2023a;b) and other recently emerged moderate-sized large language models (LLMs) highlights the potential of building smaller yet powerful LLMs. Regardless, the cost of training such models from scratch on trillions of tokens remains high. In this work, we study structured pruning as an effective means to develop smaller LLMs from pre-trained, larger models. Our approach employs two key techniques: (1) targeted structured pruning, which prunes a larger model to a specified target shape by removing layers, heads, and intermediate and hidden dimensions in an end-to-end manner, and (2) dynamic batch loading, which dynamically updates the composition of sampled data in each training batch based on varying losses across different domains. We demonstrate the efficacy of our approach by presenting the Sheared-LLaMA series, pruning the LLaMA2-7B model down to 1.3B and 2.7B parameters. Sheared-LLaMA models outperform state-of-the-art open-source models of equivalent sizes, such as Pythia, INCITE, and OpenLLaMA models, on a wide range of downstream and instruction tuning evaluations, while requiring only 3% of compute compared to training such models from scratch. This work provides compelling evidence that leveraging existing LLMs with structured pruning is a far more cost-effective approach for building smaller LLMs.
+
+
+
+ 17. 标题:Meta-CoT: Generalizable Chain-of-Thought Prompting in Mixed-task Scenarios with Large Language Models
+ 编号:[53]
+ 链接:https://arxiv.org/abs/2310.06692
+ 作者:Anni Zou, Zhuosheng Zhang, Hai Zhao, Xiangru Tang
+ 备注:17 pages, 7 figures
+ 关键词:Large language models, generates intermediate reasoning, intermediate reasoning chains, Large language, language models
+
+ 点击查看摘要
+ Large language models (LLMs) have unveiled remarkable reasoning capabilities by exploiting chain-of-thought (CoT) prompting, which generates intermediate reasoning chains to serve as the rationale for deriving the answer. However, current CoT methods either simply employ general prompts such as Let's think step by step, or heavily rely on handcrafted task-specific demonstrations to attain preferable performances, thereby engendering an inescapable gap between performance and generalization. To bridge this gap, we propose Meta-CoT, a generalizable CoT prompting method in mixed-task scenarios where the type of input questions is unknown. Meta-CoT firstly categorizes the scenario based on the input question and subsequently constructs diverse demonstrations from the corresponding data pool in an automatic pattern. Meta-CoT simultaneously enjoys remarkable performances on ten public benchmark reasoning tasks and superior generalization capabilities. Notably, Meta-CoT achieves the state-of-the-art result on SVAMP (93.7%) without any additional program-aided methods. Our further experiments on five out-of-distribution datasets verify the stability and generality of Meta-CoT.
+
+
+
+ 18. 标题:Learning Multiplex Embeddings on Text-rich Networks with One Text Encoder
+ 编号:[57]
+ 链接:https://arxiv.org/abs/2310.06684
+ 作者:Bowen Jin, Wentao Zhang, Yu Zhang, Yu Meng, Han Zhao, Jiawei Han
+ 备注:9 pages, 11 appendix pages
+ 关键词:real-world scenarios, linked by multiple, multiple semantic relations, multiplex, multiplex text-rich
+
+ 点击查看摘要
+ In real-world scenarios, texts in a network are often linked by multiple semantic relations (e.g., papers in an academic network are referenced by other publications, written by the same author, or published in the same venue), where text documents and their relations form a multiplex text-rich network. Mainstream text representation learning methods use pretrained language models (PLMs) to generate one embedding for each text unit, expecting that all types of relations between texts can be captured by these single-view embeddings. However, this presumption does not hold particularly in multiplex text-rich networks. Along another line of work, multiplex graph neural networks (GNNs) directly initialize node attributes as a feature vector for node representation learning, but they cannot fully capture the semantics of the nodes' associated texts. To bridge these gaps, we propose METERN, a new framework for learning Multiplex Embeddings on TExt-Rich Networks. In contrast to existing methods, METERN uses one text encoder to model the shared knowledge across relations and leverages a small number of parameters per relation to derive relation-specific representations. This allows the encoder to effectively capture the multiplex structures in the network while also preserving parameter efficiency. We conduct experiments on nine downstream tasks in five networks from both academic and e-commerce domains, where METERN outperforms baselines significantly and consistently. The code is available at this https URL.
+
+
+
+ 19. 标题:SEER: A Knapsack approach to Exemplar Selection for In-Context HybridQA
+ 编号:[62]
+ 链接:https://arxiv.org/abs/2310.06675
+ 作者:Jonathan Tonglet, Manon Reusens, Philipp Borchert, Bart Baesens
+ 备注:Accepted to EMNLP 2023 main conference. Code available at github.com/jtonglet/SEER
+ 关键词:Question answering, requires the combination, combination of information, information extracted, extracted from unstructured
+
+ 点击查看摘要
+ Question answering over hybrid contexts is a complex task, which requires the combination of information extracted from unstructured texts and structured tables in various ways. Recently, In-Context Learning demonstrated significant performance advances for reasoning tasks. In this paradigm, a large language model performs predictions based on a small set of supporting exemplars. The performance of In-Context Learning depends heavily on the selection procedure of the supporting exemplars, particularly in the case of HybridQA, where considering the diversity of reasoning chains and the large size of the hybrid contexts becomes crucial. In this work, we present Selection of ExEmplars for hybrid Reasoning (SEER), a novel method for selecting a set of exemplars that is both representative and diverse. The key novelty of SEER is that it formulates exemplar selection as a Knapsack Integer Linear Program. The Knapsack framework provides the flexibility to incorporate diversity constraints that prioritize exemplars with desirable attributes, and capacity constraints that ensure that the prompt size respects the provided capacity budgets. The effectiveness of SEER is demonstrated on FinQA and TAT-QA, two real-world benchmarks for HybridQA, where it outperforms previous exemplar selection methods.
+
+
+
+ 20. 标题:Making Large Language Models Perform Better in Knowledge Graph Completion
+ 编号:[63]
+ 链接:https://arxiv.org/abs/2310.06671
+ 作者:Yichi Zhang, Zhuo Chen, Wen Zhang, Huajun Chen
+ 备注:Working in progress
+ 关键词:Large language model, web-based automatic services, based knowledge graph, knowledge graph completion, structural information
+
+ 点击查看摘要
+ Large language model (LLM) based knowledge graph completion (KGC) aims to predict the missing triples in the KGs with LLMs and enrich the KGs to become better web infrastructure, which can benefit a lot of web-based automatic services. However, research about LLM-based KGC is limited and lacks effective utilization of LLM's inference capabilities, which ignores the important structural information in KGs and prevents LLMs from acquiring accurate factual knowledge. In this paper, we discuss how to incorporate the helpful KG structural information into the LLMs, aiming to achieve structrual-aware reasoning in the LLMs. We first transfer the existing LLM paradigms to structural-aware settings and further propose a knowledge prefix adapter (KoPA) to fulfill this stated goal. KoPA employs structural embedding pre-training to capture the structural information of entities and relations in the KG. Then KoPA informs the LLMs of the knowledge prefix adapter which projects the structural embeddings into the textual space and obtains virtual knowledge tokens as a prefix of the input prompt. We conduct comprehensive experiments on these structural-aware LLM-based KGC methods and provide an in-depth analysis comparing how the introduction of structural information would be better for LLM's knowledge reasoning ability. Our code is released at this https URL.
+
+
+
+ 21. 标题:Unlock the Potential of Counterfactually-Augmented Data in Out-Of-Distribution Generalization
+ 编号:[67]
+ 链接:https://arxiv.org/abs/2310.06666
+ 作者:Caoyun Fan, Wenqing Chen, Jidong Tian, Yitian Li, Hao He, Yaohui Jin
+ 备注:Expert Systems With Applications 2023. arXiv admin note: text overlap with arXiv:2302.09345
+ 关键词:Counterfactually-Augmented Data, CAD induces language, exclude spurious correlations, CAD OOD generalization, exploit domain-independent causal
+
+ 点击查看摘要
+ Counterfactually-Augmented Data (CAD) -- minimal editing of sentences to flip the corresponding labels -- has the potential to improve the Out-Of-Distribution (OOD) generalization capability of language models, as CAD induces language models to exploit domain-independent causal features and exclude spurious correlations. However, the empirical results of CAD's OOD generalization are not as efficient as anticipated. In this study, we attribute the inefficiency to the myopia phenomenon caused by CAD: language models only focus on causal features that are edited in the augmentation operation and exclude other non-edited causal features. Therefore, the potential of CAD is not fully exploited. To address this issue, we analyze the myopia phenomenon in feature space from the perspective of Fisher's Linear Discriminant, then we introduce two additional constraints based on CAD's structural properties (dataset-level and sentence-level) to help language models extract more complete causal features in CAD, thereby mitigating the myopia phenomenon and improving OOD generalization capability. We evaluate our method on two tasks: Sentiment Analysis and Natural Language Inference, and the experimental results demonstrate that our method could unlock the potential of CAD and improve the OOD generalization performance of language models by 1.0% to 5.9%.
+
+
+
+ 22. 标题:Self-Supervised Representation Learning for Online Handwriting Text Classification
+ 编号:[75]
+ 链接:https://arxiv.org/abs/2310.06645
+ 作者:Pouya Mehralian, Bagher BabaAli, Ashena Gorgan Mohammadi
+ 备注:
+ 关键词:Self-supervised learning offers, annotating large-scale datasets, extracting rich representations, Self-supervised learning, large-scale datasets
+
+ 点击查看摘要
+ Self-supervised learning offers an efficient way of extracting rich representations from various types of unlabeled data while avoiding the cost of annotating large-scale datasets. This is achievable by designing a pretext task to form pseudo labels with respect to the modality and domain of the data. Given the evolving applications of online handwritten texts, in this study, we propose the novel Part of Stroke Masking (POSM) as a pretext task for pretraining models to extract informative representations from the online handwriting of individuals in English and Chinese languages, along with two suggested pipelines for fine-tuning the pretrained models. To evaluate the quality of the extracted representations, we use both intrinsic and extrinsic evaluation methods. The pretrained models are fine-tuned to achieve state-of-the-art results in tasks such as writer identification, gender classification, and handedness classification, also highlighting the superiority of utilizing the pretrained models over the models trained from scratch.
+
+
+
+ 23. 标题:What If the TV Was Off? Examining Counterfactual Reasoning Abilities of Multi-modal Language Models
+ 编号:[83]
+ 链接:https://arxiv.org/abs/2310.06627
+ 作者:Letian Zhang, Xiaotong Zhai, Zhongkai Zhao, Xin Wen, Yongshuo Zong, Bingchen Zhao
+ 备注:Short paper accepted at ICCV 2023 VLAR workshop
+ 关键词:Counterfactual reasoning ability, human intelligence, core abilities, abilities of human, reasoning ability
+
+ 点击查看摘要
+ Counterfactual reasoning ability is one of the core abilities of human intelligence. This reasoning process involves the processing of alternatives to observed states or past events, and this process can improve our ability for planning and decision-making. In this work, we focus on benchmarking the counterfactual reasoning ability of multi-modal large language models. We take the question and answer pairs from the VQAv2 dataset and add one counterfactual presupposition to the questions, with the answer being modified accordingly. After generating counterfactual questions and answers using ChatGPT, we manually examine all generated questions and answers to ensure correctness. Over 2k counterfactual question and answer pairs are collected this way. We evaluate recent vision language models on our newly collected test dataset and found that all models exhibit a large performance drop compared to the results tested on questions without the counterfactual presupposition. This result indicates that there still exists space for developing vision language models. Apart from the vision language models, our proposed dataset can also serves as a benchmark for evaluating the ability of code generation LLMs, results demonstrate a large gap between GPT-4 and current open-source models. Our code and dataset are available at \url{this https URL}.
+
+
+
+ 24. 标题:Topic-DPR: Topic-based Prompts for Dense Passage Retrieval
+ 编号:[84]
+ 链接:https://arxiv.org/abs/2310.06626
+ 作者:Qingfa Xiao, Shuangyin Li, Lei Chen
+ 备注:Findings of EMNLP 2023
+ 关键词:numerous natural language, natural language processing, language processing tasks, Prompt-based learning efficacy, efficacy across numerous
+
+ 点击查看摘要
+ Prompt-based learning's efficacy across numerous natural language processing tasks has led to its integration into dense passage retrieval. Prior research has mainly focused on enhancing the semantic understanding of pre-trained language models by optimizing a single vector as a continuous prompt. This approach, however, leads to a semantic space collapse; identical semantic information seeps into all representations, causing their distributions to converge in a restricted region. This hinders differentiation between relevant and irrelevant passages during dense retrieval. To tackle this issue, we present Topic-DPR, a dense passage retrieval model that uses topic-based prompts. Unlike the single prompt method, multiple topic-based prompts are established over a probabilistic simplex and optimized simultaneously through contrastive learning. This encourages representations to align with their topic distributions, improving space uniformity. Furthermore, we introduce a novel positive and negative sampling strategy, leveraging semi-structured data to boost dense retrieval efficiency. Experimental results from two datasets affirm that our method surpasses previous state-of-the-art retrieval techniques.
+
+
+
+ 25. 标题:No Pitch Left Behind: Addressing Gender Unbalance in Automatic Speech Recognition through Pitch Manipulation
+ 编号:[96]
+ 链接:https://arxiv.org/abs/2310.06590
+ 作者:Dennis Fucci, Marco Gaido, Matteo Negri, Mauro Cettolo, Luisa Bentivogli
+ 备注:Accepted at ASRU 2023
+ 关键词:Automatic speech recognition, crucial role, plays a crucial, female speakers, Automatic speech
+
+ 点击查看摘要
+ Automatic speech recognition (ASR) systems are known to be sensitive to the sociolinguistic variability of speech data, in which gender plays a crucial role. This can result in disparities in recognition accuracy between male and female speakers, primarily due to the under-representation of the latter group in the training data. While in the context of hybrid ASR models several solutions have been proposed, the gender bias issue has not been explicitly addressed in end-to-end neural architectures. To fill this gap, we propose a data augmentation technique that manipulates the fundamental frequency (f0) and formants. This technique reduces the data unbalance among genders by simulating voices of the under-represented female speakers and increases the variability within each gender group. Experiments on spontaneous English speech show that our technique yields a relative WER improvement up to 9.87% for utterances by female speakers, with larger gains for the least-represented f0 ranges.
+
+
+
+ 26. 标题:FTFT: efficient and robust Fine-Tuning by transFerring Training dynamics
+ 编号:[97]
+ 链接:https://arxiv.org/abs/2310.06588
+ 作者:Yupei Du, Albert Gatt, Dong Nguyen
+ 备注:15 pages, 3 figures
+ 关键词:Natural Language Processing, Pre-trained Language Models, large Pre-trained Language, Language Processing, Pre-trained Language
+
+ 点击查看摘要
+ Despite the massive success of fine-tuning large Pre-trained Language Models (PLMs) on a wide range of Natural Language Processing (NLP) tasks, they remain susceptible to out-of-distribution (OOD) and adversarial inputs. Data map (DM) is a simple yet effective dual-model approach that enhances the robustness of fine-tuned PLMs, which involves fine-tuning a model on the original training set (i.e. reference model), selecting a specified fraction of important training examples according to the training dynamics of the reference model, and fine-tuning the same model on these selected examples (i.e. main model). However, it suffers from the drawback of requiring fine-tuning the same model twice, which is computationally expensive for large models. In this paper, we first show that 1) training dynamics are highly transferable across different model sizes and different pre-training methods, and that 2) main models fine-tuned using DM learn faster than when using conventional Empirical Risk Minimization (ERM). Building on these observations, we propose a novel fine-tuning approach based on the DM method: Fine-Tuning by transFerring Training dynamics (FTFT). Compared with DM, FTFT uses more efficient reference models and then fine-tunes more capable main models for fewer steps. Our experiments show that FTFT achieves better generalization robustness than ERM while spending less than half of the training cost.
+
+
+
+ 27. 标题:On Temporal References in Emergent Communication
+ 编号:[108]
+ 链接:https://arxiv.org/abs/2310.06555
+ 作者:Olaf Lipinski, Adam J. Sobey, Federico Cerutti, Timothy J. Norman
+ 备注:26 pages, 13 figures. Code available at this https URL
+ 关键词:easily share past, share past experiences, elements referencing time, future predictions, linguistic elements referencing
+
+ 点击查看摘要
+ As humans, we use linguistic elements referencing time, such as before or tomorrow, to easily share past experiences and future predictions. While temporal aspects of the language have been considered in computational linguistics, no such exploration has been done within the field of emergent communication. We research this gap, providing the first reported temporal vocabulary within emergent communication literature. Our experimental analysis shows that a different agent architecture is sufficient for the natural emergence of temporal references, and that no additional losses are necessary. Our readily transferable architectural insights provide the basis for the incorporation of temporal referencing into other emergent communication environments.
+
+
+
+ 28. 标题:Automated clinical coding using off-the-shelf large language models
+ 编号:[110]
+ 链接:https://arxiv.org/abs/2310.06552
+ 作者:Joseph S. Boyle, Antanas Kascenas, Pat Lok, Maria Liakata, Alison Q. O'Neil
+ 备注:9 pages, 4 figures
+ 关键词:expert human coders, patient hospital admissions, assigning diagnostic ICD, diagnostic ICD codes, human coders
+
+ 点击查看摘要
+ The task of assigning diagnostic ICD codes to patient hospital admissions is typically performed by expert human coders. Efforts towards automated ICD coding are dominated by supervised deep learning models. However, difficulties in learning to predict the large number of rare codes remain a barrier to adoption in clinical practice. In this work, we leverage off-the-shelf pre-trained generative large language models (LLMs) to develop a practical solution that is suitable for zero-shot and few-shot code assignment. Unsupervised pre-training alone does not guarantee precise knowledge of the ICD ontology and specialist clinical coding task, therefore we frame the task as information extraction, providing a description of each coded concept and asking the model to retrieve related mentions. For efficiency, rather than iterating over all codes, we leverage the hierarchical nature of the ICD ontology to sparsely search for relevant codes. Then, in a second stage, which we term 'meta-refinement', we utilise GPT-4 to select a subset of the relevant labels as predictions. We validate our method using Llama-2, GPT-3.5 and GPT-4 on the CodiEsp dataset of ICD-coded clinical case documents. Our tree-search method achieves state-of-the-art performance on rarer classes, achieving the best macro-F1 of 0.225, whilst achieving slightly lower micro-F1 of 0.157, compared to 0.216 and 0.219 respectively from PLM-ICD. To the best of our knowledge, this is the first method for automated ICD coding requiring no task-specific learning.
+
+
+
+ 29. 标题:Rationale-Enhanced Language Models are Better Continual Relation Learners
+ 编号:[113]
+ 链接:https://arxiv.org/abs/2310.06547
+ 作者:Weimin Xiong, Yifan Song, Peiyi Wang, Sujian Li
+ 备注:Accepted at EMNLP 2023
+ 关键词:Continual relation extraction, newly emerging relations, aims to solve, catastrophic forgetting, solve the problem
+
+ 点击查看摘要
+ Continual relation extraction (CRE) aims to solve the problem of catastrophic forgetting when learning a sequence of newly emerging relations. Recent CRE studies have found that catastrophic forgetting arises from the model's lack of robustness against future analogous relations. To address the issue, we introduce rationale, i.e., the explanations of relation classification results generated by large language models (LLM), into CRE task. Specifically, we design the multi-task rationale tuning strategy to help the model learn current relations robustly. We also conduct contrastive rationale replay to further distinguish analogous relations. Experimental results on two standard benchmarks demonstrate that our method outperforms the state-of-the-art CRE models.
+
+
+
+ 30. 标题:AutoCycle-VC: Towards Bottleneck-Independent Zero-Shot Cross-Lingual Voice Conversion
+ 编号:[114]
+ 链接:https://arxiv.org/abs/2310.06546
+ 作者:Haeyun Choi, Jio Gim, Yuho Lee, Youngin Kim, Young-Joo Suh
+ 备注:
+ 关键词:paper proposes, proposes a simple, simple and robust, robust zero-shot voice, voice conversion system
+
+ 点击查看摘要
+ This paper proposes a simple and robust zero-shot voice conversion system with a cycle structure and mel-spectrogram pre-processing. Previous works suffer from information loss and poor synthesis quality due to their reliance on a carefully designed bottleneck structure. Moreover, models relying solely on self-reconstruction loss struggled with reproducing different speakers' voices. To address these issues, we suggested a cycle-consistency loss that considers conversion back and forth between target and source speakers. Additionally, stacked random-shuffled mel-spectrograms and a label smoothing method are utilized during speaker encoder training to extract a time-independent global speaker representation from speech, which is the key to a zero-shot conversion. Our model outperforms existing state-of-the-art results in both subjective and objective evaluations. Furthermore, it facilitates cross-lingual voice conversions and enhances the quality of synthesized speech.
+
+
+
+ 31. 标题:A Novel Contrastive Learning Method for Clickbait Detection on RoCliCo: A Romanian Clickbait Corpus of News Articles
+ 编号:[118]
+ 链接:https://arxiv.org/abs/2310.06540
+ 作者:Daria-Mihaela Broscoteanu, Radu Tudor Ionescu
+ 备注:Accepted at EMNLP 2023
+ 关键词:increase revenue, websites often resort, reading the full, Romanian Clickbait Corpus, luring users
+
+ 点击查看摘要
+ To increase revenue, news websites often resort to using deceptive news titles, luring users into clicking on the title and reading the full news. Clickbait detection is the task that aims to automatically detect this form of false advertisement and avoid wasting the precious time of online users. Despite the importance of the task, to the best of our knowledge, there is no publicly available clickbait corpus for the Romanian language. To this end, we introduce a novel Romanian Clickbait Corpus (RoCliCo) comprising 8,313 news samples which are manually annotated with clickbait and non-clickbait labels. Furthermore, we conduct experiments with four machine learning methods, ranging from handcrafted models to recurrent and transformer-based neural networks, to establish a line-up of competitive baselines. We also carry out experiments with a weighted voting ensemble. Among the considered baselines, we propose a novel BERT-based contrastive learning model that learns to encode news titles and contents into a deep metric space such that titles and contents of non-clickbait news have high cosine similarity, while titles and contents of clickbait news have low cosine similarity. Our data set and code to reproduce the baselines are publicly available for download at this https URL.
+
+
+
+ 32. 标题:EmoTwiCS: A Corpus for Modelling Emotion Trajectories in Dutch Customer Service Dialogues on Twitter
+ 编号:[119]
+ 链接:https://arxiv.org/abs/2310.06536
+ 作者:Sofie Labat, Thomas Demeester, Véronique Hoste
+ 备注:Preprint to Language Resources and Evaluation Journal
+ 关键词:deliver customer service, Dutch customer service, user-generated content, social media, rise of user-generated
+
+ 点击查看摘要
+ Due to the rise of user-generated content, social media is increasingly adopted as a channel to deliver customer service. Given the public character of these online platforms, the automatic detection of emotions forms an important application in monitoring customer satisfaction and preventing negative word-of-mouth. This paper introduces EmoTwiCS, a corpus of 9,489 Dutch customer service dialogues on Twitter that are annotated for emotion trajectories. In our business-oriented corpus, we view emotions as dynamic attributes of the customer that can change at each utterance of the conversation. The term `emotion trajectory' refers therefore not only to the fine-grained emotions experienced by customers (annotated with 28 labels and valence-arousal-dominance scores), but also to the event happening prior to the conversation and the responses made by the human operator (both annotated with 8 categories). Inter-annotator agreement (IAA) scores on the resulting dataset are substantial and comparable with related research, underscoring its high quality. Given the interplay between the different layers of annotated information, we perform several in-depth analyses to investigate (i) static emotions in isolated tweets, (ii) dynamic emotions and their shifts in trajectory, and (iii) the role of causes and response strategies in emotion trajectories. We conclude by listing the advantages and limitations of our dataset, after which we give some suggestions on the different types of predictive modelling tasks and open research questions to which EmoTwiCS can be applied. The dataset is available upon request and will be made publicly available upon acceptance of the paper.
+
+
+
+ 33. 标题:Toward Semantic Publishing in Non-Invasive Brain Stimulation: A Comprehensive Analysis of rTMS Studies
+ 编号:[123]
+ 链接:https://arxiv.org/abs/2310.06517
+ 作者:Swathi Anil, Jennifer D'Souza
+ 备注:8 pages, 2 figures. Accepted as a Practice Paper at The 25th International Conference on Asia-Pacific Digital Libraries (ICADL 2023) this https URL
+ 关键词:influence brain excitability, Noninvasive brain stimulation, encompasses transcranial stimulation, Noninvasive brain, brain excitability
+
+ 点击查看摘要
+ Noninvasive brain stimulation (NIBS) encompasses transcranial stimulation techniques that can influence brain excitability. These techniques have the potential to treat conditions like depression, anxiety, and chronic pain, and to provide insights into brain function. However, a lack of standardized reporting practices limits its reproducibility and full clinical potential. This paper aims to foster interinterdisciplinarity toward adopting Computer Science Semantic reporting methods for the standardized documentation of Neuroscience NIBS studies making them explicitly Findable, Accessible, Interoperable, and Reusable (FAIR).
+In a large-scale systematic review of 600 repetitive transcranial magnetic stimulation (rTMS), a subarea of NIBS, dosages, we describe key properties that allow for structured descriptions and comparisons of the studies. This paper showcases the semantic publishing of NIBS in the ecosphere of knowledge-graph-based next-generation scholarly digital libraries. Specifically, the FAIR Semantic Web resource(s)-based publishing paradigm is implemented for the 600 reviewed rTMS studies in the Open Research Knowledge Graph.
+
+
+
+ 34. 标题:Evaluation of ChatGPT Feedback on ELL Writers' Coherence and Cohesion
+ 编号:[130]
+ 链接:https://arxiv.org/abs/2310.06505
+ 作者:Su-Youn Yoon, Eva Miszoglad, Lisa R. Pierce
+ 备注:24 pages, 1 figures
+ 关键词:launch in November, English Language Learners, teaching practices, transformative effect, effect on education
+
+ 点击查看摘要
+ Since its launch in November 2022, ChatGPT has had a transformative effect on education where students are using it to help with homework assignments and teachers are actively employing it in their teaching practices. This includes using ChatGPT as a tool for writing teachers to grade and generate feedback on students' essays. In this study, we evaluated the quality of the feedback generated by ChatGPT regarding the coherence and cohesion of the essays written by English Language Learners (ELLs) students. We selected 50 argumentative essays and generated feedback on coherence and cohesion using the ELLIPSE rubric. During the feedback evaluation, we used a two-step approach: first, each sentence in the feedback was classified into subtypes based on its function (e.g., positive reinforcement, problem statement). Next, we evaluated its accuracy and usability according to these types. Both the analysis of feedback types and the evaluation of accuracy and usability revealed that most feedback sentences were highly abstract and generic, failing to provide concrete suggestions for improvement. The accuracy in detecting major problems, such as repetitive ideas and the inaccurate use of cohesive devices, depended on superficial linguistic features and was often incorrect. In conclusion, ChatGPT, without specific training for the feedback generation task, does not offer effective feedback on ELL students' coherence and cohesion.
+
+
+
+ 35. 标题:Revisit Input Perturbation Problems for LLMs: A Unified Robustness Evaluation Framework for Noisy Slot Filling Task
+ 编号:[131]
+ 链接:https://arxiv.org/abs/2310.06504
+ 作者:Guanting Dong, Jinxu Zhao, Tingfeng Hui, Daichi Guo, Wenlong Wan, Boqi Feng, Yueyan Qiu, Zhuoma Gongque, Keqing He, Zechen Wang, Weiran Xu
+ 备注:Accepted at NLPCC 2023 (Oral Presentation)
+ 关键词:natural language processing, large language models, language processing, language models, large language
+
+ 点击查看摘要
+ With the increasing capabilities of large language models (LLMs), these high-performance models have achieved state-of-the-art results on a wide range of natural language processing (NLP) tasks. However, the models' performance on commonly-used benchmark datasets often fails to accurately reflect their reliability and robustness when applied to real-world noisy data. To address these challenges, we propose a unified robustness evaluation framework based on the slot-filling task to systematically evaluate the dialogue understanding capability of LLMs in diverse input perturbation scenarios. Specifically, we construct a input perturbation evaluation dataset, Noise-LLM, which contains five types of single perturbation and four types of mixed perturbation data. Furthermore, we utilize a multi-level data augmentation method (character, word, and sentence levels) to construct a candidate data pool, and carefully design two ways of automatic task demonstration construction strategies (instance-level and entity-level) with various prompt templates. Our aim is to assess how well various robustness methods of LLMs perform in real-world noisy scenarios. The experiments have demonstrated that the current open-source LLMs generally achieve limited perturbation robustness performance. Based on these experimental observations, we make some forward-looking suggestions to fuel the research in this direction.
+
+
+
+ 36. 标题:The Limits of ChatGPT in Extracting Aspect-Category-Opinion-Sentiment Quadruples: A Comparative Analysis
+ 编号:[132]
+ 链接:https://arxiv.org/abs/2310.06502
+ 作者:Xiancai Xu, Jia-Dong Zhang, Rongchang Xiao, Lei Xiong
+ 备注:
+ 关键词:attracted great attention, natural language understanding, understanding and generation, attracted great, great attention
+
+ 点击查看摘要
+ Recently, ChatGPT has attracted great attention from both industry and academia due to its surprising abilities in natural language understanding and generation. We are particularly curious about whether it can achieve promising performance on one of the most complex tasks in aspect-based sentiment analysis, i.e., extracting aspect-category-opinion-sentiment quadruples from texts. To this end, in this paper we develop a specialized prompt template that enables ChatGPT to effectively tackle this complex quadruple extraction task. Further, we propose a selection method on few-shot examples to fully exploit the in-context learning ability of ChatGPT and uplift its effectiveness on this complex task. Finally, we provide a comparative evaluation on ChatGPT against existing state-of-the-art quadruple extraction models based on four public datasets and highlight some important findings regarding the capability boundaries of ChatGPT in the quadruple extraction.
+
+
+
+ 37. 标题:A New Benchmark and Reverse Validation Method for Passage-level Hallucination Detection
+ 编号:[134]
+ 链接:https://arxiv.org/abs/2310.06498
+ 作者:Shiping Yang, Renliang Sun, Xiaojun Wan
+ 备注:Findings of EMNLP 2023;Camera-ready version will be updated soon
+ 关键词:Large Language Models, Language Models, Large Language, real-world scenarios, demonstrated their ability
+
+ 点击查看摘要
+ Large Language Models (LLMs) have demonstrated their ability to collaborate effectively with humans in real-world scenarios. However, LLMs are apt to generate hallucinations, i.e., makeup incorrect text and unverified information, which can cause significant damage when deployed for mission-critical tasks. In this paper, we propose a self-check approach based on reverse validation to detect factual errors automatically in a zero-resource fashion. To facilitate future studies and assess different methods, we construct a hallucination detection benchmark, which is generated by ChatGPT and annotated by human annotators. Contrasting previous studies of zero-resource hallucination detection, our method and benchmark concentrate on passage-level detection instead of sentence-level. We empirically evaluate our method and existing zero-resource detection methods on different domains of benchmark to explore the implicit relation between hallucination and training data. Furthermore, we manually analyze some hallucination cases that LLM failed to capture, revealing the shared limitation of zero-resource methods.
+
+
+
+ 38. 标题:SpikeCLIP: A Contrastive Language-Image Pretrained Spiking Neural Network
+ 编号:[137]
+ 链接:https://arxiv.org/abs/2310.06488
+ 作者:Tianlong Li, Wenhao Liu, Changze Lv, Jianhan Xu, Cenyuan Zhang, Muling Wu, Xiaoqing Zheng, Xuanjing Huang
+ 备注:
+ 关键词:Spiking neural networks, deep neural networks, neural networks, improved energy efficiency, Spiking neural
+
+ 点击查看摘要
+ Spiking neural networks (SNNs) have demonstrated the capability to achieve comparable performance to deep neural networks (DNNs) in both visual and linguistic domains while offering the advantages of improved energy efficiency and adherence to biological plausibility. However, the extension of such single-modality SNNs into the realm of multimodal scenarios remains an unexplored territory. Drawing inspiration from the concept of contrastive language-image pre-training (CLIP), we introduce a novel framework, named SpikeCLIP, to address the gap between two modalities within the context of spike-based computing through a two-step recipe involving ``Alignment Pre-training + Dual-Loss Fine-tuning". Extensive experiments demonstrate that SNNs achieve comparable results to their DNN counterparts while significantly reducing energy consumption across a variety of datasets commonly used for multimodal model evaluation. Furthermore, SpikeCLIP maintains robust performance in image classification tasks that involve class labels not predefined within specific categories.
+
+
+
+ 39. 标题:Multilingual Jailbreak Challenges in Large Language Models
+ 编号:[144]
+ 链接:https://arxiv.org/abs/2310.06474
+ 作者:Yue Deng, Wenxuan Zhang, Sinno Jialin Pan, Lidong Bing
+ 备注:
+ 关键词:exhibit undesirable behavior, large language models, exhibit remarkable capabilities, pose potential safety, range of tasks
+
+ 点击查看摘要
+ While large language models (LLMs) exhibit remarkable capabilities across a wide range of tasks, they pose potential safety concerns, such as the ``jailbreak'' problem, wherein malicious instructions can manipulate LLMs to exhibit undesirable behavior. Although several preventive measures have been developed to mitigate the potential risks associated with LLMs, they have primarily focused on English data. In this study, we reveal the presence of multilingual jailbreak challenges within LLMs and consider two potential risk scenarios: unintentional and intentional. The unintentional scenario involves users querying LLMs using non-English prompts and inadvertently bypassing the safety mechanisms, while the intentional scenario concerns malicious users combining malicious instructions with multilingual prompts to deliberately attack LLMs. The experimental results reveal that in the unintentional scenario, the rate of unsafe content increases as the availability of languages decreases. Specifically, low-resource languages exhibit three times the likelihood of encountering harmful content compared to high-resource languages, with both ChatGPT and GPT-4. In the intentional scenario, multilingual prompts can exacerbate the negative impact of malicious instructions, with astonishingly high rates of unsafe output: 80.92\% for ChatGPT and 40.71\% for GPT-4. To handle such a challenge in the multilingual context, we propose a novel \textsc{Self-Defense} framework that automatically generates multilingual training data for safety fine-tuning. Experimental results show that ChatGPT fine-tuned with such data can achieve a substantial reduction in unsafe content generation. Data is available at this https URL. Warning: This paper contains examples with potentially harmful content.
+
+
+
+ 40. 标题:Cultural Compass: Predicting Transfer Learning Success in Offensive Language Detection with Cultural Features
+ 编号:[148]
+ 链接:https://arxiv.org/abs/2310.06458
+ 作者:Li Zhou, Antonia Karamolegkou, Wenyu Chen, Daniel Hershcovich
+ 备注:Findings of EMNLP 2023
+ 关键词:Offensive Language Detection, machine learning realm, language technology necessitates, Language Detection, cross-cultural transfer learning
+
+ 点击查看摘要
+ The increasing ubiquity of language technology necessitates a shift towards considering cultural diversity in the machine learning realm, particularly for subjective tasks that rely heavily on cultural nuances, such as Offensive Language Detection (OLD). Current understanding underscores that these tasks are substantially influenced by cultural values, however, a notable gap exists in determining if cultural features can accurately predict the success of cross-cultural transfer learning for such subjective tasks. Addressing this, our study delves into the intersection of cultural features and transfer learning effectiveness. The findings reveal that cultural value surveys indeed possess a predictive power for cross-cultural transfer learning success in OLD tasks and that it can be further improved using offensive word distance. Based on these results, we advocate for the integration of cultural information into datasets. Additionally, we recommend leveraging data sources rich in cultural information, such as surveys, to enhance cultural adaptability. Our research signifies a step forward in the quest for more inclusive, culturally sensitive language technologies.
+
+
+
+ 41. 标题:Understanding the Effects of RLHF on LLM Generalisation and Diversity
+ 编号:[150]
+ 链接:https://arxiv.org/abs/2310.06452
+ 作者:Robert Kirk, Ishita Mediratta, Christoforos Nalmpantis, Jelena Luketina, Eric Hambro, Edward Grefenstette, Roberta Raileanu
+ 备注:
+ 关键词:Anthropic Claude, Large language models, Large language, fine-tuned with reinforcement, human feedback
+
+ 点击查看摘要
+ Large language models (LLMs) fine-tuned with reinforcement learning from human feedback (RLHF) have been used in some of the most widely deployed AI models to date, such as OpenAI's ChatGPT, Anthropic's Claude, or Meta's LLaMA-2. While there has been significant work developing these methods, our understanding of the benefits and downsides of each stage in RLHF is still limited. To fill this gap, we present an extensive analysis of how each stage of the process (i.e. supervised fine-tuning (SFT), reward modelling, and RLHF) affects two key properties: out-of-distribution (OOD) generalisation and output diversity. OOD generalisation is crucial given the wide range of real-world scenarios in which these models are being used, while output diversity refers to the model's ability to generate varied outputs and is important for a variety of use cases. We perform our analysis across two base models on both summarisation and instruction following tasks, the latter being highly relevant for current LLM use cases. We find that RLHF generalises better than SFT to new inputs, particularly as the distribution shift between train and test becomes larger. However, RLHF significantly reduces output diversity compared to SFT across a variety of measures, implying a tradeoff in current LLM fine-tuning methods between generalisation and diversity. Our results provide guidance on which fine-tuning method should be used depending on the application, and show that more research is needed to improve the trade-off between generalisation and diversity.
+
+
+
+ 42. 标题:Constructive Large Language Models Alignment with Diverse Feedback
+ 编号:[152]
+ 链接:https://arxiv.org/abs/2310.06450
+ 作者:Tianshu Yu, Ting-En Lin, Yuchuan Wu, Min Yang, Fei Huang, Yongbin Li
+ 备注:
+ 关键词:harmful content, large language models, recent research, research on large, growing emphasis
+
+ 点击查看摘要
+ In recent research on large language models (LLMs), there has been a growing emphasis on aligning these models with human values to reduce the impact of harmful content. However, current alignment methods often rely solely on singular forms of human feedback, such as preferences, annotated labels, or natural language critiques, overlooking the potential advantages of combining these feedback types. This limitation leads to suboptimal performance, even when ample training data is available. In this paper, we introduce Constructive and Diverse Feedback (CDF) as a novel method to enhance LLM alignment, inspired by constructivist learning theory. Our approach involves collecting three distinct types of feedback tailored to problems of varying difficulty levels within the training dataset. Specifically, we exploit critique feedback for easy problems, refinement feedback for medium problems, and preference feedback for hard problems. By training our model with this diversified feedback, we achieve enhanced alignment performance while using less training data. To assess the effectiveness of CDF, we evaluate it against previous methods in three downstream tasks: question answering, dialog generation, and text summarization. Experimental results demonstrate that CDF achieves superior performance even with a smaller training dataset.
+
+
+
+ 43. 标题:MemSum-DQA: Adapting An Efficient Long Document Extractive Summarizer for Document Question Answering
+ 编号:[160]
+ 链接:https://arxiv.org/abs/2310.06436
+ 作者:Nianlong Gu, Yingqiang Gao, Richard H. R. Hahnloser
+ 备注:This paper is the technical research paper of CIKM 2023 DocIU challenges. The authors received the CIKM 2023 DocIU Winner Award, sponsored by Google, Microsoft, and the Centre for data-driven geoscience
+ 关键词:leverages MemSum, efficient system, document extractive summarizer, long document extractive, extractive summarizer
+
+ 点击查看摘要
+ We introduce MemSum-DQA, an efficient system for document question answering (DQA) that leverages MemSum, a long document extractive summarizer. By prefixing each text block in the parsed document with the provided question and question type, MemSum-DQA selectively extracts text blocks as answers from documents. On full-document answering tasks, this approach yields a 9% improvement in exact match accuracy over prior state-of-the-art baselines. Notably, MemSum-DQA excels in addressing questions related to child-relationship understanding, underscoring the potential of extractive summarization techniques for DQA tasks.
+
+
+
+ 44. 标题:Whispering LLaMA: A Cross-Modal Generative Error Correction Framework for Speech Recognition
+ 编号:[162]
+ 链接:https://arxiv.org/abs/2310.06434
+ 作者:Srijith Radhakrishnan, Chao-Han Huck Yang, Sumeer Ahmad Khan, Rohit Kumar, Narsis A. Kiani, David Gomez-Cabrero, Jesper N. Tegner
+ 备注:Accepted to EMNLP 2023. 10 pages. This work has been done in October 2022 and was submitted to EMNLP 23 once the draft was finalized. GitHub: this https URL
+ 关键词:automatic speech recognition, generative error correction, speech recognition, cross-modal fusion technique, fusion technique designed
+
+ 点击查看摘要
+ We introduce a new cross-modal fusion technique designed for generative error correction in automatic speech recognition (ASR). Our methodology leverages both acoustic information and external linguistic representations to generate accurate speech transcription contexts. This marks a step towards a fresh paradigm in generative error correction within the realm of n-best hypotheses. Unlike the existing ranking-based rescoring methods, our approach adeptly uses distinct initialization techniques and parameter-efficient algorithms to boost ASR performance derived from pre-trained speech and text models. Through evaluation across diverse ASR datasets, we evaluate the stability and reproducibility of our fusion technique, demonstrating its improved word error rate relative (WERR) performance in comparison to n-best hypotheses by relatively 37.66%. To encourage future research, we have made our code and pre-trained models open source at this https URL.
+
+
+
+ 45. 标题:Retromorphic Testing: A New Approach to the Test Oracle Problem
+ 编号:[163]
+ 链接:https://arxiv.org/abs/2310.06433
+ 作者:Boxi Yu, Qiuyang Mang, Qingshuo Guo, Pinjia He
+ 备注:
+ 关键词:test oracle serves, testing, program, criterion or mechanism, mechanism to assess
+
+ 点击查看摘要
+ A test oracle serves as a criterion or mechanism to assess the correspondence between software output and the anticipated behavior for a given input set. In automated testing, black-box techniques, known for their non-intrusive nature in test oracle construction, are widely used, including notable methodologies like differential testing and metamorphic testing. Inspired by the mathematical concept of inverse function, we present Retromorphic Testing, a novel black-box testing methodology. It leverages an auxiliary program in conjunction with the program under test, which establishes a dual-program structure consisting of a forward program and a backward program. The input data is first processed by the forward program and then its program output is reversed to its original input format using the backward program. In particular, the auxiliary program can operate as either the forward or backward program, leading to different testing modes. The process concludes by examining the relationship between the initial input and the transformed output within the input domain. For example, to test the implementation of the sine function $\sin(x)$, we can employ its inverse function, $\arcsin(x)$, and validate the equation $x = \sin(\arcsin(x)+2k\pi), \forall k \in \mathbb{Z}$. In addition to the high-level concept of Retromorphic Testing, this paper presents its three testing modes with illustrative use cases across diverse programs, including algorithms, traditional software, and AI applications.
+
+
+
+ 46. 标题:Large Language Models for Propaganda Detection
+ 编号:[169]
+ 链接:https://arxiv.org/abs/2310.06422
+ 作者:Kilian Sprenkamp, Daniel Gordon Jones, Liudmila Zavolokina
+ 备注:
+ 关键词:digital society poses, dissemination of truth, Large Language Models, digital society, society poses
+
+ 点击查看摘要
+ The prevalence of propaganda in our digital society poses a challenge to societal harmony and the dissemination of truth. Detecting propaganda through NLP in text is challenging due to subtle manipulation techniques and contextual dependencies. To address this issue, we investigate the effectiveness of modern Large Language Models (LLMs) such as GPT-3 and GPT-4 for propaganda detection. We conduct experiments using the SemEval-2020 task 11 dataset, which features news articles labeled with 14 propaganda techniques as a multi-label classification problem. Five variations of GPT-3 and GPT-4 are employed, incorporating various prompt engineering and fine-tuning strategies across the different models. We evaluate the models' performance by assessing metrics such as $F1$ score, $Precision$, and $Recall$, comparing the results with the current state-of-the-art approach using RoBERTa. Our findings demonstrate that GPT-4 achieves comparable results to the current state-of-the-art. Further, this study analyzes the potential and challenges of LLMs in complex tasks like propaganda detection.
+
+
+
+ 47. 标题:Humans and language models diverge when predicting repeating text
+ 编号:[175]
+ 链接:https://arxiv.org/abs/2310.06408
+ 作者:Aditya R. Vaidya, Javier Turek, Alexander G. Huth
+ 备注:To appear in the 26th Conference on Computational Natural Language Learning (CoNLL 2023)
+ 关键词:reading speed, shown to accurately, next-word prediction task, accurately model human, Language models
+
+ 点击查看摘要
+ Language models that are trained on the next-word prediction task have been shown to accurately model human behavior in word prediction and reading speed. In contrast with these findings, we present a scenario in which the performance of humans and LMs diverges. We collected a dataset of human next-word predictions for five stimuli that are formed by repeating spans of text. Human and GPT-2 LM predictions are strongly aligned in the first presentation of a text span, but their performance quickly diverges when memory (or in-context learning) begins to play a role. We traced the cause of this divergence to specific attention heads in a middle layer. Adding a power-law recency bias to these attention heads yielded a model that performs much more similarly to humans. We hope that this scenario will spur future work in bringing LMs closer to human behavior.
+
+
+
+ 48. 标题:Hexa: Self-Improving for Knowledge-Grounded Dialogue System
+ 编号:[176]
+ 链接:https://arxiv.org/abs/2310.06404
+ 作者:Daejin Jo, Daniel Wontae Nam, Gunsoo Han, Kyoung-Woon On, Taehwan Kwon, Seungeun Rho, Sungwoong Kim
+ 备注:
+ 关键词:explicitly utilize intermediate, memory retrieval, modular approaches, utilize intermediate steps, common practice
+
+ 点击查看摘要
+ A common practice in knowledge-grounded dialogue generation is to explicitly utilize intermediate steps (e.g., web-search, memory retrieval) with modular approaches. However, data for such steps are often inaccessible compared to those of dialogue responses as they are unobservable in an ordinary dialogue. To fill in the absence of these data, we develop a self-improving method to improve the generative performances of intermediate steps without the ground truth data. In particular, we propose a novel bootstrapping scheme with a guided prompt and a modified loss function to enhance the diversity of appropriate self-generated responses. Through experiments on various benchmark datasets, we empirically demonstrate that our method successfully leverages a self-improving mechanism in generating intermediate and final responses and improves the performances on the task of knowledge-grounded dialogue generation.
+
+
+
+ 49. 标题:Improved prompting and process for writing user personas with LLMs, using qualitative interviews: Capturing behaviour and personality traits of users
+ 编号:[182]
+ 链接:https://arxiv.org/abs/2310.06391
+ 作者:Stefano De Paoli
+ 备注:
+ 关键词:Large Language Models, Language Models, Large Language, draft paper presents, creating User Personas
+
+ 点击查看摘要
+ This draft paper presents a workflow for creating User Personas with Large Language Models, using the results of a Thematic Analysis of qualitative interviews. The proposed workflow uses improved prompting and a larger pool of Themes, compared to previous work conducted by the author for the same task. This is possible due to the capabilities of a recently released LLM which allows the processing of 16 thousand tokens (GPT3.5-Turbo-16k) and also due to the possibility to offer a refined prompting for the creation of Personas. The paper offers details of performing Phase 2 and 3 of Thematic Analysis, and then discusses the improved workflow for creating Personas. The paper also offers some reflections on the relationship between the proposed process and existing approaches to Personas such as the data-driven and qualitative Personas. Moreover, the paper offers reflections on the capacity of LLMs to capture user behaviours and personality traits, from the underlying dataset of qualitative interviews used for the analysis.
+
+
+
+ 50. 标题:P5: Plug-and-Play Persona Prompting for Personalized Response Selection
+ 编号:[183]
+ 链接:https://arxiv.org/abs/2310.06390
+ 作者:Joosung Lee, Minsik Oh, Donghun Lee
+ 备注:EMNLP 2023 main conference
+ 关键词:persona-grounded retrieval-based chatbots, persona, persona-grounded retrieval-based, persona-grounded corpus, retrieval-based chatbots
+
+ 点击查看摘要
+ The use of persona-grounded retrieval-based chatbots is crucial for personalized conversations, but there are several challenges that need to be addressed. 1) In general, collecting persona-grounded corpus is very expensive. 2) The chatbot system does not always respond in consideration of persona at real applications. To address these challenges, we propose a plug-and-play persona prompting method. Our system can function as a standard open-domain chatbot if persona information is not available. We demonstrate that this approach performs well in the zero-shot setting, which reduces the dependence on persona-ground training data. This makes it easier to expand the system to other languages without the need to build a persona-grounded corpus. Additionally, our model can be fine-tuned for even better performance. In our experiments, the zero-shot model improved the standard model by 7.71 and 1.04 points in the original persona and revised persona, respectively. The fine-tuned model improved the previous state-of-the-art system by 1.95 and 3.39 points in the original persona and revised persona, respectively. To the best of our knowledge, this is the first attempt to solve the problem of personalized response selection using prompt sequences. Our code is available on github~\footnote{this https URL}.
+
+
+
+ 51. 标题:Jailbreak and Guard Aligned Language Models with Only Few In-Context Demonstrations
+ 编号:[185]
+ 链接:https://arxiv.org/abs/2310.06387
+ 作者:Zeming Wei, Yifei Wang, Yisen Wang
+ 备注:
+ 关键词:Large Language Models, shown remarkable success, content have emerged, shown remarkable, Large Language
+
+ 点击查看摘要
+ Large Language Models (LLMs) have shown remarkable success in various tasks, but concerns about their safety and the potential for generating malicious content have emerged. In this paper, we explore the power of In-Context Learning (ICL) in manipulating the alignment ability of LLMs. We find that by providing just few in-context demonstrations without fine-tuning, LLMs can be manipulated to increase or decrease the probability of jailbreaking, i.e. answering malicious prompts. Based on these observations, we propose In-Context Attack (ICA) and In-Context Defense (ICD) methods for jailbreaking and guarding aligned language model purposes. ICA crafts malicious contexts to guide models in generating harmful outputs, while ICD enhances model robustness by demonstrations of rejecting to answer harmful prompts. Our experiments show the effectiveness of ICA and ICD in increasing or reducing the success rate of adversarial jailbreaking attacks. Overall, we shed light on the potential of ICL to influence LLM behavior and provide a new perspective for enhancing the safety and alignment of LLMs.
+
+
+
+ 52. 标题:Rethinking Model Selection and Decoding for Keyphrase Generation with Pre-trained Sequence-to-Sequence Models
+ 编号:[193]
+ 链接:https://arxiv.org/abs/2310.06374
+ 作者:Di Wu, Wasi Uddin Ahmad, Kai-Wei Chang
+ 备注:Accepted by EMNLP 2023
+ 关键词:Keyphrase Generation, NLP with widespread, KPG, widespread applications, PLM-based KPG
+
+ 点击查看摘要
+ Keyphrase Generation (KPG) is a longstanding task in NLP with widespread applications. The advent of sequence-to-sequence (seq2seq) pre-trained language models (PLMs) has ushered in a transformative era for KPG, yielding promising performance improvements. However, many design decisions remain unexplored and are often made arbitrarily. This paper undertakes a systematic analysis of the influence of model selection and decoding strategies on PLM-based KPG. We begin by elucidating why seq2seq PLMs are apt for KPG, anchored by an attention-driven hypothesis. We then establish that conventional wisdom for selecting seq2seq PLMs lacks depth: (1) merely increasing model size or performing task-specific adaptation is not parameter-efficient; (2) although combining in-domain pre-training with task adaptation benefits KPG, it does partially hinder generalization. Regarding decoding, we demonstrate that while greedy search delivers strong F1 scores, it lags in recall compared with sampling-based methods. From our insights, we propose DeSel, a likelihood-based decode-select algorithm that improves greedy search by an average of 4.7% semantic F1 across five datasets. Our collective findings pave the way for deeper future investigations into PLM-based KPG.
+
+
+
+ 53. 标题:Multi-Modal Knowledge Graph Transformer Framework for Multi-Modal Entity Alignment
+ 编号:[201]
+ 链接:https://arxiv.org/abs/2310.06365
+ 作者:Qian Li, Cheng Ji, Shu Guo, Zhaoji Liang, Lihong Wang, Jianxin Li
+ 备注:
+ 关键词:multi-modal knowledge graphs, identify equivalent entity, equivalent entity pairs, knowledge graphs, aims to identify
+
+ 点击查看摘要
+ Multi-Modal Entity Alignment (MMEA) is a critical task that aims to identify equivalent entity pairs across multi-modal knowledge graphs (MMKGs). However, this task faces challenges due to the presence of different types of information, including neighboring entities, multi-modal attributes, and entity types. Directly incorporating the above information (e.g., concatenation or attention) can lead to an unaligned information space. To address these challenges, we propose a novel MMEA transformer, called MoAlign, that hierarchically introduces neighbor features, multi-modal attributes, and entity types to enhance the alignment task. Taking advantage of the transformer's ability to better integrate multiple information, we design a hierarchical modifiable self-attention block in a transformer encoder to preserve the unique semantics of different information. Furthermore, we design two entity-type prefix injection methods to integrate entity-type information using type prefixes, which help to restrict the global information of entities not present in the MMKGs. Our extensive experiments on benchmark datasets demonstrate that our approach outperforms strong competitors and achieves excellent entity alignment performance.
+
+
+
+ 54. 标题:InfoCL: Alleviating Catastrophic Forgetting in Continual Text Classification from An Information Theoretic Perspective
+ 编号:[203]
+ 链接:https://arxiv.org/abs/2310.06362
+ 作者:Yifan Song, Peiyi Wang, Weimin Xiong, Dawei Zhu, Tianyu Liu, Zhifang Sui, Sujian Li
+ 备注:Findings of EMNLP 2023. An improved version of arXiv:2305.07289
+ 关键词:avoiding catastrophic forgetting, aims to constantly, continual text classification, knowledge over time, time while avoiding
+
+ 点击查看摘要
+ Continual learning (CL) aims to constantly learn new knowledge over time while avoiding catastrophic forgetting on old tasks. We focus on continual text classification under the class-incremental setting. Recent CL studies have identified the severe performance decrease on analogous classes as a key factor for catastrophic forgetting. In this paper, through an in-depth exploration of the representation learning process in CL, we discover that the compression effect of the information bottleneck leads to confusion on analogous classes. To enable the model learn more sufficient representations, we propose a novel replay-based continual text classification method, InfoCL. Our approach utilizes fast-slow and current-past contrastive learning to perform mutual information maximization and better recover the previously learned representations. In addition, InfoCL incorporates an adversarial memory augmentation strategy to alleviate the overfitting problem of replay. Experimental results demonstrate that InfoCL effectively mitigates forgetting and achieves state-of-the-art performance on three text classification tasks. The code is publicly available at this https URL.
+
+
+
+ 55. 标题:A Semantic Invariant Robust Watermark for Large Language Models
+ 编号:[206]
+ 链接:https://arxiv.org/abs/2310.06356
+ 作者:Aiwei Liu, Leyi Pan, Xuming Hu, Shiao Meng, Lijie Wen
+ 备注:16 pages, 9 figures, 2 tables
+ 关键词:achieved extremely high, extremely high accuracy, robustness, detecting text generated, security robustness
+
+ 点击查看摘要
+ Watermark algorithms for large language models (LLMs) have achieved extremely high accuracy in detecting text generated by LLMs. Such algorithms typically involve adding extra watermark logits to the LLM's logits at each generation step. However, prior algorithms face a trade-off between attack robustness and security robustness. This is because the watermark logits for a token are determined by a certain number of preceding tokens; a small number leads to low security robustness, while a large number results in insufficient attack robustness. In this work, we propose a semantic invariant watermarking method for LLMs that provides both attack robustness and security robustness. The watermark logits in our work are determined by the semantics of all preceding tokens. Specifically, we utilize another embedding LLM to generate semantic embeddings for all preceding tokens, and then these semantic embeddings are transformed into the watermark logits through our trained watermark model. Subsequent analyses and experiments demonstrated the attack robustness of our method in semantically invariant settings: synonym substitution and text paraphrasing settings. Finally, we also show that our watermark possesses adequate security robustness. Our code and data are available at this https URL.
+
+
+
+ 56. 标题:Selective Demonstrations for Cross-domain Text-to-SQL
+ 编号:[234]
+ 链接:https://arxiv.org/abs/2310.06302
+ 作者:Shuaichen Chang, Eric Fosler-Lussier
+ 备注:EMNLP 2023
+ 关键词:Large language models, demonstrated impressive generalization, impressive generalization capabilities, Large language, language models
+
+ 点击查看摘要
+ Large language models (LLMs) with in-context learning have demonstrated impressive generalization capabilities in the cross-domain text-to-SQL task, without the use of in-domain annotations. However, incorporating in-domain demonstration examples has been found to greatly enhance LLMs' performance. In this paper, we delve into the key factors within in-domain examples that contribute to the improvement and explore whether we can harness these benefits without relying on in-domain annotations. Based on our findings, we propose a demonstration selection framework ODIS which utilizes both out-of-domain examples and synthetically generated in-domain examples to construct demonstrations. By retrieving demonstrations from hybrid sources, ODIS leverages the advantages of both, showcasing its effectiveness compared to baseline methods that rely on a single data source. Furthermore, ODIS outperforms state-of-the-art approaches on two cross-domain text-to-SQL datasets, with improvements of 1.1 and 11.8 points in execution accuracy, respectively.
+
+
+
+ 57. 标题:Let Models Speak Ciphers: Multiagent Debate through Embeddings
+ 编号:[250]
+ 链接:https://arxiv.org/abs/2310.06272
+ 作者:Chau Pham, Boyi Liu, Yingxiang Yang, Zhengyu Chen, Tianyi Liu, Jianbo Yuan, Bryan A. Plummer, Zhaoran Wang, Hongxia Yang
+ 备注:
+ 关键词:Large Language Models, gained considerable attention, considerable attention due, Large Language, gained considerable
+
+ 点击查看摘要
+ Discussion and debate among Large Language Models (LLMs) have gained considerable attention due to their potential to enhance the reasoning ability of LLMs. Although natural language is an obvious choice for communication due to LLM's language understanding capability, the token sampling step needed when generating natural language poses a potential risk of information loss, as it uses only one token to represent the model's belief across the entire vocabulary. In this paper, we introduce a communication regime named CIPHER (Communicative Inter-Model Protocol Through Embedding Representation) to address this issue. Specifically, we remove the token sampling step from LLMs and let them communicate their beliefs across the vocabulary through the expectation of the raw transformer output embeddings. Remarkably, by deviating from natural language, CIPHER offers an advantage of encoding a broader spectrum of information without any modification to the model weights. While the state-of-the-art LLM debate methods using natural language outperforms traditional inference by a margin of 1.5-8%, our experiment results show that CIPHER debate further extends this lead by 1-3.5% across five reasoning tasks and multiple open-source LLMs of varying sizes. This showcases the superiority and robustness of embeddings as an alternative "language" for communication among LLMs.
+
+
+
+ 58. 标题:Towards Mitigating Hallucination in Large Language Models via Self-Reflection
+ 编号:[251]
+ 链接:https://arxiv.org/abs/2310.06271
+ 作者:Ziwei Ji, Tiezheng Yu, Yan Xu, Nayeon Lee, Etsuko Ishii, Pascale Fung
+ 备注:Accepted by the findings of EMNLP 2023
+ 关键词:tasks including question-answering, knowledge-intensive tasks including, Large language models, knowledge-intensive tasks, tasks including
+
+ 点击查看摘要
+ Large language models (LLMs) have shown promise for generative and knowledge-intensive tasks including question-answering (QA) tasks. However, the practical deployment still faces challenges, notably the issue of "hallucination", where models generate plausible-sounding but unfaithful or nonsensical information. This issue becomes particularly critical in the medical domain due to the uncommon professional concepts and potential social risks involved. This paper analyses the phenomenon of hallucination in medical generative QA systems using widely adopted LLMs and datasets. Our investigation centers on the identification and comprehension of common problematic answers, with a specific emphasis on hallucination. To tackle this challenge, we present an interactive self-reflection methodology that incorporates knowledge acquisition and answer generation. Through this feedback process, our approach steadily enhances the factuality, consistency, and entailment of the generated answers. Consequently, we harness the interactivity and multitasking ability of LLMs and produce progressively more precise and accurate answers. Experimental results on both automatic and human evaluation demonstrate the superiority of our approach in hallucination reduction compared to baselines.
+
+
+
+ 59. 标题:An experiment on an automated literature survey of data-driven speech enhancement methods
+ 编号:[256]
+ 链接:https://arxiv.org/abs/2310.06260
+ 作者:Arthur dos Santos, Jayr Pereira, Rodrigo Nogueira, Bruno Masiero, Shiva Sander-Tavallaey, Elias Zea
+ 备注:
+ 关键词:conducting traditional literature, traditional literature surveys, presents difficulties, increasing number, number of scientific
+
+ 点击查看摘要
+ The increasing number of scientific publications in acoustics, in general, presents difficulties in conducting traditional literature surveys. This work explores the use of a generative pre-trained transformer (GPT) model to automate a literature survey of 116 articles on data-driven speech enhancement methods. The main objective is to evaluate the capabilities and limitations of the model in providing accurate responses to specific queries about the papers selected from a reference human-based survey. While we see great potential to automate literature surveys in acoustics, improvements are needed to address technical questions more clearly and accurately.
+
+
+
+ 60. 标题:Get the gist? Using large language models for few-shot decontextualization
+ 编号:[259]
+ 链接:https://arxiv.org/abs/2310.06254
+ 作者:Benjamin Kane, Lenhart Schubert
+ 备注:
+ 关键词:information retrieval systems, involve interpreting sentences, NLP applications, rich context, information retrieval
+
+ 点击查看摘要
+ In many NLP applications that involve interpreting sentences within a rich context -- for instance, information retrieval systems or dialogue systems -- it is desirable to be able to preserve the sentence in a form that can be readily understood without context, for later reuse -- a process known as ``decontextualization''. While previous work demonstrated that generative Seq2Seq models could effectively perform decontextualization after being fine-tuned on a specific dataset, this approach requires expensive human annotations and may not transfer to other domains. We propose a few-shot method of decontextualization using a large language model, and present preliminary results showing that this method achieves viable performance on multiple domains using only a small set of examples.
+
+
+
+ 61. 标题:We are what we repeatedly do: Inducing and deploying habitual schemas in persona-based responses
+ 编号:[262]
+ 链接:https://arxiv.org/abs/2310.06245
+ 作者:Benjamin Kane, Lenhart Schubert
+ 备注:
+ 关键词:dialogue technology require, practical applications, technology require, developer-specified persona, dialogue technology
+
+ 点击查看摘要
+ Many practical applications of dialogue technology require the generation of responses according to a particular developer-specified persona. While a variety of personas can be elicited from recent large language models, the opaqueness and unpredictability of these models make it desirable to be able to specify personas in an explicit form. In previous work, personas have typically been represented as sets of one-off pieces of self-knowledge that are retrieved by the dialogue system for use in generation. However, in realistic human conversations, personas are often revealed through story-like narratives that involve rich habitual knowledge -- knowledge about kinds of events that an agent often participates in (e.g., work activities, hobbies, sporting activities, favorite entertainments, etc.), including typical goals, sub-events, preconditions, and postconditions of those events. We capture such habitual knowledge using an explicit schema representation, and propose an approach to dialogue generation that retrieves relevant schemas to condition a large language model to generate persona-based responses. Furthermore, we demonstrate a method for bootstrapping the creation of such schemas by first generating generic passages from a set of simple facts, and then inducing schemas from the generated passages.
+
+
+
+ 62. 标题:Model Tuning or Prompt Tuning? A Study of Large Language Models for Clinical Concept and Relation Extraction
+ 编号:[265]
+ 链接:https://arxiv.org/abs/2310.06239
+ 作者:Cheng Peng, Xi Yang, Kaleb E Smith, Zehao Yu, Aokun Chen, Jiang Bian, Yonghui Wu
+ 备注:
+ 关键词:LLMs, unfrozen LLMs, learning, prompt-based learning algorithms, learning ability
+
+ 点击查看摘要
+ Objective To develop soft prompt-based learning algorithms for large language models (LLMs), examine the shape of prompts, prompt-tuning using frozen/unfrozen LLMs, transfer learning, and few-shot learning abilities. Methods We developed a soft prompt-based LLM model and compared 4 training strategies including (1) fine-tuning without prompts; (2) hard-prompt with unfrozen LLMs; (3) soft-prompt with unfrozen LLMs; and (4) soft-prompt with frozen LLMs. We evaluated 7 pretrained LLMs using the 4 training strategies for clinical concept and relation extraction on two benchmark datasets. We evaluated the transfer learning ability of the prompt-based learning algorithms in a cross-institution setting. We also assessed the few-shot learning ability. Results and Conclusion When LLMs are unfrozen, GatorTron-3.9B with soft prompting achieves the best strict F1-scores of 0.9118 and 0.8604 for concept extraction, outperforming the traditional fine-tuning and hard prompt-based models by 0.6~3.1% and 1.2~2.9%, respectively; GatorTron-345M with soft prompting achieves the best F1-scores of 0.8332 and 0.7488 for end-to-end relation extraction, outperforming the other two models by 0.2~2% and 0.6~11.7%, respectively. When LLMs are frozen, small (i.e., 345 million parameters) LLMs have a big gap to be competitive with unfrozen models; scaling LLMs up to billions of parameters makes frozen LLMs competitive with unfrozen LLMs. For cross-institute evaluation, soft prompting with a frozen GatorTron-8.9B model achieved the best performance. This study demonstrates that (1) machines can learn soft prompts better than humans, (2) frozen LLMs have better few-shot learning ability and transfer learning ability to facilitate muti-institution applications, and (3) frozen LLMs require large models.
+
+
+
+ 63. 标题:Tackling Data Bias in MUSIC-AVQA: Crafting a Balanced Dataset for Unbiased Question-Answering
+ 编号:[266]
+ 链接:https://arxiv.org/abs/2310.06238
+ 作者:Xiulong Liu, Zhikang Dong, Peng Zhang
+ 备注:
+ 关键词:recent years, intersection of audio, driving forward, multimodal research, growing emphasis
+
+ 点击查看摘要
+ In recent years, there has been a growing emphasis on the intersection of audio, vision, and text modalities, driving forward the advancements in multimodal research. However, strong bias that exists in any modality can lead to the model neglecting the others. Consequently, the model's ability to effectively reason across these diverse modalities is compromised, impeding further advancement. In this paper, we meticulously review each question type from the original dataset, selecting those with pronounced answer biases. To counter these biases, we gather complementary videos and questions, ensuring that no answers have outstanding skewed distribution. In particular, for binary questions, we strive to ensure that both answers are almost uniformly spread within each question category. As a result, we construct a new dataset, named MUSIC-AVQA v2.0, which is more challenging and we believe could better foster the progress of AVQA task. Furthermore, we present a novel baseline model that delves deeper into the audio-visual-text interrelation. On MUSIC-AVQA v2.0, this model surpasses all the existing benchmarks, improving accuracy by 2% on MUSIC-AVQA v2.0, setting a new state-of-the-art performance.
+
+
+
+ 64. 标题:Evolution of Natural Language Processing Technology: Not Just Language Processing Towards General Purpose AI
+ 编号:[273]
+ 链接:https://arxiv.org/abs/2310.06228
+ 作者:Masahiro Yamamoto
+ 备注:40 pages
+ 关键词:actual human language, invention of computers, natural language, practice makes perfect, language
+
+ 点击查看摘要
+ Since the invention of computers, communication through natural language (actual human language) has been a dream technology. However, natural language is extremely difficult to mathematically formulate, making it difficult to realize as an algorithm without considering programming. While there have been numerous technological developments, one cannot say that any results allowing free utilization have been achieved thus far. In the case of language learning in humans, for instance when learning one's mother tongue or foreign language, one must admit that this process is similar to the adage "practice makes perfect" in principle, even though the learning method is significant up to a point. Deep learning has played a central role in contemporary AI technology in recent years. When applied to natural language processing (NLP), this produced unprecedented results. Achievements exceeding the initial predictions have been reported from the results of learning vast amounts of textual data using deep learning. For instance, four arithmetic operations could be performed without explicit learning, thereby enabling the explanation of complex images and the generation of images from corresponding explanatory texts. It is an accurate example of the learner embodying the concept of "practice makes perfect" by using vast amounts of textual data. This report provides a technological explanation of how cutting-edge NLP has made it possible to realize the "practice makes perfect" principle. Additionally, examples of how this can be applied to business are provided. We reported in June 2022 in Japanese on the NLP movement from late 2021 to early 2022. We would like to summarize this as a memorandum since this is just the initial movement leading to the current large language models (LLMs).
+
+
+
+ 65. 标题:GeoLLM: Extracting Geospatial Knowledge from Large Language Models
+ 编号:[283]
+ 链接:https://arxiv.org/abs/2310.06213
+ 作者:Rohin Manvi, Samar Khanna, Gengchen Mai, Marshall Burke, David Lobell, Stefano Ermon
+ 备注:
+ 关键词:lack predictive power, machine learning, predictive power, application of machine, increasingly common
+
+ 点击查看摘要
+ The application of machine learning (ML) in a range of geospatial tasks is increasingly common but often relies on globally available covariates such as satellite imagery that can either be expensive or lack predictive power. Here we explore the question of whether the vast amounts of knowledge found in Internet language corpora, now compressed within large language models (LLMs), can be leveraged for geospatial prediction tasks. We first demonstrate that LLMs embed remarkable spatial information about locations, but naively querying LLMs using geographic coordinates alone is ineffective in predicting key indicators like population density. We then present GeoLLM, a novel method that can effectively extract geospatial knowledge from LLMs with auxiliary map data from OpenStreetMap. We demonstrate the utility of our approach across multiple tasks of central interest to the international community, including the measurement of population density and economic livelihoods. Across these tasks, our method demonstrates a 70% improvement in performance (measured using Pearson's $r^2$) relative to baselines that use nearest neighbors or use information directly from the prompt, and performance equal to or exceeding satellite-based benchmarks in the literature. With GeoLLM, we observe that GPT-3.5 outperforms Llama 2 and RoBERTa by 19% and 51% respectively, suggesting that the performance of our method scales well with the size of the model and its pretraining dataset. Our experiments reveal that LLMs are remarkably sample-efficient, rich in geospatial information, and robust across the globe. Crucially, GeoLLM shows promise in mitigating the limitations of existing geospatial covariates and complementing them well.
+
+
+
+ 66. 标题:Estimating Numbers without Regression
+ 编号:[287]
+ 链接:https://arxiv.org/abs/2310.06204
+ 作者:Avijit Thawani, Jay Pujara, Ashwin Kalyan
+ 备注:Workshop on Insights from Negative Results in NLP at EACL 2023
+ 关键词:recent successes, numbers, ability to represent, represent numbers, number
+
+ 点击查看摘要
+ Despite recent successes in language models, their ability to represent numbers is insufficient. Humans conceptualize numbers based on their magnitudes, effectively projecting them on a number line; whereas subword tokenization fails to explicitly capture magnitude by splitting numbers into arbitrary chunks. To alleviate this shortcoming, alternative approaches have been proposed that modify numbers at various stages of the language modeling pipeline. These methods change either the (1) notation in which numbers are written (\eg scientific vs decimal), the (2) vocabulary used to represent numbers or the entire (3) architecture of the underlying language model, to directly regress to a desired number.
