本篇博文主要展示每日从Arxiv论文网站获取的最新论文列表,以自然语言处理、信息检索、计算机视觉等类目进行划分。
+统计
+今日共更新561篇论文,其中:
+
+- 自然语言处理92篇
+- 信息检索8篇
+- 计算机视觉148篇
+
+自然语言处理
+
+ 1. 【2410.08211】LatteCLIP: Unsupervised CLIP Fine-Tuning via LMM-Synthetic Texts
+ 链接:https://arxiv.org/abs/2410.08211
+ 作者:Anh-Quan Cao,Maximilian Jaritz,Matthieu Guillaumin,Raoul de Charette,Loris Bazzani
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Large-scale vision-language pre-trained, Large-scale vision-language, applied to diverse, diverse applications, fine-tuning VLP models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large-scale vision-language pre-trained (VLP) models (e.g., CLIP) are renowned for their versatility, as they can be applied to diverse applications in a zero-shot setup. However, when these models are used in specific domains, their performance often falls short due to domain gaps or the under-representation of these domains in the training data. While fine-tuning VLP models on custom datasets with human-annotated labels can address this issue, annotating even a small-scale dataset (e.g., 100k samples) can be an expensive endeavor, often requiring expert annotators if the task is complex. To address these challenges, we propose LatteCLIP, an unsupervised method for fine-tuning CLIP models on classification with known class names in custom domains, without relying on human annotations. Our method leverages Large Multimodal Models (LMMs) to generate expressive textual descriptions for both individual images and groups of images. These provide additional contextual information to guide the fine-tuning process in the custom domains. Since LMM-generated descriptions are prone to hallucination or missing details, we introduce a novel strategy to distill only the useful information and stabilize the training. Specifically, we learn rich per-class prototype representations from noisy generated texts and dual pseudo-labels. Our experiments on 10 domain-specific datasets show that LatteCLIP outperforms pre-trained zero-shot methods by an average improvement of +4.74 points in top-1 accuracy and other state-of-the-art unsupervised methods by +3.45 points.
+
+
+
+ 2. 【2410.08202】Mono-InternVL: Pushing the Boundaries of Monolithic Multimodal Large Language Models with Endogenous Visual Pre-training
+ 链接:https://arxiv.org/abs/2410.08202
+ 作者:Gen Luo,Xue Yang,Wenhan Dou,Zhaokai Wang,Jifeng Dai,Yu Qiao,Xizhou Zhu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Large Language Models, Multimodal Large Language, Language Models, Large Language, monolithic Multimodal Large
+ 备注:
+
+ 点击查看摘要
+ Abstract:The rapid advancement of Large Language Models (LLMs) has led to an influx of efforts to extend their capabilities to multimodal tasks. Among them, growing attention has been focused on monolithic Multimodal Large Language Models (MLLMs) that integrate visual encoding and language decoding into a single LLM. Despite the structural simplicity and deployment-friendliness, training a monolithic MLLM with promising performance still remains challenging. In particular, the popular approaches adopt continuous pre-training to extend a pre-trained LLM to a monolithic MLLM, which suffers from catastrophic forgetting and leads to performance degeneration. In this paper, we aim to overcome this limitation from the perspective of delta tuning. Specifically, our core idea is to embed visual parameters into a pre-trained LLM, thereby incrementally learning visual knowledge from massive data via delta tuning, i.e., freezing the LLM when optimizing the visual parameters. Based on this principle, we present Mono-InternVL, a novel monolithic MLLM that seamlessly integrates a set of visual experts via a multimodal mixture-of-experts structure. Moreover, we propose an innovative pre-training strategy to maximize the visual capability of Mono-InternVL, namely Endogenous Visual Pre-training (EViP). In particular, EViP is designed as a progressive learning process for visual experts, which aims to fully exploit the visual knowledge from noisy data to high-quality data. To validate our approach, we conduct extensive experiments on 16 benchmarks. Experimental results not only validate the superior performance of Mono-InternVL compared to the state-of-the-art MLLM on 6 multimodal benchmarks, e.g., +113 points over InternVL-1.5 on OCRBench, but also confirm its better deployment efficiency, with first token latency reduced by up to 67%.
+
+
+
+ 3. 【2410.08197】From Exploration to Mastery: Enabling LLMs to Master Tools via Self-Driven Interactions
+ 链接:https://arxiv.org/abs/2410.08197
+ 作者:Changle Qu,Sunhao Dai,Xiaochi Wei,Hengyi Cai,Shuaiqiang Wang,Dawei Yin,Jun Xu,Ji-Rong Wen
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, enables Large Language, Language Models, Large Language, learning enables Large
+ 备注:
+
+ 点击查看摘要
+ Abstract:Tool learning enables Large Language Models (LLMs) to interact with external environments by invoking tools, serving as an effective strategy to mitigate the limitations inherent in their pre-training data. In this process, tool documentation plays a crucial role by providing usage instructions for LLMs, thereby facilitating effective tool utilization. This paper concentrates on the critical challenge of bridging the comprehension gap between LLMs and external tools due to the inadequacies and inaccuracies inherent in existing human-centric tool documentation. We propose a novel framework, DRAFT, aimed at Dynamically Refining tool documentation through the Analysis of Feedback and Trails emanating from LLMs' interactions with external tools. This methodology pivots on an innovative trial-and-error approach, consisting of three distinct learning phases: experience gathering, learning from experience, and documentation rewriting, to iteratively enhance the tool documentation. This process is further optimized by implementing a diversity-promoting exploration strategy to ensure explorative diversity and a tool-adaptive termination mechanism to prevent overfitting while enhancing efficiency. Extensive experiments on multiple datasets demonstrate that DRAFT's iterative, feedback-based refinement significantly ameliorates documentation quality, fostering a deeper comprehension and more effective utilization of tools by LLMs. Notably, our analysis reveals that the tool documentation refined via our approach demonstrates robust cross-model generalization capabilities.
+
+
+
+ 4. 【2410.08196】MathCoder2: Better Math Reasoning from Continued Pretraining on Model-translated Mathematical Code
+ 链接:https://arxiv.org/abs/2410.08196
+ 作者:Zimu Lu,Aojun Zhou,Ke Wang,Houxing Ren,Weikang Shi,Junting Pan,Mingjie Zhan,Hongsheng Li
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Code, mathematical, precision and accuracy, reasoning, mathematical reasoning
+ 备注: [this https URL](https://github.com/mathllm/MathCoder2)
+
+ 点击查看摘要
+ Abstract:Code has been shown to be effective in enhancing the mathematical reasoning abilities of large language models due to its precision and accuracy. Previous works involving continued mathematical pretraining often include code that utilizes math-related packages, which are primarily designed for fields such as engineering, machine learning, signal processing, or module testing, rather than being directly focused on mathematical reasoning. In this paper, we introduce a novel method for generating mathematical code accompanied with corresponding reasoning steps for continued pretraining. Our approach begins with the construction of a high-quality mathematical continued pretraining dataset by incorporating math-related web data, code using mathematical packages, math textbooks, and synthetic data. Next, we construct reasoning steps by extracting LaTeX expressions, the conditions needed for the expressions, and the results of the expressions from the previously collected dataset. Based on this extracted information, we generate corresponding code to accurately capture the mathematical reasoning process. Appending the generated code to each reasoning step results in data consisting of paired natural language reasoning steps and their corresponding code. Combining this data with the original dataset results in a 19.2B-token high-performing mathematical pretraining corpus, which we name MathCode-Pile. Training several popular base models with this corpus significantly improves their mathematical abilities, leading to the creation of the MathCoder2 family of models. All of our data processing and training code is open-sourced, ensuring full transparency and easy reproducibility of the entire data collection and training pipeline. The code is released at this https URL .
+
+
+
+ 5. 【2410.08193】GenARM: Reward Guided Generation with Autoregressive Reward Model for Test-time Alignment
+ 链接:https://arxiv.org/abs/2410.08193
+ 作者:Yuancheng Xu,Udari Madhushani Sehwag,Alec Koppel,Sicheng Zhu,Bang An,Furong Huang,Sumitra Ganesh
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, exhibit impressive capabilities, Language Models, exhibit impressive
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) exhibit impressive capabilities but require careful alignment with human preferences. Traditional training-time methods finetune LLMs using human preference datasets but incur significant training costs and require repeated training to handle diverse user preferences. Test-time alignment methods address this by using reward models (RMs) to guide frozen LLMs without retraining. However, existing test-time approaches rely on trajectory-level RMs which are designed to evaluate complete responses, making them unsuitable for autoregressive text generation that requires computing next-token rewards from partial responses. To address this, we introduce GenARM, a test-time alignment approach that leverages the Autoregressive Reward Model--a novel reward parametrization designed to predict next-token rewards for efficient and effective autoregressive generation. Theoretically, we demonstrate that this parametrization can provably guide frozen LLMs toward any distribution achievable by traditional RMs within the KL-regularized reinforcement learning framework. Experimental results show that GenARM significantly outperforms prior test-time alignment baselines and matches the performance of training-time methods. Additionally, GenARM enables efficient weak-to-strong guidance, aligning larger LLMs with smaller RMs without the high costs of training larger models. Furthermore, GenARM supports multi-objective alignment, allowing real-time trade-offs between preference dimensions and catering to diverse user preferences without retraining.
+
+
+
+ 6. 【2410.08182】MRAG-Bench: Vision-Centric Evaluation for Retrieval-Augmented Multimodal Models
+ 链接:https://arxiv.org/abs/2410.08182
+ 作者:Wenbo Hu,Jia-Chen Gu,Zi-Yi Dou,Mohsen Fayyaz,Pan Lu,Kai-Wei Chang,Nanyun Peng
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Existing multimodal retrieval, retrieval benchmarks primarily, benchmarks primarily focus, Existing multimodal, primarily focus
+ 备注: [this https URL](https://mragbench.github.io)
+
+ 点击查看摘要
+ Abstract:Existing multimodal retrieval benchmarks primarily focus on evaluating whether models can retrieve and utilize external textual knowledge for question answering. However, there are scenarios where retrieving visual information is either more beneficial or easier to access than textual data. In this paper, we introduce a multimodal retrieval-augmented generation benchmark, MRAG-Bench, in which we systematically identify and categorize scenarios where visually augmented knowledge is better than textual knowledge, for instance, more images from varying viewpoints. MRAG-Bench consists of 16,130 images and 1,353 human-annotated multiple-choice questions across 9 distinct scenarios. With MRAG-Bench, we conduct an evaluation of 10 open-source and 4 proprietary large vision-language models (LVLMs). Our results show that all LVLMs exhibit greater improvements when augmented with images compared to textual knowledge, confirming that MRAG-Bench is vision-centric. Additionally, we conduct extensive analysis with MRAG-Bench, which offers valuable insights into retrieval-augmented LVLMs. Notably, the top-performing model, GPT-4o, faces challenges in effectively leveraging retrieved knowledge, achieving only a 5.82% improvement with ground-truth information, in contrast to a 33.16% improvement observed in human participants. These findings highlight the importance of MRAG-Bench in encouraging the community to enhance LVLMs' ability to utilize retrieved visual knowledge more effectively.
+
+
+
+ 7. 【2410.08174】Sample then Identify: A General Framework for Risk Control and Assessment in Multimodal Large Language Models
+ 链接:https://arxiv.org/abs/2410.08174
+ 作者:Qingni Wang,Tiantian Geng,Zhiyuan Wang,Teng Wang,Bo Fu,Feng Zheng
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Multimedia (cs.MM)
+ 关键词:Multimodal Large Language, Multimodal Large, Large Language Models, significant trustworthiness issues, encounter significant trustworthiness
+ 备注: 15 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:Multimodal Large Language Models (MLLMs) exhibit promising advancements across various tasks, yet they still encounter significant trustworthiness issues. Prior studies apply Split Conformal Prediction (SCP) in language modeling to construct prediction sets with statistical guarantees. However, these methods typically rely on internal model logits or are restricted to multiple-choice settings, which hampers their generalizability and adaptability in dynamic, open-ended environments. In this paper, we introduce TRON, a two-step framework for risk control and assessment, applicable to any MLLM that supports sampling in both open-ended and closed-ended scenarios. TRON comprises two main components: (1) a novel conformal score to sample response sets of minimum size, and (2) a nonconformity score to identify high-quality responses based on self-consistency theory, controlling the error rates by two specific risk levels. Furthermore, we investigate semantic redundancy in prediction sets within open-ended contexts for the first time, leading to a promising evaluation metric for MLLMs based on average set size. Our comprehensive experiments across four Video Question-Answering (VideoQA) datasets utilizing eight MLLMs show that TRON achieves desired error rates bounded by two user-specified risk levels. Additionally, deduplicated prediction sets maintain adaptiveness while being more efficient and stable for risk assessment under different risk levels.
+
+
+
+ 8. 【2410.08164】Agent S: An Open Agentic Framework that Uses Computers Like a Human
+ 链接:https://arxiv.org/abs/2410.08164
+ 作者:Saaket Agashe,Jiuzhou Han,Shuyu Gan,Jiachen Yang,Ang Li,Xin Eric Wang
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Graphical User Interface, Graphical User, enables autonomous interaction, transforming human-computer interaction, open agentic framework
+ 备注: 23 pages, 16 figures, 9 tables
+
+ 点击查看摘要
+ Abstract:We present Agent S, an open agentic framework that enables autonomous interaction with computers through a Graphical User Interface (GUI), aimed at transforming human-computer interaction by automating complex, multi-step tasks. Agent S aims to address three key challenges in automating computer tasks: acquiring domain-specific knowledge, planning over long task horizons, and handling dynamic, non-uniform interfaces. To this end, Agent S introduces experience-augmented hierarchical planning, which learns from external knowledge search and internal experience retrieval at multiple levels, facilitating efficient task planning and subtask execution. In addition, it employs an Agent-Computer Interface (ACI) to better elicit the reasoning and control capabilities of GUI agents based on Multimodal Large Language Models (MLLMs). Evaluation on the OSWorld benchmark shows that Agent S outperforms the baseline by 9.37% on success rate (an 83.6% relative improvement) and achieves a new state-of-the-art. Comprehensive analysis highlights the effectiveness of individual components and provides insights for future improvements. Furthermore, Agent S demonstrates broad generalizability to different operating systems on a newly-released WindowsAgentArena benchmark. Code available at this https URL.
+
+
+
+ 9. 【2410.08162】he Effect of Surprisal on Reading Times in Information Seeking and Repeated Reading
+ 链接:https://arxiv.org/abs/2410.08162
+ 作者:Keren Gruteke Klein,Yoav Meiri,Omer Shubi,Yevgeni Berzak
+ 类目:Computation and Language (cs.CL)
+ 关键词:investigation in psycholinguistics, central topic, topic of investigation, processing, surprisal
+ 备注: Accepted to CoNLL
+
+ 点击查看摘要
+ Abstract:The effect of surprisal on processing difficulty has been a central topic of investigation in psycholinguistics. Here, we use eyetracking data to examine three language processing regimes that are common in daily life but have not been addressed with respect to this question: information seeking, repeated processing, and the combination of the two. Using standard regime-agnostic surprisal estimates we find that the prediction of surprisal theory regarding the presence of a linear effect of surprisal on processing times, extends to these regimes. However, when using surprisal estimates from regime-specific contexts that match the contexts and tasks given to humans, we find that in information seeking, such estimates do not improve the predictive power of processing times compared to standard surprisals. Further, regime-specific contexts yield near zero surprisal estimates with no predictive power for processing times in repeated reading. These findings point to misalignments of task and memory representations between humans and current language models, and question the extent to which such models can be used for estimating cognitively relevant quantities. We further discuss theoretical challenges posed by these results.
+
+
+
+ 10. 【2410.08146】Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning
+ 链接:https://arxiv.org/abs/2410.08146
+ 作者:Amrith Setlur,Chirag Nagpal,Adam Fisch,Xinyang Geng,Jacob Eisenstein,Rishabh Agarwal,Alekh Agarwal,Jonathan Berant,Aviral Kumar
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:large language models, promising approach, large language, reward models, language models
+ 备注:
+
+ 点击查看摘要
+ Abstract:A promising approach for improving reasoning in large language models is to use process reward models (PRMs). PRMs provide feedback at each step of a multi-step reasoning trace, potentially improving credit assignment over outcome reward models (ORMs) that only provide feedback at the final step. However, collecting dense, per-step human labels is not scalable, and training PRMs from automatically-labeled data has thus far led to limited gains. To improve a base policy by running search against a PRM or using it as dense rewards for reinforcement learning (RL), we ask: "How should we design process rewards?". Our key insight is that, to be effective, the process reward for a step should measure progress: a change in the likelihood of producing a correct response in the future, before and after taking the step, corresponding to the notion of step-level advantages in RL. Crucially, this progress should be measured under a prover policy distinct from the base policy. We theoretically characterize the set of good provers and our results show that optimizing process rewards from such provers improves exploration during test-time search and online RL. In fact, our characterization shows that weak prover policies can substantially improve a stronger base policy, which we also observe empirically. We validate our claims by training process advantage verifiers (PAVs) to predict progress under such provers, and show that compared to ORMs, test-time search against PAVs is $8\%$ more accurate, and $1.5-5\times$ more compute-efficient. Online RL with dense rewards from PAVs enables one of the first results with $5-6\times$ gain in sample efficiency, and $6\%$ gain in accuracy, over ORMs.
+
+
+
+ 11. 【2410.08145】Insight Over Sight? Exploring the Vision-Knowledge Conflicts in Multimodal LLMs
+ 链接:https://arxiv.org/abs/2410.08145
+ 作者:Xiaoyuan Liu,Wenxuan Wang,Youliang Yuan,Jen-tse Huang,Qiuzhi Liu,Pinjia He,Zhaopeng Tu
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Multimodal Large Language, Large Language Models, Multimodal Large, Large Language, contradicts model internal
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper explores the problem of commonsense-level vision-knowledge conflict in Multimodal Large Language Models (MLLMs), where visual information contradicts model's internal commonsense knowledge (see Figure 1). To study this issue, we introduce an automated pipeline, augmented with human-in-the-loop quality control, to establish a benchmark aimed at simulating and assessing the conflicts in MLLMs. Utilizing this pipeline, we have crafted a diagnostic benchmark comprising 374 original images and 1,122 high-quality question-answer (QA) pairs. This benchmark covers two types of conflict target and three question difficulty levels, providing a thorough assessment tool. Through this benchmark, we evaluate the conflict-resolution capabilities of nine representative MLLMs across various model families and find a noticeable over-reliance on textual queries. Drawing on these findings, we propose a novel prompting strategy, "Focus-on-Vision" (FoV), which markedly enhances MLLMs' ability to favor visual data over conflicting textual knowledge. Our detailed analysis and the newly proposed strategy significantly advance the understanding and mitigating of vision-knowledge conflicts in MLLMs. The data and code are made publicly available.
+
+
+
+ 12. 【2410.08143】DelTA: An Online Document-Level Translation Agent Based on Multi-Level Memory
+ 链接:https://arxiv.org/abs/2410.08143
+ 作者:Yutong Wang,Jiali Zeng,Xuebo Liu,Derek F. Wong,Fandong Meng,Jie Zhou,Min Zhang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large language models, Large language, reasonable quality improvements, achieved reasonable quality, language models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) have achieved reasonable quality improvements in machine translation (MT). However, most current research on MT-LLMs still faces significant challenges in maintaining translation consistency and accuracy when processing entire documents. In this paper, we introduce DelTA, a Document-levEL Translation Agent designed to overcome these limitations. DelTA features a multi-level memory structure that stores information across various granularities and spans, including Proper Noun Records, Bilingual Summary, Long-Term Memory, and Short-Term Memory, which are continuously retrieved and updated by auxiliary LLM-based components. Experimental results indicate that DelTA significantly outperforms strong baselines in terms of translation consistency and quality across four open/closed-source LLMs and two representative document translation datasets, achieving an increase in consistency scores by up to 4.58 percentage points and in COMET scores by up to 3.16 points on average. DelTA employs a sentence-by-sentence translation strategy, ensuring no sentence omissions and offering a memory-efficient solution compared to the mainstream method. Furthermore, DelTA improves pronoun translation accuracy, and the summary component of the agent also shows promise as a tool for query-based summarization tasks. We release our code and data at this https URL.
+
+
+
+ 13. 【2410.08133】Assessing Episodic Memory in LLMs with Sequence Order Recall Tasks
+ 链接:https://arxiv.org/abs/2410.08133
+ 作者:Mathis Pink,Vy A. Vo,Qinyuan Wu,Jianing Mu,Javier S. Turek,Uri Hasson,Kenneth A. Norman,Sebastian Michelmann,Alexander Huth,Mariya Toneva
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:primarily assessing semantic, Current LLM benchmarks, Current LLM, assessing semantic aspects, semantic relations
+ 备注:
+
+ 点击查看摘要
+ Abstract:Current LLM benchmarks focus on evaluating models' memory of facts and semantic relations, primarily assessing semantic aspects of long-term memory. However, in humans, long-term memory also includes episodic memory, which links memories to their contexts, such as the time and place they occurred. The ability to contextualize memories is crucial for many cognitive tasks and everyday functions. This form of memory has not been evaluated in LLMs with existing benchmarks. To address the gap in evaluating memory in LLMs, we introduce Sequence Order Recall Tasks (SORT), which we adapt from tasks used to study episodic memory in cognitive psychology. SORT requires LLMs to recall the correct order of text segments, and provides a general framework that is both easily extendable and does not require any additional annotations. We present an initial evaluation dataset, Book-SORT, comprising 36k pairs of segments extracted from 9 books recently added to the public domain. Based on a human experiment with 155 participants, we show that humans can recall sequence order based on long-term memory of a book. We find that models can perform the task with high accuracy when relevant text is given in-context during the SORT evaluation. However, when presented with the book text only during training, LLMs' performance on SORT falls short. By allowing to evaluate more aspects of memory, we believe that SORT will aid in the emerging development of memory-augmented models.
+
+
+
+ 14. 【2410.08130】hink Beyond Size: Dynamic Prompting for More Effective Reasoning
+ 链接:https://arxiv.org/abs/2410.08130
+ 作者:Kamesh R
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, paper presents Dynamic, presents Dynamic Prompting, capabilities of Large
+ 备注: Submitted to ICLR 2025. This is a preprint version. Future revisions will include additional evaluations and refinements
+
+ 点击查看摘要
+ Abstract:This paper presents Dynamic Prompting, a novel framework aimed at improving the reasoning capabilities of Large Language Models (LLMs). In contrast to conventional static prompting methods, Dynamic Prompting enables the adaptive modification of prompt sequences and step counts based on real-time task complexity and model performance. This dynamic adaptation facilitates more efficient problem-solving, particularly in smaller models, by reducing hallucinations and repetitive cycles. Our empirical evaluations demonstrate that Dynamic Prompting allows smaller LLMs to perform competitively with much larger models, thereby challenging the conventional emphasis on model size as the primary determinant of reasoning efficacy.
+
+
+
+ 15. 【2410.08126】Mars: Situated Inductive Reasoning in an Open-World Environment
+ 链接:https://arxiv.org/abs/2410.08126
+ 作者:Xiaojuan Tang,Jiaqi Li,Yitao Liang,Song-chun Zhu,Muhan Zhang,Zilong Zheng
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, Language Models, shown remarkable success, inductive reasoning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) trained on massive corpora have shown remarkable success in knowledge-intensive tasks. Yet, most of them rely on pre-stored knowledge. Inducing new general knowledge from a specific environment and performing reasoning with the acquired knowledge -- \textit{situated inductive reasoning}, is crucial and challenging for machine intelligence. In this paper, we design Mars, an interactive environment devised for situated inductive reasoning. It introduces counter-commonsense game mechanisms by modifying terrain, survival setting and task dependency while adhering to certain principles. In Mars, agents need to actively interact with their surroundings, derive useful rules and perform decision-making tasks in specific contexts. We conduct experiments on various RL-based and LLM-based methods, finding that they all struggle on this challenging situated inductive reasoning benchmark. Furthermore, we explore \textit{Induction from Reflection}, where we instruct agents to perform inductive reasoning from history trajectory. The superior performance underscores the importance of inductive reasoning in Mars. Through Mars, we aim to galvanize advancements in situated inductive reasoning and set the stage for developing the next generation of AI systems that can reason in an adaptive and context-sensitive way.
+
+
+
+ 16. 【2410.08115】Optima: Optimizing Effectiveness and Efficiency for LLM-Based Multi-Agent System
+ 链接:https://arxiv.org/abs/2410.08115
+ 作者:Weize Chen,Jiarui Yuan,Chen Qian,Cheng Yang,Zhiyuan Liu,Maosong Sun
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Model, Large Language, Language Model, parameter-updating optimization methods, low communication efficiency
+ 备注: Under review
+
+ 点击查看摘要
+ Abstract:Large Language Model (LLM) based multi-agent systems (MAS) show remarkable potential in collaborative problem-solving, yet they still face critical challenges: low communication efficiency, poor scalability, and a lack of effective parameter-updating optimization methods. We present Optima, a novel framework that addresses these issues by significantly enhancing both communication efficiency and task effectiveness in LLM-based MAS through LLM training. Optima employs an iterative generate, rank, select, and train paradigm with a reward function balancing task performance, token efficiency, and communication readability. We explore various RL algorithms, including Supervised Fine-Tuning, Direct Preference Optimization, and their hybrid approaches, providing insights into their effectiveness-efficiency trade-offs. We integrate Monte Carlo Tree Search-inspired techniques for DPO data generation, treating conversation turns as tree nodes to explore diverse interaction paths. Evaluated on common multi-agent tasks, including information-asymmetric question answering and complex reasoning, Optima shows consistent and substantial improvements over single-agent baselines and vanilla MAS based on Llama 3 8B, achieving up to 2.8x performance gain with less than 10\% tokens on tasks requiring heavy information exchange. Moreover, Optima's efficiency gains open new possibilities for leveraging inference-compute more effectively, leading to improved inference-time scaling laws. By addressing fundamental challenges in LLM-based MAS, Optima shows the potential towards scalable, efficient, and effective MAS (this https URL).
+
+
+
+ 17. 【2410.08113】Robust AI-Generated Text Detection by Restricted Embeddings
+ 链接:https://arxiv.org/abs/2410.08113
+ 作者:Kristian Kuznetsov,Eduard Tulchinskii,Laida Kushnareva,German Magai,Serguei Barannikov,Sergey Nikolenko,Irina Piontkovskaya
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:texts makes detecting, Growing amount, AI-generated texts makes, content more difficult, amount and quality
+ 备注: Accepted to Findings of EMNLP 2024
+
+ 点击查看摘要
+ Abstract:Growing amount and quality of AI-generated texts makes detecting such content more difficult. In most real-world scenarios, the domain (style and topic) of generated data and the generator model are not known in advance. In this work, we focus on the robustness of classifier-based detectors of AI-generated text, namely their ability to transfer to unseen generators or semantic domains. We investigate the geometry of the embedding space of Transformer-based text encoders and show that clearing out harmful linear subspaces helps to train a robust classifier, ignoring domain-specific spurious features. We investigate several subspace decomposition and feature selection strategies and achieve significant improvements over state of the art methods in cross-domain and cross-generator transfer. Our best approaches for head-wise and coordinate-based subspace removal increase the mean out-of-distribution (OOD) classification score by up to 9% and 14% in particular setups for RoBERTa and BERT embeddings respectively. We release our code and data: this https URL
+
+
+
+ 18. 【2410.08109】A Closer Look at Machine Unlearning for Large Language Models
+ 链接:https://arxiv.org/abs/2410.08109
+ 作者:Xiaojian Yuan,Tianyu Pang,Chao Du,Kejiang Chen,Weiming Zhang,Min Lin
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Large language models, Large language, raising privacy, legal concerns, memorize sensitive
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) may memorize sensitive or copyrighted content, raising privacy and legal concerns. Due to the high cost of retraining from scratch, researchers attempt to employ machine unlearning to remove specific content from LLMs while preserving the overall performance. In this paper, we discuss several issues in machine unlearning for LLMs and provide our insights on possible approaches. To address the issue of inadequate evaluation of model outputs after unlearning, we introduce three additional metrics to evaluate token diversity, sentence semantics, and factual correctness. We then categorize unlearning methods into untargeted and targeted, and discuss their issues respectively. Specifically, the behavior that untargeted unlearning attempts to approximate is unpredictable and may involve hallucinations, and existing regularization is insufficient for targeted unlearning. To alleviate these issues, we propose using the objective of maximizing entropy (ME) for untargeted unlearning and incorporate answer preservation (AP) loss as regularization for targeted unlearning. Experimental results across three scenarios, i.e., fictitious unlearning, continual unlearning, and real-world unlearning, demonstrate the effectiveness of our approaches. The code is available at this https URL.
+
+
+
+ 19. 【2410.08105】What Makes Large Language Models Reason in (Multi-Turn) Code Generation?
+ 链接:https://arxiv.org/abs/2410.08105
+ 作者:Kunhao Zheng,Juliette Decugis,Jonas Gehring,Taco Cohen,Benjamin Negrevergne,Gabriel Synnaeve
+ 类目:Computation and Language (cs.CL)
+ 关键词:popular vehicle, vehicle for improving, improving the outputs, large language models, Prompting techniques
+ 备注:
+
+ 点击查看摘要
+ Abstract:Prompting techniques such as chain-of-thought have established themselves as a popular vehicle for improving the outputs of large language models (LLMs). For code generation, however, their exact mechanics and efficacy are under-explored. We thus investigate the effects of a wide range of prompting strategies with a focus on automatic re-prompting over multiple turns and computational requirements. After systematically decomposing reasoning, instruction, and execution feedback prompts, we conduct an extensive grid search on the competitive programming benchmarks CodeContests and TACO for multiple LLM families and sizes (Llama 3.0 and 3.1, 8B, 70B, 405B, and GPT-4o). Our study reveals strategies that consistently improve performance across all models with small and large sampling budgets. We then show how finetuning with such an optimal configuration allows models to internalize the induced reasoning process and obtain improvements in performance and scalability for multi-turn code generation.
+
+
+
+ 20. 【2410.08102】Multi-Agent Collaborative Data Selection for Efficient LLM Pretraining
+ 链接:https://arxiv.org/abs/2410.08102
+ 作者:Tianyi Bai,Ling Yang,Zhen Hao Wong,Jiahui Peng,Xinlin Zhuang,Chi Zhang,Lijun Wu,Qiu Jiantao,Wentao Zhang,Binhang Yuan,Conghui He
+ 类目:Computation and Language (cs.CL)
+ 关键词:Efficient data selection, Efficient data, data selection, data, Efficient
+ 备注:
+
+ 点击查看摘要
+ Abstract:Efficient data selection is crucial to accelerate the pretraining of large language models (LLMs). While various methods have been proposed to enhance data efficiency, limited research has addressed the inherent conflicts between these approaches to achieve optimal data selection for LLM pretraining. To tackle this problem, we propose a novel multi-agent collaborative data selection mechanism. In this framework, each data selection method serves as an independent agent, and an agent console is designed to dynamically integrate the information from all agents throughout the LLM training process. We conduct extensive empirical studies to evaluate our multi-agent framework. The experimental results demonstrate that our approach significantly improves data efficiency, accelerates convergence in LLM training, and achieves an average performance gain of 10.5% across multiple language model benchmarks compared to the state-of-the-art methods.
+
+
+
+ 21. 【2410.08085】Can Knowledge Graphs Make Large Language Models More Trustworthy? An Empirical Study over Open-ended Question Answering
+ 链接:https://arxiv.org/abs/2410.08085
+ 作者:Yuan Sui,Bryan Hooi
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, integrating Knowledge Graphs, Knowledge Graphs, Large Language, Recent works integrating
+ 备注: Work in progress
+
+ 点击查看摘要
+ Abstract:Recent works integrating Knowledge Graphs (KGs) have led to promising improvements in enhancing reasoning accuracy of Large Language Models (LLMs). However, current benchmarks mainly focus on closed tasks, leaving a gap in the assessment of more complex, real-world scenarios. This gap has also obscured the evaluation of KGs' potential to mitigate the problem of hallucination in LLMs. To fill the gap, we introduce OKGQA, a new benchmark specifically designed to assess LLMs enhanced with KGs under open-ended, real-world question answering scenarios. OKGQA is designed to closely reflect the complexities of practical applications using questions from different types, and incorporates specific metrics to measure both the reduction in hallucinations and the enhancement in reasoning capabilities. To consider the scenario in which KGs may have varying levels of mistakes, we further propose another experiment setting OKGQA-P to assess model performance when the semantics and structure of KGs are deliberately perturbed and contaminated. OKGQA aims to (1) explore whether KGs can make LLMs more trustworthy in an open-ended setting, and (2) conduct a comparative analysis to shed light on methods and future directions for leveraging KGs to reduce LLMs' hallucination. We believe that this study can facilitate a more complete performance comparison and encourage continuous improvement in integrating KGs with LLMs.
+
+
+
+ 22. 【2410.08081】Packing Analysis: Packing Is More Appropriate for Large Models or Datasets in Supervised Fine-tuning
+ 链接:https://arxiv.org/abs/2410.08081
+ 作者:Shuhe Wang,Guoyin Wang,Jiwei Li,Eduard Hovy,Chen Guo
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:maximum input length, optimization technique designed, maximize hardware resource, model maximum input, hardware resource efficiency
+ 备注:
+
+ 点击查看摘要
+ Abstract:Packing, initially utilized in the pre-training phase, is an optimization technique designed to maximize hardware resource efficiency by combining different training sequences to fit the model's maximum input length. Although it has demonstrated effectiveness during pre-training, there remains a lack of comprehensive analysis for the supervised fine-tuning (SFT) stage on the following points: (1) whether packing can effectively enhance training efficiency while maintaining performance, (2) the suitable size of the model and dataset for fine-tuning with the packing method, and (3) whether packing unrelated or related training samples might cause the model to either excessively disregard or over-rely on the context.
+In this paper, we perform extensive comparisons between SFT methods using padding and packing, covering SFT datasets ranging from 69K to 1.2M and models from 8B to 70B. This provides the first comprehensive analysis of the advantages and limitations of packing versus padding, as well as practical considerations for implementing packing in various training scenarios. Our analysis covers various benchmarks, including knowledge, reasoning, and coding, as well as GPT-based evaluations, time efficiency, and other fine-tuning parameters. We also open-source our code for fine-tuning and evaluation and provide checkpoints fine-tuned on datasets of different sizes, aiming to advance future research on packing methods. Code is available at: this https URL.
+
Subjects:
+Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+Cite as:
+arXiv:2410.08081 [cs.LG]
+(or
+arXiv:2410.08081v1 [cs.LG] for this version)
+https://doi.org/10.48550/arXiv.2410.08081
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 23. 【2410.08068】aching-Inspired Integrated Prompting Framework: A Novel Approach for Enhancing Reasoning in Large Language Models
+ 链接:https://arxiv.org/abs/2410.08068
+ 作者:Wenting Tan,Dongxiao Chen,Jieting Xue,Zihao Wang,Taijie Chen
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, Large Language, Language Models, exhibit impressive performance, arithmetic reasoning tasks
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) exhibit impressive performance across various domains but still struggle with arithmetic reasoning tasks. Recent work shows the effectiveness of prompt design methods in enhancing reasoning capabilities. However, these approaches overlook crucial requirements for prior knowledge of specific concepts, theorems, and tricks to tackle most arithmetic reasoning problems successfully. To address this issue, we propose a novel and effective Teaching-Inspired Integrated Framework, which emulates the instructional process of a teacher guiding students. This method equips LLMs with essential concepts, relevant theorems, and similar problems with analogous solution approaches, facilitating the enhancement of reasoning abilities. Additionally, we introduce two new Chinese datasets, MathMC and MathToF, both with detailed explanations and answers. Experiments are conducted on nine benchmarks which demonstrates that our approach improves the reasoning accuracy of LLMs. With GPT-4 and our framework, we achieve new state-of-the-art performance on four math benchmarks (AddSub, SVAMP, Math23K and AQuA) with accuracies of 98.2% (+3.3%), 93.9% (+0.2%), 94.3% (+7.2%) and 81.1% (+1.2%). Our data and code are available at this https URL.
+
+
+
+ 24. 【2410.08058】Closing the Loop: Learning to Generate Writing Feedback via Language Model Simulated Student Revisions
+ 链接:https://arxiv.org/abs/2410.08058
+ 作者:Inderjeet Nair,Jiaye Tan,Xiaotian Su,Anne Gere,Xu Wang,Lu Wang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Providing feedback, widely recognized, recognized as crucial, crucial for refining, students' writing skills
+ 备注: Accepted to EMNLP 2024
+
+ 点击查看摘要
+ Abstract:Providing feedback is widely recognized as crucial for refining students' writing skills. Recent advances in language models (LMs) have made it possible to automatically generate feedback that is actionable and well-aligned with human-specified attributes. However, it remains unclear whether the feedback generated by these models is truly effective in enhancing the quality of student revisions. Moreover, prompting LMs with a precise set of instructions to generate feedback is nontrivial due to the lack of consensus regarding the specific attributes that can lead to improved revising performance. To address these challenges, we propose PROF that PROduces Feedback via learning from LM simulated student revisions. PROF aims to iteratively optimize the feedback generator by directly maximizing the effectiveness of students' overall revising performance as simulated by LMs. Focusing on an economic essay assignment, we empirically test the efficacy of PROF and observe that our approach not only surpasses a variety of baseline methods in effectiveness of improving students' writing but also demonstrates enhanced pedagogical values, even though it was not explicitly trained for this aspect.
+
+
+
+ 25. 【2410.08053】A Target-Aware Analysis of Data Augmentation for Hate Speech Detection
+ 链接:https://arxiv.org/abs/2410.08053
+ 作者:Camilla Casula,Sara Tonelli
+ 类目:Computation and Language (cs.CL)
+ 关键词:main threats posed, Hate speech, hate speech detection, Measuring Hate Speech, social networks
+ 备注:
+
+ 点击查看摘要
+ Abstract:Hate speech is one of the main threats posed by the widespread use of social networks, despite efforts to limit it. Although attention has been devoted to this issue, the lack of datasets and case studies centered around scarcely represented phenomena, such as ableism or ageism, can lead to hate speech detection systems that do not perform well on underrepresented identity groups. Given the unpreceded capabilities of LLMs in producing high-quality data, we investigate the possibility of augmenting existing data with generative language models, reducing target imbalance. We experiment with augmenting 1,000 posts from the Measuring Hate Speech corpus, an English dataset annotated with target identity information, adding around 30,000 synthetic examples using both simple data augmentation methods and different types of generative models, comparing autoregressive and sequence-to-sequence approaches. We find traditional DA methods to often be preferable to generative models, but the combination of the two tends to lead to the best results. Indeed, for some hate categories such as origin, religion, and disability, hate speech classification using augmented data for training improves by more than 10% F1 over the no augmentation baseline. This work contributes to the development of systems for hate speech detection that are not only better performing but also fairer and more inclusive towards targets that have been neglected so far.
+
+
+
+ 26. 【2410.08048】VerifierQ: Enhancing LLM Test Time Compute with Q-Learning-based Verifiers
+ 链接:https://arxiv.org/abs/2410.08048
+ 作者:Jianing Qi,Hao Tang,Zhigang Zhu
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:test time compute, Large Language Models, Large Language, Language Models, verifier models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advancements in test time compute, particularly through the use of verifier models, have significantly enhanced the reasoning capabilities of Large Language Models (LLMs). This generator-verifier approach closely resembles the actor-critic framework in reinforcement learning (RL). However, current verifier models in LLMs often rely on supervised fine-tuning without temporal difference learning such as Q-learning. This paper introduces VerifierQ, a novel approach that integrates Offline Q-learning into LLM verifier models. We address three key challenges in applying Q-learning to LLMs: (1) handling utterance-level Markov Decision Processes (MDPs), (2) managing large action spaces, and (3) mitigating overestimation bias. VerifierQ introduces a modified Bellman update for bounded Q-values, incorporates Implicit Q-learning (IQL) for efficient action space management, and integrates a novel Conservative Q-learning (CQL) formulation for balanced Q-value estimation. Our method enables parallel Q-value computation and improving training efficiency. While recent work has explored RL techniques like MCTS for generators, VerifierQ is among the first to investigate the verifier (critic) aspect in LLMs through Q-learning. This integration of RL principles into verifier models complements existing advancements in generator techniques, potentially enabling more robust and adaptive reasoning in LLMs. Experimental results on mathematical reasoning tasks demonstrate VerifierQ's superior performance compared to traditional supervised fine-tuning approaches, with improvements in efficiency, accuracy and robustness. By enhancing the synergy between generation and evaluation capabilities, VerifierQ contributes to the ongoing evolution of AI systems in addressing complex cognitive tasks across various domains.
+
+
+
+ 27. 【2410.08047】Divide and Translate: Compositional First-Order Logic Translation and Verification for Complex Logical Reasoning
+ 链接:https://arxiv.org/abs/2410.08047
+ 作者:Hyun Ryu,Gyeongman Kim,Hyemin S. Lee,Eunho Yang
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language model, reasoning tasks require, prompting still falls, falls short, tasks require
+ 备注:
+
+ 点击查看摘要
+ Abstract:Complex logical reasoning tasks require a long sequence of reasoning, which a large language model (LLM) with chain-of-thought prompting still falls short. To alleviate this issue, neurosymbolic approaches incorporate a symbolic solver. Specifically, an LLM only translates a natural language problem into a satisfiability (SAT) problem that consists of first-order logic formulas, and a sound symbolic solver returns a mathematically correct solution. However, we discover that LLMs have difficulties to capture complex logical semantics hidden in the natural language during translation. To resolve this limitation, we propose a Compositional First-Order Logic Translation. An LLM first parses a natural language sentence into newly defined logical dependency structures that consist of an atomic subsentence and its dependents, then sequentially translate the parsed subsentences. Since multiple logical dependency structures and sequential translations are possible for a single sentence, we also introduce two Verification algorithms to ensure more reliable results. We utilize an SAT solver to rigorously compare semantics of generated first-order logic formulas and select the most probable one. We evaluate the proposed method, dubbed CLOVER, on seven logical reasoning benchmarks and show that it outperforms the previous neurosymbolic approaches and achieves new state-of-the-art results.
+
+
+
+ 28. 【2410.08044】he Rise of AI-Generated Content in Wikipedia
+ 链接:https://arxiv.org/abs/2410.08044
+ 作者:Creston Brooks,Samuel Eggert,Denis Peskoff
+ 类目:Computation and Language (cs.CL)
+ 关键词:popular information sources, information sources raises, sources raises significant, raises significant concerns, concerns about accountability
+ 备注:
+
+ 点击查看摘要
+ Abstract:The rise of AI-generated content in popular information sources raises significant concerns about accountability, accuracy, and bias amplification. Beyond directly impacting consumers, the widespread presence of this content poses questions for the long-term viability of training language models on vast internet sweeps. We use GPTZero, a proprietary AI detector, and Binoculars, an open-source alternative, to establish lower bounds on the presence of AI-generated content in recently created Wikipedia pages. Both detectors reveal a marked increase in AI-generated content in recent pages compared to those from before the release of GPT-3.5. With thresholds calibrated to achieve a 1% false positive rate on pre-GPT-3.5 articles, detectors flag over 5% of newly created English Wikipedia articles as AI-generated, with lower percentages for German, French, and Italian articles. Flagged Wikipedia articles are typically of lower quality and are often self-promotional or partial towards a specific viewpoint on controversial topics.
+
+
+
+ 29. 【2410.08037】Composite Learning Units: Generalized Learning Beyond Parameter Updates to Transform LLMs into Adaptive Reasoners
+ 链接:https://arxiv.org/abs/2410.08037
+ 作者:Santosh Kumar Radha,Oktay Goktas
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Multiagent Systems (cs.MA)
+ 关键词:Human learning thrives, Large Language Models, Composite Learning Units, static machine learning, Human learning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Human learning thrives on the ability to learn from mistakes, adapt through feedback, and refine understanding-processes often missing in static machine learning models. In this work, we introduce Composite Learning Units (CLUs) designed to transform reasoners, such as Large Language Models (LLMs), into learners capable of generalized, continuous learning without conventional parameter updates while enhancing their reasoning abilities through continual interaction and feedback. CLUs are built on an architecture that allows a reasoning model to maintain and evolve a dynamic knowledge repository: a General Knowledge Space for broad, reusable insights and a Prompt-Specific Knowledge Space for task-specific learning. Through goal-driven interactions, CLUs iteratively refine these knowledge spaces, enabling the system to adapt dynamically to complex tasks, extract nuanced insights, and build upon past experiences autonomously. We demonstrate CLUs' effectiveness through a cryptographic reasoning task, where they continuously evolve their understanding through feedback to uncover hidden transformation rules. While conventional models struggle to grasp underlying logic, CLUs excel by engaging in an iterative, goal-oriented process. Specialized components-handling knowledge retrieval, prompt generation, and feedback analysis-work together within a reinforcing feedback loop. This approach allows CLUs to retain the memory of past failures and successes, adapt autonomously, and apply sophisticated reasoning effectively, continually learning from mistakes while also building on breakthroughs.
+
+
+
+ 30. 【2410.08027】Private Language Models via Truncated Laplacian Mechanism
+ 链接:https://arxiv.org/abs/2410.08027
+ 作者:Tianhao Huang,Tao Yang,Ivan Habernal,Lijie Hu,Di Wang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Deep learning models, Deep learning, models for NLP, truncated Laplacian mechanism, NLP tasks
+ 备注: Accepted by EMNLP 2024, Main Track
+
+ 点击查看摘要
+ Abstract:Deep learning models for NLP tasks are prone to variants of privacy attacks. To prevent privacy leakage, researchers have investigated word-level perturbations, relying on the formal guarantees of differential privacy (DP) in the embedding space. However, many existing approaches either achieve unsatisfactory performance in the high privacy regime when using the Laplacian or Gaussian mechanism, or resort to weaker relaxations of DP that are inferior to the canonical DP in terms of privacy strength. This raises the question of whether a new method for private word embedding can be designed to overcome these limitations. In this paper, we propose a novel private embedding method called the high dimensional truncated Laplacian mechanism. Specifically, we introduce a non-trivial extension of the truncated Laplacian mechanism, which was previously only investigated in one-dimensional space cases. Theoretically, we show that our method has a lower variance compared to the previous private word embedding methods. To further validate its effectiveness, we conduct comprehensive experiments on private embedding and downstream tasks using three datasets. Remarkably, even in the high privacy regime, our approach only incurs a slight decrease in utility compared to the non-private scenario.
+
+
+
+ 31. 【2410.08014】LLM Cascade with Multi-Objective Optimal Consideration
+ 链接:https://arxiv.org/abs/2410.08014
+ 作者:Kai Zhang,Liqian Peng,Congchao Wang,Alec Go,Xiaozhong Liu
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, generating natural language, Large Language, demonstrated exceptional capabilities, natural language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have demonstrated exceptional capabilities in understanding and generating natural language. However, their high deployment costs often pose a barrier to practical applications, especially. Cascading local and server models offers a promising solution to this challenge. While existing studies on LLM cascades have primarily focused on the performance-cost trade-off, real-world scenarios often involve more complex requirements. This paper introduces a novel LLM Cascade strategy with Multi-Objective Optimization, enabling LLM cascades to consider additional objectives (e.g., privacy) and better align with the specific demands of real-world applications while maintaining their original cascading abilities. Extensive experiments on three benchmarks validate the effectiveness and superiority of our approach.
+
+
+
+ 32. 【2410.07991】Human and LLM Biases in Hate Speech Annotations: A Socio-Demographic Analysis of Annotators and Targets
+ 链接:https://arxiv.org/abs/2410.07991
+ 作者:Tommaso Giorgi,Lorenzo Cima,Tiziano Fagni,Marco Avvenuti,Stefano Cresci
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Human-Computer Interaction (cs.HC)
+ 关键词:online platforms exacerbated, hate speech detection, hate speech, speech detection systems, speech detection
+ 备注:
+
+ 点击查看摘要
+ Abstract:The rise of online platforms exacerbated the spread of hate speech, demanding scalable and effective detection. However, the accuracy of hate speech detection systems heavily relies on human-labeled data, which is inherently susceptible to biases. While previous work has examined the issue, the interplay between the characteristics of the annotator and those of the target of the hate are still unexplored. We fill this gap by leveraging an extensive dataset with rich socio-demographic information of both annotators and targets, uncovering how human biases manifest in relation to the target's attributes. Our analysis surfaces the presence of widespread biases, which we quantitatively describe and characterize based on their intensity and prevalence, revealing marked differences. Furthermore, we compare human biases with those exhibited by persona-based LLMs. Our findings indicate that while persona-based LLMs do exhibit biases, these differ significantly from those of human annotators. Overall, our work offers new and nuanced results on human biases in hate speech annotations, as well as fresh insights into the design of AI-driven hate speech detection systems.
+
+
+
+ 33. 【2410.07985】Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models
+ 链接:https://arxiv.org/abs/2410.07985
+ 作者:Bofei Gao,Feifan Song,Zhe Yang,Zefan Cai,Yibo Miao,Qingxiu Dong,Lei Li,Chenghao Ma,Liang Chen,Runxin Xu,Zhengyang Tang,Benyou Wang,Daoguang Zan,Shanghaoran Quan,Ge Zhang,Lei Sha,Yichang Zhang,Xuancheng Ren,Tianyu Liu,Baobao Chang
+ 类目:Computation and Language (cs.CL)
+ 关键词:Recent advancements, large language models, advancements in large, large language, mathematical reasoning capabilities
+ 备注: 26 Pages, 17 Figures
+
+ 点击查看摘要
+ Abstract:Recent advancements in large language models (LLMs) have led to significant breakthroughs in mathematical reasoning capabilities. However, existing benchmarks like GSM8K or MATH are now being solved with high accuracy (e.g., OpenAI o1 achieves 94.8% on MATH dataset), indicating their inadequacy for truly challenging these models. To bridge this gap, we propose a comprehensive and challenging benchmark specifically designed to assess LLMs' mathematical reasoning at the Olympiad level. Unlike existing Olympiad-related benchmarks, our dataset focuses exclusively on mathematics and comprises a vast collection of 4428 competition-level problems with rigorous human annotation. These problems are meticulously categorized into over 33 sub-domains and span more than 10 distinct difficulty levels, enabling a holistic assessment of model performance in Olympiad-mathematical reasoning. Furthermore, we conducted an in-depth analysis based on this benchmark. Our experimental results show that even the most advanced models, OpenAI o1-mini and OpenAI o1-preview, struggle with highly challenging Olympiad-level problems, with 60.54% and 52.55% accuracy, highlighting significant challenges in Olympiad-level mathematical reasoning.
+
+
+
+ 34. 【2410.07959】COMPL-AI Framework: A Technical Interpretation and LLM Benchmarking Suite for the EU Artificial Intelligence Act
+ 链接:https://arxiv.org/abs/2410.07959
+ 作者:Philipp Guldimann,Alexander Spiridonov,Robin Staab,Nikola Jovanović,Mark Vero,Velko Vechev,Anna Gueorguieva,Mislav Balunović,Nikola Konstantinov,Pavol Bielik,Petar Tsankov,Martin Vechev
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computers and Society (cs.CY); Machine Learning (cs.LG)
+ 关键词:Artificial Intelligence Act, assess models' compliance, Artificial Intelligence, lacks clear technical, clear technical interpretation
+ 备注:
+
+ 点击查看摘要
+ Abstract:The EU's Artificial Intelligence Act (AI Act) is a significant step towards responsible AI development, but lacks clear technical interpretation, making it difficult to assess models' compliance. This work presents COMPL-AI, a comprehensive framework consisting of (i) the first technical interpretation of the EU AI Act, translating its broad regulatory requirements into measurable technical requirements, with the focus on large language models (LLMs), and (ii) an open-source Act-centered benchmarking suite, based on thorough surveying and implementation of state-of-the-art LLM benchmarks. By evaluating 12 prominent LLMs in the context of COMPL-AI, we reveal shortcomings in existing models and benchmarks, particularly in areas like robustness, safety, diversity, and fairness. This work highlights the need for a shift in focus towards these aspects, encouraging balanced development of LLMs and more comprehensive regulation-aligned benchmarks. Simultaneously, COMPL-AI for the first time demonstrates the possibilities and difficulties of bringing the Act's obligations to a more concrete, technical level. As such, our work can serve as a useful first step towards having actionable recommendations for model providers, and contributes to ongoing efforts of the EU to enable application of the Act, such as the drafting of the GPAI Code of Practice.
+
+
+
+ 35. 【2410.07951】Disease Entity Recognition and Normalization is Improved with Large Language Model Derived Synthetic Normalized Mentions
+ 链接:https://arxiv.org/abs/2410.07951
+ 作者:Kuleen Sasse,Shinjitha Vadlakonda,Richard E. Kennedy,John D. Osborne
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Knowledge Graphs, clinical named entity, named entity recognition, Disease Entity Recognition, entity recognition
+ 备注: 21 pages, 3 figures, 7 tables
+
+ 点击查看摘要
+ Abstract:Background: Machine learning methods for clinical named entity recognition and entity normalization systems can utilize both labeled corpora and Knowledge Graphs (KGs) for learning. However, infrequently occurring concepts may have few mentions in training corpora and lack detailed descriptions or synonyms, even in large KGs. For Disease Entity Recognition (DER) and Disease Entity Normalization (DEN), this can result in fewer high quality training examples relative to the number of known diseases. Large Language Model (LLM) generation of synthetic training examples could improve performance in these information extraction tasks.
+Methods: We fine-tuned a LLaMa-2 13B Chat LLM to generate a synthetic corpus containing normalized mentions of concepts from the Unified Medical Language System (UMLS) Disease Semantic Group. We measured overall and Out of Distribution (OOD) performance for DER and DEN, with and without synthetic data augmentation. We evaluated performance on 3 different disease corpora using 4 different data augmentation strategies, assessed using BioBERT for DER and SapBERT and KrissBERT for DEN.
+Results: Our synthetic data yielded a substantial improvement for DEN, in all 3 training corpora the top 1 accuracy of both SapBERT and KrissBERT improved by 3-9 points in overall performance and by 20-55 points in OOD data. A small improvement (1-2 points) was also seen for DER in overall performance, but only one dataset showed OOD improvement.
+Conclusion: LLM generation of normalized disease mentions can improve DEN relative to normalization approaches that do not utilize LLMs to augment data with synthetic mentions. Ablation studies indicate that performance gains for DEN were only partially attributable to improvements in OOD performance. The same approach has only a limited ability to improve DER. We make our software and dataset publicly available.
+
Comments:
+21 pages, 3 figures, 7 tables
+Subjects:
+Computation and Language (cs.CL); Machine Learning (cs.LG)
+ACMclasses:
+I.2.7; J.3
+Cite as:
+arXiv:2410.07951 [cs.CL]
+(or
+arXiv:2410.07951v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2410.07951
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)
+
+Submission history From: John Osborne [view email] [v1]
+Thu, 10 Oct 2024 14:18:34 UTC (1,574 KB)
+
+
+
+ 36. 【2410.07919】InstructBioMol: Advancing Biomolecule Understanding and Design Following Human Instructions
+ 链接:https://arxiv.org/abs/2410.07919
+ 作者:Xiang Zhuang,Keyan Ding,Tianwen Lyu,Yinuo Jiang,Xiaotong Li,Zhuoyi Xiang,Zeyuan Wang,Ming Qin,Kehua Feng,Jike Wang,Qiang Zhang,Huajun Chen
+ 类目:Computation and Language (cs.CL); Biomolecules (q-bio.BM)
+ 关键词:Understanding and designing, advancing drug discovery, natural language, synthetic biology, central to advancing
+ 备注:
+
+ 点击查看摘要
+ Abstract:Understanding and designing biomolecules, such as proteins and small molecules, is central to advancing drug discovery, synthetic biology, and enzyme engineering. Recent breakthroughs in Artificial Intelligence (AI) have revolutionized biomolecular research, achieving remarkable accuracy in biomolecular prediction and design. However, a critical gap remains between AI's computational power and researchers' intuition, using natural language to align molecular complexity with human intentions. Large Language Models (LLMs) have shown potential to interpret human intentions, yet their application to biomolecular research remains nascent due to challenges including specialized knowledge requirements, multimodal data integration, and semantic alignment between natural language and biomolecules. To address these limitations, we present InstructBioMol, a novel LLM designed to bridge natural language and biomolecules through a comprehensive any-to-any alignment of natural language, molecules, and proteins. This model can integrate multimodal biomolecules as input, and enable researchers to articulate design goals in natural language, providing biomolecular outputs that meet precise biological needs. Experimental results demonstrate InstructBioMol can understand and design biomolecules following human instructions. Notably, it can generate drug molecules with a 10% improvement in binding affinity and design enzymes that achieve an ESP Score of 70.4, making it the only method to surpass the enzyme-substrate interaction threshold of 60.0 recommended by the ESP developer. This highlights its potential to transform real-world biomolecular research.
+
+
+
+ 37. 【2410.07880】Unsupervised Data Validation Methods for Efficient Model Training
+ 链接:https://arxiv.org/abs/2410.07880
+ 作者:Yurii Paniv
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:low-resource languages, potential solutions, solutions for improving, systems for low-resource, machine learning systems
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper investigates the challenges and potential solutions for improving machine learning systems for low-resource languages. State-of-the-art models in natural language processing (NLP), text-to-speech (TTS), speech-to-text (STT), and vision-language models (VLM) rely heavily on large datasets, which are often unavailable for low-resource languages. This research explores key areas such as defining "quality data," developing methods for generating appropriate data and enhancing accessibility to model training. A comprehensive review of current methodologies, including data augmentation, multilingual transfer learning, synthetic data generation, and data selection techniques, highlights both advancements and limitations. Several open research questions are identified, providing a framework for future studies aimed at optimizing data utilization, reducing the required data quantity, and maintaining high-quality model performance. By addressing these challenges, the paper aims to make advanced machine learning models more accessible for low-resource languages, enhancing their utility and impact across various sectors.
+
+
+
+ 38. 【2410.07869】Benchmarking Agentic Workflow Generation
+ 链接:https://arxiv.org/abs/2410.07869
+ 作者:Shuofei Qiao,Runnan Fang,Zhisong Qiu,Xiaobin Wang,Ningyu Zhang,Yong Jiang,Pengjun Xie,Fei Huang,Huajun Chen
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Human-Computer Interaction (cs.HC); Machine Learning (cs.LG); Multiagent Systems (cs.MA)
+ 关键词:Large Language Models, Large Language, driven significant advancements, decomposing complex problems, Language Models
+ 备注: Work in progress
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs), with their exceptional ability to handle a wide range of tasks, have driven significant advancements in tackling reasoning and planning tasks, wherein decomposing complex problems into executable workflows is a crucial step in this process. Existing workflow evaluation frameworks either focus solely on holistic performance or suffer from limitations such as restricted scenario coverage, simplistic workflow structures, and lax evaluation standards. To this end, we introduce WorFBench, a unified workflow generation benchmark with multi-faceted scenarios and intricate graph workflow structures. Additionally, we present WorFEval, a systemic evaluation protocol utilizing subsequence and subgraph matching algorithms to accurately quantify the LLM agent's workflow generation capabilities. Through comprehensive evaluations across different types of LLMs, we discover distinct gaps between the sequence planning capabilities and graph planning capabilities of LLM agents, with even GPT-4 exhibiting a gap of around 15%. We also train two open-source models and evaluate their generalization abilities on held-out tasks. Furthermore, we observe that the generated workflows can enhance downstream tasks, enabling them to achieve superior performance with less time during inference. Code and dataset will be available at this https URL.
+
+
+
+ 39. 【2410.07839】Enhancing Language Model Reasoning via Weighted Reasoning in Self-Consistency
+ 链接:https://arxiv.org/abs/2410.07839
+ 作者:Tim Knappe,Ryan Li,Ayush Chauhan,Kaylee Chhua,Kevin Zhu,Sean O'Brien
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language models, reasoning tasks, tasks, large language, rapidly improved
+ 备注: Accepted to MATH-AI at NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:While large language models (LLMs) have rapidly improved their performance on a broad number of tasks, they still often fall short on reasoning tasks. As LLMs become more integrated in diverse real-world tasks, advancing their reasoning capabilities is crucial to their effectiveness in nuanced, complex problems. Wang et al's self-consistency framework reveals that sampling multiple rationales before taking a majority vote reliably improves model performance across various closed-answer reasoning tasks. Standard methods based on this framework aggregate the final decisions of these rationales but fail to utilize the detailed step-by-step reasoning paths applied by these paths. Our work enhances this approach by incorporating and analyzing both the reasoning paths of these rationales in addition to their final decisions before taking a majority vote. These methods not only improve the reliability of reasoning paths but also cause more robust performance on complex reasoning tasks.
+
+
+
+ 40. 【2410.07830】NusaMT-7B: Machine Translation for Low-Resource Indonesian Languages with Large Language Models
+ 链接:https://arxiv.org/abs/2410.07830
+ 作者:William Tan,Kevin Zhu
+ 类目:Computation and Language (cs.CL)
+ 关键词:demonstrated exceptional promise, Large Language Models, Large Language, Balinese and Minangkabau, demonstrated exceptional
+ 备注: Accepted to SoLaR @ NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have demonstrated exceptional promise in translation tasks for high-resource languages. However, their performance in low-resource languages is limited by the scarcity of both parallel and monolingual corpora, as well as the presence of noise. Consequently, such LLMs suffer with alignment and have lagged behind State-of-The-Art (SoTA) neural machine translation (NMT) models in these settings. This paper introduces NusaMT-7B, an LLM-based machine translation model for low-resource Indonesian languages, starting with Balinese and Minangkabau. Leveraging the pretrained LLaMA2-7B, our approach integrates continued pre-training on monolingual data, Supervised Fine-Tuning (SFT), self-learning, and an LLM-based data cleaner to reduce noise in parallel sentences. In the FLORES-200 multilingual translation benchmark, NusaMT-7B outperforms SoTA models in the spBLEU metric by up to +6.69 spBLEU in translations into Balinese and Minangkabau, but underperforms by up to -3.38 spBLEU in translations into higher-resource languages. Our results show that fine-tuned LLMs can enhance translation quality for low-resource languages, aiding in linguistic preservation and cross-cultural communication.
+
+
+
+ 41. 【2410.07827】Why do objects have many names? A study on word informativeness in language use and lexical systems
+ 链接:https://arxiv.org/abs/2410.07827
+ 作者:Eleonora Gualdoni,Gemma Boleda
+ 类目:Computation and Language (cs.CL)
+ 关键词:Human lexicons, lexical systems, Human, lexical, systems
+ 备注: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024)
+
+ 点击查看摘要
+ Abstract:Human lexicons contain many different words that speakers can use to refer to the same object, e.g., "purple" or "magenta" for the same shade of color. On the one hand, studies on language use have explored how speakers adapt their referring expressions to successfully communicate in context, without focusing on properties of the lexical system. On the other hand, studies in language evolution have discussed how competing pressures for informativeness and simplicity shape lexical systems, without tackling in-context communication. We aim at bridging the gap between these traditions, and explore why a soft mapping between referents and words is a good solution for communication, by taking into account both in-context communication and the structure of the lexicon. We propose a simple measure of informativeness for words and lexical systems, grounded in a visual space, and analyze color naming data for English and Mandarin Chinese. We conclude that optimal lexical systems are those where multiple words can apply to the same referent, conveying different amounts of information. Such systems allow speakers to maximize communication accuracy and minimize the amount of information they convey when communicating about referents in contexts.
+
+
+
+ 42. 【2410.07826】Fine-Tuning Language Models for Ethical Ambiguity: A Comparative Study of Alignment with Human Responses
+ 链接:https://arxiv.org/abs/2410.07826
+ 作者:Pranav Senthilkumar,Visshwa Balasubramanian,Prisha Jain,Aneesa Maity,Jonathan Lu,Kevin Zhu
+ 类目:Computation and Language (cs.CL)
+ 关键词:well-recognized in NLP, misinterpret human intentions, human intentions due, Language models, handling of ambiguity
+ 备注: Accepted to NeurIPS 2024, SoLaR workshop
+
+ 点击查看摘要
+ Abstract:Language models often misinterpret human intentions due to their handling of ambiguity, a limitation well-recognized in NLP research. While morally clear scenarios are more discernible to LLMs, greater difficulty is encountered in morally ambiguous contexts. In this investigation, we explored LLM calibration to show that human and LLM judgments are poorly aligned in such scenarios. We used two curated datasets from the Scruples project for evaluation: DILEMMAS, which involves pairs of distinct moral scenarios to assess the model's ability to compare and contrast ethical situations, and ANECDOTES, which presents individual narratives to evaluate the model's skill in drawing out details, interpreting, and analyzing distinct moral scenarios. Model answer probabilities were extracted for all possible choices and compared with human annotations to benchmark the alignment of three models: Llama-3.1-8b, Zephyr-7b-beta, and Mistral-7b. Significant improvements were observed after fine-tuning, with notable enhancements in both cross-entropy and Dirichlet scores, particularly in the latter. Notably, after fine-tuning, the performance of Mistral-7B-Instruct-v0.3 was on par with GPT-4o. However, the experimental models that were examined were all still outperformed by the BERT and RoBERTa models in terms of cross-entropy scores. Our fine-tuning approach, which improves the model's understanding of text distributions in a text-to-text format, effectively enhances performance and alignment in complex decision-making contexts, underscoring the need for further research to refine ethical reasoning techniques and capture human judgment nuances.
+
+
+
+ 43. 【2410.07825】Extracting and Transferring Abilities For Building Multi-lingual Ability-enhanced Large Language Models
+ 链接:https://arxiv.org/abs/2410.07825
+ 作者:Zhipeng Chen,Liang Song,Kun Zhou,Wayne Xin Zhao,Bingning Wang,Weipeng Chen,Ji-Rong Wen
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language models, Multi-lingual ability transfer, Multi-lingual Ability Extraction, Multi-lingual ability, increasingly important
+ 备注: 18 Pages. Working in progress
+
+ 点击查看摘要
+ Abstract:Multi-lingual ability transfer has become increasingly important for the broad application of large language models (LLMs). Existing work highly relies on training with the multi-lingual ability-related data, which may be not available for low-resource languages. To solve it, we propose a Multi-lingual Ability Extraction and Transfer approach, named as MAET. Our key idea is to decompose and extract language-agnostic ability-related weights from LLMs, and transfer them across different languages by simple addition and subtraction operations without training. Specially, our MAET consists of the extraction and transfer stages. In the extraction stage, we firstly locate key neurons that are highly related to specific abilities, and then employ them to extract the transferable ability-specific weights. In the transfer stage, we further select the ability-related parameter tensors, and design the merging strategy based on the linguistic and ability specific weights, to build the multi-lingual ability-enhanced LLM. To demonstrate the effectiveness of our proposed approach, we conduct extensive experiments on mathematical and scientific tasks in both high-resource lingual and low-resource lingual scenarios. Experiment results have shown that MAET can effectively and efficiently extract and transfer the advanced abilities, and outperform training-based baseline methods. Our code and data are available at \url{this https URL}.
+
+
+
+ 44. 【2410.07820】Mitigating Gender Bias in Code Large Language Models via Model Editing
+ 链接:https://arxiv.org/abs/2410.07820
+ 作者:Zhanyue Qin,Haochuan Wang,Zecheng Wang,Deyuan Liu,Cunhang Fan,Zhao Lv,Zhiying Tu,Dianhui Chu,Dianbo Sui
+ 类目:oftware Engineering (cs.SE); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:program synthesis automatically, high-quality programming code, gender bias, Factual Bias Score, large language model
+ 备注:
+
+ 点击查看摘要
+ Abstract:In recent years, with the maturation of large language model (LLM) technology and the emergence of high-quality programming code datasets, researchers have become increasingly confident in addressing the challenges of program synthesis automatically. However, since most of the training samples for LLMs are unscreened, it is inevitable that LLMs' performance may not align with real-world scenarios, leading to the presence of social bias. To evaluate and quantify the gender bias in code LLMs, we propose a dataset named CodeGenBias (Gender Bias in the Code Generation) and an evaluation metric called FB-Score (Factual Bias Score) based on the actual gender distribution of correlative professions. With the help of CodeGenBias and FB-Score, we evaluate and analyze the gender bias in eight mainstream Code LLMs. Previous work has demonstrated that model editing methods that perform well in knowledge editing have the potential to mitigate social bias in LLMs. Therefore, we develop a model editing approach named MG-Editing (Multi-Granularity model Editing), which includes the locating and editing phases. Our model editing method MG-Editing can be applied at five different levels of model parameter granularity: full parameters level, layer level, module level, row level, and neuron level. Extensive experiments not only demonstrate that our MG-Editing can effectively mitigate the gender bias in code LLMs while maintaining their general code generation capabilities, but also showcase its excellent generalization. At the same time, the experimental results show that, considering both the gender bias of the model and its general code generation capability, MG-Editing is most effective when applied at the row and neuron levels of granularity.
+
+
+
+ 45. 【2410.07819】Uncovering Overfitting in Large Language Model Editing
+ 链接:https://arxiv.org/abs/2410.07819
+ 作者:Mengqi Zhang,Xiaotian Ye,Qiang Liu,Pengjie Ren,Shu Wu,Zhumin Chen
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, Editing Overfit, Language Models, editing
+ 备注:
+
+ 点击查看摘要
+ Abstract:Knowledge editing has been proposed as an effective method for updating and correcting the internal knowledge of Large Language Models (LLMs). However, existing editing methods often struggle with complex tasks, such as multi-hop reasoning. In this paper, we identify and investigate the phenomenon of Editing Overfit, where edited models assign disproportionately high probabilities to the edit target, hindering the generalization of new knowledge in complex scenarios. We attribute this issue to the current editing paradigm, which places excessive emphasis on the direct correspondence between the input prompt and the edit target for each edit sample. To further explore this issue, we introduce a new benchmark, EVOKE (EValuation of Editing Overfit in Knowledge Editing), along with fine-grained evaluation metrics. Through comprehensive experiments and analysis, we demonstrate that Editing Overfit is prevalent in current editing methods and that common overfitting mitigation strategies are of limited effectiveness in knowledge editing. To overcome this, inspired by LLMs' knowledge recall mechanisms, we propose a new plug-and-play strategy called Learn to Inference (LTI), which introduce a Multi-stage Inference Constraint module to guide the edited models in recalling new knowledge similarly to how unedited LLMs leverage knowledge through in-context learning. Extensive experimental results across a wide range of tasks validate the effectiveness of LTI in mitigating Editing Overfit.
+
+
+
+ 46. 【2410.07809】Linguistically-Informed Multilingual Instruction Tuning: Is There an Optimal Set of Languages to Tune?
+ 链接:https://arxiv.org/abs/2410.07809
+ 作者:Gürkan Soykan,Gözde Gül Şahin
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:limited generalization capabilities, languages, Instruction tuning, perform unevenly, due to limited
+ 备注: 31 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:Multilingual language models often perform unevenly across different languages due to limited generalization capabilities for some languages. This issue is significant because of the growing interest in making universal language models that work well for all languages. Instruction tuning with multilingual instruction-response pairs has been used to improve model performance across various languages. However, this approach is challenged by high computational costs, a lack of quality tuning data for all languages, and the "curse of multilinguality" -- the performance drop per language after adding many languages. Recent studies have found that working with datasets with few languages and a smaller number of instances can be beneficial. Yet, there exists no systematic investigation into how choosing different languages affects multilingual instruction tuning. Our study proposes a method to select languages for instruction tuning in a linguistically informed way, aiming to boost model performance across languages and tasks. We use a simple algorithm to choose diverse languages and test their effectiveness on various benchmarks and open-ended questions. Our results show that this careful selection generally leads to better outcomes than choosing languages at random. We suggest a new and simple way of enhancing multilingual models by selecting diverse languages based on linguistic features that could help develop better multilingual systems and guide dataset creation efforts. All resources, including the code for language selection and multilingual instruction tuning, are made available in our official repository at this https URL enabling reproducibility and further research in this area.
+
+
+
+ 47. 【2410.07797】Rewriting Conversational Utterances with Instructed Large Language Models
+ 链接:https://arxiv.org/abs/2410.07797
+ 作者:Elnara Galimzhanova,Cristina Ioana Muntean,Franco Maria Nardini,Raffaele Perego,Guido Rocchietti
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Human-Computer Interaction (cs.HC); Information Retrieval (cs.IR)
+ 关键词:large language models, text summarization, NLP tasks, recent studies, studies have shown
+ 备注:
+
+ 点击查看摘要
+ Abstract:Many recent studies have shown the ability of large language models (LLMs) to achieve state-of-the-art performance on many NLP tasks, such as question answering, text summarization, coding, and translation. In some cases, the results provided by LLMs are on par with those of human experts. These models' most disruptive innovation is their ability to perform tasks via zero-shot or few-shot prompting. This capability has been successfully exploited to train instructed LLMs, where reinforcement learning with human feedback is used to guide the model to follow the user's requests directly. In this paper, we investigate the ability of instructed LLMs to improve conversational search effectiveness by rewriting user questions in a conversational setting. We study which prompts provide the most informative rewritten utterances that lead to the best retrieval performance. Reproducible experiments are conducted on publicly-available TREC CAST datasets. The results show that rewriting conversational utterances with instructed LLMs achieves significant improvements of up to 25.2% in MRR, 31.7% in Precision@1, 27% in NDCG@3, and 11.5% in Recall@500 over state-of-the-art techniques.
+
+
+
+ 48. 【2410.07779】Modeling User Preferences with Automatic Metrics: Creating a High-Quality Preference Dataset for Machine Translation
+ 链接:https://arxiv.org/abs/2410.07779
+ 作者:Sweta Agrawal,José G. C. de Souza,Ricardo Rei,António Farinhas,Gonçalo Faria,Patrick Fernandes,Nuno M Guerreiro,Andre Martins
+ 类目:Computation and Language (cs.CL)
+ 关键词:important step, step in developing, developing accurate, accurate and safe, Alignment
+ 备注: Accepted at EMNLP Main 2024
+
+ 点击查看摘要
