本篇博文主要展示每日从Arxiv论文网站获取的最新论文列表,以自然语言处理、信息检索、计算机视觉等类目进行划分。
+统计
+今日共更新360篇论文,其中:
+
+- 自然语言处理47篇
+- 信息检索8篇
+- 计算机视觉83篇
+
+自然语言处理
+
+ 1. 【2409.03757】Lexicon3D: Probing Visual Foundation Models for Complex 3D Scene Understanding
+ 链接:https://arxiv.org/abs/2409.03757
+ 作者:Yunze Man,Shuhong Zheng,Zhipeng Bao,Martial Hebert,Liang-Yan Gui,Yu-Xiong Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG); Robotics (cs.RO)
+ 关键词:gained increasing attention, scene encoding strategies, encoding strategies playing, increasing attention, gained increasing
+ 备注: Project page: [this https URL](https://yunzeman.github.io/lexicon3d) , Github: [this https URL](https://github.com/YunzeMan/Lexicon3D)
+
+ 点击查看摘要
+ Abstract:Complex 3D scene understanding has gained increasing attention, with scene encoding strategies playing a crucial role in this success. However, the optimal scene encoding strategies for various scenarios remain unclear, particularly compared to their image-based counterparts. To address this issue, we present a comprehensive study that probes various visual encoding models for 3D scene understanding, identifying the strengths and limitations of each model across different scenarios. Our evaluation spans seven vision foundation encoders, including image-based, video-based, and 3D foundation models. We evaluate these models in four tasks: Vision-Language Scene Reasoning, Visual Grounding, Segmentation, and Registration, each focusing on different aspects of scene understanding. Our evaluations yield key findings: DINOv2 demonstrates superior performance, video models excel in object-level tasks, diffusion models benefit geometric tasks, and language-pretrained models show unexpected limitations in language-related tasks. These insights challenge some conventional understandings, provide novel perspectives on leveraging visual foundation models, and highlight the need for more flexible encoder selection in future vision-language and scene-understanding tasks.
+
+
+
+ 2. 【2409.03753】WildVis: Open Source Visualizer for Million-Scale Chat Logs in the Wild
+ 链接:https://arxiv.org/abs/2409.03753
+ 作者:Yuntian Deng,Wenting Zhao,Jack Hessel,Xiang Ren,Claire Cardie,Yejin Choi
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Human-Computer Interaction (cs.HC); Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:offers exciting opportunities, data offers exciting, study user-chatbot interactions, conversation data offers, real-world conversation data
+ 备注:
+
+ 点击查看摘要
+ Abstract:The increasing availability of real-world conversation data offers exciting opportunities for researchers to study user-chatbot interactions. However, the sheer volume of this data makes manually examining individual conversations impractical. To overcome this challenge, we introduce WildVis, an interactive tool that enables fast, versatile, and large-scale conversation analysis. WildVis provides search and visualization capabilities in the text and embedding spaces based on a list of criteria. To manage million-scale datasets, we implemented optimizations including search index construction, embedding precomputation and compression, and caching to ensure responsive user interactions within seconds. We demonstrate WildVis's utility through three case studies: facilitating chatbot misuse research, visualizing and comparing topic distributions across datasets, and characterizing user-specific conversation patterns. WildVis is open-source and designed to be extendable, supporting additional datasets and customized search and visualization functionalities.
+
+
+
+ 3. 【2409.03752】Attention Heads of Large Language Models: A Survey
+ 链接:https://arxiv.org/abs/2409.03752
+ 作者:Zifan Zheng,Yezhaohui Wang,Yuxin Huang,Shichao Song,Bo Tang,Feiyu Xiong,Zhiyu Li
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, Language Models, advent of ChatGPT, black-box systems
+ 备注: 20 pages, 11 figures, 4 tables
+
+ 点击查看摘要
+ Abstract:Since the advent of ChatGPT, Large Language Models (LLMs) have excelled in various tasks but remain largely as black-box systems. Consequently, their development relies heavily on data-driven approaches, limiting performance enhancement through changes in internal architecture and reasoning pathways. As a result, many researchers have begun exploring the potential internal mechanisms of LLMs, aiming to identify the essence of their reasoning bottlenecks, with most studies focusing on attention heads. Our survey aims to shed light on the internal reasoning processes of LLMs by concentrating on the interpretability and underlying mechanisms of attention heads. We first distill the human thought process into a four-stage framework: Knowledge Recalling, In-Context Identification, Latent Reasoning, and Expression Preparation. Using this framework, we systematically review existing research to identify and categorize the functions of specific attention heads. Furthermore, we summarize the experimental methodologies used to discover these special heads, dividing them into two categories: Modeling-Free methods and Modeling-Required methods. Also, we outline relevant evaluation methods and benchmarks. Finally, we discuss the limitations of current research and propose several potential future directions. Our reference list is open-sourced at \url{this https URL}.
+
+
+
+ 4. 【2409.03733】Planning In Natural Language Improves LLM Search For Code Generation
+ 链接:https://arxiv.org/abs/2409.03733
+ 作者:Evan Wang,Federico Cassano,Catherine Wu,Yunfeng Bai,Will Song,Vaskar Nath,Ziwen Han,Sean Hendryx,Summer Yue,Hugh Zhang
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:scaling training compute, scaling inference compute, yielded analogous gains, training compute, compute has led
+ 备注:
+
+ 点击查看摘要
+ Abstract:While scaling training compute has led to remarkable improvements in large language models (LLMs), scaling inference compute has not yet yielded analogous gains. We hypothesize that a core missing component is a lack of diverse LLM outputs, leading to inefficient search due to models repeatedly sampling highly similar, yet incorrect generations. We empirically demonstrate that this lack of diversity can be mitigated by searching over candidate plans for solving a problem in natural language. Based on this insight, we propose PLANSEARCH, a novel search algorithm which shows strong results across HumanEval+, MBPP+, and LiveCodeBench (a contamination-free benchmark for competitive coding). PLANSEARCH generates a diverse set of observations about the problem and then uses these observations to construct plans for solving the problem. By searching over plans in natural language rather than directly over code solutions, PLANSEARCH explores a significantly more diverse range of potential solutions compared to baseline search methods. Using PLANSEARCH on top of Claude 3.5 Sonnet achieves a state-of-the-art pass@200 of 77.0% on LiveCodeBench, outperforming both the best score achieved without search (pass@1 = 41.4%) and using standard repeated sampling (pass@200 = 60.6%). Finally, we show that, across all models, search algorithms, and benchmarks analyzed, we can accurately predict performance gains due to search as a direct function of the diversity over generated ideas.
+
+
+
+ 5. 【2409.03708】RAG based Question-Answering for Contextual Response Prediction System
+ 链接:https://arxiv.org/abs/2409.03708
+ 作者:Sriram Veturi,Saurabh Vaichal,Nafis Irtiza Tripto,Reshma Lal Jagadheesh,Nian Yan
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:Large Language Models, Natural Language Processing, Large Language, Language Models, Language Processing
+ 备注: Accepted at the 1st Workshop on GenAI and RAG Systems for Enterprise, CIKM'24. 6 pages
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have shown versatility in various Natural Language Processing (NLP) tasks, including their potential as effective question-answering systems. However, to provide precise and relevant information in response to specific customer queries in industry settings, LLMs require access to a comprehensive knowledge base to avoid hallucinations. Retrieval Augmented Generation (RAG) emerges as a promising technique to address this challenge. Yet, developing an accurate question-answering framework for real-world applications using RAG entails several challenges: 1) data availability issues, 2) evaluating the quality of generated content, and 3) the costly nature of human evaluation. In this paper, we introduce an end-to-end framework that employs LLMs with RAG capabilities for industry use cases. Given a customer query, the proposed system retrieves relevant knowledge documents and leverages them, along with previous chat history, to generate response suggestions for customer service agents in the contact centers of a major retail company. Through comprehensive automated and human evaluations, we show that this solution outperforms the current BERT-based algorithms in accuracy and relevance. Our findings suggest that RAG-based LLMs can be an excellent support to human customer service representatives by lightening their workload.
+
+
+
+ 6. 【2409.03707】A Different Level Text Protection Mechanism With Differential Privacy
+ 链接:https://arxiv.org/abs/2409.03707
+ 作者:Qingwen Fu
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:BERT pre-training model, BERT pre-training, pre-training model, model and proves, proves the effectiveness
+ 备注:
+
+ 点击查看摘要
+ Abstract:The article introduces a method for extracting words of different degrees of importance based on the BERT pre-training model and proves the effectiveness of this method. The article also discusses the impact of maintaining the same perturbation results for words of different importance on the overall text utility. This method can be applied to long text protection.
+
+
+
+ 7. 【2409.03701】LAST: Language Model Aware Speech Tokenization
+ 链接:https://arxiv.org/abs/2409.03701
+ 作者:Arnon Turetzky,Yossi Adi
+ 类目:Computation and Language (cs.CL); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:perform various tasks, Speech, Speech tokenization serves, spoken language modeling, tokenization serves
+ 备注:
+
+ 点击查看摘要
+ Abstract:Speech tokenization serves as the foundation of speech language model (LM), enabling them to perform various tasks such as spoken language modeling, text-to-speech, speech-to-text, etc. Most speech tokenizers are trained independently of the LM training process, relying on separate acoustic models and quantization methods. Following such an approach may create a mismatch between the tokenization process and its usage afterward. In this study, we propose a novel approach to training a speech tokenizer by leveraging objectives from pre-trained textual LMs. We advocate for the integration of this objective into the process of learning discrete speech representations. Our aim is to transform features from a pre-trained speech model into a new feature space that enables better clustering for speech LMs. We empirically investigate the impact of various model design choices, including speech vocabulary size and text LM size. Our results demonstrate the proposed tokenization method outperforms the evaluated baselines considering both spoken language modeling and speech-to-text. More importantly, unlike prior work, the proposed method allows the utilization of a single pre-trained LM for processing both speech and text inputs, setting it apart from conventional tokenization approaches.
+
+
+
+ 8. 【2409.03668】A Fused Large Language Model for Predicting Startup Success
+ 链接:https://arxiv.org/abs/2409.03668
+ 作者:Abdurahman Maarouf,Stefan Feuerriegel,Nicolas Pröllochs
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:continuously seeking profitable, predict startup success, continuously seeking, startup success, startup
+ 备注:
+
+ 点击查看摘要
+ Abstract:Investors are continuously seeking profitable investment opportunities in startups and, hence, for effective decision-making, need to predict a startup's probability of success. Nowadays, investors can use not only various fundamental information about a startup (e.g., the age of the startup, the number of founders, and the business sector) but also textual description of a startup's innovation and business model, which is widely available through online venture capital (VC) platforms such as Crunchbase. To support the decision-making of investors, we develop a machine learning approach with the aim of locating successful startups on VC platforms. Specifically, we develop, train, and evaluate a tailored, fused large language model to predict startup success. Thereby, we assess to what extent self-descriptions on VC platforms are predictive of startup success. Using 20,172 online profiles from Crunchbase, we find that our fused large language model can predict startup success, with textual self-descriptions being responsible for a significant part of the predictive power. Our work provides a decision support tool for investors to find profitable investment opportunities.
+
+
+
+ 9. 【2409.03662】he representation landscape of few-shot learning and fine-tuning in large language models
+ 链接:https://arxiv.org/abs/2409.03662
+ 作者:Diego Doimo,Alessandro Serra,Alessio Ansuini,Alberto Cazzaniga
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:In-context learning, modern large language, supervised fine-tuning, modern large, large language models
+ 备注:
+
+ 点击查看摘要
+ Abstract:In-context learning (ICL) and supervised fine-tuning (SFT) are two common strategies for improving the performance of modern large language models (LLMs) on specific tasks. Despite their different natures, these strategies often lead to comparable performance gains. However, little is known about whether they induce similar representations inside LLMs. We approach this problem by analyzing the probability landscape of their hidden representations in the two cases. More specifically, we compare how LLMs solve the same question-answering task, finding that ICL and SFT create very different internal structures, in both cases undergoing a sharp transition in the middle of the network. In the first half of the network, ICL shapes interpretable representations hierarchically organized according to their semantic content. In contrast, the probability landscape obtained with SFT is fuzzier and semantically mixed. In the second half of the model, the fine-tuned representations develop probability modes that better encode the identity of answers, while the landscape of ICL representations is characterized by less defined peaks. Our approach reveals the diverse computational strategies developed inside LLMs to solve the same task across different conditions, allowing us to make a step towards designing optimal methods to extract information from language models.
+
+
+
+ 10. 【2409.03659】LLM-based multi-agent poetry generation in non-cooperative environments
+ 链接:https://arxiv.org/abs/2409.03659
+ 作者:Ran Zhang,Steffen Eger
+ 类目:Computation and Language (cs.CL)
+ 关键词:training process differs, process differs greatly, poetry generation, large language models, generated poetry lacks
+ 备注: preprint
+
+ 点击查看摘要
+ Abstract:Despite substantial progress of large language models (LLMs) for automatic poetry generation, the generated poetry lacks diversity while the training process differs greatly from human learning. Under the rationale that the learning process of the poetry generation systems should be more human-like and their output more diverse and novel, we introduce a framework based on social learning where we emphasize non-cooperative interactions besides cooperative interactions to encourage diversity. Our experiments are the first attempt at LLM-based multi-agent systems in non-cooperative environments for poetry generation employing both TRAINING-BASED agents (GPT-2) and PROMPTING-BASED agents (GPT-3 and GPT-4). Our evaluation based on 96k generated poems shows that our framework benefits the poetry generation process for TRAINING-BASED agents resulting in 1) a 3.0-3.7 percentage point (pp) increase in diversity and a 5.6-11.3 pp increase in novelty according to distinct and novel n-grams. The generated poetry from TRAINING-BASED agents also exhibits group divergence in terms of lexicons, styles and semantics. PROMPTING-BASED agents in our framework also benefit from non-cooperative environments and a more diverse ensemble of models with non-homogeneous agents has the potential to further enhance diversity, with an increase of 7.0-17.5 pp according to our experiments. However, PROMPTING-BASED agents show a decrease in lexical diversity over time and do not exhibit the group-based divergence intended in the social network. Our paper argues for a paradigm shift in creative tasks such as automatic poetry generation to include social learning processes (via LLM-based agent modeling) similar to human interaction.
+
+
+
+ 11. 【2409.03650】On the Limited Generalization Capability of the Implicit Reward Model Induced by Direct Preference Optimization
+ 链接:https://arxiv.org/abs/2409.03650
+ 作者:Yong Lin,Skyler Seto,Maartje ter Hoeve,Katherine Metcalf,Barry-John Theobald,Xuan Wang,Yizhe Zhang,Chen Huang,Tong Zhang
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:Human Feedback, Reinforcement Learning, aligning language models, Direct Preference Optimization, human preferences
+ 备注: 12 pages, 8 tables, 2 figures
+
+ 点击查看摘要
+ Abstract:Reinforcement Learning from Human Feedback (RLHF) is an effective approach for aligning language models to human preferences. Central to RLHF is learning a reward function for scoring human preferences. Two main approaches for learning a reward model are 1) training an EXplicit Reward Model (EXRM) as in RLHF, and 2) using an implicit reward learned from preference data through methods such as Direct Preference Optimization (DPO). Prior work has shown that the implicit reward model of DPO (denoted as DPORM) can approximate an EXRM in the limit. DPORM's effectiveness directly implies the optimality of the learned policy, and also has practical implication for LLM alignment methods including iterative DPO. However, it is unclear how well DPORM empirically matches the performance of EXRM. This work studies the accuracy at distinguishing preferred and rejected answers for both DPORM and EXRM. Our findings indicate that even though DPORM fits the training dataset comparably, it generalizes less effectively than EXRM, especially when the validation datasets contain distribution shifts. Across five out-of-distribution settings, DPORM has a mean drop in accuracy of 3% and a maximum drop of 7%. These findings highlight that DPORM has limited generalization ability and substantiates the integration of an explicit reward model in iterative DPO approaches.
+
+
+
+ 12. 【2409.03643】CDM: A Reliable Metric for Fair and Accurate Formula Recognition Evaluation
+ 链接:https://arxiv.org/abs/2409.03643
+ 作者:Bin Wang,Fan Wu,Linke Ouyang,Zhuangcheng Gu,Rui Zhang,Renqiu Xia,Bo Zhang,Conghui He
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:presents significant challenges, significant challenges due, recognition presents significant, Formula recognition presents, Formula recognition
+ 备注: Project Website: [this https URL](https://github.com/opendatalab/UniMERNet/tree/main/cdm)
+
+ 点击查看摘要
+ Abstract:Formula recognition presents significant challenges due to the complicated structure and varied notation of mathematical expressions. Despite continuous advancements in formula recognition models, the evaluation metrics employed by these models, such as BLEU and Edit Distance, still exhibit notable limitations. They overlook the fact that the same formula has diverse representations and is highly sensitive to the distribution of training data, thereby causing the unfairness in formula recognition evaluation. To this end, we propose a Character Detection Matching (CDM) metric, ensuring the evaluation objectivity by designing a image-level rather than LaTex-level metric score. Specifically, CDM renders both the model-predicted LaTeX and the ground-truth LaTeX formulas into image-formatted formulas, then employs visual feature extraction and localization techniques for precise character-level matching, incorporating spatial position information. Such a spatially-aware and character-matching method offers a more accurate and equitable evaluation compared with previous BLEU and Edit Distance metrics that rely solely on text-based character matching. Experimentally, we evaluated various formula recognition models using CDM, BLEU, and ExpRate metrics. Their results demonstrate that the CDM aligns more closely with human evaluation standards and provides a fairer comparison across different models by eliminating discrepancies caused by diverse formula representations.
+
+
+
+ 13. 【2409.03621】Attend First, Consolidate Later: On the Importance of Attention in Different LLM Layers
+ 链接:https://arxiv.org/abs/2409.03621
+ 作者:Amit Ben Artzy,Roy Schwartz
+ 类目:Computation and Language (cs.CL)
+ 关键词:serves two purposes, attention mechanism, mechanism of future, layer serves, current token
+ 备注:
+
+ 点击查看摘要
+ Abstract:In decoder-based LLMs, the representation of a given layer serves two purposes: as input to the next layer during the computation of the current token; and as input to the attention mechanism of future tokens. In this work, we show that the importance of the latter role might be overestimated. To show that, we start by manipulating the representations of previous tokens; e.g. by replacing the hidden states at some layer k with random vectors. Our experimenting with four LLMs and four tasks show that this operation often leads to small to negligible drop in performance. Importantly, this happens if the manipulation occurs in the top part of the model-k is in the final 30-50% of the layers. In contrast, doing the same manipulation in earlier layers might lead to chance level performance. We continue by switching the hidden state of certain tokens with hidden states of other tokens from another prompt; e.g., replacing the word "Italy" with "France" in "What is the capital of Italy?". We find that when applying this switch in the top 1/3 of the model, the model ignores it (answering "Rome"). However if we apply it before, the model conforms to the switch ("Paris"). Our results hint at a two stage process in transformer-based LLMs: the first part gathers input from previous tokens, while the second mainly processes that information internally.
+
+
+
+ 14. 【2409.03563】100 instances is all you need: predicting the success of a new LLM on unseen data by testing on a few instances
+ 链接:https://arxiv.org/abs/2409.03563
+ 作者:Lorenzo Pacchiardi,Lucy G. Cheke,José Hernández-Orallo
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:individual task instances, task instances, LLM, performance, instances
+ 备注: Presented at the 2024 KDD workshop on Evaluation and Trustworthiness of Generative AI Models
+
+ 点击查看摘要
+ Abstract:Predicting the performance of LLMs on individual task instances is essential to ensure their reliability in high-stakes applications. To do so, a possibility is to evaluate the considered LLM on a set of task instances and train an assessor to predict its performance based on features of the instances. However, this approach requires evaluating each new LLM on a sufficiently large set of task instances to train an assessor specific to it. In this work, we leverage the evaluation results of previously tested LLMs to reduce the number of evaluations required to predict the performance of a new LLM. In practice, we propose to test the new LLM on a small set of reference instances and train a generic assessor which predicts the performance of the LLM on an instance based on the performance of the former on the reference set and features of the instance of interest. We conduct empirical studies on HELM-Lite and KindsOfReasoning, a collection of existing reasoning datasets that we introduce, where we evaluate all instruction-fine-tuned OpenAI models until the January 2024 version of GPT4. When predicting performance on instances with the same distribution as those used to train the generic assessor, we find this achieves performance comparable to the LLM-specific assessors trained on the full set of instances. Additionally, we find that randomly selecting the reference instances performs as well as some advanced selection methods we tested. For out of distribution, however, no clear winner emerges and the overall performance is worse, suggesting that the inherent predictability of LLMs is low.
+
+
+
+ 15. 【2409.03512】From MOOC to MAIC: Reshaping Online Teaching and Learning through LLM-driven Agents
+ 链接:https://arxiv.org/abs/2409.03512
+ 作者:Jifan Yu,Zheyuan Zhang,Daniel Zhang-li,Shangqing Tu,Zhanxin Hao,Rui Miao Li,Haoxuan Li,Yuanchun Wang,Hanming Li,Linlu Gong,Jie Cao,Jiayin Lin,Jinchang Zhou,Fei Qin,Haohua Wang,Jianxiao Jiang,Lijun Deng,Yisi Zhan,Chaojun Xiao,Xusheng Dai,Xuan Yan,Nianyi Lin,Nan Zhang,Ruixin Ni,Yang Dang,Lei Hou,Yu Zhang,Xu Han,Manli Li,Juanzi Li,Zhiyuan Liu,Huiqin Liu,Maosong Sun
+ 类目:Computers and Society (cs.CY); Computation and Language (cs.CL)
+ 关键词:sparked extensive discussion, widespread adoption, uploaded to accessible, accessible and shared, scaling the dissemination
+ 备注:
+
+ 点击查看摘要
+ Abstract:Since the first instances of online education, where courses were uploaded to accessible and shared online platforms, this form of scaling the dissemination of human knowledge to reach a broader audience has sparked extensive discussion and widespread adoption. Recognizing that personalized learning still holds significant potential for improvement, new AI technologies have been continuously integrated into this learning format, resulting in a variety of educational AI applications such as educational recommendation and intelligent tutoring. The emergence of intelligence in large language models (LLMs) has allowed for these educational enhancements to be built upon a unified foundational model, enabling deeper integration. In this context, we propose MAIC (Massive AI-empowered Course), a new form of online education that leverages LLM-driven multi-agent systems to construct an AI-augmented classroom, balancing scalability with adaptivity. Beyond exploring the conceptual framework and technical innovations, we conduct preliminary experiments at Tsinghua University, one of China's leading universities. Drawing from over 100,000 learning records of more than 500 students, we obtain a series of valuable observations and initial analyses. This project will continue to evolve, ultimately aiming to establish a comprehensive open platform that supports and unifies research, technology, and applications in exploring the possibilities of online education in the era of large model AI. We envision this platform as a collaborative hub, bringing together educators, researchers, and innovators to collectively explore the future of AI-driven online education.
+
+
+
+ 16. 【2409.03454】How Much Data is Enough Data? Fine-Tuning Large Language Models for In-House Translation: Performance Evaluation Across Multiple Dataset Sizes
+ 链接:https://arxiv.org/abs/2409.03454
+ 作者:Inacio Vieira,Will Allred,Seamus Lankford,Sheila Castilho Monteiro De Sousa,Andy Way
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Decoder-only LLMs, generate high-quality translations, shown impressive performance, shown impressive, ability to learn
+ 备注:
+
+ 点击查看摘要
+ Abstract:Decoder-only LLMs have shown impressive performance in MT due to their ability to learn from extensive datasets and generate high-quality translations. However, LLMs often struggle with the nuances and style required for organisation-specific translation. In this study, we explore the effectiveness of fine-tuning Large Language Models (LLMs), particularly Llama 3 8B Instruct, leveraging translation memories (TMs), as a valuable resource to enhance accuracy and efficiency. We investigate the impact of fine-tuning the Llama 3 model using TMs from a specific organisation in the software sector. Our experiments cover five translation directions across languages of varying resource levels (English to Brazilian Portuguese, Czech, German, Finnish, and Korean). We analyse diverse sizes of training datasets (1k to 207k segments) to evaluate their influence on translation quality. We fine-tune separate models for each training set and evaluate their performance based on automatic metrics, BLEU, chrF++, TER, and COMET. Our findings reveal improvement in translation performance with larger datasets across all metrics. On average, BLEU and COMET scores increase by 13 and 25 points, respectively, on the largest training set against the baseline model. Notably, there is a performance deterioration in comparison with the baseline model when fine-tuning on only 1k and 2k examples; however, we observe a substantial improvement as the training dataset size increases. The study highlights the potential of integrating TMs with LLMs to create bespoke translation models tailored to the specific needs of businesses, thus enhancing translation quality and reducing turn-around times. This approach offers a valuable insight for organisations seeking to leverage TMs and LLMs for optimal translation outcomes, especially in narrower domains.
+
+
+
+ 17. 【2409.03444】Fine-tuning large language models for domain adaptation: Exploration of training strategies, scaling, model merging and synergistic capabilities
+ 链接:https://arxiv.org/abs/2409.03444
+ 作者:Wei Lu,Rachel K. Luu,Markus J. Buehler
+ 类目:Computation and Language (cs.CL); Materials Science (cond-mat.mtrl-sci); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, Large Language, Direct Preference Optimization, Ratio Preference Optimization, Odds Ratio Preference
+ 备注:
+
+ 点击查看摘要
+ Abstract:The advancement of Large Language Models (LLMs) for domain applications in fields such as materials science and engineering depends on the development of fine-tuning strategies that adapt models for specialized, technical capabilities. In this work, we explore the effects of Continued Pretraining (CPT), Supervised Fine-Tuning (SFT), and various preference-based optimization approaches, including Direct Preference Optimization (DPO) and Odds Ratio Preference Optimization (ORPO), on fine-tuned LLM performance. Our analysis shows how these strategies influence model outcomes and reveals that the merging of multiple fine-tuned models can lead to the emergence of capabilities that surpass the individual contributions of the parent models. We find that model merging leads to new functionalities that neither parent model could achieve alone, leading to improved performance in domain-specific assessments. Experiments with different model architectures are presented, including Llama 3.1 8B and Mistral 7B models, where similar behaviors are observed. Exploring whether the results hold also for much smaller models, we use a tiny LLM with 1.7 billion parameters and show that very small LLMs do not necessarily feature emergent capabilities under model merging, suggesting that model scaling may be a key component. In open-ended yet consistent chat conversations between a human and AI models, our assessment reveals detailed insights into how different model variants perform and show that the smallest model achieves a high intelligence score across key criteria including reasoning depth, creativity, clarity, and quantitative precision. Other experiments include the development of image generation prompts based on disparate biological material design concepts, to create new microstructures, architectural concepts, and urban design based on biological materials-inspired construction principles.
+
+
+
+ 18. 【2409.03440】Rx Strategist: Prescription Verification using LLM Agents System
+ 链接:https://arxiv.org/abs/2409.03440
+ 作者:Phuc Phan Van,Dat Nguyen Minh,An Dinh Ngoc,Huy Phan Thanh
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, protect patient safety, pharmaceutical complexity demands, complexity demands strict, modern pharmaceutical complexity
+ 备注: 17 Pages, 6 Figures, Under Review
+
+ 点击查看摘要
+ Abstract:To protect patient safety, modern pharmaceutical complexity demands strict prescription verification. We offer a new approach - Rx Strategist - that makes use of knowledge graphs and different search strategies to enhance the power of Large Language Models (LLMs) inside an agentic framework. This multifaceted technique allows for a multi-stage LLM pipeline and reliable information retrieval from a custom-built active ingredient database. Different facets of prescription verification, such as indication, dose, and possible drug interactions, are covered in each stage of the pipeline. We alleviate the drawbacks of monolithic LLM techniques by spreading reasoning over these stages, improving correctness and reliability while reducing memory demands. Our findings demonstrate that Rx Strategist surpasses many current LLMs, achieving performance comparable to that of a highly experienced clinical pharmacist. In the complicated world of modern medications, this combination of LLMs with organized knowledge and sophisticated search methods presents a viable avenue for reducing prescription errors and enhancing patient outcomes.
+
+
+
+ 19. 【2409.03381】CogniDual Framework: Self-Training Large Language Models within a Dual-System Theoretical Framework for Improving Cognitive Tasks
+ 链接:https://arxiv.org/abs/2409.03381
+ 作者:Yongxin Deng(1),Xihe Qiu(1),Xiaoyu Tan(2),Chao Qu(2),Jing Pan(3),Yuan Cheng(3),Yinghui Xu(4),Wei Chu(2) ((1) School of Electronic and Electrical Engineering, Shanghai University of Engineering Science, Shanghai, China, (2) INF Technology (Shanghai) Co., Ltd., Shanghai, China, (3) School of Art, Design and Architecture, Monash University, Melbourne, Australia, (4) Artificial Intelligence Innovation and Incubation Institute, Fudan University, Shanghai, China)
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:psychology investigates perception, investigates perception, Cognitive psychology investigates, rational System, System
+ 备注:
+
+ 点击查看摘要
+ Abstract:Cognitive psychology investigates perception, attention, memory, language, problem-solving, decision-making, and reasoning. Kahneman's dual-system theory elucidates the human decision-making process, distinguishing between the rapid, intuitive System 1 and the deliberative, rational System 2. Recent advancements have positioned large language Models (LLMs) as formidable tools nearing human-level proficiency in various cognitive tasks. Nonetheless, the presence of a dual-system framework analogous to human cognition in LLMs remains unexplored. This study introduces the \textbf{CogniDual Framework for LLMs} (CFLLMs), designed to assess whether LLMs can, through self-training, evolve from deliberate deduction to intuitive responses, thereby emulating the human process of acquiring and mastering new information. Our findings reveal the cognitive mechanisms behind LLMs' response generation, enhancing our understanding of their capabilities in cognitive psychology. Practically, self-trained models can provide faster responses to certain queries, reducing computational demands during inference.
+
+
+
+ 20. 【2409.03375】Leveraging Large Language Models through Natural Language Processing to provide interpretable Machine Learning predictions of mental deterioration in real time
+ 链接:https://arxiv.org/abs/2409.03375
+ 作者:Francisco de Arriba-Pérez,Silvia García-Méndez
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:million people worldwide, Based on official, million people, natural language analysis, official estimates
+ 备注:
+
+ 点击查看摘要
+ Abstract:Based on official estimates, 50 million people worldwide are affected by dementia, and this number increases by 10 million new patients every year. Without a cure, clinical prognostication and early intervention represent the most effective ways to delay its progression. To this end, Artificial Intelligence and computational linguistics can be exploited for natural language analysis, personalized assessment, monitoring, and treatment. However, traditional approaches need more semantic knowledge management and explicability capabilities. Moreover, using Large Language Models (LLMs) for cognitive decline diagnosis is still scarce, even though these models represent the most advanced way for clinical-patient communication using intelligent systems. Consequently, we leverage an LLM using the latest Natural Language Processing (NLP) techniques in a chatbot solution to provide interpretable Machine Learning prediction of cognitive decline in real-time. Linguistic-conceptual features are exploited for appropriate natural language analysis. Through explainability, we aim to fight potential biases of the models and improve their potential to help clinical workers in their diagnosis decisions. More in detail, the proposed pipeline is composed of (i) data extraction employing NLP-based prompt engineering; (ii) stream-based data processing including feature engineering, analysis, and selection; (iii) real-time classification; and (iv) the explainability dashboard to provide visual and natural language descriptions of the prediction outcome. Classification results exceed 80 % in all evaluation metrics, with a recall value for the mental deterioration class about 85 %. To sum up, we contribute with an affordable, flexible, non-invasive, personalized diagnostic system to this work.
+
+
+
+ 21. 【2409.03363】Con-ReCall: Detecting Pre-training Data in LLMs via Contrastive Decoding
+ 链接:https://arxiv.org/abs/2409.03363
+ 作者:Cheng Wang,Yiwei Wang,Bryan Hooi,Yujun Cai,Nanyun Peng,Kai-Wei Chang
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language models, security risks, large language, language models, models is key
+ 备注:
+
+ 点击查看摘要
+ Abstract:The training data in large language models is key to their success, but it also presents privacy and security risks, as it may contain sensitive information. Detecting pre-training data is crucial for mitigating these concerns. Existing methods typically analyze target text in isolation or solely with non-member contexts, overlooking potential insights from simultaneously considering both member and non-member contexts. While previous work suggested that member contexts provide little information due to the minor distributional shift they induce, our analysis reveals that these subtle shifts can be effectively leveraged when contrasted with non-member contexts. In this paper, we propose Con-ReCall, a novel approach that leverages the asymmetric distributional shifts induced by member and non-member contexts through contrastive decoding, amplifying subtle differences to enhance membership inference. Extensive empirical evaluations demonstrate that Con-ReCall achieves state-of-the-art performance on the WikiMIA benchmark and is robust against various text manipulation techniques.
+
+
+
+ 22. 【2409.03346】Sketch: A Toolkit for Streamlining LLM Operations
+ 链接:https://arxiv.org/abs/2409.03346
+ 作者:Xin Jiang,Xiang Li,Wenjia Ma,Xuezhi Fang,Yiqun Yao,Naitong Yu,Xuying Meng,Peng Han,Jing Li,Aixin Sun,Yequan Wang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large language models, achieved remarkable success, represented by GPT, Large language, GPT family
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) represented by GPT family have achieved remarkable success. The characteristics of LLMs lie in their ability to accommodate a wide range of tasks through a generative approach. However, the flexibility of their output format poses challenges in controlling and harnessing the model's outputs, thereby constraining the application of LLMs in various domains. In this work, we present Sketch, an innovative toolkit designed to streamline LLM operations across diverse fields. Sketch comprises the following components: (1) a suite of task description schemas and prompt templates encompassing various NLP tasks; (2) a user-friendly, interactive process for building structured output LLM services tailored to various NLP tasks; (3) an open-source dataset for output format control, along with tools for dataset construction; and (4) an open-source model based on LLaMA3-8B-Instruct that adeptly comprehends and adheres to output formatting instructions. We anticipate this initiative to bring considerable convenience to LLM users, achieving the goal of ''plug-and-play'' for various applications. The components of Sketch will be progressively open-sourced at this https URL.
+
+
+
+ 23. 【2409.03327】Normal forms in Virus Machines
+ 链接:https://arxiv.org/abs/2409.03327
+ 作者:A. Ramírez-de-Arellano,F. G. C. Cabarle,D. Orellana-Martín,M. J. Pérez-Jiménez
+ 类目:Computation and Language (cs.CL); Formal Languages and Automata Theory (cs.FL)
+ 关键词:study the computational, virus machines, normal forms, VMs, present work
+ 备注:
+
+ 点击查看摘要
+ Abstract:In the present work, we further study the computational power of virus machines (VMs in short). VMs provide a computing paradigm inspired by the transmission and replication networks of viruses. VMs consist of process units (called hosts) structured by a directed graph whose arcs are called channels and an instruction graph that controls the transmissions of virus objects among hosts. The present work complements our understanding of the computing power of VMs by introducing normal forms; these expressions restrict the features in a given computing model. Some of the features that we restrict in our normal forms include (a) the number of hosts, (b) the number of instructions, and (c) the number of virus objects in each host. After we recall some known results on the computing power of VMs we give our normal forms, such as the size of the loops in the network, proving new characterisations of family of sets, such as the finite sets, semilinear sets, or NRE.
+
+
+
+ 24. 【2409.03295】N-gram Prediction and Word Difference Representations for Language Modeling
+ 链接:https://arxiv.org/abs/2409.03295
+ 作者:DongNyeong Heo,Daniela Noemi Rim,Heeyoul Choi
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Causal language modeling, underpinning remarkable successes, recent large language, foundational framework underpinning, framework underpinning remarkable
+ 备注:
+
+ 点击查看摘要
+ Abstract:Causal language modeling (CLM) serves as the foundational framework underpinning remarkable successes of recent large language models (LLMs). Despite its success, the training approach for next word prediction poses a potential risk of causing the model to overly focus on local dependencies within a sentence. While prior studies have been introduced to predict future N words simultaneously, they were primarily applied to tasks such as masked language modeling (MLM) and neural machine translation (NMT). In this study, we introduce a simple N-gram prediction framework for the CLM task. Moreover, we introduce word difference representation (WDR) as a surrogate and contextualized target representation during model training on the basis of N-gram prediction framework. To further enhance the quality of next word prediction, we propose an ensemble method that incorporates the future N words' prediction results. Empirical evaluations across multiple benchmark datasets encompassing CLM and NMT tasks demonstrate the significant advantages of our proposed methods over the conventional CLM.
+
+
+
+ 25. 【2409.03291】LLM Detectors Still Fall Short of Real World: Case of LLM-Generated Short News-Like Posts
+ 链接:https://arxiv.org/abs/2409.03291
+ 作者:Henrique Da Silva Gameiro,Andrei Kucharavy,Ljiljana Dolamic
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Cryptography and Security (cs.CR); Machine Learning (cs.LG)
+ 关键词:large Language Models, Language Models, major concern, emergence of widely, widely available powerful
+ 备注: 20 pages, 7 tables, 13 figures, under consideration for EMNLP
+
+ 点击查看摘要
+ Abstract:With the emergence of widely available powerful LLMs, disinformation generated by large Language Models (LLMs) has become a major concern. Historically, LLM detectors have been touted as a solution, but their effectiveness in the real world is still to be proven. In this paper, we focus on an important setting in information operations -- short news-like posts generated by moderately sophisticated attackers.
+We demonstrate that existing LLM detectors, whether zero-shot or purpose-trained, are not ready for real-world use in that setting. All tested zero-shot detectors perform inconsistently with prior benchmarks and are highly vulnerable to sampling temperature increase, a trivial attack absent from recent benchmarks. A purpose-trained detector generalizing across LLMs and unseen attacks can be developed, but it fails to generalize to new human-written texts.
+We argue that the former indicates domain-specific benchmarking is needed, while the latter suggests a trade-off between the adversarial evasion resilience and overfitting to the reference human text, with both needing evaluation in benchmarks and currently absent. We believe this suggests a re-consideration of current LLM detector benchmarking approaches and provides a dynamically extensible benchmark to allow it (this https URL).
+
Comments:
+20 pages, 7 tables, 13 figures, under consideration for EMNLP
+Subjects:
+Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Cryptography and Security (cs.CR); Machine Learning (cs.LG)
+ACMclasses:
+I.2.7; K.6.5
+Cite as:
+arXiv:2409.03291 [cs.CL]
+(or
+arXiv:2409.03291v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2409.03291
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 26. 【2409.03284】xt2KG: Incremental Knowledge Graphs Construction Using Large Language Models
+ 链接:https://arxiv.org/abs/2409.03284
+ 作者:Yassir Lairgi,Ludovic Moncla,Rémy Cazabet,Khalid Benabdeslem,Pierre Cléau
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:access valuable information, challenging to access, access valuable, making it challenging, building Knowledge Graphs
+ 备注: Accepted at The International Web Information Systems Engineering conference (the WISE conference) 2024
+
+ 点击查看摘要
+ Abstract:Most available data is unstructured, making it challenging to access valuable information. Automatically building Knowledge Graphs (KGs) is crucial for structuring data and making it accessible, allowing users to search for information effectively. KGs also facilitate insights, inference, and reasoning. Traditional NLP methods, such as named entity recognition and relation extraction, are key in information retrieval but face limitations, including the use of predefined entity types and the need for supervised learning. Current research leverages large language models' capabilities, such as zero- or few-shot learning. However, unresolved and semantically duplicated entities and relations still pose challenges, leading to inconsistent graphs and requiring extensive post-processing. Additionally, most approaches are topic-dependent. In this paper, we propose iText2KG, a method for incremental, topic-independent KG construction without post-processing. This plug-and-play, zero-shot method is applicable across a wide range of KG construction scenarios and comprises four modules: Document Distiller, Incremental Entity Extractor, Incremental Relation Extractor, and Graph Integrator and Visualization. Our method demonstrates superior performance compared to baseline methods across three scenarios: converting scientific papers to graphs, websites to graphs, and CVs to graphs.
+
+
+
+ 27. 【2409.03277】ChartMoE: Mixture of Expert Connector for Advanced Chart Understanding
+ 链接:https://arxiv.org/abs/2409.03277
+ 作者:Zhengzhuo Xu,Bowen Qu,Yiyan Qi,Sinan Du,Chengjin Xu,Chun Yuan,Jian Guo
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Automatic chart understanding, Automatic chart, document parsing, chart understanding, crucial for content
+ 备注:
+
+ 点击查看摘要
+ Abstract:Automatic chart understanding is crucial for content comprehension and document parsing. Multimodal large language models (MLLMs) have demonstrated remarkable capabilities in chart understanding through domain-specific alignment and fine-tuning. However, the application of alignment training within the chart domain is still underexplored. To address this, we propose ChartMoE, which employs the mixture of expert (MoE) architecture to replace the traditional linear projector to bridge the modality gap. Specifically, we train multiple linear connectors through distinct alignment tasks, which are utilized as the foundational initialization parameters for different experts. Additionally, we introduce ChartMoE-Align, a dataset with over 900K chart-table-JSON-code quadruples to conduct three alignment tasks (chart-table/JSON/code). Combined with the vanilla connector, we initialize different experts in four distinct ways and adopt high-quality knowledge learning to further refine the MoE connector and LLM parameters. Extensive experiments demonstrate the effectiveness of the MoE connector and our initialization strategy, e.g., ChartMoE improves the accuracy of the previous state-of-the-art from 80.48% to 84.64% on the ChartQA benchmark.
