本篇博文主要展示每日从Arxiv论文网站获取的最新论文列表,以计算机视觉、自然语言处理、机器学习、人工智能等大方向进行划分。
+统计
+今日共更新385篇论文,其中:
+
+计算机视觉
+
+ 1. 标题:OpenIllumination: A Multi-Illumination Dataset for Inverse Rendering Evaluation on Real Objects
+ 编号:[1]
+ 链接:https://arxiv.org/abs/2309.07921
+ 作者:Isabella Liu, Linghao Chen, Ziyang Fu, Liwen Wu, Haian Jin, Zhong Li, Chin Ming Ryan Wong, Yi Xu, Ravi Ramamoorthi, Zexiang Xu, Hao Su
+ 备注:
+ 关键词:introduce OpenIllumination, large number, camera views, dataset, real-world dataset
+
+ 点击查看摘要
+ We introduce OpenIllumination, a real-world dataset containing over 108K
+images of 64 objects with diverse materials, captured under 72 camera views and
+a large number of different illuminations. For each image in the dataset, we
+provide accurate camera parameters, illumination ground truth, and foreground
+segmentation masks. Our dataset enables the quantitative evaluation of most
+inverse rendering and material decomposition methods for real objects. We
+examine several state-of-the-art inverse rendering methods on our dataset and
+compare their performances. The dataset and code can be found on the project
+page: this https URL.
+
+
+
+ 2. 标题:Large-Vocabulary 3D Diffusion Model with Transformer
+ 编号:[2]
+ 链接:https://arxiv.org/abs/2309.07920
+ 作者:Ziang Cao, Fangzhou Hong, Tong Wu, Liang Pan, Ziwei Liu
+ 备注:Project page at this https URL
+ 关键词:automatic generative model, highly desirable, single generative model, automatic generative, generative model
+
+ 点击查看摘要
+ Creating diverse and high-quality 3D assets with an automatic generative
+model is highly desirable. Despite extensive efforts on 3D generation, most
+existing works focus on the generation of a single category or a few
+categories. In this paper, we introduce a diffusion-based feed-forward
+framework for synthesizing massive categories of real-world 3D objects with a
+single generative model. Notably, there are three major challenges for this
+large-vocabulary 3D generation: a) the need for expressive yet efficient 3D
+representation; b) large diversity in geometry and texture across categories;
+c) complexity in the appearances of real-world objects. To this end, we propose
+a novel triplane-based 3D-aware Diffusion model with TransFormer, DiffTF, for
+handling challenges via three aspects. 1) Considering efficiency and
+robustness, we adopt a revised triplane representation and improve the fitting
+speed and accuracy. 2) To handle the drastic variations in geometry and
+texture, we regard the features of all 3D objects as a combination of
+generalized 3D knowledge and specialized 3D features. To extract generalized 3D
+knowledge from diverse categories, we propose a novel 3D-aware transformer with
+shared cross-plane attention. It learns the cross-plane relations across
+different planes and aggregates the generalized 3D knowledge with specialized
+3D features. 3) In addition, we devise the 3D-aware encoder/decoder to enhance
+the generalized 3D knowledge in the encoded triplanes for handling categories
+with complex appearances. Extensive experiments on ShapeNet and OmniObject3D
+(over 200 diverse real-world categories) convincingly demonstrate that a single
+DiffTF model achieves state-of-the-art large-vocabulary 3D object generation
+performance with large diversity, rich semantics, and high quality.
+
+
+
+ 3. 标题:Unified Human-Scene Interaction via Prompted Chain-of-Contacts
+ 编号:[3]
+ 链接:https://arxiv.org/abs/2309.07918
+ 作者:Zeqi Xiao, Tai Wang, Jingbo Wang, Jinkun Cao, Wenwei Zhang, Bo Dai, Dahua Lin, Jiangmiao Pang
+ 备注:A unified Human-Scene Interaction framework that supports versatile interactions through language commands.Project URL: this https URL .Please ignore the header of the paper
+ 关键词:virtual reality, vital component, component of fields, fields like embodied, unified HSI framework
+
+ 点击查看摘要
+ Human-Scene Interaction (HSI) is a vital component of fields like embodied AI
+and virtual reality. Despite advancements in motion quality and physical
+plausibility, two pivotal factors, versatile interaction control and the
+development of a user-friendly interface, require further exploration before
+the practical application of HSI. This paper presents a unified HSI framework,
+UniHSI, which supports unified control of diverse interactions through language
+commands. This framework is built upon the definition of interaction as Chain
+of Contacts (CoC): steps of human joint-object part pairs, which is inspired by
+the strong correlation between interaction types and human-object contact
+regions. Based on the definition, UniHSI constitutes a Large Language Model
+(LLM) Planner to translate language prompts into task plans in the form of CoC,
+and a Unified Controller that turns CoC into uniform task execution. To
+facilitate training and evaluation, we collect a new dataset named ScenePlan
+that encompasses thousands of task plans generated by LLMs based on diverse
+scenarios. Comprehensive experiments demonstrate the effectiveness of our
+framework in versatile task execution and generalizability to real scanned
+scenes. The project page is at this https URL .
+
+
+
+ 4. 标题:Looking at words and points with attention: a benchmark for text-to-shape coherence
+ 编号:[4]
+ 链接:https://arxiv.org/abs/2309.07917
+ 作者:Andrea Amaduzzi, Giuseppe Lisanti, Samuele Salti, Luigi Di Stefano
+ 备注:ICCV 2023 Workshop "AI for 3D Content Creation", Project page: this https URL, 26 pages
+ 关键词:input textual descriptions, textual descriptions lacks, textual descriptions, object generation, rapid progress
+
+ 点击查看摘要
+ While text-conditional 3D object generation and manipulation have seen rapid
+progress, the evaluation of coherence between generated 3D shapes and input
+textual descriptions lacks a clear benchmark. The reason is twofold: a) the low
+quality of the textual descriptions in the only publicly available dataset of
+text-shape pairs; b) the limited effectiveness of the metrics used to
+quantitatively assess such coherence. In this paper, we propose a comprehensive
+solution that addresses both weaknesses. Firstly, we employ large language
+models to automatically refine textual descriptions associated with shapes.
+Secondly, we propose a quantitative metric to assess text-to-shape coherence,
+through cross-attention mechanisms. To validate our approach, we conduct a user
+study and compare quantitatively our metric with existing ones. The refined
+dataset, the new metric and a set of text-shape pairs validated by the user
+study comprise a novel, fine-grained benchmark that we publicly release to
+foster research on text-to-shape coherence of text-conditioned 3D generative
+models. Benchmark available at
+this https URL.
+
+
+
+ 5. 标题:MMICL: Empowering Vision-language Model with Multi-Modal In-Context Learning
+ 编号:[5]
+ 链接:https://arxiv.org/abs/2309.07915
+ 作者:Haozhe Zhao, Zefan Cai, Shuzheng Si, Xiaojian Ma, Kaikai An, Liang Chen, Zixuan Liu, Sheng Wang, Wenjuan Han, Baobao Chang
+ 备注:Code, dataset, checkpoints, and demos are available at \href{https://github.com/HaozheZhao/MIC}{this https URL}
+ 关键词:benefiting from large, resurgence of deep, multi-modal prompts, multiple images, deep learning
+
+ 点击查看摘要
+ Starting from the resurgence of deep learning, vision-language models (VLMs)
+benefiting from large language models (LLMs) have never been so popular.
+However, while LLMs can utilize extensive background knowledge and task
+information with in-context learning, most VLMs still struggle with
+understanding complex multi-modal prompts with multiple images. The issue can
+traced back to the architectural design of VLMs or pre-training data.
+Specifically, the current VLMs primarily emphasize utilizing multi-modal data
+with a single image some, rather than multi-modal prompts with interleaved
+multiple images and text. Even though some newly proposed VLMs could handle
+user prompts with multiple images, pre-training data does not provide more
+sophisticated multi-modal prompts than interleaved image and text crawled from
+the web. We propose MMICL to address the issue by considering both the model
+and data perspectives. We introduce a well-designed architecture capable of
+seamlessly integrating visual and textual context in an interleaved manner and
+MIC dataset to reduce the gap between the training data and the complex user
+prompts in real-world applications, including: 1) multi-modal context with
+interleaved images and text, 2) textual references for each image, and 3)
+multi-image data with spatial, logical, or temporal relationships. Our
+experiments confirm that MMICL achieves new stat-of-the-art zero-shot and
+few-shot performance on a wide range of general vision-language tasks,
+especially for complex reasoning benchmarks including MME and MMBench. Our
+analysis demonstrates that MMICL effectively deals with the challenge of
+complex multi-modal prompt understanding. The experiments on ScienceQA-IMG also
+show that MMICL successfully alleviates the issue of language bias in VLMs,
+which we believe is the reason behind the advanced performance of MMICL.
+
+
+
+ 6. 标题:ALWOD: Active Learning for Weakly-Supervised Object Detection
+ 编号:[6]
+ 链接:https://arxiv.org/abs/2309.07914
+ 作者:Yuting Wang, Velibor Ilic, Jiatong Li, Branislav Kisacanin, Vladimir Pavlovic
+ 备注:published in ICCV 2023
+ 关键词:object localization labels, precise object localization, large training datasets, crucial vision task, remains challenged
+
+ 点击查看摘要
+ Object detection (OD), a crucial vision task, remains challenged by the lack
+of large training datasets with precise object localization labels. In this
+work, we propose ALWOD, a new framework that addresses this problem by fusing
+active learning (AL) with weakly and semi-supervised object detection
+paradigms. Because the performance of AL critically depends on the model
+initialization, we propose a new auxiliary image generator strategy that
+utilizes an extremely small labeled set, coupled with a large weakly tagged set
+of images, as a warm-start for AL. We then propose a new AL acquisition
+function, another critical factor in AL success, that leverages the
+student-teacher OD pair disagreement and uncertainty to effectively propose the
+most informative images to annotate. Finally, to complete the AL loop, we
+introduce a new labeling task delegated to human annotators, based on selection
+and correction of model-proposed detections, which is both rapid and effective
+in labeling the informative images. We demonstrate, across several challenging
+benchmarks, that ALWOD significantly narrows the gap between the ODs trained on
+few partially labeled but strategically selected image instances and those that
+rely on the fully-labeled data. Our code is publicly available on
+this https URL.
+
+
+
+ 7. 标题:Disentangling Spatial and Temporal Learning for Efficient Image-to-Video Transfer Learning
+ 编号:[7]
+ 链接:https://arxiv.org/abs/2309.07911
+ 作者:Zhiwu Qing, Shiwei Zhang, Ziyuan Huang, Yingya Zhang, Changxin Gao, Deli Zhao, Nong Sang
+ 备注:ICCV2023. Code: this https URL
+ 关键词:shown extraordinary capabilities, temporal modeling capabilities, CLIP have shown, unsatisfactory temporal modeling, extraordinary capabilities
+
+ 点击查看摘要
+ Recently, large-scale pre-trained language-image models like CLIP have shown
+extraordinary capabilities for understanding spatial contents, but naively
+transferring such models to video recognition still suffers from unsatisfactory
+temporal modeling capabilities. Existing methods insert tunable structures into
+or in parallel with the pre-trained model, which either requires
+back-propagation through the whole pre-trained model and is thus
+resource-demanding, or is limited by the temporal reasoning capability of the
+pre-trained structure. In this work, we present DiST, which disentangles the
+learning of spatial and temporal aspects of videos. Specifically, DiST uses a
+dual-encoder structure, where a pre-trained foundation model acts as the
+spatial encoder, and a lightweight network is introduced as the temporal
+encoder. An integration branch is inserted between the encoders to fuse
+spatio-temporal information. The disentangled spatial and temporal learning in
+DiST is highly efficient because it avoids the back-propagation of massive
+pre-trained parameters. Meanwhile, we empirically show that disentangled
+learning with an extra network for integration benefits both spatial and
+temporal understanding. Extensive experiments on five benchmarks show that DiST
+delivers better performance than existing state-of-the-art methods by
+convincing gaps. When pre-training on the large-scale Kinetics-710, we achieve
+89.7% on Kinetics-400 with a frozen ViT-L model, which verifies the scalability
+of DiST. Codes and models can be found in
+this https URL.
+
+
+
+ 8. 标题:TEMPO: Efficient Multi-View Pose Estimation, Tracking, and Forecasting
+ 编号:[8]
+ 链接:https://arxiv.org/abs/2309.07910
+ 作者:Rohan Choudhury, Kris Kitani, Laszlo A. Jeni
+ 备注:Accepted at ICCV 2023
+ 关键词:Existing volumetric methods, single time-step prediction, Existing volumetric, methods for predicting, time-step prediction
+
+ 点击查看摘要
+ Existing volumetric methods for predicting 3D human pose estimation are
+accurate, but computationally expensive and optimized for single time-step
+prediction. We present TEMPO, an efficient multi-view pose estimation model
+that learns a robust spatiotemporal representation, improving pose accuracy
+while also tracking and forecasting human pose. We significantly reduce
+computation compared to the state-of-the-art by recurrently computing
+per-person 2D pose features, fusing both spatial and temporal information into
+a single representation. In doing so, our model is able to use spatiotemporal
+context to predict more accurate human poses without sacrificing efficiency. We
+further use this representation to track human poses over time as well as
+predict future poses. Finally, we demonstrate that our model is able to
+generalize across datasets without scene-specific fine-tuning. TEMPO achieves
+10$\%$ better MPJPE with a 33$\times$ improvement in FPS compared to TesseTrack
+on the challenging CMU Panoptic Studio dataset.
+
+
+
+ 9. 标题:Boosting Unsupervised Contrastive Learning Using Diffusion-Based Data Augmentation From Scratch
+ 编号:[9]
+ 链接:https://arxiv.org/abs/2309.07909
+ 作者:Zelin Zang, Hao Luo, Kai Wang, Panpan Zhang, Fan Wang, Stan.Z Li, Yang You
+ 备注:arXiv admin note: text overlap with arXiv:2302.07944 by other authors
+ 关键词:Unsupervised contrastive learning, contrastive learning methods, data augmentation, data augmentation strategies, data
+
+ 点击查看摘要
+ Unsupervised contrastive learning methods have recently seen significant
+improvements, particularly through data augmentation strategies that aim to
+produce robust and generalizable representations. However, prevailing data
+augmentation methods, whether hand designed or based on foundation models, tend
+to rely heavily on prior knowledge or external data. This dependence often
+compromises their effectiveness and efficiency. Furthermore, the applicability
+of most existing data augmentation strategies is limited when transitioning to
+other research domains, especially science-related data. This limitation stems
+from the paucity of prior knowledge and labeled data available in these
+domains. To address these challenges, we introduce DiffAug-a novel and
+efficient Diffusion-based data Augmentation technique. DiffAug aims to ensure
+that the augmented and original data share a smoothed latent space, which is
+achieved through diffusion steps. Uniquely, unlike traditional methods, DiffAug
+first mines sufficient prior semantic knowledge about the neighborhood. This
+provides a constraint to guide the diffusion steps, eliminating the need for
+labels, external data/models, or prior knowledge. Designed as an
+architecture-agnostic framework, DiffAug provides consistent improvements.
+Specifically, it improves image classification and clustering accuracy by
+1.6%~4.5%. When applied to biological data, DiffAug improves performance by up
+to 10.1%, with an average improvement of 5.8%. DiffAug shows good performance
+in both vision and biological domains.
+
+
+
+ 10. 标题:Physically Plausible Full-Body Hand-Object Interaction Synthesis
+ 编号:[11]
+ 链接:https://arxiv.org/abs/2309.07907
+ 作者:Jona Braun, Sammy Christen, Muhammed Kocabas, Emre Aksan, Otmar Hilliges
+ 备注:Project page at this https URL
+ 关键词:synthesizing dexterous hand-object, synthesizing dexterous, dexterous hand-object interactions, full-body setting, hand-object interactions
+
+ 点击查看摘要
+ We propose a physics-based method for synthesizing dexterous hand-object
+interactions in a full-body setting. While recent advancements have addressed
+specific facets of human-object interactions, a comprehensive physics-based
+approach remains a challenge. Existing methods often focus on isolated segments
+of the interaction process and rely on data-driven techniques that may result
+in artifacts. In contrast, our proposed method embraces reinforcement learning
+(RL) and physics simulation to mitigate the limitations of data-driven
+approaches. Through a hierarchical framework, we first learn skill priors for
+both body and hand movements in a decoupled setting. The generic skill priors
+learn to decode a latent skill embedding into the motion of the underlying
+part. A high-level policy then controls hand-object interactions in these
+pretrained latent spaces, guided by task objectives of grasping and 3D target
+trajectory following. It is trained using a novel reward function that combines
+an adversarial style term with a task reward, encouraging natural motions while
+fulfilling the task incentives. Our method successfully accomplishes the
+complete interaction task, from approaching an object to grasping and
+subsequent manipulation. We compare our approach against kinematics-based
+baselines and show that it leads to more physically plausible motions.
+
+
+
+ 11. 标题:Generative Image Dynamics
+ 编号:[12]
+ 链接:https://arxiv.org/abs/2309.07906
+ 作者:Zhengqi Li, Richard Tucker, Noah Snavely, Aleksander Holynski
+ 备注:Project website: this http URL
+ 关键词:present an approach, approach to modeling, modeling an image-space, image-space prior, motion
+
+ 点击查看摘要
+ We present an approach to modeling an image-space prior on scene dynamics.
+Our prior is learned from a collection of motion trajectories extracted from
+real video sequences containing natural, oscillating motion such as trees,
+flowers, candles, and clothes blowing in the wind. Given a single image, our
+trained model uses a frequency-coordinated diffusion sampling process to
+predict a per-pixel long-term motion representation in the Fourier domain,
+which we call a neural stochastic motion texture. This representation can be
+converted into dense motion trajectories that span an entire video. Along with
+an image-based rendering module, these trajectories can be used for a number of
+downstream applications, such as turning still images into seamlessly looping
+dynamic videos, or allowing users to realistically interact with objects in
+real pictures.
+
+
+
+ 12. 标题:HandNeRF: Learning to Reconstruct Hand-Object Interaction Scene from a Single RGB Image
+ 编号:[16]
+ 链接:https://arxiv.org/abs/2309.07891
+ 作者:Hongsuk Choi, Nikhil Chavan-Dafle, Jiacheng Yuan, Volkan Isler, Hyunsoo Park
+ 备注:9 pages, 4 tables, 7 figures
+ 关键词:single RGB image, learn hand-object interaction, hand-object interaction prior, single RGB, RGB image
+
+ 点击查看摘要
+ This paper presents a method to learn hand-object interaction prior for
+reconstructing a 3D hand-object scene from a single RGB image. The inference as
+well as training-data generation for 3D hand-object scene reconstruction is
+challenging due to the depth ambiguity of a single image and occlusions by the
+hand and object. We turn this challenge into an opportunity by utilizing the
+hand shape to constrain the possible relative configuration of the hand and
+object geometry. We design a generalizable implicit function, HandNeRF, that
+explicitly encodes the correlation of the 3D hand shape features and 2D object
+features to predict the hand and object scene geometry. With experiments on
+real-world datasets, we show that HandNeRF is able to reconstruct hand-object
+scenes of novel grasp configurations more accurately than comparable methods.
+Moreover, we demonstrate that object reconstruction from HandNeRF ensures more
+accurate execution of a downstream task, such as grasping for robotic
+hand-over.
+
+
+
+ 13. 标题:A Novel Local-Global Feature Fusion Framework for Body-weight Exercise Recognition with Pressure Mapping Sensors
+ 编号:[17]
+ 链接:https://arxiv.org/abs/2309.07888
+ 作者:Davinder Pal Singh, Lala Shakti Swarup Ray, Bo Zhou, Sungho Suh, Paul Lukowicz
+ 备注:
+ 关键词:dynamic pressure maps, floor-based dynamic pressure, local-global feature fusion, feature fusion framework, global feature extraction
+
+ 点击查看摘要
+ We present a novel local-global feature fusion framework for body-weight
+exercise recognition with floor-based dynamic pressure maps. One step further
+from the existing studies using deep neural networks mainly focusing on global
+feature extraction, the proposed framework aims to combine local and global
+features using image processing techniques and the YOLO object detection to
+localize pressure profiles from different body parts and consider physical
+constraints. The proposed local feature extraction method generates two sets of
+high-level local features consisting of cropped pressure mapping and numerical
+features such as angular orientation, location on the mat, and pressure area.
+In addition, we adopt a knowledge distillation for regularization to preserve
+the knowledge of the global feature extraction and improve the performance of
+the exercise recognition. Our experimental results demonstrate a notable 11
+percent improvement in F1 score for exercise recognition while preserving
+label-specific features.
+
+
+
+ 14. 标题:mEBAL2 Database and Benchmark: Image-based Multispectral Eyeblink Detection
+ 编号:[19]
+ 链接:https://arxiv.org/abs/2309.07880
+ 作者:Roberto Daza, Aythami Morales, Julian Fierrez, Ruben Tolosana, Ruben Vera-Rodriguez
+ 备注:This paper is under consideration at Pattern Recognition Letters
+ 关键词:Attention Level estimation, Attention Level, multimodal Eye Blink, Level estimation, RGB
+
+ 点击查看摘要
+ This work introduces a new multispectral database and novel approaches for
+eyeblink detection in RGB and Near-Infrared (NIR) individual images. Our
+contributed dataset (mEBAL2, multimodal Eye Blink and Attention Level
+estimation, Version 2) is the largest existing eyeblink database, representing
+a great opportunity to improve data-driven multispectral approaches for blink
+detection and related applications (e.g., attention level estimation and
+presentation attack detection in face biometrics). mEBAL2 includes 21,100 image
+sequences from 180 different students (more than 2 million labeled images in
+total) while conducting a number of e-learning tasks of varying difficulty or
+taking a real course on HTML initiation through the edX MOOC platform. mEBAL2
+uses multiple sensors, including two Near-Infrared (NIR) and one RGB camera to
+capture facial gestures during the execution of the tasks, as well as an
+Electroencephalogram (EEG) band to get the cognitive activity of the user and
+blinking events. Furthermore, this work proposes a Convolutional Neural Network
+architecture as benchmark for blink detection on mEBAL2 with performances up to
+97%. Different training methodologies are implemented using the RGB spectrum,
+NIR spectrum, and the combination of both to enhance the performance on
+existing eyeblink detectors. We demonstrate that combining NIR and RGB images
+during training improves the performance of RGB eyeblink detectors (i.e.,
+detection based only on a RGB image). Finally, the generalization capacity of
+the proposed eyeblink detectors is validated in wilder and more challenging
+environments like the HUST-LEBW dataset to show the usefulness of mEBAL2 to
+train a new generation of data-driven approaches for eyeblink detection.
+
+
+
+ 15. 标题:Using network metrics to explore the community structure that underlies movement patterns
+ 编号:[20]
+ 链接:https://arxiv.org/abs/2309.07878
+ 作者:Anh Pham Thi Minh, Abhishek Kumar Singh, Soumya Snigdha Kundu
+ 备注:6 pages excluding References
+ 关键词:Santiago de Chile, movement patterns, analyzing the movement, aims to explore, structure of Santiago
+
+ 点击查看摘要
+ This work aims to explore the community structure of Santiago de Chile by
+analyzing the movement patterns of its residents. We use a dataset containing
+the approximate locations of home and work places for a subset of anonymized
+residents to construct a network that represents the movement patterns within
+the city. Through the analysis of this network, we aim to identify the
+communities or sub-cities that exist within Santiago de Chile and gain insights
+into the factors that drive the spatial organization of the city. We employ
+modularity optimization algorithms and clustering techniques to identify the
+communities within the network. Our results present that the novelty of
+combining community detection algorithms with segregation tools provides new
+insights to further the understanding of the complex geography of segregation
+during working hours.
+
+
+
+ 16. 标题:Gradient constrained sharpness-aware prompt learning for vision-language models
+ 编号:[28]
+ 链接:https://arxiv.org/abs/2309.07866
+ 作者:Liangchen Liu, Nannan Wang, Dawei Zhou, Xinbo Gao, Decheng Liu, Xi Yang, Tongliang Liu
+ 备注:19 pages 11 figures
+ 关键词:paper targets, unseen classes, loss, Constrained Sharpness-aware Context, Sharpness-aware Context Optimization
+
+ 点击查看摘要
+ This paper targets a novel trade-off problem in generalizable prompt learning
+for vision-language models (VLM), i.e., improving the performance on unseen
+classes while maintaining the performance on seen classes. Comparing with
+existing generalizable methods that neglect the seen classes degradation, the
+setting of this problem is more strict and fits more closely with practical
+applications. To solve this problem, we start from the optimization
+perspective, and leverage the relationship between loss landscape geometry and
+model generalization ability. By analyzing the loss landscape of the
+state-of-the-art method and the widely-used Sharpness-aware Minimization (SAM),
+we conclude that the trade-off performance correlates to both loss value and
+loss sharpness, while each of them are indispensable. However, we find the
+optimizing gradient of existing methods cannot always maintain high consistency
+with both loss value and loss sharpness during the whole optimization
+procedure. To this end, we propose an novel SAM-based method for prompt
+learning, denoted as Gradient Constrained Sharpness-aware Context Optimization
+(GCSCoOp), to dynamically constrains the optimizing gradient, thus achieving
+above two-fold optimization objective simultaneously. Extensive experiments
+verify the effectiveness of GCSCoOp in the trade-off problem.
+
+
+
+ 17. 标题:TFNet: Exploiting Temporal Cues for Fast and Accurate LiDAR Semantic Segmentation
+ 编号:[35]
+ 链接:https://arxiv.org/abs/2309.07849
+ 作者:Rong Li, ShiJie Li, Xieyuanli Chen, Teli Ma, Wang Hao, Juergen Gall, Junwei Liang
+ 备注:
+ 关键词:enabling autonomous driving, accurately and robustly, semantic segmentation plays, plays a crucial, crucial role
+
+ 点击查看摘要
+ LiDAR semantic segmentation plays a crucial role in enabling autonomous
+driving and robots to understand their surroundings accurately and robustly.
+There are different types of methods, such as point-based, range image-based,
+and polar-based. Among these, range image-based methods are widely used due to
+their balance between accuracy and speed. However, they face a significant
+challenge known as the ``many-to-one'' problem caused by the range image's
+limited horizontal and vertical angular resolution, where around 20% of the 3D
+points are occluded during model inference based on our observation. In this
+paper, we present TFNet, a range image-based LiDAR semantic segmentation method
+that utilizes temporal information to address this issue. Specifically, we
+incorporate a temporal fusion layer to extract useful information from previous
+scans and integrate it with the current scan. We then design a max-voting-based
+post-processing technique to correct false predictions, particularly those
+caused by the ``many-to-one'' issue. Experiments on two benchmarks and seven
+backbones of three modalities demonstrate the effectiveness and scalability of
+our proposed method.
+
+
+
+ 18. 标题:MC-NeRF: Muti-Camera Neural Radiance Fields for Muti-Camera Image Acquisition Systems
+ 编号:[36]
+ 链接:https://arxiv.org/abs/2309.07846
+ 作者:Yu Gao, Lutong Su, Hao Liang, Yufeng Yue, Yi Yang, Mengyin Fu
+ 备注:This manuscript is currently under review
+ 关键词:shown remarkable performance, Neural Radiance Fields, Radiance Fields, employ multi-view images, remarkable performance
+
+ 点击查看摘要
+ Neural Radiance Fields (NeRF) employ multi-view images for 3D scene
+representation and have shown remarkable performance. As one of the primary
+sources of multi-view images, multi-camera systems encounter challenges such as
+varying intrinsic parameters and frequent pose changes. Most previous
+NeRF-based methods often assume a global unique camera and seldom consider
+scenarios with multiple cameras. Besides, some pose-robust methods still remain
+susceptible to suboptimal solutions when poses are poor initialized. In this
+paper, we propose MC-NeRF, a method can jointly optimize both intrinsic and
+extrinsic parameters for bundle-adjusting Neural Radiance Fields. Firstly, we
+conduct a theoretical analysis to tackle the degenerate case and coupling issue
+that arise from the joint optimization between intrinsic and extrinsic
+parameters. Secondly, based on the proposed solutions, we introduce an
+efficient calibration image acquisition scheme for multi-camera systems,
+including the design of calibration object. Lastly, we present a global
+end-to-end network with training sequence that enables the regression of
+intrinsic and extrinsic parameters, along with the rendering network. Moreover,
+most existing datasets are designed for unique camera, we create a new dataset
+that includes four different styles of multi-camera acquisition systems,
+allowing readers to generate custom datasets. Experiments confirm the
+effectiveness of our method when each image corresponds to different camera
+parameters. Specifically, we adopt up to 110 images with 110 different
+intrinsic and extrinsic parameters, to achieve 3D scene representation without
+providing initial poses. The Code and supplementary materials are available at
+this https URL.
+
+
+
+ 19. 标题:Large-scale Weakly Supervised Learning for Road Extraction from Satellite Imagery
+ 编号:[39]
+ 链接:https://arxiv.org/abs/2309.07823
+ 作者:Shiqiao Meng, Zonglin Di, Siwei Yang, Yin Wang
+ 备注:
+ 关键词:traditional manual mapping, Automatic road extraction, manual mapping, deep learning, viable alternative
+
+ 点击查看摘要
+ Automatic road extraction from satellite imagery using deep learning is a
+viable alternative to traditional manual mapping. Therefore it has received
+considerable attention recently. However, most of the existing methods are
+supervised and require pixel-level labeling, which is tedious and error-prone.
+To make matters worse, the earth has a diverse range of terrain, vegetation,
+and man-made objects. It is well known that models trained in one area
+generalize poorly to other areas. Various shooting conditions such as light and
+angel, as well as different image processing techniques further complicate the
+issue. It is impractical to develop training data to cover all image styles.
+This paper proposes to leverage OpenStreetMap road data as weak labels and
+large scale satellite imagery to pre-train semantic segmentation models. Our
+extensive experimental results show that the prediction accuracy increases with
+the amount of the weakly labeled data, as well as the road density in the areas
+chosen for training. Using as much as 100 times more data than the widely used
+DeepGlobe road dataset, our model with the D-LinkNet architecture and the
+ResNet-50 backbone exceeds the top performer of the current DeepGlobe
+leaderboard. Furthermore, due to large-scale pre-training, our model
+generalizes much better than those trained with only the curated datasets,
+implying great application potential.
+
+
+
+ 20. 标题:Decomposition of linear tensor transformations
+ 编号:[41]
+ 链接:https://arxiv.org/abs/2309.07819
+ 作者:Claudio Turchetti
+ 备注:arXiv admin note: text overlap with arXiv:2305.02803
+ 关键词:main issues, issues in computing, determining the rank, number of rank-one, rank-one components
+
+ 点击查看摘要
+ One of the main issues in computing a tensor decomposition is how to choose
+the number of rank-one components, since there is no finite algorithms for
+determining the rank of a tensor. A commonly used approach for this purpose is
+to find a low-dimensional subspace by solving an optimization problem and
+assuming the number of components is fixed. However, even though this algorithm
+is efficient and easy to implement, it often converges to poor local minima and
+suffers from outliers and noise. The aim of this paper is to develop a
+mathematical framework for exact tensor decomposition that is able to represent
+a tensor as the sum of a finite number of low-rank tensors. In the paper three
+different problems will be carried out to derive: i) the decomposition of a
+non-negative self-adjoint tensor operator; ii) the decomposition of a linear
+tensor transformation; iii) the decomposition of a generic tensor.
+
+
+
+ 21. 标题:What Matters to Enhance Traffic Rule Compliance of Imitation Learning for Automated Driving
+ 编号:[46]
+ 链接:https://arxiv.org/abs/2309.07808
+ 作者:Hongkuan Zhou, Aifen Sui, Wei Cao, Letian Shi
+ 备注:8 pages, 2 figures
+ 关键词:faster inference time, single neural network, entire driving pipeline, inference time, research attention
+
+ 点击查看摘要
+ More research attention has recently been given to end-to-end autonomous
+driving technologies where the entire driving pipeline is replaced with a
+single neural network because of its simpler structure and faster inference
+time. Despite this appealing approach largely reducing the components in
+driving pipeline, its simplicity also leads to interpretability problems and
+safety issues arXiv:2003.06404. The trained policy is not always compliant with
+the traffic rules and it is also hard to discover the reason for the
+misbehavior because of the lack of intermediate outputs. Meanwhile, Sensors are
+also critical to autonomous driving's security and feasibility to perceive the
+surrounding environment under complex driving scenarios. In this paper, we
+proposed P-CSG, a novel penalty-based imitation learning approach with cross
+semantics generation sensor fusion technologies to increase the overall
+performance of End-to-End Autonomous Driving. We conducted an assessment of our
+model's performance using the Town 05 Long benchmark, achieving an impressive
+driving score improvement of over 15%. Furthermore, we conducted robustness
+evaluations against adversarial attacks like FGSM and Dot attacks, revealing a
+substantial increase in robustness compared to baseline models.More detailed
+information, such as code-based resources, ablation studies and videos can be
+found at this https URL.
+
+
+
+ 22. 标题:For A More Comprehensive Evaluation of 6DoF Object Pose Tracking
+ 编号:[51]
+ 链接:https://arxiv.org/abs/2309.07796
+ 作者:Yang Li, Fan Zhong, Xin Wang, Shuangbing Song, Jiachen Li, Xueying Qin, Changhe Tu
+ 备注:
+ 关键词:presented obvious limitations, tracking have presented, presented obvious, object pose tracking, YCBV
+
+ 点击查看摘要
+ Previous evaluations on 6DoF object pose tracking have presented obvious
+limitations along with the development of this area. In particular, the
+evaluation protocols are not unified for different methods, the widely-used
+YCBV dataset contains significant annotation error, and the error metrics also
+may be biased. As a result, it is hard to fairly compare the methods, which has
+became a big obstacle for developing new algorithms. In this paper we
+contribute a unified benchmark to address the above problems. For more accurate
+annotation of YCBV, we propose a multi-view multi-object global pose refinement
+method, which can jointly refine the poses of all objects and view cameras,
+resulting in sub-pixel sub-millimeter alignment errors. The limitations of
+previous scoring methods and error metrics are analyzed, based on which we
+introduce our improved evaluation methods. The unified benchmark takes both
+YCBV and BCOT as base datasets, which are shown to be complementary in scene
+categories. In experiments, we validate the precision and reliability of the
+proposed global pose refinement method with a realistic semi-synthesized
+dataset particularly for YCBV, and then present the benchmark results unifying
+learning&non-learning and RGB&RGBD methods, with some finds not discovered in
+previous studies.
+
+
+
+ 23. 标题:PRE: Vision-Language Prompt Learning with Reparameterization Encoder
+ 编号:[59]
+ 链接:https://arxiv.org/abs/2309.07760
+ 作者:Anh Pham Thi Minh
+ 备注:8 pages excluding References and Appendix
+ 关键词:Large pre-trained vision-language, demonstrated great potential, CLIP have demonstrated, pre-trained vision-language models, Large pre-trained
+
+ 点击查看摘要
+ Large pre-trained vision-language models such as CLIP have demonstrated great
+potential in zero-shot transferability to downstream tasks. However, to attain
+optimal performance, the manual selection of prompts is necessary to improve
+alignment between the downstream image distribution and the textual class
+descriptions. This manual prompt engineering is the major challenge for
+deploying such models in practice since it requires domain expertise and is
+extremely time-consuming. To avoid non-trivial prompt engineering, recent work
+Context Optimization (CoOp) introduced the concept of prompt learning to the
+vision domain using learnable textual tokens. While CoOp can achieve
+substantial improvements over manual prompts, its learned context is worse
+generalizable to wider unseen classes within the same dataset. In this work, we
+present Prompt Learning with Reparameterization Encoder (PRE) - a simple and
+efficient method that enhances the generalization ability of the learnable
+prompt to unseen classes while maintaining the capacity to learn Base classes.
+Instead of directly optimizing the prompts, PRE employs a prompt encoder to
+reparameterize the input prompt embeddings, enhancing the exploration of
+task-specific knowledge from few-shot samples. Experiments and extensive
+ablation studies on 8 benchmarks demonstrate that our approach is an efficient
+method for prompt learning. Specifically, PRE achieves a notable enhancement of
+5.60% in average accuracy on New classes and 3% in Harmonic mean compared to
+CoOp in the 16-shot setting, all achieved within a good training time.
+
+
+
+ 24. 标题:Co-Salient Object Detection with Semantic-Level Consensus Extraction and Dispersion
+ 编号:[63]
+ 链接:https://arxiv.org/abs/2309.07753
+ 作者:Peiran Xu, Yadong Mu
+ 备注:Accepted by ACM MM 2023
+ 关键词:aims to highlight, co-salient object detection, common salient object, object detection, consensus
+
+ 点击查看摘要
+ Given a group of images, co-salient object detection (CoSOD) aims to
+highlight the common salient object in each image. There are two factors
+closely related to the success of this task, namely consensus extraction, and
+the dispersion of consensus to each image. Most previous works represent the
+group consensus using local features, while we instead utilize a hierarchical
+Transformer module for extracting semantic-level consensus. Therefore, it can
+obtain a more comprehensive representation of the common object category, and
+exclude interference from other objects that share local similarities with the
+target object. In addition, we propose a Transformer-based dispersion module
+that takes into account the variation of the co-salient object in different
+scenes. It distributes the consensus to the image feature maps in an
+image-specific way while making full use of interactions within the group.
+These two modules are integrated with a ViT encoder and an FPN-like decoder to
+form an end-to-end trainable network, without additional branch and auxiliary
+loss. The proposed method is evaluated on three commonly used CoSOD datasets
+and achieves state-of-the-art performance.
+
+
+
+ 25. 标题:DT-NeRF: Decomposed Triplane-Hash Neural Radiance Fields for High-Fidelity Talking Portrait Synthesis
+ 编号:[64]
+ 链接:https://arxiv.org/abs/2309.07752
+ 作者:Yaoyu Su, Shaohui Wang, Haoqian Wang
+ 备注:5 pages, 5 figures. Submitted to ICASSP 2024
+ 关键词:decomposed triplane-hash neural, key evaluation datasets, triplane-hash neural radiance, results on key, neural radiance fields
+
+ 点击查看摘要
+ In this paper, we present the decomposed triplane-hash neural radiance fields
+(DT-NeRF), a framework that significantly improves the photorealistic rendering
+of talking faces and achieves state-of-the-art results on key evaluation
+datasets. Our architecture decomposes the facial region into two specialized
+triplanes: one specialized for representing the mouth, and the other for the
+broader facial features. We introduce audio features as residual terms and
+integrate them as query vectors into our model through an audio-mouth-face
+transformer. Additionally, our method leverages the capabilities of Neural
+Radiance Fields (NeRF) to enrich the volumetric representation of the entire
+face through additive volumetric rendering techniques. Comprehensive
+experimental evaluations corroborate the effectiveness and superiority of our
+proposed approach.
+
+
+
+ 26. 标题:OmnimatteRF: Robust Omnimatte with 3D Background Modeling
+ 编号:[65]
+ 链接:https://arxiv.org/abs/2309.07749
+ 作者:Geng Lin, Chen Gao, Jia-Bin Huang, Changil Kim, Yipeng Wang, Matthias Zwicker, Ayush Saraf
+ 备注:ICCV 2023. Project page: this https URL
+ 关键词:casually captured movies, adding interesting effects, video production professionals, assisting video production, production professionals
+
+ 点击查看摘要
+ Video matting has broad applications, from adding interesting effects to
+casually captured movies to assisting video production professionals. Matting
+with associated effects such as shadows and reflections has also attracted
+increasing research activity, and methods like Omnimatte have been proposed to
+separate dynamic foreground objects of interest into their own layers. However,
+prior works represent video backgrounds as 2D image layers, limiting their
+capacity to express more complicated scenes, thus hindering application to
+real-world videos. In this paper, we propose a novel video matting method,
+OmnimatteRF, that combines dynamic 2D foreground layers and a 3D background
+model. The 2D layers preserve the details of the subjects, while the 3D
+background robustly reconstructs scenes in real-world videos. Extensive
+experiments demonstrate that our method reconstructs scenes with better quality
+on various videos.
+
+
+
+ 27. 标题:NutritionVerse: Empirical Study of Various Dietary Intake Estimation Approaches
+ 编号:[85]
+ 链接:https://arxiv.org/abs/2309.07704
+ 作者:Chi-en Amy Tai, Matthew Keller, Saeejith Nair, Yuhao Chen, Yifan Wu, Olivia Markham, Krish Parmar, Pengcheng Xi, Heather Keller, Sharon Kirkpatrick, Alexander Wong
+ 备注:
+ 关键词:support healthy eating, Accurate dietary intake, healthy eating, quality of life, critical for informing
+
+ 点击查看摘要
+ Accurate dietary intake estimation is critical for informing policies and
+programs to support healthy eating, as malnutrition has been directly linked to
+decreased quality of life. However self-reporting methods such as food diaries
+suffer from substantial bias. Other conventional dietary assessment techniques
+and emerging alternative approaches such as mobile applications incur high time
+costs and may necessitate trained personnel. Recent work has focused on using
+computer vision and machine learning to automatically estimate dietary intake
+from food images, but the lack of comprehensive datasets with diverse
+viewpoints, modalities and food annotations hinders the accuracy and realism of
+such methods. To address this limitation, we introduce NutritionVerse-Synth,
+the first large-scale dataset of 84,984 photorealistic synthetic 2D food images
+with associated dietary information and multimodal annotations (including depth
+images, instance masks, and semantic masks). Additionally, we collect a real
+image dataset, NutritionVerse-Real, containing 889 images of 251 dishes to
+evaluate realism. Leveraging these novel datasets, we develop and benchmark
+NutritionVerse, an empirical study of various dietary intake estimation
+approaches, including indirect segmentation-based and direct prediction
+networks. We further fine-tune models pretrained on synthetic data with real
+images to provide insights into the fusion of synthetic and real data. Finally,
+we release both datasets (NutritionVerse-Synth, NutritionVerse-Real) on
+this https URL as part of an open initiative to
+accelerate machine learning for dietary sensing.
+
+
+
+ 28. 标题:Dataset Condensation via Generative Model
+ 编号:[88]
+ 链接:https://arxiv.org/abs/2309.07698
+ 作者:David Junhao Zhang, Heng Wang, Chuhui Xue, Rui Yan, Wenqing Zhang, Song Bai, Mike Zheng Shou
+ 备注:old work,done in 2022
+ 关键词:small set, lot of training, large datasets, samples, Dataset
+
+ 点击查看摘要
+ Dataset condensation aims to condense a large dataset with a lot of training
+samples into a small set. Previous methods usually condense the dataset into
+the pixels format. However, it suffers from slow optimization speed and large
+number of parameters to be optimized. When increasing image resolutions and
+classes, the number of learnable parameters grows accordingly, prohibiting
+condensation methods from scaling up to large datasets with diverse classes.
+Moreover, the relations among condensed samples have been neglected and hence
+the feature distribution of condensed samples is often not diverse. To solve
+these problems, we propose to condense the dataset into another format, a
+generative model. Such a novel format allows for the condensation of large
+datasets because the size of the generative model remains relatively stable as
+the number of classes or image resolution increases. Furthermore, an
+intra-class and an inter-class loss are proposed to model the relation of
+condensed samples. Intra-class loss aims to create more diverse samples for
+each class by pushing each sample away from the others of the same class.
+Meanwhile, inter-class loss increases the discriminability of samples by
+widening the gap between the centers of different classes. Extensive
+comparisons with state-of-the-art methods and our ablation studies confirm the
+effectiveness of our method and its individual component. To our best
+knowledge, we are the first to successfully conduct condensation on
+ImageNet-1k.
+
+
+
+ 29. 标题:CoRF : Colorizing Radiance Fields using Knowledge Distillation
+ 编号:[101]
+ 链接:https://arxiv.org/abs/2309.07668
+ 作者:Ankit Dhiman, R Srinath, Srinjay Sarkar, Lokesh R Boregowda, R Venkatesh Babu
+ 备注:AI3DCC @ ICCV 2023
+ 关键词:enable high-quality novel-view, high-quality novel-view synthesis, radiance field network, radiance field, Neural radiance field
+
+ 点击查看摘要
+ Neural radiance field (NeRF) based methods enable high-quality novel-view
+synthesis for multi-view images. This work presents a method for synthesizing
+colorized novel views from input grey-scale multi-view images. When we apply
+image or video-based colorization methods on the generated grey-scale novel
+views, we observe artifacts due to inconsistency across views. Training a
+radiance field network on the colorized grey-scale image sequence also does not
+solve the 3D consistency issue. We propose a distillation based method to
+transfer color knowledge from the colorization networks trained on natural
+images to the radiance field network. Specifically, our method uses the
+radiance field network as a 3D representation and transfers knowledge from
+existing 2D colorization methods. The experimental results demonstrate that the
+proposed method produces superior colorized novel views for indoor and outdoor
+scenes while maintaining cross-view consistency than baselines. Further, we
+show the efficacy of our method on applications like colorization of radiance
+field network trained from 1.) Infra-Red (IR) multi-view images and 2.) Old
+grey-scale multi-view image sequences.
+
+
+
+ 30. 标题:Towards Robust and Unconstrained Full Range of Rotation Head Pose Estimation
+ 编号:[106]
+ 链接:https://arxiv.org/abs/2309.07654
+ 作者:Thorsten Hempel, Ahmed A. Abdelrahman, Ayoub Al-Hamadi
+ 备注:
+ 关键词:frontal pose prediction, head pose, head pose prediction, crucial problem, problem for numerous
+
+ 点击查看摘要
+ Estimating the head pose of a person is a crucial problem for numerous
+applications that is yet mainly addressed as a subtask of frontal pose
+prediction. We present a novel method for unconstrained end-to-end head pose
+estimation to tackle the challenging task of full range of orientation head
+pose prediction. We address the issue of ambiguous rotation labels by
+introducing the rotation matrix formalism for our ground truth data and propose
+a continuous 6D rotation matrix representation for efficient and robust direct
+regression. This allows to efficiently learn full rotation appearance and to
+overcome the limitations of the current state-of-the-art. Together with new
+accumulated training data that provides full head pose rotation data and a
+geodesic loss approach for stable learning, we design an advanced model that is
+able to predict an extended range of head orientations. An extensive evaluation
+on public datasets demonstrates that our method significantly outperforms other
+state-of-the-art methods in an efficient and robust manner, while its advanced
+prediction range allows the expansion of the application area. We open-source
+our training and testing code along with our trained models:
+this https URL.
+
+
+
+ 31. 标题:Indoor Scene Reconstruction with Fine-Grained Details Using Hybrid Representation and Normal Prior Enhancement
+ 编号:[109]
+ 链接:https://arxiv.org/abs/2309.07640
+ 作者:Sheng Ye, Yubin Hu, Matthieu Lin, Yu-Hui Wen, Wang Zhao, Wenping Wang, Yong-Jin Liu
+ 备注:
+ 关键词:multi-view RGB images, multi-view RGB, texture-less regions alongside, regions alongside delicate, RGB images
+
+ 点击查看摘要
+ The reconstruction of indoor scenes from multi-view RGB images is challenging
+due to the coexistence of flat and texture-less regions alongside delicate and
+fine-grained regions. Recent methods leverage neural radiance fields aided by
+predicted surface normal priors to recover the scene geometry. These methods
+excel in producing complete and smooth results for floor and wall areas.
+However, they struggle to capture complex surfaces with high-frequency
+structures due to the inadequate neural representation and the inaccurately
+predicted normal priors. To improve the capacity of the implicit
+representation, we propose a hybrid architecture to represent low-frequency and
+high-frequency regions separately. To enhance the normal priors, we introduce a
+simple yet effective image sharpening and denoising technique, coupled with a
+network that estimates the pixel-wise uncertainty of the predicted surface
+normal vectors. Identifying such uncertainty can prevent our model from being
+misled by unreliable surface normal supervisions that hinder the accurate
+reconstruction of intricate geometries. Experiments on the benchmark datasets
+show that our method significantly outperforms existing methods in terms of
+reconstruction quality.
+
+
+
+ 32. 标题:SwitchGPT: Adapting Large Language Models for Non-Text Outputs
+ 编号:[119]
+ 链接:https://arxiv.org/abs/2309.07623
+ 作者:Xinyu Wang, Bohan Zhuang, Qi Wu
+ 备注:
+ 关键词:Large Language Models, exhibit exceptional proficiencies, Large Language, executing complex linguistic, Language Models
+
+ 点击查看摘要
+ Large Language Models (LLMs), primarily trained on text-based datasets,
+exhibit exceptional proficiencies in understanding and executing complex
+linguistic instructions via text outputs. However, they falter when requests to
+generate non-text ones. Concurrently, modality conversion models, such as
+text-to-image, despite generating high-quality images, suffer from a lack of
+extensive textual pretraining. As a result, these models are only capable of
+accommodating specific image descriptions rather than comprehending more
+complex instructions. To bridge this gap, we propose a novel approach,
+\methodname, from a modality conversion perspective that evolves a text-based
+LLM into a multi-modal one. We specifically employ a minimal dataset to
+instruct LLMs to recognize the intended output modality as directed by the
+instructions. Consequently, the adapted LLM can effectively summon various
+off-the-shelf modality conversion models from the model zoos to generate
+non-text responses. This circumvents the necessity for complicated pretraining
+that typically requires immense quantities of paired multi-modal data, while
+simultaneously inheriting the extensive knowledge of LLMs and the ability of
+high-quality generative models. To evaluate and compare the adapted multi-modal
+LLM with its traditional counterparts, we have constructed a multi-modal
+instruction benchmark that solicits diverse modality outputs. The experiment
+results reveal that, with minimal training, LLMs can be conveniently adapted to
+comprehend requests for non-text responses, thus achieving higher flexibility
+in multi-modal scenarios. Code and data will be made available at
+this https URL.
+
+
+
+ 33. 标题:Road Disease Detection based on Latent Domain Background Feature Separation and Suppression
+ 编号:[124]
+ 链接:https://arxiv.org/abs/2309.07616
+ 作者:Juwu Zheng, Jiangtao Ren
+ 备注:
+ 关键词:Road disease detection, diverse background,which introduce, background,which introduce lots, Latent Domain Background, Background Feature Separation
+
+ 点击查看摘要
+ Road disease detection is challenging due to the the small proportion of road
+damage in target region and the diverse background,which introduce lots of
+domain information.Besides, disease categories have high similarity,makes the
+detection more difficult. In this paper, we propose a new LDBFSS(Latent Domain
+Background Feature Separation and Suppression) network which could perform
+background information separation and suppression without domain supervision
+and contrastive enhancement of object features.We combine our LDBFSS network
+with YOLOv5 model to enhance disease features for better road disease
+detection. As the components of LDBFSS network, we first design a latent domain
+discovery module and a domain adversarial learning module to obtain pseudo
+domain labels through unsupervised method, guiding domain discriminator and
+model to train adversarially to suppress background information. In addition,
+we introduce a contrastive learning module and design k-instance contrastive
+loss, optimize the disease feature representation by increasing the inter-class
+distance and reducing the intra-class distance for object features. We
+conducted experiments on two road disease detection datasets, GRDDC and CNRDD,
+and compared with other models,which show an increase of nearly 4% on GRDDC
+dataset compared with optimal model, and an increase of 4.6% on CNRDD dataset.