+ Abstract:Alignment with human preferences is an important step in developing accurate and safe large language models. This is no exception in machine translation (MT), where better handling of language nuances and context-specific variations leads to improved quality. However, preference data based on human feedback can be very expensive to obtain and curate at a large scale. Automatic metrics, on the other hand, can induce preferences, but they might not match human expectations perfectly. In this paper, we propose an approach that leverages the best of both worlds. We first collect sentence-level quality assessments from professional linguists on translations generated by multiple high-quality MT systems and evaluate the ability of current automatic metrics to recover these preferences. We then use this analysis to curate a new dataset, MT-Pref (metric induced translation preference) dataset, which comprises 18k instances covering 18 language directions, using texts sourced from multiple domains post-2022. We show that aligning TOWER models on MT-Pref significantly improves translation quality on WMT23 and FLORES benchmarks.
+
+
+
+ 49. 【2410.07771】Full-Rank No More: Low-Rank Weight Training for Modern Speech Recognition Models
+ 链接:https://arxiv.org/abs/2410.07771
+ 作者:Adriana Fernandez-Lopez,Shiwei Liu,Lu Yin,Stavros Petridis,Maja Pantic
+ 类目:ound (cs.SD); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Audio and Speech Processing (eess.AS)
+ 关键词:Conformer-based speech recognition, large-scale Conformer-based speech, large-scale Conformer-based, speech recognition models, Conformer-based speech
+ 备注: Submitted to ICASSP 2025
+
+ 点击查看摘要
+ Abstract:This paper investigates the under-explored area of low-rank weight training for large-scale Conformer-based speech recognition models from scratch. Our study demonstrates the viability of this training paradigm for such models, yielding several notable findings. Firstly, we discover that applying a low-rank structure exclusively to the attention modules can unexpectedly enhance performance, even with a significant rank reduction of 12%. In contrast, feed-forward layers present greater challenges, as they begin to exhibit performance degradation with a moderate 50% rank reduction. Furthermore, we find that both initialization and layer-wise rank assignment play critical roles in successful low-rank training. Specifically, employing SVD initialization and linear layer-wise rank mapping significantly boosts the efficacy of low-rank weight training. Building on these insights, we introduce the Low-Rank Speech Model from Scratch (LR-SMS), an approach that achieves performance parity with full-rank training while delivering substantial reductions in parameters count (by at least 2x), and training time speedups (by 1.3x for ASR and 1.15x for AVSR).
+
+
+
+ 50. 【2410.07768】Dialectical Behavior Therapy Approach to LLM Prompting
+ 链接:https://arxiv.org/abs/2410.07768
+ 作者:Oxana Vitman,Nika Amaglobeli,Paul Plachinda
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Large language models, Large language, language models demonstrated, Dialectical Behavioral Therapy, CoT prompting guides
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models demonstrated state-of-the-art results on various reasoning tasks when applying the chain-of-thought (CoT) prompting technique. CoT prompting guides the model into breaking tasks into a few intermediate steps and provides step-by-step demonstrations. However, solving complex reasoning tasks remains a challenge. In this paper, we propose a novel prompting strategy inspired by Dialectical Behavioral Therapy (DBT). DBT, a form of cognitive-behavioral therapy, aims to help individuals cope with stress by developing a system of reasoning. We applied DBT's basic concepts of shaping dialog to construct prompts and conducted experiments on different datasets and LLMs with various numbers of parameters. Our results show that prompts crafted with DBT techniques significantly improve results on smaller models, achieving a 7% increase in accuracy on the StrategyQA, 4.8% on Aqua dataset using 8b parameters model, and a 16.2% increase on the StrategyQA, 5.3% on GSM8K dataset with 14b parameters model.
+
+
+
+ 51. 【2410.07765】GameTraversalBenchmark: Evaluating Planning Abilities Of Large Language Models Through Traversing 2D Game Maps
+ 链接:https://arxiv.org/abs/2410.07765
+ 作者:Muhammad Umair Nasir,Steven James,Julian Togelius
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:recently demonstrated great, demonstrated great success, understanding natural language, recently demonstrated, demonstrated great
+ 备注: Accepted at 38th Conference on Neural Information Processing Systems (NeurIPS 2024) Track on Datasets and Benchmarks
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) have recently demonstrated great success in generating and understanding natural language. While they have also shown potential beyond the domain of natural language, it remains an open question as to what extent and in which way these LLMs can plan. We investigate their planning capabilities by proposing GameTraversalBenchmark (GTB), a benchmark consisting of diverse 2D grid-based game maps. An LLM succeeds if it can traverse through given objectives, with a minimum number of steps and a minimum number of generation errors. We evaluate a number of LLMs on GTB and found that GPT-4-Turbo achieved the highest score of 44.97% on GTB\_Score (GTBS), a composite score that combines the three above criteria. Furthermore, we preliminarily test large reasoning models, namely o1, which scores $67.84\%$ on GTBS, indicating that the benchmark remains challenging for current models. Code, data, and documentation are available at this https URL.
+
+
+
+ 52. 【2410.07761】$\textit{Jump Your Steps}$: Optimizing Sampling Schedule of Discrete Diffusion Models
+ 链接:https://arxiv.org/abs/2410.07761
+ 作者:Yong-Hyun Park,Chieh-Hsin Lai,Satoshi Hayakawa,Yuhta Takida,Yuki Mitsufuji
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:discrete diffusion models, Diffusion models, Compounding Decoding Error, continuous domains, notable success
+ 备注:
+
+ 点击查看摘要
+ Abstract:Diffusion models have seen notable success in continuous domains, leading to the development of discrete diffusion models (DDMs) for discrete variables. Despite recent advances, DDMs face the challenge of slow sampling speeds. While parallel sampling methods like $\tau$-leaping accelerate this process, they introduce $\textit{Compounding Decoding Error}$ (CDE), where discrepancies arise between the true distribution and the approximation from parallel token generation, leading to degraded sample quality. In this work, we present $\textit{Jump Your Steps}$ (JYS), a novel approach that optimizes the allocation of discrete sampling timesteps by minimizing CDE without extra computational cost. More precisely, we derive a practical upper bound on CDE and propose an efficient algorithm for searching for the optimal sampling schedule. Extensive experiments across image, music, and text generation show that JYS significantly improves sampling quality, establishing it as a versatile framework for enhancing DDM performance for fast sampling.
+
+
+
+ 53. 【2410.07745】StepTool: A Step-grained Reinforcement Learning Framework for Tool Learning in LLMs
+ 链接:https://arxiv.org/abs/2410.07745
+ 作者:Yuanqing Yu,Zhefan Wang,Weizhi Ma,Zhicheng Guo,Jingtao Zhan,Shuai Wang,Chuhan Wu,Zhiqiang Guo,Min Zhang
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, acquire real-time information, real-time information retrieval, Language Models
+ 备注: Ongoning Work
+
+ 点击查看摘要
+ Abstract:Despite having powerful reasoning and inference capabilities, Large Language Models (LLMs) still need external tools to acquire real-time information retrieval or domain-specific expertise to solve complex tasks, which is referred to as tool learning. Existing tool learning methods primarily rely on tuning with expert trajectories, focusing on token-sequence learning from a linguistic perspective. However, there are several challenges: 1) imitating static trajectories limits their ability to generalize to new tasks. 2) even expert trajectories can be suboptimal, and better solution paths may exist. In this work, we introduce StepTool, a novel step-grained reinforcement learning framework to improve tool learning in LLMs. It consists of two components: Step-grained Reward Shaping, which assigns rewards at each tool interaction based on tool invocation success and its contribution to the task, and Step-grained Optimization, which uses policy gradient methods to optimize the model in a multi-step manner. Experimental results demonstrate that StepTool significantly outperforms existing methods in multi-step, tool-based tasks, providing a robust solution for complex task environments. Codes are available at this https URL.
+
+
+
+ 54. 【2410.07739】SLIM: Let LLM Learn More and Forget Less with Soft LoRA and Identity Mixture
+ 链接:https://arxiv.org/abs/2410.07739
+ 作者:Jiayi Han,Liang Du,Hongwei Du,Xiangguo Zhou,Yiwen Wu,Weibo Zheng,Donghong Han
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:downstream tasks, challenge to balance, general capabilities, training budget, downstream performance
+ 备注: 11 pages, 6 figures, 4 tables
+
+ 点击查看摘要
+ Abstract:Although many efforts have been made, it is still a challenge to balance the training budget, downstream performance, and the general capabilities of the LLMs in many applications. Training the whole model for downstream tasks is expensive, and could easily result in catastrophic forgetting. By introducing parameter-efficient fine-tuning (PEFT), the training cost could be reduced, but it still suffers from forgetting, and limits the learning on the downstream tasks. To efficiently fine-tune the LLMs with less limitation to their downstream performance while mitigating the forgetting of general capabilities, we propose a novel mixture of expert (MoE) framework based on Soft LoRA and Identity Mixture (SLIM), that allows dynamic routing between LoRA adapters and skipping connection, enables the suppression of forgetting. We adopt weight-yielding with sliding clustering for better out-of-domain distinguish to enhance the routing. We also propose to convert the mixture of low-rank adapters to the model merging formulation and introduce fast dynamic merging of LoRA adapters to keep the general capabilities of the base model. Extensive experiments demonstrate that the proposed SLIM is comparable to the state-of-the-art PEFT approaches on the downstream tasks while achieving the leading performance in mitigating catastrophic forgetting.
+
+
+
+ 55. 【2410.07706】AgentBank: Towards Generalized LLM Agents via Fine-Tuning on 50000+ Interaction Trajectories
+ 链接:https://arxiv.org/abs/2410.07706
+ 作者:Yifan Song,Weimin Xiong,Xiutian Zhao,Dawei Zhu,Wenhao Wu,Ke Wang,Cheng Li,Wei Peng,Sujian Li
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:holds significant promise, open-source large language, Fine-tuning on agent-environment, large language models, data holds significant
+ 备注: Findings of EMNLP 2024
+
+ 点击查看摘要
+ Abstract:Fine-tuning on agent-environment interaction trajectory data holds significant promise for surfacing generalized agent capabilities in open-source large language models (LLMs). In this work, we introduce AgentBank, by far the largest trajectory tuning data collection featuring more than 50k diverse high-quality interaction trajectories which comprises 16 tasks covering five distinct agent skill dimensions. Leveraging a novel annotation pipeline, we are able to scale the annotated trajectories and generate a trajectory dataset with minimized difficulty bias. Furthermore, we fine-tune LLMs on AgentBank to get a series of agent models, Samoyed. Our comparative experiments demonstrate the effectiveness of scaling the interaction trajectory data to acquire generalized agent capabilities. Additional studies also reveal some key observations regarding trajectory tuning and agent skill generalization.
+
+
+
+ 56. 【2410.07693】Multi-Facet Counterfactual Learning for Content Quality Evaluation
+ 链接:https://arxiv.org/abs/2410.07693
+ 作者:Jiasheng Zheng,Hongyu Lin,Boxi Cao,Meng Liao,Yaojie Lu,Xianpei Han,Le Sun
+ 类目:Computation and Language (cs.CL)
+ 关键词:current massive amount, essential for filtering, current massive, massive amount, content quality
+ 备注:
+
+ 点击查看摘要
+ Abstract:Evaluating the quality of documents is essential for filtering valuable content from the current massive amount of information. Conventional approaches typically rely on a single score as a supervision signal for training content quality evaluators, which is inadequate to differentiate documents with quality variations across multiple facets. In this paper, we propose Multi-facet cOunterfactual LEarning (MOLE), a framework for efficiently constructing evaluators that perceive multiple facets of content quality evaluation. Given a specific scenario, we prompt large language models to generate counterfactual content that exhibits variations in critical quality facets compared to the original document. Furthermore, we leverage a joint training strategy based on contrastive learning and supervised learning to enable the evaluator to distinguish between different quality facets, resulting in more accurate predictions of content quality scores. Experimental results on 2 datasets across different scenarios demonstrate that our proposed MOLE framework effectively improves the correlation of document content quality evaluations with human judgments, which serve as a valuable toolkit for effective information acquisition.
+
+
+
+ 57. 【2410.07677】Smart Audit System Empowered by LLM
+ 链接:https://arxiv.org/abs/2410.07677
+ 作者:Xu Yao,Xiaoxu Wu,Xi Li,Huan Xu,Chenlei Li,Ping Huang,Si Li,Xiaoning Ma,Jiulong Shan
+ 类目:Computation and Language (cs.CL)
+ 关键词:mass production environments, ensuring high product, high product standards, production environments, pivotal for ensuring
+ 备注:
+
+ 点击查看摘要
+ Abstract:Manufacturing quality audits are pivotal for ensuring high product standards in mass production environments. Traditional auditing processes, however, are labor-intensive and reliant on human expertise, posing challenges in maintaining transparency, accountability, and continuous improvement across complex global supply chains. To address these challenges, we propose a smart audit system empowered by large language models (LLMs). Our approach introduces three innovations: a dynamic risk assessment model that streamlines audit procedures and optimizes resource allocation; a manufacturing compliance copilot that enhances data processing, retrieval, and evaluation for a self-evolving manufacturing knowledge base; and a Re-act framework commonality analysis agent that provides real-time, customized analysis to empower engineers with insights for supplier improvement. These enhancements elevate audit efficiency and effectiveness, with testing scenarios demonstrating an improvement of over 24%.
+
+
+
+ 58. 【2410.07672】MACPO: Weak-to-Strong Alignment via Multi-Agent Contrastive Preference Optimization
+ 链接:https://arxiv.org/abs/2410.07672
+ 作者:Yougang Lyu,Lingyong Yan,Zihan Wang,Dawei Yin,Pengjie Ren,Maarten de Rijke,Zhaochun Ren
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:large language models, achieving near-human capabilities, weak teachers, strong students, language models
+ 备注: Under review
+
+ 点击查看摘要
+ Abstract:As large language models (LLMs) are rapidly advancing and achieving near-human capabilities, aligning them with human values is becoming more urgent. In scenarios where LLMs outperform humans, we face a weak-to-strong alignment problem where we need to effectively align strong student LLMs through weak supervision generated by weak teachers. Existing alignment methods mainly focus on strong-to-weak alignment and self-alignment settings, and it is impractical to adapt them to the much harder weak-to-strong alignment setting. To fill this gap, we propose a multi-agent contrastive preference optimization (MACPO) framework. MACPO facilitates weak teachers and strong students to learn from each other by iteratively reinforcing unfamiliar positive behaviors while penalizing familiar negative ones. To get this, we devise a mutual positive behavior augmentation strategy to encourage weak teachers and strong students to learn from each other's positive behavior and further provide higher quality positive behavior for the next iteration. Additionally, we propose a hard negative behavior construction strategy to induce weak teachers and strong students to generate familiar negative behavior by fine-tuning on negative behavioral data. Experimental results on the HH-RLHF and PKU-SafeRLHF datasets, evaluated using both automatic metrics and human judgments, demonstrate that MACPO simultaneously improves the alignment performance of strong students and weak teachers. Moreover, as the number of weak teachers increases, MACPO achieves better weak-to-strong alignment performance through more iteration optimization rounds.
+
+
+
+ 59. 【2410.07652】StablePrompt: Automatic Prompt Tuning using Reinforcement Learning for Large Language Models
+ 链接:https://arxiv.org/abs/2410.07652
+ 作者:Minchan Kwon,Gaeun Kim,Jongsuk Kim,Haeil Lee,Junmo Kim
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, usage of Large, Language Models, important issue
+ 备注: EMNLP 2024 cam-ready
+
+ 点击查看摘要
+ Abstract:Finding appropriate prompts for the specific task has become an important issue as the usage of Large Language Models (LLM) has expanded. Reinforcement Learning (RL) is widely used for prompt tuning, but its inherent instability and environmental dependency make it difficult to use in practice. In this paper, we propose StablePrompt, which strikes a balance between training stability and search space, mitigating the instability of RL and producing high-performance prompts. We formulate prompt tuning as an online RL problem between the agent and target LLM and introduce Adaptive Proximal Policy Optimization (APPO). APPO introduces an LLM anchor model to adaptively adjust the rate of policy updates. This allows for flexible prompt search while preserving the linguistic ability of the pre-trained LLM. StablePrompt outperforms previous methods on various tasks including text classification, question answering, and text generation. Our code can be found in github.
+
+
+
+ 60. 【2410.07627】Automatic Curriculum Expert Iteration for Reliable LLM Reasoning
+ 链接:https://arxiv.org/abs/2410.07627
+ 作者:Zirui Zhao,Hanze Dong,Amrita Saha,Caiming Xiong,Doyen Sahoo
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (stat.ML)
+ 关键词:generating plausible, inaccurate content, excessive refusals, persist as major, plausible but inaccurate
+ 备注: 20 pages
+
+ 点击查看摘要
+ Abstract:Hallucinations (i.e., generating plausible but inaccurate content) and laziness (i.e. excessive refusals or defaulting to "I don't know") persist as major challenges in LLM reasoning. Current efforts to reduce hallucinations primarily focus on factual errors in knowledge-grounded tasks, often neglecting hallucinations related to faulty reasoning. Meanwhile, some approaches render LLMs overly conservative, limiting their problem-solving capabilities. To mitigate hallucination and laziness in reasoning tasks, we propose Automatic Curriculum Expert Iteration (Auto-CEI) to enhance LLM reasoning and align responses to the model's capabilities--assertively answering within its limits and declining when tasks exceed them. In our method, Expert Iteration explores the reasoning trajectories near the LLM policy, guiding incorrect paths back on track to reduce compounding errors and improve robustness; it also promotes appropriate "I don't know" responses after sufficient reasoning attempts. The curriculum automatically adjusts rewards, incentivizing extended reasoning before acknowledging incapability, thereby pushing the limits of LLM reasoning and aligning its behaviour with these limits. We compare Auto-CEI with various SOTA baselines across logical reasoning, mathematics, and planning tasks, where Auto-CEI achieves superior alignment by effectively balancing assertiveness and conservativeness.
+
+
+
+ 61. 【2410.07590】urboRAG: Accelerating Retrieval-Augmented Generation with Precomputed KV Caches for Chunked Text
+ 链接:https://arxiv.org/abs/2410.07590
+ 作者:Songshuo Lu,Hua Wang,Yutian Rong,Zhi Chen,Yaohua Tang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Current Retrieval-Augmented Generation, process numerous retrieved, current RAG system, numerous retrieved document, retrieved document chunks
+ 备注:
+
+ 点击查看摘要
+ Abstract:Current Retrieval-Augmented Generation (RAG) systems concatenate and process numerous retrieved document chunks for prefill which requires a large volume of computation, therefore leading to significant latency in time-to-first-token (TTFT). To reduce the computation overhead as well as TTFT, we introduce TurboRAG, a novel RAG system that redesigns the inference paradigm of the current RAG system by first pre-computing and storing the key-value (KV) caches of documents offline, and then directly retrieving the saved KV cache for prefill. Hence, online computation of KV caches is eliminated during inference. In addition, we provide a number of insights into the mask matrix and positional embedding mechanisms, plus fine-tune a pretrained language model to maintain model accuracy of TurboRAG. Our approach is applicable to most existing large language models and their applications without any requirement in modification of models and inference systems. Experimental results across a suite of RAG benchmarks demonstrate that TurboRAG reduces TTFT by up to 9.4x compared to the conventional RAG systems (on an average of 8.6x), but reserving comparable performance to the standard RAG systems.
+
+
+
+ 62. 【2410.07589】No Free Lunch: Retrieval-Augmented Generation Undermines Fairness in LLMs, Even for Vigilant Users
+ 链接:https://arxiv.org/abs/2410.07589
+ 作者:Mengxuan Hu,Hongyi Wu,Zihan Guan,Ronghang Zhu,Dongliang Guo,Daiqing Qi,Sheng Li
+ 类目:Information Retrieval (cs.IR); Computation and Language (cs.CL)
+ 关键词:domain-specific generation capabilities, Retrieval-Augmented Generation, large language models, domain-specific generation, generation capabilities
+ 备注:
+
+ 点击查看摘要
+ Abstract:Retrieval-Augmented Generation (RAG) is widely adopted for its effectiveness and cost-efficiency in mitigating hallucinations and enhancing the domain-specific generation capabilities of large language models (LLMs). However, is this effectiveness and cost-efficiency truly a free lunch? In this study, we comprehensively investigate the fairness costs associated with RAG by proposing a practical three-level threat model from the perspective of user awareness of fairness. Specifically, varying levels of user fairness awareness result in different degrees of fairness censorship on the external dataset. We examine the fairness implications of RAG using uncensored, partially censored, and fully censored datasets. Our experiments demonstrate that fairness alignment can be easily undermined through RAG without the need for fine-tuning or retraining. Even with fully censored and supposedly unbiased external datasets, RAG can lead to biased outputs. Our findings underscore the limitations of current alignment methods in the context of RAG-based LLMs and highlight the urgent need for new strategies to ensure fairness. We propose potential mitigations and call for further research to develop robust fairness safeguards in RAG-based LLMs.
+
+
+
+ 63. 【2410.07582】Detecting Training Data of Large Language Models via Expectation Maximization
+ 链接:https://arxiv.org/abs/2410.07582
+ 作者:Gyuwan Kim,Yang Li,Evangelia Spiliopoulou,Jie Ma,Miguel Ballesteros,William Yang Wang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Cryptography and Security (cs.CR); Machine Learning (cs.LG)
+ 关键词:large language models, remains undisclosed, impressive advancements, widespread deployment, deployment of large
+ 备注: 14 pages
+
+ 点击查看摘要
+ Abstract:The widespread deployment of large language models (LLMs) has led to impressive advancements, yet information about their training data, a critical factor in their performance, remains undisclosed. Membership inference attacks (MIAs) aim to determine whether a specific instance was part of a target model's training data. MIAs can offer insights into LLM outputs and help detect and address concerns such as data contamination and compliance with privacy and copyright standards. However, applying MIAs to LLMs presents unique challenges due to the massive scale of pre-training data and the ambiguous nature of membership. Additionally, creating appropriate benchmarks to evaluate MIA methods is not straightforward, as training and test data distributions are often unknown. In this paper, we introduce EM-MIA, a novel MIA method for LLMs that iteratively refines membership scores and prefix scores via an expectation-maximization algorithm, leveraging the duality that the estimates of these scores can be improved by each other. Membership scores and prefix scores assess how each instance is likely to be a member and discriminative as a prefix, respectively. Our method achieves state-of-the-art results on the WikiMIA dataset. To further evaluate EM-MIA, we present OLMoMIA, a benchmark built from OLMo resources, which allows us to control the difficulty of MIA tasks with varying degrees of overlap between training and test data distributions. We believe that EM-MIA serves as a robust MIA method for LLMs and that OLMoMIA provides a valuable resource for comprehensively evaluating MIA approaches, thereby driving future research in this critical area.
+
+
+
+ 64. 【2410.07573】RealVul: Can We Detect Vulnerabilities in Web Applications with LLM?
+ 链接:https://arxiv.org/abs/2410.07573
+ 作者:Di Cao,Yong Liao,Xiuwei Shang
+ 类目:Cryptography and Security (cs.CR); Computation and Language (cs.CL)
+ 关键词:large language models, software vulnerability detection, latest advancements, advancements in large, sparked interest
+ 备注:
+
+ 点击查看摘要
+ Abstract:The latest advancements in large language models (LLMs) have sparked interest in their potential for software vulnerability detection. However, there is currently a lack of research specifically focused on vulnerabilities in the PHP language, and challenges in extracting samples and processing persist, hindering the model's ability to effectively capture the characteristics of specific vulnerabilities. In this paper, we present RealVul, the first LLM-based framework designed for PHP vulnerability detection, addressing these issues. By vulnerability candidate detection methods and employing techniques such as normalization, we can isolate potential vulnerability triggers while streamlining the code and eliminating unnecessary semantic information, enabling the model to better understand and learn from the generated vulnerability samples. We also address the issue of insufficient PHP vulnerability samples by improving data synthesis methods. To evaluate RealVul's performance, we conduct an extensive analysis using five distinct code LLMs on vulnerability data from 180 PHP projects. The results demonstrate a significant improvement in both effectiveness and generalization compared to existing methods, effectively boosting the vulnerability detection capabilities of these models.
+
+
+
+ 65. 【2410.07571】How Does Vision-Language Adaptation Impact the Safety of Vision Language Models?
+ 链接:https://arxiv.org/abs/2410.07571
+ 作者:Seongyun Lee,Geewook Kim,Jiyeon Kim,Hyunji Lee,Hoyeon Chang,Sue Hyun Park,Minjoon Seo
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:transforms Large Language, Large Language Models, Large Vision-Language Models, Large Language, Large Vision-Language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Vision-Language adaptation (VL adaptation) transforms Large Language Models (LLMs) into Large Vision-Language Models (LVLMs) for multimodal tasks, but this process often compromises the inherent safety capabilities embedded in the original LLMs. Despite potential harmfulness due to weakened safety measures, in-depth analysis on the effects of VL adaptation on safety remains under-explored. This study examines how VL adaptation influences safety and evaluates the impact of safety fine-tuning methods. Our analysis reveals that safety degradation occurs during VL adaptation, even when the training data is safe. While safety tuning techniques like supervised fine-tuning with safety datasets or reinforcement learning from human feedback mitigate some risks, they still lead to safety degradation and a reduction in helpfulness due to over-rejection issues. Further analysis of internal model weights suggests that VL adaptation may impact certain safety-related layers, potentially lowering overall safety levels. Additionally, our findings demonstrate that the objectives of VL adaptation and safety tuning are divergent, which often results in their simultaneous application being suboptimal. To address this, we suggest the weight merging approach as an optimal solution effectively reducing safety degradation while maintaining helpfulness. These insights help guide the development of more reliable and secure LVLMs for real-world applications.
+
+
+
+ 66. 【2410.07567】When and Where Did it Happen? An Encoder-Decoder Model to Identify Scenario Context
+ 链接:https://arxiv.org/abs/2410.07567
+ 作者:Enrique Noriega-Atala,Robert Vacareanu,Salena Torres Ashton,Adarsh Pyarelal,Clayton T. Morrison,Mihai Surdeanu
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:neural architecture finetuned, scenario context generation, context generation, mentioned in text, introduce a neural
+ 备注: 9 pages, 7 figures
+
+ 点击查看摘要
+ Abstract:We introduce a neural architecture finetuned for the task of scenario context generation: The relevant location and time of an event or entity mentioned in text. Contextualizing information extraction helps to scope the validity of automated finings when aggregating them as knowledge graphs. Our approach uses a high-quality curated dataset of time and location annotations in a corpus of epidemiology papers to train an encoder-decoder architecture. We also explored the use of data augmentation techniques during training. Our findings suggest that a relatively small fine-tuned encoder-decoder model performs better than out-of-the-box LLMs and semantic role labeling parsers to accurate predict the relevant scenario information of a particular entity or event.
+
+
+
+ 67. 【2410.07563】PLaMo-100B: A Ground-Up Language Model Designed for Japanese Proficiency
+ 链接:https://arxiv.org/abs/2410.07563
+ 作者:Kenshin Abe,Kaizaburo Chubachi,Yasuhiro Fujita,Yuta Hirokawa,Kentaro Imajo,Toshiki Kataoka,Hiroyoshi Komatsu,Hiroaki Mikami,Tsuguo Mogami,Shogo Murai,Kosuke Nakago,Daisuke Nishino,Toru Ogawa,Daisuke Okanohara,Yoshihiko Ozaki,Shotaro Sano,Shuji Suzuki,Tianqi Xu,Toshihiko Yanase(Preferred Elements, Inc.)
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Japanese proficiency, designed for Japanese, large-scale language model, language model designed, Direct Preference Optimization
+ 备注:
+
+ 点击查看摘要
+ Abstract:We introduce PLaMo-100B, a large-scale language model designed for Japanese proficiency. The model was trained from scratch using 2 trillion tokens, with architecture such as QK Normalization and Z-Loss to ensure training stability during the training process. Post-training techniques, including Supervised Fine-Tuning and Direct Preference Optimization, were applied to refine the model's performance. Benchmark evaluations suggest that PLaMo-100B performs well, particularly in Japanese-specific tasks, achieving results that are competitive with frontier models like GPT-4.
+
+
+
+ 68. 【2410.07561】AI-Press: A Multi-Agent News Generating and Feedback Simulation System Powered by Large Language Models
+ 链接:https://arxiv.org/abs/2410.07561
+ 作者:Xiawei Liu,Shiyue Yang,Xinnong Zhang,Haoyu Kuang,Libo Sun,Yihang Yang,Siming Chen,Xuanjing Huang,Zhongyu Wei
+ 类目:Computation and Language (cs.CL)
+ 关键词:transformed journalism, social platforms, platforms has transformed, public feedback, Abstract
+ 备注: 18 pages, 4 figures
+
+ 点击查看摘要
+ Abstract:The rise of various social platforms has transformed journalism. The growing demand for news content has led to the increased use of large language models (LLMs) in news production due to their speed and cost-effectiveness. However, LLMs still encounter limitations in professionalism and ethical judgment in news generation. Additionally, predicting public feedback is usually difficult before news is released. To tackle these challenges, we introduce AI-Press, an automated news drafting and polishing system based on multi-agent collaboration and Retrieval-Augmented Generation. We develop a feedback simulation system that generates public feedback considering demographic distributions. Through extensive quantitative and qualitative evaluations, our system shows significant improvements in news-generating capabilities and verifies the effectiveness of public feedback simulation.
+
+
+
+ 69. 【2410.07551】KRAG Framework for Enhancing LLMs in the Legal Domain
+ 链接:https://arxiv.org/abs/2410.07551
+ 作者:Nguyen Ha Thanh,Ken Satoh
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:introduces Knowledge Representation, Representation Augmented Generation, Knowledge Representation Augmented, Large Language Models, capabilities of Large
+ 备注: Presented at NeLaMKRR@KR, 2024 ( [arXiv:2410.05339](https://arxiv.org/abs/2410.05339) )
+
+ 点击查看摘要
+ Abstract:This paper introduces Knowledge Representation Augmented Generation (KRAG), a novel framework designed to enhance the capabilities of Large Language Models (LLMs) within domain-specific applications. KRAG points to the strategic inclusion of critical knowledge entities and relationships that are typically absent in standard data sets and which LLMs do not inherently learn. In the context of legal applications, we present Soft PROLEG, an implementation model under KRAG, which uses inference graphs to aid LLMs in delivering structured legal reasoning, argumentation, and explanations tailored to user inquiries. The integration of KRAG, either as a standalone framework or in tandem with retrieval augmented generation (RAG), markedly improves the ability of language models to navigate and solve the intricate challenges posed by legal texts and terminologies. This paper details KRAG's methodology, its implementation through Soft PROLEG, and potential broader applications, underscoring its significant role in advancing natural language understanding and processing in specialized knowledge domains.
+
+
+
+ 70. 【2410.07549】OneNet: A Fine-Tuning Free Framework for Few-Shot Entity Linking via Large Language Model Prompting
+ 链接:https://arxiv.org/abs/2410.07549
+ 作者:Xukai Liu,Ye Liu,Kai Zhang,Kehang Wang,Qi Liu,Enhong Chen
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:associating ambiguous textual, ambiguous textual mentions, Entity Linking, Large Language Models, few-shot entity linking
+ 备注: Accepted by EMNLP 2024 Main
+
+ 点击查看摘要
+ Abstract:Entity Linking (EL) is the process of associating ambiguous textual mentions to specific entities in a knowledge base. Traditional EL methods heavily rely on large datasets to enhance their performance, a dependency that becomes problematic in the context of few-shot entity linking, where only a limited number of examples are available for training. To address this challenge, we present OneNet, an innovative framework that utilizes the few-shot learning capabilities of Large Language Models (LLMs) without the need for fine-tuning. To the best of our knowledge, this marks a pioneering approach to applying LLMs to few-shot entity linking tasks. OneNet is structured around three key components prompted by LLMs: (1) an entity reduction processor that simplifies inputs by summarizing and filtering out irrelevant entities, (2) a dual-perspective entity linker that combines contextual cues and prior knowledge for precise entity linking, and (3) an entity consensus judger that employs a unique consistency algorithm to alleviate the hallucination in the entity linking reasoning. Comprehensive evaluations across seven benchmark datasets reveal that OneNet outperforms current state-of-the-art entity linking methods.
+
+
+
+ 71. 【2410.07526】MKGL: Mastery of a Three-Word Language
+ 链接:https://arxiv.org/abs/2410.07526
+ 作者:Lingbing Guo,Zhongpu Bo,Zhuo Chen,Yichi Zhang,Jiaoyan Chen,Yarong Lan,Mengshu Sun,Zhiqiang Zhang,Yangyifei Luo,Qian Li,Qiang Zhang,Wen Zhang,Huajun Chen
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large language models, significantly advanced performance, natural language processing, Large language, significantly advanced
+ 备注: NeurIPS 2024 (spotlight)
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) have significantly advanced performance across a spectrum of natural language processing (NLP) tasks. Yet, their application to knowledge graphs (KGs), which describe facts in the form of triplets and allow minimal hallucinations, remains an underexplored frontier. In this paper, we investigate the integration of LLMs with KGs by introducing a specialized KG Language (KGL), where a sentence precisely consists of an entity noun, a relation verb, and ends with another entity noun. Despite KGL's unfamiliar vocabulary to the LLM, we facilitate its learning through a tailored dictionary and illustrative sentences, and enhance context understanding via real-time KG context retrieval and KGL token embedding augmentation. Our results reveal that LLMs can achieve fluency in KGL, drastically reducing errors compared to conventional KG embedding methods on KG completion. Furthermore, our enhanced LLM shows exceptional competence in generating accurate three-word sentences from an initial entity and interpreting new unseen terms out of KGs.
+
+
+
+ 72. 【2410.07524】Upcycling Large Language Models into Mixture of Experts
+ 链接:https://arxiv.org/abs/2410.07524
+ 作者:Ethan He,Abhinav Khattar,Ryan Prenger,Vijay Korthikanti,Zijie Yan,Tong Liu,Shiqing Fan,Ashwath Aithal,Mohammad Shoeybi,Bryan Catanzaro
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:pre-trained dense language, Upcycling pre-trained dense, Upcycling, language models, Upcycling pre-trained
+ 备注:
+
+ 点击查看摘要
+ Abstract:Upcycling pre-trained dense language models into sparse mixture-of-experts (MoE) models is an efficient approach to increase the model capacity of already trained models. However, optimal techniques for upcycling at scale remain unclear. In this work, we conduct an extensive study of upcycling methods and hyperparameters for billion-parameter scale language models. We propose a novel "virtual group" initialization scheme and weight scaling approach to enable upcycling into fine-grained MoE architectures. Through ablations, we find that upcycling outperforms continued dense model training. In addition, we show that softmax-then-topK expert routing improves over topK-then-softmax approach and higher granularity MoEs can help improve accuracy. Finally, we upcycled Nemotron-4 15B on 1T tokens and compared it to a continuously trained version of the same model on the same 1T tokens: the continuous trained model achieved 65.3% MMLU, whereas the upcycled model achieved 67.6%. Our results offer insights and best practices to effectively leverage upcycling for building MoE language models.
+
+
+
+ 73. 【2410.07523】DemoShapley: Valuation of Demonstrations for In-Context Learning
+ 链接:https://arxiv.org/abs/2410.07523
+ 作者:Shan Xie,Man Luo,Chadly Daniel Stern,Mengnan Du,Lu Cheng
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:needing task-specific fine-tuning, Large language models, Large language, leveraging in-context learning, task-specific fine-tuning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) leveraging in-context learning (ICL) have set new benchmarks in few-shot learning across various tasks without needing task-specific fine-tuning. However, extensive research has demonstrated that the effectiveness of ICL is significantly influenced by the selection and ordering of demonstrations. Considering the critical role of demonstration selection in ICL, we introduce DemoShapley which is inspired by the Data Shapley valuation theorem. This approach assesses the influence of individual demonstration instances, distinguishing between those that contribute positively and those that may hinder performance. Our findings reveal that DemoShapley not only enhances model performance in terms of accuracy and fairness but also generalizes queries from domains distinct from those of the in-context demonstrations, highlighting its versatility and effectiveness in optimizing ICL demonstration selection. Last but not least, DemoShapley demonstrates its ability to aid in identifying noisy data within the demonstration set.
+
+
+
+ 74. 【2410.07520】News Reporter: A Multi-lingual LLM Framework for Broadcast T.V News
+ 链接:https://arxiv.org/abs/2410.07520
+ 作者:Tarun Jain,Yufei Gao,Sridhar Vanga,Karan Singla
+ 类目:Computation and Language (cs.CL)
+ 关键词:conversational chatbots due, provide coherent answers, varied queries, essential tools, conversational chatbots
+ 备注: 5 pages, under review at ICASSP 2025
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have fast become an essential tools to many conversational chatbots due to their ability to provide coherent answers for varied queries. Datasets used to train these LLMs are often a mix of generic and synthetic samples, thus lacking the verification needed to provide correct and verifiable answers for T.V. News.
+We collect and share a large collection of QA pairs extracted from transcripts of news recordings from various news-channels across the United States. Resultant QA pairs are then used to fine-tune an off-the-shelf LLM model. Our model surpasses base models of similar size on several open LLM benchmarks. We further integrate and propose a RAG method to improve contextualization of our answers and also point it to a verifiable news recording.
+
Comments:
+5 pages, under review at ICASSP 2025
+Subjects:
+Computation and Language (cs.CL)
+Cite as:
+arXiv:2410.07520 [cs.CL]
+(or
+arXiv:2410.07520v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2410.07520
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 75. 【2410.07513】Evolutionary Contrastive Distillation for Language Model Alignment
+ 链接:https://arxiv.org/abs/2410.07513
+ 作者:Julian Katz-Samuels,Zheng Li,Hyokun Yun,Priyanka Nigam,Yi Xu,Vaclav Petricek,Bing Yin,Trishul Chilimbi
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Evolutionary Contrastive Distillation, real-world applications, complex instructions, large language models, execute complex instructions
+ 备注:
+
+ 点击查看摘要
+ Abstract:The ability of large language models (LLMs) to execute complex instructions is essential for their real-world applications. However, several recent studies indicate that LLMs struggle with challenging instructions. In this paper, we propose Evolutionary Contrastive Distillation (ECD), a novel method for generating high-quality synthetic preference data designed to enhance the complex instruction-following capability of language models. ECD generates data that specifically illustrates the difference between a response that successfully follows a set of complex instructions and a response that is high-quality, but nevertheless makes some subtle mistakes. This is done by prompting LLMs to progressively evolve simple instructions to more complex instructions. When the complexity of an instruction is increased, the original successful response to the original instruction becomes a "hard negative" response for the new instruction, mostly meeting requirements of the new instruction, but barely missing one or two. By pairing a good response with such a hard negative response, and employing contrastive learning algorithms such as DPO, we improve language models' ability to follow complex instructions. Empirically, we observe that our method yields a 7B model that exceeds the complex instruction-following performance of current SOTA 7B models and is competitive even with open-source 70B models.
+
+
+
+ 76. 【2410.07507】hought2Text: Text Generation from EEG Signal using Large Language Models (LLMs)
+ 链接:https://arxiv.org/abs/2410.07507
+ 作者:Abhijit Mishra,Shreya Shukla,Jose Torres,Jacek Gwizdka,Shounak Roychowdhury
+ 类目:Computation and Language (cs.CL)
+ 关键词:expressing brain activity, Decoding and expressing, Large Language Models, expressing brain, brain activity
+ 备注:
+
+ 点击查看摘要
+ Abstract:Decoding and expressing brain activity in a comprehensible form is a challenging frontier in AI. This paper presents Thought2Text, which uses instruction-tuned Large Language Models (LLMs) fine-tuned with EEG data to achieve this goal. The approach involves three stages: (1) training an EEG encoder for visual feature extraction, (2) fine-tuning LLMs on image and text data, enabling multimodal description generation, and (3) further fine-tuning on EEG embeddings to generate text directly from EEG during inference. Experiments on a public EEG dataset collected for six subjects with image stimuli demonstrate the efficacy of multimodal LLMs (LLaMa-v3, Mistral-v0.3, Qwen2.5), validated using traditional language generation evaluation metrics, GPT-4 based assessments, and evaluations by human expert. This approach marks a significant advancement towards portable, low-cost "thoughts-to-text" technology with potential applications in both neuroscience and natural language processing (NLP).
+
+
+
+ 77. 【2410.07504】Using LLMs to Discover Legal Factors
+ 链接:https://arxiv.org/abs/2410.07504
+ 作者:Morgan Gray,Jaromir Savelka,Wesley Oliver,Kevin Ashley
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:foundational component, analysis and computational, legal reasoning, legal analysis, computational models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Factors are a foundational component of legal analysis and computational models of legal reasoning. These factor-based representations enable lawyers, judges, and AI and Law researchers to reason about legal cases. In this paper, we introduce a methodology that leverages large language models (LLMs) to discover lists of factors that effectively represent a legal domain. Our method takes as input raw court opinions and produces a set of factors and associated definitions. We demonstrate that a semi-automated approach, incorporating minimal human involvement, produces factor representations that can predict case outcomes with moderate success, if not yet as well as expert-defined factors can.
+
+
+
+ 78. 【2410.07495】PublicHearingBR: A Brazilian Portuguese Dataset of Public Hearing Transcripts for Summarization of Long Documents
+ 链接:https://arxiv.org/abs/2410.07495
+ 作者:Leandro Carísio Fernandes,Guilherme Zeferino Rodrigues Dobins,Roberto Lotufo,Jayr Alencar Pereira
+ 类目:Computation and Language (cs.CL)
+ 关键词:paper introduces PublicHearingBR, Brazilian Portuguese dataset, Portuguese dataset designed, summarizing long documents, introduces PublicHearingBR
+ 备注: 26 pages
+
+ 点击查看摘要
+ Abstract:This paper introduces PublicHearingBR, a Brazilian Portuguese dataset designed for summarizing long documents. The dataset consists of transcripts of public hearings held by the Brazilian Chamber of Deputies, paired with news articles and structured summaries containing the individuals participating in the hearing and their statements or opinions. The dataset supports the development and evaluation of long document summarization systems in Portuguese. Our contributions include the dataset, a hybrid summarization system to establish a baseline for future studies, and a discussion on evaluation metrics for summarization involving large language models, addressing the challenge of hallucination in the generated summaries. As a result of this discussion, the dataset also provides annotated data that can be used in Natural Language Inference tasks in Portuguese.
+
+
+
+ 79. 【2410.07491】ransducer Consistency Regularization for Speech to Text Applications
+ 链接:https://arxiv.org/abs/2410.07491
+ 作者:Cindy Tseng,Yun Tang,Vijendra Raj Apsingekar
+ 类目:Computation and Language (cs.CL); Audio and Speech Processing (eess.AS)
+ 关键词:generate consistent representation, distorted input features, improve model generalization, Consistency regularization, Transducer Consistency Regularization
+ 备注: 8 pages, 4 figures. Accepted in IEEE Spoken Language Technology Workshop 2024
+
+ 点击查看摘要
+ Abstract:Consistency regularization is a commonly used practice to encourage the model to generate consistent representation from distorted input features and improve model generalization. It shows significant improvement on various speech applications that are optimized with cross entropy criterion. However, it is not straightforward to apply consistency regularization for the transducer-based approaches, which are widely adopted for speech applications due to the competitive performance and streaming characteristic. The main challenge is from the vast alignment space of the transducer optimization criterion and not all the alignments within the space contribute to the model optimization equally. In this study, we present Transducer Consistency Regularization (TCR), a consistency regularization method for transducer models. We apply distortions such as spec augmentation and dropout to create different data views and minimize the distribution difference. We utilize occupational probabilities to give different weights on transducer output distributions, thus only alignments close to oracle alignments would contribute to the model learning. Our experiments show the proposed method is superior to other consistency regularization implementations and could effectively reduce word error rate (WER) by 4.3\% relatively comparing with a strong baseline on the \textsc{Librispeech} dataset.
+
+
+
+ 80. 【2410.07490】MoDEM: Mixture of Domain Expert Models
+ 链接:https://arxiv.org/abs/2410.07490
+ 作者:Toby Simonds,Kemal Kurniawan,Jey Han Lau
+ 类目:Computation and Language (cs.CL)
+ 关键词:combining domain prompt, large language models, models, combining domain, domain prompt routing
+ 备注:
+
+ 点击查看摘要
+ Abstract:We propose a novel approach to enhancing the performance and efficiency of large language models (LLMs) by combining domain prompt routing with domain-specialized models. We introduce a system that utilizes a BERT-based router to direct incoming prompts to the most appropriate domain expert model. These expert models are specifically tuned for domains such as health, mathematics and science. Our research demonstrates that this approach can significantly outperform general-purpose models of comparable size, leading to a superior performance-to-cost ratio across various benchmarks. The implications of this study suggest a potential paradigm shift in LLM development and deployment. Rather than focusing solely on creating increasingly large, general-purpose models, the future of AI may lie in developing ecosystems of smaller, highly specialized models coupled with sophisticated routing systems. This approach could lead to more efficient resource utilization, reduced computational costs, and superior overall performance.
+
+
+
+ 81. 【2410.07473】Localizing Factual Inconsistencies in Attributable Text Generation
+ 链接:https://arxiv.org/abs/2410.07473
+ 作者:Arie Cattan,Paul Roit,Shiyue Zhang,David Wan,Roee Aharoni,Idan Szpektor,Mohit Bansal,Ido Dagan
+ 类目:Computation and Language (cs.CL)
+ 关键词:increasing interest, hallucinations in model-generated, varying levels, model-generated texts, detecting hallucinations
+ 备注:
+
+ 点击查看摘要
+ Abstract:There has been an increasing interest in detecting hallucinations in model-generated texts, both manually and automatically, at varying levels of granularity. However, most existing methods fail to precisely pinpoint the errors. In this work, we introduce QASemConsistency, a new formalism for localizing factual inconsistencies in attributable text generation, at a fine-grained level. Drawing inspiration from Neo-Davidsonian formal semantics, we propose decomposing the generated text into minimal predicate-argument level propositions, expressed as simple question-answer (QA) pairs, and assess whether each individual QA pair is supported by a trusted reference text. As each QA pair corresponds to a single semantic relation between a predicate and an argument, QASemConsistency effectively localizes the unsupported information. We first demonstrate the effectiveness of the QASemConsistency methodology for human annotation, by collecting crowdsourced annotations of granular consistency errors, while achieving a substantial inter-annotator agreement ($\kappa 0.7)$. Then, we implement several methods for automatically detecting localized factual inconsistencies, with both supervised entailment models and open-source LLMs.
+
+
+
+ 82. 【2410.07471】SEAL: Safety-enhanced Aligned LLM Fine-tuning via Bilevel Data Selection
+ 链接:https://arxiv.org/abs/2410.07471
+ 作者:Han Shen,Pin-Yu Chen,Payel Das,Tianyi Chen
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:leveraging Large Language, Large Language Models, Large Language, boost downstream performance, leveraging Large
+ 备注:
+
+ 点击查看摘要
+ Abstract:Fine-tuning on task-specific data to boost downstream performance is a crucial step for leveraging Large Language Models (LLMs). However, previous studies have demonstrated that fine-tuning the models on several adversarial samples or even benign data can greatly comprise the model's pre-equipped alignment and safety capabilities. In this work, we propose SEAL, a novel framework to enhance safety in LLM fine-tuning. SEAL learns a data ranker based on the bilevel optimization to up rank the safe and high-quality fine-tuning data and down rank the unsafe or low-quality ones. Models trained with SEAL demonstrate superior quality over multiple baselines, with 8.5% and 9.7% win rate increase compared to random selection respectively on Llama-3-8b-Instruct and Merlinite-7b models. Our code is available on github this https URL.
+
+
+
+ 83. 【2410.07461】Is C4 Dataset Optimal for Pruning? An Investigation of Calibration Data for LLM Pruning
+ 链接:https://arxiv.org/abs/2410.07461
+ 作者:Abhinav Bandari,Lu Yin,Cheng-Yu Hsieh,Ajay Kumar Jaiswal,Tianlong Chen,Li Shen,Ranjay Krishna,Shiwei Liu
+ 类目:Computation and Language (cs.CL)
+ 关键词:make LLMs cheaper, LLM pruning, Network pruning, calibration data, LLM
+ 备注: EMNLP 2024
+
+ 点击查看摘要
+ Abstract:Network pruning has emerged as a potential solution to make LLMs cheaper to deploy. However, existing LLM pruning approaches universally rely on the C4 dataset as the calibration data for calculating pruning scores, leaving its optimality unexplored. In this study, we evaluate the choice of calibration data on LLM pruning, across a wide range of datasets that are most commonly used in LLM training and evaluation, including four pertaining datasets as well as three categories of downstream tasks encompassing nine datasets. Each downstream dataset is prompted with In-Context Learning (ICL) and Chain-of-Thought (CoT), respectively. Besides the already intriguing observation that the choice of calibration data significantly impacts the performance of pruned LLMs, our results also uncover several subtle and often unexpected findings, summarized as follows: (1) C4 is not the optimal choice for LLM pruning, even among commonly used pre-training datasets; (2) arithmetic datasets, when used as calibration data, performs on par or even better than pre-training datasets; (3) pruning with downstream datasets does not necessarily help the corresponding downstream task, compared to pre-training data; (4) ICL is widely beneficial to all data categories, whereas CoT is only useful on certain tasks. Our findings shed light on the importance of carefully selecting calibration data for LLM pruning and pave the way for more efficient deployment of these powerful models in real-world applications. We release our code at: this https URL.
+
+
+
+ 84. 【2410.07400】Advocating Character Error Rate for Multilingual ASR Evaluation
+ 链接:https://arxiv.org/abs/2410.07400
+ 作者:Thennal D K,Jesin James,Deepa P Gopinath,Muhammed Ashraf K
+ 类目:Computation and Language (cs.CL); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:Automatic speech recognition, Automatic speech, ASR, speech recognition, WER
+ 备注: 8 pages
+
+ 点击查看摘要
+ Abstract:Automatic speech recognition (ASR) systems have traditionally been evaluated using English datasets, with the word error rate (WER) serving as the predominant metric. WER's simplicity and ease of interpretation have contributed to its widespread adoption, particularly for English. However, as ASR systems expand to multilingual contexts, WER fails in various ways, particularly with morphologically complex languages or those without clear word boundaries. Our work documents the limitations of WER as an evaluation metric and advocates for the character error rate (CER) as the primary metric in multilingual ASR evaluation. We show that CER avoids many of the challenges WER faces and exhibits greater consistency across writing systems. We support our proposition by conducting human evaluations of ASR transcriptions in three languages: Malayalam, English, and Arabic, which exhibit distinct morphological characteristics. We show that CER correlates more closely with human judgments than WER, even for English. To facilitate further research, we release our human evaluation dataset for future benchmarking of ASR metrics. Our findings suggest that CER should be prioritized, or at least supplemented, in multilingual ASR evaluations to account for the varying linguistic characteristics of different languages.
+
+
+
+ 85. 【2410.07383】SparseGrad: A Selective Method for Efficient Fine-tuning of MLP Layers
+ 链接:https://arxiv.org/abs/2410.07383
+ 作者:Viktoriia Chekalina,Anna Rudenko,Gleb Mezentsev,Alexander Mikhalev,Alexander Panchenko,Ivan Oseledets
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:performance of Transformer, Transformer models, processed text, enhanced by increasing, MLP blocks
+ 备注:
+
+ 点击查看摘要
+ Abstract:The performance of Transformer models has been enhanced by increasing the number of parameters and the length of the processed text. Consequently, fine-tuning the entire model becomes a memory-intensive process. High-performance methods for parameter-efficient fine-tuning (PEFT) typically work with Attention blocks and often overlook MLP blocks, which contain about half of the model parameters. We propose a new selective PEFT method, namely SparseGrad, that performs well on MLP blocks. We transfer layer gradients to a space where only about 1\% of the layer's elements remain significant. By converting gradients into a sparse structure, we reduce the number of updated parameters. We apply SparseGrad to fine-tune BERT and RoBERTa for the NLU task and LLaMa-2 for the Question-Answering task. In these experiments, with identical memory requirements, our method outperforms LoRA and MeProp, robust popular state-of-the-art PEFT approaches.
+
+
+
+ 86. 【2410.07336】Positive-Augmented Contrastive Learning for Vision-and-Language Evaluation and Training
+ 链接:https://arxiv.org/abs/2410.07336
+ 作者:Sara Sarto,Nicholas Moratelli,Marcella Cornia,Lorenzo Baraldi,Rita Cucchiara
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Multimedia (cs.MM)
+ 关键词:significant advancements, fail to capture, capture the full, fine-grained details, existing evaluation metrics
+ 备注:
+
+ 点击查看摘要
+ Abstract:Despite significant advancements in caption generation, existing evaluation metrics often fail to capture the full quality or fine-grained details of captions. This is mainly due to their reliance on non-specific human-written references or noisy pre-training data. Still, finding an effective metric is crucial not only for captions evaluation but also for the generation phase. Metrics can indeed play a key role in the fine-tuning stage of captioning models, ultimately enhancing the quality of the generated captions. In this paper, we propose PAC-S++, a learnable metric that leverages the CLIP model, pre-trained on both web-collected and cleaned data and regularized through additional pairs of generated visual and textual positive samples. Exploiting this stronger and curated pre-training, we also apply PAC-S++ as a reward in the Self-Critical Sequence Training (SCST) stage typically employed to fine-tune captioning models. Extensive experiments on different image and video datasets highlight the effectiveness of PAC-S++ compared to popular metrics for the task, including its sensitivity to object hallucinations. Furthermore, we show that integrating PAC-S++ into the fine-tuning stage of a captioning model results in semantically richer captions with fewer repetitions and grammatical errors. Evaluations on out-of-domain benchmarks further demonstrate the efficacy of our fine-tuning approach in enhancing model capabilities. Source code and trained models are publicly available at: this https URL.
+
+
+
+ 87. 【2410.07331】DA-Code: Agent Data Science Code Generation Benchmark for Large Language Models
+ 链接:https://arxiv.org/abs/2410.07331
+ 作者:Yiming Huang,Jianwen Luo,Yan Yu,Yitong Zhang,Fangyu Lei,Yifan Wei,Shizhu He,Lifu Huang,Xiao Liu,Jun Zhao,Kang Liu
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:benchmark specifically designed, generation benchmark specifically, code generation tasks, code generation benchmark, agent-based data science
+ 备注: EMNLP 2024
+
+ 点击查看摘要
+ Abstract:We introduce DA-Code, a code generation benchmark specifically designed to assess LLMs on agent-based data science tasks. This benchmark features three core elements: First, the tasks within DA-Code are inherently challenging, setting them apart from traditional code generation tasks and demanding advanced coding skills in grounding and planning. Second, examples in DA-Code are all based on real and diverse data, covering a wide range of complex data wrangling and analytics tasks. Third, to solve the tasks, the models must utilize complex data science programming languages, to perform intricate data processing and derive the answers. We set up the benchmark in a controllable and executable environment that aligns with real-world data analysis scenarios and is scalable. The annotators meticulously design the evaluation suite to ensure the accuracy and robustness of the evaluation. We develop the DA-Agent baseline. Experiments show that although the baseline performs better than other existing frameworks, using the current best LLMs achieves only 30.5% accuracy, leaving ample room for improvement. We release our benchmark at [this https URL](this https URL).
+
+
+
+ 88. 【2410.07239】Locally Measuring Cross-lingual Lexical Alignment: A Domain and Word Level Perspective
+ 链接:https://arxiv.org/abs/2410.07239
+ 作者:Taelin Karidi,Eitan Grossman,Omri Abend
+ 类目:Computation and Language (cs.CL)
+ 关键词:aligning lexical representation, aligning language spaces, lexical representation spaces, representation spaces, focused on aligning
+ 备注:
+
+ 点击查看摘要
+ Abstract:NLP research on aligning lexical representation spaces to one another has so far focused on aligning language spaces in their entirety. However, cognitive science has long focused on a local perspective, investigating whether translation equivalents truly share the same meaning or the extent that cultural and regional influences result in meaning variations. With recent technological advances and the increasing amounts of available data, the longstanding question of cross-lingual lexical alignment can now be approached in a more data-driven manner. However, developing metrics for the task requires some methodology for comparing metric efficacy. We address this gap and present a methodology for analyzing both synthetic validations and a novel naturalistic validation using lexical gaps in the kinship domain. We further propose new metrics, hitherto unexplored on this task, based on contextualized embeddings. Our analysis spans 16 diverse languages, demonstrating that there is substantial room for improvement with the use of newer language models. Our research paves the way for more accurate and nuanced cross-lingual lexical alignment methodologies and evaluation.
+
+
+
+ 89. 【2410.07428】he First VoicePrivacy Attacker Challenge Evaluation Plan
+ 链接:https://arxiv.org/abs/2410.07428
+ 作者:Natalia Tomashenko,Xiaoxiao Miao,Emmanuel Vincent,Junichi Yamagishi
+ 类目:Audio and Speech Processing (eess.AS); Computation and Language (cs.CL); Cryptography and Security (cs.CR)
+ 关键词:VoicePrivacy Attacker Challenge, anonymization systems submitted, developing attacker systems, Grand Challenge, VoicePrivacy initiative
+ 备注:
+
+ 点击查看摘要
+ Abstract:The First VoicePrivacy Attacker Challenge is a new kind of challenge organized as part of the VoicePrivacy initiative and supported by ICASSP 2025 as the SP Grand Challenge It focuses on developing attacker systems against voice anonymization, which will be evaluated against a set of anonymization systems submitted to the VoicePrivacy 2024 Challenge. Training, development, and evaluation datasets are provided along with a baseline attacker system. Participants shall develop their attacker systems in the form of automatic speaker verification systems and submit their scores on the development and evaluation data to the organizers. To do so, they can use any additional training data and models, provided that they are openly available and declared before the specified deadline. The metric for evaluation is equal error rate (EER). Results will be presented at the ICASSP 2025 special session to which 5 selected top-ranked participants will be invited to submit and present their challenge systems.
+
+
+
+ 90. 【2410.07379】Learn from Real: Reality Defender's Submission to ASVspoof5 Challenge
+ 链接:https://arxiv.org/abs/2410.07379
+ 作者:Yi Zhu,Chirag Goel,Surya Koppisetti,Trang Tran,Ankur Kumar,Gaurav Bharaj
+ 类目:Audio and Speech Processing (eess.AS); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Audio deepfake detection, Audio deepfake, crucial to combat, combat the malicious, deepfake detection
+ 备注: Accepted into ASVspoof5 workshop
+
+ 点击查看摘要
+ Abstract:Audio deepfake detection is crucial to combat the malicious use of AI-synthesized speech. Among many efforts undertaken by the community, the ASVspoof challenge has become one of the benchmarks to evaluate the generalizability and robustness of detection models. In this paper, we present Reality Defender's submission to the ASVspoof5 challenge, highlighting a novel pretraining strategy which significantly improves generalizability while maintaining low computational cost during training. Our system SLIM learns the style-linguistics dependency embeddings from various types of bonafide speech using self-supervised contrastive learning. The learned embeddings help to discriminate spoof from bonafide speech by focusing on the relationship between the style and linguistics aspects. We evaluated our system on ASVspoof5, ASV2019, and In-the-wild. Our submission achieved minDCF of 0.1499 and EER of 5.5% on ASVspoof5 Track 1, and EER of 7.4% and 10.8% on ASV2019 and In-the-wild respectively.
+
+
+
+ 91. 【2410.07277】Swin-BERT: A Feature Fusion System designed for Speech-based Alzheimer's Dementia Detection
+ 链接:https://arxiv.org/abs/2410.07277
+ 作者:Yilin Pan,Yanpei Shi,Yijia Zhang,Mingyu Lu
+ 类目:Audio and Speech Processing (eess.AS); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Sound (cs.SD)
+ 关键词:automatic Alzheimer dementia, automatic Alzheimer, Alzheimer dementia, early stages, system
+ 备注:
+
+ 点击查看摘要
+ Abstract:Speech is usually used for constructing an automatic Alzheimer's dementia (AD) detection system, as the acoustic and linguistic abilities show a decline in people living with AD at the early stages. However, speech includes not only AD-related local and global information but also other information unrelated to cognitive status, such as age and gender. In this paper, we propose a speech-based system named Swin-BERT for automatic dementia detection. For the acoustic part, the shifted windows multi-head attention that proposed to extract local and global information from images, is used for designing our acoustic-based system. To decouple the effect of age and gender on acoustic feature extraction, they are used as an extra input of the designed acoustic system. For the linguistic part, the rhythm-related information, which varies significantly between people living with and without AD, is removed while transcribing the audio recordings into transcripts. To compensate for the removed rhythm-related information, the character-level transcripts are proposed to be used as the extra input of a word-level BERT-style system. Finally, the Swin-BERT combines the acoustic features learned from our proposed acoustic-based system with our linguistic-based system. The experiments are based on the two datasets provided by the international dementia detection challenges: the ADReSS and ADReSSo. The results show that both the proposed acoustic and linguistic systems can be better or comparable with previous research on the two datasets. Superior results are achieved by the proposed Swin-BERT system on the ADReSS and ADReSSo datasets, which are 85.58\% F-score and 87.32\% F-score respectively.
+
+
+
+ 92. 【2410.07225】Distilling Analysis from Generative Models for Investment Decisions
+ 链接:https://arxiv.org/abs/2410.07225
+ 作者:Chung-Chi Chen,Hiroya Takamura,Ichiro Kobayashi,Yusuke Miyao
+ 类目:atistical Finance (q-fin.ST); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:decisions, Professionals', stock analysts' decisions, professionals' decision-making processes, decision-making processes
+ 备注:
+
+ 点击查看摘要
+ Abstract:Professionals' decisions are the focus of every field. For example, politicians' decisions will influence the future of the country, and stock analysts' decisions will impact the market. Recognizing the influential role of professionals' perspectives, inclinations, and actions in shaping decision-making processes and future trends across multiple fields, we propose three tasks for modeling these decisions in the financial market. To facilitate this, we introduce a novel dataset, A3, designed to simulate professionals' decision-making processes. While we find current models present challenges in forecasting professionals' behaviors, particularly in making trading decisions, the proposed Chain-of-Decision approach demonstrates promising improvements. It integrates an opinion-generator-in-the-loop to provide subjective analysis based on each news item, further enhancing the proposed tasks' performance.
+
+
+信息检索
+
+ 1. 【2410.07797】Rewriting Conversational Utterances with Instructed Large Language Models
+ 链接:https://arxiv.org/abs/2410.07797
+ 作者:Elnara Galimzhanova,Cristina Ioana Muntean,Franco Maria Nardini,Raffaele Perego,Guido Rocchietti
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Human-Computer Interaction (cs.HC); Information Retrieval (cs.IR)
+ 关键词:large language models, text summarization, NLP tasks, recent studies, studies have shown
+ 备注:
+
+ 点击查看摘要
+ Abstract:Many recent studies have shown the ability of large language models (LLMs) to achieve state-of-the-art performance on many NLP tasks, such as question answering, text summarization, coding, and translation. In some cases, the results provided by LLMs are on par with those of human experts. These models' most disruptive innovation is their ability to perform tasks via zero-shot or few-shot prompting. This capability has been successfully exploited to train instructed LLMs, where reinforcement learning with human feedback is used to guide the model to follow the user's requests directly. In this paper, we investigate the ability of instructed LLMs to improve conversational search effectiveness by rewriting user questions in a conversational setting. We study which prompts provide the most informative rewritten utterances that lead to the best retrieval performance. Reproducible experiments are conducted on publicly-available TREC CAST datasets. The results show that rewriting conversational utterances with instructed LLMs achieves significant improvements of up to 25.2% in MRR, 31.7% in Precision@1, 27% in NDCG@3, and 11.5% in Recall@500 over state-of-the-art techniques.
+
+
+
+ 2. 【2410.07722】DyVo: Dynamic Vocabularies for Learned Sparse Retrieval with Entities
+ 链接:https://arxiv.org/abs/2410.07722
+ 作者:Thong Nguyen,Shubham Chatterjee,Sean MacAvaney,Ian Mackie,Jeff Dalton,Andrew Yates
+ 类目:Information Retrieval (cs.IR)
+ 关键词:Learned Sparse Retrieval, Learned Sparse, pre-trained transformers, nonsensical fragments, Sparse Retrieval
+ 备注: [this https URL](https://github.com/thongnt99/DyVo)
+
+ 点击查看摘要
+ Abstract:Learned Sparse Retrieval (LSR) models use vocabularies from pre-trained transformers, which often split entities into nonsensical fragments. Splitting entities can reduce retrieval accuracy and limits the model's ability to incorporate up-to-date world knowledge not included in the training data. In this work, we enhance the LSR vocabulary with Wikipedia concepts and entities, enabling the model to resolve ambiguities more effectively and stay current with evolving knowledge. Central to our approach is a Dynamic Vocabulary (DyVo) head, which leverages existing entity embeddings and an entity retrieval component that identifies entities relevant to a query or document. We use the DyVo head to generate entity weights, which are then merged with word piece weights to create joint representations for efficient indexing and retrieval using an inverted index. In experiments across three entity-rich document ranking datasets, the resulting DyVo model substantially outperforms state-of-the-art baselines.
+
+
+
+ 3. 【2410.07671】DISCO: A Hierarchical Disentangled Cognitive Diagnosis Framework for Interpretable Job Recommendation
+ 链接:https://arxiv.org/abs/2410.07671
+ 作者:Xiaoshan Yu,Chuan Qin,Qi Zhang,Chen Zhu,Haiping Ma,Xingyi Zhang,Hengshu Zhu
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI)
+ 关键词:created unprecedented opportunities, accurately pinpointing positions, online recruitment platforms, job seekers, skills and preferences
+ 备注: Accepted by ICDM 2024. 10 pages
+
+ 点击查看摘要
+ Abstract:The rapid development of online recruitment platforms has created unprecedented opportunities for job seekers while concurrently posing the significant challenge of quickly and accurately pinpointing positions that align with their skills and preferences. Job recommendation systems have significantly alleviated the extensive search burden for job seekers by optimizing user engagement metrics, such as clicks and applications, thus achieving notable success. In recent years, a substantial amount of research has been devoted to developing effective job recommendation models, primarily focusing on text-matching based and behavior modeling based methods. While these approaches have realized impressive outcomes, it is imperative to note that research on the explainability of recruitment recommendations remains profoundly unexplored. To this end, in this paper, we propose DISCO, a hierarchical Disentanglement based Cognitive diagnosis framework, aimed at flexibly accommodating the underlying representation learning model for effective and interpretable job recommendations. Specifically, we first design a hierarchical representation disentangling module to explicitly mine the hierarchical skill-related factors implied in hidden representations of job seekers and jobs. Subsequently, we propose level-aware association modeling to enhance information communication and robust representation learning both inter- and intra-level, which consists of the interlevel knowledge influence module and the level-wise contrastive learning. Finally, we devise an interaction diagnosis module incorporating a neural diagnosis function for effectively modeling the multi-level recruitment interaction process between job seekers and jobs, which introduces the cognitive measurement theory.
+
+
+
+ 4. 【2410.07654】Firzen: Firing Strict Cold-Start Items with Frozen Heterogeneous and Homogeneous Graphs for Recommendation
+ 链接:https://arxiv.org/abs/2410.07654
+ 作者:Hulingxiao He,Xiangteng He,Yuxin Peng,Zifei Shan,Xin Su
+ 类目:Information Retrieval (cs.IR)
+ 关键词:utilizing unique identities, represent distinct users, recommender systems literature, strict cold-start item, models utilizing unique
+ 备注: Accepted by ICDE 2024. The code is available at [this https URL](https://github.com/PKU-ICST-MIPL/Firzen_ICDE2024)
+
+ 点击查看摘要
+ Abstract:Recommendation models utilizing unique identities (IDs) to represent distinct users and items have dominated the recommender systems literature for over a decade. Since multi-modal content of items (e.g., texts and images) and knowledge graphs (KGs) may reflect the interaction-related users' preferences and items' characteristics, they have been utilized as useful side information to further improve the recommendation quality. However, the success of such methods often limits to either warm-start or strict cold-start item recommendation in which some items neither appear in the training data nor have any interactions in the test stage: (1) Some fail to learn the embedding of a strict cold-start item since side information is only utilized to enhance the warm-start ID representations; (2) The others deteriorate the performance of warm-start recommendation since unrelated multi-modal content or entities in KGs may blur the final representations. In this paper, we propose a unified framework incorporating multi-modal content of items and KGs to effectively solve both strict cold-start and warm-start recommendation termed Firzen, which extracts the user-item collaborative information over frozen heterogeneous graph (collaborative knowledge graph), and exploits the item-item semantic structures and user-user behavioral association over frozen homogeneous graphs (item-item relation graph and user-user co-occurrence graph). Furthermore, we build four unified strict cold-start evaluation benchmarks based on publicly available Amazon datasets and a real-world industrial dataset from Weixin Channels via rearranging the interaction data and constructing KGs. Extensive empirical results demonstrate that our model yields significant improvements for strict cold-start recommendation and outperforms or matches the state-of-the-art performance in the warm-start scenario.
+
+
+
+ 5. 【2410.07610】CSA: Data-efficient Mapping of Unimodal Features to Multimodal Features
+ 链接:https://arxiv.org/abs/2410.07610
+ 作者:Po-han Li,Sandeep P. Chinchali,Ufuk Topcu
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Information Retrieval (cs.IR)
+ 关键词:cross-modal retrieval, CSA, excel in tasks, Multimodal, CLIP excel
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multimodal encoders like CLIP excel in tasks such as zero-shot image classification and cross-modal retrieval. However, they require excessive training data. We propose canonical similarity analysis (CSA), which uses two unimodal encoders to replicate multimodal encoders using limited data. CSA maps unimodal features into a multimodal space, using a new similarity score to retain only the multimodal information. CSA only involves the inference of unimodal encoders and a cubic-complexity matrix decomposition, eliminating the need for extensive GPU-based model training. Experiments show that CSA outperforms CLIP while requiring $300,000\times$ fewer multimodal data pairs and $6\times$ fewer unimodal data for ImageNet classification and misinformative news captions detection. CSA surpasses the state-of-the-art method to map unimodal features to multimodal features. We also demonstrate the ability of CSA with modalities beyond image and text, paving the way for future modality pairs with limited paired multimodal data but abundant unpaired unimodal data, such as lidar and text.
+
+
+
+ 6. 【2410.07589】No Free Lunch: Retrieval-Augmented Generation Undermines Fairness in LLMs, Even for Vigilant Users
+ 链接:https://arxiv.org/abs/2410.07589
+ 作者:Mengxuan Hu,Hongyi Wu,Zihan Guan,Ronghang Zhu,Dongliang Guo,Daiqing Qi,Sheng Li
+ 类目:Information Retrieval (cs.IR); Computation and Language (cs.CL)
+ 关键词:domain-specific generation capabilities, Retrieval-Augmented Generation, large language models, domain-specific generation, generation capabilities
+ 备注:
+
+ 点击查看摘要
+ Abstract:Retrieval-Augmented Generation (RAG) is widely adopted for its effectiveness and cost-efficiency in mitigating hallucinations and enhancing the domain-specific generation capabilities of large language models (LLMs). However, is this effectiveness and cost-efficiency truly a free lunch? In this study, we comprehensively investigate the fairness costs associated with RAG by proposing a practical three-level threat model from the perspective of user awareness of fairness. Specifically, varying levels of user fairness awareness result in different degrees of fairness censorship on the external dataset. We examine the fairness implications of RAG using uncensored, partially censored, and fully censored datasets. Our experiments demonstrate that fairness alignment can be easily undermined through RAG without the need for fine-tuning or retraining. Even with fully censored and supposedly unbiased external datasets, RAG can lead to biased outputs. Our findings underscore the limitations of current alignment methods in the context of RAG-based LLMs and highlight the urgent need for new strategies to ensure fairness. We propose potential mitigations and call for further research to develop robust fairness safeguards in RAG-based LLMs.
+
+
+
+ 7. 【2410.07182】he trade-off between data minimization and fairness in collaborative filtering
+ 链接:https://arxiv.org/abs/2410.07182
+ 作者:Nasim Sonboli,Sipei Li,Mehdi Elahi,Asia Biega
+ 类目:Information Retrieval (cs.IR); Computers and Society (cs.CY); Machine Learning (cs.LG)
+ 关键词:General Data Protection, Data Protection Regulations, Protection Regulations, safeguard individuals' personal, individuals' personal information
+ 备注:
+
+ 点击查看摘要
+ Abstract:General Data Protection Regulations (GDPR) aim to safeguard individuals' personal information from harm. While full compliance is mandatory in the European Union and the California Privacy Rights Act (CPRA), it is not in other places. GDPR requires simultaneous compliance with all the principles such as fairness, accuracy, and data minimization. However, it overlooks the potential contradictions within its principles. This matter gets even more complex when compliance is required from decision-making systems. Therefore, it is essential to investigate the feasibility of simultaneously achieving the goals of GDPR and machine learning, and the potential tradeoffs that might be forced upon us. This paper studies the relationship between the principles of data minimization and fairness in recommender systems. We operationalize data minimization via active learning (AL) because, unlike many other methods, it can preserve a high accuracy while allowing for strategic data collection, hence minimizing the amount of data collection. We have implemented several active learning strategies (personalized and non-personalized) and conducted a comparative analysis focusing on accuracy and fairness on two publicly available datasets. The results demonstrate that different AL strategies may have different impacts on the accuracy of recommender systems with nearly all strategies negatively impacting fairness. There has been no to very limited work on the trade-off between data minimization and fairness, the pros and cons of active learning methods as tools for implementing data minimization, and the potential impacts of AL on fairness. By exploring these critical aspects, we offer valuable insights for developing recommender systems that are GDPR compliant.
+
+
+
+ 8. 【2410.07786】Orthogonal Nonnegative Matrix Factorization with the Kullback-Leibler divergence
+ 链接:https://arxiv.org/abs/2410.07786
+ 作者:Jean Pacifique Nkurunziza,Fulgence Nahayo,Nicolas Gillis
+ 类目:Machine Learning (stat.ML); Information Retrieval (cs.IR); Machine Learning (cs.LG); Signal Processing (eess.SP)
+ 关键词:Orthogonal nonnegative matrix, nonnegative matrix factorization, Orthogonal nonnegative, matrix factorization, approach for clustering
+ 备注: 10 pages
+
+ 点击查看摘要
+ Abstract:Orthogonal nonnegative matrix factorization (ONMF) has become a standard approach for clustering. As far as we know, most works on ONMF rely on the Frobenius norm to assess the quality of the approximation. This paper presents a new model and algorithm for ONMF that minimizes the Kullback-Leibler (KL) divergence. As opposed to the Frobenius norm which assumes Gaussian noise, the KL divergence is the maximum likelihood estimator for Poisson-distributed data, which can model better vectors of word counts in document data sets and photo counting processes in imaging. We have developed an algorithm based on alternating optimization, KL-ONMF, and show that it performs favorably with the Frobenius-norm based ONMF for document classification and hyperspectral image unmixing.
+
+
+计算机视觉
+
+ 1. 【2410.08211】LatteCLIP: Unsupervised CLIP Fine-Tuning via LMM-Synthetic Texts
+ 链接:https://arxiv.org/abs/2410.08211
+ 作者:Anh-Quan Cao,Maximilian Jaritz,Matthieu Guillaumin,Raoul de Charette,Loris Bazzani
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Large-scale vision-language pre-trained, Large-scale vision-language, applied to diverse, diverse applications, fine-tuning VLP models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large-scale vision-language pre-trained (VLP) models (e.g., CLIP) are renowned for their versatility, as they can be applied to diverse applications in a zero-shot setup. However, when these models are used in specific domains, their performance often falls short due to domain gaps or the under-representation of these domains in the training data. While fine-tuning VLP models on custom datasets with human-annotated labels can address this issue, annotating even a small-scale dataset (e.g., 100k samples) can be an expensive endeavor, often requiring expert annotators if the task is complex. To address these challenges, we propose LatteCLIP, an unsupervised method for fine-tuning CLIP models on classification with known class names in custom domains, without relying on human annotations. Our method leverages Large Multimodal Models (LMMs) to generate expressive textual descriptions for both individual images and groups of images. These provide additional contextual information to guide the fine-tuning process in the custom domains. Since LMM-generated descriptions are prone to hallucination or missing details, we introduce a novel strategy to distill only the useful information and stabilize the training. Specifically, we learn rich per-class prototype representations from noisy generated texts and dual pseudo-labels. Our experiments on 10 domain-specific datasets show that LatteCLIP outperforms pre-trained zero-shot methods by an average improvement of +4.74 points in top-1 accuracy and other state-of-the-art unsupervised methods by +3.45 points.
