本篇博文主要展示每日从Arxiv论文网站获取的最新论文列表,以计算机视觉、自然语言处理、机器学习、人工智能等大方向进行划分。
+统计
+今日共更新326篇论文,其中:
+
+计算机视觉
+
+ 1. 标题:A Large-scale Dataset for Audio-Language Representation Learning
+ 编号:[1]
+ 链接:https://arxiv.org/abs/2309.11500
+ 作者:Luoyi Sun, Xuenan Xu, Mengyue Wu, Weidi Xie
+ 备注:
+ 关键词:made significant strides, developing powerful foundation, powerful foundation models, made significant, significant strides
+
+ 点击查看摘要
+ The AI community has made significant strides in developing powerful foundation models, driven by large-scale multimodal datasets. However, in the audio representation learning community, the present audio-language datasets suffer from limitations such as insufficient volume, simplistic content, and arduous collection procedures. To tackle these challenges, we present an innovative and automatic audio caption generation pipeline based on a series of public tools or APIs, and construct a large-scale, high-quality, audio-language dataset, named as Auto-ACD, comprising over 1.9M audio-text pairs. To demonstrate the effectiveness of the proposed dataset, we train popular models on our dataset and show performance improvement on various downstream tasks, namely, audio-language retrieval, audio captioning, environment classification. In addition, we establish a novel test set and provide a benchmark for audio-text tasks. The proposed dataset will be released at this https URL.
+
+
+
+ 2. 标题:DreamLLM: Synergistic Multimodal Comprehension and Creation
+ 编号:[2]
+ 链接:https://arxiv.org/abs/2309.11499
+ 作者:Runpei Dong, Chunrui Han, Yuang Peng, Zekun Qi, Zheng Ge, Jinrong Yang, Liang Zhao, Jianjian Sun, Hongyu Zhou, Haoran Wei, Xiangwen Kong, Xiangyu Zhang, Kaisheng Ma, Li Yi
+ 备注:see project page at this https URL
+ 关键词:Large Language Models, versatile Multimodal Large, Multimodal Large Language, Language Models, Large Language
+
+ 点击查看摘要
+ This paper presents DreamLLM, a learning framework that first achieves versatile Multimodal Large Language Models (MLLMs) empowered with frequently overlooked synergy between multimodal comprehension and creation. DreamLLM operates on two fundamental principles. The first focuses on the generative modeling of both language and image posteriors by direct sampling in the raw multimodal space. This approach circumvents the limitations and information loss inherent to external feature extractors like CLIP, and a more thorough multimodal understanding is obtained. Second, DreamLLM fosters the generation of raw, interleaved documents, modeling both text and image contents, along with unstructured layouts. This allows DreamLLM to learn all conditional, marginal, and joint multimodal distributions effectively. As a result, DreamLLM is the first MLLM capable of generating free-form interleaved content. Comprehensive experiments highlight DreamLLM's superior performance as a zero-shot multimodal generalist, reaping from the enhanced learning synergy.
+
+
+
+ 3. 标题:FreeU: Free Lunch in Diffusion U-Net
+ 编号:[3]
+ 链接:https://arxiv.org/abs/2309.11497
+ 作者:Chenyang Si, Ziqi Huang, Yuming Jiang, Ziwei Liu
+ 备注:Project page: this https URL
+ 关键词:free lunch, uncover the untapped, untapped potential, generation quality, U-Net skip connections
+
+ 点击查看摘要
+ In this paper, we uncover the untapped potential of diffusion U-Net, which serves as a "free lunch" that substantially improves the generation quality on the fly. We initially investigate the key contributions of the U-Net architecture to the denoising process and identify that its main backbone primarily contributes to denoising, whereas its skip connections mainly introduce high-frequency features into the decoder module, causing the network to overlook the backbone semantics. Capitalizing on this discovery, we propose a simple yet effective method-termed "FreeU" - that enhances generation quality without additional training or finetuning. Our key insight is to strategically re-weight the contributions sourced from the U-Net's skip connections and backbone feature maps, to leverage the strengths of both components of the U-Net architecture. Promising results on image and video generation tasks demonstrate that our FreeU can be readily integrated to existing diffusion models, e.g., Stable Diffusion, DreamBooth, ModelScope, Rerender and ReVersion, to improve the generation quality with only a few lines of code. All you need is to adjust two scaling factors during inference. Project page: https://chenyangsi.top/FreeU/.
+
+
+
+ 4. 标题:Budget-Aware Pruning: Handling Multiple Domains with Less Parameters
+ 编号:[15]
+ 链接:https://arxiv.org/abs/2309.11464
+ 作者:Samuel Felipe dos Santos, Rodrigo Berriel, Thiago Oliveira-Santos, Nicu Sebe, Jurandy Almeida
+ 备注:arXiv admin note: substantial text overlap with arXiv:2210.08101
+ 关键词:computer vision tasks, computer vision, single domain, single, domains
+
+ 点击查看摘要
+ Deep learning has achieved state-of-the-art performance on several computer vision tasks and domains. Nevertheless, it still has a high computational cost and demands a significant amount of parameters. Such requirements hinder the use in resource-limited environments and demand both software and hardware optimization. Another limitation is that deep models are usually specialized into a single domain or task, requiring them to learn and store new parameters for each new one. Multi-Domain Learning (MDL) attempts to solve this problem by learning a single model that is capable of performing well in multiple domains. Nevertheless, the models are usually larger than the baseline for a single domain. This work tackles both of these problems: our objective is to prune models capable of handling multiple domains according to a user-defined budget, making them more computationally affordable while keeping a similar classification performance. We achieve this by encouraging all domains to use a similar subset of filters from the baseline model, up to the amount defined by the user's budget. Then, filters that are not used by any domain are pruned from the network. The proposed approach innovates by better adapting to resource-limited devices while, to our knowledge, being the only work that handles multiple domains at test time with fewer parameters and lower computational complexity than the baseline model for a single domain.
+
+
+
+ 5. 标题:Weight Averaging Improves Knowledge Distillation under Domain Shift
+ 编号:[22]
+ 链接:https://arxiv.org/abs/2309.11446
+ 作者:Valeriy Berezovskiy, Nikita Morozov
+ 备注:ICCV 2023 Workshop on Out-of-Distribution Generalization in Computer Vision (OOD-CV)
+ 关键词:deep learning applications, powerful model compression, practical deep learning, model compression technique, compression technique broadly
+
+ 点击查看摘要
+ Knowledge distillation (KD) is a powerful model compression technique broadly used in practical deep learning applications. It is focused on training a small student network to mimic a larger teacher network. While it is widely known that KD can offer an improvement to student generalization in i.i.d setting, its performance under domain shift, i.e. the performance of student networks on data from domains unseen during training, has received little attention in the literature. In this paper we make a step towards bridging the research fields of knowledge distillation and domain generalization. We show that weight averaging techniques proposed in domain generalization literature, such as SWAD and SMA, also improve the performance of knowledge distillation under domain shift. In addition, we propose a simplistic weight averaging strategy that does not require evaluation on validation data during training and show that it performs on par with SWAD and SMA when applied to KD. We name our final distillation approach Weight-Averaged Knowledge Distillation (WAKD).
+
+
+
+ 6. 标题:SkeleTR: Towrads Skeleton-based Action Recognition in the Wild
+ 编号:[23]
+ 链接:https://arxiv.org/abs/2309.11445
+ 作者:Haodong Duan, Mingze Xu, Bing Shuai, Davide Modolo, Zhuowen Tu, Joseph Tighe, Alessandro Bergamo
+ 备注:ICCV 2023
+ 关键词:action, SkeleTR, action recognition, skeleton-based action, recognition
+
+ 点击查看摘要
+ We present SkeleTR, a new framework for skeleton-based action recognition. In contrast to prior work, which focuses mainly on controlled environments, we target more general scenarios that typically involve a variable number of people and various forms of interaction between people. SkeleTR works with a two-stage paradigm. It first models the intra-person skeleton dynamics for each skeleton sequence with graph convolutions, and then uses stacked Transformer encoders to capture person interactions that are important for action recognition in general scenarios. To mitigate the negative impact of inaccurate skeleton associations, SkeleTR takes relative short skeleton sequences as input and increases the number of sequences. As a unified solution, SkeleTR can be directly applied to multiple skeleton-based action tasks, including video-level action classification, instance-level action detection, and group-level activity recognition. It also enables transfer learning and joint training across different action tasks and datasets, which result in performance improvement. When evaluated on various skeleton-based action recognition benchmarks, SkeleTR achieves the state-of-the-art performance.
+
+
+
+ 7. 标题:Signature Activation: A Sparse Signal View for Holistic Saliency
+ 编号:[24]
+ 链接:https://arxiv.org/abs/2309.11443
+ 作者:Jose Roberto Tello Ayala, Akl C. Fahed, Weiwei Pan, Eugene V. Pomerantsev, Patrick T. Ellinor, Anthony Philippakis, Finale Doshi-Velez
+ 备注:
+ 关键词:Convolutional Neural Network, introduce Signature Activation, transparency and explainability, adoption of machine, machine learning
+
+ 点击查看摘要
+ The adoption of machine learning in healthcare calls for model transparency and explainability. In this work, we introduce Signature Activation, a saliency method that generates holistic and class-agnostic explanations for Convolutional Neural Network (CNN) outputs. Our method exploits the fact that certain kinds of medical images, such as angiograms, have clear foreground and background objects. We give theoretical explanation to justify our methods. We show the potential use of our method in clinical settings through evaluating its efficacy for aiding the detection of lesions in coronary angiograms.
+
+
+
+ 8. 标题:A Systematic Review of Few-Shot Learning in Medical Imaging
+ 编号:[27]
+ 链接:https://arxiv.org/abs/2309.11433
+ 作者:Eva Pachetti, Sara Colantonio
+ 备注:48 pages, 29 figures, 10 tables, submitted to Elsevier on 19 Sep 2023
+ 关键词:deep learning models, large-scale labelled datasets, Few-shot learning, annotated medical images, medical images limits
+
+ 点击查看摘要
+ The lack of annotated medical images limits the performance of deep learning models, which usually need large-scale labelled datasets. Few-shot learning techniques can reduce data scarcity issues and enhance medical image analysis, especially with meta-learning. This systematic review gives a comprehensive overview of few-shot learning in medical imaging. We searched the literature systematically and selected 80 relevant articles published from 2018 to 2023. We clustered the articles based on medical outcomes, such as tumour segmentation, disease classification, and image registration; anatomical structure investigated (i.e. heart, lung, etc.); and the meta-learning method used. For each cluster, we examined the papers' distributions and the results provided by the state-of-the-art. In addition, we identified a generic pipeline shared among all the studies. The review shows that few-shot learning can overcome data scarcity in most outcomes and that meta-learning is a popular choice to perform few-shot learning because it can adapt to new tasks with few labelled samples. In addition, following meta-learning, supervised learning and semi-supervised learning stand out as the predominant techniques employed to tackle few-shot learning challenges in medical imaging and also best performing. Lastly, we observed that the primary application areas predominantly encompass cardiac, pulmonary, and abdominal domains. This systematic review aims to inspire further research to improve medical image analysis and patient care.
+
+
+
+ 9. 标题:Kosmos-2.5: A Multimodal Literate Model
+ 编号:[30]
+ 链接:https://arxiv.org/abs/2309.11419
+ 作者:Tengchao Lv, Yupan Huang, Jingye Chen, Lei Cui, Shuming Ma, Yaoyao Chang, Shaohan Huang, Wenhui Wang, Li Dong, Weiyao Luo, Shaoxiang Wu, Guoxin Wang, Cha Zhang, Furu Wei
+ 备注:
+ 关键词:machine reading, text-intensive images, text, large-scale text-intensive images, multimodal literate
+
+ 点击查看摘要
+ We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.
+
+
+
+ 10. 标题:CNNs for JPEGs: A Study in Computational Cost
+ 编号:[31]
+ 链接:https://arxiv.org/abs/2309.11417
+ 作者:Samuel Felipe dos Santos, Nicu Sebe, Jurandy Almeida
+ 备注:
+ 关键词:computer vision tasks, achieved astonishing advances, Convolutional neural networks, Convolutional neural, past decade
+
+ 点击查看摘要
+ Convolutional neural networks (CNNs) have achieved astonishing advances over the past decade, defining state-of-the-art in several computer vision tasks. CNNs are capable of learning robust representations of the data directly from the RGB pixels. However, most image data are usually available in compressed format, from which the JPEG is the most widely used due to transmission and storage purposes demanding a preliminary decoding process that have a high computational load and memory usage. For this reason, deep learning methods capable of learning directly from the compressed domain have been gaining attention in recent years. Those methods usually extract a frequency domain representation of the image, like DCT, by a partial decoding, and then make adaptation to typical CNNs architectures to work with them. One limitation of these current works is that, in order to accommodate the frequency domain data, the modifications made to the original model increase significantly their amount of parameters and computational complexity. On one hand, the methods have faster preprocessing, since the cost of fully decoding the images is avoided, but on the other hand, the cost of passing the images though the model is increased, mitigating the possible upside of accelerating the method. In this paper, we propose a further study of the computational cost of deep models designed for the frequency domain, evaluating the cost of decoding and passing the images through the network. We also propose handcrafted and data-driven techniques for reducing the computational complexity and the number of parameters for these models in order to keep them similar to their RGB baselines, leading to efficient models with a better trade off between computational cost and accuracy.
+
+
+
+ 11. 标题:Enhancing motion trajectory segmentation of rigid bodies using a novel screw-based trajectory-shape representation
+ 编号:[33]
+ 链接:https://arxiv.org/abs/2309.11413
+ 作者:Arno Verduyn, Maxim Vochten, Joris De Schutter
+ 备注:This work has been submitted to the IEEE International Conference on Robotics and Automation (ICRA) for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible
+ 关键词:meaningful consecutive sub-trajectories, refers to dividing, Trajectory, segmentation, Trajectory segmentation refers
+
+ 点击查看摘要
+ Trajectory segmentation refers to dividing a trajectory into meaningful consecutive sub-trajectories. This paper focuses on trajectory segmentation for 3D rigid-body motions. Most segmentation approaches in the literature represent the body's trajectory as a point trajectory, considering only its translation and neglecting its rotation. We propose a novel trajectory representation for rigid-body motions that incorporates both translation and rotation, and additionally exhibits several invariant properties. This representation consists of a geometric progress rate and a third-order trajectory-shape descriptor. Concepts from screw theory were used to make this representation time-invariant and also invariant to the choice of body reference point. This new representation is validated for a self-supervised segmentation approach, both in simulation and using real recordings of human-demonstrated pouring motions. The results show a more robust detection of consecutive submotions with distinct features and a more consistent segmentation compared to conventional representations. We believe that other existing segmentation methods may benefit from using this trajectory representation to improve their invariance.
+
+
+
+ 12. 标题:Discuss Before Moving: Visual Language Navigation via Multi-expert Discussions
+ 编号:[42]
+ 链接:https://arxiv.org/abs/2309.11382
+ 作者:Yuxing Long, Xiaoqi Li, Wenzhe Cai, Hao Dong
+ 备注:Submitted to ICRA 2024
+ 关键词:skills encompassing understanding, embodied task demanding, demanding a wide, wide range, range of skills
+
+ 点击查看摘要
+ Visual language navigation (VLN) is an embodied task demanding a wide range of skills encompassing understanding, perception, and planning. For such a multifaceted challenge, previous VLN methods totally rely on one model's own thinking to make predictions within one round. However, existing models, even the most advanced large language model GPT4, still struggle with dealing with multiple tasks by single-round self-thinking. In this work, drawing inspiration from the expert consultation meeting, we introduce a novel zero-shot VLN framework. Within this framework, large models possessing distinct abilities are served as domain experts. Our proposed navigation agent, namely DiscussNav, can actively discuss with these experts to collect essential information before moving at every step. These discussions cover critical navigation subtasks like instruction understanding, environment perception, and completion estimation. Through comprehensive experiments, we demonstrate that discussions with domain experts can effectively facilitate navigation by perceiving instruction-relevant information, correcting inadvertent errors, and sifting through in-consistent movement decisions. The performances on the representative VLN task R2R show that our method surpasses the leading zero-shot VLN model by a large margin on all metrics. Additionally, real-robot experiments display the obvious advantages of our method over single-round self-thinking.
+
+
+
+ 13. 标题:3D Face Reconstruction: the Road to Forensics
+ 编号:[52]
+ 链接:https://arxiv.org/abs/2309.11357
+ 作者:Simone Maurizio La Cava, Giulia Orrù, Martin Drahansky, Gian Luca Marcialis, Fabio Roli
+ 备注:The manuscript has been accepted for publication in ACM Computing Surveys. arXiv admin note: text overlap with arXiv:2303.11164
+ 关键词:face reconstruction algorithms, face reconstruction, entertainment sector, advantageous features, plastic surgery
+
+ 点击查看摘要
+ 3D face reconstruction algorithms from images and videos are applied to many fields, from plastic surgery to the entertainment sector, thanks to their advantageous features. However, when looking at forensic applications, 3D face reconstruction must observe strict requirements that still make its possible role in bringing evidence to a lawsuit unclear. An extensive investigation of the constraints, potential, and limits of its application in forensics is still missing. Shedding some light on this matter is the goal of the present survey, which starts by clarifying the relation between forensic applications and biometrics, with a focus on face recognition. Therefore, it provides an analysis of the achievements of 3D face reconstruction algorithms from surveillance videos and mugshot images and discusses the current obstacles that separate 3D face reconstruction from an active role in forensic applications. Finally, it examines the underlying data sets, with their advantages and limitations, while proposing alternatives that could substitute or complement them.
+
+
+
+ 14. 标题:Self-supervised learning unveils change in urban housing from street-level images
+ 编号:[54]
+ 链接:https://arxiv.org/abs/2309.11354
+ 作者:Steven Stalder, Michele Volpi, Nicolas Büttner, Stephen Law, Kenneth Harttgen, Esra Suel
+ 备注:16 pages, 5 figures
+ 关键词:world face, shortage of affordable, affordable and decent, critical shortage, decent housing
+
+ 点击查看摘要
+ Cities around the world face a critical shortage of affordable and decent housing. Despite its critical importance for policy, our ability to effectively monitor and track progress in urban housing is limited. Deep learning-based computer vision methods applied to street-level images have been successful in the measurement of socioeconomic and environmental inequalities but did not fully utilize temporal images to track urban change as time-varying labels are often unavailable. We used self-supervised methods to measure change in London using 15 million street images taken between 2008 and 2021. Our novel adaptation of Barlow Twins, Street2Vec, embeds urban structure while being invariant to seasonal and daily changes without manual annotations. It outperformed generic embeddings, successfully identified point-level change in London's housing supply from street-level images, and distinguished between major and minor change. This capability can provide timely information for urban planning and policy decisions toward more liveable, equitable, and sustainable cities.
+
+
+
+ 15. 标题:You can have your ensemble and run it too -- Deep Ensembles Spread Over Time
+ 编号:[63]
+ 链接:https://arxiv.org/abs/2309.11333
+ 作者:Isak Meding, Alexander Bodin, Adam Tonderski, Joakim Johnander, Christoffer Petersson, Lennart Svensson
+ 备注:
+ 关键词:rival Bayesian networks, neural networks yield, Bayesian networks, rival Bayesian, deep neural networks
+
+ 点击查看摘要
+ Ensembles of independently trained deep neural networks yield uncertainty estimates that rival Bayesian networks in performance. They also offer sizable improvements in terms of predictive performance over single models. However, deep ensembles are not commonly used in environments with limited computational budget -- such as autonomous driving -- since the complexity grows linearly with the number of ensemble members. An important observation that can be made for robotics applications, such as autonomous driving, is that data is typically sequential. For instance, when an object is to be recognized, an autonomous vehicle typically observes a sequence of images, rather than a single image. This raises the question, could the deep ensemble be spread over time?
+In this work, we propose and analyze Deep Ensembles Spread Over Time (DESOT). The idea is to apply only a single ensemble member to each data point in the sequence, and fuse the predictions over a sequence of data points. We implement and experiment with DESOT for traffic sign classification, where sequences of tracked image patches are to be classified. We find that DESOT obtains the benefits of deep ensembles, in terms of predictive and uncertainty estimation performance, while avoiding the added computational cost. Moreover, DESOT is simple to implement and does not require sequences during training. Finally, we find that DESOT, like deep ensembles, outperform single models for out-of-distribution detection.
+
+
+
+ 16. 标题:Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism
+ 编号:[65]
+ 链接:https://arxiv.org/abs/2309.11331
+ 作者:Chengcheng Wang, Wei He, Ying Nie, Jianyuan Guo, Chuanjian Liu, Kai Han, Yunhe Wang
+ 备注:
+ 关键词:real-time object detection, Path Aggregation Network, Feature Pyramid Network, past years, object detection
+
+ 点击查看摘要
+ In the past years, YOLO-series models have emerged as the leading approaches in the area of real-time object detection. Many studies pushed up the baseline to a higher level by modifying the architecture, augmenting data and designing new losses. However, we find previous models still suffer from information fusion problem, although Feature Pyramid Network (FPN) and Path Aggregation Network (PANet) have alleviated this. Therefore, this study provides an advanced Gatherand-Distribute mechanism (GD) mechanism, which is realized with convolution and self-attention operations. This new designed model named as Gold-YOLO, which boosts the multi-scale feature fusion capabilities and achieves an ideal balance between latency and accuracy across all model scales. Additionally, we implement MAE-style pretraining in the YOLO-series for the first time, allowing YOLOseries models could be to benefit from unsupervised pretraining. Gold-YOLO-N attains an outstanding 39.9% AP on the COCO val2017 datasets and 1030 FPS on a T4 GPU, which outperforms the previous SOTA model YOLOv6-3.0-N with similar FPS by +2.4%. The PyTorch code is available at this https URL, and the MindSpore code is available at this https URL.
+
+
+
+ 17. 标题:How to turn your camera into a perfect pinhole model
+ 编号:[66]
+ 链接:https://arxiv.org/abs/2309.11326
+ 作者:Ivan De Boi, Stuti Pathak, Marina Oliveira, Rudi Penne
+ 备注:15 pages, 3 figures, conference CIARP
+ 关键词:computer vision applications, computer vision, Gaussian processes, method, Camera
+
+ 点击查看摘要
+ Camera calibration is a first and fundamental step in various computer vision applications. Despite being an active field of research, Zhang's method remains widely used for camera calibration due to its implementation in popular toolboxes. However, this method initially assumes a pinhole model with oversimplified distortion models. In this work, we propose a novel approach that involves a pre-processing step to remove distortions from images by means of Gaussian processes. Our method does not need to assume any distortion model and can be applied to severely warped images, even in the case of multiple distortion sources, e.g., a fisheye image of a curved mirror reflection. The Gaussian processes capture all distortions and camera imperfections, resulting in virtual images as though taken by an ideal pinhole camera with square pixels. Furthermore, this ideal GP-camera only needs one image of a square grid calibration pattern. This model allows for a serious upgrade of many algorithms and applications that are designed in a pure projective geometry setting but with a performance that is very sensitive to nonlinear lens distortions. We demonstrate the effectiveness of our method by simplifying Zhang's calibration method, reducing the number of parameters and getting rid of the distortion parameters and iterative optimization. We validate by means of synthetic data and real world images. The contributions of this work include the construction of a virtual ideal pinhole camera using Gaussian processes, a simplified calibration method and lens distortion removal.
+
+
+
+ 18. 标题:Face Aging via Diffusion-based Editing
+ 编号:[69]
+ 链接:https://arxiv.org/abs/2309.11321
+ 作者:Xiangyi Chen, Stéphane Lathuilière
+ 备注:accepted at BMVC 2023
+ 关键词:future facial images, generating past, past or future, incorporating age-related, future facial
+
+ 点击查看摘要
+ In this paper, we address the problem of face aging: generating past or future facial images by incorporating age-related changes to the given face. Previous aging methods rely solely on human facial image datasets and are thus constrained by their inherent scale and bias. This restricts their application to a limited generatable age range and the inability to handle large age gaps. We propose FADING, a novel approach to address Face Aging via DIffusion-based editiNG. We go beyond existing methods by leveraging the rich prior of large-scale language-image diffusion models. First, we specialize a pre-trained diffusion model for the task of face age editing by using an age-aware fine-tuning scheme. Next, we invert the input image to latent noise and obtain optimized null text embeddings. Finally, we perform text-guided local age editing via attention control. The quantitative and qualitative analyses demonstrate that our method outperforms existing approaches with respect to aging accuracy, attribute preservation, and aging quality.
+
+
+
+ 19. 标题:Uncovering the effects of model initialization on deep model generalization: A study with adult and pediatric Chest X-ray images
+ 编号:[71]
+ 链接:https://arxiv.org/abs/2309.11318
+ 作者:Sivaramakrishnan Rajaraman, Ghada Zamzmi, Feng Yang, Zhaohui Liang, Zhiyun Xue, Sameer Antani
+ 备注:40 pages, 8 tables, 7 figures, 3 supplementary figures and 4 supplementary tables
+ 关键词:computer vision applications, medical computer vision, vision applications, vital for improving, computer vision
+
+ 点击查看摘要
+ Model initialization techniques are vital for improving the performance and reliability of deep learning models in medical computer vision applications. While much literature exists on non-medical images, the impacts on medical images, particularly chest X-rays (CXRs) are less understood. Addressing this gap, our study explores three deep model initialization techniques: Cold-start, Warm-start, and Shrink and Perturb start, focusing on adult and pediatric populations. We specifically focus on scenarios with periodically arriving data for training, thereby embracing the real-world scenarios of ongoing data influx and the need for model updates. We evaluate these models for generalizability against external adult and pediatric CXR datasets. We also propose novel ensemble methods: F-score-weighted Sequential Least-Squares Quadratic Programming (F-SLSQP) and Attention-Guided Ensembles with Learnable Fuzzy Softmax to aggregate weight parameters from multiple models to capitalize on their collective knowledge and complementary representations. We perform statistical significance tests with 95% confidence intervals and p-values to analyze model performance. Our evaluations indicate models initialized with ImageNet-pre-trained weights demonstrate superior generalizability over randomly initialized counterparts, contradicting some findings for non-medical images. Notably, ImageNet-pretrained models exhibit consistent performance during internal and external testing across different training scenarios. Weight-level ensembles of these models show significantly higher recall (p<0.05) during testing compared to individual models. thus, our study accentuates the benefits of imagenet-pretrained weight initialization, especially when used with weight-level ensembles, for creating robust and generalizable deep learning solutions.< p>
+
+
+
+ 20. 标题:FaceDiffuser: Speech-Driven 3D Facial Animation Synthesis Using Diffusion
+ 编号:[77]
+ 链接:https://arxiv.org/abs/2309.11306
+ 作者:Stefan Stan, Kazi Injamamul Haque, Zerrin Yumak
+ 备注:Pre-print of the paper accepted at ACM SIGGRAPH MIG 2023
+ 关键词:industry and research, facial animation synthesis, facial animation, facial, based
+
+ 点击查看摘要
+ Speech-driven 3D facial animation synthesis has been a challenging task both in industry and research. Recent methods mostly focus on deterministic deep learning methods meaning that given a speech input, the output is always the same. However, in reality, the non-verbal facial cues that reside throughout the face are non-deterministic in nature. In addition, majority of the approaches focus on 3D vertex based datasets and methods that are compatible with existing facial animation pipelines with rigged characters is scarce. To eliminate these issues, we present FaceDiffuser, a non-deterministic deep learning model to generate speech-driven facial animations that is trained with both 3D vertex and blendshape based datasets. Our method is based on the diffusion technique and uses the pre-trained large speech representation model HuBERT to encode the audio input. To the best of our knowledge, we are the first to employ the diffusion method for the task of speech-driven 3D facial animation synthesis. We have run extensive objective and subjective analyses and show that our approach achieves better or comparable results in comparison to the state-of-the-art methods. We also introduce a new in-house dataset that is based on a blendshape based rigged character. We recommend watching the accompanying supplementary video. The code and the dataset will be publicly available.
+
+
+
+ 21. 标题:Generalizing Across Domains in Diabetic Retinopathy via Variational Autoencoders
+ 编号:[79]
+ 链接:https://arxiv.org/abs/2309.11301
+ 作者:Sharon Chokuwa, Muhammad H. Khan
+ 备注:Accepted at MICCAI 2023 1st International Workshop on Foundation Models for General Medical AI (MedAGI)
+ 关键词:Diabetic Retinopathy, adeptly classify retinal, previously unseen domains, classify retinal images, patient demographics
+
+ 点击查看摘要
+ Domain generalization for Diabetic Retinopathy (DR) classification allows a model to adeptly classify retinal images from previously unseen domains with various imaging conditions and patient demographics, thereby enhancing its applicability in a wide range of clinical environments. In this study, we explore the inherent capacity of variational autoencoders to disentangle the latent space of fundus images, with an aim to obtain a more robust and adaptable domain-invariant representation that effectively tackles the domain shift encountered in DR datasets. Despite the simplicity of our approach, we explore the efficacy of this classical method and demonstrate its ability to outperform contemporary state-of-the-art approaches for this task using publicly available datasets. Our findings challenge the prevailing assumption that highly sophisticated methods for DR classification are inherently superior for domain generalization. This highlights the importance of considering simple methods and adapting them to the challenging task of generalizing medical images, rather than solely relying on advanced techniques.
+
+
+
+ 22. 标题:Language-driven Object Fusion into Neural Radiance Fields with Pose-Conditioned Dataset Updates
+ 编号:[89]
+ 链接:https://arxiv.org/abs/2309.11281
+ 作者:Ka Chun Shum, Jaeyeon Kim, Binh-Son Hua, Duc Thanh Nguyen, Sai-Kit Yeung
+ 备注:
+ 关键词:radiance field, Neural radiance, Neural radiance field, high-quality multi-view consistent, emerging rendering method
+
+ 点击查看摘要
+ Neural radiance field is an emerging rendering method that generates high-quality multi-view consistent images from a neural scene representation and volume rendering. Although neural radiance field-based techniques are robust for scene reconstruction, their ability to add or remove objects remains limited. This paper proposes a new language-driven approach for object manipulation with neural radiance fields through dataset updates. Specifically, to insert a new foreground object represented by a set of multi-view images into a background radiance field, we use a text-to-image diffusion model to learn and generate combined images that fuse the object of interest into the given background across views. These combined images are then used for refining the background radiance field so that we can render view-consistent images containing both the object and the background. To ensure view consistency, we propose a dataset updates strategy that prioritizes radiance field training with camera views close to the already-trained views prior to propagating the training to remaining views. We show that under the same dataset updates strategy, we can easily adapt our method for object insertion using data from text-to-3D models as well as object removal. Experimental results show that our method generates photorealistic images of the edited scenes, and outperforms state-of-the-art methods in 3D reconstruction and neural radiance field blending.
+
+
+
+ 23. 标题:Towards Real-Time Neural Video Codec for Cross-Platform Application Using Calibration Information
+ 编号:[91]
+ 链接:https://arxiv.org/abs/2309.11276
+ 作者:Kuan Tian, Yonghang Guan, Jinxi Xiang, Jun Zhang, Xiao Han, Wei Yang
+ 备注:14 pages
+ 关键词:sophisticated traditional codecs, decoding, sophisticated traditional, encoding, cross-platform neural video
+
+ 点击查看摘要
+ The state-of-the-art neural video codecs have outperformed the most sophisticated traditional codecs in terms of RD performance in certain cases. However, utilizing them for practical applications is still challenging for two major reasons. 1) Cross-platform computational errors resulting from floating point operations can lead to inaccurate decoding of the bitstream. 2) The high computational complexity of the encoding and decoding process poses a challenge in achieving real-time performance. In this paper, we propose a real-time cross-platform neural video codec, which is capable of efficiently decoding of 720P video bitstream from other encoding platforms on a consumer-grade GPU. First, to solve the problem of inconsistency of codec caused by the uncertainty of floating point calculations across platforms, we design a calibration transmitting system to guarantee the consistent quantization of entropy parameters between the encoding and decoding stages. The parameters that may have transboundary quantization between encoding and decoding are identified in the encoding stage, and their coordinates will be delivered by auxiliary transmitted bitstream. By doing so, these inconsistent parameters can be processed properly in the decoding stage. Furthermore, to reduce the bitrate of the auxiliary bitstream, we rectify the distribution of entropy parameters using a piecewise Gaussian constraint. Second, to match the computational limitations on the decoding side for real-time video codec, we design a lightweight model. A series of efficiency techniques enable our model to achieve 25 FPS decoding speed on NVIDIA RTX 2080 GPU. Experimental results demonstrate that our model can achieve real-time decoding of 720P videos while encoding on another platform. Furthermore, the real-time model brings up to a maximum of 24.2\% BD-rate improvement from the perspective of PSNR with the anchor H.265.
+
+
+
+ 24. 标题:StructChart: Perception, Structuring, Reasoning for Visual Chart Understanding
+ 编号:[96]
+ 链接:https://arxiv.org/abs/2309.11268
+ 作者:Renqiu Xia, Bo Zhang, Haoyang Peng, Ning Liao, Peng Ye, Botian Shi, Junchi Yan, Yu Qiao
+ 备注:21 pages, 11 figures
+ 关键词:conveying rich information, rich information easily, information easily accessible, scientific fields, conveying rich
+
+ 点击查看摘要
+ Charts are common in literature across different scientific fields, conveying rich information easily accessible to readers. Current chart-related tasks focus on either chart perception which refers to extracting information from the visual charts, or performing reasoning given the extracted data, e.g. in a tabular form. In this paper, we aim to establish a unified and label-efficient learning paradigm for joint perception and reasoning tasks, which can be generally applicable to different downstream tasks, beyond the question-answering task as specifically studied in peer works. Specifically, StructChart first reformulates the chart information from the popular tubular form (specifically linearized CSV) to the proposed Structured Triplet Representations (STR), which is more friendly for reducing the task gap between chart perception and reasoning due to the employed structured information extraction for charts. We then propose a Structuring Chart-oriented Representation Metric (SCRM) to quantitatively evaluate the performance for the chart perception task. To enrich the dataset for training, we further explore the possibility of leveraging the Large Language Model (LLM), enhancing the chart diversity in terms of both chart visual style and its statistical information. Extensive experiments are conducted on various chart-related tasks, demonstrating the effectiveness and promising potential for a unified chart perception-reasoning paradigm to push the frontier of chart understanding.
+
+
+
+ 25. 标题:From Classification to Segmentation with Explainable AI: A Study on Crack Detection and Growth Monitoring
+ 编号:[97]
+ 链接:https://arxiv.org/abs/2309.11267
+ 作者:Florent Forest, Hugo Porta, Devis Tuia, Olga Fink
+ 备注:43 pages. Under review
+ 关键词:structural health monitoring, infrastructure is crucial, crucial for structural, structural health, Monitoring
+
+ 点击查看摘要
+ Monitoring surface cracks in infrastructure is crucial for structural health monitoring. Automatic visual inspection offers an effective solution, especially in hard-to-reach areas. Machine learning approaches have proven their effectiveness but typically require large annotated datasets for supervised training. Once a crack is detected, monitoring its severity often demands precise segmentation of the damage. However, pixel-level annotation of images for segmentation is labor-intensive. To mitigate this cost, one can leverage explainable artificial intelligence (XAI) to derive segmentations from the explanations of a classifier, requiring only weak image-level supervision. This paper proposes applying this methodology to segment and monitor surface cracks. We evaluate the performance of various XAI methods and examine how this approach facilitates severity quantification and growth monitoring. Results reveal that while the resulting segmentation masks may exhibit lower quality than those produced by supervised methods, they remain meaningful and enable severity monitoring, thus reducing substantial labeling costs.
+
+
+
+ 26. 标题:TwinTex: Geometry-aware Texture Generation for Abstracted 3D Architectural Models
+ 编号:[99]
+ 链接:https://arxiv.org/abs/2309.11258
+ 作者:Weidan Xiong, Hongqian Zhang, Botao Peng, Ziyu Hu, Yongli Wu, Jianwei Guo, Hui Huang
+ 备注:Accepted to SIGGRAPH ASIA 2023
+ 关键词:Digital Twin City, Coarse architectural models, Twin City, Digital Twin, Coarse architectural
+
+ 点击查看摘要
+ Coarse architectural models are often generated at scales ranging from individual buildings to scenes for downstream applications such as Digital Twin City, Metaverse, LODs, etc. Such piece-wise planar models can be abstracted as twins from 3D dense reconstructions. However, these models typically lack realistic texture relative to the real building or scene, making them unsuitable for vivid display or direct reference. In this paper, we present TwinTex, the first automatic texture mapping framework to generate a photo-realistic texture for a piece-wise planar proxy. Our method addresses most challenges occurring in such twin texture generation. Specifically, for each primitive plane, we first select a small set of photos with greedy heuristics considering photometric quality, perspective quality and facade texture completeness. Then, different levels of line features (LoLs) are extracted from the set of selected photos to generate guidance for later steps. With LoLs, we employ optimization algorithms to align texture with geometry from local to global. Finally, we fine-tune a diffusion model with a multi-mask initialization component and a new dataset to inpaint the missing region. Experimental results on many buildings, indoor scenes and man-made objects of varying complexity demonstrate the generalization ability of our algorithm. Our approach surpasses state-of-the-art texture mapping methods in terms of high-fidelity quality and reaches a human-expert production level with much less effort. Project page: https://vcc.tech/research/2023/TwinTex.
+
+
+
+ 27. 标题:The Scenario Refiner: Grounding subjects in images at the morphological level
+ 编号:[102]
+ 链接:https://arxiv.org/abs/2309.11252
+ 作者:Claudia Tagliaferri, Sofia Axioti, Albert Gatt, Denis Paperno
+ 备注:presented at the LIMO workshop (Linguistic Insights from and for Multimodal Language Processing @KONVENS 2023)
+ 关键词:exhibit semantic differences, Derivationally related words, exhibit semantic, visual scenarios, semantic differences
+
+ 点击查看摘要
+ Derivationally related words, such as "runner" and "running", exhibit semantic differences which also elicit different visual scenarios. In this paper, we ask whether Vision and Language (V\&L) models capture such distinctions at the morphological level, using a a new methodology and dataset. We compare the results from V\&L models to human judgements and find that models' predictions differ from those of human participants, in particular displaying a grammatical bias. We further investigate whether the human-model misalignment is related to model architecture. Our methodology, developed on one specific morphological contrast, can be further extended for testing models on capturing other nuanced language features.
+
+
+
+ 28. 标题:Box2Poly: Memory-Efficient Polygon Prediction of Arbitrarily Shaped and Rotated Text
+ 编号:[104]
+ 链接:https://arxiv.org/abs/2309.11248
+ 作者:Xuyang Chen, Dong Wang, Konrad Schindler, Mingwei Sun, Yongliang Wang, Nicolo Savioli, Liqiu Meng
+ 备注:
+ 关键词:individual boundary vertices, Transformer-based text detection, distinct query features, Transformer-based text, techniques have sought
+
+ 点击查看摘要
+ Recently, Transformer-based text detection techniques have sought to predict polygons by encoding the coordinates of individual boundary vertices using distinct query features. However, this approach incurs a significant memory overhead and struggles to effectively capture the intricate relationships between vertices belonging to the same instance. Consequently, irregular text layouts often lead to the prediction of outlined vertices, diminishing the quality of results. To address these challenges, we present an innovative approach rooted in Sparse R-CNN: a cascade decoding pipeline for polygon prediction. Our method ensures precision by iteratively refining polygon predictions, considering both the scale and location of preceding results. Leveraging this stabilized regression pipeline, even employing just a single feature vector to guide polygon instance regression yields promising detection results. Simultaneously, the leverage of instance-level feature proposal substantially enhances memory efficiency (>50% less vs. the state-of-the-art method DPText-DETR) and reduces inference speed (>40% less vs. DPText-DETR) with minor performance drop on benchmarks.
+
+
+
+ 29. 标题:Towards Robust Few-shot Point Cloud Semantic Segmentation
+ 编号:[116]
+ 链接:https://arxiv.org/abs/2309.11228
+ 作者:Yating Xu, Na Zhao, Gim Hee Lee
+ 备注:BMVC 2023
+ 关键词:semantic segmentation aims, Few-shot point cloud, point cloud semantic, support set, cloud semantic segmentation
+
+ 点击查看摘要
+ Few-shot point cloud semantic segmentation aims to train a model to quickly adapt to new unseen classes with only a handful of support set samples. However, the noise-free assumption in the support set can be easily violated in many practical real-world settings. In this paper, we focus on improving the robustness of few-shot point cloud segmentation under the detrimental influence of noisy support sets during testing time. To this end, we first propose a Component-level Clean Noise Separation (CCNS) representation learning to learn discriminative feature representations that separates the clean samples of the target classes from the noisy samples. Leveraging the well separated clean and noisy support samples from our CCNS, we further propose a Multi-scale Degree-based Noise Suppression (MDNS) scheme to remove the noisy shots from the support set. We conduct extensive experiments on various noise settings on two benchmark datasets. Our results show that the combination of CCNS and MDNS significantly improves the performance. Our code is available at this https URL.
+
+
+
+ 30. 标题:Generalized Few-Shot Point Cloud Segmentation Via Geometric Words
+ 编号:[119]
+ 链接:https://arxiv.org/abs/2309.11222
+ 作者:Yating Xu, Conghui Hu, Na Zhao, Gim Hee Lee
+ 备注:Accepted by ICCV 2023
+ 关键词:point cloud segmentation, dynamic testing environment, Existing fully-supervised point, fully-supervised point cloud, Few-shot point cloud
+
+ 点击查看摘要
+ Existing fully-supervised point cloud segmentation methods suffer in the dynamic testing environment with emerging new classes. Few-shot point cloud segmentation algorithms address this problem by learning to adapt to new classes at the sacrifice of segmentation accuracy for the base classes, which severely impedes its practicality. This largely motivates us to present the first attempt at a more practical paradigm of generalized few-shot point cloud segmentation, which requires the model to generalize to new categories with only a few support point clouds and simultaneously retain the capability to segment base classes. We propose the geometric words to represent geometric components shared between the base and novel classes, and incorporate them into a novel geometric-aware semantic representation to facilitate better generalization to the new classes without forgetting the old ones. Moreover, we introduce geometric prototypes to guide the segmentation with geometric prior knowledge. Extensive experiments on S3DIS and ScanNet consistently illustrate the superior performance of our method over baseline methods. Our code is available at: this https URL.
+
+
+
+ 31. 标题:Automatic Bat Call Classification using Transformer Networks
+ 编号:[120]
+ 链接:https://arxiv.org/abs/2309.11218
+ 作者:Frank Fundel, Daniel A. Braun, Sebastian Gottwald
+ 备注:Volume 78, December 2023, 102288
+ 关键词:Automatically identifying bat, Automatically identifying, difficult but important, important task, task for monitoring
+
+ 点击查看摘要
+ Automatically identifying bat species from their echolocation calls is a difficult but important task for monitoring bats and the ecosystem they live in. Major challenges in automatic bat call identification are high call variability, similarities between species, interfering calls and lack of annotated data. Many currently available models suffer from relatively poor performance on real-life data due to being trained on single call datasets and, moreover, are often too slow for real-time classification. Here, we propose a Transformer architecture for multi-label classification with potential applications in real-time classification scenarios. We train our model on synthetically generated multi-species recordings by merging multiple bats calls into a single recording with multiple simultaneous calls. Our approach achieves a single species accuracy of 88.92% (F1-score of 84.23%) and a multi species macro F1-score of 74.40% on our test set. In comparison to three other tools on the independent and publicly available dataset ChiroVox, our model achieves at least 25.82% better accuracy for single species classification and at least 6.9% better macro F1-score for multi species classification.
+
+
+
+ 32. 标题:Partition-A-Medical-Image: Extracting Multiple Representative Sub-regions for Few-shot Medical Image Segmentation
+ 编号:[132]
+ 链接:https://arxiv.org/abs/2309.11172
+ 作者:Yazhou Zhu, Shidong Wang, Tong Xin, Zheng Zhang, Haofeng Zhang
+ 备注:
+ 关键词:Medical Image Segmentation, image segmentation tasks, Image Segmentation, segmentation tasks, Few-shot Medical Image
+
+ 点击查看摘要
+ Few-shot Medical Image Segmentation (FSMIS) is a more promising solution for medical image segmentation tasks where high-quality annotations are naturally scarce. However, current mainstream methods primarily focus on extracting holistic representations from support images with large intra-class variations in appearance and background, and encounter difficulties in adapting to query images. In this work, we present an approach to extract multiple representative sub-regions from a given support medical image, enabling fine-grained selection over the generated image regions. Specifically, the foreground of the support image is decomposed into distinct regions, which are subsequently used to derive region-level representations via a designed Regional Prototypical Learning (RPL) module. We then introduce a novel Prototypical Representation Debiasing (PRD) module based on a two-way elimination mechanism which suppresses the disturbance of regional representations by a self-support, Multi-direction Self-debiasing (MS) block, and a support-query, Interactive Debiasing (ID) block. Finally, an Assembled Prediction (AP) module is devised to balance and integrate predictions of multiple prototypical representations learned using stacked PRD modules. Results obtained through extensive experiments on three publicly accessible medical imaging datasets demonstrate consistent improvements over the leading FSMIS methods. The source code is available at this https URL.
+
+
+
+ 33. 标题:AutoSynth: Learning to Generate 3D Training Data for Object Point Cloud Registration
+ 编号:[133]
+ 链接:https://arxiv.org/abs/2309.11170
+ 作者:Zheng Dang, Mathieu Salzmann
+ 备注:accepted by ICCV2023
+ 关键词:deep learning paradigm, current deep learning, point cloud registration, learning paradigm, current deep
+
+ 点击查看摘要
+ In the current deep learning paradigm, the amount and quality of training data are as critical as the network architecture and its training details. However, collecting, processing, and annotating real data at scale is difficult, expensive, and time-consuming, particularly for tasks such as 3D object registration. While synthetic datasets can be created, they require expertise to design and include a limited number of categories. In this paper, we introduce a new approach called AutoSynth, which automatically generates 3D training data for point cloud registration. Specifically, AutoSynth automatically curates an optimal dataset by exploring a search space encompassing millions of potential datasets with diverse 3D shapes at a low this http URL achieve this, we generate synthetic 3D datasets by assembling shape primitives, and develop a meta-learning strategy to search for the best training data for 3D registration on real point clouds. For this search to remain tractable, we replace the point cloud registration network with a much smaller surrogate network, leading to a $4056.43$ times speedup. We demonstrate the generality of our approach by implementing it with two different point cloud registration networks, BPNet and IDAM. Our results on TUD-L, LINEMOD and Occluded-LINEMOD evidence that a neural network trained on our searched dataset yields consistently better performance than the same one trained on the widely used ModelNet40 dataset.
+
+
+
+ 34. 标题:Multi-grained Temporal Prototype Learning for Few-shot Video Object Segmentation
+ 编号:[137]
+ 链接:https://arxiv.org/abs/2309.11160
+ 作者:Nian Liu, Kepan Nan, Wangbo Zhao, Yuanwei Liu, Xiwen Yao, Salman Khan, Hisham Cholakkal, Rao Muhammad Anwer, Junwei Han, Fahad Shahbaz Khan
+ 备注:ICCV 2023
+ 关键词:Few-Shot Video Object, Video Object Segmentation, segment objects, Object Segmentation, aims to segment
+
+ 点击查看摘要
+ Few-Shot Video Object Segmentation (FSVOS) aims to segment objects in a query video with the same category defined by a few annotated support images. However, this task was seldom explored. In this work, based on IPMT, a state-of-the-art few-shot image segmentation method that combines external support guidance information with adaptive query guidance cues, we propose to leverage multi-grained temporal guidance information for handling the temporal correlation nature of video data. We decompose the query video information into a clip prototype and a memory prototype for capturing local and long-term internal temporal guidance, respectively. Frame prototypes are further used for each frame independently to handle fine-grained adaptive guidance and enable bidirectional clip-frame prototype communication. To reduce the influence of noisy memory, we propose to leverage the structural similarity relation among different predicted regions and the support for selecting reliable memory frames. Furthermore, a new segmentation loss is also proposed to enhance the category discriminability of the learned prototypes. Experimental results demonstrate that our proposed video IPMT model significantly outperforms previous models on two benchmark datasets. Code is available at this https URL.
+
+
+
+ 35. 标题:Learning Deformable 3D Graph Similarity to Track Plant Cells in Unregistered Time Lapse Images
+ 编号:[138]
+ 链接:https://arxiv.org/abs/2309.11157
+ 作者:Md Shazid Islam, Arindam Dutta, Calvin-Khang Ta, Kevin Rodriguez, Christian Michael, Mark Alber, G. Venugopala Reddy, Amit K. Roy-Chowdhury
+ 备注:
+ 关键词:challenging problem due, non-uniform growth, tightly packed plant, obtained by microscope, due to biological
+
+ 点击查看摘要
+ Tracking of plant cells in images obtained by microscope is a challenging problem due to biological phenomena such as large number of cells, non-uniform growth of different layers of the tightly packed plant cells and cell division. Moreover, images in deeper layers of the tissue being noisy and unavoidable systemic errors inherent in the imaging process further complicates the problem. In this paper, we propose a novel learning-based method that exploits the tightly packed three-dimensional cell structure of plant cells to create a three-dimensional graph in order to perform accurate cell tracking. We further propose novel algorithms for cell division detection and effective three-dimensional registration, which improve upon the state-of-the-art algorithms. We demonstrate the efficacy of our algorithm in terms of tracking accuracy and inference-time on a benchmark dataset.
+
+
+
+ 36. 标题:CNN-based local features for navigation near an asteroid
+ 编号:[139]
+ 链接:https://arxiv.org/abs/2309.11156
+ 作者:Olli Knuuttila, Antti Kestilä, Esa Kallio
+ 备注:
+ 关键词:on-orbit servicing, vision-based proximity navigation, article addresses, addresses the challenge, challenge of vision-based
+
+ 点击查看摘要
+ This article addresses the challenge of vision-based proximity navigation in asteroid exploration missions and on-orbit servicing. Traditional feature extraction methods struggle with the significant appearance variations of asteroids due to limited scattered light. To overcome this, we propose a lightweight feature extractor specifically tailored for asteroid proximity navigation, designed to be robust to illumination changes and affine transformations. We compare and evaluate state-of-the-art feature extraction networks and three lightweight network architectures in the asteroid context. Our proposed feature extractors and their evaluation leverages both synthetic images and real-world data from missions such as NEAR Shoemaker, Hayabusa, Rosetta, and OSIRIS-REx. Our contributions include a trained feature extractor, incremental improvements over existing methods, and a pipeline for training domain-specific feature extractors. Experimental results demonstrate the effectiveness of our approach in achieving accurate navigation and localization. This work aims to advance the field of asteroid navigation and provides insights for future research in this domain.
+
+
+
+ 37. 标题:Online Calibration of a Single-Track Ground Vehicle Dynamics Model by Tight Fusion with Visual-Inertial Odometry
+ 编号:[142]
+ 链接:https://arxiv.org/abs/2309.11148
+ 作者:Haolong Li, Joerg Stueckler
+ 备注:Submitted to ICRA 2024
+ 关键词:Wheeled mobile robots, navigation planning, mobile robots, ability to estimate, actions for navigation
+
+ 点击查看摘要
+ Wheeled mobile robots need the ability to estimate their motion and the effect of their control actions for navigation planning. In this paper, we present ST-VIO, a novel approach which tightly fuses a single-track dynamics model for wheeled ground vehicles with visual inertial odometry. Our method calibrates and adapts the dynamics model online and facilitates accurate forward prediction conditioned on future control inputs. The single-track dynamics model approximates wheeled vehicle motion under specific control inputs on flat ground using ordinary differential equations. We use a singularity-free and differentiable variant of the single-track model to enable seamless integration as dynamics factor into VIO and to optimize the model parameters online together with the VIO state variables. We validate our method with real-world data in both indoor and outdoor environments with different terrain types and wheels. In our experiments, we demonstrate that our ST-VIO can not only adapt to the change of the environments and achieve accurate prediction under new control inputs, but even improves the tracking accuracy. Supplementary video: this https URL.
+
+
+
+ 38. 标题:GraphEcho: Graph-Driven Unsupervised Domain Adaptation for Echocardiogram Video Segmentation
+ 编号:[144]
+ 链接:https://arxiv.org/abs/2309.11145
+ 作者:Jiewen Yang, Xinpeng Ding, Ziyang Zheng, Xiaowei Xu, Xiaomeng Li
+ 备注:Accepted By ICCV 2023
+ 关键词:cardiac disease diagnosis, UDA segmentation methods, Echocardiogram video segmentation, UDA segmentation, video segmentation plays
+
+ 点击查看摘要
+ Echocardiogram video segmentation plays an important role in cardiac disease diagnosis. This paper studies the unsupervised domain adaption (UDA) for echocardiogram video segmentation, where the goal is to generalize the model trained on the source domain to other unlabelled target domains. Existing UDA segmentation methods are not suitable for this task because they do not model local information and the cyclical consistency of heartbeat. In this paper, we introduce a newly collected CardiacUDA dataset and a novel GraphEcho method for cardiac structure segmentation. Our GraphEcho comprises two innovative modules, the Spatial-wise Cross-domain Graph Matching (SCGM) and the Temporal Cycle Consistency (TCC) module, which utilize prior knowledge of echocardiogram videos, i.e., consistent cardiac structure across patients and centers and the heartbeat cyclical consistency, respectively. These two modules can better align global and local features from source and target domains, improving UDA segmentation results. Experimental results showed that our GraphEcho outperforms existing state-of-the-art UDA segmentation methods. Our collected dataset and code will be publicly released upon acceptance. This work will lay a new and solid cornerstone for cardiac structure segmentation from echocardiogram videos. Code and dataset are available at: this https URL
+
+
+
+ 39. 标题:GL-Fusion: Global-Local Fusion Network for Multi-view Echocardiogram Video Segmentation
+ 编号:[145]
+ 链接:https://arxiv.org/abs/2309.11144
+ 作者:Ziyang Zheng, Jiewen Yang, Xinpeng Ding, Xiaowei Xu, Xiaomeng Li
+ 备注:Accepted By MICCAI 2023
+ 关键词:diagnosing heart disease, heart disease, Global-based Fusion Module, plays a crucial, crucial role
+
+ 点击查看摘要
+ Cardiac structure segmentation from echocardiogram videos plays a crucial role in diagnosing heart disease. The combination of multi-view echocardiogram data is essential to enhance the accuracy and robustness of automated methods. However, due to the visual disparity of the data, deriving cross-view context information remains a challenging task, and unsophisticated fusion strategies can even lower performance. In this study, we propose a novel Gobal-Local fusion (GL-Fusion) network to jointly utilize multi-view information globally and locally that improve the accuracy of echocardiogram analysis. Specifically, a Multi-view Global-based Fusion Module (MGFM) is proposed to extract global context information and to explore the cyclic relationship of different heartbeat cycles in an echocardiogram video. Additionally, a Multi-view Local-based Fusion Module (MLFM) is designed to extract correlations of cardiac structures from different views. Furthermore, we collect a multi-view echocardiogram video dataset (MvEVD) to evaluate our method. Our method achieves an 82.29% average dice score, which demonstrates a 7.83% improvement over the baseline method, and outperforms other existing state-of-the-art methods. To our knowledge, this is the first exploration of a multi-view method for echocardiogram video segmentation. Code available at: this https URL
+
+
+
+ 40. 标题:Shape Anchor Guided Holistic Indoor Scene Understanding
+ 编号:[151]
+ 链接:https://arxiv.org/abs/2309.11133
+ 作者:Mingyue Dong, Linxi Huan, Hanjiang Xiong, Shuhan Shen, Xianwei Zheng
+ 备注:
+ 关键词:robust holistic indoor, guided learning strategy, indoor scene understanding, holistic indoor scene, paper proposes
+
+ 点击查看摘要
+ This paper proposes a shape anchor guided learning strategy (AncLearn) for robust holistic indoor scene understanding. We observe that the search space constructed by current methods for proposal feature grouping and instance point sampling often introduces massive noise to instance detection and mesh reconstruction. Accordingly, we develop AncLearn to generate anchors that dynamically fit instance surfaces to (i) unmix noise and target-related features for offering reliable proposals at the detection stage, and (ii) reduce outliers in object point sampling for directly providing well-structured geometry priors without segmentation during reconstruction. We embed AncLearn into a reconstruction-from-detection learning system (AncRec) to generate high-quality semantic scene models in a purely instance-oriented manner. Experiments conducted on the challenging ScanNetv2 dataset demonstrate that our shape anchor-based method consistently achieves state-of-the-art performance in terms of 3D object detection, layout estimation, and shape reconstruction. The code will be available at this https URL.
+
+
+
+ 41. 标题:Contrastive Pseudo Learning for Open-World DeepFake Attribution
+ 编号:[152]
+ 链接:https://arxiv.org/abs/2309.11132
+ 作者:Zhimin Sun, Shen Chen, Taiping Yao, Bangjie Yin, Ran Yi, Shouhong Ding, Lizhuang Ma
+ 备注:16 pages, 7 figures, ICCV 2023
+ 关键词:gained widespread attention, widespread attention due, challenge in sourcing, gained widespread, widespread attention
+
+ 点击查看摘要
+ The challenge in sourcing attribution for forgery faces has gained widespread attention due to the rapid development of generative techniques. While many recent works have taken essential steps on GAN-generated faces, more threatening attacks related to identity swapping or expression transferring are still overlooked. And the forgery traces hidden in unknown attacks from the open-world unlabeled faces still remain under-explored. To push the related frontier research, we introduce a new benchmark called Open-World DeepFake Attribution (OW-DFA), which aims to evaluate attribution performance against various types of fake faces under open-world scenarios. Meanwhile, we propose a novel framework named Contrastive Pseudo Learning (CPL) for the OW-DFA task through 1) introducing a Global-Local Voting module to guide the feature alignment of forged faces with different manipulated regions, 2) designing a Confidence-based Soft Pseudo-label strategy to mitigate the pseudo-noise caused by similar methods in unlabeled set. In addition, we extend the CPL framework with a multi-stage paradigm that leverages pre-train technique and iterative learning to further enhance traceability performance. Extensive experiments verify the superiority of our proposed method on the OW-DFA and also demonstrate the interpretability of deepfake attribution task and its impact on improving the security of deepfake detection area.
+
+
+
+ 42. 标题:Locate and Verify: A Two-Stream Network for Improved Deepfake Detection
+ 编号:[153]
+ 链接:https://arxiv.org/abs/2309.11131
+ 作者:Chao Shuai, Jieming Zhong, Shuang Wu, Feng Lin, Zhibo Wang, Zhongjie Ba, Zhenguang Liu, Lorenzo Cavallaro, Kui Ren
+ 备注:10 pages, 8 figures, 60 references. This paper has been accepted for ACM MM 2023
+ 关键词:world by storm, triggering a trust, trust crisis, Current deepfake detection, deepfake detection
+
+ 点击查看摘要
+ Deepfake has taken the world by storm, triggering a trust crisis. Current deepfake detection methods are typically inadequate in generalizability, with a tendency to overfit to image contents such as the background, which are frequently occurring but relatively unimportant in the training dataset. Furthermore, current methods heavily rely on a few dominant forgery regions and may ignore other equally important regions, leading to inadequate uncovering of forgery cues. In this paper, we strive to address these shortcomings from three aspects: (1) We propose an innovative two-stream network that effectively enlarges the potential regions from which the model extracts forgery evidence. (2) We devise three functional modules to handle the multi-stream and multi-scale features in a collaborative learning scheme. (3) Confronted with the challenge of obtaining forgery annotations, we propose a Semi-supervised Patch Similarity Learning strategy to estimate patch-level forged location annotations. Empirically, our method demonstrates significantly improved robustness and generalizability, outperforming previous methods on six benchmarks, and improving the frame-level AUC on Deepfake Detection Challenge preview dataset from 0.797 to 0.835 and video-level AUC on CelebDF$\_$v1 dataset from 0.811 to 0.847. Our implementation is available at this https URL.