+
+
+
+ 28. 【2409.03271】Strategic Chain-of-Thought: Guiding Accurate Reasoning in LLMs through Strategy Elicitation
+ 链接:https://arxiv.org/abs/2409.03271
+ 作者:Yu Wang,Shiwan Zhao,Zhihu Wang,Heyuan Huang,Ming Fan,Yubo Zhang,Zhixing Wang,Haijun Wang,Ting Liu
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Human-Computer Interaction (cs.HC)
+ 关键词:large language models, paradigm has emerged, capabilities of large, large language, LLM performance
+ 备注:
+
+ 点击查看摘要
+ Abstract:The Chain-of-Thought (CoT) paradigm has emerged as a critical approach for enhancing the reasoning capabilities of large language models (LLMs). However, despite their widespread adoption and success, CoT methods often exhibit instability due to their inability to consistently ensure the quality of generated reasoning paths, leading to sub-optimal reasoning performance. To address this challenge, we propose the \textbf{Strategic Chain-of-Thought} (SCoT), a novel methodology designed to refine LLM performance by integrating strategic knowledge prior to generating intermediate reasoning steps. SCoT employs a two-stage approach within a single prompt: first eliciting an effective problem-solving strategy, which is then used to guide the generation of high-quality CoT paths and final answers. Our experiments across eight challenging reasoning datasets demonstrate significant improvements, including a 21.05\% increase on the GSM8K dataset and 24.13\% on the Tracking\_Objects dataset, respectively, using the Llama3-8b model. Additionally, we extend the SCoT framework to develop a few-shot method with automatically matched demonstrations, yielding even stronger results. These findings underscore the efficacy of SCoT, highlighting its potential to substantially enhance LLM performance in complex reasoning tasks.
+
+
+
+ 29. 【2409.03258】GraphInsight: Unlocking Insights in Large Language Models for Graph Structure Understanding
+ 链接:https://arxiv.org/abs/2409.03258
+ 作者:Yukun Cao,Shuo Han,Zengyi Gao,Zezhong Ding,Xike Xie,S. Kevin Zhou
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Language Models, Large Language, graph description sequences, description sequences
+ 备注:
+
+ 点击查看摘要
+ Abstract:Although Large Language Models (LLMs) have demonstrated potential in processing graphs, they struggle with comprehending graphical structure information through prompts of graph description sequences, especially as the graph size increases. We attribute this challenge to the uneven memory performance of LLMs across different positions in graph description sequences, known as ''positional biases''. To address this, we propose GraphInsight, a novel framework aimed at improving LLMs' comprehension of both macro- and micro-level graphical information. GraphInsight is grounded in two key strategies: 1) placing critical graphical information in positions where LLMs exhibit stronger memory performance, and 2) investigating a lightweight external knowledge base for regions with weaker memory performance, inspired by retrieval-augmented generation (RAG). Moreover, GraphInsight explores integrating these two strategies into LLM agent processes for composite graph tasks that require multi-step reasoning. Extensive empirical studies on benchmarks with a wide range of evaluation tasks show that GraphInsight significantly outperforms all other graph description methods (e.g., prompting techniques and reordering strategies) in understanding graph structures of varying sizes.
+
+
+
+ 30. 【2409.03257】Understanding LLM Development Through Longitudinal Study: Insights from the Open Ko-LLM Leaderboard
+ 链接:https://arxiv.org/abs/2409.03257
+ 作者:Chanjun Park,Hyeonwoo Kim
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Open Ko-LLM Leaderboard, Open Ko-LLM, restricted observation periods, Ko-LLM Leaderboard, eleven months
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper conducts a longitudinal study over eleven months to address the limitations of prior research on the Open Ko-LLM Leaderboard, which have relied on empirical studies with restricted observation periods of only five months. By extending the analysis duration, we aim to provide a more comprehensive understanding of the progression in developing Korean large language models (LLMs). Our study is guided by three primary research questions: (1) What are the specific challenges in improving LLM performance across diverse tasks on the Open Ko-LLM Leaderboard over time? (2) How does model size impact task performance correlations across various benchmarks? (3) How have the patterns in leaderboard rankings shifted over time on the Open Ko-LLM Leaderboard?. By analyzing 1,769 models over this period, our research offers a comprehensive examination of the ongoing advancements in LLMs and the evolving nature of evaluation frameworks.
+
+
+
+ 31. 【2409.03256】E2CL: Exploration-based Error Correction Learning for Embodied Agents
+ 链接:https://arxiv.org/abs/2409.03256
+ 作者:Hanlin Wang,Chak Tou Leong,Jian Wang,Wenjie Li
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:exhibiting increasing capability, Language models, utilization and reasoning, models are exhibiting, exhibiting increasing
+ 备注:
+
+ 点击查看摘要
+ Abstract:Language models are exhibiting increasing capability in knowledge utilization and reasoning. However, when applied as agents in embodied environments, they often suffer from misalignment between their intrinsic knowledge and environmental knowledge, leading to infeasible actions. Traditional environment alignment methods, such as supervised learning on expert trajectories and reinforcement learning, face limitations in covering environmental knowledge and achieving efficient convergence, respectively. Inspired by human learning, we propose Exploration-based Error Correction Learning (E2CL), a novel framework that leverages exploration-induced errors and environmental feedback to enhance environment alignment for LM-based agents. E2CL incorporates teacher-guided and teacher-free exploration to gather environmental feedback and correct erroneous actions. The agent learns to provide feedback and self-correct, thereby enhancing its adaptability to target environments. Evaluations in the Virtualhome environment demonstrate that E2CL-trained agents outperform those trained by baseline methods and exhibit superior self-correction capabilities.
+
+
+
+ 32. 【2409.03238】Preserving Empirical Probabilities in BERT for Small-sample Clinical Entity Recognition
+ 链接:https://arxiv.org/abs/2409.03238
+ 作者:Abdul Rehman,Jian Jun Zhang,Xiaosong Yang
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Named Entity Recognition, Entity Recognition, Named Entity, equitable entity recognition, encounters the challenge
+ 备注: 8 pages, 8 figures
+
+ 点击查看摘要
+ Abstract:Named Entity Recognition (NER) encounters the challenge of unbalanced labels, where certain entity types are overrepresented while others are underrepresented in real-world datasets. This imbalance can lead to biased models that perform poorly on minority entity classes, impeding accurate and equitable entity recognition. This paper explores the effects of unbalanced entity labels of the BERT-based pre-trained model. We analyze the different mechanisms of loss calculation and loss propagation for the task of token classification on randomized datasets. Then we propose ways to improve the token classification for the highly imbalanced task of clinical entity recognition.
+
+
+
+ 33. 【2409.03225】Enhancing Healthcare LLM Trust with Atypical Presentations Recalibration
+ 链接:https://arxiv.org/abs/2409.03225
+ 作者:Jeremy Qin,Bang Liu,Quoc Dinh Nguyen
+ 类目:Computation and Language (cs.CL)
+ 关键词:Black-box large language, large language models, making it essential, large language, increasingly deployed
+ 备注:
+
+ 点击查看摘要
+ Abstract:Black-box large language models (LLMs) are increasingly deployed in various environments, making it essential for these models to effectively convey their confidence and uncertainty, especially in high-stakes settings. However, these models often exhibit overconfidence, leading to potential risks and misjudgments. Existing techniques for eliciting and calibrating LLM confidence have primarily focused on general reasoning datasets, yielding only modest improvements. Accurate calibration is crucial for informed decision-making and preventing adverse outcomes but remains challenging due to the complexity and variability of tasks these models perform. In this work, we investigate the miscalibration behavior of black-box LLMs within the healthcare setting. We propose a novel method, \textit{Atypical Presentations Recalibration}, which leverages atypical presentations to adjust the model's confidence estimates. Our approach significantly improves calibration, reducing calibration errors by approximately 60\% on three medical question answering datasets and outperforming existing methods such as vanilla verbalized confidence, CoT verbalized confidence and others. Additionally, we provide an in-depth analysis of the role of atypicality within the recalibration framework.
+
+
+
+ 34. 【2409.03215】xLAM: A Family of Large Action Models to Empower AI Agent Systems
+ 链接:https://arxiv.org/abs/2409.03215
+ 作者:Jianguo Zhang,Tian Lan,Ming Zhu,Zuxin Liu,Thai Hoang,Shirley Kokane,Weiran Yao,Juntao Tan,Akshara Prabhakar,Haolin Chen,Zhiwei Liu,Yihao Feng,Tulika Awalgaonkar,Rithesh Murthy,Eric Hu,Zeyuan Chen,Ran Xu,Juan Carlos Niebles,Shelby Heinecke,Huan Wang,Silvio Savarese,Caiming Xiong
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:significant research interest, attracted significant research, research interest, agent tasks, Autonomous agents powered
+ 备注: Technical report for the Salesforce xLAM model series
+
+ 点击查看摘要
+ Abstract:Autonomous agents powered by large language models (LLMs) have attracted significant research interest. However, the open-source community faces many challenges in developing specialized models for agent tasks, driven by the scarcity of high-quality agent datasets and the absence of standard protocols in this area. We introduce and publicly release xLAM, a series of large action models designed for AI agent tasks. The xLAM series includes five models with both dense and mixture-of-expert architectures, ranging from 1B to 8x22B parameters, trained using a scalable, flexible pipeline that unifies, augments, and synthesizes diverse datasets to enhance AI agents' generalizability and performance across varied environments. Our experimental results demonstrate that xLAM consistently delivers exceptional performance across multiple agent ability benchmarks, notably securing the 1st position on the Berkeley Function-Calling Leaderboard, outperforming GPT-4, Claude-3, and many other models in terms of tool use. By releasing the xLAM series, we aim to advance the performance of open-source LLMs for autonomous AI agents, potentially accelerating progress and democratizing access to high-performance models for agent tasks. Models are available at this https URL
+
+
+
+ 35. 【2409.03203】An Effective Deployment of Diffusion LM for Data Augmentation in Low-Resource Sentiment Classification
+ 链接:https://arxiv.org/abs/2409.03203
+ 作者:Zhuowei Chen,Lianxi Wang,Yuben Wu,Xinfeng Liao,Yujia Tian,Junyang Zhong
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:imbalanced label distributions, imbalanced label, label distributions, Sentiment classification, language model
+ 备注:
+
+ 点击查看摘要
+ Abstract:Sentiment classification (SC) often suffers from low-resource challenges such as domain-specific contexts, imbalanced label distributions, and few-shot scenarios. The potential of the diffusion language model (LM) for textual data augmentation (DA) remains unexplored, moreover, textual DA methods struggle to balance the diversity and consistency of new samples. Most DA methods either perform logical modifications or rephrase less important tokens in the original sequence with the language model. In the context of SC, strong emotional tokens could act critically on the sentiment of the whole sequence. Therefore, contrary to rephrasing less important context, we propose DiffusionCLS to leverage a diffusion LM to capture in-domain knowledge and generate pseudo samples by reconstructing strong label-related tokens. This approach ensures a balance between consistency and diversity, avoiding the introduction of noise and augmenting crucial features of datasets. DiffusionCLS also comprises a Noise-Resistant Training objective to help the model generalize. Experiments demonstrate the effectiveness of our method in various low-resource scenarios including domain-specific and domain-general problems. Ablation studies confirm the effectiveness of our framework's modules, and visualization studies highlight optimal deployment conditions, reinforcing our conclusions.
+
+
+
+ 36. 【2409.03183】Bypassing DARCY Defense: Indistinguishable Universal Adversarial Triggers
+ 链接:https://arxiv.org/abs/2409.03183
+ 作者:Zuquan Peng,Yuanyuan He,Jianbing Ni,Ben Niu
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Natural Language Processing, Universal Adversarial Triggers, Neural networks, Universal Adversarial, Language Processing
+ 备注: 13 pages, 5 figures
+
+ 点击查看摘要
+ Abstract:Neural networks (NN) classification models for Natural Language Processing (NLP) are vulnerable to the Universal Adversarial Triggers (UAT) attack that triggers a model to produce a specific prediction for any input. DARCY borrows the "honeypot" concept to bait multiple trapdoors, effectively detecting the adversarial examples generated by UAT. Unfortunately, we find a new UAT generation method, called IndisUAT, which produces triggers (i.e., tokens) and uses them to craft adversarial examples whose feature distribution is indistinguishable from that of the benign examples in a randomly-chosen category at the detection layer of DARCY. The produced adversarial examples incur the maximal loss of predicting results in the DARCY-protected models. Meanwhile, the produced triggers are effective in black-box models for text generation, text inference, and reading comprehension. Finally, the evaluation results under NN models for NLP tasks indicate that the IndisUAT method can effectively circumvent DARCY and penetrate other defenses. For example, IndisUAT can reduce the true positive rate of DARCY's detection by at least 40.8% and 90.6%, and drop the accuracy by at least 33.3% and 51.6% in the RNN and CNN models, respectively. IndisUAT reduces the accuracy of the BERT's adversarial defense model by at least 34.0%, and makes the GPT-2 language model spew racist outputs even when conditioned on non-racial context.
+
+
+
+ 37. 【2409.03171】MARAGS: A Multi-Adapter System for Multi-Task Retrieval Augmented Generation Question Answering
+ 链接:https://arxiv.org/abs/2409.03171
+ 作者:Mitchell DeHaven
+ 类目:Computation and Language (cs.CL)
+ 关键词:Meta Comprehensive RAG, Meta Comprehensive, multi-adapter retrieval augmented, Comprehensive RAG, retrieval augmented generation
+ 备注: Accepted to CRAG KDD Cup 24 Workshop
+
+ 点击查看摘要
+ Abstract:In this paper we present a multi-adapter retrieval augmented generation system (MARAGS) for Meta's Comprehensive RAG (CRAG) competition for KDD CUP 2024. CRAG is a question answering dataset contains 3 different subtasks aimed at realistic question and answering RAG related tasks, with a diverse set of question topics, question types, time dynamic answers, and questions featuring entities of varying popularity.
+Our system follows a standard setup for web based RAG, which uses processed web pages to provide context for an LLM to produce generations, while also querying API endpoints for additional information. MARAGS also utilizes multiple different adapters to solve the various requirements for these tasks with a standard cross-encoder model for ranking candidate passages relevant for answering the question. Our system achieved 2nd place for Task 1 as well as 3rd place on Task 2.
+
Comments:
+Accepted to CRAG KDD Cup 24 Workshop
+Subjects:
+Computation and Language (cs.CL)
+Cite as:
+arXiv:2409.03171 [cs.CL]
+(or
+arXiv:2409.03171v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2409.03171
+Focus to learn more
+ arXiv-issued DOI via DataCite</p>
+
+
+
+
+ 38. 【2409.03166】Continual Skill and Task Learning via Dialogue
+ 链接:https://arxiv.org/abs/2409.03166
+ 作者:Weiwei Gu,Suresh Kondepudi,Lixiao Huang,Nakul Gopalan
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:sample efficiency, challenging problem, perpetually with sample, robot, skills
+ 备注:
+
+ 点击查看摘要
+ Abstract:Continual and interactive robot learning is a challenging problem as the robot is present with human users who expect the robot to learn novel skills to solve novel tasks perpetually with sample efficiency. In this work we present a framework for robots to query and learn visuo-motor robot skills and task relevant information via natural language dialog interactions with human users. Previous approaches either focus on improving the performance of instruction following agents, or passively learn novel skills or concepts. Instead, we used dialog combined with a language-skill grounding embedding to query or confirm skills and/or tasks requested by a user. To achieve this goal, we developed and integrated three different components for our agent. Firstly, we propose a novel visual-motor control policy ACT with Low Rank Adaptation (ACT-LoRA), which enables the existing SoTA ACT model to perform few-shot continual learning. Secondly, we develop an alignment model that projects demonstrations across skill embodiments into a shared embedding allowing us to know when to ask questions and/or demonstrations from users. Finally, we integrated an existing LLM to interact with a human user to perform grounded interactive continual skill learning to solve a task. Our ACT-LoRA model learns novel fine-tuned skills with a 100% accuracy when trained with only five demonstrations for a novel skill while still maintaining a 74.75% accuracy on pre-trained skills in the RLBench dataset where other models fall significantly short. We also performed a human-subjects study with 8 subjects to demonstrate the continual learning capabilities of our combined framework. We achieve a success rate of 75% in the task of sandwich making with the real robot learning from participant data demonstrating that robots can learn novel skills or task knowledge from dialogue with non-expert users using our approach.
+
+
+
+ 39. 【2409.03161】MaterialBENCH: Evaluating College-Level Materials Science Problem-Solving Abilities of Large Language Models
+ 链接:https://arxiv.org/abs/2409.03161
+ 作者:Michiko Yoshitake(1),Yuta Suzuki(2),Ryo Igarashi(1),Yoshitaka Ushiku(1),Keisuke Nagato(3) ((1) OMRON SINIC X, (2) Osaka Univ., (3) Univ. Tokyo)
+ 类目:Computation and Language (cs.CL)
+ 关键词:college-level benchmark dataset, materials science field, large language models, science field, college-level benchmark
+ 备注:
+
+ 点击查看摘要
+ Abstract:A college-level benchmark dataset for large language models (LLMs) in the materials science field, MaterialBENCH, is constructed. This dataset consists of problem-answer pairs, based on university textbooks. There are two types of problems: one is the free-response answer type, and the other is the multiple-choice type. Multiple-choice problems are constructed by adding three incorrect answers as choices to a correct answer, so that LLMs can choose one of the four as a response. Most of the problems for free-response answer and multiple-choice types overlap except for the format of the answers. We also conduct experiments using the MaterialBENCH on LLMs, including ChatGPT-3.5, ChatGPT-4, Bard (at the time of the experiments), and GPT-3.5 and GPT-4 with the OpenAI API. The differences and similarities in the performance of LLMs measured by the MaterialBENCH are analyzed and discussed. Performance differences between the free-response type and multiple-choice type in the same models and the influence of using system massages on multiple-choice problems are also studied. We anticipate that MaterialBENCH will encourage further developments of LLMs in reasoning abilities to solve more complicated problems and eventually contribute to materials research and discovery.
+
+
+
+ 40. 【2409.03155】Debate on Graph: a Flexible and Reliable Reasoning Framework for Large Language Models
+ 链接:https://arxiv.org/abs/2409.03155
+ 作者:Jie Ma,Zhitao Gao,Qi Chai,Wangchun Sun,Pinghui Wang,Hongbin Pei,Jing Tao,Lingyun Song,Jun Liu,Chen Zhang,Lizhen Cui
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, real-world applications due, knowledge graphs, Large Language, Language Models
+ 备注: 12 pages
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) may suffer from hallucinations in real-world applications due to the lack of relevant knowledge. In contrast, knowledge graphs encompass extensive, multi-relational structures that store a vast array of symbolic facts. Consequently, integrating LLMs with knowledge graphs has been extensively explored, with Knowledge Graph Question Answering (KGQA) serving as a critical touchstone for the integration. This task requires LLMs to answer natural language questions by retrieving relevant triples from knowledge graphs. However, existing methods face two significant challenges: \textit{excessively long reasoning paths distracting from the answer generation}, and \textit{false-positive relations hindering the path refinement}. In this paper, we propose an iterative interactive KGQA framework that leverages the interactive learning capabilities of LLMs to perform reasoning and Debating over Graphs (DoG). Specifically, DoG employs a subgraph-focusing mechanism, allowing LLMs to perform answer trying after each reasoning step, thereby mitigating the impact of lengthy reasoning paths. On the other hand, DoG utilizes a multi-role debate team to gradually simplify complex questions, reducing the influence of false-positive relations. This debate mechanism ensures the reliability of the reasoning process. Experimental results on five public datasets demonstrate the effectiveness and superiority of our architecture. Notably, DoG outperforms the state-of-the-art method ToG by 23.7\% and 9.1\% in accuracy on WebQuestions and GrailQA, respectively. Furthermore, the integration experiments with various LLMs on the mentioned datasets highlight the flexibility of DoG. Code is available at \url{this https URL}.
+
+
+
+ 41. 【2409.03140】GraphEx: A Graph-based Extraction Method for Advertiser Keyphrase Recommendation
+ 链接:https://arxiv.org/abs/2409.03140
+ 作者:Ashirbad Mishra,Soumik Dey,Marshall Wu,Jinyu Zhao,He Yu,Kaichen Ni,Binbin Li,Kamesh Madduri
+ 类目:Information Retrieval (cs.IR); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Extreme Multi-Label Classification, Online sellers, listed products, enhance their sales, advertisers are recommended
+ 备注:
+
+ 点击查看摘要
+ Abstract:Online sellers and advertisers are recommended keyphrases for their listed products, which they bid on to enhance their sales. One popular paradigm that generates such recommendations is Extreme Multi-Label Classification (XMC), which involves tagging/mapping keyphrases to items. We outline the limitations of using traditional item-query based tagging or mapping techniques for keyphrase recommendations on E-Commerce platforms. We introduce GraphEx, an innovative graph-based approach that recommends keyphrases to sellers using extraction of token permutations from item titles. Additionally, we demonstrate that relying on traditional metrics such as precision/recall can be misleading in practical applications, thereby necessitating a combination of metrics to evaluate performance in real-world scenarios. These metrics are designed to assess the relevance of keyphrases to items and the potential for buyer outreach. GraphEx outperforms production models at eBay, achieving the objectives mentioned above. It supports near real-time inferencing in resource-constrained production environments and scales effectively for billions of items.
+
+
+
+ 42. 【2409.03131】Well, that escalated quickly: The Single-Turn Crescendo Attack (STCA)
+ 链接:https://arxiv.org/abs/2409.03131
+ 作者:Alan Aqrawi
+ 类目:Cryptography and Security (cs.CR); Computation and Language (cs.CL)
+ 关键词:large language models, Single-Turn Crescendo Attack, multi-turn crescendo attack, crescendo attack established, Crescendo Attack
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper explores a novel approach to adversarial attacks on large language models (LLM): the Single-Turn Crescendo Attack (STCA). The STCA builds upon the multi-turn crescendo attack established by Mark Russinovich, Ahmed Salem, Ronen Eldan. Traditional multi-turn adversarial strategies gradually escalate the context to elicit harmful or controversial responses from LLMs. However, this paper introduces a more efficient method where the escalation is condensed into a single interaction. By carefully crafting the prompt to simulate an extended dialogue, the attack bypasses typical content moderation systems, leading to the generation of responses that would normally be filtered out. I demonstrate this technique through a few case studies. The results highlight vulnerabilities in current LLMs and underscore the need for more robust safeguards. This work contributes to the broader discourse on responsible AI (RAI) safety and adversarial testing, providing insights and practical examples for researchers and developers. This method is unexplored in the literature, making it a novel contribution to the field.
+
+
+
+ 43. 【2409.03115】Probing self-attention in self-supervised speech models for cross-linguistic differences
+ 链接:https://arxiv.org/abs/2409.03115
+ 作者:Sai Gopinath,Joselyn Rodriguez
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:gained traction, increase in accuracy, transformer architectures, Speech, models
+ 备注: 10 pages, 18 figures
+
+ 点击查看摘要
+ Abstract:Speech models have gained traction thanks to increase in accuracy from novel transformer architectures. While this impressive increase in performance across automatic speech recognition (ASR) benchmarks is noteworthy, there is still much that is unknown about the use of attention mechanisms for speech-related tasks. For example, while it is assumed that these models are learning language-independent (i.e., universal) speech representations, there has not yet been an in-depth exploration of what it would mean for the models to be language-independent. In the current paper, we explore this question within the realm of self-attention mechanisms of one small self-supervised speech transformer model (TERA). We find that even with a small model, the attention heads learned are diverse ranging from almost entirely diagonal to almost entirely global regardless of the training language. We highlight some notable differences in attention patterns between Turkish and English and demonstrate that the models do learn important phonological information during pretraining. We also present a head ablation study which shows that models across languages primarily rely on diagonal heads to classify phonemes.
+
+
+
+ 44. 【2409.03059】Quantification of stylistic differences in human- and ASR-produced transcripts of African American English
+ 链接:https://arxiv.org/abs/2409.03059
+ 作者:Annika Heuser,Tyler Kendall,Miguel del Rio,Quinten McNamara,Nishchal Bhandari,Corey Miller,Migüel Jetté
+ 类目:Computation and Language (cs.CL)
+ 关键词:conflate multiple sources, Common measures, automatic speech recognition, ASR performance evaluation, conflate multiple
+ 备注: Published in Interspeech 2024 Proceedings, 5 pages excluding references, 5 figures
+
+ 点击查看摘要
+ Abstract:Common measures of accuracy used to assess the performance of automatic speech recognition (ASR) systems, as well as human transcribers, conflate multiple sources of error. Stylistic differences, such as verbatim vs non-verbatim, can play a significant role in ASR performance evaluation when differences exist between training and test datasets. The problem is compounded for speech from underrepresented varieties, where the speech to orthography mapping is not as standardized. We categorize the kinds of stylistic differences between 6 transcription versions, 4 human- and 2 ASR-produced, of 10 hours of African American English (AAE) speech. Focusing on verbatim features and AAE morphosyntactic features, we investigate the interactions of these categories with how well transcripts can be compared via word error rate (WER). The results, and overall analysis, help clarify how ASR outputs are a function of the decisions made by the training data's human transcribers.
+
+
+
+ 45. 【2409.03046】Oddballness: universal anomaly detection with language models
+ 链接:https://arxiv.org/abs/2409.03046
+ 作者:Filip Graliński,Ryszard Staruch,Krzysztof Jurkiewicz
+ 类目:Computation and Language (cs.CL)
+ 关键词:totally unsupervised manner, language model, detect anomalies, unsupervised manner, totally unsupervised
+ 备注:
+
+ 点击查看摘要
+ Abstract:We present a new method to detect anomalies in texts (in general: in sequences of any data), using language models, in a totally unsupervised manner. The method considers probabilities (likelihoods) generated by a language model, but instead of focusing on low-likelihood tokens, it considers a new metric introduced in this paper: oddballness. Oddballness measures how ``strange'' a given token is according to the language model. We demonstrate in grammatical error detection tasks (a specific case of text anomaly detection) that oddballness is better than just considering low-likelihood events, if a totally unsupervised setup is assumed.
+
+
+
+ 46. 【2409.03021】CLUE: Concept-Level Uncertainty Estimation for Large Language Models
+ 链接:https://arxiv.org/abs/2409.03021
+ 作者:Yu-Hsiang Wang,Andrew Bai,Che-Ping Tsai,Cho-Jui Hsieh
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Large Language Models, Large Language, Language Models, natural language generation, demonstrated remarkable proficiency
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have demonstrated remarkable proficiency in various natural language generation (NLG) tasks. Previous studies suggest that LLMs' generation process involves uncertainty. However, existing approaches to uncertainty estimation mainly focus on sequence-level uncertainty, overlooking individual pieces of information within sequences. These methods fall short in separately assessing the uncertainty of each component in a sequence. In response, we propose a novel framework for Concept-Level Uncertainty Estimation (CLUE) for LLMs. We leverage LLMs to convert output sequences into concept-level representations, breaking down sequences into individual concepts and measuring the uncertainty of each concept separately. We conduct experiments to demonstrate that CLUE can provide more interpretable uncertainty estimation results compared with sentence-level uncertainty, and could be a useful tool for various tasks such as hallucination detection and story generation.
+
+
+
+ 47. 【2409.02976】Hallucination Detection in LLMs: Fast and Memory-Efficient Finetuned Models
+ 链接:https://arxiv.org/abs/2409.02976
+ 作者:Gabriel Y. Arteaga,Thomas B. Schön,Nicolas Pielawski
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Uncertainty estimation, high-risk settings, Large Language Models, autonomous cars, component when implementing
+ 备注: 5 pages, 3 figures
+
+ 点击查看摘要
+ Abstract:Uncertainty estimation is a necessary component when implementing AI in high-risk settings, such as autonomous cars, medicine, or insurances. Large Language Models (LLMs) have seen a surge in popularity in recent years, but they are subject to hallucinations, which may cause serious harm in high-risk settings. Despite their success, LLMs are expensive to train and run: they need a large amount of computations and memory, preventing the use of ensembling methods in practice. In this work, we present a novel method that allows for fast and memory-friendly training of LLM ensembles. We show that the resulting ensembles can detect hallucinations and are a viable approach in practice as only one GPU is needed for training and inference.
+
+
+信息检索
+
+ 1. 【2409.03753】WildVis: Open Source Visualizer for Million-Scale Chat Logs in the Wild
+ 链接:https://arxiv.org/abs/2409.03753
+ 作者:Yuntian Deng,Wenting Zhao,Jack Hessel,Xiang Ren,Claire Cardie,Yejin Choi
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Human-Computer Interaction (cs.HC); Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:offers exciting opportunities, data offers exciting, study user-chatbot interactions, conversation data offers, real-world conversation data
+ 备注:
+
+ 点击查看摘要
+ Abstract:The increasing availability of real-world conversation data offers exciting opportunities for researchers to study user-chatbot interactions. However, the sheer volume of this data makes manually examining individual conversations impractical. To overcome this challenge, we introduce WildVis, an interactive tool that enables fast, versatile, and large-scale conversation analysis. WildVis provides search and visualization capabilities in the text and embedding spaces based on a list of criteria. To manage million-scale datasets, we implemented optimizations including search index construction, embedding precomputation and compression, and caching to ensure responsive user interactions within seconds. We demonstrate WildVis's utility through three case studies: facilitating chatbot misuse research, visualizing and comparing topic distributions across datasets, and characterizing user-specific conversation patterns. WildVis is open-source and designed to be extendable, supporting additional datasets and customized search and visualization functionalities.
+
+
+
+ 2. 【2409.03708】RAG based Question-Answering for Contextual Response Prediction System
+ 链接:https://arxiv.org/abs/2409.03708
+ 作者:Sriram Veturi,Saurabh Vaichal,Nafis Irtiza Tripto,Reshma Lal Jagadheesh,Nian Yan
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:Large Language Models, Natural Language Processing, Large Language, Language Models, Language Processing
+ 备注: Accepted at the 1st Workshop on GenAI and RAG Systems for Enterprise, CIKM'24. 6 pages
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have shown versatility in various Natural Language Processing (NLP) tasks, including their potential as effective question-answering systems. However, to provide precise and relevant information in response to specific customer queries in industry settings, LLMs require access to a comprehensive knowledge base to avoid hallucinations. Retrieval Augmented Generation (RAG) emerges as a promising technique to address this challenge. Yet, developing an accurate question-answering framework for real-world applications using RAG entails several challenges: 1) data availability issues, 2) evaluating the quality of generated content, and 3) the costly nature of human evaluation. In this paper, we introduce an end-to-end framework that employs LLMs with RAG capabilities for industry use cases. Given a customer query, the proposed system retrieves relevant knowledge documents and leverages them, along with previous chat history, to generate response suggestions for customer service agents in the contact centers of a major retail company. Through comprehensive automated and human evaluations, we show that this solution outperforms the current BERT-based algorithms in accuracy and relevance. Our findings suggest that RAG-based LLMs can be an excellent support to human customer service representatives by lightening their workload.
+
+
+
+ 3. 【2409.03504】HGAMN: Heterogeneous Graph Attention Matching Network for Multilingual POI Retrieval at Baidu Maps
+ 链接:https://arxiv.org/abs/2409.03504
+ 作者:Jizhou Huang,Haifeng Wang,Yibo Sun,Miao Fan,Zhengjie Huang,Chunyuan Yuan,Yawen Li
+ 类目:Information Retrieval (cs.IR)
+ 关键词:Baidu Maps, increasing interest, interest in international, interests in multiple, international travel
+ 备注: Accepted by KDD'21
+
+ 点击查看摘要
+ Abstract:The increasing interest in international travel has raised the demand of retrieving point of interests in multiple languages. This is even superior to find local venues such as restaurants and scenic spots in unfamiliar languages when traveling abroad. Multilingual POI retrieval, enabling users to find desired POIs in a demanded language using queries in numerous languages, has become an indispensable feature of today's global map applications such as Baidu Maps. This task is non-trivial because of two key challenges: (1) visiting sparsity and (2) multilingual query-POI matching. To this end, we propose a Heterogeneous Graph Attention Matching Network (HGAMN) to concurrently address both challenges. Specifically, we construct a heterogeneous graph that contains two types of nodes: POI node and query node using the search logs of Baidu Maps. To alleviate challenge \#1, we construct edges between different POI nodes to link the low-frequency POIs with the high-frequency ones, which enables the transfer of knowledge from the latter to the former. To mitigate challenge \#2, we construct edges between POI and query nodes based on the co-occurrences between queries and POIs, where queries in different languages and formulations can be aggregated for individual POIs. Moreover, we develop an attention-based network to jointly learn node representations of the heterogeneous graph and further design a cross-attention module to fuse the representations of both types of nodes for query-POI relevance scoring. Extensive experiments conducted on large-scale real-world datasets from Baidu Maps demonstrate the superiority and effectiveness of HGAMN. In addition, HGAMN has already been deployed in production at Baidu Maps, and it successfully keeps serving hundreds of millions of requests every day.
+
+
+
+ 4. 【2409.03449】MOBIUS: Towards the Next Generation of Query-Ad Matching in Baidu's Sponsored Search
+ 链接:https://arxiv.org/abs/2409.03449
+ 作者:Miao Fan,Jiacheng Guo,Shuai Zhu,Shuo Miao,Mingming Sun,Ping Li
+ 类目:Information Retrieval (cs.IR)
+ 关键词:web search engine, largest commercial web, Baidu runs, commercial web search, sponsored search engine
+ 备注: Accepted by KDD'19
+
+ 点击查看摘要
+ Abstract:Baidu runs the largest commercial web search engine in China, serving hundreds of millions of online users every day in response to a great variety of queries. In order to build a high-efficiency sponsored search engine, we used to adopt a three-layer funnel-shaped structure to screen and sort hundreds of ads from billions of ad candidates subject to the requirement of low response latency and the restraints of computing resources. Given a user query, the top matching layer is responsible for providing semantically relevant ad candidates to the next layer, while the ranking layer at the bottom concerns more about business indicators (e.g., CPM, ROI, etc.) of those ads. The clear separation between the matching and ranking objectives results in a lower commercial return. The Mobius project has been established to address this serious issue. It is our first attempt to train the matching layer to consider CPM as an additional optimization objective besides the query-ad relevance, via directly predicting CTR (click-through rate) from billions of query-ad pairs. Specifically, this paper will elaborate on how we adopt active learning to overcome the insufficiency of click history at the matching layer when training our neural click networks offline, and how we use the SOTA ANN search technique for retrieving ads more efficiently (Here ``ANN'' stands for approximate nearest neighbor search). We contribute the solutions to Mobius-V1 as the first version of our next generation query-ad matching system.
+
+
+
+ 5. 【2409.03294】Federated Prototype-based Contrastive Learning for Privacy-Preserving Cross-domain Recommendation
+ 链接:https://arxiv.org/abs/2409.03294
+ 作者:Li Wang,Quangui Zhang,Lei Sang,Qiang Wu,Min Xu
+ 类目:Information Retrieval (cs.IR)
+ 关键词:Cross-domain recommendation, improve recommendation accuracy, recommendation accuracy, user, CDR
+ 备注:
+
+ 点击查看摘要
+ Abstract:Cross-domain recommendation (CDR) aims to improve recommendation accuracy in sparse domains by transferring knowledge from data-rich domains. However, existing CDR methods often assume the availability of user-item interaction data across domains, overlooking user privacy concerns. Furthermore, these methods suffer from performance degradation in scenarios with sparse overlapping users, as they typically depend on a large number of fully shared users for effective knowledge transfer. To address these challenges, we propose a Federated Prototype-based Contrastive Learning (CL) method for Privacy-Preserving CDR, named FedPCL-CDR. This approach utilizes non-overlapping user information and prototypes to improve multi-domain performance while protecting user privacy. FedPCL-CDR comprises two modules: local domain (client) learning and global server aggregation. In the local domain, FedPCL-CDR clusters all user data to learn representative prototypes, effectively utilizing non-overlapping user information and addressing the sparse overlapping user issue. It then facilitates knowledge transfer by employing both local and global prototypes returned from the server in a CL manner. Simultaneously, the global server aggregates representative prototypes from local domains to learn both local and global prototypes. The combination of prototypes and federated learning (FL) ensures that sensitive user data remains decentralized, with only prototypes being shared across domains, thereby protecting user privacy. Extensive experiments on four CDR tasks using two real-world datasets demonstrate that FedPCL-CDR outperforms the state-of-the-art baselines.
+
+
+
+ 6. 【2409.03284】xt2KG: Incremental Knowledge Graphs Construction Using Large Language Models
+ 链接:https://arxiv.org/abs/2409.03284
+ 作者:Yassir Lairgi,Ludovic Moncla,Rémy Cazabet,Khalid Benabdeslem,Pierre Cléau
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:access valuable information, challenging to access, access valuable, making it challenging, building Knowledge Graphs
+ 备注: Accepted at The International Web Information Systems Engineering conference (the WISE conference) 2024
+
+ 点击查看摘要
+ Abstract:Most available data is unstructured, making it challenging to access valuable information. Automatically building Knowledge Graphs (KGs) is crucial for structuring data and making it accessible, allowing users to search for information effectively. KGs also facilitate insights, inference, and reasoning. Traditional NLP methods, such as named entity recognition and relation extraction, are key in information retrieval but face limitations, including the use of predefined entity types and the need for supervised learning. Current research leverages large language models' capabilities, such as zero- or few-shot learning. However, unresolved and semantically duplicated entities and relations still pose challenges, leading to inconsistent graphs and requiring extensive post-processing. Additionally, most approaches are topic-dependent. In this paper, we propose iText2KG, a method for incremental, topic-independent KG construction without post-processing. This plug-and-play, zero-shot method is applicable across a wide range of KG construction scenarios and comprises four modules: Document Distiller, Incremental Entity Extractor, Incremental Relation Extractor, and Graph Integrator and Visualization. Our method demonstrates superior performance compared to baseline methods across three scenarios: converting scientific papers to graphs, websites to graphs, and CVs to graphs.
+
+
+
+ 7. 【2409.03140】GraphEx: A Graph-based Extraction Method for Advertiser Keyphrase Recommendation
+ 链接:https://arxiv.org/abs/2409.03140
+ 作者:Ashirbad Mishra,Soumik Dey,Marshall Wu,Jinyu Zhao,He Yu,Kaichen Ni,Binbin Li,Kamesh Madduri
+ 类目:Information Retrieval (cs.IR); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Extreme Multi-Label Classification, Online sellers, listed products, enhance their sales, advertisers are recommended
+ 备注:
+
+ 点击查看摘要
+ Abstract:Online sellers and advertisers are recommended keyphrases for their listed products, which they bid on to enhance their sales. One popular paradigm that generates such recommendations is Extreme Multi-Label Classification (XMC), which involves tagging/mapping keyphrases to items. We outline the limitations of using traditional item-query based tagging or mapping techniques for keyphrase recommendations on E-Commerce platforms. We introduce GraphEx, an innovative graph-based approach that recommends keyphrases to sellers using extraction of token permutations from item titles. Additionally, we demonstrate that relying on traditional metrics such as precision/recall can be misleading in practical applications, thereby necessitating a combination of metrics to evaluate performance in real-world scenarios. These metrics are designed to assess the relevance of keyphrases to items and the potential for buyer outreach. GraphEx outperforms production models at eBay, achieving the objectives mentioned above. It supports near real-time inferencing in resource-constrained production environments and scales effectively for billions of items.
+
+
+
+ 8. 【2409.02965】Do We Trust What They Say or What They Do? A Multimodal User Embedding Provides Personalized Explanations
+ 链接:https://arxiv.org/abs/2409.02965
+ 作者:Zhicheng Ren,Zhiping Xiao,Yizhou Sun
+ 类目:ocial and Information Networks (cs.SI); Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:analyzing social network, social network user, social media, network user data, user
+ 备注:
+
+ 点击查看摘要
+ Abstract:With the rapid development of social media, the importance of analyzing social network user data has also been put on the agenda. User representation learning in social media is a critical area of research, based on which we can conduct personalized content delivery, or detect malicious actors. Being more complicated than many other types of data, social network user data has inherent multimodal nature. Various multimodal approaches have been proposed to harness both text (i.e. post content) and relation (i.e. inter-user interaction) information to learn user embeddings of higher quality. The advent of Graph Neural Network models enables more end-to-end integration of user text embeddings and user interaction graphs in social networks. However, most of those approaches do not adequately elucidate which aspects of the data - text or graph structure information - are more helpful for predicting each specific user under a particular task, putting some burden on personalized downstream analysis and untrustworthy information filtering. We propose a simple yet effective framework called Contribution-Aware Multimodal User Embedding (CAMUE) for social networks. We have demonstrated with empirical evidence, that our approach can provide personalized explainable predictions, automatically mitigating the impact of unreliable information. We also conducted case studies to show how reasonable our results are. We observe that for most users, graph structure information is more trustworthy than text information, but there are some reasonable cases where text helps more. Our work paves the way for more explainable, reliable, and effective social media user embedding which allows for better personalized content delivery.
+
+
+计算机视觉
+
+ 1. 【2409.03757】Lexicon3D: Probing Visual Foundation Models for Complex 3D Scene Understanding
+ 链接:https://arxiv.org/abs/2409.03757
+ 作者:Yunze Man,Shuhong Zheng,Zhipeng Bao,Martial Hebert,Liang-Yan Gui,Yu-Xiong Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG); Robotics (cs.RO)
+ 关键词:gained increasing attention, scene encoding strategies, encoding strategies playing, increasing attention, gained increasing
+ 备注: Project page: [this https URL](https://yunzeman.github.io/lexicon3d) , Github: [this https URL](https://github.com/YunzeMan/Lexicon3D)
+
+ 点击查看摘要
+ Abstract:Complex 3D scene understanding has gained increasing attention, with scene encoding strategies playing a crucial role in this success. However, the optimal scene encoding strategies for various scenarios remain unclear, particularly compared to their image-based counterparts. To address this issue, we present a comprehensive study that probes various visual encoding models for 3D scene understanding, identifying the strengths and limitations of each model across different scenarios. Our evaluation spans seven vision foundation encoders, including image-based, video-based, and 3D foundation models. We evaluate these models in four tasks: Vision-Language Scene Reasoning, Visual Grounding, Segmentation, and Registration, each focusing on different aspects of scene understanding. Our evaluations yield key findings: DINOv2 demonstrates superior performance, video models excel in object-level tasks, diffusion models benefit geometric tasks, and language-pretrained models show unexpected limitations in language-related tasks. These insights challenge some conventional understandings, provide novel perspectives on leveraging visual foundation models, and highlight the need for more flexible encoder selection in future vision-language and scene-understanding tasks.