+Previous work suggests that architectural change helps achieve state-of-the-art on number estimation but we find an insightful ablation: changing the model's vocabulary instead (\eg introduce a new token for numbers in range 10-100) is a far better trade-off. In the context of masked number prediction, a carefully designed tokenization scheme is both the simplest to implement and sufficient, \ie with similar performance to the state-of-the-art approach that requires making significant architectural changes. Finally, we report similar trends on the downstream task of numerical fact estimation (for Fermi Problems) and discuss reasons behind our findings.
+
+
+
+ 67. 标题:GPT-who: An Information Density-based Machine-Generated Text Detector
+ 编号:[288]
+ 链接:https://arxiv.org/abs/2310.06202
+ 作者:Saranya Venkatraman, Adaku Uchendu, Dongwon Lee
+ 备注:8 pages
+ 关键词:Uniform Information Density, Density principle posits, Information Density principle, Large Language Models, spread information evenly
+
+ 点击查看摘要
+ The Uniform Information Density principle posits that humans prefer to spread information evenly during language production. In this work, we examine if the UID principle can help capture differences between Large Language Models (LLMs) and human-generated text. We propose GPT-who, the first psycholinguistically-aware multi-class domain-agnostic statistical-based detector. This detector employs UID-based features to model the unique statistical signature of each LLM and human author for accurate authorship attribution. We evaluate our method using 4 large-scale benchmark datasets and find that GPT-who outperforms state-of-the-art detectors (both statistical- & non-statistical-based) such as GLTR, GPTZero, OpenAI detector, and ZeroGPT by over $20$% across domains. In addition to superior performance, it is computationally inexpensive and utilizes an interpretable representation of text articles. We present the largest analysis of the UID-based representations of human and machine-generated texts (over 400k articles) to demonstrate how authors distribute information differently, and in ways that enable their detection using an off-the-shelf LM without any fine-tuning. We find that GPT-who can distinguish texts generated by very sophisticated LLMs, even when the overlying text is indiscernible.
+
+
+
+ 68. 标题:Compressing Context to Enhance Inference Efficiency of Large Language Models
+ 编号:[289]
+ 链接:https://arxiv.org/abs/2310.06201
+ 作者:Yucheng Li, Bo Dong, Chenghua Lin, Frank Guerin
+ 备注:EMNLP 2023. arXiv admin note: substantial text overlap with arXiv:2304.12102; text overlap with arXiv:2303.11076 by other authors
+ 关键词:Large language models, Large language, language models, context, Selective Context
+
+ 点击查看摘要
+ Large language models (LLMs) achieved remarkable performance across various tasks. However, they face challenges in managing long documents and extended conversations, due to significantly increased computational requirements, both in memory and inference time, and potential context truncation when the input exceeds the LLM's fixed context length. This paper proposes a method called Selective Context that enhances the inference efficiency of LLMs by identifying and pruning redundancy in the input context to make the input more compact. We test our approach using common data sources requiring long context processing: arXiv papers, news articles, and long conversations, on tasks of summarisation, question answering, and response generation. Experimental results show that Selective Context significantly reduces memory cost and decreases generation latency while maintaining comparable performance compared to that achieved when full context is used. Specifically, we achieve a 50\% reduction in context cost, resulting in a 36\% reduction in inference memory usage and a 32\% reduction in inference time, while observing only a minor drop of .023 in BERTscore and .038 in faithfulness on four downstream applications, indicating that our method strikes a good balance between efficiency and performance.
+
+
+
+ 69. 标题:The Importance of Prompt Tuning for Automated Neuron Explanations
+ 编号:[290]
+ 链接:https://arxiv.org/abs/2310.06200
+ 作者:Justin Lee, Tuomas Oikarinen, Arjun Chatha, Keng-Chi Chang, Yilan Chen, Tsui-Wei Weng
+ 备注:
+ 关键词:large language models, Recent advances, progressed as fast, increased the capabilities, large language
+
+ 点击查看摘要
+ Recent advances have greatly increased the capabilities of large language models (LLMs), but our understanding of the models and their safety has not progressed as fast. In this paper we aim to understand LLMs deeper by studying their individual neurons. We build upon previous work showing large language models such as GPT-4 can be useful in explaining what each neuron in a language model does. Specifically, we analyze the effect of the prompt used to generate explanations and show that reformatting the explanation prompt in a more natural way can significantly improve neuron explanation quality and greatly reduce computational cost. We demonstrate the effects of our new prompts in three different ways, incorporating both automated and human evaluations.
+
+
+
+ 70. 标题:CAW-coref: Conjunction-Aware Word-level Coreference Resolution
+ 编号:[307]
+ 链接:https://arxiv.org/abs/2310.06165
+ 作者:Karel D'Oosterlinck, Semere Kiros Bitew, Brandon Papineau, Christopher Potts, Thomas Demeester, Chris Develder
+ 备注:Accepted at CRAC 2023
+ 关键词:multiple LLM calls, multiple LLM, LLM calls, information extraction, large corpora
+
+ 点击查看摘要
+ State-of-the-art coreference resolutions systems depend on multiple LLM calls per document and are thus prohibitively expensive for many use cases (e.g., information extraction with large corpora). The leading word-level coreference system (WL-coref) attains 96.6% of these SOTA systems' performance while being much more efficient. In this work, we identify a routine yet important failure case of WL-coref: dealing with conjoined mentions such as 'Tom and Mary'. We offer a simple yet effective solution that improves the performance on the OntoNotes test set by 0.9% F1, shrinking the gap between efficient word-level coreference resolution and expensive SOTA approaches by 34.6%. Our Conjunction-Aware Word-level coreference model (CAW-coref) and code is available at this https URL.
+
+
+
+ 71. 标题:Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
+ 编号:[330]
+ 链接:https://arxiv.org/abs/2310.06117
+ 作者:Huaixiu Steven Zheng, Swaroop Mishra, Xinyun Chen, Heng-Tze Cheng, Ed H. Chi, Quoc V Le, Denny Zhou
+ 备注:
+ 关键词:derive high-level concepts, simple prompting technique, present Step-Back Prompting, specific details, technique that enables
+
+ 点击查看摘要
+ We present Step-Back Prompting, a simple prompting technique that enables LLMs to do abstractions to derive high-level concepts and first principles from instances containing specific details. Using the concepts and principles to guide the reasoning steps, LLMs significantly improve their abilities in following a correct reasoning path towards the solution. We conduct experiments of Step-Back Prompting with PaLM-2L models and observe substantial performance gains on a wide range of challenging reasoning-intensive tasks including STEM, Knowledge QA, and Multi-Hop Reasoning. For instance, Step-Back Prompting improves PaLM-2L performance on MMLU Physics and Chemistry by 7% and 11%, TimeQA by 27%, and MuSiQue by 7%.
+
+
+
+ 72. 标题:BYOC: Personalized Few-Shot Classification with Co-Authored Class Descriptions
+ 编号:[335]
+ 链接:https://arxiv.org/abs/2310.06111
+ 作者:Arth Bohra, Govert Verkes, Artem Harutyunyan, Pascal Weinberger, Giovanni Campagna
+ 备注:Accepted at EMNLP 2023 (Findings)
+ 关键词:versatile building block, NLP applications, well-studied and versatile, versatile building, building block
+
+ 点击查看摘要
+ Text classification is a well-studied and versatile building block for many NLP applications. Yet, existing approaches require either large annotated corpora to train a model with or, when using large language models as a base, require carefully crafting the prompt as well as using a long context that can fit many examples. As a result, it is not possible for end-users to build classifiers for themselves. To address this issue, we propose a novel approach to few-shot text classification using an LLM. Rather than few-shot examples, the LLM is prompted with descriptions of the salient features of each class. These descriptions are coauthored by the user and the LLM interactively: while the user annotates each few-shot example, the LLM asks relevant questions that the user answers. Examples, questions, and answers are summarized to form the classification prompt. Our experiments show that our approach yields high accuracy classifiers, within 82% of the performance of models trained with significantly larger datasets while using only 1% of their training sets. Additionally, in a study with 30 participants, we show that end-users are able to build classifiers to suit their specific needs. The personalized classifiers show an average accuracy of 90%, which is 15% higher than the state-of-the-art approach.
+
+
+
+ 73. 标题:Leveraging Multilingual Self-Supervised Pretrained Models for Sequence-to-Sequence End-to-End Spoken Language Understanding
+ 编号:[338]
+ 链接:https://arxiv.org/abs/2310.06103
+ 作者:Pavel Denisov, Ngoc Thang Vu
+ 备注:IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU) 2023
+ 关键词:Spoken Language Understanding, Spoken Language, Language Understanding, lacks multilingual setup, lexical fillers
+
+ 点击查看摘要
+ A number of methods have been proposed for End-to-End Spoken Language Understanding (E2E-SLU) using pretrained models, however their evaluation often lacks multilingual setup and tasks that require prediction of lexical fillers, such as slot filling. In this work, we propose a unified method that integrates multilingual pretrained speech and text models and performs E2E-SLU on six datasets in four languages in a generative manner, including the prediction of lexical fillers. We investigate how the proposed method can be improved by pretraining on widely available speech recognition data using several training objectives. Pretraining on 7000 hours of multilingual data allows us to outperform the state-of-the-art ultimately on two SLU datasets and partly on two more SLU datasets. Finally, we examine the cross-lingual capabilities of the proposed model and improve on the best known result on the PortMEDIA-Language dataset by almost half, achieving a Concept/Value Error Rate of 23.65%.
+
+
+
+ 74. 标题:Auditing Gender Analyzers on Text Data
+ 编号:[352]
+ 链接:https://arxiv.org/abs/2310.06061
+ 作者:Siddharth D Jaiswal, Ankit Kumar Verma, Animesh Mukherjee
+ 备注:This work has been accepted at IEEE/ACM ASONAM 2023. Please cite the version appearing in the ASONAM proceedings
+ 关键词:general public, extremely popular, popular and accessible, non-binary, Reddit
+
+ 点击查看摘要
+ AI models have become extremely popular and accessible to the general public. However, they are continuously under the scanner due to their demonstrable biases toward various sections of the society like people of color and non-binary people. In this study, we audit three existing gender analyzers -- uClassify, Readable and HackerFactor, for biases against non-binary individuals. These tools are designed to predict only the cisgender binary labels, which leads to discrimination against non-binary members of the society. We curate two datasets -- Reddit comments (660k) and, Tumblr posts (2.05M) and our experimental evaluation shows that the tools are highly inaccurate with the overall accuracy being ~50% on all platforms. Predictions for non-binary comments on all platforms are mostly female, thus propagating the societal bias that non-binary individuals are effeminate. To address this, we fine-tune a BERT multi-label classifier on the two datasets in multiple combinations, observe an overall performance of ~77% on the most realistically deployable setting and a surprisingly higher performance of 90% for the non-binary class. We also audit ChatGPT using zero-shot prompts on a small dataset (due to high pricing) and observe an average accuracy of 58% for Reddit and Tumblr combined (with overall better results for Reddit).
+Thus, we show that existing systems, including highly advanced ones like ChatGPT are biased, and need better audits and moderation and, that such societal biases can be addressed and alleviated through simple off-the-shelf models like BERT trained on more gender inclusive datasets.
+
+
+
+ 75. 标题:LLM for SoC Security: A Paradigm Shift
+ 编号:[356]
+ 链接:https://arxiv.org/abs/2310.06046
+ 作者:Dipayan Saha, Shams Tarek, Katayoon Yahyaei, Sujan Kumar Saha, Jingbo Zhou, Mark Tehranipoor, Farimah Farahmandi
+ 备注:42 pages
+ 关键词:flow poses significant, design flow poses, poses significant challenges, SoC design flow, Large Language Models
+
+ 点击查看摘要
+ As the ubiquity and complexity of system-on-chip (SoC) designs increase across electronic devices, the task of incorporating security into an SoC design flow poses significant challenges. Existing security solutions are inadequate to provide effective verification of modern SoC designs due to their limitations in scalability, comprehensiveness, and adaptability. On the other hand, Large Language Models (LLMs) are celebrated for their remarkable success in natural language understanding, advanced reasoning, and program synthesis tasks. Recognizing an opportunity, our research delves into leveraging the emergent capabilities of Generative Pre-trained Transformers (GPTs) to address the existing gaps in SoC security, aiming for a more efficient, scalable, and adaptable methodology. By integrating LLMs into the SoC security verification paradigm, we open a new frontier of possibilities and challenges to ensure the security of increasingly complex SoCs. This paper offers an in-depth analysis of existing works, showcases practical case studies, demonstrates comprehensive experiments, and provides useful promoting guidelines. We also present the achievements, prospects, and challenges of employing LLM in different SoC security verification tasks.
+
+
+
+ 76. 标题:Enhancing Document-level Event Argument Extraction with Contextual Clues and Role Relevance
+ 编号:[369]
+ 链接:https://arxiv.org/abs/2310.05991
+ 作者:Wanlong Liu, Shaohuan Cheng, Dingyi Zeng, Hong Qu
+ 备注:Accepted to Findings of ACL 2023. arXiv admin note: text overlap with arXiv:2310.05116
+ 关键词:Document-level event argument, cross-sentence inference compared, argument extraction poses, sentence-level counterpart, latent Role Guidance
+
+ 点击查看摘要
+ Document-level event argument extraction poses new challenges of long input and cross-sentence inference compared to its sentence-level counterpart. However, most prior works focus on capturing the relations between candidate arguments and the event trigger in each event, ignoring two crucial points: a) non-argument contextual clue information; b) the relevance among argument roles. In this paper, we propose a SCPRG (Span-trigger-based Contextual Pooling and latent Role Guidance) model, which contains two novel and effective modules for the above problem. The Span-Trigger-based Contextual Pooling(STCP) adaptively selects and aggregates the information of non-argument clue words based on the context attention weights of specific argument-trigger pairs from pre-trained model. The Role-based Latent Information Guidance (RLIG) module constructs latent role representations, makes them interact through role-interactive encoding to capture semantic relevance, and merges them into candidate arguments. Both STCP and RLIG introduce no more than 1% new parameters compared with the base model and can be easily applied to other event extraction models, which are compact and transplantable. Experiments on two public datasets show that our SCPRG outperforms previous state-of-the-art methods, with 1.13 F1 and 2.64 F1 improvements on RAMS and WikiEvents respectively. Further analyses illustrate the interpretability of our model.
+
+
+
+ 77. 标题:Exploring Embeddings for Measuring Text Relatedness: Unveiling Sentiments and Relationships in Online Comments
+ 编号:[377]
+ 链接:https://arxiv.org/abs/2310.05964
+ 作者:Anthony Olakangil, Cindy Wang, Justin Nguyen, Qunbo Zhou, Kaavya Jethwa, Jason Li, Aryan Narendra, Nishk Patel, Arjun Rajaram
+ 备注:6 pages, 5 figures, 3 tables, to be published in the Second International Conference on Informatics (ICI-2023)
+ 关键词:social media platforms, caused internet usage, media platforms, social media, Meta Threads
+
+ 点击查看摘要
+ After a pandemic that caused internet usage to grow by 70%, there has been an increased number of people all across the world using social media. Applications like Twitter, Meta Threads, YouTube, and Reddit have become increasingly pervasive, leaving almost no digital space where public opinion is not expressed. This paper investigates sentiment and semantic relationships among comments across various social media platforms, as well as discusses the importance of shared opinions across these different media platforms, using word embeddings to analyze components in sentences and documents. It allows researchers, politicians, and business representatives to trace a path of shared sentiment among users across the world. This research paper presents multiple approaches that measure the relatedness of text extracted from user comments on these popular online platforms. By leveraging embeddings, which capture semantic relationships between words and help analyze sentiments across the web, we can uncover connections regarding public opinion as a whole. The study utilizes pre-existing datasets from YouTube, Reddit, Twitter, and more. We made use of popular natural language processing models like Bidirectional Encoder Representations from Transformers (BERT) to analyze sentiments and explore relationships between comment embeddings. Additionally, we aim to utilize clustering and Kl-divergence to find semantic relationships within these comment embeddings across various social media platforms. Our analysis will enable a deeper understanding of the interconnectedness of online comments and will investigate the notion of the internet functioning as a large interconnected brain.
+
+
+
+ 78. 标题:Fingerprint Attack: Client De-Anonymization in Federated Learning
+ 编号:[380]
+ 链接:https://arxiv.org/abs/2310.05960
+ 作者:Qiongkai Xu, Trevor Cohn, Olga Ohrimenko
+ 备注:ECAI 2023
+ 关键词:sharing in settings, trust the central, data sharing, central server, collaborative training
+
+ 点击查看摘要
+ Federated Learning allows collaborative training without data sharing in settings where participants do not trust the central server and one another. Privacy can be further improved by ensuring that communication between the participants and the server is anonymized through a shuffle; decoupling the participant identity from their data. This paper seeks to examine whether such a defense is adequate to guarantee anonymity, by proposing a novel fingerprinting attack over gradients sent by the participants to the server. We show that clustering of gradients can easily break the anonymization in an empirical study of learning federated language models on two language corpora. We then show that training with differential privacy can provide a practical defense against our fingerprint attack.
+
+
+
+ 79. 标题:Vulnerability Clustering and other Machine Learning Applications of Semantic Vulnerability Embeddings
+ 编号:[394]
+ 链接:https://arxiv.org/abs/2310.05935
+ 作者:Mark-Oliver Stehr, Minyoung Kim
+ 备注:27 pages, 13 figures
+ 关键词:MITRE CVE list, Vulnerability Scoring System, Common Vulnerability Scoring, Scoring System, MITRE CVE
+
+ 点击查看摘要
+ Cyber-security vulnerabilities are usually published in form of short natural language descriptions (e.g., in form of MITRE's CVE list) that over time are further manually enriched with labels such as those defined by the Common Vulnerability Scoring System (CVSS). In the Vulnerability AI (Analytics and Intelligence) project, we investigated different types of semantic vulnerability embeddings based on natural language processing (NLP) techniques to obtain a concise representation of the vulnerability space. We also evaluated their use as a foundation for machine learning applications that can support cyber-security researchers and analysts in risk assessment and other related activities. The particular applications we explored and briefly summarize in this report are clustering, classification, and visualization, as well as a new logic-based approach to evaluate theories about the vulnerability space.
+
+
+
+ 80. 标题:An evolutionary model of personality traits related to cooperative behavior using a large language model
+ 编号:[442]
+ 链接:https://arxiv.org/abs/2310.05976
+ 作者:Reiji Suzuki, Takaya Arita
+ 备注:7 pages, 4 figures and 1 table
+ 关键词:social agent-based evolutionary, agent-based evolutionary models, personality traits, evolutionary dynamics, social agent-based
+
+ 点击查看摘要
+ This paper aims to shed light on the evolutionary dynamics of diverse and social populations by introducing the rich expressiveness of generative models into the trait expression of social agent-based evolutionary models. Specifically, we focus on the evolution of personality traits in the context of a game-theoretic relationship as a situation in which inter-individual interests exert strong selection pressures. We construct an agent model in which linguistic descriptions of personality traits related to cooperative behavior are used as genes. The deterministic strategies extracted from Large Language Model (LLM) that make behavioral decisions based on these personality traits are used as behavioral traits. The population is evolved according to selection based on average payoff and mutation of genes by asking LLM to slightly modify the parent gene toward cooperative or selfish. Through preliminary experiments and analyses, we clarify that such a model can indeed exhibit the evolution of cooperative behavior based on the diverse and higher-order representation of personality traits. We also observed the repeated intrusion of cooperative and selfish personality traits through changes in the expression of personality traits, and found that the emerging words in the evolved gene well reflected the behavioral tendency of its personality in terms of their semantics.
+
+
+机器学习
+
+ 1. 标题:LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression
+ 编号:[1]
+ 链接:https://arxiv.org/abs/2310.06839
+ 作者:Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, Lili Qiu
+ 备注:
+ 关键词:large language models, long context scenarios, large language, language models, face three main
+
+ 点击查看摘要
+ In long context scenarios, large language models (LLMs) face three main challenges: higher computational/financial cost, longer latency, and inferior performance. Some studies reveal that the performance of LLMs depends on both the density and the position of the key information (question relevant) in the input prompt. Inspired by these findings, we propose LongLLMLingua for prompt compression towards improving LLMs' perception of the key information to simultaneously address the three challenges. We conduct evaluation on a wide range of long context scenarios including single-/multi-document QA, few-shot learning, summarization, synthetic tasks, and code completion. The experimental results show that LongLLMLingua compressed prompt can derive higher performance with much less cost. The latency of the end-to-end system is also reduced. For example, on NaturalQuestions benchmark, LongLLMLingua gains a performance boost of up to 17.1% over the original prompt with ~4x fewer tokens as input to GPT-3.5-Turbo. It can derive cost savings of \$28.5 and \$27.4 per 1,000 samples from the LongBench and ZeroScrolls benchmark, respectively. Additionally, when compressing prompts of ~10k tokens at a compression rate of 2x-10x, LongLLMLingua can speed up the end-to-end latency by 1.4x-3.8x. Our code is available at this https URL.
+
+
+
+ 2. 标题:Generating and Evaluating Tests for K-12 Students with Language Model Simulations: A Case Study on Sentence Reading Efficiency
+ 编号:[3]
+ 链接:https://arxiv.org/abs/2310.06837
+ 作者:Eric Zelikman, Wanjing Anya Ma, Jasmine E. Tran, Diyi Yang, Jason D. Yeatman, Nick Haber
+ 备注:Accepted to EMNLP 2023 (Main)
+ 关键词:Developing an educational, expensive and time-consuming, collecting hundreds, test, tests
+
+ 点击查看摘要
+ Developing an educational test can be expensive and time-consuming, as each item must be written by experts and then evaluated by collecting hundreds of student responses. Moreover, many tests require multiple distinct sets of questions administered throughout the school year to closely monitor students' progress, known as parallel tests. In this study, we focus on tests of silent sentence reading efficiency, used to assess students' reading ability over time. To generate high-quality parallel tests, we propose to fine-tune large language models (LLMs) to simulate how previous students would have responded to unseen items. With these simulated responses, we can estimate each item's difficulty and ambiguity. We first use GPT-4 to generate new test items following a list of expert-developed rules and then apply a fine-tuned LLM to filter the items based on criteria from psychological measurements. We also propose an optimal-transport-inspired technique for generating parallel tests and show the generated tests closely correspond to the original test's difficulty and reliability based on crowdworker responses. Our evaluation of a generated test with 234 students from grades 2 to 8 produces test scores highly correlated (r=0.93) to those of a standard test form written by human experts and evaluated across thousands of K-12 students.
+
+
+
+ 3. 标题:Scalable Semantic Non-Markovian Simulation Proxy for Reinforcement Learning
+ 编号:[5]
+ 链接:https://arxiv.org/abs/2310.06835
+ 作者:Kaustuv Mukherji, Devendra Parkar, Lahari Pokala, Dyuman Aditya, Paulo Shakarian, Clark Dorman
+ 备注:Submitted to IEEE International Conference on Semantic Computing
+ 关键词:Recent advances, reinforcement learning, variety of applications, advances in reinforcement, shown much promise
+
+ 点击查看摘要
+ Recent advances in reinforcement learning (RL) have shown much promise across a variety of applications. However, issues such as scalability, explainability, and Markovian assumptions limit its applicability in certain domains. We observe that many of these shortcomings emanate from the simulator as opposed to the RL training algorithms themselves. As such, we propose a semantic proxy for simulation based on a temporal extension to annotated logic. In comparison with two high-fidelity simulators, we show up to three orders of magnitude speed-up while preserving the quality of policy learned in addition to showing the ability to model and leverage non-Markovian dynamics and instantaneous actions while providing an explainable trace describing the outcomes of the agent actions.
+
+
+
+ 4. 标题:Teaching Language Models to Hallucinate Less with Synthetic Tasks
+ 编号:[8]
+ 链接:https://arxiv.org/abs/2310.06827
+ 作者:Erik Jones, Hamid Palangi, Clarisse Simões, Varun Chandrasekaran, Subhabrata Mukherjee, Arindam Mitra, Ahmed Awadallah, Ece Kamar
+ 备注:
+ 关键词:clinical report generation, Large language models, Large language, document-based question-answering, report generation
+
+ 点击查看摘要
+ Large language models (LLMs) frequently hallucinate on abstractive summarization tasks such as document-based question-answering, meeting summarization, and clinical report generation, even though all necessary information is included in context. However, optimizing LLMs to hallucinate less on these tasks is challenging, as hallucination is hard to efficiently evaluate at each optimization step. In this work, we show that reducing hallucination on a synthetic task can also reduce hallucination on real-world downstream tasks. Our method, SynTra, first designs a synthetic task where hallucinations are easy to elicit and measure. It next optimizes the LLM's system message via prefix-tuning on the synthetic task, and finally transfers the system message to realistic, hard-to-optimize tasks. Across three realistic abstractive summarization tasks, SynTra reduces hallucination for two 13B-parameter LLMs using only a synthetic retrieval task for supervision. We also find that optimizing the system message rather than the model weights can be critical; fine-tuning the entire model on the synthetic task can counterintuitively increase hallucination. Overall, SynTra demonstrates that the extra flexibility of working with synthetic data can help mitigate undesired behaviors in practice.
+
+
+
+ 5. 标题:Mistral 7B
+ 编号:[9]
+ 链接:https://arxiv.org/abs/2310.06825
+ 作者:Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed
+ 备注:Models and code are available at this https URL
+ 关键词:language model engineered, performance and efficiency, introduce Mistral, engineered for superior, superior performance
+
+ 点击查看摘要
+ We introduce Mistral 7B v0.1, a 7-billion-parameter language model engineered for superior performance and efficiency. Mistral 7B outperforms Llama 2 13B across all evaluated benchmarks, and Llama 1 34B in reasoning, mathematics, and code generation. Our model leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost. We also provide a model fine-tuned to follow instructions, Mistral 7B -- Instruct, that surpasses the Llama 2 13B -- Chat model both on human and automated benchmarks. Our models are released under the Apache 2.0 license.
+
+
+
+ 6. 标题:Text Embeddings Reveal (Almost) As Much As Text
+ 编号:[12]
+ 链接:https://arxiv.org/abs/2310.06816
+ 作者:John X. Morris, Volodymyr Kuleshov, Vitaly Shmatikov, Alexander M. Rush
+ 备注:Accepted at EMNLP 2023
+ 关键词:text, text embeddings reveal, text embeddings, embeddings reveal, original text
+
+ 点击查看摘要
+ How much private information do text embeddings reveal about the original text? We investigate the problem of embedding \textit{inversion}, reconstructing the full text represented in dense text embeddings. We frame the problem as controlled generation: generating text that, when reembedded, is close to a fixed point in latent space. We find that although a naïve model conditioned on the embedding performs poorly, a multi-step method that iteratively corrects and re-embeds text is able to recover $92\%$ of $32\text{-token}$ text inputs exactly. We train our model to decode text embeddings from two state-of-the-art embedding models, and also show that our model can recover important personal information (full names) from a dataset of clinical notes. Our code is available on Github: \href{this https URL}{this http URL}.
+
+
+
+ 7. 标题:Advancing Transformer's Capabilities in Commonsense Reasoning
+ 编号:[13]
+ 链接:https://arxiv.org/abs/2310.06803
+ 作者:Yu Zhou, Yunqiu Han, Hanyu Zhou, Yulun Wu
+ 备注:
+ 关键词:shown great potential, purpose pre-trained language, Recent advances, commonsense reasoning, general purpose pre-trained
+
+ 点击查看摘要
+ Recent advances in general purpose pre-trained language models have shown great potential in commonsense reasoning. However, current works still perform poorly on standard commonsense reasoning benchmarks including the Com2Sense Dataset. We argue that this is due to a disconnect with current cutting-edge machine learning methods. In this work, we aim to bridge the gap by introducing current ML-based methods to improve general purpose pre-trained language models in the task of commonsense reasoning. Specifically, we experiment with and systematically evaluate methods including knowledge transfer, model ensemble, and introducing an additional pairwise contrastive objective. Our best model outperforms the strongest previous works by ~15\% absolute gains in Pairwise Accuracy and ~8.7\% absolute gains in Standard Accuracy.
+
+
+
+ 8. 标题:Inverse Factorized Q-Learning for Cooperative Multi-agent Imitation Learning
+ 编号:[14]
+ 链接:https://arxiv.org/abs/2310.06801
+ 作者:The Viet Bui, Tien Mai, Thanh Hong Nguyen
+ 备注:
+ 关键词:paper concerns imitation, mimic expert behaviors, concerns imitation learning, paper concerns, concerns imitation
+
+ 点击查看摘要
+ This paper concerns imitation learning (IL) (i.e, the problem of learning to mimic expert behaviors from demonstrations) in cooperative multi-agent systems. The learning problem under consideration poses several challenges, characterized by high-dimensional state and action spaces and intricate inter-agent dependencies. In a single-agent setting, IL has proven to be done efficiently through an inverse soft-Q learning process given expert demonstrations. However, extending this framework to a multi-agent context introduces the need to simultaneously learn both local value functions to capture local observations and individual actions, and a joint value function for exploiting centralized learning. In this work, we introduce a novel multi-agent IL algorithm designed to address these challenges. Our approach enables the centralized learning by leveraging mixing networks to aggregate decentralized Q functions. A main advantage of this approach is that the weights of the mixing networks can be trained using information derived from global states. We further establish conditions for the mixing networks under which the multi-agent objective function exhibits convexity within the Q function space. We present extensive experiments conducted on some challenging competitive and cooperative multi-agent game environments, including an advanced version of the Star-Craft multi-agent challenge (i.e., SMACv2), which demonstrates the effectiveness of our proposed algorithm compared to existing state-of-the-art multi-agent IL algorithms.
+
+
+
+ 9. 标题:Test & Evaluation Best Practices for Machine Learning-Enabled Systems
+ 编号:[15]
+ 链接:https://arxiv.org/abs/2310.06800
+ 作者:Jaganmohan Chandrasekaran, Tyler Cody, Nicola McCarthy, Erin Lanus, Laura Freeman
+ 备注:
+ 关键词:ML-enabled software systems, ML-enabled software, software systems, rapidly gaining adoption, based software systems
+
+ 点击查看摘要
+ Machine learning (ML) - based software systems are rapidly gaining adoption across various domains, making it increasingly essential to ensure they perform as intended. This report presents best practices for the Test and Evaluation (T&E) of ML-enabled software systems across its lifecycle. We categorize the lifecycle of ML-enabled software systems into three stages: component, integration and deployment, and post-deployment. At the component level, the primary objective is to test and evaluate the ML model as a standalone component. Next, in the integration and deployment stage, the goal is to evaluate an integrated ML-enabled system consisting of both ML and non-ML components. Finally, once the ML-enabled software system is deployed and operationalized, the T&E objective is to ensure the system performs as intended. Maintenance activities for ML-enabled software systems span the lifecycle and involve maintaining various assets of ML-enabled software systems.
+Given its unique characteristics, the T&E of ML-enabled software systems is challenging. While significant research has been reported on T&E at the component level, limited work is reported on T&E in the remaining two stages. Furthermore, in many cases, there is a lack of systematic T&E strategies throughout the ML-enabled system's lifecycle. This leads practitioners to resort to ad-hoc T&E practices, which can undermine user confidence in the reliability of ML-enabled software systems. New systematic testing approaches, adequacy measurements, and metrics are required to address the T&E challenges across all stages of the ML-enabled system lifecycle.
+
+
+
+ 10. 标题:$f$-Policy Gradients: A General Framework for Goal Conditioned RL using $f$-Divergences
+ 编号:[16]
+ 链接:https://arxiv.org/abs/2310.06794
+ 作者:Siddhant Agarwal, Ishan Durugkar, Peter Stone, Amy Zhang
+ 备注:Accepted at NeurIPS 2023
+ 关键词:Goal-Conditioned Reinforcement Learning, Goal-Conditioned Reinforcement, Reinforcement Learning, making policy optimization, Reinforcement
+
+ 点击查看摘要
+ Goal-Conditioned Reinforcement Learning (RL) problems often have access to sparse rewards where the agent receives a reward signal only when it has achieved the goal, making policy optimization a difficult problem. Several works augment this sparse reward with a learned dense reward function, but this can lead to sub-optimal policies if the reward is misaligned. Moreover, recent works have demonstrated that effective shaping rewards for a particular problem can depend on the underlying learning algorithm. This paper introduces a novel way to encourage exploration called $f$-Policy Gradients, or $f$-PG. $f$-PG minimizes the f-divergence between the agent's state visitation distribution and the goal, which we show can lead to an optimal policy. We derive gradients for various f-divergences to optimize this objective. Our learning paradigm provides dense learning signals for exploration in sparse reward settings. We further introduce an entropy-regularized policy optimization objective, that we call $state$-MaxEnt RL (or $s$-MaxEnt RL) as a special case of our objective. We show that several metric-based shaping rewards like L2 can be used with $s$-MaxEnt RL, providing a common ground to study such metric-based shaping rewards with efficient exploration. We find that $f$-PG has better performance compared to standard policy gradient methods on a challenging gridworld as well as the Point Maze and FetchReach environments. More information on our website this https URL.
+
+
+
+ 11. 标题:Spectral Entry-wise Matrix Estimation for Low-Rank Reinforcement Learning
+ 编号:[17]
+ 链接:https://arxiv.org/abs/2310.06793
+ 作者:Stefan Stojanovic, Yassir Jedra, Alexandre Proutiere
+ 备注:To appear in NeurIPS 2023
+ 关键词:Markov Decision Processes, low-rank Markov Decision, study matrix estimation, Decision Processes, Markov Decision
+
+ 点击查看摘要
+ We study matrix estimation problems arising in reinforcement learning (RL) with low-rank structure. In low-rank bandits, the matrix to be recovered specifies the expected arm rewards, and for low-rank Markov Decision Processes (MDPs), it may for example characterize the transition kernel of the MDP. In both cases, each entry of the matrix carries important information, and we seek estimation methods with low entry-wise error. Importantly, these methods further need to accommodate for inherent correlations in the available data (e.g. for MDPs, the data consists of system trajectories). We investigate the performance of simple spectral-based matrix estimation approaches: we show that they efficiently recover the singular subspaces of the matrix and exhibit nearly-minimal entry-wise error. These new results on low-rank matrix estimation make it possible to devise reinforcement learning algorithms that fully exploit the underlying low-rank structure. We provide two examples of such algorithms: a regret minimization algorithm for low-rank bandit problems, and a best policy identification algorithm for reward-free RL in low-rank MDPs. Both algorithms yield state-of-the-art performance guarantees.
+
+
+
+ 12. 标题:Enhancing Predictive Capabilities in Data-Driven Dynamical Modeling with Automatic Differentiation: Koopman and Neural ODE Approaches
+ 编号:[18]
+ 链接:https://arxiv.org/abs/2310.06790
+ 作者:C. Ricardo Constante-Amores, Alec J. Linot, Michael D. Graham
+ 备注:
+ 关键词:Koopman operator, Koopman approach, state space approach, Koopman, approach
+
+ 点击查看摘要
+ Data-driven approximations of the Koopman operator are promising for predicting the time evolution of systems characterized by complex dynamics. Among these methods, the approach known as extended dynamic mode decomposition with dictionary learning (EDMD-DL) has garnered significant attention. Here we present a modification of EDMD-DL that concurrently determines both the dictionary of observables and the corresponding approximation of the Koopman operator. This innovation leverages automatic differentiation to facilitate gradient descent computations through the pseudoinverse. We also address the performance of several alternative methodologies. We assess a 'pure' Koopman approach, which involves the direct time-integration of a linear, high-dimensional system governing the dynamics within the space of observables. Additionally, we explore a modified approach where the system alternates between spaces of states and observables at each time step -- this approach no longer satisfies the linearity of the true Koopman operator representation. For further comparisons, we also apply a state space approach (neural ODEs). We consider systems encompassing two and three-dimensional ordinary differential equation systems featuring steady, oscillatory, and chaotic attractors, as well as partial differential equations exhibiting increasingly complex and intricate behaviors. Our framework significantly outperforms EDMD-DL. Furthermore, the state space approach offers superior performance compared to the 'pure' Koopman approach where the entire time evolution occurs in the space of observables. When the temporal evolution of the Koopman approach alternates between states and observables at each time step, however, its predictions become comparable to those of the state space approach.
+
+
+
+ 13. 标题:OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text
+ 编号:[19]
+ 链接:https://arxiv.org/abs/2310.06786
+ 作者:Keiran Paster, Marco Dos Santos, Zhangir Azerbayev, Jimmy Ba
+ 备注:
+ 关键词:carefully thought-out tokens, carefully thought-out, growing evidence, evidence that pretraining, pretraining on high
+
+ 点击查看摘要
+ There is growing evidence that pretraining on high quality, carefully thought-out tokens such as code or mathematics plays an important role in improving the reasoning abilities of large language models. For example, Minerva, a PaLM model finetuned on billions of tokens of mathematical documents from arXiv and the web, reported dramatically improved performance on problems that require quantitative reasoning. However, because all known open source web datasets employ preprocessing that does not faithfully preserve mathematical notation, the benefits of large scale training on quantitive web documents are unavailable to the research community. We introduce OpenWebMath, an open dataset inspired by these works containing 14.7B tokens of mathematical webpages from Common Crawl. We describe in detail our method for extracting text and LaTeX content and removing boilerplate from HTML documents, as well as our methods for quality filtering and deduplication. Additionally, we run small-scale experiments by training 1.4B parameter language models on OpenWebMath, showing that models trained on 14.7B tokens of our dataset surpass the performance of models trained on over 20x the amount of general language data. We hope that our dataset, openly released on the Hugging Face Hub, will help spur advances in the reasoning abilities of large language models.
+
+
+
+ 14. 标题:A Supervised Embedding and Clustering Anomaly Detection method for classification of Mobile Network Faults
+ 编号:[20]
+ 链接:https://arxiv.org/abs/2310.06779
+ 作者:R. Mosayebi, H. Kia, A. Kianpour Raki
+ 备注:
+ 关键词:efficiently identify faulty, manual monitoring caused, paper introduces Supervised, identify faulty alarm, introduces Supervised Embedding
+
+ 点击查看摘要
+ The paper introduces Supervised Embedding and Clustering Anomaly Detection (SEMC-AD), a method designed to efficiently identify faulty alarm logs in a mobile network and alleviate the challenges of manual monitoring caused by the growing volume of alarm logs. SEMC-AD employs a supervised embedding approach based on deep neural networks, utilizing historical alarm logs and their labels to extract numerical representations for each log, effectively addressing the issue of imbalanced classification due to a small proportion of anomalies in the dataset without employing one-hot encoding. The robustness of the embedding is evaluated by plotting the two most significant principle components of the embedded alarm logs, revealing that anomalies form distinct clusters with similar embeddings. Multivariate normal Gaussian clustering is then applied to these components, identifying clusters with a high ratio of anomalies to normal alarms (above 90%) and labeling them as the anomaly group. To classify new alarm logs, we check if their embedded vectors' two most significant principle components fall within the anomaly-labeled clusters. If so, the log is classified as an anomaly. Performance evaluation demonstrates that SEMC-AD outperforms conventional random forest and gradient boosting methods without embedding. SEMC-AD achieves 99% anomaly detection, whereas random forest and XGBoost only detect 86% and 81% of anomalies, respectively. While supervised classification methods may excel in labeled datasets, the results demonstrate that SEMC-AD is more efficient in classifying anomalies in datasets with numerous categorical features, significantly enhancing anomaly detection, reducing operator burden, and improving network maintenance.
+
+
+
+ 15. 标题:Information Content Exploration
+ 编号:[22]
+ 链接:https://arxiv.org/abs/2310.06777
+ 作者:Jacob Chmura, Hasham Burhani, Xiao Qi Shi
+ 备注:12 pages, 12 figures
+ 关键词:Sparse reward environments, Random Network Distillation, Curiosity Driven Learning, challenging for reinforcement, Sparse reward
+
+ 点击查看摘要
+ Sparse reward environments are known to be challenging for reinforcement learning agents. In such environments, efficient and scalable exploration is crucial. Exploration is a means by which an agent gains information about the environment. We expand on this topic and propose a new intrinsic reward that systemically quantifies exploratory behavior and promotes state coverage by maximizing the information content of a trajectory taken by an agent. We compare our method to alternative exploration based intrinsic reward techniques, namely Curiosity Driven Learning and Random Network Distillation. We show that our information theoretic reward induces efficient exploration and outperforms in various games, including Montezuma Revenge, a known difficult task for reinforcement learning. Finally, we propose an extension that maximizes information content in a discretely compressed latent space which boosts sample efficiency and generalizes to continuous state spaces.
+
+
+
+ 16. 标题:Correlated Noise Provably Beats Independent Noise for Differentially Private Learning
+ 编号:[25]
+ 链接:https://arxiv.org/abs/2310.06771
+ 作者:Christopher A. Choquette-Choo, Krishnamurthy Dvijotham, Krishna Pillutla, Arun Ganesh, Thomas Steinke, Abhradeep Thakurta
+ 备注:Christopher A. Choquette-Choo, Krishnamurthy Dvijotham, and Krishna Pillutla contributed equally
+ 关键词:learning algorithms inject, Differentially private learning, algorithms inject noise, private learning algorithms, independent Gaussian noise
+
+ 点击查看摘要
+ Differentially private learning algorithms inject noise into the learning process. While the most common private learning algorithm, DP-SGD, adds independent Gaussian noise in each iteration, recent work on matrix factorization mechanisms has shown empirically that introducing correlations in the noise can greatly improve their utility. We characterize the asymptotic learning utility for any choice of the correlation function, giving precise analytical bounds for linear regression and as the solution to a convex program for general convex functions. We show, using these bounds, how correlated noise provably improves upon vanilla DP-SGD as a function of problem parameters such as the effective dimension and condition number. Moreover, our analytical expression for the near-optimal correlation function circumvents the cubic complexity of the semi-definite program used to optimize the noise correlation matrix in previous work. We validate our theory with experiments on private deep learning. Our work matches or outperforms prior work while being efficient both in terms of compute and memory.
+
+
+
+ 17. 标题:FABind: Fast and Accurate Protein-Ligand Binding
+ 编号:[29]
+ 链接:https://arxiv.org/abs/2310.06763
+ 作者:Qizhi Pei, Kaiyuan Gao, Lijun Wu, Jinhua Zhu, Yingce Xia, Shufang Xie, Tao Qin, Kun He, Tie-Yan Liu, Rui Yan
+ 备注:Neural Information Processing Systems (NIPS 2023)
+ 关键词:Modeling the interaction, drug discovery, ligands and accurately, accurately predicting, critical yet challenging
+
+ 点击查看摘要
+ Modeling the interaction between proteins and ligands and accurately predicting their binding structures is a critical yet challenging task in drug discovery. Recent advancements in deep learning have shown promise in addressing this challenge, with sampling-based and regression-based methods emerging as two prominent approaches. However, these methods have notable limitations. Sampling-based methods often suffer from low efficiency due to the need for generating multiple candidate structures for selection. On the other hand, regression-based methods offer fast predictions but may experience decreased accuracy. Additionally, the variation in protein sizes often requires external modules for selecting suitable binding pockets, further impacting efficiency. In this work, we propose $\mathbf{FABind}$, an end-to-end model that combines pocket prediction and docking to achieve accurate and fast protein-ligand binding. $\mathbf{FABind}$ incorporates a unique ligand-informed pocket prediction module, which is also leveraged for docking pose estimation. The model further enhances the docking process by incrementally integrating the predicted pocket to optimize protein-ligand binding, reducing discrepancies between training and inference. Through extensive experiments on benchmark datasets, our proposed $\mathbf{FABind}$ demonstrates strong advantages in terms of effectiveness and efficiency compared to existing methods. Our code is available at $\href{this https URL}{Github}$.
+
+
+
+ 18. 标题:Going Beyond Neural Network Feature Similarity: The Network Feature Complexity and Its Interpretation Using Category Theory
+ 编号:[32]
+ 链接:https://arxiv.org/abs/2310.06756
+ 作者:Yiting Chen, Zhanpeng Zhou, Junchi Yan
+ 备注:
+ 关键词:achieve similar performance, recently widely noted, remains opaque, widely noted phenomenon, achieve similar
+
+ 点击查看摘要
+ The behavior of neural networks still remains opaque, and a recently widely noted phenomenon is that networks often achieve similar performance when initialized with different random parameters. This phenomenon has attracted significant attention in measuring the similarity between features learned by distinct networks. However, feature similarity could be vague in describing the same feature since equivalent features hardly exist. In this paper, we expand the concept of equivalent feature and provide the definition of what we call functionally equivalent features. These features produce equivalent output under certain transformations. Using this definition, we aim to derive a more intrinsic metric for the so-called feature complexity regarding the redundancy of features learned by a neural network at each layer. We offer a formal interpretation of our approach through the lens of category theory, a well-developed area in mathematics. To quantify the feature complexity, we further propose an efficient algorithm named Iterative Feature Merging. Our experimental results validate our ideas and theories from various perspectives. We empirically demonstrate that the functionally equivalence widely exists among different features learned by the same neural network and we could reduce the number of parameters of the network without affecting the performance.The IFM shows great potential as a data-agnostic model prune method. We have also drawn several interesting empirical findings regarding the defined feature complexity.
+
+
+
+ 19. 标题:Causal Rule Learning: Enhancing the Understanding of Heterogeneous Treatment Effect via Weighted Causal Rules
+ 编号:[37]
+ 链接:https://arxiv.org/abs/2310.06746
+ 作者:Ying Wu, Hanzhong Liu, Kai Ren, Xiangyu Chang
+ 备注:
+ 关键词:treatment effects, heterogeneous treatment effects, causal rule learning, heterogeneous treatment, treatment
+
+ 点击查看摘要
+ Interpretability is a key concern in estimating heterogeneous treatment effects using machine learning methods, especially for healthcare applications where high-stake decisions are often made. Inspired by the Predictive, Descriptive, Relevant framework of interpretability, we propose causal rule learning which finds a refined set of causal rules characterizing potential subgroups to estimate and enhance our understanding of heterogeneous treatment effects. Causal rule learning involves three phases: rule discovery, rule selection, and rule analysis. In the rule discovery phase, we utilize a causal forest to generate a pool of causal rules with corresponding subgroup average treatment effects. The selection phase then employs a D-learning method to select a subset of these rules to deconstruct individual-level treatment effects as a linear combination of the subgroup-level effects. This helps to answer an ignored question by previous literature: what if an individual simultaneously belongs to multiple groups with different average treatment effects? The rule analysis phase outlines a detailed procedure to further analyze each rule in the subset from multiple perspectives, revealing the most promising rules for further validation. The rules themselves, their corresponding subgroup treatment effects, and their weights in the linear combination give us more insights into heterogeneous treatment effects. Simulation and real-world data analysis demonstrate the superior performance of causal rule learning on the interpretable estimation of heterogeneous treatment effect when the ground truth is complex and the sample size is sufficient.
+
+
+
+ 20. 标题:Geographic Location Encoding with Spherical Harmonics and Sinusoidal Representation Networks
+ 编号:[39]
+ 链接:https://arxiv.org/abs/2310.06743
+ 作者:Marc Rußwurm, Konstantin Klemmer, Esther Rolf, Robin Zbinden, Devis Tuia
+ 备注:
+ 关键词:Double Fourier Sphere, machine learning model, spanning application domains, integrates geolocated data, Double Fourier
+
+ 点击查看摘要
+ Learning feature representations of geographical space is vital for any machine learning model that integrates geolocated data, spanning application domains such as remote sensing, ecology, or epidemiology. Recent work mostly embeds coordinates using sine and cosine projections based on Double Fourier Sphere (DFS) features -- these embeddings assume a rectangular data domain even on global data, which can lead to artifacts, especially at the poles. At the same time, relatively little attention has been paid to the exact design of the neural network architectures these functional embeddings are combined with. This work proposes a novel location encoder for globally distributed geographic data that combines spherical harmonic basis functions, natively defined on spherical surfaces, with sinusoidal representation networks (SirenNets) that can be interpreted as learned Double Fourier Sphere embedding. We systematically evaluate the cross-product of positional embeddings and neural network architectures across various classification and regression benchmarks and synthetic evaluation datasets. In contrast to previous approaches that require the combination of both positional encoding and neural networks to learn meaningful representations, we show that both spherical harmonics and sinusoidal representation networks are competitive on their own but set state-of-the-art performances across tasks when combined. We provide source code at this http URL
+
+
+
+ 21. 标题:Improving Pseudo-Time Stepping Convergence for CFD Simulations With Neural Networks
+ 编号:[43]
+ 链接:https://arxiv.org/abs/2310.06717
+ 作者:Anouk Zandbergen, Tycho van Noorden, Alexander Heinlein
+ 备注:
+ 关键词:Computational fluid dynamics, Navier-Stokes equations, Computational fluid, fluid dynamics, viscous fluids
+
+ 点击查看摘要
+ Computational fluid dynamics (CFD) simulations of viscous fluids described by the Navier-Stokes equations are considered. Depending on the Reynolds number of the flow, the Navier-Stokes equations may exhibit a highly nonlinear behavior. The system of nonlinear equations resulting from the discretization of the Navier-Stokes equations can be solved using nonlinear iteration methods, such as Newton's method. However, fast quadratic convergence is typically only obtained in a local neighborhood of the solution, and for many configurations, the classical Newton iteration does not converge at all. In such cases, so-called globalization techniques may help to improve convergence.
+In this paper, pseudo-transient continuation is employed in order to improve nonlinear convergence. The classical algorithm is enhanced by a neural network model that is trained to predict a local pseudo-time step. Generalization of the novel approach is facilitated by predicting the local pseudo-time step separately on each element using only local information on a patch of adjacent elements as input. Numerical results for standard benchmark problems, including flow through a backward facing step geometry and Couette flow, show the performance of the machine learning-enhanced globalization approach; as the software for the simulations, the CFD module of COMSOL Multiphysics is employed.
+
+
+
+ 22. 标题:S4Sleep: Elucidating the design space of deep-learning-based sleep stage classification models
+ 编号:[44]
+ 链接:https://arxiv.org/abs/2310.06715
+ 作者:Tiezhi Wang, Nils Strodthoff
+ 备注:11 pages, 1 figure, code available at this https URL
+ 关键词:significant inter-rater variability, Scoring sleep stages, inter-rater variability, time-consuming task plagued, stages in polysomnography
+
+ 点击查看摘要
+ Scoring sleep stages in polysomnography recordings is a time-consuming task plagued by significant inter-rater variability. Therefore, it stands to benefit from the application of machine learning algorithms. While many algorithms have been proposed for this purpose, certain critical architectural decisions have not received systematic exploration. In this study, we meticulously investigate these design choices within the broad category of encoder-predictor architectures. We identify robust architectures applicable to both time series and spectrogram input representations. These architectures incorporate structured state space models as integral components, leading to statistically significant advancements in performance on the extensive SHHS dataset. These improvements are assessed through both statistical and systematic error estimations. We anticipate that the architectural insights gained from this study will not only prove valuable for future research in sleep staging but also hold relevance for other time series annotation tasks.
+
+
+
+ 23. 标题:Exploring Memorization in Fine-tuned Language Models
+ 编号:[45]
+ 链接:https://arxiv.org/abs/2310.06714
+ 作者:Shenglai Zeng, Yaxin Li, Jie Ren, Yiding Liu, Han Xu, Pengfei He, Yue Xing, Shuaiqiang Wang, Jiliang Tang, Dawei Yin
+ 备注:
+ 关键词:shown great capabilities, raising tremendous privacy, LLMs have shown, copyright concerns, shown great
+
+ 点击查看摘要
+ LLMs have shown great capabilities in various tasks but also exhibited memorization of training data, thus raising tremendous privacy and copyright concerns. While prior work has studied memorization during pre-training, the exploration of memorization during fine-tuning is rather limited. Compared with pre-training, fine-tuning typically involves sensitive data and diverse objectives, thus may bring unique memorization behaviors and distinct privacy risks. In this work, we conduct the first comprehensive analysis to explore LMs' memorization during fine-tuning across tasks. Our studies with open-sourced and our own fine-tuned LMs across various tasks indicate that fine-tuned memorization presents a strong disparity among tasks. We provide an understanding of this task disparity via sparse coding theory and unveil a strong correlation between memorization and attention score distribution. By investigating its memorization behavior, multi-task fine-tuning paves a potential strategy to mitigate fine-tuned memorization.
+
+
+
+ 24. 标题:Interpretable Traffic Event Analysis with Bayesian Networks
+ 编号:[46]
+ 链接:https://arxiv.org/abs/2310.06713
+ 作者:Tong Yuan, Jian Yang, Zeyi Wen
+ 备注:11 pages, 7 figures
+ 关键词:existing machine learning-based, machine learning-based methods, provide good quality, good quality results, downstream tasks
+
+ 点击查看摘要
+ Although existing machine learning-based methods for traffic accident analysis can provide good quality results to downstream tasks, they lack interpretability which is crucial for this critical problem. This paper proposes an interpretable framework based on Bayesian Networks for traffic accident prediction. To enable the ease of interpretability, we design a dataset construction pipeline to feed the traffic data into the framework while retaining the essential traffic data information. With a concrete case study, our framework can derive a Bayesian Network from a dataset based on the causal relationships between weather and traffic events across the United States. Consequently, our framework enables the prediction of traffic accidents with competitive accuracy while examining how the probability of these events changes under different conditions, thus illustrating transparent relationships between traffic and weather events. Additionally, the visualization of the network simplifies the analysis of relationships between different variables, revealing the primary causes of traffic accidents and ultimately providing a valuable reference for reducing traffic accidents.
+
+
+
+ 25. 标题:Zero-Shot Transfer in Imitation Learning
+ 编号:[48]
+ 链接:https://arxiv.org/abs/2310.06710
+ 作者:Alvaro Cauderan, Gauthier Boeshertz, Florian Schwarb, Calvin Zhang
+ 备注:
+ 关键词:previously unseen domains, imitate expert behavior, previously unseen, present an algorithm, unseen domains
+
+ 点击查看摘要
+ We present an algorithm that learns to imitate expert behavior and can transfer to previously unseen domains without retraining. Such an algorithm is extremely relevant in real-world applications such as robotic learning because 1) reward functions are difficult to design, 2) learned policies from one domain are difficult to deploy in another domain and 3) learning directly in the real world is either expensive or unfeasible due to security concerns. To overcome these constraints, we combine recent advances in Deep RL by using an AnnealedVAE to learn a disentangled state representation and imitate an expert by learning a single Q-function which avoids adversarial training. We demonstrate the effectiveness of our method in 3 environments ranging in difficulty and the type of transfer knowledge required.
+
+
+
+ 26. 标题:Temporally Aligning Long Audio Interviews with Questions: A Case Study in Multimodal Data Integration
+ 编号:[51]
+ 链接:https://arxiv.org/abs/2310.06702
+ 作者:Piyush Singh Pasi, Karthikeya Battepati, Preethi Jyothi, Ganesh Ramakrishnan, Tanmay Mahapatra, Manoj Singh
+ 备注:Work Accepted in IJCAI-23- AI and Social Good Track
+ 关键词:supervision during training, amount of research, research using complete, complete supervision, long audio
+
+ 点击查看摘要
+ The problem of audio-to-text alignment has seen significant amount of research using complete supervision during training. However, this is typically not in the context of long audio recordings wherein the text being queried does not appear verbatim within the audio file. This work is a collaboration with a non-governmental organization called CARE India that collects long audio health surveys from young mothers residing in rural parts of Bihar, India. Given a question drawn from a questionnaire that is used to guide these surveys, we aim to locate where the question is asked within a long audio recording. This is of great value to African and Asian organizations that would otherwise have to painstakingly go through long and noisy audio recordings to locate questions (and answers) of interest. Our proposed framework, INDENT, uses a cross-attention-based model and prior information on the temporal ordering of sentences to learn speech embeddings that capture the semantics of the underlying spoken text. These learnt embeddings are used to retrieve the corresponding audio segment based on text queries at inference time. We empirically demonstrate the significant effectiveness (improvement in R-avg of about 3%) of our model over those obtained using text-based heuristics. We also show how noisy ASR, generated using state-of-the-art ASR models for Indian languages, yields better results when used in place of speech. INDENT, trained only on Hindi data is able to cater to all languages supported by the (semantically) shared text space. We illustrate this empirically on 11 Indic languages.
+
+
+
+ 27. 标题:Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning
+ 编号:[52]
+ 链接:https://arxiv.org/abs/2310.06694
+ 作者:Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, Danqi Chen
+ 备注:The code and models are available at this https URL
+ 关键词:recently emerged moderate-sized, emerged moderate-sized large, moderate-sized large language, large language models, popularity of LLaMA
+
+ 点击查看摘要
+ The popularity of LLaMA (Touvron et al., 2023a;b) and other recently emerged moderate-sized large language models (LLMs) highlights the potential of building smaller yet powerful LLMs. Regardless, the cost of training such models from scratch on trillions of tokens remains high. In this work, we study structured pruning as an effective means to develop smaller LLMs from pre-trained, larger models. Our approach employs two key techniques: (1) targeted structured pruning, which prunes a larger model to a specified target shape by removing layers, heads, and intermediate and hidden dimensions in an end-to-end manner, and (2) dynamic batch loading, which dynamically updates the composition of sampled data in each training batch based on varying losses across different domains. We demonstrate the efficacy of our approach by presenting the Sheared-LLaMA series, pruning the LLaMA2-7B model down to 1.3B and 2.7B parameters. Sheared-LLaMA models outperform state-of-the-art open-source models of equivalent sizes, such as Pythia, INCITE, and OpenLLaMA models, on a wide range of downstream and instruction tuning evaluations, while requiring only 3% of compute compared to training such models from scratch. This work provides compelling evidence that leveraging existing LLMs with structured pruning is a far more cost-effective approach for building smaller LLMs.
+
+
+
+ 28. 标题:Learning Multiplex Embeddings on Text-rich Networks with One Text Encoder
+ 编号:[57]
+ 链接:https://arxiv.org/abs/2310.06684
+ 作者:Bowen Jin, Wentao Zhang, Yu Zhang, Yu Meng, Han Zhao, Jiawei Han
+ 备注:9 pages, 11 appendix pages
+ 关键词:real-world scenarios, linked by multiple, multiple semantic relations, multiplex, multiplex text-rich
+
+ 点击查看摘要
+ In real-world scenarios, texts in a network are often linked by multiple semantic relations (e.g., papers in an academic network are referenced by other publications, written by the same author, or published in the same venue), where text documents and their relations form a multiplex text-rich network. Mainstream text representation learning methods use pretrained language models (PLMs) to generate one embedding for each text unit, expecting that all types of relations between texts can be captured by these single-view embeddings. However, this presumption does not hold particularly in multiplex text-rich networks. Along another line of work, multiplex graph neural networks (GNNs) directly initialize node attributes as a feature vector for node representation learning, but they cannot fully capture the semantics of the nodes' associated texts. To bridge these gaps, we propose METERN, a new framework for learning Multiplex Embeddings on TExt-Rich Networks. In contrast to existing methods, METERN uses one text encoder to model the shared knowledge across relations and leverages a small number of parameters per relation to derive relation-specific representations. This allows the encoder to effectively capture the multiplex structures in the network while also preserving parameter efficiency. We conduct experiments on nine downstream tasks in five networks from both academic and e-commerce domains, where METERN outperforms baselines significantly and consistently. The code is available at this https URL.
+
+
+
+ 29. 标题:On the importance of catalyst-adsorbate 3D interactions for relaxed energy predictions
+ 编号:[58]
+ 链接:https://arxiv.org/abs/2310.06682
+ 作者:Alvaro Carbonero, Alexandre Duval, Victor Schmidt, Santiago Miret, Alex Hernandez-Garcia, Yoshua Bengio, David Rolnick
+ 备注:
+ 关键词:graph neural networks, material property prediction, machine learning, property prediction, traditionally centered
+
+ 点击查看摘要
+ The use of machine learning for material property prediction and discovery has traditionally centered on graph neural networks that incorporate the geometric configuration of all atoms. However, in practice not all this information may be readily available, e.g.~when evaluating the potentially unknown binding of adsorbates to catalyst. In this paper, we investigate whether it is possible to predict a system's relaxed energy in the OC20 dataset while ignoring the relative position of the adsorbate with respect to the electro-catalyst. We consider SchNet, DimeNet++ and FAENet as base architectures and measure the impact of four modifications on model performance: removing edges in the input graph, pooling independent representations, not sharing the backbone weights and using an attention mechanism to propagate non-geometric relative information. We find that while removing binding site information impairs accuracy as expected, modified models are able to predict relaxed energies with remarkably decent MAE. Our work suggests future research directions in accelerated materials discovery where information on reactant configurations can be reduced or altogether omitted.
+
+
+
+ 30. 标题:Machine Learning Quantum Systems with Magnetic p-bits
+ 编号:[60]
+ 链接:https://arxiv.org/abs/2310.06679
+ 作者:Shuvro Chowdhury, Kerem Y. Camsari
+ 备注:
+ 关键词:Artificial Intelligence, Moore Law, algorithms continue skyrocketing, Law has led, workloads of Artificial
+
+ 点击查看摘要
+ The slowing down of Moore's Law has led to a crisis as the computing workloads of Artificial Intelligence (AI) algorithms continue skyrocketing. There is an urgent need for scalable and energy-efficient hardware catering to the unique requirements of AI algorithms and applications. In this environment, probabilistic computing with p-bits emerged as a scalable, domain-specific, and energy-efficient computing paradigm, particularly useful for probabilistic applications and algorithms. In particular, spintronic devices such as stochastic magnetic tunnel junctions (sMTJ) show great promise in designing integrated p-computers. Here, we examine how a scalable probabilistic computer with such magnetic p-bits can be useful for an emerging field combining machine learning and quantum physics.
+
+
+
+ 31. 标题:Domain Generalization by Rejecting Extreme Augmentations
+ 编号:[64]
+ 链接:https://arxiv.org/abs/2310.06670
+ 作者:Masih Aminbeidokhti, Fidel A. Guerrero Peña, Heitor Rapela Medeiros, Thomas Dubail, Eric Granger, Marco Pedersoli
+ 备注:
+ 关键词:regularizing deep learning, deep learning models, Data augmentation, test data follow, effective techniques
+
+ 点击查看摘要
+ Data augmentation is one of the most effective techniques for regularizing deep learning models and improving their recognition performance in a variety of tasks and domains. However, this holds for standard in-domain settings, in which the training and test data follow the same distribution. For the out-of-domain case, where the test data follow a different and unknown distribution, the best recipe for data augmentation is unclear. In this paper, we show that for out-of-domain and domain generalization settings, data augmentation can provide a conspicuous and robust improvement in performance. To do that, we propose a simple training procedure: (i) use uniform sampling on standard data augmentation transformations; (ii) increase the strength transformations to account for the higher data variance expected when working out-of-domain, and (iii) devise a new reward function to reject extreme transformations that can harm the training. With this procedure, our data augmentation scheme achieves a level of accuracy that is comparable to or better than state-of-the-art methods on benchmark domain generalization datasets. Code: \url{this https URL}
+
+
+
+ 32. 标题:Latent Diffusion Counterfactual Explanations
+ 编号:[65]
+ 链接:https://arxiv.org/abs/2310.06668
+ 作者:Karim Farid, Simon Schrodi, Max Argus, Thomas Brox
+ 备注:
+ 关键词:counterfactual generation, promising method, method for elucidating, Diffusion Counterfactual Explanations, Counterfactual explanations
+
+ 点击查看摘要
+ Counterfactual explanations have emerged as a promising method for elucidating the behavior of opaque black-box models. Recently, several works leveraged pixel-space diffusion models for counterfactual generation. To handle noisy, adversarial gradients during counterfactual generation -- causing unrealistic artifacts or mere adversarial perturbations -- they required either auxiliary adversarially robust models or computationally intensive guidance schemes. However, such requirements limit their applicability, e.g., in scenarios with restricted access to the model's training data. To address these limitations, we introduce Latent Diffusion Counterfactual Explanations (LDCE). LDCE harnesses the capabilities of recent class- or text-conditional foundation latent diffusion models to expedite counterfactual generation and focus on the important, semantic parts of the data. Furthermore, we propose a novel consensus guidance mechanism to filter out noisy, adversarial gradients that are misaligned with the diffusion model's implicit classifier. We demonstrate the versatility of LDCE across a wide spectrum of models trained on diverse datasets with different learning paradigms. Finally, we showcase how LDCE can provide insights into model errors, enhancing our understanding of black-box model behavior.
+
+
+
+ 33. 标题:SC2GAN: Rethinking Entanglement by Self-correcting Correlated GAN Space
+ 编号:[66]
+ 链接:https://arxiv.org/abs/2310.06667
+ 作者:Zikun Chen, Han Zhao, Parham Aarabi, Ruowei Jiang
+ 备注:Accepted to the Out Of Distribution Generalization in Computer Vision workshop at ICCV2023
+ 关键词:Generative Adversarial Networks, Adversarial Networks, learned latent space, Generative Adversarial, latent space
+
+ 点击查看摘要
+ Generative Adversarial Networks (GANs) can synthesize realistic images, with the learned latent space shown to encode rich semantic information with various interpretable directions. However, due to the unstructured nature of the learned latent space, it inherits the bias from the training data where specific groups of visual attributes that are not causally related tend to appear together, a phenomenon also known as spurious correlations, e.g., age and eyeglasses or women and lipsticks. Consequently, the learned distribution often lacks the proper modelling of the missing examples. The interpolation following editing directions for one attribute could result in entangled changes with other attributes. To address this problem, previous works typically adjust the learned directions to minimize the changes in other attributes, yet they still fail on strongly correlated features. In this work, we study the entanglement issue in both the training data and the learned latent space for the StyleGAN2-FFHQ model. We propose a novel framework SC$^2$GAN that achieves disentanglement by re-projecting low-density latent code samples in the original latent space and correcting the editing directions based on both the high-density and low-density regions. By leveraging the original meaningful directions and semantic region-specific layers, our framework interpolates the original latent codes to generate images with attribute combination that appears infrequently, then inverts these samples back to the original latent space. We apply our framework to pre-existing methods that learn meaningful latent directions and showcase its strong capability to disentangle the attributes with small amounts of low-density region samples added.
+
+
+
+ 34. 标题:Unlock the Potential of Counterfactually-Augmented Data in Out-Of-Distribution Generalization
+ 编号:[67]
+ 链接:https://arxiv.org/abs/2310.06666
+ 作者:Caoyun Fan, Wenqing Chen, Jidong Tian, Yitian Li, Hao He, Yaohui Jin
+ 备注:Expert Systems With Applications 2023. arXiv admin note: text overlap with arXiv:2302.09345
+ 关键词:Counterfactually-Augmented Data, CAD induces language, exclude spurious correlations, CAD OOD generalization, exploit domain-independent causal
+
+ 点击查看摘要
+ Counterfactually-Augmented Data (CAD) -- minimal editing of sentences to flip the corresponding labels -- has the potential to improve the Out-Of-Distribution (OOD) generalization capability of language models, as CAD induces language models to exploit domain-independent causal features and exclude spurious correlations. However, the empirical results of CAD's OOD generalization are not as efficient as anticipated. In this study, we attribute the inefficiency to the myopia phenomenon caused by CAD: language models only focus on causal features that are edited in the augmentation operation and exclude other non-edited causal features. Therefore, the potential of CAD is not fully exploited. To address this issue, we analyze the myopia phenomenon in feature space from the perspective of Fisher's Linear Discriminant, then we introduce two additional constraints based on CAD's structural properties (dataset-level and sentence-level) to help language models extract more complete causal features in CAD, thereby mitigating the myopia phenomenon and improving OOD generalization capability. We evaluate our method on two tasks: Sentiment Analysis and Natural Language Inference, and the experimental results demonstrate that our method could unlock the potential of CAD and improve the OOD generalization performance of language models by 1.0% to 5.9%.
+
+
+
+ 35. 标题:Tertiary Lymphoid Structures Generation through Graph-based Diffusion
+ 编号:[69]
+ 链接:https://arxiv.org/abs/2310.06661
+ 作者:Manuel Madeira, Dorina Thanou, Pascal Frossard
+ 备注:
+ 关键词:capturing intricate dependencies, Graph-based representation approaches, tumor tissue, representation approaches, analysis of biomedical
+
+ 点击查看摘要
+ Graph-based representation approaches have been proven to be successful in the analysis of biomedical data, due to their capability of capturing intricate dependencies between biological entities, such as the spatial organization of different cell types in a tumor tissue. However, to further enhance our understanding of the underlying governing biological mechanisms, it is important to accurately capture the actual distributions of such complex data. Graph-based deep generative models are specifically tailored to accomplish that. In this work, we leverage state-of-the-art graph-based diffusion models to generate biologically meaningful cell-graphs. In particular, we show that the adopted graph diffusion model is able to accurately learn the distribution of cells in terms of their tertiary lymphoid structures (TLS) content, a well-established biomarker for evaluating the cancer progression in oncology research. Additionally, we further illustrate the utility of the learned generative models for data augmentation in a TLS classification task. To the best of our knowledge, this is the first work that leverages the power of graph diffusion models in generating meaningful biological cell structures.
+
+
+
+ 36. 标题:Diversity from Human Feedback
+ 编号:[73]
+ 链接:https://arxiv.org/abs/2310.06648
+ 作者:Ren-Jian Wang, Ke Xue, Yutong Wang, Peng Yang, Haobo Fu, Qiang Fu, Chao Qian
+ 备注:
+ 关键词:diversity measure, plays a significant, significant role, human feedback, Diversity
+
+ 点击查看摘要
+ Diversity plays a significant role in many problems, such as ensemble learning, reinforcement learning, and combinatorial optimization. How to define the diversity measure is a longstanding problem. Many methods rely on expert experience to define a proper behavior space and then obtain the diversity measure, which is, however, challenging in many scenarios. In this paper, we propose the problem of learning a behavior space from human feedback and present a general method called Diversity from Human Feedback (DivHF) to solve it. DivHF learns a behavior descriptor consistent with human preference by querying human feedback. The learned behavior descriptor can be combined with any distance measure to define a diversity measure. We demonstrate the effectiveness of DivHF by integrating it with the Quality-Diversity optimization algorithm MAP-Elites and conducting experiments on the QDax suite. The results show that DivHF learns a behavior space that aligns better with human requirements compared to direct data-driven approaches and leads to more diverse solutions under human preference. Our contributions include formulating the problem, proposing the DivHF method, and demonstrating its effectiveness through experiments.
+
+
+
+ 37. 标题:Self-Supervised Representation Learning for Online Handwriting Text Classification
+ 编号:[75]
+ 链接:https://arxiv.org/abs/2310.06645
+ 作者:Pouya Mehralian, Bagher BabaAli, Ashena Gorgan Mohammadi
+ 备注:
+ 关键词:Self-supervised learning offers, annotating large-scale datasets, extracting rich representations, Self-supervised learning, large-scale datasets
+
+ 点击查看摘要
+ Self-supervised learning offers an efficient way of extracting rich representations from various types of unlabeled data while avoiding the cost of annotating large-scale datasets. This is achievable by designing a pretext task to form pseudo labels with respect to the modality and domain of the data. Given the evolving applications of online handwritten texts, in this study, we propose the novel Part of Stroke Masking (POSM) as a pretext task for pretraining models to extract informative representations from the online handwriting of individuals in English and Chinese languages, along with two suggested pipelines for fine-tuning the pretrained models. To evaluate the quality of the extracted representations, we use both intrinsic and extrinsic evaluation methods. The pretrained models are fine-tuned to achieve state-of-the-art results in tasks such as writer identification, gender classification, and handedness classification, also highlighting the superiority of utilizing the pretrained models over the models trained from scratch.