+Experimental results prove the effectiveness and superiority of our model.
+
+
+
+ 34. 标题:Learning Quasi-Static 3D Models of Markerless Deformable Linear Objects for Bimanual Robotic Manipulation
+ 编号:[128]
+ 链接:https://arxiv.org/abs/2309.07609
+ 作者:Piotr Kicki, Michał Bidziński, Krzysztof Walas
+ 备注:Under review for IEEE Robotics and Automation Letters
+ 关键词:Deformable Linear Objects, Linear Objects, Deformable Linear, manipulation of Deformable, practical applications
+
+ 点击查看摘要
+ The robotic manipulation of Deformable Linear Objects (DLOs) is a vital and
+challenging task that is important in many practical applications. Classical
+model-based approaches to this problem require an accurate model to capture how
+robot motions affect the deformation of the DLO. Nowadays, data-driven models
+offer the best tradeoff between quality and computation time. This paper
+analyzes several learning-based 3D models of the DLO and proposes a new one
+based on the Transformer architecture that achieves superior accuracy, even on
+the DLOs of different lengths, thanks to the proposed scaling method. Moreover,
+we introduce a data augmentation technique, which improves the prediction
+performance of almost all considered DLO data-driven models. Thanks to this
+technique, even a simple Multilayer Perceptron (MLP) achieves close to
+state-of-the-art performance while being significantly faster to evaluate. In
+the experiments, we compare the performance of the learning-based 3D models of
+the DLO on several challenging datasets quantitatively and demonstrate their
+applicability in the task of shaping a DLO.
+
+
+
+ 35. 标题:Universality of underlying mechanism for successful deep learning
+ 编号:[156]
+ 链接:https://arxiv.org/abs/2309.07537
+ 作者:Yuval Meir, Yarden Tzach, Shiri Hodassman, Ofek Tevet, Ido Kanter
+ 备注:27 pages,5 figures, 6 tables. arXiv admin note: text overlap with arXiv:2305.18078
+ 关键词:successful deep learning, recently presented based, measure the quality, limited deep architecture, quantitative method
+
+ 点击查看摘要
+ An underlying mechanism for successful deep learning (DL) with a limited deep
+architecture and dataset, namely VGG-16 on CIFAR-10, was recently presented
+based on a quantitative method to measure the quality of a single filter in
+each layer. In this method, each filter identifies small clusters of possible
+output labels, with additional noise selected as labels out of the clusters.
+This feature is progressively sharpened with the layers, resulting in an
+enhanced signal-to-noise ratio (SNR) and higher accuracy. In this study, the
+suggested universal mechanism is verified for VGG-16 and EfficientNet-B0
+trained on the CIFAR-100 and ImageNet datasets with the following main results.
+First, the accuracy progressively increases with the layers, whereas the noise
+per filter typically progressively decreases. Second, for a given deep
+architecture, the maximal error rate increases approximately linearly with the
+number of output labels. Third, the average filter cluster size and the number
+of clusters per filter at the last convolutional layer adjacent to the output
+layer are almost independent of the number of dataset labels in the range [3,
+1,000], while a high SNR is preserved. The presented DL mechanism suggests
+several techniques, such as applying filter's cluster connections (AFCC), to
+improve the computational complexity and accuracy of deep architectures and
+furthermore pinpoints the simplification of pre-existing structures while
+maintaining their accuracies.
+
+
+
+ 36. 标题:A Multi-scale Generalized Shrinkage Threshold Network for Image Blind Deblurring in Remote Sensing
+ 编号:[160]
+ 链接:https://arxiv.org/abs/2309.07524
+ 作者:Yujie Feng, Yin Yang, Xiaohong Fan, Zhengpeng Zhang, Jianping Zhang
+ 备注:12 pages,
+ 关键词:earth science applications, complex imaging environments, Remote sensing, remote sensing image, imaging environments
+
+ 点击查看摘要
+ Remote sensing images are essential for many earth science applications, but
+their quality can be degraded due to limitations in sensor technology and
+complex imaging environments. To address this, various remote sensing image
+deblurring methods have been developed to restore sharp, high-quality images
+from degraded observational data. However, most traditional model-based
+deblurring methods usually require predefined hand-craft prior assumptions,
+which are difficult to handle in complex applications, and most deep
+learning-based deblurring methods are designed as a black box, lacking
+transparency and interpretability. In this work, we propose a novel blind
+deblurring learning framework based on alternating iterations of shrinkage
+thresholds, alternately updating blurring kernels and images, with the
+theoretical foundation of network design. Additionally, we propose a learnable
+blur kernel proximal mapping module to improve the blur kernel evaluation in
+the kernel domain. Then, we proposed a deep proximal mapping module in the
+image domain, which combines a generalized shrinkage threshold operator and a
+multi-scale prior feature extraction block. This module also introduces an
+attention mechanism to adaptively adjust the prior importance, thus avoiding
+the drawbacks of hand-crafted image prior terms. Thus, a novel multi-scale
+generalized shrinkage threshold network (MGSTNet) is designed to specifically
+focus on learning deep geometric prior features to enhance image restoration.
+Experiments demonstrate the superiority of our MGSTNet framework on remote
+sensing image datasets compared to existing deblurring methods.
+
+
+
+ 37. 标题:Dhan-Shomadhan: A Dataset of Rice Leaf Disease Classification for Bangladeshi Local Rice
+ 编号:[162]
+ 链接:https://arxiv.org/abs/2309.07515
+ 作者:Md. Fahad Hossain
+ 备注:
+ 关键词:rice, background, Steath Blight, dataset, diseases
+
+ 点击查看摘要
+ This dataset represents almost all the harmful diseases for rice in
+Bangladesh. This dataset consists of 1106 image of five harmful diseases called
+Brown Spot, Leaf Scaled, Rice Blast, Rice Turngo, Steath Blight in two
+different background variation named field background picture and white
+background picture. Two different background variation helps the dataset to
+perform more accurately so that the user can use this data for field use as
+well as white background for decision making. The data is collected from rice
+field of Dhaka Division. This dataset can use for rice leaf diseases
+classification, diseases detection using Computer Vision and Pattern
+Recognition for different rice leaf disease.
+
+
+
+ 38. 标题:RecycleNet: Latent Feature Recycling Leads to Iterative Decision Refinement
+ 编号:[164]
+ 链接:https://arxiv.org/abs/2309.07513
+ 作者:Gregor Koehler, Tassilo Wald, Constantin Ulrich, David Zimmerer, Paul F. Jaeger, Jörg K.H. Franke, Simon Kohl, Fabian Isensee, Klaus H. Maier-Hein
+ 备注:Accepted at 2024 Winter Conference on Applications of Computer Vision (WACV)
+ 关键词:distilling relevant information, deep learning systems, human decision-making, distilling relevant, relevant information
+
+ 点击查看摘要
+ Despite the remarkable success of deep learning systems over the last decade,
+a key difference still remains between neural network and human
+decision-making: As humans, we cannot only form a decision on the spot, but
+also ponder, revisiting an initial guess from different angles, distilling
+relevant information, arriving at a better decision. Here, we propose
+RecycleNet, a latent feature recycling method, instilling the pondering
+capability for neural networks to refine initial decisions over a number of
+recycling steps, where outputs are fed back into earlier network layers in an
+iterative fashion. This approach makes minimal assumptions about the neural
+network architecture and thus can be implemented in a wide variety of contexts.
+Using medical image segmentation as the evaluation environment, we show that
+latent feature recycling enables the network to iteratively refine initial
+predictions even beyond the iterations seen during training, converging towards
+an improved decision. We evaluate this across a variety of segmentation
+benchmarks and show consistent improvements even compared with top-performing
+segmentation methods. This allows trading increased computation time for
+improved performance, which can be beneficial, especially for safety-critical
+applications.
+
+
+
+ 39. 标题:Learning Environment-Aware Affordance for 3D Articulated Object Manipulation under Occlusions
+ 编号:[165]
+ 链接:https://arxiv.org/abs/2309.07510
+ 作者:Kai Cheng, Ruihai Wu, Yan Shen, Chuanruo Ning, Guanqi Zhan, Hao Dong
+ 备注:
+ 关键词:Perceiving and manipulating, articulated objects, home-assistant robots, objects in diverse, essential for home-assistant
+
+ 点击查看摘要
+ Perceiving and manipulating 3D articulated objects in diverse environments is
+essential for home-assistant robots. Recent studies have shown that point-level
+affordance provides actionable priors for downstream manipulation tasks.
+However, existing works primarily focus on single-object scenarios with
+homogeneous agents, overlooking the realistic constraints imposed by the
+environment and the agent's morphology, e.g., occlusions and physical
+limitations. In this paper, we propose an environment-aware affordance
+framework that incorporates both object-level actionable priors and environment
+constraints. Unlike object-centric affordance approaches, learning
+environment-aware affordance faces the challenge of combinatorial explosion due
+to the complexity of various occlusions, characterized by their quantities,
+geometries, positions and poses. To address this and enhance data efficiency,
+we introduce a novel contrastive affordance learning framework capable of
+training on scenes containing a single occluder and generalizing to scenes with
+complex occluder combinations. Experiments demonstrate the effectiveness of our
+proposed approach in learning affordance considering environment constraints.
+
+
+
+ 40. 标题:DiffTalker: Co-driven audio-image diffusion for talking faces via intermediate landmarks
+ 编号:[166]
+ 链接:https://arxiv.org/abs/2309.07509
+ 作者:Zipeng Qi, Xulong Zhang, Ning Cheng, Jing Xiao, Jianzong Wang
+ 备注:submmit to ICASSP 2024
+ 关键词:widely discussed task, Generating realistic talking, Generating realistic, numerous applications, complex and widely
+
+ 点击查看摘要
+ Generating realistic talking faces is a complex and widely discussed task
+with numerous applications. In this paper, we present DiffTalker, a novel model
+designed to generate lifelike talking faces through audio and landmark
+co-driving. DiffTalker addresses the challenges associated with directly
+applying diffusion models to audio control, which are traditionally trained on
+text-image pairs. DiffTalker consists of two agent networks: a
+transformer-based landmarks completion network for geometric accuracy and a
+diffusion-based face generation network for texture details. Landmarks play a
+pivotal role in establishing a seamless connection between the audio and image
+domains, facilitating the incorporation of knowledge from pre-trained diffusion
+models. This innovative approach efficiently produces articulate-speaking
+faces. Experimental results showcase DiffTalker's superior performance in
+producing clear and geometrically accurate talking faces, all without the need
+for additional alignment between audio and image features.
+
+
+
+ 41. 标题:Efficiently Robustify Pre-trained Models
+ 编号:[171]
+ 链接:https://arxiv.org/abs/2309.07499
+ 作者:Nishant Jain, Harkirat Behl, Yogesh Singh Rawat, Vibhav Vineet
+ 备注:
+ 关键词:high parameter count, large scale, large scale models, training large scale, deep learning algorithms
+
+ 点击查看摘要
+ A recent trend in deep learning algorithms has been towards training large
+scale models, having high parameter count and trained on big dataset. However,
+robustness of such large scale models towards real-world settings is still a
+less-explored topic. In this work, we first benchmark the performance of these
+models under different perturbations and datasets thereby representing
+real-world shifts, and highlight their degrading performance under these
+shifts. We then discuss on how complete model fine-tuning based existing
+robustification schemes might not be a scalable option given very large scale
+networks and can also lead them to forget some of the desired characterstics.
+Finally, we propose a simple and cost-effective method to solve this problem,
+inspired by knowledge transfer literature. It involves robustifying smaller
+models, at a lower computation cost, and then use them as teachers to tune a
+fraction of these large scale networks, reducing the overall computational
+overhead. We evaluate our proposed method under various vision perturbations
+including ImageNet-C,R,S,A datasets and also for transfer learning, zero-shot
+evaluation setups on different datasets. Benchmark results show that our method
+is able to induce robustness to these large scale models efficiently, requiring
+significantly lower time and also preserves the transfer learning, zero-shot
+properties of the original model which none of the existing methods are able to
+achieve.
+
+
+
+ 42. 标题:HDTR-Net: A Real-Time High-Definition Teeth Restoration Network for Arbitrary Talking Face Generation Methods
+ 编号:[173]
+ 链接:https://arxiv.org/abs/2309.07495
+ 作者:Yongyuan Li, Xiuyuan Qin, Chao Liang, Mingqiang Wei
+ 备注:15pages, 6 figures, PRCV2023
+ 关键词:reconstruct facial movements, achieve high natural, facial movements, natural lip movements, reconstruct facial
+
+ 点击查看摘要
+ Talking Face Generation (TFG) aims to reconstruct facial movements to achieve
+high natural lip movements from audio and facial features that are under
+potential connections. Existing TFG methods have made significant advancements
+to produce natural and realistic images. However, most work rarely takes visual
+quality into consideration. It is challenging to ensure lip synchronization
+while avoiding visual quality degradation in cross-modal generation methods. To
+address this issue, we propose a universal High-Definition Teeth Restoration
+Network, dubbed HDTR-Net, for arbitrary TFG methods. HDTR-Net can enhance teeth
+regions at an extremely fast speed while maintaining synchronization, and
+temporal consistency. In particular, we propose a Fine-Grained Feature Fusion
+(FGFF) module to effectively capture fine texture feature information around
+teeth and surrounding regions, and use these features to fine-grain the feature
+map to enhance the clarity of teeth. Extensive experiments show that our method
+can be adapted to arbitrary TFG methods without suffering from lip
+synchronization and frame coherence. Another advantage of HDTR-Net is its
+real-time generation ability. Also under the condition of high-definition
+restoration of talking face video synthesis, its inference speed is $300\%$
+faster than the current state-of-the-art face restoration based on
+super-resolution.
+
+
+
+ 43. 标题:EP2P-Loc: End-to-End 3D Point to 2D Pixel Localization for Large-Scale Visual Localization
+ 编号:[182]
+ 链接:https://arxiv.org/abs/2309.07471
+ 作者:Minjung Kim, Junseo Koo, Gunhee Kim
+ 备注:Accepted to ICCV 2023
+ 关键词:reference map, Visual localization, visual localization method, visual localization remains, existing visual localization
+
+ 点击查看摘要
+ Visual localization is the task of estimating a 6-DoF camera pose of a query
+image within a provided 3D reference map. Thanks to recent advances in various
+3D sensors, 3D point clouds are becoming a more accurate and affordable option
+for building the reference map, but research to match the points of 3D point
+clouds with pixels in 2D images for visual localization remains challenging.
+Existing approaches that jointly learn 2D-3D feature matching suffer from low
+inliers due to representational differences between the two modalities, and the
+methods that bypass this problem into classification have an issue of poor
+refinement. In this work, we propose EP2P-Loc, a novel large-scale visual
+localization method that mitigates such appearance discrepancy and enables
+end-to-end training for pose estimation. To increase the number of inliers, we
+propose a simple algorithm to remove invisible 3D points in the image, and find
+all 2D-3D correspondences without keypoint detection. To reduce memory usage
+and search complexity, we take a coarse-to-fine approach where we extract
+patch-level features from 2D images, then perform 2D patch classification on
+each 3D point, and obtain the exact corresponding 2D pixel coordinates through
+positional encoding. Finally, for the first time in this task, we employ a
+differentiable PnP for end-to-end training. In the experiments on newly curated
+large-scale indoor and outdoor benchmarks based on 2D-3D-S and KITTI, we show
+that our method achieves the state-of-the-art performance compared to existing
+visual localization and image-to-point cloud registration methods.
+
+
+
+ 44. 标题:Detecting Unknown Attacks in IoT Environments: An Open Set Classifier for Enhanced Network Intrusion Detection
+ 编号:[186]
+ 链接:https://arxiv.org/abs/2309.07461
+ 作者:Yasir Ali Farrukh, Syed Wali, Irfan Khan, Nathaniel D. Bastian
+ 备注:6 Pages, 5 figures
+ 关键词:Internet of Things, robust intrusion detection, integration of Internet, intrusion detection systems, Network Intrusion Detection
+
+ 点击查看摘要
+ The widespread integration of Internet of Things (IoT) devices across all
+facets of life has ushered in an era of interconnectedness, creating new
+avenues for cybersecurity challenges and underscoring the need for robust
+intrusion detection systems. However, traditional security systems are designed
+with a closed-world perspective and often face challenges in dealing with the
+ever-evolving threat landscape, where new and unfamiliar attacks are constantly
+emerging. In this paper, we introduce a framework aimed at mitigating the open
+set recognition (OSR) problem in the realm of Network Intrusion Detection
+Systems (NIDS) tailored for IoT environments. Our framework capitalizes on
+image-based representations of packet-level data, extracting spatial and
+temporal patterns from network traffic. Additionally, we integrate stacking and
+sub-clustering techniques, enabling the identification of unknown attacks by
+effectively modeling the complex and diverse nature of benign behavior. The
+empirical results prominently underscore the framework's efficacy, boasting an
+impressive 88\% detection rate for previously unseen attacks when compared
+against existing approaches and recent advancements. Future work will perform
+extensive experimentation across various openness levels and attack scenarios,
+further strengthening the adaptability and performance of our proposed solution
+in safeguarding IoT environments.
+
+
+
+ 45. 标题:Research on self-cross transformer model of point cloud change detecter
+ 编号:[194]
+ 链接:https://arxiv.org/abs/2309.07444
+ 作者:Xiaoxu Ren, Haili Sun, Zhenxin Zhang
+ 备注:
+ 关键词:urban construction industry, engineering deformation, vigorous development, point clouds, construction industry
+
+ 点击查看摘要
+ With the vigorous development of the urban construction industry, engineering
+deformation or changes often occur during the construction process. To combat
+this phenomenon, it is necessary to detect changes in order to detect
+construction loopholes in time, ensure the integrity of the project and reduce
+labor costs. Or the inconvenience and injuriousness of the road. In the study
+of change detection in 3D point clouds, researchers have published various
+research methods on 3D point clouds. Directly based on but mostly based
+ontraditional threshold distance methods (C2C, M3C2, M3C2-EP), and some are to
+convert 3D point clouds into DSM, which loses a lot of original information.
+Although deep learning is used in remote sensing methods, in terms of change
+detection of 3D point clouds, it is more converted into two-dimensional
+patches, and neural networks are rarely applied directly. We prefer that the
+network is given at the level of pixels or points. Variety. Therefore, in this
+article, our network builds a network for 3D point cloud change detection, and
+proposes a new module Cross transformer suitable for change detection.
+Simultaneously simulate tunneling data for change detection, and do test
+experiments with our network.
+
+
+
+ 46. 标题:DePT: Decoupled Prompt Tuning
+ 编号:[196]
+ 链接:https://arxiv.org/abs/2309.07439
+ 作者:Ji Zhang, Shihan Wu, Lianli Gao, Hengtao Shen, Jingkuan Song
+ 备注:13 pages
+ 关键词:tuned model generalizes, Base-New Tradeoff, prompt tuning, Decoupled Prompt Tuning, vice versa
+
+ 点击查看摘要
+ This work breaks through the Base-New Tradeoff (BNT)dilemma in prompt tuning,
+i.e., the better the tuned model generalizes to the base (or target) task, the
+worse it generalizes to new tasks, and vice versa. Specifically, through an
+in-depth analysis of the learned features of the base and new tasks, we observe
+that the BNT stems from a channel bias issue, i.e., the vast majority of
+feature channels are occupied by base-specific knowledge, resulting in the
+collapse of taskshared knowledge important to new tasks. To address this, we
+propose the Decoupled Prompt Tuning (DePT) framework, which decouples
+base-specific knowledge from feature channels into an isolated feature space
+during prompt tuning, so as to maximally preserve task-shared knowledge in the
+original feature space for achieving better zero-shot generalization on new
+tasks. Importantly, our DePT is orthogonal to existing prompt tuning methods,
+hence it can improve all of them. Extensive experiments on 11 datasets show the
+strong flexibility and effectiveness of DePT. Our code and pretrained models
+are available at this https URL.
+
+
+
+ 47. 标题:Physical Invisible Backdoor Based on Camera Imaging
+ 编号:[203]
+ 链接:https://arxiv.org/abs/2309.07428
+ 作者:Yusheng Guo, Nan Zhong, Zhenxing Qian, Xinpeng Zhang
+ 备注:
+ 关键词:Backdoor attack aims, Backdoor, aims to compromise, adversary-wanted output, Backdoor attack
+
+ 点击查看摘要
+ Backdoor attack aims to compromise a model, which returns an adversary-wanted
+output when a specific trigger pattern appears yet behaves normally for clean
+inputs. Current backdoor attacks require changing pixels of clean images, which
+results in poor stealthiness of attacks and increases the difficulty of the
+physical implementation. This paper proposes a novel physical invisible
+backdoor based on camera imaging without changing nature image pixels.
+Specifically, a compromised model returns a target label for images taken by a
+particular camera, while it returns correct results for other images. To
+implement and evaluate the proposed backdoor, we take shots of different
+objects from multi-angles using multiple smartphones to build a new dataset of
+21,500 images. Conventional backdoor attacks work ineffectively with some
+classical models, such as ResNet18, over the above-mentioned dataset.
+Therefore, we propose a three-step training strategy to mount the backdoor
+attack. First, we design and train a camera identification model with the phone
+IDs to extract the camera fingerprint feature. Subsequently, we elaborate a
+special network architecture, which is easily compromised by our backdoor
+attack, by leveraging the attributes of the CFA interpolation algorithm and
+combining it with the feature extraction block in the camera identification
+model. Finally, we transfer the backdoor from the elaborated special network
+architecture to the classical architecture model via teacher-student
+distillation learning. Since the trigger of our method is related to the
+specific phone, our attack works effectively in the physical world. Experiment
+results demonstrate the feasibility of our proposed approach and robustness
+against various backdoor defenses.
+
+
+
+ 48. 标题:JSMNet Improving Indoor Point Cloud Semantic and Instance Segmentation through Self-Attention and Multiscale
+ 编号:[204]
+ 链接:https://arxiv.org/abs/2309.07425
+ 作者:Shuochen Xu, Zhenxin Zhang
+ 备注:
+ 关键词:digital twin engineering, indoor service robots, including indoor service, point cloud, point cloud data
+
+ 点击查看摘要
+ The semantic understanding of indoor 3D point cloud data is crucial for a
+range of subsequent applications, including indoor service robots, navigation
+systems, and digital twin engineering. Global features are crucial for
+achieving high-quality semantic and instance segmentation of indoor point
+clouds, as they provide essential long-range context information. To this end,
+we propose JSMNet, which combines a multi-layer network with a global feature
+self-attention module to jointly segment three-dimensional point cloud
+semantics and instances. To better express the characteristics of indoor
+targets, we have designed a multi-resolution feature adaptive fusion module
+that takes into account the differences in point cloud density caused by
+varying scanner distances from the target. Additionally, we propose a framework
+for joint semantic and instance segmentation by integrating semantic and
+instance features to achieve superior results. We conduct experiments on S3DIS,
+which is a large three-dimensional indoor point cloud dataset. Our proposed
+method is compared against other methods, and the results show that it
+outperforms existing methods in semantic and instance segmentation and provides
+better results in target local area segmentation. Specifically, our proposed
+method outperforms PointNet (Qi et al., 2017a) by 16.0% and 26.3% in terms of
+semantic segmentation mIoU in S3DIS (Area 5) and instance segmentation mPre,
+respectively. Additionally, it surpasses ASIS (Wang et al., 2019) by 6.0% and
+4.6%, respectively, as well as JSPNet (Chen et al., 2022) by a margin of 3.3%
+for semantic segmentation mIoU and a slight improvement of 0.3% for instance
+segmentation mPre.
+
+
+
+ 49. 标题:Masked Diffusion with Task-awareness for Procedure Planning in Instructional Videos
+ 编号:[213]
+ 链接:https://arxiv.org/abs/2309.07409
+ 作者:Fen Fang, Yun Liu, Ali Koksal, Qianli Xu, Joo-Hwee Lim
+ 备注:7 pages (main text excluding references), 3 figures, 7 tables
+ 关键词:instructional videos lies, action types, procedure planning, planning in instructional, handle a large
+
+ 点击查看摘要
+ A key challenge with procedure planning in instructional videos lies in how
+to handle a large decision space consisting of a multitude of action types that
+belong to various tasks. To understand real-world video content, an AI agent
+must proficiently discern these action types (e.g., pour milk, pour water, open
+lid, close lid, etc.) based on brief visual observation. Moreover, it must
+adeptly capture the intricate semantic relation of the action types and task
+goals, along with the variable action sequences. Recently, notable progress has
+been made via the integration of diffusion models and visual representation
+learning to address the challenge. However, existing models employ rudimentary
+mechanisms to utilize task information to manage the decision space. To
+overcome this limitation, we introduce a simple yet effective enhancement - a
+masked diffusion model. The introduced mask acts akin to a task-oriented
+attention filter, enabling the diffusion/denoising process to concentrate on a
+subset of action types. Furthermore, to bolster the accuracy of task
+classification, we harness more potent visual representation learning
+techniques. In particular, we learn a joint visual-text embedding, where a text
+embedding is generated by prompting a pre-trained vision-language model to
+focus on human actions. We evaluate the method on three public datasets and
+achieve state-of-the-art performance on multiple metrics. Code is available at
+this https URL.
+
+
+
+ 50. 标题:Flexible Visual Recognition by Evidential Modeling of Confusion and Ignorance
+ 编号:[218]
+ 链接:https://arxiv.org/abs/2309.07403
+ 作者:Lei Fan, Bo Liu, Haoxiang Li, Ying Wu, Gang Hua
+ 备注:Accepted by ICCV23
+ 关键词:typical visual recognition, real-world scenarios, unknown-class images, visual recognition systems, systems could fail
+
+ 点击查看摘要
+ In real-world scenarios, typical visual recognition systems could fail under
+two major causes, i.e., the misclassification between known classes and the
+excusable misbehavior on unknown-class images. To tackle these deficiencies,
+flexible visual recognition should dynamically predict multiple classes when
+they are unconfident between choices and reject making predictions when the
+input is entirely out of the training distribution. Two challenges emerge along
+with this novel task. First, prediction uncertainty should be separately
+quantified as confusion depicting inter-class uncertainties and ignorance
+identifying out-of-distribution samples. Second, both confusion and ignorance
+should be comparable between samples to enable effective decision-making. In
+this paper, we propose to model these two sources of uncertainty explicitly
+with the theory of Subjective Logic. Regarding recognition as an
+evidence-collecting process, confusion is then defined as conflicting evidence,
+while ignorance is the absence of evidence. By predicting Dirichlet
+concentration parameters for singletons, comprehensive subjective opinions,
+including confusion and ignorance, could be achieved via further evidence
+combinations. Through a series of experiments on synthetic data analysis,
+visual recognition, and open-set detection, we demonstrate the effectiveness of
+our methods in quantifying two sources of uncertainties and dealing with
+flexible recognition.
+
+
+
+ 51. 标题:HIGT: Hierarchical Interaction Graph-Transformer for Whole Slide Image Analysis
+ 编号:[221]
+ 链接:https://arxiv.org/abs/2309.07400
+ 作者:Ziyu Guo, Weiqin Zhao, Shujun Wang, Lequan Yu
+ 备注:Accepted by MICCAI2023; Code is available in this https URL
+ 关键词:gigapixel Whole Slide, WSI, computation pathology, WSI pyramids, Slide
+
+ 点击查看摘要
+ In computation pathology, the pyramid structure of gigapixel Whole Slide
+Images (WSIs) has recently been studied for capturing various information from
+individual cell interactions to tissue microenvironments. This hierarchical
+structure is believed to be beneficial for cancer diagnosis and prognosis
+tasks. However, most previous hierarchical WSI analysis works (1) only
+characterize local or global correlations within the WSI pyramids and (2) use
+only unidirectional interaction between different resolutions, leading to an
+incomplete picture of WSI pyramids. To this end, this paper presents a novel
+Hierarchical Interaction Graph-Transformer (i.e., HIGT) for WSI analysis. With
+Graph Neural Network and Transformer as the building commons, HIGT can learn
+both short-range local information and long-range global representation of the
+WSI pyramids. Considering that the information from different resolutions is
+complementary and can benefit each other during the learning process, we
+further design a novel Bidirectional Interaction block to establish
+communication between different levels within the WSI pyramids. Finally, we
+aggregate both coarse-grained and fine-grained features learned from different
+levels together for slide-level prediction. We evaluate our methods on two
+public WSI datasets from TCGA projects, i.e., kidney carcinoma (KICA) and
+esophageal carcinoma (ESCA). Experimental results show that our HIGT
+outperforms both hierarchical and non-hierarchical state-of-the-art methods on
+both tumor subtyping and staging tasks.
+
+
+
+ 52. 标题:Semantic Adversarial Attacks via Diffusion Models
+ 编号:[222]
+ 链接:https://arxiv.org/abs/2309.07398
+ 作者:Chenan Wang, Jinhao Duan, Chaowei Xiao, Edward Kim, Matthew Stamm, Kaidi Xu
+ 备注:To appear in BMVC 2023
+ 关键词:adding adversarial perturbations, Traditional adversarial attacks, adversarial attacks concentrate, semantic adversarial attacks, latent space
+
+ 点击查看摘要
+ Traditional adversarial attacks concentrate on manipulating clean examples in
+the pixel space by adding adversarial perturbations. By contrast, semantic
+adversarial attacks focus on changing semantic attributes of clean examples,
+such as color, context, and features, which are more feasible in the real
+world. In this paper, we propose a framework to quickly generate a semantic
+adversarial attack by leveraging recent diffusion models since semantic
+information is included in the latent space of well-trained diffusion models.
+Then there are two variants of this framework: 1) the Semantic Transformation
+(ST) approach fine-tunes the latent space of the generated image and/or the
+diffusion model itself; 2) the Latent Masking (LM) approach masks the latent
+space with another target image and local backpropagation-based interpretation
+methods. Additionally, the ST approach can be applied in either white-box or
+black-box settings. Extensive experiments are conducted on CelebA-HQ and AFHQ
+datasets, and our framework demonstrates great fidelity, generalizability, and
+transferability compared to other baselines. Our approaches achieve
+approximately 100% attack success rate in multiple settings with the best FID
+as 36.61. Code is available at
+this https URL.
+
+
+
+ 53. 标题:Nucleus-aware Self-supervised Pretraining Using Unpaired Image-to-image Translation for Histopathology Images
+ 编号:[224]
+ 链接:https://arxiv.org/abs/2309.07394
+ 作者:Zhiyun Song, Penghui Du, Junpeng Yan, Kailu Li, Jianzhong Shou, Maode Lai, Yubo Fan, Yan Xu
+ 备注:
+ 关键词:enhance model performance, obtaining effective features, unlabeled data, histopathology images, attempts to enhance
+
+ 点击查看摘要
+ Self-supervised pretraining attempts to enhance model performance by
+obtaining effective features from unlabeled data, and has demonstrated its
+effectiveness in the field of histopathology images. Despite its success, few
+works concentrate on the extraction of nucleus-level information, which is
+essential for pathologic analysis. In this work, we propose a novel
+nucleus-aware self-supervised pretraining framework for histopathology images.
+The framework aims to capture the nuclear morphology and distribution
+information through unpaired image-to-image translation between histopathology
+images and pseudo mask images. The generation process is modulated by both
+conditional and stochastic style representations, ensuring the reality and
+diversity of the generated histopathology images for pretraining. Further, an
+instance segmentation guided strategy is employed to capture instance-level
+information. The experiments on 7 datasets show that the proposed pretraining
+method outperforms supervised ones on Kather classification, multiple instance
+learning, and 5 dense-prediction tasks with the transfer learning protocol, and
+yields superior results than other self-supervised approaches on 8
+semi-supervised tasks. Our project is publicly available at
+this https URL.
+
+
+
+ 54. 标题:Unleashing the Power of Depth and Pose Estimation Neural Networks by Designing Compatible Endoscopic Images
+ 编号:[226]
+ 链接:https://arxiv.org/abs/2309.07390
+ 作者:Junyang Wu, Yun Gu
+ 备注:
+ 关键词:Deep learning models, pose estimation framework, neural networks, neural, Deep learning
+
+ 点击查看摘要
+ Deep learning models have witnessed depth and pose estimation framework on
+unannotated datasets as a effective pathway to succeed in endoscopic
+navigation. Most current techniques are dedicated to developing more advanced
+neural networks to improve the accuracy. However, existing methods ignore the
+special properties of endoscopic images, resulting in an inability to fully
+unleash the power of neural networks. In this study, we conduct a detail
+analysis of the properties of endoscopic images and improve the compatibility
+of images and neural networks, to unleash the power of current neural networks.
+First, we introcude the Mask Image Modelling (MIM) module, which inputs partial
+image information instead of complete image information, allowing the network
+to recover global information from partial pixel information. This enhances the
+network' s ability to perceive global information and alleviates the phenomenon
+of local overfitting in convolutional neural networks due to local artifacts.
+Second, we propose a lightweight neural network to enhance the endoscopic
+images, to explicitly improve the compatibility between images and neural
+networks. Extensive experiments are conducted on the three public datasets and
+one inhouse dataset, and the proposed modules improve baselines by a large
+margin. Furthermore, the enhanced images we proposed, which have higher network
+compatibility, can serve as an effective data augmentation method and they are
+able to extract more stable feature points in traditional feature point
+matching tasks and achieve outstanding performance.
+
+
+
+ 55. 标题:VDialogUE: A Unified Evaluation Benchmark for Visually-grounded Dialogue
+ 编号:[228]
+ 链接:https://arxiv.org/abs/2309.07387
+ 作者:Yunshui Li, Binyuan Hui, Zhaochao Yin, Wanwei He, Run Luo, Yuxing Long, Min Yang, Fei Huang, Yongbin Li
+ 备注:
+ 关键词:integrate multiple modes, increasingly popular area, textbf, visual inputs, area of investigation
+
+ 点击查看摘要
+ Visually-grounded dialog systems, which integrate multiple modes of
+communication such as text and visual inputs, have become an increasingly
+popular area of investigation. However, the absence of a standardized
+evaluation framework poses a challenge in assessing the development of this
+field. To this end, we propose \textbf{VDialogUE}, a \textbf{V}isually-grounded
+\textbf{Dialog}ue benchmark for \textbf{U}nified \textbf{E}valuation. It
+defines five core multi-modal dialogue tasks and covers six datasets.
+Furthermore, in order to provide a comprehensive assessment of the model's
+performance across all tasks, we developed a novel evaluation metric called
+VDscore, which is based on the Analytic Hierarchy Process~(AHP) method.
+Additionally, we present a straightforward yet efficient baseline model, named
+\textbf{VISIT}~(\textbf{VIS}ually-grounded d\textbf{I}alog
+\textbf{T}ransformer), to promote the advancement of general multi-modal
+dialogue systems. It progressively builds its multi-modal foundation and
+dialogue capability via a two-stage pre-training strategy.
+We believe that the VDialogUE benchmark, along with the evaluation scripts
+and our baseline models, will accelerate the development of visually-grounded
+dialog systems and lead to the development of more sophisticated and effective
+pre-trained models.
+
+
+
+ 56. 标题:Judging a video by its bitstream cover
+ 编号:[237]
+ 链接:https://arxiv.org/abs/2309.07361
+ 作者:Yuxing Han, Yunan Ding, Jiangtao Wen, Chen Ye Gan
+ 备注:
+ 关键词:Sport and Music, understanding and retrieval, constantly being generated, Music Video, crucial for multimedia
+
+ 点击查看摘要
+ Classifying videos into distinct categories, such as Sport and Music Video,
+is crucial for multimedia understanding and retrieval, especially in an age
+where an immense volume of video content is constantly being generated.
+Traditional methods require video decompression to extract pixel-level features
+like color, texture, and motion, thereby increasing computational and storage
+demands. Moreover, these methods often suffer from performance degradation in
+low-quality videos. We present a novel approach that examines only the
+post-compression bitstream of a video to perform classification, eliminating
+the need for bitstream. We validate our approach using a custom-built data set
+comprising over 29,000 YouTube video clips, totaling 6,000 hours and spanning
+11 distinct categories. Our preliminary evaluations indicate precision,
+accuracy, and recall rates well over 80%. The algorithm operates approximately
+15,000 times faster than real-time for 30fps videos, outperforming traditional
+Dynamic Time Warping (DTW) algorithm by six orders of magnitude.
+
+
+
+ 57. 标题:Reliability-based cleaning of noisy training labels with inductive conformal prediction in multi-modal biomedical data mining
+ 编号:[249]
+ 链接:https://arxiv.org/abs/2309.07332
+ 作者:Xianghao Zhan, Qinmei Xu, Yuanning Zheng, Guangming Lu, Olivier Gevaert
+ 备注:
+ 关键词:presents a challenge, data, training data, biomedical data presents, labeling biomedical data
+
+ 点击查看摘要
+ Accurately labeling biomedical data presents a challenge. Traditional
+semi-supervised learning methods often under-utilize available unlabeled data.
+To address this, we propose a novel reliability-based training data cleaning
+method employing inductive conformal prediction (ICP). This method capitalizes
+on a small set of accurately labeled training data and leverages ICP-calculated
+reliability metrics to rectify mislabeled data and outliers within vast
+quantities of noisy training data. The efficacy of the method is validated
+across three classification tasks within distinct modalities: filtering
+drug-induced-liver-injury (DILI) literature with title and abstract, predicting
+ICU admission of COVID-19 patients through CT radiomics and electronic health
+records, and subtyping breast cancer using RNA-sequencing data. Varying levels
+of noise to the training labels were introduced through label permutation.
+Results show significant enhancements in classification performance: accuracy
+enhancement in 86 out of 96 DILI experiments (up to 11.4%), AUROC and AUPRC
+enhancements in all 48 COVID-19 experiments (up to 23.8% and 69.8%), and
+accuracy and macro-average F1 score improvements in 47 out of 48 RNA-sequencing
+experiments (up to 74.6% and 89.0%). Our method offers the potential to
+substantially boost classification performance in multi-modal biomedical
+machine learning tasks. Importantly, it accomplishes this without necessitating
+an excessive volume of meticulously curated training data.
+
+
+
+ 58. 标题:Automated Assessment of Critical View of Safety in Laparoscopic Cholecystectomy
+ 编号:[250]
+ 链接:https://arxiv.org/abs/2309.07330
+ 作者:Yunfan Li, Himanshu Gupta, Haibin Ling, IV Ramakrishnan, Prateek Prasanna, Georgios Georgakis, Aaron Sasson
+ 备注:
+ 关键词:procedures annually, common procedures, CVS, classical open cholecystectomy, CVS assessment
+
+ 点击查看摘要
+ Cholecystectomy (gallbladder removal) is one of the most common procedures in
+the US, with more than 1.2M procedures annually. Compared with classical open
+cholecystectomy, laparoscopic cholecystectomy (LC) is associated with
+significantly shorter recovery period, and hence is the preferred method.
+However, LC is also associated with an increase in bile duct injuries (BDIs),
+resulting in significant morbidity and mortality. The primary cause of BDIs
+from LCs is misidentification of the cystic duct with the bile duct. Critical
+view of safety (CVS) is the most effective of safety protocols, which is said
+to be achieved during the surgery if certain criteria are met. However, due to
+suboptimal understanding and implementation of CVS, the BDI rates have remained
+stable over the last three decades. In this paper, we develop deep-learning
+techniques to automate the assessment of CVS in LCs. An innovative aspect of
+our research is on developing specialized learning techniques by incorporating
+domain knowledge to compensate for the limited training data available in
+practice. In particular, our CVS assessment process involves a fusion of two
+segmentation maps followed by an estimation of a certain region of interest
+based on anatomical structures close to the gallbladder, and then finally
+determination of each of the three CVS criteria via rule-based assessment of
+structural information. We achieved a gain of over 11.8% in mIoU on relevant
+classes with our two-stream semantic segmentation approach when compared to a
+single-model baseline, and 1.84% in mIoU with our proposed Sobel loss function
+when compared to a Transformer-based baseline model. For CVS criteria, we
+achieved up to 16% improvement and, for the overall CVS assessment, we achieved
+5% improvement in balanced accuracy compared to DeepCVS under the same
+experiment settings.
+
+
+
+ 59. 标题:$\texttt{NePhi}$: Neural Deformation Fields for Approximately Diffeomorphic Medical Image Registration
+ 编号:[253]
+ 链接:https://arxiv.org/abs/2309.07322
+ 作者:Lin Tian, Soumyadip Sengupta, Hastings Greer, Raúl San José Estépar, Marc Niethammer
+ 备注:
+ 关键词:neural deformation model, texttt, NePhi, work proposes, approximately diffeomorphic transformations
+
+ 点击查看摘要
+ This work proposes $\texttt{NePhi}$, a neural deformation model which results
+in approximately diffeomorphic transformations. In contrast to the predominant
+voxel-based approaches, $\texttt{NePhi}$ represents deformations functionally
+which allows for memory-efficient training and inference. This is of particular
+importance for large volumetric registrations. Further, while medical image
+registration approaches representing transformation maps via multi-layer
+perceptrons have been proposed, $\texttt{NePhi}$ facilitates both pairwise
+optimization-based registration $\textit{as well as}$ learning-based
+registration via predicted or optimized global and local latent codes. Lastly,
+as deformation regularity is a highly desirable property for most medical image
+registration tasks, $\texttt{NePhi}$ makes use of gradient inverse consistency
+regularization which empirically results in approximately diffeomorphic
+transformations. We show the performance of $\texttt{NePhi}$ on two 2D
+synthetic datasets as well as on real 3D lung registration. Our results show
+that $\texttt{NePhi}$ can achieve similar accuracies as voxel-based
+representations in a single-resolution registration setting while using less
+memory and allowing for faster instance-optimization.
+
+
+
+ 60. 标题:Multi-Modal Hybrid Learning and Sequential Training for RGB-T Saliency Detection
+ 编号:[266]
+ 链接:https://arxiv.org/abs/2309.07297
+ 作者:Guangyu Ren, Jitesh Joshi, Youngjun Cho
+ 备注:8 Pages main text, 3 pages supplementary information, 12 figures
+ 关键词:computer vision task, identifying conspicuous objects, important computer vision, vision task, identifying conspicuous
+
+ 点击查看摘要
+ RGB-T saliency detection has emerged as an important computer vision task,
+identifying conspicuous objects in challenging scenes such as dark
+environments. However, existing methods neglect the characteristics of
+cross-modal features and rely solely on network structures to fuse RGB and
+thermal features. To address this, we first propose a Multi-Modal Hybrid loss
+(MMHL) that comprises supervised and self-supervised loss functions. The
+supervised loss component of MMHL distinctly utilizes semantic features from
+different modalities, while the self-supervised loss component reduces the
+distance between RGB and thermal features. We further consider both spatial and
+channel information during feature fusion and propose the Hybrid Fusion Module
+to effectively fuse RGB and thermal features. Lastly, instead of jointly
+training the network with cross-modal features, we implement a sequential
+training strategy which performs training only on RGB images in the first stage
+and then learns cross-modal features in the second stage. This training
+strategy improves saliency detection performance without computational
+overhead. Results from performance evaluation and ablation studies demonstrate
+the superior performance achieved by the proposed method compared with the
+existing state-of-the-art methods.
+
+
+
+ 61. 标题:GAN-based Algorithm for Efficient Image Inpainting
+ 编号:[267]
+ 链接:https://arxiv.org/abs/2309.07293
+ 作者:Zhengyang Han, Zehao Jiang, Yuan Ju
+ 备注:6 pages, 3 figures
+ 关键词:Global pandemic due, Global pandemic, facial recognition, pandemic due, post challenges
+
+ 点击查看摘要
+ Global pandemic due to the spread of COVID-19 has post challenges in a new
+dimension on facial recognition, where people start to wear masks. Under such
+condition, the authors consider utilizing machine learning in image inpainting
+to tackle the problem, by complete the possible face that is originally covered
+in mask. In particular, autoencoder has great potential on retaining important,
+general features of the image as well as the generative power of the generative
+adversarial network (GAN). The authors implement a combination of the two
+models, context encoders and explain how it combines the power of the two
+models and train the model with 50,000 images of influencers faces and yields a
+solid result that still contains space for improvements. Furthermore, the
+authors discuss some shortcomings with the model, their possible improvements,
+as well as some area of study for future investigation for applicative
+perspective, as well as directions to further enhance and refine the model.
+
+
+
+ 62. 标题:Unbiased Face Synthesis With Diffusion Models: Are We There Yet?
+ 编号:[272]
+ 链接:https://arxiv.org/abs/2309.07277
+ 作者:Harrison Rosenberg, Shimaa Ahmed, Guruprasad V Ramesh, Ramya Korlakai Vinayak, Kassem Fawaz
+ 备注:
+ 关键词:achieved widespread popularity, widespread popularity due, image generation capability, unprecedented image generation, achieved widespread
+
+ 点击查看摘要
+ Text-to-image diffusion models have achieved widespread popularity due to
+their unprecedented image generation capability. In particular, their ability
+to synthesize and modify human faces has spurred research into using generated
+face images in both training data augmentation and model performance
+assessments. In this paper, we study the efficacy and shortcomings of
+generative models in the context of face generation. Utilizing a combination of
+qualitative and quantitative measures, including embedding-based metrics and
+user studies, we present a framework to audit the characteristics of generated
+faces conditioned on a set of social attributes. We applied our framework on
+faces generated through state-of-the-art text-to-image diffusion models. We
+identify several limitations of face image generation that include faithfulness
+to the text prompt, demographic disparities, and distributional shifts.
+Furthermore, we present an analytical model that provides insights into how
+training data selection contributes to the performance of generative models.
+
+
+
+ 63. 标题:So you think you can track?
+ 编号:[276]
+ 链接:https://arxiv.org/abs/2309.07268
+ 作者:Derek Gloudemans, Gergely Zachár, Yanbing Wang, Junyi Ji, Matt Nice, Matt Bunting, William Barbour, Jonathan Sprinkle, Benedetto Piccoli, Maria Laura Delle Monache, Alexandre Bayen, Benjamin Seibold, Daniel B. Work
+ 备注:
+ 关键词:8-10 lane interstate, lane interstate highway, highway near Nashville, multi-camera tracking dataset, tracking dataset consisting
+
+ 点击查看摘要
+ This work introduces a multi-camera tracking dataset consisting of 234 hours
+of video data recorded concurrently from 234 overlapping HD cameras covering a
+4.2 mile stretch of 8-10 lane interstate highway near Nashville, TN. The video
+is recorded during a period of high traffic density with 500+ objects typically
+visible within the scene and typical object longevities of 3-15 minutes. GPS
+trajectories from 270 vehicle passes through the scene are manually corrected
+in the video data to provide a set of ground-truth trajectories for
+recall-oriented tracking metrics, and object detections are provided for each
+camera in the scene (159 million total before cross-camera fusion). Initial
+benchmarking of tracking-by-detection algorithms is performed against the GPS
+trajectories, and a best HOTA of only 9.5% is obtained (best recall 75.9% at
+IOU 0.1, 47.9 average IDs per ground truth object), indicating the benchmarked
+trackers do not perform sufficiently well at the long temporal and spatial
+durations required for traffic scene understanding.
+
+
+
+ 64. 标题:Mitigate Replication and Copying in Diffusion Models with Generalized Caption and Dual Fusion Enhancement
+ 编号:[281]
+ 链接:https://arxiv.org/abs/2309.07254
+ 作者:Chenghao Li, Dake Chen, Yuke Zhang, Peter A. Beerel
+ 备注:
+ 关键词:raises privacy concerns, generating high-quality images, data raises privacy, training data raises, privacy concerns
+
+ 点击查看摘要
+ While diffusion models demonstrate a remarkable capability for generating
+high-quality images, their tendency to `replicate' training data raises privacy
+concerns. Although recent research suggests that this replication may stem from
+the insufficient generalization of training data captions and duplication of
+training images, effective mitigation strategies remain elusive. To address
+this gap, our paper first introduces a generality score that measures the
+caption generality and employ large language model (LLM) to generalize training
+captions. Subsequently, we leverage generalized captions and propose a novel
+dual fusion enhancement approach to mitigate the replication of diffusion
+models. Our empirical results demonstrate that our proposed methods can
+significantly reduce replication by 43.5% compared to the original diffusion
+model while maintaining the diversity and quality of generations.
+
+
+
+ 65. 标题:LInKs "Lifting Independent Keypoints" -- Partial Pose Lifting for Occlusion Handling with Improved Accuracy in 2D-3D Human Pose Estimation
+ 编号:[285]
+ 链接:https://arxiv.org/abs/2309.07243
+ 作者:Peter Hardy, Hansung Kim
+ 备注:
+ 关键词:unsupervised learning method, present LInKs, kinematic skeletons obtained, single image, unsupervised learning
+
+ 点击查看摘要
+ We present LInKs, a novel unsupervised learning method to recover 3D human
+poses from 2D kinematic skeletons obtained from a single image, even when
+occlusions are present. Our approach follows a unique two-step process, which
+involves first lifting the occluded 2D pose to the 3D domain, followed by
+filling in the occluded parts using the partially reconstructed 3D coordinates.
+This lift-then-fill approach leads to significantly more accurate results
+compared to models that complete the pose in 2D space alone. Additionally, we
+improve the stability and likelihood estimation of normalising flows through a
+custom sampling function replacing PCA dimensionality reduction previously used
+in prior work. Furthermore, we are the first to investigate if different parts
+of the 2D kinematic skeleton can be lifted independently which we find by
+itself reduces the error of current lifting approaches. We attribute this to
+the reduction of long-range keypoint correlations. In our detailed evaluation,
+we quantify the error under various realistic occlusion scenarios, showcasing
+the versatility and applicability of our model. Our results consistently
+demonstrate the superiority of handling all types of occlusions in 3D space
+when compared to others that complete the pose in 2D space. Our approach also
+exhibits consistent accuracy in scenarios without occlusion, as evidenced by a
+7.9% reduction in reconstruction error compared to prior works on the Human3.6M
+dataset. Furthermore, our method excels in accurately retrieving complete 3D
+poses even in the presence of occlusions, making it highly applicable in
+situations where complete 2D pose information is unavailable.