+
+
+
+ 2. 【2410.08210】PointOBB-v2: Towards Simpler, Faster, and Stronger Single Point Supervised Oriented Object Detection
+ 链接:https://arxiv.org/abs/2410.08210
+ 作者:Botao Ren,Xue Yang,Yi Yu,Junwei Luo,Zhidong Deng
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:made initial progress, Single point supervised, gained attention, attention and made, made initial
+ 备注: 13 pages, 4 figures, 5 tables
+
+ 点击查看摘要
+ Abstract:Single point supervised oriented object detection has gained attention and made initial progress within the community. Diverse from those approaches relying on one-shot samples or powerful pretrained models (e.g. SAM), PointOBB has shown promise due to its prior-free feature. In this paper, we propose PointOBB-v2, a simpler, faster, and stronger method to generate pseudo rotated boxes from points without relying on any other prior. Specifically, we first generate a Class Probability Map (CPM) by training the network with non-uniform positive and negative sampling. We show that the CPM is able to learn the approximate object regions and their contours. Then, Principal Component Analysis (PCA) is applied to accurately estimate the orientation and the boundary of objects. By further incorporating a separation mechanism, we resolve the confusion caused by the overlapping on the CPM, enabling its operation in high-density scenarios. Extensive comparisons demonstrate that our method achieves a training speed 15.58x faster and an accuracy improvement of 11.60%/25.15%/21.19% on the DOTA-v1.0/v1.5/v2.0 datasets compared to the previous state-of-the-art, PointOBB. This significantly advances the cutting edge of single point supervised oriented detection in the modular track.
+
+
+
+ 3. 【2410.08209】Emerging Pixel Grounding in Large Multimodal Models Without Grounding Supervision
+ 链接:https://arxiv.org/abs/2410.08209
+ 作者:Shengcao Cao,Liang-Yan Gui,Yu-Xiong Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Current large multimodal, relate language components, Current large, large multimodal models, face challenges
+ 备注:
+
+ 点击查看摘要
+ Abstract:Current large multimodal models (LMMs) face challenges in grounding, which requires the model to relate language components to visual entities. Contrary to the common practice that fine-tunes LMMs with additional grounding supervision, we find that the grounding ability can in fact emerge in LMMs trained without explicit grounding supervision. To reveal this emerging grounding, we introduce an "attend-and-segment" method which leverages attention maps from standard LMMs to perform pixel-level segmentation. Furthermore, to enhance the grounding ability, we propose DIFFLMM, an LMM utilizing a diffusion-based visual encoder, as opposed to the standard CLIP visual encoder, and trained with the same weak supervision. Without being constrained by the biases and limited scale of grounding-specific supervision data, our approach is more generalizable and scalable. We achieve competitive performance on both grounding-specific and general visual question answering benchmarks, compared with grounding LMMs and generalist LMMs, respectively. Notably, we achieve a 44.2 grounding mask recall on grounded conversation generation without any grounding supervision, outperforming the extensively supervised model GLaMM. Project page: this https URL.
+
+
+
+ 4. 【2410.08208】SPA: 3D Spatial-Awareness Enables Effective Embodied Representation
+ 链接:https://arxiv.org/abs/2410.08208
+ 作者:Haoyi Zhu,Honghui Yang,Yating Wang,Jiange Yang,Limin Wang,Tong He
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Robotics (cs.RO)
+ 关键词:vanilla Vision Transformer, embodied representation learning, framework that emphasizes, emphasizes the importance, Vision Transformer
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this paper, we introduce SPA, a novel representation learning framework that emphasizes the importance of 3D spatial awareness in embodied AI. Our approach leverages differentiable neural rendering on multi-view images to endow a vanilla Vision Transformer (ViT) with intrinsic spatial understanding. We present the most comprehensive evaluation of embodied representation learning to date, covering 268 tasks across 8 simulators with diverse policies in both single-task and language-conditioned multi-task scenarios. The results are compelling: SPA consistently outperforms more than 10 state-of-the-art representation methods, including those specifically designed for embodied AI, vision-centric tasks, and multi-modal applications, while using less training data. Furthermore, we conduct a series of real-world experiments to confirm its effectiveness in practical scenarios. These results highlight the critical role of 3D spatial awareness for embodied representation learning. Our strongest model takes more than 6000 GPU hours to train and we are committed to open-sourcing all code and model weights to foster future research in embodied representation learning. Project Page: this https URL.
+
+
+
+ 5. 【2410.08207】DICE: Discrete Inversion Enabling Controllable Editing for Multinomial Diffusion and Masked Generative Models
+ 链接:https://arxiv.org/abs/2410.08207
+ 作者:Xiaoxiao He,Ligong Han,Quan Dao,Song Wen,Minhao Bai,Di Liu,Han Zhang,Martin Renqiang Min,Felix Juefei-Xu,Chaowei Tan,Bo Liu,Kang Li,Hongdong Li,Junzhou Huang,Faez Ahmed,Akash Srivastava,Dimitris Metaxas
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:masked language modeling, Discrete diffusion models, achieved success, success in tasks, language modeling
+ 备注:
+
+ 点击查看摘要
+ Abstract:Discrete diffusion models have achieved success in tasks like image generation and masked language modeling but face limitations in controlled content editing. We introduce DICE (Discrete Inversion for Controllable Editing), the first approach to enable precise inversion for discrete diffusion models, including multinomial diffusion and masked generative models. By recording noise sequences and masking patterns during the reverse diffusion process, DICE enables accurate reconstruction and flexible editing of discrete data without the need for predefined masks or attention manipulation. We demonstrate the effectiveness of DICE across both image and text domains, evaluating it on models such as VQ-Diffusion, Paella, and RoBERTa. Our results show that DICE preserves high data fidelity while enhancing editing capabilities, offering new opportunities for fine-grained content manipulation in discrete spaces. For project webpage, see this https URL.
+
+
+
+ 6. 【2410.08206】Interactive4D: Interactive 4D LiDAR Segmentation
+ 链接:https://arxiv.org/abs/2410.08206
+ 作者:Ilya Fradlin,Idil Esen Zulfikar,Kadir Yilmaz,Theodora Kontogianni,Bastian Leibe
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:important role, role in facilitating, LiDAR, future LiDAR datasets, Interactive
+ 备注: Under Review
+
+ 点击查看摘要
+ Abstract:Interactive segmentation has an important role in facilitating the annotation process of future LiDAR datasets. Existing approaches sequentially segment individual objects at each LiDAR scan, repeating the process throughout the entire sequence, which is redundant and ineffective. In this work, we propose interactive 4D segmentation, a new paradigm that allows segmenting multiple objects on multiple LiDAR scans simultaneously, and Interactive4D, the first interactive 4D segmentation model that segments multiple objects on superimposed consecutive LiDAR scans in a single iteration by utilizing the sequential nature of LiDAR data. While performing interactive segmentation, our model leverages the entire space-time volume, leading to more efficient segmentation. Operating on the 4D volume, it directly provides consistent instance IDs over time and also simplifies tracking annotations. Moreover, we show that click simulations are crucial for successful model training on LiDAR point clouds. To this end, we design a click simulation strategy that is better suited for the characteristics of LiDAR data. To demonstrate its accuracy and effectiveness, we evaluate Interactive4D on multiple LiDAR datasets, where Interactive4D achieves a new state-of-the-art by a large margin. Upon acceptance, we will publicly release the code and models at this https URL.
+
+
+
+ 7. 【2410.08202】Mono-InternVL: Pushing the Boundaries of Monolithic Multimodal Large Language Models with Endogenous Visual Pre-training
+ 链接:https://arxiv.org/abs/2410.08202
+ 作者:Gen Luo,Xue Yang,Wenhan Dou,Zhaokai Wang,Jifeng Dai,Yu Qiao,Xizhou Zhu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Large Language Models, Multimodal Large Language, Language Models, Large Language, monolithic Multimodal Large
+ 备注:
+
+ 点击查看摘要
+ Abstract:The rapid advancement of Large Language Models (LLMs) has led to an influx of efforts to extend their capabilities to multimodal tasks. Among them, growing attention has been focused on monolithic Multimodal Large Language Models (MLLMs) that integrate visual encoding and language decoding into a single LLM. Despite the structural simplicity and deployment-friendliness, training a monolithic MLLM with promising performance still remains challenging. In particular, the popular approaches adopt continuous pre-training to extend a pre-trained LLM to a monolithic MLLM, which suffers from catastrophic forgetting and leads to performance degeneration. In this paper, we aim to overcome this limitation from the perspective of delta tuning. Specifically, our core idea is to embed visual parameters into a pre-trained LLM, thereby incrementally learning visual knowledge from massive data via delta tuning, i.e., freezing the LLM when optimizing the visual parameters. Based on this principle, we present Mono-InternVL, a novel monolithic MLLM that seamlessly integrates a set of visual experts via a multimodal mixture-of-experts structure. Moreover, we propose an innovative pre-training strategy to maximize the visual capability of Mono-InternVL, namely Endogenous Visual Pre-training (EViP). In particular, EViP is designed as a progressive learning process for visual experts, which aims to fully exploit the visual knowledge from noisy data to high-quality data. To validate our approach, we conduct extensive experiments on 16 benchmarks. Experimental results not only validate the superior performance of Mono-InternVL compared to the state-of-the-art MLLM on 6 multimodal benchmarks, e.g., +113 points over InternVL-1.5 on OCRBench, but also confirm its better deployment efficiency, with first token latency reduced by up to 67%.
+
+
+
+ 8. 【2410.08196】MathCoder2: Better Math Reasoning from Continued Pretraining on Model-translated Mathematical Code
+ 链接:https://arxiv.org/abs/2410.08196
+ 作者:Zimu Lu,Aojun Zhou,Ke Wang,Houxing Ren,Weikang Shi,Junting Pan,Mingjie Zhan,Hongsheng Li
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Code, mathematical, precision and accuracy, reasoning, mathematical reasoning
+ 备注: [this https URL](https://github.com/mathllm/MathCoder2)
+
+ 点击查看摘要
+ Abstract:Code has been shown to be effective in enhancing the mathematical reasoning abilities of large language models due to its precision and accuracy. Previous works involving continued mathematical pretraining often include code that utilizes math-related packages, which are primarily designed for fields such as engineering, machine learning, signal processing, or module testing, rather than being directly focused on mathematical reasoning. In this paper, we introduce a novel method for generating mathematical code accompanied with corresponding reasoning steps for continued pretraining. Our approach begins with the construction of a high-quality mathematical continued pretraining dataset by incorporating math-related web data, code using mathematical packages, math textbooks, and synthetic data. Next, we construct reasoning steps by extracting LaTeX expressions, the conditions needed for the expressions, and the results of the expressions from the previously collected dataset. Based on this extracted information, we generate corresponding code to accurately capture the mathematical reasoning process. Appending the generated code to each reasoning step results in data consisting of paired natural language reasoning steps and their corresponding code. Combining this data with the original dataset results in a 19.2B-token high-performing mathematical pretraining corpus, which we name MathCode-Pile. Training several popular base models with this corpus significantly improves their mathematical abilities, leading to the creation of the MathCoder2 family of models. All of our data processing and training code is open-sourced, ensuring full transparency and easy reproducibility of the entire data collection and training pipeline. The code is released at this https URL .
+
+
+
+ 9. 【2410.08192】HybridBooth: Hybrid Prompt Inversion for Efficient Subject-Driven Generation
+ 链接:https://arxiv.org/abs/2410.08192
+ 作者:Shanyan Guan,Yanhao Ge,Ying Tai,Jian Yang,Wei Li,Mingyu You
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:shown remarkable creative, generating personalized instances, personalized instances based, Recent advancements, remarkable creative capabilities
+ 备注: ECCV 2024, the project page: [this https URL](https://sites.google.com/view/hybridbooth)
+
+ 点击查看摘要
+ Abstract:Recent advancements in text-to-image diffusion models have shown remarkable creative capabilities with textual prompts, but generating personalized instances based on specific subjects, known as subject-driven generation, remains challenging. To tackle this issue, we present a new hybrid framework called HybridBooth, which merges the benefits of optimization-based and direct-regression methods. HybridBooth operates in two stages: the Word Embedding Probe, which generates a robust initial word embedding using a fine-tuned encoder, and the Word Embedding Refinement, which further adapts the encoder to specific subject images by optimizing key parameters. This approach allows for effective and fast inversion of visual concepts into textual embedding, even from a single image, while maintaining the model's generalization capabilities.
+
+
+
+ 10. 【2410.08190】Poison-splat: Computation Cost Attack on 3D Gaussian Splatting
+ 链接:https://arxiv.org/abs/2410.08190
+ 作者:Jiahao Lu,Yifan Zhang,Qiuhong Shen,Xinchao Wang,Shuicheng Yan
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Cryptography and Security (cs.CR); Graphics (cs.GR); Machine Learning (cs.LG)
+ 关键词:Gaussian splatting, vision tasks, performance and efficiency, representation and brought, groundbreaking performance
+ 备注: Our code is available at [this https URL](https://github.com/jiahaolu97/poison-splat)
+
+ 点击查看摘要
+ Abstract:3D Gaussian splatting (3DGS), known for its groundbreaking performance and efficiency, has become a dominant 3D representation and brought progress to many 3D vision tasks. However, in this work, we reveal a significant security vulnerability that has been largely overlooked in 3DGS: the computation cost of training 3DGS could be maliciously tampered by poisoning the input data. By developing an attack named Poison-splat, we reveal a novel attack surface where the adversary can poison the input images to drastically increase the computation memory and time needed for 3DGS training, pushing the algorithm towards its worst computation complexity. In extreme cases, the attack can even consume all allocable memory, leading to a Denial-of-Service (DoS) that disrupts servers, resulting in practical damages to real-world 3DGS service vendors. Such a computation cost attack is achieved by addressing a bi-level optimization problem through three tailored strategies: attack objective approximation, proxy model rendering, and optional constrained optimization. These strategies not only ensure the effectiveness of our attack but also make it difficult to defend with simple defensive measures. We hope the revelation of this novel attack surface can spark attention to this crucial yet overlooked vulnerability of 3DGS systems.
+
+
+
+ 11. 【2410.08189】SG-Nav: Online 3D Scene Graph Prompting for LLM-based Zero-shot Object Navigation
+ 链接:https://arxiv.org/abs/2410.08189
+ 作者:Hang Yin,Xiuwei Xu,Zhenyu Wu,Jie Zhou,Jiwen Lu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:zero-shot object navigation, object navigation, object navigation methods, scene graph, object navigation framework
+ 备注: Accepted to NeurIPS 2024. Project page: [this https URL](https://bagh2178.github.io/SG-Nav/)
+
+ 点击查看摘要
+ Abstract:In this paper, we propose a new framework for zero-shot object navigation. Existing zero-shot object navigation methods prompt LLM with the text of spatially closed objects, which lacks enough scene context for in-depth reasoning. To better preserve the information of environment and fully exploit the reasoning ability of LLM, we propose to represent the observed scene with 3D scene graph. The scene graph encodes the relationships between objects, groups and rooms with a LLM-friendly structure, for which we design a hierarchical chain-of-thought prompt to help LLM reason the goal location according to scene context by traversing the nodes and edges. Moreover, benefit from the scene graph representation, we further design a re-perception mechanism to empower the object navigation framework with the ability to correct perception error. We conduct extensive experiments on MP3D, HM3D and RoboTHOR environments, where SG-Nav surpasses previous state-of-the-art zero-shot methods by more than 10% SR on all benchmarks, while the decision process is explainable. To the best of our knowledge, SG-Nav is the first zero-shot method that achieves even higher performance than supervised object navigation methods on the challenging MP3D benchmark.
+
+
+
+ 12. 【2410.08188】DifFRelight: Diffusion-Based Facial Performance Relighting
+ 链接:https://arxiv.org/abs/2410.08188
+ 作者:Mingming He,Pascal Clausen,Ahmet Levent Taşel,Li Ma,Oliver Pilarski,Wenqi Xian,Laszlo Rikker,Xueming Yu,Ryan Burgert,Ning Yu,Paul Debevec
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Graphics (cs.GR)
+ 关键词:relighting using diffusion-based, free-viewpoint facial performance, facial performance relighting, Stable Diffusion model, lighting
+ 备注: 18 pages, SIGGRAPH Asia 2024 Conference Papers (SA Conference Papers '24), December 3--6, 2024, Tokyo, Japan. Project page: [this https URL](https://www.eyelinestudios.com/research/diffrelight.html)
+
+ 点击查看摘要
+ Abstract:We present a novel framework for free-viewpoint facial performance relighting using diffusion-based image-to-image translation. Leveraging a subject-specific dataset containing diverse facial expressions captured under various lighting conditions, including flat-lit and one-light-at-a-time (OLAT) scenarios, we train a diffusion model for precise lighting control, enabling high-fidelity relit facial images from flat-lit inputs. Our framework includes spatially-aligned conditioning of flat-lit captures and random noise, along with integrated lighting information for global control, utilizing prior knowledge from the pre-trained Stable Diffusion model. This model is then applied to dynamic facial performances captured in a consistent flat-lit environment and reconstructed for novel-view synthesis using a scalable dynamic 3D Gaussian Splatting method to maintain quality and consistency in the relit results. In addition, we introduce unified lighting control by integrating a novel area lighting representation with directional lighting, allowing for joint adjustments in light size and direction. We also enable high dynamic range imaging (HDRI) composition using multiple directional lights to produce dynamic sequences under complex lighting conditions. Our evaluations demonstrate the models efficiency in achieving precise lighting control and generalizing across various facial expressions while preserving detailed features such as skintexture andhair. The model accurately reproduces complex lighting effects like eye reflections, subsurface scattering, self-shadowing, and translucency, advancing photorealism within our framework.
+
+
+
+ 13. 【2410.08184】Scaling Laws For Diffusion Transformers
+ 链接:https://arxiv.org/abs/2410.08184
+ 作者:Zhengyang Liang,Hao He,Ceyuan Yang,Bo Dai
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Diffusion transformers, achieved appealing synthesis, content recreation, image and video, achieved appealing
+ 备注:
+
+ 点击查看摘要
+ Abstract:Diffusion transformers (DiT) have already achieved appealing synthesis and scaling properties in content recreation, e.g., image and video generation. However, scaling laws of DiT are less explored, which usually offer precise predictions regarding optimal model size and data requirements given a specific compute budget. Therefore, experiments across a broad range of compute budgets, from 1e17 to 6e18 FLOPs are conducted to confirm the existence of scaling laws in DiT for the first time. Concretely, the loss of pretraining DiT also follows a power-law relationship with the involved compute. Based on the scaling law, we can not only determine the optimal model size and required data but also accurately predict the text-to-image generation loss given a model with 1B parameters and a compute budget of 1e21 FLOPs. Additionally, we also demonstrate that the trend of pre-training loss matches the generation performances (e.g., FID), even across various datasets, which complements the mapping from compute to synthesis quality and thus provides a predictable benchmark that assesses model performance and data quality at a reduced cost.
+
+
+
+ 14. 【2410.08182】MRAG-Bench: Vision-Centric Evaluation for Retrieval-Augmented Multimodal Models
+ 链接:https://arxiv.org/abs/2410.08182
+ 作者:Wenbo Hu,Jia-Chen Gu,Zi-Yi Dou,Mohsen Fayyaz,Pan Lu,Kai-Wei Chang,Nanyun Peng
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Existing multimodal retrieval, retrieval benchmarks primarily, benchmarks primarily focus, Existing multimodal, primarily focus
+ 备注: [this https URL](https://mragbench.github.io)
+
+ 点击查看摘要
+ Abstract:Existing multimodal retrieval benchmarks primarily focus on evaluating whether models can retrieve and utilize external textual knowledge for question answering. However, there are scenarios where retrieving visual information is either more beneficial or easier to access than textual data. In this paper, we introduce a multimodal retrieval-augmented generation benchmark, MRAG-Bench, in which we systematically identify and categorize scenarios where visually augmented knowledge is better than textual knowledge, for instance, more images from varying viewpoints. MRAG-Bench consists of 16,130 images and 1,353 human-annotated multiple-choice questions across 9 distinct scenarios. With MRAG-Bench, we conduct an evaluation of 10 open-source and 4 proprietary large vision-language models (LVLMs). Our results show that all LVLMs exhibit greater improvements when augmented with images compared to textual knowledge, confirming that MRAG-Bench is vision-centric. Additionally, we conduct extensive analysis with MRAG-Bench, which offers valuable insights into retrieval-augmented LVLMs. Notably, the top-performing model, GPT-4o, faces challenges in effectively leveraging retrieved knowledge, achieving only a 5.82% improvement with ground-truth information, in contrast to a 33.16% improvement observed in human participants. These findings highlight the importance of MRAG-Bench in encouraging the community to enhance LVLMs' ability to utilize retrieved visual knowledge more effectively.
+
+
+
+ 15. 【2410.08181】RGM: Reconstructing High-fidelity 3D Car Assets with Relightable 3D-GS Generative Model from a Single Image
+ 链接:https://arxiv.org/abs/2410.08181
+ 作者:Xiaoxue Chen,Jv Zheng,Hao Huang,Haoran Xu,Weihao Gu,Kangliang Chen,He xiang,Huan-ang Gao,Hao Zhao,Guyue Zhou,Yaqin Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:including video games, autonomous driving, including video, video games, virtual reality
+ 备注:
+
+ 点击查看摘要
+ Abstract:The generation of high-quality 3D car assets is essential for various applications, including video games, autonomous driving, and virtual reality. Current 3D generation methods utilizing NeRF or 3D-GS as representations for 3D objects, generate a Lambertian object under fixed lighting and lack separated modelings for material and global illumination. As a result, the generated assets are unsuitable for relighting under varying lighting conditions, limiting their applicability in downstream tasks. To address this challenge, we propose a novel relightable 3D object generative framework that automates the creation of 3D car assets, enabling the swift and accurate reconstruction of a vehicle's geometry, texture, and material properties from a single input image. Our approach begins with introducing a large-scale synthetic car dataset comprising over 1,000 high-precision 3D vehicle models. We represent 3D objects using global illumination and relightable 3D Gaussian primitives integrating with BRDF parameters. Building on this representation, we introduce a feed-forward model that takes images as input and outputs both relightable 3D Gaussians and global illumination parameters. Experimental results demonstrate that our method produces photorealistic 3D car assets that can be seamlessly integrated into road scenes with different illuminations, which offers substantial practical benefits for industrial applications.
+
+
+
+ 16. 【2410.08177】ANet: Triplet Attention Network for All-In-One Adverse Weather Image Restoration
+ 链接:https://arxiv.org/abs/2410.08177
+ 作者:Hsing-Hua Wang,Fu-Jen Tsai,Yen-Yu Lin,Chia-Wen Lin
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:unwanted degraded artifacts, remove unwanted degraded, weather conditions, Adverse weather image, weather
+ 备注: 17 pages (ACCV 2024)
+
+ 点击查看摘要
+ Abstract:Adverse weather image restoration aims to remove unwanted degraded artifacts, such as haze, rain, and snow, caused by adverse weather conditions. Existing methods achieve remarkable results for addressing single-weather conditions. However, they face challenges when encountering unpredictable weather conditions, which often happen in real-world scenarios. Although different weather conditions exhibit different degradation patterns, they share common characteristics that are highly related and complementary, such as occlusions caused by degradation patterns, color distortion, and contrast attenuation due to the scattering of atmospheric particles. Therefore, we focus on leveraging common knowledge across multiple weather conditions to restore images in a unified manner. In this paper, we propose a Triplet Attention Network (TANet) to efficiently and effectively address all-in-one adverse weather image restoration. TANet consists of Triplet Attention Block (TAB) that incorporates three types of attention mechanisms: Local Pixel-wise Attention (LPA) and Global Strip-wise Attention (GSA) to address occlusions caused by non-uniform degradation patterns, and Global Distribution Attention (GDA) to address color distortion and contrast attenuation caused by atmospheric phenomena. By leveraging common knowledge shared across different weather conditions, TANet successfully addresses multiple weather conditions in a unified manner. Experimental results show that TANet efficiently and effectively achieves state-of-the-art performance in all-in-one adverse weather image restoration. The source code is available at this https URL.
+
+
+
+ 17. 【2410.08172】On the Evaluation of Generative Robotic Simulations
+ 链接:https://arxiv.org/abs/2410.08172
+ 作者:Feng Chen,Botian Xu,Pu Hua,Peiqi Duan,Yanchao Yang,Yi Ma,Huazhe Xu
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:acquiring extensive real-world, scalable simulated robotic, extensive real-world data, simulated robotic tasks, highlighting the importance
+ 备注: Project website: [this https URL](https://sites.google.com/view/evaltasks)
+
+ 点击查看摘要
+ Abstract:Due to the difficulty of acquiring extensive real-world data, robot simulation has become crucial for parallel training and sim-to-real transfer, highlighting the importance of scalable simulated robotic tasks. Foundation models have demonstrated impressive capacities in autonomously generating feasible robotic tasks. However, this new paradigm underscores the challenge of adequately evaluating these autonomously generated tasks. To address this, we propose a comprehensive evaluation framework tailored to generative simulations. Our framework segments evaluation into three core aspects: quality, diversity, and generalization. For single-task quality, we evaluate the realism of the generated task and the completeness of the generated trajectories using large language models and vision-language models. In terms of diversity, we measure both task and data diversity through text similarity of task descriptions and world model loss trained on collected task trajectories. For task-level generalization, we assess the zero-shot generalization ability on unseen tasks of a policy trained with multiple generated tasks. Experiments conducted on three representative task generation pipelines demonstrate that the results from our framework are highly consistent with human evaluations, confirming the feasibility and validity of our approach. The findings reveal that while metrics of quality and diversity can be achieved through certain methods, no single approach excels across all metrics, suggesting a need for greater focus on balancing these different metrics. Additionally, our analysis further highlights the common challenge of low generalization capability faced by current works. Our anonymous website: this https URL.
+
+
+
+ 18. 【2410.08168】ZeroComp: Zero-shot Object Compositing from Image Intrinsics via Diffusion
+ 链接:https://arxiv.org/abs/2410.08168
+ 作者:Zitian Zhang,Frédéric Fortier-Chouinard,Mathieu Garon,Anand Bhattad,Jean-François Lalonde
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:require paired composite-scene, Stable Diffusion model, paired composite-scene images, effective zero-shot, Stable Diffusion
+ 备注:
+
+ 点击查看摘要
+ Abstract:We present ZeroComp, an effective zero-shot 3D object compositing approach that does not require paired composite-scene images during training. Our method leverages ControlNet to condition from intrinsic images and combines it with a Stable Diffusion model to utilize its scene priors, together operating as an effective rendering engine. During training, ZeroComp uses intrinsic images based on geometry, albedo, and masked shading, all without the need for paired images of scenes with and without composite objects. Once trained, it seamlessly integrates virtual 3D objects into scenes, adjusting shading to create realistic composites. We developed a high-quality evaluation dataset and demonstrate that ZeroComp outperforms methods using explicit lighting estimations and generative techniques in quantitative and human perception benchmarks. Additionally, ZeroComp extends to real and outdoor image compositing, even when trained solely on synthetic indoor data, showcasing its effectiveness in image compositing.
+
+
+
+ 19. 【2410.08165】Visual Scratchpads: Enabling Global Reasoning in Vision
+ 链接:https://arxiv.org/abs/2410.08165
+ 作者:Aryo Lotfi,Enrico Fini,Samy Bengio,Moin Nabi,Emmanuel Abbe
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:achieved remarkable success, features provide critical, local features provide, provide critical information, Modern vision models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Modern vision models have achieved remarkable success in benchmarks where local features provide critical information about the target. There is now a growing interest in solving tasks that require more global reasoning, where local features offer no significant information. These tasks are reminiscent of the connectivity tasks discussed by Minsky and Papert in 1969, which exposed the limitations of the perceptron model and contributed to the first AI winter. In this paper, we revisit such tasks by introducing four global visual benchmarks involving path findings and mazes. We show that: (1) although today's large vision models largely surpass the expressivity limitations of the early models, they still struggle with the learning efficiency; we put forward the "globality degree" notion to understand this limitation; (2) we then demonstrate that the picture changes and global reasoning becomes feasible with the introduction of "visual scratchpads"; similarly to the text scratchpads and chain-of-thoughts used in language models, visual scratchpads help break down global tasks into simpler ones; (3) we finally show that some scratchpads are better than others, in particular, "inductive scratchpads" that take steps relying on less information afford better out-of-distribution generalization and succeed for smaller model sizes.
+
+
+
+ 20. 【2410.08164】Agent S: An Open Agentic Framework that Uses Computers Like a Human
+ 链接:https://arxiv.org/abs/2410.08164
+ 作者:Saaket Agashe,Jiuzhou Han,Shuyu Gan,Jiachen Yang,Ang Li,Xin Eric Wang
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Graphical User Interface, Graphical User, enables autonomous interaction, transforming human-computer interaction, open agentic framework
+ 备注: 23 pages, 16 figures, 9 tables
+
+ 点击查看摘要
+ Abstract:We present Agent S, an open agentic framework that enables autonomous interaction with computers through a Graphical User Interface (GUI), aimed at transforming human-computer interaction by automating complex, multi-step tasks. Agent S aims to address three key challenges in automating computer tasks: acquiring domain-specific knowledge, planning over long task horizons, and handling dynamic, non-uniform interfaces. To this end, Agent S introduces experience-augmented hierarchical planning, which learns from external knowledge search and internal experience retrieval at multiple levels, facilitating efficient task planning and subtask execution. In addition, it employs an Agent-Computer Interface (ACI) to better elicit the reasoning and control capabilities of GUI agents based on Multimodal Large Language Models (MLLMs). Evaluation on the OSWorld benchmark shows that Agent S outperforms the baseline by 9.37% on success rate (an 83.6% relative improvement) and achieves a new state-of-the-art. Comprehensive analysis highlights the effectiveness of individual components and provides insights for future improvements. Furthermore, Agent S demonstrates broad generalizability to different operating systems on a newly-released WindowsAgentArena benchmark. Code available at this https URL.
+
+
+
+ 21. 【2410.08159】DART: Denoising Autoregressive Transformer for Scalable Text-to-Image Generation
+ 链接:https://arxiv.org/abs/2410.08159
+ 作者:Jiatao Gu,Yuyang Wang,Yizhe Zhang,Qihang Zhang,Dinghuai Zhang,Navdeep Jaitly,Josh Susskind,Shuangfei Zhai
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:DART, image, Markovian, visual generation, Diffusion
+ 备注: 23 pages
+
+ 点击查看摘要
+ Abstract:Diffusion models have become the dominant approach for visual generation. They are trained by denoising a Markovian process that gradually adds noise to the input. We argue that the Markovian property limits the models ability to fully utilize the generation trajectory, leading to inefficiencies during training and inference. In this paper, we propose DART, a transformer-based model that unifies autoregressive (AR) and diffusion within a non-Markovian framework. DART iteratively denoises image patches spatially and spectrally using an AR model with the same architecture as standard language models. DART does not rely on image quantization, enabling more effective image modeling while maintaining flexibility. Furthermore, DART seamlessly trains with both text and image data in a unified model. Our approach demonstrates competitive performance on class-conditioned and text-to-image generation tasks, offering a scalable, efficient alternative to traditional diffusion models. Through this unified framework, DART sets a new benchmark for scalable, high-quality image synthesis.
+
+
+
+ 22. 【2410.08152】RayEmb: Arbitrary Landmark Detection in X-Ray Images Using Ray Embedding Subspace
+ 链接:https://arxiv.org/abs/2410.08152
+ 作者:Pragyan Shrestha,Chun Xie,Yuichi Yoshii,Itaru Kitahara
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:X-ray images, orthopedic surgeries, X-ray, Intra-operative, pre-operatively acquired
+ 备注: Accepted as an oral presentation at ACCV 2024
+
+ 点击查看摘要
+ Abstract:Intra-operative 2D-3D registration of X-ray images with pre-operatively acquired CT scans is a crucial procedure in orthopedic surgeries. Anatomical landmarks pre-annotated in the CT volume can be detected in X-ray images to establish 2D-3D correspondences, which are then utilized for registration. However, registration often fails in certain view angles due to poor landmark visibility. We propose a novel method to address this issue by detecting arbitrary landmark points in X-ray images. Our approach represents 3D points as distinct subspaces, formed by feature vectors (referred to as ray embeddings) corresponding to intersecting rays. Establishing 2D-3D correspondences then becomes a task of finding ray embeddings that are close to a given subspace, essentially performing an intersection test. Unlike conventional methods for landmark estimation, our approach eliminates the need for manually annotating fixed landmarks. We trained our model using the synthetic images generated from CTPelvic1K CLINIC dataset, which contains 103 CT volumes, and evaluated it on the DeepFluoro dataset, comprising real X-ray images. Experimental results demonstrate the superiority of our method over conventional methods. The code is available at this https URL.
+
+
+
+ 23. 【2410.08151】Progressive Autoregressive Video Diffusion Models
+ 链接:https://arxiv.org/abs/2410.08151
+ 作者:Desai Xie,Zhan Xu,Yicong Hong,Hao Tan,Difan Liu,Feng Liu,Arie Kaufman,Yang Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Current frontier video, Current frontier, demonstrated remarkable results, generating high-quality videos, demonstrated remarkable
+ 备注: 15 pages, 5 figures. Our video results and code are available at [this https URL](https://desaixie.github.io/pa-vdm/)
+
+ 点击查看摘要
+ Abstract:Current frontier video diffusion models have demonstrated remarkable results at generating high-quality videos. However, they can only generate short video clips, normally around 10 seconds or 240 frames, due to computation limitations during training. In this work, we show that existing models can be naturally extended to autoregressive video diffusion models without changing the architectures. Our key idea is to assign the latent frames with progressively increasing noise levels rather than a single noise level, which allows for fine-grained condition among the latents and large overlaps between the attention windows. Such progressive video denoising allows our models to autoregressively generate video frames without quality degradation or abrupt scene changes. We present state-of-the-art results on long video generation at 1 minute (1440 frames at 24 FPS). Videos from this paper are available at this https URL.
+
+
+
+ 24. 【2410.08145】Insight Over Sight? Exploring the Vision-Knowledge Conflicts in Multimodal LLMs
+ 链接:https://arxiv.org/abs/2410.08145
+ 作者:Xiaoyuan Liu,Wenxuan Wang,Youliang Yuan,Jen-tse Huang,Qiuzhi Liu,Pinjia He,Zhaopeng Tu
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Multimodal Large Language, Large Language Models, Multimodal Large, Large Language, contradicts model internal
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper explores the problem of commonsense-level vision-knowledge conflict in Multimodal Large Language Models (MLLMs), where visual information contradicts model's internal commonsense knowledge (see Figure 1). To study this issue, we introduce an automated pipeline, augmented with human-in-the-loop quality control, to establish a benchmark aimed at simulating and assessing the conflicts in MLLMs. Utilizing this pipeline, we have crafted a diagnostic benchmark comprising 374 original images and 1,122 high-quality question-answer (QA) pairs. This benchmark covers two types of conflict target and three question difficulty levels, providing a thorough assessment tool. Through this benchmark, we evaluate the conflict-resolution capabilities of nine representative MLLMs across various model families and find a noticeable over-reliance on textual queries. Drawing on these findings, we propose a novel prompting strategy, "Focus-on-Vision" (FoV), which markedly enhances MLLMs' ability to favor visual data over conflicting textual knowledge. Our detailed analysis and the newly proposed strategy significantly advance the understanding and mitigating of vision-knowledge conflicts in MLLMs. The data and code are made publicly available.
+
+
+
+ 25. 【2410.08129】Efficient Perspective-Correct 3D Gaussian Splatting Using Hybrid Transparency
+ 链接:https://arxiv.org/abs/2410.08129
+ 作者:Florian Hahlbohm,Fabian Friederichs,Tim Weyrich,Linus Franke,Moritz Kappel,Susana Castillo,Marc Stamminger,Martin Eisemann,Marcus Magnor
+ 类目:Graphics (cs.GR); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:versatile rendering primitive, proven a versatile, Gaussian Splats, Splats, rendering primitive
+ 备注: Project page: [this https URL](https://fhahlbohm.github.io/htgs/)
+
+ 点击查看摘要
+ Abstract:3D Gaussian Splats (3DGS) have proven a versatile rendering primitive, both for inverse rendering as well as real-time exploration of scenes. In these applications, coherence across camera frames and multiple views is crucial, be it for robust convergence of a scene reconstruction or for artifact-free fly-throughs. Recent work started mitigating artifacts that break multi-view coherence, including popping artifacts due to inconsistent transparency sorting and perspective-correct outlines of (2D) splats. At the same time, real-time requirements forced such implementations to accept compromises in how transparency of large assemblies of 3D Gaussians is resolved, in turn breaking coherence in other ways. In our work, we aim at achieving maximum coherence, by rendering fully perspective-correct 3D Gaussians while using a high-quality approximation of accurate blending, hybrid transparency, on a per-pixel level, in order to retain real-time frame rates. Our fast and perspectively accurate approach for evaluation of 3D Gaussians does not require matrix inversions, thereby ensuring numerical stability and eliminating the need for special handling of degenerate splats, and the hybrid transparency formulation for blending maintains similar quality as fully resolved per-pixel transparencies at a fraction of the rendering costs. We further show that each of these two components can be independently integrated into Gaussian splatting systems. In combination, they achieve up to 2$\times$ higher frame rates, 2$\times$ faster optimization, and equal or better image quality with fewer rendering artifacts compared to traditional 3DGS on common benchmarks.
+
+
+
+ 26. 【2410.08119】Q-VLM: Post-training Quantization for Large Vision-Language Models
+ 链接:https://arxiv.org/abs/2410.08119
+ 作者:Changyuan Wang,Ziwei Wang,Xiuwei Xu,Yansong Tang,Jie Zhou,Jiwen Lu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:post-training quantization framework, efficient multi-modal inference, cross-layer dependency, optimal quantization strategy, large vision-language models
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this paper, we propose a post-training quantization framework of large vision-language models (LVLMs) for efficient multi-modal inference. Conventional quantization methods sequentially search the layer-wise rounding functions by minimizing activation discretization errors, which fails to acquire optimal quantization strategy without considering cross-layer dependency. On the contrary, we mine the cross-layer dependency that significantly influences discretization errors of the entire vision-language model, and embed this dependency into optimal quantization strategy searching with low search cost. Specifically, we observe the strong correlation between the activation entropy and the cross-layer dependency concerning output discretization errors. Therefore, we employ the entropy as the proxy to partition blocks optimally, which aims to achieve satisfying trade-offs between discretization errors and the search cost. Moreover, we optimize the visual encoder to disentangle the cross-layer dependency for fine-grained decomposition of search space, so that the search cost is further reduced without harming the quantization accuracy. Experimental results demonstrate that our method compresses the memory by 2.78x and increase generate speed by 1.44x about 13B LLaVA model without performance degradation on diverse multi-modal reasoning tasks. Code is available at this https URL.
+
+
+
+ 27. 【2410.08118】Medical Image Quality Assessment based on Probability of Necessity and Sufficiency
+ 链接:https://arxiv.org/abs/2410.08118
+ 作者:Boyu Chen,Ameenat L. Solebo,Weiye Bao,Paul Taylor
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:medical image analysis, reliable medical image, image quality assessment, image analysis, reliable medical
+ 备注:
+
+ 点击查看摘要
+ Abstract:Medical image quality assessment (MIQA) is essential for reliable medical image analysis. While deep learning has shown promise in this field, current models could be misled by spurious correlations learned from data and struggle with out-of-distribution (OOD) scenarios. To that end, we propose an MIQA framework based on a concept from causal inference: Probability of Necessity and Sufficiency (PNS). PNS measures how likely a set of features is to be both necessary (always present for an outcome) and sufficient (capable of guaranteeing an outcome) for a particular result. Our approach leverages this concept by learning hidden features from medical images with high PNS values for quality prediction. This encourages models to capture more essential predictive information, enhancing their robustness to OOD scenarios. We evaluate our framework on an Anterior Segment Optical Coherence Tomography (AS-OCT) dataset for the MIQA task and experimental results demonstrate the effectiveness of our framework.
+
+
+
+ 28. 【2410.08114】Parameter-Efficient Fine-Tuning in Spectral Domain for Point Cloud Learning
+ 链接:https://arxiv.org/abs/2410.08114
+ 作者:Dingkang Liang,Tianrui Feng,Xin Zhou,Yumeng Zhang,Zhikang Zou,Xiang Bai
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:leveraging pre-training techniques, hot research topic, point cloud, enhance point cloud, Point cloud Graph
+ 备注: The code will be made available at [this https URL](https://github.com/jerryfeng2003/PointGST)
+
+ 点击查看摘要
+ Abstract:Recently, leveraging pre-training techniques to enhance point cloud models has become a hot research topic. However, existing approaches typically require full fine-tuning of pre-trained models to achieve satisfied performance on downstream tasks, accompanying storage-intensive and computationally demanding. To address this issue, we propose a novel Parameter-Efficient Fine-Tuning (PEFT) method for point cloud, called PointGST (Point cloud Graph Spectral Tuning). PointGST freezes the pre-trained model and introduces a lightweight, trainable Point Cloud Spectral Adapter (PCSA) to fine-tune parameters in the spectral domain. The core idea is built on two observations: 1) The inner tokens from frozen models might present confusion in the spatial domain; 2) Task-specific intrinsic information is important for transferring the general knowledge to the downstream task. Specifically, PointGST transfers the point tokens from the spatial domain to the spectral domain, effectively de-correlating confusion among tokens via using orthogonal components for separating. Moreover, the generated spectral basis involves intrinsic information about the downstream point clouds, enabling more targeted tuning. As a result, PointGST facilitates the efficient transfer of general knowledge to downstream tasks while significantly reducing training costs. Extensive experiments on challenging point cloud datasets across various tasks demonstrate that PointGST not only outperforms its fully fine-tuning counterpart but also significantly reduces trainable parameters, making it a promising solution for efficient point cloud learning. It improves upon a solid baseline by +2.28%, 1.16%, and 2.78%, resulting in 99.48%, 97.76%, and 96.18% on the ScanObjNN OBJ BG, OBJ OBLY, and PB T50 RS datasets, respectively. This advancement establishes a new state-of-the-art, using only 0.67% of the trainable parameters.
+
+
+
+ 29. 【2410.08107】IncEventGS: Pose-Free Gaussian Splatting from a Single Event Camera
+ 链接:https://arxiv.org/abs/2410.08107
+ 作者:Jian Huang,Chengrui Dong,Peidong Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:achieved remarkable progress, Implicit neural representation, Gaussian Splatting, RGB and RGB-D, Implicit neural
+ 备注: Code Page: [this https URL](https://github.com/wu-cvgl/IncEventGS)
+
+ 点击查看摘要
+ Abstract:Implicit neural representation and explicit 3D Gaussian Splatting (3D-GS) for novel view synthesis have achieved remarkable progress with frame-based camera (e.g. RGB and RGB-D cameras) recently. Compared to frame-based camera, a novel type of bio-inspired visual sensor, i.e. event camera, has demonstrated advantages in high temporal resolution, high dynamic range, low power consumption and low latency. Due to its unique asynchronous and irregular data capturing process, limited work has been proposed to apply neural representation or 3D Gaussian splatting for an event camera. In this work, we present IncEventGS, an incremental 3D Gaussian Splatting reconstruction algorithm with a single event camera. To recover the 3D scene representation incrementally, we exploit the tracking and mapping paradigm of conventional SLAM pipelines for IncEventGS. Given the incoming event stream, the tracker firstly estimates an initial camera motion based on prior reconstructed 3D-GS scene representation. The mapper then jointly refines both the 3D scene representation and camera motion based on the previously estimated motion trajectory from the tracker. The experimental results demonstrate that IncEventGS delivers superior performance compared to prior NeRF-based methods and other related baselines, even we do not have the ground-truth camera poses. Furthermore, our method can also deliver better performance compared to state-of-the-art event visual odometry methods in terms of camera motion estimation. Code is publicly available at: this https URL.
+
+
+
+ 30. 【2410.08100】CrackSegDiff: Diffusion Probability Model-based Multi-modal Crack Segmentation
+ 链接:https://arxiv.org/abs/2410.08100
+ 作者:Xiaoyan Jiang,Licheng Jiang,Anjie Wang,Kaiying Zhu,Yongbin Gao
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:road condition assessments, road inspection robots, improved maintenance strategies, road inspection, road condition
+ 备注:
+
+ 点击查看摘要
+ Abstract:Integrating grayscale and depth data in road inspection robots could enhance the accuracy, reliability, and comprehensiveness of road condition assessments, leading to improved maintenance strategies and safer infrastructure. However, these data sources are often compromised by significant background noise from the pavement. Recent advancements in Diffusion Probabilistic Models (DPM) have demonstrated remarkable success in image segmentation tasks, showcasing potent denoising capabilities, as evidenced in studies like SegDiff \cite{amit2021segdiff}. Despite these advancements, current DPM-based segmentors do not fully capitalize on the potential of original image data. In this paper, we propose a novel DPM-based approach for crack segmentation, named CrackSegDiff, which uniquely fuses grayscale and range/depth images. This method enhances the reverse diffusion process by intensifying the interaction between local feature extraction via DPM and global feature extraction. Unlike traditional methods that utilize Transformers for global features, our approach employs Vm-unet \cite{ruan2024vm} to efficiently capture long-range information of the original data. The integration of features is further refined through two innovative modules: the Channel Fusion Module (CFM) and the Shallow Feature Compensation Module (SFCM). Our experimental evaluation on the three-class crack image segmentation tasks within the FIND dataset demonstrates that CrackSegDiff outperforms state-of-the-art methods, particularly excelling in the detection of shallow cracks. Code is available at this https URL.
+
+
+
+ 31. 【2410.08092】UW-SDF: Exploiting Hybrid Geometric Priors for Neural SDF Reconstruction from Underwater Multi-view Monocular Images
+ 链接:https://arxiv.org/abs/2410.08092
+ 作者:Zeyu Chen,Jingyi Tang,Gu Wang,Shengquan Li,Xinghui Li,Xiangyang Ji,Xiu Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:exploration and mapping, unique characteristics, poses a challenging, challenging problem, problem in tasks
+ 备注: 8 pages, 9 figures, presented at IROS 2024
+
+ 点击查看摘要
+ Abstract:Due to the unique characteristics of underwater environments, accurate 3D reconstruction of underwater objects poses a challenging problem in tasks such as underwater exploration and mapping. Traditional methods that rely on multiple sensor data for 3D reconstruction are time-consuming and face challenges in data acquisition in underwater scenarios. We propose UW-SDF, a framework for reconstructing target objects from multi-view underwater images based on neural SDF. We introduce hybrid geometric priors to optimize the reconstruction process, markedly enhancing the quality and efficiency of neural SDF reconstruction. Additionally, to address the challenge of segmentation consistency in multi-view images, we propose a novel few-shot multi-view target segmentation strategy using the general-purpose segmentation model (SAM), enabling rapid automatic segmentation of unseen objects. Through extensive qualitative and quantitative experiments on diverse datasets, we demonstrate that our proposed method outperforms the traditional underwater 3D reconstruction method and other neural rendering approaches in the field of underwater 3D reconstruction.
+
+
+
+ 32. 【2410.08091】Distribution Guidance Network for Weakly Supervised Point Cloud Semantic Segmentation
+ 链接:https://arxiv.org/abs/2410.08091
+ 作者:Zhiyi Pan,Wei Gao,Shan Liu,Ge Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:dense annotations inherent, point cloud semantic, cloud semantic segmentation, semantic segmentation suffers, inadequate supervision signals
+ 备注:
+
+ 点击查看摘要
+ Abstract:Despite alleviating the dependence on dense annotations inherent to fully supervised methods, weakly supervised point cloud semantic segmentation suffers from inadequate supervision signals. In response to this challenge, we introduce a novel perspective that imparts auxiliary constraints by regulating the feature space under weak supervision. Our initial investigation identifies which distributions accurately characterize the feature space, subsequently leveraging this priori to guide the alignment of the weakly supervised embeddings. Specifically, we analyze the superiority of the mixture of von Mises-Fisher distributions (moVMF) among several common distribution candidates. Accordingly, we develop a Distribution Guidance Network (DGNet), which comprises a weakly supervised learning branch and a distribution alignment branch. Leveraging reliable clustering initialization derived from the weakly supervised learning branch, the distribution alignment branch alternately updates the parameters of the moVMF and the network, ensuring alignment with the moVMF-defined latent space. Extensive experiments validate the rationality and effectiveness of our distribution choice and network design. Consequently, DGNet achieves state-of-the-art performance under multiple datasets and various weakly supervised settings.
+
+
+
+ 33. 【2410.08082】oMiE: Towards Modular Growth in Enhanced SMPL Skeleton for 3D Human with Animatable Garments
+ 链接:https://arxiv.org/abs/2410.08082
+ 作者:Yifan Zhan,Qingtian Zhu,Muyao Niu,Mingze Ma,Jiancheng Zhao,Zhihang Zhong,Xiao Sun,Yu Qiao,Yinqiang Zheng
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:complex garments, highlight a critical, overlooked factor, human tasks, garments
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this paper, we highlight a critical yet often overlooked factor in most 3D human tasks, namely modeling humans with complex garments. It is known that the parameterized formulation of SMPL is able to fit human skin; while complex garments, e.g., hand-held objects and loose-fitting garments, are difficult to get modeled within the unified framework, since their movements are usually decoupled with the human body. To enhance the capability of SMPL skeleton in response to this situation, we propose a modular growth strategy that enables the joint tree of the skeleton to expand adaptively. Specifically, our method, called ToMiE, consists of parent joints localization and external joints optimization. For parent joints localization, we employ a gradient-based approach guided by both LBS blending weights and motion kernels. Once the external joints are obtained, we proceed to optimize their transformations in SE(3) across different frames, enabling rendering and explicit animation. ToMiE manages to outperform other methods across various cases with garments, not only in rendering quality but also by offering free animation of grown joints, thereby enhancing the expressive ability of SMPL skeleton for a broader range of applications.
+
+
+
+ 34. 【2410.08074】Unstable Unlearning: The Hidden Risk of Concept Resurgence in Diffusion Models
+ 链接:https://arxiv.org/abs/2410.08074
+ 作者:Vinith M. Suriyakumar,Rohan Alur,Ayush Sekhari,Manish Raghavan,Ashia C. Wilson
+ 类目:Machine Learning (cs.LG); Cryptography and Security (cs.CR); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:web-scale datasets, rely on massive, diffusion models rely, diffusion models, diffusion
+ 备注: 20 pages, 13 figures
+
+ 点击查看摘要
+ Abstract:Text-to-image diffusion models rely on massive, web-scale datasets. Training them from scratch is computationally expensive, and as a result, developers often prefer to make incremental updates to existing models. These updates often compose fine-tuning steps (to learn new concepts or improve model performance) with "unlearning" steps (to "forget" existing concepts, such as copyrighted works or explicit content). In this work, we demonstrate a critical and previously unknown vulnerability that arises in this paradigm: even under benign, non-adversarial conditions, fine-tuning a text-to-image diffusion model on seemingly unrelated images can cause it to "relearn" concepts that were previously "unlearned." We comprehensively investigate the causes and scope of this phenomenon, which we term concept resurgence, by performing a series of experiments which compose "mass concept erasure" (the current state of the art for unlearning in text-to-image diffusion models (Lu et al., 2024)) with subsequent fine-tuning of Stable Diffusion v1.4. Our findings underscore the fragility of composing incremental model updates, and raise serious new concerns about current approaches to ensuring the safety and alignment of text-to-image diffusion models.
+
+
+
+ 35. 【2410.08069】Unlearning-based Neural Interpretations
+ 链接:https://arxiv.org/abs/2410.08069
+ 作者:Ching Lam Choi,Alexandre Duplessis,Serge Belongie
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:computing feature importance, Gradient-based interpretations, require an anchor, comparison to avoid, avoid saturation
+ 备注:
+
+ 点击查看摘要
+ Abstract:Gradient-based interpretations often require an anchor point of comparison to avoid saturation in computing feature importance. We show that current baselines defined using static functions--constant mapping, averaging or blurring--inject harmful colour, texture or frequency assumptions that deviate from model behaviour. This leads to accumulation of irregular gradients, resulting in attribution maps that are biased, fragile and manipulable. Departing from the static approach, we propose UNI to compute an (un)learnable, debiased and adaptive baseline by perturbing the input towards an unlearning direction of steepest ascent. Our method discovers reliable baselines and succeeds in erasing salient features, which in turn locally smooths the high-curvature decision boundaries. Our analyses point to unlearning as a promising avenue for generating faithful, efficient and robust interpretations.
+
+
+
+ 36. 【2410.08063】Reversible Decoupling Network for Single Image Reflection Removal
+ 链接:https://arxiv.org/abs/2410.08063
+ 作者:Hao Zhao,Mingjia Li,Qiming Hu,Xiaojie Guo
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:shown promising advances, single-image reflection removal, approaches to single-image, promising advances, single-image reflection
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent deep-learning-based approaches to single-image reflection removal have shown promising advances, primarily for two reasons: 1) the utilization of recognition-pretrained features as inputs, and 2) the design of dual-stream interaction networks. However, according to the Information Bottleneck principle, high-level semantic clues tend to be compressed or discarded during layer-by-layer propagation. Additionally, interactions in dual-stream networks follow a fixed pattern across different layers, limiting overall performance. To address these limitations, we propose a novel architecture called Reversible Decoupling Network (RDNet), which employs a reversible encoder to secure valuable information while flexibly decoupling transmission- and reflection-relevant features during the forward pass. Furthermore, we customize a transmission-rate-aware prompt generator to dynamically calibrate features, further boosting performance. Extensive experiments demonstrate the superiority of RDNet over existing SOTA methods on five widely-adopted benchmark datasets. Our code will be made publicly available.
+
+
+
+ 37. 【2410.08059】A framework for compressing unstructured scientific data via serialization
+ 链接:https://arxiv.org/abs/2410.08059
+ 作者:Viktor Reshniak,Qian Gong,Rick Archibald,Scott Klasky,Norbert Podhorszki
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:compressing unstructured scientific, unstructured scientific data, present a general, compressing unstructured, unstructured scientific
+ 备注: 6 pages, 9 figures
+
+ 点击查看摘要
+ Abstract:We present a general framework for compressing unstructured scientific data with known local connectivity. A common application is simulation data defined on arbitrary finite element meshes. The framework employs a greedy topology preserving reordering of original nodes which allows for seamless integration into existing data processing pipelines. This reordering process depends solely on mesh connectivity and can be performed offline for optimal efficiency. However, the algorithm's greedy nature also supports on-the-fly implementation. The proposed method is compatible with any compression algorithm that leverages spatial correlations within the data. The effectiveness of this approach is demonstrated on a large-scale real dataset using several compression methods, including MGARD, SZ, and ZFP.
+
+
+
+ 38. 【2410.08049】Scaling Up Your Kernels: Large Kernel Design in ConvNets towards Universal Representations
+ 链接:https://arxiv.org/abs/2410.08049
+ 作者:Yiyuan Zhang,Xiaohan Ding,Xiangyu Yue
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Convolutional Neural Networks, modern Convolutional Neural, designing modern Convolutional, Neural Networks, Convolutional Neural
+ 备注: This is the journal version of [arXiv:2203.06717](https://arxiv.org/abs/2203.06717) and [arXiv:2311.15599](https://arxiv.org/abs/2311.15599)
+
+ 点击查看摘要
+ Abstract:This paper proposes the paradigm of large convolutional kernels in designing modern Convolutional Neural Networks (ConvNets). We establish that employing a few large kernels, instead of stacking multiple smaller ones, can be a superior design strategy. Our work introduces a set of architecture design guidelines for large-kernel ConvNets that optimize their efficiency and performance. We propose the UniRepLKNet architecture, which offers systematical architecture design principles specifically crafted for large-kernel ConvNets, emphasizing their unique ability to capture extensive spatial information without deep layer stacking. This results in a model that not only surpasses its predecessors with an ImageNet accuracy of 88.0%, an ADE20K mIoU of 55.6%, and a COCO box AP of 56.4% but also demonstrates impressive scalability and performance on various modalities such as time-series forecasting, audio, point cloud, and video recognition. These results indicate the universal modeling abilities of large-kernel ConvNets with faster inference speed compared with vision transformers. Our findings reveal that large-kernel ConvNets possess larger effective receptive fields and a higher shape bias, moving away from the texture bias typical of smaller-kernel CNNs. All codes and models are publicly available at this https URL promoting further research and development in the community.
+
+
+
+ 39. 【2410.08023】GrabDAE: An Innovative Framework for Unsupervised Domain Adaptation Utilizing Grab-Mask and Denoise Auto-Encoder
+ 链接:https://arxiv.org/abs/2410.08023
+ 作者:Junzhou Chen,Xuan Wen,Ronghui Zhang,Bingtao Ren,Di Wu,Zhigang Xu,Danwei Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Unsupervised Domain Adaptation, target domain, Unsupervised Domain, Existing Unsupervised Domain, labeled source domain
+ 备注:
+
+ 点击查看摘要
+ Abstract:Unsupervised Domain Adaptation (UDA) aims to adapt a model trained on a labeled source domain to an unlabeled target domain by addressing the domain shift. Existing Unsupervised Domain Adaptation (UDA) methods often fall short in fully leveraging contextual information from the target domain, leading to suboptimal decision boundary separation during source and target domain alignment. To address this, we introduce GrabDAE, an innovative UDA framework designed to tackle domain shift in visual classification tasks. GrabDAE incorporates two key innovations: the Grab-Mask module, which blurs background information in target domain images, enabling the model to focus on essential, domain-relevant features through contrastive learning; and the Denoising Auto-Encoder (DAE), which enhances feature alignment by reconstructing features and filtering noise, ensuring a more robust adaptation to the target domain. These components empower GrabDAE to effectively handle unlabeled target domain data, significantly improving both classification accuracy and robustness. Extensive experiments on benchmark datasets, including VisDA-2017, Office-Home, and Office31, demonstrate that GrabDAE consistently surpasses state-of-the-art UDA methods, setting new performance benchmarks. By tackling UDA's critical challenges with its novel feature masking and denoising approach, GrabDAE offers both significant theoretical and practical advancements in domain adaptation.
+
+
+
+ 40. 【2410.08021】OneRef: Unified One-tower Expression Grounding and Segmentation with Mask Referring Modeling
+ 链接:https://arxiv.org/abs/2410.08021
+ 作者:Linhui Xiao,Xiaoshan Yang,Fang Peng,Yaowei Wang,Changsheng Xu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:bulky Transformer-based fusion, early-stage interaction technologies, works heavily rely, bulky Transformer-based, Transformer-based fusion
+ 备注: Accepted by NeurIPS 2024. The project page: [this https URL](https://github.com/linhuixiao/OneRef)
+
+ 点击查看摘要
+ Abstract:Constrained by the separate encoding of vision and language, existing grounding and referring segmentation works heavily rely on bulky Transformer-based fusion en-/decoders and a variety of early-stage interaction technologies. Simultaneously, the current mask visual language modeling (MVLM) fails to capture the nuanced referential relationship between image-text in referring tasks. In this paper, we propose OneRef, a minimalist referring framework built on the modality-shared one-tower transformer that unifies the visual and linguistic feature spaces. To modeling the referential relationship, we introduce a novel MVLM paradigm called Mask Referring Modeling (MRefM), which encompasses both referring-aware mask image modeling and referring-aware mask language modeling. Both modules not only reconstruct modality-related content but also cross-modal referring content. Within MRefM, we propose a referring-aware dynamic image masking strategy that is aware of the referred region rather than relying on fixed ratios or generic random masking schemes. By leveraging the unified visual language feature space and incorporating MRefM's ability to model the referential relations, our approach enables direct regression of the referring results without resorting to various complex techniques. Our method consistently surpasses existing approaches and achieves SoTA performance on both grounding and segmentation tasks, providing valuable insights for future research. Our code and models are available at this https URL.
+
+
+
+ 41. 【2410.08017】Fast Feedforward 3D Gaussian Splatting Compression
+ 链接:https://arxiv.org/abs/2410.08017
+ 作者:Yihang Chen,Qianyi Wu,Mengyao Li,Weiyao Lin,Mehrtash Harandi,Jianfei Cai
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:storage requirements pose, requirements pose challenges, Gaussian Splatting, advancing real-time, view synthesis
+ 备注: Project Page: [this https URL](https://yihangchen-ee.github.io/project_fcgs/) Code: [this https URL](https://github.com/yihangchen-ee/fcgs/)
+
+ 点击查看摘要
+ Abstract:With 3D Gaussian Splatting (3DGS) advancing real-time and high-fidelity rendering for novel view synthesis, storage requirements pose challenges for their widespread adoption. Although various compression techniques have been proposed, previous art suffers from a common limitation: for any existing 3DGS, per-scene optimization is needed to achieve compression, making the compression sluggish and slow. To address this issue, we introduce Fast Compression of 3D Gaussian Splatting (FCGS), an optimization-free model that can compress 3DGS representations rapidly in a single feed-forward pass, which significantly reduces compression time from minutes to seconds. To enhance compression efficiency, we propose a multi-path entropy module that assigns Gaussian attributes to different entropy constraint paths for balance between size and fidelity. We also carefully design both inter- and intra-Gaussian context models to remove redundancies among the unstructured Gaussian blobs. Overall, FCGS achieves a compression ratio of over 20X while maintaining fidelity, surpassing most per-scene SOTA optimization-based methods. Our code is available at: this https URL.
+
+
+
+ 42. 【2410.07995】RegionGrasp: A Novel Task for Contact Region Controllable Hand Grasp Generation
+ 链接:https://arxiv.org/abs/2410.07995
+ 作者:Yilin Wang,Chuan Guo,Li Cheng,Hai Jiang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:natural hand grasps, Hand Grasp Generation, Controllable Hand Grasp, Region Controllable Hand, machine automatically generate
+ 备注: Accepted for ECCV Workshop: HANDS@ECCV2024
+
+ 点击查看摘要
+ Abstract:Can machine automatically generate multiple distinct and natural hand grasps, given specific contact region of an object in 3D? This motivates us to consider a novel task of \textit{Region Controllable Hand Grasp Generation (RegionGrasp)}, as follows: given as input a 3D object, together with its specific surface area selected as the intended contact region, to generate a diverse set of plausible hand grasps of the object, where the thumb finger tip touches the object surface on the contact region. To address this task, RegionGrasp-CVAE is proposed, which consists of two main parts. First, to enable contact region-awareness, we propose ConditionNet as the condition encoder that includes in it a transformer-backboned object encoder, O-Enc; a pretraining strategy is adopted by O-Enc, where the point patches of object surface are randomly masked off and subsequently restored, to further capture surface geometric information of the object. Second, to realize interaction awareness, HOINet is introduced to encode hand-object interaction features by entangling high-level hand features with embedded object features through geometric-aware multi-head cross attention. Empirical evaluations demonstrate the effectiveness of our approach qualitatively and quantitatively where it is shown to compare favorably with respect to the state of the art methods.
+
+
+
+ 43. 【2410.07988】LADIMO: Face Morph Generation through Biometric Template Inversion with Latent Diffusion
+ 链接:https://arxiv.org/abs/2410.07988
+ 作者:Marcel Grimmer,Christoph Busch
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:severe security threat, face recognition systems, Face morphing, Face, face morphing approach
+ 备注:
+
+ 点击查看摘要
+ Abstract:Face morphing attacks pose a severe security threat to face recognition systems, enabling the morphed face image to be verified against multiple identities. To detect such manipulated images, the development of new face morphing methods becomes essential to increase the diversity of training datasets used for face morph detection. In this study, we present a representation-level face morphing approach, namely LADIMO, that performs morphing on two face recognition embeddings. Specifically, we train a Latent Diffusion Model to invert a biometric template - thus reconstructing the face image from an FRS latent representation. Our subsequent vulnerability analysis demonstrates the high morph attack potential in comparison to MIPGAN-II, an established GAN-based face morphing approach. Finally, we exploit the stochastic LADMIO model design in combination with our identity conditioning mechanism to create unlimited morphing attacks from a single face morph image pair. We show that each face morph variant has an individual attack success rate, enabling us to maximize the morph attack potential by applying a simple re-sampling strategy. Code and pre-trained models available here: this https URL
+
+
+
+ 44. 【2410.07987】A transition towards virtual representations of visual scenes
+ 链接:https://arxiv.org/abs/2410.07987
+ 作者:Américo Pereira,Pedro Carvalho,Luís Côrte-Real
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:extract meaningful information, Visual scene understanding, Visual scene, computer vision, vision that aims
+ 备注:
+
+ 点击查看摘要
+ Abstract:Visual scene understanding is a fundamental task in computer vision that aims to extract meaningful information from visual data. It traditionally involves disjoint and specialized algorithms for different tasks that are tailored for specific application scenarios. This can be cumbersome when designing complex systems that include processing of visual and semantic data extracted from visual scenes, which is even more noticeable nowadays with the influx of applications for virtual or augmented reality. When designing a system that employs automatic visual scene understanding to enable a precise and semantically coherent description of the underlying scene, which can be used to fuel a visualization component with 3D virtual synthesis, the lack of flexibility and unified frameworks become more prominent. To alleviate this issue and its inherent problems, we propose an architecture that addresses the challenges of visual scene understanding and description towards a 3D virtual synthesis that enables an adaptable, unified and coherent solution. Furthermore, we expose how our proposition can be of use into multiple application areas. Additionally, we also present a proof of concept system that employs our architecture to further prove its usability in practice.
+
+
+
+ 45. 【2410.07971】Generalizable and Animatable Gaussian Head Avatar
+ 链接:https://arxiv.org/abs/2410.07971
+ 作者:Xuangeng Chu,Tatsuya Harada
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:one-shot animatable head, Animatable Gaussian head, animatable head avatar, animatable head, propose Generalizable
+ 备注: NeurIPS 2024, code is available at [this https URL](https://github.com/xg-chu/GAGAvatar) , more demos are available at [this https URL](https://xg-chu.site/project_gagavatar)
+
+ 点击查看摘要
+ Abstract:In this paper, we propose Generalizable and Animatable Gaussian head Avatar (GAGAvatar) for one-shot animatable head avatar reconstruction. Existing methods rely on neural radiance fields, leading to heavy rendering consumption and low reenactment speeds. To address these limitations, we generate the parameters of 3D Gaussians from a single image in a single forward pass. The key innovation of our work is the proposed dual-lifting method, which produces high-fidelity 3D Gaussians that capture identity and facial details. Additionally, we leverage global image features and the 3D morphable model to construct 3D Gaussians for controlling expressions. After training, our model can reconstruct unseen identities without specific optimizations and perform reenactment rendering at real-time speeds. Experiments show that our method exhibits superior performance compared to previous methods in terms of reconstruction quality and expression accuracy. We believe our method can establish new benchmarks for future research and advance applications of digital avatars. Code and demos are available this https URL.
+
+
+
+ 46. 【2410.07955】Iterative Optimization Annotation Pipeline and ALSS-YOLO-Seg for Efficient Banana Plantation Segmentation in UAV Imagery
+ 链接:https://arxiv.org/abs/2410.07955
+ 作者:Ang He,Ximei Wu,Xing Xu,Jing Chen,Xiaobin Guo,Sheng Xu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Unmanned Aerial Vehicle, Aerial Vehicle, Unmanned Aerial, plant health assessment, captured images plays
+ 备注:
+
+ 点击查看摘要
+ Abstract:Precise segmentation of Unmanned Aerial Vehicle (UAV)-captured images plays a vital role in tasks such as crop yield estimation and plant health assessment in banana plantations. By identifying and classifying planted areas, crop area can be calculated, which is indispensable for accurate yield predictions. However, segmenting banana plantation scenes requires a substantial amount of annotated data, and manual labeling of these images is both time-consuming and labor-intensive, limiting the development of large-scale datasets. Furthermore, challenges such as changing target sizes, complex ground backgrounds, limited computational resources, and correct identification of crop categories make segmentation even more difficult. To address these issues, we proposed a comprehensive solution. Firstly, we designed an iterative optimization annotation pipeline leveraging SAM2's zero-shot capabilities to generate high-quality segmentation annotations, thereby reducing the cost and time associated with data annotation significantly. Secondly, we developed ALSS-YOLO-Seg, an efficient lightweight segmentation model optimized for UAV imagery. The model's backbone includes an Adaptive Lightweight Channel Splitting and Shuffling (ALSS) module to improve information exchange between channels and optimize feature extraction, aiding accurate crop identification. Additionally, a Multi-Scale Channel Attention (MSCA) module combines multi-scale feature extraction with channel attention to tackle challenges of varying target sizes and complex ground backgrounds.
+
+
+
+ 47. 【2410.07926】Multimodal Perception System for Real Open Environment
+ 链接:https://arxiv.org/abs/2410.07926
+ 作者:Yuyang Sha
+ 类目:Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:real open environment, multimodal perception system, open environment, paper presents, multimodal perception
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper presents a novel multimodal perception system for a real open environment. The proposed system includes an embedded computation platform, cameras, ultrasonic sensors, GPS, and IMU devices. Unlike the traditional frameworks, our system integrates multiple sensors with advanced computer vision algorithms to help users walk outside reliably. The system can efficiently complete various tasks, including navigating to specific locations, passing through obstacle regions, and crossing intersections. Specifically, we also use ultrasonic sensors and depth cameras to enhance obstacle avoidance performance. The path planning module is designed to find the locally optimal route based on various feedback and the user's current state. To evaluate the performance of the proposed system, we design several experiments under different scenarios. The results show that the system can help users walk efficiently and independently in complex situations.
+
+
+
+ 48. 【2410.07917】Understanding Human Activity with Uncertainty Measure for Novelty in Graph Convolutional Networks
+ 链接:https://arxiv.org/abs/2410.07917
+ 作者:Hao Xing,Darius Burschka
+ 类目:Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:developing intelligent robots, Understanding human activity, Graph Convolutional Network, Fusion Graph Convolutional, Temporal Fusion Graph
+ 备注: 15 pages, 10 figures, The International Journal of Robotics Research
+
+ 点击查看摘要
+ Abstract:Understanding human activity is a crucial aspect of developing intelligent robots, particularly in the domain of human-robot collaboration. Nevertheless, existing systems encounter challenges such as over-segmentation, attributed to errors in the up-sampling process of the decoder. In response, we introduce a promising solution: the Temporal Fusion Graph Convolutional Network. This innovative approach aims to rectify the inadequate boundary estimation of individual actions within an activity stream and mitigate the issue of over-segmentation in the temporal dimension.
+Moreover, systems leveraging human activity recognition frameworks for decision-making necessitate more than just the identification of actions. They require a confidence value indicative of the certainty regarding the correspondence between observations and training examples. This is crucial to prevent overly confident responses to unforeseen scenarios that were not part of the training data and may have resulted in mismatches due to weak similarity measures within the system. To address this, we propose the incorporation of a Spectral Normalized Residual connection aimed at enhancing efficient estimation of novelty in observations. This innovative approach ensures the preservation of input distance within the feature space by imposing constraints on the maximum gradients of weight updates. By limiting these gradients, we promote a more robust handling of novel situations, thereby mitigating the risks associated with overconfidence. Our methodology involves the use of a Gaussian process to quantify the distance in feature space.
+
Comments:
+15 pages, 10 figures, The International Journal of Robotics Research
+Subjects:
+Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV)
+Cite as:
+arXiv:2410.07917 [cs.RO]
+(or
+arXiv:2410.07917v1 [cs.RO] for this version)
+https://doi.org/10.48550/arXiv.2410.07917
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 49. 【2410.07915】A Lightweight Target-Driven Network of Stereo Matching for Inland Waterways
+ 链接:https://arxiv.org/abs/2410.07915
+ 作者:Jing Su,Yiqing Zhou,Yu Zhang,Chao Wang,Yi Wei
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Unmanned Surface Vehicles, Surface Vehicles, Unmanned Surface, navigation of Unmanned, target-driven stereo matching
+ 备注: 12 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:Stereo matching for inland waterways is one of the key technologies for the autonomous navigation of Unmanned Surface Vehicles (USVs), which involves dividing the stereo images into reference images and target images for pixel-level matching. However, due to the challenges of the inland waterway environment, such as blurred textures, large spatial scales, and computational resource constraints of the USVs platform, the participation of geometric features from the target image is required for efficient target-driven matching. Based on this target-driven concept, we propose a lightweight target-driven stereo matching neural network, named LTNet. Specifically, a lightweight and efficient 4D cost volume, named the Geometry Target Volume (GTV), is designed to fully utilize the geometric information of target features by employing the shifted target features as the filtered feature volume. Subsequently, to address the substantial texture interference and object occlusions present in the waterway environment, a Left-Right Consistency Refinement (LRR) module is proposed. The \text{LRR} utilizes the pixel-level differences in left and right disparities to introduce soft constraints, thereby enhancing the accuracy of predictions during the intermediate stages of the network. Moreover, knowledge distillation is utilized to enhance the generalization capability of lightweight models on the USVInland dataset. Furthermore, a new large-scale benchmark, named Spring, is utilized to validate the applicability of LTNet across various scenarios. In experiments on the aforementioned two datasets, LTNet achieves competitive results, with only 3.7M parameters. The code is available at this https URL .
+
+
+
+ 50. 【2410.07912】Understanding Spatio-Temporal Relations in Human-Object Interaction using Pyramid Graph Convolutional Network
+ 链接:https://arxiv.org/abs/2410.07912
+ 作者:Hao Xing,Darius Burschka
