本篇博文主要展示每日从Arxiv论文网站获取的最新论文列表,以自然语言处理、信息检索、计算机视觉等类目进行划分。
+统计
+今日共更新476篇论文,其中:
+
+- 自然语言处理83篇
+- 信息检索10篇
+- 计算机视觉96篇
+
+自然语言处理
+
+ 1. 【2410.09047】Unraveling and Mitigating Safety Alignment Degradation of Vision-Language Models
+ 链接:https://arxiv.org/abs/2410.09047
+ 作者:Qin Liu,Chao Shang,Ling Liu,Nikolaos Pappas,Jie Ma,Neha Anna John,Srikanth Doss,Lluis Marquez,Miguel Ballesteros,Yassine Benajiba
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:vision module compared, safety alignment, Vision-Language Models, safety alignment ability, safety alignment degradation
+ 备注: Preprint
+
+ 点击查看摘要
+ Abstract:The safety alignment ability of Vision-Language Models (VLMs) is prone to be degraded by the integration of the vision module compared to its LLM backbone. We investigate this phenomenon, dubbed as ''safety alignment degradation'' in this paper, and show that the challenge arises from the representation gap that emerges when introducing vision modality to VLMs. In particular, we show that the representations of multi-modal inputs shift away from that of text-only inputs which represent the distribution that the LLM backbone is optimized for. At the same time, the safety alignment capabilities, initially developed within the textual embedding space, do not successfully transfer to this new multi-modal representation space. To reduce safety alignment degradation, we introduce Cross-Modality Representation Manipulation (CMRM), an inference time representation intervention method for recovering the safety alignment ability that is inherent in the LLM backbone of VLMs, while simultaneously preserving the functional capabilities of VLMs. The empirical results show that our framework significantly recovers the alignment ability that is inherited from the LLM backbone with minimal impact on the fluency and linguistic capabilities of pre-trained VLMs even without additional training. Specifically, the unsafe rate of LLaVA-7B on multi-modal input can be reduced from 61.53% to as low as 3.15% with only inference-time intervention.
+WARNING: This paper contains examples of toxic or harmful language.
+
Comments:
+Preprint
+Subjects:
+Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+Cite as:
+arXiv:2410.09047 [cs.CL]
+(or
+arXiv:2410.09047v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2410.09047
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 2. 【2410.09045】MiRAGeNews: Multimodal Realistic AI-Generated News Detection
+ 链接:https://arxiv.org/abs/2410.09045
+ 作者:Runsheng Huang,Liam Dugan,Yue Yang,Chris Callison-Burch
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:inflammatory or misleading, recent years, proliferation of inflammatory, increasingly common, common in recent
+ 备注: EMNLP 2024 Findings
+
+ 点击查看摘要
+ Abstract:The proliferation of inflammatory or misleading "fake" news content has become increasingly common in recent years. Simultaneously, it has become easier than ever to use AI tools to generate photorealistic images depicting any scene imaginable. Combining these two -- AI-generated fake news content -- is particularly potent and dangerous. To combat the spread of AI-generated fake news, we propose the MiRAGeNews Dataset, a dataset of 12,500 high-quality real and AI-generated image-caption pairs from state-of-the-art generators. We find that our dataset poses a significant challenge to humans (60% F-1) and state-of-the-art multi-modal LLMs ( 24% F-1). Using our dataset we train a multi-modal detector (MiRAGe) that improves by +5.1% F-1 over state-of-the-art baselines on image-caption pairs from out-of-domain image generators and news publishers. We release our code and data to aid future work on detecting AI-generated content.
+
+
+
+ 3. 【2410.09040】AttnGCG: Enhancing Jailbreaking Attacks on LLMs with Attention Manipulation
+ 链接:https://arxiv.org/abs/2410.09040
+ 作者:Zijun Wang,Haoqin Tu,Jieru Mei,Bingchen Zhao,Yisen Wang,Cihang Xie
+ 类目:Computation and Language (cs.CL)
+ 关键词:Greedy Coordinate Gradient, transformer-based Large Language, optimization-based Greedy Coordinate, Large Language Models, Coordinate Gradient
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper studies the vulnerabilities of transformer-based Large Language Models (LLMs) to jailbreaking attacks, focusing specifically on the optimization-based Greedy Coordinate Gradient (GCG) strategy. We first observe a positive correlation between the effectiveness of attacks and the internal behaviors of the models. For instance, attacks tend to be less effective when models pay more attention to system prompts designed to ensure LLM safety alignment. Building on this discovery, we introduce an enhanced method that manipulates models' attention scores to facilitate LLM jailbreaking, which we term AttnGCG. Empirically, AttnGCG shows consistent improvements in attack efficacy across diverse LLMs, achieving an average increase of ~7% in the Llama-2 series and ~10% in the Gemma series. Our strategy also demonstrates robust attack transferability against both unseen harmful goals and black-box LLMs like GPT-3.5 and GPT-4. Moreover, we note our attention-score visualization is more interpretable, allowing us to gain better insights into how our targeted attention manipulation facilitates more effective jailbreaking. We release the code at this https URL.
+
+
+
+ 4. 【2410.09038】SimpleStrat: Diversifying Language Model Generation with Stratification
+ 链接:https://arxiv.org/abs/2410.09038
+ 作者:Justin Wong,Yury Orlovskiy,Michael Luo,Sanjit A. Seshia,Joseph E. Gonzalez
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Generating diverse responses, Generating diverse, synthetic data generation, search and synthetic, crucial for applications
+ 备注:
+
+ 点击查看摘要
+ Abstract:Generating diverse responses from large language models (LLMs) is crucial for applications such as planning/search and synthetic data generation, where diversity provides distinct answers across generations. Prior approaches rely on increasing temperature to increase diversity. However, contrary to popular belief, we show not only does this approach produce lower quality individual generations as temperature increases, but it depends on model's next-token probabilities being similar to the true distribution of answers. We propose \method{}, an alternative approach that uses the language model itself to partition the space into strata. At inference, a random stratum is selected and a sample drawn from within the strata. To measure diversity, we introduce CoverageQA, a dataset of underspecified questions with multiple equally plausible answers, and assess diversity by measuring KL Divergence between the output distribution and uniform distribution over valid ground truth answers. As computing probability per response/solution for proprietary models is infeasible, we measure recall on ground truth solutions. Our evaluation show using SimpleStrat achieves higher recall by 0.05 compared to GPT-4o and 0.36 average reduction in KL Divergence compared to Llama 3.
+
+
+
+ 5. 【2410.09037】Mentor-KD: Making Small Language Models Better Multi-step Reasoners
+ 链接:https://arxiv.org/abs/2410.09037
+ 作者:Hojae Lee,Junho Kim,SangKeun Lee
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, displayed remarkable performances, Large Language, Language Models, displayed remarkable
+ 备注: EMNLP 2024
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have displayed remarkable performances across various complex tasks by leveraging Chain-of-Thought (CoT) prompting. Recently, studies have proposed a Knowledge Distillation (KD) approach, reasoning distillation, which transfers such reasoning ability of LLMs through fine-tuning language models of multi-step rationales generated by LLM teachers. However, they have inadequately considered two challenges regarding insufficient distillation sets from the LLM teacher model, in terms of 1) data quality and 2) soft label provision. In this paper, we propose Mentor-KD, which effectively distills the multi-step reasoning capability of LLMs to smaller LMs while addressing the aforementioned challenges. Specifically, we exploit a mentor, intermediate-sized task-specific fine-tuned model, to augment additional CoT annotations and provide soft labels for the student model during reasoning distillation. We conduct extensive experiments and confirm Mentor-KD's effectiveness across various models and complex reasoning tasks.
+
+
+
+ 6. 【2410.09034】PEAR: A Robust and Flexible Automation Framework for Ptychography Enabled by Multiple Large Language Model Agents
+ 链接:https://arxiv.org/abs/2410.09034
+ 作者:Xiangyu Yin,Chuqiao Shi,Yimo Han,Yi Jiang
+ 类目:Computational Engineering, Finance, and Science (cs.CE); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Multiagent Systems (cs.MA)
+ 关键词:advanced computational imaging, computational imaging technique, technique in X-ray, X-ray and electron, electron microscopy
+ 备注: 18 pages, 5 figures, technical preview report
+
+ 点击查看摘要
+ Abstract:Ptychography is an advanced computational imaging technique in X-ray and electron microscopy. It has been widely adopted across scientific research fields, including physics, chemistry, biology, and materials science, as well as in industrial applications such as semiconductor characterization. In practice, obtaining high-quality ptychographic images requires simultaneous optimization of numerous experimental and algorithmic parameters. Traditionally, parameter selection often relies on trial and error, leading to low-throughput workflows and potential human bias. In this work, we develop the "Ptychographic Experiment and Analysis Robot" (PEAR), a framework that leverages large language models (LLMs) to automate data analysis in ptychography. To ensure high robustness and accuracy, PEAR employs multiple LLM agents for tasks including knowledge retrieval, code generation, parameter recommendation, and image reasoning. Our study demonstrates that PEAR's multi-agent design significantly improves the workflow success rate, even with smaller open-weight models such as LLaMA 3.1 8B. PEAR also supports various automation levels and is designed to work with customized local knowledge bases, ensuring flexibility and adaptability across different research environments.
+
+
+
+ 7. 【2410.09024】AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
+ 链接:https://arxiv.org/abs/2410.09024
+ 作者:Maksym Andriushchenko,Alexandra Souly,Mateusz Dziemian,Derek Duenas,Maxwell Lin,Justin Wang,Dan Hendrycks,Andy Zou,Zico Kolter,Matt Fredrikson,Eric Winsor,Jerome Wynne,Yarin Gal,Xander Davies
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:users design prompts, circumvent safety measures, users design, design prompts, prompts to circumvent
+ 备注:
+
+ 点击查看摘要
+ Abstract:The robustness of LLMs to jailbreak attacks, where users design prompts to circumvent safety measures and misuse model capabilities, has been studied primarily for LLMs acting as simple chatbots. Meanwhile, LLM agents -- which use external tools and can execute multi-stage tasks -- may pose a greater risk if misused, but their robustness remains underexplored. To facilitate research on LLM agent misuse, we propose a new benchmark called AgentHarm. The benchmark includes a diverse set of 110 explicitly malicious agent tasks (440 with augmentations), covering 11 harm categories including fraud, cybercrime, and harassment. In addition to measuring whether models refuse harmful agentic requests, scoring well on AgentHarm requires jailbroken agents to maintain their capabilities following an attack to complete a multi-step task. We evaluate a range of leading LLMs, and find (1) leading LLMs are surprisingly compliant with malicious agent requests without jailbreaking, (2) simple universal jailbreak templates can be adapted to effectively jailbreak agents, and (3) these jailbreaks enable coherent and malicious multi-step agent behavior and retain model capabilities. We publicly release AgentHarm to enable simple and reliable evaluation of attacks and defenses for LLM-based agents. We publicly release the benchmark at this https URL.
+
+
+
+ 8. 【2410.09019】MedMobile: A mobile-sized language model with expert-level clinical capabilities
+ 链接:https://arxiv.org/abs/2410.09019
+ 作者:Krithik Vishwanath,Jaden Stryker,Anton Alaykin,Daniel Alexander Alber,Eric Karl Oermann
+ 类目:Computation and Language (cs.CL)
+ 关键词:demonstrated expert-level reasoning, Language models, abilities in medicine, demonstrated expert-level, expert-level reasoning
+ 备注: 13 pages, 5 figures (2 main, 3 supplementary)
+
+ 点击查看摘要
+ Abstract:Language models (LMs) have demonstrated expert-level reasoning and recall abilities in medicine. However, computational costs and privacy concerns are mounting barriers to wide-scale implementation. We introduce a parsimonious adaptation of phi-3-mini, MedMobile, a 3.8 billion parameter LM capable of running on a mobile device, for medical applications. We demonstrate that MedMobile scores 75.7% on the MedQA (USMLE), surpassing the passing mark for physicians (~60%), and approaching the scores of models 100 times its size. We subsequently perform a careful set of ablations, and demonstrate that chain of thought, ensembling, and fine-tuning lead to the greatest performance gains, while unexpectedly retrieval augmented generation fails to demonstrate significant improvements
+
+
+
+ 9. 【2410.09016】Parameter-Efficient Fine-Tuning of State Space Models
+ 链接:https://arxiv.org/abs/2410.09016
+ 作者:Kevin Galim,Wonjun Kang,Yuchen Zeng,Hyung Il Koo,Kangwook Lee
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:Deep State Space, State Space Models, Deep State, Space Models, State Space
+ 备注: Code is available at [this https URL](https://github.com/furiosa-ai/ssm-peft)
+
+ 点击查看摘要
+ Abstract:Deep State Space Models (SSMs), such as Mamba (Gu Dao, 2024), have emerged as powerful tools for language modeling, offering high performance with efficient inference and linear scaling in sequence length. However, the application of parameter-efficient fine-tuning (PEFT) methods to SSM-based models remains largely unexplored. This paper aims to systematically study two key questions: (i) How do existing PEFT methods perform on SSM-based models? (ii) Which modules are most effective for fine-tuning? We conduct an empirical benchmark of four basic PEFT methods on SSM-based models. Our findings reveal that prompt-based methods (e.g., prefix-tuning) are no longer effective, an empirical result further supported by theoretical analysis. In contrast, LoRA remains effective for SSM-based models. We further investigate the optimal application of LoRA within these models, demonstrating both theoretically and experimentally that applying LoRA to linear projection matrices without modifying SSM modules yields the best results, as LoRA is not effective at tuning SSM modules. To further improve performance, we introduce LoRA with Selective Dimension tuning (SDLoRA), which selectively updates certain channels and states on SSM modules while applying LoRA to linear projection matrices. Extensive experimental results show that this approach outperforms standard LoRA.
+
+
+
+ 10. 【2410.09013】he Impact of Visual Information in Chinese Characters: Evaluating Large Models' Ability to Recognize and Utilize Radicals
+ 链接:https://arxiv.org/abs/2410.09013
+ 作者:Xiaofeng Wu,Karl Stratos,Wei Xu
+ 类目:Computation and Language (cs.CL)
+ 关键词:glyphic writing system, Chinese incorporates information-rich, incorporates information-rich visual, meaning or pronunciation, information-rich visual features
+ 备注:
+
+ 点击查看摘要
+ Abstract:The glyphic writing system of Chinese incorporates information-rich visual features in each character, such as radicals that provide hints about meaning or pronunciation. However, there has been no investigation into whether contemporary Large Language Models (LLMs) and Vision-Language Models (VLMs) can harness these sub-character features in Chinese through prompting. In this study, we establish a benchmark to evaluate LLMs' and VLMs' understanding of visual elements in Chinese characters, including radicals, composition structures, strokes, and stroke counts. Our results reveal that models surprisingly exhibit some, but still limited, knowledge of the visual information, regardless of whether images of characters are provided. To incite models' ability to use radicals, we further experiment with incorporating radicals into the prompts for Chinese language understanding tasks. We observe consistent improvement in Part-Of-Speech tagging when providing additional information about radicals, suggesting the potential to enhance CLP by integrating sub-character information.
+
+
+
+ 11. 【2410.09008】SuperCorrect: Supervising and Correcting Language Models with Error-Driven Insights
+ 链接:https://arxiv.org/abs/2410.09008
+ 作者:Ling Yang,Zhaochen Yu,Tianjun Zhang,Minkai Xu,Joseph E. Gonzalez,Bin Cui,Shuicheng Yan
+ 类目:Computation and Language (cs.CL)
+ 关键词:shown significant improvements, Large language models, student model, LLaMA have shown, shown significant
+ 备注: Project: [this https URL](https://github.com/YangLing0818/SuperCorrect-llm)
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) like GPT-4, PaLM, and LLaMA have shown significant improvements in various reasoning tasks. However, smaller models such as Llama-3-8B and DeepSeekMath-Base still struggle with complex mathematical reasoning because they fail to effectively identify and correct reasoning errors. Recent reflection-based methods aim to address these issues by enabling self-reflection and self-correction, but they still face challenges in independently detecting errors in their reasoning steps. To overcome these limitations, we propose SuperCorrect, a novel two-stage framework that uses a large teacher model to supervise and correct both the reasoning and reflection processes of a smaller student model. In the first stage, we extract hierarchical high-level and detailed thought templates from the teacher model to guide the student model in eliciting more fine-grained reasoning thoughts. In the second stage, we introduce cross-model collaborative direct preference optimization (DPO) to enhance the self-correction abilities of the student model by following the teacher's correction traces during training. This cross-model DPO approach teaches the student model to effectively locate and resolve erroneous thoughts with error-driven insights from the teacher model, breaking the bottleneck of its thoughts and acquiring new skills and knowledge to tackle challenging problems. Extensive experiments consistently demonstrate our superiority over previous methods. Notably, our SuperCorrect-7B model significantly surpasses powerful DeepSeekMath-7B by 7.8%/5.3% and Qwen2.5-Math-7B by 15.1%/6.3% on MATH/GSM8K benchmarks, achieving new SOTA performance among all 7B models. Code: this https URL
+
+
+
+ 12. 【2410.08996】Hypothesis-only Biases in Large Language Model-Elicited Natural Language Inference
+ 链接:https://arxiv.org/abs/2410.08996
+ 作者:Grace Proebsting,Adam Poliak
+ 类目:Computation and Language (cs.CL)
+ 关键词:Natural Language Inference, write Natural Language, Language Inference, Natural Language, replacing crowdsource workers
+ 备注:
+
+ 点击查看摘要
+ Abstract:We test whether replacing crowdsource workers with LLMs to write Natural Language Inference (NLI) hypotheses similarly results in annotation artifacts. We recreate a portion of the Stanford NLI corpus using GPT-4, Llama-2 and Mistral 7b, and train hypothesis-only classifiers to determine whether LLM-elicited hypotheses contain annotation artifacts. On our LLM-elicited NLI datasets, BERT-based hypothesis-only classifiers achieve between 86-96% accuracy, indicating these datasets contain hypothesis-only artifacts. We also find frequent "give-aways" in LLM-generated hypotheses, e.g. the phrase "swimming in a pool" appears in more than 10,000 contradictions generated by GPT-4. Our analysis provides empirical evidence that well-attested biases in NLI can persist in LLM-generated data.
+
+
+
+ 13. 【2410.08991】Science is Exploration: Computational Frontiers for Conceptual Metaphor Theory
+ 链接:https://arxiv.org/abs/2410.08991
+ 作者:Rebecca M. M. Hicke,Ross Deans Kristensen-McLachlan
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:conceptual metaphors, Large Language Models, Metaphors, language, natural language
+ 备注: Accepted to the 2024 Computational Humanities Research Conference (CHR)
+
+ 点击查看摘要
+ Abstract:Metaphors are everywhere. They appear extensively across all domains of natural language, from the most sophisticated poetry to seemingly dry academic prose. A significant body of research in the cognitive science of language argues for the existence of conceptual metaphors, the systematic structuring of one domain of experience in the language of another. Conceptual metaphors are not simply rhetorical flourishes but are crucial evidence of the role of analogical reasoning in human cognition. In this paper, we ask whether Large Language Models (LLMs) can accurately identify and explain the presence of such conceptual metaphors in natural language data. Using a novel prompting technique based on metaphor annotation guidelines, we demonstrate that LLMs are a promising tool for large-scale computational research on conceptual metaphors. Further, we show that LLMs are able to apply procedural guidelines designed for human annotators, displaying a surprising depth of linguistic knowledge.
+
+
+
+ 14. 【2410.08985】owards Trustworthy Knowledge Graph Reasoning: An Uncertainty Aware Perspective
+ 链接:https://arxiv.org/abs/2410.08985
+ 作者:Bo Ni,Yu Wang,Lu Cheng,Erik Blasch,Tyler Derr
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Large Language Models, coupled with Large, KG-based retrieval-augmented frameworks, Large Language, language model components
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recently, Knowledge Graphs (KGs) have been successfully coupled with Large Language Models (LLMs) to mitigate their hallucinations and enhance their reasoning capability, such as in KG-based retrieval-augmented frameworks. However, current KG-LLM frameworks lack rigorous uncertainty estimation, limiting their reliable deployment in high-stakes applications. Directly incorporating uncertainty quantification into KG-LLM frameworks presents challenges due to their complex architectures and the intricate interactions between the knowledge graph and language model components. To address this gap, we propose a new trustworthy KG-LLM framework, Uncertainty Aware Knowledge-Graph Reasoning (UAG), which incorporates uncertainty quantification into the KG-LLM framework. We design an uncertainty-aware multi-step reasoning framework that leverages conformal prediction to provide a theoretical guarantee on the prediction set. To manage the error rate of the multi-step process, we additionally introduce an error rate control module to adjust the error rate within the individual components. Extensive experiments show that our proposed UAG can achieve any pre-defined coverage rate while reducing the prediction set/interval size by 40% on average over the baselines.
+
+
+
+ 15. 【2410.08974】UniGlyph: A Seven-Segment Script for Universal Language Representation
+ 链接:https://arxiv.org/abs/2410.08974
+ 作者:G. V. Bency Sherin,A. Abijesh Euphrine,A. Lenora Moreen,L. Arun Jose
+ 类目:Computation and Language (cs.CL); Human-Computer Interaction (cs.HC); Symbolic Computation (cs.SC); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:designed to create, derived from seven-segment, UniGlyph, International Phonetic Alphabet, phonetic
+ 备注: This submission includes 23 pages and tables. No external funding has been received for this research. Acknowledgments to Jeseentha V. for contributions to the phonetic study
+
+ 点击查看摘要
+ Abstract:UniGlyph is a constructed language (conlang) designed to create a universal transliteration system using a script derived from seven-segment characters. The goal of UniGlyph is to facilitate cross-language communication by offering a flexible and consistent script that can represent a wide range of phonetic sounds. This paper explores the design of UniGlyph, detailing its script structure, phonetic mapping, and transliteration rules. The system addresses imperfections in the International Phonetic Alphabet (IPA) and traditional character sets by providing a compact, versatile method to represent phonetic diversity across languages. With pitch and length markers, UniGlyph ensures accurate phonetic representation while maintaining a small character set. Applications of UniGlyph include artificial intelligence integrations, such as natural language processing and multilingual speech recognition, enhancing communication across different languages. Future expansions are discussed, including the addition of animal phonetic sounds, where unique scripts are assigned to different species, broadening the scope of UniGlyph beyond human communication. This study presents the challenges and solutions in developing such a universal script, demonstrating the potential of UniGlyph to bridge linguistic gaps in cross-language communication, educational phonetics, and AI-driven applications.
+
+
+
+ 16. 【2410.08971】Extra Global Attention Designation Using Keyword Detection in Sparse Transformer Architectures
+ 链接:https://arxiv.org/abs/2410.08971
+ 作者:Evan Lucas,Dylan Kangas,Timothy C Havens
+ 类目:Computation and Language (cs.CL)
+ 关键词:Longformer Encoder-Decoder, sparse transformer architecture, extension to Longformer, popular sparse transformer, propose an extension
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this paper, we propose an extension to Longformer Encoder-Decoder, a popular sparse transformer architecture. One common challenge with sparse transformers is that they can struggle with encoding of long range context, such as connections between topics discussed at a beginning and end of a document. A method to selectively increase global attention is proposed and demonstrated for abstractive summarization tasks on several benchmark data sets. By prefixing the transcript with additional keywords and encoding global attention on these keywords, improvement in zero-shot, few-shot, and fine-tuned cases is demonstrated for some benchmark data sets.
+
+
+
+ 17. 【2410.08970】NoVo: Norm Voting off Hallucinations with Attention Heads in Large Language Models
+ 链接:https://arxiv.org/abs/2410.08970
+ 作者:Zheng Yi Ho,Siyuan Liang,Sen Zhang,Yibing Zhan,Dacheng Tao
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, Language Models, Large Language, Hallucinations in Large, remain a major
+ 备注:
+
+ 点击查看摘要
+ Abstract:Hallucinations in Large Language Models (LLMs) remain a major obstacle, particularly in high-stakes applications where factual accuracy is critical. While representation editing and reading methods have made strides in reducing hallucinations, their heavy reliance on specialised tools and training on in-domain samples, makes them difficult to scale and prone to overfitting. This limits their accuracy gains and generalizability to diverse datasets. This paper presents a lightweight method, Norm Voting (NoVo), which harnesses the untapped potential of attention head norms to dramatically enhance factual accuracy in zero-shot multiple-choice questions (MCQs). NoVo begins by automatically selecting truth-correlated head norms with an efficient, inference-only algorithm using only 30 random samples, allowing NoVo to effortlessly scale to diverse datasets. Afterwards, selected head norms are employed in a simple voting algorithm, which yields significant gains in prediction accuracy. On TruthfulQA MC1, NoVo surpasses the current state-of-the-art and all previous methods by an astounding margin -- at least 19 accuracy points. NoVo demonstrates exceptional generalization to 20 diverse datasets, with significant gains in over 90\% of them, far exceeding all current representation editing and reading methods. NoVo also reveals promising gains to finetuning strategies and building textual adversarial defence. NoVo's effectiveness with head norms opens new frontiers in LLM interpretability, robustness and reliability.
+
+
+
+ 18. 【2410.08968】Controllable Safety Alignment: Inference-Time Adaptation to Diverse Safety Requirements
+ 链接:https://arxiv.org/abs/2410.08968
+ 作者:Jingyu Zhang,Ahmed Elgohary,Ahmed Magooda,Daniel Khashabi,Benjamin Van Durme
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:content deemed unsafe, safety, diverse safety, large language models, current paradigm
+ 备注:
+
+ 点击查看摘要
+ Abstract:The current paradigm for safety alignment of large language models (LLMs) follows a one-size-fits-all approach: the model refuses to interact with any content deemed unsafe by the model provider. This approach lacks flexibility in the face of varying social norms across cultures and regions. In addition, users may have diverse safety needs, making a model with static safety standards too restrictive to be useful, as well as too costly to be re-aligned.
+We propose Controllable Safety Alignment (CoSA), a framework designed to adapt models to diverse safety requirements without re-training. Instead of aligning a fixed model, we align models to follow safety configs -- free-form natural language descriptions of the desired safety behaviors -- that are provided as part of the system prompt. To adjust model safety behavior, authorized users only need to modify such safety configs at inference time. To enable that, we propose CoSAlign, a data-centric method for aligning LLMs to easily adapt to diverse safety configs. Furthermore, we devise a novel controllability evaluation protocol that considers both helpfulness and configured safety, summarizing them into CoSA-Score, and construct CoSApien, a human-authored benchmark that consists of real-world LLM use cases with diverse safety requirements and corresponding evaluation prompts.
+We show that CoSAlign leads to substantial gains of controllability over strong baselines including in-context alignment. Our framework encourages better representation and adaptation to pluralistic human values in LLMs, and thereby increasing their practicality.
+
Subjects:
+Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+Cite as:
+arXiv:2410.08968 [cs.CL]
+(or
+arXiv:2410.08968v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2410.08968
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 19. 【2410.08964】Language Imbalance Driven Rewarding for Multilingual Self-improving
+ 链接:https://arxiv.org/abs/2410.08964
+ 作者:Wen Yang,Junhong Wu,Chen Wang,Chengqing Zong,Jiajun Zhang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, Large Language, Language Models, English and Chinese, Imbalance Driven Rewarding
+ 备注: Work in progress
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have achieved state-of-the-art performance across numerous tasks. However, these advancements have predominantly benefited "first-class" languages such as English and Chinese, leaving many other languages underrepresented. This imbalance, while limiting broader applications, generates a natural preference ranking between languages, offering an opportunity to bootstrap the multilingual capabilities of LLM in a self-improving manner. Thus, we propose $\textit{Language Imbalance Driven Rewarding}$, where the inherent imbalance between dominant and non-dominant languages within LLMs is leveraged as a reward signal. Iterative DPO training demonstrates that this approach not only enhances LLM performance in non-dominant languages but also improves the dominant language's capacity, thereby yielding an iterative reward signal. Fine-tuning Meta-Llama-3-8B-Instruct over two iterations of this approach results in continuous improvements in multilingual performance across instruction-following and arithmetic reasoning tasks, evidenced by an average improvement of 7.46% win rate on the X-AlpacaEval leaderboard and 13.9% accuracy on the MGSM benchmark. This work serves as an initial exploration, paving the way for multilingual self-improvement of LLMs.
+
+
+
+ 20. 【2410.08928】owards Cross-Lingual LLM Evaluation for European Languages
+ 链接:https://arxiv.org/abs/2410.08928
+ 作者:Klaudia Thellmann,Bernhard Stadler,Michael Fromm,Jasper Schulze Buschhoff,Alex Jude,Fabio Barth,Johannes Leveling,Nicolas Flores-Herr,Joachim Köhler,René Jäkel,Mehdi Ali
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Large Language Models, rise of Large, revolutionized natural language, natural language processing, Language Models
+ 备注:
+
+ 点击查看摘要
+ Abstract:The rise of Large Language Models (LLMs) has revolutionized natural language processing across numerous languages and tasks. However, evaluating LLM performance in a consistent and meaningful way across multiple European languages remains challenging, especially due to the scarcity of multilingual benchmarks. We introduce a cross-lingual evaluation approach tailored for European languages. We employ translated versions of five widely-used benchmarks to assess the capabilities of 40 LLMs across 21 European languages. Our contributions include examining the effectiveness of translated benchmarks, assessing the impact of different translation services, and offering a multilingual evaluation framework for LLMs that includes newly created datasets: EU20-MMLU, EU20-HellaSwag, EU20-ARC, EU20-TruthfulQA, and EU20-GSM8K. The benchmarks and results are made publicly available to encourage further research in multilingual LLM evaluation.
+
+
+
+ 21. 【2410.08917】AutoPersuade: A Framework for Evaluating and Explaining Persuasive Arguments
+ 链接:https://arxiv.org/abs/2410.08917
+ 作者:Till Raphael Saenger,Musashi Hinck,Justin Grimmer,Brandon M. Stewart
+ 类目:Computation and Language (cs.CL)
+ 关键词:constructing persuasive messages, persuasive messages, three-part framework, framework for constructing, constructing persuasive
+ 备注:
+
+ 点击查看摘要
+ Abstract:We introduce AutoPersuade, a three-part framework for constructing persuasive messages. First, we curate a large dataset of arguments with human evaluations. Next, we develop a novel topic model to identify argument features that influence persuasiveness. Finally, we use this model to predict the effectiveness of new arguments and assess the causal impact of different components to provide explanations. We validate AutoPersuade through an experimental study on arguments for veganism, demonstrating its effectiveness with human studies and out-of-sample predictions.
+
+
+
+ 22. 【2410.08905】Lifelong Event Detection via Optimal Transport
+ 链接:https://arxiv.org/abs/2410.08905
+ 作者:Viet Dao,Van-Cuong Pham,Quyen Tran,Thanh-Thien Le,Linh Ngo Van,Thien Huu Nguyen
+ 类目:Computation and Language (cs.CL)
+ 关键词:coming event types, formidable challenge due, Continual Event Detection, Lifelong Event Detection, Event Detection
+ 备注: Accepted to EMNLP 2024
+
+ 点击查看摘要
+ Abstract:Continual Event Detection (CED) poses a formidable challenge due to the catastrophic forgetting phenomenon, where learning new tasks (with new coming event types) hampers performance on previous ones. In this paper, we introduce a novel approach, Lifelong Event Detection via Optimal Transport (LEDOT), that leverages optimal transport principles to align the optimization of our classification module with the intrinsic nature of each class, as defined by their pre-trained language modeling. Our method integrates replay sets, prototype latent representations, and an innovative Optimal Transport component. Extensive experiments on MAVEN and ACE datasets demonstrate LEDOT's superior performance, consistently outperforming state-of-the-art baselines. The results underscore LEDOT as a pioneering solution in continual event detection, offering a more effective and nuanced approach to addressing catastrophic forgetting in evolving environments.
+
+
+
+ 23. 【2410.08900】A Benchmark for Cross-Domain Argumentative Stance Classification on Social Media
+ 链接:https://arxiv.org/abs/2410.08900
+ 作者:Jiaqing Yuan,Ruijie Xi,Munindar P. Singh
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:stance classification plays, identifying authors' viewpoints, Argumentative stance classification, stance classification, classification plays
+ 备注:
+
+ 点击查看摘要
+ Abstract:Argumentative stance classification plays a key role in identifying authors' viewpoints on specific topics. However, generating diverse pairs of argumentative sentences across various domains is challenging. Existing benchmarks often come from a single domain or focus on a limited set of topics. Additionally, manual annotation for accurate labeling is time-consuming and labor-intensive. To address these challenges, we propose leveraging platform rules, readily available expert-curated content, and large language models to bypass the need for human annotation. Our approach produces a multidomain benchmark comprising 4,498 topical claims and 30,961 arguments from three sources, spanning 21 domains. We benchmark the dataset in fully supervised, zero-shot, and few-shot settings, shedding light on the strengths and limitations of different methodologies. We release the dataset and code in this study at hidden for anonymity.
+
+
+
+ 24. 【2410.08876】RoRA-VLM: Robust Retrieval-Augmented Vision Language Models
+ 链接:https://arxiv.org/abs/2410.08876
+ 作者:Jingyuan Qi,Zhiyang Xu,Rulin Shao,Yang Chen,Jing Di,Yu Cheng,Qifan Wang,Lifu Huang
+ 类目:Computation and Language (cs.CL)
+ 关键词:Current vision-language models, multimodal knowledge snippets, retrieved multimodal knowledge, exhibit inferior performance, Current vision-language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Current vision-language models (VLMs) still exhibit inferior performance on knowledge-intensive tasks, primarily due to the challenge of accurately encoding all the associations between visual objects and scenes to their corresponding entities and background knowledge. While retrieval augmentation methods offer an efficient way to integrate external knowledge, extending them to vision-language domain presents unique challenges in (1) precisely retrieving relevant information from external sources due to the inherent discrepancy within the multimodal queries, and (2) being resilient to the irrelevant, extraneous and noisy information contained in the retrieved multimodal knowledge snippets. In this work, we introduce RORA-VLM, a novel and robust retrieval augmentation framework specifically tailored for VLMs, with two key innovations: (1) a 2-stage retrieval process with image-anchored textual-query expansion to synergistically combine the visual and textual information in the query and retrieve the most relevant multimodal knowledge snippets; and (2) a robust retrieval augmentation method that strengthens the resilience of VLMs against irrelevant information in the retrieved multimodal knowledge by injecting adversarial noises into the retrieval-augmented training process, and filters out extraneous visual information, such as unrelated entities presented in images, via a query-oriented visual token refinement strategy. We conduct extensive experiments to validate the effectiveness and robustness of our proposed methods on three widely adopted benchmark datasets. Our results demonstrate that with a minimal amount of training instance, RORA-VLM enables the base model to achieve significant performance improvement and constantly outperform state-of-the-art retrieval-augmented VLMs on all benchmarks while also exhibiting a novel zero-shot domain transfer capability.
+
+
+
+ 25. 【2410.08860】Audio Description Generation in the Era of LLMs and VLMs: A Review of Transferable Generative AI Technologies
+ 链接:https://arxiv.org/abs/2410.08860
+ 作者:Yingqiang Gao,Lukas Fischer,Alexa Lintner,Sarah Ebling
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:assist blind persons, acoustic commentaries designed, accessing digital media, digital media content, Audio descriptions
+ 备注:
+
+ 点击查看摘要
+ Abstract:Audio descriptions (ADs) function as acoustic commentaries designed to assist blind persons and persons with visual impairments in accessing digital media content on television and in movies, among other settings. As an accessibility service typically provided by trained AD professionals, the generation of ADs demands significant human effort, making the process both time-consuming and costly. Recent advancements in natural language processing (NLP) and computer vision (CV), particularly in large language models (LLMs) and vision-language models (VLMs), have allowed for getting a step closer to automatic AD generation. This paper reviews the technologies pertinent to AD generation in the era of LLMs and VLMs: we discuss how state-of-the-art NLP and CV technologies can be applied to generate ADs and identify essential research directions for the future.
+
+
+
+ 26. 【2410.08851】Measuring the Inconsistency of Large Language Models in Preferential Ranking
+ 链接:https://arxiv.org/abs/2410.08851
+ 作者:Xiutian Zhao,Ke Wang,Wei Peng
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language models', hallucination issues persist, rankings remains underexplored, recent advancements, language models'
+ 备注: In Proceedings of the 1st Workshop on Towards Knowledgeable Language Models (KnowLLM 2024)
+
+ 点击查看摘要
+ Abstract:Despite large language models' (LLMs) recent advancements, their bias and hallucination issues persist, and their ability to offer consistent preferential rankings remains underexplored. This study investigates the capacity of LLMs to provide consistent ordinal preferences, a crucial aspect in scenarios with dense decision space or lacking absolute answers. We introduce a formalization of consistency based on order theory, outlining criteria such as transitivity, asymmetry, reversibility, and independence from irrelevant alternatives. Our diagnostic experiments on selected state-of-the-art LLMs reveal their inability to meet these criteria, indicating a strong positional bias and poor transitivity, with preferences easily swayed by irrelevant alternatives. These findings highlight a significant inconsistency in LLM-generated preferential rankings, underscoring the need for further research to address these limitations.
+
+
+
+ 27. 【2410.08847】Unintentional Unalignment: Likelihood Displacement in Direct Preference Optimization
+ 链接:https://arxiv.org/abs/2410.08847
+ 作者:Noam Razin,Sadhika Malladi,Adithya Bhaskar,Danqi Chen,Sanjeev Arora,Boris Hanin
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (stat.ML)
+ 关键词:Direct Preference Optimization, Direct Preference, Preference Optimization, likelihood displacement, variants are increasingly
+ 备注: Code available at [this https URL](https://github.com/princeton-nlp/unintentional-unalignment)
+
+ 点击查看摘要
+ Abstract:Direct Preference Optimization (DPO) and its variants are increasingly used for aligning language models with human preferences. Although these methods are designed to teach a model to generate preferred responses more frequently relative to dispreferred responses, prior work has observed that the likelihood of preferred responses often decreases during training. The current work sheds light on the causes and implications of this counter-intuitive phenomenon, which we term likelihood displacement. We demonstrate that likelihood displacement can be catastrophic, shifting probability mass from preferred responses to responses with an opposite meaning. As a simple example, training a model to prefer $\texttt{No}$ over $\texttt{Never}$ can sharply increase the probability of $\texttt{Yes}$. Moreover, when aligning the model to refuse unsafe prompts, we show that such displacement can unintentionally lead to unalignment, by shifting probability mass from preferred refusal responses to harmful responses (e.g., reducing the refusal rate of Llama-3-8B-Instruct from 74.4% to 33.4%). We theoretically characterize that likelihood displacement is driven by preferences that induce similar embeddings, as measured by a centered hidden embedding similarity (CHES) score. Empirically, the CHES score enables identifying which training samples contribute most to likelihood displacement in a given dataset. Filtering out these samples effectively mitigated unintentional unalignment in our experiments. More broadly, our results highlight the importance of curating data with sufficiently distinct preferences, for which we believe the CHES score may prove valuable.
+
+
+
+ 28. 【2410.08828】Enhancing Indonesian Automatic Speech Recognition: Evaluating Multilingual Models with Diverse Speech Variabilities
+ 链接:https://arxiv.org/abs/2410.08828
+ 作者:Aulia Adila,Dessi Lestari,Ayu Purwarianti,Dipta Tanaya,Kurniawati Azizah,Sakriani Sakti
+ 类目:Computation and Language (cs.CL); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:background noise conditions, speech, ideal speech recognition, noise conditions, Indonesian
+ 备注:
+
+ 点击查看摘要
+ Abstract:An ideal speech recognition model has the capability to transcribe speech accurately under various characteristics of speech signals, such as speaking style (read and spontaneous), speech context (formal and informal), and background noise conditions (clean and moderate). Building such a model requires a significant amount of training data with diverse speech characteristics. Currently, Indonesian data is dominated by read, formal, and clean speech, leading to a scarcity of Indonesian data with other speech variabilities. To develop Indonesian automatic speech recognition (ASR), we present our research on state-of-the-art speech recognition models, namely Massively Multilingual Speech (MMS) and Whisper, as well as compiling a dataset comprising Indonesian speech with variabilities to facilitate our study. We further investigate the models' predictive ability to transcribe Indonesian speech data across different variability groups. The best results were achieved by the Whisper fine-tuned model across datasets with various characteristics, as indicated by the decrease in word error rate (WER) and character error rate (CER). Moreover, we found that speaking style variability affected model performance the most.
+
+
+
+ 29. 【2410.08821】Retriever-and-Memory: Towards Adaptive Note-Enhanced Retrieval-Augmented Generation
+ 链接:https://arxiv.org/abs/2410.08821
+ 作者:Ruobing Wang,Daren Zha,Shi Yu,Qingfei Zhao,Yuxuan Chen,Yixuan Wang,Shuo Wang,Yukun Yan,Zhenghao Liu,Xu Han,Zhiyuan Liu,Maosong Sun
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Language Models, Large Language, hallucinated outputs generated, open-domain question-answering tasks
+ 备注: 15 pages, 2 figures
+
+ 点击查看摘要
+ Abstract:Retrieval-Augmented Generation (RAG) mitigates issues of the factual errors and hallucinated outputs generated by Large Language Models (LLMs) in open-domain question-answering tasks (OpenQA) via introducing external knowledge. For complex QA, however, existing RAG methods use LLMs to actively predict retrieval timing and directly use the retrieved information for generation, regardless of whether the retrieval timing accurately reflects the actual information needs, or sufficiently considers prior retrieved knowledge, which may result in insufficient information gathering and interaction, yielding low-quality answers. To address these, we propose a generic RAG approach called Adaptive Note-Enhanced RAG (Adaptive-Note) for complex QA tasks, which includes the iterative information collector, adaptive memory reviewer, and task-oriented generator, while following a new Retriever-and-Memory paradigm. Specifically, Adaptive-Note introduces an overarching view of knowledge growth, iteratively gathering new information in the form of notes and updating them into the existing optimal knowledge structure, enhancing high-quality knowledge interactions. In addition, we employ an adaptive, note-based stop-exploration strategy to decide "what to retrieve and when to stop" to encourage sufficient knowledge exploration. We conduct extensive experiments on five complex QA datasets, and the results demonstrate the superiority and effectiveness of our method and its components. The code and data are at this https URL.
+
+
+
+ 30. 【2410.08820】Which Demographics do LLMs Default to During Annotation?
+ 链接:https://arxiv.org/abs/2410.08820
+ 作者:Christopher Bagdon,Aidan Combs,Lynn Greschner,Roman Klinger,Jiahui Li,Sean Papay,Nadine Probol,Yarik Menchaca Resendiz,Johannes Schäfer,Aswathy Velutharambath,Sabine Weber,Amelie Wührl
+ 类目:Computation and Language (cs.CL)
+ 关键词:woman might find, find it offensive, teenager might find, cultural background, assign in text
+ 备注:
+
+ 点击查看摘要
+ Abstract:Demographics and cultural background of annotators influence the labels they assign in text annotation -- for instance, an elderly woman might find it offensive to read a message addressed to a "bro", but a male teenager might find it appropriate. It is therefore important to acknowledge label variations to not under-represent members of a society. Two research directions developed out of this observation in the context of using large language models (LLM) for data annotations, namely (1) studying biases and inherent knowledge of LLMs and (2) injecting diversity in the output by manipulating the prompt with demographic information. We combine these two strands of research and ask the question to which demographics an LLM resorts to when no demographics is given. To answer this question, we evaluate which attributes of human annotators LLMs inherently mimic. Furthermore, we compare non-demographic conditioned prompts and placebo-conditioned prompts (e.g., "you are an annotator who lives in house number 5") to demographics-conditioned prompts ("You are a 45 year old man and an expert on politeness annotation. How do you rate {instance}"). We study these questions for politeness and offensiveness annotations on the POPQUORN data set, a corpus created in a controlled manner to investigate human label variations based on demographics which has not been used for LLM-based analyses so far. We observe notable influences related to gender, race, and age in demographic prompting, which contrasts with previous studies that found no such effects.
+
+
+
+ 31. 【2410.08815】StructRAG: Boosting Knowledge Intensive Reasoning of LLMs via Inference-time Hybrid Information Structurization
+ 链接:https://arxiv.org/abs/2410.08815
+ 作者:Zhuoqun Li,Xuanang Chen,Haiyang Yu,Hongyu Lin,Yaojie Lu,Qiaoyu Tang,Fei Huang,Xianpei Han,Le Sun,Yongbin Li
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:large language models, effectively enhance large, enhance large language, Retrieval-augmented generation, existing RAG methods
+ 备注:
+
+ 点击查看摘要
+ Abstract:Retrieval-augmented generation (RAG) is a key means to effectively enhance large language models (LLMs) in many knowledge-based tasks. However, existing RAG methods struggle with knowledge-intensive reasoning tasks, because useful information required to these tasks are badly scattered. This characteristic makes it difficult for existing RAG methods to accurately identify key information and perform global reasoning with such noisy augmentation. In this paper, motivated by the cognitive theories that humans convert raw information into various structured knowledge when tackling knowledge-intensive reasoning, we proposes a new framework, StructRAG, which can identify the optimal structure type for the task at hand, reconstruct original documents into this structured format, and infer answers based on the resulting structure. Extensive experiments across various knowledge-intensive tasks show that StructRAG achieves state-of-the-art performance, particularly excelling in challenging scenarios, demonstrating its potential as an effective solution for enhancing LLMs in complex real-world applications.
+
+
+
+ 32. 【2410.08814】A Social Context-aware Graph-based Multimodal Attentive Learning Framework for Disaster Content Classification during Emergencies
+ 链接:https://arxiv.org/abs/2410.08814
+ 作者:Shahid Shafi Dar,Mohammad Zia Ur Rehman,Karan Bais,Mohammed Abdul Haseeb,Nagendra Kumara
+ 类目:Computers and Society (cs.CY); Computation and Language (cs.CL)
+ 关键词:social media platforms, effective disaster response, times of crisis, public safety, prompt and precise
+ 备注:
+
+ 点击查看摘要
+ Abstract:In times of crisis, the prompt and precise classification of disaster-related information shared on social media platforms is crucial for effective disaster response and public safety. During such critical events, individuals use social media to communicate, sharing multimodal textual and visual content. However, due to the significant influx of unfiltered and diverse data, humanitarian organizations face challenges in leveraging this information efficiently. Existing methods for classifying disaster-related content often fail to model users' credibility, emotional context, and social interaction information, which are essential for accurate classification. To address this gap, we propose CrisisSpot, a method that utilizes a Graph-based Neural Network to capture complex relationships between textual and visual modalities, as well as Social Context Features to incorporate user-centric and content-centric information. We also introduce Inverted Dual Embedded Attention (IDEA), which captures both harmonious and contrasting patterns within the data to enhance multimodal interactions and provide richer insights. Additionally, we present TSEqD (Turkey-Syria Earthquake Dataset), a large annotated dataset for a single disaster event, containing 10,352 samples. Through extensive experiments, CrisisSpot demonstrated significant improvements, achieving an average F1-score gain of 9.45% and 5.01% compared to state-of-the-art methods on the publicly available CrisisMMD dataset and the TSEqD dataset, respectively.
+
+
+
+ 33. 【2410.08811】PoisonBench: Assessing Large Language Model Vulnerability to Data Poisoning
+ 链接:https://arxiv.org/abs/2410.08811
+ 作者:Tingchen Fu,Mrinank Sharma,Philip Torr,Shay B. Cohen,David Krueger,Fazl Barez
+ 类目:Cryptography and Security (cs.CR); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:aligning current LLMs, Preference learning, data poisoning, data poisoning attacks, central component
+ 备注: Tingchen Fu and Fazl Barez are core research contributors
+
+ 点击查看摘要
+ Abstract:Preference learning is a central component for aligning current LLMs, but this process can be vulnerable to data poisoning attacks. To address this concern, we introduce PoisonBench, a benchmark for evaluating large language models' susceptibility to data poisoning during preference learning. Data poisoning attacks can manipulate large language model responses to include hidden malicious content or biases, potentially causing the model to generate harmful or unintended outputs while appearing to function normally. We deploy two distinct attack types across eight realistic scenarios, assessing 21 widely-used models. Our findings reveal concerning trends: (1) Scaling up parameter size does not inherently enhance resilience against poisoning attacks; (2) There exists a log-linear relationship between the effects of the attack and the data poison ratio; (3) The effect of data poisoning can generalize to extrapolated triggers that are not included in the poisoned data. These results expose weaknesses in current preference learning techniques, highlighting the urgent need for more robust defenses against malicious models and data manipulation.