+
+
+
+ 66. 标题:LCReg: Long-Tailed Image Classification with Latent Categories based Recognition
+ 编号:[298]
+ 链接:https://arxiv.org/abs/2309.07186
+ 作者:Weide Liu, Zhonghua Wu, Yiming Wang, Henghui Ding, Fayao Liu, Jie Lin, Guosheng Lin
+ 备注:accepted by Pattern Recognition. arXiv admin note: substantial text overlap with arXiv:2206.01010
+ 关键词:long-tailed image recognition, tail classes, tackle the challenging, challenging problem, latent features
+
+ 点击查看摘要
+ In this work, we tackle the challenging problem of long-tailed image
+recognition. Previous long-tailed recognition approaches mainly focus on data
+augmentation or re-balancing strategies for the tail classes to give them more
+attention during model training. However, these methods are limited by the
+small number of training images for the tail classes, which results in poor
+feature representations. To address this issue, we propose the Latent
+Categories based long-tail Recognition (LCReg) method. Our hypothesis is that
+common latent features shared by head and tail classes can be used to improve
+feature representation. Specifically, we learn a set of class-agnostic latent
+features shared by both head and tail classes, and then use semantic data
+augmentation on the latent features to implicitly increase the diversity of the
+training sample. We conduct extensive experiments on five long-tailed image
+recognition datasets, and the results show that our proposed method
+significantly improves the baselines.
+
+
+
+ 67. 标题:Using Unsupervised and Supervised Learning and Digital Twin for Deep Convective Ice Storm Classification
+ 编号:[302]
+ 链接:https://arxiv.org/abs/2309.07173
+ 作者:Jason Swope, Steve Chien, Emily Dunkel, Xavier Bosch-Lluis, Qing Yue, William Deal
+ 备注:
+ 关键词:Ice Cloud Sensing, intelligently targets ice, Smart Ice Cloud, targets ice storms, ice storms based
+
+ 点击查看摘要
+ Smart Ice Cloud Sensing (SMICES) is a small-sat concept in which a primary
+radar intelligently targets ice storms based on information collected by a
+lookahead radiometer. Critical to the intelligent targeting is accurate
+identification of storm/cloud types from eight bands of radiance collected by
+the radiometer. The cloud types of interest are: clear sky, thin cirrus,
+cirrus, rainy anvil, and convection core.
+We describe multi-step use of Machine Learning and Digital Twin of the
+Earth's atmosphere to derive such a classifier. First, a digital twin of
+Earth's atmosphere called a Weather Research Forecast (WRF) is used generate
+simulated lookahead radiometer data as well as deeper "science" hidden
+variables. The datasets simulate a tropical region over the Caribbean and a
+non-tropical region over the Atlantic coast of the United States. A K-means
+clustering over the scientific hidden variables was utilized by human experts
+to generate an automatic labelling of the data - mapping each physical data
+point to cloud types by scientists informed by mean/centroids of hidden
+variables of the clusters. Next, classifiers were trained with the inputs of
+the simulated radiometer data and its corresponding label. The classifiers of a
+random decision forest (RDF), support vector machine (SVM), Gaussian naïve
+bayes, feed forward artificial neural network (ANN), and a convolutional neural
+network (CNN) were trained. Over the tropical dataset, the best performing
+classifier was able to identify non-storm and storm clouds with over 80%
+accuracy in each class for a held-out test set. Over the non-tropical dataset,
+the best performing classifier was able to classify non-storm clouds with over
+90% accuracy and storm clouds with over 40% accuracy. Additionally both sets of
+classifiers were shown to be resilient to instrument noise.
+
+
+
+ 68. 标题:Virchow: A Million-Slide Digital Pathology Foundation Model
+ 编号:[324]
+ 链接:https://arxiv.org/abs/2309.07778
+ 作者:Eugene Vorontsov, Alican Bozkurt, Adam Casson, George Shaikovski, Michal Zelechowski, Siqi Liu, Philippe Mathieu, Alexander van Eck, Donghun Lee, Julian Viret, Eric Robert, Yi Kan Wang, Jeremy D. Kun, Matthew C. H. Le, Jan Bernhard, Ran A. Godrich, Gerard Oakley, Ewan Millar, Matthew Hanna, Juan Retamero, William A. Moye, Razik Yousfi, Christopher Kanan, David Klimstra, Brandon Rothrock, Thomas J. Fuchs
+ 备注:
+ 关键词:enable precision medicine, decision support systems, artificial intelligence, intelligence to enable, enable precision
+
+ 点击查看摘要
+ Computational pathology uses artificial intelligence to enable precision
+medicine and decision support systems through the analysis of whole slide
+images. It has the potential to revolutionize the diagnosis and treatment of
+cancer. However, a major challenge to this objective is that for many specific
+computational pathology tasks the amount of data is inadequate for development.
+To address this challenge, we created Virchow, a 632 million parameter deep
+neural network foundation model for computational pathology. Using
+self-supervised learning, Virchow is trained on 1.5 million hematoxylin and
+eosin stained whole slide images from diverse tissue groups, which is orders of
+magnitude more data than previous works. When evaluated on downstream tasks
+including tile-level pan-cancer detection and subtyping and slide-level
+biomarker prediction, Virchow outperforms state-of-the-art systems both on
+internal datasets drawn from the same population as the pretraining data as
+well as external public datasets. Virchow achieves 93% balanced accuracy for
+pancancer tile classification, and AUCs of 0.983 for colon microsatellite
+instability status prediction and 0.967 for breast CDH1 status prediction. The
+gains in performance highlight the importance of pretraining on massive
+pathology image datasets, suggesting pretraining on even larger datasets could
+continue improving performance for many high-impact applications where limited
+amounts of training data are available, such as drug outcome prediction.
+
+
+
+ 69. 标题:Automated segmentation of rheumatoid arthritis immunohistochemistry stained synovial tissue
+ 编号:[357]
+ 链接:https://arxiv.org/abs/2309.07255
+ 作者:Amaya Gallagher-Syed, Abbas Khan, Felice Rivellese, Costantino Pitzalis, Myles J. Lewis, Gregory Slabaugh, Michael R. Barnes
+ 备注:
+ 关键词:Rheumatoid Arthritis, primarily affects, affects the joint, joint synovial tissue, synovial tissue
+
+ 点击查看摘要
+ Rheumatoid Arthritis (RA) is a chronic, autoimmune disease which primarily
+affects the joint's synovial tissue. It is a highly heterogeneous disease, with
+wide cellular and molecular variability observed in synovial tissues. Over the
+last two decades, the methods available for their study have advanced
+considerably. In particular, Immunohistochemistry stains are well suited to
+highlighting the functional organisation of samples. Yet, analysis of
+IHC-stained synovial tissue samples is still overwhelmingly done manually and
+semi-quantitatively by expert pathologists. This is because in addition to the
+fragmented nature of IHC stained synovial tissue, there exist wide variations
+in intensity and colour, strong clinical centre batch effect, as well as the
+presence of many undesirable artefacts present in gigapixel Whole Slide Images
+(WSIs), such as water droplets, pen annotation, folded tissue, blurriness, etc.
+There is therefore a strong need for a robust, repeatable automated tissue
+segmentation algorithm which can cope with this variability and provide support
+to imaging pipelines. We train a UNET on a hand-curated, heterogeneous
+real-world multi-centre clinical dataset R4RA, which contains multiple types of
+IHC staining. The model obtains a DICE score of 0.865 and successfully segments
+different types of IHC staining, as well as dealing with variance in colours,
+intensity and common WSIs artefacts from the different clinical centres. It can
+be used as the first step in an automated image analysis pipeline for synovial
+tissue samples stained with IHC, increasing speed, reproducibility and
+robustness.
+
+
+自然语言处理
+
+ 1. 标题:MMICL: Empowering Vision-language Model with Multi-Modal In-Context Learning
+ 编号:[5]
+ 链接:https://arxiv.org/abs/2309.07915
+ 作者:Haozhe Zhao, Zefan Cai, Shuzheng Si, Xiaojian Ma, Kaikai An, Liang Chen, Zixuan Liu, Sheng Wang, Wenjuan Han, Baobao Chang
+ 备注:Code, dataset, checkpoints, and demos are available at \href{https://github.com/HaozheZhao/MIC}{this https URL}
+ 关键词:benefiting from large, resurgence of deep, multi-modal prompts, multiple images, deep learning
+
+ 点击查看摘要
+ Starting from the resurgence of deep learning, vision-language models (VLMs)
+benefiting from large language models (LLMs) have never been so popular.
+However, while LLMs can utilize extensive background knowledge and task
+information with in-context learning, most VLMs still struggle with
+understanding complex multi-modal prompts with multiple images. The issue can
+traced back to the architectural design of VLMs or pre-training data.
+Specifically, the current VLMs primarily emphasize utilizing multi-modal data
+with a single image some, rather than multi-modal prompts with interleaved
+multiple images and text. Even though some newly proposed VLMs could handle
+user prompts with multiple images, pre-training data does not provide more
+sophisticated multi-modal prompts than interleaved image and text crawled from
+the web. We propose MMICL to address the issue by considering both the model
+and data perspectives. We introduce a well-designed architecture capable of
+seamlessly integrating visual and textual context in an interleaved manner and
+MIC dataset to reduce the gap between the training data and the complex user
+prompts in real-world applications, including: 1) multi-modal context with
+interleaved images and text, 2) textual references for each image, and 3)
+multi-image data with spatial, logical, or temporal relationships. Our
+experiments confirm that MMICL achieves new stat-of-the-art zero-shot and
+few-shot performance on a wide range of general vision-language tasks,
+especially for complex reasoning benchmarks including MME and MMBench. Our
+analysis demonstrates that MMICL effectively deals with the challenge of
+complex multi-modal prompt understanding. The experiments on ScienceQA-IMG also
+show that MMICL successfully alleviates the issue of language bias in VLMs,
+which we believe is the reason behind the advanced performance of MMICL.
+
+
+
+ 2. 标题:Ambiguity-Aware In-Context Learning with Large Language Models
+ 编号:[13]
+ 链接:https://arxiv.org/abs/2309.07900
+ 作者:Lingyu Gao, Aditi Chaudhary, Krishna Srinivasan, Kazuma Hashimoto, Karthik Raman, Michael Bendersky
+ 备注:13 pages in total
+ 关键词:task-specific fine-tuning required, LLM existing knowledge, In-context learning, task-specific fine-tuning, fine-tuning required
+
+ 点击查看摘要
+ In-context learning (ICL) i.e. showing LLMs only a few task-specific
+demonstrations has led to downstream gains with no task-specific fine-tuning
+required. However, LLMs are sensitive to the choice of prompts, and therefore a
+crucial research question is how to select good demonstrations for ICL. One
+effective strategy is leveraging semantic similarity between the ICL
+demonstrations and test inputs by using a text retriever, which however is
+sub-optimal as that does not consider the LLM's existing knowledge about that
+task. From prior work (Min et al., 2022), we already know that labels paired
+with the demonstrations bias the model predictions. This leads us to our
+hypothesis whether considering LLM's existing knowledge about the task,
+especially with respect to the output label space can help in a better
+demonstration selection strategy. Through extensive experimentation on three
+text classification tasks, we find that it is beneficial to not only choose
+semantically similar ICL demonstrations but also to choose those demonstrations
+that help resolve the inherent label ambiguity surrounding the test example.
+Interestingly, we find that including demonstrations that the LLM previously
+mis-classified and also fall on the test example's decision boundary, brings
+the most performance gain.
+
+
+
+ 3. 标题:Safety-Tuned LLaMAs: Lessons From Improving the Safety of Large Language Models that Follow Instructions
+ 编号:[21]
+ 链接:https://arxiv.org/abs/2309.07875
+ 作者:Federico Bianchi, Mirac Suzgun, Giuseppe Attanasio, Paul Röttger, Dan Jurafsky, Tatsunori Hashimoto, James Zou
+ 备注:
+ 关键词:large language models, Training large language, range of tasks, large language, wide range
+
+ 点击查看摘要
+ Training large language models to follow instructions makes them perform
+better on a wide range of tasks, generally becoming more helpful. However, a
+perfectly helpful model will follow even the most malicious instructions and
+readily generate harmful content. In this paper, we raise concerns over the
+safety of models that only emphasize helpfulness, not safety, in their
+instruction-tuning. We show that several popular instruction-tuned models are
+highly unsafe. Moreover, we show that adding just 3% safety examples (a few
+hundred demonstrations) in the training set when fine-tuning a model like LLaMA
+can substantially improve their safety. Our safety-tuning does not make models
+significantly less capable or helpful as measured by standard benchmarks.
+However, we do find a behavior of exaggerated safety, where too much
+safety-tuning makes models refuse to respond to reasonable prompts that
+superficially resemble unsafe ones. Our study sheds light on trade-offs in
+training LLMs to follow instructions and exhibit safe behavior.
+
+
+
+ 4. 标题:Agents: An Open-source Framework for Autonomous Language Agents
+ 编号:[26]
+ 链接:https://arxiv.org/abs/2309.07870
+ 作者:Wangchunshu Zhou, Yuchen Eleanor Jiang, Long Li, Jialong Wu, Tiannan Wang, Shi Qiu, Jintian Zhang, Jing Chen, Ruipu Wu, Shuai Wang, Shiding Zhu, Jiyu Chen, Wentao Zhang, Ningyu Zhang, Huajun Chen, Peng Cui, Mrinmaya Sachan
+ 备注:Code available at this https URL
+ 关键词:large language models, natural language interfaces, autonomous language agents, interact with environments, language agents
+
+ 点击查看摘要
+ Recent advances on large language models (LLMs) enable researchers and
+developers to build autonomous language agents that can automatically solve
+various tasks and interact with environments, humans, and other agents using
+natural language interfaces. We consider language agents as a promising
+direction towards artificial general intelligence and release Agents, an
+open-source library with the goal of opening up these advances to a wider
+non-specialist audience. Agents is carefully engineered to support important
+features including planning, memory, tool usage, multi-agent communication, and
+fine-grained symbolic control. Agents is user-friendly as it enables
+non-specialists to build, customize, test, tune, and deploy state-of-the-art
+autonomous language agents without much coding. The library is also
+research-friendly as its modularized design makes it easily extensible for
+researchers. Agents is available at this https URL.
+
+
+
+ 5. 标题:The Rise and Potential of Large Language Model Based Agents: A Survey
+ 编号:[30]
+ 链接:https://arxiv.org/abs/2309.07864
+ 作者:Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, Rui Zheng, Xiaoran Fan, Xiao Wang, Limao Xiong, Qin Liu, Yuhao Zhou, Weiran Wang, Changhao Jiang, Yicheng Zou, Xiangyang Liu, Zhangyue Yin, Shihan Dou, Rongxiang Weng, Wensen Cheng, Qi Zhang, Wenjuan Qin, Yongyan Zheng, Xipeng Qiu, Xuanjing Huan, Tao Gui
+ 备注:86 pages, 12 figures
+ 关键词:pursued artificial intelligence, long time, humanity has pursued, agents, considered a promising
+
+ 点击查看摘要
+ For a long time, humanity has pursued artificial intelligence (AI) equivalent
+to or surpassing the human level, with AI agents considered a promising vehicle
+for this pursuit. AI agents are artificial entities that sense their
+environment, make decisions, and take actions. Many efforts have been made to
+develop intelligent AI agents since the mid-20th century. However, these
+efforts have mainly focused on advancement in algorithms or training strategies
+to enhance specific capabilities or performance on particular tasks. Actually,
+what the community lacks is a sufficiently general and powerful model to serve
+as a starting point for designing AI agents that can adapt to diverse
+scenarios. Due to the versatile and remarkable capabilities they demonstrate,
+large language models (LLMs) are regarded as potential sparks for Artificial
+General Intelligence (AGI), offering hope for building general AI agents. Many
+research efforts have leveraged LLMs as the foundation to build AI agents and
+have achieved significant progress. We start by tracing the concept of agents
+from its philosophical origins to its development in AI, and explain why LLMs
+are suitable foundations for AI agents. Building upon this, we present a
+conceptual framework for LLM-based agents, comprising three main components:
+brain, perception, and action, and the framework can be tailored to suit
+different applications. Subsequently, we explore the extensive applications of
+LLM-based agents in three aspects: single-agent scenarios, multi-agent
+scenarios, and human-agent cooperation. Following this, we delve into agent
+societies, exploring the behavior and personality of LLM-based agents, the
+social phenomena that emerge when they form societies, and the insights they
+offer for human society. Finally, we discuss a range of key topics and open
+problems within the field.
+
+
+
+ 6. 标题:CiwaGAN: Articulatory information exchange
+ 编号:[31]
+ 链接:https://arxiv.org/abs/2309.07861
+ 作者:Gašper Beguš, Thomas Lu, Alan Zhou, Peter Wu, Gopala K. Anumanchipalli
+ 备注:
+ 关键词:controlling articulators, articulators and decode, Humans encode information, auditory apparatus, sounds
+
+ 点击查看摘要
+ Humans encode information into sounds by controlling articulators and decode
+information from sounds using the auditory apparatus. This paper introduces
+CiwaGAN, a model of human spoken language acquisition that combines
+unsupervised articulatory modeling with an unsupervised model of information
+exchange through the auditory modality. While prior research includes
+unsupervised articulatory modeling and information exchange separately, our
+model is the first to combine the two components. The paper also proposes an
+improved articulatory model with more interpretable internal representations.
+The proposed CiwaGAN model is the most realistic approximation of human spoken
+language acquisition using deep learning. As such, it is useful for cognitively
+plausible simulations of the human speech act.
+
+
+
+ 7. 标题:ExpertQA: Expert-Curated Questions and Attributed Answers
+ 编号:[34]
+ 链接:https://arxiv.org/abs/2309.07852
+ 作者:Chaitanya Malaviya, Subin Lee, Sihao Chen, Elizabeth Sieber, Mark Yatskar, Dan Roth
+ 备注:Dataset & code is available at this https URL
+ 关键词:provide factually correct, factually correct information, correct information supported, set of users, sophisticated and diverse
+
+ 点击查看摘要
+ As language models are adapted by a more sophisticated and diverse set of
+users, the importance of guaranteeing that they provide factually correct
+information supported by verifiable sources is critical across fields of study
+& professions. This is especially the case for high-stakes fields, such as
+medicine and law, where the risk of propagating false information is high and
+can lead to undesirable societal consequences. Previous work studying
+factuality and attribution has not focused on analyzing these characteristics
+of language model outputs in domain-specific scenarios. In this work, we
+present an evaluation study analyzing various axes of factuality and
+attribution provided in responses from a few systems, by bringing domain
+experts in the loop. Specifically, we first collect expert-curated questions
+from 484 participants across 32 fields of study, and then ask the same experts
+to evaluate generated responses to their own questions. We also ask experts to
+revise answers produced by language models, which leads to ExpertQA, a
+high-quality long-form QA dataset with 2177 questions spanning 32 fields, along
+with verified answers and attributions for claims in the answers.
+
+
+
+ 8. 标题:CATfOOD: Counterfactual Augmented Training for Improving Out-of-Domain Performance and Calibration
+ 编号:[40]
+ 链接:https://arxiv.org/abs/2309.07822
+ 作者:Rachneet Sachdeva, Martin Tutek, Iryna Gurevych
+ 备注:We make our code available at: this https URL
+ 关键词:shown remarkable capabilities, generating text conditioned, large language models, recent years, capabilities at scale
+
+ 点击查看摘要
+ In recent years, large language models (LLMs) have shown remarkable
+capabilities at scale, particularly at generating text conditioned on a prompt.
+In our work, we investigate the use of LLMs to augment training data of small
+language models~(SLMs) with automatically generated counterfactual~(CF)
+instances -- i.e. minimally altered inputs -- in order to improve
+out-of-domain~(OOD) performance of SLMs in the extractive question
+answering~(QA) setup. We show that, across various LLM generators, such data
+augmentation consistently enhances OOD performance and improves model
+calibration for both confidence-based and rationale-augmented calibrator
+models. Furthermore, these performance improvements correlate with higher
+diversity of CF instances in terms of their surface form and semantic content.
+Finally, we show that CF augmented models which are easier to calibrate also
+exhibit much lower entropy when assigning importance, indicating that
+rationale-augmented calibrators prefer concise explanations.
+
+
+
+ 9. 标题:Text Classification of Cancer Clinical Trial Eligibility Criteria
+ 编号:[44]
+ 链接:https://arxiv.org/abs/2309.07812
+ 作者:Yumeng Yang, Soumya Jayaraj, Ethan B Ludmir, Kirk Roberts
+ 备注:AMIA Annual Symposium Proceedings 2023
+ 关键词:Automatic identification, patient is eligible, eligible is complicated, stated in natural, common
+
+ 点击查看摘要
+ Automatic identification of clinical trials for which a patient is eligible
+is complicated by the fact that trial eligibility is stated in natural
+language. A potential solution to this problem is to employ text classification
+methods for common types of eligibility criteria. In this study, we focus on
+seven common exclusion criteria in cancer trials: prior malignancy, human
+immunodeficiency virus, hepatitis B, hepatitis C, psychiatric illness,
+drug/substance abuse, and autoimmune illness. Our dataset consists of 764 phase
+III cancer trials with these exclusions annotated at the trial level. We
+experiment with common transformer models as well as a new pre-trained clinical
+trial BERT model. Our results demonstrate the feasibility of automatically
+classifying common exclusion criteria. Additionally, we demonstrate the value
+of a pre-trained language model specifically for clinical trials, which yields
+the highest average performance across all criteria.
+
+
+
+ 10. 标题:Pop Quiz! Do Pre-trained Code Models Possess Knowledge of Correct API Names?
+ 编号:[48]
+ 链接:https://arxiv.org/abs/2309.07804
+ 作者:Terry Yue Zhuo, Xiaoning Du, Zhenchang Xing, Jiamou Sun, Haowei Quan, Li Li, Liming Zhu
+ 备注:
+ 关键词:CodeBERT and Codex, API, code models, code, pre-trained code models
+
+ 点击查看摘要
+ Recent breakthroughs in pre-trained code models, such as CodeBERT and Codex,
+have shown their superior performance in various downstream tasks. The
+correctness and unambiguity of API usage among these code models are crucial
+for achieving desirable program functionalities, requiring them to learn
+various API fully qualified names structurally and semantically. Recent studies
+reveal that even state-of-the-art pre-trained code models struggle with
+suggesting the correct APIs during code generation. However, the reasons for
+such poor API usage performance are barely investigated. To address this
+challenge, we propose using knowledge probing as a means of interpreting code
+models, which uses cloze-style tests to measure the knowledge stored in models.
+Our comprehensive study examines a code model's capability of understanding API
+fully qualified names from two different perspectives: API call and API import.
+Specifically, we reveal that current code models struggle with understanding
+API names, with pre-training strategies significantly affecting the quality of
+API name learning. We demonstrate that natural language context can assist code
+models in locating Python API names and generalize Python API name knowledge to
+unseen data. Our findings provide insights into the limitations and
+capabilities of current pre-trained code models, and suggest that incorporating
+API structure into the pre-training process can improve automated API usage and
+code representations. This work provides significance for advancing code
+intelligence practices and direction for future studies. All experiment
+results, data and source code used in this work are available at
+\url{this https URL}.
+
+
+
+ 11. 标题:The Dynamical Principles of Storytelling
+ 编号:[50]
+ 链接:https://arxiv.org/abs/2309.07797
+ 作者:Isidoros Doxas (1 and 2), James Meiss (3), Steven Bottone (1), Tom Strelich (4 and 5), Andrew Plummer (5 and 6), Adrienne Breland (5 and 7), Simon Dennis (8 and 9), Kathy Garvin-Doxas (9 and 10), Michael Klymkowsky (3) ((1) Northrop Grumman Corporation, (2) Some work performed at the University of Colorado, Boulder, (3) University of Colorado, Boulder, (4) Fusion Constructive LLC, (5) Work performed at Northop Grumman Corporation (6) Current Address JP Morgan, (7) Current address, GALT Aerospace, (8) University of Melbourne, (9) Work performed at the University of Colorado, Boulder, (10) Boulder Internet Technologies)
+ 备注:6 pages, 4 figures, 3 tables
+ 关键词:average narrative follow, short stories, defined in arXiv, opening part, narrative follow
+
+ 点击查看摘要
+ When considering the opening part of 1800 short stories, we find that the
+first dozen paragraphs of the average narrative follow an action principle as
+defined in arXiv:2309.06600. When the order of the paragraphs is shuffled, the
+average no longer exhibits this property. The findings show that there is a
+preferential direction we take in semantic space when starting a story,
+possibly related to a common Western storytelling tradition as implied by
+Aristotle in Poetics.
+
+
+
+ 12. 标题:Improving Multimodal Classification of Social Media Posts by Leveraging Image-Text Auxiliary tasks
+ 编号:[52]
+ 链接:https://arxiv.org/abs/2309.07794
+ 作者:Danae Sánchez Villegas, Daniel Preoţiuc-Pietro, Nikolaos Aletras
+ 备注:
+ 关键词:hate speech classification, Effectively leveraging multimodal, Effectively leveraging, sarcasm detection, speech classification
+
+ 点击查看摘要
+ Effectively leveraging multimodal information from social media posts is
+essential to various downstream tasks such as sentiment analysis, sarcasm
+detection and hate speech classification. However, combining text and image
+information is challenging because of the idiosyncratic cross-modal semantics
+with hidden or complementary information present in matching image-text pairs.
+In this work, we aim to directly model this by proposing the use of two
+auxiliary losses jointly with the main task when fine-tuning any pre-trained
+multimodal model. Image-Text Contrastive (ITC) brings image-text
+representations of a post closer together and separates them from different
+posts, capturing underlying dependencies. Image-Text Matching (ITM) facilitates
+the understanding of semantic correspondence between images and text by
+penalizing unrelated pairs. We combine these objectives with five multimodal
+models, demonstrating consistent improvements across four popular social media
+datasets. Furthermore, through detailed analysis, we shed light on the specific
+scenarios and cases where each auxiliary task proves to be most effective.
+
+
+
+ 13. 标题:Usability Evaluation of Spoken Humanoid Embodied Conversational Agents in Mobile Serious Games
+ 编号:[56]
+ 链接:https://arxiv.org/abs/2309.07773
+ 作者:Danai Korre, Judy Robertson
+ 备注:45 pages, 9 figures, 14 tables
+ 关键词:Embodied Conversational Agents, Humanoid Embodied Conversational, paper presents, presents an empirical, empirical investigation
+
+ 点击查看摘要
+ This paper presents an empirical investigation of the extent to which spoken
+Humanoid Embodied Conversational Agents (HECAs) can foster usability in mobile
+serious game (MSG) applications. The aim of the research is to assess the
+impact of multiple agents and illusion of humanness on the quality of the
+interaction. The experiment investigates two styles of agent presentation: an
+agent of high human-likeness (HECA) and an agent of low human-likeness (text).
+The purpose of the experiment is to assess whether and how agents of high
+humanlikeness can evoke the illusion of humanness and affect usability. Agents
+of high human-likeness were designed by following the ECA design model that is
+a proposed guide for ECA development. The results of the experiment with 90
+participants show that users prefer to interact with the HECAs. The difference
+between the two versions is statistically significant with a large effect size
+(d=1.01), with many of the participants justifying their choice by saying that
+the human-like characteristics of the HECA made the version more appealing.
+This research provides key information on the potential effect of HECAs on
+serious games, which can provide insight into the design of future mobile
+serious games.
+
+
+
+ 14. 标题:Echotune: A Modular Extractor Leveraging the Variable-Length Nature of Speech in ASR Tasks
+ 编号:[57]
+ 链接:https://arxiv.org/abs/2309.07765
+ 作者:Sizhou Chen, Songyang Gao, Sen Fang
+ 备注:
+ 关键词:effective for Automatic, highly effective, Transformer architecture, Automatic, Transformer
+
+ 点击查看摘要
+ The Transformer architecture has proven to be highly effective for Automatic
+Speech Recognition (ASR) tasks, becoming a foundational component for a
+plethora of research in the domain. Historically, many approaches have leaned
+on fixed-length attention windows, which becomes problematic for varied speech
+samples in duration and complexity, leading to data over-smoothing and neglect
+of essential long-term connectivity. Addressing this limitation, we introduce
+Echo-MSA, a nimble module equipped with a variable-length attention mechanism
+that accommodates a range of speech sample complexities and durations. This
+module offers the flexibility to extract speech features across various
+granularities, spanning from frames and phonemes to words and discourse. The
+proposed design captures the variable length feature of speech and addresses
+the limitations of fixed-length attention. Our evaluation leverages a parallel
+attention architecture complemented by a dynamic gating mechanism that
+amalgamates traditional attention with the Echo-MSA module output. Empirical
+evidence from our study reveals that integrating Echo-MSA into the primary
+model's training regime significantly enhances the word error rate (WER)
+performance, all while preserving the intrinsic stability of the original
+model.
+
+
+
+ 15. 标题:PROGrasp: Pragmatic Human-Robot Communication for Object Grasping
+ 编号:[60]
+ 链接:https://arxiv.org/abs/2309.07759
+ 作者:Gi-Cheon Kang, Junghyun Kim, Jaein Kim, Byoung-Tak Zhang
+ 备注:7 pages, 6 figures
+ 关键词:natural language interaction, human-robot natural language, language interaction, target object, Object
+
+ 点击查看摘要
+ Interactive Object Grasping (IOG) is the task of identifying and grasping the
+desired object via human-robot natural language interaction. Current IOG
+systems assume that a human user initially specifies the target object's
+category (e.g., bottle). Inspired by pragmatics, where humans often convey
+their intentions by relying on context to achieve goals, we introduce a new IOG
+task, Pragmatic-IOG, and the corresponding dataset, Intention-oriented
+Multi-modal Dialogue (IM-Dial). In our proposed task scenario, an
+intention-oriented utterance (e.g., "I am thirsty") is initially given to the
+robot. The robot should then identify the target object by interacting with a
+human user. Based on the task setup, we propose a new robotic system that can
+interpret the user's intention and pick up the target object, Pragmatic Object
+Grasping (PROGrasp). PROGrasp performs Pragmatic-IOG by incorporating modules
+for visual grounding, question asking, object grasping, and most importantly,
+answer interpretation for pragmatic inference. Experimental results show that
+PROGrasp is effective in offline (i.e., target object discovery) and online
+(i.e., IOG with a physical robot arm) settings.
+
+
+
+ 16. 标题:Generative AI Text Classification using Ensemble LLM Approaches
+ 编号:[61]
+ 链接:https://arxiv.org/abs/2309.07755
+ 作者:Harika Abburi, Michael Suesserman, Nirmala Pudota, Balaji Veeramani, Edward Bowen, Sanmitra Bhattacharya
+ 备注:
+ 关键词:Artificial Intelligence, shown impressive performance, variety of Artificial, natural language processing, Large Language Models
+
+ 点击查看摘要
+ Large Language Models (LLMs) have shown impressive performance across a
+variety of Artificial Intelligence (AI) and natural language processing tasks,
+such as content creation, report generation, etc. However, unregulated malign
+application of these models can create undesirable consequences such as
+generation of fake news, plagiarism, etc. As a result, accurate detection of
+AI-generated language can be crucial in responsible usage of LLMs. In this
+work, we explore 1) whether a certain body of text is AI generated or written
+by human, and 2) attribution of a specific language model in generating a body
+of text. Texts in both English and Spanish are considered. The datasets used in
+this study are provided as part of the Automated Text Identification
+(AuTexTification) shared task. For each of the research objectives stated
+above, we propose an ensemble neural model that generates probabilities from
+different pre-trained LLMs which are used as features to a Traditional Machine
+Learning (TML) classifier following it. For the first task of distinguishing
+between AI and human generated text, our model ranked in fifth and thirteenth
+place (with macro $F1$ scores of 0.733 and 0.649) for English and Spanish
+texts, respectively. For the second task on model attribution, our model ranked
+in first place with macro $F1$ scores of 0.625 and 0.653 for English and
+Spanish texts, respectively.
+
+
+
+ 17. 标题:The complementary roles of non-verbal cues for Robust Pronunciation Assessment
+ 编号:[68]
+ 链接:https://arxiv.org/abs/2309.07739
+ 作者:Yassine El Kheir, Shammur Absar Chowdhury, Ahmed Ali
+ 备注:5 pages, submitted to ICASSP 2024
+ 关键词:assessment systems focuses, pronunciation assessment systems, aspects of non-native, pronunciation assessment framework, pronunciation assessment
+
+ 点击查看摘要
+ Research on pronunciation assessment systems focuses on utilizing phonetic
+and phonological aspects of non-native (L2) speech, often neglecting the rich
+layer of information hidden within the non-verbal cues. In this study, we
+proposed a novel pronunciation assessment framework, IntraVerbalPA. % The
+framework innovatively incorporates both fine-grained frame- and abstract
+utterance-level non-verbal cues, alongside the conventional speech and phoneme
+representations. Additionally, we introduce ''Goodness of phonemic-duration''
+metric to effectively model duration distribution within the framework. Our
+results validate the effectiveness of the proposed IntraVerbalPA framework and
+its individual components, yielding performance that either matches or
+outperforms existing research works.
+
+
+
+ 18. 标题:Explaining Speech Classification Models via Word-Level Audio Segments and Paralinguistic Features
+ 编号:[71]
+ 链接:https://arxiv.org/abs/2309.07733
+ 作者:Eliana Pastor, Alkis Koudounas, Giuseppe Attanasio, Dirk Hovy, Elena Baralis
+ 备注:8 pages
+ 关键词:tabular data operate, Recent advances, data operate, advances in eXplainable, provided new insights
+
+ 点击查看摘要
+ Recent advances in eXplainable AI (XAI) have provided new insights into how
+models for vision, language, and tabular data operate. However, few approaches
+exist for understanding speech models. Existing work focuses on a few spoken
+language understanding (SLU) tasks, and explanations are difficult to interpret
+for most users. We introduce a new approach to explain speech classification
+models. We generate easy-to-interpret explanations via input perturbation on
+two information levels. 1) Word-level explanations reveal how each word-related
+audio segment impacts the outcome. 2) Paralinguistic features (e.g., prosody
+and background noise) answer the counterfactual: ``What would the model
+prediction be if we edited the audio signal in this way?'' We validate our
+approach by explaining two state-of-the-art SLU models on two speech
+classification tasks in English and Italian. Our findings demonstrate that the
+explanations are faithful to the model's inner workings and plausible to
+humans. Our method and findings pave the way for future research on
+interpreting speech models.
+
+
+
+ 19. 标题:PerPLM: Personalized Fine-tuning of Pretrained Language Models via Writer-specific Intermediate Learning and Prompts
+ 编号:[74]
+ 链接:https://arxiv.org/abs/2309.07727
+ 作者:Daisuke Oba, Naoki Yoshinaga, Masashi Toyoda
+ 备注:11 pages
+ 关键词:meanings of words, words and phrases, phrases depend, PLMs, writers
+
+ 点击查看摘要
+ The meanings of words and phrases depend not only on where they are used
+(contexts) but also on who use them (writers). Pretrained language models
+(PLMs) are powerful tools for capturing context, but they are typically
+pretrained and fine-tuned for universal use across different writers. This
+study aims to improve the accuracy of text understanding tasks by personalizing
+the fine-tuning of PLMs for specific writers. We focus on a general setting
+where only the plain text from target writers are available for
+personalization. To avoid the cost of fine-tuning and storing multiple copies
+of PLMs for different users, we exhaustively explore using writer-specific
+prompts to personalize a unified PLM. Since the design and evaluation of these
+prompts is an underdeveloped area, we introduce and compare different types of
+prompts that are possible in our setting. To maximize the potential of
+prompt-based personalized fine-tuning, we propose a personalized intermediate
+learning based on masked language modeling to extract task-independent traits
+of writers' text. Our experiments, using multiple tasks, datasets, and PLMs,
+reveal the nature of different prompts and the effectiveness of our
+intermediate learning approach.
+
+
+
+ 20. 标题:L1-aware Multilingual Mispronunciation Detection Framework
+ 编号:[78]
+ 链接:https://arxiv.org/abs/2309.07719
+ 作者:Yassine El Kheir, Shammur Absar Chwodhury, Ahmed Ali
+ 备注:5 papers, submitted to ICASSP 2024
+ 关键词:speaker native, factor for mispronunciation, phonological discrepancies, major factor, reference phoneme sequence
+
+ 点击查看摘要
+ The phonological discrepancies between a speaker's native (L1) and the
+non-native language (L2) serves as a major factor for mispronunciation. This
+paper introduces a novel multilingual MDD architecture, L1-MultiMDD, enriched
+with L1-aware speech representation. An end-to-end speech encoder is trained on
+the input signal and its corresponding reference phoneme sequence. First, an
+attention mechanism is deployed to align the input audio with the reference
+phoneme sequence. Afterwards, the L1-L2-speech embedding are extracted from an
+auxiliary model, pretrained in a multi-task setup identifying L1 and L2
+language, and are infused with the primary network. Finally, the L1-MultiMDD is
+then optimized for a unified multilingual phoneme recognition task using
+connectionist temporal classification (CTC) loss for the target languages:
+English, Arabic, and Mandarin. Our experiments demonstrate the effectiveness of
+the proposed L1-MultiMDD framework on both seen -- L2-ARTIC, LATIC, and
+AraVoiceL2v2; and unseen -- EpaDB and Speechocean762 datasets. The consistent
+gains in PER, and false rejection rate (FRR) across all target languages
+confirm our approach's robustness, efficacy, and generalizability.
+
+
+
+ 21. 标题:CoLLD: Contrastive Layer-to-layer Distillation for Compressing Multilingual Pre-trained Speech Encoders
+ 编号:[83]
+ 链接:https://arxiv.org/abs/2309.07707
+ 作者:Heng-Jui Chang, Ning Dong, Ruslan Mavlyutov, Sravya Popuri, Yu-An Chung
+ 备注:Submitted to ICASSP 2024
+ 关键词:Large-scale self-supervised pre-trained, outperform conventional approaches, Large-scale self-supervised, conventional approaches, pre-trained speech encoders
+
+ 点击查看摘要
+ Large-scale self-supervised pre-trained speech encoders outperform
+conventional approaches in speech recognition and translation tasks. Due to the
+high cost of developing these large models, building new encoders for new tasks
+and deploying them to on-device applications are infeasible. Prior studies
+propose model compression methods to address this issue, but those works focus
+on smaller models and less realistic tasks. Thus, we propose Contrastive
+Layer-to-layer Distillation (CoLLD), a novel knowledge distillation method to
+compress pre-trained speech encoders by leveraging masked prediction and
+contrastive learning to train student models to copy the behavior of a large
+teacher model. CoLLD outperforms prior methods and closes the gap between small
+and large models on multilingual speech-to-text translation and recognition
+benchmarks.
+
+
+
+ 22. 标题:Tree of Uncertain Thoughts Reasoning for Large Language Models
+ 编号:[89]
+ 链接:https://arxiv.org/abs/2309.07694
+ 作者:Shentong Mo, Miao Xin
+ 备注:
+ 关键词:allowing Large Language, Large Language Models, Large Language, recently introduced Tree, allowing Large
+
+ 点击查看摘要
+ While the recently introduced Tree of Thoughts (ToT) has heralded
+advancements in allowing Large Language Models (LLMs) to reason through
+foresight and backtracking for global decision-making, it has overlooked the
+inherent local uncertainties in intermediate decision points or "thoughts".
+These local uncertainties, intrinsic to LLMs given their potential for diverse
+responses, remain a significant concern in the reasoning process. Addressing
+this pivotal gap, we introduce the Tree of Uncertain Thoughts (TouT) - a
+reasoning framework tailored for LLMs. Our TouT effectively leverages Monte
+Carlo Dropout to quantify uncertainty scores associated with LLMs' diverse
+local responses at these intermediate steps. By marrying this local uncertainty
+quantification with global search algorithms, TouT enhances the model's
+precision in response generation. We substantiate our approach with rigorous
+experiments on two demanding planning tasks: Game of 24 and Mini Crosswords.
+The empirical evidence underscores TouT's superiority over both ToT and
+chain-of-thought prompting methods.
+
+
+
+ 23. 标题:Detecting ChatGPT: A Survey of the State of Detecting ChatGPT-Generated Text
+ 编号:[91]
+ 链接:https://arxiv.org/abs/2309.07689
+ 作者:Mahdi Dhaini, Wessel Poelman, Ege Erdogan
+ 备注:Published in the Proceedings of the Student Research Workshop associated with RANLP-2023
+ 关键词:generative language models, large language model, generating fluent human-like, fluent human-like text, generative language
+
+ 点击查看摘要
+ While recent advancements in the capabilities and widespread accessibility of
+generative language models, such as ChatGPT (OpenAI, 2022), have brought about
+various benefits by generating fluent human-like text, the task of
+distinguishing between human- and large language model (LLM) generated text has
+emerged as a crucial problem. These models can potentially deceive by
+generating artificial text that appears to be human-generated. This issue is
+particularly significant in domains such as law, education, and science, where
+ensuring the integrity of text is of the utmost importance. This survey
+provides an overview of the current approaches employed to differentiate
+between texts generated by humans and ChatGPT. We present an account of the
+different datasets constructed for detecting ChatGPT-generated text, the
+various methods utilized, what qualitative analyses into the characteristics of
+human versus ChatGPT-generated text have been performed, and finally, summarize
+our findings into general insights
+
+
+
+ 24. 标题:Assessing the nature of large language models: A caution against anthropocentrism
+ 编号:[94]
+ 链接:https://arxiv.org/abs/2309.07683
+ 作者:Ann Speed
+ 备注:30 pages, 6 figures
+ 关键词:OpenAIs chatbot, amount of public, public attention, attention and speculation, release of OpenAIs
+
+ 点击查看摘要
+ Generative AI models garnered a large amount of public attention and
+speculation with the release of OpenAIs chatbot, ChatGPT. At least two opinion
+camps exist: one excited about possibilities these models offer for fundamental
+changes to human tasks, and another highly concerned about power these models
+seem to have. To address these concerns, we assessed GPT3.5 using standard,
+normed, and validated cognitive and personality measures. For this seedling
+project, we developed a battery of tests that allowed us to estimate the
+boundaries of some of these models capabilities, how stable those capabilities
+are over a short period of time, and how they compare to humans.
+Our results indicate that GPT 3.5 is unlikely to have developed sentience,
+although its ability to respond to personality inventories is interesting. It
+did display large variability in both cognitive and personality measures over
+repeated observations, which is not expected if it had a human-like
+personality. Variability notwithstanding, GPT3.5 displays what in a human would
+be considered poor mental health, including low self-esteem and marked
+dissociation from reality despite upbeat and helpful responses.
+
+
+
+ 25. 标题:A Conversation is Worth A Thousand Recommendations: A Survey of Holistic Conversational Recommender Systems
+ 编号:[95]
+ 链接:https://arxiv.org/abs/2309.07682
+ 作者:Chuang Li, Hengchang Hu, Yan Zhang, Min-Yen Kan, Haizhou Li
+ 备注:Accepted by 5th KaRS Workshop @ ACM RecSys 2023, 8 pages
+ 关键词:Conversational recommender systems, prior CRS work, CRS, holistic CRS, recommender systems
+
+ 点击查看摘要
+ Conversational recommender systems (CRS) generate recommendations through an
+interactive process. However, not all CRS approaches use human conversations as
+their source of interaction data; the majority of prior CRS work simulates
+interactions by exchanging entity-level information. As a result, claims of
+prior CRS work do not generalise to real-world settings where conversations
+take unexpected turns, or where conversational and intent understanding is not
+perfect. To tackle this challenge, the research community has started to
+examine holistic CRS, which are trained using conversational data collected
+from real-world scenarios. Despite their emergence, such holistic approaches
+are under-explored.
+We present a comprehensive survey of holistic CRS methods by summarizing the
+literature in a structured manner. Our survey recognises holistic CRS
+approaches as having three components: 1) a backbone language model, the
+optional use of 2) external knowledge, and/or 3) external guidance. We also
+give a detailed analysis of CRS datasets and evaluation methods in real
+application scenarios. We offer our insight as to the current challenges of
+holistic CRS and possible future trends.
+
+
+
+ 26. 标题:Aligning Speakers: Evaluating and Visualizing Text-based Diarization Using Efficient Multiple Sequence Alignment (Extended Version)
+ 编号:[96]
+ 链接:https://arxiv.org/abs/2309.07677
+ 作者:Chen Gong, Peilin Wu, Jinho D. Choi
+ 备注:Accepted to the 35th IEEE International Conference on Tools with Artificial Intelligence (ICTAI) 2023
+ 关键词:text-based speaker diarization, tackling the limitations, information in text, paper presents, limitations of traditional
+
+ 点击查看摘要
+ This paper presents a novel evaluation approach to text-based speaker
+diarization (SD), tackling the limitations of traditional metrics that do not
+account for any contextual information in text. Two new metrics are proposed,
+Text-based Diarization Error Rate and Diarization F1, which perform utterance-
+and word-level evaluations by aligning tokens in reference and hypothesis
+transcripts. Our metrics encompass more types of errors compared to existing
+ones, allowing us to make a more comprehensive analysis in SD. To align tokens,
+a multiple sequence alignment algorithm is introduced that supports multiple
+sequences in the reference while handling high-dimensional alignment to the
+hypothesis using dynamic programming. Our work is packaged into two tools,
+align4d providing an API for our alignment algorithm and TranscribeView for
+visualizing and evaluating SD errors, which can greatly aid in the creation of
+high-quality data, fostering the advancement of dialogue systems.
+
+
+
+ 27. 标题:Automatic Data Visualization Generation from Chinese Natural Language Questions
+ 编号:[108]
+ 链接:https://arxiv.org/abs/2309.07650
+ 作者:Yan Ge, Victor Junqiu Wei, Yuanfeng Song, Jason Chen Zhang, Raymond Chi-Wing Wong
+ 备注:
+ 关键词:data visualization generation, Data visualization, automatic data visualization, effective tool, insights from massive
+
+ 点击查看摘要
+ Data visualization has emerged as an effective tool for getting insights from
+massive datasets. Due to the hardness of manipulating the programming languages
+of data visualization, automatic data visualization generation from natural
+languages (Text-to-Vis) is becoming increasingly popular. Despite the plethora
+of research effort on the English Text-to-Vis, studies have yet to be conducted
+on data visualization generation from questions in Chinese. Motivated by this,
+we propose a Chinese Text-to-Vis dataset in the paper and demonstrate our first
+attempt to tackle this problem. Our model integrates multilingual BERT as the
+encoder, boosts the cross-lingual ability, and infuses the $n$-gram information
+into our word representation learning. Our experimental results show that our
+dataset is challenging and deserves further research.
+
+
+
+ 28. 标题:Dynamic MOdularized Reasoning for Compositional Structured Explanation Generation
+ 编号:[118]
+ 链接:https://arxiv.org/abs/2309.07624
+ 作者:Xiyan Fu, Anette Frank
+ 备注:
+ 关键词:capabilities remain unclear, generalization capabilities remain, remain unclear, capabilities remain, solving reasoning tasks
+
+ 点击查看摘要
+ Despite the success of neural models in solving reasoning tasks, their
+compositional generalization capabilities remain unclear. In this work, we
+propose a new setting of the structured explanation generation task to
+facilitate compositional reasoning research. Previous works found that symbolic
+methods achieve superior compositionality by using pre-defined inference rules
+for iterative reasoning. But these approaches rely on brittle symbolic
+transfers and are restricted to well-defined tasks. Hence, we propose a dynamic
+modularized reasoning model, MORSE, to improve the compositional generalization
+of neural models. MORSE factorizes the inference process into a combination of
+modules, where each module represents a functional unit. Specifically, we adopt
+modularized self-attention to dynamically select and route inputs to dedicated
+heads, which specializes them to specific functions. We conduct experiments for
+increasing lengths and shapes of reasoning trees on two benchmarks to test
+MORSE's compositional generalization abilities, and find it outperforms
+competitive baselines. Model ablation and deeper analyses show the
+effectiveness of dynamic reasoning modules and their generalization abilities.
+
+
+
+ 29. 标题:Zero-shot Audio Topic Reranking using Large Language Models
+ 编号:[130]
+ 链接:https://arxiv.org/abs/2309.07606
+ 作者:Mengjie Qian, Rao Ma, Adian Liusie, Erfan Loweimi, Kate M. Knill, Mark J.F. Gales
+ 备注:
+ 关键词:traditional text query, Multimodal Video Search, project investigates, Multimodal Video, query term
+
+ 点击查看摘要
+ The Multimodal Video Search by Examples (MVSE) project investigates using
+video clips as the query term for information retrieval, rather than the more
+traditional text query. This enables far richer search modalities such as
+images, speaker, content, topic, and emotion. A key element for this process is
+highly rapid, flexible, search to support large archives, which in MVSE is
+facilitated by representing video attributes by embeddings. This work aims to
+mitigate any performance loss from this rapid archive search by examining
+reranking approaches. In particular, zero-shot reranking methods using large
+language models are investigated as these are applicable to any video archive
+audio content. Performance is evaluated for topic-based retrieval on a publicly
+available video archive, the BBC Rewind corpus. Results demonstrate that
+reranking can achieve improved retrieval ranking without the need for any
+task-specific training data.
+
+
+
+ 30. 标题:Detecting Misinformation with LLM-Predicted Credibility Signals and Weak Supervision
+ 编号:[133]
+ 链接:https://arxiv.org/abs/2309.07601
+ 作者:João A. Leite, Olesya Razuvayevskaya, Kalina Bontcheva, Carolina Scarton
+ 备注:
+ 关键词:Credibility signals represent, Credibility signals, represent a wide, wide range, range of heuristics
+
+ 点击查看摘要
+ Credibility signals represent a wide range of heuristics that are typically
+used by journalists and fact-checkers to assess the veracity of online content.
+Automating the task of credibility signal extraction, however, is very
+challenging as it requires high-accuracy signal-specific extractors to be
+trained, while there are currently no sufficiently large datasets annotated
+with all credibility signals. This paper investigates whether large language
+models (LLMs) can be prompted effectively with a set of 18 credibility signals
+to produce weak labels for each signal. We then aggregate these potentially
+noisy labels using weak supervision in order to predict content veracity. We
+demonstrate that our approach, which combines zero-shot LLM credibility signal
+labeling and weak supervision, outperforms state-of-the-art classifiers on two
+misinformation datasets without using any ground-truth labels for training. We
+also analyse the contribution of the individual credibility signals towards
+predicting content veracity, which provides new valuable insights into their
+role in misinformation detection.
+
+
+
+ 31. 标题:C-Pack: Packaged Resources To Advance General Chinese Embedding
+ 编号:[135]
+ 链接:https://arxiv.org/abs/2309.07597
+ 作者:Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighof
+ 备注:
+ 关键词:Chinese, Chinese text embeddings, significantly advance, advance the field, Chinese text
+
+ 点击查看摘要
+ We introduce C-Pack, a package of resources that significantly advance the
+field of general Chinese embeddings. C-Pack includes three critical resources.