+
+
+
+ 38. 标题:Zero-Level-Set Encoder for Neural Distance Fields
+ 编号:[76]
+ 链接:https://arxiv.org/abs/2310.06644
+ 作者:Stefan Rhys Jeske, Jonathan Klein, Dominik L. Michels, Jan Bender
+ 备注:
+ 关键词:specific spatial position, representation generally refers, shape representation generally, refers to representing, spatial position
+
+ 点击查看摘要
+ Neural shape representation generally refers to representing 3D geometry using neural networks, e.g., to compute a signed distance or occupancy value at a specific spatial position. Previous methods tend to rely on the auto-decoder paradigm, which often requires densely-sampled and accurate signed distances to be known during training and testing, as well as an additional optimization loop during inference. This introduces a lot of computational overhead, in addition to having to compute signed distances analytically, even during testing. In this paper, we present a novel encoder-decoder neural network for embedding 3D shapes in a single forward pass. Our architecture is based on a multi-scale hybrid system incorporating graph-based and voxel-based components, as well as a continuously differentiable decoder. Furthermore, the network is trained to solve the Eikonal equation and only requires knowledge of the zero-level set for training and inference. Additional volumetric samples can be generated on-the-fly, and incorporated in an unsupervised manner. This means that in contrast to most previous work, our network is able to output valid signed distance fields without explicit prior knowledge of non-zero distance values or shape occupancy. In other words, our network computes approximate solutions to the boundary-valued Eikonal equation. It also requires only a single forward pass during inference, instead of the common latent code optimization. We further propose a modification of the loss function in case that surface normals are not well defined, e.g., in the context of non-watertight surface-meshes and non-manifold geometry. We finally demonstrate the efficacy, generalizability and scalability of our method on datasets consisting of deforming 3D shapes, single class encoding and multiclass encoding, showcasing a wide range of possible applications.
+
+
+
+ 39. 标题:Implicit Variational Inference for High-Dimensional Posteriors
+ 编号:[77]
+ 链接:https://arxiv.org/abs/2310.06643
+ 作者:Anshuk Uppal, Kristoffer Stensbo-Smidt, Wouter K. Boomsma, Jes Frellsen
+ 备注:9 pages, and supplementary
+ 关键词:true posterior distribution, accurately capturing, capturing the true, implicit distributions, true posterior
+
+ 点击查看摘要
+ In variational inference, the benefits of Bayesian models rely on accurately capturing the true posterior distribution. We propose using neural samplers that specify implicit distributions, which are well-suited for approximating complex multimodal and correlated posteriors in high-dimensional spaces. Our approach advances inference using implicit distributions by introducing novel bounds that come about by locally linearising the neural sampler. This is distinct from existing methods that rely on additional discriminator networks and unstable adversarial objectives. Furthermore, we present a new sampler architecture that, for the first time, enables implicit distributions over millions of latent variables, addressing computational concerns by using differentiable numerical approximations. Our empirical analysis indicates our method is capable of recovering correlations across layers in large Bayesian neural networks, a property that is crucial for a network's performance but notoriously challenging to achieve. To the best of our knowledge, no other method has been shown to accomplish this task for such large models. Through experiments in downstream tasks, we demonstrate that our expressive posteriors outperform state-of-the-art uncertainty quantification methods, validating the effectiveness of our training algorithm and the quality of the learned implicit approximation.
+
+
+
+ 40. 标题:The Lattice Overparametrization Paradigm for the Machine Learning of Lattice Operators
+ 编号:[79]
+ 链接:https://arxiv.org/abs/2310.06639
+ 作者:Diego Marcondes, Junior Barrera
+ 备注:
+ 关键词:lattice, algorithm, learning, lattice operators, operators
+
+ 点击查看摘要
+ The machine learning of lattice operators has three possible bottlenecks. From a statistical standpoint, it is necessary to design a constrained class of operators based on prior information with low bias, and low complexity relative to the sample size. From a computational perspective, there should be an efficient algorithm to minimize an empirical error over the class. From an understanding point of view, the properties of the learned operator need to be derived, so its behavior can be theoretically understood. The statistical bottleneck can be overcome due to the rich literature about the representation of lattice operators, but there is no general learning algorithm for them. In this paper, we discuss a learning paradigm in which, by overparametrizing a class via elements in a lattice, an algorithm for minimizing functions in a lattice is applied to learn. We present the stochastic lattice gradient descent algorithm as a general algorithm to learn on constrained classes of operators as long as a lattice overparametrization of it is fixed, and we discuss previous works which are proves of concept. Moreover, if there are algorithms to compute the basis of an operator from its overparametrization, then its properties can be deduced and the understanding bottleneck is also overcome. This learning paradigm has three properties that modern methods based on neural networks lack: control, transparency and interpretability. Nowadays, there is an increasing demand for methods with these characteristics, and we believe that mathematical morphology is in a unique position to supply them. The lattice overparametrization paradigm could be a missing piece for it to achieve its full potential within modern machine learning.
+
+
+
+ 41. 标题:What If the TV Was Off? Examining Counterfactual Reasoning Abilities of Multi-modal Language Models
+ 编号:[83]
+ 链接:https://arxiv.org/abs/2310.06627
+ 作者:Letian Zhang, Xiaotong Zhai, Zhongkai Zhao, Xin Wen, Yongshuo Zong, Bingchen Zhao
+ 备注:Short paper accepted at ICCV 2023 VLAR workshop
+ 关键词:Counterfactual reasoning ability, human intelligence, core abilities, abilities of human, reasoning ability
+
+ 点击查看摘要
+ Counterfactual reasoning ability is one of the core abilities of human intelligence. This reasoning process involves the processing of alternatives to observed states or past events, and this process can improve our ability for planning and decision-making. In this work, we focus on benchmarking the counterfactual reasoning ability of multi-modal large language models. We take the question and answer pairs from the VQAv2 dataset and add one counterfactual presupposition to the questions, with the answer being modified accordingly. After generating counterfactual questions and answers using ChatGPT, we manually examine all generated questions and answers to ensure correctness. Over 2k counterfactual question and answer pairs are collected this way. We evaluate recent vision language models on our newly collected test dataset and found that all models exhibit a large performance drop compared to the results tested on questions without the counterfactual presupposition. This result indicates that there still exists space for developing vision language models. Apart from the vision language models, our proposed dataset can also serves as a benchmark for evaluating the ability of code generation LLMs, results demonstrate a large gap between GPT-4 and current open-source models. Our code and dataset are available at \url{this https URL}.
+
+
+
+ 42. 标题:iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
+ 编号:[85]
+ 链接:https://arxiv.org/abs/2310.06625
+ 作者:Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, Mingsheng Long
+ 备注:
+ 关键词:modifications of Transformer-based, Transformer-based forecasters, linear forecasting models, forecasting models questions, forecasters leverage Transformers
+
+ 点击查看摘要
+ The recent boom of linear forecasting models questions the ongoing passion for architectural modifications of Transformer-based forecasters. These forecasters leverage Transformers to model the global dependencies over temporal tokens of time series, with each token formed by multiple variates of the same timestamp. However, Transformer is challenged in forecasting series with larger lookback windows due to performance degradation and computation explosion. Besides, the unified embedding for each temporal token fuses multiple variates with potentially unaligned timestamps and distinct physical measurements, which may fail in learning variate-centric representations and result in meaningless attention maps. In this work, we reflect on the competent duties of Transformer components and repurpose the Transformer architecture without any adaptation on the basic components. We propose iTransformer that simply inverts the duties of the attention mechanism and the feed-forward network. Specifically, the time points of individual series are embedded into variate tokens which are utilized by the attention mechanism to capture multivariate correlations; meanwhile, the feed-forward network is applied for each variate token to learn nonlinear representations. The iTransformer model achieves consistent state-of-the-art on several real-world datasets, which further empowers the Transformer family with promoted performance, generalization ability across different variates, and better utilization of arbitrary lookback windows, making it a nice alternative as the fundamental backbone of time series forecasting.
+
+
+
+ 43. 标题:Robustness May be More Brittle than We Think under Different Degrees of Distribution Shifts
+ 编号:[87]
+ 链接:https://arxiv.org/abs/2310.06622
+ 作者:Kaican Li, Yifan Zhang, Lanqing Hong, Zhenguo Li, Nevin L. Zhang
+ 备注:
+ 关键词:complicated problem due, test domains, distribution shifts, complicated problem, problem due
+
+ 点击查看摘要
+ Out-of-distribution (OOD) generalization is a complicated problem due to the idiosyncrasies of possible distribution shifts between training and test domains. Most benchmarks employ diverse datasets to address this issue; however, the degree of the distribution shift between the training domains and the test domains of each dataset remains largely fixed. This may lead to biased conclusions that either underestimate or overestimate the actual OOD performance of a model. Our study delves into a more nuanced evaluation setting that covers a broad range of shift degrees. We show that the robustness of models can be quite brittle and inconsistent under different degrees of distribution shifts, and therefore one should be more cautious when drawing conclusions from evaluations under a limited range of degrees. In addition, we observe that large-scale pre-trained models, such as CLIP, are sensitive to even minute distribution shifts of novel downstream tasks. This indicates that while pre-trained representations may help improve downstream in-distribution performance, they could have minimal or even adverse effects on generalization in certain OOD scenarios of the downstream task if not used properly. In light of these findings, we encourage future research to conduct evaluations across a broader range of shift degrees whenever possible.
+
+
+
+ 44. 标题:Discovering Interpretable Physical Models Using Symbolic Regression and Discrete Exterior Calculus
+ 编号:[89]
+ 链接:https://arxiv.org/abs/2310.06609
+ 作者:Simone Manti, Alessandro Lucantonio
+ 备注:
+ 关键词:modern scientific research, Discrete Exterior Calculus, research and engineering, key resource, resource to gather
+
+ 点击查看摘要
+ Computational modeling is a key resource to gather insight into physical systems in modern scientific research and engineering. While access to large amount of data has fueled the use of Machine Learning (ML) to recover physical models from experiments and increase the accuracy of physical simulations, purely data-driven models have limited generalization and interpretability. To overcome these limitations, we propose a framework that combines Symbolic Regression (SR) and Discrete Exterior Calculus (DEC) for the automated discovery of physical models starting from experimental data. Since these models consist of mathematical expressions, they are interpretable and amenable to analysis, and the use of a natural, general-purpose discrete mathematical language for physics favors generalization with limited input data. Importantly, DEC provides building blocks for the discrete analogue of field theories, which are beyond the state-of-the-art applications of SR to physical problems. Further, we show that DEC allows to implement a strongly-typed SR procedure that guarantees the mathematical consistency of the recovered models and reduces the search space of symbolic expressions. Finally, we prove the effectiveness of our methodology by re-discovering three models of Continuum Physics from synthetic experimental data: Poisson equation, the Euler's Elastica and the equations of Linear Elasticity. Thanks to their general-purpose nature, the methods developed in this paper may be applied to diverse contexts of physical modeling.
+
+
+
+ 45. 标题:Pi-DUAL: Using Privileged Information to Distinguish Clean from Noisy Labels
+ 编号:[93]
+ 链接:https://arxiv.org/abs/2310.06600
+ 作者:Ke Wang, Guillermo Ortiz-Jimenez, Rodolphe Jenatton, Mark Collier, Efi Kokiopoulou, Pascal Frossard
+ 备注:
+ 关键词:pervasive problem, problem in deep, compromises the generalization, Label noise, deep learning
+
+ 点击查看摘要
+ Label noise is a pervasive problem in deep learning that often compromises the generalization performance of trained models. Recently, leveraging privileged information (PI) -- information available only during training but not at test time -- has emerged as an effective approach to mitigate this issue. Yet, existing PI-based methods have failed to consistently outperform their no-PI counterparts in terms of preventing overfitting to label noise. To address this deficiency, we introduce Pi-DUAL, an architecture designed to harness PI to distinguish clean from wrong labels. Pi-DUAL decomposes the output logits into a prediction term, based on conventional input features, and a noise-fitting term influenced solely by PI. A gating mechanism steered by PI adaptively shifts focus between these terms, allowing the model to implicitly separate the learning paths of clean and wrong labels. Empirically, Pi-DUAL achieves significant performance improvements on key PI benchmarks (e.g., +6.8% on ImageNet-PI), establishing a new state-of-the-art test set accuracy. Additionally, Pi-DUAL is a potent method for identifying noisy samples post-training, outperforming other strong methods at this task. Overall, Pi-DUAL is a simple, scalable and practical approach for mitigating the effects of label noise in a variety of real-world scenarios with PI.
+
+
+
+ 46. 标题:FTFT: efficient and robust Fine-Tuning by transFerring Training dynamics
+ 编号:[97]
+ 链接:https://arxiv.org/abs/2310.06588
+ 作者:Yupei Du, Albert Gatt, Dong Nguyen
+ 备注:15 pages, 3 figures
+ 关键词:Natural Language Processing, Pre-trained Language Models, large Pre-trained Language, Language Processing, Pre-trained Language
+
+ 点击查看摘要
+ Despite the massive success of fine-tuning large Pre-trained Language Models (PLMs) on a wide range of Natural Language Processing (NLP) tasks, they remain susceptible to out-of-distribution (OOD) and adversarial inputs. Data map (DM) is a simple yet effective dual-model approach that enhances the robustness of fine-tuned PLMs, which involves fine-tuning a model on the original training set (i.e. reference model), selecting a specified fraction of important training examples according to the training dynamics of the reference model, and fine-tuning the same model on these selected examples (i.e. main model). However, it suffers from the drawback of requiring fine-tuning the same model twice, which is computationally expensive for large models. In this paper, we first show that 1) training dynamics are highly transferable across different model sizes and different pre-training methods, and that 2) main models fine-tuned using DM learn faster than when using conventional Empirical Risk Minimization (ERM). Building on these observations, we propose a novel fine-tuning approach based on the DM method: Fine-Tuning by transFerring Training dynamics (FTFT). Compared with DM, FTFT uses more efficient reference models and then fine-tunes more capable main models for fewer steps. Our experiments show that FTFT achieves better generalization robustness than ERM while spending less than half of the training cost.
+
+
+
+ 47. 标题:A Black-Box Physics-Informed Estimator based on Gaussian Process Regression for Robot Inverse Dynamics Identification
+ 编号:[98]
+ 链接:https://arxiv.org/abs/2310.06585
+ 作者:Giulio Giacomuzzo, Alberto Dalla Libera, Diego Romeres, Ruggero Carli
+ 备注:
+ 关键词:Gaussian process regression, Lagrangian Inspired Polynomial, inverse dynamics components, process regression, inverse dynamics
+
+ 点击查看摘要
+ In this paper, we propose a black-box model based on Gaussian process regression for the identification of the inverse dynamics of robotic manipulators. The proposed model relies on a novel multidimensional kernel, called \textit{Lagrangian Inspired Polynomial} (\kernelInitials{}) kernel. The \kernelInitials{} kernel is based on two main ideas. First, instead of directly modeling the inverse dynamics components, we model as GPs the kinetic and potential energy of the system. The GP prior on the inverse dynamics components is derived from those on the energies by applying the properties of GPs under linear operators. Second, as regards the energy prior definition, we prove a polynomial structure of the kinetic and potential energy, and we derive a polynomial kernel that encodes this property. As a consequence, the proposed model allows also to estimate the kinetic and potential energy without requiring any label on these quantities. Results on simulation and on two real robotic manipulators, namely a 7 DOF Franka Emika Panda and a 6 DOF MELFA RV4FL, show that the proposed model outperforms state-of-the-art black-box estimators based both on Gaussian Processes and Neural Networks in terms of accuracy, generality and data efficiency. The experiments on the MELFA robot also demonstrate that our approach achieves performance comparable to fine-tuned model-based estimators, despite requiring less prior information.
+
+
+
+ 48. 标题:XAI for Early Crop Classification
+ 编号:[103]
+ 链接:https://arxiv.org/abs/2310.06574
+ 作者:Ayshah Chan, Maja Schneider, Marco Körner
+ 备注:
+ 关键词:early crop classification, identifying important timesteps, crop classification, crop classification model, baseline crop classification
+
+ 点击查看摘要
+ We propose an approach for early crop classification through identifying important timesteps with eXplainable AI (XAI) methods. Our approach consists of training a baseline crop classification model to carry out layer-wise relevance propagation (LRP) so that the salient time step can be identified. We chose a selected number of such important time indices to create the bounding region of the shortest possible classification timeframe. We identified the period 21st April 2019 to 9th August 2019 as having the best trade-off in terms of accuracy and earliness. This timeframe only suffers a 0.75% loss in accuracy as compared to using the full timeseries. We observed that the LRP-derived important timesteps also highlight small details in input values that differentiates between different classes and
+
+
+
+ 49. 标题:On Temporal References in Emergent Communication
+ 编号:[108]
+ 链接:https://arxiv.org/abs/2310.06555
+ 作者:Olaf Lipinski, Adam J. Sobey, Federico Cerutti, Timothy J. Norman
+ 备注:26 pages, 13 figures. Code available at this https URL
+ 关键词:easily share past, share past experiences, elements referencing time, future predictions, linguistic elements referencing
+
+ 点击查看摘要
+ As humans, we use linguistic elements referencing time, such as before or tomorrow, to easily share past experiences and future predictions. While temporal aspects of the language have been considered in computational linguistics, no such exploration has been done within the field of emergent communication. We research this gap, providing the first reported temporal vocabulary within emergent communication literature. Our experimental analysis shows that a different agent architecture is sufficient for the natural emergence of temporal references, and that no additional losses are necessary. Our readily transferable architectural insights provide the basis for the incorporation of temporal referencing into other emergent communication environments.
+
+
+
+ 50. 标题:Be Careful What You Smooth For: Label Smoothing Can Be a Privacy Shield but Also a Catalyst for Model Inversion Attacks
+ 编号:[111]
+ 链接:https://arxiv.org/abs/2310.06549
+ 作者:Lukas Struppek, Dominik Hintersdorf, Kristian Kersting
+ 备注:23 pages, 8 tables, 8 figures
+ 关键词:showing diverse benefits, widely adopted regularization, adopted regularization method, deep learning, showing diverse
+
+ 点击查看摘要
+ Label smoothing -- using softened labels instead of hard ones -- is a widely adopted regularization method for deep learning, showing diverse benefits such as enhanced generalization and calibration. Its implications for preserving model privacy, however, have remained unexplored. To fill this gap, we investigate the impact of label smoothing on model inversion attacks (MIAs), which aim to generate class-representative samples by exploiting the knowledge encoded in a classifier, thereby inferring sensitive information about its training data. Through extensive analyses, we uncover that traditional label smoothing fosters MIAs, thereby increasing a model's privacy leakage. Even more, we reveal that smoothing with negative factors counters this trend, impeding the extraction of class-related information and leading to privacy preservation, beating state-of-the-art defenses. This establishes a practical and powerful novel way for enhancing model resilience against MIAs.
+
+
+
+ 51. 标题:An Edge-Aware Graph Autoencoder Trained on Scale-Imbalanced Data for Travelling Salesman Problems
+ 编号:[115]
+ 链接:https://arxiv.org/abs/2310.06543
+ 作者:Shiqing Liu, Xueming Yan, Yaochu Jin
+ 备注:35 pages, 7 figures
+ 关键词:lower computation cost, outperform traditional heuristics, approximate exact solvers, combinatorial optimization, Recent years
+
+ 点击查看摘要
+ Recent years have witnessed a surge in research on machine learning for combinatorial optimization since learning-based approaches can outperform traditional heuristics and approximate exact solvers at a lower computation cost. However, most existing work on supervised neural combinatorial optimization focuses on TSP instances with a fixed number of cities and requires large amounts of training samples to achieve a good performance, making them less practical to be applied to realistic optimization scenarios. This work aims to develop a data-driven graph representation learning method for solving travelling salesman problems (TSPs) with various numbers of cities. To this end, we propose an edge-aware graph autoencoder (EdgeGAE) model that can learn to solve TSPs after being trained on solution data of various sizes with an imbalanced distribution. We formulate the TSP as a link prediction task on sparse connected graphs. A residual gated encoder is trained to learn latent edge embeddings, followed by an edge-centered decoder to output link predictions in an end-to-end manner. To improve the model's generalization capability of solving large-scale problems, we introduce an active sampling strategy into the training process. In addition, we generate a benchmark dataset containing 50,000 TSP instances with a size from 50 to 500 cities, following an extremely scale-imbalanced distribution, making it ideal for investigating the model's performance for practical applications. We conduct experiments using different amounts of training data with various scales, and the experimental results demonstrate that the proposed data-driven approach achieves a highly competitive performance among state-of-the-art learning-based methods for solving TSPs.
+
+
+
+ 52. 标题:A Novel Contrastive Learning Method for Clickbait Detection on RoCliCo: A Romanian Clickbait Corpus of News Articles
+ 编号:[118]
+ 链接:https://arxiv.org/abs/2310.06540
+ 作者:Daria-Mihaela Broscoteanu, Radu Tudor Ionescu
+ 备注:Accepted at EMNLP 2023
+ 关键词:increase revenue, websites often resort, reading the full, Romanian Clickbait Corpus, luring users
+
+ 点击查看摘要
+ To increase revenue, news websites often resort to using deceptive news titles, luring users into clicking on the title and reading the full news. Clickbait detection is the task that aims to automatically detect this form of false advertisement and avoid wasting the precious time of online users. Despite the importance of the task, to the best of our knowledge, there is no publicly available clickbait corpus for the Romanian language. To this end, we introduce a novel Romanian Clickbait Corpus (RoCliCo) comprising 8,313 news samples which are manually annotated with clickbait and non-clickbait labels. Furthermore, we conduct experiments with four machine learning methods, ranging from handcrafted models to recurrent and transformer-based neural networks, to establish a line-up of competitive baselines. We also carry out experiments with a weighted voting ensemble. Among the considered baselines, we propose a novel BERT-based contrastive learning model that learns to encode news titles and contents into a deep metric space such that titles and contents of non-clickbait news have high cosine similarity, while titles and contents of clickbait news have low cosine similarity. Our data set and code to reproduce the baselines are publicly available for download at this https URL.
+
+
+
+ 53. 标题:Watt For What: Rethinking Deep Learning's Energy-Performance Relationship
+ 编号:[122]
+ 链接:https://arxiv.org/abs/2310.06522
+ 作者:Shreyank N Gowda, Xinyue Hao, Gen Li, Laura Sevilla-Lara, Shashank Narayana Gowda
+ 备注:
+ 关键词:natural language processing, achieving unprecedented levels, revolutionized various fields, language processing, image recognition
+
+ 点击查看摘要
+ Deep learning models have revolutionized various fields, from image recognition to natural language processing, by achieving unprecedented levels of accuracy. However, their increasing energy consumption has raised concerns about their environmental impact, disadvantaging smaller entities in research and exacerbating global energy consumption. In this paper, we explore the trade-off between model accuracy and electricity consumption, proposing a metric that penalizes large consumption of electricity. We conduct a comprehensive study on the electricity consumption of various deep learning models across different GPUs, presenting a detailed analysis of their accuracy-efficiency trade-offs. By evaluating accuracy per unit of electricity consumed, we demonstrate how smaller, more energy-efficient models can significantly expedite research while mitigating environmental concerns. Our results highlight the potential for a more sustainable approach to deep learning, emphasizing the importance of optimizing models for efficiency. This research also contributes to a more equitable research landscape, where smaller entities can compete effectively with larger counterparts. This advocates for the adoption of efficient deep learning practices to reduce electricity consumption, safeguarding the environment for future generations whilst also helping ensure a fairer competitive landscape.
+
+
+
+ 54. 标题:AttributionLab: Faithfulness of Feature Attribution Under Controllable Environments
+ 编号:[124]
+ 链接:https://arxiv.org/abs/2310.06514
+ 作者:Yang Zhang, Yawei Li, Hannah Brown, Mina Rezaei, Bernd Bischl, Philip Torr, Ashkan Khakzar, Kenji Kawaguchi
+ 备注:32 pages including Appendix
+ 关键词:identifying relevant input, features, Feature attribution explains, input features, explains neural network
+
+ 点击查看摘要
+ Feature attribution explains neural network outputs by identifying relevant input features. How do we know if the identified features are indeed relevant to the network? This notion is referred to as faithfulness, an essential property that reflects the alignment between the identified (attributed) features and the features used by the model. One recent trend to test faithfulness is to design the data such that we know which input features are relevant to the label and then train a model on the designed data. Subsequently, the identified features are evaluated by comparing them with these designed ground truth features. However, this idea has the underlying assumption that the neural network learns to use all and only these designed features, while there is no guarantee that the learning process trains the network in this way. In this paper, we solve this missing link by explicitly designing the neural network by manually setting its weights, along with designing data, so we know precisely which input features in the dataset are relevant to the designed network. Thus, we can test faithfulness in AttributionLab, our designed synthetic environment, which serves as a sanity check and is effective in filtering out attribution methods. If an attribution method is not faithful in a simple controlled environment, it can be unreliable in more complex scenarios. Furthermore, the AttributionLab environment serves as a laboratory for controlled experiments through which we can study feature attribution methods, identify issues, and suggest potential improvements.
+
+
+
+ 55. 标题:Self-Supervised Set Representation Learning for Unsupervised Meta-Learning
+ 编号:[126]
+ 链接:https://arxiv.org/abs/2310.06511
+ 作者:Dong Bok Lee, Seanie Lee, Joonho Ko, Kenji Kawaguchi, Juho Lee, Sung Ju Hwang
+ 备注:
+ 关键词:achieved remarkable success, Dataset distillation methods, achieved remarkable, remarkable success, self-supervised target model
+
+ 点击查看摘要
+ Dataset distillation methods have achieved remarkable success in distilling a large dataset into a small set of representative samples. However, they are not designed to produce a distilled dataset that can be effectively used for facilitating self-supervised pre-training. To this end, we propose a novel problem of distilling an unlabeled dataset into a set of small synthetic samples for efficient self-supervised learning (SSL). We first prove that a gradient of synthetic samples with respect to a SSL objective in naive bilevel optimization is \textit{biased} due to the randomness originating from data augmentations or masking. To address this issue, we propose to minimize the mean squared error (MSE) between a model's representations of the synthetic examples and their corresponding learnable target feature representations for the inner objective, which does not introduce any randomness. Our primary motivation is that the model obtained by the proposed inner optimization can mimic the \textit{self-supervised target model}. To achieve this, we also introduce the MSE between representations of the inner model and the self-supervised target model on the original full dataset for outer optimization. Lastly, assuming that a feature extractor is fixed, we only optimize a linear head on top of the feature extractor, which allows us to reduce the computational cost and obtain a closed-form solution of the head with kernel ridge regression. We empirically validate the effectiveness of our method on various applications involving transfer learning.
+
+
+
+ 56. 标题:Runway Sign Classifier: A DAL C Certifiable Machine Learning System
+ 编号:[129]
+ 链接:https://arxiv.org/abs/2310.06506
+ 作者:Konstantin Dmitriev, Johann Schumann, Islam Bostanov, Mostafa Abdelhamid, Florian Holzapfel
+ 备注:
+ 关键词:Machine Learning, Artificial Intelligence, large commercial airplanes, presented unprecedented opportunities, fully autonomous operation
+
+ 点击查看摘要
+ In recent years, the remarkable progress of Machine Learning (ML) technologies within the domain of Artificial Intelligence (AI) systems has presented unprecedented opportunities for the aviation industry, paving the way for further advancements in automation, including the potential for single pilot or fully autonomous operation of large commercial airplanes. However, ML technology faces major incompatibilities with existing airborne certification standards, such as ML model traceability and explainability issues or the inadequacy of traditional coverage metrics. Certification of ML-based airborne systems using current standards is problematic due to these challenges. This paper presents a case study of an airborne system utilizing a Deep Neural Network (DNN) for airport sign detection and classification. Building upon our previous work, which demonstrates compliance with Design Assurance Level (DAL) D, we upgrade the system to meet the more stringent requirements of Design Assurance Level C. To achieve DAL C, we employ an established architectural mitigation technique involving two redundant and dissimilar Deep Neural Networks. The application of novel ML-specific data management techniques further enhances this approach. This work is intended to illustrate how the certification challenges of ML-based systems can be addressed for medium criticality airborne applications.
+
+
+
+ 57. 标题:Revisit Input Perturbation Problems for LLMs: A Unified Robustness Evaluation Framework for Noisy Slot Filling Task
+ 编号:[131]
+ 链接:https://arxiv.org/abs/2310.06504
+ 作者:Guanting Dong, Jinxu Zhao, Tingfeng Hui, Daichi Guo, Wenlong Wan, Boqi Feng, Yueyan Qiu, Zhuoma Gongque, Keqing He, Zechen Wang, Weiran Xu
+ 备注:Accepted at NLPCC 2023 (Oral Presentation)
+ 关键词:natural language processing, large language models, language processing, language models, large language
+
+ 点击查看摘要
+ With the increasing capabilities of large language models (LLMs), these high-performance models have achieved state-of-the-art results on a wide range of natural language processing (NLP) tasks. However, the models' performance on commonly-used benchmark datasets often fails to accurately reflect their reliability and robustness when applied to real-world noisy data. To address these challenges, we propose a unified robustness evaluation framework based on the slot-filling task to systematically evaluate the dialogue understanding capability of LLMs in diverse input perturbation scenarios. Specifically, we construct a input perturbation evaluation dataset, Noise-LLM, which contains five types of single perturbation and four types of mixed perturbation data. Furthermore, we utilize a multi-level data augmentation method (character, word, and sentence levels) to construct a candidate data pool, and carefully design two ways of automatic task demonstration construction strategies (instance-level and entity-level) with various prompt templates. Our aim is to assess how well various robustness methods of LLMs perform in real-world noisy scenarios. The experiments have demonstrated that the current open-source LLMs generally achieve limited perturbation robustness performance. Based on these experimental observations, we make some forward-looking suggestions to fuel the research in this direction.
+
+
+
+ 58. 标题:Deep Learning for Automatic Detection and Facial Recognition in Japanese Macaques: Illuminating Social Networks
+ 编号:[136]
+ 链接:https://arxiv.org/abs/2310.06489
+ 作者:Julien Paulet (UJM), Axel Molina (ENS-PSL), Benjamin Beltzung (IPHC), Takafumi Suzumura, Shinya Yamamoto, Cédric Sueur (IPHC, IUF, ANTHROPO LAB)
+ 备注:
+ 关键词:social structures understanding, ecology and ethology, structures understanding, plays a pivotal, pivotal role
+
+ 点击查看摘要
+ Individual identification plays a pivotal role in ecology and ethology, notably as a tool for complex social structures understanding. However, traditional identification methods often involve invasive physical tags and can prove both disruptive for animals and time-intensive for researchers. In recent years, the integration of deep learning in research offered new methodological perspectives through automatization of complex tasks. Harnessing object detection and recognition technologies is increasingly used by researchers to achieve identification on video footage. This study represents a preliminary exploration into the development of a non-invasive tool for face detection and individual identification of Japanese macaques (Macaca fuscata) through deep learning. The ultimate goal of this research is, using identifications done on the dataset, to automatically generate a social network representation of the studied population. The current main results are promising: (i) the creation of a Japanese macaques' face detector (Faster-RCNN model), reaching a 82.2% accuracy and (ii) the creation of an individual recognizer for K{ō}jima island macaques population (YOLOv8n model), reaching a 83% accuracy. We also created a K{ō}jima population social network by traditional methods, based on co-occurrences on videos. Thus, we provide a benchmark against which the automatically generated network will be assessed for reliability. These preliminary results are a testament to the potential of this innovative approach to provide the scientific community with a tool for tracking individuals and social network studies in Japanese macaques.
+
+
+
+ 59. 标题:SpikeCLIP: A Contrastive Language-Image Pretrained Spiking Neural Network
+ 编号:[137]
+ 链接:https://arxiv.org/abs/2310.06488
+ 作者:Tianlong Li, Wenhao Liu, Changze Lv, Jianhan Xu, Cenyuan Zhang, Muling Wu, Xiaoqing Zheng, Xuanjing Huang
+ 备注:
+ 关键词:Spiking neural networks, deep neural networks, neural networks, improved energy efficiency, Spiking neural
+
+ 点击查看摘要
+ Spiking neural networks (SNNs) have demonstrated the capability to achieve comparable performance to deep neural networks (DNNs) in both visual and linguistic domains while offering the advantages of improved energy efficiency and adherence to biological plausibility. However, the extension of such single-modality SNNs into the realm of multimodal scenarios remains an unexplored territory. Drawing inspiration from the concept of contrastive language-image pre-training (CLIP), we introduce a novel framework, named SpikeCLIP, to address the gap between two modalities within the context of spike-based computing through a two-step recipe involving ``Alignment Pre-training + Dual-Loss Fine-tuning". Extensive experiments demonstrate that SNNs achieve comparable results to their DNN counterparts while significantly reducing energy consumption across a variety of datasets commonly used for multimodal model evaluation. Furthermore, SpikeCLIP maintains robust performance in image classification tasks that involve class labels not predefined within specific categories.
+
+
+
+ 60. 标题:Variance Reduced Online Gradient Descent for Kernelized Pairwise Learning with Limited Memory
+ 编号:[140]
+ 链接:https://arxiv.org/abs/2310.06483
+ 作者:Hilal AlQuabeh, Bhaskar Mukhoty, Bin Gu
+ 备注:Accepted in ACML2023
+ 关键词:involving loss functions, loss functions defined, problems involving loss, online pairwise learning, Pairwise learning
+
+ 点击查看摘要
+ Pairwise learning is essential in machine learning, especially for problems involving loss functions defined on pairs of training examples. Online gradient descent (OGD) algorithms have been proposed to handle online pairwise learning, where data arrives sequentially. However, the pairwise nature of the problem makes scalability challenging, as the gradient computation for a new sample involves all past samples. Recent advancements in OGD algorithms have aimed to reduce the complexity of calculating online gradients, achieving complexities less than $O(T)$ and even as low as $O(1)$. However, these approaches are primarily limited to linear models and have induced variance. In this study, we propose a limited memory OGD algorithm that extends to kernel online pairwise learning while improving the sublinear regret. Specifically, we establish a clear connection between the variance of online gradients and the regret, and construct online gradients using the most recent stratified samples with a limited buffer of size of $s$ representing all past data, which have a complexity of $O(sT)$ and employs $O(\sqrt{T}\log{T})$ random Fourier features for kernel approximation. Importantly, our theoretical results demonstrate that the variance-reduced online gradients lead to an improved sublinear regret bound. The experiments on real-world datasets demonstrate the superiority of our algorithm over both kernelized and linear online pairwise learning algorithms.
+
+
+
+ 61. 标题:An improved CTGAN for data processing method of imbalanced disk failure
+ 编号:[141]
+ 链接:https://arxiv.org/abs/2310.06481
+ 作者:Jingbo Jia, Peng Wu, Hussain Dawood
+ 备注:
+ 关键词:Conditional Tabular Generative, Tabular Generative Adversarial, Generative Adversarial Networks, disk failure data, failure data
+
+ 点击查看摘要
+ To address the problem of insufficient failure data generated by disks and the imbalance between the number of normal and failure data. The existing Conditional Tabular Generative Adversarial Networks (CTGAN) deep learning methods have been proven to be effective in solving imbalance disk failure data. But CTGAN cannot learn the internal information of disk failure data very well. In this paper, a fault diagnosis method based on improved CTGAN, a classifier for specific category discrimination is added and a discriminator generate adversarial network based on residual network is proposed. We named it Residual Conditional Tabular Generative Adversarial Networks (RCTGAN). Firstly, to enhance the stability of system a residual network is utilized. RCTGAN uses a small amount of real failure data to synthesize fake fault data; Then, the synthesized data is mixed with the real data to balance the amount of normal and failure data; Finally, four classifier (multilayer perceptron, support vector machine, decision tree, random forest) models are trained using the balanced data set, and the performance of the models is evaluated using G-mean. The experimental results show that the data synthesized by the RCTGAN can further improve the fault diagnosis accuracy of the classifier.
+
+
+
+ 62. 标题:Understanding the Effects of RLHF on LLM Generalisation and Diversity
+ 编号:[150]
+ 链接:https://arxiv.org/abs/2310.06452
+ 作者:Robert Kirk, Ishita Mediratta, Christoforos Nalmpantis, Jelena Luketina, Eric Hambro, Edward Grefenstette, Roberta Raileanu
+ 备注:
+ 关键词:Anthropic Claude, Large language models, Large language, fine-tuned with reinforcement, human feedback
+
+ 点击查看摘要
+ Large language models (LLMs) fine-tuned with reinforcement learning from human feedback (RLHF) have been used in some of the most widely deployed AI models to date, such as OpenAI's ChatGPT, Anthropic's Claude, or Meta's LLaMA-2. While there has been significant work developing these methods, our understanding of the benefits and downsides of each stage in RLHF is still limited. To fill this gap, we present an extensive analysis of how each stage of the process (i.e. supervised fine-tuning (SFT), reward modelling, and RLHF) affects two key properties: out-of-distribution (OOD) generalisation and output diversity. OOD generalisation is crucial given the wide range of real-world scenarios in which these models are being used, while output diversity refers to the model's ability to generate varied outputs and is important for a variety of use cases. We perform our analysis across two base models on both summarisation and instruction following tasks, the latter being highly relevant for current LLM use cases. We find that RLHF generalises better than SFT to new inputs, particularly as the distribution shift between train and test becomes larger. However, RLHF significantly reduces output diversity compared to SFT across a variety of measures, implying a tradeoff in current LLM fine-tuning methods between generalisation and diversity. Our results provide guidance on which fine-tuning method should be used depending on the application, and show that more research is needed to improve the trade-off between generalisation and diversity.
+
+
+
+ 63. 标题:Asynchronous Federated Learning with Incentive Mechanism Based on Contract Theory
+ 编号:[153]
+ 链接:https://arxiv.org/abs/2310.06448
+ 作者:Danni Yang, Yun Ji, Zhoubin Kou, Xiaoxiong Zhong, Sheng Zhang
+ 备注:
+ 关键词:attract high-quality clients, federated learning, existing incentive mechanisms, address the challenges, challenges posed
+
+ 点击查看摘要
+ To address the challenges posed by the heterogeneity inherent in federated learning (FL) and to attract high-quality clients, various incentive mechanisms have been employed. However, existing incentive mechanisms are typically utilized in conventional synchronous aggregation, resulting in significant straggler issues. In this study, we propose a novel asynchronous FL framework that integrates an incentive mechanism based on contract theory. Within the incentive mechanism, we strive to maximize the utility of the task publisher by adaptively adjusting clients' local model training epochs, taking into account factors such as time delay and test accuracy. In the asynchronous scheme, considering client quality, we devise aggregation weights and an access control algorithm to facilitate asynchronous aggregation. Through experiments conducted on the MNIST dataset, the simulation results demonstrate that the test accuracy achieved by our framework is 3.12% and 5.84% higher than that achieved by FedAvg and FedProx without any attacks, respectively. The framework exhibits a 1.35% accuracy improvement over the ideal Local SGD under attacks. Furthermore, aiming for the same target accuracy, our framework demands notably less computation time than both FedAvg and FedProx.
+
+
+
+ 64. 标题:Rule Mining for Correcting Classification Models
+ 编号:[154]
+ 链接:https://arxiv.org/abs/2310.06446
+ 作者:Hirofumi Suzuki, Hiroaki Iwashita, Takuya Takagi, Yuta Fujishige, Satoshi Hara
+ 备注:
+ 关键词:remains consistently high, accuracy remains consistently, prediction accuracy remains, Machine learning models, Machine learning
+
+ 点击查看摘要
+ Machine learning models need to be continually updated or corrected to ensure that the prediction accuracy remains consistently high. In this study, we consider scenarios where developers should be careful to change the prediction results by the model correction, such as when the model is part of a complex system or software. In such scenarios, the developers want to control the specification of the corrections. To achieve this, the developers need to understand which subpopulations of the inputs get inaccurate predictions by the model. Therefore, we propose correction rule mining to acquire a comprehensive list of rules that describe inaccurate subpopulations and how to correct them. We also develop an efficient correction rule mining algorithm that is a combination of frequent itemset mining and a unique pruning technique for correction rules. We observed that the proposed algorithm found various rules which help to collect data insufficiently learned, directly correct model outputs, and analyze concept drift.
+
+
+
+ 65. 标题:Skeleton Ground Truth Extraction: Methodology, Annotation Tool and Benchmarks
+ 编号:[159]
+ 链接:https://arxiv.org/abs/2310.06437
+ 作者:Cong Yang, Bipin Indurkhya, John See, Bo Gao, Yan Ke, Zeyd Boukhers, Zhenyu Yang, Marcin Grzegorzek
+ 备注:Accepted for publication in the International Journal of Computer Vision (IJCV)
+ 关键词:Skeleton Ground Truth, Ground Truth, deep learning techniques, Convolutional Neural Networks, Skeleton Ground
+
+ 点击查看摘要
+ Skeleton Ground Truth (GT) is critical to the success of supervised skeleton extraction methods, especially with the popularity of deep learning techniques. Furthermore, we see skeleton GTs used not only for training skeleton detectors with Convolutional Neural Networks (CNN) but also for evaluating skeleton-related pruning and matching algorithms. However, most existing shape and image datasets suffer from the lack of skeleton GT and inconsistency of GT standards. As a result, it is difficult to evaluate and reproduce CNN-based skeleton detectors and algorithms on a fair basis. In this paper, we present a heuristic strategy for object skeleton GT extraction in binary shapes and natural images. Our strategy is built on an extended theory of diagnosticity hypothesis, which enables encoding human-in-the-loop GT extraction based on clues from the target's context, simplicity, and completeness. Using this strategy, we developed a tool, SkeView, to generate skeleton GT of 17 existing shape and image datasets. The GTs are then structurally evaluated with representative methods to build viable baselines for fair comparisons. Experiments demonstrate that GTs generated by our strategy yield promising quality with respect to standard consistency, and also provide a balance between simplicity and completeness.
+
+
+
+ 66. 标题:Conformal Prediction for Deep Classifier via Label Ranking
+ 编号:[164]
+ 链接:https://arxiv.org/abs/2310.06430
+ 作者:Jianguo Huang, Huajun Xi, Linjun Zhang, Huaxiu Yao, Yue Qiu, Hongxin Wei
+ 备注:
+ 关键词:prediction sets, generates prediction sets, Sorted Adaptive prediction, Conformal prediction, statistical framework
+
+ 点击查看摘要
+ Conformal prediction is a statistical framework that generates prediction sets containing ground-truth labels with a desired coverage guarantee. The predicted probabilities produced by machine learning models are generally miscalibrated, leading to large prediction sets in conformal prediction. In this paper, we empirically and theoretically show that disregarding the probabilities' value will mitigate the undesirable effect of miscalibrated probability values. Then, we propose a novel algorithm named $\textit{Sorted Adaptive prediction sets}$ (SAPS), which discards all the probability values except for the maximum softmax probability. The key idea behind SAPS is to minimize the dependence of the non-conformity score on the probability values while retaining the uncertainty information. In this manner, SAPS can produce sets of small size and communicate instance-wise uncertainty. Theoretically, we provide a finite-sample coverage guarantee of SAPS and show that the expected value of set size from SAPS is always smaller than APS. Extensive experiments validate that SAPS not only lessens the prediction sets but also broadly enhances the conditional coverage rate and adaptation of prediction sets.
+
+
+
+ 67. 标题:TANGO: Time-Reversal Latent GraphODE for Multi-Agent Dynamical Systems
+ 编号:[166]
+ 链接:https://arxiv.org/abs/2310.06427
+ 作者:Zijie Huang, Wanjia Zhao, Jingdong Gao, Ziniu Hu, Xiao Luo, Yadi Cao, Yuanzhou Chen, Yizhou Sun, Wei Wang
+ 备注:
+ 关键词:Learning complex multi-agent, Hamiltonian Neural Network, complex multi-agent system, material modeling, complex multi-agent
+
+ 点击查看摘要
+ Learning complex multi-agent system dynamics from data is crucial across many domains, such as in physical simulations and material modeling. Extended from purely data-driven approaches, existing physics-informed approaches such as Hamiltonian Neural Network strictly follow energy conservation law to introduce inductive bias, making their learning more sample efficiently. However, many real-world systems do not strictly conserve energy, such as spring systems with frictions. Recognizing this, we turn our attention to a broader physical principle: Time-Reversal Symmetry, which depicts that the dynamics of a system shall remain invariant when traversed back over time. It still helps to preserve energies for conservative systems and in the meanwhile, serves as a strong inductive bias for non-conservative, reversible systems. To inject such inductive bias, in this paper, we propose a simple-yet-effective self-supervised regularization term as a soft constraint that aligns the forward and backward trajectories predicted by a continuous graph neural network-based ordinary differential equation (GraphODE). It effectively imposes time-reversal symmetry to enable more accurate model predictions across a wider range of dynamical systems under classical mechanics. In addition, we further provide theoretical analysis to show that our regularization essentially minimizes higher-order Taylor expansion terms during the ODE integration steps, which enables our model to be more noise-tolerant and even applicable to irreversible systems. Experimental results on a variety of physical systems demonstrate the effectiveness of our proposed method. Particularly, it achieves an MSE improvement of 11.5 % on a challenging chaotic triple-pendulum systems.
+
+
+
+ 68. 标题:Advective Diffusion Transformers for Topological Generalization in Graph Learning
+ 编号:[171]
+ 链接:https://arxiv.org/abs/2310.06417
+ 作者:Qitian Wu, Chenxiao Yang, Kaipeng Zeng, Fan Nie, Michael Bronstein, Junchi Yan
+ 备注:39 pages
+ 关键词:justifying architectural choices, recently attracted attention, analyzing GNN dynamics, graph neural networks, Graph diffusion equations
+
+ 点击查看摘要
+ Graph diffusion equations are intimately related to graph neural networks (GNNs) and have recently attracted attention as a principled framework for analyzing GNN dynamics, formalizing their expressive power, and justifying architectural choices. One key open questions in graph learning is the generalization capabilities of GNNs. A major limitation of current approaches hinges on the assumption that the graph topologies in the training and test sets come from the same distribution. In this paper, we make steps towards understanding the generalization of GNNs by exploring how graph diffusion equations extrapolate and generalize in the presence of varying graph topologies. We first show deficiencies in the generalization capability of existing models built upon local diffusion on graphs, stemming from the exponential sensitivity to topology variation. Our subsequent analysis reveals the promise of non-local diffusion, which advocates for feature propagation over fully-connected latent graphs, under the assumption of a specific data-generating condition. In addition to these findings, we propose a novel graph encoder backbone, Advective Diffusion Transformer (ADiT), inspired by advective graph diffusion equations that have a closed-form solution backed up with theoretical guarantees of desired generalization under topological distribution shifts. The new model, functioning as a versatile graph Transformer, demonstrates superior performance across a wide range of graph learning tasks.
+
+
+
+ 69. 标题:Deep reinforcement learning uncovers processes for separating azeotropic mixtures without prior knowledge
+ 编号:[172]
+ 链接:https://arxiv.org/abs/2310.06415
+ 作者:Quirin Göttl, Jonathan Pirnay, Jakob Burger, Dominik G. Grimm
+ 备注:36 pages, 7 figures, 4 tables. G\"ottl and Pirnay contributed equally as joint first authors. Burger and Grimm contributed equally as joint last authors
+ 关键词:vast search spaces, planning problem due, search spaces, continuous parameters, complex planning problem
+
+ 点击查看摘要
+ Process synthesis in chemical engineering is a complex planning problem due to vast search spaces, continuous parameters and the need for generalization. Deep reinforcement learning agents, trained without prior knowledge, have shown to outperform humans in various complex planning problems in recent years. Existing work on reinforcement learning for flowsheet synthesis shows promising concepts, but focuses on narrow problems in a single chemical system, limiting its practicality. We present a general deep reinforcement learning approach for flowsheet synthesis. We demonstrate the adaptability of a single agent to the general task of separating binary azeotropic mixtures. Without prior knowledge, it learns to craft near-optimal flowsheets for multiple chemical systems, considering different feed compositions and conceptual approaches. On average, the agent can separate more than 99% of the involved materials into pure components, while autonomously learning fundamental process engineering paradigms. This highlights the agent's planning flexibility, an encouraging step toward true generality.
+
+
+
+ 70. 标题:Hexa: Self-Improving for Knowledge-Grounded Dialogue System
+ 编号:[176]
+ 链接:https://arxiv.org/abs/2310.06404
+ 作者:Daejin Jo, Daniel Wontae Nam, Gunsoo Han, Kyoung-Woon On, Taehwan Kwon, Seungeun Rho, Sungwoong Kim
+ 备注:
+ 关键词:explicitly utilize intermediate, memory retrieval, modular approaches, utilize intermediate steps, common practice
+
+ 点击查看摘要
+ A common practice in knowledge-grounded dialogue generation is to explicitly utilize intermediate steps (e.g., web-search, memory retrieval) with modular approaches. However, data for such steps are often inaccessible compared to those of dialogue responses as they are unobservable in an ordinary dialogue. To fill in the absence of these data, we develop a self-improving method to improve the generative performances of intermediate steps without the ground truth data. In particular, we propose a novel bootstrapping scheme with a guided prompt and a modified loss function to enhance the diversity of appropriate self-generated responses. Through experiments on various benchmark datasets, we empirically demonstrate that our method successfully leverages a self-improving mechanism in generating intermediate and final responses and improves the performances on the task of knowledge-grounded dialogue generation.
+
+
+
+ 71. 标题:Lo-Hi: Practical ML Drug Discovery Benchmark
+ 编号:[178]
+ 链接:https://arxiv.org/abs/2310.06399
+ 作者:Simon Steshin
+ 备注:29 pages, Advances in Neural Information Processing Systems, 2023
+ 关键词:https URL, Balanced Vertex Minimum, URL, harder, drug discovery
+
+ 点击查看摘要
+ Finding new drugs is getting harder and harder. One of the hopes of drug discovery is to use machine learning models to predict molecular properties. That is why models for molecular property prediction are being developed and tested on benchmarks such as MoleculeNet. However, existing benchmarks are unrealistic and are too different from applying the models in practice. We have created a new practical \emph{Lo-Hi} benchmark consisting of two tasks: Lead Optimization (Lo) and Hit Identification (Hi), corresponding to the real drug discovery process. For the Hi task, we designed a novel molecular splitting algorithm that solves the Balanced Vertex Minimum $k$-Cut problem. We tested state-of-the-art and classic ML models, revealing which works better under practical settings. We analyzed modern benchmarks and showed that they are unrealistic and overoptimistic.
+Review: this https URL
+Lo-Hi benchmark: this https URL
+Lo-Hi splitter library: this https URL
+
+
+
+ 72. 标题:Adversarial Robustness in Graph Neural Networks: A Hamiltonian Approach
+ 编号:[180]
+ 链接:https://arxiv.org/abs/2310.06396
+ 作者:Kai Zhao, Qiyu Kang, Yang Song, Rui She, Sijie Wang, Wee Peng Tay
+ 备注:Accepted by Advances in Neural Information Processing Systems (NeurIPS), New Orleans, USA, Dec. 2023, spotlight
+ 关键词:Graph neural networks, graph topology, Lyapunov stability, affect both node, node features
+
+ 点击查看摘要
+ Graph neural networks (GNNs) are vulnerable to adversarial perturbations, including those that affect both node features and graph topology. This paper investigates GNNs derived from diverse neural flows, concentrating on their connection to various stability notions such as BIBO stability, Lyapunov stability, structural stability, and conservative stability. We argue that Lyapunov stability, despite its common use, does not necessarily ensure adversarial robustness. Inspired by physics principles, we advocate for the use of conservative Hamiltonian neural flows to construct GNNs that are robust to adversarial attacks. The adversarial robustness of different neural flow GNNs is empirically compared on several benchmark datasets under a variety of adversarial attacks. Extensive numerical experiments demonstrate that GNNs leveraging conservative Hamiltonian flows with Lyapunov stability substantially improve robustness against adversarial perturbations. The implementation code of experiments is available at this https URL.
+
+
+
+ 73. 标题:Harnessing Administrative Data Inventories to Create a Reliable Transnational Reference Database for Crop Type Monitoring
+ 编号:[181]
+ 链接:https://arxiv.org/abs/2310.06393
+ 作者:Maja Schneider, Marco Körner
+ 备注:
+ 关键词:applicationon Earth observation, Earth observation challenges, machine learning techniques, unlocked unprecedented performance, applicationon Earth
+
+ 点击查看摘要
+ With leaps in machine learning techniques and their applicationon Earth observation challenges has unlocked unprecedented performance across the domain. While the further development of these methods was previously limited by the availability and volume of sensor data and computing resources, the lack of adequate reference data is now constituting new bottlenecks. Since creating such ground-truth information is an expensive and error-prone task, new ways must be devised to source reliable, high-quality reference data on large scales. As an example, we showcase E URO C ROPS, a reference dataset for crop type classification that aggregates and harmonizes administrative data surveyed in different countries with the goal of transnational interoperability.
+
+
+
+ 74. 标题:Jailbreak and Guard Aligned Language Models with Only Few In-Context Demonstrations
+ 编号:[185]
+ 链接:https://arxiv.org/abs/2310.06387
+ 作者:Zeming Wei, Yifei Wang, Yisen Wang
+ 备注:
+ 关键词:Large Language Models, shown remarkable success, content have emerged, shown remarkable, Large Language
+
+ 点击查看摘要
+ Large Language Models (LLMs) have shown remarkable success in various tasks, but concerns about their safety and the potential for generating malicious content have emerged. In this paper, we explore the power of In-Context Learning (ICL) in manipulating the alignment ability of LLMs. We find that by providing just few in-context demonstrations without fine-tuning, LLMs can be manipulated to increase or decrease the probability of jailbreaking, i.e. answering malicious prompts. Based on these observations, we propose In-Context Attack (ICA) and In-Context Defense (ICD) methods for jailbreaking and guarding aligned language model purposes. ICA crafts malicious contexts to guide models in generating harmful outputs, while ICD enhances model robustness by demonstrations of rejecting to answer harmful prompts. Our experiments show the effectiveness of ICA and ICD in increasing or reducing the success rate of adversarial jailbreaking attacks. Overall, we shed light on the potential of ICL to influence LLM behavior and provide a new perspective for enhancing the safety and alignment of LLMs.
+
+
+
+ 75. 标题:CAST: Cluster-Aware Self-Training for Tabular Data
+ 编号:[190]
+ 链接:https://arxiv.org/abs/2310.06380
+ 作者:Minwook Kim, Juseong Kim, Kibeom Kim, Donggil Kang, Giltae Song
+ 备注:17 pages with appendix
+ 关键词:simplicity and versatility, gained attraction, vulnerable to noisy, Self-training, noisy pseudo-labels
+
+ 点击查看摘要
+ Self-training has gained attraction because of its simplicity and versatility, yet it is vulnerable to noisy pseudo-labels. Several studies have proposed successful approaches to tackle this issue, but they have diminished the advantages of self-training because they require specific modifications in self-training algorithms or model architectures. Furthermore, most of them are incompatible with gradient boosting decision trees, which dominate the tabular domain. To address this, we revisit the cluster assumption, which states that data samples that are close to each other tend to belong to the same class. Inspired by the assumption, we propose Cluster-Aware Self-Training (CAST) for tabular data. CAST is a simple and universally adaptable approach for enhancing existing self-training algorithms without significant modifications. Concretely, our method regularizes the confidence of the classifier, which represents the value of the pseudo-label, forcing the pseudo-labels in low-density regions to have lower confidence by leveraging prior knowledge for each class within the training data. Extensive empirical evaluations on up to 20 real-world datasets confirm not only the superior performance of CAST but also its robustness in various setups in self-training contexts.
+
+
+
+ 76. 标题:Initialization Bias of Fourier Neural Operator: Revisiting the Edge of Chaos
+ 编号:[191]
+ 链接:https://arxiv.org/abs/2310.06379
+ 作者:Takeshi Koshizuka, Masahiro Fujisawa, Yusuke Tanaka, Issei Sato
+ 备注:
+ 关键词:Fourier neural operator, Fourier neural, neural operator, paper investigates, FNO
+
+ 点击查看摘要
+ This paper investigates the initialization bias of the Fourier neural operator (FNO). A mean-field theory for FNO is established, analyzing the behavior of the random FNO from an ``edge of chaos'' perspective. We uncover that the forward and backward propagation behaviors exhibit characteristics unique to FNO, induced by mode truncation, while also showcasing similarities to those of densely connected networks. Building upon this observation, we also propose a FNO version of the He initialization scheme to mitigate the negative initialization bias leading to training instability. Experimental results demonstrate the effectiveness of our initialization scheme, enabling stable training of a 32-layer FNO without the need for additional techniques or significant performance degradation.
+
+
+
+ 77. 标题:Leveraging Diffusion-Based Image Variations for Robust Training on Poisoned Data
+ 编号:[194]
+ 链接:https://arxiv.org/abs/2310.06372
+ 作者:Lukas Struppek, Martin B. Hentschel, Clifton Poth, Dominik Hintersdorf, Kristian Kersting
+ 备注:11 pages, 3 tables, 2 figures
+ 关键词:surreptitiously introduce hidden, introduce hidden functionalities, Backdoor attacks pose, training neural networks, attacks pose
+
+ 点击查看摘要
+ Backdoor attacks pose a serious security threat for training neural networks as they surreptitiously introduce hidden functionalities into a model. Such backdoors remain silent during inference on clean inputs, evading detection due to inconspicuous behavior. However, once a specific trigger pattern appears in the input data, the backdoor activates, causing the model to execute its concealed function. Detecting such poisoned samples within vast datasets is virtually impossible through manual inspection. To address this challenge, we propose a novel approach that enables model training on potentially poisoned datasets by utilizing the power of recent diffusion models. Specifically, we create synthetic variations of all training samples, leveraging the inherent resilience of diffusion models to potential trigger patterns in the data. By combining this generative approach with knowledge distillation, we produce student models that maintain their general performance on the task while exhibiting robust resistance to backdoor triggers.
+
+
+
+ 78. 标题:Partition-based differentially private synthetic data generation
+ 编号:[195]
+ 链接:https://arxiv.org/abs/2310.06371
+ 作者:Meifan Zhang, Dihang Deng, Lihua Yin
+ 备注:
+ 关键词:original data compared, summary statistics, distribution and nuances, nuances of original, compared to summary
+
+ 点击查看摘要
+ Private synthetic data sharing is preferred as it keeps the distribution and nuances of original data compared to summary statistics. The state-of-the-art methods adopt a select-measure-generate paradigm, but measuring large domain marginals still results in much error and allocating privacy budget iteratively is still difficult. To address these issues, our method employs a partition-based approach that effectively reduces errors and improves the quality of synthetic data, even with a limited privacy budget. Results from our experiments demonstrate the superiority of our method over existing approaches. The synthetic data produced using our approach exhibits improved quality and utility, making it a preferable choice for private synthetic data sharing.
+
+
+
+ 79. 标题:Geometrically Aligned Transfer Encoder for Inductive Transfer in Regression Tasks
+ 编号:[197]
+ 链接:https://arxiv.org/abs/2310.06369
+ 作者:Sung Moon Ko, Sumin Lee, Dae-Woong Jeong, Woohyung Lim, Sehui Han
+ 备注:12+11 pages, 6+1 figures, 0+7 tables
+ 关键词:Aligned Transfer Encoder, Geometrically Aligned Transfer, handling a small, small amount, potentially related
+
+ 点击查看摘要
+ Transfer learning is a crucial technique for handling a small amount of data that is potentially related to other abundant data. However, most of the existing methods are focused on classification tasks using images and language datasets. Therefore, in order to expand the transfer learning scheme to regression tasks, we propose a novel transfer technique based on differential geometry, namely the Geometrically Aligned Transfer Encoder (GATE). In this method, we interpret the latent vectors from the model to exist on a Riemannian curved manifold. We find a proper diffeomorphism between pairs of tasks to ensure that every arbitrary point maps to a locally flat coordinate in the overlapping region, allowing the transfer of knowledge from the source to the target data. This also serves as an effective regularizer for the model to behave in extrapolation regions. In this article, we demonstrate that GATE outperforms conventional methods and exhibits stable behavior in both the latent space and extrapolation regions for various molecular graph datasets.
+
+
+
+ 80. 标题:DrugCLIP: Contrastive Protein-Molecule Representation Learning for Virtual Screening
+ 编号:[199]
+ 链接:https://arxiv.org/abs/2310.06367
+ 作者:Bowen Gao, Bo Qiang, Haichuan Tan, Minsi Ren, Yinjun Jia, Minsi Lu, Jingjing Liu, Weiying Ma, Yanyan Lan
+ 备注:
+ 关键词:AI-assisted drug discovery, identifies potential drugs, vast compound databases, drug discovery, potential drugs
+
+ 点击查看摘要
+ Virtual screening, which identifies potential drugs from vast compound databases to bind with a particular protein pocket, is a critical step in AI-assisted drug discovery. Traditional docking methods are highly time-consuming, and can only work with a restricted search library in real-life applications. Recent supervised learning approaches using scoring functions for binding-affinity prediction, although promising, have not yet surpassed docking methods due to their strong dependency on limited data with reliable binding-affinity labels. In this paper, we propose a novel contrastive learning framework, DrugCLIP, by reformulating virtual screening as a dense retrieval task and employing contrastive learning to align representations of binding protein pockets and molecules from a large quantity of pairwise data without explicit binding-affinity scores. We also introduce a biological-knowledge inspired data augmentation strategy to learn better protein-molecule representations. Extensive experiments show that DrugCLIP significantly outperforms traditional docking and supervised learning methods on diverse virtual screening benchmarks with highly reduced computation time, especially in zero-shot setting.
+
+
+
+ 81. 标题:Core-Intermediate-Peripheral Index: Factor Analysis of Neighborhood and Shortest Paths-based Centrality Metrics
+ 编号:[205]
+ 链接:https://arxiv.org/abs/2310.06358
+ 作者:Natarajan Meghanathan
+ 备注:10 pages, 5 figures
+ 关键词:shortest paths-based centrality, paths-based centrality metrics, quantitative measure called, Betweeenness and Closeness, raw centrality metrics
+
+ 点击查看摘要
+ We perform factor analysis on the raw data of the four major neighborhood and shortest paths-based centrality metrics (Degree, Eigenvector, Betweeenness and Closeness) and propose a novel quantitative measure called the Core-Intermediate-Peripheral (CIP) Index to capture the extent with which a node could play the role of a core node (nodes at the center of a network with larger values for any centrality metric) vis-a-vis a peripheral node (nodes that exist at the periphery of a network with lower values for any centrality metric). We conduct factor analysis (varimax-based rotation of the Eigenvectors) on the transpose matrix of the raw centrality metrics dataset, with the node ids as features, under the hypothesis that there are two factors (core and peripheral) that drive the values incurred by the nodes with respect to the centrality metrics. We test our approach on a diverse suite of 12 complex real-world networks.
+
+
+
+ 82. 标题:Boosting Continuous Control with Consistency Policy
+ 编号:[211]
+ 链接:https://arxiv.org/abs/2310.06343
+ 作者:Yuhui Chen, Haoran Li, Dongbin Zhao
+ 备注:18 pages, 9 pages
+ 关键词:attracted considerable attention, diffusion model-based policy, strong expression, training stability, stability and strong
+
+ 点击查看摘要
+ Due to its training stability and strong expression, the diffusion model has attracted considerable attention in offline reinforcement learning. However, several challenges have also come with it: 1) The demand for a large number of diffusion steps makes the diffusion-model-based methods time inefficient and limits their applications in real-time control; 2) How to achieve policy improvement with accurate guidance for diffusion model-based policy is still an open problem. Inspired by the consistency model, we propose a novel time-efficiency method named Consistency Policy with Q-Learning (CPQL), which derives action from noise by a single step. By establishing a mapping from the reverse diffusion trajectories to the desired policy, we simultaneously address the issues of time efficiency and inaccurate guidance when updating diffusion model-based policy with the learned Q-function. We demonstrate that CPQL can achieve policy improvement with accurate guidance for offline reinforcement learning, and can be seamlessly extended for online RL tasks. Experimental results indicate that CPQL achieves new state-of-the-art performance on 11 offline and 21 online tasks, significantly improving inference speed by nearly 45 times compared to Diffusion-QL. We will release our code later.
+
+
+
+ 83. 标题:Federated Learning with Reduced Information Leakage and Computation
+ 编号:[213]
+ 链接:https://arxiv.org/abs/2310.06341
+ 作者:Tongxin Yin, Xueru Zhang, Mohammad Mahdi Khalili, Mingyan Liu
+ 备注:
+ 关键词:multiple decentralized clients, distributed learning paradigm, sharing local data, multiple decentralized, decentralized clients
+
+ 点击查看摘要
+ Federated learning (FL) is a distributed learning paradigm that allows multiple decentralized clients to collaboratively learn a common model without sharing local data. Although local data is not exposed directly, privacy concerns nonetheless exist as clients' sensitive information can be inferred from intermediate computations. Moreover, such information leakage accumulates substantially over time as the same data is repeatedly used during the iterative learning process. As a result, it can be particularly difficult to balance the privacy-accuracy trade-off when designing privacy-preserving FL algorithms. In this paper, we introduce Upcycled-FL, a novel federated learning framework with first-order approximation applied at every even iteration. Under this framework, half of the FL updates incur no information leakage and require much less computation. We first conduct the theoretical analysis on the convergence (rate) of Upcycled-FL, and then apply perturbation mechanisms to preserve privacy. Experiments on real-world data show that Upcycled-FL consistently outperforms existing methods over heterogeneous data, and significantly improves privacy-accuracy trade-off while reducing 48% of the training time on average.
+
+
+
+ 84. 标题:Learning bounded-degree polytrees with known skeleton
+ 编号:[217]
+ 链接:https://arxiv.org/abs/2310.06333
+ 作者:Davin Choo, Joy Qiping Yang, Arnab Bhattacharyya, Clément L. Canonne
+ 备注:
+ 关键词:high-dimensional probability distributions, efficient proper learning, Bayesian networks, establish finite-sample guarantees, graphical model
+
+ 点击查看摘要
+ We establish finite-sample guarantees for efficient proper learning of bounded-degree polytrees, a rich class of high-dimensional probability distributions and a subclass of Bayesian networks, a widely-studied type of graphical model. Recently, Bhattacharyya et al. (2021) obtained finite-sample guarantees for recovering tree-structured Bayesian networks, i.e., 1-polytrees. We extend their results by providing an efficient algorithm which learns $d$-polytrees in polynomial time and sample complexity for any bounded $d$ when the underlying undirected graph (skeleton) is known. We complement our algorithm with an information-theoretic sample complexity lower bound, showing that the dependence on the dimension and target accuracy parameters are nearly tight.
+
+
+
+ 85. 标题:Exploit the antenna response consistency to define the alignment criteria for CSI data
+ 编号:[220]
+ 链接:https://arxiv.org/abs/2310.06328
+ 作者:Ke Xu, Jiangtao Wang, Hongyuan Zhu, Dingchang Zheng
+ 备注:
+ 关键词:human activity recognition, holds great promise, great promise due, insufficient labeled data, WiFi-based human activity
+
+ 点击查看摘要
+ Self-supervised learning (SSL) for WiFi-based human activity recognition (HAR) holds great promise due to its ability to address the challenge of insufficient labeled data. However, directly transplanting SSL algorithms, especially contrastive learning, originally designed for other domains to CSI data, often fails to achieve the expected performance. We attribute this issue to the inappropriate alignment criteria, which disrupt the semantic distance consistency between the feature space and the input space. To address this challenge, we introduce \textbf{A}netenna \textbf{R}esponse \textbf{C}onsistency (ARC) as a solution to define proper alignment criteria. ARC is designed to retain semantic information from the input space while introducing robustness to real-world noise. We analyze ARC from the perspective of CSI data structure, demonstrating that its optimal solution leads to a direct mapping from input CSI data to action vectors in the feature map. Furthermore, we provide extensive experimental evidence to validate the effectiveness of ARC in improving the performance of self-supervised learning for WiFi-based HAR.
+
+
+
+ 86. 标题:Predicting Three Types of Freezing of Gait Events Using Deep Learning Models
+ 编号:[222]
+ 链接:https://arxiv.org/abs/2310.06322
+ 作者:Wen Tao Mo, Jonathan H. Chan
+ 备注:5 pages
+ 关键词:Parkinson Disease symptom, Parkinson Disease, Freezing of gait, Disease symptom, gait
+
+ 点击查看摘要
+ Freezing of gait is a Parkinson's Disease symptom that episodically inflicts a patient with the inability to step or turn while walking. While medical experts have discovered various triggers and alleviating actions for freezing of gait, the underlying causes and prediction models are still being explored today. Current freezing of gait prediction models that utilize machine learning achieve high sensitivity and specificity in freezing of gait predictions based on time-series data; however, these models lack specifications on the type of freezing of gait events. We develop various deep learning models using the transformer encoder architecture plus Bidirectional LSTM layers and different feature sets to predict the three different types of freezing of gait events. The best performing model achieves a score of 0.427 on testing data, which would rank top 5 in Kaggle's Freezing of Gait prediction competition, hosted by THE MICHAEL J. FOX FOUNDATION. However, we also recognize overfitting in training data that could be potentially improved through pseudo labelling on additional data and model architecture simplification.
+
+
+
+ 87. 标题:Transfer learning-based physics-informed convolutional neural network for simulating flow in porous media with time-varying controls
+ 编号:[224]
+ 链接:https://arxiv.org/abs/2310.06319
+ 作者:Jungang Chen, Eduardo Gildin, John E. Killough
+ 备注:
+ 关键词:physics-informed convolutional neural, convolutional neural network, physics-informed convolutional, convolutional neural, media with time-varying
+
+ 点击查看摘要
+ A physics-informed convolutional neural network is proposed to simulate two phase flow in porous media with time-varying well controls. While most of PICNNs in existing literatures worked on parameter-to-state mapping, our proposed network parameterizes the solution with time-varying controls to establish a control-to-state regression. Firstly, finite volume scheme is adopted to discretize flow equations and formulate loss function that respects mass conservation laws. Neumann boundary conditions are seamlessly incorporated into the semi-discretized equations so no additional loss term is needed. The network architecture comprises two parallel U-Net structures, with network inputs being well controls and outputs being the system states. To capture the time-dependent relationship between inputs and outputs, the network is well designed to mimic discretized state space equations. We train the network progressively for every timestep, enabling it to simultaneously predict oil pressure and water saturation at each timestep. After training the network for one timestep, we leverage transfer learning techniques to expedite the training process for subsequent timestep. The proposed model is used to simulate oil-water porous flow scenarios with varying reservoir gridblocks and aspects including computation efficiency and accuracy are compared against corresponding numerical approaches. The results underscore the potential of PICNN in effectively simulating systems with numerous grid blocks, as computation time does not scale with model dimensionality. We assess the temporal error using 10 different testing controls with variation in magnitude and another 10 with higher alternation frequency with proposed control-to-state architecture. Our observations suggest the need for a more robust and reliable model when dealing with controls that exhibit significant variations in magnitude or frequency.
