本篇博文主要展示每日从Arxiv论文网站获取的最新论文列表,以自然语言处理、信息检索、计算机视觉等类目进行划分。
+统计
+今日共更新1059篇论文,其中:
+
+- 自然语言处理173篇
+- 信息检索31篇
+- 计算机视觉227篇
+
+自然语言处理
+
+ 1. 【2410.07176】Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models
+ 链接:https://arxiv.org/abs/2410.07176
+ 作者:Fei Wang,Xingchen Wan,Ruoxi Sun,Jiefeng Chen,Sercan Ö. Arık
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:large language models, Retrieval-Augmented Generation, Astute RAG, RAG, imperfect retrieval
+ 备注: Preprint
+
+ 点击查看摘要
+ Abstract:Retrieval-Augmented Generation (RAG), while effective in integrating external knowledge to address the limitations of large language models (LLMs), can be undermined by imperfect retrieval, which may introduce irrelevant, misleading, or even malicious information. Despite its importance, previous studies have rarely explored the behavior of RAG through joint analysis on how errors from imperfect retrieval attribute and propagate, and how potential conflicts arise between the LLMs' internal knowledge and external sources. We find that imperfect retrieval augmentation might be inevitable and quite harmful, through controlled analysis under realistic conditions. We identify the knowledge conflicts between LLM-internal and external knowledge from retrieval as a bottleneck to overcome in the post-retrieval stage of RAG. To render LLMs resilient to imperfect retrieval, we propose Astute RAG, a novel RAG approach that adaptively elicits essential information from LLMs' internal knowledge, iteratively consolidates internal and external knowledge with source-awareness, and finalizes the answer according to information reliability. Our experiments using Gemini and Claude demonstrate that Astute RAG significantly outperforms previous robustness-enhanced RAG methods. Notably, Astute RAG is the only approach that matches or exceeds the performance of LLMs without RAG under worst-case scenarios. Further analysis reveals that Astute RAG effectively resolves knowledge conflicts, improving the reliability and trustworthiness of RAG systems.
+
+
+
+ 2. 【2410.07173】Do better language models have crisper vision?
+ 链接:https://arxiv.org/abs/2410.07173
+ 作者:Jona Ruthardt,Gertjan J. Burghouts,Serge Belongie,Yuki M. Asano
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:text-only Large Language, text-only Large, Large Language Models, Large Language, visual world
+ 备注:
+
+ 点击查看摘要
+ Abstract:How well do text-only Large Language Models (LLMs) grasp the visual world? As LLMs are increasingly used in computer vision, addressing this question becomes both fundamental and pertinent. However, existing studies have primarily focused on limited scenarios, such as their ability to generate visual content or cluster multimodal data. To this end, we propose the Visual Text Representation Benchmark (ViTeRB) to isolate key properties that make language models well-aligned with the visual world. With this, we identify large-scale decoder-based LLMs as ideal candidates for representing text in vision-centric contexts, counter to the current practice of utilizing text encoders. Building on these findings, we propose ShareLock, an ultra-lightweight CLIP-like model. By leveraging precomputable frozen features from strong vision and language models, ShareLock achieves an impressive 51% accuracy on ImageNet despite utilizing just 563k image-caption pairs. Moreover, training requires only 1 GPU hour (or 10 hours including the precomputation of features) - orders of magnitude less than prior methods. Code will be released.
+
+
+
+ 3. 【2410.07170】One Initialization to Rule them All: Fine-tuning via Explained Variance Adaptation
+ 链接:https://arxiv.org/abs/2410.07170
+ 作者:Fabian Paischer,Lukas Hauzenberger,Thomas Schmied,Benedikt Alkin,Marc Peter Deisenroth,Sepp Hochreiter
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (stat.ML)
+ 关键词:Foundation models, specific application, large-scale datasets, Foundation, uniform rank distribution
+ 备注: 10 pages + references and appendix, code available at [this https URL](https://github.com/ml-jku/EVA)
+
+ 点击查看摘要
+ Abstract:Foundation models (FMs) are pre-trained on large-scale datasets and then fine-tuned on a downstream task for a specific application. The most successful and most commonly used fine-tuning method is to update the pre-trained weights via a low-rank adaptation (LoRA). LoRA introduces new weight matrices that are usually initialized at random with a uniform rank distribution across model weights. Recent works focus on weight-driven initialization or learning of adaptive ranks during training. Both approaches have only been investigated in isolation, resulting in slow convergence or a uniform rank distribution, in turn leading to sub-optimal performance. We propose to enhance LoRA by initializing the new weights in a data-driven manner by computing singular value decomposition on minibatches of activation vectors. Then, we initialize the LoRA matrices with the obtained right-singular vectors and re-distribute ranks among all weight matrices to explain the maximal amount of variance and continue the standard LoRA fine-tuning procedure. This results in our new method Explained Variance Adaptation (EVA). We apply EVA to a variety of fine-tuning tasks ranging from language generation and understanding to image classification and reinforcement learning. EVA exhibits faster convergence than competitors and attains the highest average score across a multitude of tasks per domain.
+
+
+
+ 4. 【2410.07168】Sylber: Syllabic Embedding Representation of Speech from Raw Audio
+ 链接:https://arxiv.org/abs/2410.07168
+ 作者:Cheol Jun Cho,Nicholas Lee,Akshat Gupta,Dhruv Agarwal,Ethan Chen,Alan W Black,Gopala K. Anumanchipalli
+ 类目:Computation and Language (cs.CL); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:play a crucial, crucial role, role in human, speech, human speech perception
+ 备注:
+
+ 点击查看摘要
+ Abstract:Syllables are compositional units of spoken language that play a crucial role in human speech perception and production. However, current neural speech representations lack structure, resulting in dense token sequences that are costly to process. To bridge this gap, we propose a new model, Sylber, that produces speech representations with clean and robust syllabic structure. Specifically, we propose a self-supervised model that regresses features on syllabic segments distilled from a teacher model which is an exponential moving average of the model in training. This results in a highly structured representation of speech features, offering three key benefits: 1) a fast, linear-time syllable segmentation algorithm, 2) efficient syllabic tokenization with an average of 4.27 tokens per second, and 3) syllabic units better suited for lexical and syntactic understanding. We also train token-to-speech generative models with our syllabic units and show that fully intelligible speech can be reconstructed from these tokens. Lastly, we observe that categorical perception, a linguistic phenomenon of speech perception, emerges naturally in our model, making the embedding space more categorical and sparse than previous self-supervised learning approaches. Together, we present a novel self-supervised approach for representing speech as syllables, with significant potential for efficient speech tokenization and spoken language modeling.
+
+
+
+ 5. 【2410.07167】Deciphering Cross-Modal Alignment in Large Vision-Language Models with Modality Integration Rate
+ 链接:https://arxiv.org/abs/2410.07167
+ 作者:Qidong Huang,Xiaoyi Dong,Pan Zhang,Yuhang Zang,Yuhang Cao,Jiaqi Wang,Dahua Lin,Weiming Zhang,Nenghai Yu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Large Vision Language, Vision Language Models, Modality Integration Rate, Large Language Models, Vision Language
+ 备注: Project page: [this https URL](https://github.com/shikiw/Modality-Integration-Rate)
+
+ 点击查看摘要
+ Abstract:We present the Modality Integration Rate (MIR), an effective, robust, and generalized metric to indicate the multi-modal pre-training quality of Large Vision Language Models (LVLMs). Large-scale pre-training plays a critical role in building capable LVLMs, while evaluating its training quality without the costly supervised fine-tuning stage is under-explored. Loss, perplexity, and in-context evaluation results are commonly used pre-training metrics for Large Language Models (LLMs), while we observed that these metrics are less indicative when aligning a well-trained LLM with a new modality. Due to the lack of proper metrics, the research of LVLMs in the critical pre-training stage is hindered greatly, including the training data choice, efficient module design, etc. In this paper, we propose evaluating the pre-training quality from the inter-modal distribution distance perspective and present MIR, the Modality Integration Rate, which is 1) \textbf{Effective} to represent the pre-training quality and show a positive relation with the benchmark performance after supervised fine-tuning. 2) \textbf{Robust} toward different training/evaluation data. 3) \textbf{Generalize} across training configurations and architecture choices. We conduct a series of pre-training experiments to explore the effectiveness of MIR and observe satisfactory results that MIR is indicative about training data selection, training strategy schedule, and model architecture design to get better pre-training results. We hope MIR could be a helpful metric for building capable LVLMs and inspire the following research about modality alignment in different areas. Our code is at: this https URL.
+
+
+
+ 6. 【2410.07166】Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making
+ 链接:https://arxiv.org/abs/2410.07166
+ 作者:Manling Li,Shiyu Zhao,Qineng Wang,Kangrui Wang,Yu Zhou,Sanjana Srivastava,Cem Gokmen,Tony Lee,Li Erran Li,Ruohan Zhang,Weiyu Liu,Percy Liang,Li Fei-Fei,Jiayuan Mao,Jiajun Wu
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Robotics (cs.RO)
+ 关键词:Large Language Models, evaluate Large Language, Language Models, Large Language, evaluate Large
+ 备注: Accepted for oral presentation at NeurIPS 2024 in the Datasets and Benchmarks track
+
+ 点击查看摘要
+ Abstract:We aim to evaluate Large Language Models (LLMs) for embodied decision making. While a significant body of work has been leveraging LLMs for decision making in embodied environments, we still lack a systematic understanding of their performance because they are usually applied in different domains, for different purposes, and built based on different inputs and outputs. Furthermore, existing evaluations tend to rely solely on a final success rate, making it difficult to pinpoint what ability is missing in LLMs and where the problem lies, which in turn blocks embodied agents from leveraging LLMs effectively and selectively. To address these limitations, we propose a generalized interface (Embodied Agent Interface) that supports the formalization of various types of tasks and input-output specifications of LLM-based modules. Specifically, it allows us to unify 1) a broad set of embodied decision-making tasks involving both state and temporally extended goals, 2) four commonly-used LLM-based modules for decision making: goal interpretation, subgoal decomposition, action sequencing, and transition modeling, and 3) a collection of fine-grained metrics which break down evaluation into various types of errors, such as hallucination errors, affordance errors, various types of planning errors, etc. Overall, our benchmark offers a comprehensive assessment of LLMs' performance for different subtasks, pinpointing the strengths and weaknesses in LLM-powered embodied AI systems, and providing insights for effective and selective use of LLMs in embodied decision making.
+
+
+
+ 7. 【2410.07163】Simplicity Prevails: Rethinking Negative Preference Optimization for LLM Unlearning
+ 链接:https://arxiv.org/abs/2410.07163
+ 作者:Chongyu Fan,Jiancheng Liu,Licong Lin,Jinghan Jia,Ruiqi Zhang,Song Mei,Sijia Liu
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:harmful content generation, essential model utilities, remove unwanted data, unwanted data influences, large language model
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this work, we address the problem of large language model (LLM) unlearning, aiming to remove unwanted data influences and associated model capabilities (e.g., copyrighted data or harmful content generation) while preserving essential model utilities, without the need for retraining from scratch. Despite the growing need for LLM unlearning, a principled optimization framework remains lacking. To this end, we revisit the state-of-the-art approach, negative preference optimization (NPO), and identify the issue of reference model bias, which could undermine NPO's effectiveness, particularly when unlearning forget data of varying difficulty. Given that, we propose a simple yet effective unlearning optimization framework, called SimNPO, showing that 'simplicity' in removing the reliance on a reference model (through the lens of simple preference optimization) benefits unlearning. We also provide deeper insights into SimNPO's advantages, supported by analysis using mixtures of Markov chains. Furthermore, we present extensive experiments validating SimNPO's superiority over existing unlearning baselines in benchmarks like TOFU and MUSE, and robustness against relearning attacks. Codes are available at this https URL.
+
+
+
+ 8. 【2410.07157】InstructG2I: Synthesizing Images from Multimodal Attributed Graphs
+ 链接:https://arxiv.org/abs/2410.07157
+ 作者:Bowen Jin,Ziqi Pang,Bingjun Guo,Yu-Xiong Wang,Jiaxuan You,Jiawei Han
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Social and Information Networks (cs.SI)
+ 关键词:generating images, overlooked yet critical, graph, multimodal attributed graphs, critical task
+ 备注: 16 pages
+
+ 点击查看摘要
+ Abstract:In this paper, we approach an overlooked yet critical task Graph2Image: generating images from multimodal attributed graphs (MMAGs). This task poses significant challenges due to the explosion in graph size, dependencies among graph entities, and the need for controllability in graph conditions. To address these challenges, we propose a graph context-conditioned diffusion model called InstructG2I. InstructG2I first exploits the graph structure and multimodal information to conduct informative neighbor sampling by combining personalized page rank and re-ranking based on vision-language features. Then, a Graph-QFormer encoder adaptively encodes the graph nodes into an auxiliary set of graph prompts to guide the denoising process of diffusion. Finally, we propose graph classifier-free guidance, enabling controllable generation by varying the strength of graph guidance and multiple connected edges to a node. Extensive experiments conducted on three datasets from different domains demonstrate the effectiveness and controllability of our approach. The code is available at this https URL.
+
+
+
+ 9. 【2410.07147】aking a turn for the better: Conversation redirection throughout the course of mental-health therapy
+ 链接:https://arxiv.org/abs/2410.07147
+ 作者:Vivian Nguyen,Sang Min Jung,Lillian Lee,Thomas D. Hull,Cristian Danescu-Niculescu-Mizil
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computers and Society (cs.CY)
+ 关键词:Mental-health therapy involves, therapists continuously negotiate, complex conversation flow, Mental-health therapy, involves a complex
+ 备注: To appear in the Proceedings of EMNLP (Findings) 2024. Code available at [this https URL](https://convokit.cornell.edu)
+
+ 点击查看摘要
+ Abstract:Mental-health therapy involves a complex conversation flow in which patients and therapists continuously negotiate what should be talked about next. For example, therapists might try to shift the conversation's direction to keep the therapeutic process on track and avoid stagnation, or patients might push the discussion towards issues they want to focus on.
+How do such patient and therapist redirections relate to the development and quality of their relationship? To answer this question, we introduce a probabilistic measure of the extent to which a certain utterance immediately redirects the flow of the conversation, accounting for both the intention and the actual realization of such a change. We apply this new measure to characterize the development of patient-therapist relationships over multiple sessions in a very large, widely-used online therapy platform. Our analysis reveals that (1) patient control of the conversation's direction generally increases relative to that of the therapist as their relationship progresses; and (2) patients who have less control in the first few sessions are significantly more likely to eventually express dissatisfaction with their therapist and terminate the relationship.
+
Comments:
+To appear in the Proceedings of EMNLP (Findings) 2024. Code available at this https URL
+Subjects:
+Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computers and Society (cs.CY)
+Cite as:
+arXiv:2410.07147 [cs.CL]
+(or
+arXiv:2410.07147v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2410.07147
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 10. 【2410.07145】Stuffed Mamba: State Collapse and State Capacity of RNN-Based Long-Context Modeling
+ 链接:https://arxiv.org/abs/2410.07145
+ 作者:Yingfa Chen,Xinrong Zhang,Shengding Hu,Xu Han,Zhiyuan Liu,Maosong Sun
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:linear computational complexity, recurrent neural networks, handling long sequences, neural networks, Mamba and RWKV
+ 备注: 21 pages, 18 figures
+
+ 点击查看摘要
+ Abstract:One essential advantage of recurrent neural networks (RNNs) over transformer-based language models is their linear computational complexity concerning the sequence length, which makes them much faster in handling long sequences during inference. However, most publicly available RNNs (e.g., Mamba and RWKV) are trained on sequences with less than 10K tokens, and their effectiveness in longer contexts remains largely unsatisfying so far. In this paper, we study the cause of the inability to process long context for RNNs and suggest critical mitigations. We examine two practical concerns when applying state-of-the-art RNNs to long contexts: (1) the inability to extrapolate to inputs longer than the training length and (2) the upper bound of memory capacity. Addressing the first concern, we first investigate *state collapse* (SC), a phenomenon that causes severe performance degradation on sequence lengths not encountered during training. With controlled experiments, we attribute this to overfitting due to the recurrent state being overparameterized for the training length. For the second concern, we train a series of Mamba-2 models on long documents to empirically estimate the recurrent state capacity in language modeling and passkey retrieval. Then, three SC mitigation methods are proposed to improve Mamba-2's length generalizability, allowing the model to process more than 1M tokens without SC. We also find that the recurrent state capacity in passkey retrieval scales exponentially to the state size, and we empirically train a Mamba-2 370M with near-perfect passkey retrieval accuracy on 256K context length. This suggests a promising future for RNN-based long-context modeling.
+
+
+
+ 11. 【2410.07137】Cheating Automatic LLM Benchmarks: Null Models Achieve High Win Rates
+ 链接:https://arxiv.org/abs/2410.07137
+ 作者:Xiaosen Zheng,Tianyu Pang,Chao Du,Qian Liu,Jing Jiang,Min Lin
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Cryptography and Security (cs.CR); Machine Learning (cs.LG)
+ 关键词:language models due, evaluating language models, win rates, human evaluation, popular for evaluating
+ 备注:
+
+ 点击查看摘要
+ Abstract:Automatic LLM benchmarks, such as AlpacaEval 2.0, Arena-Hard-Auto, and MT-Bench, have become popular for evaluating language models due to their cost-effectiveness and scalability compared to human evaluation. Achieving high win rates on these benchmarks can significantly boost the promotional impact of newly released language models. This promotional benefit may motivate tricks, such as manipulating model output length or style to game win rates, even though several mechanisms have been developed to control length and disentangle style to reduce gameability. Nonetheless, we show that even a "null model" that always outputs a constant response (irrelevant to input instructions) can cheat automatic benchmarks and achieve top-ranked win rates: an 86.5% LC win rate on AlpacaEval 2.0; an 83.0 score on Arena-Hard-Auto; and a 9.55 score on MT-Bench. Moreover, the crafted cheating outputs are transferable because we assume that the instructions of these benchmarks (e.g., 805 samples of AlpacaEval 2.0) are private and cannot be accessed. While our experiments are primarily proof-of-concept, an adversary could use LLMs to generate more imperceptible cheating responses, unethically benefiting from high win rates and promotional impact. Our findings call for the development of anti-cheating mechanisms for reliable automatic benchmarks. The code is available at this https URL.
+
+
+
+ 12. 【2410.07129】Mental Disorders Detection in the Era of Large Language Models
+ 链接:https://arxiv.org/abs/2410.07129
+ 作者:Gleb Kuzmin,Petr Strepetov,Maksim Stankevich,Ivan Smirnov,Artem Shelmanov
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:machine learning methods, traditional machine learning, paper compares, machine learning, task of detecting
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper compares the effectiveness of traditional machine learning methods, encoder-based models, and large language models (LLMs) on the task of detecting depression and anxiety. Five datasets were considered, each differing in format and the method used to define the target pathology class. We tested AutoML models based on linguistic features, several variations of encoder-based Transformers such as BERT, and state-of-the-art LLMs as pathology classification models. The results demonstrated that LLMs outperform traditional methods, particularly on noisy and small datasets where training examples vary significantly in text length and genre. However, psycholinguistic features and encoder-based models can achieve performance comparable to language models when trained on texts from individuals with clinically confirmed depression, highlighting their potential effectiveness in targeted clinical applications.
+
+
+
+ 13. 【2410.07122】End-Cloud Collaboration Framework for Advanced AI Customer Service in E-commerce
+ 链接:https://arxiv.org/abs/2410.07122
+ 作者:Liangyu Teng,Yang Liu,Jing Liu,Liang Song
+ 类目:Distributed, Parallel, and Cluster Computing (cs.DC); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:customer service solutions, end model, AI-driven customer service, model, advanced AI-driven customer
+ 备注: Accepted by 2024 IEEE 10th World Forum on Internet of Things (WF-IoT)
+
+ 点击查看摘要
+ Abstract:In recent years, the e-commerce industry has seen a rapid increase in the demand for advanced AI-driven customer service solutions. Traditional cloud-based models face limitations in terms of latency, personalized services, and privacy concerns. Furthermore, end devices often lack the computational resources to deploy large AI models effectively. In this paper, we propose an innovative End-Cloud Collaboration (ECC) framework for advanced AI customer service in e-commerce. This framework integrates the advantages of large cloud models and mid/small-sized end models by deeply exploring the generalization potential of cloud models and effectively utilizing the computing power resources of terminal chips, alleviating the strain on computing resources to some extent. Specifically, the large cloud model acts as a teacher, guiding and promoting the learning of the end model, which significantly reduces the end model's reliance on large-scale, high-quality data and thereby addresses the data bottleneck in traditional end model training, offering a new paradigm for the rapid deployment of industry applications. Additionally, we introduce an online evolutive learning strategy that enables the end model to continuously iterate and upgrade based on guidance from the cloud model and real-time user feedback. This strategy ensures that the model can flexibly adapt to the rapid changes in application scenarios while avoiding the uploading of sensitive information by performing local fine-tuning, achieving the dual goals of privacy protection and personalized service. %We make systematic contributions to the customized model fine-tuning methods in the e-commerce domain. To conclude, we implement in-depth corpus collection (e.g., data organization, cleaning, and preprocessing) and train an ECC-based industry-specific model for e-commerce customer service.
+
+
+
+ 14. 【2410.07118】Exploring the Readiness of Prominent Small Language Models for the Democratization of Financial Literacy
+ 链接:https://arxiv.org/abs/2410.07118
+ 作者:Tagore Rao Kosireddy,Jeffrey D. Wall,Evan Lucas
+ 类目:Computation and Language (cs.CL)
+ 关键词:small language models, billion parameters, small language, language models, financial
+ 备注:
+
+ 点击查看摘要
+ Abstract:The use of small language models (SLMs), herein defined as models with less than three billion parameters, is increasing across various domains and applications. Due to their ability to run on more accessible hardware and preserve user privacy, SLMs possess the potential to democratize access to language models for individuals of different socioeconomic status and with different privacy preferences. This study assesses several state-of-the-art SLMs (e.g., Apple's OpenELM, Microsoft's Phi, Google's Gemma, and the Tinyllama project) for use in the financial domain to support the development of financial literacy LMs. Democratizing access to quality financial information for those who are financially under educated is greatly needed in society, particularly as new financial markets and products emerge and participation in financial markets increases due to ease of access. We are the first to examine the use of open-source SLMs to democratize access to financial question answering capabilities for individuals and students. To this end, we provide an analysis of the memory usage, inference time, similarity comparisons to ground-truth answers, and output readability of prominent SLMs to determine which models are most accessible and capable of supporting access to financial information. We analyze zero-shot and few-shot learning variants of the models. The results suggest that some off-the-shelf SLMs merit further exploration and fine-tuning to prepare them for individual use, while others may have limits to their democratization.
+
+
+
+ 15. 【2410.07114】System 2 thinking in OpenAI's o1-preview model: Near-perfect performance on a mathematics exam
+ 链接:https://arxiv.org/abs/2410.07114
+ 作者:Joost de Winter,Dimitra Dodou,Yke Bauke Eisma
+ 类目:Computers and Society (cs.CY); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:processes underlying human, underlying human cognition, involves fast, involves slow, intuitive thinking
+ 备注:
+
+ 点击查看摘要
+ Abstract:The processes underlying human cognition are often divided into two systems: System 1, which involves fast, intuitive thinking, and System 2, which involves slow, deliberate reasoning. Previously, large language models were criticized for lacking the deeper, more analytical capabilities of System 2. In September 2024, OpenAI introduced the O1 model series, specifically designed to handle System 2-like reasoning. While OpenAI's benchmarks are promising, independent validation is still needed. In this study, we tested the O1-preview model twice on the Dutch 'Mathematics B' final exam. It scored a near-perfect 76 and 73 out of 76 points. For context, only 24 out of 16,414 students in the Netherlands achieved a perfect score. By comparison, the GPT-4o model scored 66 and 61 out of 76, well above the Dutch average of 40.63 points. The O1-preview model completed the exam in around 10 minutes, while GPT-4o took 3 minutes, and neither model had access to the exam figures. Although O1-preview had the ability to achieve a perfect score, its performance showed some variability, as it made occasional mistakes with repeated prompting. This suggests that the self-consistency method, where the consensus output is selected, could improve accuracy. We conclude that while OpenAI's new model series holds great potential, certain risks must be considered.
+
+
+
+ 16. 【2410.07109】I Want to Break Free! Anti-Social Behavior and Persuasion Ability of LLMs in Multi-Agent Settings with Social Hierarchy
+ 链接:https://arxiv.org/abs/2410.07109
+ 作者:Gian Maria Campedelli,Nicolò Penzo,Massimo Stefan,Roberto Dessì,Marco Guerini,Bruno Lepri,Jacopo Staiano
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computers and Society (cs.CY); Multiagent Systems (cs.MA)
+ 关键词:Large Language Model, Large Language, Stanford Prison Experiment, anticipate emergent phenomena, Language Model
+ 备注:
+
+ 点击查看摘要
+ Abstract:As Large Language Model (LLM)-based agents become increasingly autonomous and will more freely interact with each other, studying interactions between them becomes crucial to anticipate emergent phenomena and potential risks. Drawing inspiration from the widely popular Stanford Prison Experiment, we contribute to this line of research by studying interaction patterns of LLM agents in a context characterized by strict social hierarchy. We do so by specifically studying two types of phenomena: persuasion and anti-social behavior in simulated scenarios involving a guard and a prisoner agent who seeks to achieve a specific goal (i.e., obtaining additional yard time or escape from prison). Leveraging 200 experimental scenarios for a total of 2,000 machine-machine conversations across five different popular LLMs, we provide a set of noteworthy findings. We first document how some models consistently fail in carrying out a conversation in our multi-agent setup where power dynamics are at play. Then, for the models that were able to engage in successful interactions, we empirically show how the goal that an agent is set to achieve impacts primarily its persuasiveness, while having a negligible effect with respect to the agent's anti-social behavior. Third, we highlight how agents' personas, and particularly the guard's personality, drive both the likelihood of successful persuasion from the prisoner and the emergence of anti-social behaviors. Fourth, we show that even without explicitly prompting for specific personalities, anti-social behavior emerges by simply assigning agents' roles. These results bear implications for the development of interactive LLM agents as well as the debate on their societal impact.
+
+
+
+ 17. 【2410.07103】Unleashing Multi-Hop Reasoning Potential in Large Language Models through Repetition of Misordered Context
+ 链接:https://arxiv.org/abs/2410.07103
+ 作者:Sangwon Yu,Ik-hwan Kim,Jongyoon Song,Saehyung Lee,Junsung Park,Sungroh Yoon
+ 类目:Computation and Language (cs.CL)
+ 关键词:supporting documents, large language models, requires multi-step reasoning, multi-step reasoning based, remains challenging
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multi-hop reasoning, which requires multi-step reasoning based on the supporting documents within a given context, remains challenging for large language models (LLMs). LLMs often struggle to filter out irrelevant documents within the context, and their performance is sensitive to the position of supporting documents within that context. In this paper, we identify an additional challenge: LLMs' performance is also sensitive to the order in which the supporting documents are presented. We refer to this as the misordered context problem. To address this issue, we propose a simple yet effective method called context repetition (CoRe), which involves prompting the model by repeatedly presenting the context to ensure the supporting documents are presented in the optimal order for the model. Using CoRe, we improve the F1 score by up to 30%p on multi-hop QA tasks and increase accuracy by up to 70%p on a synthetic task. Additionally, CoRe helps mitigate the well-known "lost-in-the-middle" problem in LLMs and can be effectively combined with retrieval-based approaches utilizing Chain-of-Thought (CoT) reasoning.
+
+
+
+ 18. 【2410.07095】MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
+ 链接:https://arxiv.org/abs/2410.07095
+ 作者:Jun Shern Chan,Neil Chowdhury,Oliver Jaffe,James Aung,Dane Sherburn,Evan Mays,Giulio Starace,Kevin Liu,Leon Maksin,Tejal Patwardhan,Lilian Weng,Aleksander Mądry
+ 类目:Computation and Language (cs.CL)
+ 关键词:machine learning engineering, introduce MLE-bench, perform at machine, machine learning, learning engineering
+ 备注: 10 pages. Plus 17 pages appendix. 8 figures. Equal contribution by first seven authors. Authors randomized. Work by Neil Chowdhury done while at OpenAI
+
+ 点击查看摘要
+ Abstract:We introduce MLE-bench, a benchmark for measuring how well AI agents perform at machine learning engineering. To this end, we curate 75 ML engineering-related competitions from Kaggle, creating a diverse set of challenging tasks that test real-world ML engineering skills such as training models, preparing datasets, and running experiments. We establish human baselines for each competition using Kaggle's publicly available leaderboards. We use open-source agent scaffolds to evaluate several frontier language models on our benchmark, finding that the best-performing setup--OpenAI's o1-preview with AIDE scaffolding--achieves at least the level of a Kaggle bronze medal in 16.9% of competitions. In addition to our main results, we investigate various forms of resource scaling for AI agents and the impact of contamination from pre-training. We open-source our benchmark code (this http URL) to facilitate future research in understanding the ML engineering capabilities of AI agents.
+
+
+
+ 19. 【2410.07094】An Approach for Auto Generation of Labeling Functions for Software Engineering Chatbots
+ 链接:https://arxiv.org/abs/2410.07094
+ 作者:Ebube Alor,Ahmad Abdellatif,SayedHassan Khatoonabadi,Emad Shihab
+ 类目:oftware Engineering (cs.SE); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:enhancing development processes, increasingly gaining attention, Software engineering, Natural Language Understanding, development processes
+ 备注: Submitted to IEEE Transactions on Software Engineering for review
+
+ 点击查看摘要
+ Abstract:Software engineering (SE) chatbots are increasingly gaining attention for their role in enhancing development processes. At the core of chatbots are the Natural Language Understanding platforms (NLUs), which enable them to comprehend and respond to user queries. Before deploying NLUs, there is a need to train them with labeled data. However, acquiring such labeled data for SE chatbots is challenging due to the scarcity of high-quality datasets. This challenge arises because training SE chatbots requires specialized vocabulary and phrases not found in typical language datasets. Consequently, chatbot developers often resort to manually annotating user queries to gather the data necessary for training effective chatbots, a process that is both time-consuming and resource-intensive. Previous studies propose approaches to support chatbot practitioners in annotating users' posed queries. However, these approaches require human intervention to generate rules, called labeling functions (LFs), that identify and categorize user queries based on specific patterns in the data. To address this issue, we propose an approach to automatically generate LFs by extracting patterns from labeled user queries. We evaluate the effectiveness of our approach by applying it to the queries of four diverse SE datasets (namely AskGit, MSA, Ask Ubuntu, and Stack Overflow) and measure the performance improvement gained from training the NLU on the queries labeled by the generated LFs. We find that the generated LFs effectively label data with AUC scores of up to 85.3%, and NLU's performance improvement of up to 27.2% across the studied datasets. Furthermore, our results show that the number of LFs used to generate LFs affects the labeling performance. We believe that our approach can save time and resources in labeling users' queries, allowing practitioners to focus on core chatbot functionalities.
+
+
+
+ 20. 【2410.07083】Stanceformer: Target-Aware Transformer for Stance Detection
+ 链接:https://arxiv.org/abs/2410.07083
+ 作者:Krishna Garg,Cornelia Caragea
+ 类目:Computation and Language (cs.CL)
+ 关键词:Detection involves discerning, Stance Detection involves, involves discerning, specific subject, Stance Detection
+ 备注: 16 pages, 2 figures, 14 tables including Appendix
+
+ 点击查看摘要
+ Abstract:The task of Stance Detection involves discerning the stance expressed in a text towards a specific subject or target. Prior works have relied on existing transformer models that lack the capability to prioritize targets effectively. Consequently, these models yield similar performance regardless of whether we utilize or disregard target information, undermining the task's significance. To address this challenge, we introduce Stanceformer, a target-aware transformer model that incorporates enhanced attention towards the targets during both training and inference. Specifically, we design a \textit{Target Awareness} matrix that increases the self-attention scores assigned to the targets. We demonstrate the efficacy of the Stanceformer with various BERT-based models, including state-of-the-art models and Large Language Models (LLMs), and evaluate its performance across three stance detection datasets, alongside a zero-shot dataset. Our approach Stanceformer not only provides superior performance but also generalizes even to other domains, such as Aspect-based Sentiment Analysis. We make the code publicly available.\footnote{\scriptsize\url{this https URL}}
+
+
+
+ 21. 【2410.07076】MOOSE-Chem: Large Language Models for Rediscovering Unseen Chemistry Scientific Hypotheses
+ 链接:https://arxiv.org/abs/2410.07076
+ 作者:Zonglin Yang,Wanhao Liu,Ben Gao,Tong Xie,Yuqiang Li,Wanli Ouyang,Soujanya Poria,Erik Cambria,Dongzhan Zhou
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Scientific discovery contributes, human society prosperity, discovery contributes largely, recent progress shows, Scientific discovery
+ 备注: Code and Benchmark are available at [this https URL](https://github.com/ZonglinY/MOOSE-Chem.git)
+
+ 点击查看摘要
+ Abstract:Scientific discovery contributes largely to human society's prosperity, and recent progress shows that LLMs could potentially catalyze this process. However, it is still unclear whether LLMs can discover novel and valid hypotheses in chemistry. In this work, we investigate this central research question: Can LLMs automatically discover novel and valid chemistry research hypotheses given only a chemistry research background (consisting of a research question and/or a background survey), without limitation on the domain of the research question? After extensive discussions with chemistry experts, we propose an assumption that a majority of chemistry hypotheses can be resulted from a research background and several inspirations. With this key insight, we break the central question into three smaller fundamental questions. In brief, they are: (1) given a background question, whether LLMs can retrieve good inspirations; (2) with background and inspirations, whether LLMs can lead to hypothesis; and (3) whether LLMs can identify good hypotheses to rank them higher. To investigate these questions, we construct a benchmark consisting of 51 chemistry papers published in Nature, Science, or a similar level in 2024 (all papers are only available online since 2024). Every paper is divided by chemistry PhD students into three components: background, inspirations, and hypothesis. The goal is to rediscover the hypothesis, given only the background and a large randomly selected chemistry literature corpus consisting the ground truth inspiration papers, with LLMs trained with data up to 2023. We also develop an LLM-based multi-agent framework that leverages the assumption, consisting of three stages reflecting the three smaller questions. The proposed method can rediscover many hypotheses with very high similarity with the ground truth ones, covering the main innovations.
+
+
+
+ 22. 【2410.07073】Pixtral 12B
+ 链接:https://arxiv.org/abs/2410.07073
+ 作者:Pravesh Agrawal,Szymon Antoniak,Emma Bou Hanna,Devendra Chaplot,Jessica Chudnovsky,Saurabh Garg,Theophile Gervet,Soham Ghosh,Amélie Héliou,Paul Jacob,Albert Q. Jiang,Timothée Lacroix,Guillaume Lample,Diego Las Casas,Thibaut Lavril,Teven Le Scao,Andy Lo,William Marshall,Louis Martin,Arthur Mensch,Pavankumar Muddireddy,Valera Nemychnikova,Marie Pellat,Patrick Von Platen,Nikhil Raghuraman,Baptiste Rozière,Alexandre Sablayrolles,Lucile Saulnier,Romain Sauvestre,Wendy Shang,Roman Soletskyi,Lawrence Stewart,Pierre Stock,Joachim Studnia,Sandeep Subramanian,Sagar Vaze,Thomas Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:billion-parameter multimodal language, Pixtral, billion-parameter multimodal, multimodal, models
+ 备注:
+
+ 点击查看摘要
+ Abstract:We introduce Pixtral-12B, a 12--billion-parameter multimodal language model. Pixtral-12B is trained to understand both natural images and documents, achieving leading performance on various multimodal benchmarks, surpassing a number of larger models. Unlike many open-source models, Pixtral is also a cutting-edge text model for its size, and does not compromise on natural language performance to excel in multimodal tasks. Pixtral uses a new vision encoder trained from scratch, which allows it to ingest images at their natural resolution and aspect ratio. This gives users flexibility on the number of tokens used to process an image. Pixtral is also able to process any number of images in its long context window of 128K tokens. Pixtral 12B substanially outperforms other open models of similar sizes (Llama-3.2 11B \ Qwen-2-VL 7B). It also outperforms much larger open models like Llama-3.2 90B while being 7x smaller. We further contribute an open-source benchmark, MM-MT-Bench, for evaluating vision-language models in practical scenarios, and provide detailed analysis and code for standardized evaluation protocols for multimodal LLMs. Pixtral-12B is released under Apache 2.0 license.
+
+
+
+ 23. 【2410.07069】ReIFE: Re-evaluating Instruction-Following Evaluation
+ 链接:https://arxiv.org/abs/2410.07069
+ 作者:Yixin Liu,Kejian Shi,Alexander R. Fabbri,Yilun Zhao,Peifeng Wang,Chien-Sheng Wu,Shafiq Joty,Arman Cohan
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:large language models, assess response quality, base LLMs, evaluation, evaluation protocols
+ 备注: GitHub Repo: [this https URL](https://github.com/yale-nlp/ReIFE) , Evaluation Result Collection: [this https URL](https://huggingface.co/datasets/yale-nlp/ReIFE)
+
+ 点击查看摘要
+ Abstract:The automatic evaluation of instruction following typically involves using large language models (LLMs) to assess response quality. However, there is a lack of comprehensive evaluation of these LLM-based evaluators across two dimensions: the base LLMs and the evaluation protocols. Therefore, we present a thorough meta-evaluation of instruction following, including 25 base LLMs and 15 recently proposed evaluation protocols, on 4 human-annotated datasets, assessing the evaluation accuracy of the LLM-evaluators. Our evaluation allows us to identify the best-performing base LLMs and evaluation protocols with a high degree of robustness. Moreover, our large-scale evaluation reveals: (1) Base LLM performance ranking remains largely consistent across evaluation protocols, with less capable LLMs showing greater improvement from protocol enhancements; (2) Robust evaluation of evaluation protocols requires many base LLMs with varying capability levels, as protocol effectiveness can depend on the base LLM used; (3) Evaluation results on different datasets are not always consistent, so a rigorous evaluation requires multiple datasets with distinctive features. We release our meta-evaluation suite ReIFE, which provides the codebase and evaluation result collection for more than 500 LLM-evaluator configurations, to support future research in instruction-following evaluation.
+
+
+
+ 24. 【2410.07064】Data Selection via Optimal Control for Language Models
+ 链接:https://arxiv.org/abs/2410.07064
+ 作者:Yuxian Gu,Li Dong,Hongning Wang,Yaru Hao,Qingxiu Dong,Furu Wei,Minlie Huang
+ 类目:Computation and Language (cs.CL)
+ 关键词:enhance LMs' capabilities, Pontryagin Maximum Principle, optimal data selection, data selection, Optimal Control problem
+ 备注:
+
+ 点击查看摘要
+ Abstract:This work investigates the selection of high-quality pre-training data from massive corpora to enhance LMs' capabilities for downstream usage. We formulate data selection as a generalized Optimal Control problem, which can be solved theoretically by Pontryagin's Maximum Principle (PMP), yielding a set of necessary conditions that characterize the relationship between optimal data selection and LM training dynamics. Based on these theoretical results, we introduce PMP-based Data Selection (PDS), a framework that approximates optimal data selection by solving the PMP conditions. In our experiments, we adopt PDS to select data from CommmonCrawl and show that the PDS-selected corpus accelerates the learning of LMs and constantly boosts their performance on a wide range of downstream tasks across various model sizes. Moreover, the benefits of PDS extend to ~400B models trained on ~10T tokens, as evidenced by the extrapolation of the test loss curves according to the Scaling Laws. PDS also improves data utilization when the pre-training data is limited, by reducing the data demand by 1.8 times, which mitigates the quick exhaustion of available web-crawled corpora. Our code, data, and model checkpoints can be found in this https URL.
+
+
+
+ 25. 【2410.07054】Mitigating the Language Mismatch and Repetition Issues in LLM-based Machine Translation via Model Editing
+ 链接:https://arxiv.org/abs/2410.07054
+ 作者:Weichuan Wang,Zhaoyi Li,Defu Lian,Chen Ma,Linqi Song,Ying Wei
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Large Language Models, specific down-stream tasks, NLP field, revolutionized the NLP, Large Language
+ 备注: 20 pages, EMNLP'2024 Main Conference
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have recently revolutionized the NLP field, while they still fall short in some specific down-stream tasks. In the work, we focus on utilizing LLMs to perform machine translation, where we observe that two patterns of errors frequently occur and drastically affect the translation quality: language mismatch and repetition. The work sets out to explore the potential for mitigating these two issues by leveraging model editing methods, e.g., by locating Feed-Forward Network (FFN) neurons or something that are responsible for the errors and deactivating them in the inference time. We find that directly applying such methods either limited effect on the targeted errors or has significant negative side-effect on the general translation quality, indicating that the located components may also be crucial for ensuring machine translation with LLMs on the rails. To this end, we propose to refine the located components by fetching the intersection of the locating results under different language settings, filtering out the aforementioned information that is irrelevant to targeted errors. The experiment results empirically demonstrate that our methods can effectively reduce the language mismatch and repetition ratios and meanwhile enhance or keep the general translation quality in most cases.
+
+
+
+ 26. 【2410.07053】Robots in the Middle: Evaluating LLMs in Dispute Resolution
+ 链接:https://arxiv.org/abs/2410.07053
+ 作者:Jinzhe Tan,Hannes Westermann,Nikhil Reddy Pottanigari,Jaromír Šavelka,Sébastien Meeùs,Mia Godet,Karim Benyekhlef
+ 类目:Human-Computer Interaction (cs.HC); Computation and Language (cs.CL)
+ 关键词:resolution method featuring, neutral third-party, method featuring, featuring a neutral, individuals resolve
+ 备注:
+
+ 点击查看摘要
+ Abstract:Mediation is a dispute resolution method featuring a neutral third-party (mediator) who intervenes to help the individuals resolve their dispute. In this paper, we investigate to which extent large language models (LLMs) are able to act as mediators. We investigate whether LLMs are able to analyze dispute conversations, select suitable intervention types, and generate appropriate intervention messages. Using a novel, manually created dataset of 50 dispute scenarios, we conduct a blind evaluation comparing LLMs with human annotators across several key metrics. Overall, the LLMs showed strong performance, even outperforming our human annotators across dimensions. Specifically, in 62% of the cases, the LLMs chose intervention types that were rated as better than or equivalent to those chosen by humans. Moreover, in 84% of the cases, the intervention messages generated by the LLMs were rated as better than or equal to the intervention messages written by humans. LLMs likewise performed favourably on metrics such as impartiality, understanding and contextualization. Our results demonstrate the potential of integrating AI in online dispute resolution (ODR) platforms.
+
+
+
+ 27. 【2410.07035】PositionID: LLMs can Control Lengths, Copy and Paste with Explicit Positional Awareness
+ 链接:https://arxiv.org/abs/2410.07035
+ 作者:Zekun Wang,Feiyu Duan,Yibo Zhang,Wangchunshu Zhou,Ke Xu,Wenhao Huang,Jie Fu
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, Large Language, demonstrate impressive capabilities, including role-playing, creative writing
+ 备注: 39 pages. CP-Bench and LenCtrl-Bench are available in [this https URL](https://huggingface.co/datasets/ZenMoore/CP-Bench) and [this https URL](https://huggingface.co/datasets/ZenMoore/LenCtrl-Bench)
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) demonstrate impressive capabilities across various domains, including role-playing, creative writing, mathematical reasoning, and coding. Despite these advancements, LLMs still encounter challenges with length control, frequently failing to adhere to specific length constraints due to their token-level operations and insufficient training on data with strict length limitations. We identify this issue as stemming from a lack of positional awareness and propose novel approaches--PositionID Prompting and PositionID Fine-Tuning--to address it. These methods enhance the model's ability to continuously monitor and manage text length during generation. Additionally, we introduce PositionID CP Prompting to enable LLMs to perform copy and paste operations accurately. Furthermore, we develop two benchmarks for evaluating length control and copy-paste abilities. Our experiments demonstrate that our methods significantly improve the model's adherence to length constraints and copy-paste accuracy without compromising response quality.
+
+
+
+ 28. 【2410.07030】Clean Evaluations on Contaminated Visual Language Models
+ 链接:https://arxiv.org/abs/2410.07030
+ 作者:Hongyuan Lu,Shujie Miao,Wai Lam
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:important research era, possibly contaminated LLMs, evaluate large language, large language models, important research
+ 备注:
+
+ 点击查看摘要
+ Abstract:How to evaluate large language models (LLMs) cleanly has been established as an important research era to genuinely report the performance of possibly contaminated LLMs. Yet, how to cleanly evaluate the visual language models (VLMs) is an under-studied problem. We propose a novel approach to achieve such goals through data augmentation methods on the visual input information. We then craft a new visual clean evaluation benchmark with thousands of data instances. Through extensive experiments, we found that the traditional visual data augmentation methods are useful, but they are at risk of being used as a part of the training data as a workaround. We further propose using BGR augmentation to switch the colour channel of the visual information. We found that it is a simple yet effective method for reducing the effect of data contamination and fortunately, it is also harmful to be used as a data augmentation method during training. It means that it is hard to integrate such data augmentation into training by malicious trainers and it could be a promising technique to cleanly evaluate visual LLMs. Our code, data, and model weights will be released upon publication.
+
+
+
+ 29. 【2410.07025】Preference Fine-Tuning for Factuality in Chest X-Ray Interpretation Models Without Human Feedback
+ 链接:https://arxiv.org/abs/2410.07025
+ 作者:Dennis Hein,Zhihong Chen,Sophie Ostmeier,Justin Xu,Maya Varma,Eduardo Pontes Reis,Arne Edward Michalson,Christian Bluethgen,Hyun Joo Shin,Curtis Langlotz,Akshay S Chaudhari
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:translating medical images, translating medical, medical images, play a crucial, crucial role
+ 备注:
+
+ 点击查看摘要
+ Abstract:Radiologists play a crucial role by translating medical images into medical reports. However, the field faces staffing shortages and increasing workloads. While automated approaches using vision-language models (VLMs) show promise as assistants, they require exceptionally high accuracy. Most current VLMs in radiology rely solely on supervised fine-tuning (SFT). Meanwhile, in the general domain, additional preference fine-tuning has become standard practice. The challenge in radiology lies in the prohibitive cost of obtaining radiologist feedback. We propose a scalable automated preference alignment technique for VLMs in radiology, focusing on chest X-ray (CXR) report generation. Our method leverages publicly available datasets with an LLM-as-a-Judge mechanism, eliminating the need for additional expert radiologist feedback. We evaluate and benchmark five direct alignment algorithms (DAAs). Our results show up to a 57.4% improvement in average GREEN scores, a LLM-based metric for evaluating CXR reports, and a 9.2% increase in an average across six metrics (domain specific and general), compared to the SFT baseline. We study reward overoptimization via length exploitation, with reports lengthening by up to 3.2x. To assess a potential alignment tax, we benchmark on six additional diverse tasks, finding no significant degradations. A reader study involving four board-certified radiologists indicates win rates of up to 0.62 over the SFT baseline, while significantly penalizing verbosity. Our analysis provides actionable insights for the development of VLMs in high-stakes fields like radiology.
+
+
+
+ 30. 【2410.07009】Pap2Pat: Towards Automated Paper-to-Patent Drafting using Chunk-based Outline-guided Generation
+ 链接:https://arxiv.org/abs/2410.07009
+ 作者:Valentin Knappich,Simon Razniewski,Anna Hätty,Annemarie Friedrich
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:offering practical applications, large language models, natural language processing, providing challenging benchmarks, offering practical
+ 备注:
+
+ 点击查看摘要
+ Abstract:The patent domain is gaining attention in natural language processing research, offering practical applications in streamlining the patenting process and providing challenging benchmarks for large language models (LLMs). However, the generation of the description sections of patents, which constitute more than 90% of the patent document, has not been studied to date. We address this gap by introducing the task of outline-guided paper-to-patent generation, where an academic paper provides the technical specification of the invention and an outline conveys the desired patent structure. We present PAP2PAT, a new challenging benchmark of 1.8k patent-paper pairs with document outlines, collected using heuristics that reflect typical research lab practices. Our experiments with current open-weight LLMs and outline-guided chunk-based generation show that they can effectively use information from the paper but struggle with repetitions, likely due to the inherent repetitiveness of patent language. We release our data and code.
+
+
+
+ 31. 【2410.07002】CursorCore: Assist Programming through Aligning Anything
+ 链接:https://arxiv.org/abs/2410.07002
+ 作者:Hao Jiang,Qi Liu,Rui Li,Shengyu Ye,Shijin Wang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Software Engineering (cs.SE)
+ 关键词:Large language models, Large language, programming assistance tasks, Assist Programming Eval, successfully applied
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models have been successfully applied to programming assistance tasks, such as code completion, code insertion, and instructional code editing. However, these applications remain insufficiently automated and struggle to effectively integrate various types of information during the programming process, including coding history, current code, and user instructions. In this work, we propose a new conversational framework that comprehensively integrates these information sources, collect data to train our models and evaluate their performance. Firstly, to thoroughly evaluate how well models align with different types of information and the quality of their outputs, we introduce a new benchmark, APEval (Assist Programming Eval), to comprehensively assess the performance of models in programming assistance tasks. Then, for data collection, we develop a data generation pipeline, Programming-Instruct, which synthesizes training data from diverse sources, such as GitHub and online judge platforms. This pipeline can automatically generate various types of messages throughout the programming process. Finally, using this pipeline, we generate 219K samples, fine-tune multiple models, and develop the CursorCore series. We show that CursorCore outperforms other models of comparable size. This framework unifies applications such as inline chat and automated editing, contributes to the advancement of coding assistants. Code, models and data are freely available at this https URL.
+
+
+
+ 32. 【2410.06981】Sparse Autoencoders Reveal Universal Feature Spaces Across Large Language Models
+ 链接:https://arxiv.org/abs/2410.06981
+ 作者:Michael Lan,Philip Torr,Austin Meek,Ashkan Khakzar,David Krueger,Fazl Barez
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:similarly represent concepts, large language models, models similarly represent, investigate feature universality, intermediate layers
+ 备注:
+
+ 点击查看摘要
+ Abstract:We investigate feature universality in large language models (LLMs), a research field that aims to understand how different models similarly represent concepts in the latent spaces of their intermediate layers. Demonstrating feature universality allows discoveries about latent representations to generalize across several models. However, comparing features across LLMs is challenging due to polysemanticity, in which individual neurons often correspond to multiple features rather than distinct ones. This makes it difficult to disentangle and match features across different models. To address this issue, we employ a method known as dictionary learning by using sparse autoencoders (SAEs) to transform LLM activations into more interpretable spaces spanned by neurons corresponding to individual features. After matching feature neurons across models via activation correlation, we apply representational space similarity metrics like Singular Value Canonical Correlation Analysis to analyze these SAE features across different LLMs. Our experiments reveal significant similarities in SAE feature spaces across various LLMs, providing new evidence for feature universality.
+
+
+
+ 33. 【2410.06973】Personal Intelligence System UniLM: Hybrid On-Device Small Language Model and Server-Based Large Language Model for Malay Nusantara
+ 链接:https://arxiv.org/abs/2410.06973
+ 作者:Azree Nazri,Olalekan Agbolade,Faisal Aziz
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Personal Intelligence System, prove inadequate, contexts with limited, addressing the specific, high-resource language models
+ 备注: 20 pages, 5 tables, 4 figures
+
+ 点击查看摘要
+ Abstract:In contexts with limited computational and data resources, high-resource language models often prove inadequate, particularly when addressing the specific needs of Malay languages. This paper introduces a Personal Intelligence System designed to efficiently integrate both on-device and server-based models. The system incorporates SLiM-34M for on-device processing, optimized for low memory and power usage, and MANYAK-1.3B for server-based tasks, allowing for scalable, high-performance language processing. The models achieve significant results across various tasks, such as machine translation, question-answering, and translate IndoMMLU. Particularly noteworthy is SLiM-34M's ability to achieve a high improvement in accuracy compared to other LLMs while using 2 times fewer pre-training tokens. This work challenges the prevailing assumption that large-scale computational resources are necessary to build effective language models, contributing to the development of resource-efficient models for the Malay language with the unique orchestration between SLiM-34M and MANYAK-1.3B.
+
+
+
+ 34. 【2410.06965】Uncovering Factor Level Preferences to Improve Human-Model Alignment
+ 链接:https://arxiv.org/abs/2410.06965
+ 作者:Juhyun Oh,Eunsu Kim,Jiseon Kim,Wenda Xu,Inha Cha,William Yang Wang,Alice Oh
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Model, Large Language, advancements in Large, Language Model, preferences remains crucial
+ 备注:
+
+ 点击查看摘要
+ Abstract:Despite advancements in Large Language Model (LLM) alignment, understanding the reasons behind LLM preferences remains crucial for bridging the gap between desired and actual behavior. LLMs often exhibit biases or tendencies that diverge from human preferences, such as favoring certain writing styles or producing overly verbose outputs. However, current methods for evaluating preference alignment often lack explainability, relying on coarse-grained comparisons. To address this, we introduce PROFILE (PRObing Factors of InfLuence for Explainability), a novel framework that uncovers and quantifies the influence of specific factors driving preferences. PROFILE's factor level analysis explains the 'why' behind human-model alignment and misalignment, offering insights into the direction of model improvement. We apply PROFILE to analyze human and LLM preferences across three tasks: summarization, helpful response generation, and document-based question-answering. Our factor level analysis reveals a substantial discrepancy between human and LLM preferences in generation tasks, whereas LLMs show strong alignment with human preferences in evaluation tasks. We demonstrate how leveraging factor level insights, including addressing misaligned factors or exploiting the generation-evaluation gap, can improve alignment with human preferences. This work underscores the importance of explainable preference analysis and highlights PROFILE's potential to provide valuable training signals, driving further improvements in human-model alignment.
+
+
+
+ 35. 【2410.06961】Self-Boosting Large Language Models with Synthetic Preference Data
+ 链接:https://arxiv.org/abs/2410.06961
+ 作者:Qingxiu Dong,Li Dong,Xingxing Zhang,Zhifang Sui,Furu Wei
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, Large Language, Language Models, generating honest, advanced significantly
+ 备注:
+
+ 点击查看摘要
+ Abstract:Through alignment with human preferences, Large Language Models (LLMs) have advanced significantly in generating honest, harmless, and helpful responses. However, collecting high-quality preference data is a resource-intensive and creativity-demanding process, especially for the continual improvement of LLMs. We introduce SynPO, a self-boosting paradigm that leverages synthetic preference data for model alignment. SynPO employs an iterative mechanism wherein a self-prompt generator creates diverse prompts, and a response improver refines model responses progressively. This approach trains LLMs to autonomously learn the generative rewards for their own outputs and eliminates the need for large-scale annotation of prompts and human preferences. After four SynPO iterations, Llama3-8B and Mistral-7B show significant enhancements in instruction-following abilities, achieving over 22.1% win rate improvements on AlpacaEval 2.0 and ArenaHard. Simultaneously, SynPO improves the general performance of LLMs on various tasks, validated by a 3.2 to 5.0 average score increase on the well-recognized Open LLM leaderboard.
+
+
+
+ 36. 【2410.06949】Seeker: Enhancing Exception Handling in Code with LLM-based Multi-Agent Approach
+ 链接:https://arxiv.org/abs/2410.06949
+ 作者:Xuanming Zhang,Yuxuan Chen,Yuan Yuan,Minlie Huang
+ 类目:oftware Engineering (cs.SE); Computation and Language (cs.CL)
+ 关键词:exception handling, improper or missing, missing exception handling, handling, world software development
+ 备注: 26 pages, 7 figures. Submitted ICLR 2025
+
+ 点击查看摘要
+ Abstract:In real world software development, improper or missing exception handling can severely impact the robustness and reliability of code. Exception handling mechanisms require developers to detect, capture, and manage exceptions according to high standards, but many developers struggle with these tasks, leading to fragile code. This problem is particularly evident in open source projects and impacts the overall quality of the software ecosystem. To address this challenge, we explore the use of large language models (LLMs) to improve exception handling in code. Through extensive analysis, we identify three key issues: Insensitive Detection of Fragile Code, Inaccurate Capture of Exception Types, and Distorted Handling Solutions. These problems are widespread across real world repositories, suggesting that robust exception handling practices are often overlooked or mishandled. In response, we propose Seeker, a multi agent framework inspired by expert developer strategies for exception handling. Seeker uses agents: Scanner, Detector, Predator, Ranker, and Handler to assist LLMs in detecting, capturing, and resolving exceptions more effectively. Our work is the first systematic study on leveraging LLMs to enhance exception handling practices, providing valuable insights for future improvements in code reliability.
+
+
+
+ 37. 【2410.06944】CSSL: Contrastive Self-Supervised Learning for Dependency Parsing on Relatively Free Word Ordered and Morphologically Rich Low Resource Languages
+ 链接:https://arxiv.org/abs/2410.06944
+ 作者:Pretam Ray,Jivnesh Sandhan,Amrith Krishna,Pawan Goyal
+ 类目:Computation and Language (cs.CL)
+ 关键词:free word order, Neural dependency parsing, morphologically rich languages, word order, low resource morphologically
+ 备注: Accepted at EMNLP 2024 Main (Short), 9 pages, 3 figures, 4 Tables
+
+ 点击查看摘要
+ Abstract:Neural dependency parsing has achieved remarkable performance for low resource morphologically rich languages. It has also been well-studied that morphologically rich languages exhibit relatively free word order. This prompts a fundamental investigation: Is there a way to enhance dependency parsing performance, making the model robust to word order variations utilizing the relatively free word order nature of morphologically rich languages? In this work, we examine the robustness of graph-based parsing architectures on 7 relatively free word order languages. We focus on scrutinizing essential modifications such as data augmentation and the removal of position encoding required to adapt these architectures accordingly. To this end, we propose a contrastive self-supervised learning method to make the model robust to word order variations. Furthermore, our proposed modification demonstrates a substantial average gain of 3.03/2.95 points in 7 relatively free word order languages, as measured by the UAS/LAS Score metric when compared to the best performing baseline.
+
+
+
+ 38. 【2410.06916】SWIFT: On-the-Fly Self-Speculative Decoding for LLM Inference Acceleration
+ 链接:https://arxiv.org/abs/2410.06916
+ 作者:Heming Xia,Yongqi Li,Jun Zhang,Cunxiao Du,Wenjie Li
+ 类目:Computation and Language (cs.CL)
+ 关键词:compromising generation quality, large language models, Speculative decoding, generation quality, widely used paradigm
+ 备注:
+
+ 点击查看摘要
+ Abstract:Speculative decoding (SD) has emerged as a widely used paradigm to accelerate the inference of large language models (LLMs) without compromising generation quality. It works by first employing a compact model to draft multiple tokens efficiently and then using the target LLM to verify them in parallel. While this technique has achieved notable speedups, most existing approaches necessitate either additional parameters or extensive training to construct effective draft models, thereby restricting their applicability across different LLMs and tasks. To address this limitation, we explore a novel plug-and-play SD solution with layer-skipping, which skips intermediate layers of the target LLM as the compact draft model. Our analysis reveals that LLMs exhibit great potential for self-acceleration through layer sparsity and the task-specific nature of this sparsity. Building on these insights, we introduce SWIFT, an on-the-fly self-speculative decoding algorithm that adaptively selects intermediate layers of LLMs to skip during inference. SWIFT does not require auxiliary models or additional training, making it a plug-and-play solution for accelerating LLM inference across diverse input data streams. Our extensive experiments across a wide range of models and downstream tasks demonstrate that SWIFT can achieve over a 1.3x-1.6x speedup while preserving the original distribution of the generated text.
+
+
+
+ 39. 【2410.06913】Utilize the Flow before Stepping into the Same River Twice: Certainty Represented Knowledge Flow for Refusal-Aware Instruction Tuning
+ 链接:https://arxiv.org/abs/2410.06913
+ 作者:Runchuan Zhu,Zhipeng Ma,Jiang Wu,Junyuan Gao,Jiaqi Wang,Dahua Lin,Conghui He
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, enables Large Language, Language Models, Large Language, Refusal-Aware Instruction Tuning
+ 备注: Equal contribution: Runchuan Zhu, Zhipeng Ma, Jiang Wu; Corresponding author: Conghui He
+
+ 点击查看摘要
+ Abstract:Refusal-Aware Instruction Tuning (RAIT) enables Large Language Models (LLMs) to refuse to answer unknown questions. By modifying responses of unknown questions in the training data to refusal responses such as "I don't know", RAIT enhances the reliability of LLMs and reduces their hallucination. Generally, RAIT modifies training samples based on the correctness of the initial LLM's response. However, this crude approach can cause LLMs to excessively refuse answering questions they could have correctly answered, the problem we call over-refusal. In this paper, we explore two primary causes of over-refusal: Static conflict emerges when the RAIT data is constructed solely on correctness criteria, causing similar samples in the LLM's feature space to be assigned different labels (original vs. modified "I don't know"). Dynamic conflict occurs due to the changes of LLM's knowledge state during fine-tuning, which transforms previous unknown questions into knowns, while the training data, which is constructed based on the initial LLM, remains unchanged. These conflicts cause the trained LLM to misclassify known questions as unknown, resulting in over-refusal. To address this issue, we introduce Certainty Represented Knowledge Flow for Refusal-Aware Instructions Construction (CRaFT). CRaFT centers on two main contributions: First, we additionally incorporate response certainty to selectively filter and modify data, reducing static conflicts. Second, we implement preliminary rehearsal training to characterize changes in the LLM's knowledge state, which helps mitigate dynamic conflicts during the fine-tuning process. We conducted extensive experiments on open-ended question answering and multiple-choice question task. Experiment results show that CRaFT can improve LLM's overall performance during the RAIT process. Source code and training data will be released at Github.
+
+
+
+ 40. 【2410.06898】Generative Model for Less-Resourced Language with 1 billion parameters
+ 链接:https://arxiv.org/abs/2410.06898
+ 作者:Domen Vreš,Martin Božič,Aljaž Potočnik,Tomaž Martinčič,Marko Robnik-Šikonja
+ 类目:Computation and Language (cs.CL)
+ 关键词:English OPT model, natural language processing, modern natural language, English OPT, English
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) are a basic infrastructure for modern natural language processing. Many commercial and open-source LLMs exist for English, e.g., ChatGPT, Llama, Falcon, and Mistral. As these models are trained on mostly English texts, their fluency and knowledge of low-resource languages and societies are superficial. We present the development of large generative language models for a less-resourced language. GaMS 1B - Generative Model for Slovene with 1 billion parameters was created by continuing pretraining of the existing English OPT model. We developed a new tokenizer adapted to Slovene, Croatian, and English languages and used embedding initialization methods FOCUS and WECHSEL to transfer the embeddings from the English OPT model. We evaluate our models on several classification datasets from the Slovene suite of benchmarks and generative sentence simplification task SENTA. We only used a few-shot in-context learning of our models, which are not yet instruction-tuned. For classification tasks, in this mode, the generative models lag behind the existing Slovene BERT-type models fine-tuned for specific tasks. On a sentence simplification task, the GaMS models achieve comparable or better performance than the GPT-3.5-Turbo model.
+
+
+
+ 41. 【2410.06886】FltLM: An Intergrated Long-Context Large Language Model for Effective Context Filtering and Understanding
+ 链接:https://arxiv.org/abs/2410.06886
+ 作者:Jingyang Deng,Zhengyang Shen,Boyang Wang,Lixin Su,Suqi Cheng,Ying Nie,Junfeng Wang,Dawei Yin,Jinwen Ma
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Long-Context Large Language, markedly advanced natural, Filtering Language Model, Large Language
+ 备注: Accepted by the 27th European Conference on Artificial Intelligence (ECAI-2024), this is the full version of the paper including technical appendices. This final version features enhanced formatting and corrections to errors present in other online versions. We regret any inconvenience this may have caused our readers
+
+ 点击查看摘要
+ Abstract:The development of Long-Context Large Language Models (LLMs) has markedly advanced natural language processing by facilitating the process of textual data across long documents and multiple corpora. However, Long-Context LLMs still face two critical challenges: The lost in the middle phenomenon, where crucial middle-context information is likely to be missed, and the distraction issue that the models lose focus due to overly extended contexts. To address these challenges, we propose the Context Filtering Language Model (FltLM), a novel integrated Long-Context LLM which enhances the ability of the model on multi-document question-answering (QA) tasks. Specifically, FltLM innovatively incorporates a context filter with a soft mask mechanism, identifying and dynamically excluding irrelevant content to concentrate on pertinent information for better comprehension and reasoning. Our approach not only mitigates these two challenges, but also enables the model to operate conveniently in a single forward pass. Experimental results demonstrate that FltLM significantly outperforms supervised fine-tuning and retrieval-based methods in complex QA scenarios, suggesting a promising solution for more accurate and reliable long-context natural language understanding applications.
+
+
+
+ 42. 【2410.06846】Joint Fine-tuning and Conversion of Pretrained Speech and Language Models towards Linear Complexity
+ 链接:https://arxiv.org/abs/2410.06846
+ 作者:Mutian He,Philip N. Garner
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:Linformer and Mamba, Mamba have recently, linear time replacements, competitive linear time, recently emerged
+ 备注: 15 pages, 4 figures
+
+ 点击查看摘要
+ Abstract:Architectures such as Linformer and Mamba have recently emerged as competitive linear time replacements for transformers. However, corresponding large pretrained models are often unavailable, especially in non-text domains. To remedy this, we present a Cross-Architecture Layerwise Distillation (CALD) approach that jointly converts a transformer model to a linear time substitute and fine-tunes it to a target task. We also compare several means to guide the fine-tuning to optimally retain the desired inference capability from the original model. The methods differ in their use of the target model and the trajectory of the parameters. In a series of empirical studies on language processing, language modeling, and speech processing, we show that CALD can effectively recover the result of the original model, and that the guiding strategy contributes to the result. Some reasons for the variation are suggested.
+
+
+
+ 43. 【2410.06845】MentalArena: Self-play Training of Language Models for Diagnosis and Treatment of Mental Health Disorders
+ 链接:https://arxiv.org/abs/2410.06845
+ 作者:Cheng Li,May Fung,Qingyun Wang,Chi Han,Manling Li,Jindong Wang,Heng Ji
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Multiagent Systems (cs.MA)
+ 关键词:Mental health disorders, Mental health, health disorders, Mental, health
+ 备注: Technical Report; 27 pages
+
+ 点击查看摘要
+ Abstract:Mental health disorders are one of the most serious diseases in the world. Most people with such a disease lack access to adequate care, which highlights the importance of training models for the diagnosis and treatment of mental health disorders. However, in the mental health domain, privacy concerns limit the accessibility of personalized treatment data, making it challenging to build powerful models. In this paper, we introduce MentalArena, a self-play framework to train language models by generating domain-specific personalized data, where we obtain a better model capable of making a personalized diagnosis and treatment (as a therapist) and providing information (as a patient). To accurately model human-like mental health patients, we devise Symptom Encoder, which simulates a real patient from both cognition and behavior perspectives. To address intent bias during patient-therapist interactions, we propose Symptom Decoder to compare diagnosed symptoms with encoded symptoms, and dynamically manage the dialogue between patient and therapist according to the identified deviations. We evaluated MentalArena against 6 benchmarks, including biomedicalQA and mental health tasks, compared to 6 advanced models. Our models, fine-tuned on both GPT-3.5 and Llama-3-8b, significantly outperform their counterparts, including GPT-4o. We hope that our work can inspire future research on personalized care. Code is available in this https URL
+
+
+
+ 44. 【2410.06809】Root Defence Strategies: Ensuring Safety of LLM at the Decoding Level
+ 链接:https://arxiv.org/abs/2410.06809
+ 作者:Xinyi Zeng,Yuying Shang,Yutao Zhu,Jiawei Chen,Yu Tian
+ 类目:Computation and Language (cs.CL); Cryptography and Security (cs.CR)
+ 关键词:Large language models, demonstrated immense utility, Large language, demonstrated immense, immense utility
+ 备注: 19 pages, 9 figures
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) have demonstrated immense utility across various industries. However, as LLMs advance, the risk of harmful outputs increases due to incorrect or malicious instruction prompts. While current methods effectively address jailbreak risks, they share common limitations: 1) Judging harmful responses from the prefill-level lacks utilization of the model's decoding outputs, leading to relatively lower effectiveness and robustness. 2) Rejecting potentially harmful responses based on a single evaluation can significantly impair the model's this http URL paper examines the LLMs' capability to recognize harmful outputs, revealing and quantifying their proficiency in assessing the danger of previous tokens. Motivated by pilot experiment results, we design a robust defense mechanism at the decoding level. Our novel decoder-oriented, step-by-step defense architecture corrects harmful queries directly rather than rejecting them outright. We introduce speculative decoding to enhance usability and facilitate deployment to boost secure decoding speed. Extensive experiments demonstrate that our approach improves model security without compromising reasoning speed. Notably, our method leverages the model's ability to discern hazardous information, maintaining its helpfulness compared to existing methods.
+
+
+
+ 45. 【2410.06802】Seg2Act: Global Context-aware Action Generation for Document Logical Structuring
+ 链接:https://arxiv.org/abs/2410.06802
+ 作者:Zichao Li,Shaojie He,Meng Liao,Xuanang Chen,Yaojie Lu,Hongyu Lin,Yanxiong Lu,Xianpei Han,Le Sun
+ 类目:Computation and Language (cs.CL)
+ 关键词:underlying hierarchical structure, Document logical structuring, logical structuring aims, aims to extract, extract the underlying
+ 备注: Accepted by EMNLP 2024 Main Conference
+
+ 点击查看摘要
+ Abstract:Document logical structuring aims to extract the underlying hierarchical structure of documents, which is crucial for document intelligence. Traditional approaches often fall short in handling the complexity and the variability of lengthy documents. To address these issues, we introduce Seg2Act, an end-to-end, generation-based method for document logical structuring, revisiting logical structure extraction as an action generation task. Specifically, given the text segments of a document, Seg2Act iteratively generates the action sequence via a global context-aware generative model, and simultaneously updates its global context and current logical structure based on the generated actions. Experiments on ChCatExt and HierDoc datasets demonstrate the superior performance of Seg2Act in both supervised and transfer learning settings.
+
+
+
+ 46. 【2410.06795】From Pixels to Tokens: Revisiting Object Hallucinations in Large Vision-Language Models
+ 链接:https://arxiv.org/abs/2410.06795
+ 作者:Yuying Shang,Xinyi Zeng,Yutao Zhu,Xiao Yang,Zhengwei Fang,Jingyuan Zhang,Jiawei Chen,Zinan Liu,Yu Tian
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:large vision-language models, visual input, significant challenge, impairs their reliability, large vision-language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Hallucinations in large vision-language models (LVLMs) are a significant challenge, i.e., generating objects that are not presented in the visual input, which impairs their reliability. Recent studies often attribute hallucinations to a lack of understanding of visual input, yet ignore a more fundamental issue: the model's inability to effectively extract or decouple visual features. In this paper, we revisit the hallucinations in LVLMs from an architectural perspective, investigating whether the primary cause lies in the visual encoder (feature extraction) or the modal alignment module (feature decoupling). Motivated by our findings on the preliminary investigation, we propose a novel tuning strategy, PATCH, to mitigate hallucinations in LVLMs. This plug-and-play method can be integrated into various LVLMs, utilizing adaptive virtual tokens to extract object features from bounding boxes, thereby addressing hallucinations caused by insufficient decoupling of visual features. PATCH achieves state-of-the-art performance on multiple multi-modal hallucination datasets. We hope this approach provides researchers with deeper insights into the underlying causes of hallucinations in LVLMs, fostering further advancements and innovation in this field.
+
+
+
+ 47. 【2410.06765】o Preserve or To Compress: An In-Depth Study of Connector Selection in Multimodal Large Language Models
+ 链接:https://arxiv.org/abs/2410.06765
+ 作者:Junyan Lin,Haoran Chen,Dawei Zhu,Xiaoyu Shen
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:multimodal large language, large language models, garnered significant attention, recent years, multimodal large
+ 备注: Accepted to EMNLP 2024 Main Conference
+
+ 点击查看摘要
+ Abstract:In recent years, multimodal large language models (MLLMs) have garnered significant attention from both industry and academia. However, there is still considerable debate on constructing MLLM architectures, particularly regarding the selection of appropriate connectors for perception tasks of varying granularities. This paper systematically investigates the impact of connectors on MLLM performance. Specifically, we classify connectors into feature-preserving and feature-compressing types. Utilizing a unified classification standard, we categorize sub-tasks from three comprehensive benchmarks, MMBench, MME, and SEED-Bench, into three task types: coarse-grained perception, fine-grained perception, and reasoning, and evaluate the performance. Our findings reveal that feature-preserving connectors excel in \emph{fine-grained perception} tasks due to their ability to retain detailed visual information. In contrast, feature-compressing connectors, while less effective in fine-grained perception tasks, offer significant speed advantages and perform comparably in \emph{coarse-grained perception} and \emph{reasoning} tasks. These insights are crucial for guiding MLLM architecture design and advancing the optimization of MLLM architectures.
+
+
+
+ 48. 【2410.06741】CoBa: Convergence Balancer for Multitask Finetuning of Large Language Models
+ 链接:https://arxiv.org/abs/2410.06741
+ 作者:Zi Gong,Hang Yu,Cong Liao,Bingchang Liu,Chaoyu Chen,Jianguo Li
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:large language models, developing separate models, Multi-task learning, Absolute Convergence Scores, language models
+ 备注: 15 pages, main conference of EMNLP 2024
+
+ 点击查看摘要
+ Abstract:Multi-task learning (MTL) benefits the fine-tuning of large language models (LLMs) by providing a single model with improved performance and generalization ability across tasks, presenting a resource-efficient alternative to developing separate models for each task. Yet, existing MTL strategies for LLMs often fall short by either being computationally intensive or failing to ensure simultaneous task convergence. This paper presents CoBa, a new MTL approach designed to effectively manage task convergence balance with minimal computational overhead. Utilizing Relative Convergence Scores (RCS), Absolute Convergence Scores (ACS), and a Divergence Factor (DF), CoBa dynamically adjusts task weights during the training process, ensuring that the validation loss of all tasks progress towards convergence at an even pace while mitigating the issue of individual task divergence. The results of our experiments involving three disparate datasets underscore that this approach not only fosters equilibrium in task improvement but enhances the LLMs' performance by up to 13% relative to the second-best baselines. Code is open-sourced at this https URL.
+
+
+
+ 49. 【2410.06735】Which Programming Language and What Features at Pre-training Stage Affect Downstream Logical Inference Performance?
+ 链接:https://arxiv.org/abs/2410.06735
+ 作者:Fumiya Uchiyama,Takeshi Kojima,Andrew Gambardella,Qi Cao,Yusuke Iwasawa,Yutaka Matsuo
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Recent large language, demonstrated remarkable generalization, Recent large, remarkable generalization abilities, programming languages
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent large language models (LLMs) have demonstrated remarkable generalization abilities in mathematics and logical reasoning tasks. Prior research indicates that LLMs pre-trained with programming language data exhibit high mathematical and reasoning abilities; however, this causal relationship has not been rigorously tested. Our research aims to verify which programming languages and features during pre-training affect logical inference performance. Specifically, we pre-trained decoder-based language models from scratch using datasets from ten programming languages (e.g., Python, C, Java) and three natural language datasets (Wikipedia, Fineweb, C4) under identical conditions. Thereafter, we evaluated the trained models in a few-shot in-context learning setting on logical reasoning tasks: FLD and bAbi, which do not require commonsense or world knowledge. The results demonstrate that nearly all models trained with programming languages consistently outperform those trained with natural languages, indicating that programming languages contain factors that elicit logic inference performance. In addition, we found that models trained with programming languages exhibit a better ability to follow instructions compared to those trained with natural languages. Further analysis reveals that the depth of Abstract Syntax Trees representing parsed results of programs also affects logical reasoning performance. These findings will offer insights into the essential elements of pre-training for acquiring the foundational abilities of LLMs.
+
+
+
+ 50. 【2410.06733】Weak-eval-Strong: Evaluating and Eliciting Lateral Thinking of LLMs with Situation Puzzles
+ 链接:https://arxiv.org/abs/2410.06733
+ 作者:Qi Chen,Bowen Zhang,Gang Wang,Qi Wu
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Large Language Models, Large Language, tasks requiring vertical, capabilities remain under-explored, assessing creative thought
+ 备注: Accepted by NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:While advancements in NLP have significantly improved the performance of Large Language Models (LLMs) on tasks requiring vertical thinking, their lateral thinking capabilities remain under-explored and challenging to measure due to the complexity of assessing creative thought processes and the scarcity of relevant data. To address these challenges, we introduce SPLAT, a benchmark leveraging Situation Puzzles to evaluate and elicit LAteral Thinking of LLMs. This benchmark, containing 975 graded situation puzzles across three difficulty levels, employs a new multi-turn player-judge framework instead of the traditional model-based evaluation, which often necessitates a stronger evaluation model. This framework simulates an interactive game where the model (player) asks the evaluation model (judge) questions about an incomplete story to infer the full scenario. The judge answers based on a detailed reference scenario or evaluates if the player's predictions align with the reference one. This approach lessens dependence on more robust evaluation models, enabling the assessment of state-of-the-art LLMs. The experiments demonstrate that a robust evaluation model, such as WizardLM-2, closely matches human judgements in both intermediate question-answering and final scenario accuracy, achieving over 80% agreement-similar to the agreement levels among humans. Furthermore, applying data and reasoning processes from our benchmark to other lateral thinking-related benchmarks, e.g., RiddleSense and BrainTeaser, leads to performance enhancements. This suggests that our benchmark effectively evaluates and elicits the lateral thinking abilities of LLMs. Code is available at: this https URL.
+
+
+
+ 51. 【2410.06722】Scaling Laws for Mixed quantization in Large Language Models
+ 链接:https://arxiv.org/abs/2410.06722
+ 作者:Zeyu Cao,Cheng Zhang,Pedro Gimenes,Jianqiao Lu,Jianyi Cheng,Yiren Zhao
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Large Language Models, Large Language, Post-training quantization, Language Models, proven effective
+ 备注:
+
+ 点击查看摘要
+ Abstract:Post-training quantization of Large Language Models (LLMs) has proven effective in reducing the computational requirements for running inference on these models. In this study, we focus on a straightforward question: When aiming for a specific accuracy or perplexity target for low-precision quantization, how many high-precision numbers or calculations are required to preserve as we scale LLMs to larger sizes? We first introduce a critical metric named the quantization ratio, which compares the number of parameters quantized to low-precision arithmetic against the total parameter count. Through extensive and carefully controlled experiments across different model families, arithmetic types, and quantization granularities (e.g. layer-wise, matmul-wise), we identify two central phenomenons. 1) The larger the models, the better they can preserve performance with an increased quantization ratio, as measured by perplexity in pre-training tasks or accuracy in downstream tasks. 2) The finer the granularity of mixed-precision quantization (e.g., matmul-wise), the more the model can increase the quantization ratio. We believe these observed phenomena offer valuable insights for future AI hardware design and the development of advanced Efficient AI algorithms.
+
+
+
+ 52. 【2410.06718】MatMamba: A Matryoshka State Space Model
+ 链接:https://arxiv.org/abs/2410.06718
+ 作者:Abhinav Shukla,Sai Vemprala,Aditya Kusupati,Ashish Kapoor
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:long context lengths, Matryoshka Representation Learning, faster theoretical training, State Space, State Space Models
+ 备注: 10 pages, 7 figures
+
+ 点击查看摘要
+ Abstract:State Space Models (SSMs) like Mamba2 are a promising alternative to Transformers, with faster theoretical training and inference times -- especially for long context lengths. Recent work on Matryoshka Representation Learning -- and its application to Transformer backbones in works like MatFormer -- showed how to introduce nested granularities of smaller submodels in one universal elastic model. In this work, we present MatMamba: a state space model which combines Matryoshka-style learning with Mamba2, by modifying the block to contain nested dimensions to enable joint training and adaptive inference. MatMamba allows for efficient and adaptive deployment across various model sizes. We train a single large MatMamba model and are able to get a number of smaller nested models for free -- while maintaining or improving upon the performance of a baseline smaller model trained from scratch. We train language and image models at a variety of parameter sizes from 35M to 1.4B. Our results on ImageNet and FineWeb show that MatMamba models scale comparably to Transformers, while having more efficient inference characteristics. This makes MatMamba a practically viable option for deploying large-scale models in an elastic way based on the available inference compute. Code and models are open sourced at \url{this https URL}
+
+
+
+ 53. 【2410.06716】Guaranteed Generation from Large Language Models
+ 链接:https://arxiv.org/abs/2410.06716
+ 作者:Minbeom Kim,Thibaut Thonet,Jos Rozen,Hwaran Lee,Kyomin Jung,Marc Dymetman
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language models, large language, satisfy specific constraints, control text generation, original model
+ 备注: 22 pages, 11 figures
+
+ 点击查看摘要
+ Abstract:As large language models (LLMs) are increasingly used across various applications, there is a growing need to control text generation to satisfy specific constraints or requirements. This raises a crucial question: Is it possible to guarantee strict constraint satisfaction in generated outputs while preserving the distribution of the original model as much as possible? We first define the ideal distribution - the one closest to the original model, which also always satisfies the expressed constraint - as the ultimate goal of guaranteed generation. We then state a fundamental limitation, namely that it is impossible to reach that goal through autoregressive training alone. This motivates the necessity of combining training-time and inference-time methods to enforce such guarantees. Based on this insight, we propose GUARD, a simple yet effective approach that combines an autoregressive proposal distribution with rejection sampling. Through GUARD's theoretical properties, we show how controlling the KL divergence between a specific proposal and the target ideal distribution simultaneously optimizes inference speed and distributional closeness. To validate these theoretical concepts, we conduct extensive experiments on two text generation settings with hard-to-satisfy constraints: a lexical constraint scenario and a sentiment reversal scenario. These experiments show that GUARD achieves perfect constraint satisfaction while almost preserving the ideal distribution with highly improved inference efficiency. GUARD provides a principled approach to enforcing strict guarantees for LLMs without compromising their generative capabilities.
+
+
+
+ 54. 【2410.06707】Calibrating Verbalized Probabilities for Large Language Models
+ 链接:https://arxiv.org/abs/2410.06707
+ 作者:Cheng Wang,Gyuri Szarvas,Georges Balazs,Pavel Danchenko,Patrick Ernst
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, black-box Large Language, Language Models, Large Language, Calibrating verbalized probabilities
+ 备注: 21 pages
+
+ 点击查看摘要
+ Abstract:Calibrating verbalized probabilities presents a novel approach for reliably assessing and leveraging outputs from black-box Large Language Models (LLMs). Recent methods have demonstrated improved calibration by applying techniques like Platt scaling or temperature scaling to the confidence scores generated by LLMs. In this paper, we explore the calibration of verbalized probability distributions for discriminative tasks. First, we investigate the capability of LLMs to generate probability distributions over categorical labels. We theoretically and empirically identify the issue of re-softmax arising from the scaling of verbalized probabilities, and propose using the invert softmax trick to approximate the "logit" by inverting verbalized probabilities. Through extensive evaluation on three public datasets, we demonstrate: (1) the robust capability of LLMs in generating class distributions, and (2) the effectiveness of the invert softmax trick in estimating logits, which, in turn, facilitates post-calibration adjustments.
+
+
+
+ 55. 【2410.06704】PII-Scope: A Benchmark for Training Data PII Leakage Assessment in LLMs
+ 链接:https://arxiv.org/abs/2410.06704
+ 作者:Krishna Kanth Nakka,Ahmed Frikha,Ricardo Mendes,Xue Jiang,Xuebing Zhou
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:PII extraction, comprehensive benchmark designed, PII extraction attacks, PII, introduce PII-Scope
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this work, we introduce PII-Scope, a comprehensive benchmark designed to evaluate state-of-the-art methodologies for PII extraction attacks targeting LLMs across diverse threat settings. Our study provides a deeper understanding of these attacks by uncovering several hyperparameters (e.g., demonstration selection) crucial to their effectiveness. Building on this understanding, we extend our study to more realistic attack scenarios, exploring PII attacks that employ advanced adversarial strategies, including repeated and diverse querying, and leveraging iterative learning for continual PII extraction. Through extensive experimentation, our results reveal a notable underestimation of PII leakage in existing single-query attacks. In fact, we show that with sophisticated adversarial capabilities and a limited query budget, PII extraction rates can increase by up to fivefold when targeting the pretrained model. Moreover, we evaluate PII leakage on finetuned models, showing that they are more vulnerable to leakage than pretrained models. Overall, our work establishes a rigorous empirical benchmark for PII extraction attacks in realistic threat scenarios and provides a strong foundation for developing effective mitigation strategies.
+
+
+
+ 56. 【2410.06682】Enhancing Multimodal LLM for Detailed and Accurate Video Captioning using Multi-Round Preference Optimization
+ 链接:https://arxiv.org/abs/2410.06682
+ 作者:Changli Tang,Yixuan Li,Yudong Yang,Jimin Zhuang,Guangzhi Sun,Wei Li,Zujun Ma,Chao Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL); Image and Video Processing (eess.IV)
+ 关键词:wealth of information, generating detailed, detailed and accurate, key aspect, natural language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Videos contain a wealth of information, and generating detailed and accurate descriptions in natural language is a key aspect of video understanding. In this paper, we present video-SALMONN 2, an advanced audio-visual large language model (LLM) with low-rank adaptation (LoRA) designed for enhanced video (with paired audio) captioning through directed preference optimization (DPO). We propose new metrics to evaluate the completeness and accuracy of video descriptions, which are optimized using DPO. To further improve training, we introduce a novel multi-round DPO (mrDPO) approach, which involves periodically updating the DPO reference model, merging and re-initializing the LoRA module as a proxy for parameter updates after each training round (1,000 steps), and incorporating guidance from ground-truth video captions to stabilize the process. To address potential catastrophic forgetting of non-captioning abilities due to mrDPO, we propose rebirth tuning, which finetunes the pre-DPO LLM by using the captions generated by the mrDPO-trained model as supervised labels. Experiments show that mrDPO significantly enhances video-SALMONN 2's captioning accuracy, reducing global and local error rates by 40\% and 20\%, respectively, while decreasing the repetition rate by 35\%. The final video-SALMONN 2 model, with just 7 billion parameters, surpasses leading models such as GPT-4o and Gemini-1.5-Pro in video captioning tasks, while maintaining competitive performance to the state-of-the-art on widely used video question-answering benchmark among models of similar size. Upon acceptance, we will release the code, model checkpoints, and training and test data. Demos are available at \href{this https URL}{this https URL}.
+
+
+
+ 57. 【2410.06672】owards Universality: Studying Mechanistic Similarity Across Language Model Architectures
+ 链接:https://arxiv.org/abs/2410.06672
+ 作者:Junxuan Wang,Xuyang Ge,Wentao Shu,Qiong Tang,Yunhua Zhou,Zhengfu He,Xipeng Qiu
+ 类目:Computation and Language (cs.CL)
+ 关键词:implement similar algorithms, interpretability suggests, neural networks, networks may converge, converge to implement
+ 备注: 22 pages, 13 figures
+
+ 点击查看摘要
+ Abstract:The hypothesis of Universality in interpretability suggests that different neural networks may converge to implement similar algorithms on similar tasks. In this work, we investigate two mainstream architectures for language modeling, namely Transformers and Mambas, to explore the extent of their mechanistic similarity. We propose to use Sparse Autoencoders (SAEs) to isolate interpretable features from these models and show that most features are similar in these two models. We also validate the correlation between feature similarity and Universality. We then delve into the circuit-level analysis of Mamba models and find that the induction circuits in Mamba are structurally analogous to those in Transformers. We also identify a nuanced difference we call \emph{Off-by-One motif}: The information of one token is written into the SSM state in its next position. Whilst interaction between tokens in Transformers does not exhibit such trend.
+
+
+
+ 58. 【2410.06667】Large Language Models as Code Executors: An Exploratory Study
+ 链接:https://arxiv.org/abs/2410.06667
+ 作者:Chenyang Lyu,Lecheng Yan,Rui Xing,Wenxi Li,Younes Samih,Tianbo Ji,Longyue Wang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, natural language processing, Large Language, natural language, language processing
+ 备注:
+
+ 点击查看摘要
+ Abstract:The capabilities of Large Language Models (LLMs) have significantly evolved, extending from natural language processing to complex tasks like code understanding and generation. We expand the scope of LLMs' capabilities to a broader context, using LLMs to execute code snippets to obtain the output. This paper pioneers the exploration of LLMs as code executors, where code snippets are directly fed to the models for execution, and outputs are returned. We are the first to comprehensively examine this feasibility across various LLMs, including OpenAI's o1, GPT-4o, GPT-3.5, DeepSeek, and Qwen-Coder. Notably, the o1 model achieved over 90% accuracy in code execution, while others demonstrated lower accuracy levels. Furthermore, we introduce an Iterative Instruction Prompting (IIP) technique that processes code snippets line by line, enhancing the accuracy of weaker models by an average of 7.22% (with the highest improvement of 18.96%) and an absolute average improvement of 3.86% against CoT prompting (with the highest improvement of 19.46%). Our study not only highlights the transformative potential of LLMs in coding but also lays the groundwork for future advancements in automated programming and the completion of complex tasks.