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:Graph Convolutional Network, Human activities recognition, temporal pyramid pooling, Pyramid Graph Convolutional, intelligent robot
+ 备注: 7 pages, 6 figures, IROS 2022 conference
+
+ 点击查看摘要
+ Abstract:Human activities recognition is an important task for an intelligent robot, especially in the field of human-robot collaboration, it requires not only the label of sub-activities but also the temporal structure of the activity. In order to automatically recognize both the label and the temporal structure in sequence of human-object interaction, we propose a novel Pyramid Graph Convolutional Network (PGCN), which employs a pyramidal encoder-decoder architecture consisting of an attention based graph convolution network and a temporal pyramid pooling module for downsampling and upsampling interaction sequence on the temporal axis, respectively. The system represents the 2D or 3D spatial relation of human and objects from the detection results in video data as a graph. To learn the human-object relations, a new attention graph convolutional network is trained to extract condensed information from the graph representation. To segment action into sub-actions, a novel temporal pyramid pooling module is proposed, which upsamples compressed features back to the original time scale and classifies actions per frame.
+We explore various attention layers, namely spatial attention, temporal attention and channel attention, and combine different upsampling decoders to test the performance on action recognition and segmentation. We evaluate our model on two challenging datasets in the field of human-object interaction recognition, i.e. Bimanual Actions and IKEA Assembly datasets. We demonstrate that our classifier significantly improves both framewise action recognition and segmentation, e.g., F1 micro and F1@50 scores on Bimanual Actions dataset are improved by $4.3\%$ and $8.5\%$ respectively.
+
Comments:
+7 pages, 6 figures, IROS 2022 conference
+Subjects:
+Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+Cite as:
+arXiv:2410.07912 [cs.CV]
+(or
+arXiv:2410.07912v1 [cs.CV] for this version)
+https://doi.org/10.48550/arXiv.2410.07912
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 51. 【2410.07901】Semi-Supervised Video Desnowing Network via Temporal Decoupling Experts and Distribution-Driven Contrastive Regularization
+ 链接:https://arxiv.org/abs/2410.07901
+ 作者:Hongtao Wu,Yijun Yang,Angelica I Aviles-Rivero,Jingjing Ren,Sixiang Chen,Haoyu Chen,Lei Zhu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:computer vision tasks, degradations present formidable, present formidable challenges, Snow degradations present, outdoor scenarios
+ 备注:
+
+ 点击查看摘要
+ Abstract:Snow degradations present formidable challenges to the advancement of computer vision tasks by the undesirable corruption in outdoor scenarios. While current deep learning-based desnowing approaches achieve success on synthetic benchmark datasets, they struggle to restore out-of-distribution real-world snowy videos due to the deficiency of paired real-world training data. To address this bottleneck, we devise a new paradigm for video desnowing in a semi-supervised spirit to involve unlabeled real data for the generalizable snow removal. Specifically, we construct a real-world dataset with 85 snowy videos, and then present a Semi-supervised Video Desnowing Network (SemiVDN) equipped by a novel Distribution-driven Contrastive Regularization. The elaborated contrastive regularization mitigates the distribution gap between the synthetic and real data, and consequently maintains the desired snow-invariant background details. Furthermore, based on the atmospheric scattering model, we introduce a Prior-guided Temporal Decoupling Experts module to decompose the physical components that make up a snowy video in a frame-correlated manner. We evaluate our SemiVDN on benchmark datasets and the collected real snowy data. The experimental results demonstrate the superiority of our approach against state-of-the-art image- and video-level desnowing methods.
+
+
+
+ 52. 【2410.07888】Deepfake detection in videos with multiple faces using geometric-fakeness features
+ 链接:https://arxiv.org/abs/2410.07888
+ 作者:Kirill Vyshegorodtsev,Dmitry Kudiyarov,Alexander Balashov,Alexander Kuzmin
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Cryptography and Security (cs.CR)
+ 关键词:recent years deepfake, video conferencing solutions, facial manipulation techniques, years deepfake detection, deepfake
+ 备注: 10 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:Due to the development of facial manipulation techniques in recent years deepfake detection in video stream became an important problem for face biometrics, brand monitoring or online video conferencing solutions. In case of a biometric authentication, if you replace a real datastream with a deepfake, you can bypass a liveness detection system. Using a deepfake in a video conference, you can penetrate into a private meeting. Deepfakes of victims or public figures can also be used by fraudsters for blackmailing, extorsion and financial fraud. Therefore, the task of detecting deepfakes is relevant to ensuring privacy and security. In existing approaches to a deepfake detection their performance deteriorates when multiple faces are present in a video simultaneously or when there are other objects erroneously classified as faces. In our research we propose to use geometric-fakeness features (GFF) that characterize a dynamic degree of a face presence in a video and its per-frame deepfake scores. To analyze temporal inconsistencies in GFFs between the frames we train a complex deep learning model that outputs a final deepfake prediction. We employ our approach to analyze videos with multiple faces that are simultaneously present in a video. Such videos often occur in practice e.g., in an online video conference. In this case, real faces appearing in a frame together with a deepfake face will significantly affect a deepfake detection and our approach allows to counter this problem. Through extensive experiments we demonstrate that our approach outperforms current state-of-the-art methods on popular benchmark datasets such as FaceForensics++, DFDC, Celeb-DF and WildDeepFake. The proposed approach remains accurate when trained to detect multiple different deepfake generation techniques.
+
+
+
+ 53. 【2410.07884】Generated Bias: Auditing Internal Bias Dynamics of Text-To-Image Generative Models
+ 链接:https://arxiv.org/abs/2410.07884
+ 作者:Abhishek Mandal,Susan Leavy,Suzanne Little
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computers and Society (cs.CY)
+ 关键词:text prompts, capable of generating, generating images, images from text, Diffusion
+ 备注:
+
+ 点击查看摘要
+ Abstract:Text-To-Image (TTI) Diffusion Models such as DALL-E and Stable Diffusion are capable of generating images from text prompts. However, they have been shown to perpetuate gender stereotypes. These models process data internally in multiple stages and employ several constituent models, often trained separately. In this paper, we propose two novel metrics to measure bias internally in these multistage multimodal models. Diffusion Bias was developed to detect and measures bias introduced by the diffusion stage of the models. Bias Amplification measures amplification of bias during the text-to-image conversion process. Our experiments reveal that TTI models amplify gender bias, the diffusion process itself contributes to bias and that Stable Diffusion v2 is more prone to gender bias than DALL-E 2.
+
+
+
+ 54. 【2410.07864】RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
+ 链接:https://arxiv.org/abs/2410.07864
+ 作者:Songming Liu,Lingxuan Wu,Bangguo Li,Hengkai Tan,Huayu Chen,Zhengyi Wang,Ke Xu,Hang Su,Jun Zhu
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:extremely challenging due, developing foundation models, multi-modal action distributions, Robotics Diffusion Transformer, diffusion foundation model
+ 备注: 10 pages, conference
+
+ 点击查看摘要
+ Abstract:Bimanual manipulation is essential in robotics, yet developing foundation models is extremely challenging due to the inherent complexity of coordinating two robot arms (leading to multi-modal action distributions) and the scarcity of training data. In this paper, we present the Robotics Diffusion Transformer (RDT), a pioneering diffusion foundation model for bimanual manipulation. RDT builds on diffusion models to effectively represent multi-modality, with innovative designs of a scalable Transformer to deal with the heterogeneity of multi-modal inputs and to capture the nonlinearity and high frequency of robotic data. To address data scarcity, we further introduce a Physically Interpretable Unified Action Space, which can unify the action representations of various robots while preserving the physical meanings of original actions, facilitating learning transferrable physical knowledge. With these designs, we managed to pre-train RDT on the largest collection of multi-robot datasets to date and scaled it up to 1.2B parameters, which is the largest diffusion-based foundation model for robotic manipulation. We finally fine-tuned RDT on a self-created multi-task bimanual dataset with over 6K+ episodes to refine its manipulation capabilities. Experiments on real robots demonstrate that RDT significantly outperforms existing methods. It exhibits zero-shot generalization to unseen objects and scenes, understands and follows language instructions, learns new skills with just 1~5 demonstrations, and effectively handles complex, dexterous tasks. We refer to this https URL for the code and videos.
+
+
+
+ 55. 【2410.07860】BA-Net: Bridge Attention in Deep Neural Networks
+ 链接:https://arxiv.org/abs/2410.07860
+ 作者:Ronghui Zhang,Runzong Zou,Yue Zhao,Zirui Zhang,Junzhou Chen,Yue Cao,Chuan Hu,Houbing Song
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:highly influential, influential in numerous, Attention, numerous computer vision, Attention mechanisms
+ 备注:
+
+ 点击查看摘要
+ Abstract:Attention mechanisms, particularly channel attention, have become highly influential in numerous computer vision tasks. Despite their effectiveness, many existing methods primarily focus on optimizing performance through complex attention modules applied at individual convolutional layers, often overlooking the synergistic interactions that can occur across multiple layers. In response to this gap, we introduce bridge attention, a novel approach designed to facilitate more effective integration and information flow between different convolutional layers. Our work extends the original bridge attention model (BAv1) by introducing an adaptive selection operator, which reduces information redundancy and optimizes the overall information exchange. This enhancement results in the development of BAv2, which achieves substantial performance improvements in the ImageNet classification task, obtaining Top-1 accuracies of 80.49% and 81.75% when using ResNet50 and ResNet101 as backbone networks, respectively. These results surpass the retrained baselines by 1.61% and 0.77%, respectively. Furthermore, BAv2 outperforms other existing channel attention techniques, such as the classical SENet101, exceeding its retrained performance by 0.52% Additionally, integrating BAv2 into advanced convolutional networks and vision transformers has led to significant gains in performance across a wide range of computer vision tasks, underscoring its broad applicability.
+
+
+
+ 56. 【2410.07858】From Logits to Hierarchies: Hierarchical Clustering made Simple
+ 链接:https://arxiv.org/abs/2410.07858
+ 作者:Emanuele Palumbo,Moritz Vandenhirtz,Alain Ryser,Imant Daunhawer,Julia E. Vogt
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:supervised machine learning, making the modeling, machine learning, intrinsically hierarchical, critical objective
+ 备注:
+
+ 点击查看摘要
+ Abstract:The structure of many real-world datasets is intrinsically hierarchical, making the modeling of such hierarchies a critical objective in both unsupervised and supervised machine learning. Recently, novel approaches for hierarchical clustering with deep architectures have been proposed. In this work, we take a critical perspective on this line of research and demonstrate that many approaches exhibit major limitations when applied to realistic datasets, partly due to their high computational complexity. In particular, we show that a lightweight procedure implemented on top of pre-trained non-hierarchical clustering models outperforms models designed specifically for hierarchical clustering. Our proposed approach is computationally efficient and applicable to any pre-trained clustering model that outputs logits, without requiring any fine-tuning. To highlight the generality of our findings, we illustrate how our method can also be applied in a supervised setup, recovering meaningful hierarchies from a pre-trained ImageNet classifier.
+
+
+
+ 57. 【2410.07857】SNN-PAR: Energy Efficient Pedestrian Attribute Recognition via Spiking Neural Networks
+ 链接:https://arxiv.org/abs/2410.07857
+ 作者:Haiyang Wang,Qian Zhu,Mowen She,Yabo Li,Haoyu Song,Minghe Xu,Xiao Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Neural and Evolutionary Computing (cs.NE)
+ 关键词:Pedestrian Attribute Recognition, Artificial neural network, Attribute Recognition, neural network, neural network based
+ 备注:
+
+ 点击查看摘要
+ Abstract:Artificial neural network based Pedestrian Attribute Recognition (PAR) has been widely studied in recent years, despite many progresses, however, the energy consumption is still high. To address this issue, in this paper, we propose a Spiking Neural Network (SNN) based framework for energy-efficient attribute recognition. Specifically, we first adopt a spiking tokenizer module to transform the given pedestrian image into spiking feature representations. Then, the output will be fed into the spiking Transformer backbone networks for energy-efficient feature extraction. We feed the enhanced spiking features into a set of feed-forward networks for pedestrian attribute recognition. In addition to the widely used binary cross-entropy loss function, we also exploit knowledge distillation from the artificial neural network to the spiking Transformer network for more accurate attribute recognition. Extensive experiments on three widely used PAR benchmark datasets fully validated the effectiveness of our proposed SNN-PAR framework. The source code of this paper is released on \url{this https URL}.
+
+
+
+ 58. 【2410.07854】HeGraphAdapter: Tuning Multi-Modal Vision-Language Models with Heterogeneous Graph Adapter
+ 链接:https://arxiv.org/abs/2410.07854
+ 作者:Yumiao Zhao,Bo Jiang,Xiao Wang,Qin Xu,Jin Tang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:Adapter-based tuning methods, shown significant potential, pre-trained Vision-Language Models, Adapter-based tuning, Heterogeneous Graph
+ 备注:
+
+ 点击查看摘要
+ Abstract:Adapter-based tuning methods have shown significant potential in transferring knowledge from pre-trained Vision-Language Models to the downstream tasks. However, after reviewing existing adapters, we find they generally fail to fully explore the interactions between different modalities in constructing task-specific knowledge. Also, existing works usually only focus on similarity matching between positive text prompts, making it challenging to distinguish the classes with high similar visual contents. To address these issues, in this paper, we propose a novel Heterogeneous Graph Adapter to achieve tuning VLMs for the downstream tasks. To be specific, we first construct a unified heterogeneous graph mode, which contains i) visual nodes, positive text nodes and negative text nodes, and ii) several types of edge connections to comprehensively model the intra-modality, inter-modality and inter-class structure knowledge together. Next, we employ a specific Heterogeneous Graph Neural Network to excavate multi-modality structure knowledge for adapting both visual and textual features for the downstream tasks. Finally, after HeGraphAdapter, we construct both text-based and visual-based classifiers simultaneously to comprehensively enhance the performance of the CLIP model. Experimental results on 11 benchmark datasets demonstrate the effectiveness and benefits of the proposed HeGraphAdapter.
+
+
+
+ 59. 【2410.07838】MinorityPrompt: Text to Minority Image Generation via Prompt Optimization
+ 链接:https://arxiv.org/abs/2410.07838
+ 作者:Soobin Um,Jong Chul Ye
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:latent diffusion models, diffusion models, latent diffusion, minority samples, models
+ 备注: 23 pages, 8 figures
+
+ 点击查看摘要
+ Abstract:We investigate the generation of minority samples using pretrained text-to-image (T2I) latent diffusion models. Minority instances, in the context of T2I generation, can be defined as ones living on low-density regions of text-conditional data distributions. They are valuable for various applications of modern T2I generators, such as data augmentation and creative AI. Unfortunately, existing pretrained T2I diffusion models primarily focus on high-density regions, largely due to the influence of guided samplers (like CFG) that are essential for producing high-quality generations. To address this, we present a novel framework to counter the high-density-focus of T2I diffusion models. Specifically, we first develop an online prompt optimization framework that can encourage the emergence of desired properties during inference while preserving semantic contents of user-provided prompts. We subsequently tailor this generic prompt optimizer into a specialized solver that promotes the generation of minority features by incorporating a carefully-crafted likelihood objective. Our comprehensive experiments, conducted across various types of T2I models, demonstrate that our approach significantly enhances the capability to produce high-quality minority instances compared to existing samplers.
+
+
+
+ 60. 【2410.07834】Multi-Scale Deformable Transformers for Student Learning Behavior Detection in Smart Classroom
+ 链接:https://arxiv.org/abs/2410.07834
+ 作者:Zhifeng Wang,Minghui Wang,Chunyan Zeng,Longlong Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Artificial Intelligence, modern educational system, task traditionally dependent, integration of Artificial, rapidly evolving
+ 备注: 19 Pages
+
+ 点击查看摘要
+ Abstract:The integration of Artificial Intelligence into the modern educational system is rapidly evolving, particularly in monitoring student behavior in classrooms, a task traditionally dependent on manual observation. This conventional method is notably inefficient, prompting a shift toward more advanced solutions like computer vision. However, existing target detection models face significant challenges such as occlusion, blurring, and scale disparity, which are exacerbated by the dynamic and complex nature of classroom settings. Furthermore, these models must adeptly handle multiple target detection. To overcome these obstacles, we introduce the Student Learning Behavior Detection with Multi-Scale Deformable Transformers (SCB-DETR), an innovative approach that utilizes large convolutional kernels for upstream feature extraction, and multi-scale feature fusion. This technique significantly improves the detection capabilities for multi-scale and occluded targets, offering a robust solution for analyzing student behavior. SCB-DETR establishes an end-to-end framework that simplifies the detection process and consistently outperforms other deep learning methods. Employing our custom Student Classroom Behavior (SCBehavior) Dataset, SCB-DETR achieves a mean Average Precision (mAP) of 0.626, which is a 1.5% improvement over the baseline model's mAP and a 6% increase in AP50. These results demonstrate SCB-DETR's superior performance in handling the uneven distribution of student behaviors and ensuring precise detection in dynamic classroom environments.
+
+
+
+ 61. 【2410.07832】LaB-CL: Localized and Balanced Contrastive Learning for improving parking slot detection
+ 链接:https://arxiv.org/abs/2410.07832
+ 作者:U Jin Jeong,Sumin Roh,Il Yong Chun
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Robotics (cs.RO)
+ 关键词:Parking slot detection, Parking slot, slot detection, autonomous parking systems, slot
+ 备注: 7 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:Parking slot detection is an essential technology in autonomous parking systems. In general, the classification problem of parking slot detection consists of two tasks, a task determining whether localized candidates are junctions of parking slots or not, and the other that identifies a shape of detected junctions. Both classification tasks can easily face biased learning toward the majority class, degrading classification performances. Yet, the data imbalance issue has been overlooked in parking slot detection. We propose the first supervised contrastive learning framework for parking slot detection, Localized and Balanced Contrastive Learning for improving parking slot detection (LaB-CL). The proposed LaB-CL framework uses two main approaches. First, we propose to include class prototypes to consider representations from all classes in every mini batch, from the local perspective. Second, we propose a new hard negative sampling scheme that selects local representations with high prediction error. Experiments with the benchmark dataset demonstrate that the proposed LaB-CL framework can outperform existing parking slot detection methods.
+
+
+
+ 62. 【2410.07824】Exploring Foundation Models in Remote Sensing Image Change Detection: A Comprehensive Survey
+ 链接:https://arxiv.org/abs/2410.07824
+ 作者:Zihan Yu,Tianxiao Li,Yuxin Zhu,Rongze Pan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:URL recent years, http URL recent, widely applied technique, http URL, URL recent
+ 备注: 14 pages
+
+ 点击查看摘要
+ Abstract:Change detection, as an important and widely applied technique in the field of remote sensing, aims to analyze changes in surface areas over time and has broad applications in areas such as environmental monitoring, urban development, and land use this http URL recent years, deep learning, especially the development of foundation models, has provided more powerful solutions for feature extraction and data fusion, effectively addressing these complexities. This paper systematically reviews the latest advancements in the field of change detection, with a focus on the application of foundation models in remote sensing tasks.
+
+
+
+ 63. 【2410.07815】Simple ReFlow: Improved Techniques for Fast Flow Models
+ 链接:https://arxiv.org/abs/2410.07815
+ 作者:Beomsu Kim,Yu-Guan Hsieh,Michal Klein,Marco Cuturi,Jong Chul Ye,Bahjat Kawar,James Thornton
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:remarkable generative performance, Diffusion and flow-matching, flow-matching models achieve, models achieve remarkable, achieve remarkable generative
+ 备注:
+
+ 点击查看摘要
+ Abstract:Diffusion and flow-matching models achieve remarkable generative performance but at the cost of many sampling steps, this slows inference and limits applicability to time-critical tasks. The ReFlow procedure can accelerate sampling by straightening generation trajectories. However, ReFlow is an iterative procedure, typically requiring training on simulated data, and results in reduced sample quality. To mitigate sample deterioration, we examine the design space of ReFlow and highlight potential pitfalls in prior heuristic practices. We then propose seven improvements for training dynamics, learning and inference, which are verified with thorough ablation studies on CIFAR10 $32 \times 32$, AFHQv2 $64 \times 64$, and FFHQ $64 \times 64$. Combining all our techniques, we achieve state-of-the-art FID scores (without / with guidance, resp.) for fast generation via neural ODEs: $2.23$ / $1.98$ on CIFAR10, $2.30$ / $1.91$ on AFHQv2, $2.84$ / $2.67$ on FFHQ, and $3.49$ / $1.74$ on ImageNet-64, all with merely $9$ neural function evaluations.
+
+
+
+ 64. 【2410.07801】Robotic framework for autonomous manipulation of laboratory equipment with different degrees of transparency via 6D pose estimation
+ 链接:https://arxiv.org/abs/2410.07801
+ 作者:Maria Makarova,Daria Trinitatova,Dzmitry Tsetserukou
+ 类目:Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV); Software Engineering (cs.SE); Systems and Control (eess.SY)
+ 关键词:changing external conditions, special operator skills, require special operator, systems operate autonomously, modern robotic systems
+ 备注: Accepted to the 2024 IEEE International Conference on Robotics and Biomimetics (IEEE ROBIO 2024), 8 pages, 11 figures
+
+ 点击查看摘要
+ Abstract:Many modern robotic systems operate autonomously, however they often lack the ability to accurately analyze the environment and adapt to changing external conditions, while teleoperation systems often require special operator skills. In the field of laboratory automation, the number of automated processes is growing, however such systems are usually developed to perform specific tasks. In addition, many of the objects used in this field are transparent, making it difficult to analyze them using visual channels. The contributions of this work include the development of a robotic framework with autonomous mode for manipulating liquid-filled objects with different degrees of transparency in complex pose combinations. The conducted experiments demonstrated the robustness of the designed visual perception system to accurately estimate object poses for autonomous manipulation, and confirmed the performance of the algorithms in dexterous operations such as liquid dispensing. The proposed robotic framework can be applied for laboratory automation, since it allows solving the problem of performing non-trivial manipulation tasks with the analysis of object poses of varying degrees of transparency and liquid levels, requiring high accuracy and repeatability.
+
+
+
+ 65. 【2410.07795】Optimal-State Dynamics Estimation for Physics-based Human Motion Capture from Videos
+ 链接:https://arxiv.org/abs/2410.07795
+ 作者:Cuong Le,Viktor Johansson,Manon Kok,Bastian Wandt
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:made significant progress, recent years, capture from monocular, monocular videos, videos has made
+ 备注: 16 pages, 7 figure, accepted to NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:Human motion capture from monocular videos has made significant progress in recent years. However, modern approaches often produce temporal artifacts, e.g. in form of jittery motion and struggle to achieve smooth and physically plausible motions. Explicitly integrating physics, in form of internal forces and exterior torques, helps alleviating these artifacts. Current state-of-the-art approaches make use of an automatic PD controller to predict torques and reaction forces in order to re-simulate the input kinematics, i.e. the joint angles of a predefined skeleton. However, due to imperfect physical models, these methods often require simplifying assumptions and extensive preprocessing of the input kinematics to achieve good performance. To this end, we propose a novel method to selectively incorporate the physics models with the kinematics observations in an online setting, inspired by a neural Kalman-filtering approach. We develop a control loop as a meta-PD controller to predict internal joint torques and external reaction forces, followed by a physics-based motion simulation. A recurrent neural network is introduced to realize a Kalman filter that attentively balances the kinematics input and simulated motion, resulting in an optimal-state dynamics prediction. We show that this filtering step is crucial to provide an online supervision that helps balancing the shortcoming of the respective input motions, thus being important for not only capturing accurate global motion trajectories but also producing physically plausible human poses. The proposed approach excels in the physics-based human pose estimation task and demonstrates the physical plausibility of the predictive dynamics, compared to state of the art. The code is available on this https URL
+
+
+
+ 66. 【2410.07790】Enhancing Hyperspectral Image Prediction with Contrastive Learning in Low-Label Regime
+ 链接:https://arxiv.org/abs/2410.07790
+ 作者:Salma Haidar,José Oramas
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Self-supervised contrastive learning, Self-supervised contrastive, limited labelled data, addressing the challenge, challenge of limited
+ 备注:
+
+ 点击查看摘要
+ Abstract:Self-supervised contrastive learning is an effective approach for addressing the challenge of limited labelled data. This study builds upon the previously established two-stage patch-level, multi-label classification method for hyperspectral remote sensing imagery. We evaluate the method's performance for both the single-label and multi-label classification tasks, particularly under scenarios of limited training data. The methodology unfolds in two stages. Initially, we focus on training an encoder and a projection network using a contrastive learning approach. This step is crucial for enhancing the ability of the encoder to discern patterns within the unlabelled data. Next, we employ the pre-trained encoder to guide the training of two distinct predictors: one for multi-label and another for single-label classification. Empirical results on four public datasets show that the predictors trained with our method perform better than those trained under fully supervised techniques. Notably, the performance is maintained even when the amount of training data is reduced by $50\%$. This advantage is consistent across both tasks. The method's effectiveness comes from its streamlined architecture. This design allows for retraining the encoder along with the predictor. As a result, the encoder becomes more adaptable to the features identified by the classifier, improving the overall classification performance. Qualitative analysis reveals the contrastive-learning-based encoder's capability to provide representations that allow separation among classes and identify location-based features despite not being explicitly trained for that. This observation indicates the method's potential in uncovering implicit spatial information within the data.
+
+
+
+ 67. 【2410.07783】CLIP Multi-modal Hashing for Multimedia Retrieval
+ 链接:https://arxiv.org/abs/2410.07783
+ 作者:Jian Zhu,Mingkai Sheng,Zhangmin Huang,Jingfei Chang,Jinling Jiang,Jian Long,Cheng Luo,Lei Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Multi-modal hashing methods, Multi-modal hashing, CLIP Multi-modal Hashing, binary hash code, hashing methods
+ 备注: Accepted by 31st International Conference on MultiMedia Modeling (MMM2025)
+
+ 点击查看摘要
+ Abstract:Multi-modal hashing methods are widely used in multimedia retrieval, which can fuse multi-source data to generate binary hash code. However, the individual backbone networks have limited feature expression capabilities and are not jointly pre-trained on large-scale unsupervised multi-modal data, resulting in low retrieval accuracy. To address this issue, we propose a novel CLIP Multi-modal Hashing (CLIPMH) method. Our method employs the CLIP framework to extract both text and vision features and then fuses them to generate hash code. Due to enhancement on each modal feature, our method has great improvement in the retrieval performance of multi-modal hashing methods. Compared with state-of-the-art unsupervised and supervised multi-modal hashing methods, experiments reveal that the proposed CLIPMH can significantly improve performance (a maximum increase of 8.38% in mAP).
+
+
+
+ 68. 【2410.07780】Neural Semantic Map-Learning for Autonomous Vehicles
+ 链接:https://arxiv.org/abs/2410.07780
+ 作者:Markus Herb,Nassir Navab,Federico Tombari
+ 类目:Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:demand detailed maps, vehicles demand detailed, Autonomous vehicles demand, reliably through traffic, safe operation
+ 备注: Accepted at 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2024)
+
+ 点击查看摘要
+ Abstract:Autonomous vehicles demand detailed maps to maneuver reliably through traffic, which need to be kept up-to-date to ensure a safe operation. A promising way to adapt the maps to the ever-changing road-network is to use crowd-sourced data from a fleet of vehicles. In this work, we present a mapping system that fuses local submaps gathered from a fleet of vehicles at a central instance to produce a coherent map of the road environment including drivable area, lane markings, poles, obstacles and more as a 3D mesh. Each vehicle contributes locally reconstructed submaps as lightweight meshes, making our method applicable to a wide range of reconstruction methods and sensor modalities. Our method jointly aligns and merges the noisy and incomplete local submaps using a scene-specific Neural Signed Distance Field, which is supervised using the submap meshes to predict a fused environment representation. We leverage memory-efficient sparse feature-grids to scale to large areas and introduce a confidence score to model uncertainty in scene reconstruction. Our approach is evaluated on two datasets with different local mapping methods, showing improved pose alignment and reconstruction over existing methods. Additionally, we demonstrate the benefit of multi-session mapping and examine the required amount of data to enable high-fidelity map learning for autonomous vehicles.
+
+
+
+ 69. 【2410.07771】Full-Rank No More: Low-Rank Weight Training for Modern Speech Recognition Models
+ 链接:https://arxiv.org/abs/2410.07771
+ 作者:Adriana Fernandez-Lopez,Shiwei Liu,Lu Yin,Stavros Petridis,Maja Pantic
+ 类目:ound (cs.SD); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Audio and Speech Processing (eess.AS)
+ 关键词:Conformer-based speech recognition, large-scale Conformer-based speech, large-scale Conformer-based, speech recognition models, Conformer-based speech
+ 备注: Submitted to ICASSP 2025
+
+ 点击查看摘要
+ Abstract:This paper investigates the under-explored area of low-rank weight training for large-scale Conformer-based speech recognition models from scratch. Our study demonstrates the viability of this training paradigm for such models, yielding several notable findings. Firstly, we discover that applying a low-rank structure exclusively to the attention modules can unexpectedly enhance performance, even with a significant rank reduction of 12%. In contrast, feed-forward layers present greater challenges, as they begin to exhibit performance degradation with a moderate 50% rank reduction. Furthermore, we find that both initialization and layer-wise rank assignment play critical roles in successful low-rank training. Specifically, employing SVD initialization and linear layer-wise rank mapping significantly boosts the efficacy of low-rank weight training. Building on these insights, we introduce the Low-Rank Speech Model from Scratch (LR-SMS), an approach that achieves performance parity with full-rank training while delivering substantial reductions in parameters count (by at least 2x), and training time speedups (by 1.3x for ASR and 1.15x for AVSR).
+
+
+
+ 70. 【2410.07763】HARIVO: Harnessing Text-to-Image Models for Video Generation
+ 链接:https://arxiv.org/abs/2410.07763
+ 作者:Mingi Kwon,Seoung Wug Oh,Yang Zhou,Difan Liu,Joon-Young Lee,Haoran Cai,Baqiao Liu,Feng Liu,Youngjung Uh
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:create diffusion-based video, create diffusion-based, diffusion-based video models, diffusion-based video, video
+ 备注: ECCV2024
+
+ 点击查看摘要
+ Abstract:We present a method to create diffusion-based video models from pretrained Text-to-Image (T2I) models. Recently, AnimateDiff proposed freezing the T2I model while only training temporal layers. We advance this method by proposing a unique architecture, incorporating a mapping network and frame-wise tokens, tailored for video generation while maintaining the diversity and creativity of the original T2I model. Key innovations include novel loss functions for temporal smoothness and a mitigating gradient sampling technique, ensuring realistic and temporally consistent video generation despite limited public video data. We have successfully integrated video-specific inductive biases into the architecture and loss functions. Our method, built on the frozen StableDiffusion model, simplifies training processes and allows for seamless integration with off-the-shelf models like ControlNet and DreamBooth. project page: this https URL
+
+
+
+ 71. 【2410.07761】$\textit{Jump Your Steps}$: Optimizing Sampling Schedule of Discrete Diffusion Models
+ 链接:https://arxiv.org/abs/2410.07761
+ 作者:Yong-Hyun Park,Chieh-Hsin Lai,Satoshi Hayakawa,Yuhta Takida,Yuki Mitsufuji
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:discrete diffusion models, Diffusion models, Compounding Decoding Error, continuous domains, notable success
+ 备注:
+
+ 点击查看摘要
+ Abstract:Diffusion models have seen notable success in continuous domains, leading to the development of discrete diffusion models (DDMs) for discrete variables. Despite recent advances, DDMs face the challenge of slow sampling speeds. While parallel sampling methods like $\tau$-leaping accelerate this process, they introduce $\textit{Compounding Decoding Error}$ (CDE), where discrepancies arise between the true distribution and the approximation from parallel token generation, leading to degraded sample quality. In this work, we present $\textit{Jump Your Steps}$ (JYS), a novel approach that optimizes the allocation of discrete sampling timesteps by minimizing CDE without extra computational cost. More precisely, we derive a practical upper bound on CDE and propose an efficient algorithm for searching for the optimal sampling schedule. Extensive experiments across image, music, and text generation show that JYS significantly improves sampling quality, establishing it as a versatile framework for enhancing DDM performance for fast sampling.
+
+
+
+ 72. 【2410.07758】HeightFormer: A Semantic Alignment Monocular 3D Object Detection Method from Roadside Perspective
+ 链接:https://arxiv.org/abs/2410.07758
+ 作者:Pei Liu(1),Zihao Zhang(2),Haipeng Liu(3),Nanfang Zheng(4),Meixin Zhu(1),Ziyuan Pu(4) ((1) Intelligent Transportation Thrust, Systems Hub, The Hong Kong University of Science and Technology (Guangzhou), (2) School of Cyber Science and Engineering, Southeast University, (3) Li Auto Inc, (4) School of Transportation, Southeast University)
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:received extensive attention, applying roadside sensors, object detection technology, traffic object detection, critical technology
+ 备注:
+
+ 点击查看摘要
+ Abstract:The on-board 3D object detection technology has received extensive attention as a critical technology for autonomous driving, while few studies have focused on applying roadside sensors in 3D traffic object detection. Existing studies achieve the projection of 2D image features to 3D features through height estimation based on the frustum. However, they did not consider the height alignment and the extraction efficiency of bird's-eye-view features. We propose a novel 3D object detection framework integrating Spatial Former and Voxel Pooling Former to enhance 2D-to-3D projection based on height estimation. Extensive experiments were conducted using the Rope3D and DAIR-V2X-I dataset, and the results demonstrated the outperformance of the proposed algorithm in the detection of both vehicles and cyclists. These results indicate that the algorithm is robust and generalized under various detection scenarios. Improving the accuracy of 3D object detection on the roadside is conducive to building a safe and trustworthy intelligent transportation system of vehicle-road coordination and promoting the large-scale application of autonomous driving. The code and pre-trained models will be released on this https URL.
+
+
+
+ 73. 【2410.07757】MMHead: Towards Fine-grained Multi-modal 3D Facial Animation
+ 链接:https://arxiv.org/abs/2410.07757
+ 作者:Sijing Wu,Yunhao Li,Yichao Yan,Huiyu Duan,Ziwei Liu,Guangtao Zhai
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:attracted considerable attention, facial animation, considerable attention due, facial, animation
+ 备注: Accepted by ACMMM 2024. Project page: [this https URL](https://wsj-sjtu.github.io/MMHead/)
+
+ 点击查看摘要
+ Abstract:3D facial animation has attracted considerable attention due to its extensive applications in the multimedia field. Audio-driven 3D facial animation has been widely explored with promising results. However, multi-modal 3D facial animation, especially text-guided 3D facial animation is rarely explored due to the lack of multi-modal 3D facial animation dataset. To fill this gap, we first construct a large-scale multi-modal 3D facial animation dataset, MMHead, which consists of 49 hours of 3D facial motion sequences, speech audios, and rich hierarchical text annotations. Each text annotation contains abstract action and emotion descriptions, fine-grained facial and head movements (i.e., expression and head pose) descriptions, and three possible scenarios that may cause such emotion. Concretely, we integrate five public 2D portrait video datasets, and propose an automatic pipeline to 1) reconstruct 3D facial motion sequences from monocular videos; and 2) obtain hierarchical text annotations with the help of AU detection and ChatGPT. Based on the MMHead dataset, we establish benchmarks for two new tasks: text-induced 3D talking head animation and text-to-3D facial motion generation. Moreover, a simple but efficient VQ-VAE-based method named MM2Face is proposed to unify the multi-modal information and generate diverse and plausible 3D facial motions, which achieves competitive results on both benchmarks. Extensive experiments and comprehensive analysis demonstrate the significant potential of our dataset and benchmarks in promoting the development of multi-modal 3D facial animation.
+
+
+
+ 74. 【2410.07753】Synthesizing Multi-Class Surgical Datasets with Anatomy-Aware Diffusion Models
+ 链接:https://arxiv.org/abs/2410.07753
+ 作者:Danush Kumar Venkatesh,Dominik Rivoir,Micha Pfeiffer,Fiona Kolbinger,Stefanie Speidel
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:providing intraoperative assistance, automatically recognizing anatomical, computer-assisted surgery, automatically recognizing, intraoperative assistance
+ 备注:
+
+ 点击查看摘要
+ Abstract:In computer-assisted surgery, automatically recognizing anatomical organs is crucial for understanding the surgical scene and providing intraoperative assistance. While machine learning models can identify such structures, their deployment is hindered by the need for labeled, diverse surgical datasets with anatomical annotations. Labeling multiple classes (i.e., organs) in a surgical scene is time-intensive, requiring medical experts. Although synthetically generated images can enhance segmentation performance, maintaining both organ structure and texture during generation is challenging. We introduce a multi-stage approach using diffusion models to generate multi-class surgical datasets with annotations. Our framework improves anatomy awareness by training organ specific models with an inpainting objective guided by binary segmentation masks. The organs are generated with an inference pipeline using pre-trained ControlNet to maintain the organ structure. The synthetic multi-class datasets are constructed through an image composition step, ensuring structural and textural consistency. This versatile approach allows the generation of multi-class datasets from real binary datasets and simulated surgical masks. We thoroughly evaluate the generated datasets on image quality and downstream segmentation, achieving a $15\%$ improvement in segmentation scores when combined with real images. Our codebase this https URL
+
+
+
+ 75. 【2410.07752】VBench: Redesigning Video-Language Evaluation
+ 链接:https://arxiv.org/abs/2410.07752
+ 作者:Daniel Cores,Michael Dorkenwald,Manuel Mucientes,Cees G. M. Snoek,Yuki M. Asano
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Large language models, Large language, demonstrated impressive performance, demonstrated impressive, integrated with vision
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models have demonstrated impressive performance when integrated with vision models even enabling video understanding. However, evaluating these video models presents its own unique challenges, for which several benchmarks have been proposed. In this paper, we show that the currently most used video-language benchmarks can be solved without requiring much temporal reasoning. We identified three main issues in existing datasets: (i) static information from single frames is often sufficient to solve the tasks (ii) the text of the questions and candidate answers is overly informative, allowing models to answer correctly without relying on any visual input (iii) world knowledge alone can answer many of the questions, making the benchmarks a test of knowledge replication rather than visual reasoning. In addition, we found that open-ended question-answering benchmarks for video understanding suffer from similar issues while the automatic evaluation process with LLMs is unreliable, making it an unsuitable alternative. As a solution, we propose TVBench, a novel open-source video multiple-choice question-answering benchmark, and demonstrate through extensive evaluations that it requires a high level of temporal understanding. Surprisingly, we find that most recent state-of-the-art video-language models perform similarly to random performance on TVBench, with only Gemini-Pro and Tarsier clearly surpassing this baseline.
+
+
+
+ 76. 【2410.07733】MGMapNet: Multi-Granularity Representation Learning for End-to-End Vectorized HD Map Construction
+ 链接:https://arxiv.org/abs/2410.07733
+ 作者:Jing Yang,Minyue Jiang,Sen Yang,Xiao Tan,Yingying Li,Errui Ding,Hanli Wang,Jingdong Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:typically requires capturing, Vectorized High-Definition, construction of Vectorized, map typically requires, typically requires
+ 备注:
+
+ 点击查看摘要
+ Abstract:The construction of Vectorized High-Definition (HD) map typically requires capturing both category and geometry information of map elements. Current state-of-the-art methods often adopt solely either point-level or instance-level representation, overlooking the strong intrinsic relationships between points and instances. In this work, we propose a simple yet efficient framework named MGMapNet (Multi-Granularity Map Network) to model map element with a multi-granularity representation, integrating both coarse-grained instance-level and fine-grained point-level queries. Specifically, these two granularities of queries are generated from the multi-scale bird's eye view (BEV) features using a proposed Multi-Granularity Aggregator. In this module, instance-level query aggregates features over the entire scope covered by an instance, and the point-level query aggregates features locally. Furthermore, a Point Instance Interaction module is designed to encourage information exchange between instance-level and point-level queries. Experimental results demonstrate that the proposed MGMapNet achieves state-of-the-art performance, surpassing MapTRv2 by 5.3 mAP on nuScenes and 4.4 mAP on Argoverse2 respectively.
+
+
+
+ 77. 【2410.07718】Hallo2: Long-Duration and High-Resolution Audio-Driven Portrait Image Animation
+ 链接:https://arxiv.org/abs/2410.07718
+ 作者:Jiahao Cui,Hui Li,Yao Yao,Hao Zhu,Hanlin Shang,Kaihui Cheng,Hang Zhou,Siyu Zhu,Jingdong Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:diffusion-based generative models, Recent advances, latent diffusion-based generative, achieved impressive results, diffusion-based generative
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advances in latent diffusion-based generative models for portrait image animation, such as Hallo, have achieved impressive results in short-duration video synthesis. In this paper, we present updates to Hallo, introducing several design enhancements to extend its capabilities. First, we extend the method to produce long-duration videos. To address substantial challenges such as appearance drift and temporal artifacts, we investigate augmentation strategies within the image space of conditional motion frames. Specifically, we introduce a patch-drop technique augmented with Gaussian noise to enhance visual consistency and temporal coherence over long duration. Second, we achieve 4K resolution portrait video generation. To accomplish this, we implement vector quantization of latent codes and apply temporal alignment techniques to maintain coherence across the temporal dimension. By integrating a high-quality decoder, we realize visual synthesis at 4K resolution. Third, we incorporate adjustable semantic textual labels for portrait expressions as conditional inputs. This extends beyond traditional audio cues to improve controllability and increase the diversity of the generated content. To the best of our knowledge, Hallo2, proposed in this paper, is the first method to achieve 4K resolution and generate hour-long, audio-driven portrait image animations enhanced with textual prompts. We have conducted extensive experiments to evaluate our method on publicly available datasets, including HDTF, CelebV, and our introduced "Wild" dataset. The experimental results demonstrate that our approach achieves state-of-the-art performance in long-duration portrait video animation, successfully generating rich and controllable content at 4K resolution for duration extending up to tens of minutes. Project page this https URL
+
+
+
+ 78. 【2410.07707】MotionGS: Exploring Explicit Motion Guidance for Deformable 3D Gaussian Splatting
+ 链接:https://arxiv.org/abs/2410.07707
+ 作者:Ruijie Zhu,Yanzhe Liang,Hanzhi Chang,Jiacheng Deng,Jiahao Lu,Wenfei Yang,Tianzhu Zhang,Yongdong Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR); Machine Learning (cs.LG)
+ 关键词:Gaussian Splatting, Dynamic scene reconstruction, long-term challenge, Gaussian splatting framework, Gaussian
+ 备注: Accepted by NeurIPS 2024. 21 pages, 14 figures,7 tables
+
+ 点击查看摘要
+ Abstract:Dynamic scene reconstruction is a long-term challenge in the field of 3D vision. Recently, the emergence of 3D Gaussian Splatting has provided new insights into this problem. Although subsequent efforts rapidly extend static 3D Gaussian to dynamic scenes, they often lack explicit constraints on object motion, leading to optimization difficulties and performance degradation. To address the above issues, we propose a novel deformable 3D Gaussian splatting framework called MotionGS, which explores explicit motion priors to guide the deformation of 3D Gaussians. Specifically, we first introduce an optical flow decoupling module that decouples optical flow into camera flow and motion flow, corresponding to camera movement and object motion respectively. Then the motion flow can effectively constrain the deformation of 3D Gaussians, thus simulating the motion of dynamic objects. Additionally, a camera pose refinement module is proposed to alternately optimize 3D Gaussians and camera poses, mitigating the impact of inaccurate camera poses. Extensive experiments in the monocular dynamic scenes validate that MotionGS surpasses state-of-the-art methods and exhibits significant superiority in both qualitative and quantitative results. Project page: this https URL
+
+
+
+ 79. 【2410.07695】st-Time Intensity Consistency Adaptation for Shadow Detection
+ 链接:https://arxiv.org/abs/2410.07695
+ 作者:Leyi Zhu,Weihuang Liu,Xinyi Chen,Zimeng Li,Xuhang Chen,Zhen Wang,Chi-Man Pun
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:accurate scene understanding, object geometry, scene context, computer vision, variations in illumination
+ 备注: 15 pages, 5 figures, published to ICONIP 2024
+
+ 点击查看摘要
+ Abstract:Shadow detection is crucial for accurate scene understanding in computer vision, yet it is challenged by the diverse appearances of shadows caused by variations in illumination, object geometry, and scene context. Deep learning models often struggle to generalize to real-world images due to the limited size and diversity of training datasets. To address this, we introduce TICA, a novel framework that leverages light-intensity information during test-time adaptation to enhance shadow detection accuracy. TICA exploits the inherent inconsistencies in light intensity across shadow regions to guide the model toward a more consistent prediction. A basic encoder-decoder model is initially trained on a labeled dataset for shadow detection. Then, during the testing phase, the network is adjusted for each test sample by enforcing consistent intensity predictions between two augmented input image versions. This consistency training specifically targets both foreground and background intersection regions to identify shadow regions within images accurately for robust adaptation. Extensive evaluations on the ISTD and SBU shadow detection datasets reveal that TICA significantly demonstrates that TICA outperforms existing state-of-the-art methods, achieving superior results in balanced error rate (BER).
+
+
+
+ 80. 【2410.07691】Growing Efficient Accurate and Robust Neural Networks on the Edge
+ 链接:https://arxiv.org/abs/2410.07691
+ 作者:Vignesh Sundaresha,Naresh Shanbhag
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:occurring common corruptions, deep learning systems, computational complexity coupled, naturally occurring common, resource-constrained Edge devices
+ 备注: 10 pages
+
+ 点击查看摘要
+ Abstract:The ubiquitous deployment of deep learning systems on resource-constrained Edge devices is hindered by their high computational complexity coupled with their fragility to out-of-distribution (OOD) data, especially to naturally occurring common corruptions. Current solutions rely on the Cloud to train and compress models before deploying to the Edge. This incurs high energy and latency costs in transmitting locally acquired field data to the Cloud while also raising privacy concerns. We propose GEARnn (Growing Efficient, Accurate, and Robust neural networks) to grow and train robust networks in-situ, i.e., completely on the Edge device. Starting with a low-complexity initial backbone network, GEARnn employs One-Shot Growth (OSG) to grow a network satisfying the memory constraints of the Edge device using clean data, and robustifies the network using Efficient Robust Augmentation (ERA) to obtain the final network. We demonstrate results on a NVIDIA Jetson Xavier NX, and analyze the trade-offs between accuracy, robustness, model size, energy consumption, and training time. Our results demonstrate the construction of efficient, accurate, and robust networks entirely on an Edge device.
+
+
+
+ 81. 【2410.07689】When the Small-Loss Trick is Not Enough: Multi-Label Image Classification with Noisy Labels Applied to CCTV Sewer Inspections
+ 链接:https://arxiv.org/abs/2410.07689
+ 作者:Keryan Chelouche,Marie Lachaize(VERI),Marine Bernard(VERI),Louise Olgiati,Remi Cuingnet
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:efficient Closed-Circuit Television, Closed-Circuit Television, label noise, sewerage networks, heavily relies
+ 备注:
+
+ 点击查看摘要
+ Abstract:The maintenance of sewerage networks, with their millions of kilometers of pipe, heavily relies on efficient Closed-Circuit Television (CCTV) inspections. Many promising approaches based on multi-label image classification have leveraged databases of historical inspection reports to automate these inspections. However, the significant presence of label noise in these databases, although known, has not been addressed. While extensive research has explored the issue of label noise in singlelabel classification (SLC), little attention has been paid to label noise in multi-label classification (MLC). To address this, we first adapted three sample selection SLC methods (Co-teaching, CoSELFIE, and DISC) that have proven robust to label noise. Our findings revealed that sample selection based solely on the small-loss trick can handle complex label noise, but it is sub-optimal. Adapting hybrid sample selection methods to noisy MLC appeared to be a more promising approach. In light of this, we developed a novel method named MHSS (Multi-label Hybrid Sample Selection) based on CoSELFIE. Through an in-depth comparative study, we demonstrated the superior performance of our approach in dealing with both synthetic complex noise and real noise, thus contributing to the ongoing efforts towards effective automation of CCTV sewer pipe inspections.
+
+
+
+ 82. 【2410.07688】PokeFlex: A Real-World Dataset of Deformable Objects for Robotics
+ 链接:https://arxiv.org/abs/2410.07688
+ 作者:Jan Obrist,Miguel Zamora,Hehui Zheng,Ronan Hinchet,Firat Ozdemir,Juan Zarate,Robert K. Katzschmann,Stelian Coros
+ 类目:Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:shown great potential, solving challenging manipulation, challenging manipulation tasks, Data-driven methods, shown great
+ 备注:
+
+ 点击查看摘要
+ Abstract:Data-driven methods have shown great potential in solving challenging manipulation tasks, however, their application in the domain of deformable objects has been constrained, in part, by the lack of data. To address this, we propose PokeFlex, a dataset featuring real-world paired and annotated multimodal data that includes 3D textured meshes, point clouds, RGB images, and depth maps. Such data can be leveraged for several downstream tasks such as online 3D mesh reconstruction, and it can potentially enable underexplored applications such as the real-world deployment of traditional control methods based on mesh simulations. To deal with the challenges posed by real-world 3D mesh reconstruction, we leverage a professional volumetric capture system that allows complete 360° reconstruction. PokeFlex consists of 18 deformable objects with varying stiffness and shapes. Deformations are generated by dropping objects onto a flat surface or by poking the objects with a robot arm. Interaction forces and torques are also reported for the latter case. Using different data modalities, we demonstrated a use case for the PokeFlex dataset in online 3D mesh reconstruction. We refer the reader to our website ( this https URL ) for demos and examples of our dataset.
+
+
+
+ 83. 【2410.07679】Relational Diffusion Distillation for Efficient Image Generation
+ 链接:https://arxiv.org/abs/2410.07679
+ 作者:Weilun Feng,Chuanguang Yang,Zhulin An,Libo Huang,Boyu Diao,Fei Wang,Yongjun Xu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:scarce computing resources, high inference delay, inference delay hinders, achieved remarkable performance, image generation
+ 备注:
+
+ 点击查看摘要
+ Abstract:Although the diffusion model has achieved remarkable performance in the field of image generation, its high inference delay hinders its wide application in edge devices with scarce computing resources. Therefore, many training-free sampling methods have been proposed to reduce the number of sampling steps required for diffusion models. However, they perform poorly under a very small number of sampling steps. Thanks to the emergence of knowledge distillation technology, the existing training scheme methods have achieved excellent results at very low step numbers. However, the current methods mainly focus on designing novel diffusion model sampling methods with knowledge distillation. How to transfer better diffusion knowledge from teacher models is a more valuable problem but rarely studied. Therefore, we propose Relational Diffusion Distillation (RDD), a novel distillation method tailored specifically for distilling diffusion models. Unlike existing methods that simply align teacher and student models at pixel level or feature distributions, our method introduces cross-sample relationship interaction during the distillation process and alleviates the memory constraints induced by multiple sample interactions. Our RDD significantly enhances the effectiveness of the progressive distillation framework within the diffusion model. Extensive experiments on several datasets (e.g., CIFAR-10 and ImageNet) demonstrate that our proposed RDD leads to 1.47 FID decrease under 1 sampling step compared to state-of-the-art diffusion distillation methods and achieving 256x speed-up compared to DDIM strategy. Code is available at this https URL.
+
+
+
+ 84. 【2410.07669】Delta-ICM: Entropy Modeling with Delta Function for Learned Image Compression
+ 链接:https://arxiv.org/abs/2410.07669
+ 作者:Takahiro Shindo,Taiju Watanabe,Yui Tatsumi,Hiroshi Watanabe
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:Image Coding, ICM, Image, computer vision progresses, Coding for Machines
+ 备注:
+
+ 点击查看摘要
+ Abstract:Image Coding for Machines (ICM) is becoming more important as research in computer vision progresses. ICM is a vital research field that pursues the use of images for image recognition models, facilitating efficient image transmission and storage. The demand for recognition models is growing rapidly among the general public, and their performance continues to improve. To meet these needs, exchanging image data between consumer devices and cloud AI using ICM technology could be one possible solution. In ICM, various image compression methods have adopted Learned Image Compression (LIC). LIC includes an entropy model for estimating the bitrate of latent features, and the design of this model significantly affects its performance. Typically, LIC methods assume that the distribution of latent features follows a normal distribution. This assumption is effective for compressing images intended for human vision. However, employing an entropy model based on normal distribution is inefficient in ICM due to the limitation of image parts that require precise decoding. To address this, we propose Delta-ICM, which uses a probability distribution based on a delta function. Assuming the delta distribution as a distribution of latent features reduces the entropy of image portions unnecessary for machines. We compress the remaining portions using an entropy model based on normal distribution, similar to existing methods. Delta-ICM selects between the entropy model based on the delta distribution and the one based on the normal distribution for each latent feature. Our method outperforms existing ICM methods in image compression performance aimed at machines.
+
+
+
+ 85. 【2410.07659】MotionAura: Generating High-Quality and Motion Consistent Videos using Discrete Diffusion
+ 链接:https://arxiv.org/abs/2410.07659
+ 作者:Onkar Susladkar,Jishu Sen Gupta,Chirag Sehgal,Sparsh Mittal,Rekha Singhal
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:presents significant challenges, Vector-Quantization Variational Autoencoder, combines Variational Autoencoders, spatio-temporal complexity, data presents significant
+ 备注: Under submission at a conference
+
+ 点击查看摘要
+ Abstract:The spatio-temporal complexity of video data presents significant challenges in tasks such as compression, generation, and inpainting. We present four key contributions to address the challenges of spatiotemporal video processing. First, we introduce the 3D Mobile Inverted Vector-Quantization Variational Autoencoder (3D-MBQ-VAE), which combines Variational Autoencoders (VAEs) with masked token modeling to enhance spatiotemporal video compression. The model achieves superior temporal consistency and state-of-the-art (SOTA) reconstruction quality by employing a novel training strategy with full frame masking. Second, we present MotionAura, a text-to-video generation framework that utilizes vector-quantized diffusion models to discretize the latent space and capture complex motion dynamics, producing temporally coherent videos aligned with text prompts. Third, we propose a spectral transformer-based denoising network that processes video data in the frequency domain using the Fourier Transform. This method effectively captures global context and long-range dependencies for high-quality video generation and denoising. Lastly, we introduce a downstream task of Sketch Guided Video Inpainting. This task leverages Low-Rank Adaptation (LoRA) for parameter-efficient fine-tuning. Our models achieve SOTA performance on a range of benchmarks. Our work offers robust frameworks for spatiotemporal modeling and user-driven video content manipulation. We will release the code, datasets, and models in open-source.
+
+
+
+ 86. 【2410.07658】SeMv-3D: Towards Semantic and Mutil-view Consistency simultaneously for General Text-to-3D Generation with Triplane Priors
+ 链接:https://arxiv.org/abs/2410.07658
+ 作者:Xiao Cai,Pengpeng Zeng,Lianli Gao,Junchen Zhu,Jiaxin Zhang,Sitong Su,Heng Tao Shen,Jingkuan Song
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Recent advancements, advancements in generic, remarkable by fine-tuning, multi-view consistency, models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advancements in generic 3D content generation from text prompts have been remarkable by fine-tuning text-to-image diffusion (T2I) models or employing these T2I models as priors to learn a general text-to-3D model. While fine-tuning-based methods ensure great alignment between text and generated views, i.e., semantic consistency, their ability to achieve multi-view consistency is hampered by the absence of 3D constraints, even in limited view. In contrast, prior-based methods focus on regressing 3D shapes with any view that maintains uniformity and coherence across views, i.e., multi-view consistency, but such approaches inevitably compromise visual-textual alignment, leading to a loss of semantic details in the generated objects. To achieve semantic and multi-view consistency simultaneously, we propose SeMv-3D, a novel framework for general text-to-3d generation. Specifically, we propose a Triplane Prior Learner (TPL) that learns triplane priors with 3D spatial features to maintain consistency among different views at the 3D level, e.g., geometry and texture. Moreover, we design a Semantic-aligned View Synthesizer (SVS) that preserves the alignment between 3D spatial features and textual semantics in latent space. In SVS, we devise a simple yet effective batch sampling and rendering strategy that can generate arbitrary views in a single feed-forward inference. Extensive experiments present our SeMv-3D's superiority over state-of-the-art performances with semantic and multi-view consistency in any view. Our code and more visual results are available at this https URL.
+
+
+
+ 87. 【2410.07648】FLIER: Few-shot Language Image Models Embedded with Latent Representations
+ 链接:https://arxiv.org/abs/2410.07648
+ 作者:Zhinuo Zhou,Peng Zhou,Xiaoyong Pan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Contrastive Language-Image Pre-training, low-data regimes scenes, Language-Image Pre-training, Contrastive Language-Image, shown impressive abilities
+ 备注: 8 pages,3 figures
+
+ 点击查看摘要
+ Abstract:As the boosting development of large vision-language models like Contrastive Language-Image Pre-training (CLIP), many CLIP-like methods have shown impressive abilities on visual recognition, especially in low-data regimes scenes. However, we have noticed that most of these methods are limited to introducing new modifications on text and image encoder. Recently, latent diffusion models (LDMs) have shown good ability on image generation. The potent capabilities of LDMs direct our focus towards the latent representations sampled by UNet. Inspired by the conjecture in CoOp that learned prompts encode meanings beyond the existing vocabulary, we assume that, for deep models, the latent representations are concise and accurate understanding of images, in which high-frequency, imperceptible details are abstracted away. In this paper, we propose a Few-shot Language Image model Embedded with latent Representations (FLIER) for image recognition by introducing a latent encoder jointly trained with CLIP's image encoder, it incorporates pre-trained vision-language knowledge of CLIP and the latent representations from Stable Diffusion. We first generate images and corresponding latent representations via Stable Diffusion with the textual inputs from GPT-3. With latent representations as "models-understandable pixels", we introduce a flexible convolutional neural network with two convolutional layers to be the latent encoder, which is simpler than most encoders in vision-language models. The latent encoder is jointly trained with CLIP's image encoder, transferring pre-trained knowledge to downstream tasks better. Experiments and extensive ablation studies on various visual classification tasks demonstrate that FLIER performs state-of-the-art on 11 datasets for most few-shot classification.
+
+
+
+ 88. 【2410.07635】Shift and matching queries for video semantic segmentation
+ 链接:https://arxiv.org/abs/2410.07635
+ 作者:Tsubasa Mizuno,Toru Tamaki
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:preserve temporal consistency, applying image segmentation, popular task, temporal consistency, image segmentation models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Video segmentation is a popular task, but applying image segmentation models frame-by-frame to videos does not preserve temporal consistency. In this paper, we propose a method to extend a query-based image segmentation model to video using feature shift and query matching. The method uses a query-based architecture, where decoded queries represent segmentation masks. These queries should be matched before performing the feature shift to ensure that the shifted queries represent the same mask across different frames. Experimental results on CityScapes-VPS and VSPW show significant improvements from the baselines, highlighting the method's effectiveness in enhancing segmentation quality while efficiently reusing pre-trained weights.
+
+
+
+ 89. 【2410.07633】DPL: Cross-quality DeepFake Detection via Dual Progressive Learning
+ 链接:https://arxiv.org/abs/2410.07633
+ 作者:Dongliang Zhang,Yunfei Li,Jiaran Zhou,Yuezun Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Real-world DeepFake videos, Real-world DeepFake, cross-quality DeepFake detection, DeepFake detection, compression operations
+ 备注: ACCV 2024
+
+ 点击查看摘要
+ Abstract:Real-world DeepFake videos often undergo various compression operations, resulting in a range of video qualities. These varying qualities diversify the pattern of forgery traces, significantly increasing the difficulty of DeepFake detection. To address this challenge, we introduce a new Dual Progressive Learning (DPL) framework for cross-quality DeepFake detection. We liken this task to progressively drilling for underground water, where low-quality videos require more effort than high-quality ones. To achieve this, we develop two sequential-based branches to "drill waters" with different efforts. The first branch progressively excavates the forgery traces according to the levels of video quality, i.e., time steps, determined by a dedicated CLIP-based indicator. In this branch, a Feature Selection Module is designed to adaptively assign appropriate features to the corresponding time steps. Considering that different techniques may introduce varying forgery traces within the same video quality, we design a second branch targeting forgery identifiability as complementary. This branch operates similarly and shares the feature selection module with the first branch. Our design takes advantage of the sequential model where computational units share weights across different time steps and can memorize previous progress, elegantly achieving progressive learning while maintaining reasonable memory costs. Extensive experiments demonstrate the superiority of our method for cross-quality DeepFake detection.
+
+
+
+ 90. 【2410.07625】MorCode: Face Morphing Attack Generation using Generative Codebooks
+ 链接:https://arxiv.org/abs/2410.07625
+ 作者:Aravinda Reddy PN,Raghavendra Ramachandra,Sushma Venkatesh,Krothapalli Sreenivasa Rao,Pabitra Mitra,Rakesh Krishna
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Generative Adversarial Networks, multiple facial images, Face recognition systems, morphing generation, face morphing
+ 备注:
+
+ 点击查看摘要
+ Abstract:Face recognition systems (FRS) can be compromised by face morphing attacks, which blend textural and geometric information from multiple facial images. The rapid evolution of generative AI, especially Generative Adversarial Networks (GAN) or Diffusion models, where encoded images are interpolated to generate high-quality face morphing images. In this work, we present a novel method for the automatic face morphing generation method \textit{MorCode}, which leverages a contemporary encoder-decoder architecture conditioned on codebook learning to generate high-quality morphing images. Extensive experiments were performed on the newly constructed morphing dataset using five state-of-the-art morphing generation techniques using both digital and print-scan data. The attack potential of the proposed morphing generation technique, \textit{MorCode}, was benchmarked using three different face recognition systems. The obtained results indicate the highest attack potential of the proposed \textit{MorCode} when compared with five state-of-the-art morphing generation methods on both digital and print scan data.
+
+
+
+ 91. 【2410.07618】Moyun: A Diffusion-Based Model for Style-Specific Chinese Calligraphy Generation
+ 链接:https://arxiv.org/abs/2410.07618
+ 作者:Kaiyuan Liu,Jiahao Mei,Hengyu Zhang,Yihuai Zhang,Xingjiao Wu,Daoguo Dong,Liang He
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Chinese calligraphy generation, achieved style transfer, style remains challenging, character style remains, Chinese calligraphy
+ 备注:
+
+ 点击查看摘要
+ Abstract:Although Chinese calligraphy generation has achieved style transfer, generating calligraphy by specifying the calligrapher, font, and character style remains challenging. To address this, we propose a new Chinese calligraphy generation model 'Moyun' , which replaces the Unet in the Diffusion model with Vision Mamba and introduces the TripleLabel control mechanism to achieve controllable calligraphy generation. The model was tested on our large-scale dataset 'Mobao' of over 1.9 million images, and the results demonstrate that 'Moyun' can effectively control the generation process and produce calligraphy in the specified style. Even for calligraphy the calligrapher has not written, 'Moyun' can generate calligraphy that matches the style of the calligrapher.
+
+
+
+ 92. 【2410.07617】Prototype-based Optimal Transport for Out-of-Distribution Detection
+ 链接:https://arxiv.org/abs/2410.07617
+ 作者:Ao Ke,Wenlong Chen,Chuanwen Feng,Yukun Cao,Xike Xie,S.Kevin Zhou,Lei Feng
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:deep neural networks, OOD, OOD inputs, OOD data, real-world deployment
+ 备注:
+
+ 点击查看摘要
+ Abstract:Detecting Out-of-Distribution (OOD) inputs is crucial for improving the reliability of deep neural networks in the real-world deployment. In this paper, inspired by the inherent distribution shift between ID and OOD data, we propose a novel method that leverages optimal transport to measure the distribution discrepancy between test inputs and ID prototypes. The resulting transport costs are used to quantify the individual contribution of each test input to the overall discrepancy, serving as a desirable measure for OOD detection. To address the issue that solely relying on the transport costs to ID prototypes is inadequate for identifying OOD inputs closer to ID data, we generate virtual outliers to approximate the OOD region via linear extrapolation. By combining the transport costs to ID prototypes with the costs to virtual outliers, the detection of OOD data near ID data is emphasized, thereby enhancing the distinction between ID and OOD inputs. Experiments demonstrate the superiority of our method over state-of-the-art methods.
+
+
+
+ 93. 【2410.07613】Explainability of Deep Neural Networks for Brain Tumor Detection
+ 链接:https://arxiv.org/abs/2410.07613
+ 作者:S.Park,J.Kim
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:supporting healthcare professionals, Convolutional Neural Networks, Medical image classification, image classification, classification is crucial
+ 备注: 10 pages, 13 figures
+
+ 点击查看摘要
+ Abstract:Medical image classification is crucial for supporting healthcare professionals in decision-making and training. While Convolutional Neural Networks (CNNs) have traditionally dominated this field, Transformer-based models are gaining attention. In this study, we apply explainable AI (XAI) techniques to assess the performance of various models on real-world medical data and identify areas for improvement. We compare CNN models such as VGG-16, ResNet-50, and EfficientNetV2L with a Transformer model: ViT-Base-16. Our results show that data augmentation has little impact, but hyperparameter tuning and advanced modeling improve performance. CNNs, particularly VGG-16 and ResNet-50, outperform ViT-Base-16 and EfficientNetV2L, likely due to underfitting from limited data. XAI methods like LIME and SHAP further reveal that better-performing models visualize tumors more effectively. These findings suggest that CNNs with shallower architectures are more effective for small datasets and can support medical decision-making.
+
+
+
+ 94. 【2410.07610】CSA: Data-efficient Mapping of Unimodal Features to Multimodal Features
+ 链接:https://arxiv.org/abs/2410.07610
+ 作者:Po-han Li,Sandeep P. Chinchali,Ufuk Topcu
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Information Retrieval (cs.IR)
+ 关键词:cross-modal retrieval, CSA, excel in tasks, Multimodal, CLIP excel
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multimodal encoders like CLIP excel in tasks such as zero-shot image classification and cross-modal retrieval. However, they require excessive training data. We propose canonical similarity analysis (CSA), which uses two unimodal encoders to replicate multimodal encoders using limited data. CSA maps unimodal features into a multimodal space, using a new similarity score to retain only the multimodal information. CSA only involves the inference of unimodal encoders and a cubic-complexity matrix decomposition, eliminating the need for extensive GPU-based model training. Experiments show that CSA outperforms CLIP while requiring $300,000\times$ fewer multimodal data pairs and $6\times$ fewer unimodal data for ImageNet classification and misinformative news captions detection. CSA surpasses the state-of-the-art method to map unimodal features to multimodal features. We also demonstrate the ability of CSA with modalities beyond image and text, paving the way for future modality pairs with limited paired multimodal data but abundant unpaired unimodal data, such as lidar and text.
+
+
+
+ 95. 【2410.07605】A Variational Bayesian Inference Theory of Elasticity and Its Mixed Probabilistic Finite Element Method for Inverse Deformation Solutions in Any Dimension
+ 链接:https://arxiv.org/abs/2410.07605
+ 作者:Chao Wang,Shaofan Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Numerical Analysis (math.NA)
+ 关键词:variational Bayesian inference, Bayesian inference theory, Bayesian inference, Bayesian inference Finite, Bayesian inference network
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this work, we have developed a variational Bayesian inference theory of elasticity, which is accomplished by using a mixed Variational Bayesian inference Finite Element Method (VBI-FEM) that can be used to solve the inverse deformation problems of continua. In the proposed variational Bayesian inference theory of continuum mechanics, the elastic strain energy is used as a prior in a Bayesian inference network, which can intelligently recover the detailed continuum deformation mappings with only given the information on the deformed and undeformed continuum body shapes without knowing the interior deformation and the precise actual boundary conditions, both traction as well as displacement boundary conditions, and the actual material constitutive relation. Moreover, we have implemented the related finite element formulation in a computational probabilistic mechanics framework. To numerically solve mixed variational problem, we developed an operator splitting or staggered algorithm that consists of the finite element (FE) step and the Bayesian learning (BL) step as an analogue of the well-known the Expectation-Maximization (EM) algorithm. By solving the mixed probabilistic Galerkin variational problem, we demonstrated that the proposed method is able to inversely predict continuum deformation mappings with strong discontinuity or fracture without knowing the external load conditions. The proposed method provides a robust machine intelligent solution for the long-sought-after inverse problem solution, which has been a major challenge in structure failure forensic pattern analysis in past several decades. The proposed method may become a promising artificial intelligence-based inverse method for solving general partial differential equations.
+
+
+
+ 96. 【2410.07600】RNA: Video Editing with ROI-based Neural Atlas
+ 链接:https://arxiv.org/abs/2410.07600
+ 作者:Jaekyeong Lee,Geonung Kim,Sunghyun Cho
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Social Network Service, video-based Social Network, Network Service, Social Network, video-based Social
+ 备注: ACCV2024
+
+ 点击查看摘要
+ Abstract:With the recent growth of video-based Social Network Service (SNS) platforms, the demand for video editing among common users has increased. However, video editing can be challenging due to the temporally-varying factors such as camera movement and moving objects. While modern atlas-based video editing methods have addressed these issues, they often fail to edit videos including complex motion or multiple moving objects, and demand excessive computational cost, even for very simple edits. In this paper, we propose a novel region-of-interest (ROI)-based video editing framework: ROI-based Neural Atlas (RNA). Unlike prior work, RNA allows users to specify editing regions, simplifying the editing process by removing the need for foreground separation and atlas modeling for foreground objects. However, this simplification presents a unique challenge: acquiring a mask that effectively handles occlusions in the edited area caused by moving objects, without relying on an additional segmentation model. To tackle this, we propose a novel mask refinement approach designed for this specific challenge. Moreover, we introduce a soft neural atlas model for video reconstruction to ensure high-quality editing results. Extensive experiments show that RNA offers a more practical and efficient editing solution, applicable to a wider range of videos with superior quality compared to prior methods.
+
+
+
+ 97. 【2410.07599】Causal Image Modeling for Efficient Visual Understanding
+ 链接:https://arxiv.org/abs/2410.07599
+ 作者:Feng Wang,Timing Yang,Yaodong Yu,Sucheng Ren,Guoyizhe Wei,Angtian Wang,Wei Shao,Yuyin Zhou,Alan Yuille,Cihang Xie
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:learn visual representations, employ uni-directional language, uni-directional language models, Adventurer series models, causal image modeling
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this work, we present a comprehensive analysis of causal image modeling and introduce the Adventurer series models where we treat images as sequences of patch tokens and employ uni-directional language models to learn visual representations. This modeling paradigm allows us to process images in a recurrent formulation with linear complexity relative to the sequence length, which can effectively address the memory and computation explosion issues posed by high-resolution and fine-grained images. In detail, we introduce two simple designs that seamlessly integrate image inputs into the causal inference framework: a global pooling token placed at the beginning of the sequence and a flipping operation between every two layers. Extensive empirical studies demonstrate the significant efficiency and effectiveness of this causal image modeling paradigm. For example, our base-sized Adventurer model attains a competitive test accuracy of 84.0% on the standard ImageNet-1k benchmark with 216 images/s training throughput, which is 5.3 times more efficient than vision transformers to achieve the same result.
+
+
+
+ 98. 【2410.07597】Fine-detailed Neural Indoor Scene Reconstruction using multi-level importance sampling and multi-view consistency
+ 链接:https://arxiv.org/abs/2410.07597
+ 作者:Xinghui Li,Yuchen Ji,Xiansong Lai,Wanting Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:impressive performance, indoor scenarios, simplicity and impressive, Recently, popular due
+ 备注: 7 pages, 3 figures, International Conference on Image Processing
+
+ 点击查看摘要
+ Abstract:Recently, neural implicit 3D reconstruction in indoor scenarios has become popular due to its simplicity and impressive performance. Previous works could produce complete results leveraging monocular priors of normal or depth. However, they may suffer from over-smoothed reconstructions and long-time optimization due to unbiased sampling and inaccurate monocular priors. In this paper, we propose a novel neural implicit surface reconstruction method, named FD-NeuS, to learn fine-detailed 3D models using multi-level importance sampling strategy and multi-view consistency methodology. Specifically, we leverage segmentation priors to guide region-based ray sampling, and use piecewise exponential functions as weights to pilot 3D points sampling along the rays, ensuring more attention on important regions. In addition, we introduce multi-view feature consistency and multi-view normal consistency as supervision and uncertainty respectively, which further improve the reconstruction of details. Extensive quantitative and qualitative results show that FD-NeuS outperforms existing methods in various scenes.
+
+
+
+ 99. 【2410.07593】A Unified Debiasing Approach for Vision-Language Models across Modalities and Tasks
+ 链接:https://arxiv.org/abs/2410.07593
+ 作者:Hoin Jung,Taeuk Jang,Xiaoqian Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:enabled complex multimodal, Recent advancements, image data simultaneously, complex multimodal tasks, data simultaneously
+ 备注: NeurIPS 2024, the Thirty-Eighth Annual Conference on Neural Information Processing Systems
+
+ 点击查看摘要