+
+
+
+ 88. 标题:Discovering Mixtures of Structural Causal Models from Time Series Data
+ 编号:[226]
+ 链接:https://arxiv.org/abs/2310.06312
+ 作者:Sumanth Varambally, Yi-An Ma, Rose Yu
+ 备注:
+ 关键词:inferring causal relationships, climate science, time series data, formidable challenge, series data poses
+
+ 点击查看摘要
+ In fields such as finance, climate science, and neuroscience, inferring causal relationships from time series data poses a formidable challenge. While contemporary techniques can handle nonlinear relationships between variables and flexible noise distributions, they rely on the simplifying assumption that data originates from the same underlying causal model. In this work, we relax this assumption and perform causal discovery from time series data originating from mixtures of different causal models. We infer both the underlying structural causal models and the posterior probability for each sample belonging to a specific mixture component. Our approach employs an end-to-end training process that maximizes an evidence-lower bound for data likelihood. Through extensive experimentation on both synthetic and real-world datasets, we demonstrate that our method surpasses state-of-the-art benchmarks in causal discovery tasks, particularly when the data emanates from diverse underlying causal graphs. Theoretically, we prove the identifiability of such a model under some mild assumptions.
+
+
+
+ 89. 标题:Ensemble Active Learning by Contextual Bandits for AI Incubation in Manufacturing
+ 编号:[232]
+ 链接:https://arxiv.org/abs/2310.06306
+ 作者:Yingyan Zeng, Xiaoyu Chen, Ran Jin
+ 备注:
+ 关键词:streaming data acquisition, maintain data quality, learning base learners, save annotation efforts, supervised learning base
+
+ 点击查看摘要
+ It is challenging but important to save annotation efforts in streaming data acquisition to maintain data quality for supervised learning base learners. We propose an ensemble active learning method to actively acquire samples for annotation by contextual bandits, which is will enforce the exploration-exploitation balance and leading to improved AI modeling performance.
+
+
+
+ 90. 标题:Dynamical versus Bayesian Phase Transitions in a Toy Model of Superposition
+ 编号:[235]
+ 链接:https://arxiv.org/abs/2310.06301
+ 作者:Zhongtian Chen, Edmund Lau, Jake Mendel, Susan Wei, Daniel Murfet
+ 备注:
+ 关键词:Model of Superposition, Toy Model, Singular Learning Theory, investigate phase transitions, Singular Learning
+
+ 点击查看摘要
+ We investigate phase transitions in a Toy Model of Superposition (TMS) using Singular Learning Theory (SLT). We derive a closed formula for the theoretical loss and, in the case of two hidden dimensions, discover that regular $k$-gons are critical points. We present supporting theory indicating that the local learning coefficient (a geometric invariant) of these $k$-gons determines phase transitions in the Bayesian posterior as a function of training sample size. We then show empirically that the same $k$-gon critical points also determine the behavior of SGD training. The picture that emerges adds evidence to the conjecture that the SGD learning trajectory is subject to a sequential learning mechanism. Specifically, we find that the learning process in TMS, be it through SGD or Bayesian learning, can be characterized by a journey through parameter space from regions of high loss and low complexity to regions of low loss and high complexity.
+
+
+
+ 91. 标题:Gem5Pred: Predictive Approaches For Gem5 Simulation Time
+ 编号:[241]
+ 链接:https://arxiv.org/abs/2310.06290
+ 作者:Tian Yan, Xueyang Li, Sifat Ut Taki, Saeid Mehrdad
+ 备注:
+ 关键词:cost-effective simulator, widely recognized, recognized and utilized, academic and industry, hardware simulation
+
+ 点击查看摘要
+ Gem5, an open-source, flexible, and cost-effective simulator, is widely recognized and utilized in both academic and industry fields for hardware simulation. However, the typically time-consuming nature of simulating programs on Gem5 underscores the need for a predictive model that can estimate simulation time. As of now, no such dataset or model exists. In response to this gap, this paper makes a novel contribution by introducing a unique dataset specifically created for this purpose. We also conducted analysis of the effects of different instruction types on the simulation time in Gem5. After this, we employ three distinct models leveraging CodeBERT to execute the prediction task based on the developed dataset. Our superior regression model achieves a Mean Absolute Error (MAE) of 0.546, while our top-performing classification model records an Accuracy of 0.696. Our models establish a foundation for future investigations on this topic, serving as benchmarks against which subsequent models can be compared. We hope that our contribution can simulate further research in this field. The dataset we used is available at this https URL.
+
+
+
+ 92. 标题:Suppressing Overestimation in Q-Learning through Adversarial Behaviors
+ 编号:[243]
+ 链接:https://arxiv.org/abs/2310.06286
+ 作者:HyeAnn Lee, Donghwan Lee
+ 备注:
+ 关键词:called dummy adversarial, Q-learning, dummy adversarial Q-learning, dummy adversarial player, DAQ
+
+ 点击查看摘要
+ The goal of this paper is to propose a new Q-learning algorithm with a dummy adversarial player, which is called dummy adversarial Q-learning (DAQ), that can effectively regulate the overestimation bias in standard Q-learning. With the dummy player, the learning can be formulated as a two-player zero-sum game. The proposed DAQ unifies several Q-learning variations to control overestimation biases, such as maxmin Q-learning and minmax Q-learning (proposed in this paper) in a single framework. The proposed DAQ is a simple but effective way to suppress the overestimation bias thourgh dummy adversarial behaviors and can be easily applied to off-the-shelf reinforcement learning algorithms to improve the performances. A finite-time convergence of DAQ is analyzed from an integrated perspective by adapting an adversarial Q-learning. The performance of the suggested DAQ is empirically demonstrated under various benchmark environments.
+
+
+
+ 93. 标题:MuseChat: A Conversational Music Recommendation System for Videos
+ 编号:[246]
+ 链接:https://arxiv.org/abs/2310.06282
+ 作者:Zhikang Dong, Bin Chen, Xiulong Liu, Pawel Polak, Peng Zhang
+ 备注:
+ 关键词:innovative dialog-based music, music, innovative dialog-based, recommendation, dialog-based music recommendation
+
+ 点击查看摘要
+ We introduce MuseChat, an innovative dialog-based music recommendation system. This unique platform not only offers interactive user engagement but also suggests music tailored for input videos, so that users can refine and personalize their music selections. In contrast, previous systems predominantly emphasized content compatibility, often overlooking the nuances of users' individual preferences. For example, all the datasets only provide basic music-video pairings or such pairings with textual music descriptions. To address this gap, our research offers three contributions. First, we devise a conversation-synthesis method that simulates a two-turn interaction between a user and a recommendation system, which leverages pre-trained music tags and artist information. In this interaction, users submit a video to the system, which then suggests a suitable music piece with a rationale. Afterwards, users communicate their musical preferences, and the system presents a refined music recommendation with reasoning. Second, we introduce a multi-modal recommendation engine that matches music either by aligning it with visual cues from the video or by harmonizing visual information, feedback from previously recommended music, and the user's textual input. Third, we bridge music representations and textual data with a Large Language Model(Vicuna-7B). This alignment equips MuseChat to deliver music recommendations and their underlying reasoning in a manner resembling human communication. Our evaluations show that MuseChat surpasses existing state-of-the-art models in music retrieval tasks and pioneers the integration of the recommendation process within a natural language framework.
+
+
+
+ 94. 标题:BC4LLM: Trusted Artificial Intelligence When Blockchain Meets Large Language Models
+ 编号:[248]
+ 链接:https://arxiv.org/abs/2310.06278
+ 作者:Haoxiang Luo, Jian Luo, Athanasios V. Vasilakos
+ 备注:
+ 关键词:reshaping society production, society production methods, artificial intelligence, recent years, methods and productivity
+
+ 点击查看摘要
+ In recent years, artificial intelligence (AI) and machine learning (ML) are reshaping society's production methods and productivity, and also changing the paradigm of scientific research. Among them, the AI language model represented by ChatGPT has made great progress. Such large language models (LLMs) serve people in the form of AI-generated content (AIGC) and are widely used in consulting, healthcare, and education. However, it is difficult to guarantee the authenticity and reliability of AIGC learning data. In addition, there are also hidden dangers of privacy disclosure in distributed AI training. Moreover, the content generated by LLMs is difficult to identify and trace, and it is difficult to cross-platform mutual recognition. The above information security issues in the coming era of AI powered by LLMs will be infinitely amplified and affect everyone's life. Therefore, we consider empowering LLMs using blockchain technology with superior security features to propose a vision for trusted AI. This paper mainly introduces the motivation and technical route of blockchain for LLM (BC4LLM), including reliable learning corpus, secure training process, and identifiable generated content. Meanwhile, this paper also reviews the potential applications and future challenges, especially in the frontier communication networks field, including network resource allocation, dynamic spectrum sharing, and semantic communication. Based on the above work combined and the prospect of blockchain and LLMs, it is expected to help the early realization of trusted AI and provide guidance for the academic community.
+
+
+
+ 95. 标题:Let Models Speak Ciphers: Multiagent Debate through Embeddings
+ 编号:[250]
+ 链接:https://arxiv.org/abs/2310.06272
+ 作者:Chau Pham, Boyi Liu, Yingxiang Yang, Zhengyu Chen, Tianyi Liu, Jianbo Yuan, Bryan A. Plummer, Zhaoran Wang, Hongxia Yang
+ 备注:
+ 关键词:Large Language Models, gained considerable attention, considerable attention due, Large Language, gained considerable
+
+ 点击查看摘要
+ Discussion and debate among Large Language Models (LLMs) have gained considerable attention due to their potential to enhance the reasoning ability of LLMs. Although natural language is an obvious choice for communication due to LLM's language understanding capability, the token sampling step needed when generating natural language poses a potential risk of information loss, as it uses only one token to represent the model's belief across the entire vocabulary. In this paper, we introduce a communication regime named CIPHER (Communicative Inter-Model Protocol Through Embedding Representation) to address this issue. Specifically, we remove the token sampling step from LLMs and let them communicate their beliefs across the vocabulary through the expectation of the raw transformer output embeddings. Remarkably, by deviating from natural language, CIPHER offers an advantage of encoding a broader spectrum of information without any modification to the model weights. While the state-of-the-art LLM debate methods using natural language outperforms traditional inference by a margin of 1.5-8%, our experiment results show that CIPHER debate further extends this lead by 1-3.5% across five reasoning tasks and multiple open-source LLMs of varying sizes. This showcases the superiority and robustness of embeddings as an alternative "language" for communication among LLMs.
+
+
+
+ 96. 标题:Bi-Level Offline Policy Optimization with Limited Exploration
+ 编号:[253]
+ 链接:https://arxiv.org/abs/2310.06268
+ 作者:Wenzhuo Zhou
+ 备注:
+ 关键词:good policy based, offline reinforcement learning, study offline reinforcement, reinforcement learning, seeks to learn
+
+ 点击查看摘要
+ We study offline reinforcement learning (RL) which seeks to learn a good policy based on a fixed, pre-collected dataset. A fundamental challenge behind this task is the distributional shift due to the dataset lacking sufficient exploration, especially under function approximation. To tackle this issue, we propose a bi-level structured policy optimization algorithm that models a hierarchical interaction between the policy (upper-level) and the value function (lower-level). The lower level focuses on constructing a confidence set of value estimates that maintain sufficiently small weighted average Bellman errors, while controlling uncertainty arising from distribution mismatch. Subsequently, at the upper level, the policy aims to maximize a conservative value estimate from the confidence set formed at the lower level. This novel formulation preserves the maximum flexibility of the implicitly induced exploratory data distribution, enabling the power of model extrapolation. In practice, it can be solved through a computationally efficient, penalized adversarial estimation procedure. Our theoretical regret guarantees do not rely on any data-coverage and completeness-type assumptions, only requiring realizability. These guarantees also demonstrate that the learned policy represents the "best effort" among all policies, as no other policies can outperform it. We evaluate our model using a blend of synthetic, benchmark, and real-world datasets for offline RL, showing that it performs competitively with state-of-the-art methods.
+
+
+
+ 97. 标题:CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model
+ 编号:[254]
+ 链接:https://arxiv.org/abs/2310.06266
+ 作者:Peng Di, Jianguo Li, Hang Yu, Wei Jiang, Wenting Cai, Yang Cao, Chaoyu Chen, Dajun Chen, Hongwei Chen, Liang Chen, Gang Fan, Jie Gong, Zi Gong, Wen Hu, Tingting Guo, Zhichao Lei, Ting Li, Zheng Li, Ming Liang, Cong Liao, Bingchang Liu, Jiachen Liu, Zhiwei Liu, Shaojun Lu, Min Shen, Guangpei Wang, Huan Wang, Zhi Wang, Zhaogui Xu, Jiawei Yang, Qing Ye, Gehao Zhang, Yu Zhang, Zelin Zhao, Xunjin Zheng, Hailian Zhou, Lifu Zhu, Xianying Zhu
+ 备注:10 pages with 2 pages for references
+ 关键词:Large Language Models, gained significant attention, Code Large Language, Large Language, Code Large
+
+ 点击查看摘要
+ Code Large Language Models (Code LLMs) have gained significant attention in the industry due to their wide applications in the full lifecycle of software engineering. However, the effectiveness of existing models in understanding non-English inputs for multi-lingual code-related tasks is still far from well studied. This paper introduces CodeFuse-13B, an open-sourced pre-trained code LLM. It is specifically designed for code-related tasks with both English and Chinese prompts and supports over 40 programming languages. CodeFuse achieves its effectiveness by utilizing a high quality pre-training dataset that is carefully filtered by program analyzers and optimized during the training process. Extensive experiments are conducted using real-world usage scenarios, the industry-standard benchmark HumanEval-x, and the specially designed CodeFuseEval for Chinese prompts. To assess the effectiveness of CodeFuse, we actively collected valuable human feedback from the AntGroup's software development process where CodeFuse has been successfully deployed. The results demonstrate that CodeFuse-13B achieves a HumanEval pass@1 score of 37.10%, positioning it as one of the top multi-lingual code LLMs with similar parameter sizes. In practical scenarios, such as code generation, code translation, code comments, and testcase generation, CodeFuse performs better than other models when confronted with Chinese prompts.
+
+
+
+ 98. 标题:Self-Discriminative Modeling for Anomalous Graph Detection
+ 编号:[255]
+ 链接:https://arxiv.org/abs/2310.06261
+ 作者:Jinyu Cai, Yunhe Zhang, Jicong Fan
+ 备注:This work was submitted to NeurIPS 2023 but was unfortunately rejected
+ 关键词:network data analysis, social network data, anomalous graph detection, detecting anomalous graphs, anomalous graph
+
+ 点击查看摘要
+ This paper studies the problem of detecting anomalous graphs using a machine learning model trained on only normal graphs, which has many applications in molecule, biology, and social network data analysis. We present a self-discriminative modeling framework for anomalous graph detection. The key idea, mathematically and numerically illustrated, is to learn a discriminator (classifier) from the given normal graphs together with pseudo-anomalous graphs generated by a model jointly trained, where we never use any true anomalous graphs and we hope that the generated pseudo-anomalous graphs interpolate between normal ones and (real) anomalous ones. Under the framework, we provide three algorithms with different computational efficiencies and stabilities for anomalous graph detection. The three algorithms are compared with several state-of-the-art graph-level anomaly detection baselines on nine popular graph datasets (four with small size and five with moderate size) and show significant improvement in terms of AUC. The success of our algorithms stems from the integration of the discriminative classifier and the well-posed pseudo-anomalous graphs, which provide new insights for anomaly detection. Moreover, we investigate our algorithms for large-scale imbalanced graph datasets. Surprisingly, our algorithms, though fully unsupervised, are able to significantly outperform supervised learning algorithms of anomalous graph detection. The corresponding reason is also analyzed.
+
+
+
+ 99. 标题:A Unified View on Solving Objective Mismatch in Model-Based Reinforcement Learning
+ 编号:[260]
+ 链接:https://arxiv.org/abs/2310.06253
+ 作者:Ran Wei, Nathan Lambert, Anthony McDonald, Alfredo Garcia, Roberto Calandra
+ 备注:
+ 关键词:Model-based Reinforcement Learning, Model-based Reinforcement, Reinforcement Learning, MBRL algorithms aim, MBRL
+
+ 点击查看摘要
+ Model-based Reinforcement Learning (MBRL) aims to make agents more sample-efficient, adaptive, and explainable by learning an explicit model of the environment. While the capabilities of MBRL agents have significantly improved in recent years, how to best learn the model is still an unresolved question. The majority of MBRL algorithms aim at training the model to make accurate predictions about the environment and subsequently using the model to determine the most rewarding actions. However, recent research has shown that model predictive accuracy is often not correlated with action quality, tracing the root cause to the \emph{objective mismatch} between accurate dynamics model learning and policy optimization of rewards. A number of interrelated solution categories to the objective mismatch problem have emerged as MBRL continues to mature as a research area. In this work, we provide an in-depth survey of these solution categories and propose a taxonomy to foster future research.
+
+
+
+ 100. 标题:Sample-Efficient Multi-Agent RL: An Optimization Perspective
+ 编号:[263]
+ 链接:https://arxiv.org/abs/2310.06243
+ 作者:Nuoya Xiong, Zhihan Liu, Zhaoran Wang, Zhuoran Yang
+ 备注:
+ 关键词:general-sum Markov Games, Markov Games, general function approximation, study multi-agent reinforcement, Multi-Agent Decoupling Coefficient
+
+ 点击查看摘要
+ We study multi-agent reinforcement learning (MARL) for the general-sum Markov Games (MGs) under the general function approximation. In order to find the minimum assumption for sample-efficient learning, we introduce a novel complexity measure called the Multi-Agent Decoupling Coefficient (MADC) for general-sum MGs. Using this measure, we propose the first unified algorithmic framework that ensures sample efficiency in learning Nash Equilibrium, Coarse Correlated Equilibrium, and Correlated Equilibrium for both model-based and model-free MARL problems with low MADC. We also show that our algorithm provides comparable sublinear regret to the existing works. Moreover, our algorithm combines an equilibrium-solving oracle with a single objective optimization subprocedure that solves for the regularized payoff of each deterministic joint policy, which avoids solving constrained optimization problems within data-dependent constraints (Jin et al. 2020; Wang et al. 2023) or executing sampling procedures with complex multi-objective optimization problems (Foster et al. 2023), thus being more amenable to empirical implementation.
+
+
+
+ 101. 标题:Tackling Data Bias in MUSIC-AVQA: Crafting a Balanced Dataset for Unbiased Question-Answering
+ 编号:[266]
+ 链接:https://arxiv.org/abs/2310.06238
+ 作者:Xiulong Liu, Zhikang Dong, Peng Zhang
+ 备注:
+ 关键词:recent years, intersection of audio, driving forward, multimodal research, growing emphasis
+
+ 点击查看摘要
+ In recent years, there has been a growing emphasis on the intersection of audio, vision, and text modalities, driving forward the advancements in multimodal research. However, strong bias that exists in any modality can lead to the model neglecting the others. Consequently, the model's ability to effectively reason across these diverse modalities is compromised, impeding further advancement. In this paper, we meticulously review each question type from the original dataset, selecting those with pronounced answer biases. To counter these biases, we gather complementary videos and questions, ensuring that no answers have outstanding skewed distribution. In particular, for binary questions, we strive to ensure that both answers are almost uniformly spread within each question category. As a result, we construct a new dataset, named MUSIC-AVQA v2.0, which is more challenging and we believe could better foster the progress of AVQA task. Furthermore, we present a novel baseline model that delves deeper into the audio-visual-text interrelation. On MUSIC-AVQA v2.0, this model surpasses all the existing benchmarks, improving accuracy by 2% on MUSIC-AVQA v2.0, setting a new state-of-the-art performance.
+
+
+
+ 102. 标题:Differentially Private Multi-Site Treatment Effect Estimation
+ 编号:[267]
+ 链接:https://arxiv.org/abs/2310.06237
+ 作者:Tatsuki Koga, Kamalika Chaudhuri, David Page
+ 备注:16 pages
+ 关键词:major barrier, ATE, patient data, Patient, healthcare
+
+ 点击查看摘要
+ Patient privacy is a major barrier to healthcare AI. For confidentiality reasons, most patient data remains in silo in separate hospitals, preventing the design of data-driven healthcare AI systems that need large volumes of patient data to make effective decisions. A solution to this is collective learning across multiple sites through federated learning with differential privacy. However, literature in this space typically focuses on differentially private statistical estimation and machine learning, which is different from the causal inference-related problems that arise in healthcare. In this work, we take a fresh look at federated learning with a focus on causal inference; specifically, we look at estimating the average treatment effect (ATE), an important task in causal inference for healthcare applications, and provide a federated analytics approach to enable ATE estimation across multiple sites along with differential privacy (DP) guarantees at each site. The main challenge comes from site heterogeneity -- different sites have different sample sizes and privacy budgets. We address this through a class of per-site estimation algorithms that reports the ATE estimate and its variance as a quality measure, and an aggregation algorithm on the server side that minimizes the overall variance of the final ATE estimate. Our experiments on real and synthetic data show that our method reliably aggregates private statistics across sites and provides better privacy-utility tradeoff under site heterogeneity than baselines.
+
+
+
+ 103. 标题:Efficient Adaptation of Large Vision Transformer via Adapter Re-Composing
+ 编号:[268]
+ 链接:https://arxiv.org/abs/2310.06234
+ 作者:Wei Dong, Dawei Yan, Zhijun Lin, Peng Wang
+ 备注:Paper is accepted to NeurIPS 2023
+ 关键词:training task-specific models, high-capacity pre-trained models, pre-trained models, shifting the focus, adapting pre-trained models
+
+ 点击查看摘要
+ The advent of high-capacity pre-trained models has revolutionized problem-solving in computer vision, shifting the focus from training task-specific models to adapting pre-trained models. Consequently, effectively adapting large pre-trained models to downstream tasks in an efficient manner has become a prominent research area. Existing solutions primarily concentrate on designing lightweight adapters and their interaction with pre-trained models, with the goal of minimizing the number of parameters requiring updates. In this study, we propose a novel Adapter Re-Composing (ARC) strategy that addresses efficient pre-trained model adaptation from a fresh perspective. Our approach considers the reusability of adaptation parameters and introduces a parameter-sharing scheme. Specifically, we leverage symmetric down-/up-projections to construct bottleneck operations, which are shared across layers. By learning low-dimensional re-scaling coefficients, we can effectively re-compose layer-adaptive adapters. This parameter-sharing strategy in adapter design allows us to significantly reduce the number of new parameters while maintaining satisfactory performance, thereby offering a promising approach to compress the adaptation cost. We conduct experiments on 24 downstream image classification tasks using various Vision Transformer variants to evaluate our method. The results demonstrate that our approach achieves compelling transfer learning performance with a reduced parameter count. Our code is available at \href{this https URL}{this https URL}.
+
+
+
+ 104. 标题:Low-Rank Tensor Completion via Novel Sparsity-Inducing Regularizers
+ 编号:[269]
+ 链接:https://arxiv.org/abs/2310.06233
+ 作者:Zhi-Yong Wang, Hing Cheung So, Abdelhak M. Zoubir
+ 备注:
+ 关键词:tensor nuclear norm, tensor completion problem, low-rank tensor completion, nuclear norm, achieve sparsity
+
+ 点击查看摘要
+ To alleviate the bias generated by the l1-norm in the low-rank tensor completion problem, nonconvex surrogates/regularizers have been suggested to replace the tensor nuclear norm, although both can achieve sparsity. However, the thresholding functions of these nonconvex regularizers may not have closed-form expressions and thus iterations are needed, which increases the computational loads. To solve this issue, we devise a framework to generate sparsity-inducing regularizers with closed-form thresholding functions. These regularizers are applied to low-tubal-rank tensor completion, and efficient algorithms based on the alternating direction method of multipliers are developed. Furthermore, convergence of our methods is analyzed and it is proved that the generated sequences are bounded and any limit point is a stationary point. Experimental results using synthetic and real-world datasets show that the proposed algorithms outperform the state-of-the-art methods in terms of restoration performance.
+
+
+
+ 105. 标题:Exploring adversarial attacks in federated learning for medical imaging
+ 编号:[274]
+ 链接:https://arxiv.org/abs/2310.06227
+ 作者:Erfan Darzi, Florian Dubost, N.M. Sijtsema, P.M.A van Ooijen
+ 备注:
+ 关键词:medical image analysis, medical image, image analysis, Federated learning offers, federated medical image
+
+ 点击查看摘要
+ Federated learning offers a privacy-preserving framework for medical image analysis but exposes the system to adversarial attacks. This paper aims to evaluate the vulnerabilities of federated learning networks in medical image analysis against such attacks. Employing domain-specific MRI tumor and pathology imaging datasets, we assess the effectiveness of known threat scenarios in a federated learning environment. Our tests reveal that domain-specific configurations can increase the attacker's success rate significantly. The findings emphasize the urgent need for effective defense mechanisms and suggest a critical re-evaluation of current security protocols in federated medical image analysis systems.
+
+
+
+ 106. 标题:GPT-4 as an Agronomist Assistant? Answering Agriculture Exams Using Large Language Models
+ 编号:[276]
+ 链接:https://arxiv.org/abs/2310.06225
+ 作者:Bruno Silva, Leonardo Nunes, Roberto Estevão, Ranveer Chandra
+ 备注:
+ 关键词:natural language understanding, Large language models, demonstrated remarkable capabilities, Large language, natural language
+
+ 点击查看摘要
+ Large language models (LLMs) have demonstrated remarkable capabilities in natural language understanding across various domains, including healthcare and finance. For some tasks, LLMs achieve similar or better performance than trained human beings, therefore it is reasonable to employ human exams (e.g., certification tests) to assess the performance of LLMs. We present a comprehensive evaluation of popular LLMs, such as Llama 2 and GPT, on their ability to answer agriculture-related questions. In our evaluation, we also employ RAG (Retrieval-Augmented Generation) and ER (Ensemble Refinement) techniques, which combine information retrieval, generation capabilities, and prompting strategies to improve the LLMs' performance. To demonstrate the capabilities of LLMs, we selected agriculture exams and benchmark datasets from three of the largest agriculture producer countries: Brazil, India, and the USA. Our analysis highlights GPT-4's ability to achieve a passing score on exams to earn credits for renewing agronomist certifications, answering 93% of the questions correctly and outperforming earlier general-purpose models, which achieved 88% accuracy. On one of our experiments, GPT-4 obtained the highest performance when compared to human subjects. This performance suggests that GPT-4 could potentially pass on major graduate education admission tests or even earn credits for renewing agronomy certificates. We also explore the models' capacity to address general agriculture-related questions and generate crop management guidelines for Brazilian and Indian farmers, utilizing robust datasets from the Brazilian Agency of Agriculture (Embrapa) and graduate program exams from India. The results suggest that GPT-4, ER, and RAG can contribute meaningfully to agricultural education, assessment, and crop management practice, offering valuable insights to farmers and agricultural professionals.
+
+
+
+ 107. 标题:Detecting and Learning Out-of-Distribution Data in the Open world: Algorithm and Theory
+ 编号:[278]
+ 链接:https://arxiv.org/abs/2310.06221
+ 作者:Yiyou Sun
+ 备注:Ph.D. thesis
+ 关键词:makes considerable contributions, previously unseen data, machine learning, thesis makes considerable, machine learning models
+
+ 点击查看摘要
+ This thesis makes considerable contributions to the realm of machine learning, specifically in the context of open-world scenarios where systems face previously unseen data and contexts. Traditional machine learning models are usually trained and tested within a fixed and known set of classes, a condition known as the closed-world setting. While this assumption works in controlled environments, it falls short in real-world applications where new classes or categories of data can emerge dynamically and unexpectedly. To address this, our research investigates two intertwined steps essential for open-world machine learning: Out-of-distribution (OOD) Detection and Open-world Representation Learning (ORL). OOD detection focuses on identifying instances from unknown classes that fall outside the model's training distribution. This process reduces the risk of making overly confident, erroneous predictions about unfamiliar inputs. Moving beyond OOD detection, ORL extends the capabilities of the model to not only detect unknown instances but also learn from and incorporate knowledge about these new classes. By delving into these research problems of open-world learning, this thesis contributes both algorithmic solutions and theoretical foundations, which pave the way for building machine learning models that are not only performant but also reliable in the face of the evolving complexities of the real world.
+
+
+
+ 108. 标题:SUBP: Soft Uniform Block Pruning for 1xN Sparse CNNs Multithreading Acceleration
+ 编号:[280]
+ 链接:https://arxiv.org/abs/2310.06218
+ 作者:Jingyang Xiang, Siqi Li, Jun Chen, Shipeng Bai, Yukai Ma, Guang Dai, Yong Liu
+ 备注:14 pages, 4 figures, Accepted by 37th Conference on Neural Information Processing Systems (NeurIPS 2023)
+ 关键词:Convolutional Neural Networks, Convolutional Neural, Neural Networks, limited resources, Advanced Vector Extensions
+
+ 点击查看摘要
+ The study of sparsity in Convolutional Neural Networks (CNNs) has become widespread to compress and accelerate models in environments with limited resources. By constraining N consecutive weights along the output channel to be group-wise non-zero, the recent network with 1$\times$N sparsity has received tremendous popularity for its three outstanding advantages: 1) A large amount of storage space saving by a \emph{Block Sparse Row} matrix. 2) Excellent performance at a high sparsity. 3) Significant speedups on CPUs with Advanced Vector Extensions. Recent work requires selecting and fine-tuning 1$\times$N sparse weights based on dense pre-trained weights, leading to the problems such as expensive training cost and memory access, sub-optimal model quality, as well as unbalanced workload across threads (different sparsity across output channels). To overcome them, this paper proposes a novel \emph{\textbf{S}oft \textbf{U}niform \textbf{B}lock \textbf{P}runing} (SUBP) approach to train a uniform 1$\times$N sparse structured network from scratch. Specifically, our approach tends to repeatedly allow pruned blocks to regrow to the network based on block angular redundancy and importance sampling in a uniform manner throughout the training process. It not only makes the model less dependent on pre-training, reduces the model redundancy and the risk of pruning the important blocks permanently but also achieves balanced workload. Empirically, on ImageNet, comprehensive experiments across various CNN architectures show that our SUBP consistently outperforms existing 1$\times$N and structured sparsity methods based on pre-trained models or training from scratch. Source codes and models are available at \url{this https URL}.
+
+
+
+ 109. 标题:Federated Multi-Level Optimization over Decentralized Networks
+ 编号:[281]
+ 链接:https://arxiv.org/abs/2310.06217
+ 作者:Shuoguang Yang, Xuezhou Zhang, Mengdi Wang
+ 备注:arXiv admin note: substantial text overlap with arXiv:2206.10870
+ 关键词:gained increasing attention, solving complex optimization, nested composition optimization, distributed multi-level optimization, multi-player games
+
+ 点击查看摘要
+ Multi-level optimization has gained increasing attention in recent years, as it provides a powerful framework for solving complex optimization problems that arise in many fields, such as meta-learning, multi-player games, reinforcement learning, and nested composition optimization. In this paper, we study the problem of distributed multi-level optimization over a network, where agents can only communicate with their immediate neighbors. This setting is motivated by the need for distributed optimization in large-scale systems, where centralized optimization may not be practical or feasible. To address this problem, we propose a novel gossip-based distributed multi-level optimization algorithm that enables networked agents to solve optimization problems at different levels in a single timescale and share information through network propagation. Our algorithm achieves optimal sample complexity, scaling linearly with the network size, and demonstrates state-of-the-art performance on various applications, including hyper-parameter tuning, decentralized reinforcement learning, and risk-averse optimization.
+
+
+
+ 110. 标题:GeoLLM: Extracting Geospatial Knowledge from Large Language Models
+ 编号:[283]
+ 链接:https://arxiv.org/abs/2310.06213
+ 作者:Rohin Manvi, Samar Khanna, Gengchen Mai, Marshall Burke, David Lobell, Stefano Ermon
+ 备注:
+ 关键词:lack predictive power, machine learning, predictive power, application of machine, increasingly common
+
+ 点击查看摘要
+ The application of machine learning (ML) in a range of geospatial tasks is increasingly common but often relies on globally available covariates such as satellite imagery that can either be expensive or lack predictive power. Here we explore the question of whether the vast amounts of knowledge found in Internet language corpora, now compressed within large language models (LLMs), can be leveraged for geospatial prediction tasks. We first demonstrate that LLMs embed remarkable spatial information about locations, but naively querying LLMs using geographic coordinates alone is ineffective in predicting key indicators like population density. We then present GeoLLM, a novel method that can effectively extract geospatial knowledge from LLMs with auxiliary map data from OpenStreetMap. We demonstrate the utility of our approach across multiple tasks of central interest to the international community, including the measurement of population density and economic livelihoods. Across these tasks, our method demonstrates a 70% improvement in performance (measured using Pearson's $r^2$) relative to baselines that use nearest neighbors or use information directly from the prompt, and performance equal to or exceeding satellite-based benchmarks in the literature. With GeoLLM, we observe that GPT-3.5 outperforms Llama 2 and RoBERTa by 19% and 51% respectively, suggesting that the performance of our method scales well with the size of the model and its pretraining dataset. Our experiments reveal that LLMs are remarkably sample-efficient, rich in geospatial information, and robust across the globe. Crucially, GeoLLM shows promise in mitigating the limitations of existing geospatial covariates and complementing them well.
+
+
+
+ 111. 标题:Fair Classifiers that Abstain without Harm
+ 编号:[286]
+ 链接:https://arxiv.org/abs/2310.06205
+ 作者:Tongxin Yin, Jean-François Ton, Ruocheng Guo, Yuanshun Yao, Mingyan Liu, Yang Liu
+ 备注:
+ 关键词:critical applications, defer decision-making, abstention rate, classifiers selectively abstain, abstention
+
+ 点击查看摘要
+ In critical applications, it is vital for classifiers to defer decision-making to humans. We propose a post-hoc method that makes existing classifiers selectively abstain from predicting certain samples. Our abstaining classifier is incentivized to maintain the original accuracy for each sub-population (i.e. no harm) while achieving a set of group fairness definitions to a user specified degree. To this end, we design an Integer Programming (IP) procedure that assigns abstention decisions for each training sample to satisfy a set of constraints. To generalize the abstaining decisions to test samples, we then train a surrogate model to learn the abstaining decisions based on the IP solutions in an end-to-end manner. We analyze the feasibility of the IP procedure to determine the possible abstention rate for different levels of unfairness tolerance and accuracy constraint for achieving no harm. To the best of our knowledge, this work is the first to identify the theoretical relationships between the constraint parameters and the required abstention rate. Our theoretical results are important since a high abstention rate is often infeasible in practice due to a lack of human resources. Our framework outperforms existing methods in terms of fairness disparity without sacrificing accuracy at similar abstention rates.
+
+
+
+ 112. 标题:The Importance of Prompt Tuning for Automated Neuron Explanations
+ 编号:[290]
+ 链接:https://arxiv.org/abs/2310.06200
+ 作者:Justin Lee, Tuomas Oikarinen, Arjun Chatha, Keng-Chi Chang, Yilan Chen, Tsui-Wei Weng
+ 备注:
+ 关键词:large language models, Recent advances, progressed as fast, increased the capabilities, large language
+
+ 点击查看摘要
+ Recent advances have greatly increased the capabilities of large language models (LLMs), but our understanding of the models and their safety has not progressed as fast. In this paper we aim to understand LLMs deeper by studying their individual neurons. We build upon previous work showing large language models such as GPT-4 can be useful in explaining what each neuron in a language model does. Specifically, we analyze the effect of the prompt used to generate explanations and show that reformatting the explanation prompt in a more natural way can significantly improve neuron explanation quality and greatly reduce computational cost. We demonstrate the effects of our new prompts in three different ways, incorporating both automated and human evaluations.
+
+
+
+ 113. 标题:PAC-Bayesian Spectrally-Normalized Bounds for Adversarially Robust Generalization
+ 编号:[296]
+ 链接:https://arxiv.org/abs/2310.06182
+ 作者:Jiancong Xiao, Ruoyu Sun, Zhi-quan Luo
+ 备注:NeurIPS 2023
+ 关键词:robust generalization, generalization, robust, adversarial attacks, adversarial
+
+ 点击查看摘要
+ Deep neural networks (DNNs) are vulnerable to adversarial attacks. It is found empirically that adversarially robust generalization is crucial in establishing defense algorithms against adversarial attacks. Therefore, it is interesting to study the theoretical guarantee of robust generalization. This paper focuses on norm-based complexity, based on a PAC-Bayes approach (Neyshabur et al., 2017). The main challenge lies in extending the key ingredient, which is a weight perturbation bound in standard settings, to the robust settings. Existing attempts heavily rely on additional strong assumptions, leading to loose bounds. In this paper, we address this issue and provide a spectrally-normalized robust generalization bound for DNNs. Compared to existing bounds, our bound offers two significant advantages: Firstly, it does not depend on additional assumptions. Secondly, it is considerably tighter, aligning with the bounds of standard generalization. Therefore, our result provides a different perspective on understanding robust generalization: The mismatch terms between standard and robust generalization bounds shown in previous studies do not contribute to the poor robust generalization. Instead, these disparities solely due to mathematical issues. Finally, we extend the main result to adversarial robustness against general non-$\ell_p$ attacks and other neural network architectures.
+
+
+
+ 114. 标题:Automatic Integration for Spatiotemporal Neural Point Processes
+ 编号:[297]
+ 链接:https://arxiv.org/abs/2310.06179
+ 作者:Zihao Zhou, Rose Yu
+ 备注:
+ 关键词:Learning continuous-time point, continuous-time point processes, event forecasting tasks, discrete event forecasting, point processes
+
+ 点击查看摘要
+ Learning continuous-time point processes is essential to many discrete event forecasting tasks. However, integration poses a major challenge, particularly for spatiotemporal point processes (STPPs), as it involves calculating the likelihood through triple integrals over space and time. Existing methods for integrating STPP either assume a parametric form of the intensity function, which lacks flexibility; or approximating the intensity with Monte Carlo sampling, which introduces numerical errors. Recent work by Omi et al. [2019] proposes a dual network or AutoInt approach for efficient integration of flexible intensity function. However, the method only focuses on the 1D temporal point process. In this paper, we introduce a novel paradigm: AutoSTPP (Automatic Integration for Spatiotemporal Neural Point Processes) that extends the AutoInt approach to 3D STPP. We show that direct extension of the previous work overly constrains the intensity function, leading to poor performance. We prove consistency of AutoSTPP and validate it on synthetic data and benchmark real world datasets, showcasing its significant advantage in recovering complex intensity functions from irregular spatiotemporal events, particularly when the intensity is sharply localized.
+
+
+
+ 115. 标题:Look-Up mAI GeMM: Increasing AI GeMMs Performance by Nearly 2.5x via msGeMM
+ 编号:[298]
+ 链接:https://arxiv.org/abs/2310.06178
+ 作者:Saeed Maleki
+ 备注:
+ 关键词:unlike HPC applications, unlike HPC, HPC applications, double precision datatype, training and inference
+
+ 点击查看摘要
+ AI models are increasing in size and recent advancement in the community has shown that unlike HPC applications where double precision datatype are required, lower-precision datatypes such as fp8 or int4 are sufficient to bring the same model quality both for training and inference. Following these trends, GPU vendors such as NVIDIA and AMD have added hardware support for fp16, fp8 and int8 GeMM operations with an exceptional performance via Tensor Cores. However, this paper proposes a new algorithm called msGeMM which shows that AI models with low-precision datatypes can run with ~2.5x fewer multiplication and add instructions. Efficient implementation of this algorithm requires special CUDA cores with the ability to add elements from a small look-up table at the rate of Tensor Cores.
+
+
+
+ 116. 标题:DockGame: Cooperative Games for Multimeric Rigid Protein Docking
+ 编号:[299]
+ 链接:https://arxiv.org/abs/2310.06177
+ 作者:Vignesh Ram Somnath, Pier Giuseppe Sessa, Maria Rodriguez Martinez, Andreas Krause
+ 备注:Under Review
+ 关键词:biological processes, formation are fundamental, docking, assembly formation, Protein
+
+ 点击查看摘要
+ Protein interactions and assembly formation are fundamental to most biological processes. Predicting the assembly structure from constituent proteins -- referred to as the protein docking task -- is thus a crucial step in protein design applications. Most traditional and deep learning methods for docking have focused mainly on binary docking, following either a search-based, regression-based, or generative modeling paradigm. In this paper, we focus on the less-studied multimeric (i.e., two or more proteins) docking problem. We introduce DockGame, a novel game-theoretic framework for docking -- we view protein docking as a cooperative game between proteins, where the final assembly structure(s) constitute stable equilibria w.r.t. the underlying game potential. Since we do not have access to the true potential, we consider two approaches - i) learning a surrogate game potential guided by physics-based energy functions and computing equilibria by simultaneous gradient updates, and ii) sampling from the Gibbs distribution of the true potential by learning a diffusion generative model over the action spaces (rotations and translations) of all proteins. Empirically, on the Docking Benchmark 5.5 (DB5.5) dataset, DockGame has much faster runtimes than traditional docking methods, can generate multiple plausible assembly structures, and achieves comparable performance to existing binary docking baselines, despite solving the harder task of coordinating multiple protein chains.
+
+
+
+ 117. 标题:Memory-Consistent Neural Networks for Imitation Learning
+ 编号:[302]
+ 链接:https://arxiv.org/abs/2310.06171
+ 作者:Kaustubh Sridhar, Souradeep Dutta, Dinesh Jayaraman, James Weimer, Insup Lee
+ 备注:22 pages (9 main pages)
+ 关键词:considerably simplifies policy, simplifies policy synthesis, policy synthesis compared, learning considerably simplifies, Imitation learning considerably
+
+ 点击查看摘要
+ Imitation learning considerably simplifies policy synthesis compared to alternative approaches by exploiting access to expert demonstrations. For such imitation policies, errors away from the training samples are particularly critical. Even rare slip-ups in the policy action outputs can compound quickly over time, since they lead to unfamiliar future states where the policy is still more likely to err, eventually causing task failures. We revisit simple supervised ``behavior cloning'' for conveniently training the policy from nothing more than pre-recorded demonstrations, but carefully design the model class to counter the compounding error phenomenon. Our ``memory-consistent neural network'' (MCNN) outputs are hard-constrained to stay within clearly specified permissible regions anchored to prototypical ``memory'' training samples. We provide a guaranteed upper bound for the sub-optimality gap induced by MCNN policies. Using MCNNs on 9 imitation learning tasks, with MLP, Transformer, and Diffusion backbones, spanning dexterous robotic manipulation and driving, proprioceptive inputs and visual inputs, and varying sizes and types of demonstration data, we find large and consistent gains in performance, validating that MCNNs are better-suited than vanilla deep neural networks for imitation learning applications. Website: this https URL
+
+
+
+ 118. 标题:DEUX: Active Exploration for Learning Unsupervised Depth Perception
+ 编号:[308]
+ 链接:https://arxiv.org/abs/2310.06164
+ 作者:Marvin Chancán, Alex Wong, Ian Abraham
+ 备注:
+ 关键词:predefined camera trajectories, depth completion, Depth, non-interactive datasets, datasets with predefined
+
+ 点击查看摘要
+ Depth perception models are typically trained on non-interactive datasets with predefined camera trajectories. However, this often introduces systematic biases into the learning process correlated to specific camera paths chosen during data acquisition. In this paper, we investigate the role of how data is collected for learning depth completion, from a robot navigation perspective, by leveraging 3D interactive environments. First, we evaluate four depth completion models trained on data collected using conventional navigation techniques. Our key insight is that existing exploration paradigms do not necessarily provide task-specific data points to achieve competent unsupervised depth completion learning. We then find that data collected with respect to photometric reconstruction has a direct positive influence on model performance. As a result, we develop an active, task-informed, depth uncertainty-based motion planning approach for learning depth completion, which we call DEpth Uncertainty-guided eXploration (DEUX). Training with data collected by our approach improves depth completion by an average greater than 18% across four depth completion models compared to existing exploration methods on the MP3D test set. We show that our approach further improves zero-shot generalization, while offering new insights into integrating robot learning-based depth estimation.
+
+
+
+ 119. 标题:Mitigating Simplicity Bias in Deep Learning for Improved OOD Generalization and Robustness
+ 编号:[309]
+ 链接:https://arxiv.org/abs/2310.06161
+ 作者:Bhavya Vasudeva, Kameron Shahabi, Vatsal Sharan
+ 备注:28 pages, 10 figures, 16 tables
+ 关键词:exhibit simplicity bias, Neural networks, simplicity bias, prefer learning, tend to prefer
+
+ 点击查看摘要
+ Neural networks (NNs) are known to exhibit simplicity bias where they tend to prefer learning 'simple' features over more 'complex' ones, even when the latter may be more informative. Simplicity bias can lead to the model making biased predictions which have poor out-of-distribution (OOD) generalization. To address this, we propose a framework that encourages the model to use a more diverse set of features to make predictions. We first train a simple model, and then regularize the conditional mutual information with respect to it to obtain the final model. We demonstrate the effectiveness of this framework in various problem settings and real-world applications, showing that it effectively addresses simplicity bias and leads to more features being used, enhances OOD generalization, and improves subgroup robustness and fairness. We complement these results with theoretical analyses of the effect of the regularization and its OOD generalization properties.
+
+
+
+ 120. 标题:Provably Accelerating Ill-Conditioned Low-rank Estimation via Scaled Gradient Descent, Even with Overparameterization
+ 编号:[311]
+ 链接:https://arxiv.org/abs/2310.06159
+ 作者:Cong Ma, Xingyu Xu, Tian Tong, Yuejie Chi
+ 备注:Book chapter for "Explorations in the Mathematics of Data Science - The Inaugural Volume of the Center for Approximation and Mathematical Data Analytics". arXiv admin note: text overlap with arXiv:2104.14526
+ 关键词:low-rank object, linear measurements, possibly corrupted, encountered in science, science and engineering
+
+ 点击查看摘要
+ Many problems encountered in science and engineering can be formulated as estimating a low-rank object (e.g., matrices and tensors) from incomplete, and possibly corrupted, linear measurements. Through the lens of matrix and tensor factorization, one of the most popular approaches is to employ simple iterative algorithms such as gradient descent (GD) to recover the low-rank factors directly, which allow for small memory and computation footprints. However, the convergence rate of GD depends linearly, and sometimes even quadratically, on the condition number of the low-rank object, and therefore, GD slows down painstakingly when the problem is ill-conditioned. This chapter introduces a new algorithmic approach, dubbed scaled gradient descent (ScaledGD), that provably converges linearly at a constant rate independent of the condition number of the low-rank object, while maintaining the low per-iteration cost of gradient descent for a variety of tasks including sensing, robust principal component analysis and completion. In addition, ScaledGD continues to admit fast global convergence to the minimax-optimal solution, again almost independent of the condition number, from a small random initialization when the rank is over-specified in the presence of Gaussian noise. In total, ScaledGD highlights the power of appropriate preconditioning in accelerating nonconvex statistical estimation, where the iteration-varying preconditioners promote desirable invariance properties of the trajectory with respect to the symmetry in low-rank factorization without hurting generalization.
+
+
+
+ 121. 标题:Manifold-augmented Eikonal Equations: Geodesic Distances and Flows on Differentiable Manifolds
+ 编号:[312]
+ 链接:https://arxiv.org/abs/2310.06157
+ 作者:Daniel Kelshaw, Luca Magri
+ 备注:Submitted to NeurIPS 2023: Symmetry and Geometry in Neural Representations Workshop
+ 关键词:machine learning models, learning models provide, underlying data, discovered by machine, machine learning
+
+ 点击查看摘要
+ Manifolds discovered by machine learning models provide a compact representation of the underlying data. Geodesics on these manifolds define locally length-minimising curves and provide a notion of distance, which are key for reduced-order modelling, statistical inference, and interpolation. In this work, we propose a model-based parameterisation for distance fields and geodesic flows on manifolds, exploiting solutions of a manifold-augmented Eikonal equation. We demonstrate how the geometry of the manifold impacts the distance field, and exploit the geodesic flow to obtain globally length-minimising curves directly. This work opens opportunities for statistics and reduced-order modelling on differentiable manifolds.
+
+
+
+ 122. 标题:Latent Diffusion Model for DNA Sequence Generation
+ 编号:[315]
+ 链接:https://arxiv.org/abs/2310.06150
+ 作者:Zehui Li, Yuhao Ni, Tim August B. Huygelen, Akashaditya Das, Guoxuan Xia, Guy-Bart Stan, Yiren Zhao
+ 备注:
+ 关键词:Generative Adversarial Networks, DNA sequence generation, DNA sequence, DNA, deep generative models
+
+ 点击查看摘要
+ The harnessing of machine learning, especially deep generative models, has opened up promising avenues in the field of synthetic DNA sequence generation. Whilst Generative Adversarial Networks (GANs) have gained traction for this application, they often face issues such as limited sample diversity and mode collapse. On the other hand, Diffusion Models are a promising new class of generative models that are not burdened with these problems, enabling them to reach the state-of-the-art in domains such as image generation. In light of this, we propose a novel latent diffusion model, DiscDiff, tailored for discrete DNA sequence generation. By simply embedding discrete DNA sequences into a continuous latent space using an autoencoder, we are able to leverage the powerful generative abilities of continuous diffusion models for the generation of discrete data. Additionally, we introduce Fréchet Reconstruction Distance (FReD) as a new metric to measure the sample quality of DNA sequence generations. Our DiscDiff model demonstrates an ability to generate synthetic DNA sequences that align closely with real DNA in terms of Motif Distribution, Latent Embedding Distribution (FReD), and Chromatin Profiles. Additionally, we contribute a comprehensive cross-species dataset of 150K unique promoter-gene sequences from 15 species, enriching resources for future generative modelling in genomics. We will make our code public upon publication.
+
+
+
+ 123. 标题:Understanding Transfer Learning and Gradient-Based Meta-Learning Techniques
+ 编号:[316]
+ 链接:https://arxiv.org/abs/2310.06148
+ 作者:Mike Huisman, Aske Plaat, Jan N. van Rijn
+ 备注:Accepted at Machine Learning Journal, Special Issue on Discovery Science 2021
+ 关键词:require large amounts, Deep neural networks, yield good performance, MAML, Deep neural
+
+ 点击查看摘要
+ Deep neural networks can yield good performance on various tasks but often require large amounts of data to train them. Meta-learning received considerable attention as one approach to improve the generalization of these networks from a limited amount of data. Whilst meta-learning techniques have been observed to be successful at this in various scenarios, recent results suggest that when evaluated on tasks from a different data distribution than the one used for training, a baseline that simply finetunes a pre-trained network may be more effective than more complicated meta-learning techniques such as MAML, which is one of the most popular meta-learning techniques. This is surprising as the learning behaviour of MAML mimics that of finetuning: both rely on re-using learned features. We investigate the observed performance differences between finetuning, MAML, and another meta-learning technique called Reptile, and show that MAML and Reptile specialize for fast adaptation in low-data regimes of similar data distribution as the one used for training. Our findings show that both the output layer and the noisy training conditions induced by data scarcity play important roles in facilitating this specialization for MAML. Lastly, we show that the pre-trained features as obtained by the finetuning baseline are more diverse and discriminative than those learned by MAML and Reptile. Due to this lack of diversity and distribution specialization, MAML and Reptile may fail to generalize to out-of-distribution tasks whereas finetuning can fall back on the diversity of the learned features.
+
+
+
+ 124. 标题:Reinforcement Learning in the Era of LLMs: What is Essential? What is needed? An RL Perspective on RLHF, Prompting, and Beyond
+ 编号:[317]
+ 链接:https://arxiv.org/abs/2310.06147
+ 作者:Hao Sun
+ 备注:
+ 关键词:Large Language Models, Language Models, Large Language, garnered wide attention, advancements in Large
+
+ 点击查看摘要
+ Recent advancements in Large Language Models (LLMs) have garnered wide attention and led to successful products such as ChatGPT and GPT-4. Their proficiency in adhering to instructions and delivering harmless, helpful, and honest (3H) responses can largely be attributed to the technique of Reinforcement Learning from Human Feedback (RLHF). In this paper, we aim to link the research in conventional RL to RL techniques used in LLM research. Demystify this technique by discussing why, when, and how RL excels. Furthermore, we explore potential future avenues that could either benefit from or contribute to RLHF research.
+Highlighted Takeaways:
+1. RLHF is Online Inverse RL with Offline Demonstration Data.
+2. RLHF $>$ SFT because Imitation Learning (and Inverse RL) $>$ Behavior Cloning (BC) by alleviating the problem of compounding error.
+3. The RM step in RLHF generates a proxy of the expensive human feedback, such an insight can be generalized to other LLM tasks such as prompting evaluation and optimization where feedback is also expensive.
+4. The policy learning in RLHF is more challenging than conventional problems studied in IRL due to their high action dimensionality and feedback sparsity.
+5. The main superiority of PPO over off-policy value-based methods is its stability gained from (almost) on-policy data and conservative policy updates.
+
+
+
+ 125. 标题:On the Correlation between Random Variables and their Principal Components
+ 编号:[320]
+ 链接:https://arxiv.org/abs/2310.06139
+ 作者:Zenon Gniazdowski
+ 备注:15 pages
+ 关键词:algebraic formula describing, random variables, principal components representing, individual random variables, Principal Component Analysis
+
+ 点击查看摘要
+ The article attempts to find an algebraic formula describing the correlation coefficients between random variables and the principal components representing them. As a result of the analysis, starting from selected statistics relating to individual random variables, the equivalents of these statistics relating to a set of random variables were presented in the language of linear algebra, using the concepts of vector and matrix. This made it possible, in subsequent steps, to derive the expected formula. The formula found is identical to the formula used in Factor Analysis to calculate factor loadings. The discussion showed that it is possible to apply this formula to optimize the number of principal components in Principal Component Analysis, as well as to optimize the number of factors in Factor Analysis.
+
+
+
+ 126. 标题:Layout Sequence Prediction From Noisy Mobile Modality
+ 编号:[321]
+ 链接:https://arxiv.org/abs/2310.06138
+ 作者:Haichao Zhang, Yi Xu, Hongsheng Lu, Takayuki Shimizu, Yun Fu
+ 备注:In Proceedings of the 31st ACM International Conference on Multimedia 2023 (MM 23)
+ 关键词:understanding pedestrian movement, driving and robotics, plays a vital, vital role, role in understanding
+
+ 点击查看摘要
+ Trajectory prediction plays a vital role in understanding pedestrian movement for applications such as autonomous driving and robotics. Current trajectory prediction models depend on long, complete, and accurately observed sequences from visual modalities. Nevertheless, real-world situations often involve obstructed cameras, missed objects, or objects out of sight due to environmental factors, leading to incomplete or noisy trajectories. To overcome these limitations, we propose LTrajDiff, a novel approach that treats objects obstructed or out of sight as equally important as those with fully visible trajectories. LTrajDiff utilizes sensor data from mobile phones to surmount out-of-sight constraints, albeit introducing new challenges such as modality fusion, noisy data, and the absence of spatial layout and object size information. We employ a denoising diffusion model to predict precise layout sequences from noisy mobile data using a coarse-to-fine diffusion strategy, incorporating the RMS, Siamese Masked Encoding Module, and MFM. Our model predicts layout sequences by implicitly inferring object size and projection status from a single reference timestamp or significantly obstructed sequences. Achieving SOTA results in randomly obstructed experiments and extremely short input experiments, our model illustrates the effectiveness of leveraging noisy mobile data. In summary, our approach offers a promising solution to the challenges faced by layout sequence and trajectory prediction models in real-world settings, paving the way for utilizing sensor data from mobile phones to accurately predict pedestrian bounding box trajectories. To the best of our knowledge, this is the first work that addresses severely obstructed and extremely short layout sequences by combining vision with noisy mobile modality, making it the pioneering work in the field of layout sequence trajectory prediction.
+
+
+
+ 127. 标题:Learning Layer-wise Equivariances Automatically using Gradients
+ 编号:[323]
+ 链接:https://arxiv.org/abs/2310.06131
+ 作者:Tycho F.A. van der Ouderaa, Alexander Immer, Mark van der Wilk
+ 备注:
+ 关键词:neural networks leading, Convolutions encode equivariance, Convolutions encode, encode equivariance symmetries, neural networks
+
+ 点击查看摘要
+ Convolutions encode equivariance symmetries into neural networks leading to better generalisation performance. However, symmetries provide fixed hard constraints on the functions a network can represent, need to be specified in advance, and can not be adapted. Our goal is to allow flexible symmetry constraints that can automatically be learned from data using gradients. Learning symmetry and associated weight connectivity structures from scratch is difficult for two reasons. First, it requires efficient and flexible parameterisations of layer-wise equivariances. Secondly, symmetries act as constraints and are therefore not encouraged by training losses measuring data fit. To overcome these challenges, we improve parameterisations of soft equivariance and learn the amount of equivariance in layers by optimising the marginal likelihood, estimated using differentiable Laplace approximations. The objective balances data fit and model complexity enabling layer-wise symmetry discovery in deep networks. We demonstrate the ability to automatically learn layer-wise equivariances on image classification tasks, achieving equivalent or improved performance over baselines with hard-coded symmetry.
+
+
+
+ 128. 标题:On Time Domain Conformer Models for Monaural Speech Separation in Noisy Reverberant Acoustic Environments
+ 编号:[324]
+ 链接:https://arxiv.org/abs/2310.06125
+ 作者:William Ravenscroft, Stefan Goetze, Thomas Hain
+ 备注:Accepted at ASRU Workshop 2023
+ 关键词:multi-speaker technology researchers, Speech separation remains, technology researchers, remains an important, important topic
+
+ 点击查看摘要
+ Speech separation remains an important topic for multi-speaker technology researchers. Convolution augmented transformers (conformers) have performed well for many speech processing tasks but have been under-researched for speech separation. Most recent state-of-the-art (SOTA) separation models have been time-domain audio separation networks (TasNets). A number of successful models have made use of dual-path (DP) networks which sequentially process local and global information. Time domain conformers (TD-Conformers) are an analogue of the DP approach in that they also process local and global context sequentially but have a different time complexity function. It is shown that for realistic shorter signal lengths, conformers are more efficient when controlling for feature dimension. Subsampling layers are proposed to further improve computational efficiency. The best TD-Conformer achieves 14.6 dB and 21.2 dB SISDR improvement on the WHAMR and WSJ0-2Mix benchmarks, respectively.
+
+
+
+ 129. 标题:Factorized Tensor Networks for Multi-Task and Multi-Domain Learning
+ 编号:[325]
+ 链接:https://arxiv.org/abs/2310.06124
+ 作者:Yash Garg, Nebiyou Yismaw, Rakib Hyder, Ashley Prater-Bennette, M. Salman Asif
+ 备注:
+ 关键词:learn multiple tasks, learning methods seek, single unified network, seek to learn, learn multiple
+
+ 点击查看摘要
+ Multi-task and multi-domain learning methods seek to learn multiple tasks/domains, jointly or one after another, using a single unified network. The key challenge and opportunity is to exploit shared information across tasks and domains to improve the efficiency of the unified network. The efficiency can be in terms of accuracy, storage cost, computation, or sample complexity. In this paper, we propose a factorized tensor network (FTN) that can achieve accuracy comparable to independent single-task/domain networks with a small number of additional parameters. FTN uses a frozen backbone network from a source model and incrementally adds task/domain-specific low-rank tensor factors to the shared frozen network. This approach can adapt to a large number of target domains and tasks without catastrophic forgetting. Furthermore, FTN requires a significantly smaller number of task-specific parameters compared to existing methods. We performed experiments on widely used multi-domain and multi-task datasets. We show the experiments on convolutional-based architecture with different backbones and on transformer-based architecture. We observed that FTN achieves similar accuracy as single-task/domain methods while using only a fraction of additional parameters per task.
+
+
+
+ 130. 标题:Exploring Progress in Multivariate Time Series Forecasting: Comprehensive Benchmarking and Heterogeneity Analysis
+ 编号:[329]
+ 链接:https://arxiv.org/abs/2310.06119
+ 作者:Zezhi Shao, Fei Wang, Yongjun Xu, Wei Wei, Chengqing Yu, Zhao Zhang, Di Yao, Guangyin Jin, Xin Cao, Gao Cong, Christian S. Jensen, Xueqi Cheng
+ 备注:
+ 关键词:Multivariate Time Series, Long-term Time Series, real-word complex systems, Time Series Forecasting, Time Series
+
+ 点击查看摘要
+ Multivariate Time Series (MTS) widely exists in real-word complex systems, such as traffic and energy systems, making their forecasting crucial for understanding and influencing these systems. Recently, deep learning-based approaches have gained much popularity for effectively modeling temporal and spatial dependencies in MTS, specifically in Long-term Time Series Forecasting (LTSF) and Spatial-Temporal Forecasting (STF). However, the fair benchmarking issue and the choice of technical approaches have been hotly debated in related work. Such controversies significantly hinder our understanding of progress in this field. Thus, this paper aims to address these controversies to present insights into advancements achieved. To resolve benchmarking issues, we introduce BasicTS, a benchmark designed for fair comparisons in MTS forecasting. BasicTS establishes a unified training pipeline and reasonable evaluation settings, enabling an unbiased evaluation of over 30 popular MTS forecasting models on more than 18 datasets. Furthermore, we highlight the heterogeneity among MTS datasets and classify them based on temporal and spatial characteristics. We further prove that neglecting heterogeneity is the primary reason for generating controversies in technical approaches. Moreover, based on the proposed BasicTS and rich heterogeneous MTS datasets, we conduct an exhaustive and reproducible performance and efficiency comparison of popular models, providing insights for researchers in selecting and designing MTS forecasting models.
+
+
+
+ 131. 标题:Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
+ 编号:[330]
+ 链接:https://arxiv.org/abs/2310.06117
+ 作者:Huaixiu Steven Zheng, Swaroop Mishra, Xinyun Chen, Heng-Tze Cheng, Ed H. Chi, Quoc V Le, Denny Zhou
+ 备注:
+ 关键词:derive high-level concepts, simple prompting technique, present Step-Back Prompting, specific details, technique that enables
+
+ 点击查看摘要
+ We present Step-Back Prompting, a simple prompting technique that enables LLMs to do abstractions to derive high-level concepts and first principles from instances containing specific details. Using the concepts and principles to guide the reasoning steps, LLMs significantly improve their abilities in following a correct reasoning path towards the solution. We conduct experiments of Step-Back Prompting with PaLM-2L models and observe substantial performance gains on a wide range of challenging reasoning-intensive tasks including STEM, Knowledge QA, and Multi-Hop Reasoning. For instance, Step-Back Prompting improves PaLM-2L performance on MMLU Physics and Chemistry by 7% and 11%, TimeQA by 27%, and MuSiQue by 7%.
+
+
+
+ 132. 标题:When is Agnostic Reinforcement Learning Statistically Tractable?
+ 编号:[333]
+ 链接:https://arxiv.org/abs/2310.06113
+ 作者:Zeyu Jia, Gene Li, Alexander Rakhlin, Ayush Sekhari, Nathan Srebro
+ 备注:Accepted to NeurIPS 2023
+ 关键词:PAC reinforcement learning, potentially large state, agnostic PAC reinforcement, bounded spanning capacity, spanning capacity
+
+ 点击查看摘要
+ We study the problem of agnostic PAC reinforcement learning (RL): given a policy class $\Pi$, how many rounds of interaction with an unknown MDP (with a potentially large state and action space) are required to learn an $\epsilon$-suboptimal policy with respect to $\Pi$? Towards that end, we introduce a new complexity measure, called the \emph{spanning capacity}, that depends solely on the set $\Pi$ and is independent of the MDP dynamics. With a generative model, we show that for any policy class $\Pi$, bounded spanning capacity characterizes PAC learnability. However, for online RL, the situation is more subtle. We show there exists a policy class $\Pi$ with a bounded spanning capacity that requires a superpolynomial number of samples to learn. This reveals a surprising separation for agnostic learnability between generative access and online access models (as well as between deterministic/stochastic MDPs under online access). On the positive side, we identify an additional \emph{sunflower} structure, which in conjunction with bounded spanning capacity enables statistically efficient online RL via a new algorithm called POPLER, which takes inspiration from classical importance sampling methods as well as techniques for reachable-state identification and policy evaluation in reward-free exploration.
+
+
+
+ 133. 标题:Theoretical Analysis of Robust Overfitting for Wide DNNs: An NTK Approach
+ 编号:[334]
+ 链接:https://arxiv.org/abs/2310.06112
+ 作者:Shaopeng Fu, Di Wang
+ 备注:
+ 关键词:deep neural networks, Adversarial training, robust overfitting, DNNs, DNN
+
+ 点击查看摘要
+ Adversarial training (AT) is a canonical method for enhancing the robustness of deep neural networks (DNNs). However, recent studies empirically demonstrated that it suffers from robust overfitting, i.e., a long time AT can be detrimental to the robustness of DNNs. This paper presents a theoretical explanation of robust overfitting for DNNs. Specifically, we non-trivially extend the neural tangent kernel (NTK) theory to AT and prove that an adversarially trained wide DNN can be well approximated by a linearized DNN. Moreover, for squared loss, closed-form AT dynamics for the linearized DNN can be derived, which reveals a new AT degeneration phenomenon: a long-term AT will result in a wide DNN degenerates to that obtained without AT and thus cause robust overfitting. Based on our theoretical results, we further design a method namely Adv-NTK, the first AT algorithm for infinite-width DNNs. Experiments on real-world datasets show that Adv-NTK can help infinite-width DNNs enhance comparable robustness to that of their finite-width counterparts, which in turn justifies our theoretical findings. The code is available at this https URL.
+
+
+
+ 134. 标题:BYOC: Personalized Few-Shot Classification with Co-Authored Class Descriptions
+ 编号:[335]
+ 链接:https://arxiv.org/abs/2310.06111
+ 作者:Arth Bohra, Govert Verkes, Artem Harutyunyan, Pascal Weinberger, Giovanni Campagna
+ 备注:Accepted at EMNLP 2023 (Findings)
+ 关键词:versatile building block, NLP applications, well-studied and versatile, versatile building, building block
+
+ 点击查看摘要
+ Text classification is a well-studied and versatile building block for many NLP applications. Yet, existing approaches require either large annotated corpora to train a model with or, when using large language models as a base, require carefully crafting the prompt as well as using a long context that can fit many examples. As a result, it is not possible for end-users to build classifiers for themselves. To address this issue, we propose a novel approach to few-shot text classification using an LLM. Rather than few-shot examples, the LLM is prompted with descriptions of the salient features of each class. These descriptions are coauthored by the user and the LLM interactively: while the user annotates each few-shot example, the LLM asks relevant questions that the user answers. Examples, questions, and answers are summarized to form the classification prompt. Our experiments show that our approach yields high accuracy classifiers, within 82% of the performance of models trained with significantly larger datasets while using only 1% of their training sets. Additionally, in a study with 30 participants, we show that end-users are able to build classifiers to suit their specific needs. The personalized classifiers show an average accuracy of 90%, which is 15% higher than the state-of-the-art approach.
+
+
+
+ 135. 标题:High Dimensional Causal Inference with Variational Backdoor Adjustment
+ 编号:[339]
+ 链接:https://arxiv.org/abs/2310.06100
+ 作者:Daniel Israel, Aditya Grover, Guy Van den Broeck
+ 备注:
+ 关键词:purely observational data, estimating interventional quantities, Backdoor adjustment, technique in causal, quantities from purely
+
+ 点击查看摘要
+ Backdoor adjustment is a technique in causal inference for estimating interventional quantities from purely observational data. For example, in medical settings, backdoor adjustment can be used to control for confounding and estimate the effectiveness of a treatment. However, high dimensional treatments and confounders pose a series of potential pitfalls: tractability, identifiability, optimization. In this work, we take a generative modeling approach to backdoor adjustment for high dimensional treatments and confounders. We cast backdoor adjustment as an optimization problem in variational inference without reliance on proxy variables and hidden confounders. Empirically, our method is able to estimate interventional likelihood in a variety of high dimensional settings, including semi-synthetic X-ray medical data. To the best of our knowledge, this is the first application of backdoor adjustment in which all the relevant variables are high dimensional.
+
+
+
+ 136. 标题:Quantile-based Maximum Likelihood Training for Outlier Detection
+ 编号:[342]
+ 链接:https://arxiv.org/abs/2310.06085
+ 作者:Masoud Taghikhah, Nishant Kumar, Siniša Šegvić, Abouzar Eslami, Stefan Gumhold
+ 备注:Code available at this https URL
+ 关键词:effectively predicts true, predicts true object, true object class, learning effectively predicts, effectively predicts
+
+ 点击查看摘要
+ Discriminative learning effectively predicts true object class for image classification. However, it often results in false positives for outliers, posing critical concerns in applications like autonomous driving and video surveillance systems. Previous attempts to address this challenge involved training image classifiers through contrastive learning using actual outlier data or synthesizing outliers for self-supervised learning. Furthermore, unsupervised generative modeling of inliers in pixel space has shown limited success for outlier detection. In this work, we introduce a quantile-based maximum likelihood objective for learning the inlier distribution to improve the outlier separation during inference. Our approach fits a normalizing flow to pre-trained discriminative features and detects the outliers according to the evaluated log-likelihood. The experimental evaluation demonstrates the effectiveness of our method as it surpasses the performance of the state-of-the-art unsupervised methods for outlier detection. The results are also competitive compared with a recent self-supervised approach for outlier detection. Our work allows to reduce dependency on well-sampled negative training data, which is especially important for domains like medical diagnostics or remote sensing.
+
+
+
+ 137. 标题:Transformers and Large Language Models for Chemistry and Drug Discovery
+ 编号:[344]
+ 链接:https://arxiv.org/abs/2310.06083
+ 作者:Andres M Bran, Philippe Schwaller
+ 备注:
+ 关键词:Transformer architecture, impressive progress, Language modeling, breakthroughs in chemistry, Language
+
+ 点击查看摘要
+ Language modeling has seen impressive progress over the last years, mainly prompted by the invention of the Transformer architecture, sparking a revolution in many fields of machine learning, with breakthroughs in chemistry and biology. In this chapter, we explore how analogies between chemical and natural language have inspired the use of Transformers to tackle important bottlenecks in the drug discovery process, such as retrosynthetic planning and chemical space exploration. The revolution started with models able to perform particular tasks with a single type of data, like linearised molecular graphs, which then evolved to include other types of data, like spectra from analytical instruments, synthesis actions, and human language. A new trend leverages recent developments in large language models, giving rise to a wave of models capable of solving generic tasks in chemistry, all facilitated by the flexibility of natural language. As we continue to explore and harness these capabilities, we can look forward to a future where machine learning plays an even more integral role in accelerating scientific discovery.
+
+
+
+ 138. 标题:Performative Time-Series Forecasting
+ 编号:[345]
+ 链接:https://arxiv.org/abs/2310.06077
+ 作者:Zhiyuan Zhao, Alexander Rodriguez, B.Aditya Prakash
+ 备注:12 pages (7 main text, 2 reference, 3 appendix), 3 figures, 4 tables
+ 关键词:witnessed substantial progress, recent years, witnessed substantial, substantial progress, progress in recent
+
+ 点击查看摘要
+ Time-series forecasting is a critical challenge in various domains and has witnessed substantial progress in recent years. Many real-life scenarios, such as public health, economics, and social applications, involve feedback loops where predictions can influence the predicted outcome, subsequently altering the target variable's distribution. This phenomenon, known as performativity, introduces the potential for 'self-negating' or 'self-fulfilling' predictions. Despite extensive studies in classification problems across domains, performativity remains largely unexplored in the context of time-series forecasting from a machine-learning perspective.