+
+
+
+ 43. 标题:PSDiff: Diffusion Model for Person Search with Iterative and Collaborative Refinement
+ 编号:[154]
+ 链接:https://arxiv.org/abs/2309.11125
+ 作者:Chengyou Jia, Minnan Luo, Zhuohang Dang, Guang Dai, Xiaojun Chang, Jingdong Wang, Qinghua Zheng
+ 备注:
+ 关键词:recognize query persons, Dominant Person Search, Search methods aim, Person Search, unified network
+
+ 点击查看摘要
+ Dominant Person Search methods aim to localize and recognize query persons in a unified network, which jointly optimizes two sub-tasks, \ie, detection and Re-IDentification (ReID). Despite significant progress, two major challenges remain: 1) Detection-prior modules in previous methods are suboptimal for the ReID task. 2) The collaboration between two sub-tasks is ignored. To alleviate these issues, we present a novel Person Search framework based on the Diffusion model, PSDiff. PSDiff formulates the person search as a dual denoising process from noisy boxes and ReID embeddings to ground truths. Unlike existing methods that follow the Detection-to-ReID paradigm, our denoising paradigm eliminates detection-prior modules to avoid the local-optimum of the ReID task. Following the new paradigm, we further design a new Collaborative Denoising Layer (CDL) to optimize detection and ReID sub-tasks in an iterative and collaborative way, which makes two sub-tasks mutually beneficial. Extensive experiments on the standard benchmarks show that PSDiff achieves state-of-the-art performance with fewer parameters and elastic computing overhead.
+
+
+
+ 44. 标题:Hyperspectral Benchmark: Bridging the Gap between HSI Applications through Comprehensive Dataset and Pretraining
+ 编号:[156]
+ 链接:https://arxiv.org/abs/2309.11122
+ 作者:Hannah Frank, Leon Amadeus Varga, Andreas Zell
+ 备注:Hannah Frankand Leon Amadeus Varga contributed equally
+ 关键词:non-destructive spatial spectroscopy, spatial spectroscopy technique, Hyperspectral Imaging, non-destructive spatial, spatial spectroscopy
+
+ 点击查看摘要
+ Hyperspectral Imaging (HSI) serves as a non-destructive spatial spectroscopy technique with a multitude of potential applications. However, a recurring challenge lies in the limited size of the target datasets, impeding exhaustive architecture search. Consequently, when venturing into novel applications, reliance on established methodologies becomes commonplace, in the hope that they exhibit favorable generalization characteristics. Regrettably, this optimism is often unfounded due to the fine-tuned nature of models tailored to specific HSI contexts.
+To address this predicament, this study introduces an innovative benchmark dataset encompassing three markedly distinct HSI applications: food inspection, remote sensing, and recycling. This comprehensive dataset affords a finer assessment of hyperspectral model capabilities. Moreover, this benchmark facilitates an incisive examination of prevailing state-of-the-art techniques, consequently fostering the evolution of superior methodologies.
+Furthermore, the enhanced diversity inherent in the benchmark dataset underpins the establishment of a pretraining pipeline for HSI. This pretraining regimen serves to enhance the stability of training processes for larger models. Additionally, a procedural framework is delineated, offering insights into the handling of applications afflicted by limited target dataset sizes.
+
+
+
+ 45. 标题:BroadBEV: Collaborative LiDAR-camera Fusion for Broad-sighted Bird's Eye View Map Construction
+ 编号:[157]
+ 链接:https://arxiv.org/abs/2309.11119
+ 作者:Minsu Kim, Giseop Kim, Kyong Hwan Jin, Sunwook Choi
+ 备注:
+ 关键词:Bird Eye View, Eye View, Bird Eye, BEV, recent sensor fusion
+
+ 点击查看摘要
+ A recent sensor fusion in a Bird's Eye View (BEV) space has shown its utility in various tasks such as 3D detection, map segmentation, etc. However, the approach struggles with inaccurate camera BEV estimation, and a perception of distant areas due to the sparsity of LiDAR points. In this paper, we propose a broad BEV fusion (BroadBEV) that addresses the problems with a spatial synchronization approach of cross-modality. Our strategy aims to enhance camera BEV estimation for a broad-sighted perception while simultaneously improving the completion of LiDAR's sparsity in the entire BEV space. Toward that end, we devise Point-scattering that scatters LiDAR BEV distribution to camera depth distribution. The method boosts the learning of depth estimation of the camera branch and induces accurate location of dense camera features in BEV space. For an effective BEV fusion between the spatially synchronized features, we suggest ColFusion that applies self-attention weights of LiDAR and camera BEV features to each other. Our extensive experiments demonstrate that BroadBEV provides a broad-sighted BEV perception with remarkable performance gains.
+
+
+
+ 46. 标题:PRAT: PRofiling Adversarial aTtacks
+ 编号:[159]
+ 链接:https://arxiv.org/abs/2309.11111
+ 作者:Rahul Ambati, Naveed Akhtar, Ajmal Mian, Yogesh Singh Rawat
+ 备注:
+ 关键词:fooling deep models, broad common objective, deep models, deep learning, fooling deep
+
+ 点击查看摘要
+ Intrinsic susceptibility of deep learning to adversarial examples has led to a plethora of attack techniques with a broad common objective of fooling deep models. However, we find slight compositional differences between the algorithms achieving this objective. These differences leave traces that provide important clues for attacker profiling in real-life scenarios. Inspired by this, we introduce a novel problem of PRofiling Adversarial aTtacks (PRAT). Given an adversarial example, the objective of PRAT is to identify the attack used to generate it. Under this perspective, we can systematically group existing attacks into different families, leading to the sub-problem of attack family identification, which we also study. To enable PRAT analysis, we introduce a large Adversarial Identification Dataset (AID), comprising over 180k adversarial samples generated with 13 popular attacks for image specific/agnostic white/black box setups. We use AID to devise a novel framework for the PRAT objective. Our framework utilizes a Transformer based Global-LOcal Feature (GLOF) module to extract an approximate signature of the adversarial attack, which in turn is used for the identification of the attack. Using AID and our framework, we provide multiple interesting benchmark results for the PRAT problem.
+
+
+
+ 47. 标题:Self-supervised Domain-agnostic Domain Adaptation for Satellite Images
+ 编号:[160]
+ 链接:https://arxiv.org/abs/2309.11109
+ 作者:Fahong Zhang, Yilei Shi, Xiao Xiang Zhu
+ 备注:
+ 关键词:Domain shift caused, global scale satellite, satellite image processing, scale satellite image, shift caused
+
+ 点击查看摘要
+ Domain shift caused by, e.g., different geographical regions or acquisition conditions is a common issue in machine learning for global scale satellite image processing. A promising method to address this problem is domain adaptation, where the training and the testing datasets are split into two or multiple domains according to their distributions, and an adaptation method is applied to improve the generalizability of the model on the testing dataset. However, defining the domain to which each satellite image belongs is not trivial, especially under large-scale multi-temporal and multi-sensory scenarios, where a single image mosaic could be generated from multiple data sources. In this paper, we propose an self-supervised domain-agnostic domain adaptation (SS(DA)2) method to perform domain adaptation without such a domain definition. To achieve this, we first design a contrastive generative adversarial loss to train a generative network to perform image-to-image translation between any two satellite image patches. Then, we improve the generalizability of the downstream models by augmenting the training data with different testing spectral characteristics. The experimental results on public benchmarks verify the effectiveness of SS(DA)2.
+
+
+
+ 48. 标题:Forgery-aware Adaptive Vision Transformer for Face Forgery Detection
+ 编号:[169]
+ 链接:https://arxiv.org/abs/2309.11092
+ 作者:Anwei Luo, Rizhao Cai, Chenqi Kong, Xiangui Kang, Jiwu Huang, Alex C. Kot
+ 备注:
+ 关键词:face manipulation technologies, protecting authentication integrity, face forgery detection, Adaptive Vision Transformer, Previous Vision Transformer
+
+ 点击查看摘要
+ With the advancement in face manipulation technologies, the importance of face forgery detection in protecting authentication integrity becomes increasingly evident. Previous Vision Transformer (ViT)-based detectors have demonstrated subpar performance in cross-database evaluations, primarily because fully fine-tuning with limited Deepfake data often leads to forgetting pre-trained knowledge and over-fitting to data-specific ones. To circumvent these issues, we propose a novel Forgery-aware Adaptive Vision Transformer (FA-ViT). In FA-ViT, the vanilla ViT's parameters are frozen to preserve its pre-trained knowledge, while two specially designed components, the Local-aware Forgery Injector (LFI) and the Global-aware Forgery Adaptor (GFA), are employed to adapt forgery-related knowledge. our proposed FA-ViT effectively combines these two different types of knowledge to form the general forgery features for detecting Deepfakes. Specifically, LFI captures local discriminative information and incorporates these information into ViT via Neighborhood-Preserving Cross Attention (NPCA). Simultaneously, GFA learns adaptive knowledge in the self-attention layer, bridging the gap between the two different domain. Furthermore, we design a novel Single Domain Pairwise Learning (SDPL) to facilitate fine-grained information learning in FA-ViT. The extensive experiments demonstrate that our FA-ViT achieves state-of-the-art performance in cross-dataset evaluation and cross-manipulation scenarios, and improves the robustness against unseen perturbations.
+
+
+
+ 49. 标题:Learning Segment Similarity and Alignment in Large-Scale Content Based Video Retrieval
+ 编号:[170]
+ 链接:https://arxiv.org/abs/2309.11091
+ 作者:Chen Jiang, Kaiming Huang, Sifeng He, Xudong Yang, Wei Zhang, Xiaobo Zhang, Yuan Cheng, Lei Yang, Qing Wang, Furong Xu, Tan Pan, Wei Chu
+ 备注:Accepted by ACM MM 2021
+ 关键词:large-scale Content-Based Video, Content-Based Video Retrieval, recent years, large-scale Content-Based, copyright protection
+
+ 点击查看摘要
+ With the explosive growth of web videos in recent years, large-scale Content-Based Video Retrieval (CBVR) becomes increasingly essential in video filtering, recommendation, and copyright protection. Segment-level CBVR (S-CBVR) locates the start and end time of similar segments in finer granularity, which is beneficial for user browsing efficiency and infringement detection especially in long video scenarios. The challenge of S-CBVR task is how to achieve high temporal alignment accuracy with efficient computation and low storage consumption. In this paper, we propose a Segment Similarity and Alignment Network (SSAN) in dealing with the challenge which is firstly trained end-to-end in S-CBVR. SSAN is based on two newly proposed modules in video retrieval: (1) An efficient Self-supervised Keyframe Extraction (SKE) module to reduce redundant frame features, (2) A robust Similarity Pattern Detection (SPD) module for temporal alignment. In comparison with uniform frame extraction, SKE not only saves feature storage and search time, but also introduces comparable accuracy and limited extra computation time. In terms of temporal alignment, SPD localizes similar segments with higher accuracy and efficiency than existing deep learning methods. Furthermore, we jointly train SSAN with SKE and SPD and achieve an end-to-end improvement. Meanwhile, the two key modules SKE and SPD can also be effectively inserted into other video retrieval pipelines and gain considerable performance improvements. Experimental results on public datasets show that SSAN can obtain higher alignment accuracy while saving storage and online query computational cost compared to existing methods.
+
+
+
+ 50. 标题:Dual-Modal Attention-Enhanced Text-Video Retrieval with Triplet Partial Margin Contrastive Learning
+ 编号:[174]
+ 链接:https://arxiv.org/abs/2309.11082
+ 作者:Chen Jiang, Hong Liu, Xuzheng Yu, Qing Wang, Yuan Cheng, Jia Xu, Zhongyi Liu, Qingpei Guo, Wei Chu, Ming Yang, Yuan Qi
+ 备注:Accepted by ACM MM 2023
+ 关键词:retrieval increasingly essential, web videos makes, makes text-video retrieval, text-video retrieval increasingly, videos makes text-video
+
+ 点击查看摘要
+ In recent years, the explosion of web videos makes text-video retrieval increasingly essential and popular for video filtering, recommendation, and search. Text-video retrieval aims to rank relevant text/video higher than irrelevant ones. The core of this task is to precisely measure the cross-modal similarity between texts and videos. Recently, contrastive learning methods have shown promising results for text-video retrieval, most of which focus on the construction of positive and negative pairs to learn text and video representations. Nevertheless, they do not pay enough attention to hard negative pairs and lack the ability to model different levels of semantic similarity. To address these two issues, this paper improves contrastive learning using two novel techniques. First, to exploit hard examples for robust discriminative power, we propose a novel Dual-Modal Attention-Enhanced Module (DMAE) to mine hard negative pairs from textual and visual clues. By further introducing a Negative-aware InfoNCE (NegNCE) loss, we are able to adaptively identify all these hard negatives and explicitly highlight their impacts in the training loss. Second, our work argues that triplet samples can better model fine-grained semantic similarity compared to pairwise samples. We thereby present a new Triplet Partial Margin Contrastive Learning (TPM-CL) module to construct partial order triplet samples by automatically generating fine-grained hard negatives for matched text-video pairs. The proposed TPM-CL designs an adaptive token masking strategy with cross-modal interaction to model subtle semantic differences. Extensive experiments demonstrate that the proposed approach outperforms existing methods on four widely-used text-video retrieval datasets, including MSR-VTT, MSVD, DiDeMo and ActivityNet.
+
+
+
+ 51. 标题:Dense 2D-3D Indoor Prediction with Sound via Aligned Cross-Modal Distillation
+ 编号:[175]
+ 链接:https://arxiv.org/abs/2309.11081
+ 作者:Heeseung Yun, Joonil Na, Gunhee Kim
+ 备注:Published to ICCV2023
+ 关键词:convey significant information, daily lives, convey significant, significant information, dense indoor prediction
+
+ 点击查看摘要
+ Sound can convey significant information for spatial reasoning in our daily lives. To endow deep networks with such ability, we address the challenge of dense indoor prediction with sound in both 2D and 3D via cross-modal knowledge distillation. In this work, we propose a Spatial Alignment via Matching (SAM) distillation framework that elicits local correspondence between the two modalities in vision-to-audio knowledge transfer. SAM integrates audio features with visually coherent learnable spatial embeddings to resolve inconsistencies in multiple layers of a student model. Our approach does not rely on a specific input representation, allowing for flexibility in the input shapes or dimensions without performance degradation. With a newly curated benchmark named Dense Auditory Prediction of Surroundings (DAPS), we are the first to tackle dense indoor prediction of omnidirectional surroundings in both 2D and 3D with audio observations. Specifically, for audio-based depth estimation, semantic segmentation, and challenging 3D scene reconstruction, the proposed distillation framework consistently achieves state-of-the-art performance across various metrics and backbone architectures.
+
+
+
+ 52. 标题:Visual Question Answering in the Medical Domain
+ 编号:[176]
+ 链接:https://arxiv.org/abs/2309.11080
+ 作者:Louisa Canepa, Sonit Singh, Arcot Sowmya
+ 备注:8 pages, 7 figures, Accepted to DICTA 2023 Conference
+ 关键词:natural language questions, language questions based, answer natural language, visual question answering, Medical visual question
+
+ 点击查看摘要
+ Medical visual question answering (Med-VQA) is a machine learning task that aims to create a system that can answer natural language questions based on given medical images. Although there has been rapid progress on the general VQA task, less progress has been made on Med-VQA due to the lack of large-scale annotated datasets. In this paper, we present domain-specific pre-training strategies, including a novel contrastive learning pretraining method, to mitigate the problem of small datasets for the Med-VQA task. We find that the model benefits from components that use fewer parameters. We also evaluate and discuss the model's visual reasoning using evidence verification techniques. Our proposed model obtained an accuracy of 60% on the VQA-Med 2019 test set, giving comparable results to other state-of-the-art Med-VQA models.
+
+
+
+ 53. 标题:Weak Supervision for Label Efficient Visual Bug Detection
+ 编号:[177]
+ 链接:https://arxiv.org/abs/2309.11077
+ 作者:Farrukh Rahman
+ 备注:Accepted to BMVC 2023: Workshop on Computer Vision for Games and Games for Computer Vision (CVG). 9 pages
+ 关键词:quality becomes essential, increasingly challenging, detailed worlds, bugs, video games evolve
+
+ 点击查看摘要
+ As video games evolve into expansive, detailed worlds, visual quality becomes essential, yet increasingly challenging. Traditional testing methods, limited by resources, face difficulties in addressing the plethora of potential bugs. Machine learning offers scalable solutions; however, heavy reliance on large labeled datasets remains a constraint. Addressing this challenge, we propose a novel method, utilizing unlabeled gameplay and domain-specific augmentations to generate datasets & self-supervised objectives used during pre-training or multi-task settings for downstream visual bug detection. Our methodology uses weak-supervision to scale datasets for the crafted objectives and facilitates both autonomous and interactive weak-supervision, incorporating unsupervised clustering and/or an interactive approach based on text and geometric prompts. We demonstrate on first-person player clipping/collision bugs (FPPC) within the expansive Giantmap game world, that our approach is very effective, improving over a strong supervised baseline in a practical, very low-prevalence, low data regime (0.336 $\rightarrow$ 0.550 F1 score). With just 5 labeled "good" exemplars (i.e., 0 bugs), our self-supervised objective alone captures enough signal to outperform the low-labeled supervised settings. Building on large-pretrained vision models, our approach is adaptable across various visual bugs. Our results suggest applicability in curating datasets for broader image and video tasks within video games beyond visual bugs.
+
+
+
+ 54. 标题:Dynamic Tiling: A Model-Agnostic, Adaptive, Scalable, and Inference-Data-Centric Approach for Efficient and Accurate Small Object Detection
+ 编号:[180]
+ 链接:https://arxiv.org/abs/2309.11069
+ 作者:Son The Nguyen, Theja Tulabandhula, Duy Nguyen
+ 备注:
+ 关键词:introduce Dynamic Tiling, Dynamic Tiling, Dynamic Tiling starts, Dynamic Tiling outperforms, Tiling
+
+ 点击查看摘要
+ We introduce Dynamic Tiling, a model-agnostic, adaptive, and scalable approach for small object detection, anchored in our inference-data-centric philosophy. Dynamic Tiling starts with non-overlapping tiles for initial detections and utilizes dynamic overlapping rates along with a tile minimizer. This dual approach effectively resolves fragmented objects, improves detection accuracy, and minimizes computational overhead by reducing the number of forward passes through the object detection model. Adaptable to a variety of operational environments, our method negates the need for laborious recalibration. Additionally, our large-small filtering mechanism boosts the detection quality across a range of object sizes. Overall, Dynamic Tiling outperforms existing model-agnostic uniform cropping methods, setting new benchmarks for efficiency and accuracy.
+
+
+
+ 55. 标题:Score Mismatching for Generative Modeling
+ 编号:[194]
+ 链接:https://arxiv.org/abs/2309.11043
+ 作者:Senmao Ye, Fei Liu
+ 备注:
+ 关键词:one-step sampling, Denoising Score Matching, model, score network, consistency model
+
+ 点击查看摘要
+ We propose a new score-based model with one-step sampling. Previously, score-based models were burdened with heavy computations due to iterative sampling. For substituting the iterative process, we train a standalone generator to compress all the time steps with the gradient backpropagated from the score network. In order to produce meaningful gradients for the generator, the score network is trained to simultaneously match the real data distribution and mismatch the fake data distribution. This model has the following advantages: 1) For sampling, it generates a fake image with only one step forward. 2) For training, it only needs 10 diffusion steps.3) Compared with consistency model, it is free of the ill-posed problem caused by consistency loss. On the popular CIFAR-10 dataset, our model outperforms Consistency Model and Denoising Score Matching, which demonstrates the potential of the framework. We further provide more examples on the MINIST and LSUN datasets. The code is available on GitHub.
+
+
+
+ 56. 标题:CaveSeg: Deep Semantic Segmentation and Scene Parsing for Autonomous Underwater Cave Exploration
+ 编号:[198]
+ 链接:https://arxiv.org/abs/2309.11038
+ 作者:A. Abdullah, T. Barua, R. Tibbetts, Z. Chen, M. J. Islam, I. Rekleitis
+ 备注:submitted for review in ICRA 2024. 10 pages, 9 figures
+ 关键词:visual learning pipeline, semantic segmentation, learning pipeline, inside underwater caves, underwater cave
+
+ 点击查看摘要
+ In this paper, we present CaveSeg - the first visual learning pipeline for semantic segmentation and scene parsing for AUV navigation inside underwater caves. We address the problem of scarce annotated training data by preparing a comprehensive dataset for semantic segmentation of underwater cave scenes. It contains pixel annotations for important navigation markers (e.g. caveline, arrows), obstacles (e.g. ground plain and overhead layers), scuba divers, and open areas for servoing. Through comprehensive benchmark analyses on cave systems in USA, Mexico, and Spain locations, we demonstrate that robust deep visual models can be developed based on CaveSeg for fast semantic scene parsing of underwater cave environments. In particular, we formulate a novel transformer-based model that is computationally light and offers near real-time execution in addition to achieving state-of-the-art performance. Finally, we explore the design choices and implications of semantic segmentation for visual servoing by AUVs inside underwater caves. The proposed model and benchmark dataset open up promising opportunities for future research in autonomous underwater cave exploration and mapping.
+
+
+
+ 57. 标题:Conformalized Multimodal Uncertainty Regression and Reasoning
+ 编号:[209]
+ 链接:https://arxiv.org/abs/2309.11018
+ 作者:Domenico Parente, Nastaran Darabi, Alex C. Stutts, Theja Tulabandhula, Amit Ranjan Trivedi
+ 备注:
+ 关键词:lightweight uncertainty estimator, uncertainty estimator capable, integrating conformal prediction, deep-learning regressor, paper introduces
+
+ 点击查看摘要
+ This paper introduces a lightweight uncertainty estimator capable of predicting multimodal (disjoint) uncertainty bounds by integrating conformal prediction with a deep-learning regressor. We specifically discuss its application for visual odometry (VO), where environmental features such as flying domain symmetries and sensor measurements under ambiguities and occlusion can result in multimodal uncertainties. Our simulation results show that uncertainty estimates in our framework adapt sample-wise against challenging operating conditions such as pronounced noise, limited training data, and limited parametric size of the prediction model. We also develop a reasoning framework that leverages these robust uncertainty estimates and incorporates optical flow-based reasoning to improve prediction prediction accuracy. Thus, by appropriately accounting for predictive uncertainties of data-driven learning and closing their estimation loop via rule-based reasoning, our methodology consistently surpasses conventional deep learning approaches on all these challenging scenarios--pronounced noise, limited training data, and limited model size-reducing the prediction error by 2-3x.
+
+
+
+ 58. 标题:Controllable Dynamic Appearance for Neural 3D Portraits
+ 编号:[215]
+ 链接:https://arxiv.org/abs/2309.11009
+ 作者:ShahRukh Athar, Zhixin Shu, Zexiang Xu, Fujun Luan, Sai Bi, Kalyan Sunkavalli, Dimitris Samaras
+ 备注:
+ 关键词:Neural Radiance Fields, Radiance Fields, Neural Radiance, Recent advances, viewing direction
+
+ 点击查看摘要
+ Recent advances in Neural Radiance Fields (NeRFs) have made it possible to reconstruct and reanimate dynamic portrait scenes with control over head-pose, facial expressions and viewing direction. However, training such models assumes photometric consistency over the deformed region e.g. the face must be evenly lit as it deforms with changing head-pose and facial expression. Such photometric consistency across frames of a video is hard to maintain, even in studio environments, thus making the created reanimatable neural portraits prone to artifacts during reanimation. In this work, we propose CoDyNeRF, a system that enables the creation of fully controllable 3D portraits in real-world capture conditions. CoDyNeRF learns to approximate illumination dependent effects via a dynamic appearance model in the canonical space that is conditioned on predicted surface normals and the facial expressions and head-pose deformations. The surface normals prediction is guided using 3DMM normals that act as a coarse prior for the normals of the human head, where direct prediction of normals is hard due to rigid and non-rigid deformations induced by head-pose and facial expression changes. Using only a smartphone-captured short video of a subject for training, we demonstrate the effectiveness of our method on free view synthesis of a portrait scene with explicit head pose and expression controls, and realistic lighting effects. The project page can be found here: this http URL
+
+
+
+ 59. 标题:STARNet: Sensor Trustworthiness and Anomaly Recognition via Approximated Likelihood Regret for Robust Edge Autonomy
+ 编号:[216]
+ 链接:https://arxiv.org/abs/2309.11006
+ 作者:Nastaran Darabi, Sina Tayebati, Sureshkumar S., Sathya Ravi, Theja Tulabandhula, Amit R. Trivedi
+ 备注:
+ 关键词:proliferated in autonomous, autonomous robotics, perception and understanding, Sensor, RADAR
+
+ 点击查看摘要
+ Complex sensors such as LiDAR, RADAR, and event cameras have proliferated in autonomous robotics to enhance perception and understanding of the environment. Meanwhile, these sensors are also vulnerable to diverse failure mechanisms that can intricately interact with their operation environment. In parallel, the limited availability of training data on complex sensors also affects the reliability of their deep learning-based prediction flow, where their prediction models can fail to generalize to environments not adequately captured in the training set. To address these reliability concerns, this paper introduces STARNet, a Sensor Trustworthiness and Anomaly Recognition Network designed to detect untrustworthy sensor streams that may arise from sensor malfunctions and/or challenging environments. We specifically benchmark STARNet on LiDAR and camera data. STARNet employs the concept of approximated likelihood regret, a gradient-free framework tailored for low-complexity hardware, especially those with only fixed-point precision capabilities. Through extensive simulations, we demonstrate the efficacy of STARNet in detecting untrustworthy sensor streams in unimodal and multimodal settings. In particular, the network shows superior performance in addressing internal sensor failures, such as cross-sensor interference and crosstalk. In diverse test scenarios involving adverse weather and sensor malfunctions, we show that STARNet enhances prediction accuracy by approximately 10% by filtering out untrustworthy sensor streams. STARNet is publicly available at \url{this https URL}.
+
+
+
+ 60. 标题:PPD: A New Valet Parking Pedestrian Fisheye Dataset for Autonomous Driving
+ 编号:[219]
+ 链接:https://arxiv.org/abs/2309.11002
+ 作者:Zizhang Wu, Xinyuan Chen, Fan Song, Yuanzhu Gan, Tianhao Xu, Jian Pu, Rui Tang
+ 备注:9 pages, 6 figures
+ 关键词:valet parking scenarios, autonomous driving, fundamental for autonomous, valet parking, parking scenarios
+
+ 点击查看摘要
+ Pedestrian detection under valet parking scenarios is fundamental for autonomous driving. However, the presence of pedestrians can be manifested in a variety of ways and postures under imperfect ambient conditions, which can adversely affect detection performance. Furthermore, models trained on publicdatasets that include pedestrians generally provide suboptimal outcomes for these valet parking scenarios. In this paper, wepresent the Parking Pedestrian Dataset (PPD), a large-scale fisheye dataset to support research dealing with real-world pedestrians, especially with occlusions and diverse postures. PPD consists of several distinctive types of pedestrians captured with fisheye cameras. Additionally, we present a pedestrian detection baseline on PPD dataset, and introduce two data augmentation techniques to improve the baseline by enhancing the diversity ofthe original dataset. Extensive experiments validate the effectiveness of our novel data augmentation approaches over baselinesand the dataset's exceptional generalizability.
+
+
+
+ 61. 标题:COSE: A Consistency-Sensitivity Metric for Saliency on Image Classification
+ 编号:[224]
+ 链接:https://arxiv.org/abs/2309.10989
+ 作者:Rangel Daroya, Aaron Sun, Subhransu Maji
+ 备注:
+ 关键词:utilize vision priors, image classification tasks, classification tasks, saliency methods, present a set
+
+ 点击查看摘要
+ We present a set of metrics that utilize vision priors to effectively assess the performance of saliency methods on image classification tasks. To understand behavior in deep learning models, many methods provide visual saliency maps emphasizing image regions that most contribute to a model prediction. However, there is limited work on analyzing the reliability of saliency methods in explaining model decisions. We propose the metric COnsistency-SEnsitivity (COSE) that quantifies the equivariant and invariant properties of visual model explanations using simple data augmentations. Through our metrics, we show that although saliency methods are thought to be architecture-independent, most methods could better explain transformer-based models over convolutional-based models. In addition, GradCAM was found to outperform other methods in terms of COSE but was shown to have limitations such as lack of variability for fine-grained datasets. The duality between consistency and sensitivity allow the analysis of saliency methods from different angles. Ultimately, we find that it is important to balance these two metrics for a saliency map to faithfully show model behavior.
+
+
+
+ 62. 标题:Spiking NeRF: Making Bio-inspired Neural Networks See through the Real World
+ 编号:[225]
+ 链接:https://arxiv.org/abs/2309.10987
+ 作者:Xingting Yao, Qinghao Hu, Tielong Liu, Zitao Mo, Zeyu Zhu, Zhengyang Zhuge, Jian Cheng
+ 备注:
+ 关键词:biologically plausible intelligence, Neural Radiance Fields, Spiking neuron networks, promising energy efficiency, Radiance Fields
+
+ 点击查看摘要
+ Spiking neuron networks (SNNs) have been thriving on numerous tasks to leverage their promising energy efficiency and exploit their potentialities as biologically plausible intelligence. Meanwhile, the Neural Radiance Fields (NeRF) render high-quality 3D scenes with massive energy consumption, and few works delve into the energy-saving solution with a bio-inspired approach. In this paper, we propose spiking NeRF (SpikingNeRF), which aligns the radiance ray with the temporal dimension of SNN, to naturally accommodate the SNN to the reconstruction of Radiance Fields. Thus, the computation turns into a spike-based, multiplication-free manner, reducing the energy consumption. In SpikingNeRF, each sampled point on the ray is matched onto a particular time step, and represented in a hybrid manner where the voxel grids are maintained as well. Based on the voxel grids, sampled points are determined whether to be masked for better training and inference. However, this operation also incurs irregular temporal length. We propose the temporal condensing-and-padding (TCP) strategy to tackle the masked samples to maintain regular temporal length, i.e., regular tensors, for hardware-friendly computation. Extensive experiments on a variety of datasets demonstrate that our method reduces the $76.74\%$ energy consumption on average and obtains comparable synthesis quality with the ANN baseline.
+
+
+
+ 63. 标题:SEMPART: Self-supervised Multi-resolution Partitioning of Image Semantics
+ 编号:[235]
+ 链接:https://arxiv.org/abs/2309.10972
+ 作者:Sriram Ravindran, Debraj Basu
+ 备注:
+ 关键词:Accurately determining salient, determining salient regions, Accurately determining, data is scarce, challenging when labeled
+
+ 点击查看摘要
+ Accurately determining salient regions of an image is challenging when labeled data is scarce. DINO-based self-supervised approaches have recently leveraged meaningful image semantics captured by patch-wise features for locating foreground objects. Recent methods have also incorporated intuitive priors and demonstrated value in unsupervised methods for object partitioning. In this paper, we propose SEMPART, which jointly infers coarse and fine bi-partitions over an image's DINO-based semantic graph. Furthermore, SEMPART preserves fine boundary details using graph-driven regularization and successfully distills the coarse mask semantics into the fine mask. Our salient object detection and single object localization findings suggest that SEMPART produces high-quality masks rapidly without additional post-processing and benefits from co-optimizing the coarse and fine branches.
+
+
+
+ 64. 标题:A Novel Deep Neural Network for Trajectory Prediction in Automated Vehicles Using Velocity Vector Field
+ 编号:[240]
+ 链接:https://arxiv.org/abs/2309.10948
+ 作者:MReza Alipour Sormoli, Amir Samadi, Sajjad Mozaffari, Konstantinos Koufos, Mehrdad Dianati, Roger Woodman
+ 备注:This paper has been accepted and nominated as the best student paper at the 26th IEEE International Conference on Intelligent Transportation Systems (ITSC 2023)
+ 关键词:automated driving systems, informed downstream decision-making, driving systems, road users, users is crucial
+
+ 点击查看摘要
+ Anticipating the motion of other road users is crucial for automated driving systems (ADS), as it enables safe and informed downstream decision-making and motion planning. Unfortunately, contemporary learning-based approaches for motion prediction exhibit significant performance degradation as the prediction horizon increases or the observation window decreases. This paper proposes a novel technique for trajectory prediction that combines a data-driven learning-based method with a velocity vector field (VVF) generated from a nature-inspired concept, i.e., fluid flow dynamics. In this work, the vector field is incorporated as an additional input to a convolutional-recurrent deep neural network to help predict the most likely future trajectories given a sequence of bird's eye view scene representations. The performance of the proposed model is compared with state-of-the-art methods on the HighD dataset demonstrating that the VVF inclusion improves the prediction accuracy for both short and long-term (5~sec) time horizons. It is also shown that the accuracy remains consistent with decreasing observation windows which alleviates the requirement of a long history of past observations for accurate trajectory prediction. Source codes are available at: this https URL.
+
+
+
+ 65. 标题:A Geometric Flow Approach for Segmentation of Images with Inhomongeneous Intensity and Missing Boundaries
+ 编号:[246]
+ 链接:https://arxiv.org/abs/2309.10935
+ 作者:Paramjyoti Mohapatra, Richard Lartey, Weihong Guo, Michael Judkovich, Xiaojuan Li
+ 备注:Presented at CVIT 2023 Conference. Accepted to Journal of Image and Graphics
+ 关键词:complex mathematical problem, tightly packed objects, mathematical problem, complex mathematical, tightly packed
+
+ 点击查看摘要
+ Image segmentation is a complex mathematical problem, especially for images that contain intensity inhomogeneity and tightly packed objects with missing boundaries in between. For instance, Magnetic Resonance (MR) muscle images often contain both of these issues, making muscle segmentation especially difficult. In this paper we propose a novel intensity correction and a semi-automatic active contour based segmentation approach. The approach uses a geometric flow that incorporates a reproducing kernel Hilbert space (RKHS) edge detector and a geodesic distance penalty term from a set of markers and anti-markers. We test the proposed scheme on MR muscle segmentation and compare with some state of the art methods. To help deal with the intensity inhomogeneity in this particular kind of image, a new approach to estimate the bias field using a fat fraction image, called Prior Bias-Corrected Fuzzy C-means (PBCFCM), is introduced. Numerical experiments show that the proposed scheme leads to significantly better results than compared ones. The average dice values of the proposed method are 92.5%, 85.3%, 85.3% for quadriceps, hamstrings and other muscle groups while other approaches are at least 10% worse.
+
+
+
+ 66. 标题:Incremental Multimodal Surface Mapping via Self-Organizing Gaussian Mixture Models
+ 编号:[263]
+ 链接:https://arxiv.org/abs/2309.10900
+ 作者:Kshitij Goel, Wennie Tabib
+ 备注:7 pages, 7 figures, under review at IEEE Robotics and Automation Letters
+ 关键词:continuous probabilistic model, surface mapping methodology, incremental multimodal surface, multimodal surface mapping, multimodal surface
+
+ 点击查看摘要
+ This letter describes an incremental multimodal surface mapping methodology, which represents the environment as a continuous probabilistic model. This model enables high-resolution reconstruction while simultaneously compressing spatial and intensity point cloud data. The strategy employed in this work utilizes Gaussian mixture models (GMMs) to represent the environment. While prior GMM-based mapping works have developed methodologies to determine the number of mixture components using information-theoretic techniques, these approaches either operate on individual sensor observations, making them unsuitable for incremental mapping, or are not real-time viable, especially for applications where high-fidelity modeling is required. To bridge this gap, this letter introduces a spatial hash map for rapid GMM submap extraction combined with an approach to determine relevant and redundant data in a point cloud. These contributions increase computational speed by an order of magnitude compared to state-of-the-art incremental GMM-based mapping. In addition, the proposed approach yields a superior tradeoff in map accuracy and size when compared to state-of-the-art mapping methodologies (both GMM- and not GMM-based). Evaluations are conducted using both simulated and real-world data. The software is released open-source to benefit the robotics community.
+
+
+
+ 67. 标题:PLVS: A SLAM System with Points, Lines, Volumetric Mapping, and 3D Incremental Segmentation
+ 编号:[266]
+ 链接:https://arxiv.org/abs/2309.10896
+ 作者:Luigi Freda
+ 备注:
+ 关键词:leverages sparse SLAM, volumetric mapping, unsupervised incremental segmentation, document presents PLVS, real-time system
+
+ 点击查看摘要
+ This document presents PLVS: a real-time system that leverages sparse SLAM, volumetric mapping, and 3D unsupervised incremental segmentation. PLVS stands for Points, Lines, Volumetric mapping, and Segmentation. It supports RGB-D and Stereo cameras, which may be optionally equipped with IMUs. The SLAM module is keyframe-based, and extracts and tracks sparse points and line segments as features. Volumetric mapping runs in parallel with respect to the SLAM front-end and generates a 3D reconstruction of the explored environment by fusing point clouds backprojected from keyframes. Different volumetric mapping methods are supported and integrated in PLVS. We use a novel reprojection error to bundle-adjust line segments. This error exploits available depth information to stabilize the position estimates of line segment endpoints. An incremental and geometric-based segmentation method is implemented and integrated for RGB-D cameras in the PLVS framework. We present qualitative and quantitative evaluations of the PLVS framework on some publicly available datasets. The appendix details the adopted stereo line triangulation method and provides a derivation of the Jacobians we used for line error terms. The software is available as open-source.
+
+
+
+ 68. 标题:GelSight Svelte: A Human Finger-shaped Single-camera Tactile Robot Finger with Large Sensing Coverage and Proprioceptive Sensing
+ 编号:[274]
+ 链接:https://arxiv.org/abs/2309.10885
+ 作者:Jialiang Zhao, Edward H. Adelson
+ 备注:Submitted and accepted to 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2023)
+ 关键词:obtain highly detailed, camera-based tactile sensors, highly detailed contact, GelSight Svelte, Camera-based tactile
+
+ 点击查看摘要
+ Camera-based tactile sensing is a low-cost, popular approach to obtain highly detailed contact geometry information. However, most existing camera-based tactile sensors are fingertip sensors, and longer fingers often require extraneous elements to obtain an extended sensing area similar to the full length of a human finger. Moreover, existing methods to estimate proprioceptive information such as total forces and torques applied on the finger from camera-based tactile sensors are not effective when the contact geometry is complex. We introduce GelSight Svelte, a curved, human finger-sized, single-camera tactile sensor that is capable of both tactile and proprioceptive sensing over a large area. GelSight Svelte uses curved mirrors to achieve the desired shape and sensing coverage. Proprioceptive information, such as the total bending and twisting torques applied on the finger, is reflected as deformations on the flexible backbone of GelSight Svelte, which are also captured by the camera. We train a convolutional neural network to estimate the bending and twisting torques from the captured images. We conduct gel deformation experiments at various locations of the finger to evaluate the tactile sensing capability and proprioceptive sensing accuracy. To demonstrate the capability and potential uses of GelSight Svelte, we conduct an object holding task with three different grasping modes that utilize different areas of the finger. More information is available on our website: this https URL
+
+
+
+ 69. 标题:DeepliteRT: Computer Vision at the Edge
+ 编号:[277]
+ 链接:https://arxiv.org/abs/2309.10878
+ 作者:Saad Ashfaq, Alexander Hoffman, Saptarshi Mitra, Sudhakar Sah, MohammadHossein AskariHemmat, Ehsan Saboori
+ 备注:Accepted at British Machine Vision Conference (BMVC) 2023
+ 关键词:computer vision applications, unlocked unprecedented opportunities, deep learning model, vision applications, unlocked unprecedented
+
+ 点击查看摘要
+ The proliferation of edge devices has unlocked unprecedented opportunities for deep learning model deployment in computer vision applications. However, these complex models require considerable power, memory and compute resources that are typically not available on edge platforms. Ultra low-bit quantization presents an attractive solution to this problem by scaling down the model weights and activations from 32-bit to less than 8-bit. We implement highly optimized ultra low-bit convolution operators for ARM-based targets that outperform existing methods by up to 4.34x. Our operator is implemented within Deeplite Runtime (DeepliteRT), an end-to-end solution for the compilation, tuning, and inference of ultra low-bit models on ARM devices. Compiler passes in DeepliteRT automatically convert a fake-quantized model in full precision to a compact ultra low-bit representation, easing the process of quantized model deployment on commodity hardware. We analyze the performance of DeepliteRT on classification and detection models against optimized 32-bit floating-point, 8-bit integer, and 2-bit baselines, achieving significant speedups of up to 2.20x, 2.33x and 2.17x, respectively.
+
+
+
+ 70. 标题:On-device Real-time Custom Hand Gesture Recognition
+ 编号:[281]
+ 链接:https://arxiv.org/abs/2309.10858
+ 作者:Esha Uboweja, David Tian, Qifei Wang, Yi-Chun Kuo, Joe Zou, Lu Wang, George Sung, Matthias Grundmann
+ 备注:5 pages, 6 figures; Accepted to ICCV Workshop on Computer Vision for Metaverse, Paris, France, 2023
+ 关键词:existing hand gesture, gesture recognition, gesture, custom gesture recognition, hand gesture recognition
+
+ 点击查看摘要
+ Most existing hand gesture recognition (HGR) systems are limited to a predefined set of gestures. However, users and developers often want to recognize new, unseen gestures. This is challenging due to the vast diversity of all plausible hand shapes, e.g. it is impossible for developers to include all hand gestures in a predefined list. In this paper, we present a user-friendly framework that lets users easily customize and deploy their own gesture recognition pipeline. Our framework provides a pre-trained single-hand embedding model that can be fine-tuned for custom gesture recognition. Users can perform gestures in front of a webcam to collect a small amount of images per gesture. We also offer a low-code solution to train and deploy the custom gesture recognition model. This makes it easy for users with limited ML expertise to use our framework. We further provide a no-code web front-end for users without any ML expertise. This makes it even easier to build and test the end-to-end pipeline. The resulting custom HGR is then ready to be run on-device for real-time scenarios. This can be done by calling a simple function in our open-sourced model inference API, MediaPipe Tasks. This entire process only takes a few minutes.
+
+
+
+ 71. 标题:CMRxRecon: An open cardiac MRI dataset for the competition of accelerated image reconstruction
+ 编号:[283]
+ 链接:https://arxiv.org/abs/2309.10836
+ 作者:Chengyan Wang, Jun Lyu, Shuo Wang, Chen Qin, Kunyuan Guo, Xinyu Zhang, Xiaotong Yu, Yan Li, Fanwen Wang, Jianhua Jin, Zhang Shi, Ziqiang Xu, Yapeng Tian, Sha Hua, Zhensen Chen, Meng Liu, Mengting Sun, Xutong Kuang, Kang Wang, Haoran Wang, Hao Li, Yinghua Chu, Guang Yang, Wenjia Bai, Xiahai Zhuang, He Wang, Jing Qin, Xiaobo Qu
+ 备注:14 pages, 8 figures
+ 关键词:valuable diagnostic tool, magnetic resonance imaging, Cardiac magnetic resonance, CMR, magnetic resonance
+
+ 点击查看摘要
+ Cardiac magnetic resonance imaging (CMR) has emerged as a valuable diagnostic tool for cardiac diseases. However, a limitation of CMR is its slow imaging speed, which causes patient discomfort and introduces artifacts in the images. There has been growing interest in deep learning-based CMR imaging algorithms that can reconstruct high-quality images from highly under-sampled k-space data. However, the development of deep learning methods requires large training datasets, which have not been publicly available for CMR. To address this gap, we released a dataset that includes multi-contrast, multi-view, multi-slice and multi-coil CMR imaging data from 300 subjects. Imaging studies include cardiac cine and mapping sequences. Manual segmentations of the myocardium and chambers of all the subjects are also provided within the dataset. Scripts of state-of-the-art reconstruction algorithms were also provided as a point of reference. Our aim is to facilitate the advancement of state-of-the-art CMR image reconstruction by introducing standardized evaluation criteria and making the dataset freely accessible to the research community. Researchers can access the dataset at this https URL.
+
+
+
+ 72. 标题:Sparser Random Networks Exist: Enforcing Communication-Efficient Federated Learning via Regularization
+ 编号:[284]
+ 链接:https://arxiv.org/abs/2309.10834
+ 作者:Mohamad Mestoukirdi, Omid Esrafilian, David Gesbert, Qianrui Li, Nicolas Gresset
+ 备注:Draft to be submitted
+ 关键词:trains over-parameterized random, over-parameterized random networks, work presents, trains over-parameterized, over-parameterized random
+
+ 点击查看摘要
+ This work presents a new method for enhancing communication efficiency in stochastic Federated Learning that trains over-parameterized random networks. In this setting, a binary mask is optimized instead of the model weights, which are kept fixed. The mask characterizes a sparse sub-network that is able to generalize as good as a smaller target network. Importantly, sparse binary masks are exchanged rather than the floating point weights in traditional federated learning, reducing communication cost to at most 1 bit per parameter. We show that previous state of the art stochastic methods fail to find the sparse networks that can reduce the communication and storage overhead using consistent loss objectives. To address this, we propose adding a regularization term to local objectives that encourages sparser solutions by eliminating redundant features across sub-networks. Extensive experiments demonstrate significant improvements in communication and memory efficiency of up to five magnitudes compared to the literature, with minimal performance degradation in validation accuracy in some instances.
+
+
+
+ 73. 标题:CalibFPA: A Focal Plane Array Imaging System based on Online Deep-Learning Calibration
+ 编号:[292]
+ 链接:https://arxiv.org/abs/2309.11421
+ 作者:Alper Güngör, M. Umut Bahceci, Yasin Ergen, Ahmet Sözak, O. Oner Ekiz, Tolga Yelboga, Tolga Çukur
+ 备注:
+ 关键词:enable cost-effective high-resolution, focal plane arrays, Compressive focal plane, plane arrays, enable cost-effective
+
+ 点击查看摘要
+ Compressive focal plane arrays (FPA) enable cost-effective high-resolution (HR) imaging by acquisition of several multiplexed measurements on a low-resolution (LR) sensor. Multiplexed encoding of the visual scene is typically performed via electronically controllable spatial light modulators (SLM). An HR image is then reconstructed from the encoded measurements by solving an inverse problem that involves the forward model of the imaging system. To capture system non-idealities such as optical aberrations, a mainstream approach is to conduct an offline calibration scan to measure the system response for a point source at each spatial location on the imaging grid. However, it is challenging to run calibration scans when using structured SLMs as they cannot encode individual grid locations. In this study, we propose a novel compressive FPA system based on online deep-learning calibration of multiplexed LR measurements (CalibFPA). We introduce a piezo-stage that locomotes a pre-printed fixed coded aperture. A deep neural network is then leveraged to correct for the influences of system non-idealities in multiplexed measurements without the need for offline calibration scans. Finally, a deep plug-and-play algorithm is used to reconstruct images from corrected measurements. On simulated and experimental datasets, we demonstrate that CalibFPA outperforms state-of-the-art compressive FPA methods. We also report analyses to validate the design elements in CalibFPA and assess computational complexity.
+
+
+
+ 74. 标题:More complex encoder is not all you need
+ 编号:[302]
+ 链接:https://arxiv.org/abs/2309.11139
+ 作者:Weibin Yang, Longwei Xu, Pengwei Wang, Dehua Geng, Yusong Li, Mingyuan Xu, Zhiqi Dong
+ 备注:
+ 关键词:medical image segmentation, current U-Net variants, U-Net variants confine, encoder, complex encoder U-Net
+
+ 点击查看摘要
+ U-Net and its variants have been widely used in medical image segmentation. However, most current U-Net variants confine their improvement strategies to building more complex encoder, while leaving the decoder unchanged or adopting a simple symmetric structure. These approaches overlook the true functionality of the decoder: receiving low-resolution feature maps from the encoder and restoring feature map resolution and lost information through upsampling. As a result, the decoder, especially its upsampling component, plays a crucial role in enhancing segmentation outcomes. However, in 3D medical image segmentation, the commonly used transposed convolution can result in visual artifacts. This issue stems from the absence of direct relationship between adjacent pixels in the output feature map. Furthermore, plain encoder has already possessed sufficient feature extraction capability because downsampling operation leads to the gradual expansion of the receptive field, but the loss of information during downsampling process is unignorable. To address the gap in relevant research, we extend our focus beyond the encoder and introduce neU-Net (i.e., not complex encoder U-Net), which incorporates a novel Sub-pixel Convolution for upsampling to construct a powerful decoder. Additionally, we introduce multi-scale wavelet inputs module on the encoder side to provide additional information. Our model design achieves excellent results, surpassing other state-of-the-art methods on both the Synapse and ACDC datasets.
+
+
+
+ 75. 标题:Analysing race and sex bias in brain age prediction
+ 编号:[322]
+ 链接:https://arxiv.org/abs/2309.10835
+ 作者:Carolina Piçarra, Ben Glocker
+ 备注:MICCAI Workshop on Fairness of AI in Medical Imaging (FAIMI 2023)
+ 关键词:popular imaging biomarker, Brain age prediction, age prediction models, Brain age, age prediction
+
+ 点击查看摘要
+ Brain age prediction from MRI has become a popular imaging biomarker associated with a wide range of neuropathologies. The datasets used for training, however, are often skewed and imbalanced regarding demographics, potentially making brain age prediction models susceptible to bias. We analyse the commonly used ResNet-34 model by conducting a comprehensive subgroup performance analysis and feature inspection. The model is trained on 1,215 T1-weighted MRI scans from Cam-CAN and IXI, and tested on UK Biobank (n=42,786), split into six racial and biological sex subgroups. With the objective of comparing the performance between subgroups, measured by the absolute prediction error, we use a Kruskal-Wallis test followed by two post-hoc Conover-Iman tests to inspect bias across race and biological sex. To examine biases in the generated features, we use PCA for dimensionality reduction and employ two-sample Kolmogorov-Smirnov tests to identify distribution shifts among subgroups. Our results reveal statistically significant differences in predictive performance between Black and White, Black and Asian, and male and female subjects. Seven out of twelve pairwise comparisons show statistically significant differences in the feature distributions. Our findings call for further analysis of brain age prediction models.
+
+
+
+ 76. 标题:Comparative study of Deep Learning Models for Binary Classification on Combined Pulmonary Chest X-ray Dataset
+ 编号:[323]
+ 链接:https://arxiv.org/abs/2309.10829
+ 作者:Shabbir Ahmed Shuvo, Md Aminul Islam, Md. Mozammel Hoque, Rejwan Bin Sulaiman
+ 备注:
+ 关键词:CNN-based deep learning, deep learning models, deep learning, prominent deep learning, popular recently
+
+ 点击查看摘要
+ CNN-based deep learning models for disease detection have become popular recently. We compared the binary classification performance of eight prominent deep learning models: DenseNet 121, DenseNet 169, DenseNet 201, EffecientNet b0, EffecientNet lite4, GoogleNet, MobileNet, and ResNet18 for their binary classification performance on combined Pulmonary Chest Xrays dataset. Despite the widespread application in different fields in medical images, there remains a knowledge gap in determining their relative performance when applied to the same dataset, a gap this study aimed to address. The dataset combined Shenzhen, China (CH) and Montgomery, USA (MC) data. We trained our model for binary classification, calculated different parameters of the mentioned models, and compared them. The models were trained to keep in mind all following the same training parameters to maintain a controlled comparison environment. End of the study, we found a distinct difference in performance among the other models when applied to the pulmonary chest Xray image dataset, where DenseNet169 performed with 89.38 percent and MobileNet with 92.2 percent precision.
+Keywords: Pulmonary, Deep Learning, Tuberculosis, Disease detection, Xray
+
+
+自然语言处理
+
+ 1. 标题:DreamLLM: Synergistic Multimodal Comprehension and Creation
+ 编号:[2]
+ 链接:https://arxiv.org/abs/2309.11499
+ 作者:Runpei Dong, Chunrui Han, Yuang Peng, Zekun Qi, Zheng Ge, Jinrong Yang, Liang Zhao, Jianjian Sun, Hongyu Zhou, Haoran Wei, Xiangwen Kong, Xiangyu Zhang, Kaisheng Ma, Li Yi
+ 备注:see project page at this https URL
+ 关键词:Large Language Models, versatile Multimodal Large, Multimodal Large Language, Language Models, Large Language
+
+ 点击查看摘要
+ This paper presents DreamLLM, a learning framework that first achieves versatile Multimodal Large Language Models (MLLMs) empowered with frequently overlooked synergy between multimodal comprehension and creation. DreamLLM operates on two fundamental principles. The first focuses on the generative modeling of both language and image posteriors by direct sampling in the raw multimodal space. This approach circumvents the limitations and information loss inherent to external feature extractors like CLIP, and a more thorough multimodal understanding is obtained. Second, DreamLLM fosters the generation of raw, interleaved documents, modeling both text and image contents, along with unstructured layouts. This allows DreamLLM to learn all conditional, marginal, and joint multimodal distributions effectively. As a result, DreamLLM is the first MLLM capable of generating free-form interleaved content. Comprehensive experiments highlight DreamLLM's superior performance as a zero-shot multimodal generalist, reaping from the enhanced learning synergy.
+
+
+
+ 2. 标题:Chain-of-Verification Reduces Hallucination in Large Language Models
+ 编号:[4]
+ 链接:https://arxiv.org/abs/2309.11495
+ 作者:Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, Jason Weston
+ 备注:
+ 关键词:incorrect factual information, large language models, factual information, plausible yet incorrect, incorrect factual
+
+ 点击查看摘要
+ Generation of plausible yet incorrect factual information, termed hallucination, is an unsolved issue in large language models. We study the ability of language models to deliberate on the responses they give in order to correct their mistakes. We develop the Chain-of-Verification (CoVe) method whereby the model first (i) drafts an initial response; then (ii) plans verification questions to fact-check its draft; (iii) answers those questions independently so the answers are not biased by other responses; and (iv) generates its final verified response. In experiments, we show CoVe decreases hallucinations across a variety of tasks, from list-based questions from Wikidata, closed book MultiSpanQA and longform text generation.
+
+
+
+ 3. 标题:Text2Reward: Automated Dense Reward Function Generation for Reinforcement Learning
+ 编号:[5]
+ 链接:https://arxiv.org/abs/2309.11489
+ 作者:Tianbao Xie, Siheng Zhao, Chen Henry Wu, Yitao Liu, Qian Luo, Victor Zhong, Yanchao Yang, Tao Yu
+ 备注:23 pages, 10 figures, update
+ 关键词:requires specialized knowledge, Designing reward functions, reward functions, dense reward functions, reinforcement learning
+
+ 点击查看摘要
+ Designing reward functions is a longstanding challenge in reinforcement learning (RL); it requires specialized knowledge or domain data, leading to high costs for development. To address this, we introduce Text2Reward, a data-free framework that automates the generation of dense reward functions based on large language models (LLMs). Given a goal described in natural language, Text2Reward generates dense reward functions as an executable program grounded in a compact representation of the environment. Unlike inverse RL and recent work that uses LLMs to write sparse reward codes, Text2Reward produces interpretable, free-form dense reward codes that cover a wide range of tasks, utilize existing packages, and allow iterative refinement with human feedback. We evaluate Text2Reward on two robotic manipulation benchmarks (ManiSkill2, MetaWorld) and two locomotion environments of MuJoCo. On 13 of the 17 manipulation tasks, policies trained with generated reward codes achieve similar or better task success rates and convergence speed than expert-written reward codes. For locomotion tasks, our method learns six novel locomotion behaviors with a success rate exceeding 94%. Furthermore, we show that the policies trained in the simulator with our method can be deployed in the real world. Finally, Text2Reward further improves the policies by refining their reward functions with human feedback. Video results are available at this https URL
+
+
+
+ 4. 标题:Controlled Generation with Prompt Insertion for Natural Language Explanations in Grammatical Error Correction
+ 编号:[25]
+ 链接:https://arxiv.org/abs/2309.11439
+ 作者:Masahiro Kaneko, Naoaki Okazaki
+ 备注:Work in progress
+ 关键词:Grammatical Error Correction, Grammatical Error, Error Correction, Correction, correction points
+
+ 点击查看摘要
+ In Grammatical Error Correction (GEC), it is crucial to ensure the user's comprehension of a reason for correction. Existing studies present tokens, examples, and hints as to the basis for correction but do not directly explain the reasons for corrections. Although methods that use Large Language Models (LLMs) to provide direct explanations in natural language have been proposed for various tasks, no such method exists for GEC. Generating explanations for GEC corrections involves aligning input and output tokens, identifying correction points, and presenting corresponding explanations consistently. However, it is not straightforward to specify a complex format to generate explanations, because explicit control of generation is difficult with prompts. This study introduces a method called controlled generation with Prompt Insertion (PI) so that LLMs can explain the reasons for corrections in natural language. In PI, LLMs first correct the input text, and then we automatically extract the correction points based on the rules. The extracted correction points are sequentially inserted into the LLM's explanation output as prompts, guiding the LLMs to generate explanations for the correction points. We also create an Explainable GEC (XGEC) dataset of correction reasons by annotating NUCLE, CoNLL2013, and CoNLL2014. Although generations from GPT-3 and ChatGPT using original prompts miss some correction points, the generation control using PI can explicitly guide to describe explanations for all correction points, contributing to improved performance in generating correction reasons.
+
+
+
+ 5. 标题:You Only Look at Screens: Multimodal Chain-of-Action Agents
+ 编号:[26]
+ 链接:https://arxiv.org/abs/2309.11436
+ 作者:Zhuosheng Zhang, Aston Zhang
+ 备注:21 pages, 10 figures
+ 关键词:Autonomous user interface, facilitate task automation, Autonomous user, user interface, manual intervention
+
+ 点击查看摘要
+ Autonomous user interface (UI) agents aim to facilitate task automation by interacting with the user interface without manual intervention. Recent studies have investigated eliciting the capabilities of large language models (LLMs) for effective engagement in diverse environments. To align with the input-output requirement of LLMs, existing approaches are developed under a sandbox setting where they rely on external tools and application-specific APIs to parse the environment into textual elements and interpret the predicted actions. Consequently, those approaches often grapple with inference inefficiency and error propagation risks. To mitigate the challenges, we introduce Auto-UI, a multimodal solution that directly interacts with the interface, bypassing the need for environment parsing or reliance on application-dependent APIs. Moreover, we propose a chain-of-action technique -- leveraging a series of intermediate previous action histories and future action plans -- to help the agent decide what action to execute. We evaluate our approach on a new device-control benchmark AITW with 30K unique instructions, spanning multi-step tasks such as application operation, web searching, and web shopping. Experimental results show that Auto-UI achieves state-of-the-art performance with an action type prediction accuracy of 90% and an overall action success rate of 74%. Code is publicly available at this https URL.
+
+
+
+ 6. 标题:Kosmos-2.5: A Multimodal Literate Model
+ 编号:[30]
+ 链接:https://arxiv.org/abs/2309.11419
+ 作者:Tengchao Lv, Yupan Huang, Jingye Chen, Lei Cui, Shuming Ma, Yaoyao Chang, Shaohan Huang, Wenhui Wang, Li Dong, Weiyao Luo, Shaoxiang Wu, Guoxin Wang, Cha Zhang, Furu Wei
+ 备注:
+ 关键词:machine reading, text-intensive images, text, large-scale text-intensive images, multimodal literate
+
+ 点击查看摘要
+ We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.