+ Abstract:Recent advancements in Vision-Language Models (VLMs) have enabled complex multimodal tasks by processing text and image data simultaneously, significantly enhancing the field of artificial intelligence. However, these models often exhibit biases that can skew outputs towards societal stereotypes, thus necessitating debiasing strategies. Existing debiasing methods focus narrowly on specific modalities or tasks, and require extensive retraining. To address these limitations, this paper introduces Selective Feature Imputation for Debiasing (SFID), a novel methodology that integrates feature pruning and low confidence imputation (LCI) to effectively reduce biases in VLMs. SFID is versatile, maintaining the semantic integrity of outputs and costly effective by eliminating the need for retraining. Our experimental results demonstrate SFID's effectiveness across various VLMs tasks including zero-shot classification, text-to-image retrieval, image captioning, and text-to-image generation, by significantly reducing gender biases without compromising performance. This approach not only enhances the fairness of VLMs applications but also preserves their efficiency and utility across diverse scenarios.
+
+
+
+ 100. 【2410.07590】urboRAG: Accelerating Retrieval-Augmented Generation with Precomputed KV Caches for Chunked Text
+ 链接:https://arxiv.org/abs/2410.07590
+ 作者:Songshuo Lu,Hua Wang,Yutian Rong,Zhi Chen,Yaohua Tang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Current Retrieval-Augmented Generation, process numerous retrieved, current RAG system, numerous retrieved document, retrieved document chunks
+ 备注:
+
+ 点击查看摘要
+ Abstract:Current Retrieval-Augmented Generation (RAG) systems concatenate and process numerous retrieved document chunks for prefill which requires a large volume of computation, therefore leading to significant latency in time-to-first-token (TTFT). To reduce the computation overhead as well as TTFT, we introduce TurboRAG, a novel RAG system that redesigns the inference paradigm of the current RAG system by first pre-computing and storing the key-value (KV) caches of documents offline, and then directly retrieving the saved KV cache for prefill. Hence, online computation of KV caches is eliminated during inference. In addition, we provide a number of insights into the mask matrix and positional embedding mechanisms, plus fine-tune a pretrained language model to maintain model accuracy of TurboRAG. Our approach is applicable to most existing large language models and their applications without any requirement in modification of models and inference systems. Experimental results across a suite of RAG benchmarks demonstrate that TurboRAG reduces TTFT by up to 9.4x compared to the conventional RAG systems (on an average of 8.6x), but reserving comparable performance to the standard RAG systems.
+
+
+
+ 101. 【2410.07579】ddy: Efficient Large-Scale Dataset Distillation via Taylor-Approximated Matching
+ 链接:https://arxiv.org/abs/2410.07579
+ 作者:Ruonan Yu,Songhua Liu,Jingwen Ye,Xinchao Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:enabling models trained, real data, condensation refers, refers to compressing, generalize effectively
+ 备注: Accepted by ECCV2024
+
+ 点击查看摘要
+ Abstract:Dataset distillation or condensation refers to compressing a large-scale dataset into a much smaller one, enabling models trained on this synthetic dataset to generalize effectively on real data. Tackling this challenge, as defined, relies on a bi-level optimization algorithm: a novel model is trained in each iteration within a nested loop, with gradients propagated through an unrolled computation graph. However, this approach incurs high memory and time complexity, posing difficulties in scaling up to large datasets such as ImageNet. Addressing these concerns, this paper introduces Teddy, a Taylor-approximated dataset distillation framework designed to handle large-scale dataset and enhance efficiency. On the one hand, backed up by theoretical analysis, we propose a memory-efficient approximation derived from Taylor expansion, which transforms the original form dependent on multi-step gradients to a first-order one. On the other hand, rather than repeatedly training a novel model in each iteration, we unveil that employing a pre-cached pool of weak models, which can be generated from a single base model, enhances both time efficiency and performance concurrently, particularly when dealing with large-scale datasets. Extensive experiments demonstrate that the proposed Teddy attains state-of-the-art efficiency and performance on the Tiny-ImageNet and original-sized ImageNet-1K dataset, notably surpassing prior methods by up to 12.8%, while reducing 46.6% runtime. Our code will be available at this https URL.
+
+
+
+ 102. 【2410.07577】3D Vision-Language Gaussian Splatting
+ 链接:https://arxiv.org/abs/2410.07577
+ 作者:Qucheng Peng,Benjamin Planche,Zhongpai Gao,Meng Zheng,Anwesa Choudhuri,Terrence Chen,Chen Chen,Ziyan Wu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Recent advancements, autonomous driving, augmented reality, scene understanding, applications in robotics
+ 备注: main paper + supplementary material
+
+ 点击查看摘要
+ Abstract:Recent advancements in 3D reconstruction methods and vision-language models have propelled the development of multi-modal 3D scene understanding, which has vital applications in robotics, autonomous driving, and virtual/augmented reality. However, current multi-modal scene understanding approaches have naively embedded semantic representations into 3D reconstruction methods without striking a balance between visual and language modalities, which leads to unsatisfying semantic rasterization of translucent or reflective objects, as well as over-fitting on color modality. To alleviate these limitations, we propose a solution that adequately handles the distinct visual and semantic modalities, i.e., a 3D vision-language Gaussian splatting model for scene understanding, to put emphasis on the representation learning of language modality. We propose a novel cross-modal rasterizer, using modality fusion along with a smoothed semantic indicator for enhancing semantic rasterization. We also employ a camera-view blending technique to improve semantic consistency between existing and synthesized views, thereby effectively mitigating over-fitting. Extensive experiments demonstrate that our method achieves state-of-the-art performance in open-vocabulary semantic segmentation, surpassing existing methods by a significant margin.
+
+
+
+ 103. 【2410.07571】How Does Vision-Language Adaptation Impact the Safety of Vision Language Models?
+ 链接:https://arxiv.org/abs/2410.07571
+ 作者:Seongyun Lee,Geewook Kim,Jiyeon Kim,Hyunji Lee,Hoyeon Chang,Sue Hyun Park,Minjoon Seo
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:transforms Large Language, Large Language Models, Large Vision-Language Models, Large Language, Large Vision-Language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Vision-Language adaptation (VL adaptation) transforms Large Language Models (LLMs) into Large Vision-Language Models (LVLMs) for multimodal tasks, but this process often compromises the inherent safety capabilities embedded in the original LLMs. Despite potential harmfulness due to weakened safety measures, in-depth analysis on the effects of VL adaptation on safety remains under-explored. This study examines how VL adaptation influences safety and evaluates the impact of safety fine-tuning methods. Our analysis reveals that safety degradation occurs during VL adaptation, even when the training data is safe. While safety tuning techniques like supervised fine-tuning with safety datasets or reinforcement learning from human feedback mitigate some risks, they still lead to safety degradation and a reduction in helpfulness due to over-rejection issues. Further analysis of internal model weights suggests that VL adaptation may impact certain safety-related layers, potentially lowering overall safety levels. Additionally, our findings demonstrate that the objectives of VL adaptation and safety tuning are divergent, which often results in their simultaneous application being suboptimal. To address this, we suggest the weight merging approach as an optimal solution effectively reducing safety degradation while maintaining helpfulness. These insights help guide the development of more reliable and secure LVLMs for real-world applications.
+
+
+
+ 104. 【2410.07540】CoPESD: A Multi-Level Surgical Motion Dataset for Training Large Vision-Language Models to Co-Pilot Endoscopic Submucosal Dissection
+ 链接:https://arxiv.org/abs/2410.07540
+ 作者:Guankun Wang,Han Xiao,Huxin Gao,Renrui Zhang,Long Bai,Xiaoxiao Yang,Zhen Li,Hongsheng Li,Hongliang Ren
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:minimizing recurrence rates, ESD, enables rapid resection, minimizing recurrence, long-term overall survival
+ 备注:
+
+ 点击查看摘要
+ Abstract:submucosal dissection (ESD) enables rapid resection of large lesions, minimizing recurrence rates and improving long-term overall survival. Despite these advantages, ESD is technically challenging and carries high risks of complications, necessitating skilled surgeons and precise instruments. Recent advancements in Large Visual-Language Models (LVLMs) offer promising decision support and predictive planning capabilities for robotic systems, which can augment the accuracy of ESD and reduce procedural risks. However, existing datasets for multi-level fine-grained ESD surgical motion understanding are scarce and lack detailed annotations. In this paper, we design a hierarchical decomposition of ESD motion granularity and introduce a multi-level surgical motion dataset (CoPESD) for training LVLMs as the robotic \textbf{Co}-\textbf{P}ilot of \textbf{E}ndoscopic \textbf{S}ubmucosal \textbf{D}issection. CoPESD includes 17,679 images with 32,699 bounding boxes and 88,395 multi-level motions, from over 35 hours of ESD videos for both robot-assisted and conventional surgeries. CoPESD enables granular analysis of ESD motions, focusing on the complex task of submucosal dissection. Extensive experiments on the LVLMs demonstrate the effectiveness of CoPESD in training LVLMs to predict following surgical robotic motions. As the first multimodal ESD motion dataset, CoPESD supports advanced research in ESD instruction-following and surgical automation. The dataset is available at \href{this https URL}{this https URL.}}
+
+
+
+ 105. 【2410.07536】I-Max: Maximize the Resolution Potential of Pre-trained Rectified Flow Transformers with Projected Flow
+ 链接:https://arxiv.org/abs/2410.07536
+ 作者:Ruoyi Du,Dongyang Liu,Le Zhuo,Qin Qi,Hongsheng Li,Zhanyu Ma,Peng Gao
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Rectified Flow Transformers, offer superior training, Rectified Flow, Flow Transformers, offer superior
+ 备注:
+
+ 点击查看摘要
+ Abstract:Rectified Flow Transformers (RFTs) offer superior training and inference efficiency, making them likely the most viable direction for scaling up diffusion models. However, progress in generation resolution has been relatively slow due to data quality and training costs. Tuning-free resolution extrapolation presents an alternative, but current methods often reduce generative stability, limiting practical application. In this paper, we review existing resolution extrapolation methods and introduce the I-Max framework to maximize the resolution potential of Text-to-Image RFTs. I-Max features: (i) a novel Projected Flow strategy for stable extrapolation and (ii) an advanced inference toolkit for generalizing model knowledge to higher resolutions. Experiments with Lumina-Next-2K and Flux.1-dev demonstrate I-Max's ability to enhance stability in resolution extrapolation and show that it can bring image detail emergence and artifact correction, confirming the practical value of tuning-free resolution extrapolation.
+
+
+
+ 106. 【2410.07528】CountMamba: Exploring Multi-directional Selective State-Space Models for Plant Counting
+ 链接:https://arxiv.org/abs/2410.07528
+ 作者:Hulingxiao He,Yaqi Zhang,Jinglin Xu,Yuxin Peng
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:pollination yield estimation, including seed breeding, plant counting tasks, stage of agriculture, seed breeding
+ 备注: Accepted by PRCV 2024
+
+ 点击查看摘要
+ Abstract:Plant counting is essential in every stage of agriculture, including seed breeding, germination, cultivation, fertilization, pollination yield estimation, and harvesting. Inspired by the fact that humans count objects in high-resolution images by sequential scanning, we explore the potential of handling plant counting tasks via state space models (SSMs) for generating counting results. In this paper, we propose a new counting approach named CountMamba that constructs multiple counting experts to scan from various directions simultaneously. Specifically, we design a Multi-directional State-Space Group to process the image patch sequences in multiple orders and aim to simulate different counting experts. We also design Global-Local Adaptive Fusion to adaptively aggregate global features extracted from multiple directions and local features extracted from the CNN branch in a sample-wise manner. Extensive experiments demonstrate that the proposed CountMamba performs competitively on various plant counting tasks, including maize tassels, wheat ears, and sorghum head counting.
+
+
+
+ 107. 【2410.07514】O1O: Grouping of Known Classes to Identify Unknown Objects as Odd-One-Out
+ 链接:https://arxiv.org/abs/2410.07514
+ 作者:Mısra Yavuz,Fatma Güney
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:detection methods trained, methods trained, fixed set, objects, classes
+ 备注: Accepted at ACCV 2024 (Oral)
+
+ 点击查看摘要
+ Abstract:Object detection methods trained on a fixed set of known classes struggle to detect objects of unknown classes in the open-world setting. Current fixes involve adding approximate supervision with pseudo-labels corresponding to candidate locations of objects, typically obtained in a class-agnostic manner. While previous approaches mainly rely on the appearance of objects, we find that geometric cues improve unknown recall. Although additional supervision from pseudo-labels helps to detect unknown objects, it also introduces confusion for known classes. We observed a notable decline in the model's performance for detecting known objects in the presence of noisy pseudo-labels. Drawing inspiration from studies on human cognition, we propose to group known classes into superclasses. By identifying similarities between classes within a superclass, we can identify unknown classes through an odd-one-out scoring mechanism. Our experiments on open-world detection benchmarks demonstrate significant improvements in unknown recall, consistently across all tasks. Crucially, we achieve this without compromising known performance, thanks to better partitioning of the feature space with superclasses.
+
+
+
+ 108. 【2410.07500】Learning to Generate Diverse Pedestrian Movements from Web Videos with Noisy Labels
+ 链接:https://arxiv.org/abs/2410.07500
+ 作者:Zhizheng Liu,Joe Lin,Wayne Wu,Bolei Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Understanding and modeling, pedestrian movements, modeling pedestrian movements, pedestrian, real world
+ 备注: Project Page: [this https URL](https://genforce.github.io/PedGen/)
+
+ 点击查看摘要
+ Abstract:Understanding and modeling pedestrian movements in the real world is crucial for applications like motion forecasting and scene simulation. Many factors influence pedestrian movements, such as scene context, individual characteristics, and goals, which are often ignored by the existing human generation methods. Web videos contain natural pedestrian behavior and rich motion context, but annotating them with pre-trained predictors leads to noisy labels. In this work, we propose learning diverse pedestrian movements from web videos. We first curate a large-scale dataset called CityWalkers that captures diverse real-world pedestrian movements in urban scenes. Then, based on CityWalkers, we propose a generative model called PedGen for diverse pedestrian movement generation. PedGen introduces automatic label filtering to remove the low-quality labels and a mask embedding to train with partial labels. It also contains a novel context encoder that lifts the 2D scene context to 3D and can incorporate various context factors in generating realistic pedestrian movements in urban scenes. Experiments show that PedGen outperforms existing baseline methods for pedestrian movement generation by learning from noisy labels and incorporating the context factors. In addition, PedGen achieves zero-shot generalization in both real-world and simulated environments. The code, model, and data will be made publicly available at this https URL .
+
+
+
+ 109. 【2410.07499】Dense Optimizer : An Information Entropy-Guided Structural Search Method for Dense-like Neural Network Design
+ 链接:https://arxiv.org/abs/2410.07499
+ 作者:Liu Tianyuan,Hou Libin,Wang Linyuan,Song Xiyu,Yan Bin
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Dense Convolutional Network, Dense Optimizer, Dense Convolutional, efficient structure, Convolutional Network
+ 备注: 7 pages,3 figures
+
+ 点击查看摘要
+ Abstract:Dense Convolutional Network has been continuously refined to adopt a highly efficient and compact architecture, owing to its lightweight and efficient structure. However, the current Dense-like architectures are mainly designed manually, it becomes increasingly difficult to adjust the channels and reuse level based on past experience. As such, we propose an architecture search method called Dense Optimizer that can search high-performance dense-like network automatically. In Dense Optimizer, we view the dense network as a hierarchical information system, maximize the network's information entropy while constraining the distribution of the entropy across each stage via a power law, thereby constructing an optimization problem. We also propose a branch-and-bound optimization algorithm, tightly integrates power-law principle with search space scaling to solve the optimization problem efficiently. The superiority of Dense Optimizer has been validated on different computer vision benchmark datasets. Specifically, Dense Optimizer completes high-quality search but only costs 4 hours with one CPU. Our searched model DenseNet-OPT achieved a top 1 accuracy of 84.3% on CIFAR-100, which is 5.97% higher than the original one.
+
+
+
+ 110. 【2410.07475】Progressive Multi-Modal Fusion for Robust 3D Object Detection
+ 链接:https://arxiv.org/abs/2410.07475
+ 作者:Rohit Mohan,Daniele Cattaneo,Florian Drews,Abhinav Valada
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Bird Eye View, Multi-sensor fusion, crucial for accurate, autonomous driving, cameras and LiDAR
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multi-sensor fusion is crucial for accurate 3D object detection in autonomous driving, with cameras and LiDAR being the most commonly used sensors. However, existing methods perform sensor fusion in a single view by projecting features from both modalities either in Bird's Eye View (BEV) or Perspective View (PV), thus sacrificing complementary information such as height or geometric proportions. To address this limitation, we propose ProFusion3D, a progressive fusion framework that combines features in both BEV and PV at both intermediate and object query levels. Our architecture hierarchically fuses local and global features, enhancing the robustness of 3D object detection. Additionally, we introduce a self-supervised mask modeling pre-training strategy to improve multi-modal representation learning and data efficiency through three novel objectives. Extensive experiments on nuScenes and Argoverse2 datasets conclusively demonstrate the efficacy of ProFusion3D. Moreover, ProFusion3D is robust to sensor failure, demonstrating strong performance when only one modality is available.
+
+
+
+ 111. 【2410.07463】Language-Guided Joint Audio-Visual Editing via One-Shot Adaptation
+ 链接:https://arxiv.org/abs/2410.07463
+ 作者:Susan Liang,Chao Huang,Yapeng Tian,Anurag Kumar,Chenliang Xu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:task called language-guided, called language-guided joint, editing, called language-guided, audio-visual
+ 备注: ACCV 2024
+
+ 点击查看摘要
+ Abstract:In this paper, we introduce a novel task called language-guided joint audio-visual editing. Given an audio and image pair of a sounding event, this task aims at generating new audio-visual content by editing the given sounding event conditioned on the language guidance. For instance, we can alter the background environment of a sounding object while keeping its appearance unchanged, or we can add new sounds contextualized to the visual content. To address this task, we propose a new diffusion-based framework for joint audio-visual editing and introduce two key ideas. Firstly, we propose a one-shot adaptation approach to tailor generative diffusion models for audio-visual content editing. With as few as one audio-visual sample, we jointly transfer the audio and vision diffusion models to the target domain. After fine-tuning, our model enables consistent generation of this audio-visual sample. Secondly, we introduce a cross-modal semantic enhancement approach. We observe that when using language as content editing guidance, the vision branch may overlook editing requirements. This phenomenon, termed catastrophic neglect, hampers audio-visual alignment during content editing. We therefore enhance semantic consistency between language and vision to mitigate this issue. Extensive experiments validate the effectiveness of our method in language-based audio-visual editing and highlight its superiority over several baseline approaches. We recommend that readers visit our project page for more details: this https URL.
+
+
+
+ 112. 【2410.07460】Generalizing Segmentation Foundation Model Under Sim-to-real Domain-shift for Guidewire Segmentation in X-ray Fluoroscopy
+ 链接:https://arxiv.org/abs/2410.07460
+ 作者:Yuxuan Wen,Evgenia Roussinova,Olivier Brina,Paolo Machi,Mohamed Bouri
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:enhance procedural accuracy, complex vascular pathways, endovascular interventions holds, significantly enhance procedural, providing critical feedback
+ 备注:
+
+ 点击查看摘要
+ Abstract:Guidewire segmentation during endovascular interventions holds the potential to significantly enhance procedural accuracy, improving visualization and providing critical feedback that can support both physicians and robotic systems in navigating complex vascular pathways. Unlike supervised segmentation networks, which need many expensive expert-annotated labels, sim-to-real domain adaptation approaches utilize synthetic data from simulations, offering a cost-effective solution. The success of models like Segment-Anything (SAM) has driven advancements in image segmentation foundation models with strong zero/few-shot generalization through prompt engineering. However, they struggle with medical images like X-ray fluoroscopy and the domain-shifts of the data. Given the challenges of acquiring annotation and the accessibility of labeled simulation data, we propose a sim-to-real domain adaption framework with a coarse-to-fine strategy to adapt SAM to X-ray fluoroscopy guidewire segmentation without any annotation on the target domain. We first generate the pseudo-labels by utilizing a simple source image style transfer technique that preserves the guidewire structure. Then, we develop a weakly supervised self-training architecture to fine-tune an end-to-end student SAM with the coarse labels by imposing consistency regularization and supervision from the teacher SAM network. We validate the effectiveness of the proposed method on a publicly available Cardiac dataset and an in-house Neurovascular dataset, where our method surpasses both pre-trained SAM and many state-of-the-art domain adaptation techniques by a large margin. Our code will be made public on GitHub soon.
+
+
+
+ 113. 【2410.07447】nyLidarNet: 2D LiDAR-based End-to-End Deep Learning Model for F1TENTH Autonomous Racing
+ 链接:https://arxiv.org/abs/2410.07447
+ 作者:Mohammed Misbah Zarrar,Qitao Weng,Bakhbyergyen Yerjan,Ahmet Soyyigit,Heechul Yun
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:raw sensory data, Prior research, sensory data, research has demonstrated, demonstrated the effectiveness
+ 备注:
+
+ 点击查看摘要
+ Abstract:Prior research has demonstrated the effectiveness of end-to-end deep learning for robotic navigation, where the control signals are directly derived from raw sensory data. However, the majority of existing end-to-end navigation solutions are predominantly camera-based. In this paper, we introduce TinyLidarNet, a lightweight 2D LiDAR-based end-to-end deep learning model for autonomous racing. An F1TENTH vehicle using TinyLidarNet won 3rd place in the 12th F1TENTH Autonomous Grand Prix competition, demonstrating its competitive performance. We systematically analyze its performance on untrained tracks and computing requirements for real-time processing. We find that TinyLidarNet's 1D Convolutional Neural Network (CNN) based architecture significantly outperforms widely used Multi-Layer Perceptron (MLP) based architecture. In addition, we show that it can be processed in real-time on low-end micro-controller units (MCUs).
+
+
+
+ 114. 【2410.07442】Self-Supervised Learning for Real-World Object Detection: a Survey
+ 链接:https://arxiv.org/abs/2410.07442
+ 作者:Alina Ciocarlan,Sidonie Lefebvre,Sylvie Le Hégarat-Mascle,Arnaud Woiselle
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Masked Image Modeling, Self-Supervised Learning, SSL, object detection, small object detection
+ 备注:
+
+ 点击查看摘要
+ Abstract:Self-Supervised Learning (SSL) has emerged as a promising approach in computer vision, enabling networks to learn meaningful representations from large unlabeled datasets. SSL methods fall into two main categories: instance discrimination and Masked Image Modeling (MIM). While instance discrimination is fundamental to SSL, it was originally designed for classification and may be less effective for object detection, particularly for small objects. In this survey, we focus on SSL methods specifically tailored for real-world object detection, with an emphasis on detecting small objects in complex environments. Unlike previous surveys, we offer a detailed comparison of SSL strategies, including object-level instance discrimination and MIM methods, and assess their effectiveness for small object detection using both CNN and ViT-based architectures. Specifically, our benchmark is performed on the widely-used COCO dataset, as well as on a specialized real-world dataset focused on vehicle detection in infrared remote sensing imagery. We also assess the impact of pre-training on custom domain-specific datasets, highlighting how certain SSL strategies are better suited for handling uncurated data.
+Our findings highlight that instance discrimination methods perform well with CNN-based encoders, while MIM methods are better suited for ViT-based architectures and custom dataset pre-training. This survey provides a practical guide for selecting optimal SSL strategies, taking into account factors such as backbone architecture, object size, and custom pre-training requirements. Ultimately, we show that choosing an appropriate SSL pre-training strategy, along with a suitable encoder, significantly enhances performance in real-world object detection, particularly for small object detection in frugal settings.
+
Subjects:
+Computer Vision and Pattern Recognition (cs.CV)
+Cite as:
+arXiv:2410.07442 [cs.CV]
+(or
+arXiv:2410.07442v1 [cs.CV] for this version)
+https://doi.org/10.48550/arXiv.2410.07442
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 115. 【2410.07441】Zero-Shot Generalization of Vision-Based RL Without Data Augmentation
+ 链接:https://arxiv.org/abs/2410.07441
+ 作者:Sumeet Batra,Gaurav S. Sukhatme
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:Generalizing vision-based reinforcement, vision-based reinforcement learning, Generalizing vision-based, reinforcement learning, open challenge
+ 备注:
+
+ 点击查看摘要
+ Abstract:Generalizing vision-based reinforcement learning (RL) agents to novel environments remains a difficult and open challenge. Current trends are to collect large-scale datasets or use data augmentation techniques to prevent overfitting and improve downstream generalization. However, the computational and data collection costs increase exponentially with the number of task variations and can destabilize the already difficult task of training RL agents. In this work, we take inspiration from recent advances in computational neuroscience and propose a model, Associative Latent DisentAnglement (ALDA), that builds on standard off-policy RL towards zero-shot generalization. Specifically, we revisit the role of latent disentanglement in RL and show how combining it with a model of associative memory achieves zero-shot generalization on difficult task variations without relying on data augmentation. Finally, we formally show that data augmentation techniques are a form of weak disentanglement and discuss the implications of this insight.
+
+
+
+ 116. 【2410.07437】Robust infrared small target detection using self-supervised and a contrario paradigms
+ 链接:https://arxiv.org/abs/2410.07437
+ 作者:Alina Ciocarlan,Sylvie Le Hégarat-Mascle,Sidonie Lefebvre,Arnaud Woiselle
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Detecting small targets, defense applications due, Detecting small, Infrared Small Target, infrared images poses
+ 备注:
+
+ 点击查看摘要
+ Abstract:Detecting small targets in infrared images poses significant challenges in defense applications due to the presence of complex backgrounds and the small size of the targets. Traditional object detection methods often struggle to balance high detection rates with low false alarm rates, especially when dealing with small objects. In this paper, we introduce a novel approach that combines a contrario paradigm with Self-Supervised Learning (SSL) to improve Infrared Small Target Detection (IRSTD). On the one hand, the integration of an a contrario criterion into a YOLO detection head enhances feature map responses for small and unexpected objects while effectively controlling false alarms. On the other hand, we explore SSL techniques to overcome the challenges of limited annotated data, common in IRSTD tasks. Specifically, we benchmark several representative SSL strategies for their effectiveness in improving small object detection performance. Our findings show that instance discrimination methods outperform masked image modeling strategies when applied to YOLO-based small object detection. Moreover, the combination of the a contrario and SSL paradigms leads to significant performance improvements, narrowing the gap with state-of-the-art segmentation methods and even outperforming them in frugal settings. This two-pronged approach offers a robust solution for improving IRSTD performance, particularly under challenging conditions.
+
+
+
+ 117. 【2410.07434】Surgical Depth Anything: Depth Estimation for Surgical Scenes using Foundation Models
+ 链接:https://arxiv.org/abs/2410.07434
+ 作者:Ange Lou,Yamin Li,Yike Zhang,Jack Noble
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Monocular depth estimation, Monocular depth, reconstruction algorithms, crucial for tracking, tracking and reconstruction
+ 备注:
+
+ 点击查看摘要
+ Abstract:Monocular depth estimation is crucial for tracking and reconstruction algorithms, particularly in the context of surgical videos. However, the inherent challenges in directly obtaining ground truth depth maps during surgery render supervised learning approaches impractical. While many self-supervised methods based on Structure from Motion (SfM) have shown promising results, they rely heavily on high-quality camera motion and require optimization on a per-patient basis. These limitations can be mitigated by leveraging the current state-of-the-art foundational model for depth estimation, Depth Anything. However, when directly applied to surgical scenes, Depth Anything struggles with issues such as blurring, bleeding, and reflections, resulting in suboptimal performance. This paper presents a fine-tuning of the Depth Anything model specifically for the surgical domain, aiming to deliver more accurate pixel-wise depth maps tailored to the unique requirements and challenges of surgical environments. Our fine-tuning approach significantly improves the model's performance in surgical scenes, reducing errors related to blurring and reflections, and achieving a more reliable and precise depth estimation.
+
+
+
+ 118. 【2410.07421】Segmenting objects with Bayesian fusion of active contour models and convnet priors
+ 链接:https://arxiv.org/abs/2410.07421
+ 作者:Przemyslaw Polewski,Jacquelyn Shelton,Wei Yao,Marco Heurich
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:great practical significance, core computer vision, computer vision task, Convolutional Neural Network, Deep Shape Models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Instance segmentation is a core computer vision task with great practical significance. Recent advances, driven by large-scale benchmark datasets, have yielded good general-purpose Convolutional Neural Network (CNN)-based methods. Natural Resource Monitoring (NRM) utilizes remote sensing imagery with generally known scale and containing multiple overlapping instances of the same class, wherein the object contours are jagged and highly irregular. This is in stark contrast with the regular man-made objects found in classic benchmark datasets. We address this problem and propose a novel instance segmentation method geared towards NRM imagery. We formulate the problem as Bayesian maximum a posteriori inference which, in learning the individual object contours, incorporates shape, location, and position priors from state-of-the-art CNN architectures, driving a simultaneous level-set evolution of multiple object contours. We employ loose coupling between the CNNs that supply the priors and the active contour process, allowing a drop-in replacement of new network architectures. Moreover, we introduce a novel prior for contour shape, namely, a class of Deep Shape Models based on architectures from Generative Adversarial Networks (GANs). These Deep Shape Models are in essence a non-linear generalization of the classic Eigenshape formulation. In experiments, we tackle the challenging, real-world problem of segmenting individual dead tree crowns and delineating precise contours. We compare our method to two leading general-purpose instance segmentation methods - Mask R-CNN and K-net - on color infrared aerial imagery. Results show our approach to significantly outperform both methods in terms of reconstruction quality of tree crown contours. Furthermore, use of the GAN-based deep shape model prior yields significant improvement of all results over the vanilla Eigenshape prior.
+
+
+
+ 119. 【2410.07418】NeRF-Accelerated Ecological Monitoring in Mixed-Evergreen Redwood Forest
+ 链接:https://arxiv.org/abs/2410.07418
+ 作者:Adam Korycki,Cory Yeaton,Gregory S. Gilbert,Colleen Josephson,Steve McGuire
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:critical observational data, observational data needed, critical observational, observational data, data needed
+ 备注:
+
+ 点击查看摘要
+ Abstract:Forest mapping provides critical observational data needed to understand the dynamics of forest environments. Notably, tree diameter at breast height (DBH) is a metric used to estimate forest biomass and carbon dioxide (CO$_2$) sequestration. Manual methods of forest mapping are labor intensive and time consuming, a bottleneck for large-scale mapping efforts. Automated mapping relies on acquiring dense forest reconstructions, typically in the form of point clouds. Terrestrial laser scanning (TLS) and mobile laser scanning (MLS) generate point clouds using expensive LiDAR sensing, and have been used successfully to estimate tree diameter. Neural radiance fields (NeRFs) are an emergent technology enabling photorealistic, vision-based reconstruction by training a neural network on a sparse set of input views. In this paper, we present a comparison of MLS and NeRF forest reconstructions for the purpose of trunk diameter estimation in a mixed-evergreen Redwood forest. In addition, we propose an improved DBH-estimation method using convex-hull modeling. Using this approach, we achieved 1.68 cm RMSE, which consistently outperformed standard cylinder modeling approaches. Our code contributions and forest datasets are freely available at this https URL.
+
+
+
+ 120. 【2410.07415】3D2M Dataset: A 3-Dimension diverse Mesh Dataset
+ 链接:https://arxiv.org/abs/2410.07415
+ 作者:Sankarshan Dasgupta
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:attracting significant attention, area of research, attracting significant, industry alike, prominent area
+ 备注: 6 pages, 1 figures, 2 tables
+
+ 点击查看摘要
+ Abstract:Three-dimensional (3D) reconstruction has emerged as a prominent area of research, attracting significant attention from academia and industry alike. Among the various applications of 3D reconstruction, facial reconstruction poses some of the most formidable challenges. Additionally, each individuals facial structure is unique, requiring algorithms to be robust enough to handle this variability while maintaining fidelity to the original features. This article presents a comprehensive dataset of 3D meshes featuring a diverse range of facial structures and corresponding facial landmarks. The dataset comprises 188 3D facial meshes, including 73 from female candidates and 114 from male candidates. It encompasses a broad representation of ethnic backgrounds, with contributions from 45 different ethnicities, ensuring a rich diversity in facial characteristics. Each facial mesh is accompanied by key points that accurately annotate the relevant features, facilitating precise analysis and manipulation. This dataset is particularly valuable for applications such as facial re targeting, the study of facial structure components, and real-time person representation in video streams. By providing a robust resource for researchers and developers, it aims to advance the field of 3D facial reconstruction and related technologies.
+
+
+
+ 121. 【2410.07410】Aligning Motion-Blurred Images Using Contrastive Learning on Overcomplete Pixels
+ 链接:https://arxiv.org/abs/2410.07410
+ 作者:Leonid Pogorelyuk,Stefan T. Radev
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:learning overcomplete pixel-level, motion blur, invariant to motion, overcomplete pixel-level features, contrastive objective
+ 备注: 8 pages, 3 figures
+
+ 点击查看摘要
+ Abstract:We propose a new contrastive objective for learning overcomplete pixel-level features that are invariant to motion blur. Other invariances (e.g., pose, illumination, or weather) can be learned by applying the corresponding transformations on unlabeled images during self-supervised training. We showcase that a simple U-Net trained with our objective can produce local features useful for aligning the frames of an unseen video captured with a moving camera under realistic and challenging conditions. Using a carefully designed toy example, we also show that the overcomplete pixels can encode the identity of objects in an image and the pixel coordinates relative to these objects.
+
+
+
+ 122. 【2410.07405】Exploring Efficient Foundational Multi-modal Models for Video Summarization
+ 链接:https://arxiv.org/abs/2410.07405
+ 作者:Karan Samel,Apoorva Beedu,Nitish Sontakke,Irfan Essa
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:generate text outputs, models, model, language model, Foundational models
+ 备注: 11 pages, 4 figures
+
+ 点击查看摘要
+ Abstract:Foundational models are able to generate text outputs given prompt instructions and text, audio, or image inputs. Recently these models have been combined to perform tasks on video, such as video summarization. Such video foundation models perform pre-training by aligning outputs from each modality-specific model into the same embedding space. Then the embeddings from each model are used within a language model, which is fine-tuned on a desired instruction set. Aligning each modality during pre-training is computationally expensive and prevents rapid testing of different base modality models. During fine-tuning, evaluation is carried out within in-domain videos where it is hard to understand the generalizability and data efficiency of these methods. To alleviate these issues we propose a plug-and-play video language model. It directly uses the texts generated from each input modality into the language model, avoiding pre-training alignment overhead. Instead of fine-tuning we leverage few-shot instruction adaptation strategies. We compare the performance versus the computational costs for our plug-and-play style method and baseline tuning methods. Finally, we explore the generalizability of each method during domain shift and present insights on what data is useful when training data is limited. Through this analysis, we present practical insights on how to leverage multi-modal foundational models for effective results given realistic compute and data limitations.
+
+
+
+ 123. 【2410.07401】Enhancing Soccer Camera Calibration Through Keypoint Exploitation
+ 链接:https://arxiv.org/abs/2410.07401
+ 作者:Nikolay S. Falaleev,Ruilong Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:enabling precise scene, precise scene geometry, scene geometry interpretation, supporting sports analytics, sports analytics tasks
+ 备注: 7th ACM International Workshop on Multimedia Content Analysis in Sports
+
+ 点击查看摘要
+ Abstract:Accurate camera calibration is essential for transforming 2D images from camera sensors into 3D world coordinates, enabling precise scene geometry interpretation and supporting sports analytics tasks such as player tracking, offside detection, and performance analysis. However, obtaining a sufficient number of high-quality point pairs remains a significant challenge for both traditional and deep learning-based calibration methods. This paper introduces a multi-stage pipeline that addresses this challenge by leveraging the structural features of the football pitch. Our approach significantly increases the number of usable points for calibration by exploiting line-line and line-conic intersections, points on the conics, and other geometric features. To mitigate the impact of imperfect annotations, we employ data fitting techniques. Our pipeline utilizes deep learning for keypoint and line detection and incorporates geometric constraints based on real-world pitch dimensions. A voter algorithm iteratively selects the most reliable keypoints, further enhancing calibration accuracy. We evaluated our approach on the largest football broadcast camera calibration dataset available, and secured the top position in the SoccerNet Camera Calibration Challenge 2023 [arXiv:2309.06006], which demonstrates the effectiveness of our method in real-world scenarios. The project code is available at this https URL .
+
+
+
+ 124. 【2410.07394】Structured Spatial Reasoning with Open Vocabulary Object Detectors
+ 链接:https://arxiv.org/abs/2410.07394
+ 作者:Negar Nejatishahidin,Madhukar Reddy Vongala,Jana Kosecka
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Language Models, Active Vision Dataset, spatial reasoning tasks, object rearrangement, object search
+ 备注:
+
+ 点击查看摘要
+ Abstract:Reasoning about spatial relationships between objects is essential for many real-world robotic tasks, such as fetch-and-delivery, object rearrangement, and object search. The ability to detect and disambiguate different objects and identify their location is key to successful completion of these tasks. Several recent works have used powerful Vision and Language Models (VLMs) to unlock this capability in robotic agents. In this paper we introduce a structured probabilistic approach that integrates rich 3D geometric features with state-of-the-art open-vocabulary object detectors to enhance spatial reasoning for robotic perception. The approach is evaluated and compared against zero-shot performance of the state-of-the-art Vision and Language Models (VLMs) on spatial reasoning tasks. To enable this comparison, we annotate spatial clauses in real-world RGB-D Active Vision Dataset [1] and conduct experiments on this and the synthetic Semantic Abstraction [2] dataset. Results demonstrate the effectiveness of the proposed method, showing superior performance of grounding spatial relations over state of the art open-source VLMs by more than 20%.
+
+
+
+ 125. 【2410.07385】En masse scanning and automated surfacing of small objects using Micro-CT
+ 链接:https://arxiv.org/abs/2410.07385
+ 作者:Riley C. W. O'Neill,Katrina Yezzi-Woodley,Jeff Calder,Peter J. Olver
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:computationally intensive analyses, Modern archaeological methods, high resolution scanning, Modern archaeological, large datasets
+ 备注: 36 pages, 12 figures, 2 tables. Source code available at [this https URL](https://github.com/oneil571/AMAAZE-MCT-Processing)
+
+ 点击查看摘要
+ Abstract:Modern archaeological methods increasingly utilize 3D virtual representations of objects, computationally intensive analyses, high resolution scanning, large datasets, and machine learning. With higher resolution scans, challenges surrounding computational power, memory, and file storage quickly arise. Processing and analyzing high resolution scans often requires memory-intensive workflows, which are infeasible for most computers and increasingly necessitate the use of super-computers or innovative methods for processing on standard computers. Here we introduce a novel protocol for en-masse micro-CT scanning of small objects with a {\em mostly-automated} processing workflow that functions in memory-limited settings. We scanned 1,112 animal bone fragments using just 10 micro-CT scans, which were post-processed into individual PLY files. Notably, our methods can be applied to any object (with discernible density from the packaging material) making this method applicable to a variety of inquiries and fields including paleontology, geology, electrical engineering, and materials science. Further, our methods may immediately be adopted by scanning institutes to pool customer orders together and offer more affordable scanning. The work presented herein is part of a larger program facilitated by the international and multi-disciplinary research consortium known as Anthropological and Mathematical Analysis of Archaeological and Zooarchaeological Evidence (AMAAZE). AMAAZE unites experts in anthropology, mathematics, and computer science to develop new methods for mass-scale virtual archaeological research. Overall, our new scanning method and processing workflows lay the groundwork and set the standard for future mass-scale, high resolution scanning studies.
+
+
+
+ 126. 【2410.07336】Positive-Augmented Contrastive Learning for Vision-and-Language Evaluation and Training
+ 链接:https://arxiv.org/abs/2410.07336
+ 作者:Sara Sarto,Nicholas Moratelli,Marcella Cornia,Lorenzo Baraldi,Rita Cucchiara
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Multimedia (cs.MM)
+ 关键词:significant advancements, fail to capture, capture the full, fine-grained details, existing evaluation metrics
+ 备注:
+
+ 点击查看摘要
+ Abstract:Despite significant advancements in caption generation, existing evaluation metrics often fail to capture the full quality or fine-grained details of captions. This is mainly due to their reliance on non-specific human-written references or noisy pre-training data. Still, finding an effective metric is crucial not only for captions evaluation but also for the generation phase. Metrics can indeed play a key role in the fine-tuning stage of captioning models, ultimately enhancing the quality of the generated captions. In this paper, we propose PAC-S++, a learnable metric that leverages the CLIP model, pre-trained on both web-collected and cleaned data and regularized through additional pairs of generated visual and textual positive samples. Exploiting this stronger and curated pre-training, we also apply PAC-S++ as a reward in the Self-Critical Sequence Training (SCST) stage typically employed to fine-tune captioning models. Extensive experiments on different image and video datasets highlight the effectiveness of PAC-S++ compared to popular metrics for the task, including its sensitivity to object hallucinations. Furthermore, we show that integrating PAC-S++ into the fine-tuning stage of a captioning model results in semantically richer captions with fewer repetitions and grammatical errors. Evaluations on out-of-domain benchmarks further demonstrate the efficacy of our fine-tuning approach in enhancing model capabilities. Source code and trained models are publicly available at: this https URL.
+
+
+
+ 127. 【2410.07303】Rectified Diffusion: Straightness Is Not Your Need in Rectified Flow
+ 链接:https://arxiv.org/abs/2410.07303
+ 作者:Fu-Yun Wang,Ling Yang,Zhaoyang Huang,Mengdi Wang,Hongsheng Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:solving generative ODEs, computationally intensive nature, improved visual generation, slow generation speed, generation speed due
+ 备注:
+
+ 点击查看摘要
+ Abstract:Diffusion models have greatly improved visual generation but are hindered by slow generation speed due to the computationally intensive nature of solving generative ODEs. Rectified flow, a widely recognized solution, improves generation speed by straightening the ODE path. Its key components include: 1) using the diffusion form of flow-matching, 2) employing $\boldsymbol v$-prediction, and 3) performing rectification (a.k.a. reflow). In this paper, we argue that the success of rectification primarily lies in using a pretrained diffusion model to obtain matched pairs of noise and samples, followed by retraining with these matched noise-sample pairs. Based on this, components 1) and 2) are unnecessary. Furthermore, we highlight that straightness is not an essential training target for rectification; rather, it is a specific case of flow-matching models. The more critical training target is to achieve a first-order approximate ODE path, which is inherently curved for models like DDPM and Sub-VP. Building on this insight, we propose Rectified Diffusion, which generalizes the design space and application scope of rectification to encompass the broader category of diffusion models, rather than being restricted to flow-matching models. We validate our method on Stable Diffusion v1-5 and Stable Diffusion XL. Our method not only greatly simplifies the training procedure of rectified flow-based previous works (e.g., InstaFlow) but also achieves superior performance with even lower training cost. Our code is available at this https URL.
+
+
+
+ 128. 【2410.07299】owards Generalisable Time Series Understanding Across Domains
+ 链接:https://arxiv.org/abs/2410.07299
+ 作者:Özgün Turgut,Philip Müller,Martin J. Menten,Daniel Rueckert
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:datasets unlocks foundational, natural language processing, large datasets unlocks, time series, unlocks foundational model
+ 备注:
+
+ 点击查看摘要
+ Abstract:In natural language processing and computer vision, self-supervised pre-training on large datasets unlocks foundational model capabilities across domains and tasks. However, this potential has not yet been realised in time series analysis, where existing methods disregard the heterogeneous nature of time series characteristics. Time series are prevalent in many domains, including medicine, engineering, natural sciences, and finance, but their characteristics vary significantly in terms of variate count, inter-variate relationships, temporal dynamics, and sampling frequency. This inherent heterogeneity across domains prevents effective pre-training on large time series corpora. To address this issue, we introduce OTiS, an open model for general time series analysis, that has been specifically designed to handle multi-domain heterogeneity. We propose a novel pre-training paradigm including a tokeniser with learnable domain-specific signatures, a dual masking strategy to capture temporal causality, and a normalised cross-correlation loss to model long-range dependencies. Our model is pre-trained on a large corpus of 640,187 samples and 11 billion time points spanning 8 distinct domains, enabling it to analyse time series from any (unseen) domain. In comprehensive experiments across 15 diverse applications - including classification, regression, and forecasting - OTiS showcases its ability to accurately capture domain-specific data characteristics and demonstrates its competitiveness against state-of-the-art baselines. Our code and pre-trained weights are publicly available at this https URL.
+
+
+
+ 129. 【2410.07298】Enhancing Performance of Point Cloud Completion Networks with Consistency Loss
+ 链接:https://arxiv.org/abs/2410.07298
+ 作者:Kevin Tirta Wijaya,Christofel Rio Goenawan,Seung-Hyun Kong
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Point cloud completion, proposed consistency loss, Point cloud, consistency loss, point completion network
+ 备注: First version of Paper "Enhancing Performance of Point Cloud Completion Networks with Consistency Loss" by Kevin Tirta Wijaya and Christofel Rio Goenawan. In process submission to Neurocomputing Journal 2024
+
+ 点击查看摘要
+ Abstract:Point cloud completion networks are conventionally trained to minimize the disparities between the completed point cloud and the ground-truth counterpart. However, an incomplete object-level point cloud can have multiple valid completion solutions when it is examined in isolation. This one-to-many mapping issue can cause contradictory supervision signals to the network because the loss function may produce different values for identical input-output pairs of the network. In many cases, this issue could adversely affect the network optimization process. In this work, we propose to enhance the conventional learning objective using a novel completion consistency loss to mitigate the one-to-many mapping problem. Specifically, the proposed consistency loss ensure that a point cloud completion network generates a coherent completion solution for incomplete objects originating from the same source point cloud. Experimental results across multiple well-established datasets and benchmarks demonstrated the proposed completion consistency loss have excellent capability to enhance the completion performance of various existing networks without any modification to the design of the networks. The proposed consistency loss enhances the performance of the point completion network without affecting the inference speed, thereby increasing the accuracy of point cloud completion. Notably, a state-of-the-art point completion network trained with the proposed consistency loss can achieve state-of-the-art accuracy on the challenging new MVP dataset. The code and result of experiment various point completion models using proposed consistency loss will be available at: this https URL .
+
+
+
+ 130. 【2410.07296】ReinDiffuse: Crafting Physically Plausible Motions with Reinforced Diffusion Model
+ 链接:https://arxiv.org/abs/2410.07296
+ 作者:Gaoge Han,Mingjiang Liang,Jinglei Tang,Yongkang Cheng,Wei Liu,Shaoli Huang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Generating human motion, Generating human, challenging task, motion diffusion model, diffusion model
+ 备注: Accepted by WACV 2025 in Round 1
+
+ 点击查看摘要
+ Abstract:Generating human motion from textual descriptions is a challenging task. Existing methods either struggle with physical credibility or are limited by the complexities of physics simulations. In this paper, we present \emph{ReinDiffuse} that combines reinforcement learning with motion diffusion model to generate physically credible human motions that align with textual descriptions. Our method adapts Motion Diffusion Model to output a parameterized distribution of actions, making them compatible with reinforcement learning paradigms. We employ reinforcement learning with the objective of maximizing physically plausible rewards to optimize motion generation for physical fidelity. Our approach outperforms existing state-of-the-art models on two major datasets, HumanML3D and KIT-ML, achieving significant improvements in physical plausibility and motion quality. Project: \url{this https URL}
+
+
+
+ 131. 【2410.07278】Retrieval Replace Reduction: An effective visual token reduction method via semantic match
+ 链接:https://arxiv.org/abs/2410.07278
+ 作者:Yingen Liu,Fan Wu,Ruihui Li,Zhuo Tang,Kenli Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:large language models, Multimodal large language, demonstrated strong performance, language models, training from scratch
+ 备注: 8 pages, 2 figures,3 tables
+
+ 点击查看摘要
+ Abstract:Multimodal large language models (MLLMs) have demonstrated strong performance across various tasks without requiring training from scratch. However, they face significant computational and memory constraints, particularly when processing multimodal inputs that exceed context length, limiting their scalability. In this paper, we introduce a new approach, \textbf{TRSM} (\textbf{T}oken \textbf{R}eduction via \textbf{S}emantic \textbf{M}atch), which effectively reduces the number of visual tokens without compromising MLLM performance. Inspired by how humans process multimodal tasks, TRSM leverages semantic information from one modality to match relevant semantics in another, reducing the number of visual this http URL, to retain task relevant visual tokens, we use the text prompt as a query vector to retrieve the most similar vectors from the visual prompt and merge them with the text tokens. Based on experimental results, when applied to LLaVA-1.5\cite{liu2023}, our approach compresses the visual tokens by 20\%, achieving comparable performance across diverse visual question-answering and reasoning tasks.
+
+
+
+ 132. 【2410.07274】Mitigation of gender bias in automatic facial non-verbal behaviors generation
+ 链接:https://arxiv.org/abs/2410.07274
+ 作者:Alice Delbosc(TALEP, LIS, AMU),Magalie Ochs(LIS, AMU, R2I),Nicolas Sabouret(CPU, LISN),Brian Ravenet(CPU, LISN),Stephane Ayache(AMU, LIS, QARMA)
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Human-Computer Interaction (cs.HC); Machine Learning (cs.LG); Neural and Evolutionary Computing (cs.NE)
+ 关键词:interactive agents focuses, social interactive agents, social interactive, believability and synchronization, Research
+ 备注:
+
+ 点击查看摘要
+ Abstract:Research on non-verbal behavior generation for social interactive agents focuses mainly on the believability and synchronization of non-verbal cues with speech. However, existing models, predominantly based on deep learning architectures, often perpetuate biases inherent in the training data. This raises ethical concerns, depending on the intended application of these agents. This paper addresses these issues by first examining the influence of gender on facial non-verbal behaviors. We concentrate on gaze, head movements, and facial expressions. We introduce a classifier capable of discerning the gender of a speaker from their non-verbal cues. This classifier achieves high accuracy on both real behavior data, extracted using state-of-the-art tools, and synthetic data, generated from a model developed in previous this http URL upon this work, we present a new model, FairGenderGen, which integrates a gender discriminator and a gradient reversal layer into our previous behavior generation model. This new model generates facial non-verbal behaviors from speech features, mitigating gender sensitivity in the generated behaviors. Our experiments demonstrate that the classifier, developed in the initial phase, is no longer effective in distinguishing the gender of the speaker from the generated non-verbal behaviors.
+
+
+
+ 133. 【2410.07273】BELM: Bidirectional Explicit Linear Multi-step Sampler for Exact Inversion in Diffusion Models
+ 链接:https://arxiv.org/abs/2410.07273
+ 作者:Fangyikang Wang,Hubery Yin,Yuejiang Dong,Huminhao Zhu,Chao Zhang,Hanbin Zhao,Hui Qian,Chen Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:exact inversion samplers, exact inversion, diffusion model sampling, heuristic exact inversion, inversion samplers
+ 备注: accepted paper by NeurIPS
+
+ 点击查看摘要
+ Abstract:The inversion of diffusion model sampling, which aims to find the corresponding initial noise of a sample, plays a critical role in various tasks. Recently, several heuristic exact inversion samplers have been proposed to address the inexact inversion issue in a training-free manner. However, the theoretical properties of these heuristic samplers remain unknown and they often exhibit mediocre sampling quality. In this paper, we introduce a generic formulation, \emph{Bidirectional Explicit Linear Multi-step} (BELM) samplers, of the exact inversion samplers, which includes all previously proposed heuristic exact inversion samplers as special cases. The BELM formulation is derived from the variable-stepsize-variable-formula linear multi-step method via integrating a bidirectional explicit constraint. We highlight this bidirectional explicit constraint is the key of mathematically exact inversion. We systematically investigate the Local Truncation Error (LTE) within the BELM framework and show that the existing heuristic designs of exact inversion samplers yield sub-optimal LTE. Consequently, we propose the Optimal BELM (O-BELM) sampler through the LTE minimization approach. We conduct additional analysis to substantiate the theoretical stability and global convergence property of the proposed optimal sampler. Comprehensive experiments demonstrate our O-BELM sampler establishes the exact inversion property while achieving high-quality sampling. Additional experiments in image editing and image interpolation highlight the extensive potential of applying O-BELM in varying applications.
+
+
+
+ 134. 【2410.07268】Learning Content-Aware Multi-Modal Joint Input Pruning via Bird's-Eye-View Representation
+ 链接:https://arxiv.org/abs/2410.07268
+ 作者:Yuxin Li,Yiheng Li,Xulei Yang,Mengying Yu,Zihang Huang,Xiaojun Wu,Chai Kiat Yeo
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:substantial academic attention, recently garnered substantial, garnered substantial academic, autonomous driving, representation has recently
+ 备注:
+
+ 点击查看摘要
+ Abstract:In the landscape of autonomous driving, Bird's-Eye-View (BEV) representation has recently garnered substantial academic attention, serving as a transformative framework for the fusion of multi-modal sensor inputs. This BEV paradigm effectively shifts the sensor fusion challenge from a rule-based methodology to a data-centric approach, thereby facilitating more nuanced feature extraction from an array of heterogeneous sensors. Notwithstanding its evident merits, the computational overhead associated with BEV-based techniques often mandates high-capacity hardware infrastructures, thus posing challenges for practical, real-world implementations. To mitigate this limitation, we introduce a novel content-aware multi-modal joint input pruning technique. Our method leverages BEV as a shared anchor to algorithmically identify and eliminate non-essential sensor regions prior to their introduction into the perception model's backbone. We validatethe efficacy of our approach through extensive experiments on the NuScenes dataset, demonstrating substantial computational efficiency without sacrificing perception accuracy. To the best of our knowledge, this work represents the first attempt to alleviate the computational burden from the input pruning point.
+
+
+
+ 135. 【2410.07266】Spiking GS: Towards High-Accuracy and Low-Cost Surface Reconstruction via Spiking Neuron-based Gaussian Splatting
+ 链接:https://arxiv.org/abs/2410.07266
+ 作者:Weixing Zhang,Zongrui Li,De Ma,Huajin Tang,Xudong Jiang,Qian Zheng,Gang Pan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Gaussian Splatting, scenes in minutes, Gaussian Splatting pipeline, capable of reconstructing, Gaussians
+ 备注:
+
+ 点击查看摘要
+ Abstract:3D Gaussian Splatting is capable of reconstructing 3D scenes in minutes. Despite recent advances in improving surface reconstruction accuracy, the reconstructed results still exhibit bias and suffer from inefficiency in storage and training. This paper provides a different observation on the cause of the inefficiency and the reconstruction bias, which is attributed to the integration of the low-opacity parts (LOPs) of the generated Gaussians. We show that LOPs consist of Gaussians with overall low-opacity (LOGs) and the low-opacity tails (LOTs) of Gaussians. We propose Spiking GS to reduce such two types of LOPs by integrating spiking neurons into the Gaussian Splatting pipeline. Specifically, we introduce global and local full-precision integrate-and-fire spiking neurons to the opacity and representation function of flattened 3D Gaussians, respectively. Furthermore, we enhance the density control strategy with spiking neurons' thresholds and an new criterion on the scale of Gaussians. Our method can represent more accurate reconstructed surfaces at a lower cost. The code is available at \url{this https URL}.
+
+
+
+ 136. 【2410.07211】Neural Contrast: Leveraging Generative Editing for Graphic Design Recommendations
+ 链接:https://arxiv.org/abs/2410.07211
+ 作者:Marian Lupascu,Ionut Mironica,Mihai-Sorin Stupariu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR); Human-Computer Interaction (cs.HC); Machine Learning (cs.LG)
+ 关键词:Creating visually appealing, visually appealing composites, appealing composites requires, composites requires optimizing, Creating visually
+ 备注: 14 pages, 5 figures, Paper sent and accepted as a poster at PRICAI 2024
+
+ 点击查看摘要
+ Abstract:Creating visually appealing composites requires optimizing both text and background for compatibility. Previous methods have focused on simple design strategies, such as changing text color or adding background shapes for contrast. These approaches are often destructive, altering text color or partially obstructing the background image. Another method involves placing design elements in non-salient and contrasting regions, but this isn't always effective, especially with patterned backgrounds. To address these challenges, we propose a generative approach using a diffusion model. This method ensures the altered regions beneath design assets exhibit low saliency while enhancing contrast, thereby improving the visibility of the design asset.
+
+
+
+ 137. 【2410.07201】SpaRG: Sparsely Reconstructed Graphs for Generalizable fMRI Analysis
+ 链接:https://arxiv.org/abs/2410.07201
+ 作者:Camila González,Yanis Miraoui,Yiran Fan,Ehsan Adeli,Kilian M. Pohl
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Magnetic Resonance Imaging, functional Magnetic Resonance, resting-state functional Magnetic, Resonance Imaging, Magnetic Resonance
+ 备注:
+
+ 点击查看摘要
+ Abstract:Deep learning can help uncover patterns in resting-state functional Magnetic Resonance Imaging (rs-fMRI) associated with psychiatric disorders and personal traits. Yet the problem of interpreting deep learning findings is rarely more evident than in fMRI analyses, as the data is sensitive to scanning effects and inherently difficult to visualize. We propose a simple approach to mitigate these challenges grounded on sparsification and self-supervision. Instead of extracting post-hoc feature attributions to uncover functional connections that are important to the target task, we identify a small subset of highly informative connections during training and occlude the rest. To this end, we jointly train a (1) sparse input mask, (2) variational autoencoder (VAE), and (3) downstream classifier in an end-to-end fashion. While we need a portion of labeled samples to train the classifier, we optimize the sparse mask and VAE with unlabeled data from additional acquisition sites, retaining only the input features that generalize well. We evaluate our method - Sparsely Reconstructed Graphs (SpaRG) - on the public ABIDE dataset for the task of sex classification, training with labeled cases from 18 sites and adapting the model to two additional out-of-distribution sites with a portion of unlabeled samples. For a relatively coarse parcellation (64 regions), SpaRG utilizes only 1% of the original connections while improving the classification accuracy across domains. Our code can be found at this http URL.
+
+
+
+ 138. 【2410.07194】chnical Report: Competition Solution For Modelscope-Sora
+ 链接:https://arxiv.org/abs/2410.07194
+ 作者:Shengfu Chen,Hailong Liu,Wenzhao Wei
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:presents the approach, approach adopted, focuses on fine-tuning, video generation models, Modelscope-Sora challenge
+ 备注:
+
+ 点击查看摘要
+ Abstract:This report presents the approach adopted in the Modelscope-Sora challenge, which focuses on fine-tuning data for video generation models. The challenge evaluates participants' ability to analyze, clean, and generate high-quality datasets for video-based text-to-video tasks under specific computational constraints. The provided methodology involves data processing techniques such as video description generation, filtering, and acceleration. This report outlines the procedures and tools utilized to enhance the quality of training data, ensuring improved performance in text-to-video generation models.
+
+
+
+ 139. 【2410.07185】Margin-bounded Confidence Scores for Out-of-Distribution Detection
+ 链接:https://arxiv.org/abs/2410.07185
+ 作者:Lakpa D. Tamang,Mohamed Reda Bouadjenek,Richard Dazeley,Sunil Aryal
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Machine Learning applications, critical Machine Learning, accurately classifying in-distribution, critical Machine, medical image diagnosis
+ 备注: 10 pages, 5 figures, IEEE Conference in Data Mining 2024
+
+ 点击查看摘要
+ Abstract:In many critical Machine Learning applications, such as autonomous driving and medical image diagnosis, the detection of out-of-distribution (OOD) samples is as crucial as accurately classifying in-distribution (ID) inputs. Recently Outlier Exposure (OE) based methods have shown promising results in detecting OOD inputs via model fine-tuning with auxiliary outlier data. However, most of the previous OE-based approaches emphasize more on synthesizing extra outlier samples or introducing regularization to diversify OOD sample space, which is rather unquantifiable in practice. In this work, we propose a novel and straightforward method called Margin bounded Confidence Scores (MaCS) to address the nontrivial OOD detection problem by enlarging the disparity between ID and OOD scores, which in turn makes the decision boundary more compact facilitating effective segregation with a simple threshold. Specifically, we augment the learning objective of an OE regularized classifier with a supplementary constraint, which penalizes high confidence scores for OOD inputs compared to that of ID and significantly enhances the OOD detection performance while maintaining the ID classification accuracy. Extensive experiments on various benchmark datasets for image classification tasks demonstrate the effectiveness of the proposed method by significantly outperforming state-of-the-art (S.O.T.A) methods on various benchmarking metrics. The code is publicly available at this https URL
+
+
+
+ 140. 【2410.06468】Does Spatial Cognition Emerge in Frontier Models?
+ 链接:https://arxiv.org/abs/2410.06468
+ 作者:Santhosh Kumar Ramakrishnan,Erik Wijmans,Philipp Kraehenbuehl,Vladlen Koltun
+ 类目:Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:present SPACE, Abstract, models, benchmark, spatial
+ 备注:
+
+ 点击查看摘要
+ Abstract:Not yet. We present SPACE, a benchmark that systematically evaluates spatial cognition in frontier models. Our benchmark builds on decades of research in cognitive science. It evaluates large-scale mapping abilities that are brought to bear when an organism traverses physical environments, smaller-scale reasoning about object shapes and layouts, and cognitive infrastructure such as spatial attention and memory. For many tasks, we instantiate parallel presentations via text and images, allowing us to benchmark both large language models and large multimodal models. Results suggest that contemporary frontier models fall short of the spatial intelligence of animals, performing near chance level on a number of classic tests of animal cognition.
+
+
+
+ 141. 【2410.07924】ICPR 2024 Competition on Multiple Sclerosis Lesion Segmentation -- Methods and Results
+ 链接:https://arxiv.org/abs/2410.07924
+ 作者:Alessia Rondinella,Francesco Guarnera,Elena Crispino,Giulia Russo,Clara Di Lorenzo,Davide Maimone,Francesco Pappalardo,Sebastiano Battiato
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:multiple sclerosis lesions, Multiple Sclerosis, segmenting multiple sclerosis, Sclerosis Lesion Segmentation, sclerosis lesions
+ 备注:
+
+ 点击查看摘要
+ Abstract:This report summarizes the outcomes of the ICPR 2024 Competition on Multiple Sclerosis Lesion Segmentation (MSLesSeg). The competition aimed to develop methods capable of automatically segmenting multiple sclerosis lesions in MRI scans. Participants were provided with a novel annotated dataset comprising a heterogeneous cohort of MS patients, featuring both baseline and follow-up MRI scans acquired at different hospitals. MSLesSeg focuses on developing algorithms that can independently segment multiple sclerosis lesions of an unexamined cohort of patients. This segmentation approach aims to overcome current benchmarks by eliminating user interaction and ensuring robust lesion detection at different timepoints, encouraging innovation and promoting methodological advances.
+
+
+
+ 142. 【2410.07908】ONCOPILOT: A Promptable CT Foundation Model For Solid Tumor Evaluation
+ 链接:https://arxiv.org/abs/2410.07908
+ 作者:Léo Machado,Hélène Philippe,Élodie Ferreres,Julien Khlaut,Julie Dupuis,Korentin Le Floch,Denis Habip Gatenyo,Pascal Roux,Jules Grégory,Maxime Ronot,Corentin Dancette,Daniel Tordjman,Pierre Manceron,Paul Hérent
+ 类目:Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:diverse shapes, proteiform phenomenon, displaying complex, locations and displaying, tumors emerging
+ 备注:
+
+ 点击查看摘要
+ Abstract:Carcinogenesis is a proteiform phenomenon, with tumors emerging in various locations and displaying complex, diverse shapes. At the crucial intersection of research and clinical practice, it demands precise and flexible assessment. However, current biomarkers, such as RECIST 1.1's long and short axis measurements, fall short of capturing this complexity, offering an approximate estimate of tumor burden and a simplistic representation of a more intricate process. Additionally, existing supervised AI models face challenges in addressing the variability in tumor presentations, limiting their clinical utility. These limitations arise from the scarcity of annotations and the models' focus on narrowly defined tasks.
+To address these challenges, we developed ONCOPILOT, an interactive radiological foundation model trained on approximately 7,500 CT scans covering the whole body, from both normal anatomy and a wide range of oncological cases. ONCOPILOT performs 3D tumor segmentation using visual prompts like point-click and bounding boxes, outperforming state-of-the-art models (e.g., nnUnet) and achieving radiologist-level accuracy in RECIST 1.1 measurements. The key advantage of this foundation model is its ability to surpass state-of-the-art performance while keeping the radiologist in the loop, a capability that previous models could not achieve. When radiologists interactively refine the segmentations, accuracy improves further. ONCOPILOT also accelerates measurement processes and reduces inter-reader variability, facilitating volumetric analysis and unlocking new biomarkers for deeper insights.
+This AI assistant is expected to enhance the precision of RECIST 1.1 measurements, unlock the potential of volumetric biomarkers, and improve patient stratification and clinical care, while seamlessly integrating into the radiological workflow.
+
Subjects:
+Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+Cite as:
+arXiv:2410.07908 [eess.IV]
+(or
+arXiv:2410.07908v1 [eess.IV] for this version)
+https://doi.org/10.48550/arXiv.2410.07908
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 143. 【2410.07876】FDDM: Frequency-Decomposed Diffusion Model for Rectum Cancer Dose Prediction in Radiotherapy
+ 链接:https://arxiv.org/abs/2410.07876
+ 作者:Xin Liao,Zhenghao Feng,Jianghong Xiao,Xingchen Peng,Yan Wang
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Accurate dose distribution, dose distribution prediction, Accurate dose, dose map, coarse dose map
+ 备注:
+
+ 点击查看摘要
+ Abstract:Accurate dose distribution prediction is crucial in the radiotherapy planning. Although previous methods based on convolutional neural network have shown promising performance, they have the problem of over-smoothing, leading to prediction without important high-frequency details. Recently, diffusion model has achieved great success in computer vision, which excels in generating images with more high-frequency details, yet suffers from time-consuming and extensive computational resource consumption. To alleviate these problems, we propose Frequency-Decomposed Diffusion Model (FDDM) that refines the high-frequency subbands of the dose map. To be specific, we design a Coarse Dose Prediction Module (CDPM) to first predict a coarse dose map and then utilize discrete wavelet transform to decompose the coarse dose map into a low-frequency subband and three high?frequency subbands. There is a notable difference between the coarse predicted results and ground truth in high?frequency subbands. Therefore, we design a diffusion-based module called High-Frequency Refinement Module (HFRM) that performs diffusion operation in the high?frequency components of the dose map instead of the original dose map. Extensive experiments on an in-house dataset verify the effectiveness of our approach.
+
+
+
+ 144. 【2410.07685】Breaking the curse of dimensionality in structured density estimation
+ 链接:https://arxiv.org/abs/2410.07685
+ 作者:Robert A. Vandermeulen,Wai Ming Tai,Bryon Aragam
+ 类目:Machine Learning (stat.ML); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Statistics Theory (math.ST)
+ 关键词:Markov conditions implied, structured multivariate density, curse of dimensionality, estimating a structured, structured multivariate
+ 备注: Work accepted to NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:We consider the problem of estimating a structured multivariate density, subject to Markov conditions implied by an undirected graph. In the worst case, without Markovian assumptions, this problem suffers from the curse of dimensionality. Our main result shows how the curse of dimensionality can be avoided or greatly alleviated under the Markov property, and applies to arbitrary graphs. While existing results along these lines focus on sparsity or manifold assumptions, we introduce a new graphical quantity called "graph resilience" and show how it controls the sample complexity. Surprisingly, although one might expect the sample complexity of this problem to scale with local graph parameters such as the degree, this turns out not to be the case. Through explicit examples, we compute uniform deviation bounds and illustrate how the curse of dimensionality in density estimation can thus be circumvented. Notable examples where the rate improves substantially include sequential, hierarchical, and spatial data.
+
+
+
+ 145. 【2410.07663】DDSR: Single-Step Diffusion with Two Discriminators for Super Resolution
+ 链接:https://arxiv.org/abs/2410.07663
+ 作者:Sohwi Kim,Tae-Kyun Kim
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:increasingly being specialized, Super-resolution, diffusion-based super-resolution, Abstract, diffusion-based super-resolution method
+ 备注:
+
+ 点击查看摘要
+ Abstract:Super-resolution methods are increasingly being specialized for both real-world and face-specific tasks. However, many existing approaches rely on simplistic degradation models, which limits their ability to handle complex and unknown degradation patterns effectively. While diffusion-based super-resolution techniques have recently shown impressive results, they are still constrained by the need for numerous inference steps. To address this, we propose TDDSR, an efficient single-step diffusion-based super-resolution method. Our method, distilled from a pre-trained teacher model and based on a diffusion network, performs super-resolution in a single step. It integrates a learnable downsampler to capture diverse degradation patterns and employs two discriminators, one for high-resolution and one for low-resolution images, to enhance the overall performance. Experimental results demonstrate its effectiveness across real-world and face-specific SR tasks, achieving performance comparable to, or even surpassing, another single-step method, previous state-of-the-art models, and the teacher model.
+
+
+
+ 146. 【2410.07545】Calibration of 3D Single-pixel Imaging Systems with a Calibration Field
+ 链接:https://arxiv.org/abs/2410.07545
+ 作者:Xinyue Ma,Chenxing Wang
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:ffexibly applied, SPI, promising imaging technique, Abstract, SPI systems
+ 备注:
+
+ 点击查看摘要
+ Abstract:3D single-pixel imaging (SPI) is a promising imaging technique that can be ffexibly applied to various wavebands. The main challenge in 3D SPI is that the calibration usually requires a large number of standard points as references, which are tricky to capture using single-pixel detectors. Conventional solutions involve sophisticated device deployment and cumbersome operations, resulting in hundreds of images needed for calibration. In our work, we construct a Calibration Field (CaliF) to efffciently generate the standard points from one single image. A high accuracy of the CaliF is guaranteed by the technique of deep learning and digital twin. We perform experiments with our new method to verify its validity and accuracy. We believe our work holds great potential in 3D SPI systems or even general imaging systems.
+
+
+
+ 147. 【2410.07503】Modeling Alzheimer's Disease: From Memory Loss to Plaque Tangles Formation
+ 链接:https://arxiv.org/abs/2410.07503
+ 作者:Sai Nag Anurag Nangunoori,Akshara Karthic Mahadevan
+ 类目:Neurons and Cognition (q-bio.NC); Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:employ the Hopfield, Hopfield model, biochemical processes characteristic, Alzheimer disease, Alzheimer
+ 备注: 8 pages, 4 figures
+
+ 点击查看摘要
+ Abstract:We employ the Hopfield model as a simplified framework to explore both the memory deficits and the biochemical processes characteristic of Alzheimer's disease. By simulating neuronal death and synaptic degradation through increasing the number of stored patterns and introducing noise into the synaptic weights, we demonstrate hallmark symptoms of dementia, including memory loss, confusion, and delayed retrieval times. As the network's capacity is exceeded, retrieval errors increase, mirroring the cognitive confusion observed in Alzheimer's patients. Additionally, we simulate the impact of synaptic degradation by varying the sparsity of the weight matrix, showing impaired memory recall and reduced retrieval success as noise levels increase. Furthermore, we extend our model to connect memory loss with biochemical processes linked to Alzheimer's. By simulating the role of reduced insulin sensitivity over time, we show how it can trigger increased calcium influx into mitochondria, leading to misfolded proteins and the formation of amyloid plaques. These findings, modeled over time, suggest that both neuronal degradation and metabolic factors contribute to the progressive decline seen in Alzheimer's disease. Our work offers a computational framework for understanding the dual impact of synaptic and metabolic dysfunction in neurodegenerative diseases.
+
+
+
+ 148. 【2410.07269】Deep Learning for Surgical Instrument Recognition and Segmentation in Robotic-Assisted Surgeries: A Systematic Review
+ 链接:https://arxiv.org/abs/2410.07269
+ 作者:Fatimaelzahraa Ali Ahmed,Mahmoud Yousef,Mariam Ali Ahmed,Hasan Omar Ali,Anns Mahboob,Hazrat Ali,Zubair Shah,Omar Aboumarzouk,Abdulla Al Ansari,Shidin Balakrishnan
+ 类目:Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Applying deep learning, minimally invasive surgeries, robot-assisted minimally invasive, Applying deep, surgical
+ 备注: 57 pages, 9 figures, Accepted for publication in Artificial Intelligence Reviews journal [this https URL](https://link.springer.com/journal/10462>)
+
+ 点击查看摘要
+ Abstract:Applying deep learning (DL) for annotating surgical instruments in robot-assisted minimally invasive surgeries (MIS) represents a significant advancement in surgical technology. This systematic review examines 48 studies that and advanced DL methods and architectures. These sophisticated DL models have shown notable improvements in the precision and efficiency of detecting and segmenting surgical tools. The enhanced capabilities of these models support various clinical applications, including real-time intraoperative guidance, comprehensive postoperative evaluations, and objective assessments of surgical skills. By accurately identifying and segmenting surgical instruments in video data, DL models provide detailed feedback to surgeons, thereby improving surgical outcomes and reducing complication risks. Furthermore, the application of DL in surgical education is transformative. The review underscores the significant impact of DL on improving the accuracy of skill assessments and the overall quality of surgical training programs. However, implementing DL in surgical tool detection and segmentation faces challenges, such as the need for large, accurately annotated datasets to train these models effectively. The manual annotation process is labor-intensive and time-consuming, posing a significant bottleneck. Future research should focus on automating the detection and segmentation process and enhancing the robustness of DL models against environmental variations. Expanding the application of DL models across various surgical specialties will be essential to fully realize this technology's potential. Integrating DL with other emerging technologies, such as augmented reality (AR), also offers promising opportunities to further enhance the precision and efficacy of surgical procedures.
+
+
+