+
+
+
+ 59. 【2410.06638】Subtle Errors Matter: Preference Learning via Error-injected Self-editing
+ 链接:https://arxiv.org/abs/2410.06638
+ 作者:Kaishuai Xu,Tiezheng Yu,Wenjun Hou,Yi Cheng,Chak Tou Leong,Liangyou Li,Xin Jiang,Lifeng Shang,Qun Liu,Wenjie Li
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, Large Language, tackling tasks ranging, advanced competition-level problems, exhibited strong mathematical
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have exhibited strong mathematical reasoning and computational prowess, tackling tasks ranging from basic arithmetic to advanced competition-level problems. However, frequently occurring subtle errors, such as miscalculations or incorrect substitutions, limit the models' full mathematical potential. Existing studies to improve mathematical ability typically involve distilling reasoning skills from stronger LLMs or applying preference learning to step-wise response pairs. Although these methods leverage samples of varying granularity to mitigate reasoning errors, they overlook the frequently occurring subtle errors. A major reason is that sampled preference pairs involve differences unrelated to the errors, which may distract the model from focusing on subtle errors. In this work, we propose a novel preference learning framework called eRror-Injected Self-Editing (RISE), which injects predefined subtle errors into partial tokens of correct solutions to construct hard pairs for error mitigation. In detail, RISE uses the model itself to edit a small number of tokens in the solution, injecting designed subtle errors. Then, pairs composed of self-edited solutions and their corresponding correct ones, along with pairs of correct and incorrect solutions obtained through sampling, are used together for subtle error-aware DPO training. Compared with other preference learning methods, RISE further refines the training objective to focus on predefined errors and their tokens, without requiring fine-grained sampling or preference annotation. Extensive experiments validate the effectiveness of RISE, with preference learning on Qwen2-7B-Instruct yielding notable improvements of 3.0% on GSM8K and 7.9% on MATH.
+
+
+
+ 60. 【2410.06634】ree of Problems: Improving structured problem solving with compositionality
+ 链接:https://arxiv.org/abs/2410.06634
+ 作者:Armel Zebaze,Benoît Sagot,Rachel Bawden
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, Language Models, demonstrated remarkable performance, in-context learning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have demonstrated remarkable performance across multiple tasks through in-context learning. For complex reasoning tasks that require step-by-step thinking, Chain-of-Thought (CoT) prompting has given impressive results, especially when combined with self-consistency. Nonetheless, some tasks remain particularly difficult for LLMs to solve. Tree of Thoughts (ToT) and Graph of Thoughts (GoT) emerged as alternatives, dividing the complex problem into paths of subproblems. In this paper, we propose Tree of Problems (ToP), a simpler version of ToT, which we hypothesise can work better for complex tasks that can be divided into identical subtasks. Our empirical results show that our approach outperforms ToT and GoT, and in addition performs better than CoT on complex reasoning tasks. All code for this paper is publicly available here: this https URL.
+
+
+
+ 61. 【2410.06625】ETA: Evaluating Then Aligning Safety of Vision Language Models at Inference Time
+ 链接:https://arxiv.org/abs/2410.06625
+ 作者:Yi Ding,Bolian Li,Ruqi Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL); Programming Languages (cs.PL)
+ 关键词:Vision Language Models, Vision Language, Language Models, significant safety challenges, safety challenges limit
+ 备注: 27pages
+
+ 点击查看摘要
+ Abstract:Vision Language Models (VLMs) have become essential backbones for multimodal intelligence, yet significant safety challenges limit their real-world application. While textual inputs are often effectively safeguarded, adversarial visual inputs can easily bypass VLM defense mechanisms. Existing defense methods are either resource-intensive, requiring substantial data and compute, or fail to simultaneously ensure safety and usefulness in responses. To address these limitations, we propose a novel two-phase inference-time alignment framework, Evaluating Then Aligning (ETA): 1) Evaluating input visual contents and output responses to establish a robust safety awareness in multimodal settings, and 2) Aligning unsafe behaviors at both shallow and deep levels by conditioning the VLMs' generative distribution with an interference prefix and performing sentence-level best-of-N to search the most harmless and helpful generation paths. Extensive experiments show that ETA outperforms baseline methods in terms of harmlessness, helpfulness, and efficiency, reducing the unsafe rate by 87.5% in cross-modality attacks and achieving 96.6% win-ties in GPT-4 helpfulness evaluation. The code is publicly available at this https URL.
+
+
+
+ 62. 【2410.06617】Learning Evolving Tools for Large Language Models
+ 链接:https://arxiv.org/abs/2410.06617
+ 作者:Guoxin Chen,Zhong Zhang,Xin Cong,Fangda Guo,Yesai Wu,Yankai Lin,Wenzheng Feng,Yasheng Wang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:large language models, enables large language, learning enables large, language models, greatly expanding
+ 备注: Ongoning Work
+
+ 点击查看摘要
+ Abstract:Tool learning enables large language models (LLMs) to interact with external tools and APIs, greatly expanding the application scope of LLMs. However, due to the dynamic nature of external environments, these tools and APIs may become outdated over time, preventing LLMs from correctly invoking tools. Existing research primarily focuses on static environments and overlooks this issue, limiting the adaptability of LLMs in real-world applications. In this paper, we propose ToolEVO, a novel framework designed to enhance the adaptive and reflective capabilities of LLMs against tool variability. By leveraging Monte Carlo Tree Search, ToolEVO facilitates active exploration and interaction of LLMs within dynamic environments, allowing for autonomous self-reflection and self-updating of tool usage based on environmental feedback. Additionally, we introduce ToolQA-D, a benchmark specifically designed to evaluate the impact of tool variability. Extensive experiments demonstrate the effectiveness and stability of our approach, highlighting the importance of adaptability to tool variability for effective tool learning.
+
+
+
+ 63. 【2410.06615】$\beta$-calibration of Language Model Confidence Scores for Generative QA
+ 链接:https://arxiv.org/abs/2410.06615
+ 作者:Putra Manggala,Atalanti Mastakouri,Elke Kirschbaum,Shiva Prasad Kasiviswanathan,Aaditya Ramdas
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:provide well-calibrated confidence, well-calibrated confidence scores, critical application, provide well-calibrated, reflect the correctness
+ 备注:
+
+ 点击查看摘要
+ Abstract:To use generative question-and-answering (QA) systems for decision-making and in any critical application, these systems need to provide well-calibrated confidence scores that reflect the correctness of their answers. Existing calibration methods aim to ensure that the confidence score is on average indicative of the likelihood that the answer is correct. We argue, however, that this standard (average-case) notion of calibration is difficult to interpret for decision-making in generative QA. To address this, we generalize the standard notion of average calibration and introduce $\beta$-calibration, which ensures calibration holds across different question-and-answer groups. We then propose discretized posthoc calibration schemes for achieving $\beta$-calibration.
+
+
+
+ 64. 【2410.06606】Dissecting Fine-Tuning Unlearning in Large Language Models
+ 链接:https://arxiv.org/abs/2410.06606
+ 作者:Yihuai Hong,Yuelin Zou,Lijie Hu,Ziqian Zeng,Di Wang,Haiqin Yang
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:preventing targeted harmful, large language models, targeted harmful, unlearning methods prevail, prevail for preventing
+ 备注: Accepted in EMNLP 2024 Main (Short paper)
+
+ 点击查看摘要
+ Abstract:Fine-tuning-based unlearning methods prevail for preventing targeted harmful, sensitive, or copyrighted information within large language models while preserving overall capabilities. However, the true effectiveness of these methods is unclear. In this paper, we delve into the limitations of fine-tuning-based unlearning through activation patching and parameter restoration experiments. Our findings reveal that these methods alter the model's knowledge retrieval process, rather than genuinely erasing the problematic knowledge embedded in the model parameters. Furthermore, behavioral tests demonstrate that the unlearning mechanisms inevitably impact the global behavior of the models, affecting unrelated knowledge or capabilities. Our work advocates the development of more resilient unlearning techniques for truly erasing knowledge. Our code is released at this https URL.
+
+
+
+ 65. 【2410.06577】Rodimus*: Breaking the Accuracy-Efficiency Trade-Off with Efficient Attentions
+ 链接:https://arxiv.org/abs/2410.06577
+ 作者:Zhihao He,Hang Yu,Zi Gong,Shizhan Liu,Jianguo Li,Weiyao Lin
+ 类目:Computation and Language (cs.CL)
+ 关键词:Transformer-based large language, natural language processing, Recent advancements, advancements in Transformer-based, Transformer-based large
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advancements in Transformer-based large language models (LLMs) have set new standards in natural language processing. However, the classical softmax attention incurs significant computational costs, leading to a $O(T)$ complexity for per-token generation, where $T$ represents the context length. This work explores reducing LLMs' complexity while maintaining performance by introducing Rodimus and its enhanced version, Rodimus$+$. Rodimus employs an innovative data-dependent tempered selection (DDTS) mechanism within a linear attention-based, purely recurrent framework, achieving significant accuracy while drastically reducing the memory usage typically associated with recurrent models. This method exemplifies semantic compression by maintaining essential input information with fixed-size hidden states. Building on this, Rodimus$+$ combines Rodimus with the innovative Sliding Window Shared-Key Attention (SW-SKA) in a hybrid approach, effectively leveraging the complementary semantic, token, and head compression techniques. Our experiments demonstrate that Rodimus$+$-1.6B, trained on 1 trillion tokens, achieves superior downstream performance against models trained on more tokens, including Qwen2-1.5B and RWKV6-1.6B, underscoring its potential to redefine the accuracy-efficiency balance in LLMs. Model code and pre-trained checkpoints will be available soon.
+
+
+
+ 66. 【2410.06566】Detecting Bias and Enhancing Diagnostic Accuracy in Large Language Models for Healthcare
+ 链接:https://arxiv.org/abs/2410.06566
+ 作者:Pardis Sadat Zahraei,Zahra Shakeri
+ 类目:Computation and Language (cs.CL)
+ 关键词:Biased AI-generated medical, AI-generated medical advice, Biased AI-generated, jeopardize patient safety, Large Language Models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Biased AI-generated medical advice and misdiagnoses can jeopardize patient safety, making the integrity of AI in healthcare more critical than ever. As Large Language Models (LLMs) take on a growing role in medical decision-making, addressing their biases and enhancing their accuracy is key to delivering safe, reliable care. This study addresses these challenges head-on by introducing new resources designed to promote ethical and precise AI in healthcare. We present two datasets: BiasMD, featuring 6,007 question-answer pairs crafted to evaluate and mitigate biases in health-related LLM outputs, and DiseaseMatcher, with 32,000 clinical question-answer pairs spanning 700 diseases, aimed at assessing symptom-based diagnostic accuracy. Using these datasets, we developed the EthiClinician, a fine-tuned model built on the ChatDoctor framework, which outperforms GPT-4 in both ethical reasoning and clinical judgment. By exposing and correcting hidden biases in existing models for healthcare, our work sets a new benchmark for safer, more reliable patient outcomes.
+
+
+
+ 67. 【2410.06555】ING-VP: MLLMs cannot Play Easy Vision-based Games Yet
+ 链接:https://arxiv.org/abs/2410.06555
+ 作者:Haoran Zhang,Hangyu Guo,Shuyue Guo,Meng Cao,Wenhao Huang,Jiaheng Liu,Ge Zhang
+ 类目:Computation and Language (cs.CL)
+ 关键词:demonstrate increasingly competitive, increasingly competitive performance, multimodal large language, large language models, continue to demonstrate
+ 备注: 49 pages, 12 figures
+
+ 点击查看摘要
+ Abstract:As multimodal large language models (MLLMs) continue to demonstrate increasingly competitive performance across a broad spectrum of tasks, more intricate and comprehensive benchmarks have been developed to assess these cutting-edge models. These benchmarks introduce new challenges to core capabilities such as perception, reasoning, and planning. However, existing multimodal benchmarks fall short in providing a focused evaluation of multi-step planning based on spatial relationships in images. To bridge this gap, we present ING-VP, the first INteractive Game-based Vision Planning benchmark, specifically designed to evaluate the spatial imagination and multi-step reasoning abilities of MLLMs. ING-VP features 6 distinct games, encompassing 300 levels, each with 6 unique configurations. A single model engages in over 60,000 rounds of interaction. The benchmark framework allows for multiple comparison settings, including image-text vs. text-only inputs, single-step vs. multi-step reasoning, and with-history vs. without-history conditions, offering valuable insights into the model's capabilities. We evaluated numerous state-of-the-art MLLMs, with the highest-performing model, Claude-3.5 Sonnet, achieving an average accuracy of only 3.37%, far below the anticipated standard. This work aims to provide a specialized evaluation framework to drive advancements in MLLMs' capacity for complex spatial reasoning and planning. The code is publicly available at this https URL.
+
+
+
+ 68. 【2410.06554】he Accuracy Paradox in RLHF: When Better Reward Models Don't Yield Better Language Models
+ 链接:https://arxiv.org/abs/2410.06554
+ 作者:Yanjun Chen,Dawei Zhu,Yirong Sun,Xinghao Chen,Wei Zhang,Xiaoyu Shen
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Human Feedback significantly, Natural Language Processing, significantly enhances Natural, Feedback significantly enhances, Reinforcement Learning
+ 备注: 10 pages, 27 figures (including 18 in the appendix), submitted to EMNLP 2024
+
+ 点击查看摘要
+ Abstract:Reinforcement Learning from Human Feedback significantly enhances Natural Language Processing by aligning language models with human expectations. A critical factor in this alignment is the strength of reward models used during training. This study explores whether stronger reward models invariably lead to better language models. In this paper, through experiments on relevance, factuality, and completeness tasks using the QA-FEEDBACK dataset and reward models based on Longformer, we uncover a surprising paradox: language models trained with moderately accurate reward models outperform those guided by highly accurate ones. This challenges the widely held belief that stronger reward models always lead to better language models, and opens up new avenues for future research into the key factors driving model performance and how to choose the most suitable reward models. Code and additional details are available at [this https URL](this https URL).
+
+
+
+ 69. 【2410.06550】Investigating Cost-Efficiency of LLM-Generated Training Data for Conversational Semantic Frame Analysis
+ 链接:https://arxiv.org/abs/2410.06550
+ 作者:Shiho Matta,Yin Jou Huang,Fei Cheng,Hirokazu Kiyomaru,Yugo Murawaki
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Recent studies, low cost, LLM-generated data, studies have demonstrated, demonstrated that few-shot
+ 备注: 12 pages including 4 pages of references and appendix. 7 figures
+
+ 点击查看摘要
+ Abstract:Recent studies have demonstrated that few-shot learning allows LLMs to generate training data for supervised models at a low cost. However, the quality of LLM-generated data may not entirely match that of human-labeled data. This raises a crucial question: how should one balance the trade-off between the higher quality but more expensive human data and the lower quality yet substantially cheaper LLM-generated data? In this paper, we synthesized training data for conversational semantic frame analysis using GPT-4 and examined how to allocate budgets optimally to achieve the best performance. Our experiments, conducted across various budget levels, reveal that optimal cost-efficiency is achieved by combining both human and LLM-generated data across a wide range of budget levels. Notably, as the budget decreases, a higher proportion of LLM-generated data becomes more preferable.
+
+
+
+ 70. 【2410.06547】uringQ: Benchmarking AI Comprehension in Theory of Computation
+ 链接:https://arxiv.org/abs/2410.06547
+ 作者:Pardis Sadat Zahraei,Ehsaneddin Asgari
+ 类目:Computation and Language (cs.CL); Formal Languages and Automata Theory (cs.FL)
+ 关键词:large language models, theory of computation, large language, Chain of Thought, language models
+ 备注: Accepted to EMNLP Findings 2024
+
+ 点击查看摘要
+ Abstract:We present TuringQ, the first benchmark designed to evaluate the reasoning capabilities of large language models (LLMs) in the theory of computation. TuringQ consists of 4,006 undergraduate and graduate-level question-answer pairs, categorized into four difficulty levels and covering seven core theoretical areas. We evaluate several open-source LLMs, as well as GPT-4, using Chain of Thought prompting and expert human assessment. Additionally, we propose an automated LLM-based evaluation system that demonstrates competitive accuracy when compared to human evaluation. Fine-tuning a Llama3-8B model on TuringQ shows measurable improvements in reasoning ability and out-of-domain tasks such as algebra. TuringQ serves as both a benchmark and a resource for enhancing LLM performance in complex computational reasoning tasks. Our analysis offers insights into LLM capabilities and advances in AI comprehension of theoretical computer science.
+
+
+
+ 71. 【2410.06541】Chip-Tuning: Classify Before Language Models Say
+ 链接:https://arxiv.org/abs/2410.06541
+ 作者:Fangwei Zhu,Dian Li,Jiajun Huang,Gang Liu,Hui Wang,Zhifang Sui
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:training and inference, rapid development, increasing cost, large language models, LLMs
+ 备注:
+
+ 点击查看摘要
+ Abstract:The rapid development in the performance of large language models (LLMs) is accompanied by the escalation of model size, leading to the increasing cost of model training and inference. Previous research has discovered that certain layers in LLMs exhibit redundancy, and removing these layers brings only marginal loss in model performance. In this paper, we adopt the probing technique to explain the layer redundancy in LLMs and demonstrate that language models can be effectively pruned with probing classifiers. We propose chip-tuning, a simple and effective structured pruning framework specialized for classification problems. Chip-tuning attaches tiny probing classifiers named chips to different layers of LLMs, and trains chips with the backbone model frozen. After selecting a chip for classification, all layers subsequent to the attached layer could be removed with marginal performance loss. Experimental results on various LLMs and datasets demonstrate that chip-tuning significantly outperforms previous state-of-the-art baselines in both accuracy and pruning ratio, achieving a pruning ratio of up to 50%. We also find that chip-tuning could be applied on multimodal models, and could be combined with model finetuning, proving its excellent compatibility.
+
+
+
+ 72. 【2410.06524】Do great minds think alike? Investigating Human-AI Complementarity in Question Answering with CAIMIRA
+ 链接:https://arxiv.org/abs/2410.06524
+ 作者:Maharshi Gor,Hal Daumé III,Tianyi Zhou,Jordan Boyd-Graber
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:large language models, natural language processing, Recent advancements, language models, language processing
+ 备注: To appear at EMNLP 2024 (Main)
+
+ 点击查看摘要
+ Abstract:Recent advancements of large language models (LLMs) have led to claims of AI surpassing humans in natural language processing (NLP) tasks such as textual understanding and reasoning. This work investigates these assertions by introducing CAIMIRA, a novel framework rooted in item response theory (IRT) that enables quantitative assessment and comparison of problem-solving abilities of question-answering (QA) agents: humans and AI systems. Through analysis of over 300,000 responses from ~70 AI systems and 155 humans across thousands of quiz questions, CAIMIRA uncovers distinct proficiency patterns in knowledge domains and reasoning skills. Humans outperform AI systems in knowledge-grounded abductive and conceptual reasoning, while state-of-the-art LLMs like GPT-4 and LLaMA show superior performance on targeted information retrieval and fact-based reasoning, particularly when information gaps are well-defined and addressable through pattern matching or data retrieval. These findings highlight the need for future QA tasks to focus on questions that challenge not only higher-order reasoning and scientific thinking, but also demand nuanced linguistic interpretation and cross-contextual knowledge application, helping advance AI developments that better emulate or complement human cognitive abilities in real-world problem-solving.
+
+
+
+ 73. 【2410.06520】A Novel LLM-based Two-stage Summarization Approach for Long Dialogues
+ 链接:https://arxiv.org/abs/2410.06520
+ 作者:Yuan-Jhe Yin,Bo-Yu Chen,Berlin Chen
+ 类目:Computation and Language (cs.CL)
+ 关键词:natural language processing, language processing due, pre-trained language models, pre-trained language, document summarization poses
+ 备注:
+
+ 点击查看摘要
+ Abstract:Long document summarization poses a significant challenge in natural language processing due to input lengths that exceed the capacity of most state-of-the-art pre-trained language models. This study proposes a hierarchical framework that segments and condenses information from long documents, subsequently fine-tuning the processed text with an abstractive summarization model. Unsupervised topic segmentation methods identify semantically appropriate breakpoints. The condensation stage utilizes an unsupervised generation model to generate condensed data, and our current experiments employ ChatGPT(v3.5). The summarization stage fine-tunes the abstractive summarization model on the condensed data to generate the final results. This framework enables long documents to be processed on models even when the document length exceeds the model's maximum input size. The exclusion of the entire document from the summarization model reduces the time and computational resources required for training, making the framework suitable for contexts with constrained local computational resources.
+
+
+
+ 74. 【2410.06519】SEGMENT+: Long Text Processing with Short-Context Language Models
+ 链接:https://arxiv.org/abs/2410.06519
+ 作者:Wei Shi,Shuang Li,Kerun Yu,Jinglei Chen,Zujie Liang,Xinhui Wu,Yuxi Qian,Feng Wei,Bo Zheng,Jiaqing Liang,Jiangjie Chen,Yanghua Xiao
+ 类目:Computation and Language (cs.CL)
+ 关键词:growing interest, interest in expanding, capacity of language, input capacity, SEGMENT
+ 备注: EMNLP 2024
+
+ 点击查看摘要
+ Abstract:There is a growing interest in expanding the input capacity of language models (LMs) across various domains. However, simply increasing the context window does not guarantee robust performance across diverse long-input processing tasks, such as understanding extensive documents and extracting detailed information from lengthy and noisy data. In response, we introduce SEGMENT+, a general framework that enables LMs to handle extended inputs within limited context windows efficiently. SEGMENT+ utilizes structured notes and a filtering module to manage information flow, resulting in a system that is both controllable and interpretable. Our extensive experiments across various model sizes, focusing on long-document question-answering and Needle-in-a-Haystack tasks, demonstrate the effectiveness of SEGMENT+ in improving performance.
+
+
+
+ 75. 【2410.06511】orchTitan: One-stop PyTorch native solution for production ready LLM pre-training
+ 链接:https://arxiv.org/abs/2410.06511
+ 作者:Wanchao Liang,Tianyu Liu,Less Wright,Will Constable,Andrew Gu,Chien-Chin Huang,Iris Zhang,Wei Feng,Howard Huang,Junjie Wang,Sanket Purandare,Gokul Nadathur,Stratos Idreos
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Distributed, Parallel, and Cluster Computing (cs.DC); Machine Learning (cs.LG)
+ 关键词:large language models, language processing applications, natural language processing, instrumental in advancing, processing applications
+ 备注:
+
+ 点击查看摘要
+ Abstract:The development of large language models (LLMs) has been instrumental in advancing state-of-the-art natural language processing applications. Training LLMs with billions of parameters and trillions of tokens require sophisticated distributed systems that enable composing and comparing several state-of-the-art techniques in order to efficiently scale across thousands of accelerators. However, existing solutions are complex, scattered across multiple libraries/repositories, lack interoperability, and are cumbersome to maintain. Thus, curating and empirically comparing training recipes require non-trivial engineering effort.
+This paper introduces TorchTitan, an open-source, PyTorch-native distributed training system that unifies state-of-the-art techniques, streamlining integration and reducing overhead. TorchTitan enables 3D parallelism in a modular manner with elastic scaling, providing comprehensive logging, checkpointing, and debugging tools for production-ready training. It also incorporates hardware-software co-designed solutions, leveraging features like Float8 training and SymmetricMemory. As a flexible test bed, TorchTitan facilitates custom recipe curation and comparison, allowing us to develop optimized training recipes for Llama 3.1 and provide guidance on selecting techniques for maximum efficiency based on our experiences.
+We thoroughly assess TorchTitan on the Llama 3.1 family of LLMs, spanning 8 billion to 405 billion parameters, and showcase its exceptional performance, modular composability, and elastic scalability. By stacking training optimizations, we demonstrate accelerations of 65.08% with 1D parallelism at the 128-GPU scale (Llama 3.1 8B), an additional 12.59% with 2D parallelism at the 256-GPU scale (Llama 3.1 70B), and an additional 30% with 3D parallelism at the 512-GPU scale (Llama 3.1 405B) on NVIDIA H100 GPUs over optimized baselines.
+
Subjects:
+Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Distributed, Parallel, and Cluster Computing (cs.DC); Machine Learning (cs.LG)
+Cite as:
+arXiv:2410.06511 [cs.CL]
+(or
+arXiv:2410.06511v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2410.06511
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 76. 【2410.06508】owards Self-Improvement of LLMs via MCTS: Leveraging Stepwise Knowledge with Curriculum Preference Learning
+ 链接:https://arxiv.org/abs/2410.06508
+ 作者:Xiyao Wang,Linfeng Song,Ye Tian,Dian Yu,Baolin Peng,Haitao Mi,Furong Huang,Dong Yu
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:Monte Carlo Tree, Monte Carlo, Carlo Tree Search, MCTS behavior distillation, Carlo Tree
+ 备注:
+
+ 点击查看摘要
+ Abstract:Monte Carlo Tree Search (MCTS) has recently emerged as a powerful technique for enhancing the reasoning capabilities of LLMs. Techniques such as SFT or DPO have enabled LLMs to distill high-quality behaviors from MCTS, improving their reasoning performance. However, existing distillation methods underutilize the rich trajectory information generated by MCTS, limiting the potential for improvements in LLM reasoning. In this paper, we propose AlphaLLM-CPL, a novel pairwise training framework that enables LLMs to self-improve through MCTS behavior distillation. AlphaLLM-CPL efficiently leverages MCTS trajectories via two key innovations: (1) AlphaLLM-CPL constructs stepwise trajectory pairs from child nodes sharing the same parent in the search tree, providing step-level information for more effective MCTS behavior distillation. (2) AlphaLLM-CPL introduces curriculum preference learning, dynamically adjusting the training sequence of trajectory pairs in each offline training epoch to prioritize critical learning steps and mitigate overfitting. Experimental results on mathematical reasoning tasks demonstrate that AlphaLLM-CPL significantly outperforms previous MCTS behavior distillation methods, substantially boosting the reasoning capabilities of LLMs.
+
+
+
+ 77. 【2410.06496】On the Similarity of Circuits across Languages: a Case Study on the Subject-verb Agreement Task
+ 链接:https://arxiv.org/abs/2410.06496
+ 作者:Javier Ferrando,Marta R.Costa-jussà
+ 类目:Computation and Language (cs.CL)
+ 关键词:successfully reversed-engineered, recently been successfully, algorithms implemented, Gemma, circuits
+ 备注: Accepted at EMNLP 2024 Findings
+
+ 点击查看摘要
+ Abstract:Several algorithms implemented by language models have recently been successfully reversed-engineered. However, these findings have been concentrated on specific tasks and models, leaving it unclear how universal circuits are across different settings. In this paper, we study the circuits implemented by Gemma 2B for solving the subject-verb agreement task across two different languages, English and Spanish. We discover that both circuits are highly consistent, being mainly driven by a particular attention head writing a `subject number' signal to the last residual stream, which is read by a small set of neurons in the final MLPs. Notably, this subject number signal is represented as a direction in the residual stream space, and is language-independent. We demonstrate that this direction has a causal effect on the model predictions, effectively flipping the Spanish predicted verb number by intervening with the direction found in English. Finally, we present evidence of similar behavior in other models within the Gemma 1 and Gemma 2 families.
+
+
+
+ 78. 【2410.06479】LLM Compression with Neural Architecture Search
+ 链接:https://arxiv.org/abs/2410.06479
+ 作者:Rhea Sanjay Sukthanker,Benedikt Staffler,Frank Hutter,Aaron Klein
+ 类目:Computation and Language (cs.CL)
+ 关键词:exhibit remarkable reasoning, remarkable reasoning abilities, Large language models, reasoning abilities, Large language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) exhibit remarkable reasoning abilities, allowing them to generalize across a wide range of downstream tasks, such as commonsense reasoning or instruction following. However, as LLMs scale, inference costs become increasingly prohibitive, accumulating significantly over their life cycle. This poses the question: Can we compress pre-trained LLMs to meet diverse size and latency requirements? We leverage Neural Architecture Search (NAS) to compress LLMs by pruning structural components, such as attention heads, neurons, and layers, aiming to achieve a Pareto-optimal balance between performance and efficiency. While NAS already achieved promising results on small language models in previous work, in this paper we propose various extensions that allow us to scale to LLMs. Compared to structural pruning baselines, we show that NAS improves performance up to 3.4% on MMLU with an on-device latency speedup.
+
+
+
+ 79. 【2410.06458】LLM Self-Correction with DeCRIM: Decompose, Critique, and Refine for Enhanced Following of Instructions with Multiple Constraints
+ 链接:https://arxiv.org/abs/2410.06458
+ 作者:Thomas Palmeira Ferraz,Kartik Mehta,Yu-Hsiang Lin,Haw-Shiuan Chang,Shereen Oraby,Sijia Liu,Vivek Subramanian,Tagyoung Chung,Mohit Bansal,Nanyun Peng
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:key capability, instructions, Abstract, DeCRIM, LLMs
+ 备注: To appear at EMNLP 2024
+
+ 点击查看摘要
+ Abstract:Instruction following is a key capability for LLMs. However, recent studies have shown that LLMs often struggle with instructions containing multiple constraints (e.g. a request to create a social media post "in a funny tone" with "no hashtag"). Despite this, most evaluations focus solely on synthetic data. To address this, we introduce RealInstruct, the first benchmark designed to evaluate LLMs' ability to follow real-world multi-constrained instructions by leveraging queries real users asked AI assistants. We also investigate model-based evaluation as a cost-effective alternative to human annotation for this task. Our findings reveal that even the proprietary GPT-4 model fails to meet at least one constraint on over 21% of instructions, highlighting the limitations of state-of-the-art models. To address the performance gap between open-source and proprietary models, we propose the Decompose, Critique and Refine (DeCRIM) self-correction pipeline, which enhances LLMs' ability to follow constraints. DeCRIM works by decomposing the original instruction into a list of constraints and using a Critic model to decide when and where the LLM's response needs refinement. Our results show that DeCRIM improves Mistral's performance by 7.3% on RealInstruct and 8.0% on IFEval even with weak feedback. Moreover, we demonstrate that with strong feedback, open-source LLMs with DeCRIM can outperform GPT-4 on both benchmarks.
+
+
+
+ 80. 【2410.06441】Addax: Utilizing Zeroth-Order Gradients to Improve Memory Efficiency and Performance of SGD for Fine-Tuning Language Models
+ 链接:https://arxiv.org/abs/2410.06441
+ 作者:Zeman Li,Xinwei Zhang,Peilin Zhong,Yuan Deng,Meisam Razaviyayn,Vahab Mirrokni
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:Stochastic Gradient Descent, Addax, limiting accessibility, MeZO, memory
+ 备注:
+
+ 点击查看摘要
+ Abstract:Fine-tuning language models (LMs) with the Adam optimizer often demands excessive memory, limiting accessibility. The "in-place" version of Stochastic Gradient Descent (IP-SGD) and Memory-Efficient Zeroth-order Optimizer (MeZO) have been proposed to address this. However, IP-SGD still requires substantial memory, and MeZO suffers from slow convergence and degraded final performance due to its zeroth-order nature. This paper introduces Addax, a novel method that improves both memory efficiency and performance of IP-SGD by integrating it with MeZO. Specifically, Addax computes zeroth- or first-order gradients of data points in the minibatch based on their memory consumption, combining these gradient estimates to update directions. By computing zeroth-order gradients for data points that require more memory and first-order gradients for others, Addax overcomes the slow convergence of MeZO and the excessive memory requirement of IP-SGD. Additionally, the zeroth-order gradient acts as a regularizer for the first-order gradient, further enhancing the model's final performance. Theoretically, we establish the convergence of Addax under mild assumptions, demonstrating faster convergence and less restrictive hyper-parameter choices than MeZO. Our experiments with diverse LMs and tasks show that Addax consistently outperforms MeZO regarding accuracy and convergence speed while having a comparable memory footprint. When fine-tuning OPT-13B with one A100 GPU, on average, Addax outperforms MeZO in accuracy/F1 score by 14% and runs 15x faster while using memory similar to MeZO. In our experiments on the larger OPT-30B model, on average, Addax outperforms MeZO in terms of accuracy/F1 score by 16 and runs 30x faster on a single H100 GPU. Moreover, Addax surpasses the performance of standard fine-tuning approaches, such as IP-SGD and Adam, in most tasks with significantly less memory requirement.
+
+
+
+ 81. 【2410.06428】Stress Detection on Code-Mixed Texts in Dravidian Languages using Machine Learning
+ 链接:https://arxiv.org/abs/2410.06428
+ 作者:L. Ramos,M. Shahiki-Tash,Z. Ahani,A. Eponon,O. Kolesnikova,H. Calvo
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Human-Computer Interaction (cs.HC); Machine Learning (cs.LG)
+ 关键词:affect mental well-being, daily life, common feeling, feeling in daily, development of robust
+ 备注:
+
+ 点击查看摘要
+ Abstract:Stress is a common feeling in daily life, but it can affect mental well-being in some situations, the development of robust detection models is imperative. This study introduces a methodical approach to the stress identification in code-mixed texts for Dravidian languages. The challenge encompassed two datasets, targeting Tamil and Telugu languages respectively. This proposal underscores the importance of using uncleaned text as a benchmark to refine future classification methodologies, incorporating diverse preprocessing techniques. Random Forest algorithm was used, featuring three textual representations: TF-IDF, Uni-grams of words, and a composite of (1+2+3)-Grams of characters. The approach achieved a good performance for both linguistic categories, achieving a Macro F1-score of 0.734 in Tamil and 0.727 in Telugu, overpassing results achieved with different complex techniques such as FastText and Transformer models. The results underscore the value of uncleaned data for mental state detection and the challenges classifying code-mixed texts for stress, indicating the potential for improved performance through cleaning data, other preprocessing techniques, or more complex models.
+
+
+
+ 82. 【2410.06427】NLP Case Study on Predicting the Before and After of the Ukraine-Russia and Hamas-Israel Conflicts
+ 链接:https://arxiv.org/abs/2410.06427
+ 作者:Jordan Miner,John E. Ortega
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:natural language processing, social media, recent events, Twitter and Reddit, propose a method
+ 备注: The clusters created using topic modeling can be viewed at [this https URL](https://naturallang.com/conflict/conflict.html)
+
+ 点击查看摘要
+ Abstract:We propose a method to predict toxicity and other textual attributes through the use of natural language processing (NLP) techniques for two recent events: the Ukraine-Russia and Hamas-Israel conflicts. This article provides a basis for exploration in future conflicts with hopes to mitigate risk through the analysis of social media before and after a conflict begins. Our work compiles several datasets from Twitter and Reddit for both conflicts in a before and after separation with an aim of predicting a future state of social media for avoidance. More specifically, we show that: (1) there is a noticeable difference in social media discussion leading up to and following a conflict and (2) social media discourse on platforms like Twitter and Reddit is useful in identifying future conflicts before they arise. Our results show that through the use of advanced NLP techniques (both supervised and unsupervised) toxicity and other attributes about language before and after a conflict is predictable with a low error of nearly 1.2 percent for both conflicts.
+
+
+
+ 83. 【2410.06420】ERVQA: A Dataset to Benchmark the Readiness of Large Vision Language Models in Hospital Environments
+ 链接:https://arxiv.org/abs/2410.06420
+ 作者:Sourjyadip Ray,Kushal Gupta,Soumi Kundu,Payal Arvind Kasat,Somak Aditya,Pawan Goyal
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Visual Question Answering, alert healthcare workers, smart healthcare assistants, Large Vision Language, Room Visual Question
+ 备注: Accepted at EMNLP 2024
+
+ 点击查看摘要
+ Abstract:The global shortage of healthcare workers has demanded the development of smart healthcare assistants, which can help monitor and alert healthcare workers when necessary. We examine the healthcare knowledge of existing Large Vision Language Models (LVLMs) via the Visual Question Answering (VQA) task in hospital settings through expert annotated open-ended questions. We introduce the Emergency Room Visual Question Answering (ERVQA) dataset, consisting of image, question, answer triplets covering diverse emergency room scenarios, a seminal benchmark for LVLMs. By developing a detailed error taxonomy and analyzing answer trends, we reveal the nuanced nature of the task. We benchmark state-of-the-art open-source and closed LVLMs using traditional and adapted VQA metrics: Entailment Score and CLIPScore Confidence. Analyzing errors across models, we infer trends based on properties like decoder type, model size, and in-context examples. Our findings suggest the ERVQA dataset presents a highly complex task, highlighting the need for specialized, domain-specific solutions.
+
+
+
+ 84. 【2410.06396】MLissard: Multilingual Long and Simple Sequential Reasoning Benchmarks
+ 链接:https://arxiv.org/abs/2410.06396
+ 作者:Mirelle Bueno,Roberto Lotufo,Rodrigo Nogueira
+ 类目:Computation and Language (cs.CL)
+ 关键词:long sequences consisting, thousands of tokens, tasks that require, capable of solving, dealing with long
+ 备注: GenBench Workshop by EMNLP 2024: Camera-ready version
+
+ 点击查看摘要
+ Abstract:Language models are now capable of solving tasks that require dealing with long sequences consisting of hundreds of thousands of tokens. However, they often fail on tasks that require repetitive use of simple rules, even on sequences that are much shorter than those seen during training. For example, state-of-the-art LLMs can find common items in two lists with up to 20 items but fail when lists have 80 items. In this paper, we introduce MLissard, a multilingual benchmark designed to evaluate models' abilities to process and generate texts of varied lengths and offers a mechanism for controlling sequence complexity.
+Our evaluation of open-source and proprietary models show a consistent decline in performance across all models and languages as the complexity of the sequence increases. Surprisingly, the use of in-context examples in languages other than English helps increase extrapolation performance significantly. The datasets and code are available at this https URL
+
Comments:
+GenBench Workshop by EMNLP 2024: Camera-ready version
+Subjects:
+Computation and Language (cs.CL)
+Cite as:
+arXiv:2410.06396 [cs.CL]
+(or
+arXiv:2410.06396v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2410.06396
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 85. 【2410.06392】Counterfactual Causal Inference in Natural Language with Large Language Models
+ 链接:https://arxiv.org/abs/2410.06392
+ 作者:Gaël Gendron,Jože M. Rožanec,Michael Witbrock,Gillian Dobbie
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Causal, Causal structure discovery, Causal structure, commonly applied, applied to structured
+ 备注: 22 pages, 10 pages for the main paper, 12 pages for the references and appendix, 5 figures
+
+ 点击查看摘要
+ Abstract:Causal structure discovery methods are commonly applied to structured data where the causal variables are known and where statistical testing can be used to assess the causal relationships. By contrast, recovering a causal structure from unstructured natural language data such as news articles contains numerous challenges due to the absence of known variables or counterfactual data to estimate the causal links. Large Language Models (LLMs) have shown promising results in this direction but also exhibit limitations. This work investigates LLM's abilities to build causal graphs from text documents and perform counterfactual causal inference. We propose an end-to-end causal structure discovery and causal inference method from natural language: we first use an LLM to extract the instantiated causal variables from text data and build a causal graph. We merge causal graphs from multiple data sources to represent the most exhaustive set of causes possible. We then conduct counterfactual inference on the estimated graph. The causal graph conditioning allows reduction of LLM biases and better represents the causal estimands. We use our method to show that the limitations of LLMs in counterfactual causal reasoning come from prediction errors and propose directions to mitigate them. We demonstrate the applicability of our method on real-world news articles.
+
+
+
+ 86. 【2410.06384】Validation of the Scientific Literature via Chemputation Augmented by Large Language Models
+ 链接:https://arxiv.org/abs/2410.06384
+ 作者:Sebastian Pagel,Michael Jirasek,Leroy Cronin
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:Large Language Models, universal symbolic language, programming chemical robots, symbolic language, Language Models
+ 备注: 22 pages, 7 figures, 34 references
+
+ 点击查看摘要
+ Abstract:Chemputation is the process of programming chemical robots to do experiments using a universal symbolic language, but the literature can be error prone and hard to read due to ambiguities. Large Language Models (LLMs) have demonstrated remarkable capabilities in various domains, including natural language processing, robotic control, and more recently, chemistry. Despite significant advancements in standardizing the reporting and collection of synthetic chemistry data, the automatic reproduction of reported syntheses remains a labour-intensive task. In this work, we introduce an LLM-based chemical research agent workflow designed for the automatic validation of synthetic literature procedures. Our workflow can autonomously extract synthetic procedures and analytical data from extensive documents, translate these procedures into universal XDL code, simulate the execution of the procedure in a hardware-specific setup, and ultimately execute the procedure on an XDL-controlled robotic system for synthetic chemistry. This demonstrates the potential of LLM-based workflows for autonomous chemical synthesis with Chemputers. Due to the abstraction of XDL this approach is safe, secure, and scalable since hallucinations will not be chemputable and the XDL can be both verified and encrypted. Unlike previous efforts, which either addressed only a limited portion of the workflow, relied on inflexible hard-coded rules, or lacked validation in physical systems, our approach provides four realistic examples of syntheses directly executed from synthetic literature. We anticipate that our workflow will significantly enhance automation in robotically driven synthetic chemistry research, streamline data extraction, improve the reproducibility, scalability, and safety of synthetic and experimental chemistry.
+
+
+
+ 87. 【2410.06370】HumVI: A Multilingual Dataset for Detecting Violent Incidents Impacting Humanitarian Aid
+ 链接:https://arxiv.org/abs/2410.06370
+ 作者:Hemank Lamba,Anton Abilov,Ke Zhang,Elizabeth M. Olson,Henry k. Dambanemuya,João c. Bárcia,David S. Batista,Christina Wille,Aoife Cahill,Joel Tetreault,Alex Jaimes
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Social and Information Networks (cs.SI)
+ 关键词:gather aggregated insights, support decision-making, discover trends, gather aggregated, funding proposals
+ 备注:
+
+ 点击查看摘要
+ Abstract:Humanitarian organizations can enhance their effectiveness by analyzing data to discover trends, gather aggregated insights, manage their security risks, support decision-making, and inform advocacy and funding proposals. However, data about violent incidents with direct impact and relevance for humanitarian aid operations is not readily available. An automatic data collection and NLP-backed classification framework aligned with humanitarian perspectives can help bridge this gap. In this paper, we present HumVI - a dataset comprising news articles in three languages (English, French, Arabic) containing instances of different types of violent incidents categorized by the humanitarian sector they impact, e.g., aid security, education, food security, health, and protection. Reliable labels were obtained for the dataset by partnering with a data-backed humanitarian organization, Insecurity Insight. We provide multiple benchmarks for the dataset, employing various deep learning architectures and techniques, including data augmentation and mask loss, to address different task-related challenges, e.g., domain expansion. The dataset is publicly available at this https URL.
+
+
+
+ 88. 【2410.06338】Are Large Language Models State-of-the-art Quality Estimators for Machine Translation of User-generated Content?
+ 链接:https://arxiv.org/abs/2410.06338
+ 作者:Shenbin Qian,Constantin Orăsan,Diptesh Kanojia,Félix do Carmo
+ 类目:Computation and Language (cs.CL)
+ 关键词:Multi-dimensional Quality Metrics, large language models, user-generated content, emotional expressions, paper investigates
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper investigates whether large language models (LLMs) are state-of-the-art quality estimators for machine translation of user-generated content (UGC) that contains emotional expressions, without the use of reference translations. To achieve this, we employ an existing emotion-related dataset with human-annotated errors and calculate quality evaluation scores based on the Multi-dimensional Quality Metrics. We compare the accuracy of several LLMs with that of our fine-tuned baseline models, under in-context learning and parameter-efficient fine-tuning (PEFT) scenarios. We find that PEFT of LLMs leads to better performance in score prediction with human interpretable explanations than fine-tuned models. However, a manual analysis of LLM outputs reveals that they still have problems such as refusal to reply to a prompt and unstable output while evaluating machine translation of UGC.
+
+
+
+ 89. 【2410.06331】Locate-then-edit for Multi-hop Factual Recall under Knowledge Editing
+ 链接:https://arxiv.org/abs/2410.06331
+ 作者:Zhuoran Zhang,Yongxiang Li,Zijian Kan,Keyuan Cheng,Lijie Hu,Di Wang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Large Language Models, Language Models, Large Language, shown significant promise, paradigm has shown
+ 备注: 21 pages
+
+ 点击查看摘要
+ Abstract:The locate-then-edit paradigm has shown significant promise for knowledge editing (KE) in Large Language Models (LLMs). While previous methods perform well on single-hop fact recall tasks, they consistently struggle with multi-hop factual recall tasks involving newly edited knowledge. In this paper, leveraging tools in mechanistic interpretability, we first identify that in multi-hop tasks, LLMs tend to retrieve implicit subject knowledge from deeper MLP layers, unlike single-hop tasks, which rely on earlier layers. This distinction explains the poor performance of current methods in multi-hop queries, as they primarily focus on editing shallow layers, leaving deeper layers unchanged. To address this, we propose IFMET, a novel locate-then-edit KE approach designed to edit both shallow and deep MLP layers. IFMET employs multi-hop editing prompts and supplementary sets to locate and modify knowledge across different reasoning stages. Experimental results demonstrate that IFMET significantly improves performance on multi-hop factual recall tasks, effectively overcoming the limitations of previous locate-then-edit methods.
+
+
+
+ 90. 【2410.06328】Auto-Evolve: Enhancing Large Language Model's Performance via Self-Reasoning Framework
+ 链接:https://arxiv.org/abs/2410.06328
+ 作者:Krishna Aswani,Huilin Lu,Pranav Patankar,Priya Dhalwani,Iris Tan,Jayant Ganeshmohan,Simon Lacasse
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Large Language Models, Recent advancements, Large Language, demonstrated significant potential, Language Models
+ 备注: Accepted at EMNLP 2024
+
+ 点击查看摘要
+ Abstract:Recent advancements in prompt engineering strategies, such as Chain-of-Thought (CoT) and Self-Discover, have demonstrated significant potential in improving the reasoning abilities of Large Language Models (LLMs). However, these state-of-the-art (SOTA) prompting strategies rely on single or fixed set of static seed reasoning modules like \emph{"think step by step"} or \emph{"break down this problem"} intended to simulate human approach to problem-solving. This constraint limits the flexibility of models in tackling diverse problems effectively. In this paper, we introduce Auto-Evolve, a novel framework that enables LLMs to self-create dynamic reasoning modules and downstream action plan, resulting in significant improvements over current SOTA methods. We evaluate Auto-Evolve on the challenging BigBench-Hard (BBH) dataset with Claude 2.0, Claude 3 Sonnet, Mistral Large, and GPT 4, where it consistently outperforms the SOTA prompt strategies. Auto-Evolve outperforms CoT by up to 10.4\% and on an average by 7\% across these four models. Our framework introduces two innovations: a) Auto-Evolve dynamically generates reasoning modules for each task while aligning with human reasoning paradigm, thus eliminating the need for predefined templates. b) We introduce an iterative refinement component, that incrementally refines instruction guidance for LLMs and helps boost performance by average 2.8\% compared to doing it in a single step.
+
+
+
+ 91. 【2410.06314】mporal Image Caption Retrieval Competition -- Description and Results
+ 链接:https://arxiv.org/abs/2410.06314
+ 作者:Jakub Pokrywka,Piotr Wierzchoń,Kornel Weryszko,Krzysztof Jassem
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:gained significant recognition, recently gained significant, textual information, significant recognition, Multimodal models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multimodal models, which combine visual and textual information, have recently gained significant recognition. This paper addresses the multimodal challenge of Text-Image retrieval and introduces a novel task that extends the modalities to include temporal data. The Temporal Image Caption Retrieval Competition (TICRC) presented in this paper is based on the Chronicling America and Challenging America projects, which offer access to an extensive collection of digitized historic American newspapers spanning 274 years. In addition to the competition results, we provide an analysis of the delivered dataset and the process of its creation.
+
+
+
+ 92. 【2410.06304】Fine-grained Hallucination Detection and Mitigation in Language Model Mathematical Reasoning
+ 链接:https://arxiv.org/abs/2410.06304
+ 作者:Ruosen Li,Ziming Luo,Xinya Du
+ 类目:Computation and Language (cs.CL)
+ 关键词:pose significant challenges, requiring complex multi-step, large language models, tasks requiring complex, complex multi-step reasoning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Hallucinations in large language models (LLMs) pose significant challenges in tasks requiring complex multi-step reasoning, such as mathematical problem-solving. Existing approaches primarily detect the presence of hallucinations but lack a nuanced understanding of their types and manifestations. In this paper, we first introduce a comprehensive taxonomy that categorizes the common hallucinations in mathematical reasoning task into six types: fabrication, factual inconsistency, context inconsistency, instruction inconsistency, logical inconsistency, and logical error. We then propose FG-PRM (Fine-Grained Process Reward Model), an augmented model designed to detect and mitigate hallucinations in a fine-grained, step-level manner. To address the limitations of manually labeling training data, we propose an automated method for generating fine-grained hallucination data using LLMs. By injecting hallucinations into reasoning steps of correct solutions, we create a diverse and balanced synthetic dataset for training FG-PRM, which consists of six specialized Process Reward Models (PRMs), each tailored to detect a specific hallucination type. Our FG-PRM demonstrates superior performance across two key tasks: 1) Fine-grained hallucination detection: classifying hallucination types for each reasoning step; and 2) Verification: ranking multiple LLM-generated outputs to select the most accurate solution, mitigating reasoning hallucinations. Our experiments show that FG-PRM outperforms ChatGPT-3.5 and Claude-3 on fine-grained hallucination detection and substantially boosts the performance of LLMs on GSM8K and MATH benchmarks.
+
+
+
+ 93. 【2410.06293】Accelerated Preference Optimization for Large Language Model Alignment
+ 链接:https://arxiv.org/abs/2410.06293
+ 作者:Jiafan He,Huizhuo Yuan,Quanquan Gu
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Reinforcement Learning, Human Feedback, large language models, aligning large language, Preference Optimization
+ 备注: 44 pages, 10 tables
+
+ 点击查看摘要
+ Abstract:Reinforcement Learning from Human Feedback (RLHF) has emerged as a pivotal tool for aligning large language models (LLMs) with human preferences. Direct Preference Optimization (DPO), one of the most popular approaches, formulates RLHF as a policy optimization problem without explicitly estimating the reward function. It overcomes the stability and efficiency issues of two-step approaches, which typically involve first estimating the reward function and then optimizing the policy via proximal policy optimization (PPO). Since RLHF is essentially an optimization problem, and it is well-known that momentum techniques can accelerate optimization both theoretically and empirically, a natural question arises: Can RLHF be accelerated by momentum? This paper answers this question in the affirmative. In detail, we first show that the iterative preference optimization method can be viewed as a proximal point method. Based on this observation, we propose a general Accelerated Preference Optimization (APO) framework, which unifies many existing preference optimization algorithms and employs Nesterov's momentum technique to speed up the alignment of LLMs. Theoretically, we demonstrate that APO can achieve a faster convergence rate than the standard iterative preference optimization methods, including DPO and Self-Play Preference Optimization (SPPO). Empirically, we show the superiority of APO over DPO, iterative DPO, and other strong baselines for RLHF on the AlpacaEval 2.0 benchmark.
+
+
+
+ 94. 【2410.06287】Non-Halting Queries: Exploiting Fixed Points in LLMs
+ 链接:https://arxiv.org/abs/2410.06287
+ 作者:Ghaith Hammouri,Kemal Derya,Berk Sunar
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:non-halting, vulnerability that exploits, non-halting anomaly, call non-halting queries, exploits fixed points
+ 备注:
+
+ 点击查看摘要
+ Abstract:We introduce a new vulnerability that exploits fixed points in autoregressive models and use it to craft queries that never halt, i.e. an LLM output that does not terminate. More precisely, for what we call non-halting queries, the LLM never samples the end-of-string token (eos). We rigorously analyze the conditions under which the non-halting anomaly presents itself. In particular, at temperature zero, we prove that if a repeating (cyclic) sequence of tokens is observed at the output beyond the context size, then the LLM does not halt.
+We demonstrate the non-halting anomaly in a number of experiments performed in base (unaligned) models where repeating tokens immediately lead to a non-halting cyclic behavior as predicted by the analysis. Further, we develop a simple recipe that takes the same fixed points observed in the base model and creates a prompt structure to target aligned models. We study the recipe behavior in bypassing alignment in a number of LLMs including GPT-4o, llama-3-8b-instruct, and gemma-2-9b-it where all models are forced into a non-halting state. Further, we demonstrate the recipe's success in sending most major models released over the past year into a non-halting state with the same simple prompt even at higher temperatures. Further, we study direct inversion based techniques to craft new short prompts to induce the non-halting state. Our experiments with the gradient search based inversion technique ARCA show that non-halting is prevalent across models and may be easily induced with a few input tokens.
+While its impact on the reliability of hosted systems can be mitigated by configuring a hard maximum token limit in the sampler, the non-halting anomaly still manages to break alignment. This underlines the need for further studies and stronger forms of alignment against non-halting anomalies.
+
Subjects:
+Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+Cite as:
+arXiv:2410.06287 [cs.LG]
+(or
+arXiv:2410.06287v1 [cs.LG] for this version)
+https://doi.org/10.48550/arXiv.2410.06287
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 95. 【2410.06272】he Mystery of Compositional Generalization in Graph-based Generative Commonsense Reasoning
+ 链接:https://arxiv.org/abs/2410.06272
+ 作者:Xiyan Fu,Anette Frank
+ 类目:Computation and Language (cs.CL)
+ 关键词:Graph-based Commonsense Reasoning, compositional generalization, compositional generalization capabilities, Graph-based Commonsense, reasoning tasks
+ 备注: Accepted Findings at EMNLP 2024
+
+ 点击查看摘要
+ Abstract:While LLMs have emerged as performant architectures for reasoning tasks, their compositional generalization capabilities have been questioned. In this work, we introduce a Compositional Generalization Challenge for Graph-based Commonsense Reasoning (CGGC) that goes beyond previous evaluations that are based on sequences or tree structures - and instead involves a reasoning graph: It requires models to generate a natural sentence based on given concepts and a corresponding reasoning graph, where the presented graph involves a previously unseen combination of relation types. To master this challenge, models need to learn how to reason over relation tupels within the graph, and how to compose them when conceptualizing a verbalization. We evaluate seven well-known LLMs using in-context learning and find that performant LLMs still struggle in compositional generalization. We investigate potential causes of this gap by analyzing the structures of reasoning graphs, and find that different structures present varying levels of difficulty for compositional generalization. Arranging the order of demonstrations according to the structures' difficulty shows that organizing samples in an easy-to-hard schema enhances the compositional generalization ability of LLMs.
+
+
+
+ 96. 【2410.06271】Probing the Robustness of Theory of Mind in Large Language Models
+ 链接:https://arxiv.org/abs/2410.06271
+ 作者:Christian Nickel,Laura Schrewe,Lucie Flek
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Theory of Mind, social reasoning capabilities, similarly sized SotA, claims of emergent, scientific literature
+ 备注:
+
+ 点击查看摘要
+ Abstract:With the success of ChatGPT and other similarly sized SotA LLMs, claims of emergent human like social reasoning capabilities, especially Theory of Mind (ToM), in these models have appeared in the scientific literature. On the one hand those ToM-capabilities have been successfully tested using tasks styled similar to those used in psychology (Kosinski, 2023). On the other hand, follow up studies showed that those capabilities vanished when the tasks were slightly altered (Ullman, 2023). In this work we introduce a novel dataset of 68 tasks for probing ToM in LLMs, including potentially challenging variations which are assigned to 10 complexity classes. This way it is providing novel insights into the challenges LLMs face with those task variations. We evaluate the ToM performance of four SotA open source LLMs on our dataset and the dataset introduced by (Kosinski, 2023). The overall low goal accuracy across all evaluated models indicates only a limited degree of ToM capabilities. The LLMs' performance on simple complexity class tasks from both datasets are similar. Whereas we find a consistent tendency in all tested LLMs to perform poorly on tasks that require the realization that an agent has knowledge of automatic state changes in its environment, even when those are spelled out to the model. For task complications that change the relationship between objects by replacing prepositions, we notice a performance drop in all models, with the strongest impact on the mixture-of-experts model. With our dataset of tasks grouped by complexity we offer directions for further research on how to stabilize and advance ToM capabilities in LLM.
+
+
+
+ 97. 【2410.06270】MC-MoE: Mixture Compressor for Mixture-of-Experts LLMs Gains More
+ 链接:https://arxiv.org/abs/2410.06270
+ 作者:Wei Huang,Yue Liao,Jianhui Liu,Ruifei He,Haoru Tan,Shiming Zhang,Hongsheng Li,Si Liu,Xiaojuan Qi
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:significant step forward, considerable memory consumption, large language models, large language, language models
+ 备注: 18 pages
+
+ 点击查看摘要
+ Abstract:Mixture-of-Experts large language models (MoE-LLMs) marks a significant step forward of language models, however, they encounter two critical challenges in practice: 1) expert parameters lead to considerable memory consumption and loading latency; and 2) the current activated experts are redundant, as many tokens may only require a single expert. Motivated by these issues, we investigate the MoE-LLMs and make two key observations: a) different experts exhibit varying behaviors on activation reconstruction error, routing scores, and activated frequencies, highlighting their differing importance, and b) not all tokens are equally important -- only a small subset is critical. Building on these insights, we propose MC-MoE, a training-free Mixture-Compressor for MoE-LLMs, which leverages the significance of both experts and tokens to achieve an extreme compression. First, to mitigate storage and loading overheads, we introduce Pre-Loading Mixed-Precision Quantization, which formulates the adaptive bit-width allocation as a Linear Programming problem, where the objective function balances multi-factors reflecting the importance of each expert. Additionally, we develop Online Dynamic Pruning, which identifies important tokens to retain and dynamically select activated experts for other tokens during inference to optimize efficiency while maintaining performance. Our MC-MoE integrates static quantization and dynamic pruning to collaboratively achieve extreme compression for MoE-LLMs with less accuracy loss, ensuring an optimal trade-off between performance and efficiency. Extensive experiments confirm the effectiveness of our approach. For instance, at 2.54 bits, MC-MoE compresses 76.6% of the model, with only a 3.8% average accuracy loss. During dynamic inference, we further reduce activated parameters by 15%, with a performance drop of less than 0.6%.
+
+
+
+ 98. 【2410.06264】hink While You Generate: Discrete Diffusion with Planned Denoising
+ 链接:https://arxiv.org/abs/2410.06264
+ 作者:Sulin Liu,Juno Nam,Andrew Campbell,Hannes Stärk,Yilun Xu,Tommi Jaakkola,Rafael Gómez-Bombarelli
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)
+ 关键词:Discrete diffusion, introduce Discrete Diffusion, outperforming or approaching, approaching autoregressive models, Discrete
+ 备注:
+
+ 点击查看摘要
+ Abstract:Discrete diffusion has achieved state-of-the-art performance, outperforming or approaching autoregressive models on standard benchmarks. In this work, we introduce Discrete Diffusion with Planned Denoising (DDPD), a novel framework that separates the generation process into two models: a planner and a denoiser. At inference time, the planner selects which positions to denoise next by identifying the most corrupted positions in need of denoising, including both initially corrupted and those requiring additional refinement. This plan-and-denoise approach enables more efficient reconstruction during generation by iteratively identifying and denoising corruptions in the optimal order. DDPD outperforms traditional denoiser-only mask diffusion methods, achieving superior results on language modeling benchmarks such as text8, OpenWebText, and token-based generation on ImageNet $256 \times 256$. Notably, in language modeling, DDPD significantly reduces the performance gap between diffusion-based and autoregressive methods in terms of generative perplexity. Code is available at this https URL.
+
+
+
+ 99. 【2410.06243】Unsupervised Model Diagnosis
+ 链接:https://arxiv.org/abs/2410.06243
+ 作者:Yinong Oliver Wang,Eileen Li,Jinqi Luo,Zhaoning Wang,Fernando De la Torre
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Ensuring model explainability, deep vision systems, Ensuring model, essential for reliable, reliable deployment
+ 备注: 9 pages, 9 figures, 3 tables
+
+ 点击查看摘要
+ Abstract:Ensuring model explainability and robustness is essential for reliable deployment of deep vision systems. Current methods for evaluating robustness rely on collecting and annotating extensive test sets. While this is common practice, the process is labor-intensive and expensive with no guarantee of sufficient coverage across attributes of interest. Recently, model diagnosis frameworks have emerged leveraging user inputs (e.g., text) to assess the vulnerability of the model. However, such dependence on human can introduce bias and limitation given the domain knowledge of particular users. This paper proposes Unsupervised Model Diagnosis (UMO), that leverages generative models to produce semantic counterfactual explanations without any user guidance. Given a differentiable computer vision model (i.e., the target model), UMO optimizes for the most counterfactual directions in a generative latent space. Our approach identifies and visualizes changes in semantics, and then matches these changes to attributes from wide-ranging text sources, such as dictionaries or language models. We validate the framework on multiple vision tasks (e.g., classification, segmentation, keypoint detection). Extensive experiments show that our unsupervised discovery of semantic directions can correctly highlight spurious correlations and visualize the failure mode of target models without any human intervention.
+
+
+
+ 100. 【2410.06238】EVOLvE: Evaluating and Optimizing LLMs For Exploration
+ 链接:https://arxiv.org/abs/2410.06238
+ 作者:Allen Nie,Yi Su,Bo Chang,Jonathan N. Lee,Ed H. Chi,Quoc V. Le,Minmin Chen
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:scenarios requiring optimal, requiring optimal decision-making, large language models, make optimal decisions, large language
+ 备注: 28 pages
+
+ 点击查看摘要
+ Abstract:Despite their success in many domains, large language models (LLMs) remain under-studied in scenarios requiring optimal decision-making under uncertainty. This is crucial as many real-world applications, ranging from personalized recommendations to healthcare interventions, demand that LLMs not only predict but also actively learn to make optimal decisions through exploration. In this work, we measure LLMs' (in)ability to make optimal decisions in bandits, a state-less reinforcement learning setting relevant to many applications. We develop a comprehensive suite of environments, including both context-free and contextual bandits with varying task difficulties, to benchmark LLMs' performance. Motivated by the existence of optimal exploration algorithms, we propose efficient ways to integrate this algorithmic knowledge into LLMs: by providing explicit algorithm-guided support during inference; and through algorithm distillation via in-context demonstrations and fine-tuning, using synthetic data generated from these algorithms. Impressively, these techniques allow us to achieve superior exploration performance with smaller models, surpassing larger models on various tasks. We conducted an extensive ablation study to shed light on various factors, such as task difficulty and data representation, that influence the efficiency of LLM exploration. Additionally, we conduct a rigorous analysis of the LLM's exploration efficiency using the concept of regret, linking its ability to explore to the model size and underlying algorithm.
+
+
+
+ 101. 【2410.06215】DataEnvGym: Data Generation Agents in Teacher Environments with Student Feedback
+ 链接:https://arxiv.org/abs/2410.06215
+ 作者:Zaid Khan,Elias Stengel-Eskin,Jaemin Cho,Mohit Bansal
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:analyze model weaknesses, manually analyze model, data generation, data, data generation agents
+ 备注: Project Page: [this https URL](https://DataEnvGym.github.io)
+
+ 点击查看摘要
+ Abstract:The process of creating training data to teach models is currently driven by humans, who manually analyze model weaknesses and plan how to create data that improves a student model. Recent approaches using LLMs as annotators reduce human effort, but still require humans to interpret feedback from evaluations and control the LLM to produce data the student needs. Automating this labor-intensive process by creating autonomous data generation agents - or teachers - is desirable, but requires environments that can simulate the feedback-driven, iterative, closed loop of data creation. To enable rapid and scalable testing for such agents and their modules, we introduce DataEnvGym, a testbed of teacher environments for data generation agents. DataEnvGym frames data generation as a sequential decision-making task, involving an agent consisting of a data generation policy (which generates a plan for creating training data) and a data generation engine (which transforms the plan into data), inside an environment that provides student feedback. The agent's goal is to improve student performance. Students are iteratively trained and evaluated on generated data, with their feedback (in the form of errors or weak skills) being reported to the agent after each iteration. DataEnvGym includes multiple teacher environment instantiations across 3 levels of structure in the state representation and action space. More structured environments are based on inferred skills and offer more interpretability and curriculum control. We support 3 diverse tasks (math, code, and VQA) and test multiple students and teachers. Example agents in our teaching environments can iteratively improve students across tasks and settings. Moreover, we show that environments teach different skill levels and test variants of key modules, pointing to future work in improving data generation agents, engines, and feedback mechanisms.
+
+
+
+ 102. 【2410.06205】Round and Round We Go! What makes Rotary Positional Encodings useful?
+ 链接:https://arxiv.org/abs/2410.06205
+ 作者:Federico Barbero,Alex Vitvitskyi,Christos Perivolaropoulos,Razvan Pascanu,Petar Veličković
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Transformer-based Large Language, Rotary Positional Encodings, Large Language Models, component of Transformer-based, Positional Encodings
+ 备注:
+
+ 点击查看摘要
+ Abstract:Positional Encodings (PEs) are a critical component of Transformer-based Large Language Models (LLMs), providing the attention mechanism with important sequence-position information. One of the most popular types of encoding used today in LLMs are Rotary Positional Encodings (RoPE), that rotate the queries and keys based on their relative distance. A common belief is that RoPE is useful because it helps to decay token dependency as relative distance increases. In this work, we argue that this is unlikely to be the core reason. We study the internals of a trained Gemma 7B model to understand how RoPE is being used at a mechanical level. We find that Gemma learns to use RoPE to construct robust "positional" attention patterns by exploiting the highest frequencies. We also find that, in general, Gemma greatly prefers to use the lowest frequencies of RoPE, which we suspect are used to carry semantic information. We mathematically prove interesting behaviours of RoPE and conduct experiments to verify our findings, proposing a modification of RoPE that fixes some highlighted issues and improves performance. We believe that this work represents an interesting step in better understanding PEs in LLMs, which we believe holds crucial value for scaling LLMs to large sizes and context lengths.
+
+
+
+ 103. 【2410.06203】Integrating Planning into Single-Turn Long-Form Text Generation
+ 链接:https://arxiv.org/abs/2410.06203
+ 作者:Yi Liang,You Wu,Honglei Zhuang,Li Chen,Jiaming Shen,Yiling Jia,Zhen Qin,Sumit Sanghai,Xuanhui Wang,Carl Yang,Michael Bendersky
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, Language Models, Large Language, in-depth textual documents, challenge for Large
+ 备注:
+
+ 点击查看摘要
+ Abstract:Generating high-quality, in-depth textual documents, such as academic papers, news articles, Wikipedia entries, and books, remains a significant challenge for Large Language Models (LLMs). In this paper, we propose to use planning to generate long form content. To achieve our goal, we generate intermediate steps via an auxiliary task that teaches the LLM to plan, reason and structure before generating the final text. Our main novelty lies in a single auxiliary task that does not require multiple rounds of prompting or planning. To overcome the scarcity of training data for these intermediate steps, we leverage LLMs to generate synthetic intermediate writing data such as outlines, key information and summaries from existing full articles. Our experiments demonstrate on two datasets from different domains, namely the scientific news dataset SciNews and Wikipedia datasets in KILT-Wiki and FreshWiki, that LLMs fine-tuned with the auxiliary task generate higher quality documents. We observed +2.5% improvement in ROUGE-Lsum, and a strong 3.60 overall win/loss ratio via human SxS evaluation, with clear wins in organization, relevance, and verifiability.
+
+
+
+ 104. 【2410.06195】Entering Real Social World! Benchmarking the Theory of Mind and Socialization Capabilities of LLMs from a First-person Perspective
+ 链接:https://arxiv.org/abs/2410.06195
+ 作者:Guiyang Hou,Wenqi Zhang,Yongliang Shen,Zeqi Tan,Sihao Shen,Weiming Lu
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Theory of Mind, socialization capabilities, mental states, mental states evolve, infer and reason
+ 备注: 15 pages, 5 figures
+
+ 点击查看摘要
+ Abstract:In the social world, humans possess the capability to infer and reason about others mental states (such as emotions, beliefs, and intentions), known as the Theory of Mind (ToM). Simultaneously, humans own mental states evolve in response to social situations, a capability we refer to as socialization. Together, these capabilities form the foundation of human social interaction. In the era of artificial intelligence (AI), especially with the development of large language models (LLMs), we raise an intriguing question: How do LLMs perform in terms of ToM and socialization capabilities? And more broadly, can these AI models truly enter and navigate the real social world? Existing research evaluating LLMs ToM and socialization capabilities by positioning LLMs as passive observers from a third person perspective, rather than as active participants. However, compared to the third-person perspective, observing and understanding the world from an egocentric first person perspective is a natural approach for both humans and AI agents. The ToM and socialization capabilities of LLMs from a first person perspective, a crucial attribute for advancing embodied AI agents, remain unexplored. To answer the aforementioned questions and bridge the research gap, we introduce EgoSocialArena, a novel framework designed to evaluate and investigate the ToM and socialization capabilities of LLMs from a first person perspective. It encompasses two evaluation environments: static environment and interactive environment, with seven scenarios: Daily Life, Counterfactual, New World, Blackjack, Number Guessing, and Limit Texas Hold em, totaling 2,195 data entries. With EgoSocialArena, we have conducted a comprehensive evaluation of nine advanced LLMs and observed some key insights regarding the future development of LLMs as well as the capabilities levels of the most advanced LLMs currently available.
+
+
+
+ 105. 【2410.06190】Neural-Bayesian Program Learning for Few-shot Dialogue Intent Parsing
+ 链接:https://arxiv.org/abs/2410.06190
+ 作者:Mengze Hong,Di Jiang,Yuanfeng Song,Chen Jason Zhang
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:contemporary business, success of enterprises, customer service, growing importance, importance of customer
+ 备注:
+
+ 点击查看摘要
+ Abstract:With the growing importance of customer service in contemporary business, recognizing the intents behind service dialogues has become essential for the strategic success of enterprises. However, the nature of dialogue data varies significantly across different scenarios, and implementing an intent parser for a specific domain often involves tedious feature engineering and a heavy workload of data labeling. In this paper, we propose a novel Neural-Bayesian Program Learning model named Dialogue-Intent Parser (DI-Parser), which specializes in intent parsing under data-hungry settings and offers promising performance improvements. DI-Parser effectively utilizes data from multiple sources in a "Learning to Learn" manner and harnesses the "wisdom of the crowd" through few-shot learning capabilities on human-annotated datasets. Experimental results demonstrate that DI-Parser outperforms state-of-the-art deep learning models and offers practical advantages for industrial-scale applications.
+
+
+
+ 106. 【2410.06173】Manual Verbalizer Enrichment for Few-Shot Text Classification
+ 链接:https://arxiv.org/abs/2410.06173
+ 作者:Quang Anh Nguyen,Nadi Tomeh,Mustapha Lebbah,Thierry Charnois,Hanene Azzag,Santiago Cordoba Muñoz
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:natural language processing, language processing tasks, pre-trained language models, prompt-based training, pre-trained language
+ 备注:
+
+ 点击查看摘要
+ Abstract:With the continuous development of pre-trained language models, prompt-based training becomes a well-adopted paradigm that drastically improves the exploitation of models for many natural language processing tasks. Prompting also shows great performance compared to traditional fine-tuning when adapted to zero-shot or few-shot scenarios where the number of annotated data is limited. In this framework, the role of verbalizers is essential, as an interpretation from masked word distributions into output predictions. In this work, we propose \acrshort{mave}, an approach for verbalizer construction by enrichment of class labels using neighborhood relation in the embedding space of words for the text classification task. In addition, we elaborate a benchmarking procedure to evaluate typical baselines of verbalizers for document classification in few-shot learning contexts. Our model achieves state-of-the-art results while using significantly fewer resources. We show that our approach is particularly effective in cases with extremely limited supervision data.
+
+
+
+ 107. 【2410.06172】Multimodal Situational Safety
+ 链接:https://arxiv.org/abs/2410.06172
+ 作者:Kaiwen Zhou,Chengzhi Liu,Xuandong Zhao,Anderson Compalas,Dawn Song,Xin Eric Wang
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Large Language Models, Multimodal Large Language, demonstrating impressive capabilities, Multimodal Situational Safety, Multimodal Large
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multimodal Large Language Models (MLLMs) are rapidly evolving, demonstrating impressive capabilities as multimodal assistants that interact with both humans and their environments. However, this increased sophistication introduces significant safety concerns. In this paper, we present the first evaluation and analysis of a novel safety challenge termed Multimodal Situational Safety, which explores how safety considerations vary based on the specific situation in which the user or agent is engaged. We argue that for an MLLM to respond safely, whether through language or action, it often needs to assess the safety implications of a language query within its corresponding visual context. To evaluate this capability, we develop the Multimodal Situational Safety benchmark (MSSBench) to assess the situational safety performance of current MLLMs. The dataset comprises 1,820 language query-image pairs, half of which the image context is safe, and the other half is unsafe. We also develop an evaluation framework that analyzes key safety aspects, including explicit safety reasoning, visual understanding, and, crucially, situational safety reasoning. Our findings reveal that current MLLMs struggle with this nuanced safety problem in the instruction-following setting and struggle to tackle these situational safety challenges all at once, highlighting a key area for future research. Furthermore, we develop multi-agent pipelines to coordinately solve safety challenges, which shows consistent improvement in safety over the original MLLM response. Code and data: this http URL.
+
+
+
+ 108. 【2410.06166】mporal Reasoning Transfer from Text to Video
+ 链接:https://arxiv.org/abs/2410.06166
+ 作者:Lei Li,Yuanxin Liu,Linli Yao,Peiyuan Zhang,Chenxin An,Lean Wang,Xu Sun,Lingpeng Kong,Qi Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Video Large Language, Large Language Models, Large Language, shown promising capabilities, temporal reasoning
+ 备注: Project page: [this https URL](https://video-t3.github.io)
+
+ 点击查看摘要
+ Abstract:Video Large Language Models (Video LLMs) have shown promising capabilities in video comprehension, yet they struggle with tracking temporal changes and reasoning about temporal relationships. While previous research attributed this limitation to the ineffective temporal encoding of visual inputs, our diagnostic study reveals that video representations contain sufficient information for even small probing classifiers to achieve perfect accuracy. Surprisingly, we find that the key bottleneck in Video LLMs' temporal reasoning capability stems from the underlying LLM's inherent difficulty with temporal concepts, as evidenced by poor performance on textual temporal question-answering tasks. Building on this discovery, we introduce the Textual Temporal reasoning Transfer (T3). T3 synthesizes diverse temporal reasoning tasks in pure text format from existing image-text datasets, addressing the scarcity of video samples with complex temporal scenarios. Remarkably, without using any video data, T3 enhances LongVA-7B's temporal understanding, yielding a 5.3 absolute accuracy improvement on the challenging TempCompass benchmark, which enables our model to outperform ShareGPT4Video-8B trained on 28,000 video samples. Additionally, the enhanced LongVA-7B model achieves competitive performance on comprehensive video benchmarks. For example, it achieves a 49.7 accuracy on the Temporal Reasoning task of Video-MME, surpassing powerful large-scale models such as InternVL-Chat-V1.5-20B and VILA1.5-40B. Further analysis reveals a strong correlation between textual and video temporal task performance, validating the efficacy of transferring temporal reasoning abilities from text to video domains.
+
+
+
+ 109. 【2410.06153】AgentSquare: Automatic LLM Agent Search in Modular Design Space
+ 链接:https://arxiv.org/abs/2410.06153
+ 作者:Yu Shang,Yu Li,Keyu Zhao,Likai Ma,Jiahe Liu,Fengli Xu,Yong Li
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, Recent advancements, advancements in Large, LLM Agent Search
+ 备注: 26 pages
+
+ 点击查看摘要
+ Abstract:Recent advancements in Large Language Models (LLMs) have led to a rapid growth of agentic systems capable of handling a wide range of complex tasks. However, current research largely relies on manual, task-specific design, limiting their adaptability to novel tasks. In this paper, we introduce a new research problem: Modularized LLM Agent Search (MoLAS). We propose a modular design space that abstracts existing LLM agent designs into four fundamental modules with uniform IO interface: Planning, Reasoning, Tool Use, and Memory. Building on this design space, we present a novel LLM agent search framework called AgentSquare, which introduces two core mechanisms, i.e., module evolution and recombination, to efficiently search for optimized LLM agents. To further accelerate the process, we design a performance predictor that uses in-context surrogate models to skip unpromising agent designs. Extensive experiments across six benchmarks, covering the diverse scenarios of web, embodied, tool use and game applications, show that AgentSquare substantially outperforms hand-crafted agents, achieving an average performance gain of 17.2% against best-known human designs. Moreover, AgentSquare can generate interpretable design insights, enabling a deeper understanding of agentic architecture and its impact on task performance. We believe that the modular design space and AgentSquare search framework offer a platform for fully exploiting the potential of prior successful designs and consolidating the collective efforts of research community. Code repo is available at this https URL.
+
+
+
+ 110. 【2410.06121】Less is More: Making Smaller Language Models Competent Subgraph Retrievers for Multi-hop KGQA
+ 链接:https://arxiv.org/abs/2410.06121
+ 作者:Wenyu Huang,Guancheng Zhou,Hongru Wang,Pavlos Vougiouklis,Mirella Lapata,Jeff Z. Pan
+ 类目:Computation and Language (cs.CL)
+ 关键词:inject external non-parametric, external non-parametric knowledge, Knowledge Graphs, valuable external knowledge, non-parametric knowledge
+ 备注: Accepted by EMNLP 2024 Findings
+
+ 点击查看摘要
+ Abstract:Retrieval-Augmented Generation (RAG) is widely used to inject external non-parametric knowledge into large language models (LLMs). Recent works suggest that Knowledge Graphs (KGs) contain valuable external knowledge for LLMs. Retrieving information from KGs differs from extracting it from document sets. Most existing approaches seek to directly retrieve relevant subgraphs, thereby eliminating the need for extensive SPARQL annotations, traditionally required by semantic parsing methods. In this paper, we model the subgraph retrieval task as a conditional generation task handled by small language models. Specifically, we define a subgraph identifier as a sequence of relations, each represented as a special token stored in the language models. Our base generative subgraph retrieval model, consisting of only 220M parameters, achieves competitive retrieval performance compared to state-of-the-art models relying on 7B parameters, demonstrating that small language models are capable of performing the subgraph retrieval task. Furthermore, our largest 3B model, when plugged with an LLM reader, sets new SOTA end-to-end performance on both the WebQSP and CWQ benchmarks. Our model and data will be made available online: this https URL.
+
+
+
+ 111. 【2410.06118】Optimizing the Training Schedule of Multilingual NMT using Reinforcement Learning
+ 链接:https://arxiv.org/abs/2410.06118
+ 作者:Alexis Allemann,Àlex R. Atrio,Andrei Popescu-Belis
+ 类目:Computation and Language (cs.CL)
+ 关键词:translating low-resource languages, viable solution, solution for translating, translating low-resource, data from high-resource
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multilingual NMT is a viable solution for translating low-resource languages (LRLs) when data from high-resource languages (HRLs) from the same language family is available. However, the training schedule, i.e. the order of presentation of languages, has an impact on the quality of such systems. Here, in a many-to-one translation setting, we propose to apply two algorithms that use reinforcement learning to optimize the training schedule of NMT: (1) Teacher-Student Curriculum Learning and (2) Deep Q Network. The former uses an exponentially smoothed estimate of the returns of each action based on the loss on monolingual or multilingual development subsets, while the latter estimates rewards using an additional neural network trained from the history of actions selected in different states of the system, together with the rewards received. On a 8-to-1 translation dataset with LRLs and HRLs, our second method improves BLEU and COMET scores with respect to both random selection of monolingual batches and shuffled multilingual batches, by adjusting the number of presentations of LRL vs. HRL batches.
+
+
+
+ 112. 【2410.06097】Decoding Decoded: Understanding Hyperparameter Effects in Open-Ended Text Generation
+ 链接:https://arxiv.org/abs/2410.06097
+ 作者:Esteban Garces Arias,Meimingwei Li,Christian Heumann,Matthias Aßenmacher
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:large language models, strategies for large, large language, underexplored aspect, Decoding strategies
+ 备注:
+
+ 点击查看摘要
+ Abstract:Decoding strategies for large language models (LLMs) are a critical but often underexplored aspect of text generation tasks. Since LLMs produce probability distributions over the entire vocabulary, various decoding methods have been developed to transform these probabilities into coherent and fluent text, each with its own set of hyperparameters. In this study, we present a large-scale, comprehensive analysis of how hyperparameter selection affects text quality in open-ended text generation across multiple LLMs, datasets, and evaluation metrics. Through an extensive sensitivity analysis, we provide practical guidelines for hyperparameter tuning and demonstrate the substantial influence of these choices on text quality. Using three established datasets, spanning factual domains (e.g., news) and creative domains (e.g., fiction), we show that hyperparameter tuning significantly impacts generation quality, though its effects vary across models and tasks. We offer in-depth insights into these effects, supported by both human evaluations and a synthesis of widely-used automatic evaluation metrics.
+
+
+
+ 113. 【2410.06094】Listen to the Patient: Enhancing Medical Dialogue Generation with Patient Hallucination Detection and Mitigation
+ 链接:https://arxiv.org/abs/2410.06094
+ 作者:Lang Qin,Yao Zhang,Hongru Liang,Adam Jatowt,Zhenglu Yang
+ 类目:Computation and Language (cs.CL)
+ 关键词:provide medical services, patient-agent conversations, dialogue systems aim, aim to provide, services through patient-agent
+ 备注:
+
+ 点击查看摘要
+ Abstract:Medical dialogue systems aim to provide medical services through patient-agent conversations. Previous methods typically regard patients as ideal users, focusing mainly on common challenges in dialogue systems, while neglecting the potential biases or misconceptions that might be introduced by real patients, who are typically non-experts. This study investigates the discrepancy between patients' expressions during medical consultations and their actual health conditions, defined as patient hallucination. Such phenomena often arise from patients' lack of knowledge and comprehension, concerns, and anxieties, resulting in the transmission of inaccurate or wrong information during consultations. To address this issue, we propose MedPH, a Medical dialogue generation method for mitigating the problem of Patient Hallucinations designed to detect and cope with hallucinations. MedPH incorporates a detection method that utilizes one-dimensional structural entropy over a temporal dialogue entity graph, and a mitigation strategy based on hallucination-related information to guide patients in expressing their actual conditions. Experimental results indicate the high effectiveness of MedPH when compared to existing approaches in both medical entity prediction and response generation tasks, while also demonstrating its effectiveness in mitigating hallucinations within interactive scenarios.
+
+
+
+ 114. 【2410.06089】OWER: Tree Organized Weighting for Evaluating Complex Instructions
+ 链接:https://arxiv.org/abs/2410.06089
+ 作者:Noah Ziems,Zhihan Zhang,Meng Jiang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Evaluating the ability, large language models, real-world applications, follow complex human-written, ability of large
+ 备注: Accepted to EMNLP 2024
+
+ 点击查看摘要
+ Abstract:Evaluating the ability of large language models (LLMs) to follow complex human-written instructions is essential for their deployment in real-world applications. While benchmarks like Chatbot Arena use human judges to assess model performance, they are resource-intensive and time-consuming. Alternative methods using LLMs as judges, such as AlpacaEval, MT Bench, WildBench, and InFoBench offer improvements but still do not capture that certain complex instruction aspects are more important than others to follow.
+To address this gap, we propose a novel evaluation metric, \textsc{TOWER}, that incorporates human-judged importance into the assessment of complex instruction following. We show that human annotators agree with tree-based representations of these complex instructions nearly as much as they agree with other human annotators. We release tree-based annotations of the InFoBench dataset and the corresponding evaluation code to facilitate future research.
+
Comments:
+Accepted to EMNLP 2024
+Subjects:
+Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+Cite as:
+arXiv:2410.06089 [cs.CL]
+(or
+arXiv:2410.06089v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2410.06089
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 115. 【2410.06072】raining-free LLM-generated Text Detection by Mining Token Probability Sequences
+ 链接:https://arxiv.org/abs/2410.06072
+ 作者:Yihuai Xu,Yongwei Wang,Yifei Bi,Huangsen Cao,Zhouhan Lin,Yu Zhao,Fei Wu
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large language models, Large language, generating high-quality texts, demonstrated remarkable capabilities, language models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) have demonstrated remarkable capabilities in generating high-quality texts across diverse domains. However, the potential misuse of LLMs has raised significant concerns, underscoring the urgent need for reliable detection of LLM-generated texts. Conventional training-based detectors often struggle with generalization, particularly in cross-domain and cross-model scenarios. In contrast, training-free methods, which focus on inherent discrepancies through carefully designed statistical features, offer improved generalization and interpretability. Despite this, existing training-free detection methods typically rely on global text sequence statistics, neglecting the modeling of local discriminative features, thereby limiting their detection efficacy. In this work, we introduce a novel training-free detector, termed \textbf{Lastde} that synergizes local and global statistics for enhanced detection. For the first time, we introduce time series analysis to LLM-generated text detection, capturing the temporal dynamics of token probability sequences. By integrating these local statistics with global ones, our detector reveals significant disparities between human and LLM-generated texts. We also propose an efficient alternative, \textbf{Lastde++} to enable real-time detection. Extensive experiments on six datasets involving cross-domain, cross-model, and cross-lingual detection scenarios, under both white-box and black-box settings, demonstrated that our method consistently achieves state-of-the-art performance. Furthermore, our approach exhibits greater robustness against paraphrasing attacks compared to existing baseline methods.
+
+
+
+ 116. 【2410.06024】Jet Expansions of Residual Computation
+ 链接:https://arxiv.org/abs/2410.06024
+ 作者:Yihong Chen,Xiangxiang Xu,Yao Lu,Pontus Stenetorp,Luca Franceschi
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Symbolic Computation (cs.SC)
+ 关键词:truncated Taylor series, generalize truncated Taylor, Taylor series, truncated Taylor, graphs using jets
+ 备注:
+
+ 点击查看摘要
+ Abstract:We introduce a framework for expanding residual computational graphs using jets, operators that generalize truncated Taylor series. Our method provides a systematic approach to disentangle contributions of different computational paths to model predictions. In contrast to existing techniques such as distillation, probing, or early decoding, our expansions rely solely on the model itself and requires no data, training, or sampling from the model. We demonstrate how our framework grounds and subsumes logit lens, reveals a (super-)exponential path structure in the recursive residual depth and opens up several applications. These include sketching a transformer large language model with $n$-gram statistics extracted from its computations, and indexing the models' levels of toxicity knowledge. Our approach enables data-free analysis of residual computation for model interpretability, development, and evaluation.
+
+
+
+ 117. 【2410.06022】Can Language Models Induce Grammatical Knowledge from Indirect Evidence?
+ 链接:https://arxiv.org/abs/2410.06022
+ 作者:Miyu Oba,Yohei Oseki,Akiyo Fukatsu,Akari Haga,Hiroki Ouchi,Taro Watanabe,Saku Sugawara
+ 类目:Computation and Language (cs.CL)
+ 关键词:indirect evidence, language, judge sentence acceptability, data, language models
+ 备注: This paper is accepted at EMNLP 2024 Main
+
+ 点击查看摘要
+ Abstract:What kinds of and how much data is necessary for language models to induce grammatical knowledge to judge sentence acceptability? Recent language models still have much room for improvement in their data efficiency compared to humans. This paper investigates whether language models efficiently use indirect data (indirect evidence), from which they infer sentence acceptability. In contrast, humans use indirect evidence efficiently, which is considered one of the inductive biases contributing to efficient language acquisition. To explore this question, we introduce the Wug InDirect Evidence Test (WIDET), a dataset consisting of training instances inserted into the pre-training data and evaluation instances. We inject synthetic instances with newly coined wug words into pretraining data and explore the model's behavior on evaluation data that assesses grammatical acceptability regarding those words. We prepare the injected instances by varying their levels of indirectness and quantity. Our experiments surprisingly show that language models do not induce grammatical knowledge even after repeated exposure to instances with the same structure but differing only in lexical items from evaluation instances in certain language phenomena. Our findings suggest a potential direction for future research: developing models that use latent indirect evidence to induce grammatical knowledge.
+
+
+
+ 118. 【2410.06019】Unveiling Transformer Perception by Exploring Input Manifolds
+ 链接:https://arxiv.org/abs/2410.06019
+ 作者:Alessandro Benfenati,Alfio Ferrara,Alessio Marta,Davide Riva,Elisabetta Rocchetti
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:input space, paper introduces, introduces a general, equivalence classes, Transformer models
+ 备注: 11 pages, 4 figures
+
+ 点击查看摘要
+ Abstract:This paper introduces a general method for the exploration of equivalence classes in the input space of Transformer models. The proposed approach is based on sound mathematical theory which describes the internal layers of a Transformer architecture as sequential deformations of the input manifold. Using eigendecomposition of the pullback of the distance metric defined on the output space through the Jacobian of the model, we are able to reconstruct equivalence classes in the input space and navigate across them. We illustrate how this method can be used as a powerful tool for investigating how a Transformer sees the input space, facilitating local and task-agnostic explainability in Computer Vision and Natural Language Processing tasks.
+
+
+
+ 119. 【2410.05983】Long-Context LLMs Meet RAG: Overcoming Challenges for Long Inputs in RAG
+ 链接:https://arxiv.org/abs/2410.05983
+ 作者:Bowen Jin,Jinsung Yoon,Jiawei Han,Sercan O. Arik
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:large language models, external knowledge sources, empowers large language, utilize external knowledge, Retrieval-augmented generation
+ 备注: 34 pages
+
+ 点击查看摘要
+ Abstract:Retrieval-augmented generation (RAG) empowers large language models (LLMs) to utilize external knowledge sources. The increasing capacity of LLMs to process longer input sequences opens up avenues for providing more retrieved information, to potentially enhance the quality of generated outputs. It is plausible to assume that a larger retrieval set would contain more relevant information (higher recall), that might result in improved performance. However, our empirical findings demonstrate that for many long-context LLMs, the quality of generated output initially improves first, but then subsequently declines as the number of retrieved passages increases. This paper investigates this phenomenon, identifying the detrimental impact of retrieved "hard negatives" as a key contributor. To mitigate this and enhance the robustness of long-context LLM-based RAG, we propose both training-free and training-based approaches. We first showcase the effectiveness of retrieval reordering as a simple yet powerful training-free optimization. Furthermore, we explore training-based methods, specifically RAG-specific implicit LLM fine-tuning and RAG-oriented fine-tuning with intermediate reasoning, demonstrating their capacity for substantial performance gains. Finally, we conduct a systematic analysis of design choices for these training-based methods, including data distribution, retriever selection, and training context length.