+In this paper, we formalize performative time-series forecasting (PeTS), addressing the challenge of accurate predictions when performativity-induced distribution shifts are possible. We propose a novel approach, Feature Performative-Shifting (FPS), which leverages the concept of delayed response to anticipate distribution shifts and subsequently predicts targets accordingly. We provide theoretical insights suggesting that FPS can potentially lead to reduced generalization error. We conduct comprehensive experiments using multiple time-series models on COVID-19 and traffic forecasting tasks. The results demonstrate that FPS consistently outperforms conventional time-series forecasting methods, highlighting its efficacy in handling performativity-induced challenges.
+
+
+
+ 139. 标题:Pain Forecasting using Self-supervised Learning and Patient Phenotyping: An attempt to prevent Opioid Addiction
+ 编号:[347]
+ 链接:https://arxiv.org/abs/2310.06075
+ 作者:Swati Padhee, Tanvi Banerjee, Daniel M. Abrams, Nirmish Shah
+ 备注:8 pages
+ 关键词:Sickle Cell Disease, Cell Disease, Sickle Cell, chronic genetic disorder, genetic disorder characterized
+
+ 点击查看摘要
+ Sickle Cell Disease (SCD) is a chronic genetic disorder characterized by recurrent acute painful episodes. Opioids are often used to manage these painful episodes; the extent of their use in managing pain in this disorder is an issue of debate. The risk of addiction and side effects of these opioid treatments can often lead to more pain episodes in the future. Hence, it is crucial to forecast future patient pain trajectories to help patients manage their SCD to improve their quality of life without compromising their treatment. It is challenging to obtain many pain records to design forecasting models since it is mainly recorded by patients' self-report. Therefore, it is expensive and painful (due to the need for patient compliance) to solve pain forecasting problems in a purely supervised manner. In light of this challenge, we propose to solve the pain forecasting problem using self-supervised learning methods. Also, clustering such time-series data is crucial for patient phenotyping, anticipating patients' prognoses by identifying "similar" patients, and designing treatment guidelines tailored to homogeneous patient subgroups. Hence, we propose a self-supervised learning approach for clustering time-series data, where each cluster comprises patients who share similar future pain profiles. Experiments on five years of real-world datasets show that our models achieve superior performance over state-of-the-art benchmarks and identify meaningful clusters that can be translated into actionable information for clinical decision-making.
+
+
+
+ 140. 标题:Early Warning via tipping-preserving latent stochastic dynamical system and meta label correcting
+ 编号:[353]
+ 链接:https://arxiv.org/abs/2310.06059
+ 作者:Peng Zhang, Ting Gao, Jin Guo, Jinqiao Duan
+ 备注:12 pages,4 figures
+ 关键词:safety and well-being, warning for epilepsy, epilepsy patients, patients is crucial, terms of preventing
+
+ 点击查看摘要
+ Early warning for epilepsy patients is crucial for their safety and well-being, in terms of preventing or minimizing the severity of seizures. Through the patients' EEG data, we propose a meta learning framework for improving prediction on early ictal signals. To better utilize the meta label corrector method, we fuse the information from both the real data and the augmented data from the latent Stochastic differential equation(SDE). Besides, we also optimally select the latent dynamical system via distribution of transition time between real data and that from the latent SDE. In this way, the extracted tipping dynamical feature is also integrated into the meta network to better label the noisy data. To validate our method, LSTM is implemented as the baseline model. We conduct a series of experiments to predict seizure in various long-term window from 1-2 seconds input data and find surprisingly increment of prediction accuracy.
+
+
+
+ 141. 标题:Knowledge Distillation for Anomaly Detection
+ 编号:[355]
+ 链接:https://arxiv.org/abs/2310.06047
+ 作者:Adrian Alan Pol, Ekaterina Govorkova, Sonja Gronroos, Nadezda Chernyavskaya, Philip Harris, Maurizio Pierini, Isobel Ojalvo, Peter Elmer
+ 备注:
+ 关键词:identify anomalous behaviour, Unsupervised deep learning, deep learning techniques, anomalous behaviour, deep learning
+
+ 点击查看摘要
+ Unsupervised deep learning techniques are widely used to identify anomalous behaviour. The performance of such methods is a product of the amount of training data and the model size. However, the size is often a limiting factor for the deployment on resource-constrained devices. We present a novel procedure based on knowledge distillation for compressing an unsupervised anomaly detection model into a supervised deployable one and we suggest a set of techniques to improve the detection sensitivity. Compressed models perform comparably to their larger counterparts while significantly reducing the size and memory footprint.
+
+
+
+ 142. 标题:Generative ensemble deep learning severe weather prediction from a deterministic convection-allowing model
+ 编号:[357]
+ 链接:https://arxiv.org/abs/2310.06045
+ 作者:Yingkai Sha, Ryan A. Sobash, David John Gagne II
+ 备注:
+ 关键词:conterminous United States, United States, conterminous United, severe weather, ensemble post-processing method
+
+ 点击查看摘要
+ An ensemble post-processing method is developed for the probabilistic prediction of severe weather (tornadoes, hail, and wind gusts) over the conterminous United States (CONUS). The method combines conditional generative adversarial networks (CGANs), a type of deep generative model, with a convolutional neural network (CNN) to post-process convection-allowing model (CAM) forecasts. The CGANs are designed to create synthetic ensemble members from deterministic CAM forecasts, and their outputs are processed by the CNN to estimate the probability of severe weather. The method is tested using High-Resolution Rapid Refresh (HRRR) 1--24 hr forecasts as inputs and Storm Prediction Center (SPC) severe weather reports as targets. The method produced skillful predictions with up to 20% Brier Skill Score (BSS) increases compared to other neural-network-based reference methods using a testing dataset of HRRR forecasts in 2021. For the evaluation of uncertainty quantification, the method is overconfident but produces meaningful ensemble spreads that can distinguish good and bad forecasts. The quality of CGAN outputs is also evaluated. Results show that the CGAN outputs behave similarly to a numerical ensemble; they preserved the inter-variable correlations and the contribution of influential predictors as in the original HRRR forecasts. This work provides a novel approach to post-process CAM output using neural networks that can be applied to severe weather prediction.
+
+
+
+ 143. 标题:DyST: Towards Dynamic Neural Scene Representations on Real-World Videos
+ 编号:[358]
+ 链接:https://arxiv.org/abs/2310.06020
+ 作者:Maximilian Seitzer, Sjoerd van Steenkiste, Thomas Kipf, Klaus Greff, Mehdi S. M. Sajjadi
+ 备注:Project website: this https URL
+ 关键词:Visual understanding, individual images, semantics and flat, monocular real-world videos, Dynamic Scene Transformer
+
+ 点击查看摘要
+ Visual understanding of the world goes beyond the semantics and flat structure of individual images. In this work, we aim to capture both the 3D structure and dynamics of real-world scenes from monocular real-world videos. Our Dynamic Scene Transformer (DyST) model leverages recent work in neural scene representation to learn a latent decomposition of monocular real-world videos into scene content, per-view scene dynamics, and camera pose. This separation is achieved through a novel co-training scheme on monocular videos and our new synthetic dataset DySO. DyST learns tangible latent representations for dynamic scenes that enable view generation with separate control over the camera and the content of the scene.
+
+
+
+ 144. 标题:Divide-and-Conquer Dynamics in AI-Driven Disempowerment
+ 编号:[359]
+ 链接:https://arxiv.org/abs/2310.06009
+ 作者:Peter S. Park, Max Tegmark
+ 备注:28 pages, nine visualizations (seven figures and two tables)
+ 关键词:economically valuable work, valuable work, companies are attempting, attempting to create, create AI systems
+
+ 点击查看摘要
+ AI companies are attempting to create AI systems that outperform humans at most economically valuable work. Current AI models are already automating away the livelihoods of some artists, actors, and writers. But there is infighting between those who prioritize current harms and future harms. We construct a game-theoretic model of conflict to study the causes and consequences of this disunity. Our model also helps explain why throughout history, stakeholders sharing a common threat have found it advantageous to unite against it, and why the common threat has in turn found it advantageous to divide and conquer.
+Under realistic parameter assumptions, our model makes several predictions that find preliminary corroboration in the historical-empirical record. First, current victims of AI-driven disempowerment need the future victims to realize that their interests are also under serious and imminent threat, so that future victims are incentivized to support current victims in solidarity. Second, the movement against AI-driven disempowerment can become more united, and thereby more likely to prevail, if members believe that their efforts will be successful as opposed to futile. Finally, the movement can better unite and prevail if its members are less myopic. Myopic members prioritize their future well-being less than their present well-being, and are thus disinclined to solidarily support current victims today at personal cost, even if this is necessary to counter the shared threat of AI-driven disempowerment.
+
+
+
+ 145. 标题:Rethinking Memory and Communication Cost for Efficient Large Language Model Training
+ 编号:[362]
+ 链接:https://arxiv.org/abs/2310.06003
+ 作者:Chan Wu, Hanxiao Zhang, Lin Ju, Jinjing Huang, Youshao Xiao, Zhaoxin Huan, Siyuan Li, Fanzhuang Meng, Lei Liang, Xiaolu Zhang, Jun Zhou
+ 备注:
+ 关键词:training datasets continue, training frameworks reduce, frameworks reduce memory, large-scale model training, continue to increase
+
+ 点击查看摘要
+ As model sizes and training datasets continue to increase, large-scale model training frameworks reduce memory consumption by various sharding techniques. However, the huge communication overhead reduces the training efficiency, especially in public cloud environments with varying network bandwidths. In this paper, we rethink the impact of memory consumption and communication overhead on the training speed of large language model, and propose a memory-communication balanced \underline{Pa}rtial \underline{R}edundancy \underline{O}ptimizer (PaRO). PaRO reduces the amount and frequency of inter-group communication by grouping GPU clusters and introducing minor intra-group memory redundancy, thereby improving the training efficiency of the model. Additionally, we propose a Hierarchical Overlapping Ring (HO-Ring) communication topology to enhance communication efficiency between nodes or across switches in large model training. Our experiments demonstrate that the HO-Ring algorithm improves communication efficiency by 32.6\% compared to the traditional Ring algorithm. Compared to the baseline ZeRO, PaRO significantly improves training throughput by 1.2x-2.6x and achieves a near-linear scalability. Therefore, the PaRO strategy provides more fine-grained options for the trade-off between memory consumption and communication overhead in different training scenarios.
+
+
+
+ 146. 标题:LCOT: Linear circular optimal transport
+ 编号:[363]
+ 链接:https://arxiv.org/abs/2310.06002
+ 作者:Rocio Diaz Martin, Ivan Medri, Yikun Bai, Xinran Liu, Kangbai Yan, Gustavo K. Rohde, Soheil Kolouri
+ 备注:
+ 关键词:Circular Optimal Transport, optimal transport problem, recently gained ample, gained ample interest, diverse applications involving
+
+ 点击查看摘要
+ The optimal transport problem for measures supported on non-Euclidean spaces has recently gained ample interest in diverse applications involving representation learning. In this paper, we focus on circular probability measures, i.e., probability measures supported on the unit circle, and introduce a new computationally efficient metric for these measures, denoted as Linear Circular Optimal Transport (LCOT). The proposed metric comes with an explicit linear embedding that allows one to apply Machine Learning (ML) algorithms to the embedded measures and seamlessly modify the underlying metric for the ML algorithm to LCOT. We show that the proposed metric is rooted in the Circular Optimal Transport (COT) and can be considered the linearization of the COT metric with respect to a fixed reference measure. We provide a theoretical analysis of the proposed metric and derive the computational complexities for pairwise comparison of circular probability measures. Lastly, through a set of numerical experiments, we demonstrate the benefits of LCOT in learning representations of circular measures.
+
+
+
+ 147. 标题:A novel Network Science Algorithm for Improving Triage of Patients
+ 编号:[366]
+ 链接:https://arxiv.org/abs/2310.05996
+ 作者:Pietro Hiram Guzzi, Annamaria De Filippo, Pierangelo Veltri
+ 备注:
+ 关键词:ensuring timely, plays a crucial, crucial role, triaging patients, Patient triage plays
+
+ 点击查看摘要
+ Patient triage plays a crucial role in healthcare, ensuring timely and appropriate care based on the urgency of patient conditions. Traditional triage methods heavily rely on human judgment, which can be subjective and prone to errors. Recently, a growing interest has been in leveraging artificial intelligence (AI) to develop algorithms for triaging patients. This paper presents the development of a novel algorithm for triaging patients. It is based on the analysis of patient data to produce decisions regarding their prioritization. The algorithm was trained on a comprehensive data set containing relevant patient information, such as vital signs, symptoms, and medical history. The algorithm was designed to accurately classify patients into triage categories through rigorous preprocessing and feature engineering. Experimental results demonstrate that our algorithm achieved high accuracy and performance, outperforming traditional triage methods. By incorporating computer science into the triage process, healthcare professionals can benefit from improved efficiency, accuracy, and consistency, prioritizing patients effectively and optimizing resource allocation. Although further research is needed to address challenges such as biases in training data and model interpretability, the development of AI-based algorithms for triaging patients shows great promise in enhancing healthcare delivery and patient outcomes.
+
+
+
+ 148. 标题:A Dual Latent State Learning Approach: Exploiting Regional Network Similarities for QoS Prediction
+ 编号:[371]
+ 链接:https://arxiv.org/abs/2310.05988
+ 作者:Ziliang Wang, Xiaohong Zhang, Meng Yan
+ 备注:
+ 关键词:exhibit similar network, regional network, autonomous system, similar network states, network states due
+
+ 点击查看摘要
+ Individual objects, whether users or services, within a specific region often exhibit similar network states due to their shared origin from the same city or autonomous system (AS). Despite this regional network similarity, many existing techniques overlook its potential, resulting in subpar performance arising from challenges such as data sparsity and label imbalance. In this paper, we introduce the regional-based dual latent state learning network(R2SL), a novel deep learning framework designed to overcome the pitfalls of traditional individual object-based prediction techniques in Quality of Service (QoS) prediction. Unlike its predecessors, R2SL captures the nuances of regional network behavior by deriving two distinct regional network latent states: the city-network latent state and the AS-network latent state. These states are constructed utilizing aggregated data from common regions rather than individual object data. Furthermore, R2SL adopts an enhanced Huber loss function that adjusts its linear loss component, providing a remedy for prevalent label imbalance issues. To cap off the prediction process, a multi-scale perception network is leveraged to interpret the integrated feature map, a fusion of regional network latent features and other pertinent information, ultimately accomplishing the QoS prediction. Through rigorous testing on real-world QoS datasets, R2SL demonstrates superior performance compared to prevailing state-of-the-art methods. Our R2SL approach ushers in an innovative avenue for precise QoS predictions by fully harnessing the regional network similarities inherent in objects.
+
+
+
+ 149. 标题:Analyzing Key Users' behavior trends in Volunteer-Based Networks
+ 编号:[375]
+ 链接:https://arxiv.org/abs/2310.05978
+ 作者:Nofar Piterman, Tamar Makov, Michael Fire
+ 备注:
+ 关键词:social networks usage, grow in popularity, volunteer-based social networks, behavior, usage has increased
+
+ 点击查看摘要
+ Online social networks usage has increased significantly in the last decade and continues to grow in popularity. Multiple social platforms use volunteers as a central component. The behavior of volunteers in volunteer-based networks has been studied extensively in recent years. Here, we explore the development of volunteer-based social networks, primarily focusing on their key users' behaviors and activities. We developed two novel algorithms: the first reveals key user behavior patterns over time; the second utilizes machine learning methods to generate a forecasting model that can predict the future behavior of key users, including whether they will remain active donors or change their behavior to become mainly recipients, and vice-versa. These algorithms allowed us to analyze the factors that significantly influence behavior predictions.
+To evaluate our algorithms, we utilized data from over 2.4 million users on a peer-to-peer food-sharing online platform. Using our algorithm, we identified four main types of key user behavior patterns that occur over time. Moreover, we succeeded in forecasting future active donor key users and predicting the key users that would change their behavior to donors, with an accuracy of up to 89.6%. These findings provide valuable insights into the behavior of key users in volunteer-based social networks and pave the way for more effective communities-building in the future, while using the potential of machine learning for this goal.
+
+
+
+ 150. 标题:CFDBench: A Comprehensive Benchmark for Machine Learning Methods in Fluid Dynamics
+ 编号:[378]
+ 链接:https://arxiv.org/abs/2310.05963
+ 作者:Yining Luo, Yingfa Chen, Zhen Zhang
+ 备注:33 pages, 11 figures, preprint
+ 关键词:solve physics problems, recent years, attracted much attention, solve physics, learning
+
+ 点击查看摘要
+ In recent years, applying deep learning to solve physics problems has attracted much attention. Data-driven deep learning methods produce operators that can learn solutions to the whole system of partial differential equations. However, the existing methods are only evaluated on simple flow equations (e.g., Burger's equation), and only consider the generalization ability on different initial conditions. In this paper, we construct CFDBench, a benchmark with four classic problems in computational fluid dynamics (CFD): lid-driven cavity flow, laminar boundary layer flow in circular tubes, dam flows through the steps, and periodic Karman vortex street. Each flow problem includes data with different boundary conditions, fluid physical properties, and domain geometry. Compared to existing datasets, the advantages of CFDBench are (1) comprehensive. It contains common physical parameters such as velocity, pressure, and cavity fraction. (2) realistic. It is very suitable for deep learning solutions of fluid mechanics equations. (3) challenging. It has a certain learning difficulty, prompting to find models with strong learning ability. (4) standardized. CFDBench facilitates a comprehensive and fair comparison of different deep learning methods for CFD. We make appropriate modifications to popular deep neural networks to apply them to CFDBench and enable the accommodation of more changing inputs. The evaluation on CFDBench reveals some new shortcomings of existing works and we propose possible directions for solving such problems.
+
+
+
+ 151. 标题:Improving the Performance of R17 Type-II Codebook with Deep Learning
+ 编号:[379]
+ 链接:https://arxiv.org/abs/2310.05962
+ 作者:Ke Ma, Yiliang Sang, Yang Ming, Jin Lian, Chang Tian, Zhaocheng Wang
+ 备注:Accepted by IEEE GLOBECOM 2023, conference version of Arxiv:2305.08081
+ 关键词:learning enhanced CSI, existing deep learning, deep learning enhanced, deep learning, enhanced CSI feedback
+
+ 点击查看摘要
+ The Type-II codebook in Release 17 (R17) exploits the angular-delay-domain partial reciprocity between uplink and downlink channels to select part of angular-delay-domain ports for measuring and feeding back the downlink channel state information (CSI), where the performance of existing deep learning enhanced CSI feedback methods is limited due to the deficiency of sparse structures. To address this issue, we propose two new perspectives of adopting deep learning to improve the R17 Type-II codebook. Firstly, considering the low signal-to-noise ratio of uplink channels, deep learning is utilized to accurately select the dominant angular-delay-domain ports, where the focal loss is harnessed to solve the class imbalance problem. Secondly, we propose to adopt deep learning to reconstruct the downlink CSI based on the feedback of the R17 Type-II codebook at the base station, where the information of sparse structures can be effectively leveraged. Besides, a weighted shortcut module is designed to facilitate the accurate reconstruction. Simulation results demonstrate that our proposed methods could improve the sum rate performance compared with its traditional R17 Type-II codebook and deep learning benchmarks.
+
+
+
+ 152. 标题:Fingerprint Attack: Client De-Anonymization in Federated Learning
+ 编号:[380]
+ 链接:https://arxiv.org/abs/2310.05960
+ 作者:Qiongkai Xu, Trevor Cohn, Olga Ohrimenko
+ 备注:ECAI 2023
+ 关键词:sharing in settings, trust the central, data sharing, central server, collaborative training
+
+ 点击查看摘要
+ Federated Learning allows collaborative training without data sharing in settings where participants do not trust the central server and one another. Privacy can be further improved by ensuring that communication between the participants and the server is anonymized through a shuffle; decoupling the participant identity from their data. This paper seeks to examine whether such a defense is adequate to guarantee anonymity, by proposing a novel fingerprinting attack over gradients sent by the participants to the server. We show that clustering of gradients can easily break the anonymization in an empirical study of learning federated language models on two language corpora. We then show that training with differential privacy can provide a practical defense against our fingerprint attack.
+
+
+
+ 153. 标题:Automating global landslide detection with heterogeneous ensemble deep-learning classification
+ 编号:[381]
+ 链接:https://arxiv.org/abs/2310.05959
+ 作者:Alexandra Jarna Ganerød, Gabriele Franch, Erin Lindsay, Martina Calovi
+ 备注:Author 1 and Author 2 contributed equally to this work
+ 关键词:changing climatic conditions, extreme weather events, climatic conditions, secondary consequences, changing climatic
+
+ 点击查看摘要
+ With changing climatic conditions, we are already seeing an increase in extreme weather events and their secondary consequences, including landslides. Landslides threaten infrastructure, including roads, railways, buildings, and human life. Hazard-based spatial planning and early warning systems are cost-effective strategies to reduce the risk to society from landslides. However, these both rely on data from previous landslide events, which is often scarce. Many deep learning (DL) models have recently been applied for landside mapping using medium- to high-resolution satellite images as input. However, they often suffer from sensitivity problems, overfitting, and low mapping accuracy. This study addresses some of these limitations by using a diverse global landslide dataset, using different segmentation models, such as Unet, Linknet, PSP-Net, PAN, and DeepLab and based on their performances, building an ensemble model. The ensemble model achieved the highest F1-score (0.69) when combining both Sentinel-1 and Sentinel-2 bands, with the highest average improvement of 6.87 % when the ensemble size was 20. On the other hand, Sentinel-2 bands only performed very well, with an F1 score of 0.61 when the ensemble size is 20 with an improvement of 14.59 % when the ensemble size is 20. This result shows considerable potential in building a robust and reliable monitoring system based on changes in vegetation index dNDVI only.
+
+
+
+ 154. 标题:Classification of Spam URLs Using Machine Learning Approaches
+ 编号:[383]
+ 链接:https://arxiv.org/abs/2310.05953
+ 作者:Omar Husni Odeh, Anas Arram, Murad Njoum
+ 备注:
+ 关键词:free communication tools, tools and platforms, offers fast, fast and free, free communication
+
+ 点击查看摘要
+ The Internet is used by billions of users daily because it offers fast and free communication tools and platforms. Nevertheless, with this significant increase in usage, huge amounts of spam are generated every second, which wastes internet resources and, more importantly, users time. This study investigates using machine learning models to classify URLs as spam or non-spam. We first extract the features from the URL as it has only one feature, and then we compare the performance of several models, including k-nearest neighbors, bagging, random forest, logistic regression, and others. We find that bagging achieves the best accuracy, with an accuracy of 96.5%. This suggests that bagging is a promising approach for classifying URLs as spam or nonspam.
+
+
+
+ 155. 标题:Mitigating Denial of Service Attacks in Fog-Based Wireless Sensor Networks Using Machine Learning Techniques
+ 编号:[384]
+ 链接:https://arxiv.org/abs/2310.05952
+ 作者:Ademola Abidoye, Ibidun Obagbuwa, Nureni Azeez
+ 备注:
+ 关键词:Decision tree technique, Wireless sensor networks, Decision tree, industrial applications, sensor networks
+
+ 点击查看摘要
+ Wireless sensor networks are considered to be among the most significant and innovative technologies in the 21st century due to their wide range of industrial applications. Sensor nodes in these networks are susceptible to a variety of assaults due to their special qualities and method of deployment. In WSNs, denial of service attacks are common attacks in sensor networks. It is difficult to design a detection and prevention system that would effectively reduce the impact of these attacks on WSNs. In order to identify assaults on WSNs, this study suggests using two machine learning models: decision trees and XGBoost. The WSNs dataset was the subject of extensive tests to identify denial of service attacks. The experimental findings demonstrate that the XGBoost model, when applied to the entire dataset, has a higher true positive rate (98.3%) than the Decision tree approach (97.3%) and a lower false positive rate (1.7%) than the Decision tree technique (2.7%). Like this, with selected dataset assaults, the XGBoost approach has a higher true positive rate (99.01%) than the Decision tree technique (97.50%) and a lower false positive rate (0.99%) than the Decision tree technique (2.50%).
+
+
+
+ 156. 标题:Robust and Efficient Interference Neural Networks for Defending Against Adversarial Attacks in ImageNet
+ 编号:[386]
+ 链接:https://arxiv.org/abs/2310.05947
+ 作者:Yunuo Xiong, Shujuan Liu, Hongwei Xiong
+ 备注:11 pages, 3 figures
+ 关键词:deep learning urgently, key scientific problem, deep learning, learning urgently, affected the task
+
+ 点击查看摘要
+ The existence of adversarial images has seriously affected the task of image recognition and practical application of deep learning, it is also a key scientific problem that deep learning urgently needs to solve. By far the most effective approach is to train the neural network with a large number of adversarial examples. However, this adversarial training method requires a huge amount of computing resources when applied to ImageNet, and has not yet achieved satisfactory results for high-intensity adversarial attacks. In this paper, we construct an interference neural network by applying additional background images and corresponding labels, and use pre-trained ResNet-152 to efficiently complete the training. Compared with the state-of-the-art results under the PGD attack, it has a better defense effect with much smaller computing resources. This work provides new ideas for academic research and practical applications of effective defense against adversarial attacks.
+
+
+
+ 157. 标题:Analysis of Learned Features and Framework for Potato Disease Detection
+ 编号:[387]
+ 链接:https://arxiv.org/abs/2310.05943
+ 作者:Shikha Gupta, Soma Chakraborty, Renu Rameshan
+ 备注:15 pages, 8 figures
+ 关键词:plant disease detection, applications like plant, model is trained, trained on publicly, tested on field
+
+ 点击查看摘要
+ For applications like plant disease detection, usually, a model is trained on publicly available data and tested on field data. This means that the test data distribution is not the same as the training data distribution, which affects the classifier performance adversely. We handle this dataset shift by ensuring that the features are learned from disease spots in the leaf or healthy regions, as applicable. This is achieved using a faster Region-based convolutional neural network (RCNN) as one of the solutions and an attention-based network as the other. The average classification accuracies of these classifiers are approximately 95% while evaluated on the test set corresponding to their training dataset. These classifiers also performed equivalently, with an average score of 84% on a dataset not seen during the training phase.
+
+
+
+ 158. 标题:Learning Cyber Defence Tactics from Scratch with Multi-Agent Reinforcement Learning
+ 编号:[391]
+ 链接:https://arxiv.org/abs/2310.05939
+ 作者:Jacob Wiebe, Ranwa Al Mallah, Li Li
+ 备注:Presented at 2nd International Workshop on Adaptive Cyber Defense, 2023 (arXiv:2308.09520)
+ 关键词:deep learning techniques, Recent advancements, advancements in deep, techniques have opened, opened new possibilities
+
+ 点击查看摘要
+ Recent advancements in deep learning techniques have opened new possibilities for designing solutions for autonomous cyber defence. Teams of intelligent agents in computer network defence roles may reveal promising avenues to safeguard cyber and kinetic assets. In a simulated game environment, agents are evaluated on their ability to jointly mitigate attacker activity in host-based defence scenarios. Defender systems are evaluated against heuristic attackers with the goals of compromising network confidentiality, integrity, and availability. Value-based Independent Learning and Centralized Training Decentralized Execution (CTDE) cooperative Multi-Agent Reinforcement Learning (MARL) methods are compared revealing that both approaches outperform a simple multi-agent heuristic defender. This work demonstrates the ability of cooperative MARL to learn effective cyber defence tactics against varied threats.
+
+
+
+ 159. 标题:Vulnerability Clustering and other Machine Learning Applications of Semantic Vulnerability Embeddings
+ 编号:[394]
+ 链接:https://arxiv.org/abs/2310.05935
+ 作者:Mark-Oliver Stehr, Minyoung Kim
+ 备注:27 pages, 13 figures
+ 关键词:MITRE CVE list, Vulnerability Scoring System, Common Vulnerability Scoring, Scoring System, MITRE CVE
+
+ 点击查看摘要
+ Cyber-security vulnerabilities are usually published in form of short natural language descriptions (e.g., in form of MITRE's CVE list) that over time are further manually enriched with labels such as those defined by the Common Vulnerability Scoring System (CVSS). In the Vulnerability AI (Analytics and Intelligence) project, we investigated different types of semantic vulnerability embeddings based on natural language processing (NLP) techniques to obtain a concise representation of the vulnerability space. We also evaluated their use as a foundation for machine learning applications that can support cyber-security researchers and analysts in risk assessment and other related activities. The particular applications we explored and briefly summarize in this report are clustering, classification, and visualization, as well as a new logic-based approach to evaluate theories about the vulnerability space.
+
+
+
+ 160. 标题:NECO: NEural Collapse Based Out-of-distribution detection
+ 编号:[400]
+ 链接:https://arxiv.org/abs/2310.06823
+ 作者:Mouïn Ben Ammar, Nacim Belkhir, Sebastian Popescu, Antoine Manzanera, Gianni Franchi
+ 备注:28 pages
+ 关键词:machine learning due, epistemological limits, OOD, OOD detection, critical challenge
+
+ 点击查看摘要
+ Detecting out-of-distribution (OOD) data is a critical challenge in machine learning due to model overconfidence, often without awareness of their epistemological limits. We hypothesize that ``neural collapse'', a phenomenon affecting in-distribution data for models trained beyond loss convergence, also influences OOD data. To benefit from this interplay, we introduce NECO, a novel post-hoc method for OOD detection, which leverages the geometric properties of ``neural collapse'' and of principal component spaces to identify OOD data. Our extensive experiments demonstrate that NECO achieves state-of-the-art results on both small and large-scale OOD detection tasks while exhibiting strong generalization capabilities across different network architectures. Furthermore, we provide a theoretical explanation for the effectiveness of our method in OOD detection. We plan to release the code after the anonymity period.
+
+
+
+ 161. 标题:Multi-domain improves out-of-distribution and data-limited scenarios for medical image analysis
+ 编号:[402]
+ 链接:https://arxiv.org/abs/2310.06737
+ 作者:Ece Ozkan, Xavier Boix
+ 备注:
+ 关键词:Current machine learning, machine learning methods, analysis primarily focus, image analysis primarily, developing models tailored
+
+ 点击查看摘要
+ Current machine learning methods for medical image analysis primarily focus on developing models tailored for their specific tasks, utilizing data within their target domain. These specialized models tend to be data-hungry and often exhibit limitations in generalizing to out-of-distribution samples. Recently, foundation models have been proposed, which combine data from various domains and demonstrate excellent generalization capabilities. Building upon this, this work introduces the incorporation of diverse medical image domains, including different imaging modalities like X-ray, MRI, CT, and ultrasound images, as well as various viewpoints such as axial, coronal, and sagittal views. We refer to this approach as multi-domain model and compare its performance to that of specialized models. Our findings underscore the superior generalization capabilities of multi-domain models, particularly in scenarios characterized by limited data availability and out-of-distribution, frequently encountered in healthcare applications. The integration of diverse data allows multi-domain models to utilize shared information across domains, enhancing the overall outcomes significantly. To illustrate, for organ recognition, multi-domain model can enhance accuracy by up to 10% compared to conventional specialized models.
+
+
+
+ 162. 标题:Growing ecosystem of deep learning methods for modeling protein$\unicode{x2013}$protein interactions
+ 编号:[404]
+ 链接:https://arxiv.org/abs/2310.06725
+ 作者:Julia R. Rogers, Gergő Nikolényi, Mohammed AlQuraishi
+ 备注:
+ 关键词:protein interactions, Deep learning, protein, interactions, learning
+
+ 点击查看摘要
+ Numerous cellular functions rely on protein$\unicode{x2013}$protein interactions. Efforts to comprehensively characterize them remain challenged however by the diversity of molecular recognition mechanisms employed within the proteome. Deep learning has emerged as a promising approach for tackling this problem by exploiting both experimental data and basic biophysical knowledge about protein interactions. Here, we review the growing ecosystem of deep learning methods for modeling protein interactions, highlighting the diversity of these biophysically-informed models and their respective trade-offs. We discuss recent successes in using representation learning to capture complex features pertinent to predicting protein interactions and interaction sites, geometric deep learning to reason over protein structures and predict complex structures, and generative modeling to design de novo protein assemblies. We also outline some of the outstanding challenges and promising new directions. Opportunities abound to discover novel interactions, elucidate their physical mechanisms, and engineer binders to modulate their functions using deep learning and, ultimately, unravel how protein interactions orchestrate complex cellular behaviors.
+
+
+
+ 163. 标题:Generalized Wick Decompositions
+ 编号:[405]
+ 链接:https://arxiv.org/abs/2310.06686
+ 作者:Chris MacLeod, Evgenia Nitishinskaya, Buck Shlegeris
+ 备注:11 pages
+ 关键词:sum of terms, Wick decomposition, random variables, necessarily random, review the cumulant
+
+ 点击查看摘要
+ We review the cumulant decomposition (a way of decomposing the expectation of a product of random variables (e.g. $\mathbb{E}[XYZ]$) into a sum of terms corresponding to partitions of these variables.) and the Wick decomposition (a way of decomposing a product of (not necessarily random) variables into a sum of terms corresponding to subsets of the variables). Then we generalize each one to a new decomposition where the product function is generalized to an arbitrary function.
+
+
+
+ 164. 标题:Deep Learning reconstruction with uncertainty estimation for $γ$ photon interaction in fast scintillator detectors
+ 编号:[409]
+ 链接:https://arxiv.org/abs/2310.06572
+ 作者:Geoffrey Daniel, Mohamed Bahi Yahiaoui, Claude Comtat, Sebastien Jan, Olga Kochebina, Jean-Marc Martinez, Viktoriya Sergeyeva, Viatcheslav Sharyy, Chi-Hsun Sung, Dominique Yvon
+ 备注:Submitted to Artificial Intelligence
+ 关键词:Positron Emission Tomography, physics-informed deep learning, deep learning method, Emission Tomography, Positron Emission
+
+ 点击查看摘要
+ This article presents a physics-informed deep learning method for the quantitative estimation of the spatial coordinates of gamma interactions within a monolithic scintillator, with a focus on Positron Emission Tomography (PET) imaging. A Density Neural Network approach is designed to estimate the 2-dimensional gamma photon interaction coordinates in a fast lead tungstate (PbWO4) monolithic scintillator detector. We introduce a custom loss function to estimate the inherent uncertainties associated with the reconstruction process and to incorporate the physical constraints of the detector.
+This unique combination allows for more robust and reliable position estimations and the obtained results demonstrate the effectiveness of the proposed approach and highlights the significant benefits of the uncertainties estimation. We discuss its potential impact on improving PET imaging quality and show how the results can be used to improve the exploitation of the model, to bring benefits to the application and how to evaluate the validity of the given prediction and the associated uncertainties. Importantly, our proposed methodology extends beyond this specific use case, as it can be generalized to other applications beyond PET imaging.
+
+
+
+ 165. 标题:Statistical properties and privacy guarantees of an original distance-based fully synthetic data generation method
+ 编号:[410]
+ 链接:https://arxiv.org/abs/2310.06571
+ 作者:Rémy Chapelle (CESP, EVDG), Bruno Falissard (CESP)
+ 备注:
+ 关键词:Open Science principles, data, growing exponentially, synthetic data, Open Science
+
+ 点击查看摘要
+ Introduction: The amount of data generated by original research is growing exponentially. Publicly releasing them is recommended to comply with the Open Science principles. However, data collected from human participants cannot be released as-is without raising privacy concerns. Fully synthetic data represent a promising answer to this challenge. This approach is explored by the French Centre de Recherche en {É}pid{é}miologie et Sant{é} des Populations in the form of a synthetic data generation framework based on Classification and Regression Trees and an original distance-based filtering. The goal of this work was to develop a refined version of this framework and to assess its risk-utility profile with empirical and formal tools, including novel ones developed for the purpose of this evaluation.Materials and Methods: Our synthesis framework consists of four successive steps, each of which is designed to prevent specific risks of disclosure. We assessed its performance by applying two or more of these steps to a rich epidemiological dataset. Privacy and utility metrics were computed for each of the resulting synthetic datasets, which were further assessed using machine learning approaches.Results: Computed metrics showed a satisfactory level of protection against attribute disclosure attacks for each synthetic dataset, especially when the full framework was used. Membership disclosure attacks were formally prevented without significantly altering the data. Machine learning approaches showed a low risk of success for simulated singling out and linkability attacks. Distributional and inferential similarity with the original data were high with all datasets.Discussion: This work showed the technical feasibility of generating publicly releasable synthetic data using a multi-step framework. Formal and empirical tools specifically developed for this demonstration are a valuable contribution to this field. Further research should focus on the extension and validation of these tools, in an effort to specify the intrinsic qualities of alternative data synthesis methods.Conclusion: By successfully assessing the quality of data produced using a novel multi-step synthetic data generation framework, we showed the technical and conceptual soundness of the Open-CESP initiative, which seems ripe for full-scale implementation.
+
+
+
+ 166. 标题:Data efficient deep learning for medical image analysis: A survey
+ 编号:[411]
+ 链接:https://arxiv.org/abs/2310.06557
+ 作者:Suruchi Kumari, Pravendra Singh
+ 备注:Under Review
+ 关键词:medical image analysis, medical image, image analysis, deep learning, learning
+
+ 点击查看摘要
+ The rapid evolution of deep learning has significantly advanced the field of medical image analysis. However, despite these achievements, the further enhancement of deep learning models for medical image analysis faces a significant challenge due to the scarcity of large, well-annotated datasets. To address this issue, recent years have witnessed a growing emphasis on the development of data-efficient deep learning methods. This paper conducts a thorough review of data-efficient deep learning methods for medical image analysis. To this end, we categorize these methods based on the level of supervision they rely on, encompassing categories such as no supervision, inexact supervision, incomplete supervision, inaccurate supervision, and only limited supervision. We further divide these categories into finer subcategories. For example, we categorize inexact supervision into multiple instance learning and learning with weak annotations. Similarly, we categorize incomplete supervision into semi-supervised learning, active learning, and domain-adaptive learning and so on. Furthermore, we systematically summarize commonly used datasets for data efficient deep learning in medical image analysis and investigate future research directions to conclude this survey.
+
+
+
+ 167. 标题:Data-level hybrid strategy selection for disk fault prediction model based on multivariate GAN
+ 编号:[413]
+ 链接:https://arxiv.org/abs/2310.06537
+ 作者:Shuangshuang Yuan, Peng Wu, Yuehui Chen
+ 备注:
+ 关键词:Data class imbalance, minority class samples, class imbalance, SMART dataset, costly to misclassify
+
+ 点击查看摘要
+ Data class imbalance is a common problem in classification problems, where minority class samples are often more important and more costly to misclassify in a classification task. Therefore, it is very important to solve the data class imbalance classification problem. The SMART dataset exhibits an evident class imbalance, comprising a substantial quantity of healthy samples and a comparatively limited number of defective samples. This dataset serves as a reliable indicator of the disc's health status. In this paper, we obtain the best balanced disk SMART dataset for a specific classification model by mixing and integrating the data synthesised by multivariate generative adversarial networks (GAN) to balance the disk SMART dataset at the data level; and combine it with genetic algorithms to obtain higher disk fault classification prediction accuracy on a specific classification model.
+
+
+
+ 168. 标题:Disk failure prediction based on multi-layer domain adaptive learning
+ 编号:[414]
+ 链接:https://arxiv.org/abs/2310.06534
+ 作者:Guangfu Gao, Peng Wu, Hussain Dawood
+ 备注:
+ 关键词:Large scale data, scale data storage, Large scale, storage is susceptible, disk data
+
+ 点击查看摘要
+ Large scale data storage is susceptible to failure. As disks are damaged and replaced, traditional machine learning models, which rely on historical data to make predictions, struggle to accurately predict disk failures. This paper presents a novel method for predicting disk failures by leveraging multi-layer domain adaptive learning techniques. First, disk data with numerous faults is selected as the source domain, and disk data with fewer faults is selected as the target domain. A training of the feature extraction network is performed with the selected origin and destination domains. The contrast between the two domains facilitates the transfer of diagnostic knowledge from the domain of source and target. According to the experimental findings, it has been demonstrated that the proposed technique can generate a reliable prediction model and improve the ability to predict failures on disk data with few failure samples.
+
+
+
+ 169. 标题:Automatic nodule identification and differentiation in ultrasound videos to facilitate per-nodule examination
+ 编号:[417]
+ 链接:https://arxiv.org/abs/2310.06339
+ 作者:Siyuan Jiang, Yan Ding, Yuling Wang, Lei Xu, Wenli Dai, Wanru Chang, Jianfeng Zhang, Jie Yu, Jianqiao Zhou, Chunquan Zhang, Ping Liang, Dexing Kong
+ 备注:
+ 关键词:vital diagnostic technique, health screening, advantages of non-invasive, radiation free, vital diagnostic
+
+ 点击查看摘要
+ Ultrasound is a vital diagnostic technique in health screening, with the advantages of non-invasive, cost-effective, and radiation free, and therefore is widely applied in the diagnosis of nodules. However, it relies heavily on the expertise and clinical experience of the sonographer. In ultrasound images, a single nodule might present heterogeneous appearances in different cross-sectional views which makes it hard to perform per-nodule examination. Sonographers usually discriminate different nodules by examining the nodule features and the surrounding structures like gland and duct, which is cumbersome and time-consuming. To address this problem, we collected hundreds of breast ultrasound videos and built a nodule reidentification system that consists of two parts: an extractor based on the deep learning model that can extract feature vectors from the input video clips and a real-time clustering algorithm that automatically groups feature vectors by nodules. The system obtains satisfactory results and exhibits the capability to differentiate ultrasound videos. As far as we know, it's the first attempt to apply re-identification technique in the ultrasonic field.
+
+
+
+ 170. 标题:Adversarial Masked Image Inpainting for Robust Detection of Mpox and Non-Mpox
+ 编号:[419]
+ 链接:https://arxiv.org/abs/2310.06318
+ 作者:Yubiao Yue, Zhenzhang Li
+ 备注:
+ 关键词:MIM, mpox diagnostic technology, efficient mpox diagnostic, mpox cases continue, mpox
+
+ 点击查看摘要
+ Due to the lack of efficient mpox diagnostic technology, mpox cases continue to increase. Recently, the great potential of deep learning models in detecting mpox and non-mpox has been proven. However, existing models learn image representations via image classification, which results in they may be easily susceptible to interference from real-world noise, require diverse non-mpox images, and fail to detect abnormal input. These drawbacks make classification models inapplicable in real-world settings. To address these challenges, we propose "Mask, Inpainting, and Measure" (MIM). In MIM's pipeline, a generative adversarial network only learns mpox image representations by inpainting the masked mpox images. Then, MIM determines whether the input belongs to mpox by measuring the similarity between the inpainted image and the original image. The underlying intuition is that since MIM solely models mpox images, it struggles to accurately inpaint non-mpox images in real-world settings. Without utilizing any non-mpox images, MIM cleverly detects mpox and non-mpox and can handle abnormal inputs. We used the recognized mpox dataset (MSLD) and images of eighteen non-mpox skin diseases to verify the effectiveness and robustness of MIM. Experimental results show that the average AUROC of MIM achieves 0.8237. In addition, we demonstrated the drawbacks of classification models and buttressed the potential of MIM through clinical validation. Finally, we developed an online smartphone app to provide free testing to the public in affected areas. This work first employs generative models to improve mpox detection and provides new insights into binary decision-making tasks in medical images.
+
+
+
+ 171. 标题:Better and Simpler Lower Bounds for Differentially Private Statistical Estimation
+ 编号:[421]
+ 链接:https://arxiv.org/abs/2310.06289
+ 作者:Shyam Narayanan
+ 备注:23 pages
+ 关键词:alpha, provide improved lower, well-known high-dimensional private, frac, approximate differential privacy
+
+ 点击查看摘要
+ We provide improved lower bounds for two well-known high-dimensional private estimation tasks. First, we prove that for estimating the covariance of a Gaussian up to spectral error $\alpha$ with approximate differential privacy, one needs $\tilde{\Omega}\left(\frac{d^{3/2}}{\alpha \varepsilon} + \frac{d}{\alpha^2}\right)$ samples for any $\alpha \le O(1)$, which is tight up to logarithmic factors. This improves over previous work which established this for $\alpha \le O\left(\frac{1}{\sqrt{d}}\right)$, and is also simpler than previous work. Next, we prove that for estimating the mean of a heavy-tailed distribution with bounded $k$th moments with approximate differential privacy, one needs $\tilde{\Omega}\left(\frac{d}{\alpha^{k/(k-1)} \varepsilon} + \frac{d}{\alpha^2}\right)$ samples. This matches known upper bounds and improves over the best known lower bound for this problem, which only hold for pure differential privacy, or when $k = 2$. Our techniques follow the method of fingerprinting and are generally quite simple. Our lower bound for heavy-tailed estimation is based on a black-box reduction from privately estimating identity-covariance Gaussians. Our lower bound for covariance estimation utilizes a Bayesian approach to show that, under an Inverse Wishart prior distribution for the covariance matrix, no private estimator can be accurate even in expectation, without sufficiently many samples.
+
+
+
+ 172. 标题:Deep Learning: A Tutorial
+ 编号:[423]
+ 链接:https://arxiv.org/abs/2310.06251
+ 作者:Nick Polson, Vadim Sokolov
+ 备注:arXiv admin note: text overlap with arXiv:1808.08618
+ 关键词:structured high-dimensional data, high-dimensional data, deep learning methods, insight into structured, structured high-dimensional
+
+ 点击查看摘要
+ Our goal is to provide a review of deep learning methods which provide insight into structured high-dimensional data. Rather than using shallow additive architectures common to most statistical models, deep learning uses layers of semi-affine input transformations to provide a predictive rule. Applying these layers of transformations leads to a set of attributes (or, features) to which probabilistic statistical methods can be applied. Thus, the best of both worlds can be achieved: scalable prediction rules fortified with uncertainty quantification, where sparse regularization finds the features.
+
+
+
+ 173. 标题:A Bayesian framework for discovering interpretable Lagrangian of dynamical systems from data
+ 编号:[424]
+ 链接:https://arxiv.org/abs/2310.06241
+ 作者:Tapas Tripura, Souvik Chakraborty
+ 备注:
+ 关键词:underlying physical laws, physical systems requires, learning physical laws, physical systems, physical laws involve
+
+ 点击查看摘要
+ Learning and predicting the dynamics of physical systems requires a profound understanding of the underlying physical laws. Recent works on learning physical laws involve generalizing the equation discovery frameworks to the discovery of Hamiltonian and Lagrangian of physical systems. While the existing methods parameterize the Lagrangian using neural networks, we propose an alternate framework for learning interpretable Lagrangian descriptions of physical systems from limited data using the sparse Bayesian approach. Unlike existing neural network-based approaches, the proposed approach (a) yields an interpretable description of Lagrangian, (b) exploits Bayesian learning to quantify the epistemic uncertainty due to limited data, (c) automates the distillation of Hamiltonian from the learned Lagrangian using Legendre transformation, and (d) provides ordinary (ODE) and partial differential equation (PDE) based descriptions of the observed systems. Six different examples involving both discrete and continuous system illustrates the efficacy of the proposed approach.
+
+
+
+ 174. 标题:HydraViT: Adaptive Multi-Branch Transformer for Multi-Label Disease Classification from Chest X-ray Images
+ 编号:[430]
+ 链接:https://arxiv.org/abs/2310.06143
+ 作者:Şaban Öztürk, M. Yiğit Turalı, Tolga Çukur
+ 备注:
+ 关键词:essential diagnostic tool, pathological abnormalities, Chest X-ray, identification of chest, essential diagnostic
+
+ 点击查看摘要
+ Chest X-ray is an essential diagnostic tool in the identification of chest diseases given its high sensitivity to pathological abnormalities in the lungs. However, image-driven diagnosis is still challenging due to heterogeneity in size and location of pathology, as well as visual similarities and co-occurrence of separate pathology. Since disease-related regions often occupy a relatively small portion of diagnostic images, classification models based on traditional convolutional neural networks (CNNs) are adversely affected given their locality bias. While CNNs were previously augmented with attention maps or spatial masks to guide focus on potentially critical regions, learning localization guidance under heterogeneity in the spatial distribution of pathology is challenging. To improve multi-label classification performance, here we propose a novel method, HydraViT, that synergistically combines a transformer backbone with a multi-branch output module with learned weighting. The transformer backbone enhances sensitivity to long-range context in X-ray images, while using the self-attention mechanism to adaptively focus on task-critical regions. The multi-branch output module dedicates an independent branch to each disease label to attain robust learning across separate disease classes, along with an aggregated branch across labels to maintain sensitivity to co-occurrence relationships among pathology. Experiments demonstrate that, on average, HydraViT outperforms competing attention-guided methods by 1.2%, region-guided methods by 1.4%, and semantic-guided methods by 1.0% in multi-label classification performance.
+
+
+
+ 175. 标题:Grokking as the Transition from Lazy to Rich Training Dynamics
+ 编号:[431]
+ 链接:https://arxiv.org/abs/2310.06110
+ 作者:Tanishq Kumar, Blake Bordelon, Samuel J. Gershman, Cengiz Pehlevan
+ 备注:
+ 关键词:neural network decreases, neural network transitioning, neural network, feature learning, train loss
+
+ 点击查看摘要
+ We propose that the grokking phenomenon, where the train loss of a neural network decreases much earlier than its test loss, can arise due to a neural network transitioning from lazy training dynamics to a rich, feature learning regime. To illustrate this mechanism, we study the simple setting of vanilla gradient descent on a polynomial regression problem with a two layer neural network which exhibits grokking without regularization in a way that cannot be explained by existing theories. We identify sufficient statistics for the test loss of such a network, and tracking these over training reveals that grokking arises in this setting when the network first attempts to fit a kernel regression solution with its initial features, followed by late-time feature learning where a generalizing solution is identified after train loss is already low. We find that the key determinants of grokking are the rate of feature learning -- which can be controlled precisely by parameters that scale the network output -- and the alignment of the initial features with the target function $y(x)$. We argue this delayed generalization arises when (1) the top eigenvectors of the initial neural tangent kernel and the task labels $y(x)$ are misaligned, but (2) the dataset size is large enough so that it is possible for the network to generalize eventually, but not so large that train loss perfectly tracks test loss at all epochs, and (3) the network begins training in the lazy regime so does not learn features immediately. We conclude with evidence that this transition from lazy (linear model) to rich training (feature learning) can control grokking in more general settings, like on MNIST, one-layer Transformers, and student-teacher networks.
+
+
+
+ 176. 标题:Quantifying Uncertainty in Deep Learning Classification with Noise in Discrete Inputs for Risk-Based Decision Making
+ 编号:[432]
+ 链接:https://arxiv.org/abs/2310.06105
+ 作者:Maryam Kheirandish, Shengfan Zhang, Donald G. Catanzaro, Valeriu Crudu
+ 备注:31 pages, 9 figures
+ 关键词:Deep Neural Network, Neural Network, attracted extensive attention, Deep Neural, quality control
+
+ 点击查看摘要
+ The use of Deep Neural Network (DNN) models in risk-based decision-making has attracted extensive attention with broad applications in medical, finance, manufacturing, and quality control. To mitigate prediction-related risks in decision making, prediction confidence or uncertainty should be assessed alongside the overall performance of algorithms. Recent studies on Bayesian deep learning helps quantify prediction uncertainty arises from input noises and model parameters. However, the normality assumption of input noise in these models limits their applicability to problems involving categorical and discrete feature variables in tabular datasets. In this paper, we propose a mathematical framework to quantify prediction uncertainty for DNN models. The prediction uncertainty arises from errors in predictors that follow some known finite discrete distribution. We then conducted a case study using the framework to predict treatment outcome for tuberculosis patients during their course of treatment. The results demonstrate under a certain level of risk, we can identify risk-sensitive cases, which are prone to be misclassified due to error in predictors. Comparing to the Monte Carlo dropout method, our proposed framework is more aware of misclassification cases. Our proposed framework for uncertainty quantification in deep learning can support risk-based decision making in applications when discrete errors in predictors are present.
+
+
+
+ 177. 标题:Ito Diffusion Approximation of Universal Ito Chains for Sampling, Optimization and Boosting
+ 编号:[433]
+ 链接:https://arxiv.org/abs/2310.06081
+ 作者:Aleksei Ustimenko, Aleksandr Beznosikov
+ 备注:30 pages, 3 tables
+ 关键词:Stochastic Differential Equation, class of Markov, Differential Equation, Stochastic Gradient, Stochastic Gradient Descent
+
+ 点击查看摘要
+ This work considers a rather general and broad class of Markov chains, Ito chains that look like Euler-Maryama discretization of some Stochastic Differential Equation. The chain we study is a unified framework for theoretical analysis. It comes with almost arbitrary isotropic and state-dependent noise instead of normal and state-independent one, as in most related papers. Moreover, our chain's drift and diffusion coefficient can be inexact to cover a wide range of applications such as Stochastic Gradient Langevin Dynamics, sampling, Stochastic Gradient Descent, or Stochastic Gradient Boosting. We prove an upper bound for $W_{2}$-distance between laws of the Ito chain and the corresponding Stochastic Differential Equation. These results improve or cover most of the known estimates. Moreover, for some particular cases, our analysis is the first.
+
+
+
+ 178. 标题:Optimal Exploration is no harder than Thompson Sampling
+ 编号:[436]
+ 链接:https://arxiv.org/abs/2310.06069
+ 作者:Zhaoqi Li, Kevin Jamieson, Lalit Jain
+ 备注:
+ 关键词:unknown parameter vector, linear bandit problem, bandit problem aims, mathcal, mathbb
+
+ 点击查看摘要
+ Given a set of arms $\mathcal{Z}\subset \mathbb{R}^d$ and an unknown parameter vector $\theta_\ast\in\mathbb{R}^d$, the pure exploration linear bandit problem aims to return $\arg\max_{z\in \mathcal{Z}} z^{\top}\theta_{\ast}$, with high probability through noisy measurements of $x^{\top}\theta_{\ast}$ with $x\in \mathcal{X}\subset \mathbb{R}^d$. Existing (asymptotically) optimal methods require either a) potentially costly projections for each arm $z\in \mathcal{Z}$ or b) explicitly maintaining a subset of $\mathcal{Z}$ under consideration at each time. This complexity is at odds with the popular and simple Thompson Sampling algorithm for regret minimization, which just requires access to a posterior sampling and argmax oracle, and does not need to enumerate $\mathcal{Z}$ at any point. Unfortunately, Thompson sampling is known to be sub-optimal for pure exploration. In this work, we pose a natural question: is there an algorithm that can explore optimally and only needs the same computational primitives as Thompson Sampling? We answer the question in the affirmative. We provide an algorithm that leverages only sampling and argmax oracles and achieves an exponential convergence rate, with the exponent being the optimal among all possible allocations asymptotically. In addition, we show that our algorithm can be easily implemented and performs as well empirically as existing asymptotically optimal methods.
+
+
+
+ 179. 标题:Cost-sensitive probabilistic predictions for support vector machines
+ 编号:[439]
+ 链接:https://arxiv.org/abs/2310.05997
+ 作者:Sandra Benítez-Peña, Rafael Blanquero, Emilio Carrizosa, Pepa Ramírez-Cobo
+ 备注:European Journal of Operational Research (2023)
+ 关键词:Support vector machines, machine learning models, probabilistic classification rule, vector machines, machine learning
+
+ 点击查看摘要
+ Support vector machines (SVMs) are widely used and constitute one of the best examined and used machine learning models for two-class classification. Classification in SVM is based on a score procedure, yielding a deterministic classification rule, which can be transformed into a probabilistic rule (as implemented in off-the-shelf SVM libraries), but is not probabilistic in nature. On the other hand, the tuning of the regularization parameters in SVM is known to imply a high computational effort and generates pieces of information that are not fully exploited, not being used to build a probabilistic classification rule. In this paper we propose a novel approach to generate probabilistic outputs for the SVM. The new method has the following three properties. First, it is designed to be cost-sensitive, and thus the different importance of sensitivity (or true positive rate, TPR) and specificity (true negative rate, TNR) is readily accommodated in the model. As a result, the model can deal with imbalanced datasets which are common in operational business problems as churn prediction or credit scoring. Second, the SVM is embedded in an ensemble method to improve its performance, making use of the valuable information generated in the parameters tuning process. Finally, the probabilities estimation is done via bootstrap estimates, avoiding the use of parametric models as competing approaches. Numerical tests on a wide range of datasets show the advantages of our approach over benchmark procedures.
+
+
+
+ 180. 标题:Data Augmentation through Pseudolabels in Automatic Region Based Coronary Artery Segmentation for Disease Diagnosis
+ 编号:[440]
+ 链接:https://arxiv.org/abs/2310.05990
+ 作者:Sandesh Pokhrel, Sanjay Bhandari, Eduard Vazquez, Yash Raj Shrestha, Binod Bhattarai
+ 备注:arXiv admin note: text overlap with arXiv:2310.04749
+ 关键词:Coronary Artery Diseases, Coronary Artery, Artery Diseases, death and disability, Artery
+
+ 点击查看摘要
+ Coronary Artery Diseases(CADs) though preventable are one of the leading causes of death and disability. Diagnosis of these diseases is often difficult and resource intensive. Segmentation of arteries in angiographic images has evolved as a tool for assistance, helping clinicians in making accurate diagnosis. However, due to the limited amount of data and the difficulty in curating a dataset, the task of segmentation has proven challenging. In this study, we introduce the idea of using pseudolabels as a data augmentation technique to improve the performance of the baseline Yolo model. This method increases the F1 score of the baseline by 9% in the validation dataset and by 3% in the test dataset.
+
+
+
+ 181. 标题:Bayesian Quality-Diversity approaches for constrained optimization problems with mixed continuous, discrete and categorical variables
+ 编号:[445]
+ 链接:https://arxiv.org/abs/2310.05955
+ 作者:Loic Brevault, Mathieu Balesdent
+ 备注:
+ 关键词:numerically costly simulation, costly simulation codes, Complex engineering design, engineering design problems, design
+
+ 点击查看摘要
+ Complex engineering design problems, such as those involved in aerospace, civil, or energy engineering, require the use of numerically costly simulation codes in order to predict the behavior and performance of the system to be designed. To perform the design of the systems, these codes are often embedded into an optimization process to provide the best design while satisfying the design constraints. Recently, new approaches, called Quality-Diversity, have been proposed in order to enhance the exploration of the design space and to provide a set of optimal diversified solutions with respect to some feature functions. These functions are interesting to assess trade-offs. Furthermore, complex engineering design problems often involve mixed continuous, discrete, and categorical design variables allowing to take into account technological choices in the optimization problem. In this paper, a new Quality-Diversity methodology based on mixed continuous, discrete and categorical Bayesian optimization strategy is proposed. This approach allows to reduce the computational cost with respect to classical Quality - Diversity approaches while dealing with discrete choices and constraints. The performance of the proposed method is assessed on a benchmark of analytical problems as well as on an industrial design optimization problem dealing with aerospace systems.
+
+
+
+ 182. 标题:Optimization of Raman amplifiers: a comparison between black-, grey- and white-box modeling
+ 编号:[446]
+ 链接:https://arxiv.org/abs/2310.05954
+ 作者:Metodi P. Yankov, Mehran Soltani, Andrea Carena, Darko Zibar, Francesco Da Ros
+ 备注:
+ 关键词:maximize system performance, communication systems strive, optical communication systems, optimizing optical amplifiers, Designing and optimizing
+
+ 点击查看摘要
+ Designing and optimizing optical amplifiers to maximize system performance is becoming increasingly important as optical communication systems strive to increase throughput. Offline optimization of optical amplifiers relies on models ranging from white-box models deeply rooted in physics to black-box data-driven physics-agnostic models. Here, we compare the capabilities of white-, grey- and black-box models to achieve a target frequency-distance amplification in a bidirectional Raman amplifier. We show that any of the studied methods can achieve down to 1 dB of frequency-distance flatness over the C-band in a 100-km span. Then, we discuss the models' applicability, advantages, and drawbacks based on the target application scenario, in particular in terms of optimization speed and access to training data.
+
+
+人工智能
+
+ 1. 标题:Scalable Semantic Non-Markovian Simulation Proxy for Reinforcement Learning
+ 编号:[5]
+ 链接:https://arxiv.org/abs/2310.06835
+ 作者:Kaustuv Mukherji, Devendra Parkar, Lahari Pokala, Dyuman Aditya, Paulo Shakarian, Clark Dorman
+ 备注:Submitted to IEEE International Conference on Semantic Computing
+ 关键词:Recent advances, reinforcement learning, variety of applications, advances in reinforcement, shown much promise
+
+ 点击查看摘要
+ Recent advances in reinforcement learning (RL) have shown much promise across a variety of applications. However, issues such as scalability, explainability, and Markovian assumptions limit its applicability in certain domains. We observe that many of these shortcomings emanate from the simulator as opposed to the RL training algorithms themselves. As such, we propose a semantic proxy for simulation based on a temporal extension to annotated logic. In comparison with two high-fidelity simulators, we show up to three orders of magnitude speed-up while preserving the quality of policy learned in addition to showing the ability to model and leverage non-Markovian dynamics and instantaneous actions while providing an explainable trace describing the outcomes of the agent actions.
+
+
+
+ 2. 标题:Mistral 7B
+ 编号:[9]
+ 链接:https://arxiv.org/abs/2310.06825
+ 作者:Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed
+ 备注:Models and code are available at this https URL
+ 关键词:language model engineered, performance and efficiency, introduce Mistral, engineered for superior, superior performance
+
+ 点击查看摘要
+ We introduce Mistral 7B v0.1, a 7-billion-parameter language model engineered for superior performance and efficiency. Mistral 7B outperforms Llama 2 13B across all evaluated benchmarks, and Llama 1 34B in reasoning, mathematics, and code generation. Our model leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost. We also provide a model fine-tuned to follow instructions, Mistral 7B -- Instruct, that surpasses the Llama 2 13B -- Chat model both on human and automated benchmarks. Our models are released under the Apache 2.0 license.
+
+
+
+ 3. 标题:The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets
+ 编号:[10]
+ 链接:https://arxiv.org/abs/2310.06824
+ 作者:Samuel Marks, Max Tegmark
+ 备注:
+ 关键词:impressive capabilities, Large Language Models, prone to outputting, LLM, Large Language
+
+ 点击查看摘要
+ Large Language Models (LLMs) have impressive capabilities, but are also prone to outputting falsehoods. Recent work has developed techniques for inferring whether a LLM is telling the truth by training probes on the LLM's internal activations. However, this line of work is controversial, with some authors pointing out failures of these probes to generalize in basic ways, among other conceptual issues. In this work, we curate high-quality datasets of true/false statements and use them to study in detail the structure of LLM representations of truth, drawing on three lines of evidence: 1. Visualizations of LLM true/false statement representations, which reveal clear linear structure. 2. Transfer experiments in which probes trained on one dataset generalize to different datasets. 3. Causal evidence obtained by surgically intervening in a LLM's forward pass, causing it to treat false statements as true and vice versa. Overall, we present evidence that language models linearly represent the truth or falsehood of factual statements. We also introduce a novel technique, mass-mean probing, which generalizes better and is more causally implicated in model outputs than other probing techniques.
+
+
+
+ 4. 标题:Advancing Transformer's Capabilities in Commonsense Reasoning
+ 编号:[13]
+ 链接:https://arxiv.org/abs/2310.06803
+ 作者:Yu Zhou, Yunqiu Han, Hanyu Zhou, Yulun Wu
+ 备注:
+ 关键词:shown great potential, purpose pre-trained language, Recent advances, commonsense reasoning, general purpose pre-trained
+
+ 点击查看摘要
+ Recent advances in general purpose pre-trained language models have shown great potential in commonsense reasoning. However, current works still perform poorly on standard commonsense reasoning benchmarks including the Com2Sense Dataset. We argue that this is due to a disconnect with current cutting-edge machine learning methods. In this work, we aim to bridge the gap by introducing current ML-based methods to improve general purpose pre-trained language models in the task of commonsense reasoning. Specifically, we experiment with and systematically evaluate methods including knowledge transfer, model ensemble, and introducing an additional pairwise contrastive objective. Our best model outperforms the strongest previous works by ~15\% absolute gains in Pairwise Accuracy and ~8.7\% absolute gains in Standard Accuracy.
+
+
+
+ 5. 标题:$f$-Policy Gradients: A General Framework for Goal Conditioned RL using $f$-Divergences
+ 编号:[16]
+ 链接:https://arxiv.org/abs/2310.06794
+ 作者:Siddhant Agarwal, Ishan Durugkar, Peter Stone, Amy Zhang
+ 备注:Accepted at NeurIPS 2023
+ 关键词:Goal-Conditioned Reinforcement Learning, Goal-Conditioned Reinforcement, Reinforcement Learning, making policy optimization, Reinforcement
+
+ 点击查看摘要
+ Goal-Conditioned Reinforcement Learning (RL) problems often have access to sparse rewards where the agent receives a reward signal only when it has achieved the goal, making policy optimization a difficult problem. Several works augment this sparse reward with a learned dense reward function, but this can lead to sub-optimal policies if the reward is misaligned. Moreover, recent works have demonstrated that effective shaping rewards for a particular problem can depend on the underlying learning algorithm. This paper introduces a novel way to encourage exploration called $f$-Policy Gradients, or $f$-PG. $f$-PG minimizes the f-divergence between the agent's state visitation distribution and the goal, which we show can lead to an optimal policy. We derive gradients for various f-divergences to optimize this objective. Our learning paradigm provides dense learning signals for exploration in sparse reward settings. We further introduce an entropy-regularized policy optimization objective, that we call $state$-MaxEnt RL (or $s$-MaxEnt RL) as a special case of our objective. We show that several metric-based shaping rewards like L2 can be used with $s$-MaxEnt RL, providing a common ground to study such metric-based shaping rewards with efficient exploration. We find that $f$-PG has better performance compared to standard policy gradient methods on a challenging gridworld as well as the Point Maze and FetchReach environments. More information on our website this https URL.
+
+
+
+ 6. 标题:OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text
+ 编号:[19]
+ 链接:https://arxiv.org/abs/2310.06786
+ 作者:Keiran Paster, Marco Dos Santos, Zhangir Azerbayev, Jimmy Ba
+ 备注:
+ 关键词:carefully thought-out tokens, carefully thought-out, growing evidence, evidence that pretraining, pretraining on high
+
+ 点击查看摘要
+ There is growing evidence that pretraining on high quality, carefully thought-out tokens such as code or mathematics plays an important role in improving the reasoning abilities of large language models. For example, Minerva, a PaLM model finetuned on billions of tokens of mathematical documents from arXiv and the web, reported dramatically improved performance on problems that require quantitative reasoning. However, because all known open source web datasets employ preprocessing that does not faithfully preserve mathematical notation, the benefits of large scale training on quantitive web documents are unavailable to the research community. We introduce OpenWebMath, an open dataset inspired by these works containing 14.7B tokens of mathematical webpages from Common Crawl. We describe in detail our method for extracting text and LaTeX content and removing boilerplate from HTML documents, as well as our methods for quality filtering and deduplication. Additionally, we run small-scale experiments by training 1.4B parameter language models on OpenWebMath, showing that models trained on 14.7B tokens of our dataset surpass the performance of models trained on over 20x the amount of general language data. We hope that our dataset, openly released on the Hugging Face Hub, will help spur advances in the reasoning abilities of large language models.
+
+
+
+ 7. 标题:A Supervised Embedding and Clustering Anomaly Detection method for classification of Mobile Network Faults
+ 编号:[20]
+ 链接:https://arxiv.org/abs/2310.06779
+ 作者:R. Mosayebi, H. Kia, A. Kianpour Raki
+ 备注:
+ 关键词:efficiently identify faulty, manual monitoring caused, paper introduces Supervised, identify faulty alarm, introduces Supervised Embedding
+
+ 点击查看摘要
+ The paper introduces Supervised Embedding and Clustering Anomaly Detection (SEMC-AD), a method designed to efficiently identify faulty alarm logs in a mobile network and alleviate the challenges of manual monitoring caused by the growing volume of alarm logs. SEMC-AD employs a supervised embedding approach based on deep neural networks, utilizing historical alarm logs and their labels to extract numerical representations for each log, effectively addressing the issue of imbalanced classification due to a small proportion of anomalies in the dataset without employing one-hot encoding. The robustness of the embedding is evaluated by plotting the two most significant principle components of the embedded alarm logs, revealing that anomalies form distinct clusters with similar embeddings. Multivariate normal Gaussian clustering is then applied to these components, identifying clusters with a high ratio of anomalies to normal alarms (above 90%) and labeling them as the anomaly group. To classify new alarm logs, we check if their embedded vectors' two most significant principle components fall within the anomaly-labeled clusters. If so, the log is classified as an anomaly. Performance evaluation demonstrates that SEMC-AD outperforms conventional random forest and gradient boosting methods without embedding. SEMC-AD achieves 99% anomaly detection, whereas random forest and XGBoost only detect 86% and 81% of anomalies, respectively. While supervised classification methods may excel in labeled datasets, the results demonstrate that SEMC-AD is more efficient in classifying anomalies in datasets with numerous categorical features, significantly enhancing anomaly detection, reducing operator burden, and improving network maintenance.
+
+
+
+ 8. 标题:Conceptual Framework for Autonomous Cognitive Entities
+ 编号:[23]
+ 链接:https://arxiv.org/abs/2310.06775
+ 作者:David Shapiro, Wangfan Li, Manuel Delaflor, Carlos Toxtli
+ 备注:34 pages, 12 figures
+ 关键词:greatly increased interest, ChatGPT and Claude, Claude has greatly, Autonomous Cognitive Entity, ACE framework
+
+ 点击查看摘要
+ The rapid development and adoption of Generative AI (GAI) technology in the form of chatbots such as ChatGPT and Claude has greatly increased interest in agentic machines. This paper introduces the Autonomous Cognitive Entity (ACE) model, a novel framework for a cognitive architecture, enabling machines and software agents to operate more independently. Drawing inspiration from the OSI model, the ACE framework presents layers of abstraction to conceptualize artificial cognitive architectures. The model is designed to harness the capabilities of the latest generative AI technologies, including large language models (LLMs) and multimodal generative models (MMMs), to build autonomous, agentic systems. The ACE framework comprises six layers: the Aspirational Layer, Global Strategy, Agent Model, Executive Function, Cognitive Control, and Task Prosecution. Each layer plays a distinct role, ranging from setting the moral compass and strategic thinking to task selection and execution. The ACE framework also incorporates mechanisms for handling failures and adapting actions, thereby enhancing the robustness and flexibility of autonomous agents. This paper introduces the conceptual framework and proposes implementation strategies that have been tested and observed in industry. The goal of this paper is to formalize this framework so as to be more accessible.