+
+
+
+ 34. 【2410.08800】Data Processing for the OpenGPT-X Model Family
+ 链接:https://arxiv.org/abs/2410.08800
+ 作者:Nicolo' Brandizzi,Hammam Abdelwahab,Anirban Bhowmick,Lennard Helmer,Benny Jörg Stein,Pavel Denisov,Qasid Saleem,Michael Fromm,Mehdi Ali,Richard Rutmann,Farzad Naderi,Mohamad Saif Agy,Alexander Schwirjow,Fabian Küch,Luzian Hahn,Malte Ostendorff,Pedro Ortiz Suarez,Georg Rehm,Dennis Wegener,Nicolas Flores-Herr,Joachim Köhler,Johannes Leveling
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language models, large-scale initiative aimed, high-performance multilingual large, multilingual large language, paper presents
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper presents a comprehensive overview of the data preparation pipeline developed for the OpenGPT-X project, a large-scale initiative aimed at creating open and high-performance multilingual large language models (LLMs). The project goal is to deliver models that cover all major European languages, with a particular focus on real-world applications within the European Union. We explain all data processing steps, starting with the data selection and requirement definition to the preparation of the final datasets for model training. We distinguish between curated data and web data, as each of these categories is handled by distinct pipelines, with curated data undergoing minimal filtering and web data requiring extensive filtering and deduplication. This distinction guided the development of specialized algorithmic solutions for both pipelines. In addition to describing the processing methodologies, we provide an in-depth analysis of the datasets, increasing transparency and alignment with European data regulations. Finally, we share key insights and challenges faced during the project, offering recommendations for future endeavors in large-scale multilingual data preparation for LLMs.
+
+
+
+ 35. 【2410.08793】On the State of NLP Approaches to Modeling Depression in Social Media: A Post-COVID-19 Outlook
+ 链接:https://arxiv.org/abs/2410.08793
+ 作者:Ana-Maria Bucur,Andreea-Codrina Moldovan,Krutika Parvatikar,Marcos Zampieri,Ashiqur R. KhudaBukhsh,Liviu P. Dinu
+ 类目:Computation and Language (cs.CL)
+ 关键词:mental health conditions, predicting mental health, mental health, Computational approaches, past years
+ 备注:
+
+ 点击查看摘要
+ Abstract:Computational approaches to predicting mental health conditions in social media have been substantially explored in the past years. Multiple surveys have been published on this topic, providing the community with comprehensive accounts of the research in this area. Among all mental health conditions, depression is the most widely studied due to its worldwide prevalence. The COVID-19 global pandemic, starting in early 2020, has had a great impact on mental health worldwide. Harsh measures employed by governments to slow the spread of the virus (e.g., lockdowns) and the subsequent economic downturn experienced in many countries have significantly impacted people's lives and mental health. Studies have shown a substantial increase of above 50% in the rate of depression in the population. In this context, we present a survey on natural language processing (NLP) approaches to modeling depression in social media, providing the reader with a post-COVID-19 outlook. This survey contributes to the understanding of the impacts of the pandemic on modeling depression in social media. We outline how state-of-the-art approaches and new datasets have been used in the context of the COVID-19 pandemic. Finally, we also discuss ethical issues in collecting and processing mental health data, considering fairness, accountability, and ethics.
+
+
+
+ 36. 【2410.08766】Integrating Supertag Features into Neural Discontinuous Constituent Parsing
+ 链接:https://arxiv.org/abs/2410.08766
+ 作者:Lukas Mielczarek
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Formal Languages and Automata Theory (cs.FL)
+ 关键词:natural-language processing, essential in natural-language, widely used description, parsing, DPTB for English
+ 备注: Bachelor's Thesis. Supervised by Dr. Kilian Evang and Univ.-Prof. Dr. Laura Kallmeyer
+
+ 点击查看摘要
+ Abstract:Syntactic parsing is essential in natural-language processing, with constituent structure being one widely used description of syntax. Traditional views of constituency demand that constituents consist of adjacent words, but this poses challenges in analysing syntax with non-local dependencies, common in languages like German. Therefore, in a number of treebanks like NeGra and TIGER for German and DPTB for English, long-range dependencies are represented by crossing edges. Various grammar formalisms have been used to describe discontinuous trees - often with high time complexities for parsing. Transition-based parsing aims at reducing this factor by eliminating the need for an explicit grammar. Instead, neural networks are trained to produce trees given raw text input using supervised learning on large annotated corpora. An elegant proposal for a stack-free transition-based parser developed by Coavoux and Cohen (2019) successfully allows for the derivation of any discontinuous constituent tree over a sentence in worst-case quadratic time.
+The purpose of this work is to explore the introduction of supertag information into transition-based discontinuous constituent parsing. In lexicalised grammar formalisms like CCG (Steedman, 1989) informative categories are assigned to the words in a sentence and act as the building blocks for composing the sentence's syntax. These supertags indicate a word's structural role and syntactic relationship with surrounding items. The study examines incorporating supertag information by using a dedicated supertagger as additional input for a neural parser (pipeline) and by jointly training a neural model for both parsing and supertagging (multi-task). In addition to CCG, several other frameworks (LTAG-spinal, LCFRS) and sequence labelling tasks (chunking, dependency parsing) will be compared in terms of their suitability as auxiliary tasks for parsing.
+
Comments:
+Bachelor’s Thesis. Supervised by Dr. Kilian Evang and Univ.-Prof. Dr. Laura Kallmeyer
+Subjects:
+Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Formal Languages and Automata Theory (cs.FL)
+Cite as:
+arXiv:2410.08766 [cs.CL]
+(or
+arXiv:2410.08766v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2410.08766
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 37. 【2410.08764】Measuring the Groundedness of Legal Question-Answering Systems
+ 链接:https://arxiv.org/abs/2410.08764
+ 作者:Dietrich Trautmann,Natalia Ostapuk,Quentin Grail,Adrian Alan Pol,Guglielmo Bonifazi,Shang Gao,Martin Gajek
+ 类目:Computation and Language (cs.CL)
+ 关键词:paramount importance, high-stakes domains, legal question-answering, generative AI systems, responses
+ 备注: to appear NLLP @ EMNLP 2024
+
+ 点击查看摘要
+ Abstract:In high-stakes domains like legal question-answering, the accuracy and trustworthiness of generative AI systems are of paramount importance. This work presents a comprehensive benchmark of various methods to assess the groundedness of AI-generated responses, aiming to significantly enhance their reliability. Our experiments include similarity-based metrics and natural language inference models to evaluate whether responses are well-founded in the given contexts. We also explore different prompting strategies for large language models to improve the detection of ungrounded responses. We validated the effectiveness of these methods using a newly created grounding classification corpus, designed specifically for legal queries and corresponding responses from retrieval-augmented prompting, focusing on their alignment with source material. Our results indicate potential in groundedness classification of generated responses, with the best method achieving a macro-F1 score of 0.8. Additionally, we evaluated the methods in terms of their latency to determine their suitability for real-world applications, as this step typically follows the generation process. This capability is essential for processes that may trigger additional manual verification or automated response regeneration. In summary, this study demonstrates the potential of various detection methods to improve the trustworthiness of generative AI in legal settings.
+
+
+
+ 38. 【2410.08731】Developing a Pragmatic Benchmark for Assessing Korean Legal Language Understanding in Large Language Models
+ 链接:https://arxiv.org/abs/2410.08731
+ 作者:Yeeun Kim,Young Rok Choi,Eunkyung Choi,Jinhwan Choi,Hai Jin Park,Wonseok Hwang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Uniform Bar Exam, Large language models, demonstrated remarkable performance, efficacy remains limited, passing the Uniform
+ 备注: EMNLP 2024 Findings
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) have demonstrated remarkable performance in the legal domain, with GPT-4 even passing the Uniform Bar Exam in the U.S. However their efficacy remains limited for non-standardized tasks and tasks in languages other than English. This underscores the need for careful evaluation of LLMs within each legal system before application. Here, we introduce KBL, a benchmark for assessing the Korean legal language understanding of LLMs, consisting of (1) 7 legal knowledge tasks (510 examples), (2) 4 legal reasoning tasks (288 examples), and (3) the Korean bar exam (4 domains, 53 tasks, 2,510 examples). First two datasets were developed in close collaboration with lawyers to evaluate LLMs in practical scenarios in a certified manner. Furthermore, considering legal practitioners' frequent use of extensive legal documents for research, we assess LLMs in both a closed book setting, where they rely solely on internal knowledge, and a retrieval-augmented generation (RAG) setting, using a corpus of Korean statutes and precedents. The results indicate substantial room and opportunities for improvement.
+
+
+
+ 39. 【2410.08728】From N-grams to Pre-trained Multilingual Models For Language Identification
+ 链接:https://arxiv.org/abs/2410.08728
+ 作者:Thapelo Sindane,Vukosi Marivate
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:South African languages, Large Pre-trained Multilingual, South African, Pre-trained Multilingual models, African languages
+ 备注: The paper has been accepted at The 4th International Conference on Natural Language Processing for Digital Humanities (NLP4DH 2024)
+
+ 点击查看摘要
+ Abstract:In this paper, we investigate the use of N-gram models and Large Pre-trained Multilingual models for Language Identification (LID) across 11 South African languages. For N-gram models, this study shows that effective data size selection remains crucial for establishing effective frequency distributions of the target languages, that efficiently model each language, thus, improving language ranking. For pre-trained multilingual models, we conduct extensive experiments covering a diverse set of massively pre-trained multilingual (PLM) models -- mBERT, RemBERT, XLM-r, and Afri-centric multilingual models -- AfriBERTa, Afro-XLMr, AfroLM, and Serengeti. We further compare these models with available large-scale Language Identification tools: Compact Language Detector v3 (CLD V3), AfroLID, GlotLID, and OpenLID to highlight the importance of focused-based LID. From these, we show that Serengeti is a superior model across models: N-grams to Transformers on average. Moreover, we propose a lightweight BERT-based LID model (za_BERT_lid) trained with NHCLT + Vukzenzele corpus, which performs on par with our best-performing Afri-centric models.
+
+
+
+ 40. 【2410.08703】On the token distance modeling ability of higher RoPE attention dimension
+ 链接:https://arxiv.org/abs/2410.08703
+ 作者:Xiangyu Hong,Che Jiang,Biqing Qi,Fandong Meng,Mo Yu,Bowen Zhou,Jie Zhou
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Rotary position embedding, shown promising results, Rotary position, based on Rotary, position embedding
+ 备注:
+
+ 点击查看摘要
+ Abstract:Length extrapolation algorithms based on Rotary position embedding (RoPE) have shown promising results in extending the context length of language models. However, understanding how position embedding can capture longer-range contextual information remains elusive. Based on the intuition that different dimensions correspond to different frequency of changes in RoPE encoding, we conducted a dimension-level analysis to investigate the correlation between a hidden dimension of an attention head and its contribution to capturing long-distance dependencies. Using our correlation metric, we identified a particular type of attention heads, which we named Positional Heads, from various length-extrapolated models. These heads exhibit a strong focus on long-range information interaction and play a pivotal role in long input processing, as evidence by our ablation. We further demonstrate the correlation between the efficiency of length extrapolation and the extension of the high-dimensional attention allocation of these heads. The identification of Positional Heads provides insights for future research in long-text comprehension.
+
+
+
+ 41. 【2410.08698】SocialGaze: Improving the Integration of Human Social Norms in Large Language Models
+ 链接:https://arxiv.org/abs/2410.08698
+ 作者:Anvesh Rao Vijjini,Rakesh R. Menon,Jiayi Fu,Shashank Srivastava,Snigdha Chaturvedi
+ 类目:Computation and Language (cs.CL); Computers and Society (cs.CY)
+ 关键词:research has explored, explored enhancing, enhancing the reasoning, reasoning capabilities, capabilities of large
+ 备注:
+
+ 点击查看摘要
+ Abstract:While much research has explored enhancing the reasoning capabilities of large language models (LLMs) in the last few years, there is a gap in understanding the alignment of these models with social values and norms. We introduce the task of judging social acceptance. Social acceptance requires models to judge and rationalize the acceptability of people's actions in social situations. For example, is it socially acceptable for a neighbor to ask others in the community to keep their pets indoors at night? We find that LLMs' understanding of social acceptance is often misaligned with human consensus. To alleviate this, we introduce SocialGaze, a multi-step prompting framework, in which a language model verbalizes a social situation from multiple perspectives before forming a judgment. Our experiments demonstrate that the SocialGaze approach improves the alignment with human judgments by up to 11 F1 points with the GPT-3.5 model. We also identify biases and correlations in LLMs in assigning blame that is related to features such as the gender (males are significantly more likely to be judged unfairly) and age (LLMs are more aligned with humans for older narrators).
+
+
+
+ 42. 【2410.08696】AMPO: Automatic Multi-Branched Prompt Optimization
+ 链接:https://arxiv.org/abs/2410.08696
+ 作者:Sheng Yang,Yurong Wu,Yan Gao,Zineng Zhou,Bin Benjamin Zhu,Xiaodi Sun,Jian-Guang Lou,Zhiming Ding,Anbang Hu,Yuan Fang,Yunsong Li,Junyan Chen,Linjun Yang
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language models, language models, important to enhance, enhance the performance, performance of large
+ 备注: 13 pages, 7 figures, 6 tables
+
+ 点击查看摘要
+ Abstract:Prompt engineering is very important to enhance the performance of large language models (LLMs). When dealing with complex issues, prompt engineers tend to distill multiple patterns from examples and inject relevant solutions to optimize the prompts, achieving satisfying results. However, existing automatic prompt optimization techniques are only limited to producing single flow instructions, struggling with handling diverse patterns. In this paper, we present AMPO, an automatic prompt optimization method that can iteratively develop a multi-branched prompt using failure cases as feedback. Our goal is to explore a novel way of structuring prompts with multi-branches to better handle multiple patterns in complex tasks, for which we introduce three modules: Pattern Recognition, Branch Adjustment, and Branch Pruning. In experiments across five tasks, AMPO consistently achieves the best results. Additionally, our approach demonstrates significant optimization efficiency due to our adoption of a minimal search strategy.
+
+
+
+ 43. 【2410.08674】Guidelines for Fine-grained Sentence-level Arabic Readability Annotation
+ 链接:https://arxiv.org/abs/2410.08674
+ 作者:Nizar Habash,Hanada Taha-Thomure,Khalid N. Elmadani,Zeina Zeino,Abdallah Abushmaes
+ 类目:Computation and Language (cs.CL)
+ 关键词:Arabic Readability Evaluation, Readability Evaluation Corpus, Balanced Arabic Readability, Arabic language resources, language resources aligned
+ 备注: 16 pages, 3 figures
+
+ 点击查看摘要
+ Abstract:This paper presents the foundational framework and initial findings of the Balanced Arabic Readability Evaluation Corpus (BAREC) project, designed to address the need for comprehensive Arabic language resources aligned with diverse readability levels. Inspired by the Taha/Arabi21 readability reference, BAREC aims to provide a standardized reference for assessing sentence-level Arabic text readability across 19 distinct levels, ranging in targets from kindergarten to postgraduate comprehension. Our ultimate goal with BAREC is to create a comprehensive and balanced corpus that represents a wide range of genres, topics, and regional variations through a multifaceted approach combining manual annotation with AI-driven tools. This paper focuses on our meticulous annotation guidelines, demonstrated through the analysis of 10,631 sentences/phrases (113,651 words). The average pairwise inter-annotator agreement, measured by Quadratic Weighted Kappa, is 79.9%, reflecting a high level of substantial agreement. We also report competitive results for benchmarking automatic readability assessment. We will make the BAREC corpus and guidelines openly accessible to support Arabic language research and education.
+
+
+
+ 44. 【2410.08661】QEFT: Quantization for Efficient Fine-Tuning of LLMs
+ 链接:https://arxiv.org/abs/2410.08661
+ 作者:Changhun Lee,Jun-gyu Jin,Younghyun Cho,Eunhyeok Park
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:large language models, keeping inference efficient, highly important, rapid growth, large language
+ 备注: Accepted at Findings of EMNLP 2024
+
+ 点击查看摘要
+ Abstract:With the rapid growth in the use of fine-tuning for large language models (LLMs), optimizing fine-tuning while keeping inference efficient has become highly important. However, this is a challenging task as it requires improvements in all aspects, including inference speed, fine-tuning speed, memory consumption, and, most importantly, model quality. Previous studies have attempted to achieve this by combining quantization with fine-tuning, but they have failed to enhance all four aspects simultaneously. In this study, we propose a new lightweight technique called Quantization for Efficient Fine-Tuning (QEFT). QEFT accelerates both inference and fine-tuning, is supported by robust theoretical foundations, offers high flexibility, and maintains good hardware compatibility. Our extensive experiments demonstrate that QEFT matches the quality and versatility of full-precision parameter-efficient fine-tuning, while using fewer resources. Our code is available at this https URL.
+
+
+
+ 45. 【2410.08642】More than Memes: A Multimodal Topic Modeling Approach to Conspiracy Theories on Telegram
+ 链接:https://arxiv.org/abs/2410.08642
+ 作者:Elisabeth Steffen
+ 类目:ocial and Information Networks (cs.SI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:German-language Telegram channels, related content online, conspiracy theories, German-language Telegram, traditionally focused
+ 备注: 11 pages, 11 figures
+
+ 点击查看摘要
+ Abstract:Research on conspiracy theories and related content online has traditionally focused on textual data. To address the increasing prevalence of (audio-)visual data on social media, and to capture the evolving and dynamic nature of this communication, researchers have begun to explore the potential of unsupervised approaches for analyzing multimodal online content. Our research contributes to this field by exploring the potential of multimodal topic modeling for analyzing conspiracy theories in German-language Telegram channels. Our work uses the BERTopic topic modeling approach in combination with CLIP for the analysis of textual and visual data. We analyze a corpus of ~40, 000 Telegram messages posted in October 2023 in 571 German-language Telegram channels known for disseminating conspiracy theories and other deceptive content. We explore the potentials and challenges of this approach for studying a medium-sized corpus of user-generated, text-image online content. We offer insights into the dominant topics across modalities, different text and image genres discovered during the analysis, quantitative inter-modal topic analyses, and a qualitative case study of textual, visual, and multimodal narrative strategies in the communication of conspiracy theories.
+
+
+
+ 46. 【2410.08632】Words as Beacons: Guiding RL Agents with High-Level Language Prompts
+ 链接:https://arxiv.org/abs/2410.08632
+ 作者:Unai Ruiz-Gonzalez,Alain Andres,Pedro G.Bascoy,Javier Del Ser
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:pose significant challenges, Large Language Models, incomplete learning processes, leverages Large Language, pose significant
+ 备注:
+
+ 点击查看摘要
+ Abstract:Sparse reward environments in reinforcement learning (RL) pose significant challenges for exploration, often leading to inefficient or incomplete learning processes. To tackle this issue, this work proposes a teacher-student RL framework that leverages Large Language Models (LLMs) as "teachers" to guide the agent's learning process by decomposing complex tasks into subgoals. Due to their inherent capability to understand RL environments based on a textual description of structure and purpose, LLMs can provide subgoals to accomplish the task defined for the environment in a similar fashion to how a human would do. In doing so, three types of subgoals are proposed: positional targets relative to the agent, object representations, and language-based instructions generated directly by the LLM. More importantly, we show that it is possible to query the LLM only during the training phase, enabling agents to operate within the environment without any LLM intervention. We assess the performance of this proposed framework by evaluating three state-of-the-art open-source LLMs (Llama, DeepSeek, Qwen) eliciting subgoals across various procedurally generated environment of the MiniGrid benchmark. Experimental results demonstrate that this curriculum-based approach accelerates learning and enhances exploration in complex tasks, achieving up to 30 to 200 times faster convergence in training steps compared to recent baselines designed for sparse reward environments.
+
+
+
+ 47. 【2410.08623】Retrieving Contextual Information for Long-Form Question Answering using Weak Supervision
+ 链接:https://arxiv.org/abs/2410.08623
+ 作者:Philipp Christmann,Svitlana Vakulenko,Ionut Teodor Sorodoc,Bill Byrne,Adrià de Gispert
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:aims at generating, generating in-depth answers, generating in-depth, Long-form question answering, providing relevant information
+ 备注: Accepted at EMNLP 2024 (Findings)
+
+ 点击查看摘要
+ Abstract:Long-form question answering (LFQA) aims at generating in-depth answers to end-user questions, providing relevant information beyond the direct answer. However, existing retrievers are typically optimized towards information that directly targets the question, missing out on such contextual information. Furthermore, there is a lack of training data for relevant context. To this end, we propose and compare different weak supervision techniques to optimize retrieval for contextual information. Experiments demonstrate improvements on the end-to-end QA performance on ASQA, a dataset for long-form question answering. Importantly, as more contextual information is retrieved, we improve the relevant page recall for LFQA by 14.7% and the groundedness of generated long-form answers by 12.5%. Finally, we show that long-form answers often anticipate likely follow-up questions, via experiments on a conversational QA dataset.
+
+
+
+ 48. 【2410.08601】StraGo: Harnessing Strategic Guidance for Prompt Optimization
+ 链接:https://arxiv.org/abs/2410.08601
+ 作者:Yurong Wu,Yan Gao,Bin Benjamin Zhu,Zineng Zhou,Xiaodi Sun,Sheng Yang,Jian-Guang Lou,Zhiming Ding,Linjun Yang
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language models, prompt optimization, engineering is pivotal, pivotal for harnessing, Prompt
+ 备注: 19 pages, 3 figures, 20 tables
+
+ 点击查看摘要
+ Abstract:Prompt engineering is pivotal for harnessing the capabilities of large language models (LLMs) across diverse applications. While existing prompt optimization methods improve prompt effectiveness, they often lead to prompt drifting, where newly generated prompts can adversely impact previously successful cases while addressing failures. Furthermore, these methods tend to rely heavily on LLMs' intrinsic capabilities for prompt optimization tasks. In this paper, we introduce StraGo (Strategic-Guided Optimization), a novel approach designed to mitigate prompt drifting by leveraging insights from both successful and failed cases to identify critical factors for achieving optimization objectives. StraGo employs a how-to-do methodology, integrating in-context learning to formulate specific, actionable strategies that provide detailed, step-by-step guidance for prompt optimization. Extensive experiments conducted across a range of tasks, including reasoning, natural language understanding, domain-specific knowledge, and industrial applications, demonstrate StraGo's superior performance. It establishes a new state-of-the-art in prompt optimization, showcasing its ability to deliver stable and effective prompt improvements.
+
+
+
+ 49. 【2410.08598】Parameter-Efficient Fine-Tuning of Large Language Models using Semantic Knowledge Tuning
+ 链接:https://arxiv.org/abs/2410.08598
+ 作者:Nusrat Jahan Prottasha,Asif Mahmud,Md. Shohanur Islam Sobuj,Prakash Bhat,Md Kowsher,Niloofar Yousefi,Ozlem Ozmen Garibay
+ 类目:Computation and Language (cs.CL)
+ 关键词:low computational cost, gaining significant popularity, Large Language Models, Large Language, computational cost
+ 备注: Accepted in Nature Scientific Reports
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) are gaining significant popularity in recent years for specialized tasks using prompts due to their low computational cost. Standard methods like prefix tuning utilize special, modifiable tokens that lack semantic meaning and require extensive training for best performance, often falling short. In this context, we propose a novel method called Semantic Knowledge Tuning (SK-Tuning) for prompt and prefix tuning that employs meaningful words instead of random tokens. This method involves using a fixed LLM to understand and process the semantic content of the prompt through zero-shot capabilities. Following this, it integrates the processed prompt with the input text to improve the model's performance on particular tasks. Our experimental results show that SK-Tuning exhibits faster training times, fewer parameters, and superior performance on tasks such as text classification and understanding compared to other tuning methods. This approach offers a promising method for optimizing the efficiency and effectiveness of LLMs in processing language tasks.
+
+
+
+ 50. 【2410.08565】Baichuan-Omni Technical Report
+ 链接:https://arxiv.org/abs/2410.08565
+ 作者:Yadong Li,Haoze Sun,Mingan Lin,Tianpeng Li,Guosheng Dong,Tao Zhang,Bowen Ding,Wei Song,Zhenglin Cheng,Yuqi Huo,Song Chen,Xu Li,Da Pan,Shusen Zhang,Xin Wu,Zheng Liang,Jun Liu,Tao Zhang,Keer Lu,Yaqi Zhao,Yanjun Shen,Fan Yang,Kaicheng Yu,Tao Lin,Jianhua Xu,Zenan Zhou,Weipeng Chen
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:high-performing open-source counterpart, salient multimodal capabilities, Large Language Model, multimodal interactive experience, Multimodal Large Language
+ 备注:
+
+ 点击查看摘要
+ Abstract:The salient multimodal capabilities and interactive experience of GPT-4o highlight its critical role in practical applications, yet it lacks a high-performing open-source counterpart. In this paper, we introduce Baichuan-Omni, the first open-source 7B Multimodal Large Language Model (MLLM) adept at concurrently processing and analyzing modalities of image, video, audio, and text, while delivering an advanced multimodal interactive experience and strong performance. We propose an effective multimodal training schema starting with 7B model and proceeding through two stages of multimodal alignment and multitask fine-tuning across audio, image, video, and text modal. This approach equips the language model with the ability to handle visual and audio data effectively. Demonstrating strong performance across various omni-modal and multimodal benchmarks, we aim for this contribution to serve as a competitive baseline for the open-source community in advancing multimodal understanding and real-time interaction.
+
+
+
+ 51. 【2410.08564】Similar Phrases for Cause of Actions of Civil Cases
+ 链接:https://arxiv.org/abs/2410.08564
+ 作者:Ho-Chien Huang,Chao-Lin Liu
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Taiwanese judicial system, Taiwanese judicial, relevant legal judgments, identifying relevant legal, judicial system
+ 备注: 10 pages, 4 figures, 3 tables(including appendix)
+
+ 点击查看摘要
+ Abstract:In the Taiwanese judicial system, Cause of Actions (COAs) are essential for identifying relevant legal judgments. However, the lack of standardized COA labeling creates challenges in filtering cases using basic methods. This research addresses this issue by leveraging embedding and clustering techniques to analyze the similarity between COAs based on cited legal articles. The study implements various similarity measures, including Dice coefficient and Pearson's correlation coefficient. An ensemble model combines rankings, and social network analysis identifies clusters of related COAs. This approach enhances legal analysis by revealing inconspicuous connections between COAs, offering potential applications in legal research beyond civil law.
+
+
+
+ 52. 【2410.08553】Balancing Innovation and Privacy: Data Security Strategies in Natural Language Processing Applications
+ 链接:https://arxiv.org/abs/2410.08553
+ 作者:Shaobo Liu,Guiran Liu,Binrong Zhu,Yuanshuai Luo,Linxiao Wu,Rui Wang
+ 类目:Cryptography and Security (cs.CR); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Natural Language Processing, Natural Language, Language Processing, privacy, privacy protection
+ 备注:
+
+ 点击查看摘要
+ Abstract:This research addresses privacy protection in Natural Language Processing (NLP) by introducing a novel algorithm based on differential privacy, aimed at safeguarding user data in common applications such as chatbots, sentiment analysis, and machine translation. With the widespread application of NLP technology, the security and privacy protection of user data have become important issues that need to be solved urgently. This paper proposes a new privacy protection algorithm designed to effectively prevent the leakage of user sensitive information. By introducing a differential privacy mechanism, our model ensures the accuracy and reliability of data analysis results while adding random noise. This method not only reduces the risk caused by data leakage but also achieves effective processing of data while protecting user privacy. Compared to traditional privacy methods like data anonymization and homomorphic encryption, our approach offers significant advantages in terms of computational efficiency and scalability while maintaining high accuracy in data analysis. The proposed algorithm's efficacy is demonstrated through performance metrics such as accuracy (0.89), precision (0.85), and recall (0.88), outperforming other methods in balancing privacy and utility. As privacy protection regulations become increasingly stringent, enterprises and developers must take effective measures to deal with privacy risks. Our research provides an important reference for the application of privacy protection technology in the field of NLP, emphasizing the need to achieve a balance between technological innovation and user privacy. In the future, with the continuous advancement of technology, privacy protection will become a core element of data-driven applications and promote the healthy development of the entire industry.
+
+
+
+ 53. 【2410.08545】Humanity in AI: Detecting the Personality of Large Language Models
+ 链接:https://arxiv.org/abs/2410.08545
+ 作者:Baohua Zhan,Yongyi Huang,Wenyao Cui,Huaping Zhang,Jianyun Shang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, Large Language, Language Models, personality, Large
+ 备注:
+
+ 点击查看摘要
+ Abstract:Questionnaires are a common method for detecting the personality of Large Language Models (LLMs). However, their reliability is often compromised by two main issues: hallucinations (where LLMs produce inaccurate or irrelevant responses) and the sensitivity of responses to the order of the presented options. To address these issues, we propose combining text mining with questionnaires method. Text mining can extract psychological features from the LLMs' responses without being affected by the order of options. Furthermore, because this method does not rely on specific answers, it reduces the influence of hallucinations. By normalizing the scores from both methods and calculating the root mean square error, our experiment results confirm the effectiveness of this approach. To further investigate the origins of personality traits in LLMs, we conduct experiments on both pre-trained language models (PLMs), such as BERT and GPT, as well as conversational models (ChatLLMs), such as ChatGPT. The results show that LLMs do contain certain personalities, for example, ChatGPT and ChatGLM exhibit the personality traits of 'Conscientiousness'. Additionally, we find that the personalities of LLMs are derived from their pre-trained data. The instruction data used to train ChatLLMs can enhance the generation of data containing personalities and expose their hidden personality. We compare the results with the human average personality score, and we find that the personality of FLAN-T5 in PLMs and ChatGPT in ChatLLMs is more similar to that of a human, with score differences of 0.34 and 0.22, respectively.
+
+
+
+ 54. 【2410.08527】Scaling Laws for Predicting Downstream Performance in LLMs
+ 链接:https://arxiv.org/abs/2410.08527
+ 作者:Yangyi Chen,Binxuan Huang,Yifan Gao,Zhengyang Wang,Jingfeng Yang,Heng Ji
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:large language models, Precise estimation, performance, pre-training loss, downstream performance
+ 备注:
+
+ 点击查看摘要
+ Abstract:Precise estimation of downstream performance in large language models (LLMs) prior to training is essential for guiding their development process. Scaling laws analysis utilizes the statistics of a series of significantly smaller sampling language models (LMs) to predict the performance of the target LLM. For downstream performance prediction, the critical challenge lies in the emergent abilities in LLMs that occur beyond task-specific computational thresholds. In this work, we focus on the pre-training loss as a more computation-efficient metric for performance estimation. Our two-stage approach consists of first estimating a function that maps computational resources (e.g., FLOPs) to the pre-training Loss using a series of sampling models, followed by mapping the pre-training loss to downstream task Performance after the critical "emergent phase". In preliminary experiments, this FLP solution accurately predicts the performance of LLMs with 7B and 13B parameters using a series of sampling LMs up to 3B, achieving error margins of 5% and 10%, respectively, and significantly outperforming the FLOPs-to-Performance approach. This motivates FLP-M, a fundamental approach for performance prediction that addresses the practical need to integrate datasets from multiple sources during pre-training, specifically blending general corpora with code data to accurately represent the common necessity. FLP-M extends the power law analytical function to predict domain-specific pre-training loss based on FLOPs across data sources, and employs a two-layer neural network to model the non-linear relationship between multiple domain-specific loss and downstream performance. By utilizing a 3B LLM trained on a specific ratio and a series of smaller sampling LMs, FLP-M can effectively forecast the performance of 3B and 7B LLMs across various data mixtures for most benchmarks within 10% error margins.
+
+
+
+ 55. 【2410.08526】"I Am the One and Only, Your Cyber BFF": Understanding the Impact of GenAI Requires Understanding the Impact of Anthropomorphic AI
+ 链接:https://arxiv.org/abs/2410.08526
+ 作者:Myra Cheng,Alicia DeVrio,Lisa Egede,Su Lin Blodgett,Alexandra Olteanu
+ 类目:Computers and Society (cs.CY); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:generating outputs, anthropomorphic behaviors, increasingly prone, scholars increasingly raising, increasingly raising concerns
+ 备注:
+
+ 点击查看摘要
+ Abstract:Many state-of-the-art generative AI (GenAI) systems are increasingly prone to anthropomorphic behaviors, i.e., to generating outputs that are perceived to be human-like. While this has led to scholars increasingly raising concerns about possible negative impacts such anthropomorphic AI systems can give rise to, anthropomorphism in AI development, deployment, and use remains vastly overlooked, understudied, and underspecified. In this perspective, we argue that we cannot thoroughly map the social impacts of generative AI without mapping the social impacts of anthropomorphic AI, and outline a call to action.
+
+
+
+ 56. 【2410.08521】Improving Legal Entity Recognition Using a Hybrid Transformer Model and Semantic Filtering Approach
+ 链接:https://arxiv.org/abs/2410.08521
+ 作者:Duraimurugan Rajamanickam
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:Legal Entity Recognition, Entity Recognition, automating legal workflows, compliance monitoring, contract analysis
+ 备注: 7 pages, 1 table
+
+ 点击查看摘要
+ Abstract:Legal Entity Recognition (LER) is critical in automating legal workflows such as contract analysis, compliance monitoring, and litigation support. Existing approaches, including rule-based systems and classical machine learning models, struggle with the complexity of legal documents and domain specificity, particularly in handling ambiguities and nested entity structures. This paper proposes a novel hybrid model that enhances the accuracy and precision of Legal-BERT, a transformer model fine-tuned for legal text processing, by introducing a semantic similarity-based filtering mechanism. We evaluate the model on a dataset of 15,000 annotated legal documents, achieving an F1 score of 93.4%, demonstrating significant improvements in precision and recall over previous methods.
+
+
+
+ 57. 【2410.08481】Generation with Dynamic Vocabulary
+ 链接:https://arxiv.org/abs/2410.08481
+ 作者:Yanting Liu,Tao Ji,Changzhi Sun,Yuanbin Wu,Xiaoling Wang
+ 类目:Computation and Language (cs.CL)
+ 关键词:dynamic vocabulary, text spans, standard language model, arbitrary text spans, Abstract
+ 备注: EMNLP 2024
+
+ 点击查看摘要
+ Abstract:We introduce a new dynamic vocabulary for language models. It can involve arbitrary text spans during generation. These text spans act as basic generation bricks, akin to tokens in the traditional static vocabularies. We show that, the ability to generate multi-tokens atomically improve both generation quality and efficiency (compared to the standard language model, the MAUVE metric is increased by 25%, the latency is decreased by 20%). The dynamic vocabulary can be deployed in a plug-and-play way, thus is attractive for various downstream applications. For example, we demonstrate that dynamic vocabulary can be applied to different domains in a training-free manner. It also helps to generate reliable citations in question answering tasks (substantially enhancing citation results without compromising answer accuracy).
+
+
+
+ 58. 【2410.08475】GIVE: Structured Reasoning with Knowledge Graph Inspired Veracity Extrapolation
+ 链接:https://arxiv.org/abs/2410.08475
+ 作者:Jiashu He,Mingyu Derek Ma,Jinxuan Fan,Dan Roth,Wei Wang,Alejandro Ribeiro
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Existing retrieval-based reasoning, Existing retrieval-based, retrieval-based reasoning approaches, large language models, provide domain knowledge
+ 备注:
+
+ 点击查看摘要
+ Abstract:Existing retrieval-based reasoning approaches for large language models (LLMs) heavily rely on the density and quality of the non-parametric knowledge source to provide domain knowledge and explicit reasoning chain. However, inclusive knowledge sources are expensive and sometimes infeasible to build for scientific or corner domains. To tackle the challenges, we introduce Graph Inspired Veracity Extrapolation (GIVE), a novel reasoning framework that integrates the parametric and non-parametric memories to enhance both knowledge retrieval and faithful reasoning processes on very sparse knowledge graphs. By leveraging the external structured knowledge to inspire LLM to model the interconnections among relevant concepts, our method facilitates a more logical and step-wise reasoning approach akin to experts' problem-solving, rather than gold answer retrieval. Specifically, the framework prompts LLMs to decompose the query into crucial concepts and attributes, construct entity groups with relevant entities, and build an augmented reasoning chain by probing potential relationships among node pairs across these entity groups. Our method incorporates both factual and extrapolated linkages to enable comprehensive understanding and response generation. Extensive experiments on reasoning-intense benchmarks on biomedical and commonsense QA demonstrate the effectiveness of our proposed method. Specifically, GIVE enables GPT3.5-turbo to outperform advanced models like GPT4 without any additional training cost, thereby underscoring the efficacy of integrating structured information and internal reasoning ability of LLMs for tackling specialized tasks with limited external resources.
+
+
+
+ 59. 【2410.08474】SPORTU: A Comprehensive Sports Understanding Benchmark for Multimodal Large Language Models
+ 链接:https://arxiv.org/abs/2410.08474
+ 作者:Haotian Xia,Zhengbang Yang,Junbo Zou,Rhys Tracy,Yuqing Wang,Chi Lu,Christopher Lai,Yanjun He,Xun Shao,Zhuoqing Xie,Yuan-fang Wang,Weining Shen,Hanjie Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Multimodal Large Language, Large Language Models, Multimodal Large, Language Models, Large Language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multimodal Large Language Models (MLLMs) are advancing the ability to reason about complex sports scenarios by integrating textual and visual information. To comprehensively evaluate their capabilities, we introduce SPORTU, a benchmark designed to assess MLLMs across multi-level sports reasoning tasks. SPORTU comprises two key components: SPORTU-text, featuring 900 multiple-choice questions with human-annotated explanations for rule comprehension and strategy understanding. This component focuses on testing models' ability to reason about sports solely through question-answering (QA), without requiring visual inputs; SPORTU-video, consisting of 1,701 slow-motion video clips across 7 different sports and 12,048 QA pairs, designed to assess multi-level reasoning, from simple sports recognition to complex tasks like foul detection and rule application. We evaluate four prevalent LLMs mainly utilizing few-shot learning paradigms supplemented by chain-of-thought (CoT) prompting on the SPORTU-text part. We evaluate four LLMs using few-shot learning and chain-of-thought (CoT) prompting on SPORTU-text. GPT-4o achieves the highest accuracy of 71%, but still falls short of human-level performance, highlighting room for improvement in rule comprehension and reasoning. The evaluation for the SPORTU-video part includes 7 proprietary and 6 open-source MLLMs. Experiments show that models fall short on hard tasks that require deep reasoning and rule-based understanding. Claude-3.5-Sonnet performs the best with only 52.6% accuracy on the hard task, showing large room for improvement. We hope that SPORTU will serve as a critical step toward evaluating models' capabilities in sports understanding and reasoning.
+
+
+
+ 60. 【2410.08469】Semantic Token Reweighting for Interpretable and Controllable Text Embeddings in CLIP
+ 链接:https://arxiv.org/abs/2410.08469
+ 作者:Eunji Kim,Kyuhong Shim,Simyung Chang,Sungroh Yoon
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Vision-Language Models, translating textual input, embedding space shared, natural language, encoder within Vision-Language
+ 备注: Accepted at EMNLP 2024 Findings
+
+ 点击查看摘要
+ Abstract:A text encoder within Vision-Language Models (VLMs) like CLIP plays a crucial role in translating textual input into an embedding space shared with images, thereby facilitating the interpretative analysis of vision tasks through natural language. Despite the varying significance of different textual elements within a sentence depending on the context, efforts to account for variation of importance in constructing text embeddings have been lacking. We propose a framework of Semantic Token Reweighting to build Interpretable text embeddings (SToRI), which incorporates controllability as well. SToRI refines the text encoding process in CLIP by differentially weighting semantic elements based on contextual importance, enabling finer control over emphasis responsive to data-driven insights and user preferences. The efficacy of SToRI is demonstrated through comprehensive experiments on few-shot image classification and image retrieval tailored to user preferences.
+
+
+
+ 61. 【2410.08458】Simultaneous Reward Distillation and Preference Learning: Get You a Language Model Who Can Do Both
+ 链接:https://arxiv.org/abs/2410.08458
+ 作者:Abhijnan Nath,Changsoo Jung,Ethan Seefried,Nikhil Krishnaswamy
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:building usable generative, usable generative large, generative large language, large language models, Direct Preference Optimization
+ 备注:
+
+ 点击查看摘要
+ Abstract:Reward modeling of human preferences is one of the cornerstones of building usable generative large language models (LLMs). While traditional RLHF-based alignment methods explicitly maximize the expected rewards from a separate reward model, more recent supervised alignment methods like Direct Preference Optimization (DPO) circumvent this phase to avoid problems including model drift and reward overfitting. Although popular due to its simplicity, DPO and similar direct alignment methods can still lead to degenerate policies, and rely heavily on the Bradley-Terry-based preference formulation to model reward differences between pairs of candidate outputs. This formulation is challenged by non-deterministic or noisy preference labels, for example human scoring of two candidate outputs is of low confidence. In this paper, we introduce DRDO (Direct Reward Distillation and policy-Optimization), a supervised knowledge distillation-based preference alignment method that simultaneously models rewards and preferences to avoid such degeneracy. DRDO directly mimics rewards assigned by an oracle while learning human preferences from a novel preference likelihood formulation. Our experimental results on the Ultrafeedback and TL;DR datasets demonstrate that policies trained using DRDO surpass previous methods such as DPO and e-DPO in terms of expected rewards and are more robust, on average, to noisy preference signals as well as out-of-distribution (OOD) settings.
+
+
+
+ 62. 【2410.08437】$\forall$uto$\exists$$\lor\!\land$L: Autonomous Evaluation of LLMs for Truth Maintenance and Reasoning Tasks
+ 链接:https://arxiv.org/abs/2410.08437
+ 作者:Rushang Karia,Daniel Bramblett,Daksh Dobhal,Siddharth Srivastava
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Large Language Model, scaling Large Language, Language Model, Large Language, scaling Large
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper presents $\forall$uto$\exists$$\lor\!\land$L, a novel benchmark for scaling Large Language Model (LLM) assessment in formal tasks with clear notions of correctness, such as truth maintenance in translation and logical reasoning. $\forall$uto$\exists$$\lor\!\land$L is the first benchmarking paradigm that offers several key advantages necessary for scaling objective evaluation of LLMs without human labeling: (a) ability to evaluate LLMs of increasing sophistication by auto-generating tasks at different levels of difficulty; (b) auto-generation of ground truth that eliminates dependence on expensive and time-consuming human annotation; (c) the use of automatically generated, randomized datasets that mitigate the ability of successive LLMs to overfit to static datasets used in many contemporary benchmarks. Empirical analysis shows that an LLM's performance on $\forall$uto$\exists$$\lor\!\land$L is highly indicative of its performance on a diverse array of other benchmarks focusing on translation and reasoning tasks, making it a valuable autonomous evaluation paradigm in settings where hand-curated datasets can be hard to obtain and/or update.
+
+
+
+ 63. 【2410.08436】Exploring the Role of Reasoning Structures for Constructing Proofs in Multi-Step Natural Language Reasoning with Large Language Models
+ 链接:https://arxiv.org/abs/2410.08436
+ 作者:Zi'ou Zheng,Christopher Malon,Martin Renqiang Min,Xiaodan Zhu
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, multi-step reasoning tasks, improving models' explainability, complex multi-step reasoning, performing complex multi-step
+ 备注: Accepted by EMNLP2024 main conference
+
+ 点击查看摘要
+ Abstract:When performing complex multi-step reasoning tasks, the ability of Large Language Models (LLMs) to derive structured intermediate proof steps is important for ensuring that the models truly perform the desired reasoning and for improving models' explainability. This paper is centred around a focused study: whether the current state-of-the-art generalist LLMs can leverage the structures in a few examples to better construct the proof structures with \textit{in-context learning}. Our study specifically focuses on structure-aware demonstration and structure-aware pruning. We demonstrate that they both help improve performance. A detailed analysis is provided to help understand the results.
+
+
+
+ 64. 【2410.08431】oRetrieval Augmented Generation for 10 Large Language Models and its Generalizability in Assessing Medical Fitness
+ 链接:https://arxiv.org/abs/2410.08431
+ 作者:Yu He Ke,Liyuan Jin,Kabilan Elangovan,Hairil Rizal Abdullah,Nan Liu,Alex Tiong Heng Sia,Chai Rick Soh,Joshua Yi Min Tung,Jasmine Chiat Ling Ong,Chang-Fu Kuo,Shao-Chun Wu,Vesela P. Kovacheva,Daniel Shu Wei Ting
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, Large Language, Retrieval Augmented Generation, specialized clinical knowledge, lack specialized clinical
+ 备注: arXiv admin note: substantial text overlap with [arXiv:2402.01733](https://arxiv.org/abs/2402.01733)
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) show potential for medical applications but often lack specialized clinical knowledge. Retrieval Augmented Generation (RAG) allows customization with domain-specific information, making it suitable for healthcare. This study evaluates the accuracy, consistency, and safety of RAG models in determining fitness for surgery and providing preoperative instructions. We developed LLM-RAG models using 35 local and 23 international preoperative guidelines and tested them against human-generated responses. A total of 3,682 responses were evaluated. Clinical documents were processed using Llamaindex, and 10 LLMs, including GPT3.5, GPT4, and Claude-3, were assessed. Fourteen clinical scenarios were analyzed, focusing on seven aspects of preoperative instructions. Established guidelines and expert judgment were used to determine correct responses, with human-generated answers serving as comparisons. The LLM-RAG models generated responses within 20 seconds, significantly faster than clinicians (10 minutes). The GPT4 LLM-RAG model achieved the highest accuracy (96.4% vs. 86.6%, p=0.016), with no hallucinations and producing correct instructions comparable to clinicians. Results were consistent across both local and international guidelines. This study demonstrates the potential of LLM-RAG models for preoperative healthcare tasks, highlighting their efficiency, scalability, and reliability.
+
+
+
+ 65. 【2410.08414】Understanding the Interplay between Parametric and Contextual Knowledge for Large Language Models
+ 链接:https://arxiv.org/abs/2410.08414
+ 作者:Sitao Cheng,Liangming Pan,Xunjian Yin,Xinyi Wang,William Yang Wang
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large language models, encode vast amounts, Large language, language models, encode vast
+ 备注: 27 pages, 8 figures and 17 tables
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) encode vast amounts of knowledge during pre-training (parametric knowledge, or PK) and can further be enhanced by incorporating contextual knowledge (CK). Can LLMs effectively integrate their internal PK with external CK to solve complex problems? In this paper, we investigate the dynamic interaction between PK and CK, categorizing their relationships into four types: Supportive, Complementary, Conflicting, and Irrelevant. To support this investigation, we introduce ECHOQA, a benchmark spanning scientific, factual, and commonsense knowledge. Our results show that LLMs tend to suppress their PK when contextual information is available, even when it is complementary or irrelevant. While tailored instructions can encourage LLMs to rely more on their PK, they still struggle to fully leverage it. These findings reveal a key vulnerability in LLMs, raising concerns about their reliability in knowledge-intensive tasks. Resources are available at this https URL Interplay.