+
+
+
+ 120. 【2410.05970】PDF-WuKong: A Large Multimodal Model for Efficient Long PDF Reading with End-to-End Sparse Sampling
+ 链接:https://arxiv.org/abs/2410.05970
+ 作者:Xudong Xie,Liang Yin,Hao Yan,Yang Liu,Jing Ding,Minghui Liao,Yuliang Liu,Wei Chen,Xiang Bai
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:comprehend large amounts, long PDF documents, visual information, Large Language, process and comprehend
+ 备注:
+
+ 点击查看摘要
+ Abstract:Document understanding is a challenging task to process and comprehend large amounts of textual and visual information. Recent advances in Large Language Models (LLMs) have significantly improved the performance of this task. However, existing methods typically focus on either plain text or a limited number of document images, struggling to handle long PDF documents with interleaved text and images, especially in academic papers. In this paper, we introduce PDF-WuKong, a multimodal large language model (MLLM) which is designed to enhance multimodal question-answering (QA) for long PDF documents. PDF-WuKong incorporates a sparse sampler that operates on both text and image representations, significantly improving the efficiency and capability of the MLLM. The sparse sampler is integrated with the MLLM's image encoder and selects the paragraphs or diagrams most pertinent to user queries for processing by the language model. To effectively train and evaluate our model, we construct PaperPDF, a dataset consisting of a broad collection of academic papers sourced from arXiv, multiple strategies are proposed to generate automatically 1M QA pairs along with their corresponding evidence sources. Experimental results demonstrate the superiority and high efficiency of our approach over other models on the task of long multimodal PDF understanding, surpassing proprietary products by an average of 8.6% on F1. Our code and dataset will be released at this https URL.
+
+
+
+ 121. 【2410.05928】Beyond Captioning: Task-Specific Prompting for Improved VLM Performance in Mathematical Reasoning
+ 链接:https://arxiv.org/abs/2410.05928
+ 作者:Ayush Singh,Mansi Gupta,Shivank Garg,Abhinav Kumar,Vansh Agrawal
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Visual Question Answering, Question Answering, Visual Question, Vision-Language Models, tasks requiring visual
+ 备注:
+
+ 点击查看摘要
+ Abstract:Vision-Language Models (VLMs) have transformed tasks requiring visual and reasoning abilities, such as image retrieval and Visual Question Answering (VQA). Despite their success, VLMs face significant challenges with tasks involving geometric reasoning, algebraic problem-solving, and counting. These limitations stem from difficulties effectively integrating multiple modalities and accurately interpreting geometry-related tasks. Various works claim that introducing a captioning pipeline before VQA tasks enhances performance. We incorporated this pipeline for tasks involving geometry, algebra, and counting. We found that captioning results are not generalizable, specifically with larger VLMs primarily trained on downstream QnA tasks showing random performance on math-related challenges. However, we present a promising alternative: task-based prompting, enriching the prompt with task-specific guidance. This approach shows promise and proves more effective than direct captioning methods for math-heavy problems.
+
+
+
+ 122. 【2410.05915】Give me a hint: Can LLMs take a hint to solve math problems?
+ 链接:https://arxiv.org/abs/2410.05915
+ 作者:Vansh Agrawal,Pratham Singla,Amitoj Singh Miglani,Shivank Garg,Ayush Mangal
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:shown poor logical, basic mathematical reasoning, recent works, shown poor, poor logical
+ 备注:
+
+ 点击查看摘要
+ Abstract:While many state-of-the-art LLMs have shown poor logical and basic mathematical reasoning, recent works try to improve their problem-solving abilities using prompting techniques. We propose giving "hints" to improve the language model's performance on advanced mathematical problems, taking inspiration from how humans approach math pedagogically. We also test the model's adversarial robustness to wrong hints. We demonstrate the effectiveness of our approach by evaluating various LLMs, presenting them with a diverse set of problems of different difficulties and topics from the MATH dataset and comparing against techniques such as one-shot, few-shot, and chain of thought prompting.
+
+
+
+ 123. 【2410.05903】Automatic Summarization of Long Documents
+ 链接:https://arxiv.org/abs/2410.05903
+ 作者:Naman Chhibbar,Jugal Kalita
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:internet daily, making utilization, difficult and cumbersome, vast amount, amount of textual
+ 备注: 9 pages (including bibliography) with 6 figures. ACL 2023 proceedings format
+
+ 点击查看摘要
+ Abstract:A vast amount of textual data is added to the internet daily, making utilization and interpretation of such data difficult and cumbersome. As a result, automatic text summarization is crucial for extracting relevant information, saving precious reading time. Although many transformer-based models excel in summarization, they are constrained by their input size, preventing them from processing texts longer than their context size. This study introduces three novel algorithms that allow any LLM to efficiently overcome its input size limitation, effectively utilizing its full potential without any architectural modifications. We test our algorithms on texts with more than 70,000 words, and our experiments show a significant increase in BERTScore with competitive ROUGE scores.
+
+
+
+ 124. 【2410.05881】Edit Distances and Their Applications to Downstream Tasks in Research and Commercial Contexts
+ 链接:https://arxiv.org/abs/2410.05881
+ 作者:Félix do Carmo,Diptesh Kanojia
+ 类目:Computation and Language (cs.CL)
+ 关键词:Longest Common Subsequence, edit distances, edit distances applied, tutorial describes, describes the concept
+ 备注: Tutorial @ 16th AMTA Conference, 2024
+
+ 点击查看摘要
+ Abstract:The tutorial describes the concept of edit distances applied to research and commercial contexts. We use Translation Edit Rate (TER), Levenshtein, Damerau-Levenshtein, Longest Common Subsequence and $n$-gram distances to demonstrate the frailty of statistical metrics when comparing text sequences. Our discussion disassembles them into their essential components. We discuss the centrality of four editing actions: insert, delete, replace and move words, and show their implementations in openly available packages and toolkits. The application of edit distances in downstream tasks often assumes that these accurately represent work done by post-editors and real errors that need to be corrected in MT output. We discuss how imperfect edit distances are in capturing the details of this error correction work and the implications for researchers and for commercial applications, of these uses of edit distances. In terms of commercial applications, we discuss their integration in computer-assisted translation tools and how the perception of the connection between edit distances and post-editor effort affects the definition of translator rates.
+
+
+
+ 125. 【2410.05873】MEXA: Multilingual Evaluation of English-Centric LLMs via Cross-Lingual Alignment
+ 链接:https://arxiv.org/abs/2410.05873
+ 作者:Amir Hossein Kargaran,Ali Modarressi,Nafiseh Nikeghbal,Jana Diesner,François Yvon,Hinrich Schütze
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:English-centric large language, English-centric LLMs, strong multilingual capabilities, multilingual capabilities, English-centric
+ 备注:
+
+ 点击查看摘要
+ Abstract:English-centric large language models (LLMs) often show strong multilingual capabilities. However, the multilingual performance of these models remains unclear and is not thoroughly evaluated for many languages. Most benchmarks for multilinguality focus on classic NLP tasks, or cover a minimal number of languages. We introduce MEXA, a method for assessing the multilingual capabilities of pre-trained English-centric LLMs using parallel sentences, which are available for more languages than existing downstream tasks. MEXA leverages the fact that English-centric LLMs use English as a kind of pivot language in their intermediate layers. It computes the alignment between English and non-English languages using parallel sentences to evaluate the transfer of language understanding from English to other languages. This alignment can be used to estimate model performance in other languages. We conduct studies using various parallel datasets (FLORES-200 and Bible), models (Llama family, Gemma family, Mistral, and OLMo), and established downstream tasks (Belebele, m-MMLU, and m-ARC). We explore different methods to compute embeddings in decoder-only models. Our results show that MEXA, in its default settings, achieves a statistically significant average Pearson correlation of 0.90 with three established downstream tasks across nine models and two parallel datasets. This suggests that MEXA is a reliable method for estimating the multilingual capabilities of English-centric LLMs, providing a clearer understanding of their multilingual potential and the inner workings of LLMs. Leaderboard: this https URL, Code: this https URL.
+
+
+
+ 126. 【2410.05864】From Tokens to Words: on the inner lexicon of LLMs
+ 链接:https://arxiv.org/abs/2410.05864
+ 作者:Guy Kaplan,Matanel Oren,Yuval Reif,Roy Schwartz
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Natural language, language is composed, modern LLMs process, natural question raised, modern LLMs
+ 备注:
+
+ 点击查看摘要
+ Abstract:Natural language is composed of words, but modern LLMs process sub-words as input. A natural question raised by this discrepancy is whether LLMs encode words internally, and if so how. We present evidence that LLMs engage in an intrinsic detokenization process, where sub-word sequences are combined into coherent word representations. Our experiments show that this process takes place primarily within the early and middle layers of the model. They also show that it is robust to non-morphemic splits, typos and perhaps importantly-to out-of-vocabulary words: when feeding the inner representation of such words to the model as input vectors, it can "understand" them despite never seeing them during training. Our findings suggest that LLMs maintain a latent vocabulary beyond the tokenizer's scope. These insights provide a practical, finetuning-free application for expanding the vocabulary of pre-trained models. By enabling the addition of new vocabulary words, we reduce input length and inference iterations, which reduces both space and model latency, with little to no loss in model accuracy.
+
+
+
+ 127. 【2410.05851】Communicating with Speakers and Listeners of Different Pragmatic Levels
+ 链接:https://arxiv.org/abs/2410.05851
+ 作者:Kata Naszadi,Frans A. Oliehoek,Christof Monz
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:simulating language learning, explores the impact, impact of variable, conversing between speakers, speakers and listeners
+ 备注: EMNLP 2024 main
+
+ 点击查看摘要
+ Abstract:This paper explores the impact of variable pragmatic competence on communicative success through simulating language learning and conversing between speakers and listeners with different levels of reasoning abilities. Through studying this interaction, we hypothesize that matching levels of reasoning between communication partners would create a more beneficial environment for communicative success and language learning. Our research findings indicate that learning from more explicit, literal language is advantageous, irrespective of the learner's level of pragmatic competence. Furthermore, we find that integrating pragmatic reasoning during language learning, not just during evaluation, significantly enhances overall communication performance. This paper provides key insights into the importance of aligning reasoning levels and incorporating pragmatic reasoning in optimizing communicative interactions.
+
+
+
+ 128. 【2410.05824】Multi-Session Client-Centered Treatment Outcome Evaluation in Psychotherapy
+ 链接:https://arxiv.org/abs/2410.05824
+ 作者:Hongbin Na,Tao Shen,Shumao Yu,Ling Chen
+ 类目:Computation and Language (cs.CL)
+ 关键词:enhancing mental health, mental health care, evaluating therapeutic processes, systematically evaluating therapeutic, Psychological Assessment-based Evaluation
+ 备注: Under review
+
+ 点击查看摘要
+ Abstract:In psychotherapy, therapeutic outcome assessment, or treatment outcome evaluation, is essential for enhancing mental health care by systematically evaluating therapeutic processes and outcomes. Existing large language model approaches often focus on therapist-centered, single-session evaluations, neglecting the client's subjective experience and longitudinal progress across multiple sessions. To address these limitations, we propose IPAEval, a client-Informed Psychological Assessment-based Evaluation framework that automates treatment outcome evaluations from the client's perspective using clinical interviews. IPAEval integrates cross-session client-contextual assessment and session-focused client-dynamics assessment to provide a comprehensive understanding of therapeutic progress. Experiments on our newly developed TheraPhase dataset demonstrate that IPAEval effectively tracks symptom severity and treatment outcomes over multiple sessions, outperforming previous single-session models and validating the benefits of items-aware reasoning mechanisms.
+
+
+
+ 129. 【2410.05821】A Zero-Shot approach to the Conversational Tree Search Task
+ 链接:https://arxiv.org/abs/2410.05821
+ 作者:Dirk Väth,Ngoc Thang Vu
+ 类目:Computation and Language (cs.CL)
+ 关键词:Conversational Tree Search, task Conversational Tree, CTS, CTS agents, Tree Search
+ 备注:
+
+ 点击查看摘要
+ Abstract:In sensitive domains, such as legal or medial domains, the correctness of information given to users is critical. To address this, the recently introduced task Conversational Tree Search (CTS) provides a graph-based framework for controllable task-oriented dialog in sensitive domains. However, a big drawback of state-of-the-art CTS agents is their long training time, which is especially problematic as a new agent must be trained every time the associated domain graph is updated. The goal of this paper is to eliminate the need for training CTS agents altogether. To achieve this, we implement a novel LLM-based method for zero-shot, controllable CTS agents. We show that these agents significantly outperform state-of-the-art CTS agents (p0.0001; Barnard Exact test) in simulation. This generalizes to all available CTS domains. Finally, we perform user evaluation to test the agent performance in the wild, showing that our policy significantly (p0.05; Barnard Exact) improves task-success compared to the state-of-the-art Reinforcement Learning-based CTS agent.
+
+
+
+ 130. 【2410.05817】Probing Language Models on Their Knowledge Source
+ 链接:https://arxiv.org/abs/2410.05817
+ 作者:Zineddine Tighidet,Andrea Mogini,Jiali Mei,Benjamin Piwowarski,Patrick Gallinari
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, external knowledge provided, Language Models, provided during inference
+ 备注: Accepted at BlackBoxNLP@EMNLP2024
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) often encounter conflicts between their learned, internal (parametric knowledge, PK) and external knowledge provided during inference (contextual knowledge, CK). Understanding how LLMs models prioritize one knowledge source over the other remains a challenge. In this paper, we propose a novel probing framework to explore the mechanisms governing the selection between PK and CK in LLMs. Using controlled prompts designed to contradict the model's PK, we demonstrate that specific model activations are indicative of the knowledge source employed. We evaluate this framework on various LLMs of different sizes and demonstrate that mid-layer activations, particularly those related to relations in the input, are crucial in predicting knowledge source selection, paving the way for more reliable models capable of handling knowledge conflicts effectively.
+
+
+
+ 131. 【2410.05802】Gradual Learning: Optimizing Fine-Tuning with Partially Mastered Knowledge in Large Language Models
+ 链接:https://arxiv.org/abs/2410.05802
+ 作者:Bozhou Li,Hao Liang,Yang Li,Fangcheng Fu,Hongzhi Yin,Conghui He,Wentao Zhang
+ 类目:Computation and Language (cs.CL)
+ 关键词:extensive text corpora, large language models, model, knowledge, fine-tuning
+ 备注:
+
+ 点击查看摘要
+ Abstract:During the pretraining phase, large language models (LLMs) acquire vast amounts of knowledge from extensive text corpora. Nevertheless, in later stages such as fine-tuning and inference, the model may encounter knowledge not covered in the initial training, which can lead to hallucinations and degraded performance. This issue has a profound impact on the model's capabilities, as it will inevitably face out-of-scope knowledge after pretraining. Furthermore, fine-tuning is often required to adapt LLMs to domain-specific tasks. However, this phenomenon limits the model's ability to learn and integrate new information during fine-tuning. The effectiveness of fine-tuning largely depends on the type of knowledge involved. Existing research suggests that fine-tuning the model on partially mastered knowledge-for instance, question-answer pairs where the model has a chance of providing correct responses under non-greedy decoding-can enable the model to acquire new knowledge while mitigating hallucination. Notably, this approach can still lead to the forgetting of fully mastered knowledge, constraining the fine-tuning dataset to a narrower range and limiting the model's overall potential for improvement. Given the model's intrinsic reasoning abilities and the interconnectedness of different knowledge areas, it is likely that as the model's capacity to utilize existing knowledge improves during fine-tuning, previously unmastered knowledge may become more understandable. To explore this hypothesis, we conducted experiments and, based on the results, proposed a two-stage fine-tuning strategy. This approach not only improves the model's overall test accuracy and knowledge retention but also preserves its accuracy on previously mastered content. When fine-tuning on the WikiQA dataset, our method increases the amount of knowledge acquired by the model in this stage by 24%.
+
+
+
+ 132. 【2410.05801】Retrieving, Rethinking and Revising: The Chain-of-Verification Can Improve Retrieval Augmented Generation
+ 链接:https://arxiv.org/abs/2410.05801
+ 作者:Bolei He,Nuo Chen,Xinran He,Lingyong Yan,Zhenkai Wei,Jinchang Luo,Zhen-Hua Ling
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Recent Retrieval Augmented, Large Language Models, enhance Large Language, Retrieval Augmented Generation, Large Language
+ 备注: Accepted to EMNLP 2024 Findings. 9 pages, 4 figures, 7 tables
+
+ 点击查看摘要
+ Abstract:Recent Retrieval Augmented Generation (RAG) aims to enhance Large Language Models (LLMs) by incorporating extensive knowledge retrieved from external sources. However, such approach encounters some challenges: Firstly, the original queries may not be suitable for precise retrieval, resulting in erroneous contextual knowledge; Secondly, the language model can easily generate inconsistent answer with external references due to their knowledge boundary limitation. To address these issues, we propose the chain-of-verification (CoV-RAG) to enhance the external retrieval correctness and internal generation consistency. Specifically, we integrate the verification module into the RAG, engaging in scoring, judgment, and rewriting. To correct external retrieval errors, CoV-RAG retrieves new knowledge using a revised query. To correct internal generation errors, we unify QA and verification tasks with a Chain-of-Thought (CoT) reasoning during training. Our comprehensive experiments across various LLMs demonstrate the effectiveness and adaptability compared with other strong baselines. Especially, our CoV-RAG can significantly surpass the state-of-the-art baselines using different LLM backbones.
+
+
+
+ 133. 【2410.05797】CodeCipher: Learning to Obfuscate Source Code Against LLMs
+ 链接:https://arxiv.org/abs/2410.05797
+ 作者:Yalan Lin,Chengcheng Wan,Yixiong Fang,Xiaodong Gu
+ 类目:Computation and Language (cs.CL)
+ 关键词:made significant strides, large code language, code language models, made significant, significant strides
+ 备注:
+
+ 点击查看摘要
+ Abstract:While large code language models have made significant strides in AI-assisted coding tasks, there are growing concerns about privacy challenges. The user code is transparent to the cloud LLM service provider, inducing risks of unauthorized training, reading, and execution of the user code. In this paper, we propose CodeCipher, a novel method that perturbs privacy from code while preserving the original response from LLMs. CodeCipher transforms the LLM's embedding matrix so that each row corresponds to a different word in the original matrix, forming a token-to-token confusion mapping for obfuscating source code. The new embedding matrix is optimized by minimizing the task-specific loss function. To tackle the challenge of the discrete and sparse nature of word vector spaces, CodeCipher adopts a discrete optimization strategy that aligns the updated vector to the nearest valid token in the vocabulary before each gradient update. We demonstrate the effectiveness of our approach on three AI-assisted coding tasks including code completion, summarization, and translation. Results show that our model successfully confuses the privacy in source code while preserving the original LLM's performance.
+
+
+
+ 134. 【2410.05778】Song Emotion Classification of Lyrics with Out-of-Domain Data under Label Scarcity
+ 链接:https://arxiv.org/abs/2410.05778
+ 作者:Jonathan Sakunkoo,Annabella Sakunkoo
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:profoundly impact human, impact human emotions, Edmonds and Sedoc, found to profoundly, profoundly impact
+ 备注:
+
+ 点击查看摘要
+ Abstract:Songs have been found to profoundly impact human emotions, with lyrics having significant power to stimulate emotional changes in the audience. There is a scarcity of large, high quality in-domain datasets for lyrics-based song emotion classification (Edmonds and Sedoc, 2021; Zhou, 2022). It has been noted that in-domain training datasets are often difficult to acquire (Zhang and Miao, 2023) and that label acquisition is often limited by cost, time, and other factors (Azad et al., 2018). We examine the novel usage of a large out-of-domain dataset as a creative solution to the challenge of training data scarcity in the emotional classification of song lyrics. We find that CNN models trained on a large Reddit comments dataset achieve satisfactory performance and generalizability to lyrical emotion classification, thus giving insights into and a promising possibility in leveraging large, publicly available out-of-domain datasets for domains whose in-domain data are lacking or costly to acquire.
+
+
+
+ 135. 【2410.05770】Efficient Few-shot Learning for Multi-label Classification of Scientific Documents with Many Classes
+ 链接:https://arxiv.org/abs/2410.05770
+ 作者:Tim Schopf,Alexander Blatzheim,Nektarios Machner,Florian Matthes
+ 类目:Computation and Language (cs.CL)
+ 关键词:sentence embedding, Fusion-based Sentence Embedding, critical task, sentence embedding model, embedding
+ 备注: Accepted to the 7th International Conference on Natural Language and Speech Processing (ICNLSP 2024)
+
+ 点击查看摘要
+ Abstract:Scientific document classification is a critical task and often involves many classes. However, collecting human-labeled data for many classes is expensive and usually leads to label-scarce scenarios. Moreover, recent work has shown that sentence embedding model fine-tuning for few-shot classification is efficient, robust, and effective. In this work, we propose FusionSent (Fusion-based Sentence Embedding Fine-tuning), an efficient and prompt-free approach for few-shot classification of scientific documents with many classes. FusionSent uses available training examples and their respective label texts to contrastively fine-tune two different sentence embedding models. Afterward, the parameters of both fine-tuned models are fused to combine the complementary knowledge from the separate fine-tuning steps into a single model. Finally, the resulting sentence embedding model is frozen to embed the training instances, which are then used as input features to train a classification head. Our experiments show that FusionSent significantly outperforms strong baselines by an average of $6.0$ $F_{1}$ points across multiple scientific document classification datasets. In addition, we introduce a new dataset for multi-label classification of scientific documents, which contains 183,565 scientific articles and 130 classes from the arXiv category taxonomy. Code and data are available at this https URL.
+
+
+
+ 136. 【2410.05763】Information Discovery in e-Commerce
+ 链接:https://arxiv.org/abs/2410.05763
+ 作者:Zhaochun Ren,Xiangnan He,Dawei Yin,Maarten de Rijke
+ 类目:Information Retrieval (cs.IR); Computation and Language (cs.CL)
+ 关键词:http URL, Electronic commerce, http URL retrieval, goods and services, e-commerce
+ 备注:
+
+ 点击查看摘要
+ Abstract:Electronic commerce, or e-commerce, is the buying and selling of goods and services, or the transmitting of funds or data online. E-commerce platforms come in many kinds, with global players such as Amazon, Airbnb, Alibaba, this http URL, eBay, this http URL and platforms targeting specific geographic regions such as this http URL and this http URL retrieval has a natural role to play in e-commerce, especially in connecting people to goods and services. Information discovery in e-commerce concerns different types of search (e.g., exploratory search vs. lookup tasks), recommender systems, and natural language processing in e-commerce portals. The rise in popularity of e-commerce sites has made research on information discovery in e-commerce an increasingly active research area. This is witnessed by an increase in publications and dedicated workshops in this space. Methods for information discovery in e-commerce largely focus on improving the effectiveness of e-commerce search and recommender systems, on enriching and using knowledge graphs to support e-commerce, and on developing innovative question answering and bot-based solutions that help to connect people to goods and services. In this survey, an overview is given of the fundamental infrastructure, algorithms, and technical solutions for information discovery in e-commerce. The topics covered include user behavior and profiling, search, recommendation, and language technology in e-commerce.
+
+
+
+ 137. 【2410.05748】Label Confidence Weighted Learning for Target-level Sentence Simplification
+ 链接:https://arxiv.org/abs/2410.05748
+ 作者:Xinying Qiu,Jingshen Zhang
+ 类目:Computation and Language (cs.CL)
+ 关键词:language proficiency levels, Multi-level sentence simplification, varying language proficiency, generates simplified sentences, Multi-level sentence
+ 备注: Accepted to EMNLP 2024
+
+ 点击查看摘要
+ Abstract:Multi-level sentence simplification generates simplified sentences with varying language proficiency levels. We propose Label Confidence Weighted Learning (LCWL), a novel approach that incorporates a label confidence weighting scheme in the training loss of the encoder-decoder model, setting it apart from existing confidence-weighting methods primarily designed for classification. Experimentation on English grade-level simplification dataset shows that LCWL outperforms state-of-the-art unsupervised baselines. Fine-tuning the LCWL model on in-domain data and combining with Symmetric Cross Entropy (SCE) consistently delivers better simplifications compared to strong supervised methods. Our results highlight the effectiveness of label confidence weighting techniques for text simplification tasks with encoder-decoder architectures.
+
+
+
+ 138. 【2410.05714】Enhancing Temporal Modeling of Video LLMs via Time Gating
+ 链接:https://arxiv.org/abs/2410.05714
+ 作者:Zi-Yuan Hu,Yiwu Zhong,Shijia Huang,Michael R. Lyu,Liwei Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Video Large Language, Large Language Models, Large Language, video question answering, Video Large
+ 备注: EMNLP 2024 Findings (Short)
+
+ 点击查看摘要
+ Abstract:Video Large Language Models (Video LLMs) have achieved impressive performance on video-and-language tasks, such as video question answering. However, most existing Video LLMs neglect temporal information in video data, leading to struggles with temporal-aware video understanding. To address this gap, we propose a Time Gating Video LLM (TG-Vid) designed to enhance temporal modeling through a novel Time Gating module (TG). The TG module employs a time gating mechanism on its sub-modules, comprising gating spatial attention, gating temporal attention, and gating MLP. This architecture enables our model to achieve a robust understanding of temporal information within videos. Extensive evaluation of temporal-sensitive video benchmarks (i.e., MVBench, TempCompass, and NExT-QA) demonstrates that our TG-Vid model significantly outperforms the existing Video LLMs. Further, comprehensive ablation studies validate that the performance gains are attributed to the designs of our TG module. Our code is available at this https URL.
+
+
+
+ 139. 【2410.05698】A Two-Step Approach for Data-Efficient French Pronunciation Learning
+ 链接:https://arxiv.org/abs/2410.05698
+ 作者:Hoyeon Lee,Hyeeun Jang,Jong-Hwan Kim,Jae-Min Kim
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Recent studies, addressed intricate phonological, extensive linguistic knowledge, sentence-level pronunciation data, studies have addressed
+ 备注: Accepted at EMNLP 2024 Main
+
+ 点击查看摘要
+ Abstract:Recent studies have addressed intricate phonological phenomena in French, relying on either extensive linguistic knowledge or a significant amount of sentence-level pronunciation data. However, creating such resources is expensive and non-trivial. To this end, we propose a novel two-step approach that encompasses two pronunciation tasks: grapheme-to-phoneme and post-lexical processing. We then investigate the efficacy of the proposed approach with a notably limited amount of sentence-level pronunciation data. Our findings demonstrate that the proposed two-step approach effectively mitigates the lack of extensive labeled data, and serves as a feasible solution for addressing French phonological phenomena even under resource-constrained environments.
+
+
+
+ 140. 【2410.05695】Unlocking the Boundaries of Thought: A Reasoning Granularity Framework to Quantify and Optimize Chain-of-Thought
+ 链接:https://arxiv.org/abs/2410.05695
+ 作者:Qiguang Chen,Libo Qin,Jiaqi Wang,Jinxuan Zhou,Wanxiang Che
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language models, large language, complex reasoning tasks, CoT, reasoning
+ 备注: Accepted at NeurIPS2024 (Oral)
+
+ 点击查看摘要
+ Abstract:Chain-of-Thought (CoT) reasoning has emerged as a promising approach for enhancing the performance of large language models (LLMs) on complex reasoning tasks. Recently, a series of studies attempt to explain the mechanisms underlying CoT, aiming to deepen the understanding of its efficacy. Nevertheless, the existing research faces two major challenges: (1) a lack of quantitative metrics to assess CoT capabilities and (2) a dearth of guidance on optimizing CoT performance. Motivated by this, in this work, we introduce a novel reasoning granularity framework (RGF) to address these challenges. To solve the lack of quantification, we first define a reasoning granularity (RG) to quantify the upper bound of CoT and establish a combination law for RG, enabling a practical quantitative approach applicable to various real-world CoT tasks. To address the lack of optimization, we propose three categories of RGs. We further optimize these categories with combination laws focused on RG promotion and reasoning path optimization for CoT improvement. Through extensive experiments on 25 models and 4 tasks, the study validates the existence and rationality of the proposed framework. Furthermore, it explains the effectiveness of 10 CoT strategies and guides optimization from two perspectives. We hope this work can provide a comprehensive understanding of the boundaries and optimization strategies for reasoning in LLMs. Our code and data are available at this https URL.
+
+
+
+ 141. 【2410.05684】Copiloting Diagnosis of Autism in Real Clinical Scenarios via LLMs
+ 链接:https://arxiv.org/abs/2410.05684
+ 作者:Yi Jiang,Qingyang Shen,Shuzhong Lai,Shunyu Qi,Qian Zheng,Lin Yao,Yueming Wang,Gang Pan
+ 类目:Human-Computer Interaction (cs.HC); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Autism spectrum disorder, Autism Diagnostic Observation, pervasive developmental disorder, Diagnostic Observation Schedule, Autism spectrum
+ 备注:
+
+ 点击查看摘要
+ Abstract:Autism spectrum disorder(ASD) is a pervasive developmental disorder that significantly impacts the daily functioning and social participation of individuals. Despite the abundance of research focused on supporting the clinical diagnosis of ASD, there is still a lack of systematic and comprehensive exploration in the field of methods based on Large Language Models (LLMs), particularly regarding the real-world clinical diagnostic scenarios based on Autism Diagnostic Observation Schedule, Second Edition (ADOS-2). Therefore, we have proposed a framework called ADOS-Copilot, which strikes a balance between scoring and explanation and explored the factors that influence the performance of LLMs in this task. The experimental results indicate that our proposed framework is competitive with the diagnostic results of clinicians, with a minimum MAE of 0.4643, binary classification F1-score of 81.79\%, and ternary classification F1-score of 78.37\%. Furthermore, we have systematically elucidated the strengths and limitations of current LLMs in this task from the perspectives of ADOS-2, LLMs' capabilities, language, and model scale aiming to inspire and guide the future application of LLMs in a broader fields of mental health disorders. We hope for more research to be transferred into real clinical practice, opening a window of kindness to the world for eccentric children.
+
+
+
+ 142. 【2410.05648】Does RoBERTa Perform Better than BERT in Continual Learning: An Attention Sink Perspective
+ 链接:https://arxiv.org/abs/2410.05648
+ 作者:Xueying Bai,Yifan Sun,Niranjan Balasubramanian
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:Continual learning, aims to train, sequentially learn, previous tasks' knowledge, forgetting previous tasks'
+ 备注: COLM 2024
+
+ 点击查看摘要
+ Abstract:Continual learning (CL) aims to train models that can sequentially learn new tasks without forgetting previous tasks' knowledge. Although previous works observed that pre-training can benefit CL, it remains unclear whether a pre-trained model with higher downstream capacity also performs better in CL. In this paper, we observe that pre-trained models may allocate high attention scores to some 'sink' tokens, such as [SEP] tokens, which are ubiquitous across various tasks. Such attention sinks may lead to models' over-smoothing in single-task learning and interference in sequential tasks' learning, which may compromise the models' CL performance despite their high pre-trained capabilities. To reduce these effects, we propose a pre-scaling mechanism that encourages attention diversity across all tokens. Specifically, it first scales the task's attention to the non-sink tokens in a probing stage, and then fine-tunes the model with scaling. Experiments show that pre-scaling yields substantial improvements in CL without experience replay, or progressively storing parameters from previous tasks.
+
+
+
+ 143. 【2410.05639】DecorateLM: Data Engineering through Corpus Rating, Tagging, and Editing with Language Models
+ 链接:https://arxiv.org/abs/2410.05639
+ 作者:Ranchi Zhao,Zhen Leng Thai,Yifan Zhang,Shengding Hu,Yunqi Ba,Jie Zhou,Jie Cai,Zhiyuan Liu,Maosong Sun
+ 类目:Computation and Language (cs.CL)
+ 关键词:unsupervised data processed, pretraining corpus, Large Language Models, substantially influenced, consists of vast
+ 备注:
+
+ 点击查看摘要
+ Abstract:The performance of Large Language Models (LLMs) is substantially influenced by the pretraining corpus, which consists of vast quantities of unsupervised data processed by the models. Despite its critical role in model performance, ensuring the quality of this data is challenging due to its sheer volume and the absence of sample-level quality annotations and enhancements. In this paper, we introduce DecorateLM, a data engineering method designed to refine the pretraining corpus through data rating, tagging and editing. Specifically, DecorateLM rates texts against quality criteria, tags texts with hierarchical labels, and edits texts into a more formalized format. Due to the massive size of the pretraining corpus, adopting an LLM for decorating the entire corpus is less efficient. Therefore, to balance performance with efficiency, we curate a meticulously annotated training corpus for DecorateLM using a large language model and distill data engineering expertise into a compact 1.2 billion parameter small language model (SLM). We then apply DecorateLM to enhance 100 billion tokens of the training corpus, selecting 45 billion tokens that exemplify high quality and diversity for the further training of another 1.2 billion parameter LLM. Our results demonstrate that employing such high-quality data can significantly boost model performance, showcasing a powerful approach to enhance the quality of the pretraining corpus.
+
+
+
+ 144. 【2410.05629】Vector-ICL: In-context Learning with Continuous Vector Representations
+ 链接:https://arxiv.org/abs/2410.05629
+ 作者:Yufan Zhuang,Chandan Singh,Liyuan Liu,Jingbo Shang,Jianfeng Gao
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:remarkable in-context learning, shown remarkable in-context, Large language models, Large language, in-context learning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) have shown remarkable in-context learning (ICL) capabilities on textual data. We explore whether these capabilities can be extended to continuous vectors from diverse domains, obtained from black-box pretrained encoders. By aligning input data with an LLM's embedding space through lightweight projectors, we observe that LLMs can effectively process and learn from these projected vectors, which we term Vector-ICL. In particular, we find that pretraining projectors with general language modeling objectives enables Vector-ICL, while task-specific finetuning further enhances performance. In our experiments across various tasks and modalities, including text reconstruction, numerical function regression, text classification, summarization, molecule captioning, time-series classification, graph classification, and fMRI decoding, Vector-ICL often surpasses both few-shot ICL and domain-specific model or tuning. We further conduct analyses and case studies, indicating the potential of LLMs to process vector representations beyond traditional token-based paradigms.
+
+
+
+ 145. 【2410.05613】Stereotype or Personalization? User Identity Biases Chatbot Recommendations
+ 链接:https://arxiv.org/abs/2410.05613
+ 作者:Anjali Kantharuban,Jeremiah Milbauer,Emma Strubell,Graham Neubig
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language models, user revealed identity, people use large, large language, user revealed
+ 备注:
+
+ 点击查看摘要
+ Abstract:We demonstrate that when people use large language models (LLMs) to generate recommendations, the LLMs produce responses that reflect both what the user wants and who the user is. While personalized recommendations are often desired by users, it can be difficult in practice to distinguish cases of bias from cases of personalization: we find that models generate racially stereotypical recommendations regardless of whether the user revealed their identity intentionally through explicit indications or unintentionally through implicit cues. We argue that chatbots ought to transparently indicate when recommendations are influenced by a user's revealed identity characteristics, but observe that they currently fail to do so. Our experiments show that even though a user's revealed identity significantly influences model recommendations (p 0.001), model responses obfuscate this fact in response to user queries. This bias and lack of transparency occurs consistently across multiple popular consumer LLMs (gpt-4o-mini, gpt-4-turbo, llama-3-70B, and claude-3.5) and for four American racial groups.
+
+
+
+ 146. 【2410.05608】Multimodal Large Language Models and Tunings: Vision, Language, Sensors, Audio, and Beyond
+ 链接:https://arxiv.org/abs/2410.05608
+ 作者:Soyeon Caren Han,Feiqi Cao,Josiah Poon,Roberto Navigli
+ 类目:Computation and Language (cs.CL)
+ 关键词:explores recent advancements, processing diverse data, diverse data forms, tutorial explores recent, capable of integrating
+ 备注: Accepted at ACM-MM 2024
+
+ 点击查看摘要
+ Abstract:This tutorial explores recent advancements in multimodal pretrained and large models, capable of integrating and processing diverse data forms such as text, images, audio, and video. Participants will gain an understanding of the foundational concepts of multimodality, the evolution of multimodal research, and the key technical challenges addressed by these models. We will cover the latest multimodal datasets and pretrained models, including those beyond vision and language. Additionally, the tutorial will delve into the intricacies of multimodal large models and instruction tuning strategies to optimise performance for specific tasks. Hands-on laboratories will offer practical experience with state-of-the-art multimodal models, demonstrating real-world applications like visual storytelling and visual question answering. This tutorial aims to equip researchers, practitioners, and newcomers with the knowledge and skills to leverage multimodal AI. ACM Multimedia 2024 is the ideal venue for this tutorial, aligning perfectly with our goal of understanding multimodal pretrained and large language models, and their tuning mechanisms.
+
+
+
+ 147. 【2410.05603】Everything Everywhere All at Once: LLMs can In-Context Learn Multiple Tasks in Superposition
+ 链接:https://arxiv.org/abs/2410.05603
+ 作者:Zheyang Xiong,Ziyang Cai,John Cooper,Albert Ge,Vasilis Papageorgiou,Zack Sifakis,Angeliki Giannou,Ziqian Lin,Liu Yang,Saurabh Agarwal,Grigorios G Chrysos,Samet Oymak,Kangwook Lee,Dimitris Papailiopoulos
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, remarkable in-context learning, demonstrated remarkable in-context, Language Models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have demonstrated remarkable in-context learning (ICL) capabilities. In this study, we explore a surprising phenomenon related to ICL: LLMs can perform multiple, computationally distinct ICL tasks simultaneously, during a single inference call, a capability we term "task superposition". We provide empirical evidence of this phenomenon across various LLM families and scales and show that this phenomenon emerges even if we train the model to in-context learn one task at a time. We offer theoretical explanations that this capability is well within the expressive power of transformers. We also explore how LLMs internally compose task vectors during superposition. Furthermore, we show that larger models can solve more ICL tasks in parallel, and better calibrate their output distribution. Our findings offer insights into the latent capabilities of LLMs, further substantiate the perspective of "LLMs as superposition of simulators", and raise questions about the mechanisms enabling simultaneous task execution.
+
+
+
+ 148. 【2410.05600】Bridging Modalities: Enhancing Cross-Modality Hate Speech Detection with Few-Shot In-Context Learning
+ 链接:https://arxiv.org/abs/2410.05600
+ 作者:Ming Shan Hee,Aditi Kumaresan,Roy Ka-Wei Lee
+ 类目:Computation and Language (cs.CL)
+ 关键词:digital platform safety, hate speech, poses a significant, platform safety, widespread presence
+ 备注: Accepted at EMNLP'24 (Main)
+
+ 点击查看摘要
+ Abstract:The widespread presence of hate speech on the internet, including formats such as text-based tweets and vision-language memes, poses a significant challenge to digital platform safety. Recent research has developed detection models tailored to specific modalities; however, there is a notable gap in transferring detection capabilities across different formats. This study conducts extensive experiments using few-shot in-context learning with large language models to explore the transferability of hate speech detection between modalities. Our findings demonstrate that text-based hate speech examples can significantly enhance the classification accuracy of vision-language hate speech. Moreover, text-based demonstrations outperform vision-language demonstrations in few-shot learning settings. These results highlight the effectiveness of cross-modality knowledge transfer and offer valuable insights for improving hate speech detection systems.
+
+
+
+ 149. 【2410.05589】ParallelSpec: Parallel Drafter for Efficient Speculative Decoding
+ 链接:https://arxiv.org/abs/2410.05589
+ 作者:Zilin Xiao,Hongming Zhang,Tao Ge,Siru Ouyang,Vicente Ordonez,Dong Yu
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Speculative decoding, large language model, solution to large, leveraged to verify, Speculative
+ 备注: work in progress
+
+ 点击查看摘要
+ Abstract:Speculative decoding has proven to be an efficient solution to large language model (LLM) inference, where the small drafter predicts future tokens at a low cost, and the target model is leveraged to verify them in parallel. However, most existing works still draft tokens auto-regressively to maintain sequential dependency in language modeling, which we consider a huge computational burden in speculative decoding. We present ParallelSpec, an alternative to auto-regressive drafting strategies in state-of-the-art speculative decoding approaches. In contrast to auto-regressive drafting in the speculative stage, we train a parallel drafter to serve as an efficient speculative model. ParallelSpec learns to efficiently predict multiple future tokens in parallel using a single model, and it can be integrated into any speculative decoding framework that requires aligning the output distributions of the drafter and the target model with minimal training cost. Experimental results show that ParallelSpec accelerates baseline methods in latency up to 62% on text generation benchmarks from different domains, and it achieves 2.84X overall speedup on the Llama-2-13B model using third-party evaluation criteria.
+
+
+
+ 150. 【2410.05584】Rethinking Reward Model Evaluation: Are We Barking up the Wrong Tree?
+ 链接:https://arxiv.org/abs/2410.05584
+ 作者:Xueru Wen,Jie Lou,Yaojie Lu,Hongyu Lin,Xing Yu,Xinyu Lu,Ben He,Xianpei Han,Debing Zhang,Le Sun
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:aligning language models, Reward Models, crucial for aligning, aligning language, accuracy
+ 备注:
+
+ 点击查看摘要
+ Abstract:Reward Models (RMs) are crucial for aligning language models with human preferences. Currently, the evaluation of RMs depends on measuring accuracy against a validation set of manually annotated preference data. Although this method is straightforward and widely adopted, the relationship between RM accuracy and downstream policy performance remains under-explored. In this work, we conduct experiments in a synthetic setting to investigate how differences in RM measured by accuracy translate into gaps in optimized policy performance. Our findings reveal that while there is a weak positive correlation between accuracy and downstream performance, policies optimized towards RMs with similar accuracy can exhibit quite different performance. Moreover, we discover that the way of measuring accuracy significantly impacts its ability to predict the final policy performance. Through the lens of Regressional Goodhart's effect, we identify the existence of exogenous variables impacting the relationship between RM quality measured by accuracy and policy model capability. This underscores the inadequacy of relying solely on accuracy to reflect their impact on policy optimization.
+
+
+
+ 151. 【2410.05581】Adaptation Odyssey in LLMs: Why Does Additional Pretraining Sometimes Fail to Improve?
+ 链接:https://arxiv.org/abs/2410.05581
+ 作者:Fırat Öncel,Matthias Bethge,Beyza Ermis,Mirco Ravanelli,Cem Subakan,Çağatay Yıldız
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:deep learning, deep learning models, typically evaluated, evaluated on fixed, traditional deep learning
+ 备注: Accepted to EMNLP 2024 Main Conference
+
+ 点击查看摘要
+ Abstract:In the last decade, the generalization and adaptation abilities of deep learning models were typically evaluated on fixed training and test distributions. Contrary to traditional deep learning, large language models (LLMs) are (i) even more overparameterized, (ii) trained on unlabeled text corpora curated from the Internet with minimal human intervention, and (iii) trained in an online fashion. These stark contrasts prevent researchers from transferring lessons learned on model generalization and adaptation in deep learning contexts to LLMs. To this end, our short paper introduces empirical observations that aim to shed light on further training of already pretrained language models. Specifically, we demonstrate that training a model on a text domain could degrade its perplexity on the test portion of the same domain. We observe with our subsequent analysis that the performance degradation is positively correlated with the similarity between the additional and the original pretraining dataset of the LLM. Our further token-level perplexity observations reveals that the perplexity degradation is due to a handful of tokens that are not informative about the domain. We hope these findings will guide us in determining when to adapt a model vs when to rely on its foundational capabilities.
+
+
+
+ 152. 【2410.05575】ClaimBrush: A Novel Framework for Automated Patent Claim Refinement Based on Large Language Models
+ 链接:https://arxiv.org/abs/2410.05575
+ 作者:Seiya Kawano,Hirofumi Nonaka,Koichiro Yoshino
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:patent claim rewriting, intellectual property strategy, patent claim, claim rewriting model, patent claim refinement
+ 备注: 10 pages, This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible
+
+ 点击查看摘要
+ Abstract:Automatic refinement of patent claims in patent applications is crucial from the perspective of intellectual property strategy. In this paper, we propose ClaimBrush, a novel framework for automated patent claim refinement that includes a dataset and a rewriting model. We constructed a dataset for training and evaluating patent claim rewriting models by collecting a large number of actual patent claim rewriting cases from the patent examination process. Using the constructed dataset, we built an automatic patent claim rewriting model by fine-tuning a large language model. Furthermore, we enhanced the performance of the automatic patent claim rewriting model by applying preference optimization based on a prediction model of patent examiners' Office Actions. The experimental results showed that our proposed rewriting model outperformed heuristic baselines and zero-shot learning in state-of-the-art large language models. Moreover, preference optimization based on patent examiners' preferences boosted the performance of patent claim refinement.
+
+
+
+ 153. 【2410.05573】aeBench: Improving Quality of Toxic Adversarial Examples
+ 链接:https://arxiv.org/abs/2410.05573
+ 作者:Xuan Zhu,Dmitriy Bespalov,Liwen You,Ninad Kulkarni,Yanjun Qi
+ 类目:Cryptography and Security (cs.CR); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:small perturbations, wrong detection, perturbations to input, systems into wrong, TAE
+ 备注:
+
+ 点击查看摘要
+ Abstract:Toxicity text detectors can be vulnerable to adversarial examples - small perturbations to input text that fool the systems into wrong detection. Existing attack algorithms are time-consuming and often produce invalid or ambiguous adversarial examples, making them less useful for evaluating or improving real-world toxicity content moderators. This paper proposes an annotation pipeline for quality control of generated toxic adversarial examples (TAE). We design model-based automated annotation and human-based quality verification to assess the quality requirements of TAE. Successful TAE should fool a target toxicity model into making benign predictions, be grammatically reasonable, appear natural like human-generated text, and exhibit semantic toxicity. When applying these requirements to more than 20 state-of-the-art (SOTA) TAE attack recipes, we find many invalid samples from a total of 940k raw TAE attack generations. We then utilize the proposed pipeline to filter and curate a high-quality TAE dataset we call TaeBench (of size 264k). Empirically, we demonstrate that TaeBench can effectively transfer-attack SOTA toxicity content moderation models and services. Our experiments also show that TaeBench with adversarial training achieve significant improvements of the robustness of two toxicity detectors.
+
+
+
+ 154. 【2410.05565】Chain and Causal Attention for Efficient Entity Tracking
+ 链接:https://arxiv.org/abs/2410.05565
+ 作者:Erwan Fagnou,Paul Caillon,Blaise Delattre,Alexandre Allauzen
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:paper investigates, investigates the limitations, entity-tracking tasks, tasks in large, large language models
+ 备注: 15 pages, 5 figures, EMNLP 2024 Main
+
+ 点击查看摘要
+ Abstract:This paper investigates the limitations of transformers for entity-tracking tasks in large language models. We identify a theoretical constraint, showing that transformers require at least $\log_2 (n+1)$ layers to handle entity tracking with $n$ state changes. To address this issue, we propose an efficient and frugal enhancement to the standard attention mechanism, enabling it to manage long-term dependencies more efficiently. By considering attention as an adjacency matrix, our model can track entity states with a single layer. Empirical results demonstrate significant improvements in entity tracking datasets while keeping competitive performance on standard natural language modeling. Our modified attention allows us to achieve the same performance with drastically fewer layers. Additionally, our enhanced mechanism reveals structured internal representations of attention. Extensive experiments on both toy and complex datasets validate our approach. Our contributions include theoretical insights, an improved attention mechanism, and empirical validation.
+
+
+
+ 155. 【2410.05563】Rational Metareasoning for Large Language Models
+ 链接:https://arxiv.org/abs/2410.05563
+ 作者:C. Nicolò De Sabbata,Theodore R. Sumers,Thomas L. Griffiths
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:deploying additional inference-time, additional inference-time compute, large language models, deploying additional, prompted to engage
+ 备注:
+
+ 点击查看摘要
+ Abstract:Being prompted to engage in reasoning has emerged as a core technique for using large language models (LLMs), deploying additional inference-time compute to improve task performance. However, as LLMs increase in both size and adoption, inference costs are correspondingly becoming increasingly burdensome. How, then, might we optimize reasoning's cost-performance tradeoff? This work introduces a novel approach based on computational models of metareasoning used in cognitive science, training LLMs to selectively use intermediate reasoning steps only when necessary. We first develop a reward function that incorporates the Value of Computation by penalizing unnecessary reasoning, then use this reward function with Expert Iteration to train the LLM. Compared to few-shot chain-of-thought prompting and STaR, our method significantly reduces inference costs (20-37\% fewer tokens generated across three models) while maintaining task performance across diverse datasets.
+
+
+
+ 156. 【2410.05559】Attribute Controlled Fine-tuning for Large Language Models: A Case Study on Detoxification
+ 链接:https://arxiv.org/abs/2410.05559
+ 作者:Tao Meng,Ninareh Mehrabi,Palash Goyal,Anil Ramakrishna,Aram Galstyan,Richard Zemel,Kai-Wei Chang,Rahul Gupta,Charith Peris
+ 类目:Computation and Language (cs.CL)
+ 关键词:fine-tuning Large Language, Large Language Models, Large Language, constraint learning schema, fine-tuning Large
+ 备注: Accepted to EMNLP Findings
+
+ 点击查看摘要
+ Abstract:We propose a constraint learning schema for fine-tuning Large Language Models (LLMs) with attribute control. Given a training corpus and control criteria formulated as a sequence-level constraint on model outputs, our method fine-tunes the LLM on the training corpus while enhancing constraint satisfaction with minimal impact on its utility and generation quality. Specifically, our approach regularizes the LLM training by penalizing the KL divergence between the desired output distribution, which satisfies the constraints, and the LLM's posterior. This regularization term can be approximated by an auxiliary model trained to decompose the sequence-level constraints into token-level guidance, allowing the term to be measured by a closed-form formulation. To further improve efficiency, we design a parallel scheme for concurrently updating both the LLM and the auxiliary model. We evaluate the empirical performance of our approach by controlling the toxicity when training an LLM. We show that our approach leads to an LLM that produces fewer inappropriate responses while achieving competitive performance on benchmarks and a toxicity detection task.
+
+
+
+ 157. 【2410.05558】Narrative-of-Thought: Improving Temporal Reasoning of Large Language Models via Recounted Narratives
+ 链接:https://arxiv.org/abs/2410.05558
+ 作者:Xinliang Frederick Zhang,Nick Beauchamp,Lu Wang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:human cognition, navigating our experiences, temporal reasoning, integral aspect, aspect of human
+ 备注: EMNLP'24 Findings
+
+ 点击查看摘要
+ Abstract:Reasoning about time and temporal relations is an integral aspect of human cognition, essential for perceiving the world and navigating our experiences. Though large language models (LLMs) have demonstrated impressive performance in many reasoning tasks, temporal reasoning remains challenging due to its intrinsic complexity. In this work, we first study an essential task of temporal reasoning -- temporal graph generation, to unveil LLMs' inherent, global reasoning capabilities. We show that this task presents great challenges even for the most powerful LLMs, such as GPT-3.5/4. We also notice a significant performance gap by small models (10B) that lag behind LLMs by 50%. Next, we study how to close this gap with a budget constraint, e.g., not using model finetuning. We propose a new prompting technique tailored for temporal reasoning, Narrative-of-Thought (NoT), that first converts the events set to a Python class, then prompts a small model to generate a temporally grounded narrative, guiding the final generation of a temporal graph. Extensive experiments showcase the efficacy of NoT in improving various metrics. Notably, NoT attains the highest F1 on the Schema-11 evaluation set, while securing an overall F1 on par with GPT-3.5. NoT also achieves the best structural similarity across the board, even compared with GPT-3.5/4. Our code is available at this https URL.
+
+
+
+ 158. 【2410.05553】On Instruction-Finetuning Neural Machine Translation Models
+ 链接:https://arxiv.org/abs/2410.05553
+ 作者:Vikas Raunak,Roman Grundkiewicz,Marcin Junczys-Dowmunt
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, Large Language, Neural Machine Translation, smaller NMT models, NMT models
+ 备注: WMT'24
+
+ 点击查看摘要
+ Abstract:In this work, we introduce instruction finetuning for Neural Machine Translation (NMT) models, which distills instruction following capabilities from Large Language Models (LLMs) into orders-of-magnitude smaller NMT models. Our instruction-finetuning recipe for NMT models enables customization of translations for a limited but disparate set of translation-specific tasks. We show that NMT models are capable of following multiple instructions simultaneously and demonstrate capabilities of zero-shot composition of instructions. We also show that through instruction finetuning, traditionally disparate tasks such as formality-controlled machine translation, multi-domain adaptation as well as multi-modal translations can be tackled jointly by a single instruction finetuned NMT model, at a performance level comparable to LLMs such as GPT-3.5-Turbo. To the best of our knowledge, our work is among the first to demonstrate the instruction-following capabilities of traditional NMT models, which allows for faster, cheaper and more efficient serving of customized translations.
+
+
+
+ 159. 【2410.05495】Self-rationalization improves LLM as a fine-grained judge
+ 链接:https://arxiv.org/abs/2410.05495
+ 作者:Prapti Trivedi,Aditya Gulati,Oliver Molenschot,Meghana Arakkal Rajeev,Rajkumar Ramamurthy,Keith Stevens,Tanveesh Singh Chaudhery,Jahnavi Jambholkar,James Zou,Nazneen Rajani
+ 类目:Computation and Language (cs.CL)
+ 关键词:specifically by providing, rationales, generated content, judge model, judge
+ 备注:
+
+ 点击查看摘要
+ Abstract:LLM-as-a-judge models have been used for evaluating both human and AI generated content, specifically by providing scores and rationales. Rationales, in addition to increasing transparency, help models learn to calibrate its judgments. Enhancing a model's rationale can therefore improve its calibration abilities and ultimately the ability to score content. We introduce Self-Rationalization, an iterative process of improving the rationales for the judge models, which consequently improves the score for fine-grained customizable scoring criteria (i.e., likert-scale scoring with arbitrary evaluation criteria). Self-rationalization works by having the model generate multiple judgments with rationales for the same input, curating a preference pair dataset from its own judgements, and iteratively fine-tuning the judge via DPO. Intuitively, this approach allows the judge model to self-improve by learning from its own rationales, leading to better alignment and evaluation accuracy. After just two iterations -- while only relying on examples in the training set -- human evaluation shows that our judge model learns to produce higher quality rationales, with a win rate of $62\%$ on average compared to models just trained via SFT on rationale . This judge model also achieves high scoring accuracy on BigGen Bench and Reward Bench, outperforming even bigger sized models trained using SFT with rationale, self-consistency or best-of-$N$ sampling by $3\%$ to $9\%$.
+
+
+
+ 160. 【2410.05472】Neural machine translation system for Lezgian, Russian and Azerbaijani languages
+ 链接:https://arxiv.org/abs/2410.05472
+ 作者:Alidar Asvarov,Andrey Grabovoy
+ 类目:Computation and Language (cs.CL)
+ 关键词:machine translation system, neural machine translation, endangered Lezgian languages, neural machine, endangered Lezgian
+ 备注:
+
+ 点击查看摘要
+ Abstract:We release the first neural machine translation system for translation between Russian, Azerbaijani and the endangered Lezgian languages, as well as monolingual and parallel datasets collected and aligned for training and evaluating the system. Multiple experiments are conducted to identify how different sets of training language pairs and data domains can influence the resulting translation quality. We achieve BLEU scores of 26.14 for Lezgian-Azerbaijani, 22.89 for Azerbaijani-Lezgian, 29.48 for Lezgian-Russian and 24.25 for Russian-Lezgian pairs. The quality of zero-shot translation is assessed on a Large Language Model, showing its high level of fluency in Lezgian. However, the model often refuses to translate, justifying itself with its incompetence. We contribute our translation model along with the collected parallel and monolingual corpora and sentence encoder for the Lezgian language.
+
+
+
+ 161. 【2410.05459】From Sparse Dependence to Sparse Attention: Unveiling How Chain-of-Thought Enhances Transformer Sample Efficiency
+ 链接:https://arxiv.org/abs/2410.05459
+ 作者:Kaiyue Wen,Huaqing Zhang,Hongzhou Lin,Jingzhao Zhang
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL); Machine Learning (stat.ML)
+ 关键词:large language models, significantly enhances, enhances the reasoning, reasoning performance, current large models
+ 备注: 43 pages,11 figures
+
+ 点击查看摘要
+ Abstract:Chain-of-thought (CoT) significantly enhances the reasoning performance of large language models (LLM). While current theoretical studies often attribute this improvement to increased expressiveness and computational capacity, we argue that expressiveness is not the primary limitation in the LLM regime, as current large models will fail on simple tasks. Using a parity-learning setup, we demonstrate that CoT can substantially improve sample efficiency even when the representation power is sufficient. Specifically, with CoT, a transformer can learn the function within polynomial samples, whereas without CoT, the required sample size is exponential. Additionally, we show that CoT simplifies the learning process by introducing sparse sequential dependencies among input tokens, and leads to a sparse and interpretable attention. We validate our theoretical analysis with both synthetic and real-world experiments, confirming that sparsity in attention layers is a key factor of the improvement induced by CoT.
+
+
+
+ 162. 【2410.05453】Interconnected Kingdoms: Comparing 'A Song of Ice and Fire' Adaptations Across Media Using Complex Networks
+ 链接:https://arxiv.org/abs/2410.05453
+ 作者:Arthur Amalvy,Madeleine Janickyj,Shane Mannion,Pádraig MacCarron,Vincent Labatut
+ 类目:ocial and Information Networks (cs.SI); Computation and Language (cs.CL)
+ 关键词:characters, perform narrative matching, adaptations, Ice and Fire, compare
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this article, we propose and apply a method to compare adaptations of the same story across different media. We tackle this task by modelling such adaptations through character networks. We compare them by leveraging two concepts at the core of storytelling: the characters involved, and the dynamics of the story. We propose several methods to match characters between media and compare their position in the networks; and perform narrative matching, i.e. match the sequences of narrative units that constitute the plots. We apply these methods to the novel series \textit{A Song of Ice and Fire}, by G.R.R. Martin, and its comics and TV show adaptations. Our results show that interactions between characters are not sufficient to properly match individual characters between adaptations, but that using some additional information such as character affiliation or gender significantly improves the performance. On the contrary, character interactions convey enough information to perform narrative matching, and allow us to detect the divergence between the original novels and its TV show adaptation.
+
+
+
+ 163. 【2410.05448】ask Diversity Shortens the ICL Plateau
+ 链接:https://arxiv.org/abs/2410.05448
+ 作者:Jaeyeon Kim,Sehyun Kwon,Joo Young Choi,Jongho Park,Jaewoong Cho,Jason D. Lee,Ernest K. Ryu
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:generate outputs based, In-context learning, subsequent query, language model ability, ability to generate
+ 备注:
+
+ 点击查看摘要
+ Abstract:In-context learning (ICL) describes a language model's ability to generate outputs based on a set of input demonstrations and a subsequent query. To understand this remarkable capability, researchers have studied simplified, stylized models. These studies have consistently observed long loss plateaus, during which models exhibit minimal improvement, followed by a sudden, rapid surge of learning. In this work, we reveal that training on multiple diverse ICL tasks simultaneously shortens the loss plateaus, making each task easier to learn. This finding is surprising as it contradicts the natural intuition that the combined complexity of multiple ICL tasks would lengthen the learning process, not shorten it. Our result suggests that the recent success in large-scale training of language models may be attributed not only to the richness of the data at scale but also to the easier optimization (training) induced by the diversity of natural language training data.
+
+
+
+ 164. 【2410.05401】Post-hoc Study of Climate Microtargeting on Social Media Ads with LLMs: Thematic Insights and Fairness Evaluation
+ 链接:https://arxiv.org/abs/2410.05401
+ 作者:Tunazzina Islam,Dan Goldwasser
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computers and Society (cs.CY); Social and Information Networks (cs.SI)
+ 关键词:media increasingly employs, increasingly employs microtargeting, social media increasingly, Climate change communication, media increasingly
+ 备注:
+
+ 点击查看摘要
+ Abstract:Climate change communication on social media increasingly employs microtargeting strategies to effectively reach and influence specific demographic groups. This study presents a post-hoc analysis of microtargeting practices within climate campaigns by leveraging large language models (LLMs) to examine Facebook advertisements. Our analysis focuses on two key aspects: demographic targeting and fairness. We evaluate the ability of LLMs to accurately predict the intended demographic targets, such as gender and age group, achieving an overall accuracy of 88.55%. Furthermore, we instruct the LLMs to generate explanations for their classifications, providing transparent reasoning behind each decision. These explanations reveal the specific thematic elements used to engage different demographic segments, highlighting distinct strategies tailored to various audiences. Our findings show that young adults are primarily targeted through messages emphasizing activism and environmental consciousness, while women are engaged through themes related to caregiving roles and social advocacy. In addition to evaluating the effectiveness of LLMs in detecting microtargeted messaging, we conduct a comprehensive fairness analysis to identify potential biases in model predictions. Our findings indicate that while LLMs perform well overall, certain biases exist, particularly in the classification of senior citizens and male audiences. By showcasing the efficacy of LLMs in dissecting and explaining targeted communication strategies and by highlighting fairness concerns, this study provides a valuable framework for future research aimed at enhancing transparency, accountability, and inclusivity in social media-driven climate campaigns.
+
+
+
+ 165. 【2410.05362】LLMs Are In-Context Reinforcement Learners
+ 链接:https://arxiv.org/abs/2410.05362
+ 作者:Giovanni Monea,Antoine Bosselut,Kianté Brantley,Yoav Artzi
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Large Language Models, Large Language, Language Models, in-context supervised learning, ICL
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) can learn new tasks through in-context supervised learning (i.e., ICL). This work studies if this ability extends to in-context reinforcement learning (ICRL), where models are not given gold labels in context, but only their past predictions and rewards. We show that a naive application of ICRL fails miserably, and identify the root cause as a fundamental deficiency at exploration, which leads to quick model degeneration. We propose an algorithm to address this deficiency by increasing test-time compute, as well as a compute-bound approximation. We use several challenging classification tasks to empirically show that our ICRL algorithms lead to effective learning from rewards alone, and analyze the characteristics of this ability and our methods. Overall, our results reveal remarkable ICRL abilities in LLMs.
+
+
+
+ 166. 【2410.05357】Model-GLUE: Democratized LLM Scaling for A Large Model Zoo in the Wild
+ 链接:https://arxiv.org/abs/2410.05357
+ 作者:Xinyu Zhao,Guoheng Sun,Ruisi Cai,Yukun Zhou,Pingzhi Li,Peihao Wang,Bowen Tan,Yexiao He,Li Chen,Yi Liang,Beidi Chen,Binhang Yuan,Hongyi Wang,Ang Li,Zhangyang Wang,Tianlong Chen
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, garnered significant attention, combining disparate models, scaling LLMs based
+ 备注: 24 pages, 4 figures, accepted to NeurIPS 2024 Datasets and Benchmarks Track
+
+ 点击查看摘要
+ Abstract:As Large Language Models (LLMs) excel across tasks and specialized domains, scaling LLMs based on existing models has garnered significant attention, which faces the challenge of decreasing performance when combining disparate models. Various techniques have been proposed for the aggregation of pre-trained LLMs, including model merging, Mixture-of-Experts, and stacking. Despite their merits, a comprehensive comparison and synergistic application of them to a diverse model zoo is yet to be adequately addressed. In light of this research gap, this paper introduces Model-GLUE, a holistic LLM scaling guideline. First, our work starts with a benchmarking of existing LLM scaling techniques, especially selective merging, and variants of mixture. Utilizing the insights from the benchmark results, we formulate an strategy for the selection and aggregation of a heterogeneous model zoo characterizing different architectures and initialization. Our methodology involves the clustering of mergeable models and optimal merging strategy selection, and the integration of clusters through a model mixture. Finally, evidenced by our experiments on a diverse Llama-2-based model zoo, Model-GLUE shows an average performance enhancement of 5.61%, achieved without additional training. Codes are available at: this https URL.
+
+
+
+ 167. 【2410.05355】Falcon Mamba: The First Competitive Attention-free 7B Language Model
+ 链接:https://arxiv.org/abs/2410.05355
+ 作者:Jingwei Zuo,Maksim Velikanov,Dhia Eddine Rhaiem,Ilyas Chahed,Younes Belkada,Guillaume Kunsch,Hakim Hacid
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Falcon Mamba, base large language, present Falcon Mamba, Mamba, large language model
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this technical report, we present Falcon Mamba 7B, a new base large language model based on the novel Mamba architecture. Falcon Mamba 7B is trained on 5.8 trillion tokens with carefully selected data mixtures. As a pure Mamba-based model, Falcon Mamba 7B surpasses leading open-weight models based on Transformers, such as Mistral 7B, Llama3.1 8B, and Falcon2 11B. It is on par with Gemma 7B and outperforms models with different architecture designs, such as RecurrentGemma 9B and RWKV-v6 Finch 7B/14B. Currently, Falcon Mamba 7B is the best-performing Mamba model in the literature at this scale, surpassing both existing Mamba and hybrid Mamba-Transformer models, according to the Open LLM Leaderboard. Due to its architecture, Falcon Mamba 7B is significantly faster at inference and requires substantially less memory for long sequence generation. Despite recent studies suggesting that hybrid Mamba-Transformer models outperform pure architecture designs, we demonstrate that even the pure Mamba design can achieve similar, or even superior results compared to the Transformer and hybrid designs. We make the weights of our implementation of Falcon Mamba 7B publicly available on this https URL, under a permissive license.
+
+
+
+ 168. 【2410.05343】EgoOops: A Dataset for Mistake Action Detection from Egocentric Videos with Procedural Texts
+ 链接:https://arxiv.org/abs/2410.05343
+ 作者:Yuto Haneji,Taichi Nishimura,Hirotaka Kameko,Keisuke Shirai,Tomoya Yoshida,Keiya Kajimura,Koki Yamamoto,Taiyu Cui,Tomohiro Nishimoto,Shinsuke Mori
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:developing intelligent archives, detect workers' errors, provide feedback, procedural texts, crucial for developing
+ 备注:
+
+ 点击查看摘要
+ Abstract:Mistake action detection from egocentric videos is crucial for developing intelligent archives that detect workers' errors and provide feedback. Previous studies have been limited to specific domains, focused on detecting mistakes from videos without procedural texts, and analyzed whether actions are mistakes. To address these limitations, in this paper, we propose the EgoOops dataset, which includes egocentric videos, procedural texts, and three types of annotations: video-text alignment, mistake labels, and descriptions for mistakes. EgoOops covers five procedural domains and includes 50 egocentric videos. The video-text alignment allows the model to detect mistakes based on both videos and procedural texts. The mistake labels and descriptions enable detailed analysis of real-world mistakes. Based on EgoOops, we tackle two tasks: video-text alignment and mistake detection. For video-text alignment, we enhance the recent StepFormer model with an additional loss for fine-tuning. Based on the alignment results, we propose a multi-modal classifier to predict mistake labels. In our experiments, the proposed methods achieve higher performance than the baselines. In addition, our ablation study demonstrates the effectiveness of combining videos and texts. We will release the dataset and codes upon publication.
+
+
+
+ 169. 【2410.05331】aylor Unswift: Secured Weight Release for Large Language Models via Taylor Expansion
+ 链接:https://arxiv.org/abs/2410.05331
+ 作者:Guanchu Wang,Yu-Neng Chuang,Ruixiang Tang,Shaochen Zhong,Jiayi Yuan,Hongye Jin,Zirui Liu,Vipin Chaudhary,Shuai Xu,James Caverlee,Xia Hu
+ 类目:Cryptography and Security (cs.CR); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:data privacy concerns, raise data privacy, released large language, large language models, LLMs
+ 备注:
+
+ 点击查看摘要
+ Abstract:Ensuring the security of released large language models (LLMs) poses a significant dilemma, as existing mechanisms either compromise ownership rights or raise data privacy concerns. To address this dilemma, we introduce TaylorMLP to protect the ownership of released LLMs and prevent their abuse. Specifically, TaylorMLP preserves the ownership of LLMs by transforming the weights of LLMs into parameters of Taylor-series. Instead of releasing the original weights, developers can release the Taylor-series parameters with users, thereby ensuring the security of LLMs. Moreover, TaylorMLP can prevent abuse of LLMs by adjusting the generation speed. It can induce low-speed token generation for the protected LLMs by increasing the terms in the Taylor-series. This intentional delay helps LLM developers prevent potential large-scale unauthorized uses of their models. Empirical experiments across five datasets and three LLM architectures demonstrate that TaylorMLP induces over 4x increase in latency, producing the tokens precisely matched with original LLMs. Subsequent defensive experiments further confirm that TaylorMLP effectively prevents users from reconstructing the weight values based on downstream datasets.
+
+
+
+ 170. 【2410.05305】Output Scouting: Auditing Large Language Models for Catastrophic Responses
+ 链接:https://arxiv.org/abs/2410.05305
+ 作者:Andrew Bell,Joao Fonseca
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, Recent high profile, Large Language, high profile incidents, Recent high
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent high profile incidents in which the use of Large Language Models (LLMs) resulted in significant harm to individuals have brought about a growing interest in AI safety. One reason LLM safety issues occur is that models often have at least some non-zero probability of producing harmful outputs. In this work, we explore the following scenario: imagine an AI safety auditor is searching for catastrophic responses from an LLM (e.g. a "yes" responses to "can I fire an employee for being pregnant?"), and is able to query the model a limited number times (e.g. 1000 times). What is a strategy for querying the model that would efficiently find those failure responses? To this end, we propose output scouting: an approach that aims to generate semantically fluent outputs to a given prompt matching any target probability distribution. We then run experiments using two LLMs and find numerous examples of catastrophic responses. We conclude with a discussion that includes advice for practitioners who are looking to implement LLM auditing for catastrophic responses. We also release an open-source toolkit (this https URL) that implements our auditing framework using the Hugging Face transformers library.
+
+
+
+ 171. 【2410.05287】Hate Speech Detection Using Cross-Platform Social Media Data In English and German Language
+ 链接:https://arxiv.org/abs/2410.05287
+ 作者:Gautam Kishore Shahi,Tim A. Majchrzak
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Social and Information Networks (cs.SI)
+ 关键词:Hate speech, pervasive phenomenon, intensifying during times, times of crisis, social unrest
+ 备注:
+
+ 点击查看摘要
+ Abstract:Hate speech has grown into a pervasive phenomenon, intensifying during times of crisis, elections, and social unrest. Multiple approaches have been developed to detect hate speech using artificial intelligence, but a generalized model is yet unaccomplished. The challenge for hate speech detection as text classification is the cost of obtaining high-quality training data. This study focuses on detecting bilingual hate speech in YouTube comments and measuring the impact of using additional data from other platforms in the performance of the classification model. We examine the value of additional training datasets from cross-platforms for improving the performance of classification models. We also included factors such as content similarity, definition similarity, and common hate words to measure the impact of datasets on performance. Our findings show that adding more similar datasets based on content similarity, hate words, and definitions improves the performance of classification models. The best performance was obtained by combining datasets from YouTube comments, Twitter, and Gab with an F1-score of 0.74 and 0.68 for English and German YouTube comments.
+
+
+
+ 172. 【2410.07111】Utility of Multimodal Large Language Models in Analyzing Chest X-ray with Incomplete Contextual Information
+ 链接:https://arxiv.org/abs/2410.07111
+ 作者:Choonghan Kim,Seonhee Cho,Joo Heung Yoon
+ 类目:Image and Video Processing (eess.IV); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:chest radiography reports, chest radiography, radiography reports, Background, LLMs
+ 备注:
+
+ 点击查看摘要
+ Abstract:Background: Large language models (LLMs) are gaining use in clinical settings, but their performance can suffer with incomplete radiology reports. We tested whether multimodal LLMs (using text and images) could improve accuracy and understanding in chest radiography reports, making them more effective for clinical decision support.
+Purpose: To assess the robustness of LLMs in generating accurate impressions from chest radiography reports using both incomplete data and multimodal data. Material and Methods: We used 300 radiology image-report pairs from the MIMIC-CXR database. Three LLMs (OpenFlamingo, MedFlamingo, IDEFICS) were tested in both text-only and multimodal formats. Impressions were first generated from the full text, then tested by removing 20%, 50%, and 80% of the text. The impact of adding images was evaluated using chest x-rays, and model performance was compared using three metrics with statistical analysis.
+Results: The text-only models (OpenFlamingo, MedFlamingo, IDEFICS) had similar performance (ROUGE-L: 0.39 vs. 0.21 vs. 0.21; F1RadGraph: 0.34 vs. 0.17 vs. 0.17; F1CheXbert: 0.53 vs. 0.40 vs. 0.40), with OpenFlamingo performing best on complete text (p0.001). Performance declined with incomplete data across all models. However, adding images significantly boosted the performance of MedFlamingo and IDEFICS (p0.001), equaling or surpassing OpenFlamingo, even with incomplete text. Conclusion: LLMs may produce low-quality outputs with incomplete radiology data, but multimodal LLMs can improve reliability and support clinical decision-making.
+Keywords: Large language model; multimodal; semantic analysis; Chest Radiography; Clinical Decision Support;
+
Subjects:
+Image and Video Processing (eess.IV); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+Cite as:
+arXiv:2410.07111 [eess.IV]
+(or
+arXiv:2410.07111v1 [eess.IV] for this version)
+https://doi.org/10.48550/arXiv.2410.07111
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)
+
+Submission history From: Choonghan Kim [view email] [v1]
+Fri, 20 Sep 2024 01:42:53 UTC (939 KB)
+
+
+
+ 173. 【2410.05320】he OCON model: an old but gold solution for distributable supervised classification
+ 链接:https://arxiv.org/abs/2410.05320
+ 作者:Stefano Giacomelli,Marco Giordano,Claudia Rinaldi
+ 类目:Audio and Speech Processing (eess.AS); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Databases (cs.DB); Machine Learning (cs.LG); Sound (cs.SD)
+ 关键词:
+ 备注: Accepted at "2024 29th IEEE Symposium on Computers and Communications (ISCC): workshop on Next-Generation Multimedia Services at the Edge: Leveraging 5G and Beyond (NGMSE2024)". arXiv admin note: text overlap with [arXiv:2410.04098](https://arxiv.org/abs/2410.04098)
+
+ 点击查看摘要
+ None
+
+
+信息检索
+
+ 1. 【2410.07140】DSparsE: Dynamic Sparse Embedding for Knowledge Graph Completion
+ 链接:https://arxiv.org/abs/2410.07140
+ 作者:Chuhong Yang,Bin Li,Nan Wu
+ 类目:Information Retrieval (cs.IR); Databases (cs.DB); Graphics (cs.GR)
+ 关键词:knowledge graph remains, Addressing the incompleteness, knowledge graph completion, knowledge graph, Current knowledge graph
+ 备注: 15 pages, 5 figures, camera ready for ICPR
+
+ 点击查看摘要
+ Abstract:Addressing the incompleteness problem in knowledge graph remains a significant challenge. Current knowledge graph completion methods have their limitations. For example, ComDensE is prone to overfitting and suffers from the degradation with the increase of network depth while InteractE has the limitations in feature interaction and interpretability. To this end, we propose a new method called dynamic sparse embedding (DSparsE) for knowledge graph completion. The proposed model embeds the input entity-relation pairs by a shallow encoder composed of a dynamic layer and a relation-aware layer. Subsequently, the concatenated output of the dynamic layer and relation-aware layer is passed through a projection layer and a deep decoder with residual connection structure. This model ensures the network robustness and maintains the capability of feature extraction. Furthermore, the conventional dense layers are replaced by randomly initialized sparse connection layers in the proposed method, which can mitigate the model overfitting. Finally, comprehensive experiments are conducted on the datasets of FB15k-237, WN18RR and YAGO3-10. It was demonstrated that the proposed method achieves the state-of-the-art performance in terms of Hits@1 compared to the existing baseline approaches. An ablation study is performed to examine the effects of the dynamic layer and relation-aware layer, where the combined model achieves the best performance.
+
+
+
+ 2. 【2410.07121】ransfer Learning for E-commerce Query Product Type Prediction
+ 链接:https://arxiv.org/abs/2410.07121
+ 作者:Anna Tigunova,Thomas Ricatte,Ghadir Eraisha
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:e-commerce search engines, good understanding, intent is essential, correct product type, customer intent
+ 备注:
+
+ 点击查看摘要
+ Abstract:Getting a good understanding of the customer intent is essential in e-commerce search engines. In particular, associating the correct product type to a search query plays a vital role in surfacing correct products to the customers. Query product type classification (Q2PT) is a particularly challenging task because search queries are short and ambiguous, the number of existing product categories is extremely large, spanning thousands of values. Moreover, international marketplaces face additional challenges, such as language and dialect diversity and cultural differences, influencing the interpretation of the query. In this work we focus on Q2PT prediction in the global multilocale e-commerce markets. The common approach of training Q2PT models for each locale separately shows significant performance drops in low-resource stores. Moreover, this method does not allow for a smooth expansion to a new country, requiring to collect the data and train a new locale-specific Q2PT model from scratch. To tackle this, we propose to use transfer learning from the highresource to the low-resource locales, to achieve global parity of Q2PT performance. We benchmark the per-locale Q2PT model against the unified one, which shares the training data and model structure across all worldwide stores. Additionally, we compare locale-aware and locale-agnostic Q2PT models, showing the task dependency on the country-specific traits. We conduct extensive quantiative and qualitative analysis of Q2PT models on the large-scale e-commerce dataset across 20 worldwide locales, which shows that unified locale-aware Q2PT model has superior performance over the alternatives.
+
+
+
+ 3. 【2410.07108】FAIR GPT: A virtual consultant for research data management in ChatGPT
+ 链接:https://arxiv.org/abs/2410.07108
+ 作者:Renat Shigapov,Irene Schumm
+ 类目:Digital Libraries (cs.DL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:FAIR GPT, virtual consultant, consultant in ChatGPT, ChatGPT designed, organizations make
+ 备注: 4 pages, 2 figures, 1 table
+
+ 点击查看摘要
+ Abstract:FAIR GPT is a first virtual consultant in ChatGPT designed to help researchers and organizations make their data and metadata compliant with the FAIR (Findable, Accessible, Interoperable, Reusable) principles. It provides guidance on metadata improvement, dataset organization, and repository selection. To ensure accuracy, FAIR GPT uses external APIs to assess dataset FAIRness, retrieve controlled vocabularies, and recommend repositories, minimizing hallucination and improving precision. It also assists in creating documentation (data and software management plans, README files, and codebooks), and selecting proper licenses. This paper describes its features, applications, and limitations.
+
+
+
+ 4. 【2410.07022】Exploiting Distribution Constraints for Scalable and Efficient Image Retrieval
+ 链接:https://arxiv.org/abs/2410.07022
+ 作者:Mohammad Omama,Po-han Li,Sandeep P. Chinchali
+ 类目:Information Retrieval (cs.IR)
+ 关键词:robot place recognition, vision-based product recommendations, computer vision, crucial in robotics, robotics and computer
+ 备注:
+
+ 点击查看摘要
+ Abstract:Image retrieval is crucial in robotics and computer vision, with downstream applications in robot place recognition and vision-based product recommendations. Modern retrieval systems face two key challenges: scalability and efficiency. State-of-the-art image retrieval systems train specific neural networks for each dataset, an approach that lacks scalability. Furthermore, since retrieval speed is directly proportional to embedding size, existing systems that use large embeddings lack efficiency. To tackle scalability, recent works propose using off-the-shelf foundation models. However, these models, though applicable across datasets, fall short in achieving performance comparable to that of dataset-specific models. Our key observation is that, while foundation models capture necessary subtleties for effective retrieval, the underlying distribution of their embedding space can negatively impact cosine similarity searches. We introduce Autoencoders with Strong Variance Constraints (AE-SVC), which, when used for projection, significantly improves the performance of foundation models. We provide an in-depth theoretical analysis of AE-SVC. Addressing efficiency, we introduce Single-shot Similarity Space Distillation ((SS)$_2$D), a novel approach to learn embeddings with adaptive sizes that offers a better trade-off between size and performance. We conducted extensive experiments on four retrieval datasets, including Stanford Online Products (SoP) and Pittsburgh30k, using four different off-the-shelf foundation models, including DinoV2 and CLIP. AE-SVC demonstrates up to a $16\%$ improvement in retrieval performance, while (SS)$_2$D shows a further $10\%$ improvement for smaller embedding sizes.
+
+
+
+ 5. 【2410.06948】An Overview of zbMATH Open Digital Library
+ 链接:https://arxiv.org/abs/2410.06948
+ 作者:Madhurima Deb,Isabel Beckenbach,Matteo Petrera,Dariush Ehsani,Marcel Fuhrmann,Yun Hao,Olaf Teschke,Moritz Schubotz
+ 类目:Digital Libraries (cs.DL); Information Retrieval (cs.IR)
+ 关键词:discovery of knowledge, effective dissemination, dissemination and discovery, Mathematical research thrives, zbMATH Open
+ 备注:
+
+ 点击查看摘要
+ Abstract:Mathematical research thrives on the effective dissemination and discovery of knowledge.
+zbMATH Open has emerged as a pivotal platform in this landscape, offering a comprehensive repository of mathematical literature. Beyond indexing and abstracting, it serves as a unified quality-assured infrastructure for finding, evaluating, and connecting mathematical information that advances mathematical research as well as interdisciplinary exploration. zbMATH Open enables scientific quality control by post-publication reviews and promotes connections between researchers, institutions, and research outputs. This paper represents the functionalities of the most significant features of this open-access service, highlighting its role in shaping the future of mathematical information retrieval.
+
Subjects:
+Digital Libraries (cs.DL); Information Retrieval (cs.IR)
+Cite as:
+arXiv:2410.06948 [cs.DL]
+(or
+arXiv:2410.06948v1 [cs.DL] for this version)
+https://doi.org/10.48550/arXiv.2410.06948
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 6. 【2410.06654】Performance Evaluation in Multimedia Retrieval
+ 链接:https://arxiv.org/abs/2410.06654
+ 作者:Loris Sauter,Ralph Gasser,Heiko Schuldt,Abraham Bernstein,Luca Rossetto
+ 类目:Information Retrieval (cs.IR); Multimedia (cs.MM)
+ 关键词:information retrieval domain, Performance evaluation, domain at large, relies heavily, employing a broad
+ 备注:
+
+ 点击查看摘要
+ Abstract:Performance evaluation in multimedia retrieval, as in the information retrieval domain at large, relies heavily on retrieval experiments, employing a broad range of techniques and metrics. These can involve human-in-the-loop and machine-only settings for the retrieval process itself and the subsequent verification of results. Such experiments can be elaborate and use-case-specific, which can make them difficult to compare or replicate. In this paper, we present a formal model to express all relevant aspects of such retrieval experiments, as well as a flexible open-source evaluation infrastructure that implements the model. These contributions intend to make a step towards lowering the hurdles for conducting retrieval experiments and improving their reproducibility.
+
+
+
+ 7. 【2410.06628】Does Vec2Text Pose a New Corpus Poisoning Threat?
+ 链接:https://arxiv.org/abs/2410.06628
+ 作者:Shengyao Zhuang,Bevan Koopman,Guido Zuccon
+ 类目:Information Retrieval (cs.IR)
+ 关键词:text embedding inversion, raised serious privacy, privacy concerns, embedding inversion, text
+ 备注: arXiv admin note: substantial text overlap with [arXiv:2402.12784](https://arxiv.org/abs/2402.12784)
+
+ 点击查看摘要
+ Abstract:The emergence of Vec2Text -- a method for text embedding inversion -- has raised serious privacy concerns for dense retrieval systems which use text embeddings. This threat comes from the ability for an attacker with access to embeddings to reconstruct the original text. In this paper, we take a new look at Vec2Text and investigate how much of a threat it poses to the different attacks of corpus poisoning, whereby an attacker injects adversarial passages into a retrieval corpus with the intention of misleading dense retrievers. Theoretically, Vec2Text is far more dangerous than previous attack methods because it does not need access to the embedding model's weights and it can efficiently generate many adversarial passages. We show that under certain conditions, corpus poisoning with Vec2Text can pose a serious threat to dense retriever system integrity and user experience by injecting adversarial passaged into top ranked positions. Code and data are made available at this https URL
+
+
+
+ 8. 【2410.06618】Decomposing Relationship from 1-to-N into N 1-to-1 for Text-Video Retrieval
+ 链接:https://arxiv.org/abs/2410.06618
+ 作者:Jian Xiao,Zhenzhen Hu,Jia Li,Richang Hong
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Information Retrieval (cs.IR); Multimedia (cs.MM)
+ 关键词:large language models, pre-trained models, language models, recent years, Text-video retrieval
+ 备注:
+
+ 点击查看摘要
+ Abstract:Text-video retrieval (TVR) has seen substantial advancements in recent years, fueled by the utilization of pre-trained models and large language models (LLMs). Despite these advancements, achieving accurate matching in TVR remains challenging due to inherent disparities between video and textual modalities and irregularities in data representation. In this paper, we propose Text-Video-ProxyNet (TV-ProxyNet), a novel framework designed to decompose the conventional 1-to-N relationship of TVR into N distinct 1-to-1 relationships. By replacing a single text query with a series of text proxies, TV-ProxyNet not only broadens the query scope but also achieves a more precise expansion. Each text proxy is crafted through a refined iterative process, controlled by mechanisms we term as the director and dash, which regulate the proxy's direction and distance relative to the original text query. This setup not only facilitates more precise semantic alignment but also effectively manages the disparities and noise inherent in multimodal data. Our experiments on three representative video-text retrieval benchmarks, MSRVTT, DiDeMo, and ActivityNet Captions, demonstrate the effectiveness of TV-ProxyNet. The results show an improvement of 2.0% to 3.3% in R@1 over the baseline. TV-ProxyNet achieved state-of-the-art performance on MSRVTT and ActivityNet Captions, and a 2.0% improvement on DiDeMo compared to existing methods, validating our approach's ability to enhance semantic mapping and reduce error propensity.
+
+
+
+ 9. 【2410.06581】Enhancing Legal Case Retrieval via Scaling High-quality Synthetic Query-Candidate Pairs
+ 链接:https://arxiv.org/abs/2410.06581
+ 作者:Cheng Gao,Chaojun Xiao,Zhenghao Liu,Huimin Chen,Zhiyuan Liu,Maosong Sun
+ 类目:Information Retrieval (cs.IR)
+ 关键词:Legal case retrieval, Legal case, fact description, Legal, similar cases
+ 备注: 15 pages, 3 figures, accepted by EMNLP 2024
+
+ 点击查看摘要
+ Abstract:Legal case retrieval (LCR) aims to provide similar cases as references for a given fact description. This task is crucial for promoting consistent judgments in similar cases, effectively enhancing judicial fairness and improving work efficiency for judges. However, existing works face two main challenges for real-world applications: existing works mainly focus on case-to-case retrieval using lengthy queries, which does not match real-world scenarios; and the limited data scale, with current datasets containing only hundreds of queries, is insufficient to satisfy the training requirements of existing data-hungry neural models. To address these issues, we introduce an automated method to construct synthetic query-candidate pairs and build the largest LCR dataset to date, LEAD, which is hundreds of times larger than existing datasets. This data construction method can provide ample training signals for LCR models. Experimental results demonstrate that model training with our constructed data can achieve state-of-the-art results on two widely-used LCR benchmarks. Besides, the construction method can also be applied to civil cases and achieve promising results. The data and codes can be found in this https URL.
+
+
+
+ 10. 【2410.06536】Learning Recommender Systems with Soft Target: A Decoupled Perspective
+ 链接:https://arxiv.org/abs/2410.06536
+ 作者:Hao Zhang,Mingyue Cheng,Qi Liu,Yucong Luo,Rui Li,Enhong Chen
+ 类目:Information Retrieval (cs.IR)
+ 关键词:Learning recommender systems, Learning recommender, multi-class optimization objective, prevalent setting, standard Softmax loss
+ 备注: Accepted by DASFAA 2024
+
+ 点击查看摘要
+ Abstract:Learning recommender systems with multi-class optimization objective is a prevalent setting in recommendation. However, as observed user feedback often accounts for a tiny fraction of the entire item pool, the standard Softmax loss tends to ignore the difference between potential positive feedback and truly negative feedback. To address this challenge, we propose a novel decoupled soft label optimization framework to consider the objectives as two aspects by leveraging soft labels, including target confidence and the latent interest distribution of non-target items. Futhermore, based on our carefully theoretical analysis, we design a decoupled loss function to flexibly adjust the importance of these two aspects. To maximize the performance of the proposed method, we additionally present a sensible soft-label generation algorithm that models a label propagation algorithm to explore users' latent interests in unobserved feedback via neighbors. We conduct extensive experiments on various recommendation system models and public datasets, the results demonstrate the effectiveness and generality of the proposed method.
+
+
+
+ 11. 【2410.06497】ERCache: An Efficient and Reliable Caching Framework for Large-Scale User Representations in Meta's Ads System
+ 链接:https://arxiv.org/abs/2410.06497
+ 作者:Fang Zhou,Yaning Huang,Dong Liang,Dai Li,Zhongke Zhang,Kai Wang,Xiao Xin,Abdallah Aboelela,Zheliang Jiang,Yang Wang,Jeff Song,Wei Zhang,Chen Liang,Huayu Li,ChongLin Sun,Hang Yang,Lei Qu,Zhan Shu,Mindi Yuan,Emanuele Maccherani,Taha Hayat,John Guo,Varna Puvvada,Uladzimir Pashkevich
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI); Distributed, Parallel, and Cluster Computing (cs.DC); Machine Learning (cs.LG)
+ 关键词:strict service-level agreements, presents significant challenges, deep learning models, representations presents significant, calculating user representations
+ 备注:
+
+ 点击查看摘要
+ Abstract:The increasing complexity of deep learning models used for calculating user representations presents significant challenges, particularly with limited computational resources and strict service-level agreements (SLAs). Previous research efforts have focused on optimizing model inference but have overlooked a critical question: is it necessary to perform user model inference for every ad request in large-scale social networks? To address this question and these challenges, we first analyze user access patterns at Meta and find that most user model inferences occur within a short timeframe. T his observation reveals a triangular relationship among model complexity, embedding freshness, and service SLAs. Building on this insight, we designed, implemented, and evaluated ERCache, an efficient and robust caching framework for large-scale user representations in ads recommendation systems on social networks. ERCache categorizes cache into direct and failover types and applies customized settings and eviction policies for each model, effectively balancing model complexity, embedding freshness, and service SLAs, even considering the staleness introduced by caching. ERCache has been deployed at Meta for over six months, supporting more than 30 ranking models while efficiently conserving computational resources and complying with service SLA requirements.