+1) C-MTEB is a comprehensive benchmark for Chinese text embeddings covering 6
+tasks and 35 datasets. 2) C-MTP is a massive text embedding dataset curated
+from labeled and unlabeled Chinese corpora for training embedding models. 3)
+C-TEM is a family of embedding models covering multiple sizes. Our models
+outperform all prior Chinese text embeddings on C-MTEB by up to +10% upon the
+time of the release. We also integrate and optimize the entire suite of
+training methods for C-TEM. Along with our resources on general Chinese
+embedding, we release our data and models for English text embeddings. The
+English models achieve state-of-the-art performance on MTEB benchmark;
+meanwhile, our released English data is 2 times larger than the Chinese data.
+All these resources are made publicly available at
+this https URL.
+
+
+
+ 32. 标题:Revisiting Supertagging for HPSG
+ 编号:[138]
+ 链接:https://arxiv.org/abs/2309.07590
+ 作者:Olga Zamaraeva, Carlos Gómez-Rodríguez
+ 备注:9 pages, 0 figures
+ 关键词:trained on HPSG-based, usual WSJ section, HPSG-based treebanks, treebanks feature high-quality, SVM and neural
+
+ 点击查看摘要
+ We present new supertaggers trained on HPSG-based treebanks. These treebanks
+feature high-quality annotation based on a well-developed linguistic theory and
+include diverse and challenging test datasets, beyond the usual WSJ section 23
+and Wikipedia data. HPSG supertagging has previously relied on MaxEnt-based
+models. We use SVM and neural CRF- and BERT-based methods and show that both
+SVM and neural supertaggers achieve considerably higher accuracy compared to
+the baseline. Our fine-tuned BERT-based tagger achieves 97.26% accuracy on 1000
+sentences from WSJ23 and 93.88% on the completely out-of-domain The Cathedral
+and the Bazaar (cb)). We conclude that it therefore makes sense to integrate
+these new supertaggers into modern HPSG parsers, and we also hope that the
+diverse and difficult datasets we used here will gain more popularity in the
+field. We contribute the complete dataset reformatted for token classification.
+
+
+
+ 33. 标题:Adaptive Prompt Learning with Distilled Connective Knowledge for Implicit Discourse Relation Recognition
+ 编号:[149]
+ 链接:https://arxiv.org/abs/2309.07561
+ 作者:Bang Wang, Zhenglin Wang, Wei Xiang, Yijun Mo
+ 备注:
+ 关键词:Implicit discourse relation, Implicit discourse, discourse relation, discourse relation recognition, aims at recognizing
+
+ 点击查看摘要
+ Implicit discourse relation recognition (IDRR) aims at recognizing the
+discourse relation between two text segments without an explicit connective.
+Recently, the prompt learning has just been applied to the IDRR task with great
+performance improvements over various neural network-based approaches. However,
+the discrete nature of the state-art-of-art prompting approach requires manual
+design of templates and answers, a big hurdle for its practical applications.
+In this paper, we propose a continuous version of prompt learning together with
+connective knowledge distillation, called AdaptPrompt, to reduce manual design
+efforts via continuous prompting while further improving performance via
+knowledge transfer. In particular, we design and train a few virtual tokens to
+form continuous templates and automatically select the most suitable one by
+gradient search in the embedding space. We also design an answer-relation
+mapping rule to generate a few virtual answers as the answer space.
+Furthermore, we notice the importance of annotated connectives in the training
+dataset and design a teacher-student architecture for knowledge transfer.
+Experiments on the up-to-date PDTB Corpus V3.0 validate our design objectives
+in terms of the better relation recognition performance over the
+state-of-the-art competitors.
+
+
+
+ 34. 标题:DBLPLink: An Entity Linker for the DBLP Scholarly Knowledge Graph
+ 编号:[152]
+ 链接:https://arxiv.org/abs/2309.07545
+ 作者:Debayan Banerjee, Arefa, Ricardo Usbeck, Chris Biemann
+ 备注:Accepted at International Semantic Web Conference (ISWC) 2023 Posters & Demo Track
+ 关键词:DBLP scholarly knowledge, scholarly knowledge graph, web application named, application named DBLPLink, DBLP scholarly
+
+ 点击查看摘要
+ In this work, we present a web application named DBLPLink, which performs
+entity linking over the DBLP scholarly knowledge graph. DBLPLink uses
+text-to-text pre-trained language models, such as T5, to produce entity label
+spans from an input text question. Entity candidates are fetched from a
+database based on the labels, and an entity re-ranker sorts them based on
+entity embeddings, such as TransE, DistMult and ComplEx. The results are
+displayed so that users may compare and contrast the results between T5-small,
+T5-base and the different KG embeddings used. The demo can be accessed at
+this https URL.
+
+
+
+ 35. 标题:Direct Text to Speech Translation System using Acoustic Units
+ 编号:[178]
+ 链接:https://arxiv.org/abs/2309.07478
+ 作者:Victoria Mingote, Pablo Gimeno, Luis Vicente, Sameer Khurana, Antoine Laurent, Jarod Duret
+ 备注:5 pages, 4 figures
+ 关键词:discrete acoustic units, paper proposes, speech, speech translation, acoustic units
+
+ 点击查看摘要
+ This paper proposes a direct text to speech translation system using discrete
+acoustic units. This framework employs text in different source languages as
+input to generate speech in the target language without the need for text
+transcriptions in this language. Motivated by the success of acoustic units in
+previous works for direct speech to speech translation systems, we use the same
+pipeline to extract the acoustic units using a speech encoder combined with a
+clustering algorithm. Once units are obtained, an encoder-decoder architecture
+is trained to predict them. Then a vocoder generates speech from units. Our
+approach for direct text to speech translation was tested on the new CVSS
+corpus with two different text mBART models employed as initialisation. The
+systems presented report competitive performance for most of the language pairs
+evaluated. Besides, results show a remarkable improvement when initialising our
+proposed architecture with a model pre-trained with more languages.
+
+
+
+ 36. 标题:Are Large Language Model-based Evaluators the Solution to Scaling Up Multilingual Evaluation?
+ 编号:[185]
+ 链接:https://arxiv.org/abs/2309.07462
+ 作者:Rishav Hada, Varun Gumma, Adrian de Wynter, Harshita Diddee, Mohamed Ahmed, Monojit Choudhury, Kalika Bali, Sunayana Sitaram
+ 备注:
+ 关键词:Large Language Models, demonstrated impressive performance, Question Answering, demonstrated impressive, Natural Language Processing
+
+ 点击查看摘要
+ Large Language Models (LLMs) have demonstrated impressive performance on
+Natural Language Processing (NLP) tasks, such as Question Answering,
+Summarization, and Classification. The use of LLMs as evaluators, that can rank
+or score the output of other models (usually LLMs) has become increasingly
+popular, due to the limitations of current evaluation techniques including the
+lack of appropriate benchmarks, metrics, cost, and access to human annotators.
+While LLMs are capable of handling approximately 100 languages, the majority of
+languages beyond the top 20 lack systematic evaluation across various tasks,
+metrics, and benchmarks. This creates an urgent need to scale up multilingual
+evaluation to ensure a precise understanding of LLM performance across diverse
+languages. LLM-based evaluators seem like the perfect solution to this problem,
+as they do not require human annotators, human-created references, or
+benchmarks and can theoretically be used to evaluate any language covered by
+the LLM. In this paper, we investigate whether LLM-based evaluators can help
+scale up multilingual evaluation. Specifically, we calibrate LLM-based
+evaluation against 20k human judgments of five metrics across three
+text-generation tasks in eight languages. Our findings indicate that LLM-based
+evaluators may exhibit bias towards higher scores and should be used with
+caution and should always be calibrated with a dataset of native speaker
+judgments, particularly in low-resource and non-Latin script languages.
+
+
+
+ 37. 标题:SIB-200: A Simple, Inclusive, and Big Evaluation Dataset for Topic Classification in 200+ Languages and Dialects
+ 编号:[193]
+ 链接:https://arxiv.org/abs/2309.07445
+ 作者:David Ifeoluwa Adelani, Hannah Liu, Xiaoyu Shen, Nikita Vassilyev, Jesujoba O. Alabi, Yanke Mao, Haonan Gao, Annie En-Shiun Lee
+ 备注:under submission
+ 关键词:Natural Language Understanding, natural language processing, natural language, languages, multilingual natural language
+
+ 点击查看摘要
+ Despite the progress we have recorded in the last few years in multilingual
+natural language processing, evaluation is typically limited to a small set of
+languages with available datasets which excludes a large number of low-resource
+languages. In this paper, we created SIB-200 -- a large-scale open-sourced
+benchmark dataset for topic classification in 200 languages and dialects to
+address the lack of evaluation dataset for Natural Language Understanding
+(NLU). For many of the languages covered in SIB-200, this is the first publicly
+available evaluation dataset for NLU. The dataset is based on Flores-200
+machine translation corpus. We annotated the English portion of the dataset and
+extended the sentence-level annotation to the remaining 203 languages covered
+in the corpus. Despite the simplicity of this task, our evaluation in
+full-supervised setting, cross-lingual transfer setting and prompting of large
+language model setting show that there is still a large gap between the
+performance of high-resource and low-resource languages when multilingual
+evaluation is scaled to numerous world languages. We found that languages
+unseen during the pre-training of multilingual language models,
+under-represented language families (like Nilotic and Altantic-Congo), and
+languages from the regions of Africa, Americas, Oceania and South East Asia,
+often have the lowest performance on our topic classification dataset. We hope
+our dataset will encourage a more inclusive evaluation of multilingual language
+models on a more diverse set of languages. this https URL
+
+
+
+ 38. 标题:Clinical Text Summarization: Adapting Large Language Models Can Outperform Human Experts
+ 编号:[201]
+ 链接:https://arxiv.org/abs/2309.07430
+ 作者:Dave Van Veen, Cara Van Uden, Louis Blankemeier, Jean-Benoit Delbrouck, Asad Aali, Christian Bluethgen, Anuj Pareek, Malgorzata Polacin, William Collins, Neera Ahuja, Curtis P. Langlotz, Jason Hom, Sergios Gatidis, John Pauly, Akshay S. Chaudhari
+ 备注:23 pages, 22 figures
+ 关键词:vast textual data, summarizing key information, key information imposes, Sifting through vast, allocate their time
+
+ 点击查看摘要
+ Sifting through vast textual data and summarizing key information imposes a
+substantial burden on how clinicians allocate their time. Although large
+language models (LLMs) have shown immense promise in natural language
+processing (NLP) tasks, their efficacy across diverse clinical summarization
+tasks has not yet been rigorously examined. In this work, we employ domain
+adaptation methods on eight LLMs, spanning six datasets and four distinct
+summarization tasks: radiology reports, patient questions, progress notes, and
+doctor-patient dialogue. Our thorough quantitative assessment reveals
+trade-offs between models and adaptation methods in addition to instances where
+recent advances in LLMs may not lead to improved results. Further, in a
+clinical reader study with six physicians, we depict that summaries from the
+best adapted LLM are preferable to human summaries in terms of completeness and
+correctness. Our ensuing qualitative analysis delineates mutual challenges
+faced by both LLMs and human experts. Lastly, we correlate traditional
+quantitative NLP metrics with reader study scores to enhance our understanding
+of how these metrics align with physician preferences. Our research marks the
+first evidence of LLMs outperforming human experts in clinical text
+summarization across multiple tasks. This implies that integrating LLMs into
+clinical workflows could alleviate documentation burden, empowering clinicians
+to focus more on personalized patient care and other irreplaceable human
+aspects of medicine.
+
+
+
+ 39. 标题:Semantic Parsing in Limited Resource Conditions
+ 编号:[202]
+ 链接:https://arxiv.org/abs/2309.07429
+ 作者:Zhuang Li
+ 备注:PhD thesis, year of award 2023, 172 pages
+ 关键词:thesis explores challenges, specifically focusing, explores challenges, focusing on scenarios, data
+
+ 点击查看摘要
+ This thesis explores challenges in semantic parsing, specifically focusing on
+scenarios with limited data and computational resources. It offers solutions
+using techniques like automatic data curation, knowledge transfer, active
+learning, and continual learning.
+For tasks with no parallel training data, the thesis proposes generating
+synthetic training examples from structured database schemas. When there is
+abundant data in a source domain but limited parallel data in a target domain,
+knowledge from the source is leveraged to improve parsing in the target domain.
+For multilingual situations with limited data in the target languages, the
+thesis introduces a method to adapt parsers using a limited human translation
+budget. Active learning is applied to select source-language samples for manual
+translation, maximizing parser performance in the target language. In addition,
+an alternative method is also proposed to utilize machine translation services,
+supplemented by human-translated data, to train a more effective parser.
+When computational resources are limited, a continual learning approach is
+introduced to minimize training time and computational memory. This maintains
+the parser's efficiency in previously learned tasks while adapting it to new
+tasks, mitigating the problem of catastrophic forgetting.
+Overall, the thesis provides a comprehensive set of methods to improve
+semantic parsing in resource-constrained conditions.
+
+
+
+ 40. 标题:ChatGPT MT: Competitive for High- (but not Low-) Resource Languages
+ 编号:[205]
+ 链接:https://arxiv.org/abs/2309.07423
+ 作者:Nathaniel R. Robinson, Perez Ogayo, David R. Mortensen, Graham Neubig
+ 备注:27 pages, 9 figures, 14 tables
+ 关键词:including machine translation, implicitly learn, including machine, machine translation, learn to perform
+
+ 点击查看摘要
+ Large language models (LLMs) implicitly learn to perform a range of language
+tasks, including machine translation (MT). Previous studies explore aspects of
+LLMs' MT capabilities. However, there exist a wide variety of languages for
+which recent LLM MT performance has never before been evaluated. Without
+published experimental evidence on the matter, it is difficult for speakers of
+the world's diverse languages to know how and whether they can use LLMs for
+their languages. We present the first experimental evidence for an expansive
+set of 204 languages, along with MT cost analysis, using the FLORES-200
+benchmark. Trends reveal that GPT models approach or exceed traditional MT
+model performance for some high-resource languages (HRLs) but consistently lag
+for low-resource languages (LRLs), under-performing traditional MT for 84.1% of
+languages we covered. Our analysis reveals that a language's resource level is
+the most important feature in determining ChatGPT's relative ability to
+translate it, and suggests that ChatGPT is especially disadvantaged for LRLs
+and African languages.
+
+
+
+ 41. 标题:CPPF: A contextual and post-processing-free model for automatic speech recognition
+ 编号:[211]
+ 链接:https://arxiv.org/abs/2309.07413
+ 作者:Lei Zhang, Zhengkun Tian, Xiang Chen, Jiaming Sun, Hongyu Xiang, Ke Ding, Guanglu Wan
+ 备注:Submitted to ICASSP2024
+ 关键词:recent years, increasingly widespread, widespread in recent, ASR, ASR systems
+
+ 点击查看摘要
+ ASR systems have become increasingly widespread in recent years. However,
+their textual outputs often require post-processing tasks before they can be
+practically utilized. To address this issue, we draw inspiration from the
+multifaceted capabilities of LLMs and Whisper, and focus on integrating
+multiple ASR text processing tasks related to speech recognition into the ASR
+model. This integration not only shortens the multi-stage pipeline, but also
+prevents the propagation of cascading errors, resulting in direct generation of
+post-processed text. In this study, we focus on ASR-related processing tasks,
+including Contextual ASR and multiple ASR post processing tasks. To achieve
+this objective, we introduce the CPPF model, which offers a versatile and
+highly effective alternative to ASR processing. CPPF seamlessly integrates
+these tasks without any significant loss in recognition performance.
+
+
+
+ 42. 标题:Advancing Regular Language Reasoning in Linear Recurrent Neural Networks
+ 编号:[212]
+ 链接:https://arxiv.org/abs/2309.07412
+ 作者:Ting-Han Fan, Ta-Chung Chi, Alexander I. Rudnicky
+ 备注:The first two authors contributed equally to this work
+ 关键词:linear recurrent neural, recurrent neural networks, recent studies, linear recurrent, neural networks
+
+ 点击查看摘要
+ In recent studies, linear recurrent neural networks (LRNNs) have achieved
+Transformer-level performance in natural language modeling and long-range
+modeling while offering rapid parallel training and constant inference costs.
+With the resurged interest in LRNNs, we study whether they can learn the hidden
+rules in training sequences, such as the grammatical structures of regular
+language. We theoretically analyze some existing LRNNs and discover their
+limitations on regular language. Motivated by the analysis, we propose a new
+LRNN equipped with a block-diagonal and input-dependent transition matrix.
+Experiments suggest that the proposed model is the only LRNN that can perform
+length extrapolation on regular language tasks such as Sum, Even Pair, and
+Modular Arithmetic.
+
+
+
+ 43. 标题:DebCSE: Rethinking Unsupervised Contrastive Sentence Embedding Learning in the Debiasing Perspective
+ 编号:[223]
+ 链接:https://arxiv.org/abs/2309.07396
+ 作者:Pu Miao, Zeyao Du, Junlin Zhang
+ 备注:
+ 关键词:word frequency biases, prior studies, studies have suggested, suggested that word, word frequency
+
+ 点击查看摘要
+ Several prior studies have suggested that word frequency biases can cause the
+Bert model to learn indistinguishable sentence embeddings. Contrastive learning
+schemes such as SimCSE and ConSERT have already been adopted successfully in
+unsupervised sentence embedding to improve the quality of embeddings by
+reducing this bias. However, these methods still introduce new biases such as
+sentence length bias and false negative sample bias, that hinders model's
+ability to learn more fine-grained semantics. In this paper, we reexamine the
+challenges of contrastive sentence embedding learning from a debiasing
+perspective and argue that effectively eliminating the influence of various
+biases is crucial for learning high-quality sentence embeddings. We think all
+those biases are introduced by simple rules for constructing training data in
+contrastive learning and the key for contrastive learning sentence embedding is
+to mimic the distribution of training data in supervised machine learning in
+unsupervised way. We propose a novel contrastive framework for sentence
+embedding, termed DebCSE, which can eliminate the impact of these biases by an
+inverse propensity weighted sampling method to select high-quality positive and
+negative pairs according to both the surface and semantic similarity between
+sentences. Extensive experiments on semantic textual similarity (STS)
+benchmarks reveal that DebCSE significantly outperforms the latest
+state-of-the-art models with an average Spearman's correlation coefficient of
+80.33% on BERTbase.
+
+
+
+ 44. 标题:VDialogUE: A Unified Evaluation Benchmark for Visually-grounded Dialogue
+ 编号:[228]
+ 链接:https://arxiv.org/abs/2309.07387
+ 作者:Yunshui Li, Binyuan Hui, Zhaochao Yin, Wanwei He, Run Luo, Yuxing Long, Min Yang, Fei Huang, Yongbin Li
+ 备注:
+ 关键词:integrate multiple modes, increasingly popular area, textbf, visual inputs, area of investigation
+
+ 点击查看摘要
+ Visually-grounded dialog systems, which integrate multiple modes of
+communication such as text and visual inputs, have become an increasingly
+popular area of investigation. However, the absence of a standardized
+evaluation framework poses a challenge in assessing the development of this
+field. To this end, we propose \textbf{VDialogUE}, a \textbf{V}isually-grounded
+\textbf{Dialog}ue benchmark for \textbf{U}nified \textbf{E}valuation. It
+defines five core multi-modal dialogue tasks and covers six datasets.
+Furthermore, in order to provide a comprehensive assessment of the model's
+performance across all tasks, we developed a novel evaluation metric called
+VDscore, which is based on the Analytic Hierarchy Process~(AHP) method.
+Additionally, we present a straightforward yet efficient baseline model, named
+\textbf{VISIT}~(\textbf{VIS}ually-grounded d\textbf{I}alog
+\textbf{T}ransformer), to promote the advancement of general multi-modal
+dialogue systems. It progressively builds its multi-modal foundation and
+dialogue capability via a two-stage pre-training strategy.
+We believe that the VDialogUE benchmark, along with the evaluation scripts
+and our baseline models, will accelerate the development of visually-grounded
+dialog systems and lead to the development of more sophisticated and effective
+pre-trained models.
+
+
+
+ 45. 标题:An Interactive Framework for Profiling News Media Sources
+ 编号:[229]
+ 链接:https://arxiv.org/abs/2309.07384
+ 作者:Nikhil Mehta, Dan Goldwasser
+ 备注:
+ 关键词:content published, sway beliefs, recent rise, intent to sway, Large Language Models
+
+ 点击查看摘要
+ The recent rise of social media has led to the spread of large amounts of
+fake and biased news, content published with the intent to sway beliefs. While
+detecting and profiling the sources that spread this news is important to
+maintain a healthy society, it is challenging for automated systems.
+In this paper, we propose an interactive framework for news media profiling.
+It combines the strengths of graph based news media profiling models,
+Pre-trained Large Language Models, and human insight to characterize the social
+context on social media. Experimental results show that with as little as 5
+human interactions, our framework can rapidly detect fake and biased news
+media, even in the most challenging settings of emerging news events, where
+test data is unseen.
+
+
+
+ 46. 标题:Less is More for Long Document Summary Evaluation by LLMs
+ 编号:[231]
+ 链接:https://arxiv.org/abs/2309.07382
+ 作者:Yunshu Wu, Hayate Iso, Pouya Pezeshkpour, Nikita Bhutani, Estevam Hruschka
+ 备注:Work in progress
+ 关键词:Large Language Models, Language Models, shown promising performance, Large Language, high computational costs
+
+ 点击查看摘要
+ Large Language Models (LLMs) have shown promising performance in summary
+evaluation tasks, yet they face challenges such as high computational costs and
+the Lost-in-the-Middle problem where important information in the middle of
+long documents is often overlooked. To address these issues, this paper
+introduces a novel approach, Extract-then-Evaluate, which involves extracting
+key sentences from a long source document and then evaluating the summary by
+prompting LLMs. The results reveal that the proposed method not only
+significantly reduces evaluation costs but also exhibits a higher correlation
+with human evaluations. Furthermore, we provide practical recommendations for
+optimal document length and sentence extraction methods, contributing to the
+development of cost-effective yet more accurate methods for LLM-based text
+generation evaluation.
+
+
+
+ 47. 标题:Learning from Auxiliary Sources in Argumentative Revision Classification
+ 编号:[247]
+ 链接:https://arxiv.org/abs/2309.07334
+ 作者:Tazin Afrin, Diane Litman
+ 备注:
+ 关键词:classify desirable reasoning, desirable reasoning revisions, argumentative writing, develop models, models to classify
+
+ 点击查看摘要
+ We develop models to classify desirable reasoning revisions in argumentative
+writing. We explore two approaches -- multi-task learning and transfer learning
+-- to take advantage of auxiliary sources of revision data for similar tasks.
+Results of intrinsic and extrinsic evaluations show that both approaches can
+indeed improve classifier performance over baselines. While multi-task learning
+shows that training on different sources of data at the same time may improve
+performance, transfer-learning better represents the relationship between the
+data.
+
+
+
+ 48. 标题:Traveling Words: A Geometric Interpretation of Transformers
+ 编号:[254]
+ 链接:https://arxiv.org/abs/2309.07315
+ 作者:Raul Molina
+ 备注:
+ 关键词:natural language processing, internal mechanisms remains, language processing, remains a challenge, significantly advanced
+
+ 点击查看摘要
+ Transformers have significantly advanced the field of natural language
+processing, but comprehending their internal mechanisms remains a challenge. In
+this paper, we introduce a novel geometric perspective that elucidates the
+inner mechanisms of transformer operations. Our primary contribution is
+illustrating how layer normalization confines the latent features to a
+hyper-sphere, subsequently enabling attention to mold the semantic
+representation of words on this surface. This geometric viewpoint seamlessly
+connects established properties such as iterative refinement and contextual
+embeddings. We validate our insights by probing a pre-trained 124M parameter
+GPT-2 model. Our findings reveal clear query-key attention patterns in early
+layers and build upon prior observations regarding the subject-specific nature
+of attention heads at deeper layers. Harnessing these geometric insights, we
+present an intuitive understanding of transformers, depicting them as processes
+that model the trajectory of word particles along the hyper-sphere.
+
+
+
+ 49. 标题:Sudden Drops in the Loss: Syntax Acquisition, Phase Transitions, and Simplicity Bias in MLMs
+ 编号:[256]
+ 链接:https://arxiv.org/abs/2309.07311
+ 作者:Angelica Chen, Ravid Schwartz-Ziv, Kyunghyun Cho, Matthew L. Leavitt, Naomi Saphra
+ 备注:
+ 关键词:research in NLP, NLP focuses, fully trained model, SAS, interpretability research
+
+ 点击查看摘要
+ Most interpretability research in NLP focuses on understanding the behavior
+and features of a fully trained model. However, certain insights into model
+behavior may only be accessible by observing the trajectory of the training
+process. In this paper, we present a case study of syntax acquisition in masked
+language models (MLMs). Our findings demonstrate how analyzing the evolution of
+interpretable artifacts throughout training deepens our understanding of
+emergent behavior. In particular, we study Syntactic Attention Structure (SAS),
+a naturally emerging property of MLMs wherein specific Transformer heads tend
+to focus on specific syntactic relations. We identify a brief window in
+training when models abruptly acquire SAS and find that this window is
+concurrent with a steep drop in loss. Moreover, SAS precipitates the subsequent
+acquisition of linguistic capabilities. We then examine the causal role of SAS
+by introducing a regularizer to manipulate SAS during training, and demonstrate
+that SAS is necessary for the development of grammatical capabilities. We
+further find that SAS competes with other beneficial traits and capabilities
+during training, and that briefly suppressing SAS can improve model quality.
+These findings reveal a real-world example of the relationship between
+disadvantageous simplicity bias and interpretable breakthrough training
+dynamics.
+
+
+
+ 50. 标题:In-Contextual Bias Suppression for Large Language Models
+ 编号:[283]
+ 链接:https://arxiv.org/abs/2309.07251
+ 作者:Daisuke Oba, Masahiro Kaneko, Danushka Bollegala
+ 备注:13 pages
+ 关键词:range of NLP, Large, NLP tasks, wide range, NLP
+
+ 点击查看摘要
+ Despite their impressive performance in a wide range of NLP tasks, Large
+Language Models (LLMs) have been reported to encode worrying-levels of gender
+bias. Prior work has proposed debiasing methods that require human labelled
+examples, data augmentation and fine-tuning of the LLMs, which are
+computationally costly. Moreover, one might not even have access to the
+internal parameters for performing debiasing such as in the case of
+commercially available LLMs such as GPT-4. To address this challenge we propose
+bias suppression, a novel alternative to debiasing that does not require access
+to model parameters. We show that text-based preambles, generated from manually
+designed templates covering counterfactual statements, can accurately suppress
+gender biases in LLMs. Moreover, we find that descriptive sentences for
+occupations can further suppress gender biases. Interestingly, we find that
+bias suppression has a minimal adverse effect on downstream task performance,
+while effectively mitigating the gender biases.
+
+
+
+ 51. 标题:Exploring Large Language Models for Ontology Alignment
+ 编号:[303]
+ 链接:https://arxiv.org/abs/2309.07172
+ 作者:Yuan He, Jiaoyan Chen, Hang Dong, Ian Horrocks
+ 备注:Accepted at ISWC 2023 (Posters and Demos)
+ 关键词:generative Large Language, recent generative Large, Large Language, generative Large, work investigates
+
+ 点击查看摘要
+ This work investigates the applicability of recent generative Large Language
+Models (LLMs), such as the GPT series and Flan-T5, to ontology alignment for
+identifying concept equivalence mappings across ontologies. To test the
+zero-shot performance of Flan-T5-XXL and GPT-3.5-turbo, we leverage challenging
+subsets from two equivalence matching datasets of the OAEI Bio-ML track, taking
+into account concept labels and structural contexts. Preliminary findings
+suggest that LLMs have the potential to outperform existing ontology alignment
+systems like BERTMap, given careful framework and prompt design.
+
+
+
+ 52. 标题:Incorporating Class-based Language Model for Named Entity Recognition in Factorized Neural Transducer
+ 编号:[332]
+ 链接:https://arxiv.org/abs/2309.07648
+ 作者:Peng Wang, Yifan Yang, Zheng Liang, Tian Tan, Shiliang Zhang, Xie Chen
+ 备注:
+ 关键词:excellent strides made, named entity recognition, recent years, semantic understanding, named entity
+
+ 点击查看摘要
+ In spite of the excellent strides made by end-to-end (E2E) models in speech
+recognition in recent years, named entity recognition is still challenging but
+critical for semantic understanding. In order to enhance the ability to
+recognize named entities in E2E models, previous studies mainly focus on
+various rule-based or attention-based contextual biasing algorithms. However,
+their performance might be sensitive to the biasing weight or degraded by
+excessive attention to the named entity list, along with a risk of false
+triggering. Inspired by the success of the class-based language model (LM) in
+named entity recognition in conventional hybrid systems and the effective
+decoupling of acoustic and linguistic information in the factorized neural
+Transducer (FNT), we propose a novel E2E model to incorporate class-based LMs
+into FNT, which is referred as C-FNT. In C-FNT, the language model score of
+named entities can be associated with the name class instead of its surface
+form. The experimental results show that our proposed C-FNT presents
+significant error reduction in named entities without hurting performance in
+general word recognition.
+
+
+
+ 53. 标题:PromptASR for contextualized ASR with controllable style
+ 编号:[342]
+ 链接:https://arxiv.org/abs/2309.07414
+ 作者:Xiaoyu Yang, Wei Kang, Zengwei Yao, Yifan Yang, Liyong Guo, Fangjun Kuang, Long Lin, Daniel Povey
+ 备注:Submitted to ICASSP2024
+ 关键词:large language models, provide context information, logical relationships, crucial to large, large language
+
+ 点击查看摘要
+ Prompts are crucial to large language models as they provide context
+information such as topic or logical relationships. Inspired by this, we
+propose PromptASR, a framework that integrates prompts in end-to-end automatic
+speech recognition (E2E ASR) systems to achieve contextualized ASR with
+controllable style of transcriptions. Specifically, a dedicated text encoder
+encodes the text prompts and the encodings are injected into the speech encoder
+by cross-attending the features from two modalities. When using the ground
+truth text from preceding utterances as content prompt, the proposed system
+achieves 21.9% and 6.8% relative word error rate reductions on a book reading
+dataset and an in-house dataset compared to a baseline ASR system. The system
+can also take word-level biasing lists as prompt to improve recognition
+accuracy on rare words. An additional style prompt can be given to the text
+encoder and guide the ASR system to output different styles of transcriptions.
+The code is available at icefall.
+
+
+
+ 54. 标题:Hybrid Attention-based Encoder-decoder Model for Efficient Language Model Adaptation
+ 编号:[348]
+ 链接:https://arxiv.org/abs/2309.07369
+ 作者:Shaoshi Ling, Guoli Ye, Rui Zhao, Yifan Gong
+ 备注:
+ 关键词:speech recognition model, recent years, model, widely successful, successful in recent
+
+ 点击查看摘要
+ Attention-based encoder-decoder (AED) speech recognition model has been
+widely successful in recent years. However, the joint optimization of acoustic
+model and language model in end-to-end manner has created challenges for text
+adaptation. In particular, effectively, quickly and inexpensively adapting text
+has become a primary concern for deploying AED systems in industry. To address
+this issue, we propose a novel model, the hybrid attention-based
+encoder-decoder (HAED) speech recognition model that preserves the modularity
+of conventional hybrid automatic speech recognition systems. Our HAED model
+separates the acoustic and language models, allowing for the use of
+conventional text-based language model adaptation techniques. We demonstrate
+that the proposed HAED model yields 21\% Word Error Rate (WER) improvements in
+relative when out-of-domain text data is used for language model adaptation,
+and with only a minor degradation in WER on a general test set compared with
+conventional AED model.
+
+
+机器学习
+
+ 1. 标题:Boosting Unsupervised Contrastive Learning Using Diffusion-Based Data Augmentation From Scratch
+ 编号:[9]
+ 链接:https://arxiv.org/abs/2309.07909
+ 作者:Zelin Zang, Hao Luo, Kai Wang, Panpan Zhang, Fan Wang, Stan.Z Li, Yang You
+ 备注:arXiv admin note: text overlap with arXiv:2302.07944 by other authors
+ 关键词:Unsupervised contrastive learning, contrastive learning methods, data augmentation, data augmentation strategies, data
+
+ 点击查看摘要
+ Unsupervised contrastive learning methods have recently seen significant
+improvements, particularly through data augmentation strategies that aim to
+produce robust and generalizable representations. However, prevailing data
+augmentation methods, whether hand designed or based on foundation models, tend
+to rely heavily on prior knowledge or external data. This dependence often
+compromises their effectiveness and efficiency. Furthermore, the applicability
+of most existing data augmentation strategies is limited when transitioning to
+other research domains, especially science-related data. This limitation stems
+from the paucity of prior knowledge and labeled data available in these
+domains. To address these challenges, we introduce DiffAug-a novel and
+efficient Diffusion-based data Augmentation technique. DiffAug aims to ensure
+that the augmented and original data share a smoothed latent space, which is
+achieved through diffusion steps. Uniquely, unlike traditional methods, DiffAug
+first mines sufficient prior semantic knowledge about the neighborhood. This
+provides a constraint to guide the diffusion steps, eliminating the need for
+labels, external data/models, or prior knowledge. Designed as an
+architecture-agnostic framework, DiffAug provides consistent improvements.
+Specifically, it improves image classification and clustering accuracy by
+1.6%~4.5%. When applied to biological data, DiffAug improves performance by up
+to 10.1%, with an average improvement of 5.8%. DiffAug shows good performance
+in both vision and biological domains.
+
+
+
+ 2. 标题:Physically Plausible Full-Body Hand-Object Interaction Synthesis
+ 编号:[11]
+ 链接:https://arxiv.org/abs/2309.07907
+ 作者:Jona Braun, Sammy Christen, Muhammed Kocabas, Emre Aksan, Otmar Hilliges
+ 备注:Project page at this https URL
+ 关键词:synthesizing dexterous hand-object, synthesizing dexterous, dexterous hand-object interactions, full-body setting, hand-object interactions
+
+ 点击查看摘要
+ We propose a physics-based method for synthesizing dexterous hand-object
+interactions in a full-body setting. While recent advancements have addressed
+specific facets of human-object interactions, a comprehensive physics-based
+approach remains a challenge. Existing methods often focus on isolated segments
+of the interaction process and rely on data-driven techniques that may result
+in artifacts. In contrast, our proposed method embraces reinforcement learning
+(RL) and physics simulation to mitigate the limitations of data-driven
+approaches. Through a hierarchical framework, we first learn skill priors for
+both body and hand movements in a decoupled setting. The generic skill priors
+learn to decode a latent skill embedding into the motion of the underlying
+part. A high-level policy then controls hand-object interactions in these
+pretrained latent spaces, guided by task objectives of grasping and 3D target
+trajectory following. It is trained using a novel reward function that combines
+an adversarial style term with a task reward, encouraging natural motions while
+fulfilling the task incentives. Our method successfully accomplishes the
+complete interaction task, from approaching an object to grasping and
+subsequent manipulation. We compare our approach against kinematics-based
+baselines and show that it leads to more physically plausible motions.
+
+
+
+ 3. 标题:Improving physics-informed DeepONets with hard constraints
+ 编号:[14]
+ 链接:https://arxiv.org/abs/2309.07899
+ 作者:Rüdiger Brecht, Dmytro R. Popovych, Alex Bihlo, Roman O. Popovych
+ 备注:15 pages, 5 figures, 4 tables; release version
+ 关键词:neural networks, networks still rely, rely on accurately, initial conditions, Current physics-informed
+
+ 点击查看摘要
+ Current physics-informed (standard or operator) neural networks still rely on
+accurately learning the initial conditions of the system they are solving. In
+contrast, standard numerical methods evolve such initial conditions without
+needing to learn these. In this study, we propose to improve current
+physics-informed deep learning strategies such that initial conditions do not
+need to be learned and are represented exactly in the predicted solution.
+Moreover, this method guarantees that when a DeepONet is applied multiple times
+to time step a solution, the resulting function is continuous.
+
+
+
+ 4. 标题:A Novel Local-Global Feature Fusion Framework for Body-weight Exercise Recognition with Pressure Mapping Sensors
+ 编号:[17]
+ 链接:https://arxiv.org/abs/2309.07888
+ 作者:Davinder Pal Singh, Lala Shakti Swarup Ray, Bo Zhou, Sungho Suh, Paul Lukowicz
+ 备注:
+ 关键词:dynamic pressure maps, floor-based dynamic pressure, local-global feature fusion, feature fusion framework, global feature extraction
+
+ 点击查看摘要
+ We present a novel local-global feature fusion framework for body-weight
+exercise recognition with floor-based dynamic pressure maps. One step further
+from the existing studies using deep neural networks mainly focusing on global
+feature extraction, the proposed framework aims to combine local and global
+features using image processing techniques and the YOLO object detection to
+localize pressure profiles from different body parts and consider physical
+constraints. The proposed local feature extraction method generates two sets of
+high-level local features consisting of cropped pressure mapping and numerical
+features such as angular orientation, location on the mat, and pressure area.
+In addition, we adopt a knowledge distillation for regularization to preserve
+the knowledge of the global feature extraction and improve the performance of
+the exercise recognition. Our experimental results demonstrate a notable 11
+percent improvement in F1 score for exercise recognition while preserving
+label-specific features.
+
+
+
+ 5. 标题:Some notes concerning a generalized KMM-type optimization method for density ratio estimation
+ 编号:[18]
+ 链接:https://arxiv.org/abs/2309.07887
+ 作者:Cristian Daniel Alecsa
+ 备注:17 pages, 4 figures
+ 关键词:present paper, paper we introduce, introduce new optimization, optimization algorithms, density ratio estimation
+
+ 点击查看摘要
+ In the present paper we introduce new optimization algorithms for the task of
+density ratio estimation. More precisely, we consider extending the well-known
+KMM method using the construction of a suitable loss function, in order to
+encompass more general situations involving the estimation of density ratio
+with respect to subsets of the training data and test data, respectively. The
+associated codes can be found at this https URL.
+
+
+
+ 6. 标题:Beta Diffusion
+ 编号:[27]
+ 链接:https://arxiv.org/abs/2309.07867
+ 作者:Mingyuan Zhou, Tianqi Chen, Zhendong Wang, Huangjie Zheng
+ 备注:
+ 关键词:beta diffusion, introduce beta diffusion, bounded ranges, beta, method that integrates
+
+ 点击查看摘要
+ We introduce beta diffusion, a novel generative modeling method that
+integrates demasking and denoising to generate data within bounded ranges.
+Using scaled and shifted beta distributions, beta diffusion utilizes
+multiplicative transitions over time to create both forward and reverse
+diffusion processes, maintaining beta distributions in both the forward
+marginals and the reverse conditionals, given the data at any point in time.
+Unlike traditional diffusion-based generative models relying on additive
+Gaussian noise and reweighted evidence lower bounds (ELBOs), beta diffusion is
+multiplicative and optimized with KL-divergence upper bounds (KLUBs) derived
+from the convexity of the KL divergence. We demonstrate that the proposed KLUBs
+are more effective for optimizing beta diffusion compared to negative ELBOs,
+which can also be derived as the KLUBs of the same KL divergence with its two
+arguments swapped. The loss function of beta diffusion, expressed in terms of
+Bregman divergence, further supports the efficacy of KLUBs for optimization.
+Experimental results on both synthetic data and natural images demonstrate the
+unique capabilities of beta diffusion in generative modeling of range-bounded
+data and validate the effectiveness of KLUBs in optimizing diffusion models,
+thereby making them valuable additions to the family of diffusion-based
+generative models and the optimization techniques used to train them.
+
+
+
+ 7. 标题:Directed Scattering for Knowledge Graph-based Cellular Signaling Analysis
+ 编号:[43]
+ 链接:https://arxiv.org/abs/2309.07813
+ 作者:Aarthi Venkat, Joyce Chew, Ferran Cardoso Rodriguez, Christopher J. Tape, Michael Perlmutter, Smita Krishnaswamy
+ 备注:5 pages, 3 figures
+ 关键词:chemical reaction networks, natural model, molecular interaction, interaction or chemical, chemical reaction
+
+ 点击查看摘要
+ Directed graphs are a natural model for many phenomena, in particular
+scientific knowledge graphs such as molecular interaction or chemical reaction
+networks that define cellular signaling relationships. In these situations,
+source nodes typically have distinct biophysical properties from sinks. Due to
+their ordered and unidirectional relationships, many such networks also have
+hierarchical and multiscale structure. However, the majority of methods
+performing node- and edge-level tasks in machine learning do not take these
+properties into account, and thus have not been leveraged effectively for
+scientific tasks such as cellular signaling network inference. We propose a new
+framework called Directed Scattering Autoencoder (DSAE) which uses a directed
+version of a geometric scattering transform, combined with the non-linear
+dimensionality reduction properties of an autoencoder and the geometric
+properties of the hyperbolic space to learn latent hierarchies. We show this
+method outperforms numerous others on tasks such as embedding directed graphs
+and learning cellular signaling networks.
+
+
+
+ 8. 标题:Text Classification of Cancer Clinical Trial Eligibility Criteria
+ 编号:[44]
+ 链接:https://arxiv.org/abs/2309.07812
+ 作者:Yumeng Yang, Soumya Jayaraj, Ethan B Ludmir, Kirk Roberts
+ 备注:AMIA Annual Symposium Proceedings 2023
+ 关键词:Automatic identification, patient is eligible, eligible is complicated, stated in natural, common
+
+ 点击查看摘要
+ Automatic identification of clinical trials for which a patient is eligible
+is complicated by the fact that trial eligibility is stated in natural
+language. A potential solution to this problem is to employ text classification
+methods for common types of eligibility criteria. In this study, we focus on
+seven common exclusion criteria in cancer trials: prior malignancy, human
+immunodeficiency virus, hepatitis B, hepatitis C, psychiatric illness,
+drug/substance abuse, and autoimmune illness. Our dataset consists of 764 phase
+III cancer trials with these exclusions annotated at the trial level. We
+experiment with common transformer models as well as a new pre-trained clinical
+trial BERT model. Our results demonstrate the feasibility of automatically
+classifying common exclusion criteria. Additionally, we demonstrate the value
+of a pre-trained language model specifically for clinical trials, which yields
+the highest average performance across all criteria.
+
+
+
+ 9. 标题:Communication Efficient Private Federated Learning Using Dithering
+ 编号:[45]
+ 链接:https://arxiv.org/abs/2309.07809
+ 作者:Burak Hasircioglu, Deniz Gunduz
+ 备注:
+ 关键词:ensuring efficient communication, federated learning, task of preserving, ensuring efficient, fundamental challenge
+
+ 点击查看摘要
+ The task of preserving privacy while ensuring efficient communication is a
+fundamental challenge in federated learning. In this work, we tackle this
+challenge in the trusted aggregator model, and propose a solution that achieves
+both objectives simultaneously. We show that employing a quantization scheme
+based on subtractive dithering at the clients can effectively replicate the
+normal noise addition process at the aggregator. This implies that we can
+guarantee the same level of differential privacy against other clients while
+substantially reducing the amount of communication required, as opposed to
+transmitting full precision gradients and using central noise addition. We also
+experimentally demonstrate that the accuracy of our proposed approach matches
+that of the full precision gradient method.
+
+
+
+ 10. 标题:What Matters to Enhance Traffic Rule Compliance of Imitation Learning for Automated Driving
+ 编号:[46]
+ 链接:https://arxiv.org/abs/2309.07808
+ 作者:Hongkuan Zhou, Aifen Sui, Wei Cao, Letian Shi
+ 备注:8 pages, 2 figures
+ 关键词:faster inference time, single neural network, entire driving pipeline, inference time, research attention
+
+ 点击查看摘要
+ More research attention has recently been given to end-to-end autonomous
+driving technologies where the entire driving pipeline is replaced with a
+single neural network because of its simpler structure and faster inference
+time. Despite this appealing approach largely reducing the components in
+driving pipeline, its simplicity also leads to interpretability problems and
+safety issues arXiv:2003.06404. The trained policy is not always compliant with
+the traffic rules and it is also hard to discover the reason for the
+misbehavior because of the lack of intermediate outputs. Meanwhile, Sensors are
+also critical to autonomous driving's security and feasibility to perceive the
+surrounding environment under complex driving scenarios. In this paper, we
+proposed P-CSG, a novel penalty-based imitation learning approach with cross
+semantics generation sensor fusion technologies to increase the overall
+performance of End-to-End Autonomous Driving. We conducted an assessment of our
+model's performance using the Town 05 Long benchmark, achieving an impressive
+driving score improvement of over 15%. Furthermore, we conducted robustness
+evaluations against adversarial attacks like FGSM and Dot attacks, revealing a
+substantial increase in robustness compared to baseline models.More detailed
+information, such as code-based resources, ablation studies and videos can be
+found at this https URL.
+
+
+
+ 11. 标题:Improving Multimodal Classification of Social Media Posts by Leveraging Image-Text Auxiliary tasks
+ 编号:[52]
+ 链接:https://arxiv.org/abs/2309.07794
+ 作者:Danae Sánchez Villegas, Daniel Preoţiuc-Pietro, Nikolaos Aletras
+ 备注:
+ 关键词:hate speech classification, Effectively leveraging multimodal, Effectively leveraging, sarcasm detection, speech classification
+
+ 点击查看摘要
+ Effectively leveraging multimodal information from social media posts is
+essential to various downstream tasks such as sentiment analysis, sarcasm
+detection and hate speech classification. However, combining text and image
+information is challenging because of the idiosyncratic cross-modal semantics
+with hidden or complementary information present in matching image-text pairs.
+In this work, we aim to directly model this by proposing the use of two
+auxiliary losses jointly with the main task when fine-tuning any pre-trained
+multimodal model. Image-Text Contrastive (ITC) brings image-text
+representations of a post closer together and separates them from different
+posts, capturing underlying dependencies. Image-Text Matching (ITM) facilitates
+the understanding of semantic correspondence between images and text by
+penalizing unrelated pairs. We combine these objectives with five multimodal
+models, demonstrating consistent improvements across four popular social media
+datasets. Furthermore, through detailed analysis, we shed light on the specific
+scenarios and cases where each auxiliary task proves to be most effective.
+
+
+
+ 12. 标题:PRE: Vision-Language Prompt Learning with Reparameterization Encoder
+ 编号:[59]
+ 链接:https://arxiv.org/abs/2309.07760
+ 作者:Anh Pham Thi Minh
+ 备注:8 pages excluding References and Appendix
+ 关键词:Large pre-trained vision-language, demonstrated great potential, CLIP have demonstrated, pre-trained vision-language models, Large pre-trained
+
+ 点击查看摘要
+ Large pre-trained vision-language models such as CLIP have demonstrated great
+potential in zero-shot transferability to downstream tasks. However, to attain
+optimal performance, the manual selection of prompts is necessary to improve
+alignment between the downstream image distribution and the textual class
+descriptions. This manual prompt engineering is the major challenge for
+deploying such models in practice since it requires domain expertise and is
+extremely time-consuming. To avoid non-trivial prompt engineering, recent work
+Context Optimization (CoOp) introduced the concept of prompt learning to the
+vision domain using learnable textual tokens. While CoOp can achieve
+substantial improvements over manual prompts, its learned context is worse
+generalizable to wider unseen classes within the same dataset. In this work, we
+present Prompt Learning with Reparameterization Encoder (PRE) - a simple and
+efficient method that enhances the generalization ability of the learnable
+prompt to unseen classes while maintaining the capacity to learn Base classes.
+Instead of directly optimizing the prompts, PRE employs a prompt encoder to
+reparameterize the input prompt embeddings, enhancing the exploration of
+task-specific knowledge from few-shot samples. Experiments and extensive
+ablation studies on 8 benchmarks demonstrate that our approach is an efficient
+method for prompt learning. Specifically, PRE achieves a notable enhancement of
+5.60% in average accuracy on New classes and 3% in Harmonic mean compared to
+CoOp in the 16-shot setting, all achieved within a good training time.
+
+
+
+ 13. 标题:Interpretability is in the Mind of the Beholder: A Causal Framework for Human-interpretable Representation Learning
+ 编号:[67]
+ 链接:https://arxiv.org/abs/2309.07742
+ 作者:Emanuele Marconato, Andrea Passerini, Stefano Teso
+ 备注:
+ 关键词:Focus in Explainable, defined in terms, terms of low-level, encoded in terms, explanations defined
+
+ 点击查看摘要
+ Focus in Explainable AI is shifting from explanations defined in terms of
+low-level elements, such as input features, to explanations encoded in terms of
+interpretable concepts learned from data. How to reliably acquire such concepts
+is, however, still fundamentally unclear. An agreed-upon notion of concept
+interpretability is missing, with the result that concepts used by both
+post-hoc explainers and concept-based neural networks are acquired through a
+variety of mutually incompatible strategies. Critically, most of these neglect
+the human side of the problem: a representation is understandable only insofar
+as it can be understood by the human at the receiving end. The key challenge in
+Human-interpretable Representation Learning (HRL) is how to model and
+operationalize this human element. In this work, we propose a mathematical
+framework for acquiring interpretable representations suitable for both
+post-hoc explainers and concept-based neural networks. Our formalization of HRL
+builds on recent advances in causal representation learning and explicitly
+models a human stakeholder as an external observer. This allows us to derive a
+principled notion of alignment between the machine representation and the
+vocabulary of concepts understood by the human. In doing so, we link alignment
+and interpretability through a simple and intuitive name transfer game, and
+clarify the relationship between alignment and a well-known property of
+representations, namely disentanglment. We also show that alignment is linked
+to the issue of undesirable correlations among concepts, also known as concept
+leakage, and to content-style separation, all through a general
+information-theoretic reformulation of these properties. Our conceptualization
+aims to bridge the gap between the human and algorithmic sides of
+interpretability and establish a stepping stone for new research on
+human-interpretable representations.
+
+
+
+ 14. 标题:Understanding Vector-Valued Neural Networks and Their Relationship with Real and Hypercomplex-Valued Neural Networks
+ 编号:[79]
+ 链接:https://arxiv.org/abs/2309.07716
+ 作者:Marcos Eduardo Valle
+ 备注:
+ 关键词:neural networks, traditional neural networks, neural, intercorrelation between feature, deep learning models
+
+ 点击查看摘要
+ Despite the many successful applications of deep learning models for
+multidimensional signal and image processing, most traditional neural networks
+process data represented by (multidimensional) arrays of real numbers. The
+intercorrelation between feature channels is usually expected to be learned
+from the training data, requiring numerous parameters and careful training. In
+contrast, vector-valued neural networks are conceived to process arrays of
+vectors and naturally consider the intercorrelation between feature channels.