+
+
+
+ 66. 【2410.08393】he Effects of Hallucinations in Synthetic Training Data for Relation Extraction
+ 链接:https://arxiv.org/abs/2410.08393
+ 作者:Steven Rogulsky,Nicholas Popovic,Michael Färber
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:constructing knowledge graphs, Relation extraction, knowledge graphs, foundation for training, constructing knowledge
+ 备注: Accepted at KBC-LM@ISWC'24
+
+ 点击查看摘要
+ Abstract:Relation extraction is crucial for constructing knowledge graphs, with large high-quality datasets serving as the foundation for training, fine-tuning, and evaluating models. Generative data augmentation (GDA) is a common approach to expand such datasets. However, this approach often introduces hallucinations, such as spurious facts, whose impact on relation extraction remains underexplored. In this paper, we examine the effects of hallucinations on the performance of relation extraction on the document and sentence levels. Our empirical study reveals that hallucinations considerably compromise the ability of models to extract relations from text, with recall reductions between 19.1% and 39.2%. We identify that relevant hallucinations impair the model's performance, while irrelevant hallucinations have a minimal impact. Additionally, we develop methods for the detection of hallucinations to improve data quality and model performance. Our approaches successfully classify texts as either 'hallucinated' or 'clean,' achieving high F1-scores of 83.8% and 92.2%. These methods not only assist in removing hallucinations but also help in estimating their prevalence within datasets, which is crucial for selecting high-quality data. Overall, our work confirms the profound impact of relevant hallucinations on the effectiveness of relation extraction models.
+
+
+
+ 67. 【2410.08391】KV Prediction for Improved Time to First Token
+ 链接:https://arxiv.org/abs/2410.08391
+ 作者:Maxwell Horton,Qingqing Cao,Chenfan Sun,Yanzi Jin,Sachin Mehta,Mohammad Rastegari,Moin Nabi
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Inference with transformer-based, language models begins, transformer-based language models, prompt processing step, transformer-based language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Inference with transformer-based language models begins with a prompt processing step. In this step, the model generates the first output token and stores the KV cache needed for future generation steps. This prompt processing step can be computationally expensive, taking 10s of seconds or more for billion-parameter models on edge devices when prompt lengths or batch sizes rise. This degrades user experience by introducing significant latency into the model's outputs. To reduce the time spent producing the first output (known as the ``time to first token'', or TTFT) of a pretrained model, we introduce a novel method called KV Prediction. In our method, a small auxiliary model is used to process the prompt and produce an approximation of the KV cache used by a base model. This approximated KV cache is then used with the base model for autoregressive generation without the need to query the auxiliary model again. We demonstrate that our method produces a pareto-optimal efficiency-accuracy trade-off when compared to baselines. On TriviaQA, we demonstrate relative accuracy improvements in the range of $15\%-50\%$ across a range of TTFT FLOPs budgets. We also demonstrate accuracy improvements of up to $30\%$ on HumanEval python code completion at fixed TTFT FLOPs budgets. Additionally, we benchmark models on an Apple M2 Pro CPU and demonstrate that our improvement in FLOPs translates to a TTFT speedup on hardware. We release our code at this https URL .
+
+
+
+ 68. 【2410.08388】GUS-Net: Social Bias Classification in Text with Generalizations, Unfairness, and Stereotypes
+ 链接:https://arxiv.org/abs/2410.08388
+ 作者:Maximus Powers,Hua Wei,Umang Mavani,Harshitha Reddy Jonala,Ansh Tiwari
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:natural language processing, critical challenge, bias detection, large language models, bias
+ 备注:
+
+ 点击查看摘要
+ Abstract:The detection of bias in natural language processing (NLP) is a critical challenge, particularly with the increasing use of large language models (LLMs) in various domains. This paper introduces GUS-Net, an innovative approach to bias detection that focuses on three key types of biases: (G)eneralizations, (U)nfairness, and (S)tereotypes. GUS-Net leverages generative AI and automated agents to create a comprehensive synthetic dataset, enabling robust multi-label token classification. Our methodology enhances traditional bias detection methods by incorporating the contextual encodings of pre-trained models, resulting in improved accuracy and depth in identifying biased entities. Through extensive experiments, we demonstrate that GUS-Net outperforms state-of-the-art techniques, achieving superior performance in terms of accuracy, F1-score, and Hamming Loss. The findings highlight GUS-Net's effectiveness in capturing a wide range of biases across diverse contexts, making it a valuable tool for social bias detection in text. This study contributes to the ongoing efforts in NLP to address implicit bias, providing a pathway for future research and applications in various fields. The Jupyter notebooks used to create the dataset and model are available at: this https URL.
+Warning: This paper contains examples of harmful language, and reader discretion is recommended.
+
Subjects:
+Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+Cite as:
+arXiv:2410.08388 [cs.CL]
+(or
+arXiv:2410.08388v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2410.08388
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 69. 【2410.08375】Evaluating Transformer Models for Suicide Risk Detection on Social Media
+ 链接:https://arxiv.org/abs/2410.08375
+ 作者:Jakub Pokrywka,Jeremi I. Kaczmarek,Edward J. Gorzelańczyk
+ 类目:Computation and Language (cs.CL)
+ 关键词:social media, suicide risk, social media posts, potential life-saving implications, suicide risk detection
+ 备注:
+
+ 点击查看摘要
+ Abstract:The detection of suicide risk in social media is a critical task with potential life-saving implications. This paper presents a study on leveraging state-of-the-art natural language processing solutions for identifying suicide risk in social media posts as a submission for the "IEEE BigData 2024 Cup: Detection of Suicide Risk on Social Media" conducted by the kubapok team. We experimented with the following configurations of transformer-based models: fine-tuned DeBERTa, GPT-4o with CoT and few-shot prompting, and fine-tuned GPT-4o. The task setup was to classify social media posts into four categories: indicator, ideation, behavior, and attempt. Our findings demonstrate that the fine-tuned GPT-4o model outperforms two other configurations, achieving high accuracy in identifying suicide risk. Notably, our model achieved second place in the competition. By demonstrating that straightforward, general-purpose models can achieve state-of-the-art results, we propose that these models, combined with minimal tuning, may have the potential to be effective solutions for automated suicide risk detection on social media.
+
+
+
+ 70. 【2410.08371】Merging in a Bottle: Differentiable Adaptive Merging (DAM) and the Path from Averaging to Automation
+ 链接:https://arxiv.org/abs/2410.08371
+ 作者:Thomas Gauthier-Caron,Shamane Siriwardhana,Elliot Stein,Malikeh Ehghaghi,Charles Goddard,Mark McQuade,Jacob Solawetz,Maxime Labonne
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:requiring substantial retraining, separate language models, achieving a balance, substantial retraining, systems can combine
+ 备注: 11 pages, 1 figure, and 3 tables
+
+ 点击查看摘要
+ Abstract:By merging models, AI systems can combine the distinct strengths of separate language models, achieving a balance between multiple capabilities without requiring substantial retraining. However, the integration process can be intricate due to differences in training methods and fine-tuning, typically necessitating specialized knowledge and repeated refinement. This paper explores model merging techniques across a spectrum of complexity, examining where automated methods like evolutionary strategies stand compared to hyperparameter-driven approaches such as DARE, TIES-Merging and simpler methods like Model Soups. In addition, we introduce Differentiable Adaptive Merging (DAM), an efficient, adaptive merging approach as an alternative to evolutionary merging that optimizes model integration through scaling coefficients, minimizing computational demands. Our findings reveal that even simple averaging methods, like Model Soups, perform competitively when model similarity is high, underscoring each technique's unique strengths and limitations. We open-sourced DAM, including the implementation code and experiment pipeline, on GitHub: this https URL.
+
+
+
+ 71. 【2410.08352】Revealing COVID-19's Social Dynamics: Diachronic Semantic Analysis of Vaccine and Symptom Discourse on Twitter
+ 链接:https://arxiv.org/abs/2410.08352
+ 作者:Zeqiang Wang,Jiageng Wu,Yuqi Wang,Wei Wang,Jie Yang,Jon Johnson,Nishanth Sastry,Suparna De
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR); Social and Information Networks (cs.SI)
+ 关键词:vast textual data, textual data generated, data generated daily, social impacts due, behavior of people
+ 备注:
+
+ 点击查看摘要
+ Abstract:Social media is recognized as an important source for deriving insights into public opinion dynamics and social impacts due to the vast textual data generated daily and the 'unconstrained' behavior of people interacting on these platforms. However, such analyses prove challenging due to the semantic shift phenomenon, where word meanings evolve over time. This paper proposes an unsupervised dynamic word embedding method to capture longitudinal semantic shifts in social media data without predefined anchor words. The method leverages word co-occurrence statistics and dynamic updating to adapt embeddings over time, addressing the challenges of data sparseness, imbalanced distributions, and synergistic semantic effects. Evaluated on a large COVID-19 Twitter dataset, the method reveals semantic evolution patterns of vaccine- and symptom-related entities across different pandemic stages, and their potential correlations with real-world statistics. Our key contributions include the dynamic embedding technique, empirical analysis of COVID-19 semantic shifts, and discussions on enhancing semantic shift modeling for computational social science research. This study enables capturing longitudinal semantic dynamics on social media to understand public discourse and collective phenomena.
+
+
+
+ 72. 【2410.08351】Nonlinear second-order dynamics describe labial constriction trajectories across languages and contexts
+ 链接:https://arxiv.org/abs/2410.08351
+ 作者:Michael C. Stern,Jason A. Shaw
+ 类目:Computation and Language (cs.CL); Adaptation and Self-Organizing Systems (nlin.AO)
+ 关键词:English and Mandarin, labial constriction trajectories, labial constriction, Mandarin, English
+ 备注:
+
+ 点击查看摘要
+ Abstract:We investigate the dynamics of labial constriction trajectories during the production of /b/ and /m/ in English and Mandarin. We find that, across languages and contexts, the ratio of instantaneous displacement to instantaneous velocity generally follows an exponential decay curve from movement onset to movement offset. We formalize this empirical discovery in a differential equation and, in combination with an assumption of point attractor dynamics, derive a nonlinear second-order dynamical system describing labial constriction trajectories. The equation has only two parameters, T and r. T corresponds to the target state and r corresponds to movement rapidity. Thus, each of the parameters corresponds to a phonetically relevant dimension of control. Nonlinear regression demonstrates that the model provides excellent fits to individual movement trajectories. Moreover, trajectories simulated from the model qualitatively match empirical trajectories, and capture key kinematic variables like duration, peak velocity, and time to achieve peak velocity. The model constitutes a proposal for the dynamics of individual articulatory movements, and thus offers a novel foundation from which to understand additional influences on articulatory kinematics like prosody, inter-movement coordination, and stochastic noise.
+
+
+
+ 73. 【2410.08334】Exploring Natural Language-Based Strategies for Efficient Number Learning in Children through Reinforcement Learning
+ 链接:https://arxiv.org/abs/2410.08334
+ 作者:Tirthankar Mittra
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Multiagent Systems (cs.MA)
+ 关键词:children learn numbers, paper investigates, investigates how children, children learn, reinforcement learning
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper investigates how children learn numbers using the framework of reinforcement learning (RL), with a focus on the impact of language instructions. The motivation for using reinforcement learning stems from its parallels with psychological learning theories in controlled environments. By using state of the art deep reinforcement learning models, we simulate and analyze the effects of various forms of language instructions on number acquisition. Our findings indicate that certain linguistic structures more effectively improve numerical comprehension in RL agents. Additionally, our model predicts optimal sequences for presenting numbers to RL agents which enhance their speed of learning. This research provides valuable insights into the interplay between language and numerical cognition, with implications for both educational strategies and the development of artificial intelligence systems designed to support early childhood learning.
+
+
+
+ 74. 【2410.08328】Agents Thinking Fast and Slow: A Talker-Reasoner Architecture
+ 链接:https://arxiv.org/abs/2410.08328
+ 作者:Konstantina Christakopoulou,Shibl Mourad,Maja Matarić
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Large language models, Large language, natural conversation, language models, models have enabled
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models have enabled agents of all kinds to interact with users through natural conversation. Consequently, agents now have two jobs: conversing and planning/reasoning. Their conversational responses must be informed by all available information, and their actions must help to achieve goals. This dichotomy between conversing with the user and doing multi-step reasoning and planning can be seen as analogous to the human systems of "thinking fast and slow" as introduced by Kahneman. Our approach is comprised of a "Talker" agent (System 1) that is fast and intuitive, and tasked with synthesizing the conversational response; and a "Reasoner" agent (System 2) that is slower, more deliberative, and more logical, and is tasked with multi-step reasoning and planning, calling tools, performing actions in the world, and thereby producing the new agent state. We describe the new Talker-Reasoner architecture and discuss its advantages, including modularity and decreased latency. We ground the discussion in the context of a sleep coaching agent, in order to demonstrate real-world relevance.
+
+
+
+ 75. 【2410.08327】Evaluating Differentially Private Synthetic Data Generation in High-Stakes Domains
+ 链接:https://arxiv.org/abs/2410.08327
+ 作者:Krithika Ramesh,Nupoor Gandhi,Pulkit Madaan,Lisa Bauer,Charith Peris,Anjalie Field
+ 类目:Computation and Language (cs.CL)
+ 关键词:anonymizing text data, text data hinders, deployment of NLP, social services, difficulty of anonymizing
+ 备注: Accepted to EMNLP 2024 (Findings)
+
+ 点击查看摘要
+ Abstract:The difficulty of anonymizing text data hinders the development and deployment of NLP in high-stakes domains that involve private data, such as healthcare and social services. Poorly anonymized sensitive data cannot be easily shared with annotators or external researchers, nor can it be used to train public models. In this work, we explore the feasibility of using synthetic data generated from differentially private language models in place of real data to facilitate the development of NLP in these domains without compromising privacy. In contrast to prior work, we generate synthetic data for real high-stakes domains, and we propose and conduct use-inspired evaluations to assess data quality. Our results show that prior simplistic evaluations have failed to highlight utility, privacy, and fairness issues in the synthetic data. Overall, our work underscores the need for further improvements to synthetic data generation for it to be a viable way to enable privacy-preserving data sharing.
+
+
+
+ 76. 【2410.08324】he language of sound search: Examining User Queries in Audio Search Engines
+ 链接:https://arxiv.org/abs/2410.08324
+ 作者:Benno Weck,Frederic Font
+ 类目:Computation and Language (cs.CL); Human-Computer Interaction (cs.HC); Information Retrieval (cs.IR); Machine Learning (cs.LG); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:study examines textual, general audio retrieval, audio retrieval, audio retrieval systems, text-based audio retrieval
+ 备注: Accepted at DCASE 2024. Supplementary materials at [this https URL](https://doi.org/10.5281/zenodo.13622537)
+
+ 点击查看摘要
+ Abstract:This study examines textual, user-written search queries within the context of sound search engines, encompassing various applications such as foley, sound effects, and general audio retrieval. Current research inadequately addresses real-world user needs and behaviours in designing text-based audio retrieval systems. To bridge this gap, we analysed search queries from two sources: a custom survey and Freesound website query logs. The survey was designed to collect queries for an unrestricted, hypothetical sound search engine, resulting in a dataset that captures user intentions without the constraints of existing systems. This dataset is also made available for sharing with the research community. In contrast, the Freesound query logs encompass approximately 9 million search requests, providing a comprehensive view of real-world usage patterns. Our findings indicate that survey queries are generally longer than Freesound queries, suggesting users prefer detailed queries when not limited by system constraints. Both datasets predominantly feature keyword-based queries, with few survey participants using full sentences. Key factors influencing survey queries include the primary sound source, intended usage, perceived location, and the number of sound sources. These insights are crucial for developing user-centred, effective text-based audio retrieval systems, enhancing our understanding of user behaviour in sound search contexts.
+
+
+
+ 77. 【2410.08320】Do You Know What You Are Talking About? Characterizing Query-Knowledge Relevance For Reliable Retrieval Augmented Generation
+ 链接:https://arxiv.org/abs/2410.08320
+ 作者:Zhuohang Li,Jiaxin Zhang,Chao Yan,Kamalika Das,Sricharan Kumar,Murat Kantarcioglu,Bradley A. Malin
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Language models, external knowledge corpus, hallucinations and misinformation, suffer from hallucinations, knowledge corpus
+ 备注:
+
+ 点击查看摘要
+ Abstract:Language models (LMs) are known to suffer from hallucinations and misinformation. Retrieval augmented generation (RAG) that retrieves verifiable information from an external knowledge corpus to complement the parametric knowledge in LMs provides a tangible solution to these problems. However, the generation quality of RAG is highly dependent on the relevance between a user's query and the retrieved documents. Inaccurate responses may be generated when the query is outside of the scope of knowledge represented in the external knowledge corpus or if the information in the corpus is out-of-date. In this work, we establish a statistical framework that assesses how well a query can be answered by an RAG system by capturing the relevance of knowledge. We introduce an online testing procedure that employs goodness-of-fit (GoF) tests to inspect the relevance of each user query to detect out-of-knowledge queries with low knowledge relevance. Additionally, we develop an offline testing framework that examines a collection of user queries, aiming to detect significant shifts in the query distribution which indicates the knowledge corpus is no longer sufficiently capable of supporting the interests of the users. We demonstrate the capabilities of these strategies through a systematic evaluation on eight question-answering (QA) datasets, the results of which indicate that the new testing framework is an efficient solution to enhance the reliability of existing RAG systems.
+
+
+
+ 78. 【2410.08319】MELO: An Evaluation Benchmark for Multilingual Entity Linking of Occupations
+ 链接:https://arxiv.org/abs/2410.08319
+ 作者:Federico Retyk,Luis Gasco,Casimiro Pio Carrino,Daniel Deniz,Rabih Zbib
+ 类目:Computation and Language (cs.CL)
+ 关键词:ESCO Occupations multilingual, Multilingual Entity Linking, Occupations multilingual taxonomy, ESCO Occupations, Occupations multilingual
+ 备注: Accepted to the 4th Workshop on Recommender Systems for Human Resources (RecSys in HR 2024) as part of RecSys 2024
+
+ 点击查看摘要
+ Abstract:We present the Multilingual Entity Linking of Occupations (MELO) Benchmark, a new collection of 48 datasets for evaluating the linking of entity mentions in 21 languages to the ESCO Occupations multilingual taxonomy. MELO was built using high-quality, pre-existent human annotations. We conduct experiments with simple lexical models and general-purpose sentence encoders, evaluated as bi-encoders in a zero-shot setup, to establish baselines for future research. The datasets and source code for standardized evaluation are publicly available at this https URL
+
+
+
+ 79. 【2410.08316】HyperDPO: Hypernetwork-based Multi-Objective Fine-Tuning Framework
+ 链接:https://arxiv.org/abs/2410.08316
+ 作者:Yinuo Ren,Tesi Xiao,Michael Shavlovsky,Lexing Ying,Holakou Rahmanian
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL); Optimization and Control (math.OC)
+ 关键词:Direct Preference Optimization, LLM alignment, efficient LLM alignment, Multi-Objective Fine-Tuning, faces the Multi-Objective
+ 备注:
+
+ 点击查看摘要
+ Abstract:In LLM alignment and many other ML applications, one often faces the Multi-Objective Fine-Tuning (MOFT) problem, i.e. fine-tuning an existing model with datasets labeled w.r.t. different objectives simultaneously. To address the challenge, we propose the HyperDPO framework, a hypernetwork-based approach that extends the Direct Preference Optimization (DPO) technique, originally developed for efficient LLM alignment with preference data, to accommodate the MOFT settings. By substituting the Bradley-Terry-Luce model in DPO with the Plackett-Luce model, our framework is capable of handling a wide range of MOFT tasks that involve listwise ranking datasets. Compared with previous approaches, HyperDPO enjoys an efficient one-shot training process for profiling the Pareto front of auxiliary objectives, and offers flexible post-training control over trade-offs. Additionally, we propose a novel Hyper Prompt Tuning design, that conveys continuous weight across objectives to transformer-based models without altering their architecture. We demonstrate the effectiveness and efficiency of the HyperDPO framework through its applications to various tasks, including Learning-to-Rank (LTR) and LLM alignment, highlighting its viability for large-scale ML deployments.
+
+
+
+ 80. 【2410.08299】Privately Learning from Graphs with Applications in Fine-tuning Large Language Models
+ 链接:https://arxiv.org/abs/2410.08299
+ 作者:Haoteng Yin,Rongzhe Wei,Eli Chien,Pan Li
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL); Cryptography and Security (cs.CR)
+ 关键词:complementing data modalities, Graphs offer unique, offer unique insights, interactions between entities, modalities like text
+ 备注:
+
+ 点击查看摘要
+ Abstract:Graphs offer unique insights into relationships and interactions between entities, complementing data modalities like text, images, and videos. By incorporating relational information from graph data, AI models can extend their capabilities beyond traditional tasks. However, relational data in sensitive domains such as finance and healthcare often contain private information, making privacy preservation crucial. Existing privacy-preserving methods, such as DP-SGD, which rely on gradient decoupling assumptions, are not well-suited for relational learning due to the inherent dependencies between coupled training samples. To address this challenge, we propose a privacy-preserving relational learning pipeline that decouples dependencies in sampled relations during training, ensuring differential privacy through a tailored application of DP-SGD. We apply this method to fine-tune large language models (LLMs) on sensitive graph data, and tackle the associated computational complexities. Our approach is evaluated on LLMs of varying sizes (e.g., BERT, Llama2) using real-world relational data from four text-attributed graphs. The results demonstrate significant improvements in relational learning tasks, all while maintaining robust privacy guarantees during training. Additionally, we explore the trade-offs between privacy, utility, and computational efficiency, offering insights into the practical deployment of our approach. Code is available at this https URL.
+
+
+
+ 81. 【2410.08289】Increasing the Difficulty of Automatically Generated Questions via Reinforcement Learning with Synthetic Preference
+ 链接:https://arxiv.org/abs/2410.08289
+ 作者:William Thorne,Ambrose Robinson,Bohua Peng,Chenghua Lin,Diana Maynard
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:sector increasingly adopts, increasingly adopts technologies, personalised search experiences, Retrieval-Augmented Generation, heritage sector increasingly
+ 备注: is to be published in NLP4DH 2024
+
+ 点击查看摘要
+ Abstract:As the cultural heritage sector increasingly adopts technologies like Retrieval-Augmented Generation (RAG) to provide more personalised search experiences and enable conversations with collections data, the demand for specialised evaluation datasets has grown. While end-to-end system testing is essential, it's equally important to assess individual components. We target the final, answering task, which is well-suited to Machine Reading Comprehension (MRC). Although existing MRC datasets address general domains, they lack the specificity needed for cultural heritage information. Unfortunately, the manual creation of such datasets is prohibitively expensive for most heritage institutions. This paper presents a cost-effective approach for generating domain-specific MRC datasets with increased difficulty using Reinforcement Learning from Human Feedback (RLHF) from synthetic preference data. Our method leverages the performance of existing question-answering models on a subset of SQuAD to create a difficulty metric, assuming that more challenging questions are answered correctly less frequently. This research contributes: (1) A methodology for increasing question difficulty using PPO and synthetic data; (2) Empirical evidence of the method's effectiveness, including human evaluation; (3) An in-depth error analysis and study of emergent phenomena; and (4) An open-source codebase and set of three llama-2-chat adapters for reproducibility and adaptation.
+
+
+
+ 82. 【2410.03521】LCMDC: Large-scale Chinese Medical Dialogue Corpora for Automatic Triage and Medical Consultation
+ 链接:https://arxiv.org/abs/2410.03521
+ 作者:Xinyuan Wang,Haozhou Li,Dingfang Zheng,Qinke Peng
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:pandemic underscored major, underscored major deficiencies, online medical services, traditional healthcare systems, pandemic underscored
+ 备注:
+
+ 点击查看摘要
+ Abstract:The global COVID-19 pandemic underscored major deficiencies in traditional healthcare systems, hastening the advancement of online medical services, especially in medical triage and consultation. However, existing studies face two main challenges. First, the scarcity of large-scale, publicly available, domain-specific medical datasets due to privacy concerns, with current datasets being small and limited to a few diseases, limiting the effectiveness of triage methods based on Pre-trained Language Models (PLMs). Second, existing methods lack medical knowledge and struggle to accurately understand professional terms and expressions in patient-doctor consultations. To overcome these obstacles, we construct the Large-scale Chinese Medical Dialogue Corpora (LCMDC), comprising a Coarse-grained Triage dataset with 439,630 samples, a Fine-grained Diagnosis dataset with 199,600 samples, and a Medical Consultation dataset with 472,418 items, thereby addressing the data shortage in this field. Moreover, we further propose a novel triage system that combines BERT-based supervised learning with prompt learning, as well as a GPT-based medical consultation model using reinforcement learning. To enhance domain knowledge acquisition, we pre-trained PLMs using our self-constructed background corpus. Experimental results on the LCMDC demonstrate the efficacy of our proposed systems.
+
+
+
+ 83. 【2410.08250】Exploring ASR-Based Wav2Vec2 for Automated Speech Disorder Assessment: Insights and Analysis
+ 链接:https://arxiv.org/abs/2410.08250
+ 作者:Tuan Nguyen,Corinne Fredouille,Alain Ghio,Mathieu Balaguer,Virginie Woisard
+ 类目:Audio and Speech Processing (eess.AS); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Sound (cs.SD)
+ 关键词:Neck Cancer speech, Cancer speech contexts, Head and Neck, Neck Cancer, yielding impressive results
+ 备注: Accepted at the Spoken Language Technology (SLT) Conference 2024
+
+ 点击查看摘要
+ Abstract:With the rise of SSL and ASR technologies, the Wav2Vec2 ASR-based model has been fine-tuned for automated speech disorder quality assessment tasks, yielding impressive results and setting a new baseline for Head and Neck Cancer speech contexts. This demonstrates that the ASR dimension from Wav2Vec2 closely aligns with assessment dimensions. Despite its effectiveness, this system remains a black box with no clear interpretation of the connection between the model ASR dimension and clinical assessments. This paper presents the first analysis of this baseline model for speech quality assessment, focusing on intelligibility and severity tasks. We conduct a layer-wise analysis to identify key layers and compare different SSL and ASR Wav2Vec2 models based on pre-trained data. Additionally, post-hoc XAI methods, including Canonical Correlation Analysis (CCA) and visualization techniques, are used to track model evolution and visualize embeddings for enhanced interpretability.
+
+
+信息检索
+
+ 1. 【2410.08877】Interdependency Matters: Graph Alignment for Multivariate Time Series Anomaly Detection
+ 链接:https://arxiv.org/abs/2410.08877
+ 作者:Yuanyi Wang,Haifeng Sun,Chengsen Wang,Mengde Zhu,Jingyu Wang,Wei Tang,Qi Qi,Zirui Zhuang,Jianxin Liao
+ 类目:Machine Learning (cs.LG); Databases (cs.DB); Information Retrieval (cs.IR); Multimedia (cs.MM)
+ 关键词:Anomaly detection, MTS Anomaly Detection, multivariate time series, mining and industry, Anomaly
+ 备注:
+
+ 点击查看摘要
+ Abstract:Anomaly detection in multivariate time series (MTS) is crucial for various applications in data mining and industry. Current industrial methods typically approach anomaly detection as an unsupervised learning task, aiming to identify deviations by estimating the normal distribution in noisy, label-free datasets. These methods increasingly incorporate interdependencies between channels through graph structures to enhance accuracy. However, the role of interdependencies is more critical than previously understood, as shifts in interdependencies between MTS channels from normal to anomalous data are significant. This observation suggests that \textit{anomalies could be detected by changes in these interdependency graph series}. To capitalize on this insight, we introduce MADGA (MTS Anomaly Detection via Graph Alignment), which redefines anomaly detection as a graph alignment (GA) problem that explicitly utilizes interdependencies for anomaly detection. MADGA dynamically transforms subsequences into graphs to capture the evolving interdependencies, and Graph alignment is performed between these graphs, optimizing an alignment plan that minimizes cost, effectively minimizing the distance for normal data and maximizing it for anomalous data. Uniquely, our GA approach involves explicit alignment of both nodes and edges, employing Wasserstein distance for nodes and Gromov-Wasserstein distance for edges. To our knowledge, this is the first application of GA to MTS anomaly detection that explicitly leverages interdependency for this purpose. Extensive experiments on diverse real-world datasets validate the effectiveness of MADGA, demonstrating its capability to detect anomalies and differentiate interdependencies, consistently achieving state-of-the-art across various scenarios.
+
+
+
+ 2. 【2410.08801】A Methodology for Evaluating RAG Systems: A Case Study On Configuration Dependency Validation
+ 链接:https://arxiv.org/abs/2410.08801
+ 作者:Sebastian Simon,Alina Mailach,Johannes Dorn,Norbert Siegmund
+ 类目:oftware Engineering (cs.SE); Information Retrieval (cs.IR)
+ 关键词:large language models, Retrieval-augmented generation, RAG systems, RAG, missing knowledge
+ 备注:
+
+ 点击查看摘要
+ Abstract:Retrieval-augmented generation (RAG) is an umbrella of different components, design decisions, and domain-specific adaptations to enhance the capabilities of large language models and counter their limitations regarding hallucination and outdated and missing knowledge. Since it is unclear which design decisions lead to a satisfactory performance, developing RAG systems is often experimental and needs to follow a systematic and sound methodology to gain sound and reliable results. However, there is currently no generally accepted methodology for RAG evaluation despite a growing interest in this technology. In this paper, we propose a first blueprint of a methodology for a sound and reliable evaluation of RAG systems and demonstrate its applicability on a real-world software engineering research task: the validation of configuration dependencies across software technologies. In summary, we make two novel contributions: (i) A novel, reusable methodological design for evaluating RAG systems, including a demonstration that represents a guideline, and (ii) a RAG system, which has been developed following this methodology, that achieves the highest accuracy in the field of dependency validation. For the blueprint's demonstration, the key insights are the crucial role of choosing appropriate baselines and metrics, the necessity for systematic RAG refinements derived from qualitative failure analysis, as well as the reporting practices of key design decision to foster replication and evaluation.
+
+
+
+ 3. 【2410.08740】Hespi: A pipeline for automatically detecting information from hebarium specimen sheets
+ 链接:https://arxiv.org/abs/2410.08740
+ 作者:Robert Turnbull,Emily Fitzgerald,Karen Thompson,Joanne L. Birch
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:conservation sciences, Optical Character Recognition, Specimen, data, Specimen sheet PIpeline
+ 备注:
+
+ 点击查看摘要
+ Abstract:Specimen associated biodiversity data are sought after for biological, environmental, climate, and conservation sciences. A rate shift is required for the extraction of data from specimen images to eliminate the bottleneck that the reliance on human-mediated transcription of these data represents. We applied advanced computer vision techniques to develop the `Hespi' (HErbarium Specimen sheet PIpeline), which extracts a pre-catalogue subset of collection data on the institutional labels on herbarium specimens from their digital images. The pipeline integrates two object detection models; the first detects bounding boxes around text-based labels and the second detects bounding boxes around text-based data fields on the primary institutional label. The pipeline classifies text-based institutional labels as printed, typed, handwritten, or a combination and applies Optical Character Recognition (OCR) and Handwritten Text Recognition (HTR) for data extraction. The recognized text is then corrected against authoritative databases of taxon names. The extracted text is also corrected with the aide of a multimodal Large Language Model (LLM). Hespi accurately detects and extracts text for test datasets including specimen sheet images from international herbaria. The components of the pipeline are modular and users can train their own models with their own data and use them in place of the models provided.
+
+
+
+ 4. 【2410.08623】Retrieving Contextual Information for Long-Form Question Answering using Weak Supervision
+ 链接:https://arxiv.org/abs/2410.08623
+ 作者:Philipp Christmann,Svitlana Vakulenko,Ionut Teodor Sorodoc,Bill Byrne,Adrià de Gispert
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:aims at generating, generating in-depth answers, generating in-depth, Long-form question answering, providing relevant information
+ 备注: Accepted at EMNLP 2024 (Findings)
+
+ 点击查看摘要
+ Abstract:Long-form question answering (LFQA) aims at generating in-depth answers to end-user questions, providing relevant information beyond the direct answer. However, existing retrievers are typically optimized towards information that directly targets the question, missing out on such contextual information. Furthermore, there is a lack of training data for relevant context. To this end, we propose and compare different weak supervision techniques to optimize retrieval for contextual information. Experiments demonstrate improvements on the end-to-end QA performance on ASQA, a dataset for long-form question answering. Importantly, as more contextual information is retrieved, we improve the relevant page recall for LFQA by 14.7% and the groundedness of generated long-form answers by 12.5%. Finally, we show that long-form answers often anticipate likely follow-up questions, via experiments on a conversational QA dataset.
+
+
+
+ 5. 【2410.08583】Intent-Enhanced Data Augmentation for Sequential Recommendation
+ 链接:https://arxiv.org/abs/2410.08583
+ 作者:Shuai Chen,Zhoujun Li
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI)
+ 关键词:sequential recommendation algorithms, mine dynamic user, sequential recommendation, dynamic user intent, recommendation algorithms focuses
+ 备注: 14 pages, 3 figures
+
+ 点击查看摘要
+ Abstract:The research on intent-enhanced sequential recommendation algorithms focuses on how to better mine dynamic user intent based on user behavior data for sequential recommendation tasks. Various data augmentation methods are widely applied in current sequential recommendation algorithms, effectively enhancing the ability to capture user intent. However, these widely used data augmentation methods often rely on a large amount of random sampling, which can introduce excessive noise into the training data, blur user intent, and thus negatively affect recommendation performance. Additionally, these methods have limited approaches to utilizing augmented data, failing to fully leverage the augmented samples. We propose an intent-enhanced data augmentation method for sequential recommendation(\textbf{IESRec}), which constructs positive and negative samples based on user behavior sequences through intent-segment insertion. On one hand, the generated positive samples are mixed with the original training data, and they are trained together to improve recommendation performance. On the other hand, the generated positive and negative samples are used to build a contrastive loss function, enhancing recommendation performance through self-supervised training. Finally, the main recommendation task is jointly trained with the contrastive learning loss minimization task. Experiments on three real-world datasets validate the effectiveness of our IESRec model.
+
+
+
+ 6. 【2410.08521】Improving Legal Entity Recognition Using a Hybrid Transformer Model and Semantic Filtering Approach
+ 链接:https://arxiv.org/abs/2410.08521
+ 作者:Duraimurugan Rajamanickam
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:Legal Entity Recognition, Entity Recognition, automating legal workflows, compliance monitoring, contract analysis
+ 备注: 7 pages, 1 table
+
+ 点击查看摘要
+ Abstract:Legal Entity Recognition (LER) is critical in automating legal workflows such as contract analysis, compliance monitoring, and litigation support. Existing approaches, including rule-based systems and classical machine learning models, struggle with the complexity of legal documents and domain specificity, particularly in handling ambiguities and nested entity structures. This paper proposes a novel hybrid model that enhances the accuracy and precision of Legal-BERT, a transformer model fine-tuned for legal text processing, by introducing a semantic similarity-based filtering mechanism. We evaluate the model on a dataset of 15,000 annotated legal documents, achieving an F1 score of 93.4%, demonstrating significant improvements in precision and recall over previous methods.
+
+
+
+ 7. 【2410.08478】Personalized Item Embeddings in Federated Multimodal Recommendation
+ 链接:https://arxiv.org/abs/2410.08478
+ 作者:Zhiwei Li,Guodong Long,Jing Jiang,Chengqi Zhang
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Federated recommendation systems, protecting user privacy, recommendation systems play, play a crucial, crucial role
+ 备注: 12 pages, 4 figures, 5 tables, conference
+
+ 点击查看摘要
+ Abstract:Federated recommendation systems play a crucial role in protecting user privacy. However, existing methods primarily rely on ID-based item embeddings, overlooking the rich multimodal information of items. To address this limitation, we propose a novel Federated Multimodal Recommendation System called FedMR. FedMR leverages a foundation model on the server side to encode multimodal data, such as images and text, associated with items. To tackle the challenge of data heterogeneity caused by varying user preferences, FedMR introduces a Mixing Feature Fusion Module on the client. This module dynamically adjusts the weights of different fusion strategies based on user interaction history, generating personalized item embeddings that capture fine-grained user preferences. FedMR is compatible with existing ID-based federated recommendation systems, improving their performances without modifying the original framework. Our experiments on four real-world multimodal recommendation datasets demonstrate the effectiveness of FedMR. Our code is available at this https URL.
+
+
+
+ 8. 【2410.08393】he Effects of Hallucinations in Synthetic Training Data for Relation Extraction
+ 链接:https://arxiv.org/abs/2410.08393
+ 作者:Steven Rogulsky,Nicholas Popovic,Michael Färber
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:constructing knowledge graphs, Relation extraction, knowledge graphs, foundation for training, constructing knowledge
+ 备注: Accepted at KBC-LM@ISWC'24
+
+ 点击查看摘要
+ Abstract:Relation extraction is crucial for constructing knowledge graphs, with large high-quality datasets serving as the foundation for training, fine-tuning, and evaluating models. Generative data augmentation (GDA) is a common approach to expand such datasets. However, this approach often introduces hallucinations, such as spurious facts, whose impact on relation extraction remains underexplored. In this paper, we examine the effects of hallucinations on the performance of relation extraction on the document and sentence levels. Our empirical study reveals that hallucinations considerably compromise the ability of models to extract relations from text, with recall reductions between 19.1% and 39.2%. We identify that relevant hallucinations impair the model's performance, while irrelevant hallucinations have a minimal impact. Additionally, we develop methods for the detection of hallucinations to improve data quality and model performance. Our approaches successfully classify texts as either 'hallucinated' or 'clean,' achieving high F1-scores of 83.8% and 92.2%. These methods not only assist in removing hallucinations but also help in estimating their prevalence within datasets, which is crucial for selecting high-quality data. Overall, our work confirms the profound impact of relevant hallucinations on the effectiveness of relation extraction models.
+
+
+
+ 9. 【2410.08352】Revealing COVID-19's Social Dynamics: Diachronic Semantic Analysis of Vaccine and Symptom Discourse on Twitter
+ 链接:https://arxiv.org/abs/2410.08352
+ 作者:Zeqiang Wang,Jiageng Wu,Yuqi Wang,Wei Wang,Jie Yang,Jon Johnson,Nishanth Sastry,Suparna De
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR); Social and Information Networks (cs.SI)
+ 关键词:vast textual data, textual data generated, data generated daily, social impacts due, behavior of people
+ 备注:
+
+ 点击查看摘要
+ Abstract:Social media is recognized as an important source for deriving insights into public opinion dynamics and social impacts due to the vast textual data generated daily and the 'unconstrained' behavior of people interacting on these platforms. However, such analyses prove challenging due to the semantic shift phenomenon, where word meanings evolve over time. This paper proposes an unsupervised dynamic word embedding method to capture longitudinal semantic shifts in social media data without predefined anchor words. The method leverages word co-occurrence statistics and dynamic updating to adapt embeddings over time, addressing the challenges of data sparseness, imbalanced distributions, and synergistic semantic effects. Evaluated on a large COVID-19 Twitter dataset, the method reveals semantic evolution patterns of vaccine- and symptom-related entities across different pandemic stages, and their potential correlations with real-world statistics. Our key contributions include the dynamic embedding technique, empirical analysis of COVID-19 semantic shifts, and discussions on enhancing semantic shift modeling for computational social science research. This study enables capturing longitudinal semantic dynamics on social media to understand public discourse and collective phenomena.
+
+
+
+ 10. 【2410.08324】he language of sound search: Examining User Queries in Audio Search Engines
+ 链接:https://arxiv.org/abs/2410.08324
+ 作者:Benno Weck,Frederic Font
+ 类目:Computation and Language (cs.CL); Human-Computer Interaction (cs.HC); Information Retrieval (cs.IR); Machine Learning (cs.LG); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:study examines textual, general audio retrieval, audio retrieval, audio retrieval systems, text-based audio retrieval
+ 备注: Accepted at DCASE 2024. Supplementary materials at [this https URL](https://doi.org/10.5281/zenodo.13622537)
+
+ 点击查看摘要
+ Abstract:This study examines textual, user-written search queries within the context of sound search engines, encompassing various applications such as foley, sound effects, and general audio retrieval. Current research inadequately addresses real-world user needs and behaviours in designing text-based audio retrieval systems. To bridge this gap, we analysed search queries from two sources: a custom survey and Freesound website query logs. The survey was designed to collect queries for an unrestricted, hypothetical sound search engine, resulting in a dataset that captures user intentions without the constraints of existing systems. This dataset is also made available for sharing with the research community. In contrast, the Freesound query logs encompass approximately 9 million search requests, providing a comprehensive view of real-world usage patterns. Our findings indicate that survey queries are generally longer than Freesound queries, suggesting users prefer detailed queries when not limited by system constraints. Both datasets predominantly feature keyword-based queries, with few survey participants using full sentences. Key factors influencing survey queries include the primary sound source, intended usage, perceived location, and the number of sound sources. These insights are crucial for developing user-centred, effective text-based audio retrieval systems, enhancing our understanding of user behaviour in sound search contexts.
+
+
+计算机视觉
+
+ 1. 【2410.09049】SceneCraft: Layout-Guided 3D Scene Generation
+ 链接:https://arxiv.org/abs/2410.09049
+ 作者:Xiuyu Yang,Yunze Man,Jun-Kun Chen,Yu-Xiong Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:modeling tools, task with traditional, tedious and challenging, challenging task, user specifications
+ 备注: NeurIPS 2024. Code: [this https URL](https://github.com/OrangeSodahub/SceneCraft) Project Page: [this https URL](https://orangesodahub.github.io/SceneCraft)
+
+ 点击查看摘要
+ Abstract:The creation of complex 3D scenes tailored to user specifications has been a tedious and challenging task with traditional 3D modeling tools. Although some pioneering methods have achieved automatic text-to-3D generation, they are generally limited to small-scale scenes with restricted control over the shape and texture. We introduce SceneCraft, a novel method for generating detailed indoor scenes that adhere to textual descriptions and spatial layout preferences provided by users. Central to our method is a rendering-based technique, which converts 3D semantic layouts into multi-view 2D proxy maps. Furthermore, we design a semantic and depth conditioned diffusion model to generate multi-view images, which are used to learn a neural radiance field (NeRF) as the final scene representation. Without the constraints of panorama image generation, we surpass previous methods in supporting complicated indoor space generation beyond a single room, even as complicated as a whole multi-bedroom apartment with irregular shapes and layouts. Through experimental analysis, we demonstrate that our method significantly outperforms existing approaches in complex indoor scene generation with diverse textures, consistent geometry, and realistic visual quality. Code and more results are available at: this https URL
+
+
+
+ 2. 【2410.09045】MiRAGeNews: Multimodal Realistic AI-Generated News Detection
+ 链接:https://arxiv.org/abs/2410.09045
+ 作者:Runsheng Huang,Liam Dugan,Yue Yang,Chris Callison-Burch
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:inflammatory or misleading, recent years, proliferation of inflammatory, increasingly common, common in recent
+ 备注: EMNLP 2024 Findings
+
+ 点击查看摘要
+ Abstract:The proliferation of inflammatory or misleading "fake" news content has become increasingly common in recent years. Simultaneously, it has become easier than ever to use AI tools to generate photorealistic images depicting any scene imaginable. Combining these two -- AI-generated fake news content -- is particularly potent and dangerous. To combat the spread of AI-generated fake news, we propose the MiRAGeNews Dataset, a dataset of 12,500 high-quality real and AI-generated image-caption pairs from state-of-the-art generators. We find that our dataset poses a significant challenge to humans (60% F-1) and state-of-the-art multi-modal LLMs ( 24% F-1). Using our dataset we train a multi-modal detector (MiRAGe) that improves by +5.1% F-1 over state-of-the-art baselines on image-caption pairs from out-of-domain image generators and news publishers. We release our code and data to aid future work on detecting AI-generated content.
+
+
+
+ 3. 【2410.09032】Alberta Wells Dataset: Pinpointing Oil and Gas Wells from Satellite Imagery
+ 链接:https://arxiv.org/abs/2410.09032
+ 作者:Pratinav Seth,Michelle Lin,Brefo Dwamena Yaw,Jade Boutot,Mary Kang,David Rolnick
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:leaching methane, oil and gas, atmosphere and toxic, toxic compounds, Alberta Energy Regulator
+ 备注:
+
+ 点击查看摘要
+ Abstract:Millions of abandoned oil and gas wells are scattered across the world, leaching methane into the atmosphere and toxic compounds into the groundwater. Many of these locations are unknown, preventing the wells from being plugged and their polluting effects averted. Remote sensing is a relatively unexplored tool for pinpointing abandoned wells at scale. We introduce the first large-scale benchmark dataset for this problem, leveraging medium-resolution multi-spectral satellite imagery from Planet Labs. Our curated dataset comprises over 213,000 wells (abandoned, suspended, and active) from Alberta, a region with especially high well density, sourced from the Alberta Energy Regulator and verified by domain experts. We evaluate baseline algorithms for well detection and segmentation, showing the promise of computer vision approaches but also significant room for improvement.
+
+
+
+ 4. 【2410.09010】CVAM-Pose: Conditional Variational Autoencoder for Multi-Object Monocular Pose Estimation
+ 链接:https://arxiv.org/abs/2410.09010
+ 作者:Jianyu Zhao,Wei Quan,Bogdan J. Matuszewski
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Estimating rigid objects', Estimating rigid, rigid objects' poses, computer vision, augmented reality
+ 备注: BMVC 2024, oral presentation, the main paper and supplementary materials are included
+
+ 点击查看摘要
+ Abstract:Estimating rigid objects' poses is one of the fundamental problems in computer vision, with a range of applications across automation and augmented reality. Most existing approaches adopt one network per object class strategy, depend heavily on objects' 3D models, depth data, and employ a time-consuming iterative refinement, which could be impractical for some applications. This paper presents a novel approach, CVAM-Pose, for multi-object monocular pose estimation that addresses these limitations. The CVAM-Pose method employs a label-embedded conditional variational autoencoder network, to implicitly abstract regularised representations of multiple objects in a single low-dimensional latent space. This autoencoding process uses only images captured by a projective camera and is robust to objects' occlusion and scene clutter. The classes of objects are one-hot encoded and embedded throughout the network. The proposed label-embedded pose regression strategy interprets the learnt latent space representations utilising continuous pose representations. Ablation tests and systematic evaluations demonstrate the scalability and efficiency of the CVAM-Pose method for multi-object scenarios. The proposed CVAM-Pose outperforms competing latent space approaches. For example, it is respectively 25% and 20% better than AAE and Multi-Path methods, when evaluated using the $\mathrm{AR_{VSD}}$ metric on the Linemod-Occluded dataset. It also achieves results somewhat comparable to methods reliant on 3D models reported in BOP challenges. Code available: this https URL
+
+
+
+ 5. 【2410.09009】Semantic Score Distillation Sampling for Compositional Text-to-3D Generation
+ 链接:https://arxiv.org/abs/2410.09009
+ 作者:Ling Yang,Zixiang Zhang,Junlin Han,Bohan Zeng,Runjia Li,Philip Torr,Wentao Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:textual descriptions remains, Score Distillation Sampling, Distillation Sampling, assets from textual, vision research
+ 备注: Project: [this https URL](https://github.com/YangLing0818/SemanticSDS-3D)
+
+ 点击查看摘要
+ Abstract:Generating high-quality 3D assets from textual descriptions remains a pivotal challenge in computer graphics and vision research. Due to the scarcity of 3D data, state-of-the-art approaches utilize pre-trained 2D diffusion priors, optimized through Score Distillation Sampling (SDS). Despite progress, crafting complex 3D scenes featuring multiple objects or intricate interactions is still difficult. To tackle this, recent methods have incorporated box or layout guidance. However, these layout-guided compositional methods often struggle to provide fine-grained control, as they are generally coarse and lack expressiveness. To overcome these challenges, we introduce a novel SDS approach, Semantic Score Distillation Sampling (SemanticSDS), designed to effectively improve the expressiveness and accuracy of compositional text-to-3D generation. Our approach integrates new semantic embeddings that maintain consistency across different rendering views and clearly differentiate between various objects and parts. These embeddings are transformed into a semantic map, which directs a region-specific SDS process, enabling precise optimization and compositional generation. By leveraging explicit semantic guidance, our method unlocks the compositional capabilities of existing pre-trained diffusion models, thereby achieving superior quality in 3D content generation, particularly for complex objects and scenes. Experimental results demonstrate that our SemanticSDS framework is highly effective for generating state-of-the-art complex 3D content. Code: this https URL
+
+
+
+ 6. 【2410.09004】DA-Ada: Learning Domain-Aware Adapter for Domain Adaptive Object Detection
+ 链接:https://arxiv.org/abs/2410.09004
+ 作者:Haochen Li,Rui Zhang,Hantao Yao,Xin Zhang,Yifan Hao,Xinkai Song,Xiaqing Li,Yongwei Zhao,Ling Li,Yunji Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:generalize detectors trained, annotated source domain, Domain, knowledge, aims to generalize
+ 备注: Accepted by NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:Domain adaptive object detection (DAOD) aims to generalize detectors trained on an annotated source domain to an unlabelled target domain. As the visual-language models (VLMs) can provide essential general knowledge on unseen images, freezing the visual encoder and inserting a domain-agnostic adapter can learn domain-invariant knowledge for DAOD. However, the domain-agnostic adapter is inevitably biased to the source domain. It discards some beneficial knowledge discriminative on the unlabelled domain, i.e., domain-specific knowledge of the target domain. To solve the issue, we propose a novel Domain-Aware Adapter (DA-Ada) tailored for the DAOD task. The key point is exploiting domain-specific knowledge between the essential general knowledge and domain-invariant knowledge. DA-Ada consists of the Domain-Invariant Adapter (DIA) for learning domain-invariant knowledge and the Domain-Specific Adapter (DSA) for injecting the domain-specific knowledge from the information discarded by the visual encoder. Comprehensive experiments over multiple DAOD tasks show that DA-Ada can efficiently infer a domain-aware visual encoder for boosting domain adaptive object detection. Our code is available at this https URL.