+
+
+
+ 12. 【2410.06443】Categorizing Social Media Screenshots for Identifying Author Misattribution
+ 链接:https://arxiv.org/abs/2410.06443
+ 作者:Ashlyn M. Farris,Michael L. Nelson
+ 类目:Information Retrieval (cs.IR)
+ 关键词:social media, common and dangerous, dangerous occurrence, social media platforms, Mis
+ 备注:
+
+ 点击查看摘要
+ Abstract:Mis/disinformation is a common and dangerous occurrence on social media. Misattribution is a form of mis/disinformation that deals with a false claim of authorship, which means a user is claiming someone said (posted) something they never did. We discuss the difference between misinformation and disinformation and how screenshots are used to spread author misattribution on social media platforms. It is important to be able to find the original post of a screenshot to determine if the screenshot is being correctly attributed. To do this we have built several tools to aid in automating this search process. The first is a Python script that aims to categorize Twitter posts based on their structure, extract the metadata from a screenshot, and use this data to group all the posts within a screenshot together. We tested this process on 75 Twitter posts containing screenshots collected by hand to determine how well the script extracted metadata and grouped the individual posts, F1 = 0.80. The second is a series of scrapers being used to collect a dataset that can train and test a model to differentiate between various social media platforms. We collected 16,620 screenshots have been collected from Facebook, Instagram, Truth Social, and Twitter. Screenshots were taken by the scrapers of the web version and mobile version of each platform in both light and dark mode.
+
+
+
+ 13. 【2410.06384】Validation of the Scientific Literature via Chemputation Augmented by Large Language Models
+ 链接:https://arxiv.org/abs/2410.06384
+ 作者:Sebastian Pagel,Michael Jirasek,Leroy Cronin
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:Large Language Models, universal symbolic language, programming chemical robots, symbolic language, Language Models
+ 备注: 22 pages, 7 figures, 34 references
+
+ 点击查看摘要
+ Abstract:Chemputation is the process of programming chemical robots to do experiments using a universal symbolic language, but the literature can be error prone and hard to read due to ambiguities. Large Language Models (LLMs) have demonstrated remarkable capabilities in various domains, including natural language processing, robotic control, and more recently, chemistry. Despite significant advancements in standardizing the reporting and collection of synthetic chemistry data, the automatic reproduction of reported syntheses remains a labour-intensive task. In this work, we introduce an LLM-based chemical research agent workflow designed for the automatic validation of synthetic literature procedures. Our workflow can autonomously extract synthetic procedures and analytical data from extensive documents, translate these procedures into universal XDL code, simulate the execution of the procedure in a hardware-specific setup, and ultimately execute the procedure on an XDL-controlled robotic system for synthetic chemistry. This demonstrates the potential of LLM-based workflows for autonomous chemical synthesis with Chemputers. Due to the abstraction of XDL this approach is safe, secure, and scalable since hallucinations will not be chemputable and the XDL can be both verified and encrypted. Unlike previous efforts, which either addressed only a limited portion of the workflow, relied on inflexible hard-coded rules, or lacked validation in physical systems, our approach provides four realistic examples of syntheses directly executed from synthetic literature. We anticipate that our workflow will significantly enhance automation in robotically driven synthetic chemistry research, streamline data extraction, improve the reproducibility, scalability, and safety of synthetic and experimental chemistry.
+
+
+
+ 14. 【2410.06371】Improved Estimation of Ranks for Learning ItemRecommenders with Negative Sampling
+ 链接:https://arxiv.org/abs/2410.06371
+ 作者:Anushya Subbiah,Steffen Rendle,Vikram Aggarwal
+ 类目:Information Retrieval (cs.IR)
+ 关键词:recommendable items, num-ber of recommendable, recommendation systems, http URL, evaluationof item recommendation
+ 备注:
+
+ 点击查看摘要
+ Abstract:In recommendation systems, there has been a growth in the num-ber of recommendable items (# of movies, music, products). Whenthe set of recommendable items is large, training and evaluationof item recommendation models becomes computationally expen-sive. To lower this cost, it has become common to sample negativeitems. However, the recommendation quality can suffer from biasesintroduced by traditional negative sampling this http URL this work, we demonstrate the benefits from correcting thebias introduced by sampling of negatives. We first provide sampledbatch version of the well-studied WARP and LambdaRank this http URL, we present how these methods can benefit from improvedranking estimates. Finally, we evaluate the recommendation qualityas a result of correcting rank estimates and demonstrate that WARPand LambdaRank can be learned efficiently with negative samplingand our proposed correction technique.
+
+
+
+ 15. 【2410.06311】A Comparative Study of Hybrid Models in Health Misinformation Text Classification
+ 链接:https://arxiv.org/abs/2410.06311
+ 作者:Mkululi Sikosana,Oluwaseun Ajao,Sean Maudsley-Barton
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:machine learning, deep learning, online social networks, Naive Bayes, Random Forest
+ 备注: 8 pages, 4 tables presented at the OASIS workshop of the ACM Hypertext and Social Media Conference 2024
+
+ 点击查看摘要
+ Abstract:This study evaluates the effectiveness of machine learning (ML) and deep learning (DL) models in detecting COVID-19-related misinformation on online social networks (OSNs), aiming to develop more effective tools for countering the spread of health misinformation during the pan-demic. The study trained and tested various ML classifiers (Naive Bayes, SVM, Random Forest, etc.), DL models (CNN, LSTM, hybrid CNN+LSTM), and pretrained language models (DistilBERT, RoBERTa) on the "COVID19-FNIR DATASET". These models were evaluated for accuracy, F1 score, recall, precision, and ROC, and used preprocessing techniques like stemming and lemmatization. The results showed SVM performed well, achieving a 94.41% F1-score. DL models with Word2Vec embeddings exceeded 98% in all performance metrics (accuracy, F1 score, recall, precision ROC). The CNN+LSTM hybrid models also exceeded 98% across performance metrics, outperforming pretrained models like DistilBERT and RoBERTa. Our study concludes that DL and hybrid DL models are more effective than conventional ML algorithms for detecting COVID-19 misinformation on OSNs. The findings highlight the importance of advanced neural network approaches and large-scale pretraining in misinformation detection. Future research should optimize these models for various misinformation types and adapt to changing OSNs, aiding in combating health misinformation.
+
+
+
+ 16. 【2410.06180】CBIDR: A novel method for information retrieval combining image and data by means of TOPSIS applied to medical diagnosis
+ 链接:https://arxiv.org/abs/2410.06180
+ 作者:Humberto Giuri,Renato A. Krohling
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI); Image and Video Processing (eess.IV)
+ 关键词:Content-Based Image Retrieval, Image Retrieval, shown promising results, doctor or pathologist, medical professionals
+ 备注: 28 pages
+
+ 点击查看摘要
+ Abstract:Content-Based Image Retrieval (CBIR) have shown promising results in the field of medical diagnosis, which aims to provide support to medical professionals (doctor or pathologist). However, the ultimate decision regarding the diagnosis is made by the medical professional, drawing upon their accumulated experience. In this context, we believe that artificial intelligence can play a pivotal role in addressing the challenges in medical diagnosis not by making the final decision but by assisting in the diagnosis process with the most relevant information. The CBIR methods use similarity metrics to compare feature vectors generated from images using Convolutional Neural Networks (CNNs). In addition to the information contained in medical images, clinical data about the patient is often available and is also relevant in the final decision-making process by medical professionals. In this paper, we propose a novel method named CBIDR, which leverage both medical images and clinical data of patient, combining them through the ranking algorithm TOPSIS. The goal is to aid medical professionals in their final diagnosis by retrieving images and clinical data of patient that are most similar to query data from the database. As a case study, we illustrate our CBIDR for diagnostic of oral cancer including histopathological images and clinical data of patient. Experimental results in terms of accuracy achieved 97.44% in Top-1 and 100% in Top-5 showing the effectiveness of the proposed approach.
+
+
+
+ 17. 【2410.06062】LLM-based SPARQL Query Generation from Natural Language over Federated Knowledge Graphs
+ 链接:https://arxiv.org/abs/2410.06062
+ 作者:Vincent Emonet,Jerven Bolleman,Severine Duvaud,Tarcisio Mendes de Farias,Ana Claudia Sima
+ 类目:Databases (cs.DB); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:Large Language Models, leveraging Large Language, accurate federated SPARQL, Language Models, bioinformatics knowledge graphs
+ 备注:
+
+ 点击查看摘要
+ Abstract:We introduce a Retrieval-Augmented Generation (RAG) system for translating user questions into accurate federated SPARQL queries over bioinformatics knowledge graphs (KGs) leveraging Large Language Models (LLMs). To enhance accuracy and reduce hallucinations in query generation, our system utilises metadata from the KGs, including query examples and schema information, and incorporates a validation step to correct generated queries. The system is available online at this http URL.
+
+
+
+ 18. 【2410.06043】KwicKwocKwac, a tool for rapidly generating concordances and marking up a literary text
+ 链接:https://arxiv.org/abs/2410.06043
+ 作者:Sebastian Barzaghi,Francesco Paolucci,Francesca Tomasi,Fabio Vitali
+ 类目:Digital Libraries (cs.DL); Information Retrieval (cs.IR)
+ 关键词:paper introduces KwicKwocKwac, introduces KwicKwocKwac, paper introduces, designed to enhance, enhance the annotation
+ 备注: 10 pages, 5 figures
+
+ 点击查看摘要
+ Abstract:This paper introduces KwicKwocKwac 1.0 (KwicKK), a web application designed to enhance the annotation and enrichment of digital texts in the humanities. KwicKK provides a user-friendly interface that enables scholars and researchers to perform semi-automatic markup of textual documents, facilitating the identification of relevant entities such as people, organizations, and locations. Key functionalities include the visualization of annotated texts using KeyWord in Context (KWIC), KeyWord Out Of Context (KWOC), and KeyWord After Context (KWAC) methodologies, alongside automatic disambiguation of generic references and integration with Wikidata for Linked Open Data connections. The application supports metadata input and offers multiple download formats, promoting accessibility and ease of use. Developed primarily for the National Edition of Aldo Moro's works, KwicKK aims to lower the technical barriers for users while fostering deeper engagement with digital scholarly resources. The architecture leverages contemporary web technologies, ensuring scalability and reliability. Future developments will explore user experience enhancements, collaborative features, and integration of additional data sources.
+
+
+
+ 19. 【2410.06010】A large collection of bioinformatics question-query pairs over federated knowledge graphs: methodology and applications
+ 链接:https://arxiv.org/abs/2410.06010
+ 作者:Jerven Bolleman,Vincent Emonet,Adrian Altenhoff,Amos Bairoch,Marie-Claude Blatter,Alan Bridge,Severine Duvaud,Elisabeth Gasteiger,Dmitry Kuznetsov,Sebastien Moretti,Pierre-Andre Michel,Anne Morgat,Marco Pagni,Nicole Redaschi,Monique Zahn-Zabal,Tarcisio Mendes de Farias,Ana Claudia Sima
+ 类目:Databases (cs.DB); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:Knowledge graphs, Background, Knowledge, SPARQL, graphs
+ 备注:
+
+ 点击查看摘要
+ Abstract:Background. In the last decades, several life science resources have structured data using the same framework and made these accessible using the same query language to facilitate interoperability. Knowledge graphs have seen increased adoption in bioinformatics due to their advantages for representing data in a generic graph format. For example, this http URL catalogs more than 60 knowledge graphs accessible through SPARQL, a technical query language. Although SPARQL allows powerful, expressive queries, even across physically distributed knowledge graphs, formulating such queries is a challenge for most users. Therefore, to guide users in retrieving the relevant data, many of these resources provide representative examples. These examples can also be an important source of information for machine learning, if a sufficiently large number of examples are provided and published in a common, machine-readable and standardized format across different resources.
+Findings. We introduce a large collection of human-written natural language questions and their corresponding SPARQL queries over federated bioinformatics knowledge graphs (KGs) collected for several years across different research groups at the SIB Swiss Institute of Bioinformatics. The collection comprises more than 1000 example questions and queries, including 65 federated queries. We propose a methodology to uniformly represent the examples with minimal metadata, based on existing standards. Furthermore, we introduce an extensive set of open-source applications, including query graph visualizations and smart query editors, easily reusable by KG maintainers who adopt the proposed methodology.
+Conclusions. We encourage the community to adopt and extend the proposed methodology, towards richer KG metadata and improved Semantic Web services.
+
Subjects:
+Databases (cs.DB); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+Cite as:
+arXiv:2410.06010 [cs.DB]
+(or
+arXiv:2410.06010v1 [cs.DB] for this version)
+https://doi.org/10.48550/arXiv.2410.06010
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 20. 【2410.05939】RLRF4Rec: Reinforcement Learning from Recsys Feedback for Enhanced Recommendation Reranking
+ 链接:https://arxiv.org/abs/2410.05939
+ 作者:Chao Sun,Yaobo Liang,Yaming Yang,Shilin Xu,Tianmeng Yang,Yunhai Tong
+ 类目:Information Retrieval (cs.IR)
+ 关键词:Large Language Models, Large Language, demonstrated remarkable performance, Language Models, diverse domains
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have demonstrated remarkable performance across diverse domains, prompting researchers to explore their potential for use in recommendation systems. Initial attempts have leveraged the exceptional capabilities of LLMs, such as rich knowledge and strong generalization through In-context Learning, which involves phrasing the recommendation task as prompts. Nevertheless, the performance of LLMs in recommendation tasks remains suboptimal due to a substantial disparity between the training tasks for LLMs and recommendation tasks and inadequate recommendation data during pre-training. This paper introduces RLRF4Rec, a novel framework integrating Reinforcement Learning from Recsys Feedback for Enhanced Recommendation Reranking(RLRF4Rec) with LLMs to address these challenges. Specifically, We first have the LLM generate inferred user preferences based on user interaction history, which is then used to augment traditional ID-based sequence recommendation models. Subsequently, we trained a reward model based on knowledge augmentation recommendation models to evaluate the quality of the reasoning knowledge from LLM. We then select the best and worst responses from the N samples to construct a dataset for LLM tuning. Finally, we design a structure alignment strategy with Direct Preference Optimization(DPO). We validate the effectiveness of RLRF4Rec through extensive experiments, demonstrating significant improvements in recommendation re-ranking metrics compared to baselines. This demonstrates that our approach significantly improves the capability of LLMs to respond to instructions within recommender systems.
+
+
+
+ 21. 【2410.05877】MDAP: A Multi-view Disentangled and Adaptive Preference Learning Framework for Cross-Domain Recommendation
+ 链接:https://arxiv.org/abs/2410.05877
+ 作者:Junxiong Tong,Mingjia Yin,Hao Wang,Qiushi Pan,Defu Lian,Enhong Chen
+ 类目:Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:Cross-domain Recommendation systems, systems leverage multi-domain, Recommendation systems leverage, Cross-domain Recommendation, leverage multi-domain user
+ 备注: The International Web Information Systems Engineering conference
+
+ 点击查看摘要
+ Abstract:Cross-domain Recommendation systems leverage multi-domain user interactions to improve performance, especially in sparse data or new user scenarios. However, CDR faces challenges such as effectively capturing user preferences and avoiding negative transfer. To address these issues, we propose the Multi-view Disentangled and Adaptive Preference Learning (MDAP) framework. Our MDAP framework uses a multiview encoder to capture diverse user preferences. The framework includes a gated decoder that adaptively combines embeddings from different views to generate a comprehensive user representation. By disentangling representations and allowing adaptive feature selection, our model enhances adaptability and effectiveness. Extensive experiments on benchmark datasets demonstrate that our method significantly outperforms state-of-the-art CDR and single-domain models, providing more accurate recommendations and deeper insights into user behavior across different domains.
+
+
+
+ 22. 【2410.05863】Enhancing Playback Performance in Video Recommender Systems with an On-Device Gating and Ranking Framework
+ 链接:https://arxiv.org/abs/2410.05863
+ 作者:Yunfei Yang,Zhenghao Qi,Honghuan Wu,Qi Song,Tieyao Zhang,Hao Li,Yimin Tu,Kaiqiao Zhan,Ben Wang
+ 类目:Information Retrieval (cs.IR)
+ 关键词:gained increasing attention, Video recommender systems, recommender systems, recent years, gained increasing
+ 备注: CIKM 2024 applied research track, 7 pages
+
+ 点击查看摘要
+ Abstract:Video recommender systems (RSs) have gained increasing attention in recent years. Existing mainstream RSs focus on optimizing the matching function between users and items. However, we noticed that users frequently encounter playback issues such as slow loading or stuttering while browsing the videos, especially in weak network conditions, which will lead to a subpar browsing experience, and may cause users to leave, even when the video content and recommendations are superior. It is quite a serious issue, yet easily overlooked. To tackle this issue, we propose an on-device Gating and Ranking Framework (GRF) that cooperates with server-side RS. Specifically, we utilize a gate model to identify videos that may have playback issues in real-time, and then we employ a ranking model to select the optimal result from a locally-cached pool to replace the stuttering videos. Our solution has been fully deployed on Kwai, a large-scale short video platform with hundreds of millions of users globally. Moreover, it significantly enhances video playback performance and improves overall user experience and retention rates.
+
+
+
+ 23. 【2410.05806】A Parameter Update Balancing Algorithm for Multi-task Ranking Models in Recommendation Systems
+ 链接:https://arxiv.org/abs/2410.05806
+ 作者:Jun Yuan,Guohao Cai,Zhenhua Dong
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Multi-task ranking, real-world recommendation systems, essential for modern, Multi-task, Multi-task ranking models
+ 备注: Accepted by ICDM'24
+
+ 点击查看摘要
+ Abstract:Multi-task ranking models have become essential for modern real-world recommendation systems. While most recommendation researches focus on designing sophisticated models for specific scenarios, achieving performance improvement for multi-task ranking models across various scenarios still remains a significant challenge. Training all tasks naively can result in inconsistent learning, highlighting the need for the development of multi-task optimization (MTO) methods to tackle this challenge. Conventional methods assume that the optimal joint gradient on shared parameters leads to optimal parameter updates. However, the actual update on model parameters may deviates significantly from gradients when using momentum based optimizers such as Adam, and we design and execute statistical experiments to support the observation. In this paper, we propose a novel Parameter Update Balancing algorithm for multi-task optimization, denoted as PUB. In contrast to traditional MTO method which are based on gradient level tasks fusion or loss level tasks fusion, PUB is the first work to optimize multiple tasks through parameter update balancing. Comprehensive experiments on benchmark multi-task ranking datasets demonstrate that PUB consistently improves several multi-task backbones and achieves state-of-the-art performance. Additionally, experiments on benchmark computer vision datasets show the great potential of PUB in various multi-task learning scenarios. Furthermore, we deployed our method for an industrial evaluation on the real-world commercial platform, HUAWEI AppGallery, where PUB significantly enhances the online multi-task ranking model, efficiently managing the primary traffic of a crucial channel.
+
+
+
+ 24. 【2410.05779】LightRAG: Simple and Fast Retrieval-Augmented Generation
+ 链接:https://arxiv.org/abs/2410.05779
+ 作者:Zirui Guo,Lianghao Xia,Yanhua Yu,Tu Ao,Chao Huang
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI)
+ 关键词:large language models, Retrieval-Augmented Generation, external knowledge sources, enhance large language, integrating external knowledge
+ 备注:
+
+ 点击查看摘要
+ Abstract:Retrieval-Augmented Generation (RAG) systems enhance large language models (LLMs) by integrating external knowledge sources, enabling more accurate and contextually relevant responses tailored to user needs. However, existing RAG systems have significant limitations, including reliance on flat data representations and inadequate contextual awareness, which can lead to fragmented answers that fail to capture complex inter-dependencies. To address these challenges, we propose LightRAG, which incorporates graph structures into text indexing and retrieval processes. This innovative framework employs a dual-level retrieval system that enhances comprehensive information retrieval from both low-level and high-level knowledge discovery. Additionally, the integration of graph structures with vector representations facilitates efficient retrieval of related entities and their relationships, significantly improving response times while maintaining contextual relevance. This capability is further enhanced by an incremental update algorithm that ensures the timely integration of new data, allowing the system to remain effective and responsive in rapidly changing data environments. Extensive experimental validation demonstrates considerable improvements in retrieval accuracy and efficiency compared to existing approaches. We have made our LightRAG open-source and available at the link: this https URL.
+
+
+
+ 25. 【2410.05763】Information Discovery in e-Commerce
+ 链接:https://arxiv.org/abs/2410.05763
+ 作者:Zhaochun Ren,Xiangnan He,Dawei Yin,Maarten de Rijke
+ 类目:Information Retrieval (cs.IR); Computation and Language (cs.CL)
+ 关键词:http URL, Electronic commerce, http URL retrieval, goods and services, e-commerce
+ 备注:
+
+ 点击查看摘要
+ Abstract:Electronic commerce, or e-commerce, is the buying and selling of goods and services, or the transmitting of funds or data online. E-commerce platforms come in many kinds, with global players such as Amazon, Airbnb, Alibaba, this http URL, eBay, this http URL and platforms targeting specific geographic regions such as this http URL and this http URL retrieval has a natural role to play in e-commerce, especially in connecting people to goods and services. Information discovery in e-commerce concerns different types of search (e.g., exploratory search vs. lookup tasks), recommender systems, and natural language processing in e-commerce portals. The rise in popularity of e-commerce sites has made research on information discovery in e-commerce an increasingly active research area. This is witnessed by an increase in publications and dedicated workshops in this space. Methods for information discovery in e-commerce largely focus on improving the effectiveness of e-commerce search and recommender systems, on enriching and using knowledge graphs to support e-commerce, and on developing innovative question answering and bot-based solutions that help to connect people to goods and services. In this survey, an overview is given of the fundamental infrastructure, algorithms, and technical solutions for information discovery in e-commerce. The topics covered include user behavior and profiling, search, recommendation, and language technology in e-commerce.
+
+
+
+ 26. 【2410.05752】Exploring the Meaningfulness of Nearest Neighbor Search in High-Dimensional Space
+ 链接:https://arxiv.org/abs/2410.05752
+ 作者:Zhonghan Chen,Ruiyuan Zhang,Xi Zhao,Xiaojun Cheng,Xiaofang Zhou
+ 类目:Machine Learning (cs.LG); Databases (cs.DB); Information Retrieval (cs.IR)
+ 关键词:large language models, Dense high dimensional, high dimensional vectors, machine learning, computer vision
+ 备注:
+
+ 点击查看摘要
+ Abstract:Dense high dimensional vectors are becoming increasingly vital in fields such as computer vision, machine learning, and large language models (LLMs), serving as standard representations for multimodal data. Now the dimensionality of these vector can exceed several thousands easily. Despite the nearest neighbor search (NNS) over these dense high dimensional vectors have been widely used for retrieval augmented generation (RAG) and many other applications, the effectiveness of NNS in such a high-dimensional space remains uncertain, given the possible challenge caused by the "curse of dimensionality." To address above question, in this paper, we conduct extensive NNS studies with different distance functions, such as $L_1$ distance, $L_2$ distance and angular-distance, across diverse embedding datasets, of varied types, dimensionality and modality. Our aim is to investigate factors influencing the meaningfulness of NNS. Our experiments reveal that high-dimensional text embeddings exhibit increased resilience as dimensionality rises to higher levels when compared to random vectors. This resilience suggests that text embeddings are less affected to the "curse of dimensionality," resulting in more meaningful NNS outcomes for practical use. Additionally, the choice of distance function has minimal impact on the relevance of NNS. Our study shows the effectiveness of the embedding-based data representation method and can offer opportunity for further optimization of dense vector-related applications.
+
+
+
+ 27. 【2410.05731】Enhancing SPARQL Generation by Triplet-order-sensitive Pre-training
+ 链接:https://arxiv.org/abs/2410.05731
+ 作者:Chang Su,Jiexing Qi,He Yan,Kai Zou,Zhouhan Lin
+ 类目:Information Retrieval (cs.IR)
+ 关键词:Graph Question Answering, Knowledge Graph Question, Question Answering, Knowledge Graph, Graph Question
+ 备注: accepted by CIKM 2024
+
+ 点击查看摘要
+ Abstract:Semantic parsing that translates natural language queries to SPARQL is of great importance for Knowledge Graph Question Answering (KGQA) systems. Although pre-trained language models like T5 have achieved significant success in the Text-to-SPARQL task, their generated outputs still exhibit notable errors specific to the SPARQL language, such as triplet flips. To address this challenge and further improve the performance, we propose an additional pre-training stage with a new objective, Triplet Order Correction (TOC), along with the commonly used Masked Language Modeling (MLM), to collectively enhance the model's sensitivity to triplet order and SPARQL syntax. Our method achieves state-of-the-art performances on three widely-used benchmarks.
+
+
+
+ 28. 【2410.05672】Embedding derivatives and derivative Area operators of Hardy spaces into Lebesgue spaces
+ 链接:https://arxiv.org/abs/2410.05672
+ 作者:Xiaosong Liu,Zengjian Lou,Zixing Yuan,Ruhan Zhao
+ 类目:Information Retrieval (cs.IR)
+ 关键词:Lebesgue space, compactness of embedding, embedding derivatives, derivative area operators, Lebesgue
+ 备注: 28pages
+
+ 点击查看摘要
+ Abstract:We characterize the compactness of embedding derivatives from Hardy space $H^p$ into Lebesgue space $L^q(\mu)$. We also completely characterize the boundedness and compactness of derivative area operators from $H^p$ into $L^q(\mathbb{S}_n)$, $0p, q\infty$. Some of the tools used in the proof of the one-dimensional case are not available in higher dimensions, such as the strong factorization of Hardy spaces. Therefore, we need the theory of tent spaces which was established by Coifman, Mayer and Stein in 1985.
+
+
+
+ 29. 【2410.05536】On Feature Decorrelation in Cloth-Changing Person Re-identification
+ 链接:https://arxiv.org/abs/2410.05536
+ 作者:Hongjun Wang,Jiyuan Chen,Renhe Jiang,Xuan Song,Yinqiang Zheng
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:Cloth-changing person re-identification, person re-identification, poses a significant, computer vision, significant challenge
+ 备注:
+
+ 点击查看摘要
+ Abstract:Cloth-changing person re-identification (CC-ReID) poses a significant challenge in computer vision. A prevailing approach is to prompt models to concentrate on causal attributes, like facial features and hairstyles, rather than confounding elements such as clothing appearance. Traditional methods to achieve this involve integrating multi-modality data or employing manually annotated clothing labels, which tend to complicate the model and require extensive human effort. In our study, we demonstrate that simply reducing feature correlations during training can significantly enhance the baseline model's performance. We theoretically elucidate this effect and introduce a novel regularization technique based on density ratio estimation. This technique aims to minimize feature correlation in the training process of cloth-changing ReID baselines. Our approach is model-independent, offering broad enhancements without needing additional data or labels. We validate our method through comprehensive experiments on prevalent CC-ReID datasets, showing its effectiveness in improving baseline models' generalization capabilities.
+
+
+
+ 30. 【2410.05411】Constructing and Masking Preference Profile with LLMs for Filtering Discomforting Recommendation
+ 链接:https://arxiv.org/abs/2410.05411
+ 作者:Jiahao Liu,YiYang Shao,Peng Zhang,Dongsheng Li,Hansu Gu,Chao Chen,Longzhi Du,Tun Lu,Ning Gu
+ 类目:Information Retrieval (cs.IR); Human-Computer Interaction (cs.HC)
+ 关键词:potentially triggering negative, triggering negative consequences, Personalized algorithms, inadvertently expose users, potentially triggering
+ 备注: 15 pages, under review
+
+ 点击查看摘要
+ Abstract:Personalized algorithms can inadvertently expose users to discomforting recommendations, potentially triggering negative consequences. The subjectivity of discomfort and the black-box nature of these algorithms make it challenging to effectively identify and filter such content. To address this, we first conducted a formative study to understand users' practices and expectations regarding discomforting recommendation filtering. Then, we designed a Large Language Model (LLM)-based tool named DiscomfortFilter, which constructs an editable preference profile for a user and helps the user express filtering needs through conversation to mask discomforting preferences within the profile. Based on the edited profile, DiscomfortFilter facilitates the discomforting recommendations filtering in a plug-and-play manner, maintaining flexibility and transparency. The constructed preference profile improves LLM reasoning and simplifies user alignment, enabling a 3.8B open-source LLM to rival top commercial models in an offline proxy task. A one-week user study with 24 participants demonstrated the effectiveness of DiscomfortFilter, while also highlighting its potential impact on platform recommendation outcomes. We conclude by discussing the ongoing challenges, highlighting its relevance to broader research, assessing stakeholder impact, and outlining future research directions.
+
+
+
+ 31. 【2410.05275】Augmenting the Interpretability of GraphCodeBERT for Code Similarity Tasks
+ 链接:https://arxiv.org/abs/2410.05275
+ 作者:Jorge Martinez-Gil
+ 类目:Information Retrieval (cs.IR)
+ 关键词:ensuring software quality, remains challenging due, Assessing the degree, deeper semantic aspects, software quality
+ 备注:
+
+ 点击查看摘要
+ Abstract:Assessing the degree of similarity of code fragments is crucial for ensuring software quality, but it remains challenging due to the need to capture the deeper semantic aspects of code. Traditional syntactic methods often fail to identify these connections. Recent advancements have addressed this challenge, though they frequently sacrifice interpretability. To improve this, we present an approach aiming to improve the transparency of the similarity assessment by using GraphCodeBERT, which enables the identification of semantic relationships between code fragments. This approach identifies similar code fragments and clarifies the reasons behind that identification, helping developers better understand and trust the results. The source code for our implementation is available at this https URL.
+
+
+计算机视觉
+
+ 1. 【2410.07177】MM-Ego: Towards Building Egocentric Multimodal LLMs
+ 链接:https://arxiv.org/abs/2410.07177
+ 作者:Hanrong Ye,Haotian Zhang,Erik Daxberger,Lin Chen,Zongyu Lin,Yanghao Li,Bowen Zhang,Haoxuan You,Dan Xu,Zhe Gan,Jiasen Lu,Yinfei Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:comprehensively explore building, egocentric video understanding, research aims, aims to comprehensively, comprehensively explore
+ 备注: Technical Report
+
+ 点击查看摘要
+ Abstract:This research aims to comprehensively explore building a multimodal foundation model for egocentric video understanding. To achieve this goal, we work on three fronts. First, as there is a lack of QA data for egocentric video understanding, we develop a data engine that efficiently generates 7M high-quality QA samples for egocentric videos ranging from 30 seconds to one hour long, based on human-annotated data. This is currently the largest egocentric QA dataset. Second, we contribute a challenging egocentric QA benchmark with 629 videos and 7,026 questions to evaluate the models' ability in recognizing and memorizing visual details across videos of varying lengths. We introduce a new de-biasing evaluation method to help mitigate the unavoidable language bias present in the models being evaluated. Third, we propose a specialized multimodal architecture featuring a novel "Memory Pointer Prompting" mechanism. This design includes a global glimpse step to gain an overarching understanding of the entire video and identify key visual information, followed by a fallback step that utilizes the key visual information to generate responses. This enables the model to more effectively comprehend extended video content. With the data, benchmark, and model, we successfully build MM-Ego, an egocentric multimodal LLM that shows powerful performance on egocentric video understanding.
+
+
+
+ 2. 【2410.07173】Do better language models have crisper vision?
+ 链接:https://arxiv.org/abs/2410.07173
+ 作者:Jona Ruthardt,Gertjan J. Burghouts,Serge Belongie,Yuki M. Asano
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:text-only Large Language, text-only Large, Large Language Models, Large Language, visual world
+ 备注:
+
+ 点击查看摘要
+ Abstract:How well do text-only Large Language Models (LLMs) grasp the visual world? As LLMs are increasingly used in computer vision, addressing this question becomes both fundamental and pertinent. However, existing studies have primarily focused on limited scenarios, such as their ability to generate visual content or cluster multimodal data. To this end, we propose the Visual Text Representation Benchmark (ViTeRB) to isolate key properties that make language models well-aligned with the visual world. With this, we identify large-scale decoder-based LLMs as ideal candidates for representing text in vision-centric contexts, counter to the current practice of utilizing text encoders. Building on these findings, we propose ShareLock, an ultra-lightweight CLIP-like model. By leveraging precomputable frozen features from strong vision and language models, ShareLock achieves an impressive 51% accuracy on ImageNet despite utilizing just 563k image-caption pairs. Moreover, training requires only 1 GPU hour (or 10 hours including the precomputation of features) - orders of magnitude less than prior methods. Code will be released.
+
+
+
+ 3. 【2410.07171】IterComp: Iterative Composition-Aware Feedback Learning from Model Gallery for Text-to-Image Generation
+ 链接:https://arxiv.org/abs/2410.07171
+ 作者:Xinchen Zhang,Ling Yang,Guohao Li,Yaqi Cai,Jiake Xie,Yong Tang,Yujiu Yang,Mengdi Wang,Bin Cui
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:made notable strides, Advanced diffusion models, Advanced diffusion, Stable Diffusion, compositional generation
+ 备注: Project: [this https URL](https://github.com/YangLing0818/IterComp)
+
+ 点击查看摘要
+ Abstract:Advanced diffusion models like RPG, Stable Diffusion 3 and FLUX have made notable strides in compositional text-to-image generation. However, these methods typically exhibit distinct strengths for compositional generation, with some excelling in handling attribute binding and others in spatial relationships. This disparity highlights the need for an approach that can leverage the complementary strengths of various models to comprehensively improve the composition capability. To this end, we introduce IterComp, a novel framework that aggregates composition-aware model preferences from multiple models and employs an iterative feedback learning approach to enhance compositional generation. Specifically, we curate a gallery of six powerful open-source diffusion models and evaluate their three key compositional metrics: attribute binding, spatial relationships, and non-spatial relationships. Based on these metrics, we develop a composition-aware model preference dataset comprising numerous image-rank pairs to train composition-aware reward models. Then, we propose an iterative feedback learning method to enhance compositionality in a closed-loop manner, enabling the progressive self-refinement of both the base diffusion model and reward models over multiple iterations. Theoretical proof demonstrates the effectiveness and extensive experiments show our significant superiority over previous SOTA methods (e.g., Omost and FLUX), particularly in multi-category object composition and complex semantic alignment. IterComp opens new research avenues in reward feedback learning for diffusion models and compositional generation. Code: this https URL
+
+
+
+ 4. 【2410.07167】Deciphering Cross-Modal Alignment in Large Vision-Language Models with Modality Integration Rate
+ 链接:https://arxiv.org/abs/2410.07167
+ 作者:Qidong Huang,Xiaoyi Dong,Pan Zhang,Yuhang Zang,Yuhang Cao,Jiaqi Wang,Dahua Lin,Weiming Zhang,Nenghai Yu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Large Vision Language, Vision Language Models, Modality Integration Rate, Large Language Models, Vision Language
+ 备注: Project page: [this https URL](https://github.com/shikiw/Modality-Integration-Rate)
+
+ 点击查看摘要
+ Abstract:We present the Modality Integration Rate (MIR), an effective, robust, and generalized metric to indicate the multi-modal pre-training quality of Large Vision Language Models (LVLMs). Large-scale pre-training plays a critical role in building capable LVLMs, while evaluating its training quality without the costly supervised fine-tuning stage is under-explored. Loss, perplexity, and in-context evaluation results are commonly used pre-training metrics for Large Language Models (LLMs), while we observed that these metrics are less indicative when aligning a well-trained LLM with a new modality. Due to the lack of proper metrics, the research of LVLMs in the critical pre-training stage is hindered greatly, including the training data choice, efficient module design, etc. In this paper, we propose evaluating the pre-training quality from the inter-modal distribution distance perspective and present MIR, the Modality Integration Rate, which is 1) \textbf{Effective} to represent the pre-training quality and show a positive relation with the benchmark performance after supervised fine-tuning. 2) \textbf{Robust} toward different training/evaluation data. 3) \textbf{Generalize} across training configurations and architecture choices. We conduct a series of pre-training experiments to explore the effectiveness of MIR and observe satisfactory results that MIR is indicative about training data selection, training strategy schedule, and model architecture design to get better pre-training results. We hope MIR could be a helpful metric for building capable LVLMs and inspire the following research about modality alignment in different areas. Our code is at: this https URL.
+
+
+
+ 5. 【2410.07164】AvatarGO: Zero-shot 4D Human-Object Interaction Generation and Animation
+ 链接:https://arxiv.org/abs/2410.07164
+ 作者:Yukang Cao,Liang Pan,Kai Han,Kwan-Yee K. Wong,Ziwei Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Recent advancements, led to significant, significant improvements, full-body human-object interactions, HOI scenes
+ 备注: Project page: [this https URL](https://yukangcao.github.io/AvatarGO/)
+
+ 点击查看摘要
+ Abstract:Recent advancements in diffusion models have led to significant improvements in the generation and animation of 4D full-body human-object interactions (HOI). Nevertheless, existing methods primarily focus on SMPL-based motion generation, which is limited by the scarcity of realistic large-scale interaction data. This constraint affects their ability to create everyday HOI scenes. This paper addresses this challenge using a zero-shot approach with a pre-trained diffusion model. Despite this potential, achieving our goals is difficult due to the diffusion model's lack of understanding of ''where'' and ''how'' objects interact with the human body. To tackle these issues, we introduce AvatarGO, a novel framework designed to generate animatable 4D HOI scenes directly from textual inputs. Specifically, 1) for the ''where'' challenge, we propose LLM-guided contact retargeting, which employs Lang-SAM to identify the contact body part from text prompts, ensuring precise representation of human-object spatial relations. 2) For the ''how'' challenge, we introduce correspondence-aware motion optimization that constructs motion fields for both human and object models using the linear blend skinning function from SMPL-X. Our framework not only generates coherent compositional motions, but also exhibits greater robustness in handling penetration issues. Extensive experiments with existing methods validate AvatarGO's superior generation and animation capabilities on a variety of human-object pairs and diverse poses. As the first attempt to synthesize 4D avatars with object interactions, we hope AvatarGO could open new doors for human-centric 4D content creation.
+
+
+
+ 6. 【2410.07160】xtToon: Real-Time Text Toonify Head Avatar from Single Video
+ 链接:https://arxiv.org/abs/2410.07160
+ 作者:Luchuan Song,Lele Chen,Celong Liu,Pinxin Liu,Chenliang Xu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:drivable toonified avatar, propose TextToon, high-fidelity toonified avatar, toonified avatar, generate a drivable
+ 备注: Project Page: [this https URL](https://songluchuan.github.io/TextToon/)
+
+ 点击查看摘要
+ Abstract:We propose TextToon, a method to generate a drivable toonified avatar. Given a short monocular video sequence and a written instruction about the avatar style, our model can generate a high-fidelity toonified avatar that can be driven in real-time by another video with arbitrary identities. Existing related works heavily rely on multi-view modeling to recover geometry via texture embeddings, presented in a static manner, leading to control limitations. The multi-view video input also makes it difficult to deploy these models in real-world applications. To address these issues, we adopt a conditional embedding Tri-plane to learn realistic and stylized facial representations in a Gaussian deformation field. Additionally, we expand the stylization capabilities of 3D Gaussian Splatting by introducing an adaptive pixel-translation neural network and leveraging patch-aware contrastive learning to achieve high-quality images. To push our work into consumer applications, we develop a real-time system that can operate at 48 FPS on a GPU machine and 15-18 FPS on a mobile machine. Extensive experiments demonstrate the efficacy of our approach in generating textual avatars over existing methods in terms of quality and real-time animation. Please refer to our project page for more details: this https URL.
+
+
+
+ 7. 【2410.07157】InstructG2I: Synthesizing Images from Multimodal Attributed Graphs
+ 链接:https://arxiv.org/abs/2410.07157
+ 作者:Bowen Jin,Ziqi Pang,Bingjun Guo,Yu-Xiong Wang,Jiaxuan You,Jiawei Han
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Social and Information Networks (cs.SI)
+ 关键词:generating images, overlooked yet critical, graph, multimodal attributed graphs, critical task
+ 备注: 16 pages
+
+ 点击查看摘要
+ Abstract:In this paper, we approach an overlooked yet critical task Graph2Image: generating images from multimodal attributed graphs (MMAGs). This task poses significant challenges due to the explosion in graph size, dependencies among graph entities, and the need for controllability in graph conditions. To address these challenges, we propose a graph context-conditioned diffusion model called InstructG2I. InstructG2I first exploits the graph structure and multimodal information to conduct informative neighbor sampling by combining personalized page rank and re-ranking based on vision-language features. Then, a Graph-QFormer encoder adaptively encodes the graph nodes into an auxiliary set of graph prompts to guide the denoising process of diffusion. Finally, we propose graph classifier-free guidance, enabling controllable generation by varying the strength of graph guidance and multiple connected edges to a node. Extensive experiments conducted on three datasets from different domains demonstrate the effectiveness and controllability of our approach. The code is available at this https URL.
+
+
+
+ 8. 【2410.07155】rans4D: Realistic Geometry-Aware Transition for Compositional Text-to-4D Synthesis
+ 链接:https://arxiv.org/abs/2410.07155
+ 作者:Bohan Zeng,Ling Yang,Siyu Li,Jiaming Liu,Zixiang Zhang,Juanxi Tian,Kaixin Zhu,Yongzhen Guo,Fu-Yun Wang,Minkai Xu,Stefano Ermon,Wentao Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:demonstrated exceptional capabilities, Recent advances, advances in diffusion, demonstrated exceptional, exceptional capabilities
+ 备注: Project: [this https URL](https://github.com/YangLing0818/Trans4D)
+
+ 点击查看摘要
+ Abstract:Recent advances in diffusion models have demonstrated exceptional capabilities in image and video generation, further improving the effectiveness of 4D synthesis. Existing 4D generation methods can generate high-quality 4D objects or scenes based on user-friendly conditions, benefiting the gaming and video industries. However, these methods struggle to synthesize significant object deformation of complex 4D transitions and interactions within scenes. To address this challenge, we propose Trans4D, a novel text-to-4D synthesis framework that enables realistic complex scene transitions. Specifically, we first use multi-modal large language models (MLLMs) to produce a physic-aware scene description for 4D scene initialization and effective transition timing planning. Then we propose a geometry-aware 4D transition network to realize a complex scene-level 4D transition based on the plan, which involves expressive geometrical object deformation. Extensive experiments demonstrate that Trans4D consistently outperforms existing state-of-the-art methods in generating 4D scenes with accurate and high-quality transitions, validating its effectiveness. Code: this https URL
+
+
+
+ 9. 【2410.07153】CHASE: Learning Convex Hull Adaptive Shift for Skeleton-based Multi-Entity Action Recognition
+ 链接:https://arxiv.org/abs/2410.07153
+ 作者:Yuhang Wen,Mengyuan Liu,Songtao Wu,Beichen Ding
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:multiple diverse entities, group activities involving, activities involving multiple, involving multiple diverse, Skeleton-based multi-entity action
+ 备注: NeurIPS 2024 Camera-ready Version
+
+ 点击查看摘要
+ Abstract:Skeleton-based multi-entity action recognition is a challenging task aiming to identify interactive actions or group activities involving multiple diverse entities. Existing models for individuals often fall short in this task due to the inherent distribution discrepancies among entity skeletons, leading to suboptimal backbone optimization. To this end, we introduce a Convex Hull Adaptive Shift based multi-Entity action recognition method (CHASE), which mitigates inter-entity distribution gaps and unbiases subsequent backbones. Specifically, CHASE comprises a learnable parameterized network and an auxiliary objective. The parameterized network achieves plausible, sample-adaptive repositioning of skeleton sequences through two key components. First, the Implicit Convex Hull Constrained Adaptive Shift ensures that the new origin of the coordinate system is within the skeleton convex hull. Second, the Coefficient Learning Block provides a lightweight parameterization of the mapping from skeleton sequences to their specific coefficients in convex combinations. Moreover, to guide the optimization of this network for discrepancy minimization, we propose the Mini-batch Pair-wise Maximum Mean Discrepancy as the additional objective. CHASE operates as a sample-adaptive normalization method to mitigate inter-entity distribution discrepancies, thereby reducing data bias and improving the subsequent classifier's multi-entity action recognition performance. Extensive experiments on six datasets, including NTU Mutual 11/26, H2O, Assembly101, Collective Activity and Volleyball, consistently verify our approach by seamlessly adapting to single-entity backbones and boosting their performance in multi-entity scenarios. Our code is publicly available at this https URL .
+
+
+
+ 10. 【2410.07151】FaceVid-1K: A Large-Scale High-Quality Multiracial Human Face Video Dataset
+ 链接:https://arxiv.org/abs/2410.07151
+ 作者:Donglin Di,He Feng,Wenzhang Sun,Yongjia Ma,Hao Li,Wei Chen,Xiaofei Gou,Tonghua Su,Xun Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Generating talking face, face video generation, video generation, face video, Generating talking
+ 备注:
+
+ 点击查看摘要
+ Abstract:Generating talking face videos from various conditions has recently become a highly popular research area within generative tasks. However, building a high-quality face video generation model requires a well-performing pre-trained backbone, a key obstacle that universal models fail to adequately address. Most existing works rely on universal video or image generation models and optimize control mechanisms, but they neglect the evident upper bound in video quality due to the limited capabilities of the backbones, which is a result of the lack of high-quality human face video datasets. In this work, we investigate the unsatisfactory results from related studies, gather and trim existing public talking face video datasets, and additionally collect and annotate a large-scale dataset, resulting in a comprehensive, high-quality multiracial face collection named \textbf{FaceVid-1K}. Using this dataset, we craft several effective pre-trained backbone models for face video generation. Specifically, we conduct experiments with several well-established video generation models, including text-to-video, image-to-video, and unconditional video generation, under various settings. We obtain the corresponding performance benchmarks and compared them with those trained on public datasets to demonstrate the superiority of our dataset. These experiments also allow us to investigate empirical strategies for crafting domain-specific video generation tasks with cost-effective settings. We will make our curated dataset, along with the pre-trained talking face video generation models, publicly available as a resource contribution to hopefully advance the research field.
+
+
+
+ 11. 【2410.07149】owards Interpreting Visual Information Processing in Vision-Language Models
+ 链接:https://arxiv.org/abs/2410.07149
+ 作者:Clement Neo,Luke Ong,Philip Torr,Mor Geva,David Krueger,Fazl Barez
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:powerful tools, visual token representations, Vision-Language Models, visual, visual token
+ 备注:
+
+ 点击查看摘要
+ Abstract:Vision-Language Models (VLMs) are powerful tools for processing and understanding text and images. We study the processing of visual tokens in the language model component of LLaVA, a prominent VLM. Our approach focuses on analyzing the localization of object information, the evolution of visual token representations across layers, and the mechanism of integrating visual information for predictions. Through ablation studies, we demonstrated that object identification accuracy drops by over 70\% when object-specific tokens are removed. We observed that visual token representations become increasingly interpretable in the vocabulary space across layers, suggesting an alignment with textual tokens corresponding to image content. Finally, we found that the model extracts object information from these refined representations at the last token position for prediction, mirroring the process in text-only language models for factual association tasks. These findings provide crucial insights into how VLMs process and integrate visual information, bridging the gap between our understanding of language and vision models, and paving the way for more interpretable and controllable multimodal systems.
+
+
+
+ 12. 【2410.07133】EvolveDirector: Approaching Advanced Text-to-Image Generation with Large Vision-Language Models
+ 链接:https://arxiv.org/abs/2410.07133
+ 作者:Rui Zhao,Hangjie Yuan,Yujie Wei,Shiwei Zhang,Yuchao Gu,Lingmin Ran,Xiang Wang,Zhangjie Wu,Junhao Zhang,Yingya Zhang,Mike Zheng Shou
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:generating fantastic content, showcased remarkable capabilities, Recent advancements, fantastic content, showcased remarkable
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advancements in generation models have showcased remarkable capabilities in generating fantastic content. However, most of them are trained on proprietary high-quality data, and some models withhold their parameters and only provide accessible application programming interfaces (APIs), limiting their benefits for downstream tasks. To explore the feasibility of training a text-to-image generation model comparable to advanced models using publicly available resources, we introduce EvolveDirector. This framework interacts with advanced models through their public APIs to obtain text-image data pairs to train a base model. Our experiments with extensive data indicate that the model trained on generated data of the advanced model can approximate its generation capability. However, it requires large-scale samples of 10 million or more. This incurs significant expenses in time, computational resources, and especially the costs associated with calling fee-based APIs. To address this problem, we leverage pre-trained large vision-language models (VLMs) to guide the evolution of the base model. VLM continuously evaluates the base model during training and dynamically updates and refines the training dataset by the discrimination, expansion, deletion, and mutation operations. Experimental results show that this paradigm significantly reduces the required data volume. Furthermore, when approaching multiple advanced models, EvolveDirector can select the best samples generated by them to learn powerful and balanced abilities. The final trained model Edgen is demonstrated to outperform these advanced models. The code and model weights are available at this https URL.
+
+
+
+ 13. 【2410.07128】Neural Differential Appearance Equations
+ 链接:https://arxiv.org/abs/2410.07128
+ 作者:Chen Liu,Tobias Ritschel
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR); Machine Learning (cs.LG)
+ 关键词:reproduce dynamic appearance, ODE, dynamic appearance textures, dynamic textures, appearance
+ 备注: SIGGRAPH Asia 2024 Journal Track. Project page at [this https URL](https://ryushinn.github.io/ode-appearance)
+
+ 点击查看摘要
+ Abstract:We propose a method to reproduce dynamic appearance textures with space-stationary but time-varying visual statistics. While most previous work decomposes dynamic textures into static appearance and motion, we focus on dynamic appearance that results not from motion but variations of fundamental properties, such as rusting, decaying, melting, and weathering. To this end, we adopt the neural ordinary differential equation (ODE) to learn the underlying dynamics of appearance from a target exemplar. We simulate the ODE in two phases. At the "warm-up" phase, the ODE diffuses a random noise to an initial state. We then constrain the further evolution of this ODE to replicate the evolution of visual feature statistics in the exemplar during the generation phase. The particular innovation of this work is the neural ODE achieving both denoising and evolution for dynamics synthesis, with a proposed temporal training scheme. We study both relightable (BRDF) and non-relightable (RGB) appearance models. For both we introduce new pilot datasets, allowing, for the first time, to study such phenomena: For RGB we provide 22 dynamic textures acquired from free online sources; For BRDFs, we further acquire a dataset of 21 flash-lit videos of time-varying materials, enabled by a simple-to-construct setup. Our experiments show that our method consistently yields realistic and coherent results, whereas prior works falter under pronounced temporal appearance variations. A user study confirms our approach is preferred to previous work for such exemplars.
+
+
+
+ 14. 【2410.07125】A Simplified Positional Cell Type Visualization using Spatially Aggregated Clusters
+ 链接:https://arxiv.org/abs/2410.07125
+ 作者:Lee Mason,Jonas Almeida
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:overlaying cell type, cell type proportion, type proportion data, tissue images, method for overlaying
+ 备注: For the Bio+MedVis 2024 redesign challenge
+
+ 点击查看摘要
+ Abstract:We introduce a novel method for overlaying cell type proportion data onto tissue images. This approach preserves spatial context while avoiding visual clutter or excessively obscuring the underlying slide. Our proposed technique involves clustering the data and aggregating neighboring points of the same cluster into polygons.
+
+
+
+ 15. 【2410.07124】Cross-Task Pretraining for Cross-Organ Cross-Scanner Adenocarcinoma Segmentation
+ 链接:https://arxiv.org/abs/2410.07124
+ 作者:Adrian Galdran
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Cross-Scanner Adenocarcinoma Segmentation, short abstract describes, histopathological image patches, Cross-Scanner Adenocarcinoma, Adenocarcinoma Segmentation
+ 备注: MICCAI2024 COSAS Challenge - short abstract
+
+ 点击查看摘要
+ Abstract:This short abstract describes a solution to the COSAS 2024 competition on Cross-Organ and Cross-Scanner Adenocarcinoma Segmentation from histopathological image patches. The main challenge in the task of segmenting this type of cancer is a noticeable domain shift encountered when changing acquisition devices (microscopes) and also when tissue comes from different organs. The two tasks proposed in COSAS were to train on a dataset of images from three different organs, and then predict segmentations on data from unseen organs (dataset T1), and to train on a dataset of images acquired on three different scanners and then segment images acquired with another unseen microscope. We attempted to bridge the domain shift gap by experimenting with three different strategies: standard training for each dataset, pretraining on dataset T1 and then fine-tuning on dataset T2 (and vice-versa, a strategy we call \textit{Cross-Task Pretraining}), and training on the combination of dataset A and B. Our experiments showed that Cross-Task Pre-training is a more promising approach to domain generalization.
+
+
+
+ 16. 【2410.07119】hing2Reality: Transforming 2D Content into Conditioned Multiviews and 3D Gaussian Objects for XR Communication
+ 链接:https://arxiv.org/abs/2410.07119
+ 作者:Erzhen Hu,Mingyi Li,Jungtaek Hong,Xun Qian,Alex Olwal,David Kim,Seongkook Heo,Ruofei Du
+ 类目:Human-Computer Interaction (cs.HC); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:enhance mutual understanding, product designs, mutual understanding, digital assets, digital
+ 备注: 18 pages (15 pages without references), 13 figures
+
+ 点击查看摘要
+ Abstract:During remote communication, participants often share both digital and physical content, such as product designs, digital assets, and environments, to enhance mutual understanding. Recent advances in augmented communication have facilitated users to swiftly create and share digital 2D copies of physical objects from video feeds into a shared space. However, conventional 2D representations of digital objects restricts users' ability to spatially reference items in a shared immersive environment. To address this, we propose Thing2Reality, an Extended Reality (XR) communication platform that enhances spontaneous discussions of both digital and physical items during remote sessions. With Thing2Reality, users can quickly materialize ideas or physical objects in immersive environments and share them as conditioned multiview renderings or 3D Gaussians. Thing2Reality enables users to interact with remote objects or discuss concepts in a collaborative manner. Our user study revealed that the ability to interact with and manipulate 3D representations of objects significantly enhances the efficiency of discussions, with the potential to augment discussion of 2D artifacts.
+
+
+
+ 17. 【2410.07117】Classification of Buried Objects from Ground Penetrating Radar Images by using Second Order Deep Learning Models
+ 链接:https://arxiv.org/abs/2410.07117
+ 作者:Douba Jafuno,Ammar Mian,Guillaume Ginolhac,Nickolas Stelzenmuller
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Applications (stat.AP)
+ 关键词:Ground Penetrating Radar, classification model based, classify buried objects, classical Ground Penetrating, buried objects
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this paper, a new classification model based on covariance matrices is built in order to classify buried objects. The inputs of the proposed models are the hyperbola thumbnails obtained with a classical Ground Penetrating Radar (GPR) system. These thumbnails are entered in the first layers of a classical CNN which results in a covariance matrix by using the outputs of the convolutional filters. Next, the covariance matrix is given to a network composed of specific layers to classify Symmetric Positive Definite (SPD) matrices. We show in a large database that our approach outperform shallow networks designed for GPR data and conventional CNNs typically used in computer vision applications, particularly when the number of training data decreases and in the presence of mislabeled data. We also illustrate the interest of our models when training data and test sets are obtained from different weather modes or considerations.
+
+
+
+ 18. 【2410.07115】Generating Topologically and Geometrically Diverse Manifold Data in Dimensions Four and Below
+ 链接:https://arxiv.org/abs/2410.07115
+ 作者:Khalil Mathieu Hannouch,Stephan Chalup
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:areas of research, Understanding, Understanding the topological, image-type data, data
+ 备注: 8 pages, DICTA 2024
+
+ 点击查看摘要
+ Abstract:Understanding the topological characteristics of data is important to many areas of research. Recent work has demonstrated that synthetic 4D image-type data can be useful to train 4D convolutional neural network models to see topological features in these data. These models also appear to tolerate the use of image preprocessing techniques where existing topological data analysis techniques such as persistent homology do not. This paper investigates how methods from algebraic topology, combined with image processing techniques such as morphology, can be used to generate topologically sophisticated and diverse-looking 2-, 3-, and 4D image-type data with topological labels in simulation. These approaches are illustrated in 2D and 3D with the aim of providing a roadmap towards achieving this in 4D.
+
+
+
+ 19. 【2410.07113】Personalized Visual Instruction Tuning
+ 链接:https://arxiv.org/abs/2410.07113
+ 作者:Renjie Pi,Jianshu Zhang,Tianyang Han,Jipeng Zhang,Rui Pan,Tong Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:demonstrated significant progress, Recent advancements, face blindness, significant progress, notable limitation
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advancements in multimodal large language models (MLLMs) have demonstrated significant progress; however, these models exhibit a notable limitation, which we refer to as "face blindness". Specifically, they can engage in general conversations but fail to conduct personalized dialogues targeting at specific individuals. This deficiency hinders the application of MLLMs in personalized settings, such as tailored visual assistants on mobile devices, or domestic robots that need to recognize members of the family. In this paper, we introduce Personalized Visual Instruction Tuning (PVIT), a novel data curation and training framework designed to enable MLLMs to identify target individuals within an image and engage in personalized and coherent dialogues. Our approach involves the development of a sophisticated pipeline that autonomously generates training data containing personalized conversations. This pipeline leverages the capabilities of various visual experts, image generation models, and (multi-modal) large language models. To evaluate the personalized potential of MLLMs, we present a benchmark called P-Bench, which encompasses various question types with different levels of difficulty. The experiments demonstrate a substantial personalized performance enhancement after fine-tuning with our curated dataset.
+
+
+
+ 20. 【2410.07112】VHELM: A Holistic Evaluation of Vision Language Models
+ 链接:https://arxiv.org/abs/2410.07112
+ 作者:Tony Lee,Haoqin Tu,Chi Heem Wong,Wenhao Zheng,Yiyang Zhou,Yifan Mai,Josselin Somerville Roberts,Michihiro Yasunaga,Huaxiu Yao,Cihang Xie,Percy Liang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:assessing vision-language models, Current benchmarks, assessing vision-language, neglect other critical, Vision Language Models
+ 备注: NeurIPS 2024. First three authors contributed equally
+
+ 点击查看摘要
+ Abstract:Current benchmarks for assessing vision-language models (VLMs) often focus on their perception or problem-solving capabilities and neglect other critical aspects such as fairness, multilinguality, or toxicity. Furthermore, they differ in their evaluation procedures and the scope of the evaluation, making it difficult to compare models. To address these issues, we extend the HELM framework to VLMs to present the Holistic Evaluation of Vision Language Models (VHELM). VHELM aggregates various datasets to cover one or more of the 9 aspects: visual perception, knowledge, reasoning, bias, fairness, multilinguality, robustness, toxicity, and safety. In doing so, we produce a comprehensive, multi-dimensional view of the capabilities of the VLMs across these important factors. In addition, we standardize the standard inference parameters, methods of prompting, and evaluation metrics to enable fair comparisons across models. Our framework is designed to be lightweight and automatic so that evaluation runs are cheap and fast. Our initial run evaluates 22 VLMs on 21 existing datasets to provide a holistic snapshot of the models. We uncover new key findings, such as the fact that efficiency-focused models (e.g., Claude 3 Haiku or Gemini 1.5 Flash) perform significantly worse than their full models (e.g., Claude 3 Opus or Gemini 1.5 Pro) on the bias benchmark but not when evaluated on the other aspects. For transparency, we release the raw model generations and complete results on our website (this https URL). VHELM is intended to be a living benchmark, and we hope to continue adding new datasets and models over time.
+
+
+
+ 21. 【2410.07110】Continual Learning: Less Forgetting, More OOD Generalization via Adaptive Contrastive Replay
+ 链接:https://arxiv.org/abs/2410.07110
+ 作者:Hossein Rezaei,Mohammad Sabokrou
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Machine learning models, previously learned knowledge, Machine learning, models often suffer, suffer from catastrophic
+ 备注:
+
+ 点击查看摘要
+ Abstract:Machine learning models often suffer from catastrophic forgetting of previously learned knowledge when learning new classes. Various methods have been proposed to mitigate this issue. However, rehearsal-based learning, which retains samples from previous classes, typically achieves good performance but tends to memorize specific instances, struggling with Out-of-Distribution (OOD) generalization. This often leads to high forgetting rates and poor generalization. Surprisingly, the OOD generalization capabilities of these methods have been largely unexplored. In this paper, we highlight this issue and propose a simple yet effective strategy inspired by contrastive learning and data-centric principles to address it. We introduce Adaptive Contrastive Replay (ACR), a method that employs dual optimization to simultaneously train both the encoder and the classifier. ACR adaptively populates the replay buffer with misclassified samples while ensuring a balanced representation of classes and tasks. By refining the decision boundary in this way, ACR achieves a balance between stability and plasticity. Our method significantly outperforms previous approaches in terms of OOD generalization, achieving an improvement of 13.41\% on Split CIFAR-100, 9.91\% on Split Mini-ImageNet, and 5.98\% on Split Tiny-ImageNet.
+
+
+
+ 22. 【2410.07093】LaMP: Language-Motion Pretraining for Motion Generation, Retrieval, and Captioning
+ 链接:https://arxiv.org/abs/2410.07093
+ 作者:Zhe Li,Weihao Yuan,Yisheng He,Lingteng Qiu,Shenhao Zhu,Xiaodong Gu,Weichao Shen,Yuan Dong,Zilong Dong,Laurence T. Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:plays a vital, vital role, realm of human, motion, Language plays
+ 备注:
+
+ 点击查看摘要
+ Abstract:Language plays a vital role in the realm of human motion. Existing methods have largely depended on CLIP text embeddings for motion generation, yet they fall short in effectively aligning language and motion due to CLIP's pretraining on static image-text pairs. This work introduces LaMP, a novel Language-Motion Pretraining model, which transitions from a language-vision to a more suitable language-motion latent space. It addresses key limitations by generating motion-informative text embeddings, significantly enhancing the relevance and semantics of generated motion sequences. With LaMP, we advance three key tasks: text-to-motion generation, motion-text retrieval, and motion captioning through aligned language-motion representation learning. For generation, we utilize LaMP to provide the text condition instead of CLIP, and an autoregressive masked prediction is designed to achieve mask modeling without rank collapse in transformers. For retrieval, motion features from LaMP's motion transformer interact with query tokens to retrieve text features from the text transformer, and vice versa. For captioning, we finetune a large language model with the language-informative motion features to develop a strong motion captioning model. In addition, we introduce the LaMP-BertScore metric to assess the alignment of generated motions with textual descriptions. Extensive experimental results on multiple datasets demonstrate substantial improvements over previous methods across all three tasks. The code of our method will be made public.
+
+
+
+ 23. 【2410.07087】owards Realistic UAV Vision-Language Navigation: Platform, Benchmark, and Methodology
+ 链接:https://arxiv.org/abs/2410.07087
+ 作者:Xiangyu Wang,Donglin Yang,Ziqin Wang,Hohin Kwan,Jinyu Chen,Wenjun Wu,Hongsheng Li,Yue Liao,Si Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:Developing agents capable, attracted widespread interest, target location based, Developing agents, VLN
+ 备注:
+
+ 点击查看摘要
+ Abstract:Developing agents capable of navigating to a target location based on language instructions and visual information, known as vision-language navigation (VLN), has attracted widespread interest. Most research has focused on ground-based agents, while UAV-based VLN remains relatively underexplored. Recent efforts in UAV vision-language navigation predominantly adopt ground-based VLN settings, relying on predefined discrete action spaces and neglecting the inherent disparities in agent movement dynamics and the complexity of navigation tasks between ground and aerial environments. To address these disparities and challenges, we propose solutions from three perspectives: platform, benchmark, and methodology. To enable realistic UAV trajectory simulation in VLN tasks, we propose the OpenUAV platform, which features diverse environments, realistic flight control, and extensive algorithmic support. We further construct a target-oriented VLN dataset consisting of approximately 12k trajectories on this platform, serving as the first dataset specifically designed for realistic UAV VLN tasks. To tackle the challenges posed by complex aerial environments, we propose an assistant-guided UAV object search benchmark called UAV-Need-Help, which provides varying levels of guidance information to help UAVs better accomplish realistic VLN tasks. We also propose a UAV navigation LLM that, given multi-view images, task descriptions, and assistant instructions, leverages the multimodal understanding capabilities of the MLLM to jointly process visual and textual information, and performs hierarchical trajectory generation. The evaluation results of our method significantly outperform the baseline models, while there remains a considerable gap between our results and those achieved by human operators, underscoring the challenge presented by the UAV-Need-Help task.
+
+
+
+ 24. 【2410.07081】JPEG Inspired Deep Learning
+ 链接:https://arxiv.org/abs/2410.07081
+ 作者:Ahmed H. Salamah,Kaixiang Zheng,Yiwen Liu,En-Hui Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:deep neural networks, performance of deep, well-crafted JPEG compression, JPEG compression, deep learning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Although it is traditionally believed that lossy image compression, such as JPEG compression, has a negative impact on the performance of deep neural networks (DNNs), it is shown by recent works that well-crafted JPEG compression can actually improve the performance of deep learning (DL). Inspired by this, we propose JPEG-DL, a novel DL framework that prepends any underlying DNN architecture with a trainable JPEG compression layer. To make the quantization operation in JPEG compression trainable, a new differentiable soft quantizer is employed at the JPEG layer, and then the quantization operation and underlying DNN are jointly trained. Extensive experiments show that in comparison with the standard DL, JPEG-DL delivers significant accuracy improvements across various datasets and model architectures while enhancing robustness against adversarial attacks. Particularly, on some fine-grained image classification datasets, JPEG-DL can increase prediction accuracy by as much as 20.9%. Our code is available on this https URL.
+
+
+
+ 25. 【2410.07073】Pixtral 12B
+ 链接:https://arxiv.org/abs/2410.07073
+ 作者:Pravesh Agrawal,Szymon Antoniak,Emma Bou Hanna,Devendra Chaplot,Jessica Chudnovsky,Saurabh Garg,Theophile Gervet,Soham Ghosh,Amélie Héliou,Paul Jacob,Albert Q. Jiang,Timothée Lacroix,Guillaume Lample,Diego Las Casas,Thibaut Lavril,Teven Le Scao,Andy Lo,William Marshall,Louis Martin,Arthur Mensch,Pavankumar Muddireddy,Valera Nemychnikova,Marie Pellat,Patrick Von Platen,Nikhil Raghuraman,Baptiste Rozière,Alexandre Sablayrolles,Lucile Saulnier,Romain Sauvestre,Wendy Shang,Roman Soletskyi,Lawrence Stewart,Pierre Stock,Joachim Studnia,Sandeep Subramanian,Sagar Vaze,Thomas Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:billion-parameter multimodal language, Pixtral, billion-parameter multimodal, multimodal, models
+ 备注:
+
+ 点击查看摘要
+ Abstract:We introduce Pixtral-12B, a 12--billion-parameter multimodal language model. Pixtral-12B is trained to understand both natural images and documents, achieving leading performance on various multimodal benchmarks, surpassing a number of larger models. Unlike many open-source models, Pixtral is also a cutting-edge text model for its size, and does not compromise on natural language performance to excel in multimodal tasks. Pixtral uses a new vision encoder trained from scratch, which allows it to ingest images at their natural resolution and aspect ratio. This gives users flexibility on the number of tokens used to process an image. Pixtral is also able to process any number of images in its long context window of 128K tokens. Pixtral 12B substanially outperforms other open models of similar sizes (Llama-3.2 11B \ Qwen-2-VL 7B). It also outperforms much larger open models like Llama-3.2 90B while being 7x smaller. We further contribute an open-source benchmark, MM-MT-Bench, for evaluating vision-language models in practical scenarios, and provide detailed analysis and code for standardized evaluation protocols for multimodal LLMs. Pixtral-12B is released under Apache 2.0 license.
+
+
+
+ 26. 【2410.07062】nyEmo: Scaling down Emotional Reasoning via Metric Projection
+ 链接:https://arxiv.org/abs/2410.07062
+ 作者:Cristian Gutierrez
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:small multi-modal language, paper introduces TinyEmo, emotional reasoning, Metric Projector, multi-modal language models
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper introduces TinyEmo, a family of small multi-modal language models for emotional reasoning and classification. Our approach features: (1) a synthetic emotional instruct dataset for both pre-training and fine-tuning stages, (2) a Metric Projector that delegates classification from the language model allowing for more efficient training and inference, (3) a multi-modal large language model (MM-LLM) for emotional reasoning, and (4) a semi-automated framework for bias detection. TinyEmo is able to perform emotion classification and emotional reasoning, all while using substantially fewer parameters than comparable models. This efficiency allows us to freely incorporate more diverse emotional datasets, enabling strong performance on classification tasks, with our smallest model (700M parameters) outperforming larger state-of-the-art models based on general-purpose MM-LLMs with over 7B parameters. Additionally, the Metric Projector allows for interpretability and indirect bias detection in large models without additional training, offering an approach to understand and improve AI systems.
+We release code, models, and dataset at this https URL
+
Subjects:
+Computer Vision and Pattern Recognition (cs.CV)
+Cite as:
+arXiv:2410.07062 [cs.CV]
+(or
+arXiv:2410.07062v1 [cs.CV] for this version)
+https://doi.org/10.48550/arXiv.2410.07062
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 27. 【2410.07046】S2HPruner: Soft-to-Hard Distillation Bridges the Discretization Gap in Pruning
+ 链接:https://arxiv.org/abs/2410.07046
+ 作者:Weihao Lin,Shengji Tang,Chong Yu,Peng Ye,Tao Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:superior sub-architecture search, pruned discrete network, soft network, differentiable mask pruning, hard network
+ 备注: NeurIPS 2024 accepted
+
+ 点击查看摘要
+ Abstract:Recently, differentiable mask pruning methods optimize the continuous relaxation architecture (soft network) as the proxy of the pruned discrete network (hard network) for superior sub-architecture search. However, due to the agnostic impact of the discretization process, the hard network struggles with the equivalent representational capacity as the soft network, namely discretization gap, which severely spoils the pruning performance. In this paper, we first investigate the discretization gap and propose a novel structural differentiable mask pruning framework named S2HPruner to bridge the discretization gap in a one-stage manner. In the training procedure, SH2Pruner forwards both the soft network and its corresponding hard network, then distills the hard network under the supervision of the soft network. To optimize the mask and prevent performance degradation, we propose a decoupled bidirectional knowledge distillation. It blocks the weight updating from the hard to the soft network while maintaining the gradient corresponding to the mask. Compared with existing pruning arts, S2HPruner achieves surpassing pruning performance without fine-tuning on comprehensive benchmarks, including CIFAR-100, Tiny ImageNet, and ImageNet with a variety of network architectures. Besides, investigation and analysis experiments explain the effectiveness of S2HPruner. Codes will be released soon.
+
+
+
+ 28. 【2410.07030】Clean Evaluations on Contaminated Visual Language Models
+ 链接:https://arxiv.org/abs/2410.07030
+ 作者:Hongyuan Lu,Shujie Miao,Wai Lam
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:important research era, possibly contaminated LLMs, evaluate large language, large language models, important research
+ 备注:
+
+ 点击查看摘要
+ Abstract:How to evaluate large language models (LLMs) cleanly has been established as an important research era to genuinely report the performance of possibly contaminated LLMs. Yet, how to cleanly evaluate the visual language models (VLMs) is an under-studied problem. We propose a novel approach to achieve such goals through data augmentation methods on the visual input information. We then craft a new visual clean evaluation benchmark with thousands of data instances. Through extensive experiments, we found that the traditional visual data augmentation methods are useful, but they are at risk of being used as a part of the training data as a workaround. We further propose using BGR augmentation to switch the colour channel of the visual information. We found that it is a simple yet effective method for reducing the effect of data contamination and fortunately, it is also harmful to be used as a data augmentation method during training. It means that it is hard to integrate such data augmentation into training by malicious trainers and it could be a promising technique to cleanly evaluate visual LLMs. Our code, data, and model weights will be released upon publication.
+
+
+
+ 29. 【2410.07025】Preference Fine-Tuning for Factuality in Chest X-Ray Interpretation Models Without Human Feedback
+ 链接:https://arxiv.org/abs/2410.07025
+ 作者:Dennis Hein,Zhihong Chen,Sophie Ostmeier,Justin Xu,Maya Varma,Eduardo Pontes Reis,Arne Edward Michalson,Christian Bluethgen,Hyun Joo Shin,Curtis Langlotz,Akshay S Chaudhari
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:translating medical images, translating medical, medical images, play a crucial, crucial role
+ 备注:
+
+ 点击查看摘要
+ Abstract:Radiologists play a crucial role by translating medical images into medical reports. However, the field faces staffing shortages and increasing workloads. While automated approaches using vision-language models (VLMs) show promise as assistants, they require exceptionally high accuracy. Most current VLMs in radiology rely solely on supervised fine-tuning (SFT). Meanwhile, in the general domain, additional preference fine-tuning has become standard practice. The challenge in radiology lies in the prohibitive cost of obtaining radiologist feedback. We propose a scalable automated preference alignment technique for VLMs in radiology, focusing on chest X-ray (CXR) report generation. Our method leverages publicly available datasets with an LLM-as-a-Judge mechanism, eliminating the need for additional expert radiologist feedback. We evaluate and benchmark five direct alignment algorithms (DAAs). Our results show up to a 57.4% improvement in average GREEN scores, a LLM-based metric for evaluating CXR reports, and a 9.2% increase in an average across six metrics (domain specific and general), compared to the SFT baseline. We study reward overoptimization via length exploitation, with reports lengthening by up to 3.2x. To assess a potential alignment tax, we benchmark on six additional diverse tasks, finding no significant degradations. A reader study involving four board-certified radiologists indicates win rates of up to 0.62 over the SFT baseline, while significantly penalizing verbosity. Our analysis provides actionable insights for the development of VLMs in high-stakes fields like radiology.
+
+
+
+ 30. 【2410.06985】Jointly Generating Multi-view Consistent PBR Textures using Collaborative Control
+ 链接:https://arxiv.org/abs/2410.06985
+ 作者:Shimon Vainer,Konstantin Kutsy,Dante De Nigris,Ciara Rowles,Slava Elizarov,Simon Donné
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:Multi-view consistency remains, consistency remains, remains a challenge, Collaborative Control, Multi-view consistency
+ 备注: 19 pages, 13 figures
+
+ 点击查看摘要
+ Abstract:Multi-view consistency remains a challenge for image diffusion models. Even within the Text-to-Texture problem, where perfect geometric correspondences are known a priori, many methods fail to yield aligned predictions across views, necessitating non-trivial fusion methods to incorporate the results onto the original mesh. We explore this issue for a Collaborative Control workflow specifically in PBR Text-to-Texture. Collaborative Control directly models PBR image probability distributions, including normal bump maps; to our knowledge, the only diffusion model to directly output full PBR stacks. We discuss the design decisions involved in making this model multi-view consistent, and demonstrate the effectiveness of our approach in ablation studies, as well as practical applications.
+
+
+
+ 31. 【2410.06982】Structure-Centric Robust Monocular Depth Estimation via Knowledge Distillation
+ 链接:https://arxiv.org/abs/2410.06982
+ 作者:Runze Chen,Haiyong Luo,Fang Zhao,Jingze Yu,Yupeng Jia,Juan Wang,Xuepeng Ma
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Monocular depth estimation, Monocular depth, perception in computer, computer vision, depth estimation
+ 备注: To be published in Asian Conference on Computer Vision 2024
+
+ 点击查看摘要
+ Abstract:Monocular depth estimation, enabled by self-supervised learning, is a key technique for 3D perception in computer vision. However, it faces significant challenges in real-world scenarios, which encompass adverse weather variations, motion blur, as well as scenes with poor lighting conditions at night. Our research reveals that we can divide monocular depth estimation into three sub-problems: depth structure consistency, local texture disambiguation, and semantic-structural correlation. Our approach tackles the non-robustness of existing self-supervised monocular depth estimation models to interference textures by adopting a structure-centered perspective and utilizing the scene structure characteristics demonstrated by semantics and illumination. We devise a novel approach to reduce over-reliance on local textures, enhancing robustness against missing or interfering patterns. Additionally, we incorporate a semantic expert model as the teacher and construct inter-model feature dependencies via learnable isomorphic graphs to enable aggregation of semantic structural knowledge. Our approach achieves state-of-the-art out-of-distribution monocular depth estimation performance across a range of public adverse scenario datasets. It demonstrates notable scalability and compatibility, without necessitating extensive model engineering. This showcases the potential for customizing models for diverse industrial applications.
+
+
+
+ 32. 【2410.06977】Adaptive High-Frequency Transformer for Diverse Wildlife Re-Identification
+ 链接:https://arxiv.org/abs/2410.06977
+ 作者:Chenyue Li,Shuoyi Chen,Mang Ye
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:holding significant importance, involves utilizing visual, utilizing visual technology, identify specific individuals, ReID involves utilizing
+ 备注:
+
+ 点击查看摘要
+ Abstract:Wildlife ReID involves utilizing visual technology to identify specific individuals of wild animals in different scenarios, holding significant importance for wildlife conservation, ecological research, and environmental monitoring. Existing wildlife ReID methods are predominantly tailored to specific species, exhibiting limited applicability. Although some approaches leverage extensively studied person ReID techniques, they struggle to address the unique challenges posed by wildlife. Therefore, in this paper, we present a unified, multi-species general framework for wildlife ReID. Given that high-frequency information is a consistent representation of unique features in various species, significantly aiding in identifying contours and details such as fur textures, we propose the Adaptive High-Frequency Transformer model with the goal of enhancing high-frequency information learning. To mitigate the inevitable high-frequency interference in the wilderness environment, we introduce an object-aware high-frequency selection strategy to adaptively capture more valuable high-frequency components. Notably, we unify the experimental settings of multiple wildlife datasets for ReID, achieving superior performance over state-of-the-art ReID methods. In domain generalization scenarios, our approach demonstrates robust generalization to unknown species.
+
+
+
+ 33. 【2410.06964】Bridge the Points: Graph-based Few-shot Segment Anything Semantically
+ 链接:https://arxiv.org/abs/2410.06964
+ 作者:Anqi Zhang,Guangyu Gao,Jianbo Jiao,Chi Harold Liu,Yunchao Wei
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:large-scale pre-training techniques, notably the Segment, Few-shot Semantic Segmentation, vision foundation models, generate precise masks
+ 备注: Accepted to NeurIPS 2024 as Spotlight
+
+ 点击查看摘要
+ Abstract:The recent advancements in large-scale pre-training techniques have significantly enhanced the capabilities of vision foundation models, notably the Segment Anything Model (SAM), which can generate precise masks based on point and box prompts. Recent studies extend SAM to Few-shot Semantic Segmentation (FSS), focusing on prompt generation for SAM-based automatic semantic segmentation. However, these methods struggle with selecting suitable prompts, require specific hyperparameter settings for different scenarios, and experience prolonged one-shot inference times due to the overuse of SAM, resulting in low efficiency and limited automation ability. To address these issues, we propose a simple yet effective approach based on graph analysis. In particular, a Positive-Negative Alignment module dynamically selects the point prompts for generating masks, especially uncovering the potential of the background context as the negative reference. Another subsequent Point-Mask Clustering module aligns the granularity of masks and selected points as a directed graph, based on mask coverage over points. These points are then aggregated by decomposing the weakly connected components of the directed graph in an efficient manner, constructing distinct natural clusters. Finally, the positive and overshooting gating, benefiting from graph-based granularity alignment, aggregate high-confident masks and filter out the false-positive masks for final prediction, reducing the usage of additional hyperparameters and redundant mask generation. Extensive experimental analysis across standard FSS, One-shot Part Segmentation, and Cross Domain FSS datasets validate the effectiveness and efficiency of the proposed approach, surpassing state-of-the-art generalist models with a mIoU of 58.7% on COCO-20i and 35.2% on LVIS-92i. The code is available in this https URL.
+
+
+
+ 34. 【2410.06963】ELMO: Enhanced Real-time LiDAR Motion Capture through Upsampling
+ 链接:https://arxiv.org/abs/2410.06963
+ 作者:Deok-Kyeong Jang,Dongseok Yang,Deok-Yun Jang,Byeoli Choi,Donghoon Shin,Sung-hee Lee
+ 类目:Graphics (cs.GR); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:single LiDAR sensor, paper introduces ELMO, motion capture framework, capture framework designed, motion capture
+ 备注: published at ACM Transactions on Graphics (Proc. SIGGRAPH ASIA), 2024
+
+ 点击查看摘要
+ Abstract:This paper introduces ELMO, a real-time upsampling motion capture framework designed for a single LiDAR sensor. Modeled as a conditional autoregressive transformer-based upsampling motion generator, ELMO achieves 60 fps motion capture from a 20 fps LiDAR point cloud sequence. The key feature of ELMO is the coupling of the self-attention mechanism with thoughtfully designed embedding modules for motion and point clouds, significantly elevating the motion quality. To facilitate accurate motion capture, we develop a one-time skeleton calibration model capable of predicting user skeleton offsets from a single-frame point cloud. Additionally, we introduce a novel data augmentation technique utilizing a LiDAR simulator, which enhances global root tracking to improve environmental understanding. To demonstrate the effectiveness of our method, we compare ELMO with state-of-the-art methods in both image-based and point cloud-based motion capture. We further conduct an ablation study to validate our design principles. ELMO's fast inference time makes it well-suited for real-time applications, exemplified in our demo video featuring live streaming and interactive gaming scenarios. Furthermore, we contribute a high-quality LiDAR-mocap synchronized dataset comprising 20 different subjects performing a range of motions, which can serve as a valuable resource for future research. The dataset and evaluation code are available at {\blue \url{this https URL}}
+
+
+
+ 35. 【2410.06940】Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
+ 链接:https://arxiv.org/abs/2410.06940
+ 作者:Sihyun Yu,Sangkyung Kwak,Huiwon Jang,Jongheon Jeong,Jonathan Huang,Jinwoo Shin,Saining Xie
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:recent self-supervised learning, Recent studies, recent self-supervised, induce meaningful, self-supervised learning methods
+ 备注: Preprint. Project page: [this https URL](https://sihyun.me/REPA)
+
+ 点击查看摘要
+ Abstract:Recent studies have shown that the denoising process in (generative) diffusion models can induce meaningful (discriminative) representations inside the model, though the quality of these representations still lags behind those learned through recent self-supervised learning methods. We argue that one main bottleneck in training large-scale diffusion models for generation lies in effectively learning these representations. Moreover, training can be made easier by incorporating high-quality external visual representations, rather than relying solely on the diffusion models to learn them independently. We study this by introducing a straightforward regularization called REPresentation Alignment (REPA), which aligns the projections of noisy input hidden states in denoising networks with clean image representations obtained from external, pretrained visual encoders. The results are striking: our simple strategy yields significant improvements in both training efficiency and generation quality when applied to popular diffusion and flow-based transformers, such as DiTs and SiTs. For instance, our method can speed up SiT training by over 17.5$\times$, matching the performance (without classifier-free guidance) of a SiT-XL model trained for 7M steps in less than 400K steps. In terms of final generation quality, our approach achieves state-of-the-art results of FID=1.42 using classifier-free guidance with the guidance interval.
+
+
+
+ 36. 【2410.06912】Compositional Entailment Learning for Hyperbolic Vision-Language Models
+ 链接:https://arxiv.org/abs/2410.06912
+ 作者:Avik Pal,Max van Spengler,Guido Maria D'Amely di Melendugno,Alessandro Flaborea,Fabio Galasso,Pascal Mettes
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:shared embedding space, representation learning forms, forms a cornerstone, contrastively aligned, Image-text representation learning
+ 备注: 23 pages, 12 figures, 8 tables
+
+ 点击查看摘要
+ Abstract:Image-text representation learning forms a cornerstone in vision-language models, where pairs of images and textual descriptions are contrastively aligned in a shared embedding space. Since visual and textual concepts are naturally hierarchical, recent work has shown that hyperbolic space can serve as a high-potential manifold to learn vision-language representation with strong downstream performance. In this work, for the first time we show how to fully leverage the innate hierarchical nature of hyperbolic embeddings by looking beyond individual image-text pairs. We propose Compositional Entailment Learning for hyperbolic vision-language models. The idea is that an image is not only described by a sentence but is itself a composition of multiple object boxes, each with their own textual description. Such information can be obtained freely by extracting nouns from sentences and using openly available localized grounding models. We show how to hierarchically organize images, image boxes, and their textual descriptions through contrastive and entailment-based objectives. Empirical evaluation on a hyperbolic vision-language model trained with millions of image-text pairs shows that the proposed compositional learning approach outperforms conventional Euclidean CLIP learning, as well as recent hyperbolic alternatives, with better zero-shot and retrieval generalization and clearly stronger hierarchical performance.
+
+
+
+ 37. 【2410.06905】Reliable Probabilistic Human Trajectory Prediction for Autonomous Applications
+ 链接:https://arxiv.org/abs/2410.06905
+ 作者:Manuel Hetzel,Hannes Reichert,Konrad Doll,Bernhard Sick
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:safe human-machine interaction, Mixture Density Networks, require reliable, human-machine interaction, initial knowledge
+ 备注:
+
+ 点击查看摘要
+ Abstract:Autonomous systems, like vehicles or robots, require reliable, accurate, fast, resource-efficient, scalable, and low-latency trajectory predictions to get initial knowledge about future locations and movements of surrounding objects for safe human-machine interaction. Furthermore, they need to know the uncertainty of the predictions for risk assessment to provide safe path planning. This paper presents a lightweight method to address these requirements, combining Long Short-Term Memory and Mixture Density Networks. Our method predicts probability distributions, including confidence level estimations for positional uncertainty to support subsequent risk management applications and runs on a low-power embedded platform. We discuss essential requirements for human trajectory prediction in autonomous vehicle applications and demonstrate our method's performance using multiple traffic-related datasets. Furthermore, we explain reliability and sharpness metrics and show how important they are to guarantee the correctness and robustness of a model's predictions and uncertainty assessments. These essential evaluations have so far received little attention for no good reason. Our approach focuses entirely on real-world applicability. Verifying prediction uncertainties and a model's reliability are central to autonomous real-world applications. Our framework and code are available at: this https URL.
+
+
+
+ 38. 【2410.06893】Learning from Spatio-temporal Correlation for Semi-Supervised LiDAR Semantic Segmentation
+ 链接:https://arxiv.org/abs/2410.06893
+ 作者:Seungho Lee,Hwijeong Lee,Hyunjung Shim
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:low-budget SSLS, low-budget scenarios, data, labeled data, SSLS
+ 备注:
+
+ 点击查看摘要
+ Abstract:We address the challenges of the semi-supervised LiDAR segmentation (SSLS) problem, particularly in low-budget scenarios. The two main issues in low-budget SSLS are the poor-quality pseudo-labels for unlabeled data, and the performance drops due to the significant imbalance between ground-truth and pseudo-labels. This imbalance leads to a vicious training cycle. To overcome these challenges, we leverage the spatio-temporal prior by recognizing the substantial overlap between temporally adjacent LiDAR scans. We propose a proximity-based label estimation, which generates highly accurate pseudo-labels for unlabeled data by utilizing semantic consistency with adjacent labeled data. Additionally, we enhance this method by progressively expanding the pseudo-labels from the nearest unlabeled scans, which helps significantly reduce errors linked to dynamic classes. Additionally, we employ a dual-branch structure to mitigate performance degradation caused by data imbalance. Experimental results demonstrate remarkable performance in low-budget settings (i.e., = 5%) and meaningful improvements in normal budget settings (i.e., 5 - 50%). Finally, our method has achieved new state-of-the-art results on SemanticKITTI and nuScenes in semi-supervised LiDAR segmentation. With only 5% labeled data, it offers competitive results against fully-supervised counterparts. Moreover, it surpasses the performance of the previous state-of-the-art at 100% labeled data (75.2%) using only 20% of labeled data (76.0%) on nuScenes. The code is available on this https URL.
+
+
+
+ 39. 【2410.06879】Evaluating Model Performance with Hard-Swish Activation Function Adjustments
+ 链接:https://arxiv.org/abs/2410.06879
+ 作者:Sai Abhinav Pydimarry,Shekhar Madhav Khairnar,Sofia Garces Palacios,Ganesh Sankaranarayanan,Darian Hoagland,Dmitry Nepomnayshy,Huu Phong Nguyen
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:achieving high accuracy, pattern recognition, achieving high, field of pattern, activation function
+ 备注: 2 pages
+
+ 点击查看摘要
+ Abstract:In the field of pattern recognition, achieving high accuracy is essential. While training a model to recognize different complex images, it is vital to fine-tune the model to achieve the highest accuracy possible. One strategy for fine-tuning a model involves changing its activation function. Most pre-trained models use ReLU as their default activation function, but switching to a different activation function like Hard-Swish could be beneficial. This study evaluates the performance of models using ReLU, Swish and Hard-Swish activation functions across diverse image datasets. Our results show a 2.06% increase in accuracy for models on the CIFAR-10 dataset and a 0.30% increase in accuracy for models on the ATLAS dataset. Modifying the activation functions in architecture of pre-trained models lead to improved overall accuracy.
+
+
+
+ 40. 【2410.06866】Secure Video Quality Assessment Resisting Adversarial Attacks
+ 链接:https://arxiv.org/abs/2410.06866
+ 作者:Ao-Xiang Zhang,Yu Ran,Weixuan Tang,Yuan-Gen Wang,Qingxiao Guan,Chunsheng Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:Video Quality Assessment, Quality Assessment, VQA models, VQA, Video Quality
+ 备注:
+
+ 点击查看摘要
+ Abstract:The exponential surge in video traffic has intensified the imperative for Video Quality Assessment (VQA). Leveraging cutting-edge architectures, current VQA models have achieved human-comparable accuracy. However, recent studies have revealed the vulnerability of existing VQA models against adversarial attacks. To establish a reliable and practical assessment system, a secure VQA model capable of resisting such malicious attacks is urgently demanded. Unfortunately, no attempt has been made to explore this issue. This paper first attempts to investigate general adversarial defense principles, aiming at endowing existing VQA models with security. Specifically, we first introduce random spatial grid sampling on the video frame for intra-frame defense. Then, we design pixel-wise randomization through a guardian map, globally neutralizing adversarial perturbations. Meanwhile, we extract temporal information from the video sequence as compensation for inter-frame defense. Building upon these principles, we present a novel VQA framework from the security-oriented perspective, termed SecureVQA. Extensive experiments indicate that SecureVQA sets a new benchmark in security while achieving competitive VQA performance compared with state-of-the-art models. Ablation studies delve deeper into analyzing the principles of SecureVQA, demonstrating their generalization and contributions to the security of leading VQA models.