+Consequently, they usually have fewer parameters and often undergo more robust
+training than traditional neural networks. This paper aims to present a broad
+framework for vector-valued neural networks, referred to as V-nets. In this
+context, hypercomplex-valued neural networks are regarded as vector-valued
+models with additional algebraic properties. Furthermore, this paper explains
+the relationship between vector-valued and traditional neural networks.
+Precisely, a vector-valued neural network can be obtained by placing
+restrictions on a real-valued model to consider the intercorrelation between
+feature channels. Finally, we show how V-nets, including hypercomplex-valued
+neural networks, can be implemented in current deep-learning libraries as
+real-valued networks.
+
+
+
+ 15. 标题:Market-GAN: Adding Control to Financial Market Data Generation with Semantic Context
+ 编号:[82]
+ 链接:https://arxiv.org/abs/2309.07708
+ 作者:Haochong Xia, Shuo Sun, Xinrun Wang, Bo An
+ 备注:
+ 关键词:enhancing forecasting accuracy, strategic financial decision-making, Financial simulators play, fostering strategic financial, managing risks
+
+ 点击查看摘要
+ Financial simulators play an important role in enhancing forecasting
+accuracy, managing risks, and fostering strategic financial decision-making.
+Despite the development of financial market simulation methodologies, existing
+frameworks often struggle with adapting to specialized simulation context. We
+pinpoint the challenges as i) current financial datasets do not contain context
+labels; ii) current techniques are not designed to generate financial data with
+context as control, which demands greater precision compared to other
+modalities; iii) the inherent difficulties in generating context-aligned,
+high-fidelity data given the non-stationary, noisy nature of financial data. To
+address these challenges, our contributions are: i) we proposed the Contextual
+Market Dataset with market dynamics, stock ticker, and history state as
+context, leveraging a market dynamics modeling method that combines linear
+regression and Dynamic Time Warping clustering to extract market dynamics; ii)
+we present Market-GAN, a novel architecture incorporating a Generative
+Adversarial Networks (GAN) for the controllable generation with context, an
+autoencoder for learning low-dimension features, and supervisors for knowledge
+transfer; iii) we introduce a two-stage training scheme to ensure that
+Market-GAN captures the intrinsic market distribution with multiple objectives.
+In the pertaining stage, with the use of the autoencoder and supervisors, we
+prepare the generator with a better initialization for the adversarial training
+stage. We propose a set of holistic evaluation metrics that consider alignment,
+fidelity, data usability on downstream tasks, and market facts. We evaluate
+Market-GAN with the Dow Jones Industrial Average data from 2000 to 2023 and
+showcase superior performance in comparison to 4 state-of-the-art time-series
+generative models.
+
+
+
+ 16. 标题:Causal Entropy and Information Gain for Measuring Causal Control
+ 编号:[86]
+ 链接:https://arxiv.org/abs/2309.07703
+ 作者:Francisco Nunes Ferreira Quialheiro Simoes, Mehdi Dastani, Thijs van Ommen
+ 备注:16 pages. Accepted at the third XI-ML workshop of ECAI 2023. To appear in the Springer CCIS book series
+ 关键词:Artificial intelligence models, methods commonly lack, Artificial intelligence, commonly lack causal, causal
+
+ 点击查看摘要
+ Artificial intelligence models and methods commonly lack causal
+interpretability. Despite the advancements in interpretable machine learning
+(IML) methods, they frequently assign importance to features which lack causal
+influence on the outcome variable. Selecting causally relevant features among
+those identified as relevant by these methods, or even before model training,
+would offer a solution. Feature selection methods utilizing information
+theoretical quantities have been successful in identifying statistically
+relevant features. However, the information theoretical quantities they are
+based on do not incorporate causality, rendering them unsuitable for such
+scenarios. To address this challenge, this article proposes information
+theoretical quantities that incorporate the causal structure of the system,
+which can be used to evaluate causal importance of features for some given
+outcome variable. Specifically, we introduce causal versions of entropy and
+mutual information, termed causal entropy and causal information gain, which
+are designed to assess how much control a feature provides over the outcome
+variable. These newly defined quantities capture changes in the entropy of a
+variable resulting from interventions on other variables. Fundamental results
+connecting these quantities to the existence of causal effects are derived. The
+use of causal information gain in feature selection is demonstrated,
+highlighting its superiority over standard mutual information in revealing
+which features provide control over a chosen outcome variable. Our
+investigation paves the way for the development of methods with improved
+interpretability in domains involving causation.
+
+
+
+ 17. 标题:Tree of Uncertain Thoughts Reasoning for Large Language Models
+ 编号:[89]
+ 链接:https://arxiv.org/abs/2309.07694
+ 作者:Shentong Mo, Miao Xin
+ 备注:
+ 关键词:allowing Large Language, Large Language Models, Large Language, recently introduced Tree, allowing Large
+
+ 点击查看摘要
+ While the recently introduced Tree of Thoughts (ToT) has heralded
+advancements in allowing Large Language Models (LLMs) to reason through
+foresight and backtracking for global decision-making, it has overlooked the
+inherent local uncertainties in intermediate decision points or "thoughts".
+These local uncertainties, intrinsic to LLMs given their potential for diverse
+responses, remain a significant concern in the reasoning process. Addressing
+this pivotal gap, we introduce the Tree of Uncertain Thoughts (TouT) - a
+reasoning framework tailored for LLMs. Our TouT effectively leverages Monte
+Carlo Dropout to quantify uncertainty scores associated with LLMs' diverse
+local responses at these intermediate steps. By marrying this local uncertainty
+quantification with global search algorithms, TouT enhances the model's
+precision in response generation. We substantiate our approach with rigorous
+experiments on two demanding planning tasks: Game of 24 and Mini Crosswords.
+The empirical evidence underscores TouT's superiority over both ToT and
+chain-of-thought prompting methods.
+
+
+
+ 18. 标题:deepFDEnet: A Novel Neural Network Architecture for Solving Fractional Differential Equations
+ 编号:[93]
+ 链接:https://arxiv.org/abs/2309.07684
+ 作者:Ali Nosrati Firoozsalari, Hassan Dana Mazraeh, Alireza Afzal Aghaei, Kourosh Parand
+ 备注:
+ 关键词:deep neural network, fractional differential equations, differential equations accurately, primary goal, deep neural
+
+ 点击查看摘要
+ The primary goal of this research is to propose a novel architecture for a
+deep neural network that can solve fractional differential equations
+accurately. A Gaussian integration rule and a $L_1$ discretization technique
+are used in the proposed design. In each equation, a deep neural network is
+used to approximate the unknown function. Three forms of fractional
+differential equations have been examined to highlight the method's
+versatility: a fractional ordinary differential equation, a fractional order
+integrodifferential equation, and a fractional order partial differential
+equation. The results show that the proposed architecture solves different
+forms of fractional differential equations with excellent precision.
+
+
+
+ 19. 标题:Goal Space Abstraction in Hierarchical Reinforcement Learning via Set-Based Reachability Analysis
+ 编号:[97]
+ 链接:https://arxiv.org/abs/2309.07675
+ 作者:Mehdi Zadem, Sergio Mover, Sao Mai Nguyen
+ 备注:
+ 关键词:Open-ended learning benefits, learning benefits immensely, goal representation, benefits immensely, structure knowledge
+
+ 点击查看摘要
+ Open-ended learning benefits immensely from the use of symbolic methods for
+goal representation as they offer ways to structure knowledge for efficient and
+transferable learning. However, the existing Hierarchical Reinforcement
+Learning (HRL) approaches relying on symbolic reasoning are often limited as
+they require a manual goal representation. The challenge in autonomously
+discovering a symbolic goal representation is that it must preserve critical
+information, such as the environment dynamics. In this paper, we propose a
+developmental mechanism for goal discovery via an emergent representation that
+abstracts (i.e., groups together) sets of environment states that have similar
+roles in the task. We introduce a Feudal HRL algorithm that concurrently learns
+both the goal representation and a hierarchical policy. The algorithm uses
+symbolic reachability analysis for neural networks to approximate the
+transition relation among sets of states and to refine the goal representation.
+We evaluate our approach on complex navigation tasks, showing the learned
+representation is interpretable, transferrable and results in data efficient
+learning.
+
+
+
+ 20. 标题:Physics-constrained robust learning of open-form PDEs from limited and noisy data
+ 编号:[98]
+ 链接:https://arxiv.org/abs/2309.07672
+ 作者:Mengge Du, Longfeng Nie, Siyu Lou, Yuntian Chenc, Dongxiao Zhang
+ 备注:
+ 关键词:encountering noisy observations, underlying governing equations, Unveiling the underlying, significant challenge, remains a significant
+
+ 点击查看摘要
+ Unveiling the underlying governing equations of nonlinear dynamic systems
+remains a significant challenge, especially when encountering noisy
+observations and no prior knowledge available. This study proposes R-DISCOVER,
+a framework designed to robustly uncover open-form partial differential
+equations (PDEs) from limited and noisy data. The framework operates through
+two alternating update processes: discovering and embedding. The discovering
+phase employs symbolic representation and a reinforcement learning (RL)-guided
+hybrid PDE generator to efficiently produce diverse open-form PDEs with tree
+structures. A neural network-based predictive model fits the system response
+and serves as the reward evaluator for the generated PDEs. PDEs with superior
+fits are utilized to iteratively optimize the generator via the RL method and
+the best-performing PDE is selected by a parameter-free stability metric. The
+embedding phase integrates the initially identified PDE from the discovering
+process as a physical constraint into the predictive model for robust training.
+The traversal of PDE trees automates the construction of the computational
+graph and the embedding process without human intervention. Numerical
+experiments demonstrate our framework's capability to uncover governing
+equations from nonlinear dynamic systems with limited and highly noisy data and
+outperform other physics-informed neural network-based discovery methods. This
+work opens new potential for exploring real-world systems with limited
+understanding.
+
+
+
+ 21. 标题:Federated Dataset Dictionary Learning for Multi-Source Domain Adaptation
+ 编号:[99]
+ 链接:https://arxiv.org/abs/2309.07670
+ 作者:Fabiola Espinosa Castellon, Eduardo Fernandes Montesuma, Fred Ngolè Mboula, Aurélien Mayoue, Antoine Souloumiac, Cédric Gouy-Pallier
+ 备注:7 pages,2 figures
+ 关键词:distributional shift exists, distributional shift, shift exists, exists among clients, Dataset Dictionary Learning
+
+ 点击查看摘要
+ In this article, we propose an approach for federated domain adaptation, a
+setting where distributional shift exists among clients and some have unlabeled
+data. The proposed framework, FedDaDiL, tackles the resulting challenge through
+dictionary learning of empirical distributions. In our setting, clients'
+distributions represent particular domains, and FedDaDiL collectively trains a
+federated dictionary of empirical distributions. In particular, we build upon
+the Dataset Dictionary Learning framework by designing collaborative
+communication protocols and aggregation operations. The chosen protocols keep
+clients' data private, thus enhancing overall privacy compared to its
+centralized counterpart. We empirically demonstrate that our approach
+successfully generates labeled data on the target domain with extensive
+experiments on (i) Caltech-Office, (ii) TEP, and (iii) CWRU benchmarks.
+Furthermore, we compare our method to its centralized counterpart and other
+benchmarks in federated domain adaptation.
+
+
+
+ 22. 标题:Multi-Source Domain Adaptation meets Dataset Distillation through Dataset Dictionary Learning
+ 编号:[102]
+ 链接:https://arxiv.org/abs/2309.07666
+ 作者:Eduardo Fernandes Montesuma, Fred Ngolè Mboula, Antoine Souloumiac
+ 备注:7 pages,4 figures
+ 关键词:Multi-Source Domain Adaptation, Dataset Distillation, Multi-Source Domain, Dataset Dictionary Learning, labeled source domains
+
+ 点击查看摘要
+ In this paper, we consider the intersection of two problems in machine
+learning: Multi-Source Domain Adaptation (MSDA) and Dataset Distillation (DD).
+On the one hand, the first considers adapting multiple heterogeneous labeled
+source domains to an unlabeled target domain. On the other hand, the second
+attacks the problem of synthesizing a small summary containing all the
+information about the datasets. We thus consider a new problem called MSDA-DD.
+To solve it, we adapt previous works in the MSDA literature, such as
+Wasserstein Barycenter Transport and Dataset Dictionary Learning, as well as DD
+method Distribution Matching. We thoroughly experiment with this novel problem
+on four benchmarks (Caltech-Office 10, Tennessee-Eastman Process, Continuous
+Stirred Tank Reactor, and Case Western Reserve University), where we show that,
+even with as little as 1 sample per class, one achieves state-of-the-art
+adaptation performance.
+
+
+
+ 23. 标题:Feature Engineering in Learning-to-Rank for Community Question Answering Task
+ 编号:[127]
+ 链接:https://arxiv.org/abs/2309.07610
+ 作者:Nafis Sajid, Md Rashidul Hasan, Muhammad Ibrahim
+ 备注:20 pages
+ 关键词:Internet-based platforms, Community question answering, provide solutions, forums are Internet-based, CQA
+
+ 点击查看摘要
+ Community question answering (CQA) forums are Internet-based platforms where
+users ask questions about a topic and other expert users try to provide
+solutions. Many CQA forums such as Quora, Stackoverflow, Yahoo!Answer,
+StackExchange exist with a lot of user-generated data. These data are leveraged
+in automated CQA ranking systems where similar questions (and answers) are
+presented in response to the query of the user. In this work, we empirically
+investigate a few aspects of this domain. Firstly, in addition to traditional
+features like TF-IDF, BM25 etc., we introduce a BERT-based feature that
+captures the semantic similarity between the question and answer. Secondly,
+most of the existing research works have focused on features extracted only
+from the question part; features extracted from answers have not been explored
+extensively. We combine both types of features in a linear fashion. Thirdly,
+using our proposed concepts, we conduct an empirical investigation with
+different rank-learning algorithms, some of which have not been used so far in
+CQA domain. On three standard CQA datasets, our proposed framework achieves
+state-of-the-art performance. We also analyze importance of the features we use
+in our investigation. This work is expected to guide the practitioners to
+select a better set of features for the CQA retrieval task.
+
+
+
+ 24. 标题:Learning Quasi-Static 3D Models of Markerless Deformable Linear Objects for Bimanual Robotic Manipulation
+ 编号:[128]
+ 链接:https://arxiv.org/abs/2309.07609
+ 作者:Piotr Kicki, Michał Bidziński, Krzysztof Walas
+ 备注:Under review for IEEE Robotics and Automation Letters
+ 关键词:Deformable Linear Objects, Linear Objects, Deformable Linear, manipulation of Deformable, practical applications
+
+ 点击查看摘要
+ The robotic manipulation of Deformable Linear Objects (DLOs) is a vital and
+challenging task that is important in many practical applications. Classical
+model-based approaches to this problem require an accurate model to capture how
+robot motions affect the deformation of the DLO. Nowadays, data-driven models
+offer the best tradeoff between quality and computation time. This paper
+analyzes several learning-based 3D models of the DLO and proposes a new one
+based on the Transformer architecture that achieves superior accuracy, even on
+the DLOs of different lengths, thanks to the proposed scaling method. Moreover,
+we introduce a data augmentation technique, which improves the prediction
+performance of almost all considered DLO data-driven models. Thanks to this
+technique, even a simple Multilayer Perceptron (MLP) achieves close to
+state-of-the-art performance while being significantly faster to evaluate. In
+the experiments, we compare the performance of the learning-based 3D models of
+the DLO on several challenging datasets quantitatively and demonstrate their
+applicability in the task of shaping a DLO.
+
+
+
+ 25. 标题:Turning Dross Into Gold Loss: is BERT4Rec really better than SASRec?
+ 编号:[132]
+ 链接:https://arxiv.org/abs/2309.07602
+ 作者:Anton Klenitskiy, Alexey Vasilev
+ 备注:
+ 关键词:Recently sequential recommendations, next-item prediction task, Recently sequential, recommender systems, sequential recommendations
+
+ 点击查看摘要
+ Recently sequential recommendations and next-item prediction task has become
+increasingly popular in the field of recommender systems. Currently, two
+state-of-the-art baselines are Transformer-based models SASRec and BERT4Rec.
+Over the past few years, there have been quite a few publications comparing
+these two algorithms and proposing new state-of-the-art models. In most of the
+publications, BERT4Rec achieves better performance than SASRec. But BERT4Rec
+uses cross-entropy over softmax for all items, while SASRec uses negative
+sampling and calculates binary cross-entropy loss for one positive and one
+negative item. In our work, we show that if both models are trained with the
+same loss, which is used by BERT4Rec, then SASRec will significantly outperform
+BERT4Rec both in terms of quality and training speed. In addition, we show that
+SASRec could be effectively trained with negative sampling and still outperform
+BERT4Rec, but the number of negative examples should be much larger than one.
+
+
+
+ 26. 标题:Detecting Misinformation with LLM-Predicted Credibility Signals and Weak Supervision
+ 编号:[133]
+ 链接:https://arxiv.org/abs/2309.07601
+ 作者:João A. Leite, Olesya Razuvayevskaya, Kalina Bontcheva, Carolina Scarton
+ 备注:
+ 关键词:Credibility signals represent, Credibility signals, represent a wide, wide range, range of heuristics
+
+ 点击查看摘要
+ Credibility signals represent a wide range of heuristics that are typically
+used by journalists and fact-checkers to assess the veracity of online content.
+Automating the task of credibility signal extraction, however, is very
+challenging as it requires high-accuracy signal-specific extractors to be
+trained, while there are currently no sufficiently large datasets annotated
+with all credibility signals. This paper investigates whether large language
+models (LLMs) can be prompted effectively with a set of 18 credibility signals
+to produce weak labels for each signal. We then aggregate these potentially
+noisy labels using weak supervision in order to predict content veracity. We
+demonstrate that our approach, which combines zero-shot LLM credibility signal
+labeling and weak supervision, outperforms state-of-the-art classifiers on two
+misinformation datasets without using any ground-truth labels for training. We
+also analyse the contribution of the individual credibility signals towards
+predicting content veracity, which provides new valuable insights into their
+role in misinformation detection.
+
+
+
+ 27. 标题:Statistically Valid Variable Importance Assessment through Conditional Permutations
+ 编号:[137]
+ 链接:https://arxiv.org/abs/2309.07593
+ 作者:Ahmad Chamma (1 and 2 and 3), Denis A. Engemann (4), Bertrand Thirion (1 and 2 and 3) ((1) Inria, (2) Universite Paris Saclay, (3) CEA, (4) Roche Pharma Research and Early Development, Neuroscience and Rare Diseases, Roche Innovation Center Basel, F. Hoffmann-La Roche Ltd., Basel, Switzerland)
+ 备注:
+ 关键词:CPI, complex learners, crucial step, step in machine-learning, machine-learning applications
+
+ 点击查看摘要
+ Variable importance assessment has become a crucial step in machine-learning
+applications when using complex learners, such as deep neural networks, on
+large-scale data. Removal-based importance assessment is currently the
+reference approach, particularly when statistical guarantees are sought to
+justify variable inclusion. It is often implemented with variable permutation
+schemes. On the flip side, these approaches risk misidentifying unimportant
+variables as important in the presence of correlations among covariates. Here
+we develop a systematic approach for studying Conditional Permutation
+Importance (CPI) that is model agnostic and computationally lean, as well as
+reusable benchmarks of state-of-the-art variable importance estimators. We show
+theoretically and empirically that $\textit{CPI}$ overcomes the limitations of
+standard permutation importance by providing accurate type-I error control.
+When used with a deep neural network, $\textit{CPI}$ consistently showed top
+accuracy across benchmarks. An empirical benchmark on real-world data analysis
+in a large-scale medical dataset showed that $\textit{CPI}$ provides a more
+parsimonious selection of statistically significant variables. Our results
+suggest that $\textit{CPI}$ can be readily used as drop-in replacement for
+permutation-based methods.
+
+
+
+ 28. 标题:Structure-Preserving Transformers for Sequences of SPD Matrices
+ 编号:[142]
+ 链接:https://arxiv.org/abs/2309.07579
+ 作者:Mathieu Seraphim, Alexis Lechervy, Florian Yger, Luc Brun, Olivier Etard
+ 备注:Submitted to the ICASSP 2024 Conference
+ 关键词:Transformer-based auto-attention mechanisms, context-reliant data types, Transformer-based auto-attention, Symmetric Positive Definite, data types
+
+ 点击查看摘要
+ In recent years, Transformer-based auto-attention mechanisms have been
+successfully applied to the analysis of a variety of context-reliant data
+types, from texts to images and beyond, including data from non-Euclidean
+geometries. In this paper, we present such a mechanism, designed to classify
+sequences of Symmetric Positive Definite matrices while preserving their
+Riemannian geometry throughout the analysis. We apply our method to automatic
+sleep staging on timeseries of EEG-derived covariance matrices from a standard
+dataset, obtaining high levels of stage-wise performance.
+
+
+
+ 29. 标题:Equivariant Data Augmentation for Generalization in Offline Reinforcement Learning
+ 编号:[143]
+ 链接:https://arxiv.org/abs/2309.07578
+ 作者:Cristina Pinneri, Sarah Bechtle, Markus Wulfmeier, Arunkumar Byravan, Jingwei Zhang, William F. Whitney, Martin Riedmiller
+ 备注:
+ 关键词:offline reinforcement learning, reinforcement learning, address the challenge, challenge of generalization, additional interaction
+
+ 点击查看摘要
+ We present a novel approach to address the challenge of generalization in
+offline reinforcement learning (RL), where the agent learns from a fixed
+dataset without any additional interaction with the environment. Specifically,
+we aim to improve the agent's ability to generalize to out-of-distribution
+goals. To achieve this, we propose to learn a dynamics model and check if it is
+equivariant with respect to a fixed type of transformation, namely translations
+in the state space. We then use an entropy regularizer to increase the
+equivariant set and augment the dataset with the resulting transformed samples.
+Finally, we learn a new policy offline based on the augmented dataset, with an
+off-the-shelf offline RL algorithm. Our experimental results demonstrate that
+our approach can greatly improve the test performance of the policy on the
+considered environments.
+
+
+
+ 30. 标题:Naturalistic Robot Arm Trajectory Generation via Representation Learning
+ 编号:[151]
+ 链接:https://arxiv.org/abs/2309.07550
+ 作者:Jayjun Lee, Adam J. Spiers
+ 备注:4 pages, 3 figures
+ 关键词:household environments suggests, integration of manipulator, household environments, environments suggests, predictable and human-like
+
+ 点击查看摘要
+ The integration of manipulator robots in household environments suggests a
+need for more predictable and human-like robot motion. This holds especially
+true for wheelchair-mounted assistive robots that can support the independence
+of people with paralysis. One method of generating naturalistic motion
+trajectories is via the imitation of human demonstrators. This paper explores a
+self-supervised imitation learning method using an autoregressive
+spatio-temporal graph neural network for an assistive drinking task. We address
+learning from diverse human motion trajectory data that were captured via
+wearable IMU sensors on a human arm as the action-free task demonstrations.
+Observed arm motion data from several participants is used to generate natural
+and functional drinking motion trajectories for a UR5e robot arm.
+
+
+
+ 31. 标题:VerilogEval: Evaluating Large Language Models for Verilog Code Generation
+ 编号:[153]
+ 链接:https://arxiv.org/abs/2309.07544
+ 作者:Mingjie Liu, Nathaniel Pinckney, Brucek Khailany, Haoxing Ren
+ 备注:ICCAD 2023 Invited Paper
+ 关键词:Verilog code generation, Verilog code, increasing popularity, popularity of large, Verilog
+
+ 点击查看摘要
+ The increasing popularity of large language models (LLMs) has paved the way
+for their application in diverse domains. This paper proposes a benchmarking
+framework tailored specifically for evaluating LLM performance in the context
+of Verilog code generation for hardware design and verification. We present a
+comprehensive evaluation dataset consisting of 156 problems from the Verilog
+instructional website HDLBits. The evaluation set consists of a diverse set of
+Verilog code generation tasks, ranging from simple combinational circuits to
+complex finite state machines. The Verilog code completions can be
+automatically tested for functional correctness by comparing the transient
+simulation outputs of the generated design with a golden solution. We also
+demonstrate that the Verilog code generation capability of pretrained language
+models could be improved with supervised fine-tuning by bootstrapping with LLM
+generated synthetic problem-code pairs.
+
+
+
+ 32. 标题:Adaptive approximation of monotone functions
+ 编号:[157]
+ 链接:https://arxiv.org/abs/2309.07530
+ 作者:Pierre Gaillard (Thoth), Sébastien Gerchinovitz (IMT), Étienne de Montbrun (TSE-R)
+ 备注:
+ 关键词:compact real intervals, mathcal, norm by sequentially, real intervals, study the classical
+
+ 点击查看摘要
+ We study the classical problem of approximating a non-decreasing function $f:
+\mathcal{X} \to \mathcal{Y}$ in $L^p(\mu)$ norm by sequentially querying its
+values, for known compact real intervals $\mathcal{X}$, $\mathcal{Y}$ and a
+known probability measure $\mu$ on $\cX$. For any function~$f$ we characterize
+the minimum number of evaluations of $f$ that algorithms need to guarantee an
+approximation $\hat{f}$ with an $L^p(\mu)$ error below $\epsilon$ after
+stopping. Unlike worst-case results that hold uniformly over all $f$, our
+complexity measure is dependent on each specific function $f$. To address this
+problem, we introduce GreedyBox, a generalization of an algorithm originally
+proposed by Novak (1992) for numerical integration. We prove that GreedyBox
+achieves an optimal sample complexity for any function $f$, up to logarithmic
+factors. Additionally, we uncover results regarding piecewise-smooth functions.
+Perhaps as expected, the $L^p(\mu)$ error of GreedyBox decreases much faster
+for piecewise-$C^2$ functions than predicted by the algorithm (without any
+knowledge on the smoothness of $f$). A simple modification even achieves
+optimal minimax approximation rates for such functions, which we compute
+explicitly. In particular, our findings highlight multiple performance gaps
+between adaptive and non-adaptive algorithms, smooth and piecewise-smooth
+functions, as well as monotone or non-monotone functions. Finally, we provide
+numerical experiments to support our theoretical results.
+
+
+
+ 33. 标题:Learning Beyond Similarities: Incorporating Dissimilarities between Positive Pairs in Self-Supervised Time Series Learning
+ 编号:[158]
+ 链接:https://arxiv.org/abs/2309.07526
+ 作者:Adrian Atienza, Jakob Bardram, Sadasivan Puthusserypady
+ 备注:
+ 关键词:successive inputs, identifying similarities, Introducing Distilled Encoding, similarities, SSL
+
+ 点击查看摘要
+ By identifying similarities between successive inputs, Self-Supervised
+Learning (SSL) methods for time series analysis have demonstrated their
+effectiveness in encoding the inherent static characteristics of temporal data.
+However, an exclusive emphasis on similarities might result in representations
+that overlook the dynamic attributes critical for modeling cardiovascular
+diseases within a confined subject cohort. Introducing Distilled Encoding
+Beyond Similarities (DEBS), this paper pioneers an SSL approach that transcends
+mere similarities by integrating dissimilarities among positive pairs. The
+framework is applied to electrocardiogram (ECG) signals, leading to a notable
+enhancement of +10\% in the detection accuracy of Atrial Fibrillation (AFib)
+across diverse subjects. DEBS underscores the potential of attaining a more
+refined representation by encoding the dynamic characteristics of time series
+data, tapping into dissimilarities during the optimization process. Broadly,
+the strategy delineated in this study holds the promise of unearthing novel
+avenues for advancing SSL methodologies tailored to temporal data.
+
+
+
+ 34. 标题:Massively-Parallel Heat Map Sorting and Applications To Explainable Clustering
+ 编号:[175]
+ 链接:https://arxiv.org/abs/2309.07486
+ 作者:Sepideh Aghamolaei, Mohammad Ghodsi
+ 备注:
+ 关键词:heat map sorting, map sorting problem, points labeled, introduce the heat, heat map
+
+ 点击查看摘要
+ Given a set of points labeled with $k$ labels, we introduce the heat map
+sorting problem as reordering and merging the points and dimensions while
+preserving the clusters (labels). A cluster is preserved if it remains
+connected, i.e., if it is not split into several clusters and no two clusters
+are merged.
+We prove the problem is NP-hard and we give a fixed-parameter algorithm with
+a constant number of rounds in the massively parallel computation model, where
+each machine has a sublinear memory and the total memory of the machines is
+linear. We give an approximation algorithm for a NP-hard special case of the
+problem. We empirically compare our algorithm with k-means and density-based
+clustering (DBSCAN) using a dimensionality reduction via locality-sensitive
+hashing on several directed and undirected graphs of email and computer
+networks.
+
+
+
+ 35. 标题:Improved Auto-Encoding using Deterministic Projected Belief Networks
+ 编号:[177]
+ 链接:https://arxiv.org/abs/2309.07481
+ 作者:Paul M Baggenstoss
+ 备注:
+ 关键词:deterministic projected belief, projected belief network, trainable compound activation, compound activation functions, exploit the unique
+
+ 点击查看摘要
+ In this paper, we exploit the unique properties of a deterministic projected
+belief network (D-PBN) to take full advantage of trainable compound activation
+functions (TCAs). A D-PBN is a type of auto-encoder that operates by "backing
+up" through a feed-forward neural network. TCAs are activation functions with
+complex monotonic-increasing shapes that change the distribution of the data so
+that the linear transformation that follows is more effective. Because a D-PBN
+operates by "backing up", the TCAs are inverted in the reconstruction process,
+restoring the original distribution of the data, thus taking advantage of a
+given TCA in both analysis and reconstruction. In this paper, we show that a
+D-PBN auto-encoder with TCAs can significantly out-perform standard
+auto-encoders including variational auto-encoders.
+
+
+
+ 36. 标题:Direct Text to Speech Translation System using Acoustic Units
+ 编号:[178]
+ 链接:https://arxiv.org/abs/2309.07478
+ 作者:Victoria Mingote, Pablo Gimeno, Luis Vicente, Sameer Khurana, Antoine Laurent, Jarod Duret
+ 备注:5 pages, 4 figures
+ 关键词:discrete acoustic units, paper proposes, speech, speech translation, acoustic units
+
+ 点击查看摘要
+ This paper proposes a direct text to speech translation system using discrete
+acoustic units. This framework employs text in different source languages as
+input to generate speech in the target language without the need for text
+transcriptions in this language. Motivated by the success of acoustic units in
+previous works for direct speech to speech translation systems, we use the same
+pipeline to extract the acoustic units using a speech encoder combined with a
+clustering algorithm. Once units are obtained, an encoder-decoder architecture
+is trained to predict them. Then a vocoder generates speech from units. Our
+approach for direct text to speech translation was tested on the new CVSS
+corpus with two different text mBART models employed as initialisation. The
+systems presented report competitive performance for most of the language pairs
+evaluated. Besides, results show a remarkable improvement when initialising our
+proposed architecture with a model pre-trained with more languages.
+
+
+
+ 37. 标题:Detecting Unknown Attacks in IoT Environments: An Open Set Classifier for Enhanced Network Intrusion Detection
+ 编号:[186]
+ 链接:https://arxiv.org/abs/2309.07461
+ 作者:Yasir Ali Farrukh, Syed Wali, Irfan Khan, Nathaniel D. Bastian
+ 备注:6 Pages, 5 figures
+ 关键词:Internet of Things, robust intrusion detection, integration of Internet, intrusion detection systems, Network Intrusion Detection
+
+ 点击查看摘要
+ The widespread integration of Internet of Things (IoT) devices across all
+facets of life has ushered in an era of interconnectedness, creating new
+avenues for cybersecurity challenges and underscoring the need for robust
+intrusion detection systems. However, traditional security systems are designed
+with a closed-world perspective and often face challenges in dealing with the
+ever-evolving threat landscape, where new and unfamiliar attacks are constantly
+emerging. In this paper, we introduce a framework aimed at mitigating the open
+set recognition (OSR) problem in the realm of Network Intrusion Detection
+Systems (NIDS) tailored for IoT environments. Our framework capitalizes on
+image-based representations of packet-level data, extracting spatial and
+temporal patterns from network traffic. Additionally, we integrate stacking and
+sub-clustering techniques, enabling the identification of unknown attacks by
+effectively modeling the complex and diverse nature of benign behavior. The
+empirical results prominently underscore the framework's efficacy, boasting an
+impressive 88\% detection rate for previously unseen attacks when compared
+against existing approaches and recent advancements. Future work will perform
+extensive experimentation across various openness levels and attack scenarios,
+further strengthening the adaptability and performance of our proposed solution
+in safeguarding IoT environments.
+
+
+
+ 38. 标题:Is Solving Graph Neural Tangent Kernel Equivalent to Training Graph Neural Network?
+ 编号:[190]
+ 链接:https://arxiv.org/abs/2309.07452
+ 作者:Lianke Qin, Zhao Song, Baocheng Sun
+ 备注:
+ 关键词:Neural Tangent Kernel, Tangent Kernel, Graph Neural Tangent, infinitely-wide neural network, Neural Tangent
+
+ 点击查看摘要
+ A rising trend in theoretical deep learning is to understand why deep
+learning works through Neural Tangent Kernel (NTK) [jgh18], a kernel method
+that is equivalent to using gradient descent to train a multi-layer
+infinitely-wide neural network. NTK is a major step forward in the theoretical
+deep learning because it allows researchers to use traditional mathematical
+tools to analyze properties of deep neural networks and to explain various
+neural network techniques from a theoretical view. A natural extension of NTK
+on graph learning is \textit{Graph Neural Tangent Kernel (GNTK)}, and
+researchers have already provide GNTK formulation for graph-level regression
+and show empirically that this kernel method can achieve similar accuracy as
+GNNs on various bioinformatics datasets [dhs+19]. The remaining question now is
+whether solving GNTK regression is equivalent to training an infinite-wide
+multi-layer GNN using gradient descent. In this paper, we provide three new
+theoretical results. First, we formally prove this equivalence for graph-level
+regression. Second, we present the first GNTK formulation for node-level
+regression. Finally, we prove the equivalence for node-level regression.
+
+
+
+ 39. 标题:TensorFlow Chaotic Prediction and Blow Up
+ 编号:[191]
+ 链接:https://arxiv.org/abs/2309.07450
+ 作者:M. Andrecut
+ 备注:10 pages, 3 figures
+ 关键词:learning in general, spatiotemporal chaotic dynamics, TensorFlow library, challenging tasks, machine learning
+
+ 点击查看摘要
+ Predicting the dynamics of chaotic systems is one of the most challenging
+tasks for neural networks, and machine learning in general. Here we aim to
+predict the spatiotemporal chaotic dynamics of a high-dimensional non-linear
+system. In our attempt we use the TensorFlow library, representing the state of
+the art for deep neural networks training and prediction. While our results are
+encouraging, and show that the dynamics of the considered system can be
+predicted for short time, we also indirectly discovered an unexpected and
+undesirable behavior of the TensorFlow library. More specifically, the longer
+term prediction of the system's chaotic behavior quickly deteriorates and blows
+up due to the nondeterministic behavior of the TensorFlow library. Here we
+provide numerical evidence of the short time prediction ability, and of the
+longer term predictability blow up.
+
+
+
+ 40. 标题:A Fast Optimization View: Reformulating Single Layer Attention in LLM Based on Tensor and SVM Trick, and Solving It in Matrix Multiplication Time
+ 编号:[208]
+ 链接:https://arxiv.org/abs/2309.07418
+ 作者:Yeqi Gao, Zhao Song, Weixin Wang, Junze Yin
+ 备注:
+ 关键词:mathbb, Large language models, times, mathsf, Large language
+
+ 点击查看摘要
+ Large language models (LLMs) have played a pivotal role in revolutionizing
+various facets of our daily existence. Solving attention regression is a
+fundamental task in optimizing LLMs. In this work, we focus on giving a
+provable guarantee for the one-layer attention network objective function
+$L(X,Y) = \sum_{j_0 = 1}^n \sum_{i_0 = 1}^d ( \langle \langle \exp(
+\mathsf{A}_{j_0} x ) , {\bf 1}_n \rangle^{-1} \exp( \mathsf{A}_{j_0} x ), A_{3}
+Y_{*,i_0} \rangle - b_{j_0,i_0} )^2$. Here $\mathsf{A} \in \mathbb{R}^{n^2
+\times d^2}$ is Kronecker product between $A_1 \in \mathbb{R}^{n \times d}$ and
+$A_2 \in \mathbb{R}^{n \times d}$. $A_3$ is a matrix in $\mathbb{R}^{n \times
+d}$, $\mathsf{A}_{j_0} \in \mathbb{R}^{n \times d^2}$ is the $j_0$-th block of
+$\mathsf{A}$. The $X, Y \in \mathbb{R}^{d \times d}$ are variables we want to
+learn. $B \in \mathbb{R}^{n \times d}$ and $b_{j_0,i_0} \in \mathbb{R}$ is one
+entry at $j_0$-th row and $i_0$-th column of $B$, $Y_{*,i_0} \in \mathbb{R}^d$
+is the $i_0$-column vector of $Y$, and $x \in \mathbb{R}^{d^2}$ is the
+vectorization of $X$.
+In a multi-layer LLM network, the matrix $B \in \mathbb{R}^{n \times d}$ can
+be viewed as the output of a layer, and $A_1= A_2 = A_3 \in \mathbb{R}^{n
+\times d}$ can be viewed as the input of a layer. The matrix version of $x$ can
+be viewed as $QK^\top$ and $Y$ can be viewed as $V$. We provide an iterative
+greedy algorithm to train loss function $L(X,Y)$ up $\epsilon$ that runs in
+$\widetilde{O}( ({\cal T}_{\mathrm{mat}}(n,n,d) + {\cal
+T}_{\mathrm{mat}}(n,d,d) + d^{2\omega}) \log(1/\epsilon) )$ time. Here ${\cal
+T}_{\mathrm{mat}}(a,b,c)$ denotes the time of multiplying $a \times b$ matrix
+another $b \times c$ matrix, and $\omega\approx 2.37$ denotes the exponent of
+matrix multiplication.
+
+
+
+ 41. 标题:Advancing Regular Language Reasoning in Linear Recurrent Neural Networks
+ 编号:[212]
+ 链接:https://arxiv.org/abs/2309.07412
+ 作者:Ting-Han Fan, Ta-Chung Chi, Alexander I. Rudnicky
+ 备注:The first two authors contributed equally to this work
+ 关键词:linear recurrent neural, recurrent neural networks, recent studies, linear recurrent, neural networks
+
+ 点击查看摘要
+ In recent studies, linear recurrent neural networks (LRNNs) have achieved
+Transformer-level performance in natural language modeling and long-range
+modeling while offering rapid parallel training and constant inference costs.
+With the resurged interest in LRNNs, we study whether they can learn the hidden
+rules in training sequences, such as the grammatical structures of regular
+language. We theoretically analyze some existing LRNNs and discover their
+limitations on regular language. Motivated by the analysis, we propose a new
+LRNN equipped with a block-diagonal and input-dependent transition matrix.
+Experiments suggest that the proposed model is the only LRNN that can perform
+length extrapolation on regular language tasks such as Sum, Even Pair, and
+Modular Arithmetic.
+
+
+
+ 42. 标题:Semi-supervised Domain Adaptation on Graphs with Contrastive Learning and Minimax Entropy
+ 编号:[219]
+ 链接:https://arxiv.org/abs/2309.07402
+ 作者:Jiaren Xiao, Quanyu Dai, Xiao Shen, Xiaochen Xie, Jing Dai, James Lam, Ka-Wai Kwok
+ 备注:
+ 关键词:real-world applications due, data labeling, frequently encountered, encountered in real-world, real-world applications
+
+ 点击查看摘要
+ Label scarcity in a graph is frequently encountered in real-world
+applications due to the high cost of data labeling. To this end,
+semi-supervised domain adaptation (SSDA) on graphs aims to leverage the
+knowledge of a labeled source graph to aid in node classification on a target
+graph with limited labels. SSDA tasks need to overcome the domain gap between
+the source and target graphs. However, to date, this challenging research
+problem has yet to be formally considered by the existing approaches designed
+for cross-graph node classification. To tackle the SSDA problem on graphs, a
+novel method called SemiGCL is proposed, which benefits from graph contrastive
+learning and minimax entropy training. SemiGCL generates informative node
+representations by contrasting the representations learned from a graph's local
+and global views. Additionally, SemiGCL is adversarially optimized with the
+entropy loss of unlabeled target nodes to reduce domain divergence.
+Experimental results on benchmark datasets demonstrate that SemiGCL outperforms
+the state-of-the-art baselines on the SSDA tasks.
+
+
+
+ 43. 标题:Semantic Adversarial Attacks via Diffusion Models
+ 编号:[222]
+ 链接:https://arxiv.org/abs/2309.07398
+ 作者:Chenan Wang, Jinhao Duan, Chaowei Xiao, Edward Kim, Matthew Stamm, Kaidi Xu
+ 备注:To appear in BMVC 2023
+ 关键词:adding adversarial perturbations, Traditional adversarial attacks, adversarial attacks concentrate, semantic adversarial attacks, latent space
+
+ 点击查看摘要
+ Traditional adversarial attacks concentrate on manipulating clean examples in
+the pixel space by adding adversarial perturbations. By contrast, semantic
+adversarial attacks focus on changing semantic attributes of clean examples,
+such as color, context, and features, which are more feasible in the real
+world. In this paper, we propose a framework to quickly generate a semantic
+adversarial attack by leveraging recent diffusion models since semantic
+information is included in the latent space of well-trained diffusion models.
+Then there are two variants of this framework: 1) the Semantic Transformation
+(ST) approach fine-tunes the latent space of the generated image and/or the
+diffusion model itself; 2) the Latent Masking (LM) approach masks the latent
+space with another target image and local backpropagation-based interpretation
+methods. Additionally, the ST approach can be applied in either white-box or
+black-box settings. Extensive experiments are conducted on CelebA-HQ and AFHQ
+datasets, and our framework demonstrates great fidelity, generalizability, and
+transferability compared to other baselines. Our approaches achieve
+approximately 100% attack success rate in multiple settings with the best FID
+as 36.61. Code is available at
+this https URL.
+
+
+
+ 44. 标题:EnCodecMAE: Leveraging neural codecs for universal audio representation learning
+ 编号:[225]
+ 链接:https://arxiv.org/abs/2309.07391
+ 作者:Leonardo Pepino, Pablo Riera, Luciana Ferrer
+ 备注:Submitted to ICASSP 2024
+ 关键词:obtain foundational models, downstream tasks involving, obtain foundational, variety of downstream, tasks involving speech
+
+ 点击查看摘要
+ The goal of universal audio representation learning is to obtain foundational
+models that can be used for a variety of downstream tasks involving speech,
+music or environmental sounds. To approach this problem, methods inspired by
+self-supervised models from NLP, like BERT, are often used and adapted to
+audio. These models rely on the discrete nature of text, hence adopting this
+type of approach for audio processing requires either a change in the learning
+objective or mapping the audio signal to a set of discrete classes. In this
+work, we explore the use of EnCodec, a neural audio codec, to generate discrete
+targets for learning an universal audio model based on a masked autoencoder
+(MAE). We evaluate this approach, which we call EncodecMAE, on a wide range of
+audio tasks spanning speech, music and environmental sounds, achieving
+performances comparable or better than leading audio representation models.
+
+
+
+ 45. 标题:Rates of Convergence in Certain Native Spaces of Approximations used in Reinforcement Learning
+ 编号:[230]
+ 链接:https://arxiv.org/abs/2309.07383
+ 作者:Ali Bouland, Shengyuan Niu, Sai Tej Paruchuri, Andrew Kurdila, John Burns, Eugenio Schuster
+ 备注:7 pages, 4 figures
+ 关键词:reproducing kernel Hilbert, kernel Hilbert spaces, paper studies convergence, kernel Hilbert, studies convergence rates
+
+ 点击查看摘要
+ This paper studies convergence rates for some value function approximations
+that arise in a collection of reproducing kernel Hilbert spaces (RKHS)
+$H(\Omega)$. By casting an optimal control problem in a specific class of
+native spaces, strong rates of convergence are derived for the operator
+equation that enables offline approximations that appear in policy iteration.
+Explicit upper bounds on error in value function approximations are derived in
+terms of power function $\Pwr_{H,N}$ for the space of finite dimensional
+approximants $H_N$ in the native space $H(\Omega)$. These bounds are geometric
+in nature and refine some well-known, now classical results concerning
+convergence of approximations of value functions.
+
+
+
+ 46. 标题:Beta quantile regression for robust estimation of uncertainty in the presence of outliers
+ 编号:[234]
+ 链接:https://arxiv.org/abs/2309.07374
+ 作者:Haleh Akrami, Omar Zamzam, Anand Joshi, Sergul Aydore, Richard Leahy
+ 备注:
+ 关键词:generate prediction intervals, estimate aleatoric uncertainty, deep neural networks, Quantile Regression, prediction intervals
+
+ 点击查看摘要
+ Quantile Regression (QR) can be used to estimate aleatoric uncertainty in
+deep neural networks and can generate prediction intervals. Quantifying
+uncertainty is particularly important in critical applications such as clinical
+diagnosis, where a realistic assessment of uncertainty is essential in
+determining disease status and planning the appropriate treatment. The most
+common application of quantile regression models is in cases where the
+parametric likelihood cannot be specified. Although quantile regression is
+quite robust to outlier response observations, it can be sensitive to outlier
+covariate observations (features). Outlier features can compromise the
+performance of deep learning regression problems such as style translation,
+image reconstruction, and deep anomaly detection, potentially leading to
+misleading conclusions. To address this problem, we propose a robust solution
+for quantile regression that incorporates concepts from robust divergence. We
+compare the performance of our proposed method with (i) least trimmed quantile
+regression and (ii) robust regression based on the regularization of
+case-specific parameters in a simple real dataset in the presence of outlier.
+These methods have not been applied in a deep learning framework. We also
+demonstrate the applicability of the proposed method by applying it to a
+medical imaging translation task using diffusion models.
+
+
+
+ 47. 标题:Hodge-Aware Contrastive Learning
+ 编号:[236]
+ 链接:https://arxiv.org/abs/2309.07364
+ 作者:Alexander Möllers, Alexander Immer, Vincent Fortuin, Elvin Isufi
+ 备注:4 pages, 2 figures
+ 关键词:complexes prove effective, Simplicial complexes prove, multiway dependencies, complexes prove, prove effective
+
+ 点击查看摘要
+ Simplicial complexes prove effective in modeling data with multiway
+dependencies, such as data defined along the edges of networks or within other
+higher-order structures. Their spectrum can be decomposed into three
+interpretable subspaces via the Hodge decomposition, resulting foundational in
+numerous applications. We leverage this decomposition to develop a contrastive
+self-supervised learning approach for processing simplicial data and generating
+embeddings that encapsulate specific spectral information.Specifically, we
+encode the pertinent data invariances through simplicial neural networks and
+devise augmentations that yield positive contrastive examples with suitable
+spectral properties for downstream tasks. Additionally, we reweight the
+significance of negative examples in the contrastive loss, considering the
+similarity of their Hodge components to the anchor. By encouraging a stronger
+separation among less similar instances, we obtain an embedding space that
+reflects the spectral properties of the data. The numerical results on two
+standard edge flow classification tasks show a superior performance even when
+compared to supervised learning techniques. Our findings underscore the
+importance of adopting a spectral perspective for contrastive learning with
+higher-order data.
+
+
+
+ 48. 标题:Efficient Learning of PDEs via Taylor Expansion and Sparse Decomposition into Value and Fourier Domains
+ 编号:[244]
+ 链接:https://arxiv.org/abs/2309.07344
+ 作者:Md Nasim, Yexiang Xue
+ 备注:
+ 关键词:Partial Differential Equations, Differential Equations, Partial Differential, scientific discovery, pace of scientific
+
+ 点击查看摘要
+ Accelerating the learning of Partial Differential Equations (PDEs) from
+experimental data will speed up the pace of scientific discovery. Previous
+randomized algorithms exploit sparsity in PDE updates for acceleration. However
+such methods are applicable to a limited class of decomposable PDEs, which have
+sparse features in the value domain. We propose Reel, which accelerates the
+learning of PDEs via random projection and has much broader applicability. Reel
+exploits the sparsity by decomposing dense updates into sparse ones in both the
+value and frequency domains. This decomposition enables efficient learning when
+the source of the updates consists of gradually changing terms across large
+areas (sparse in the frequency domain) in addition to a few rapid updates
+concentrated in a small set of "interfacial" regions (sparse in the value
+domain). Random projection is then applied to compress the sparse signals for
+learning. To expand the model applicability, Taylor series expansion is used in
+Reel to approximate the nonlinear PDE updates with polynomials in the
+decomposable form. Theoretically, we derive a constant factor approximation
+between the projected loss function and the original one with poly-logarithmic
+number of projected dimensions. Experimentally, we provide empirical evidence
+that our proposed Reel can lead to faster learning of PDE models (70-98%
+reduction in training time when the data is compressed to 1% of its original
+size) with comparable quality as the non-compressed models.
+
+
+
+ 49. 标题:Reliability-based cleaning of noisy training labels with inductive conformal prediction in multi-modal biomedical data mining
+ 编号:[249]
+ 链接:https://arxiv.org/abs/2309.07332
+ 作者:Xianghao Zhan, Qinmei Xu, Yuanning Zheng, Guangming Lu, Olivier Gevaert
+ 备注:
+ 关键词:presents a challenge, data, training data, biomedical data presents, labeling biomedical data
+
+ 点击查看摘要
+ Accurately labeling biomedical data presents a challenge. Traditional
+semi-supervised learning methods often under-utilize available unlabeled data.
+To address this, we propose a novel reliability-based training data cleaning
+method employing inductive conformal prediction (ICP). This method capitalizes
+on a small set of accurately labeled training data and leverages ICP-calculated
+reliability metrics to rectify mislabeled data and outliers within vast
+quantities of noisy training data. The efficacy of the method is validated
+across three classification tasks within distinct modalities: filtering
+drug-induced-liver-injury (DILI) literature with title and abstract, predicting
+ICU admission of COVID-19 patients through CT radiomics and electronic health
+records, and subtyping breast cancer using RNA-sequencing data. Varying levels
+of noise to the training labels were introduced through label permutation.
+Results show significant enhancements in classification performance: accuracy
+enhancement in 86 out of 96 DILI experiments (up to 11.4%), AUROC and AUPRC
+enhancements in all 48 COVID-19 experiments (up to 23.8% and 69.8%), and
+accuracy and macro-average F1 score improvements in 47 out of 48 RNA-sequencing
+experiments (up to 74.6% and 89.0%). Our method offers the potential to
+substantially boost classification performance in multi-modal biomedical
+machine learning tasks. Importantly, it accomplishes this without necessitating
+an excessive volume of meticulously curated training data.