/Fig1_pretrain_finetune.png)
/Fig2_eda1.png)
/Fig2_eda2.png)
/Fig2_eda3.png)
/Fig3_reweight.png)
/Fig5_model1.png)
/Fig5_attention_mask.png)
/Fig4_wwm.png)
/Fig5_model2.png)
/Fig5_model3.png)
/Fig7_ensemble1.png)
/Fig6_res1.png)
/Fig6_res2.png)


%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_text_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_entity_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/model.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/dont_stop_pretraining.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/a.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/b.png)

%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/lengths_histplot.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_entity_lengths.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_label_dist.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/%E6%80%BB%E4%BD%93%E6%96%B9%E6%A1%88.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/pretrain_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/finetune_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/rdrop.png)

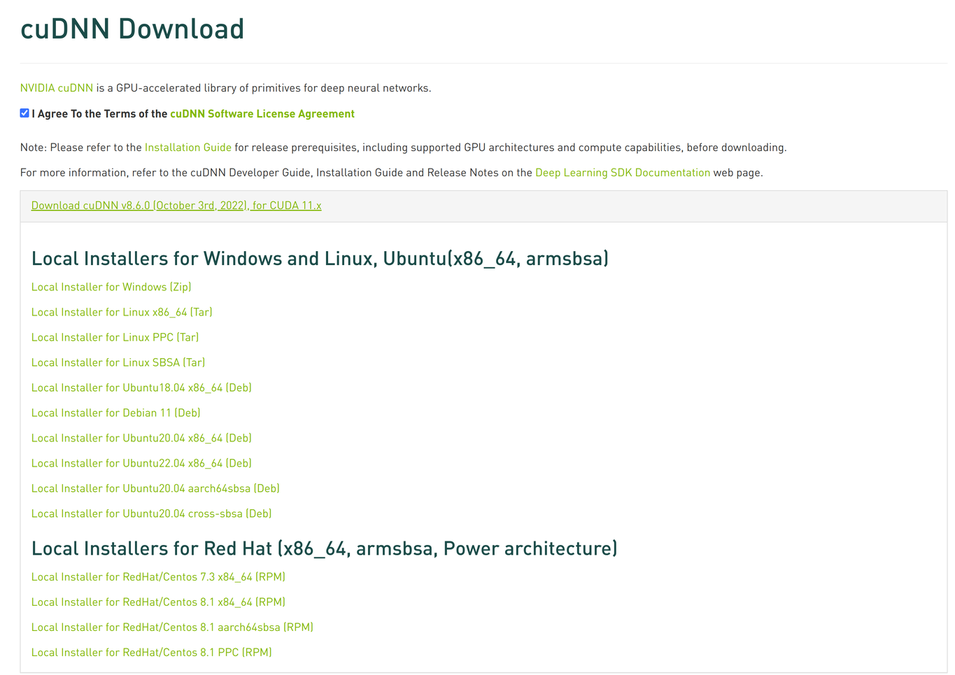
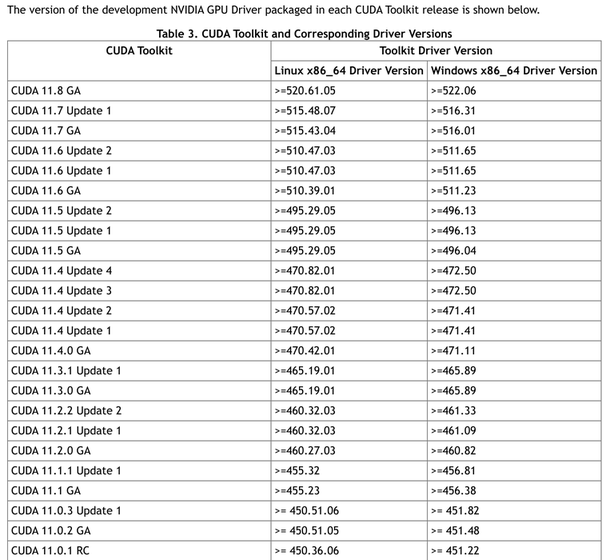