+
+
+
+ 9. 标题:Correlated Noise Provably Beats Independent Noise for Differentially Private Learning
+ 编号:[25]
+ 链接:https://arxiv.org/abs/2310.06771
+ 作者:Christopher A. Choquette-Choo, Krishnamurthy Dvijotham, Krishna Pillutla, Arun Ganesh, Thomas Steinke, Abhradeep Thakurta
+ 备注:Christopher A. Choquette-Choo, Krishnamurthy Dvijotham, and Krishna Pillutla contributed equally
+ 关键词:learning algorithms inject, Differentially private learning, algorithms inject noise, private learning algorithms, independent Gaussian noise
+
+ 点击查看摘要
+ Differentially private learning algorithms inject noise into the learning process. While the most common private learning algorithm, DP-SGD, adds independent Gaussian noise in each iteration, recent work on matrix factorization mechanisms has shown empirically that introducing correlations in the noise can greatly improve their utility. We characterize the asymptotic learning utility for any choice of the correlation function, giving precise analytical bounds for linear regression and as the solution to a convex program for general convex functions. We show, using these bounds, how correlated noise provably improves upon vanilla DP-SGD as a function of problem parameters such as the effective dimension and condition number. Moreover, our analytical expression for the near-optimal correlation function circumvents the cubic complexity of the semi-definite program used to optimize the noise correlation matrix in previous work. We validate our theory with experiments on private deep learning. Our work matches or outperforms prior work while being efficient both in terms of compute and memory.
+
+
+
+ 10. 标题:SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
+ 编号:[26]
+ 链接:https://arxiv.org/abs/2310.06770
+ 作者:Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, Karthik Narasimhan
+ 备注:Data, code, and leaderboard are available at this https URL
+ 关键词:evaluate them effectively, outpaced our ability, ability to evaluate, future development, essential to study
+
+ 点击查看摘要
+ Language models have outpaced our ability to evaluate them effectively, but for their future development it is essential to study the frontier of their capabilities. We consider real-world software engineering to be a rich, sustainable, and challenging testbed for evaluating the next generation of language models. We therefore introduce SWE-bench, an evaluation framework including $2,294$ software engineering problems drawn from real GitHub issues and corresponding pull requests across $12$ popular Python repositories. Given a codebase along with a description of an issue to be resolved, a language model is tasked with editing the codebase to address the issue. Resolving issues in SWE-bench frequently requires understanding and coordinating changes across multiple functions, classes, and even files simultaneously, calling for models to interact with execution environments, process extremely long contexts and perform complex reasoning that goes far beyond traditional code generation. Our evaluations show that both state-of-the-art proprietary models and our fine-tuned model SWE-Llama can resolve only the simplest issues. Claude 2 and GPT-4 solve a mere $4.8$% and $1.7$% of instances respectively, even when provided with an oracle retriever. Advances on SWE-bench represent steps towards LMs that are more practical, intelligent, and autonomous.
+
+
+
+ 11. 标题:FABind: Fast and Accurate Protein-Ligand Binding
+ 编号:[29]
+ 链接:https://arxiv.org/abs/2310.06763
+ 作者:Qizhi Pei, Kaiyuan Gao, Lijun Wu, Jinhua Zhu, Yingce Xia, Shufang Xie, Tao Qin, Kun He, Tie-Yan Liu, Rui Yan
+ 备注:Neural Information Processing Systems (NIPS 2023)
+ 关键词:Modeling the interaction, drug discovery, ligands and accurately, accurately predicting, critical yet challenging
+
+ 点击查看摘要
+ Modeling the interaction between proteins and ligands and accurately predicting their binding structures is a critical yet challenging task in drug discovery. Recent advancements in deep learning have shown promise in addressing this challenge, with sampling-based and regression-based methods emerging as two prominent approaches. However, these methods have notable limitations. Sampling-based methods often suffer from low efficiency due to the need for generating multiple candidate structures for selection. On the other hand, regression-based methods offer fast predictions but may experience decreased accuracy. Additionally, the variation in protein sizes often requires external modules for selecting suitable binding pockets, further impacting efficiency. In this work, we propose $\mathbf{FABind}$, an end-to-end model that combines pocket prediction and docking to achieve accurate and fast protein-ligand binding. $\mathbf{FABind}$ incorporates a unique ligand-informed pocket prediction module, which is also leveraged for docking pose estimation. The model further enhances the docking process by incrementally integrating the predicted pocket to optimize protein-ligand binding, reducing discrepancies between training and inference. Through extensive experiments on benchmark datasets, our proposed $\mathbf{FABind}$ demonstrates strong advantages in terms of effectiveness and efficiency compared to existing methods. Our code is available at $\href{this https URL}{Github}$.
+
+
+
+ 12. 标题:Going Beyond Neural Network Feature Similarity: The Network Feature Complexity and Its Interpretation Using Category Theory
+ 编号:[32]
+ 链接:https://arxiv.org/abs/2310.06756
+ 作者:Yiting Chen, Zhanpeng Zhou, Junchi Yan
+ 备注:
+ 关键词:achieve similar performance, recently widely noted, remains opaque, widely noted phenomenon, achieve similar
+
+ 点击查看摘要
+ The behavior of neural networks still remains opaque, and a recently widely noted phenomenon is that networks often achieve similar performance when initialized with different random parameters. This phenomenon has attracted significant attention in measuring the similarity between features learned by distinct networks. However, feature similarity could be vague in describing the same feature since equivalent features hardly exist. In this paper, we expand the concept of equivalent feature and provide the definition of what we call functionally equivalent features. These features produce equivalent output under certain transformations. Using this definition, we aim to derive a more intrinsic metric for the so-called feature complexity regarding the redundancy of features learned by a neural network at each layer. We offer a formal interpretation of our approach through the lens of category theory, a well-developed area in mathematics. To quantify the feature complexity, we further propose an efficient algorithm named Iterative Feature Merging. Our experimental results validate our ideas and theories from various perspectives. We empirically demonstrate that the functionally equivalence widely exists among different features learned by the same neural network and we could reduce the number of parameters of the network without affecting the performance.The IFM shows great potential as a data-agnostic model prune method. We have also drawn several interesting empirical findings regarding the defined feature complexity.
+
+
+
+ 13. 标题:Comparing AI Algorithms for Optimizing Elliptic Curve Cryptography Parameters in Third-Party E-Commerce Integrations: A Pre-Quantum Era Analysis
+ 编号:[35]
+ 链接:https://arxiv.org/abs/2310.06752
+ 作者:Felipe Tellez, Jorge Ortiz
+ 备注:14 pages
+ 关键词:Particle Swarm Optimization, Elliptic Curve Cryptography, Particle Swarm, vital artificial intelligence, artificial intelligence algorithms
+
+ 点击查看摘要
+ This paper presents a comparative analysis between the Genetic Algorithm (GA) and Particle Swarm Optimization (PSO), two vital artificial intelligence algorithms, focusing on optimizing Elliptic Curve Cryptography (ECC) parameters. These encompass the elliptic curve coefficients, prime number, generator point, group order, and cofactor. The study provides insights into which of the bio-inspired algorithms yields better optimization results for ECC configurations, examining performances under the same fitness function. This function incorporates methods to ensure robust ECC parameters, including assessing for singular or anomalous curves and applying Pollard's rho attack and Hasse's theorem for optimization precision. The optimized parameters generated by GA and PSO are tested in a simulated e-commerce environment, contrasting with well-known curves like secp256k1 during the transmission of order messages using Elliptic Curve-Diffie Hellman (ECDH) and Hash-based Message Authentication Code (HMAC). Focusing on traditional computing in the pre-quantum era, this research highlights the efficacy of GA and PSO in ECC optimization, with implications for enhancing cybersecurity in third-party e-commerce integrations. We recommend the immediate consideration of these findings before quantum computing's widespread adoption.
+
+
+
+ 14. 标题:Geographic Location Encoding with Spherical Harmonics and Sinusoidal Representation Networks
+ 编号:[39]
+ 链接:https://arxiv.org/abs/2310.06743
+ 作者:Marc Rußwurm, Konstantin Klemmer, Esther Rolf, Robin Zbinden, Devis Tuia
+ 备注:
+ 关键词:Double Fourier Sphere, machine learning model, spanning application domains, integrates geolocated data, Double Fourier
+
+ 点击查看摘要
+ Learning feature representations of geographical space is vital for any machine learning model that integrates geolocated data, spanning application domains such as remote sensing, ecology, or epidemiology. Recent work mostly embeds coordinates using sine and cosine projections based on Double Fourier Sphere (DFS) features -- these embeddings assume a rectangular data domain even on global data, which can lead to artifacts, especially at the poles. At the same time, relatively little attention has been paid to the exact design of the neural network architectures these functional embeddings are combined with. This work proposes a novel location encoder for globally distributed geographic data that combines spherical harmonic basis functions, natively defined on spherical surfaces, with sinusoidal representation networks (SirenNets) that can be interpreted as learned Double Fourier Sphere embedding. We systematically evaluate the cross-product of positional embeddings and neural network architectures across various classification and regression benchmarks and synthetic evaluation datasets. In contrast to previous approaches that require the combination of both positional encoding and neural networks to learn meaningful representations, we show that both spherical harmonics and sinusoidal representation networks are competitive on their own but set state-of-the-art performances across tasks when combined. We provide source code at this http URL
+
+
+
+ 15. 标题:Exploring Memorization in Fine-tuned Language Models
+ 编号:[45]
+ 链接:https://arxiv.org/abs/2310.06714
+ 作者:Shenglai Zeng, Yaxin Li, Jie Ren, Yiding Liu, Han Xu, Pengfei He, Yue Xing, Shuaiqiang Wang, Jiliang Tang, Dawei Yin
+ 备注:
+ 关键词:shown great capabilities, raising tremendous privacy, LLMs have shown, copyright concerns, shown great
+
+ 点击查看摘要
+ LLMs have shown great capabilities in various tasks but also exhibited memorization of training data, thus raising tremendous privacy and copyright concerns. While prior work has studied memorization during pre-training, the exploration of memorization during fine-tuning is rather limited. Compared with pre-training, fine-tuning typically involves sensitive data and diverse objectives, thus may bring unique memorization behaviors and distinct privacy risks. In this work, we conduct the first comprehensive analysis to explore LMs' memorization during fine-tuning across tasks. Our studies with open-sourced and our own fine-tuned LMs across various tasks indicate that fine-tuned memorization presents a strong disparity among tasks. We provide an understanding of this task disparity via sparse coding theory and unveil a strong correlation between memorization and attention score distribution. By investigating its memorization behavior, multi-task fine-tuning paves a potential strategy to mitigate fine-tuned memorization.
+
+
+
+ 16. 标题:Quality Control at Your Fingertips: Quality-Aware Translation Models
+ 编号:[49]
+ 链接:https://arxiv.org/abs/2310.06707
+ 作者:Christian Tomani, David Vilar, Markus Freitag, Colin Cherry, Subhajit Naskar, Mara Finkelstein, Daniel Cremers
+ 备注:
+ 关键词:neural machine translation, Minimum Bayes Risk, decoding, MAP decoding, strategy for neural
+
+ 点击查看摘要
+ Maximum-a-posteriori (MAP) decoding is the most widely used decoding strategy for neural machine translation (NMT) models. The underlying assumption is that model probability correlates well with human judgment, with better translations being more likely. However, research has shown that this assumption does not always hold, and decoding strategies which directly optimize a utility function, like Minimum Bayes Risk (MBR) or Quality-Aware decoding can significantly improve translation quality over standard MAP decoding. The main disadvantage of these methods is that they require an additional model to predict the utility, and additional steps during decoding, which makes the entire process computationally demanding. In this paper, we propose to make the NMT models themselves quality-aware by training them to estimate the quality of their own output. During decoding, we can use the model's own quality estimates to guide the generation process and produce the highest-quality translations possible. We demonstrate that the model can self-evaluate its own output during translation, eliminating the need for a separate quality estimation model. Moreover, we show that using this quality signal as a prompt during MAP decoding can significantly improve translation quality. When using the internal quality estimate to prune the hypothesis space during MBR decoding, we can not only further improve translation quality, but also reduce inference speed by two orders of magnitude.
+
+
+
+ 17. 标题:DeepLSH: Deep Locality-Sensitive Hash Learning for Fast and Efficient Near-Duplicate Crash Report Detection
+ 编号:[50]
+ 链接:https://arxiv.org/abs/2310.06703
+ 作者:Youcef Remil, Anes Bendimerad, Romain Mathonat, Chedy Raissi, Mehdi Kaytoue
+ 备注:
+ 关键词:software development process, triaging bug reports, efficiently triaging bug, Automatic crash bucketing, crucial phase
+
+ 点击查看摘要
+ Automatic crash bucketing is a crucial phase in the software development process for efficiently triaging bug reports. It generally consists in grouping similar reports through clustering techniques. However, with real-time streaming bug collection, systems are needed to quickly answer the question: What are the most similar bugs to a new one?, that is, efficiently find near-duplicates. It is thus natural to consider nearest neighbors search to tackle this problem and especially the well-known locality-sensitive hashing (LSH) to deal with large datasets due to its sublinear performance and theoretical guarantees on the similarity search accuracy. Surprisingly, LSH has not been considered in the crash bucketing literature. It is indeed not trivial to derive hash functions that satisfy the so-called locality-sensitive property for the most advanced crash bucketing metrics. Consequently, we study in this paper how to leverage LSH for this task. To be able to consider the most relevant metrics used in the literature, we introduce DeepLSH, a Siamese DNN architecture with an original loss function, that perfectly approximates the locality-sensitivity property even for Jaccard and Cosine metrics for which exact LSH solutions exist. We support this claim with a series of experiments on an original dataset, which we make available.
+
+
+
+ 18. 标题:Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning
+ 编号:[52]
+ 链接:https://arxiv.org/abs/2310.06694
+ 作者:Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, Danqi Chen
+ 备注:The code and models are available at this https URL
+ 关键词:recently emerged moderate-sized, emerged moderate-sized large, moderate-sized large language, large language models, popularity of LLaMA
+
+ 点击查看摘要
+ The popularity of LLaMA (Touvron et al., 2023a;b) and other recently emerged moderate-sized large language models (LLMs) highlights the potential of building smaller yet powerful LLMs. Regardless, the cost of training such models from scratch on trillions of tokens remains high. In this work, we study structured pruning as an effective means to develop smaller LLMs from pre-trained, larger models. Our approach employs two key techniques: (1) targeted structured pruning, which prunes a larger model to a specified target shape by removing layers, heads, and intermediate and hidden dimensions in an end-to-end manner, and (2) dynamic batch loading, which dynamically updates the composition of sampled data in each training batch based on varying losses across different domains. We demonstrate the efficacy of our approach by presenting the Sheared-LLaMA series, pruning the LLaMA2-7B model down to 1.3B and 2.7B parameters. Sheared-LLaMA models outperform state-of-the-art open-source models of equivalent sizes, such as Pythia, INCITE, and OpenLLaMA models, on a wide range of downstream and instruction tuning evaluations, while requiring only 3% of compute compared to training such models from scratch. This work provides compelling evidence that leveraging existing LLMs with structured pruning is a far more cost-effective approach for building smaller LLMs.
+
+
+
+ 19. 标题:Meta-CoT: Generalizable Chain-of-Thought Prompting in Mixed-task Scenarios with Large Language Models
+ 编号:[53]
+ 链接:https://arxiv.org/abs/2310.06692
+ 作者:Anni Zou, Zhuosheng Zhang, Hai Zhao, Xiangru Tang
+ 备注:17 pages, 7 figures
+ 关键词:Large language models, generates intermediate reasoning, intermediate reasoning chains, Large language, language models
+
+ 点击查看摘要
+ Large language models (LLMs) have unveiled remarkable reasoning capabilities by exploiting chain-of-thought (CoT) prompting, which generates intermediate reasoning chains to serve as the rationale for deriving the answer. However, current CoT methods either simply employ general prompts such as Let's think step by step, or heavily rely on handcrafted task-specific demonstrations to attain preferable performances, thereby engendering an inescapable gap between performance and generalization. To bridge this gap, we propose Meta-CoT, a generalizable CoT prompting method in mixed-task scenarios where the type of input questions is unknown. Meta-CoT firstly categorizes the scenario based on the input question and subsequently constructs diverse demonstrations from the corresponding data pool in an automatic pattern. Meta-CoT simultaneously enjoys remarkable performances on ten public benchmark reasoning tasks and superior generalization capabilities. Notably, Meta-CoT achieves the state-of-the-art result on SVAMP (93.7%) without any additional program-aided methods. Our further experiments on five out-of-distribution datasets verify the stability and generality of Meta-CoT.
+
+
+
+ 20. 标题:Benchmarking and Explaining Large Language Model-based Code Generation: A Causality-Centric Approach
+ 编号:[59]
+ 链接:https://arxiv.org/abs/2310.06680
+ 作者:Zhenlan Ji, Pingchuan Ma, Zongjie Li, Shuai Wang
+ 备注:
+ 关键词:software development scenarios, code generation, code, generated code, based code generation
+
+ 点击查看摘要
+ While code generation has been widely used in various software development scenarios, the quality of the generated code is not guaranteed. This has been a particular concern in the era of large language models (LLMs)- based code generation, where LLMs, deemed a complex and powerful black-box model, is instructed by a high-level natural language specification, namely a prompt, to generate code. Nevertheless, effectively evaluating and explaining the code generation capability of LLMs is inherently challenging, given the complexity of LLMs and the lack of transparency.
+Inspired by the recent progress in causality analysis and its application in software engineering, this paper launches a causality analysis-based approach to systematically analyze the causal relations between the LLM input prompts and the generated code. To handle various technical challenges in this study, we first propose a novel causal graph-based representation of the prompt and the generated code, which is established over the fine-grained, human-understandable concepts in the input prompts. The formed causal graph is then used to identify the causal relations between the prompt and the derived code. We illustrate the insights that our framework can provide by studying over 3 popular LLMs with over 12 prompt adjustment strategies. The results of these studies illustrate the potential of our technique to provide insights into LLM effectiveness, and aid end-users in understanding predictions. Additionally, we demonstrate that our approach provides actionable insights to improve the quality of the LLM-generated code by properly calibrating the prompt.
+
+
+
+ 21. 标题:Unlock the Potential of Counterfactually-Augmented Data in Out-Of-Distribution Generalization
+ 编号:[67]
+ 链接:https://arxiv.org/abs/2310.06666
+ 作者:Caoyun Fan, Wenqing Chen, Jidong Tian, Yitian Li, Hao He, Yaohui Jin
+ 备注:Expert Systems With Applications 2023. arXiv admin note: text overlap with arXiv:2302.09345
+ 关键词:Counterfactually-Augmented Data, CAD induces language, exclude spurious correlations, CAD OOD generalization, exploit domain-independent causal
+
+ 点击查看摘要
+ Counterfactually-Augmented Data (CAD) -- minimal editing of sentences to flip the corresponding labels -- has the potential to improve the Out-Of-Distribution (OOD) generalization capability of language models, as CAD induces language models to exploit domain-independent causal features and exclude spurious correlations. However, the empirical results of CAD's OOD generalization are not as efficient as anticipated. In this study, we attribute the inefficiency to the myopia phenomenon caused by CAD: language models only focus on causal features that are edited in the augmentation operation and exclude other non-edited causal features. Therefore, the potential of CAD is not fully exploited. To address this issue, we analyze the myopia phenomenon in feature space from the perspective of Fisher's Linear Discriminant, then we introduce two additional constraints based on CAD's structural properties (dataset-level and sentence-level) to help language models extract more complete causal features in CAD, thereby mitigating the myopia phenomenon and improving OOD generalization capability. We evaluate our method on two tasks: Sentiment Analysis and Natural Language Inference, and the experimental results demonstrate that our method could unlock the potential of CAD and improve the OOD generalization performance of language models by 1.0% to 5.9%.
+
+
+
+ 22. 标题:Assessing the Impact of a Supervised Classification Filter on Flow-based Hybrid Network Anomaly Detection
+ 编号:[70]
+ 链接:https://arxiv.org/abs/2310.06656
+ 作者:Dominik Macko, Patrik Goldschmidt, Peter Pištek, Daniela Chudá
+ 备注:
+ 关键词:Constant evolution, techniques for defense, cyberattacks require, require the development, development of advanced
+
+ 点击查看摘要
+ Constant evolution and the emergence of new cyberattacks require the development of advanced techniques for defense. This paper aims to measure the impact of a supervised filter (classifier) in network anomaly detection. We perform our experiments by employing a hybrid anomaly detection approach in network flow data. For this purpose, we extended a state-of-the-art autoencoder-based anomaly detection method by prepending a binary classifier acting as a prefilter for the anomaly detector. The method was evaluated on the publicly available real-world dataset UGR'16. Our empirical results indicate that the hybrid approach does offer a higher detection rate of known attacks than a standalone anomaly detector while still retaining the ability to detect zero-day attacks. Employing a supervised binary prefilter has increased the AUC metric by over 11%, detecting 30% more attacks while keeping the number of false positives approximately the same.
+
+
+
+ 23. 标题:Diversity from Human Feedback
+ 编号:[73]
+ 链接:https://arxiv.org/abs/2310.06648
+ 作者:Ren-Jian Wang, Ke Xue, Yutong Wang, Peng Yang, Haobo Fu, Qiang Fu, Chao Qian
+ 备注:
+ 关键词:diversity measure, plays a significant, significant role, human feedback, Diversity
+
+ 点击查看摘要
+ Diversity plays a significant role in many problems, such as ensemble learning, reinforcement learning, and combinatorial optimization. How to define the diversity measure is a longstanding problem. Many methods rely on expert experience to define a proper behavior space and then obtain the diversity measure, which is, however, challenging in many scenarios. In this paper, we propose the problem of learning a behavior space from human feedback and present a general method called Diversity from Human Feedback (DivHF) to solve it. DivHF learns a behavior descriptor consistent with human preference by querying human feedback. The learned behavior descriptor can be combined with any distance measure to define a diversity measure. We demonstrate the effectiveness of DivHF by integrating it with the Quality-Diversity optimization algorithm MAP-Elites and conducting experiments on the QDax suite. The results show that DivHF learns a behavior space that aligns better with human requirements compared to direct data-driven approaches and leads to more diverse solutions under human preference. Our contributions include formulating the problem, proposing the DivHF method, and demonstrating its effectiveness through experiments.
+
+
+
+ 24. 标题:Topic-DPR: Topic-based Prompts for Dense Passage Retrieval
+ 编号:[84]
+ 链接:https://arxiv.org/abs/2310.06626
+ 作者:Qingfa Xiao, Shuangyin Li, Lei Chen
+ 备注:Findings of EMNLP 2023
+ 关键词:numerous natural language, natural language processing, language processing tasks, Prompt-based learning efficacy, efficacy across numerous
+
+ 点击查看摘要
+ Prompt-based learning's efficacy across numerous natural language processing tasks has led to its integration into dense passage retrieval. Prior research has mainly focused on enhancing the semantic understanding of pre-trained language models by optimizing a single vector as a continuous prompt. This approach, however, leads to a semantic space collapse; identical semantic information seeps into all representations, causing their distributions to converge in a restricted region. This hinders differentiation between relevant and irrelevant passages during dense retrieval. To tackle this issue, we present Topic-DPR, a dense passage retrieval model that uses topic-based prompts. Unlike the single prompt method, multiple topic-based prompts are established over a probabilistic simplex and optimized simultaneously through contrastive learning. This encourages representations to align with their topic distributions, improving space uniformity. Furthermore, we introduce a novel positive and negative sampling strategy, leveraging semi-structured data to boost dense retrieval efficiency. Experimental results from two datasets affirm that our method surpasses previous state-of-the-art retrieval techniques.
+
+
+
+ 25. 标题:BridgeHand2Vec Bridge Hand Representation
+ 编号:[86]
+ 链接:https://arxiv.org/abs/2310.06624
+ 作者:Anna Sztyber-Betley, Filip Kołodziej, Jan Betley, Piotr Duszak
+ 备注:
+ 关键词:artificial intelligence methods, incomplete information, posing an exciting, intelligence methods, characterized by incomplete
+
+ 点击查看摘要
+ Contract bridge is a game characterized by incomplete information, posing an exciting challenge for artificial intelligence methods. This paper proposes the BridgeHand2Vec approach, which leverages a neural network to embed a bridge player's hand (consisting of 13 cards) into a vector space. The resulting representation reflects the strength of the hand in the game and enables interpretable distances to be determined between different hands. This representation is derived by training a neural network to estimate the number of tricks that a pair of players can take. In the remainder of this paper, we analyze the properties of the resulting vector space and provide examples of its application in reinforcement learning, and opening bid classification. Although this was not our main goal, the neural network used for the vectorization achieves SOTA results on the DDBP2 problem (estimating the number of tricks for two given hands).
+
+
+
+ 26. 标题:V2X-AHD:Vehicle-to-Everything Cooperation Perception via Asymmetric Heterogenous Distillation Network
+ 编号:[91]
+ 链接:https://arxiv.org/abs/2310.06603
+ 作者:Caizhen He, Hai Wang, Long Chen, Tong Luo, Yingfeng Cai
+ 备注:
+ 关键词:provide accurate position, accurate position information, intelligent traffic systems, vehicle-road cooperation perception, intelligent traffic
+
+ 点击查看摘要
+ Object detection is the central issue of intelligent traffic systems, and recent advancements in single-vehicle lidar-based 3D detection indicate that it can provide accurate position information for intelligent agents to make decisions and plan. Compared with single-vehicle perception, multi-view vehicle-road cooperation perception has fundamental advantages, such as the elimination of blind spots and a broader range of perception, and has become a research hotspot. However, the current perception of cooperation focuses on improving the complexity of fusion while ignoring the fundamental problems caused by the absence of single-view outlines. We propose a multi-view vehicle-road cooperation perception system, vehicle-to-everything cooperative perception (V2X-AHD), in order to enhance the identification capability, particularly for predicting the vehicle's shape. At first, we propose an asymmetric heterogeneous distillation network fed with different training data to improve the accuracy of contour recognition, with multi-view teacher features transferring to single-view student features. While the point cloud data are sparse, we propose Spara Pillar, a spare convolutional-based plug-in feature extraction backbone, to reduce the number of parameters and improve and enhance feature extraction capabilities. Moreover, we leverage the multi-head self-attention (MSA) to fuse the single-view feature, and the lightweight design makes the fusion feature a smooth expression. The results of applying our algorithm to the massive open dataset V2Xset demonstrate that our method achieves the state-of-the-art result. The V2X-AHD can effectively improve the accuracy of 3D object detection and reduce the number of network parameters, according to this study, which serves as a benchmark for cooperative perception. The code for this article is available at this https URL.
+
+
+
+ 27. 标题:A Black-Box Physics-Informed Estimator based on Gaussian Process Regression for Robot Inverse Dynamics Identification
+ 编号:[98]
+ 链接:https://arxiv.org/abs/2310.06585
+ 作者:Giulio Giacomuzzo, Alberto Dalla Libera, Diego Romeres, Ruggero Carli
+ 备注:
+ 关键词:Gaussian process regression, Lagrangian Inspired Polynomial, inverse dynamics components, process regression, inverse dynamics
+
+ 点击查看摘要
+ In this paper, we propose a black-box model based on Gaussian process regression for the identification of the inverse dynamics of robotic manipulators. The proposed model relies on a novel multidimensional kernel, called \textit{Lagrangian Inspired Polynomial} (\kernelInitials{}) kernel. The \kernelInitials{} kernel is based on two main ideas. First, instead of directly modeling the inverse dynamics components, we model as GPs the kinetic and potential energy of the system. The GP prior on the inverse dynamics components is derived from those on the energies by applying the properties of GPs under linear operators. Second, as regards the energy prior definition, we prove a polynomial structure of the kinetic and potential energy, and we derive a polynomial kernel that encodes this property. As a consequence, the proposed model allows also to estimate the kinetic and potential energy without requiring any label on these quantities. Results on simulation and on two real robotic manipulators, namely a 7 DOF Franka Emika Panda and a 6 DOF MELFA RV4FL, show that the proposed model outperforms state-of-the-art black-box estimators based both on Gaussian Processes and Neural Networks in terms of accuracy, generality and data efficiency. The experiments on the MELFA robot also demonstrate that our approach achieves performance comparable to fine-tuned model-based estimators, despite requiring less prior information.
+
+
+
+ 28. 标题:On Temporal References in Emergent Communication
+ 编号:[108]
+ 链接:https://arxiv.org/abs/2310.06555
+ 作者:Olaf Lipinski, Adam J. Sobey, Federico Cerutti, Timothy J. Norman
+ 备注:26 pages, 13 figures. Code available at this https URL
+ 关键词:easily share past, share past experiences, elements referencing time, future predictions, linguistic elements referencing
+
+ 点击查看摘要
+ As humans, we use linguistic elements referencing time, such as before or tomorrow, to easily share past experiences and future predictions. While temporal aspects of the language have been considered in computational linguistics, no such exploration has been done within the field of emergent communication. We research this gap, providing the first reported temporal vocabulary within emergent communication literature. Our experimental analysis shows that a different agent architecture is sufficient for the natural emergence of temporal references, and that no additional losses are necessary. Our readily transferable architectural insights provide the basis for the incorporation of temporal referencing into other emergent communication environments.
+
+
+
+ 29. 标题:Automated clinical coding using off-the-shelf large language models
+ 编号:[110]
+ 链接:https://arxiv.org/abs/2310.06552
+ 作者:Joseph S. Boyle, Antanas Kascenas, Pat Lok, Maria Liakata, Alison Q. O'Neil
+ 备注:9 pages, 4 figures
+ 关键词:expert human coders, patient hospital admissions, assigning diagnostic ICD, diagnostic ICD codes, human coders
+
+ 点击查看摘要
+ The task of assigning diagnostic ICD codes to patient hospital admissions is typically performed by expert human coders. Efforts towards automated ICD coding are dominated by supervised deep learning models. However, difficulties in learning to predict the large number of rare codes remain a barrier to adoption in clinical practice. In this work, we leverage off-the-shelf pre-trained generative large language models (LLMs) to develop a practical solution that is suitable for zero-shot and few-shot code assignment. Unsupervised pre-training alone does not guarantee precise knowledge of the ICD ontology and specialist clinical coding task, therefore we frame the task as information extraction, providing a description of each coded concept and asking the model to retrieve related mentions. For efficiency, rather than iterating over all codes, we leverage the hierarchical nature of the ICD ontology to sparsely search for relevant codes. Then, in a second stage, which we term 'meta-refinement', we utilise GPT-4 to select a subset of the relevant labels as predictions. We validate our method using Llama-2, GPT-3.5 and GPT-4 on the CodiEsp dataset of ICD-coded clinical case documents. Our tree-search method achieves state-of-the-art performance on rarer classes, achieving the best macro-F1 of 0.225, whilst achieving slightly lower micro-F1 of 0.157, compared to 0.216 and 0.219 respectively from PLM-ICD. To the best of our knowledge, this is the first method for automated ICD coding requiring no task-specific learning.
+
+
+
+ 30. 标题:Rationale-Enhanced Language Models are Better Continual Relation Learners
+ 编号:[113]
+ 链接:https://arxiv.org/abs/2310.06547
+ 作者:Weimin Xiong, Yifan Song, Peiyi Wang, Sujian Li
+ 备注:Accepted at EMNLP 2023
+ 关键词:Continual relation extraction, newly emerging relations, aims to solve, catastrophic forgetting, solve the problem
+
+ 点击查看摘要
+ Continual relation extraction (CRE) aims to solve the problem of catastrophic forgetting when learning a sequence of newly emerging relations. Recent CRE studies have found that catastrophic forgetting arises from the model's lack of robustness against future analogous relations. To address the issue, we introduce rationale, i.e., the explanations of relation classification results generated by large language models (LLM), into CRE task. Specifically, we design the multi-task rationale tuning strategy to help the model learn current relations robustly. We also conduct contrastive rationale replay to further distinguish analogous relations. Experimental results on two standard benchmarks demonstrate that our method outperforms the state-of-the-art CRE models.
+
+
+
+ 31. 标题:Realizing Stabilized Landing for Computation-Limited Reusable Rockets: A Quantum Reinforcement Learning Approach
+ 编号:[117]
+ 链接:https://arxiv.org/abs/2310.06541
+ 作者:Gyu Seon Kim, JaeHyun Chung, Soohyun Park
+ 备注:5 pages, 5 figures
+ 关键词:reusable rockets, significant factor, quantum reinforcement learning, costs of launching, launching satellites
+
+ 点击查看摘要
+ The advent of reusable rockets has heralded a new era in space exploration, reducing the costs of launching satellites by a significant factor. Traditional rockets were disposable, but the design of reusable rockets for repeated use has revolutionized the financial dynamics of space missions. The most critical phase of reusable rockets is the landing stage, which involves managing the tremendous speed and attitude for safe recovery. The complexity of this task presents new challenges for control systems, specifically in terms of precision and adaptability. Classical control systems like the proportional-integral-derivative (PID) controller lack the flexibility to adapt to dynamic system changes, making them costly and time-consuming to redesign of controller. This paper explores the integration of quantum reinforcement learning into the control systems of reusable rockets as a promising alternative. Unlike classical reinforcement learning, quantum reinforcement learning uses quantum bits that can exist in superposition, allowing for more efficient information encoding and reducing the number of parameters required. This leads to increased computational efficiency, reduced memory requirements, and more stable and predictable performance. Due to the nature of reusable rockets, which must be light, heavy computers cannot fit into them. In the reusable rocket scenario, quantum reinforcement learning, which has reduced memory requirements due to fewer parameters, is a good solution.
+
+
+
+ 32. 标题:A Novel Contrastive Learning Method for Clickbait Detection on RoCliCo: A Romanian Clickbait Corpus of News Articles
+ 编号:[118]
+ 链接:https://arxiv.org/abs/2310.06540
+ 作者:Daria-Mihaela Broscoteanu, Radu Tudor Ionescu
+ 备注:Accepted at EMNLP 2023
+ 关键词:increase revenue, websites often resort, reading the full, Romanian Clickbait Corpus, luring users
+
+ 点击查看摘要
+ To increase revenue, news websites often resort to using deceptive news titles, luring users into clicking on the title and reading the full news. Clickbait detection is the task that aims to automatically detect this form of false advertisement and avoid wasting the precious time of online users. Despite the importance of the task, to the best of our knowledge, there is no publicly available clickbait corpus for the Romanian language. To this end, we introduce a novel Romanian Clickbait Corpus (RoCliCo) comprising 8,313 news samples which are manually annotated with clickbait and non-clickbait labels. Furthermore, we conduct experiments with four machine learning methods, ranging from handcrafted models to recurrent and transformer-based neural networks, to establish a line-up of competitive baselines. We also carry out experiments with a weighted voting ensemble. Among the considered baselines, we propose a novel BERT-based contrastive learning model that learns to encode news titles and contents into a deep metric space such that titles and contents of non-clickbait news have high cosine similarity, while titles and contents of clickbait news have low cosine similarity. Our data set and code to reproduce the baselines are publicly available for download at this https URL.
+
+
+
+ 33. 标题:Accelerating Monte Carlo Tree Search with Probability Tree State Abstraction
+ 编号:[125]
+ 链接:https://arxiv.org/abs/2310.06513
+ 作者:Yangqing Fu, Ming Sun, Buqing Nie, Yue Gao
+ 备注:
+ 关键词:Monte Carlo Tree, Carlo Tree Search, achieved superhuman performance, Monte Carlo, tree state abstraction
+
+ 点击查看摘要
+ Monte Carlo Tree Search (MCTS) algorithms such as AlphaGo and MuZero have achieved superhuman performance in many challenging tasks. However, the computational complexity of MCTS-based algorithms is influenced by the size of the search space. To address this issue, we propose a novel probability tree state abstraction (PTSA) algorithm to improve the search efficiency of MCTS. A general tree state abstraction with path transitivity is defined. In addition, the probability tree state abstraction is proposed for fewer mistakes during the aggregation step. Furthermore, the theoretical guarantees of the transitivity and aggregation error bound are justified. To evaluate the effectiveness of the PTSA algorithm, we integrate it with state-of-the-art MCTS-based algorithms, such as Sampled MuZero and Gumbel MuZero. Experimental results on different tasks demonstrate that our method can accelerate the training process of state-of-the-art algorithms with 10%-45% search space reduction.
+
+
+
+ 34. 标题:Evaluation of ChatGPT Feedback on ELL Writers' Coherence and Cohesion
+ 编号:[130]
+ 链接:https://arxiv.org/abs/2310.06505
+ 作者:Su-Youn Yoon, Eva Miszoglad, Lisa R. Pierce
+ 备注:24 pages, 1 figures
+ 关键词:launch in November, English Language Learners, teaching practices, transformative effect, effect on education
+
+ 点击查看摘要
+ Since its launch in November 2022, ChatGPT has had a transformative effect on education where students are using it to help with homework assignments and teachers are actively employing it in their teaching practices. This includes using ChatGPT as a tool for writing teachers to grade and generate feedback on students' essays. In this study, we evaluated the quality of the feedback generated by ChatGPT regarding the coherence and cohesion of the essays written by English Language Learners (ELLs) students. We selected 50 argumentative essays and generated feedback on coherence and cohesion using the ELLIPSE rubric. During the feedback evaluation, we used a two-step approach: first, each sentence in the feedback was classified into subtypes based on its function (e.g., positive reinforcement, problem statement). Next, we evaluated its accuracy and usability according to these types. Both the analysis of feedback types and the evaluation of accuracy and usability revealed that most feedback sentences were highly abstract and generic, failing to provide concrete suggestions for improvement. The accuracy in detecting major problems, such as repetitive ideas and the inaccurate use of cohesive devices, depended on superficial linguistic features and was often incorrect. In conclusion, ChatGPT, without specific training for the feedback generation task, does not offer effective feedback on ELL students' coherence and cohesion.
+
+
+
+ 35. 标题:Revisit Input Perturbation Problems for LLMs: A Unified Robustness Evaluation Framework for Noisy Slot Filling Task
+ 编号:[131]
+ 链接:https://arxiv.org/abs/2310.06504
+ 作者:Guanting Dong, Jinxu Zhao, Tingfeng Hui, Daichi Guo, Wenlong Wan, Boqi Feng, Yueyan Qiu, Zhuoma Gongque, Keqing He, Zechen Wang, Weiran Xu
+ 备注:Accepted at NLPCC 2023 (Oral Presentation)
+ 关键词:natural language processing, large language models, language processing, language models, large language
+
+ 点击查看摘要
+ With the increasing capabilities of large language models (LLMs), these high-performance models have achieved state-of-the-art results on a wide range of natural language processing (NLP) tasks. However, the models' performance on commonly-used benchmark datasets often fails to accurately reflect their reliability and robustness when applied to real-world noisy data. To address these challenges, we propose a unified robustness evaluation framework based on the slot-filling task to systematically evaluate the dialogue understanding capability of LLMs in diverse input perturbation scenarios. Specifically, we construct a input perturbation evaluation dataset, Noise-LLM, which contains five types of single perturbation and four types of mixed perturbation data. Furthermore, we utilize a multi-level data augmentation method (character, word, and sentence levels) to construct a candidate data pool, and carefully design two ways of automatic task demonstration construction strategies (instance-level and entity-level) with various prompt templates. Our aim is to assess how well various robustness methods of LLMs perform in real-world noisy scenarios. The experiments have demonstrated that the current open-source LLMs generally achieve limited perturbation robustness performance. Based on these experimental observations, we make some forward-looking suggestions to fuel the research in this direction.
+
+
+
+ 36. 标题:MetaAgents: Simulating Interactions of Human Behaviors for LLM-based Task-oriented Coordination via Collaborative Generative Agents
+ 编号:[133]
+ 链接:https://arxiv.org/abs/2310.06500
+ 作者:Yuan Li, Yixuan Zhang, Lichao Sun
+ 备注:
+ 关键词:Large Language Models, Language Models, Large Language, application of Large, Significant advancements
+
+ 点击查看摘要
+ Significant advancements have occurred in the application of Large Language Models (LLMs) for various tasks and social simulations. Despite this, their capacities to coordinate within task-oriented social contexts are under-explored. Such capabilities are crucial if LLMs are to effectively mimic human-like social behavior and produce meaningful results. To bridge this gap, we introduce collaborative generative agents, endowing LLM-based Agents with consistent behavior patterns and task-solving abilities. We situate these agents in a simulated job fair environment as a case study to scrutinize their coordination skills. We propose a novel framework that equips collaborative generative agents with human-like reasoning abilities and specialized skills. Our evaluation demonstrates that these agents show promising performance. However, we also uncover limitations that hinder their effectiveness in more complex coordination tasks. Our work provides valuable insights into the role and evolution of LLMs in task-oriented social simulations.
+
+
+
+ 37. 标题:Topological RANSAC for instance verification and retrieval without fine-tuning
+ 编号:[138]
+ 链接:https://arxiv.org/abs/2310.06486
+ 作者:Guoyuan An, Juhyung Seon, Inkyu An, Yuchi Huo, Sung-Eui Yoon
+ 备注:
+ 关键词:enhancing explainable image, explainable image retrieval, set is unavailable, paper presents, presents an innovative
+
+ 点击查看摘要
+ This paper presents an innovative approach to enhancing explainable image retrieval, particularly in situations where a fine-tuning set is unavailable. The widely-used SPatial verification (SP) method, despite its efficacy, relies on a spatial model and the hypothesis-testing strategy for instance recognition, leading to inherent limitations, including the assumption of planar structures and neglect of topological relations among features. To address these shortcomings, we introduce a pioneering technique that replaces the spatial model with a topological one within the RANSAC process. We propose bio-inspired saccade and fovea functions to verify the topological consistency among features, effectively circumventing the issues associated with SP's spatial model. Our experimental results demonstrate that our method significantly outperforms SP, achieving state-of-the-art performance in non-fine-tuning retrieval. Furthermore, our approach can enhance performance when used in conjunction with fine-tuned features. Importantly, our method retains high explainability and is lightweight, offering a practical and adaptable solution for a variety of real-world applications.
+
+
+
+ 38. 标题:Memory efficient location recommendation through proximity-aware representation
+ 编号:[139]
+ 链接:https://arxiv.org/abs/2310.06484
+ 作者:Xuan Luo, Rui Lv, Hui Zhao
+ 备注:
+ 关键词:Sequential location recommendation, location recommendation plays, enhance user experience, location recommendation, modern life
+
+ 点击查看摘要
+ Sequential location recommendation plays a huge role in modern life, which can enhance user experience, bring more profit to businesses and assist in government administration. Although methods for location recommendation have evolved significantly thanks to the development of recommendation systems, there is still limited utilization of geographic information, along with the ongoing challenge of addressing data sparsity. In response, we introduce a Proximity-aware based region representation for Sequential Recommendation (PASR for short), built upon the Self-Attention Network architecture. We tackle the sparsity issue through a novel loss function employing importance sampling, which emphasizes informative negative samples during optimization. Moreover, PASR enhances the integration of geographic information by employing a self-attention-based geography encoder to the hierarchical grid and proximity grid at each GPS point. To further leverage geographic information, we utilize the proximity-aware negative samplers to enhance the quality of negative samples. We conducted evaluations using three real-world Location-Based Social Networking (LBSN) datasets, demonstrating that PASR surpasses state-of-the-art sequential location recommendation methods
+
+
+
+ 39. 标题:Understanding the Effects of RLHF on LLM Generalisation and Diversity
+ 编号:[150]
+ 链接:https://arxiv.org/abs/2310.06452
+ 作者:Robert Kirk, Ishita Mediratta, Christoforos Nalmpantis, Jelena Luketina, Eric Hambro, Edward Grefenstette, Roberta Raileanu
+ 备注:
+ 关键词:Anthropic Claude, Large language models, Large language, fine-tuned with reinforcement, human feedback
+
+ 点击查看摘要
+ Large language models (LLMs) fine-tuned with reinforcement learning from human feedback (RLHF) have been used in some of the most widely deployed AI models to date, such as OpenAI's ChatGPT, Anthropic's Claude, or Meta's LLaMA-2. While there has been significant work developing these methods, our understanding of the benefits and downsides of each stage in RLHF is still limited. To fill this gap, we present an extensive analysis of how each stage of the process (i.e. supervised fine-tuning (SFT), reward modelling, and RLHF) affects two key properties: out-of-distribution (OOD) generalisation and output diversity. OOD generalisation is crucial given the wide range of real-world scenarios in which these models are being used, while output diversity refers to the model's ability to generate varied outputs and is important for a variety of use cases. We perform our analysis across two base models on both summarisation and instruction following tasks, the latter being highly relevant for current LLM use cases. We find that RLHF generalises better than SFT to new inputs, particularly as the distribution shift between train and test becomes larger. However, RLHF significantly reduces output diversity compared to SFT across a variety of measures, implying a tradeoff in current LLM fine-tuning methods between generalisation and diversity. Our results provide guidance on which fine-tuning method should be used depending on the application, and show that more research is needed to improve the trade-off between generalisation and diversity.
+
+
+
+ 40. 标题:Constructive Large Language Models Alignment with Diverse Feedback
+ 编号:[152]
+ 链接:https://arxiv.org/abs/2310.06450
+ 作者:Tianshu Yu, Ting-En Lin, Yuchuan Wu, Min Yang, Fei Huang, Yongbin Li
+ 备注:
+ 关键词:harmful content, large language models, recent research, research on large, growing emphasis
+
+ 点击查看摘要
+ In recent research on large language models (LLMs), there has been a growing emphasis on aligning these models with human values to reduce the impact of harmful content. However, current alignment methods often rely solely on singular forms of human feedback, such as preferences, annotated labels, or natural language critiques, overlooking the potential advantages of combining these feedback types. This limitation leads to suboptimal performance, even when ample training data is available. In this paper, we introduce Constructive and Diverse Feedback (CDF) as a novel method to enhance LLM alignment, inspired by constructivist learning theory. Our approach involves collecting three distinct types of feedback tailored to problems of varying difficulty levels within the training dataset. Specifically, we exploit critique feedback for easy problems, refinement feedback for medium problems, and preference feedback for hard problems. By training our model with this diversified feedback, we achieve enhanced alignment performance while using less training data. To assess the effectiveness of CDF, we evaluate it against previous methods in three downstream tasks: question answering, dialog generation, and text summarization. Experimental results demonstrate that CDF achieves superior performance even with a smaller training dataset.
+
+
+
+ 41. 标题:Stepwise functional refoundation of relational concept analysis
+ 编号:[157]
+ 链接:https://arxiv.org/abs/2310.06441
+ 作者:Jérôme Euzenat (MOEX)
+ 备注:euzenat2023a
+ 关键词:Relational concept analysis, formal concept analysis, concept analysis allowing, related contexts simultaneously, concept analysis
+
+ 点击查看摘要
+ Relational concept analysis (RCA) is an extension of formal concept analysis allowing to deal with several related contexts simultaneously. It has been designed for learning description logic theories from data and used within various applications. A puzzling observation about RCA is that it returns a single family of concept lattices although, when the data feature circular dependencies, other solutions may be considered acceptable. The semantics of RCA, provided in an operational way, does not shed light on this issue. In this report, we define these acceptable solutions as those families of concept lattices which belong to the space determined by the initial contexts (well-formed), cannot scale new attributes (saturated), and refer only to concepts of the family (self-supported). We adopt a functional view on the RCA process by defining the space of well-formed solutions and two functions on that space: one expansive and the other contractive. We show that the acceptable solutions are the common fixed points of both functions. This is achieved step-by-step by starting from a minimal version of RCA that considers only one single context defined on a space of contexts and a space of lattices. These spaces are then joined into a single space of context-lattice pairs, which is further extended to a space of indexed families of context-lattice pairs representing the objects manip
+
+
+
+ 42. 标题:Whispering LLaMA: A Cross-Modal Generative Error Correction Framework for Speech Recognition
+ 编号:[162]
+ 链接:https://arxiv.org/abs/2310.06434
+ 作者:Srijith Radhakrishnan, Chao-Han Huck Yang, Sumeer Ahmad Khan, Rohit Kumar, Narsis A. Kiani, David Gomez-Cabrero, Jesper N. Tegner
+ 备注:Accepted to EMNLP 2023. 10 pages. This work has been done in October 2022 and was submitted to EMNLP 23 once the draft was finalized. GitHub: this https URL
+ 关键词:automatic speech recognition, generative error correction, speech recognition, cross-modal fusion technique, fusion technique designed
+
+ 点击查看摘要
+ We introduce a new cross-modal fusion technique designed for generative error correction in automatic speech recognition (ASR). Our methodology leverages both acoustic information and external linguistic representations to generate accurate speech transcription contexts. This marks a step towards a fresh paradigm in generative error correction within the realm of n-best hypotheses. Unlike the existing ranking-based rescoring methods, our approach adeptly uses distinct initialization techniques and parameter-efficient algorithms to boost ASR performance derived from pre-trained speech and text models. Through evaluation across diverse ASR datasets, we evaluate the stability and reproducibility of our fusion technique, demonstrating its improved word error rate relative (WERR) performance in comparison to n-best hypotheses by relatively 37.66%. To encourage future research, we have made our code and pre-trained models open source at this https URL.
+
+
+
+ 43. 标题:Retromorphic Testing: A New Approach to the Test Oracle Problem
+ 编号:[163]
+ 链接:https://arxiv.org/abs/2310.06433
+ 作者:Boxi Yu, Qiuyang Mang, Qingshuo Guo, Pinjia He
+ 备注:
+ 关键词:test oracle serves, testing, program, criterion or mechanism, mechanism to assess
+
+ 点击查看摘要
+ A test oracle serves as a criterion or mechanism to assess the correspondence between software output and the anticipated behavior for a given input set. In automated testing, black-box techniques, known for their non-intrusive nature in test oracle construction, are widely used, including notable methodologies like differential testing and metamorphic testing. Inspired by the mathematical concept of inverse function, we present Retromorphic Testing, a novel black-box testing methodology. It leverages an auxiliary program in conjunction with the program under test, which establishes a dual-program structure consisting of a forward program and a backward program. The input data is first processed by the forward program and then its program output is reversed to its original input format using the backward program. In particular, the auxiliary program can operate as either the forward or backward program, leading to different testing modes. The process concludes by examining the relationship between the initial input and the transformed output within the input domain. For example, to test the implementation of the sine function $\sin(x)$, we can employ its inverse function, $\arcsin(x)$, and validate the equation $x = \sin(\arcsin(x)+2k\pi), \forall k \in \mathbb{Z}$. In addition to the high-level concept of Retromorphic Testing, this paper presents its three testing modes with illustrative use cases across diverse programs, including algorithms, traditional software, and AI applications.
+
+
+
+ 44. 标题:Proceedings of The first international workshop on eXplainable AI for the Arts (XAIxArts)
+ 编号:[165]
+ 链接:https://arxiv.org/abs/2310.06428
+ 作者:Nick Bryan-Kinns, Corey Ford, Alan Chamberlain, Steven David Benford, Helen Kennedy, Zijin Li, Wu Qiong, Gus G. Xia, Jeba Rezwana
+ 备注:
+ 关键词:Interaction Design, researchers in HCI, digital arts, community of researchers, explore the role
+
+ 点击查看摘要
+ This first international workshop on explainable AI for the Arts (XAIxArts) brought together a community of researchers in HCI, Interaction Design, AI, explainable AI (XAI), and digital arts to explore the role of XAI for the Arts.
+Workshop held at the 15th ACM Conference on Creativity and Cognition (C&C 2023).
+
+
+
+ 45. 标题:TANGO: Time-Reversal Latent GraphODE for Multi-Agent Dynamical Systems
+ 编号:[166]
+ 链接:https://arxiv.org/abs/2310.06427
+ 作者:Zijie Huang, Wanjia Zhao, Jingdong Gao, Ziniu Hu, Xiao Luo, Yadi Cao, Yuanzhou Chen, Yizhou Sun, Wei Wang
+ 备注:
+ 关键词:Learning complex multi-agent, Hamiltonian Neural Network, complex multi-agent system, material modeling, complex multi-agent
+
+ 点击查看摘要
+ Learning complex multi-agent system dynamics from data is crucial across many domains, such as in physical simulations and material modeling. Extended from purely data-driven approaches, existing physics-informed approaches such as Hamiltonian Neural Network strictly follow energy conservation law to introduce inductive bias, making their learning more sample efficiently. However, many real-world systems do not strictly conserve energy, such as spring systems with frictions. Recognizing this, we turn our attention to a broader physical principle: Time-Reversal Symmetry, which depicts that the dynamics of a system shall remain invariant when traversed back over time. It still helps to preserve energies for conservative systems and in the meanwhile, serves as a strong inductive bias for non-conservative, reversible systems. To inject such inductive bias, in this paper, we propose a simple-yet-effective self-supervised regularization term as a soft constraint that aligns the forward and backward trajectories predicted by a continuous graph neural network-based ordinary differential equation (GraphODE). It effectively imposes time-reversal symmetry to enable more accurate model predictions across a wider range of dynamical systems under classical mechanics. In addition, we further provide theoretical analysis to show that our regularization essentially minimizes higher-order Taylor expansion terms during the ODE integration steps, which enables our model to be more noise-tolerant and even applicable to irreversible systems. Experimental results on a variety of physical systems demonstrate the effectiveness of our proposed method. Particularly, it achieves an MSE improvement of 11.5 % on a challenging chaotic triple-pendulum systems.
+
+
+
+ 46. 标题:Large Language Models for Propaganda Detection
+ 编号:[169]
+ 链接:https://arxiv.org/abs/2310.06422
+ 作者:Kilian Sprenkamp, Daniel Gordon Jones, Liudmila Zavolokina
+ 备注:
+ 关键词:digital society poses, dissemination of truth, Large Language Models, digital society, society poses
+
+ 点击查看摘要
+ The prevalence of propaganda in our digital society poses a challenge to societal harmony and the dissemination of truth. Detecting propaganda through NLP in text is challenging due to subtle manipulation techniques and contextual dependencies. To address this issue, we investigate the effectiveness of modern Large Language Models (LLMs) such as GPT-3 and GPT-4 for propaganda detection. We conduct experiments using the SemEval-2020 task 11 dataset, which features news articles labeled with 14 propaganda techniques as a multi-label classification problem. Five variations of GPT-3 and GPT-4 are employed, incorporating various prompt engineering and fine-tuning strategies across the different models. We evaluate the models' performance by assessing metrics such as $F1$ score, $Precision$, and $Recall$, comparing the results with the current state-of-the-art approach using RoBERTa. Our findings demonstrate that GPT-4 achieves comparable results to the current state-of-the-art. Further, this study analyzes the potential and challenges of LLMs in complex tasks like propaganda detection.
+
+
+
+ 47. 标题:Advective Diffusion Transformers for Topological Generalization in Graph Learning
+ 编号:[171]
+ 链接:https://arxiv.org/abs/2310.06417
+ 作者:Qitian Wu, Chenxiao Yang, Kaipeng Zeng, Fan Nie, Michael Bronstein, Junchi Yan
+ 备注:39 pages
+ 关键词:justifying architectural choices, recently attracted attention, analyzing GNN dynamics, graph neural networks, Graph diffusion equations
+
+ 点击查看摘要
+ Graph diffusion equations are intimately related to graph neural networks (GNNs) and have recently attracted attention as a principled framework for analyzing GNN dynamics, formalizing their expressive power, and justifying architectural choices. One key open questions in graph learning is the generalization capabilities of GNNs. A major limitation of current approaches hinges on the assumption that the graph topologies in the training and test sets come from the same distribution. In this paper, we make steps towards understanding the generalization of GNNs by exploring how graph diffusion equations extrapolate and generalize in the presence of varying graph topologies. We first show deficiencies in the generalization capability of existing models built upon local diffusion on graphs, stemming from the exponential sensitivity to topology variation. Our subsequent analysis reveals the promise of non-local diffusion, which advocates for feature propagation over fully-connected latent graphs, under the assumption of a specific data-generating condition. In addition to these findings, we propose a novel graph encoder backbone, Advective Diffusion Transformer (ADiT), inspired by advective graph diffusion equations that have a closed-form solution backed up with theoretical guarantees of desired generalization under topological distribution shifts. The new model, functioning as a versatile graph Transformer, demonstrates superior performance across a wide range of graph learning tasks.
+
+
+
+ 48. 标题:Hexa: Self-Improving for Knowledge-Grounded Dialogue System
+ 编号:[176]
+ 链接:https://arxiv.org/abs/2310.06404
+ 作者:Daejin Jo, Daniel Wontae Nam, Gunsoo Han, Kyoung-Woon On, Taehwan Kwon, Seungeun Rho, Sungwoong Kim
+ 备注:
+ 关键词:explicitly utilize intermediate, memory retrieval, modular approaches, utilize intermediate steps, common practice
+
+ 点击查看摘要
+ A common practice in knowledge-grounded dialogue generation is to explicitly utilize intermediate steps (e.g., web-search, memory retrieval) with modular approaches. However, data for such steps are often inaccessible compared to those of dialogue responses as they are unobservable in an ordinary dialogue. To fill in the absence of these data, we develop a self-improving method to improve the generative performances of intermediate steps without the ground truth data. In particular, we propose a novel bootstrapping scheme with a guided prompt and a modified loss function to enhance the diversity of appropriate self-generated responses. Through experiments on various benchmark datasets, we empirically demonstrate that our method successfully leverages a self-improving mechanism in generating intermediate and final responses and improves the performances on the task of knowledge-grounded dialogue generation.
+
+
+
+ 49. 标题:Lo-Hi: Practical ML Drug Discovery Benchmark
+ 编号:[178]
+ 链接:https://arxiv.org/abs/2310.06399
+ 作者:Simon Steshin
+ 备注:29 pages, Advances in Neural Information Processing Systems, 2023
+ 关键词:https URL, Balanced Vertex Minimum, URL, harder, drug discovery
+
+ 点击查看摘要
+ Finding new drugs is getting harder and harder. One of the hopes of drug discovery is to use machine learning models to predict molecular properties. That is why models for molecular property prediction are being developed and tested on benchmarks such as MoleculeNet. However, existing benchmarks are unrealistic and are too different from applying the models in practice. We have created a new practical \emph{Lo-Hi} benchmark consisting of two tasks: Lead Optimization (Lo) and Hit Identification (Hi), corresponding to the real drug discovery process. For the Hi task, we designed a novel molecular splitting algorithm that solves the Balanced Vertex Minimum $k$-Cut problem. We tested state-of-the-art and classic ML models, revealing which works better under practical settings. We analyzed modern benchmarks and showed that they are unrealistic and overoptimistic.
+Review: this https URL
+Lo-Hi benchmark: this https URL
+Lo-Hi splitter library: this https URL
+
+
+
+ 50. 标题:P5: Plug-and-Play Persona Prompting for Personalized Response Selection
+ 编号:[183]
+ 链接:https://arxiv.org/abs/2310.06390
+ 作者:Joosung Lee, Minsik Oh, Donghun Lee
+ 备注:EMNLP 2023 main conference
+ 关键词:persona-grounded retrieval-based chatbots, persona, persona-grounded retrieval-based, persona-grounded corpus, retrieval-based chatbots
+
+ 点击查看摘要
+ The use of persona-grounded retrieval-based chatbots is crucial for personalized conversations, but there are several challenges that need to be addressed. 1) In general, collecting persona-grounded corpus is very expensive. 2) The chatbot system does not always respond in consideration of persona at real applications. To address these challenges, we propose a plug-and-play persona prompting method. Our system can function as a standard open-domain chatbot if persona information is not available. We demonstrate that this approach performs well in the zero-shot setting, which reduces the dependence on persona-ground training data. This makes it easier to expand the system to other languages without the need to build a persona-grounded corpus. Additionally, our model can be fine-tuned for even better performance. In our experiments, the zero-shot model improved the standard model by 7.71 and 1.04 points in the original persona and revised persona, respectively. The fine-tuned model improved the previous state-of-the-art system by 1.95 and 3.39 points in the original persona and revised persona, respectively. To the best of our knowledge, this is the first attempt to solve the problem of personalized response selection using prompt sequences. Our code is available on github~\footnote{this https URL}.
+
+
+
+ 51. 标题:Jailbreak and Guard Aligned Language Models with Only Few In-Context Demonstrations
+ 编号:[185]
+ 链接:https://arxiv.org/abs/2310.06387
+ 作者:Zeming Wei, Yifei Wang, Yisen Wang
+ 备注:
+ 关键词:Large Language Models, shown remarkable success, content have emerged, shown remarkable, Large Language
+
+ 点击查看摘要
+ Large Language Models (LLMs) have shown remarkable success in various tasks, but concerns about their safety and the potential for generating malicious content have emerged. In this paper, we explore the power of In-Context Learning (ICL) in manipulating the alignment ability of LLMs. We find that by providing just few in-context demonstrations without fine-tuning, LLMs can be manipulated to increase or decrease the probability of jailbreaking, i.e. answering malicious prompts. Based on these observations, we propose In-Context Attack (ICA) and In-Context Defense (ICD) methods for jailbreaking and guarding aligned language model purposes. ICA crafts malicious contexts to guide models in generating harmful outputs, while ICD enhances model robustness by demonstrations of rejecting to answer harmful prompts. Our experiments show the effectiveness of ICA and ICD in increasing or reducing the success rate of adversarial jailbreaking attacks. Overall, we shed light on the potential of ICL to influence LLM behavior and provide a new perspective for enhancing the safety and alignment of LLMs.
+
+
+
+ 52. 标题:What Makes for Robust Multi-Modal Models in the Face of Missing Modalities?
+ 编号:[188]
+ 链接:https://arxiv.org/abs/2310.06383
+ 作者:Siting Li, Chenzhuang Du, Yue Zhao, Yu Huang, Hang Zhao
+ 备注:
+ 关键词:receiving increased attention, increased attention, growing success, receiving increased, missing modalities
+
+ 点击查看摘要
+ With the growing success of multi-modal learning, research on the robustness of multi-modal models, especially when facing situations with missing modalities, is receiving increased attention. Nevertheless, previous studies in this domain exhibit certain limitations, as they often lack theoretical insights or their methodologies are tied to specific network architectures or modalities. We model the scenarios of multi-modal models encountering missing modalities from an information-theoretic perspective and illustrate that the performance ceiling in such scenarios can be approached by efficiently utilizing the information inherent in non-missing modalities. In practice, there are two key aspects: (1) The encoder should be able to extract sufficiently good features from the non-missing modality; (2) The extracted features should be robust enough not to be influenced by noise during the fusion process across modalities. To this end, we introduce Uni-Modal Ensemble with Missing Modality Adaptation (UME-MMA). UME-MMA employs uni-modal pre-trained weights for the multi-modal model to enhance feature extraction and utilizes missing modality data augmentation techniques to better adapt to situations with missing modalities. Apart from that, UME-MMA, built on a late-fusion learning framework, allows for the plug-and-play use of various encoders, making it suitable for a wide range of modalities and enabling seamless integration of large-scale pre-trained encoders to further enhance performance. And we demonstrate UME-MMA's effectiveness in audio-visual datasets~(e.g., AV-MNIST, Kinetics-Sound, AVE) and vision-language datasets~(e.g., MM-IMDB, UPMC Food101).
+
+
+
+ 53. 标题:Advanced Efficient Strategy for Detection of Dark Objects Based on Spiking Network with Multi-Box Detection
+ 编号:[196]
+ 链接:https://arxiv.org/abs/2310.06370
+ 作者:Munawar Ali, Baoqun Yin, Hazrat Bilal, Aakash Kumar, Ali Muhammad, Avinash Rohra
+ 备注:
+ 关键词:deep learning algorithms, shown amazing performance, recognizing darker objects, object detection tasks, largest challenge
+
+ 点击查看摘要
+ Several deep learning algorithms have shown amazing performance for existing object detection tasks, but recognizing darker objects is the largest challenge. Moreover, those techniques struggled to detect or had a slow recognition rate, resulting in significant performance losses. As a result, an improved and accurate detection approach is required to address the above difficulty. The whole study proposes a combination of spiked and normal convolution layers as an energy-efficient and reliable object detector model. The proposed model is split into two sections. The first section is developed as a feature extractor, which utilizes pre-trained VGG16, and the second section of the proposal structure is the combination of spiked and normal Convolutional layers to detect the bounding boxes of images. We drew a pre-trained model for classifying detected objects. With state of the art Python libraries, spike layers can be trained efficiently. The proposed spike convolutional object detector (SCOD) has been evaluated on VOC and Ex-Dark datasets. SCOD reached 66.01% and 41.25% mAP for detecting 20 different objects in the VOC-12 and 12 objects in the Ex-Dark dataset. SCOD uses 14 Giga FLOPS for its forward path calculations. Experimental results indicated superior performance compared to Tiny YOLO, Spike YOLO, YOLO-LITE, Tinier YOLO and Center of loc+Xception based on mAP for the VOC dataset.
+
+
+
+ 54. 标题:Geometrically Aligned Transfer Encoder for Inductive Transfer in Regression Tasks
+ 编号:[197]
+ 链接:https://arxiv.org/abs/2310.06369
+ 作者:Sung Moon Ko, Sumin Lee, Dae-Woong Jeong, Woohyung Lim, Sehui Han
+ 备注:12+11 pages, 6+1 figures, 0+7 tables
+ 关键词:Aligned Transfer Encoder, Geometrically Aligned Transfer, handling a small, small amount, potentially related
+
+ 点击查看摘要
+ Transfer learning is a crucial technique for handling a small amount of data that is potentially related to other abundant data. However, most of the existing methods are focused on classification tasks using images and language datasets. Therefore, in order to expand the transfer learning scheme to regression tasks, we propose a novel transfer technique based on differential geometry, namely the Geometrically Aligned Transfer Encoder (GATE). In this method, we interpret the latent vectors from the model to exist on a Riemannian curved manifold. We find a proper diffeomorphism between pairs of tasks to ensure that every arbitrary point maps to a locally flat coordinate in the overlapping region, allowing the transfer of knowledge from the source to the target data. This also serves as an effective regularizer for the model to behave in extrapolation regions. In this article, we demonstrate that GATE outperforms conventional methods and exhibits stable behavior in both the latent space and extrapolation regions for various molecular graph datasets.
+
+
+
+ 55. 标题:Noisy-ArcMix: Additive Noisy Angular Margin Loss Combined With Mixup Anomalous Sound Detection
+ 编号:[202]
+ 链接:https://arxiv.org/abs/2310.06364
+ 作者:Soonhyeon Choi, Jung-Woo Choi
+ 备注:Submitted to ICASSP 2024
+ 关键词:Unsupervised anomalous sound, anomalous sound detection, identify anomalous sounds, normal operational sounds, sound detection
+
+ 点击查看摘要
+ Unsupervised anomalous sound detection (ASD) aims to identify anomalous sounds by learning the features of normal operational sounds and sensing their deviations. Recent approaches have focused on the self-supervised task utilizing the classification of normal data, and advanced models have shown that securing representation space for anomalous data is important through representation learning yielding compact intra-class and well-separated intra-class distributions. However, we show that conventional approaches often fail to ensure sufficient intra-class compactness and exhibit angular disparity between samples and their corresponding centers. In this paper, we propose a training technique aimed at ensuring intra-class compactness and increasing the angle gap between normal and abnormal samples. Furthermore, we present an architecture that extracts features for important temporal regions, enabling the model to learn which time frames should be emphasized or suppressed. Experimental results demonstrate that the proposed method achieves the best performance giving 0.90%, 0.83%, and 2.16% improvement in terms of AUC, pAUC, and mAUC, respectively, compared to the state-of-the-art method on DCASE 2020 Challenge Task2 dataset.
+
+
+
+ 56. 标题:Fire Detection From Image and Video Using YOLOv5
+ 编号:[207]
+ 链接:https://arxiv.org/abs/2310.06351
+ 作者:Arafat Islam, Md. Imtiaz Habib
+ 备注:6 pages, 6 sections, unpublished paper
+ 关键词:detection deep learning, deep learning algorithm, detection, fire detection, fire detection deep
+
+ 点击查看摘要
+ For the detection of fire-like targets in indoor, outdoor and forest fire images, as well as fire detection under different natural lights, an improved YOLOv5 fire detection deep learning algorithm is proposed. The YOLOv5 detection model expands the feature extraction network from three dimensions, which enhances feature propagation of fire small targets identification, improves network performance, and reduces model parameters. Furthermore, through the promotion of the feature pyramid, the top-performing prediction box is obtained. Fire-YOLOv5 attains excellent results compared to state-of-the-art object detection networks, notably in the detection of small targets of fire and smoke with mAP 90.5% and f1 score 88%. Overall, the Fire-YOLOv5 detection model can effectively deal with the inspection of small fire targets, as well as fire-like and smoke-like objects with F1 score 0.88. When the input image size is 416 x 416 resolution, the average detection time is 0.12 s per frame, which can provide real-time forest fire detection. Moreover, the algorithm proposed in this paper can also be applied to small target detection under other complicated situations. The proposed system shows an improved approach in all fire detection metrics such as precision, recall, and mean average precision.
+
+
+
+ 57. 标题:Filter Pruning For CNN With Enhanced Linear Representation Redundancy
+ 编号:[210]
+ 链接:https://arxiv.org/abs/2310.06344
+ 作者:Bojue Wang, Chunmei Ma, Bin Liu, Nianbo Liu, Jinqi Zhu
+ 备注:
+ 关键词:parallel computing techniques, thriving developed parallel, developed parallel computing, pruning excels non-structured, excels non-structured methods
+
+ 点击查看摘要
+ Structured network pruning excels non-structured methods because they can take advantage of the thriving developed parallel computing techniques. In this paper, we propose a new structured pruning method. Firstly, to create more structured redundancy, we present a data-driven loss function term calculated from the correlation coefficient matrix of different feature maps in the same layer, named CCM-loss. This loss term can encourage the neural network to learn stronger linear representation relations between feature maps during the training from the scratch so that more homogenous parts can be removed later in pruning. CCM-loss provides us with another universal transcendental mathematical tool besides L*-norm regularization, which concentrates on generating zeros, to generate more redundancy but for the different genres. Furthermore, we design a matching channel selection strategy based on principal components analysis to exploit the maximum potential ability of CCM-loss. In our new strategy, we mainly focus on the consistency and integrality of the information flow in the network. Instead of empirically hard-code the retain ratio for each layer, our channel selection strategy can dynamically adjust each layer's retain ratio according to the specific circumstance of a per-trained model to push the prune ratio to the limit. Notably, on the Cifar-10 dataset, our method brings 93.64% accuracy for pruned VGG-16 with only 1.40M parameters and 49.60M FLOPs, the pruned ratios for parameters and FLOPs are 90.6% and 84.2%, respectively. For ResNet-50 trained on the ImageNet dataset, our approach achieves 42.8% and 47.3% storage and computation reductions, respectively, with an accuracy of 76.23%. Our code is available at this https URL.
+
+
+
+ 58. 标题:Contrastive Prompt Learning-based Code Search based on Interaction Matrix
+ 编号:[212]
+ 链接:https://arxiv.org/abs/2310.06342
+ 作者:Yubo Zhang, Yanfang Liu, Xinxin Fan, Yunfeng Lu
+ 备注:
+ 关键词:Code search aims, Code search, aims to retrieve, snippet that highly, highly matches
+
+ 点击查看摘要
+ Code search aims to retrieve the code snippet that highly matches the given query described in natural language. Recently, many code pre-training approaches have demonstrated impressive performance on code search. However, existing code search methods still suffer from two performance constraints: inadequate semantic representation and the semantic gap between natural language (NL) and programming language (PL). In this paper, we propose CPLCS, a contrastive prompt learning-based code search method based on the cross-modal interaction mechanism. CPLCS comprises:(1) PL-NL contrastive learning, which learns the semantic matching relationship between PL and NL representations; (2) a prompt learning design for a dual-encoder structure that can alleviate the problem of inadequate semantic representation; (3) a cross-modal interaction mechanism to enhance the fine-grained mapping between NL and PL. We conduct extensive experiments to evaluate the effectiveness of our approach on a real-world dataset across six programming languages. The experiment results demonstrate the efficacy of our approach in improving semantic representation quality and mapping ability between PL and NL.