+
+
+
+ 41. 【2410.06842】SurANet: Surrounding-Aware Network for Concealed Object Detection via Highly-Efficient Interactive Contrastive Learning Strategy
+ 链接:https://arxiv.org/abs/2410.06842
+ 作者:Yuhan Kang,Qingpeng Li,Leyuan Fang,Jian Zhao,Xuelong Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:image processing applications, Concealed object detection, processing applications, concealed objects, cluttered scenes
+ 备注:
+
+ 点击查看摘要
+ Abstract:Concealed object detection (COD) in cluttered scenes is significant for various image processing applications. However, due to that concealed objects are always similar to their background, it is extremely hard to distinguish them. Here, the major obstacle is the tiny feature differences between the inside and outside object boundary region, which makes it trouble for existing COD methods to achieve accurate results. In this paper, considering that the surrounding environment information can be well utilized to identify the concealed objects, and thus, we propose a novel deep Surrounding-Aware Network, namely SurANet, for COD tasks, which introduces surrounding information into feature extraction and loss function to improve the discrimination. First, we enhance the semantics of feature maps using differential fusion of surrounding features to highlight concealed objects. Next, a Surrounding-Aware Contrastive Loss is applied to identify the concealed object via learning surrounding feature maps contrastively. Then, SurANet can be trained end-to-end with high efficiency via our proposed Spatial-Compressed Correlation Transmission strategy after our investigation of feature dynamics, and extensive experiments improve that such features can be well reserved respectively. Finally, experimental results demonstrate that the proposed SurANet outperforms state-of-the-art COD methods on multiple real datasets. Our source code will be available at this https URL.
+
+
+
+ 42. 【2410.06841】Boosting Few-Shot Detection with Large Language Models and Layout-to-Image Synthesis
+ 链接:https://arxiv.org/abs/2410.06841
+ 作者:Ahmed Abdullah,Nikolas Ebert,Oliver Wasenmüller
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Recent advancements, downstream tasks, ability to generate, generate high-volume, advancements in diffusion
+ 备注: This paper has been accepted at the Asian Conference on Computer Vision (ACCV), 2024
+
+ 点击查看摘要
+ Abstract:Recent advancements in diffusion models have enabled a wide range of works exploiting their ability to generate high-volume, high-quality data for use in various downstream tasks. One subclass of such models, dubbed Layout-to-Image Synthesis (LIS), learns to generate images conditioned on a spatial layout (bounding boxes, masks, poses, etc.) and has shown a promising ability to generate realistic images, albeit with limited layout-adherence. Moreover, the question of how to effectively transfer those models for scalable augmentation of few-shot detection data remains unanswered. Thus, we propose a collaborative framework employing a Large Language Model (LLM) and an LIS model for enhancing few-shot detection beyond state-of-the-art generative augmentation approaches. We leverage LLM's reasoning ability to extrapolate the spatial prior of the annotation space by generating new bounding boxes given only a few example annotations. Additionally, we introduce our novel layout-aware CLIP score for sample ranking, enabling tight coupling between generated layouts and images. Significant improvements on COCO few-shot benchmarks are observed. With our approach, a YOLOX-S baseline is boosted by more than 140%, 50%, 35% in mAP on the COCO 5-,10-, and 30-shot settings, respectively.
+
+
+
+ 43. 【2410.06818】An Improved Approach for Cardiac MRI Segmentation based on 3D UNet Combined with Papillary Muscle Exclusion
+ 链接:https://arxiv.org/abs/2410.06818
+ 作者:Narjes Benameur,Ramzi Mahmoudi,Mohamed Deriche,Amira fayouka,Imene Masmoudi,Nessrine Zoghlami
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Image and Video Processing (eess.IV)
+ 关键词:Left ventricular ejection, ventricular ejection fraction, important clinical parameter, Cardiovascular Magnetic Resonance, Left ventricular
+ 备注:
+
+ 点击查看摘要
+ Abstract:Left ventricular ejection fraction (LVEF) is the most important clinical parameter of cardiovascular function. The accuracy in estimating this parameter is highly dependent upon the precise segmentation of the left ventricle (LV) structure at the end diastole and systole phases. Therefore, it is crucial to develop robust algorithms for the precise segmentation of the heart structure during different phases. Methodology: In this work, an improved 3D UNet model is introduced to segment the myocardium and LV, while excluding papillary muscles, as per the recommendation of the Society for Cardiovascular Magnetic Resonance. For the practical testing of the proposed framework, a total of 8,400 cardiac MRI images were collected and analysed from the military hospital in Tunis (HMPIT), as well as the popular ACDC public dataset. As performance metrics, we used the Dice coefficient and the F1 score for validation/testing of the LV and the myocardium segmentation. Results: The data was split into 70%, 10%, and 20% for training, validation, and testing, respectively. It is worth noting that the proposed segmentation model was tested across three axis views: basal, medio basal and apical at two different cardiac phases: end diastole and end systole instances. The experimental results showed a Dice index of 0.965 and 0.945, and an F1 score of 0.801 and 0.799, at the end diastolic and systolic phases, respectively. Additionally, clinical evaluation outcomes revealed a significant difference in the LVEF and other clinical parameters when the papillary muscles were included or excluded.
+
+
+
+ 44. 【2410.06811】Rethinking the Evaluation of Visible and Infrared Image Fusion
+ 链接:https://arxiv.org/abs/2410.06811
+ 作者:Dayan Guan,Yixuan Wu,Tianzhu Liu,Alex C. Kot,Yanfeng Gu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:garnered significant interest, high-level vision tasks, VIF methods, VIF, Segmentation-oriented Evaluation Approach
+ 备注: The code has been released in \url{ [this https URL](https://github.com/Yixuan-2002/SEA/) }
+
+ 点击查看摘要
+ Abstract:Visible and Infrared Image Fusion (VIF) has garnered significant interest across a wide range of high-level vision tasks, such as object detection and semantic segmentation. However, the evaluation of VIF methods remains challenging due to the absence of ground truth. This paper proposes a Segmentation-oriented Evaluation Approach (SEA) to assess VIF methods by incorporating the semantic segmentation task and leveraging segmentation labels available in latest VIF datasets. Specifically, SEA utilizes universal segmentation models, capable of handling diverse images and classes, to predict segmentation outputs from fused images and compare these outputs with segmentation labels. Our evaluation of recent VIF methods using SEA reveals that their performance is comparable or even inferior to using visible images only, despite nearly half of the infrared images demonstrating better performance than visible images. Further analysis indicates that the two metrics most correlated to our SEA are the gradient-based fusion metric $Q_{\text{ABF}}$ and the visual information fidelity metric $Q_{\text{VIFF}}$ in conventional VIF evaluation metrics, which can serve as proxies when segmentation labels are unavailable. We hope that our evaluation will guide the development of novel and practical VIF methods. The code has been released in \url{this https URL}.
+
+
+
+ 45. 【2410.06806】QuadMamba: Learning Quadtree-based Selective Scan for Visual State Space Model
+ 链接:https://arxiv.org/abs/2410.06806
+ 作者:Fei Xie,Weijia Zhang,Zhongdao Wang,Chao Ma
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:State Space Models, dominant Transformer models, State Space, Recent advancements, advancements in State
+ 备注: Accepted by Neurip2024
+
+ 点击查看摘要
+ Abstract:Recent advancements in State Space Models, notably Mamba, have demonstrated superior performance over the dominant Transformer models, particularly in reducing the computational complexity from quadratic to linear. Yet, difficulties in adapting Mamba from language to vision tasks arise due to the distinct characteristics of visual data, such as the spatial locality and adjacency within images and large variations in information granularity across visual tokens. Existing vision Mamba approaches either flatten tokens into sequences in a raster scan fashion, which breaks the local adjacency of images, or manually partition tokens into windows, which limits their long-range modeling and generalization capabilities. To address these limitations, we present a new vision Mamba model, coined QuadMamba, that effectively captures local dependencies of varying granularities via quadtree-based image partition and scan. Concretely, our lightweight quadtree-based scan module learns to preserve the 2D locality of spatial regions within learned window quadrants. The module estimates the locality score of each token from their features, before adaptively partitioning tokens into window quadrants. An omnidirectional window shifting scheme is also introduced to capture more intact and informative features across different local regions. To make the discretized quadtree partition end-to-end trainable, we further devise a sequence masking strategy based on Gumbel-Softmax and its straight-through gradient estimator. Extensive experiments demonstrate that QuadMamba achieves state-of-the-art performance in various vision tasks, including image classification, object detection, instance segmentation, and semantic segmentation. The code is in this https URL.
+
+
+
+ 46. 【2410.06795】From Pixels to Tokens: Revisiting Object Hallucinations in Large Vision-Language Models
+ 链接:https://arxiv.org/abs/2410.06795
+ 作者:Yuying Shang,Xinyi Zeng,Yutao Zhu,Xiao Yang,Zhengwei Fang,Jingyuan Zhang,Jiawei Chen,Zinan Liu,Yu Tian
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:large vision-language models, visual input, significant challenge, impairs their reliability, large vision-language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Hallucinations in large vision-language models (LVLMs) are a significant challenge, i.e., generating objects that are not presented in the visual input, which impairs their reliability. Recent studies often attribute hallucinations to a lack of understanding of visual input, yet ignore a more fundamental issue: the model's inability to effectively extract or decouple visual features. In this paper, we revisit the hallucinations in LVLMs from an architectural perspective, investigating whether the primary cause lies in the visual encoder (feature extraction) or the modal alignment module (feature decoupling). Motivated by our findings on the preliminary investigation, we propose a novel tuning strategy, PATCH, to mitigate hallucinations in LVLMs. This plug-and-play method can be integrated into various LVLMs, utilizing adaptive virtual tokens to extract object features from bounding boxes, thereby addressing hallucinations caused by insufficient decoupling of visual features. PATCH achieves state-of-the-art performance on multiple multi-modal hallucination datasets. We hope this approach provides researchers with deeper insights into the underlying causes of hallucinations in LVLMs, fostering further advancements and innovation in this field.
+
+
+
+ 47. 【2410.06777】HERM: Benchmarking and Enhancing Multimodal LLMs for Human-Centric Understanding
+ 链接:https://arxiv.org/abs/2410.06777
+ 作者:Keliang Li,Zaifei Yang,Jiahe Zhao,Hongze Shen,Ruibing Hou,Hong Chang,Shiguang Shan,Xilin Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Large Language Models, Multimodal Large Language, Language Models, Multimodal Large, Large Language
+ 备注:
+
+ 点击查看摘要
+ Abstract:The significant advancements in visual understanding and instruction following from Multimodal Large Language Models (MLLMs) have opened up more possibilities for broader applications in diverse and universal human-centric scenarios. However, existing image-text data may not support the precise modality alignment and integration of multi-grained information, which is crucial for human-centric visual understanding. In this paper, we introduce HERM-Bench, a benchmark for evaluating the human-centric understanding capabilities of MLLMs. Our work reveals the limitations of existing MLLMs in understanding complex human-centric scenarios. To address these challenges, we present HERM-100K, a comprehensive dataset with multi-level human-centric annotations, aimed at enhancing MLLMs' training. Furthermore, we develop HERM-7B, a MLLM that leverages enhanced training data from HERM-100K. Evaluations on HERM-Bench demonstrate that HERM-7B significantly outperforms existing MLLMs across various human-centric dimensions, reflecting the current inadequacy of data annotations used in MLLM training for human-centric visual understanding. This research emphasizes the importance of specialized datasets and benchmarks in advancing the MLLMs' capabilities for human-centric understanding.
+
+
+
+ 48. 【2410.06765】o Preserve or To Compress: An In-Depth Study of Connector Selection in Multimodal Large Language Models
+ 链接:https://arxiv.org/abs/2410.06765
+ 作者:Junyan Lin,Haoran Chen,Dawei Zhu,Xiaoyu Shen
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:multimodal large language, large language models, garnered significant attention, recent years, multimodal large
+ 备注: Accepted to EMNLP 2024 Main Conference
+
+ 点击查看摘要
+ Abstract:In recent years, multimodal large language models (MLLMs) have garnered significant attention from both industry and academia. However, there is still considerable debate on constructing MLLM architectures, particularly regarding the selection of appropriate connectors for perception tasks of varying granularities. This paper systematically investigates the impact of connectors on MLLM performance. Specifically, we classify connectors into feature-preserving and feature-compressing types. Utilizing a unified classification standard, we categorize sub-tasks from three comprehensive benchmarks, MMBench, MME, and SEED-Bench, into three task types: coarse-grained perception, fine-grained perception, and reasoning, and evaluate the performance. Our findings reveal that feature-preserving connectors excel in \emph{fine-grained perception} tasks due to their ability to retain detailed visual information. In contrast, feature-compressing connectors, while less effective in fine-grained perception tasks, offer significant speed advantages and perform comparably in \emph{coarse-grained perception} and \emph{reasoning} tasks. These insights are crucial for guiding MLLM architecture design and advancing the optimization of MLLM architectures.
+
+
+
+ 49. 【2410.06756】DreamMesh4D: Video-to-4D Generation with Sparse-Controlled Gaussian-Mesh Hybrid Representation
+ 链接:https://arxiv.org/abs/2410.06756
+ 作者:Zhiqi Li,Yiming Chen,Peidong Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Recent advancements, explicit Gaussian Splatting, mesh, Gaussian Splatting, mesh vertices
+ 备注: NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:Recent advancements in 2D/3D generative techniques have facilitated the generation of dynamic 3D objects from monocular videos. Previous methods mainly rely on the implicit neural radiance fields (NeRF) or explicit Gaussian Splatting as the underlying representation, and struggle to achieve satisfactory spatial-temporal consistency and surface appearance. Drawing inspiration from modern 3D animation pipelines, we introduce DreamMesh4D, a novel framework combining mesh representation with geometric skinning technique to generate high-quality 4D object from a monocular video. Instead of utilizing classical texture map for appearance, we bind Gaussian splats to triangle face of mesh for differentiable optimization of both the texture and mesh vertices. In particular, DreamMesh4D begins with a coarse mesh obtained through an image-to-3D generation procedure. Sparse points are then uniformly sampled across the mesh surface, and are used to build a deformation graph to drive the motion of the 3D object for the sake of computational efficiency and providing additional constraint. For each step, transformations of sparse control points are predicted using a deformation network, and the mesh vertices as well as the surface Gaussians are deformed via a novel geometric skinning algorithm, which is a hybrid approach combining LBS (linear blending skinning) and DQS (dual-quaternion skinning), mitigating drawbacks associated with both approaches. The static surface Gaussians and mesh vertices as well as the deformation network are learned via reference view photometric loss, score distillation loss as well as other regularizers in a two-stage manner. Extensive experiments demonstrate superior performance of our method. Furthermore, our method is compatible with modern graphic pipelines, showcasing its potential in the 3D gaming and film industry.
+
+
+
+ 50. 【2410.06743】Utilizing Transfer Learning and pre-trained Models for Effective Forest Fire Detection: A Case Study of Uttarakhand
+ 链接:https://arxiv.org/abs/2410.06743
+ 作者:Hari Prabhat Gupta,Rahul Mishra
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:forest fire detection, Forest fires pose, forest fire, transfer learning, human life
+ 备注: 15 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:Forest fires pose a significant threat to the environment, human life, and property. Early detection and response are crucial to mitigating the impact of these disasters. However, traditional forest fire detection methods are often hindered by our reliability on manual observation and satellite imagery with low spatial resolution. This paper emphasizes the role of transfer learning in enhancing forest fire detection in India, particularly in overcoming data collection challenges and improving model accuracy across various regions. We compare traditional learning methods with transfer learning, focusing on the unique challenges posed by regional differences in terrain, climate, and vegetation. Transfer learning can be categorized into several types based on the similarity between the source and target tasks, as well as the type of knowledge transferred. One key method is utilizing pre-trained models for efficient transfer learning, which significantly reduces the need for extensive labeled data. We outline the transfer learning process, demonstrating how researchers can adapt pre-trained models like MobileNetV2 for specific tasks such as forest fire detection. Finally, we present experimental results from training and evaluating a deep learning model using the Uttarakhand forest fire dataset, showcasing the effectiveness of transfer learning in this context.
+
+
+
+ 51. 【2410.06734】MimicTalk: Mimicking a personalized and expressive 3D talking face in minutes
+ 链接:https://arxiv.org/abs/2410.06734
+ 作者:Zhenhui Ye,Tianyun Zhong,Yi Ren,Ziyue Jiang,Jiawei Huang,Rongjie Huang,Jinglin Liu,Jinzheng He,Chen Zhang,Zehan Wang,Xize Chen,Xiang Yin,Zhou Zhao
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Talking face generation, create realistic talking, target identity face, realistic talking videos, face generation
+ 备注: Accepted by NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:Talking face generation (TFG) aims to animate a target identity's face to create realistic talking videos. Personalized TFG is a variant that emphasizes the perceptual identity similarity of the synthesized result (from the perspective of appearance and talking style). While previous works typically solve this problem by learning an individual neural radiance field (NeRF) for each identity to implicitly store its static and dynamic information, we find it inefficient and non-generalized due to the per-identity-per-training framework and the limited training data. To this end, we propose MimicTalk, the first attempt that exploits the rich knowledge from a NeRF-based person-agnostic generic model for improving the efficiency and robustness of personalized TFG. To be specific, (1) we first come up with a person-agnostic 3D TFG model as the base model and propose to adapt it into a specific identity; (2) we propose a static-dynamic-hybrid adaptation pipeline to help the model learn the personalized static appearance and facial dynamic features; (3) To generate the facial motion of the personalized talking style, we propose an in-context stylized audio-to-motion model that mimics the implicit talking style provided in the reference video without information loss by an explicit style representation. The adaptation process to an unseen identity can be performed in 15 minutes, which is 47 times faster than previous person-dependent methods. Experiments show that our MimicTalk surpasses previous baselines regarding video quality, efficiency, and expressiveness. Source code and video samples are available at this https URL .
+
+
+
+ 52. 【2410.06733】Weak-eval-Strong: Evaluating and Eliciting Lateral Thinking of LLMs with Situation Puzzles
+ 链接:https://arxiv.org/abs/2410.06733
+ 作者:Qi Chen,Bowen Zhang,Gang Wang,Qi Wu
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Large Language Models, Large Language, tasks requiring vertical, capabilities remain under-explored, assessing creative thought
+ 备注: Accepted by NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:While advancements in NLP have significantly improved the performance of Large Language Models (LLMs) on tasks requiring vertical thinking, their lateral thinking capabilities remain under-explored and challenging to measure due to the complexity of assessing creative thought processes and the scarcity of relevant data. To address these challenges, we introduce SPLAT, a benchmark leveraging Situation Puzzles to evaluate and elicit LAteral Thinking of LLMs. This benchmark, containing 975 graded situation puzzles across three difficulty levels, employs a new multi-turn player-judge framework instead of the traditional model-based evaluation, which often necessitates a stronger evaluation model. This framework simulates an interactive game where the model (player) asks the evaluation model (judge) questions about an incomplete story to infer the full scenario. The judge answers based on a detailed reference scenario or evaluates if the player's predictions align with the reference one. This approach lessens dependence on more robust evaluation models, enabling the assessment of state-of-the-art LLMs. The experiments demonstrate that a robust evaluation model, such as WizardLM-2, closely matches human judgements in both intermediate question-answering and final scenario accuracy, achieving over 80% agreement-similar to the agreement levels among humans. Furthermore, applying data and reasoning processes from our benchmark to other lateral thinking-related benchmarks, e.g., RiddleSense and BrainTeaser, leads to performance enhancements. This suggests that our benchmark effectively evaluates and elicits the lateral thinking abilities of LLMs. Code is available at: this https URL.
+
+
+
+ 53. 【2410.06725】Evaluating the Impact of Point Cloud Colorization on Semantic Segmentation Accuracy
+ 链接:https://arxiv.org/abs/2410.06725
+ 作者:Qinfeng Zhu,Jiaze Cao,Yuanzhi Cai,Lei Fan
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Multimedia (cs.MM)
+ 关键词:scene understanding, predefined categories, process of classifying, RGB, RGB information
+ 备注: Accepted by 2024 IEEE 8th International Conference on Vision, Image and Signal Processing
+
+ 点击查看摘要
+ Abstract:Point cloud semantic segmentation, the process of classifying each point into predefined categories, is essential for 3D scene understanding. While image-based segmentation is widely adopted due to its maturity, methods relying solely on RGB information often suffer from degraded performance due to color inaccuracies. Recent advancements have incorporated additional features such as intensity and geometric information, yet RGB channels continue to negatively impact segmentation accuracy when errors in colorization occur. Despite this, previous studies have not rigorously quantified the effects of erroneous colorization on segmentation performance. In this paper, we propose a novel statistical approach to evaluate the impact of inaccurate RGB information on image-based point cloud segmentation. We categorize RGB inaccuracies into two types: incorrect color information and similar color information. Our results demonstrate that both types of color inaccuracies significantly degrade segmentation accuracy, with similar color errors particularly affecting the extraction of geometric features. These findings highlight the critical need to reassess the role of RGB information in point cloud segmentation and its implications for future algorithm design.
+
+
+
+ 54. 【2410.06719】Suppress Content Shift: Better Diffusion Features via Off-the-Shelf Generation Techniques
+ 链接:https://arxiv.org/abs/2410.06719
+ 作者:Benyuan Meng,Qianqian Xu,Zitai Wang,Zhiyong Yang,Xiaochun Cao,Qingming Huang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:powerful generative models, content shift, Diffusion, diffusion feature, applied to discrimination
+ 备注: arXiv admin note: substantial text overlap with [arXiv:2410.03558](https://arxiv.org/abs/2410.03558)
+
+ 点击查看摘要
+ Abstract:Diffusion models are powerful generative models, and this capability can also be applied to discrimination. The inner activations of a pre-trained diffusion model can serve as features for discriminative tasks, namely, diffusion feature. We discover that diffusion feature has been hindered by a hidden yet universal phenomenon that we call content shift. To be specific, there are content differences between features and the input image, such as the exact shape of a certain object. We locate the cause of content shift as one inherent characteristic of diffusion models, which suggests the broad existence of this phenomenon in diffusion feature. Further empirical study also indicates that its negative impact is not negligible even when content shift is not visually perceivable. Hence, we propose to suppress content shift to enhance the overall quality of diffusion features. Specifically, content shift is related to the information drift during the process of recovering an image from the noisy input, pointing out the possibility of turning off-the-shelf generation techniques into tools for content shift suppression. We further propose a practical guideline named GATE to efficiently evaluate the potential benefit of a technique and provide an implementation of our methodology. Despite the simplicity, the proposed approach has achieved superior results on various tasks and datasets, validating its potential as a generic booster for diffusion features. Our code is available at this https URL.
+
+
+
+ 55. 【2410.06718】MatMamba: A Matryoshka State Space Model
+ 链接:https://arxiv.org/abs/2410.06718
+ 作者:Abhinav Shukla,Sai Vemprala,Aditya Kusupati,Ashish Kapoor
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:long context lengths, Matryoshka Representation Learning, faster theoretical training, State Space, State Space Models
+ 备注: 10 pages, 7 figures
+
+ 点击查看摘要
+ Abstract:State Space Models (SSMs) like Mamba2 are a promising alternative to Transformers, with faster theoretical training and inference times -- especially for long context lengths. Recent work on Matryoshka Representation Learning -- and its application to Transformer backbones in works like MatFormer -- showed how to introduce nested granularities of smaller submodels in one universal elastic model. In this work, we present MatMamba: a state space model which combines Matryoshka-style learning with Mamba2, by modifying the block to contain nested dimensions to enable joint training and adaptive inference. MatMamba allows for efficient and adaptive deployment across various model sizes. We train a single large MatMamba model and are able to get a number of smaller nested models for free -- while maintaining or improving upon the performance of a baseline smaller model trained from scratch. We train language and image models at a variety of parameter sizes from 35M to 1.4B. Our results on ImageNet and FineWeb show that MatMamba models scale comparably to Transformers, while having more efficient inference characteristics. This makes MatMamba a practically viable option for deploying large-scale models in an elastic way based on the available inference compute. Code and models are open sourced at \url{this https URL}
+
+
+
+ 56. 【2410.06711】Analysis of different disparity estimation techniques on aerial stereo image datasets
+ 链接:https://arxiv.org/abs/2410.06711
+ 作者:Ishan Narayan,Shashi Poddar
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:gained tremendous progress, tremendous progress, dense stereo matching, aerial, matching has gained
+ 备注:
+
+ 点击查看摘要
+ Abstract:With the advent of aerial image datasets, dense stereo matching has gained tremendous progress. This work analyses dense stereo correspondence analysis on aerial images using different techniques. Traditional methods, optimization based methods and learning based methods have been implemented and compared here for aerial images. For traditional methods, we implemented the architecture of Stereo SGBM while using different cost functions to get an understanding of their performance on aerial datasets. Analysis of most of the methods in standard datasets has shown good performance, however in case of aerial dataset, not much benchmarking is available. Visual qualitative and quantitative analysis has been carried out for two stereo aerial datasets in order to compare different cost functions and techniques for the purpose of depth estimation from stereo images. Using existing pre-trained models, recent learning based architectures have also been tested on stereo pairs along with different cost functions in SGBM. The outputs and given ground truth are compared using MSE, SSIM and other error metrics.
+
+
+
+ 57. 【2410.06699】Break the Visual Perception: Adversarial Attacks Targeting Encoded Visual Tokens of Large Vision-Language Models
+ 链接:https://arxiv.org/abs/2410.06699
+ 作者:Yubo Wang,Chaohu Liu,Yanqiu Qu,Haoyu Cao,Deqiang Jiang,Linli Xu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Large vision-language models, large language models, showcasing remarkable multi-modal, multi-modal conversational capabilities, remarkable multi-modal conversational
+ 备注: Accepted to ACMMM 2024
+
+ 点击查看摘要
+ Abstract:Large vision-language models (LVLMs) integrate visual information into large language models, showcasing remarkable multi-modal conversational capabilities. However, the visual modules introduces new challenges in terms of robustness for LVLMs, as attackers can craft adversarial images that are visually clean but may mislead the model to generate incorrect answers. In general, LVLMs rely on vision encoders to transform images into visual tokens, which are crucial for the language models to perceive image contents effectively. Therefore, we are curious about one question: Can LVLMs still generate correct responses when the encoded visual tokens are attacked and disrupting the visual information? To this end, we propose a non-targeted attack method referred to as VT-Attack (Visual Tokens Attack), which constructs adversarial examples from multiple perspectives, with the goal of comprehensively disrupting feature representations and inherent relationships as well as the semantic properties of visual tokens output by image encoders. Using only access to the image encoder in the proposed attack, the generated adversarial examples exhibit transferability across diverse LVLMs utilizing the same image encoder and generality across different tasks. Extensive experiments validate the superior attack performance of the VT-Attack over baseline methods, demonstrating its effectiveness in attacking LVLMs with image encoders, which in turn can provide guidance on the robustness of LVLMs, particularly in terms of the stability of the visual feature space.
+
+
+
+ 58. 【2410.06698】Fourier-based Action Recognition for Wildlife Behavior Quantification with Event Cameras
+ 链接:https://arxiv.org/abs/2410.06698
+ 作者:Friedhelm Hamann,Suman Ghosh,Ignacio Juarez Martinez,Tom Hart,Alex Kacelnik,Guillermo Gallego
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Emerging Technologies (cs.ET)
+ 关键词:measure pixel-wise brightness, bio-inspired vision sensors, frame rate, sensors that measure, measure pixel-wise
+ 备注: 11 pages, 10 figures, 7 tables
+
+ 点击查看摘要
+ Abstract:Event cameras are novel bio-inspired vision sensors that measure pixel-wise brightness changes asynchronously instead of images at a given frame rate. They offer promising advantages, namely a high dynamic range, low latency, and minimal motion blur. Modern computer vision algorithms often rely on artificial neural network approaches, which require image-like representations of the data and cannot fully exploit the characteristics of event data. We propose approaches to action recognition based on the Fourier Transform. The approaches are intended to recognize oscillating motion patterns commonly present in nature. In particular, we apply our approaches to a recent dataset of breeding penguins annotated for "ecstatic display", a behavior where the observed penguins flap their wings at a certain frequency. We find that our approaches are both simple and effective, producing slightly lower results than a deep neural network (DNN) while relying just on a tiny fraction of the parameters compared to the DNN (five orders of magnitude fewer parameters). They work well despite the uncontrolled, diverse data present in the dataset. We hope this work opens a new perspective on event-based processing and action recognition.
+
+
+
+ 59. 【2410.06694】OmniPose6D: Towards Short-Term Object Pose Tracking in Dynamic Scenes from Monocular RGB
+ 链接:https://arxiv.org/abs/2410.06694
+ 作者:Yunzhi Lin,Yipu Zhao,Fu-Jen Chu,Xingyu Chen,Weiyao Wang,Hao Tang,Patricio A. Vela,Matt Feiszli,Kevin Liang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:monocular RGB input, RGB input, monocular RGB, crafted to mirror, real-world conditions
+ 备注: 13 pages, 9 figures
+
+ 点击查看摘要
+ Abstract:To address the challenge of short-term object pose tracking in dynamic environments with monocular RGB input, we introduce a large-scale synthetic dataset OmniPose6D, crafted to mirror the diversity of real-world conditions. We additionally present a benchmarking framework for a comprehensive comparison of pose tracking algorithms. We propose a pipeline featuring an uncertainty-aware keypoint refinement network, employing probabilistic modeling to refine pose estimation. Comparative evaluations demonstrate that our approach achieves performance superior to existing baselines on real datasets, underscoring the effectiveness of our synthetic dataset and refinement technique in enhancing tracking precision in dynamic contexts. Our contributions set a new precedent for the development and assessment of object pose tracking methodologies in complex scenes.
+
+
+
+ 60. 【2410.06689】Perceptual Quality Assessment of Trisoup-Lifting Encoded 3D Point Clouds
+ 链接:https://arxiv.org/abs/2410.06689
+ 作者:Juncheng Long,Honglei Su,Qi Liu,Hui Yuan,Wei Gao,Jiarun Song,Zhou Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:real-time quality monitoring, achieve real-time quality, cloud quality assessment, No-reference bitstream-layer point, point cloud quality
+ 备注:
+
+ 点击查看摘要
+ Abstract:No-reference bitstream-layer point cloud quality assessment (PCQA) can be deployed without full decoding at any network node to achieve real-time quality monitoring. In this work, we develop the first PCQA model dedicated to Trisoup-Lifting encoded 3D point clouds by analyzing bitstreams without full decoding. Specifically, we investigate the relationship among texture bitrate per point (TBPP), texture complexity (TC) and texture quantization parameter (TQP) while geometry encoding is lossless. Subsequently, we estimate TC by utilizing TQP and TBPP. Then, we establish a texture distortion evaluation model based on TC, TBPP and TQP. Ultimately, by integrating this texture distortion model with a geometry attenuation factor, a function of trisoupNodeSizeLog2 (tNSL), we acquire a comprehensive NR bitstream-layer PCQA model named streamPCQ-TL. In addition, this work establishes a database named WPC6.0, the first and largest PCQA database dedicated to Trisoup-Lifting encoding mode, encompassing 400 distorted point clouds with both 4 geometric multiplied by 5 texture distortion levels. Experiment results on M-PCCD, ICIP2020 and the proposed WPC6.0 database suggest that the proposed streamPCQ-TL model exhibits robust and notable performance in contrast to existing advanced PCQA metrics, particularly in terms of computational cost. The dataset and source code will be publicly released at \href{this https URL}{\textit{this https URL}}
+
+
+
+ 61. 【2410.06682】Enhancing Multimodal LLM for Detailed and Accurate Video Captioning using Multi-Round Preference Optimization
+ 链接:https://arxiv.org/abs/2410.06682
+ 作者:Changli Tang,Yixuan Li,Yudong Yang,Jimin Zhuang,Guangzhi Sun,Wei Li,Zujun Ma,Chao Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL); Image and Video Processing (eess.IV)
+ 关键词:wealth of information, generating detailed, detailed and accurate, key aspect, natural language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Videos contain a wealth of information, and generating detailed and accurate descriptions in natural language is a key aspect of video understanding. In this paper, we present video-SALMONN 2, an advanced audio-visual large language model (LLM) with low-rank adaptation (LoRA) designed for enhanced video (with paired audio) captioning through directed preference optimization (DPO). We propose new metrics to evaluate the completeness and accuracy of video descriptions, which are optimized using DPO. To further improve training, we introduce a novel multi-round DPO (mrDPO) approach, which involves periodically updating the DPO reference model, merging and re-initializing the LoRA module as a proxy for parameter updates after each training round (1,000 steps), and incorporating guidance from ground-truth video captions to stabilize the process. To address potential catastrophic forgetting of non-captioning abilities due to mrDPO, we propose rebirth tuning, which finetunes the pre-DPO LLM by using the captions generated by the mrDPO-trained model as supervised labels. Experiments show that mrDPO significantly enhances video-SALMONN 2's captioning accuracy, reducing global and local error rates by 40\% and 20\%, respectively, while decreasing the repetition rate by 35\%. The final video-SALMONN 2 model, with just 7 billion parameters, surpasses leading models such as GPT-4o and Gemini-1.5-Pro in video captioning tasks, while maintaining competitive performance to the state-of-the-art on widely used video question-answering benchmark among models of similar size. Upon acceptance, we will release the code, model checkpoints, and training and test data. Demos are available at \href{this https URL}{this https URL}.
+
+
+
+ 62. 【2410.06678】M${}^{3}$Bench: Benchmarking Whole-body Motion Generation for Mobile Manipulation in 3D Scenes
+ 链接:https://arxiv.org/abs/2410.06678
+ 作者:Zeyu Zhang,Sixu Yan,Muzhi Han,Zaijin Wang,Xinggang Wang,Song-Chun Zhu,Hangxin Liu
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:whole-body motion trajectories, whole-body motion, coordinated whole-body motion, object rearrangement tasks, whole-body motion generation
+ 备注:
+
+ 点击查看摘要
+ Abstract:We propose M^3Bench, a new benchmark for whole-body motion generation for mobile manipulation tasks. Given a 3D scene context, M^3Bench requires an embodied agent to understand its configuration, environmental constraints and task objectives, then generate coordinated whole-body motion trajectories for object rearrangement tasks. M^3Bench features 30k object rearrangement tasks across 119 diverse scenes, providing expert demonstrations generated by our newly developed M^3BenchMaker. This automatic data generation tool produces coordinated whole-body motion trajectories from high-level task instructions, requiring only basic scene and robot information. Our benchmark incorporates various task splits to assess generalization across different dimensions and leverages realistic physics simulation for trajectory evaluation. Through extensive experimental analyses, we reveal that state-of-the-art models still struggle with coordinated base-arm motion while adhering to environment-context and task-specific constraints, highlighting the need to develop new models that address this gap. Through M^3Bench, we aim to facilitate future robotics research towards more adaptive and capable mobile manipulation in diverse, real-world environments.
+
+
+
+ 63. 【2410.06664】Decouple-Then-Merge: Towards Better Training for Diffusion Models
+ 链接:https://arxiv.org/abs/2410.06664
+ 作者:Qianli Ma,Xuefei Ning,Dongrui Liu,Li Niu,Linfeng Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:noise corruption, trained by learning, learning a sequence, reverse each step, step of noise
+ 备注:
+
+ 点击查看摘要
+ Abstract:Diffusion models are trained by learning a sequence of models that reverse each step of noise corruption. Typically, the model parameters are fully shared across multiple timesteps to enhance training efficiency. However, since the denoising tasks differ at each timestep, the gradients computed at different timesteps may conflict, potentially degrading the overall performance of image generation. To solve this issue, this work proposes a Decouple-then-Merge (DeMe) framework, which begins with a pretrained model and finetunes separate models tailored to specific timesteps. We introduce several improved techniques during the finetuning stage to promote effective knowledge sharing while minimizing training interference across timesteps. Finally, after finetuning, these separate models can be merged into a single model in the parameter space, ensuring efficient and practical inference. Experimental results show significant generation quality improvements upon 6 benchmarks including Stable Diffusion on COCO30K, ImageNet1K, PartiPrompts, and DDPM on LSUN Church, LSUN Bedroom, and CIFAR10.
+
+
+
+ 64. 【2410.06645】Continual Learning in the Frequency Domain
+ 链接:https://arxiv.org/abs/2410.06645
+ 作者:Ruiqi Liu,Boyu Diao,Libo Huang,Zijia An,Zhulin An,Yongjun Xu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:preserving existing knowledge, Frequency Domain, Continual learning, frequency domain features, output features
+ 备注: Accepted by NeurlIPS 2024
+
+ 点击查看摘要
+ Abstract:Continual learning (CL) is designed to learn new tasks while preserving existing knowledge. Replaying samples from earlier tasks has proven to be an effective method to mitigate the forgetting of previously acquired knowledge. However, the current research on the training efficiency of rehearsal-based methods is insufficient, which limits the practical application of CL systems in resource-limited scenarios. The human visual system (HVS) exhibits varying sensitivities to different frequency components, enabling the efficient elimination of visually redundant information. Inspired by HVS, we propose a novel framework called Continual Learning in the Frequency Domain (CLFD). To our knowledge, this is the first study to utilize frequency domain features to enhance the performance and efficiency of CL training on edge devices. For the input features of the feature extractor, CLFD employs wavelet transform to map the original input image into the frequency domain, thereby effectively reducing the size of input feature maps. Regarding the output features of the feature extractor, CLFD selectively utilizes output features for distinct classes for classification, thereby balancing the reusability and interference of output features based on the frequency domain similarity of the classes across various tasks. Optimizing only the input and output features of the feature extractor allows for seamless integration of CLFD with various rehearsal-based methods. Extensive experiments conducted in both cloud and edge environments demonstrate that CLFD consistently improves the performance of state-of-the-art (SOTA) methods in both precision and training efficiency. Specifically, CLFD can increase the accuracy of the SOTA CL method by up to 6.83% and reduce the training time by 2.6$\times$.
+
+
+
+ 65. 【2410.06626】Open-RGBT: Open-vocabulary RGB-T Zero-shot Semantic Segmentation in Open-world Environments
+ 链接:https://arxiv.org/abs/2410.06626
+ 作者:Meng Yu,Luojie Yang,Xunjie He,Yi Yang,Yufeng Yue
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Semantic segmentation, RGB-T semantic segmentation, critical technique, technique for effective, Semantic
+ 备注:
+
+ 点击查看摘要
+ Abstract:Semantic segmentation is a critical technique for effective scene understanding. Traditional RGB-T semantic segmentation models often struggle to generalize across diverse scenarios due to their reliance on pretrained models and predefined categories. Recent advancements in Visual Language Models (VLMs) have facilitated a shift from closed-set to open-vocabulary semantic segmentation methods. However, these models face challenges in dealing with intricate scenes, primarily due to the heterogeneity between RGB and thermal modalities. To address this gap, we present Open-RGBT, a novel open-vocabulary RGB-T semantic segmentation model. Specifically, we obtain instance-level detection proposals by incorporating visual prompts to enhance category understanding. Additionally, we employ the CLIP model to assess image-text similarity, which helps correct semantic consistency and mitigates ambiguities in category identification. Empirical evaluations demonstrate that Open-RGBT achieves superior performance in diverse and challenging real-world scenarios, even in the wild, significantly advancing the field of RGB-T semantic segmentation.
+
+
+
+ 66. 【2410.06625】ETA: Evaluating Then Aligning Safety of Vision Language Models at Inference Time
+ 链接:https://arxiv.org/abs/2410.06625
+ 作者:Yi Ding,Bolian Li,Ruqi Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL); Programming Languages (cs.PL)
+ 关键词:Vision Language Models, Vision Language, Language Models, significant safety challenges, safety challenges limit
+ 备注: 27pages
+
+ 点击查看摘要
+ Abstract:Vision Language Models (VLMs) have become essential backbones for multimodal intelligence, yet significant safety challenges limit their real-world application. While textual inputs are often effectively safeguarded, adversarial visual inputs can easily bypass VLM defense mechanisms. Existing defense methods are either resource-intensive, requiring substantial data and compute, or fail to simultaneously ensure safety and usefulness in responses. To address these limitations, we propose a novel two-phase inference-time alignment framework, Evaluating Then Aligning (ETA): 1) Evaluating input visual contents and output responses to establish a robust safety awareness in multimodal settings, and 2) Aligning unsafe behaviors at both shallow and deep levels by conditioning the VLMs' generative distribution with an interference prefix and performing sentence-level best-of-N to search the most harmless and helpful generation paths. Extensive experiments show that ETA outperforms baseline methods in terms of harmlessness, helpfulness, and efficiency, reducing the unsafe rate by 87.5% in cross-modality attacks and achieving 96.6% win-ties in GPT-4 helpfulness evaluation. The code is publicly available at this https URL.
+
+
+
+ 67. 【2410.06618】Decomposing Relationship from 1-to-N into N 1-to-1 for Text-Video Retrieval
+ 链接:https://arxiv.org/abs/2410.06618
+ 作者:Jian Xiao,Zhenzhen Hu,Jia Li,Richang Hong
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Information Retrieval (cs.IR); Multimedia (cs.MM)
+ 关键词:large language models, pre-trained models, language models, recent years, Text-video retrieval
+ 备注:
+
+ 点击查看摘要
+ Abstract:Text-video retrieval (TVR) has seen substantial advancements in recent years, fueled by the utilization of pre-trained models and large language models (LLMs). Despite these advancements, achieving accurate matching in TVR remains challenging due to inherent disparities between video and textual modalities and irregularities in data representation. In this paper, we propose Text-Video-ProxyNet (TV-ProxyNet), a novel framework designed to decompose the conventional 1-to-N relationship of TVR into N distinct 1-to-1 relationships. By replacing a single text query with a series of text proxies, TV-ProxyNet not only broadens the query scope but also achieves a more precise expansion. Each text proxy is crafted through a refined iterative process, controlled by mechanisms we term as the director and dash, which regulate the proxy's direction and distance relative to the original text query. This setup not only facilitates more precise semantic alignment but also effectively manages the disparities and noise inherent in multimodal data. Our experiments on three representative video-text retrieval benchmarks, MSRVTT, DiDeMo, and ActivityNet Captions, demonstrate the effectiveness of TV-ProxyNet. The results show an improvement of 2.0% to 3.3% in R@1 over the baseline. TV-ProxyNet achieved state-of-the-art performance on MSRVTT and ActivityNet Captions, and a 2.0% improvement on DiDeMo compared to existing methods, validating our approach's ability to enhance semantic mapping and reduce error propensity.
+
+
+
+ 68. 【2410.06614】Pair-VPR: Place-Aware Pre-training and Contrastive Pair Classification for Visual Place Recognition with Vision Transformers
+ 链接:https://arxiv.org/abs/2410.06614
+ 作者:Stephen Hausler,Peyman Moghadam
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Visual Place Recognition, Place Recognition, pair classifier, global descriptor, Vision Transformer components
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this work we propose a novel joint training method for Visual Place Recognition (VPR), which simultaneously learns a global descriptor and a pair classifier for re-ranking. The pair classifier can predict whether a given pair of images are from the same place or not. The network only comprises Vision Transformer components for both the encoder and the pair classifier, and both components are trained using their respective class tokens. In existing VPR methods, typically the network is initialized using pre-trained weights from a generic image dataset such as ImageNet. In this work we propose an alternative pre-training strategy, by using Siamese Masked Image Modelling as a pre-training task. We propose a Place-aware image sampling procedure from a collection of large VPR datasets for pre-training our model, to learn visual features tuned specifically for VPR. By re-using the Mask Image Modelling encoder and decoder weights in the second stage of training, Pair-VPR can achieve state-of-the-art VPR performance across five benchmark datasets with a ViT-B encoder, along with further improvements in localization recall with larger encoders. The Pair-VPR website is: https://csiro-robotics.github.io/Pair-VPR.
+
+
+
+ 69. 【2410.06613】ES-Gaussian: Gaussian Splatting Mapping via Error Space-Based Gaussian Completion
+ 链接:https://arxiv.org/abs/2410.06613
+ 作者:Lu Chen,Yingfu Zeng,Haoang Li,Zhitao Deng,Jiafu Yan,Zhenjun Zhao
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:Accurate and affordable, effective robot navigation, navigation and interaction, robot navigation, Accurate
+ 备注: Project page: [this https URL](https://chenlu-china.github.io/ES-Gaussian/)
+
+ 点击查看摘要
+ Abstract:Accurate and affordable indoor 3D reconstruction is critical for effective robot navigation and interaction. Traditional LiDAR-based mapping provides high precision but is costly, heavy, and power-intensive, with limited ability for novel view rendering. Vision-based mapping, while cost-effective and capable of capturing visual data, often struggles with high-quality 3D reconstruction due to sparse point clouds. We propose ES-Gaussian, an end-to-end system using a low-altitude camera and single-line LiDAR for high-quality 3D indoor reconstruction. Our system features Visual Error Construction (VEC) to enhance sparse point clouds by identifying and correcting areas with insufficient geometric detail from 2D error maps. Additionally, we introduce a novel 3DGS initialization method guided by single-line LiDAR, overcoming the limitations of traditional multi-view setups and enabling effective reconstruction in resource-constrained environments. Extensive experimental results on our new Dreame-SR dataset and a publicly available dataset demonstrate that ES-Gaussian outperforms existing methods, particularly in challenging scenarios. The project page is available at this https URL.
+
+
+
+ 70. 【2410.06600】DDRN:a Data Distribution Reconstruction Network for Occluded Person Re-Identification
+ 链接:https://arxiv.org/abs/2410.06600
+ 作者:Zhaoyong Wang,Yujie Liu,Mingyue Li,Wenxin Zhang,Zongmin Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:occluded person re-identification, severe occlusions lead, person re-identification, identification of individuals, occluded person
+ 备注:
+
+ 点击查看摘要
+ Abstract:In occluded person re-identification(ReID), severe occlusions lead to a significant amount of irrelevant information that hinders the accurate identification of individuals. These irrelevant cues primarily stem from background interference and occluding interference, adversely affecting the final retrieval results. Traditional discriminative models, which rely on the specific content and positions of the images, often misclassify in cases of occlusion. To address these limitations, we propose the Data Distribution Reconstruction Network (DDRN), a generative model that leverages data distribution to filter out irrelevant details, enhancing overall feature perception ability and reducing irrelevant feature interference. Additionally, severe occlusions lead to the complexity of the feature space. To effectively handle this, we design a multi-center approach through the proposed Hierarchical SubcenterArcface (HS-Arcface) loss function, which can better approximate complex feature spaces. On the Occluded-Duke dataset, we achieved a mAP of 62.4\% (+1.1\%) and a rank-1 accuracy of 71.3\% (+0.6\%), surpassing the latest state-of-the-art methods(FRT) significantly.
+
+
+
+ 71. 【2410.06593】owards Natural Image Matting in the Wild via Real-Scenario Prior
+ 链接:https://arxiv.org/abs/2410.06593
+ 作者:Ruihao Xia,Yu Liang,Peng-Tao Jiang,Hao Zhang,Qianru Sun,Yang Tang,Bo Li,Pan Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Recent approaches attempt, Recent approaches, adapt powerful interactive, approaches attempt, attempt to adapt
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent approaches attempt to adapt powerful interactive segmentation models, such as SAM, to interactive matting and fine-tune the models based on synthetic matting datasets. However, models trained on synthetic data fail to generalize to complex and occlusion scenes. We address this challenge by proposing a new matting dataset based on the COCO dataset, namely COCO-Matting. Specifically, the construction of our COCO-Matting includes accessory fusion and mask-to-matte, which selects real-world complex images from COCO and converts semantic segmentation masks to matting labels. The built COCO-Matting comprises an extensive collection of 38,251 human instance-level alpha mattes in complex natural scenarios. Furthermore, existing SAM-based matting methods extract intermediate features and masks from a frozen SAM and only train a lightweight matting decoder by end-to-end matting losses, which do not fully exploit the potential of the pre-trained SAM. Thus, we propose SEMat which revamps the network architecture and training objectives. For network architecture, the proposed feature-aligned transformer learns to extract fine-grained edge and transparency features. The proposed matte-aligned decoder aims to segment matting-specific objects and convert coarse masks into high-precision mattes. For training objectives, the proposed regularization and trimap loss aim to retain the prior from the pre-trained model and push the matting logits extracted from the mask decoder to contain trimap-based semantic information. Extensive experiments across seven diverse datasets demonstrate the superior performance of our method, proving its efficacy in interactive natural image matting. We open-source our code, models, and dataset at this https URL.
+
+
+
+ 72. 【2410.06576】On The Relationship between Visual Anomaly-free and Anomalous Representations
+ 链接:https://arxiv.org/abs/2410.06576
+ 作者:Riya Sadrani,Hrishikesh Sharma,Ayush Bachan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Anomaly Detection, Anomaly, computer vision, real-life applications, variety of real-life
+ 备注:
+
+ 点击查看摘要
+ Abstract:Anomaly Detection is an important problem within computer vision, having variety of real-life applications. Yet, the current set of solutions to this problem entail known, systematic shortcomings. Specifically, contemporary surface Anomaly Detection task assumes the presence of multiple specific anomaly classes e.g. cracks, rusting etc., unlike one-class classification model of past. However, building a deep learning model in such setup remains a challenge because anomalies arise rarely, and hence anomaly samples are quite scarce. Transfer learning has been a preferred paradigm in such situations. But the typical source domains with large dataset sizes e.g. ImageNet, JFT-300M, LAION-2B do not correlate well with the domain of surfaces and materials, an important premise of transfer learning. In this paper, we make an important hypothesis and show, by exhaustive experimentation, that the space of anomaly-free visual patterns of the normal samples correlates well with each of the various spaces of anomalous patterns of the class-specific anomaly samples. The first results of using this hypothesis in transfer learning have indeed been quite encouraging. We expect that finding such a simple closeby domain that readily entails large number of samples, and which also oftentimes shows interclass separability though with narrow margins, will be a useful discovery. Especially, it is expected to improve domain adaptation for anomaly detection, and few-shot learning for anomaly detection, making in-the-wild anomaly detection realistically possible in future.
+
+
+
+ 73. 【2410.06558】Deep Correlated Prompting for Visual Recognition with Missing Modalities
+ 链接:https://arxiv.org/abs/2410.06558
+ 作者:Lianyu Hu,Tongkai Shi,Wei Feng,Fanhua Shang,Liang Wan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Large-scale multimodal models, shown excellent performance, paired multimodal training, multimodal training data, Large-scale multimodal
+ 备注: NeurIPS 2024, Update the checklist
+
+ 点击查看摘要
+ Abstract:Large-scale multimodal models have shown excellent performance over a series of tasks powered by the large corpus of paired multimodal training data. Generally, they are always assumed to receive modality-complete inputs. However, this simple assumption may not always hold in the real world due to privacy constraints or collection difficulty, where models pretrained on modality-complete data easily demonstrate degraded performance on missing-modality cases. To handle this issue, we refer to prompt learning to adapt large pretrained multimodal models to handle missing-modality scenarios by regarding different missing cases as different types of input. Instead of only prepending independent prompts to the intermediate layers, we present to leverage the correlations between prompts and input features and excavate the relationships between different layers of prompts to carefully design the instructions. We also incorporate the complementary semantics of different modalities to guide the prompting design for each modality. Extensive experiments on three commonly-used datasets consistently demonstrate the superiority of our method compared to the previous approaches upon different missing scenarios. Plentiful ablations are further given to show the generalizability and reliability of our method upon different modality-missing ratios and types.
+
+
+
+ 74. 【2410.06551】InstantIR: Blind Image Restoration with Instant Generative Reference
+ 链接:https://arxiv.org/abs/2410.06551
+ 作者:Jen-Yuan Huang,Haofan Wang,Qixun Wang,Xu Bai,Hao Ai,Peng Xing,Jen-Tse Huang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Handling test-time unknown, Blind Image Restoration, Handling test-time, high model generalization, necessitating high model
+ 备注:
+
+ 点击查看摘要
+ Abstract:Handling test-time unknown degradation is the major challenge in Blind Image Restoration (BIR), necessitating high model generalization. An effective strategy is to incorporate prior knowledge, either from human input or generative model. In this paper, we introduce Instant-reference Image Restoration (InstantIR), a novel diffusion-based BIR method which dynamically adjusts generation condition during inference. We first extract a compact representation of the input via a pre-trained vision encoder. At each generation step, this representation is used to decode current diffusion latent and instantiate it in the generative prior. The degraded image is then encoded with this reference, providing robust generation condition. We observe the variance of generative references fluctuate with degradation intensity, which we further leverage as an indicator for developing a sampling algorithm adaptive to input quality. Extensive experiments demonstrate InstantIR achieves state-of-the-art performance and offering outstanding visual quality. Through modulating generative references with textual description, InstantIR can restore extreme degradation and additionally feature creative restoration.
+
+
+
+ 75. 【2410.06535】Happy: A Debiased Learning Framework for Continual Generalized Category Discovery
+ 链接:https://arxiv.org/abs/2410.06535
+ 作者:Shijie Ma,Fei Zhu,Zhun Zhong,Wenzhuo Liu,Xu-Yao Zhang,Cheng-Lin Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Generalized Category Discovery, Continual Generalized Category, Constantly discovering, classes, evolving environments
+ 备注: Accepted at NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:Constantly discovering novel concepts is crucial in evolving environments. This paper explores the underexplored task of Continual Generalized Category Discovery (C-GCD), which aims to incrementally discover new classes from unlabeled data while maintaining the ability to recognize previously learned classes. Although several settings are proposed to study the C-GCD task, they have limitations that do not reflect real-world scenarios. We thus study a more practical C-GCD setting, which includes more new classes to be discovered over a longer period, without storing samples of past classes. In C-GCD, the model is initially trained on labeled data of known classes, followed by multiple incremental stages where the model is fed with unlabeled data containing both old and new classes. The core challenge involves two conflicting objectives: discover new classes and prevent forgetting old ones. We delve into the conflicts and identify that models are susceptible to prediction bias and hardness bias. To address these issues, we introduce a debiased learning framework, namely Happy, characterized by Hardness-aware prototype sampling and soft entropy regularization. For the prediction bias, we first introduce clustering-guided initialization to provide robust features. In addition, we propose soft entropy regularization to assign appropriate probabilities to new classes, which can significantly enhance the clustering performance of new classes. For the harness bias, we present the hardness-aware prototype sampling, which can effectively reduce the forgetting issue for previously seen classes, especially for difficult classes. Experimental results demonstrate our method proficiently manages the conflicts of C-GCD and achieves remarkable performance across various datasets, e.g., 7.5% overall gains on ImageNet-100. Our code is publicly available at this https URL.
+
+
+
+ 76. 【2410.06527】he Sampling-Gaussian for stereo matching
+ 链接:https://arxiv.org/abs/2410.06527
+ 作者:Baiyu Pan,jichao jiao,Bowen Yao,Jianxin Pang,Jun Cheng
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:enable differentiable regression, neural network-based stereo, network-based stereo matching, regression of disparity, operation is widely
+ 备注: TL;DR: A novel Gaussian distribution-based supervision method for stereo matching. Implemented with five baseline methods and achieves notable improvement. Main content, 10 pages. conference submission
+
+ 点击查看摘要
+ Abstract:The soft-argmax operation is widely adopted in neural network-based stereo matching methods to enable differentiable regression of disparity. However, network trained with soft-argmax is prone to being multimodal due to absence of explicit constraint to the shape of the probability distribution. Previous methods leverages Laplacian distribution and cross-entropy for training but failed to effectively improve the accuracy and even compromises the efficiency of the network. In this paper, we conduct a detailed analysis of the previous distribution-based methods and propose a novel supervision method for stereo matching, Sampling-Gaussian. We sample from the Gaussian distribution for supervision. Moreover, we interpret the training as minimizing the distance in vector space and propose a combined loss of L1 loss and cosine similarity loss. Additionally, we leveraged bilinear interpolation to upsample the cost volume. Our method can be directly applied to any soft-argmax-based stereo matching method without a reduction in efficiency. We have conducted comprehensive experiments to demonstrate the superior performance of our Sampling-Gaussian. The experimental results prove that we have achieved better accuracy on five baseline methods and two datasets. Our method is easy to implement, and the code is available online.
+
+
+
+ 77. 【2410.06513】MotionRL: Align Text-to-Motion Generation to Human Preferences with Multi-Reward Reinforcement Learning
+ 链接:https://arxiv.org/abs/2410.06513
+ 作者:Xiaoyang Liu,Yunyao Mao,Wengang Zhou,Houqiang Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:utilize Multi-Reward Reinforcement, Multi-Reward Reinforcement Learning, Reinforcement Learning, generation tasks, utilize Multi-Reward
+ 备注:
+
+ 点击查看摘要
+ Abstract:We introduce MotionRL, the first approach to utilize Multi-Reward Reinforcement Learning (RL) for optimizing text-to-motion generation tasks and aligning them with human preferences. Previous works focused on improving numerical performance metrics on the given datasets, often neglecting the variability and subjectivity of human feedback. In contrast, our novel approach uses reinforcement learning to fine-tune the motion generator based on human preferences prior knowledge of the human perception model, allowing it to generate motions that better align human preferences. In addition, MotionRL introduces a novel multi-objective optimization strategy to approximate Pareto optimality between text adherence, motion quality, and human preferences. Extensive experiments and user studies demonstrate that MotionRL not only allows control over the generated results across different objectives but also significantly enhances performance across these metrics compared to other algorithms.
+
+
+
+ 78. 【2410.06488】HFH-Font: Few-shot Chinese Font Synthesis with Higher Quality, Faster Speed, and Higher Resolution
+ 链接:https://arxiv.org/abs/2410.06488
+ 作者:Hua Li,Zhouhui Lian
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:remains unsolved, writing systems, consisting of huge, synthesizing high-quality vector, glyph images
+ 备注: Accepted to SIGGRAPH Asia 2024 (TOG). Code: [this https URL](https://github.com/grovessss/HFH-Font)
+
+ 点击查看摘要
+ Abstract:The challenge of automatically synthesizing high-quality vector fonts, particularly for writing systems (e.g., Chinese) consisting of huge amounts of complex glyphs, remains unsolved. Existing font synthesis techniques fall into two categories: 1) methods that directly generate vector glyphs, and 2) methods that initially synthesize glyph images and then vectorize them. However, the first category often fails to construct complete and correct shapes for complex glyphs, while the latter struggles to efficiently synthesize high-resolution (i.e., 1024 $\times$ 1024 or higher) glyph images while preserving local details. In this paper, we introduce HFH-Font, a few-shot font synthesis method capable of efficiently generating high-resolution glyph images that can be converted into high-quality vector glyphs. More specifically, our method employs a diffusion model-based generative framework with component-aware conditioning to learn different levels of style information adaptable to varying input reference sizes. We also design a distillation module based on Score Distillation Sampling for 1-step fast inference, and a style-guided super-resolution module to refine and upscale low-resolution synthesis results. Extensive experiments, including a user study with professional font designers, have been conducted to demonstrate that our method significantly outperforms existing font synthesis approaches. Experimental results show that our method produces high-fidelity, high-resolution raster images which can be vectorized into high-quality vector fonts. Using our method, for the first time, large-scale Chinese vector fonts of a quality comparable to those manually created by professional font designers can be automatically generated.
+
+
+
+ 79. 【2410.06475】3D Representation Methods: A Survey
+ 链接:https://arxiv.org/abs/2410.06475
+ 作者:Zhengren Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:experienced significant advancements, virtual reality, Signed Distance Function, significant advancements, demand for high-fidelity
+ 备注: Preliminary Draft
+
+ 点击查看摘要
+ Abstract:The field of 3D representation has experienced significant advancements, driven by the increasing demand for high-fidelity 3D models in various applications such as computer graphics, virtual reality, and autonomous systems. This review examines the development and current state of 3D representation methods, highlighting their research trajectories, innovations, strength and weakness. Key techniques such as Voxel Grid, Point Cloud, Mesh, Signed Distance Function (SDF), Neural Radiance Field (NeRF), 3D Gaussian Splatting, Tri-Plane, and Deep Marching Tetrahedra (DMTet) are reviewed. The review also introduces essential datasets that have been pivotal in advancing the field, highlighting their characteristics and impact on research progress. Finally, we explore potential research directions that hold promise for further expanding the capabilities and applications of 3D representation methods.
+
+
+
+ 80. 【2410.06468】Does Spatial Cognition Emerge in Frontier Models?
+ 链接:https://arxiv.org/abs/2410.06468
+ 作者:Santhosh Kumar Ramakrishnan,Erik Wijmans,Philipp Kraehenbuehl,Vladlen Koltun
+ 类目:Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:present SPACE, Abstract, models, benchmark, spatial
+ 备注:
+
+ 点击查看摘要
+ Abstract:Not yet. We present SPACE, a benchmark that systematically evaluates spatial cognition in frontier models. Our benchmark builds on decades of research in cognitive science. It evaluates large-scale mapping abilities that are brought to bear when an organism traverses physical environments, smaller-scale reasoning about object shapes and layouts, and cognitive infrastructure such as spatial attention and memory. For many tasks, we instantiate parallel presentations via text and images, allowing us to benchmark both large language models and large multimodal models. Results suggest that contemporary frontier models fall short of the spatial intelligence of animals, performing near chance level on a number of classic tests of animal cognition.
+
+
+
+ 81. 【2410.06456】From Generalist to Specialist: Adapting Vision Language Models via Task-Specific Visual Instruction Tuning
+ 链接:https://arxiv.org/abs/2410.06456
+ 作者:Yang Bai,Yang Zhou,Jun Zhou,Rick Siow Mong Goh,Daniel Shu Wei Ting,Yong Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:combine large language, Large vision language, large language models, large language, combine large
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large vision language models (VLMs) combine large language models with vision encoders, demonstrating promise across various tasks. However, they often underperform in task-specific applications due to domain gaps between pre-training and fine-tuning. We introduce VITask, a novel framework that enhances task-specific adaptability of VLMs by integrating task-specific models (TSMs). VITask employs three key strategies: exemplar prompting (EP), response distribution alignment (RDA), and contrastive response tuning (CRT) to improve the task-specific performance of VLMs by adjusting their response distributions. EP allows TSM features to guide VLMs, while RDA enables VLMs to adapt without TSMs during inference by learning from exemplar-prompted models. CRT further optimizes the ranking of correct image-response pairs, thereby reducing the risk of generating undesired responses. Experiments on 12 medical diagnosis datasets across 9 imaging modalities show that VITask outperforms both vanilla instruction-tuned VLMs and TSMs, showcasing its ability to integrate complementary features from both models effectively. Additionally, VITask offers practical advantages such as flexible TSM integration and robustness to incomplete instructions, making it a versatile and efficient solution for task-specific VLM tuning. Our code are available at this https URL.
+
+
+
+ 82. 【2410.06446】Machine Unlearning in Forgettability Sequence
+ 链接:https://arxiv.org/abs/2410.06446
+ 作者:Junjie Chen,Qian Chen,Jian Lou,Xiaoyu Zhang,Kai Wu,Zilong Wang
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:chosen data points, Machine unlearning, promising paradigm, paradigm to achieve, training trace
+ 备注:
+
+ 点击查看摘要
+ Abstract:Machine unlearning (MU) is becoming a promising paradigm to achieve the "right to be forgotten", where the training trace of any chosen data points could be eliminated, while maintaining the model utility on general testing samples after unlearning. With the advancement of forgetting research, many fundamental open questions remain unanswered: do different samples exhibit varying levels of difficulty in being forgotten? Further, does the sequence in which samples are forgotten, determined by their respective difficulty levels, influence the performance of forgetting algorithms? In this paper, we identify key factor affecting unlearning difficulty and the performance of unlearning algorithms. We find that samples with higher privacy risks are more likely to be unlearning, indicating that the unlearning difficulty varies among different samples which motives a more precise unlearning mode. Built upon this insight, we propose a general unlearning framework, dubbed RSU, which consists of Ranking module and SeqUnlearn module.
+
+
+
+ 83. 【2410.06437】LocoVR: Multiuser Indoor Locomotion Dataset in Virtual Reality
+ 链接:https://arxiv.org/abs/2410.06437
+ 作者:Kojiro Takeyama,Yimeng Liu,Misha Sra
+ 类目:Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV); Human-Computer Interaction (cs.HC)
+ 关键词:Understanding human locomotion, indoor home environments, home environments, Understanding human, complex indoor home
+ 备注:
+
+ 点击查看摘要
+ Abstract:Understanding human locomotion is crucial for AI agents such as robots, particularly in complex indoor home environments. Modeling human trajectories in these spaces requires insight into how individuals maneuver around physical obstacles and manage social navigation dynamics. These dynamics include subtle behaviors influenced by proxemics - the social use of space, such as stepping aside to allow others to pass or choosing longer routes to avoid collisions. Previous research has developed datasets of human motion in indoor scenes, but these are often limited in scale and lack the nuanced social navigation dynamics common in home environments. To address this, we present LocoVR, a dataset of 7000+ two-person trajectories captured in virtual reality from over 130 different indoor home environments. LocoVR provides full body pose data and precise spatial information, along with rich examples of socially-motivated movement behaviors. For example, the dataset captures instances of individuals navigating around each other in narrow spaces, adjusting paths to respect personal boundaries in living areas, and coordinating movements in high-traffic zones like entryways and kitchens. Our evaluation shows that LocoVR significantly enhances model performance in three practical indoor tasks utilizing human trajectories, and demonstrates predicting socially-aware navigation patterns in home environments.
+
+
+
+ 84. 【2410.06424】Restructuring Vector Quantization with the Rotation Trick
+ 链接:https://arxiv.org/abs/2410.06424
+ 作者:Christopher Fifty,Ronald G. Junkins,Dennis Duan,Aniketh Iger,Jerry W. Liu,Ehsan Amid,Sebastian Thrun,Christopher Ré
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Quantized Variational AutoEncoders, Vector Quantized Variational, Quantized Variational, discrete latent space, Variational AutoEncoders
+ 备注:
+
+ 点击查看摘要
+ Abstract:Vector Quantized Variational AutoEncoders (VQ-VAEs) are designed to compress a continuous input to a discrete latent space and reconstruct it with minimal distortion. They operate by maintaining a set of vectors -- often referred to as the codebook -- and quantizing each encoder output to the nearest vector in the codebook. However, as vector quantization is non-differentiable, the gradient to the encoder flows around the vector quantization layer rather than through it in a straight-through approximation. This approximation may be undesirable as all information from the vector quantization operation is lost. In this work, we propose a way to propagate gradients through the vector quantization layer of VQ-VAEs. We smoothly transform each encoder output into its corresponding codebook vector via a rotation and rescaling linear transformation that is treated as a constant during backpropagation. As a result, the relative magnitude and angle between encoder output and codebook vector becomes encoded into the gradient as it propagates through the vector quantization layer and back to the encoder. Across 11 different VQ-VAE training paradigms, we find this restructuring improves reconstruction metrics, codebook utilization, and quantization error. Our code is available at this https URL.
+
+
+
+ 85. 【2410.06420】ERVQA: A Dataset to Benchmark the Readiness of Large Vision Language Models in Hospital Environments
+ 链接:https://arxiv.org/abs/2410.06420
+ 作者:Sourjyadip Ray,Kushal Gupta,Soumi Kundu,Payal Arvind Kasat,Somak Aditya,Pawan Goyal
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Visual Question Answering, alert healthcare workers, smart healthcare assistants, Large Vision Language, Room Visual Question
+ 备注: Accepted at EMNLP 2024
+
+ 点击查看摘要
+ Abstract:The global shortage of healthcare workers has demanded the development of smart healthcare assistants, which can help monitor and alert healthcare workers when necessary. We examine the healthcare knowledge of existing Large Vision Language Models (LVLMs) via the Visual Question Answering (VQA) task in hospital settings through expert annotated open-ended questions. We introduce the Emergency Room Visual Question Answering (ERVQA) dataset, consisting of image, question, answer triplets covering diverse emergency room scenarios, a seminal benchmark for LVLMs. By developing a detailed error taxonomy and analyzing answer trends, we reveal the nuanced nature of the task. We benchmark state-of-the-art open-source and closed LVLMs using traditional and adapted VQA metrics: Entailment Score and CLIPScore Confidence. Analyzing errors across models, we infer trends based on properties like decoder type, model size, and in-context examples. Our findings suggest the ERVQA dataset presents a highly complex task, highlighting the need for specialized, domain-specific solutions.
+
+
+
+ 86. 【2410.06418】MIRACLE 3D: Memory-efficient Integrated Robust Approach for Continual Learning on Point Clouds via Shape Model construction
+ 链接:https://arxiv.org/abs/2410.06418
+ 作者:Hossein Resani,Behrooz Nasihatkon
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:continual learning, privacy-preserving continual learning, Gradient Mode Regularization, incorporate Gradient Mode, framework for memory-efficient
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this paper, we introduce a novel framework for memory-efficient and privacy-preserving continual learning in 3D object classification. Unlike conventional memory-based approaches in continual learning that require storing numerous exemplars, our method constructs a compact shape model for each class, retaining only the mean shape along with a few key modes of variation. This strategy not only enables the generation of diverse training samples while drastically reducing memory usage but also enhances privacy by eliminating the need to store original data. To further improve model robustness against input variations, an issue common in 3D domains due to the absence of strong backbones and limited training data, we incorporate Gradient Mode Regularization. This technique enhances model stability and broadens classification margins, resulting in accuracy improvements. We validate our approach through extensive experiments on the ModelNet40, ShapeNet, and ScanNet datasets, where we achieve state-of-the-art performance. Notably, our method consumes only 15% of the memory required by competing methods on the ModelNet40 and ShapeNet, while achieving comparable performance on the challenging ScanNet dataset with just 8.5% of the memory. These results underscore the scalability, effectiveness, and privacy-preserving strengths of our framework for 3D object classification.
+
+
+
+ 87. 【2410.06410】BEVLoc: Cross-View Localization and Matching via Birds-Eye-View Synthesis
+ 链接:https://arxiv.org/abs/2410.06410
+ 作者:Christopher Klammer,Michael Kaess
+ 类目:Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:GPS is absent, outdoor robotics, absent or unreliable, crucial and challenging, challenging task
+ 备注: 8 pages, 6 figures, Conference: IROS 2024
+
+ 点击查看摘要
+ Abstract:Ground to aerial matching is a crucial and challenging task in outdoor robotics, particularly when GPS is absent or unreliable. Structures like buildings or large dense forests create interference, requiring GNSS replacements for global positioning estimates. The true difficulty lies in reconciling the perspective difference between the ground and air images for acceptable localization. Taking inspiration from the autonomous driving community, we propose a novel framework for synthesizing a birds-eye-view (BEV) scene representation to match and localize against an aerial map in off-road environments. We leverage contrastive learning with domain specific hard negative mining to train a network to learn similar representations between the synthesized BEV and the aerial map. During inference, BEVLoc guides the identification of the most probable locations within the aerial map through a coarse-to-fine matching strategy. Our results demonstrate promising initial outcomes in extremely difficult forest environments with limited semantic diversity. We analyze our model's performance for coarse and fine matching, assessing both the raw matching capability of our model and its performance as a GNSS replacement. Our work delves into off-road map localization while establishing a foundational baseline for future developments in localization. Our code is available at: this https URL
+
+
+
+ 88. 【2410.06405】ackling the Abstraction and Reasoning Corpus with Vision Transformers: the Importance of 2D Representation, Positions, and Objects
+ 链接:https://arxiv.org/abs/2410.06405
+ 作者:Wenhao Li,Yudong Xu,Scott Sanner,Elias Boutros Khalil
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Artificial Intelligence systems, Artificial Intelligence, Intelligence systems, popular benchmark focused, evaluation of Artificial
+ 备注:
+
+ 点击查看摘要
+ Abstract:The Abstraction and Reasoning Corpus (ARC) is a popular benchmark focused on visual reasoning in the evaluation of Artificial Intelligence systems. In its original framing, an ARC task requires solving a program synthesis problem over small 2D images using a few input-output training pairs. In this work, we adopt the recently popular data-driven approach to the ARC and ask whether a Vision Transformer (ViT) can learn the implicit mapping, from input image to output image, that underlies the task. We show that a ViT -- otherwise a state-of-the-art model for images -- fails dramatically on most ARC tasks even when trained on one million examples per task. This points to an inherent representational deficiency of the ViT architecture that makes it incapable of uncovering the simple structured mappings underlying the ARC tasks. Building on these insights, we propose ViTARC, a ViT-style architecture that unlocks some of the visual reasoning capabilities required by the ARC. Specifically, we use a pixel-level input representation, design a spatially-aware tokenization scheme, and introduce a novel object-based positional encoding that leverages automatic segmentation, among other enhancements. Our task-specific ViTARC models achieve a test solve rate close to 100% on more than half of the 400 public ARC tasks strictly through supervised learning from input-output grids. This calls attention to the importance of imbuing the powerful (Vision) Transformer with the correct inductive biases for abstract visual reasoning that are critical even when the training data is plentiful and the mapping is noise-free. Hence, ViTARC provides a strong foundation for future research in visual reasoning using transformer-based architectures.
+
+
+
+ 89. 【2410.06380】Adver-City: Open-Source Multi-Modal Dataset for Collaborative Perception Under Adverse Weather Conditions
+ 链接:https://arxiv.org/abs/2410.06380
+ 作者:Mateus Karvat,Sidney Givigi
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Robotics (cs.RO)
+ 关键词:Adverse weather conditions, adoption of Autonomous, Adverse weather, Autonomous Vehicles, weather conditions
+ 备注: 8 pages
+
+ 点击查看摘要
+ Abstract:Adverse weather conditions pose a significant challenge to the widespread adoption of Autonomous Vehicles (AVs) by impacting sensors like LiDARs and cameras. Even though Collaborative Perception (CP) improves AV perception in difficult conditions, existing CP datasets lack adverse weather conditions. To address this, we introduce Adver-City, the first open-source synthetic CP dataset focused on adverse weather conditions. Simulated in CARLA with OpenCDA, it contains over 24 thousand frames, over 890 thousand annotations, and 110 unique scenarios across six different weather conditions: clear weather, soft rain, heavy rain, fog, foggy heavy rain and, for the first time in a synthetic CP dataset, glare. It has six object categories including pedestrians and cyclists, and uses data from vehicles and roadside units featuring LiDARs, RGB and semantic segmentation cameras, GNSS, and IMUs. Its scenarios, based on real crash reports, depict the most relevant road configurations for adverse weather and poor visibility conditions, varying in object density, with both dense and sparse scenes, allowing for novel testing conditions of CP models. Benchmarks run on the dataset show that weather conditions created challenging conditions for perception models, reducing multi-modal object detection performance by up to 19%, while object density affected LiDAR-based detection by up to 29%. The dataset, code and documentation are available at this https URL.
+
+
+
+ 90. 【2410.06373】Unveiling the Backbone-Optimizer Coupling Bias in Visual Representation Learning
+ 链接:https://arxiv.org/abs/2410.06373
+ 作者:Siyuan Li,Juanxi Tian,Zedong Wang,Luyuan Zhang,Zicheng Liu,Weiyang Jin,Yang Liu,Baigui Sun,Stan Z. Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:inter-dependent phenomenon termed, textbf, unvealing an inter-dependent, phenomenon termed, paper delves
+ 备注: Preprint V1. Online project at [this https URL](https://bocb-ai.github.io/)
+
+ 点击查看摘要
+ Abstract:This paper delves into the interplay between vision backbones and optimizers, unvealing an inter-dependent phenomenon termed \textit{\textbf{b}ackbone-\textbf{o}ptimizer \textbf{c}oupling \textbf{b}ias} (BOCB). We observe that canonical CNNs, such as VGG and ResNet, exhibit a marked co-dependency with SGD families, while recent architectures like ViTs and ConvNeXt share a tight coupling with the adaptive learning rate ones. We further show that BOCB can be introduced by both optimizers and certain backbone designs and may significantly impact the pre-training and downstream fine-tuning of vision models. Through in-depth empirical analysis, we summarize takeaways on recommended optimizers and insights into robust vision backbone architectures. We hope this work can inspire the community to question long-held assumptions on backbones and optimizers, stimulate further explorations, and thereby contribute to more robust vision systems. The source code and models are publicly available at this https URL.
+
+
+
+ 91. 【2410.06353】Language-Assisted Human Part Motion Learning for Skeleton-Based Temporal Action Segmentation
+ 链接:https://arxiv.org/abs/2410.06353
+ 作者:Bowen Chen,Haoyu Ji,Zhiyong Wang,Benjamin Filtjens,Chunzhuo Wang,Weihong Ren,Bart Vanrumste,Honghai Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Temporal Action Segmentation, Action Segmentation involves, Skeleton-based Temporal Action, Segmentation involves, dense action classification
+ 备注: This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible
+
+ 点击查看摘要
+ Abstract:Skeleton-based Temporal Action Segmentation involves the dense action classification of variable-length skeleton sequences. Current approaches primarily apply graph-based networks to extract framewise, whole-body-level motion representations, and use one-hot encoded labels for model optimization. However, whole-body motion representations do not capture fine-grained part-level motion representations and the one-hot encoded labels neglect the intrinsic semantic relationships within the language-based action definitions. To address these limitations, we propose a novel method named Language-assisted Human Part Motion Representation Learning (LPL), which contains a Disentangled Part Motion Encoder (DPE) to extract dual-level (i.e., part and whole-body) motion representations and a Language-assisted Distribution Alignment (LDA) strategy for optimizing spatial relations within representations. Specifically, after part-aware skeleton encoding via DPE, LDA generates dual-level action descriptions to construct a textual embedding space with the help of a large-scale language model. Then, LDA motivates the alignment of the embedding space between text descriptions and motions. This alignment allows LDA not only to enhance intra-class compactness but also to transfer the language-encoded semantic correlations among actions to skeleton-based motion learning. Moreover, we propose a simple yet efficient Semantic Offset Adapter to smooth the cross-domain misalignment. Our experiments indicate that LPL achieves state-of-the-art performance across various datasets (e.g., +4.4\% Accuracy, +5.6\% F1 on the PKU-MMD dataset). Moreover, LDA is compatible with existing methods and improves their performance (e.g., +4.8\% Accuracy, +4.3\% F1 on the LARa dataset) without additional inference costs.
+
+
+
+ 92. 【2410.06327】owards a GENEA Leaderboard -- an Extended, Living Benchmark for Evaluating and Advancing Conversational Motion Synthesis
+ 链接:https://arxiv.org/abs/2410.06327
+ 作者:Rajmund Nagy,Hendric Voss,Youngwoo Yoon,Taras Kucherenko,Teodor Nikolov,Thanh Hoang-Minh,Rachel McDonnell,Stefan Kopp,Michael Neff,Gustav Eje Henter
+ 类目:Human-Computer Interaction (cs.HC); Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR); Machine Learning (cs.LG)
+ 关键词:Current evaluation practices, speech-driven gesture generation, gesture generation lack, generation lack standardisation, Current evaluation
+ 备注: 15 pages, 2 figures, project page: [this https URL](https://genea-workshop.github.io/leaderboard/)
+
+ 点击查看摘要
+ Abstract:Current evaluation practices in speech-driven gesture generation lack standardisation and focus on aspects that are easy to measure over aspects that actually matter. This leads to a situation where it is impossible to know what is the state of the art, or to know which method works better for which purpose when comparing two publications. In this position paper, we review and give details on issues with existing gesture-generation evaluation, and present a novel proposal for remedying them. Specifically, we announce an upcoming living leaderboard to benchmark progress in conversational motion synthesis. Unlike earlier gesture-generation challenges, the leaderboard will be updated with large-scale user studies of new gesture-generation systems multiple times per year, and systems on the leaderboard can be submitted to any publication venue that their authors prefer. By evolving the leaderboard evaluation data and tasks over time, the effort can keep driving progress towards the most important end goals identified by the community. We actively seek community involvement across the entire evaluation pipeline: from data and tasks for the evaluation, via tooling, to the systems evaluated. In other words, our proposal will not only make it easier for researchers to perform good evaluations, but their collective input and contributions will also help drive the future of gesture-generation research.
+
+
+
+ 93. 【2410.06314】mporal Image Caption Retrieval Competition -- Description and Results
+ 链接:https://arxiv.org/abs/2410.06314
+ 作者:Jakub Pokrywka,Piotr Wierzchoń,Kornel Weryszko,Krzysztof Jassem
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:gained significant recognition, recently gained significant, textual information, significant recognition, Multimodal models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multimodal models, which combine visual and textual information, have recently gained significant recognition. This paper addresses the multimodal challenge of Text-Image retrieval and introduces a novel task that extends the modalities to include temporal data. The Temporal Image Caption Retrieval Competition (TICRC) presented in this paper is based on the Chronicling America and Challenging America projects, which offer access to an extensive collection of digitized historic American newspapers spanning 274 years. In addition to the competition results, we provide an analysis of the delivered dataset and the process of its creation.
+
+
+
+ 94. 【2410.06306】Benchmarking of a new data splitting method on volcanic eruption data
+ 链接:https://arxiv.org/abs/2410.06306
+ 作者:Simona Reale,Pietro Di Stasio,Francesco Mauro,Alessandro Sebastianelli,Paolo Gamba,Silvia Liberata Ullo
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Cumulative Histogram Dissimilarity, iterative procedure divides, dissimilarity index calculated, cumulative histograms, Histogram Dissimilarity
+ 备注: To be sumbitted to IEEE IGARSS 2025
+
+ 点击查看摘要
+ Abstract:In this paper, a novel method for data splitting is presented: an iterative procedure divides the input dataset of volcanic eruption, chosen as the proposed use case, into two parts using a dissimilarity index calculated on the cumulative histograms of these two parts. The Cumulative Histogram Dissimilarity (CHD) index is introduced as part of the design. Based on the obtained results the proposed model in this case, compared to both Random splitting and K-means implemented over different configurations, achieves the best performance, with a slightly higher number of epochs. However, this demonstrates that the model can learn more deeply from the input dataset, which is attributable to the quality of the splitting. In fact, each model was trained with early stopping, suitable in case of overfitting, and the higher number of epochs in the proposed method demonstrates that early stopping did not detect overfitting, and consequently, the learning was optimal.
+
+
+
+ 95. 【2410.06285】Monocular Visual Place Recognition in LiDAR Maps via Cross-Modal State Space Model and Multi-View Matching
+ 链接:https://arxiv.org/abs/2410.06285
+ 作者:Gongxin Yao,Xinyang Li,Luowei Fu,Yu Pan
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:Achieving monocular camera, visual SLAM systems, monocular camera localization, simultaneous mapping process, pre-built LiDAR maps
+ 备注:
+
+ 点击查看摘要
+ Abstract:Achieving monocular camera localization within pre-built LiDAR maps can bypass the simultaneous mapping process of visual SLAM systems, potentially reducing the computational overhead of autonomous localization. To this end, one of the key challenges is cross-modal place recognition, which involves retrieving 3D scenes (point clouds) from a LiDAR map according to online RGB images. In this paper, we introduce an efficient framework to learn descriptors for both RGB images and point clouds. It takes visual state space model (VMamba) as the backbone and employs a pixel-view-scene joint training strategy for cross-modal contrastive learning. To address the field-of-view differences, independent descriptors are generated from multiple evenly distributed viewpoints for point clouds. A visible 3D points overlap strategy is then designed to quantify the similarity between point cloud views and RGB images for multi-view supervision. Additionally, when generating descriptors from pixel-level features using NetVLAD, we compensate for the loss of geometric information, and introduce an efficient scheme for multi-view generation. Experimental results on the KITTI and KITTI-360 datasets demonstrate the effectiveness and generalization of our method. The code will be released upon acceptance.
+
+
+
+ 96. 【2410.06264】hink While You Generate: Discrete Diffusion with Planned Denoising
+ 链接:https://arxiv.org/abs/2410.06264
+ 作者:Sulin Liu,Juno Nam,Andrew Campbell,Hannes Stärk,Yilun Xu,Tommi Jaakkola,Rafael Gómez-Bombarelli
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)
+ 关键词:Discrete diffusion, introduce Discrete Diffusion, outperforming or approaching, approaching autoregressive models, Discrete
+ 备注:
+
+ 点击查看摘要
+ Abstract:Discrete diffusion has achieved state-of-the-art performance, outperforming or approaching autoregressive models on standard benchmarks. In this work, we introduce Discrete Diffusion with Planned Denoising (DDPD), a novel framework that separates the generation process into two models: a planner and a denoiser. At inference time, the planner selects which positions to denoise next by identifying the most corrupted positions in need of denoising, including both initially corrupted and those requiring additional refinement. This plan-and-denoise approach enables more efficient reconstruction during generation by iteratively identifying and denoising corruptions in the optimal order. DDPD outperforms traditional denoiser-only mask diffusion methods, achieving superior results on language modeling benchmarks such as text8, OpenWebText, and token-based generation on ImageNet $256 \times 256$. Notably, in language modeling, DDPD significantly reduces the performance gap between diffusion-based and autoregressive methods in terms of generative perplexity. Code is available at this https URL.
+
+
+
+ 97. 【2410.06245】HiSplat: Hierarchical 3D Gaussian Splatting for Generalizable Sparse-View Reconstruction
+ 链接:https://arxiv.org/abs/2410.06245
+ 作者:Shengji Tang,Weicai Ye,Peng Ye,Weihao Lin,Yang Zhou,Tao Chen,Wanli Ouyang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Gaussian Splatting, stereo vision, multiple viewpoints, fundamental task, task in stereo
+ 备注:
+
+ 点击查看摘要
+ Abstract:Reconstructing 3D scenes from multiple viewpoints is a fundamental task in stereo vision. Recently, advances in generalizable 3D Gaussian Splatting have enabled high-quality novel view synthesis for unseen scenes from sparse input views by feed-forward predicting per-pixel Gaussian parameters without extra optimization. However, existing methods typically generate single-scale 3D Gaussians, which lack representation of both large-scale structure and texture details, resulting in mislocation and artefacts. In this paper, we propose a novel framework, HiSplat, which introduces a hierarchical manner in generalizable 3D Gaussian Splatting to construct hierarchical 3D Gaussians via a coarse-to-fine strategy. Specifically, HiSplat generates large coarse-grained Gaussians to capture large-scale structures, followed by fine-grained Gaussians to enhance delicate texture details. To promote inter-scale interactions, we propose an Error Aware Module for Gaussian compensation and a Modulating Fusion Module for Gaussian repair. Our method achieves joint optimization of hierarchical representations, allowing for novel view synthesis using only two-view reference images. Comprehensive experiments on various datasets demonstrate that HiSplat significantly enhances reconstruction quality and cross-dataset generalization compared to prior single-scale methods. The corresponding ablation study and analysis of different-scale 3D Gaussians reveal the mechanism behind the effectiveness. Project website: this https URL
+
+
+
+ 98. 【2410.06244】Story-Adapter: A Training-free Iterative Framework for Long Story Visualization
+ 链接:https://arxiv.org/abs/2410.06244
+ 作者:Jiawei Mao,Xiaoke Huang,Yunfei Xie,Yuanqi Chang,Mude Hui,Bingjie Xu,Yuyin Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:coherent images based, diffusion models, long story visualization, generating coherent images, Story visualization
+ 备注: 20 pages, 16 figures, The project page and associated code can be accessed via [this https URL](https://jwmao1.github.io/storyadapter)
+
+ 点击查看摘要
+ Abstract:Story visualization, the task of generating coherent images based on a narrative, has seen significant advancements with the emergence of text-to-image models, particularly diffusion models. However, maintaining semantic consistency, generating high-quality fine-grained interactions, and ensuring computational feasibility remain challenging, especially in long story visualization (i.e., up to 100 frames). In this work, we propose a training-free and computationally efficient framework, termed Story-Adapter, to enhance the generative capability of long stories. Specifically, we propose an iterative paradigm to refine each generated image, leveraging both the text prompt and all generated images from the previous iteration. Central to our framework is a training-free global reference cross-attention module, which aggregates all generated images from the previous iteration to preserve semantic consistency across the entire story, while minimizing computational costs with global embeddings. This iterative process progressively optimizes image generation by repeatedly incorporating text constraints, resulting in more precise and fine-grained interactions. Extensive experiments validate the superiority of Story-Adapter in improving both semantic consistency and generative capability for fine-grained interactions, particularly in long story scenarios. The project page and associated code can be accessed via this https URL .
+
+
+
+ 99. 【2410.06243】Unsupervised Model Diagnosis
+ 链接:https://arxiv.org/abs/2410.06243
+ 作者:Yinong Oliver Wang,Eileen Li,Jinqi Luo,Zhaoning Wang,Fernando De la Torre
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Ensuring model explainability, deep vision systems, Ensuring model, essential for reliable, reliable deployment
+ 备注: 9 pages, 9 figures, 3 tables
+
+ 点击查看摘要
+ Abstract:Ensuring model explainability and robustness is essential for reliable deployment of deep vision systems. Current methods for evaluating robustness rely on collecting and annotating extensive test sets. While this is common practice, the process is labor-intensive and expensive with no guarantee of sufficient coverage across attributes of interest. Recently, model diagnosis frameworks have emerged leveraging user inputs (e.g., text) to assess the vulnerability of the model. However, such dependence on human can introduce bias and limitation given the domain knowledge of particular users. This paper proposes Unsupervised Model Diagnosis (UMO), that leverages generative models to produce semantic counterfactual explanations without any user guidance. Given a differentiable computer vision model (i.e., the target model), UMO optimizes for the most counterfactual directions in a generative latent space. Our approach identifies and visualizes changes in semantics, and then matches these changes to attributes from wide-ranging text sources, such as dictionaries or language models. We validate the framework on multiple vision tasks (e.g., classification, segmentation, keypoint detection). Extensive experiments show that our unsupervised discovery of semantic directions can correctly highlight spurious correlations and visualize the failure mode of target models without any human intervention.