+
+
+
+ 2. 【2409.03755】DC-Solver: Improving Predictor-Corrector Diffusion Sampler via Dynamic Compensation
+ 链接:https://arxiv.org/abs/2409.03755
+ 作者:Wenliang Zhao,Haolin Wang,Jie Zhou,Jiwen Lu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Diffusion probabilistic models, computationally expensive due, shown remarkable performance, predictor-corrector diffusion samplers, probabilistic models
+ 备注: Accepted by ECCV 2024
+
+ 点击查看摘要
+ Abstract:Diffusion probabilistic models (DPMs) have shown remarkable performance in visual synthesis but are computationally expensive due to the need for multiple evaluations during the sampling. Recent predictor-corrector diffusion samplers have significantly reduced the required number of function evaluations (NFE), but inherently suffer from a misalignment issue caused by the extra corrector step, especially with a large classifier-free guidance scale (CFG). In this paper, we introduce a new fast DPM sampler called DC-Solver, which leverages dynamic compensation (DC) to mitigate the misalignment of the predictor-corrector samplers. The dynamic compensation is controlled by compensation ratios that are adaptive to the sampling steps and can be optimized on only 10 datapoints by pushing the sampling trajectory toward a ground truth trajectory. We further propose a cascade polynomial regression (CPR) which can instantly predict the compensation ratios on unseen sampling configurations. Additionally, we find that the proposed dynamic compensation can also serve as a plug-and-play module to boost the performance of predictor-only samplers. Extensive experiments on both unconditional sampling and conditional sampling demonstrate that our DC-Solver can consistently improve the sampling quality over previous methods on different DPMs with a wide range of resolutions up to 1024$\times$1024. Notably, we achieve 10.38 FID (NFE=5) on unconditional FFHQ and 0.394 MSE (NFE=5, CFG=7.5) on Stable-Diffusion-2.1. Code is available at this https URL
+
+
+
+ 3. 【2409.03754】Foundation Model or Finetune? Evaluation of few-shot semantic segmentation for river pollution
+ 链接:https://arxiv.org/abs/2409.03754
+ 作者:Marga Don,Stijn Pinson,Blanca Guillen Cebrian,Yuki M. Asano
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Foundation models, popular topic, topic of research, Foundation, Abstract
+ 备注: Accepted at ECCV 2024 Green Foundation Models workshop
+
+ 点击查看摘要
+ Abstract:Foundation models (FMs) are a popular topic of research in AI. Their ability to generalize to new tasks and datasets without retraining or needing an abundance of data makes them an appealing candidate for applications on specialist datasets. In this work, we compare the performance of FMs to finetuned pre-trained supervised models in the task of semantic segmentation on an entirely new dataset. We see that finetuned models consistently outperform the FMs tested, even in cases were data is scarce. We release the code and dataset for this work on GitHub.
+
+
+
+ 4. 【2409.03745】ArtiFade: Learning to Generate High-quality Subject from Blemished Images
+ 链接:https://arxiv.org/abs/2409.03745
+ 作者:Shuya Yang,Shaozhe Hao,Yukang Cao,Kwan-Yee K. Wong
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:witnessed remarkable advancements, generation has witnessed, witnessed remarkable, remarkable advancements, ability to learn
+ 备注:
+
+ 点击查看摘要
+ Abstract:Subject-driven text-to-image generation has witnessed remarkable advancements in its ability to learn and capture characteristics of a subject using only a limited number of images. However, existing methods commonly rely on high-quality images for training and may struggle to generate reasonable images when the input images are blemished by artifacts. This is primarily attributed to the inadequate capability of current techniques in distinguishing subject-related features from disruptive artifacts. In this paper, we introduce ArtiFade to tackle this issue and successfully generate high-quality artifact-free images from blemished datasets. Specifically, ArtiFade exploits fine-tuning of a pre-trained text-to-image model, aiming to remove artifacts. The elimination of artifacts is achieved by utilizing a specialized dataset that encompasses both unblemished images and their corresponding blemished counterparts during fine-tuning. ArtiFade also ensures the preservation of the original generative capabilities inherent within the diffusion model, thereby enhancing the overall performance of subject-driven methods in generating high-quality and artifact-free images. We further devise evaluation benchmarks tailored for this task. Through extensive qualitative and quantitative experiments, we demonstrate the generalizability of ArtiFade in effective artifact removal under both in-distribution and out-of-distribution scenarios.
+
+
+
+ 5. 【2409.03718】Geometry Image Diffusion: Fast and Data-Efficient Text-to-3D with Image-Based Surface Representation
+ 链接:https://arxiv.org/abs/2409.03718
+ 作者:Slava Elizarov,Ciara Rowles,Simon Donné
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:textual descriptions remains, challenging problem due, Geometry Image Diffusion, computational cost, Generating high-quality
+ 备注: 11 pages, 9 figures, Project page: [this https URL](https://unity-research.github.io/Geometry-Image-Diffusion.github.io/)
+
+ 点击查看摘要
+ Abstract:Generating high-quality 3D objects from textual descriptions remains a challenging problem due to computational cost, the scarcity of 3D data, and complex 3D representations. We introduce Geometry Image Diffusion (GIMDiffusion), a novel Text-to-3D model that utilizes geometry images to efficiently represent 3D shapes using 2D images, thereby avoiding the need for complex 3D-aware architectures. By integrating a Collaborative Control mechanism, we exploit the rich 2D priors of existing Text-to-Image models such as Stable Diffusion. This enables strong generalization even with limited 3D training data (allowing us to use only high-quality training data) as well as retaining compatibility with guidance techniques such as IPAdapter. In short, GIMDiffusion enables the generation of 3D assets at speeds comparable to current Text-to-Image models. The generated objects consist of semantically meaningful, separate parts and include internal structures, enhancing both usability and versatility.
+
+
+
+ 6. 【2409.03685】View-Invariant Policy Learning via Zero-Shot Novel View Synthesis
+ 链接:https://arxiv.org/abs/2409.03685
+ 作者:Stephen Tian,Blake Wulfe,Kyle Sargent,Katherine Liu,Sergey Zakharov,Vitor Guizilini,Jiajun Wu
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Large-scale visuomotor policy, visuomotor policy learning, generalizable manipulation systems, visuomotor policy, promising approach
+ 备注: Accepted to CoRL 2024
+
+ 点击查看摘要
+ Abstract:Large-scale visuomotor policy learning is a promising approach toward developing generalizable manipulation systems. Yet, policies that can be deployed on diverse embodiments, environments, and observational modalities remain elusive. In this work, we investigate how knowledge from large-scale visual data of the world may be used to address one axis of variation for generalizable manipulation: observational viewpoint. Specifically, we study single-image novel view synthesis models, which learn 3D-aware scene-level priors by rendering images of the same scene from alternate camera viewpoints given a single input image. For practical application to diverse robotic data, these models must operate zero-shot, performing view synthesis on unseen tasks and environments. We empirically analyze view synthesis models within a simple data-augmentation scheme that we call View Synthesis Augmentation (VISTA) to understand their capabilities for learning viewpoint-invariant policies from single-viewpoint demonstration data. Upon evaluating the robustness of policies trained with our method to out-of-distribution camera viewpoints, we find that they outperform baselines in both simulated and real-world manipulation tasks. Videos and additional visualizations are available at this https URL.
+
+
+
+ 7. 【2409.03644】RealisHuman: A Two-Stage Approach for Refining Malformed Human Parts in Generated Images
+ 链接:https://arxiv.org/abs/2409.03644
+ 作者:Benzhi Wang,Jingkai Zhou,Jingqi Bai,Yang Yang,Weihua Chen,Fan Wang,Zhen Lei
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Generative Adversarial Networks, Adversarial Networks, Generative Adversarial, outperforming traditional frameworks, revolutionized visual generation
+ 备注:
+
+ 点击查看摘要
+ Abstract:In recent years, diffusion models have revolutionized visual generation, outperforming traditional frameworks like Generative Adversarial Networks (GANs). However, generating images of humans with realistic semantic parts, such as hands and faces, remains a significant challenge due to their intricate structural complexity. To address this issue, we propose a novel post-processing solution named RealisHuman. The RealisHuman framework operates in two stages. First, it generates realistic human parts, such as hands or faces, using the original malformed parts as references, ensuring consistent details with the original image. Second, it seamlessly integrates the rectified human parts back into their corresponding positions by repainting the surrounding areas to ensure smooth and realistic blending. The RealisHuman framework significantly enhances the realism of human generation, as demonstrated by notable improvements in both qualitative and quantitative metrics. Code is available at this https URL.
+
+
+
+ 8. 【2409.03643】CDM: A Reliable Metric for Fair and Accurate Formula Recognition Evaluation
+ 链接:https://arxiv.org/abs/2409.03643
+ 作者:Bin Wang,Fan Wu,Linke Ouyang,Zhuangcheng Gu,Rui Zhang,Renqiu Xia,Bo Zhang,Conghui He
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:presents significant challenges, significant challenges due, recognition presents significant, Formula recognition presents, Formula recognition
+ 备注: Project Website: [this https URL](https://github.com/opendatalab/UniMERNet/tree/main/cdm)
+
+ 点击查看摘要
+ Abstract:Formula recognition presents significant challenges due to the complicated structure and varied notation of mathematical expressions. Despite continuous advancements in formula recognition models, the evaluation metrics employed by these models, such as BLEU and Edit Distance, still exhibit notable limitations. They overlook the fact that the same formula has diverse representations and is highly sensitive to the distribution of training data, thereby causing the unfairness in formula recognition evaluation. To this end, we propose a Character Detection Matching (CDM) metric, ensuring the evaluation objectivity by designing a image-level rather than LaTex-level metric score. Specifically, CDM renders both the model-predicted LaTeX and the ground-truth LaTeX formulas into image-formatted formulas, then employs visual feature extraction and localization techniques for precise character-level matching, incorporating spatial position information. Such a spatially-aware and character-matching method offers a more accurate and equitable evaluation compared with previous BLEU and Edit Distance metrics that rely solely on text-based character matching. Experimentally, we evaluated various formula recognition models using CDM, BLEU, and ExpRate metrics. Their results demonstrate that the CDM aligns more closely with human evaluation standards and provides a fairer comparison across different models by eliminating discrepancies caused by diverse formula representations.
+
+
+
+ 9. 【2409.03634】Surface-Centric Modeling for High-Fidelity Generalizable Neural Surface Reconstruction
+ 链接:https://arxiv.org/abs/2409.03634
+ 作者:Rui Peng,Shihe Shen,Kaiqiang Xiong,Huachen Gao,Jianbo Jiao,Xiaodong Gu,Ronggang Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:attracted widespread attention, Reconstructing the high-fidelity, multi-view images, recent years, critical and practical
+ 备注: ECCV 2024 Accepted
+
+ 点击查看摘要
+ Abstract:Reconstructing the high-fidelity surface from multi-view images, especially sparse images, is a critical and practical task that has attracted widespread attention in recent years. However, existing methods are impeded by the memory constraint or the requirement of ground-truth depths and cannot recover satisfactory geometric details. To this end, we propose SuRF, a new Surface-centric framework that incorporates a new Region sparsification based on a matching Field, achieving good trade-offs between performance, efficiency and scalability. To our knowledge, this is the first unsupervised method achieving end-to-end sparsification powered by the introduced matching field, which leverages the weight distribution to efficiently locate the boundary regions containing surface. Instead of predicting an SDF value for each voxel, we present a new region sparsification approach to sparse the volume by judging whether the voxel is inside the surface region. In this way, our model can exploit higher frequency features around the surface with less memory and computational consumption. Extensive experiments on multiple benchmarks containing complex large-scale scenes show that our reconstructions exhibit high-quality details and achieve new state-of-the-art performance, i.e., 46% improvements with 80% less memory consumption. Code is available at this https URL.
+
+
+
+ 10. 【2409.03605】SegTalker: Segmentation-based Talking Face Generation with Mask-guided Local Editing
+ 链接:https://arxiv.org/abs/2409.03605
+ 作者:Lingyu Xiong,Xize Cheng,Jintao Tan,Xianjia Wu,Xiandong Li,Lei Zhu,Fei Ma,Minglei Li,Huang Xu,Zhihu Hu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:Audio-driven talking face, face generation aims, Audio-driven talking, input audio, talking face generation
+ 备注: 10 pages, 7 figures, 3 tables
+
+ 点击查看摘要
+ Abstract:Audio-driven talking face generation aims to synthesize video with lip movements synchronized to input audio. However, current generative techniques face challenges in preserving intricate regional textures (skin, teeth). To address the aforementioned challenges, we propose a novel framework called SegTalker to decouple lip movements and image textures by introducing segmentation as intermediate representation. Specifically, given the mask of image employed by a parsing network, we first leverage the speech to drive the mask and generate talking segmentation. Then we disentangle semantic regions of image into style codes using a mask-guided encoder. Ultimately, we inject the previously generated talking segmentation and style codes into a mask-guided StyleGAN to synthesize video frame. In this way, most of textures are fully preserved. Moreover, our approach can inherently achieve background separation and facilitate mask-guided facial local editing. In particular, by editing the mask and swapping the region textures from a given reference image (e.g. hair, lip, eyebrows), our approach enables facial editing seamlessly when generating talking face video. Experiments demonstrate that our proposed approach can effectively preserve texture details and generate temporally consistent video while remaining competitive in lip synchronization. Quantitative and qualitative results on the HDTF and MEAD datasets illustrate the superior performance of our method over existing methods.
+
+
+
+ 11. 【2409.03600】CDiff: Triple Condition Diffusion Model with 3D Constraints for Stylizing Synthetic Faces
+ 链接:https://arxiv.org/abs/2409.03600
+ 作者:Bernardo Biesseck,Pedro Vidal,Luiz Coelho,Roger Granada,David Menotti|
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Condition Diffusion Model, Triple Condition Diffusion, include a large, large number, numerous samples
+ 备注: SIBGRAPI 2024
+
+ 点击查看摘要
+ Abstract:A robust face recognition model must be trained using datasets that include a large number of subjects and numerous samples per subject under varying conditions (such as pose, expression, age, noise, and occlusion). Due to ethical and privacy concerns, large-scale real face datasets have been discontinued, such as MS1MV3, and synthetic face generators have been proposed, utilizing GANs and Diffusion Models, such as SYNFace, SFace, DigiFace-1M, IDiff-Face, DCFace, and GANDiffFace, aiming to supply this demand. Some of these methods can produce high-fidelity realistic faces, but with low intra-class variance, while others generate high-variance faces with low identity consistency. In this paper, we propose a Triple Condition Diffusion Model (TCDiff) to improve face style transfer from real to synthetic faces through 2D and 3D facial constraints, enhancing face identity consistency while keeping the necessary high intra-class variance. Face recognition experiments using 1k, 2k, and 5k classes of our new dataset for training outperform state-of-the-art synthetic datasets in real face benchmarks such as LFW, CFP-FP, AgeDB, and BUPT. Our source code is available at: this https URL.
+
+
+
+ 12. 【2409.03598】A practical approach to evaluating the adversarial distance for machine learning classifiers
+ 链接:https://arxiv.org/abs/2409.03598
+ 作者:Georg Siedel,Ekagra Gupta,Andrey Morozov
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:ensure consistent performance, adversarial, machine learning, adversarial robustness, critical for machine
+ 备注: Accepted manuscript at International Mechanical Engineering Congress and Exposition IMECE2024
+
+ 点击查看摘要
+ Abstract:Robustness is critical for machine learning (ML) classifiers to ensure consistent performance in real-world applications where models may encounter corrupted or adversarial inputs. In particular, assessing the robustness of classifiers to adversarial inputs is essential to protect systems from vulnerabilities and thus ensure safety in use. However, methods to accurately compute adversarial robustness have been challenging for complex ML models and high-dimensional data. Furthermore, evaluations typically measure adversarial accuracy on specific attack budgets, limiting the informative value of the resulting metrics. This paper investigates the estimation of the more informative adversarial distance using iterative adversarial attacks and a certification approach. Combined, the methods provide a comprehensive evaluation of adversarial robustness by computing estimates for the upper and lower bounds of the adversarial distance. We present visualisations and ablation studies that provide insights into how this evaluation method should be applied and parameterised. We find that our adversarial attack approach is effective compared to related implementations, while the certification method falls short of expectations. The approach in this paper should encourage a more informative way of evaluating the adversarial robustness of ML classifiers.
+
+
+
+ 13. 【2409.03583】xt-Guided Mixup Towards Long-Tailed Image Categorization
+ 链接:https://arxiv.org/abs/2409.03583
+ 作者:Richard Franklin,Jiawei Yao,Deyang Zhong,Qi Qian,Juhua Hu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:require heavy amounts, training deep neural, challenges traditional approaches, deep neural networks, class label distribution
+ 备注: Accepted by BMVC'24, code is available at [this https URL](https://github.com/rsamf/text-guided-mixup)
+
+ 点击查看摘要
+ Abstract:In many real-world applications, the frequency distribution of class labels for training data can exhibit a long-tailed distribution, which challenges traditional approaches of training deep neural networks that require heavy amounts of balanced data. Gathering and labeling data to balance out the class label distribution can be both costly and time-consuming. Many existing solutions that enable ensemble learning, re-balancing strategies, or fine-tuning applied to deep neural networks are limited by the inert problem of few class samples across a subset of classes. Recently, vision-language models like CLIP have been observed as effective solutions to zero-shot or few-shot learning by grasping a similarity between vision and language features for image and text pairs. Considering that large pre-trained vision-language models may contain valuable side textual information for minor classes, we propose to leverage text supervision to tackle the challenge of long-tailed learning. Concretely, we propose a novel text-guided mixup technique that takes advantage of the semantic relations between classes recognized by the pre-trained text encoder to help alleviate the long-tailed problem. Our empirical study on benchmark long-tailed tasks demonstrates the effectiveness of our proposal with a theoretical guarantee. Our code is available at this https URL.
+
+
+
+ 14. 【2409.03556】MaskVal: Simple but Effective Uncertainty Quantification for 6D Pose Estimation
+ 链接:https://arxiv.org/abs/2409.03556
+ 作者:Philipp Quentin,Daniel Goehring
+ 类目:Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:predictable operational performance, utmost importance, importance to ensure, predictable operational, pose
+ 备注:
+
+ 点击查看摘要
+ Abstract:For the use of 6D pose estimation in robotic applications, reliable poses are of utmost importance to ensure a safe, reliable and predictable operational performance. Despite these requirements, state-of-the-art 6D pose estimators often do not provide any uncertainty quantification for their pose estimates at all, or if they do, it has been shown that the uncertainty provided is only weakly correlated with the actual true error. To address this issue, we investigate a simple but effective uncertainty quantification, that we call MaskVal, which compares the pose estimates with their corresponding instance segmentations by rendering and does not require any modification of the pose estimator itself. Despite its simplicity, MaskVal significantly outperforms a state-of-the-art ensemble method on both a dataset and a robotic setup. We show that by using MaskVal, the performance of a state-of-the-art 6D pose estimator is significantly improved towards a safe and reliable operation. In addition, we propose a new and specific approach to compare and evaluate uncertainty quantification methods for 6D pose estimation in the context of robotic manipulation.
+
+
+
+ 15. 【2409.03555】Unified Framework for Neural Network Compression via Decomposition and Optimal Rank Selection
+ 链接:https://arxiv.org/abs/2409.03555
+ 作者:Ali Aghababaei-Harandi,Massih-Reza Amini
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:complex neural networks, significant computational resources, neural networks demand, networks demand significant, demand significant computational
+ 备注:
+
+ 点击查看摘要
+ Abstract:Despite their high accuracy, complex neural networks demand significant computational resources, posing challenges for deployment on resource-constrained devices such as mobile phones and embedded systems. Compression algorithms have been developed to address these challenges by reducing model size and computational demands while maintaining accuracy. Among these approaches, factorization methods based on tensor decomposition are theoretically sound and effective. However, they face difficulties in selecting the appropriate rank for decomposition. This paper tackles this issue by presenting a unified framework that simultaneously applies decomposition and optimal rank selection, employing a composite compression loss within defined rank constraints. Our approach includes an automatic rank search in a continuous space, efficiently identifying optimal rank configurations without the use of training data, making it computationally efficient. Combined with a subsequent fine-tuning step, our approach maintains the performance of highly compressed models on par with their original counterparts. Using various benchmark datasets, we demonstrate the efficacy of our method through a comprehensive analysis.
+
+
+
+ 16. 【2409.03553】Organized Grouped Discrete Representation for Object-Centric Learning
+ 链接:https://arxiv.org/abs/2409.03553
+ 作者:Rongzhen Zhao,Vivienne Wang,Juho Kannala,Joni Pajarinen
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:represents dense image, represents dense, Variational Autoencoder, Grouped Discrete Representation, dense image
+ 备注:
+
+ 点击查看摘要
+ Abstract:Object-Centric Learning (OCL) represents dense image or video pixels as sparse object features. Representative methods utilize discrete representation composed of Variational Autoencoder (VAE) template features to suppress pixel-level information redundancy and guide object-level feature aggregation. The most recent advancement, Grouped Discrete Representation (GDR), further decomposes these template features into attributes. However, its naive channel grouping as decomposition may erroneously group channels belonging to different attributes together and discretize them as sub-optimal template attributes, which losses information and harms expressivity. We propose Organized GDR (OGDR) to organize channels belonging to the same attributes together for correct decomposition from features into attributes. In unsupervised segmentation experiments, OGDR is fully superior to GDR in augmentating classical transformer-based OCL methods; it even improves state-of-the-art diffusion-based ones. Codebook PCA and representation similarity analyses show that compared with GDR, our OGDR eliminates redundancy and preserves information better for guiding object representation learning. The source code is available in the supplementary material.
+
+
+
+ 17. 【2409.03550】DKDM: Data-Free Knowledge Distillation for Diffusion Models with Any Architecture
+ 链接:https://arxiv.org/abs/2409.03550
+ 作者:Qianlong Xiang,Miao Zhang,Yuzhang Shang,Jianlong Wu,Yan Yan,Liqiang Nie
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:high computational demands, demonstrated exceptional generative, exceptional generative capabilities, slow inference speeds, Diffusion models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Diffusion models (DMs) have demonstrated exceptional generative capabilities across various areas, while they are hindered by slow inference speeds and high computational demands during deployment. The most common way to accelerate DMs involves reducing the number of denoising steps during generation, achieved through faster sampling solvers or knowledge distillation (KD). In contrast to prior approaches, we propose a novel method that transfers the capability of large pretrained DMs to faster architectures. Specifically, we employ KD in a distinct manner to compress DMs by distilling their generative ability into more rapid variants. Furthermore, considering that the source data is either unaccessible or too enormous to store for current generative models, we introduce a new paradigm for their distillation without source data, termed Data-Free Knowledge Distillation for Diffusion Models (DKDM). Generally, our established DKDM framework comprises two main components: 1) a DKDM objective that uses synthetic denoising data produced by pretrained DMs to optimize faster DMs without source data, and 2) a dynamic iterative distillation method that flexibly organizes the synthesis of denoising data, preventing it from slowing down the optimization process as the generation is slow. To our knowledge, this is the first attempt at using KD to distill DMs into any architecture in a data-free manner. Importantly, our DKDM is orthogonal to most existing acceleration methods, such as denoising step reduction, quantization and pruning. Experiments show that our DKDM is capable of deriving 2x faster DMs with performance remaining on par with the baseline. Notably, our DKDM enables pretrained DMs to function as "datasets" for training new DMs.
+
+
+
+ 18. 【2409.03543】Prediction Accuracy Reliability: Classification and Object Localization under Distribution Shift
+ 链接:https://arxiv.org/abs/2409.03543
+ 作者:Fabian Diet,Moussa Kassem Sbeyti,Michelle Karg
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Natural distribution shift, convolutional neural networks, distribution shift, Natural distribution, neural networks
+ 备注: This preprint has not undergone any post-submission improvements or corrections
+
+ 点击查看摘要
+ Abstract:Natural distribution shift causes a deterioration in the perception performance of convolutional neural networks (CNNs). This comprehensive analysis for real-world traffic data addresses: 1) investigating the effect of natural distribution shift and weather augmentations on both detection quality and confidence estimation, 2) evaluating model performance for both classification and object localization, and 3) benchmarking two common uncertainty quantification methods - Ensembles and different variants of Monte-Carlo (MC) Dropout - under natural and close-to-natural distribution shift. For this purpose, a novel dataset has been curated from publicly available autonomous driving datasets. The in-distribution (ID) data is based on cutouts of a single object, for which both class and bounding box annotations are available. The six distribution-shift datasets cover adverse weather scenarios, simulated rain and fog, corner cases, and out-of-distribution data. A granular analysis of CNNs under distribution shift allows to quantize the impact of different types of shifts on both, task performance and confidence estimation: ConvNeXt-Tiny is more robust than EfficientNet-B0; heavy rain degrades classification stronger than localization, contrary to heavy fog; integrating MC-Dropout into selected layers only has the potential to enhance task performance and confidence estimation, whereby the identification of these layers depends on the type of distribution shift and the considered task.
+
+
+
+ 19. 【2409.03530】Use of triplet loss for facial restoration in low-resolution images
+ 链接:https://arxiv.org/abs/2409.03530
+ 作者:Sebastian Pulgar,Domingo Mery
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Cryptography and Security (cs.CR)
+ 关键词:achieving impressive results, recent years, biometric tool, achieving impressive, numerous datasets
+ 备注: 10 pages, 8 figures
+
+ 点击查看摘要
+ Abstract:In recent years, facial recognition (FR) models have become the most widely used biometric tool, achieving impressive results on numerous datasets. However, inherent hardware challenges or shooting distances often result in low-resolution images, which significantly impact the performance of FR models. To address this issue, several solutions have been proposed, including super-resolution (SR) models that generate highly realistic faces. Despite these efforts, significant improvements in FR algorithms have not been achieved. We propose a novel SR model FTLGAN, which focuses on generating high-resolution images that preserve individual identities rather than merely improving image quality, thereby maximizing the performance of FR models. The results are compelling, demonstrating a mean value of d' 21% above the best current state-of-the-art models, specifically having a value of d' = 1.099 and AUC = 0.78 for 14x14 pixels, d' = 2.112 and AUC = 0.92 for 28x28 pixels, and d' = 3.049 and AUC = 0.98 for 56x56 pixels. The contributions of this study are significant in several key areas. Firstly, a notable improvement in facial recognition performance has been achieved in low-resolution images, specifically at resolutions of 14x14, 28x28, and 56x56 pixels. Secondly, the enhancements demonstrated by FTLGAN show a consistent response across all resolutions, delivering outstanding performance uniformly, unlike other comparative models. Thirdly, an innovative approach has been implemented using triplet loss logic, enabling the training of the super-resolution model solely with real images, contrasting with current models, and expanding potential real-world applications. Lastly, this study introduces a novel model that specifically addresses the challenge of improving classification performance in facial recognition systems by integrating facial recognition quality as a loss during model training.
+
+
+
+ 20. 【2409.03525】FrozenSeg: Harmonizing Frozen Foundation Models for Open-Vocabulary Segmentation
+ 链接:https://arxiv.org/abs/2409.03525
+ 作者:Xi Chen,Haosen Yang,Sheng Jin,Xiatian Zhu,Hongxun Yao
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Open-vocabulary segmentation poses, poses significant challenges, segmentation poses significant, Open-vocabulary segmentation, unconstrained environments
+ 备注: 14 pages, 9 figures
+
+ 点击查看摘要
+ Abstract:Open-vocabulary segmentation poses significant challenges, as it requires segmenting and recognizing objects across an open set of categories in unconstrained environments. Building on the success of powerful vision-language (ViL) foundation models, such as CLIP, recent efforts sought to harness their zero-short capabilities to recognize unseen categories. Despite notable performance improvements, these models still encounter the critical issue of generating precise mask proposals for unseen categories and scenarios, resulting in inferior segmentation performance eventually. To address this challenge, we introduce a novel approach, FrozenSeg, designed to integrate spatial knowledge from a localization foundation model (e.g., SAM) and semantic knowledge extracted from a ViL model (e.g., CLIP), in a synergistic framework. Taking the ViL model's visual encoder as the feature backbone, we inject the space-aware feature into the learnable queries and CLIP features within the transformer decoder. In addition, we devise a mask proposal ensemble strategy for further improving the recall rate and mask quality. To fully exploit pre-trained knowledge while minimizing training overhead, we freeze both foundation models, focusing optimization efforts solely on a lightweight transformer decoder for mask proposal generation-the performance bottleneck. Extensive experiments demonstrate that FrozenSeg advances state-of-the-art results across various segmentation benchmarks, trained exclusively on COCO panoptic data, and tested in a zero-shot manner. Code is available at this https URL.
+
+
+
+ 21. 【2409.03521】Have Large Vision-Language Models Mastered Art History?
+ 链接:https://arxiv.org/abs/2409.03521
+ 作者:Ombretta Strafforello,Derya Soydaner,Michiel Willems,Anne-Sofie Maerten,Stefanie De Winter
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:large Vision-Language Models, Vision-Language Models, recently established, established new baselines, multiple domains
+ 备注:
+
+ 点击查看摘要
+ Abstract:The emergence of large Vision-Language Models (VLMs) has recently established new baselines in image classification across multiple domains. However, the performance of VLMs in the specific task of artwork classification, particularly art style classification of paintings - a domain traditionally mastered by art historians - has not been explored yet. Artworks pose a unique challenge compared to natural images due to their inherently complex and diverse structures, characterized by variable compositions and styles. Art historians have long studied the unique aspects of artworks, with style prediction being a crucial component of their discipline. This paper investigates whether large VLMs, which integrate visual and textual data, can effectively predict the art historical attributes of paintings. We conduct an in-depth analysis of four VLMs, namely CLIP, LLaVA, OpenFlamingo, and GPT-4o, focusing on zero-shot classification of art style, author and time period using two public benchmarks of artworks. Additionally, we present ArTest, a well-curated test set of artworks, including pivotal paintings studied by art historians.
+
+
+
+ 22. 【2409.03516】LMLT: Low-to-high Multi-Level Vision Transformer for Image Super-Resolution
+ 链接:https://arxiv.org/abs/2409.03516
+ 作者:Jeongsoo Kim,Jongho Nang,Junsuk Choe
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Recent Vision Transformer, Recent Vision, Vision Transformer, demonstrated impressive performance, demonstrated impressive
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent Vision Transformer (ViT)-based methods for Image Super-Resolution have demonstrated impressive performance. However, they suffer from significant complexity, resulting in high inference times and memory usage. Additionally, ViT models using Window Self-Attention (WSA) face challenges in processing regions outside their windows. To address these issues, we propose the Low-to-high Multi-Level Transformer (LMLT), which employs attention with varying feature sizes for each head. LMLT divides image features along the channel dimension, gradually reduces spatial size for lower heads, and applies self-attention to each head. This approach effectively captures both local and global information. By integrating the results from lower heads into higher heads, LMLT overcomes the window boundary issues in self-attention. Extensive experiments show that our model significantly reduces inference time and GPU memory usage while maintaining or even surpassing the performance of state-of-the-art ViT-based Image Super-Resolution methods. Our codes are availiable at this https URL.
+
+
+
+ 23. 【2409.03514】Blended Latent Diffusion under Attention Control for Real-World Video Editing
+ 链接:https://arxiv.org/abs/2409.03514
+ 作者:Deyin Liu,Lin Yuanbo Wu,Xianghua Xie
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:face grand challenges, editing methods tend, current video editing, Due to lack, build on pre-trained
+ 备注:
+
+ 点击查看摘要
+ Abstract:Due to lack of fully publicly available text-to-video models, current video editing methods tend to build on pre-trained text-to-image generation models, however, they still face grand challenges in dealing with the local editing of video with temporal information. First, although existing methods attempt to focus on local area editing by a pre-defined mask, the preservation of the outside-area background is non-ideal due to the spatially entire generation of each frame. In addition, specially providing a mask by user is an additional costly undertaking, so an autonomous masking strategy integrated into the editing process is desirable. Last but not least, image-level pretrained model hasn't learned temporal information across frames of a video which is vital for expressing the motion and dynamics. In this paper, we propose to adapt a image-level blended latent diffusion model to perform local video editing tasks. Specifically, we leverage DDIM inversion to acquire the latents as background latents instead of the randomly noised ones to better preserve the background information of the input video. We further introduce an autonomous mask manufacture mechanism derived from cross-attention maps in diffusion steps. Finally, we enhance the temporal consistency across video frames by transforming the self-attention blocks of U-Net into temporal-spatial blocks. Through extensive experiments, our proposed approach demonstrates effectiveness in different real-world video editing tasks.
+
+
+
+ 24. 【2409.03509】Domain-Guided Weight Modulation for Semi-Supervised Domain Generalization
+ 链接:https://arxiv.org/abs/2409.03509
+ 作者:Chamuditha Jayanaga Galappaththige,Zachary Izzo,Xilin He,Honglu Zhou,Muhammad Haris Khan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:low developmental costs, great practical significance, practical significance due, unseen domain data, deep learning models
+ 备注: Accepted at WACV25
+
+ 点击查看摘要
+ Abstract:Unarguably, deep learning models capable of generalizing to unseen domain data while leveraging a few labels are of great practical significance due to low developmental costs. In search of this endeavor, we study the challenging problem of semi-supervised domain generalization (SSDG), where the goal is to learn a domain-generalizable model while using only a small fraction of labeled data and a relatively large fraction of unlabeled data. Domain generalization (DG) methods show subpar performance under the SSDG setting, whereas semi-supervised learning (SSL) methods demonstrate relatively better performance, however, they are considerably poor compared to the fully-supervised DG methods. Towards handling this new, but challenging problem of SSDG, we propose a novel method that can facilitate the generation of accurate pseudo-labels under various domain shifts. This is accomplished by retaining the domain-level specialism in the classifier during training corresponding to each source domain. Specifically, we first create domain-level information vectors on the fly which are then utilized to learn a domain-aware mask for modulating the classifier's weights. We provide a mathematical interpretation for the effect of this modulation procedure on both pseudo-labeling and model training. Our method is plug-and-play and can be readily applied to different SSL baselines for SSDG. Extensive experiments on six challenging datasets in two different SSDG settings show that our method provides visible gains over the various strong SSL-based SSDG baselines.
+
+
+
+ 25. 【2409.03501】owards Data-Centric Face Anti-Spoofing: Improving Cross-domain Generalization via Physics-based Data Synthesis
+ 链接:https://arxiv.org/abs/2409.03501
+ 作者:Rizhao Cai,Cecelia Soh,Zitong Yu,Haoliang Li,Wenhan Yang,Alex Kot
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Face Anti-Spoofing, FAS, data, cross-domain, domain gap
+ 备注: Accepted by International Journal of Computer Vision (IJCV) in Sept 2024
+
+ 点击查看摘要
+ Abstract:Face Anti-Spoofing (FAS) research is challenged by the cross-domain problem, where there is a domain gap between the training and testing data. While recent FAS works are mainly model-centric, focusing on developing domain generalization algorithms for improving cross-domain performance, data-centric research for face anti-spoofing, improving generalization from data quality and quantity, is largely ignored. Therefore, our work starts with data-centric FAS by conducting a comprehensive investigation from the data perspective for improving cross-domain generalization of FAS models. More specifically, at first, based on physical procedures of capturing and recapturing, we propose task-specific FAS data augmentation (FAS-Aug), which increases data diversity by synthesizing data of artifacts, such as printing noise, color distortion, moiré pattern, \textit{etc}. Our experiments show that using our FAS augmentation can surpass traditional image augmentation in training FAS models to achieve better cross-domain performance. Nevertheless, we observe that models may rely on the augmented artifacts, which are not environment-invariant, and using FAS-Aug may have a negative effect. As such, we propose Spoofing Attack Risk Equalization (SARE) to prevent models from relying on certain types of artifacts and improve the generalization performance. Last but not least, our proposed FAS-Aug and SARE with recent Vision Transformer backbones can achieve state-of-the-art performance on the FAS cross-domain generalization protocols. The implementation is available at this https URL.
+
+
+
+ 26. 【2409.03487】ScreenMark: Watermarking Arbitrary Visual Content on Screen
+ 链接:https://arxiv.org/abs/2409.03487
+ 作者:Xiujian Liang,Gaozhi Liu,Yichao Si,Xiaoxiao Hu,Zhenxing Qian,Xinpeng Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:protecting multimedia content, Digital watermarking, protecting multimedia, Screen Content, Digital
+ 备注:
+
+ 点击查看摘要
+ Abstract:Digital watermarking has demonstrated its effectiveness in protecting multimedia content. However, existing watermarking are predominantly tailored for specific media types, rendering them less effective for the protection of content displayed on computer screens, which is often multimodal and dynamic. Visual Screen Content (VSC), is particularly susceptible to theft and leakage via screenshots, a vulnerability that current watermarking methods fail to adequately this http URL tackle these challenges, we propose ScreenMark, a robust and practical watermarking method designed specifically for arbitrary VSC protection. ScreenMark utilizes a three-stage progressive watermarking framework. Initially, inspired by diffusion principles, we initialize the mutual transformation between regular watermark information and irregular watermark patterns. Subsequently, these patterns are integrated with screen content using a pre-multiplication alpha blending technique, supported by a pre-trained screen decoder for accurate watermark retrieval. The progressively complex distorter enhances the robustness of the watermark in real-world screenshot scenarios. Finally, the model undergoes fine-tuning guided by a joint-level distorter to ensure optimal this http URL validate the effectiveness of ScreenMark, we compiled a dataset comprising 100,000 screenshots from various devices and resolutions. Extensive experiments across different datasets confirm the method's superior robustness, imperceptibility, and practical applicability.
+
+
+
+ 27. 【2409.03470】Improving Uncertainty-Error Correspondence in Deep Bayesian Medical Image Segmentation
+ 链接:https://arxiv.org/abs/2409.03470
+ 作者:Prerak Mody,Nicolas F. Chaves-de-Plaza,Chinmay Rao,Eleftheria Astrenidou,Mischa de Ridder,Nienke Hoekstra,Klaus Hildebrandt,Marius Staring
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Human-Computer Interaction (cs.HC); Machine Learning (cs.LG)
+ 关键词:medical image segmentation, Increased usage, learning in medical, medical image, image segmentation
+ 备注: Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) [this https URL](https://melba-journal.org/2024:018)
+
+ 点击查看摘要
+ Abstract:Increased usage of automated tools like deep learning in medical image segmentation has alleviated the bottleneck of manual contouring. This has shifted manual labour to quality assessment (QA) of automated contours which involves detecting errors and correcting them. A potential solution to semi-automated QA is to use deep Bayesian uncertainty to recommend potentially erroneous regions, thus reducing time spent on error detection. Previous work has investigated the correspondence between uncertainty and error, however, no work has been done on improving the "utility" of Bayesian uncertainty maps such that it is only present in inaccurate regions and not in the accurate ones. Our work trains the FlipOut model with the Accuracy-vs-Uncertainty (AvU) loss which promotes uncertainty to be present only in inaccurate regions. We apply this method on datasets of two radiotherapy body sites, c.f. head-and-neck CT and prostate MR scans. Uncertainty heatmaps (i.e. predictive entropy) are evaluated against voxel inaccuracies using Receiver Operating Characteristic (ROC) and Precision-Recall (PR) curves. Numerical results show that when compared to the Bayesian baseline the proposed method successfully suppresses uncertainty for accurate voxels, with similar presence of uncertainty for inaccurate voxels. Code to reproduce experiments is available at this https URL
+
+
+
+ 28. 【2409.03460】LowFormer: Hardware Efficient Design for Convolutional Transformer Backbones
+ 链接:https://arxiv.org/abs/2409.03460
+ 作者:Moritz Nottebaum,Matteo Dunnhofer,Christian Micheloni
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:transformer blocks, mixture of convolutions, convolutions and transformer, Research, efficient vision backbones
+ 备注: Accepted at WACV 2025. Features 11 pages in total
+
+ 点击查看摘要
+ Abstract:Research in efficient vision backbones is evolving into models that are a mixture of convolutions and transformer blocks. A smart combination of both, architecture-wise and component-wise is mandatory to excel in the speedaccuracy trade-off. Most publications focus on maximizing accuracy and utilize MACs (multiply accumulate operations) as an efficiency metric. The latter however often do not measure accurately how fast a model actually is due to factors like memory access cost and degree of parallelism. We analyzed common modules and architectural design choices for backbones not in terms of MACs, but rather in actual throughput and latency, as the combination of the latter two is a better representation of the efficiency of models in real applications. We applied the conclusions taken from that analysis to create a recipe for increasing hardware-efficiency in macro design. Additionally we introduce a simple slimmed-down version of MultiHead Self-Attention, that aligns with our analysis. We combine both macro and micro design to create a new family of hardware-efficient backbone networks called LowFormer. LowFormer achieves a remarkable speedup in terms of throughput and latency, while achieving similar or better accuracy than current state-of-the-art efficient backbones. In order to prove the generalizability of our hardware-efficient design, we evaluate our method on GPU, mobile GPU and ARM CPU. We further show that the downstream tasks object detection and semantic segmentation profit from our hardware-efficient architecture. Code and models are available at this https URL altair199797/LowFormer.