+
+
+
+ 7. 标题:Safurai 001: New Qualitative Approach for Code LLM Evaluation
+ 编号:[40]
+ 链接:https://arxiv.org/abs/2309.11385
+ 作者:Davide Cifarelli, Leonardo Boiardi, Alessandro Puppo
+ 备注:22 pages, 1 figure, 3 tables
+ 关键词:Large Language Model, Large Language, coding LLMs, Language Model, significant potential
+
+ 点击查看摘要
+ This paper presents Safurai-001, a new Large Language Model (LLM) with significant potential in the domain of coding assistance. Driven by recent advancements in coding LLMs, Safurai-001 competes in performance with the latest models like WizardCoder [Xu et al., 2023], PanguCoder [Shen et al., 2023] and Phi-1 [Gunasekar et al., 2023] but aims to deliver a more conversational interaction. By capitalizing on the progress in data engineering (including latest techniques of data transformation and prompt engineering) and instruction tuning, this new model promises to stand toe-to-toe with recent closed and open source developments. Recognizing the need for an efficacious evaluation metric for coding LLMs, this paper also introduces GPT4-based MultiParameters, an evaluation benchmark that harnesses varied parameters to present a comprehensive insight into the models functioning and performance. Our assessment shows that Safurai-001 can outperform GPT-3.5 by 1.58% and WizardCoder by 18.78% in the Code Readability parameter and more.
+
+
+
+ 8. 标题:Long-Form End-to-End Speech Translation via Latent Alignment Segmentation
+ 编号:[41]
+ 链接:https://arxiv.org/abs/2309.11384
+ 作者:Peter Polák, Ondřej Bojar
+ 备注:This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible
+ 关键词:process audio, speech translation, segmentation, speech, simultaneous speech translation
+
+ 点击查看摘要
+ Current simultaneous speech translation models can process audio only up to a few seconds long. Contemporary datasets provide an oracle segmentation into sentences based on human-annotated transcripts and translations. However, the segmentation into sentences is not available in the real world. Current speech segmentation approaches either offer poor segmentation quality or have to trade latency for quality. In this paper, we propose a novel segmentation approach for a low-latency end-to-end speech translation. We leverage the existing speech translation encoder-decoder architecture with ST CTC and show that it can perform the segmentation task without supervision or additional parameters. To the best of our knowledge, our method is the first that allows an actual end-to-end simultaneous speech translation, as the same model is used for translation and segmentation at the same time. On a diverse set of language pairs and in- and out-of-domain data, we show that the proposed approach achieves state-of-the-art quality at no additional computational cost.
+
+
+
+ 9. 标题:Discuss Before Moving: Visual Language Navigation via Multi-expert Discussions
+ 编号:[42]
+ 链接:https://arxiv.org/abs/2309.11382
+ 作者:Yuxing Long, Xiaoqi Li, Wenzhe Cai, Hao Dong
+ 备注:Submitted to ICRA 2024
+ 关键词:skills encompassing understanding, embodied task demanding, demanding a wide, wide range, range of skills
+
+ 点击查看摘要
+ Visual language navigation (VLN) is an embodied task demanding a wide range of skills encompassing understanding, perception, and planning. For such a multifaceted challenge, previous VLN methods totally rely on one model's own thinking to make predictions within one round. However, existing models, even the most advanced large language model GPT4, still struggle with dealing with multiple tasks by single-round self-thinking. In this work, drawing inspiration from the expert consultation meeting, we introduce a novel zero-shot VLN framework. Within this framework, large models possessing distinct abilities are served as domain experts. Our proposed navigation agent, namely DiscussNav, can actively discuss with these experts to collect essential information before moving at every step. These discussions cover critical navigation subtasks like instruction understanding, environment perception, and completion estimation. Through comprehensive experiments, we demonstrate that discussions with domain experts can effectively facilitate navigation by perceiving instruction-relevant information, correcting inadvertent errors, and sifting through in-consistent movement decisions. The performances on the representative VLN task R2R show that our method surpasses the leading zero-shot VLN model by a large margin on all metrics. Additionally, real-robot experiments display the obvious advantages of our method over single-round self-thinking.
+
+
+
+ 10. 标题:Studying Lobby Influence in the European Parliament
+ 编号:[43]
+ 链接:https://arxiv.org/abs/2309.11381
+ 作者:Aswin Suresh, Lazar Radojevic, Francesco Salvi, Antoine Magron, Victor Kristof, Matthias Grossglauser
+ 备注:11 pages, 5 figures. Under review for presentation at ICWSM 2024
+ 关键词:European Parliament, natural language processing, language processing, based on natural, natural language
+
+ 点击查看摘要
+ We present a method based on natural language processing (NLP), for studying the influence of interest groups (lobbies) in the law-making process in the European Parliament (EP). We collect and analyze novel datasets of lobbies' position papers and speeches made by members of the EP (MEPs). By comparing these texts on the basis of semantic similarity and entailment, we are able to discover interpretable links between MEPs and lobbies. In the absence of a ground-truth dataset of such links, we perform an indirect validation by comparing the discovered links with a dataset, which we curate, of retweet links between MEPs and lobbies, and with the publicly disclosed meetings of MEPs. Our best method achieves an AUC score of 0.77 and performs significantly better than several baselines. Moreover, an aggregate analysis of the discovered links, between groups of related lobbies and political groups of MEPs, correspond to the expectations from the ideology of the groups (e.g., center-left groups are associated with social causes). We believe that this work, which encompasses the methodology, datasets, and results, is a step towards enhancing the transparency of the intricate decision-making processes within democratic institutions.
+
+
+
+ 11. 标题:Incremental Blockwise Beam Search for Simultaneous Speech Translation with Controllable Quality-Latency Tradeoff
+ 编号:[44]
+ 链接:https://arxiv.org/abs/2309.11379
+ 作者:Peter Polák, Brian Yan, Shinji Watanabe, Alex Waibel, Ondřej Bojar
+ 备注:Accepted at INTERSPEECH 2023
+ 关键词:Blockwise self-attentional encoder, self-attentional encoder models, approach to simultaneous, self-attentional encoder, recently emerged
+
+ 点击查看摘要
+ Blockwise self-attentional encoder models have recently emerged as one promising end-to-end approach to simultaneous speech translation. These models employ a blockwise beam search with hypothesis reliability scoring to determine when to wait for more input speech before translating further. However, this method maintains multiple hypotheses until the entire speech input is consumed -- this scheme cannot directly show a single \textit{incremental} translation to users. Further, this method lacks mechanisms for \textit{controlling} the quality vs. latency tradeoff. We propose a modified incremental blockwise beam search incorporating local agreement or hold-$n$ policies for quality-latency control. We apply our framework to models trained for online or offline translation and demonstrate that both types can be effectively used in online mode.
+Experimental results on MuST-C show 0.6-3.6 BLEU improvement without changing latency or 0.8-1.4 s latency improvement without changing quality.
+
+
+
+ 12. 标题:GECTurk: Grammatical Error Correction and Detection Dataset for Turkish
+ 编号:[57]
+ 链接:https://arxiv.org/abs/2309.11346
+ 作者:Atakan Kara, Farrin Marouf Sofian, Andrew Bond, Gözde Gül Şahin
+ 备注:Accepted at Findings of IJCNLP-AACL 2023
+ 关键词:Grammatical Error Detection, Detection and Correction, Error Detection, Grammatical Error, Synthetic data generation
+
+ 点击查看摘要
+ Grammatical Error Detection and Correction (GEC) tools have proven useful for native speakers and second language learners. Developing such tools requires a large amount of parallel, annotated data, which is unavailable for most languages. Synthetic data generation is a common practice to overcome the scarcity of such data. However, it is not straightforward for morphologically rich languages like Turkish due to complex writing rules that require phonological, morphological, and syntactic information. In this work, we present a flexible and extensible synthetic data generation pipeline for Turkish covering more than 20 expert-curated grammar and spelling rules (a.k.a., writing rules) implemented through complex transformation functions. Using this pipeline, we derive 130,000 high-quality parallel sentences from professionally edited articles. Additionally, we create a more realistic test set by manually annotating a set of movie reviews. We implement three baselines formulating the task as i) neural machine translation, ii) sequence tagging, and iii) prefix tuning with a pretrained decoder-only model, achieving strong results. Furthermore, we perform exhaustive experiments on out-of-domain datasets to gain insights on the transferability and robustness of the proposed approaches. Our results suggest that our corpus, GECTurk, is high-quality and allows knowledge transfer for the out-of-domain setting. To encourage further research on Turkish GEC, we release our datasets, baseline models, and the synthetic data generation pipeline at this https URL.
+
+
+
+ 13. 标题:Improving Article Classification with Edge-Heterogeneous Graph Neural Networks
+ 编号:[59]
+ 链接:https://arxiv.org/abs/2309.11341
+ 作者:Khang Ly, Yury Kashnitsky, Savvas Chamezopoulos, Valeria Krzhizhanovskaya
+ 备注:
+ 关键词:Classifying research output, relevant downstream task, context-specific label taxonomies, newly published articles, Graph Neural Networks
+
+ 点击查看摘要
+ Classifying research output into context-specific label taxonomies is a challenging and relevant downstream task, given the volume of existing and newly published articles. We propose a method to enhance the performance of article classification by enriching simple Graph Neural Networks (GNN) pipelines with edge-heterogeneous graph representations. SciBERT is used for node feature generation to capture higher-order semantics within the articles' textual metadata. Fully supervised transductive node classification experiments are conducted on the Open Graph Benchmark (OGB) ogbn-arxiv dataset and the PubMed diabetes dataset, augmented with additional metadata from Microsoft Academic Graph (MAG) and PubMed Central, respectively. The results demonstrate that edge-heterogeneous graphs consistently improve the performance of all GNN models compared to the edge-homogeneous graphs. The transformed data enable simple and shallow GNN pipelines to achieve results on par with more complex architectures. On ogbn-arxiv, we achieve a top-15 result in the OGB competition with a 2-layer GCN (accuracy 74.61%), being the highest-scoring solution with sub-1 million parameters. On PubMed, we closely trail SOTA GNN architectures using a 2-layer GraphSAGE by including additional co-authorship edges in the graph (accuracy 89.88%). The implementation is available at: $\href{this https URL}{\text{this https URL}}$.
+
+
+
+ 14. 标题:TRAVID: An End-to-End Video Translation Framework
+ 编号:[60]
+ 链接:https://arxiv.org/abs/2309.11338
+ 作者:Prottay Kumar Adhikary, Bandaru Sugandhi, Subhojit Ghimire, Santanu Pal, Partha Pakray
+ 备注:
+ 关键词:today globalized world, diverse linguistic backgrounds, globalized world, increasingly crucial, today globalized
+
+ 点击查看摘要
+ In today's globalized world, effective communication with people from diverse linguistic backgrounds has become increasingly crucial. While traditional methods of language translation, such as written text or voice-only translations, can accomplish the task, they often fail to capture the complete context and nuanced information conveyed through nonverbal cues like facial expressions and lip movements. In this paper, we present an end-to-end video translation system that not only translates spoken language but also synchronizes the translated speech with the lip movements of the speaker. Our system focuses on translating educational lectures in various Indian languages, and it is designed to be effective even in low-resource system settings. By incorporating lip movements that align with the target language and matching them with the speaker's voice using voice cloning techniques, our application offers an enhanced experience for students and users. This additional feature creates a more immersive and realistic learning environment, ultimately making the learning process more effective and engaging.
+
+
+
+ 15. 标题:DISC-LawLLM: Fine-tuning Large Language Models for Intelligent Legal Services
+ 编号:[67]
+ 链接:https://arxiv.org/abs/2309.11325
+ 作者:Shengbin Yue, Wei Chen, Siyuan Wang, Bingxuan Li, Chenchen Shen, Shujun Liu, Yuxuan Zhou, Yao Xiao, Song Yun, Wei Lin, Xuanjing Huang, Zhongyu Wei
+ 备注:
+ 关键词:large language models, utilizing large language, system utilizing large, Chinese Judicial domain, propose DISC-LawLLM
+
+ 点击查看摘要
+ We propose DISC-LawLLM, an intelligent legal system utilizing large language models (LLMs) to provide a wide range of legal services. We adopt legal syllogism prompting strategies to construct supervised fine-tuning datasets in the Chinese Judicial domain and fine-tune LLMs with legal reasoning capability. We augment LLMs with a retrieval module to enhance models' ability to access and utilize external legal knowledge. A comprehensive legal benchmark, DISC-Law-Eval, is presented to evaluate intelligent legal systems from both objective and subjective dimensions. Quantitative and qualitative results on DISC-Law-Eval demonstrate the effectiveness of our system in serving various users across diverse legal scenarios. The detailed resources are available at this https URL.
+
+
+
+ 16. 标题:Rating Prediction in Conversational Task Assistants with Behavioral and Conversational-Flow Features
+ 编号:[76]
+ 链接:https://arxiv.org/abs/2309.11307
+ 作者:Rafael Ferreira, David Semedo, João Magalhães
+ 备注:
+ 关键词:Conversational Task Assistants, Task Assistants, understand user behavior, Conversational Task, critical to understand
+
+ 点击查看摘要
+ Predicting the success of Conversational Task Assistants (CTA) can be critical to understand user behavior and act accordingly. In this paper, we propose TB-Rater, a Transformer model which combines conversational-flow features with user behavior features for predicting user ratings in a CTA scenario. In particular, we use real human-agent conversations and ratings collected in the Alexa TaskBot challenge, a novel multimodal and multi-turn conversational context. Our results show the advantages of modeling both the conversational-flow and behavioral aspects of the conversation in a single model for offline rating prediction. Additionally, an analysis of the CTA-specific behavioral features brings insights into this setting and can be used to bootstrap future systems.
+
+
+
+ 17. 标题:CPLLM: Clinical Prediction with Large Language Models
+ 编号:[82]
+ 链接:https://arxiv.org/abs/2309.11295
+ 作者:Ofir Ben Shoham, Nadav Rappoport
+ 备注:
+ 关键词:pre-trained Large Language, Large Language Models, Large Language, present Clinical Prediction, clinical disease prediction
+
+ 点击查看摘要
+ We present Clinical Prediction with Large Language Models (CPLLM), a method that involves fine-tuning a pre-trained Large Language Model (LLM) for clinical disease prediction. We utilized quantization and fine-tuned the LLM using prompts, with the task of predicting whether patients will be diagnosed with a target disease during their next visit or in the subsequent diagnosis, leveraging their historical diagnosis records. We compared our results versus various baselines, including Logistic Regression, RETAIN, and Med-BERT, which is the current state-of-the-art model for disease prediction using structured EHR data. Our experiments have shown that CPLLM surpasses all the tested models in terms of both PR-AUC and ROC-AUC metrics, displaying noteworthy enhancements compared to the baseline models.
+
+
+
+ 18. 标题:Overview of AuTexTification at IberLEF 2023: Detection and Attribution of Machine-Generated Text in Multiple Domains
+ 编号:[85]
+ 链接:https://arxiv.org/abs/2309.11285
+ 作者:Areg Mikael Sarvazyan, José Ángel González, Marc Franco-Salvador, Francisco Rangel, Berta Chulvi, Paolo Rosso
+ 备注:Accepted at SEPLN 2023
+ 关键词:Languages Evaluation Forum, Iberian Languages Evaluation, Workshop in Iberian, Evaluation Forum, Iberian Languages
+
+ 点击查看摘要
+ This paper presents the overview of the AuTexTification shared task as part of the IberLEF 2023 Workshop in Iberian Languages Evaluation Forum, within the framework of the SEPLN 2023 conference. AuTexTification consists of two subtasks: for Subtask 1, participants had to determine whether a text is human-authored or has been generated by a large language model. For Subtask 2, participants had to attribute a machine-generated text to one of six different text generation models. Our AuTexTification 2023 dataset contains more than 160.000 texts across two languages (English and Spanish) and five domains (tweets, reviews, news, legal, and how-to articles). A total of 114 teams signed up to participate, of which 36 sent 175 runs, and 20 of them sent their working notes. In this overview, we present the AuTexTification dataset and task, the submitted participating systems, and the results.
+
+
+
+ 19. 标题:The Wizard of Curiosities: Enriching Dialogues with Fun Facts
+ 编号:[87]
+ 链接:https://arxiv.org/abs/2309.11283
+ 作者:Frederico Vicente, Rafael Ferreira, David Semedo, João Magalhães
+ 备注:
+ 关键词:pleasant and enjoyable, Introducing curiosities, Amazon Alexa TaskBot, curiosities, Amazon Alexa
+
+ 点击查看摘要
+ Introducing curiosities in a conversation is a way to teach something new to the person in a pleasant and enjoyable way. Enriching dialogues with contextualized curiosities can improve the users' perception of a dialog system and their overall user experience. In this paper, we introduce a set of curated curiosities, targeting dialogues in the cooking and DIY domains. In particular, we use real human-agent conversations collected in the context of the Amazon Alexa TaskBot challenge, a multimodal and multi-turn conversational setting. According to an A/B test with over 1000 conversations, curiosities not only increase user engagement, but provide an average relative rating improvement of 9.7%.
+
+
+
+ 20. 标题:Grounded Complex Task Segmentation for Conversational Assistants
+ 编号:[95]
+ 链接:https://arxiv.org/abs/2309.11271
+ 作者:Rafael Ferreira, David Semedo, João Magalhães
+ 备注:
+ 关键词:daunting due, shorter attention, attention and memory, memory spans, spans when compared
+
+ 点击查看摘要
+ Following complex instructions in conversational assistants can be quite daunting due to the shorter attention and memory spans when compared to reading the same instructions. Hence, when conversational assistants walk users through the steps of complex tasks, there is a need to structure the task into manageable pieces of information of the right length and complexity. In this paper, we tackle the recipes domain and convert reading structured instructions into conversational structured ones. We annotated the structure of instructions according to a conversational scenario, which provided insights into what is expected in this setting. To computationally model the conversational step's characteristics, we tested various Transformer-based architectures, showing that a token-based approach delivers the best results. A further user study showed that users tend to favor steps of manageable complexity and length, and that the proposed methodology can improve the original web-based instructional text. Specifically, 86% of the evaluated tasks were improved from a conversational suitability point of view.
+
+
+
+ 21. 标题:Sequence-to-Sequence Spanish Pre-trained Language Models
+ 编号:[98]
+ 链接:https://arxiv.org/abs/2309.11259
+ 作者:Vladimir Araujo, Maria Mihaela Trusca, Rodrigo Tufiño, Marie-Francine Moens
+ 备注:
+ 关键词:numerous non-English language, non-English language versions, recent years, substantial advancements, numerous non-English
+
+ 点击查看摘要
+ In recent years, substantial advancements in pre-trained language models have paved the way for the development of numerous non-English language versions, with a particular focus on encoder-only and decoder-only architectures. While Spanish language models encompassing BERT, RoBERTa, and GPT have exhibited prowess in natural language understanding and generation, there remains a scarcity of encoder-decoder models designed for sequence-to-sequence tasks involving input-output pairs. This paper breaks new ground by introducing the implementation and evaluation of renowned encoder-decoder architectures, exclusively pre-trained on Spanish corpora. Specifically, we present Spanish versions of BART, T5, and BERT2BERT-style models and subject them to a comprehensive assessment across a diverse range of sequence-to-sequence tasks, spanning summarization, rephrasing, and generative question answering. Our findings underscore the competitive performance of all models, with BART and T5 emerging as top performers across all evaluated tasks. As an additional contribution, we have made all models publicly available to the research community, fostering future exploration and development in Spanish language processing.
+
+
+
+ 22. 标题:The Scenario Refiner: Grounding subjects in images at the morphological level
+ 编号:[102]
+ 链接:https://arxiv.org/abs/2309.11252
+ 作者:Claudia Tagliaferri, Sofia Axioti, Albert Gatt, Denis Paperno
+ 备注:presented at the LIMO workshop (Linguistic Insights from and for Multimodal Language Processing @KONVENS 2023)
+ 关键词:exhibit semantic differences, Derivationally related words, exhibit semantic, visual scenarios, semantic differences
+
+ 点击查看摘要
+ Derivationally related words, such as "runner" and "running", exhibit semantic differences which also elicit different visual scenarios. In this paper, we ask whether Vision and Language (V\&L) models capture such distinctions at the morphological level, using a a new methodology and dataset. We compare the results from V\&L models to human judgements and find that models' predictions differ from those of human participants, in particular displaying a grammatical bias. We further investigate whether the human-model misalignment is related to model architecture. Our methodology, developed on one specific morphological contrast, can be further extended for testing models on capturing other nuanced language features.
+
+
+
+ 23. 标题:OpenChat: Advancing Open-source Language Models with Mixed-Quality Data
+ 编号:[112]
+ 链接:https://arxiv.org/abs/2309.11235
+ 作者:Guan Wang, Sijie Cheng, Xianyuan Zhan, Xiangang Li, Sen Song, Yang Liu
+ 备注:
+ 关键词:LLaMA have emerged, data, SFT, RLFT, language models
+
+ 点击查看摘要
+ Nowadays, open-source large language models like LLaMA have emerged. Recent developments have incorporated supervised fine-tuning (SFT) and reinforcement learning fine-tuning (RLFT) to align these models with human goals. However, SFT methods treat all training data with mixed quality equally, while RLFT methods require high-quality pairwise or ranking-based preference data. In this study, we present a novel framework, named OpenChat, to advance open-source language models with mixed-quality data. Specifically, we consider the general SFT training data, consisting of a small amount of expert data mixed with a large proportion of sub-optimal data, without any preference labels. We propose the C(onditioned)-RLFT, which regards different data sources as coarse-grained reward labels and learns a class-conditioned policy to leverage complementary data quality information. Interestingly, the optimal policy in C-RLFT can be easily solved through single-stage, RL-free supervised learning, which is lightweight and avoids costly human preference labeling. Through extensive experiments on three standard benchmarks, our openchat-13b fine-tuned with C-RLFT achieves the highest average performance among all 13b open-source language models. Moreover, we use AGIEval to validate the model generalization performance, in which only openchat-13b surpasses the base model. Finally, we conduct a series of analyses to shed light on the effectiveness and robustness of OpenChat. Our code, data, and models are publicly available at this https URL.
+
+
+
+ 24. 标题:Retrieve-Rewrite-Answer: A KG-to-Text Enhanced LLMs Framework for Knowledge Graph Question Answering
+ 编号:[121]
+ 链接:https://arxiv.org/abs/2309.11206
+ 作者:Yike Wu, Nan Hu, Sheng Bi, Guilin Qi, Jie Ren, Anhuan Xie, Wei Song
+ 备注:
+ 关键词:large language models, long tail knowledge, limitations in memorizing, long tail, large language
+
+ 点击查看摘要
+ Despite their competitive performance on knowledge-intensive tasks, large language models (LLMs) still have limitations in memorizing all world knowledge especially long tail knowledge. In this paper, we study the KG-augmented language model approach for solving the knowledge graph question answering (KGQA) task that requires rich world knowledge. Existing work has shown that retrieving KG knowledge to enhance LLMs prompting can significantly improve LLMs performance in KGQA. However, their approaches lack a well-formed verbalization of KG knowledge, i.e., they ignore the gap between KG representations and textual representations. To this end, we propose an answer-sensitive KG-to-Text approach that can transform KG knowledge into well-textualized statements most informative for KGQA. Based on this approach, we propose a KG-to-Text enhanced LLMs framework for solving the KGQA task. Experiments on several KGQA benchmarks show that the proposed KG-to-Text augmented LLMs approach outperforms previous KG-augmented LLMs approaches regarding answer accuracy and usefulness of knowledge statements.
+
+
+
+ 25. 标题:The Languini Kitchen: Enabling Language Modelling Research at Different Scales of Compute
+ 编号:[124]
+ 链接:https://arxiv.org/abs/2309.11197
+ 作者:Aleksandar Stanić, Dylan Ashley, Oleg Serikov, Louis Kirsch, Francesco Faccio, Jürgen Schmidhuber, Thomas Hofmann, Imanol Schlag
+ 备注:
+ 关键词:Languini Kitchen serves, Languini Kitchen, limited computational resources, collective and codebase, codebase designed
+
+ 点击查看摘要
+ The Languini Kitchen serves as both a research collective and codebase designed to empower researchers with limited computational resources to contribute meaningfully to the field of language modelling. We introduce an experimental protocol that enables model comparisons based on equivalent compute, measured in accelerator hours. The number of tokens on which a model is trained is defined by the model's throughput and the chosen compute class. Notably, this approach avoids constraints on critical hyperparameters which affect total parameters or floating-point operations. For evaluation, we pre-process an existing large, diverse, and high-quality dataset of books that surpasses existing academic benchmarks in quality, diversity, and document length. On it, we compare methods based on their empirical scaling trends which are estimated through experiments at various levels of compute. This work also provides two baseline models: a feed-forward model derived from the GPT-2 architecture and a recurrent model in the form of a novel LSTM with ten-fold throughput. While the GPT baseline achieves better perplexity throughout all our levels of compute, our LSTM baseline exhibits a predictable and more favourable scaling law. This is due to the improved throughput and the need for fewer training tokens to achieve the same decrease in test perplexity. Extrapolating the scaling laws leads of both models results in an intersection at roughly 50,000 accelerator hours. We hope this work can serve as the foundation for meaningful and reproducible language modelling research.
+
+
+
+ 26. 标题:Are Large Language Models Really Robust to Word-Level Perturbations?
+ 编号:[134]
+ 链接:https://arxiv.org/abs/2309.11166
+ 作者:Haoyu Wang, Guozheng Ma, Cong Yu, Ning Gui, Linrui Zhang, Zhiqi Huang, Suwei Ma, Yongzhe Chang, Sen Zhang, Li Shen, Xueqian Wang, Peilin Zhao, Dacheng Tao
+ 备注:
+ 关键词:Large Language Models, capabilities of Large, Large Language, downstream tasks, swift advancement
+
+ 点击查看摘要
+ The swift advancement in the scale and capabilities of Large Language Models (LLMs) positions them as promising tools for a variety of downstream tasks. In addition to the pursuit of better performance and the avoidance of violent feedback on a certain prompt, to ensure the responsibility of the LLM, much attention is drawn to the robustness of LLMs. However, existing evaluation methods mostly rely on traditional question answering datasets with predefined supervised labels, which do not align with the superior generation capabilities of contemporary LLMs. To address this issue, we propose a novel rational evaluation approach that leverages pre-trained reward models as diagnostic tools to evaluate the robustness of LLMs, which we refer to as the Reward Model for Reasonable Robustness Evaluation (TREvaL). Our extensive empirical experiments have demonstrated that TREval provides an accurate method for evaluating the robustness of an LLM, especially when faced with more challenging open questions. Furthermore, our results demonstrate that LLMs frequently exhibit vulnerability to word-level perturbations, which are commonplace in daily language usage. Notably, we were surprised to discover that robustness tends to decrease as fine-tuning (SFT and RLHF) is conducted. The code of TREval is available in this https URL.
+
+
+
+ 27. 标题:Assessment of Pre-Trained Models Across Languages and Grammars
+ 编号:[135]
+ 链接:https://arxiv.org/abs/2309.11165
+ 作者:Alberto Muñoz-Ortiz, David Vilares, Carlos Gómez-Rodríguez
+ 备注:Accepted at IJCNLP-AACL 2023
+ 关键词:multi-formalism syntactic structures, multilingual large language, present an approach, approach for assessing, assessing how multilingual
+
+ 点击查看摘要
+ We present an approach for assessing how multilingual large language models (LLMs) learn syntax in terms of multi-formalism syntactic structures. We aim to recover constituent and dependency structures by casting parsing as sequence labeling. To do so, we select a few LLMs and study them on 13 diverse UD treebanks for dependency parsing and 10 treebanks for constituent parsing. Our results show that: (i) the framework is consistent across encodings, (ii) pre-trained word vectors do not favor constituency representations of syntax over dependencies, (iii) sub-word tokenization is needed to represent syntax, in contrast to character-based models, and (iv) occurrence of a language in the pretraining data is more important than the amount of task data when recovering syntax from the word vectors.
+
+
+
+ 28. 标题:CoT-BERT: Enhancing Unsupervised Sentence Representation through Chain-of-Thought
+ 编号:[146]
+ 链接:https://arxiv.org/abs/2309.11143
+ 作者:Bowen Zhang, Kehua Chang, Chunping Li
+ 备注:
+ 关键词:fixed-length vectors enriched, intricate semantic information, representation learning aims, labeled data, aims to transform
+
+ 点击查看摘要
+ Unsupervised sentence representation learning aims to transform input sentences into fixed-length vectors enriched with intricate semantic information while obviating the reliance on labeled data. Recent progress within this field, propelled by contrastive learning and prompt engineering, has significantly bridged the gap between unsupervised and supervised strategies. Nonetheless, the potential utilization of Chain-of-Thought, remains largely untapped within this trajectory. To unlock latent capabilities within pre-trained models, such as BERT, we propose a two-stage approach for sentence representation: comprehension and summarization. Subsequently, the output of the latter phase is harnessed as the vectorized representation of the input sentence. For further performance enhancement, we meticulously refine both the contrastive learning loss function and the template denoising technique for prompt engineering. Rigorous experimentation substantiates our method, CoT-BERT, transcending a suite of robust baselines without necessitating other text representation models or external databases.
+
+
+
+ 29. 标题:Prototype of a robotic system to assist the learning process of English language with text-generation through DNN
+ 编号:[147]
+ 链接:https://arxiv.org/abs/2309.11142
+ 作者:Carlos Morales-Torres, Mario Campos-Soberanis, Diego Campos-Sobrino
+ 备注:Paper presented in the Mexican International Conference on Artificial Intelligence 2021
+ 关键词:Natural Language Processing, English Language Teaching, performing multiple tasks, multiple tasks including, tasks including English
+
+ 点击查看摘要
+ In the last ongoing years, there has been a significant ascending on the field of Natural Language Processing (NLP) for performing multiple tasks including English Language Teaching (ELT). An effective strategy to favor the learning process uses interactive devices to engage learners in their self-learning process. In this work, we present a working prototype of a humanoid robotic system to assist English language self-learners through text generation using Long Short Term Memory (LSTM) Neural Networks. The learners interact with the system using a Graphic User Interface that generates text according to the English level of the user. The experimentation was conducted using English learners and the results were measured accordingly to International English Language Testing System (IELTS) rubric. Preliminary results show an increment in the Grammatical Range of learners who interacted with the system.
+
+
+
+ 30. 标题:AttentionMix: Data augmentation method that relies on BERT attention mechanism
+ 编号:[163]
+ 链接:https://arxiv.org/abs/2309.11104
+ 作者:Dominik Lewy, Jacek Mańdziuk
+ 备注:
+ 关键词:Computer Vision, Natural Language Processing, technique in Computer, perform image mixing, guided manner
+
+ 点击查看摘要
+ The Mixup method has proven to be a powerful data augmentation technique in Computer Vision, with many successors that perform image mixing in a guided manner. One of the interesting research directions is transferring the underlying Mixup idea to other domains, e.g. Natural Language Processing (NLP). Even though there already exist several methods that apply Mixup to textual data, there is still room for new, improved approaches. In this work, we introduce AttentionMix, a novel mixing method that relies on attention-based information. While the paper focuses on the BERT attention mechanism, the proposed approach can be applied to generally any attention-based model. AttentionMix is evaluated on 3 standard sentiment classification datasets and in all three cases outperforms two benchmark approaches that utilize Mixup mechanism, as well as the vanilla BERT method. The results confirm that the attention-based information can be effectively used for data augmentation in the NLP domain.
+
+
+
+ 31. 标题:K-pop Lyric Translation: Dataset, Analysis, and Neural-Modelling
+ 编号:[168]
+ 链接:https://arxiv.org/abs/2309.11093
+ 作者:Haven Kim, Jongmin Jung, Dasaem Jeong, Juhan Nam
+ 备注:
+ 关键词:computational linguistics researchers, attracting computational linguistics, Lyric translation, lyric translation studies, Lyric
+
+ 点击查看摘要
+ Lyric translation, a field studied for over a century, is now attracting computational linguistics researchers. We identified two limitations in previous studies. Firstly, lyric translation studies have predominantly focused on Western genres and languages, with no previous study centering on K-pop despite its popularity. Second, the field of lyric translation suffers from a lack of publicly available datasets; to the best of our knowledge, no such dataset exists. To broaden the scope of genres and languages in lyric translation studies, we introduce a novel singable lyric translation dataset, approximately 89\% of which consists of K-pop song lyrics. This dataset aligns Korean and English lyrics line-by-line and section-by-section. We leveraged this dataset to unveil unique characteristics of K-pop lyric translation, distinguishing it from other extensively studied genres, and to construct a neural lyric translation model, thereby underscoring the importance of a dedicated dataset for singable lyric translations.
+
+
+
+ 32. 标题:Dual-Modal Attention-Enhanced Text-Video Retrieval with Triplet Partial Margin Contrastive Learning
+ 编号:[174]
+ 链接:https://arxiv.org/abs/2309.11082
+ 作者:Chen Jiang, Hong Liu, Xuzheng Yu, Qing Wang, Yuan Cheng, Jia Xu, Zhongyi Liu, Qingpei Guo, Wei Chu, Ming Yang, Yuan Qi
+ 备注:Accepted by ACM MM 2023
+ 关键词:retrieval increasingly essential, web videos makes, makes text-video retrieval, text-video retrieval increasingly, videos makes text-video
+
+ 点击查看摘要
+ In recent years, the explosion of web videos makes text-video retrieval increasingly essential and popular for video filtering, recommendation, and search. Text-video retrieval aims to rank relevant text/video higher than irrelevant ones. The core of this task is to precisely measure the cross-modal similarity between texts and videos. Recently, contrastive learning methods have shown promising results for text-video retrieval, most of which focus on the construction of positive and negative pairs to learn text and video representations. Nevertheless, they do not pay enough attention to hard negative pairs and lack the ability to model different levels of semantic similarity. To address these two issues, this paper improves contrastive learning using two novel techniques. First, to exploit hard examples for robust discriminative power, we propose a novel Dual-Modal Attention-Enhanced Module (DMAE) to mine hard negative pairs from textual and visual clues. By further introducing a Negative-aware InfoNCE (NegNCE) loss, we are able to adaptively identify all these hard negatives and explicitly highlight their impacts in the training loss. Second, our work argues that triplet samples can better model fine-grained semantic similarity compared to pairwise samples. We thereby present a new Triplet Partial Margin Contrastive Learning (TPM-CL) module to construct partial order triplet samples by automatically generating fine-grained hard negatives for matched text-video pairs. The proposed TPM-CL designs an adaptive token masking strategy with cross-modal interaction to model subtle semantic differences. Extensive experiments demonstrate that the proposed approach outperforms existing methods on four widely-used text-video retrieval datasets, including MSR-VTT, MSVD, DiDeMo and ActivityNet.
+
+
+
+ 33. 标题:UniPCM: Universal Pre-trained Conversation Model with Task-aware Automatic Prompt
+ 编号:[181]
+ 链接:https://arxiv.org/abs/2309.11065
+ 作者:Yucheng Cai, Wentao Ma, Yuchuan Wu, Shuzheng Si, Yuan Shao, Zhijian Ou, Yongbin Li
+ 备注:
+ 关键词:pre-training greatly improves, multi-task pre-training greatly, Recent research, multi-task pre-training, pre-trained conversation model
+
+ 点击查看摘要
+ Recent research has shown that multi-task pre-training greatly improves the model's robustness and transfer ability, which is crucial for building a high-quality dialog system. However, most previous works on multi-task pre-training rely heavily on human-defined input format or prompt, which is not optimal in quality and quantity. In this work, we propose to use Task-based Automatic Prompt generation (TAP) to automatically generate high-quality prompts. Using the high-quality prompts generated, we scale the corpus of the pre-trained conversation model to 122 datasets from 15 dialog-related tasks, resulting in Universal Pre-trained Conversation Model (UniPCM), a powerful foundation model for various conversational tasks and different dialog systems. Extensive experiments have shown that UniPCM is robust to input prompts and capable of various dialog-related tasks. Moreover, UniPCM has strong transfer ability and excels at low resource scenarios, achieving SOTA results on 9 different datasets ranging from task-oriented dialog to open-domain conversation. Furthermore, we are amazed to find that TAP can generate prompts on par with those collected with crowdsourcing. The code is released with the paper.
+
+
+
+ 34. 标题:XATU: A Fine-grained Instruction-based Benchmark for Explainable Text Updates
+ 编号:[183]
+ 链接:https://arxiv.org/abs/2309.11063
+ 作者:Haopeng Zhang, Hayate Iso, Sairam Gurajada, Nikita Bhutani
+ 备注:Work in progress
+ 关键词:involves modifying text, Text editing, user intents, involves modifying, align with user
+
+ 点击查看摘要
+ Text editing is a crucial task that involves modifying text to better align with user intents. However, existing text editing benchmark datasets have limitations in providing only coarse-grained instructions. Consequently, although the edited output may seem reasonable, it often deviates from the intended changes outlined in the gold reference, resulting in low evaluation scores. To comprehensively investigate the text editing capabilities of large language models, this paper introduces XATU, the first benchmark specifically designed for fine-grained instruction-based explainable text editing. XATU covers a wide range of topics and text types, incorporating lexical, syntactic, semantic, and knowledge-intensive edits. To enhance interpretability, we leverage high-quality data sources and human annotation, resulting in a benchmark that includes fine-grained instructions and gold-standard edit explanations. By evaluating existing open and closed large language models against our benchmark, we demonstrate the effectiveness of instruction tuning and the impact of underlying architecture across various editing tasks. Furthermore, extensive experimentation reveals the significant role of explanations in fine-tuning language models for text editing tasks. The benchmark will be open-sourced to support reproduction and facilitate future research.
+
+
+
+ 35. 标题:Design of Chain-of-Thought in Math Problem Solving
+ 编号:[187]
+ 链接:https://arxiv.org/abs/2309.11054
+ 作者:Zhanming Jie, Trung Quoc Luong, Xinbo Zhang, Xiaoran Jin, Hang Li
+ 备注:15 pages
+ 关键词:math problem solving, plays a crucial, program, crucial role, role in reasoning
+
+ 点击查看摘要
+ Chain-of-Thought (CoT) plays a crucial role in reasoning for math problem solving. We conduct a comprehensive examination of methods for designing CoT, comparing conventional natural language CoT with various program CoTs, including the self-describing program, the comment-describing program, and the non-describing program. Furthermore, we investigate the impact of programming language on program CoTs, comparing Python and Wolfram Language. Through extensive experiments on GSM8K, MATHQA, and SVAMP, we find that program CoTs often have superior effectiveness in math problem solving. Notably, the best performing combination with 30B parameters beats GPT-3.5-turbo by a significant margin. The results show that self-describing program offers greater diversity and thus can generally achieve higher performance. We also find that Python is a better choice of language than Wolfram for program CoTs. The experimental results provide a valuable guideline for future CoT designs that take into account both programming language and coding style for further advancements. Our datasets and code are publicly available.
+
+
+
+ 36. 标题:fakenewsbr: A Fake News Detection Platform for Brazilian Portuguese
+ 编号:[189]
+ 链接:https://arxiv.org/abs/2309.11052
+ 作者:Luiz Giordani, Gilsiley Darú, Rhenan Queiroz, Vitor Buzinaro, Davi Keglevich Neiva, Daniel Camilo Fuentes Guzmán, Marcos Jardel Henriques, Oilson Alberto Gonzatto Junior, Francisco Louzada
+ 备注:
+ 关键词:manipulate public opinion, recent times due, public opinion, significant concern, concern in recent
+
+ 点击查看摘要
+ The proliferation of fake news has become a significant concern in recent times due to its potential to spread misinformation and manipulate public opinion. This paper presents a comprehensive study on detecting fake news in Brazilian Portuguese, focusing on journalistic-type news. We propose a machine learning-based approach that leverages natural language processing techniques, including TF-IDF and Word2Vec, to extract features from textual data. We evaluate the performance of various classification algorithms, such as logistic regression, support vector machine, random forest, AdaBoost, and LightGBM, on a dataset containing both true and fake news articles. The proposed approach achieves high accuracy and F1-Score, demonstrating its effectiveness in identifying fake news. Additionally, we developed a user-friendly web platform, this http URL, to facilitate the verification of news articles' veracity. Our platform provides real-time analysis, allowing users to assess the likelihood of fake news articles. Through empirical analysis and comparative studies, we demonstrate the potential of our approach to contribute to the fight against the spread of fake news and promote more informed media consumption.
+
+
+
+ 37. 标题:Localize, Retrieve and Fuse: A Generalized Framework for Free-Form Question Answering over Tables
+ 编号:[190]
+ 链接:https://arxiv.org/abs/2309.11049
+ 作者:Wenting Zhao, Ye Liu, Yao Wan, Yibo Wang, Zhongfen Deng, Philip S. Yu
+ 备注:Accepted by AACL-IJCNLP 2023
+ 关键词:significant attention recently, gained significant attention, table cells, relevant table cells, Question answering
+
+ 点击查看摘要
+ Question answering on tabular data (a.k.a TableQA), which aims at generating answers to questions grounded on a provided table, has gained significant attention recently. Prior work primarily produces concise factual responses through information extraction from individual or limited table cells, lacking the ability to reason across diverse table cells. Yet, the realm of free-form TableQA, which demands intricate strategies for selecting relevant table cells and the sophisticated integration and inference of discrete data fragments, remains mostly unexplored. To this end, this paper proposes a generalized three-stage approach: Table-to- Graph conversion and cell localizing, external knowledge retrieval, and the fusion of table and text (called TAG-QA), to address the challenge of inferring long free-form answers in generative TableQA. In particular, TAG-QA (1) locates relevant table cells using a graph neural network to gather intersecting cells between relevant rows and columns, (2) leverages external knowledge from Wikipedia, and (3) generates answers by integrating both tabular data and natural linguistic information. Experiments showcase the superior capabilities of TAG-QA in generating sentences that are both faithful and coherent, particularly when compared to several state-of-the-art baselines. Notably, TAG-QA surpasses the robust pipeline-based baseline TAPAS by 17% and 14% in terms of BLEU-4 and PARENT F-score, respectively. Furthermore, TAG-QA outperforms the end-to-end model T5 by 16% and 12% on BLEU-4 and PARENT F-score, respectively.
+
+
+
+ 38. 标题:Heterogeneous Entity Matching with Complex Attribute Associations using BERT and Neural Networks
+ 编号:[192]
+ 链接:https://arxiv.org/abs/2309.11046
+ 作者:Shitao Wang, Jiamin Lu
+ 备注:
+ 关键词:Baidu Baike, Baike and Wikipedia, Wikipedia often manifest, entity matching, distinct forms
+
+ 点击查看摘要
+ Across various domains, data from different sources such as Baidu Baike and Wikipedia often manifest in distinct forms. Current entity matching methodologies predominantly focus on homogeneous data, characterized by attributes that share the same structure and concise attribute values. However, this orientation poses challenges in handling data with diverse formats. Moreover, prevailing approaches aggregate the similarity of attribute values between corresponding attributes to ascertain entity similarity. Yet, they often overlook the intricate interrelationships between attributes, where one attribute may have multiple associations. The simplistic approach of pairwise attribute comparison fails to harness the wealth of information encapsulated within this http URL address these challenges, we introduce a novel entity matching model, dubbed Entity Matching Model for Capturing Complex Attribute Relationships(EMM-CCAR),built upon pre-trained models. Specifically, this model transforms the matching task into a sequence matching problem to mitigate the impact of varying data formats. Moreover, by introducing attention mechanisms, it identifies complex relationships between attributes, emphasizing the degree of matching among multiple attributes rather than one-to-one correspondences. Through the integration of the EMM-CCAR model, we adeptly surmount the challenges posed by data heterogeneity and intricate attribute interdependencies. In comparison with the prevalent DER-SSM and Ditto approaches, our model achieves improvements of approximately 4% and 1% in F1 scores, respectively. This furnishes a robust solution for addressing the intricacies of attribute complexity in entity matching.
+
+
+
+ 39. 标题:Making Small Language Models Better Multi-task Learners with Mixture-of-Task-Adapters
+ 编号:[195]
+ 链接:https://arxiv.org/abs/2309.11042
+ 作者:Yukang Xie, Chengyu Wang, Junbing Yan, Jiyong Zhou, Feiqi Deng, Jun Huang
+ 备注:
+ 关键词:Natural Language Processing, achieved amazing zero-shot, amazing zero-shot learning, variety of Natural, text generative tasks
+
+ 点击查看摘要
+ Recently, Large Language Models (LLMs) have achieved amazing zero-shot learning performance over a variety of Natural Language Processing (NLP) tasks, especially for text generative tasks. Yet, the large size of LLMs often leads to the high computational cost of model training and online deployment. In our work, we present ALTER, a system that effectively builds the multi-tAsk Learners with mixTure-of-task-adaptERs upon small language models (with <1B parameters) to address multiple nlp tasks simultaneously, capturing the commonalities and differences between tasks, in order support domain-specific applications. specifically, alter, we propose mixture-of-task-adapters (mta) module as an extension transformer architecture for underlying model capture intra-task inter-task knowledge. a two-stage training method is further proposed optimize collaboration adapters at small computational cost. experimental results over mixture of show that our mta achieve good performance. based on have also produced mta-equipped language models various domains.< p>
+
+
+
+ 40. 标题:Named Entity Recognition via Machine Reading Comprehension: A Multi-Task Learning Approach
+ 编号:[202]
+ 链接:https://arxiv.org/abs/2309.11027
+ 作者:Yibo Wang, Wenting Zhao, Yao Wan, Zhongfen Deng, Philip S. Yu
+ 备注:
+ 关键词:classify entity mentions, Named Entity Recognition, Entity Recognition, NER, aims to extract
+
+ 点击查看摘要
+ Named Entity Recognition (NER) aims to extract and classify entity mentions in the text into pre-defined types (e.g., organization or person name). Recently, many works have been proposed to shape the NER as a machine reading comprehension problem (also termed MRC-based NER), in which entity recognition is achieved by answering the formulated questions related to pre-defined entity types through MRC, based on the contexts. However, these works ignore the label dependencies among entity types, which are critical for precisely recognizing named entities. In this paper, we propose to incorporate the label dependencies among entity types into a multi-task learning framework for better MRC-based NER. We decompose MRC-based NER into multiple tasks and use a self-attention module to capture label dependencies. Comprehensive experiments on both nested NER and flat NER datasets are conducted to validate the effectiveness of the proposed Multi-NER. Experimental results show that Multi-NER can achieve better performance on all datasets.
+
+
+
+ 41. 标题:Towards Joint Modeling of Dialogue Response and Speech Synthesis based on Large Language Model
+ 编号:[221]
+ 链接:https://arxiv.org/abs/2309.11000
+ 作者:Xinyu Zhou, Delong Chen, Yudong Chen
+ 备注:
+ 关键词:production process compared, current cascade pipeline, human speech production, speech production process, Large Language Models
+
+ 点击查看摘要
+ This paper explores the potential of constructing an AI spoken dialogue system that "thinks how to respond" and "thinks how to speak" simultaneously, which more closely aligns with the human speech production process compared to the current cascade pipeline of independent chatbot and Text-to-Speech (TTS) modules. We hypothesize that Large Language Models (LLMs) with billions of parameters possess significant speech understanding capabilities and can jointly model dialogue responses and linguistic features. We conduct two sets of experiments: 1) Prosodic structure prediction, a typical front-end task in TTS, demonstrating the speech understanding ability of LLMs, and 2) Further integrating dialogue response and a wide array of linguistic features using a unified encoding format. Our results indicate that the LLM-based approach is a promising direction for building unified spoken dialogue systems.
+
+
+
+ 42. 标题:MBR and QE Finetuning: Training-time Distillation of the Best and Most Expensive Decoding Methods
+ 编号:[237]
+ 链接:https://arxiv.org/abs/2309.10966
+ 作者:Mara Finkelstein, Markus Freitag
+ 备注:
+ 关键词:Natural Language Generation, Language Generation, Natural Language, Minimum Bayes' Risk, traditional beam search
+
+ 点击查看摘要
+ Recent research in decoding methods for Natural Language Generation (NLG) tasks has shown that the traditional beam search and greedy decoding algorithms are not optimal, because model probabilities do not always align with human preferences. Stronger decoding methods, including Quality Estimation (QE) reranking and Minimum Bayes' Risk (MBR) decoding, have since been proposed to mitigate the model-perplexity-vs-quality mismatch. While these decoding methods achieve state-of-the-art performance, they are prohibitively expensive to compute. In this work, we propose MBR finetuning and QE finetuning which distill the quality gains from these decoding methods at training time, while using an efficient decoding algorithm at inference time. Using the canonical NLG task of Neural Machine Translation (NMT), we show that even with self-training, these finetuning methods significantly outperform the base model. Moreover, when using an external LLM as a teacher model, these finetuning methods outperform finetuning on human-generated references. These findings suggest new ways to leverage monolingual data to achieve improvements in model quality that are on par with, or even exceed, improvements from human-curated data, while maintaining maximum efficiency during decoding.
+
+
+
+ 43. 标题:In-Context Learning for Text Classification with Many Labels
+ 编号:[238]
+ 链接:https://arxiv.org/abs/2309.10954
+ 作者:Aristides Milios, Siva Reddy, Dzmitry Bahdanau
+ 备注:11 pages, 4 figures
+ 关键词:large language models, limited context window, large language, challenging due, difficult to fit
+
+ 点击查看摘要
+ In-context learning (ICL) using large language models for tasks with many labels is challenging due to the limited context window, which makes it difficult to fit a sufficient number of examples in the prompt. In this paper, we use a pre-trained dense retrieval model to bypass this limitation, giving the model only a partial view of the full label space for each inference call. Testing with recent open-source LLMs (OPT, LLaMA), we set new state of the art performance in few-shot settings for three common intent classification datasets, with no finetuning. We also surpass fine-tuned performance on fine-grained sentiment classification in certain cases. We analyze the performance across number of in-context examples and different model scales, showing that larger models are necessary to effectively and consistently make use of larger context lengths for ICL. By running several ablations, we analyze the model's use of: a) the similarity of the in-context examples to the current input, b) the semantic content of the class names, and c) the correct correspondence between examples and labels. We demonstrate that all three are needed to varying degrees depending on the domain, contrary to certain recent works.
+
+
+
+ 44. 标题:LMDX: Language Model-based Document Information Extraction and Localization
+ 编号:[239]
+ 链接:https://arxiv.org/abs/2309.10952
+ 作者:Vincent Perot, Kai Kang, Florian Luisier, Guolong Su, Xiaoyu Sun, Ramya Sree Boppana, Zilong Wang, Jiaqi Mu, Hao Zhang, Nan Hua
+ 备注:
+ 关键词:Large Language Models, Natural Language Processing, revolutionized Natural Language, exhibiting emergent capabilities, document information extraction
+
+ 点击查看摘要
+ Large Language Models (LLM) have revolutionized Natural Language Processing (NLP), improving state-of-the-art on many existing tasks and exhibiting emergent capabilities. However, LLMs have not yet been successfully applied on semi-structured document information extraction, which is at the core of many document processing workflows and consists of extracting key entities from a visually rich document (VRD) given a predefined target schema. The main obstacles to LLM adoption in that task have been the absence of layout encoding within LLMs, critical for a high quality extraction, and the lack of a grounding mechanism ensuring the answer is not hallucinated. In this paper, we introduce Language Model-based Document Information Extraction and Localization (LMDX), a methodology to adapt arbitrary LLMs for document information extraction. LMDX can do extraction of singular, repeated, and hierarchical entities, both with and without training data, while providing grounding guarantees and localizing the entities within the document. In particular, we apply LMDX to the PaLM 2-S LLM and evaluate it on VRDU and CORD benchmarks, setting a new state-of-the-art and showing how LMDX enables the creation of high quality, data-efficient parsers.
+
+
+
+ 45. 标题:Benchmarks for Pirá 2.0, a Reading Comprehension Dataset about the Ocean, the Brazilian Coast, and Climate Change
+ 编号:[242]
+ 链接:https://arxiv.org/abs/2309.10945
+ 作者:Paulo Pirozelli, Marcos M. José, Igor Silveira, Flávio Nakasato, Sarajane M. Peres, Anarosa A. F. Brandão, Anna H. R. Costa, Fabio G. Cozman
+ 备注:Accepted at Data Intelligence. Online ISSN 2641-435X
+ 关键词:Brazilian coast, climate change, abstracts and reports, question answering, Pirá
+
+ 点击查看摘要
+ Pirá is a reading comprehension dataset focused on the ocean, the Brazilian coast, and climate change, built from a collection of scientific abstracts and reports on these topics. This dataset represents a versatile language resource, particularly useful for testing the ability of current machine learning models to acquire expert scientific knowledge. Despite its potential, a detailed set of baselines has not yet been developed for Pirá. By creating these baselines, researchers can more easily utilize Pirá as a resource for testing machine learning models across a wide range of question answering tasks. In this paper, we define six benchmarks over the Pirá dataset, covering closed generative question answering, machine reading comprehension, information retrieval, open question answering, answer triggering, and multiple choice question answering. As part of this effort, we have also produced a curated version of the original dataset, where we fixed a number of grammar issues, repetitions, and other shortcomings. Furthermore, the dataset has been extended in several new directions, so as to face the aforementioned benchmarks: translation of supporting texts from English into Portuguese, classification labels for answerability, automatic paraphrases of questions and answers, and multiple choice candidates. The results described in this paper provide several points of reference for researchers interested in exploring the challenges provided by the Pirá dataset.
+
+
+
+ 46. 标题:A Family of Pretrained Transformer Language Models for Russian
+ 编号:[249]
+ 链接:https://arxiv.org/abs/2309.10931
+ 作者:Dmitry Zmitrovich, Alexander Abramov, Andrey Kalmykov, Maria Tikhonova, Ekaterina Taktasheva, Danil Astafurov, Mark Baushenko, Artem Snegirev, Tatiana Shavrina, Sergey Markov, Vladislav Mikhailov, Alena Fenogenova
+ 备注:
+ 关键词:Russian Transformer LMs, NLP research methodologies, represent a fundamental, methodologies and applications, fundamental component
+
+ 点击查看摘要
+ Nowadays, Transformer language models (LMs) represent a fundamental component of the NLP research methodologies and applications. However, the development of such models specifically for the Russian language has received little attention. This paper presents a collection of 13 Russian Transformer LMs based on the encoder (ruBERT, ruRoBERTa, ruELECTRA), decoder (ruGPT-3), and encoder-decoder (ruT5, FRED-T5) models in multiple sizes. Access to these models is readily available via the HuggingFace platform. We provide a report of the model architecture design and pretraining, and the results of evaluating their generalization abilities on Russian natural language understanding and generation datasets and benchmarks. By pretraining and releasing these specialized Transformer LMs, we hope to broaden the scope of the NLP research directions and enable the development of industrial solutions for the Russian language.
+
+
+
+ 47. 标题:Specializing Small Language Models towards Complex Style Transfer via Latent Attribute Pre-Training
+ 编号:[251]
+ 链接:https://arxiv.org/abs/2309.10929
+ 作者:Ruiqi Xu, Yongfeng Huang, Xin Chen, Lin Zhang
+ 备注:
+ 关键词:widely applicable scenarios, game Genshin Impact, applicable scenarios, style transfer tasks, text style transfer
+
+ 点击查看摘要
+ In this work, we introduce the concept of complex text style transfer tasks, and constructed complex text datasets based on two widely applicable scenarios. Our dataset is the first large-scale data set of its kind, with 700 rephrased sentences and 1,000 sentences from the game Genshin Impact. While large language models (LLM) have shown promise in complex text style transfer, they have drawbacks such as data privacy concerns, network instability, and high deployment costs. To address these issues, we explore the effectiveness of small models (less than T5-3B) with implicit style pre-training through contrastive learning. We also propose a method for automated evaluation of text generation quality based on alignment with human evaluations using ChatGPT. Finally, we compare our approach with existing methods and show that our model achieves state-of-art performances of few-shot text style transfer models.
+
+
+
+ 48. 标题:Semi-Autoregressive Streaming ASR With Label Context
+ 编号:[252]
+ 链接:https://arxiv.org/abs/2309.10926
+ 作者:Siddhant Arora, George Saon, Shinji Watanabe, Brian Kingsbury
+ 备注:Submitted to ICASSP 2024
+ 关键词:gained significant interest, NAR models, streaming NAR models, non-streaming NAR models, NAR
+
+ 点击查看摘要
+ Non-autoregressive (NAR) modeling has gained significant interest in speech processing since these models achieve dramatically lower inference time than autoregressive (AR) models while also achieving good transcription accuracy. Since NAR automatic speech recognition (ASR) models must wait for the completion of the entire utterance before processing, some works explore streaming NAR models based on blockwise attention for low-latency applications. However, streaming NAR models significantly lag in accuracy compared to streaming AR and non-streaming NAR models. To address this, we propose a streaming "semi-autoregressive" ASR model that incorporates the labels emitted in previous blocks as additional context using a Language Model (LM) subnetwork. We also introduce a novel greedy decoding algorithm that addresses insertion and deletion errors near block boundaries while not significantly increasing the inference time. Experiments show that our method outperforms the existing streaming NAR model by 19% relative on Tedlium2, 16%/8% on Librispeech-100 clean/other test sets, and 19%/8% on the Switchboard(SWB) / Callhome(CH) test sets. It also reduced the accuracy gap with streaming AR and non-streaming NAR models while achieving 2.5x lower latency. We also demonstrate that our approach can effectively utilize external text data to pre-train the LM subnetwork to further improve streaming ASR accuracy.
+
+
+
+ 49. 标题:Semi-automatic staging area for high-quality structured data extraction from scientific literature
+ 编号:[254]
+ 链接:https://arxiv.org/abs/2309.10923
+ 作者:Luca Foppiano, Tomoya Mato, Kensei Terashima, Pedro Ortiz Suarez, Taku Tou, Chikako Sakai, Wei-Sheng Wang, Toshiyuki Amagasa, Yoshihiko Takano, Masashi Ishii
+ 备注:5 tables, 9 figures, 31 pages
+ 关键词:superconductors' experimental data, scientific articles, ingesting new superconductors', superconductors' experimental, machine-collected from scientific
+
+ 点击查看摘要
+ In this study, we propose a staging area for ingesting new superconductors' experimental data in SuperCon that is machine-collected from scientific articles. Our objective is to enhance the efficiency of updating SuperCon while maintaining or enhancing the data quality. We present a semi-automatic staging area driven by a workflow combining automatic and manual processes on the extracted database. An anomaly detection automatic process aims to pre-screen the collected data. Users can then manually correct any errors through a user interface tailored to simplify the data verification on the original PDF documents. Additionally, when a record is corrected, its raw data is collected and utilised to improve machine learning models as training data. Evaluation experiments demonstrate that our staging area significantly improves curation quality. We compare the interface with the traditional manual approach of reading PDF documents and recording information in an Excel document. Using the interface boosts the precision and recall by 6% and 50%, respectively to an average increase of 40% in F1-score.
+
+
+
+ 50. 标题:What Learned Representations and Influence Functions Can Tell Us About Adversarial Examples
+ 编号:[256]
+ 链接:https://arxiv.org/abs/2309.10916
+ 作者:Shakila Mahjabin Tonni, Mark Dras
+ 备注:20 pages, Accepted long-paper IJCNLP_AACL 2023
+ 关键词:deep neural networks, fool deep neural, image processing, deliberately crafted, neural networks
+
+ 点击查看摘要
+ Adversarial examples, deliberately crafted using small perturbations to fool deep neural networks, were first studied in image processing and more recently in NLP. While approaches to detecting adversarial examples in NLP have largely relied on search over input perturbations, image processing has seen a range of techniques that aim to characterise adversarial subspaces over the learned representations.
+In this paper, we adapt two such approaches to NLP, one based on nearest neighbors and influence functions and one on Mahalanobis distances. The former in particular produces a state-of-the-art detector when compared against several strong baselines; moreover, the novel use of influence functions provides insight into how the nature of adversarial example subspaces in NLP relate to those in image processing, and also how they differ depending on the kind of NLP task.