+
+
+
+ 7. 【2410.08983】DEL: Discrete Element Learner for Learning 3D Particle Dynamics with Neural Rendering
+ 链接:https://arxiv.org/abs/2410.08983
+ 作者:Jiaxu Wang,Jingkai Sun,Junhao He,Ziyi Zhang,Qiang Zhang,Mingyuan Sun,Renjing Xu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR); Machine Learning (cs.LG)
+ 关键词:show great potential, simulating particle dynamics, great potential, potential for simulating, per-particle correspondences
+ 备注:
+
+ 点击查看摘要
+ Abstract:Learning-based simulators show great potential for simulating particle dynamics when 3D groundtruth is available, but per-particle correspondences are not always accessible. The development of neural rendering presents a new solution to this field to learn 3D dynamics from 2D images by inverse rendering. However, existing approaches still suffer from ill-posed natures resulting from the 2D to 3D uncertainty, for example, specific 2D images can correspond with various 3D particle distributions. To mitigate such uncertainty, we consider a conventional, mechanically interpretable framework as the physical priors and extend it to a learning-based version. In brief, we incorporate the learnable graph kernels into the classic Discrete Element Analysis (DEA) framework to implement a novel mechanics-integrated learning system. In this case, the graph network kernels are only used for approximating some specific mechanical operators in the DEA framework rather than the whole dynamics mapping. By integrating the strong physics priors, our methods can effectively learn the dynamics of various materials from the partial 2D observations in a unified manner. Experiments show that our approach outperforms other learned simulators by a large margin in this context and is robust to different renderers, fewer training samples, and fewer camera views.
+
+
+
+ 8. 【2410.08956】Rapid Grassmannian Averaging with Chebyshev Polynomials
+ 链接:https://arxiv.org/abs/2410.08956
+ 作者:Brighton Ancelin,Alex Saad-Falcon,Kason Ancelin,Justin Romberg
+ 类目:Numerical Analysis (math.NA); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Optimization and Control (math.OC)
+ 关键词:Rapid Grassmannian Averaging, Decentralized Rapid Grassmannian, Grassmannian Averaging, Rapid Grassmannian, Grassmannian
+ 备注: Submitted to ICLR 2025
+
+ 点击查看摘要
+ Abstract:We propose new algorithms to efficiently average a collection of points on a Grassmannian manifold in both the centralized and decentralized settings. Grassmannian points are used ubiquitously in machine learning, computer vision, and signal processing to represent data through (often low-dimensional) subspaces. While averaging these points is crucial to many tasks (especially in the decentralized setting), existing methods unfortunately remain computationally expensive due to the non-Euclidean geometry of the manifold. Our proposed algorithms, Rapid Grassmannian Averaging (RGrAv) and Decentralized Rapid Grassmannian Averaging (DRGrAv), overcome this challenge by leveraging the spectral structure of the problem to rapidly compute an average using only small matrix multiplications and QR factorizations. We provide a theoretical guarantee of optimality and present numerical experiments which demonstrate that our algorithms outperform state-of-the-art methods in providing high accuracy solutions in minimal time. Additional experiments showcase the versatility of our algorithms to tasks such as K-means clustering on video motion data, establishing RGrAv and DRGrAv as powerful tools for generic Grassmannian averaging.
+
+
+
+ 9. 【2410.08946】Parallel Watershed Partitioning: GPU-Based Hierarchical Image Segmentation
+ 链接:https://arxiv.org/abs/2410.08946
+ 作者:Varduhi Yeghiazaryan,Yeva Gabrielyan,Irina Voiculescu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Distributed, Parallel, and Cluster Computing (cs.DC)
+ 关键词:processing applications rely, applications rely, Abstract, similar, image
+ 备注:
+
+ 点击查看摘要
+ Abstract:Many image processing applications rely on partitioning an image into disjoint regions whose pixels are 'similar.' The watershed and waterfall transforms are established mathematical morphology pixel clustering techniques. They are both relevant to modern applications where groups of pixels are to be decided upon in one go, or where adjacency information is relevant. We introduce three new parallel partitioning algorithms for GPUs. By repeatedly applying watershed algorithms, we produce waterfall results which form a hierarchy of partition regions over an input image. Our watershed algorithms attain competitive execution times in both 2D and 3D, processing an 800 megavoxel image in less than 1.4 sec. We also show how to use this fully deterministic image partitioning as a pre-processing step to machine learning based semantic segmentation. This replaces the role of superpixel algorithms, and results in comparable accuracy and faster training times.
+
+
+
+ 10. 【2410.08941】MeshGS: Adaptive Mesh-Aligned Gaussian Splatting for High-Quality Rendering
+ 链接:https://arxiv.org/abs/2410.08941
+ 作者:Jaehoon Choi,Yonghan Lee,Hyungtae Lee,Heesung Kwon,Dinesh Manocha
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Gaussian splats, Gaussian, Gaussian splatting, loosely-bound Gaussian splats, splats
+ 备注: ACCV (Asian Conference on Computer Vision) 2024
+
+ 点击查看摘要
+ Abstract:Recently, 3D Gaussian splatting has gained attention for its capability to generate high-fidelity rendering results. At the same time, most applications such as games, animation, and AR/VR use mesh-based representations to represent and render 3D scenes. We propose a novel approach that integrates mesh representation with 3D Gaussian splats to perform high-quality rendering of reconstructed real-world scenes. In particular, we introduce a distance-based Gaussian splatting technique to align the Gaussian splats with the mesh surface and remove redundant Gaussian splats that do not contribute to the rendering. We consider the distance between each Gaussian splat and the mesh surface to distinguish between tightly-bound and loosely-bound Gaussian splats. The tightly-bound splats are flattened and aligned well with the mesh geometry. The loosely-bound Gaussian splats are used to account for the artifacts in reconstructed 3D meshes in terms of rendering. We present a training strategy of binding Gaussian splats to the mesh geometry, and take into account both types of splats. In this context, we introduce several regularization techniques aimed at precisely aligning tightly-bound Gaussian splats with the mesh surface during the training process. We validate the effectiveness of our method on large and unbounded scene from mip-NeRF 360 and Deep Blending datasets. Our method surpasses recent mesh-based neural rendering techniques by achieving a 2dB higher PSNR, and outperforms mesh-based Gaussian splatting methods by 1.3 dB PSNR, particularly on the outdoor mip-NeRF 360 dataset, demonstrating better rendering quality. We provide analyses for each type of Gaussian splat and achieve a reduction in the number of Gaussian splats by 30% compared to the original 3D Gaussian splatting.
+
+
+
+ 11. 【2410.08926】Zero-Shot Pupil Segmentation with SAM 2: A Case Study of Over 14 Million Images
+ 链接:https://arxiv.org/abs/2410.08926
+ 作者:Virmarie Maquiling,Sean Anthony Byrne,Diederick C. Niehorster,Marco Carminati,Enkelejda Kasneci
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Human-Computer Interaction (cs.HC)
+ 关键词:advancing gaze estimation, eye tracking technologies, vision foundation model, tracking technologies, explore the transformative
+ 备注: Virmarie Maquiling and Sean Anthony Byrne contributed equally to this paper, 8 pages, 3 figures, CHI Case Study, pre-print
+
+ 点击查看摘要
+ Abstract:We explore the transformative potential of SAM 2, a vision foundation model, in advancing gaze estimation and eye tracking technologies. By significantly reducing annotation time, lowering technical barriers through its ease of deployment, and enhancing segmentation accuracy, SAM 2 addresses critical challenges faced by researchers and practitioners. Utilizing its zero-shot segmentation capabilities with minimal user input-a single click per video-we tested SAM 2 on over 14 million eye images from diverse datasets, including virtual reality setups and the world's largest unified dataset recorded using wearable eye trackers. Remarkably, in pupil segmentation tasks, SAM 2 matches the performance of domain-specific models trained solely on eye images, achieving competitive mean Intersection over Union (mIoU) scores of up to 93% without fine-tuning. Additionally, we provide our code and segmentation masks for these widely used datasets to promote further research.
+
+
+
+ 12. 【2410.08925】HyperPg -- Prototypical Gaussians on the Hypersphere for Interpretable Deep Learning
+ 链接:https://arxiv.org/abs/2410.08925
+ 作者:Maximilian Xiling Li,Korbinian Franz Rudolf,Nils Blank,Rudolf Lioutikov
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:interpretable alternative, black-box deep learning, Prototype Learning methods, Learning methods provide, deep learning models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Prototype Learning methods provide an interpretable alternative to black-box deep learning models. Approaches such as ProtoPNet learn, which part of a test image "look like" known prototypical parts from training images, combining predictive power with the inherent interpretability of case-based reasoning. However, existing approaches have two main drawbacks: A) They rely solely on deterministic similarity scores without statistical confidence. B) The prototypes are learned in a black-box manner without human input. This work introduces HyperPg, a new prototype representation leveraging Gaussian distributions on a hypersphere in latent space, with learnable mean and variance. HyperPg prototypes adapt to the spread of clusters in the latent space and output likelihood scores. The new architecture, HyperPgNet, leverages HyperPg to learn prototypes aligned with human concepts from pixel-level annotations. Consequently, each prototype represents a specific concept such as color, image texture, or part of the image subject. A concept extraction pipeline built on foundation models provides pixel-level annotations, significantly reducing human labeling effort. Experiments on CUB-200-2011 and Stanford Cars datasets demonstrate that HyperPgNet outperforms other prototype learning architectures while using fewer parameters and training steps. Additionally, the concept-aligned HyperPg prototypes are learned transparently, enhancing model interpretability.
+
+
+
+ 13. 【2410.08920】Efficient Hyperparameter Importance Assessment for CNNs
+ 链接:https://arxiv.org/abs/2410.08920
+ 作者:Ruinan Wang,Ian Nabney,Mohammad Golbabaee
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:impacting models' robustness, profoundly impacting models', machine learning pipeline, Convolutional Neural Networks, profoundly impacting
+ 备注: 15 pages
+
+ 点击查看摘要
+ Abstract:Hyperparameter selection is an essential aspect of the machine learning pipeline, profoundly impacting models' robustness, stability, and generalization capabilities. Given the complex hyperparameter spaces associated with Neural Networks and the constraints of computational resources and time, optimizing all hyperparameters becomes impractical. In this context, leveraging hyperparameter importance assessment (HIA) can provide valuable guidance by narrowing down the search space. This enables machine learning practitioners to focus their optimization efforts on the hyperparameters with the most significant impact on model performance while conserving time and resources. This paper aims to quantify the importance weights of some hyperparameters in Convolutional Neural Networks (CNNs) with an algorithm called N-RReliefF, laying the groundwork for applying HIA methodologies in the Deep Learning field. We conduct an extensive study by training over ten thousand CNN models across ten popular image classification datasets, thereby acquiring a comprehensive dataset containing hyperparameter configuration instances and their corresponding performance metrics. It is demonstrated that among the investigated hyperparameters, the top five important hyperparameters of the CNN model are the number of convolutional layers, learning rate, dropout rate, optimizer and epoch.
+
+
+
+ 14. 【2410.08895】Calibrated Cache Model for Few-Shot Vision-Language Model Adaptation
+ 链接:https://arxiv.org/abs/2410.08895
+ 作者:Kun Ding,Qiang Yu,Haojian Zhang,Gaofeng Meng,Shiming Xiang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Cache-based approaches stand, adapting vision-language models, Cache-based approaches, cache model, existing cache model
+ 备注: submitted to IJCV
+
+ 点击查看摘要
+ Abstract:Cache-based approaches stand out as both effective and efficient for adapting vision-language models (VLMs). Nonetheless, the existing cache model overlooks three crucial aspects. 1) Pre-trained VLMs are mainly optimized for image-text similarity, neglecting the importance of image-image similarity, leading to a gap between pre-training and adaptation. 2) The current cache model is based on the Nadaraya-Watson (N-W) estimator, which disregards the intricate relationships among training samples while constructing weight function. 3) Under the condition of limited samples, the logits generated by cache model are of high uncertainty, directly using these logits without accounting for the confidence could be problematic. This work presents three calibration modules aimed at addressing the above challenges. Similarity Calibration refines the image-image similarity by using unlabeled images. We add a learnable projection layer with residual connection on top of the pre-trained image encoder of CLIP and optimize the parameters by minimizing self-supervised contrastive loss. Weight Calibration introduces a precision matrix into the weight function to adequately model the relation between training samples, transforming the existing cache model to a Gaussian Process (GP) regressor, which could be more accurate than N-W estimator. Confidence Calibration leverages the predictive variances computed by GP Regression to dynamically re-scale the logits of cache model, ensuring that the cache model's outputs are appropriately adjusted based on their confidence levels. Besides, to reduce the high complexity of GPs, we further propose a group-based learning strategy. Integrating the above designs, we propose both training-free and training-required variants. Extensive experiments on 11 few-shot classification datasets validate that the proposed methods can achieve state-of-the-art performance.
+
+
+
+ 15. 【2410.08889】Exploiting Memory-aware Q-distribution Prediction for Nuclear Fusion via Modern Hopfield Network
+ 链接:https://arxiv.org/abs/2410.08889
+ 作者:Qingchuan Ma,Shiao Wang,Tong Zheng,Xiaodong Dai,Yifeng Wang,Qingquan Yang,Xiao Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:clean energy solutions, advancing clean energy, long-term stable nuclear, Modern Hopfield Networks, nuclear fusion task
+ 备注:
+
+ 点击查看摘要
+ Abstract:This study addresses the critical challenge of predicting the Q-distribution in long-term stable nuclear fusion task, a key component for advancing clean energy solutions. We introduce an innovative deep learning framework that employs Modern Hopfield Networks to incorporate associative memory from historical shots. Utilizing a newly compiled dataset, we demonstrate the effectiveness of our approach in enhancing Q-distribution prediction. The proposed method represents a significant advancement by leveraging historical memory information for the first time in this context, showcasing improved prediction accuracy and contributing to the optimization of nuclear fusion research.
+
+
+
+ 16. 【2410.08885】Can GPTs Evaluate Graphic Design Based on Design Principles?
+ 链接:https://arxiv.org/abs/2410.08885
+ 作者:Daichi Haraguchi,Naoto Inoue,Wataru Shimoda,Hayato Mitani,Seiichi Uchida,Kota Yamaguchi
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:foundation models show, models show promising, show promising capability, Large Multimodal Models, Recent advancements
+ 备注: Accepted to SIGGRAPH Asia 2024 (Technical Communications Track)
+
+ 点击查看摘要
+ Abstract:Recent advancements in foundation models show promising capability in graphic design generation. Several studies have started employing Large Multimodal Models (LMMs) to evaluate graphic designs, assuming that LMMs can properly assess their quality, but it is unclear if the evaluation is reliable. One way to evaluate the quality of graphic design is to assess whether the design adheres to fundamental graphic design principles, which are the designer's common practice. In this paper, we compare the behavior of GPT-based evaluation and heuristic evaluation based on design principles using human annotations collected from 60 subjects. Our experiments reveal that, while GPTs cannot distinguish small details, they have a reasonably good correlation with human annotation and exhibit a similar tendency to heuristic metrics based on design principles, suggesting that they are indeed capable of assessing the quality of graphic design. Our dataset is available at this https URL .
+
+
+
+ 17. 【2410.08879】Multi-modal Fusion based Q-distribution Prediction for Controlled Nuclear Fusion
+ 链接:https://arxiv.org/abs/2410.08879
+ 作者:Shiao Wang,Yifeng Wang,Qingchuan Ma,Xiao Wang,Ning Yan,Qingquan Yang,Guosheng Xu,Jin Tang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:crucial research direction, solving prediction challenges, deep learning emerging, controlled nuclear fusion, crucial research
+ 备注:
+
+ 点击查看摘要
+ Abstract:Q-distribution prediction is a crucial research direction in controlled nuclear fusion, with deep learning emerging as a key approach to solving prediction challenges. In this paper, we leverage deep learning techniques to tackle the complexities of Q-distribution prediction. Specifically, we explore multimodal fusion methods in computer vision, integrating 2D line image data with the original 1D data to form a bimodal input. Additionally, we employ the Transformer's attention mechanism for feature extraction and the interactive fusion of bimodal information. Extensive experiments validate the effectiveness of our approach, significantly reducing prediction errors in Q-distribution.
+
+
+
+ 18. 【2410.08860】Audio Description Generation in the Era of LLMs and VLMs: A Review of Transferable Generative AI Technologies
+ 链接:https://arxiv.org/abs/2410.08860
+ 作者:Yingqiang Gao,Lukas Fischer,Alexa Lintner,Sarah Ebling
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:assist blind persons, acoustic commentaries designed, accessing digital media, digital media content, Audio descriptions
+ 备注:
+
+ 点击查看摘要
+ Abstract:Audio descriptions (ADs) function as acoustic commentaries designed to assist blind persons and persons with visual impairments in accessing digital media content on television and in movies, among other settings. As an accessibility service typically provided by trained AD professionals, the generation of ADs demands significant human effort, making the process both time-consuming and costly. Recent advancements in natural language processing (NLP) and computer vision (CV), particularly in large language models (LLMs) and vision-language models (VLMs), have allowed for getting a step closer to automatic AD generation. This paper reviews the technologies pertinent to AD generation in the era of LLMs and VLMs: we discuss how state-of-the-art NLP and CV technologies can be applied to generate ADs and identify essential research directions for the future.
+
+
+
+ 19. 【2410.08840】Learning Interaction-aware 3D Gaussian Splatting for One-shot Hand Avatars
+ 链接:https://arxiv.org/abs/2410.08840
+ 作者:Xuan Huang,Hanhui Li,Wanquan Liu,Xiaodan Liang,Yiqiang Yan,Yuhao Cheng,Chengqiang Gao
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:create animatable avatars, Gaussian Splatting, propose to create, create animatable, animatable avatars
+ 备注: Accepted to NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:In this paper, we propose to create animatable avatars for interacting hands with 3D Gaussian Splatting (GS) and single-image inputs. Existing GS-based methods designed for single subjects often yield unsatisfactory results due to limited input views, various hand poses, and occlusions. To address these challenges, we introduce a novel two-stage interaction-aware GS framework that exploits cross-subject hand priors and refines 3D Gaussians in interacting areas. Particularly, to handle hand variations, we disentangle the 3D presentation of hands into optimization-based identity maps and learning-based latent geometric features and neural texture maps. Learning-based features are captured by trained networks to provide reliable priors for poses, shapes, and textures, while optimization-based identity maps enable efficient one-shot fitting of out-of-distribution hands. Furthermore, we devise an interaction-aware attention module and a self-adaptive Gaussian refinement module. These modules enhance image rendering quality in areas with intra- and inter-hand interactions, overcoming the limitations of existing GS-based methods. Our proposed method is validated via extensive experiments on the large-scale InterHand2.6M dataset, and it significantly improves the state-of-the-art performance in image quality. Project Page: \url{this https URL}.
+
+
+
+ 20. 【2410.08826】owards virtual painting recolouring using Vision Transformer on X-Ray Fluorescence datacubes
+ 链接:https://arxiv.org/abs/2410.08826
+ 作者:Alessandro Bombini,Fernando García-Avello Bofías,Francesca Giambi,Chiara Ruberto
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Applied Physics (physics.app-ph)
+ 关键词:perform virtual painting, virtual painting recolouring, Deep Variational Embedding, X-Ray Fluorescence, Variational Embedding network
+ 备注: v1: 20 pages, 10 figures; link to code repository
+
+ 点击查看摘要
+ Abstract:In this contribution, we define (and test) a pipeline to perform virtual painting recolouring using raw data of X-Ray Fluorescence (XRF) analysis on pictorial artworks. To circumvent the small dataset size, we generate a synthetic dataset, starting from a database of XRF spectra; furthermore, to ensure a better generalisation capacity (and to tackle the issue of in-memory size and inference time), we define a Deep Variational Embedding network to embed the XRF spectra into a lower dimensional, K-Means friendly, metric space.
+We thus train a set of models to assign coloured images to embedded XRF images. We report here the devised pipeline performances in terms of visual quality metrics, and we close on a discussion on the results.
+
Comments:
+v1: 20 pages, 10 figures; link to code repository
+Subjects:
+Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Applied Physics (physics.app-ph)
+ACMclasses:
+I.4.m; J.2
+Cite as:
+arXiv:2410.08826 [cs.CV]
+(or
+arXiv:2410.08826v1 [cs.CV] for this version)
+https://doi.org/10.48550/arXiv.2410.08826
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 21. 【2410.08824】One-shot Generative Domain Adaptation in 3D GANs
+ 链接:https://arxiv.org/abs/2410.08824
+ 作者:Ziqiang Li,Yi Wu,Chaoyue Wang,Xue Rui,Bin Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:necessitates extensive training, ensure stable training, extensive training data, generation necessitates extensive, image generation necessitates
+ 备注: IJCV
+
+ 点击查看摘要
+ Abstract:3D-aware image generation necessitates extensive training data to ensure stable training and mitigate the risk of overfitting. This paper first considers a novel task known as One-shot 3D Generative Domain Adaptation (GDA), aimed at transferring a pre-trained 3D generator from one domain to a new one, relying solely on a single reference image. One-shot 3D GDA is characterized by the pursuit of specific attributes, namely, high fidelity, large diversity, cross-domain consistency, and multi-view consistency. Within this paper, we introduce 3D-Adapter, the first one-shot 3D GDA method, for diverse and faithful generation. Our approach begins by judiciously selecting a restricted weight set for fine-tuning, and subsequently leverages four advanced loss functions to facilitate adaptation. An efficient progressive fine-tuning strategy is also implemented to enhance the adaptation process. The synergy of these three technological components empowers 3D-Adapter to achieve remarkable performance, substantiated both quantitatively and qualitatively, across all desired properties of 3D GDA. Furthermore, 3D-Adapter seamlessly extends its capabilities to zero-shot scenarios, and preserves the potential for crucial tasks such as interpolation, reconstruction, and editing within the latent space of the pre-trained generator. Code will be available at this https URL.
+
+
+
+ 22. 【2410.08810】LIME-Eval: Rethinking Low-light Image Enhancement Evaluation via Object Detection
+ 链接:https://arxiv.org/abs/2410.08810
+ 作者:Mingjia Li,Hao Zhao,Xiaojie Guo
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:paired ground-truth information, high-level vision tasks, ground-truth information, high-level vision, absence of paired
+ 备注:
+
+ 点击查看摘要
+ Abstract:Due to the nature of enhancement--the absence of paired ground-truth information, high-level vision tasks have been recently employed to evaluate the performance of low-light image enhancement. A widely-used manner is to see how accurately an object detector trained on enhanced low-light images by different candidates can perform with respect to annotated semantic labels. In this paper, we first demonstrate that the mentioned approach is generally prone to overfitting, and thus diminishes its measurement reliability. In search of a proper evaluation metric, we propose LIME-Bench, the first online benchmark platform designed to collect human preferences for low-light enhancement, providing a valuable dataset for validating the correlation between human perception and automated evaluation metrics. We then customize LIME-Eval, a novel evaluation framework that utilizes detectors pre-trained on standard-lighting datasets without object annotations, to judge the quality of enhanced images. By adopting an energy-based strategy to assess the accuracy of output confidence maps, our LIME-Eval can simultaneously bypass biases associated with retraining detectors and circumvent the reliance on annotations for dim images. Comprehensive experiments are provided to reveal the effectiveness of our LIME-Eval. Our benchmark platform (this https URL) and code (this https URL) are available online.
+
+
+
+ 23. 【2410.08797】CoTCoNet: An Optimized Coupled Transformer-Convolutional Network with an Adaptive Graph Reconstruction for Leukemia Detection
+ 链接:https://arxiv.org/abs/2410.08797
+ 作者:Chandravardhan Singh Raghaw,Arnav Sharma,Shubhi Bansa,Mohammad Zia Ur Rehman,Nagendra Kumar
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:accurate blood smear, blood smear analysis, Swift and accurate, effective diagnostic method, accurate blood
+ 备注:
+
+ 点击查看摘要
+ Abstract:Swift and accurate blood smear analysis is an effective diagnostic method for leukemia and other hematological malignancies. However, manual leukocyte count and morphological evaluation using a microscope is time-consuming and prone to errors. Conventional image processing methods also exhibit limitations in differentiating cells due to the visual similarity between malignant and benign cell morphology. This limitation is further compounded by the skewed training data that hinders the extraction of reliable and pertinent features. In response to these challenges, we propose an optimized Coupled Transformer Convolutional Network (CoTCoNet) framework for the classification of leukemia, which employs a well-designed transformer integrated with a deep convolutional network to effectively capture comprehensive global features and scalable spatial patterns, enabling the identification of complex and large-scale hematological features. Further, the framework incorporates a graph-based feature reconstruction module to reveal the hidden or unobserved hard-to-see biological features of leukocyte cells and employs a Population-based Meta-Heuristic Algorithm for feature selection and optimization. To mitigate data imbalance issues, we employ a synthetic leukocyte generator. In the evaluation phase, we initially assess CoTCoNet on a dataset containing 16,982 annotated cells, and it achieves remarkable accuracy and F1-Score rates of 0.9894 and 0.9893, respectively. To broaden the generalizability of our model, we evaluate it across four publicly available diverse datasets, which include the aforementioned dataset. This evaluation demonstrates that our method outperforms current state-of-the-art approaches. We also incorporate an explainability approach in the form of feature visualization closely aligned with cell annotations to provide a deeper understanding of the framework.
+
+
+
+ 24. 【2410.08792】VLM See, Robot Do: Human Demo Video to Robot Action Plan via Vision Language Model
+ 链接:https://arxiv.org/abs/2410.08792
+ 作者:Beichen Wang,Juexiao Zhang,Shuwen Dong,Irving Fang,Chen Feng
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Vision Language Models, Vision Language, Language Models, common sense reasoning, recently been adopted
+ 备注:
+
+ 点击查看摘要
+ Abstract:Vision Language Models (VLMs) have recently been adopted in robotics for their capability in common sense reasoning and generalizability. Existing work has applied VLMs to generate task and motion planning from natural language instructions and simulate training data for robot learning. In this work, we explore using VLM to interpret human demonstration videos and generate robot task planning. Our method integrates keyframe selection, visual perception, and VLM reasoning into a pipeline. We named it SeeDo because it enables the VLM to ''see'' human demonstrations and explain the corresponding plans to the robot for it to ''do''. To validate our approach, we collected a set of long-horizon human videos demonstrating pick-and-place tasks in three diverse categories and designed a set of metrics to comprehensively benchmark SeeDo against several baselines, including state-of-the-art video-input VLMs. The experiments demonstrate SeeDo's superior performance. We further deployed the generated task plans in both a simulation environment and on a real robot arm.
+
+
+
+ 25. 【2410.08781】VideoSAM: Open-World Video Segmentation
+ 链接:https://arxiv.org/abs/2410.08781
+ 作者:Pinxue Guo,Zixu Zhao,Jianxiong Gao,Chongruo Wu,Tong He,Zheng Zhang,Tianjun Xiao,Wenqiang Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:autonomous driving, essential for advancing, open-world settings, settings where continuous, continuous perception
+ 备注:
+
+ 点击查看摘要
+ Abstract:Video segmentation is essential for advancing robotics and autonomous driving, particularly in open-world settings where continuous perception and object association across video frames are critical. While the Segment Anything Model (SAM) has excelled in static image segmentation, extending its capabilities to video segmentation poses significant challenges. We tackle two major hurdles: a) SAM's embedding limitations in associating objects across frames, and b) granularity inconsistencies in object segmentation. To this end, we introduce VideoSAM, an end-to-end framework designed to address these challenges by improving object tracking and segmentation consistency in dynamic environments. VideoSAM integrates an agglomerated backbone, RADIO, enabling object association through similarity metrics and introduces Cycle-ack-Pairs Propagation with a memory mechanism for stable object tracking. Additionally, we incorporate an autoregressive object-token mechanism within the SAM decoder to maintain consistent granularity across frames. Our method is extensively evaluated on the UVO and BURST benchmarks, and robotic videos from RoboTAP, demonstrating its effectiveness and robustness in real-world scenarios. All codes will be available.
+
+
+
+ 26. 【2410.08779】HpEIS: Learning Hand Pose Embeddings for Multimedia Interactive Systems
+ 链接:https://arxiv.org/abs/2410.08779
+ 作者:Songpei Xu,Xuri Ge,Chaitanya Kaul,Roderick Murray-Smith
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Human-Computer Interaction (cs.HC)
+ 关键词:Embedding Interactive System, Hand-pose Embedding Interactive, Variational Autoencoder, Embedding Interactive, two-dimensional visual space
+ 备注: 6 pages, 8 figures, 3 tables
+
+ 点击查看摘要
+ Abstract:We present a novel Hand-pose Embedding Interactive System (HpEIS) as a virtual sensor, which maps users' flexible hand poses to a two-dimensional visual space using a Variational Autoencoder (VAE) trained on a variety of hand poses. HpEIS enables visually interpretable and guidable support for user explorations in multimedia collections, using only a camera as an external hand pose acquisition device. We identify general usability issues associated with system stability and smoothing requirements through pilot experiments with expert and inexperienced users. We then design stability and smoothing improvements, including hand-pose data augmentation, an anti-jitter regularisation term added to loss function, stabilising post-processing for movement turning points and smoothing post-processing based on One Euro Filters. In target selection experiments (n=12), we evaluate HpEIS by measures of task completion time and the final distance to target points, with and without the gesture guidance window condition. Experimental responses indicate that HpEIS provides users with a learnable, flexible, stable and smooth mid-air hand movement interaction experience.
+
+
+
+ 27. 【2410.08769】Efficient Multi-Object Tracking on Edge Devices via Reconstruction-Based Channel Pruning
+ 链接:https://arxiv.org/abs/2410.08769
+ 作者:Jan Müller,Adrian Pigors
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:addressing critical security, Jetson Orin Nano, technologies presents, advancement of multi-object, presents the dual
+ 备注:
+
+ 点击查看摘要
+ Abstract:The advancement of multi-object tracking (MOT) technologies presents the dual challenge of maintaining high performance while addressing critical security and privacy concerns. In applications such as pedestrian tracking, where sensitive personal data is involved, the potential for privacy violations and data misuse becomes a significant issue if data is transmitted to external servers. To mitigate these risks, processing data directly on an edge device, such as a smart camera, has emerged as a viable solution. Edge computing ensures that sensitive information remains local, thereby aligning with stringent privacy principles and significantly reducing network latency. However, the implementation of MOT on edge devices is not without its challenges. Edge devices typically possess limited computational resources, necessitating the development of highly optimized algorithms capable of delivering real-time performance under these constraints. The disparity between the computational requirements of state-of-the-art MOT algorithms and the capabilities of edge devices emphasizes a significant obstacle. To address these challenges, we propose a neural network pruning method specifically tailored to compress complex networks, such as those used in modern MOT systems. This approach optimizes MOT performance by ensuring high accuracy and efficiency within the constraints of limited edge devices, such as NVIDIA's Jetson Orin Nano. By applying our pruning method, we achieve model size reductions of up to 70% while maintaining a high level of accuracy and further improving performance on the Jetson Orin Nano, demonstrating the effectiveness of our approach for edge computing applications.
+
+
+
+ 28. 【2410.08743】Look Gauss, No Pose: Novel View Synthesis using Gaussian Splatting without Accurate Pose Initialization
+ 链接:https://arxiv.org/abs/2410.08743
+ 作者:Christian Schmidt,Jens Piekenbrinck,Bastian Leibe
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:posed input images, Gaussian Splatting, Gaussian Splatting framework, novel-view synthesis, input images
+ 备注: Accepted in IROS 2024
+
+ 点击查看摘要
+ Abstract:3D Gaussian Splatting has recently emerged as a powerful tool for fast and accurate novel-view synthesis from a set of posed input images. However, like most novel-view synthesis approaches, it relies on accurate camera pose information, limiting its applicability in real-world scenarios where acquiring accurate camera poses can be challenging or even impossible. We propose an extension to the 3D Gaussian Splatting framework by optimizing the extrinsic camera parameters with respect to photometric residuals. We derive the analytical gradients and integrate their computation with the existing high-performance CUDA implementation. This enables downstream tasks such as 6-DoF camera pose estimation as well as joint reconstruction and camera refinement. In particular, we achieve rapid convergence and high accuracy for pose estimation on real-world scenes. Our method enables fast reconstruction of 3D scenes without requiring accurate pose information by jointly optimizing geometry and camera poses, while achieving state-of-the-art results in novel-view synthesis. Our approach is considerably faster to optimize than most competing methods, and several times faster in rendering. We show results on real-world scenes and complex trajectories through simulated environments, achieving state-of-the-art results on LLFF while reducing runtime by two to four times compared to the most efficient competing method. Source code will be available at this https URL .
+
+
+
+ 29. 【2410.08740】Hespi: A pipeline for automatically detecting information from hebarium specimen sheets
+ 链接:https://arxiv.org/abs/2410.08740
+ 作者:Robert Turnbull,Emily Fitzgerald,Karen Thompson,Joanne L. Birch
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:conservation sciences, Optical Character Recognition, Specimen, data, Specimen sheet PIpeline
+ 备注:
+
+ 点击查看摘要
+ Abstract:Specimen associated biodiversity data are sought after for biological, environmental, climate, and conservation sciences. A rate shift is required for the extraction of data from specimen images to eliminate the bottleneck that the reliance on human-mediated transcription of these data represents. We applied advanced computer vision techniques to develop the `Hespi' (HErbarium Specimen sheet PIpeline), which extracts a pre-catalogue subset of collection data on the institutional labels on herbarium specimens from their digital images. The pipeline integrates two object detection models; the first detects bounding boxes around text-based labels and the second detects bounding boxes around text-based data fields on the primary institutional label. The pipeline classifies text-based institutional labels as printed, typed, handwritten, or a combination and applies Optical Character Recognition (OCR) and Handwritten Text Recognition (HTR) for data extraction. The recognized text is then corrected against authoritative databases of taxon names. The extracted text is also corrected with the aide of a multimodal Large Language Model (LLM). Hespi accurately detects and extracts text for test datasets including specimen sheet images from international herbaria. The components of the pipeline are modular and users can train their own models with their own data and use them in place of the models provided.
+
+
+
+ 30. 【2410.08739】MMLF: Multi-modal Multi-class Late Fusion for Object Detection with Uncertainty Estimation
+ 链接:https://arxiv.org/abs/2410.08739
+ 作者:Qihang Yang,Yang Zhao,Hong Cheng
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Systems and Control (eess.SY)
+ 关键词:driving necessitates advanced, necessitates advanced object, Autonomous driving necessitates, single-modal approaches, late fusion
+ 备注:
+
+ 点击查看摘要
+ Abstract:Autonomous driving necessitates advanced object detection techniques that integrate information from multiple modalities to overcome the limitations associated with single-modal approaches. The challenges of aligning diverse data in early fusion and the complexities, along with overfitting issues introduced by deep fusion, underscore the efficacy of late fusion at the decision level. Late fusion ensures seamless integration without altering the original detector's network structure. This paper introduces a pioneering Multi-modal Multi-class Late Fusion method, designed for late fusion to enable multi-class detection. Fusion experiments conducted on the KITTI validation and official test datasets illustrate substantial performance improvements, presenting our model as a versatile solution for multi-modal object detection in autonomous driving. Moreover, our approach incorporates uncertainty analysis into the classification fusion process, rendering our model more transparent and trustworthy and providing more reliable insights into category predictions.
+
+
+
+ 31. 【2410.08734】Gradients Stand-in for Defending Deep Leakage in Federated Learning
+ 链接:https://arxiv.org/abs/2410.08734
+ 作者:H. Yi,H. Ren,C. Hu,Y. Li,J. Deng,X. Xie
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Federated Learning, localizing sensitive data, shifting the paradigm, reinforce privacy protections, paradigm towards localizing
+ 备注:
+
+ 点击查看摘要
+ Abstract:Federated Learning (FL) has become a cornerstone of privacy protection, shifting the paradigm towards localizing sensitive data while only sending model gradients to a central server. This strategy is designed to reinforce privacy protections and minimize the vulnerabilities inherent in centralized data storage systems. Despite its innovative approach, recent empirical studies have highlighted potential weaknesses in FL, notably regarding the exchange of gradients. In response, this study introduces a novel, efficacious method aimed at safeguarding against gradient leakage, namely, ``AdaDefense". Following the idea that model convergence can be achieved by using different types of optimization methods, we suggest using a local stand-in rather than the actual local gradient for global gradient aggregation on the central server. This proposed approach not only effectively prevents gradient leakage, but also ensures that the overall performance of the model remains largely unaffected. Delving into the theoretical dimensions, we explore how gradients may inadvertently leak private information and present a theoretical framework supporting the efficacy of our proposed method. Extensive empirical tests, supported by popular benchmark experiments, validate that our approach maintains model integrity and is robust against gradient leakage, marking an important step in our pursuit of safe and efficient FL.
+
+
+
+ 32. 【2410.08713】Impact of Surface Reflections in Maritime Obstacle Detection
+ 链接:https://arxiv.org/abs/2410.08713
+ 作者:Samed Yalçın,Hazım Kemal Ekenel
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Maritime obstacle detection, unmanned surface vehicles, Maritime obstacle, obstacle detection aims, obstacle detection
+ 备注: Accepted at RROW2024 Workshop @ British Machine Vision Conference (BMVC) 2024
+
+ 点击查看摘要
+ Abstract:Maritime obstacle detection aims to detect possible obstacles for autonomous driving of unmanned surface vehicles. In the context of maritime obstacle detection, the water surface can act like a mirror on certain circumstances, causing reflections on imagery. Previous works have indicated surface reflections as a source of false positives for object detectors in maritime obstacle detection tasks. In this work, we show that surface reflections indeed adversely affect detector performance. We measure the effect of reflections by testing on two custom datasets, which we make publicly available. The first one contains imagery with reflections, while in the second reflections are inpainted. We show that the reflections reduce mAP by 1.2 to 9.6 points across various detectors. To remove false positives on reflections, we propose a novel filtering approach named Heatmap Based Sliding Filter. We show that the proposed method reduces the total number of false positives by 34.64% while minimally affecting true positives. We also conduct qualitative analysis and show that the proposed method indeed removes false positives on the reflections. The datasets can be found on this https URL.
+
+
+
+ 33. 【2410.08695】Dynamic Multimodal Evaluation with Flexible Complexity by Vision-Language Bootstrapping
+ 链接:https://arxiv.org/abs/2410.08695
+ 作者:Yue Yang,Shuibai Zhang,Wenqi Shao,Kaipeng Zhang,Yi Bin,Yu Wang,Ping Luo
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Large Vision-Language Models, demonstrated remarkable capabilities, Large Vision-Language, Vision-Language Models, perception and reasoning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities across multimodal tasks such as visual perception and reasoning, leading to good performance on various multimodal evaluation benchmarks. However, these benchmarks keep a static nature and overlap with the pre-training data, resulting in fixed complexity constraints and data contamination issues. This raises the concern regarding the validity of the evaluation. To address these two challenges, we introduce a dynamic multimodal evaluation protocol called Vision-Language Bootstrapping (VLB). VLB provides a robust and comprehensive assessment for LVLMs with reduced data contamination and flexible complexity. To this end, VLB dynamically generates new visual question-answering samples through a multimodal bootstrapping module that modifies both images and language, while ensuring that newly generated samples remain consistent with the original ones by a judge module. By composing various bootstrapping strategies, VLB offers dynamic variants of existing benchmarks with diverse complexities, enabling the evaluation to co-evolve with the ever-evolving capabilities of LVLMs. Extensive experimental results across multiple benchmarks, including SEEDBench, MMBench, and MME, show that VLB significantly reduces data contamination and exposes performance limitations of LVLMs.
+
+
+
+ 34. 【2410.08688】Chain-of-Restoration: Multi-Task Image Restoration Models are Zero-Shot Step-by-Step Universal Image Restorers
+ 链接:https://arxiv.org/abs/2410.08688
+ 作者:Jin Cao,Deyu Meng,Xiangyong Cao
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:typically targeting isolated, previous works typically, works typically targeting, isolated degradation types, targeting isolated degradation
+ 备注: 11 pages, 9 figures
+
+ 点击查看摘要
+ Abstract:Despite previous works typically targeting isolated degradation types, recent research has increasingly focused on addressing composite degradations which involve a complex interplay of multiple different isolated degradations. Recognizing the challenges posed by the exponential number of possible degradation combinations, we propose Universal Image Restoration (UIR), a new task setting that requires models to be trained on a set of degradation bases and then remove any degradation that these bases can potentially compose in a zero-shot manner. Inspired by the Chain-of-Thought which prompts LLMs to address problems step-by-step, we propose the Chain-of-Restoration (CoR), which instructs models to step-by-step remove unknown composite degradations. By integrating a simple Degradation Discriminator into pre-trained multi-task models, CoR facilitates the process where models remove one degradation basis per step, continuing this process until the image is fully restored from the unknown composite degradation. Extensive experiments show that CoR significantly improves model performance in removing composite degradations, achieving results comparable to or surpassing those of State-of-The-Art (SoTA) methods trained on all degradations. The code will be released at this https URL.
+
+
+
+ 35. 【2410.08687】Uncertainty Estimation and Out-of-Distribution Detection for LiDAR Scene Semantic Segmentation
+ 链接:https://arxiv.org/abs/2410.08687
+ 作者:Hanieh Shojaei,Qianqian Zou,Max Mehltretter
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:environments requires autonomous, requires autonomous vehicles, Safe navigation, LiDAR scene segmentation, Gaussian Mixture Model
+ 备注: Accepted for publication in the Proceedings of the European Conference on Computer Vision (ECCV) 2024
+
+ 点击查看摘要
+ Abstract:Safe navigation in new environments requires autonomous vehicles and robots to accurately interpret their surroundings, relying on LiDAR scene segmentation, out-of-distribution (OOD) obstacle detection, and uncertainty computation. We propose a method to distinguish in-distribution (ID) from OOD samples and quantify both epistemic and aleatoric uncertainties using the feature space of a single deterministic model. After training a semantic segmentation network, a Gaussian Mixture Model (GMM) is fitted to its feature space. OOD samples are detected by checking if their squared Mahalanobis distances to each Gaussian component conform to a chi-squared distribution, eliminating the need for an additional OOD training set. Given that the estimated mean and covariance matrix of a multivariate Gaussian distribution follow Gaussian and Inverse-Wishart distributions, multiple GMMs are generated by sampling from these distributions to assess epistemic uncertainty through classification variability. Aleatoric uncertainty is derived from the entropy of responsibility values within Gaussian components. Comparing our method with deep ensembles and logit-sampling for uncertainty computation demonstrates its superior performance in real-world applications for quantifying epistemic and aleatoric uncertainty, as well as detecting OOD samples. While deep ensembles miss some highly uncertain samples, our method successfully detects them and assigns high epistemic uncertainty.
+
+
+
+ 36. 【2410.08680】Gait Sequence Upsampling using Diffusion Models for single LiDAR sensors
+ 链接:https://arxiv.org/abs/2410.08680
+ 作者:Jeongho Ahn,Kazuto Nakashima,Koki Yoshino,Yumi Iwashita,Ryo Kurazume
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:traditional RGB cameras, RGB cameras, gait-based person identification, traditional RGB, varying lighting conditions
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recently, 3D LiDAR has emerged as a promising technique in the field of gait-based person identification, serving as an alternative to traditional RGB cameras, due to its robustness under varying lighting conditions and its ability to capture 3D geometric information. However, long capture distances or the use of low-cost LiDAR sensors often result in sparse human point clouds, leading to a decline in identification performance. To address these challenges, we propose a sparse-to-dense upsampling model for pedestrian point clouds in LiDAR-based gait recognition, named LidarGSU, which is designed to improve the generalization capability of existing identification models. Our method utilizes diffusion probabilistic models (DPMs), which have shown high fidelity in generative tasks such as image completion. In this work, we leverage DPMs on sparse sequential pedestrian point clouds as conditional masks in a video-to-video translation approach, applied in an inpainting manner. We conducted extensive experiments on the SUSTeck1K dataset to evaluate the generative quality and recognition performance of the proposed method. Furthermore, we demonstrate the applicability of our upsampling model using a real-world dataset, captured with a low-resolution sensor across varying measurement distances.
+
+
+
+ 37. 【2410.08675】Bukva: Russian Sign Language Alphabet
+ 链接:https://arxiv.org/abs/2410.08675
+ 作者:Karina Kvanchiani,Petr Surovtsev,Alexander Nagaev,Elizaveta Petrova,Alexander Kapitanov
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Russian Sign Language, Russian fingerspelling alphabet, paper investigates, Russian fingerspelling, dactyl
+ 备注: Preptrint. Title: "Bukva: Russian Sign Language Alphabet". 9 pages
+
+ 点击查看摘要
+ Abstract:This paper investigates the recognition of the Russian fingerspelling alphabet, also known as the Russian Sign Language (RSL) dactyl. Dactyl is a component of sign languages where distinct hand movements represent individual letters of a written language. This method is used to spell words without specific signs, such as proper nouns or technical terms. The alphabet learning simulator is an essential isolated dactyl recognition application. There is a notable issue of data shortage in isolated dactyl recognition: existing Russian dactyl datasets lack subject heterogeneity, contain insufficient samples, or cover only static signs. We provide Bukva, the first full-fledged open-source video dataset for RSL dactyl recognition. It contains 3,757 videos with more than 101 samples for each RSL alphabet sign, including dynamic ones. We utilized crowdsourcing platforms to increase the subject's heterogeneity, resulting in the participation of 155 deaf and hard-of-hearing experts in the dataset creation. We use a TSM (Temporal Shift Module) block to handle static and dynamic signs effectively, achieving 83.6% top-1 accuracy with a real-time inference with CPU only. The dataset, demo code, and pre-trained models are publicly available.