+
+
+
+ 50. 标题:Traveling Words: A Geometric Interpretation of Transformers
+ 编号:[254]
+ 链接:https://arxiv.org/abs/2309.07315
+ 作者:Raul Molina
+ 备注:
+ 关键词:natural language processing, internal mechanisms remains, language processing, remains a challenge, significantly advanced
+
+ 点击查看摘要
+ Transformers have significantly advanced the field of natural language
+processing, but comprehending their internal mechanisms remains a challenge. In
+this paper, we introduce a novel geometric perspective that elucidates the
+inner mechanisms of transformer operations. Our primary contribution is
+illustrating how layer normalization confines the latent features to a
+hyper-sphere, subsequently enabling attention to mold the semantic
+representation of words on this surface. This geometric viewpoint seamlessly
+connects established properties such as iterative refinement and contextual
+embeddings. We validate our insights by probing a pre-trained 124M parameter
+GPT-2 model. Our findings reveal clear query-key attention patterns in early
+layers and build upon prior observations regarding the subject-specific nature
+of attention heads at deeper layers. Harnessing these geometric insights, we
+present an intuitive understanding of transformers, depicting them as processes
+that model the trajectory of word particles along the hyper-sphere.
+
+
+
+ 51. 标题:User Training with Error Augmentation for Electromyogram-based Gesture Classification
+ 编号:[269]
+ 链接:https://arxiv.org/abs/2309.07289
+ 作者:Yunus Bicer, Niklas Smedemark-Margulies, Basak Celik, Elifnur Sunger, Ryan Orendorff, Stephanie Naufel, Tales Imbiriba, Deniz Erdo{ğ}mu{ş}, Eugene Tunik, Mathew Yarossi
+ 备注:10 pages, 10 figures
+ 关键词:extracting surface electromyographic, surface electromyographic, wrist-band configuration, designed and tested, tested a system
+
+ 点击查看摘要
+ We designed and tested a system for real-time control of a user interface by
+extracting surface electromyographic (sEMG) activity from eight electrodes in a
+wrist-band configuration. sEMG data were streamed into a machine-learning
+algorithm that classified hand gestures in real-time. After an initial model
+calibration, participants were presented with one of three types of feedback
+during a human-learning stage: veridical feedback, in which predicted
+probabilities from the gesture classification algorithm were displayed without
+alteration, modified feedback, in which we applied a hidden augmentation of
+error to these probabilities, and no feedback. User performance was then
+evaluated in a series of minigames, in which subjects were required to use
+eight gestures to manipulate their game avatar to complete a task. Experimental
+results indicated that, relative to baseline, the modified feedback condition
+led to significantly improved accuracy and improved gesture class separation.
+These findings suggest that real-time feedback in a gamified user interface
+with manipulation of feedback may enable intuitive, rapid, and accurate task
+acquisition for sEMG-based gesture recognition applications.
+
+
+
+ 52. 标题:Unbiased Face Synthesis With Diffusion Models: Are We There Yet?
+ 编号:[272]
+ 链接:https://arxiv.org/abs/2309.07277
+ 作者:Harrison Rosenberg, Shimaa Ahmed, Guruprasad V Ramesh, Ramya Korlakai Vinayak, Kassem Fawaz
+ 备注:
+ 关键词:achieved widespread popularity, widespread popularity due, image generation capability, unprecedented image generation, achieved widespread
+
+ 点击查看摘要
+ Text-to-image diffusion models have achieved widespread popularity due to
+their unprecedented image generation capability. In particular, their ability
+to synthesize and modify human faces has spurred research into using generated
+face images in both training data augmentation and model performance
+assessments. In this paper, we study the efficacy and shortcomings of
+generative models in the context of face generation. Utilizing a combination of
+qualitative and quantitative measures, including embedding-based metrics and
+user studies, we present a framework to audit the characteristics of generated
+faces conditioned on a set of social attributes. We applied our framework on
+faces generated through state-of-the-art text-to-image diffusion models. We
+identify several limitations of face image generation that include faithfulness
+to the text prompt, demographic disparities, and distributional shifts.
+Furthermore, we present an analytical model that provides insights into how
+training data selection contributes to the performance of generative models.
+
+
+
+ 53. 标题:Safe and Accelerated Deep Reinforcement Learning-based O-RAN Slicing: A Hybrid Transfer Learning Approach
+ 编号:[277]
+ 链接:https://arxiv.org/abs/2309.07265
+ 作者:Ahmad M. Nagib, Hatem Abou-Zeid, Hossam S. Hassanein
+ 备注:This paper has been accepted for publication in a future issue of IEEE Journal on Selected Areas in Communications (JSAC)
+ 关键词:architecture supports intelligent, radio access network, open radio access, supports intelligent network, RAN intelligent controllers
+
+ 点击查看摘要
+ The open radio access network (O-RAN) architecture supports intelligent
+network control algorithms as one of its core capabilities. Data-driven
+applications incorporate such algorithms to optimize radio access network (RAN)
+functions via RAN intelligent controllers (RICs). Deep reinforcement learning
+(DRL) algorithms are among the main approaches adopted in the O-RAN literature
+to solve dynamic radio resource management problems. However, despite the
+benefits introduced by the O-RAN RICs, the practical adoption of DRL algorithms
+in real network deployments falls behind. This is primarily due to the slow
+convergence and unstable performance exhibited by DRL agents upon deployment
+and when facing previously unseen network conditions. In this paper, we address
+these challenges by proposing transfer learning (TL) as a core component of the
+training and deployment workflows for the DRL-based closed-loop control of
+O-RAN functionalities. To this end, we propose and design a hybrid TL-aided
+approach that leverages the advantages of both policy reuse and distillation TL
+methods to provide safe and accelerated convergence in DRL-based O-RAN slicing.
+We conduct a thorough experiment that accommodates multiple services, including
+real VR gaming traffic to reflect practical scenarios of O-RAN slicing. We also
+propose and implement policy reuse and distillation-aided DRL and non-TL-aided
+DRL as three separate baselines. The proposed hybrid approach shows at least:
+7.7% and 20.7% improvements in the average initial reward value and the
+percentage of converged scenarios, and a 64.6% decrease in reward variance
+while maintaining fast convergence and enhancing the generalizability compared
+with the baselines.
+
+
+
+ 54. 标题:Solving Recurrence Relations using Machine Learning, with Application to Cost Analysis
+ 编号:[280]
+ 链接:https://arxiv.org/abs/2309.07259
+ 作者:Maximiliano Klemen, Miguel Á. Carreira-Perpiñán, Pedro Lopez-Garcia
+ 备注:In Proceedings ICLP 2023, arXiv:2308.14898
+ 关键词:input data sizes, analysis infers information, Automatic static cost, static cost analysis, cost analysis infers
+
+ 点击查看摘要
+ Automatic static cost analysis infers information about the resources used by
+programs without actually running them with concrete data, and presents such
+information as functions of input data sizes. Most of the analysis tools for
+logic programs (and other languages) are based on setting up recurrence
+relations representing (bounds on) the computational cost of predicates, and
+solving them to find closed-form functions that are equivalent to (or a bound
+on) them. Such recurrence solving is a bottleneck in current tools: many of the
+recurrences that arise during the analysis cannot be solved with current
+solvers, such as Computer Algebra Systems (CASs), so that specific methods for
+different classes of recurrences need to be developed. We address such a
+challenge by developing a novel, general approach for solving arbitrary,
+constrained recurrence relations, that uses machine-learning sparse regression
+techniques to guess a candidate closed-form function, and a combination of an
+SMT-solver and a CAS to check whether such function is actually a solution of
+the recurrence. We have implemented a prototype and evaluated it with
+recurrences generated by a cost analysis system (the one in CiaoPP). The
+experimental results are quite promising, showing that our approach can find
+closed-form solutions, in a reasonable time, for classes of recurrences that
+cannot be solved by such a system, nor by current CASs.
+
+
+
+ 55. 标题:Autotuning Apache TVM-based Scientific Applications Using Bayesian Optimization
+ 编号:[287]
+ 链接:https://arxiv.org/abs/2309.07235
+ 作者:Xingfu Wu, Praveen Paramasivam, Valerie Taylor
+ 备注:
+ 关键词:Tensor Virtual Machine, Lower Upper, Artificial Intelligence, open source machine, source machine learning
+
+ 点击查看摘要
+ Apache TVM (Tensor Virtual Machine), an open source machine learning compiler
+framework designed to optimize computations across various hardware platforms,
+provides an opportunity to improve the performance of dense matrix
+factorizations such as LU (Lower Upper) decomposition and Cholesky
+decomposition on GPUs and AI (Artificial Intelligence) accelerators. In this
+paper, we propose a new TVM autotuning framework using Bayesian Optimization
+and use the TVM tensor expression language to implement linear algebra kernels
+such as LU, Cholesky, and 3mm. We use these scientific computation kernels to
+evaluate the effectiveness of our methods on a GPU cluster, called Swing, at
+Argonne National Laboratory. We compare the proposed autotuning framework with
+the TVM autotuning framework AutoTVM with four tuners and find that our
+framework outperforms AutoTVM in most cases.
+
+
+
+ 56. 标题:EarthPT: a foundation model for Earth Observation
+ 编号:[289]
+ 链接:https://arxiv.org/abs/2309.07207
+ 作者:Michael J. Smith, Luke Fleming, James E. Geach
+ 备注:7 pages, 4 figures, submitted to NeurIPS CCAI workshop
+ 关键词:Earth Observation, Difference Vegetation Index, Normalised Difference Vegetation, pretrained transformer, Earth
+
+ 点击查看摘要
+ We introduce EarthPT -- an Earth Observation (EO) pretrained transformer.
+EarthPT is a 700 million parameter decoding transformer foundation model
+trained in an autoregressive self-supervised manner and developed specifically
+with EO use-cases in mind. We demonstrate that EarthPT is an effective
+forecaster that can accurately predict future pixel-level surface reflectances
+across the 400-2300 nm range well into the future. For example, forecasts of
+the evolution of the Normalised Difference Vegetation Index (NDVI) have a
+typical error of approximately 0.05 (over a natural range of -1 -> 1) at the
+pixel level over a five month test set horizon, out-performing simple
+phase-folded models based on historical averaging. We also demonstrate that
+embeddings learnt by EarthPT hold semantically meaningful information and could
+be exploited for downstream tasks such as highly granular, dynamic land use
+classification. Excitingly, we note that the abundance of EO data provides us
+with -- in theory -- quadrillions of training tokens. Therefore, if we assume
+that EarthPT follows neural scaling laws akin to those derived for Large
+Language Models (LLMs), there is currently no data-imposed limit to scaling
+EarthPT and other similar `Large Observation Models.'
+
+
+
+ 57. 标题:Latent Representation and Simulation of Markov Processes via Time-Lagged Information Bottleneck
+ 编号:[292]
+ 链接:https://arxiv.org/abs/2309.07200
+ 作者:Marco Federici, Patrick Forré, Ryota Tomioka, Bastiaan S. Veeling
+ 备注:10 pages, 14 figures
+ 关键词:Markov processes, processes are widely, widely used mathematical, describing dynamic systems, mathematical models
+
+ 点击查看摘要
+ Markov processes are widely used mathematical models for describing dynamic
+systems in various fields. However, accurately simulating large-scale systems
+at long time scales is computationally expensive due to the short time steps
+required for accurate integration. In this paper, we introduce an inference
+process that maps complex systems into a simplified representational space and
+models large jumps in time. To achieve this, we propose Time-lagged Information
+Bottleneck (T-IB), a principled objective rooted in information theory, which
+aims to capture relevant temporal features while discarding high-frequency
+information to simplify the simulation task and minimize the inference error.
+Our experiments demonstrate that T-IB learns information-optimal
+representations for accurately modeling the statistical properties and dynamics
+of the original process at a selected time lag, outperforming existing
+time-lagged dimensionality reduction methods.
+
+
+
+ 58. 标题:Mitigating Adversarial Attacks in Federated Learning with Trusted Execution Environments
+ 编号:[293]
+ 链接:https://arxiv.org/abs/2309.07197
+ 作者:Simon Queyrut, Valerio Schiavoni, Pascal Felber
+ 备注:12 pages, 4 figures, to be published in Proceedings 23rd International Conference on Distributed Computing Systems. arXiv admin note: substantial text overlap with arXiv:2308.04373
+ 关键词:machine learning model, user data privacy, preserve user data, learning model updates, federated learning
+
+ 点击查看摘要
+ The main premise of federated learning (FL) is that machine learning model
+updates are computed locally to preserve user data privacy. This approach
+avoids by design user data to ever leave the perimeter of their device. Once
+the updates aggregated, the model is broadcast to all nodes in the federation.
+However, without proper defenses, compromised nodes can probe the model inside
+their local memory in search for adversarial examples, which can lead to
+dangerous real-world scenarios. For instance, in image-based applications,
+adversarial examples consist of images slightly perturbed to the human eye
+getting misclassified by the local model. These adversarial images are then
+later presented to a victim node's counterpart model to replay the attack.
+Typical examples harness dissemination strategies such as altered traffic signs
+(patch attacks) no longer recognized by autonomous vehicles or seemingly
+unaltered samples that poison the local dataset of the FL scheme to undermine
+its robustness. Pelta is a novel shielding mechanism leveraging Trusted
+Execution Environments (TEEs) that reduce the ability of attackers to craft
+adversarial samples. Pelta masks inside the TEE the first part of the
+back-propagation chain rule, typically exploited by attackers to craft the
+malicious samples. We evaluate Pelta on state-of-the-art accurate models using
+three well-established datasets: CIFAR-10, CIFAR-100 and ImageNet. We show the
+effectiveness of Pelta in mitigating six white-box state-of-the-art adversarial
+attacks, such as Projected Gradient Descent, Momentum Iterative Method, Auto
+Projected Gradient Descent, the Carlini & Wagner attack. In particular, Pelta
+constitutes the first attempt at defending an ensemble model against the
+Self-Attention Gradient attack to the best of our knowledge. Our code is
+available to the research community at this https URL.
+
+
+
+ 59. 标题:Attention-based Dynamic Graph Convolutional Recurrent Neural Network for Traffic Flow Prediction in Highway Transportation
+ 编号:[294]
+ 链接:https://arxiv.org/abs/2309.07196
+ 作者:Tianpu Zhang, Weilong Ding, Mengda Xing
+ 备注:
+ 关键词:spatial feature extraction, feature extraction, important tools, tools for spatial, spatial feature
+
+ 点击查看摘要
+ As one of the important tools for spatial feature extraction, graph
+convolution has been applied in a wide range of fields such as traffic flow
+prediction. However, current popular works of graph convolution cannot
+guarantee spatio-temporal consistency in a long period. The ignorance of
+correlational dynamics, convolutional locality and temporal comprehensiveness
+would limit predictive accuracy. In this paper, a novel Attention-based Dynamic
+Graph Convolutional Recurrent Neural Network (ADGCRNN) is proposed to improve
+traffic flow prediction in highway transportation. Three temporal resolutions
+of data sequence are effectively integrated by self-attention to extract
+characteristics; multi-dynamic graphs and their weights are dynamically created
+to compliantly combine the varying characteristics; a dedicated gated kernel
+emphasizing highly relative nodes is introduced on these complete graphs to
+reduce overfitting for graph convolution operations. Experiments on two public
+datasets show our work better than state-of-the-art baselines, and case studies
+of a real Web system prove practical benefit in highway transportation.
+
+
+
+ 60. 标题:Learning From Drift: Federated Learning on Non-IID Data via Drift Regularization
+ 编号:[296]
+ 链接:https://arxiv.org/abs/2309.07189
+ 作者:Yeachan Kim, Bonggun Shin
+ 备注:
+ 关键词:learning algorithms perform, Non-IID data, identically distributed, IID data, algorithms perform
+
+ 点击查看摘要
+ Federated learning algorithms perform reasonably well on independent and
+identically distributed (IID) data. They, on the other hand, suffer greatly
+from heterogeneous environments, i.e., Non-IID data. Despite the fact that many
+research projects have been done to address this issue, recent findings
+indicate that they are still sub-optimal when compared to training on IID data.
+In this work, we carefully analyze the existing methods in heterogeneous
+environments. Interestingly, we find that regularizing the classifier's outputs
+is quite effective in preventing performance degradation on Non-IID data.
+Motivated by this, we propose Learning from Drift (LfD), a novel method for
+effectively training the model in heterogeneous settings. Our scheme
+encapsulates two key components: drift estimation and drift regularization.
+Specifically, LfD first estimates how different the local model is from the
+global model (i.e., drift). The local model is then regularized such that it
+does not fall in the direction of the estimated drift. In the experiment, we
+evaluate each method through the lens of the five aspects of federated
+learning, i.e., Generalization, Heterogeneity, Scalability, Forgetting, and
+Efficiency. Comprehensive evaluation results clearly support the superiority of
+LfD in federated learning with Non-IID data.
+
+
+
+ 61. 标题:Multi-step prediction of chlorophyll concentration based on Adaptive Graph-Temporal Convolutional Network with Series Decomposition
+ 编号:[297]
+ 链接:https://arxiv.org/abs/2309.07187
+ 作者:Ying Chen, Xiao Li, Hongbo Zhang, Wenyang Song, Chongxuan Xv
+ 备注:12 pages, 10 figures, 3 tables, 45 references
+ 关键词:Chlorophyll concentration, chlorophyll concentration change, evaluating water quality, reflect the nutritional, nutritional status
+
+ 点击查看摘要
+ Chlorophyll concentration can well reflect the nutritional status and algal
+blooms of water bodies, and is an important indicator for evaluating water
+quality. The prediction of chlorophyll concentration change trend is of great
+significance to environmental protection and aquaculture. However, there is a
+complex and indistinguishable nonlinear relationship between many factors
+affecting chlorophyll concentration. In order to effectively mine the nonlinear
+features contained in the data. This paper proposes a time-series decomposition
+adaptive graph-time convolutional network ( AGTCNSD ) prediction model.
+Firstly, the original sequence is decomposed into trend component and periodic
+component by moving average method. Secondly, based on the graph convolutional
+neural network, the water quality parameter data is modeled, and a parameter
+embedding matrix is defined. The idea of matrix decomposition is used to assign
+weight parameters to each node. The adaptive graph convolution learns the
+relationship between different water quality parameters, updates the state
+information of each parameter, and improves the learning ability of the update
+relationship between nodes. Finally, time dependence is captured by time
+convolution to achieve multi-step prediction of chlorophyll concentration. The
+validity of the model is verified by the water quality data of the coastal city
+Beihai. The results show that the prediction effect of this method is better
+than other methods. It can be used as a scientific resource for environmental
+management decision-making.
+
+
+
+ 62. 标题:The Grand Illusion: The Myth of Software Portability and Implications for ML Progress
+ 编号:[299]
+ 链接:https://arxiv.org/abs/2309.07181
+ 作者:Fraser Mince, Dzung Dinh, Jonas Kgomo, Neil Thompson, Sara Hooker
+ 备注:28 pages, 13 figures, repo can be found at associated this https URL
+ 关键词:Pushing the boundaries, requires exploring, machine learning, hardware, tooling stacks
+
+ 点击查看摘要
+ Pushing the boundaries of machine learning often requires exploring different
+hardware and software combinations. However, the freedom to experiment across
+different tooling stacks can be at odds with the drive for efficiency, which
+has produced increasingly specialized AI hardware and incentivized
+consolidation around a narrow set of ML frameworks. Exploratory research can be
+restricted if software and hardware are co-evolving, making it even harder to
+stray away from mainstream ideas that work well with popular tooling stacks.
+While this friction increasingly impacts the rate of innovation in machine
+learning, to our knowledge the lack of portability in tooling has not been
+quantified. In this work, we ask: How portable are popular ML software
+frameworks? We conduct a large-scale study of the portability of mainstream ML
+frameworks across different hardware types. Our findings paint an uncomfortable
+picture -- frameworks can lose more than 40% of their key functions when ported
+to other hardware. Worse, even when functions are portable, the slowdown in
+their performance can be extreme and render performance untenable.
+Collectively, our results reveal how costly straying from a narrow set of
+hardware-software combinations can be - and suggest that specialization of
+hardware impedes innovation in machine learning research.
+
+
+
+ 63. 标题:Optimal and Fair Encouragement Policy Evaluation and Learning
+ 编号:[300]
+ 链接:https://arxiv.org/abs/2309.07176
+ 作者:Angela Zhou
+ 备注:
+ 关键词:optimal treatment rules, impossible to compel, compel individuals, presence of human, human non-adherence
+
+ 点击查看摘要
+ In consequential domains, it is often impossible to compel individuals to
+take treatment, so that optimal policy rules are merely suggestions in the
+presence of human non-adherence to treatment recommendations. In these same
+domains, there may be heterogeneity both in who responds in taking-up
+treatment, and heterogeneity in treatment efficacy. While optimal treatment
+rules can maximize causal outcomes across the population, access parity
+constraints or other fairness considerations can be relevant in the case of
+encouragement. For example, in social services, a persistent puzzle is the gap
+in take-up of beneficial services among those who may benefit from them the
+most. When in addition the decision-maker has distributional preferences over
+both access and average outcomes, the optimal decision rule changes. We study
+causal identification, statistical variance-reduced estimation, and robust
+estimation of optimal treatment rules, including under potential violations of
+positivity. We consider fairness constraints such as demographic parity in
+treatment take-up, and other constraints, via constrained optimization. Our
+framework can be extended to handle algorithmic recommendations under an
+often-reasonable covariate-conditional exclusion restriction, using our
+robustness checks for lack of positivity in the recommendation. We develop a
+two-stage algorithm for solving over parametrized policy classes under general
+constraints to obtain variance-sensitive regret bounds. We illustrate the
+methods in two case studies based on data from randomized encouragement to
+enroll in insurance and from pretrial supervised release with electronic
+monitoring.
+
+
+
+ 64. 标题:HurriCast: An Automatic Framework Using Machine Learning and Statistical Modeling for Hurricane Forecasting
+ 编号:[301]
+ 链接:https://arxiv.org/abs/2309.07174
+ 作者:Shouwei Gao, Meiyan Gao, Yuepeng Li, Wenqian Dong
+ 备注:This paper includes 7 pages and 8 figures. And we submitted it up to the SC23 workshop. This is only a preprinting
+ 关键词:present major challenges, Hurricanes present major, devastating impacts, present major, major challenges
+
+ 点击查看摘要
+ Hurricanes present major challenges in the U.S. due to their devastating
+impacts. Mitigating these risks is important, and the insurance industry is
+central in this effort, using intricate statistical models for risk assessment.
+However, these models often neglect key temporal and spatial hurricane patterns
+and are limited by data scarcity. This study introduces a refined approach
+combining the ARIMA model and K-MEANS to better capture hurricane trends, and
+an Autoencoder for enhanced hurricane simulations. Our experiments show that
+this hybrid methodology effectively simulate historical hurricane behaviors
+while providing detailed projections of potential future trajectories and
+intensities. Moreover, by leveraging a comprehensive yet selective dataset, our
+simulations enrich the current understanding of hurricane patterns and offer
+actionable insights for risk management strategies.
+
+
+
+ 65. 标题:Using Unsupervised and Supervised Learning and Digital Twin for Deep Convective Ice Storm Classification
+ 编号:[302]
+ 链接:https://arxiv.org/abs/2309.07173
+ 作者:Jason Swope, Steve Chien, Emily Dunkel, Xavier Bosch-Lluis, Qing Yue, William Deal
+ 备注:
+ 关键词:Ice Cloud Sensing, intelligently targets ice, Smart Ice Cloud, targets ice storms, ice storms based
+
+ 点击查看摘要
+ Smart Ice Cloud Sensing (SMICES) is a small-sat concept in which a primary
+radar intelligently targets ice storms based on information collected by a
+lookahead radiometer. Critical to the intelligent targeting is accurate
+identification of storm/cloud types from eight bands of radiance collected by
+the radiometer. The cloud types of interest are: clear sky, thin cirrus,
+cirrus, rainy anvil, and convection core.
+We describe multi-step use of Machine Learning and Digital Twin of the
+Earth's atmosphere to derive such a classifier. First, a digital twin of
+Earth's atmosphere called a Weather Research Forecast (WRF) is used generate
+simulated lookahead radiometer data as well as deeper "science" hidden
+variables. The datasets simulate a tropical region over the Caribbean and a
+non-tropical region over the Atlantic coast of the United States. A K-means
+clustering over the scientific hidden variables was utilized by human experts
+to generate an automatic labelling of the data - mapping each physical data
+point to cloud types by scientists informed by mean/centroids of hidden
+variables of the clusters. Next, classifiers were trained with the inputs of
+the simulated radiometer data and its corresponding label. The classifiers of a
+random decision forest (RDF), support vector machine (SVM), Gaussian naïve
+bayes, feed forward artificial neural network (ANN), and a convolutional neural
+network (CNN) were trained. Over the tropical dataset, the best performing
+classifier was able to identify non-storm and storm clouds with over 80%
+accuracy in each class for a held-out test set. Over the non-tropical dataset,
+the best performing classifier was able to classify non-storm clouds with over
+90% accuracy and storm clouds with over 40% accuracy. Additionally both sets of
+classifiers were shown to be resilient to instrument noise.
+
+
+
+ 66. 标题:Exploring Large Language Models for Ontology Alignment
+ 编号:[303]
+ 链接:https://arxiv.org/abs/2309.07172
+ 作者:Yuan He, Jiaoyan Chen, Hang Dong, Ian Horrocks
+ 备注:Accepted at ISWC 2023 (Posters and Demos)
+ 关键词:generative Large Language, recent generative Large, Large Language, generative Large, work investigates
+
+ 点击查看摘要
+ This work investigates the applicability of recent generative Large Language
+Models (LLMs), such as the GPT series and Flan-T5, to ontology alignment for
+identifying concept equivalence mappings across ontologies. To test the
+zero-shot performance of Flan-T5-XXL and GPT-3.5-turbo, we leverage challenging
+subsets from two equivalence matching datasets of the OAEI Bio-ML track, taking
+into account concept labels and structural contexts. Preliminary findings
+suggest that LLMs have the potential to outperform existing ontology alignment
+systems like BERTMap, given careful framework and prompt design.
+
+
+
+ 67. 标题:Goal Space Abstraction in Hierarchical Reinforcement Learning via Reachability Analysis
+ 编号:[304]
+ 链接:https://arxiv.org/abs/2309.07168
+ 作者:Mehdi Zadem (LIX, U2IS), Sergio Mover (LIX), Sao Mai Nguyen (U2IS, Flowers, IMT Atlantique - INFO, Lab-STICC_RAMBO)
+ 备注:
+ 关键词:Open-ended learning benefits, learning benefits immensely, existing Hierarchical Reinforcement, benefits immensely, structure knowledge
+
+ 点击查看摘要
+ Open-ended learning benefits immensely from the use of symbolic methods for
+goal representation as they offer ways to structure knowledge for efficient and
+transferable learning. However, the existing Hierarchical Reinforcement
+Learning (HRL) approaches relying on symbolic reasoning are often limited as
+they require a manual goal representation. The challenge in autonomously
+discovering a symbolic goal representation is that it must preserve critical
+information, such as the environment dynamics. In this work, we propose a
+developmental mechanism for subgoal discovery via an emergent representation
+that abstracts (i.e., groups together) sets of environment states that have
+similar roles in the task. We create a HRL algorithm that gradually learns this
+representation along with the policies and evaluate it on navigation tasks to
+show the learned representation is interpretable and results in data
+efficiency.
+
+
+
+ 68. 标题:Compressed Real Numbers for AI: a case-study using a RISC-V CPU
+ 编号:[307]
+ 链接:https://arxiv.org/abs/2309.07158
+ 作者:Federico Rossi, Marco Cococcioni, Roger Ferrer Ibàñez, Jesùs Labarta, Filippo Mantovani, Marc Casas, Emanuele Ruffaldi, Sergio Saponara
+ 备注:
+ 关键词:Deep Neural Networks, single precision IEEE, Deep Neural, Neural Networks, floating point numbers
+
+ 点击查看摘要
+ As recently demonstrated, Deep Neural Networks (DNN), usually trained using
+single precision IEEE 754 floating point numbers (binary32), can also work
+using lower precision. Therefore, 16-bit and 8-bit compressed format have
+attracted considerable attention. In this paper, we focused on two families of
+formats that have already achieved interesting results in compressing binary32
+numbers in machine learning applications, without sensible degradation of the
+accuracy: bfloat and posit. Even if 16-bit and 8-bit bfloat/posit are routinely
+used for reducing the storage of the weights/biases of trained DNNs, the
+inference still often happens on the 32-bit FPU of the CPU (especially if GPUs
+are not available). In this paper we propose a way to decompress a tensor of
+bfloat/posits just before computations, i.e., after the compressed operands
+have been loaded within the vector registers of a vector capable CPU, in order
+to save bandwidth usage and increase cache efficiency. Finally, we show the
+architectural parameters and considerations under which this solution is
+advantageous with respect to the uncompressed one.
+
+
+
+ 69. 标题:Distribution Grid Line Outage Identification with Unknown Pattern and Performance Guarantee
+ 编号:[308]
+ 链接:https://arxiv.org/abs/2309.07157
+ 作者:Chenhan Xiao, Yizheng Liao, Yang Weng
+ 备注:12 pages
+ 关键词:Line outage identification, essential for sustainable, sustainable grid operation, outage, Line outage
+
+ 点击查看摘要
+ Line outage identification in distribution grids is essential for sustainable
+grid operation. In this work, we propose a practical yet robust detection
+approach that utilizes only readily available voltage magnitudes, eliminating
+the need for costly phase angles or power flow data. Given the sensor data,
+many existing detection methods based on change-point detection require prior
+knowledge of outage patterns, which are unknown for real-world outage
+scenarios. To remove this impractical requirement, we propose a data-driven
+method to learn the parameters of the post-outage distribution through gradient
+descent. However, directly using gradient descent presents feasibility issues.
+To address this, we modify our approach by adding a Bregman divergence
+constraint to control the trajectory of the parameter updates, which eliminates
+the feasibility problems. As timely operation is the key nowadays, we prove
+that the optimal parameters can be learned with convergence guarantees via
+leveraging the statistical and physical properties of voltage data. We evaluate
+our approach using many representative distribution grids and real load
+profiles with 17 outage configurations. The results show that we can detect and
+localize the outage in a timely manner with only voltage magnitudes and without
+assuming a prior knowledge of outage patterns.
+
+
+
+ 70. 标题:Finding Influencers in Complex Networks: An Effective Deep Reinforcement Learning Approach
+ 编号:[309]
+ 链接:https://arxiv.org/abs/2309.07153
+ 作者:Changan Liu, Changjun Fan, Zhongzhi Zhang
+ 备注:
+ 关键词:computationally challenging task, hard nature, social network analysis, practically important, important but computationally
+
+ 点击查看摘要
+ Maximizing influences in complex networks is a practically important but
+computationally challenging task for social network analysis, due to its NP-
+hard nature. Most current approximation or heuristic methods either require
+tremendous human design efforts or achieve unsatisfying balances between
+effectiveness and efficiency. Recent machine learning attempts only focus on
+speed but lack performance enhancement. In this paper, different from previous
+attempts, we propose an effective deep reinforcement learning model that
+achieves superior performances over traditional best influence maximization
+algorithms. Specifically, we design an end-to-end learning framework that
+combines graph neural network as the encoder and reinforcement learning as the
+decoder, named DREIM. Trough extensive training on small synthetic graphs,
+DREIM outperforms the state-of-the-art baseline methods on very large synthetic
+and real-world networks on solution quality, and we also empirically show its
+linear scalability with regard to the network size, which demonstrates its
+superiority in solving this problem.
+
+
+
+ 71. 标题:Bringing PDEs to JAX with forward and reverse modes automatic differentiation
+ 编号:[311]
+ 链接:https://arxiv.org/abs/2309.07137
+ 作者:Ivan Yashchuk
+ 备注:Published as a workshop paper at ICLR 2020 DeepDiffEq workshop
+ 关键词:Partial differential equations, Partial differential, physical phenomena, describe a variety, variety of physical
+
+ 点击查看摘要
+ Partial differential equations (PDEs) are used to describe a variety of
+physical phenomena. Often these equations do not have analytical solutions and
+numerical approximations are used instead. One of the common methods to solve
+PDEs is the finite element method. Computing derivative information of the
+solution with respect to the input parameters is important in many tasks in
+scientific computing. We extend JAX automatic differentiation library with an
+interface to Firedrake finite element library. High-level symbolic
+representation of PDEs allows bypassing differentiating through low-level
+possibly many iterations of the underlying nonlinear solvers. Differentiating
+through Firedrake solvers is done using tangent-linear and adjoint equations.
+This enables the efficient composition of finite element solvers with arbitrary
+differentiable programs. The code is available at
+this http URL.
+
+
+
+ 72. 标题:Choosing a Proxy Metric from Past Experiments
+ 编号:[314]
+ 链接:https://arxiv.org/abs/2309.07893
+ 作者:Nilesh Tripuraneni, Lee Richardson, Alexander D'Amour, Jacopo Soriano, Steve Yadlowsky
+ 备注:
+ 关键词:optimal proxy metric, long-term metric, proxy metric, randomized experiments, outcome of interest
+
+ 点击查看摘要
+ In many randomized experiments, the treatment effect of the long-term metric
+(i.e. the primary outcome of interest) is often difficult or infeasible to
+measure. Such long-term metrics are often slow to react to changes and
+sufficiently noisy they are challenging to faithfully estimate in short-horizon
+experiments. A common alternative is to measure several short-term proxy
+metrics in the hope they closely track the long-term metric -- so they can be
+used to effectively guide decision-making in the near-term. We introduce a new
+statistical framework to both define and construct an optimal proxy metric for
+use in a homogeneous population of randomized experiments. Our procedure first
+reduces the construction of an optimal proxy metric in a given experiment to a
+portfolio optimization problem which depends on the true latent treatment
+effects and noise level of experiment under consideration. We then denoise the
+observed treatment effects of the long-term metric and a set of proxies in a
+historical corpus of randomized experiments to extract estimates of the latent
+treatment effects for use in the optimization problem. One key insight derived
+from our approach is that the optimal proxy metric for a given experiment is
+not apriori fixed; rather it should depend on the sample size (or effective
+noise level) of the randomized experiment for which it is deployed. To
+instantiate and evaluate our framework, we employ our methodology in a large
+corpus of randomized experiments from an industrial recommendation system and
+construct proxy metrics that perform favorably relative to several baselines.
+
+
+
+ 73. 标题:Identifying the Group-Theoretic Structure of Machine-Learned Symmetries
+ 编号:[316]
+ 链接:https://arxiv.org/abs/2309.07860
+ 作者:Roy T. Forestano, Konstantin T. Matchev, Katia Matcheva, Alexander Roman, Eyup B. Unlu, Sarunas Verner
+ 备注:10 pages, 8 figures, 2 tables
+ 关键词:deriving symmetry transformations, important physics quantities, preserve important physics, recently successfully, transformations that preserve
+
+ 点击查看摘要
+ Deep learning was recently successfully used in deriving symmetry
+transformations that preserve important physics quantities. Being completely
+agnostic, these techniques postpone the identification of the discovered
+symmetries to a later stage. In this letter we propose methods for examining
+and identifying the group-theoretic structure of such machine-learned
+symmetries. We design loss functions which probe the subalgebra structure
+either during the deep learning stage of symmetry discovery or in a subsequent
+post-processing stage. We illustrate the new methods with examples from the
+U(n) Lie group family, obtaining the respective subalgebra decompositions. As
+an application to particle physics, we demonstrate the identification of the
+residual symmetries after the spontaneous breaking of non-Abelian gauge
+symmetries like SU(3) and SU(5) which are commonly used in model building.
+
+
+
+ 74. 标题:Learning to Warm-Start Fixed-Point Optimization Algorithms
+ 编号:[318]
+ 链接:https://arxiv.org/abs/2309.07835
+ 作者:Rajiv Sambharya, Georgina Hall, Brandon Amos, Bartolomeo Stellato
+ 备注:
+ 关键词:warm-start fixed-point optimization, introduce a machine-learning, fixed-point optimization algorithms, warm starts, fixed-point
+
+ 点击查看摘要
+ We introduce a machine-learning framework to warm-start fixed-point
+optimization algorithms. Our architecture consists of a neural network mapping
+problem parameters to warm starts, followed by a predefined number of
+fixed-point iterations. We propose two loss functions designed to either
+minimize the fixed-point residual or the distance to a ground truth solution.
+In this way, the neural network predicts warm starts with the end-to-end goal
+of minimizing the downstream loss. An important feature of our architecture is
+its flexibility, in that it can predict a warm start for fixed-point algorithms
+run for any number of steps, without being limited to the number of steps it
+has been trained on. We provide PAC-Bayes generalization bounds on unseen data
+for common classes of fixed-point operators: contractive, linearly convergent,
+and averaged. Applying this framework to well-known applications in control,
+statistics, and signal processing, we observe a significant reduction in the
+number of iterations and solution time required to solve these problems,
+through learned warm starts.
+
+
+
+ 75. 标题:Virchow: A Million-Slide Digital Pathology Foundation Model
+ 编号:[324]
+ 链接:https://arxiv.org/abs/2309.07778
+ 作者:Eugene Vorontsov, Alican Bozkurt, Adam Casson, George Shaikovski, Michal Zelechowski, Siqi Liu, Philippe Mathieu, Alexander van Eck, Donghun Lee, Julian Viret, Eric Robert, Yi Kan Wang, Jeremy D. Kun, Matthew C. H. Le, Jan Bernhard, Ran A. Godrich, Gerard Oakley, Ewan Millar, Matthew Hanna, Juan Retamero, William A. Moye, Razik Yousfi, Christopher Kanan, David Klimstra, Brandon Rothrock, Thomas J. Fuchs
+ 备注:
+ 关键词:enable precision medicine, decision support systems, artificial intelligence, intelligence to enable, enable precision
+
+ 点击查看摘要
+ Computational pathology uses artificial intelligence to enable precision
+medicine and decision support systems through the analysis of whole slide
+images. It has the potential to revolutionize the diagnosis and treatment of
+cancer. However, a major challenge to this objective is that for many specific
+computational pathology tasks the amount of data is inadequate for development.
+To address this challenge, we created Virchow, a 632 million parameter deep
+neural network foundation model for computational pathology. Using
+self-supervised learning, Virchow is trained on 1.5 million hematoxylin and
+eosin stained whole slide images from diverse tissue groups, which is orders of
+magnitude more data than previous works. When evaluated on downstream tasks
+including tile-level pan-cancer detection and subtyping and slide-level
+biomarker prediction, Virchow outperforms state-of-the-art systems both on
+internal datasets drawn from the same population as the pretraining data as
+well as external public datasets. Virchow achieves 93% balanced accuracy for
+pancancer tile classification, and AUCs of 0.983 for colon microsatellite
+instability status prediction and 0.967 for breast CDH1 status prediction. The
+gains in performance highlight the importance of pretraining on massive
+pathology image datasets, suggesting pretraining on even larger datasets could
+continue improving performance for many high-impact applications where limited
+amounts of training data are available, such as drug outcome prediction.
+
+
+
+ 76. 标题:Variational Quantum Linear Solver enhanced Quantum Support Vector Machine
+ 编号:[326]
+ 链接:https://arxiv.org/abs/2309.07770
+ 作者:Jianming Yi, Kalyani Suresh, Ali Moghiseh, Norbert Wehn
+ 备注:
+ 关键词:Support Vector Machines, Quantum Support Vector, machine learning tasks, supervised machine learning, Support Vector
+
+ 点击查看摘要
+ Quantum Support Vector Machines (QSVM) play a vital role in using quantum
+resources for supervised machine learning tasks, such as classification.
+However, current methods are strongly limited in terms of scalability on Noisy
+Intermediate Scale Quantum (NISQ) devices. In this work, we propose a novel
+approach called the Variational Quantum Linear Solver (VQLS) enhanced QSVM.
+This is built upon our idea of utilizing the variational quantum linear solver
+to solve system of linear equations of a least squares-SVM on a NISQ device.
+The implementation of our approach is evaluated by an extensive series of
+numerical experiments with the Iris dataset, which consists of three distinct
+iris plant species. Based on this, we explore the practicality and
+effectiveness of our algorithm by constructing a classifier capable of
+classification in a feature space ranging from one to seven dimensions.
+Furthermore, by strategically exploiting both classical and quantum computing
+for various subroutines of our algorithm, we effectively mitigate practical
+challenges associated with the implementation. These include significant
+improvement in the trainability of the variational ansatz and notable
+reductions in run-time for cost calculations. Based on the numerical
+experiments, our approach exhibits the capability of identifying a separating
+hyperplane in an 8-dimensional feature space. Moreover, it consistently
+demonstrated strong performance across various instances with the same dataset.
+
+
+
+ 77. 标题:A DenseNet-based method for decoding auditory spatial attention with EEG
+ 编号:[329]
+ 链接:https://arxiv.org/abs/2309.07690
+ 作者:Xiran Xu, Bo Wang, Yujie Yan, Xihong Wu, Jing Chen
+ 备注:
+ 关键词:Auditory spatial attention, spatial attention detection, auditory attention decoding, ASAD methods, Auditory spatial
+
+ 点击查看摘要
+ Auditory spatial attention detection (ASAD) aims to decode the attended
+spatial location with EEG in a multiple-speaker setting. ASAD methods are
+inspired by the brain lateralization of cortical neural responses during the
+processing of auditory spatial attention, and show promising performance for
+the task of auditory attention decoding (AAD) with neural recordings. In the
+previous ASAD methods, the spatial distribution of EEG electrodes is not fully
+exploited, which may limit the performance of these methods. In the present
+work, by transforming the original EEG channels into a two-dimensional (2D)
+spatial topological map, the EEG data is transformed into a three-dimensional
+(3D) arrangement containing spatial-temporal information. And then a 3D deep
+convolutional neural network (DenseNet-3D) is used to extract temporal and
+spatial features of the neural representation for the attended locations. The
+results show that the proposed method achieves higher decoding accuracy than
+the state-of-the-art (SOTA) method (94.4% compared to XANet's 90.6%) with
+1-second decision window for the widely used KULeuven (KUL) dataset, and the
+code to implement our work is available on Github:
+this https URL
+
+
+
+ 78. 标题:Benchmarking machine learning models for quantum state classification
+ 编号:[330]
+ 链接:https://arxiv.org/abs/2309.07679
+ 作者:Edoardo Pedicillo, Andrea Pasquale, Stefano Carrazza
+ 备注:9 pages, 3 figures, CHEP2023 proceedings
+ 关键词:growing field, information is processed, processed by two-levels, two-levels quantum states, Quantum computing
+
+ 点击查看摘要
+ Quantum computing is a growing field where the information is processed by
+two-levels quantum states known as qubits. Current physical realizations of
+qubits require a careful calibration, composed by different experiments, due to
+noise and decoherence phenomena. Among the different characterization
+experiments, a crucial step is to develop a model to classify the measured
+state by discriminating the ground state from the excited state. In this
+proceedings we benchmark multiple classification techniques applied to real
+quantum devices.
+
+
+
+ 79. 标题:Dataset Size Dependence of Rate-Distortion Curve and Threshold of Posterior Collapse in Linear VAE
+ 编号:[331]
+ 链接:https://arxiv.org/abs/2309.07663
+ 作者:Yuma Ichikawa, Koji Hukushima
+ 备注:16 pages, 3 figures
+ 关键词:Variational Autoencoder, variational posterior, representation learning, posterior collapse, aligns closely
+
+ 点击查看摘要
+ In the Variational Autoencoder (VAE), the variational posterior often aligns
+closely with the prior, which is known as posterior collapse and hinders the
+quality of representation learning. To mitigate this problem, an adjustable
+hyperparameter beta has been introduced in the VAE. This paper presents a
+closed-form expression to assess the relationship between the beta in VAE, the
+dataset size, the posterior collapse, and the rate-distortion curve by
+analyzing a minimal VAE in a high-dimensional limit. These results clarify that
+a long plateau in the generalization error emerges with a relatively larger
+beta. As the beta increases, the length of the plateau extends and then becomes
+infinite beyond a certain beta threshold. This implies that the choice of beta,
+unlike the usual regularization parameters, can induce posterior collapse
+regardless of the dataset size. Thus, beta is a risky parameter that requires
+careful tuning. Furthermore, considering the dataset-size dependence on the
+rate-distortion curve, a relatively large dataset is required to obtain a
+rate-distortion curve with high rates. Extensive numerical experiments support
+our analysis.
+
+
+
+ 80. 标题:Proximal Bellman mappings for reinforcement learning and their application to robust adaptive filtering
+ 编号:[335]
+ 链接:https://arxiv.org/abs/2309.07548
+ 作者:Yuki Akiyama, Konstantinos Slavakis
+ 备注:arXiv admin note: text overlap with arXiv:2210.11755
+ 关键词:proximal Bellman mappings, classical Bellman mappings, Bellman mappings, proximal Bellman, theoretical core
+
+ 点击查看摘要
+ This paper aims at the algorithmic/theoretical core of reinforcement learning
+(RL) by introducing the novel class of proximal Bellman mappings. These
+mappings are defined in reproducing kernel Hilbert spaces (RKHSs), to benefit
+from the rich approximation properties and inner product of RKHSs, they are
+shown to belong to the powerful Hilbertian family of (firmly) nonexpansive
+mappings, regardless of the values of their discount factors, and possess ample
+degrees of design freedom to even reproduce attributes of the classical Bellman
+mappings and to pave the way for novel RL designs. An approximate
+policy-iteration scheme is built on the proposed class of mappings to solve the
+problem of selecting online, at every time instance, the "optimal" exponent $p$
+in a $p$-norm loss to combat outliers in linear adaptive filtering, without
+training data and any knowledge on the statistical properties of the outliers.
+Numerical tests on synthetic data showcase the superior performance of the
+proposed framework over several non-RL and kernel-based RL schemes.
+
+
+
+ 81. 标题:SC-MAD: Mixtures of Higher-order Networks for Data Augmentation
+ 编号:[340]
+ 链接:https://arxiv.org/abs/2309.07453
+ 作者:Madeline Navarro, Santiago Segarra
+ 备注:5 pages, 1 figure, 1 table
+ 关键词:multiway interactions motivate, graph-based pairwise connections, higher-order relations, myriad complex systems, multiway interactions
+
+ 点击查看摘要
+ The myriad complex systems with multiway interactions motivate the extension
+of graph-based pairwise connections to higher-order relations. In particular,
+the simplicial complex has inspired generalizations of graph neural networks
+(GNNs) to simplicial complex-based models. Learning on such systems requires
+large amounts of data, which can be expensive or impossible to obtain. We
+propose data augmentation of simplicial complexes through both linear and
+nonlinear mixup mechanisms that return mixtures of existing labeled samples. In
+addition to traditional pairwise mixup, we present a convex clustering mixup
+approach for a data-driven relationship among several simplicial complexes. We
+theoretically demonstrate that the resultant synthetic simplicial complexes
+interpolate among existing data with respect to homomorphism densities. Our
+method is demonstrated on both synthetic and real-world datasets for simplicial
+complex classification.
+
+
+
+ 82. 标题:The kernel-balanced equation for deep neural networks
+ 编号:[349]
+ 链接:https://arxiv.org/abs/2309.07367
+ 作者:Kenichi Nakazato
+ 备注:
+ 关键词:Deep neural networks, Deep neural, shown many fruitful, fruitful applications, neural networks
+
+ 点击查看摘要
+ Deep neural networks have shown many fruitful applications in this decade. A
+network can get the generalized function through training with a finite
+dataset. The degree of generalization is a realization of the proximity scale
+in the data space. Specifically, the scale is not clear if the dataset is
+complicated. Here we consider a network for the distribution estimation of the
+dataset. We show the estimation is unstable and the instability depends on the
+data density and training duration. We derive the kernel-balanced equation,
+which gives a short phenomenological description of the solution. The equation
+tells us the reason for the instability and the mechanism of the scale. The
+network outputs a local average of the dataset as a prediction and the scale of
+averaging is determined along the equation. The scale gradually decreases along
+training and finally results in instability in our case.
+
+
+
+ 83. 标题:Tackling the dimensions in imaging genetics with CLUB-PLS
+ 编号:[351]
+ 链接:https://arxiv.org/abs/2309.07352
+ 作者:Andre Altmann, Ana C Lawry Aquila, Neda Jahanshad, Paul M Thompson, Marco Lorenzi
+ 备注:12 pages, 4 Figures, 2 Tables
+ 关键词:link high-dimensional data, brain imaging data, high dimensional data, dimensional data, data
+
+ 点击查看摘要
+ A major challenge in imaging genetics and similar fields is to link
+high-dimensional data in one domain, e.g., genetic data, to high dimensional
+data in a second domain, e.g., brain imaging data. The standard approach in the
+area are mass univariate analyses across genetic factors and imaging
+phenotypes. That entails executing one genome-wide association study (GWAS) for
+each pre-defined imaging measure. Although this approach has been tremendously
+successful, one shortcoming is that phenotypes must be pre-defined.
+Consequently, effects that are not confined to pre-selected regions of interest
+or that reflect larger brain-wide patterns can easily be missed. In this work
+we introduce a Partial Least Squares (PLS)-based framework, which we term
+Cluster-Bootstrap PLS (CLUB-PLS), that can work with large input dimensions in
+both domains as well as with large sample sizes. One key factor of the
+framework is to use cluster bootstrap to provide robust statistics for single
+input features in both domains. We applied CLUB-PLS to investigating the
+genetic basis of surface area and cortical thickness in a sample of 33,000
+subjects from the UK Biobank. We found 107 genome-wide significant
+locus-phenotype pairs that are linked to 386 different genes. We found that a
+vast majority of these loci could be technically validated at a high rate:
+using classic GWAS or Genome-Wide Inferred Statistics (GWIS) we found that 85
+locus-phenotype pairs exceeded the genome-wide suggestive (P<1e-05) threshold.< p>
+
+
+
+ 84. 标题:Efficient quantum recurrent reinforcement learning via quantum reservoir computing
+ 编号:[352]
+ 链接:https://arxiv.org/abs/2309.07339
+ 作者:Samuel Yen-Chi Chen
+ 备注:
+ 关键词:solve sequential decision-making, sequential decision-making tasks, showcasing empirical quantum, Quantum reinforcement learning, reinforcement learning
+
+ 点击查看摘要
+ Quantum reinforcement learning (QRL) has emerged as a framework to solve
+sequential decision-making tasks, showcasing empirical quantum advantages. A
+notable development is through quantum recurrent neural networks (QRNNs) for
+memory-intensive tasks such as partially observable environments. However, QRL
+models incorporating QRNN encounter challenges such as inefficient training of
+QRL with QRNN, given that the computation of gradients in QRNN is both
+computationally expensive and time-consuming. This work presents a novel
+approach to address this challenge by constructing QRL agents utilizing
+QRNN-based reservoirs, specifically employing quantum long short-term memory
+(QLSTM). QLSTM parameters are randomly initialized and fixed without training.