+
+
+
+ 29. 【2409.03458】Non-Uniform Illumination Attack for Fooling Convolutional Neural Networks
+ 链接:https://arxiv.org/abs/2409.03458
+ 作者:Akshay Jain,Shiv Ram Dubey,Satish Kumar Singh,KC Santosh,Bidyut Baran Chaudhuri
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Convolutional Neural Networks, Convolutional Neural, Neural Networks, made remarkable strides, NUI
+ 备注:
+
+ 点击查看摘要
+ Abstract:Convolutional Neural Networks (CNNs) have made remarkable strides; however, they remain susceptible to vulnerabilities, particularly in the face of minor image perturbations that humans can easily recognize. This weakness, often termed as 'attacks', underscores the limited robustness of CNNs and the need for research into fortifying their resistance against such manipulations. This study introduces a novel Non-Uniform Illumination (NUI) attack technique, where images are subtly altered using varying NUI masks. Extensive experiments are conducted on widely-accepted datasets including CIFAR10, TinyImageNet, and CalTech256, focusing on image classification with 12 different NUI attack models. The resilience of VGG, ResNet, MobilenetV3-small and InceptionV3 models against NUI attacks are evaluated. Our results show a substantial decline in the CNN models' classification accuracy when subjected to NUI attacks, indicating their vulnerability under non-uniform illumination. To mitigate this, a defense strategy is proposed, including NUI-attacked images, generated through the new NUI transformation, into the training set. The results demonstrate a significant enhancement in CNN model performance when confronted with perturbed images affected by NUI attacks. This strategy seeks to bolster CNN models' resilience against NUI attacks.
+
+
+
+ 30. 【2409.03456】LM-Gaussian: Boost Sparse-view 3D Gaussian Splatting with Large Model Priors
+ 链接:https://arxiv.org/abs/2409.03456
+ 作者:Hanyang Yu,Xiaoxiao Long,Ping Tan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:large-scale vision models, vision models, address sparse-view reconstruction, aim to address, large-scale vision
+ 备注: Project page: [this https URL](https://hanyangyu1021.github.io/lm-gaussian.github.io/)
+
+ 点击查看摘要
+ Abstract:We aim to address sparse-view reconstruction of a 3D scene by leveraging priors from large-scale vision models. While recent advancements such as 3D Gaussian Splatting (3DGS) have demonstrated remarkable successes in 3D reconstruction, these methods typically necessitate hundreds of input images that densely capture the underlying scene, making them time-consuming and impractical for real-world applications. However, sparse-view reconstruction is inherently ill-posed and under-constrained, often resulting in inferior and incomplete outcomes. This is due to issues such as failed initialization, overfitting on input images, and a lack of details. To mitigate these challenges, we introduce LM-Gaussian, a method capable of generating high-quality reconstructions from a limited number of images. Specifically, we propose a robust initialization module that leverages stereo priors to aid in the recovery of camera poses and the reliable point clouds. Additionally, a diffusion-based refinement is iteratively applied to incorporate image diffusion priors into the Gaussian optimization process to preserve intricate scene details. Finally, we utilize video diffusion priors to further enhance the rendered images for realistic visual effects. Overall, our approach significantly reduces the data acquisition requirements compared to previous 3DGS methods. We validate the effectiveness of our framework through experiments on various public datasets, demonstrating its potential for high-quality 360-degree scene reconstruction. Visual results are on our website.
+
+
+
+ 31. 【2409.03455】Data-free Distillation with Degradation-prompt Diffusion for Multi-weather Image Restoration
+ 链接:https://arxiv.org/abs/2409.03455
+ 作者:Pei Wang,Xiaotong Luo,Yuan Xie,Yanyun Qu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:witnessed incredible progress, expensive data acquisition, data acquisition impair, increasing model capacity, Multi-weather image restoration
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multi-weather image restoration has witnessed incredible progress, while the increasing model capacity and expensive data acquisition impair its applications in memory-limited devices. Data-free distillation provides an alternative for allowing to learn a lightweight student model from a pre-trained teacher model without relying on the original training data. The existing data-free learning methods mainly optimize the models with the pseudo data generated by GANs or the real data collected from the Internet. However, they inevitably suffer from the problems of unstable training or domain shifts with the original data. In this paper, we propose a novel Data-free Distillation with Degradation-prompt Diffusion framework for multi-weather Image Restoration (D4IR). It replaces GANs with pre-trained diffusion models to avoid model collapse and incorporates a degradation-aware prompt adapter to facilitate content-driven conditional diffusion for generating domain-related images. Specifically, a contrast-based degradation prompt adapter is firstly designed to capture degradation-aware prompts from web-collected degraded images. Then, the collected unpaired clean images are perturbed to latent features of stable diffusion, and conditioned with the degradation-aware prompts to synthesize new domain-related degraded images for knowledge distillation. Experiments illustrate that our proposal achieves comparable performance to the model distilled with original training data, and is even superior to other mainstream unsupervised methods.
+
+
+
+ 32. 【2409.03451】Automatic occlusion removal from 3D maps for maritime situational awareness
+ 链接:https://arxiv.org/abs/2409.03451
+ 作者:Felix Sattler,Borja Carrillo Perez,Maurice Stephan,Sarah Barnes
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:specifically targeting occlusion, targeting occlusion removal, large-scale maritime environments, occlusion removal, removal in large-scale
+ 备注: Preprint of SPIE Sensor + Imaging 2024 conference paper
+
+ 点击查看摘要
+ Abstract:We introduce a novel method for updating 3D geospatial models, specifically targeting occlusion removal in large-scale maritime environments. Traditional 3D reconstruction techniques often face problems with dynamic objects, like cars or vessels, that obscure the true environment, leading to inaccurate models or requiring extensive manual editing. Our approach leverages deep learning techniques, including instance segmentation and generative inpainting, to directly modify both the texture and geometry of 3D meshes without the need for costly reprocessing. By selectively targeting occluding objects and preserving static elements, the method enhances both geometric and visual accuracy. This approach not only preserves structural and textural details of map data but also maintains compatibility with current geospatial standards, ensuring robust performance across diverse datasets. The results demonstrate significant improvements in 3D model fidelity, making this method highly applicable for maritime situational awareness and the dynamic display of auxiliary information.
+
+
+
+ 33. 【2409.03438】Shuffle Vision Transformer: Lightweight, Fast and Efficient Recognition of Driver Facial Expression
+ 链接:https://arxiv.org/abs/2409.03438
+ 作者:Ibtissam Saadi,Douglas W. Cunningham,Taleb-ahmed Abdelmalik,Abdenour Hadid,Yassin El Hillali
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:facial expression recognition, computationally intensive, rendering them unsuitable, Existing methods, expression recognition
+ 备注: Accepted for publication in The 6th IEEE International Conference on Artificial Intelligence Circuits and Systems (IEEE AICAS 2024), 5 pages, 3 figures
+
+ 点击查看摘要
+ Abstract:Existing methods for driver facial expression recognition (DFER) are often computationally intensive, rendering them unsuitable for real-time applications. In this work, we introduce a novel transfer learning-based dual architecture, named ShuffViT-DFER, which elegantly combines computational efficiency and accuracy. This is achieved by harnessing the strengths of two lightweight and efficient models using convolutional neural network (CNN) and vision transformers (ViT). We efficiently fuse the extracted features to enhance the performance of the model in accurately recognizing the facial expressions of the driver. Our experimental results on two benchmarking and public datasets, KMU-FED and KDEF, highlight the validity of our proposed method for real-time application with superior performance when compared to state-of-the-art methods.
+
+
+
+ 34. 【2409.03434】A Key-Driven Framework for Identity-Preserving Face Anonymization
+ 链接:https://arxiv.org/abs/2409.03434
+ 作者:Miaomiao Wang,Guang Hua,Sheng Li,Guorui Feng
+ 类目:Cryptography and Security (cs.CR); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Virtual faces, Virtual, face, original face, original
+ 备注: Accepted by NDSS Symposium 2025. Please cite this paper as "Miaomiao Wang, Guang Hua, Sheng Li, and Guorui Feng. A Key-Driven Framework for Identity-Preserving Face Anonymization. In the 32nd Annual Network and Distributed System Security Symposium (NDSS 2025)."
+
+ 点击查看摘要
+ Abstract:Virtual faces are crucial content in the metaverse. Recently, attempts have been made to generate virtual faces for privacy protection. Nevertheless, these virtual faces either permanently remove the identifiable information or map the original identity into a virtual one, which loses the original identity forever. In this study, we first attempt to address the conflict between privacy and identifiability in virtual faces, where a key-driven face anonymization and authentication recognition (KFAAR) framework is proposed. Concretely, the KFAAR framework consists of a head posture-preserving virtual face generation (HPVFG) module and a key-controllable virtual face authentication (KVFA) module. The HPVFG module uses a user key to project the latent vector of the original face into a virtual one. Then it maps the virtual vectors to obtain an extended encoding, based on which the virtual face is generated. By simultaneously adding a head posture and facial expression correction module, the virtual face has the same head posture and facial expression as the original face. During the authentication, we propose a KVFA module to directly recognize the virtual faces using the correct user key, which can obtain the original identity without exposing the original face image. We also propose a multi-task learning objective to train HPVFG and KVFA. Extensive experiments demonstrate the advantages of the proposed HPVFG and KVFA modules, which effectively achieve both facial anonymity and identifiability.
+
+
+
+ 35. 【2409.03431】UV-Mamba: A DCN-Enhanced State Space Model for Urban Village Boundary Identification in High-Resolution Remote Sensing Images
+ 链接:https://arxiv.org/abs/2409.03431
+ 作者:Lulin Li,Ben Chen,Xuechao Zou,Junliang Xing,Pin Tao
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:diverse geographical environments, highly challenging task, urban village boundaries, remote sensing images, high-resolution remote sensing
+ 备注: 5 pages, 4 figures, 2 tables
+
+ 点击查看摘要
+ Abstract:Owing to the diverse geographical environments, intricate landscapes, and high-density settlements, the automatic identification of urban village boundaries using remote sensing images is a highly challenging task. This paper proposes a novel and efficient neural network model called UV-Mamba for accurate boundary detection in high-resolution remote sensing images. UV-Mamba mitigates the memory loss problem in long sequence modeling, which arises in state space model (SSM) with increasing image size, by incorporating deformable convolutions (DCN). Its architecture utilizes an encoder-decoder framework, includes an encoder with four deformable state space augmentation (DSSA) blocks for efficient multi-level semantic extraction and a decoder to integrate the extracted semantic information. We conducted experiments on the Beijing and Xi'an datasets, and the results show that UV-Mamba achieves state-of-the-art performance. Specifically, our model achieves 73.3% and 78.1% IoU on the Beijing and Xi'an datasets, respectively, representing improvements of 1.2% and 3.4% IoU over the previous best model, while also being 6x faster in inference speed and 40x smaller in parameter count. Source code and pre-trained models are available in the supplementary material.
+
+
+
+ 36. 【2409.03424】Weight Conditioning for Smooth Optimization of Neural Networks
+ 链接:https://arxiv.org/abs/2409.03424
+ 作者:Hemanth Saratchandran,Thomas X. Wang,Simon Lucey
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:term weight conditioning, Neural Radiance Fields, Convolutional Neural Networks, neural network weight, neural network
+ 备注: ECCV 2024
+
+ 点击查看摘要
+ Abstract:In this article, we introduce a novel normalization technique for neural network weight matrices, which we term weight conditioning. This approach aims to narrow the gap between the smallest and largest singular values of the weight matrices, resulting in better-conditioned matrices. The inspiration for this technique partially derives from numerical linear algebra, where well-conditioned matrices are known to facilitate stronger convergence results for iterative solvers. We provide a theoretical foundation demonstrating that our normalization technique smoothens the loss landscape, thereby enhancing convergence of stochastic gradient descent algorithms. Empirically, we validate our normalization across various neural network architectures, including Convolutional Neural Networks (CNNs), Vision Transformers (ViT), Neural Radiance Fields (NeRF), and 3D shape modeling. Our findings indicate that our normalization method is not only competitive but also outperforms existing weight normalization techniques from the literature.
+
+
+
+ 37. 【2409.03420】mPLUG-DocOwl2: High-resolution Compressing for OCR-free Multi-page Document Understanding
+ 链接:https://arxiv.org/abs/2409.03420
+ 作者:Anwen Hu,Haiyang Xu,Liang Zhang,Jiabo Ye,Ming Yan,Ji Zhang,Qin Jin,Fei Huang,Jingren Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Multimodel Large Language, Large Language Models, Multimodel Large, Large Language, achieved promising OCR-free
+ 备注: 15 pages, 7 figures
+
+ 点击查看摘要
+ Abstract:Multimodel Large Language Models(MLLMs) have achieved promising OCR-free Document Understanding performance by increasing the supported resolution of document images. However, this comes at the cost of generating thousands of visual tokens for a single document image, leading to excessive GPU memory and slower inference times, particularly in multi-page document comprehension. In this work, to address these challenges, we propose a High-resolution DocCompressor module to compress each high-resolution document image into 324 tokens, guided by low-resolution global visual features. With this compression module, to strengthen multi-page document comprehension ability and balance both token efficiency and question-answering performance, we develop the DocOwl2 under a three-stage training framework: Single-image Pretraining, Multi-image Continue-pretraining, and Multi-task Finetuning. DocOwl2 sets a new state-of-the-art across multi-page document understanding benchmarks and reduces first token latency by more than 50%, demonstrating advanced capabilities in multi-page questioning answering, explanation with evidence pages, and cross-page structure understanding. Additionally, compared to single-image MLLMs trained on similar data, our DocOwl2 achieves comparable single-page understanding performance with less than 20% of the visual tokens. Our codes, models, and data are publicly available at this https URL.
+
+
+
+ 38. 【2409.03412】G-LMM: Enhancing Medical Image Segmentation Accuracy through Text-Guided Large Multi-Modal Model
+ 链接:https://arxiv.org/abs/2409.03412
+ 作者:Yihao Zhao,Enhao Zhong,Cuiyun Yuan,Yang Li,Man Zhao,Chunxia Li,Jun Hu,Chenbin Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Medical Physics (physics.med-ph)
+ 关键词:Text-Guided Large Multi-Modal, Large Multi-Modal Model, Text-Guided Large, leverages textual descriptions, Large Multi-Modal
+ 备注: 11 pages, 2 figures
+
+ 点击查看摘要
+ Abstract:We propose TG-LMM (Text-Guided Large Multi-Modal Model), a novel approach that leverages textual descriptions of organs to enhance segmentation accuracy in medical images. Existing medical image segmentation methods face several challenges: current medical automatic segmentation models do not effectively utilize prior knowledge, such as descriptions of organ locations; previous text-visual models focus on identifying the target rather than improving the segmentation accuracy; prior models attempt to use prior knowledge to enhance accuracy but do not incorporate pre-trained models. To address these issues, TG-LMM integrates prior knowledge, specifically expert descriptions of the spatial locations of organs, into the segmentation process. Our model utilizes pre-trained image and text encoders to reduce the number of training parameters and accelerate the training process. Additionally, we designed a comprehensive image-text information fusion structure to ensure thorough integration of the two modalities of data. We evaluated TG-LMM on three authoritative medical image datasets, encompassing the segmentation of various parts of the human body. Our method demonstrated superior performance compared to existing approaches, such as MedSAM, SAM and nnUnet.
+
+
+
+ 39. 【2409.03404】KAN See In the Dark
+ 链接:https://arxiv.org/abs/2409.03404
+ 作者:Aoxiang Ning,Minglong Xue,Jinhong He,Chengyun Song
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Existing low-light image, complex nonlinear relationship, low-light image enhancement, low-light images due, Existing low-light
+ 备注:
+
+ 点击查看摘要
+ Abstract:Existing low-light image enhancement methods are difficult to fit the complex nonlinear relationship between normal and low-light images due to uneven illumination and noise effects. The recently proposed Kolmogorov-Arnold networks (KANs) feature spline-based convolutional layers and learnable activation functions, which can effectively capture nonlinear dependencies. In this paper, we design a KAN-Block based on KANs and innovatively apply it to low-light image enhancement. This method effectively alleviates the limitations of current methods constrained by linear network structures and lack of interpretability, further demonstrating the potential of KANs in low-level vision tasks. Given the poor perception of current low-light image enhancement methods and the stochastic nature of the inverse diffusion process, we further introduce frequency-domain perception for visually oriented enhancement. Extensive experiments demonstrate the competitive performance of our method on benchmark datasets. The code will be available at: this https URL}{this https URL.
+
+
+
+ 40. 【2409.03385】Make Graph-based Referring Expression Comprehension Great Again through Expression-guided Dynamic Gating and Regression
+ 链接:https://arxiv.org/abs/2409.03385
+ 作者:Jingcheng Ke,Dele Wang,Jun-Cheng Chen,I-Hong Jhuo,Chia-Wen Lin,Yen-Yu Lin
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:referring expression comprehension, existing graph-based methods, expression comprehension, common belief, complex models
+ 备注: 12 pages to appear in IEEE Transactions on Multimedia
+
+ 点击查看摘要
+ Abstract:One common belief is that with complex models and pre-training on large-scale datasets, transformer-based methods for referring expression comprehension (REC) perform much better than existing graph-based methods. We observe that since most graph-based methods adopt an off-the-shelf detector to locate candidate objects (i.e., regions detected by the object detector), they face two challenges that result in subpar performance: (1) the presence of significant noise caused by numerous irrelevant objects during reasoning, and (2) inaccurate localization outcomes attributed to the provided detector. To address these issues, we introduce a plug-and-adapt module guided by sub-expressions, called dynamic gate constraint (DGC), which can adaptively disable irrelevant proposals and their connections in graphs during reasoning. We further introduce an expression-guided regression strategy (EGR) to refine location prediction. Extensive experimental results on the RefCOCO, RefCOCO+, RefCOCOg, Flickr30K, RefClef, and Ref-reasoning datasets demonstrate the effectiveness of the DGC module and the EGR strategy in consistently boosting the performances of various graph-based REC methods. Without any pretaining, the proposed graph-based method achieves better performance than the state-of-the-art (SOTA) transformer-based methods.
+
+
+
+ 41. 【2409.03358】MouseSIS: A Frames-and-Events Dataset for Space-Time Instance Segmentation of Mice
+ 链接:https://arxiv.org/abs/2409.03358
+ 作者:Friedhelm Hamann,Hanxiong Li,Paul Mieske,Lars Lewejohann,Guillermo Gallego
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Robotics (cs.RO)
+ 关键词:made remarkable progress, Enabled by large, recent years, made remarkable, remarkable progress
+ 备注: 18 pages, 5 figures, ECCV Workshops
+
+ 点击查看摘要
+ Abstract:Enabled by large annotated datasets, tracking and segmentation of objects in videos has made remarkable progress in recent years. Despite these advancements, algorithms still struggle under degraded conditions and during fast movements. Event cameras are novel sensors with high temporal resolution and high dynamic range that offer promising advantages to address these challenges. However, annotated data for developing learning-based mask-level tracking algorithms with events is not available. To this end, we introduce: ($i$) a new task termed \emph{space-time instance segmentation}, similar to video instance segmentation, whose goal is to segment instances throughout the entire duration of the sensor input (here, the input are quasi-continuous events and optionally aligned frames); and ($ii$) \emph{\dname}, a dataset for the new task, containing aligned grayscale frames and events. It includes annotated ground-truth labels (pixel-level instance segmentation masks) of a group of up to seven freely moving and interacting mice. We also provide two reference methods, which show that leveraging event data can consistently improve tracking performance, especially when used in combination with conventional cameras. The results highlight the potential of event-aided tracking in difficult scenarios. We hope our dataset opens the field of event-based video instance segmentation and enables the development of robust tracking algorithms for challenging conditions.\url{this https URL}
+
+
+
+ 42. 【2409.03354】Few-Shot Continual Learning for Activity Recognition in Classroom Surveillance Images
+ 链接:https://arxiv.org/abs/2409.03354
+ 作者:Yilei Qian,Kanglei Geng,Kailong Chen,Shaoxu Cheng,Linfeng Xu,Hongliang Li,Fanman Meng,Qingbo Wu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:gaining increasing attention, activity recognition, image activity recognition, field is gaining, activity recognition called
+ 备注:
+
+ 点击查看摘要
+ Abstract:The application of activity recognition in the "AI + Education" field is gaining increasing attention. However, current work mainly focuses on the recognition of activities in manually captured videos and a limited number of activity types, with little attention given to recognizing activities in surveillance images from real classrooms. In real classroom settings, normal teaching activities such as reading, account for a large proportion of samples, while rare non-teaching activities such as eating, continue to appear. This requires a model that can learn non-teaching activities from few samples without forgetting the normal teaching activities, which necessitates fewshot continual learning (FSCL) capability. To address this gap, we constructed a continual learning dataset focused on classroom surveillance image activity recognition called ARIC (Activity Recognition in Classroom). The dataset has advantages such as multiple perspectives, a wide variety of activities, and real-world scenarios, but it also presents challenges like similar activities and imbalanced sample distribution. To overcome these challenges, we designed a few-shot continual learning method that combines supervised contrastive learning (SCL) and an adaptive covariance classifier (ACC). During the base phase, we proposed a SCL approach based on feature augmentation to enhance the model's generalization ability. In the incremental phase, we employed an ACC to more accurately describe the distribution of new classes. Experimental results demonstrate that our method outperforms other existing methods on the ARIC dataset.
+
+
+
+ 43. 【2409.03336】Eetimating Indoor Scene Depth Maps from Ultrasonic Echoes
+ 链接:https://arxiv.org/abs/2409.03336
+ 作者:Junpei Honma,Akisato Kimura,Go Irie
+ 类目:ound (cs.SD); Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM); Audio and Speech Processing (eess.AS)
+ 关键词:indoor scenes requires, scenes requires dedicated, dedicated depth sensors, requires dedicated depth, depth estimation
+ 备注: ICIP 2024
+
+ 点击查看摘要
+ Abstract:Measuring 3D geometric structures of indoor scenes requires dedicated depth sensors, which are not always available. Echo-based depth estimation has recently been studied as a promising alternative solution. All previous studies have assumed the use of echoes in the audible range. However, one major problem is that audible echoes cannot be used in quiet spaces or other situations where producing audible sounds is prohibited. In this paper, we consider echo-based depth estimation using inaudible ultrasonic echoes. While ultrasonic waves provide high measurement accuracy in theory, the actual depth estimation accuracy when ultrasonic echoes are used has remained unclear, due to its disadvantage of being sensitive to noise and susceptible to attenuation. We first investigate the depth estimation accuracy when the frequency of the sound source is restricted to the high-frequency band, and found that the accuracy decreased when the frequency was limited to ultrasonic ranges. Based on this observation, we propose a novel deep learning method to improve the accuracy of ultrasonic echo-based depth estimation by using audible echoes as auxiliary data only during training. Experimental results with a public dataset demonstrate that our method improves the estimation accuracy.
+
+
+
+ 44. 【2409.03326】Enhancing User-Centric Privacy Protection: An Interactive Framework through Diffusion Models and Machine Unlearning
+ 链接:https://arxiv.org/abs/2409.03326
+ 作者:Huaxi Huang,Xin Yuan,Qiyu Liao,Dadong Wang,Tongliang Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:multimedia data analysis, privacy protection, privacy, realm of multimedia, escalated concerns
+ 备注:
+
+ 点击查看摘要
+ Abstract:In the realm of multimedia data analysis, the extensive use of image datasets has escalated concerns over privacy protection within such data. Current research predominantly focuses on privacy protection either in data sharing or upon the release of trained machine learning models. Our study pioneers a comprehensive privacy protection framework that safeguards image data privacy concurrently during data sharing and model publication. We propose an interactive image privacy protection framework that utilizes generative machine learning models to modify image information at the attribute level and employs machine unlearning algorithms for the privacy preservation of model parameters. This user-interactive framework allows for adjustments in privacy protection intensity based on user feedback on generated images, striking a balance between maximal privacy safeguarding and maintaining model performance. Within this framework, we instantiate two modules: a differential privacy diffusion model for protecting attribute information in images and a feature unlearning algorithm for efficient updates of the trained model on the revised image dataset. Our approach demonstrated superiority over existing methods on facial datasets across various attribute classifications.
+
+
+
+ 45. 【2409.03320】YOLO-PPA based Efficient Traffic Sign Detection for Cruise Control in Autonomous Driving
+ 链接:https://arxiv.org/abs/2409.03320
+ 作者:Jingyu Zhang,Wenqing Zhang,Chaoyi Tan,Xiangtian Li,Qianyi Sun
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:autonomous driving systems, traffic signs efficiently, detect traffic signs, traffic sign detection, proposed YOLO PPA
+ 备注:
+
+ 点击查看摘要
+ Abstract:It is very important to detect traffic signs efficiently and accurately in autonomous driving systems. However, the farther the distance, the smaller the traffic signs. Existing object detection algorithms can hardly detect these small scaled this http URL addition, the performance of embedded devices on vehicles limits the scale of detection this http URL address these challenges, a YOLO PPA based traffic sign detection algorithm is proposed in this paper.The experimental results on the GTSDB dataset show that compared to the original YOLO, the proposed method improves inference efficiency by 11.2%. The mAP 50 is also improved by 93.2%, which demonstrates the effectiveness of the proposed YOLO PPA.
+
+
+
+ 46. 【2409.03303】Improving Robustness to Multiple Spurious Correlations by Multi-Objective Optimization
+ 链接:https://arxiv.org/abs/2409.03303
+ 作者:Nayeong Kim,Juwon Kang,Sungsoo Ahn,Jungseul Ok,Suha Kwak
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:multiple biases, unbiased and accurate, accurate model, multiple, training
+ 备注: International Conference on Machine Learning 2024
+
+ 点击查看摘要
+ Abstract:We study the problem of training an unbiased and accurate model given a dataset with multiple biases. This problem is challenging since the multiple biases cause multiple undesirable shortcuts during training, and even worse, mitigating one may exacerbate the other. We propose a novel training method to tackle this challenge. Our method first groups training data so that different groups induce different shortcuts, and then optimizes a linear combination of group-wise losses while adjusting their weights dynamically to alleviate conflicts between the groups in performance; this approach, rooted in the multi-objective optimization theory, encourages to achieve the minimax Pareto solution. We also present a new benchmark with multiple biases, dubbed MultiCelebA, for evaluating debiased training methods under realistic and challenging scenarios. Our method achieved the best on three datasets with multiple biases, and also showed superior performance on conventional single-bias datasets.
+
+
+
+ 47. 【2409.03277】ChartMoE: Mixture of Expert Connector for Advanced Chart Understanding
+ 链接:https://arxiv.org/abs/2409.03277
+ 作者:Zhengzhuo Xu,Bowen Qu,Yiyan Qi,Sinan Du,Chengjin Xu,Chun Yuan,Jian Guo
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Automatic chart understanding, Automatic chart, document parsing, chart understanding, crucial for content
+ 备注:
+
+ 点击查看摘要
+ Abstract:Automatic chart understanding is crucial for content comprehension and document parsing. Multimodal large language models (MLLMs) have demonstrated remarkable capabilities in chart understanding through domain-specific alignment and fine-tuning. However, the application of alignment training within the chart domain is still underexplored. To address this, we propose ChartMoE, which employs the mixture of expert (MoE) architecture to replace the traditional linear projector to bridge the modality gap. Specifically, we train multiple linear connectors through distinct alignment tasks, which are utilized as the foundational initialization parameters for different experts. Additionally, we introduce ChartMoE-Align, a dataset with over 900K chart-table-JSON-code quadruples to conduct three alignment tasks (chart-table/JSON/code). Combined with the vanilla connector, we initialize different experts in four distinct ways and adopt high-quality knowledge learning to further refine the MoE connector and LLM parameters. Extensive experiments demonstrate the effectiveness of the MoE connector and our initialization strategy, e.g., ChartMoE improves the accuracy of the previous state-of-the-art from 80.48% to 84.64% on the ChartQA benchmark.
+
+
+
+ 48. 【2409.03272】OccLLaMA: An Occupancy-Language-Action Generative World Model for Autonomous Driving
+ 链接:https://arxiv.org/abs/2409.03272
+ 作者:Julong Wei,Shanshuai Yuan,Pengfei Li,Qingda Hu,Zhongxue Gan,Wenchao Ding
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:spurred their applications, autonomous driving, large language models, multi-modal large language, applications in autonomous
+ 备注:
+
+ 点击查看摘要
+ Abstract:The rise of multi-modal large language models(MLLMs) has spurred their applications in autonomous driving. Recent MLLM-based methods perform action by learning a direct mapping from perception to action, neglecting the dynamics of the world and the relations between action and world dynamics. In contrast, human beings possess world model that enables them to simulate the future states based on 3D internal visual representation and plan actions accordingly. To this end, we propose OccLLaMA, an occupancy-language-action generative world model, which uses semantic occupancy as a general visual representation and unifies vision-language-action(VLA) modalities through an autoregressive model. Specifically, we introduce a novel VQVAE-like scene tokenizer to efficiently discretize and reconstruct semantic occupancy scenes, considering its sparsity and classes imbalance. Then, we build a unified multi-modal vocabulary for vision, language and action. Furthermore, we enhance LLM, specifically LLaMA, to perform the next token/scene prediction on the unified vocabulary to complete multiple tasks in autonomous driving. Extensive experiments demonstrate that OccLLaMA achieves competitive performance across multiple tasks, including 4D occupancy forecasting, motion planning, and visual question answering, showcasing its potential as a foundation model in autonomous driving.
+
+
+
+ 49. 【2409.03270】SVP: Style-Enhanced Vivid Portrait Talking Head Diffusion Model
+ 链接:https://arxiv.org/abs/2409.03270
+ 作者:Weipeng Tan,Chuming Lin,Chengming Xu,Xiaozhong Ji,Junwei Zhu,Chengjie Wang,Yanwei Fu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Talking Head Generation, Talking Head, broad application prospects, Head Generation, film production
+ 备注:
+
+ 点击查看摘要
+ Abstract:Talking Head Generation (THG), typically driven by audio, is an important and challenging task with broad application prospects in various fields such as digital humans, film production, and virtual reality. While diffusion model-based THG methods present high quality and stable content generation, they often overlook the intrinsic style which encompasses personalized features such as speaking habits and facial expressions of a video. As consequence, the generated video content lacks diversity and vividness, thus being limited in real life scenarios. To address these issues, we propose a novel framework named Style-Enhanced Vivid Portrait (SVP) which fully leverages style-related information in THG. Specifically, we first introduce the novel probabilistic style prior learning to model the intrinsic style as a Gaussian distribution using facial expressions and audio embedding. The distribution is learned through the 'bespoked' contrastive objective, effectively capturing the dynamic style information in each video. Then we finetune a pretrained Stable Diffusion (SD) model to inject the learned intrinsic style as a controlling signal via cross attention. Experiments show that our model generates diverse, vivid, and high-quality videos with flexible control over intrinsic styles, outperforming existing state-of-the-art methods.
+
+
+
+ 50. 【2409.03261】Bones Can't Be Triangles: Accurate and Efficient Vertebrae Keypoint Estimation through Collaborative Error Revision
+ 链接:https://arxiv.org/abs/2409.03261
+ 作者:Jinhee Kim,Taesung Kim,Jaegul Choo
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Recent advances, minimizing user intervention, vertebrae keypoint estimation, keypoint estimation, enhanced accuracy
+ 备注: 33 pages, ECCV 2024, Project Page: [this https URL](https://ts-kim.github.io/KeyBot/)
+
+ 点击查看摘要
+ Abstract:Recent advances in interactive keypoint estimation methods have enhanced accuracy while minimizing user intervention. However, these methods require user input for error correction, which can be costly in vertebrae keypoint estimation where inaccurate keypoints are densely clustered or overlap. We introduce a novel approach, KeyBot, specifically designed to identify and correct significant and typical errors in existing models, akin to user revision. By characterizing typical error types and using simulated errors for training, KeyBot effectively corrects these errors and significantly reduces user workload. Comprehensive quantitative and qualitative evaluations on three public datasets confirm that KeyBot significantly outperforms existing methods, achieving state-of-the-art performance in interactive vertebrae keypoint estimation. The source code and demo video are available at: this https URL
+
+
+
+ 51. 【2409.03254】Granular-ball Representation Learning for Deep CNN on Learning with Label Noise
+ 链接:https://arxiv.org/abs/2409.03254
+ 作者:Dawei Dai,Hao Zhu,Shuyin Xia,Guoyin Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:deep CNN models, actual scenarios, automatically annotated, manually or automatically, noise is inevitably
+ 备注:
+
+ 点击查看摘要
+ Abstract:In actual scenarios, whether manually or automatically annotated, label noise is inevitably generated in the training data, which can affect the effectiveness of deep CNN models. The popular solutions require data cleaning or designing additional optimizations to punish the data with mislabeled data, thereby enhancing the robustness of models. However, these methods come at the cost of weakening or even losing some data during the training process. As we know, content is the inherent attribute of an image that does not change with changes in annotations. In this study, we propose a general granular-ball computing (GBC) module that can be embedded into a CNN model, where the classifier finally predicts the label of granular-ball ($gb$) samples instead of each individual samples. Specifically, considering the classification task: (1) in forward process, we split the input samples as $gb$ samples at feature-level, each of which can correspond to multiple samples with varying numbers and share one single label; (2) during the backpropagation process, we modify the gradient allocation strategy of the GBC module to enable it to propagate normally; and (3) we develop an experience replay policy to ensure the stability of the training process. Experiments demonstrate that the proposed method can improve the robustness of CNN models with no additional data or optimization.
+
+
+
+ 52. 【2409.03252】Gr-IoU: Ground-Intersection over Union for Robust Multi-Object Tracking with 3D Geometric Constraints
+ 链接:https://arxiv.org/abs/2409.03252
+ 作者:Keisuke Toida,Naoki Kato,Osamu Segawa,Takeshi Nakamura,Kazuhiro Hotta
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:problem in multi-object, data association problem, multi-object tracking, association problem, tracking objects detected
+ 备注: Accepted for the ECCV 2024 Workshop on Affective Behavior Analysis in-the-wild(ABAW)
+
+ 点击查看摘要
+ Abstract:We propose a Ground IoU (Gr-IoU) to address the data association problem in multi-object tracking. When tracking objects detected by a camera, it often occurs that the same object is assigned different IDs in consecutive frames, especially when objects are close to each other or overlapping. To address this issue, we introduce Gr-IoU, which takes into account the 3D structure of the scene. Gr-IoU transforms traditional bounding boxes from the image space to the ground plane using the vanishing point geometry. The IoU calculated with these transformed bounding boxes is more sensitive to the front-to-back relationships of objects, thereby improving data association accuracy and reducing ID switches. We evaluated our Gr-IoU method on the MOT17 and MOT20 datasets, which contain diverse tracking scenarios including crowded scenes and sequences with frequent occlusions. Experimental results demonstrated that Gr-IoU outperforms conventional real-time methods without appearance features.
+
+
+
+ 53. 【2409.03249】Multiple weather images restoration using the task transformer and adaptive mixup strategy
+ 链接:https://arxiv.org/abs/2409.03249
+ 作者:Yang Wen,Anyu Lai,Bo Qian,Hao Wang,Wuzhen Shi,Wenming Cao
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:severe weather removal, removal predominantly focuses, weather, weather removal, weather removal predominantly
+ 备注: 10 pages, 5 figures and 2 table
+
+ 点击查看摘要
+ Abstract:The current state-of-the-art in severe weather removal predominantly focuses on single-task applications, such as rain removal, haze removal, and snow removal. However, real-world weather conditions often consist of a mixture of several weather types, and the degree of weather mixing in autonomous driving scenarios remains unknown. In the presence of complex and diverse weather conditions, a single weather removal model often encounters challenges in producing clear images from severe weather images. Therefore, there is a need for the development of multi-task severe weather removal models that can effectively handle mixed weather conditions and improve image quality in autonomous driving scenarios. In this paper, we introduce a novel multi-task severe weather removal model that can effectively handle complex weather conditions in an adaptive manner. Our model incorporates a weather task sequence generator, enabling the self-attention mechanism to selectively focus on features specific to different weather types. To tackle the challenge of repairing large areas of weather degradation, we introduce Fast Fourier Convolution (FFC) to increase the receptive field. Additionally, we propose an adaptive upsampling technique that effectively processes both the weather task information and underlying image features by selectively retaining relevant information. Our proposed model has achieved state-of-the-art performance on the publicly available dataset.
+
+
+
+ 54. 【2409.03245】UAV (Unmanned Aerial Vehicles): Diverse Applications of UAV Datasets in Segmentation, Classification, Detection, and Tracking
+ 链接:https://arxiv.org/abs/2409.03245
+ 作者:Md. Mahfuzur Rahman,Sunzida Siddique,Marufa Kamal,Rakib Hossain Rifat,Kishor Datta Gupta
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:providing unmatched adaptability, Unmanned Aerial Vehicles, Unmanned Aerial, diverse research domains, UAV datasets
+ 备注:
+
+ 点击查看摘要
+ Abstract:Unmanned Aerial Vehicles (UAVs), have greatly revolutionized the process of gathering and analyzing data in diverse research domains, providing unmatched adaptability and effectiveness. This paper presents a thorough examination of Unmanned Aerial Vehicle (UAV) datasets, emphasizing their wide range of applications and progress. UAV datasets consist of various types of data, such as satellite imagery, images captured by drones, and videos. These datasets can be categorized as either unimodal or multimodal, offering a wide range of detailed and comprehensive information. These datasets play a crucial role in disaster damage assessment, aerial surveillance, object recognition, and tracking. They facilitate the development of sophisticated models for tasks like semantic segmentation, pose estimation, vehicle re-identification, and gesture recognition. By leveraging UAV datasets, researchers can significantly enhance the capabilities of computer vision models, thereby advancing technology and improving our understanding of complex, dynamic environments from an aerial perspective. This review aims to encapsulate the multifaceted utility of UAV datasets, emphasizing their pivotal role in driving innovation and practical applications in multiple domains.
+
+
+
+ 55. 【2409.03236】Unveiling Context-Related Anomalies: Knowledge Graph Empowered Decoupling of Scene and Action for Human-Related Video Anomaly Detection
+ 链接:https://arxiv.org/abs/2409.03236
+ 作者:Chenglizhao Chen,Xinyu Liu,Mengke Song,Luming Li,Xu Yu,Shanchen Pang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:surveillance applications, crucial for surveillance, Detecting anomalies, scenes, methods
+ 备注: 13pages, 9 figures
+
+ 点击查看摘要
+ Abstract:Detecting anomalies in human-related videos is crucial for surveillance applications. Current methods primarily include appearance-based and action-based techniques. Appearance-based methods rely on low-level visual features such as color, texture, and shape. They learn a large number of pixel patterns and features related to known scenes during training, making them effective in detecting anomalies within these familiar contexts. However, when encountering new or significantly changed scenes, i.e., unknown scenes, they often fail because existing SOTA methods do not effectively capture the relationship between actions and their surrounding scenes, resulting in low generalization. In contrast, action-based methods focus on detecting anomalies in human actions but are usually less informative because they tend to overlook the relationship between actions and their scenes, leading to incorrect detection. For instance, the normal event of running on the beach and the abnormal event of running on the street might both be considered normal due to the lack of scene information. In short, current methods struggle to integrate low-level visual and high-level action features, leading to poor anomaly detection in varied and complex scenes. To address this challenge, we propose a novel decoupling-based architecture for human-related video anomaly detection (DecoAD). DecoAD significantly improves the integration of visual and action features through the decoupling and interweaving of scenes and actions, thereby enabling a more intuitive and accurate understanding of complex behaviors and scenes. DecoAD supports fully supervised, weakly supervised, and unsupervised settings.
+
+
+
+ 56. 【2409.03228】Labeled-to-Unlabeled Distribution Alignment for Partially-Supervised Multi-Organ Medical Image Segmentation
+ 链接:https://arxiv.org/abs/2409.03228
+ 作者:Xixi Jiang,Dong Zhang,Xiang Li,Kangyi Liu,Kwang-Ting Cheng,Xin Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:medical image segmentation, image segmentation aims, unified semantic segmentation, semantic segmentation model, multi-organ medical image
+ 备注: Accepted by Medical Image Analysis
+
+ 点击查看摘要
+ Abstract:Partially-supervised multi-organ medical image segmentation aims to develop a unified semantic segmentation model by utilizing multiple partially-labeled datasets, with each dataset providing labels for a single class of organs. However, the limited availability of labeled foreground organs and the absence of supervision to distinguish unlabeled foreground organs from the background pose a significant challenge, which leads to a distribution mismatch between labeled and unlabeled pixels. Although existing pseudo-labeling methods can be employed to learn from both labeled and unlabeled pixels, they are prone to performance degradation in this task, as they rely on the assumption that labeled and unlabeled pixels have the same distribution. In this paper, to address the problem of distribution mismatch, we propose a labeled-to-unlabeled distribution alignment (LTUDA) framework that aligns feature distributions and enhances discriminative capability. Specifically, we introduce a cross-set data augmentation strategy, which performs region-level mixing between labeled and unlabeled organs to reduce distribution discrepancy and enrich the training set. Besides, we propose a prototype-based distribution alignment method that implicitly reduces intra-class variation and increases the separation between the unlabeled foreground and background. This can be achieved by encouraging consistency between the outputs of two prototype classifiers and a linear classifier. Extensive experimental results on the AbdomenCT-1K dataset and a union of four benchmark datasets (including LiTS, MSD-Spleen, KiTS, and NIH82) demonstrate that our method outperforms the state-of-the-art partially-supervised methods by a considerable margin, and even surpasses the fully-supervised methods. The source code is publicly available at this https URL.