+
+
+
+ 38. 【2410.08673】SpikeBottleNet: Energy Efficient Spike Neural Network Partitioning for Feature Compression in Device-Edge Co-Inference Systems
+ 链接:https://arxiv.org/abs/2410.08673
+ 作者:Maruf Hassan,Steven Davy
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:intelligent mobile applications, mobile applications highlights, deploying powerful deep, powerful deep learning, deep learning models
+ 备注: The paper consists of 7 pages and 3 figures. It was submitted to ECAI-2024, and the authors are currently working on improving it based on the review
+
+ 点击查看摘要
+ Abstract:The advent of intelligent mobile applications highlights the crucial demand for deploying powerful deep learning models on resource-constrained mobile devices. An effective solution in this context is the device-edge co-inference framework, which partitions a deep neural network between a mobile device and a nearby edge server. This approach requires balancing on-device computations and communication costs, often achieved through compressed intermediate feature transmission. Conventional deep neural network architectures require continuous data processing, leading to substantial energy consumption by edge devices. This motivates exploring binary, event-driven activations enabled by spiking neural networks (SNNs), known for their extremely energy efficiency. In this research, we propose a novel architecture named SpikeBottleNet, a significant improvement to the existing architecture by integrating SNNs. A key aspect of our investigation is the development of an intermediate feature compression technique specifically designed for SNNs. This technique leverages a split computing approach for SNNs to partition complex architectures, such as Spike ResNet50. By incorporating the power of SNNs within device-edge co-inference systems, experimental results demonstrate that our SpikeBottleNet achieves a significant bit compression ratio of up to 256x in the final convolutional layer while maintaining high classification accuracy with only a 2.5% reduction. Moreover, compared to the baseline BottleNet++ architecture, our framework reduces the transmitted feature size at earlier splitting points by 75%. Furthermore, in terms of the energy efficiency of edge devices, our methodology surpasses the baseline by a factor of up to 98, demonstrating significant enhancements in both efficiency and performance.
+
+
+
+ 39. 【2410.08669】SmartPretrain: Model-Agnostic and Dataset-Agnostic Representation Learning for Motion Prediction
+ 链接:https://arxiv.org/abs/2410.08669
+ 作者:Yang Zhou,Hao Shao,Letian Wang,Steven L. Waslander,Hongsheng Li,Yu Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Robotics (cs.RO)
+ 关键词:Predicting the future, motion prediction, autonomous vehicles, safely in dynamic, surrounding agents
+ 备注: 11 pages, 5 figures
+
+ 点击查看摘要
+ Abstract:Predicting the future motion of surrounding agents is essential for autonomous vehicles (AVs) to operate safely in dynamic, human-robot-mixed environments. However, the scarcity of large-scale driving datasets has hindered the development of robust and generalizable motion prediction models, limiting their ability to capture complex interactions and road geometries. Inspired by recent advances in natural language processing (NLP) and computer vision (CV), self-supervised learning (SSL) has gained significant attention in the motion prediction community for learning rich and transferable scene representations. Nonetheless, existing pre-training methods for motion prediction have largely focused on specific model architectures and single dataset, limiting their scalability and generalizability. To address these challenges, we propose SmartPretrain, a general and scalable SSL framework for motion prediction that is both model-agnostic and dataset-agnostic. Our approach integrates contrastive and reconstructive SSL, leveraging the strengths of both generative and discriminative paradigms to effectively represent spatiotemporal evolution and interactions without imposing architectural constraints. Additionally, SmartPretrain employs a dataset-agnostic scenario sampling strategy that integrates multiple datasets, enhancing data volume, diversity, and robustness. Extensive experiments on multiple datasets demonstrate that SmartPretrain consistently improves the performance of state-of-the-art prediction models across datasets, data splits and main metrics. For instance, SmartPretrain significantly reduces the MissRate of Forecast-MAE by 10.6%. These results highlight SmartPretrain's effectiveness as a unified, scalable solution for motion prediction, breaking free from the limitations of the small-data regime. Codes are available at this https URL
+
+
+
+ 40. 【2410.08649】E-Motion: Future Motion Simulation via Event Sequence Diffusion
+ 链接:https://arxiv.org/abs/2410.08649
+ 作者:Song Wu,Zhiyu Zhu,Junhui Hou,Guangming Shi,Jinjian Wu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:typical object future, Forecasting a typical, object future motion, typical object, critical task
+ 备注: NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:Forecasting a typical object's future motion is a critical task for interpreting and interacting with dynamic environments in computer vision. Event-based sensors, which could capture changes in the scene with exceptional temporal granularity, may potentially offer a unique opportunity to predict future motion with a level of detail and precision previously unachievable. Inspired by that, we propose to integrate the strong learning capacity of the video diffusion model with the rich motion information of an event camera as a motion simulation framework. Specifically, we initially employ pre-trained stable video diffusion models to adapt the event sequence dataset. This process facilitates the transfer of extensive knowledge from RGB videos to an event-centric domain. Moreover, we introduce an alignment mechanism that utilizes reinforcement learning techniques to enhance the reverse generation trajectory of the diffusion model, ensuring improved performance and accuracy. Through extensive testing and validation, we demonstrate the effectiveness of our method in various complex scenarios, showcasing its potential to revolutionize motion flow prediction in computer vision applications such as autonomous vehicle guidance, robotic navigation, and interactive media. Our findings suggest a promising direction for future research in enhancing the interpretative power and predictive accuracy of computer vision systems.
+
+
+
+ 41. 【2410.08645】Boosting Open-Vocabulary Object Detection by Handling Background Samples
+ 链接:https://arxiv.org/abs/2410.08645
+ 作者:Ruizhe Zeng,Lu Zhang,Xu Yang,Zhiyong Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:candidate vocabulary list, accurately detecting objects, open-vocabulary detectors, Open-vocabulary object detection, task of accurately
+ 备注: 16 pages, 5 figures, Accepted to ICONIP 2024
+
+ 点击查看摘要
+ Abstract:Open-vocabulary object detection is the task of accurately detecting objects from a candidate vocabulary list that includes both base and novel categories. Currently, numerous open-vocabulary detectors have achieved success by leveraging the impressive zero-shot capabilities of CLIP. However, we observe that CLIP models struggle to effectively handle background images (i.e. images without corresponding labels) due to their language-image learning methodology. This limitation results in suboptimal performance for open-vocabulary detectors that rely on CLIP when processing background samples. In this paper, we propose Background Information Representation for open-vocabulary Detector (BIRDet), a novel approach to address the limitations of CLIP in handling background samples. Specifically, we design Background Information Modeling (BIM) to replace the single, fixed background embedding in mainstream open-vocabulary detectors with dynamic scene information, and prompt it into image-related background representations. This method effectively enhances the ability to classify oversized regions as background. Besides, we introduce Partial Object Suppression (POS), an algorithm that utilizes the ratio of overlap area to address the issue of misclassifying partial regions as foreground. Experiments on OV-COCO and OV-LVIS benchmarks demonstrate that our proposed model is capable of achieving performance enhancements across various open-vocabulary detectors.
+
+
+
+ 42. 【2410.08642】More than Memes: A Multimodal Topic Modeling Approach to Conspiracy Theories on Telegram
+ 链接:https://arxiv.org/abs/2410.08642
+ 作者:Elisabeth Steffen
+ 类目:ocial and Information Networks (cs.SI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:German-language Telegram channels, related content online, conspiracy theories, German-language Telegram, traditionally focused
+ 备注: 11 pages, 11 figures
+
+ 点击查看摘要
+ Abstract:Research on conspiracy theories and related content online has traditionally focused on textual data. To address the increasing prevalence of (audio-)visual data on social media, and to capture the evolving and dynamic nature of this communication, researchers have begun to explore the potential of unsupervised approaches for analyzing multimodal online content. Our research contributes to this field by exploring the potential of multimodal topic modeling for analyzing conspiracy theories in German-language Telegram channels. Our work uses the BERTopic topic modeling approach in combination with CLIP for the analysis of textual and visual data. We analyze a corpus of ~40, 000 Telegram messages posted in October 2023 in 571 German-language Telegram channels known for disseminating conspiracy theories and other deceptive content. We explore the potentials and challenges of this approach for studying a medium-sized corpus of user-generated, text-image online content. We offer insights into the dominant topics across modalities, different text and image genres discovered during the analysis, quantitative inter-modal topic analyses, and a qualitative case study of textual, visual, and multimodal narrative strategies in the communication of conspiracy theories.
+
+
+
+ 43. 【2410.08641】Multi-Source Temporal Attention Network for Precipitation Nowcasting
+ 链接:https://arxiv.org/abs/2410.08641
+ 作者:Rafael Pablos Sarabia,Joachim Nyborg,Morten Birk,Jeppe Liborius Sjørup,Anders Lillevang Vesterholt,Ira Assent
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Precipitation nowcasting, climate change, industries and plays, plays a significant, significant role
+ 备注:
+
+ 点击查看摘要
+ Abstract:Precipitation nowcasting is crucial across various industries and plays a significant role in mitigating and adapting to climate change. We introduce an efficient deep learning model for precipitation nowcasting, capable of predicting rainfall up to 8 hours in advance with greater accuracy than existing operational physics-based and extrapolation-based models. Our model leverages multi-source meteorological data and physics-based forecasts to deliver high-resolution predictions in both time and space. It captures complex spatio-temporal dynamics through temporal attention networks and is optimized using data quality maps and dynamic thresholds. Experiments demonstrate that our model outperforms state-of-the-art, and highlight its potential for fast reliable responses to evolving weather conditions.
+
+
+
+ 44. 【2410.08620】Natural Language Induced Adversarial Images
+ 链接:https://arxiv.org/abs/2410.08620
+ 作者:Xiaopei Zhu,Peiyang Xu,Guanning Zeng,Yingpeng Dong,Xiaolin Hu
+ 类目:Cryptography and Security (cs.CR); Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:deep learning models, adversarial, shows the vulnerability, build more robust, Research
+ 备注: Carmera-ready version. To appear in ACM MM 2024
+
+ 点击查看摘要
+ Abstract:Research of adversarial attacks is important for AI security because it shows the vulnerability of deep learning models and helps to build more robust models. Adversarial attacks on images are most widely studied, which include noise-based attacks, image editing-based attacks, and latent space-based attacks. However, the adversarial examples crafted by these methods often lack sufficient semantic information, making it challenging for humans to understand the failure modes of deep learning models under natural conditions. To address this limitation, we propose a natural language induced adversarial image attack method. The core idea is to leverage a text-to-image model to generate adversarial images given input prompts, which are maliciously constructed to lead to misclassification for a target model. To adopt commercial text-to-image models for synthesizing more natural adversarial images, we propose an adaptive genetic algorithm (GA) for optimizing discrete adversarial prompts without requiring gradients and an adaptive word space reduction method for improving query efficiency. We further used CLIP to maintain the semantic consistency of the generated images. In our experiments, we found that some high-frequency semantic information such as "foggy", "humid", "stretching", etc. can easily cause classifier errors. This adversarial semantic information exists not only in generated images but also in photos captured in the real world. We also found that some adversarial semantic information can be transferred to unknown classification tasks. Furthermore, our attack method can transfer to different text-to-image models (e.g., Midjourney, DALL-E 3, etc.) and image classifiers. Our code is available at: this https URL.
+
+
+
+ 45. 【2410.08613】Cross-Modal Bidirectional Interaction Model for Referring Remote Sensing Image Segmentation
+ 链接:https://arxiv.org/abs/2410.08613
+ 作者:Zhe Dong,Yuzhe Sun,Yanfeng Gu,Tianzhu Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:remote sensing image, referring remote sensing, sensing image segmentation, remote sensing, sensing image
+ 备注:
+
+ 点击查看摘要
+ Abstract:Given a natural language expression and a remote sensing image, the goal of referring remote sensing image segmentation (RRSIS) is to generate a pixel-level mask of the target object identified by the referring expression. In contrast to natural scenarios, expressions in RRSIS often involve complex geospatial relationships, with target objects of interest that vary significantly in scale and lack visual saliency, thereby increasing the difficulty of achieving precise segmentation. To address the aforementioned challenges, a novel RRSIS framework is proposed, termed the cross-modal bidirectional interaction model (CroBIM). Specifically, a context-aware prompt modulation (CAPM) module is designed to integrate spatial positional relationships and task-specific knowledge into the linguistic features, thereby enhancing the ability to capture the target object. Additionally, a language-guided feature aggregation (LGFA) module is introduced to integrate linguistic information into multi-scale visual features, incorporating an attention deficit compensation mechanism to enhance feature aggregation. Finally, a mutual-interaction decoder (MID) is designed to enhance cross-modal feature alignment through cascaded bidirectional cross-attention, thereby enabling precise segmentation mask prediction. To further forster the research of RRSIS, we also construct RISBench, a new large-scale benchmark dataset comprising 52,472 image-language-label triplets. Extensive benchmarking on RISBench and two other prevalent datasets demonstrates the superior performance of the proposed CroBIM over existing state-of-the-art (SOTA) methods. The source code for CroBIM and the RISBench dataset will be publicly available at this https URL
+
+
+
+ 46. 【2410.08612】Synth-SONAR: Sonar Image Synthesis with Enhanced Diversity and Realism via Dual Diffusion Models and GPT Prompting
+ 链接:https://arxiv.org/abs/2410.08612
+ 作者:Purushothaman Natarajan,Kamal Basha,Athira Nambiar
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:marine biology, Sonar, Sonar image synthesis, underwater exploration, crucial for advancing
+ 备注: 12 pages, 5 tables and 9 figures
+
+ 点击查看摘要
+ Abstract:Sonar image synthesis is crucial for advancing applications in underwater exploration, marine biology, and defence. Traditional methods often rely on extensive and costly data collection using sonar sensors, jeopardizing data quality and diversity. To overcome these limitations, this study proposes a new sonar image synthesis framework, Synth-SONAR leveraging diffusion models and GPT prompting. The key novelties of Synth-SONAR are threefold: First, by integrating Generative AI-based style injection techniques along with publicly available real/simulated data, thereby producing one of the largest sonar data corpus for sonar research. Second, a dual text-conditioning sonar diffusion model hierarchy synthesizes coarse and fine-grained sonar images with enhanced quality and diversity. Third, high-level (coarse) and low-level (detailed) text-based sonar generation methods leverage advanced semantic information available in visual language models (VLMs) and GPT-prompting. During inference, the method generates diverse and realistic sonar images from textual prompts, bridging the gap between textual descriptions and sonar image generation. This marks the application of GPT-prompting in sonar imagery for the first time, to the best of our knowledge. Synth-SONAR achieves state-of-the-art results in producing high-quality synthetic sonar datasets, significantly enhancing their diversity and realism.
+
+
+
+ 47. 【2410.08611】Conjugated Semantic Pool Improves OOD Detection with Pre-trained Vision-Language Models
+ 链接:https://arxiv.org/abs/2410.08611
+ 作者:Mengyuan Chen,Junyu Gao,Changsheng Xu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:pre-trained vision-language model, potential OOD labels, OOD labels, extensive semantic pool, selecting potential OOD
+ 备注: 28 pages, accepted by NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:A straightforward pipeline for zero-shot out-of-distribution (OOD) detection involves selecting potential OOD labels from an extensive semantic pool and then leveraging a pre-trained vision-language model to perform classification on both in-distribution (ID) and OOD labels. In this paper, we theorize that enhancing performance requires expanding the semantic pool, while increasing the expected probability of selected OOD labels being activated by OOD samples, and ensuring low mutual dependence among the activations of these OOD labels. A natural expansion manner is to adopt a larger lexicon; however, the inevitable introduction of numerous synonyms and uncommon words fails to meet the above requirements, indicating that viable expansion manners move beyond merely selecting words from a lexicon. Since OOD detection aims to correctly classify input images into ID/OOD class groups, we can "make up" OOD label candidates which are not standard class names but beneficial for the process. Observing that the original semantic pool is comprised of unmodified specific class names, we correspondingly construct a conjugated semantic pool (CSP) consisting of modified superclass names, each serving as a cluster center for samples sharing similar properties across different categories. Consistent with our established theory, expanding OOD label candidates with the CSP satisfies the requirements and outperforms existing works by 7.89% in FPR95. Codes are available in this https URL.
+
+
+
+ 48. 【2410.08608】xt-To-Image with Generative Adversarial Networks
+ 链接:https://arxiv.org/abs/2410.08608
+ 作者:Mehrshad Momen-Tayefeh
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Generating realistic images, Generating realistic, Generative Adversarial Networks, computer vision, field of computer
+ 备注:
+
+ 点击查看摘要
+ Abstract:Generating realistic images from human texts is one of the most challenging problems in the field of computer vision (CV). The meaning of descriptions given can be roughly reflected by existing text-to-image approaches. In this paper, our main purpose is to propose a brief comparison between five different methods base on the Generative Adversarial Networks (GAN) to make image from the text. In addition, each model architectures synthesis images with different resolution. Furthermore, the best and worst obtained resolutions is 64*64, 256*256 respectively. However, we checked and compared some metrics that introduce the accuracy of each model. Also, by doing this study, we found out the best model for this problem by comparing these different approaches essential metrics.
+
+
+
+ 49. 【2410.08593】VERIFIED: A Video Corpus Moment Retrieval Benchmark for Fine-Grained Video Understanding
+ 链接:https://arxiv.org/abs/2410.08593
+ 作者:Houlun Chen,Xin Wang,Hong Chen,Zeyang Zhang,Wei Feng,Bin Huang,Jia Jia,Wenwu Zhu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Corpus Moment Retrieval, Existing Video Corpus, Moment Retrieval, underline, hinders precise video
+ 备注: Accepted by 38th NeurIPS Datasets Benchmarks Track (NeurIPS 2024)
+
+ 点击查看摘要
+ Abstract:Existing Video Corpus Moment Retrieval (VCMR) is limited to coarse-grained understanding, which hinders precise video moment localization when given fine-grained queries. In this paper, we propose a more challenging fine-grained VCMR benchmark requiring methods to localize the best-matched moment from the corpus with other partially matched candidates. To improve the dataset construction efficiency and guarantee high-quality data annotations, we propose VERIFIED, an automatic \underline{V}id\underline{E}o-text annotation pipeline to generate captions with \underline{R}el\underline{I}able \underline{FI}n\underline{E}-grained statics and \underline{D}ynamics. Specifically, we resort to large language models (LLM) and large multimodal models (LMM) with our proposed Statics and Dynamics Enhanced Captioning modules to generate diverse fine-grained captions for each video. To filter out the inaccurate annotations caused by the LLM hallucination, we propose a Fine-Granularity Aware Noise Evaluator where we fine-tune a video foundation model with disturbed hard-negatives augmented contrastive and matching losses. With VERIFIED, we construct a more challenging fine-grained VCMR benchmark containing Charades-FIG, DiDeMo-FIG, and ActivityNet-FIG which demonstrate a high level of annotation quality. We evaluate several state-of-the-art VCMR models on the proposed dataset, revealing that there is still significant scope for fine-grained video understanding in VCMR. Code and Datasets are in \href{this https URL}{this https URL}.
+
+
+
+ 50. 【2410.08592】VIBES -- Vision Backbone Efficient Selection
+ 链接:https://arxiv.org/abs/2410.08592
+ 作者:Joris Guerin,Shray Bansal,Amirreza Shaban,Paulo Mann,Harshvardhan Gazula
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:specific target tasks, efficiently selecting high-performance, selecting high-performance pre-trained, high-performance pre-trained vision, target tasks
+ 备注: 9 pages, 4 figures, under review at WACV 2025
+
+ 点击查看摘要
+ Abstract:This work tackles the challenge of efficiently selecting high-performance pre-trained vision backbones for specific target tasks. Although exhaustive search within a finite set of backbones can solve this problem, it becomes impractical for large datasets and backbone pools. To address this, we introduce Vision Backbone Efficient Selection (VIBES), which aims to quickly find well-suited backbones, potentially trading off optimality for efficiency. We propose several simple yet effective heuristics to address VIBES and evaluate them across four diverse computer vision datasets. Our results show that these approaches can identify backbones that outperform those selected from generic benchmarks, even within a limited search budget of one hour on a single GPU. We reckon VIBES marks a paradigm shift from benchmarks to task-specific optimization.
+
+
+
+ 51. 【2410.08584】ZipVL: Efficient Large Vision-Language Models with Dynamic Token Sparsification and KV Cache Compression
+ 链接:https://arxiv.org/abs/2410.08584
+ 作者:Yefei He,Feng Chen,Jing Liu,Wenqi Shao,Hong Zhou,Kaipeng Zhang,Bohan Zhuang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:scenarios involving high-resolution, involving high-resolution images, large vision-language models, fetching the key-value, images or videos
+ 备注: 15 pages
+
+ 点击查看摘要
+ Abstract:The efficiency of large vision-language models (LVLMs) is constrained by the computational bottleneck of the attention mechanism during the prefill phase and the memory bottleneck of fetching the key-value (KV) cache in the decoding phase, particularly in scenarios involving high-resolution images or videos. Visual content often exhibits substantial redundancy, resulting in highly sparse attention maps within LVLMs. This sparsity can be leveraged to accelerate attention computation or compress the KV cache through various approaches. However, most studies focus on addressing only one of these bottlenecks and do not adequately support dynamic adjustment of sparsity concerning distinct layers or tasks. In this paper, we present ZipVL, an efficient inference framework designed for LVLMs that resolves both computation and memory bottlenecks through a dynamic ratio allocation strategy of important tokens. This ratio is adaptively determined based on the layer-specific distribution of attention scores, rather than fixed hyper-parameters, thereby improving efficiency for less complex tasks while maintaining high performance for more challenging ones. Then we select important tokens based on their normalized attention scores and perform attention mechanism solely on those important tokens to accelerate the prefill phase. To mitigate the memory bottleneck in the decoding phase, we employ mixed-precision quantization to the KV cache, where high-bit quantization is used for caches of important tokens, while low-bit quantization is applied to those of less importance. Our experiments demonstrate that ZipVL can accelerate the prefill phase by 2.6$\times$ and reduce GPU memory usage by 50.0%, with a minimal accuracy reduction of only 0.2% on Video-MME benchmark over LongVA-7B model, effectively enhancing the generation efficiency of LVLMs.
+
+
+
+ 52. 【2410.08582】DeBiFormer: Vision Transformer with Deformable Agent Bi-level Routing Attention
+ 链接:https://arxiv.org/abs/2410.08582
+ 作者:Nguyen Huu Bao Long,Chenyu Zhang,Yuzhi Shi,Tsubasa Hirakawa,Takayoshi Yamashita,Tohgoroh Matsui,Hironobu Fujiyoshi
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:demonstrated superior performance, Deformable Bi-level Routing, Bi-level Routing Attention, demonstrated superior, superior performance
+ 备注: 20 pages, 7 figures. arXiv admin note: text overlap with [arXiv:2303.08810](https://arxiv.org/abs/2303.08810) by other authors
+
+ 点击查看摘要
+ Abstract:Vision Transformers with various attention modules have demonstrated superior performance on vision tasks. While using sparsity-adaptive attention, such as in DAT, has yielded strong results in image classification, the key-value pairs selected by deformable points lack semantic relevance when fine-tuning for semantic segmentation tasks. The query-aware sparsity attention in BiFormer seeks to focus each query on top-k routed regions. However, during attention calculation, the selected key-value pairs are influenced by too many irrelevant queries, reducing attention on the more important ones. To address these issues, we propose the Deformable Bi-level Routing Attention (DBRA) module, which optimizes the selection of key-value pairs using agent queries and enhances the interpretability of queries in attention maps. Based on this, we introduce the Deformable Bi-level Routing Attention Transformer (DeBiFormer), a novel general-purpose vision transformer built with the DBRA module. DeBiFormer has been validated on various computer vision tasks, including image classification, object detection, and semantic segmentation, providing strong evidence of its this http URL is available at {this https URL}
+
+
+
+ 53. 【2410.08567】Diffusion-Based Depth Inpainting for Transparent and Reflective Objects
+ 链接:https://arxiv.org/abs/2410.08567
+ 作者:Tianyu Sun,Dingchang Hu,Yixiang Dai,Guijin Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:imaging techniques due, Transparent and reflective, reflective objects, everyday lives, present a significant
+ 备注:
+
+ 点击查看摘要
+ Abstract:Transparent and reflective objects, which are common in our everyday lives, present a significant challenge to 3D imaging techniques due to their unique visual and optical properties. Faced with these types of objects, RGB-D cameras fail to capture the real depth value with their accurate spatial information. To address this issue, we propose DITR, a diffusion-based Depth Inpainting framework specifically designed for Transparent and Reflective objects. This network consists of two stages, including a Region Proposal stage and a Depth Inpainting stage. DITR dynamically analyzes the optical and geometric depth loss and inpaints them automatically. Furthermore, comprehensive experimental results demonstrate that DITR is highly effective in depth inpainting tasks of transparent and reflective objects with robust adaptability.
+
+
+
+ 54. 【2410.08565】Baichuan-Omni Technical Report
+ 链接:https://arxiv.org/abs/2410.08565
+ 作者:Yadong Li,Haoze Sun,Mingan Lin,Tianpeng Li,Guosheng Dong,Tao Zhang,Bowen Ding,Wei Song,Zhenglin Cheng,Yuqi Huo,Song Chen,Xu Li,Da Pan,Shusen Zhang,Xin Wu,Zheng Liang,Jun Liu,Tao Zhang,Keer Lu,Yaqi Zhao,Yanjun Shen,Fan Yang,Kaicheng Yu,Tao Lin,Jianhua Xu,Zenan Zhou,Weipeng Chen
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:high-performing open-source counterpart, salient multimodal capabilities, Large Language Model, multimodal interactive experience, Multimodal Large Language
+ 备注:
+
+ 点击查看摘要
+ Abstract:The salient multimodal capabilities and interactive experience of GPT-4o highlight its critical role in practical applications, yet it lacks a high-performing open-source counterpart. In this paper, we introduce Baichuan-Omni, the first open-source 7B Multimodal Large Language Model (MLLM) adept at concurrently processing and analyzing modalities of image, video, audio, and text, while delivering an advanced multimodal interactive experience and strong performance. We propose an effective multimodal training schema starting with 7B model and proceeding through two stages of multimodal alignment and multitask fine-tuning across audio, image, video, and text modal. This approach equips the language model with the ability to handle visual and audio data effectively. Demonstrating strong performance across various omni-modal and multimodal benchmarks, we aim for this contribution to serve as a competitive baseline for the open-source community in advancing multimodal understanding and real-time interaction.
+
+
+
+ 55. 【2410.08551】Context-Aware Full Body Anonymization using Text-to-Image Diffusion Models
+ 链接:https://arxiv.org/abs/2410.08551
+ 作者:Pascl Zwick,Kevin Roesch,Marvin Klemp,Oliver Bringmann
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:real world datasets, plays a key, key role, role in protecting, protecting sensible information
+ 备注:
+
+ 点击查看摘要
+ Abstract:Anonymization plays a key role in protecting sensible information of individuals in real world datasets. Self-driving cars for example need high resolution facial features to track people and their viewing direction to predict future behaviour and react accordingly. In order to protect people's privacy whilst keeping important features in the dataset, it is important to replace the full body of a person with a highly detailed anonymized one. In contrast to doing face anonymization, full body replacement decreases the ability of recognizing people by their hairstyle or clothes. In this paper, we propose a workflow for full body person anonymization utilizing Stable Diffusion as a generative backend. Text-to-image diffusion models, like Stable Diffusion, OpenAI's DALL-E or Midjourney, have become very popular in recent time, being able to create photorealistic images from a single text prompt. We show that our method outperforms state-of-the art anonymization pipelines with respect to image quality, resolution, Inception Score (IS) and Frechet Inception Distance (FID). Additionally, our method is invariant with respect to the image generator and thus able to be used with the latest models available.
+
+
+
+ 56. 【2410.08534】Quality Prediction of AI Generated Images and Videos: Emerging Trends and Opportunities
+ 链接:https://arxiv.org/abs/2410.08534
+ 作者:Abhijay Ghildyal,Yuanhan Chen,Saman Zadtootaghaj,Nabajeet Barman,Alan C. Bovik
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:creating realistic images, generation models capable, video generation models, Video Quality Assessment, Image Quality Assessment
+ 备注: "The abstract field cannot be longer than 1,920 characters", the abstract appearing here is slightly shorter than that in the PDF file
+
+ 点击查看摘要
+ Abstract:The advent of AI has influenced many aspects of human life, from self-driving cars and intelligent chatbots to text-based image and video generation models capable of creating realistic images and videos based on user prompts (text-to-image, image-to-image, and image-to-video). AI-based methods for image and video super resolution, video frame interpolation, denoising, and compression have already gathered significant attention and interest in the industry and some solutions are already being implemented in real-world products and services. However, to achieve widespread integration and acceptance, AI-generated and enhanced content must be visually accurate, adhere to intended use, and maintain high visual quality to avoid degrading the end user's quality of experience (QoE).
+One way to monitor and control the visual "quality" of AI-generated and -enhanced content is by deploying Image Quality Assessment (IQA) and Video Quality Assessment (VQA) models. However, most existing IQA and VQA models measure visual fidelity in terms of "reconstruction" quality against a pristine reference content and were not designed to assess the quality of "generative" artifacts. To address this, newer metrics and models have recently been proposed, but their performance evaluation and overall efficacy have been limited by datasets that were too small or otherwise lack representative content and/or distortion capacity; and by performance measures that can accurately report the success of an IQA/VQA model for "GenAI". This paper examines the current shortcomings and possibilities presented by AI-generated and enhanced image and video content, with a particular focus on end-user perceived quality. Finally, we discuss open questions and make recommendations for future work on the "GenAI" quality assessment problems, towards further progressing on this interesting and relevant field of research.
+
Comments:
+“The abstract field cannot be longer than 1,920 characters”, the abstract appearing here is slightly shorter than that in the PDF file
+Subjects:
+Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+Cite as:
+arXiv:2410.08534 [cs.CV]
+(or
+arXiv:2410.08534v1 [cs.CV] for this version)
+https://doi.org/10.48550/arXiv.2410.08534
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 57. 【2410.08531】Diffusion Models Need Visual Priors for Image Generation
+ 链接:https://arxiv.org/abs/2410.08531
+ 作者:Xiaoyu Yue,Zidong Wang,Zeyu Lu,Shuyang Sun,Meng Wei,Wanli Ouyang,Lei Bai,Luping Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Conventional class-guided diffusion, Conventional class-guided, correct semantic content, models generally succeed, class-guided diffusion models
+ 备注: Preprint
+
+ 点击查看摘要
+ Abstract:Conventional class-guided diffusion models generally succeed in generating images with correct semantic content, but often struggle with texture details. This limitation stems from the usage of class priors, which only provide coarse and limited conditional information. To address this issue, we propose Diffusion on Diffusion (DoD), an innovative multi-stage generation framework that first extracts visual priors from previously generated samples, then provides rich guidance for the diffusion model leveraging visual priors from the early stages of diffusion sampling. Specifically, we introduce a latent embedding module that employs a compression-reconstruction approach to discard redundant detail information from the conditional samples in each stage, retaining only the semantic information for guidance. We evaluate DoD on the popular ImageNet-$256 \times 256$ dataset, reducing 7$\times$ training cost compared to SiT and DiT with even better performance in terms of the FID-50K score. Our largest model DoD-XL achieves an FID-50K score of 1.83 with only 1 million training steps, which surpasses other state-of-the-art methods without bells and whistles during inference.
+
+
+
+ 58. 【2410.08530】Ego3DT: Tracking Every 3D Object in Ego-centric Videos
+ 链接:https://arxiv.org/abs/2410.08530
+ 作者:Shengyu Hao,Wenhao Chai,Zhonghan Zhao,Meiqi Sun,Wendi Hu,Jieyang Zhou,Yixian Zhao,Qi Li,Yizhou Wang,Xi Li,Gaoang Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:brought ego-centric perspectives, contemporary research, growing interest, interest in embodied, embodied intelligence
+ 备注: Accepted by ACM Multimedia 2024
+
+ 点击查看摘要
+ Abstract:The growing interest in embodied intelligence has brought ego-centric perspectives to contemporary research. One significant challenge within this realm is the accurate localization and tracking of objects in ego-centric videos, primarily due to the substantial variability in viewing angles. Addressing this issue, this paper introduces a novel zero-shot approach for the 3D reconstruction and tracking of all objects from the ego-centric video. We present Ego3DT, a novel framework that initially identifies and extracts detection and segmentation information of objects within the ego environment. Utilizing information from adjacent video frames, Ego3DT dynamically constructs a 3D scene of the ego view using a pre-trained 3D scene reconstruction model. Additionally, we have innovated a dynamic hierarchical association mechanism for creating stable 3D tracking trajectories of objects in ego-centric videos. Moreover, the efficacy of our approach is corroborated by extensive experiments on two newly compiled datasets, with 1.04x - 2.90x in HOTA, showcasing the robustness and accuracy of our method in diverse ego-centric scenarios.
+
+
+
+ 59. 【2410.08529】VOVTrack: Exploring the Potentiality in Videos for Open-Vocabulary Object Tracking
+ 链接:https://arxiv.org/abs/2410.08529
+ 作者:Zekun Qian,Ruize Han,Junhui Hou,Linqi Song,Wei Feng
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:base classes, diverse object categories, unseen categories, represents a critical, categories
+ 备注:
+
+ 点击查看摘要
+ Abstract:Open-vocabulary multi-object tracking (OVMOT) represents a critical new challenge involving the detection and tracking of diverse object categories in videos, encompassing both seen categories (base classes) and unseen categories (novel classes). This issue amalgamates the complexities of open-vocabulary object detection (OVD) and multi-object tracking (MOT). Existing approaches to OVMOT often merge OVD and MOT methodologies as separate modules, predominantly focusing on the problem through an image-centric lens. In this paper, we propose VOVTrack, a novel method that integrates object states relevant to MOT and video-centric training to address this challenge from a video object tracking standpoint. First, we consider the tracking-related state of the objects during tracking and propose a new prompt-guided attention mechanism for more accurate localization and classification (detection) of the time-varying objects. Subsequently, we leverage raw video data without annotations for training by formulating a self-supervised object similarity learning technique to facilitate temporal object association (tracking). Experimental results underscore that VOVTrack outperforms existing methods, establishing itself as a state-of-the-art solution for open-vocabulary tracking task.
+
+
+
+ 60. 【2410.08509】A Bayesian Approach to Weakly-supervised Laparoscopic Image Segmentation
+ 链接:https://arxiv.org/abs/2410.08509
+ 作者:Zhou Zheng,Yuichiro Hayashi,Masahiro Oda,Takayuki Kitasaka,Kensaku Mori
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:study weakly-supervised laparoscopic, study weakly-supervised, comprehensive Bayesian framework, weakly-supervised laparoscopic image, Bayesian deep learning
+ 备注: Early acceptance at MICCAI 2024. Supplementary material included. Minor typo corrections in notation have been made
+
+ 点击查看摘要
+ Abstract:In this paper, we study weakly-supervised laparoscopic image segmentation with sparse annotations. We introduce a novel Bayesian deep learning approach designed to enhance both the accuracy and interpretability of the model's segmentation, founded upon a comprehensive Bayesian framework, ensuring a robust and theoretically validated method. Our approach diverges from conventional methods that directly train using observed images and their corresponding weak annotations. Instead, we estimate the joint distribution of both images and labels given the acquired data. This facilitates the sampling of images and their high-quality pseudo-labels, enabling the training of a generalizable segmentation model. Each component of our model is expressed through probabilistic formulations, providing a coherent and interpretable structure. This probabilistic nature benefits accurate and practical learning from sparse annotations and equips our model with the ability to quantify uncertainty. Extensive evaluations with two public laparoscopic datasets demonstrated the efficacy of our method, which consistently outperformed existing methods. Furthermore, our method was adapted for scribble-supervised cardiac multi-structure segmentation, presenting competitive performance compared to previous methods. The code is available at this https URL.
+
+
+
+ 61. 【2410.08474】SPORTU: A Comprehensive Sports Understanding Benchmark for Multimodal Large Language Models
+ 链接:https://arxiv.org/abs/2410.08474
+ 作者:Haotian Xia,Zhengbang Yang,Junbo Zou,Rhys Tracy,Yuqing Wang,Chi Lu,Christopher Lai,Yanjun He,Xun Shao,Zhuoqing Xie,Yuan-fang Wang,Weining Shen,Hanjie Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Multimodal Large Language, Large Language Models, Multimodal Large, Language Models, Large Language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multimodal Large Language Models (MLLMs) are advancing the ability to reason about complex sports scenarios by integrating textual and visual information. To comprehensively evaluate their capabilities, we introduce SPORTU, a benchmark designed to assess MLLMs across multi-level sports reasoning tasks. SPORTU comprises two key components: SPORTU-text, featuring 900 multiple-choice questions with human-annotated explanations for rule comprehension and strategy understanding. This component focuses on testing models' ability to reason about sports solely through question-answering (QA), without requiring visual inputs; SPORTU-video, consisting of 1,701 slow-motion video clips across 7 different sports and 12,048 QA pairs, designed to assess multi-level reasoning, from simple sports recognition to complex tasks like foul detection and rule application. We evaluate four prevalent LLMs mainly utilizing few-shot learning paradigms supplemented by chain-of-thought (CoT) prompting on the SPORTU-text part. We evaluate four LLMs using few-shot learning and chain-of-thought (CoT) prompting on SPORTU-text. GPT-4o achieves the highest accuracy of 71%, but still falls short of human-level performance, highlighting room for improvement in rule comprehension and reasoning. The evaluation for the SPORTU-video part includes 7 proprietary and 6 open-source MLLMs. Experiments show that models fall short on hard tasks that require deep reasoning and rule-based understanding. Claude-3.5-Sonnet performs the best with only 52.6% accuracy on the hard task, showing large room for improvement. We hope that SPORTU will serve as a critical step toward evaluating models' capabilities in sports understanding and reasoning.
+
+
+
+ 62. 【2410.08470】DAT: Dialogue-Aware Transformer with Modality-Group Fusion for Human Engagement Estimation
+ 链接:https://arxiv.org/abs/2410.08470
+ 作者:Jia Li,Yangchen Yu,Yin Chen,Yu Zhang,Peng Jia,Yunbo Xu,Ziqiang Li,Meng Wang,Richang Hong
+ 类目:Human-Computer Interaction (cs.HC); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:attracting increasing research, increasing research interests, understanding human social, Engagement estimation plays, human social behaviors
+ 备注: 1st Place on the NoXi Base dataset in the Multi-Domain Engagement Estimation Challenge held by MultiMediate 24, accepted by ACM Multimedia 2024. The source code is available at \url{ [this https URL](https://github.com/MSA-LMC/DAT) }
+
+ 点击查看摘要
+ Abstract:Engagement estimation plays a crucial role in understanding human social behaviors, attracting increasing research interests in fields such as affective computing and human-computer interaction. In this paper, we propose a Dialogue-Aware Transformer framework (DAT) with Modality-Group Fusion (MGF), which relies solely on audio-visual input and is language-independent, for estimating human engagement in conversations. Specifically, our method employs a modality-group fusion strategy that independently fuses audio and visual features within each modality for each person before inferring the entire audio-visual content. This strategy significantly enhances the model's performance and robustness. Additionally, to better estimate the target participant's engagement levels, the introduced Dialogue-Aware Transformer considers both the participant's behavior and cues from their conversational partners. Our method was rigorously tested in the Multi-Domain Engagement Estimation Challenge held by MultiMediate'24, demonstrating notable improvements in engagement-level regression precision over the baseline model. Notably, our approach achieves a CCC score of 0.76 on the NoXi Base test set and an average CCC of 0.64 across the NoXi Base, NoXi-Add, and MPIIGI test sets.
+
+
+
+ 63. 【2410.08469】Semantic Token Reweighting for Interpretable and Controllable Text Embeddings in CLIP
+ 链接:https://arxiv.org/abs/2410.08469
+ 作者:Eunji Kim,Kyuhong Shim,Simyung Chang,Sungroh Yoon
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Vision-Language Models, translating textual input, embedding space shared, natural language, encoder within Vision-Language
+ 备注: Accepted at EMNLP 2024 Findings
+
+ 点击查看摘要
+ Abstract:A text encoder within Vision-Language Models (VLMs) like CLIP plays a crucial role in translating textual input into an embedding space shared with images, thereby facilitating the interpretative analysis of vision tasks through natural language. Despite the varying significance of different textual elements within a sentence depending on the context, efforts to account for variation of importance in constructing text embeddings have been lacking. We propose a framework of Semantic Token Reweighting to build Interpretable text embeddings (SToRI), which incorporates controllability as well. SToRI refines the text encoding process in CLIP by differentially weighting semantic elements based on contextual importance, enabling finer control over emphasis responsive to data-driven insights and user preferences. The efficacy of SToRI is demonstrated through comprehensive experiments on few-shot image classification and image retrieval tailored to user preferences.
+
+
+
+ 64. 【2410.08466】Aligned Divergent Pathways for Omni-Domain Generalized Person Re-Identification
+ 链接:https://arxiv.org/abs/2410.08466
+ 作者:Eugene P.W. Ang,Shan Lin,Alex C. Kot
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Person Re-identification, Person ReID, Person, advanced significantly, Generalization Person ReID
+ 备注: 2024 International Conference on Electrical, Computer and Energy Technologies (ICECET)
+
+ 点击查看摘要
+ Abstract:Person Re-identification (Person ReID) has advanced significantly in fully supervised and domain generalized Person R e ID. However, methods developed for one task domain transfer poorly to the other. An ideal Person ReID method should be effective regardless of the number of domains involved in training or testing. Furthermore, given training data from the target domain, it should perform at least as well as state-of-the-art (SOTA) fully supervised Person ReID methods. We call this paradigm Omni-Domain Generalization Person ReID, referred to as ODG-ReID, and propose a way to achieve this by expanding compatible backbone architectures into multiple diverse pathways. Our method, Aligned Divergent Pathways (ADP), first converts a base architecture into a multi-branch structure by copying the tail of the original backbone. We design our module Dynamic Max-Deviance Adaptive Instance Normalization (DyMAIN) that encourages learning of generalized features that are robust to omni-domain directions and apply DyMAIN to the branches of ADP. Our proposed Phased Mixture-of-Cosines (PMoC) coordinates a mix of stable and turbulent learning rate schedules among branches for further diversified learning. Finally, we realign the feature space between branches with our proposed Dimensional Consistency Metric Loss (DCML). ADP outperforms the state-of-the-art (SOTA) results for multi-source domain generalization and supervised ReID within the same domain. Furthermore, our method demonstrates improvement on a wide range of single-source domain generalization benchmarks, achieving Omni-Domain Generalization over Person ReID tasks.
+
+
+
+ 65. 【2410.08460】Diverse Deep Feature Ensemble Learning for Omni-Domain Generalized Person Re-identification
+ 链接:https://arxiv.org/abs/2410.08460
+ 作者:Eugene P.W. Ang,Shan Lin,Alex C. Kot
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Person Re-identification, Person ReID, Person, Re-identification, ReID
+ 备注: ICMIP '24: Proceedings of the 2024 9th International Conference on Multimedia and Image Processing, Pages 64 - 71
+
+ 点击查看摘要
+ Abstract:Person Re-identification (Person ReID) has progressed to a level where single-domain supervised Person ReID performance has saturated. However, such methods experience a significant drop in performance when trained and tested across different datasets, motivating the development of domain generalization techniques. However, our research reveals that domain generalization methods significantly underperform single-domain supervised methods on single dataset benchmarks. An ideal Person ReID method should be effective regardless of the number of domains involved, and when test domain data is available for training it should perform as well as state-of-the-art (SOTA) fully supervised methods. This is a paradigm that we call Omni-Domain Generalization Person ReID (ODG-ReID). We propose a way to achieve ODG-ReID by creating deep feature diversity with self-ensembles. Our method, Diverse Deep Feature Ensemble Learning (D2FEL), deploys unique instance normalization patterns that generate multiple diverse views and recombines these views into a compact encoding. To the best of our knowledge, our work is one of few to consider omni-domain generalization in Person ReID, and we advance the study of applying feature ensembles in Person ReID. D2FEL significantly improves and matches the SOTA performance for major domain generalization and single-domain supervised benchmarks.
+
+
+
+ 66. 【2410.08456】A Unified Deep Semantic Expansion Framework for Domain-Generalized Person Re-identification
+ 链接:https://arxiv.org/abs/2410.08456
+ 作者:Eugene P.W. Ang,Shan Lin,Alex C. Kot
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Supervised Person Re-identification, Supervised Person, achieved excellent performance, Person Re-identification, Generalized Person Re-identification
+ 备注: Neurocomputing Volume 600, 1 October 2024, 128120. 15 pages
+
+ 点击查看摘要
+ Abstract:Supervised Person Re-identification (Person ReID) methods have achieved excellent performance when training and testing within one camera network. However, they usually suffer from considerable performance degradation when applied to different camera systems. In recent years, many Domain Adaptation Person ReID methods have been proposed, achieving impressive performance without requiring labeled data from the target domain. However, these approaches still need the unlabeled data of the target domain during the training process, making them impractical in many real-world scenarios. Our work focuses on the more practical Domain Generalized Person Re-identification (DG-ReID) problem. Given one or more source domains, it aims to learn a generalized model that can be applied to unseen target domains. One promising research direction in DG-ReID is the use of implicit deep semantic feature expansion, and our previous method, Domain Embedding Expansion (DEX), is one such example that achieves powerful results in DG-ReID. However, in this work we show that DEX and other similar implicit deep semantic feature expansion methods, due to limitations in their proposed loss function, fail to reach their full potential on large evaluation benchmarks as they have a tendency to saturate too early. Leveraging on this analysis, we propose Unified Deep Semantic Expansion, our novel framework that unifies implicit and explicit semantic feature expansion techniques in a single framework to mitigate this early over-fitting and achieve a new state-of-the-art (SOTA) in all DG-ReID benchmarks. Further, we apply our method on more general image retrieval tasks, also surpassing the current SOTA in all of these benchmarks by wide margins.
+
+
+
+ 67. 【2410.08454】HorGait: Advancing Gait Recognition with Efficient High-Order Spatial Interactions in LiDAR Point Clouds
+ 链接:https://arxiv.org/abs/2410.08454
+ 作者:Jiaxing Hao,Yanxi Wang,Zhigang Chang,Hongmin Gao,Zihao Cheng,Chen Wu,Xin Zhao,Peiye Fang,Rachmat Muwardi
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:remote biometric technology, extreme lighting conditions, Transformer architecture, Gait recognition, Transformer
+ 备注:
+
+ 点击查看摘要
+ Abstract:Gait recognition is a remote biometric technology that utilizes the dynamic characteristics of human movement to identify individuals even under various extreme lighting conditions. Due to the limitation in spatial perception capability inherent in 2D gait representations, LiDAR can directly capture 3D gait features and represent them as point clouds, reducing environmental and lighting interference in recognition while significantly advancing privacy protection. For complex 3D representations, shallow networks fail to achieve accurate recognition, making vision Transformers the foremost prevalent method. However, the prevalence of dumb patches has limited the widespread use of Transformer architecture in gait recognition. This paper proposes a method named HorGait, which utilizes a hybrid model with a Transformer architecture for gait recognition on the planar projection of 3D point clouds from LiDAR. Specifically, it employs a hybrid model structure called LHM Block to achieve input adaptation, long-range, and high-order spatial interaction of the Transformer architecture. Additionally, it uses large convolutional kernel CNNs to segment the input representation, replacing attention windows to reduce dumb patches. We conducted extensive experiments, and the results show that HorGait achieves state-of-the-art performance among Transformer architecture methods on the SUSTech1K dataset, verifying that the hybrid model can complete the full Transformer process and perform better in point cloud planar projection. The outstanding performance of HorGait offers new insights for the future application of the Transformer architecture in gait recognition.