+The model is trained using the asynchronous advantage actor-aritic (A3C)
+algorithm. Through numerical simulations, we validate the efficacy of our
+QLSTM-Reservoir RL framework. Its performance is assessed on standard
+benchmarks, demonstrating comparable results to a fully trained QLSTM RL model
+with identical architecture and training settings.
+
+
+
+ 85. 标题:Simultaneous inference for generalized linear models with unmeasured confounders
+ 编号:[356]
+ 链接:https://arxiv.org/abs/2309.07261
+ 作者:Jin-Hong Du, Larry Wasserman, Kathryn Roeder
+ 备注:61 pages, 8 figures
+ 关键词:differentially expressed genes, identify differentially expressed, Tens of thousands, expressed genes, thousands of simultaneous
+
+ 点击查看摘要
+ Tens of thousands of simultaneous hypothesis tests are routinely performed in
+genomic studies to identify differentially expressed genes. However, due to
+unmeasured confounders, many standard statistical approaches may be
+substantially biased. This paper investigates the large-scale hypothesis
+testing problem for multivariate generalized linear models in the presence of
+confounding effects. Under arbitrary confounding mechanisms, we propose a
+unified statistical estimation and inference framework that harnesses
+orthogonal structures and integrates linear projections into three key stages.
+It first leverages multivariate responses to separate marginal and uncorrelated
+confounding effects, recovering the confounding coefficients' column space.
+Subsequently, latent factors and primary effects are jointly estimated,
+utilizing $\ell_1$-regularization for sparsity while imposing orthogonality
+onto confounding coefficients. Finally, we incorporate projected and weighted
+bias-correction steps for hypothesis testing. Theoretically, we establish
+various effects' identification conditions and non-asymptotic error bounds. We
+show effective Type-I error control of asymptotic $z$-tests as sample and
+response sizes approach infinity. Numerical experiments demonstrate that the
+proposed method controls the false discovery rate by the Benjamini-Hochberg
+procedure and is more powerful than alternative methods. By comparing
+single-cell RNA-seq counts from two groups of samples, we demonstrate the
+suitability of adjusting confounding effects when significant covariates are
+absent from the model.
+
+
+
+ 86. 标题:All you need is spin: SU(2) equivariant variational quantum circuits based on spin networks
+ 编号:[359]
+ 链接:https://arxiv.org/abs/2309.07250
+ 作者:Richard D. P. East, Guillermo Alonso-Linaje, Chae-Yeun Park
+ 备注:36+14 pages
+ 关键词:algorithms require architectures, run efficiently, require architectures, architectures that naturally, naturally constrain
+
+ 点击查看摘要
+ Variational algorithms require architectures that naturally constrain the
+optimisation space to run efficiently. In geometric quantum machine learning,
+one achieves this by encoding group structure into parameterised quantum
+circuits to include the symmetries of a problem as an inductive bias. However,
+constructing such circuits is challenging as a concrete guiding principle has
+yet to emerge. In this paper, we propose the use of spin networks, a form of
+directed tensor network invariant under a group transformation, to devise SU(2)
+equivariant quantum circuit ansätze -- circuits possessing spin rotation
+symmetry. By changing to the basis that block diagonalises SU(2) group action,
+these networks provide a natural building block for constructing parameterised
+equivariant quantum circuits. We prove that our construction is mathematically
+equivalent to other known constructions, such as those based on twirling and
+generalised permutations, but more direct to implement on quantum hardware. The
+efficacy of our constructed circuits is tested by solving the ground state
+problem of SU(2) symmetric Heisenberg models on the one-dimensional triangular
+lattice and on the Kagome lattice. Our results highlight that our equivariant
+circuits boost the performance of quantum variational algorithms, indicating
+broader applicability to other real-world problems.
+
+
+
+ 87. 标题:A Robust SINDy Approach by Combining Neural Networks and an Integral Form
+ 编号:[360]
+ 链接:https://arxiv.org/abs/2309.07193
+ 作者:Ali Forootani, Pawan Goyal, Peter Benner
+ 备注:
+ 关键词:research for decades, active field, field of research, scarce data, noisy and scarce
+
+ 点击查看摘要
+ The discovery of governing equations from data has been an active field of
+research for decades. One widely used methodology for this purpose is sparse
+regression for nonlinear dynamics, known as SINDy. Despite several attempts,
+noisy and scarce data still pose a severe challenge to the success of the SINDy
+approach. In this work, we discuss a robust method to discover nonlinear
+governing equations from noisy and scarce data. To do this, we make use of
+neural networks to learn an implicit representation based on measurement data
+so that not only it produces the output in the vicinity of the measurements but
+also the time-evolution of output can be described by a dynamical system.
+Additionally, we learn such a dynamic system in the spirit of the SINDy
+framework. Leveraging the implicit representation using neural networks, we
+obtain the derivative information -- required for SINDy -- using an automatic
+differentiation tool. To enhance the robustness of our methodology, we further
+incorporate an integral condition on the output of the implicit networks.
+Furthermore, we extend our methodology to handle data collected from multiple
+initial conditions. We demonstrate the efficiency of the proposed methodology
+to discover governing equations under noisy and scarce data regimes by means of
+several examples and compare its performance with existing methods.
+
+
+
+ 88. 标题:The effect of data augmentation and 3D-CNN depth on Alzheimer's Disease detection
+ 编号:[361]
+ 链接:https://arxiv.org/abs/2309.07192
+ 作者:Rosanna Turrisi, Alessandro Verri, Annalisa Barla
+ 备注:
+ 关键词:outperforming traditional statistical, Machine Learning, traditional statistical techniques, outperforming traditional, promising approach
+
+ 点击查看摘要
+ Machine Learning (ML) has emerged as a promising approach in healthcare,
+outperforming traditional statistical techniques. However, to establish ML as a
+reliable tool in clinical practice, adherence to best practices regarding data
+handling, experimental design, and model evaluation is crucial. This work
+summarizes and strictly observes such practices to ensure reproducible and
+reliable ML. Specifically, we focus on Alzheimer's Disease (AD) detection,
+which serves as a paradigmatic example of challenging problem in healthcare. We
+investigate the impact of different data augmentation techniques and model
+complexity on the overall performance. We consider MRI data from ADNI dataset
+to address a classification problem employing 3D Convolutional Neural Network
+(CNN). The experiments are designed to compensate for data scarcity and initial
+random parameters by utilizing cross-validation and multiple training trials.
+Within this framework, we train 15 predictive models, considering three
+different data augmentation strategies and five distinct 3D CNN architectures,
+each varying in the number of convolutional layers. Specifically, the
+augmentation strategies are based on affine transformations, such as zoom,
+shift, and rotation, applied concurrently or separately. The combined effect of
+data augmentation and model complexity leads to a variation in prediction
+performance up to 10% of accuracy. When affine transformation are applied
+separately, the model is more accurate, independently from the adopted
+architecture. For all strategies, the model accuracy followed a concave
+behavior at increasing number of convolutional layers, peaking at an
+intermediate value of layers. The best model (8 CL, (B)) is the most stable
+across cross-validation folds and training trials, reaching excellent
+performance both on the testing set and on an external test set.
+
+
+
+ 89. 标题:Predicting Survival Time of Ball Bearings in the Presence of Censoring
+ 编号:[362]
+ 链接:https://arxiv.org/abs/2309.07188
+ 作者:Christian Marius Lillelund, Fernando Pannullo, Morten Opprud Jakobsen, Christian Fischer Pedersen
+ 备注:Accepted at AAAI Fall Symposium 2023 on Survival Prediction
+ 关键词:bearings find widespread, Ball bearings find, find widespread, manufacturing and mechanical, machine learning
+
+ 点击查看摘要
+ Ball bearings find widespread use in various manufacturing and mechanical
+domains, and methods based on machine learning have been widely adopted in the
+field to monitor wear and spot defects before they lead to failures. Few
+studies, however, have addressed the problem of censored data, in which failure
+is not observed. In this paper, we propose a novel approach to predict the time
+to failure in ball bearings using survival analysis. First, we analyze bearing
+data in the frequency domain and annotate when a bearing fails by comparing the
+Kullback-Leibler divergence and the standard deviation between its break-in
+frequency bins and its break-out frequency bins. Second, we train several
+survival models to estimate the time to failure based on the annotated data and
+covariates extracted from the time domain, such as skewness, kurtosis and
+entropy. The models give a probabilistic prediction of risk over time and allow
+us to compare the survival function between groups of bearings. We demonstrate
+our approach on the XJTU and PRONOSTIA datasets. On XJTU, the best result is a
+0.70 concordance-index and 0.21 integrated Brier score. On PRONOSTIA, the best
+is a 0.76 concordance-index and 0.19 integrated Brier score. Our work motivates
+further work on incorporating censored data in models for predictive
+maintenance.
+
+
+
+ 90. 标题:Audio-Based Classification of Respiratory Diseases using Advanced Signal Processing and Machine Learning for Assistive Diagnosis Support
+ 编号:[364]
+ 链接:https://arxiv.org/abs/2309.07183
+ 作者:Constantino Álvarez Casado, Manuel Lage Cañellas, Matteo Pedone, Xiaoting Wu, Miguel Bordallo López
+ 备注:5 pages, 2 figures, 3 tables, Conference paper
+ 关键词:Empirical Mode Decomposition, global healthcare, combines Empirical Mode, Mode Decomposition, advance rapid screening
+
+ 点击查看摘要
+ In global healthcare, respiratory diseases are a leading cause of mortality,
+underscoring the need for rapid and accurate diagnostics. To advance rapid
+screening techniques via auscultation, our research focuses on employing one of
+the largest publicly available medical database of respiratory sounds to train
+multiple machine learning models able to classify different health conditions.
+Our method combines Empirical Mode Decomposition (EMD) and spectral analysis to
+extract physiologically relevant biosignals from acoustic data, closely tied to
+cardiovascular and respiratory patterns, making our approach apart in its
+departure from conventional audio feature extraction practices. We use Power
+Spectral Density analysis and filtering techniques to select Intrinsic Mode
+Functions (IMFs) strongly correlated with underlying physiological phenomena.
+These biosignals undergo a comprehensive feature extraction process for
+predictive modeling. Initially, we deploy a binary classification model that
+demonstrates a balanced accuracy of 87% in distinguishing between healthy and
+diseased individuals. Subsequently, we employ a six-class classification model
+that achieves a balanced accuracy of 72% in diagnosing specific respiratory
+conditions like pneumonia and chronic obstructive pulmonary disease (COPD). For
+the first time, we also introduce regression models that estimate age and body
+mass index (BMI) based solely on acoustic data, as well as a model for gender
+classification. Our findings underscore the potential of this approach to
+significantly enhance assistive and remote diagnostic capabilities.
+
+
+
+ 91. 标题:Sleep Stage Classification Using a Pre-trained Deep Learning Model
+ 编号:[365]
+ 链接:https://arxiv.org/abs/2309.07182
+ 作者:Hassan Ardeshir, Mohammad Araghi
+ 备注:7 pages, 5 figures, 1 table
+ 关键词:common human diseases, sleep disorders, diagnosing sleep disorders, common human, sleep stages
+
+ 点击查看摘要
+ One of the common human diseases is sleep disorders. The classification of
+sleep stages plays a fundamental role in diagnosing sleep disorders, monitoring
+treatment effectiveness, and understanding the relationship between sleep
+stages and various health conditions. A precise and efficient classification of
+these stages can significantly enhance our understanding of sleep-related
+phenomena and ultimately lead to improved health outcomes and disease
+treatment.
+Models others propose are often time-consuming and lack sufficient accuracy,
+especially in stage N1. The main objective of this research is to present a
+machine-learning model called "EEGMobile". This model utilizes pre-trained
+models and learns from electroencephalogram (EEG) spectrograms of brain
+signals. The model achieved an accuracy of 86.97% on a publicly available
+dataset named "Sleep-EDF20", outperforming other models proposed by different
+researchers. Moreover, it recorded an accuracy of 56.4% in stage N1, which is
+better than other models. These findings demonstrate that this model has the
+potential to achieve better results for the treatment of this disease.
+
+
+
+ 92. 标题:CloudBrain-NMR: An Intelligent Cloud Computing Platform for NMR Spectroscopy Processing, Reconstruction and Analysis
+ 编号:[366]
+ 链接:https://arxiv.org/abs/2309.07178
+ 作者:Di Guo, Sijin Li, Jun Liu, Zhangren Tu, Tianyu Qiu, Jingjing Xu, Liubin Feng, Donghai Lin, Qing Hong, Meijin Lin, Yanqin Lin, Xiaobo Qu
+ 备注:11 pages, 13 figures
+ 关键词:Nuclear Magnetic Resonance, Magnetic Resonance, studying molecular structure, Nuclear Magnetic, powerful analytical tool
+
+ 点击查看摘要
+ Nuclear Magnetic Resonance (NMR) spectroscopy has served as a powerful
+analytical tool for studying molecular structure and dynamics in chemistry and
+biology. However, the processing of raw data acquired from NMR spectrometers
+and subsequent quantitative analysis involves various specialized tools, which
+necessitates comprehensive knowledge in programming and NMR. Particularly, the
+emerging deep learning tools is hard to be widely used in NMR due to the
+sophisticated setup of computation. Thus, NMR processing is not an easy task
+for chemist and biologists. In this work, we present CloudBrain-NMR, an
+intelligent online cloud computing platform designed for NMR data reading,
+processing, reconstruction, and quantitative analysis. The platform is
+conveniently accessed through a web browser, eliminating the need for any
+program installation on the user side. CloudBrain-NMR uses parallel computing
+with graphics processing units and central processing units, resulting in
+significantly shortened computation time. Furthermore, it incorporates
+state-of-the-art deep learning-based algorithms offering comprehensive
+functionalities that allow users to complete the entire processing procedure
+without relying on additional software. This platform has empowered NMR
+applications with advanced artificial intelligence processing. CloudBrain-NMR
+is openly accessible for free usage at this https URL
+
+
+
+ 93. 标题:MELAGE: A purely python based Neuroimaging software (Neonatal)
+ 编号:[367]
+ 链接:https://arxiv.org/abs/2309.07175
+ 作者:Bahram Jafrasteh, Simón Pedro Lubián López, Isabel Benavente Fernández
+ 备注:
+ 关键词:pioneering Python-based neuroimaging, Python-based neuroimaging software, pioneering Python-based, Python-based neuroimaging, MELAGE
+
+ 点击查看摘要
+ MELAGE, a pioneering Python-based neuroimaging software, emerges as a
+versatile tool for the visualization, processing, and analysis of medical
+images. Initially conceived to address the unique challenges of processing 3D
+ultrasound and MRI brain images during the neonatal period, MELAGE exhibits
+remarkable adaptability, extending its utility to the domain of adult human
+brain imaging. At its core, MELAGE features a semi-automatic brain extraction
+tool empowered by a deep learning module, ensuring precise and efficient brain
+structure extraction from MRI and 3D Ultrasound data. Moreover, MELAGE offers a
+comprehensive suite of features, encompassing dynamic 3D visualization,
+accurate measurements, and interactive image segmentation. This transformative
+software holds immense promise for researchers and clinicians, offering
+streamlined image analysis, seamless integration with deep learning algorithms,
+and broad applicability in the realm of medical imaging.
+
+
+
+ 94. 标题:Overview of Human Activity Recognition Using Sensor Data
+ 编号:[368]
+ 链接:https://arxiv.org/abs/2309.07170
+ 作者:Rebeen Ali Hamad, Wai Lok Woo, Bo Wei, Longzhi Yang
+ 备注:
+ 关键词:Human activity recognition, essential research field, HAR, Human activity, activity recognition
+
+ 点击查看摘要
+ Human activity recognition (HAR) is an essential research field that has been
+used in different applications including home and workplace automation,
+security and surveillance as well as healthcare. Starting from conventional
+machine learning methods to the recently developing deep learning techniques
+and the Internet of things, significant contributions have been shown in the
+HAR area in the last decade. Even though several review and survey studies have
+been published, there is a lack of sensor-based HAR overview studies focusing
+on summarising the usage of wearable sensors and smart home sensors data as
+well as applications of HAR and deep learning techniques. Hence, we overview
+sensor-based HAR, discuss several important applications that rely on HAR, and
+highlight the most common machine learning methods that have been used for HAR.
+Finally, several challenges of HAR are explored that should be addressed to
+further improve the robustness of HAR.
+
+
+
+ 95. 标题:Frequency Convergence of Complexon Shift Operators
+ 编号:[369]
+ 链接:https://arxiv.org/abs/2309.07169
+ 作者:Purui Zhang, Xingchao Jian, Feng Ji, Wee Peng Tay, Bihan Wen
+ 备注:7 pages, 0 figures
+ 关键词:vertices and edges, model structures, structures with higher, higher order, order than vertices
+
+ 点击查看摘要
+ Topological signal processing (TSP) utilizes simplicial complexes to model
+structures with higher order than vertices and edges. In this paper, we study
+the transferability of TSP via a generalized higher-order version of graphon,
+known as complexon. We recall the notion of a complexon as the limit of a
+simplicial complex sequence [1]. Inspired by the integral operator form of
+graphon shift operators, we construct a marginal complexon and complexon shift
+operator (CSO) according to components of all possible dimensions from the
+complexon. We investigate the CSO's eigenvalues and eigenvectors, and relate
+them to a new family of weighted adjacency matrices. We prove that when a
+simplicial complex sequence converges to a complexon, the eigenvalues of the
+corresponding CSOs converge to that of the limit complexon. These results hint
+at learning transferability on large simplicial complexes or simplicial complex
+sequences, which generalize the graphon signal processing framework.
+
+
+
+ 96. 标题:Systematic Review of Experimental Paradigms and Deep Neural Networks for Electroencephalography-Based Cognitive Workload Detection
+ 编号:[371]
+ 链接:https://arxiv.org/abs/2309.07163
+ 作者:Vishnu KN, Cota Navin Gupta
+ 备注:10 Pages, 4 figures
+ 关键词:based cognitive workload, summarizes a systematic, EEG signals, article summarizes, based cognitive
+
+ 点击查看摘要
+ This article summarizes a systematic review of the electroencephalography
+(EEG)-based cognitive workload (CWL) estimation. The focus of the article is
+twofold: identify the disparate experimental paradigms used for reliably
+eliciting discreet and quantifiable levels of cognitive load and the specific
+nature and representational structure of the commonly used input formulations
+in deep neural networks (DNNs) used for signal classification. The analysis
+revealed a number of studies using EEG signals in its native representation of
+a two-dimensional matrix for offline classification of CWL. However, only a few
+studies adopted an online or pseudo-online classification strategy for
+real-time CWL estimation. Further, only a couple of interpretable DNNs and a
+single generative model were employed for cognitive load detection till date
+during this review. More often than not, researchers were using DNNs as
+black-box type models. In conclusion, DNNs prove to be valuable tools for
+classifying EEG signals, primarily due to the substantial modeling power
+provided by the depth of their network architecture. It is further suggested
+that interpretable and explainable DNN models must be employed for cognitive
+workload estimation since existing methods are limited in the face of the
+non-stationary nature of the signal.
+
+
+
+ 97. 标题:A Strong and Simple Deep Learning Baseline for BCI MI Decoding
+ 编号:[372]
+ 链接:https://arxiv.org/abs/2309.07159
+ 作者:Yassine El Ouahidi, Vincent Gripon, Bastien Pasdeloup, Ghaith Bouallegue, Nicolas Farrugia, Giulia Lioi
+ 备注:
+ 关键词:convolutional neural network, Motor Imagery decoding, EEG Motor Imagery, Motor Imagery, Motor Imagery datasets
+
+ 点击查看摘要
+ We propose EEG-SimpleConv, a straightforward 1D convolutional neural network
+for Motor Imagery decoding in BCI. Our main motivation is to propose a very
+simple baseline to compare to, using only very standard ingredients from the
+literature. We evaluate its performance on four EEG Motor Imagery datasets,
+including simulated online setups, and compare it to recent Deep Learning and
+Machine Learning approaches. EEG-SimpleConv is at least as good or far more
+efficient than other approaches, showing strong knowledge-transfer capabilities
+across subjects, at the cost of a low inference time. We advocate that using
+off-the-shelf ingredients rather than coming with ad-hoc solutions can
+significantly help the adoption of Deep Learning approaches for BCI. We make
+the code of the models and the experiments accessible.
+
+
+
+ 98. 标题:A Deep Dive into Sleep: Single-Channel EEG-Based Sleep Stage Classification with Model Interpretability
+ 编号:[373]
+ 链接:https://arxiv.org/abs/2309.07156
+ 作者:Shivam Sharma, Suvadeep Maiti, S.Mythirayee, Srijithesh Rajendran, Bapi Raju
+ 备注:
+ 关键词:occupies a significant, significant portion, fundamental physiological process, Sleep, sleep stage classification
+
+ 点击查看摘要
+ Sleep, a fundamental physiological process, occupies a significant portion of
+our lives. Accurate classification of sleep stages serves as a crucial tool for
+evaluating sleep quality and identifying probable sleep disorders. This work
+introduces a novel methodology that utilises a SE-Resnet-Bi-LSTM architecture
+to classify sleep into five separate stages. The classification process is
+based on the analysis of single-channel electroencephalograms (EEGs). The
+framework that has been suggested consists of two fundamental elements: a
+feature extractor that utilises SE-ResNet, and a temporal context encoder that
+use stacks of Bi-LSTM units.The effectiveness of our approach is substantiated
+by thorough assessments conducted on three different datasets, namely
+SLeepEDF-20, SleepEDF-78, and SHHS. Significantly, our methodology attains
+notable levels of accuracy, specifically 87.5\%, 83.9\%, and 87.8\%, along with
+macro-F1 scores of 82.5, 78.9, and 81.9 for the corresponding datasets.
+Notably, we introduce the utilization of 1D-GradCAM visualization to shed light
+on the decision-making process of our model in the realm of sleep stage
+classification. This visualization method not only provides valuable insights
+into the model's classification rationale but also aligns its outcomes with the
+annotations made by sleep experts. One notable feature of our research is the
+integration of an expedited training approach, which effectively preserves the
+model's resilience in terms of performance. The experimental evaluations
+conducted provide a comprehensive evaluation of the effectiveness of our
+proposed model in comparison to existing approaches, highlighting its potential
+for practical applications.
+
+
+
+ 99. 标题:Decoding visual brain representations from electroencephalography through Knowledge Distillation and latent diffusion models
+ 编号:[376]
+ 链接:https://arxiv.org/abs/2309.07149
+ 作者:Matteo Ferrante, Tommaso Boccato, Stefano Bargione, Nicola Toschi
+ 备注:
+ 关键词:thriving research domain, brain-computer interfaces, representations from human, context of brain-computer, Decoding visual representations
+
+ 点击查看摘要
+ Decoding visual representations from human brain activity has emerged as a
+thriving research domain, particularly in the context of brain-computer
+interfaces. Our study presents an innovative method that employs to classify
+and reconstruct images from the ImageNet dataset using electroencephalography
+(EEG) data from subjects that had viewed the images themselves (i.e. "brain
+decoding"). We analyzed EEG recordings from 6 participants, each exposed to 50
+images spanning 40 unique semantic categories. These EEG readings were
+converted into spectrograms, which were then used to train a convolutional
+neural network (CNN), integrated with a knowledge distillation procedure based
+on a pre-trained Contrastive Language-Image Pre-Training (CLIP)-based image
+classification teacher network. This strategy allowed our model to attain a
+top-5 accuracy of 80%, significantly outperforming a standard CNN and various
+RNN-based benchmarks. Additionally, we incorporated an image reconstruction
+mechanism based on pre-trained latent diffusion models, which allowed us to
+generate an estimate of the images which had elicited EEG activity. Therefore,
+our architecture not only decodes images from neural activity but also offers a
+credible image reconstruction from EEG only, paving the way for e.g. swift,
+individualized feedback experiments. Our research represents a significant step
+forward in connecting neural signals with visual cognition.
+
+
+
+ 100. 标题:DGSD: Dynamical Graph Self-Distillation for EEG-Based Auditory Spatial Attention Detection
+ 编号:[377]
+ 链接:https://arxiv.org/abs/2309.07147
+ 作者:Cunhang Fan, Hongyu Zhang, Wei Huang, Jun Xue, Jianhua Tao, Jiangyan Yi, Zhao Lv, Xiaopei Wu
+ 备注:
+ 关键词:detect target speaker, EEG signals, aims to detect, multi-speaker environment, detect target
+
+ 点击查看摘要
+ Auditory Attention Detection (AAD) aims to detect target speaker from brain
+signals in a multi-speaker environment. Although EEG-based AAD methods have
+shown promising results in recent years, current approaches primarily rely on
+traditional convolutional neural network designed for processing Euclidean data
+like images. This makes it challenging to handle EEG signals, which possess
+non-Euclidean characteristics. In order to address this problem, this paper
+proposes a dynamical graph self-distillation (DGSD) approach for AAD, which
+does not require speech stimuli as input. Specifically, to effectively
+represent the non-Euclidean properties of EEG signals, dynamical graph
+convolutional networks are applied to represent the graph structure of EEG
+signals, which can also extract crucial features related to auditory spatial
+attention in EEG signals. In addition, to further improve AAD detection
+performance, self-distillation, consisting of feature distillation and
+hierarchical distillation strategies at each layer, is integrated. These
+strategies leverage features and classification results from the deepest
+network layers to guide the learning of shallow layers. Our experiments are
+conducted on two publicly available datasets, KUL and DTU. Under a 1-second
+time window, we achieve results of 90.0\% and 79.6\% accuracy on KUL and DTU,
+respectively. We compare our DGSD method with competitive baselines, and the
+experimental results indicate that the detection performance of our proposed
+DGSD method is not only superior to the best reproducible baseline but also
+significantly reduces the number of trainable parameters by approximately 100
+times.
+
+
+
+ 101. 标题:ETP: Learning Transferable ECG Representations via ECG-Text Pre-training
+ 编号:[378]
+ 链接:https://arxiv.org/abs/2309.07145
+ 作者:Che Liu, Zhongwei Wan, Sibo Cheng, Mi Zhang, Rossella Arcucci
+ 备注:under review
+ 关键词:non-invasive diagnostic tool, cardiovascular healthcare, non-invasive diagnostic, diagnostic tool, ECG
+
+ 点击查看摘要
+ In the domain of cardiovascular healthcare, the Electrocardiogram (ECG)
+serves as a critical, non-invasive diagnostic tool. Although recent strides in
+self-supervised learning (SSL) have been promising for ECG representation
+learning, these techniques often require annotated samples and struggle with
+classes not present in the fine-tuning stages. To address these limitations, we
+introduce ECG-Text Pre-training (ETP), an innovative framework designed to
+learn cross-modal representations that link ECG signals with textual reports.
+For the first time, this framework leverages the zero-shot classification task
+in the ECG domain. ETP employs an ECG encoder along with a pre-trained language
+model to align ECG signals with their corresponding textual reports. The
+proposed framework excels in both linear evaluation and zero-shot
+classification tasks, as demonstrated on the PTB-XL and CPSC2018 datasets,
+showcasing its ability for robust and generalizable cross-modal ECG feature
+learning.
+
+
+
+ 102. 标题:Design of Recognition and Evaluation System for Table Tennis Players' Motor Skills Based on Artificial Intelligence
+ 编号:[379]
+ 链接:https://arxiv.org/abs/2309.07141
+ 作者:Zhuo-yong Shi, Ye-tao Jia, Ke-xin Zhang, Ding-han Wang, Long-meng Ji, Yong Wu
+ 备注:34pages, 16figures
+ 关键词:table tennis, wearable devices, table tennis sport, table tennis players', improves wearable devices
+
+ 点击查看摘要
+ With the rapid development of electronic science and technology, the research
+on wearable devices is constantly updated, but for now, it is not comprehensive
+for wearable devices to recognize and analyze the movement of specific sports.
+Based on this, this paper improves wearable devices of table tennis sport, and
+realizes the pattern recognition and evaluation of table tennis players' motor
+skills through artificial intelligence. Firstly, a device is designed to
+collect the movement information of table tennis players and the actual
+movement data is processed. Secondly, a sliding window is made to divide the
+collected motion data into a characteristic database of six table tennis
+benchmark movements. Thirdly, motion features were constructed based on feature
+engineering, and motor skills were identified for different models after
+dimensionality reduction. Finally, the hierarchical evaluation system of motor
+skills is established with the loss functions of different evaluation indexes.
+The results show that in the recognition of table tennis players' motor skills,
+the feature-based BP neural network proposed in this paper has higher
+recognition accuracy and stronger generalization ability than the traditional
+convolutional neural network.
+
+
+
+ 103. 标题:Short-term power load forecasting method based on CNN-SAEDN-Res
+ 编号:[380]
+ 链接:https://arxiv.org/abs/2309.07140
+ 作者:Yang Cui, Han Zhu, Yijian Wang, Lu Zhang, Yang Li
+ 备注:in Chinese language, Accepted by Electric Power Automation Equipment
+ 关键词:neural network, deep learning, convolutional neural network, difficult to process, process by sequence
+
+ 点击查看摘要
+ In deep learning, the load data with non-temporal factors are difficult to
+process by sequence models. This problem results in insufficient precision of
+the prediction. Therefore, a short-term load forecasting method based on
+convolutional neural network (CNN), self-attention encoder-decoder network
+(SAEDN) and residual-refinement (Res) is proposed. In this method, feature
+extraction module is composed of a two-dimensional convolutional neural
+network, which is used to mine the local correlation between data and obtain
+high-dimensional data features. The initial load fore-casting module consists
+of a self-attention encoder-decoder network and a feedforward neural network
+(FFN). The module utilizes self-attention mechanisms to encode high-dimensional
+features. This operation can obtain the global correlation between data.
+Therefore, the model is able to retain important information based on the
+coupling relationship between the data in data mixed with non-time series
+factors. Then, self-attention decoding is per-formed and the feedforward neural
+network is used to regression initial load. This paper introduces the residual
+mechanism to build the load optimization module. The module generates residual
+load values to optimize the initial load. The simulation results show that the
+proposed load forecasting method has advantages in terms of prediction accuracy
+and prediction stability.
+
+
+
+ 104. 标题:Self-Supervised Blind Source Separation via Multi-Encoder Autoencoders
+ 编号:[381]
+ 链接:https://arxiv.org/abs/2309.07138
+ 作者:Matthew B. Webster, Joonnyong Lee
+ 备注:17 pages, 8 figures, submitted to Information Sciences
+ 关键词:involves separating sources, mixing system, involves separating, blind source separation, task of blind
+
+ 点击查看摘要
+ The task of blind source separation (BSS) involves separating sources from a
+mixture without prior knowledge of the sources or the mixing system. This is a
+challenging problem that often requires making restrictive assumptions about
+both the mixing system and the sources. In this paper, we propose a novel
+method for addressing BSS of non-linear mixtures by leveraging the natural
+feature subspace specialization ability of multi-encoder autoencoders with
+fully self-supervised learning without strong priors. During the training
+phase, our method unmixes the input into the separate encoding spaces of the
+multi-encoder network and then remixes these representations within the decoder
+for a reconstruction of the input. Then to perform source inference, we
+introduce a novel encoding masking technique whereby masking out all but one of
+the encodings enables the decoder to estimate a source signal. To this end, we
+also introduce a so-called pathway separation loss that encourages sparsity
+between the unmixed encoding spaces throughout the decoder's layers and a
+so-called zero reconstruction loss on the decoder for coherent source
+estimations. In order to carefully evaluate our method, we conduct experiments
+on a toy dataset and with real-world biosignal recordings from a
+polysomnography sleep study for extracting respiration.
+
+
+
+ 105. 标题:Masked Transformer for Electrocardiogram Classification
+ 编号:[382]
+ 链接:https://arxiv.org/abs/2309.07136
+ 作者:Ya Zhou, Xiaolin Diao, Yanni Huo, Yang Liu, Xiaohan Fan, Wei Zhao
+ 备注:
+ 关键词:important diagnostic tools, ECG, important diagnostic, diagnostic tools, tools in clinical
+
+ 点击查看摘要
+ Electrocardiogram (ECG) is one of the most important diagnostic tools in
+clinical applications. With the advent of advanced algorithms, various deep
+learning models have been adopted for ECG tasks. However, the potential of
+Transformers for ECG data is not yet realized, despite their widespread success
+in computer vision and natural language processing. In this work, we present a
+useful masked Transformer method for ECG classification referred to as MTECG,
+which expands the application of masked autoencoders to ECG time series. We
+construct a dataset comprising 220,251 ECG recordings with a broad range of
+diagnoses annoated by medical experts to explore the properties of MTECG. Under
+the proposed training strategies, a lightweight model with 5.7M parameters
+performs stably well on a broad range of masking ratios (5%-75%). The ablation
+studies highlight the importance of fluctuated reconstruction targets, training
+schedule length, layer-wise LR decay and DropPath rate. The experiments on both
+private and public ECG datasets demonstrate that MTECG-T significantly
+outperforms the recent state-of-the-art algorithms in ECG classification.
+
+
+
+ 106. 标题:EpiDeNet: An Energy-Efficient Approach to Seizure Detection for Embedded Systems
+ 编号:[383]
+ 链接:https://arxiv.org/abs/2309.07135
+ 作者:Thorir Mar Ingolfsson, Upasana Chakraborty, Xiaying Wang, Sandor Beniczky, Pauline Ducouret, Simone Benatti, Philippe Ryvlin, Andrea Cossettini, Luca Benini
+ 备注:5 pages, 4 tables, 1 figure, Accepted at BioCAS 2023
+ 关键词:prevalent neurological disorder, continuous monitoring coupled, effective patient treatment, individuals globally, patient treatment
+
+ 点击查看摘要
+ Epilepsy is a prevalent neurological disorder that affects millions of
+individuals globally, and continuous monitoring coupled with automated seizure
+detection appears as a necessity for effective patient treatment. To enable
+long-term care in daily-life conditions, comfortable and smart wearable devices
+with long battery life are required, which in turn set the demand for
+resource-constrained and energy-efficient computing solutions. In this context,
+the development of machine learning algorithms for seizure detection faces the
+challenge of heavily imbalanced datasets. This paper introduces EpiDeNet, a new
+lightweight seizure detection network, and Sensitivity-Specificity Weighted
+Cross-Entropy (SSWCE), a new loss function that incorporates sensitivity and
+specificity, to address the challenge of heavily unbalanced datasets. The
+proposed EpiDeNet-SSWCE approach demonstrates the successful detection of
+91.16% and 92.00% seizure events on two different datasets (CHB-MIT and
+PEDESITE, respectively), with only four EEG channels. A three-window majority
+voting-based smoothing scheme combined with the SSWCE loss achieves 3x
+reduction of false positives to 1.18 FP/h. EpiDeNet is well suited for
+implementation on low-power embedded platforms, and we evaluate its performance
+on two ARM Cortex-based platforms (M4F/M7) and two parallel ultra-low power
+(PULP) systems (GAP8, GAP9). The most efficient implementation (GAP9) achieves
+an energy efficiency of 40 GMAC/s/W, with an energy consumption per inference
+of only 0.051 mJ at high performance (726.46 MMAC/s), outperforming the best
+ARM Cortex-based solutions by approximately 160x in energy efficiency. The
+EpiDeNet-SSWCE method demonstrates effective and accurate seizure detection
+performance on heavily imbalanced datasets, while being suited for
+implementation on energy-constrained platforms.
+
+
+
+ 107. 标题:Entropy-based machine learning model for diagnosis and monitoring of Parkinson's Disease in smart IoT environment
+ 编号:[384]
+ 链接:https://arxiv.org/abs/2309.07134
+ 作者:Maksim Belyaev, Murugappan Murugappan, Andrei Velichko, Dmitry Korzun
+ 备注:19 pages, 10 figures, 2 tables
+ 关键词:monitoring Parkinson disease, Internet of Things, efficient machine learning, computationally efficient machine, Parkinson disease
+
+ 点击查看摘要
+ The study presents the concept of a computationally efficient machine
+learning (ML) model for diagnosing and monitoring Parkinson's disease (PD) in
+an Internet of Things (IoT) environment using rest-state EEG signals (rs-EEG).
+We computed different types of entropy from EEG signals and found that Fuzzy
+Entropy performed the best in diagnosing and monitoring PD using rs-EEG. We
+also investigated different combinations of signal frequency ranges and EEG
+channels to accurately diagnose PD. Finally, with a fewer number of features
+(11 features), we achieved a maximum classification accuracy (ARKF) of ~99.9%.
+The most prominent frequency range of EEG signals has been identified, and we
+have found that high classification accuracy depends on low-frequency signal
+components (0-4 Hz). Moreover, the most informative signals were mainly
+received from the right hemisphere of the head (F8, P8, T8, FC6). Furthermore,
+we assessed the accuracy of the diagnosis of PD using three different lengths
+of EEG data (150-1000 samples). Because the computational complexity is reduced
+by reducing the input data. As a result, we have achieved a maximum mean
+accuracy of 99.9% for a sample length (LEEG) of 1000 (~7.8 seconds), 98.2% with
+a LEEG of 800 (~6.2 seconds), and 79.3% for LEEG = 150 (~1.2 seconds). By
+reducing the number of features and segment lengths, the computational cost of
+classification can be reduced. Lower-performance smart ML sensors can be used
+in IoT environments for enhances human resilience to PD.
+
+
+
+ 108. 标题:Using wearable device-based machine learning models to autonomously identify older adults with poor cognition
+ 编号:[385]
+ 链接:https://arxiv.org/abs/2309.07133
+ 作者:Collin Sakal, Tingyou Li, Juan Li, Xinyue Li
+ 备注:
+ 关键词:patients and clinicians, time-consuming for patients, Digit Symbol Substitution, Animal Fluency Test, models
+
+ 点击查看摘要
+ Conducting cognitive tests is time-consuming for patients and clinicians.
+Wearable device-based prediction models allow for continuous health monitoring
+under normal living conditions and could offer an alternative to identifying
+older adults with cognitive impairments for early interventions. In this study,
+we first derived novel wearable-based features related to circadian rhythms,
+ambient light exposure, physical activity levels, sleep, and signal processing.
+Then, we quantified the ability of wearable-based machine-learning models to
+predict poor cognition based on outcomes from the Digit Symbol Substitution
+Test (DSST), the Consortium to Establish a Registry for Alzheimers Disease
+Word-Learning subtest (CERAD-WL), and the Animal Fluency Test (AFT). We found
+that the wearable-based models had significantly higher AUCs when predicting
+all three cognitive outcomes compared to benchmark models containing age, sex,
+education, marital status, household income, diabetic status, depression
+symptoms, and functional independence scores. In addition to uncovering
+previously unidentified wearable-based features that are predictive of poor
+cognition such as the standard deviation of the midpoints of each persons most
+active 10-hour periods and least active 5-hour periods, our paper provides
+proof-of-concept that wearable-based machine learning models can be used to
+autonomously screen older adults for possible cognitive impairments. Such
+models offer cost-effective alternatives to conducting initial screenings
+manually in clinical settings.
+
+
+人工智能
+
+ 1. 标题:MMICL: Empowering Vision-language Model with Multi-Modal In-Context Learning
+ 编号:[5]
+ 链接:https://arxiv.org/abs/2309.07915
+ 作者:Haozhe Zhao, Zefan Cai, Shuzheng Si, Xiaojian Ma, Kaikai An, Liang Chen, Zixuan Liu, Sheng Wang, Wenjuan Han, Baobao Chang
+ 备注:Code, dataset, checkpoints, and demos are available at \href{https://github.com/HaozheZhao/MIC}{this https URL}
+ 关键词:benefiting from large, resurgence of deep, multi-modal prompts, multiple images, deep learning
+
+ 点击查看摘要
+ Starting from the resurgence of deep learning, vision-language models (VLMs)
+benefiting from large language models (LLMs) have never been so popular.
+However, while LLMs can utilize extensive background knowledge and task
+information with in-context learning, most VLMs still struggle with
+understanding complex multi-modal prompts with multiple images. The issue can
+traced back to the architectural design of VLMs or pre-training data.
+Specifically, the current VLMs primarily emphasize utilizing multi-modal data
+with a single image some, rather than multi-modal prompts with interleaved
+multiple images and text. Even though some newly proposed VLMs could handle
+user prompts with multiple images, pre-training data does not provide more
+sophisticated multi-modal prompts than interleaved image and text crawled from
+the web. We propose MMICL to address the issue by considering both the model
+and data perspectives. We introduce a well-designed architecture capable of
+seamlessly integrating visual and textual context in an interleaved manner and
+MIC dataset to reduce the gap between the training data and the complex user
+prompts in real-world applications, including: 1) multi-modal context with
+interleaved images and text, 2) textual references for each image, and 3)
+multi-image data with spatial, logical, or temporal relationships. Our
+experiments confirm that MMICL achieves new stat-of-the-art zero-shot and
+few-shot performance on a wide range of general vision-language tasks,
+especially for complex reasoning benchmarks including MME and MMBench. Our
+analysis demonstrates that MMICL effectively deals with the challenge of
+complex multi-modal prompt understanding. The experiments on ScienceQA-IMG also
+show that MMICL successfully alleviates the issue of language bias in VLMs,
+which we believe is the reason behind the advanced performance of MMICL.
+
+
+
+ 2. 标题:Beta Diffusion
+ 编号:[27]
+ 链接:https://arxiv.org/abs/2309.07867
+ 作者:Mingyuan Zhou, Tianqi Chen, Zhendong Wang, Huangjie Zheng
+ 备注:
+ 关键词:beta diffusion, introduce beta diffusion, bounded ranges, beta, method that integrates
+
+ 点击查看摘要
+ We introduce beta diffusion, a novel generative modeling method that
+integrates demasking and denoising to generate data within bounded ranges.
+Using scaled and shifted beta distributions, beta diffusion utilizes
+multiplicative transitions over time to create both forward and reverse
+diffusion processes, maintaining beta distributions in both the forward
+marginals and the reverse conditionals, given the data at any point in time.
+Unlike traditional diffusion-based generative models relying on additive
+Gaussian noise and reweighted evidence lower bounds (ELBOs), beta diffusion is
+multiplicative and optimized with KL-divergence upper bounds (KLUBs) derived
+from the convexity of the KL divergence. We demonstrate that the proposed KLUBs
+are more effective for optimizing beta diffusion compared to negative ELBOs,
+which can also be derived as the KLUBs of the same KL divergence with its two
+arguments swapped. The loss function of beta diffusion, expressed in terms of
+Bregman divergence, further supports the efficacy of KLUBs for optimization.
+Experimental results on both synthetic data and natural images demonstrate the
+unique capabilities of beta diffusion in generative modeling of range-bounded
+data and validate the effectiveness of KLUBs in optimizing diffusion models,
+thereby making them valuable additions to the family of diffusion-based
+generative models and the optimization techniques used to train them.
+
+
+
+ 3. 标题:The Rise and Potential of Large Language Model Based Agents: A Survey
+ 编号:[30]
+ 链接:https://arxiv.org/abs/2309.07864
+ 作者:Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, Rui Zheng, Xiaoran Fan, Xiao Wang, Limao Xiong, Qin Liu, Yuhao Zhou, Weiran Wang, Changhao Jiang, Yicheng Zou, Xiangyang Liu, Zhangyue Yin, Shihan Dou, Rongxiang Weng, Wensen Cheng, Qi Zhang, Wenjuan Qin, Yongyan Zheng, Xipeng Qiu, Xuanjing Huan, Tao Gui
+ 备注:86 pages, 12 figures
+ 关键词:pursued artificial intelligence, long time, humanity has pursued, agents, considered a promising
+
+ 点击查看摘要
+ For a long time, humanity has pursued artificial intelligence (AI) equivalent
+to or surpassing the human level, with AI agents considered a promising vehicle
+for this pursuit. AI agents are artificial entities that sense their
+environment, make decisions, and take actions. Many efforts have been made to
+develop intelligent AI agents since the mid-20th century. However, these
+efforts have mainly focused on advancement in algorithms or training strategies
+to enhance specific capabilities or performance on particular tasks. Actually,
+what the community lacks is a sufficiently general and powerful model to serve
+as a starting point for designing AI agents that can adapt to diverse
+scenarios. Due to the versatile and remarkable capabilities they demonstrate,
+large language models (LLMs) are regarded as potential sparks for Artificial
+General Intelligence (AGI), offering hope for building general AI agents. Many
+research efforts have leveraged LLMs as the foundation to build AI agents and
+have achieved significant progress. We start by tracing the concept of agents
+from its philosophical origins to its development in AI, and explain why LLMs
+are suitable foundations for AI agents. Building upon this, we present a
+conceptual framework for LLM-based agents, comprising three main components:
+brain, perception, and action, and the framework can be tailored to suit
+different applications. Subsequently, we explore the extensive applications of
+LLM-based agents in three aspects: single-agent scenarios, multi-agent
+scenarios, and human-agent cooperation. Following this, we delve into agent
+societies, exploring the behavior and personality of LLM-based agents, the
+social phenomena that emerge when they form societies, and the insights they
+offer for human society. Finally, we discuss a range of key topics and open
+problems within the field.
+
+
+
+ 4. 标题:CiwaGAN: Articulatory information exchange
+ 编号:[31]
+ 链接:https://arxiv.org/abs/2309.07861
+ 作者:Gašper Beguš, Thomas Lu, Alan Zhou, Peter Wu, Gopala K. Anumanchipalli
+ 备注:
+ 关键词:controlling articulators, articulators and decode, Humans encode information, auditory apparatus, sounds
+
+ 点击查看摘要
+ Humans encode information into sounds by controlling articulators and decode
+information from sounds using the auditory apparatus. This paper introduces
+CiwaGAN, a model of human spoken language acquisition that combines
+unsupervised articulatory modeling with an unsupervised model of information
+exchange through the auditory modality. While prior research includes
+unsupervised articulatory modeling and information exchange separately, our
+model is the first to combine the two components. The paper also proposes an
+improved articulatory model with more interpretable internal representations.
+The proposed CiwaGAN model is the most realistic approximation of human spoken
+language acquisition using deep learning. As such, it is useful for cognitively
+plausible simulations of the human speech act.
+
+
+
+ 5. 标题:ExpertQA: Expert-Curated Questions and Attributed Answers
+ 编号:[34]
+ 链接:https://arxiv.org/abs/2309.07852
+ 作者:Chaitanya Malaviya, Subin Lee, Sihao Chen, Elizabeth Sieber, Mark Yatskar, Dan Roth
+ 备注:Dataset & code is available at this https URL
+ 关键词:provide factually correct, factually correct information, correct information supported, set of users, sophisticated and diverse
+
+ 点击查看摘要
+ As language models are adapted by a more sophisticated and diverse set of
+users, the importance of guaranteeing that they provide factually correct
+information supported by verifiable sources is critical across fields of study
+& professions. This is especially the case for high-stakes fields, such as
+medicine and law, where the risk of propagating false information is high and
+can lead to undesirable societal consequences. Previous work studying
+factuality and attribution has not focused on analyzing these characteristics
+of language model outputs in domain-specific scenarios. In this work, we
+present an evaluation study analyzing various axes of factuality and
+attribution provided in responses from a few systems, by bringing domain
+experts in the loop. Specifically, we first collect expert-curated questions
+from 484 participants across 32 fields of study, and then ask the same experts
+to evaluate generated responses to their own questions. We also ask experts to
+revise answers produced by language models, which leads to ExpertQA, a
+high-quality long-form QA dataset with 2177 questions spanning 32 fields, along
+with verified answers and attributions for claims in the answers.
+
+
+
+ 6. 标题:Two Timin': Repairing Smart Contracts With A Two-Layered Approach
+ 编号:[37]
+ 链接:https://arxiv.org/abs/2309.07841
+ 作者:Abhinav Jain, Ehan Masud, Michelle Han, Rohan Dhillon, Sumukh Rao, Arya Joshi, Salar Cheema, Saurav Kumar
+ 备注:Submitted to the 2023 ICI Conference
+ 关键词:blockchain technology, risks and benefits, modern relevance, relevance of blockchain, present both substantial
+
+ 点击查看摘要
+ Due to the modern relevance of blockchain technology, smart contracts present
+both substantial risks and benefits. Vulnerabilities within them can trigger a
+cascade of consequences, resulting in significant losses. Many current papers
+primarily focus on classifying smart contracts for malicious intent, often
+relying on limited contract characteristics, such as bytecode or opcode. This
+paper proposes a novel, two-layered framework: 1) classifying and 2) directly
+repairing malicious contracts. Slither's vulnerability report is combined with
+source code and passed through a pre-trained RandomForestClassifier (RFC) and
+Large Language Models (LLMs), classifying and repairing each suggested
+vulnerability. Experiments demonstrate the effectiveness of fine-tuned and
+prompt-engineered LLMs. The smart contract repair models, built from
+pre-trained GPT-3.5-Turbo and fine-tuned Llama-2-7B models, reduced the overall
+vulnerability count by 97.5% and 96.7% respectively. A manual inspection of
+repaired contracts shows that all retain functionality, indicating that the
+proposed method is appropriate for automatic batch classification and repair of
+vulnerabilities in smart contracts.
+
+
+
+ 7. 标题:VAPOR: Holonomic Legged Robot Navigation in Outdoor Vegetation Using Offline Reinforcement Learning
+ 编号:[38]
+ 链接:https://arxiv.org/abs/2309.07832
+ 作者:Kasun Weerakoon, Adarsh Jagan Sathyamoorthy, Mohamed Elnoor, Dinesh Manocha
+ 备注:
+ 关键词:present VAPOR, densely vegetated outdoor, vegetated outdoor environments, densely vegetated, autonomous legged robot
+
+ 点击查看摘要
+ We present VAPOR, a novel method for autonomous legged robot navigation in
+unstructured, densely vegetated outdoor environments using Offline
+Reinforcement Learning (RL). Our method trains a novel RL policy from unlabeled
+data collected in real outdoor vegetation. This policy uses height and
+intensity-based cost maps derived from 3D LiDAR point clouds, a goal cost map,
+and processed proprioception data as state inputs, and learns the physical and
+geometric properties of the surrounding vegetation such as height, density, and
+solidity/stiffness for navigation. Instead of using end-to-end policy actions,
+the fully-trained RL policy's Q network is used to evaluate dynamically
+feasible robot actions generated from a novel adaptive planner capable of
+navigating through dense narrow passages and preventing entrapment in
+vegetation such as tall grass and bushes. We demonstrate our method's
+capabilities on a legged robot in complex outdoor vegetation. We observe an
+improvement in success rates, a decrease in average power consumption, and
+decrease in normalized trajectory length compared to both existing end-to-end
+offline RL and outdoor navigation methods.