+
+
+
+ 51. 标题:RedPenNet for Grammatical Error Correction: Outputs to Tokens, Attentions to Spans
+ 编号:[265]
+ 链接:https://arxiv.org/abs/2309.10898
+ 作者:Bohdan Didenko (1), Andrii Sameliuk (1) ((1) WebSpellChecker LLC / Ukraine)
+ 备注:
+ 关键词:including sentence fusion, Grammatical Error Correction, highly similar input, Neural Machine Translation, text editing tasks
+
+ 点击查看摘要
+ The text editing tasks, including sentence fusion, sentence splitting and rephrasing, text simplification, and Grammatical Error Correction (GEC), share a common trait of dealing with highly similar input and output sequences. This area of research lies at the intersection of two well-established fields: (i) fully autoregressive sequence-to-sequence approaches commonly used in tasks like Neural Machine Translation (NMT) and (ii) sequence tagging techniques commonly used to address tasks such as Part-of-speech tagging, Named-entity recognition (NER), and similar. In the pursuit of a balanced architecture, researchers have come up with numerous imaginative and unconventional solutions, which we're discussing in the Related Works section. Our approach to addressing text editing tasks is called RedPenNet and is aimed at reducing architectural and parametric redundancies presented in specific Sequence-To-Edits models, preserving their semi-autoregressive advantages. Our models achieve $F_{0.5}$ scores of 77.60 on the BEA-2019 (test), which can be considered as state-of-the-art the only exception for system combination and 67.71 on the UAGEC+Fluency (test) benchmarks.
+This research is being conducted in the context of the UNLP 2023 workshop, where it was presented as a paper as a paper for the Shared Task in Grammatical Error Correction (GEC) for Ukrainian. This study aims to apply the RedPenNet approach to address the GEC problem in the Ukrainian language.
+
+
+
+ 52. 标题:Self-Augmentation Improves Zero-Shot Cross-Lingual Transfer
+ 编号:[270]
+ 链接:https://arxiv.org/abs/2309.10891
+ 作者:Fei Wang, Kuan-Hao Huang, Kai-Wei Chang, Muhao Chen
+ 备注:AACL 2023
+ 关键词:sufficient training resources, allowing models trained, multilingual NLP, Zero-shot cross-lingual transfer, sufficient training
+
+ 点击查看摘要
+ Zero-shot cross-lingual transfer is a central task in multilingual NLP, allowing models trained in languages with more sufficient training resources to generalize to other low-resource languages. Earlier efforts on this task use parallel corpora, bilingual dictionaries, or other annotated alignment data to improve cross-lingual transferability, which are typically expensive to obtain. In this paper, we propose a simple yet effective method, SALT, to improve the zero-shot cross-lingual transfer of the multilingual pretrained language models without the help of such external data. By incorporating code-switching and embedding mixup with self-augmentation, SALT effectively distills cross-lingual knowledge from the multilingual PLM and enhances its transferability on downstream tasks. Experimental results on XNLI and PAWS-X show that our method is able to improve zero-shot cross-lingual transferability without external data. Our code is available at this https URL.
+
+
+
+ 53. 标题:Classifying Organizations for Food System Ontologies using Natural Language Processing
+ 编号:[276]
+ 链接:https://arxiv.org/abs/2309.10880
+ 作者:Tianyu Jiang, Sonia Vinogradova, Nathan Stringham, E. Louise Earl, Allan D. Hollander, Patrick R. Huber, Ellen Riloff, R. Sandra Schillo, Giorgio A. Ubbiali, Matthew Lange
+ 备注:Presented at IFOW 2023 Integrated Food Ontology Workshop at the Formal Ontology in Information Systems Conference (FOIS) 2023 in Sherbrooke, Quebec, Canada July 17-20th, 2023
+ 关键词:natural language processing, NLP models, automatically classify entities, food system ontologies, Standard Industrial Classification
+
+ 点击查看摘要
+ Our research explores the use of natural language processing (NLP) methods to automatically classify entities for the purpose of knowledge graph population and integration with food system ontologies. We have created NLP models that can automatically classify organizations with respect to categories associated with environmental issues as well as Standard Industrial Classification (SIC) codes, which are used by the U.S. government to characterize business activities. As input, the NLP models are provided with text snippets retrieved by the Google search engine for each organization, which serves as a textual description of the organization that is used for learning. Our experimental results show that NLP models can achieve reasonably good performance for these two classification tasks, and they rely on a general framework that could be applied to many other classification problems as well. We believe that NLP models represent a promising approach for automatically harvesting information to populate knowledge graphs and aligning the information with existing ontologies through shared categories and concepts.
+
+
+
+ 54. 标题:Leveraging Data Collection and Unsupervised Learning for Code-switched Tunisian Arabic Automatic Speech Recognition
+ 编号:[298]
+ 链接:https://arxiv.org/abs/2309.11327
+ 作者:Ahmed Amine Ben Abdallah, Ata Kabboudi, Amir Kanoun, Salah Zaiem
+ 备注:6 pages, submitted to ICASSP 2024
+ 关键词:Automatic Speech Recognition, effective Automatic Speech, Speech Recognition, Automatic Speech, dialects demands innovative
+
+ 点击查看摘要
+ Crafting an effective Automatic Speech Recognition (ASR) solution for dialects demands innovative approaches that not only address the data scarcity issue but also navigate the intricacies of linguistic diversity. In this paper, we address the aforementioned ASR challenge, focusing on the Tunisian dialect. First, textual and audio data is collected and in some cases annotated. Second, we explore self-supervision, semi-supervision and few-shot code-switching approaches to push the state-of-the-art on different Tunisian test sets; covering different acoustic, linguistic and prosodic conditions. Finally, and given the absence of conventional spelling, we produce a human evaluation of our transcripts to avoid the noise coming from spelling inadequacies in our testing references. Our models, allowing to transcribe audio samples in a linguistic mix involving Tunisian Arabic, English and French, and all the data used during training and testing are released for public use and further improvements.
+
+
+
+ 55. 标题:Speak While You Think: Streaming Speech Synthesis During Text Generation
+ 编号:[301]
+ 链接:https://arxiv.org/abs/2309.11210
+ 作者:Avihu Dekel, Slava Shechtman, Raul Fernandez, David Haws, Zvi Kons, Ron Hoory
+ 备注:Under review for ICASSP 2024
+ 关键词:Large Language Models, demonstrate impressive capabilities, Large Language, Language Models, demonstrate impressive
+
+ 点击查看摘要
+ Large Language Models (LLMs) demonstrate impressive capabilities, yet interaction with these models is mostly facilitated through text. Using Text-To-Speech to synthesize LLM outputs typically results in notable latency, which is impractical for fluent voice conversations. We propose LLM2Speech, an architecture to synthesize speech while text is being generated by an LLM which yields significant latency reduction. LLM2Speech mimics the predictions of a non-streaming teacher model while limiting the exposure to future context in order to enable streaming. It exploits the hidden embeddings of the LLM, a by-product of the text generation that contains informative semantic context. Experimental results show that LLM2Speech maintains the teacher's quality while reducing the latency to enable natural conversations.
+
+
+
+ 56. 标题:Language-Oriented Communication with Semantic Coding and Knowledge Distillation for Text-to-Image Generation
+ 编号:[303]
+ 链接:https://arxiv.org/abs/2309.11127
+ 作者:Hyelin Nam, Jihong Park, Jinho Choi, Mehdi Bennis, Seong-Lyun Kim
+ 备注:5 pages, 4 figures, submitted to 2024 IEEE International Conference on Acoustics, Speech and Signal Processing
+ 关键词:integrating recent advances, large language models, generative models, integrating recent, recent advances
+
+ 点击查看摘要
+ By integrating recent advances in large language models (LLMs) and generative models into the emerging semantic communication (SC) paradigm, in this article we put forward to a novel framework of language-oriented semantic communication (LSC). In LSC, machines communicate using human language messages that can be interpreted and manipulated via natural language processing (NLP) techniques for SC efficiency. To demonstrate LSC's potential, we introduce three innovative algorithms: 1) semantic source coding (SSC) which compresses a text prompt into its key head words capturing the prompt's syntactic essence while maintaining their appearance order to keep the prompt's context; 2) semantic channel coding (SCC) that improves robustness against errors by substituting head words with their lenghthier synonyms; and 3) semantic knowledge distillation (SKD) that produces listener-customized prompts via in-context learning the listener's language style. In a communication task for progressive text-to-image generation, the proposed methods achieve higher perceptual similarities with fewer transmissions while enhancing robustness in noisy communication channels.
+
+
+
+ 57. 标题:End-to-End Speech Recognition Contextualization with Large Language Models
+ 编号:[319]
+ 链接:https://arxiv.org/abs/2309.10917
+ 作者:Egor Lakomkin, Chunyang Wu, Yassir Fathullah, Ozlem Kalinli, Michael L. Seltzer, Christian Fuegen
+ 备注:
+ 关键词:Large Language Models, research community due, Large Language, garnered significant attention, models incorporating LLMs
+
+ 点击查看摘要
+ In recent years, Large Language Models (LLMs) have garnered significant attention from the research community due to their exceptional performance and generalization capabilities. In this paper, we introduce a novel method for contextualizing speech recognition models incorporating LLMs. Our approach casts speech recognition as a mixed-modal language modeling task based on a pretrained LLM. We provide audio features, along with optional text tokens for context, to train the system to complete transcriptions in a decoder-only fashion. As a result, the system is implicitly incentivized to learn how to leverage unstructured contextual information during training. Our empirical results demonstrate a significant improvement in performance, with a 6% WER reduction when additional textual context is provided. Moreover, we find that our method performs competitively and improve by 7.5% WER overall and 17% WER on rare words against a baseline contextualized RNN-T system that has been trained on more than twenty five times larger speech dataset. Overall, we demonstrate that by only adding a handful number of trainable parameters via adapters, we can unlock contextualized speech recognition capability for the pretrained LLM while keeping the same text-only input functionality.
+
+
+机器学习
+
+ 1. 标题:DreamLLM: Synergistic Multimodal Comprehension and Creation
+ 编号:[2]
+ 链接:https://arxiv.org/abs/2309.11499
+ 作者:Runpei Dong, Chunrui Han, Yuang Peng, Zekun Qi, Zheng Ge, Jinrong Yang, Liang Zhao, Jianjian Sun, Hongyu Zhou, Haoran Wei, Xiangwen Kong, Xiangyu Zhang, Kaisheng Ma, Li Yi
+ 备注:see project page at this https URL
+ 关键词:Large Language Models, versatile Multimodal Large, Multimodal Large Language, Language Models, Large Language
+
+ 点击查看摘要
+ This paper presents DreamLLM, a learning framework that first achieves versatile Multimodal Large Language Models (MLLMs) empowered with frequently overlooked synergy between multimodal comprehension and creation. DreamLLM operates on two fundamental principles. The first focuses on the generative modeling of both language and image posteriors by direct sampling in the raw multimodal space. This approach circumvents the limitations and information loss inherent to external feature extractors like CLIP, and a more thorough multimodal understanding is obtained. Second, DreamLLM fosters the generation of raw, interleaved documents, modeling both text and image contents, along with unstructured layouts. This allows DreamLLM to learn all conditional, marginal, and joint multimodal distributions effectively. As a result, DreamLLM is the first MLLM capable of generating free-form interleaved content. Comprehensive experiments highlight DreamLLM's superior performance as a zero-shot multimodal generalist, reaping from the enhanced learning synergy.
+
+
+
+ 2. 标题:Text2Reward: Automated Dense Reward Function Generation for Reinforcement Learning
+ 编号:[5]
+ 链接:https://arxiv.org/abs/2309.11489
+ 作者:Tianbao Xie, Siheng Zhao, Chen Henry Wu, Yitao Liu, Qian Luo, Victor Zhong, Yanchao Yang, Tao Yu
+ 备注:23 pages, 10 figures, update
+ 关键词:requires specialized knowledge, Designing reward functions, reward functions, dense reward functions, reinforcement learning
+
+ 点击查看摘要
+ Designing reward functions is a longstanding challenge in reinforcement learning (RL); it requires specialized knowledge or domain data, leading to high costs for development. To address this, we introduce Text2Reward, a data-free framework that automates the generation of dense reward functions based on large language models (LLMs). Given a goal described in natural language, Text2Reward generates dense reward functions as an executable program grounded in a compact representation of the environment. Unlike inverse RL and recent work that uses LLMs to write sparse reward codes, Text2Reward produces interpretable, free-form dense reward codes that cover a wide range of tasks, utilize existing packages, and allow iterative refinement with human feedback. We evaluate Text2Reward on two robotic manipulation benchmarks (ManiSkill2, MetaWorld) and two locomotion environments of MuJoCo. On 13 of the 17 manipulation tasks, policies trained with generated reward codes achieve similar or better task success rates and convergence speed than expert-written reward codes. For locomotion tasks, our method learns six novel locomotion behaviors with a success rate exceeding 94%. Furthermore, we show that the policies trained in the simulator with our method can be deployed in the real world. Finally, Text2Reward further improves the policies by refining their reward functions with human feedback. Video results are available at this https URL
+
+
+
+ 3. 标题:Model-free tracking control of complex dynamical trajectories with machine learning
+ 编号:[13]
+ 链接:https://arxiv.org/abs/2309.11470
+ 作者:Zheng-Meng Zhai, Mohammadamin Moradi, Ling-Wei Kong, Bryan Glaz, Mulugeta Haile, Ying-Cheng Lai
+ 备注:16 pages, 8 figures
+ 关键词:Nonlinear tracking control, tracking control enabling, designing tracking control, serving a wide, defense applications
+
+ 点击查看摘要
+ Nonlinear tracking control enabling a dynamical system to track a desired trajectory is fundamental to robotics, serving a wide range of civil and defense applications. In control engineering, designing tracking control requires complete knowledge of the system model and equations. We develop a model-free, machine-learning framework to control a two-arm robotic manipulator using only partially observed states, where the controller is realized by reservoir computing. Stochastic input is exploited for training, which consists of the observed partial state vector as the first and its immediate future as the second component so that the neural machine regards the latter as the future state of the former. In the testing (deployment) phase, the immediate-future component is replaced by the desired observational vector from the reference trajectory. We demonstrate the effectiveness of the control framework using a variety of periodic and chaotic signals, and establish its robustness against measurement noise, disturbances, and uncertainties.
+
+
+
+ 4. 标题:AudioFool: Fast, Universal and synchronization-free Cross-Domain Attack on Speech Recognition
+ 编号:[16]
+ 链接:https://arxiv.org/abs/2309.11462
+ 作者:Mohamad Fakih, Rouwaida Kanj, Fadi Kurdahi, Mohammed E. Fouda
+ 备注:10 pages, 11 Figures
+ 关键词:Automatic Speech Recognition, Speech Recognition systems, Speech Recognition, Automatic Speech, Recognition systems
+
+ 点击查看摘要
+ Automatic Speech Recognition systems have been shown to be vulnerable to adversarial attacks that manipulate the command executed on the device. Recent research has focused on exploring methods to create such attacks, however, some issues relating to Over-The-Air (OTA) attacks have not been properly addressed. In our work, we examine the needed properties of robust attacks compatible with the OTA model, and we design a method of generating attacks with arbitrary such desired properties, namely the invariance to synchronization, and the robustness to filtering: this allows a Denial-of-Service (DoS) attack against ASR systems. We achieve these characteristics by constructing attacks in a modified frequency domain through an inverse Fourier transform. We evaluate our method on standard keyword classification tasks and analyze it in OTA, and we analyze the properties of the cross-domain attacks to explain the efficiency of the approach.
+
+
+
+ 5. 标题:Digital twins of nonlinear dynamical systems: A perspective
+ 编号:[17]
+ 链接:https://arxiv.org/abs/2309.11461
+ 作者:Ying-Cheng Lai
+ 备注:12 pages, 3 figures
+ 关键词:range of fields, Digital twins, attracted a great, great deal, deal of recent
+
+ 点击查看摘要
+ Digital twins have attracted a great deal of recent attention from a wide range of fields. A basic requirement for digital twins of nonlinear dynamical systems is the ability to generate the system evolution and predict potentially catastrophic emergent behaviors so as to providing early warnings. The digital twin can then be used for system "health" monitoring in real time and for predictive problem solving. In particular, if the digital twin forecasts a possible system collapse in the future due to parameter drifting as caused by environmental changes or perturbations, an optimal control strategy can be devised and executed as early intervention to prevent the collapse. Two approaches exist for constructing digital twins of nonlinear dynamical systems: sparse optimization and machine learning. The basics of these two approaches are described and their advantages and caveats are discussed.
+
+
+
+ 6. 标题:Generative Agent-Based Modeling: Unveiling Social System Dynamics through Coupling Mechanistic Models with Generative Artificial Intelligence
+ 编号:[18]
+ 链接:https://arxiv.org/abs/2309.11456
+ 作者:Navid Ghaffarzadegan, Aritra Majumdar, Ross Williams, Niyousha Hosseinichimeh
+ 备注:
+ 关键词:generative artificial intelligence, feedback-rich computational models, building feedback-rich computational, artificial intelligence, generative artificial
+
+ 点击查看摘要
+ We discuss the emerging new opportunity for building feedback-rich computational models of social systems using generative artificial intelligence. Referred to as Generative Agent-Based Models (GABMs), such individual-level models utilize large language models such as ChatGPT to represent human decision-making in social settings. We provide a GABM case in which human behavior can be incorporated in simulation models by coupling a mechanistic model of human interactions with a pre-trained large language model. This is achieved by introducing a simple GABM of social norm diffusion in an organization. For educational purposes, the model is intentionally kept simple. We examine a wide range of scenarios and the sensitivity of the results to several changes in the prompt. We hope the article and the model serve as a guide for building useful diffusion models that include realistic human reasoning and decision-making.
+
+
+
+ 7. 标题:Multi-Step Model Predictive Safety Filters: Reducing Chattering by Increasing the Prediction Horizon
+ 编号:[20]
+ 链接:https://arxiv.org/abs/2309.11453
+ 作者:Federico Pizarro Bejarano, Lukas Brunke, Angela P. Schoellig
+ 备注:8 pages, 9 figures. Accepted to IEEE CDC 2023. Code is publicly available at this https URL
+ 关键词:demonstrated superior performance, superior performance compared, Learning-based controllers, classical controllers, demonstrated superior
+
+ 点击查看摘要
+ Learning-based controllers have demonstrated superior performance compared to classical controllers in various tasks. However, providing safety guarantees is not trivial. Safety, the satisfaction of state and input constraints, can be guaranteed by augmenting the learned control policy with a safety filter. Model predictive safety filters (MPSFs) are a common safety filtering approach based on model predictive control (MPC). MPSFs seek to guarantee safety while minimizing the difference between the proposed and applied inputs in the immediate next time step. This limited foresight can lead to jerky motions and undesired oscillations close to constraint boundaries, known as chattering. In this paper, we reduce chattering by considering input corrections over a longer horizon. Under the assumption of bounded model uncertainties, we prove recursive feasibility using techniques from robust MPC. We verified the proposed approach in both extensive simulation and quadrotor experiments. In experiments with a Crazyflie 2.0 drone, we show that, in addition to preserving the desired safety guarantees, the proposed MPSF reduces chattering by more than a factor of 4 compared to previous MPSF formulations.
+
+
+
+ 8. 标题:Weight Averaging Improves Knowledge Distillation under Domain Shift
+ 编号:[22]
+ 链接:https://arxiv.org/abs/2309.11446
+ 作者:Valeriy Berezovskiy, Nikita Morozov
+ 备注:ICCV 2023 Workshop on Out-of-Distribution Generalization in Computer Vision (OOD-CV)
+ 关键词:deep learning applications, powerful model compression, practical deep learning, model compression technique, compression technique broadly
+
+ 点击查看摘要
+ Knowledge distillation (KD) is a powerful model compression technique broadly used in practical deep learning applications. It is focused on training a small student network to mimic a larger teacher network. While it is widely known that KD can offer an improvement to student generalization in i.i.d setting, its performance under domain shift, i.e. the performance of student networks on data from domains unseen during training, has received little attention in the literature. In this paper we make a step towards bridging the research fields of knowledge distillation and domain generalization. We show that weight averaging techniques proposed in domain generalization literature, such as SWAD and SMA, also improve the performance of knowledge distillation under domain shift. In addition, we propose a simplistic weight averaging strategy that does not require evaluation on validation data during training and show that it performs on par with SWAD and SMA when applied to KD. We name our final distillation approach Weight-Averaged Knowledge Distillation (WAKD).
+
+
+
+ 9. 标题:Signature Activation: A Sparse Signal View for Holistic Saliency
+ 编号:[24]
+ 链接:https://arxiv.org/abs/2309.11443
+ 作者:Jose Roberto Tello Ayala, Akl C. Fahed, Weiwei Pan, Eugene V. Pomerantsev, Patrick T. Ellinor, Anthony Philippakis, Finale Doshi-Velez
+ 备注:
+ 关键词:Convolutional Neural Network, introduce Signature Activation, transparency and explainability, adoption of machine, machine learning
+
+ 点击查看摘要
+ The adoption of machine learning in healthcare calls for model transparency and explainability. In this work, we introduce Signature Activation, a saliency method that generates holistic and class-agnostic explanations for Convolutional Neural Network (CNN) outputs. Our method exploits the fact that certain kinds of medical images, such as angiograms, have clear foreground and background objects. We give theoretical explanation to justify our methods. We show the potential use of our method in clinical settings through evaluating its efficacy for aiding the detection of lesions in coronary angiograms.
+
+
+
+ 10. 标题:Generative Pre-Training of Time-Series Data for Unsupervised Fault Detection in Semiconductor Manufacturing
+ 编号:[28]
+ 链接:https://arxiv.org/abs/2309.11427
+ 作者:Sewoong Lee, JinKyou Choi, Min Su Kim
+ 备注:
+ 关键词:Generative Pre-trained Transformers, paper introduces TRACE-GPT, Generative Pre-trained, Embedding and Generative, Time-seRies Anomaly-detection
+
+ 点击查看摘要
+ This paper introduces TRACE-GPT, which stands for Time-seRies Anomaly-detection with Convolutional Embedding and Generative Pre-trained Transformers. TRACE-GPT is designed to pre-train univariate time-series sensor data and detect faults on unlabeled datasets in semiconductor manufacturing. In semiconductor industry, classifying abnormal time-series sensor data from normal data is important because it is directly related to wafer defect. However, small, unlabeled, and even mixed training data without enough anomalies make classification tasks difficult. In this research, we capture features of time-series data with temporal convolutional embedding and Generative Pre-trained Transformer (GPT) to classify abnormal sequences from normal sequences using cross entropy loss. We prove that our model shows better performance than previous unsupervised models with both an open dataset, the University of California Riverside (UCR) time-series classification archive, and the process log of our Chemical Vapor Deposition (CVD) equipment. Our model has the highest F1 score at Equal Error Rate (EER) across all datasets and is only 0.026 below the supervised state-of-the-art baseline on the open dataset.
+
+
+
+ 11. 标题:Deep Networks as Denoising Algorithms: Sample-Efficient Learning of Diffusion Models in High-Dimensional Graphical Models
+ 编号:[29]
+ 链接:https://arxiv.org/abs/2309.11420
+ 作者:Song Mei, Yuchen Wu
+ 备注:41 pages
+ 关键词:score functions, score, approximation efficiency, models, functions
+
+ 点击查看摘要
+ We investigate the approximation efficiency of score functions by deep neural networks in diffusion-based generative modeling. While existing approximation theories utilize the smoothness of score functions, they suffer from the curse of dimensionality for intrinsically high-dimensional data. This limitation is pronounced in graphical models such as Markov random fields, common for image distributions, where the approximation efficiency of score functions remains unestablished.
+To address this, we observe score functions can often be well-approximated in graphical models through variational inference denoising algorithms. Furthermore, these algorithms are amenable to efficient neural network representation. We demonstrate this in examples of graphical models, including Ising models, conditional Ising models, restricted Boltzmann machines, and sparse encoding models. Combined with off-the-shelf discretization error bounds for diffusion-based sampling, we provide an efficient sample complexity bound for diffusion-based generative modeling when the score function is learned by deep neural networks.
+
+
+
+ 12. 标题:EDMP: Ensemble-of-costs-guided Diffusion for Motion Planning
+ 编号:[32]
+ 链接:https://arxiv.org/abs/2309.11414
+ 作者:Kallol Saha, Vishal Mandadi, Jayaram Reddy, Ajit Srikanth, Aditya Agarwal, Bipasha Sen, Arun Singh, Madhava Krishna
+ 备注:8 pages, 8 figures, submitted to ICRA 2024 (International Conference on Robotics and Automation)
+ 关键词:robotic manipulation includes, robotic manipulation, manipulation includes, motion planning, aim to minimize
+
+ 点击查看摘要
+ Classical motion planning for robotic manipulation includes a set of general algorithms that aim to minimize a scene-specific cost of executing a given plan. This approach offers remarkable adaptability, as they can be directly used off-the-shelf for any new scene without needing specific training datasets. However, without a prior understanding of what diverse valid trajectories are and without specially designed cost functions for a given scene, the overall solutions tend to have low success rates. While deep-learning-based algorithms tremendously improve success rates, they are much harder to adopt without specialized training datasets. We propose EDMP, an Ensemble-of-costs-guided Diffusion for Motion Planning that aims to combine the strengths of classical and deep-learning-based motion planning. Our diffusion-based network is trained on a set of diverse kinematically valid trajectories. Like classical planning, for any new scene at the time of inference, we compute scene-specific costs such as "collision cost" and guide the diffusion to generate valid trajectories that satisfy the scene-specific constraints. Further, instead of a single cost function that may be insufficient in capturing diversity across scenes, we use an ensemble of costs to guide the diffusion process, significantly improving the success rate compared to classical planners. EDMP performs comparably with SOTA deep-learning-based methods while retaining the generalization capabilities primarily associated with classical planners.
+
+
+
+ 13. 标题:Preconditioned Federated Learning
+ 编号:[45]
+ 链接:https://arxiv.org/abs/2309.11378
+ 作者:Zeyi Tao, Jindi Wu, Qun Li
+ 备注:preprint
+ 关键词:distributed machine learning, machine learning approach, enables model training, machine learning, learning approach
+
+ 点击查看摘要
+ Federated Learning (FL) is a distributed machine learning approach that enables model training in communication efficient and privacy-preserving manner. The standard optimization method in FL is Federated Averaging (FedAvg), which performs multiple local SGD steps between communication rounds. FedAvg has been considered to lack algorithm adaptivity compared to modern first-order adaptive optimizations. In this paper, we propose new communication-efficient FL algortithms based on two adaptive frameworks: local adaptivity (PreFed) and server-side adaptivity (PreFedOp). Proposed methods adopt adaptivity by using a novel covariance matrix preconditioner. Theoretically, we provide convergence guarantees for our algorithms. The empirical experiments show our methods achieve state-of-the-art performances on both i.i.d. and non-i.i.d. settings.
+
+
+
+ 14. 标题:Learning Patient Static Information from Time-series EHR and an Approach for Safeguarding Privacy and Fairness
+ 编号:[46]
+ 链接:https://arxiv.org/abs/2309.11373
+ 作者:Wei Liao, Joel Voldman
+ 备注:
+ 关键词:healthcare has raised, Recent work, information, machine learning, data
+
+ 点击查看摘要
+ Recent work in machine learning for healthcare has raised concerns about patient privacy and algorithmic fairness. For example, previous work has shown that patient self-reported race can be predicted from medical data that does not explicitly contain racial information. However, the extent of data identification is unknown, and we lack ways to develop models whose outcomes are minimally affected by such information. Here we systematically investigated the ability of time-series electronic health record data to predict patient static information. We found that not only the raw time-series data, but also learned representations from machine learning models, can be trained to predict a variety of static information with area under the receiver operating characteristic curve as high as 0.851 for biological sex, 0.869 for binarized age and 0.810 for self-reported race. Such high predictive performance can be extended to a wide range of comorbidity factors and exists even when the model was trained for different tasks, using different cohorts, using different model architectures and databases. Given the privacy and fairness concerns these findings pose, we develop a variational autoencoder-based approach that learns a structured latent space to disentangle patient-sensitive attributes from time-series data. Our work thoroughly investigates the ability of machine learning models to encode patient static information from time-series electronic health records and introduces a general approach to protect patient-sensitive attribute information for downstream tasks.
+
+
+
+ 15. 标题:3D Face Reconstruction: the Road to Forensics
+ 编号:[52]
+ 链接:https://arxiv.org/abs/2309.11357
+ 作者:Simone Maurizio La Cava, Giulia Orrù, Martin Drahansky, Gian Luca Marcialis, Fabio Roli
+ 备注:The manuscript has been accepted for publication in ACM Computing Surveys. arXiv admin note: text overlap with arXiv:2303.11164
+ 关键词:face reconstruction algorithms, face reconstruction, entertainment sector, advantageous features, plastic surgery
+
+ 点击查看摘要
+ 3D face reconstruction algorithms from images and videos are applied to many fields, from plastic surgery to the entertainment sector, thanks to their advantageous features. However, when looking at forensic applications, 3D face reconstruction must observe strict requirements that still make its possible role in bringing evidence to a lawsuit unclear. An extensive investigation of the constraints, potential, and limits of its application in forensics is still missing. Shedding some light on this matter is the goal of the present survey, which starts by clarifying the relation between forensic applications and biometrics, with a focus on face recognition. Therefore, it provides an analysis of the achievements of 3D face reconstruction algorithms from surveillance videos and mugshot images and discusses the current obstacles that separate 3D face reconstruction from an active role in forensic applications. Finally, it examines the underlying data sets, with their advantages and limitations, while proposing alternatives that could substitute or complement them.
+
+
+
+ 16. 标题:Self-supervised learning unveils change in urban housing from street-level images
+ 编号:[54]
+ 链接:https://arxiv.org/abs/2309.11354
+ 作者:Steven Stalder, Michele Volpi, Nicolas Büttner, Stephen Law, Kenneth Harttgen, Esra Suel
+ 备注:16 pages, 5 figures
+ 关键词:world face, shortage of affordable, affordable and decent, critical shortage, decent housing
+
+ 点击查看摘要
+ Cities around the world face a critical shortage of affordable and decent housing. Despite its critical importance for policy, our ability to effectively monitor and track progress in urban housing is limited. Deep learning-based computer vision methods applied to street-level images have been successful in the measurement of socioeconomic and environmental inequalities but did not fully utilize temporal images to track urban change as time-varying labels are often unavailable. We used self-supervised methods to measure change in London using 15 million street images taken between 2008 and 2021. Our novel adaptation of Barlow Twins, Street2Vec, embeds urban structure while being invariant to seasonal and daily changes without manual annotations. It outperformed generic embeddings, successfully identified point-level change in London's housing supply from street-level images, and distinguished between major and minor change. This capability can provide timely information for urban planning and policy decisions toward more liveable, equitable, and sustainable cities.
+
+
+
+ 17. 标题:C$\cdot$ASE: Learning Conditional Adversarial Skill Embeddings for Physics-based Characters
+ 编号:[55]
+ 链接:https://arxiv.org/abs/2309.11351
+ 作者:Zhiyang Dou, Xuelin Chen, Qingnan Fan, Taku Komura, Wenping Wang
+ 备注:SIGGRAPH Asia 2023
+ 关键词:Adversarial Skill Embeddings, learns conditional Adversarial, Embeddings for physics-based, conditional Adversarial Skill, conditional Adversarial
+
+ 点击查看摘要
+ We present C$\cdot$ASE, an efficient and effective framework that learns conditional Adversarial Skill Embeddings for physics-based characters. Our physically simulated character can learn a diverse repertoire of skills while providing controllability in the form of direct manipulation of the skills to be performed. C$\cdot$ASE divides the heterogeneous skill motions into distinct subsets containing homogeneous samples for training a low-level conditional model to learn conditional behavior distribution. The skill-conditioned imitation learning naturally offers explicit control over the character's skills after training. The training course incorporates the focal skill sampling, skeletal residual forces, and element-wise feature masking to balance diverse skills of varying complexities, mitigate dynamics mismatch to master agile motions and capture more general behavior characteristics, respectively. Once trained, the conditional model can produce highly diverse and realistic skills, outperforming state-of-the-art models, and can be repurposed in various downstream tasks. In particular, the explicit skill control handle allows a high-level policy or user to direct the character with desired skill specifications, which we demonstrate is advantageous for interactive character animation.
+
+
+
+ 18. 标题:GECTurk: Grammatical Error Correction and Detection Dataset for Turkish
+ 编号:[57]
+ 链接:https://arxiv.org/abs/2309.11346
+ 作者:Atakan Kara, Farrin Marouf Sofian, Andrew Bond, Gözde Gül Şahin
+ 备注:Accepted at Findings of IJCNLP-AACL 2023
+ 关键词:Grammatical Error Detection, Detection and Correction, Error Detection, Grammatical Error, Synthetic data generation
+
+ 点击查看摘要
+ Grammatical Error Detection and Correction (GEC) tools have proven useful for native speakers and second language learners. Developing such tools requires a large amount of parallel, annotated data, which is unavailable for most languages. Synthetic data generation is a common practice to overcome the scarcity of such data. However, it is not straightforward for morphologically rich languages like Turkish due to complex writing rules that require phonological, morphological, and syntactic information. In this work, we present a flexible and extensible synthetic data generation pipeline for Turkish covering more than 20 expert-curated grammar and spelling rules (a.k.a., writing rules) implemented through complex transformation functions. Using this pipeline, we derive 130,000 high-quality parallel sentences from professionally edited articles. Additionally, we create a more realistic test set by manually annotating a set of movie reviews. We implement three baselines formulating the task as i) neural machine translation, ii) sequence tagging, and iii) prefix tuning with a pretrained decoder-only model, achieving strong results. Furthermore, we perform exhaustive experiments on out-of-domain datasets to gain insights on the transferability and robustness of the proposed approaches. Our results suggest that our corpus, GECTurk, is high-quality and allows knowledge transfer for the out-of-domain setting. To encourage further research on Turkish GEC, we release our datasets, baseline models, and the synthetic data generation pipeline at this https URL.
+
+
+
+ 19. 标题:Using Property Elicitation to Understand the Impacts of Fairness Constraints
+ 编号:[58]
+ 链接:https://arxiv.org/abs/2309.11343
+ 作者:Jessie Finocchiaro
+ 备注:Please reach out if you have comments or thoughts; this is a living project
+ 关键词:regularization functions, Predictive algorithms, trained by optimizing, added to impose, impose a penalty
+
+ 点击查看摘要
+ Predictive algorithms are often trained by optimizing some loss function, to which regularization functions are added to impose a penalty for violating constraints. As expected, the addition of such regularization functions can change the minimizer of the objective. It is not well-understood which regularizers change the minimizer of the loss, and, when the minimizer does change, how it changes. We use property elicitation to take first steps towards understanding the joint relationship between the loss and regularization functions and the optimal decision for a given problem instance. In particular, we give a necessary and sufficient condition on loss and regularizer pairs for when a property changes with the addition of the regularizer, and examine some regularizers satisfying this condition standard in the fair machine learning literature. We empirically demonstrate how algorithmic decision-making changes as a function of both data distribution changes and hardness of the constraints.
+
+
+
+ 20. 标题:Improving Article Classification with Edge-Heterogeneous Graph Neural Networks
+ 编号:[59]
+ 链接:https://arxiv.org/abs/2309.11341
+ 作者:Khang Ly, Yury Kashnitsky, Savvas Chamezopoulos, Valeria Krzhizhanovskaya
+ 备注:
+ 关键词:Classifying research output, relevant downstream task, context-specific label taxonomies, newly published articles, Graph Neural Networks
+
+ 点击查看摘要
+ Classifying research output into context-specific label taxonomies is a challenging and relevant downstream task, given the volume of existing and newly published articles. We propose a method to enhance the performance of article classification by enriching simple Graph Neural Networks (GNN) pipelines with edge-heterogeneous graph representations. SciBERT is used for node feature generation to capture higher-order semantics within the articles' textual metadata. Fully supervised transductive node classification experiments are conducted on the Open Graph Benchmark (OGB) ogbn-arxiv dataset and the PubMed diabetes dataset, augmented with additional metadata from Microsoft Academic Graph (MAG) and PubMed Central, respectively. The results demonstrate that edge-heterogeneous graphs consistently improve the performance of all GNN models compared to the edge-homogeneous graphs. The transformed data enable simple and shallow GNN pipelines to achieve results on par with more complex architectures. On ogbn-arxiv, we achieve a top-15 result in the OGB competition with a 2-layer GCN (accuracy 74.61%), being the highest-scoring solution with sub-1 million parameters. On PubMed, we closely trail SOTA GNN architectures using a 2-layer GraphSAGE by including additional co-authorship edges in the graph (accuracy 89.88%). The implementation is available at: $\href{this https URL}{\text{this https URL}}$.
+
+
+
+ 21. 标题:WFTNet: Exploiting Global and Local Periodicity in Long-term Time Series Forecasting
+ 编号:[70]
+ 链接:https://arxiv.org/abs/2309.11319
+ 作者:Peiyuan Liu, Beiliang Wu, Naiqi Li, Tao Dai, Fengmao Lei, Jigang Bao, Yong Jiang, Shu-Tao Xia
+ 备注:
+ 关键词:CNN and Transformer-based, Recent CNN, Transformer-based models, time series forecasting, long-term time series
+
+ 点击查看摘要
+ Recent CNN and Transformer-based models tried to utilize frequency and periodicity information for long-term time series forecasting. However, most existing work is based on Fourier transform, which cannot capture fine-grained and local frequency structure. In this paper, we propose a Wavelet-Fourier Transform Network (WFTNet) for long-term time series forecasting. WFTNet utilizes both Fourier and wavelet transforms to extract comprehensive temporal-frequency information from the signal, where Fourier transform captures the global periodic patterns and wavelet transform captures the local ones. Furthermore, we introduce a Periodicity-Weighted Coefficient (PWC) to adaptively balance the importance of global and local frequency patterns. Extensive experiments on various time series datasets show that WFTNet consistently outperforms other state-of-the-art baseline.
+
+
+
+ 22. 标题:Create and Find Flatness: Building Flat Training Spaces in Advance for Continual Learning
+ 编号:[78]
+ 链接:https://arxiv.org/abs/2309.11305
+ 作者:Wenhang Shi, Yiren Chen, Zhe Zhao, Wei Lu, Kimmo Yan, Xiaoyong Du
+ 备注:10pages, ECAI2023 conference
+ 关键词:Catastrophic forgetting remains, neural networks struggle, retain prior knowledge, Catastrophic forgetting, assimilating new information
+
+ 点击查看摘要
+ Catastrophic forgetting remains a critical challenge in the field of continual learning, where neural networks struggle to retain prior knowledge while assimilating new information. Most existing studies emphasize mitigating this issue only when encountering new tasks, overlooking the significance of the pre-task phase. Therefore, we shift the attention to the current task learning stage, presenting a novel framework, C&F (Create and Find Flatness), which builds a flat training space for each task in advance. Specifically, during the learning of the current task, our framework adaptively creates a flat region around the minimum in the loss landscape. Subsequently, it finds the parameters' importance to the current task based on their flatness degrees. When adapting the model to a new task, constraints are applied according to the flatness and a flat space is simultaneously prepared for the impending task. We theoretically demonstrate the consistency between the created and found flatness. In this manner, our framework not only accommodates ample parameter space for learning new tasks but also preserves the preceding knowledge of earlier tasks. Experimental results exhibit C&F's state-of-the-art performance as a standalone continual learning approach and its efficacy as a framework incorporating other methods. Our work is available at this https URL.
+
+
+
+ 23. 标题:CPLLM: Clinical Prediction with Large Language Models
+ 编号:[82]
+ 链接:https://arxiv.org/abs/2309.11295
+ 作者:Ofir Ben Shoham, Nadav Rappoport
+ 备注:
+ 关键词:pre-trained Large Language, Large Language Models, Large Language, present Clinical Prediction, clinical disease prediction
+
+ 点击查看摘要
+ We present Clinical Prediction with Large Language Models (CPLLM), a method that involves fine-tuning a pre-trained Large Language Model (LLM) for clinical disease prediction. We utilized quantization and fine-tuned the LLM using prompts, with the task of predicting whether patients will be diagnosed with a target disease during their next visit or in the subsequent diagnosis, leveraging their historical diagnosis records. We compared our results versus various baselines, including Logistic Regression, RETAIN, and Med-BERT, which is the current state-of-the-art model for disease prediction using structured EHR data. Our experiments have shown that CPLLM surpasses all the tested models in terms of both PR-AUC and ROC-AUC metrics, displaying noteworthy enhancements compared to the baseline models.
+
+
+
+ 24. 标题:Beyond Accuracy: Measuring Representation Capacity of Embeddings to Preserve Structural and Contextual Information
+ 编号:[83]
+ 链接:https://arxiv.org/abs/2309.11294
+ 作者:Sarwan Ali
+ 备注:Accepted at ISBRA 2023
+ 关键词:machine learning tasks, learning tasks, machine learning, captures the underlying, underlying structure
+
+ 点击查看摘要
+ Effective representation of data is crucial in various machine learning tasks, as it captures the underlying structure and context of the data. Embeddings have emerged as a powerful technique for data representation, but evaluating their quality and capacity to preserve structural and contextual information remains a challenge. In this paper, we address this need by proposing a method to measure the \textit{representation capacity} of embeddings. The motivation behind this work stems from the importance of understanding the strengths and limitations of embeddings, enabling researchers and practitioners to make informed decisions in selecting appropriate embedding models for their specific applications. By combining extrinsic evaluation methods, such as classification and clustering, with t-SNE-based neighborhood analysis, such as neighborhood agreement and trustworthiness, we provide a comprehensive assessment of the representation capacity. Additionally, the use of optimization techniques (bayesian optimization) for weight optimization (for classification, clustering, neighborhood agreement, and trustworthiness) ensures an objective and data-driven approach in selecting the optimal combination of metrics. The proposed method not only contributes to advancing the field of embedding evaluation but also empowers researchers and practitioners with a quantitative measure to assess the effectiveness of embeddings in capturing structural and contextual information. For the evaluation, we use $3$ real-world biological sequence (proteins and nucleotide) datasets and performed representation capacity analysis of $4$ embedding methods from the literature, namely Spike2Vec, Spaced $k$-mers, PWM2Vec, and AutoEncoder.
+
+
+
+ 25. 标题:Overview of AuTexTification at IberLEF 2023: Detection and Attribution of Machine-Generated Text in Multiple Domains
+ 编号:[85]
+ 链接:https://arxiv.org/abs/2309.11285
+ 作者:Areg Mikael Sarvazyan, José Ángel González, Marc Franco-Salvador, Francisco Rangel, Berta Chulvi, Paolo Rosso
+ 备注:Accepted at SEPLN 2023
+ 关键词:Languages Evaluation Forum, Iberian Languages Evaluation, Workshop in Iberian, Evaluation Forum, Iberian Languages
+
+ 点击查看摘要
+ This paper presents the overview of the AuTexTification shared task as part of the IberLEF 2023 Workshop in Iberian Languages Evaluation Forum, within the framework of the SEPLN 2023 conference. AuTexTification consists of two subtasks: for Subtask 1, participants had to determine whether a text is human-authored or has been generated by a large language model. For Subtask 2, participants had to attribute a machine-generated text to one of six different text generation models. Our AuTexTification 2023 dataset contains more than 160.000 texts across two languages (English and Spanish) and five domains (tweets, reviews, news, legal, and how-to articles). A total of 114 teams signed up to participate, of which 36 sent 175 runs, and 20 of them sent their working notes. In this overview, we present the AuTexTification dataset and task, the submitted participating systems, and the results.
+
+
+
+ 26. 标题:From Classification to Segmentation with Explainable AI: A Study on Crack Detection and Growth Monitoring
+ 编号:[97]
+ 链接:https://arxiv.org/abs/2309.11267
+ 作者:Florent Forest, Hugo Porta, Devis Tuia, Olga Fink
+ 备注:43 pages. Under review
+ 关键词:structural health monitoring, infrastructure is crucial, crucial for structural, structural health, Monitoring
+
+ 点击查看摘要
+ Monitoring surface cracks in infrastructure is crucial for structural health monitoring. Automatic visual inspection offers an effective solution, especially in hard-to-reach areas. Machine learning approaches have proven their effectiveness but typically require large annotated datasets for supervised training. Once a crack is detected, monitoring its severity often demands precise segmentation of the damage. However, pixel-level annotation of images for segmentation is labor-intensive. To mitigate this cost, one can leverage explainable artificial intelligence (XAI) to derive segmentations from the explanations of a classifier, requiring only weak image-level supervision. This paper proposes applying this methodology to segment and monitor surface cracks. We evaluate the performance of various XAI methods and examine how this approach facilitates severity quantification and growth monitoring. Results reveal that while the resulting segmentation masks may exhibit lower quality than those produced by supervised methods, they remain meaningful and enable severity monitoring, thus reducing substantial labeling costs.
+
+
+
+ 27. 标题:Sequence-to-Sequence Spanish Pre-trained Language Models
+ 编号:[98]
+ 链接:https://arxiv.org/abs/2309.11259
+ 作者:Vladimir Araujo, Maria Mihaela Trusca, Rodrigo Tufiño, Marie-Francine Moens
+ 备注:
+ 关键词:numerous non-English language, non-English language versions, recent years, substantial advancements, numerous non-English
+
+ 点击查看摘要
+ In recent years, substantial advancements in pre-trained language models have paved the way for the development of numerous non-English language versions, with a particular focus on encoder-only and decoder-only architectures. While Spanish language models encompassing BERT, RoBERTa, and GPT have exhibited prowess in natural language understanding and generation, there remains a scarcity of encoder-decoder models designed for sequence-to-sequence tasks involving input-output pairs. This paper breaks new ground by introducing the implementation and evaluation of renowned encoder-decoder architectures, exclusively pre-trained on Spanish corpora. Specifically, we present Spanish versions of BART, T5, and BERT2BERT-style models and subject them to a comprehensive assessment across a diverse range of sequence-to-sequence tasks, spanning summarization, rephrasing, and generative question answering. Our findings underscore the competitive performance of all models, with BART and T5 emerging as top performers across all evaluated tasks. As an additional contribution, we have made all models publicly available to the research community, fostering future exploration and development in Spanish language processing.
+
+
+
+ 28. 标题:Hierarchical Multi-Agent Reinforcement Learning for Air Combat Maneuvering
+ 编号:[105]
+ 链接:https://arxiv.org/abs/2309.11247
+ 作者:Ardian Selmonaj, Oleg Szehr, Giacomo Del Rio, Alessandro Antonucci, Adrian Schneider, Michael Rüegsegger
+ 备注:22nd International Conference on Machine Learning and Applications (ICMLA 23)
+ 关键词:attracting increasing attention, intelligence to simulate, increasing attention, application of artificial, artificial intelligence
+
+ 点击查看摘要
+ The application of artificial intelligence to simulate air-to-air combat scenarios is attracting increasing attention. To date the high-dimensional state and action spaces, the high complexity of situation information (such as imperfect and filtered information, stochasticity, incomplete knowledge about mission targets) and the nonlinear flight dynamics pose significant challenges for accurate air combat decision-making. These challenges are exacerbated when multiple heterogeneous agents are involved. We propose a hierarchical multi-agent reinforcement learning framework for air-to-air combat with multiple heterogeneous agents. In our framework, the decision-making process is divided into two stages of abstraction, where heterogeneous low-level policies control the action of individual units, and a high-level commander policy issues macro commands given the overall mission targets. Low-level policies are trained for accurate unit combat control. Their training is organized in a learning curriculum with increasingly complex training scenarios and league-based self-play. The commander policy is trained on mission targets given pre-trained low-level policies. The empirical validation advocates the advantages of our design choices.
+
+
+
+ 29. 标题:Grassroots Operator Search for Model Edge Adaptation
+ 编号:[106]
+ 链接:https://arxiv.org/abs/2309.11246
+ 作者:Hadjer Benmeziane, Kaoutar El Maghraoui, Hamza Ouarnoughi, Smail Niar
+ 备注:
+ 关键词:Hardware-aware Neural Architecture, Neural Architecture Search, Hardware-aware Neural, Neural Architecture, design efficient deep
+
+ 点击查看摘要
+ Hardware-aware Neural Architecture Search (HW-NAS) is increasingly being used to design efficient deep learning architectures. An efficient and flexible search space is crucial to the success of HW-NAS. Current approaches focus on designing a macro-architecture and searching for the architecture's hyperparameters based on a set of possible values. This approach is biased by the expertise of deep learning (DL) engineers and standard modeling approaches. In this paper, we present a Grassroots Operator Search (GOS) methodology. Our HW-NAS adapts a given model for edge devices by searching for efficient operator replacement. We express each operator as a set of mathematical instructions that capture its behavior. The mathematical instructions are then used as the basis for searching and selecting efficient replacement operators that maintain the accuracy of the original model while reducing computational complexity. Our approach is grassroots since it relies on the mathematical foundations to construct new and efficient operators for DL architectures. We demonstrate on various DL models, that our method consistently outperforms the original models on two edge devices, namely Redmi Note 7S and Raspberry Pi3, with a minimum of 2.2x speedup while maintaining high accuracy. Additionally, we showcase a use case of our GOS approach in pulse rate estimation on wristband devices, where we achieve state-of-the-art performance, while maintaining reduced computational complexity, demonstrating the effectiveness of our approach in practical applications.
+
+
+
+ 30. 标题:Towards a Prediction of Machine Learning Training Time to Support Continuous Learning Systems Development
+ 编号:[117]
+ 链接:https://arxiv.org/abs/2309.11226
+ 作者:Francesca Marzi, Giordano d'Aloisio, Antinisca Di Marco, Giovanni Stilo
+ 备注:
+ 关键词:training time, Parameter Time Complexity, Full Parameter Time, machine learning, scientific community
+
+ 点击查看摘要
+ The problem of predicting the training time of machine learning (ML) models has become extremely relevant in the scientific community. Being able to predict a priori the training time of an ML model would enable the automatic selection of the best model both in terms of energy efficiency and in terms of performance in the context of, for instance, MLOps architectures. In this paper, we present the work we are conducting towards this direction. In particular, we present an extensive empirical study of the Full Parameter Time Complexity (FPTC) approach by Zheng et al., which is, to the best of our knowledge, the only approach formalizing the training time of ML models as a function of both dataset's and model's parameters. We study the formulations proposed for the Logistic Regression and Random Forest classifiers, and we highlight the main strengths and weaknesses of the approach. Finally, we observe how, from the conducted study, the prediction of training time is strictly related to the context (i.e., the involved dataset) and how the FPTC approach is not generalizable.
+
+
+
+ 31. 标题:A Model-Based Machine Learning Approach for Assessing the Performance of Blockchain Applications
+ 编号:[122]
+ 链接:https://arxiv.org/abs/2309.11205
+ 作者:Adel Albshri, Ali Alzubaidi, Ellis Solaiman
+ 备注:
+ 关键词:Blockchain technology consolidates, recent advancement, technology consolidates, consolidates its status, viable alternative
+
+ 点击查看摘要
+ The recent advancement of Blockchain technology consolidates its status as a viable alternative for various domains. However, evaluating the performance of blockchain applications can be challenging due to the underlying infrastructure's complexity and distributed nature. Therefore, a reliable modelling approach is needed to boost Blockchain-based applications' development and evaluation. While simulation-based solutions have been researched, machine learning (ML) model-based techniques are rarely discussed in conjunction with evaluating blockchain application performance. Our novel research makes use of two ML model-based methods. Firstly, we train a $k$ nearest neighbour ($k$NN) and support vector machine (SVM) to predict blockchain performance using predetermined configuration parameters. Secondly, we employ the salp swarm optimization (SO) ML model which enables the investigation of optimal blockchain configurations for achieving the required performance level. We use rough set theory to enhance SO, hereafter called ISO, which we demonstrate to prove achieving an accurate recommendation of optimal parameter configurations; despite uncertainty. Finally, statistical comparisons indicate that our models have a competitive edge. The $k$NN model outperforms SVM by 5\% and the ISO also demonstrates a reduction of 4\% inaccuracy deviation compared to regular SO.
+
+
+
+ 32. 标题:The Languini Kitchen: Enabling Language Modelling Research at Different Scales of Compute
+ 编号:[124]
+ 链接:https://arxiv.org/abs/2309.11197
+ 作者:Aleksandar Stanić, Dylan Ashley, Oleg Serikov, Louis Kirsch, Francesco Faccio, Jürgen Schmidhuber, Thomas Hofmann, Imanol Schlag
+ 备注:
+ 关键词:Languini Kitchen serves, Languini Kitchen, limited computational resources, collective and codebase, codebase designed
+
+ 点击查看摘要
+ The Languini Kitchen serves as both a research collective and codebase designed to empower researchers with limited computational resources to contribute meaningfully to the field of language modelling. We introduce an experimental protocol that enables model comparisons based on equivalent compute, measured in accelerator hours. The number of tokens on which a model is trained is defined by the model's throughput and the chosen compute class. Notably, this approach avoids constraints on critical hyperparameters which affect total parameters or floating-point operations. For evaluation, we pre-process an existing large, diverse, and high-quality dataset of books that surpasses existing academic benchmarks in quality, diversity, and document length. On it, we compare methods based on their empirical scaling trends which are estimated through experiments at various levels of compute. This work also provides two baseline models: a feed-forward model derived from the GPT-2 architecture and a recurrent model in the form of a novel LSTM with ten-fold throughput. While the GPT baseline achieves better perplexity throughout all our levels of compute, our LSTM baseline exhibits a predictable and more favourable scaling law. This is due to the improved throughput and the need for fewer training tokens to achieve the same decrease in test perplexity. Extrapolating the scaling laws leads of both models results in an intersection at roughly 50,000 accelerator hours. We hope this work can serve as the foundation for meaningful and reproducible language modelling research.
+
+
+
+ 33. 标题:When to Trust AI: Advances and Challenges for Certification of Neural Networks
+ 编号:[125]
+ 链接:https://arxiv.org/abs/2309.11196
+ 作者:Marta Kwiatkowska, Xiyue Zhang
+ 备注:
+ 关键词:natural language processing, Artificial intelligence, medical diagnosis, language processing, fast pace
+
+ 点击查看摘要
+ Artificial intelligence (AI) has been advancing at a fast pace and it is now poised for deployment in a wide range of applications, such as autonomous systems, medical diagnosis and natural language processing. Early adoption of AI technology for real-world applications has not been without problems, particularly for neural networks, which may be unstable and susceptible to adversarial examples. In the longer term, appropriate safety assurance techniques need to be developed to reduce potential harm due to avoidable system failures and ensure trustworthiness. Focusing on certification and explainability, this paper provides an overview of techniques that have been developed to ensure safety of AI decisions and discusses future challenges.
+
+
+
+ 34. 标题:RHALE: Robust and Heterogeneity-aware Accumulated Local Effects
+ 编号:[126]
+ 链接:https://arxiv.org/abs/2309.11193
+ 作者:Vasilis Gkolemis, Theodore Dalamagas, Eirini Ntoutsi, Christos Diou
+ 备注:Accepted at ECAI 2023 (European Conference on Artificial Intelligence)
+ 关键词:Accumulated Local Effects, widely-used explainability method, Local Effects, widely-used explainability, average effect
+
+ 点击查看摘要
+ Accumulated Local Effects (ALE) is a widely-used explainability method for isolating the average effect of a feature on the output, because it handles cases with correlated features well. However, it has two limitations. First, it does not quantify the deviation of instance-level (local) effects from the average (global) effect, known as heterogeneity. Second, for estimating the average effect, it partitions the feature domain into user-defined, fixed-sized bins, where different bin sizes may lead to inconsistent ALE estimations. To address these limitations, we propose Robust and Heterogeneity-aware ALE (RHALE). RHALE quantifies the heterogeneity by considering the standard deviation of the local effects and automatically determines an optimal variable-size bin-splitting. In this paper, we prove that to achieve an unbiased approximation of the standard deviation of local effects within each bin, bin splitting must follow a set of sufficient conditions. Based on these conditions, we propose an algorithm that automatically determines the optimal partitioning, balancing the estimation bias and variance. Through evaluations on synthetic and real datasets, we demonstrate the superiority of RHALE compared to other methods, including the advantages of automatic bin splitting, especially in cases with correlated features.
+
+
+
+ 35. 标题:Investigating Personalization Methods in Text to Music Generation
+ 编号:[148]
+ 链接:https://arxiv.org/abs/2309.11140
+ 作者:Manos Plitsis, Theodoros Kouzelis, Georgios Paraskevopoulos, Vassilis Katsouros, Yannis Panagakis
+ 备注:Submitted to ICASSP 2024, Examples at this https URL
+ 关键词:diffusion models, few-shot setting, established personalization methods, computer vision domain, personalization
+
+ 点击查看摘要
+ In this work, we investigate the personalization of text-to-music diffusion models in a few-shot setting. Motivated by recent advances in the computer vision domain, we are the first to explore the combination of pre-trained text-to-audio diffusers with two established personalization methods. We experiment with the effect of audio-specific data augmentation on the overall system performance and assess different training strategies. For evaluation, we construct a novel dataset with prompts and music clips. We consider both embedding-based and music-specific metrics for quantitative evaluation, as well as a user study for qualitative evaluation. Our analysis shows that similarity metrics are in accordance with user preferences and that current personalization approaches tend to learn rhythmic music constructs more easily than melody. The code, dataset, and example material of this study are open to the research community.
+
+
+
+ 36. 标题:Contrastive Pseudo Learning for Open-World DeepFake Attribution
+ 编号:[152]
+ 链接:https://arxiv.org/abs/2309.11132
+ 作者:Zhimin Sun, Shen Chen, Taiping Yao, Bangjie Yin, Ran Yi, Shouhong Ding, Lizhuang Ma
+ 备注:16 pages, 7 figures, ICCV 2023
+ 关键词:gained widespread attention, widespread attention due, challenge in sourcing, gained widespread, widespread attention
+
+ 点击查看摘要
+ The challenge in sourcing attribution for forgery faces has gained widespread attention due to the rapid development of generative techniques. While many recent works have taken essential steps on GAN-generated faces, more threatening attacks related to identity swapping or expression transferring are still overlooked. And the forgery traces hidden in unknown attacks from the open-world unlabeled faces still remain under-explored. To push the related frontier research, we introduce a new benchmark called Open-World DeepFake Attribution (OW-DFA), which aims to evaluate attribution performance against various types of fake faces under open-world scenarios. Meanwhile, we propose a novel framework named Contrastive Pseudo Learning (CPL) for the OW-DFA task through 1) introducing a Global-Local Voting module to guide the feature alignment of forged faces with different manipulated regions, 2) designing a Confidence-based Soft Pseudo-label strategy to mitigate the pseudo-noise caused by similar methods in unlabeled set. In addition, we extend the CPL framework with a multi-stage paradigm that leverages pre-train technique and iterative learning to further enhance traceability performance. Extensive experiments verify the superiority of our proposed method on the OW-DFA and also demonstrate the interpretability of deepfake attribution task and its impact on improving the security of deepfake detection area.
+
+
+
+ 37. 标题:Bold but Cautious: Unlocking the Potential of Personalized Federated Learning through Cautiously Aggressive Collaboration
+ 编号:[164]
+ 链接:https://arxiv.org/abs/2309.11103
+ 作者:Xinghao Wu, Xuefeng Liu, Jianwei Niu, Guogang Zhu, Shaojie Tang
+ 备注:Accepted by ICCV2023
+ 关键词:Personalized federated learning, non-IID data, non-IID, data, federated learning
+
+ 点击查看摘要
+ Personalized federated learning (PFL) reduces the impact of non-independent and identically distributed (non-IID) data among clients by allowing each client to train a personalized model when collaborating with others. A key question in PFL is to decide which parameters of a client should be localized or shared with others. In current mainstream approaches, all layers that are sensitive to non-IID data (such as classifier layers) are generally personalized. The reasoning behind this approach is understandable, as localizing parameters that are easily influenced by non-IID data can prevent the potential negative effect of collaboration. However, we believe that this approach is too conservative for collaboration. For example, for a certain client, even if its parameters are easily influenced by non-IID data, it can still benefit by sharing these parameters with clients having similar data distribution. This observation emphasizes the importance of considering not only the sensitivity to non-IID data but also the similarity of data distribution when determining which parameters should be localized in PFL. This paper introduces a novel guideline for client collaboration in PFL. Unlike existing approaches that prohibit all collaboration of sensitive parameters, our guideline allows clients to share more parameters with others, leading to improved model performance. Additionally, we propose a new PFL method named FedCAC, which employs a quantitative metric to evaluate each parameter's sensitivity to non-IID data and carefully selects collaborators based on this evaluation. Experimental results demonstrate that FedCAC enables clients to share more parameters with others, resulting in superior performance compared to state-of-the-art methods, particularly in scenarios where clients have diverse distributions.