+
+
+
+ 68. 【2410.08410】Human Stone Toolmaking Action Grammar (HSTAG): A Challenging Benchmark for Fine-grained Motor Behavior Recognition
+ 链接:https://arxiv.org/abs/2410.08410
+ 作者:Cheng Liu,Xuyang Yan,Zekun Zhang,Cheng Ding,Tianhao Zhao,Shaya Jannati,Cynthia Martinez,Dietrich Stout
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:past decade, Human Stone Toolmaking, witnessed the development, growing number, Toolmaking Action Grammar
+ 备注: 8 pages, 4 figures, accepted by the 11th IEEE International Conference on Data Science and Advanced Analytics (DSAA)
+
+ 点击查看摘要
+ Abstract:Action recognition has witnessed the development of a growing number of novel algorithms and datasets in the past decade. However, the majority of public benchmarks were constructed around activities of daily living and annotated at a rather coarse-grained level, which lacks diversity in domain-specific datasets, especially for rarely seen domains. In this paper, we introduced Human Stone Toolmaking Action Grammar (HSTAG), a meticulously annotated video dataset showcasing previously undocumented stone toolmaking behaviors, which can be used for investigating the applications of advanced artificial intelligence techniques in understanding a rapid succession of complex interactions between two hand-held objects. HSTAG consists of 18,739 video clips that record 4.5 hours of experts' activities in stone toolmaking. Its unique features include (i) brief action durations and frequent transitions, mirroring the rapid changes inherent in many motor behaviors; (ii) multiple angles of view and switches among multiple tools, increasing intra-class variability; (iii) unbalanced class distributions and high similarity among different action sequences, adding difficulty in capturing distinct patterns for each action. Several mainstream action recognition models are used to conduct experimental analysis, which showcases the challenges and uniqueness of HSTAG this https URL.
+
+
+
+ 69. 【2410.08409】Optimizing YOLO Architectures for Optimal Road Damage Detection and Classification: A Comparative Study from YOLOv7 to YOLOv10
+ 链接:https://arxiv.org/abs/2410.08409
+ 作者:Vung Pham,Lan Dong Thi Ngoc,Duy-Linh Bui
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Maintaining roadway infrastructure, sustainable transportation system, Maintaining roadway, ensuring a safe, transportation system
+ 备注: Invited paper in the Optimized Road Damage Detection Challenge (ORDDC'2024), a track in the IEEE BigData 2024 Challenge
+
+ 点击查看摘要
+ Abstract:Maintaining roadway infrastructure is essential for ensuring a safe, efficient, and sustainable transportation system. However, manual data collection for detecting road damage is time-consuming, labor-intensive, and poses safety risks. Recent advancements in artificial intelligence, particularly deep learning, offer a promising solution for automating this process using road images. This paper presents a comprehensive workflow for road damage detection using deep learning models, focusing on optimizations for inference speed while preserving detection accuracy. Specifically, to accommodate hardware limitations, large images are cropped, and lightweight models are utilized. Additionally, an external pothole dataset is incorporated to enhance the detection of this underrepresented damage class. The proposed approach employs multiple model architectures, including a custom YOLOv7 model with Coordinate Attention layers and a Tiny YOLOv7 model, which are trained and combined to maximize detection performance. The models are further reparameterized to optimize inference efficiency. Experimental results demonstrate that the ensemble of the custom YOLOv7 model with three Coordinate Attention layers and the default Tiny YOLOv7 model achieves an F1 score of 0.7027 with an inference speed of 0.0547 seconds per image. The complete pipeline, including data preprocessing, model training, and inference scripts, is publicly available on the project's GitHub repository, enabling reproducibility and facilitating further research.
+
+
+
+ 70. 【2410.08405】AgroGPT: Efficient Agricultural Vision-Language Model with Expert Tuning
+ 链接:https://arxiv.org/abs/2410.08405
+ 作者:Muhammad Awais,Ali Husain Salem Abdulla Alharthi,Amandeep Kumar,Hisham Cholakkal,Rao Muhammad Anwer
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Significant progress, capitalizing on vast, made in advancing, vast repositories, Significant
+ 备注:
+
+ 点击查看摘要
+ Abstract:Significant progress has been made in advancing large multimodal conversational models (LMMs), capitalizing on vast repositories of image-text data available online. Despite this progress, these models often encounter substantial domain gaps, hindering their ability to engage in complex conversations across new domains. Recent efforts have aimed to mitigate this issue, albeit relying on domain-specific image-text data to curate instruction-tuning data. However, many domains, such as agriculture, lack such vision-language data. In this work, we propose an approach to construct instruction-tuning data that harnesses vision-only data for the agriculture domain. We utilize diverse agricultural datasets spanning multiple domains, curate class-specific information, and employ large language models (LLMs) to construct an expert-tuning set, resulting in a 70k expert-tuning dataset called AgroInstruct. Subsequently, we expert-tuned and created AgroGPT, an efficient LMM that can hold complex agriculture-related conversations and provide useful insights. We also develop AgroEvals for evaluation and compare {AgroGPT's} performance with large open and closed-source models. {AgroGPT} excels at identifying fine-grained agricultural concepts, can act as an agriculture expert, and provides helpful information for multimodal agriculture questions. The code, datasets, and models are available at this https URL.
+
+
+
+ 71. 【2410.08365】Are We Ready for Real-Time LiDAR Semantic Segmentation in Autonomous Driving?
+ 链接:https://arxiv.org/abs/2410.08365
+ 作者:Samir Abou Haidar,Alexandre Chariot,Mehdi Darouich,Cyril Joly,Jean-Emmanuel Deschaud
+ 类目:Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:point clouds typically, clouds typically generated, point clouds, detection and recognition, perception framework
+ 备注: Accepted to IROS 2024 PPNIV Workshop
+
+ 点击查看摘要
+ Abstract:Within a perception framework for autonomous mobile and robotic systems, semantic analysis of 3D point clouds typically generated by LiDARs is key to numerous applications, such as object detection and recognition, and scene reconstruction. Scene semantic segmentation can be achieved by directly integrating 3D spatial data with specialized deep neural networks. Although this type of data provides rich geometric information regarding the surrounding environment, it also presents numerous challenges: its unstructured and sparse nature, its unpredictable size, and its demanding computational requirements. These characteristics hinder the real-time semantic analysis, particularly on resource-constrained hardware architectures that constitute the main computational components of numerous robotic applications. Therefore, in this paper, we investigate various 3D semantic segmentation methodologies and analyze their performance and capabilities for resource-constrained inference on embedded NVIDIA Jetson platforms. We evaluate them for a fair comparison through a standardized training protocol and data augmentations, providing benchmark results on the Jetson AGX Orin and AGX Xavier series for two large-scale outdoor datasets: SemanticKITTI and nuScenes.
+
+
+
+ 72. 【2410.08338】me Traveling to Defend Against Adversarial Example Attacks in Image Classification
+ 链接:https://arxiv.org/abs/2410.08338
+ 作者:Anthony Etim,Jakub Szefer
+ 类目:Cryptography and Security (cs.CR); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:traffic sign, traffic sign classification, critical threat, sign, Adversarial attacks
+ 备注:
+
+ 点击查看摘要
+ Abstract:Adversarial example attacks have emerged as a critical threat to machine learning. Adversarial attacks in image classification abuse various, minor modifications to the image that confuse the image classification neural network -- while the image still remains recognizable to humans. One important domain where the attacks have been applied is in the automotive setting with traffic sign classification. Researchers have demonstrated that adding stickers, shining light, or adding shadows are all different means to make machine learning inference algorithms mis-classify the traffic signs. This can cause potentially dangerous situations as a stop sign is recognized as a speed limit sign causing vehicles to ignore it and potentially leading to accidents. To address these attacks, this work focuses on enhancing defenses against such adversarial attacks. This work shifts the advantage to the user by introducing the idea of leveraging historical images and majority voting. While the attacker modifies a traffic sign that is currently being processed by the victim's machine learning inference, the victim can gain advantage by examining past images of the same traffic sign. This work introduces the notion of ''time traveling'' and uses historical Street View images accessible to anybody to perform inference on different, past versions of the same traffic sign. In the evaluation, the proposed defense has 100% effectiveness against latest adversarial example attack on traffic sign classification algorithm.
+
+
+
+ 73. 【2410.08332】Level of agreement between emotions generated by Artificial Intelligence and human evaluation: a methodological proposal
+ 链接:https://arxiv.org/abs/2410.08332
+ 作者:Miguel Carrasco,Cesar Gonzalez-Martin,Sonia Navajas-Torrente,Raul Dastres
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:highly subjective, capable of conveying, experience is highly, emotions, conveying emotions
+ 备注: 29 pages
+
+ 点击查看摘要
+ Abstract:Images are capable of conveying emotions, but emotional experience is highly subjective. Advances in artificial intelligence have enabled the generation of images based on emotional descriptions. However, the level of agreement between the generative images and human emotional responses has not yet been evaluated. To address this, 20 artistic landscapes were generated using StyleGAN2-ADA. Four variants evoking positive emotions (contentment, amusement) and negative emotions (fear, sadness) were created for each image, resulting in 80 pictures. An online questionnaire was designed using this material, in which 61 observers classified the generated images. Statistical analyses were performed on the collected data to determine the level of agreement among participants, between the observer's responses, and the AI-generated emotions. A generally good level of agreement was found, with better results for negative emotions. However, the study confirms the subjectivity inherent in emotional evaluation.
+
+
+
+ 74. 【2410.08326】Neural Architecture Search of Hybrid Models for NPU-CIM Heterogeneous AR/VR Devices
+ 链接:https://arxiv.org/abs/2410.08326
+ 作者:Yiwei Zhao,Ziyun Li,Win-San Khwa,Xiaoyu Sun,Sai Qian Zhang,Syed Shakib Sarwar,Kleber Hugo Stangherlin,Yi-Lun Lu,Jorge Tomas Gomez,Jae-Sun Seo,Phillip B. Gibbons,Barbara De Salvo,Chiao Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Hardware Architecture (cs.AR); Machine Learning (cs.LG); Performance (cs.PF)
+ 关键词:Augmented Reality applications, Virtual Reality, Augmented Reality, Reality applications, Reality and Augmented
+ 备注:
+
+ 点击查看摘要
+ Abstract:Low-Latency and Low-Power Edge AI is essential for Virtual Reality and Augmented Reality applications. Recent advances show that hybrid models, combining convolution layers (CNN) and transformers (ViT), often achieve superior accuracy/performance tradeoff on various computer vision and machine learning (ML) tasks. However, hybrid ML models can pose system challenges for latency and energy-efficiency due to their diverse nature in dataflow and memory access patterns. In this work, we leverage the architecture heterogeneity from Neural Processing Units (NPU) and Compute-In-Memory (CIM) and perform diverse execution schemas to efficiently execute these hybrid models. We also introduce H4H-NAS, a Neural Architecture Search framework to design efficient hybrid CNN/ViT models for heterogeneous edge systems with both NPU and CIM. Our H4H-NAS approach is powered by a performance estimator built with NPU performance results measured on real silicon, and CIM performance based on industry IPs. H4H-NAS searches hybrid CNN/ViT models with fine granularity and achieves significant (up to 1.34%) top-1 accuracy improvement on ImageNet dataset. Moreover, results from our Algo/HW co-design reveal up to 56.08% overall latency and 41.72% energy improvements by introducing such heterogeneous computing over baseline solutions. The framework guides the design of hybrid network architectures and system architectures of NPU+CIM heterogeneous systems.
+
+
+
+ 75. 【2410.08321】Music Genre Classification using Large Language Models
+ 链接:https://arxiv.org/abs/2410.08321
+ 作者:Mohamed El Amine Meguenani,Alceu de Souza Britto Jr.,Alessandro Lameiras Koerich
+ 类目:ound (cs.SD); Computer Vision and Pattern Recognition (cs.CV); Audio and Speech Processing (eess.AS)
+ 关键词:pre-trained large language, large language models, paper exploits, capabilities of pre-trained, pre-trained large
+ 备注: 7 pages
+
+ 点击查看摘要
+ Abstract:This paper exploits the zero-shot capabilities of pre-trained large language models (LLMs) for music genre classification. The proposed approach splits audio signals into 20 ms chunks and processes them through convolutional feature encoders, a transformer encoder, and additional layers for coding audio units and generating feature vectors. The extracted feature vectors are used to train a classification head. During inference, predictions on individual chunks are aggregated for a final genre classification. We conducted a comprehensive comparison of LLMs, including WavLM, HuBERT, and wav2vec 2.0, with traditional deep learning architectures like 1D and 2D convolutional neural networks (CNNs) and the audio spectrogram transformer (AST). Our findings demonstrate the superior performance of the AST model, achieving an overall accuracy of 85.5%, surpassing all other models evaluated. These results highlight the potential of LLMs and transformer-based architectures for advancing music information retrieval tasks, even in zero-shot scenarios.
+
+
+
+ 76. 【2410.08282】FusionSense: Bridging Common Sense, Vision, and Touch for Robust Sparse-View Reconstruction
+ 链接:https://arxiv.org/abs/2410.08282
+ 作者:Irving Fang,Kairui Shi,Xujin He,Siqi Tan,Yifan Wang,Hanwen Zhao,Hung-Jui Huang,Wenzhen Yuan,Chen Feng,Jing Zhang
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:Humans effortlessly integrate, Humans effortlessly, effortlessly integrate common-sense, integrate common-sense knowledge, effortlessly integrate
+ 备注:
+
+ 点击查看摘要
+ Abstract:Humans effortlessly integrate common-sense knowledge with sensory input from vision and touch to understand their surroundings. Emulating this capability, we introduce FusionSense, a novel 3D reconstruction framework that enables robots to fuse priors from foundation models with highly sparse observations from vision and tactile sensors. FusionSense addresses three key challenges: (i) How can robots efficiently acquire robust global shape information about the surrounding scene and objects? (ii) How can robots strategically select touch points on the object using geometric and common-sense priors? (iii) How can partial observations such as tactile signals improve the overall representation of the object? Our framework employs 3D Gaussian Splatting as a core representation and incorporates a hierarchical optimization strategy involving global structure construction, object visual hull pruning and local geometric constraints. This advancement results in fast and robust perception in environments with traditionally challenging objects that are transparent, reflective, or dark, enabling more downstream manipulation or navigation tasks. Experiments on real-world data suggest that our framework outperforms previously state-of-the-art sparse-view methods. All code and data are open-sourced on the project website.
+
+
+
+ 77. 【2410.08261】Meissonic: Revitalizing Masked Generative Transformers for Efficient High-Resolution Text-to-Image Synthesis
+ 链接:https://arxiv.org/abs/2410.08261
+ 作者:Jinbin Bai,Tian Ye,Wei Chow,Enxin Song,Qing-Guo Chen,Xiangtai Li,Zhen Dong,Lei Zhu,Shuicheng Yan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:made significant strides, paradigm remains fundamentally, Stable Diffusion, unified language-vision models, complicating the development
+ 备注:
+
+ 点击查看摘要
+ Abstract:Diffusion models, such as Stable Diffusion, have made significant strides in visual generation, yet their paradigm remains fundamentally different from autoregressive language models, complicating the development of unified language-vision models. Recent efforts like LlamaGen have attempted autoregressive image generation using discrete VQVAE tokens, but the large number of tokens involved renders this approach inefficient and slow. In this work, we present Meissonic, which elevates non-autoregressive masked image modeling (MIM) text-to-image to a level comparable with state-of-the-art diffusion models like SDXL. By incorporating a comprehensive suite of architectural innovations, advanced positional encoding strategies, and optimized sampling conditions, Meissonic substantially improves MIM's performance and efficiency. Additionally, we leverage high-quality training data, integrate micro-conditions informed by human preference scores, and employ feature compression layers to further enhance image fidelity and resolution. Our model not only matches but often exceeds the performance of existing models like SDXL in generating high-quality, high-resolution images. Extensive experiments validate Meissonic's capabilities, demonstrating its potential as a new standard in text-to-image synthesis. We release a model checkpoint capable of producing $1024 \times 1024$ resolution images.
+
+
+
+ 78. 【2410.08260】Koala-36M: A Large-scale Video Dataset Improving Consistency between Fine-grained Conditions and Video Content
+ 链接:https://arxiv.org/abs/2410.08260
+ 作者:Qiuheng Wang,Yukai Shi,Jiarong Ou,Rui Chen,Ke Lin,Jiahao Wang,Boyuan Jiang,Haotian Yang,Mingwu Zheng,Xin Tao,Fei Yang,Pengfei Wan,Di Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:visual generation technologies, generation technologies continue, continue to advance, expanded rapidly, technologies continue
+ 备注: Project page: [this https URL](https://koala36m.github.io/)
+
+ 点击查看摘要
+ Abstract:As visual generation technologies continue to advance, the scale of video datasets has expanded rapidly, and the quality of these datasets is critical to the performance of video generation models. We argue that temporal splitting, detailed captions, and video quality filtering are three key factors that determine dataset quality. However, existing datasets exhibit various limitations in these areas. To address these challenges, we introduce Koala-36M, a large-scale, high-quality video dataset featuring accurate temporal splitting, detailed captions, and superior video quality. The core of our approach lies in improving the consistency between fine-grained conditions and video content. Specifically, we employ a linear classifier on probability distributions to enhance the accuracy of transition detection, ensuring better temporal consistency. We then provide structured captions for the splitted videos, with an average length of 200 words, to improve text-video alignment. Additionally, we develop a Video Training Suitability Score (VTSS) that integrates multiple sub-metrics, allowing us to filter high-quality videos from the original corpus. Finally, we incorporate several metrics into the training process of the generation model, further refining the fine-grained conditions. Our experiments demonstrate the effectiveness of our data processing pipeline and the quality of the proposed Koala-36M dataset. Our dataset and code will be released at this https URL.
+
+
+
+ 79. 【2410.08258】In Search of Forgotten Domain Generalization
+ 链接:https://arxiv.org/abs/2410.08258
+ 作者:Prasanna Mayilvahanan,Roland S. Zimmermann,Thaddäus Wiedemer,Evgenia Rusak,Attila Juhos,Matthias Bethge,Wieland Brendel
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:OOD, generalize to unseen, strictly OOD, OOD generalization, model OOD performance
+ 备注:
+
+ 点击查看摘要
+ Abstract:Out-of-Domain (OOD) generalization is the ability of a model trained on one or more domains to generalize to unseen domains. In the ImageNet era of computer vision, evaluation sets for measuring a model's OOD performance were designed to be strictly OOD with respect to style. However, the emergence of foundation models and expansive web-scale datasets has obfuscated this evaluation process, as datasets cover a broad range of domains and risk test domain contamination. In search of the forgotten domain generalization, we create large-scale datasets subsampled from LAION -- LAION-Natural and LAION-Rendition -- that are strictly OOD to corresponding ImageNet and DomainNet test sets in terms of style. Training CLIP models on these datasets reveals that a significant portion of their performance is explained by in-domain examples. This indicates that the OOD generalization challenges from the ImageNet era still prevail and that training on web-scale data merely creates the illusion of OOD generalization. Furthermore, through a systematic exploration of combining natural and rendition datasets in varying proportions, we identify optimal mixing ratios for model generalization across these domains. Our datasets and results re-enable meaningful assessment of OOD robustness at scale -- a crucial prerequisite for improving model robustness.
+
+
+
+ 80. 【2410.08257】Neural Material Adaptor for Visual Grounding of Intrinsic Dynamics
+ 链接:https://arxiv.org/abs/2410.08257
+ 作者:Junyi Cao,Shanyan Guan,Yanhao Ge,Wei Li,Xiaokang Yang,Chao Ma
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR); Machine Learning (cs.LG)
+ 关键词:humans effortlessly discern, effortlessly discern intrinsic, Neural Material Adaptor, modern AI systems, systems often struggle
+ 备注: NeurIPS 2024, the project page: [this https URL](https://xjay18.github.io/projects/neuma.html)
+
+ 点击查看摘要
+ Abstract:While humans effortlessly discern intrinsic dynamics and adapt to new scenarios, modern AI systems often struggle. Current methods for visual grounding of dynamics either use pure neural-network-based simulators (black box), which may violate physical laws, or traditional physical simulators (white box), which rely on expert-defined equations that may not fully capture actual dynamics. We propose the Neural Material Adaptor (NeuMA), which integrates existing physical laws with learned corrections, facilitating accurate learning of actual dynamics while maintaining the generalizability and interpretability of physical priors. Additionally, we propose Particle-GS, a particle-driven 3D Gaussian Splatting variant that bridges simulation and observed images, allowing back-propagate image gradients to optimize the simulator. Comprehensive experiments on various dynamics in terms of grounded particle accuracy, dynamic rendering quality, and generalization ability demonstrate that NeuMA can accurately capture intrinsic dynamics.
+
+
+
+ 81. 【2410.08230】Finetuning YOLOv9 for Vehicle Detection: Deep Learning for Intelligent Transportation Systems in Dhaka, Bangladesh
+ 链接:https://arxiv.org/abs/2410.08230
+ 作者:Shahriar Ahmad Fahim
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:caused numerous transportation, vehicle detection system, numerous transportation challenges, Intelligent Transportation Systems, Rapid urbanization
+ 备注: 16 pages, 10 figures
+
+ 点击查看摘要
+ Abstract:Rapid urbanization in megacities around the world, like Dhaka, has caused numerous transportation challenges that need to be addressed. Emerging technologies of deep learning and artificial intelligence can help us solve these problems to move towards Intelligent Transportation Systems (ITS) in the city. The government of Bangladesh recognizes the integration of ITS to ensure smart mobility as a vital step towards the development plan "Smart Bangladesh Vision 2041", but faces challenges in understanding ITS, its effects, and directions to implement. A vehicle detection system can pave the way to understanding traffic congestion, finding mobility patterns, and ensuring traffic surveillance. So, this paper proposes a fine-tuned object detector, the YOLOv9 model to detect native vehicles trained on a Bangladesh-based dataset. Results show that the fine-tuned YOLOv9 model achieved a mean Average Precision (mAP) of 0.934 at the Intersection over Union (IoU) threshold of 0.5, achieving state-of-the-art performance over past studies on Bangladesh-based datasets, shown through a comparison. Later, by suggesting the model to be deployed on CCTVs (closed circuit television) on the roads, a conceptual technique is proposed to process the vehicle detection model output data in a graph structure creating a vehicle detection system in the city. Finally, applications of such vehicle detection system are discussed showing a framework on how it can solve further ITS research questions, to provide a rationale for policymakers to implement the proposed vehicle detection system in the city.
+
+
+
+ 82. 【2410.08229】Improving Spiking Neural Network Accuracy With Color Model Information Encoded Bit Planes
+ 链接:https://arxiv.org/abs/2410.08229
+ 作者:Nhan T. Luu,Thang C. Truong,Duong T. Luu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Neural and Evolutionary Computing (cs.NE); Image and Video Processing (eess.IV)
+ 关键词:Spiking neural networks, small memory footprint, low energy consumption, Spiking neural, neural networks
+ 备注:
+
+ 点击查看摘要
+ Abstract:Spiking neural networks (SNNs) have emerged as a promising paradigm in computational neuroscience and artificial intelligence, offering advantages such as low energy consumption and small memory footprint. However, their practical adoption is constrained by several challenges, prominently among them being performance optimization. In this study, we present a novel approach to enhance the performance of SNNs through a new encoding method that exploits bit planes derived from various color models of input image data for spike encoding. Our proposed technique is designed to improve the computational accuracy of SNNs compared to conventional methods without increasing model size. Through extensive experimental validation, we demonstrate the effectiveness of our encoding strategy in achieving performance gain across multiple computer vision tasks. To the best of our knowledge, this is the first research endeavor applying color spaces within the context of SNNs. By leveraging the unique characteristics of color spaces, we hope to unlock new potentials in SNNs performance, potentially paving the way for more efficient and effective SNNs models in future researches and applications.
+
+
+
+ 83. 【2409.09566】Learning Transferable Features for Implicit Neural Representations
+ 链接:https://arxiv.org/abs/2409.09566
+ 作者:Kushal Vyas,Ahmed Imtiaz Humayun,Aniket Dashpute,Richard G. Baraniuk,Ashok Veeraraghavan,Guha Balakrishnan
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Implicit neural representations, Implicit neural, variety of applications, learned neural features, demonstrated success
+ 备注:
+
+ 点击查看摘要
+ Abstract:Implicit neural representations (INRs) have demonstrated success in a variety of applications, including inverse problems and neural rendering. An INR is typically trained to capture one signal of interest, resulting in learned neural features that are highly attuned to that signal. Assumed to be less generalizable, we explore the aspect of transferability of such learned neural features for fitting similar signals. We introduce a new INR training framework, STRAINER that learns transferrable features for fitting INRs to new signals from a given distribution, faster and with better reconstruction quality. Owing to the sequential layer-wise affine operations in an INR, we propose to learn transferable representations by sharing initial encoder layers across multiple INRs with independent decoder layers. At test time, the learned encoder representations are transferred as initialization for an otherwise randomly initialized INR. We find STRAINER to yield extremely powerful initialization for fitting images from the same domain and allow for $\approx +10dB$ gain in signal quality early on compared to an untrained INR itself. STRAINER also provides a simple way to encode data-driven priors in INRs. We evaluate STRAINER on multiple in-domain and out-of-domain signal fitting tasks and inverse problems and further provide detailed analysis and discussion on the transferability of STRAINER's features. Our demo can be accessed at this https URL .
+
+
+
+ 84. 【2403.13807】Editing Massive Concepts in Text-to-Image Diffusion Models
+ 链接:https://arxiv.org/abs/2403.13807
+ 作者:Tianwei Xiong,Yue Wu,Enze Xie,Yue Wu,Zhenguo Li,Xihui Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:generating outdated, biased content, risk of generating, diffusion models suffer, massive concept editing
+ 备注: Project page: [this https URL](https://silentview.github.io/EMCID/) . Code: [this https URL](https://github.com/SilentView/EMCID)
+
+ 点击查看摘要
+ Abstract:Text-to-image diffusion models suffer from the risk of generating outdated, copyrighted, incorrect, and biased content. While previous methods have mitigated the issues on a small scale, it is essential to handle them simultaneously in larger-scale real-world scenarios. We propose a two-stage method, Editing Massive Concepts In Diffusion Models (EMCID). The first stage performs memory optimization for each individual concept with dual self-distillation from text alignment loss and diffusion noise prediction loss. The second stage conducts massive concept editing with multi-layer, closed form model editing. We further propose a comprehensive benchmark, named ImageNet Concept Editing Benchmark (ICEB), for evaluating massive concept editing for T2I models with two subtasks, free-form prompts, massive concept categories, and extensive evaluation metrics. Extensive experiments conducted on our proposed benchmark and previous benchmarks demonstrate the superior scalability of EMCID for editing up to 1,000 concepts, providing a practical approach for fast adjustment and re-deployment of T2I diffusion models in real-world applications.
+
+
+
+ 85. 【2410.08861】A foundation model for generalizable disease diagnosis in chest X-ray images
+ 链接:https://arxiv.org/abs/2410.08861
+ 作者:Lijian Xu,Ziyu Ni,Hao Sun,Hongsheng Li,Shaoting Zhang
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Medical artificial intelligence, providing robust tools, Medical artificial, unlabelled CXR images, artificial intelligence
+ 备注:
+
+ 点击查看摘要
+ Abstract:Medical artificial intelligence (AI) is revolutionizing the interpretation of chest X-ray (CXR) images by providing robust tools for disease diagnosis. However, the effectiveness of these AI models is often limited by their reliance on large amounts of task-specific labeled data and their inability to generalize across diverse clinical settings. To address these challenges, we introduce CXRBase, a foundational model designed to learn versatile representations from unlabelled CXR images, facilitating efficient adaptation to various clinical tasks. CXRBase is initially trained on a substantial dataset of 1.04 million unlabelled CXR images using self-supervised learning methods. This approach allows the model to discern meaningful patterns without the need for explicit labels. After this initial phase, CXRBase is fine-tuned with labeled data to enhance its performance in disease detection, enabling accurate classification of chest diseases. CXRBase provides a generalizable solution to improve model performance and alleviate the annotation workload of experts to enable broad clinical AI applications from chest imaging.
+
+
+
+ 86. 【2410.08677】On the impact of key design aspects in simulated Hybrid Quantum Neural Networks for Earth Observation
+ 链接:https://arxiv.org/abs/2410.08677
+ 作者:Lorenzo Papa,Alessandro Sebastianelli,Gabriele Meoni,Irene Amerini
+ 类目:Quantum Physics (quant-ph); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:improving machine learning, computing has introduced, introduced novel perspectives, perspectives for tackling, tackling and improving
+ 备注:
+
+ 点击查看摘要
+ Abstract:Quantum computing has introduced novel perspectives for tackling and improving machine learning tasks. Moreover, the integration of quantum technologies together with well-known deep learning (DL) architectures has emerged as a potential research trend gaining attraction across various domains, such as Earth Observation (EO) and many other research fields. However, prior related works in EO literature have mainly focused on convolutional architectural advancements, leaving several essential topics unexplored. Consequently, this research investigates through three cases of study fundamental aspects of hybrid quantum machine models for EO tasks aiming to provide a solid groundwork for future research studies towards more adequate simulations and looking at the post-NISQ era. More in detail, we firstly (1) investigate how different quantum libraries behave when training hybrid quantum models, assessing their computational efficiency and effectiveness. Secondly, (2) we analyze the stability/sensitivity to initialization values (i.e., seed values) in both traditional model and quantum-enhanced counterparts. Finally, (3) we explore the benefits of hybrid quantum attention-based models in EO applications, examining how integrating quantum circuits into ViTs can improve model performance.
+
+
+
+ 87. 【2410.08646】Fully Unsupervised Dynamic MRI Reconstruction via Diffeo-Temporal Equivariance
+ 链接:https://arxiv.org/abs/2410.08646
+ 作者:Andrew Wang,Mike Davies
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Reconstructing dynamic MRI, free breathing motion, resolution real-time imaging, MRI image sequences, higher spatiotemporal resolution
+ 备注: Pre-print
+
+ 点击查看摘要
+ Abstract:Reconstructing dynamic MRI image sequences from undersampled accelerated measurements is crucial for faster and higher spatiotemporal resolution real-time imaging of cardiac motion, free breathing motion and many other applications. Classical paradigms, such as gated cine MRI, assume periodicity, disallowing imaging of true motion. Supervised deep learning methods are fundamentally flawed as, in dynamic imaging, ground truth fully-sampled videos are impossible to truly obtain. We propose an unsupervised framework to learn to reconstruct dynamic MRI sequences from undersampled measurements alone by leveraging natural geometric spatiotemporal equivariances of MRI. Dynamic Diffeomorphic Equivariant Imaging (DDEI) significantly outperforms state-of-the-art unsupervised methods such as SSDU on highly accelerated dynamic cardiac imaging. Our method is agnostic to the underlying neural network architecture and can be used to adapt the latest models and post-processing approaches. Our code and video demos are at this https URL.
+
+
+
+ 88. 【2410.08588】ViT3D Alignment of LLaMA3: 3D Medical Image Report Generation
+ 链接:https://arxiv.org/abs/2410.08588
+ 作者:Siyou Li,Beining Xu,Yihao Luo,Dong Nie,Le Zhang
+ 类目:Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:medical report generation, Automatic medical report, produce detailed text, detailed text reports, automatic MRG
+ 备注:
+
+ 点击查看摘要
+ Abstract:Automatic medical report generation (MRG), which aims to produce detailed text reports from medical images, has emerged as a critical task in this domain. MRG systems can enhance radiological workflows by reducing the time and effort required for report writing, thereby improving diagnostic efficiency. In this work, we present a novel approach for automatic MRG utilizing a multimodal large language model. Specifically, we employed the 3D Vision Transformer (ViT3D) image encoder introduced from M3D-CLIP to process 3D scans and use the Asclepius-Llama3-8B as the language model to generate the text reports by auto-regressive decoding. The experiment shows our model achieved an average Green score of 0.3 on the MRG task validation set and an average accuracy of 0.61 on the visual question answering (VQA) task validation set, outperforming the baseline model. Our approach demonstrates the effectiveness of the ViT3D alignment of LLaMA3 for automatic MRG and VQA tasks by tuning the model on a small dataset.
+
+
+
+ 89. 【2410.08490】CAS-GAN for Contrast-free Angiography Synthesis
+ 链接:https://arxiv.org/abs/2410.08490
+ 作者:De-Xing Huang,Xiao-Hu Zhou,Mei-Jiang Gui,Xiao-Liang Xie,Shi-Qi Liu,Shuang-Yi Wang,Hao Li,Tian-Yu Xiang,Zeng-Guang Hou
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:posing substantial health, substantial health risks, numerous interventional procedures, Iodinated contrast agents, interventional procedures
+ 备注: 8 pages, 4 figures
+
+ 点击查看摘要
+ Abstract:Iodinated contrast agents are widely utilized in numerous interventional procedures, yet posing substantial health risks to patients. This paper presents CAS-GAN, a novel GAN framework that serves as a ``virtual contrast agent" to synthesize X-ray angiographies via disentanglement representation learning and vessel semantic guidance, thereby reducing the reliance on iodinated agents during interventional procedures. Specifically, our approach disentangles X-ray angiographies into background and vessel components, leveraging medical prior knowledge. A specialized predictor then learns to map the interrelationships between these components. Additionally, a vessel semantic-guided generator and a corresponding loss function are introduced to enhance the visual fidelity of generated images. Experimental results on the XCAD dataset demonstrate the state-of-the-art performance of our CAS-GAN, achieving a FID of 5.94 and a MMD of 0.017. These promising results highlight CAS-GAN's potential for clinical applications.
+
+
+
+ 90. 【2410.08485】Beyond GFVC: A Progressive Face Video Compression Framework with Adaptive Visual Tokens
+ 链接:https://arxiv.org/abs/2410.08485
+ 作者:Bolin Chen,Shanzhi Yin,Zihan Zhang,Jie Chen,Ru-Ling Liao,Lingyu Zhu,Shiqi Wang,Yan Ye
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:deep generative models, Face Video Compression, diverse application functionalities, Generative Face Video, face video coding
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recently, deep generative models have greatly advanced the progress of face video coding towards promising rate-distortion performance and diverse application functionalities. Beyond traditional hybrid video coding paradigms, Generative Face Video Compression (GFVC) relying on the strong capabilities of deep generative models and the philosophy of early Model-Based Coding (MBC) can facilitate the compact representation and realistic reconstruction of visual face signal, thus achieving ultra-low bitrate face video communication. However, these GFVC algorithms are sometimes faced with unstable reconstruction quality and limited bitrate ranges. To address these problems, this paper proposes a novel Progressive Face Video Compression framework, namely PFVC, that utilizes adaptive visual tokens to realize exceptional trade-offs between reconstruction robustness and bandwidth intelligence. In particular, the encoder of the proposed PFVC projects the high-dimensional face signal into adaptive visual tokens in a progressive manner, whilst the decoder can further reconstruct these adaptive visual tokens for motion estimation and signal synthesis with different granularity levels. Experimental results demonstrate that the proposed PFVC framework can achieve better coding flexibility and superior rate-distortion performance in comparison with the latest Versatile Video Coding (VVC) codec and the state-of-the-art GFVC algorithms. The project page can be found at this https URL.
+
+
+
+ 91. 【2410.08397】VoxelPrompt: A Vision-Language Agent for Grounded Medical Image Analysis
+ 链接:https://arxiv.org/abs/2410.08397
+ 作者:Andrew Hoopes,Victor Ion Butoi,John V. Guttag,Adrian V. Dalca
+ 类目:Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:agent-driven vision-language framework, tackles diverse radiological, analytical metrics, agent-driven vision-language, joint modeling
+ 备注: 21 pages, 5 figures, vision-language agent, medical image analysis, neuroimage foundation model
+
+ 点击查看摘要
+ Abstract:We present VoxelPrompt, an agent-driven vision-language framework that tackles diverse radiological tasks through joint modeling of natural language, image volumes, and analytical metrics. VoxelPrompt is multi-modal and versatile, leveraging the flexibility of language interaction while providing quantitatively grounded image analysis. Given a variable number of 3D medical volumes, such as MRI and CT scans, VoxelPrompt employs a language agent that iteratively predicts executable instructions to solve a task specified by an input prompt. These instructions communicate with a vision network to encode image features and generate volumetric outputs (e.g., segmentations). VoxelPrompt interprets the results of intermediate instructions and plans further actions to compute discrete measures (e.g., tumor growth across a series of scans) and present relevant outputs to the user. We evaluate this framework in a sandbox of diverse neuroimaging tasks, and we show that the single VoxelPrompt model can delineate hundreds of anatomical and pathological features, measure many complex morphological properties, and perform open-language analysis of lesion characteristics. VoxelPrompt carries out these objectives with accuracy similar to that of fine-tuned, single-task models for segmentation and visual question-answering, while facilitating a much larger range of tasks. Therefore, by supporting accurate image processing with language interaction, VoxelPrompt provides comprehensive utility for numerous imaging tasks that traditionally require specialized models to address.
+
+
+
+ 92. 【2410.08231】A Real Benchmark Swell Noise Dataset for Performing Seismic Data Denoising via Deep Learning
+ 链接:https://arxiv.org/abs/2410.08231
+ 作者:Pablo M. Barros,Roosevelt de L. Sardinha,Giovanny A. M. Arboleda,Lessandro de S. S. Valente,Isabelle R. V. de Melo,Albino Aveleda,André Bulcão,Sergio L. Netto,Alexandre G. Evsukoff
+ 类目:Geophysics (physics.geo-ph); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:deep learning, computer vision, creation of open, tested and compared, compared with reproducible
+ 备注:
+
+ 点击查看摘要
+ Abstract:The recent development of deep learning (DL) methods for computer vision has been driven by the creation of open benchmark datasets on which new algorithms can be tested and compared with reproducible results. Although DL methods have many applications in geophysics, few real seismic datasets are available for benchmarking DL models, especially for denoising real data, which is one of the main problems in seismic data processing scenarios in the oil and gas industry. This article presents a benchmark dataset composed of synthetic seismic data corrupted with noise extracted from a filtering process implemented on real data. In this work, a comparison between two well-known DL-based denoising models is conducted on this dataset, which is proposed as a benchmark for accelerating the development of new solutions for seismic data denoising. This work also introduces a new evaluation metric that can capture small variations in model results. The results show that DL models are effective at denoising seismic data, but some issues remain to be solved.
+
+
+
+ 93. 【2410.08228】Multi-Atlas Brain Network Classification through Consistency Distillation and Complementary Information Fusion
+ 链接:https://arxiv.org/abs/2410.08228
+ 作者:Jiaxing Xu,Mengcheng Lan,Xia Dong,Kai He,Wei Zhang,Qingtian Bian,Yiping Ke
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:identifying distinctive patterns, identifying distinctive, brain, brain network classification, atlases
+ 备注:
+
+ 点击查看摘要
+ Abstract:In the realm of neuroscience, identifying distinctive patterns associated with neurological disorders via brain networks is crucial. Resting-state functional magnetic resonance imaging (fMRI) serves as a primary tool for mapping these networks by correlating blood-oxygen-level-dependent (BOLD) signals across different brain regions, defined as regions of interest (ROIs). Constructing these brain networks involves using atlases to parcellate the brain into ROIs based on various hypotheses of brain division. However, there is no standard atlas for brain network classification, leading to limitations in detecting abnormalities in disorders. Some recent methods have proposed utilizing multiple atlases, but they neglect consistency across atlases and lack ROI-level information exchange. To tackle these limitations, we propose an Atlas-Integrated Distillation and Fusion network (AIDFusion) to improve brain network classification using fMRI data. AIDFusion addresses the challenge of utilizing multiple atlases by employing a disentangle Transformer to filter out inconsistent atlas-specific information and distill distinguishable connections across atlases. It also incorporates subject- and population-level consistency constraints to enhance cross-atlas consistency. Additionally, AIDFusion employs an inter-atlas message-passing mechanism to fuse complementary information across brain regions. Experimental results on four datasets of different diseases demonstrate the effectiveness and efficiency of AIDFusion compared to state-of-the-art methods. A case study illustrates AIDFusion extract patterns that are both interpretable and consistent with established neuroscience findings.
+
+
+
+ 94. 【2410.08223】Removal of clouds from satellite images using time compositing techniques
+ 链接:https://arxiv.org/abs/2410.08223
+ 作者:Atma Bharathi Mani,Nagashree TR,Manavalan P,Diwakar PG
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:function, quantitative study, deterrent to qualitative, qualitative and quantitative, min
+ 备注: 10 pages, 8 figures
+
+ 点击查看摘要
+ Abstract:Clouds in satellite images are a deterrent to qualitative and quantitative study. Time compositing methods compare a series of co-registered images and retrieve only those pixels that have comparatively lesser cloud cover for the resultant image. Two different approaches of time compositing were tested. The first method recoded the clouds to value 0 on all the constituent images and ran a 'max' function. The second method directly ran a 'min' function without recoding on all the images for the resultant image. The 'max' function gave a highly mottled image while the 'min' function gave a superior quality image with smoother texture. Persistent clouds on all constituent images were retained in both methods, but they were readily identifiable and easily extractable in the 'max' function image as they were recoded to 0, while that in the 'min' function appeared with varying DN values. Hence a hybrid technique was created which recodes the clouds to value 255 and runs a 'min' function. This method preserved the quality of the 'min' function and the advantage of retrieving clouds as in the 'max' function image. The models were created using Erdas Imagine Modeler 9.1 and MODIS 250 m resolution images of coastal Karnataka in the months of May, June 2008 were used. A detailed investigation on the different methods is described and scope for automating different techniques is discussed.
+
+
+
+ 95. 【2410.08218】A Visual-Analytical Approach for Automatic Detection of Cyclonic Events in Satellite Observations
+ 链接:https://arxiv.org/abs/2410.08218
+ 作者:Akash Agrawal,Mayesh Mohapatra,Abhinav Raja,Paritosh Tiwari,Vishwajeet Pattanaik,Neeru Jaiswal,Arpit Agarwal,Punit Rathore
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Atmospheric and Oceanic Physics (physics.ao-ph)
+ 关键词:catastrophic weather events, holds crucial significance, predicting catastrophic weather, North Indian Ocean, tropical cyclones holds
+ 备注: 10 pages, 22 figures
+
+ 点击查看摘要
+ Abstract:Estimating the location and intensity of tropical cyclones holds crucial significance for predicting catastrophic weather events. In this study, we approach this task as a detection and regression challenge, specifically over the North Indian Ocean (NIO) region where best tracks location and wind speed information serve as the labels. The current process for cyclone detection and intensity estimation involves physics-based simulation studies which are time-consuming, only using image features will automate the process for significantly faster and more accurate predictions. While conventional methods typically necessitate substantial prior knowledge for training, we are exploring alternative approaches to enhance efficiency. This research aims to focus specifically on cyclone detection, intensity estimation and related aspects using only image input and data-driven approaches and will lead to faster inference time and automate the process as opposed to current NWP models being utilized at SAC. In context to algorithm development, a novel two stage detection and intensity estimation module is proposed. In the first level detection we try to localize the cyclone over an entire image as captured by INSAT3D over the NIO (North Indian Ocean). For the intensity estimation task, we propose a CNN-LSTM network, which works on the cyclone centered images, utilizing a ResNet-18 backbone, by which we are able to capture both temporal and spatial characteristics.
+
+
+
+ 96. 【2406.17804】A Review of Electromagnetic Elimination Methods for low-field portable MRI scanner
+ 链接:https://arxiv.org/abs/2406.17804
+ 作者:Wanyu Bian
+ 类目:Medical Physics (physics.med-ph); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Image and Video Processing (eess.IV)
+ 关键词:eliminating electromagnetic interference, deep learning, deep learning methods, EMI, EMI elimination
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper presents a comprehensive analysis of both conventional and deep learning methods for eliminating electromagnetic interference (EMI) in MRI systems. We explore the underlying principles and implementation of traditional analytical and adaptive EMI elimination techniques, as well as cutting-edge deep learning approaches. Through a detailed comparison, the strengths and limitations of each method are highlighted. Recent advancements in active EMI elimination utilizing multiple external EMI receiver coils and analytical techniques are discussed alongside the superior performance of deep learning methods, which leverage neural networks trained on extensive MRI data. While deep learning methods demonstrate significant improvements in EMI suppression, enhancing diagnostic capabilities and accessibility of MRI technology, they also introduce potential security and safety concerns, especially in production and commercial applications. This study underscores the need to address these challenges to fully realize the benefits of deep learning in EMI elimination. The findings suggest a balanced approach, combining the reliability of conventional methods with the advanced capabilities of deep learning, to develop more robust and effective EMI suppression strategies in MRI systems.