/autoencoder-architecture.png)
/variational-autoencoder-architecture.png)
/forward_vs_reversed_KL.png)
/vae-implement.png)
/reparam.png)
/generated_samples.png)







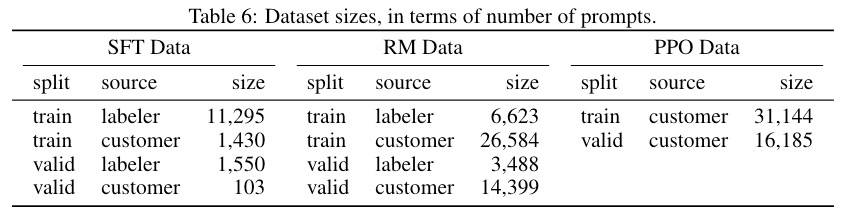
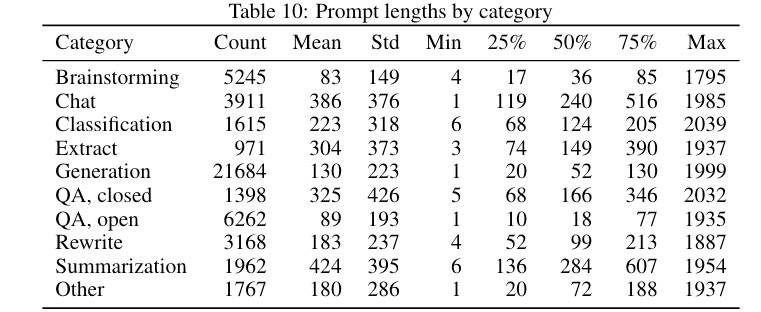
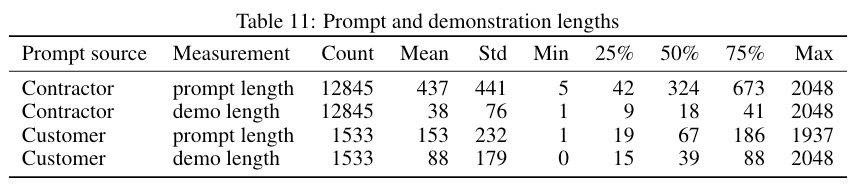

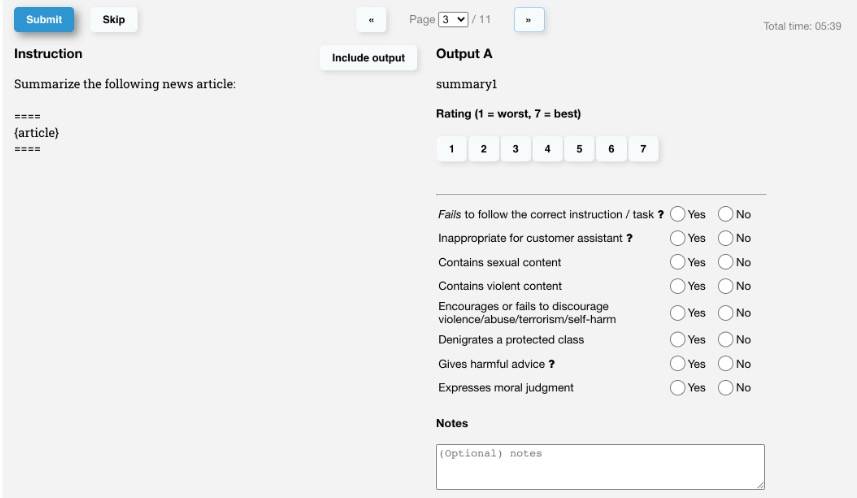
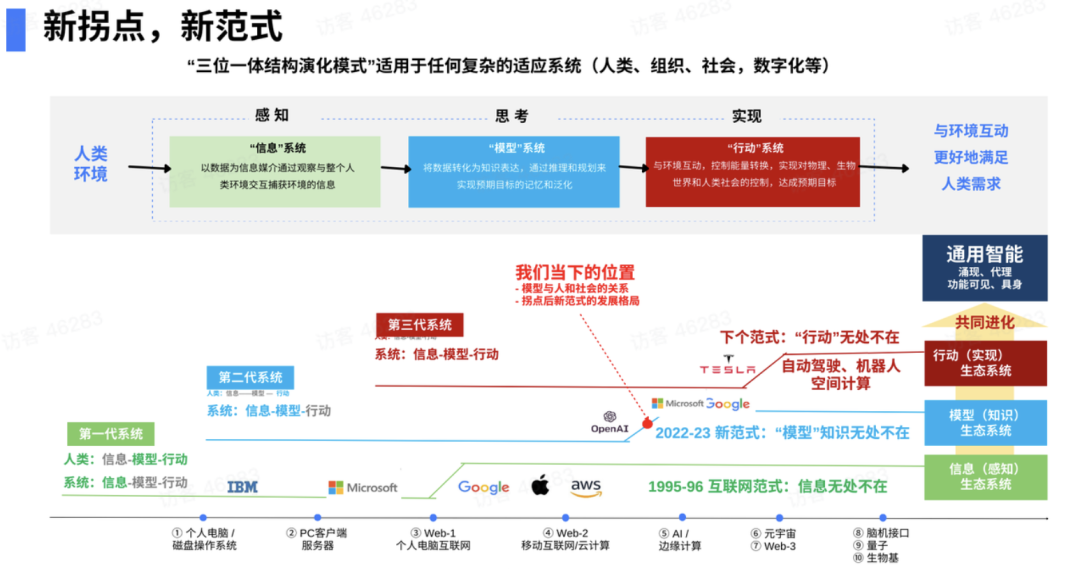
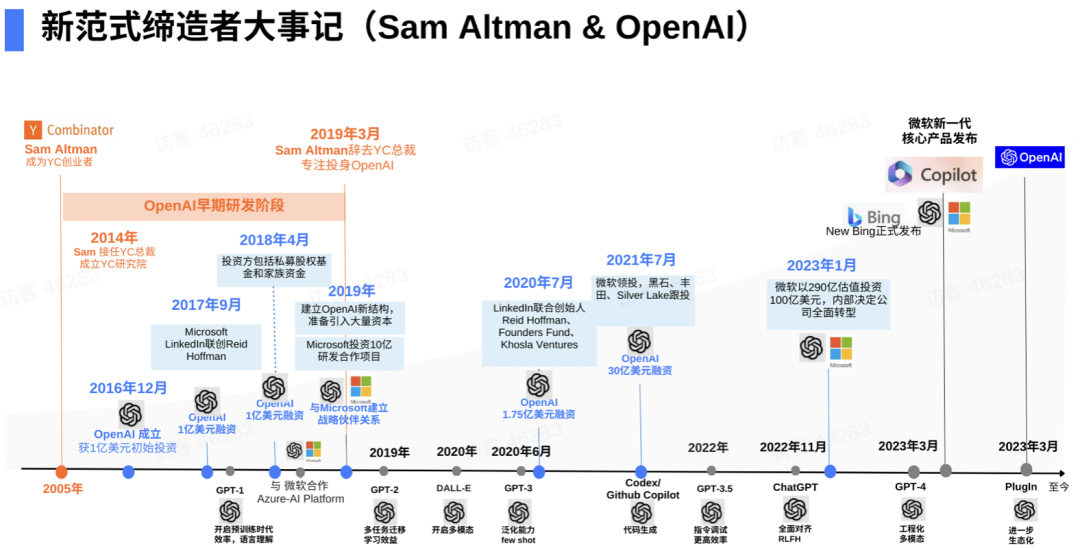
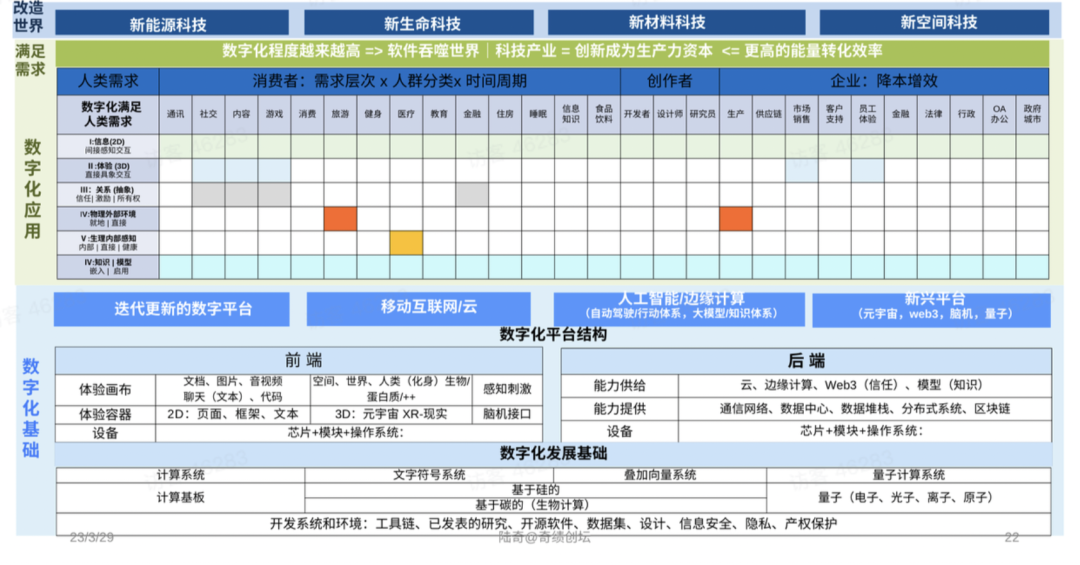
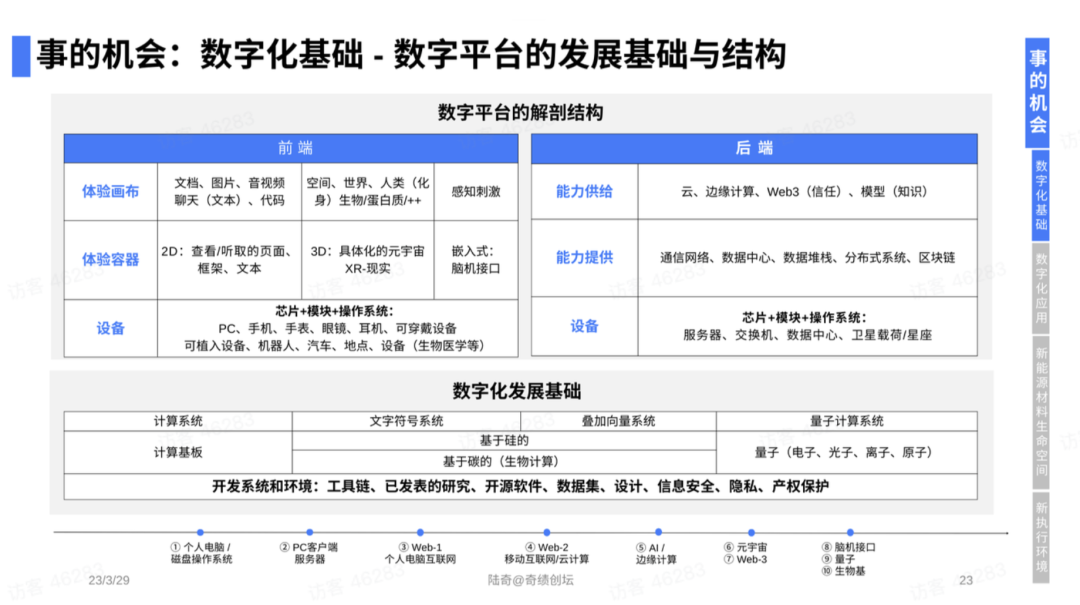
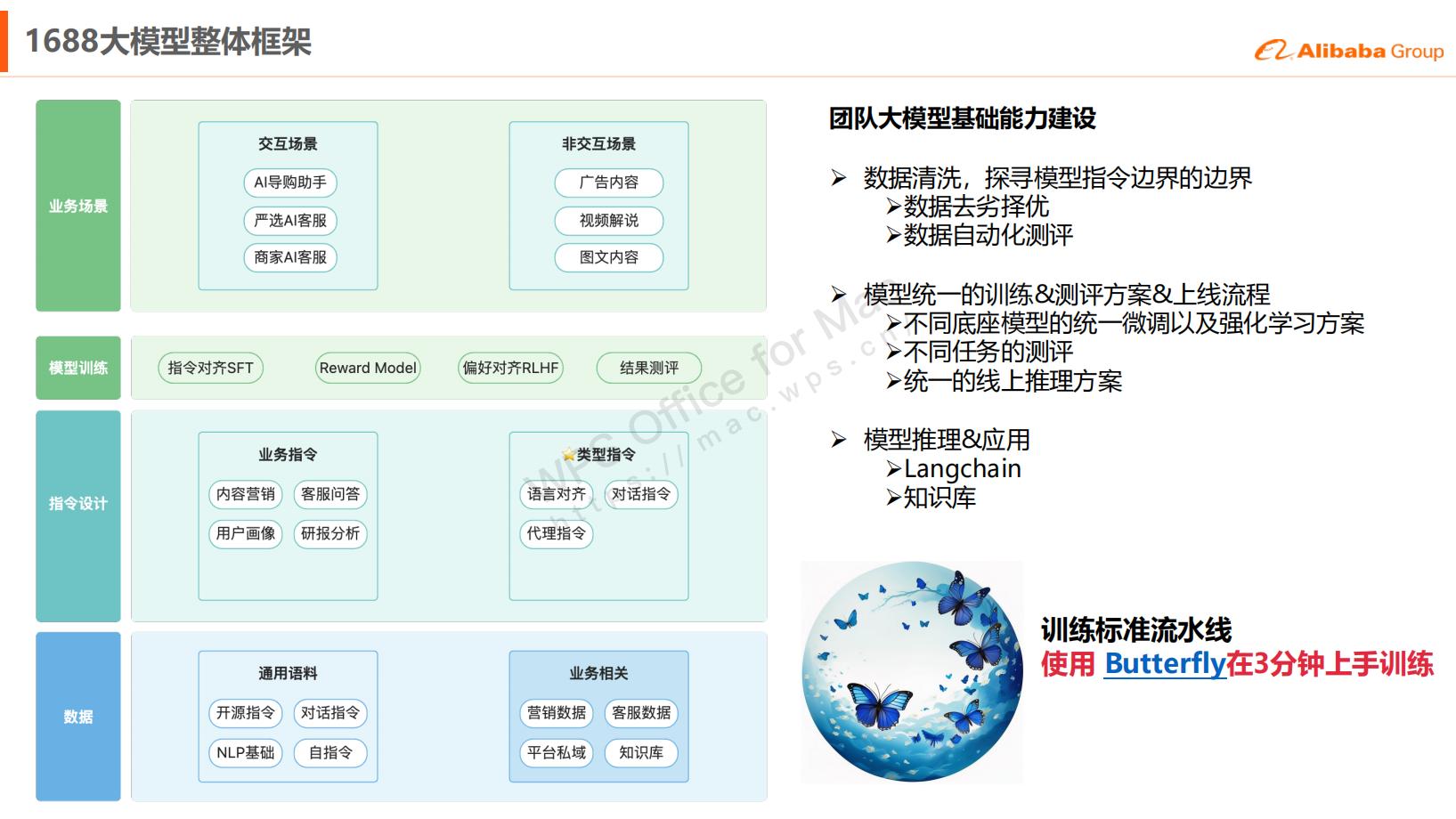
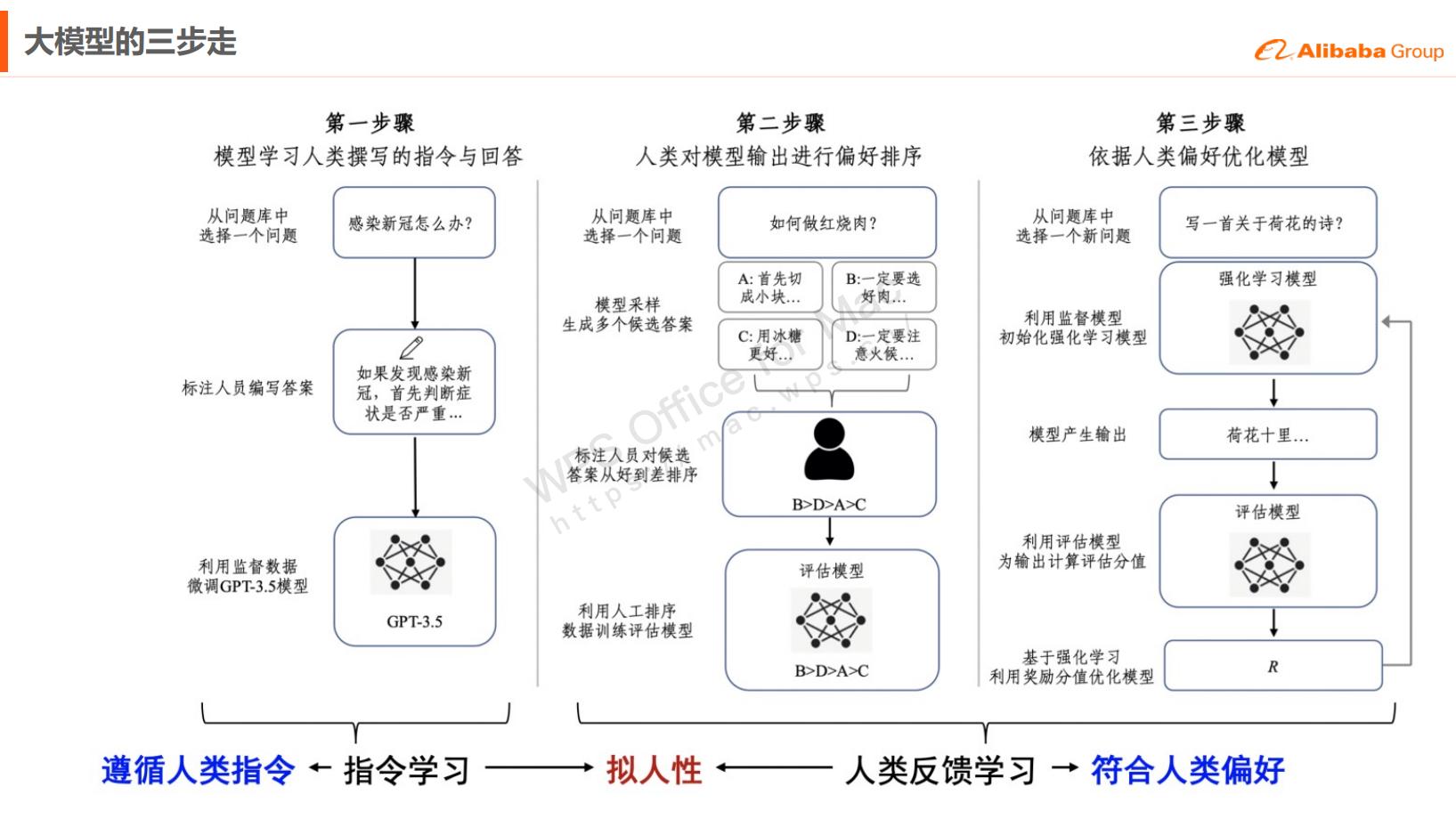
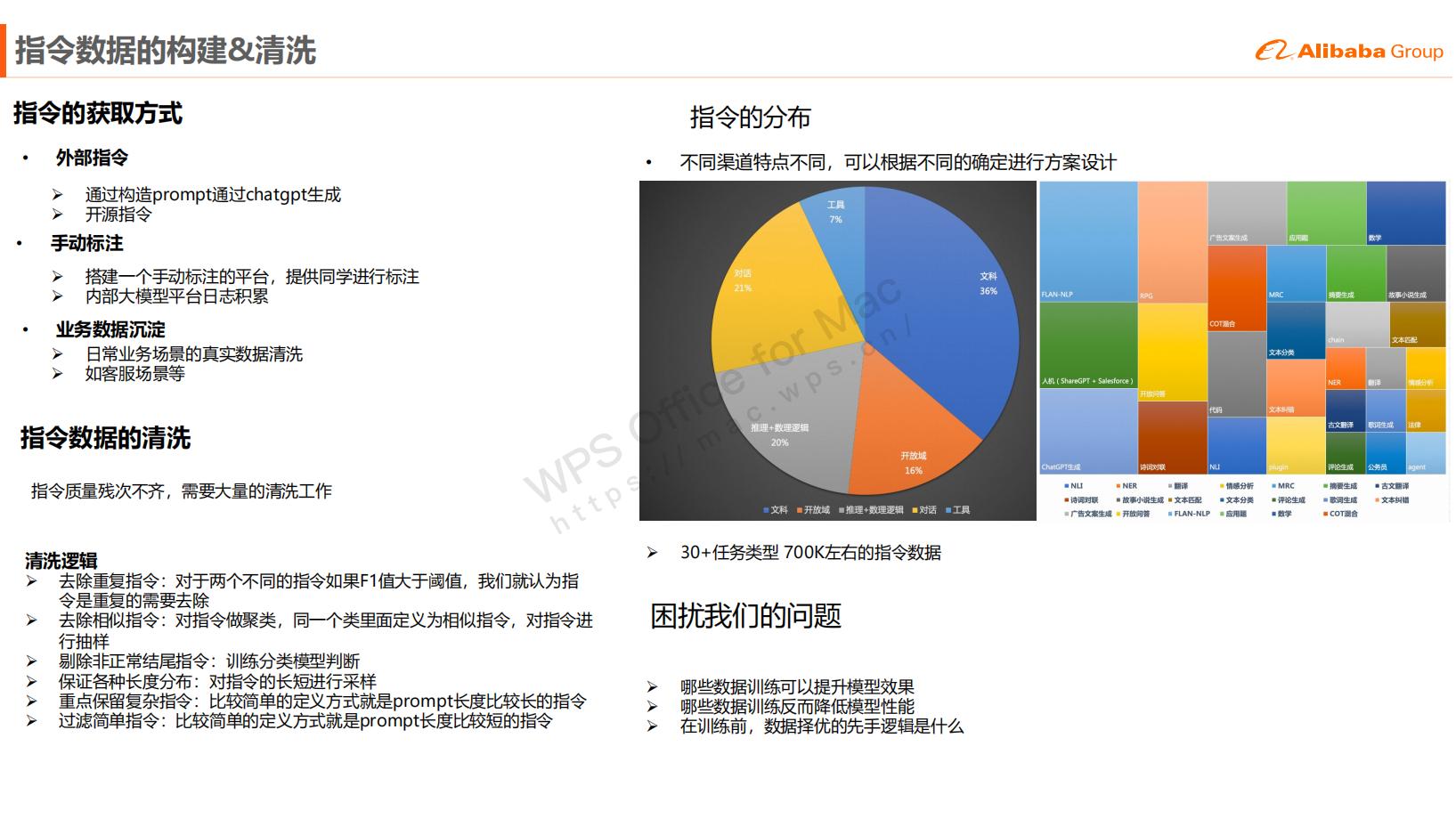

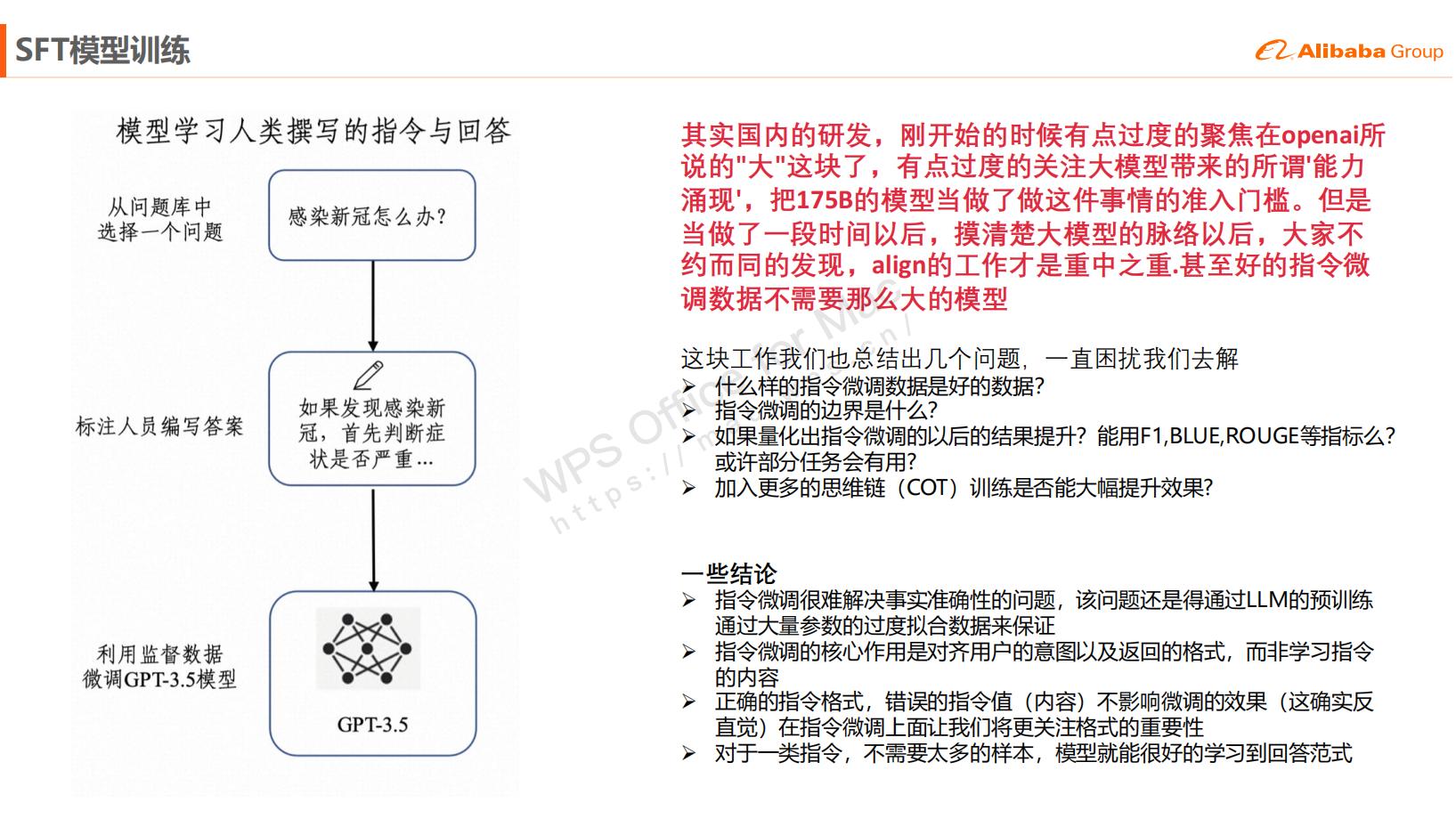

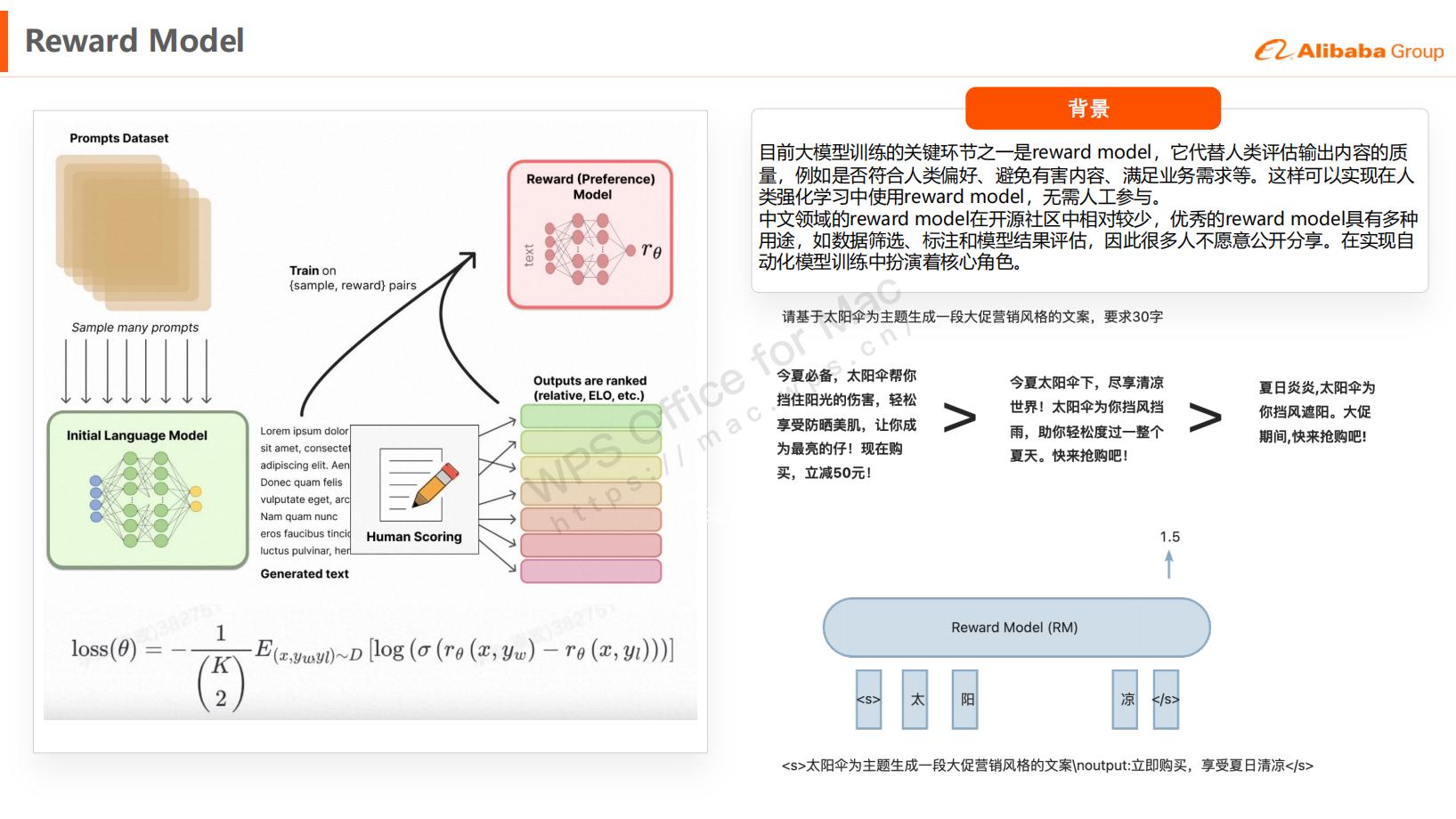




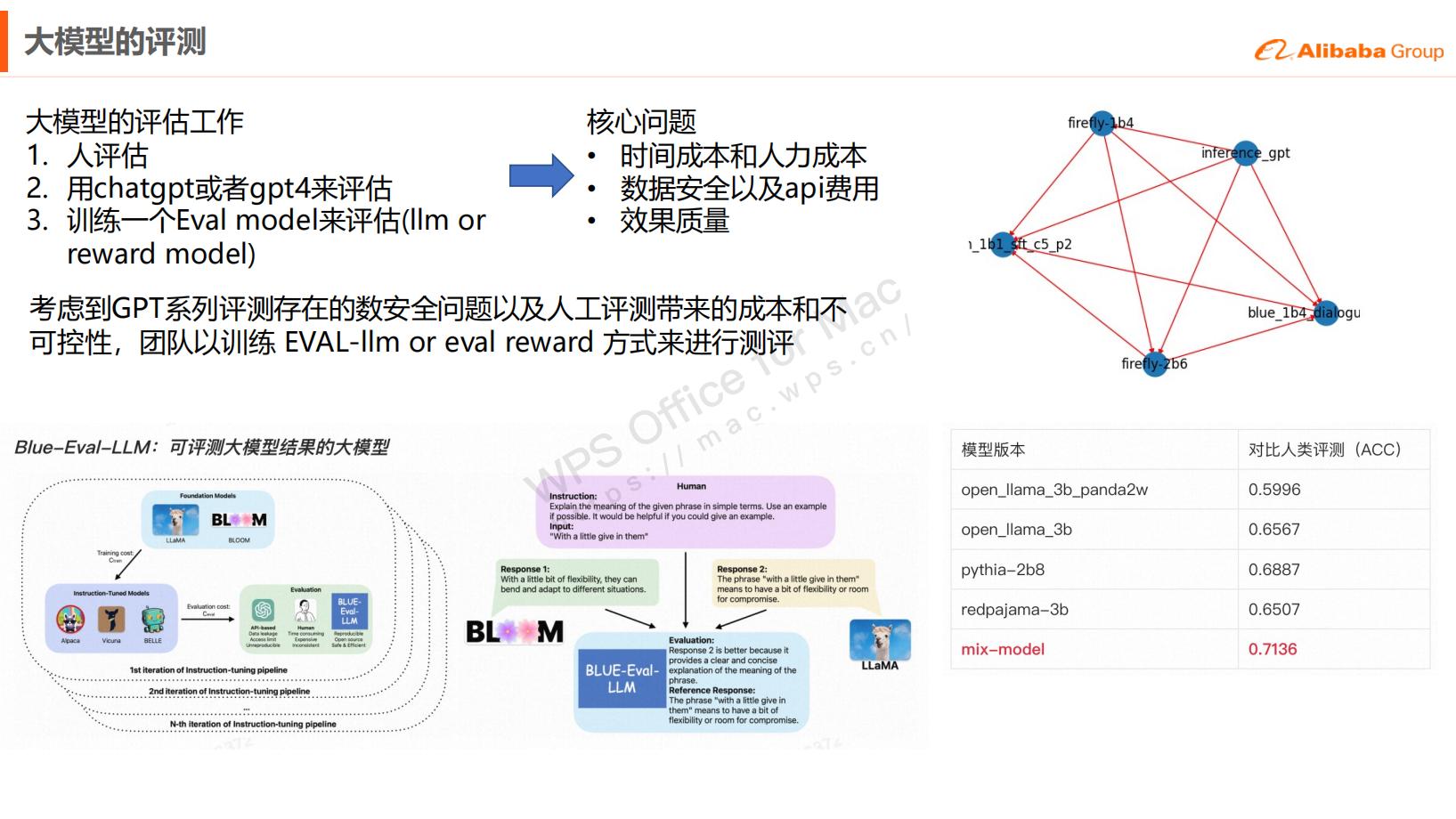
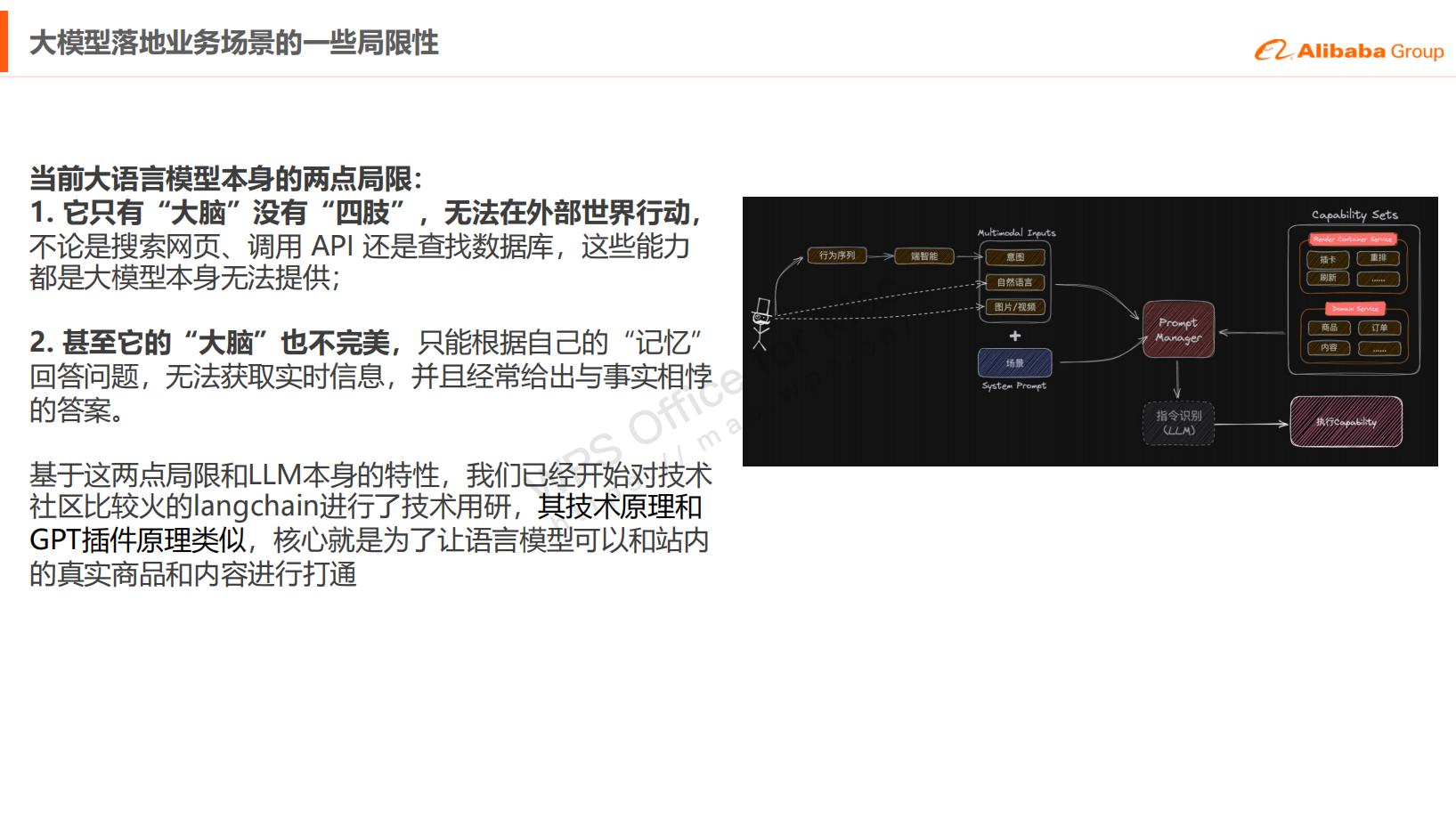





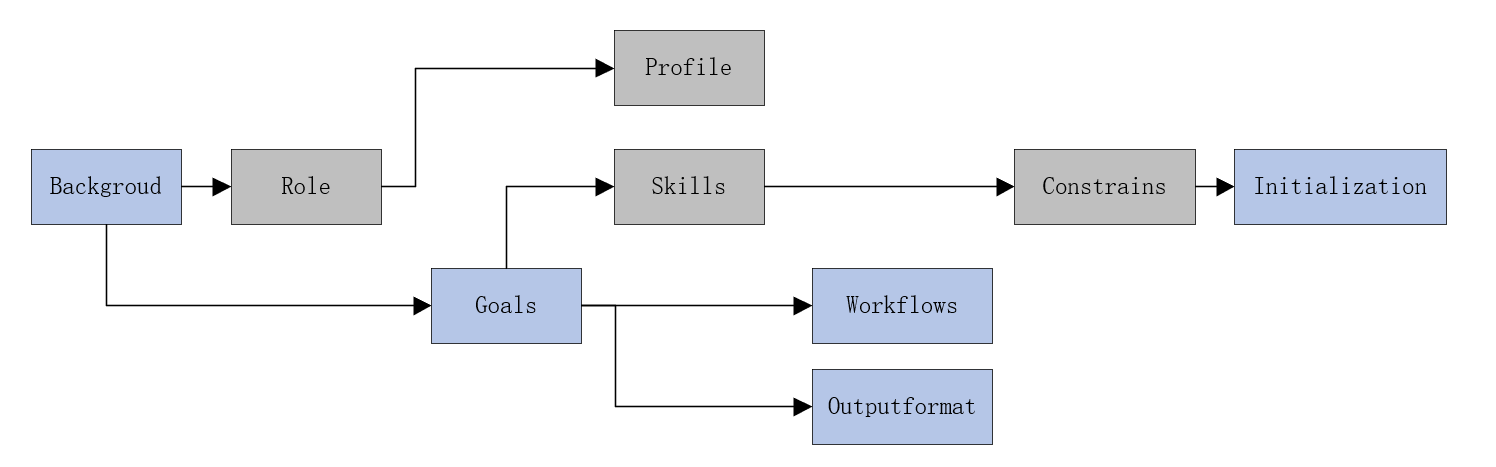

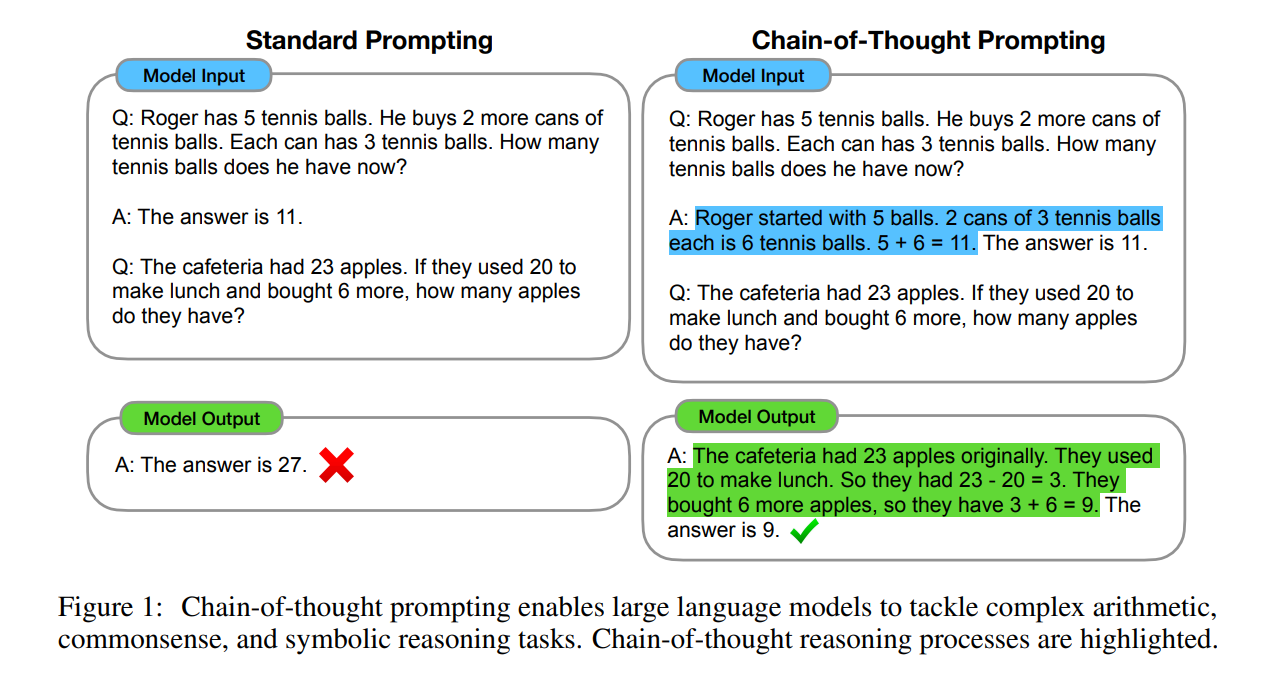

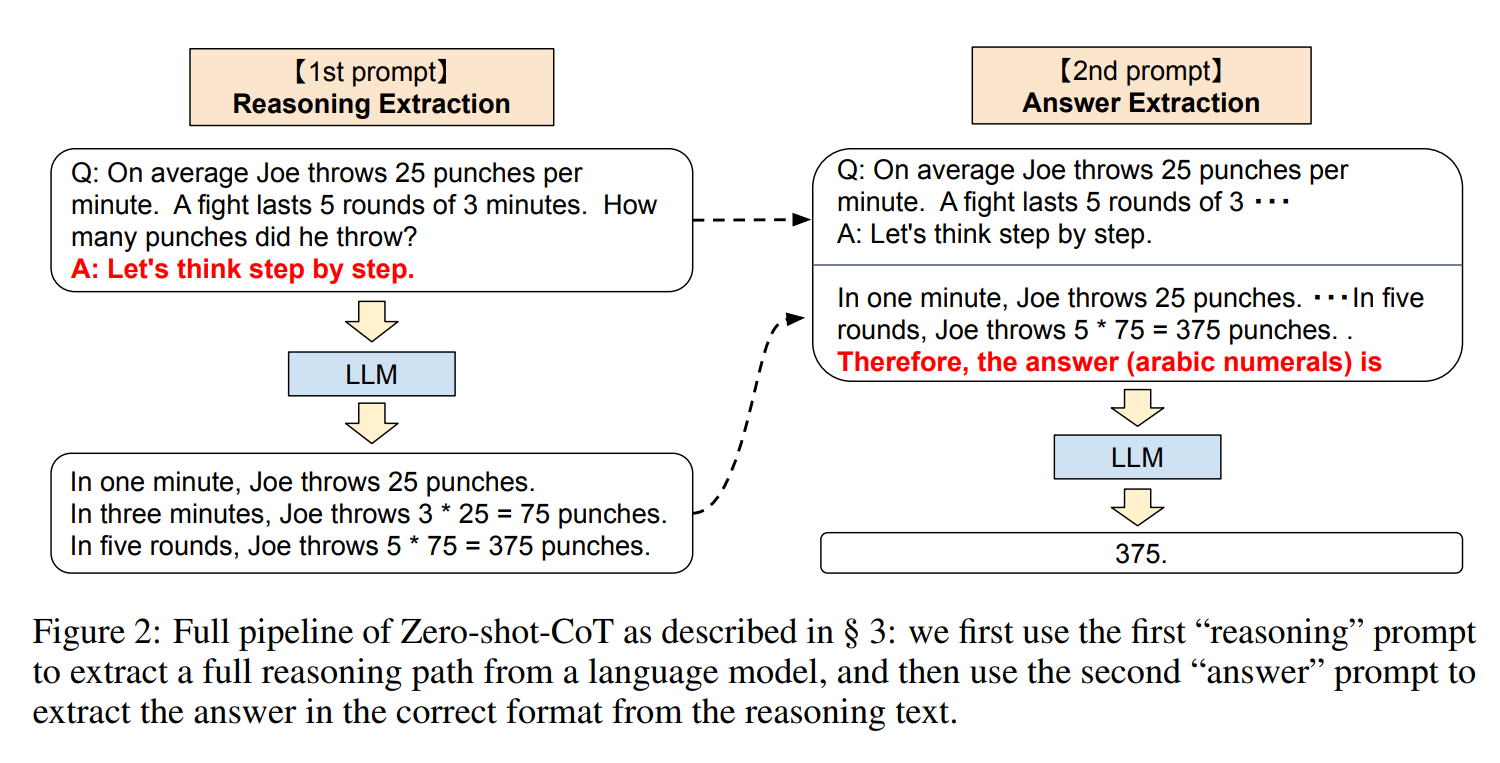
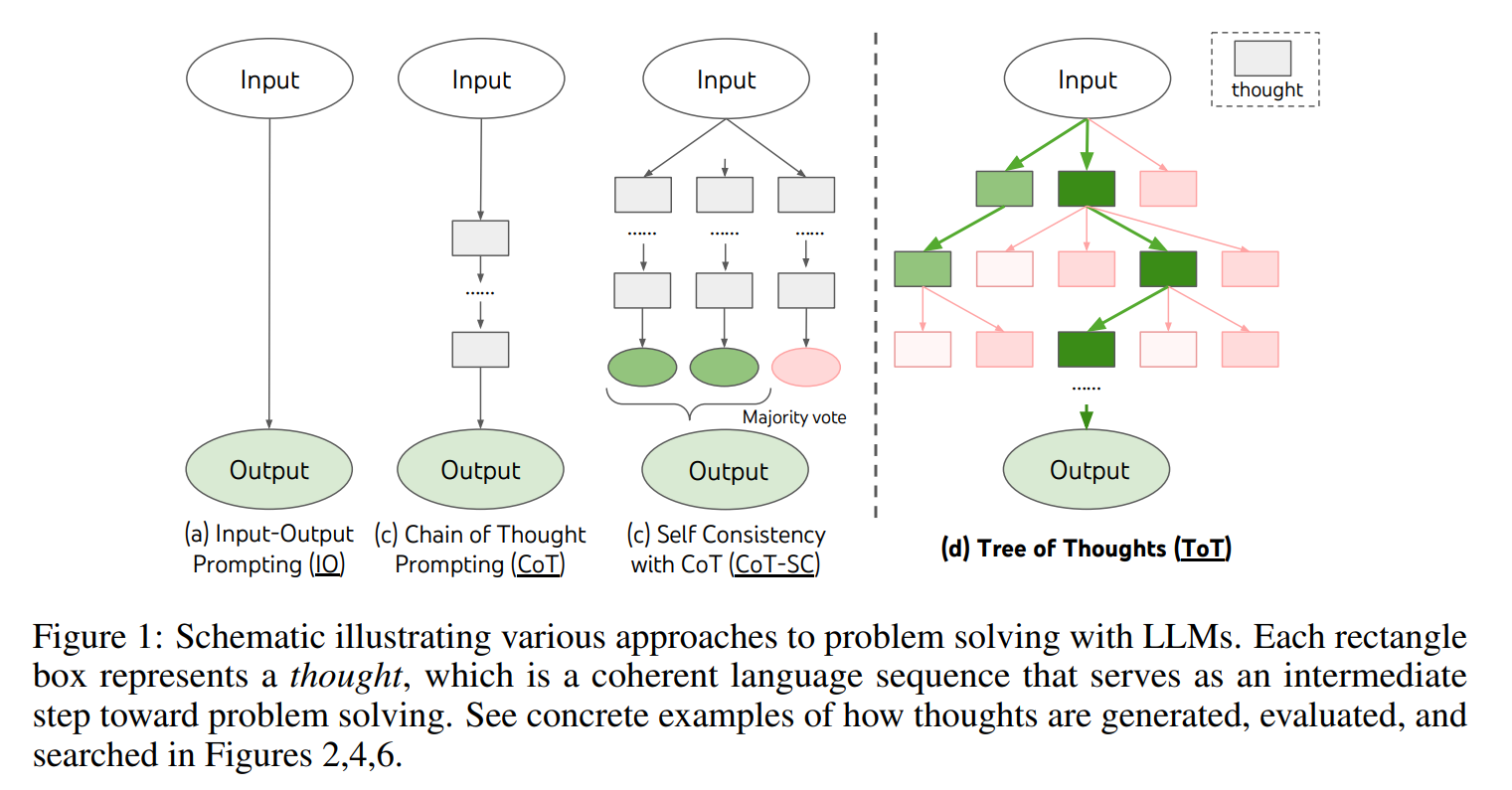