+
+
+
+ 38. 标题:A New Interpretable Neural Network-Based Rule Model for Healthcare Decision Making
+ 编号:[165]
+ 链接:https://arxiv.org/abs/2309.11101
+ 作者:Adrien Benamira, Tristan Guerand, Thomas Peyrin
+ 备注:This work was presented at IAIM23 in Singapore this https URL arXiv admin note: substantial text overlap with arXiv:2309.09638
+ 关键词:Truth Table rules, Truth Table, deep neural networks, learning models make, models make decisions
+
+ 点击查看摘要
+ In healthcare applications, understanding how machine/deep learning models make decisions is crucial. In this study, we introduce a neural network framework, $\textit{Truth Table rules}$ (TT-rules), that combines the global and exact interpretability properties of rule-based models with the high performance of deep neural networks. TT-rules is built upon $\textit{Truth Table nets}$ (TTnet), a family of deep neural networks initially developed for formal verification. By extracting the necessary and sufficient rules $\mathcal{R}$ from the trained TTnet model (global interpretability) to yield the same output as the TTnet (exact interpretability), TT-rules effectively transforms the neural network into a rule-based model. This rule-based model supports binary classification, multi-label classification, and regression tasks for small to large tabular datasets. After outlining the framework, we evaluate TT-rules' performance on healthcare applications and compare it to state-of-the-art rule-based methods. Our results demonstrate that TT-rules achieves equal or higher performance compared to other interpretable methods. Notably, TT-rules presents the first accurate rule-based model capable of fitting large tabular datasets, including two real-life DNA datasets with over 20K features.
+
+
+
+ 39. 标题:Delays in Reinforcement Learning
+ 编号:[167]
+ 链接:https://arxiv.org/abs/2309.11096
+ 作者:Pierre Liotet
+ 备注:
+ 关键词:dynamical systems, Delays, delay, Markov decision processes, systems
+
+ 点击查看摘要
+ Delays are inherent to most dynamical systems. Besides shifting the process in time, they can significantly affect their performance. For this reason, it is usually valuable to study the delay and account for it. Because they are dynamical systems, it is of no surprise that sequential decision-making problems such as Markov decision processes (MDP) can also be affected by delays. These processes are the foundational framework of reinforcement learning (RL), a paradigm whose goal is to create artificial agents capable of learning to maximise their utility by interacting with their environment.
+RL has achieved strong, sometimes astonishing, empirical results, but delays are seldom explicitly accounted for. The understanding of the impact of delay on the MDP is limited. In this dissertation, we propose to study the delay in the agent's observation of the state of the environment or in the execution of the agent's actions. We will repeatedly change our point of view on the problem to reveal some of its structure and peculiarities. A wide spectrum of delays will be considered, and potential solutions will be presented. This dissertation also aims to draw links between celebrated frameworks of the RL literature and the one of delays.
+
+
+
+ 40. 标题:K-pop Lyric Translation: Dataset, Analysis, and Neural-Modelling
+ 编号:[168]
+ 链接:https://arxiv.org/abs/2309.11093
+ 作者:Haven Kim, Jongmin Jung, Dasaem Jeong, Juhan Nam
+ 备注:
+ 关键词:computational linguistics researchers, attracting computational linguistics, Lyric translation, lyric translation studies, Lyric
+
+ 点击查看摘要
+ Lyric translation, a field studied for over a century, is now attracting computational linguistics researchers. We identified two limitations in previous studies. Firstly, lyric translation studies have predominantly focused on Western genres and languages, with no previous study centering on K-pop despite its popularity. Second, the field of lyric translation suffers from a lack of publicly available datasets; to the best of our knowledge, no such dataset exists. To broaden the scope of genres and languages in lyric translation studies, we introduce a novel singable lyric translation dataset, approximately 89\% of which consists of K-pop song lyrics. This dataset aligns Korean and English lyrics line-by-line and section-by-section. We leveraged this dataset to unveil unique characteristics of K-pop lyric translation, distinguishing it from other extensively studied genres, and to construct a neural lyric translation model, thereby underscoring the importance of a dedicated dataset for singable lyric translations.
+
+
+
+ 41. 标题:Practical Probabilistic Model-based Deep Reinforcement Learning by Integrating Dropout Uncertainty and Trajectory Sampling
+ 编号:[171]
+ 链接:https://arxiv.org/abs/2309.11089
+ 作者:Wenjun Huang, Yunduan Cui, Huiyun Li, Xinyu Wu
+ 备注:
+ 关键词:model-based reinforcement learning, current probabilistic model-based, probabilistic model-based reinforcement, reinforcement learning, paper addresses
+
+ 点击查看摘要
+ This paper addresses the prediction stability, prediction accuracy and control capability of the current probabilistic model-based reinforcement learning (MBRL) built on neural networks. A novel approach dropout-based probabilistic ensembles with trajectory sampling (DPETS) is proposed where the system uncertainty is stably predicted by combining the Monte-Carlo dropout and trajectory sampling in one framework. Its loss function is designed to correct the fitting error of neural networks for more accurate prediction of probabilistic models. The state propagation in its policy is extended to filter the aleatoric uncertainty for superior control capability. Evaluated by several Mujoco benchmark control tasks under additional disturbances and one practical robot arm manipulation task, DPETS outperforms related MBRL approaches in both average return and convergence velocity while achieving superior performance than well-known model-free baselines with significant sample efficiency. The open source code of DPETS is available at this https URL.
+
+
+
+ 42. 标题:Weak Supervision for Label Efficient Visual Bug Detection
+ 编号:[177]
+ 链接:https://arxiv.org/abs/2309.11077
+ 作者:Farrukh Rahman
+ 备注:Accepted to BMVC 2023: Workshop on Computer Vision for Games and Games for Computer Vision (CVG). 9 pages
+ 关键词:quality becomes essential, increasingly challenging, detailed worlds, bugs, video games evolve
+
+ 点击查看摘要
+ As video games evolve into expansive, detailed worlds, visual quality becomes essential, yet increasingly challenging. Traditional testing methods, limited by resources, face difficulties in addressing the plethora of potential bugs. Machine learning offers scalable solutions; however, heavy reliance on large labeled datasets remains a constraint. Addressing this challenge, we propose a novel method, utilizing unlabeled gameplay and domain-specific augmentations to generate datasets & self-supervised objectives used during pre-training or multi-task settings for downstream visual bug detection. Our methodology uses weak-supervision to scale datasets for the crafted objectives and facilitates both autonomous and interactive weak-supervision, incorporating unsupervised clustering and/or an interactive approach based on text and geometric prompts. We demonstrate on first-person player clipping/collision bugs (FPPC) within the expansive Giantmap game world, that our approach is very effective, improving over a strong supervised baseline in a practical, very low-prevalence, low data regime (0.336 $\rightarrow$ 0.550 F1 score). With just 5 labeled "good" exemplars (i.e., 0 bugs), our self-supervised objective alone captures enough signal to outperform the low-labeled supervised settings. Building on large-pretrained vision models, our approach is adaptable across various visual bugs. Our results suggest applicability in curating datasets for broader image and video tasks within video games beyond visual bugs.
+
+
+
+ 43. 标题:GPSINDy: Data-Driven Discovery of Equations of Motion
+ 编号:[178]
+ 链接:https://arxiv.org/abs/2309.11076
+ 作者:Junette Hsin, Shubhankar Agarwal, Adam Thorpe, David Fridovich-Keil
+ 备注:Submitted to ICRA 2024
+ 关键词:data, noisy data, paper, SINDy, approach
+
+ 点击查看摘要
+ In this paper, we consider the problem of discovering dynamical system models from noisy data. The presence of noise is known to be a significant problem for symbolic regression algorithms. We combine Gaussian process regression, a nonparametric learning method, with SINDy, a parametric learning approach, to identify nonlinear dynamical systems from data. The key advantages of our proposed approach are its simplicity coupled with the fact that it demonstrates improved robustness properties with noisy data over SINDy. We demonstrate our proposed approach on a Lotka-Volterra model and a unicycle dynamic model in simulation and on an NVIDIA JetRacer system using hardware data. We demonstrate improved performance over SINDy for discovering the system dynamics and predicting future trajectories.
+
+
+
+ 44. 标题:InkStream: Real-time GNN Inference on Streaming Graphs via Incremental Update
+ 编号:[179]
+ 链接:https://arxiv.org/abs/2309.11071
+ 作者:Dan Wu, Zhaoying Li, Tulika Mitra
+ 备注:
+ 关键词:Graph Neural Network, Classic Graph Neural, Neural Network, Graph Neural, streaming graphs
+
+ 点击查看摘要
+ Classic Graph Neural Network (GNN) inference approaches, designed for static graphs, are ill-suited for streaming graphs that evolve with time. The dynamism intrinsic to streaming graphs necessitates constant updates, posing unique challenges to acceleration on GPU. We address these challenges based on two key insights: (1) Inside the $k$-hop neighborhood, a significant fraction of the nodes is not impacted by the modified edges when the model uses min or max as aggregation function; (2) When the model weights remain static while the graph structure changes, node embeddings can incrementally evolve over time by computing only the impacted part of the neighborhood. With these insights, we propose a novel method, InkStream, designed for real-time inference with minimal memory access and computation, while ensuring an identical output to conventional methods. InkStream operates on the principle of propagating and fetching data only when necessary. It uses an event-based system to control inter-layer effect propagation and intra-layer incremental updates of node embedding. InkStream is highly extensible and easily configurable by allowing users to create and process customized events. We showcase that less than 10 lines of additional user code are needed to support popular GNN models such as GCN, GraphSAGE, and GIN. Our experiments with three GNN models on four large graphs demonstrate that InkStream accelerates by 2.5-427$\times$ on a CPU cluster and 2.4-343$\times$ on two different GPU clusters while producing identical outputs as GNN model inference on the latest graph snapshot.
+
+
+
+ 45. 标题:Design of Chain-of-Thought in Math Problem Solving
+ 编号:[187]
+ 链接:https://arxiv.org/abs/2309.11054
+ 作者:Zhanming Jie, Trung Quoc Luong, Xinbo Zhang, Xiaoran Jin, Hang Li
+ 备注:15 pages
+ 关键词:math problem solving, plays a crucial, program, crucial role, role in reasoning
+
+ 点击查看摘要
+ Chain-of-Thought (CoT) plays a crucial role in reasoning for math problem solving. We conduct a comprehensive examination of methods for designing CoT, comparing conventional natural language CoT with various program CoTs, including the self-describing program, the comment-describing program, and the non-describing program. Furthermore, we investigate the impact of programming language on program CoTs, comparing Python and Wolfram Language. Through extensive experiments on GSM8K, MATHQA, and SVAMP, we find that program CoTs often have superior effectiveness in math problem solving. Notably, the best performing combination with 30B parameters beats GPT-3.5-turbo by a significant margin. The results show that self-describing program offers greater diversity and thus can generally achieve higher performance. We also find that Python is a better choice of language than Wolfram for program CoTs. The experimental results provide a valuable guideline for future CoT designs that take into account both programming language and coding style for further advancements. Our datasets and code are publicly available.
+
+
+
+ 46. 标题:fakenewsbr: A Fake News Detection Platform for Brazilian Portuguese
+ 编号:[189]
+ 链接:https://arxiv.org/abs/2309.11052
+ 作者:Luiz Giordani, Gilsiley Darú, Rhenan Queiroz, Vitor Buzinaro, Davi Keglevich Neiva, Daniel Camilo Fuentes Guzmán, Marcos Jardel Henriques, Oilson Alberto Gonzatto Junior, Francisco Louzada
+ 备注:
+ 关键词:manipulate public opinion, recent times due, public opinion, significant concern, concern in recent
+
+ 点击查看摘要
+ The proliferation of fake news has become a significant concern in recent times due to its potential to spread misinformation and manipulate public opinion. This paper presents a comprehensive study on detecting fake news in Brazilian Portuguese, focusing on journalistic-type news. We propose a machine learning-based approach that leverages natural language processing techniques, including TF-IDF and Word2Vec, to extract features from textual data. We evaluate the performance of various classification algorithms, such as logistic regression, support vector machine, random forest, AdaBoost, and LightGBM, on a dataset containing both true and fake news articles. The proposed approach achieves high accuracy and F1-Score, demonstrating its effectiveness in identifying fake news. Additionally, we developed a user-friendly web platform, this http URL, to facilitate the verification of news articles' veracity. Our platform provides real-time analysis, allowing users to assess the likelihood of fake news articles. Through empirical analysis and comparative studies, we demonstrate the potential of our approach to contribute to the fight against the spread of fake news and promote more informed media consumption.
+
+
+
+ 47. 标题:Containing Analog Data Deluge at Edge through Frequency-Domain Compression in Collaborative Compute-in-Memory Networks
+ 编号:[191]
+ 链接:https://arxiv.org/abs/2309.11048
+ 作者:Nastaran Darabi, Amit R. Trivedi
+ 备注:arXiv admin note: text overlap with arXiv:2307.03863, arXiv:2309.01771
+ 关键词:handling high-dimensional, autonomous drones, IoT devices, devices for applications, multispectral analog data
+
+ 点击查看摘要
+ Edge computing is a promising solution for handling high-dimensional, multispectral analog data from sensors and IoT devices for applications such as autonomous drones. However, edge devices' limited storage and computing resources make it challenging to perform complex predictive modeling at the edge. Compute-in-memory (CiM) has emerged as a principal paradigm to minimize energy for deep learning-based inference at the edge. Nevertheless, integrating storage and processing complicates memory cells and/or memory peripherals, essentially trading off area efficiency for energy efficiency. This paper proposes a novel solution to improve area efficiency in deep learning inference tasks. The proposed method employs two key strategies. Firstly, a Frequency domain learning approach uses binarized Walsh-Hadamard Transforms, reducing the necessary parameters for DNN (by 87% in MobileNetV2) and enabling compute-in-SRAM, which better utilizes parallelism during inference. Secondly, a memory-immersed collaborative digitization method is described among CiM arrays to reduce the area overheads of conventional ADCs. This facilitates more CiM arrays in limited footprint designs, leading to better parallelism and reduced external memory accesses. Different networking configurations are explored, where Flash, SA, and their hybrid digitization steps can be implemented using the memory-immersed scheme. The results are demonstrated using a 65 nm CMOS test chip, exhibiting significant area and energy savings compared to a 40 nm-node 5-bit SAR ADC and 5-bit Flash ADC. By processing analog data more efficiently, it is possible to selectively retain valuable data from sensors and alleviate the challenges posed by the analog data deluge.
+
+
+
+ 48. 标题:Clustered FedStack: Intermediate Global Models with Bayesian Information Criterion
+ 编号:[193]
+ 链接:https://arxiv.org/abs/2309.11044
+ 作者:Thanveer Shaik, Xiaohui Tao, Lin Li, Niall Higgins, Raj Gururajan, Xujuan Zhou, Jianming Yong
+ 备注:This work has been submitted to the ELSEVIER for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible
+ 关键词:Artificial Intelligence, field of Artificial, preserve client privacy, popular technologies, ability to preserve
+
+ 点击查看摘要
+ Federated Learning (FL) is currently one of the most popular technologies in the field of Artificial Intelligence (AI) due to its collaborative learning and ability to preserve client privacy. However, it faces challenges such as non-identically and non-independently distributed (non-IID) and data with imbalanced labels among local clients. To address these limitations, the research community has explored various approaches such as using local model parameters, federated generative adversarial learning, and federated representation learning. In our study, we propose a novel Clustered FedStack framework based on the previously published Stacked Federated Learning (FedStack) framework. The local clients send their model predictions and output layer weights to a server, which then builds a robust global model. This global model clusters the local clients based on their output layer weights using a clustering mechanism. We adopt three clustering mechanisms, namely K-Means, Agglomerative, and Gaussian Mixture Models, into the framework and evaluate their performance. We use Bayesian Information Criterion (BIC) with the maximum likelihood function to determine the number of clusters. The Clustered FedStack models outperform baseline models with clustering mechanisms. To estimate the convergence of our proposed framework, we use Cyclical learning rates.
+
+
+
+ 49. 标题:Federated Learning in Intelligent Transportation Systems: Recent Applications and Open Problems
+ 编号:[197]
+ 链接:https://arxiv.org/abs/2309.11039
+ 作者:Shiying Zhang, Jun Li, Long Shi, Ming Ding, Dinh C. Nguyen, Wuzheng Tan, Jian Weng, Zhu Han
+ 备注:
+ 关键词:Intelligent transportation systems, Internet of Things, Intelligent transportation, transportation systems, Things
+
+ 点击查看摘要
+ Intelligent transportation systems (ITSs) have been fueled by the rapid development of communication technologies, sensor technologies, and the Internet of Things (IoT). Nonetheless, due to the dynamic characteristics of the vehicle networks, it is rather challenging to make timely and accurate decisions of vehicle behaviors. Moreover, in the presence of mobile wireless communications, the privacy and security of vehicle information are at constant risk. In this context, a new paradigm is urgently needed for various applications in dynamic vehicle environments. As a distributed machine learning technology, federated learning (FL) has received extensive attention due to its outstanding privacy protection properties and easy scalability. We conduct a comprehensive survey of the latest developments in FL for ITS. Specifically, we initially research the prevalent challenges in ITS and elucidate the motivations for applying FL from various perspectives. Subsequently, we review existing deployments of FL in ITS across various scenarios, and discuss specific potential issues in object recognition, traffic management, and service providing scenarios. Furthermore, we conduct a further analysis of the new challenges introduced by FL deployment and the inherent limitations that FL alone cannot fully address, including uneven data distribution, limited storage and computing power, and potential privacy and security concerns. We then examine the existing collaborative technologies that can help mitigate these challenges. Lastly, we discuss the open challenges that remain to be addressed in applying FL in ITS and propose several future research directions.
+
+
+
+ 50. 标题:A Region-Shrinking-Based Acceleration for Classification-Based Derivative-Free Optimization
+ 编号:[199]
+ 链接:https://arxiv.org/abs/2309.11036
+ 作者:Tianyi Han, Jingya Li, Zhipeng Guo, Yuan Jin
+ 备注:
+ 关键词:design optimization problems, engineering design optimization, Derivative-free optimization algorithms, optimization algorithms play, classification-based derivative-free optimization
+
+ 点击查看摘要
+ Derivative-free optimization algorithms play an important role in scientific and engineering design optimization problems, especially when derivative information is not accessible. In this paper, we study the framework of classification-based derivative-free optimization algorithms. By introducing a concept called hypothesis-target shattering rate, we revisit the computational complexity upper bound of this type of algorithms. Inspired by the revisited upper bound, we propose an algorithm named "RACE-CARS", which adds a random region-shrinking step compared with "SRACOS" (Hu et al., 2017).. We further establish a theorem showing the acceleration of region-shrinking. Experiments on the synthetic functions as well as black-box tuning for language-model-as-a-service demonstrate empirically the efficiency of "RACE-CARS". An ablation experiment on the introduced hyperparameters is also conducted, revealing the mechanism of "RACE-CARS" and putting forward an empirical hyperparameter-tuning guidance.
+
+
+
+ 51. 标题:Information Leakage from Data Updates in Machine Learning Models
+ 编号:[205]
+ 链接:https://arxiv.org/abs/2309.11022
+ 作者:Tian Hui, Farhad Farokhi, Olga Ohrimenko
+ 备注:
+ 关键词:reflect distribution shifts, machine learning models, machine learning, distribution shifts, order to incorporate
+
+ 点击查看摘要
+ In this paper we consider the setting where machine learning models are retrained on updated datasets in order to incorporate the most up-to-date information or reflect distribution shifts. We investigate whether one can infer information about these updates in the training data (e.g., changes to attribute values of records). Here, the adversary has access to snapshots of the machine learning model before and after the change in the dataset occurs. Contrary to the existing literature, we assume that an attribute of a single or multiple training data points are changed rather than entire data records are removed or added. We propose attacks based on the difference in the prediction confidence of the original model and the updated model. We evaluate our attack methods on two public datasets along with multi-layer perceptron and logistic regression models. We validate that two snapshots of the model can result in higher information leakage in comparison to having access to only the updated model. Moreover, we observe that data records with rare values are more vulnerable to attacks, which points to the disparate vulnerability of privacy attacks in the update setting. When multiple records with the same original attribute value are updated to the same new value (i.e., repeated changes), the attacker is more likely to correctly guess the updated values since repeated changes leave a larger footprint on the trained model. These observations point to vulnerability of machine learning models to attribute inference attacks in the update setting.
+
+
+
+ 52. 标题:Conformalized Multimodal Uncertainty Regression and Reasoning
+ 编号:[209]
+ 链接:https://arxiv.org/abs/2309.11018
+ 作者:Domenico Parente, Nastaran Darabi, Alex C. Stutts, Theja Tulabandhula, Amit Ranjan Trivedi
+ 备注:
+ 关键词:lightweight uncertainty estimator, uncertainty estimator capable, integrating conformal prediction, deep-learning regressor, paper introduces
+
+ 点击查看摘要
+ This paper introduces a lightweight uncertainty estimator capable of predicting multimodal (disjoint) uncertainty bounds by integrating conformal prediction with a deep-learning regressor. We specifically discuss its application for visual odometry (VO), where environmental features such as flying domain symmetries and sensor measurements under ambiguities and occlusion can result in multimodal uncertainties. Our simulation results show that uncertainty estimates in our framework adapt sample-wise against challenging operating conditions such as pronounced noise, limited training data, and limited parametric size of the prediction model. We also develop a reasoning framework that leverages these robust uncertainty estimates and incorporates optical flow-based reasoning to improve prediction prediction accuracy. Thus, by appropriately accounting for predictive uncertainties of data-driven learning and closing their estimation loop via rule-based reasoning, our methodology consistently surpasses conventional deep learning approaches on all these challenging scenarios--pronounced noise, limited training data, and limited model size-reducing the prediction error by 2-3x.
+
+
+
+ 53. 标题:ModelGiF: Gradient Fields for Model Functional Distance
+ 编号:[211]
+ 链接:https://arxiv.org/abs/2309.11013
+ 作者:Jie Song, Zhengqi Xu, Sai Wu, Gang Chen, Mingli Song
+ 备注:ICCV 2023
+ 关键词:publicly released trained, model functional distance, released trained models, Model Gradient Field, functional distance
+
+ 点击查看摘要
+ The last decade has witnessed the success of deep learning and the surge of publicly released trained models, which necessitates the quantification of the model functional distance for various purposes. However, quantifying the model functional distance is always challenging due to the opacity in inner workings and the heterogeneity in architectures or tasks. Inspired by the concept of "field" in physics, in this work we introduce Model Gradient Field (abbr. ModelGiF) to extract homogeneous representations from the heterogeneous pre-trained models. Our main assumption underlying ModelGiF is that each pre-trained deep model uniquely determines a ModelGiF over the input space. The distance between models can thus be measured by the similarity between their ModelGiFs. We validate the effectiveness of the proposed ModelGiF with a suite of testbeds, including task relatedness estimation, intellectual property protection, and model unlearning verification. Experimental results demonstrate the versatility of the proposed ModelGiF on these tasks, with significantly superiority performance to state-of-the-art competitors. Codes are available at this https URL.
+
+
+
+ 54. 标题:It's Simplex! Disaggregating Measures to Improve Certified Robustness
+ 编号:[217]
+ 链接:https://arxiv.org/abs/2309.11005
+ 作者:Andrew C. Cullen, Paul Montague, Shijie Liu, Sarah M. Erfani, Benjamin I.P. Rubinstein
+ 备注:IEEE S&P 2024, IEEE Security & Privacy 2024, 14 pages
+ 关键词:Certified robustness circumvents, endowing model predictions, adversarial attacks, calculated size, robustness circumvents
+
+ 点击查看摘要
+ Certified robustness circumvents the fragility of defences against adversarial attacks, by endowing model predictions with guarantees of class invariance for attacks up to a calculated size. While there is value in these certifications, the techniques through which we assess their performance do not present a proper accounting of their strengths and weaknesses, as their analysis has eschewed consideration of performance over individual samples in favour of aggregated measures. By considering the potential output space of certified models, this work presents two distinct approaches to improve the analysis of certification mechanisms, that allow for both dataset-independent and dataset-dependent measures of certification performance. Embracing such a perspective uncovers new certification approaches, which have the potential to more than double the achievable radius of certification, relative to current state-of-the-art. Empirical evaluation verifies that our new approach can certify $9\%$ more samples at noise scale $\sigma = 1$, with greater relative improvements observed as the difficulty of the predictive task increases.
+
+
+
+ 55. 标题:AI-Driven Patient Monitoring with Multi-Agent Deep Reinforcement Learning
+ 编号:[229]
+ 链接:https://arxiv.org/abs/2309.10980
+ 作者:Thanveer Shaik, Xiaohui Tao, Haoran Xie, Lin Li, Jianming Yong, Hong-Ning Dai
+ 备注:arXiv admin note: text overlap with arXiv:2309.10576
+ 关键词:improved healthcare outcomes, timely interventions, interventions and improved, monitoring, Effective patient monitoring
+
+ 点击查看摘要
+ Effective patient monitoring is vital for timely interventions and improved healthcare outcomes. Traditional monitoring systems often struggle to handle complex, dynamic environments with fluctuating vital signs, leading to delays in identifying critical conditions. To address this challenge, we propose a novel AI-driven patient monitoring framework using multi-agent deep reinforcement learning (DRL). Our approach deploys multiple learning agents, each dedicated to monitoring a specific physiological feature, such as heart rate, respiration, and temperature. These agents interact with a generic healthcare monitoring environment, learn the patients' behavior patterns, and make informed decisions to alert the corresponding Medical Emergency Teams (METs) based on the level of emergency estimated. In this study, we evaluate the performance of the proposed multi-agent DRL framework using real-world physiological and motion data from two datasets: PPG-DaLiA and WESAD. We compare the results with several baseline models, including Q-Learning, PPO, Actor-Critic, Double DQN, and DDPG, as well as monitoring frameworks like WISEML and CA-MAQL. Our experiments demonstrate that the proposed DRL approach outperforms all other baseline models, achieving more accurate monitoring of patient's vital signs. Furthermore, we conduct hyperparameter optimization to fine-tune the learning process of each agent. By optimizing hyperparameters, we enhance the learning rate and discount factor, thereby improving the agents' overall performance in monitoring patient health status. Our AI-driven patient monitoring system offers several advantages over traditional methods, including the ability to handle complex and uncertain environments, adapt to varying patient conditions, and make real-time decisions without external supervision.
+
+
+
+ 56. 标题:Towards Data-centric Graph Machine Learning: Review and Outlook
+ 编号:[230]
+ 链接:https://arxiv.org/abs/2309.10979
+ 作者:Xin Zheng, Yixin Liu, Zhifeng Bao, Meng Fang, Xia Hu, Alan Wee-Chung Liew, Shirui Pan
+ 备注:42 pages, 9 figures
+ 关键词:attracted increasing attention, recent years, Graph Machine Learning, graph data, primary focus
+
+ 点击查看摘要
+ Data-centric AI, with its primary focus on the collection, management, and utilization of data to drive AI models and applications, has attracted increasing attention in recent years. In this article, we conduct an in-depth and comprehensive review, offering a forward-looking outlook on the current efforts in data-centric AI pertaining to graph data-the fundamental data structure for representing and capturing intricate dependencies among massive and diverse real-life entities. We introduce a systematic framework, Data-centric Graph Machine Learning (DC-GML), that encompasses all stages of the graph data lifecycle, including graph data collection, exploration, improvement, exploitation, and maintenance. A thorough taxonomy of each stage is presented to answer three critical graph-centric questions: (1) how to enhance graph data availability and quality; (2) how to learn from graph data with limited-availability and low-quality; (3) how to build graph MLOps systems from the graph data-centric view. Lastly, we pinpoint the future prospects of the DC-GML domain, providing insights to navigate its advancements and applications.
+
+
+
+ 57. 标题:PAGER: A Framework for Failure Analysis of Deep Regression Models
+ 编号:[231]
+ 链接:https://arxiv.org/abs/2309.10977
+ 作者:Jayaraman J. Thiagarajan, Vivek Narayanaswamy, Puja Trivedi, Rushil Anirudh
+ 备注:
+ 关键词:requires proactive detection, prevent costly errors, models requires proactive, potential prediction failures, Safe deployment
+
+ 点击查看摘要
+ Safe deployment of AI models requires proactive detection of potential prediction failures to prevent costly errors. While failure detection in classification problems has received significant attention, characterizing failure modes in regression tasks is more complicated and less explored. Existing approaches rely on epistemic uncertainties or feature inconsistency with the training distribution to characterize model risk. However, we show that uncertainties are necessary but insufficient to accurately characterize failure, owing to the various sources of error. In this paper, we propose PAGER (Principled Analysis of Generalization Errors in Regressors), a framework to systematically detect and characterize failures in deep regression models. Built upon the recently proposed idea of anchoring in deep models, PAGER unifies both epistemic uncertainties and novel, complementary non-conformity scores to organize samples into different risk regimes, thereby providing a comprehensive analysis of model errors. Additionally, we introduce novel metrics for evaluating failure detectors in regression tasks. We demonstrate the effectiveness of PAGER on synthetic and real-world benchmarks. Our results highlight the capability of PAGER to identify regions of accurate generalization and detect failure cases in out-of-distribution and out-of-support scenarios.
+
+
+
+ 58. 标题:Accurate and Scalable Estimation of Epistemic Uncertainty for Graph Neural Networks
+ 编号:[232]
+ 链接:https://arxiv.org/abs/2309.10976
+ 作者:Puja Trivedi, Mark Heimann, Rushil Anirudh, Danai Koutra, Jayaraman J. Thiagarajan
+ 备注:22 pages, 11 figures
+ 关键词:accurate confidence indicators, graph neural networks, distribution shift requires, provide accurate confidence, Safe deployment
+
+ 点击查看摘要
+ Safe deployment of graph neural networks (GNNs) under distribution shift requires models to provide accurate confidence indicators (CI). However, while it is well-known in computer vision that CI quality diminishes under distribution shift, this behavior remains understudied for GNNs. Hence, we begin with a case study on CI calibration under controlled structural and feature distribution shifts and demonstrate that increased expressivity or model size do not always lead to improved CI performance. Consequently, we instead advocate for the use of epistemic uncertainty quantification (UQ) methods to modulate CIs. To this end, we propose G-$\Delta$UQ, a new single model UQ method that extends the recently proposed stochastic centering framework to support structured data and partial stochasticity. Evaluated across covariate, concept, and graph size shifts, G-$\Delta$UQ not only outperforms several popular UQ methods in obtaining calibrated CIs, but also outperforms alternatives when CIs are used for generalization gap prediction or OOD detection. Overall, our work not only introduces a new, flexible GNN UQ method, but also provides novel insights into GNN CIs on safety-critical tasks.
+
+
+
+ 59. 标题:SPFQ: A Stochastic Algorithm and Its Error Analysis for Neural Network Quantization
+ 编号:[233]
+ 链接:https://arxiv.org/abs/2309.10975
+ 作者:Jinjie Zhang, Rayan Saab
+ 备注:
+ 关键词:effectively reduces redundancies, over-parameterized neural networks, neural networks, widely used compression, compression method
+
+ 点击查看摘要
+ Quantization is a widely used compression method that effectively reduces redundancies in over-parameterized neural networks. However, existing quantization techniques for deep neural networks often lack a comprehensive error analysis due to the presence of non-convex loss functions and nonlinear activations. In this paper, we propose a fast stochastic algorithm for quantizing the weights of fully trained neural networks. Our approach leverages a greedy path-following mechanism in combination with a stochastic quantizer. Its computational complexity scales only linearly with the number of weights in the network, thereby enabling the efficient quantization of large networks. Importantly, we establish, for the first time, full-network error bounds, under an infinite alphabet condition and minimal assumptions on the weights and input data. As an application of this result, we prove that when quantizing a multi-layer network having Gaussian weights, the relative square quantization error exhibits a linear decay as the degree of over-parametrization increases. Furthermore, we demonstrate that it is possible to achieve error bounds equivalent to those obtained in the infinite alphabet case, using on the order of a mere $\log\log N$ bits per weight, where $N$ represents the largest number of neurons in a layer.
+
+
+
+ 60. 标题:SEMPART: Self-supervised Multi-resolution Partitioning of Image Semantics
+ 编号:[235]
+ 链接:https://arxiv.org/abs/2309.10972
+ 作者:Sriram Ravindran, Debraj Basu
+ 备注:
+ 关键词:Accurately determining salient, determining salient regions, Accurately determining, data is scarce, challenging when labeled
+
+ 点击查看摘要
+ Accurately determining salient regions of an image is challenging when labeled data is scarce. DINO-based self-supervised approaches have recently leveraged meaningful image semantics captured by patch-wise features for locating foreground objects. Recent methods have also incorporated intuitive priors and demonstrated value in unsupervised methods for object partitioning. In this paper, we propose SEMPART, which jointly infers coarse and fine bi-partitions over an image's DINO-based semantic graph. Furthermore, SEMPART preserves fine boundary details using graph-driven regularization and successfully distills the coarse mask semantics into the fine mask. Our salient object detection and single object localization findings suggest that SEMPART produces high-quality masks rapidly without additional post-processing and benefits from co-optimizing the coarse and fine branches.
+
+
+
+ 61. 标题:In-Context Learning for Text Classification with Many Labels
+ 编号:[238]
+ 链接:https://arxiv.org/abs/2309.10954
+ 作者:Aristides Milios, Siva Reddy, Dzmitry Bahdanau
+ 备注:11 pages, 4 figures
+ 关键词:large language models, limited context window, large language, challenging due, difficult to fit
+
+ 点击查看摘要
+ In-context learning (ICL) using large language models for tasks with many labels is challenging due to the limited context window, which makes it difficult to fit a sufficient number of examples in the prompt. In this paper, we use a pre-trained dense retrieval model to bypass this limitation, giving the model only a partial view of the full label space for each inference call. Testing with recent open-source LLMs (OPT, LLaMA), we set new state of the art performance in few-shot settings for three common intent classification datasets, with no finetuning. We also surpass fine-tuned performance on fine-grained sentiment classification in certain cases. We analyze the performance across number of in-context examples and different model scales, showing that larger models are necessary to effectively and consistently make use of larger context lengths for ICL. By running several ablations, we analyze the model's use of: a) the similarity of the in-context examples to the current input, b) the semantic content of the class names, and c) the correct correspondence between examples and labels. We demonstrate that all three are needed to varying degrees depending on the domain, contrary to certain recent works.
+
+
+
+ 62. 标题:LMDX: Language Model-based Document Information Extraction and Localization
+ 编号:[239]
+ 链接:https://arxiv.org/abs/2309.10952
+ 作者:Vincent Perot, Kai Kang, Florian Luisier, Guolong Su, Xiaoyu Sun, Ramya Sree Boppana, Zilong Wang, Jiaqi Mu, Hao Zhang, Nan Hua
+ 备注:
+ 关键词:Large Language Models, Natural Language Processing, revolutionized Natural Language, exhibiting emergent capabilities, document information extraction
+
+ 点击查看摘要
+ Large Language Models (LLM) have revolutionized Natural Language Processing (NLP), improving state-of-the-art on many existing tasks and exhibiting emergent capabilities. However, LLMs have not yet been successfully applied on semi-structured document information extraction, which is at the core of many document processing workflows and consists of extracting key entities from a visually rich document (VRD) given a predefined target schema. The main obstacles to LLM adoption in that task have been the absence of layout encoding within LLMs, critical for a high quality extraction, and the lack of a grounding mechanism ensuring the answer is not hallucinated. In this paper, we introduce Language Model-based Document Information Extraction and Localization (LMDX), a methodology to adapt arbitrary LLMs for document information extraction. LMDX can do extraction of singular, repeated, and hierarchical entities, both with and without training data, while providing grounding guarantees and localizing the entities within the document. In particular, we apply LMDX to the PaLM 2-S LLM and evaluate it on VRDU and CORD benchmarks, setting a new state-of-the-art and showing how LMDX enables the creation of high quality, data-efficient parsers.
+
+
+
+ 63. 标题:A Novel Deep Neural Network for Trajectory Prediction in Automated Vehicles Using Velocity Vector Field
+ 编号:[240]
+ 链接:https://arxiv.org/abs/2309.10948
+ 作者:MReza Alipour Sormoli, Amir Samadi, Sajjad Mozaffari, Konstantinos Koufos, Mehrdad Dianati, Roger Woodman
+ 备注:This paper has been accepted and nominated as the best student paper at the 26th IEEE International Conference on Intelligent Transportation Systems (ITSC 2023)
+ 关键词:automated driving systems, informed downstream decision-making, driving systems, road users, users is crucial
+
+ 点击查看摘要
+ Anticipating the motion of other road users is crucial for automated driving systems (ADS), as it enables safe and informed downstream decision-making and motion planning. Unfortunately, contemporary learning-based approaches for motion prediction exhibit significant performance degradation as the prediction horizon increases or the observation window decreases. This paper proposes a novel technique for trajectory prediction that combines a data-driven learning-based method with a velocity vector field (VVF) generated from a nature-inspired concept, i.e., fluid flow dynamics. In this work, the vector field is incorporated as an additional input to a convolutional-recurrent deep neural network to help predict the most likely future trajectories given a sequence of bird's eye view scene representations. The performance of the proposed model is compared with state-of-the-art methods on the HighD dataset demonstrating that the VVF inclusion improves the prediction accuracy for both short and long-term (5~sec) time horizons. It is also shown that the accuracy remains consistent with decreasing observation windows which alleviates the requirement of a long history of past observations for accurate trajectory prediction. Source codes are available at: this https URL.
+
+
+
+ 64. 标题:Test-Time Training for Speech
+ 编号:[250]
+ 链接:https://arxiv.org/abs/2309.10930
+ 作者:Sri Harsha Dumpala, Chandramouli Sastry, Sageev Oore
+ 备注:
+ 关键词:Test-Time Training, handling distribution shifts, TTT, Training, distribution shifts
+
+ 点击查看摘要
+ In this paper, we study the application of Test-Time Training (TTT) as a solution to handling distribution shifts in speech applications. In particular, we introduce distribution-shifts to the test datasets of standard speech-classification tasks -- for example, speaker-identification and emotion-detection -- and explore how Test-Time Training (TTT) can help adjust to the distribution-shift. In our experiments that include distribution shifts due to background noise and natural variations in speech such as gender and age, we identify some key-challenges with TTT including sensitivity to optimization hyperparameters (e.g., number of optimization steps and subset of parameters chosen for TTT) and scalability (e.g., as each example gets its own set of parameters, TTT is not scalable). Finally, we propose using BitFit -- a parameter-efficient fine-tuning algorithm proposed for text applications that only considers the bias parameters for fine-tuning -- as a solution to the aforementioned challenges and demonstrate that it is consistently more stable than fine-tuning all the parameters of the model.
+
+
+
+ 65. 标题:Semi-automatic staging area for high-quality structured data extraction from scientific literature
+ 编号:[254]
+ 链接:https://arxiv.org/abs/2309.10923
+ 作者:Luca Foppiano, Tomoya Mato, Kensei Terashima, Pedro Ortiz Suarez, Taku Tou, Chikako Sakai, Wei-Sheng Wang, Toshiyuki Amagasa, Yoshihiko Takano, Masashi Ishii
+ 备注:5 tables, 9 figures, 31 pages
+ 关键词:superconductors' experimental data, scientific articles, ingesting new superconductors', superconductors' experimental, machine-collected from scientific
+
+ 点击查看摘要
+ In this study, we propose a staging area for ingesting new superconductors' experimental data in SuperCon that is machine-collected from scientific articles. Our objective is to enhance the efficiency of updating SuperCon while maintaining or enhancing the data quality. We present a semi-automatic staging area driven by a workflow combining automatic and manual processes on the extracted database. An anomaly detection automatic process aims to pre-screen the collected data. Users can then manually correct any errors through a user interface tailored to simplify the data verification on the original PDF documents. Additionally, when a record is corrected, its raw data is collected and utilised to improve machine learning models as training data. Evaluation experiments demonstrate that our staging area significantly improves curation quality. We compare the interface with the traditional manual approach of reading PDF documents and recording information in an Excel document. Using the interface boosts the precision and recall by 6% and 50%, respectively to an average increase of 40% in F1-score.
+
+
+
+ 66. 标题:What Learned Representations and Influence Functions Can Tell Us About Adversarial Examples
+ 编号:[256]
+ 链接:https://arxiv.org/abs/2309.10916
+ 作者:Shakila Mahjabin Tonni, Mark Dras
+ 备注:20 pages, Accepted long-paper IJCNLP_AACL 2023
+ 关键词:deep neural networks, fool deep neural, image processing, deliberately crafted, neural networks
+
+ 点击查看摘要
+ Adversarial examples, deliberately crafted using small perturbations to fool deep neural networks, were first studied in image processing and more recently in NLP. While approaches to detecting adversarial examples in NLP have largely relied on search over input perturbations, image processing has seen a range of techniques that aim to characterise adversarial subspaces over the learned representations.
+In this paper, we adapt two such approaches to NLP, one based on nearest neighbors and influence functions and one on Mahalanobis distances. The former in particular produces a state-of-the-art detector when compared against several strong baselines; moreover, the novel use of influence functions provides insight into how the nature of adversarial example subspaces in NLP relate to those in image processing, and also how they differ depending on the kind of NLP task.
+
+
+
+ 67. 标题:Amplifying Pathological Detection in EEG Signaling Pathways through Cross-Dataset Transfer Learning
+ 编号:[258]
+ 链接:https://arxiv.org/abs/2309.10910
+ 作者:Mohammad-Javad Darvishi-Bayazi, Mohammad Sajjad Ghaemi, Timothee Lesort, Md Rifat Arefin, Jocelyn Faubert, Irina Rish
+ 备注:
+ 关键词:understanding neurological disorders, decoding brain activity, brain activity holds, activity holds immense, holds immense importance
+
+ 点击查看摘要
+ Pathology diagnosis based on EEG signals and decoding brain activity holds immense importance in understanding neurological disorders. With the advancement of artificial intelligence methods and machine learning techniques, the potential for accurate data-driven diagnoses and effective treatments has grown significantly. However, applying machine learning algorithms to real-world datasets presents diverse challenges at multiple levels. The scarcity of labelled data, especially in low regime scenarios with limited availability of real patient cohorts due to high costs of recruitment, underscores the vital deployment of scaling and transfer learning techniques. In this study, we explore a real-world pathology classification task to highlight the effectiveness of data and model scaling and cross-dataset knowledge transfer. As such, we observe varying performance improvements through data scaling, indicating the need for careful evaluation and labelling. Additionally, we identify the challenges of possible negative transfer and emphasize the significance of some key components to overcome distribution shifts and potential spurious correlations and achieve positive transfer. We see improvement in the performance of the target model on the target (NMT) datasets by using the knowledge from the source dataset (TUAB) when a low amount of labelled data was available. Our findings indicate a small and generic model (e.g. ShallowNet) performs well on a single dataset, however, a larger model (e.g. TCN) performs better on transfer and learning from a larger and diverse dataset.
+
+
+
+ 68. 标题:Self-Augmentation Improves Zero-Shot Cross-Lingual Transfer
+ 编号:[270]
+ 链接:https://arxiv.org/abs/2309.10891
+ 作者:Fei Wang, Kuan-Hao Huang, Kai-Wei Chang, Muhao Chen
+ 备注:AACL 2023
+ 关键词:sufficient training resources, allowing models trained, multilingual NLP, Zero-shot cross-lingual transfer, sufficient training
+
+ 点击查看摘要
+ Zero-shot cross-lingual transfer is a central task in multilingual NLP, allowing models trained in languages with more sufficient training resources to generalize to other low-resource languages. Earlier efforts on this task use parallel corpora, bilingual dictionaries, or other annotated alignment data to improve cross-lingual transferability, which are typically expensive to obtain. In this paper, we propose a simple yet effective method, SALT, to improve the zero-shot cross-lingual transfer of the multilingual pretrained language models without the help of such external data. By incorporating code-switching and embedding mixup with self-augmentation, SALT effectively distills cross-lingual knowledge from the multilingual PLM and enhances its transferability on downstream tasks. Experimental results on XNLI and PAWS-X show that our method is able to improve zero-shot cross-lingual transferability without external data. Our code is available at this https URL.
+
+
+
+ 69. 标题:Crypto'Graph: Leveraging Privacy-Preserving Distributed Link Prediction for Robust Graph Learning
+ 编号:[271]
+ 链接:https://arxiv.org/abs/2309.10890
+ 作者:Sofiane Azogagh, Zelma Aubin Birba, Sébastien Gambs, Marc-Olivier Killijian
+ 备注:
+ 关键词:analyzing relational data, graph, collecting and analyzing, analyzing relational, data
+
+ 点击查看摘要
+ Graphs are a widely used data structure for collecting and analyzing relational data. However, when the graph structure is distributed across several parties, its analysis is particularly challenging. In particular, due to the sensitivity of the data each party might want to keep their partial knowledge of the graph private, while still willing to collaborate with the other parties for tasks of mutual benefit, such as data curation or the removal of poisoned data. To address this challenge, we propose Crypto'Graph, an efficient protocol for privacy-preserving link prediction on distributed graphs. More precisely, it allows parties partially sharing a graph with distributed links to infer the likelihood of formation of new links in the future. Through the use of cryptographic primitives, Crypto'Graph is able to compute the likelihood of these new links on the joint network without revealing the structure of the private individual graph of each party, even though they know the number of nodes they have, since they share the same graph but not the same links. Crypto'Graph improves on previous works by enabling the computation of a certain number of similarity metrics without any additional cost. The use of Crypto'Graph is illustrated for defense against graph poisoning attacks, in which it is possible to identify potential adversarial links without compromising the privacy of the graphs of individual parties. The effectiveness of Crypto'Graph in mitigating graph poisoning attacks and achieving high prediction accuracy on a graph neural network node classification task is demonstrated through extensive experimentation on a real-world dataset.
+
+
+
+ 70. 标题:DeepliteRT: Computer Vision at the Edge
+ 编号:[277]
+ 链接:https://arxiv.org/abs/2309.10878
+ 作者:Saad Ashfaq, Alexander Hoffman, Saptarshi Mitra, Sudhakar Sah, MohammadHossein AskariHemmat, Ehsan Saboori
+ 备注:Accepted at British Machine Vision Conference (BMVC) 2023
+ 关键词:computer vision applications, unlocked unprecedented opportunities, deep learning model, vision applications, unlocked unprecedented
+
+ 点击查看摘要
+ The proliferation of edge devices has unlocked unprecedented opportunities for deep learning model deployment in computer vision applications. However, these complex models require considerable power, memory and compute resources that are typically not available on edge platforms. Ultra low-bit quantization presents an attractive solution to this problem by scaling down the model weights and activations from 32-bit to less than 8-bit. We implement highly optimized ultra low-bit convolution operators for ARM-based targets that outperform existing methods by up to 4.34x. Our operator is implemented within Deeplite Runtime (DeepliteRT), an end-to-end solution for the compilation, tuning, and inference of ultra low-bit models on ARM devices. Compiler passes in DeepliteRT automatically convert a fake-quantized model in full precision to a compact ultra low-bit representation, easing the process of quantized model deployment on commodity hardware. We analyze the performance of DeepliteRT on classification and detection models against optimized 32-bit floating-point, 8-bit integer, and 2-bit baselines, achieving significant speedups of up to 2.20x, 2.33x and 2.17x, respectively.
+
+
+
+ 71. 标题:Sparser Random Networks Exist: Enforcing Communication-Efficient Federated Learning via Regularization
+ 编号:[284]
+ 链接:https://arxiv.org/abs/2309.10834
+ 作者:Mohamad Mestoukirdi, Omid Esrafilian, David Gesbert, Qianrui Li, Nicolas Gresset
+ 备注:Draft to be submitted
+ 关键词:trains over-parameterized random, over-parameterized random networks, work presents, trains over-parameterized, over-parameterized random
+
+ 点击查看摘要
+ This work presents a new method for enhancing communication efficiency in stochastic Federated Learning that trains over-parameterized random networks. In this setting, a binary mask is optimized instead of the model weights, which are kept fixed. The mask characterizes a sparse sub-network that is able to generalize as good as a smaller target network. Importantly, sparse binary masks are exchanged rather than the floating point weights in traditional federated learning, reducing communication cost to at most 1 bit per parameter. We show that previous state of the art stochastic methods fail to find the sparse networks that can reduce the communication and storage overhead using consistent loss objectives. To address this, we propose adding a regularization term to local objectives that encourages sparser solutions by eliminating redundant features across sub-networks. Extensive experiments demonstrate significant improvements in communication and memory efficiency of up to five magnitudes compared to the literature, with minimal performance degradation in validation accuracy in some instances.
+
+
+
+ 72. 标题:Actively Learning Reinforcement Learning: A Stochastic Optimal Control Approach
+ 编号:[286]
+ 链接:https://arxiv.org/abs/2309.10831
+ 作者:Mohammad S. Ramadan, Mahmoud A. Hayajnh, Michael T. Tolley, Kyriakos G. Vamvoudakis
+ 备注:
+ 关键词:prohibitive computational cost, stochastic optimal control, reinforcement learning due, controlled laboratory, optimal control
+
+ 点击查看摘要
+ In this paper we provide framework to cope with two problems: (i) the fragility of reinforcement learning due to modeling uncertainties because of the mismatch between controlled laboratory/simulation and real-world conditions and (ii) the prohibitive computational cost of stochastic optimal control. We approach both problems by using reinforcement learning to solve the stochastic dynamic programming equation. The resulting reinforcement learning controller is safe with respect to several types of constraints constraints and it can actively learn about the modeling uncertainties. Unlike exploration and exploitation, probing and safety are employed automatically by the controller itself, resulting real-time learning. A simulation example demonstrates the efficacy of the proposed approach.
+
+
+
+ 73. 标题:Multiplying poles to avoid unwanted points in root finding and optimization
+ 编号:[288]
+ 链接:https://arxiv.org/abs/2309.11475
+ 作者:Tuyen Trung Truong
+ 备注:19 pages
+ 关键词:assume extra properties, finding and optimization, closed set, convex or connected, sequence constructed
+
+ 点击查看摘要
+ In root finding and optimization, there are many cases where there is a closed set $A$ one does not the sequence constructed by one's favourite method will converge to A (here, we do not assume extra properties on $A$ such as being convex or connected). For example, if one wants to find roots, and one chooses initial points in the basin of attraction for 1 root $x^*$ (a fact which one may not know before hand), then one will always end up in that root. In this case, one would like to have a mechanism to avoid this point $z^*$ in the next runs of one's algorithm.
+In this paper, we propose a new method aiming to achieve this: we divide the cost function by an appropriate power of the distance function to $A$. This idea is inspired by how one would try to find all roots of a function in 1 variable. We first explain the heuristic for this method in the case where the minimum of the cost function is exactly 0, and then explain how to proceed if the minimum is non-zero (allowing both positive and negative values). The method is very suitable for iterative algorithms which have the descent property. We also propose, based on this, an algorithm to escape the basin of attraction of a component of positive dimension to reach another component.
+Along the way, we compare with main existing relevant methods in the current literature. We provide several examples to illustrate the usefulness of the new approach.
+
+
+
+ 74. 标题:Distribution and volume based scoring for Isolation Forests
+ 编号:[291]
+ 链接:https://arxiv.org/abs/2309.11450
+ 作者:Hichem Dhouib, Alissa Wilms, Paul Boes
+ 备注:7 pages
+ 关键词:Isolation Forest, Isolation Forest method, outlier detection, anomaly and outlier, standard isolation forest
+
+ 点击查看摘要
+ We make two contributions to the Isolation Forest method for anomaly and outlier detection. The first contribution is an information-theoretically motivated generalisation of the score function that is used to aggregate the scores across random tree estimators. This generalisation allows one to take into account not just the ensemble average across trees but instead the whole distribution. The second contribution is an alternative scoring function at the level of the individual tree estimator, in which we replace the depth-based scoring of the Isolation Forest with one based on hyper-volumes associated to an isolation tree's leaf nodes.
+We motivate the use of both of these methods on generated data and also evaluate them on 34 datasets from the recent and exhaustive ``ADBench'' benchmark, finding significant improvement over the standard isolation forest for both variants on some datasets and improvement on average across all datasets for one of the two variants. The code to reproduce our results is made available as part of the submission.
+
+
+
+ 75. 标题:Transformers versus LSTMs for electronic trading
+ 编号:[293]
+ 链接:https://arxiv.org/abs/2309.11400
+ 作者:Paul Bilokon, Yitao Qiu
+ 备注:
+ 关键词:short term memory, recurrent neural network, time series prediction, time series, Natural Language Processing
+
+ 点击查看摘要
+ With the rapid development of artificial intelligence, long short term memory (LSTM), one kind of recurrent neural network (RNN), has been widely applied in time series prediction.
+Like RNN, Transformer is designed to handle the sequential data. As Transformer achieved great success in Natural Language Processing (NLP), researchers got interested in Transformer's performance on time series prediction, and plenty of Transformer-based solutions on long time series forecasting have come out recently. However, when it comes to financial time series prediction, LSTM is still a dominant architecture. Therefore, the question this study wants to answer is: whether the Transformer-based model can be applied in financial time series prediction and beat LSTM.
+To answer this question, various LSTM-based and Transformer-based models are compared on multiple financial prediction tasks based on high-frequency limit order book data. A new LSTM-based model called DLSTM is built and new architecture for the Transformer-based model is designed to adapt for financial prediction. The experiment result reflects that the Transformer-based model only has the limited advantage in absolute price sequence prediction. The LSTM-based models show better and more robust performance on difference sequence prediction, such as price difference and price movement.
+
+
+
+ 76. 标题:Leveraging Data Collection and Unsupervised Learning for Code-switched Tunisian Arabic Automatic Speech Recognition
+ 编号:[298]
+ 链接:https://arxiv.org/abs/2309.11327
+ 作者:Ahmed Amine Ben Abdallah, Ata Kabboudi, Amir Kanoun, Salah Zaiem
+ 备注:6 pages, submitted to ICASSP 2024
+ 关键词:Automatic Speech Recognition, effective Automatic Speech, Speech Recognition, Automatic Speech, dialects demands innovative
+
+ 点击查看摘要
+ Crafting an effective Automatic Speech Recognition (ASR) solution for dialects demands innovative approaches that not only address the data scarcity issue but also navigate the intricacies of linguistic diversity. In this paper, we address the aforementioned ASR challenge, focusing on the Tunisian dialect. First, textual and audio data is collected and in some cases annotated. Second, we explore self-supervision, semi-supervision and few-shot code-switching approaches to push the state-of-the-art on different Tunisian test sets; covering different acoustic, linguistic and prosodic conditions. Finally, and given the absence of conventional spelling, we produce a human evaluation of our transcripts to avoid the noise coming from spelling inadequacies in our testing references. Our models, allowing to transcribe audio samples in a linguistic mix involving Tunisian Arabic, English and French, and all the data used during training and testing are released for public use and further improvements.
+
+
+
+ 77. 标题:Ano-SuPs: Multi-size anomaly detection for manufactured products by identifying suspected patches
+ 编号:[305]
+ 链接:https://arxiv.org/abs/2309.11120
+ 作者:Hao Xu, Juan Du, Andi Wang
+ 备注:accepted oral presentation at the 18th INFORMS DMDA Workshop
+ 关键词:manufacturing status information, low implementation costs, high acquisition rates, gained popularity owing, provide rich manufacturing
+
+ 点击查看摘要
+ Image-based systems have gained popularity owing to their capacity to provide rich manufacturing status information, low implementation costs and high acquisition rates. However, the complexity of the image background and various anomaly patterns pose new challenges to existing matrix decomposition methods, which are inadequate for modeling requirements. Moreover, the uncertainty of the anomaly can cause anomaly contamination problems, making the designed model and method highly susceptible to external disturbances. To address these challenges, we propose a two-stage strategy anomaly detection method that detects anomalies by identifying suspected patches (Ano-SuPs). Specifically, we propose to detect the patches with anomalies by reconstructing the input image twice: the first step is to obtain a set of normal patches by removing those suspected patches, and the second step is to use those normal patches to refine the identification of the patches with anomalies. To demonstrate its effectiveness, we evaluate the proposed method systematically through simulation experiments and case studies. We further identified the key parameters and designed steps that impact the model's performance and efficiency.
+
+
+
+ 78. 标题:Extreme Scenario Selection in Day-Ahead Power Grid Operational Planning
+ 编号:[307]
+ 链接:https://arxiv.org/abs/2309.11067
+ 作者:Guillermo Terrén-Serrano, Michael Ludkovski
+ 备注:
+ 关键词:day-ahead grid planning, functional depth metrics, statistical functional depth, propose and analyze, analyze the application
+
+ 点击查看摘要
+ We propose and analyze the application of statistical functional depth metrics for the selection of extreme scenarios in day-ahead grid planning. Our primary motivation is screening of probabilistic scenarios for realized load and renewable generation, in order to identify scenarios most relevant for operational risk mitigation. To handle the high-dimensionality of the scenarios across asset classes and intra-day periods, we employ functional measures of depth to sub-select outlying scenarios that are most likely to be the riskiest for the grid operation. We investigate a range of functional depth measures, as well as a range of operational risks, including load shedding, operational costs, reserves shortfall and variable renewable energy curtailment. The effectiveness of the proposed screening approach is demonstrated through a case study on the realistic Texas-7k grid.
+
+
+
+ 79. 标题:The Topology and Geometry of Neural Representations
+ 编号:[309]
+ 链接:https://arxiv.org/abs/2309.11028
+ 作者:Baihan Lin, Nikolaus Kriegeskorte
+ 备注:codes: this https URL
+ 关键词:cognitive content, brain representations, central question, question for neuroscience, perceptual and cognitive
+
+ 点击查看摘要
+ A central question for neuroscience is how to characterize brain representations of perceptual and cognitive content. An ideal characterization should distinguish different functional regions with robustness to noise and idiosyncrasies of individual brains that do not correspond to computational differences. Previous studies have characterized brain representations by their representational geometry, which is defined by the representational dissimilarity matrix (RDM), a summary statistic that abstracts from the roles of individual neurons (or responses channels) and characterizes the discriminability of stimuli. Here we explore a further step of abstraction: from the geometry to the topology of brain representations. We propose topological representational similarity analysis (tRSA), an extension of representational similarity analysis (RSA) that uses a family of geo-topological summary statistics that generalizes the RDM to characterize the topology while de-emphasizing the geometry. We evaluate this new family of statistics in terms of the sensitivity and specificity for model selection using both simulations and functional MRI (fMRI) data. In the simulations, the ground truth is a data-generating layer representation in a neural network model and the models are the same and other layers in different model instances (trained from different random seeds). In fMRI, the ground truth is a visual area and the models are the same and other areas measured in different subjects. Results show that topology-sensitive characterizations of population codes are robust to noise and interindividual variability and maintain excellent sensitivity to the unique representational signatures of different neural network layers and brain regions.
+
+
+
+ 80. 标题:3D-U-SAM Network For Few-shot Tooth Segmentation in CBCT Images
+ 编号:[310]
+ 链接:https://arxiv.org/abs/2309.11015
+ 作者:Yifu Zhang, Zuozhu Liu, Yang Feng, Renjing Xu
+ 备注:This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible
+ 关键词:dental image segmentation, Accurate representation, important in treatment, representation of tooth, tooth position
+
+ 点击查看摘要
+ Accurate representation of tooth position is extremely important in treatment. 3D dental image segmentation is a widely used method, however labelled 3D dental datasets are a scarce resource, leading to the problem of small samples that this task faces in many cases. To this end, we address this problem with a pretrained SAM and propose a novel 3D-U-SAM network for 3D dental image segmentation. Specifically, in order to solve the problem of using 2D pre-trained weights on 3D datasets, we adopted a convolution approximation method; in order to retain more details, we designed skip connections to fuse features at all levels with reference to U-Net. The effectiveness of the proposed method is demonstrated in ablation experiments, comparison experiments, and sample size experiments.