+
+
+
+ 57. 【2409.03223】Why mamba is effective? Exploit Linear Transformer-Mamba Network for Multi-Modality Image Fusion
+ 链接:https://arxiv.org/abs/2409.03223
+ 作者:Chenguang Zhu,Shan Gao,Huafeng Chen,Guangqian Guo,Chaowei Wang,Yaoxing Wang,Chen Shu Lei,Quanjiang Fan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Multi-modality image fusion, render high-quality fusion, Multi-modality image, high-quality fusion images, image fusion aims
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multi-modality image fusion aims to integrate the merits of images from different sources and render high-quality fusion images. However, existing feature extraction and fusion methods are either constrained by inherent local reduction bias and static parameters during inference (CNN) or limited by quadratic computational complexity (Transformers), and cannot effectively extract and fuse features. To solve this problem, we propose a dual-branch image fusion network called Tmamba. It consists of linear Transformer and Mamba, which has global modeling capabilities while maintaining linear complexity. Due to the difference between the Transformer and Mamba structures, the features extracted by the two branches carry channel and position information respectively. T-M interaction structure is designed between the two branches, using global learnable parameters and convolutional layers to transfer position and channel information respectively. We further propose cross-modal interaction at the attention level to obtain cross-modal attention. Experiments show that our Tmamba achieves promising results in multiple fusion tasks, including infrared-visible image fusion and medical image fusion. Code with checkpoints will be available after the peer-review process.
+
+
+
+ 58. 【2409.03213】Optimizing 3D Gaussian Splatting for Sparse Viewpoint Scene Reconstruction
+ 链接:https://arxiv.org/abs/2409.03213
+ 作者:Shen Chen,Jiale Zhou,Lei Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Neural Radiance Fields, Radiance Fields, Neural Radiance, computational overhead compared, Gaussian Splatting
+ 备注:
+
+ 点击查看摘要
+ Abstract:3D Gaussian Splatting (3DGS) has emerged as a promising approach for 3D scene representation, offering a reduction in computational overhead compared to Neural Radiance Fields (NeRF). However, 3DGS is susceptible to high-frequency artifacts and demonstrates suboptimal performance under sparse viewpoint conditions, thereby limiting its applicability in robotics and computer vision. To address these limitations, we introduce SVS-GS, a novel framework for Sparse Viewpoint Scene reconstruction that integrates a 3D Gaussian smoothing filter to suppress artifacts. Furthermore, our approach incorporates a Depth Gradient Profile Prior (DGPP) loss with a dynamic depth mask to sharpen edges and 2D diffusion with Score Distillation Sampling (SDS) loss to enhance geometric consistency in novel view synthesis. Experimental evaluations on the MipNeRF-360 and SeaThru-NeRF datasets demonstrate that SVS-GS markedly improves 3D reconstruction from sparse viewpoints, offering a robust and efficient solution for scene understanding in robotics and computer vision applications.
+
+
+
+ 59. 【2409.03212】Bi-capacity Choquet Integral for Sensor Fusion with Label Uncertainty
+ 链接:https://arxiv.org/abs/2409.03212
+ 作者:Hersh Vakharia,Xiaoxiao Du
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:improve reliability, Multiple Instance Learning, Sensor fusion combines, multiple sensor sources, Choquet integral
+ 备注: 10 pages, 7 figures, 7 tables; Accepted to 2024 FUZZ-IEEE and presented at 2024 IEEE WCCI; Code available at [this https URL](https://github.com/hvak/Bi-MIChI)
+
+ 点击查看摘要
+ Abstract:Sensor fusion combines data from multiple sensor sources to improve reliability, robustness, and accuracy of data interpretation. The Fuzzy Integral (FI), in particular, the Choquet integral (ChI), is often used as a powerful nonlinear aggregator for fusion across multiple sensors. However, existing supervised ChI learning algorithms typically require precise training labels for each input data point, which can be difficult or impossible to obtain. Additionally, prior work on ChI fusion is often based only on the normalized fuzzy measures, which bounds the fuzzy measure values between [0, 1]. This can be limiting in cases where the underlying scales of input data sources are bipolar (i.e., between [-1, 1]). To address these challenges, this paper proposes a novel Choquet integral-based fusion framework, named Bi-MIChI (pronounced "bi-mi-kee"), which uses bi-capacities to represent the interactions between pairs of subsets of the input sensor sources on a bi-polar scale. This allows for extended non-linear interactions between the sensor sources and can lead to interesting fusion results. Bi-MIChI also addresses label uncertainty through Multiple Instance Learning, where training labels are applied to "bags" (sets) of data instead of per-instance. Our proposed Bi-MIChI framework shows effective classification and detection performance on both synthetic and real-world experiments for sensor fusion with label uncertainty. We also provide detailed analyses on the behavior of the fuzzy measures to demonstrate our fusion process.
+
+
+
+ 60. 【2409.03209】Seg: An Iterative Refinement-based Framework for Training-free Segmentation
+ 链接:https://arxiv.org/abs/2409.03209
+ 作者:Lin Sun,Jiale Cao,Jin Xie,Fahad Shahbaz Khan,Yanwei Pang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Stable diffusion, strong semantic clue, demonstrated strong image, strong image synthesis, employing stable diffusion
+ 备注:
+
+ 点击查看摘要
+ Abstract:Stable diffusion has demonstrated strong image synthesis ability to given text descriptions, suggesting it to contain strong semantic clue for grouping objects. Inspired by this, researchers have explored employing stable diffusion for trainingfree segmentation. Most existing approaches either simply employ cross-attention map or refine it by self-attention map, to generate segmentation masks. We believe that iterative refinement with self-attention map would lead to better results. However, we mpirically demonstrate that such a refinement is sub-optimal likely due to the self-attention map containing irrelevant global information which hampers accurately refining cross-attention map with multiple iterations. To address this, we propose an iterative refinement framework for training-free segmentation, named iSeg, having an entropy-reduced self-attention module which utilizes a gradient descent scheme to reduce the entropy of self-attention map, thereby suppressing the weak responses corresponding to irrelevant global information. Leveraging the entropy-reduced self-attention module, our iSeg stably improves refined crossattention map with iterative refinement. Further, we design a category-enhanced cross-attention module to generate accurate cross-attention map, providing a better initial input for iterative refinement. Extensive experiments across different datasets and diverse segmentation tasks reveal the merits of proposed contributions, leading to promising performance on diverse segmentation tasks. For unsupervised semantic segmentation on Cityscapes, our iSeg achieves an absolute gain of 3.8% in terms of mIoU compared to the best existing training-free approach in literature. Moreover, our proposed iSeg can support segmentation with different kind of images and interactions.
+
+
+
+ 61. 【2409.03206】C-LLaVA: Rethinking the Transfer from Image to Video Understanding with Temporal Considerations
+ 链接:https://arxiv.org/abs/2409.03206
+ 作者:Mingze Gao,Jingyu Liu,Mingda Li,Jiangtao Xie,Qingbin Liu,Bo Zhao,Xi Chen,Hui Xiong
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Multimodal Large Language, Large Language Models, Multimodal Large, Large Language, significantly improved performance
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multimodal Large Language Models (MLLMs) have significantly improved performance across various image-language applications. Recently, there has been a growing interest in adapting image pre-trained MLLMs for video-related tasks. However, most efforts concentrate on enhancing the vision encoder and projector components, while the core part, Large Language Models (LLMs), remains comparatively under-explored. In this paper, we propose two strategies to enhance the model's capability in video understanding tasks by improving inter-layer attention computation in LLMs. Specifically, the first approach focuses on the enhancement of Rotary Position Embedding (RoPE) with Temporal-Aware Dual RoPE, which introduces temporal position information to strengthen the MLLM's temporal modeling capabilities while preserving the relative position relationships of both visual and text tokens. The second approach involves enhancing the Attention Mask with the Frame-wise Block Causal Attention Mask, a simple yet effective method that broadens visual token interactions within and across video frames while maintaining the causal inference mechanism. Based on these proposed methods, we adapt LLaVA for video understanding tasks, naming it Temporal-Considered LLaVA (TC-LLaVA). Our TC-LLaVA achieves new state-of-the-art performance across various video understanding benchmarks with only supervised fine-tuning (SFT) on video-related datasets.
+
+
+
+ 62. 【2409.03200】Active Fake: DeepFake Camouflage
+ 链接:https://arxiv.org/abs/2409.03200
+ 作者:Pu Sun,Honggang Qi,Yuezun Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:gained significant attention, significant attention due, manipulate facial attributes, Deep Neural Networks, high realism
+ 备注:
+
+ 点击查看摘要
+ Abstract:DeepFake technology has gained significant attention due to its ability to manipulate facial attributes with high realism, raising serious societal concerns. Face-Swap DeepFake is the most harmful among these techniques, which fabricates behaviors by swapping original faces with synthesized ones. Existing forensic methods, primarily based on Deep Neural Networks (DNNs), effectively expose these manipulations and have become important authenticity indicators. However, these methods mainly concentrate on capturing the blending inconsistency in DeepFake faces, raising a new security issue, termed Active Fake, emerges when individuals intentionally create blending inconsistency in their authentic videos to evade responsibility. This tactic is called DeepFake Camouflage. To achieve this, we introduce a new framework for creating DeepFake camouflage that generates blending inconsistencies while ensuring imperceptibility, effectiveness, and transferability. This framework, optimized via an adversarial learning strategy, crafts imperceptible yet effective inconsistencies to mislead forensic detectors. Extensive experiments demonstrate the effectiveness and robustness of our method, highlighting the need for further research in active fake detection.
+
+
+
+ 63. 【2409.03198】RoomDiffusion: A Specialized Diffusion Model in the Interior Design Industry
+ 链接:https://arxiv.org/abs/2409.03198
+ 作者:Zhaowei Wang,Ying Hao,Hao Wei,Qing Xiao,Lulu Chen,Yulong Li,Yue Yang,Tianyi Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:design remains underexplored, Recent advancements, visual content generation, significantly transformed visual, transformed visual content
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advancements in text-to-image diffusion models have significantly transformed visual content generation, yet their application in specialized fields such as interior design remains underexplored. In this paper, we present RoomDiffusion, a pioneering diffusion model meticulously tailored for the interior design industry. To begin with, we build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. Subsequently, techniques such as multiaspect training, multi-stage fine-tune and model fusion are applied to enhance both the visual appeal and precision of the generated results. Lastly, leveraging the latent consistency Distillation method, we distill and expedite the model for optimal efficiency. Unlike existing models optimized for general scenarios, RoomDiffusion addresses specific challenges in interior design, such as lack of fashion, high furniture duplication rate, and inaccurate style. Through our holistic human evaluation protocol with more than 20 professional human evaluators, RoomDiffusion demonstrates industry-leading performance in terms of aesthetics, accuracy, and efficiency, surpassing all existing open source models such as stable diffusion and SDXL.
+
+
+
+ 64. 【2409.03192】PEPL: Precision-Enhanced Pseudo-Labeling for Fine-Grained Image Classification in Semi-Supervised Learning
+ 链接:https://arxiv.org/abs/2409.03192
+ 作者:Bowen Tian,Songning Lai,Lujundong Li,Zhihao Shuai,Runwei Guan,Tian Wu,Yutao Yue
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:computer vision technologies, witnessed significant advancements, vision technologies, Fine-grained image classification, advent of deep
+ 备注: Under review
+
+ 点击查看摘要
+ Abstract:Fine-grained image classification has witnessed significant advancements with the advent of deep learning and computer vision technologies. However, the scarcity of detailed annotations remains a major challenge, especially in scenarios where obtaining high-quality labeled data is costly or time-consuming. To address this limitation, we introduce Precision-Enhanced Pseudo-Labeling(PEPL) approach specifically designed for fine-grained image classification within a semi-supervised learning framework. Our method leverages the abundance of unlabeled data by generating high-quality pseudo-labels that are progressively refined through two key phases: initial pseudo-label generation and semantic-mixed pseudo-label generation. These phases utilize Class Activation Maps (CAMs) to accurately estimate the semantic content and generate refined labels that capture the essential details necessary for fine-grained classification. By focusing on semantic-level information, our approach effectively addresses the limitations of standard data augmentation and image-mixing techniques in preserving critical fine-grained features. We achieve state-of-the-art performance on benchmark datasets, demonstrating significant improvements over existing semi-supervised strategies, with notable boosts in accuracy and robustness.Our code has been open sourced at this https URL.
+
+
+
+ 65. 【2409.03190】Mastoidectomy Multi-View Synthesis from a Single Microscopy Image
+ 链接:https://arxiv.org/abs/2409.03190
+ 作者:Yike Zhang,Jack Noble
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:Cochlear Implant, procedures involve performing, procedures involve, involve performing, performing an invasive
+ 备注: Submitted to Medical Imaging 2025: Image-Guided Procedures, Robotic Interventions, and Modeling
+
+ 点击查看摘要
+ Abstract:Cochlear Implant (CI) procedures involve performing an invasive mastoidectomy to insert an electrode array into the cochlea. In this paper, we introduce a novel pipeline that is capable of generating synthetic multi-view videos from a single CI microscope image. In our approach, we use a patient's pre-operative CT scan to predict the post-mastoidectomy surface using a method designed for this purpose. We manually align the surface with a selected microscope frame to obtain an accurate initial pose of the reconstructed CT mesh relative to the microscope. We then perform UV projection to transfer the colors from the frame to surface textures. Novel views of the textured surface can be used to generate a large dataset of synthetic frames with ground truth poses. We evaluated the quality of synthetic views rendered using Pytorch3D and PyVista. We found both rendering engines lead to similarly high-quality synthetic novel-view frames compared to ground truth with a structural similarity index for both methods averaging about 0.86. A large dataset of novel views with known poses is critical for ongoing training of a method to automatically estimate microscope pose for 2D to 3D registration with the pre-operative CT to facilitate augmented reality surgery. This dataset will empower various downstream tasks, such as integrating Augmented Reality (AR) in the OR, tracking surgical tools, and supporting other video analysis studies.
+
+
+
+ 66. 【2409.03114】Developing, Analyzing, and Evaluating Self-Drive Algorithms Using Drive-by-Wire Electric Vehicles
+ 链接:https://arxiv.org/abs/2409.03114
+ 作者:Beñat Froemming-Aldanondo,Tatiana Rastoskueva,Michael Evans,Marcial Machado,Anna Vadella,Rickey Johnson,Luis Escamilla,Milan Jostes,Devson Butani,Ryan Kaddis,Chan-Jin Chung,Joshua Siegel
+ 类目:Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:effective autonomous driving, Robot Operating System, essential for safe, safe and effective, effective autonomous
+ 备注: Supported by the National Science Foundation under Grants No. 2150292 and 2150096
+
+ 点击查看摘要
+ Abstract:Reliable lane-following algorithms are essential for safe and effective autonomous driving. This project was primarily focused on developing and evaluating different lane-following programs to find the most reliable algorithm for a Vehicle to Everything (V2X) project. The algorithms were first tested on a simulator and then with real vehicles equipped with a drive-by-wire system using ROS (Robot Operating System). Their performance was assessed through reliability, comfort, speed, and adaptability metrics. The results show that the two most reliable approaches detect both lane lines and use unsupervised learning to separate them. These approaches proved to be robust in various driving scenarios, making them suitable candidates for integration into the V2X project.
+
+
+
+ 67. 【2409.03109】FIDAVL: Fake Image Detection and Attribution using Vision-Language Model
+ 链接:https://arxiv.org/abs/2409.03109
+ 作者:Mamadou Keita,Wassim Hamidouche,Hessen Bougueffa Eutamene,Abdelmalik Taleb-Ahmed,Abdenour Hadid
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Cryptography and Security (cs.CR)
+ 关键词:Fake Image Detection, introduce FIDAVL, Vision-Language Model, Detection and Attribution, FIDAVL
+ 备注:
+
+ 点击查看摘要
+ Abstract:We introduce FIDAVL: Fake Image Detection and Attribution using a Vision-Language Model. FIDAVL is a novel and efficient mul-titask approach inspired by the synergies between vision and language processing. Leveraging the benefits of zero-shot learning, FIDAVL exploits the complementarity between vision and language along with soft prompt-tuning strategy to detect fake images and accurately attribute them to their originating source models. We conducted extensive experiments on a comprehensive dataset comprising synthetic images generated by various state-of-the-art models. Our results demonstrate that FIDAVL achieves an encouraging average detection accuracy of 95.42% and F1-score of 95.47% while also obtaining noteworthy performance metrics, with an average F1-score of 92.64% and ROUGE-L score of 96.50% for attributing synthetic images to their respective source generation models. The source code of this work will be publicly released at this https URL.
+
+
+
+ 68. 【2409.03106】Spatial Diffusion for Cell Layout Generation
+ 链接:https://arxiv.org/abs/2409.03106
+ 作者:Chen Li,Xiaoling Hu,Shahira Abousamra,Meilong Xu,Chao Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:augment training sets, augment training, training sets, Generative models, Generative
+ 备注: 12 pages, 4 figures, accepted by MICCAI 2024
+
+ 点击查看摘要
+ Abstract:Generative models, such as GANs and diffusion models, have been used to augment training sets and boost performances in different tasks. We focus on generative models for cell detection instead, i.e., locating and classifying cells in given pathology images. One important information that has been largely overlooked is the spatial patterns of the cells. In this paper, we propose a spatial-pattern-guided generative model for cell layout generation. Specifically, a novel diffusion model guided by spatial features and generates realistic cell layouts has been proposed. We explore different density models as spatial features for the diffusion model. In downstream tasks, we show that the generated cell layouts can be used to guide the generation of high-quality pathology images. Augmenting with these images can significantly boost the performance of SOTA cell detection methods. The code is available at this https URL.
+
+
+
+ 69. 【2409.03062】MobileUNETR: A Lightweight End-To-End Hybrid Vision Transformer For Efficient Medical Image Segmentation
+ 链接:https://arxiv.org/abs/2409.03062
+ 作者:Shehan Perera,Yunus Erzurumlu,Deepak Gulati,Alper Yilmaz
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:medical image analysis, cancer segmentation poses, poses a significant, significant challenge, challenge in medical
+ 备注: Accepted at ECCV 2024 - BioImage Computing Workshop (Oral)
+
+ 点击查看摘要
+ Abstract:Skin cancer segmentation poses a significant challenge in medical image analysis. Numerous existing solutions, predominantly CNN-based, face issues related to a lack of global contextual understanding. Alternatively, some approaches resort to large-scale Transformer models to bridge the global contextual gaps, but at the expense of model size and computational complexity. Finally many Transformer based approaches rely primarily on CNN based decoders overlooking the benefits of Transformer based decoding models. Recognizing these limitations, we address the need efficient lightweight solutions by introducing MobileUNETR, which aims to overcome the performance constraints associated with both CNNs and Transformers while minimizing model size, presenting a promising stride towards efficient image segmentation. MobileUNETR has 3 main features. 1) MobileUNETR comprises of a lightweight hybrid CNN-Transformer encoder to help balance local and global contextual feature extraction in an efficient manner; 2) A novel hybrid decoder that simultaneously utilizes low-level and global features at different resolutions within the decoding stage for accurate mask generation; 3) surpassing large and complex architectures, MobileUNETR achieves superior performance with 3 million parameters and a computational complexity of 1.3 GFLOP resulting in 10x and 23x reduction in parameters and FLOPS, respectively. Extensive experiments have been conducted to validate the effectiveness of our proposed method on four publicly available skin lesion segmentation datasets, including ISIC 2016, ISIC 2017, ISIC 2018, and PH2 datasets. The code will be publicly available at: this https URL
+
+
+
+ 70. 【2409.03061】Incorporating dense metric depth into neural 3D representations for view synthesis and relighting
+ 链接:https://arxiv.org/abs/2409.03061
+ 作者:Arkadeep Narayan Chaudhury,Igor Vasiljevic,Sergey Zakharov,Vitor Guizilini,Rares Ambrus,Srinivasa Narasimhan,Christopher G. Atkeson
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR); Robotics (cs.RO)
+ 关键词:Synthesizing accurate geometry, Synthesizing accurate, convenient product capture, virtual reality, autonomous driving
+ 备注: Project webpage: [this https URL](https://stereomfc.github.io)
+
+ 点击查看摘要
+ Abstract:Synthesizing accurate geometry and photo-realistic appearance of small scenes is an active area of research with compelling use cases in gaming, virtual reality, robotic-manipulation, autonomous driving, convenient product capture, and consumer-level photography. When applying scene geometry and appearance estimation techniques to robotics, we found that the narrow cone of possible viewpoints due to the limited range of robot motion and scene clutter caused current estimation techniques to produce poor quality estimates or even fail. On the other hand, in robotic applications, dense metric depth can often be measured directly using stereo and illumination can be controlled. Depth can provide a good initial estimate of the object geometry to improve reconstruction, while multi-illumination images can facilitate relighting. In this work we demonstrate a method to incorporate dense metric depth into the training of neural 3D representations and address an artifact observed while jointly refining geometry and appearance by disambiguating between texture and geometry edges. We also discuss a multi-flash stereo camera system developed to capture the necessary data for our pipeline and show results on relighting and view synthesis with a few training views.
+
+
+
+ 71. 【2409.03043】Can Your Generative Model Detect Out-of-Distribution Covariate Shift?
+ 链接:https://arxiv.org/abs/2409.03043
+ 作者:Christiaan Viviers,Amaan Valiuddin,Francisco Caetano,Lemar Abdi,Lena Filatova,Peter de With,Fons van der Sommen
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:high-level image statistics, normal and In-Distribution, high-level image, distribution shift aims, OOD detection
+ 备注: ECCV 2024
+
+ 点击查看摘要
+ Abstract:Detecting Out-of-Distribution~(OOD) sensory data and covariate distribution shift aims to identify new test examples with different high-level image statistics to the captured, normal and In-Distribution (ID) set. Existing OOD detection literature largely focuses on semantic shift with little-to-no consensus over covariate shift. Generative models capture the ID data in an unsupervised manner, enabling them to effectively identify samples that deviate significantly from this learned distribution, irrespective of the downstream task. In this work, we elucidate the ability of generative models to detect and quantify domain-specific covariate shift through extensive analyses that involves a variety of models. To this end, we conjecture that it is sufficient to detect most occurring sensory faults (anomalies and deviations in global signals statistics) by solely modeling high-frequency signal-dependent and independent details. We propose a novel method, CovariateFlow, for OOD detection, specifically tailored to covariate heteroscedastic high-frequency image-components using conditional Normalizing Flows (cNFs). Our results on CIFAR10 vs. CIFAR10-C and ImageNet200 vs. ImageNet200-C demonstrate the effectiveness of the method by accurately detecting OOD covariate shift. This work contributes to enhancing the fidelity of imaging systems and aiding machine learning models in OOD detection in the presence of covariate shift.
+
+
+
+ 72. 【2409.03034】MDNF: Multi-Diffusion-Nets for Neural Fields on Meshes
+ 链接:https://arxiv.org/abs/2409.03034
+ 作者:Avigail Cohen Rimon,Tal Shnitzer,Mirela Ben Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Fourier Filter Bank, Neural Fourier Filter, frequency domains, framework for representing, triangle meshes
+ 备注:
+
+ 点击查看摘要
+ Abstract:We propose a novel framework for representing neural fields on triangle meshes that is multi-resolution across both spatial and frequency domains. Inspired by the Neural Fourier Filter Bank (NFFB), our architecture decomposes the spatial and frequency domains by associating finer spatial resolution levels with higher frequency bands, while coarser resolutions are mapped to lower frequencies. To achieve geometry-aware spatial decomposition we leverage multiple DiffusionNet components, each associated with a different spatial resolution level. Subsequently, we apply a Fourier feature mapping to encourage finer resolution levels to be associated with higher frequencies. The final signal is composed in a wavelet-inspired manner using a sine-activated MLP, aggregating higher-frequency signals on top of lower-frequency ones. Our architecture attains high accuracy in learning complex neural fields and is robust to discontinuities, exponential scale variations of the target field, and mesh modification. We demonstrate the effectiveness of our approach through its application to diverse neural fields, such as synthetic RGB functions, UV texture coordinates, and vertex normals, illustrating different challenges. To validate our method, we compare its performance against two alternatives, showcasing the advantages of our multi-resolution architecture.
+
+
+
+ 73. 【2409.03032】A General Albedo Recovery Approach for Aerial Photogrammetric Images through Inverse Rendering
+ 链接:https://arxiv.org/abs/2409.03032
+ 作者:Shuang Song,Rongjun Qin
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:Modeling outdoor scenes, complicated unmodeled physics, Modeling outdoor, ill-posed problem due, volume scattering
+ 备注: ISPRS Journal of Photogrammetry and Remote Sensing
+
+ 点击查看摘要
+ Abstract:Modeling outdoor scenes for the synthetic 3D environment requires the recovery of reflectance/albedo information from raw images, which is an ill-posed problem due to the complicated unmodeled physics in this process (e.g., indirect lighting, volume scattering, specular reflection). The problem remains unsolved in a practical context. The recovered albedo can facilitate model relighting and shading, which can further enhance the realism of rendered models and the applications of digital twins. Typically, photogrammetric 3D models simply take the source images as texture materials, which inherently embed unwanted lighting artifacts (at the time of capture) into the texture. Therefore, these polluted textures are suboptimal for a synthetic environment to enable realistic rendering. In addition, these embedded environmental lightings further bring challenges to photo-consistencies across different images that cause image-matching uncertainties. This paper presents a general image formation model for albedo recovery from typical aerial photogrammetric images under natural illuminations and derives the inverse model to resolve the albedo information through inverse rendering intrinsic image decomposition. Our approach builds on the fact that both the sun illumination and scene geometry are estimable in aerial photogrammetry, thus they can provide direct inputs for this ill-posed problem. This physics-based approach does not require additional input other than data acquired through the typical drone-based photogrammetric collection and was shown to favorably outperform existing approaches. We also demonstrate that the recovered albedo image can in turn improve typical image processing tasks in photogrammetry such as feature and dense matching, edge, and line extraction.
+
+
+
+ 74. 【2409.03025】No Detail Left Behind: Revisiting Self-Retrieval for Fine-Grained Image Captioning
+ 链接:https://arxiv.org/abs/2409.03025
+ 作者:Manu Gaur,Darshan Singh S,Makarand Tapaswi
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:unable to generate, trained on data, generate fine-grained captions, Visual Caption Boosting, human annotations
+ 备注:
+
+ 点击查看摘要
+ Abstract:Image captioning systems are unable to generate fine-grained captions as they are trained on data that is either noisy (alt-text) or generic (human annotations). This is further exacerbated by maximum likelihood training that encourages generation of frequently occurring phrases. Previous works have tried to address this limitation by fine-tuning captioners with a self-retrieval (SR) reward. However, we find that SR fine-tuning has a tendency to reduce caption faithfulness and even hallucinate. In this work, we circumvent this bottleneck by improving the MLE initialization of the captioning system and designing a curriculum for the SR fine-tuning process. To this extent, we present (1) Visual Caption Boosting, a novel framework to instill fine-grainedness in generic image captioning datasets while remaining anchored in human annotations; and (2) BagCurri, a carefully designed training curriculum that more optimally leverages the contrastive nature of the self-retrieval reward. Jointly, they enable the captioner to describe fine-grained aspects in the image while preserving faithfulness to ground-truth captions. Our approach outperforms previous work by +8.9% on SR against 99 random distractors (RD100) (Dessi et al., 2023); and +7.6% on ImageCoDe.
+Additionally, existing metrics to evaluate captioning systems fail to reward diversity or evaluate a model's fine-grained understanding ability. Our third contribution addresses this by proposing self-retrieval from the lens of evaluation. We introduce TrueMatch, a benchmark comprising bags of highly similar images that uses SR to assess the captioner's ability to capture subtle visual distinctions. We evaluate and compare several state-of-the-art open-source MLLMs on TrueMatch, and find that our SR approach outperforms them all by a significant margin (e.g. +4.8% - 7.1% over Cambrian) while having 1-2 orders of magnitude fewer parameters.
+
Subjects:
+Computer Vision and Pattern Recognition (cs.CV)
+Cite as:
+arXiv:2409.03025 [cs.CV]
+(or
+arXiv:2409.03025v1 [cs.CV] for this version)
+https://doi.org/10.48550/arXiv.2409.03025
+Focus to learn more
+ arXiv-issued DOI via DataCite</p>
+
+
+
+
+ 75. 【2409.03022】Boundless: Generating Photorealistic Synthetic Data for Object Detection in Urban Streetscapes
+ 链接:https://arxiv.org/abs/2409.03022
+ 作者:Mehmet Kerem Turkcan,Ian Li,Chengbo Zang,Javad Ghaderi,Gil Zussman,Zoran Kostic
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:dense urban streetscapes, photo-realistic synthetic data, data generation system, highly accurate object, enabling highly accurate
+ 备注:
+
+ 点击查看摘要
+ Abstract:We introduce Boundless, a photo-realistic synthetic data generation system for enabling highly accurate object detection in dense urban streetscapes. Boundless can replace massive real-world data collection and manual ground-truth object annotation (labeling) with an automated and configurable process. Boundless is based on the Unreal Engine 5 (UE5) City Sample project with improvements enabling accurate collection of 3D bounding boxes across different lighting and scene variability conditions.
+We evaluate the performance of object detection models trained on the dataset generated by Boundless when used for inference on a real-world dataset acquired from medium-altitude cameras. We compare the performance of the Boundless-trained model against the CARLA-trained model and observe an improvement of 7.8 mAP. The results we achieved support the premise that synthetic data generation is a credible methodology for training/fine-tuning scalable object detection models for urban scenes.
+
Subjects:
+Computer Vision and Pattern Recognition (cs.CV)
+Cite as:
+arXiv:2409.03022 [cs.CV]
+(or
+arXiv:2409.03022v1 [cs.CV] for this version)
+https://doi.org/10.48550/arXiv.2409.03022
+Focus to learn more
+ arXiv-issued DOI via DataCite</p>
+
+
+
+
+ 76. 【2409.03012】Design and Evaluation of Camera-Centric Mobile Crowdsourcing Applications
+ 链接:https://arxiv.org/abs/2409.03012
+ 作者:Abby Stylianou,Michelle Brachman,Albatool Wazzan,Samuel Black,Richard Souvenir
+ 类目:Human-Computer Interaction (cs.HC); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:underlies automated methods, machine learning, fine-grained recognition, underlies automated, automated methods
+ 备注:
+
+ 点击查看摘要
+ Abstract:The data that underlies automated methods in computer vision and machine learning, such as image retrieval and fine-grained recognition, often comes from crowdsourcing. In contexts that rely on the intrinsic motivation of users, we seek to understand how the application design affects a user's willingness to contribute and the quantity and quality of the data they capture. In this project, we designed three versions of a camera-based mobile crowdsourcing application, which varied in the amount of labeling effort requested of the user and conducted a user study to evaluate the trade-off between the level of user-contributed information requested and the quantity and quality of labeled images collected. The results suggest that higher levels of user labeling do not lead to reduced contribution. Users collected and annotated the most images using the application version with the highest requested level of labeling with no decrease in user satisfaction. In preliminary experiments, the additional labeled data supported increased performance on an image retrieval task.
+
+
+
+ 77. 【2409.02979】Vec2Face: Scaling Face Dataset Generation with Loosely Constrained Vectors
+ 链接:https://arxiv.org/abs/2409.02979
+ 作者:Haiyu Wu,Jaskirat Singh,Sicong Tian,Liang Zheng,Kevin W. Bowyer
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:non-existent persons, paper studies, synthesize face images, face, identities
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper studies how to synthesize face images of non-existent persons, to create a dataset that allows effective training of face recognition (FR) models. Two important goals are (1) the ability to generate a large number of distinct identities (inter-class separation) with (2) a wide variation in appearance of each identity (intra-class variation). However, existing works 1) are typically limited in how many well-separated identities can be generated and 2) either neglect or use a separate editing model for attribute augmentation. We propose Vec2Face, a holistic model that uses only a sampled vector as input and can flexibly generate and control face images and their attributes. Composed of a feature masked autoencoder and a decoder, Vec2Face is supervised by face image reconstruction and can be conveniently used in inference. Using vectors with low similarity among themselves as inputs, Vec2Face generates well-separated identities. Randomly perturbing an input identity vector within a small range allows Vec2Face to generate faces of the same identity with robust variation in face attributes. It is also possible to generate images with designated attributes by adjusting vector values with a gradient descent method. Vec2Face has efficiently synthesized as many as 300K identities with 15 million total images, whereas 60K is the largest number of identities created in the previous works. FR models trained with the generated HSFace datasets, from 10k to 300k identities, achieve state-of-the-art accuracy, from 92% to 93.52%, on five real-world test sets. For the first time, our model created using a synthetic training set achieves higher accuracy than the model created using a same-scale training set of real face images (on the CALFW test set).
+
+
+
+ 78. 【2409.02958】Multi-Modal Adapter for Vision-Language Models
+ 链接:https://arxiv.org/abs/2409.02958
+ 作者:Dominykas Seputis,Serghei Mihailov,Soham Chatterjee,Zehao Xiao
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Large pre-trained vision-language, Large pre-trained, pre-trained vision-language models, requiring retraining, image classification tasks
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large pre-trained vision-language models, such as CLIP, have demonstrated state-of-the-art performance across a wide range of image classification tasks, without requiring retraining. Few-shot CLIP is competitive with existing specialized architectures that were trained on the downstream tasks. Recent research demonstrates that the performance of CLIP can be further improved using lightweight adaptation approaches. However, previous methods adapt different modalities of the CLIP model individually, ignoring the interactions and relationships between visual and textual representations. In this work, we propose Multi-Modal Adapter, an approach for Multi-Modal adaptation of CLIP. Specifically, we add a trainable Multi-Head Attention layer that combines text and image features to produce an additive adaptation of both. Multi-Modal Adapter demonstrates improved generalizability, based on its performance on unseen classes compared to existing adaptation methods. We perform additional ablations and investigations to validate and interpret the proposed approach.
+
+
+
+ 79. 【2409.03519】ssue Concepts: supervised foundation models in computational pathology
+ 链接:https://arxiv.org/abs/2409.03519
+ 作者:Till Nicke,Jan Raphael Schaefer,Henning Hoefener,Friedrich Feuerhake,Dorit Merhof,Fabian Kiessling,Johannes Lotz
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:quantitative biomarker evaluation, Tissue Concepts encoder, Tissue Concepts, support diagnostic tasks, Tissue Concepts model
+ 备注: 22 Pages, 3 Figures, submitted to and under revision at Computers in Biology and Medicine
+
+ 点击查看摘要
+ Abstract:Due to the increasing workload of pathologists, the need for automation to support diagnostic tasks and quantitative biomarker evaluation is becoming more and more apparent. Foundation models have the potential to improve generalizability within and across centers and serve as starting points for data efficient development of specialized yet robust AI models. However, the training foundation models themselves is usually very expensive in terms of data, computation, and time. This paper proposes a supervised training method that drastically reduces these expenses. The proposed method is based on multi-task learning to train a joint encoder, by combining 16 different classification, segmentation, and detection tasks on a total of 912,000 patches. Since the encoder is capable of capturing the properties of the samples, we term it the Tissue Concepts encoder. To evaluate the performance and generalizability of the Tissue Concepts encoder across centers, classification of whole slide images from four of the most prevalent solid cancers - breast, colon, lung, and prostate - was used. The experiments show that the Tissue Concepts model achieve comparable performance to models trained with self-supervision, while requiring only 6% of the amount of training patches. Furthermore, the Tissue Concepts encoder outperforms an ImageNet pre-trained encoder on both in-domain and out-of-domain data.
+
+
+
+ 80. 【2409.03367】BConvL-Net: A Hybrid Deep Learning Architecture for Robust Medical Image Segmentation
+ 链接:https://arxiv.org/abs/2409.03367
+ 作者:Shahzaib Iqbal,Tariq M. Khan,Syed S. Naqvi,Asim Naveed,Erik Meijering
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:shown great potential, automated medical image, disease diagnostics, medical image segmentation, shown great
+ 备注:
+
+ 点击查看摘要
+ Abstract:Deep learning has shown great potential for automated medical image segmentation to improve the precision and speed of disease diagnostics. However, the task presents significant difficulties due to variations in the scale, shape, texture, and contrast of the pathologies. Traditional convolutional neural network (CNN) models have certain limitations when it comes to effectively modelling multiscale context information and facilitating information interaction between skip connections across levels. To overcome these limitations, a novel deep learning architecture is introduced for medical image segmentation, taking advantage of CNNs and vision transformers. Our proposed model, named TBConvL-Net, involves a hybrid network that combines the local features of a CNN encoder-decoder architecture with long-range and temporal dependencies using biconvolutional long-short-term memory (LSTM) networks and vision transformers (ViT). This enables the model to capture contextual channel relationships in the data and account for the uncertainty of segmentation over time. Additionally, we introduce a novel composite loss function that considers both the segmentation robustness and the boundary agreement of the predicted output with the gold standard. Our proposed model shows consistent improvement over the state of the art on ten publicly available datasets of seven different medical imaging modalities.
+
+
+
+ 81. 【2409.03179】Perceptual-Distortion Balanced Image Super-Resolution is a Multi-Objective Optimization Problem
+ 链接:https://arxiv.org/abs/2409.03179
+ 作者:Qiwen Zhu,Yanjie Wang,Shilv Cai,Liqun Chen,Jiahuan Zhou,Luxin Yan,Sheng Zhong,Xu Zou
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:PSNR and SSIM, pixel-based regression losses, blurry images due, Training Single-Image Super-Resolution, distortion metrics scores
+ 备注:
+
+ 点击查看摘要
+ Abstract:Training Single-Image Super-Resolution (SISR) models using pixel-based regression losses can achieve high distortion metrics scores (e.g., PSNR and SSIM), but often results in blurry images due to insufficient recovery of high-frequency details. Conversely, using GAN or perceptual losses can produce sharp images with high perceptual metric scores (e.g., LPIPS), but may introduce artifacts and incorrect textures. Balancing these two types of losses can help achieve a trade-off between distortion and perception, but the challenge lies in tuning the loss function weights. To address this issue, we propose a novel method that incorporates Multi-Objective Optimization (MOO) into the training process of SISR models to balance perceptual quality and distortion. We conceptualize the relationship between loss weights and image quality assessment (IQA) metrics as black-box objective functions to be optimized within our Multi-Objective Bayesian Optimization Super-Resolution (MOBOSR) framework. This approach automates the hyperparameter tuning process, reduces overall computational cost, and enables the use of numerous loss functions simultaneously. Extensive experiments demonstrate that MOBOSR outperforms state-of-the-art methods in terms of both perceptual quality and distortion, significantly advancing the perception-distortion Pareto frontier. Our work points towards a new direction for future research on balancing perceptual quality and fidelity in nearly all image restoration tasks. The source code and pretrained models are available at: this https URL.
+
+
+
+ 82. 【2409.03110】MSTT-199: MRI Dataset for Musculoskeletal Soft Tissue Tumor Segmentation
+ 链接:https://arxiv.org/abs/2409.03110
+ 作者:Tahsin Reasat,Stephen Chenard,Akhil Rekulapelli,Nicholas Chadwick,Joanna Shechtel,Katherine van Schaik,David S. Smith,Joshua Lawrenz
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Accurate musculoskeletal soft, influencing patient outcomes, Accurate musculoskeletal, musculoskeletal soft tissue, response to treatment
+ 备注: Dataset will be made publicly available after the acceptance of the paper
+
+ 点击查看摘要
+ Abstract:Accurate musculoskeletal soft tissue tumor segmentation is vital for assessing tumor size, location, diagnosis, and response to treatment, thereby influencing patient outcomes. However, segmentation of these tumors requires clinical expertise, and an automated segmentation model would save valuable time for both clinician and patient. Training an automatic model requires a large dataset of annotated images. In this work, we describe the collection of an MR imaging dataset of 199 musculoskeletal soft tissue tumors from 199 patients. We trained segmentation models on this dataset and then benchmarked them on a publicly available dataset. Our model achieved the state-of-the-art dice score of 0.79 out of the box without any fine tuning, which shows the diversity and utility of our curated dataset. We analyzed the model predictions and found that its performance suffered on fibrous and vascular tumors due to their diverse anatomical location, size, and intensity heterogeneity. The code and models are available in the following github repository, this https URL
+
+
+
+ 83. 【2409.03087】Coupling AI and Citizen Science in Creation of Enhanced Training Dataset for Medical Image Segmentation
+ 链接:https://arxiv.org/abs/2409.03087
+ 作者:Amir Syahmi,Xiangrong Lu,Yinxuan Li,Haoxuan Yao,Hanjun Jiang,Ishita Acharya,Shiyi Wang,Yang Nan,Xiaodan Xing,Guang Yang
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Recent advancements, high-quality annotated datasets, enhanced diagnostic capabilities, greatly enhanced diagnostic, artificial intelligence
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advancements in medical imaging and artificial intelligence (AI) have greatly enhanced diagnostic capabilities, but the development of effective deep learning (DL) models is still constrained by the lack of high-quality annotated datasets. The traditional manual annotation process by medical experts is time- and resource-intensive, limiting the scalability of these datasets. In this work, we introduce a robust and versatile framework that combines AI and crowdsourcing to improve both the quality and quantity of medical image datasets across different modalities. Our approach utilises a user-friendly online platform that enables a diverse group of crowd annotators to label medical images efficiently. By integrating the MedSAM segmentation AI with this platform, we accelerate the annotation process while maintaining expert-level quality through an algorithm that merges crowd-labelled images. Additionally, we employ pix2pixGAN, a generative AI model, to expand the training dataset with synthetic images that capture realistic morphological features. These methods are combined into a cohesive framework designed to produce an enhanced dataset, which can serve as a universal pre-processing pipeline to boost the training of any medical deep learning segmentation model. Our results demonstrate that this framework significantly improves model performance, especially when training data is limited.
+
+
+