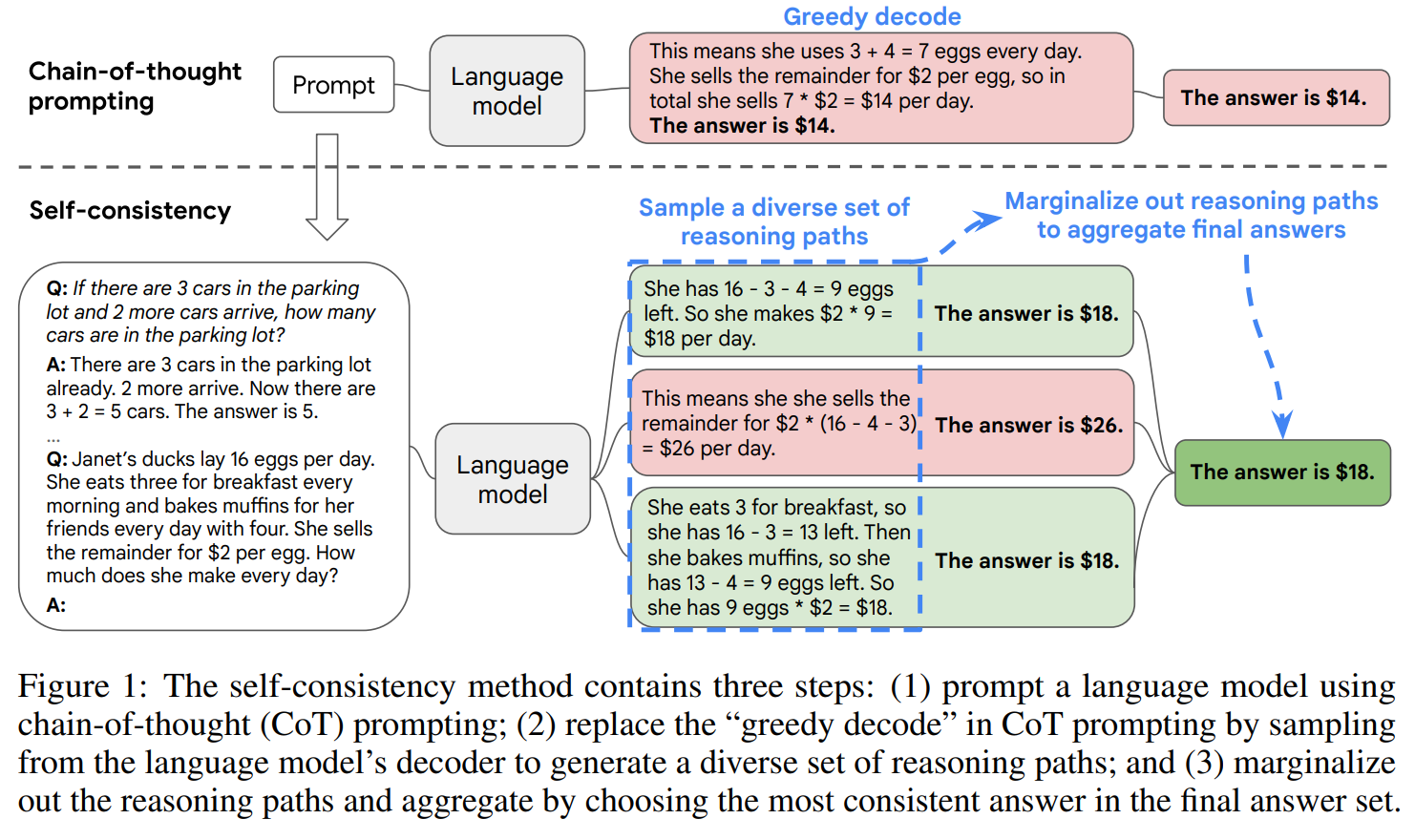



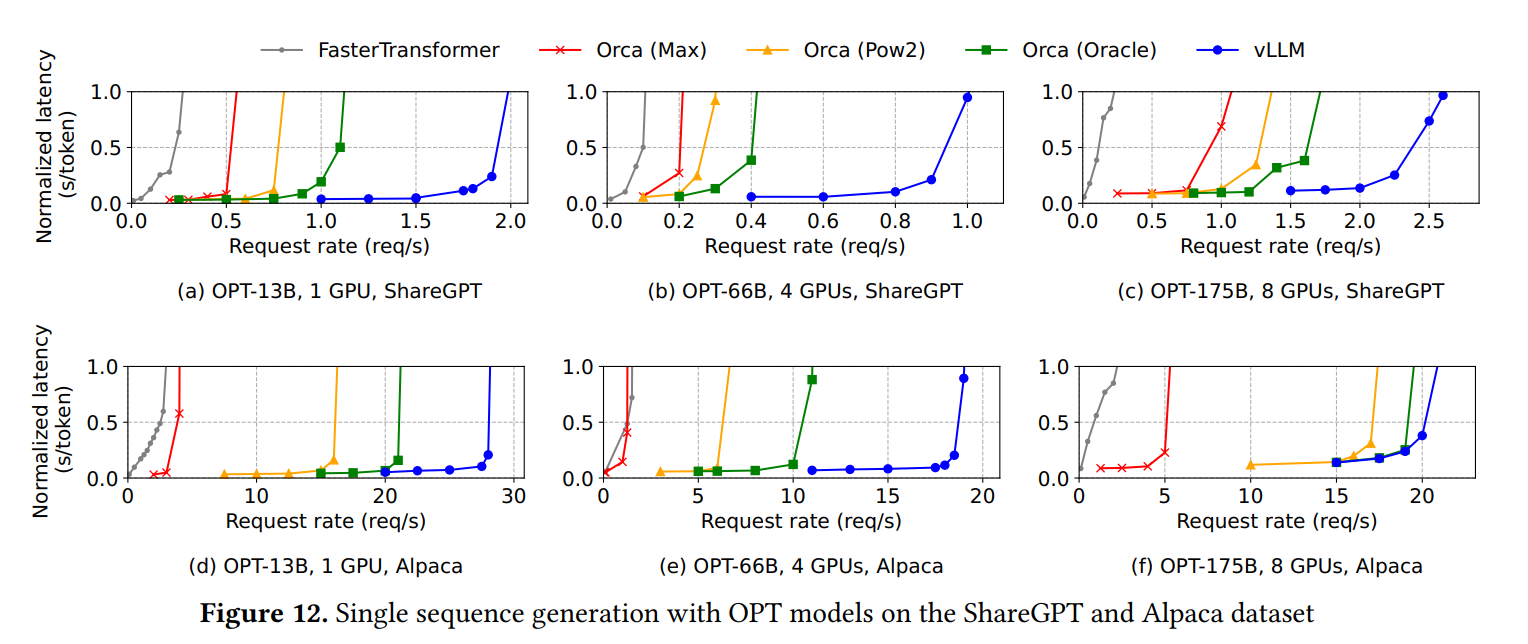
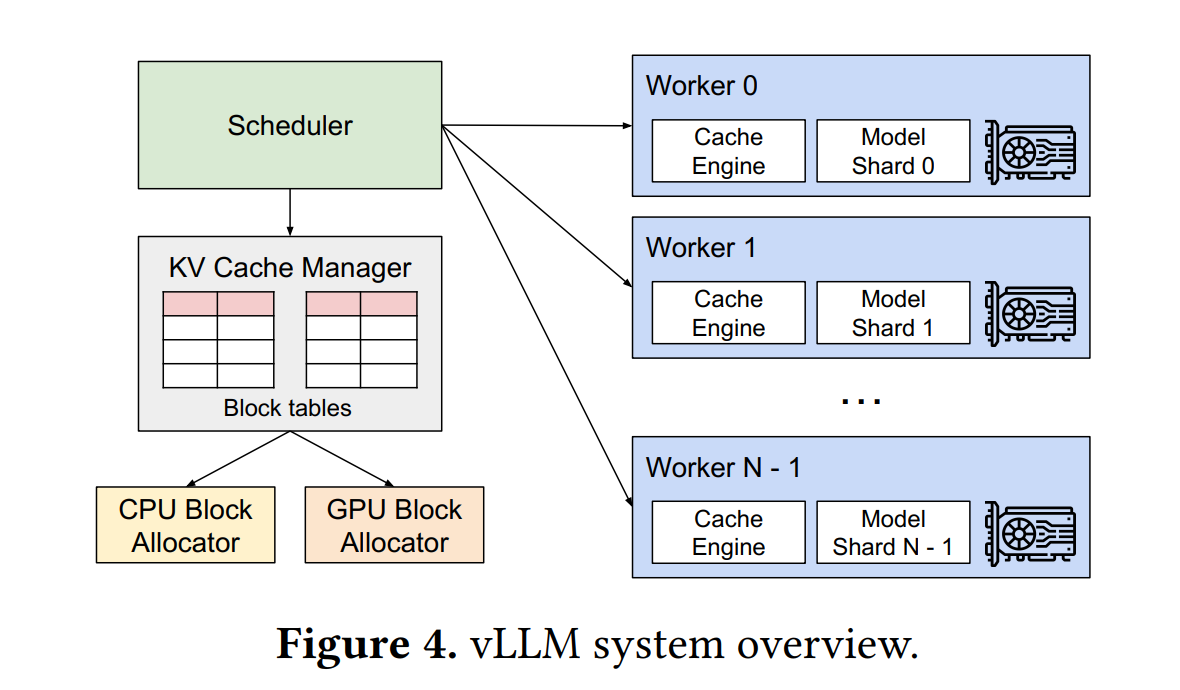
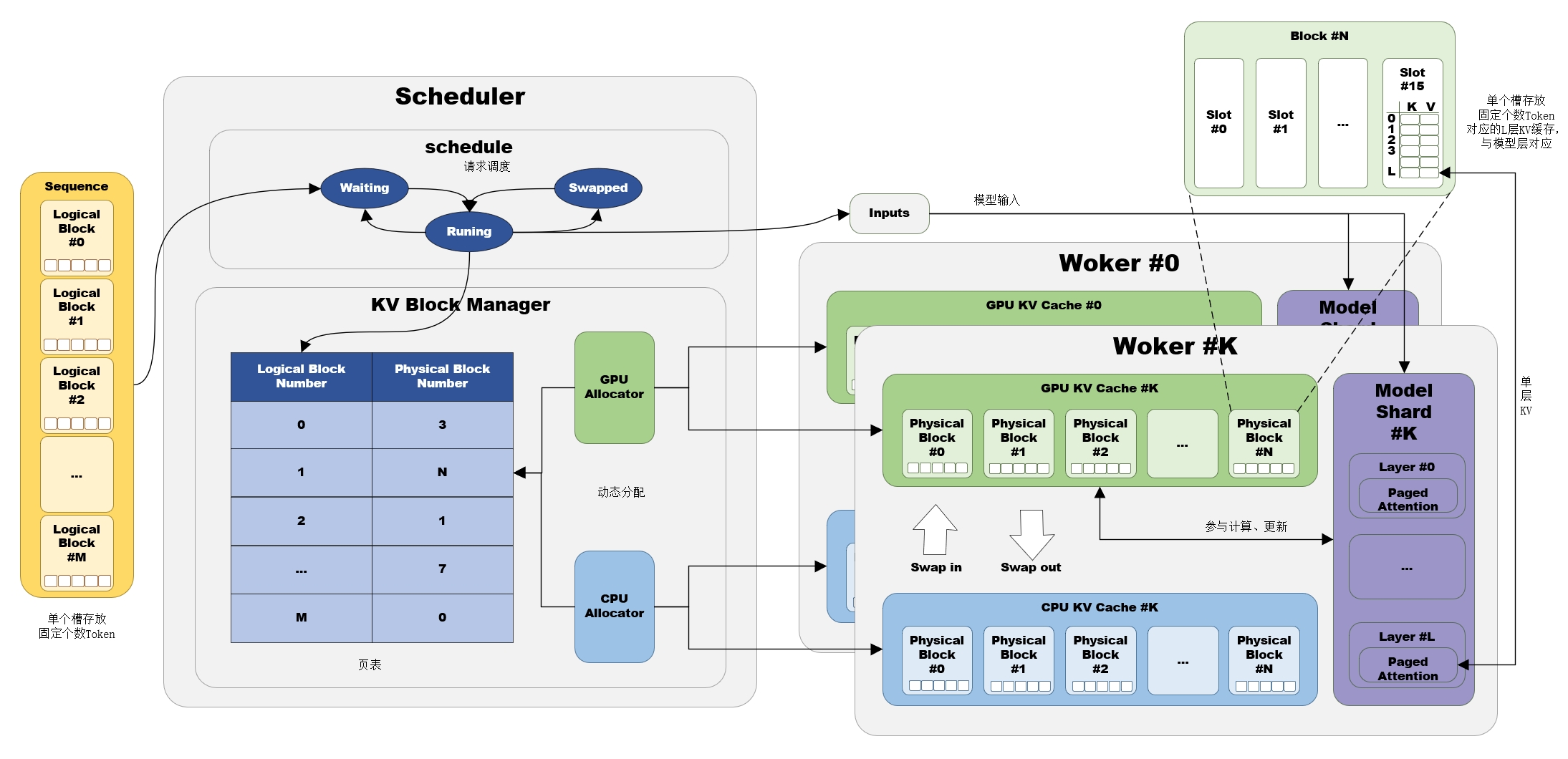
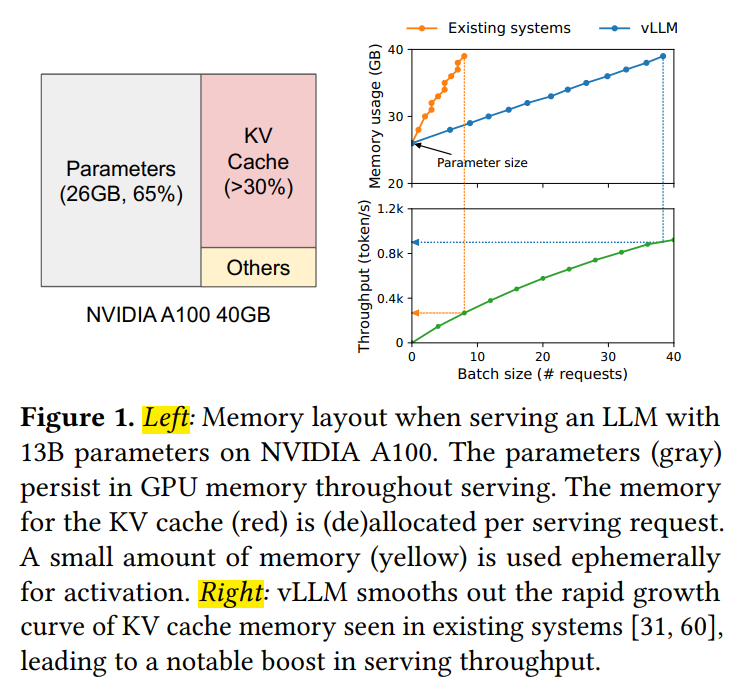
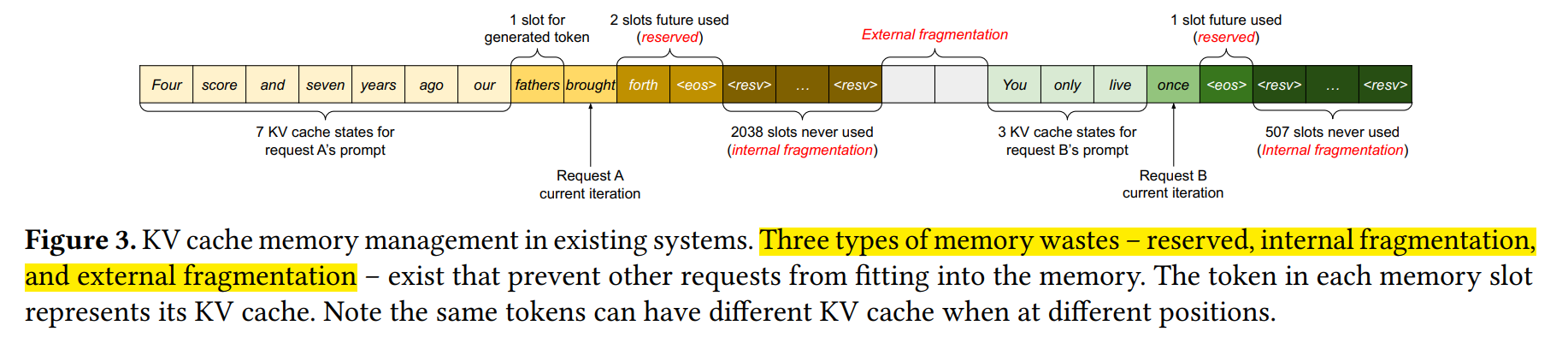
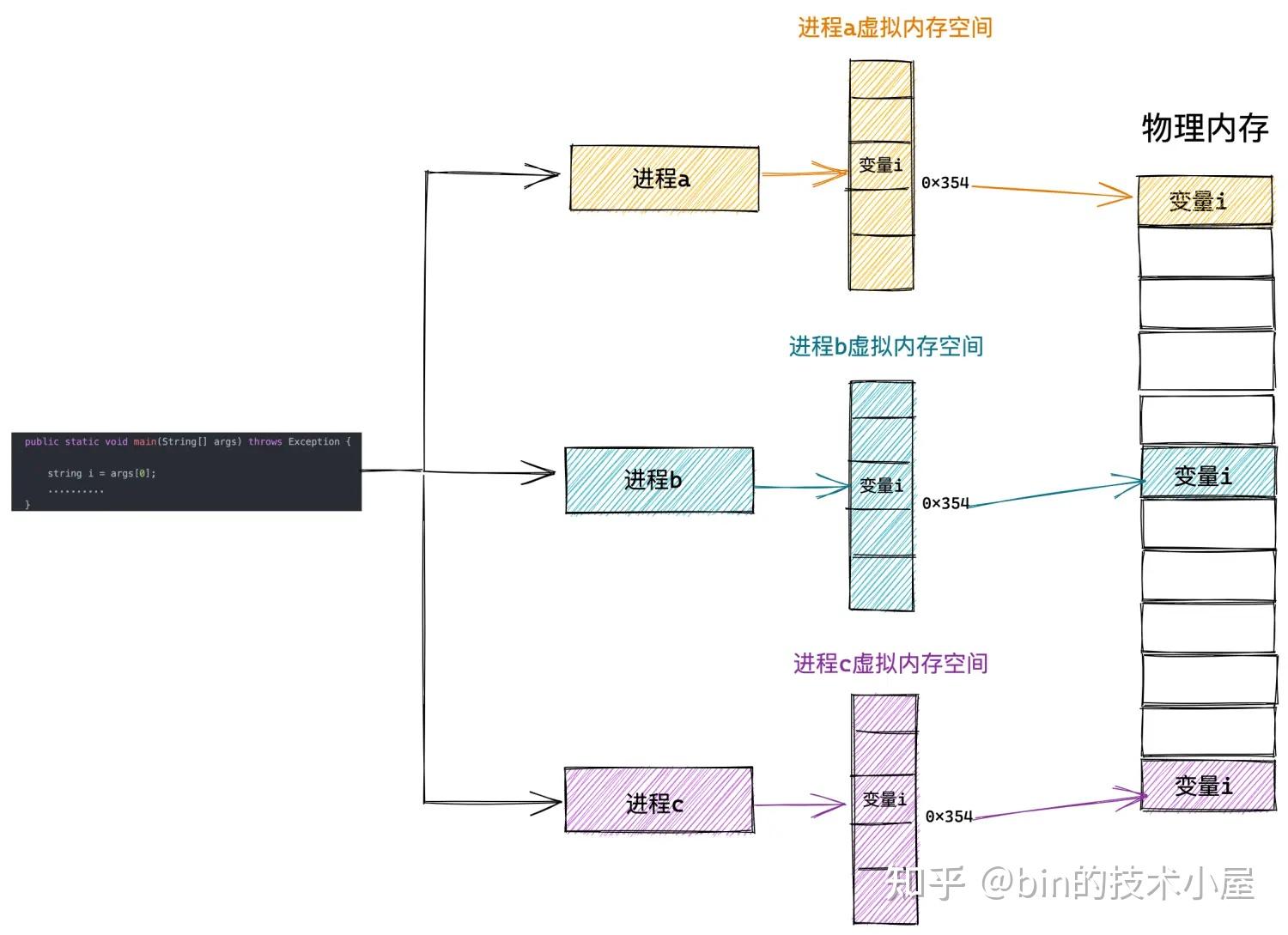
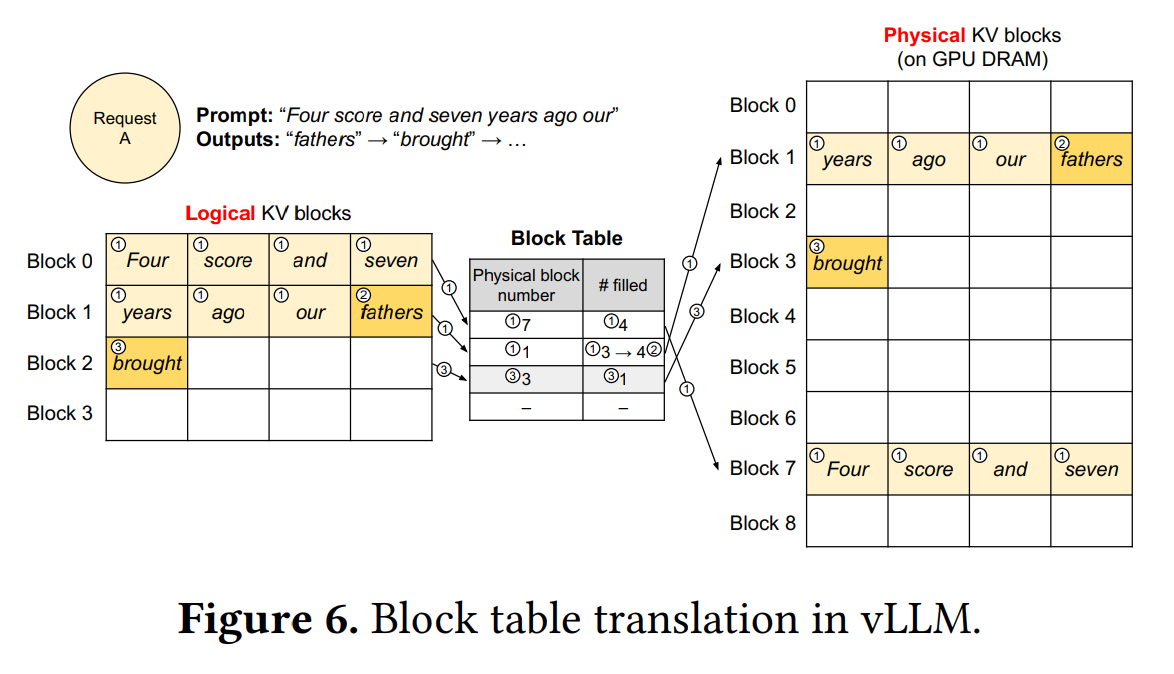
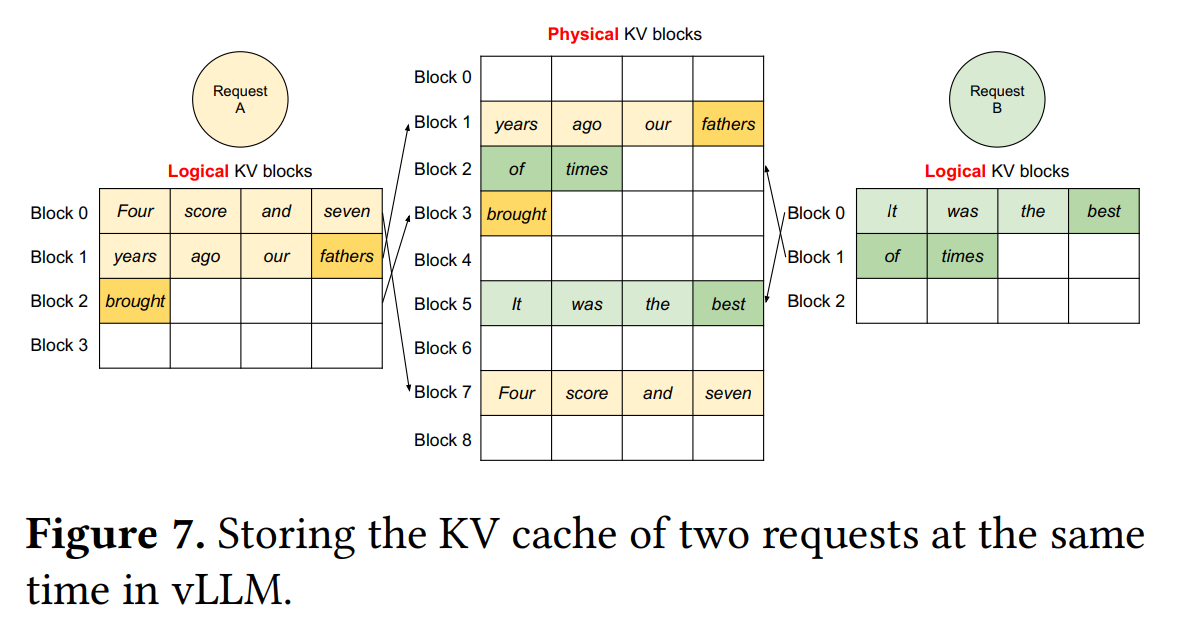
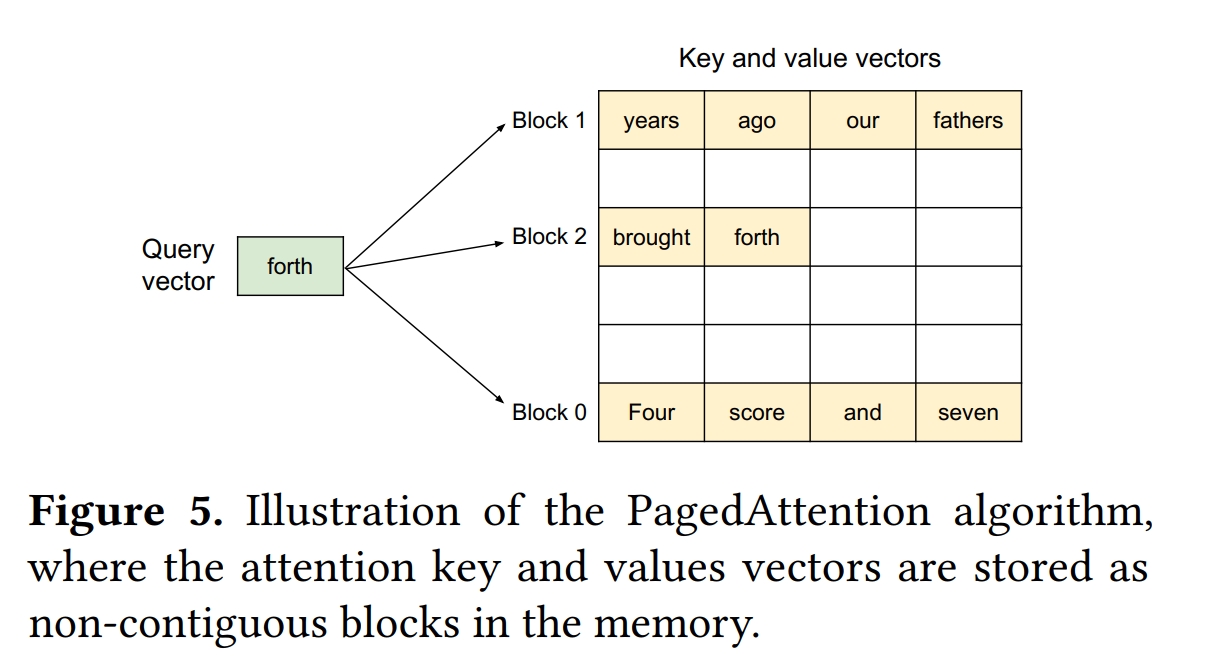
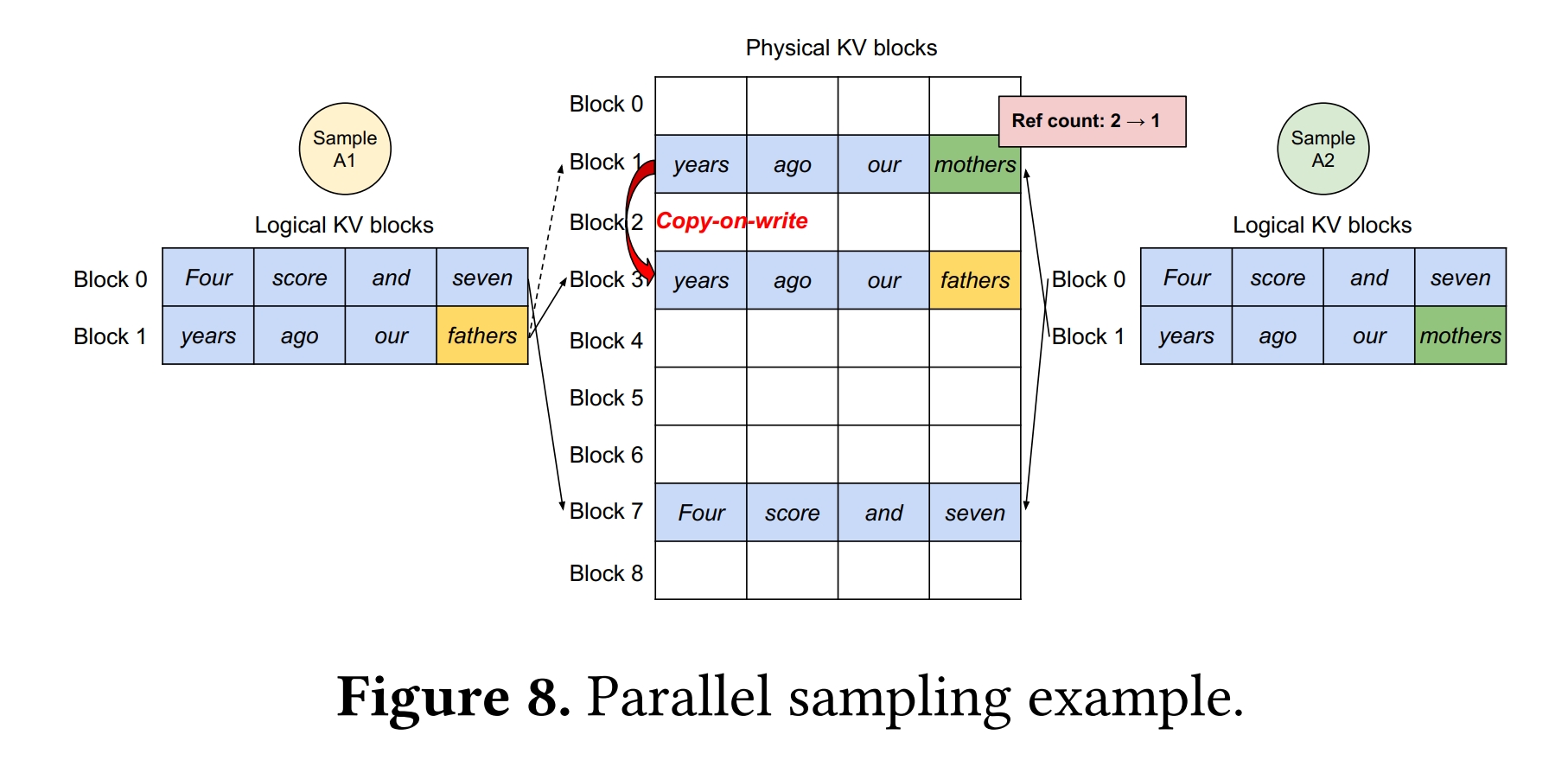
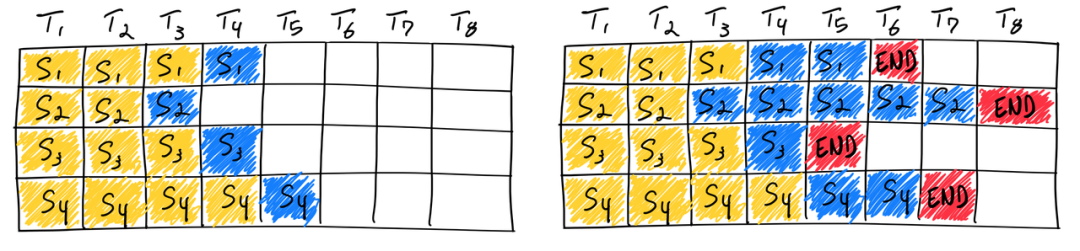
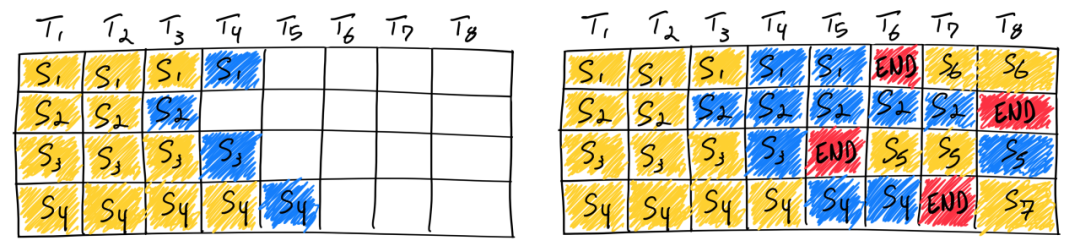
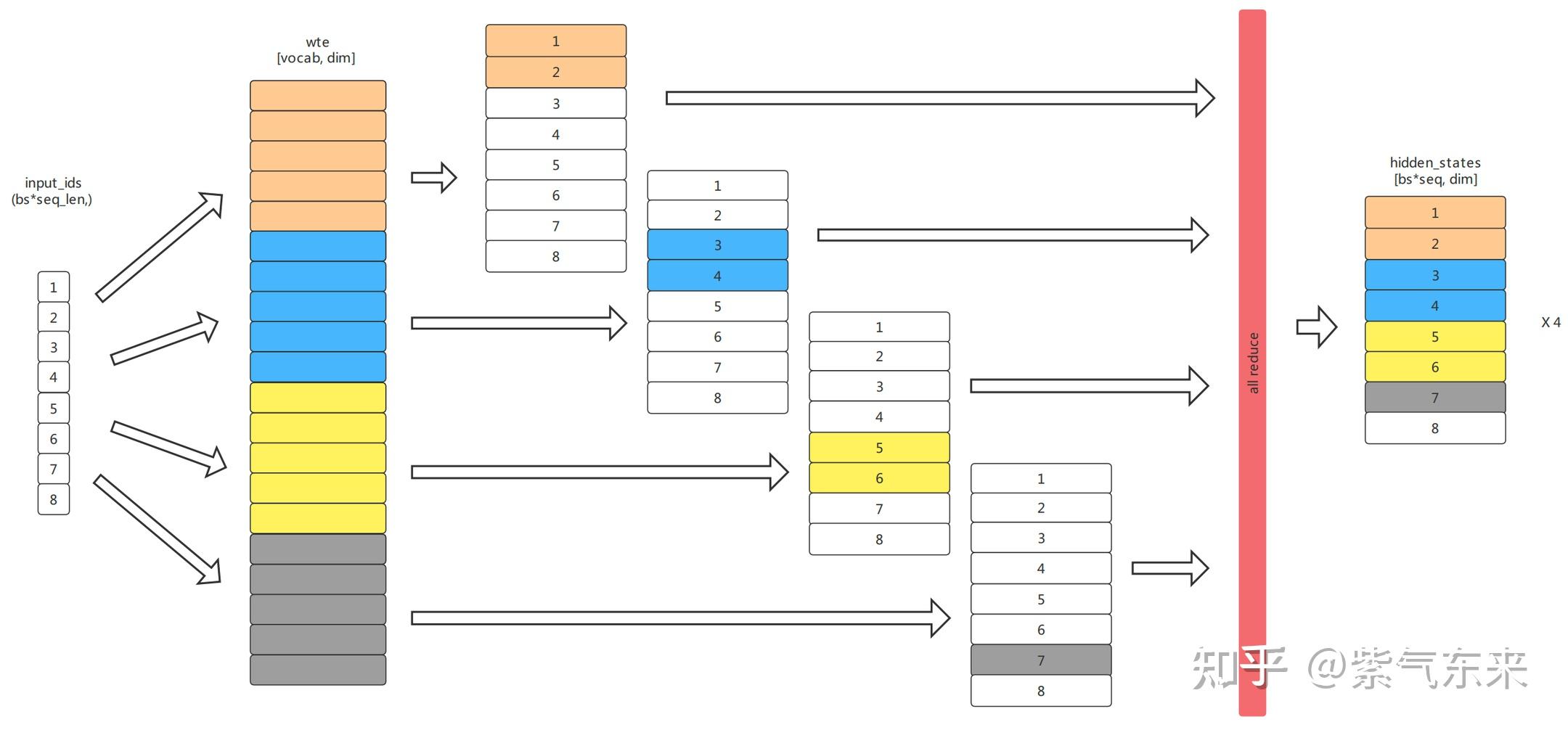
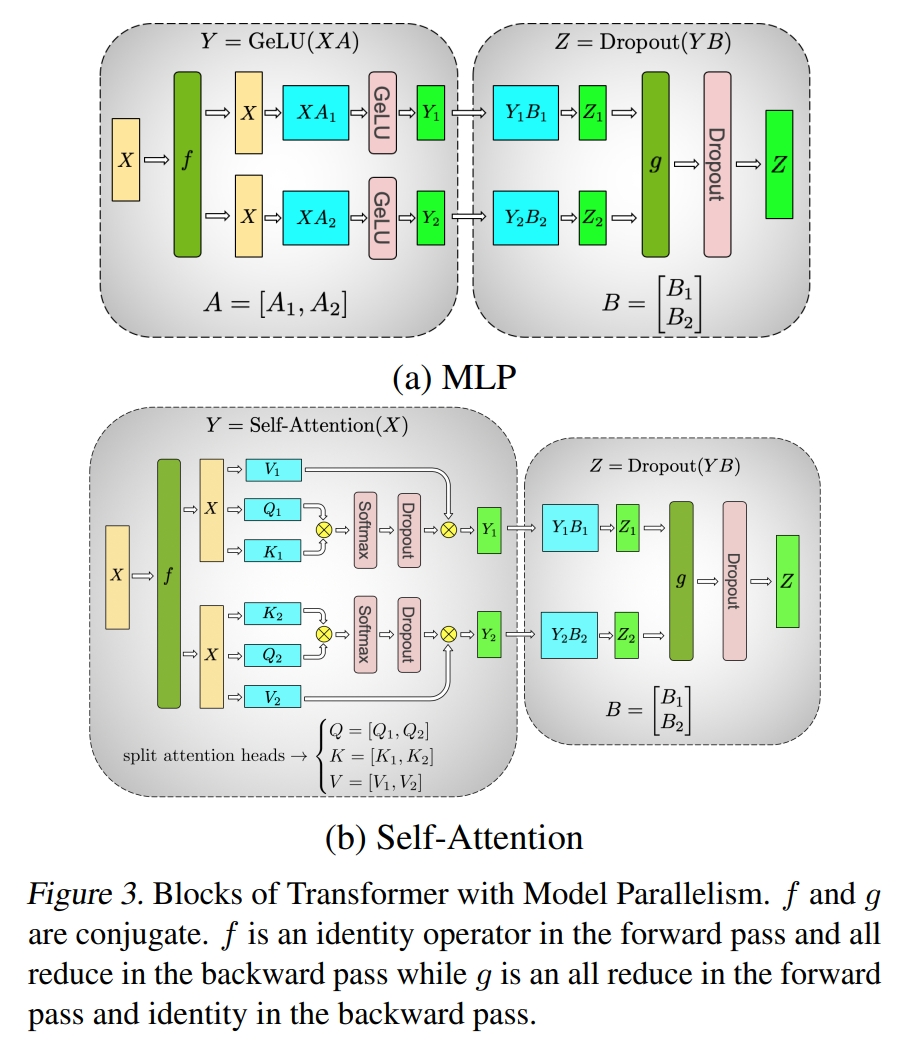
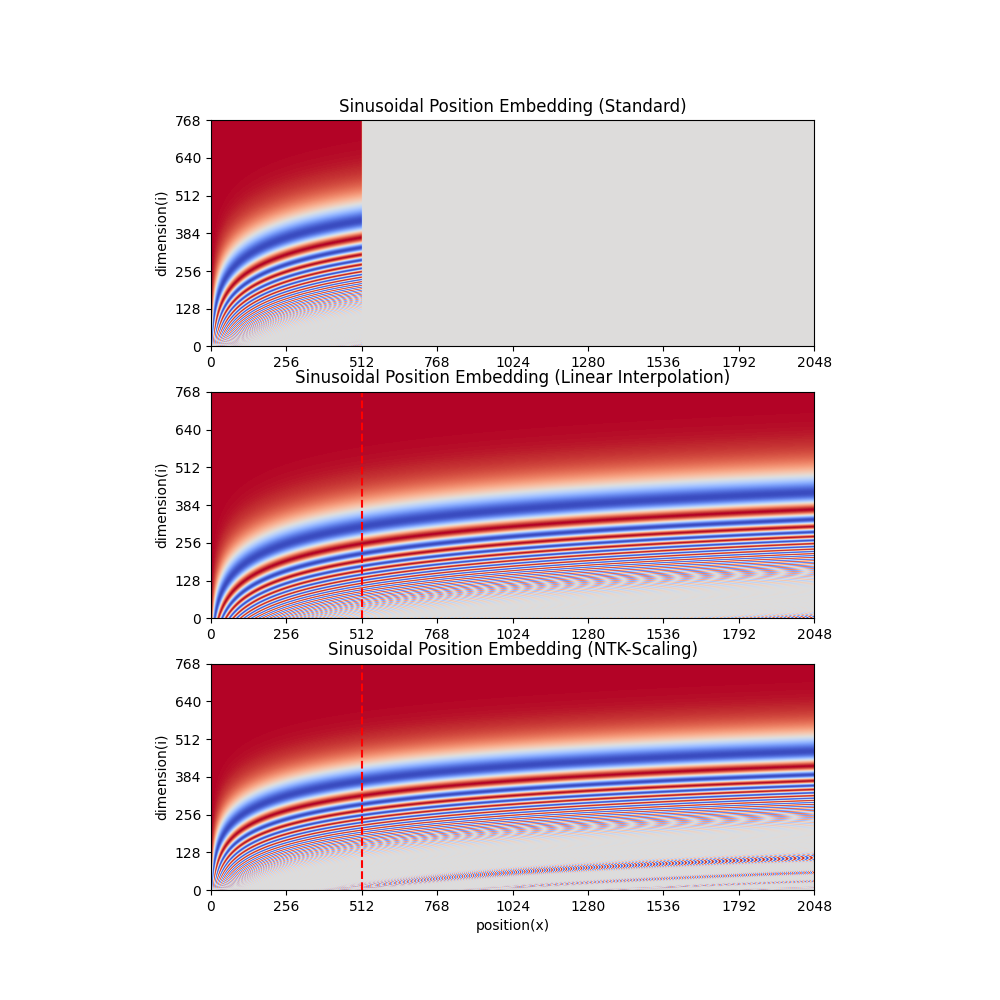
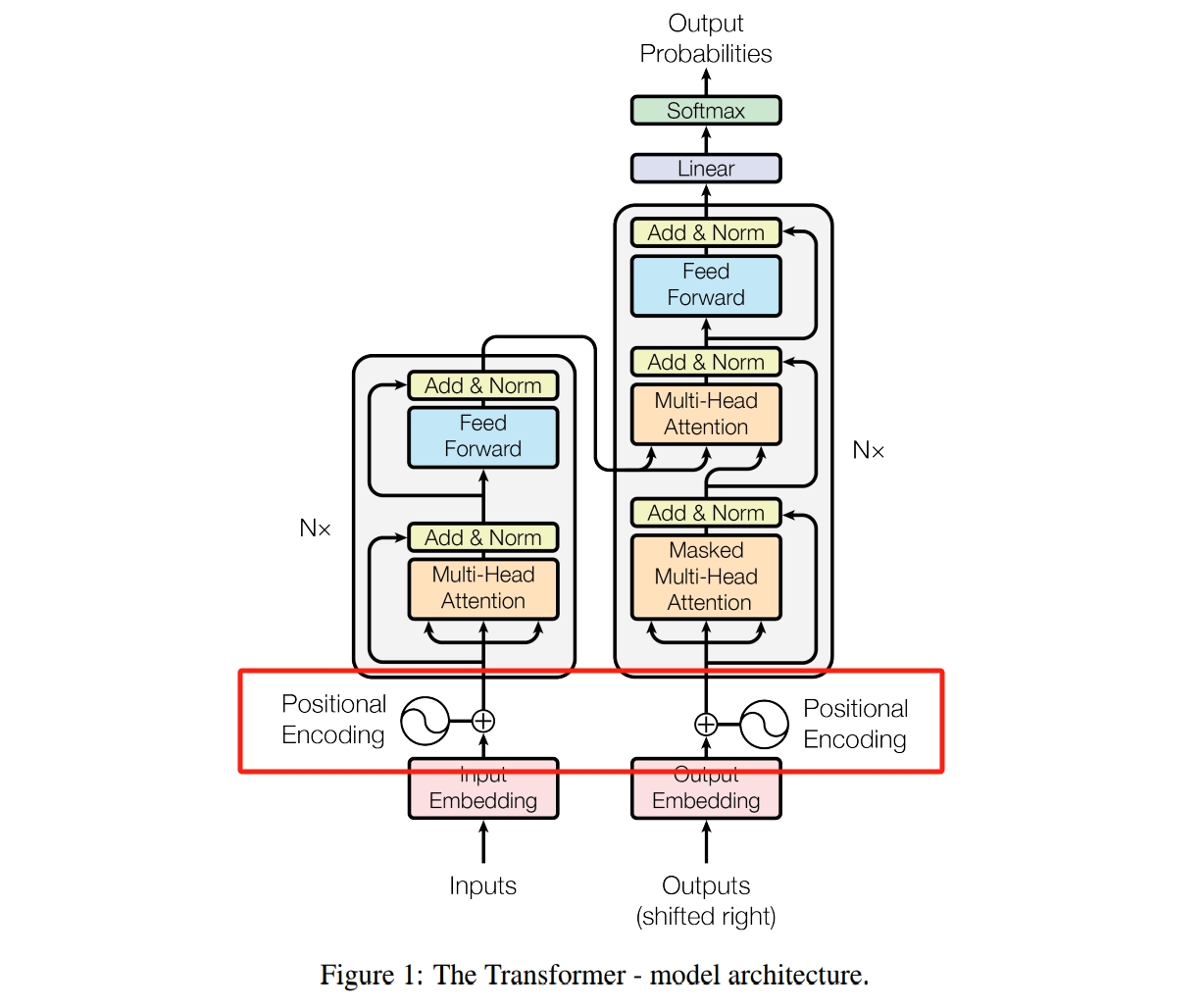
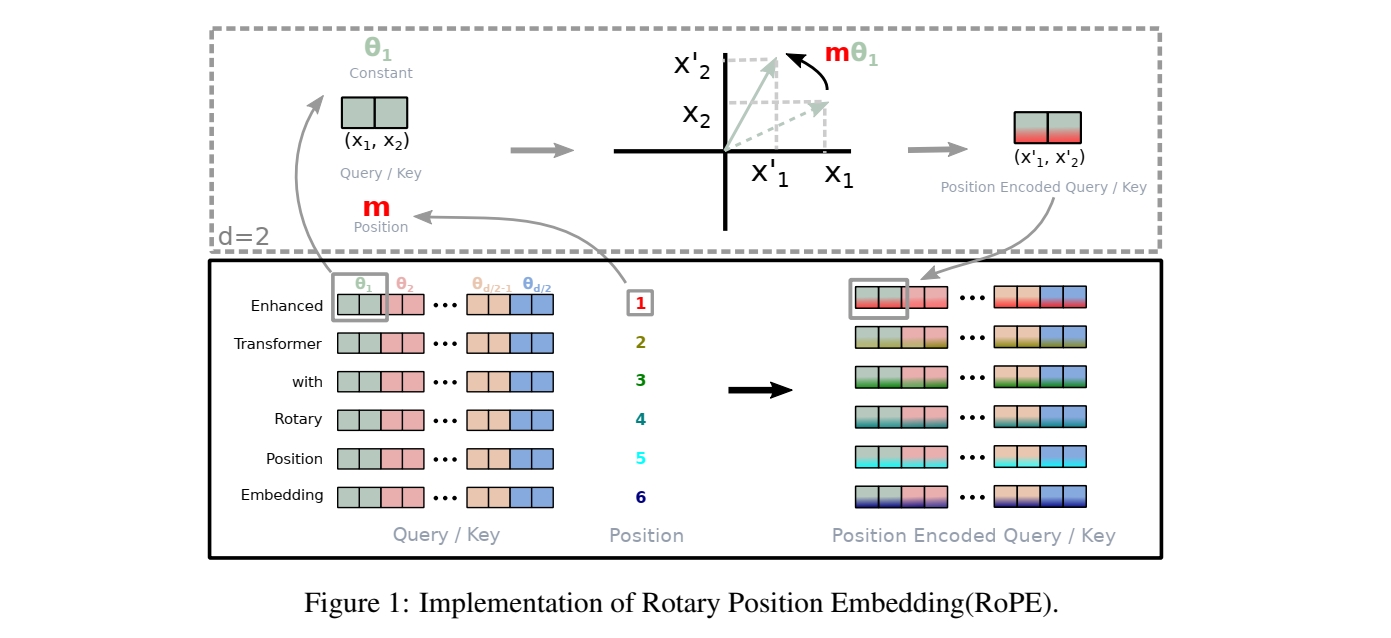
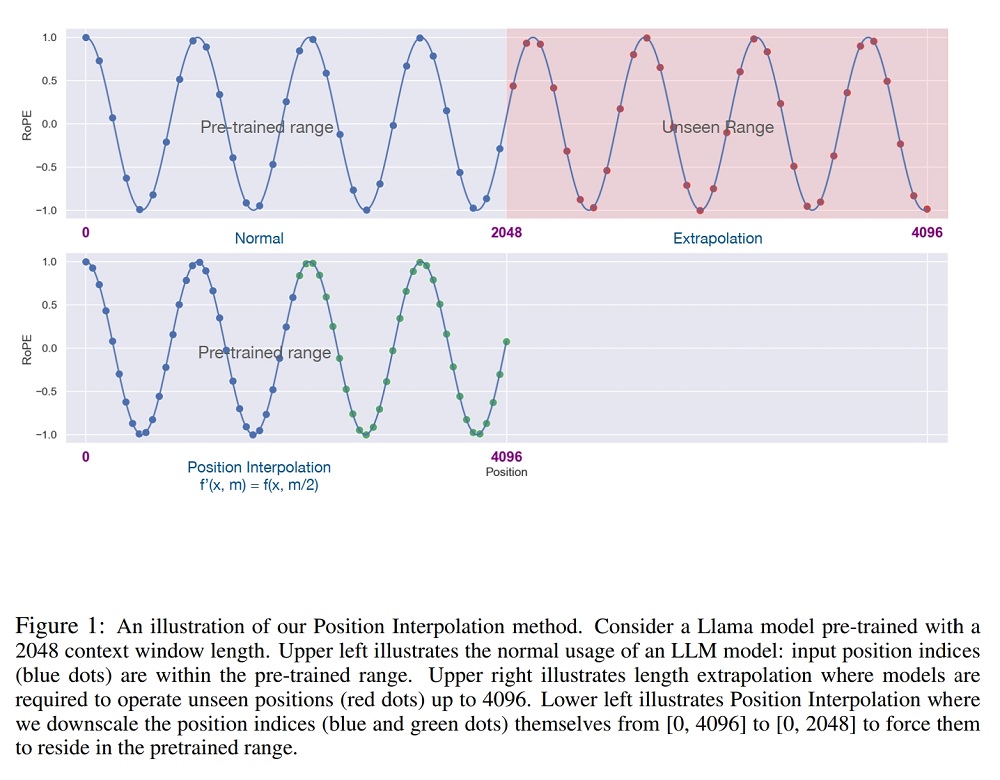
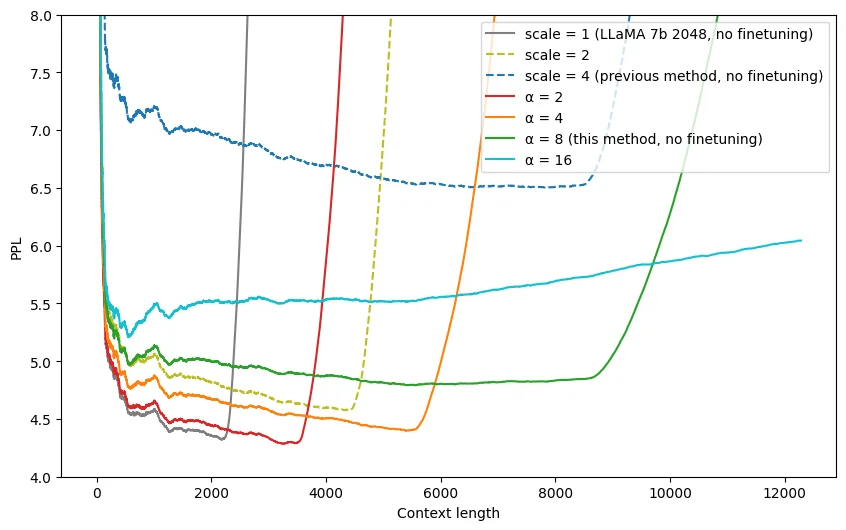
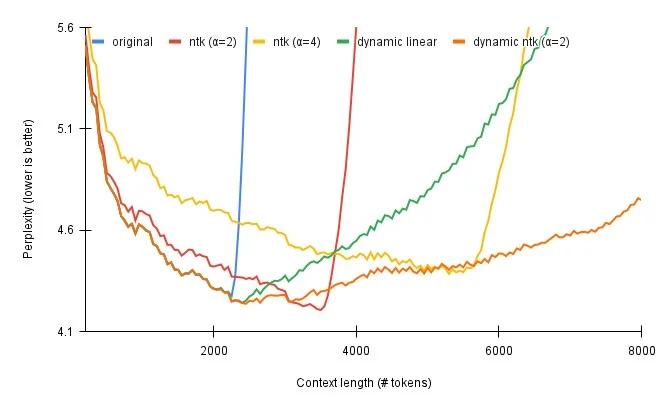
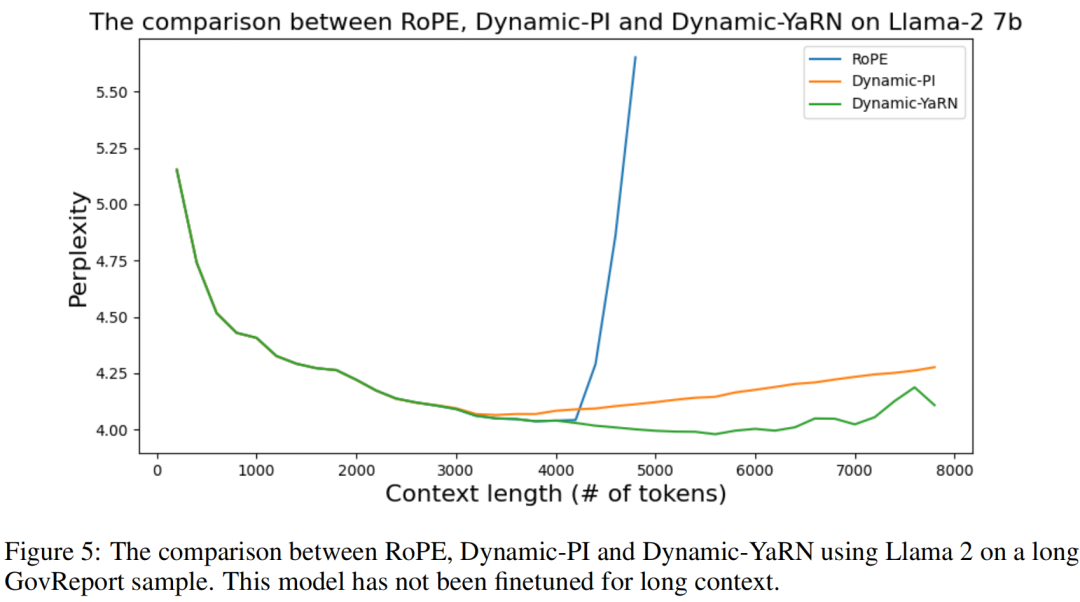










 ' +
+ '
' +
+ '