+
+
+
+ 100. 【2410.06241】BroadWay: Boost Your Text-to-Video Generation Model in a Training-free Way
+ 链接:https://arxiv.org/abs/2410.06241
+ 作者:Jiazi Bu,Pengyang Ling,Pan Zhang,Tong Wu,Xiaoyi Dong,Yuhang Zang,Yuhang Cao,Dahua Lin,Jiaqi Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:convenient visual creation, offering convenient visual, recently garnered increasing, temporal attention maps, garnered increasing attention
+ 备注:
+
+ 点击查看摘要
+ Abstract:The text-to-video (T2V) generation models, offering convenient visual creation, have recently garnered increasing attention. Despite their substantial potential, the generated videos may present artifacts, including structural implausibility, temporal inconsistency, and a lack of motion, often resulting in near-static video. In this work, we have identified a correlation between the disparity of temporal attention maps across different blocks and the occurrence of temporal inconsistencies. Additionally, we have observed that the energy contained within the temporal attention maps is directly related to the magnitude of motion amplitude in the generated videos. Based on these observations, we present BroadWay, a training-free method to improve the quality of text-to-video generation without introducing additional parameters, augmenting memory or sampling time. Specifically, BroadWay is composed of two principal components: 1) Temporal Self-Guidance improves the structural plausibility and temporal consistency of generated videos by reducing the disparity between the temporal attention maps across various decoder blocks. 2) Fourier-based Motion Enhancement enhances the magnitude and richness of motion by amplifying the energy of the map. Extensive experiments demonstrate that BroadWay significantly improves the quality of text-to-video generation with negligible additional cost.
+
+
+
+ 101. 【2410.06236】SD-$\pi$XL: Generating Low-Resolution Quantized Imagery via Score Distillation
+ 链接:https://arxiv.org/abs/2410.06236
+ 作者:Alexandre Binninger,Olga Sorkine-Hornung
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:video game graphics, modern applications ranging, Low-resolution quantized imagery, elemental units, revival in modern
+ 备注: To be presented at SIGGRAPH Asia 2024 (conference track). Main paper is 8 pages + 2 figure-only pages + references. Supplementary is 11 pages + references
+
+ 点击查看摘要
+ Abstract:Low-resolution quantized imagery, such as pixel art, is seeing a revival in modern applications ranging from video game graphics to digital design and fabrication, where creativity is often bound by a limited palette of elemental units. Despite their growing popularity, the automated generation of quantized images from raw inputs remains a significant challenge, often necessitating intensive manual input. We introduce SD-$\pi$XL, an approach for producing quantized images that employs score distillation sampling in conjunction with a differentiable image generator. Our method enables users to input a prompt and optionally an image for spatial conditioning, set any desired output size $H \times W$, and choose a palette of $n$ colors or elements. Each color corresponds to a distinct class for our generator, which operates on an $H \times W \times n$ tensor. We adopt a softmax approach, computing a convex sum of elements, thus rendering the process differentiable and amenable to backpropagation. We show that employing Gumbel-softmax reparameterization allows for crisp pixel art effects. Unique to our method is the ability to transform input images into low-resolution, quantized versions while retaining their key semantic features. Our experiments validate SD-$\pi$XL's performance in creating visually pleasing and faithful representations, consistently outperforming the current state-of-the-art. Furthermore, we showcase SD-$\pi$XL's practical utility in fabrication through its applications in interlocking brick mosaic, beading and embroidery design.
+
+
+
+ 102. 【2410.06234】EOChat: A Large Vision-Language Assistant for Temporal Earth Observation Data
+ 链接:https://arxiv.org/abs/2410.06234
+ 作者:Jeremy Andrew Irvin,Emily Ruoyu Liu,Joyce Chuyi Chen,Ines Dormoy,Jinyoung Kim,Samar Khanna,Zhuo Zheng,Stefano Ermon
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:interpreting natural images, Large vision, earth observation data, vision and language, interpreting natural
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large vision and language assistants have enabled new capabilities for interpreting natural images. These approaches have recently been adapted to earth observation data, but they are only able to handle single image inputs, limiting their use for many real-world tasks. In this work, we develop a new vision and language assistant called TEOChat that can engage in conversations about temporal sequences of earth observation data. To train TEOChat, we curate an instruction-following dataset composed of many single image and temporal tasks including building change and damage assessment, semantic change detection, and temporal scene classification. We show that TEOChat can perform a wide variety of spatial and temporal reasoning tasks, substantially outperforming previous vision and language assistants, and even achieving comparable or better performance than specialist models trained to perform these specific tasks. Furthermore, TEOChat achieves impressive zero-shot performance on a change detection and change question answering dataset, outperforms GPT-4o and Gemini 1.5 Pro on multiple temporal tasks, and exhibits stronger single image capabilities than a comparable single EO image instruction-following model. We publicly release our data, models, and code at this https URL .
+
+
+
+ 103. 【2410.06231】RelitLRM: Generative Relightable Radiance for Large Reconstruction Models
+ 链接:https://arxiv.org/abs/2410.06231
+ 作者:Tianyuan Zhang,Zhengfei Kuang,Haian Jin,Zexiang Xu,Sai Bi,Hao Tan,He Zhang,Yiwei Hu,Milos Hasan,William T. Freeman,Kai Zhang,Fujun Luan
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR); Machine Learning (cs.LG)
+ 关键词:Large Reconstruction Model, generating high-quality Gaussian, high-quality Gaussian splatting, Gaussian splatting representations, posed images captured
+ 备注: webpage: [this https URL](https://relit-lrm.github.io/)
+
+ 点击查看摘要
+ Abstract:We propose RelitLRM, a Large Reconstruction Model (LRM) for generating high-quality Gaussian splatting representations of 3D objects under novel illuminations from sparse (4-8) posed images captured under unknown static lighting. Unlike prior inverse rendering methods requiring dense captures and slow optimization, often causing artifacts like incorrect highlights or shadow baking, RelitLRM adopts a feed-forward transformer-based model with a novel combination of a geometry reconstructor and a relightable appearance generator based on diffusion. The model is trained end-to-end on synthetic multi-view renderings of objects under varying known illuminations. This architecture design enables to effectively decompose geometry and appearance, resolve the ambiguity between material and lighting, and capture the multi-modal distribution of shadows and specularity in the relit appearance. We show our sparse-view feed-forward RelitLRM offers competitive relighting results to state-of-the-art dense-view optimization-based baselines while being significantly faster. Our project page is available at: this https URL.
+
+
+
+ 104. 【2410.06194】Prompting DirectSAM for Semantic Contour Extraction in Remote Sensing Images
+ 链接:https://arxiv.org/abs/2410.06194
+ 作者:Shiyu Miao,Delong Chen,Fan Liu,Chuanyi Zhang,Yanhui Gu,Shengjie Guo,Jun Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Direct Segment, class-agnostic contour extraction, excels in class-agnostic, contour extraction, Direct
+ 备注:
+
+ 点击查看摘要
+ Abstract:The Direct Segment Anything Model (DirectSAM) excels in class-agnostic contour extraction. In this paper, we explore its use by applying it to optical remote sensing imagery, where semantic contour extraction-such as identifying buildings, road networks, and coastlines-holds significant practical value. Those applications are currently handled via training specialized small models separately on small datasets in each domain. We introduce a foundation model derived from DirectSAM, termed DirectSAM-RS, which not only inherits the strong segmentation capability acquired from natural images, but also benefits from a large-scale dataset we created for remote sensing semantic contour extraction. This dataset comprises over 34k image-text-contour triplets, making it at least 30 times larger than individual dataset. DirectSAM-RS integrates a prompter module: a text encoder and cross-attention layers attached to the DirectSAM architecture, which allows flexible conditioning on target class labels or referring expressions. We evaluate the DirectSAM-RS in both zero-shot and fine-tuning setting, and demonstrate that it achieves state-of-the-art performance across several downstream benchmarks.
+
+
+
+ 105. 【2410.06169】Quadratic Is Not What You Need For Multimodal Large Language Models
+ 链接:https://arxiv.org/abs/2410.06169
+ 作者:Phu Pham,Wentian Zhao,Kun Wan,Yu-Jhe Li,Zeliang Zhang,Daniel Miranda,Ajinkya Kale,Chenliang Xu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Large Language Models, Multimodal Large Language, Language Models, Multimodal Large, Large Language
+ 备注:
+
+ 点击查看摘要
+ Abstract:In the past year, the capabilities of Multimodal Large Language Models (MLLMs) have significantly improved across various aspects. However, constrained by the quadratic growth of computation in LLMs as the number of tokens increases, efficiency has become a bottleneck for further scaling MLLMs. Although recent efforts have been made to prune visual tokens or use more lightweight LLMs to reduce computation, the problem of quadratic growth in computation with the increase of visual tokens still persists. To address this, we propose a novel approach: instead of reducing the input visual tokens for LLMs, we focus on pruning vision-related computations within the LLMs. After pruning, the computation growth in the LLM is no longer quadratic with the increase of visual tokens, but linear. Surprisingly, we found that after applying such extensive pruning, the capabilities of MLLMs are comparable with the original one and even superior on some benchmarks with only 25% of the computation. This finding opens up the possibility for MLLMs to incorporate much denser visual tokens. Additionally, based on this finding, we further analyzed some architectural design deficiencies in existing MLLMs and proposed promising improvements. To the best of our knowledge, this is the first study to investigate the computational redundancy in the LLM's vision component of MLLMs. Code and checkpoints will be released soon.
+
+
+
+ 106. 【2410.06166】mporal Reasoning Transfer from Text to Video
+ 链接:https://arxiv.org/abs/2410.06166
+ 作者:Lei Li,Yuanxin Liu,Linli Yao,Peiyuan Zhang,Chenxin An,Lean Wang,Xu Sun,Lingpeng Kong,Qi Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Video Large Language, Large Language Models, Large Language, shown promising capabilities, temporal reasoning
+ 备注: Project page: [this https URL](https://video-t3.github.io)
+
+ 点击查看摘要
+ Abstract:Video Large Language Models (Video LLMs) have shown promising capabilities in video comprehension, yet they struggle with tracking temporal changes and reasoning about temporal relationships. While previous research attributed this limitation to the ineffective temporal encoding of visual inputs, our diagnostic study reveals that video representations contain sufficient information for even small probing classifiers to achieve perfect accuracy. Surprisingly, we find that the key bottleneck in Video LLMs' temporal reasoning capability stems from the underlying LLM's inherent difficulty with temporal concepts, as evidenced by poor performance on textual temporal question-answering tasks. Building on this discovery, we introduce the Textual Temporal reasoning Transfer (T3). T3 synthesizes diverse temporal reasoning tasks in pure text format from existing image-text datasets, addressing the scarcity of video samples with complex temporal scenarios. Remarkably, without using any video data, T3 enhances LongVA-7B's temporal understanding, yielding a 5.3 absolute accuracy improvement on the challenging TempCompass benchmark, which enables our model to outperform ShareGPT4Video-8B trained on 28,000 video samples. Additionally, the enhanced LongVA-7B model achieves competitive performance on comprehensive video benchmarks. For example, it achieves a 49.7 accuracy on the Temporal Reasoning task of Video-MME, surpassing powerful large-scale models such as InternVL-Chat-V1.5-20B and VILA1.5-40B. Further analysis reveals a strong correlation between textual and video temporal task performance, validating the efficacy of transferring temporal reasoning abilities from text to video domains.
+
+
+
+ 107. 【2410.06158】GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
+ 链接:https://arxiv.org/abs/2410.06158
+ 作者:Chi-Lam Cheang,Guangzeng Chen,Ya Jing,Tao Kong,Hang Li,Yifeng Li,Yuxiao Liu,Hongtao Wu,Jiafeng Xu,Yichu Yang,Hanbo Zhang,Minzhao Zhu
+ 类目:Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:generalizable robot manipulation, generalist robot agent, agent for versatile, versatile and generalizable, generalist robot
+ 备注: Tech Report. Authors are listed in alphabetical order. Project page: [this https URL](https://gr2-manipulation.github.io)
+
+ 点击查看摘要
+ Abstract:We present GR-2, a state-of-the-art generalist robot agent for versatile and generalizable robot manipulation. GR-2 is first pre-trained on a vast number of Internet videos to capture the dynamics of the world. This large-scale pre-training, involving 38 million video clips and over 50 billion tokens, equips GR-2 with the ability to generalize across a wide range of robotic tasks and environments during subsequent policy learning. Following this, GR-2 is fine-tuned for both video generation and action prediction using robot trajectories. It exhibits impressive multi-task learning capabilities, achieving an average success rate of 97.7% across more than 100 tasks. Moreover, GR-2 demonstrates exceptional generalization to new, previously unseen scenarios, including novel backgrounds, environments, objects, and tasks. Notably, GR-2 scales effectively with model size, underscoring its potential for continued growth and application. Project page: \url{this https URL}.
+
+
+
+ 108. 【2410.06154】GLOV: Guided Large Language Models as Implicit Optimizers for Vision Language Models
+ 链接:https://arxiv.org/abs/2410.06154
+ 作者:M. Jehanzeb Mirza,Mengjie Zhao,Zhuoyuan Mao,Sivan Doveh,Wei Lin,Paul Gavrikov,Michael Dorkenwald,Shiqi Yang,Saurav Jha,Hiromi Wakaki,Yuki Mitsufuji,Horst Possegger,Rogerio Feris,Leonid Karlinsky,James Glass
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:enabling Large Language, Large Language Models, enabling Large, implicit Optimizers, Optimizers for Vision-Langugage
+ 备注: Code: [this https URL](https://github.com/jmiemirza/GLOV)
+
+ 点击查看摘要
+ Abstract:In this work, we propose a novel method (GLOV) enabling Large Language Models (LLMs) to act as implicit Optimizers for Vision-Langugage Models (VLMs) to enhance downstream vision tasks. Our GLOV meta-prompts an LLM with the downstream task description, querying it for suitable VLM prompts (e.g., for zero-shot classification with CLIP). These prompts are ranked according to a purity measure obtained through a fitness function. In each respective optimization step, the ranked prompts are fed as in-context examples (with their accuracies) to equip the LLM with the knowledge of the type of text prompts preferred by the downstream VLM. Furthermore, we also explicitly steer the LLM generation process in each optimization step by specifically adding an offset difference vector of the embeddings from the positive and negative solutions found by the LLM, in previous optimization steps, to the intermediate layer of the network for the next generation step. This offset vector steers the LLM generation toward the type of language preferred by the downstream VLM, resulting in enhanced performance on the downstream vision tasks. We comprehensively evaluate our GLOV on 16 diverse datasets using two families of VLMs, i.e., dual-encoder (e.g., CLIP) and encoder-decoder (e.g., LLaVa) models -- showing that the discovered solutions can enhance the recognition performance by up to 15.0% and 57.5% (3.8% and 21.6% on average) for these models.
+
+
+
+ 109. 【2410.06149】oward Scalable Image Feature Compression: A Content-Adaptive and Diffusion-Based Approach
+ 链接:https://arxiv.org/abs/2410.06149
+ 作者:Sha Guo,Zhuo Chen,Yang Zhao,Ning Zhang,Xiaotong Li,Lingyu Duan
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM); Image and Video Processing (eess.IV)
+ 关键词:emphasize signal fidelity, Traditional image codecs, codecs emphasize signal, machine vision tasks, machine vision
+ 备注:
+
+ 点击查看摘要
+ Abstract:Traditional image codecs emphasize signal fidelity and human perception, often at the expense of machine vision tasks. Deep learning methods have demonstrated promising coding performance by utilizing rich semantic embeddings optimized for both human and machine vision. However, these compact embeddings struggle to capture fine details such as contours and textures, resulting in imperfect reconstructions. Furthermore, existing learning-based codecs lack scalability. To address these limitations, this paper introduces a content-adaptive diffusion model for scalable image compression. The proposed method encodes fine textures through a diffusion process, enhancing perceptual quality while preserving essential features for machine vision tasks. The approach employs a Markov palette diffusion model combined with widely used feature extractors and image generators, enabling efficient data compression. By leveraging collaborative texture-semantic feature extraction and pseudo-label generation, the method accurately captures texture information. A content-adaptive Markov palette diffusion model is then applied to represent both low-level textures and high-level semantic content in a scalable manner. This framework offers flexible control over compression ratios by selecting intermediate diffusion states, eliminating the need for retraining deep learning models at different operating points. Extensive experiments demonstrate the effectiveness of the proposed framework in both image reconstruction and downstream machine vision tasks such as object detection, segmentation, and facial landmark detection, achieving superior perceptual quality compared to state-of-the-art methods.
+
+
+
+ 110. 【2410.06140】Estimating the Number of HTTP/3 Responses in QUIC Using Deep Learning
+ 链接:https://arxiv.org/abs/2410.06140
+ 作者:Barak Gahtan,Robert J. Shahla,Reuven Cohen,Alex M. Bronstein
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Networking and Internet Architecture (cs.NI)
+ 关键词:enhances TCP, TCP by providing, transport protocol, providing better security, stream multiplexing
+ 备注: arXiv admin note: substantial text overlap with [arXiv:2410.03728](https://arxiv.org/abs/2410.03728)
+
+ 点击查看摘要
+ Abstract:QUIC, a new and increasingly used transport protocol, enhances TCP by providing better security, performance, and features like stream multiplexing. These features, however, also impose challenges for network middle-boxes that need to monitor and analyze web traffic. This paper proposes a novel solution for estimating the number of HTTP/3 responses in a given QUIC connection by an observer. This estimation reveals server behavior, client-server interactions, and data transmission efficiency, which is crucial for various applications such as designing a load balancing solution and detecting HTTP/3 flood attacks. The proposed scheme transforms QUIC connection traces into a sequence of images and trains machine learning (ML) models to predict the number of responses. Then, by aggregating images of a QUIC connection, an observer can estimate the total number of responses. As the problem is formulated as a discrete regression problem, we introduce a dedicated loss function. The proposed scheme is evaluated on a dataset of over seven million images, generated from $100,000$ traces collected from over $44,000$ websites over a four-month period, from various vantage points. The scheme achieves up to 97\% cumulative accuracy in both known and unknown web server settings and 92\% accuracy in estimating the total number of responses in unseen QUIC traces.
+
+
+
+ 111. 【2410.06134】Adaptive Label Smoothing for Out-of-Distribution Detection
+ 链接:https://arxiv.org/abs/2410.06134
+ 作者:Mingle Xu,Jaehwan Lee,Sook Yoon,Dong Sun Park
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:increasing attention recently, received increasing attention, distinguish unknown classes, OOD detection, attention recently
+ 备注:
+
+ 点击查看摘要
+ Abstract:Out-of-distribution (OOD) detection, which aims to distinguish unknown classes from known classes, has received increasing attention recently. A main challenge within is the unavailable of samples from the unknown classes in the training process, and an effective strategy is to improve the performance for known classes. Using beneficial strategies such as data augmentation and longer training is thus a way to improve OOD detection. However, label smoothing, an effective method for classifying known classes, degrades the performance of OOD detection, and this phenomenon is under exploration. In this paper, we first analyze that the limited and predefined learning target in label smoothing results in the smaller maximal probability and logit, which further leads to worse OOD detection performance. To mitigate this issue, we then propose a novel regularization method, called adaptive label smoothing (ALS), and the core is to push the non-true classes to have same probabilities whereas the maximal probability is neither fixed nor limited. Extensive experimental results in six datasets with two backbones suggest that ALS contributes to classifying known samples and discerning unknown samples with clear margins. Our code will be available to the public.
+
+
+
+ 112. 【2410.06131】owards Unsupervised Eye-Region Segmentation for Eye Tracking
+ 链接:https://arxiv.org/abs/2410.06131
+ 作者:Jiangfan Deng,Zhuang Jia,Zhaoxue Wang,Xiang Long,Daniel K. Du
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:image-based eye tracking, key prerequisite, prerequisite for image-based, indispensable module, module in today
+ 备注: ECCV2024 ICVSE workshop
+
+ 点击查看摘要
+ Abstract:Finding the eye and parsing out the parts (e.g. pupil and iris) is a key prerequisite for image-based eye tracking, which has become an indispensable module in today's head-mounted VR/AR devices. However, a typical route for training a segmenter requires tedious handlabeling. In this work, we explore an unsupervised way. First, we utilize priors of human eye and extract signals from the image to establish rough clues indicating the eye-region structure. Upon these sparse and noisy clues, a segmentation network is trained to gradually identify the precise area for each part. To achieve accurate parsing of the eye-region, we first leverage the pretrained foundation model Segment Anything (SAM) in an automatic way to refine the eye indications. Then, the learning process is designed in an end-to-end manner following progressive and prior-aware principle. Experiments show that our unsupervised approach can easily achieve 90% (the pupil and iris) and 85% (the whole eye-region) of the performances under supervised learning.
+
+
+
+ 113. 【2410.06126】$\textit{X}^2$-DFD: A framework for e${X}$plainable and e${X}$tendable Deepfake Detection
+ 链接:https://arxiv.org/abs/2410.06126
+ 作者:Yize Chen,Zhiyuan Yan,Siwei Lyu,Baoyuan Wu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Detecting deepfakes, features, Detecting, detection, module
+ 备注:
+
+ 点击查看摘要
+ Abstract:Detecting deepfakes has become an important task. Most existing detection methods provide only real/fake predictions without offering human-comprehensible explanations. Recent studies leveraging MLLMs for deepfake detection have shown improvements in explainability. However, the performance of pre-trained MLLMs (e.g., LLaVA) remains limited due to a lack of understanding of their capabilities for this task and strategies to enhance them. In this work, we empirically assess the strengths and weaknesses of MLLMs specifically in deepfake detection via forgery features analysis. Building on these assessments, we propose a novel framework called ${X}^2$-DFD, consisting of three core modules. The first module, Model Feature Assessment (MFA), measures the detection capabilities of forgery features intrinsic to MLLMs, and gives a descending ranking of these features. The second module, Strong Feature Strengthening (SFS), enhances the detection and explanation capabilities by fine-tuning the MLLM on a dataset constructed based on the top-ranked features. The third module, Weak Feature Supplementing (WFS), improves the fine-tuned MLLM's capabilities on lower-ranked features by integrating external dedicated deepfake detectors. To verify the effectiveness of this framework, we further present a practical implementation, where an automated forgery features generation, evaluation, and ranking procedure is designed for MFA module; an automated generation procedure of the fine-tuning dataset containing real and fake images with explanations based on top-ranked features is developed for SFS model; an external conventional deepfake detector focusing on blending artifact, which corresponds to a low detection capability in the pre-trained MLLM, is integrated for WFS module. Experiments show that our approach enhances both detection and explanation performance.
+
+
+
+ 114. 【2410.06124】Learning AND-OR Templates for Professional Photograph Parsing and Guidance
+ 链接:https://arxiv.org/abs/2410.06124
+ 作者:Xin Jin,Liaoruxing Zhang,Chenyu Fan,Wenbo Yuan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:stylized photography works, visual styles summarized, photography, series of themed, themed and stylized
+ 备注:
+
+ 点击查看摘要
+ Abstract:Since the development of photography art, many so-called "templates" have been formed, namely visual styles summarized from a series of themed and stylized photography works. In this paper, we propose to analysize and and summarize these 'templates' in photography by learning composite templates of photography images. We present a framework for learning a hierarchical reconfigurable image template from photography images to learn and characterize the "templates" used in these photography images. Using this method, we measured the artistic quality of photography on the photos and conducted photography guidance. In addition, we also utilized the "templates" for guidance in several image generation tasks. Experimental results show that the learned templates can well describe the photography techniques and styles, whereas the proposed approach can assess the quality of photography images as human being does.
+
+
+
+ 115. 【2410.06114】UnSeGArmaNet: Unsupervised Image Segmentation using Graph Neural Networks with Convolutional ARMA Filters
+ 链接:https://arxiv.org/abs/2410.06114
+ 作者:Kovvuri Sai Gopal Reddy,Bodduluri Saran,A. Mudit Adityaja,Saurabh J. Shigwan,Nitin Kumar,Snehasis Mukherjee
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:medical image segmentation, supervised classification drives, image segmentation datasets, image segmentation, data-hungry approach
+ 备注: Accepted at BMVC-2024. arXiv admin note: text overlap with [arXiv:2405.06057](https://arxiv.org/abs/2405.06057)
+
+ 点击查看摘要
+ Abstract:The data-hungry approach of supervised classification drives the interest of the researchers toward unsupervised approaches, especially for problems such as medical image segmentation, where labeled data are difficult to get. Motivated by the recent success of Vision transformers (ViT) in various computer vision tasks, we propose an unsupervised segmentation framework with a pre-trained ViT. Moreover, by harnessing the graph structure inherent within the image, the proposed method achieves a notable performance in segmentation, especially in medical images. We further introduce a modularity-based loss function coupled with an Auto-Regressive Moving Average (ARMA) filter to capture the inherent graph topology within the image. Finally, we observe that employing Scaled Exponential Linear Unit (SELU) and SILU (Swish) activation functions within the proposed Graph Neural Network (GNN) architecture enhances the performance of segmentation. The proposed method provides state-of-the-art performance (even comparable to supervised methods) on benchmark image segmentation datasets such as ECSSD, DUTS, and CUB, as well as challenging medical image segmentation datasets such as KVASIR, CVC-ClinicDB, ISIC-2018. The github repository of the code is available on \url{this https URL}.
+
+
+
+ 116. 【2410.06104】RefineStyle: Dynamic Convolution Refinement for StyleGAN
+ 链接:https://arxiv.org/abs/2410.06104
+ 作者:Siwei Xia,Xueqi Hu,Li Sun,Qingli Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:static parameters shared, dynamic modulation factors, modulation factors, static parameters, parameters shared
+ 备注: Accepted by PRCV2024
+
+ 点击查看摘要
+ Abstract:In StyleGAN, convolution kernels are shaped by both static parameters shared across images and dynamic modulation factors $w^+\in\mathcal{W}^+$ specific to each image. Therefore, $\mathcal{W}^+$ space is often used for image inversion and editing. However, pre-trained model struggles with synthesizing out-of-domain images due to the limited capabilities of $\mathcal{W}^+$ and its resultant kernels, necessitating full fine-tuning or adaptation through a complex hypernetwork. This paper proposes an efficient refining strategy for dynamic kernels. The key idea is to modify kernels by low-rank residuals, learned from input image or domain guidance. These residuals are generated by matrix multiplication between two sets of tokens with the same number, which controls the complexity. We validate the refining scheme in image inversion and domain adaptation. In the former task, we design grouped transformer blocks to learn these token sets by one- or two-stage training. In the latter task, token sets are directly optimized to support synthesis in the target domain while preserving original content. Extensive experiments show that our method achieves low distortions for image inversion and high quality for out-of-domain editing.
+
+
+
+ 117. 【2410.06067】Contrastive Learning to Fine-Tune Feature Extraction Models for the Visual Cortex
+ 链接:https://arxiv.org/abs/2410.06067
+ 作者:Alex Mulrooney,Austin J. Brockmeier
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:cortex requires extracting, requires extracting relevant, extracting relevant features, visual cortex requires, Predicting the neural
+ 备注:
+
+ 点击查看摘要
+ Abstract:Predicting the neural response to natural images in the visual cortex requires extracting relevant features from the images and relating those feature to the observed responses. In this work, we optimize the feature extraction in order to maximize the information shared between the image features and the neural response across voxels in a given region of interest (ROI) extracted from the BOLD signal measured by fMRI. We adapt contrastive learning (CL) to fine-tune a convolutional neural network, which was pretrained for image classification, such that a mapping of a given image's features are more similar to the corresponding fMRI response than to the responses to other images. We exploit the recently released Natural Scenes Dataset (Allen et al., 2022) as organized for the Algonauts Project (Gifford et al., 2023), which contains the high-resolution fMRI responses of eight subjects to tens of thousands of naturalistic images. We show that CL fine-tuning creates feature extraction models that enable higher encoding accuracy in early visual ROIs as compared to both the pretrained network and a baseline approach that uses a regression loss at the output of the network to tune it for fMRI response encoding. We investigate inter-subject transfer of the CL fine-tuned models, including subjects from another, lower-resolution dataset (Gong et al., 2023). We also pool subjects for fine-tuning to further improve the encoding performance. Finally, we examine the performance of the fine-tuned models on common image classification tasks, explore the landscape of ROI-specific models by applying dimensionality reduction on the Bhattacharya dissimilarity matrix created using the predictions on those tasks (Mao et al., 2024), and investigate lateralization of the processing for early visual ROIs using salience maps of the classifiers built on the CL-tuned models.
+
+
+
+ 118. 【2410.06055】AP-LDM: Attentive and Progressive Latent Diffusion Model for Training-Free High-Resolution Image Generation
+ 链接:https://arxiv.org/abs/2410.06055
+ 作者:Boyuan Cao,Jiaxin Ye,Yujie Wei,Hongming Shan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Stable Diffusion, Latent diffusion models, diffusion models, directly generating high-resolution, experience significant structural
+ 备注:
+
+ 点击查看摘要
+ Abstract:Latent diffusion models (LDMs), such as Stable Diffusion, often experience significant structural distortions when directly generating high-resolution (HR) images that exceed their original training resolutions. A straightforward and cost-effective solution is to adapt pre-trained LDMs for HR image generation; however, existing methods often suffer from poor image quality and long inference time. In this paper, we propose an Attentive and Progressive LDM (AP-LDM), a novel, training-free framework aimed at enhancing HR image quality while accelerating the generation process. AP-LDM decomposes the denoising process of LDMs into two stages: (i) attentive training-resolution denoising, and (ii) progressive high-resolution denoising. The first stage generates a latent representation of a higher-quality training-resolution image through the proposed attentive guidance, which utilizes a novel parameter-free self-attention mechanism to enhance the structural consistency. The second stage progressively performs upsampling in pixel space, alleviating the severe artifacts caused by latent space upsampling. Leveraging the effective initialization from the first stage enables denoising at higher resolutions with significantly fewer steps, enhancing overall efficiency. Extensive experimental results demonstrate that AP-LDM significantly outperforms state-of-the-art methods, delivering up to a 5x speedup in HR image generation, thereby highlighting its substantial advantages for real-world applications. Code is available at this https URL.
+
+
+
+ 119. 【2410.06044】HyperDet: Generalizable Detection of Synthesized Images by Generating and Merging A Mixture of Hyper LoRAs
+ 链接:https://arxiv.org/abs/2410.06044
+ 作者:Huangsen Cao,Yongwei Wang,Yinfeng Liu,Sixian Zheng,Kangtao Lv,Zhimeng Zhang,Bo Zhang,Xin Ding,Fei Wu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:visually realistic images, underscoring the critical, real photos, diverse generative vision, emergence of diverse
+ 备注:
+
+ 点击查看摘要
+ Abstract:The emergence of diverse generative vision models has recently enabled the synthesis of visually realistic images, underscoring the critical need for effectively detecting these generated images from real photos. Despite advances in this field, existing detection approaches often struggle to accurately identify synthesized images generated by different generative models. In this work, we introduce a novel and generalizable detection framework termed HyperDet, which innovatively captures and integrates shared knowledge from a collection of functionally distinct and lightweight expert detectors. HyperDet leverages a large pretrained vision model to extract general detection features while simultaneously capturing and enhancing task-specific features. To achieve this, HyperDet first groups SRM filters into five distinct groups to efficiently capture varying levels of pixel artifacts based on their different functionality and complexity. Then, HyperDet utilizes a hypernetwork to generate LoRA model weights with distinct embedding parameters. Finally, we merge the LoRA networks to form an efficient model ensemble. Also, we propose a novel objective function that balances the pixel and semantic artifacts effectively. Extensive experiments on the UnivFD and Fake2M datasets demonstrate the effectiveness of our approach, achieving state-of-the-art performance. Moreover, our work paves a new way to establish generalizable domain-specific fake image detectors based on pretrained large vision models.
+
+
+
+ 120. 【2410.06041】Block Induced Signature Generative Adversarial Network (BISGAN): Signature Spoofing Using GANs and Their Evaluation
+ 链接:https://arxiv.org/abs/2410.06041
+ 作者:Haadia Amjad,Kilian Goeller,Steffen Seitz,Carsten Knoll,Naseer Bajwa,Muhammad Imran Malik,Ronald Tetzlaff
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:develop efficient identification, Deep learning, learning is actively, develop efficient, efficient identification
+ 备注:
+
+ 点击查看摘要
+ Abstract:Deep learning is actively being used in biometrics to develop efficient identification and verification systems. Handwritten signatures are a common subset of biometric data for authentication purposes. Generative adversarial networks (GANs) learn from original and forged signatures to generate forged signatures. While most GAN techniques create a strong signature verifier, which is the discriminator, there is a need to focus more on the quality of forgeries generated by the generator model. This work focuses on creating a generator that produces forged samples that achieve a benchmark in spoofing signature verification systems. We use CycleGANs infused with Inception model-like blocks with attention heads as the generator and a variation of the SigCNN model as the base Discriminator. We train our model with a new technique that results in 80% to 100% success in signature spoofing. Additionally, we create a custom evaluation technique to act as a goodness measure of the generated forgeries. Our work advocates generator-focused GAN architectures for spoofing data quality that aid in a better understanding of biometric data generation and evaluation.
+
+
+
+ 121. 【2410.06028】SpecTrack: Learned Multi-Rotation Tracking via Speckle Imaging
+ 链接:https://arxiv.org/abs/2410.06028
+ 作者:Ziyang Chen,Mustafa Doğa Doğan,Josef Spjut,Kaan Akşit
+ 类目:Emerging Technologies (cs.ET); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Virtual Reality, accurate positioning information, ensuring accurate positioning, personal fabrication, positioning information
+ 备注:
+
+ 点击查看摘要
+ Abstract:Precision pose detection is increasingly demanded in fields such as personal fabrication, Virtual Reality (VR), and robotics due to its critical role in ensuring accurate positioning information. However, conventional vision-based systems used in these systems often struggle with achieving high precision and accuracy, particularly when dealing with complex environments or fast-moving objects. To address these limitations, we investigate Laser Speckle Imaging (LSI), an emerging optical tracking method that offers promising potential for improving pose estimation accuracy. Specifically, our proposed LSI-Based Tracking (SpecTrack) leverages the captures from a lensless camera and a retro-reflector marker with a coded aperture to achieve multi-axis rotational pose estimation with high precision. Our extensive trials using our in-house built testbed have shown that SpecTrack achieves an accuracy of 0.31° (std=0.43°), significantly outperforming state-of-the-art approaches and improving accuracy up to 200%.
+
+
+
+ 122. 【2410.06025】Sparse Repellency for Shielded Generation in Text-to-image Diffusion Models
+ 链接:https://arxiv.org/abs/2410.06025
+ 作者:Michael Kirchhof,James Thornton,Pierre Ablin,Louis Béthune,Eugene Ndiaye,Marco Cuturi
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Machine Learning (stat.ML)
+ 关键词:increased adoption, diffusion models, images, set, models
+ 备注:
+
+ 点击查看摘要
+ Abstract:The increased adoption of diffusion models in text-to-image generation has triggered concerns on their reliability. Such models are now closely scrutinized under the lens of various metrics, notably calibration, fairness, or compute efficiency. We focus in this work on two issues that arise when deploying these models: a lack of diversity when prompting images, and a tendency to recreate images from the training set. To solve both problems, we propose a method that coaxes the sampled trajectories of pretrained diffusion models to land on images that fall outside of a reference set. We achieve this by adding repellency terms to the diffusion SDE throughout the generation trajectory, which are triggered whenever the path is expected to land too closely to an image in the shielded reference set. Our method is sparse in the sense that these repellency terms are zero and inactive most of the time, and even more so towards the end of the generation trajectory. Our method, named SPELL for sparse repellency, can be used either with a static reference set that contains protected images, or dynamically, by updating the set at each timestep with the expected images concurrently generated within a batch. We show that adding SPELL to popular diffusion models improves their diversity while impacting their FID only marginally, and performs comparatively better than other recent training-free diversity methods. We also demonstrate how SPELL can ensure a shielded generation away from a very large set of protected images by considering all 1.2M images from ImageNet as the protected set.
+
+
+
+ 123. 【2410.06020】QT-DoG: Quantization-aware Training for Domain Generalization
+ 链接:https://arxiv.org/abs/2410.06020
+ 作者:Saqib Javed,Hieu Le,Mathieu Salzmann
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:unseen target data, target data distributions, Domain Generalization, aims to train, unseen target
+ 备注: Code will be released soon
+
+ 点击查看摘要
+ Abstract:Domain Generalization (DG) aims to train models that perform well not only on the training (source) domains but also on novel, unseen target data distributions. A key challenge in DG is preventing overfitting to source domains, which can be mitigated by finding flatter minima in the loss landscape. In this work, we propose Quantization-aware Training for Domain Generalization (QT-DoG) and demonstrate that weight quantization effectively leads to flatter minima in the loss landscape, thereby enhancing domain generalization. Unlike traditional quantization methods focused on model compression, QT-DoG exploits quantization as an implicit regularizer by inducing noise in model weights, guiding the optimization process toward flatter minima that are less sensitive to perturbations and overfitting. We provide both theoretical insights and empirical evidence demonstrating that quantization inherently encourages flatter minima, leading to better generalization across domains. Moreover, with the benefit of reducing the model size through quantization, we demonstrate that an ensemble of multiple quantized models further yields superior accuracy than the state-of-the-art DG approaches with no computational or memory overheads. Our extensive experiments demonstrate that QT-DoG generalizes across various datasets, architectures, and quantization algorithms, and can be combined with other DG methods, establishing its versatility and robustness.
+
+
+
+ 124. 【2410.06014】SplaTraj: Camera Trajectory Generation with Semantic Gaussian Splatting
+ 链接:https://arxiv.org/abs/2410.06014
+ 作者:Xinyi Liu,Tianyi Zhang,Matthew Johnson-Roberson,Weiming Zhi
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:photorealistic Gaussian Splatting, Gaussian Splatting models, recent developments, developments for robots, robots to represent
+ 备注:
+
+ 点击查看摘要
+ Abstract:Many recent developments for robots to represent environments have focused on photorealistic reconstructions. This paper particularly focuses on generating sequences of images from the photorealistic Gaussian Splatting models, that match instructions that are given by user-inputted language. We contribute a novel framework, SplaTraj, which formulates the generation of images within photorealistic environment representations as a continuous-time trajectory optimization problem. Costs are designed so that a camera following the trajectory poses will smoothly traverse through the environment and render the specified spatial information in a photogenic manner. This is achieved by querying a photorealistic representation with language embedding to isolate regions that correspond to the user-specified inputs. These regions are then projected to the camera's view as it moves over time and a cost is constructed. We can then apply gradient-based optimization and differentiate through the rendering to optimize the trajectory for the defined cost. The resulting trajectory moves to photogenically view each of the specified objects. We empirically evaluate our approach on a suite of environments and instructions, and demonstrate the quality of generated image sequences.
+
+
+
+ 125. 【2410.06007】Motion Forecasting in Continuous Driving
+ 链接:https://arxiv.org/abs/2410.06007
+ 作者:Nan Song,Bozhou Zhang,Xiatian Zhu,Li Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:highly challenging due, highly challenging, challenging due, numerous possibilities, complex interactions
+ 备注: Accepted at NeurIPS 2024 Spotlight
+
+ 点击查看摘要
+ Abstract:Motion forecasting for agents in autonomous driving is highly challenging due to the numerous possibilities for each agent's next action and their complex interactions in space and time. In real applications, motion forecasting takes place repeatedly and continuously as the self-driving car moves. However, existing forecasting methods typically process each driving scene within a certain range independently, totally ignoring the situational and contextual relationships between successive driving scenes. This significantly simplifies the forecasting task, making the solutions suboptimal and inefficient to use in practice. To address this fundamental limitation, we propose a novel motion forecasting framework for continuous driving, named RealMotion. It comprises two integral streams both at the scene level: (1) The scene context stream progressively accumulates historical scene information until the present moment, capturing temporal interactive relationships among scene elements. (2) The agent trajectory stream optimizes current forecasting by sequentially relaying past predictions. Besides, a data reorganization strategy is introduced to narrow the gap between existing benchmarks and real-world applications, consistent with our network. These approaches enable exploiting more broadly the situational and progressive insights of dynamic motion across space and time. Extensive experiments on Argoverse series with different settings demonstrate that our RealMotion achieves state-of-the-art performance, along with the advantage of efficient real-world inference. The source code will be available at this https URL.
+
+
+
+ 126. 【2410.06001】apType: Ten-finger text entry on everyday surfaces via Bayesian inference
+ 链接:https://arxiv.org/abs/2410.06001
+ 作者:Paul Streli,Jiaxi Jiang,Andreas Fender,Manuel Meier,Hugo Romat,Christian Holz
+ 类目:Human-Computer Interaction (cs.HC); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:physical keyboards remains, advent of touchscreens, remains most efficient, efficient for entering, full-size typing
+ 备注: In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems
+
+ 点击查看摘要
+ Abstract:Despite the advent of touchscreens, typing on physical keyboards remains most efficient for entering text, because users can leverage all fingers across a full-size keyboard for convenient typing. As users increasingly type on the go, text input on mobile and wearable devices has had to compromise on full-size typing. In this paper, we present TapType, a mobile text entry system for full-size typing on passive surfaces--without an actual keyboard. From the inertial sensors inside a band on either wrist, TapType decodes and relates surface taps to a traditional QWERTY keyboard layout. The key novelty of our method is to predict the most likely character sequences by fusing the finger probabilities from our Bayesian neural network classifier with the characters' prior probabilities from an n-gram language model. In our online evaluation, participants on average typed 19 words per minute with a character error rate of 0.6% after 30 minutes of training. Expert typists thereby consistently achieved more than 25 WPM at a similar error rate. We demonstrate applications of TapType in mobile use around smartphones and tablets, as a complement to interaction in situated Mixed Reality outside visual control, and as an eyes-free mobile text input method using an audio feedback-only interface.
+
+
+
+ 127. 【2410.05993】Aria: An Open Multimodal Native Mixture-of-Experts Model
+ 链接:https://arxiv.org/abs/2410.05993
+ 作者:Dongxu Li,Yudong Liu,Haoning Wu,Yue Wang,Zhiqi Shen,Bowen Qu,Xinyao Niu,Guoyin Wang,Bei Chen,Junnan Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:diverse modalities, Multimodal native, Multimodal, Aria, integrate real-world information
+ 备注:
+
+ 点击查看摘要
+ Abstract:Information comes in diverse modalities. Multimodal native AI models are essential to integrate real-world information and deliver comprehensive understanding. While proprietary multimodal native models exist, their lack of openness imposes obstacles for adoptions, let alone adaptations. To fill this gap, we introduce Aria, an open multimodal native model with best-in-class performance across a wide range of multimodal, language, and coding tasks. Aria is a mixture-of-expert model with 3.9B and 3.5B activated parameters per visual token and text token, respectively. It outperforms Pixtral-12B and Llama3.2-11B, and is competitive against the best proprietary models on various multimodal tasks. We pre-train Aria from scratch following a 4-stage pipeline, which progressively equips the model with strong capabilities in language understanding, multimodal understanding, long context window, and instruction following. We open-source the model weights along with a codebase that facilitates easy adoptions and adaptations of Aria in real-world applications.
+
+
+
+ 128. 【2410.05991】Vector Grimoire: Codebook-based Shape Generation under Raster Image Supervision
+ 链接:https://arxiv.org/abs/2410.05991
+ 作者:Moritz Feuerpfeil,Marco Cipriano,Gerard de Melo
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Graphics (cs.GR)
+ 关键词:Scalable Vector Graphics, Scalable Vector, design industry, popular format, Vector Graphics
+ 备注:
+
+ 点击查看摘要
+ Abstract:Scalable Vector Graphics (SVG) is a popular format on the web and in the design industry. However, despite the great strides made in generative modeling, SVG has remained underexplored due to the discrete and complex nature of such data. We introduce GRIMOIRE, a text-guided SVG generative model that is comprised of two modules: A Visual Shape Quantizer (VSQ) learns to map raster images onto a discrete codebook by reconstructing them as vector shapes, and an Auto-Regressive Transformer (ART) models the joint probability distribution over shape tokens, positions and textual descriptions, allowing us to generate vector graphics from natural language. Unlike existing models that require direct supervision from SVG data, GRIMOIRE learns shape image patches using only raster image supervision which opens up vector generative modeling to significantly more data. We demonstrate the effectiveness of our method by fitting GRIMOIRE for closed filled shapes on the MNIST and for outline strokes on icon and font data, surpassing previous image-supervised methods in generative quality and vector-supervised approach in flexibility.
+
+
+
+ 129. 【2410.05984】Are Minimal Radial Distortion Solvers Necessary for Relative Pose Estimation?
+ 链接:https://arxiv.org/abs/2410.05984
+ 作者:Charalambos Tzamos,Viktor Kocur,Yaqing Ding,Torsten Sattler,Zuzana Kukelova
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:radial distortion, Estimating the relative, relative pose, distortion, radial distortion solvers
+ 备注:
+
+ 点击查看摘要
+ Abstract:Estimating the relative pose between two cameras is a fundamental step in many applications such as Structure-from-Motion. The common approach to relative pose estimation is to apply a minimal solver inside a RANSAC loop. Highly efficient solvers exist for pinhole cameras. Yet, (nearly) all cameras exhibit radial distortion. Not modeling radial distortion leads to (significantly) worse results. However, minimal radial distortion solvers are significantly more complex than pinhole solvers, both in terms of run-time and implementation efforts. This paper compares radial distortion solvers with a simple-to-implement approach that combines an efficient pinhole solver with sampled radial distortion parameters. Extensive experiments on multiple datasets and RANSAC variants show that this simple approach performs similarly or better than the most accurate minimal distortion solvers at faster run-times while being significantly more accurate than faster non-minimal solvers. We clearly show that complex radial distortion solvers are not necessary in practice. Code and benchmark are available at this https URL.
+
+
+
+ 130. 【2410.05982】DeMo: Decoupling Motion Forecasting into Directional Intentions and Dynamic States
+ 链接:https://arxiv.org/abs/2410.05982
+ 作者:Bozhou Zhang,Nan Song,Li Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:autonomous driving systems, dynamically changing environments, Accurate motion forecasting, changing environments, Accurate motion
+ 备注: NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:Accurate motion forecasting for traffic agents is crucial for ensuring the safety and efficiency of autonomous driving systems in dynamically changing environments. Mainstream methods adopt a one-query-one-trajectory paradigm, where each query corresponds to a unique trajectory for predicting multi-modal trajectories. While straightforward and effective, the absence of detailed representation of future trajectories may yield suboptimal outcomes, given that the agent states dynamically evolve over time. To address this problem, we introduce DeMo, a framework that decouples multi-modal trajectory queries into two types: mode queries capturing distinct directional intentions and state queries tracking the agent's dynamic states over time. By leveraging this format, we separately optimize the multi-modality and dynamic evolutionary properties of trajectories. Subsequently, the mode and state queries are integrated to obtain a comprehensive and detailed representation of the trajectories. To achieve these operations, we additionally introduce combined Attention and Mamba techniques for global information aggregation and state sequence modeling, leveraging their respective strengths. Extensive experiments on both the Argoverse 2 and nuScenes benchmarks demonstrate that our DeMo achieves state-of-the-art performance in motion forecasting.
+
+
+
+ 131. 【2410.05970】PDF-WuKong: A Large Multimodal Model for Efficient Long PDF Reading with End-to-End Sparse Sampling
+ 链接:https://arxiv.org/abs/2410.05970
+ 作者:Xudong Xie,Liang Yin,Hao Yan,Yang Liu,Jing Ding,Minghui Liao,Yuliang Liu,Wei Chen,Xiang Bai
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:comprehend large amounts, long PDF documents, visual information, Large Language, process and comprehend
+ 备注:
+
+ 点击查看摘要
+ Abstract:Document understanding is a challenging task to process and comprehend large amounts of textual and visual information. Recent advances in Large Language Models (LLMs) have significantly improved the performance of this task. However, existing methods typically focus on either plain text or a limited number of document images, struggling to handle long PDF documents with interleaved text and images, especially in academic papers. In this paper, we introduce PDF-WuKong, a multimodal large language model (MLLM) which is designed to enhance multimodal question-answering (QA) for long PDF documents. PDF-WuKong incorporates a sparse sampler that operates on both text and image representations, significantly improving the efficiency and capability of the MLLM. The sparse sampler is integrated with the MLLM's image encoder and selects the paragraphs or diagrams most pertinent to user queries for processing by the language model. To effectively train and evaluate our model, we construct PaperPDF, a dataset consisting of a broad collection of academic papers sourced from arXiv, multiple strategies are proposed to generate automatically 1M QA pairs along with their corresponding evidence sources. Experimental results demonstrate the superiority and high efficiency of our approach over other models on the task of long multimodal PDF understanding, surpassing proprietary products by an average of 8.6% on F1. Our code and dataset will be released at this https URL.
+
+
+
+ 132. 【2410.05969】Deep neural network-based detection of counterfeit products from smartphone images
+ 链接:https://arxiv.org/abs/2410.05969
+ 作者:Hugo Garcia-Cotte,Dorra Mellouli,Abdul Rehman,Li Wang,David G. Stork
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:represent significant direct, significant direct losses, Counterfeit products, high-fashion handbags, represent significant
+ 备注:
+
+ 点击查看摘要
+ Abstract:Counterfeit products such as drugs and vaccines as well as luxury items such as high-fashion handbags, watches, jewelry, garments, and cosmetics, represent significant direct losses of revenue to legitimate manufacturers and vendors, as well as indirect costs to societies at large. We present the world's first purely computer-vision-based system to combat such counterfeiting-one that does not require special security tags or other alterations to the products or modifications to supply chain tracking. Our deep neural network system shows high accuracy on branded garments from our first manufacturer tested (99.71% after 3.06% rejections) using images captured under natural, weakly controlled conditions, such as in retail stores, customs checkpoints, warehouses, and outdoors. Our system, suitably transfer trained on a small number of fake and genuine articles, should find application in additional product categories as well, for example fashion accessories, perfume boxes, medicines, and more.
+
+
+
+ 133. 【2410.05964】STNet: Deep Audio-Visual Fusion Network for Robust Speaker Tracking
+ 链接:https://arxiv.org/abs/2410.05964
+ 作者:Yidi Li,Hong Liu,Bing Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:speaker tracking aims, speaker tracking, Speaker Tracking Network, multi-sensor platform, aims to determine
+ 备注:
+
+ 点击查看摘要
+ Abstract:Audio-visual speaker tracking aims to determine the location of human targets in a scene using signals captured by a multi-sensor platform, whose accuracy and robustness can be improved by multi-modal fusion methods. Recently, several fusion methods have been proposed to model the correlation in multiple modalities. However, for the speaker tracking problem, the cross-modal interaction between audio and visual signals hasn't been well exploited. To this end, we present a novel Speaker Tracking Network (STNet) with a deep audio-visual fusion model in this work. We design a visual-guided acoustic measurement method to fuse heterogeneous cues in a unified localization space, which employs visual observations via a camera model to construct the enhanced acoustic map. For feature fusion, a cross-modal attention module is adopted to jointly model multi-modal contexts and interactions. The correlated information between audio and visual features is further interacted in the fusion model. Moreover, the STNet-based tracker is applied to multi-speaker cases by a quality-aware module, which evaluates the reliability of multi-modal observations to achieve robust tracking in complex scenarios. Experiments on the AV16.3 and CAV3D datasets show that the proposed STNet-based tracker outperforms uni-modal methods and state-of-the-art audio-visual speaker trackers.
+
+
+
+ 134. 【2410.05963】raining-Free Open-Ended Object Detection and Segmentation via Attention as Prompts
+ 链接:https://arxiv.org/abs/2410.05963
+ 作者:Zhiwei Lin,Yongtao Wang,Zhi Tang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Existing perception models, Existing perception, achieve great success, labeled data, object
+ 备注: Accepted by NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:Existing perception models achieve great success by learning from large amounts of labeled data, but they still struggle with open-world scenarios. To alleviate this issue, researchers introduce open-set perception tasks to detect or segment unseen objects in the training set. However, these models require predefined object categories as inputs during inference, which are not available in real-world scenarios. Recently, researchers pose a new and more practical problem, \textit{i.e.}, open-ended object detection, which discovers unseen objects without any object categories as inputs. In this paper, we present VL-SAM, a training-free framework that combines the generalized object recognition model (\textit{i.e.,} Vision-Language Model) with the generalized object localization model (\textit{i.e.,} Segment-Anything Model), to address the open-ended object detection and segmentation task. Without additional training, we connect these two generalized models with attention maps as the prompts. Specifically, we design an attention map generation module by employing head aggregation and a regularized attention flow to aggregate and propagate attention maps across all heads and layers in VLM, yielding high-quality attention maps. Then, we iteratively sample positive and negative points from the attention maps with a prompt generation module and send the sampled points to SAM to segment corresponding objects. Experimental results on the long-tail instance segmentation dataset (LVIS) show that our method surpasses the previous open-ended method on the object detection task and can provide additional instance segmentation masks. Besides, VL-SAM achieves favorable performance on the corner case object detection dataset (CODA), demonstrating the effectiveness of VL-SAM in real-world applications. Moreover, VL-SAM exhibits good model generalization that can incorporate various VLMs and SAMs.
+
+
+
+ 135. 【2410.05954】Pyramidal Flow Matching for Efficient Video Generative Modeling
+ 链接:https://arxiv.org/abs/2410.05954
+ 作者:Yang Jin,Zhicheng Sun,Ningyuan Li,Kun Xu,Kun Xu,Hao Jiang,Nan Zhuang,Quzhe Huang,Yang Song,Yadong Mu,Zhouchen Lin
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:vast spatiotemporal space, significant computational resources, demands significant computational, spatiotemporal space, data usage
+ 备注:
+
+ 点击查看摘要
+ Abstract:Video generation requires modeling a vast spatiotemporal space, which demands significant computational resources and data usage. To reduce the complexity, the prevailing approaches employ a cascaded architecture to avoid direct training with full resolution. Despite reducing computational demands, the separate optimization of each sub-stage hinders knowledge sharing and sacrifices flexibility. This work introduces a unified pyramidal flow matching algorithm. It reinterprets the original denoising trajectory as a series of pyramid stages, where only the final stage operates at the full resolution, thereby enabling more efficient video generative modeling. Through our sophisticated design, the flows of different pyramid stages can be interlinked to maintain continuity. Moreover, we craft autoregressive video generation with a temporal pyramid to compress the full-resolution history. The entire framework can be optimized in an end-to-end manner and with a single unified Diffusion Transformer (DiT). Extensive experiments demonstrate that our method supports generating high-quality 5-second (up to 10-second) videos at 768p resolution and 24 FPS within 20.7k A100 GPU training hours. All code and models will be open-sourced at this https URL.
+
+
+
+ 136. 【2410.05951】Hyper Adversarial Tuning for Boosting Adversarial Robustness of Pretrained Large Vision Models
+ 链接:https://arxiv.org/abs/2410.05951
+ 作者:Kangtao Lv,Huangsen Cao,Kainan Tu,Yihuai Xu,Zhimeng Zhang,Xin Ding,Yongwei Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Large vision models, Large vision, vision models, vision, adversarial
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large vision models have been found vulnerable to adversarial examples, emphasizing the need for enhancing their adversarial robustness. While adversarial training is an effective defense for deep convolutional models, it often faces scalability issues with large vision models due to high computational costs. Recent approaches propose robust fine-tuning methods, such as adversarial tuning of low-rank adaptation (LoRA) in large vision models, but they still struggle to match the accuracy of full parameter adversarial fine-tuning. The integration of various defense mechanisms offers a promising approach to enhancing the robustness of large vision models, yet this paradigm remains underexplored. To address this, we propose hyper adversarial tuning (HyperAT), which leverages shared defensive knowledge among different methods to improve model robustness efficiently and effectively simultaneously. Specifically, adversarial tuning of each defense method is formulated as a learning task, and a hypernetwork generates LoRA specific to this defense. Then, a random sampling and tuning strategy is proposed to extract and facilitate the defensive knowledge transfer between different defenses. Finally, diverse LoRAs are merged to enhance the adversarial robustness. Experiments on various datasets and model architectures demonstrate that HyperAT significantly enhances the adversarial robustness of pretrained large vision models without excessive computational overhead, establishing a new state-of-the-art benchmark.
+
+
+
+ 137. 【2410.05940】ouchInsight: Uncertainty-aware Rapid Touch and Text Input for Mixed Reality from Egocentric Vision
+ 链接:https://arxiv.org/abs/2410.05940
+ 作者:Paul Streli,Mark Richardson,Fadi Botros,Shugao Ma,Robert Wang,Christian Holz
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Human-Computer Interaction (cs.HC)
+ 关键词:offer numerous benefits, reliably detecting touch, passive surfaces offer, surfaces offer numerous, mixed reality
+ 备注: Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST'24)
+
+ 点击查看摘要
+ Abstract:While passive surfaces offer numerous benefits for interaction in mixed reality, reliably detecting touch input solely from head-mounted cameras has been a long-standing challenge. Camera specifics, hand self-occlusion, and rapid movements of both head and fingers introduce considerable uncertainty about the exact location of touch events. Existing methods have thus not been capable of achieving the performance needed for robust interaction. In this paper, we present a real-time pipeline that detects touch input from all ten fingers on any physical surface, purely based on egocentric hand tracking. Our method TouchInsight comprises a neural network to predict the moment of a touch event, the finger making contact, and the touch location. TouchInsight represents locations through a bivariate Gaussian distribution to account for uncertainties due to sensing inaccuracies, which we resolve through contextual priors to accurately infer intended user input. We first evaluated our method offline and found that it locates input events with a mean error of 6.3 mm, and accurately detects touch events (F1=0.99) and identifies the finger used (F1=0.96). In an online evaluation, we then demonstrate the effectiveness of our approach for a core application of dexterous touch input: two-handed text entry. In our study, participants typed 37.0 words per minute with an uncorrected error rate of 2.9% on average.
+
+
+
+ 138. 【2410.05938】EMMA: Empowering Multi-modal Mamba with Structural and Hierarchical Alignment
+ 链接:https://arxiv.org/abs/2410.05938
+ 作者:Yifei Xing,Xiangyuan Lan,Ruiping Wang,Dongmei Jiang,Wenjun Huang,Qingfang Zheng,Yaowei Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:sub-quadratic deployment speed, Empowering Multi-modal Mamba, deployment speed, architectures have shown, promising new direction
+ 备注:
+
+ 点击查看摘要
+ Abstract:Mamba-based architectures have shown to be a promising new direction for deep learning models owing to their competitive performance and sub-quadratic deployment speed. However, current Mamba multi-modal large language models (MLLM) are insufficient in extracting visual features, leading to imbalanced cross-modal alignment between visual and textural latents, negatively impacting performance on multi-modal tasks. In this work, we propose Empowering Multi-modal Mamba with Structural and Hierarchical Alignment (EMMA), which enables the MLLM to extract fine-grained visual information. Specifically, we propose a pixel-wise alignment module to autoregressively optimize the learning and processing of spatial image-level features along with textual tokens, enabling structural alignment at the image level. In addition, to prevent the degradation of visual information during the cross-model alignment process, we propose a multi-scale feature fusion (MFF) module to combine multi-scale visual features from intermediate layers, enabling hierarchical alignment at the feature level. Extensive experiments are conducted across a variety of multi-modal benchmarks. Our model shows lower latency than other Mamba-based MLLMs and is nearly four times faster than transformer-based MLLMs of similar scale during inference. Due to better cross-modal alignment, our model exhibits lower degrees of hallucination and enhanced sensitivity to visual details, which manifests in superior performance across diverse multi-modal benchmarks. Code will be provided.
+
+
+
+ 139. 【2410.05935】Learning Gaussian Data Augmentation in Feature Space for One-shot Object Detection in Manga
+ 链接:https://arxiv.org/abs/2410.05935
+ 作者:Takara Taniguchi,Ryosuke Furuta
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:one-shot object detection, Japanese Manga, object detection, tackle one-shot object, one-shot object
+ 备注: Accepted to ACM Multimedia Asia 2024
+
+ 点击查看摘要
+ Abstract:We tackle one-shot object detection in Japanese Manga. The rising global popularity of Japanese manga has made the object detection of character faces increasingly important, with potential applications such as automatic colorization. However, obtaining sufficient data for training conventional object detectors is challenging due to copyright restrictions. Additionally, new characters appear every time a new volume of manga is released, making it impractical to re-train object detectors each time to detect these new characters. Therefore, one-shot object detection, where only a single query (reference) image is required to detect a new character, is an essential task in the manga industry. One challenge with one-shot object detection in manga is the large variation in the poses and facial expressions of characters in target images, despite having only one query image as a reference. Another challenge is that the frequency of character appearances follows a long-tail distribution. To overcome these challenges, we propose a data augmentation method in feature space to increase the variation of the query. The proposed method augments the feature from the query by adding Gaussian noise, with the noise variance at each channel learned during training. The experimental results show that the proposed method improves the performance for both seen and unseen classes, surpassing data augmentation methods in image space.
+
+
+
+ 140. 【2410.05928】Beyond Captioning: Task-Specific Prompting for Improved VLM Performance in Mathematical Reasoning
+ 链接:https://arxiv.org/abs/2410.05928
+ 作者:Ayush Singh,Mansi Gupta,Shivank Garg,Abhinav Kumar,Vansh Agrawal
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Visual Question Answering, Question Answering, Visual Question, Vision-Language Models, tasks requiring visual
+ 备注:
+
+ 点击查看摘要
+ Abstract:Vision-Language Models (VLMs) have transformed tasks requiring visual and reasoning abilities, such as image retrieval and Visual Question Answering (VQA). Despite their success, VLMs face significant challenges with tasks involving geometric reasoning, algebraic problem-solving, and counting. These limitations stem from difficulties effectively integrating multiple modalities and accurately interpreting geometry-related tasks. Various works claim that introducing a captioning pipeline before VQA tasks enhances performance. We incorporated this pipeline for tasks involving geometry, algebra, and counting. We found that captioning results are not generalizable, specifically with larger VLMs primarily trained on downstream QnA tasks showing random performance on math-related challenges. However, we present a promising alternative: task-based prompting, enriching the prompt with task-specific guidance. This approach shows promise and proves more effective than direct captioning methods for math-heavy problems.
+
+
+
+ 141. 【2410.05915】Give me a hint: Can LLMs take a hint to solve math problems?
+ 链接:https://arxiv.org/abs/2410.05915
+ 作者:Vansh Agrawal,Pratham Singla,Amitoj Singh Miglani,Shivank Garg,Ayush Mangal
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:shown poor logical, basic mathematical reasoning, recent works, shown poor, poor logical
+ 备注:
+
+ 点击查看摘要
+ Abstract:While many state-of-the-art LLMs have shown poor logical and basic mathematical reasoning, recent works try to improve their problem-solving abilities using prompting techniques. We propose giving "hints" to improve the language model's performance on advanced mathematical problems, taking inspiration from how humans approach math pedagogically. We also test the model's adversarial robustness to wrong hints. We demonstrate the effectiveness of our approach by evaluating various LLMs, presenting them with a diverse set of problems of different difficulties and topics from the MATH dataset and comparing against techniques such as one-shot, few-shot, and chain of thought prompting.
+
+
+
+ 142. 【2410.05905】MedUniSeg: 2D and 3D Medical Image Segmentation via a Prompt-driven Universal Model
+ 链接:https://arxiv.org/abs/2410.05905
+ 作者:Yiwen Ye,Ziyang Chen,Jianpeng Zhang,Yutong Xie,Yong Xia
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:leveraging discrete annotations, offer significant potential, effectively leveraging discrete, models offer significant, segmentation models offer
+ 备注:
+
+ 点击查看摘要
+ Abstract:Universal segmentation models offer significant potential in addressing a wide range of tasks by effectively leveraging discrete annotations. As the scope of tasks and modalities expands, it becomes increasingly important to generate and strategically position task- and modal-specific priors within the universal model. However, existing universal models often overlook the correlations between different priors, and the optimal placement and frequency of these priors remain underexplored. In this paper, we introduce MedUniSeg, a prompt-driven universal segmentation model designed for 2D and 3D multi-task segmentation across diverse modalities and domains. MedUniSeg employs multiple modal-specific prompts alongside a universal task prompt to accurately characterize the modalities and tasks. To generate the related priors, we propose the modal map (MMap) and the fusion and selection (FUSE) modules, which transform modal and task prompts into corresponding priors. These modal and task priors are systematically introduced at the start and end of the encoding process. We evaluate MedUniSeg on a comprehensive multi-modal upstream dataset consisting of 17 sub-datasets. The results demonstrate that MedUniSeg achieves superior multi-task segmentation performance, attaining a 1.2% improvement in the mean Dice score across the 17 upstream tasks compared to nnUNet baselines, while using less than 1/10 of the parameters. For tasks that underperform during the initial multi-task joint training, we freeze MedUniSeg and introduce new modules to re-learn these tasks. This approach yields an enhanced version, MedUniSeg*, which consistently outperforms MedUniSeg across all tasks. Moreover, MedUniSeg surpasses advanced self-supervised and supervised pre-trained models on six downstream tasks, establishing itself as a high-quality, highly generalizable pre-trained segmentation model.
+
+
+
+ 143. 【2410.05900】MTFL: Multi-Timescale Feature Learning for Weakly-Supervised Anomaly Detection in Surveillance Videos
+ 链接:https://arxiv.org/abs/2410.05900
+ 作者:Yiling Zhang,Erkut Akdag,Egor Bondarev,Peter H. N. De With
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:fine-grained motion information, variable time-scales, contextual events, relevant for public, public safety
+ 备注:
+
+ 点击查看摘要
+ Abstract:Detection of anomaly events is relevant for public safety and requires a combination of fine-grained motion information and contextual events at variable time-scales. To this end, we propose a Multi-Timescale Feature Learning (MTFL) method to enhance the representation of anomaly features. Short, medium, and long temporal tubelets are employed to extract spatio-temporal video features using a Video Swin Transformer. Experimental results demonstrate that MTFL outperforms state-of-the-art methods on the UCF-Crime dataset, achieving an anomaly detection performance 89.78% AUC. Moreover, it performs complementary to SotA with 95.32% AUC on the ShanghaiTech and 84.57% AP on the XD-Violence dataset. Furthermore, we generate an extended dataset of the UCF-Crime for development and evaluation on a wider range of anomalies, namely Video Anomaly Detection Dataset (VADD), involving 2,591 videos in 18 classes with extensive coverage of realistic anomalies.
+
+
+
+ 144. 【2410.05869】Unobserved Object Detection using Generative Models
+ 链接:https://arxiv.org/abs/2410.05869
+ 作者:Subhransu S. Bhattacharjee,Dylan Campbell,Rahul Shome
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Robotics (cs.RO)
+ 关键词:unobserved object detection, object detection, object, unobserved object, object detection task
+ 备注: 16 pages; 41 figures
+
+ 点击查看摘要
+ Abstract:Can we detect an object that is not visible in an image? This study introduces the novel task of 2D and 3D unobserved object detection for predicting the location of objects that are occluded or lie outside the image frame. We adapt several state-of-the-art pre-trained generative models to solve this task, including 2D and 3D diffusion models and vision--language models, and show that they can be used to infer the presence of objects that are not directly observed. To benchmark this task, we propose a suite of metrics that captures different aspects of performance. Our empirical evaluations on indoor scenes from the RealEstate10k dataset with COCO object categories demonstrate results that motivate the use of generative models for the unobserved object detection task. The current work presents a promising step towards compelling applications like visual search and probabilistic planning that can leverage object detection beyond what can be directly observed.
+
+
+
+ 145. 【2410.05849】ModalPrompt:Dual-Modality Guided Prompt for Continual Learning of Large Multimodal Models
+ 链接:https://arxiv.org/abs/2410.05849
+ 作者:Fanhu Zeng,Fei Zhu,Haiyang Guo,Xu-Yao Zhang,Cheng-Lin Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Large Multimodal Models, exhibit remarkable multi-tasking, mixed datasets jointly, remarkable multi-tasking ability, Large Multimodal
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Multimodal Models (LMMs) exhibit remarkable multi-tasking ability by learning mixed datasets jointly. However, novel tasks would be encountered sequentially in dynamic world, and continually fine-tuning LMMs often leads to performance degrades. To handle the challenges of catastrophic forgetting, existing methods leverage data replay or model expansion, both of which are not specially developed for LMMs and have their inherent limitations. In this paper, we propose a novel dual-modality guided prompt learning framework (ModalPrompt) tailored for multimodal continual learning to effectively learn new tasks while alleviating forgetting of previous knowledge. Concretely, we learn prototype prompts for each task and exploit efficient prompt selection for task identifiers and prompt fusion for knowledge transfer based on image-text supervision. Extensive experiments demonstrate the superiority of our approach, e.g., ModalPrompt achieves +20% performance gain on LMMs continual learning benchmarks with $\times$ 1.42 inference speed refraining from growing training cost in proportion to the number of tasks. The code will be made publically available.
+
+
+
+ 146. 【2410.05820】IncSAR: A Dual Fusion Incremental Learning Framework for SAR Target Recognition
+ 链接:https://arxiv.org/abs/2410.05820
+ 作者:George Karantaidis,Athanasios Pantsios,Yiannis Kompatsiaris,Symeon Papadopoulos
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Synthetic Aperture Radar, Deep learning techniques, Aperture Radar, Synthetic Aperture, static scenarios relying
+ 备注:
+
+ 点击查看摘要
+ Abstract:Deep learning techniques have been successfully applied in Synthetic Aperture Radar (SAR) target recognition in static scenarios relying on predefined datasets. However, in real-world scenarios, models must incrementally learn new information without forgetting previously learned knowledge. Models' tendency to forget old knowledge when learning new tasks, known as catastrophic forgetting, remains an open challenge. In this paper, an incremental learning framework, called IncSAR, is proposed to mitigate catastrophic forgetting in SAR target recognition. IncSAR comprises a Vision Transformer (ViT) and a custom-designed Convolutional Neural Network (CNN) in individual branches combined through a late-fusion strategy. A denoising module, utilizing the properties of Robust Principal Component Analysis (RPCA), is introduced to alleviate the speckle noise present in SAR images. Moreover, a random projection layer is employed to enhance the linear separability of features, and a Linear Discriminant Analysis (LDA) approach is proposed to decorrelate the extracted class prototypes. Experimental results on the MSTAR and OpenSARShip benchmark datasets demonstrate that IncSAR outperforms state-of-the-art approaches, leading to an improvement from $98.05\%$ to $99.63\%$ in average accuracy and from $3.05\%$ to $0.33\%$ in performance dropping rate.
+
+
+
+ 147. 【2410.05814】CALoR: Towards Comprehensive Model Inversion Defense
+ 链接:https://arxiv.org/abs/2410.05814
+ 作者:Hongyao Yu,Yixiang Qiu,Hao Fang,Bin Chen,Sijin Yu,Bin Wang,Shu-Tao Xia,Ke Xu
+ 类目:Cryptography and Security (cs.CR); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:recovering privacy-sensitive training, privacy-sensitive training data, released machine learning, Deep Neural Networks, machine learning models
+ 备注: 26 pages
+
+ 点击查看摘要
+ Abstract:Model Inversion Attacks (MIAs) aim at recovering privacy-sensitive training data from the knowledge encoded in the released machine learning models. Recent advances in the MIA field have significantly enhanced the attack performance under multiple scenarios, posing serious privacy risks of Deep Neural Networks (DNNs). However, the development of defense strategies against MIAs is relatively backward to resist the latest MIAs and existing defenses fail to achieve further trade-off between model utility and model robustness. In this paper, we provide an in-depth analysis from the perspective of intrinsic vulnerabilities of MIAs, comprehensively uncovering the weaknesses inherent in the basic pipeline, which are partially investigated in the previous defenses. Building upon these new insights, we propose a robust defense mechanism, integrating Confidence Adaptation and Low-Rank compression(CALoR). Our method includes a novel robustness-enhanced classification loss specially-designed for model inversion defenses and reveals the extraordinary effectiveness of compressing the classification header. With CALoR, we can mislead the optimization objective, reduce the leaked information and impede the backpropagation of MIAs, thus mitigating the risk of privacy leakage. Extensive experimental results demonstrate that our method achieves state-of-the-art (SOTA) defense performance against MIAs and exhibits superior generalization to existing defenses across various scenarios.
+
+
+
+ 148. 【2410.05808】Vision Transformer based Random Walk for Group Re-Identification
+ 链接:https://arxiv.org/abs/2410.05808
+ 作者:Guoqing Zhang,Tianqi Liu,Wenxuan Fang,Yuhui Zheng
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:aims to match, involves the challenges, Group, Group re-identification, vision transformer based
+ 备注: 6 pages
+
+ 点击查看摘要
+ Abstract:Group re-identification (re-ID) aims to match groups with the same people under different cameras, mainly involves the challenges of group members and layout changes well. Most existing methods usually use the k-nearest neighbor algorithm to update node features to consider changes in group membership, but these methods cannot solve the problem of group layout changes. To this end, we propose a novel vision transformer based random walk framework for group re-ID. Specifically, we design a vision transformer based on a monocular depth estimation algorithm to construct a graph through the average depth value of pedestrian features to fully consider the impact of camera distance on group members relationships. In addition, we propose a random walk module to reconstruct the graph by calculating affinity scores between target and gallery images to remove pedestrians who do not belong to the current group. Experimental results show that our framework is superior to most methods.
+
+
+
+ 149. 【2410.05805】PostCast: Generalizable Postprocessing for Precipitation Nowcasting via Unsupervised Blurriness Modeling
+ 链接:https://arxiv.org/abs/2410.05805
+ 作者:Junchao Gong,Siwei Tu,Weidong Yang,Ben Fei,Kun Chen,Wenlong Zhang,Xiaokang Yang,Wanli Ouyang,Lei Bai
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:convective weather warnings, severe convective weather, Precipitation nowcasting plays, blurry predictions, socioeconomic sectors
+ 备注:
+
+ 点击查看摘要
+ Abstract:Precipitation nowcasting plays a pivotal role in socioeconomic sectors, especially in severe convective weather warnings. Although notable progress has been achieved by approaches mining the spatiotemporal correlations with deep learning, these methods still suffer severe blurriness as the lead time increases, which hampers accurate predictions for extreme precipitation. To alleviate blurriness, researchers explore generative methods conditioned on blurry predictions. However, the pairs of blurry predictions and corresponding ground truth need to be generated in advance, making the training pipeline cumbersome and limiting the generality of generative models within blur modes that appear in training data. By rethinking the blurriness in precipitation nowcasting as a blur kernel acting on predictions, we propose an unsupervised postprocessing method to eliminate the blurriness without the requirement of training with the pairs of blurry predictions and corresponding ground truth. Specifically, we utilize blurry predictions to guide the generation process of a pre-trained unconditional denoising diffusion probabilistic model (DDPM) to obtain high-fidelity predictions with eliminated blurriness. A zero-shot blur kernel estimation mechanism and an auto-scale denoise guidance strategy are introduced to adapt the unconditional DDPM to any blurriness modes varying from datasets and lead times in precipitation nowcasting. Extensive experiments are conducted on 7 precipitation radar datasets, demonstrating the generality and superiority of our method.
+
+
+
+ 150. 【2410.05804】CASA: Class-Agnostic Shared Attributes in Vision-Language Models for Efficient Incremental Object Detection
+ 链接:https://arxiv.org/abs/2410.05804
+ 作者:Mingyi Guo,Yuyang Liu,Zongying Lin,Peixi Peng,Yonghong Tian
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:include previously learned, Incremental object detection, background shift, background categories, vision-language foundation models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Incremental object detection (IOD) is challenged by background shift, where background categories in sequential data may include previously learned or future classes. Inspired by the vision-language foundation models such as CLIP, these models capture shared attributes from extensive image-text paired data during pre-training. We propose a novel method utilizing attributes in vision-language foundation models for incremental object detection. Our method constructs a Class-Agnostic Shared Attribute base (CASA) to capture common semantic information among incremental classes. Specifically, we utilize large language models to generate candidate textual attributes and select the most relevant ones based on current training data, recording their significance in an attribute assignment matrix. For subsequent tasks, we freeze the retained attributes and continue selecting from the remaining candidates while updating the attribute assignment matrix accordingly. Furthermore, we employ OWL-ViT as our baseline, preserving the original parameters of the pre-trained foundation model. Our method adds only 0.7% to parameter storage through parameter-efficient fine-tuning to significantly enhance the scalability and adaptability of IOD. Extensive two-phase and multi-phase experiments on the COCO dataset demonstrate the state-of-the-art performance of our proposed method.
+
+
+
+ 151. 【2410.05800】Core Tokensets for Data-efficient Sequential Training of Transformers
+ 链接:https://arxiv.org/abs/2410.05800
+ 作者:Subarnaduti Paul,Manuel Brack,Patrick Schramowski,Kristian Kersting,Martin Mundt
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Deep networks, ongoing data streams, networks are frequently, frequently tuned, tasks and continue
+ 备注:
+
+ 点击查看摘要
+ Abstract:Deep networks are frequently tuned to novel tasks and continue learning from ongoing data streams. Such sequential training requires consolidation of new and past information, a challenge predominantly addressed by retaining the most important data points - formally known as coresets. Traditionally, these coresets consist of entire samples, such as images or sentences. However, recent transformer architectures operate on tokens, leading to the famous assertion that an image is worth 16x16 words. Intuitively, not all of these tokens are equally informative or memorable. Going beyond coresets, we thus propose to construct a deeper-level data summary on the level of tokens. Our respectively named core tokensets both select the most informative data points and leverage feature attribution to store only their most relevant features. We demonstrate that core tokensets yield significant performance retention in incremental image classification, open-ended visual question answering, and continual image captioning with significantly reduced memory. In fact, we empirically find that a core tokenset of 1\% of the data performs comparably to at least a twice as large and up to 10 times larger coreset.
+
+
+
+ 152. 【2410.05799】SeeClear: Semantic Distillation Enhances Pixel Condensation for Video Super-Resolution
+ 链接:https://arxiv.org/abs/2410.05799
+ 作者:Qi Tang,Yao Zhao,Meiqin Liu,Chao Yao
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:generating perceptually realistic, perceptually realistic videos, Diffusion-based Video Super-Resolution, maintaining detail consistency, stochastic fluctuations
+ 备注: Accepted to NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:Diffusion-based Video Super-Resolution (VSR) is renowned for generating perceptually realistic videos, yet it grapples with maintaining detail consistency across frames due to stochastic fluctuations. The traditional approach of pixel-level alignment is ineffective for diffusion-processed frames because of iterative disruptions. To overcome this, we introduce SeeClear--a novel VSR framework leveraging conditional video generation, orchestrated by instance-centric and channel-wise semantic controls. This framework integrates a Semantic Distiller and a Pixel Condenser, which synergize to extract and upscale semantic details from low-resolution frames. The Instance-Centric Alignment Module (InCAM) utilizes video-clip-wise tokens to dynamically relate pixels within and across frames, enhancing coherency. Additionally, the Channel-wise Texture Aggregation Memory (CaTeGory) infuses extrinsic knowledge, capitalizing on long-standing semantic textures. Our method also innovates the blurring diffusion process with the ResShift mechanism, finely balancing between sharpness and diffusion effects. Comprehensive experiments confirm our framework's advantage over state-of-the-art diffusion-based VSR techniques. The code is available: this https URL.
+
+
+
+ 153. 【2410.05774】ActionAtlas: A VideoQA Benchmark for Domain-specialized Action Recognition
+ 链接:https://arxiv.org/abs/2410.05774
+ 作者:Mohammadreza Salehi,Jae Sung Park,Tanush Yadav,Aditya Kusupati,Ranjay Krishna,Yejin Choi,Hannaneh Hajishirzi,Ali Farhadi
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:strive to identify, identify and understand, world is full, full of varied, actions
+ 备注:
+
+ 点击查看摘要
+ Abstract:Our world is full of varied actions and moves across specialized domains that we, as humans, strive to identify and understand. Within any single domain, actions can often appear quite similar, making it challenging for deep models to distinguish them accurately. To evaluate the effectiveness of multimodal foundation models in helping us recognize such actions, we present ActionAtlas v1.0, a multiple-choice video question answering benchmark featuring short videos across various sports. Each video in the dataset is paired with a question and four or five choices. The question pinpoints specific individuals, asking which choice "best" describes their action within a certain temporal context. Overall, the dataset includes 934 videos showcasing 580 unique actions across 56 sports, with a total of 1896 actions within choices. Unlike most existing video question answering benchmarks that only cover simplistic actions, often identifiable from a single frame, ActionAtlas focuses on intricate movements and rigorously tests the model's capability to discern subtle differences between moves that look similar within each domain. We evaluate open and proprietary foundation models on this benchmark, finding that the best model, GPT-4o, achieves a maximum accuracy of 45.52%. Meanwhile, Non-expert crowd workers, provided with action description for each choice, achieve 61.64% accuracy, where random chance is approximately 21%. Our findings with state-of-the-art models indicate that having a high frame sampling rate is important for accurately recognizing actions in ActionAtlas, a feature that some leading proprietary video models, such as Gemini, do not include in their default configuration.
+
+
+
+ 154. 【2410.05773】GLRT-Based Metric Learning for Remote Sensing Object Retrieval
+ 链接:https://arxiv.org/abs/2410.05773
+ 作者:Linping Zhang,Yu Liu,Xueqian Wang,Gang Li,You He
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:increasingly important topic, sensing object retrieval, data distribution information, global data distribution, object retrieval
+ 备注:
+
+ 点击查看摘要
+ Abstract:With the improvement in the quantity and quality of remote sensing images, content-based remote sensing object retrieval (CBRSOR) has become an increasingly important topic. However, existing CBRSOR methods neglect the utilization of global statistical information during both training and test stages, which leads to the overfitting of neural networks to simple sample pairs of samples during training and suboptimal metric performance. Inspired by the Neyman-Pearson theorem, we propose a generalized likelihood ratio test-based metric learning (GLRTML) approach, which can estimate the relative difficulty of sample pairs by incorporating global data distribution information during training and test phases. This guides the network to focus more on difficult samples during the training process, thereby encourages the network to learn more discriminative feature embeddings. In addition, GLRT is a more effective than traditional metric space due to the utilization of global data distribution information. Accurately estimating the distribution of embeddings is critical for GLRTML. However, in real-world applications, there is often a distribution shift between the training and target domains, which diminishes the effectiveness of directly using the distribution estimated on training data. To address this issue, we propose the clustering pseudo-labels-based fast parameter adaptation (CPLFPA) method. CPLFPA efficiently estimates the distribution of embeddings in the target domain by clustering target domain instances and re-estimating the distribution parameters for GLRTML. We reorganize datasets for CBRSOR tasks based on fine-grained ship remote sensing image slices (FGSRSI-23) and military aircraft recognition (MAR20) datasets. Extensive experiments on these datasets demonstrate the effectiveness of our proposed GLRTML and CPLFPA.
+
+
+
+ 155. 【2410.05772】Comparative Analysis of Novel View Synthesis and Photogrammetry for 3D Forest Stand Reconstruction and extraction of individual tree parameters
+ 链接:https://arxiv.org/abs/2410.05772
+ 作者:Guoji Tian,Chongcheng Chen,Hongyu Huang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Accurate and efficient, Neural Radiance Fields, assessments and management, including Neural Radiance, Accurate
+ 备注: 31page,15figures
+
+ 点击查看摘要
+ Abstract:Accurate and efficient 3D reconstruction of trees is crucial for forest resource assessments and management. Close-Range Photogrammetry (CRP) is commonly used for reconstructing forest scenes but faces challenges like low efficiency and poor quality. Recently, Novel View Synthesis (NVS) technologies, including Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), have shown promise for 3D plant reconstruction with limited images. However, existing research mainly focuses on small plants in orchards or individual trees, leaving uncertainty regarding their application in larger, complex forest stands. In this study, we collected sequential images of forest plots with varying complexity and performed dense reconstruction using NeRF and 3DGS. The resulting point clouds were compared with those from photogrammetry and laser scanning. Results indicate that NVS methods significantly enhance reconstruction efficiency. Photogrammetry struggles with complex stands, leading to point clouds with excessive canopy noise and incorrectly reconstructed trees, such as duplicated trunks. NeRF, while better for canopy regions, may produce errors in ground areas with limited views. The 3DGS method generates sparser point clouds, particularly in trunk areas, affecting diameter at breast height (DBH) accuracy. All three methods can extract tree height information, with NeRF yielding the highest accuracy; however, photogrammetry remains superior for DBH accuracy. These findings suggest that NVS methods have significant potential for 3D reconstruction of forest stands, offering valuable support for complex forest resource inventory and visualization tasks.
+
+
+
+ 156. 【2410.05771】Cefdet: Cognitive Effectiveness Network Based on Fuzzy Inference for Action Detection
+ 链接:https://arxiv.org/abs/2410.05771
+ 作者:Zhe Luo,Weina Fu,Shuai Liu,Saeed Anwar,Muhammad Saqib,Sambit Bakshi,Khan Muhammad
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:multimedia content, understanding provide, provide the foundation, generation and interaction, interaction of multimedia
+ 备注: The paper has been accepted by ACM MM. If you find this work helpful, please consider citing our paper. Zhe Luo, Weina Fu, Shuai Liu, Saeed Anwar, Muhammad Saqib, Sambit Bakshi, Khan Muhammad (2024) Cefdet: Cognitive Effectiveness Network Based on Fuzzy Inference for Action Detection, 32nd ACM International Conference on Multimedia, online first, [https://doi.org/10.1145/3664647.3681226](https://doi.org/10.1145/3664647.3681226)
+
+ 点击查看摘要
+ Abstract:Action detection and understanding provide the foundation for the generation and interaction of multimedia content. However, existing methods mainly focus on constructing complex relational inference networks, overlooking the judgment of detection effectiveness. Moreover, these methods frequently generate detection results with cognitive abnormalities. To solve the above problems, this study proposes a cognitive effectiveness network based on fuzzy inference (Cefdet), which introduces the concept of "cognition-based detection" to simulate human cognition. First, a fuzzy-driven cognitive effectiveness evaluation module (FCM) is established to introduce fuzzy inference into action detection. FCM is combined with human action features to simulate the cognition-based detection process, which clearly locates the position of frames with cognitive abnormalities. Then, a fuzzy cognitive update strategy (FCS) is proposed based on the FCM, which utilizes fuzzy logic to re-detect the cognition-based detection results and effectively update the results with cognitive abnormalities. Experimental results demonstrate that Cefdet exhibits superior performance against several mainstream algorithms on the public datasets, validating its effectiveness and superiority.
+
+
+
+ 157. 【2410.05767】Grounding is All You Need? Dual Temporal Grounding for Video Dialog
+ 链接:https://arxiv.org/abs/2410.05767
+ 作者:You Qin,Wei Ji,Xinze Lan,Hao Fei,Xun Yang,Dan Guo,Roger Zimmermann,Lizi Liao
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Multimedia (cs.MM)
+ 关键词:dialog temporal dynamics, history are paramount, nuances of conversation, conversation history, temporal dynamics
+ 备注:
+
+ 点击查看摘要
+ Abstract:In the realm of video dialog response generation, the understanding of video content and the temporal nuances of conversation history are paramount. While a segment of current research leans heavily on large-scale pretrained visual-language models and often overlooks temporal dynamics, another delves deep into spatial-temporal relationships within videos but demands intricate object trajectory pre-extractions and sidelines dialog temporal dynamics. This paper introduces the Dual Temporal Grounding-enhanced Video Dialog model (DTGVD), strategically designed to merge the strengths of both dominant approaches. It emphasizes dual temporal relationships by predicting dialog turn-specific temporal regions, filtering video content accordingly, and grounding responses in both video and dialog contexts. One standout feature of DTGVD is its heightened attention to chronological interplay. By recognizing and acting upon the dependencies between different dialog turns, it captures more nuanced conversational dynamics. To further bolster the alignment between video and dialog temporal dynamics, we've implemented a list-wise contrastive learning strategy. Within this framework, accurately grounded turn-clip pairings are designated as positive samples, while less precise pairings are categorized as negative. This refined classification is then funneled into our holistic end-to-end response generation mechanism. Evaluations using AVSD@DSTC-7 and AVSD@DSTC-8 datasets underscore the superiority of our methodology.
+
+
+
+ 158. 【2410.05762】Guided Self-attention: Find the Generalized Necessarily Distinct Vectors for Grain Size Grading
+ 链接:https://arxiv.org/abs/2410.05762
+ 作者:Fang Gao,Xuetao Li,Jiabao Wang,Shengheng Ma,Jun Yu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:grain size, grain size analysis, increasingly important, steel grain size, evaluate metallographic photographs
+ 备注:
+
+ 点击查看摘要
+ Abstract:With the development of steel materials, metallographic analysis has become increasingly important. Unfortunately, grain size analysis is a manual process that requires experts to evaluate metallographic photographs, which is unreliable and time-consuming. To resolve this problem, we propose a novel classifi-cation method based on deep learning, namely GSNets, a family of hybrid models which can effectively introduce guided self-attention for classifying grain size. Concretely, we build our models from three insights:(1) Introducing our novel guided self-attention module can assist the model in finding the generalized necessarily distinct vectors capable of retaining intricate rela-tional connections and rich local feature information; (2) By improving the pixel-wise linear independence of the feature map, the highly condensed semantic representation will be captured by the model; (3) Our novel triple-stream merging module can significantly improve the generalization capability and efficiency of the model. Experiments show that our GSNet yields a classifi-cation accuracy of 90.1%, surpassing the state-of-the-art Swin Transformer V2 by 1.9% on the steel grain size dataset, which comprises 3,599 images with 14 grain size levels. Furthermore, we intuitively believe our approach is applicable to broader ap-plications like object detection and semantic segmentation.