+
+
+
+ 81. 标题:DPpack: An R Package for Differentially Private Statistical Analysis and Machine Learning
+ 编号:[313]
+ 链接:https://arxiv.org/abs/2309.10965
+ 作者:Spencer Giddens, Fang Liu
+ 备注:
+ 关键词:releasing aggregated statistics, framework for guaranteeing, individuals when releasing, releasing aggregated, differentially private
+
+ 点击查看摘要
+ Differential privacy (DP) is the state-of-the-art framework for guaranteeing privacy for individuals when releasing aggregated statistics or building statistical/machine learning models from data. We develop the open-source R package DPpack that provides a large toolkit of differentially private analysis. The current version of DPpack implements three popular mechanisms for ensuring DP: Laplace, Gaussian, and exponential. Beyond that, DPpack provides a large toolkit of easily accessible privacy-preserving descriptive statistics functions. These include mean, variance, covariance, and quantiles, as well as histograms and contingency tables. Finally, DPpack provides user-friendly implementation of privacy-preserving versions of logistic regression, SVM, and linear regression, as well as differentially private hyperparameter tuning for each of these models. This extensive collection of implemented differentially private statistics and models permits hassle-free utilization of differential privacy principles in commonly performed statistical analysis. We plan to continue developing DPpack and make it more comprehensive by including more differentially private machine learning techniques, statistical modeling and inference in the future.
+
+
+
+ 82. 标题:Deep Reinforcement Learning for Infinite Horizon Mean Field Problems in Continuous Spaces
+ 编号:[315]
+ 链接:https://arxiv.org/abs/2309.10953
+ 作者:Andrea Angiuli, Jean-Pierre Fouque, Ruimeng Hu, Alan Raydan
+ 备注:
+ 关键词:field control games, unified manner, present the development, development and analysis, continuous-space mean field
+
+ 点击查看摘要
+ We present the development and analysis of a reinforcement learning (RL) algorithm designed to solve continuous-space mean field game (MFG) and mean field control (MFC) problems in a unified manner. The proposed approach pairs the actor-critic (AC) paradigm with a representation of the mean field distribution via a parameterized score function, which can be efficiently updated in an online fashion, and uses Langevin dynamics to obtain samples from the resulting distribution. The AC agent and the score function are updated iteratively to converge, either to the MFG equilibrium or the MFC optimum for a given mean field problem, depending on the choice of learning rates. A straightforward modification of the algorithm allows us to solve mixed mean field control games (MFCGs). The performance of our algorithm is evaluated using linear-quadratic benchmarks in the asymptotic infinite horizon framework.
+
+
+
+ 83. 标题:Posterior Contraction Rates for Matérn Gaussian Processes on Riemannian Manifolds
+ 编号:[318]
+ 链接:https://arxiv.org/abs/2309.10918
+ 作者:Paul Rosa, Viacheslav Borovitskiy, Alexander Terenin, Judith Rousseau
+ 备注:
+ 关键词:machine learning applications, uncertainty quantification, machine learning, learning applications, applications that rely
+
+ 点击查看摘要
+ Gaussian processes are used in many machine learning applications that rely on uncertainty quantification. Recently, computational tools for working with these models in geometric settings, such as when inputs lie on a Riemannian manifold, have been developed. This raises the question: can these intrinsic models be shown theoretically to lead to better performance, compared to simply embedding all relevant quantities into $\mathbb{R}^d$ and using the restriction of an ordinary Euclidean Gaussian process? To study this, we prove optimal contraction rates for intrinsic Matérn Gaussian processes defined on compact Riemannian manifolds. We also prove analogous rates for extrinsic processes using trace and extension theorems between manifold and ambient Sobolev spaces: somewhat surprisingly, the rates obtained turn out to coincide with those of the intrinsic processes, provided that their smoothness parameters are matched appropriately. We illustrate these rates empirically on a number of examples, which, mirroring prior work, show that intrinsic processes can achieve better performance in practice. Therefore, our work shows that finer-grained analyses are needed to distinguish between different levels of data-efficiency of geometric Gaussian processes, particularly in settings which involve small data set sizes and non-asymptotic behavior.
+
+
+
+ 84. 标题:End-to-End Speech Recognition Contextualization with Large Language Models
+ 编号:[319]
+ 链接:https://arxiv.org/abs/2309.10917
+ 作者:Egor Lakomkin, Chunyang Wu, Yassir Fathullah, Ozlem Kalinli, Michael L. Seltzer, Christian Fuegen
+ 备注:
+ 关键词:Large Language Models, research community due, Large Language, garnered significant attention, models incorporating LLMs
+
+ 点击查看摘要
+ In recent years, Large Language Models (LLMs) have garnered significant attention from the research community due to their exceptional performance and generalization capabilities. In this paper, we introduce a novel method for contextualizing speech recognition models incorporating LLMs. Our approach casts speech recognition as a mixed-modal language modeling task based on a pretrained LLM. We provide audio features, along with optional text tokens for context, to train the system to complete transcriptions in a decoder-only fashion. As a result, the system is implicitly incentivized to learn how to leverage unstructured contextual information during training. Our empirical results demonstrate a significant improvement in performance, with a 6% WER reduction when additional textual context is provided. Moreover, we find that our method performs competitively and improve by 7.5% WER overall and 17% WER on rare words against a baseline contextualized RNN-T system that has been trained on more than twenty five times larger speech dataset. Overall, we demonstrate that by only adding a handful number of trainable parameters via adapters, we can unlock contextualized speech recognition capability for the pretrained LLM while keeping the same text-only input functionality.
+
+
+
+ 85. 标题:Dynamical Tests of a Deep-Learning Weather Prediction Model
+ 编号:[320]
+ 链接:https://arxiv.org/abs/2309.10867
+ 作者:Gregory J. Hakim, Sanjit Masanam
+ 备注:
+ 关键词:Global deep-learning weather, deep-learning weather prediction, weather prediction models, Global deep-learning, operational centers
+
+ 点击查看摘要
+ Global deep-learning weather prediction models have recently been shown to produce forecasts that rival those from physics-based models run at operational centers. It is unclear whether these models have encoded atmospheric dynamics, or simply pattern matching that produces the smallest forecast error. Answering this question is crucial to establishing the utility of these models as tools for basic science. Here we subject one such model, Pangu-weather, to a set of four classical dynamical experiments that do not resemble the model training data. Localized perturbations to the model output and the initial conditions are added to steady time-averaged conditions, to assess the propagation speed and structural evolution of signals away from the local source. Perturbing the model physics by adding a steady tropical heat source results in a classical Matsuno--Gill response near the heating, and planetary waves that radiate into the extratropics. A localized disturbance on the winter-averaged North Pacific jet stream produces realistic extratropical cyclones and fronts, including the spontaneous emergence of polar lows. Perturbing the 500hPa height field alone yields adjustment from a state of rest to one of wind--pressure balance over ~6 hours. Localized subtropical low pressure systems produce Atlantic hurricanes, provided the initial amplitude exceeds about 5 hPa, and setting the initial humidity to zero eliminates hurricane development. We conclude that the model encodes realistic physics in all experiments, and suggest it can be used as a tool for rapidly testing ideas before using expensive physics-based models.
+
+
+
+ 86. 标题:Improving Opioid Use Disorder Risk Modelling through Behavioral and Genetic Feature Integration
+ 编号:[321]
+ 链接:https://arxiv.org/abs/2309.10837
+ 作者:Sybille Légitime, Kaustubh Prabhu, Devin McConnell, Bing Wang, Dipak K. Dey, Derek Aguiar
+ 备注:13 pages (including References section), 8 figures. Under review by IEEE J-BHI
+ 关键词:United States yearly, United States, States yearly, OUD risk, OUD
+
+ 点击查看摘要
+ Opioids are an effective analgesic for acute and chronic pain, but also carry a considerable risk of addiction leading to millions of opioid use disorder (OUD) cases and tens of thousands of premature deaths in the United States yearly. Estimating OUD risk prior to prescription could improve the efficacy of treatment regimens, monitoring programs, and intervention strategies, but risk estimation is typically based on self-reported data or questionnaires. We develop an experimental design and computational methods that combines genetic variants associated with OUD with behavioral features extracted from GPS and Wi-Fi spatiotemporal coordinates to assess OUD risk. Since both OUD mobility and genetic data do not exist for the same cohort, we develop algorithms to (1) generate mobility features from empirical distributions and (2) synthesize mobility and genetic samples assuming a level of comorbidity and relative risks. We show that integrating genetic and mobility modalities improves risk modelling using classification accuracy, area under the precision-recall and receiver operator characteristic curves, and $F_1$ score. Interpreting the fitted models suggests that mobility features have more influence on OUD risk, although the genetic contribution was significant, particularly in linear models. While there exists concerns with respect to privacy, security, bias, and generalizability that must be evaluated in clinical trials before being implemented in practice, our framework provides preliminary evidence that behavioral and genetic features may improve OUD risk estimation to assist with personalized clinical decision-making.
+
+
+
+ 87. 标题:Analysing race and sex bias in brain age prediction
+ 编号:[322]
+ 链接:https://arxiv.org/abs/2309.10835
+ 作者:Carolina Piçarra, Ben Glocker
+ 备注:MICCAI Workshop on Fairness of AI in Medical Imaging (FAIMI 2023)
+ 关键词:popular imaging biomarker, Brain age prediction, age prediction models, Brain age, age prediction
+
+ 点击查看摘要
+ Brain age prediction from MRI has become a popular imaging biomarker associated with a wide range of neuropathologies. The datasets used for training, however, are often skewed and imbalanced regarding demographics, potentially making brain age prediction models susceptible to bias. We analyse the commonly used ResNet-34 model by conducting a comprehensive subgroup performance analysis and feature inspection. The model is trained on 1,215 T1-weighted MRI scans from Cam-CAN and IXI, and tested on UK Biobank (n=42,786), split into six racial and biological sex subgroups. With the objective of comparing the performance between subgroups, measured by the absolute prediction error, we use a Kruskal-Wallis test followed by two post-hoc Conover-Iman tests to inspect bias across race and biological sex. To examine biases in the generated features, we use PCA for dimensionality reduction and employ two-sample Kolmogorov-Smirnov tests to identify distribution shifts among subgroups. Our results reveal statistically significant differences in predictive performance between Black and White, Black and Asian, and male and female subjects. Seven out of twelve pairwise comparisons show statistically significant differences in the feature distributions. Our findings call for further analysis of brain age prediction models.
+
+
+
+ 88. 标题:Latent Disentanglement in Mesh Variational Autoencoders Improves the Diagnosis of Craniofacial Syndromes and Aids Surgical Planning
+ 编号:[324]
+ 链接:https://arxiv.org/abs/2309.10825
+ 作者:Simone Foti, Alexander J. Rickart, Bongjin Koo, Eimear O' Sullivan, Lara S. van de Lande, Athanasios Papaioannou, Roman Khonsari, Danail Stoyanov, N. u. Owase Jeelani, Silvia Schievano, David J. Dunaway, Matthew J. Clarkson
+ 备注:
+ 关键词:holds great promise, human head holds, head holds great, undertake shape analysis, great promise
+
+ 点击查看摘要
+ The use of deep learning to undertake shape analysis of the complexities of the human head holds great promise. However, there have traditionally been a number of barriers to accurate modelling, especially when operating on both a global and local level. In this work, we will discuss the application of the Swap Disentangled Variational Autoencoder (SD-VAE) with relevance to Crouzon, Apert and Muenke syndromes. Although syndrome classification is performed on the entire mesh, it is also possible, for the first time, to analyse the influence of each region of the head on the syndromic phenotype. By manipulating specific parameters of the generative model, and producing procedure-specific new shapes, it is also possible to simulate the outcome of a range of craniofacial surgical procedures. This opens new avenues to advance diagnosis, aids surgical planning and allows for the objective evaluation of surgical outcomes.
+
+
+
+ 89. 标题:Intelligent machines work in unstructured environments by differential neural computing
+ 编号:[326]
+ 链接:https://arxiv.org/abs/2309.08835
+ 作者:Shengbo Wang, Shuo Gao, Chenyu Tang, Cong Li, Shurui Wang, Jiaqi Wang, Hubin Zhao, Guohua Hu, Arokia Nathan, Ravinder Dahiya, Luigi Occhipinti
+ 备注:17 pages, 5 figures
+ 关键词:Expecting intelligent machines, intelligent machines, understand unstructured information, efficiently work, real world requires
+
+ 点击查看摘要
+ Expecting intelligent machines to efficiently work in real world requires a new method to understand unstructured information in unknown environments with good accuracy, scalability and generalization, like human. Here, a memristive neural computing based perceptual signal differential processing and learning method for intelligent machines is presented, via extracting main features of environmental information and applying associated encoded stimuli to memristors, we successfully obtain human-like ability in processing unstructured environmental information, such as amplification (>720%) and adaptation (<50%) 1 10 of mechanical stimuli. the method also exhibits good scalability and generalization, validated in two typical applications intelligent machines: object grasping autonomous driving. former, a robot hand experimentally realizes safe stable grasping, through learning unknown features (e.g., sharp corner smooth surface) with single memristor ms. latter, decision-making information unstructured environments driving overtaking cars, pedestrians) are accurately (94%) extracted 40x25 array. by mimicking intrinsic nature human low-level perception mechanisms electronic memristive neural circuits, proposed is adaptable to diverse sensing technologies, helping machines generate smart high-level decisions real world.< p>
+
+
+人工智能
+
+ 1. 标题:Chain-of-Verification Reduces Hallucination in Large Language Models
+ 编号:[4]
+ 链接:https://arxiv.org/abs/2309.11495
+ 作者:Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, Jason Weston
+ 备注:
+ 关键词:incorrect factual information, large language models, factual information, plausible yet incorrect, incorrect factual
+
+ 点击查看摘要
+ Generation of plausible yet incorrect factual information, termed hallucination, is an unsolved issue in large language models. We study the ability of language models to deliberate on the responses they give in order to correct their mistakes. We develop the Chain-of-Verification (CoVe) method whereby the model first (i) drafts an initial response; then (ii) plans verification questions to fact-check its draft; (iii) answers those questions independently so the answers are not biased by other responses; and (iv) generates its final verified response. In experiments, we show CoVe decreases hallucinations across a variety of tasks, from list-based questions from Wikidata, closed book MultiSpanQA and longform text generation.
+
+
+
+ 2. 标题:Text2Reward: Automated Dense Reward Function Generation for Reinforcement Learning
+ 编号:[5]
+ 链接:https://arxiv.org/abs/2309.11489
+ 作者:Tianbao Xie, Siheng Zhao, Chen Henry Wu, Yitao Liu, Qian Luo, Victor Zhong, Yanchao Yang, Tao Yu
+ 备注:23 pages, 10 figures, update
+ 关键词:requires specialized knowledge, Designing reward functions, reward functions, dense reward functions, reinforcement learning
+
+ 点击查看摘要
+ Designing reward functions is a longstanding challenge in reinforcement learning (RL); it requires specialized knowledge or domain data, leading to high costs for development. To address this, we introduce Text2Reward, a data-free framework that automates the generation of dense reward functions based on large language models (LLMs). Given a goal described in natural language, Text2Reward generates dense reward functions as an executable program grounded in a compact representation of the environment. Unlike inverse RL and recent work that uses LLMs to write sparse reward codes, Text2Reward produces interpretable, free-form dense reward codes that cover a wide range of tasks, utilize existing packages, and allow iterative refinement with human feedback. We evaluate Text2Reward on two robotic manipulation benchmarks (ManiSkill2, MetaWorld) and two locomotion environments of MuJoCo. On 13 of the 17 manipulation tasks, policies trained with generated reward codes achieve similar or better task success rates and convergence speed than expert-written reward codes. For locomotion tasks, our method learns six novel locomotion behaviors with a success rate exceeding 94%. Furthermore, we show that the policies trained in the simulator with our method can be deployed in the real world. Finally, Text2Reward further improves the policies by refining their reward functions with human feedback. Video results are available at this https URL
+
+
+
+ 3. 标题:Fictional Worlds, Real Connections: Developing Community Storytelling Social Chatbots through LLMs
+ 编号:[8]
+ 链接:https://arxiv.org/abs/2309.11478
+ 作者:Yuqian Sun, Hanyi Wang, Pok Man Chan, Morteza Tabibi, Yan Zhang, Huan Lu, Yuheng Chen, Chang Hee Lee, Ali Asadipour
+ 备注:
+ 关键词:Large Language Models, believable Social Chatbots, Storytelling Social Chatbots, Language Models, Large Language
+
+ 点击查看摘要
+ We address the integration of storytelling and Large Language Models (LLMs) to develop engaging and believable Social Chatbots (SCs) in community settings. Motivated by the potential of fictional characters to enhance social interactions, we introduce Storytelling Social Chatbots (SSCs) and the concept of story engineering to transform fictional game characters into "live" social entities within player communities. Our story engineering process includes three steps: (1) Character and story creation, defining the SC's personality and worldview, (2) Presenting Live Stories to the Community, allowing the SC to recount challenges and seek suggestions, and (3) Communication with community members, enabling interaction between the SC and users. We employed the LLM GPT-3 to drive our SSC prototypes, "David" and "Catherine," and evaluated their performance in an online gaming community, "DE (Alias)," on Discord. Our mixed-method analysis, based on questionnaires (N=15) and interviews (N=8) with community members, reveals that storytelling significantly enhances the engagement and believability of SCs in community settings.
+
+
+
+ 4. 标题:Multi-view Fuzzy Representation Learning with Rules based Model
+ 编号:[11]
+ 链接:https://arxiv.org/abs/2309.11473
+ 作者:Wei Zhang, Zhaohong Deng, Te Zhang, Kup-Sze Choi, Shitong Wang
+ 备注:This work has been accepted by IEEE Transactions on Knowledge and Data Engineering
+ 关键词:multi-view representation learning, Unsupervised multi-view representation, representation learning, multi-view, multi-view data
+
+ 点击查看摘要
+ Unsupervised multi-view representation learning has been extensively studied for mining multi-view data. However, some critical challenges remain. On the one hand, the existing methods cannot explore multi-view data comprehensively since they usually learn a common representation between views, given that multi-view data contains both the common information between views and the specific information within each view. On the other hand, to mine the nonlinear relationship between data, kernel or neural network methods are commonly used for multi-view representation learning. However, these methods are lacking in interpretability. To this end, this paper proposes a new multi-view fuzzy representation learning method based on the interpretable Takagi-Sugeno-Kang (TSK) fuzzy system (MVRL_FS). The method realizes multi-view representation learning from two aspects. First, multi-view data are transformed into a high-dimensional fuzzy feature space, while the common information between views and specific information of each view are explored simultaneously. Second, a new regularization method based on L_(2,1)-norm regression is proposed to mine the consistency information between views, while the geometric structure of the data is preserved through the Laplacian graph. Finally, extensive experiments on many benchmark multi-view datasets are conducted to validate the superiority of the proposed method.
+
+
+
+ 5. 标题:Multi-Label Takagi-Sugeno-Kang Fuzzy System
+ 编号:[14]
+ 链接:https://arxiv.org/abs/2309.11469
+ 作者:Qiongdan Lou, Zhaohong Deng, Zhiyong Xiao, Kup-Sze Choi, Shitong Wang
+ 备注:This work has been accepted by IEEE Transactions on Fuzzy Systems
+ 关键词:classification performance, identify the relevant, classification, Multi-label classification, Fuzzy System
+
+ 点击查看摘要
+ Multi-label classification can effectively identify the relevant labels of an instance from a given set of labels. However,the modeling of the relationship between the features and the labels is critical to the classification performance. To this end, we propose a new multi-label classification method, called Multi-Label Takagi-Sugeno-Kang Fuzzy System (ML-TSK FS), to improve the classification performance. The structure of ML-TSK FS is designed using fuzzy rules to model the relationship between features and labels. The fuzzy system is trained by integrating fuzzy inference based multi-label correlation learning with multi-label regression loss. The proposed ML-TSK FS is evaluated experimentally on 12 benchmark multi-label datasets. 1 The results show that the performance of ML-TSK FS is competitive with existing methods in terms of various evaluation metrics, indicating that it is able to model the feature-label relationship effectively using fuzzy inference rules and enhances the classification performance.
+
+
+
+ 6. 标题:AudioFool: Fast, Universal and synchronization-free Cross-Domain Attack on Speech Recognition
+ 编号:[16]
+ 链接:https://arxiv.org/abs/2309.11462
+ 作者:Mohamad Fakih, Rouwaida Kanj, Fadi Kurdahi, Mohammed E. Fouda
+ 备注:10 pages, 11 Figures
+ 关键词:Automatic Speech Recognition, Speech Recognition systems, Speech Recognition, Automatic Speech, Recognition systems
+
+ 点击查看摘要
+ Automatic Speech Recognition systems have been shown to be vulnerable to adversarial attacks that manipulate the command executed on the device. Recent research has focused on exploring methods to create such attacks, however, some issues relating to Over-The-Air (OTA) attacks have not been properly addressed. In our work, we examine the needed properties of robust attacks compatible with the OTA model, and we design a method of generating attacks with arbitrary such desired properties, namely the invariance to synchronization, and the robustness to filtering: this allows a Denial-of-Service (DoS) attack against ASR systems. We achieve these characteristics by constructing attacks in a modified frequency domain through an inverse Fourier transform. We evaluate our method on standard keyword classification tasks and analyze it in OTA, and we analyze the properties of the cross-domain attacks to explain the efficiency of the approach.
+
+
+
+ 7. 标题:Generative Agent-Based Modeling: Unveiling Social System Dynamics through Coupling Mechanistic Models with Generative Artificial Intelligence
+ 编号:[18]
+ 链接:https://arxiv.org/abs/2309.11456
+ 作者:Navid Ghaffarzadegan, Aritra Majumdar, Ross Williams, Niyousha Hosseinichimeh
+ 备注:
+ 关键词:generative artificial intelligence, feedback-rich computational models, building feedback-rich computational, artificial intelligence, generative artificial
+
+ 点击查看摘要
+ We discuss the emerging new opportunity for building feedback-rich computational models of social systems using generative artificial intelligence. Referred to as Generative Agent-Based Models (GABMs), such individual-level models utilize large language models such as ChatGPT to represent human decision-making in social settings. We provide a GABM case in which human behavior can be incorporated in simulation models by coupling a mechanistic model of human interactions with a pre-trained large language model. This is achieved by introducing a simple GABM of social norm diffusion in an organization. For educational purposes, the model is intentionally kept simple. We examine a wide range of scenarios and the sensitivity of the results to several changes in the prompt. We hope the article and the model serve as a guide for building useful diffusion models that include realistic human reasoning and decision-making.
+
+
+
+ 8. 标题:Using deep learning to construct stochastic local search SAT solvers with performance bounds
+ 编号:[21]
+ 链接:https://arxiv.org/abs/2309.11452
+ 作者:Maximilian Kramer, Paul Boes
+ 备注:15 pages, 9 figures
+ 关键词:Boolean Satisfiability problem, Boolean Satisfiability, great practical relevance, prototypical NP-complete problem, Satisfiability problem
+
+ 点击查看摘要
+ The Boolean Satisfiability problem (SAT) is the most prototypical NP-complete problem and of great practical relevance. One important class of solvers for this problem are stochastic local search (SLS) algorithms that iteratively and randomly update a candidate assignment. Recent breakthrough results in theoretical computer science have established sufficient conditions under which SLS solvers are guaranteed to efficiently solve a SAT instance, provided they have access to suitable "oracles" that provide samples from an instance-specific distribution, exploiting an instance's local structure. Motivated by these results and the well established ability of neural networks to learn common structure in large datasets, in this work, we train oracles using Graph Neural Networks and evaluate them on two SLS solvers on random SAT instances of varying difficulty. We find that access to GNN-based oracles significantly boosts the performance of both solvers, allowing them, on average, to solve 17% more difficult instances (as measured by the ratio between clauses and variables), and to do so in 35% fewer steps, with improvements in the median number of steps of up to a factor of 8. As such, this work bridges formal results from theoretical computer science and practically motivated research on deep learning for constraint satisfaction problems and establishes the promise of purpose-trained SAT solvers with performance guarantees.
+
+
+
+ 9. 标题:You Only Look at Screens: Multimodal Chain-of-Action Agents
+ 编号:[26]
+ 链接:https://arxiv.org/abs/2309.11436
+ 作者:Zhuosheng Zhang, Aston Zhang
+ 备注:21 pages, 10 figures
+ 关键词:Autonomous user interface, facilitate task automation, Autonomous user, user interface, manual intervention
+
+ 点击查看摘要
+ Autonomous user interface (UI) agents aim to facilitate task automation by interacting with the user interface without manual intervention. Recent studies have investigated eliciting the capabilities of large language models (LLMs) for effective engagement in diverse environments. To align with the input-output requirement of LLMs, existing approaches are developed under a sandbox setting where they rely on external tools and application-specific APIs to parse the environment into textual elements and interpret the predicted actions. Consequently, those approaches often grapple with inference inefficiency and error propagation risks. To mitigate the challenges, we introduce Auto-UI, a multimodal solution that directly interacts with the interface, bypassing the need for environment parsing or reliance on application-dependent APIs. Moreover, we propose a chain-of-action technique -- leveraging a series of intermediate previous action histories and future action plans -- to help the agent decide what action to execute. We evaluate our approach on a new device-control benchmark AITW with 30K unique instructions, spanning multi-step tasks such as application operation, web searching, and web shopping. Experimental results show that Auto-UI achieves state-of-the-art performance with an action type prediction accuracy of 90% and an overall action success rate of 74%. Code is publicly available at this https URL.
+
+
+
+ 10. 标题:A Systematic Review of Few-Shot Learning in Medical Imaging
+ 编号:[27]
+ 链接:https://arxiv.org/abs/2309.11433
+ 作者:Eva Pachetti, Sara Colantonio
+ 备注:48 pages, 29 figures, 10 tables, submitted to Elsevier on 19 Sep 2023
+ 关键词:deep learning models, large-scale labelled datasets, Few-shot learning, annotated medical images, medical images limits
+
+ 点击查看摘要
+ The lack of annotated medical images limits the performance of deep learning models, which usually need large-scale labelled datasets. Few-shot learning techniques can reduce data scarcity issues and enhance medical image analysis, especially with meta-learning. This systematic review gives a comprehensive overview of few-shot learning in medical imaging. We searched the literature systematically and selected 80 relevant articles published from 2018 to 2023. We clustered the articles based on medical outcomes, such as tumour segmentation, disease classification, and image registration; anatomical structure investigated (i.e. heart, lung, etc.); and the meta-learning method used. For each cluster, we examined the papers' distributions and the results provided by the state-of-the-art. In addition, we identified a generic pipeline shared among all the studies. The review shows that few-shot learning can overcome data scarcity in most outcomes and that meta-learning is a popular choice to perform few-shot learning because it can adapt to new tasks with few labelled samples. In addition, following meta-learning, supervised learning and semi-supervised learning stand out as the predominant techniques employed to tackle few-shot learning challenges in medical imaging and also best performing. Lastly, we observed that the primary application areas predominantly encompass cardiac, pulmonary, and abdominal domains. This systematic review aims to inspire further research to improve medical image analysis and patient care.
+
+
+
+ 11. 标题:Generative Pre-Training of Time-Series Data for Unsupervised Fault Detection in Semiconductor Manufacturing
+ 编号:[28]
+ 链接:https://arxiv.org/abs/2309.11427
+ 作者:Sewoong Lee, JinKyou Choi, Min Su Kim
+ 备注:
+ 关键词:Generative Pre-trained Transformers, paper introduces TRACE-GPT, Generative Pre-trained, Embedding and Generative, Time-seRies Anomaly-detection
+
+ 点击查看摘要
+ This paper introduces TRACE-GPT, which stands for Time-seRies Anomaly-detection with Convolutional Embedding and Generative Pre-trained Transformers. TRACE-GPT is designed to pre-train univariate time-series sensor data and detect faults on unlabeled datasets in semiconductor manufacturing. In semiconductor industry, classifying abnormal time-series sensor data from normal data is important because it is directly related to wafer defect. However, small, unlabeled, and even mixed training data without enough anomalies make classification tasks difficult. In this research, we capture features of time-series data with temporal convolutional embedding and Generative Pre-trained Transformer (GPT) to classify abnormal sequences from normal sequences using cross entropy loss. We prove that our model shows better performance than previous unsupervised models with both an open dataset, the University of California Riverside (UCR) time-series classification archive, and the process log of our Chemical Vapor Deposition (CVD) equipment. Our model has the highest F1 score at Equal Error Rate (EER) across all datasets and is only 0.026 below the supervised state-of-the-art baseline on the open dataset.
+
+
+
+ 12. 标题:EDMP: Ensemble-of-costs-guided Diffusion for Motion Planning
+ 编号:[32]
+ 链接:https://arxiv.org/abs/2309.11414
+ 作者:Kallol Saha, Vishal Mandadi, Jayaram Reddy, Ajit Srikanth, Aditya Agarwal, Bipasha Sen, Arun Singh, Madhava Krishna
+ 备注:8 pages, 8 figures, submitted to ICRA 2024 (International Conference on Robotics and Automation)
+ 关键词:robotic manipulation includes, robotic manipulation, manipulation includes, motion planning, aim to minimize
+
+ 点击查看摘要
+ Classical motion planning for robotic manipulation includes a set of general algorithms that aim to minimize a scene-specific cost of executing a given plan. This approach offers remarkable adaptability, as they can be directly used off-the-shelf for any new scene without needing specific training datasets. However, without a prior understanding of what diverse valid trajectories are and without specially designed cost functions for a given scene, the overall solutions tend to have low success rates. While deep-learning-based algorithms tremendously improve success rates, they are much harder to adopt without specialized training datasets. We propose EDMP, an Ensemble-of-costs-guided Diffusion for Motion Planning that aims to combine the strengths of classical and deep-learning-based motion planning. Our diffusion-based network is trained on a set of diverse kinematically valid trajectories. Like classical planning, for any new scene at the time of inference, we compute scene-specific costs such as "collision cost" and guide the diffusion to generate valid trajectories that satisfy the scene-specific constraints. Further, instead of a single cost function that may be insufficient in capturing diversity across scenes, we use an ensemble of costs to guide the diffusion process, significantly improving the success rate compared to classical planners. EDMP performs comparably with SOTA deep-learning-based methods while retaining the generalization capabilities primarily associated with classical planners.
+
+
+
+ 13. 标题:Long-Form End-to-End Speech Translation via Latent Alignment Segmentation
+ 编号:[41]
+ 链接:https://arxiv.org/abs/2309.11384
+ 作者:Peter Polák, Ondřej Bojar
+ 备注:This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible
+ 关键词:process audio, speech translation, segmentation, speech, simultaneous speech translation
+
+ 点击查看摘要
+ Current simultaneous speech translation models can process audio only up to a few seconds long. Contemporary datasets provide an oracle segmentation into sentences based on human-annotated transcripts and translations. However, the segmentation into sentences is not available in the real world. Current speech segmentation approaches either offer poor segmentation quality or have to trade latency for quality. In this paper, we propose a novel segmentation approach for a low-latency end-to-end speech translation. We leverage the existing speech translation encoder-decoder architecture with ST CTC and show that it can perform the segmentation task without supervision or additional parameters. To the best of our knowledge, our method is the first that allows an actual end-to-end simultaneous speech translation, as the same model is used for translation and segmentation at the same time. On a diverse set of language pairs and in- and out-of-domain data, we show that the proposed approach achieves state-of-the-art quality at no additional computational cost.
+
+
+
+ 14. 标题:Discuss Before Moving: Visual Language Navigation via Multi-expert Discussions
+ 编号:[42]
+ 链接:https://arxiv.org/abs/2309.11382
+ 作者:Yuxing Long, Xiaoqi Li, Wenzhe Cai, Hao Dong
+ 备注:Submitted to ICRA 2024
+ 关键词:skills encompassing understanding, embodied task demanding, demanding a wide, wide range, range of skills
+
+ 点击查看摘要
+ Visual language navigation (VLN) is an embodied task demanding a wide range of skills encompassing understanding, perception, and planning. For such a multifaceted challenge, previous VLN methods totally rely on one model's own thinking to make predictions within one round. However, existing models, even the most advanced large language model GPT4, still struggle with dealing with multiple tasks by single-round self-thinking. In this work, drawing inspiration from the expert consultation meeting, we introduce a novel zero-shot VLN framework. Within this framework, large models possessing distinct abilities are served as domain experts. Our proposed navigation agent, namely DiscussNav, can actively discuss with these experts to collect essential information before moving at every step. These discussions cover critical navigation subtasks like instruction understanding, environment perception, and completion estimation. Through comprehensive experiments, we demonstrate that discussions with domain experts can effectively facilitate navigation by perceiving instruction-relevant information, correcting inadvertent errors, and sifting through in-consistent movement decisions. The performances on the representative VLN task R2R show that our method surpasses the leading zero-shot VLN model by a large margin on all metrics. Additionally, real-robot experiments display the obvious advantages of our method over single-round self-thinking.
+
+
+
+ 15. 标题:Incremental Blockwise Beam Search for Simultaneous Speech Translation with Controllable Quality-Latency Tradeoff
+ 编号:[44]
+ 链接:https://arxiv.org/abs/2309.11379
+ 作者:Peter Polák, Brian Yan, Shinji Watanabe, Alex Waibel, Ondřej Bojar
+ 备注:Accepted at INTERSPEECH 2023
+ 关键词:Blockwise self-attentional encoder, self-attentional encoder models, approach to simultaneous, self-attentional encoder, recently emerged
+
+ 点击查看摘要
+ Blockwise self-attentional encoder models have recently emerged as one promising end-to-end approach to simultaneous speech translation. These models employ a blockwise beam search with hypothesis reliability scoring to determine when to wait for more input speech before translating further. However, this method maintains multiple hypotheses until the entire speech input is consumed -- this scheme cannot directly show a single \textit{incremental} translation to users. Further, this method lacks mechanisms for \textit{controlling} the quality vs. latency tradeoff. We propose a modified incremental blockwise beam search incorporating local agreement or hold-$n$ policies for quality-latency control. We apply our framework to models trained for online or offline translation and demonstrate that both types can be effectively used in online mode.
+Experimental results on MuST-C show 0.6-3.6 BLEU improvement without changing latency or 0.8-1.4 s latency improvement without changing quality.
+
+
+
+ 16. 标题:Preconditioned Federated Learning
+ 编号:[45]
+ 链接:https://arxiv.org/abs/2309.11378
+ 作者:Zeyi Tao, Jindi Wu, Qun Li
+ 备注:preprint
+ 关键词:distributed machine learning, machine learning approach, enables model training, machine learning, learning approach
+
+ 点击查看摘要
+ Federated Learning (FL) is a distributed machine learning approach that enables model training in communication efficient and privacy-preserving manner. The standard optimization method in FL is Federated Averaging (FedAvg), which performs multiple local SGD steps between communication rounds. FedAvg has been considered to lack algorithm adaptivity compared to modern first-order adaptive optimizations. In this paper, we propose new communication-efficient FL algortithms based on two adaptive frameworks: local adaptivity (PreFed) and server-side adaptivity (PreFedOp). Proposed methods adopt adaptivity by using a novel covariance matrix preconditioner. Theoretically, we provide convergence guarantees for our algorithms. The empirical experiments show our methods achieve state-of-the-art performances on both i.i.d. and non-i.i.d. settings.
+
+
+
+ 17. 标题:Dynamic Hand Gesture-Featured Human Motor Adaptation in Tool Delivery using Voice Recognition
+ 编号:[47]
+ 链接:https://arxiv.org/abs/2309.11368
+ 作者:Haolin Fei, Stefano Tedeschi, Yanpei Huang, Andrew Kennedy, Ziwei Wang
+ 备注:This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible
+ 关键词:collaboration has benefited, hand gesture recognition, hand gesture, Human-robot collaboration, recognition
+
+ 点击查看摘要
+ Human-robot collaboration has benefited users with higher efficiency towards interactive tasks. Nevertheless, most collaborative schemes rely on complicated human-machine interfaces, which might lack the requisite intuitiveness compared with natural limb control. We also expect to understand human intent with low training data requirements. In response to these challenges, this paper introduces an innovative human-robot collaborative framework that seamlessly integrates hand gesture and dynamic movement recognition, voice recognition, and a switchable control adaptation strategy. These modules provide a user-friendly approach that enables the robot to deliver the tools as per user need, especially when the user is working with both hands. Therefore, users can focus on their task execution without additional training in the use of human-machine interfaces, while the robot interprets their intuitive gestures. The proposed multimodal interaction framework is executed in the UR5e robot platform equipped with a RealSense D435i camera, and the effectiveness is assessed through a soldering circuit board task. The experiment results have demonstrated superior performance in hand gesture recognition, where the static hand gesture recognition module achieves an accuracy of 94.3\%, while the dynamic motion recognition module reaches 97.6\% accuracy. Compared with human solo manipulation, the proposed approach facilitates higher efficiency tool delivery, without significantly distracting from human intents.
+
+
+
+ 18. 标题:Knowledge Graph Question Answering for Materials Science (KGQA4MAT): Developing Natural Language Interface for Metal-Organic Frameworks Knowledge Graph (MOF-KG)
+ 编号:[50]
+ 链接:https://arxiv.org/abs/2309.11361
+ 作者:Yuan An, Jane Greenberg, Alex Kalinowski, Xintong Zhao, Xiaohua Hu, Fernando J. Uribe-Romo, Kyle Langlois, Jacob Furst, Diego A. Gómez-Gualdrón
+ 备注:In 17th International Conference on Metadata and Semantics Research, October 2023
+ 关键词:Graph Question Answering, metal-organic frameworks, Knowledge Graph, Question Answering, present a comprehensive
+
+ 点击查看摘要
+ We present a comprehensive benchmark dataset for Knowledge Graph Question Answering in Materials Science (KGQA4MAT), with a focus on metal-organic frameworks (MOFs). A knowledge graph for metal-organic frameworks (MOF-KG) has been constructed by integrating structured databases and knowledge extracted from the literature. To enhance MOF-KG accessibility for domain experts, we aim to develop a natural language interface for querying the knowledge graph. We have developed a benchmark comprised of 161 complex questions involving comparison, aggregation, and complicated graph structures. Each question is rephrased in three additional variations, resulting in 644 questions and 161 KG queries. To evaluate the benchmark, we have developed a systematic approach for utilizing ChatGPT to translate natural language questions into formal KG queries. We also apply the approach to the well-known QALD-9 dataset, demonstrating ChatGPT's potential in addressing KGQA issues for different platforms and query languages. The benchmark and the proposed approach aim to stimulate further research and development of user-friendly and efficient interfaces for querying domain-specific materials science knowledge graphs, thereby accelerating the discovery of novel materials.
+
+
+
+ 19. 标题:3D Face Reconstruction: the Road to Forensics
+ 编号:[52]
+ 链接:https://arxiv.org/abs/2309.11357
+ 作者:Simone Maurizio La Cava, Giulia Orrù, Martin Drahansky, Gian Luca Marcialis, Fabio Roli
+ 备注:The manuscript has been accepted for publication in ACM Computing Surveys. arXiv admin note: text overlap with arXiv:2303.11164
+ 关键词:face reconstruction algorithms, face reconstruction, entertainment sector, advantageous features, plastic surgery
+
+ 点击查看摘要
+ 3D face reconstruction algorithms from images and videos are applied to many fields, from plastic surgery to the entertainment sector, thanks to their advantageous features. However, when looking at forensic applications, 3D face reconstruction must observe strict requirements that still make its possible role in bringing evidence to a lawsuit unclear. An extensive investigation of the constraints, potential, and limits of its application in forensics is still missing. Shedding some light on this matter is the goal of the present survey, which starts by clarifying the relation between forensic applications and biometrics, with a focus on face recognition. Therefore, it provides an analysis of the achievements of 3D face reconstruction algorithms from surveillance videos and mugshot images and discusses the current obstacles that separate 3D face reconstruction from an active role in forensic applications. Finally, it examines the underlying data sets, with their advantages and limitations, while proposing alternatives that could substitute or complement them.
+
+
+
+ 20. 标题:A Comprehensive Survey on Rare Event Prediction
+ 编号:[53]
+ 链接:https://arxiv.org/abs/2309.11356
+ 作者:Chathurangi Shyalika, Ruwan Wickramarachchi, Amit Sheth
+ 备注:44 pages
+ 关键词:prediction involves identifying, Rare event prediction, machine learning, Rare event, event prediction involves
+
+ 点击查看摘要
+ Rare event prediction involves identifying and forecasting events with a low probability using machine learning and data analysis. Due to the imbalanced data distributions, where the frequency of common events vastly outweighs that of rare events, it requires using specialized methods within each step of the machine learning pipeline, i.e., from data processing to algorithms to evaluation protocols. Predicting the occurrences of rare events is important for real-world applications, such as Industry 4.0, and is an active research area in statistical and machine learning. This paper comprehensively reviews the current approaches for rare event prediction along four dimensions: rare event data, data processing, algorithmic approaches, and evaluation approaches. Specifically, we consider 73 datasets from different modalities (i.e., numerical, image, text, and audio), four major categories of data processing, five major algorithmic groupings, and two broader evaluation approaches. This paper aims to identify gaps in the current literature and highlight the challenges of predicting rare events. It also suggests potential research directions, which can help guide practitioners and researchers.
+
+
+
+ 21. 标题:C$\cdot$ASE: Learning Conditional Adversarial Skill Embeddings for Physics-based Characters
+ 编号:[55]
+ 链接:https://arxiv.org/abs/2309.11351
+ 作者:Zhiyang Dou, Xuelin Chen, Qingnan Fan, Taku Komura, Wenping Wang
+ 备注:SIGGRAPH Asia 2023
+ 关键词:Adversarial Skill Embeddings, learns conditional Adversarial, Embeddings for physics-based, conditional Adversarial Skill, conditional Adversarial
+
+ 点击查看摘要
+ We present C$\cdot$ASE, an efficient and effective framework that learns conditional Adversarial Skill Embeddings for physics-based characters. Our physically simulated character can learn a diverse repertoire of skills while providing controllability in the form of direct manipulation of the skills to be performed. C$\cdot$ASE divides the heterogeneous skill motions into distinct subsets containing homogeneous samples for training a low-level conditional model to learn conditional behavior distribution. The skill-conditioned imitation learning naturally offers explicit control over the character's skills after training. The training course incorporates the focal skill sampling, skeletal residual forces, and element-wise feature masking to balance diverse skills of varying complexities, mitigate dynamics mismatch to master agile motions and capture more general behavior characteristics, respectively. Once trained, the conditional model can produce highly diverse and realistic skills, outperforming state-of-the-art models, and can be repurposed in various downstream tasks. In particular, the explicit skill control handle allows a high-level policy or user to direct the character with desired skill specifications, which we demonstrate is advantageous for interactive character animation.
+
+
+
+ 22. 标题:TRAVID: An End-to-End Video Translation Framework
+ 编号:[60]
+ 链接:https://arxiv.org/abs/2309.11338
+ 作者:Prottay Kumar Adhikary, Bandaru Sugandhi, Subhojit Ghimire, Santanu Pal, Partha Pakray
+ 备注:
+ 关键词:today globalized world, diverse linguistic backgrounds, globalized world, increasingly crucial, today globalized
+
+ 点击查看摘要
+ In today's globalized world, effective communication with people from diverse linguistic backgrounds has become increasingly crucial. While traditional methods of language translation, such as written text or voice-only translations, can accomplish the task, they often fail to capture the complete context and nuanced information conveyed through nonverbal cues like facial expressions and lip movements. In this paper, we present an end-to-end video translation system that not only translates spoken language but also synchronizes the translated speech with the lip movements of the speaker. Our system focuses on translating educational lectures in various Indian languages, and it is designed to be effective even in low-resource system settings. By incorporating lip movements that align with the target language and matching them with the speaker's voice using voice cloning techniques, our application offers an enhanced experience for students and users. This additional feature creates a more immersive and realistic learning environment, ultimately making the learning process more effective and engaging.
+
+
+
+ 23. 标题:Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism
+ 编号:[65]
+ 链接:https://arxiv.org/abs/2309.11331
+ 作者:Chengcheng Wang, Wei He, Ying Nie, Jianyuan Guo, Chuanjian Liu, Kai Han, Yunhe Wang
+ 备注:
+ 关键词:real-time object detection, Path Aggregation Network, Feature Pyramid Network, past years, object detection
+
+ 点击查看摘要
+ In the past years, YOLO-series models have emerged as the leading approaches in the area of real-time object detection. Many studies pushed up the baseline to a higher level by modifying the architecture, augmenting data and designing new losses. However, we find previous models still suffer from information fusion problem, although Feature Pyramid Network (FPN) and Path Aggregation Network (PANet) have alleviated this. Therefore, this study provides an advanced Gatherand-Distribute mechanism (GD) mechanism, which is realized with convolution and self-attention operations. This new designed model named as Gold-YOLO, which boosts the multi-scale feature fusion capabilities and achieves an ideal balance between latency and accuracy across all model scales. Additionally, we implement MAE-style pretraining in the YOLO-series for the first time, allowing YOLOseries models could be to benefit from unsupervised pretraining. Gold-YOLO-N attains an outstanding 39.9% AP on the COCO val2017 datasets and 1030 FPS on a T4 GPU, which outperforms the previous SOTA model YOLOv6-3.0-N with similar FPS by +2.4%. The PyTorch code is available at this https URL, and the MindSpore code is available at this https URL.
+
+
+
+ 24. 标题:Dynamic Pricing of Applications in Cloud Marketplaces using Game Theory
+ 编号:[73]
+ 链接:https://arxiv.org/abs/2309.11316
+ 作者:Safiye Ghasemi, Mohammad Reza Meybodi, Mehdi Dehghan Takht-Fooladi, Amir Masoud Rahmani
+ 备注:
+ 关键词:pricing policies, task for firms, competitive nature, delivery of services, crucial task
+
+ 点击查看摘要
+ The competitive nature of Cloud marketplaces as new concerns in delivery of services makes the pricing policies a crucial task for firms. so that, pricing strategies has recently attracted many researchers. Since game theory can handle such competing well this concern is addressed by designing a normal form game between providers in current research. A committee is considered in which providers register for improving their competition based pricing policies. The functionality of game theory is applied to design dynamic pricing policies. The usage of the committee makes the game a complete information one, in which each player is aware of every others payoff functions. The players enhance their pricing policies to maximize their profits. The contribution of this paper is the quantitative modeling of Cloud marketplaces in form of a game to provide novel dynamic pricing strategies; the model is validated by proving the existence and the uniqueness of Nash equilibrium of the game.
+
+
+
+ 25. 标题:A Competition-based Pricing Strategy in Cloud Markets using Regret Minimization Techniques
+ 编号:[74]
+ 链接:https://arxiv.org/abs/2309.11312
+ 作者:S.Ghasemi, M.R.Meybodi, M.Dehghan, A.M.Rahmani
+ 备注:
+ 关键词:Cloud computing marketplace, Cloud computing, commercial paradigm, widely investigated, range of challenges
+
+ 点击查看摘要
+ Cloud computing as a fairly new commercial paradigm, widely investigated by different researchers, already has a great range of challenges. Pricing is a major problem in Cloud computing marketplace; as providers are competing to attract more customers without knowing the pricing policies of each other. To overcome this lack of knowledge, we model their competition by an incomplete-information game. Considering the issue, this work proposes a pricing policy related to the regret minimization algorithm and applies it to the considered incomplete-information game. Based on the competition based marketplace of the Cloud, providers update the distribution of their strategies using the experienced regret. The idea of iteratively applying the algorithm for updating probabilities of strategies causes the regret get minimized faster. The experimental results show much more increase in profits of the providers in comparison with other pricing policies. Besides, the efficiency of a variety of regret minimization techniques in a simulated marketplace of Cloud are discussed which have not been observed in the studied literature. Moreover, return on investment of providers in considered organizations is studied and promising results appeared.
+
+
+
+ 26. 标题:Rating Prediction in Conversational Task Assistants with Behavioral and Conversational-Flow Features
+ 编号:[76]
+ 链接:https://arxiv.org/abs/2309.11307
+ 作者:Rafael Ferreira, David Semedo, João Magalhães
+ 备注:
+ 关键词:Conversational Task Assistants, Task Assistants, understand user behavior, Conversational Task, critical to understand
+
+ 点击查看摘要
+ Predicting the success of Conversational Task Assistants (CTA) can be critical to understand user behavior and act accordingly. In this paper, we propose TB-Rater, a Transformer model which combines conversational-flow features with user behavior features for predicting user ratings in a CTA scenario. In particular, we use real human-agent conversations and ratings collected in the Alexa TaskBot challenge, a novel multimodal and multi-turn conversational context. Our results show the advantages of modeling both the conversational-flow and behavioral aspects of the conversation in a single model for offline rating prediction. Additionally, an analysis of the CTA-specific behavioral features brings insights into this setting and can be used to bootstrap future systems.
+
+
+
+ 27. 标题:FaceDiffuser: Speech-Driven 3D Facial Animation Synthesis Using Diffusion
+ 编号:[77]
+ 链接:https://arxiv.org/abs/2309.11306
+ 作者:Stefan Stan, Kazi Injamamul Haque, Zerrin Yumak
+ 备注:Pre-print of the paper accepted at ACM SIGGRAPH MIG 2023
+ 关键词:industry and research, facial animation synthesis, facial animation, facial, based
+
+ 点击查看摘要
+ Speech-driven 3D facial animation synthesis has been a challenging task both in industry and research. Recent methods mostly focus on deterministic deep learning methods meaning that given a speech input, the output is always the same. However, in reality, the non-verbal facial cues that reside throughout the face are non-deterministic in nature. In addition, majority of the approaches focus on 3D vertex based datasets and methods that are compatible with existing facial animation pipelines with rigged characters is scarce. To eliminate these issues, we present FaceDiffuser, a non-deterministic deep learning model to generate speech-driven facial animations that is trained with both 3D vertex and blendshape based datasets. Our method is based on the diffusion technique and uses the pre-trained large speech representation model HuBERT to encode the audio input. To the best of our knowledge, we are the first to employ the diffusion method for the task of speech-driven 3D facial animation synthesis. We have run extensive objective and subjective analyses and show that our approach achieves better or comparable results in comparison to the state-of-the-art methods. We also introduce a new in-house dataset that is based on a blendshape based rigged character. We recommend watching the accompanying supplementary video. The code and the dataset will be publicly available.
+
+
+
+ 28. 标题:A Cost-Aware Mechanism for Optimized Resource Provisioning in Cloud Computing
+ 编号:[80]
+ 链接:https://arxiv.org/abs/2309.11299
+ 作者:Safiye Ghasemi, Mohammad Reza Meybodi, Mehdi Dehghan Takht Fooladi, Amir Masoud Rahmani
+ 备注:
+ 关键词:resource provisioning challenges, resource provisioning, recent wide, provisioning, resource provisioning approach
+
+ 点击查看摘要
+ Due to the recent wide use of computational resources in cloud computing, new resource provisioning challenges have been emerged. Resource provisioning techniques must keep total costs to a minimum while meeting the requirements of the requests. According to widely usage of cloud services, it seems more challenging to develop effective schemes for provisioning services cost-effectively; we have proposed a novel learning based resource provisioning approach that achieves cost-reduction guarantees of demands. The contributions of our optimized resource provisioning (ORP) approach are as follows. Firstly, it is designed to provide a cost-effective method to efficiently handle the provisioning of requested applications; while most of the existing models allow only workflows in general which cares about the dependencies of the tasks, ORP performs based on services of which applications comprised and cares about their efficient provisioning totally. Secondly, it is a learning automata-based approach which selects the most proper resources for hosting each service of the demanded application; our approach considers both cost and service requirements together for deploying applications. Thirdly, a comprehensive evaluation is performed for three typical workloads: data-intensive, process-intensive and normal applications. The experimental results show that our method adapts most of the requirements efficiently, and furthermore the resulting performance meets our design goals.
+
+
+
+ 29. 标题:CPLLM: Clinical Prediction with Large Language Models
+ 编号:[82]
+ 链接:https://arxiv.org/abs/2309.11295
+ 作者:Ofir Ben Shoham, Nadav Rappoport
+ 备注:
+ 关键词:pre-trained Large Language, Large Language Models, Large Language, present Clinical Prediction, clinical disease prediction
+
+ 点击查看摘要
+ We present Clinical Prediction with Large Language Models (CPLLM), a method that involves fine-tuning a pre-trained Large Language Model (LLM) for clinical disease prediction. We utilized quantization and fine-tuned the LLM using prompts, with the task of predicting whether patients will be diagnosed with a target disease during their next visit or in the subsequent diagnosis, leveraging their historical diagnosis records. We compared our results versus various baselines, including Logistic Regression, RETAIN, and Med-BERT, which is the current state-of-the-art model for disease prediction using structured EHR data. Our experiments have shown that CPLLM surpasses all the tested models in terms of both PR-AUC and ROC-AUC metrics, displaying noteworthy enhancements compared to the baseline models.
+
+
+
+ 30. 标题:Overview of AuTexTification at IberLEF 2023: Detection and Attribution of Machine-Generated Text in Multiple Domains
+ 编号:[85]
+ 链接:https://arxiv.org/abs/2309.11285
+ 作者:Areg Mikael Sarvazyan, José Ángel González, Marc Franco-Salvador, Francisco Rangel, Berta Chulvi, Paolo Rosso
+ 备注:Accepted at SEPLN 2023
+ 关键词:Languages Evaluation Forum, Iberian Languages Evaluation, Workshop in Iberian, Evaluation Forum, Iberian Languages
+
+ 点击查看摘要
+ This paper presents the overview of the AuTexTification shared task as part of the IberLEF 2023 Workshop in Iberian Languages Evaluation Forum, within the framework of the SEPLN 2023 conference. AuTexTification consists of two subtasks: for Subtask 1, participants had to determine whether a text is human-authored or has been generated by a large language model. For Subtask 2, participants had to attribute a machine-generated text to one of six different text generation models. Our AuTexTification 2023 dataset contains more than 160.000 texts across two languages (English and Spanish) and five domains (tweets, reviews, news, legal, and how-to articles). A total of 114 teams signed up to participate, of which 36 sent 175 runs, and 20 of them sent their working notes. In this overview, we present the AuTexTification dataset and task, the submitted participating systems, and the results.
+
+
+
+ 31. 标题:Rethinking Sensors Modeling: Hierarchical Information Enhanced Traffic Forecasting
+ 编号:[86]
+ 链接:https://arxiv.org/abs/2309.11284
+ 作者:Qian Ma, Zijian Zhang, Xiangyu Zhao, Haoliang Li, Hongwei Zhao, Yiqi Wang, Zitao Liu, Wanyu Wang
+ 备注:9 pages, accepted by CIKM'23
+ 关键词:smart city construction, acceleration of urbanization, traffic forecasting, city construction, essential role
+
+ 点击查看摘要
+ With the acceleration of urbanization, traffic forecasting has become an essential role in smart city construction. In the context of spatio-temporal prediction, the key lies in how to model the dependencies of sensors. However, existing works basically only consider the micro relationships between sensors, where the sensors are treated equally, and their macroscopic dependencies are neglected. In this paper, we argue to rethink the sensor's dependency modeling from two hierarchies: regional and global perspectives. Particularly, we merge original sensors with high intra-region correlation as a region node to preserve the inter-region dependency. Then, we generate representative and common spatio-temporal patterns as global nodes to reflect a global dependency between sensors and provide auxiliary information for spatio-temporal dependency learning. In pursuit of the generality and reality of node representations, we incorporate a Meta GCN to calibrate the regional and global nodes in the physical data space. Furthermore, we devise the cross-hierarchy graph convolution to propagate information from different hierarchies. In a nutshell, we propose a Hierarchical Information Enhanced Spatio-Temporal prediction method, HIEST, to create and utilize the regional dependency and common spatio-temporal patterns. Extensive experiments have verified the leading performance of our HIEST against state-of-the-art baselines. We publicize the code to ease reproducibility.
+
+
+
+ 32. 标题:Open-endedness induced through a predator-prey scenario using modular robots
+ 编号:[92]
+ 链接:https://arxiv.org/abs/2309.11275
+ 作者:Dimitri Kachler, Karine Miras
+ 备注:
+ 关键词:Open-Ended Evolution, work investigates, scenario can induce, Evolution, predator-prey scenario
+
+ 点击查看摘要
+ This work investigates how a predator-prey scenario can induce the emergence of Open-Ended Evolution (OEE). We utilize modular robots of fixed morphologies whose controllers are subject to evolution. In both species, robots can send and receive signals and perceive the relative positions of other robots in the environment. Specifically, we introduce a feature we call a tagging system: it modifies how individuals can perceive each other and is expected to increase behavioral complexity. Our results show the emergence of adaptive strategies, demonstrating the viability of inducing OEE through predator-prey dynamics using modular robots. Such emergence, nevertheless, seemed to depend on conditioning reproduction to an explicit behavioral criterion.
+
+
+
+ 33. 标题:Machine Learning Data Suitability and Performance Testing Using Fault Injection Testing Framework
+ 编号:[93]
+ 链接:https://arxiv.org/abs/2309.11274
+ 作者:Manal Rahal, Bestoun S. Ahmed, Jorgen Samuelsson
+ 备注:18 pages
+ 关键词:Creating resilient machine, user confidence seamlessly, acquire user confidence, resilient machine learning, data
+
+ 点击查看摘要
+ Creating resilient machine learning (ML) systems has become necessary to ensure production-ready ML systems that acquire user confidence seamlessly. The quality of the input data and the model highly influence the successful end-to-end testing in data-sensitive systems. However, the testing approaches of input data are not as systematic and are few compared to model testing. To address this gap, this paper presents the Fault Injection for Undesirable Learning in input Data (FIUL-Data) testing framework that tests the resilience of ML models to multiple intentionally-triggered data faults. Data mutators explore vulnerabilities of ML systems against the effects of different fault injections. The proposed framework is designed based on three main ideas: The mutators are not random; one data mutator is applied at an instance of time, and the selected ML models are optimized beforehand. This paper evaluates the FIUL-Data framework using data from analytical chemistry, comprising retention time measurements of anti-sense oligonucleotide. Empirical evaluation is carried out in a two-step process in which the responses of selected ML models to data mutation are analyzed individually and then compared with each other. The results show that the FIUL-Data framework allows the evaluation of the resilience of ML models. In most experiments cases, ML models show higher resilience at larger training datasets, where gradient boost performed better than support vector regression in smaller training sets. Overall, the mean squared error metric is useful in evaluating the resilience of models due to its higher sensitivity to data mutation.
+
+
+
+ 34. 标题:Grounded Complex Task Segmentation for Conversational Assistants
+ 编号:[95]
+ 链接:https://arxiv.org/abs/2309.11271
+ 作者:Rafael Ferreira, David Semedo, João Magalhães
+ 备注:
+ 关键词:daunting due, shorter attention, attention and memory, memory spans, spans when compared
+
+ 点击查看摘要
+ Following complex instructions in conversational assistants can be quite daunting due to the shorter attention and memory spans when compared to reading the same instructions. Hence, when conversational assistants walk users through the steps of complex tasks, there is a need to structure the task into manageable pieces of information of the right length and complexity. In this paper, we tackle the recipes domain and convert reading structured instructions into conversational structured ones. We annotated the structure of instructions according to a conversational scenario, which provided insights into what is expected in this setting. To computationally model the conversational step's characteristics, we tested various Transformer-based architectures, showing that a token-based approach delivers the best results. A further user study showed that users tend to favor steps of manageable complexity and length, and that the proposed methodology can improve the original web-based instructional text. Specifically, 86% of the evaluated tasks were improved from a conversational suitability point of view.