+
+
+





/Fig1_pretrain_finetune.png)
/Fig2_eda1.png)
/Fig2_eda2.png)
/Fig2_eda3.png)
/Fig3_reweight.png)
/Fig5_model1.png)
/Fig5_attention_mask.png)
/Fig4_wwm.png)
/Fig5_model2.png)
/Fig5_model3.png)
/Fig7_ensemble1.png)
/Fig6_res1.png)
/Fig6_res2.png)


%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_text_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_entity_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/model.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/dont_stop_pretraining.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/a.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/b.png)

%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/lengths_histplot.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_entity_lengths.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_label_dist.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/%E6%80%BB%E4%BD%93%E6%96%B9%E6%A1%88.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/pretrain_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/finetune_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/rdrop.png)


/autoencoder-architecture.png)
/variational-autoencoder-architecture.png)
/forward_vs_reversed_KL.png)
/vae-implement.png)
/reparam.png)
/generated_samples.png)







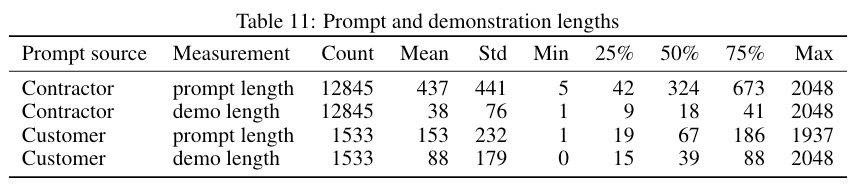

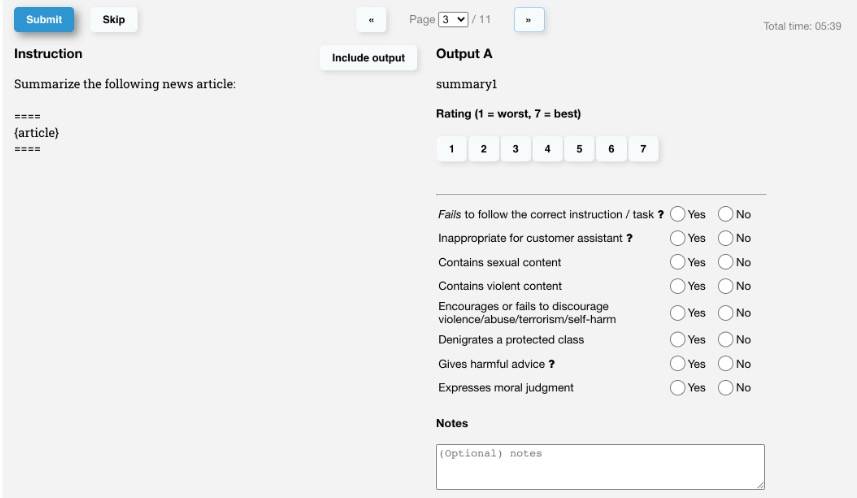
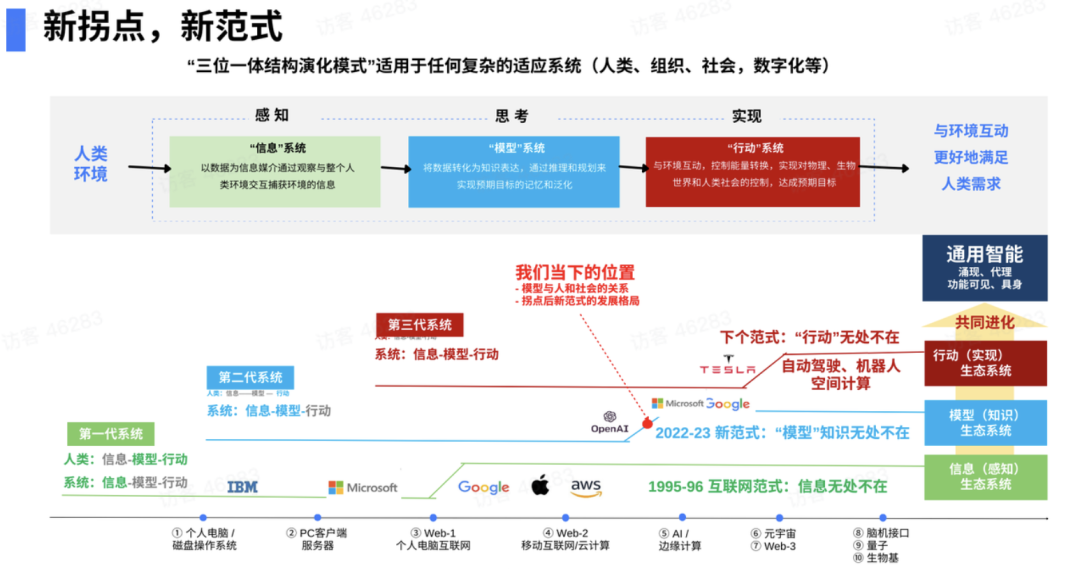