/Fig1_pretrain_finetune.png)
/Fig2_eda1.png)
/Fig2_eda2.png)
/Fig2_eda3.png)
/Fig3_reweight.png)
/Fig5_model1.png)
/Fig5_attention_mask.png)
/Fig4_wwm.png)
/Fig5_model2.png)
/Fig5_model3.png)
/Fig7_ensemble1.png)
/Fig6_res1.png)
/Fig6_res2.png)


%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_text_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_entity_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/model.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/dont_stop_pretraining.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/a.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/b.png)

%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/lengths_histplot.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_entity_lengths.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_label_dist.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/%E6%80%BB%E4%BD%93%E6%96%B9%E6%A1%88.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/pretrain_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/finetune_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/rdrop.png)


/autoencoder-architecture.png)
/variational-autoencoder-architecture.png)
/forward_vs_reversed_KL.png)
/vae-implement.png)
/reparam.png)
/generated_samples.png)







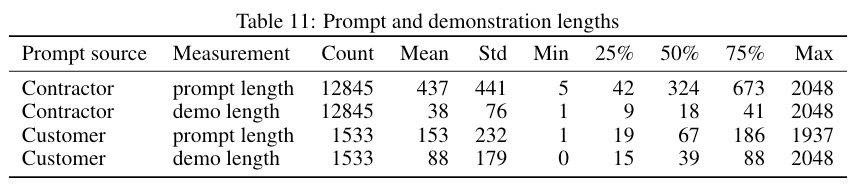

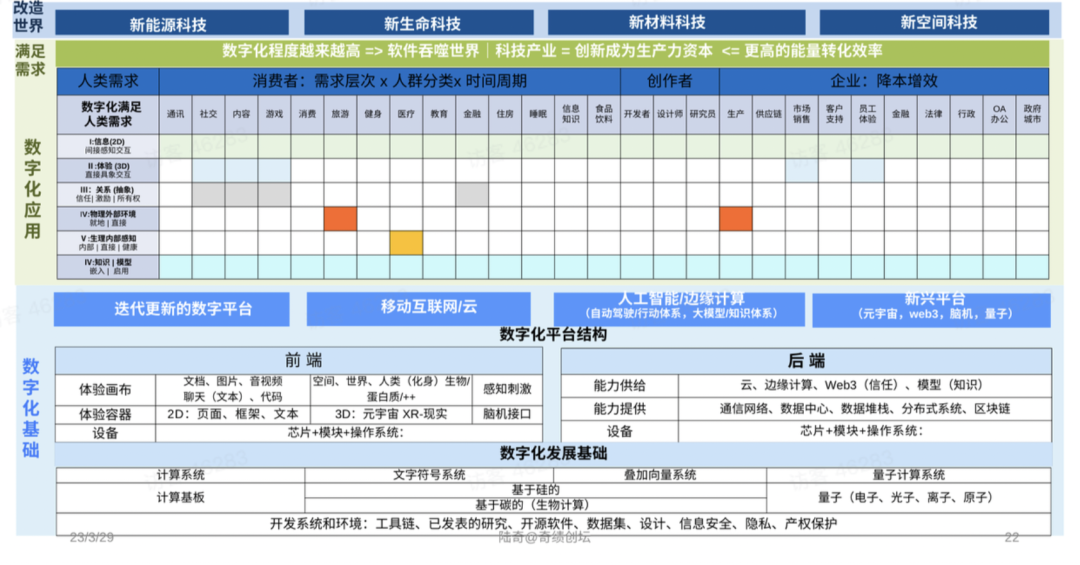
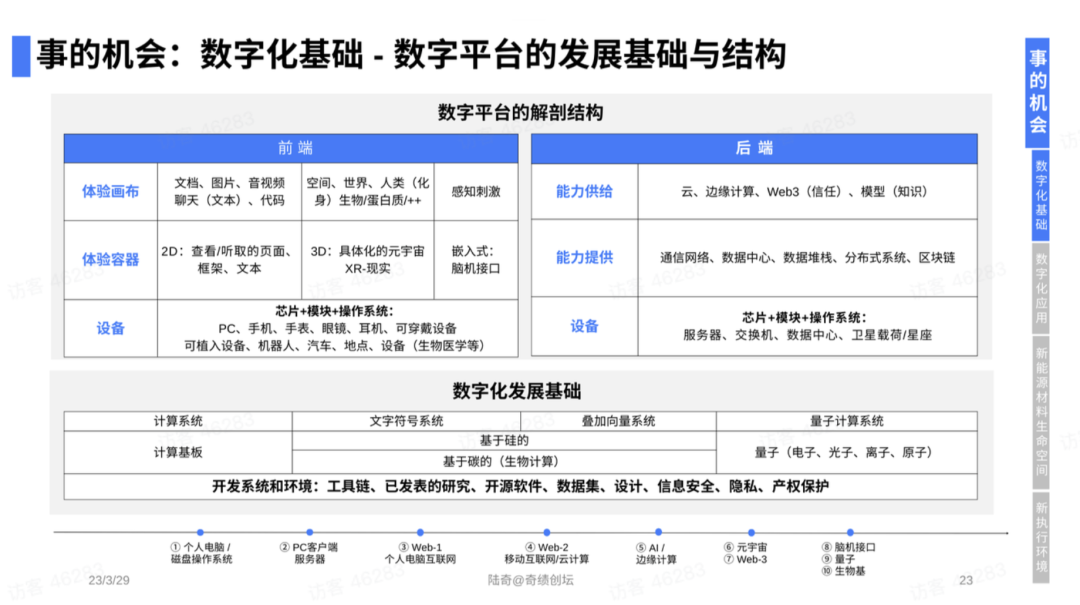
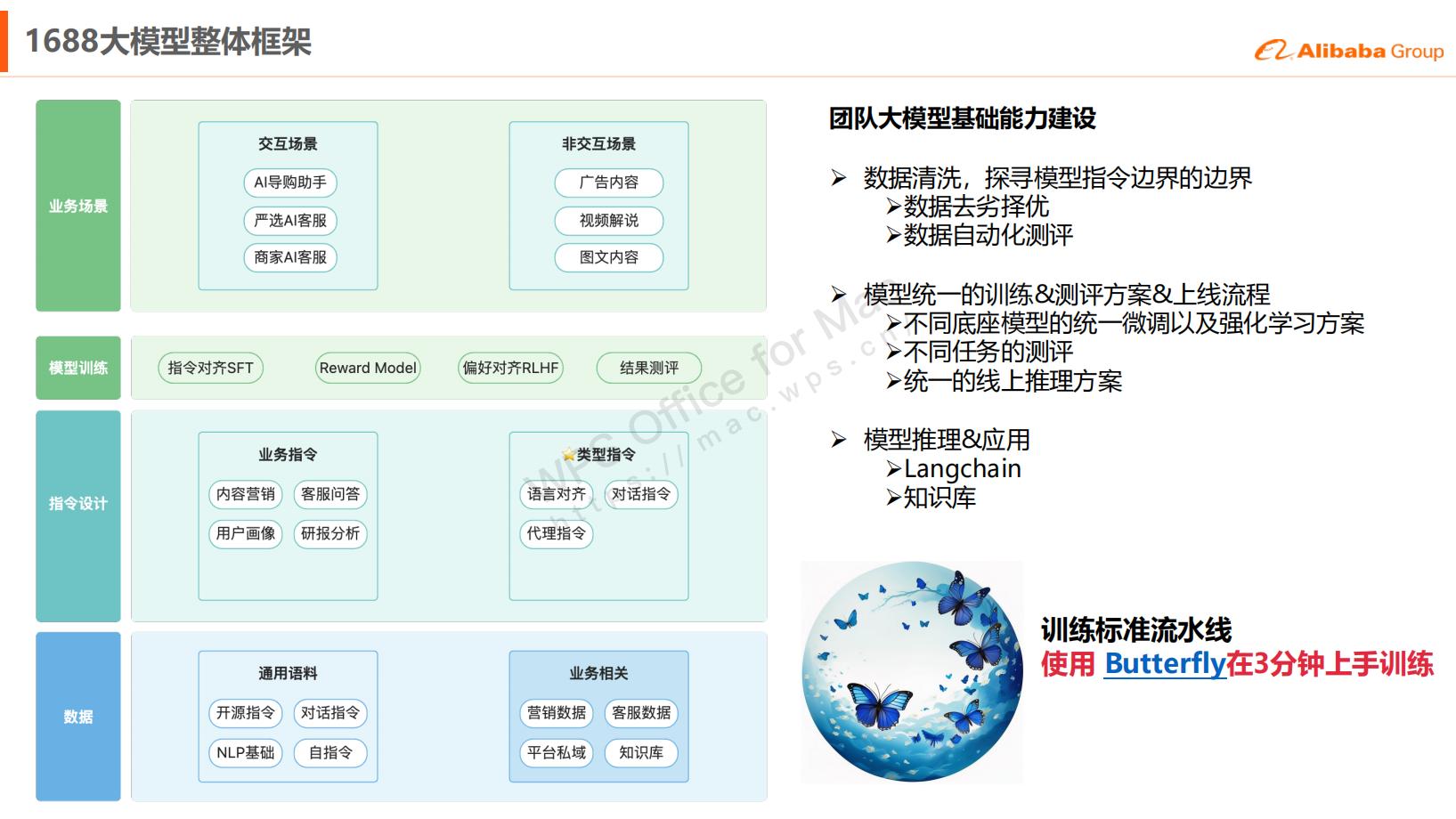
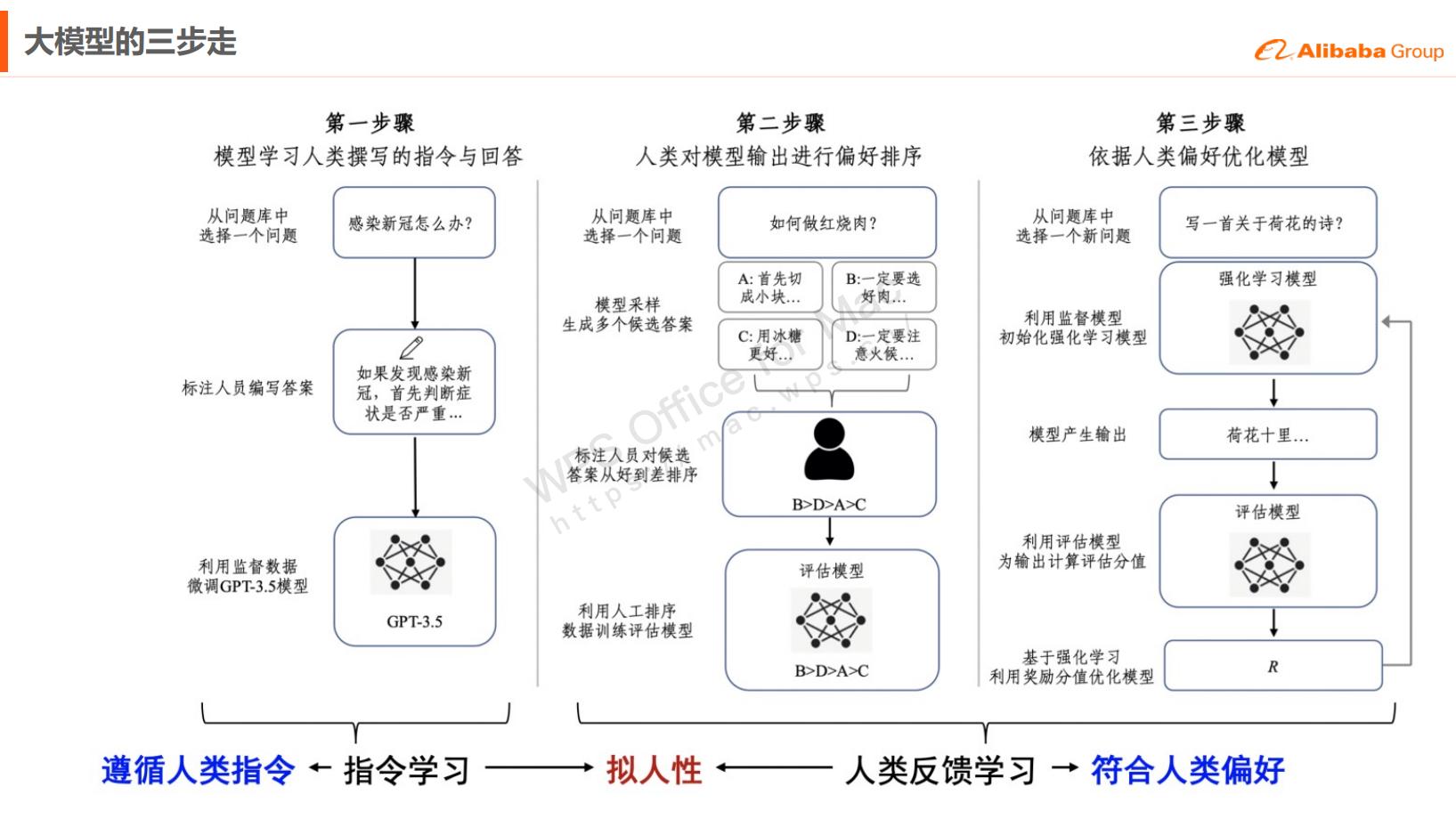
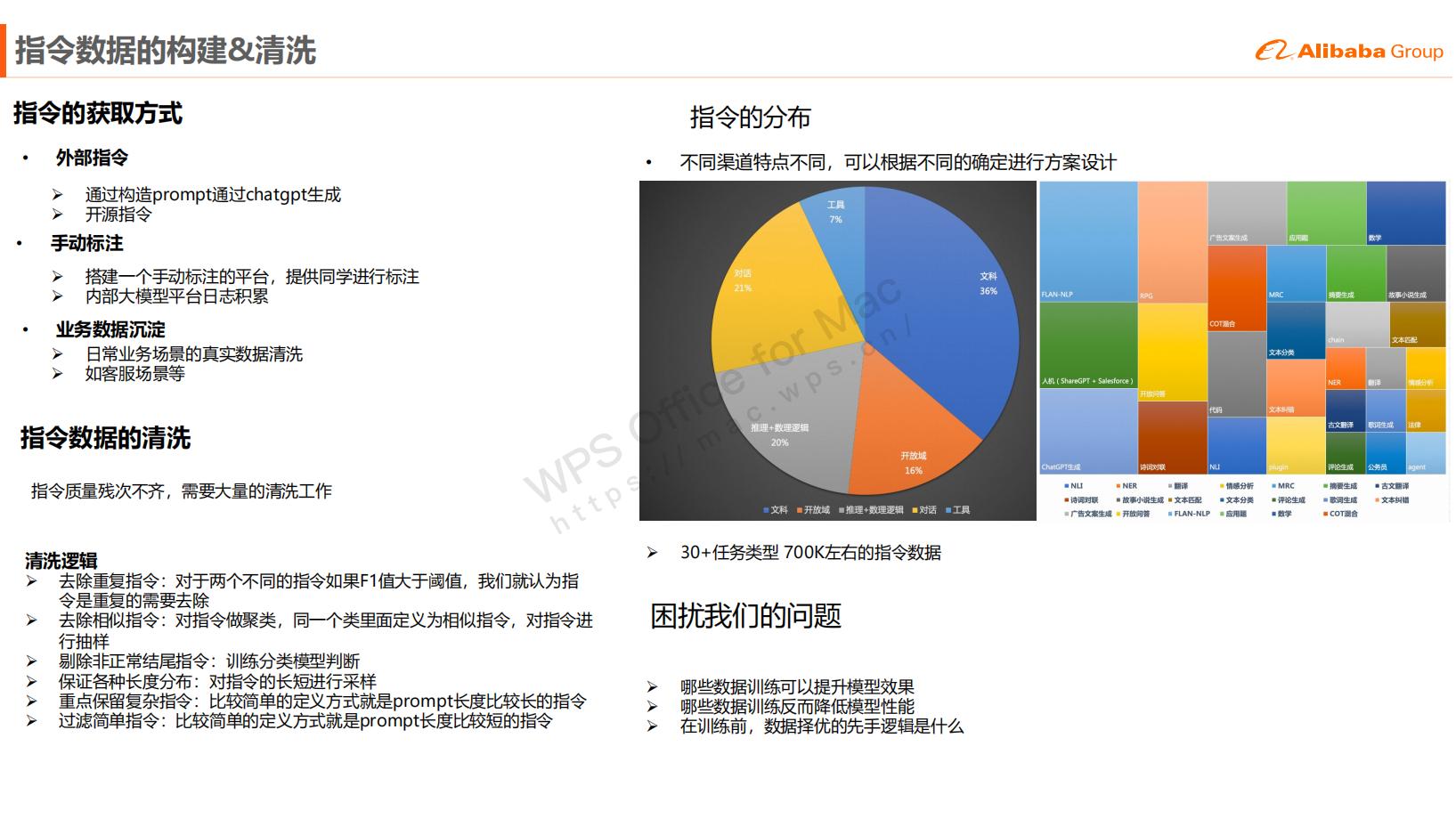