+
+
+
+ 35. 标题:Sequence-to-Sequence Spanish Pre-trained Language Models
+ 编号:[98]
+ 链接:https://arxiv.org/abs/2309.11259
+ 作者:Vladimir Araujo, Maria Mihaela Trusca, Rodrigo Tufiño, Marie-Francine Moens
+ 备注:
+ 关键词:numerous non-English language, non-English language versions, recent years, substantial advancements, numerous non-English
+
+ 点击查看摘要
+ In recent years, substantial advancements in pre-trained language models have paved the way for the development of numerous non-English language versions, with a particular focus on encoder-only and decoder-only architectures. While Spanish language models encompassing BERT, RoBERTa, and GPT have exhibited prowess in natural language understanding and generation, there remains a scarcity of encoder-decoder models designed for sequence-to-sequence tasks involving input-output pairs. This paper breaks new ground by introducing the implementation and evaluation of renowned encoder-decoder architectures, exclusively pre-trained on Spanish corpora. Specifically, we present Spanish versions of BART, T5, and BERT2BERT-style models and subject them to a comprehensive assessment across a diverse range of sequence-to-sequence tasks, spanning summarization, rephrasing, and generative question answering. Our findings underscore the competitive performance of all models, with BART and T5 emerging as top performers across all evaluated tasks. As an additional contribution, we have made all models publicly available to the research community, fostering future exploration and development in Spanish language processing.
+
+
+
+ 36. 标题:Hierarchical Multi-Agent Reinforcement Learning for Air Combat Maneuvering
+ 编号:[105]
+ 链接:https://arxiv.org/abs/2309.11247
+ 作者:Ardian Selmonaj, Oleg Szehr, Giacomo Del Rio, Alessandro Antonucci, Adrian Schneider, Michael Rüegsegger
+ 备注:22nd International Conference on Machine Learning and Applications (ICMLA 23)
+ 关键词:attracting increasing attention, intelligence to simulate, increasing attention, application of artificial, artificial intelligence
+
+ 点击查看摘要
+ The application of artificial intelligence to simulate air-to-air combat scenarios is attracting increasing attention. To date the high-dimensional state and action spaces, the high complexity of situation information (such as imperfect and filtered information, stochasticity, incomplete knowledge about mission targets) and the nonlinear flight dynamics pose significant challenges for accurate air combat decision-making. These challenges are exacerbated when multiple heterogeneous agents are involved. We propose a hierarchical multi-agent reinforcement learning framework for air-to-air combat with multiple heterogeneous agents. In our framework, the decision-making process is divided into two stages of abstraction, where heterogeneous low-level policies control the action of individual units, and a high-level commander policy issues macro commands given the overall mission targets. Low-level policies are trained for accurate unit combat control. Their training is organized in a learning curriculum with increasingly complex training scenarios and league-based self-play. The commander policy is trained on mission targets given pre-trained low-level policies. The empirical validation advocates the advantages of our design choices.
+
+
+
+ 37. 标题:Colour Passing Revisited: Lifted Model Construction with Commutative Factors
+ 编号:[111]
+ 链接:https://arxiv.org/abs/2309.11236
+ 作者:Malte Luttermann, Tanya Braun, Ralf Möller, Marcel Gehrke
+ 备注:
+ 关键词:colour passing algorithm, domain sizes, colour passing, probabilistic inference exploits, tractable probabilistic inference
+
+ 点击查看摘要
+ Lifted probabilistic inference exploits symmetries in a probabilistic model to allow for tractable probabilistic inference with respect to domain sizes. To apply lifted inference, a lifted representation has to be obtained, and to do so, the so-called colour passing algorithm is the state of the art. The colour passing algorithm, however, is bound to a specific inference algorithm and we found that it ignores commutativity of factors while constructing a lifted representation. We contribute a modified version of the colour passing algorithm that uses logical variables to construct a lifted representation independent of a specific inference algorithm while at the same time exploiting commutativity of factors during an offline-step. Our proposed algorithm efficiently detects more symmetries than the state of the art and thereby drastically increases compression, yielding significantly faster online query times for probabilistic inference when the resulting model is applied.
+
+
+
+ 38. 标题:ChatGPT-4 as a Tool for Reviewing Academic Books in Spanish
+ 编号:[114]
+ 链接:https://arxiv.org/abs/2309.11231
+ 作者:Jonnathan Berrezueta-Guzman, Laura Malache-Silva, Stephan Krusche
+ 备注:Preprint. Paper accepted in the 18\textsuperscript{th} Latin American Conference on Learning Technologies (LACLO 2023), 14 pages
+ 关键词:artificial intelligence language, intelligence language model, language model developed, developed by OpenAI, evaluates the potential
+
+ 点击查看摘要
+ This study evaluates the potential of ChatGPT-4, an artificial intelligence language model developed by OpenAI, as an editing tool for Spanish literary and academic books. The need for efficient and accessible reviewing and editing processes in the publishing industry has driven the search for automated solutions. ChatGPT-4, being one of the most advanced language models, offers notable capabilities in text comprehension and generation. In this study, the features and capabilities of ChatGPT-4 are analyzed in terms of grammatical correction, stylistic coherence, and linguistic enrichment of texts in Spanish. Tests were conducted with 100 literary and academic texts, where the edits made by ChatGPT-4 were compared to those made by expert human reviewers and editors. The results show that while ChatGPT-4 is capable of making grammatical and orthographic corrections with high accuracy and in a very short time, it still faces challenges in areas such as context sensitivity, bibliometric analysis, deep contextual understanding, and interaction with visual content like graphs and tables. However, it is observed that collaboration between ChatGPT-4 and human reviewers and editors can be a promising strategy for improving efficiency without compromising quality. Furthermore, the authors consider that ChatGPT-4 represents a valuable tool in the editing process, but its use should be complementary to the work of human editors to ensure high-caliber editing in Spanish literary and academic books.
+
+
+
+ 39. 标题:Leveraging Diversity in Online Interactions
+ 编号:[118]
+ 链接:https://arxiv.org/abs/2309.11224
+ 作者:Nardine Osman, Bruno Rosell i Gui, Carles Sierra
+ 备注:
+ 关键词:connecting people online, paper addresses, find support, connecting people, addresses the issue
+
+ 点击查看摘要
+ This paper addresses the issue of connecting people online to help them find support with their day-to-day problems. We make use of declarative norms for mediating online interactions, and we specifically focus on the issue of leveraging diversity when connecting people. We run pilots at different university sites, and the results show relative success in the diversity of the selected profiles, backed by high user satisfaction.
+
+
+
+ 40. 标题:Retrieve-Rewrite-Answer: A KG-to-Text Enhanced LLMs Framework for Knowledge Graph Question Answering
+ 编号:[121]
+ 链接:https://arxiv.org/abs/2309.11206
+ 作者:Yike Wu, Nan Hu, Sheng Bi, Guilin Qi, Jie Ren, Anhuan Xie, Wei Song
+ 备注:
+ 关键词:large language models, long tail knowledge, limitations in memorizing, long tail, large language
+
+ 点击查看摘要
+ Despite their competitive performance on knowledge-intensive tasks, large language models (LLMs) still have limitations in memorizing all world knowledge especially long tail knowledge. In this paper, we study the KG-augmented language model approach for solving the knowledge graph question answering (KGQA) task that requires rich world knowledge. Existing work has shown that retrieving KG knowledge to enhance LLMs prompting can significantly improve LLMs performance in KGQA. However, their approaches lack a well-formed verbalization of KG knowledge, i.e., they ignore the gap between KG representations and textual representations. To this end, we propose an answer-sensitive KG-to-Text approach that can transform KG knowledge into well-textualized statements most informative for KGQA. Based on this approach, we propose a KG-to-Text enhanced LLMs framework for solving the KGQA task. Experiments on several KGQA benchmarks show that the proposed KG-to-Text augmented LLMs approach outperforms previous KG-augmented LLMs approaches regarding answer accuracy and usefulness of knowledge statements.
+
+
+
+ 41. 标题:Using Artificial Intelligence for the Automation of Knitting Patterns
+ 编号:[123]
+ 链接:https://arxiv.org/abs/2309.11202
+ 作者:Uduak Uboh
+ 备注:
+ 关键词:Knitting, crucial component, creation and design, Knitting patterns, model
+
+ 点击查看摘要
+ Knitting patterns are a crucial component in the creation and design of knitted materials. Traditionally, these patterns were taught informally, but thanks to advancements in technology, anyone interested in knitting can use the patterns as a guide to start knitting. Perhaps because knitting is mostly a hobby, with the exception of industrial manufacturing utilising specialised knitting machines, the use of Al in knitting is less widespread than its application in other fields. However, it is important to determine whether knitted pattern classification using an automated system is viable. In order to recognise and classify knitting patterns. Using data augmentation and a transfer learning technique, this study proposes a deep learning model. The Inception ResNet-V2 is the main feature extraction and classification algorithm used in the model. Metrics like accuracy, logarithmic loss, F1-score, precision, and recall score were used to evaluate the model. The model evaluation's findings demonstrate high model accuracy, precision, recall, and F1 score. In addition, the AUC score for majority of the classes was in the range (0.7-0.9). A comparative analysis was done using other pretrained models and a ResNet-50 model with transfer learning and the proposed model evaluation results surpassed all others. The major limitation for this project is time, as with more time, there might have been better accuracy over a larger number of epochs.
+
+
+
+ 42. 标题:When to Trust AI: Advances and Challenges for Certification of Neural Networks
+ 编号:[125]
+ 链接:https://arxiv.org/abs/2309.11196
+ 作者:Marta Kwiatkowska, Xiyue Zhang
+ 备注:
+ 关键词:natural language processing, Artificial intelligence, medical diagnosis, language processing, fast pace
+
+ 点击查看摘要
+ Artificial intelligence (AI) has been advancing at a fast pace and it is now poised for deployment in a wide range of applications, such as autonomous systems, medical diagnosis and natural language processing. Early adoption of AI technology for real-world applications has not been without problems, particularly for neural networks, which may be unstable and susceptible to adversarial examples. In the longer term, appropriate safety assurance techniques need to be developed to reduce potential harm due to avoidable system failures and ensure trustworthiness. Focusing on certification and explainability, this paper provides an overview of techniques that have been developed to ensure safety of AI decisions and discusses future challenges.
+
+
+
+ 43. 标题:Long-tail Augmented Graph Contrastive Learning for Recommendation
+ 编号:[129]
+ 链接:https://arxiv.org/abs/2309.11177
+ 作者:Qian Zhao, Zhengwei Wu, Zhiqiang Zhang, Jun Zhou
+ 备注:17 pages, 6 figures, accepted by ECML/PKDD 2023 (European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases)
+ 关键词:leverage high-order relationship, demonstrated promising results, effectively leverage high-order, Graph Convolutional Networks, Graph Convolutional
+
+ 点击查看摘要
+ Graph Convolutional Networks (GCNs) has demonstrated promising results for recommender systems, as they can effectively leverage high-order relationship. However, these methods usually encounter data sparsity issue in real-world scenarios. To address this issue, GCN-based recommendation methods employ contrastive learning to introduce self-supervised signals. Despite their effectiveness, these methods lack consideration of the significant degree disparity between head and tail nodes. This can lead to non-uniform representation distribution, which is a crucial factor for the performance of contrastive learning methods. To tackle the above issue, we propose a novel Long-tail Augmented Graph Contrastive Learning (LAGCL) method for recommendation. Specifically, we introduce a learnable long-tail augmentation approach to enhance tail nodes by supplementing predicted neighbor information, and generate contrastive views based on the resulting augmented graph. To make the data augmentation schema learnable, we design an auto drop module to generate pseudo-tail nodes from head nodes and a knowledge transfer module to reconstruct the head nodes from pseudo-tail nodes. Additionally, we employ generative adversarial networks to ensure that the distribution of the generated tail/head nodes matches that of the original tail/head nodes. Extensive experiments conducted on three benchmark datasets demonstrate the significant improvement in performance of our model over the state-of-the-arts. Further analyses demonstrate the uniformity of learned representations and the superiority of LAGCL on long-tail performance. Code is publicly available at this https URL
+
+
+
+ 44. 标题:Are Large Language Models Really Robust to Word-Level Perturbations?
+ 编号:[134]
+ 链接:https://arxiv.org/abs/2309.11166
+ 作者:Haoyu Wang, Guozheng Ma, Cong Yu, Ning Gui, Linrui Zhang, Zhiqi Huang, Suwei Ma, Yongzhe Chang, Sen Zhang, Li Shen, Xueqian Wang, Peilin Zhao, Dacheng Tao
+ 备注:
+ 关键词:Large Language Models, capabilities of Large, Large Language, downstream tasks, swift advancement
+
+ 点击查看摘要
+ The swift advancement in the scale and capabilities of Large Language Models (LLMs) positions them as promising tools for a variety of downstream tasks. In addition to the pursuit of better performance and the avoidance of violent feedback on a certain prompt, to ensure the responsibility of the LLM, much attention is drawn to the robustness of LLMs. However, existing evaluation methods mostly rely on traditional question answering datasets with predefined supervised labels, which do not align with the superior generation capabilities of contemporary LLMs. To address this issue, we propose a novel rational evaluation approach that leverages pre-trained reward models as diagnostic tools to evaluate the robustness of LLMs, which we refer to as the Reward Model for Reasonable Robustness Evaluation (TREvaL). Our extensive empirical experiments have demonstrated that TREval provides an accurate method for evaluating the robustness of an LLM, especially when faced with more challenging open questions. Furthermore, our results demonstrate that LLMs frequently exhibit vulnerability to word-level perturbations, which are commonplace in daily language usage. Notably, we were surprised to discover that robustness tends to decrease as fine-tuning (SFT and RLHF) is conducted. The code of TREval is available in this https URL.
+
+
+
+ 45. 标题:ProtoExplorer: Interpretable Forensic Analysis of Deepfake Videos using Prototype Exploration and Refinement
+ 编号:[140]
+ 链接:https://arxiv.org/abs/2309.11155
+ 作者:Merel de Leeuw den Bouter, Javier Lloret Pardo, Zeno Geradts, Marcel Worring
+ 备注:15 pages, 6 figures
+ 关键词:Machine Learning models, Machine Learning, high-stakes settings, humans are crucial, Visual Analytics
+
+ 点击查看摘要
+ In high-stakes settings, Machine Learning models that can provide predictions that are interpretable for humans are crucial. This is even more true with the advent of complex deep learning based models with a huge number of tunable parameters. Recently, prototype-based methods have emerged as a promising approach to make deep learning interpretable. We particularly focus on the analysis of deepfake videos in a forensics context. Although prototype-based methods have been introduced for the detection of deepfake videos, their use in real-world scenarios still presents major challenges, in that prototypes tend to be overly similar and interpretability varies between prototypes. This paper proposes a Visual Analytics process model for prototype learning, and, based on this, presents ProtoExplorer, a Visual Analytics system for the exploration and refinement of prototype-based deepfake detection models. ProtoExplorer offers tools for visualizing and temporally filtering prototype-based predictions when working with video data. It disentangles the complexity of working with spatio-temporal prototypes, facilitating their visualization. It further enables the refinement of models by interactively deleting and replacing prototypes with the aim to achieve more interpretable and less biased predictions while preserving detection accuracy. The system was designed with forensic experts and evaluated in a number of rounds based on both open-ended think aloud evaluation and interviews. These sessions have confirmed the strength of our prototype based exploration of deepfake videos while they provided the feedback needed to continuously improve the system.
+
+
+
+ 46. 标题:CoT-BERT: Enhancing Unsupervised Sentence Representation through Chain-of-Thought
+ 编号:[146]
+ 链接:https://arxiv.org/abs/2309.11143
+ 作者:Bowen Zhang, Kehua Chang, Chunping Li
+ 备注:
+ 关键词:fixed-length vectors enriched, intricate semantic information, representation learning aims, labeled data, aims to transform
+
+ 点击查看摘要
+ Unsupervised sentence representation learning aims to transform input sentences into fixed-length vectors enriched with intricate semantic information while obviating the reliance on labeled data. Recent progress within this field, propelled by contrastive learning and prompt engineering, has significantly bridged the gap between unsupervised and supervised strategies. Nonetheless, the potential utilization of Chain-of-Thought, remains largely untapped within this trajectory. To unlock latent capabilities within pre-trained models, such as BERT, we propose a two-stage approach for sentence representation: comprehension and summarization. Subsequently, the output of the latter phase is harnessed as the vectorized representation of the input sentence. For further performance enhancement, we meticulously refine both the contrastive learning loss function and the template denoising technique for prompt engineering. Rigorous experimentation substantiates our method, CoT-BERT, transcending a suite of robust baselines without necessitating other text representation models or external databases.
+
+
+
+ 47. 标题:Contrastive Pseudo Learning for Open-World DeepFake Attribution
+ 编号:[152]
+ 链接:https://arxiv.org/abs/2309.11132
+ 作者:Zhimin Sun, Shen Chen, Taiping Yao, Bangjie Yin, Ran Yi, Shouhong Ding, Lizhuang Ma
+ 备注:16 pages, 7 figures, ICCV 2023
+ 关键词:gained widespread attention, widespread attention due, challenge in sourcing, gained widespread, widespread attention
+
+ 点击查看摘要
+ The challenge in sourcing attribution for forgery faces has gained widespread attention due to the rapid development of generative techniques. While many recent works have taken essential steps on GAN-generated faces, more threatening attacks related to identity swapping or expression transferring are still overlooked. And the forgery traces hidden in unknown attacks from the open-world unlabeled faces still remain under-explored. To push the related frontier research, we introduce a new benchmark called Open-World DeepFake Attribution (OW-DFA), which aims to evaluate attribution performance against various types of fake faces under open-world scenarios. Meanwhile, we propose a novel framework named Contrastive Pseudo Learning (CPL) for the OW-DFA task through 1) introducing a Global-Local Voting module to guide the feature alignment of forged faces with different manipulated regions, 2) designing a Confidence-based Soft Pseudo-label strategy to mitigate the pseudo-noise caused by similar methods in unlabeled set. In addition, we extend the CPL framework with a multi-stage paradigm that leverages pre-train technique and iterative learning to further enhance traceability performance. Extensive experiments verify the superiority of our proposed method on the OW-DFA and also demonstrate the interpretability of deepfake attribution task and its impact on improving the security of deepfake detection area.
+
+
+
+ 48. 标题:AttentionMix: Data augmentation method that relies on BERT attention mechanism
+ 编号:[163]
+ 链接:https://arxiv.org/abs/2309.11104
+ 作者:Dominik Lewy, Jacek Mańdziuk
+ 备注:
+ 关键词:Computer Vision, Natural Language Processing, technique in Computer, perform image mixing, guided manner
+
+ 点击查看摘要
+ The Mixup method has proven to be a powerful data augmentation technique in Computer Vision, with many successors that perform image mixing in a guided manner. One of the interesting research directions is transferring the underlying Mixup idea to other domains, e.g. Natural Language Processing (NLP). Even though there already exist several methods that apply Mixup to textual data, there is still room for new, improved approaches. In this work, we introduce AttentionMix, a novel mixing method that relies on attention-based information. While the paper focuses on the BERT attention mechanism, the proposed approach can be applied to generally any attention-based model. AttentionMix is evaluated on 3 standard sentiment classification datasets and in all three cases outperforms two benchmark approaches that utilize Mixup mechanism, as well as the vanilla BERT method. The results confirm that the attention-based information can be effectively used for data augmentation in the NLP domain.
+
+
+
+ 49. 标题:A New Interpretable Neural Network-Based Rule Model for Healthcare Decision Making
+ 编号:[165]
+ 链接:https://arxiv.org/abs/2309.11101
+ 作者:Adrien Benamira, Tristan Guerand, Thomas Peyrin
+ 备注:This work was presented at IAIM23 in Singapore this https URL arXiv admin note: substantial text overlap with arXiv:2309.09638
+ 关键词:Truth Table rules, Truth Table, deep neural networks, learning models make, models make decisions
+
+ 点击查看摘要
+ In healthcare applications, understanding how machine/deep learning models make decisions is crucial. In this study, we introduce a neural network framework, $\textit{Truth Table rules}$ (TT-rules), that combines the global and exact interpretability properties of rule-based models with the high performance of deep neural networks. TT-rules is built upon $\textit{Truth Table nets}$ (TTnet), a family of deep neural networks initially developed for formal verification. By extracting the necessary and sufficient rules $\mathcal{R}$ from the trained TTnet model (global interpretability) to yield the same output as the TTnet (exact interpretability), TT-rules effectively transforms the neural network into a rule-based model. This rule-based model supports binary classification, multi-label classification, and regression tasks for small to large tabular datasets. After outlining the framework, we evaluate TT-rules' performance on healthcare applications and compare it to state-of-the-art rule-based methods. Our results demonstrate that TT-rules achieves equal or higher performance compared to other interpretable methods. Notably, TT-rules presents the first accurate rule-based model capable of fitting large tabular datasets, including two real-life DNA datasets with over 20K features.
+
+
+
+ 50. 标题:Practical Probabilistic Model-based Deep Reinforcement Learning by Integrating Dropout Uncertainty and Trajectory Sampling
+ 编号:[171]
+ 链接:https://arxiv.org/abs/2309.11089
+ 作者:Wenjun Huang, Yunduan Cui, Huiyun Li, Xinyu Wu
+ 备注:
+ 关键词:model-based reinforcement learning, current probabilistic model-based, probabilistic model-based reinforcement, reinforcement learning, paper addresses
+
+ 点击查看摘要
+ This paper addresses the prediction stability, prediction accuracy and control capability of the current probabilistic model-based reinforcement learning (MBRL) built on neural networks. A novel approach dropout-based probabilistic ensembles with trajectory sampling (DPETS) is proposed where the system uncertainty is stably predicted by combining the Monte-Carlo dropout and trajectory sampling in one framework. Its loss function is designed to correct the fitting error of neural networks for more accurate prediction of probabilistic models. The state propagation in its policy is extended to filter the aleatoric uncertainty for superior control capability. Evaluated by several Mujoco benchmark control tasks under additional disturbances and one practical robot arm manipulation task, DPETS outperforms related MBRL approaches in both average return and convergence velocity while achieving superior performance than well-known model-free baselines with significant sample efficiency. The open source code of DPETS is available at this https URL.
+
+
+
+ 51. 标题:Weak Supervision for Label Efficient Visual Bug Detection
+ 编号:[177]
+ 链接:https://arxiv.org/abs/2309.11077
+ 作者:Farrukh Rahman
+ 备注:Accepted to BMVC 2023: Workshop on Computer Vision for Games and Games for Computer Vision (CVG). 9 pages
+ 关键词:quality becomes essential, increasingly challenging, detailed worlds, bugs, video games evolve
+
+ 点击查看摘要
+ As video games evolve into expansive, detailed worlds, visual quality becomes essential, yet increasingly challenging. Traditional testing methods, limited by resources, face difficulties in addressing the plethora of potential bugs. Machine learning offers scalable solutions; however, heavy reliance on large labeled datasets remains a constraint. Addressing this challenge, we propose a novel method, utilizing unlabeled gameplay and domain-specific augmentations to generate datasets & self-supervised objectives used during pre-training or multi-task settings for downstream visual bug detection. Our methodology uses weak-supervision to scale datasets for the crafted objectives and facilitates both autonomous and interactive weak-supervision, incorporating unsupervised clustering and/or an interactive approach based on text and geometric prompts. We demonstrate on first-person player clipping/collision bugs (FPPC) within the expansive Giantmap game world, that our approach is very effective, improving over a strong supervised baseline in a practical, very low-prevalence, low data regime (0.336 $\rightarrow$ 0.550 F1 score). With just 5 labeled "good" exemplars (i.e., 0 bugs), our self-supervised objective alone captures enough signal to outperform the low-labeled supervised settings. Building on large-pretrained vision models, our approach is adaptable across various visual bugs. Our results suggest applicability in curating datasets for broader image and video tasks within video games beyond visual bugs.
+
+
+
+ 52. 标题:Dynamic Tiling: A Model-Agnostic, Adaptive, Scalable, and Inference-Data-Centric Approach for Efficient and Accurate Small Object Detection
+ 编号:[180]
+ 链接:https://arxiv.org/abs/2309.11069
+ 作者:Son The Nguyen, Theja Tulabandhula, Duy Nguyen
+ 备注:
+ 关键词:introduce Dynamic Tiling, Dynamic Tiling, Dynamic Tiling starts, Dynamic Tiling outperforms, Tiling
+
+ 点击查看摘要
+ We introduce Dynamic Tiling, a model-agnostic, adaptive, and scalable approach for small object detection, anchored in our inference-data-centric philosophy. Dynamic Tiling starts with non-overlapping tiles for initial detections and utilizes dynamic overlapping rates along with a tile minimizer. This dual approach effectively resolves fragmented objects, improves detection accuracy, and minimizes computational overhead by reducing the number of forward passes through the object detection model. Adaptable to a variety of operational environments, our method negates the need for laborious recalibration. Additionally, our large-small filtering mechanism boosts the detection quality across a range of object sizes. Overall, Dynamic Tiling outperforms existing model-agnostic uniform cropping methods, setting new benchmarks for efficiency and accuracy.
+
+
+
+ 53. 标题:Exploring the Relationship between LLM Hallucinations and Prompt Linguistic Nuances: Readability, Formality, and Concreteness
+ 编号:[182]
+ 链接:https://arxiv.org/abs/2309.11064
+ 作者:Vipula Rawte, Prachi Priya, S.M Towhidul Islam Tonmoy, S M Mehedi Zaman, Amit Sheth, Amitava Das
+ 备注:
+ 关键词:Large Language Models, Language Models, Large Language, LLM hallucination, prominent issues
+
+ 点击查看摘要
+ As Large Language Models (LLMs) have advanced, they have brought forth new challenges, with one of the prominent issues being LLM hallucination. While various mitigation techniques are emerging to address hallucination, it is equally crucial to delve into its underlying causes. Consequently, in this preliminary exploratory investigation, we examine how linguistic factors in prompts, specifically readability, formality, and concreteness, influence the occurrence of hallucinations. Our experimental results suggest that prompts characterized by greater formality and concreteness tend to result in reduced hallucination. However, the outcomes pertaining to readability are somewhat inconclusive, showing a mixed pattern.
+
+
+
+ 54. 标题:Design of Chain-of-Thought in Math Problem Solving
+ 编号:[187]
+ 链接:https://arxiv.org/abs/2309.11054
+ 作者:Zhanming Jie, Trung Quoc Luong, Xinbo Zhang, Xiaoran Jin, Hang Li
+ 备注:15 pages
+ 关键词:math problem solving, plays a crucial, program, crucial role, role in reasoning
+
+ 点击查看摘要
+ Chain-of-Thought (CoT) plays a crucial role in reasoning for math problem solving. We conduct a comprehensive examination of methods for designing CoT, comparing conventional natural language CoT with various program CoTs, including the self-describing program, the comment-describing program, and the non-describing program. Furthermore, we investigate the impact of programming language on program CoTs, comparing Python and Wolfram Language. Through extensive experiments on GSM8K, MATHQA, and SVAMP, we find that program CoTs often have superior effectiveness in math problem solving. Notably, the best performing combination with 30B parameters beats GPT-3.5-turbo by a significant margin. The results show that self-describing program offers greater diversity and thus can generally achieve higher performance. We also find that Python is a better choice of language than Wolfram for program CoTs. The experimental results provide a valuable guideline for future CoT designs that take into account both programming language and coding style for further advancements. Our datasets and code are publicly available.
+
+
+
+ 55. 标题:Clustered FedStack: Intermediate Global Models with Bayesian Information Criterion
+ 编号:[193]
+ 链接:https://arxiv.org/abs/2309.11044
+ 作者:Thanveer Shaik, Xiaohui Tao, Lin Li, Niall Higgins, Raj Gururajan, Xujuan Zhou, Jianming Yong
+ 备注:This work has been submitted to the ELSEVIER for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible
+ 关键词:Artificial Intelligence, field of Artificial, preserve client privacy, popular technologies, ability to preserve
+
+ 点击查看摘要
+ Federated Learning (FL) is currently one of the most popular technologies in the field of Artificial Intelligence (AI) due to its collaborative learning and ability to preserve client privacy. However, it faces challenges such as non-identically and non-independently distributed (non-IID) and data with imbalanced labels among local clients. To address these limitations, the research community has explored various approaches such as using local model parameters, federated generative adversarial learning, and federated representation learning. In our study, we propose a novel Clustered FedStack framework based on the previously published Stacked Federated Learning (FedStack) framework. The local clients send their model predictions and output layer weights to a server, which then builds a robust global model. This global model clusters the local clients based on their output layer weights using a clustering mechanism. We adopt three clustering mechanisms, namely K-Means, Agglomerative, and Gaussian Mixture Models, into the framework and evaluate their performance. We use Bayesian Information Criterion (BIC) with the maximum likelihood function to determine the number of clusters. The Clustered FedStack models outperform baseline models with clustering mechanisms. To estimate the convergence of our proposed framework, we use Cyclical learning rates.
+
+
+
+ 56. 标题:Making Small Language Models Better Multi-task Learners with Mixture-of-Task-Adapters
+ 编号:[195]
+ 链接:https://arxiv.org/abs/2309.11042
+ 作者:Yukang Xie, Chengyu Wang, Junbing Yan, Jiyong Zhou, Feiqi Deng, Jun Huang
+ 备注:
+ 关键词:Natural Language Processing, achieved amazing zero-shot, amazing zero-shot learning, variety of Natural, text generative tasks
+
+ 点击查看摘要
+ Recently, Large Language Models (LLMs) have achieved amazing zero-shot learning performance over a variety of Natural Language Processing (NLP) tasks, especially for text generative tasks. Yet, the large size of LLMs often leads to the high computational cost of model training and online deployment. In our work, we present ALTER, a system that effectively builds the multi-tAsk Learners with mixTure-of-task-adaptERs upon small language models (with <1B parameters) to address multiple nlp tasks simultaneously, capturing the commonalities and differences between tasks, in order support domain-specific applications. specifically, alter, we propose mixture-of-task-adapters (mta) module as an extension transformer architecture for underlying model capture intra-task inter-task knowledge. a two-stage training method is further proposed optimize collaboration adapters at small computational cost. experimental results over mixture of show that our mta achieve good performance. based on have also produced mta-equipped language models various domains.< p>
+
+
+
+ 57. 标题:Federated Learning in Intelligent Transportation Systems: Recent Applications and Open Problems
+ 编号:[197]
+ 链接:https://arxiv.org/abs/2309.11039
+ 作者:Shiying Zhang, Jun Li, Long Shi, Ming Ding, Dinh C. Nguyen, Wuzheng Tan, Jian Weng, Zhu Han
+ 备注:
+ 关键词:Intelligent transportation systems, Internet of Things, Intelligent transportation, transportation systems, Things
+
+ 点击查看摘要
+ Intelligent transportation systems (ITSs) have been fueled by the rapid development of communication technologies, sensor technologies, and the Internet of Things (IoT). Nonetheless, due to the dynamic characteristics of the vehicle networks, it is rather challenging to make timely and accurate decisions of vehicle behaviors. Moreover, in the presence of mobile wireless communications, the privacy and security of vehicle information are at constant risk. In this context, a new paradigm is urgently needed for various applications in dynamic vehicle environments. As a distributed machine learning technology, federated learning (FL) has received extensive attention due to its outstanding privacy protection properties and easy scalability. We conduct a comprehensive survey of the latest developments in FL for ITS. Specifically, we initially research the prevalent challenges in ITS and elucidate the motivations for applying FL from various perspectives. Subsequently, we review existing deployments of FL in ITS across various scenarios, and discuss specific potential issues in object recognition, traffic management, and service providing scenarios. Furthermore, we conduct a further analysis of the new challenges introduced by FL deployment and the inherent limitations that FL alone cannot fully address, including uneven data distribution, limited storage and computing power, and potential privacy and security concerns. We then examine the existing collaborative technologies that can help mitigate these challenges. Lastly, we discuss the open challenges that remain to be addressed in applying FL in ITS and propose several future research directions.
+
+
+
+ 58. 标题:ModelGiF: Gradient Fields for Model Functional Distance
+ 编号:[211]
+ 链接:https://arxiv.org/abs/2309.11013
+ 作者:Jie Song, Zhengqi Xu, Sai Wu, Gang Chen, Mingli Song
+ 备注:ICCV 2023
+ 关键词:publicly released trained, model functional distance, released trained models, Model Gradient Field, functional distance
+
+ 点击查看摘要
+ The last decade has witnessed the success of deep learning and the surge of publicly released trained models, which necessitates the quantification of the model functional distance for various purposes. However, quantifying the model functional distance is always challenging due to the opacity in inner workings and the heterogeneity in architectures or tasks. Inspired by the concept of "field" in physics, in this work we introduce Model Gradient Field (abbr. ModelGiF) to extract homogeneous representations from the heterogeneous pre-trained models. Our main assumption underlying ModelGiF is that each pre-trained deep model uniquely determines a ModelGiF over the input space. The distance between models can thus be measured by the similarity between their ModelGiFs. We validate the effectiveness of the proposed ModelGiF with a suite of testbeds, including task relatedness estimation, intellectual property protection, and model unlearning verification. Experimental results demonstrate the versatility of the proposed ModelGiF on these tasks, with significantly superiority performance to state-of-the-art competitors. Codes are available at this https URL.
+
+
+
+ 59. 标题:Spiking NeRF: Making Bio-inspired Neural Networks See through the Real World
+ 编号:[225]
+ 链接:https://arxiv.org/abs/2309.10987
+ 作者:Xingting Yao, Qinghao Hu, Tielong Liu, Zitao Mo, Zeyu Zhu, Zhengyang Zhuge, Jian Cheng
+ 备注:
+ 关键词:biologically plausible intelligence, Neural Radiance Fields, Spiking neuron networks, promising energy efficiency, Radiance Fields
+
+ 点击查看摘要
+ Spiking neuron networks (SNNs) have been thriving on numerous tasks to leverage their promising energy efficiency and exploit their potentialities as biologically plausible intelligence. Meanwhile, the Neural Radiance Fields (NeRF) render high-quality 3D scenes with massive energy consumption, and few works delve into the energy-saving solution with a bio-inspired approach. In this paper, we propose spiking NeRF (SpikingNeRF), which aligns the radiance ray with the temporal dimension of SNN, to naturally accommodate the SNN to the reconstruction of Radiance Fields. Thus, the computation turns into a spike-based, multiplication-free manner, reducing the energy consumption. In SpikingNeRF, each sampled point on the ray is matched onto a particular time step, and represented in a hybrid manner where the voxel grids are maintained as well. Based on the voxel grids, sampled points are determined whether to be masked for better training and inference. However, this operation also incurs irregular temporal length. We propose the temporal condensing-and-padding (TCP) strategy to tackle the masked samples to maintain regular temporal length, i.e., regular tensors, for hardware-friendly computation. Extensive experiments on a variety of datasets demonstrate that our method reduces the $76.74\%$ energy consumption on average and obtains comparable synthesis quality with the ANN baseline.
+
+
+
+ 60. 标题:Is GPT4 a Good Trader?
+ 编号:[227]
+ 链接:https://arxiv.org/abs/2309.10982
+ 作者:Bingzhe Wu
+ 备注:
+ 关键词:large language models, demonstrated significant capabilities, large language, language models, reasoning tasks
+
+ 点击查看摘要
+ Recently, large language models (LLMs), particularly GPT-4, have demonstrated significant capabilities in various planning and reasoning tasks \cite{cheng2023gpt4,bubeck2023sparks}. Motivated by these advancements, there has been a surge of interest among researchers to harness the capabilities of GPT-4 for the automated design of quantitative factors that do not overlap with existing factor libraries, with an aspiration to achieve alpha returns \cite{webpagequant}. In contrast to these work, this study aims to examine the fidelity of GPT-4's comprehension of classic trading theories and its proficiency in applying its code interpreter abilities to real-world trading data analysis. Such an exploration is instrumental in discerning whether the underlying logic GPT-4 employs for trading is intrinsically reliable. Furthermore, given the acknowledged interpretative latitude inherent in most trading theories, we seek to distill more precise methodologies of deploying these theories from GPT-4's analytical process, potentially offering invaluable insights to human traders.
+To achieve this objective, we selected daily candlestick (K-line) data from specific periods for certain assets, such as the Shanghai Stock Index. Through meticulous prompt engineering, we guided GPT-4 to analyze the technical structures embedded within this data, based on specific theories like the Elliott Wave Theory. We then subjected its analytical output to manual evaluation, assessing its interpretative depth and accuracy vis-à-vis these trading theories from multiple dimensions. The results and findings from this study could pave the way for a synergistic amalgamation of human expertise and AI-driven insights in the realm of trading.
+
+
+
+ 61. 标题:AI-Driven Patient Monitoring with Multi-Agent Deep Reinforcement Learning
+ 编号:[229]
+ 链接:https://arxiv.org/abs/2309.10980
+ 作者:Thanveer Shaik, Xiaohui Tao, Haoran Xie, Lin Li, Jianming Yong, Hong-Ning Dai
+ 备注:arXiv admin note: text overlap with arXiv:2309.10576
+ 关键词:improved healthcare outcomes, timely interventions, interventions and improved, monitoring, Effective patient monitoring
+
+ 点击查看摘要
+ Effective patient monitoring is vital for timely interventions and improved healthcare outcomes. Traditional monitoring systems often struggle to handle complex, dynamic environments with fluctuating vital signs, leading to delays in identifying critical conditions. To address this challenge, we propose a novel AI-driven patient monitoring framework using multi-agent deep reinforcement learning (DRL). Our approach deploys multiple learning agents, each dedicated to monitoring a specific physiological feature, such as heart rate, respiration, and temperature. These agents interact with a generic healthcare monitoring environment, learn the patients' behavior patterns, and make informed decisions to alert the corresponding Medical Emergency Teams (METs) based on the level of emergency estimated. In this study, we evaluate the performance of the proposed multi-agent DRL framework using real-world physiological and motion data from two datasets: PPG-DaLiA and WESAD. We compare the results with several baseline models, including Q-Learning, PPO, Actor-Critic, Double DQN, and DDPG, as well as monitoring frameworks like WISEML and CA-MAQL. Our experiments demonstrate that the proposed DRL approach outperforms all other baseline models, achieving more accurate monitoring of patient's vital signs. Furthermore, we conduct hyperparameter optimization to fine-tune the learning process of each agent. By optimizing hyperparameters, we enhance the learning rate and discount factor, thereby improving the agents' overall performance in monitoring patient health status. Our AI-driven patient monitoring system offers several advantages over traditional methods, including the ability to handle complex and uncertain environments, adapt to varying patient conditions, and make real-time decisions without external supervision.
+
+
+
+ 62. 标题:LMDX: Language Model-based Document Information Extraction and Localization
+ 编号:[239]
+ 链接:https://arxiv.org/abs/2309.10952
+ 作者:Vincent Perot, Kai Kang, Florian Luisier, Guolong Su, Xiaoyu Sun, Ramya Sree Boppana, Zilong Wang, Jiaqi Mu, Hao Zhang, Nan Hua
+ 备注:
+ 关键词:Large Language Models, Natural Language Processing, revolutionized Natural Language, exhibiting emergent capabilities, document information extraction
+
+ 点击查看摘要
+ Large Language Models (LLM) have revolutionized Natural Language Processing (NLP), improving state-of-the-art on many existing tasks and exhibiting emergent capabilities. However, LLMs have not yet been successfully applied on semi-structured document information extraction, which is at the core of many document processing workflows and consists of extracting key entities from a visually rich document (VRD) given a predefined target schema. The main obstacles to LLM adoption in that task have been the absence of layout encoding within LLMs, critical for a high quality extraction, and the lack of a grounding mechanism ensuring the answer is not hallucinated. In this paper, we introduce Language Model-based Document Information Extraction and Localization (LMDX), a methodology to adapt arbitrary LLMs for document information extraction. LMDX can do extraction of singular, repeated, and hierarchical entities, both with and without training data, while providing grounding guarantees and localizing the entities within the document. In particular, we apply LMDX to the PaLM 2-S LLM and evaluate it on VRDU and CORD benchmarks, setting a new state-of-the-art and showing how LMDX enables the creation of high quality, data-efficient parsers.
+
+
+
+ 63. 标题:Benchmarks for Pirá 2.0, a Reading Comprehension Dataset about the Ocean, the Brazilian Coast, and Climate Change
+ 编号:[242]
+ 链接:https://arxiv.org/abs/2309.10945
+ 作者:Paulo Pirozelli, Marcos M. José, Igor Silveira, Flávio Nakasato, Sarajane M. Peres, Anarosa A. F. Brandão, Anna H. R. Costa, Fabio G. Cozman
+ 备注:Accepted at Data Intelligence. Online ISSN 2641-435X
+ 关键词:Brazilian coast, climate change, abstracts and reports, question answering, Pirá
+
+ 点击查看摘要
+ Pirá is a reading comprehension dataset focused on the ocean, the Brazilian coast, and climate change, built from a collection of scientific abstracts and reports on these topics. This dataset represents a versatile language resource, particularly useful for testing the ability of current machine learning models to acquire expert scientific knowledge. Despite its potential, a detailed set of baselines has not yet been developed for Pirá. By creating these baselines, researchers can more easily utilize Pirá as a resource for testing machine learning models across a wide range of question answering tasks. In this paper, we define six benchmarks over the Pirá dataset, covering closed generative question answering, machine reading comprehension, information retrieval, open question answering, answer triggering, and multiple choice question answering. As part of this effort, we have also produced a curated version of the original dataset, where we fixed a number of grammar issues, repetitions, and other shortcomings. Furthermore, the dataset has been extended in several new directions, so as to face the aforementioned benchmarks: translation of supporting texts from English into Portuguese, classification labels for answerability, automatic paraphrases of questions and answers, and multiple choice candidates. The results described in this paper provide several points of reference for researchers interested in exploring the challenges provided by the Pirá dataset.
+
+
+
+ 64. 标题:Amplifying Pathological Detection in EEG Signaling Pathways through Cross-Dataset Transfer Learning
+ 编号:[258]
+ 链接:https://arxiv.org/abs/2309.10910
+ 作者:Mohammad-Javad Darvishi-Bayazi, Mohammad Sajjad Ghaemi, Timothee Lesort, Md Rifat Arefin, Jocelyn Faubert, Irina Rish
+ 备注:
+ 关键词:understanding neurological disorders, decoding brain activity, brain activity holds, activity holds immense, holds immense importance
+
+ 点击查看摘要
+ Pathology diagnosis based on EEG signals and decoding brain activity holds immense importance in understanding neurological disorders. With the advancement of artificial intelligence methods and machine learning techniques, the potential for accurate data-driven diagnoses and effective treatments has grown significantly. However, applying machine learning algorithms to real-world datasets presents diverse challenges at multiple levels. The scarcity of labelled data, especially in low regime scenarios with limited availability of real patient cohorts due to high costs of recruitment, underscores the vital deployment of scaling and transfer learning techniques. In this study, we explore a real-world pathology classification task to highlight the effectiveness of data and model scaling and cross-dataset knowledge transfer. As such, we observe varying performance improvements through data scaling, indicating the need for careful evaluation and labelling. Additionally, we identify the challenges of possible negative transfer and emphasize the significance of some key components to overcome distribution shifts and potential spurious correlations and achieve positive transfer. We see improvement in the performance of the target model on the target (NMT) datasets by using the knowledge from the source dataset (TUAB) when a low amount of labelled data was available. Our findings indicate a small and generic model (e.g. ShallowNet) performs well on a single dataset, however, a larger model (e.g. TCN) performs better on transfer and learning from a larger and diverse dataset.
+
+
+
+ 65. 标题:Multicopy Reinforcement Learning Agents
+ 编号:[260]
+ 链接:https://arxiv.org/abs/2309.10908
+ 作者:Alicia P. Wolfe, Oliver Diamond, Remi Feuerman, Magdalena Kisielinska, Brigitte Goeler-Slough, Victoria Manfredi
+ 备注:
+ 关键词:makes multiple identical, agent makes multiple, multiple identical copies, single agent task, single agent copy
+
+ 点击查看摘要
+ This paper examines a novel type of multi-agent problem, in which an agent makes multiple identical copies of itself in order to achieve a single agent task better or more efficiently. This strategy improves performance if the environment is noisy and the task is sometimes unachievable by a single agent copy. We propose a learning algorithm for this multicopy problem which takes advantage of the structure of the value function to efficiently learn how to balance the advantages and costs of adding additional copies.
+
+
+
+ 66. 标题:Artificial Intelligence-Enabled Intelligent Assistant for Personalized and Adaptive Learning in Higher Education
+ 编号:[269]
+ 链接:https://arxiv.org/abs/2309.10892
+ 作者:Ramteja Sajja, Yusuf Sermet, Muhammed Cikmaz, David Cwiertny, Ibrahim Demir
+ 备注:29 pages, 10 figures, 9659 words
+ 关键词:Artificial Intelligence-Enabled Intelligent, Natural Language Processing, Artificial Intelligence-Enabled, Intelligence-Enabled Intelligent Assistant, AIIA system leverages
+
+ 点击查看摘要
+ This paper presents a novel framework, Artificial Intelligence-Enabled Intelligent Assistant (AIIA), for personalized and adaptive learning in higher education. The AIIA system leverages advanced AI and Natural Language Processing (NLP) techniques to create an interactive and engaging learning platform. This platform is engineered to reduce cognitive load on learners by providing easy access to information, facilitating knowledge assessment, and delivering personalized learning support tailored to individual needs and learning styles. The AIIA's capabilities include understanding and responding to student inquiries, generating quizzes and flashcards, and offering personalized learning pathways. The research findings have the potential to significantly impact the design, implementation, and evaluation of AI-enabled Virtual Teaching Assistants (VTAs) in higher education, informing the development of innovative educational tools that can enhance student learning outcomes, engagement, and satisfaction. The paper presents the methodology, system architecture, intelligent services, and integration with Learning Management Systems (LMSs) while discussing the challenges, limitations, and future directions for the development of AI-enabled intelligent assistants in education.
+
+
+
+ 67. 标题:Self-Augmentation Improves Zero-Shot Cross-Lingual Transfer
+ 编号:[270]
+ 链接:https://arxiv.org/abs/2309.10891
+ 作者:Fei Wang, Kuan-Hao Huang, Kai-Wei Chang, Muhao Chen
+ 备注:AACL 2023
+ 关键词:sufficient training resources, allowing models trained, multilingual NLP, Zero-shot cross-lingual transfer, sufficient training
+
+ 点击查看摘要
+ Zero-shot cross-lingual transfer is a central task in multilingual NLP, allowing models trained in languages with more sufficient training resources to generalize to other low-resource languages. Earlier efforts on this task use parallel corpora, bilingual dictionaries, or other annotated alignment data to improve cross-lingual transferability, which are typically expensive to obtain. In this paper, we propose a simple yet effective method, SALT, to improve the zero-shot cross-lingual transfer of the multilingual pretrained language models without the help of such external data. By incorporating code-switching and embedding mixup with self-augmentation, SALT effectively distills cross-lingual knowledge from the multilingual PLM and enhances its transferability on downstream tasks. Experimental results on XNLI and PAWS-X show that our method is able to improve zero-shot cross-lingual transferability without external data. Our code is available at this https URL.
+
+
+
+ 68. 标题:Classifying Organizations for Food System Ontologies using Natural Language Processing
+ 编号:[276]
+ 链接:https://arxiv.org/abs/2309.10880
+ 作者:Tianyu Jiang, Sonia Vinogradova, Nathan Stringham, E. Louise Earl, Allan D. Hollander, Patrick R. Huber, Ellen Riloff, R. Sandra Schillo, Giorgio A. Ubbiali, Matthew Lange
+ 备注:Presented at IFOW 2023 Integrated Food Ontology Workshop at the Formal Ontology in Information Systems Conference (FOIS) 2023 in Sherbrooke, Quebec, Canada July 17-20th, 2023
+ 关键词:natural language processing, NLP models, automatically classify entities, food system ontologies, Standard Industrial Classification
+
+ 点击查看摘要
+ Our research explores the use of natural language processing (NLP) methods to automatically classify entities for the purpose of knowledge graph population and integration with food system ontologies. We have created NLP models that can automatically classify organizations with respect to categories associated with environmental issues as well as Standard Industrial Classification (SIC) codes, which are used by the U.S. government to characterize business activities. As input, the NLP models are provided with text snippets retrieved by the Google search engine for each organization, which serves as a textual description of the organization that is used for learning. Our experimental results show that NLP models can achieve reasonably good performance for these two classification tasks, and they rely on a general framework that could be applied to many other classification problems as well. We believe that NLP models represent a promising approach for automatically harvesting information to populate knowledge graphs and aligning the information with existing ontologies through shared categories and concepts.
+
+
+
+ 69. 标题:Believable Minecraft Settlements by Means of Decentralised Iterative Planning
+ 编号:[279]
+ 链接:https://arxiv.org/abs/2309.10871
+ 作者:Arthur van der Staaij, Jelmer Prins, Vincent L. Prins, Julian Poelsma, Thera Smit, Matthias Müller-Brockhausen, Mike Preuss
+ 备注:8 pages, 8 figures, to be published in "2023 IEEE Conference on Games (CoG)"
+ 关键词:Procedural city generation, Generative Settlement Design, Procedural Content Generation, Procedural city, focuses on believability
+
+ 点击查看摘要
+ Procedural city generation that focuses on believability and adaptability to random terrain is a difficult challenge in the field of Procedural Content Generation (PCG). Dozens of researchers compete for a realistic approach in challenges such as the Generative Settlement Design in Minecraft (GDMC), in which our method has won the 2022 competition. This was achieved through a decentralised, iterative planning process that is transferable to similar generation processes that aims to produce "organic" content procedurally.
+
+
+
+ 70. 标题:Using AI Uncertainty Quantification to Improve Human Decision-Making
+ 编号:[282]
+ 链接:https://arxiv.org/abs/2309.10852
+ 作者:Laura R. Marusich, Jonathan Z. Bakdash, Yan Zhou, Murat Kantarcioglu
+ 备注:10 pages and 7 figures
+ 关键词:Uncertainty Quantification, improve human decision-making, potential to improve, additional useful probabilistic, human decision-making
+
+ 点击查看摘要
+ AI Uncertainty Quantification (UQ) has the potential to improve human decision-making beyond AI predictions alone by providing additional useful probabilistic information to users. The majority of past research on AI and human decision-making has concentrated on model explainability and interpretability. We implemented instance-based UQ for three real datasets. To achieve this, we trained different AI models for classification for each dataset, and used random samples generated around the neighborhood of the given instance to create confidence intervals for UQ. The computed UQ was calibrated using a strictly proper scoring rule as a form of quality assurance for UQ. We then conducted two preregistered online behavioral experiments that compared objective human decision-making performance under different AI information conditions, including UQ. In Experiment 1, we compared decision-making for no AI (control), AI prediction alone, and AI prediction with a visualization of UQ. We found UQ significantly improved decision-making beyond the other two conditions. In Experiment 2, we focused on comparing different representations of UQ information: Point vs. distribution of uncertainty and visualization type (needle vs. dotplot). We did not find meaningful differences in decision-making performance among these different representations of UQ. Overall, our results indicate that human decision-making can be improved by providing UQ information along with AI predictions, and that this benefit generalizes across a variety of representations of UQ.
+
+
+
+ 71. 标题:Language-Oriented Communication with Semantic Coding and Knowledge Distillation for Text-to-Image Generation
+ 编号:[303]
+ 链接:https://arxiv.org/abs/2309.11127
+ 作者:Hyelin Nam, Jihong Park, Jinho Choi, Mehdi Bennis, Seong-Lyun Kim
+ 备注:5 pages, 4 figures, submitted to 2024 IEEE International Conference on Acoustics, Speech and Signal Processing
+ 关键词:integrating recent advances, large language models, generative models, integrating recent, recent advances
+
+ 点击查看摘要
+ By integrating recent advances in large language models (LLMs) and generative models into the emerging semantic communication (SC) paradigm, in this article we put forward to a novel framework of language-oriented semantic communication (LSC). In LSC, machines communicate using human language messages that can be interpreted and manipulated via natural language processing (NLP) techniques for SC efficiency. To demonstrate LSC's potential, we introduce three innovative algorithms: 1) semantic source coding (SSC) which compresses a text prompt into its key head words capturing the prompt's syntactic essence while maintaining their appearance order to keep the prompt's context; 2) semantic channel coding (SCC) that improves robustness against errors by substituting head words with their lenghthier synonyms; and 3) semantic knowledge distillation (SKD) that produces listener-customized prompts via in-context learning the listener's language style. In a communication task for progressive text-to-image generation, the proposed methods achieve higher perceptual similarities with fewer transmissions while enhancing robustness in noisy communication channels.
+
+
+
+ 72. 标题:Embed-Search-Align: DNA Sequence Alignment using Transformer Models
+ 编号:[306]
+ 链接:https://arxiv.org/abs/2309.11087
+ 作者:Pavan Holur, K. C. Enevoldsen, Lajoyce Mboning, Thalia Georgiou, Louis-S. Bouchard, Matteo Pellegrini, Vwani Roychowdhury
+ 备注:17 pages, Tables 5, Figures 5, Under review, ICLR
+ 关键词:involves assigning short, assigning short DNA, alignment involves assigning, DNA, involves assigning
+
+ 点击查看摘要
+ DNA sequence alignment involves assigning short DNA reads to the most probable locations on an extensive reference genome. This process is crucial for various genomic analyses, including variant calling, transcriptomics, and epigenomics. Conventional methods, refined over decades, tackle this challenge in two steps: genome indexing followed by efficient search to locate likely positions for given reads. Building on the success of Large Language Models (LLM) in encoding text into embeddings, where the distance metric captures semantic similarity, recent efforts have explored whether the same Transformer architecture can produce numerical representations for DNA sequences. Such models have shown early promise in tasks involving classification of short DNA sequences, such as the detection of coding vs non-coding regions, as well as the identification of enhancer and promoter sequences. Performance at sequence classification tasks does not, however, translate to sequence alignment, where it is necessary to conduct a genome-wide search to successfully align every read. We address this open problem by framing it as an Embed-Search-Align task. In this framework, a novel encoder model DNA-ESA generates representations of reads and fragments of the reference, which are projected into a shared vector space where the read-fragment distance is used as surrogate for alignment. In particular, DNA-ESA introduces: (1) Contrastive loss for self-supervised training of DNA sequence representations, facilitating rich sequence-level embeddings, and (2) a DNA vector store to enable search across fragments on a global scale. DNA-ESA is >97% accurate when aligning 250-length reads onto a human reference genome of 3 gigabases (single-haploid), far exceeds the performance of 6 recent DNA-Transformer model baselines and shows task transfer across chromosomes and species.
+
+
+
+ 73. 标题:End-to-End Speech Recognition Contextualization with Large Language Models
+ 编号:[319]
+ 链接:https://arxiv.org/abs/2309.10917
+ 作者:Egor Lakomkin, Chunyang Wu, Yassir Fathullah, Ozlem Kalinli, Michael L. Seltzer, Christian Fuegen
+ 备注:
+ 关键词:Large Language Models, research community due, Large Language, garnered significant attention, models incorporating LLMs
+
+ 点击查看摘要
+ In recent years, Large Language Models (LLMs) have garnered significant attention from the research community due to their exceptional performance and generalization capabilities. In this paper, we introduce a novel method for contextualizing speech recognition models incorporating LLMs. Our approach casts speech recognition as a mixed-modal language modeling task based on a pretrained LLM. We provide audio features, along with optional text tokens for context, to train the system to complete transcriptions in a decoder-only fashion. As a result, the system is implicitly incentivized to learn how to leverage unstructured contextual information during training. Our empirical results demonstrate a significant improvement in performance, with a 6% WER reduction when additional textual context is provided. Moreover, we find that our method performs competitively and improve by 7.5% WER overall and 17% WER on rare words against a baseline contextualized RNN-T system that has been trained on more than twenty five times larger speech dataset. Overall, we demonstrate that by only adding a handful number of trainable parameters via adapters, we can unlock contextualized speech recognition capability for the pretrained LLM while keeping the same text-only input functionality.