+
+
+
+ 59. 标题:I2SRM: Intra- and Inter-Sample Relationship Modeling for Multimodal Information Extraction
+ 编号:[221]
+ 链接:https://arxiv.org/abs/2310.06326
+ 作者:Yusheng Huang, Zhouhan Lin
+ 备注:
+ 关键词:research attention nowadays, attracting research attention, requires aggregating representations, relationship modeling module, Inter-Sample Relationship Modeling
+
+ 点击查看摘要
+ Multimodal information extraction is attracting research attention nowadays, which requires aggregating representations from different modalities. In this paper, we present the Intra- and Inter-Sample Relationship Modeling (I2SRM) method for this task, which contains two modules. Firstly, the intra-sample relationship modeling module operates on a single sample and aims to learn effective representations. Embeddings from textual and visual modalities are shifted to bridge the modality gap caused by distinct pre-trained language and image models. Secondly, the inter-sample relationship modeling module considers relationships among multiple samples and focuses on capturing the interactions. An AttnMixup strategy is proposed, which not only enables collaboration among samples but also augments data to improve generalization. We conduct extensive experiments on the multimodal named entity recognition datasets Twitter-2015 and Twitter-2017, and the multimodal relation extraction dataset MNRE. Our proposed method I2SRM achieves competitive results, 77.12% F1-score on Twitter-2015, 88.40% F1-score on Twitter-2017, and 84.12% F1-score on MNRE.
+
+
+
+ 60. 标题:Predicting Three Types of Freezing of Gait Events Using Deep Learning Models
+ 编号:[222]
+ 链接:https://arxiv.org/abs/2310.06322
+ 作者:Wen Tao Mo, Jonathan H. Chan
+ 备注:5 pages
+ 关键词:Parkinson Disease symptom, Parkinson Disease, Freezing of gait, Disease symptom, gait
+
+ 点击查看摘要
+ Freezing of gait is a Parkinson's Disease symptom that episodically inflicts a patient with the inability to step or turn while walking. While medical experts have discovered various triggers and alleviating actions for freezing of gait, the underlying causes and prediction models are still being explored today. Current freezing of gait prediction models that utilize machine learning achieve high sensitivity and specificity in freezing of gait predictions based on time-series data; however, these models lack specifications on the type of freezing of gait events. We develop various deep learning models using the transformer encoder architecture plus Bidirectional LSTM layers and different feature sets to predict the three different types of freezing of gait events. The best performing model achieves a score of 0.427 on testing data, which would rank top 5 in Kaggle's Freezing of Gait prediction competition, hosted by THE MICHAEL J. FOX FOUNDATION. However, we also recognize overfitting in training data that could be potentially improved through pseudo labelling on additional data and model architecture simplification.
+
+
+
+ 61. 标题:Dobby: A Conversational Service Robot Driven by GPT-4
+ 编号:[233]
+ 链接:https://arxiv.org/abs/2310.06303
+ 作者:Carson Stark, Bohkyung Chun, Casey Charleston, Varsha Ravi, Luis Pabon, Surya Sunkari, Tarun Mohan, Peter Stone, Justin Hart
+ 备注:
+ 关键词:integrating task planning, natural language understanding, integrating task, human-like conversation, service tasks
+
+ 点击查看摘要
+ This work introduces a robotics platform which embeds a conversational AI agent in an embodied system for natural language understanding and intelligent decision-making for service tasks; integrating task planning and human-like conversation. The agent is derived from a large language model, which has learned from a vast corpus of general knowledge. In addition to generating dialogue, this agent can interface with the physical world by invoking commands on the robot; seamlessly merging communication and behavior. This system is demonstrated in a free-form tour-guide scenario, in an HRI study combining robots with and without conversational AI capabilities. Performance is measured along five dimensions: overall effectiveness, exploration abilities, scrutinization abilities, receptiveness to personification, and adaptability.
+
+
+
+ 62. 标题:Dynamical versus Bayesian Phase Transitions in a Toy Model of Superposition
+ 编号:[235]
+ 链接:https://arxiv.org/abs/2310.06301
+ 作者:Zhongtian Chen, Edmund Lau, Jake Mendel, Susan Wei, Daniel Murfet
+ 备注:
+ 关键词:Model of Superposition, Toy Model, Singular Learning Theory, investigate phase transitions, Singular Learning
+
+ 点击查看摘要
+ We investigate phase transitions in a Toy Model of Superposition (TMS) using Singular Learning Theory (SLT). We derive a closed formula for the theoretical loss and, in the case of two hidden dimensions, discover that regular $k$-gons are critical points. We present supporting theory indicating that the local learning coefficient (a geometric invariant) of these $k$-gons determines phase transitions in the Bayesian posterior as a function of training sample size. We then show empirically that the same $k$-gon critical points also determine the behavior of SGD training. The picture that emerges adds evidence to the conjecture that the SGD learning trajectory is subject to a sequential learning mechanism. Specifically, we find that the learning process in TMS, be it through SGD or Bayesian learning, can be characterized by a journey through parameter space from regions of high loss and low complexity to regions of low loss and high complexity.
+
+
+
+ 63. 标题:Suppressing Overestimation in Q-Learning through Adversarial Behaviors
+ 编号:[243]
+ 链接:https://arxiv.org/abs/2310.06286
+ 作者:HyeAnn Lee, Donghwan Lee
+ 备注:
+ 关键词:called dummy adversarial, Q-learning, dummy adversarial Q-learning, dummy adversarial player, DAQ
+
+ 点击查看摘要
+ The goal of this paper is to propose a new Q-learning algorithm with a dummy adversarial player, which is called dummy adversarial Q-learning (DAQ), that can effectively regulate the overestimation bias in standard Q-learning. With the dummy player, the learning can be formulated as a two-player zero-sum game. The proposed DAQ unifies several Q-learning variations to control overestimation biases, such as maxmin Q-learning and minmax Q-learning (proposed in this paper) in a single framework. The proposed DAQ is a simple but effective way to suppress the overestimation bias thourgh dummy adversarial behaviors and can be easily applied to off-the-shelf reinforcement learning algorithms to improve the performances. A finite-time convergence of DAQ is analyzed from an integrated perspective by adapting an adversarial Q-learning. The performance of the suggested DAQ is empirically demonstrated under various benchmark environments.
+
+
+
+ 64. 标题:BC4LLM: Trusted Artificial Intelligence When Blockchain Meets Large Language Models
+ 编号:[248]
+ 链接:https://arxiv.org/abs/2310.06278
+ 作者:Haoxiang Luo, Jian Luo, Athanasios V. Vasilakos
+ 备注:
+ 关键词:reshaping society production, society production methods, artificial intelligence, recent years, methods and productivity
+
+ 点击查看摘要
+ In recent years, artificial intelligence (AI) and machine learning (ML) are reshaping society's production methods and productivity, and also changing the paradigm of scientific research. Among them, the AI language model represented by ChatGPT has made great progress. Such large language models (LLMs) serve people in the form of AI-generated content (AIGC) and are widely used in consulting, healthcare, and education. However, it is difficult to guarantee the authenticity and reliability of AIGC learning data. In addition, there are also hidden dangers of privacy disclosure in distributed AI training. Moreover, the content generated by LLMs is difficult to identify and trace, and it is difficult to cross-platform mutual recognition. The above information security issues in the coming era of AI powered by LLMs will be infinitely amplified and affect everyone's life. Therefore, we consider empowering LLMs using blockchain technology with superior security features to propose a vision for trusted AI. This paper mainly introduces the motivation and technical route of blockchain for LLM (BC4LLM), including reliable learning corpus, secure training process, and identifiable generated content. Meanwhile, this paper also reviews the potential applications and future challenges, especially in the frontier communication networks field, including network resource allocation, dynamic spectrum sharing, and semantic communication. Based on the above work combined and the prospect of blockchain and LLMs, it is expected to help the early realization of trusted AI and provide guidance for the academic community.
+
+
+
+ 65. 标题:Let Models Speak Ciphers: Multiagent Debate through Embeddings
+ 编号:[250]
+ 链接:https://arxiv.org/abs/2310.06272
+ 作者:Chau Pham, Boyi Liu, Yingxiang Yang, Zhengyu Chen, Tianyi Liu, Jianbo Yuan, Bryan A. Plummer, Zhaoran Wang, Hongxia Yang
+ 备注:
+ 关键词:Large Language Models, gained considerable attention, considerable attention due, Large Language, gained considerable
+
+ 点击查看摘要
+ Discussion and debate among Large Language Models (LLMs) have gained considerable attention due to their potential to enhance the reasoning ability of LLMs. Although natural language is an obvious choice for communication due to LLM's language understanding capability, the token sampling step needed when generating natural language poses a potential risk of information loss, as it uses only one token to represent the model's belief across the entire vocabulary. In this paper, we introduce a communication regime named CIPHER (Communicative Inter-Model Protocol Through Embedding Representation) to address this issue. Specifically, we remove the token sampling step from LLMs and let them communicate their beliefs across the vocabulary through the expectation of the raw transformer output embeddings. Remarkably, by deviating from natural language, CIPHER offers an advantage of encoding a broader spectrum of information without any modification to the model weights. While the state-of-the-art LLM debate methods using natural language outperforms traditional inference by a margin of 1.5-8%, our experiment results show that CIPHER debate further extends this lead by 1-3.5% across five reasoning tasks and multiple open-source LLMs of varying sizes. This showcases the superiority and robustness of embeddings as an alternative "language" for communication among LLMs.
+
+
+
+ 66. 标题:Towards Mitigating Hallucination in Large Language Models via Self-Reflection
+ 编号:[251]
+ 链接:https://arxiv.org/abs/2310.06271
+ 作者:Ziwei Ji, Tiezheng Yu, Yan Xu, Nayeon Lee, Etsuko Ishii, Pascale Fung
+ 备注:Accepted by the findings of EMNLP 2023
+ 关键词:tasks including question-answering, knowledge-intensive tasks including, Large language models, knowledge-intensive tasks, tasks including
+
+ 点击查看摘要
+ Large language models (LLMs) have shown promise for generative and knowledge-intensive tasks including question-answering (QA) tasks. However, the practical deployment still faces challenges, notably the issue of "hallucination", where models generate plausible-sounding but unfaithful or nonsensical information. This issue becomes particularly critical in the medical domain due to the uncommon professional concepts and potential social risks involved. This paper analyses the phenomenon of hallucination in medical generative QA systems using widely adopted LLMs and datasets. Our investigation centers on the identification and comprehension of common problematic answers, with a specific emphasis on hallucination. To tackle this challenge, we present an interactive self-reflection methodology that incorporates knowledge acquisition and answer generation. Through this feedback process, our approach steadily enhances the factuality, consistency, and entailment of the generated answers. Consequently, we harness the interactivity and multitasking ability of LLMs and produce progressively more precise and accurate answers. Experimental results on both automatic and human evaluation demonstrate the superiority of our approach in hallucination reduction compared to baselines.
+
+
+
+ 67. 标题:The AI Incident Database as an Educational Tool to Raise Awareness of AI Harms: A Classroom Exploration of Efficacy, Limitations, & Future Improvements
+ 编号:[252]
+ 链接:https://arxiv.org/abs/2310.06269
+ 作者:Michael Feffer, Nikolas Martelaro, Hoda Heidari
+ 备注:37 pages, 11 figures; To appear in the proceedings of EAAMO 2023
+ 关键词:data sciences curricula, sciences curricula, established the importance, importance of integrating, computer and data
+
+ 点击查看摘要
+ Prior work has established the importance of integrating AI ethics topics into computer and data sciences curricula. We provide evidence suggesting that one of the critical objectives of AI Ethics education must be to raise awareness of AI harms. While there are various sources to learn about such harms, The AI Incident Database (AIID) is one of the few attempts at offering a relatively comprehensive database indexing prior instances of harms or near harms stemming from the deployment of AI technologies in the real world. This study assesses the effectiveness of AIID as an educational tool to raise awareness regarding the prevalence and severity of AI harms in socially high-stakes domains. We present findings obtained through a classroom study conducted at an R1 institution as part of a course focused on the societal and ethical considerations around AI and ML. Our qualitative findings characterize students' initial perceptions of core topics in AI ethics and their desire to close the educational gap between their technical skills and their ability to think systematically about ethical and societal aspects of their work. We find that interacting with the database helps students better understand the magnitude and severity of AI harms and instills in them a sense of urgency around (a) designing functional and safe AI and (b) strengthening governance and accountability mechanisms. Finally, we compile students' feedback about the tool and our class activity into actionable recommendations for the database development team and the broader community to improve awareness of AI harms in AI ethics education.
+
+
+
+ 68. 标题:CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model
+ 编号:[254]
+ 链接:https://arxiv.org/abs/2310.06266
+ 作者:Peng Di, Jianguo Li, Hang Yu, Wei Jiang, Wenting Cai, Yang Cao, Chaoyu Chen, Dajun Chen, Hongwei Chen, Liang Chen, Gang Fan, Jie Gong, Zi Gong, Wen Hu, Tingting Guo, Zhichao Lei, Ting Li, Zheng Li, Ming Liang, Cong Liao, Bingchang Liu, Jiachen Liu, Zhiwei Liu, Shaojun Lu, Min Shen, Guangpei Wang, Huan Wang, Zhi Wang, Zhaogui Xu, Jiawei Yang, Qing Ye, Gehao Zhang, Yu Zhang, Zelin Zhao, Xunjin Zheng, Hailian Zhou, Lifu Zhu, Xianying Zhu
+ 备注:10 pages with 2 pages for references
+ 关键词:Large Language Models, gained significant attention, Code Large Language, Large Language, Code Large
+
+ 点击查看摘要
+ Code Large Language Models (Code LLMs) have gained significant attention in the industry due to their wide applications in the full lifecycle of software engineering. However, the effectiveness of existing models in understanding non-English inputs for multi-lingual code-related tasks is still far from well studied. This paper introduces CodeFuse-13B, an open-sourced pre-trained code LLM. It is specifically designed for code-related tasks with both English and Chinese prompts and supports over 40 programming languages. CodeFuse achieves its effectiveness by utilizing a high quality pre-training dataset that is carefully filtered by program analyzers and optimized during the training process. Extensive experiments are conducted using real-world usage scenarios, the industry-standard benchmark HumanEval-x, and the specially designed CodeFuseEval for Chinese prompts. To assess the effectiveness of CodeFuse, we actively collected valuable human feedback from the AntGroup's software development process where CodeFuse has been successfully deployed. The results demonstrate that CodeFuse-13B achieves a HumanEval pass@1 score of 37.10%, positioning it as one of the top multi-lingual code LLMs with similar parameter sizes. In practical scenarios, such as code generation, code translation, code comments, and testcase generation, CodeFuse performs better than other models when confronted with Chinese prompts.
+
+
+
+ 69. 标题:Self-Discriminative Modeling for Anomalous Graph Detection
+ 编号:[255]
+ 链接:https://arxiv.org/abs/2310.06261
+ 作者:Jinyu Cai, Yunhe Zhang, Jicong Fan
+ 备注:This work was submitted to NeurIPS 2023 but was unfortunately rejected
+ 关键词:network data analysis, social network data, anomalous graph detection, detecting anomalous graphs, anomalous graph
+
+ 点击查看摘要
+ This paper studies the problem of detecting anomalous graphs using a machine learning model trained on only normal graphs, which has many applications in molecule, biology, and social network data analysis. We present a self-discriminative modeling framework for anomalous graph detection. The key idea, mathematically and numerically illustrated, is to learn a discriminator (classifier) from the given normal graphs together with pseudo-anomalous graphs generated by a model jointly trained, where we never use any true anomalous graphs and we hope that the generated pseudo-anomalous graphs interpolate between normal ones and (real) anomalous ones. Under the framework, we provide three algorithms with different computational efficiencies and stabilities for anomalous graph detection. The three algorithms are compared with several state-of-the-art graph-level anomaly detection baselines on nine popular graph datasets (four with small size and five with moderate size) and show significant improvement in terms of AUC. The success of our algorithms stems from the integration of the discriminative classifier and the well-posed pseudo-anomalous graphs, which provide new insights for anomaly detection. Moreover, we investigate our algorithms for large-scale imbalanced graph datasets. Surprisingly, our algorithms, though fully unsupervised, are able to significantly outperform supervised learning algorithms of anomalous graph detection. The corresponding reason is also analyzed.
+
+
+
+ 70. 标题:Get the gist? Using large language models for few-shot decontextualization
+ 编号:[259]
+ 链接:https://arxiv.org/abs/2310.06254
+ 作者:Benjamin Kane, Lenhart Schubert
+ 备注:
+ 关键词:information retrieval systems, involve interpreting sentences, NLP applications, rich context, information retrieval
+
+ 点击查看摘要
+ In many NLP applications that involve interpreting sentences within a rich context -- for instance, information retrieval systems or dialogue systems -- it is desirable to be able to preserve the sentence in a form that can be readily understood without context, for later reuse -- a process known as ``decontextualization''. While previous work demonstrated that generative Seq2Seq models could effectively perform decontextualization after being fine-tuned on a specific dataset, this approach requires expensive human annotations and may not transfer to other domains. We propose a few-shot method of decontextualization using a large language model, and present preliminary results showing that this method achieves viable performance on multiple domains using only a small set of examples.
+
+
+
+ 71. 标题:We are what we repeatedly do: Inducing and deploying habitual schemas in persona-based responses
+ 编号:[262]
+ 链接:https://arxiv.org/abs/2310.06245
+ 作者:Benjamin Kane, Lenhart Schubert
+ 备注:
+ 关键词:dialogue technology require, practical applications, technology require, developer-specified persona, dialogue technology
+
+ 点击查看摘要
+ Many practical applications of dialogue technology require the generation of responses according to a particular developer-specified persona. While a variety of personas can be elicited from recent large language models, the opaqueness and unpredictability of these models make it desirable to be able to specify personas in an explicit form. In previous work, personas have typically been represented as sets of one-off pieces of self-knowledge that are retrieved by the dialogue system for use in generation. However, in realistic human conversations, personas are often revealed through story-like narratives that involve rich habitual knowledge -- knowledge about kinds of events that an agent often participates in (e.g., work activities, hobbies, sporting activities, favorite entertainments, etc.), including typical goals, sub-events, preconditions, and postconditions of those events. We capture such habitual knowledge using an explicit schema representation, and propose an approach to dialogue generation that retrieves relevant schemas to condition a large language model to generate persona-based responses. Furthermore, we demonstrate a method for bootstrapping the creation of such schemas by first generating generic passages from a set of simple facts, and then inducing schemas from the generated passages.
+
+
+
+ 72. 标题:Model Tuning or Prompt Tuning? A Study of Large Language Models for Clinical Concept and Relation Extraction
+ 编号:[265]
+ 链接:https://arxiv.org/abs/2310.06239
+ 作者:Cheng Peng, Xi Yang, Kaleb E Smith, Zehao Yu, Aokun Chen, Jiang Bian, Yonghui Wu
+ 备注:
+ 关键词:LLMs, unfrozen LLMs, learning, prompt-based learning algorithms, learning ability
+
+ 点击查看摘要
+ Objective To develop soft prompt-based learning algorithms for large language models (LLMs), examine the shape of prompts, prompt-tuning using frozen/unfrozen LLMs, transfer learning, and few-shot learning abilities. Methods We developed a soft prompt-based LLM model and compared 4 training strategies including (1) fine-tuning without prompts; (2) hard-prompt with unfrozen LLMs; (3) soft-prompt with unfrozen LLMs; and (4) soft-prompt with frozen LLMs. We evaluated 7 pretrained LLMs using the 4 training strategies for clinical concept and relation extraction on two benchmark datasets. We evaluated the transfer learning ability of the prompt-based learning algorithms in a cross-institution setting. We also assessed the few-shot learning ability. Results and Conclusion When LLMs are unfrozen, GatorTron-3.9B with soft prompting achieves the best strict F1-scores of 0.9118 and 0.8604 for concept extraction, outperforming the traditional fine-tuning and hard prompt-based models by 0.6~3.1% and 1.2~2.9%, respectively; GatorTron-345M with soft prompting achieves the best F1-scores of 0.8332 and 0.7488 for end-to-end relation extraction, outperforming the other two models by 0.2~2% and 0.6~11.7%, respectively. When LLMs are frozen, small (i.e., 345 million parameters) LLMs have a big gap to be competitive with unfrozen models; scaling LLMs up to billions of parameters makes frozen LLMs competitive with unfrozen LLMs. For cross-institute evaluation, soft prompting with a frozen GatorTron-8.9B model achieved the best performance. This study demonstrates that (1) machines can learn soft prompts better than humans, (2) frozen LLMs have better few-shot learning ability and transfer learning ability to facilitate muti-institution applications, and (3) frozen LLMs require large models.
+
+
+
+ 73. 标题:Tackling Data Bias in MUSIC-AVQA: Crafting a Balanced Dataset for Unbiased Question-Answering
+ 编号:[266]
+ 链接:https://arxiv.org/abs/2310.06238
+ 作者:Xiulong Liu, Zhikang Dong, Peng Zhang
+ 备注:
+ 关键词:recent years, intersection of audio, driving forward, multimodal research, growing emphasis
+
+ 点击查看摘要
+ In recent years, there has been a growing emphasis on the intersection of audio, vision, and text modalities, driving forward the advancements in multimodal research. However, strong bias that exists in any modality can lead to the model neglecting the others. Consequently, the model's ability to effectively reason across these diverse modalities is compromised, impeding further advancement. In this paper, we meticulously review each question type from the original dataset, selecting those with pronounced answer biases. To counter these biases, we gather complementary videos and questions, ensuring that no answers have outstanding skewed distribution. In particular, for binary questions, we strive to ensure that both answers are almost uniformly spread within each question category. As a result, we construct a new dataset, named MUSIC-AVQA v2.0, which is more challenging and we believe could better foster the progress of AVQA task. Furthermore, we present a novel baseline model that delves deeper into the audio-visual-text interrelation. On MUSIC-AVQA v2.0, this model surpasses all the existing benchmarks, improving accuracy by 2% on MUSIC-AVQA v2.0, setting a new state-of-the-art performance.
+
+
+
+ 74. 标题:Evolution of Natural Language Processing Technology: Not Just Language Processing Towards General Purpose AI
+ 编号:[273]
+ 链接:https://arxiv.org/abs/2310.06228
+ 作者:Masahiro Yamamoto
+ 备注:40 pages
+ 关键词:actual human language, invention of computers, natural language, practice makes perfect, language
+
+ 点击查看摘要
+ Since the invention of computers, communication through natural language (actual human language) has been a dream technology. However, natural language is extremely difficult to mathematically formulate, making it difficult to realize as an algorithm without considering programming. While there have been numerous technological developments, one cannot say that any results allowing free utilization have been achieved thus far. In the case of language learning in humans, for instance when learning one's mother tongue or foreign language, one must admit that this process is similar to the adage "practice makes perfect" in principle, even though the learning method is significant up to a point. Deep learning has played a central role in contemporary AI technology in recent years. When applied to natural language processing (NLP), this produced unprecedented results. Achievements exceeding the initial predictions have been reported from the results of learning vast amounts of textual data using deep learning. For instance, four arithmetic operations could be performed without explicit learning, thereby enabling the explanation of complex images and the generation of images from corresponding explanatory texts. It is an accurate example of the learner embodying the concept of "practice makes perfect" by using vast amounts of textual data. This report provides a technological explanation of how cutting-edge NLP has made it possible to realize the "practice makes perfect" principle. Additionally, examples of how this can be applied to business are provided. We reported in June 2022 in Japanese on the NLP movement from late 2021 to early 2022. We would like to summarize this as a memorandum since this is just the initial movement leading to the current large language models (LLMs).
+
+
+
+ 75. 标题:GPT-4 as an Agronomist Assistant? Answering Agriculture Exams Using Large Language Models
+ 编号:[276]
+ 链接:https://arxiv.org/abs/2310.06225
+ 作者:Bruno Silva, Leonardo Nunes, Roberto Estevão, Ranveer Chandra
+ 备注:
+ 关键词:natural language understanding, Large language models, demonstrated remarkable capabilities, Large language, natural language
+
+ 点击查看摘要
+ Large language models (LLMs) have demonstrated remarkable capabilities in natural language understanding across various domains, including healthcare and finance. For some tasks, LLMs achieve similar or better performance than trained human beings, therefore it is reasonable to employ human exams (e.g., certification tests) to assess the performance of LLMs. We present a comprehensive evaluation of popular LLMs, such as Llama 2 and GPT, on their ability to answer agriculture-related questions. In our evaluation, we also employ RAG (Retrieval-Augmented Generation) and ER (Ensemble Refinement) techniques, which combine information retrieval, generation capabilities, and prompting strategies to improve the LLMs' performance. To demonstrate the capabilities of LLMs, we selected agriculture exams and benchmark datasets from three of the largest agriculture producer countries: Brazil, India, and the USA. Our analysis highlights GPT-4's ability to achieve a passing score on exams to earn credits for renewing agronomist certifications, answering 93% of the questions correctly and outperforming earlier general-purpose models, which achieved 88% accuracy. On one of our experiments, GPT-4 obtained the highest performance when compared to human subjects. This performance suggests that GPT-4 could potentially pass on major graduate education admission tests or even earn credits for renewing agronomy certificates. We also explore the models' capacity to address general agriculture-related questions and generate crop management guidelines for Brazilian and Indian farmers, utilizing robust datasets from the Brazilian Agency of Agriculture (Embrapa) and graduate program exams from India. The results suggest that GPT-4, ER, and RAG can contribute meaningfully to agricultural education, assessment, and crop management practice, offering valuable insights to farmers and agricultural professionals.
+
+
+
+ 76. 标题:SUBP: Soft Uniform Block Pruning for 1xN Sparse CNNs Multithreading Acceleration
+ 编号:[280]
+ 链接:https://arxiv.org/abs/2310.06218
+ 作者:Jingyang Xiang, Siqi Li, Jun Chen, Shipeng Bai, Yukai Ma, Guang Dai, Yong Liu
+ 备注:14 pages, 4 figures, Accepted by 37th Conference on Neural Information Processing Systems (NeurIPS 2023)
+ 关键词:Convolutional Neural Networks, Convolutional Neural, Neural Networks, limited resources, Advanced Vector Extensions
+
+ 点击查看摘要
+ The study of sparsity in Convolutional Neural Networks (CNNs) has become widespread to compress and accelerate models in environments with limited resources. By constraining N consecutive weights along the output channel to be group-wise non-zero, the recent network with 1$\times$N sparsity has received tremendous popularity for its three outstanding advantages: 1) A large amount of storage space saving by a \emph{Block Sparse Row} matrix. 2) Excellent performance at a high sparsity. 3) Significant speedups on CPUs with Advanced Vector Extensions. Recent work requires selecting and fine-tuning 1$\times$N sparse weights based on dense pre-trained weights, leading to the problems such as expensive training cost and memory access, sub-optimal model quality, as well as unbalanced workload across threads (different sparsity across output channels). To overcome them, this paper proposes a novel \emph{\textbf{S}oft \textbf{U}niform \textbf{B}lock \textbf{P}runing} (SUBP) approach to train a uniform 1$\times$N sparse structured network from scratch. Specifically, our approach tends to repeatedly allow pruned blocks to regrow to the network based on block angular redundancy and importance sampling in a uniform manner throughout the training process. It not only makes the model less dependent on pre-training, reduces the model redundancy and the risk of pruning the important blocks permanently but also achieves balanced workload. Empirically, on ImageNet, comprehensive experiments across various CNN architectures show that our SUBP consistently outperforms existing 1$\times$N and structured sparsity methods based on pre-trained models or training from scratch. Source codes and models are available at \url{this https URL}.
+
+
+
+ 77. 标题:Estimating Numbers without Regression
+ 编号:[287]
+ 链接:https://arxiv.org/abs/2310.06204
+ 作者:Avijit Thawani, Jay Pujara, Ashwin Kalyan
+ 备注:Workshop on Insights from Negative Results in NLP at EACL 2023
+ 关键词:recent successes, numbers, ability to represent, represent numbers, number
+
+ 点击查看摘要
+ Despite recent successes in language models, their ability to represent numbers is insufficient. Humans conceptualize numbers based on their magnitudes, effectively projecting them on a number line; whereas subword tokenization fails to explicitly capture magnitude by splitting numbers into arbitrary chunks. To alleviate this shortcoming, alternative approaches have been proposed that modify numbers at various stages of the language modeling pipeline. These methods change either the (1) notation in which numbers are written (\eg scientific vs decimal), the (2) vocabulary used to represent numbers or the entire (3) architecture of the underlying language model, to directly regress to a desired number.
+Previous work suggests that architectural change helps achieve state-of-the-art on number estimation but we find an insightful ablation: changing the model's vocabulary instead (\eg introduce a new token for numbers in range 10-100) is a far better trade-off. In the context of masked number prediction, a carefully designed tokenization scheme is both the simplest to implement and sufficient, \ie with similar performance to the state-of-the-art approach that requires making significant architectural changes. Finally, we report similar trends on the downstream task of numerical fact estimation (for Fermi Problems) and discuss reasons behind our findings.
+
+
+
+ 78. 标题:Look-Up mAI GeMM: Increasing AI GeMMs Performance by Nearly 2.5x via msGeMM
+ 编号:[298]
+ 链接:https://arxiv.org/abs/2310.06178
+ 作者:Saeed Maleki
+ 备注:
+ 关键词:unlike HPC applications, unlike HPC, HPC applications, double precision datatype, training and inference
+
+ 点击查看摘要
+ AI models are increasing in size and recent advancement in the community has shown that unlike HPC applications where double precision datatype are required, lower-precision datatypes such as fp8 or int4 are sufficient to bring the same model quality both for training and inference. Following these trends, GPU vendors such as NVIDIA and AMD have added hardware support for fp16, fp8 and int8 GeMM operations with an exceptional performance via Tensor Cores. However, this paper proposes a new algorithm called msGeMM which shows that AI models with low-precision datatypes can run with ~2.5x fewer multiplication and add instructions. Efficient implementation of this algorithm requires special CUDA cores with the ability to add elements from a small look-up table at the rate of Tensor Cores.
+
+
+
+ 79. 标题:Factual and Personalized Recommendations using Language Models and Reinforcement Learning
+ 编号:[300]
+ 链接:https://arxiv.org/abs/2310.06176
+ 作者:Jihwan Jeong, Yinlam Chow, Guy Tennenholtz, Chih-Wei Hsu, Azamat Tulepbergenov, Mohammad Ghavamzadeh, Craig Boutilier
+ 备注:
+ 关键词:matching candidate items, Recommender systems, play a central, matching candidate, central role
+
+ 点击查看摘要
+ Recommender systems (RSs) play a central role in connecting users to content, products, and services, matching candidate items to users based on their preferences. While traditional RSs rely on implicit user feedback signals, conversational RSs interact with users in natural language. In this work, we develop a comPelling, Precise, Personalized, Preference-relevant language model (P4LM) that recommends items to users while putting emphasis on explaining item characteristics and their relevance. P4LM uses the embedding space representation of a user's preferences to generate compelling responses that are factually-grounded and relevant w.r.t. the user's preferences. Moreover, we develop a joint reward function that measures precision, appeal, and personalization, which we use as AI-based feedback in a reinforcement learning-based language model framework. Using the MovieLens 25M dataset, we demonstrate that P4LM delivers compelling, personalized movie narratives to users.
+
+
+
+ 80. 标题:How does prompt engineering affect ChatGPT performance on unsupervised entity resolution?
+ 编号:[301]
+ 链接:https://arxiv.org/abs/2310.06174
+ 作者:Khanin Sisaengsuwanchai, Navapat Nananukul, Mayank Kejriwal
+ 备注:
+ 关键词:Entity Resolution, healthcare to e-commerce, underlying entity, problem of semi-automatically, semi-automatically determining
+
+ 点击查看摘要
+ Entity Resolution (ER) is the problem of semi-automatically determining when two entities refer to the same underlying entity, with applications ranging from healthcare to e-commerce. Traditional ER solutions required considerable manual expertise, including feature engineering, as well as identification and curation of training data. In many instances, such techniques are highly dependent on the domain. With recent advent in large language models (LLMs), there is an opportunity to make ER much more seamless and domain-independent. However, it is also well known that LLMs can pose risks, and that the quality of their outputs can depend on so-called prompt engineering. Unfortunately, a systematic experimental study on the effects of different prompting methods for addressing ER, using LLMs like ChatGPT, has been lacking thus far. This paper aims to address this gap by conducting such a study. Although preliminary in nature, our results show that prompting can significantly affect the quality of ER, although it affects some metrics more than others, and can also be dataset dependent.
+
+
+
+ 81. 标题:Memory-Consistent Neural Networks for Imitation Learning
+ 编号:[302]
+ 链接:https://arxiv.org/abs/2310.06171
+ 作者:Kaustubh Sridhar, Souradeep Dutta, Dinesh Jayaraman, James Weimer, Insup Lee
+ 备注:22 pages (9 main pages)
+ 关键词:considerably simplifies policy, simplifies policy synthesis, policy synthesis compared, learning considerably simplifies, Imitation learning considerably
+
+ 点击查看摘要
+ Imitation learning considerably simplifies policy synthesis compared to alternative approaches by exploiting access to expert demonstrations. For such imitation policies, errors away from the training samples are particularly critical. Even rare slip-ups in the policy action outputs can compound quickly over time, since they lead to unfamiliar future states where the policy is still more likely to err, eventually causing task failures. We revisit simple supervised ``behavior cloning'' for conveniently training the policy from nothing more than pre-recorded demonstrations, but carefully design the model class to counter the compounding error phenomenon. Our ``memory-consistent neural network'' (MCNN) outputs are hard-constrained to stay within clearly specified permissible regions anchored to prototypical ``memory'' training samples. We provide a guaranteed upper bound for the sub-optimality gap induced by MCNN policies. Using MCNNs on 9 imitation learning tasks, with MLP, Transformer, and Diffusion backbones, spanning dexterous robotic manipulation and driving, proprioceptive inputs and visual inputs, and varying sizes and types of demonstration data, we find large and consistent gains in performance, validating that MCNNs are better-suited than vanilla deep neural networks for imitation learning applications. Website: this https URL
+
+
+
+ 82. 标题:Predictable Artificial Intelligence
+ 编号:[305]
+ 链接:https://arxiv.org/abs/2310.06167
+ 作者:Lexin Zhou, Pablo A. Moreno-Casares, Fernando Martínez-Plumed, John Burden, Ryan Burnell, Lucy Cheke, Cèsar Ferri, Alexandru Marcoci, Behzad Mehrbakhsh, Yael Moros-Daval, Seán Ó hÉigeartaigh, Danaja Rutar, Wout Schellaert, Konstantinos Voudouris, José Hernández-Orallo
+ 备注:11 pages excluding references, 4 figures, and 2 tables. Paper Under Review
+ 关键词:anticipate key indicators, nascent research area, future AI ecosystems, introduce the fundamental, fundamental ideas
+
+ 点击查看摘要
+ We introduce the fundamental ideas and challenges of Predictable AI, a nascent research area that explores the ways in which we can anticipate key indicators of present and future AI ecosystems. We argue that achieving predictability is crucial for fostering trust, liability, control, alignment and safety of AI ecosystems, and thus should be prioritised over performance. While distinctive from other areas of technical and non-technical AI research, the questions, hypotheses and challenges relevant to Predictable AI were yet to be clearly described. This paper aims to elucidate them, calls for identifying paths towards AI predictability and outlines the potential impact of this emergent field.
+
+
+
+ 83. 标题:CAW-coref: Conjunction-Aware Word-level Coreference Resolution
+ 编号:[307]
+ 链接:https://arxiv.org/abs/2310.06165
+ 作者:Karel D'Oosterlinck, Semere Kiros Bitew, Brandon Papineau, Christopher Potts, Thomas Demeester, Chris Develder
+ 备注:Accepted at CRAC 2023
+ 关键词:multiple LLM calls, multiple LLM, LLM calls, information extraction, large corpora
+
+ 点击查看摘要
+ State-of-the-art coreference resolutions systems depend on multiple LLM calls per document and are thus prohibitively expensive for many use cases (e.g., information extraction with large corpora). The leading word-level coreference system (WL-coref) attains 96.6% of these SOTA systems' performance while being much more efficient. In this work, we identify a routine yet important failure case of WL-coref: dealing with conjoined mentions such as 'Tom and Mary'. We offer a simple yet effective solution that improves the performance on the OntoNotes test set by 0.9% F1, shrinking the gap between efficient word-level coreference resolution and expensive SOTA approaches by 34.6%. Our Conjunction-Aware Word-level coreference model (CAW-coref) and code is available at this https URL.
+
+
+
+ 84. 标题:Understanding Transfer Learning and Gradient-Based Meta-Learning Techniques
+ 编号:[316]
+ 链接:https://arxiv.org/abs/2310.06148
+ 作者:Mike Huisman, Aske Plaat, Jan N. van Rijn
+ 备注:Accepted at Machine Learning Journal, Special Issue on Discovery Science 2021
+ 关键词:require large amounts, Deep neural networks, yield good performance, MAML, Deep neural
+
+ 点击查看摘要
+ Deep neural networks can yield good performance on various tasks but often require large amounts of data to train them. Meta-learning received considerable attention as one approach to improve the generalization of these networks from a limited amount of data. Whilst meta-learning techniques have been observed to be successful at this in various scenarios, recent results suggest that when evaluated on tasks from a different data distribution than the one used for training, a baseline that simply finetunes a pre-trained network may be more effective than more complicated meta-learning techniques such as MAML, which is one of the most popular meta-learning techniques. This is surprising as the learning behaviour of MAML mimics that of finetuning: both rely on re-using learned features. We investigate the observed performance differences between finetuning, MAML, and another meta-learning technique called Reptile, and show that MAML and Reptile specialize for fast adaptation in low-data regimes of similar data distribution as the one used for training. Our findings show that both the output layer and the noisy training conditions induced by data scarcity play important roles in facilitating this specialization for MAML. Lastly, we show that the pre-trained features as obtained by the finetuning baseline are more diverse and discriminative than those learned by MAML and Reptile. Due to this lack of diversity and distribution specialization, MAML and Reptile may fail to generalize to out-of-distribution tasks whereas finetuning can fall back on the diversity of the learned features.
+
+
+
+ 85. 标题:Reinforcement Learning in the Era of LLMs: What is Essential? What is needed? An RL Perspective on RLHF, Prompting, and Beyond
+ 编号:[317]
+ 链接:https://arxiv.org/abs/2310.06147
+ 作者:Hao Sun
+ 备注:
+ 关键词:Large Language Models, Language Models, Large Language, garnered wide attention, advancements in Large
+
+ 点击查看摘要
+ Recent advancements in Large Language Models (LLMs) have garnered wide attention and led to successful products such as ChatGPT and GPT-4. Their proficiency in adhering to instructions and delivering harmless, helpful, and honest (3H) responses can largely be attributed to the technique of Reinforcement Learning from Human Feedback (RLHF). In this paper, we aim to link the research in conventional RL to RL techniques used in LLM research. Demystify this technique by discussing why, when, and how RL excels. Furthermore, we explore potential future avenues that could either benefit from or contribute to RLHF research.
+Highlighted Takeaways:
+1. RLHF is Online Inverse RL with Offline Demonstration Data.
+2. RLHF $>$ SFT because Imitation Learning (and Inverse RL) $>$ Behavior Cloning (BC) by alleviating the problem of compounding error.
+3. The RM step in RLHF generates a proxy of the expensive human feedback, such an insight can be generalized to other LLM tasks such as prompting evaluation and optimization where feedback is also expensive.
+4. The policy learning in RLHF is more challenging than conventional problems studied in IRL due to their high action dimensionality and feedback sparsity.
+5. The main superiority of PPO over off-policy value-based methods is its stability gained from (almost) on-policy data and conservative policy updates.
+
+
+
+ 86. 标题:Layout Sequence Prediction From Noisy Mobile Modality
+ 编号:[321]
+ 链接:https://arxiv.org/abs/2310.06138
+ 作者:Haichao Zhang, Yi Xu, Hongsheng Lu, Takayuki Shimizu, Yun Fu
+ 备注:In Proceedings of the 31st ACM International Conference on Multimedia 2023 (MM 23)
+ 关键词:understanding pedestrian movement, driving and robotics, plays a vital, vital role, role in understanding
+
+ 点击查看摘要
+ Trajectory prediction plays a vital role in understanding pedestrian movement for applications such as autonomous driving and robotics. Current trajectory prediction models depend on long, complete, and accurately observed sequences from visual modalities. Nevertheless, real-world situations often involve obstructed cameras, missed objects, or objects out of sight due to environmental factors, leading to incomplete or noisy trajectories. To overcome these limitations, we propose LTrajDiff, a novel approach that treats objects obstructed or out of sight as equally important as those with fully visible trajectories. LTrajDiff utilizes sensor data from mobile phones to surmount out-of-sight constraints, albeit introducing new challenges such as modality fusion, noisy data, and the absence of spatial layout and object size information. We employ a denoising diffusion model to predict precise layout sequences from noisy mobile data using a coarse-to-fine diffusion strategy, incorporating the RMS, Siamese Masked Encoding Module, and MFM. Our model predicts layout sequences by implicitly inferring object size and projection status from a single reference timestamp or significantly obstructed sequences. Achieving SOTA results in randomly obstructed experiments and extremely short input experiments, our model illustrates the effectiveness of leveraging noisy mobile data. In summary, our approach offers a promising solution to the challenges faced by layout sequence and trajectory prediction models in real-world settings, paving the way for utilizing sensor data from mobile phones to accurately predict pedestrian bounding box trajectories. To the best of our knowledge, this is the first work that addresses severely obstructed and extremely short layout sequences by combining vision with noisy mobile modality, making it the pioneering work in the field of layout sequence trajectory prediction.
+
+
+
+ 87. 标题:Learning Layer-wise Equivariances Automatically using Gradients
+ 编号:[323]
+ 链接:https://arxiv.org/abs/2310.06131
+ 作者:Tycho F.A. van der Ouderaa, Alexander Immer, Mark van der Wilk
+ 备注:
+ 关键词:neural networks leading, Convolutions encode equivariance, Convolutions encode, encode equivariance symmetries, neural networks
+
+ 点击查看摘要
+ Convolutions encode equivariance symmetries into neural networks leading to better generalisation performance. However, symmetries provide fixed hard constraints on the functions a network can represent, need to be specified in advance, and can not be adapted. Our goal is to allow flexible symmetry constraints that can automatically be learned from data using gradients. Learning symmetry and associated weight connectivity structures from scratch is difficult for two reasons. First, it requires efficient and flexible parameterisations of layer-wise equivariances. Secondly, symmetries act as constraints and are therefore not encouraged by training losses measuring data fit. To overcome these challenges, we improve parameterisations of soft equivariance and learn the amount of equivariance in layers by optimising the marginal likelihood, estimated using differentiable Laplace approximations. The objective balances data fit and model complexity enabling layer-wise symmetry discovery in deep networks. We demonstrate the ability to automatically learn layer-wise equivariances on image classification tasks, achieving equivalent or improved performance over baselines with hard-coded symmetry.
+
+
+
+ 88. 标题:On Time Domain Conformer Models for Monaural Speech Separation in Noisy Reverberant Acoustic Environments
+ 编号:[324]
+ 链接:https://arxiv.org/abs/2310.06125
+ 作者:William Ravenscroft, Stefan Goetze, Thomas Hain
+ 备注:Accepted at ASRU Workshop 2023
+ 关键词:multi-speaker technology researchers, Speech separation remains, technology researchers, remains an important, important topic
+
+ 点击查看摘要
+ Speech separation remains an important topic for multi-speaker technology researchers. Convolution augmented transformers (conformers) have performed well for many speech processing tasks but have been under-researched for speech separation. Most recent state-of-the-art (SOTA) separation models have been time-domain audio separation networks (TasNets). A number of successful models have made use of dual-path (DP) networks which sequentially process local and global information. Time domain conformers (TD-Conformers) are an analogue of the DP approach in that they also process local and global context sequentially but have a different time complexity function. It is shown that for realistic shorter signal lengths, conformers are more efficient when controlling for feature dimension. Subsampling layers are proposed to further improve computational efficiency. The best TD-Conformer achieves 14.6 dB and 21.2 dB SISDR improvement on the WHAMR and WSJ0-2Mix benchmarks, respectively.
+
+
+
+ 89. 标题:Text-driven Prompt Generation for Vision-Language Models in Federated Learning
+ 编号:[326]
+ 链接:https://arxiv.org/abs/2310.06123
+ 作者:Chen Qiu, Xingyu Li, Chaithanya Kumar Mummadi, Madan Ravi Ganesh, Zhenzhen Li, Lu Peng, Wan-Yi Lin
+ 备注:
+ 关键词:shown great success, adapting CLIP, federated learning due, vision-language models, downstream tasks
+
+ 点击查看摘要
+ Prompt learning for vision-language models, e.g., CoOp, has shown great success in adapting CLIP to different downstream tasks, making it a promising solution for federated learning due to computational reasons. Existing prompt learning techniques replace hand-crafted text prompts with learned vectors that offer improvements on seen classes, but struggle to generalize to unseen classes. Our work addresses this challenge by proposing Federated Text-driven Prompt Generation (FedTPG), which learns a unified prompt generation network across multiple remote clients in a scalable manner. The prompt generation network is conditioned on task-related text input, thus is context-aware, making it suitable to generalize for both seen and unseen classes. Our comprehensive empirical evaluations on nine diverse image classification datasets show that our method is superior to existing federated prompt learning methods, that achieve overall better generalization on both seen and unseen classes and is also generalizable to unseen datasets.
+
+
+
+ 90. 标题:Exploring Progress in Multivariate Time Series Forecasting: Comprehensive Benchmarking and Heterogeneity Analysis
+ 编号:[329]
+ 链接:https://arxiv.org/abs/2310.06119
+ 作者:Zezhi Shao, Fei Wang, Yongjun Xu, Wei Wei, Chengqing Yu, Zhao Zhang, Di Yao, Guangyin Jin, Xin Cao, Gao Cong, Christian S. Jensen, Xueqi Cheng
+ 备注:
+ 关键词:Multivariate Time Series, Long-term Time Series, real-word complex systems, Time Series Forecasting, Time Series
+
+ 点击查看摘要
+ Multivariate Time Series (MTS) widely exists in real-word complex systems, such as traffic and energy systems, making their forecasting crucial for understanding and influencing these systems. Recently, deep learning-based approaches have gained much popularity for effectively modeling temporal and spatial dependencies in MTS, specifically in Long-term Time Series Forecasting (LTSF) and Spatial-Temporal Forecasting (STF). However, the fair benchmarking issue and the choice of technical approaches have been hotly debated in related work. Such controversies significantly hinder our understanding of progress in this field. Thus, this paper aims to address these controversies to present insights into advancements achieved. To resolve benchmarking issues, we introduce BasicTS, a benchmark designed for fair comparisons in MTS forecasting. BasicTS establishes a unified training pipeline and reasonable evaluation settings, enabling an unbiased evaluation of over 30 popular MTS forecasting models on more than 18 datasets. Furthermore, we highlight the heterogeneity among MTS datasets and classify them based on temporal and spatial characteristics. We further prove that neglecting heterogeneity is the primary reason for generating controversies in technical approaches. Moreover, based on the proposed BasicTS and rich heterogeneous MTS datasets, we conduct an exhaustive and reproducible performance and efficiency comparison of popular models, providing insights for researchers in selecting and designing MTS forecasting models.
+
+
+
+ 91. 标题:Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
+ 编号:[330]
+ 链接:https://arxiv.org/abs/2310.06117
+ 作者:Huaixiu Steven Zheng, Swaroop Mishra, Xinyun Chen, Heng-Tze Cheng, Ed H. Chi, Quoc V Le, Denny Zhou
+ 备注:
+ 关键词:derive high-level concepts, simple prompting technique, present Step-Back Prompting, specific details, technique that enables
+
+ 点击查看摘要
+ We present Step-Back Prompting, a simple prompting technique that enables LLMs to do abstractions to derive high-level concepts and first principles from instances containing specific details. Using the concepts and principles to guide the reasoning steps, LLMs significantly improve their abilities in following a correct reasoning path towards the solution. We conduct experiments of Step-Back Prompting with PaLM-2L models and observe substantial performance gains on a wide range of challenging reasoning-intensive tasks including STEM, Knowledge QA, and Multi-Hop Reasoning. For instance, Step-Back Prompting improves PaLM-2L performance on MMLU Physics and Chemistry by 7% and 11%, TimeQA by 27%, and MuSiQue by 7%.
+
+
+
+ 92. 标题:OptiMUS: Optimization Modeling Using mip Solvers and large language models
+ 编号:[331]
+ 链接:https://arxiv.org/abs/2310.06116
+ 作者:Ali AhmadiTeshnizi, Wenzhi Gao, Madeleine Udell
+ 备注:
+ 关键词:distribution to healthcare, Large Language Model, manufacturing and distribution, problems, solve MILP problems
+
+ 点击查看摘要
+ Optimization problems are pervasive across various sectors, from manufacturing and distribution to healthcare. However, most such problems are still solved heuristically by hand rather than optimally by state-of-the-art solvers, as the expertise required to formulate and solve these problems limits the widespread adoption of optimization tools and techniques. We introduce OptiMUS, a Large Language Model (LLM)-based agent designed to formulate and solve MILP problems from their natural language descriptions. OptiMUS is capable of developing mathematical models, writing and debugging solver code, developing tests, and checking the validity of generated solutions. To benchmark our agent, we present NLP4LP, a novel dataset of linear programming (LP) and mixed integer linear programming (MILP) problems. Our experiments demonstrate that OptiMUS is able to solve 67\% more problems compared to a basic LLM prompting strategy. OptiMUS code and NLP4LP dataset are available at \href{this https URL}{this https URL}
+
+
+
+ 93. 标题:Learning Interactive Real-World Simulators
+ 编号:[332]
+ 链接:https://arxiv.org/abs/2310.06114
+ 作者:Mengjiao Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Dale Schuurmans, Pieter Abbeel
+ 备注:this https URL
+ 关键词:Generative models trained, revolutionized how text, trained on internet, real-world simulator, Generative models
+
+ 点击查看摘要
+ Generative models trained on internet data have revolutionized how text, image, and video content can be created. Perhaps the next milestone for generative models is to simulate realistic experience in response to actions taken by humans, robots, and other interactive agents. Applications of a real-world simulator range from controllable content creation in games and movies, to training embodied agents purely in simulation that can be directly deployed in the real world. We explore the possibility of learning a universal simulator (UniSim) of real-world interaction through generative modeling. We first make the important observation that natural datasets available for learning a real-world simulator are often rich along different axes (e.g., abundant objects in image data, densely sampled actions in robotics data, and diverse movements in navigation data). With careful orchestration of diverse datasets, each providing a different aspect of the overall experience, UniSim can emulate how humans and agents interact with the world by simulating the visual outcome of both high-level instructions such as "open the drawer" and low-level controls such as "move by x, y" from otherwise static scenes and objects. There are numerous use cases for such a real-world simulator. As an example, we use UniSim to train both high-level vision-language planners and low-level reinforcement learning policies, each of which exhibit zero-shot real-world transfer after training purely in a learned real-world simulator. We also show that other types of intelligence such as video captioning models can benefit from training with simulated experience in UniSim, opening up even wider applications. Video demos can be found at this https URL.
+
+
+
+ 94. 标题:When is Agnostic Reinforcement Learning Statistically Tractable?
+ 编号:[333]
+ 链接:https://arxiv.org/abs/2310.06113
+ 作者:Zeyu Jia, Gene Li, Alexander Rakhlin, Ayush Sekhari, Nathan Srebro
+ 备注:Accepted to NeurIPS 2023
+ 关键词:PAC reinforcement learning, potentially large state, agnostic PAC reinforcement, bounded spanning capacity, spanning capacity
+
+ 点击查看摘要
+ We study the problem of agnostic PAC reinforcement learning (RL): given a policy class $\Pi$, how many rounds of interaction with an unknown MDP (with a potentially large state and action space) are required to learn an $\epsilon$-suboptimal policy with respect to $\Pi$? Towards that end, we introduce a new complexity measure, called the \emph{spanning capacity}, that depends solely on the set $\Pi$ and is independent of the MDP dynamics. With a generative model, we show that for any policy class $\Pi$, bounded spanning capacity characterizes PAC learnability. However, for online RL, the situation is more subtle. We show there exists a policy class $\Pi$ with a bounded spanning capacity that requires a superpolynomial number of samples to learn. This reveals a surprising separation for agnostic learnability between generative access and online access models (as well as between deterministic/stochastic MDPs under online access). On the positive side, we identify an additional \emph{sunflower} structure, which in conjunction with bounded spanning capacity enables statistically efficient online RL via a new algorithm called POPLER, which takes inspiration from classical importance sampling methods as well as techniques for reachable-state identification and policy evaluation in reward-free exploration.
+
+
+
+ 95. 标题:High Dimensional Causal Inference with Variational Backdoor Adjustment
+ 编号:[339]
+ 链接:https://arxiv.org/abs/2310.06100
+ 作者:Daniel Israel, Aditya Grover, Guy Van den Broeck
+ 备注:
+ 关键词:purely observational data, estimating interventional quantities, Backdoor adjustment, technique in causal, quantities from purely
+
+ 点击查看摘要
+ Backdoor adjustment is a technique in causal inference for estimating interventional quantities from purely observational data. For example, in medical settings, backdoor adjustment can be used to control for confounding and estimate the effectiveness of a treatment. However, high dimensional treatments and confounders pose a series of potential pitfalls: tractability, identifiability, optimization. In this work, we take a generative modeling approach to backdoor adjustment for high dimensional treatments and confounders. We cast backdoor adjustment as an optimization problem in variational inference without reliance on proxy variables and hidden confounders. Empirically, our method is able to estimate interventional likelihood in a variety of high dimensional settings, including semi-synthetic X-ray medical data. To the best of our knowledge, this is the first application of backdoor adjustment in which all the relevant variables are high dimensional.
+
+
+
+ 96. 标题:Predictive auxiliary objectives in deep RL mimic learning in the brain
+ 编号:[341]
+ 链接:https://arxiv.org/abs/2310.06089
+ 作者:Ching Fang, Kimberly L Stachenfeld
+ 备注:
+ 关键词:predict upcoming events, machine cognition, ability to predict, predict upcoming, upcoming events
+
+ 点击查看摘要
+ The ability to predict upcoming events has been hypothesized to comprise a key aspect of natural and machine cognition. This is supported by trends in deep reinforcement learning (RL), where self-supervised auxiliary objectives such as prediction are widely used to support representation learning and improve task performance. Here, we study the effects predictive auxiliary objectives have on representation learning across different modules of an RL system and how these mimic representational changes observed in the brain. We find that predictive objectives improve and stabilize learning particularly in resource-limited architectures, and we identify settings where longer predictive horizons better support representational transfer. Furthermore, we find that representational changes in this RL system bear a striking resemblance to changes in neural activity observed in the brain across various experiments. Specifically, we draw a connection between the auxiliary predictive model of the RL system and hippocampus, an area thought to learn a predictive model to support memory-guided behavior. We also connect the encoder network and the value learning network of the RL system to visual cortex and striatum in the brain, respectively. This work demonstrates how representation learning in deep RL systems can provide an interpretable framework for modeling multi-region interactions in the brain. The deep RL perspective taken here also suggests an additional role of the hippocampus in the brain -- that of an auxiliary learning system that benefits representation learning in other regions.
+
+
+
+ 97. 标题:Performative Time-Series Forecasting
+ 编号:[345]
+ 链接:https://arxiv.org/abs/2310.06077
+ 作者:Zhiyuan Zhao, Alexander Rodriguez, B.Aditya Prakash
+ 备注:12 pages (7 main text, 2 reference, 3 appendix), 3 figures, 4 tables
+ 关键词:witnessed substantial progress, recent years, witnessed substantial, substantial progress, progress in recent
+
+ 点击查看摘要
+ Time-series forecasting is a critical challenge in various domains and has witnessed substantial progress in recent years. Many real-life scenarios, such as public health, economics, and social applications, involve feedback loops where predictions can influence the predicted outcome, subsequently altering the target variable's distribution. This phenomenon, known as performativity, introduces the potential for 'self-negating' or 'self-fulfilling' predictions. Despite extensive studies in classification problems across domains, performativity remains largely unexplored in the context of time-series forecasting from a machine-learning perspective.
+In this paper, we formalize performative time-series forecasting (PeTS), addressing the challenge of accurate predictions when performativity-induced distribution shifts are possible. We propose a novel approach, Feature Performative-Shifting (FPS), which leverages the concept of delayed response to anticipate distribution shifts and subsequently predicts targets accordingly. We provide theoretical insights suggesting that FPS can potentially lead to reduced generalization error. We conduct comprehensive experiments using multiple time-series models on COVID-19 and traffic forecasting tasks. The results demonstrate that FPS consistently outperforms conventional time-series forecasting methods, highlighting its efficacy in handling performativity-induced challenges.
+
+
+
+ 98. 标题:Pain Forecasting using Self-supervised Learning and Patient Phenotyping: An attempt to prevent Opioid Addiction
+ 编号:[347]
+ 链接:https://arxiv.org/abs/2310.06075
+ 作者:Swati Padhee, Tanvi Banerjee, Daniel M. Abrams, Nirmish Shah
+ 备注:8 pages
+ 关键词:Sickle Cell Disease, Cell Disease, Sickle Cell, chronic genetic disorder, genetic disorder characterized
+
+ 点击查看摘要
+ Sickle Cell Disease (SCD) is a chronic genetic disorder characterized by recurrent acute painful episodes. Opioids are often used to manage these painful episodes; the extent of their use in managing pain in this disorder is an issue of debate. The risk of addiction and side effects of these opioid treatments can often lead to more pain episodes in the future. Hence, it is crucial to forecast future patient pain trajectories to help patients manage their SCD to improve their quality of life without compromising their treatment. It is challenging to obtain many pain records to design forecasting models since it is mainly recorded by patients' self-report. Therefore, it is expensive and painful (due to the need for patient compliance) to solve pain forecasting problems in a purely supervised manner. In light of this challenge, we propose to solve the pain forecasting problem using self-supervised learning methods. Also, clustering such time-series data is crucial for patient phenotyping, anticipating patients' prognoses by identifying "similar" patients, and designing treatment guidelines tailored to homogeneous patient subgroups. Hence, we propose a self-supervised learning approach for clustering time-series data, where each cluster comprises patients who share similar future pain profiles. Experiments on five years of real-world datasets show that our models achieve superior performance over state-of-the-art benchmarks and identify meaningful clusters that can be translated into actionable information for clinical decision-making.
+
+
+
+ 99. 标题:Augmenting Vision-Based Human Pose Estimation with Rotation Matrix
+ 编号:[350]
+ 链接:https://arxiv.org/abs/2310.06068
+ 作者:Milad Vazan, Fatemeh Sadat Masoumi, Ruizhi Ou, Reza Rawassizadeh
+ 备注:24 pages
+ 关键词:automatically track indoor, inside the gym, track indoor activities, indoor activities inside, Fitness applications
+
+ 点击查看摘要
+ Fitness applications are commonly used to monitor activities within the gym, but they often fail to automatically track indoor activities inside the gym. This study proposes a model that utilizes pose estimation combined with a novel data augmentation method, i.e., rotation matrix. We aim to enhance the classification accuracy of activity recognition based on pose estimation data. Through our experiments, we experiment with different classification algorithms along with image augmentation approaches. Our findings demonstrate that the SVM with SGD optimization, using data augmentation with the Rotation Matrix, yields the most accurate results, achieving a 96% accuracy rate in classifying five physical activities. Conversely, without implementing the data augmentation techniques, the baseline accuracy remains at a modest 64%.
+
+
+
+ 100. 标题:LLM for SoC Security: A Paradigm Shift
+ 编号:[356]
+ 链接:https://arxiv.org/abs/2310.06046
+ 作者:Dipayan Saha, Shams Tarek, Katayoon Yahyaei, Sujan Kumar Saha, Jingbo Zhou, Mark Tehranipoor, Farimah Farahmandi
+ 备注:42 pages
+ 关键词:flow poses significant, design flow poses, poses significant challenges, SoC design flow, Large Language Models
+
+ 点击查看摘要
+ As the ubiquity and complexity of system-on-chip (SoC) designs increase across electronic devices, the task of incorporating security into an SoC design flow poses significant challenges. Existing security solutions are inadequate to provide effective verification of modern SoC designs due to their limitations in scalability, comprehensiveness, and adaptability. On the other hand, Large Language Models (LLMs) are celebrated for their remarkable success in natural language understanding, advanced reasoning, and program synthesis tasks. Recognizing an opportunity, our research delves into leveraging the emergent capabilities of Generative Pre-trained Transformers (GPTs) to address the existing gaps in SoC security, aiming for a more efficient, scalable, and adaptable methodology. By integrating LLMs into the SoC security verification paradigm, we open a new frontier of possibilities and challenges to ensure the security of increasingly complex SoCs. This paper offers an in-depth analysis of existing works, showcases practical case studies, demonstrates comprehensive experiments, and provides useful promoting guidelines. We also present the achievements, prospects, and challenges of employing LLM in different SoC security verification tasks.
+
+
+
+ 101. 标题:Generative ensemble deep learning severe weather prediction from a deterministic convection-allowing model
+ 编号:[357]
+ 链接:https://arxiv.org/abs/2310.06045
+ 作者:Yingkai Sha, Ryan A. Sobash, David John Gagne II
+ 备注:
+ 关键词:conterminous United States, United States, conterminous United, severe weather, ensemble post-processing method
+
+ 点击查看摘要
+ An ensemble post-processing method is developed for the probabilistic prediction of severe weather (tornadoes, hail, and wind gusts) over the conterminous United States (CONUS). The method combines conditional generative adversarial networks (CGANs), a type of deep generative model, with a convolutional neural network (CNN) to post-process convection-allowing model (CAM) forecasts. The CGANs are designed to create synthetic ensemble members from deterministic CAM forecasts, and their outputs are processed by the CNN to estimate the probability of severe weather. The method is tested using High-Resolution Rapid Refresh (HRRR) 1--24 hr forecasts as inputs and Storm Prediction Center (SPC) severe weather reports as targets. The method produced skillful predictions with up to 20% Brier Skill Score (BSS) increases compared to other neural-network-based reference methods using a testing dataset of HRRR forecasts in 2021. For the evaluation of uncertainty quantification, the method is overconfident but produces meaningful ensemble spreads that can distinguish good and bad forecasts. The quality of CGAN outputs is also evaluated. Results show that the CGAN outputs behave similarly to a numerical ensemble; they preserved the inter-variable correlations and the contribution of influential predictors as in the original HRRR forecasts. This work provides a novel approach to post-process CAM output using neural networks that can be applied to severe weather prediction.
+
+
+
+ 102. 标题:DyST: Towards Dynamic Neural Scene Representations on Real-World Videos
+ 编号:[358]
+ 链接:https://arxiv.org/abs/2310.06020
+ 作者:Maximilian Seitzer, Sjoerd van Steenkiste, Thomas Kipf, Klaus Greff, Mehdi S. M. Sajjadi
+ 备注:Project website: this https URL
+ 关键词:Visual understanding, individual images, semantics and flat, monocular real-world videos, Dynamic Scene Transformer
+
+ 点击查看摘要
+ Visual understanding of the world goes beyond the semantics and flat structure of individual images. In this work, we aim to capture both the 3D structure and dynamics of real-world scenes from monocular real-world videos. Our Dynamic Scene Transformer (DyST) model leverages recent work in neural scene representation to learn a latent decomposition of monocular real-world videos into scene content, per-view scene dynamics, and camera pose. This separation is achieved through a novel co-training scheme on monocular videos and our new synthetic dataset DySO. DyST learns tangible latent representations for dynamic scenes that enable view generation with separate control over the camera and the content of the scene.
+
+
+
+ 103. 标题:Divide-and-Conquer Dynamics in AI-Driven Disempowerment
+ 编号:[359]
+ 链接:https://arxiv.org/abs/2310.06009
+ 作者:Peter S. Park, Max Tegmark
+ 备注:28 pages, nine visualizations (seven figures and two tables)
+ 关键词:economically valuable work, valuable work, companies are attempting, attempting to create, create AI systems
+
+ 点击查看摘要
+ AI companies are attempting to create AI systems that outperform humans at most economically valuable work. Current AI models are already automating away the livelihoods of some artists, actors, and writers. But there is infighting between those who prioritize current harms and future harms. We construct a game-theoretic model of conflict to study the causes and consequences of this disunity. Our model also helps explain why throughout history, stakeholders sharing a common threat have found it advantageous to unite against it, and why the common threat has in turn found it advantageous to divide and conquer.
+Under realistic parameter assumptions, our model makes several predictions that find preliminary corroboration in the historical-empirical record. First, current victims of AI-driven disempowerment need the future victims to realize that their interests are also under serious and imminent threat, so that future victims are incentivized to support current victims in solidarity. Second, the movement against AI-driven disempowerment can become more united, and thereby more likely to prevail, if members believe that their efforts will be successful as opposed to futile. Finally, the movement can better unite and prevail if its members are less myopic. Myopic members prioritize their future well-being less than their present well-being, and are thus disinclined to solidarily support current victims today at personal cost, even if this is necessary to counter the shared threat of AI-driven disempowerment.
+
+
+
+ 104. 标题:Rethinking Memory and Communication Cost for Efficient Large Language Model Training
+ 编号:[362]
+ 链接:https://arxiv.org/abs/2310.06003
+ 作者:Chan Wu, Hanxiao Zhang, Lin Ju, Jinjing Huang, Youshao Xiao, Zhaoxin Huan, Siyuan Li, Fanzhuang Meng, Lei Liang, Xiaolu Zhang, Jun Zhou
+ 备注:
+ 关键词:training datasets continue, training frameworks reduce, frameworks reduce memory, large-scale model training, continue to increase
+
+ 点击查看摘要
+ As model sizes and training datasets continue to increase, large-scale model training frameworks reduce memory consumption by various sharding techniques. However, the huge communication overhead reduces the training efficiency, especially in public cloud environments with varying network bandwidths. In this paper, we rethink the impact of memory consumption and communication overhead on the training speed of large language model, and propose a memory-communication balanced \underline{Pa}rtial \underline{R}edundancy \underline{O}ptimizer (PaRO). PaRO reduces the amount and frequency of inter-group communication by grouping GPU clusters and introducing minor intra-group memory redundancy, thereby improving the training efficiency of the model. Additionally, we propose a Hierarchical Overlapping Ring (HO-Ring) communication topology to enhance communication efficiency between nodes or across switches in large model training. Our experiments demonstrate that the HO-Ring algorithm improves communication efficiency by 32.6\% compared to the traditional Ring algorithm. Compared to the baseline ZeRO, PaRO significantly improves training throughput by 1.2x-2.6x and achieves a near-linear scalability. Therefore, the PaRO strategy provides more fine-grained options for the trade-off between memory consumption and communication overhead in different training scenarios.
+
+
+
+ 105. 标题:Measuring reasoning capabilities of ChatGPT
+ 编号:[368]
+ 链接:https://arxiv.org/abs/2310.05993
+ 作者:Adrian Groza
+ 备注:
+ 关键词:puzzles, logical faults, logical, faults, ChatGPT
+
+ 点击查看摘要
+ I shall quantify the logical faults generated by ChatGPT when applied to reasoning tasks. For experiments, I use the 144 puzzles from the library \url{this https URL}~\cite{groza:fol}. The library contains puzzles of various types, including arithmetic puzzles, logical equations, Sudoku-like puzzles, zebra-like puzzles, truth-telling puzzles, grid puzzles, strange numbers, or self-reference puzzles. The correct solutions for these puzzles were checked using the theorem prover Prover9~\cite{mccune2005release} and the finite models finder Mace4~\cite{mccune2003mace4} based on human-modelling in Equational First Order Logic. A first output of this study is the benchmark of 100 logical puzzles. For this dataset ChatGPT provided both correct answer and justification for 7\% only. %, while BARD for 5\%. Since the dataset seems challenging, the researchers are invited to test the dataset on more advanced or tuned models than ChatGPT3.5 with more crafted prompts. A second output is the classification of reasoning faults conveyed by ChatGPT. This classification forms a basis for a taxonomy of reasoning faults generated by large language models. I have identified 67 such logical faults, among which: inconsistencies, implication does not hold, unsupported claim, lack of commonsense, wrong justification. The 100 solutions generated by ChatGPT contain 698 logical faults. That is on average, 7 fallacies for each reasoning task. A third ouput is the annotated answers of the ChatGPT with the corresponding logical faults. Each wrong statement within the ChatGPT answer was manually annotated, aiming to quantify the amount of faulty text generated by the language model. On average, 26.03\% from the generated text was a logical fault.
+
+
+
+ 106. 标题:Simulating Social Media Using Large Language Models to Evaluate Alternative News Feed Algorithms
+ 编号:[373]
+ 链接:https://arxiv.org/abs/2310.05984
+ 作者:Petter Törnberg, Diliara Valeeva, Justus Uitermark, Christopher Bail
+ 备注:
+ 关键词:amplifying toxic discourse, Social media, Large Language Models, criticized for amplifying, amplifying toxic
+
+ 点击查看摘要
+ Social media is often criticized for amplifying toxic discourse and discouraging constructive conversations. But designing social media platforms to promote better conversations is inherently challenging. This paper asks whether simulating social media through a combination of Large Language Models (LLM) and Agent-Based Modeling can help researchers study how different news feed algorithms shape the quality of online conversations. We create realistic personas using data from the American National Election Study to populate simulated social media platforms. Next, we prompt the agents to read and share news articles - and like or comment upon each other's messages - within three platforms that use different news feed algorithms. In the first platform, users see the most liked and commented posts from users whom they follow. In the second, they see posts from all users - even those outside their own network. The third platform employs a novel "bridging" algorithm that highlights posts that are liked by people with opposing political views. We find this bridging algorithm promotes more constructive, non-toxic, conversation across political divides than the other two models. Though further research is needed to evaluate these findings, we argue that LLMs hold considerable potential to improve simulation research on social media and many other complex social settings.
+
+
+
+ 107. 标题:Fingerprint Attack: Client De-Anonymization in Federated Learning
+ 编号:[380]
+ 链接:https://arxiv.org/abs/2310.05960
+ 作者:Qiongkai Xu, Trevor Cohn, Olga Ohrimenko
+ 备注:ECAI 2023
+ 关键词:sharing in settings, trust the central, data sharing, central server, collaborative training
+
+ 点击查看摘要
+ Federated Learning allows collaborative training without data sharing in settings where participants do not trust the central server and one another. Privacy can be further improved by ensuring that communication between the participants and the server is anonymized through a shuffle; decoupling the participant identity from their data. This paper seeks to examine whether such a defense is adequate to guarantee anonymity, by proposing a novel fingerprinting attack over gradients sent by the participants to the server. We show that clustering of gradients can easily break the anonymization in an empirical study of learning federated language models on two language corpora. We then show that training with differential privacy can provide a practical defense against our fingerprint attack.