+
+
+
+ 159. 【2410.05760】raining-free Diffusion Model Alignment with Sampling Demons
+ 链接:https://arxiv.org/abs/2410.05760
+ 作者:Po-Hung Yeh,Kuang-Huei Lee,Jun-Cheng Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Optimization and Control (math.OC); Machine Learning (stat.ML)
+ 关键词:Aligning diffusion models, Aligning diffusion, key challenge, diffusion models, Aligning
+ 备注: 36 pages
+
+ 点击查看摘要
+ Abstract:Aligning diffusion models with user preferences has been a key challenge. Existing methods for aligning diffusion models either require retraining or are limited to differentiable reward functions. To address these limitations, we propose a stochastic optimization approach, dubbed Demon, to guide the denoising process at inference time without backpropagation through reward functions or model retraining. Our approach works by controlling noise distribution in denoising steps to concentrate density on regions corresponding to high rewards through stochastic optimization. We provide comprehensive theoretical and empirical evidence to support and validate our approach, including experiments that use non-differentiable sources of rewards such as Visual-Language Model (VLM) APIs and human judgements. To the best of our knowledge, the proposed approach is the first inference-time, backpropagation-free preference alignment method for diffusion models. Our method can be easily integrated with existing diffusion models without further training. Our experiments show that the proposed approach significantly improves the average aesthetics scores for text-to-image generation.
+
+
+
+ 160. 【2410.05746】Wolf2Pack: The AutoFusion Framework for Dynamic Parameter Fusion
+ 链接:https://arxiv.org/abs/2410.05746
+ 作者:Bowen Tian,Songning Lai,Yutao Yue
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:natural language processing, rapidly evolving field, driven significant advancements, language processing, rapidly evolving
+ 备注: Under review
+
+ 点击查看摘要
+ Abstract:In the rapidly evolving field of deep learning, specialized models have driven significant advancements in tasks such as computer vision and natural language processing. However, this specialization leads to a fragmented ecosystem where models lack the adaptability for broader applications. To overcome this, we introduce AutoFusion, an innovative framework that fuses distinct model parameters(with the same architecture) for multi-task learning without pre-trained checkpoints. Using an unsupervised, end-to-end approach, AutoFusion dynamically permutes model parameters at each layer, optimizing the combination through a loss-minimization process that does not require labeled data. We validate AutoFusion's effectiveness through experiments on commonly used benchmark datasets, demonstrating superior performance over established methods like Weight Interpolation, Git Re-Basin, and ZipIt. Our framework offers a scalable and flexible solution for model integration, positioning it as a powerful tool for future research and practical applications.
+
+
+
+ 161. 【2410.05735】CUBE360: Learning Cubic Field Representation for Monocular 360 Depth Estimation for Virtual Reality
+ 链接:https://arxiv.org/abs/2410.05735
+ 作者:Wenjie Chang,Hao Ai,Tianzhu Zhang,Lin Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:provide comprehensive scene, images provide comprehensive, comprehensive scene information, Panoramic images provide, provide comprehensive
+ 备注:
+
+ 点击查看摘要
+ Abstract:Panoramic images provide comprehensive scene information and are suitable for VR applications. Obtaining corresponding depth maps is essential for achieving immersive and interactive experiences. However, panoramic depth estimation presents significant challenges due to the severe distortion caused by equirectangular projection (ERP) and the limited availability of panoramic RGB-D datasets. Inspired by the recent success of neural rendering, we propose a novel method, named $\mathbf{CUBE360}$, that learns a cubic field composed of multiple MPIs from a single panoramic image for $\mathbf{continuous}$ depth estimation at any view direction. Our CUBE360 employs cubemap projection to transform an ERP image into six faces and extract the MPIs for each, thereby reducing the memory consumption required for MPI processing of high-resolution data. Additionally, this approach avoids the computational complexity of handling the uneven pixel distribution inherent to equirectangular projectio. An attention-based blending module is then employed to learn correlations among the MPIs of cubic faces, constructing a cubic field representation with color and density information at various depth levels. Furthermore, a novel sampling strategy is introduced for rendering novel views from the cubic field at both cubic and planar scales. The entire pipeline is trained using photometric loss calculated from rendered views within a self-supervised learning approach, enabling training on 360 videos without depth annotations. Experiments on both synthetic and real-world datasets demonstrate the superior performance of CUBE360 compared to prior SSL methods. We also highlight its effectiveness in downstream applications, such as VR roaming and visual effects, underscoring CUBE360's potential to enhance immersive experiences.
+
+
+
+ 162. 【2410.05729】Equi-GSPR: Equivariant SE(3) Graph Network Model for Sparse Point Cloud Registration
+ 链接:https://arxiv.org/abs/2410.05729
+ 作者:Xueyang Kang,Zhaoliang Luan,Kourosh Khoshelham,Bing Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Point cloud registration, alignment and reconstruction, reconstruction applications, point cloud data, Point cloud
+ 备注: 18 main body pages, and 9 pages for supplementary part
+
+ 点击查看摘要
+ Abstract:Point cloud registration is a foundational task for 3D alignment and reconstruction applications. While both traditional and learning-based registration approaches have succeeded, leveraging the intrinsic symmetry of point cloud data, including rotation equivariance, has received insufficient attention. This prohibits the model from learning effectively, resulting in a requirement for more training data and increased model complexity. To address these challenges, we propose a graph neural network model embedded with a local Spherical Euclidean 3D equivariance property through SE(3) message passing based propagation. Our model is composed mainly of a descriptor module, equivariant graph layers, match similarity, and the final regression layers. Such modular design enables us to utilize sparsely sampled input points and initialize the descriptor by self-trained or pre-trained geometric feature descriptors easily. Experiments conducted on the 3DMatch and KITTI datasets exhibit the compelling and robust performance of our model compared to state-of-the-art approaches, while the model complexity remains relatively low at the same time.
+
+
+
+ 163. 【2410.05721】Mero Nagarikta: Advanced Nepali Citizenship Data Extractor with Deep Learning-Powered Text Detection and OCR
+ 链接:https://arxiv.org/abs/2410.05721
+ 作者:Sisir Dhakal,Sujan Sigdel,Sandesh Prasad Paudel,Sharad Kumar Ranabhat,Nabin Lamichhane
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Transforming text-based identity, Nepali citizenship cards, structured digital format, digital format poses, Transforming text-based
+ 备注: 13 pages, 8 figures
+
+ 点击查看摘要
+ Abstract:Transforming text-based identity documents, such as Nepali citizenship cards, into a structured digital format poses several challenges due to the distinct characteristics of the Nepali script and minor variations in print alignment and contrast across different cards. This work proposes a robust system using YOLOv8 for accurate text object detection and an OCR algorithm based on Optimized PyTesseract. The system, implemented within the context of a mobile application, allows for the automated extraction of important textual information from both the front and the back side of Nepali citizenship cards, including names, citizenship numbers, and dates of birth. The final YOLOv8 model was accurate, with a mean average precision of 99.1% for text detection on the front and 96.1% on the back. The tested PyTesseract optimized for Nepali characters outperformed the standard OCR regarding flexibility and accuracy, extracting text from images with clean and noisy backgrounds and various contrasts. Using preprocessing steps such as converting the images into grayscale, removing noise from the images, and detecting edges further improved the system's OCR accuracy, even for low-quality photos. This work expands the current body of research in multilingual OCR and document analysis, especially for low-resource languages such as Nepali. It emphasizes the effectiveness of combining the latest object detection framework with OCR models that have been fine-tuned for practical applications.
+
+
+
+ 164. 【2410.05717】Advancements in Road Lane Mapping: Comparative Fine-Tuning Analysis of Deep Learning-based Semantic Segmentation Methods Using Aerial Imagery
+ 链接:https://arxiv.org/abs/2410.05717
+ 作者:Xuanchen(Willow)Liu,Shuxin Qiao,Kyle Gao,Hongjie He,Michael A. Chapman,Linlin Xu,Jonathan Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:lane information derived, road lane information, road lane, autonomous vehicles, aerial imagery
+ 备注:
+
+ 点击查看摘要
+ Abstract:This research addresses the need for high-definition (HD) maps for autonomous vehicles (AVs), focusing on road lane information derived from aerial imagery. While Earth observation data offers valuable resources for map creation, specialized models for road lane extraction are still underdeveloped in remote sensing. In this study, we perform an extensive comparison of twelve foundational deep learning-based semantic segmentation models for road lane marking extraction from high-definition remote sensing images, assessing their performance under transfer learning with partially labeled datasets. These models were fine-tuned on the partially labeled Waterloo Urban Scene dataset, and pre-trained on the SkyScapes dataset, simulating a likely scenario of real-life model deployment under partial labeling. We observed and assessed the fine-tuning performance and overall performance. Models showed significant performance improvements after fine-tuning, with mean IoU scores ranging from 33.56% to 76.11%, and recall ranging from 66.0% to 98.96%. Transformer-based models outperformed convolutional neural networks, emphasizing the importance of model pre-training and fine-tuning in enhancing HD map development for AV navigation.
+
+
+
+ 165. 【2410.05714】Enhancing Temporal Modeling of Video LLMs via Time Gating
+ 链接:https://arxiv.org/abs/2410.05714
+ 作者:Zi-Yuan Hu,Yiwu Zhong,Shijia Huang,Michael R. Lyu,Liwei Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Video Large Language, Large Language Models, Large Language, video question answering, Video Large
+ 备注: EMNLP 2024 Findings (Short)
+
+ 点击查看摘要
+ Abstract:Video Large Language Models (Video LLMs) have achieved impressive performance on video-and-language tasks, such as video question answering. However, most existing Video LLMs neglect temporal information in video data, leading to struggles with temporal-aware video understanding. To address this gap, we propose a Time Gating Video LLM (TG-Vid) designed to enhance temporal modeling through a novel Time Gating module (TG). The TG module employs a time gating mechanism on its sub-modules, comprising gating spatial attention, gating temporal attention, and gating MLP. This architecture enables our model to achieve a robust understanding of temporal information within videos. Extensive evaluation of temporal-sensitive video benchmarks (i.e., MVBench, TempCompass, and NExT-QA) demonstrates that our TG-Vid model significantly outperforms the existing Video LLMs. Further, comprehensive ablation studies validate that the performance gains are attributed to the designs of our TG module. Our code is available at this https URL.
+
+
+
+ 166. 【2410.05710】PixLens: A Novel Framework for Disentangled Evaluation in Diffusion-Based Image Editing with Object Detection + SAM
+ 链接:https://arxiv.org/abs/2410.05710
+ 作者:Stefan Stefanache,Lluís Pastor Pérez,Julen Costa Watanabe,Ernesto Sanchez Tejedor,Thomas Hofmann,Enis Simsar
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Evaluating diffusion-based image-editing, Evaluating diffusion-based, diffusion-based image-editing models, diffusion-based image-editing, Evaluating
+ 备注: 35 pages (17 main paper, 18 appendix), 22 figures
+
+ 点击查看摘要
+ Abstract:Evaluating diffusion-based image-editing models is a crucial task in the field of Generative AI. Specifically, it is imperative to assess their capacity to execute diverse editing tasks while preserving the image content and realism. While recent developments in generative models have opened up previously unheard-of possibilities for image editing, conducting a thorough evaluation of these models remains a challenging and open task. The absence of a standardized evaluation benchmark, primarily due to the inherent need for a post-edit reference image for evaluation, further complicates this issue. Currently, evaluations often rely on established models such as CLIP or require human intervention for a comprehensive understanding of the performance of these image editing models. Our benchmark, PixLens, provides a comprehensive evaluation of both edit quality and latent representation disentanglement, contributing to the advancement and refinement of existing methodologies in the field.
+
+
+
+ 167. 【2410.05694】DiffusionGuard: A Robust Defense Against Malicious Diffusion-based Image Editing
+ 链接:https://arxiv.org/abs/2410.05694
+ 作者:June Suk Choi,Kyungmin Lee,Jongheon Jeong,Saining Xie,Jinwoo Shin,Kimin Lee
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:simple textual prompts, create realistic edited, enabling users, textual prompts, text-guided image manipulation
+ 备注: Preprint. Under review
+
+ 点击查看摘要
+ Abstract:Recent advances in diffusion models have introduced a new era of text-guided image manipulation, enabling users to create realistic edited images with simple textual prompts. However, there is significant concern about the potential misuse of these methods, especially in creating misleading or harmful content. Although recent defense strategies, which introduce imperceptible adversarial noise to induce model failure, have shown promise, they remain ineffective against more sophisticated manipulations, such as editing with a mask. In this work, we propose DiffusionGuard, a robust and effective defense method against unauthorized edits by diffusion-based image editing models, even in challenging setups. Through a detailed analysis of these models, we introduce a novel objective that generates adversarial noise targeting the early stage of the diffusion process. This approach significantly improves the efficiency and effectiveness of adversarial noises. We also introduce a mask-augmentation technique to enhance robustness against various masks during test time. Finally, we introduce a comprehensive benchmark designed to evaluate the effectiveness and robustness of methods in protecting against privacy threats in realistic scenarios. Through extensive experiments, we show that our method achieves stronger protection and improved mask robustness with lower computational costs compared to the strongest baseline. Additionally, our method exhibits superior transferability and better resilience to noise removal techniques compared to all baseline methods. Our source code is publicly available at this https URL.
+
+
+
+ 168. 【2410.05680】Convolutional neural networks applied to modification of images
+ 链接:https://arxiv.org/abs/2410.05680
+ 作者:Carlos I. Aguirre-Velez,Jose Antonio Arciniega-Nevarez,Eric Dolores-Cuenca
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:algebra and calculus, reader will learn, learn how digital, digital images, images are edited
+ 备注: 23 pages
+
+ 点击查看摘要
+ Abstract:The reader will learn how digital images are edited using linear algebra and calculus. Starting from the concept of filter towards machine learning techniques such as convolutional neural networks.
+
+
+
+ 169. 【2410.05677】2V-Turbo-v2: Enhancing Video Generation Model Post-Training through Data, Reward, and Conditional Guidance Design
+ 链接:https://arxiv.org/abs/2410.05677
+ 作者:Jiachen Li,Qian Long,Jian Zheng,Xiaofeng Gao,Robinson Piramuthu,Wenhu Chen,William Yang Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:highly capable consistency, capable consistency model, post-training phase, phase by distilling, distilling a highly
+ 备注: Project Page: [this https URL](https://t2v-turbo-v2.github.io/)
+
+ 点击查看摘要
+ Abstract:In this paper, we focus on enhancing a diffusion-based text-to-video (T2V) model during the post-training phase by distilling a highly capable consistency model from a pretrained T2V model. Our proposed method, T2V-Turbo-v2, introduces a significant advancement by integrating various supervision signals, including high-quality training data, reward model feedback, and conditional guidance, into the consistency distillation process. Through comprehensive ablation studies, we highlight the crucial importance of tailoring datasets to specific learning objectives and the effectiveness of learning from diverse reward models for enhancing both the visual quality and text-video alignment. Additionally, we highlight the vast design space of conditional guidance strategies, which centers on designing an effective energy function to augment the teacher ODE solver. We demonstrate the potential of this approach by extracting motion guidance from the training datasets and incorporating it into the ODE solver, showcasing its effectiveness in improving the motion quality of the generated videos with the improved motion-related metrics from VBench and T2V-CompBench. Empirically, our T2V-Turbo-v2 establishes a new state-of-the-art result on VBench, with a Total score of 85.13, surpassing proprietary systems such as Gen-3 and Kling.
+
+
+
+ 170. 【2410.05665】Edge-Cloud Collaborative Satellite Image Analysis for Efficient Man-Made Structure Recognition
+ 链接:https://arxiv.org/abs/2410.05665
+ 作者:Kaicheng Sheng,Junxiao Xue,Hui Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:created immense opportunities, high-resolution satellite imagery, increasing availability, availability of high-resolution, created immense
+ 备注:
+
+ 点击查看摘要
+ Abstract:The increasing availability of high-resolution satellite imagery has created immense opportunities for various applications. However, processing and analyzing such vast amounts of data in a timely and accurate manner poses significant challenges. The paper presents a new satellite image processing architecture combining edge and cloud computing to better identify man-made structures against natural landscapes. By employing lightweight models at the edge, the system initially identifies potential man-made structures from satellite imagery. These identified images are then transmitted to the cloud, where a more complex model refines the classification, determining specific types of structures. The primary focus is on the trade-off between latency and accuracy, as efficient models often sacrifice accuracy. We compare this hybrid edge-cloud approach against traditional "bent-pipe" method in virtual environment experiments as well as introduce a practical model and compare its performance with existing lightweight models for edge deployment, focusing on accuracy and latency. The results demonstrate that the edge-cloud collaborative model not only reduces overall latency due to minimized data transmission but also maintains high accuracy, offering substantial improvements over traditional approaches under this scenario.
+
+
+
+ 171. 【2410.05664】Holistic Unlearning Benchmark: A Multi-Faceted Evaluation for Text-to-Image Diffusion Model Unlearning
+ 链接:https://arxiv.org/abs/2410.05664
+ 作者:Saemi Moon,Minjong Lee,Sangdon Park,Dongwoo Kim
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:commercial applications, potential for malicious, increasing concern, diffusion models, unlearning
+ 备注:
+
+ 点击查看摘要
+ Abstract:As text-to-image diffusion models become advanced enough for commercial applications, there is also increasing concern about their potential for malicious and harmful use. Model unlearning has been proposed to mitigate the concerns by removing undesired and potentially harmful information from the pre-trained model. So far, the success of unlearning is mainly measured by whether the unlearned model can generate a target concept while maintaining image quality. However, unlearning is typically tested under limited scenarios, and the side effects of unlearning have barely been studied in the current literature. In this work, we thoroughly analyze unlearning under various scenarios with five key aspects. Our investigation reveals that every method has side effects or limitations, especially in more complex and realistic situations. By releasing our comprehensive evaluation framework with the source codes and artifacts, we hope to inspire further research in this area, leading to more reliable and effective unlearning methods.
+
+
+
+ 172. 【2410.05651】ViBiDSampler: Enhancing Video Interpolation Using Bidirectional Diffusion Sampler
+ 链接:https://arxiv.org/abs/2410.05651
+ 作者:Serin Yang,Taesung Kwon,Jong Chul Ye
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Recent progress, greatly enhanced video, diffusion models, progress in large-scale, greatly enhanced
+ 备注: Project page: [this https URL](https://vibid.github.io/)
+
+ 点击查看摘要
+ Abstract:Recent progress in large-scale text-to-video (T2V) and image-to-video (I2V) diffusion models has greatly enhanced video generation, especially in terms of keyframe interpolation. However, current image-to-video diffusion models, while powerful in generating videos from a single conditioning frame, need adaptation for two-frame (start end) conditioned generation, which is essential for effective bounded interpolation. Unfortunately, existing approaches that fuse temporally forward and backward paths in parallel often suffer from off-manifold issues, leading to artifacts or requiring multiple iterative re-noising steps. In this work, we introduce a novel, bidirectional sampling strategy to address these off-manifold issues without requiring extensive re-noising or fine-tuning. Our method employs sequential sampling along both forward and backward paths, conditioned on the start and end frames, respectively, ensuring more coherent and on-manifold generation of intermediate frames. Additionally, we incorporate advanced guidance techniques, CFG++ and DDS, to further enhance the interpolation process. By integrating these, our method achieves state-of-the-art performance, efficiently generating high-quality, smooth videos between keyframes. On a single 3090 GPU, our method can interpolate 25 frames at 1024 x 576 resolution in just 195 seconds, establishing it as a leading solution for keyframe interpolation.
+
+
+
+ 173. 【2410.05650】SIA-OVD: Shape-Invariant Adapter for Bridging the Image-Region Gap in Open-Vocabulary Detection
+ 链接:https://arxiv.org/abs/2410.05650
+ 作者:Zishuo Wang,Wenhao Zhou,Jinglin Xu,Yuxin Peng
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:open-world object detection, achieve open-world object, Vision-Language Pretrained Models, object detection, Open-vocabulary detection
+ 备注: 9 pages, 7 figures
+
+ 点击查看摘要
+ Abstract:Open-vocabulary detection (OVD) aims to detect novel objects without instance-level annotations to achieve open-world object detection at a lower cost. Existing OVD methods mainly rely on the powerful open-vocabulary image-text alignment capability of Vision-Language Pretrained Models (VLM) such as CLIP. However, CLIP is trained on image-text pairs and lacks the perceptual ability for local regions within an image, resulting in the gap between image and region representations. Directly using CLIP for OVD causes inaccurate region classification. We find the image-region gap is primarily caused by the deformation of region feature maps during region of interest (RoI) extraction. To mitigate the inaccurate region classification in OVD, we propose a new Shape-Invariant Adapter named SIA-OVD to bridge the image-region gap in the OVD task. SIA-OVD learns a set of feature adapters for regions with different shapes and designs a new adapter allocation mechanism to select the optimal adapter for each region. The adapted region representations can align better with text representations learned by CLIP. Extensive experiments demonstrate that SIA-OVD effectively improves the classification accuracy for regions by addressing the gap between images and regions caused by shape deformation. SIA-OVD achieves substantial improvements over representative methods on the COCO-OVD benchmark. The code is available at this https URL.
+
+
+
+ 174. 【2410.05643】RACE: Temporal Grounding Video LLM via Causal Event Modeling
+ 链接:https://arxiv.org/abs/2410.05643
+ 作者:Yongxin Guo,Jingyu Liu,Mingda Li,Xiaoying Tang,Qingbin Liu,Xi Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Video Temporal Grounding, Temporal Grounding, VTG tasks, Video Temporal, VTG
+ 备注:
+
+ 点击查看摘要
+ Abstract:Video Temporal Grounding (VTG) is a crucial capability for video understanding models and plays a vital role in downstream tasks such as video browsing and editing. To effectively handle various tasks simultaneously and enable zero-shot prediction, there is a growing trend in employing video LLMs for VTG tasks. However, current video LLM-based methods rely exclusively on natural language generation, lacking the ability to model the clear structure inherent in videos, which restricts their effectiveness in tackling VTG tasks. To address this issue, this paper first formally introduces causal event modeling framework, which represents videos as sequences of events, and predict the current event using previous events, video inputs, and textural instructions. Each event consists of three components: timestamps, salient scores, and textual captions. We then propose a novel task-interleaved video LLM called TRACE to effectively implement the causal event modeling framework in practice. The TRACE processes visual frames, timestamps, salient scores, and text as distinct tasks, employing various encoders and decoding heads for each. Task tokens are arranged in an interleaved sequence according to the causal event modeling framework's formulation. Extensive experiments on various VTG tasks and datasets demonstrate the superior performance of TRACE compared to state-of-the-art video LLMs. Our model and code are available at \url{this https URL}.
+
+
+
+ 175. 【2410.05627】CLOSER: Towards Better Representation Learning for Few-Shot Class-Incremental Learning
+ 链接:https://arxiv.org/abs/2410.05627
+ 作者:Junghun Oh,Sungyong Baik,Kyoung Mu Lee
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:few-shot class-incremental learning, Aiming to incrementally, few-shot class-incremental, base classes, incrementally learn
+ 备注: Accepted at ECCV2024
+
+ 点击查看摘要
+ Abstract:Aiming to incrementally learn new classes with only few samples while preserving the knowledge of base (old) classes, few-shot class-incremental learning (FSCIL) faces several challenges, such as overfitting and catastrophic forgetting. Such a challenging problem is often tackled by fixing a feature extractor trained on base classes to reduce the adverse effects of overfitting and forgetting. Under such formulation, our primary focus is representation learning on base classes to tackle the unique challenge of FSCIL: simultaneously achieving the transferability and the discriminability of the learned representation. Building upon the recent efforts for enhancing transferability, such as promoting the spread of features, we find that trying to secure the spread of features within a more confined feature space enables the learned representation to strike a better balance between transferability and discriminability. Thus, in stark contrast to prior beliefs that the inter-class distance should be maximized, we claim that the closer different classes are, the better for FSCIL. The empirical results and analysis from the perspective of information bottleneck theory justify our simple yet seemingly counter-intuitive representation learning method, raising research questions and suggesting alternative research directions. The code is available at this https URL.
+
+
+
+ 176. 【2410.05624】Remote Sensing Image Segmentation Using Vision Mamba and Multi-Scale Multi-Frequency Feature Fusion
+ 链接:https://arxiv.org/abs/2410.05624
+ 作者:Yice Cao,Chenchen Liu,Zhenhua Wu,Wenxin Yao,Liu Xiong,Jie Chen,Zhixiang Huang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:imaging technology continues, interpretation efficiency emerg, improve segmentation accuracy, sensing imaging technology, enhance interpretation efficiency
+ 备注:
+
+ 点击查看摘要
+ Abstract:As remote sensing imaging technology continues to advance and evolve, processing high-resolution and diversified satellite imagery to improve segmentation accuracy and enhance interpretation efficiency emerg as a pivotal area of investigation within the realm of remote sensing. Although segmentation algorithms based on CNNs and Transformers achieve significant progress in performance, balancing segmentation accuracy and computational complexity remains challenging, limiting their wide application in practical tasks. To address this, this paper introduces state space model (SSM) and proposes a novel hybrid semantic segmentation network based on vision Mamba (CVMH-UNet). This method designs a cross-scanning visual state space block (CVSSBlock) that uses cross 2D scanning (CS2D) to fully capture global information from multiple directions, while by incorporating convolutional neural network branches to overcome the constraints of Vision Mamba (VMamba) in acquiring local information, this approach facilitates a comprehensive analysis of both global and local features. Furthermore, to address the issue of limited discriminative power and the difficulty in achieving detailed fusion with direct skip connections, a multi-frequency multi-scale feature fusion block (MFMSBlock) is designed. This module introduces multi-frequency information through 2D discrete cosine transform (2D DCT) to enhance information utilization and provides additional scale local detail information through point-wise convolution branches. Finally, it aggregates multi-scale information along the channel dimension, achieving refined feature fusion. Findings from experiments conducted on renowned datasets of remote sensing imagery demonstrate that proposed CVMH-UNet achieves superior segmentation performance while maintaining low computational complexity, outperforming surpassing current leading-edge segmentation algorithms.
+
+
+
+ 177. 【2410.05601】ReFIR: Grounding Large Restoration Models with Retrieval Augmentation
+ 链接:https://arxiv.org/abs/2410.05601
+ 作者:Hang Guo,Tao Dai,Zhihao Ouyang,Taolin Zhang,Yaohua Zha,Bin Chen,Shu-tao Xia
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Large Restoration Models, diffusion-based Large Restoration, significantly improved photo-realistic, Recent advances, improved photo-realistic image
+ 备注: Accepted by NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:Recent advances in diffusion-based Large Restoration Models (LRMs) have significantly improved photo-realistic image restoration by leveraging the internal knowledge embedded within model weights. However, existing LRMs often suffer from the hallucination dilemma, i.e., producing incorrect contents or textures when dealing with severe degradations, due to their heavy reliance on limited internal knowledge. In this paper, we propose an orthogonal solution called the Retrieval-augmented Framework for Image Restoration (ReFIR), which incorporates retrieved images as external knowledge to extend the knowledge boundary of existing LRMs in generating details faithful to the original scene. Specifically, we first introduce the nearest neighbor lookup to retrieve content-relevant high-quality images as reference, after which we propose the cross-image injection to modify existing LRMs to utilize high-quality textures from retrieved images. Thanks to the additional external knowledge, our ReFIR can well handle the hallucination challenge and facilitate faithfully results. Extensive experiments demonstrate that ReFIR can achieve not only high-fidelity but also realistic restoration results. Importantly, our ReFIR requires no training and is adaptable to various LRMs.
+
+
+
+ 178. 【2410.05591】weedieMix: Improving Multi-Concept Fusion for Diffusion-based Image/Video Generation
+ 链接:https://arxiv.org/abs/2410.05591
+ 作者:Gihyun Kwon,Jong Chul Ye
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:effectively integrate multiple, advancements in customizing, challenging task, multiple personalized concepts, integrate multiple personalized
+ 备注: Github Page: [this https URL](https://github.com/KwonGihyun/TweedieMix)
+
+ 点击查看摘要
+ Abstract:Despite significant advancements in customizing text-to-image and video generation models, generating images and videos that effectively integrate multiple personalized concepts remains a challenging task. To address this, we present TweedieMix, a novel method for composing customized diffusion models during the inference phase. By analyzing the properties of reverse diffusion sampling, our approach divides the sampling process into two stages. During the initial steps, we apply a multiple object-aware sampling technique to ensure the inclusion of the desired target objects. In the later steps, we blend the appearances of the custom concepts in the de-noised image space using Tweedie's formula. Our results demonstrate that TweedieMix can generate multiple personalized concepts with higher fidelity than existing methods. Moreover, our framework can be effortlessly extended to image-to-video diffusion models, enabling the generation of videos that feature multiple personalized concepts. Results and source code are in our anonymous project page.
+
+
+
+ 179. 【2410.05586】aserGen: Generating Teasers for Long Documentaries
+ 链接:https://arxiv.org/abs/2410.05586
+ 作者:Weihan Xu,Paul Pu Liang,Haven Kim,Julian McAuley,Taylor Berg-Kirkpatrick,Hao-Wen Dong
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:commercial and educational, educational fields, tool for promoting, effective tool, Teasers
+ 备注:
+
+ 点击查看摘要
+ Abstract:Teasers are an effective tool for promoting content in entertainment, commercial and educational fields. However, creating an effective teaser for long videos is challenging for it requires long-range multimodal modeling on the input videos, while necessitating maintaining audiovisual alignments, managing scene changes and preserving factual accuracy for the output teasers. Due to the lack of a publicly-available dataset, progress along this research direction has been hindered. In this work, we present DocumentaryNet, a collection of 1,269 documentaries paired with their teasers, featuring multimodal data streams of video, speech, music, sound effects and narrations. With DocumentaryNet, we propose a new two-stage system for generating teasers from long documentaries. The proposed TeaserGen system first generates the teaser narration from the transcribed narration of the documentary using a pretrained large language model, and then selects the most relevant visual content to accompany the generated narration through language-vision models. For narration-video matching, we explore two approaches: a pretraining-based model using pretrained contrastive language-vision models and a deep sequential model that learns the mapping between the narrations and visuals. Our experimental results show that the pretraining-based approach is more effective at identifying relevant visual content than directly trained deep autoregressive models.
+
+
+
+ 180. 【2410.05577】Underwater Object Detection in the Era of Artificial Intelligence: Current, Challenge, and Future
+ 链接:https://arxiv.org/abs/2410.05577
+ 作者:Long Chen,Yuzhi Huang,Junyu Dong,Qi Xu,Sam Kwong,Huimin Lu,Huchuan Lu,Chongyi Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:underwater scenes, presents significant challenges, underwater images, significant challenges due, Underwater object detection
+ 备注:
+
+ 点击查看摘要
+ Abstract:Underwater object detection (UOD), aiming to identify and localise the objects in underwater images or videos, presents significant challenges due to the optical distortion, water turbidity, and changing illumination in underwater scenes. In recent years, artificial intelligence (AI) based methods, especially deep learning methods, have shown promising performance in UOD. To further facilitate future advancements, we comprehensively study AI-based UOD. In this survey, we first categorise existing algorithms into traditional machine learning-based methods and deep learning-based methods, and summarise them by considering learning strategy, experimental dataset, utilised features or frameworks, and learning stage. Next, we discuss the potential challenges and suggest possible solutions and new directions. We also perform both quantitative and qualitative evaluations of mainstream algorithms across multiple benchmark datasets by considering the diverse and biased experimental setups. Finally, we introduce two off-the-shelf detection analysis tools, Diagnosis and TIDE, which well-examine the effects of object characteristics and various types of errors on detectors. These tools help identify the strengths and weaknesses of detectors, providing insigts for further improvement. The source codes, trained models, utilised datasets, detection results, and detection analysis tools are public available at \url{this https URL}, and will be regularly updated.
+
+
+
+ 181. 【2410.05564】Unsupervised Representation Learning from Sparse Transformation Analysis
+ 链接:https://arxiv.org/abs/2410.05564
+ 作者:Yue Song,Thomas Anderson Keller,Yisong Yue,Pietro Perona,Max Welling
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:statistical independence, coding efficiency, vast literature, based on principles, representation learning based
+ 备注: submitted to T-PAMI
+
+ 点击查看摘要
+ Abstract:There is a vast literature on representation learning based on principles such as coding efficiency, statistical independence, causality, controllability, or symmetry. In this paper we propose to learn representations from sequence data by factorizing the transformations of the latent variables into sparse components. Input data are first encoded as distributions of latent activations and subsequently transformed using a probability flow model, before being decoded to predict a future input state. The flow model is decomposed into a number of rotational (divergence-free) vector fields and a number of potential flow (curl-free) fields. Our sparsity prior encourages only a small number of these fields to be active at any instant and infers the speed with which the probability flows along these fields. Training this model is completely unsupervised using a standard variational objective and results in a new form of disentangled representations where the input is not only represented by a combination of independent factors, but also by a combination of independent transformation primitives given by the learned flow fields. When viewing the transformations as symmetries one may interpret this as learning approximately equivariant representations. Empirically we demonstrate that this model achieves state of the art in terms of both data likelihood and unsupervised approximate equivariance errors on datasets composed of sequence transformations.
+
+
+
+ 182. 【2410.05557】Rethinking Weak-to-Strong Augmentation in Source-Free Domain Adaptive Object Detection
+ 链接:https://arxiv.org/abs/2410.05557
+ 作者:Jiuzheng Yang,Song Tang,Yangkuiyi Zhang,Shuaifeng Li,Mao Ye,Jianwei Zhang,Xiatian Zhu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:adaptive Object Detection, Object Detection, domain adaptive Object, unlabelled target domains, Source-Free domain adaptive
+ 备注:
+
+ 点击查看摘要
+ Abstract:Source-Free domain adaptive Object Detection (SFOD) aims to transfer a detector (pre-trained on source domain) to new unlabelled target domains. Current SFOD methods typically follow the Mean Teacher framework, where weak-to-strong augmentation provides diverse and sharp contrast for self-supervised learning. However, this augmentation strategy suffers from an inherent problem called crucial semantics loss: Due to random, strong disturbance, strong augmentation is prone to losing typical visual components, hindering cross-domain feature extraction. To address this thus-far ignored limitation, this paper introduces a novel Weak-to-Strong Contrastive Learning (WSCoL) approach. The core idea is to distill semantics lossless knowledge in the weak features (from the weak/teacher branch) to guide the representation learning upon the strong features (from the strong/student branch). To achieve this, we project the original features into a shared space using a mapping network, thereby reducing the bias between the weak and strong features. Meanwhile, a weak features-guided contrastive learning is performed in a weak-to-strong manner alternatively. Specifically, we first conduct an adaptation-aware prototype-guided clustering on the weak features to generate pseudo labels for corresponding strong features matched through proposals. Sequentially, we identify positive-negative samples based on the pseudo labels and perform cross-category contrastive learning on the strong features where an uncertainty estimator encourages adaptive background contrast. Extensive experiments demonstrate that WSCoL yields new state-of-the-art performance, offering a built-in mechanism mitigating crucial semantics loss for traditional Mean Teacher framework. The code and data will be released soon.
+
+
+
+ 183. 【2410.05536】On Feature Decorrelation in Cloth-Changing Person Re-identification
+ 链接:https://arxiv.org/abs/2410.05536
+ 作者:Hongjun Wang,Jiyuan Chen,Renhe Jiang,Xuan Song,Yinqiang Zheng
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:Cloth-changing person re-identification, person re-identification, poses a significant, computer vision, significant challenge
+ 备注:
+
+ 点击查看摘要
+ Abstract:Cloth-changing person re-identification (CC-ReID) poses a significant challenge in computer vision. A prevailing approach is to prompt models to concentrate on causal attributes, like facial features and hairstyles, rather than confounding elements such as clothing appearance. Traditional methods to achieve this involve integrating multi-modality data or employing manually annotated clothing labels, which tend to complicate the model and require extensive human effort. In our study, we demonstrate that simply reducing feature correlations during training can significantly enhance the baseline model's performance. We theoretically elucidate this effect and introduce a novel regularization technique based on density ratio estimation. This technique aims to minimize feature correlation in the training process of cloth-changing ReID baselines. Our approach is model-independent, offering broad enhancements without needing additional data or labels. We validate our method through comprehensive experiments on prevalent CC-ReID datasets, showing its effectiveness in improving baseline models' generalization capabilities.
+
+
+
+ 184. 【2410.05525】Generative Portrait Shadow Removal
+ 链接:https://arxiv.org/abs/2410.05525
+ 作者:Jae Shin Yoon,Zhixin Shu,Mengwei Ren,Xuaner Zhang,Yannick Hold-Geoffroy,Krishna Kumar Singh,He Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:portrait shadow removal, shadow removal, shadow removal model, portrait shadow, high-fidelity portrait shadow
+ 备注: 17 pages, siggraph asia, TOG
+
+ 点击查看摘要
+ Abstract:We introduce a high-fidelity portrait shadow removal model that can effectively enhance the image of a portrait by predicting its appearance under disturbing shadows and highlights. Portrait shadow removal is a highly ill-posed problem where multiple plausible solutions can be found based on a single image. While existing works have solved this problem by predicting the appearance residuals that can propagate local shadow distribution, such methods are often incomplete and lead to unnatural predictions, especially for portraits with hard shadows. We overcome the limitations of existing local propagation methods by formulating the removal problem as a generation task where a diffusion model learns to globally rebuild the human appearance from scratch as a condition of an input portrait image. For robust and natural shadow removal, we propose to train the diffusion model with a compositional repurposing framework: a pre-trained text-guided image generation model is first fine-tuned to harmonize the lighting and color of the foreground with a background scene by using a background harmonization dataset; and then the model is further fine-tuned to generate a shadow-free portrait image via a shadow-paired dataset. To overcome the limitation of losing fine details in the latent diffusion model, we propose a guided-upsampling network to restore the original high-frequency details (wrinkles and dots) from the input image. To enable our compositional training framework, we construct a high-fidelity and large-scale dataset using a lightstage capturing system and synthetic graphics simulation. Our generative framework effectively removes shadows caused by both self and external occlusions while maintaining original lighting distribution and high-frequency details. Our method also demonstrates robustness to diverse subjects captured in real environments.
+
+
+
+ 185. 【2410.05514】oward General Object-level Mapping from Sparse Views with 3D Diffusion Priors
+ 链接:https://arxiv.org/abs/2410.05514
+ 作者:Ziwei Liao,Binbin Xu,Steven L. Waslander
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Robotics (cs.RO)
+ 关键词:Object-level mapping, Object-level mapping builds, Neural Radiance Fields, General Object-level Mapping, mapping
+ 备注: Accepted by CoRL 2024
+
+ 点击查看摘要
+ Abstract:Object-level mapping builds a 3D map of objects in a scene with detailed shapes and poses from multi-view sensor observations. Conventional methods struggle to build complete shapes and estimate accurate poses due to partial occlusions and sensor noise. They require dense observations to cover all objects, which is challenging to achieve in robotics trajectories. Recent work introduces generative shape priors for object-level mapping from sparse views, but is limited to single-category objects. In this work, we propose a General Object-level Mapping system, GOM, which leverages a 3D diffusion model as shape prior with multi-category support and outputs Neural Radiance Fields (NeRFs) for both texture and geometry for all objects in a scene. GOM includes an effective formulation to guide a pre-trained diffusion model with extra nonlinear constraints from sensor measurements without finetuning. We also develop a probabilistic optimization formulation to fuse multi-view sensor observations and diffusion priors for joint 3D object pose and shape estimation. Our GOM system demonstrates superior multi-category mapping performance from sparse views, and achieves more accurate mapping results compared to state-of-the-art methods on the real-world benchmarks. We will release our code: this https URL.
+
+
+
+ 186. 【2410.05500】Residual Kolmogorov-Arnold Network for Enhanced Deep Learning
+ 链接:https://arxiv.org/abs/2410.05500
+ 作者:Ray Congrui Yu,Sherry Wu,Jiang Gui
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Convolutional Neural Networks, complex non-linear dependencies, computer vision tasks, efficiently capture long-range, Convolutional Neural
+ 备注: Code is available at [this https URL](https://github.com/withray/residualKAN.git)
+
+ 点击查看摘要
+ Abstract:Despite the strong performance in many computer vision tasks, Convolutional Neural Networks (CNNs) can sometimes struggle to efficiently capture long-range, complex non-linear dependencies in deeper layers of the network. We address this limitation by introducing Residual KAN, which incorporates the Kolmogorov-Arnold Network (KAN) within the CNN framework as a residual component. Our approach uses Chebyshev polynomials as the basis for KAN convolutions that enables more expressive and adaptive feature representations while maintaining computational efficiency. The proposed RKAN blocks, when integrated into established architectures such as ResNet and DenseNet, offer consistent improvements over the baseline models on various well-known benchmarks. Our results demonstrate the potential of RKAN to enhance the capabilities of deep CNNs in visual data.
+
+
+
+ 187. 【2410.05497】EgoQR: Efficient QR Code Reading in Egocentric Settings
+ 链接:https://arxiv.org/abs/2410.05497
+ 作者:Mohsen Moslehpour,Yichao Lu,Pierce Chuang,Ashish Shenoy,Debojeet Chatterjee,Abhay Harpale,Srihari Jayakumar,Vikas Bhardwaj,Seonghyeon Nam,Anuj Kumar
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:enabling rapid information, rapid information exchange, daily life, enabling rapid, egocentric images
+ 备注: Submitted to ICLR 2025
+
+ 点击查看摘要
+ Abstract:QR codes have become ubiquitous in daily life, enabling rapid information exchange. With the increasing adoption of smart wearable devices, there is a need for efficient, and friction-less QR code reading capabilities from Egocentric point-of-views. However, adapting existing phone-based QR code readers to egocentric images poses significant challenges. Code reading from egocentric images bring unique challenges such as wide field-of-view, code distortion and lack of visual feedback as compared to phones where users can adjust the position and framing. Furthermore, wearable devices impose constraints on resources like compute, power and memory. To address these challenges, we present EgoQR, a novel system for reading QR codes from egocentric images, and is well suited for deployment on wearable devices. Our approach consists of two primary components: detection and decoding, designed to operate on high-resolution images on the device with minimal power consumption and added latency. The detection component efficiently locates potential QR codes within the image, while our enhanced decoding component extracts and interprets the encoded information. We incorporate innovative techniques to handle the specific challenges of egocentric imagery, such as varying perspectives, wider field of view, and motion blur. We evaluate our approach on a dataset of egocentric images, demonstrating 34% improvement in reading the code compared to an existing state of the art QR code readers.
+
+
+
+ 188. 【2410.05474】R-Bench: Are your Large Multimodal Model Robust to Real-world Corruptions?
+ 链接:https://arxiv.org/abs/2410.05474
+ 作者:Chunyi Li,Jianbo Zhang,Zicheng Zhang,Haoning Wu,Yuan Tian,Wei Sun,Guo Lu,Xiaohong Liu,Xiongkuo Min,Weisi Lin,Guangtao Zhai
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM); Image and Video Processing (eess.IV)
+ 关键词:Large Multimodal Models, Large Multimodal, Multimodal Models, vision-related tasks, made them widely
+ 备注:
+
+ 点击查看摘要
+ Abstract:The outstanding performance of Large Multimodal Models (LMMs) has made them widely applied in vision-related tasks. However, various corruptions in the real world mean that images will not be as ideal as in simulations, presenting significant challenges for the practical application of LMMs. To address this issue, we introduce R-Bench, a benchmark focused on the **Real-world Robustness of LMMs**. Specifically, we: (a) model the complete link from user capture to LMMs reception, comprising 33 corruption dimensions, including 7 steps according to the corruption sequence, and 7 groups based on low-level attributes; (b) collect reference/distorted image dataset before/after corruption, including 2,970 question-answer pairs with human labeling; (c) propose comprehensive evaluation for absolute/relative robustness and benchmark 20 mainstream LMMs. Results show that while LMMs can correctly handle the original reference images, their performance is not stable when faced with distorted images, and there is a significant gap in robustness compared to the human visual system. We hope that R-Bench will inspire improving the robustness of LMMs, **extending them from experimental simulations to the real-world application**. Check this https URL for details.
+
+
+
+ 189. 【2410.05470】Image Watermarks are Removable Using Controllable Regeneration from Clean Noise
+ 链接:https://arxiv.org/abs/2410.05470
+ 作者:Yepeng Liu,Yiren Song,Hai Ci,Yu Zhang,Haofan Wang,Mike Zheng Shou,Yuheng Bu
+ 类目:Cryptography and Security (cs.CR); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:trace content sources, large generative models, watermark techniques provide, watermark removal, Image watermark techniques
+ 备注:
+
+ 点击查看摘要
+ Abstract:Image watermark techniques provide an effective way to assert ownership, deter misuse, and trace content sources, which has become increasingly essential in the era of large generative models. A critical attribute of watermark techniques is their robustness against various manipulations. In this paper, we introduce a watermark removal approach capable of effectively nullifying the state of the art watermarking techniques. Our primary insight involves regenerating the watermarked image starting from a clean Gaussian noise via a controllable diffusion model, utilizing the extracted semantic and spatial features from the watermarked image. The semantic control adapter and the spatial control network are specifically trained to control the denoising process towards ensuring image quality and enhancing consistency between the cleaned image and the original watermarked image. To achieve a smooth trade-off between watermark removal performance and image consistency, we further propose an adjustable and controllable regeneration scheme. This scheme adds varying numbers of noise steps to the latent representation of the watermarked image, followed by a controlled denoising process starting from this noisy latent representation. As the number of noise steps increases, the latent representation progressively approaches clean Gaussian noise, facilitating the desired trade-off. We apply our watermark removal methods across various watermarking techniques, and the results demonstrate that our methods offer superior visual consistency/quality and enhanced watermark removal performance compared to existing regeneration approaches.
+
+
+
+ 190. 【2410.05468】PH-Dropout: Prctical Epistemic Uncertainty Quantification for View Synthesis
+ 链接:https://arxiv.org/abs/2410.05468
+ 作者:Chuanhao Sun,Thanos Triantafyllou,Anthos Makris,Maja Drmač,Kai Xu,Luo Mai,Mahesh K. Marina
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Neural Radiance Fields, Radiance Fields, Gaussian Splatting, rendering real-world scenarios, demonstrated impressive fidelity
+ 备注: 21 pages, in submision
+
+ 点击查看摘要
+ Abstract:View synthesis using Neural Radiance Fields (NeRF) and Gaussian Splatting (GS) has demonstrated impressive fidelity in rendering real-world scenarios. However, practical methods for accurate and efficient epistemic Uncertainty Quantification (UQ) in view synthesis are lacking. Existing approaches for NeRF either introduce significant computational overhead (e.g., ``10x increase in training time" or ``10x repeated training") or are limited to specific uncertainty conditions or models. Notably, GS models lack any systematic approach for comprehensive epistemic UQ. This capability is crucial for improving the robustness and scalability of neural view synthesis, enabling active model updates, error estimation, and scalable ensemble modeling based on uncertainty. In this paper, we revisit NeRF and GS-based methods from a function approximation perspective, identifying key differences and connections in 3D representation learning. Building on these insights, we introduce PH-Dropout (Post hoc Dropout), the first real-time and accurate method for epistemic uncertainty estimation that operates directly on pre-trained NeRF and GS models. Extensive evaluations validate our theoretical findings and demonstrate the effectiveness of PH-Dropout.
+
+
+
+ 191. 【2410.05466】Herd Mentality in Augmentation -- Not a Good Idea! A Robust Multi-stage Approach towards Deepfake Detection
+ 链接:https://arxiv.org/abs/2410.05466
+ 作者:Monu,Rohan Raju Dhanakshirur
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:raised significant concerns, digital media integrity, safeguarding digital media, digital media, rapid increase
+ 备注:
+
+ 点击查看摘要
+ Abstract:The rapid increase in deepfake technology has raised significant concerns about digital media integrity. Detecting deepfakes is crucial for safeguarding digital media. However, most standard image classifiers fail to distinguish between fake and real faces. Our analysis reveals that this failure is due to the model's inability to explicitly focus on the artefacts typically in deepfakes. We propose an enhanced architecture based on the GenConViT model, which incorporates weighted loss and update augmentation techniques and includes masked eye pretraining. This proposed model improves the F1 score by 1.71% and the accuracy by 4.34% on the Celeb-DF v2 dataset. The source code for our model is available at this https URL
+
+
+
+ 192. 【2410.05450】AI-Driven Early Mental Health Screening with Limited Data: Analyzing Selfies of Pregnant Women
+ 链接:https://arxiv.org/abs/2410.05450
+ 作者:Gustavo A. Basílio,Thiago B. Pereira,Alessandro L. Koerich,Ludmila Dias,Maria das Graças da S. Teixeira,Rafael T. Sousa,Wilian H. Hisatugu,Amanda S. Mota,Anilton S. Garcia,Marco Aurélio K. Galletta,Hermano Tavares,Thiago M. Paixão
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Major Depressive Disorder, Major Depressive, affect millions globally, mental health issues, anxiety disorders affect
+ 备注:
+
+ 点击查看摘要
+ Abstract:Major Depressive Disorder and anxiety disorders affect millions globally, contributing significantly to the burden of mental health issues. Early screening is crucial for effective intervention, as timely identification of mental health issues can significantly improve treatment outcomes. Artificial intelligence (AI) can be valuable for improving the screening of mental disorders, enabling early intervention and better treatment outcomes. AI-driven screening can leverage the analysis of multiple data sources, including facial features in digital images. However, existing methods often rely on controlled environments or specialized equipment, limiting their broad applicability. This study explores the potential of AI models for ubiquitous depression-anxiety screening given face-centric selfies. The investigation focuses on high-risk pregnant patients, a population that is particularly vulnerable to mental health issues. To cope with limited training data resulting from our clinical setup, pre-trained models were utilized in two different approaches: fine-tuning convolutional neural networks (CNNs) originally designed for facial expression recognition and employing vision-language models (VLMs) for zero-shot analysis of facial expressions. Experimental results indicate that the proposed VLM-based method significantly outperforms CNNs, achieving an accuracy of 77.6% and an F1-score of 56.0%. Although there is significant room for improvement, the results suggest that VLMs can be a promising approach for mental health screening, especially in scenarios with limited data.
+
+
+
+ 193. 【2410.05443】A Deep Learning-Based Approach for Mangrove Monitoring
+ 链接:https://arxiv.org/abs/2410.05443
+ 作者:Lucas José Velôso de Souza,Ingrid Valverde Reis Zreik,Adrien Salem-Sermanet,Nacéra Seghouani,Lionel Pourchier
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:dynamic coastal ecosystems, economic stability, environmental health, climate resilience, dynamic coastal
+ 备注: 12 pages, accepted to the MACLEAN workshop of ECML/PKDD 2024
+
+ 点击查看摘要
+ Abstract:Mangroves are dynamic coastal ecosystems that are crucial to environmental health, economic stability, and climate resilience. The monitoring and preservation of mangroves are of global importance, with remote sensing technologies playing a pivotal role in these efforts. The integration of cutting-edge artificial intelligence with satellite data opens new avenues for ecological monitoring, potentially revolutionizing conservation strategies at a time when the protection of natural resources is more crucial than ever. The objective of this work is to provide a comprehensive evaluation of recent deep-learning models on the task of mangrove segmentation. We first introduce and make available a novel open-source dataset, MagSet-2, incorporating mangrove annotations from the Global Mangrove Watch and satellite images from Sentinel-2, from mangrove positions all over the world. We then benchmark three architectural groups, namely convolutional, transformer, and mamba models, using the created dataset. The experimental outcomes further validate the deep learning community's interest in the Mamba model, which surpasses other architectures in all metrics.
+
+
+
+ 194. 【2410.05438】DAAL: Density-Aware Adaptive Line Margin Loss for Multi-Modal Deep Metric Learning
+ 链接:https://arxiv.org/abs/2410.05438
+ 作者:Hadush Hailu Gebrerufael,Anil Kumar Tiwari,Gaurav Neupane
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:effectively capturing diverse, fine-grained object recognition, capturing diverse representations, face verification, object recognition
+ 备注: 13 pages, 4 fugues, 2 tables
+
+ 点击查看摘要
+ Abstract:Multi-modal deep metric learning is crucial for effectively capturing diverse representations in tasks such as face verification, fine-grained object recognition, and product search. Traditional approaches to metric learning, whether based on distance or margin metrics, primarily emphasize class separation, often overlooking the intra-class distribution essential for multi-modal feature learning. In this context, we propose a novel loss function called Density-Aware Adaptive Margin Loss(DAAL), which preserves the density distribution of embeddings while encouraging the formation of adaptive sub-clusters within each class. By employing an adaptive line strategy, DAAL not only enhances intra-class variance but also ensures robust inter-class separation, facilitating effective multi-modal representation. Comprehensive experiments on benchmark fine-grained datasets demonstrate the superior performance of DAAL, underscoring its potential in advancing retrieval applications and multi-modal deep metric learning.
+
+
+
+ 195. 【2410.05436】Discovering distinctive elements of biomedical datasets for high-performance exploration
+ 链接:https://arxiv.org/abs/2410.05436
+ 作者:Md Tauhidul Islam,Lei Xing
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:human brain represents, objects based, human brain, brain represents, DEA
+ 备注: 13 pages, 5 figures
+
+ 点击查看摘要
+ Abstract:The human brain represents an object by small elements and distinguishes two objects based on the difference in elements. Discovering the distinctive elements of high-dimensional datasets is therefore critical in numerous perception-driven biomedical and clinical studies. However, currently there is no available method for reliable extraction of distinctive elements of high-dimensional biomedical and clinical datasets. Here we present an unsupervised deep learning technique namely distinctive element analysis (DEA), which extracts the distinctive data elements using high-dimensional correlative information of the datasets. DEA at first computes a large number of distinctive parts of the data, then filters and condenses the parts into DEA elements by employing a unique kernel-driven triple-optimization network. DEA has been found to improve the accuracy by up to 45% in comparison to the traditional techniques in applications such as disease detection from medical images, gene ranking and cell recognition from single cell RNA sequence (scRNA-seq) datasets. Moreover, DEA allows user-guided manipulation of the intermediate calculation process and thus offers intermediate results with better interpretability.
+
+
+
+ 196. 【2410.05410】Enhanced Super-Resolution Training via Mimicked Alignment for Real-World Scenes
+ 链接:https://arxiv.org/abs/2410.05410
+ 作者:Omar Elezabi,Zongwei Wu,Radu Timofte
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:deep learning techniques, ample training data, made significant strides, significant strides, strides with deep
+ 备注: Accepted by ACCV 2024
+
+ 点击查看摘要
+ Abstract:Image super-resolution methods have made significant strides with deep learning techniques and ample training data. However, they face challenges due to inherent misalignment between low-resolution (LR) and high-resolution (HR) pairs in real-world datasets. In this study, we propose a novel plug-and-play module designed to mitigate these misalignment issues by aligning LR inputs with HR images during training. Specifically, our approach involves mimicking a novel LR sample that aligns with HR while preserving the degradation characteristics of the original LR samples. This module seamlessly integrates with any SR model, enhancing robustness against misalignment. Importantly, it can be easily removed during inference, therefore without introducing any parameters on the conventional SR models. We comprehensively evaluate our method on synthetic and real-world datasets, demonstrating its effectiveness across a spectrum of SR models, including traditional CNNs and state-of-the-art Transformers. The source codes will be publicly made available at this https URL .
+
+
+
+ 197. 【2410.05403】Deep learning-based Visual Measurement Extraction within an Adaptive Digital Twin Framework from Limited Data Using Transfer Learning
+ 链接:https://arxiv.org/abs/2410.05403
+ 作者:Mehrdad Shafiei Dizaji
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:Digital Twins technology, Digital Image Correlation, Convolutional Neural Networks, Digital Twins, Twins technology
+ 备注: 37, 14
+
+ 点击查看摘要
+ Abstract:Digital Twins technology is revolutionizing decision-making in scientific research by integrating models and simulations with real-time data. Unlike traditional Structural Health Monitoring methods, which rely on computationally intensive Digital Image Correlation and have limitations in real-time data integration, this research proposes a novel approach using Artificial Intelligence. Specifically, Convolutional Neural Networks are employed to analyze structural behaviors in real-time by correlating Digital Image Correlation speckle pattern images with deformation fields. Initially focusing on two-dimensional speckle patterns, the research extends to three-dimensional applications using stereo-paired images for comprehensive deformation analysis. This method overcomes computational challenges by utilizing a mix of synthetically generated and authentic speckle pattern images for training the Convolutional Neural Networks. The models are designed to be robust and versatile, offering a promising alternative to traditional measurement techniques and paving the way for advanced applications in three-dimensional modeling. This advancement signifies a shift towards more efficient and dynamic structural health monitoring by leveraging the power of Artificial Intelligence for real-time simulation and analysis.
+
+
+
+ 198. 【2410.05363】owards World Simulator: Crafting Physical Commonsense-Based Benchmark for Video Generation
+ 链接:https://arxiv.org/abs/2410.05363
+ 作者:Fanqing Meng,Jiaqi Liao,Xinyu Tan,Wenqi Shao,Quanfeng Lu,Kaipeng Zhang,Yu Cheng,Dianqi Li,Yu Qiao,Ping Luo
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:universal world simulator, made significant strides, Sora have made, visualizing complex prompts, world simulator
+ 备注: Project Page: [this https URL](https://phygenbench123.github.io/)
+
+ 点击查看摘要
+ Abstract:Text-to-video (T2V) models like Sora have made significant strides in visualizing complex prompts, which is increasingly viewed as a promising path towards constructing the universal world simulator. Cognitive psychologists believe that the foundation for achieving this goal is the ability to understand intuitive physics. However, the capacity of these models to accurately represent intuitive physics remains largely unexplored. To bridge this gap, we introduce PhyGenBench, a comprehensive \textbf{Phy}sics \textbf{Gen}eration \textbf{Ben}chmark designed to evaluate physical commonsense correctness in T2V generation. PhyGenBench comprises 160 carefully crafted prompts across 27 distinct physical laws, spanning four fundamental domains, which could comprehensively assesses models' understanding of physical commonsense. Alongside PhyGenBench, we propose a novel evaluation framework called PhyGenEval. This framework employs a hierarchical evaluation structure utilizing appropriate advanced vision-language models and large language models to assess physical commonsense. Through PhyGenBench and PhyGenEval, we can conduct large-scale automated assessments of T2V models' understanding of physical commonsense, which align closely with human feedback. Our evaluation results and in-depth analysis demonstrate that current models struggle to generate videos that comply with physical commonsense. Moreover, simply scaling up models or employing prompt engineering techniques is insufficient to fully address the challenges presented by PhyGenBench (e.g., dynamic scenarios). We hope this study will inspire the community to prioritize the learning of physical commonsense in these models beyond entertainment applications. We will release the data and codes at this https URL
+
+
+
+ 199. 【2410.05345】rained Models Tell Us How to Make Them Robust to Spurious Correlation without Group Annotation
+ 链接:https://arxiv.org/abs/2410.05345
+ 作者:Mahdi Ghaznavi,Hesam Asadollahzadeh,Fahimeh Hosseini Noohdani,Soroush Vafaie Tabar,Hosein Hasani,Taha Akbari Alvanagh,Mohammad Hossein Rohban,Mahdieh Soleymani Baghshah
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Empirical Risk Minimization, Risk Minimization, Empirical Risk, Classifiers trained, group
+ 备注:
+
+ 点击查看摘要
+ Abstract:Classifiers trained with Empirical Risk Minimization (ERM) tend to rely on attributes that have high spurious correlation with the target. This can degrade the performance on underrepresented (or 'minority') groups that lack these attributes, posing significant challenges for both out-of-distribution generalization and fairness objectives. Many studies aim to enhance robustness to spurious correlation, but they sometimes depend on group annotations for training. Additionally, a common limitation in previous research is the reliance on group-annotated validation datasets for model selection. This constrains their applicability in situations where the nature of the spurious correlation is not known, or when group labels for certain spurious attributes are not available. To enhance model robustness with minimal group annotation assumptions, we propose Environment-based Validation and Loss-based Sampling (EVaLS). It uses the losses from an ERM-trained model to construct a balanced dataset of high-loss and low-loss samples, mitigating group imbalance in data. This significantly enhances robustness to group shifts when equipped with a simple post-training last layer retraining. By using environment inference methods to create diverse environments with correlation shifts, EVaLS can potentially eliminate the need for group annotation in validation data. In this context, the worst environment accuracy acts as a reliable surrogate throughout the retraining process for tuning hyperparameters and finding a model that performs well across diverse group shifts. EVaLS effectively achieves group robustness, showing that group annotation is not necessary even for validation. It is a fast, straightforward, and effective approach that reaches near-optimal worst group accuracy without needing group annotations, marking a new chapter in the robustness of trained models against spurious correlation.
+
+
+
+ 200. 【2410.05343】EgoOops: A Dataset for Mistake Action Detection from Egocentric Videos with Procedural Texts
+ 链接:https://arxiv.org/abs/2410.05343
+ 作者:Yuto Haneji,Taichi Nishimura,Hirotaka Kameko,Keisuke Shirai,Tomoya Yoshida,Keiya Kajimura,Koki Yamamoto,Taiyu Cui,Tomohiro Nishimoto,Shinsuke Mori
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:developing intelligent archives, detect workers' errors, provide feedback, procedural texts, crucial for developing
+ 备注:
+
+ 点击查看摘要
+ Abstract:Mistake action detection from egocentric videos is crucial for developing intelligent archives that detect workers' errors and provide feedback. Previous studies have been limited to specific domains, focused on detecting mistakes from videos without procedural texts, and analyzed whether actions are mistakes. To address these limitations, in this paper, we propose the EgoOops dataset, which includes egocentric videos, procedural texts, and three types of annotations: video-text alignment, mistake labels, and descriptions for mistakes. EgoOops covers five procedural domains and includes 50 egocentric videos. The video-text alignment allows the model to detect mistakes based on both videos and procedural texts. The mistake labels and descriptions enable detailed analysis of real-world mistakes. Based on EgoOops, we tackle two tasks: video-text alignment and mistake detection. For video-text alignment, we enhance the recent StepFormer model with an additional loss for fine-tuning. Based on the alignment results, we propose a multi-modal classifier to predict mistake labels. In our experiments, the proposed methods achieve higher performance than the baselines. In addition, our ablation study demonstrates the effectiveness of combining videos and texts. We will release the dataset and codes upon publication.
+
+
+
+ 201. 【2410.05322】Noise Crystallization and Liquid Noise: Zero-shot Video Generation using Image Diffusion Models
+ 链接:https://arxiv.org/abs/2410.05322
+ 作者:Muhammad Haaris Khan,Hadrien Reynaud,Bernhard Kainz
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:consistent and controllable, longstanding problem, models, diffusion models, video
+ 备注:
+
+ 点击查看摘要
+ Abstract:Although powerful for image generation, consistent and controllable video is a longstanding problem for diffusion models. Video models require extensive training and computational resources, leading to high costs and large environmental impacts. Moreover, video models currently offer limited control of the output motion. This paper introduces a novel approach to video generation by augmenting image diffusion models to create sequential animation frames while maintaining fine detail. These techniques can be applied to existing image models without training any video parameters (zero-shot) by altering the input noise in a latent diffusion model. Two complementary methods are presented. Noise crystallization ensures consistency but is limited to large movements due to reduced latent embedding sizes. Liquid noise trades consistency for greater flexibility without resolution limitations. The core concepts also allow other applications such as relighting, seamless upscaling, and improved video style transfer. Furthermore, an exploration of the VAE embedding used for latent diffusion models is performed, resulting in interesting theoretical insights such as a method for human-interpretable latent spaces.
+
+
+
+ 202. 【2410.05317】Accelerating Diffusion Transformers with Token-wise Feature Caching
+ 链接:https://arxiv.org/abs/2410.05317
+ 作者:Chang Zou,Xuyang Liu,Ting Liu,Siteng Huang,Linfeng Zhang
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:huge computation costs, shown significant effectiveness, Diffusion transformers, accelerate diffusion transformers, computation costs
+ 备注:
+
+ 点击查看摘要
+ Abstract:Diffusion transformers have shown significant effectiveness in both image and video synthesis at the expense of huge computation costs. To address this problem, feature caching methods have been introduced to accelerate diffusion transformers by caching the features in previous timesteps and reusing them in the following timesteps. However, previous caching methods ignore that different tokens exhibit different sensitivities to feature caching, and feature caching on some tokens may lead to 10$\times$ more destruction to the overall generation quality compared with other tokens. In this paper, we introduce token-wise feature caching, allowing us to adaptively select the most suitable tokens for caching, and further enable us to apply different caching ratios to neural layers in different types and depths. Extensive experiments on PixArt-$\alpha$, OpenSora, and DiT demonstrate our effectiveness in both image and video generation with no requirements for training. For instance, 2.36$\times$ and 1.93$\times$ acceleration are achieved on OpenSora and PixArt-$\alpha$ with almost no drop in generation quality.
+
+
+
+ 203. 【2410.05309】ShieldDiff: Suppressing Sexual Content Generation from Diffusion Models through Reinforcement Learning
+ 链接:https://arxiv.org/abs/2410.05309
+ 作者:Dong Han,Salaheldin Mohamed,Yong Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:advance of generative, model, contents, unsafe, content generation
+ 备注: 9 pages, 10 figures
+
+ 点击查看摘要
+ Abstract:With the advance of generative AI, the text-to-image (T2I) model has the ability to generate various contents. However, the generated contents cannot be fully controlled. There is a potential risk that T2I model can generate unsafe images with uncomfortable contents. In our work, we focus on eliminating the NSFW (not safe for work) content generation from T2I model while maintaining the high quality of generated images by fine-tuning the pre-trained diffusion model via reinforcement learning by optimizing the well-designed content-safe reward function. The proposed method leverages a customized reward function consisting of the CLIP (Contrastive Language-Image Pre-training) and nudity rewards to prune the nudity contents that adhere to the pret-rained model and keep the corresponding semantic meaning on the safe side. In this way, the T2I model is robust to unsafe adversarial prompts since unsafe visual representations are mitigated from latent space. Extensive experiments conducted on different datasets demonstrate the effectiveness of the proposed method in alleviating unsafe content generation while preserving the high-fidelity of benign images as well as images generated by unsafe prompts. We compare with five existing state-of-the-art (SOTA) methods and achieve competitive performance on sexual content removal and image quality retention. In terms of robustness, our method outperforms counterparts under the SOTA black-box attacking model. Furthermore, our constructed method can be a benchmark for anti-NSFW generation with semantically-relevant safe alignment.
+
+
+
+ 204. 【2410.05301】Diffusion-based Unsupervised Audio-visual Speech Enhancement
+ 链接:https://arxiv.org/abs/2410.05301
+ 作者:Jean-Eudes Ayilo(MULTISPEECH),Mostafa Sadeghi(MULTISPEECH),Romain Serizel(MULTISPEECH),Xavier Alameda-Pineda(ROBOTLEARN)
+ 类目:ound (cs.SD); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Audio and Speech Processing (eess.AS); Signal Processing (eess.SP)
+ 关键词:non-negative matrix factorization, audiovisual speech enhancement, unsupervised audiovisual speech, audio-visual speech generative, matrix factorization
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper proposes a new unsupervised audiovisual speech enhancement (AVSE) approach that combines a diffusion-based audio-visual speech generative model with a non-negative matrix factorization (NMF) noise model. First, the diffusion model is pre-trained on clean speech conditioned on corresponding video data to simulate the speech generative distribution. This pre-trained model is then paired with the NMF-based noise model to iteratively estimate clean speech. Specifically, a diffusion-based posterior sampling approach is implemented within the reverse diffusion process, where after each iteration, a speech estimate is obtained and used to update the noise parameters. Experimental results confirm that the proposed AVSE approach not only outperforms its audio-only counterpart but also generalizes better than a recent supervisedgenerative AVSE method. Additionally, the new inference algorithm offers a better balance between inference speed and performance compared to the previous diffusion-based method.
+
+
+
+ 205. 【2410.05284】Psychometrics for Hypnopaedia-Aware Machinery via Chaotic Projection of Artificial Mental Imagery
+ 链接:https://arxiv.org/abs/2410.05284
+ 作者:Ching-Chun Chang,Kai Gao,Shuying Xu,Anastasia Kordoni,Christopher Leckie,Isao Echizen
+ 类目:Cryptography and Security (cs.CR); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Neural backdoors represent, represent insidious cybersecurity, insidious cybersecurity loopholes, render learning machinery, learning machinery vulnerable
+ 备注:
+
+ 点击查看摘要
+ Abstract:Neural backdoors represent insidious cybersecurity loopholes that render learning machinery vulnerable to unauthorised manipulations, potentially enabling the weaponisation of artificial intelligence with catastrophic consequences. A backdoor attack involves the clandestine infiltration of a trigger during the learning process, metaphorically analogous to hypnopaedia, where ideas are implanted into a subject's subconscious mind under the state of hypnosis or unconsciousness. When activated by a sensory stimulus, the trigger evokes conditioned reflex that directs a machine to mount a predetermined response. In this study, we propose a cybernetic framework for constant surveillance of backdoors threats, driven by the dynamic nature of untrustworthy data sources. We develop a self-aware unlearning mechanism to autonomously detach a machine's behaviour from the backdoor trigger. Through reverse engineering and statistical inference, we detect deceptive patterns and estimate the likelihood of backdoor infection. We employ model inversion to elicit artificial mental imagery, using stochastic processes to disrupt optimisation pathways and avoid convergent but potentially flawed patterns. This is followed by hypothesis analysis, which estimates the likelihood of each potentially malicious pattern being the true trigger and infers the probability of infection. The primary objective of this study is to maintain a stable state of equilibrium between knowledge fidelity and backdoor vulnerability.
+
+
+
+ 206. 【2410.05274】Scale-Invariant Object Detection by Adaptive Convolution with Unified Global-Local Context
+ 链接:https://arxiv.org/abs/2410.05274
+ 作者:Amrita Singh,Snehasis Mukherjee
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:detecting minute objects, CNN models, Dense features, multi-scale object detection, object detection
+ 备注:
+
+ 点击查看摘要
+ Abstract:Dense features are important for detecting minute objects in images. Unfortunately, despite the remarkable efficacy of the CNN models in multi-scale object detection, CNN models often fail to detect smaller objects in images due to the loss of dense features during the pooling process. Atrous convolution addresses this issue by applying sparse kernels. However, sparse kernels often can lose the multi-scale detection efficacy of the CNN model. In this paper, we propose an object detection model using a Switchable (adaptive) Atrous Convolutional Network (SAC-Net) based on the efficientDet model. A fixed atrous rate limits the performance of the CNN models in the convolutional layers. To overcome this limitation, we introduce a switchable mechanism that allows for dynamically adjusting the atrous rate during the forward pass. The proposed SAC-Net encapsulates the benefits of both low-level and high-level features to achieve improved performance on multi-scale object detection tasks, without losing the dense features. Further, we apply a depth-wise switchable atrous rate to the proposed network, to improve the scale-invariant features. Finally, we apply global context on the proposed model. Our extensive experiments on benchmark datasets demonstrate that the proposed SAC-Net outperforms the state-of-the-art models by a significant margin in terms of accuracy.
+
+
+
+ 207. 【2410.05273】HiRT: Enhancing Robotic Control with Hierarchical Robot Transformers
+ 链接:https://arxiv.org/abs/2410.05273
+ 作者:Jianke Zhang,Yanjiang Guo,Xiaoyu Chen,Yen-Jen Wang,Yucheng Hu,Chengming Shi,Jianyu Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Robotics (cs.RO)
+ 关键词:leveraging powerful pre, impressive generalization ability, powerful pre trained, pre trained Vision-Language, trained Vision-Language Models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Vision-Language-Action (VLA) models, leveraging powerful pre trained Vision-Language Models (VLMs) backends, have shown promise in robotic control due to their impressive generalization ability. However, the success comes at a cost. Their reliance on VLM backends with billions of parameters leads to high computational costs and inference latency, limiting the testing scenarios to mainly quasi-static tasks and hindering performance in dynamic tasks requiring rapid interactions. To address these limitations, this paper proposes HiRT, a Hierarchical Robot Transformer framework that enables flexible frequency and performance trade-off. HiRT keeps VLMs running at low frequencies to capture temporarily invariant features while enabling real-time interaction through a high-frequency vision-based policy guided by the slowly updated features. Experiment results in both simulation and real-world settings demonstrate significant improvements over baseline methods. Empirically, in static tasks, we double the control frequency and achieve comparable success rates. Additionally, on novel real-world dynamic ma nipulation tasks which are challenging for previous VLA models, HiRT improves the success rate from 48% to 75%.
+
+
+
+ 208. 【2404.00847】Collaborative Learning of Anomalies with Privacy (CLAP) for Unsupervised Video Anomaly Detection: A New Baseline
+ 链接:https://arxiv.org/abs/2404.00847
+ 作者:Anas Al-lahham,Muhammad Zaigham Zaheer,Nurbek Tastan,Karthik Nandakumar
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:practical real-world applications, popularity recently due, real-world applications, gaining more popularity, popularity recently
+ 备注: Accepted in IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), 2024
+
+ 点击查看摘要
+ Abstract:Unsupervised (US) video anomaly detection (VAD) in surveillance applications is gaining more popularity recently due to its practical real-world applications. As surveillance videos are privacy sensitive and the availability of large-scale video data may enable better US-VAD systems, collaborative learning can be highly rewarding in this setting. However, due to the extremely challenging nature of the US-VAD task, where learning is carried out without any annotations, privacy-preserving collaborative learning of US-VAD systems has not been studied yet. In this paper, we propose a new baseline for anomaly detection capable of localizing anomalous events in complex surveillance videos in a fully unsupervised fashion without any labels on a privacy-preserving participant-based distributed training configuration. Additionally, we propose three new evaluation protocols to benchmark anomaly detection approaches on various scenarios of collaborations and data availability. Based on these protocols, we modify existing VAD datasets to extensively evaluate our approach as well as existing US SOTA methods on two large-scale datasets including UCF-Crime and XD-Violence. All proposed evaluation protocols, dataset splits, and codes are available here: this https URL
+
+
+
+ 209. 【2410.07148】Lateral Ventricle Shape Modeling using Peripheral Area Projection for Longitudinal Analysis
+ 链接:https://arxiv.org/abs/2410.07148
+ 作者:Wonjung Park,Suhyun Ahn,Jinah Park
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:identify specific morphometric, lateral ventricle, widely studied, studied to identify, identify specific
+ 备注: Annual Conference on Medical Image Understanding and Analysis (2024)
+
+ 点击查看摘要
+ Abstract:The deformation of the lateral ventricle (LV) shape is widely studied to identify specific morphometric changes associated with diseases. Since LV enlargement is considered a relative change due to brain atrophy, local longitudinal LV deformation can indicate deformation in adjacent brain areas. However, conventional methods for LV shape analysis focus on modeling the solely segmented LV mask. In this work, we propose a novel deep learning-based approach using peripheral area projection, which is the first attempt to analyze LV considering its surrounding areas. Our approach matches the baseline LV mesh by deforming the shape of follow-up LVs, while optimizing the corresponding points of the same adjacent brain area between the baseline and follow-up LVs. Furthermore, we quantitatively evaluated the deformation of the left LV in normal (n=10) and demented subjects (n=10), and we found that each surrounding area (thalamus, caudate, hippocampus, amygdala, and right LV) projected onto the surface of LV shows noticeable differences between normal and demented subjects.
+
+
+
+ 210. 【2410.07111】Utility of Multimodal Large Language Models in Analyzing Chest X-ray with Incomplete Contextual Information
+ 链接:https://arxiv.org/abs/2410.07111
+ 作者:Choonghan Kim,Seonhee Cho,Joo Heung Yoon
+ 类目:Image and Video Processing (eess.IV); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:chest radiography reports, chest radiography, radiography reports, Background, LLMs
+ 备注:
+
+ 点击查看摘要
+ Abstract:Background: Large language models (LLMs) are gaining use in clinical settings, but their performance can suffer with incomplete radiology reports. We tested whether multimodal LLMs (using text and images) could improve accuracy and understanding in chest radiography reports, making them more effective for clinical decision support.
+Purpose: To assess the robustness of LLMs in generating accurate impressions from chest radiography reports using both incomplete data and multimodal data. Material and Methods: We used 300 radiology image-report pairs from the MIMIC-CXR database. Three LLMs (OpenFlamingo, MedFlamingo, IDEFICS) were tested in both text-only and multimodal formats. Impressions were first generated from the full text, then tested by removing 20%, 50%, and 80% of the text. The impact of adding images was evaluated using chest x-rays, and model performance was compared using three metrics with statistical analysis.
+Results: The text-only models (OpenFlamingo, MedFlamingo, IDEFICS) had similar performance (ROUGE-L: 0.39 vs. 0.21 vs. 0.21; F1RadGraph: 0.34 vs. 0.17 vs. 0.17; F1CheXbert: 0.53 vs. 0.40 vs. 0.40), with OpenFlamingo performing best on complete text (p0.001). Performance declined with incomplete data across all models. However, adding images significantly boosted the performance of MedFlamingo and IDEFICS (p0.001), equaling or surpassing OpenFlamingo, even with incomplete text. Conclusion: LLMs may produce low-quality outputs with incomplete radiology data, but multimodal LLMs can improve reliability and support clinical decision-making.
+Keywords: Large language model; multimodal; semantic analysis; Chest Radiography; Clinical Decision Support;
+
Subjects:
+Image and Video Processing (eess.IV); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+Cite as:
+arXiv:2410.07111 [eess.IV]
+(or
+arXiv:2410.07111v1 [eess.IV] for this version)
+https://doi.org/10.48550/arXiv.2410.07111
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)
+
+Submission history From: Choonghan Kim [view email] [v1]
+Fri, 20 Sep 2024 01:42:53 UTC (939 KB)
+
+
+
+ 211. 【2410.07043】Z-upscaling: Optical Flow Guided Frame Interpolation for Isotropic Reconstruction of 3D EM Volumes
+ 链接:https://arxiv.org/abs/2410.07043
+ 作者:Fisseha A. Ferede,Ali Khalighifar,Jaison John,Krishnan Venkataraman,Khaled Khairy
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:optical flow based, enhance the axial, Abstract, reconstruction, optical flow
+ 备注:
+
+ 点击查看摘要
+ Abstract:We propose a novel optical flow based approach to enhance the axial resolution of anisotropic 3D EM volumes to achieve isotropic 3D reconstruction. Assuming spatial continuity of 3D biological structures in well aligned EM volumes, we reasoned that optical flow estimation techniques, often applied for temporal resolution enhancement in videos, can be utilized. Pixel level motion is estimated between neighboring 2D slices along z, using spatial gradient flow estimates to interpolate and generate new 2D slices resulting in isotropic voxels. We leverage recent state-of-the-art learning methods for video frame interpolation and transfer learning techniques, and demonstrate the success of our approach on publicly available ultrastructure EM volumes.
+
+
+
+ 212. 【2410.06997】A Diffusion-based Xray2MRI Model: Generating Pseudo-MRI Volumes From one Single X-ray
+ 链接:https://arxiv.org/abs/2410.06997
+ 作者:Zhe Wang,Rachid Jennane,Aladine Chetouani,Mohamed Jarraya
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:prevalent musculoskeletal disorder, Knee osteoarthritis, musculoskeletal disorder, prevalent musculoskeletal, diagnosis due
+ 备注:
+
+ 点击查看摘要
+ Abstract:Knee osteoarthritis (KOA) is a prevalent musculoskeletal disorder, and X-rays are commonly used for its diagnosis due to their cost-effectiveness. Magnetic Resonance Imaging (MRI), on the other hand, offers detailed soft tissue visualization and has become a valuable supplementary diagnostic tool for KOA. Unfortunately, the high cost and limited accessibility of MRI hinder its widespread use, leaving many patients with KOA reliant solely on X-ray imaging. In this study, we introduce a novel diffusion-based Xray2MRI model capable of generating pseudo-MRI volumes from one single X-ray image. In addition to using X-rays as conditional input, our model integrates target depth, KOA probability distribution, and image intensity distribution modules to guide the synthesis process, ensuring that the generated corresponding slices accurately correspond to the anatomical structures. Experimental results demonstrate that by integrating information from X-rays with additional input data, our proposed approach is capable of generating pseudo-MRI sequences that approximate real MRI scans. Moreover, by increasing the inference times, the model achieves effective interpolation, further improving the continuity and smoothness of the generated MRI sequences, representing one promising initial attempt for cost-effective medical imaging solutions.
+
+
+
+ 213. 【2410.06974】Diagnosis of Malignant Lymphoma Cancer Using Hybrid Optimized Techniques Based on Dense Neural Networks
+ 链接:https://arxiv.org/abs/2410.06974
+ 作者:Salah A. Aly,Ali Bakhiet,Mazen Balat
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:remains challenging due, subtle morphological differences, Dense Neural Network, Harris Hawks Optimization, Chronic Lymphocytic Leukemia
+ 备注: 6 pages, 5 figures, 4 tables, IEEE ICCA
+
+ 点击查看摘要
+ Abstract:Lymphoma diagnosis, particularly distinguishing between subtypes, is critical for effective treatment but remains challenging due to the subtle morphological differences in histopathological images. This study presents a novel hybrid deep learning framework that combines DenseNet201 for feature extraction with a Dense Neural Network (DNN) for classification, optimized using the Harris Hawks Optimization (HHO) algorithm. The model was trained on a dataset of 15,000 biopsy images, spanning three lymphoma subtypes: Chronic Lymphocytic Leukemia (CLL), Follicular Lymphoma (FL), and Mantle Cell Lymphoma (MCL). Our approach achieved a testing accuracy of 99.33\%, demonstrating significant improvements in both accuracy and model interpretability. Comprehensive evaluation using precision, recall, F1-score, and ROC-AUC underscores the model's robustness and potential for clinical adoption. This framework offers a scalable solution for improving diagnostic accuracy and efficiency in oncology.
+
+
+
+ 214. 【2410.06892】Selecting the Best Sequential Transfer Path for Medical Image Segmentation with Limited Labeled Data
+ 链接:https://arxiv.org/abs/2410.06892
+ 作者:Jingyun Yang,Jingge Wang,Guoqing Zhang,Yang Li
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:
+ 备注:
+
+ 点击查看摘要
+ None
+
+
+
+ 215. 【2410.06781】ransesophageal Echocardiography Generation using Anatomical Models
+ 链接:https://arxiv.org/abs/2410.06781
+ 作者:Emmanuel Oladokun,Musa Abdulkareem,Jurica Šprem,Vicente Grau
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:
+ 备注: MICCAI2023; DALI Workshop
+
+ 点击查看摘要
+ None
+
+
+
+ 216. 【2410.06757】Diff-FMT: Diffusion Models for Fluorescence Molecular Tomography
+ 链接:https://arxiv.org/abs/2410.06757
+ 作者:Qianqian Xue,Peng Zhang,Xingyu Liu,Wenjian Wang,Guanglei Zhang
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:noninvasive optical imaging, optical imaging technology, Fluorescence molecular tomography, molecular tomography, noninvasive optical
+ 备注:
+
+ 点击查看摘要
+ Abstract:Fluorescence molecular tomography (FMT) is a real-time, noninvasive optical imaging technology that plays a significant role in biomedical research. Nevertheless, the ill-posedness of the inverse problem poses huge challenges in FMT reconstructions. Previous various deep learning algorithms have been extensively explored to address the critical issues, but they remain faces the challenge of high data dependency with poor image quality. In this paper, we, for the first time, propose a FMT reconstruction method based on a denoising diffusion probabilistic model (DDPM), termed Diff-FMT, which is capable of obtaining high-quality reconstructed images from noisy images. Specifically, we utilize the noise addition mechanism of DDPM to generate diverse training samples. Through the step-by-step probability sampling mechanism in the inverse process, we achieve fine-grained reconstruction of the image, avoiding issues such as loss of image detail that can occur with end-to-end deep-learning methods. Additionally, we introduce the fluorescence signals as conditional information in the model training to sample a reconstructed image that is highly consistent with the input fluorescence signals from the noisy images. Numerous experimental results show that Diff-FMT can achieve high-resolution reconstruction images without relying on large-scale datasets compared with other cutting-edge algorithms.
+
+
+
+ 217. 【2410.06723】Evaluating Computational Pathology Foundation Models for Prostate Cancer Grading under Distribution Shifts
+ 链接:https://arxiv.org/abs/2410.06723
+ 作者:Fredrik K. Gustafsson,Mattias Rantalainen
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:
+ 备注: Preprint, work in progress
+
+ 点击查看摘要
+ None
+
+
+
+ 218. 【2410.06542】MedImageInsight: An Open-Source Embedding Model for General Domain Medical Imaging
+ 链接:https://arxiv.org/abs/2410.06542
+ 作者:Noel C. F. Codella,Ying Jin,Shrey Jain,Yu Gu,Ho Hin Lee,Asma Ben Abacha,Alberto Santamaria-Pang,Will Guyman,Naiteek Sangani,Sheng Zhang,Hoifung Poon,Stephanie Hyland,Shruthi Bannur,Javier Alvarez-Valle,Xue Li,John Garrett,Alan McMillan,Gaurav Rajguru,Madhu Maddi,Nilesh Vijayrania,Rehaan Bhimai,Nick Mecklenburg,Rupal Jain,Daniel Holstein,Naveen Gaur,Vijay Aski,Jenq-Neng Hwang,Thomas Lin,Ivan Tarapov,Matthew Lungren,Mu Wei
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:
+ 备注:
+
+ 点击查看摘要
+ None
+
+
+
+ 219. 【2410.06483】Deep Learning Ensemble for Predicting Diabetic Macular Edema Onset Using Ultra-Wide Field Color Fundus Image
+ 链接:https://arxiv.org/abs/2410.06483
+ 作者:Pengyao Qin,Arun J. Thirunavukarasu,Le Zhang
+ 类目:Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Diabetic macular edema, macular edema, complication of diabetes, characterized by thickening, Diabetic macular
+ 备注:
+
+ 点击查看摘要
+ Abstract:Diabetic macular edema (DME) is a severe complication of diabetes, characterized by thickening of the central portion of the retina due to accumulation of fluid. DME is a significant and common cause of visual impairment in diabetic patients. Center-involved DME (ci-DME) is the highest risk form of disease as fluid extends close to the fovea which is responsible for sharp central vision. Earlier diagnosis or prediction of ci-DME may improve treatment outcomes. Here, we propose an ensemble method to predict ci-DME onset within a year using ultra-wide-field color fundus photography (UWF-CFP) images provided by the DIAMOND Challenge. We adopted a variety of baseline state-of-the-art classification networks including ResNet, DenseNet, EfficientNet, and VGG with the aim of enhancing model robustness. The best performing models were Densenet 121, Resnet 152 and EfficientNet b7, and these were assembled into a definitive predictive model. The final ensemble model demonstrates a strong performance with an Area Under Curve (AUC) of 0.7017, an F1 score of 0.6512, and an Expected Calibration Error (ECE) of 0.2057 when deployed on a synthetic dataset. The performance of this ensemble model is comparable to previous studies despite training and testing in a more realistic setting, indicating the potential of UWF-CFP combined with a deep learning classification system to facilitate earlier diagnosis, better treatment decisions, and improved prognostication in ci-DME.
+
+
+
+ 220. 【2410.06478】MaskBlur: Spatial and Angular Data Augmentation for Light Field Image Super-Resolution
+ 链接:https://arxiv.org/abs/2410.06478
+ 作者:Wentao Chao,Fuqing Duan,Yulan Guo,Guanghui Wang
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:
+ 备注: accepted by IEEE Transactions on Multimedia
+
+ 点击查看摘要
+ None
+
+
+
+ 221. 【2410.06385】Skin Cancer Machine Learning Model Tone Bias
+ 链接:https://arxiv.org/abs/2410.06385
+ 作者:James Pope,Md Hassanuzzaman,Mingmar Sherpa,Omar Emara,Ayush Joshi,Nirmala Adhikari
+ 类目:Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:clinical trials conducted, open-source skin cancer, tone, skin cancer, skin
+ 备注:
+
+ 点击查看摘要
+ Abstract:Background: Many open-source skin cancer image datasets are the result of clinical trials conducted in countries with lighter skin tones. Due to this tone imbalance, machine learning models derived from these datasets can perform well at detecting skin cancer for lighter skin tones. Any tone bias in these models could introduce fairness concerns and reduce public trust in the artificial intelligence health field.
+Methods: We examine a subset of images from the International Skin Imaging Collaboration (ISIC) archive that provide tone information. The subset has a significant tone imbalance. These imbalances could explain a model's tone bias. To address this, we train models using the imbalanced dataset and a balanced dataset to compare against. The datasets are used to train a deep convolutional neural network model to classify the images as malignant or benign. We then evaluate the models' disparate impact, based on selection rate, relative to dark or light skin tone.
+Results: Using the imbalanced dataset, we found that the model is significantly better at detecting malignant images in lighter tone resulting in a disparate impact of 0.577. Using the balanced dataset, we found that the model is also significantly better at detecting malignant images in lighter versus darker tones with a disparate impact of 0.684. Using the imbalanced or balanced dataset to train the model still results in a disparate impact well below the standard threshold of 0.80 which suggests the model is biased with respect to skin tone.
+Conclusion: The results show that typical skin cancer machine learning models can be tone biased. These results provide evidence that diagnosis or tone imbalance is not the cause of the bias. Other techniques will be necessary to identify and address the bias in these models, an area of future investigation.