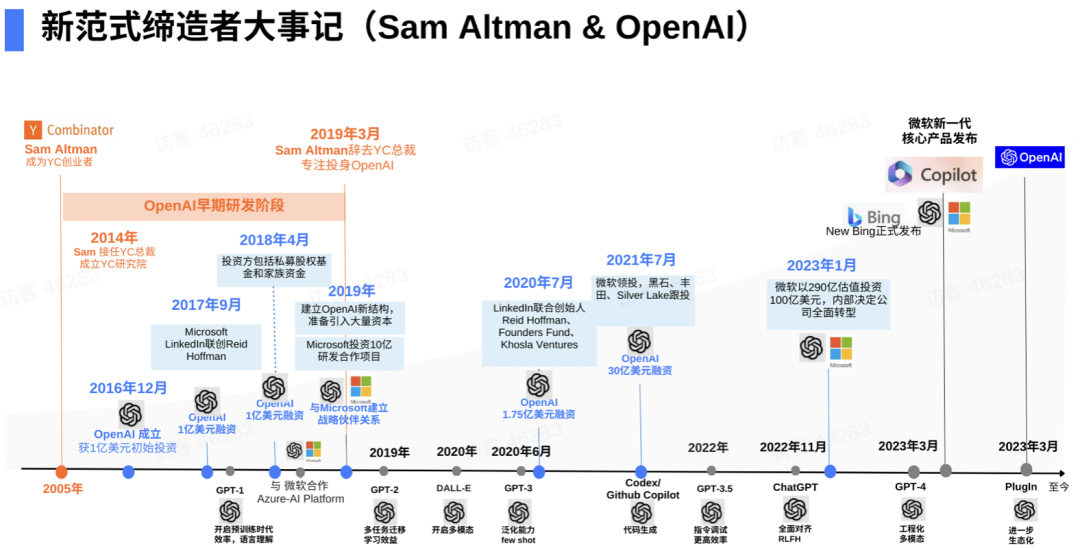
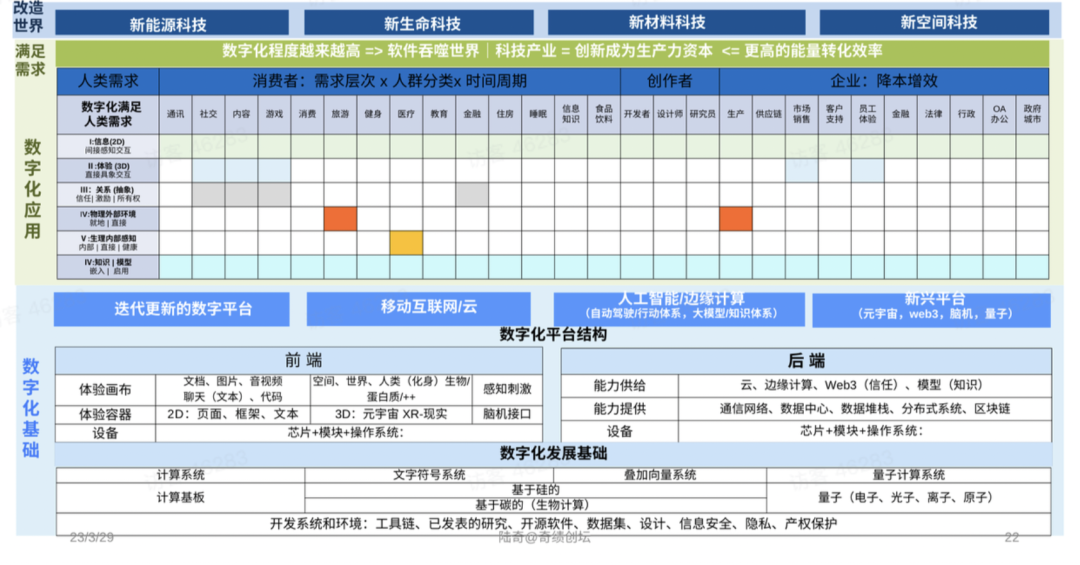
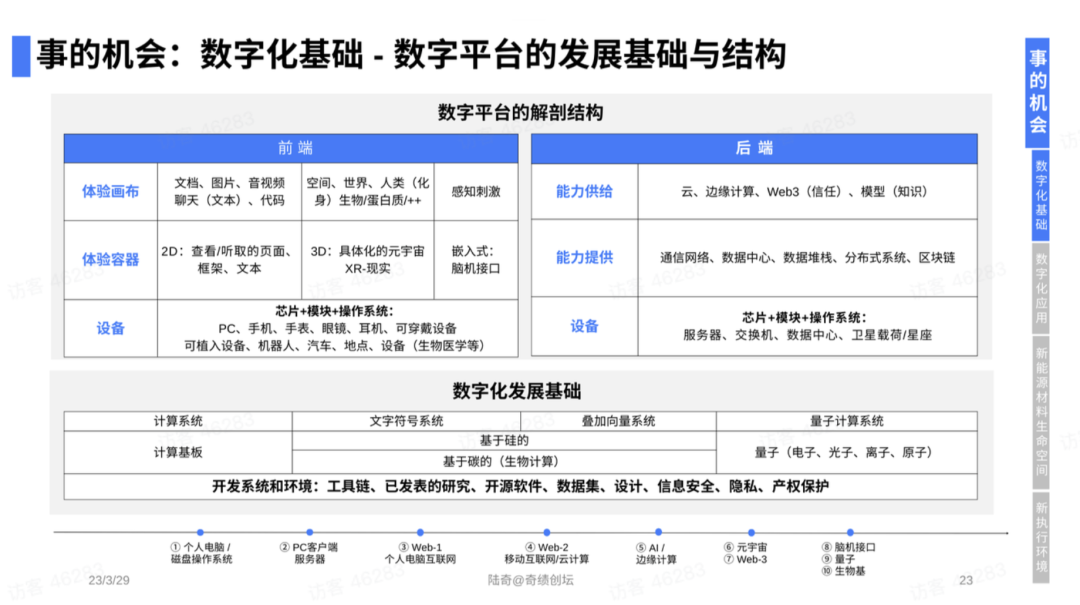
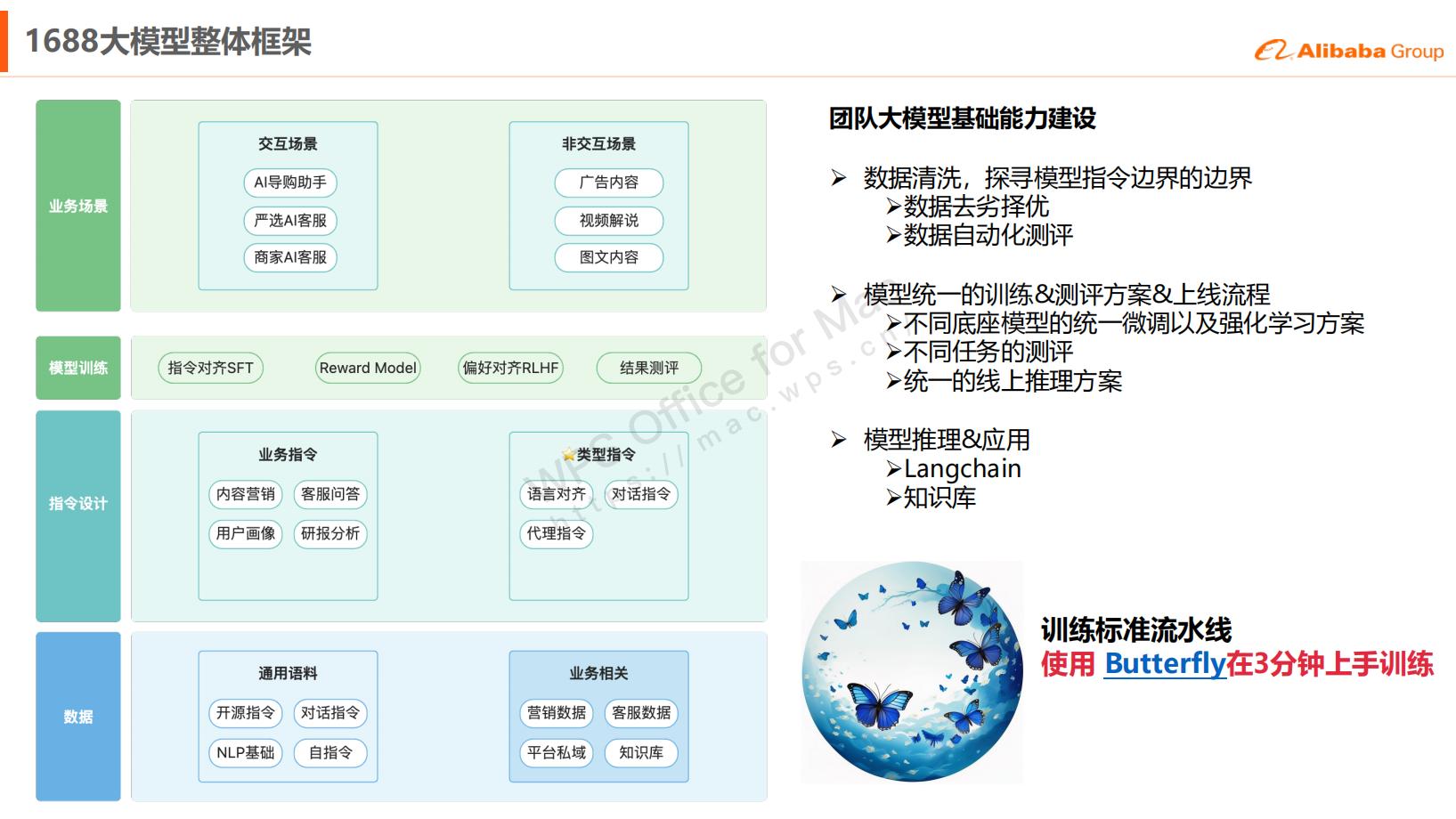
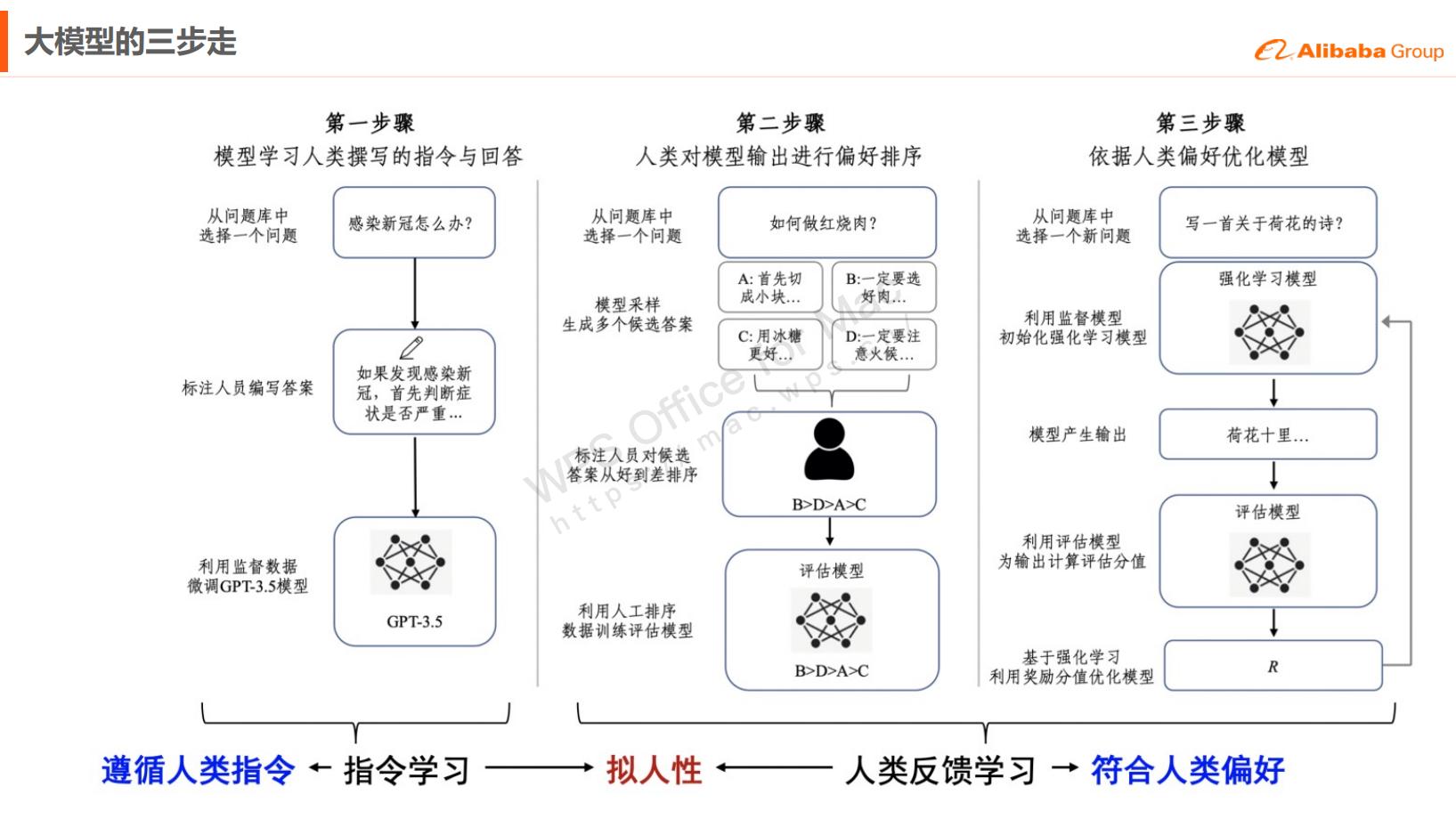
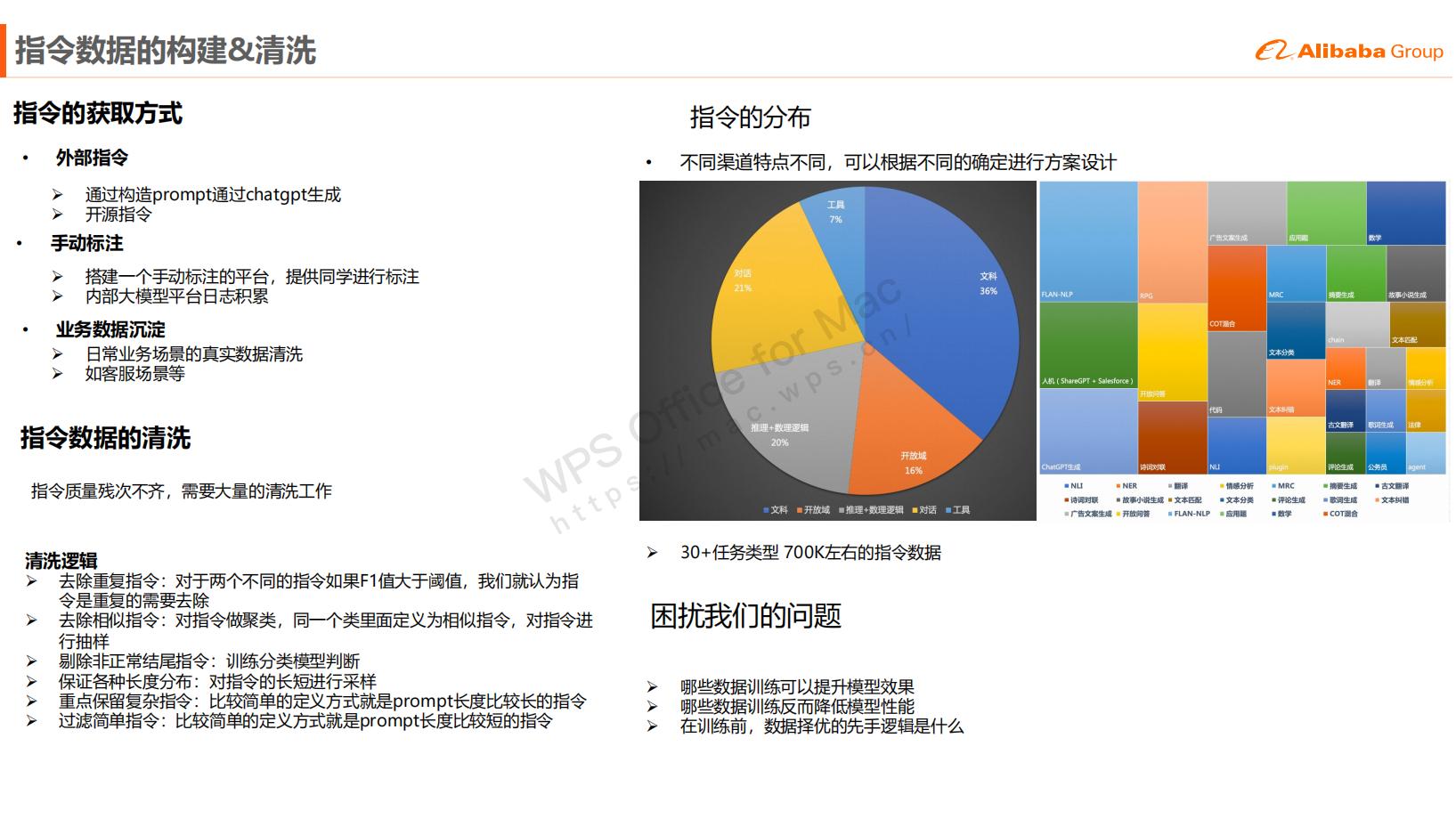


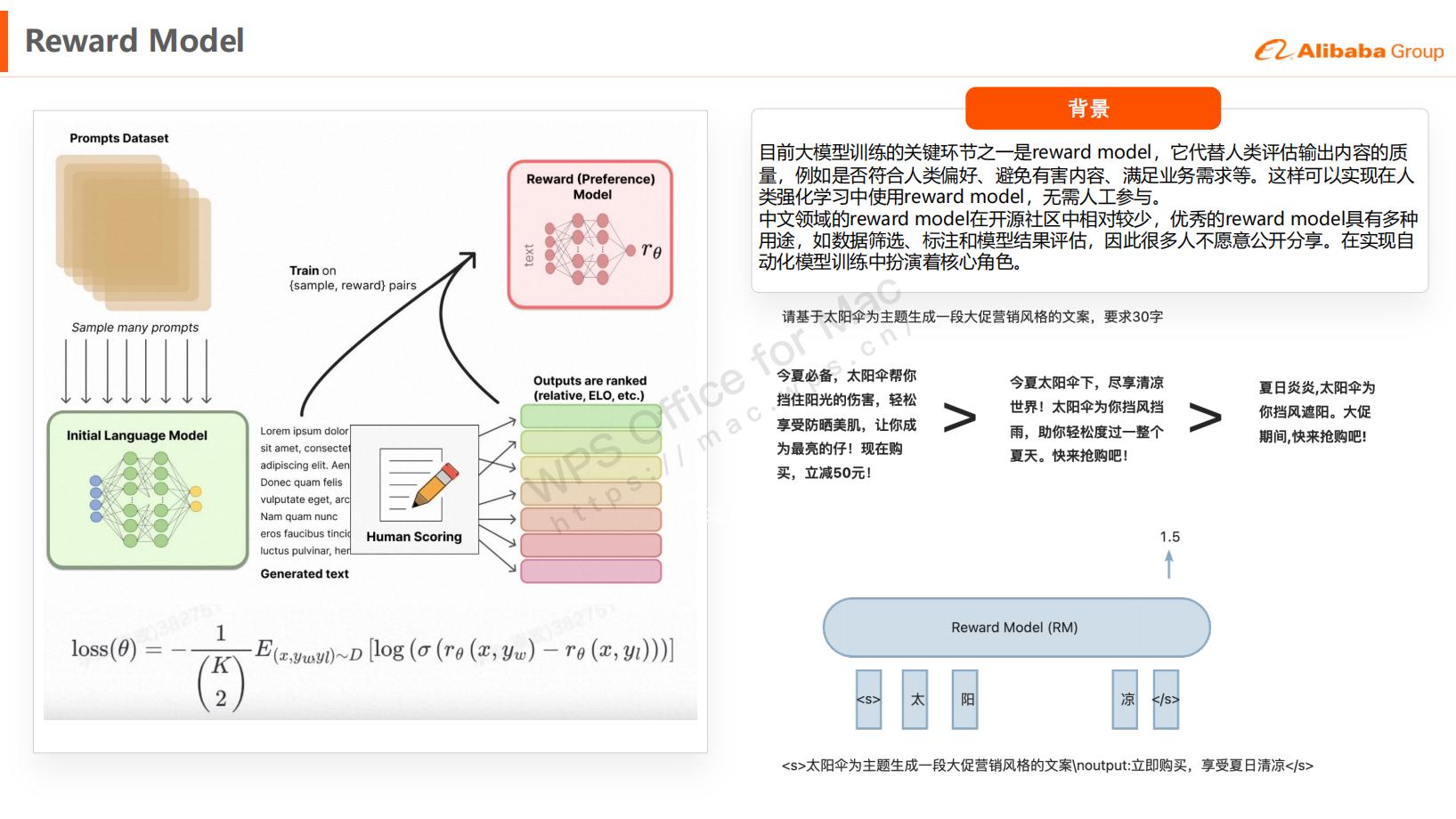




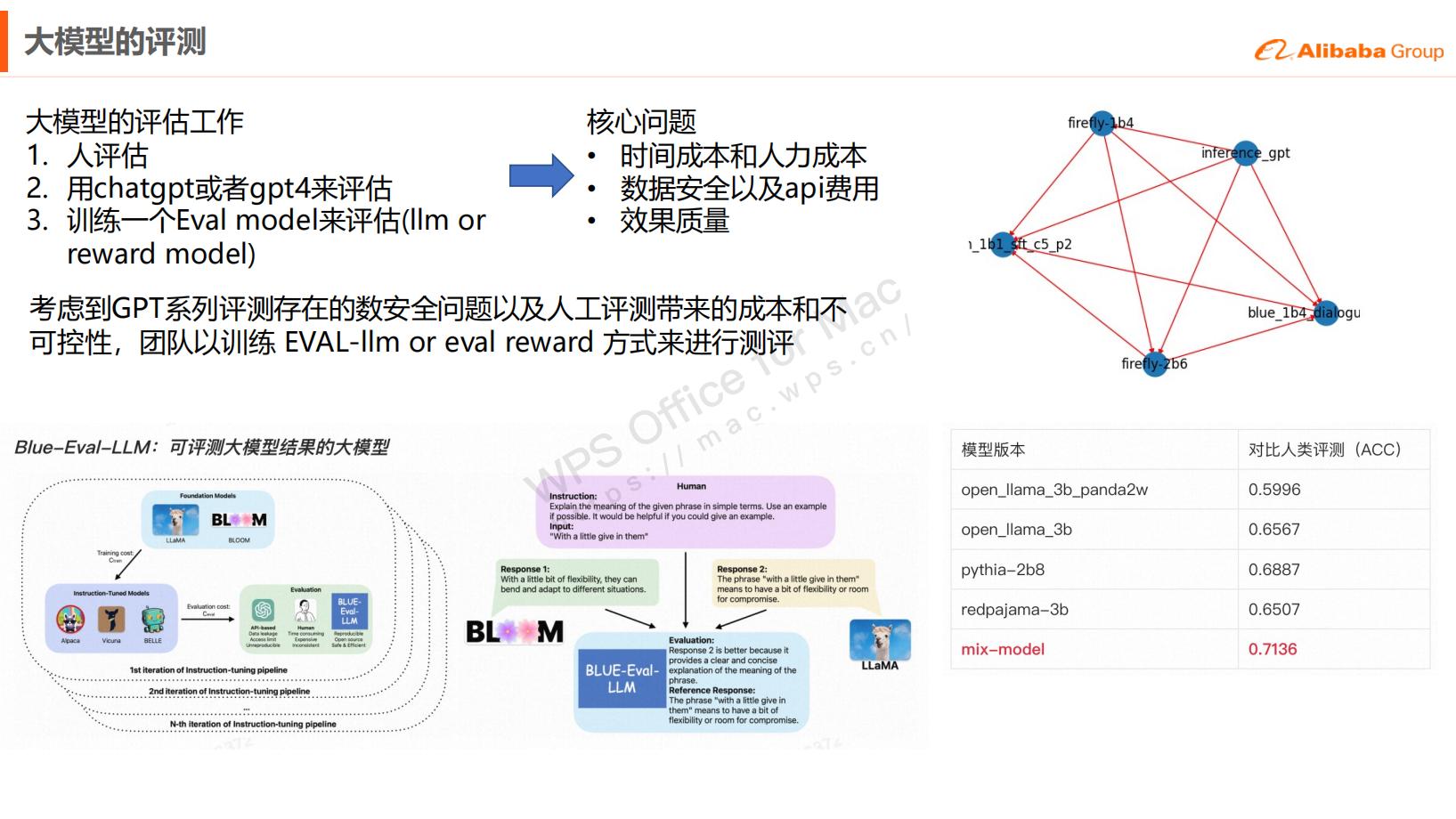
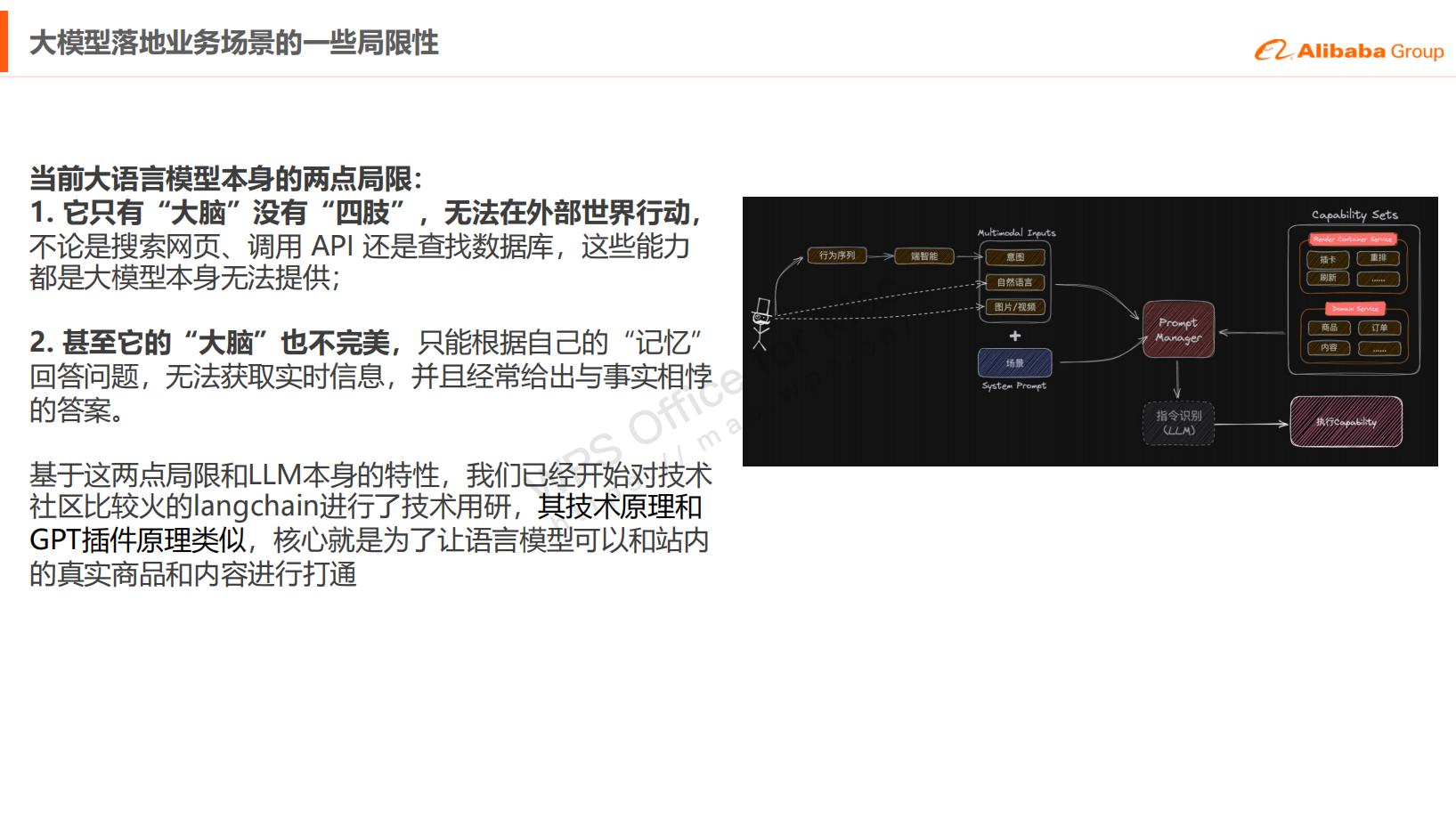






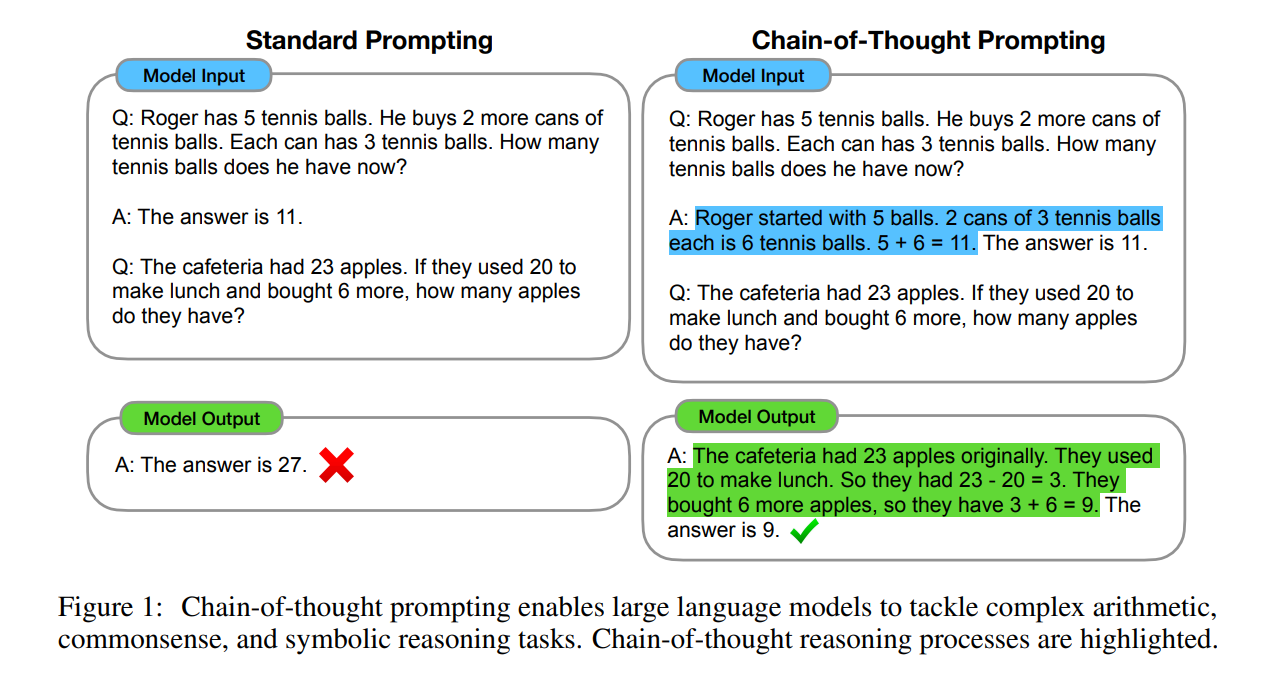

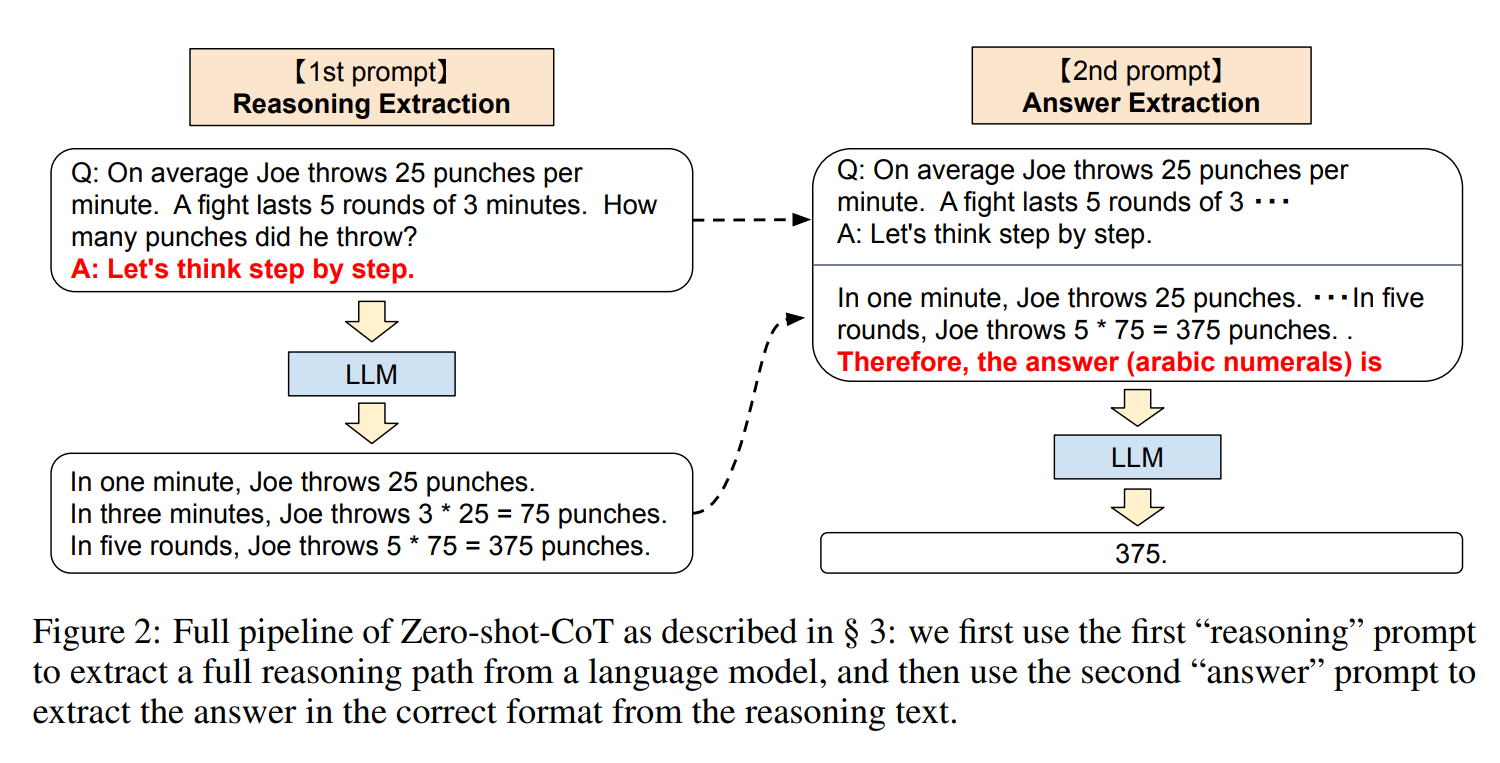
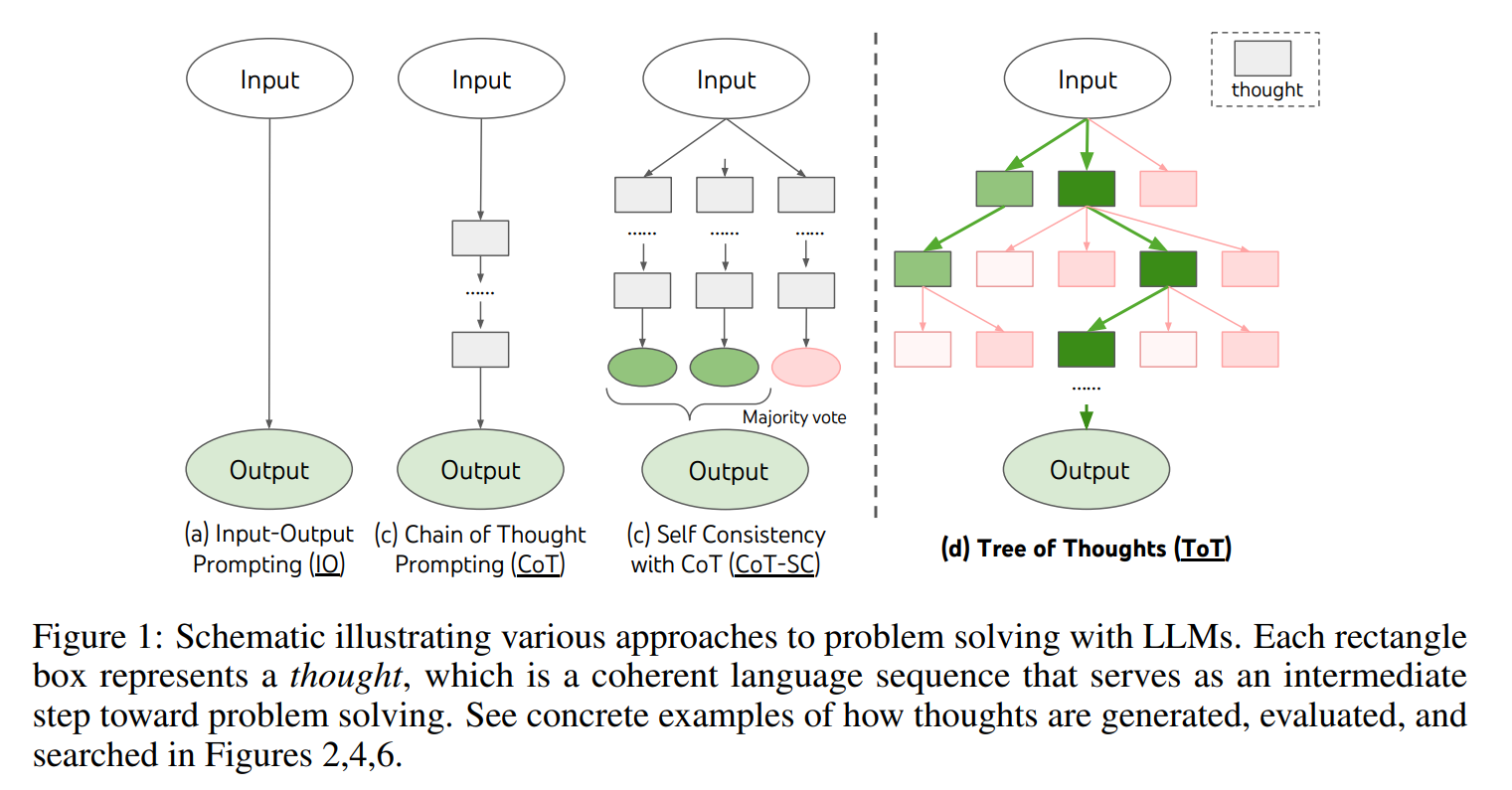


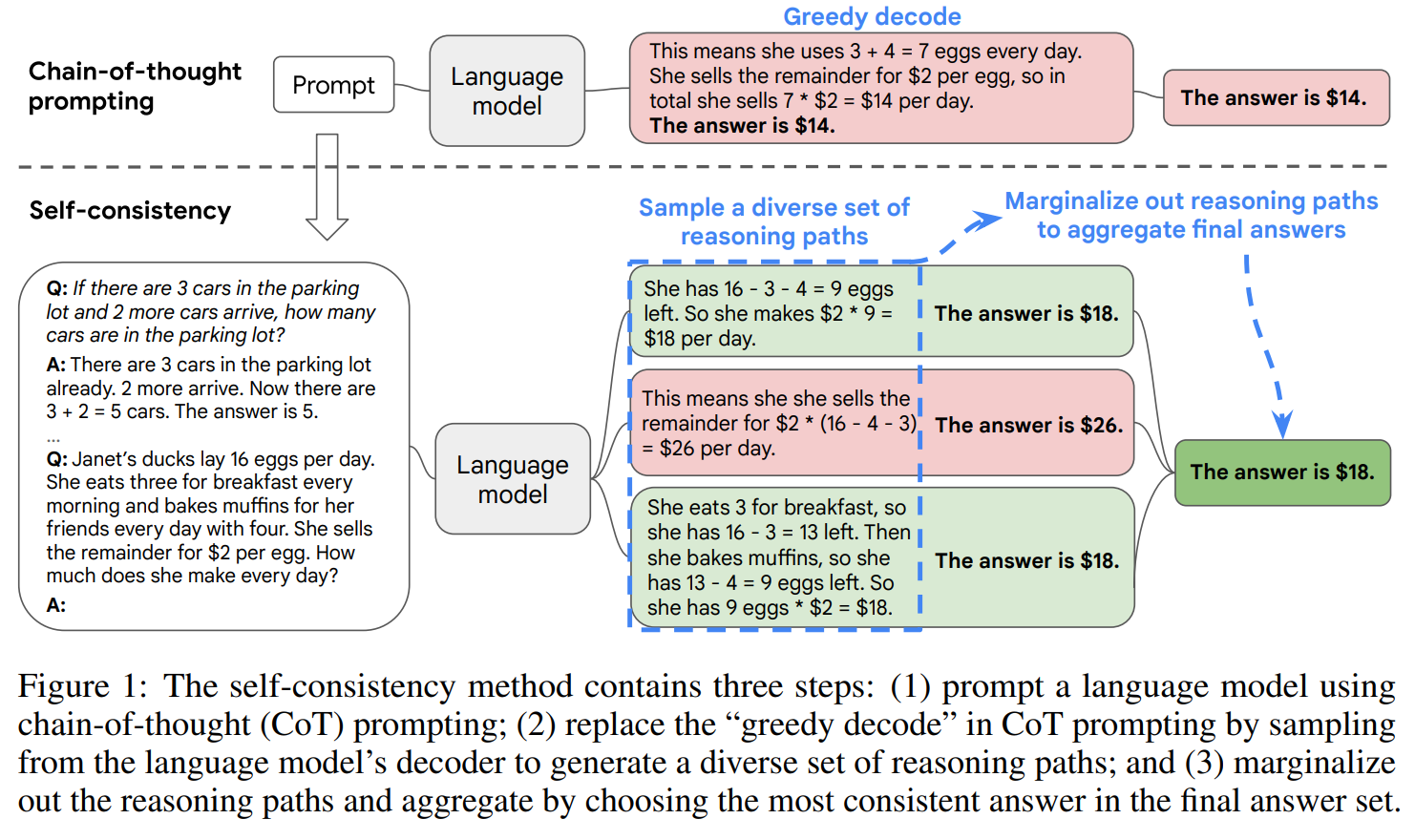
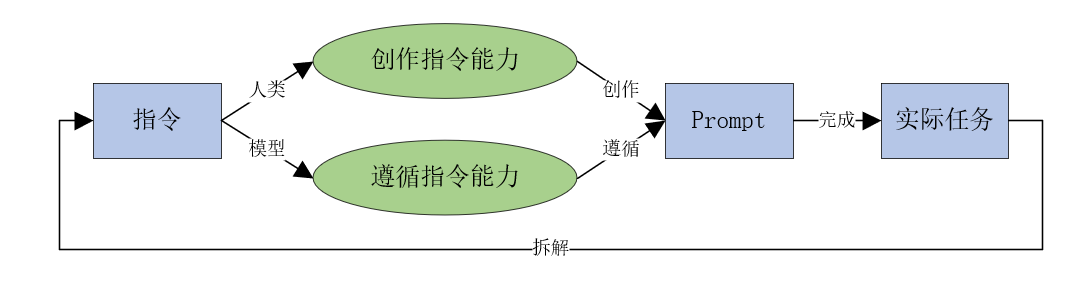



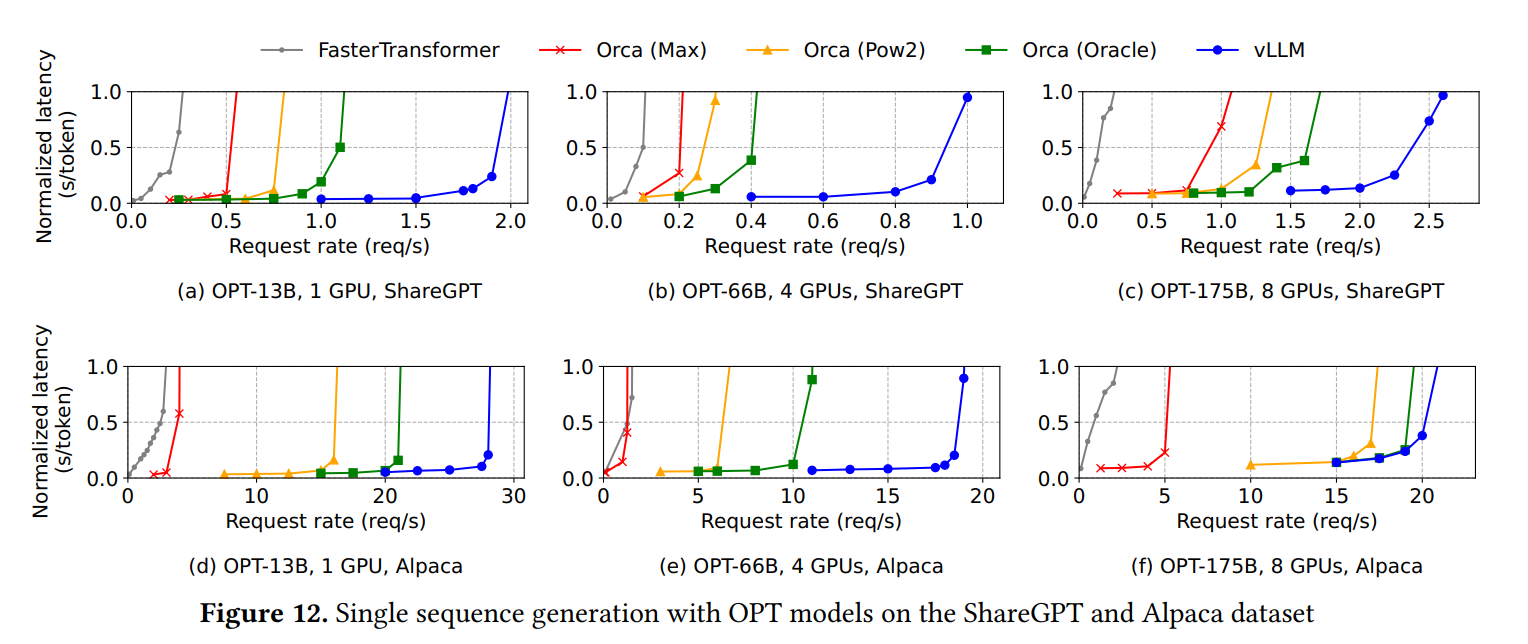
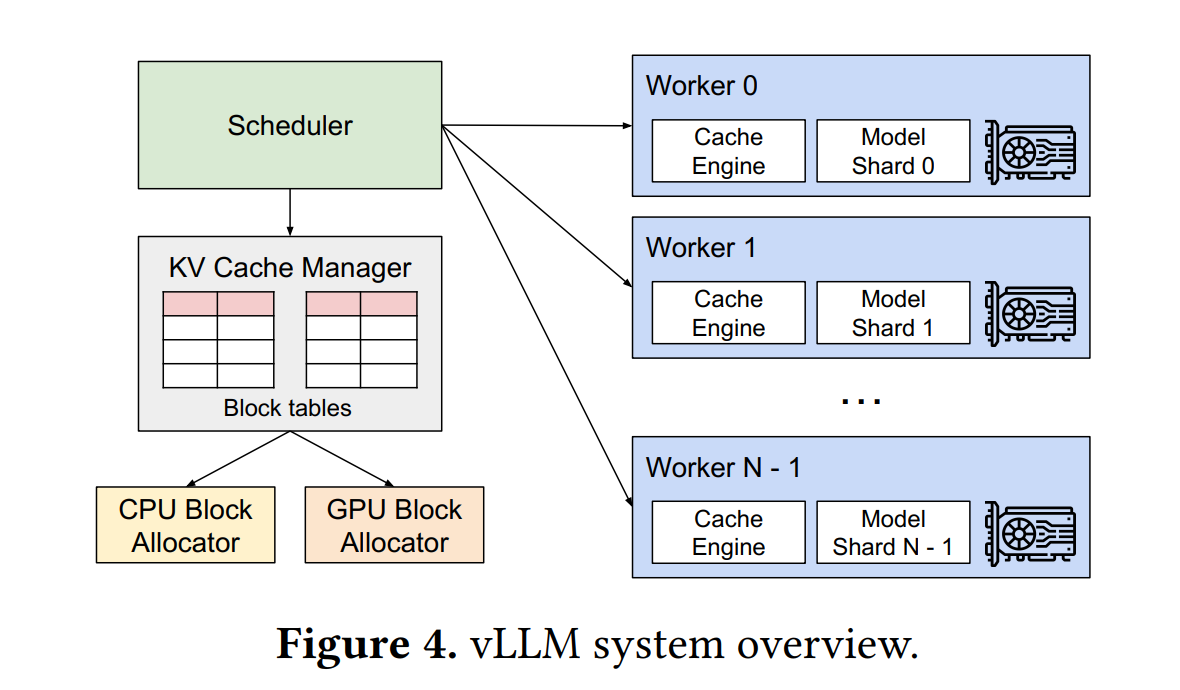
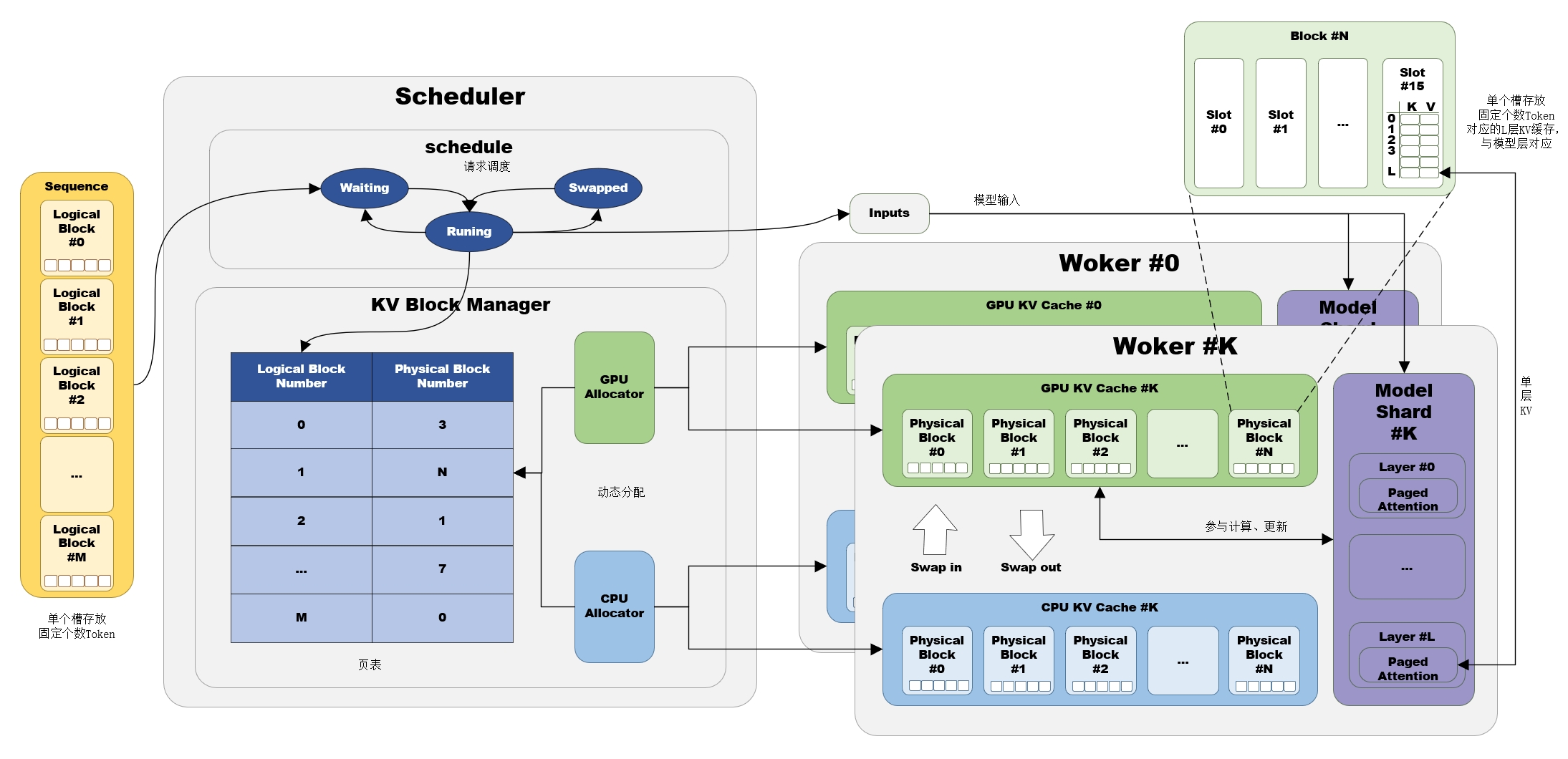
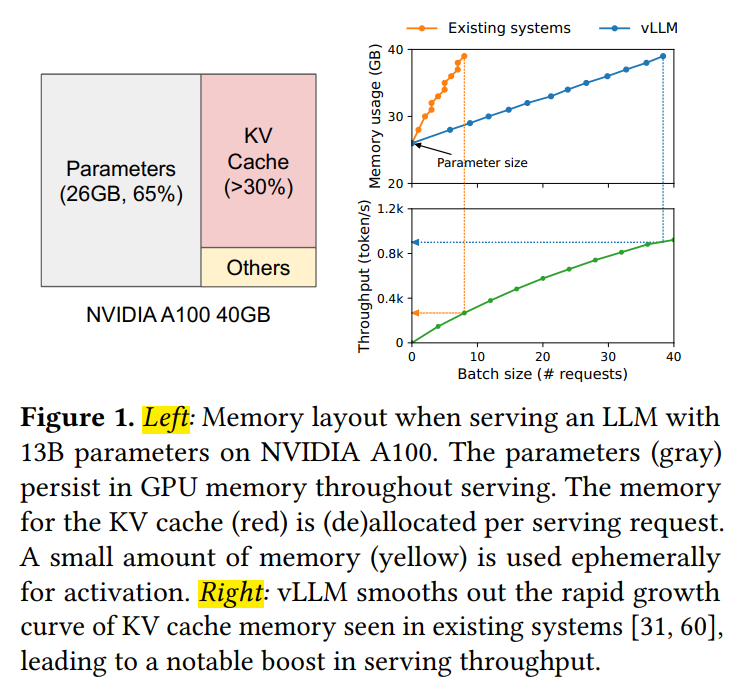
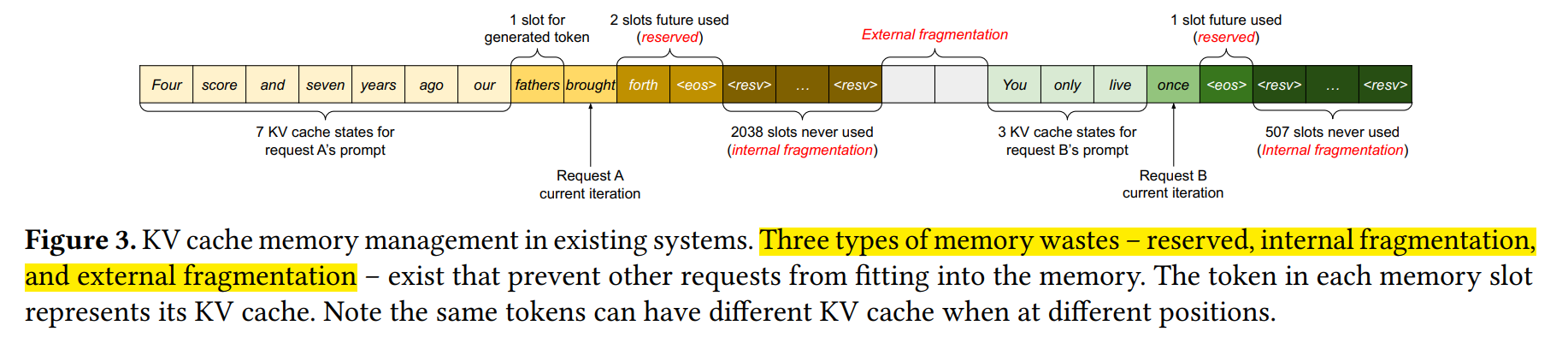
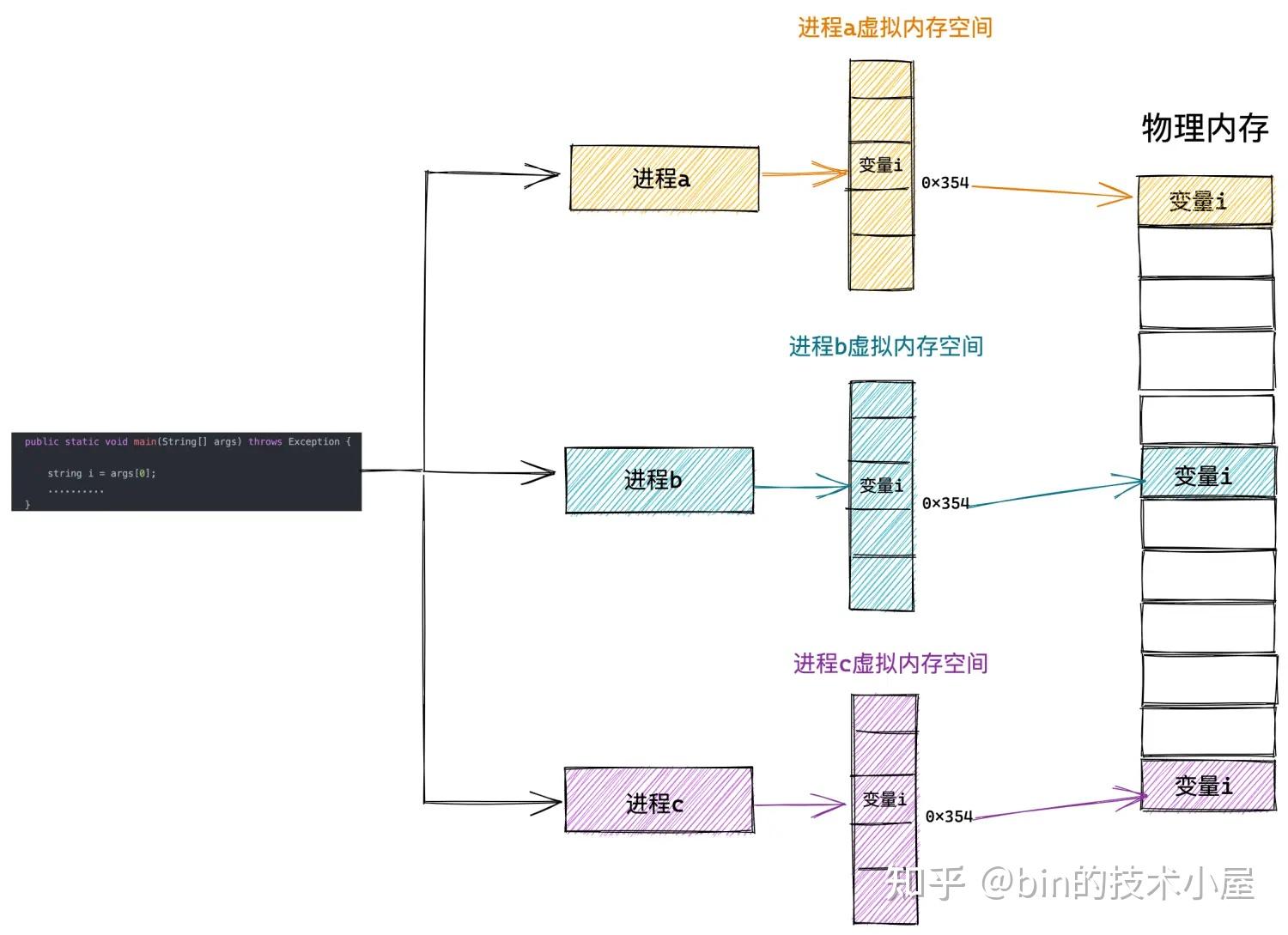
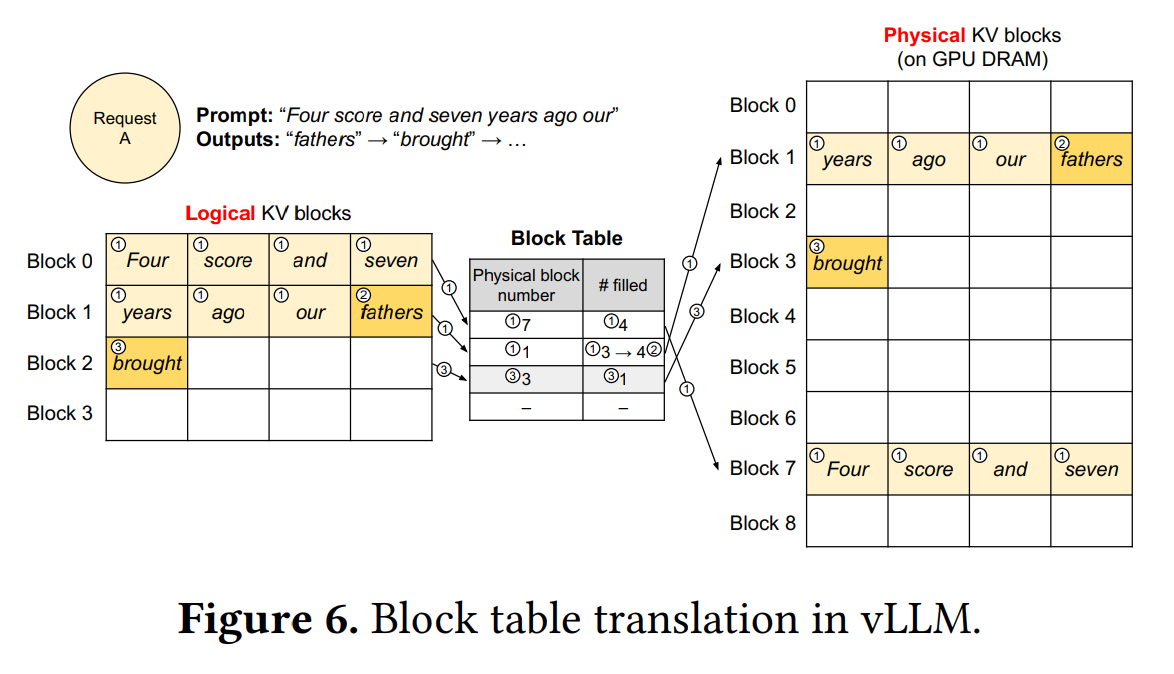
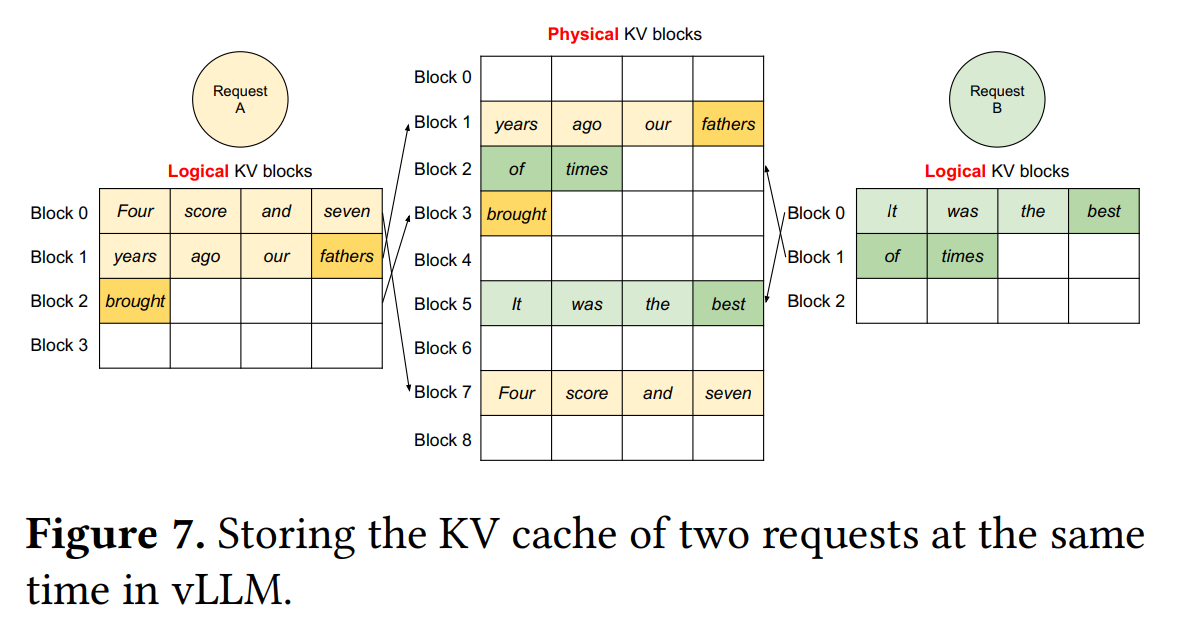
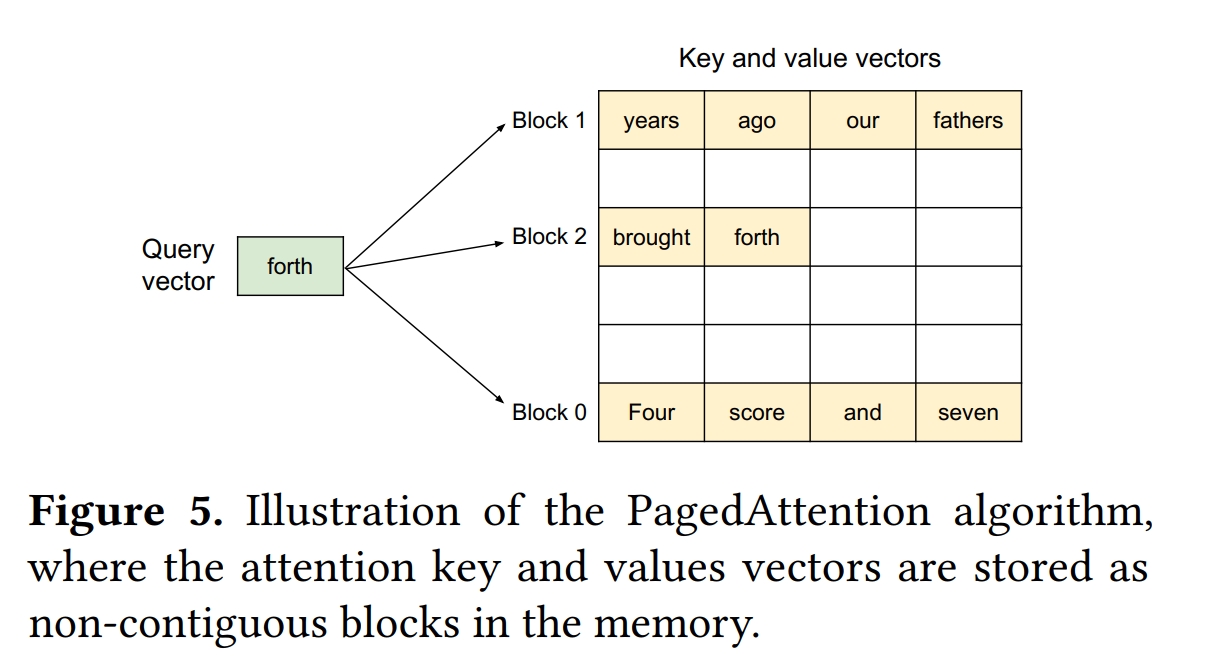
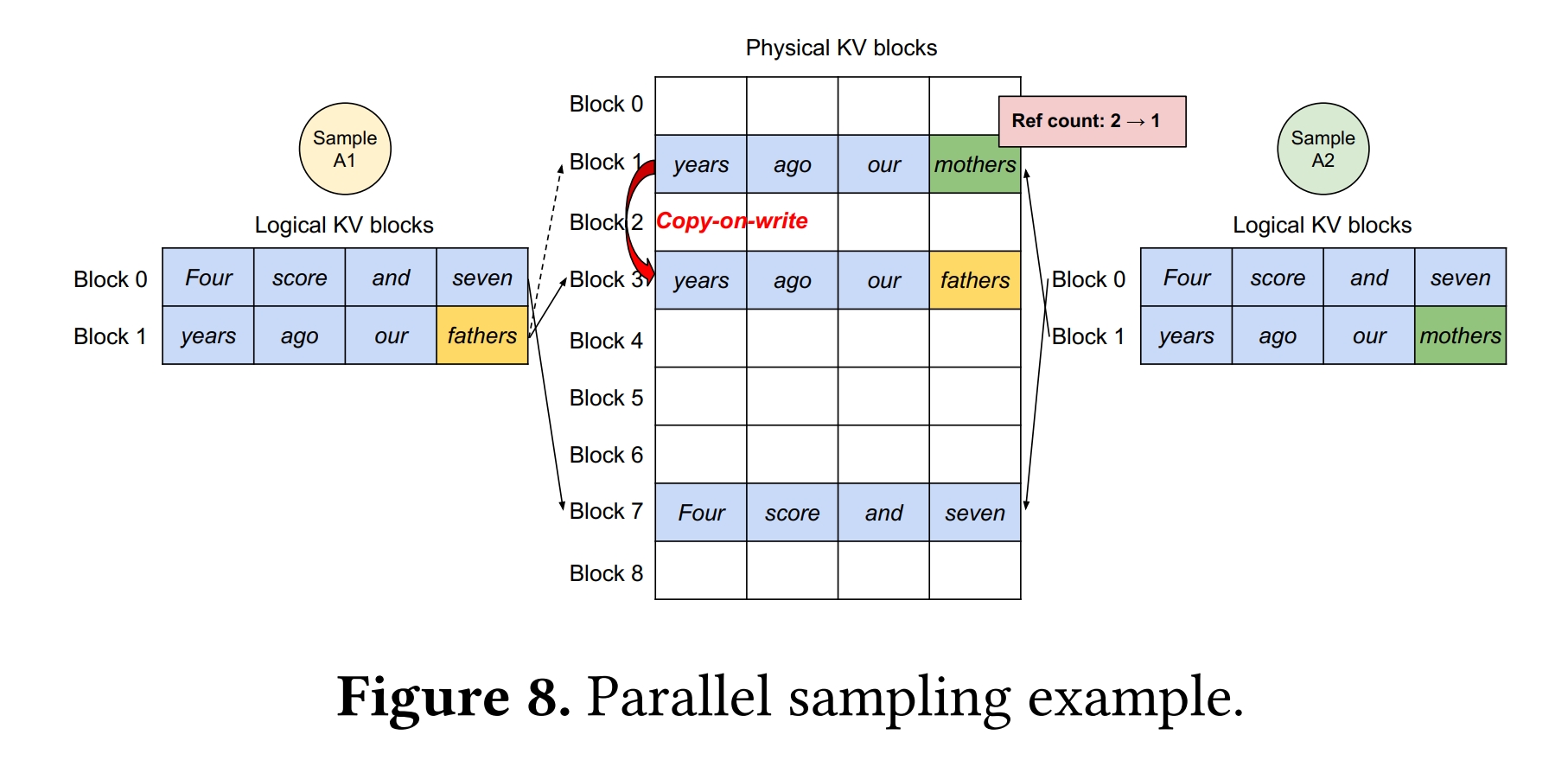
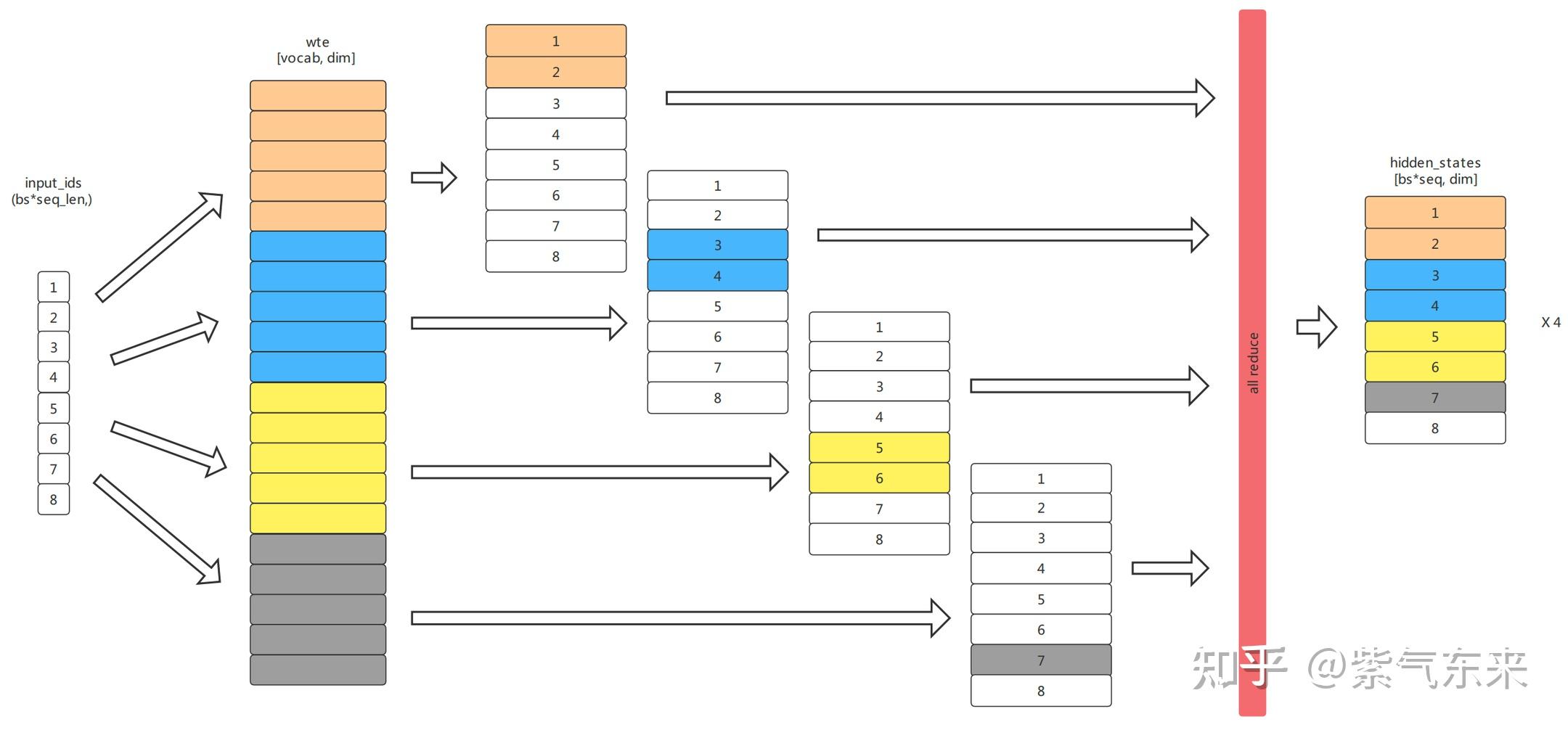
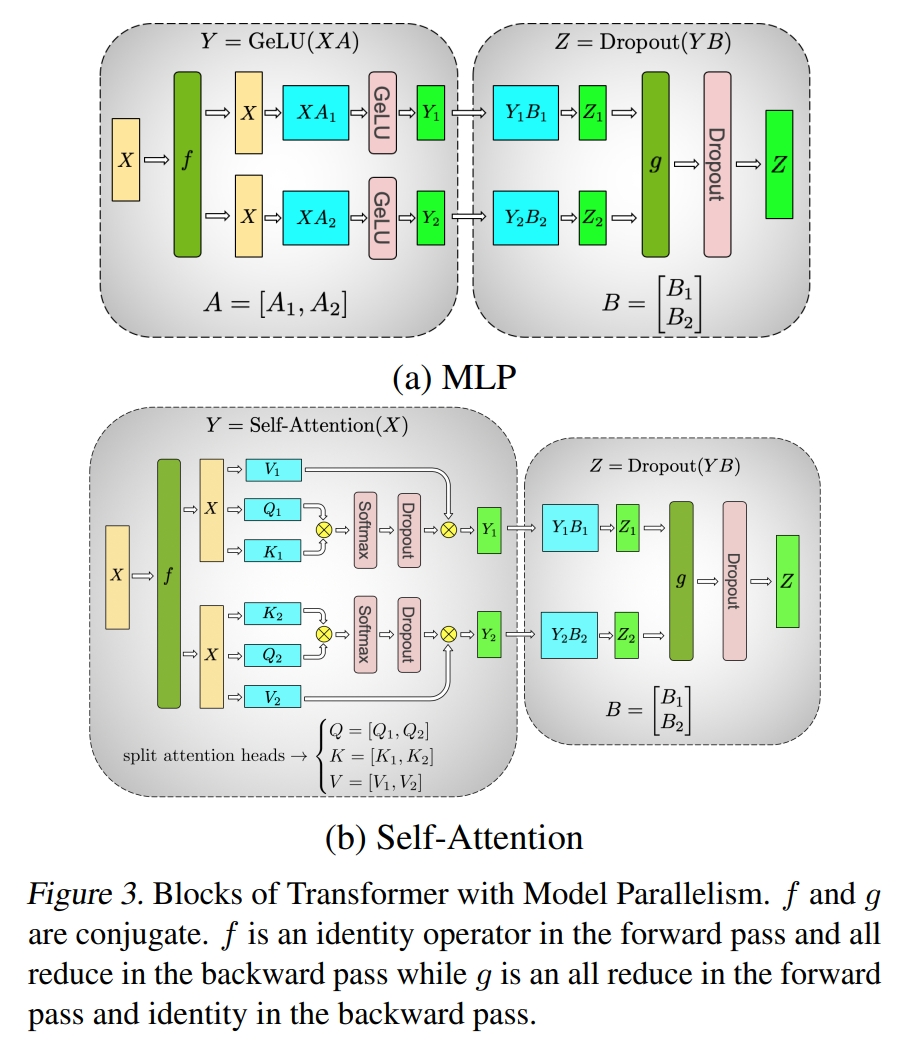
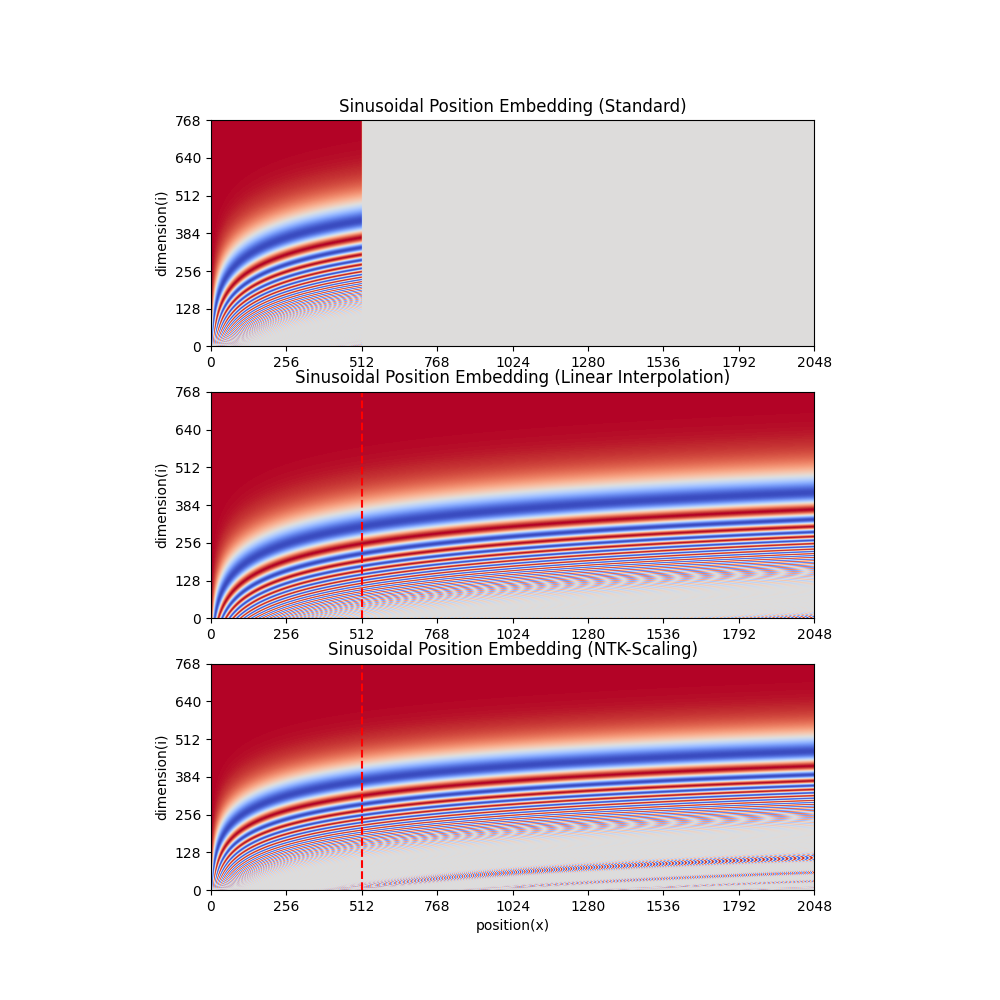
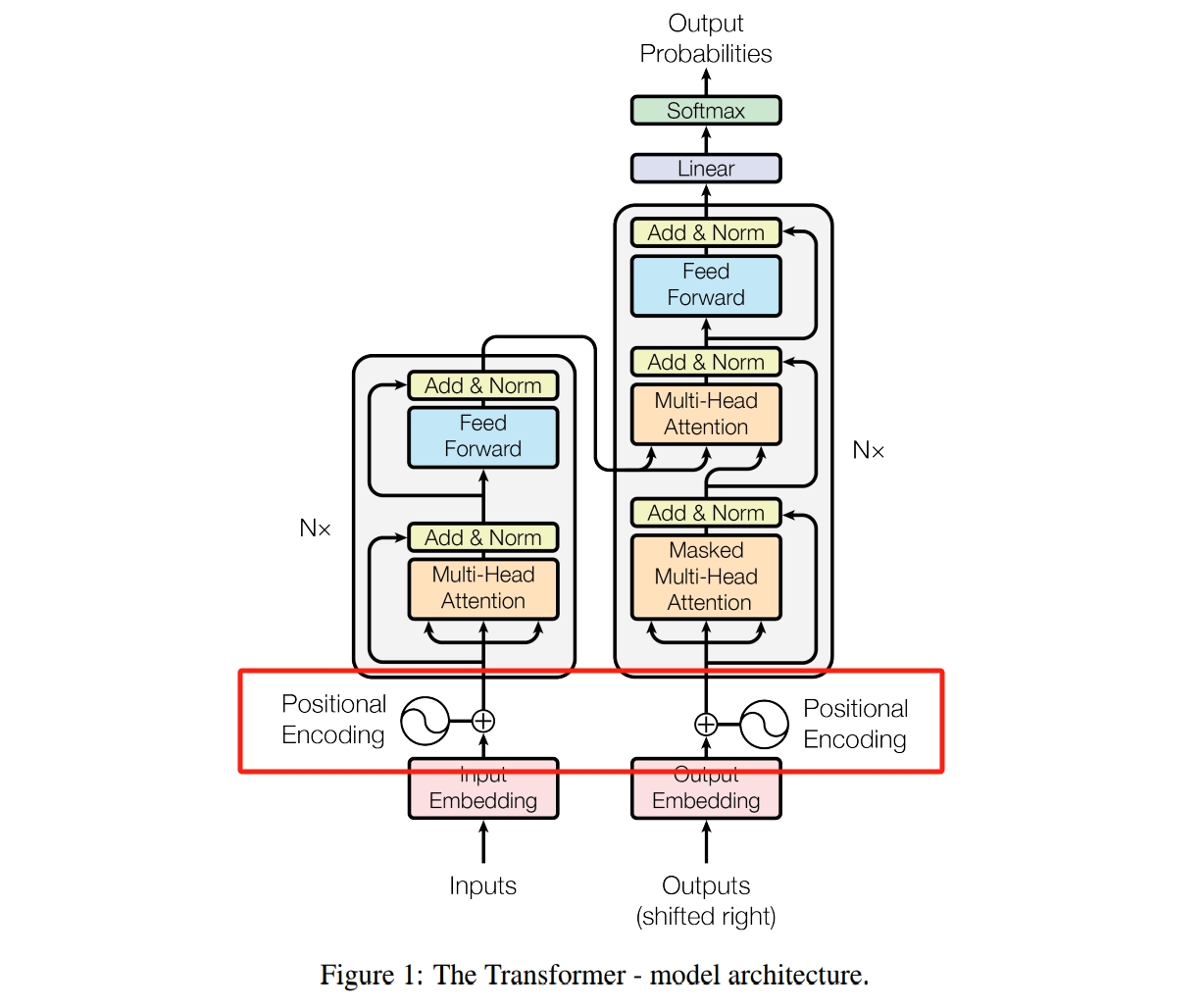
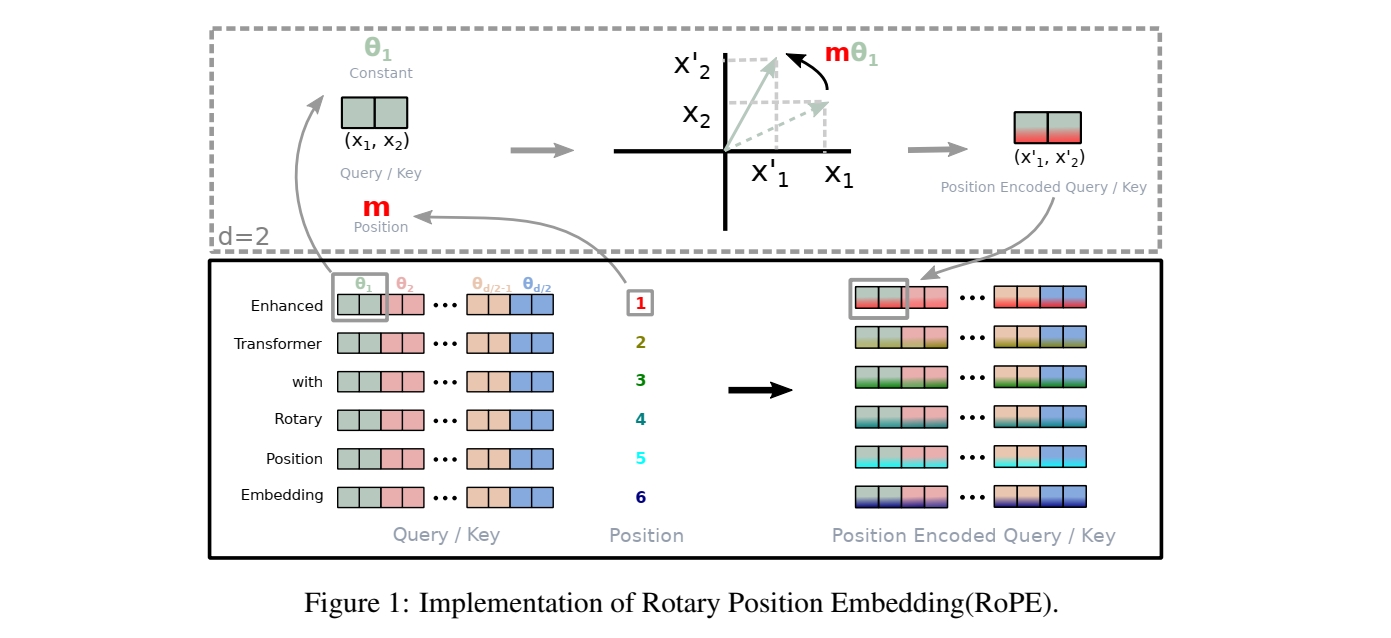
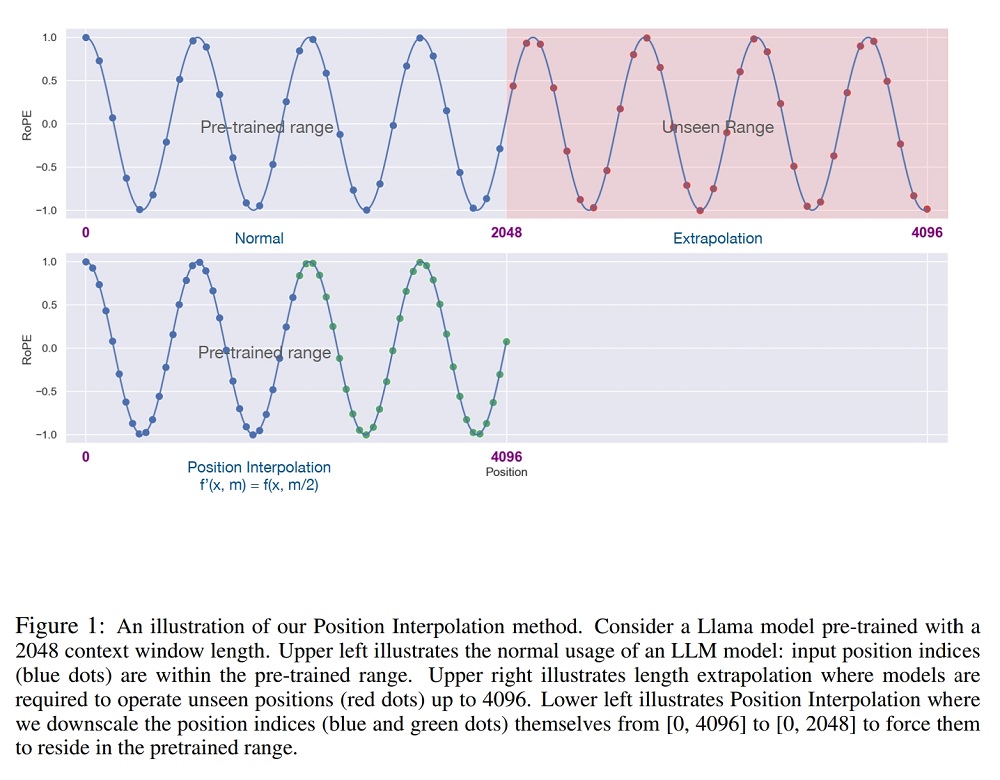
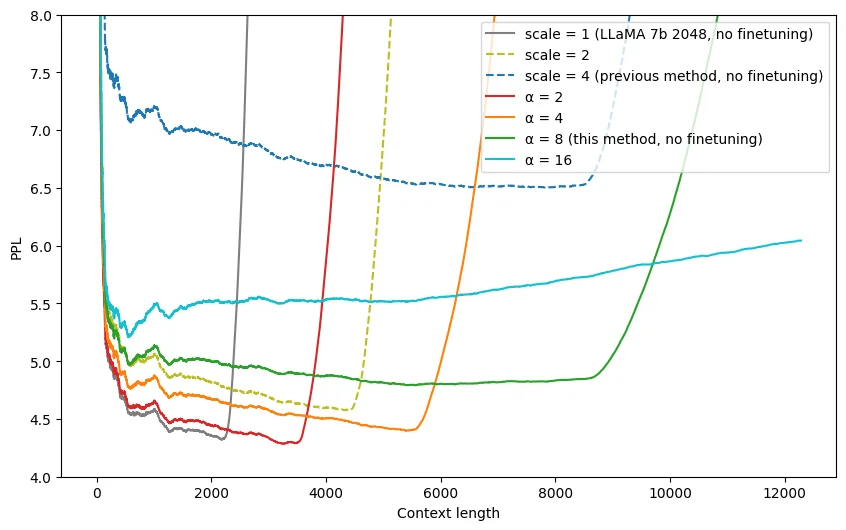
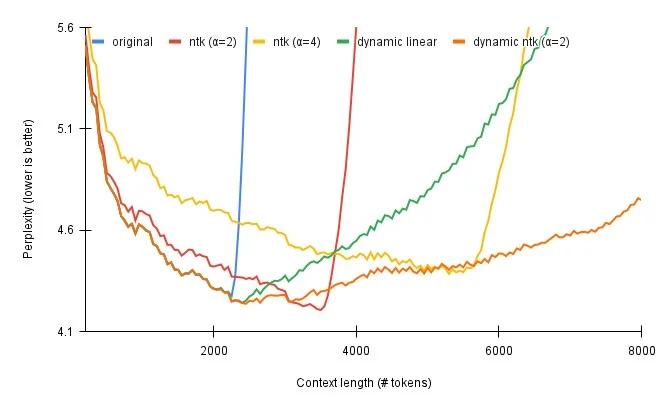
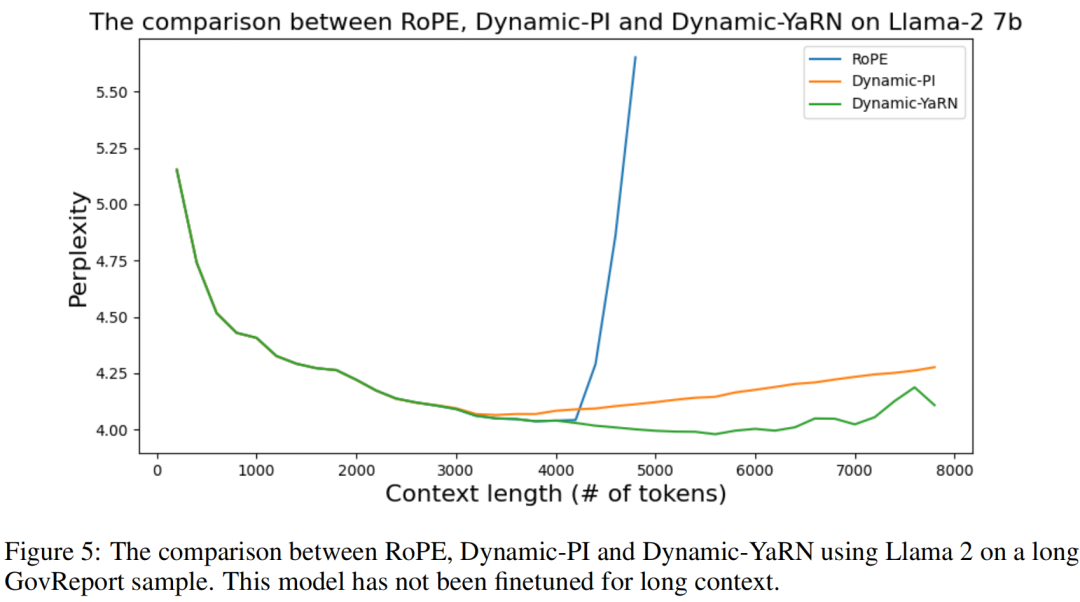











 ' +
+ '
' +
+ '