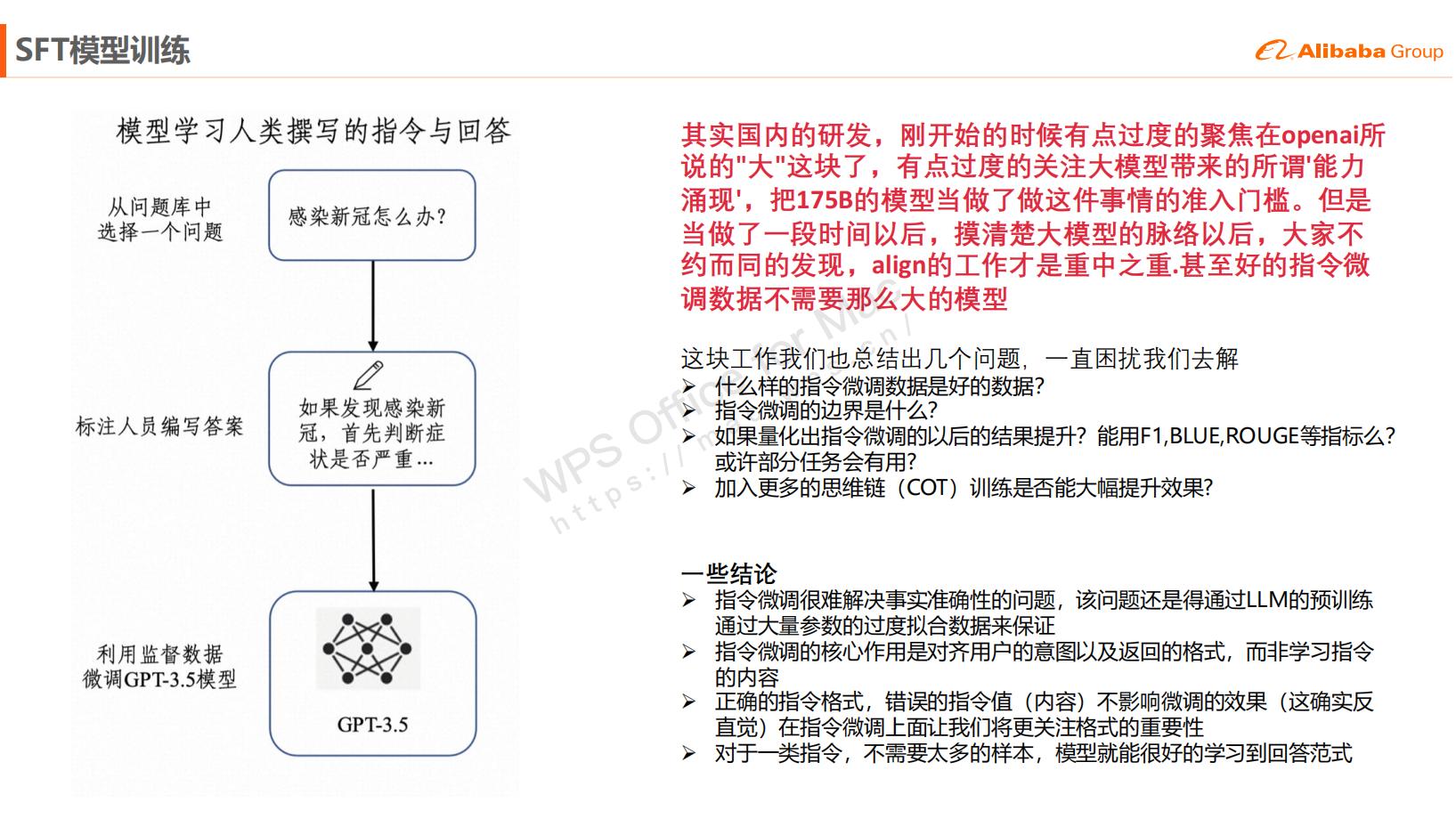

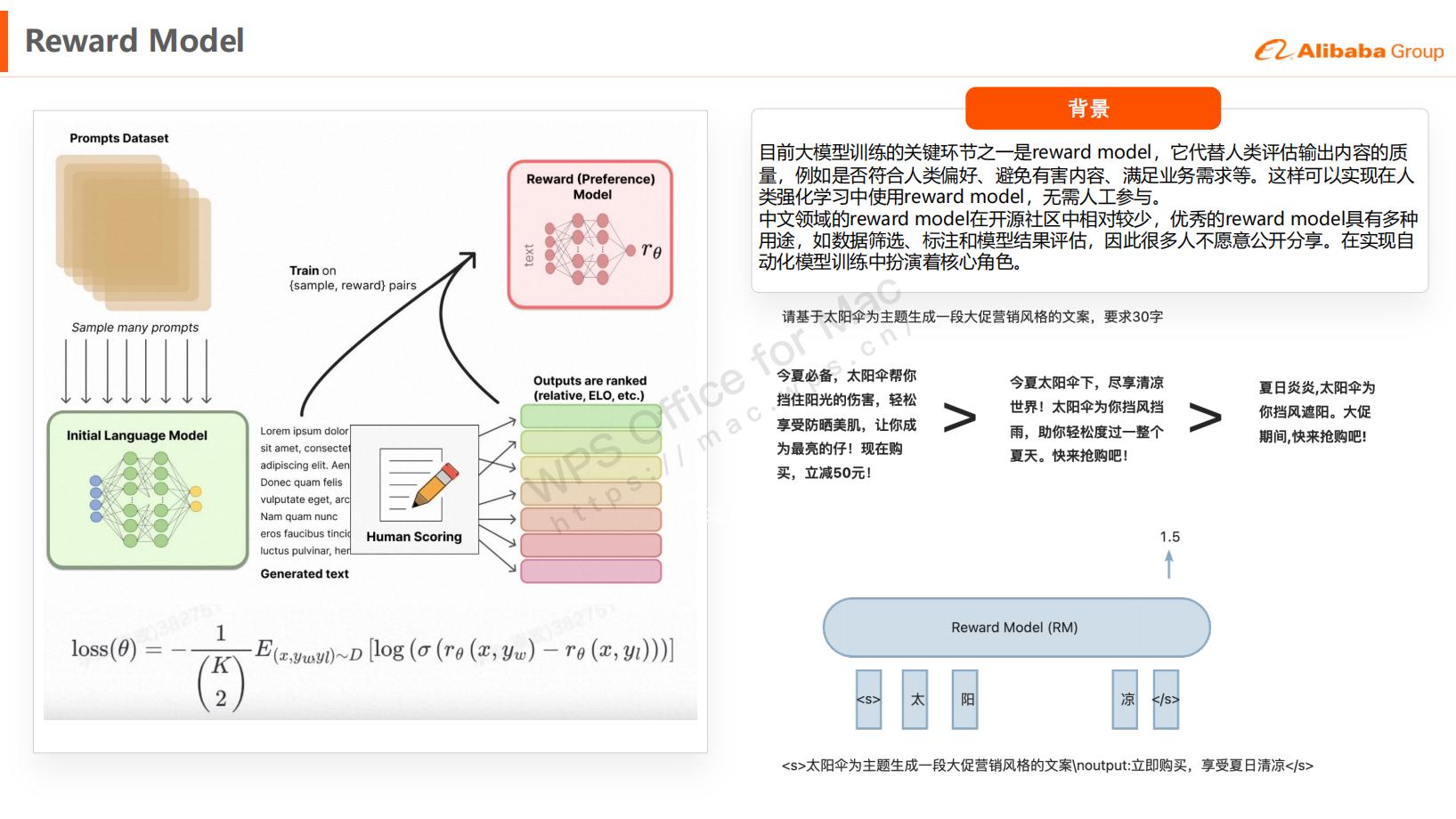




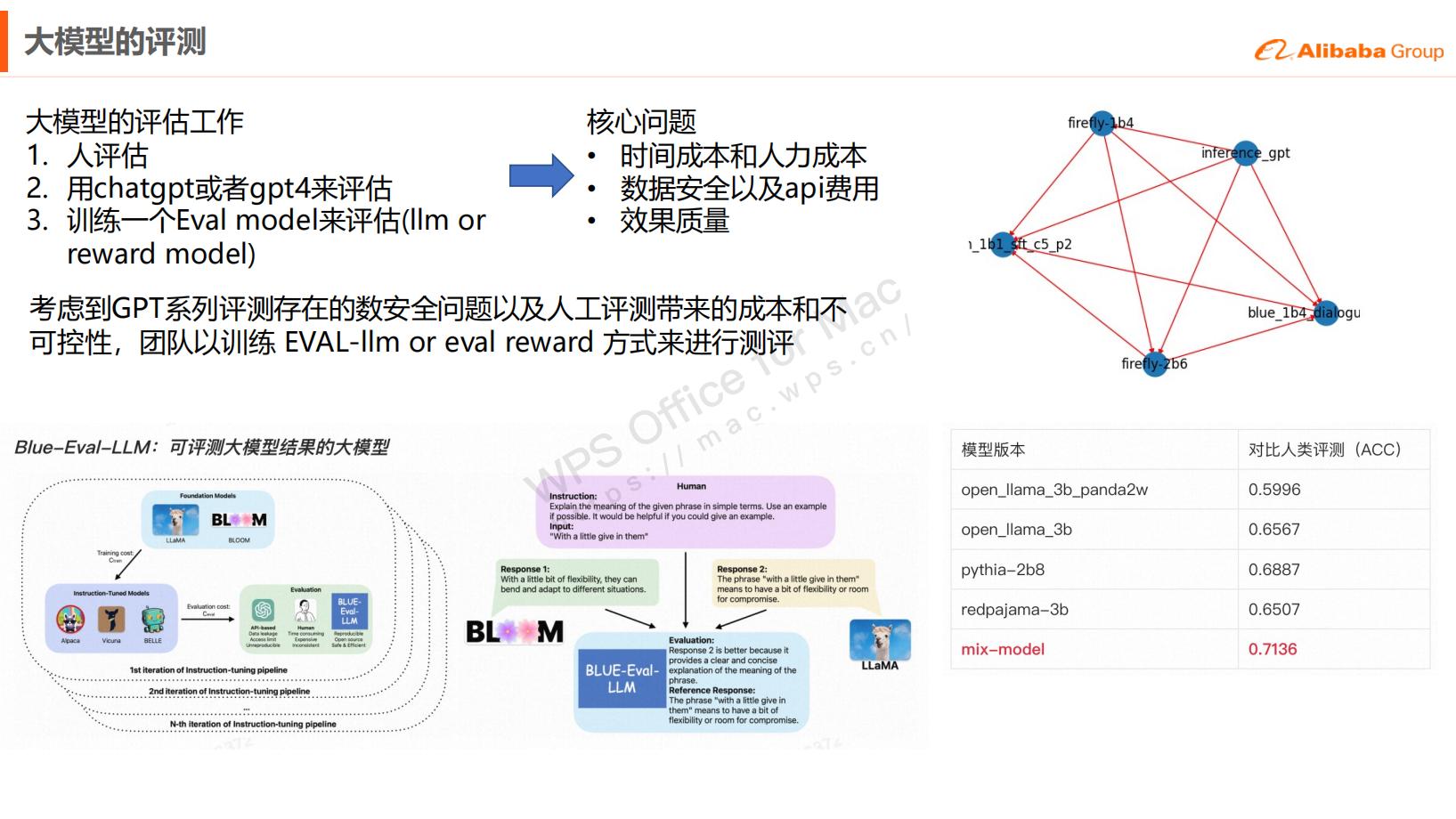
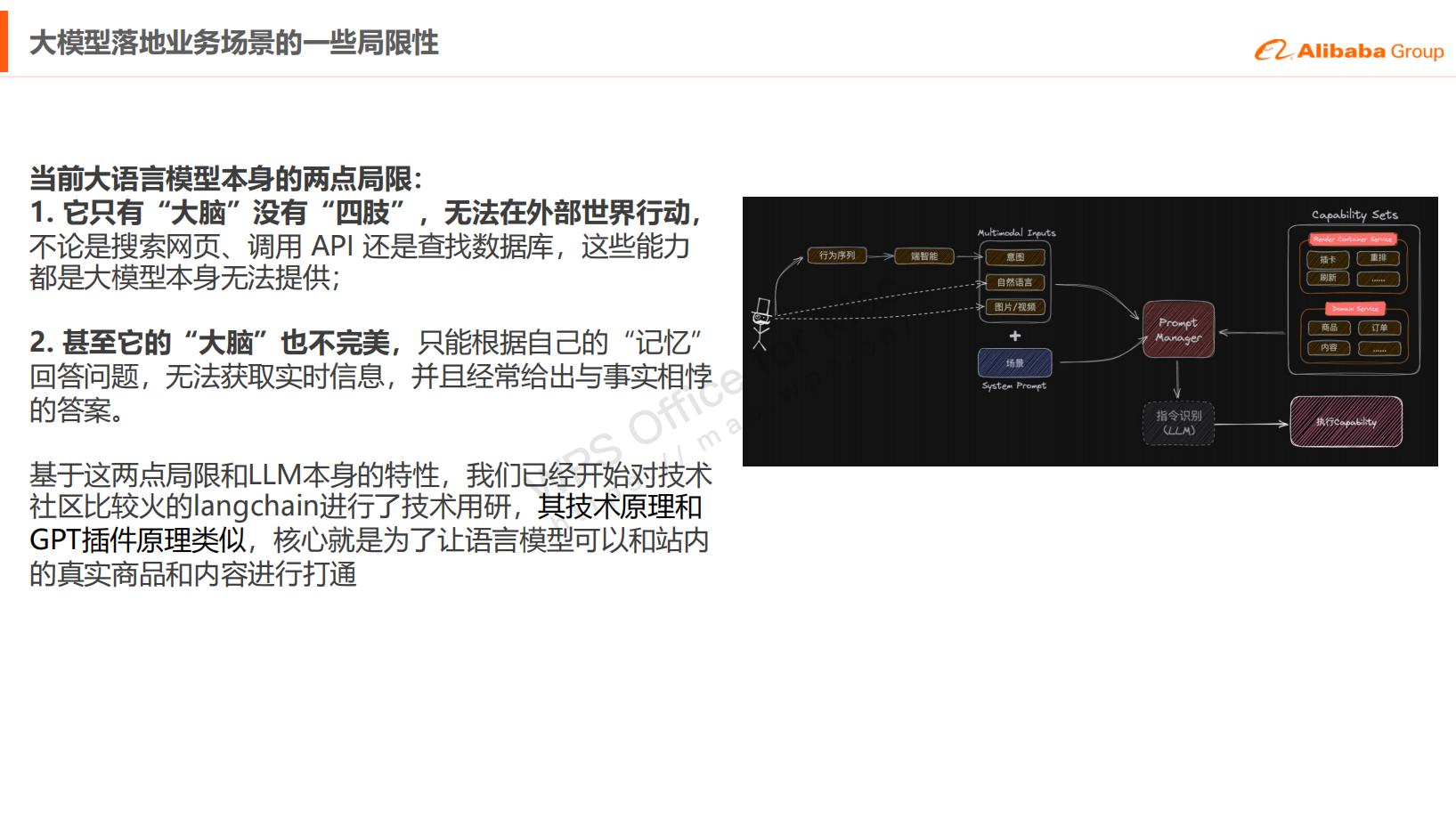





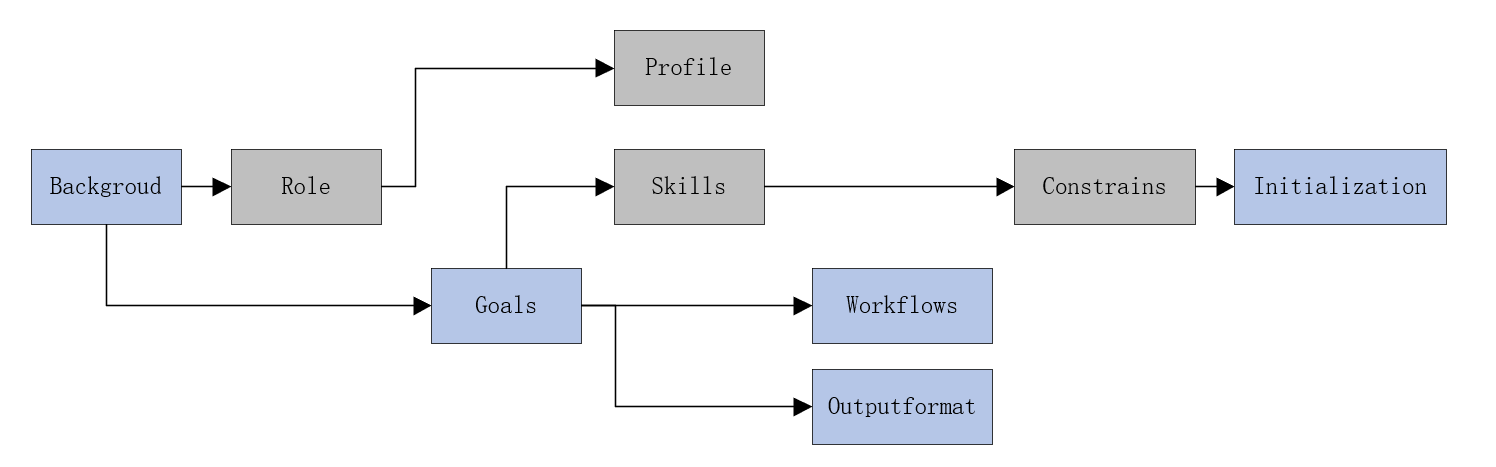

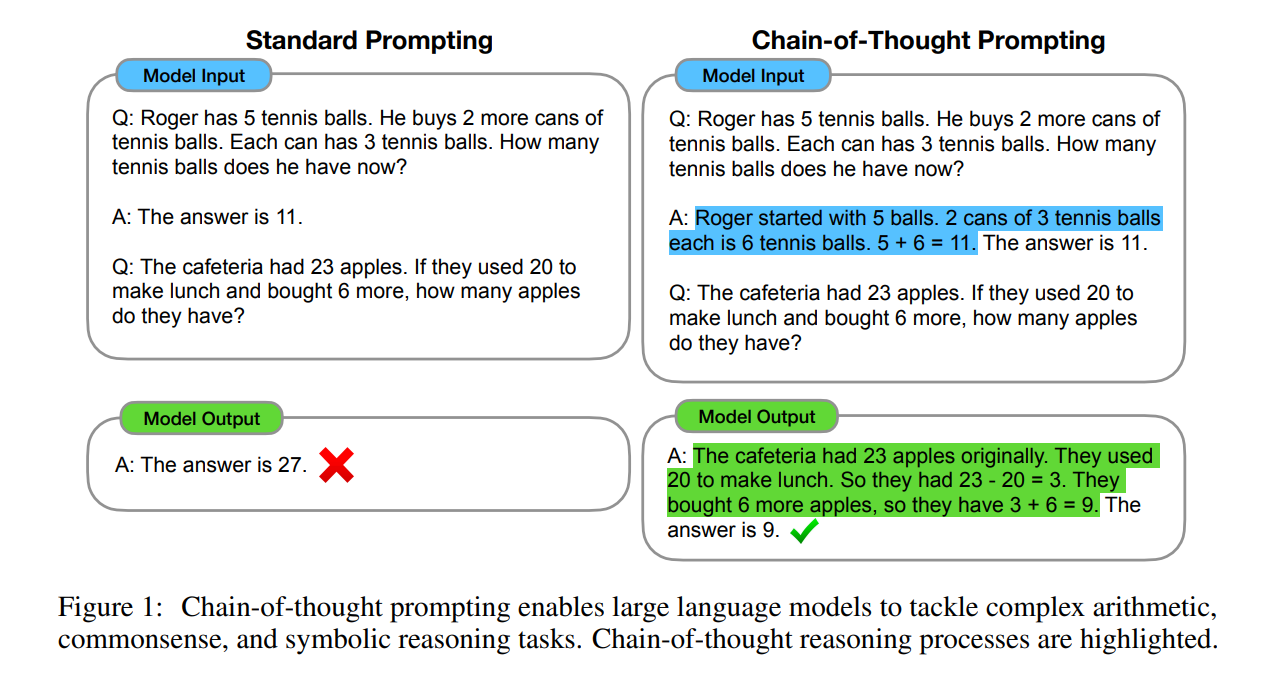

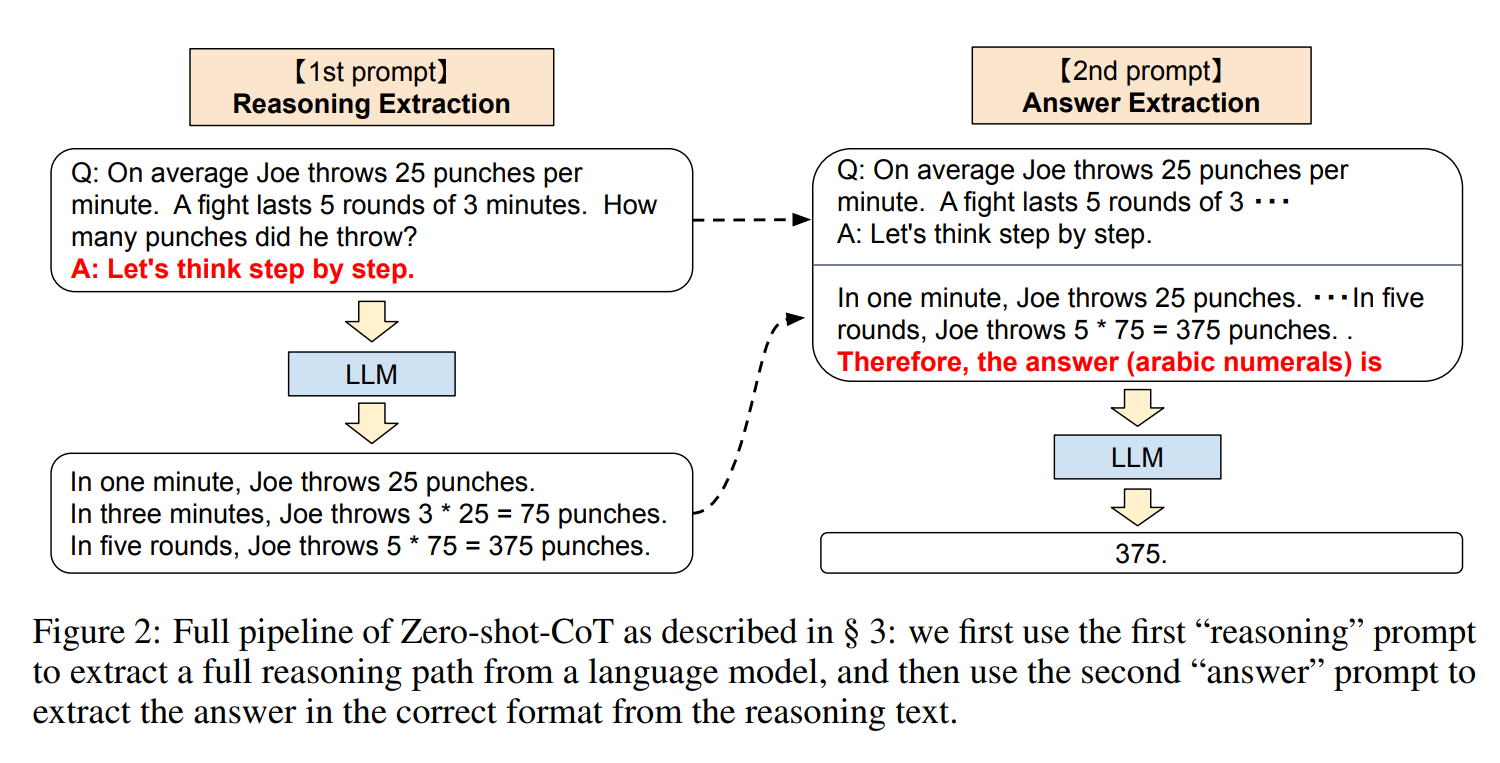
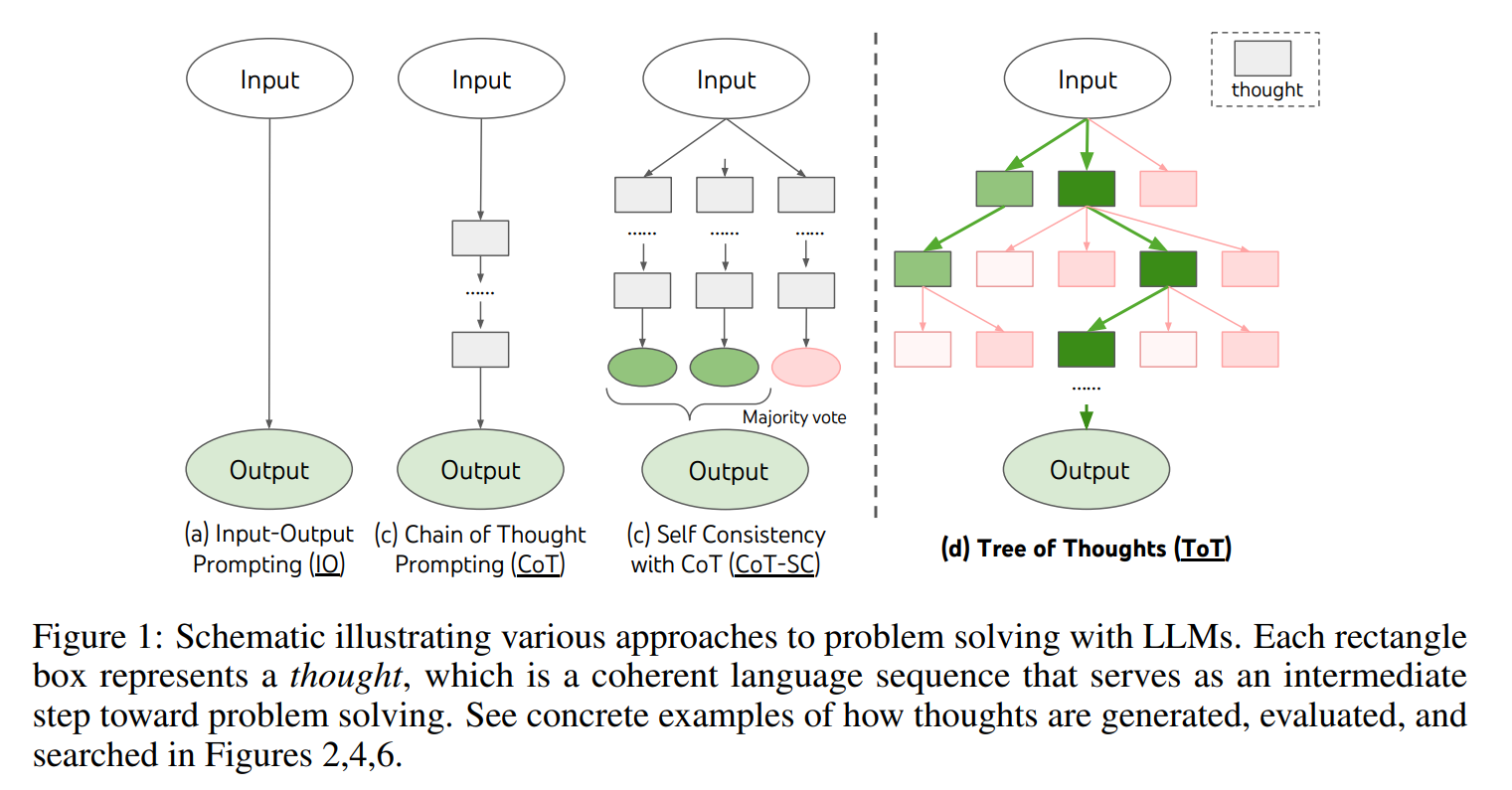


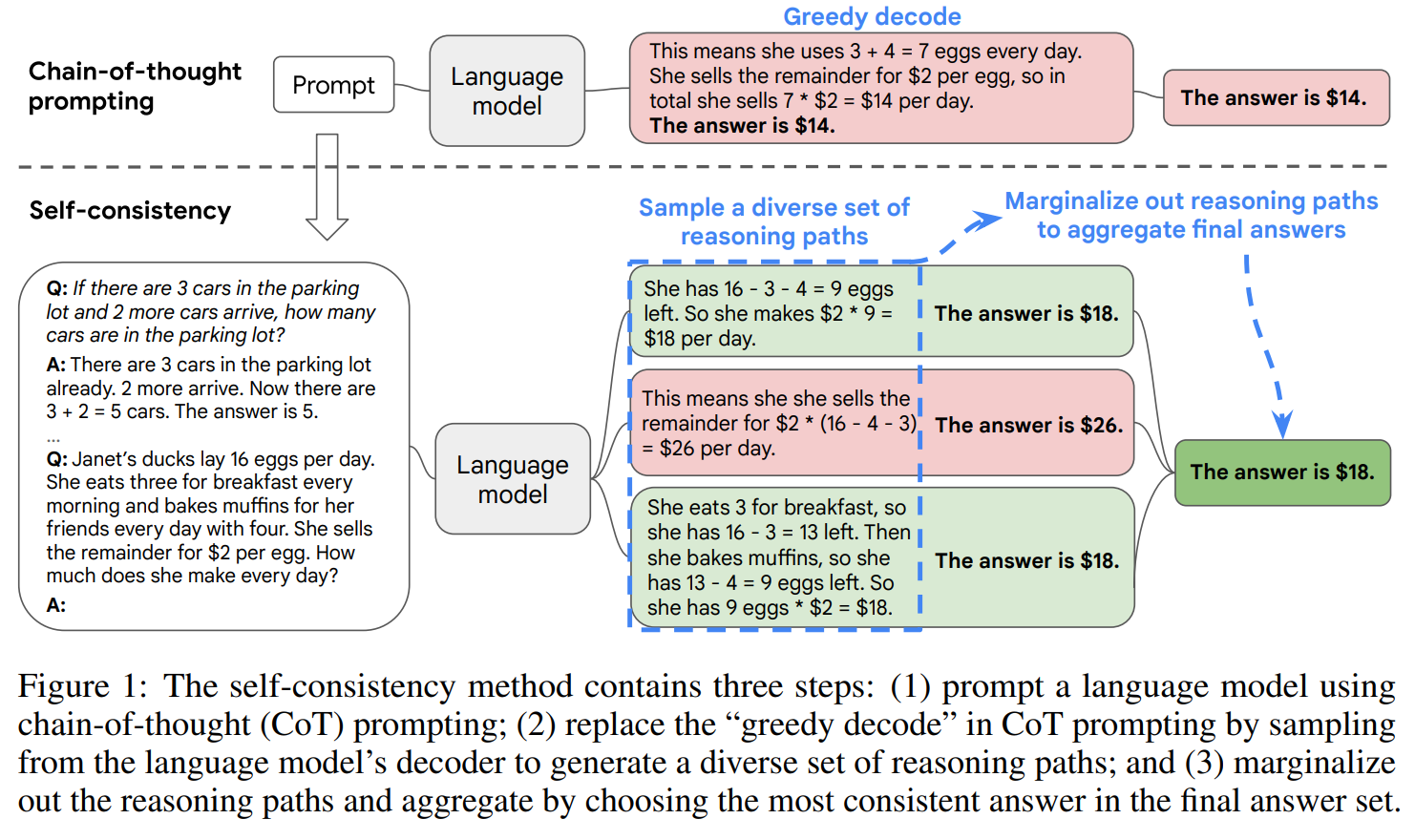
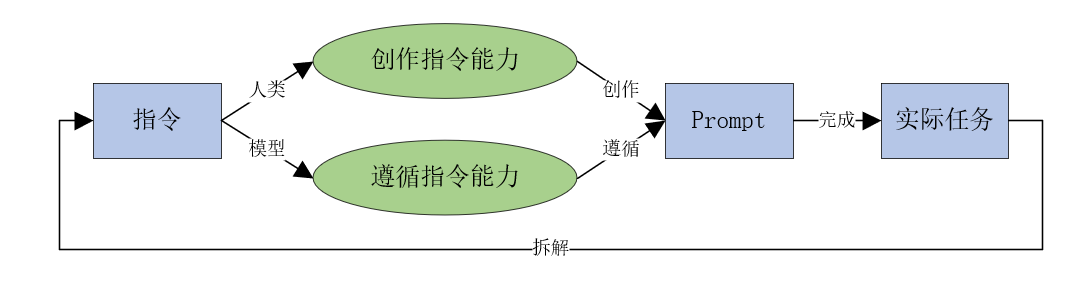