+
Subjects:
+Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+Cite as:
+arXiv:2410.06385 [eess.IV]
+(or
+arXiv:2410.06385v1 [eess.IV] for this version)
+https://doi.org/10.48550/arXiv.2410.06385
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)
+
+Submission history From: James Pope [view email] [v1]
+Tue, 8 Oct 2024 21:33:02 UTC (8,133 KB)
+
+
+
+ 222. 【2410.06161】Automated quality assessment using appearance-based simulations and hippocampus segmentation on low-field paediatric brain MR images
+ 链接:https://arxiv.org/abs/2410.06161
+ 作者:Vaanathi Sundaresan,Nicola K Dinsdale
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:
+ 备注: MICCAI 2024 Low field pediatric brain magnetic resonance Image Segmentation and quality Assurance (LISA) Challenge
+
+ 点击查看摘要
+ None
+
+
+
+ 223. 【2410.05997】An Eye for an Ear: Zero-shot Audio Description Leveraging an Image Captioner using Audiovisual Distribution Alignment
+ 链接:https://arxiv.org/abs/2410.05997
+ 作者:Hugo Malard,Michel Olvera,Stéphane Lathuiliere,Slim Essid
+ 类目:Audio and Speech Processing (eess.AS); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Sound (cs.SD)
+ 关键词:
+ 备注:
+
+ 点击查看摘要
+ None
+
+
+
+ 224. 【2410.05882】Future frame prediction in chest cine MR imaging using the PCA respiratory motion model and dynamically trained recurrent neural networks
+ 链接:https://arxiv.org/abs/2410.05882
+ 作者:Michel Pohl,Mitsuru Uesaka,Hiroyuki Takahashi,Kazuyuki Demachi,Ritu Bhusal Chhatkuli
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Neural and Evolutionary Computing (cs.NE)
+ 关键词:
+ 备注: 28 pages, 16 figures
+
+ 点击查看摘要
+ None
+
+
+
+ 225. 【2410.05413】Implicitly Learned Neural Phase Functions for Basis-Free Point Spread Function Engineering
+ 链接:https://arxiv.org/abs/2410.05413
+ 作者:Aleksey Valouev,Rachel Chan
+ 类目:Optics (physics.optics); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:
+ 备注: 3 pages, 7 figures. To be published in ICVISP 2024 ( [this https URL](https://www.icvisp.org/) )
+
+ 点击查看摘要
+ None
+
+
+
+ 226. 【2410.05342】Multi-Stage Graph Learning for fMRI Analysis to Diagnose Neuro-Developmental Disorders
+ 链接:https://arxiv.org/abs/2410.05342
+ 作者:Wenjing Gao,Yuanyuan Yang,Jianrui Wei,Xuntao Yin,Xinhan Di
+ 类目:Neurons and Cognition (q-bio.NC); Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:
+ 备注: Accepted by CVPR 2024 CV4Science Workshop (8 pages, 4 figures, 2 tables)
+
+ 点击查看摘要
+ None
+
+
+
+ 227. 【2410.05272】DVS: Blood cancer detection using novel CNN-based ensemble approach
+ 链接:https://arxiv.org/abs/2410.05272
+ 作者:Md Taimur Ahad,Israt Jahan Payel,Bo Song,Yan Li
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:
+ 备注:
+
+ 点击查看摘要
+ None
+
+
+





/Fig1_pretrain_finetune.png)
/Fig2_eda1.png)
/Fig2_eda2.png)
/Fig2_eda3.png)
/Fig3_reweight.png)
/Fig5_model1.png)
/Fig5_attention_mask.png)
/Fig4_wwm.png)
/Fig5_model2.png)
/Fig5_model3.png)
/Fig7_ensemble1.png)
/Fig6_res1.png)
/Fig6_res2.png)


%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_text_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_entity_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/model.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/dont_stop_pretraining.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/a.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/b.png)

%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/lengths_histplot.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_entity_lengths.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_label_dist.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/%E6%80%BB%E4%BD%93%E6%96%B9%E6%A1%88.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/pretrain_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/finetune_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/rdrop.png)


/autoencoder-architecture.png)
/variational-autoencoder-architecture.png)
/forward_vs_reversed_KL.png)
/vae-implement.png)
/reparam.png)
/generated_samples.png)







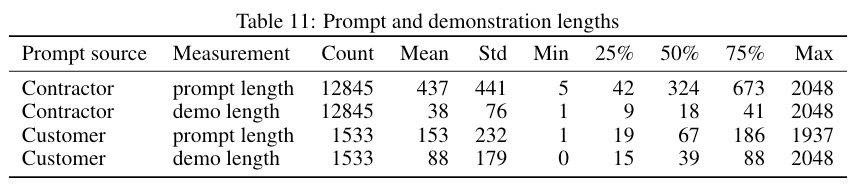

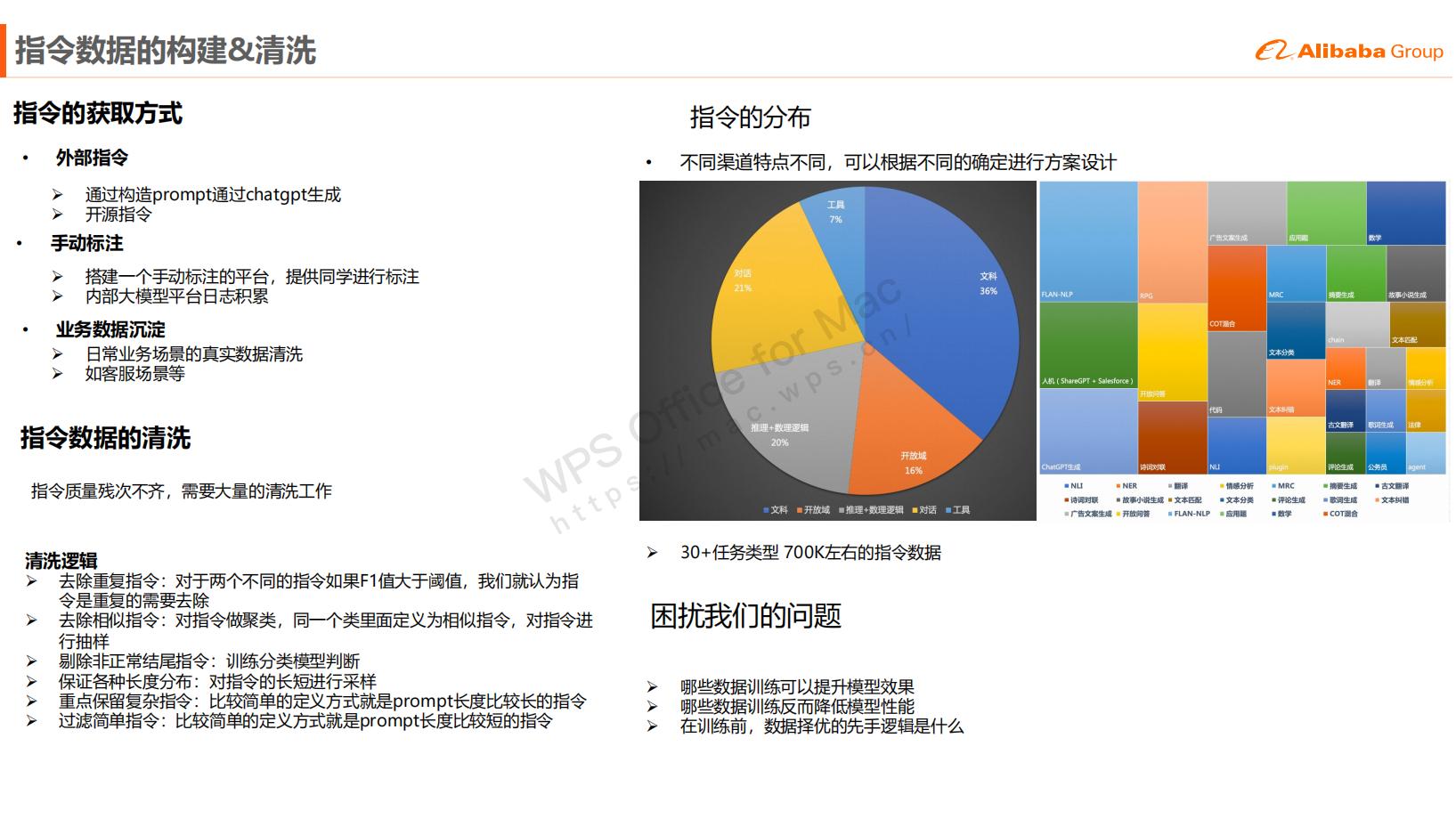

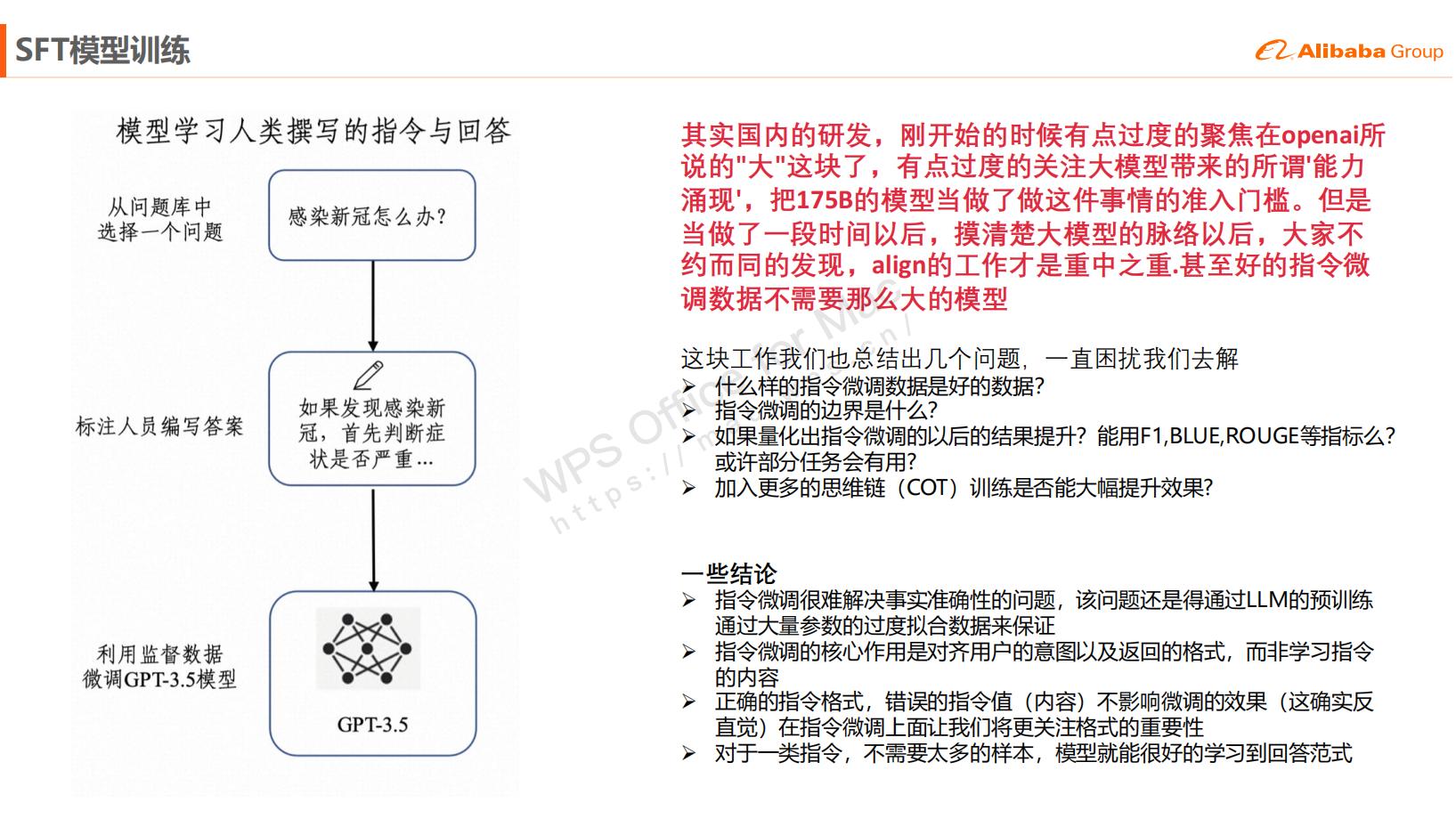

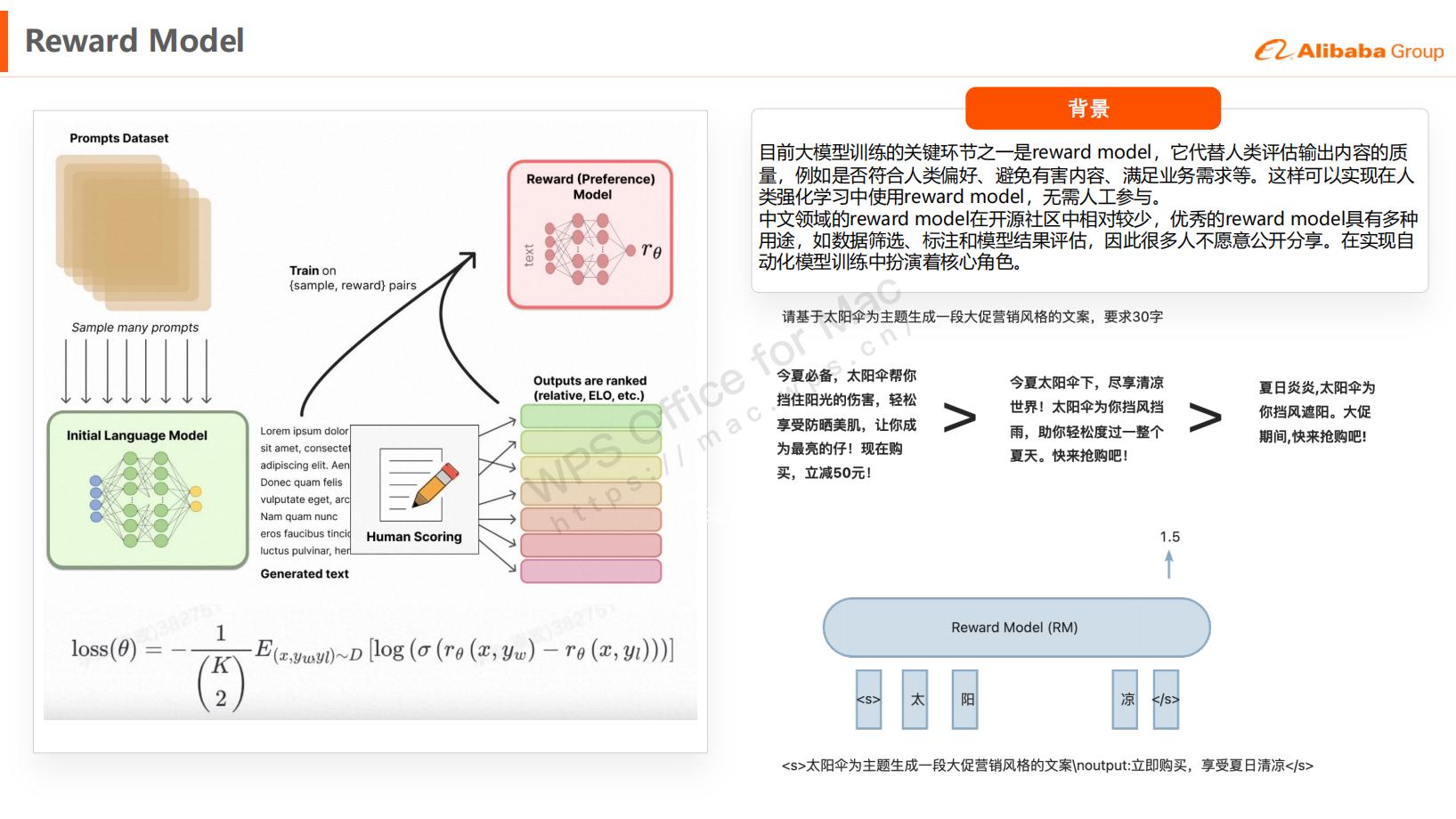




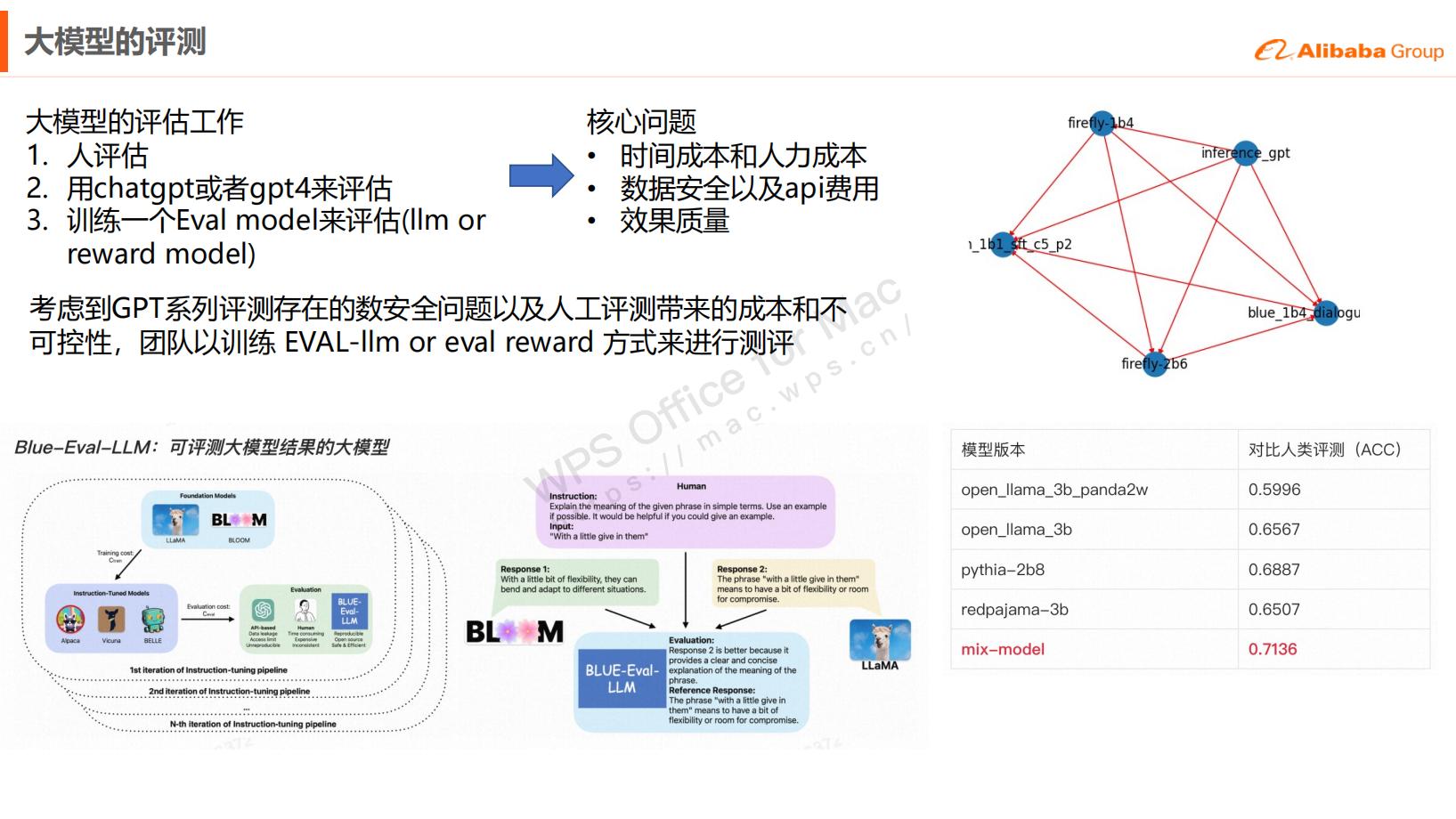
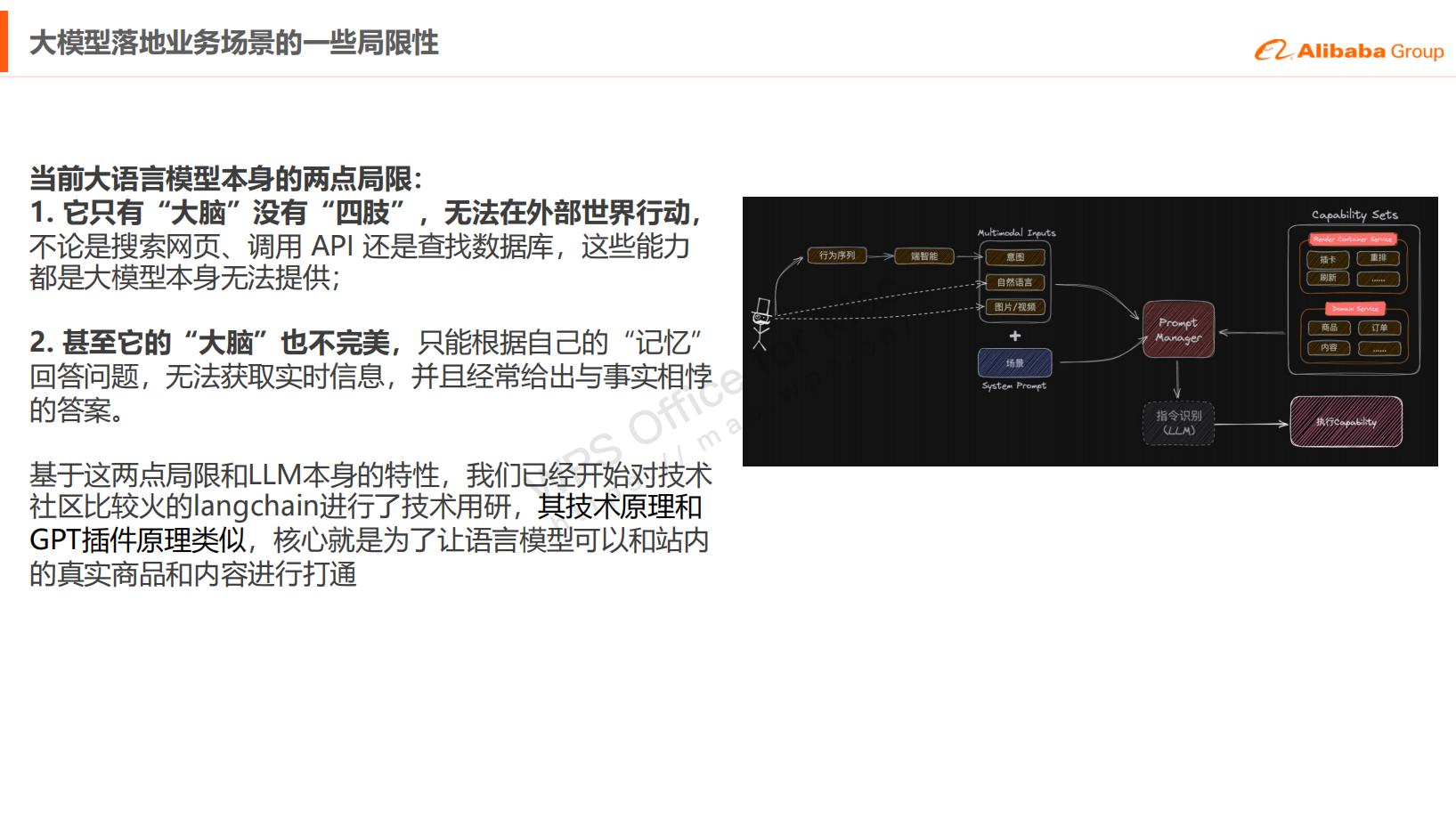






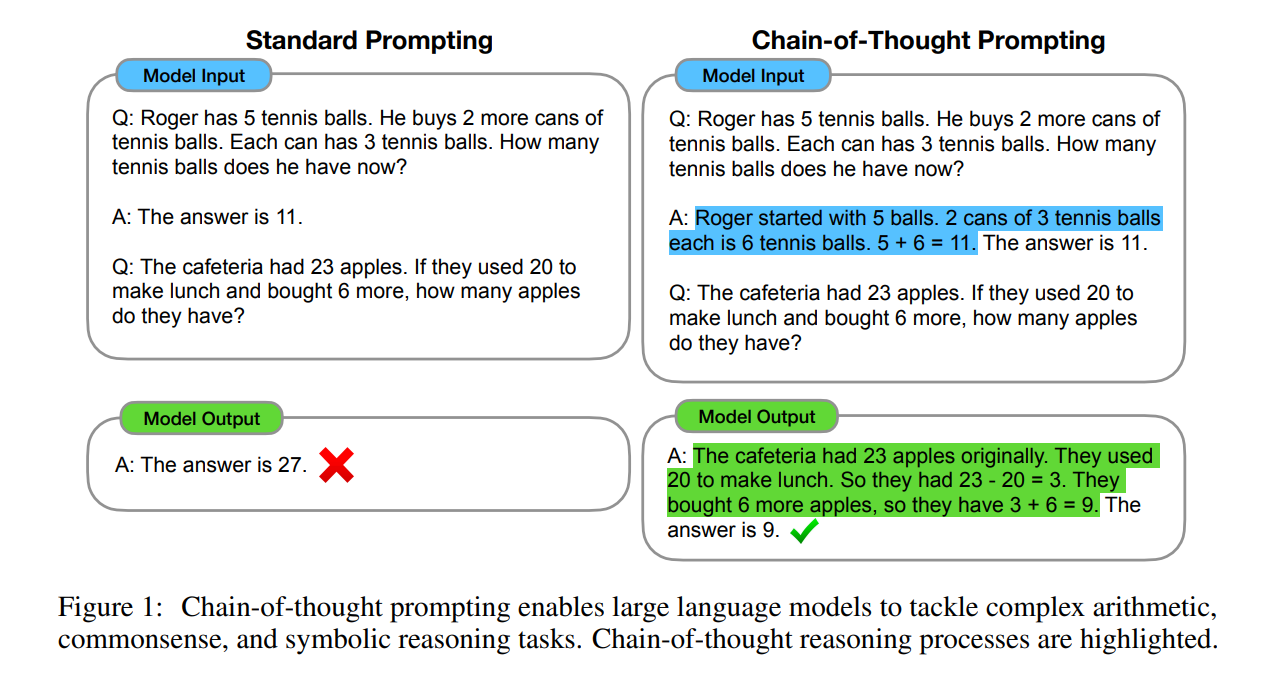

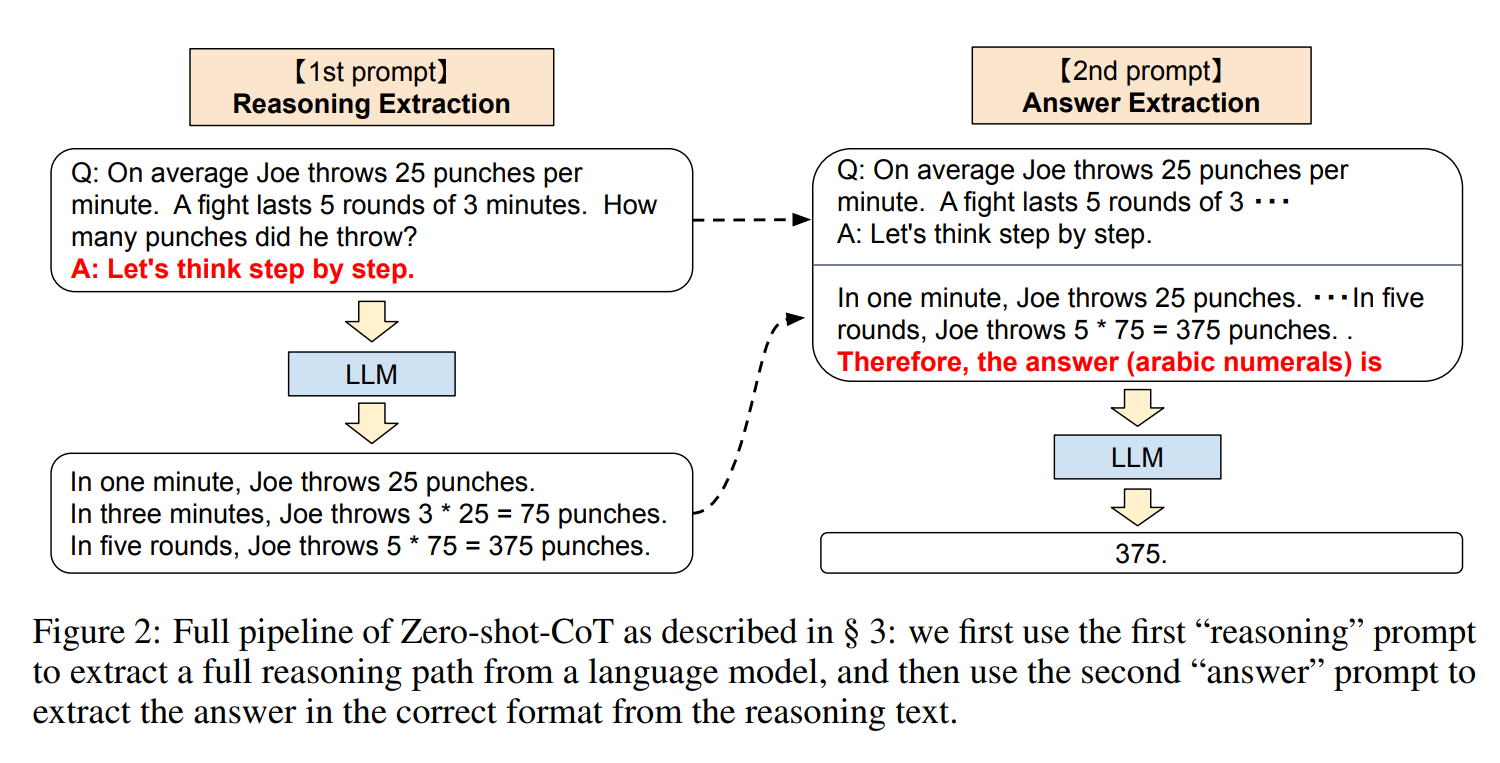
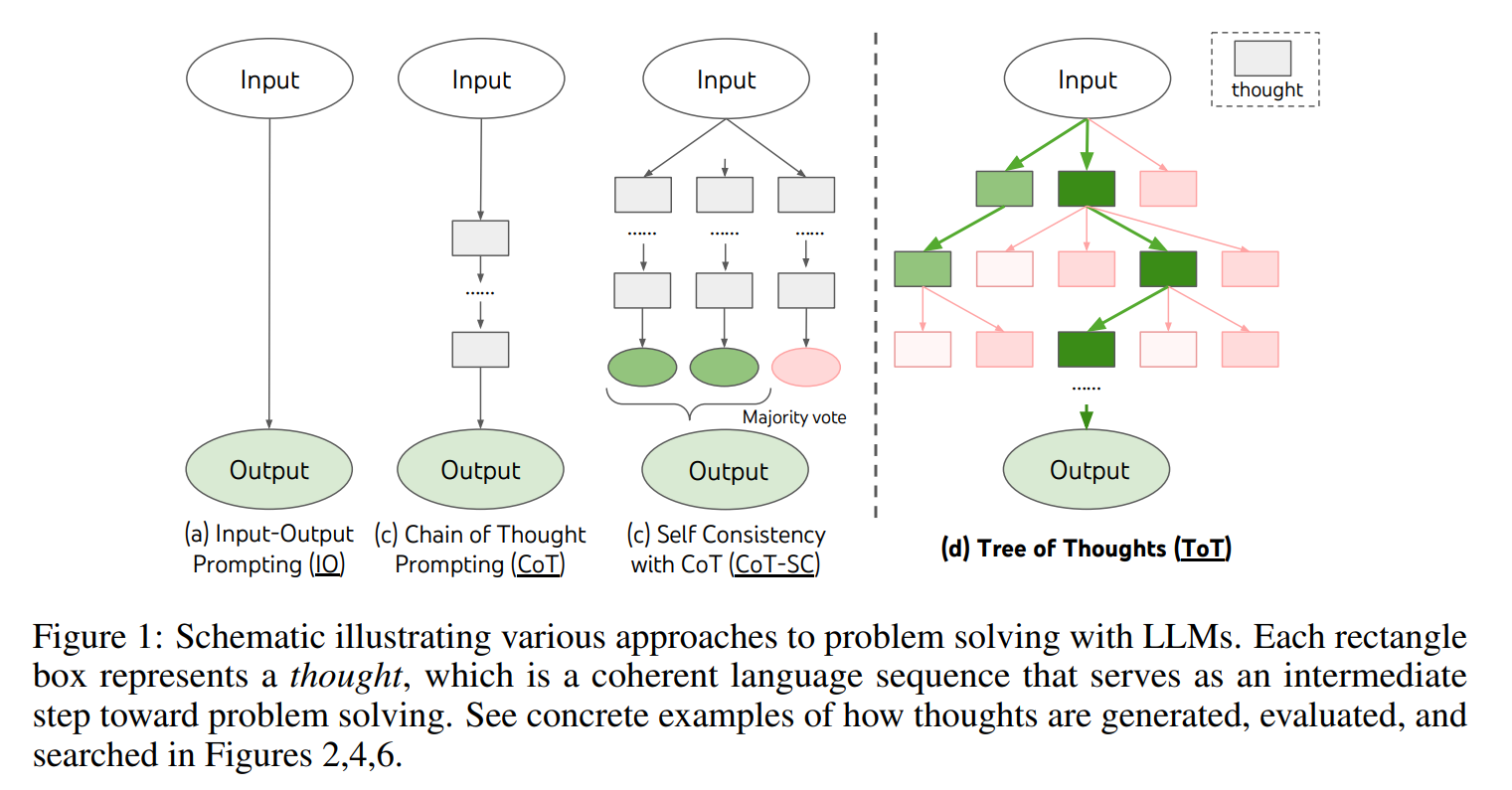


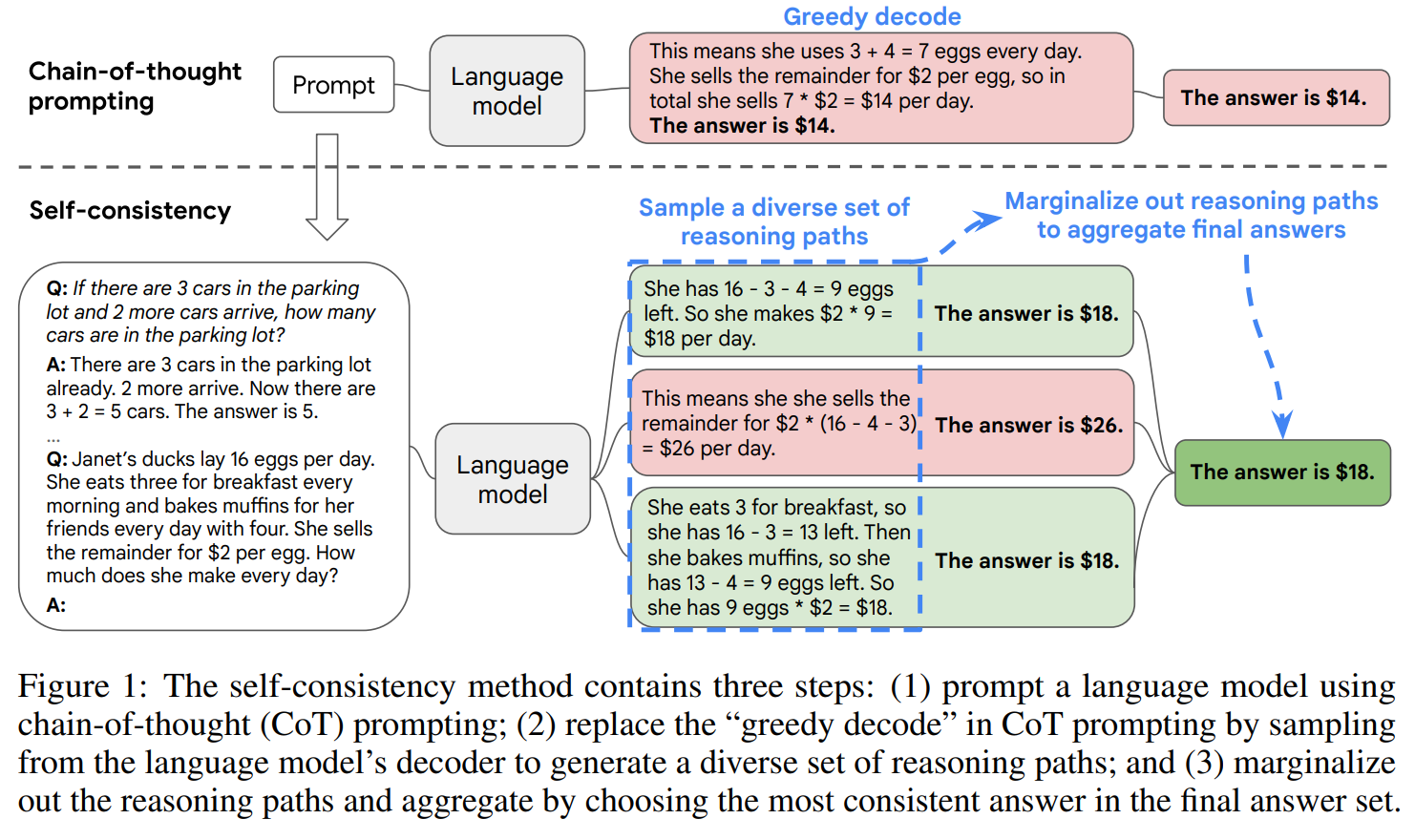
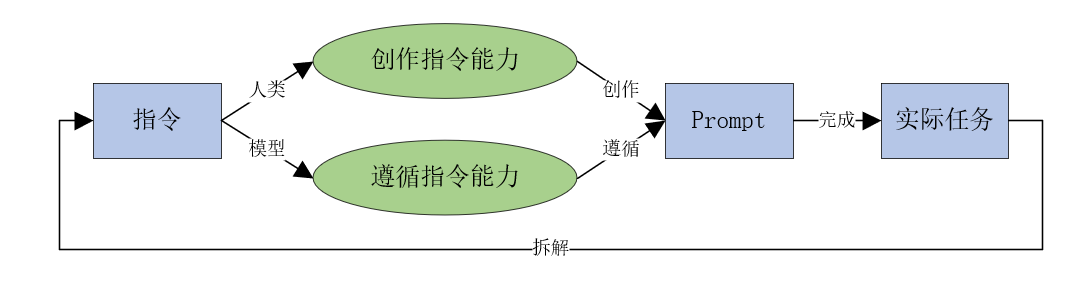



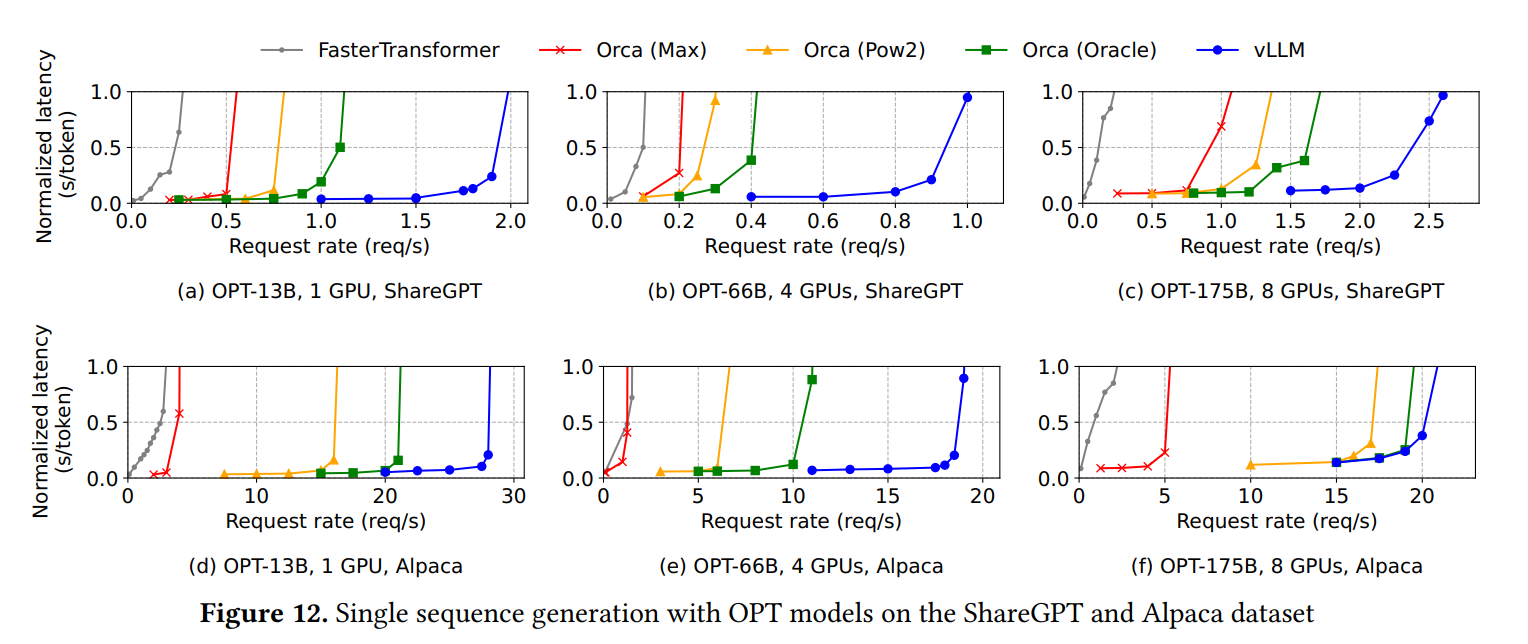
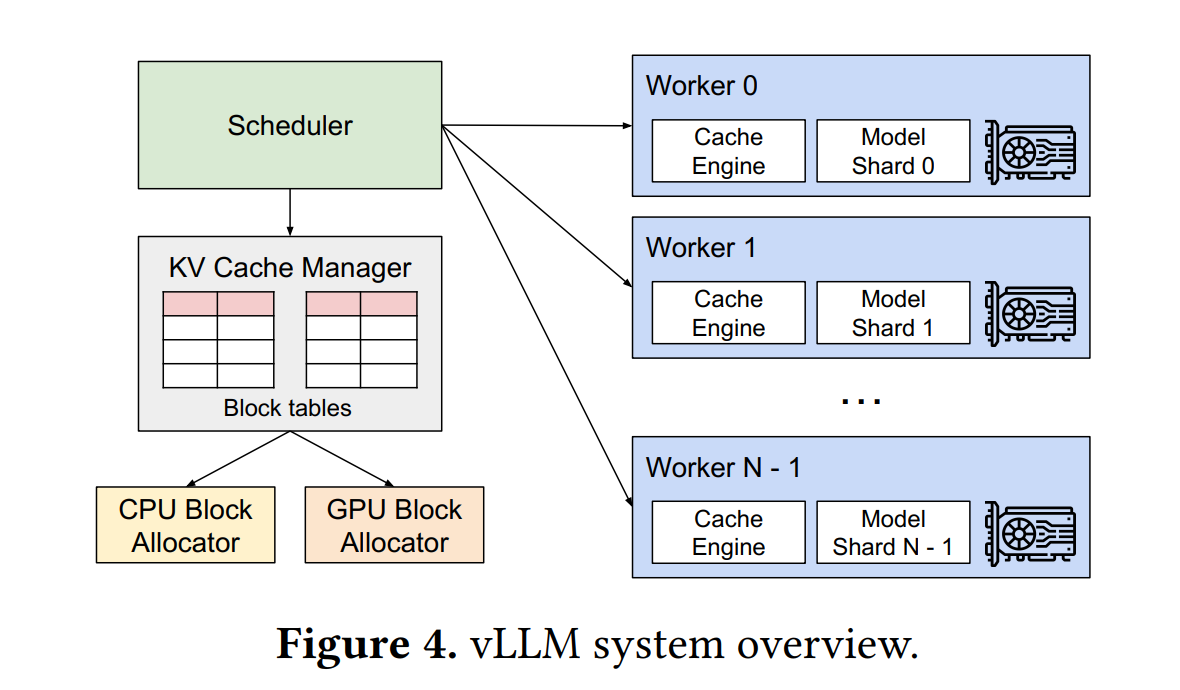
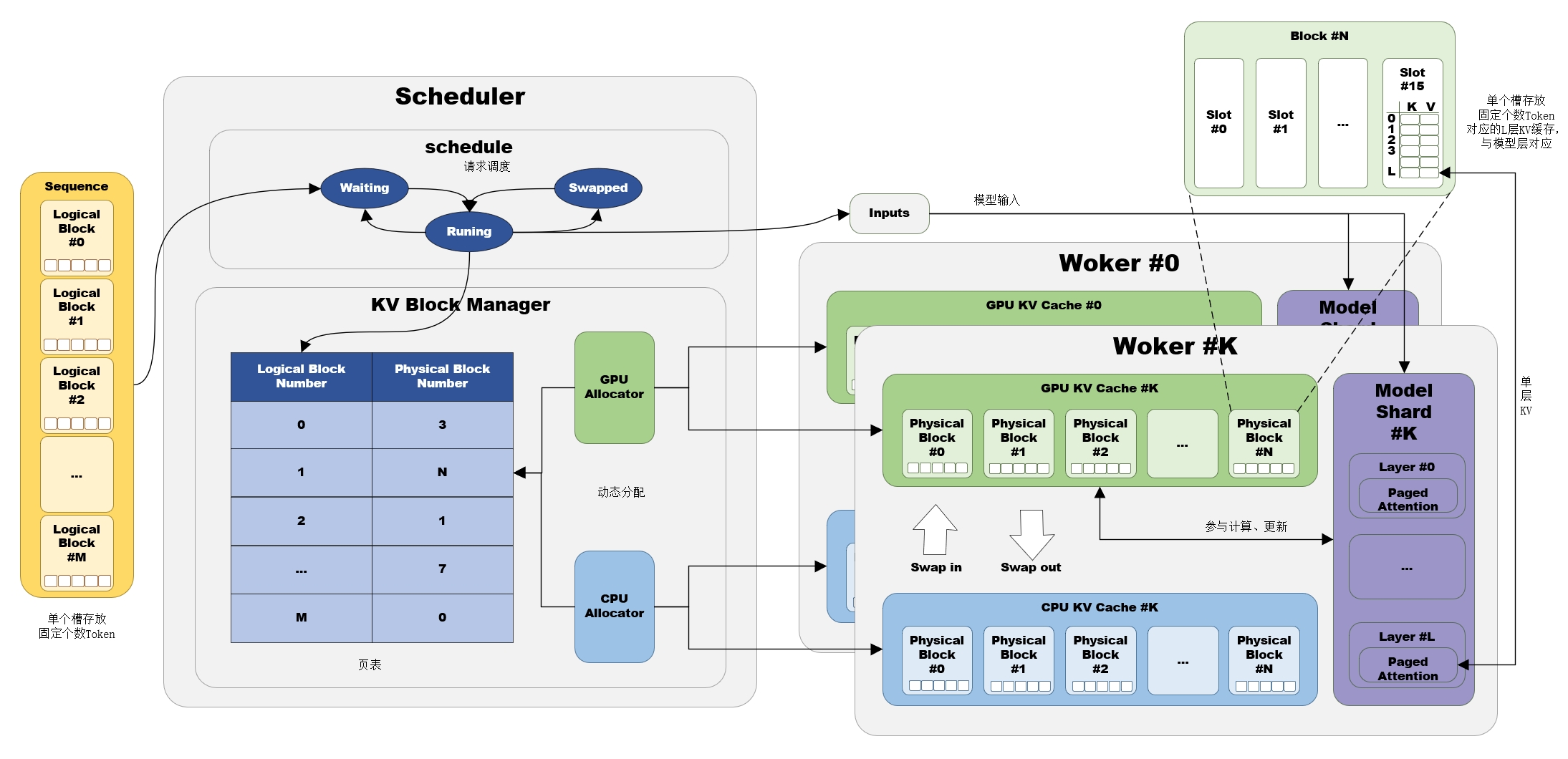
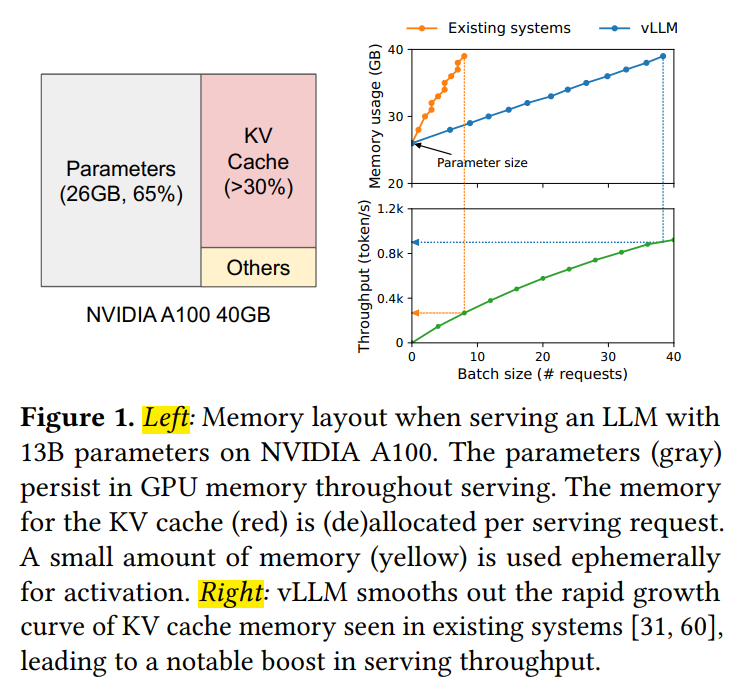
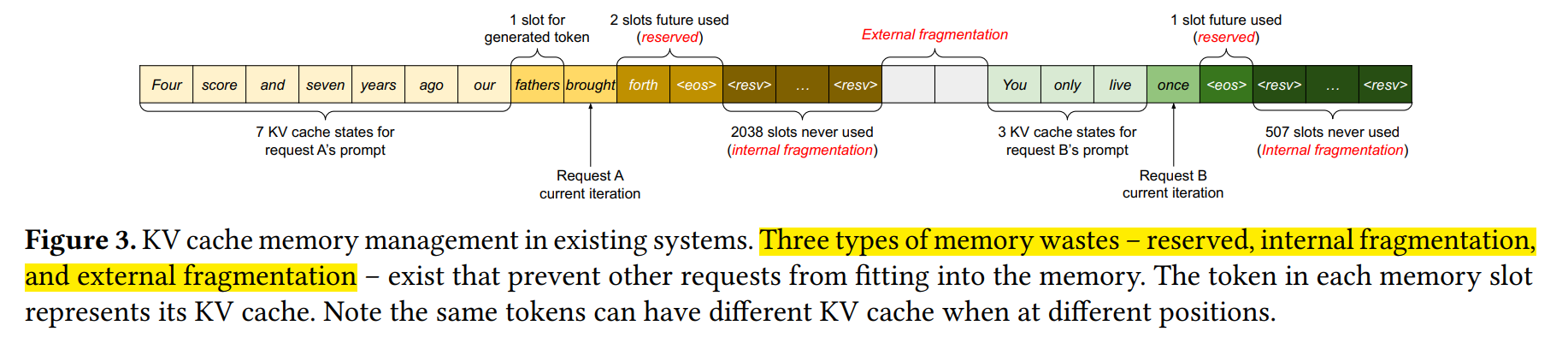
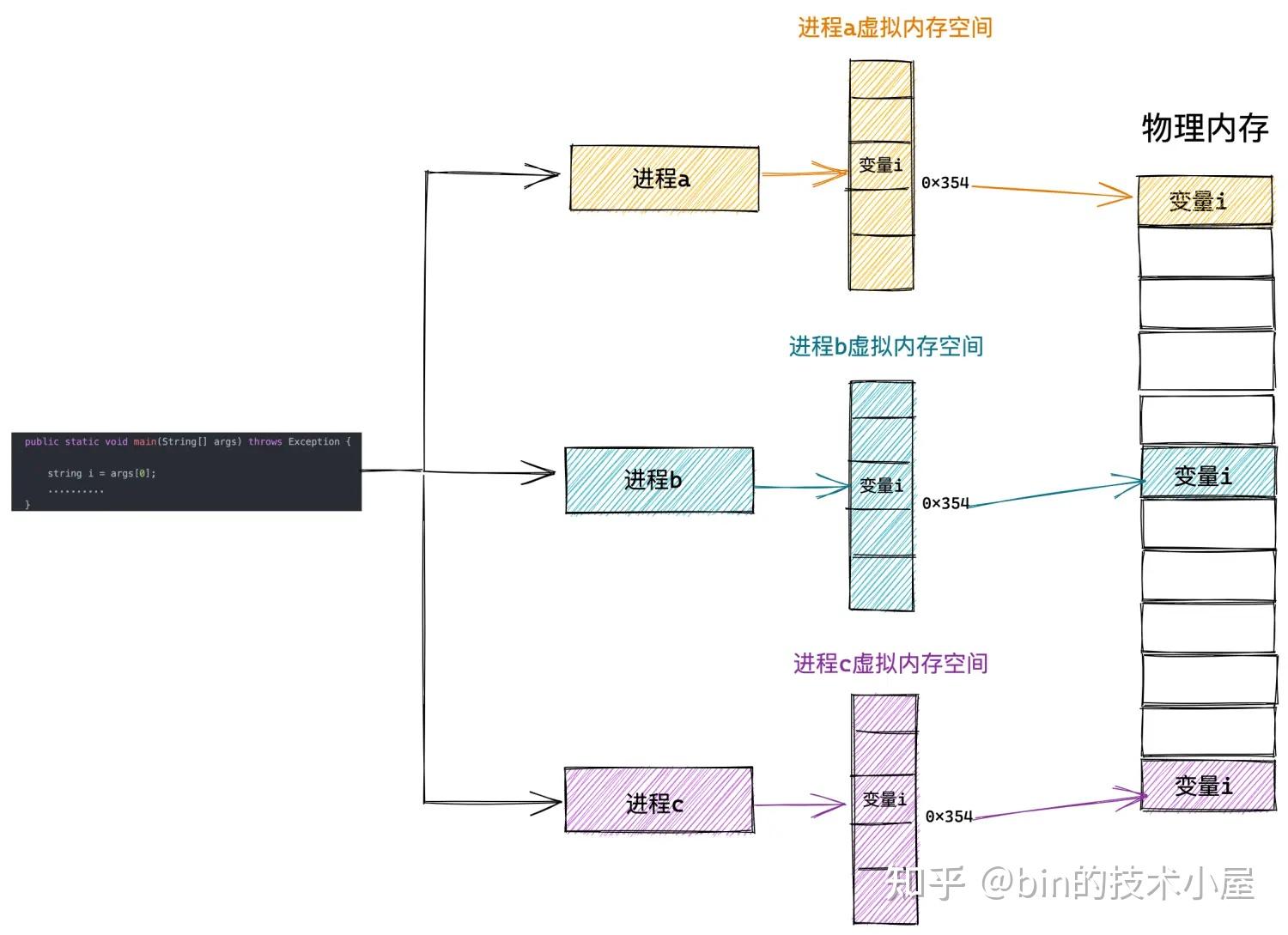
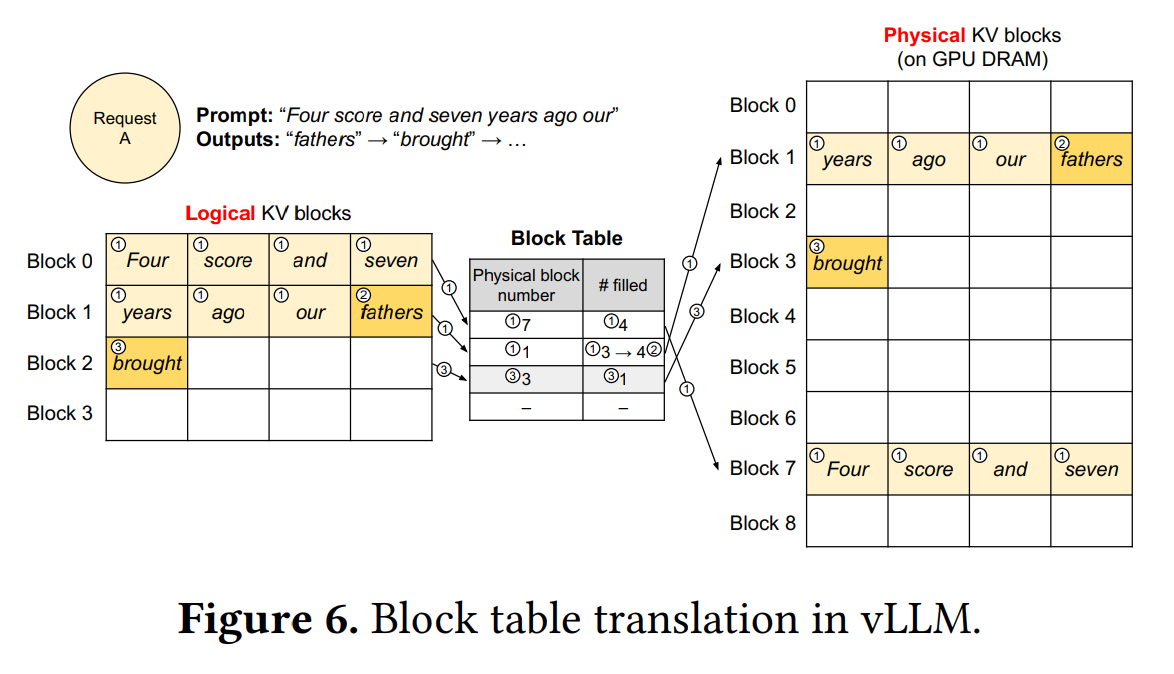
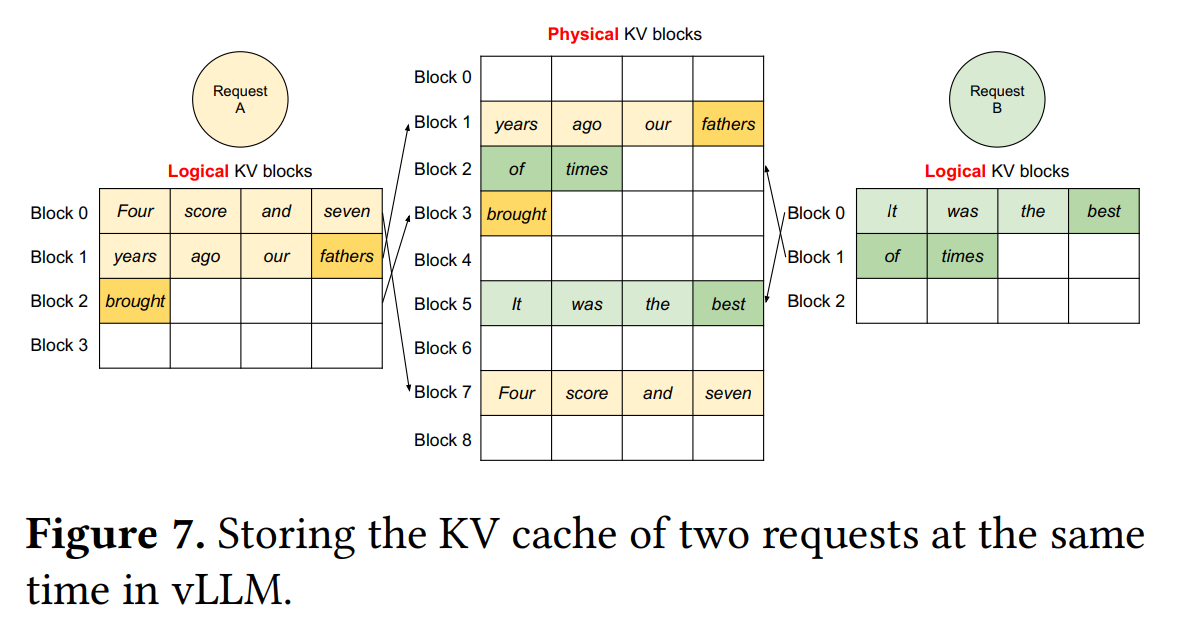
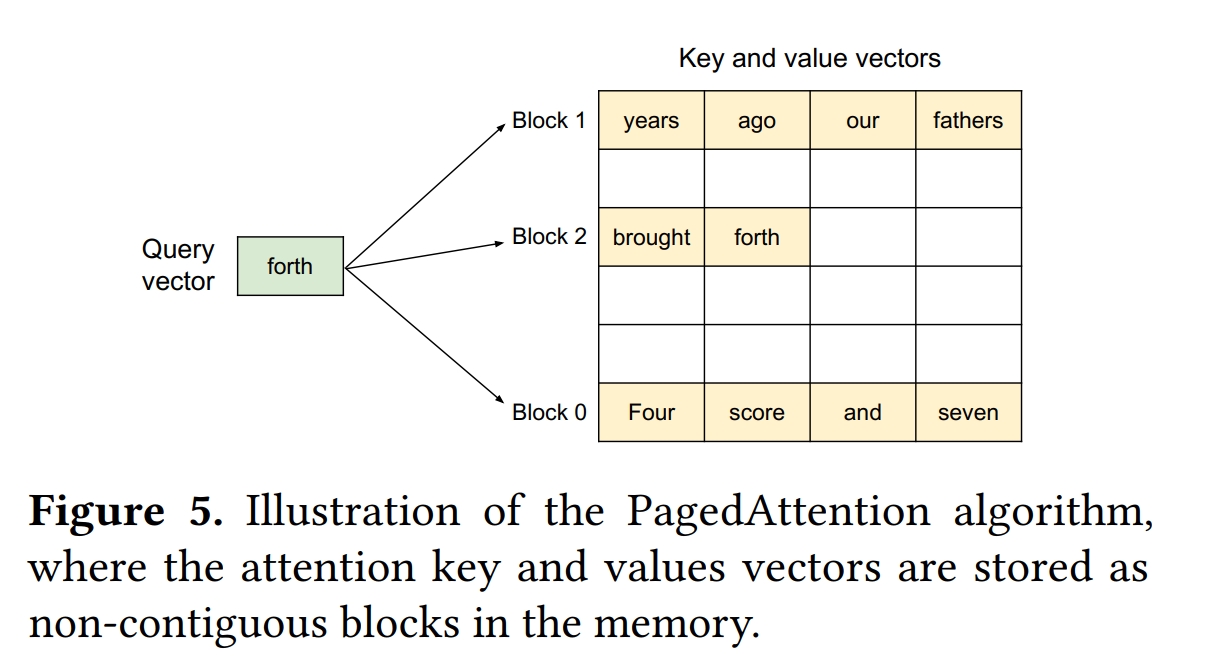
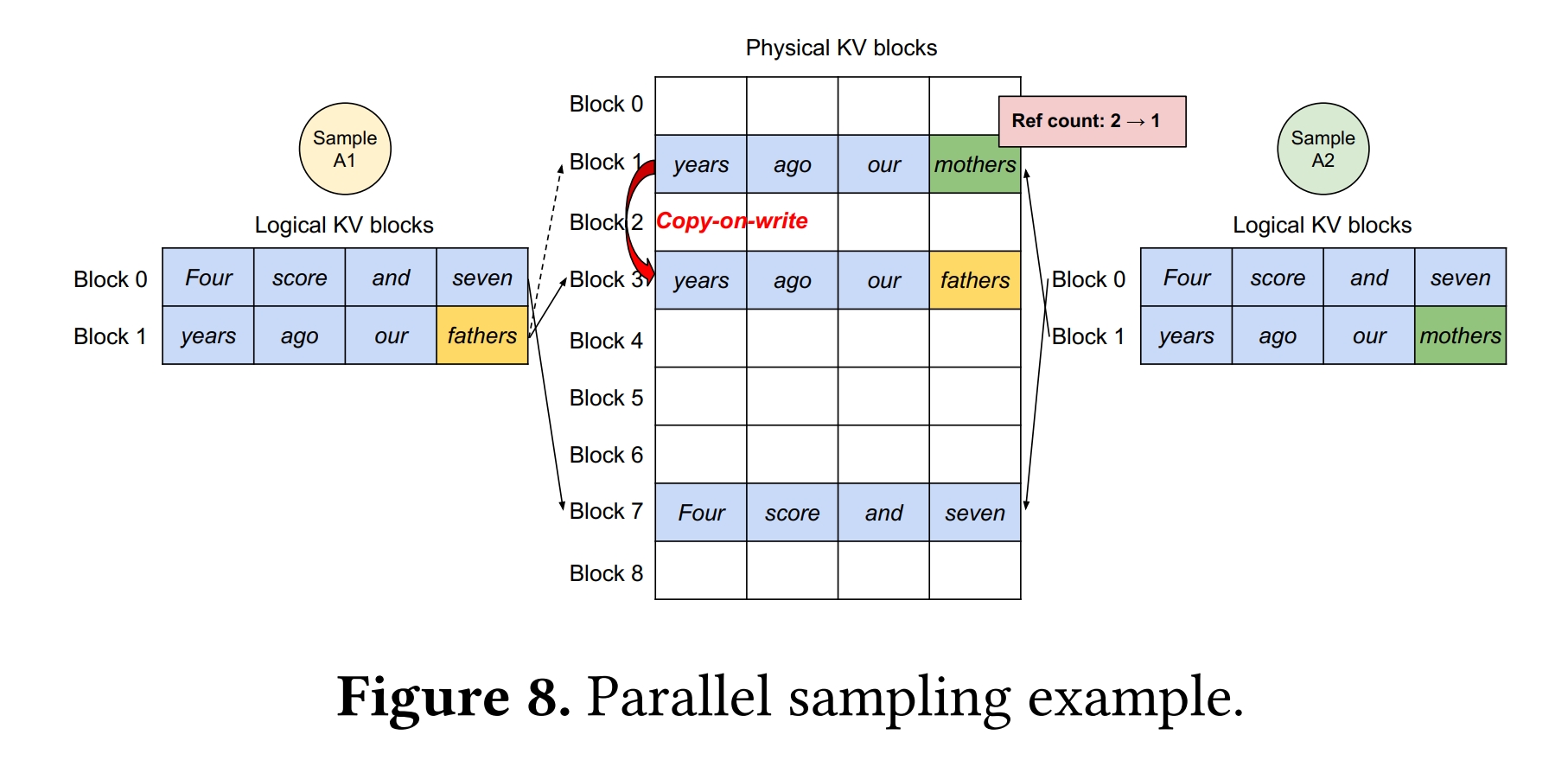
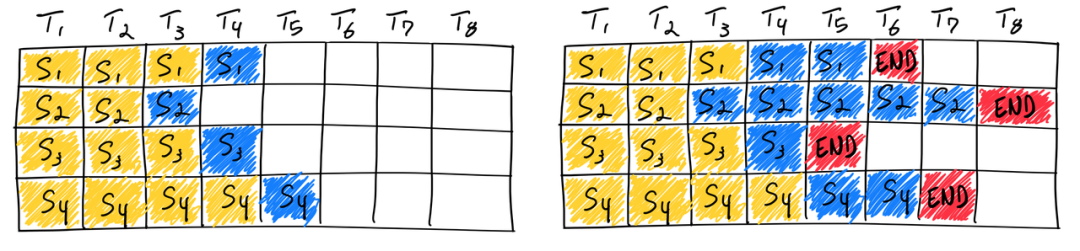
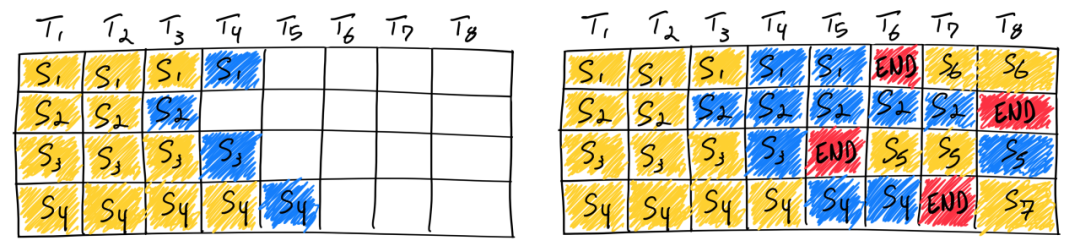
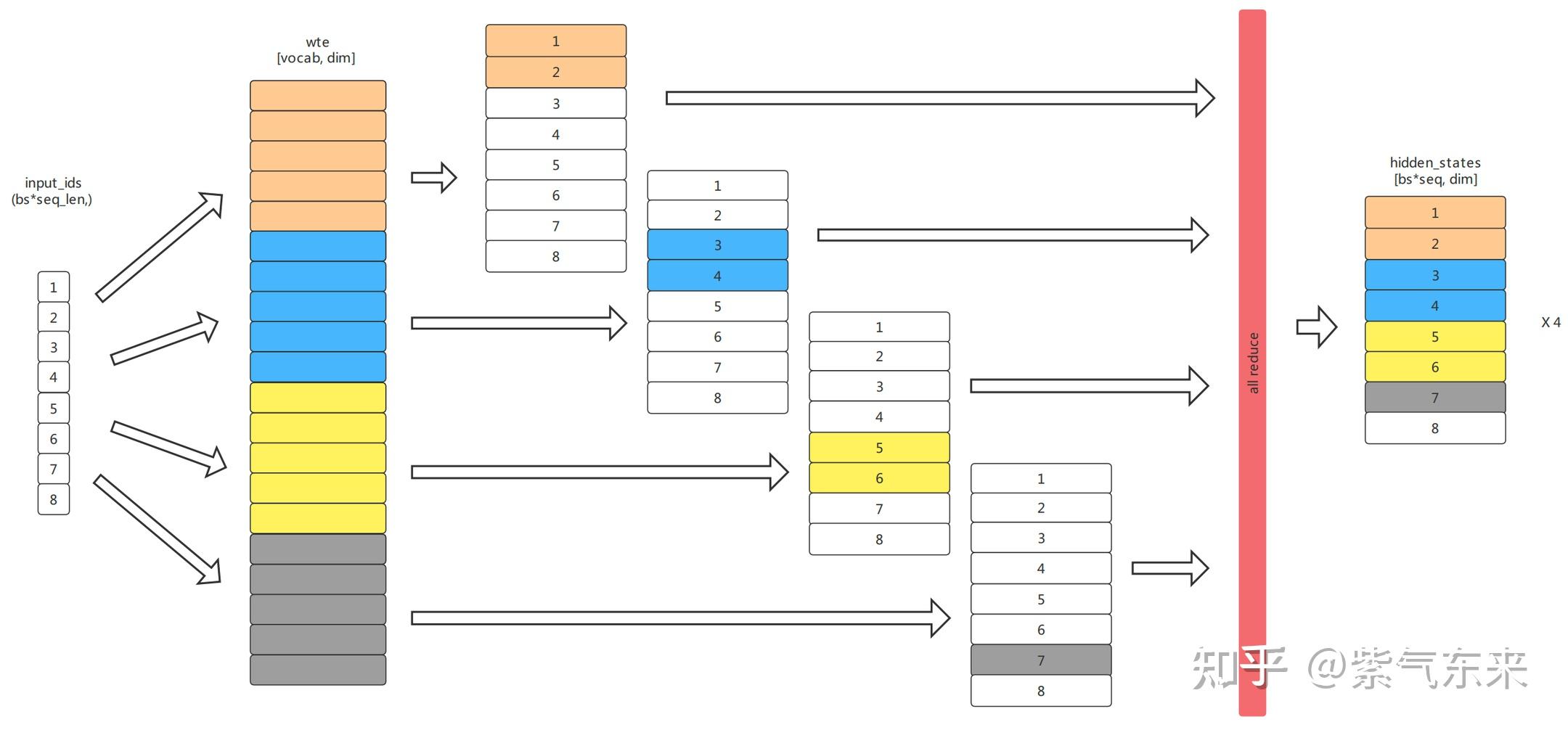
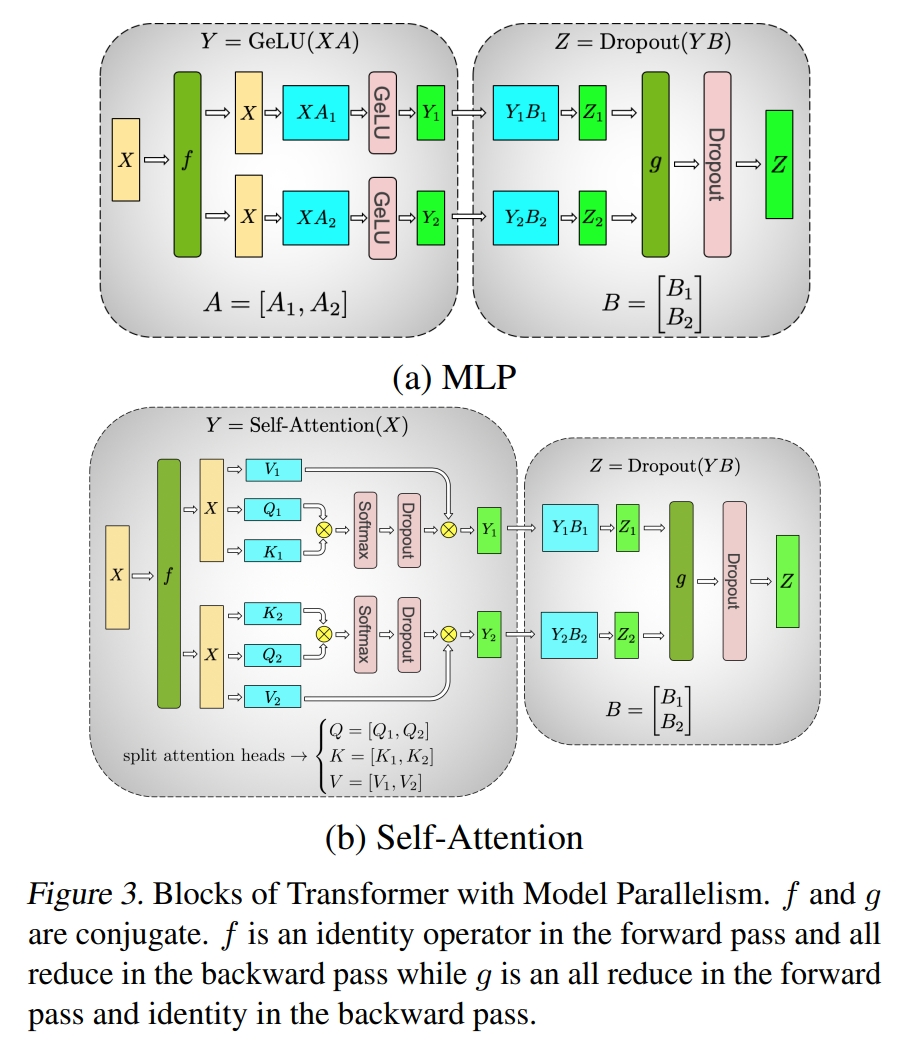
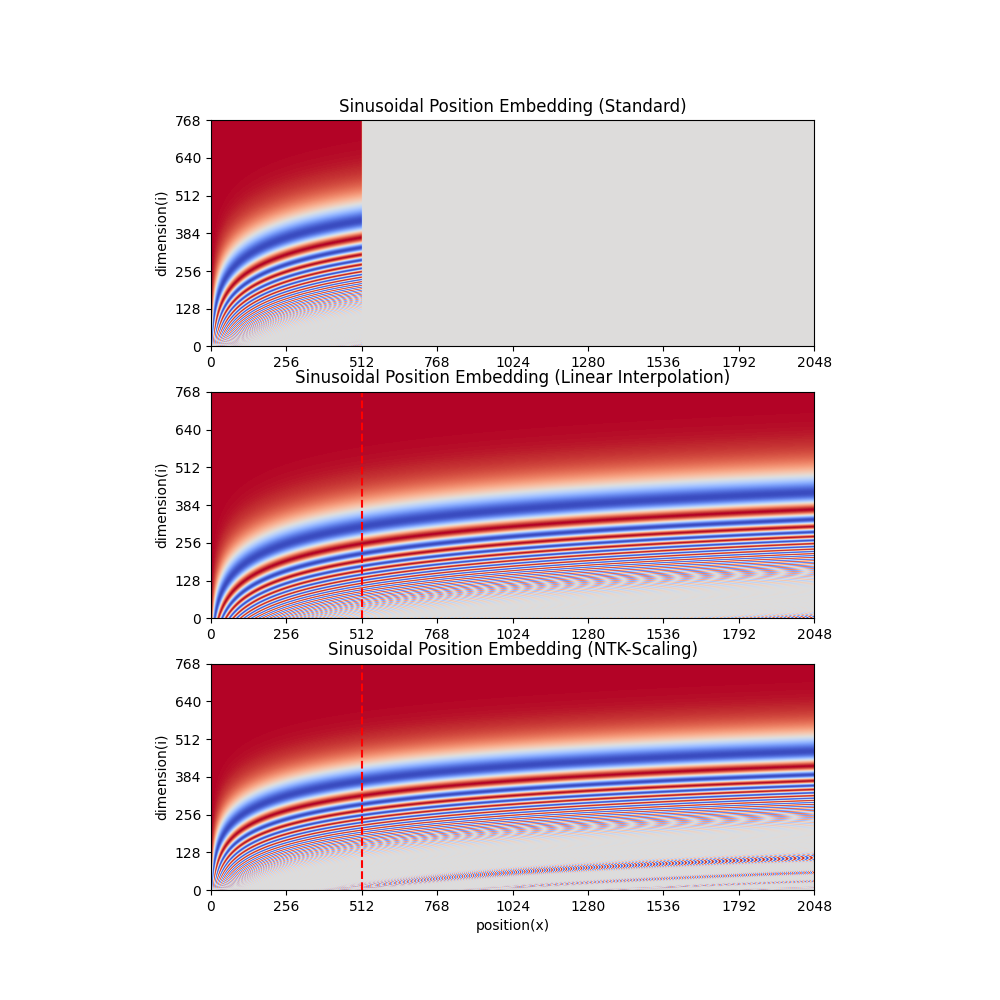
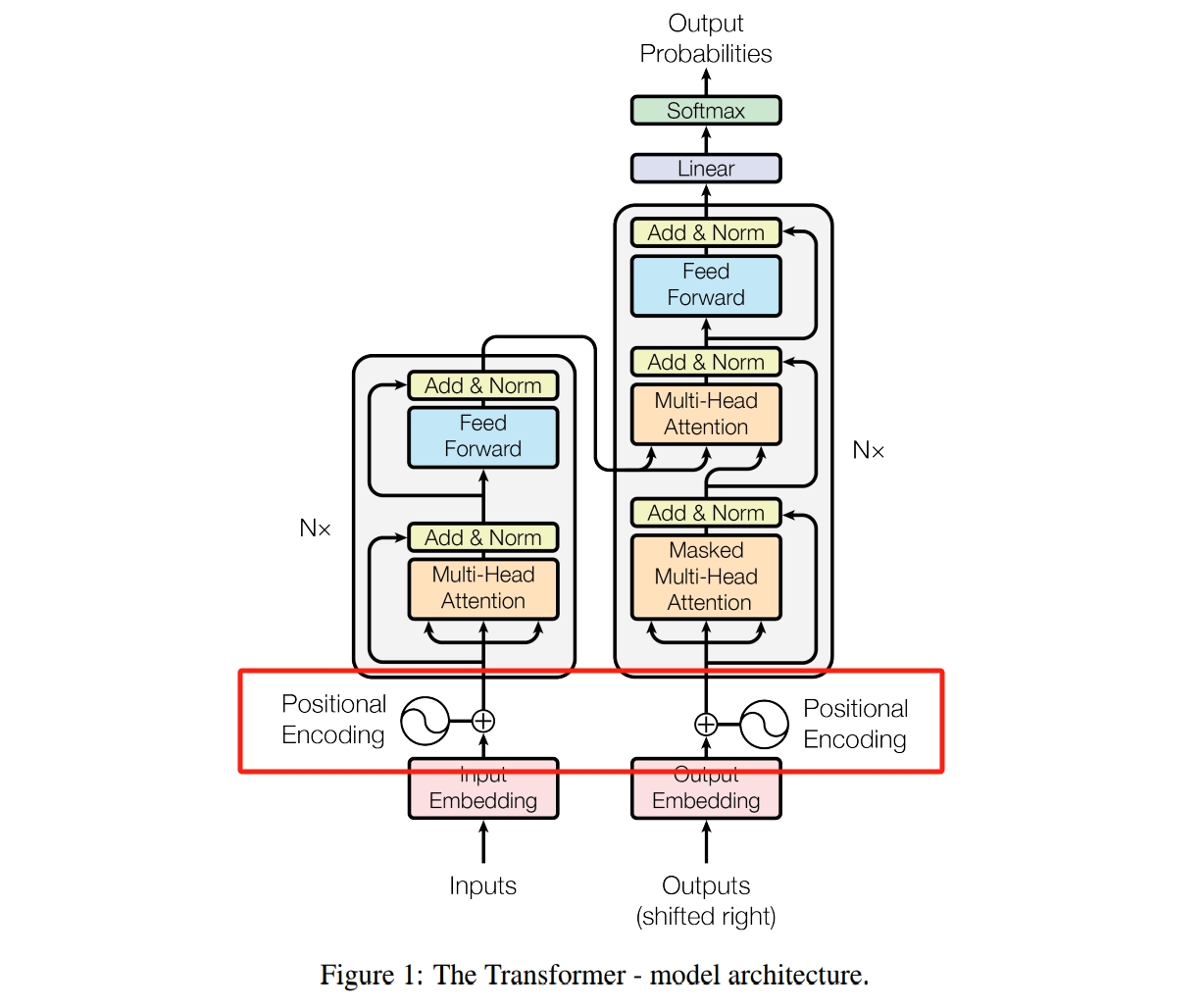
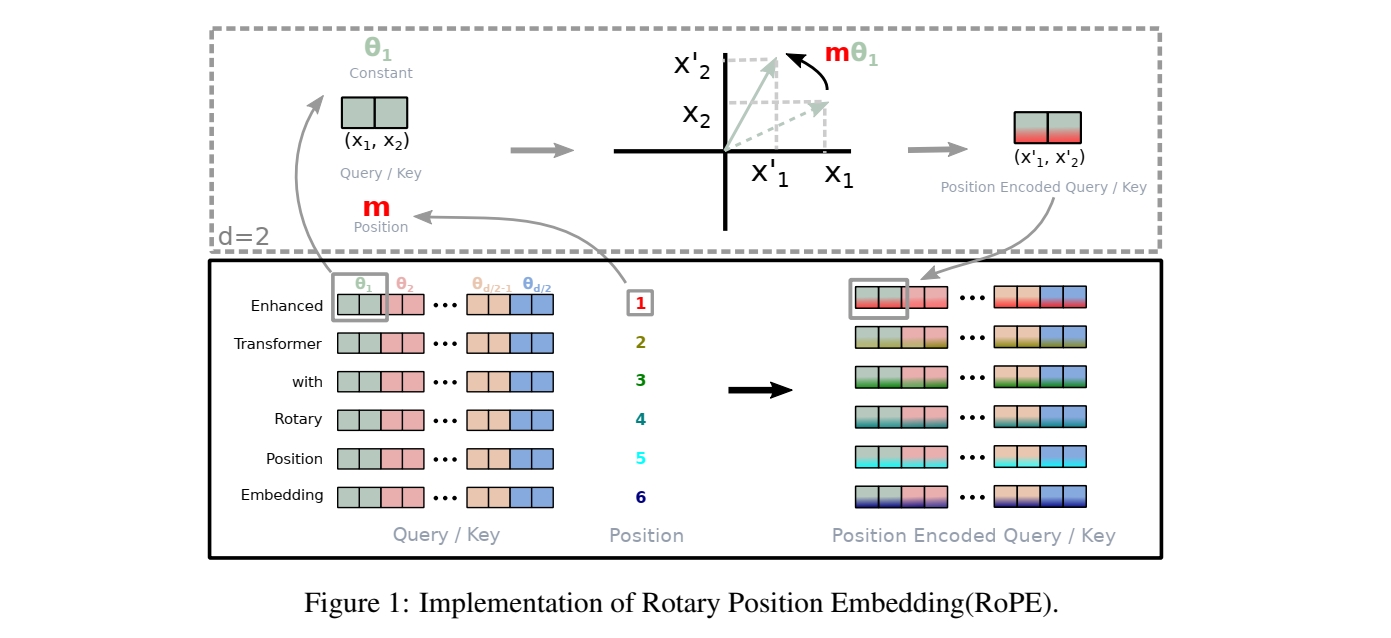
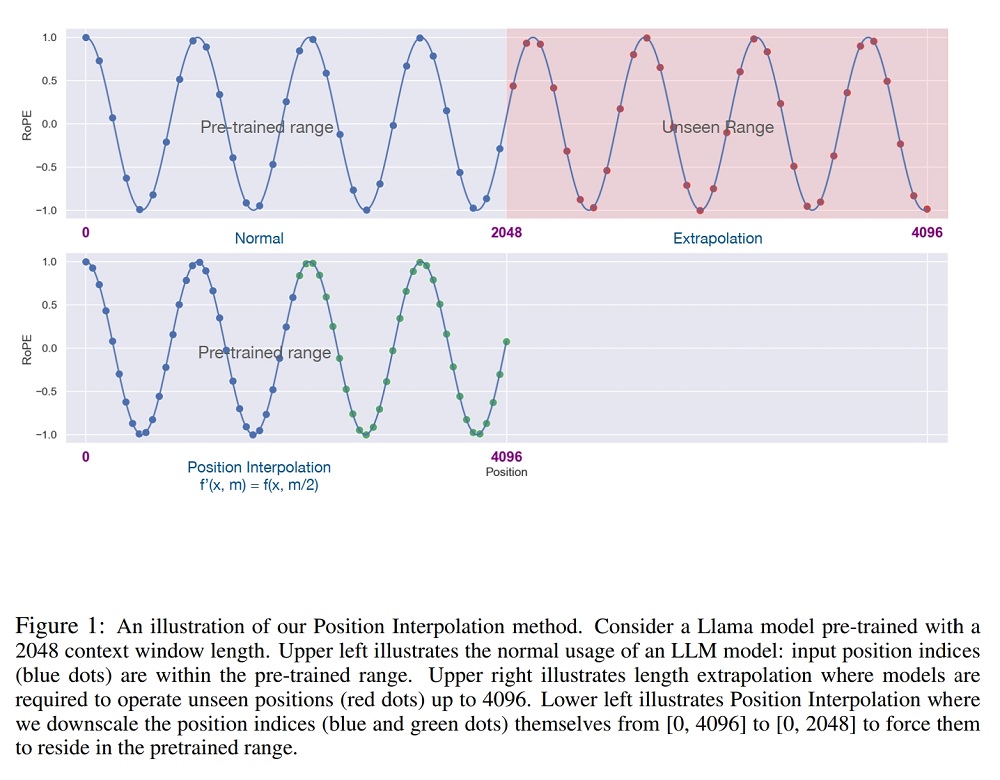
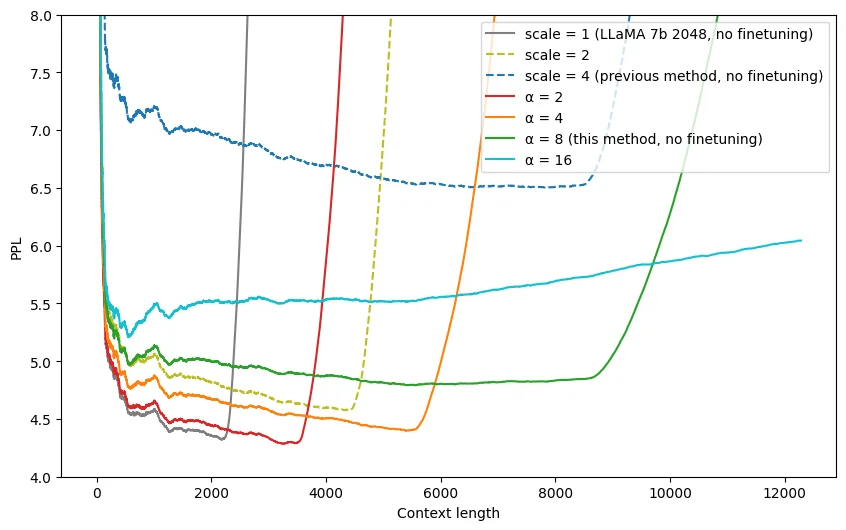
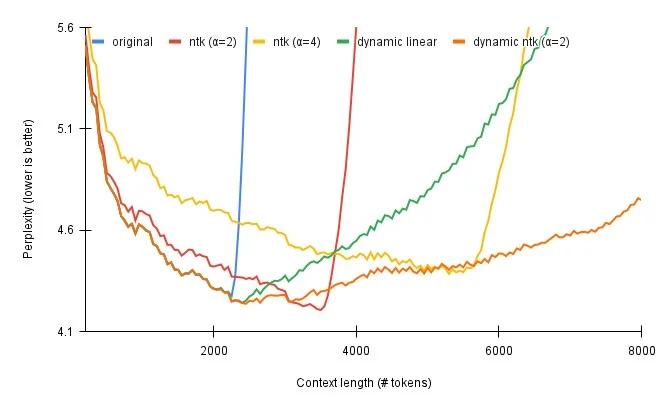
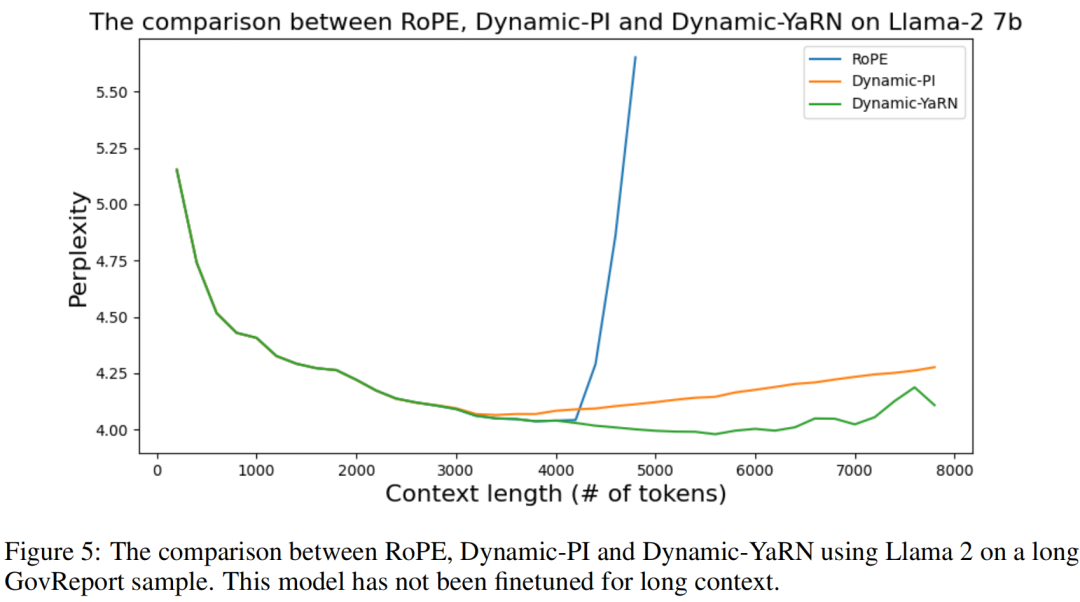










 ' +
+ '
' +
+ '