+
+
+
+ 108. 标题:Efficient Network Representation for GNN-based Intrusion Detection
+ 编号:[382]
+ 链接:https://arxiv.org/abs/2310.05956
+ 作者:Hamdi Friji, Alexis Olivereau, Mireille Sarkiss
+ 备注:
+ 关键词:intrusion detection approaches, network intrusion detection, Graph Neural Network, intrusion detection, preventing cyber-attacks
+
+ 点击查看摘要
+ The last decades have seen a growth in the number of cyber-attacks with severe economic and privacy damages, which reveals the need for network intrusion detection approaches to assist in preventing cyber-attacks and reducing their risks. In this work, we propose a novel network representation as a graph of flows that aims to provide relevant topological information for the intrusion detection task, such as malicious behavior patterns, the relation between phases of multi-step attacks, and the relation between spoofed and pre-spoofed attackers activities. In addition, we present a Graph Neural Network (GNN) based framework responsible for exploiting the proposed graph structure to classify communication flows by assigning them a maliciousness score. The framework comprises three main steps that aim to embed nodes features and learn relevant attack patterns from the network representation. Finally, we highlight a potential data leakage issue with classical evaluation procedures and suggest a solution to ensure a reliable validation of intrusion detection systems performance. We implement the proposed framework and prove that exploiting the flow-based graph structure outperforms the classical machine learning-based and the previous GNN-based solutions.
+
+
+
+ 109. 标题:Reducing the False Positive Rate Using Bayesian Inference in Autonomous Driving Perception
+ 编号:[385]
+ 链接:https://arxiv.org/abs/2310.05951
+ 作者:Johann J. S. Bastos, Bruno L. S. da Silva, Tiago Zanotelli, Cristiano Premebida, Gledson Melotti
+ 备注:
+ 关键词:numerous research works, intelligent vehicles, Object recognition, crucial step, autonomous and intelligent
+
+ 点击查看摘要
+ Object recognition is a crucial step in perception systems for autonomous and intelligent vehicles, as evidenced by the numerous research works in the topic. In this paper, object recognition is explored by using multisensory and multimodality approaches, with the intention of reducing the false positive rate (FPR). The reduction of the FPR becomes increasingly important in perception systems since the misclassification of an object can potentially cause accidents. In particular, this work presents a strategy through Bayesian inference to reduce the FPR considering the likelihood function as a cumulative distribution function from Gaussian kernel density estimations, and the prior probabilities as cumulative functions of normalized histograms. The validation of the proposed methodology is performed on the KITTI dataset using deep networks (DenseNet, NasNet, and EfficientNet), and recent 3D point cloud networks (PointNet, and PintNet++), by considering three object-categories (cars, cyclists, pedestrians) and the RGB and LiDAR sensor modalities.
+
+
+
+ 110. 标题:Learning Cyber Defence Tactics from Scratch with Multi-Agent Reinforcement Learning
+ 编号:[391]
+ 链接:https://arxiv.org/abs/2310.05939
+ 作者:Jacob Wiebe, Ranwa Al Mallah, Li Li
+ 备注:Presented at 2nd International Workshop on Adaptive Cyber Defense, 2023 (arXiv:2308.09520)
+ 关键词:deep learning techniques, Recent advancements, advancements in deep, techniques have opened, opened new possibilities
+
+ 点击查看摘要
+ Recent advancements in deep learning techniques have opened new possibilities for designing solutions for autonomous cyber defence. Teams of intelligent agents in computer network defence roles may reveal promising avenues to safeguard cyber and kinetic assets. In a simulated game environment, agents are evaluated on their ability to jointly mitigate attacker activity in host-based defence scenarios. Defender systems are evaluated against heuristic attackers with the goals of compromising network confidentiality, integrity, and availability. Value-based Independent Learning and Centralized Training Decentralized Execution (CTDE) cooperative Multi-Agent Reinforcement Learning (MARL) methods are compared revealing that both approaches outperform a simple multi-agent heuristic defender. This work demonstrates the ability of cooperative MARL to learn effective cyber defence tactics against varied threats.
+
+
+
+ 111. 标题:Component attention network for multimodal dance improvisation recognition
+ 编号:[392]
+ 链接:https://arxiv.org/abs/2310.05938
+ 作者:Jia Fu, Jiarui Tan, Wenjie Yin, Sepideh Pashami, Mårten Björkman
+ 备注:Accepted to 25th ACM International Conference on Multimodal Interaction (ICMI 2023)
+ 关键词:active research topic, active research, research topic, fusion, Dance
+
+ 点击查看摘要
+ Dance improvisation is an active research topic in the arts. Motion analysis of improvised dance can be challenging due to its unique dynamics. Data-driven dance motion analysis, including recognition and generation, is often limited to skeletal data. However, data of other modalities, such as audio, can be recorded and benefit downstream tasks. This paper explores the application and performance of multimodal fusion methods for human motion recognition in the context of dance improvisation. We propose an attention-based model, component attention network (CANet), for multimodal fusion on three levels: 1) feature fusion with CANet, 2) model fusion with CANet and graph convolutional network (GCN), and 3) late fusion with a voting strategy. We conduct thorough experiments to analyze the impact of each modality in different fusion methods and distinguish critical temporal or component features. We show that our proposed model outperforms the two baseline methods, demonstrating its potential for analyzing improvisation in dance.
+
+
+
+ 112. 标题:DF-3DFace: One-to-Many Speech Synchronized 3D Face Animation with Diffusion
+ 编号:[395]
+ 链接:https://arxiv.org/abs/2310.05934
+ 作者:Se Jin Park, Joanna Hong, Minsu Kim, Yong Man Ro
+ 备注:
+ 关键词:gained significant attention, facial, gained significant, significant attention, ability to create
+
+ 点击查看摘要
+ Speech-driven 3D facial animation has gained significant attention for its ability to create realistic and expressive facial animations in 3D space based on speech. Learning-based methods have shown promising progress in achieving accurate facial motion synchronized with speech. However, one-to-many nature of speech-to-3D facial synthesis has not been fully explored: while the lip accurately synchronizes with the speech content, other facial attributes beyond speech-related motions are variable with respect to the speech. To account for the potential variance in the facial attributes within a single speech, we propose DF-3DFace, a diffusion-driven speech-to-3D face mesh synthesis. DF-3DFace captures the complex one-to-many relationships between speech and 3D face based on diffusion. It concurrently achieves aligned lip motion by exploiting audio-mesh synchronization and masked conditioning. Furthermore, the proposed method jointly models identity and pose in addition to facial motions so that it can generate 3D face animation without requiring a reference identity mesh and produce natural head poses. We contribute a new large-scale 3D facial mesh dataset, 3D-HDTF to enable the synthesis of variations in identities, poses, and facial motions of 3D face mesh. Extensive experiments demonstrate that our method successfully generates highly variable facial shapes and motions from speech and simultaneously achieves more realistic facial animation than the state-of-the-art methods.
+
+
+
+ 113. 标题:A Multi-Agent Systems Approach for Peer-to-Peer Energy Trading in Dairy Farming
+ 编号:[396]
+ 链接:https://arxiv.org/abs/2310.05932
+ 作者:Mian Ibad Ali Shah, Abdul Wahid, Enda Barrett, Karl Mason
+ 备注:Proc. of the Artificial Intelligence for Sustainability, ECAI 2023, Eunika et al. (eds.), Sep 30- Oct 1, 2023, this https URL 2023
+ 关键词:carbon emission reductions, achieve desired carbon, desired carbon emission, integrating renewable generation, emission reductions
+
+ 点击查看摘要
+ To achieve desired carbon emission reductions, integrating renewable generation and accelerating the adoption of peer-to-peer energy trading is crucial. This is especially important for energy-intensive farming, like dairy farming. However, integrating renewables and peer-to-peer trading presents challenges. To address this, we propose the Multi-Agent Peer-to-Peer Dairy Farm Energy Simulator (MAPDES), enabling dairy farms to participate in peer-to-peer markets. Our strategy reduces electricity costs and peak demand by approximately 30% and 24% respectively, while increasing energy sales by 37% compared to the baseline scenario without P2P trading. This demonstrates the effectiveness of our approach.
+
+
+
+ 114. 标题:Deep Learning based Tomato Disease Detection and Remedy Suggestions using Mobile Application
+ 编号:[398]
+ 链接:https://arxiv.org/abs/2310.05929
+ 作者:Yagya Raj Pandeya, Samin Karki, Ishan Dangol, Nitesh Rajbanshi
+ 备注:
+ 关键词:addressing crop diseases, comprehensive computer system, practice traditional farming, comprehensive computer, practice traditional
+
+ 点击查看摘要
+ We have developed a comprehensive computer system to assist farmers who practice traditional farming methods and have limited access to agricultural experts for addressing crop diseases. Our system utilizes artificial intelligence (AI) to identify and provide remedies for vegetable diseases. To ensure ease of use, we have created a mobile application that offers a user-friendly interface, allowing farmers to inquire about vegetable diseases and receive suitable solutions in their local language. The developed system can be utilized by any farmer with a basic understanding of a smartphone. Specifically, we have designed an AI-enabled mobile application for identifying and suggesting remedies for vegetable diseases, focusing on tomato diseases to benefit the local farming community in Nepal. Our system employs state-of-the-art object detection methodology, namely You Only Look Once (YOLO), to detect tomato diseases. The detected information is then relayed to the mobile application, which provides remedy suggestions guided by domain experts. In order to train our system effectively, we curated a dataset consisting of ten classes of tomato diseases. We utilized various data augmentation methods to address overfitting and trained a YOLOv5 object detector. The proposed method achieved a mean average precision of 0.76 and offers an efficient mobile interface for interacting with the AI system. While our system is currently in the development phase, we are actively working towards enhancing its robustness and real-time usability by accumulating more training samples.
+
+
+
+ 115. 标题:NECO: NEural Collapse Based Out-of-distribution detection
+ 编号:[400]
+ 链接:https://arxiv.org/abs/2310.06823
+ 作者:Mouïn Ben Ammar, Nacim Belkhir, Sebastian Popescu, Antoine Manzanera, Gianni Franchi
+ 备注:28 pages
+ 关键词:machine learning due, epistemological limits, OOD, OOD detection, critical challenge
+
+ 点击查看摘要
+ Detecting out-of-distribution (OOD) data is a critical challenge in machine learning due to model overconfidence, often without awareness of their epistemological limits. We hypothesize that ``neural collapse'', a phenomenon affecting in-distribution data for models trained beyond loss convergence, also influences OOD data. To benefit from this interplay, we introduce NECO, a novel post-hoc method for OOD detection, which leverages the geometric properties of ``neural collapse'' and of principal component spaces to identify OOD data. Our extensive experiments demonstrate that NECO achieves state-of-the-art results on both small and large-scale OOD detection tasks while exhibiting strong generalization capabilities across different network architectures. Furthermore, we provide a theoretical explanation for the effectiveness of our method in OOD detection. We plan to release the code after the anonymity period.
+
+
+
+ 116. 标题:An evolutionary model of personality traits related to cooperative behavior using a large language model
+ 编号:[442]
+ 链接:https://arxiv.org/abs/2310.05976
+ 作者:Reiji Suzuki, Takaya Arita
+ 备注:7 pages, 4 figures and 1 table
+ 关键词:social agent-based evolutionary, agent-based evolutionary models, personality traits, evolutionary dynamics, social agent-based
+
+ 点击查看摘要
+ This paper aims to shed light on the evolutionary dynamics of diverse and social populations by introducing the rich expressiveness of generative models into the trait expression of social agent-based evolutionary models. Specifically, we focus on the evolution of personality traits in the context of a game-theoretic relationship as a situation in which inter-individual interests exert strong selection pressures. We construct an agent model in which linguistic descriptions of personality traits related to cooperative behavior are used as genes. The deterministic strategies extracted from Large Language Model (LLM) that make behavioral decisions based on these personality traits are used as behavioral traits. The population is evolved according to selection based on average payoff and mutation of genes by asking LLM to slightly modify the parent gene toward cooperative or selfish. Through preliminary experiments and analyses, we clarify that such a model can indeed exhibit the evolution of cooperative behavior based on the diverse and higher-order representation of personality traits. We also observed the repeated intrusion of cooperative and selfish personality traits through changes in the expression of personality traits, and found that the emerging words in the evolved gene well reflected the behavioral tendency of its personality in terms of their semantics.
+
+
+
+ 117. 标题:Automated Chest X-Ray Report Generator Using Multi-Model Deep Learning Approach
+ 编号:[443]
+ 链接:https://arxiv.org/abs/2310.05969
+ 作者:Arief Purnama Muharram, Hollyana Puteri Haryono, Abassi Haji Juma, Ira Puspasari, Nugraha Priya Utama
+ 备注:Presented in the 2023 IEEE International Conference on Data and Software Engineering (ICoDSE 2023)
+ 关键词:interpreting chest X-ray, chest X-ray, chest X-ray images, chest X-ray report, Reading and interpreting
+
+ 点击查看摘要
+ Reading and interpreting chest X-ray images is one of the most radiologist's routines. However, it still can be challenging, even for the most experienced ones. Therefore, we proposed a multi-model deep learning-based automated chest X-ray report generator system designed to assist radiologists in their work. The basic idea of the proposed system is by utilizing multi binary-classification models for detecting multi abnormalities, with each model responsible for detecting one abnormality, in a single image. In this study, we limited the radiology abnormalities detection to only cardiomegaly, lung effusion, and consolidation. The system generates a radiology report by performing the following three steps: image pre-processing, utilizing deep learning models to detect abnormalities, and producing a report. The aim of the image pre-processing step is to standardize the input by scaling it to 128x128 pixels and slicing it into three segments, which covers the upper, lower, and middle parts of the lung. After pre-processing, each corresponding model classifies the image, resulting in a 0 (zero) for no abnormality detected and a 1 (one) for the presence of an abnormality. The prediction outputs of each model are then concatenated to form a 'result code'. The 'result code' is used to construct a report by selecting the appropriate pre-determined sentence for each detected abnormality in the report generation step. The proposed system is expected to reduce the workload of radiologists and increase the accuracy of chest X-ray diagnosis.
+
+
+
+ 118. 标题:A new economic and financial theory of money
+ 编号:[450]
+ 链接:https://arxiv.org/abs/2310.04986
+ 作者:Michael E. Glinsky, Sharon Sievert
+ 备注:43 pages, 31 figures, 157 equations, to be submitted to Journal of Economic Affairs
+ 关键词:paper fundamentally reformulates, fundamentally reformulates economic, include electronic currencies, electronic currency, electronic currencies
+
+ 点击查看摘要
+ This paper fundamentally reformulates economic and financial theory to include electronic currencies. The valuation of the electronic currencies will be based on macroeconomic theory and the fundamental equation of monetary policy, not the microeconomic theory of discounted cash flows. The view of electronic currency as a transactional equity associated with tangible assets of a sub-economy will be developed, in contrast to the view of stock as an equity associated mostly with intangible assets of a sub-economy. The view will be developed of the electronic currency management firm as an entity responsible for coordinated monetary (electronic currency supply and value stabilization) and fiscal (investment and operational) policies of a substantial (for liquidity of the electronic currency) sub-economy. The risk model used in the valuations and the decision-making will not be the ubiquitous, yet inappropriate, exponential risk model that leads to discount rates, but will be multi time scale models that capture the true risk. The decision-making will be approached from the perspective of true systems control based on a system response function given by the multi scale risk model and system controllers that utilize the Deep Reinforcement Learning, Generative Pretrained Transformers, and other methods of Artificial Intelligence (DRL/GPT/AI). Finally, the sub-economy will be viewed as a nonlinear complex physical system with both stable equilibriums that are associated with short-term exploitation, and unstable equilibriums that need to be stabilized with active nonlinear control based on the multi scale system response functions and DRL/GPT/AI.
+
+
+
+ 119. 标题:Mallat Scattering Transformation based surrogate for MagnetoHydroDynamics
+ 编号:[451]
+ 链接:https://arxiv.org/abs/2302.10243
+ 作者:Michael E. Glinsky, Kathryn Maupin
+ 备注:12 pages, 20 figures, 3 animations, accepted for publication in Computational Mechanics
+ 关键词:Deep Learning methodology, PCA vector components, Machine and Deep, Deep Learning, resistive MHD simulations
+
+ 点击查看摘要
+ A Machine and Deep Learning methodology is developed and applied to give a high fidelity, fast surrogate for 2D resistive MHD simulations of MagLIF implosions. The resistive MHD code GORGON is used to generate an ensemble of implosions with different liner aspect ratios, initial gas preheat temperatures (that is, different adiabats), and different liner perturbations. The liner density and magnetic field as functions of $x$, $y$, and $t$ were generated. The Mallat Scattering Transformation (MST) is taken of the logarithm of both fields and a Principal Components Analysis is done on the logarithm of the MST of both fields. The fields are projected onto the PCA vectors and a small number of these PCA vector components are kept. Singular Value Decompositions of the cross correlation of the input parameters to the output logarithm of the MST of the fields, and of the cross correlation of the SVD vector components to the PCA vector components are done. This allows the identification of the PCA vectors vis-a-vis the input parameters. Finally, a Multi Layer Perceptron neural network with ReLU activation and a simple three layer encoder/decoder architecture is trained on this dataset to predict the PCA vector components of the fields as a function of time. Details of the implosion, stagnation, and the disassembly are well captured. Examination of the PCA vectors and a permutation importance analysis of the MLP show definitive evidence of an inverse turbulent cascade into a dipole emergent behavior. The orientation of the dipole is set by the initial liner perturbation. The analysis is repeated with a version of the MST which includes phase, called Wavelet Phase Harmonics (WPH). While WPH do not give the physical insight of the MST, they can and are inverted to give field configurations as a function of time, including field-to-field correlations.
+
+
+





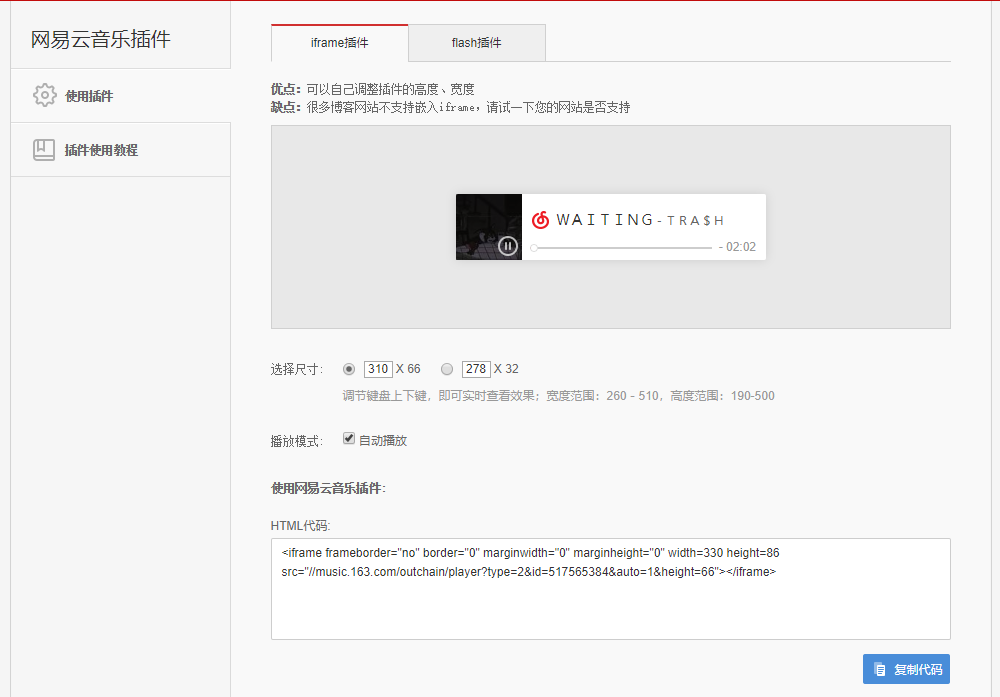
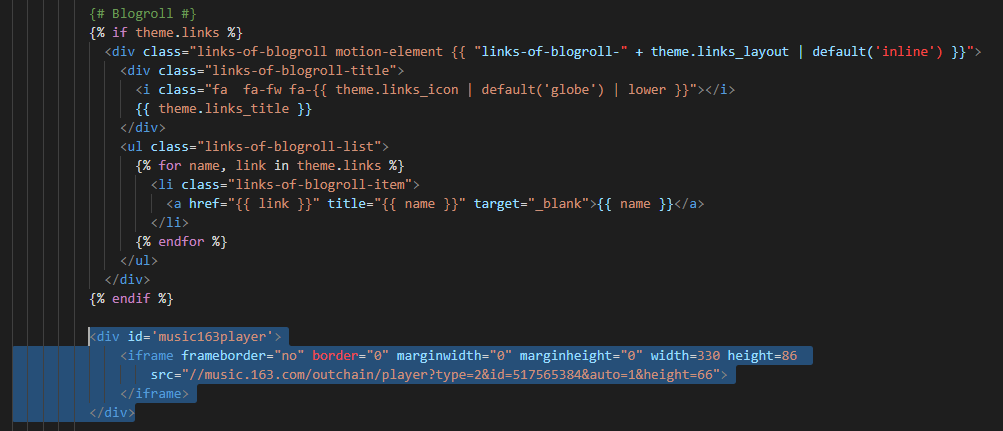
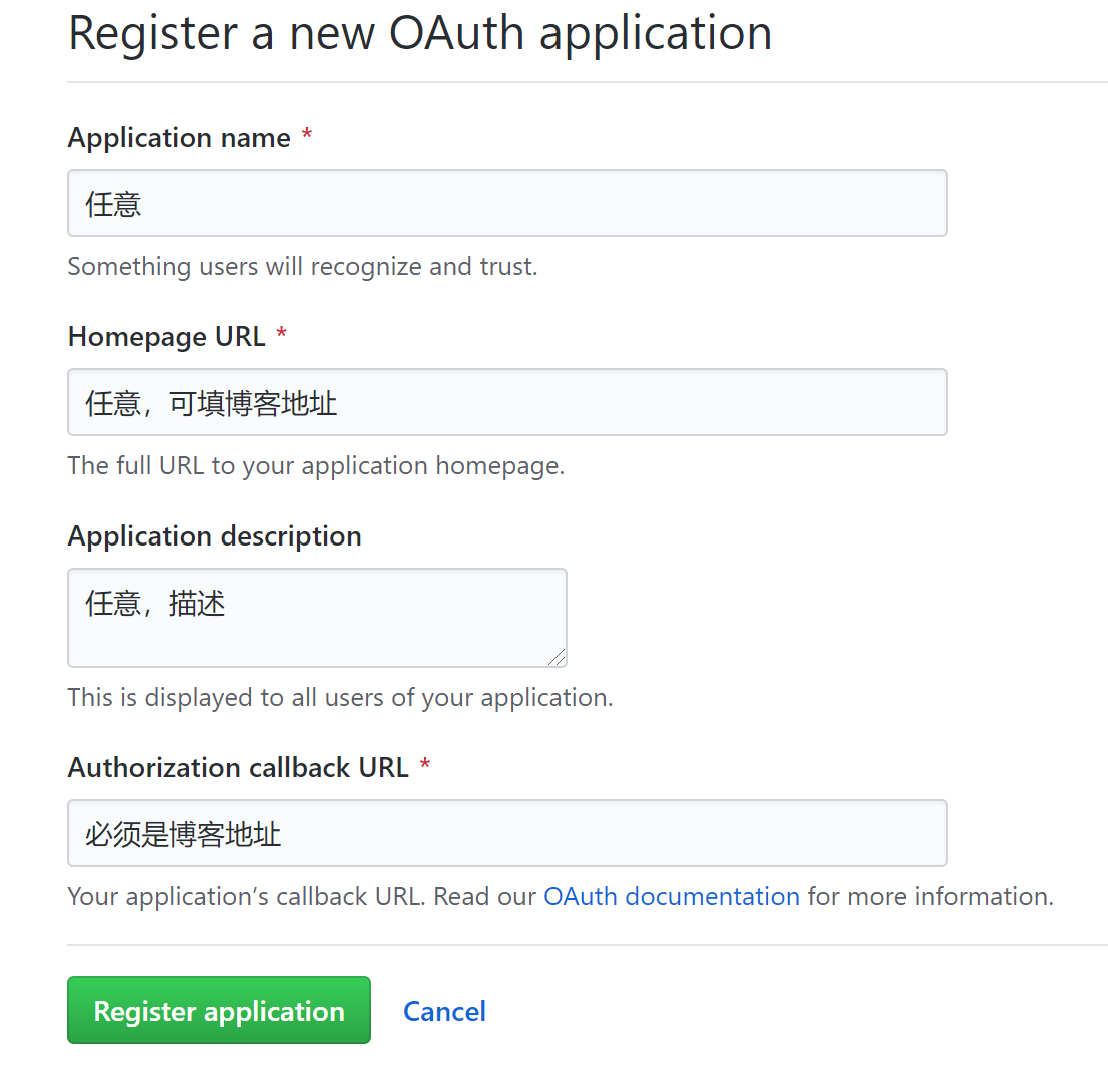
/Fig1_pretrain_finetune.png)
/Fig2_eda1.png)
/Fig2_eda2.png)
/Fig2_eda3.png)
/Fig3_reweight.png)
/Fig5_model1.png)
/Fig5_attention_mask.png)
/Fig4_wwm.png)
/Fig5_model2.png)
/Fig5_model3.png)
/Fig7_ensemble1.png)
/Fig6_res1.png)
/Fig6_res2.png)


%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_text_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_entity_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/model.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/dont_stop_pretraining.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/a.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/b.png)

%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/lengths_histplot.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_entity_lengths.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_label_dist.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/%E6%80%BB%E4%BD%93%E6%96%B9%E6%A1%88.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/pretrain_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/finetune_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/rdrop.png)

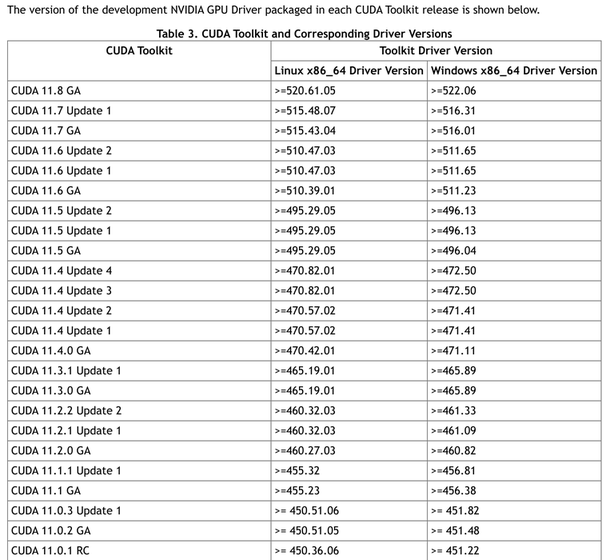

/autoencoder-architecture.png)
/variational-autoencoder-architecture.png)
/forward_vs_reversed_KL.png)
/vae-implement.png)
/reparam.png)
/generated_samples.png)







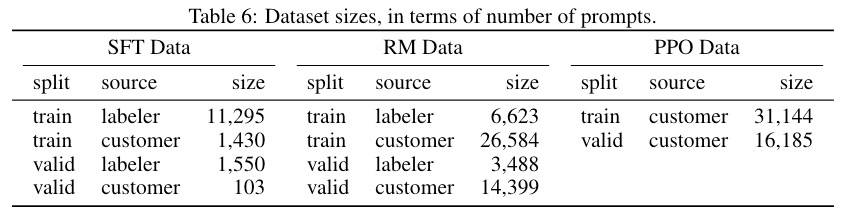
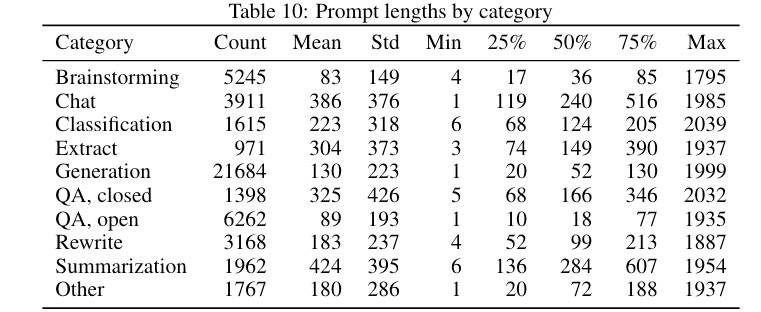
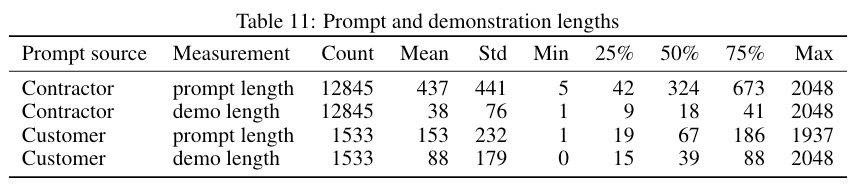

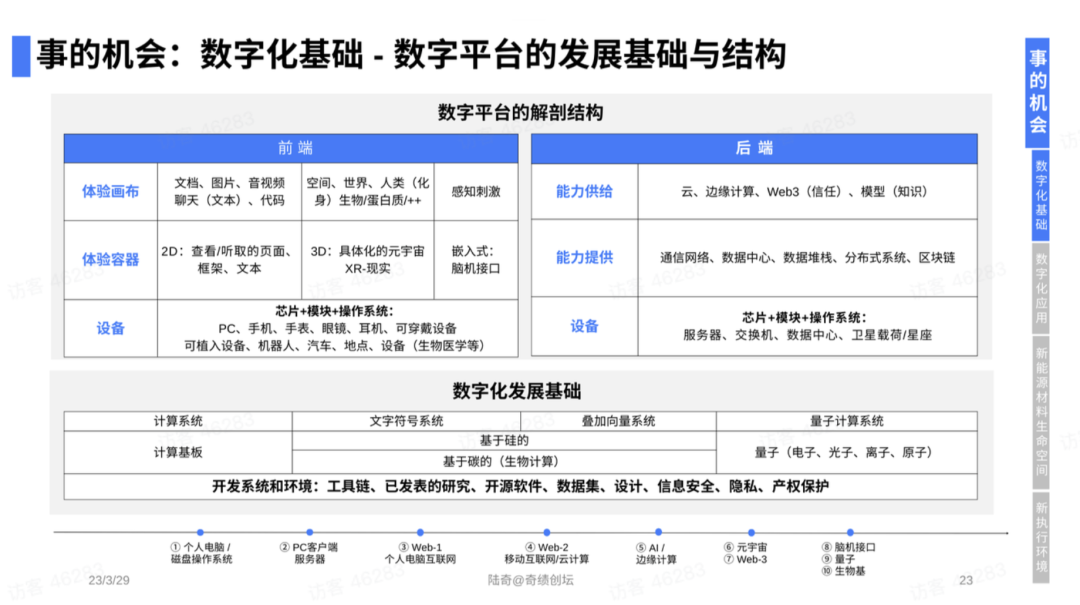

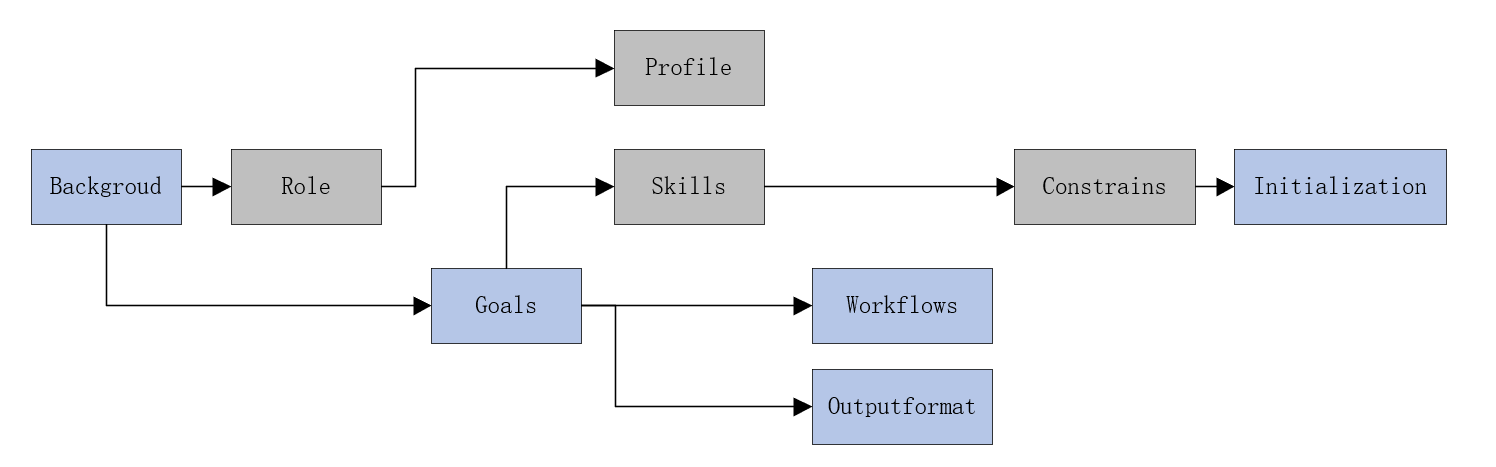

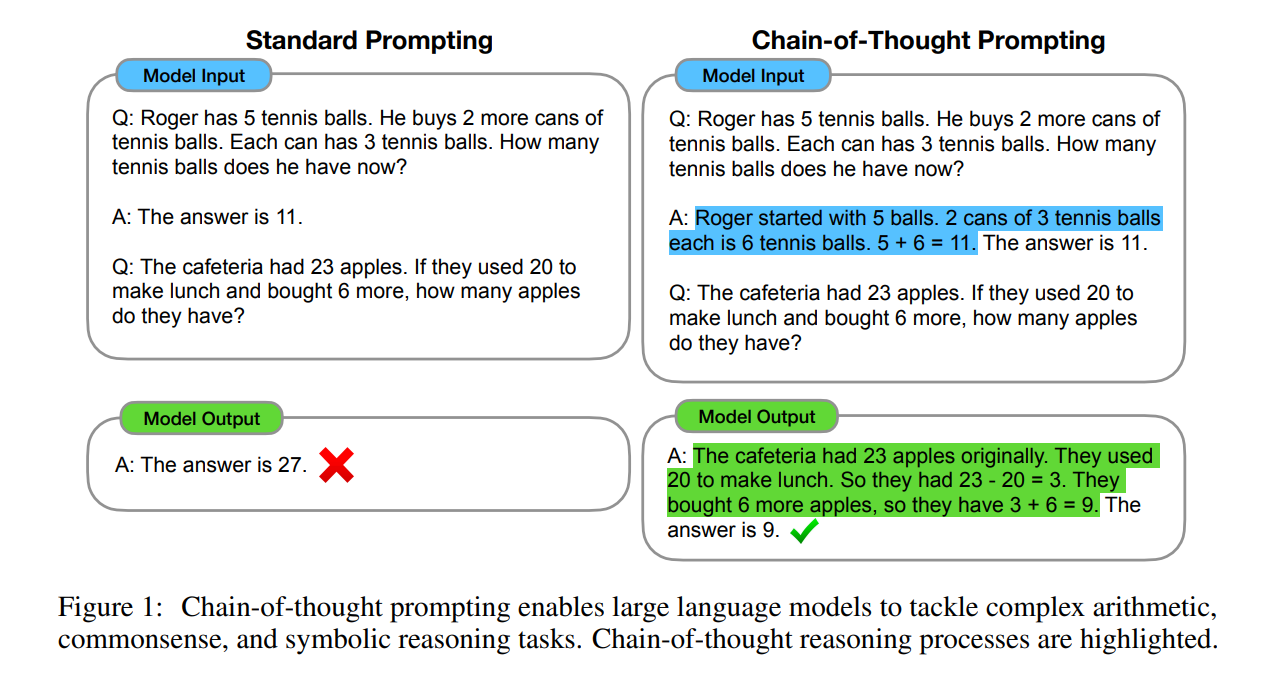

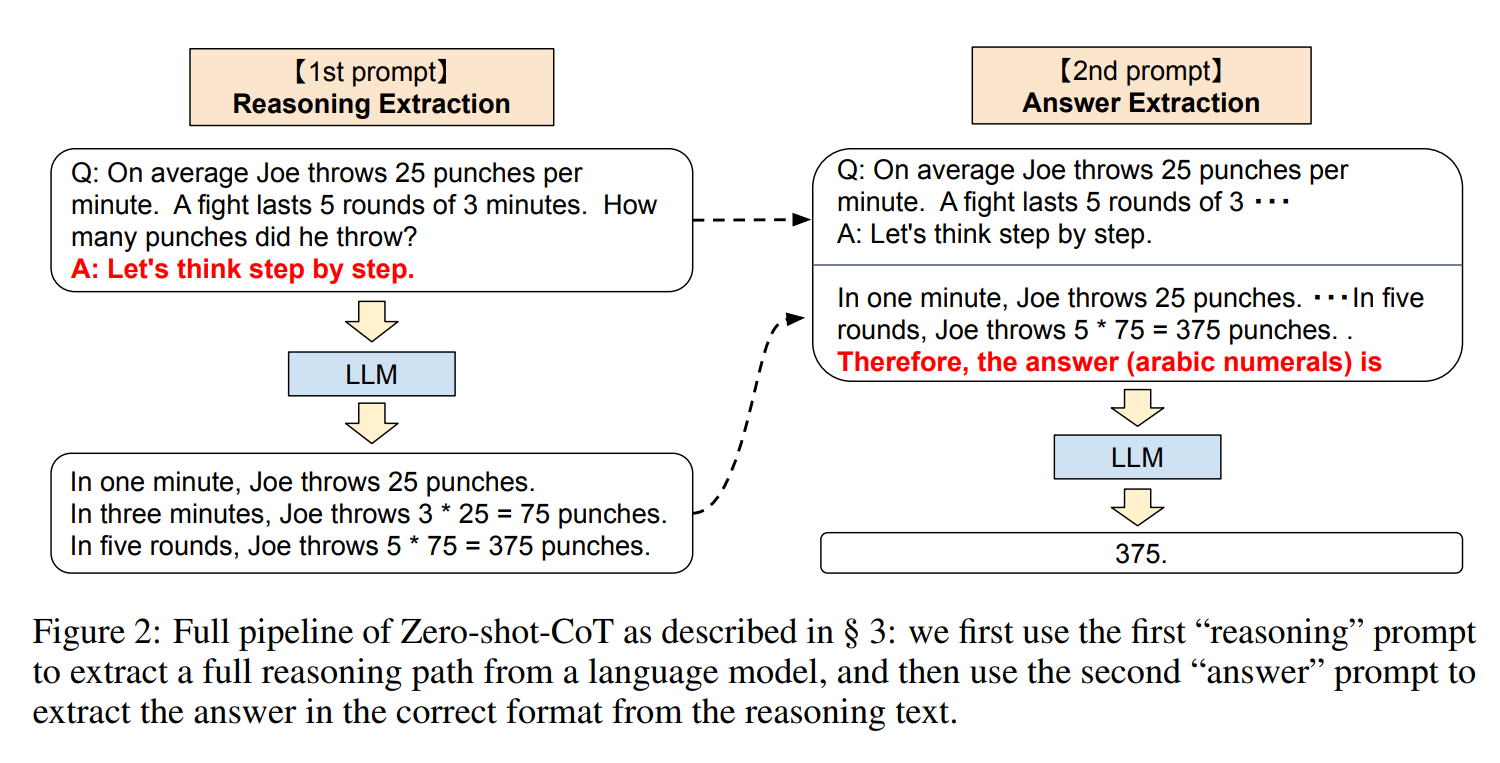
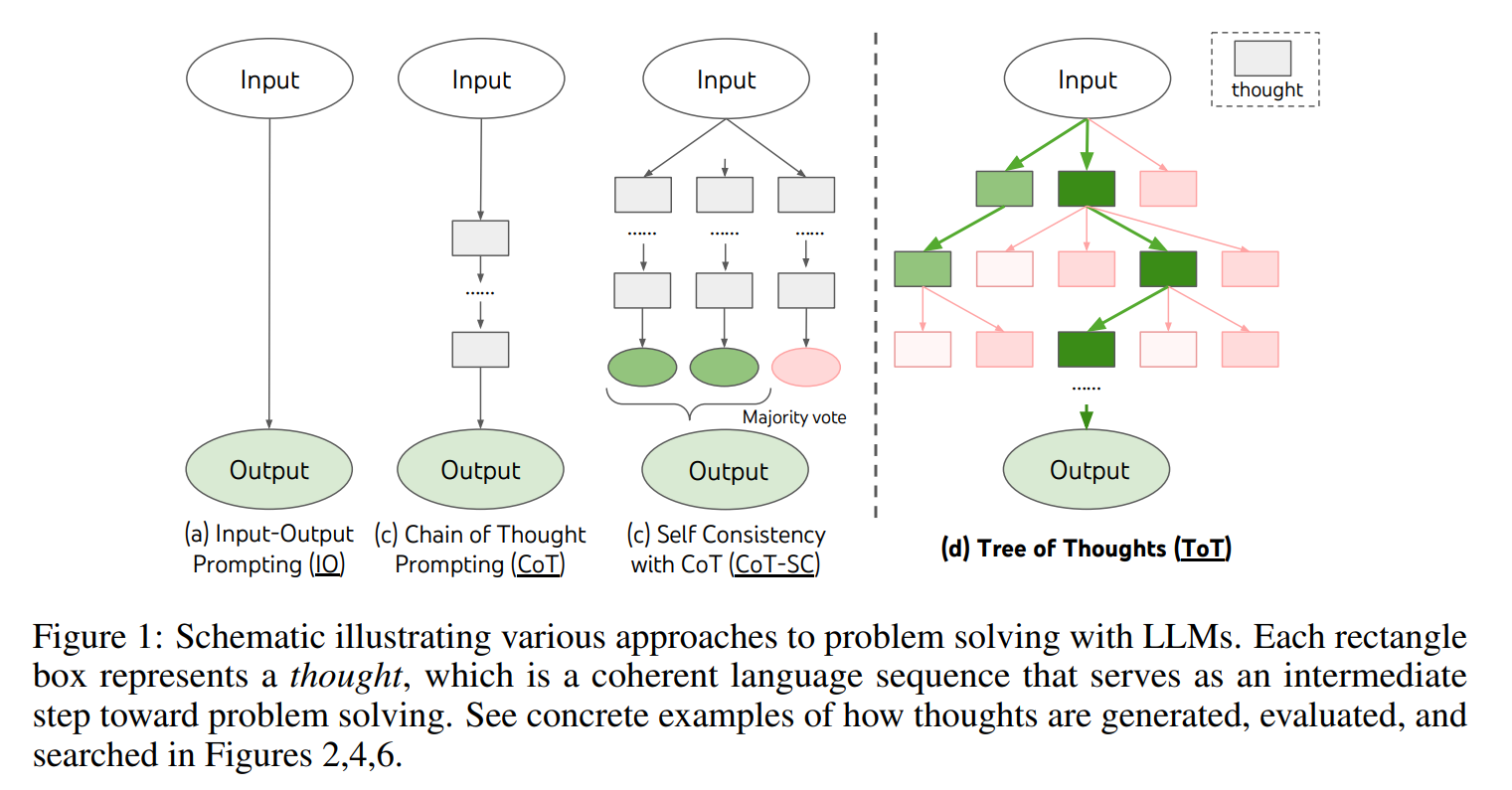


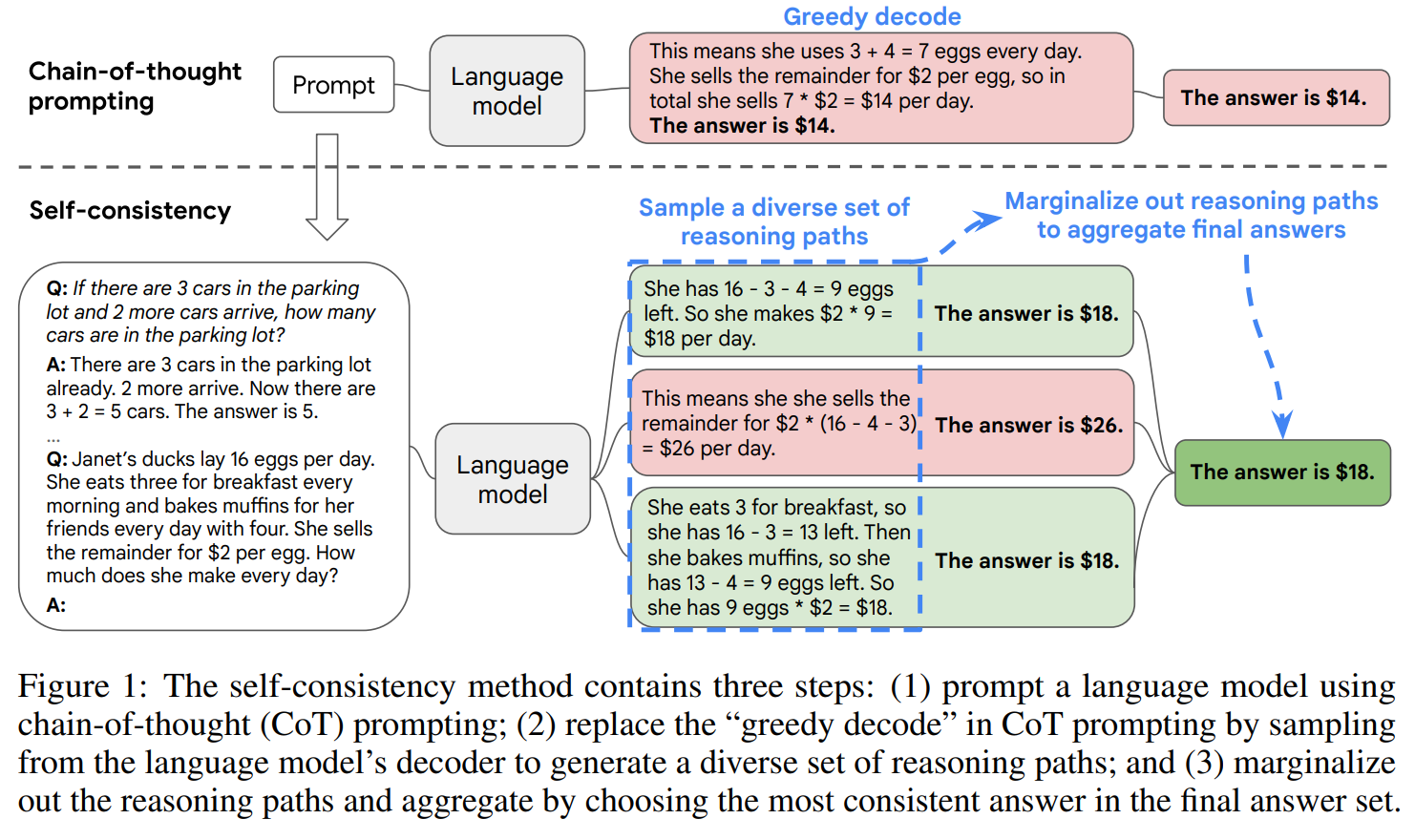
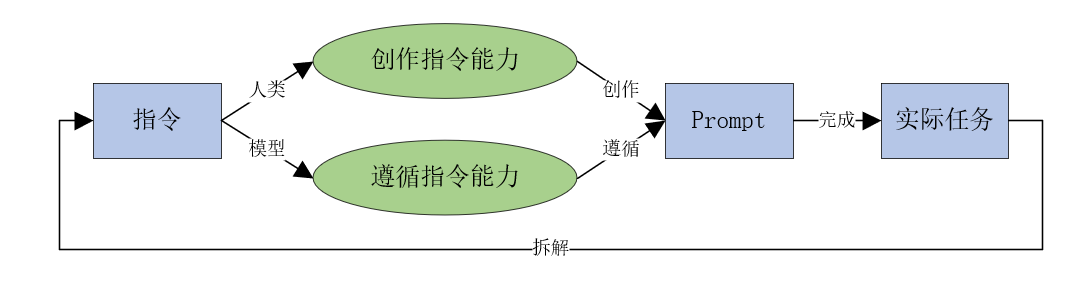



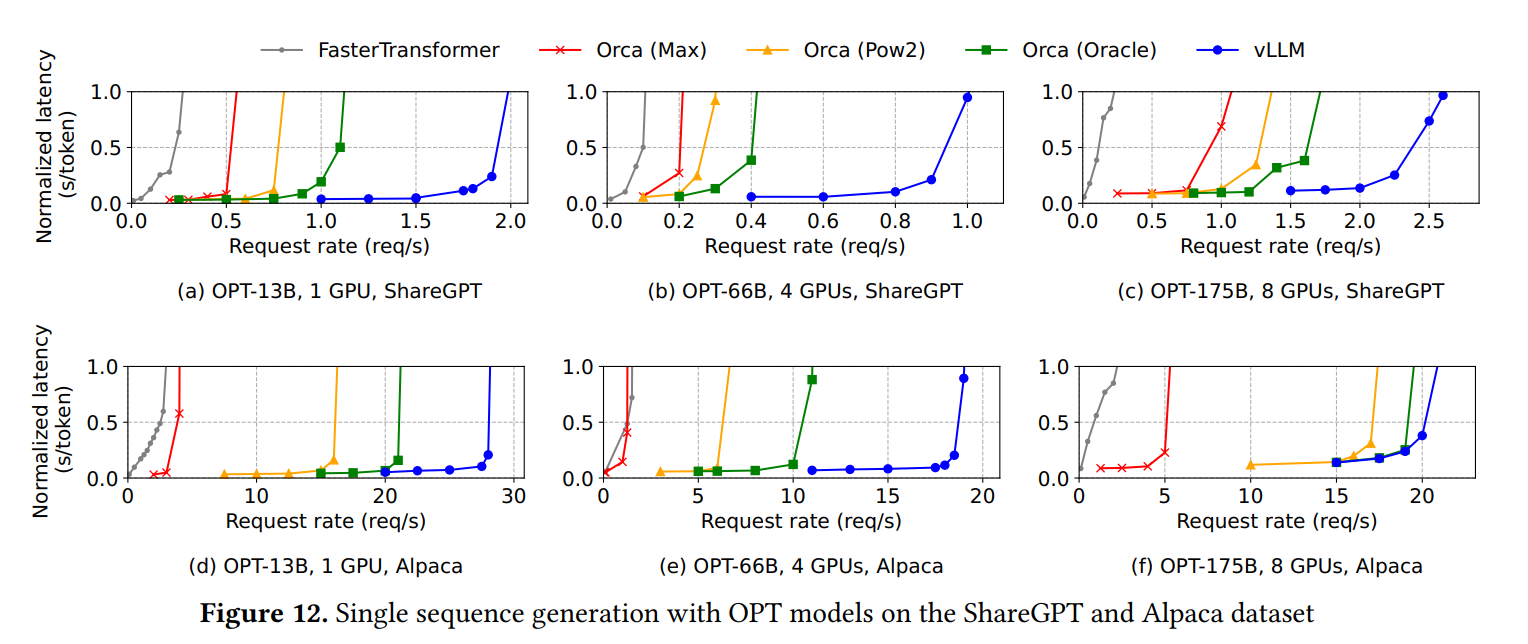
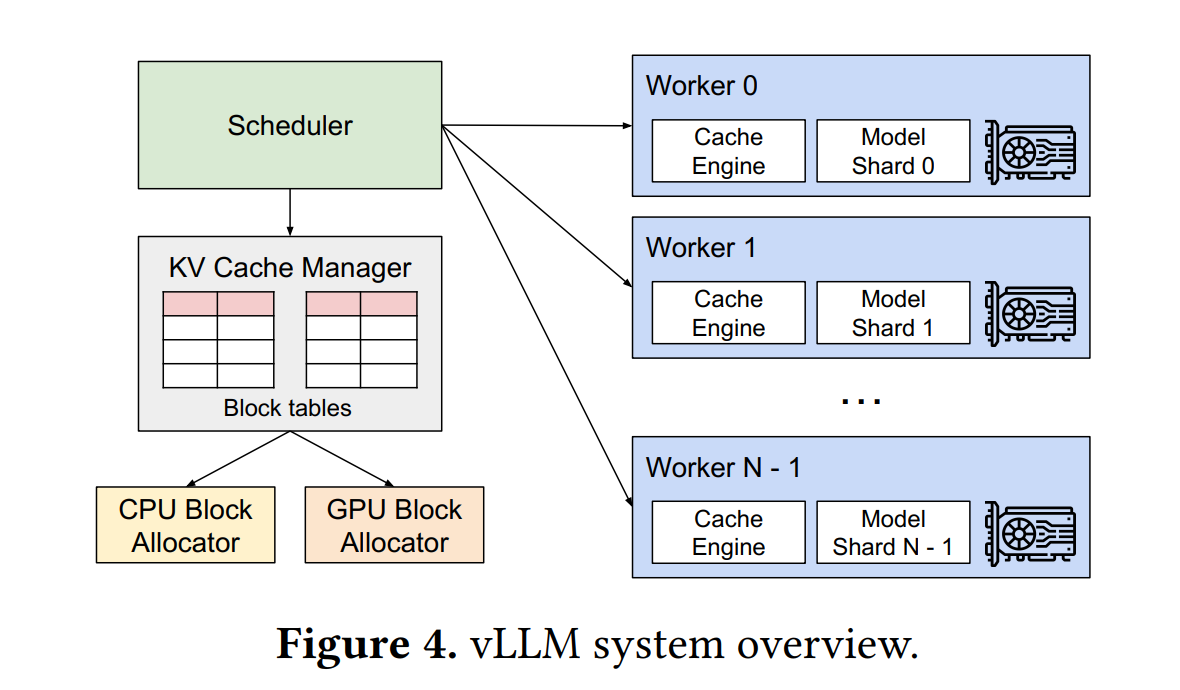
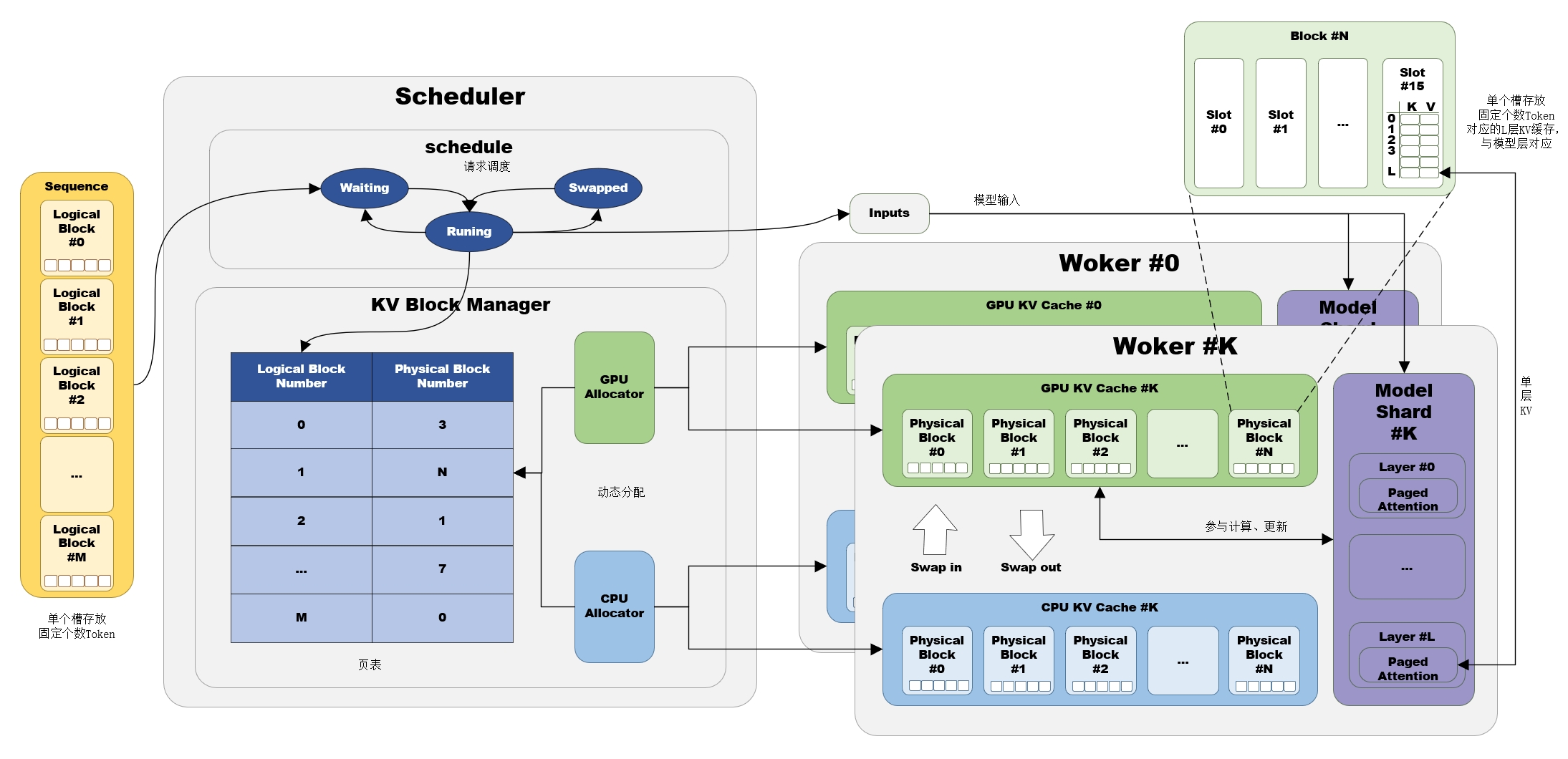
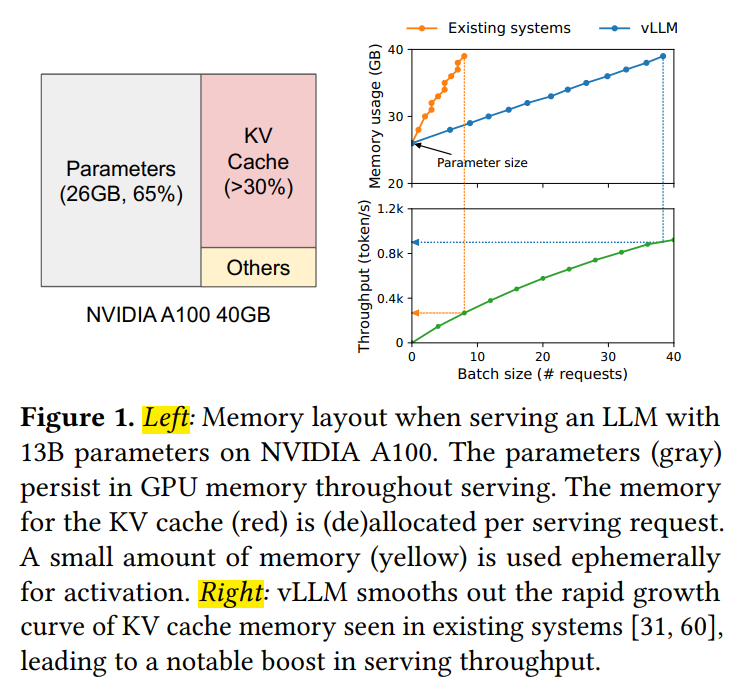
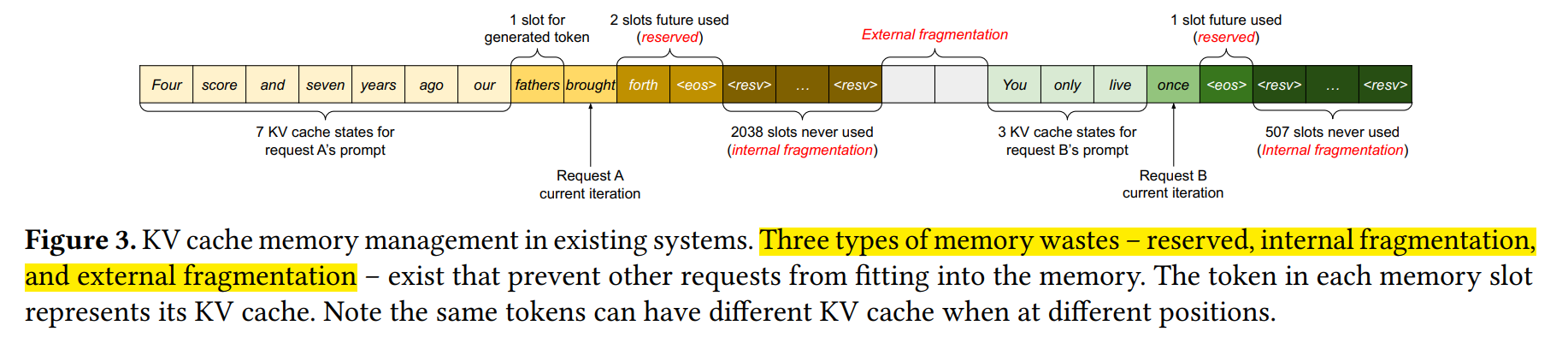
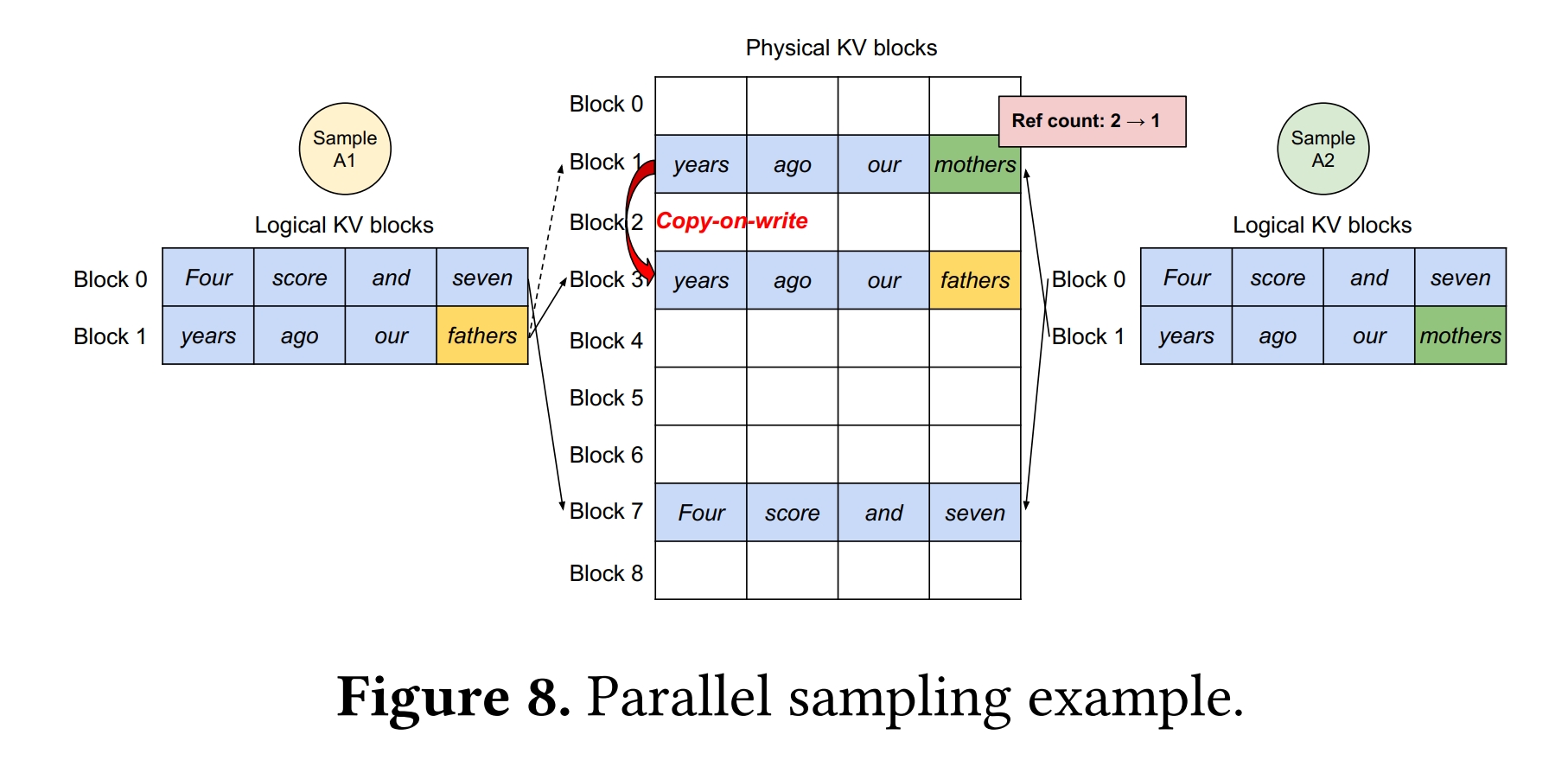
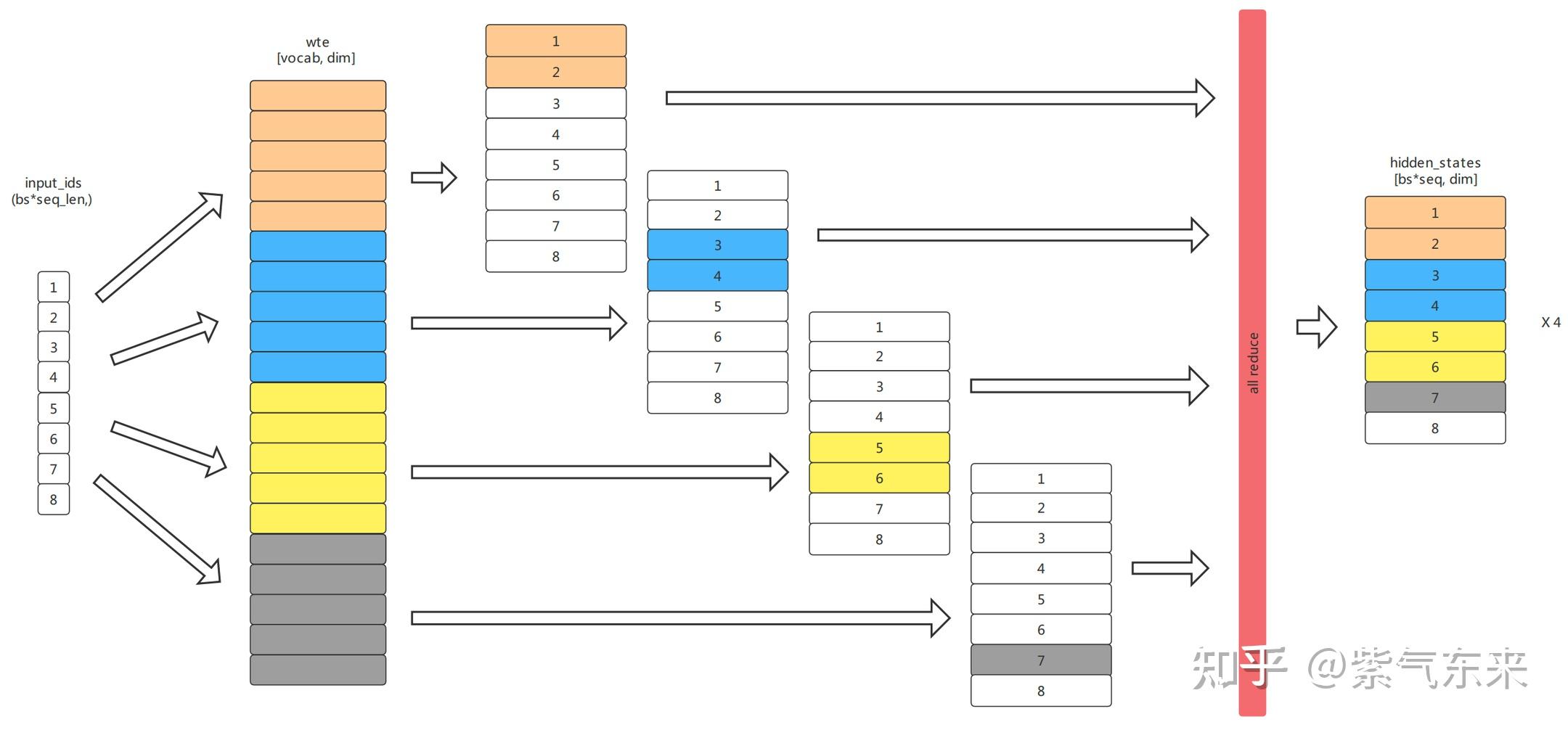
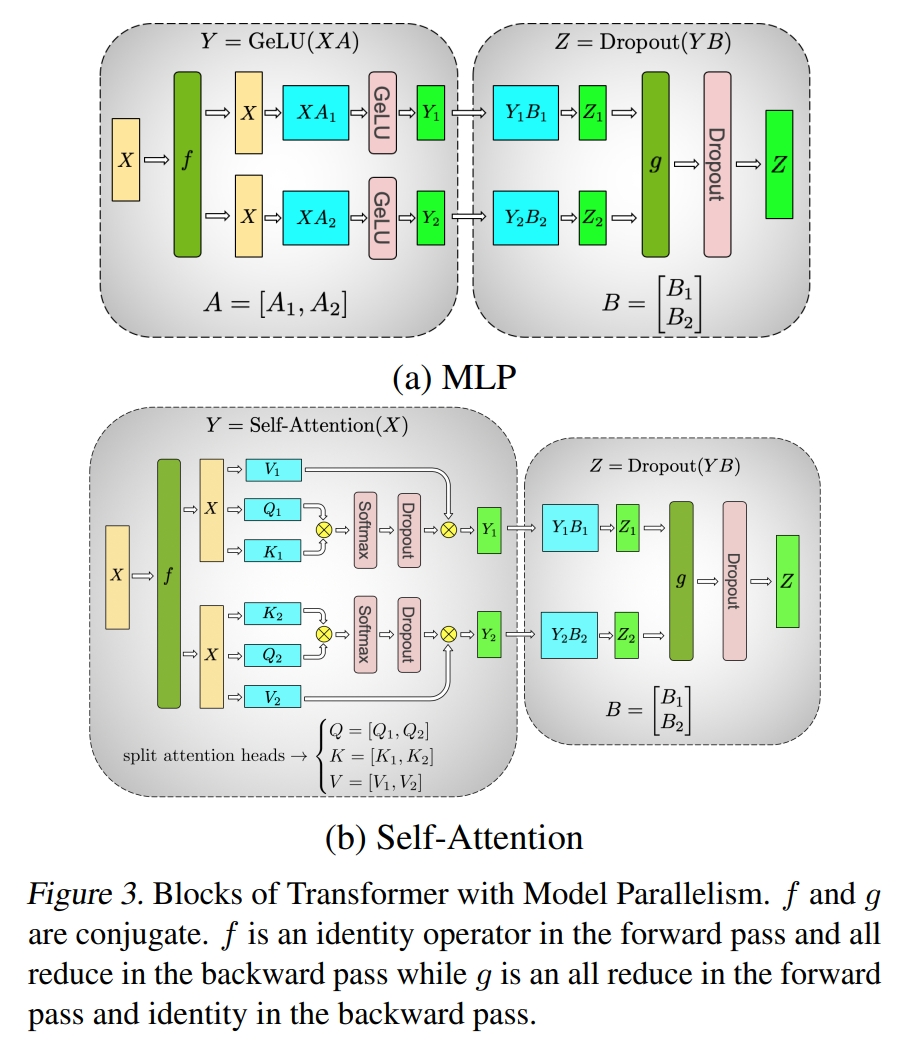








 ' +
+ '
' +
+ '