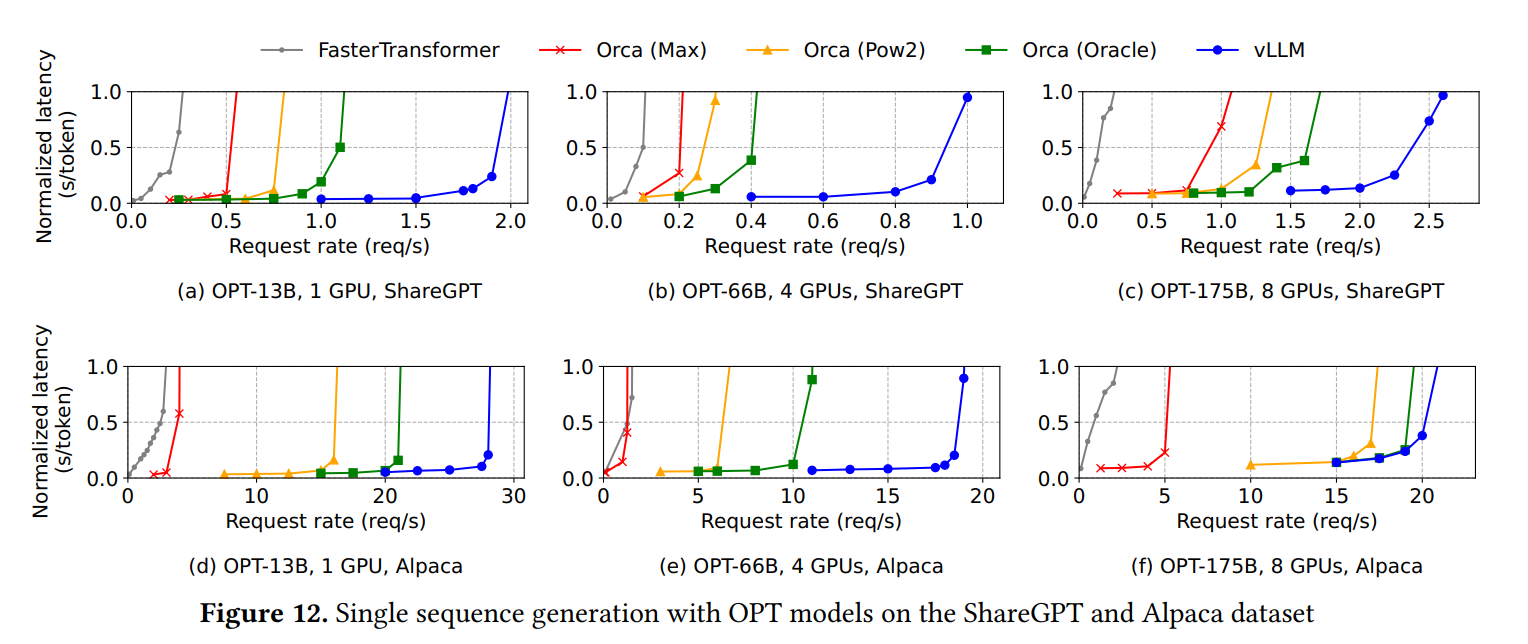
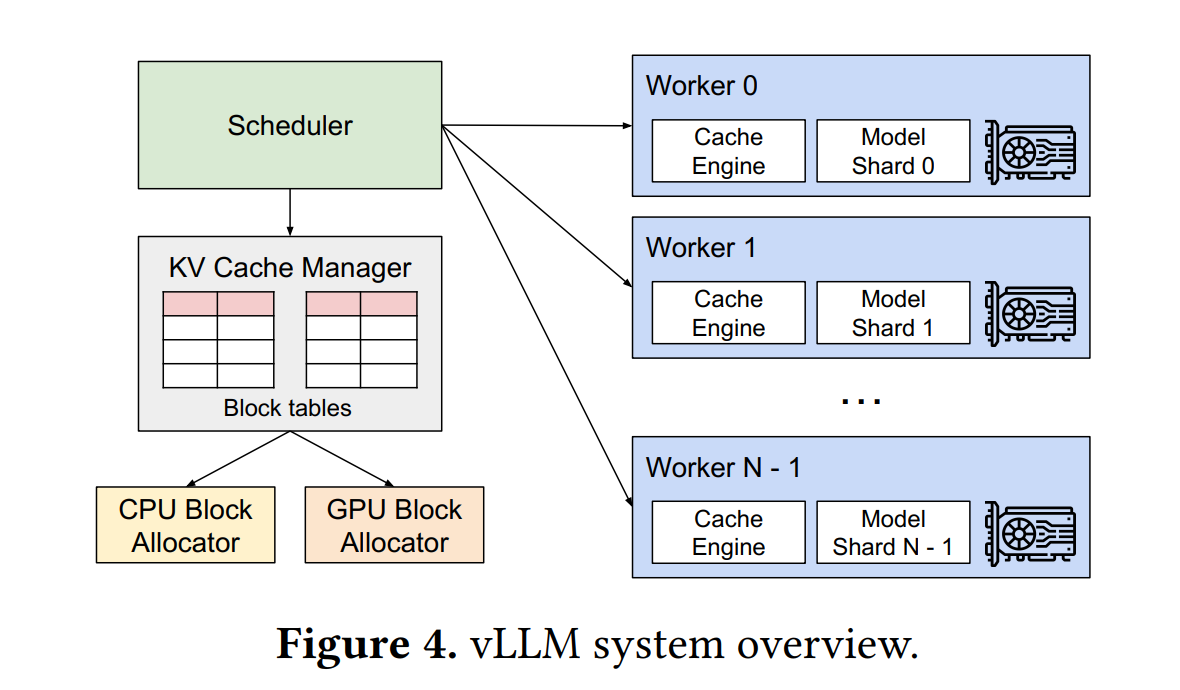
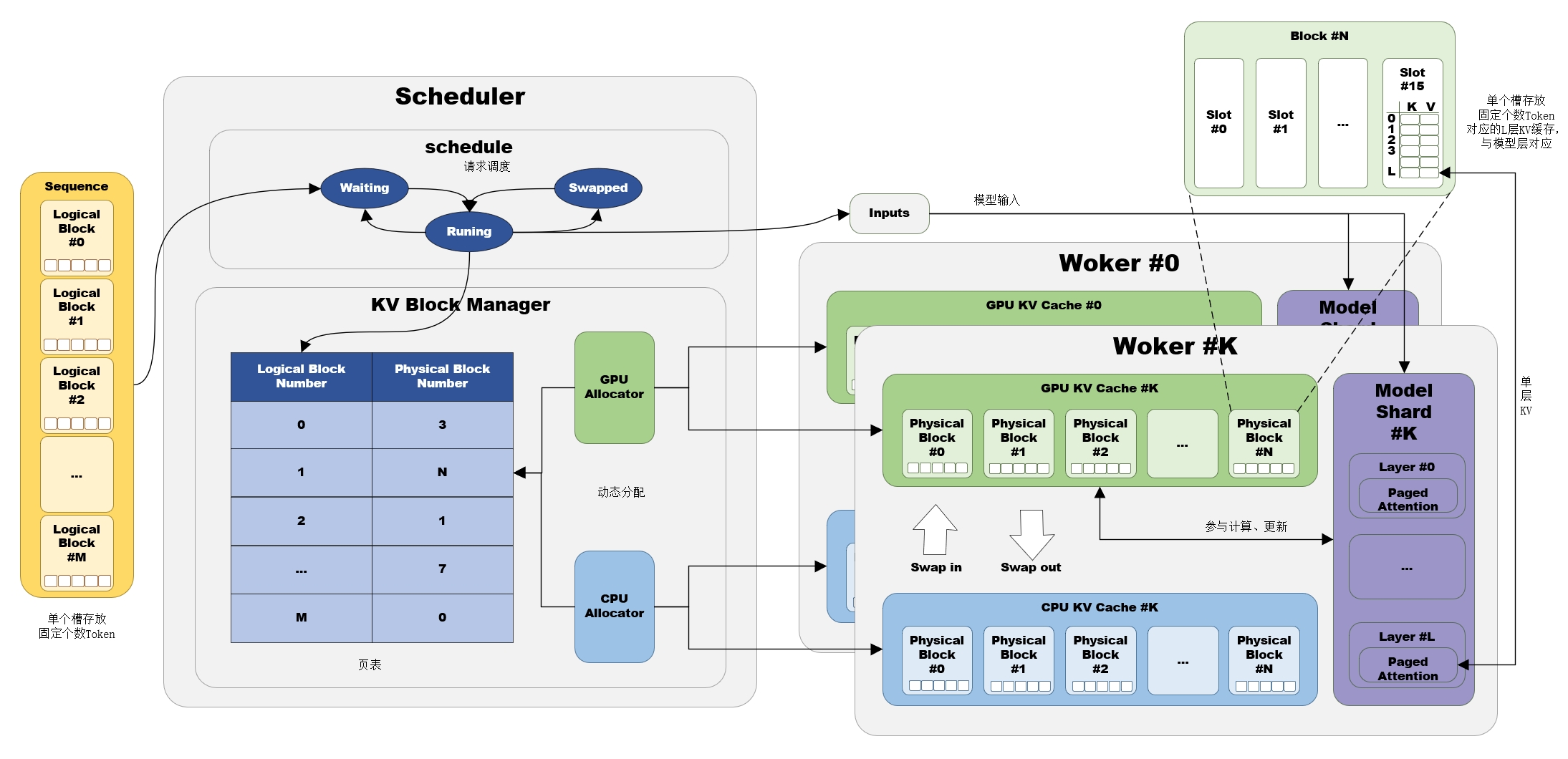
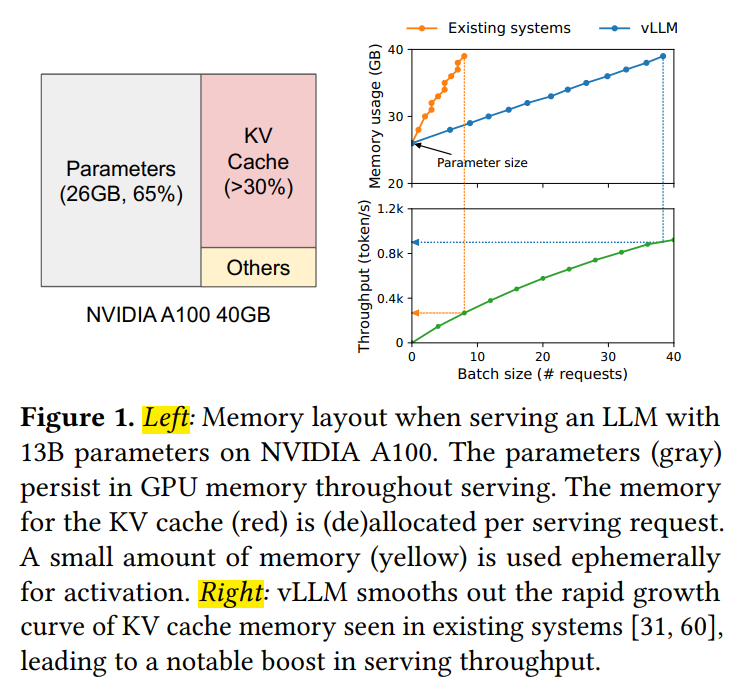
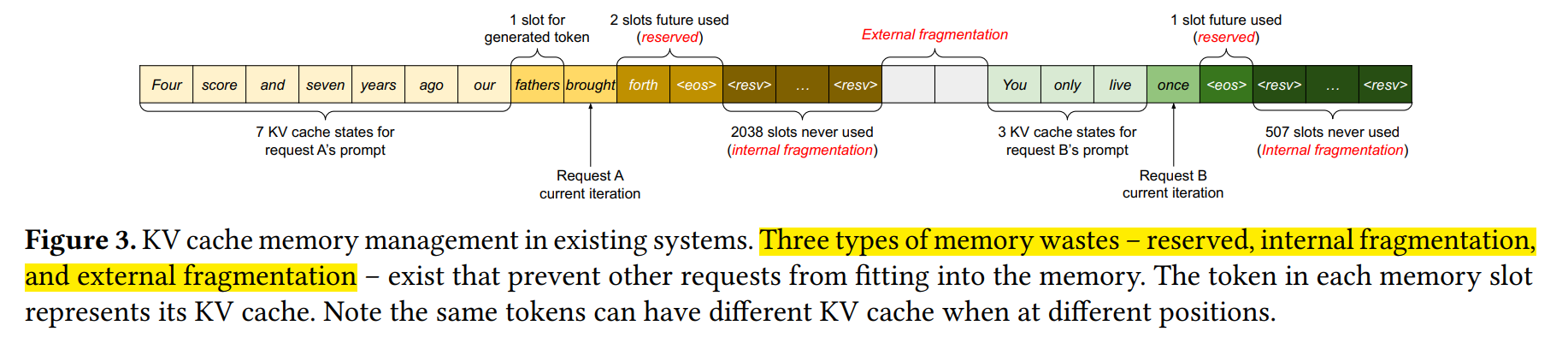
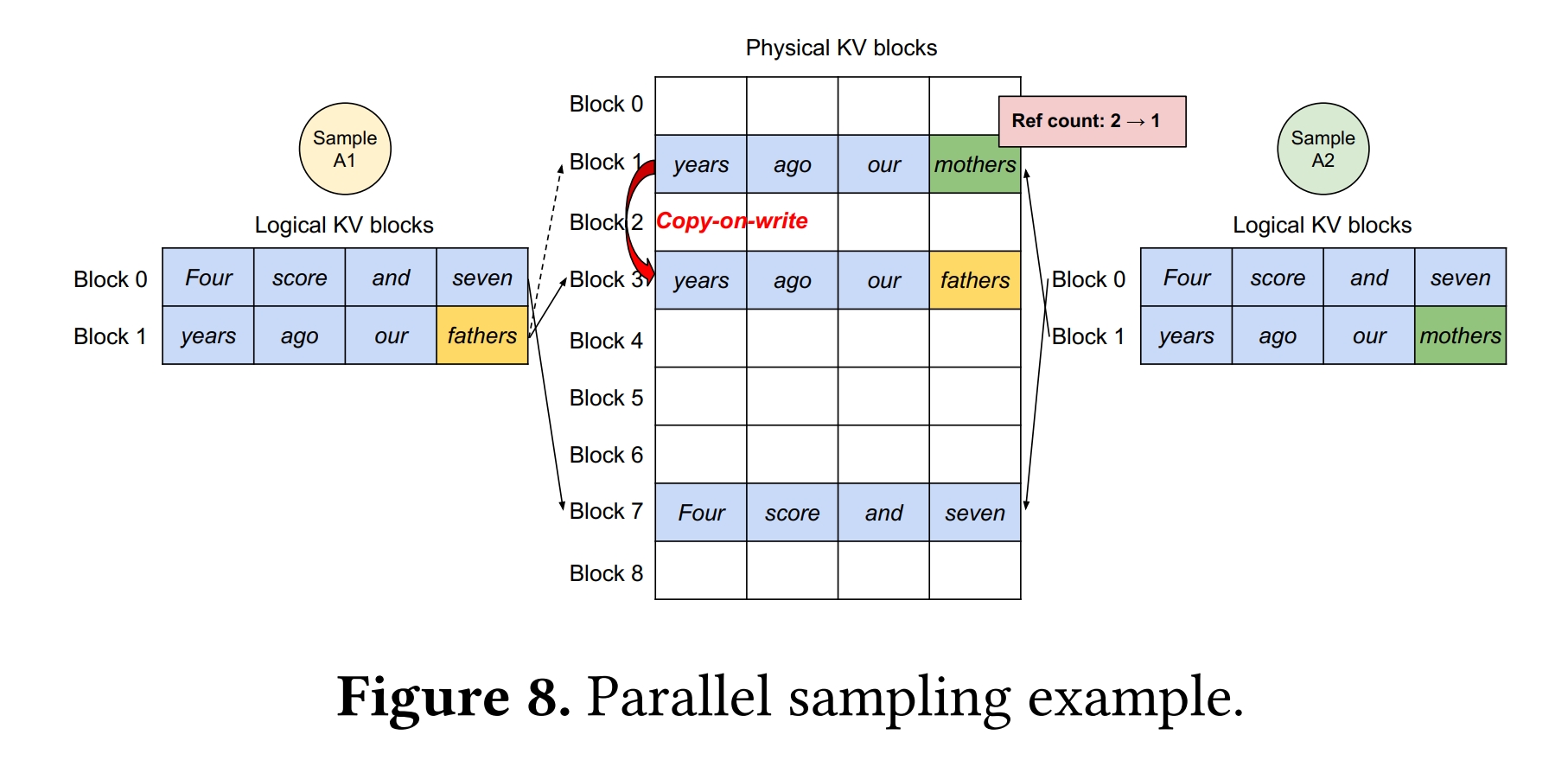
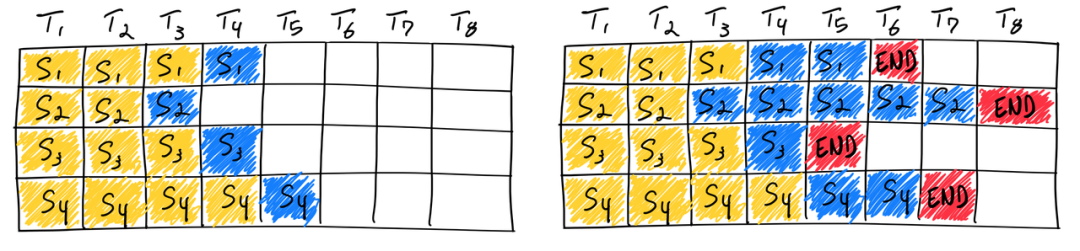
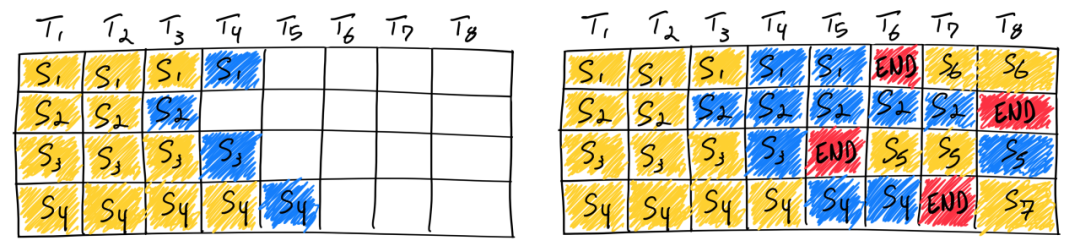
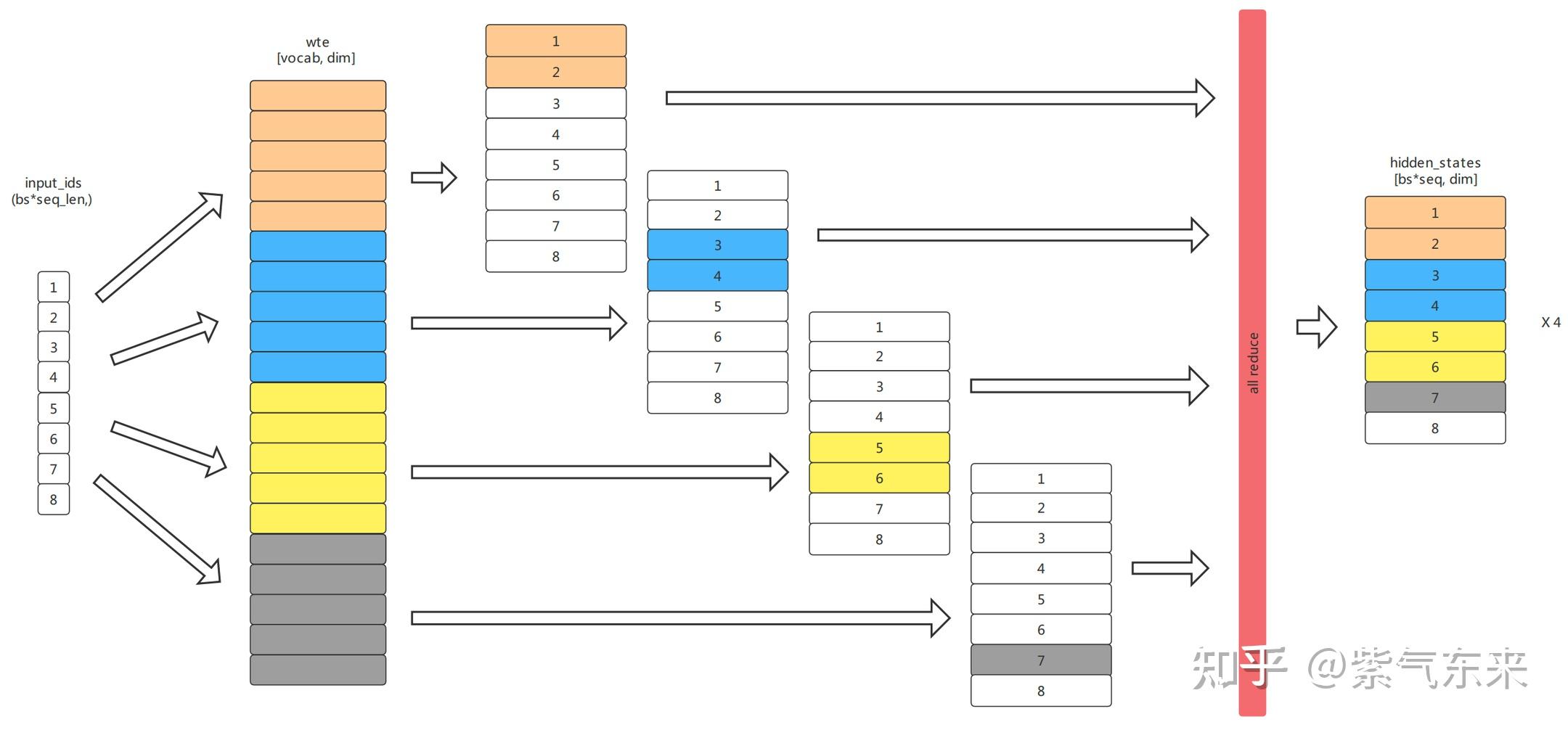
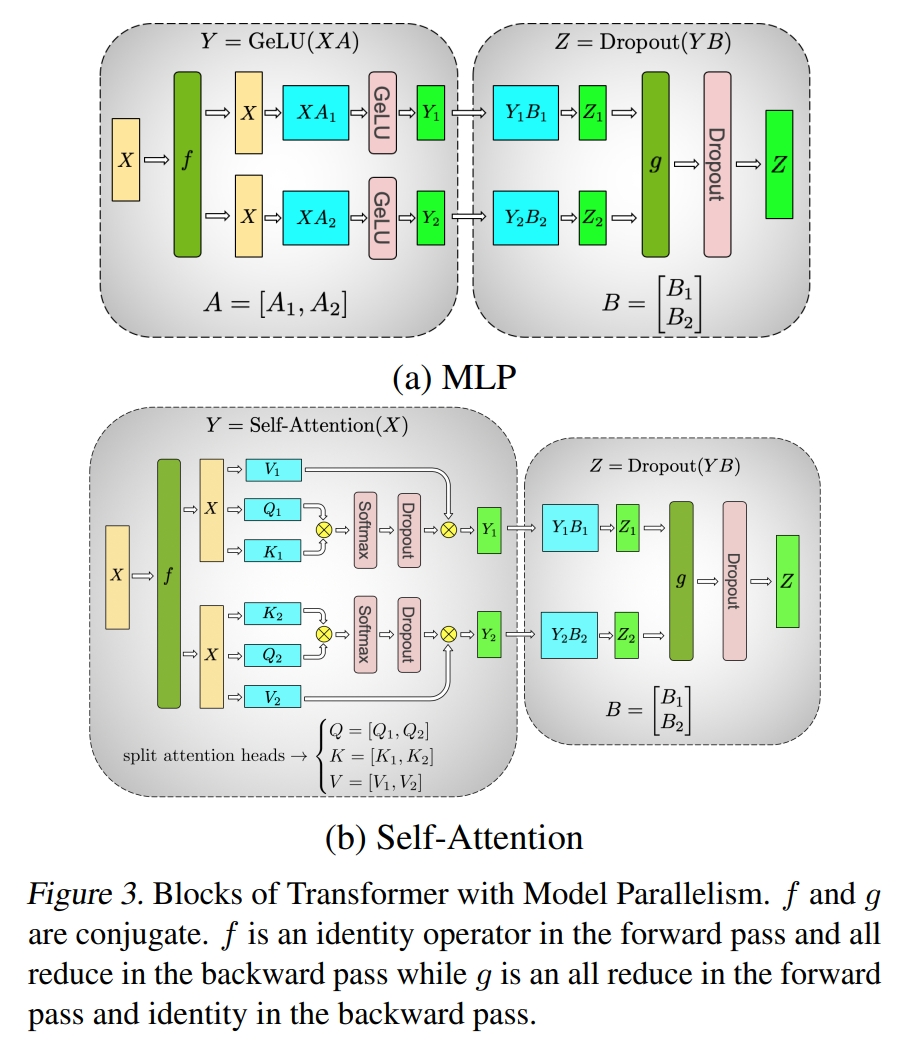
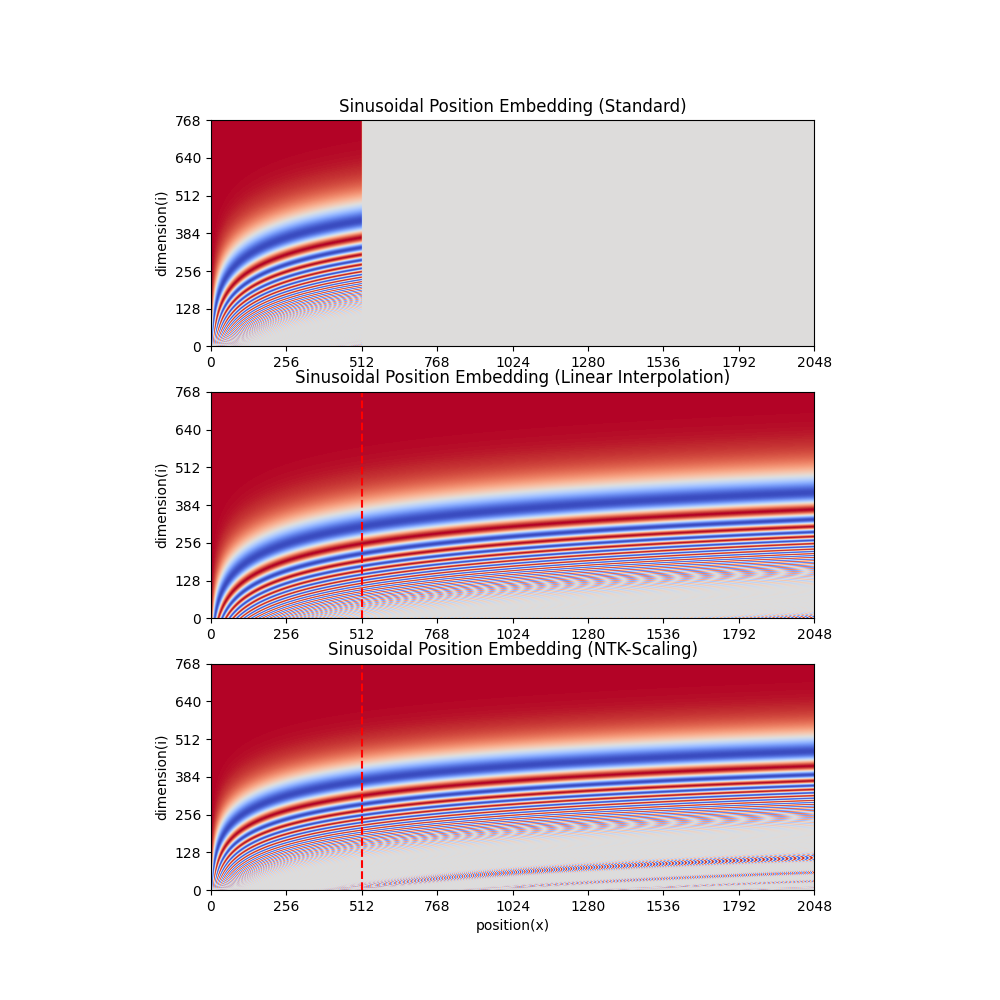
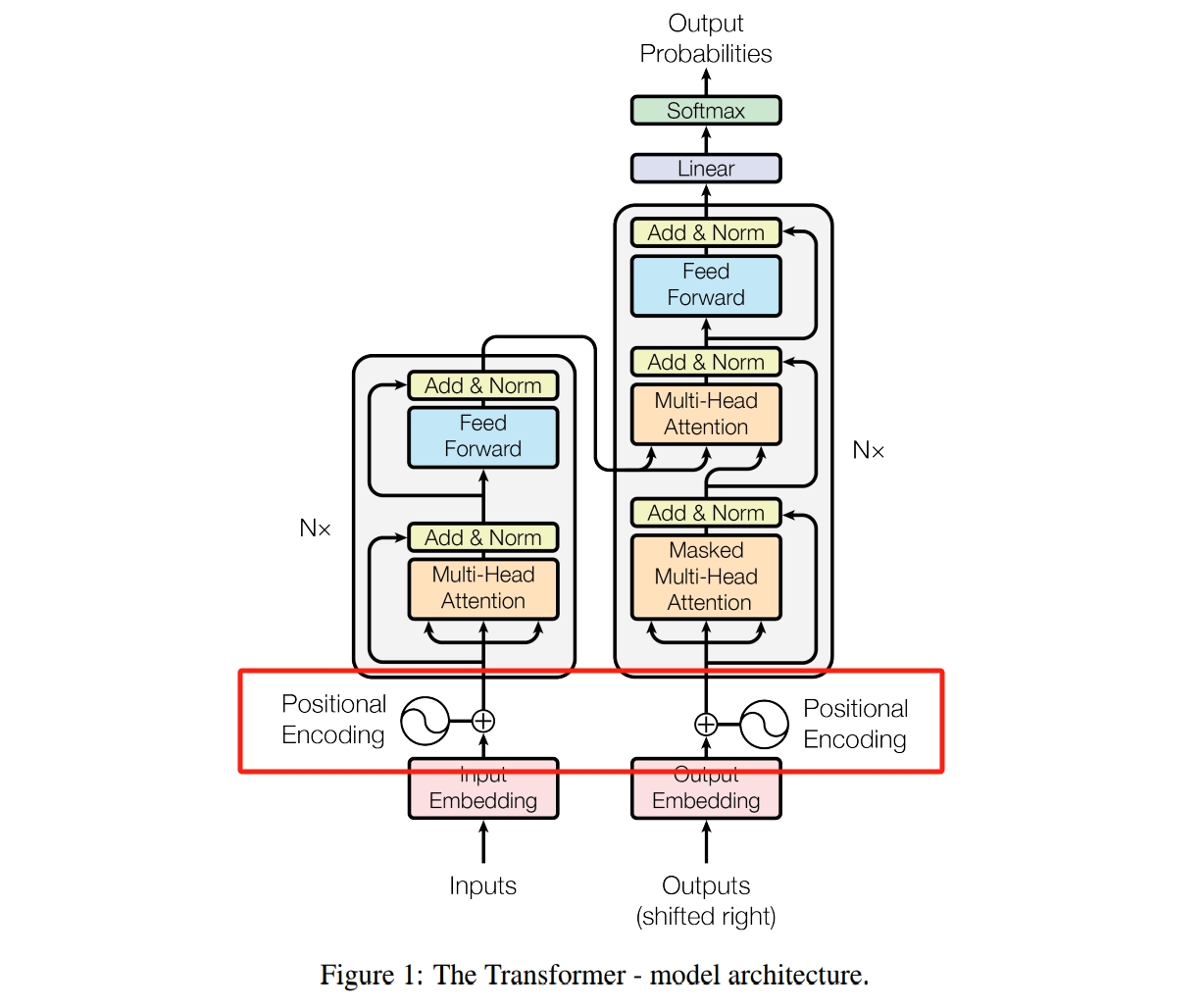
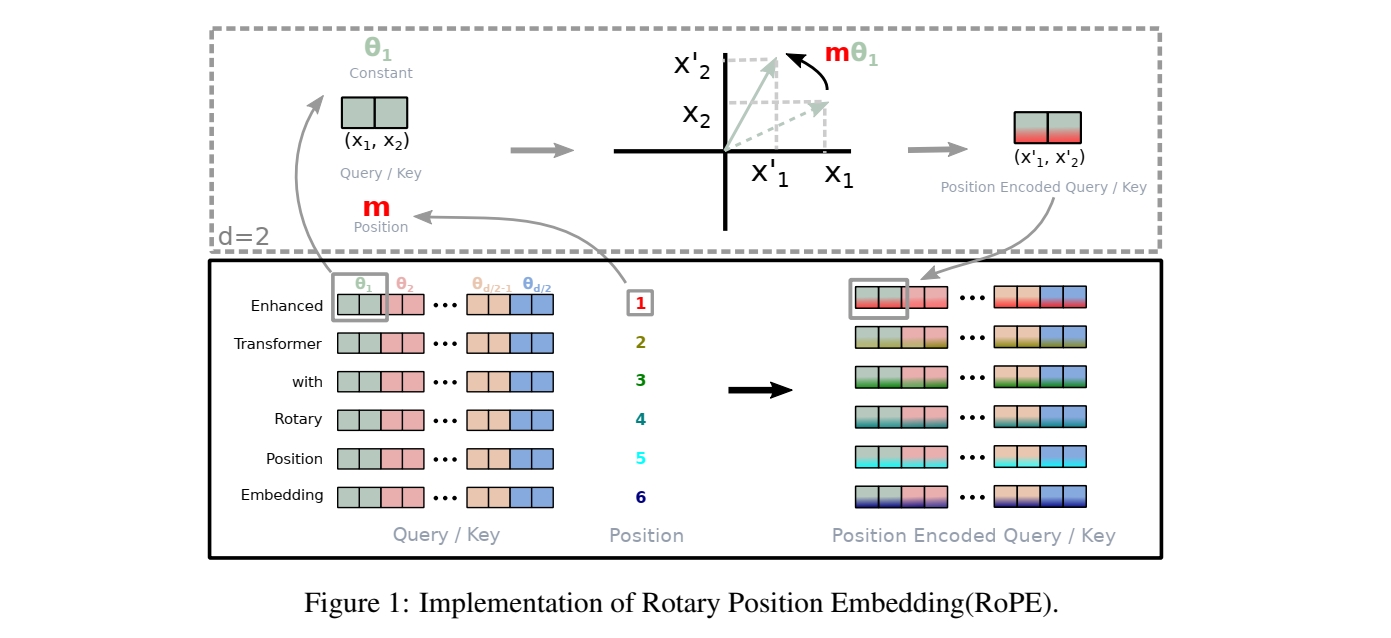
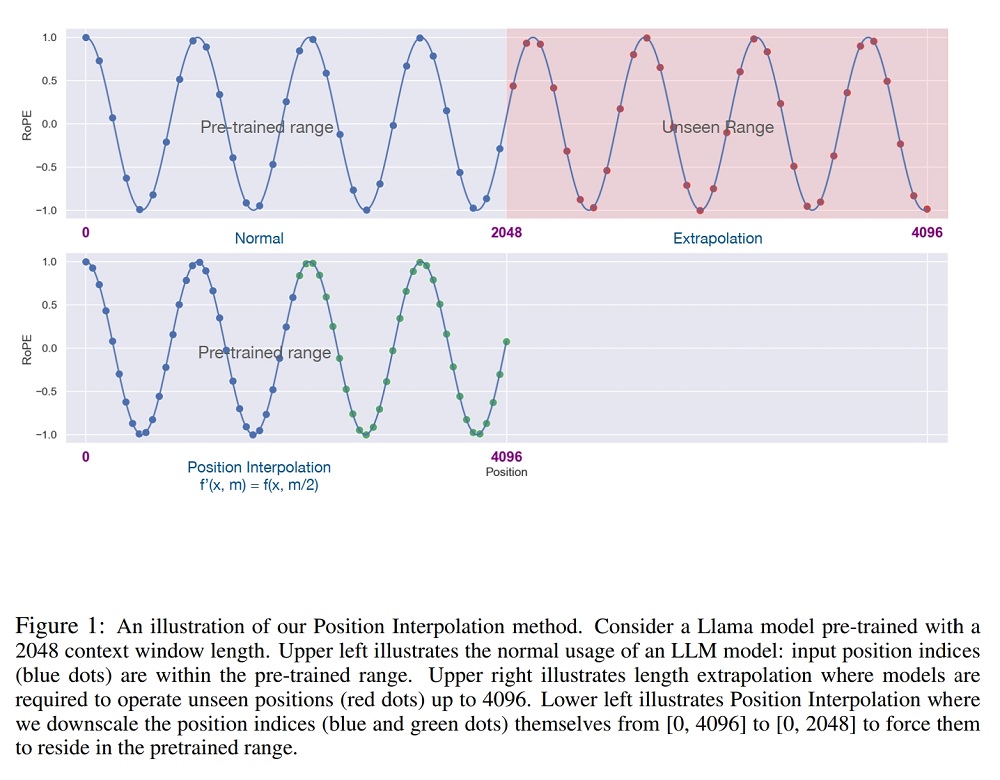
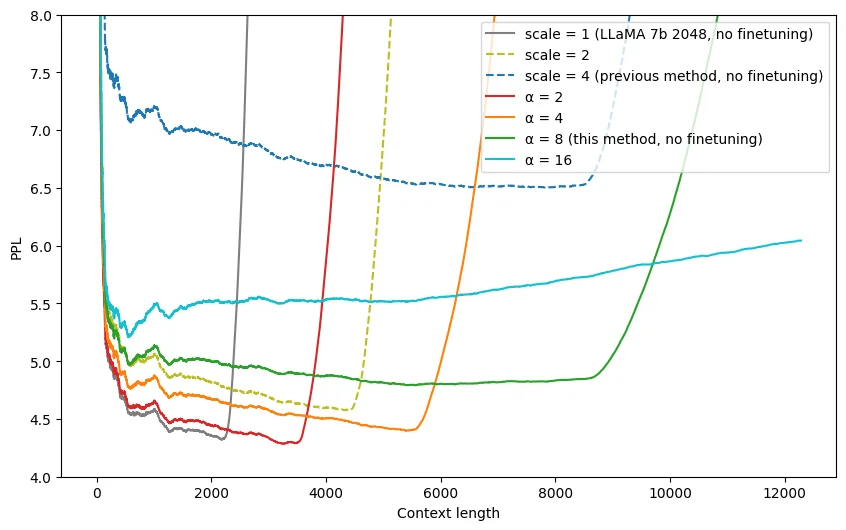
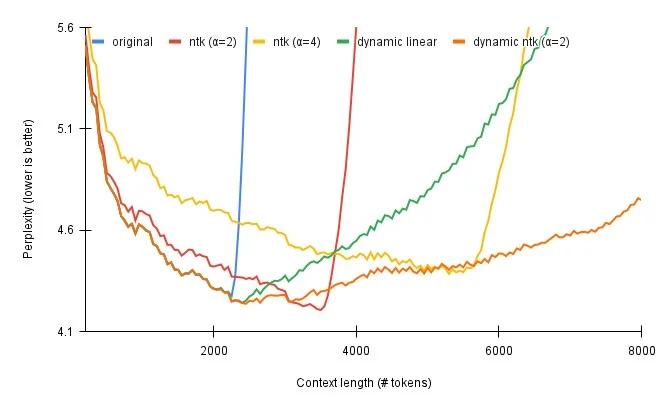
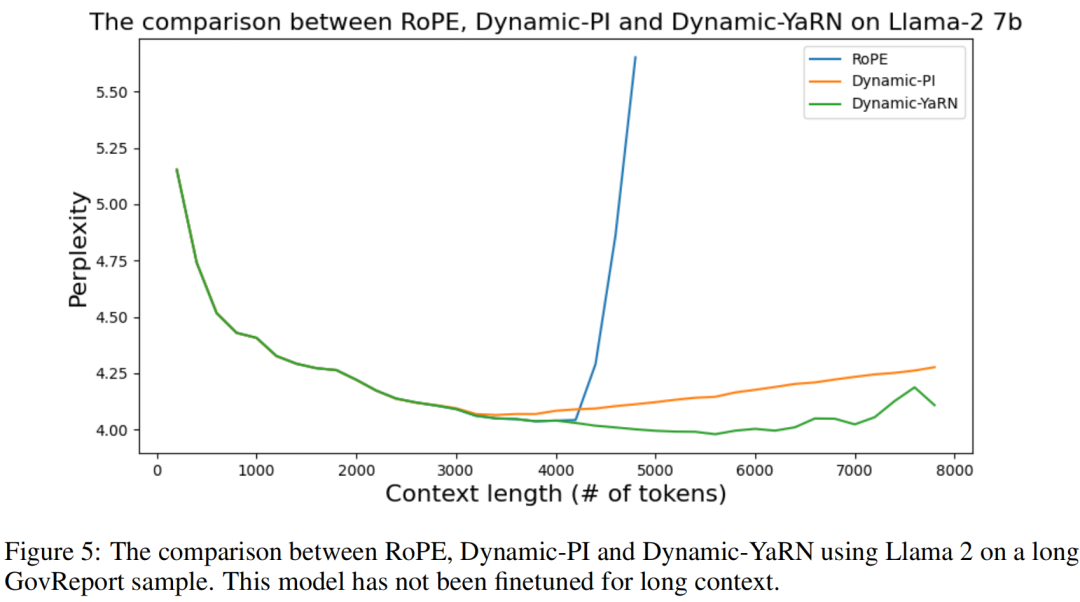










 ' +
+ '
' +
+ '