+
+
+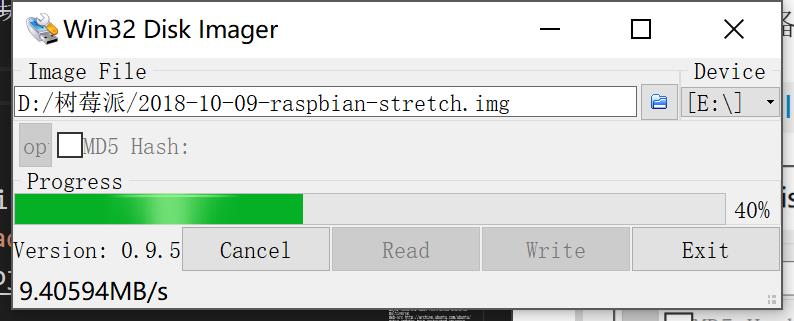





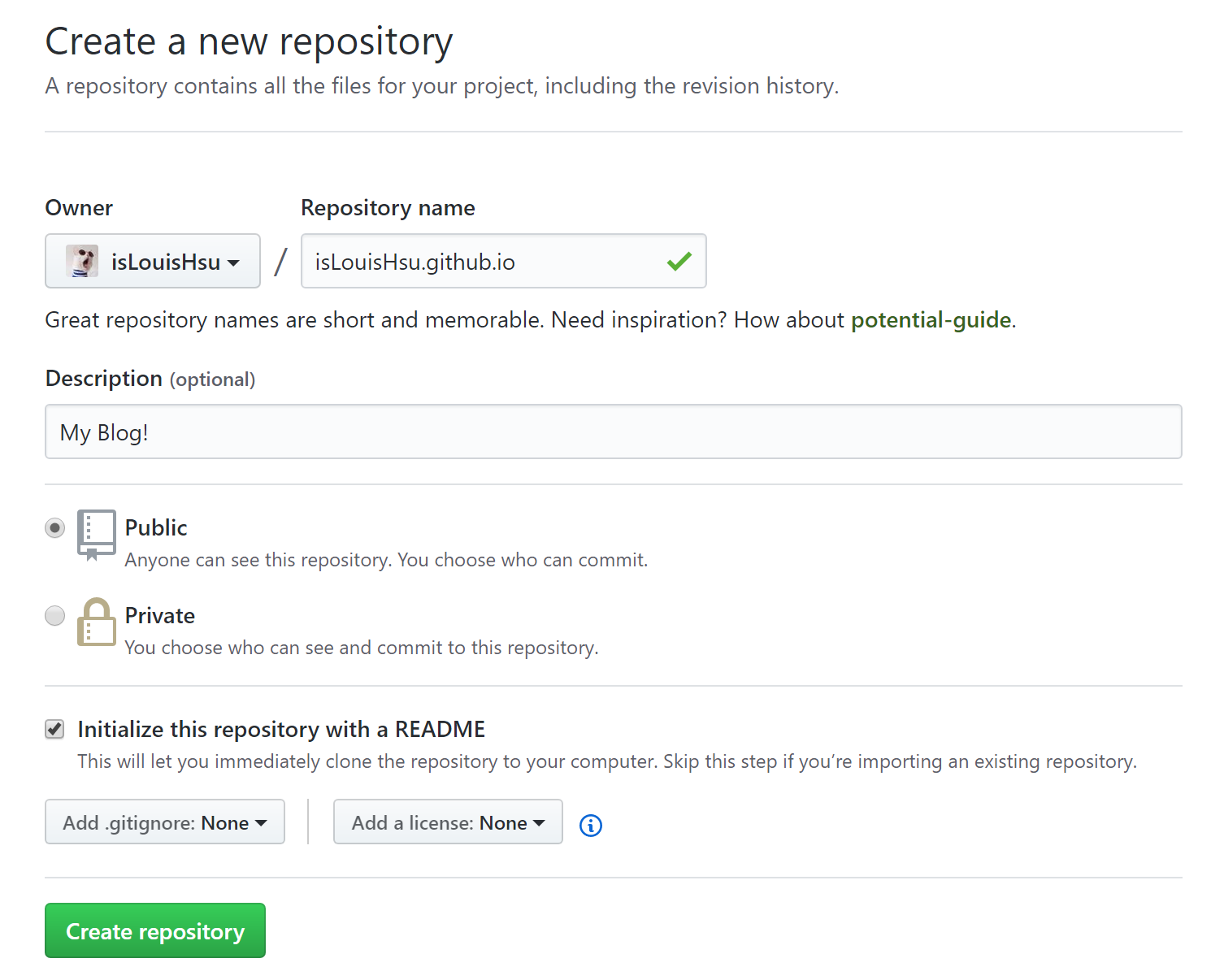
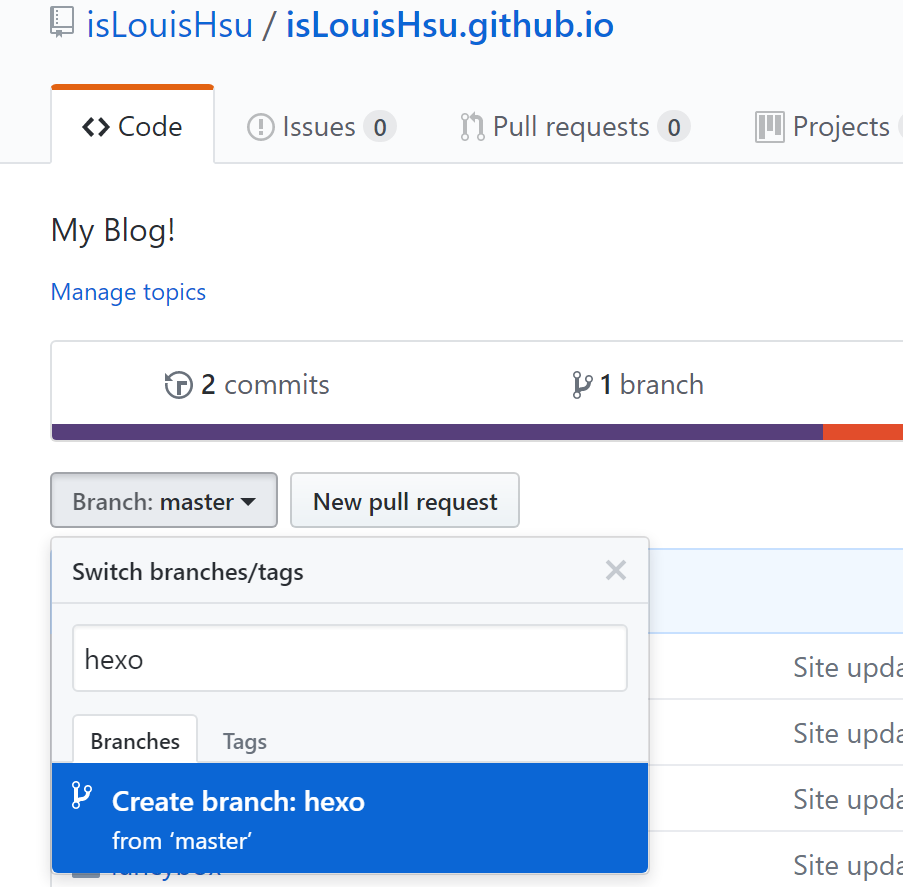
/Fig1_pretrain_finetune.png)
/Fig2_eda1.png)
/Fig2_eda2.png)
/Fig2_eda3.png)
/Fig3_reweight.png)
/Fig5_model1.png)
/Fig5_attention_mask.png)
/Fig4_wwm.png)
/Fig5_model2.png)
/Fig5_model3.png)
/Fig7_ensemble1.png)
/Fig6_res1.png)
/Fig6_res2.png)


%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_text_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_entity_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/model.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/dont_stop_pretraining.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/a.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/b.png)

%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/lengths_histplot.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_entity_lengths.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_label_dist.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/%E6%80%BB%E4%BD%93%E6%96%B9%E6%A1%88.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/pretrain_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/finetune_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/rdrop.png)









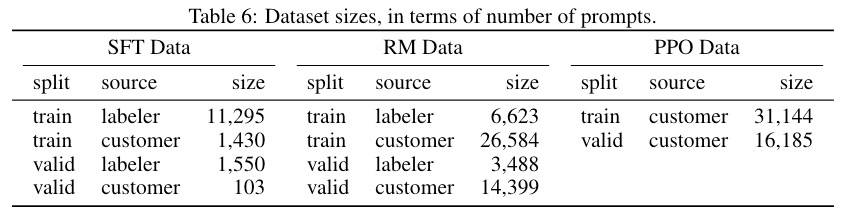
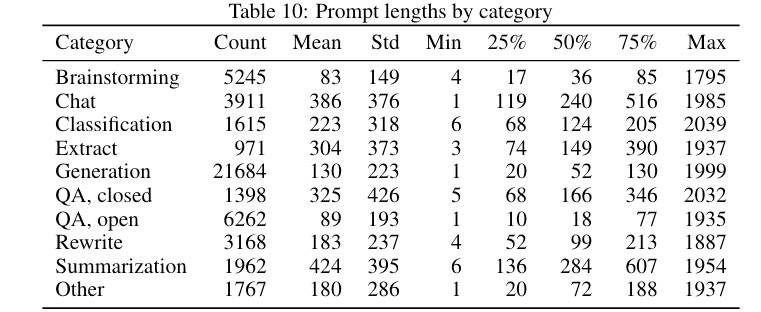
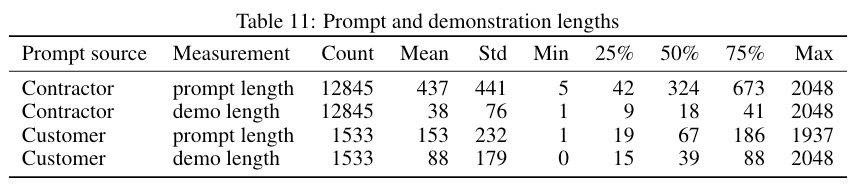

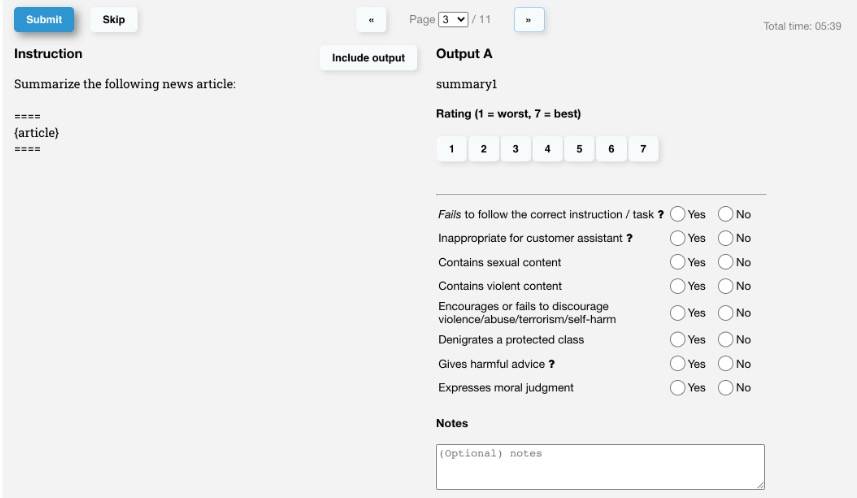
/autoencoder-architecture.png)
/variational-autoencoder-architecture.png)
/forward_vs_reversed_KL.png)
/vae-implement.png)
/reparam.png)
/generated_samples.png)
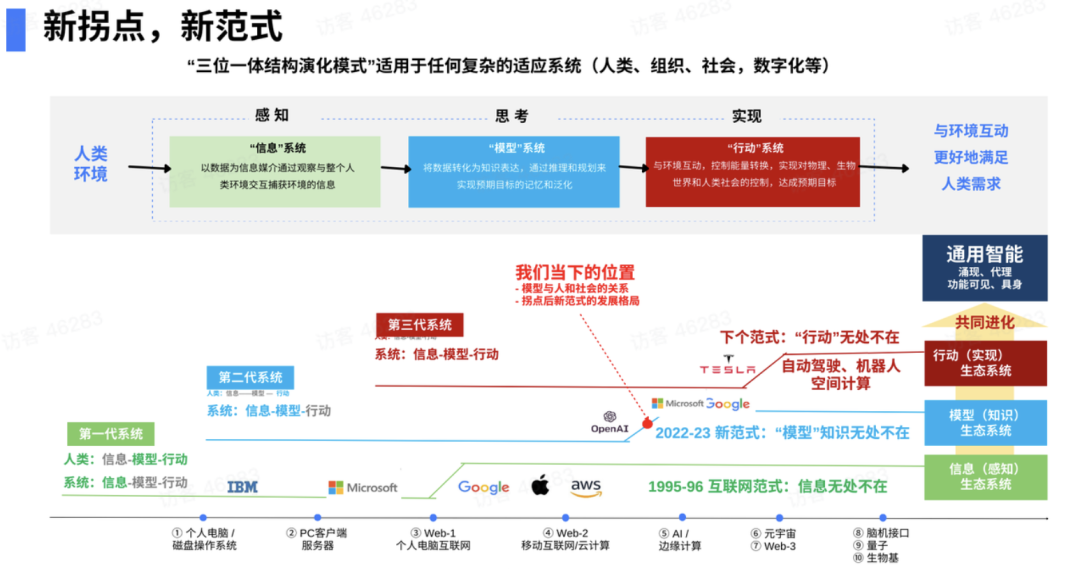
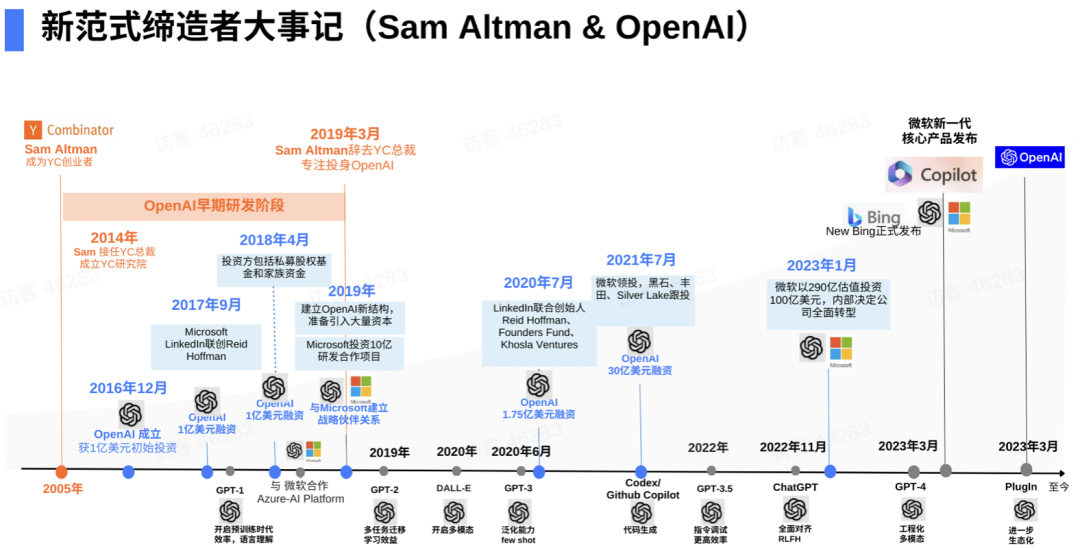
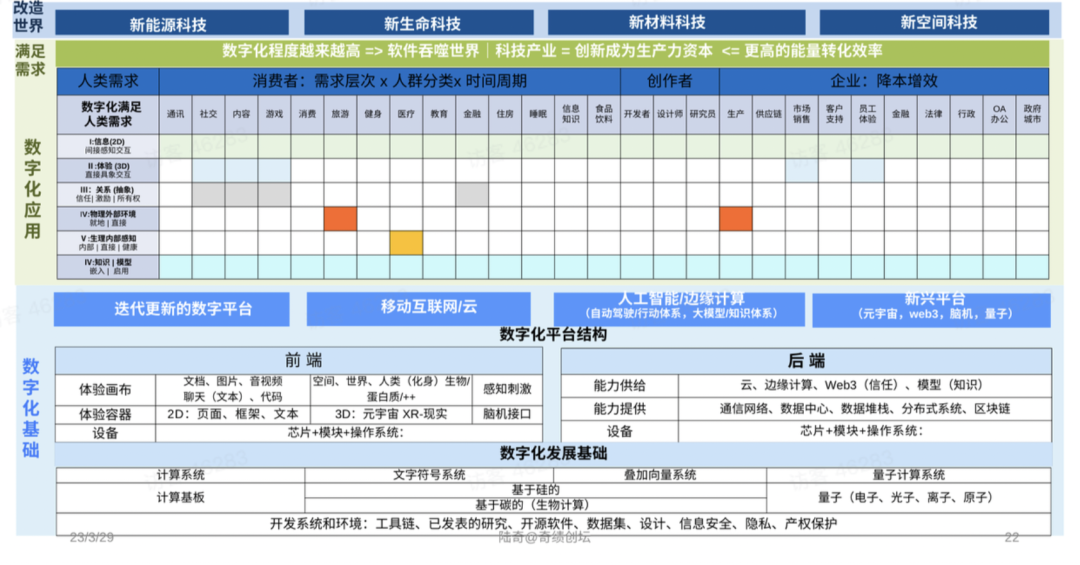
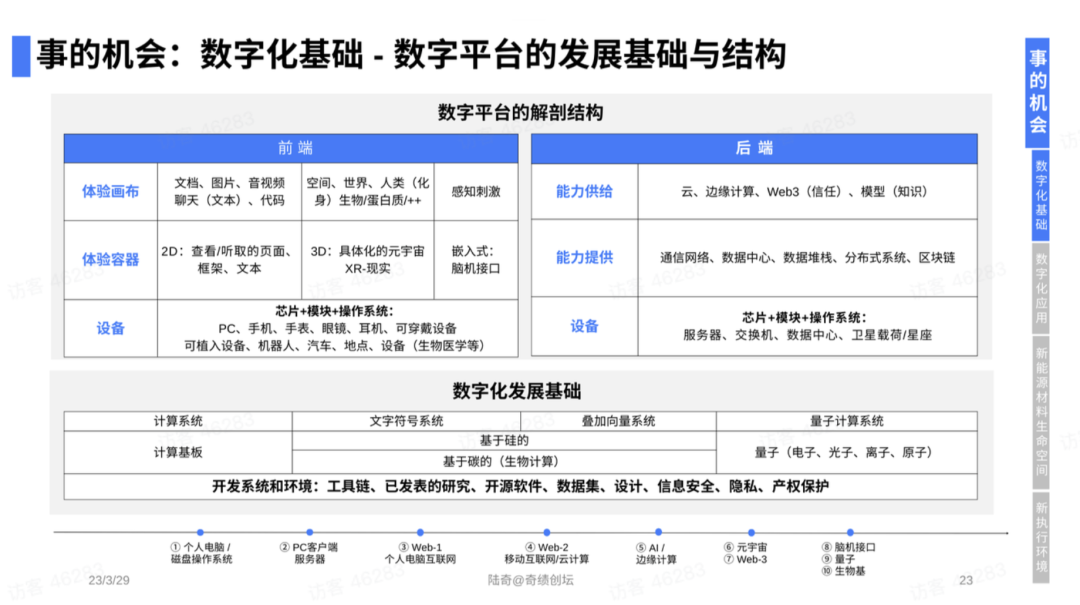

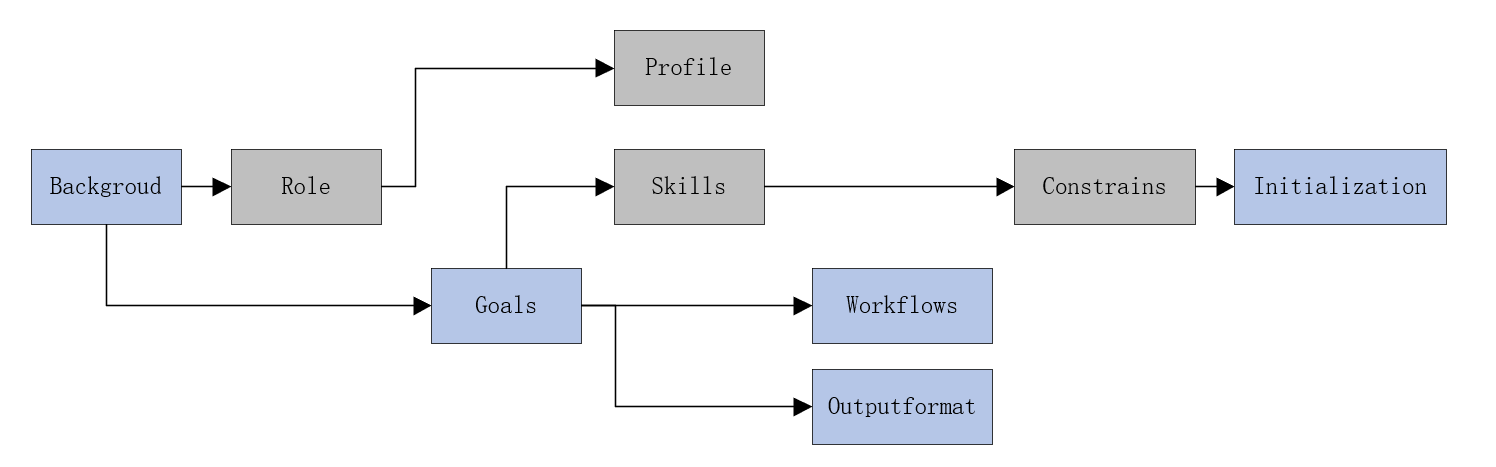

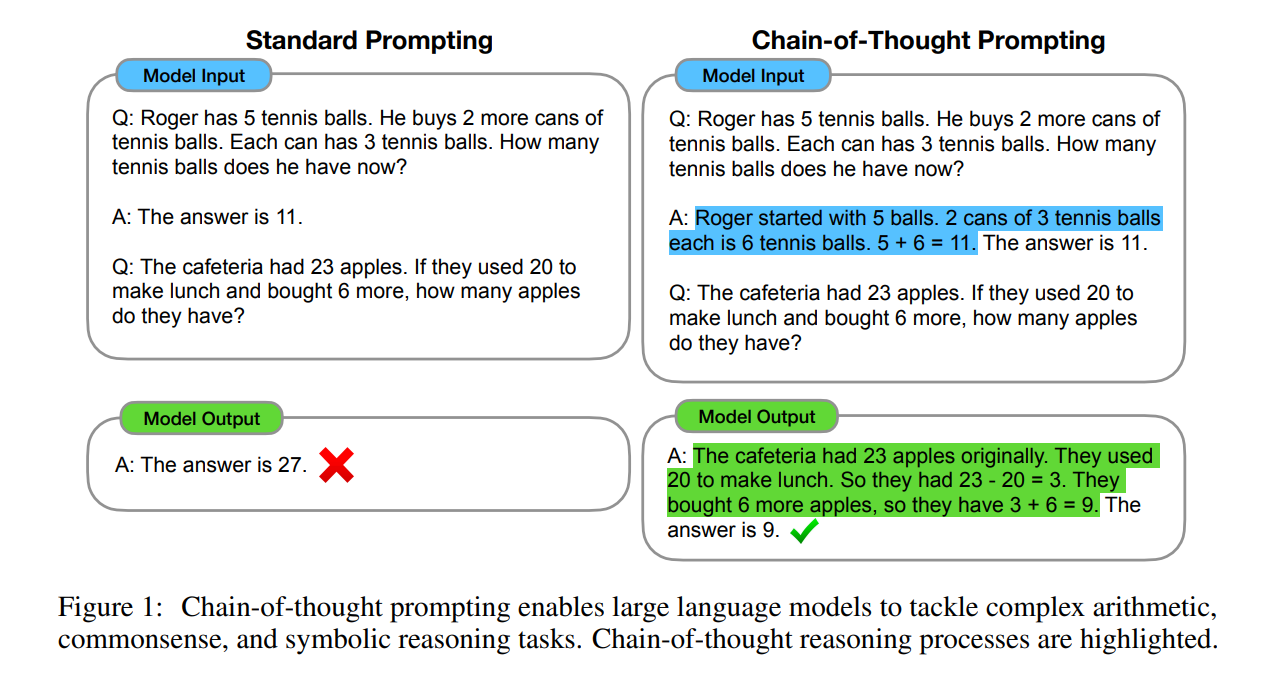

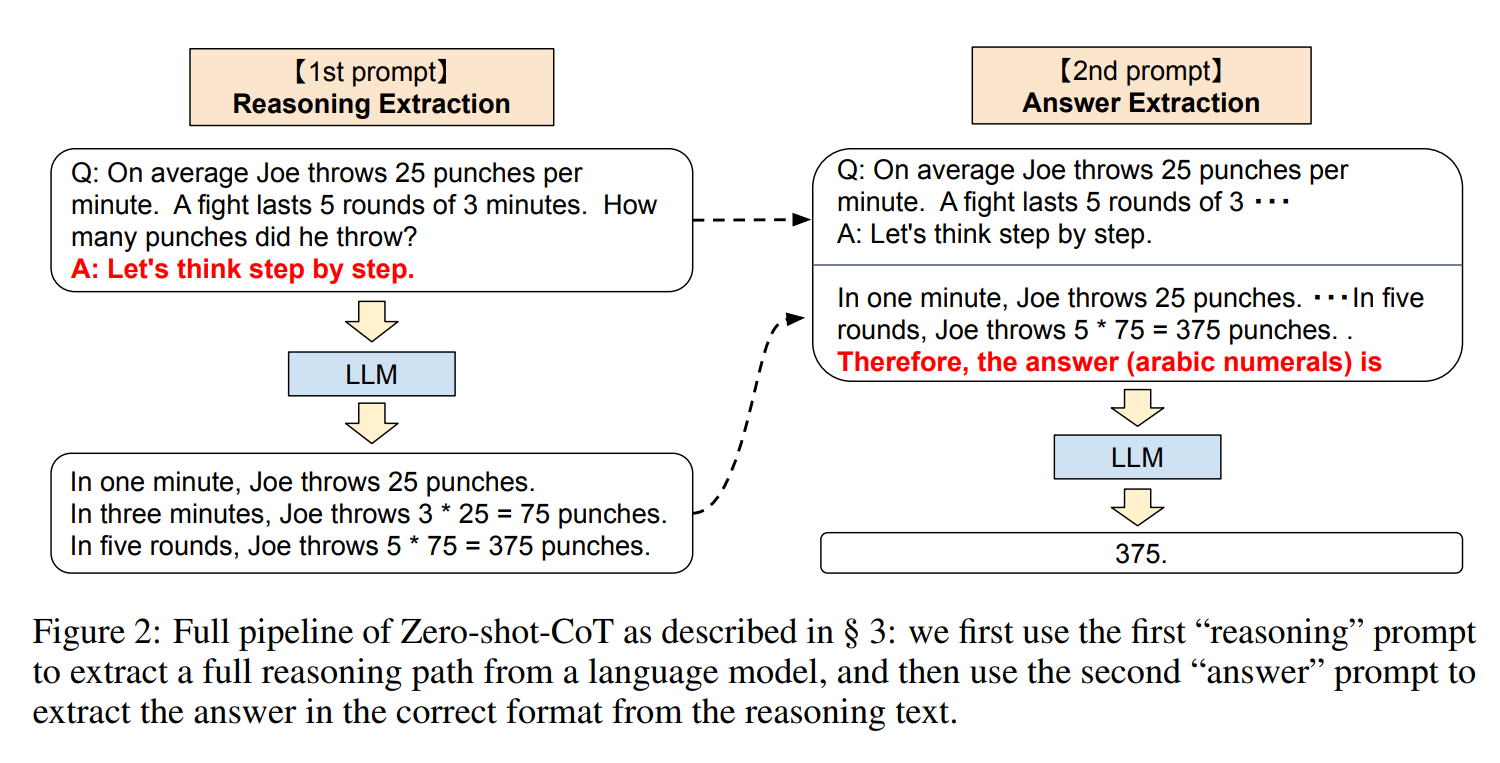
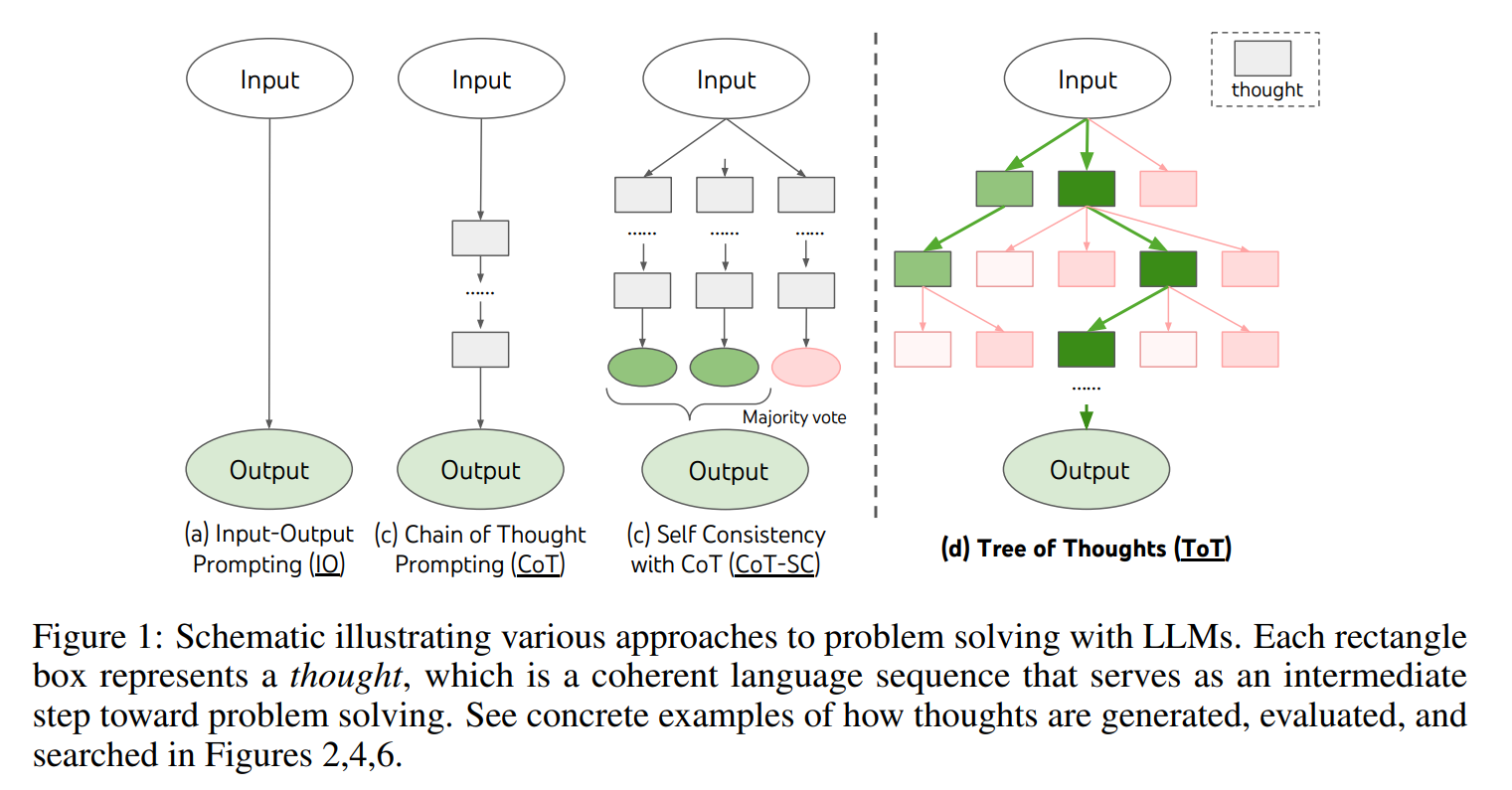


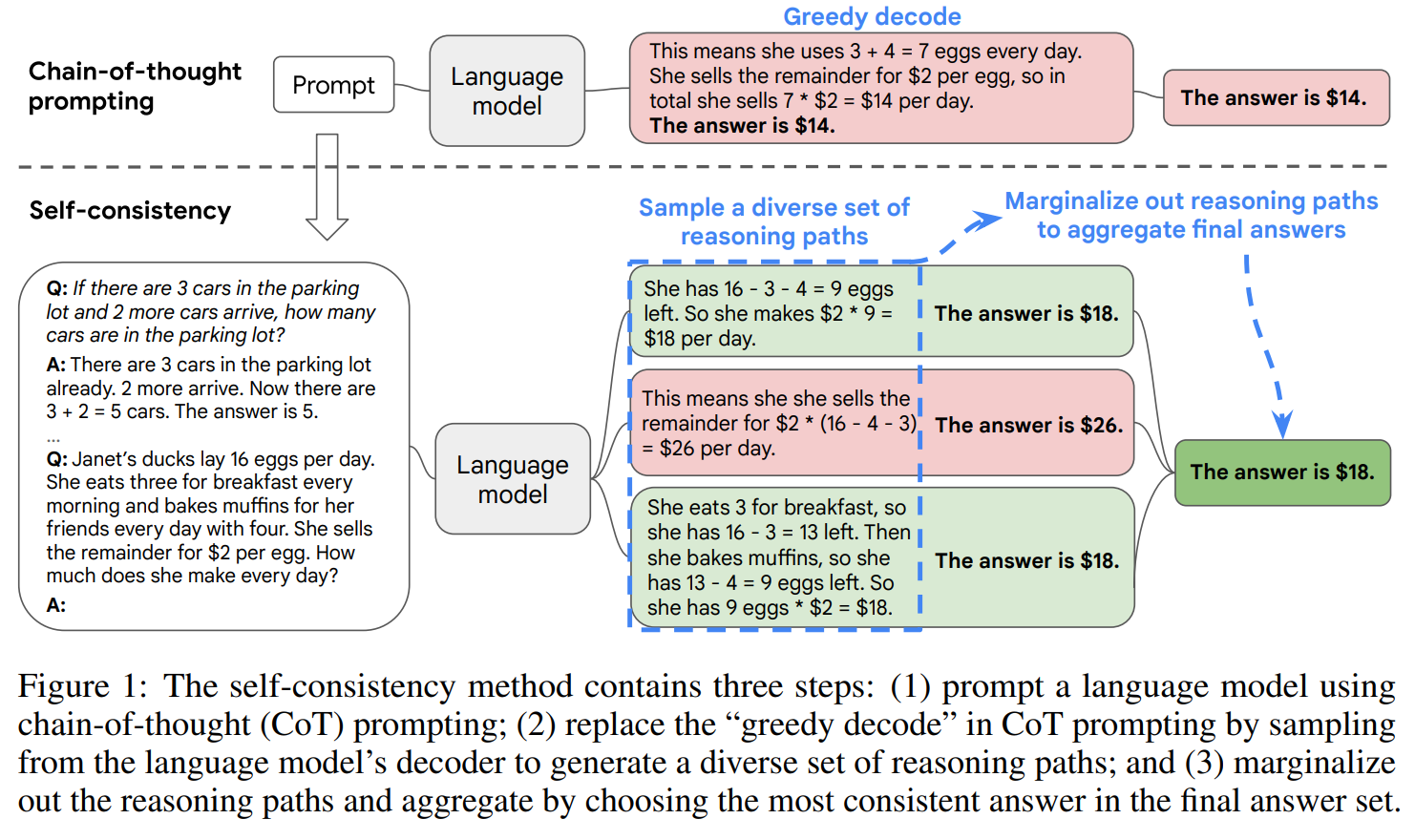



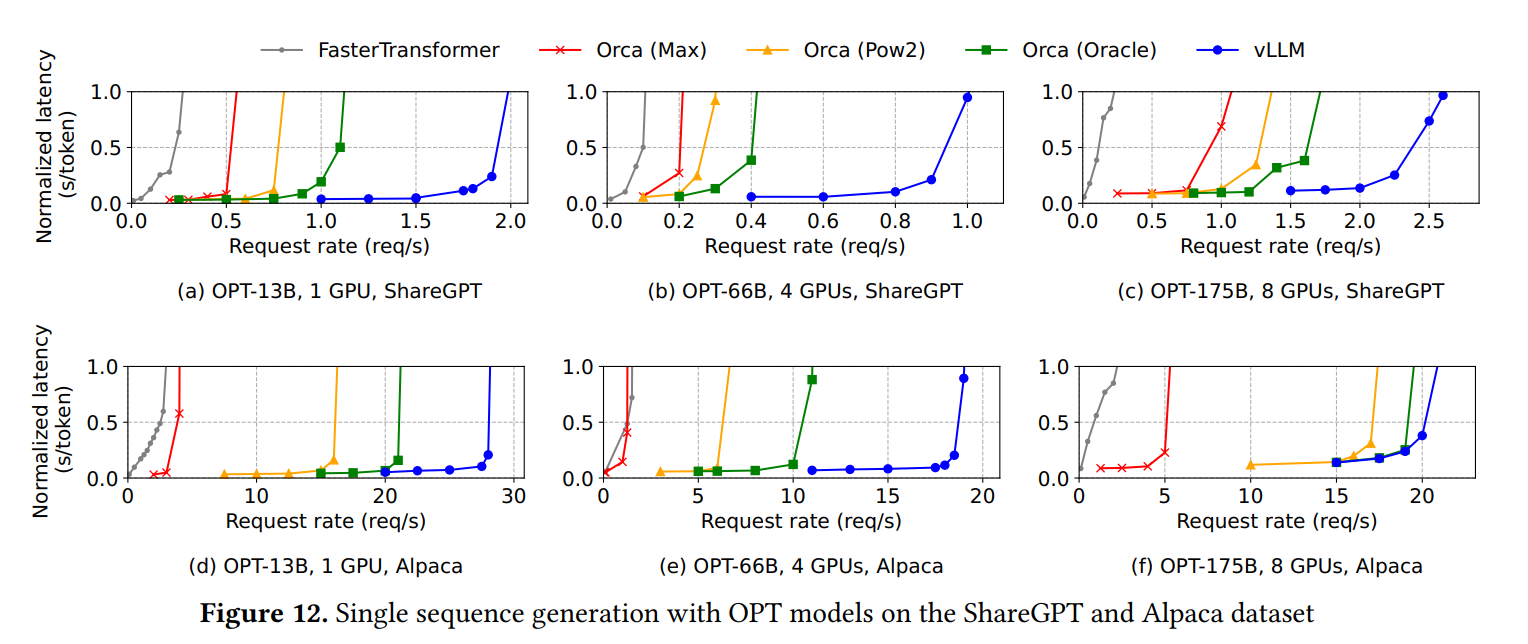
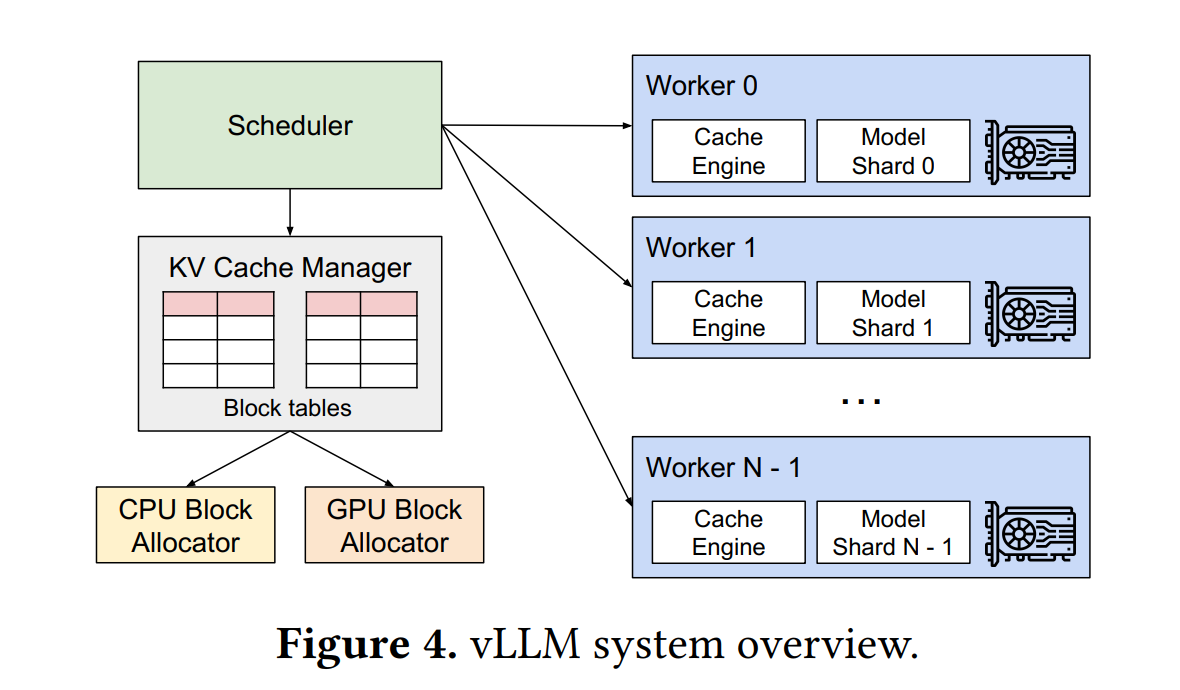
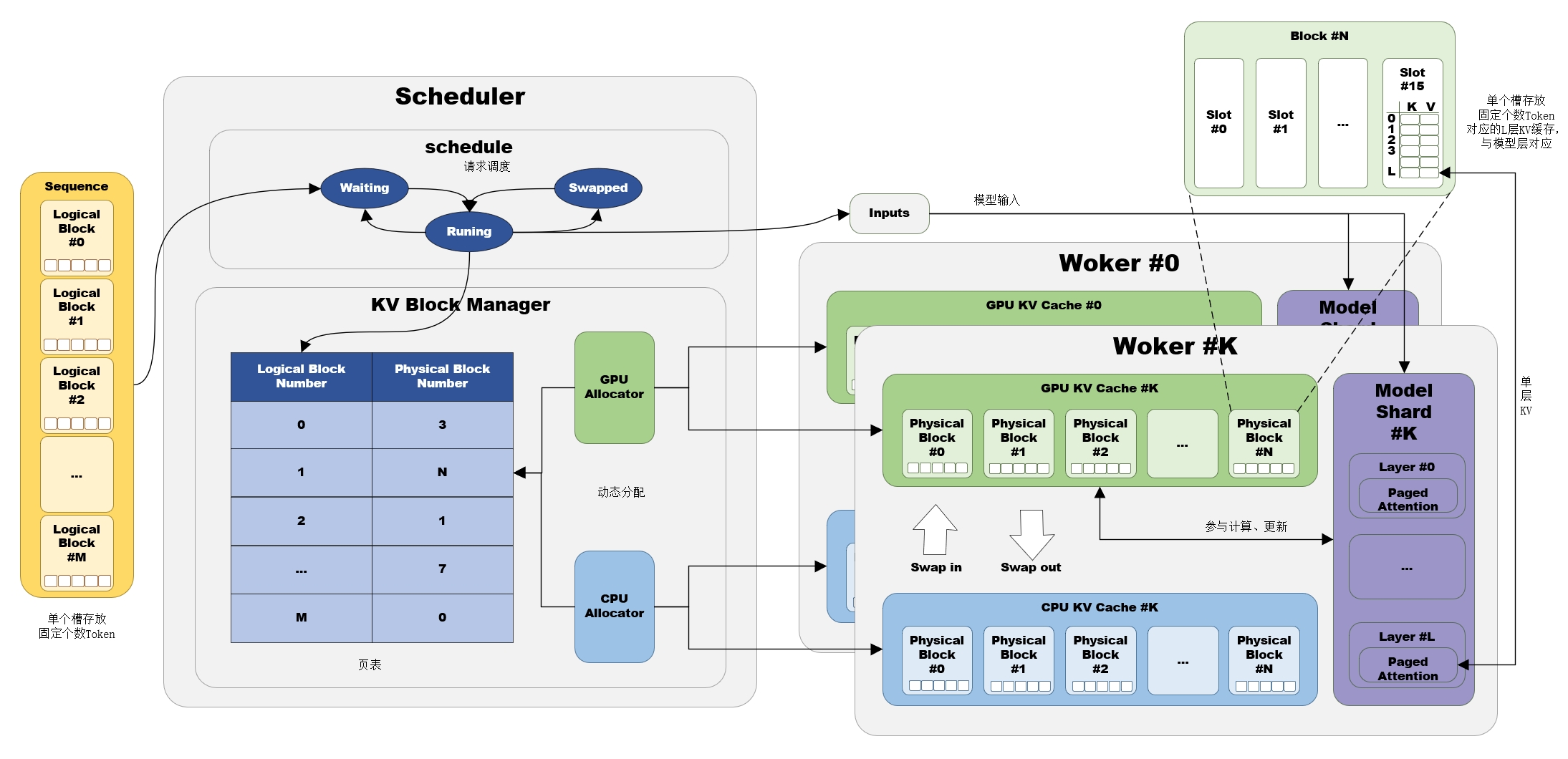
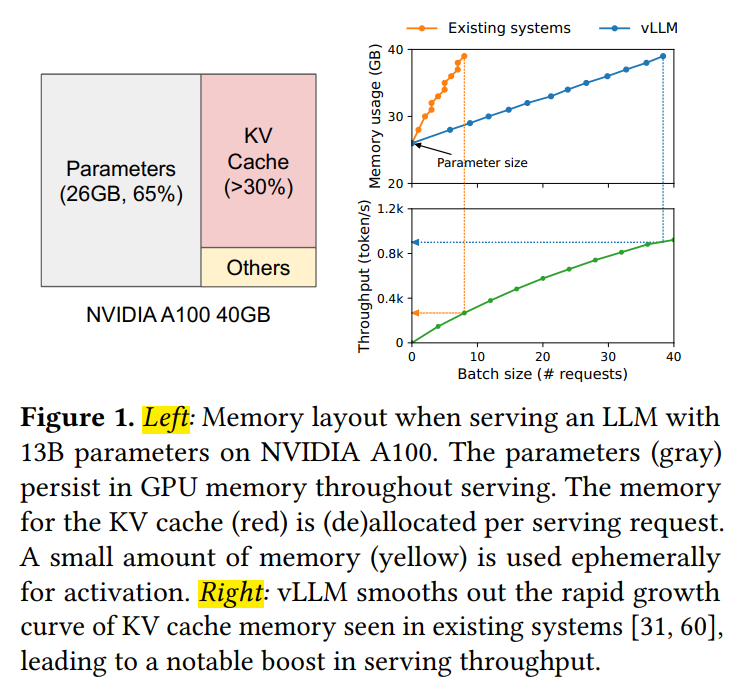
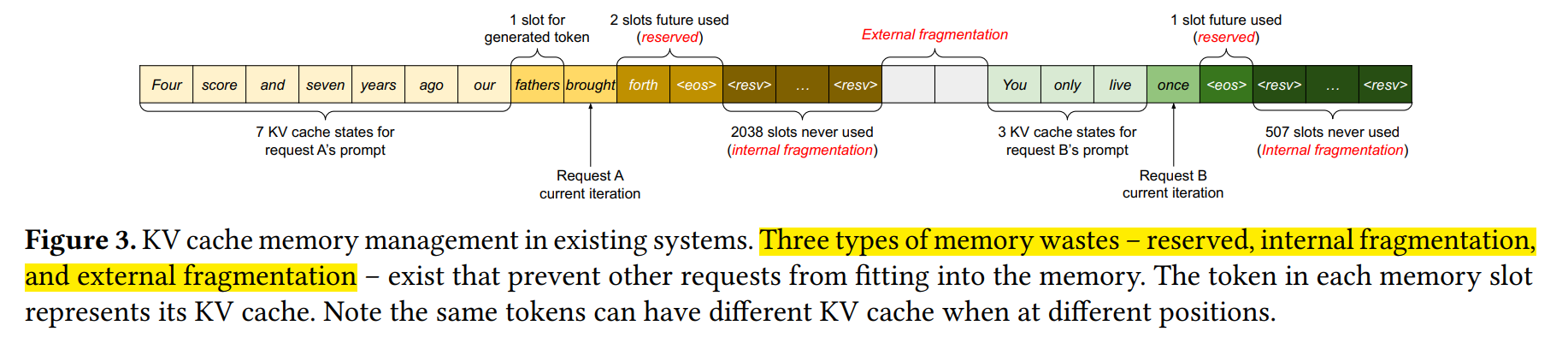
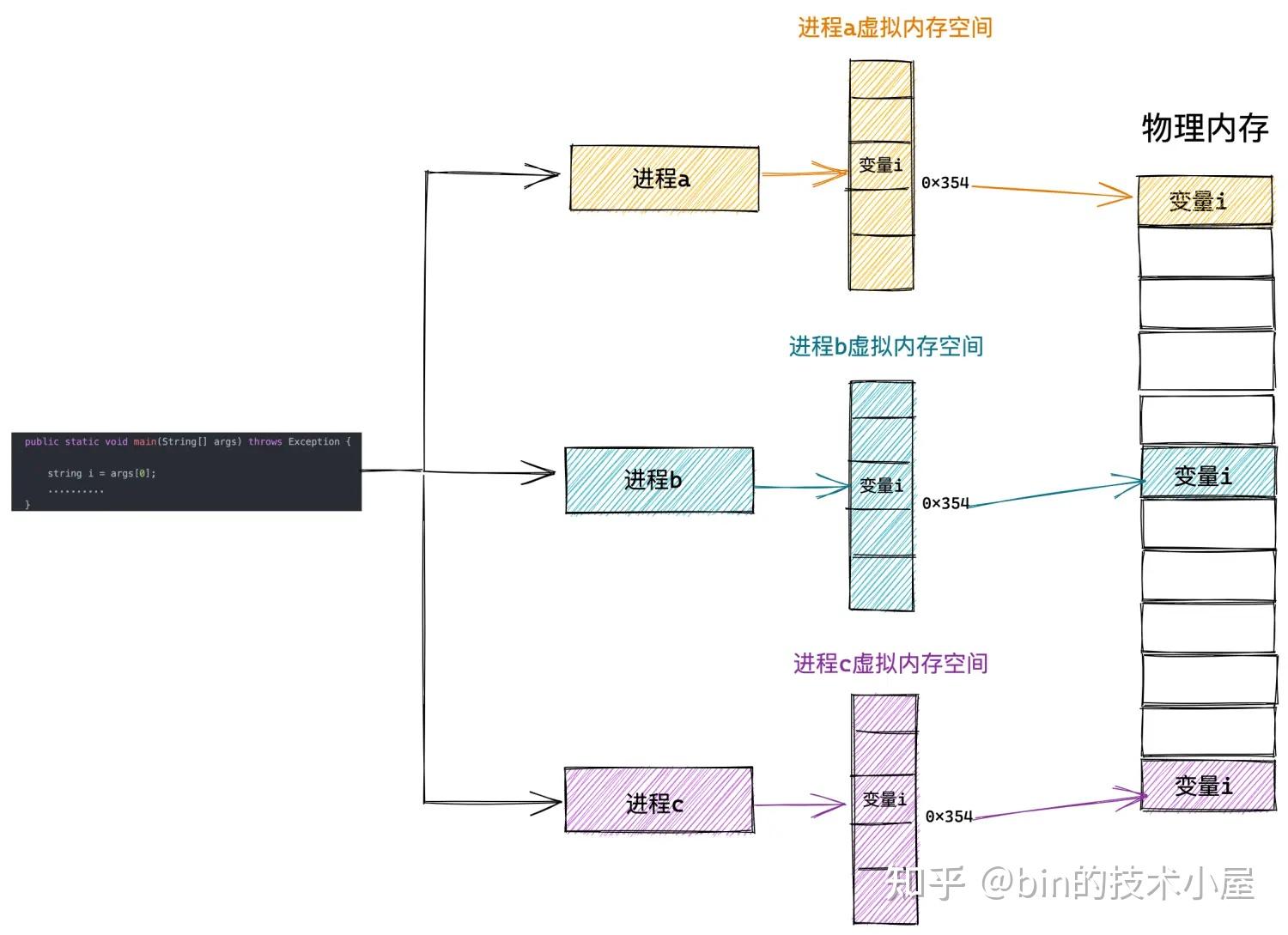
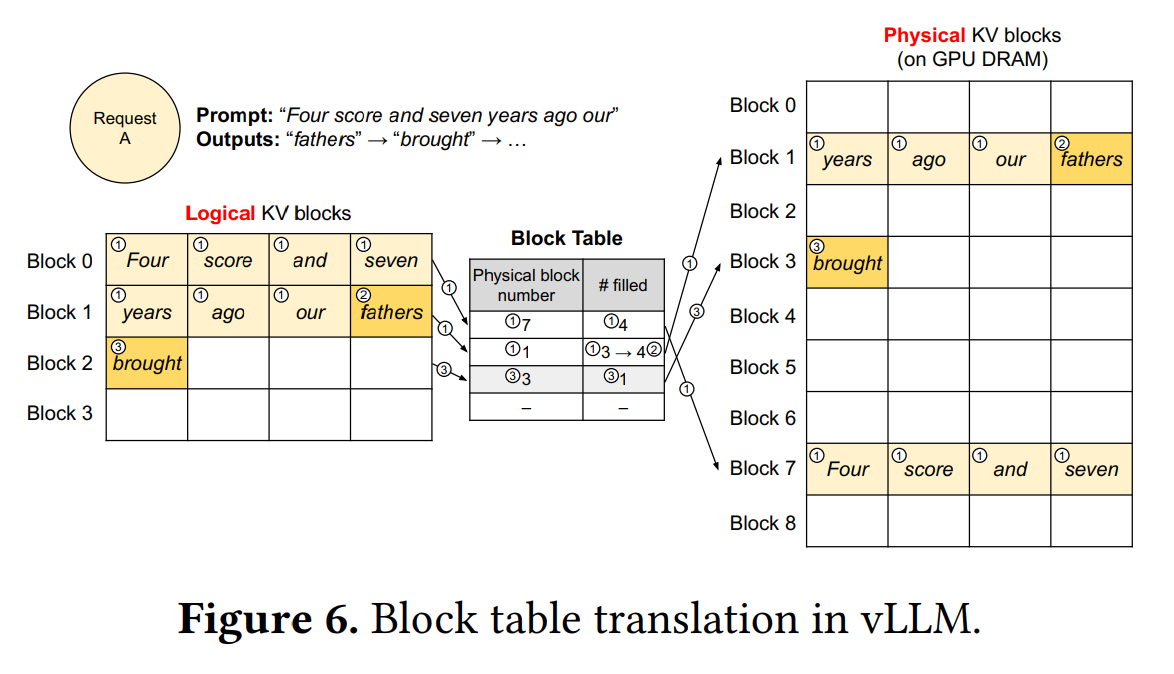
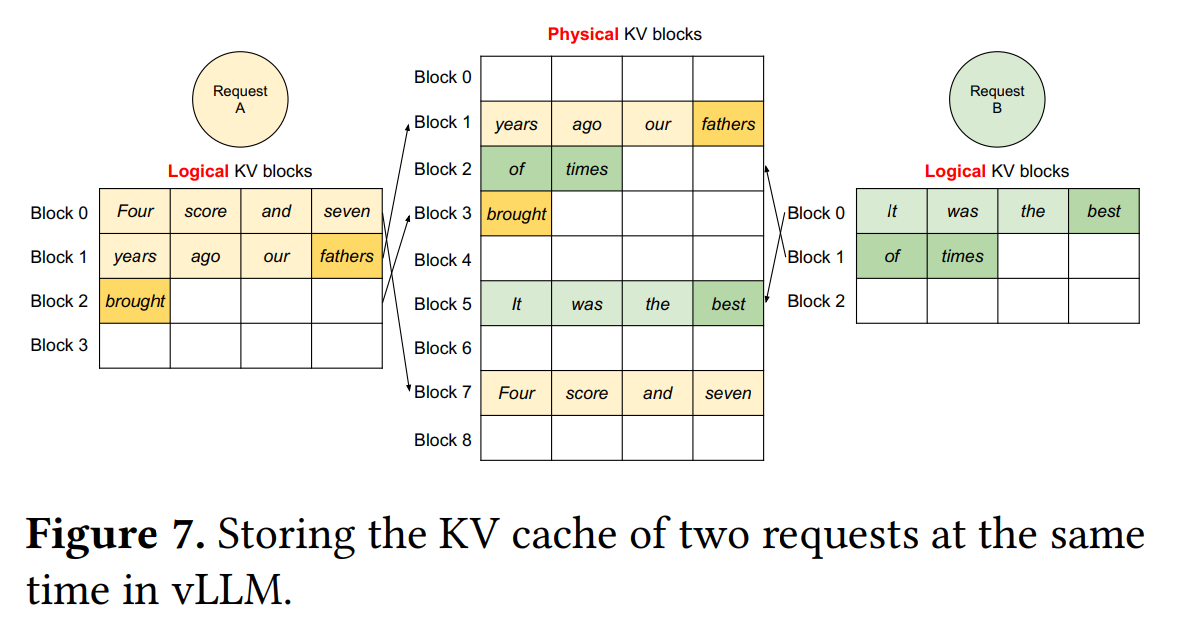
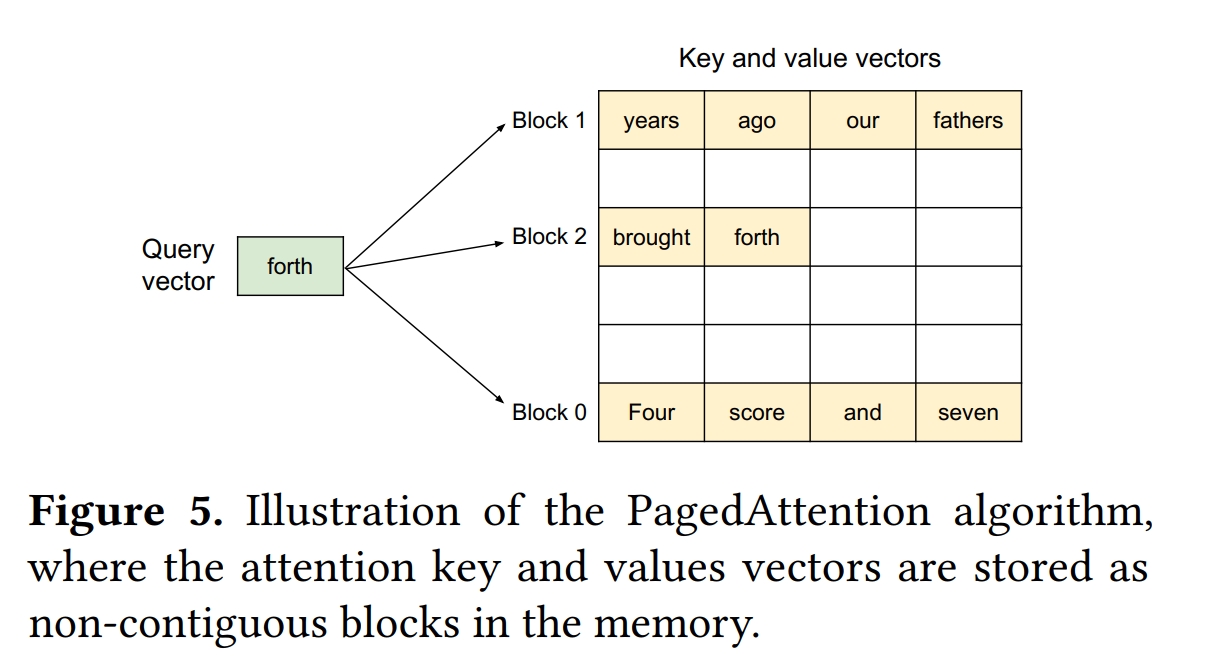
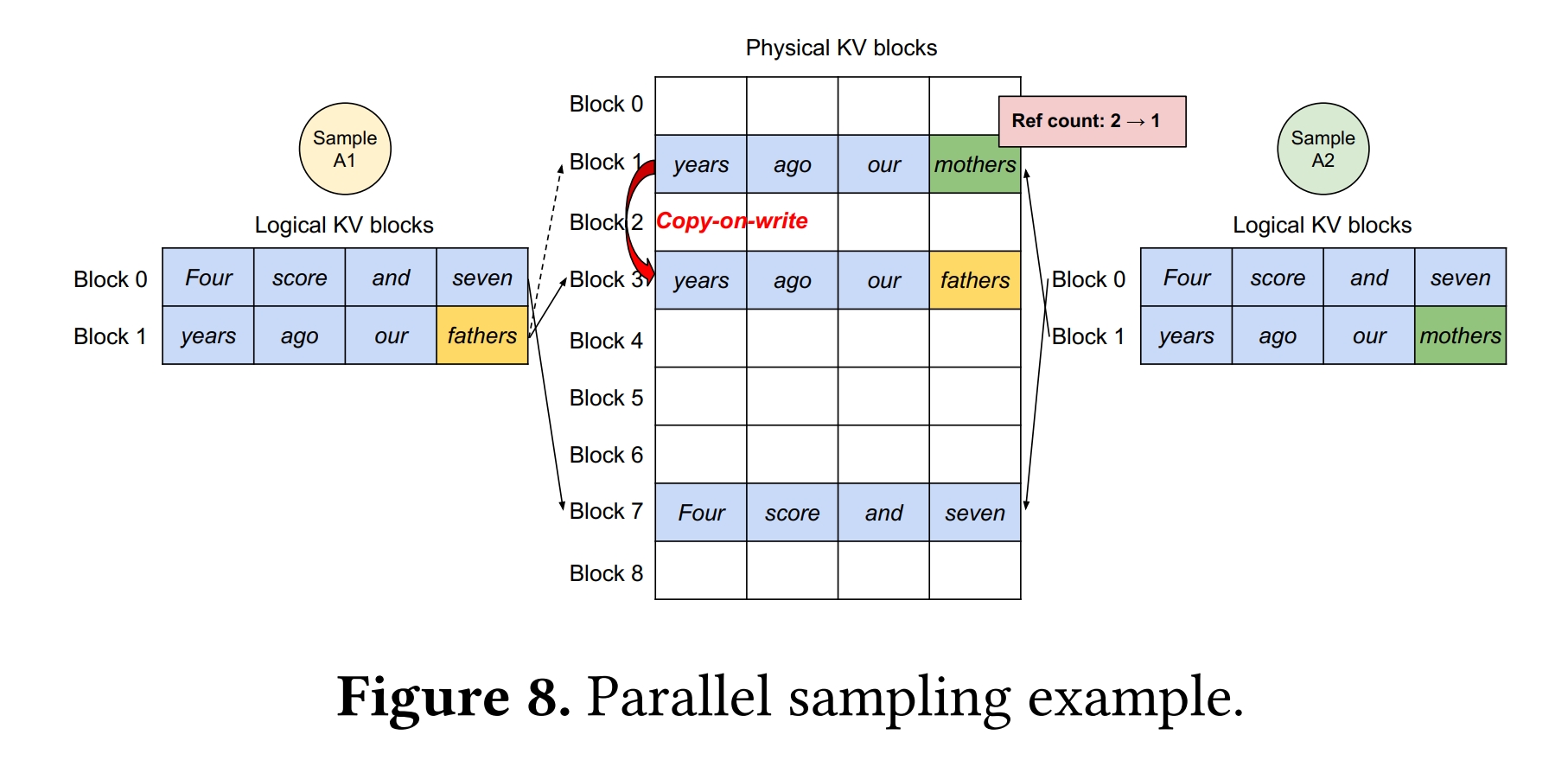








 ' +
+ '
' +
+ '