+
+
+
+ 8. 标题:Large-scale Weakly Supervised Learning for Road Extraction from Satellite Imagery
+ 编号:[39]
+ 链接:https://arxiv.org/abs/2309.07823
+ 作者:Shiqiao Meng, Zonglin Di, Siwei Yang, Yin Wang
+ 备注:
+ 关键词:traditional manual mapping, Automatic road extraction, manual mapping, deep learning, viable alternative
+
+ 点击查看摘要
+ Automatic road extraction from satellite imagery using deep learning is a
+viable alternative to traditional manual mapping. Therefore it has received
+considerable attention recently. However, most of the existing methods are
+supervised and require pixel-level labeling, which is tedious and error-prone.
+To make matters worse, the earth has a diverse range of terrain, vegetation,
+and man-made objects. It is well known that models trained in one area
+generalize poorly to other areas. Various shooting conditions such as light and
+angel, as well as different image processing techniques further complicate the
+issue. It is impractical to develop training data to cover all image styles.
+This paper proposes to leverage OpenStreetMap road data as weak labels and
+large scale satellite imagery to pre-train semantic segmentation models. Our
+extensive experimental results show that the prediction accuracy increases with
+the amount of the weakly labeled data, as well as the road density in the areas
+chosen for training. Using as much as 100 times more data than the widely used
+DeepGlobe road dataset, our model with the D-LinkNet architecture and the
+ResNet-50 backbone exceeds the top performer of the current DeepGlobe
+leaderboard. Furthermore, due to large-scale pre-training, our model
+generalizes much better than those trained with only the curated datasets,
+implying great application potential.
+
+
+
+ 9. 标题:What Matters to Enhance Traffic Rule Compliance of Imitation Learning for Automated Driving
+ 编号:[46]
+ 链接:https://arxiv.org/abs/2309.07808
+ 作者:Hongkuan Zhou, Aifen Sui, Wei Cao, Letian Shi
+ 备注:8 pages, 2 figures
+ 关键词:faster inference time, single neural network, entire driving pipeline, inference time, research attention
+
+ 点击查看摘要
+ More research attention has recently been given to end-to-end autonomous
+driving technologies where the entire driving pipeline is replaced with a
+single neural network because of its simpler structure and faster inference
+time. Despite this appealing approach largely reducing the components in
+driving pipeline, its simplicity also leads to interpretability problems and
+safety issues arXiv:2003.06404. The trained policy is not always compliant with
+the traffic rules and it is also hard to discover the reason for the
+misbehavior because of the lack of intermediate outputs. Meanwhile, Sensors are
+also critical to autonomous driving's security and feasibility to perceive the
+surrounding environment under complex driving scenarios. In this paper, we
+proposed P-CSG, a novel penalty-based imitation learning approach with cross
+semantics generation sensor fusion technologies to increase the overall
+performance of End-to-End Autonomous Driving. We conducted an assessment of our
+model's performance using the Town 05 Long benchmark, achieving an impressive
+driving score improvement of over 15%. Furthermore, we conducted robustness
+evaluations against adversarial attacks like FGSM and Dot attacks, revealing a
+substantial increase in robustness compared to baseline models.More detailed
+information, such as code-based resources, ablation studies and videos can be
+found at this https URL.
+
+
+
+ 10. 标题:PRE: Vision-Language Prompt Learning with Reparameterization Encoder
+ 编号:[59]
+ 链接:https://arxiv.org/abs/2309.07760
+ 作者:Anh Pham Thi Minh
+ 备注:8 pages excluding References and Appendix
+ 关键词:Large pre-trained vision-language, demonstrated great potential, CLIP have demonstrated, pre-trained vision-language models, Large pre-trained
+
+ 点击查看摘要
+ Large pre-trained vision-language models such as CLIP have demonstrated great
+potential in zero-shot transferability to downstream tasks. However, to attain
+optimal performance, the manual selection of prompts is necessary to improve
+alignment between the downstream image distribution and the textual class
+descriptions. This manual prompt engineering is the major challenge for
+deploying such models in practice since it requires domain expertise and is
+extremely time-consuming. To avoid non-trivial prompt engineering, recent work
+Context Optimization (CoOp) introduced the concept of prompt learning to the
+vision domain using learnable textual tokens. While CoOp can achieve
+substantial improvements over manual prompts, its learned context is worse
+generalizable to wider unseen classes within the same dataset. In this work, we
+present Prompt Learning with Reparameterization Encoder (PRE) - a simple and
+efficient method that enhances the generalization ability of the learnable
+prompt to unseen classes while maintaining the capacity to learn Base classes.
+Instead of directly optimizing the prompts, PRE employs a prompt encoder to
+reparameterize the input prompt embeddings, enhancing the exploration of
+task-specific knowledge from few-shot samples. Experiments and extensive
+ablation studies on 8 benchmarks demonstrate that our approach is an efficient
+method for prompt learning. Specifically, PRE achieves a notable enhancement of
+5.60% in average accuracy on New classes and 3% in Harmonic mean compared to
+CoOp in the 16-shot setting, all achieved within a good training time.
+
+
+
+ 11. 标题:Generative AI Text Classification using Ensemble LLM Approaches
+ 编号:[61]
+ 链接:https://arxiv.org/abs/2309.07755
+ 作者:Harika Abburi, Michael Suesserman, Nirmala Pudota, Balaji Veeramani, Edward Bowen, Sanmitra Bhattacharya
+ 备注:
+ 关键词:Artificial Intelligence, shown impressive performance, variety of Artificial, natural language processing, Large Language Models
+
+ 点击查看摘要
+ Large Language Models (LLMs) have shown impressive performance across a
+variety of Artificial Intelligence (AI) and natural language processing tasks,
+such as content creation, report generation, etc. However, unregulated malign
+application of these models can create undesirable consequences such as
+generation of fake news, plagiarism, etc. As a result, accurate detection of
+AI-generated language can be crucial in responsible usage of LLMs. In this
+work, we explore 1) whether a certain body of text is AI generated or written
+by human, and 2) attribution of a specific language model in generating a body
+of text. Texts in both English and Spanish are considered. The datasets used in
+this study are provided as part of the Automated Text Identification
+(AuTexTification) shared task. For each of the research objectives stated
+above, we propose an ensemble neural model that generates probabilities from
+different pre-trained LLMs which are used as features to a Traditional Machine
+Learning (TML) classifier following it. For the first task of distinguishing
+between AI and human generated text, our model ranked in fifth and thirteenth
+place (with macro $F1$ scores of 0.733 and 0.649) for English and Spanish
+texts, respectively. For the second task on model attribution, our model ranked
+in first place with macro $F1$ scores of 0.625 and 0.653 for English and
+Spanish texts, respectively.
+
+
+
+ 12. 标题:AIDPS:Adaptive Intrusion Detection and Prevention System for Underwater Acoustic Sensor Networks
+ 编号:[72]
+ 链接:https://arxiv.org/abs/2309.07730
+ 作者:Soumadeep Das, Aryan Mohammadi Pasikhani, Prosanta Gope, John A. Clark, Chintan Patel, Biplab Sikdar
+ 备注:
+ 关键词:Acoustic Sensor Networks, Underwater Acoustic Sensor, Sensor Networks, Acoustic Sensor, Underwater Acoustic
+
+ 点击查看摘要
+ Underwater Acoustic Sensor Networks (UW-ASNs) are predominantly used for
+underwater environments and find applications in many areas. However, a lack of
+security considerations, the unstable and challenging nature of the underwater
+environment, and the resource-constrained nature of the sensor nodes used for
+UW-ASNs (which makes them incapable of adopting security primitives) make the
+UW-ASN prone to vulnerabilities. This paper proposes an Adaptive decentralised
+Intrusion Detection and Prevention System called AIDPS for UW-ASNs. The
+proposed AIDPS can improve the security of the UW-ASNs so that they can
+efficiently detect underwater-related attacks (e.g., blackhole, grayhole and
+flooding attacks). To determine the most effective configuration of the
+proposed construction, we conduct a number of experiments using several
+state-of-the-art machine learning algorithms (e.g., Adaptive Random Forest
+(ARF), light gradient-boosting machine, and K-nearest neighbours) and concept
+drift detection algorithms (e.g., ADWIN, kdqTree, and Page-Hinkley). Our
+experimental results show that incremental ARF using ADWIN provides optimal
+performance when implemented with One-class support vector machine (SVM)
+anomaly-based detectors. Furthermore, our extensive evaluation results also
+show that the proposed scheme outperforms state-of-the-art bench-marking
+methods while providing a wider range of desirable features such as scalability
+and complexity.
+
+
+
+ 13. 标题:NutritionVerse: Empirical Study of Various Dietary Intake Estimation Approaches
+ 编号:[85]
+ 链接:https://arxiv.org/abs/2309.07704
+ 作者:Chi-en Amy Tai, Matthew Keller, Saeejith Nair, Yuhao Chen, Yifan Wu, Olivia Markham, Krish Parmar, Pengcheng Xi, Heather Keller, Sharon Kirkpatrick, Alexander Wong
+ 备注:
+ 关键词:support healthy eating, Accurate dietary intake, healthy eating, quality of life, critical for informing
+
+ 点击查看摘要
+ Accurate dietary intake estimation is critical for informing policies and
+programs to support healthy eating, as malnutrition has been directly linked to
+decreased quality of life. However self-reporting methods such as food diaries
+suffer from substantial bias. Other conventional dietary assessment techniques
+and emerging alternative approaches such as mobile applications incur high time
+costs and may necessitate trained personnel. Recent work has focused on using
+computer vision and machine learning to automatically estimate dietary intake
+from food images, but the lack of comprehensive datasets with diverse
+viewpoints, modalities and food annotations hinders the accuracy and realism of
+such methods. To address this limitation, we introduce NutritionVerse-Synth,
+the first large-scale dataset of 84,984 photorealistic synthetic 2D food images
+with associated dietary information and multimodal annotations (including depth
+images, instance masks, and semantic masks). Additionally, we collect a real
+image dataset, NutritionVerse-Real, containing 889 images of 251 dishes to
+evaluate realism. Leveraging these novel datasets, we develop and benchmark
+NutritionVerse, an empirical study of various dietary intake estimation
+approaches, including indirect segmentation-based and direct prediction
+networks. We further fine-tune models pretrained on synthetic data with real
+images to provide insights into the fusion of synthetic and real data. Finally,
+we release both datasets (NutritionVerse-Synth, NutritionVerse-Real) on
+this https URL as part of an open initiative to
+accelerate machine learning for dietary sensing.
+
+
+
+ 14. 标题:Tree of Uncertain Thoughts Reasoning for Large Language Models
+ 编号:[89]
+ 链接:https://arxiv.org/abs/2309.07694
+ 作者:Shentong Mo, Miao Xin
+ 备注:
+ 关键词:allowing Large Language, Large Language Models, Large Language, recently introduced Tree, allowing Large
+
+ 点击查看摘要
+ While the recently introduced Tree of Thoughts (ToT) has heralded
+advancements in allowing Large Language Models (LLMs) to reason through
+foresight and backtracking for global decision-making, it has overlooked the
+inherent local uncertainties in intermediate decision points or "thoughts".
+These local uncertainties, intrinsic to LLMs given their potential for diverse
+responses, remain a significant concern in the reasoning process. Addressing
+this pivotal gap, we introduce the Tree of Uncertain Thoughts (TouT) - a
+reasoning framework tailored for LLMs. Our TouT effectively leverages Monte
+Carlo Dropout to quantify uncertainty scores associated with LLMs' diverse
+local responses at these intermediate steps. By marrying this local uncertainty
+quantification with global search algorithms, TouT enhances the model's
+precision in response generation. We substantiate our approach with rigorous
+experiments on two demanding planning tasks: Game of 24 and Mini Crosswords.
+The empirical evidence underscores TouT's superiority over both ToT and
+chain-of-thought prompting methods.
+
+
+
+ 15. 标题:Detecting ChatGPT: A Survey of the State of Detecting ChatGPT-Generated Text
+ 编号:[91]
+ 链接:https://arxiv.org/abs/2309.07689
+ 作者:Mahdi Dhaini, Wessel Poelman, Ege Erdogan
+ 备注:Published in the Proceedings of the Student Research Workshop associated with RANLP-2023
+ 关键词:generative language models, large language model, generating fluent human-like, fluent human-like text, generative language
+
+ 点击查看摘要
+ While recent advancements in the capabilities and widespread accessibility of
+generative language models, such as ChatGPT (OpenAI, 2022), have brought about
+various benefits by generating fluent human-like text, the task of
+distinguishing between human- and large language model (LLM) generated text has
+emerged as a crucial problem. These models can potentially deceive by
+generating artificial text that appears to be human-generated. This issue is
+particularly significant in domains such as law, education, and science, where
+ensuring the integrity of text is of the utmost importance. This survey
+provides an overview of the current approaches employed to differentiate
+between texts generated by humans and ChatGPT. We present an account of the
+different datasets constructed for detecting ChatGPT-generated text, the
+various methods utilized, what qualitative analyses into the characteristics of
+human versus ChatGPT-generated text have been performed, and finally, summarize
+our findings into general insights
+
+
+
+ 16. 标题:deepFDEnet: A Novel Neural Network Architecture for Solving Fractional Differential Equations
+ 编号:[93]
+ 链接:https://arxiv.org/abs/2309.07684
+ 作者:Ali Nosrati Firoozsalari, Hassan Dana Mazraeh, Alireza Afzal Aghaei, Kourosh Parand
+ 备注:
+ 关键词:deep neural network, fractional differential equations, differential equations accurately, primary goal, deep neural
+
+ 点击查看摘要
+ The primary goal of this research is to propose a novel architecture for a
+deep neural network that can solve fractional differential equations
+accurately. A Gaussian integration rule and a $L_1$ discretization technique
+are used in the proposed design. In each equation, a deep neural network is
+used to approximate the unknown function. Three forms of fractional
+differential equations have been examined to highlight the method's
+versatility: a fractional ordinary differential equation, a fractional order
+integrodifferential equation, and a fractional order partial differential
+equation. The results show that the proposed architecture solves different
+forms of fractional differential equations with excellent precision.
+
+
+
+ 17. 标题:Assessing the nature of large language models: A caution against anthropocentrism
+ 编号:[94]
+ 链接:https://arxiv.org/abs/2309.07683
+ 作者:Ann Speed
+ 备注:30 pages, 6 figures
+ 关键词:OpenAIs chatbot, amount of public, public attention, attention and speculation, release of OpenAIs
+
+ 点击查看摘要
+ Generative AI models garnered a large amount of public attention and
+speculation with the release of OpenAIs chatbot, ChatGPT. At least two opinion
+camps exist: one excited about possibilities these models offer for fundamental
+changes to human tasks, and another highly concerned about power these models
+seem to have. To address these concerns, we assessed GPT3.5 using standard,
+normed, and validated cognitive and personality measures. For this seedling
+project, we developed a battery of tests that allowed us to estimate the
+boundaries of some of these models capabilities, how stable those capabilities
+are over a short period of time, and how they compare to humans.
+Our results indicate that GPT 3.5 is unlikely to have developed sentience,
+although its ability to respond to personality inventories is interesting. It
+did display large variability in both cognitive and personality measures over
+repeated observations, which is not expected if it had a human-like
+personality. Variability notwithstanding, GPT3.5 displays what in a human would
+be considered poor mental health, including low self-esteem and marked
+dissociation from reality despite upbeat and helpful responses.
+
+
+
+ 18. 标题:Federated Dataset Dictionary Learning for Multi-Source Domain Adaptation
+ 编号:[99]
+ 链接:https://arxiv.org/abs/2309.07670
+ 作者:Fabiola Espinosa Castellon, Eduardo Fernandes Montesuma, Fred Ngolè Mboula, Aurélien Mayoue, Antoine Souloumiac, Cédric Gouy-Pallier
+ 备注:7 pages,2 figures
+ 关键词:distributional shift exists, distributional shift, shift exists, exists among clients, Dataset Dictionary Learning
+
+ 点击查看摘要
+ In this article, we propose an approach for federated domain adaptation, a
+setting where distributional shift exists among clients and some have unlabeled
+data. The proposed framework, FedDaDiL, tackles the resulting challenge through
+dictionary learning of empirical distributions. In our setting, clients'
+distributions represent particular domains, and FedDaDiL collectively trains a
+federated dictionary of empirical distributions. In particular, we build upon
+the Dataset Dictionary Learning framework by designing collaborative
+communication protocols and aggregation operations. The chosen protocols keep
+clients' data private, thus enhancing overall privacy compared to its
+centralized counterpart. We empirically demonstrate that our approach
+successfully generates labeled data on the target domain with extensive
+experiments on (i) Caltech-Office, (ii) TEP, and (iii) CWRU benchmarks.
+Furthermore, we compare our method to its centralized counterpart and other
+benchmarks in federated domain adaptation.
+
+
+
+ 19. 标题:Multi-Source Domain Adaptation meets Dataset Distillation through Dataset Dictionary Learning
+ 编号:[102]
+ 链接:https://arxiv.org/abs/2309.07666
+ 作者:Eduardo Fernandes Montesuma, Fred Ngolè Mboula, Antoine Souloumiac
+ 备注:7 pages,4 figures
+ 关键词:Multi-Source Domain Adaptation, Dataset Distillation, Multi-Source Domain, Dataset Dictionary Learning, labeled source domains
+
+ 点击查看摘要
+ In this paper, we consider the intersection of two problems in machine
+learning: Multi-Source Domain Adaptation (MSDA) and Dataset Distillation (DD).
+On the one hand, the first considers adapting multiple heterogeneous labeled
+source domains to an unlabeled target domain. On the other hand, the second
+attacks the problem of synthesizing a small summary containing all the
+information about the datasets. We thus consider a new problem called MSDA-DD.
+To solve it, we adapt previous works in the MSDA literature, such as
+Wasserstein Barycenter Transport and Dataset Dictionary Learning, as well as DD
+method Distribution Matching. We thoroughly experiment with this novel problem
+on four benchmarks (Caltech-Office 10, Tennessee-Eastman Process, Continuous
+Stirred Tank Reactor, and Case Western Reserve University), where we show that,
+even with as little as 1 sample per class, one achieves state-of-the-art
+adaptation performance.
+
+
+
+ 20. 标题:Feature Engineering in Learning-to-Rank for Community Question Answering Task
+ 编号:[127]
+ 链接:https://arxiv.org/abs/2309.07610
+ 作者:Nafis Sajid, Md Rashidul Hasan, Muhammad Ibrahim
+ 备注:20 pages
+ 关键词:Internet-based platforms, Community question answering, provide solutions, forums are Internet-based, CQA
+
+ 点击查看摘要
+ Community question answering (CQA) forums are Internet-based platforms where
+users ask questions about a topic and other expert users try to provide
+solutions. Many CQA forums such as Quora, Stackoverflow, Yahoo!Answer,
+StackExchange exist with a lot of user-generated data. These data are leveraged
+in automated CQA ranking systems where similar questions (and answers) are
+presented in response to the query of the user. In this work, we empirically
+investigate a few aspects of this domain. Firstly, in addition to traditional
+features like TF-IDF, BM25 etc., we introduce a BERT-based feature that
+captures the semantic similarity between the question and answer. Secondly,
+most of the existing research works have focused on features extracted only
+from the question part; features extracted from answers have not been explored
+extensively. We combine both types of features in a linear fashion. Thirdly,
+using our proposed concepts, we conduct an empirical investigation with
+different rank-learning algorithms, some of which have not been used so far in
+CQA domain. On three standard CQA datasets, our proposed framework achieves
+state-of-the-art performance. We also analyze importance of the features we use
+in our investigation. This work is expected to guide the practitioners to
+select a better set of features for the CQA retrieval task.
+
+
+
+ 21. 标题:Turning Dross Into Gold Loss: is BERT4Rec really better than SASRec?
+ 编号:[132]
+ 链接:https://arxiv.org/abs/2309.07602
+ 作者:Anton Klenitskiy, Alexey Vasilev
+ 备注:
+ 关键词:Recently sequential recommendations, next-item prediction task, Recently sequential, recommender systems, sequential recommendations
+
+ 点击查看摘要
+ Recently sequential recommendations and next-item prediction task has become
+increasingly popular in the field of recommender systems. Currently, two
+state-of-the-art baselines are Transformer-based models SASRec and BERT4Rec.
+Over the past few years, there have been quite a few publications comparing
+these two algorithms and proposing new state-of-the-art models. In most of the
+publications, BERT4Rec achieves better performance than SASRec. But BERT4Rec
+uses cross-entropy over softmax for all items, while SASRec uses negative
+sampling and calculates binary cross-entropy loss for one positive and one
+negative item. In our work, we show that if both models are trained with the
+same loss, which is used by BERT4Rec, then SASRec will significantly outperform
+BERT4Rec both in terms of quality and training speed. In addition, we show that
+SASRec could be effectively trained with negative sampling and still outperform
+BERT4Rec, but the number of negative examples should be much larger than one.
+
+
+
+ 22. 标题:Detecting Misinformation with LLM-Predicted Credibility Signals and Weak Supervision
+ 编号:[133]
+ 链接:https://arxiv.org/abs/2309.07601
+ 作者:João A. Leite, Olesya Razuvayevskaya, Kalina Bontcheva, Carolina Scarton
+ 备注:
+ 关键词:Credibility signals represent, Credibility signals, represent a wide, wide range, range of heuristics
+
+ 点击查看摘要
+ Credibility signals represent a wide range of heuristics that are typically
+used by journalists and fact-checkers to assess the veracity of online content.
+Automating the task of credibility signal extraction, however, is very
+challenging as it requires high-accuracy signal-specific extractors to be
+trained, while there are currently no sufficiently large datasets annotated
+with all credibility signals. This paper investigates whether large language
+models (LLMs) can be prompted effectively with a set of 18 credibility signals
+to produce weak labels for each signal. We then aggregate these potentially
+noisy labels using weak supervision in order to predict content veracity. We
+demonstrate that our approach, which combines zero-shot LLM credibility signal
+labeling and weak supervision, outperforms state-of-the-art classifiers on two
+misinformation datasets without using any ground-truth labels for training. We
+also analyse the contribution of the individual credibility signals towards
+predicting content veracity, which provides new valuable insights into their
+role in misinformation detection.
+
+
+
+ 23. 标题:C-Pack: Packaged Resources To Advance General Chinese Embedding
+ 编号:[135]
+ 链接:https://arxiv.org/abs/2309.07597
+ 作者:Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighof
+ 备注:
+ 关键词:Chinese, Chinese text embeddings, significantly advance, advance the field, Chinese text
+
+ 点击查看摘要
+ We introduce C-Pack, a package of resources that significantly advance the
+field of general Chinese embeddings. C-Pack includes three critical resources.
+1) C-MTEB is a comprehensive benchmark for Chinese text embeddings covering 6
+tasks and 35 datasets. 2) C-MTP is a massive text embedding dataset curated
+from labeled and unlabeled Chinese corpora for training embedding models. 3)
+C-TEM is a family of embedding models covering multiple sizes. Our models
+outperform all prior Chinese text embeddings on C-MTEB by up to +10% upon the
+time of the release. We also integrate and optimize the entire suite of
+training methods for C-TEM. Along with our resources on general Chinese
+embedding, we release our data and models for English text embeddings. The
+English models achieve state-of-the-art performance on MTEB benchmark;
+meanwhile, our released English data is 2 times larger than the Chinese data.
+All these resources are made publicly available at
+this https URL.
+
+
+
+ 24. 标题:Neuro-Symbolic Recommendation Model based on Logic Query
+ 编号:[136]
+ 链接:https://arxiv.org/abs/2309.07594
+ 作者:Maonian Wu, Bang Chen, Shaojun Zhu, Bo Zheng, Wei Peng, Mingyi Zhang
+ 备注:17 pages, 6 figures
+ 关键词:logic, recommendation, recommendation system assists, based, system assists users
+
+ 点击查看摘要
+ A recommendation system assists users in finding items that are relevant to
+them. Existing recommendation models are primarily based on predicting
+relationships between users and items and use complex matching models or
+incorporate extensive external information to capture association patterns in
+data. However, recommendation is not only a problem of inductive statistics
+using data; it is also a cognitive task of reasoning decisions based on
+knowledge extracted from information. Hence, a logic system could naturally be
+incorporated for the reasoning in a recommendation task. However, although
+hard-rule approaches based on logic systems can provide powerful reasoning
+ability, they struggle to cope with inconsistent and incomplete knowledge in
+real-world tasks, especially for complex tasks such as recommendation.
+Therefore, in this paper, we propose a neuro-symbolic recommendation model,
+which transforms the user history interactions into a logic expression and then
+transforms the recommendation prediction into a query task based on this logic
+expression. The logic expressions are then computed based on the modular logic
+operations of the neural network. We also construct an implicit logic encoder
+to reasonably reduce the complexity of the logic computation. Finally, a user's
+interest items can be queried in the vector space based on the computation
+results. Experiments on three well-known datasets verified that our method
+performs better compared to state of the art shallow, deep, session, and
+reasoning models.
+
+
+
+ 25. 标题:Statistically Valid Variable Importance Assessment through Conditional Permutations
+ 编号:[137]
+ 链接:https://arxiv.org/abs/2309.07593
+ 作者:Ahmad Chamma (1 and 2 and 3), Denis A. Engemann (4), Bertrand Thirion (1 and 2 and 3) ((1) Inria, (2) Universite Paris Saclay, (3) CEA, (4) Roche Pharma Research and Early Development, Neuroscience and Rare Diseases, Roche Innovation Center Basel, F. Hoffmann-La Roche Ltd., Basel, Switzerland)
+ 备注:
+ 关键词:CPI, complex learners, crucial step, step in machine-learning, machine-learning applications
+
+ 点击查看摘要
+ Variable importance assessment has become a crucial step in machine-learning
+applications when using complex learners, such as deep neural networks, on
+large-scale data. Removal-based importance assessment is currently the
+reference approach, particularly when statistical guarantees are sought to
+justify variable inclusion. It is often implemented with variable permutation
+schemes. On the flip side, these approaches risk misidentifying unimportant
+variables as important in the presence of correlations among covariates. Here
+we develop a systematic approach for studying Conditional Permutation
+Importance (CPI) that is model agnostic and computationally lean, as well as
+reusable benchmarks of state-of-the-art variable importance estimators. We show
+theoretically and empirically that $\textit{CPI}$ overcomes the limitations of
+standard permutation importance by providing accurate type-I error control.
+When used with a deep neural network, $\textit{CPI}$ consistently showed top
+accuracy across benchmarks. An empirical benchmark on real-world data analysis
+in a large-scale medical dataset showed that $\textit{CPI}$ provides a more
+parsimonious selection of statistically significant variables. Our results
+suggest that $\textit{CPI}$ can be readily used as drop-in replacement for
+permutation-based methods.
+
+
+
+ 26. 标题:Equivariant Data Augmentation for Generalization in Offline Reinforcement Learning
+ 编号:[143]
+ 链接:https://arxiv.org/abs/2309.07578
+ 作者:Cristina Pinneri, Sarah Bechtle, Markus Wulfmeier, Arunkumar Byravan, Jingwei Zhang, William F. Whitney, Martin Riedmiller
+ 备注:
+ 关键词:offline reinforcement learning, reinforcement learning, address the challenge, challenge of generalization, additional interaction
+
+ 点击查看摘要
+ We present a novel approach to address the challenge of generalization in
+offline reinforcement learning (RL), where the agent learns from a fixed
+dataset without any additional interaction with the environment. Specifically,
+we aim to improve the agent's ability to generalize to out-of-distribution
+goals. To achieve this, we propose to learn a dynamics model and check if it is
+equivariant with respect to a fixed type of transformation, namely translations
+in the state space. We then use an entropy regularizer to increase the
+equivariant set and augment the dataset with the resulting transformed samples.
+Finally, we learn a new policy offline based on the augmented dataset, with an
+off-the-shelf offline RL algorithm. Our experimental results demonstrate that
+our approach can greatly improve the test performance of the policy on the
+considered environments.
+
+
+
+ 27. 标题:Speech-to-Speech Translation with Discrete-Unit-Based Style Transfer
+ 编号:[146]
+ 链接:https://arxiv.org/abs/2309.07566
+ 作者:Yongqi Wang, Jionghao Bai, Rongjie Huang, Ruiqi Li, Zhiqing Hong, Zhou Zhao
+ 备注:5 pages, 1 figure. submitted to ICASSP 2024
+ 关键词:achieved remarkable accuracy, remarkable accuracy, representations has achieved, achieved remarkable, unable to preserve
+
+ 点击查看摘要
+ Direct speech-to-speech translation (S2ST) with discrete self-supervised
+representations has achieved remarkable accuracy, but is unable to preserve the
+speaker timbre of the source speech during translation. Meanwhile, the scarcity
+of high-quality speaker-parallel data poses a challenge for learning style
+transfer between source and target speech. We propose an S2ST framework with an
+acoustic language model based on discrete units from a self-supervised model
+and a neural codec for style transfer. The acoustic language model leverages
+self-supervised in-context learning, acquiring the ability for style transfer
+without relying on any speaker-parallel data, thereby overcoming the issue of
+data scarcity. By using extensive training data, our model achieves zero-shot
+cross-lingual style transfer on previously unseen source languages. Experiments
+show that our model generates translated speeches with high fidelity and style
+similarity. Audio samples are available at this http URL .
+
+
+
+ 28. 标题:SingFake: Singing Voice Deepfake Detection
+ 编号:[159]
+ 链接:https://arxiv.org/abs/2309.07525
+ 作者:Yongyi Zang, You Zhang, Mojtaba Heydari, Zhiyao Duan
+ 备注:Submitted to ICASSP 2024
+ 关键词:unauthorized voice usage, singing voice deepfake, singing voice, artists and industry, industry stakeholders
+
+ 点击查看摘要
+ The rise of singing voice synthesis presents critical challenges to artists
+and industry stakeholders over unauthorized voice usage. Unlike synthesized
+speech, synthesized singing voices are typically released in songs containing
+strong background music that may hide synthesis artifacts. Additionally,
+singing voices present different acoustic and linguistic characteristics from
+speech utterances. These unique properties make singing voice deepfake
+detection a relevant but significantly different problem from synthetic speech
+detection. In this work, we propose the singing voice deepfake detection task.
+We first present SingFake, the first curated in-the-wild dataset consisting of
+28.93 hours of bonafide and 29.40 hours of deepfake song clips in five
+languages from 40 singers. We provide a train/val/test split where the test
+sets include various scenarios. We then use SingFake to evaluate four
+state-of-the-art speech countermeasure systems trained on speech utterances. We
+find these systems lag significantly behind their performance on speech test
+data. When trained on SingFake, either using separated vocal tracks or song
+mixtures, these systems show substantial improvement. However, our evaluations
+also identify challenges associated with unseen singers, communication codecs,
+languages, and musical contexts, calling for dedicated research into singing
+voice deepfake detection. The SingFake dataset and related resources are
+available online.
+
+
+
+ 29. 标题:Learning Environment-Aware Affordance for 3D Articulated Object Manipulation under Occlusions
+ 编号:[165]
+ 链接:https://arxiv.org/abs/2309.07510
+ 作者:Kai Cheng, Ruihai Wu, Yan Shen, Chuanruo Ning, Guanqi Zhan, Hao Dong
+ 备注:
+ 关键词:Perceiving and manipulating, articulated objects, home-assistant robots, objects in diverse, essential for home-assistant
+
+ 点击查看摘要
+ Perceiving and manipulating 3D articulated objects in diverse environments is
+essential for home-assistant robots. Recent studies have shown that point-level
+affordance provides actionable priors for downstream manipulation tasks.
+However, existing works primarily focus on single-object scenarios with
+homogeneous agents, overlooking the realistic constraints imposed by the
+environment and the agent's morphology, e.g., occlusions and physical
+limitations. In this paper, we propose an environment-aware affordance
+framework that incorporates both object-level actionable priors and environment
+constraints. Unlike object-centric affordance approaches, learning
+environment-aware affordance faces the challenge of combinatorial explosion due
+to the complexity of various occlusions, characterized by their quantities,
+geometries, positions and poses. To address this and enhance data efficiency,
+we introduce a novel contrastive affordance learning framework capable of
+training on scenes containing a single occluder and generalizing to scenes with
+complex occluder combinations. Experiments demonstrate the effectiveness of our
+proposed approach in learning affordance considering environment constraints.
+
+
+
+ 30. 标题:Connected Autonomous Vehicle Motion Planning with Video Predictions from Smart, Self-Supervised Infrastructure
+ 编号:[169]
+ 链接:https://arxiv.org/abs/2309.07504
+ 作者:Jiankai Sun, Shreyas Kousik, David Fridovich-Keil, Mac Schwager
+ 备注:2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC)
+ 关键词:Connected autonomous vehicles, Connected autonomous, autonomous vehicles, promise to enhance, enhance safety
+
+ 点击查看摘要
+ Connected autonomous vehicles (CAVs) promise to enhance safety, efficiency,
+and sustainability in urban transportation. However, this is contingent upon a
+CAV correctly predicting the motion of surrounding agents and planning its own
+motion safely. Doing so is challenging in complex urban environments due to
+frequent occlusions and interactions among many agents. One solution is to
+leverage smart infrastructure to augment a CAV's situational awareness; the
+present work leverages a recently proposed "Self-Supervised Traffic Advisor"
+(SSTA) framework of smart sensors that teach themselves to generate and
+broadcast useful video predictions of road users. In this work, SSTA
+predictions are modified to predict future occupancy instead of raw video,
+which reduces the data footprint of broadcast predictions. The resulting
+predictions are used within a planning framework, demonstrating that this
+design can effectively aid CAV motion planning. A variety of numerical
+experiments study the key factors that make SSTA outputs useful for practical
+CAV planning in crowded urban environments.
+
+
+
+ 31. 标题:HDTR-Net: A Real-Time High-Definition Teeth Restoration Network for Arbitrary Talking Face Generation Methods
+ 编号:[173]
+ 链接:https://arxiv.org/abs/2309.07495
+ 作者:Yongyuan Li, Xiuyuan Qin, Chao Liang, Mingqiang Wei
+ 备注:15pages, 6 figures, PRCV2023
+ 关键词:reconstruct facial movements, achieve high natural, facial movements, natural lip movements, reconstruct facial
+
+ 点击查看摘要
+ Talking Face Generation (TFG) aims to reconstruct facial movements to achieve
+high natural lip movements from audio and facial features that are under
+potential connections. Existing TFG methods have made significant advancements
+to produce natural and realistic images. However, most work rarely takes visual
+quality into consideration. It is challenging to ensure lip synchronization
+while avoiding visual quality degradation in cross-modal generation methods. To
+address this issue, we propose a universal High-Definition Teeth Restoration
+Network, dubbed HDTR-Net, for arbitrary TFG methods. HDTR-Net can enhance teeth
+regions at an extremely fast speed while maintaining synchronization, and
+temporal consistency. In particular, we propose a Fine-Grained Feature Fusion
+(FGFF) module to effectively capture fine texture feature information around
+teeth and surrounding regions, and use these features to fine-grain the feature
+map to enhance the clarity of teeth. Extensive experiments show that our method
+can be adapted to arbitrary TFG methods without suffering from lip
+synchronization and frame coherence. Another advantage of HDTR-Net is its
+real-time generation ability. Also under the condition of high-definition
+restoration of talking face video synthesis, its inference speed is $300\%$
+faster than the current state-of-the-art face restoration based on
+super-resolution.
+
+
+
+ 32. 标题:Where2Explore: Few-shot Affordance Learning for Unseen Novel Categories of Articulated Objects
+ 编号:[181]
+ 链接:https://arxiv.org/abs/2309.07473
+ 作者:Chuanruo Ning, Ruihai Wu, Haoran Lu, Kaichun Mo, Hao Dong
+ 备注:
+ 关键词:task in robotics, fundamental yet challenging, challenging task, Articulated object manipulation, Articulated object
+
+ 点击查看摘要
+ Articulated object manipulation is a fundamental yet challenging task in
+robotics. Due to significant geometric and semantic variations across object
+categories, previous manipulation models struggle to generalize to novel
+categories. Few-shot learning is a promising solution for alleviating this
+issue by allowing robots to perform a few interactions with unseen objects.
+However, extant approaches often necessitate costly and inefficient test-time
+interactions with each unseen instance. Recognizing this limitation, we observe
+that despite their distinct shapes, different categories often share similar
+local geometries essential for manipulation, such as pullable handles and
+graspable edges - a factor typically underutilized in previous few-shot
+learning works. To harness this commonality, we introduce 'Where2Explore', an
+affordance learning framework that effectively explores novel categories with
+minimal interactions on a limited number of instances. Our framework explicitly
+estimates the geometric similarity across different categories, identifying
+local areas that differ from shapes in the training categories for efficient
+exploration while concurrently transferring affordance knowledge to similar
+parts of the objects. Extensive experiments in simulated and real-world
+environments demonstrate our framework's capacity for efficient few-shot
+exploration and generalization.
+
+
+
+ 33. 标题:Detecting Unknown Attacks in IoT Environments: An Open Set Classifier for Enhanced Network Intrusion Detection
+ 编号:[186]
+ 链接:https://arxiv.org/abs/2309.07461
+ 作者:Yasir Ali Farrukh, Syed Wali, Irfan Khan, Nathaniel D. Bastian
+ 备注:6 Pages, 5 figures
+ 关键词:Internet of Things, robust intrusion detection, integration of Internet, intrusion detection systems, Network Intrusion Detection
+
+ 点击查看摘要
+ The widespread integration of Internet of Things (IoT) devices across all
+facets of life has ushered in an era of interconnectedness, creating new
+avenues for cybersecurity challenges and underscoring the need for robust
+intrusion detection systems. However, traditional security systems are designed
+with a closed-world perspective and often face challenges in dealing with the
+ever-evolving threat landscape, where new and unfamiliar attacks are constantly
+emerging. In this paper, we introduce a framework aimed at mitigating the open
+set recognition (OSR) problem in the realm of Network Intrusion Detection
+Systems (NIDS) tailored for IoT environments. Our framework capitalizes on
+image-based representations of packet-level data, extracting spatial and
+temporal patterns from network traffic. Additionally, we integrate stacking and
+sub-clustering techniques, enabling the identification of unknown attacks by
+effectively modeling the complex and diverse nature of benign behavior. The
+empirical results prominently underscore the framework's efficacy, boasting an
+impressive 88\% detection rate for previously unseen attacks when compared
+against existing approaches and recent advancements. Future work will perform
+extensive experimentation across various openness levels and attack scenarios,
+further strengthening the adaptability and performance of our proposed solution
+in safeguarding IoT environments.
+
+
+
+ 34. 标题:Towards Artificial General Intelligence (AGI) in the Internet of Things (IoT): Opportunities and Challenges
+ 编号:[197]
+ 链接:https://arxiv.org/abs/2309.07438
+ 作者:Fei Dou, Jin Ye, Geng Yuan, Qin Lu, Wei Niu, Haijian Sun, Le Guan, Guoyu Lu, Gengchen Mai, Ninghao Liu, Jin Lu, Zhengliang Liu, Zihao Wu, Chenjiao Tan, Shaochen Xu, Xianqiao Wang, Guoming Li, Lilong Chai, Sheng Li, Jin Sun, Hongyue Sun, Yunli Shao, Changying Li, Tianming Liu, Wenzhan Song
+ 备注:
+ 关键词:Artificial General Intelligence, human cognitive abilities, engenders significant anticipation, General Intelligence, Artificial General
+
+ 点击查看摘要
+ Artificial General Intelligence (AGI), possessing the capacity to comprehend,
+learn, and execute tasks with human cognitive abilities, engenders significant
+anticipation and intrigue across scientific, commercial, and societal arenas.
+This fascination extends particularly to the Internet of Things (IoT), a
+landscape characterized by the interconnection of countless devices, sensors,
+and systems, collectively gathering and sharing data to enable intelligent
+decision-making and automation. This research embarks on an exploration of the
+opportunities and challenges towards achieving AGI in the context of the IoT.
+Specifically, it starts by outlining the fundamental principles of IoT and the
+critical role of Artificial Intelligence (AI) in IoT systems. Subsequently, it
+delves into AGI fundamentals, culminating in the formulation of a conceptual
+framework for AGI's seamless integration within IoT. The application spectrum
+for AGI-infused IoT is broad, encompassing domains ranging from smart grids,
+residential environments, manufacturing, and transportation to environmental
+monitoring, agriculture, healthcare, and education. However, adapting AGI to
+resource-constrained IoT settings necessitates dedicated research efforts.
+Furthermore, the paper addresses constraints imposed by limited computing
+resources, intricacies associated with large-scale IoT communication, as well
+as the critical concerns pertaining to security and privacy.
+
+
+
+ 35. 标题:Semantic Parsing in Limited Resource Conditions
+ 编号:[202]
+ 链接:https://arxiv.org/abs/2309.07429
+ 作者:Zhuang Li
+ 备注:PhD thesis, year of award 2023, 172 pages
+ 关键词:thesis explores challenges, specifically focusing, explores challenges, focusing on scenarios, data
+
+ 点击查看摘要
+ This thesis explores challenges in semantic parsing, specifically focusing on
+scenarios with limited data and computational resources. It offers solutions
+using techniques like automatic data curation, knowledge transfer, active
+learning, and continual learning.
+For tasks with no parallel training data, the thesis proposes generating
+synthetic training examples from structured database schemas. When there is
+abundant data in a source domain but limited parallel data in a target domain,
+knowledge from the source is leveraged to improve parsing in the target domain.
+For multilingual situations with limited data in the target languages, the
+thesis introduces a method to adapt parsers using a limited human translation
+budget. Active learning is applied to select source-language samples for manual
+translation, maximizing parser performance in the target language. In addition,
+an alternative method is also proposed to utilize machine translation services,
+supplemented by human-translated data, to train a more effective parser.
+When computational resources are limited, a continual learning approach is
+introduced to minimize training time and computational memory. This maintains
+the parser's efficiency in previously learned tasks while adapting it to new
+tasks, mitigating the problem of catastrophic forgetting.
+Overall, the thesis provides a comprehensive set of methods to improve
+semantic parsing in resource-constrained conditions.
+
+
+
+ 36. 标题:JSMNet Improving Indoor Point Cloud Semantic and Instance Segmentation through Self-Attention and Multiscale
+ 编号:[204]
+ 链接:https://arxiv.org/abs/2309.07425
+ 作者:Shuochen Xu, Zhenxin Zhang
+ 备注:
+ 关键词:digital twin engineering, indoor service robots, including indoor service, point cloud, point cloud data
+
+ 点击查看摘要
+ The semantic understanding of indoor 3D point cloud data is crucial for a
+range of subsequent applications, including indoor service robots, navigation
+systems, and digital twin engineering. Global features are crucial for
+achieving high-quality semantic and instance segmentation of indoor point
+clouds, as they provide essential long-range context information. To this end,
+we propose JSMNet, which combines a multi-layer network with a global feature
+self-attention module to jointly segment three-dimensional point cloud
+semantics and instances. To better express the characteristics of indoor
+targets, we have designed a multi-resolution feature adaptive fusion module
+that takes into account the differences in point cloud density caused by
+varying scanner distances from the target. Additionally, we propose a framework
+for joint semantic and instance segmentation by integrating semantic and
+instance features to achieve superior results. We conduct experiments on S3DIS,
+which is a large three-dimensional indoor point cloud dataset. Our proposed
+method is compared against other methods, and the results show that it
+outperforms existing methods in semantic and instance segmentation and provides
+better results in target local area segmentation. Specifically, our proposed
+method outperforms PointNet (Qi et al., 2017a) by 16.0% and 26.3% in terms of
+semantic segmentation mIoU in S3DIS (Area 5) and instance segmentation mPre,
+respectively. Additionally, it surpasses ASIS (Wang et al., 2019) by 6.0% and
+4.6%, respectively, as well as JSPNet (Chen et al., 2022) by a margin of 3.3%
+for semantic segmentation mIoU and a slight improvement of 0.3% for instance
+segmentation mPre.
+
+
+
+ 37. 标题:Client-side Gradient Inversion Against Federated Learning from Poisoning
+ 编号:[210]
+ 链接:https://arxiv.org/abs/2309.07415
+ 作者:Jiaheng Wei, Yanjun Zhang, Leo Yu Zhang, Chao Chen, Shirui Pan, Kok-Leong Ong, Jun Zhang, Yang Xiang
+ 备注:
+ 关键词:Federated Learning, sharing data directly, enables distributed participants, mobile devices, distributed participants
+
+ 点击查看摘要
+ Federated Learning (FL) enables distributed participants (e.g., mobile
+devices) to train a global model without sharing data directly to a central
+server. Recent studies have revealed that FL is vulnerable to gradient
+inversion attack (GIA), which aims to reconstruct the original training samples
+and poses high risk against the privacy of clients in FL. However, most
+existing GIAs necessitate control over the server and rely on strong prior
+knowledge including batch normalization and data distribution information. In
+this work, we propose Client-side poisoning Gradient Inversion (CGI), which is
+a novel attack method that can be launched from clients. For the first time, we
+show the feasibility of a client-side adversary with limited knowledge being
+able to recover the training samples from the aggregated global model. We take
+a distinct approach in which the adversary utilizes a malicious model that
+amplifies the loss of a specific targeted class of interest. When honest
+clients employ the poisoned global model, the gradients of samples belonging to
+the targeted class are magnified, making them the dominant factor in the
+aggregated update. This enables the adversary to effectively reconstruct the
+private input belonging to other clients using the aggregated update. In
+addition, our CGI also features its ability to remain stealthy against
+Byzantine-robust aggregation rules (AGRs). By optimizing malicious updates and
+blending benign updates with a malicious replacement vector, our method remains
+undetected by these defense mechanisms. To evaluate the performance of CGI, we
+conduct experiments on various benchmark datasets, considering representative
+Byzantine-robust AGRs, and exploring diverse FL settings with different levels
+of adversary knowledge about the data. Our results demonstrate that CGI
+consistently and successfully extracts training input in all tested scenarios.
+
+
+
+ 38. 标题:FunCodec: A Fundamental, Reproducible and Integrable Open-source Toolkit for Neural Speech Codec
+ 编号:[217]
+ 链接:https://arxiv.org/abs/2309.07405
+ 作者:Zhihao Du, Shiliang Zhang, Kai Hu, Siqi Zheng
+ 备注:5 pages, 3 figures, submitted to ICASSP 2024
+ 关键词:open-source speech processing, paper presents FunCodec, neural speech codec, fundamental neural speech, paper presents
+
+ 点击查看摘要
+ This paper presents FunCodec, a fundamental neural speech codec toolkit,
+which is an extension of the open-source speech processing toolkit FunASR.
+FunCodec provides reproducible training recipes and inference scripts for the
+latest neural speech codec models, such as SoundStream and Encodec. Thanks to
+the unified design with FunASR, FunCodec can be easily integrated into
+downstream tasks, such as speech recognition. Along with FunCodec, pre-trained
+models are also provided, which can be used for academic or generalized
+purposes. Based on the toolkit, we further propose the frequency-domain codec
+models, FreqCodec, which can achieve comparable speech quality with much lower
+computation and parameter complexity. Experimental results show that, under the
+same compression ratio, FunCodec can achieve better reconstruction quality
+compared with other toolkits and released models. We also demonstrate that the
+pre-trained models are suitable for downstream tasks, including automatic
+speech recognition and personalized text-to-speech synthesis. This toolkit is
+publicly available at this https URL.
+
+
+
+ 39. 标题:Multi-Grade Deep Learning for Partial Differential Equations with Applications to the Burgers Equation
+ 编号:[220]
+ 链接:https://arxiv.org/abs/2309.07401
+ 作者:Yuesheng Xu, Taishan Zeng
+ 备注:
+ 关键词:nonlinear partial differential, solving nonlinear partial, multi-grade deep learning, deep learning, partial differential equations
+
+ 点击查看摘要
+ We develop in this paper a multi-grade deep learning method for solving
+nonlinear partial differential equations (PDEs). Deep neural networks (DNNs)
+have received super performance in solving PDEs in addition to their
+outstanding success in areas such as natural language processing, computer
+vision, and robotics. However, training a very deep network is often a
+challenging task. As the number of layers of a DNN increases, solving a
+large-scale non-convex optimization problem that results in the DNN solution of
+PDEs becomes more and more difficult, which may lead to a decrease rather than
+an increase in predictive accuracy. To overcome this challenge, we propose a
+two-stage multi-grade deep learning (TS-MGDL) method that breaks down the task
+of learning a DNN into several neural networks stacked on top of each other in
+a staircase-like manner. This approach allows us to mitigate the complexity of
+solving the non-convex optimization problem with large number of parameters and
+learn residual components left over from previous grades efficiently. We prove
+that each grade/stage of the proposed TS-MGDL method can reduce the value of
+the loss function and further validate this fact through numerical experiments.
+Although the proposed method is applicable to general PDEs, implementation in
+this paper focuses only on the 1D, 2D, and 3D viscous Burgers equations.
+Experimental results show that the proposed two-stage multi-grade deep learning
+method enables efficient learning of solutions of the equations and outperforms
+existing single-grade deep learning methods in predictive accuracy.
+Specifically, the predictive errors of the single-grade deep learning are
+larger than those of the TS-MGDL method in 26-60, 4-31 and 3-12 times, for the
+1D, 2D, and 3D equations, respectively.
+
+
+
+ 40. 标题:Semantic Adversarial Attacks via Diffusion Models
+ 编号:[222]
+ 链接:https://arxiv.org/abs/2309.07398
+ 作者:Chenan Wang, Jinhao Duan, Chaowei Xiao, Edward Kim, Matthew Stamm, Kaidi Xu
+ 备注:To appear in BMVC 2023
+ 关键词:adding adversarial perturbations, Traditional adversarial attacks, adversarial attacks concentrate, semantic adversarial attacks, latent space
+
+ 点击查看摘要
+ Traditional adversarial attacks concentrate on manipulating clean examples in
+the pixel space by adding adversarial perturbations. By contrast, semantic
+adversarial attacks focus on changing semantic attributes of clean examples,
+such as color, context, and features, which are more feasible in the real
+world. In this paper, we propose a framework to quickly generate a semantic
+adversarial attack by leveraging recent diffusion models since semantic
+information is included in the latent space of well-trained diffusion models.
+Then there are two variants of this framework: 1) the Semantic Transformation
+(ST) approach fine-tunes the latent space of the generated image and/or the
+diffusion model itself; 2) the Latent Masking (LM) approach masks the latent
+space with another target image and local backpropagation-based interpretation
+methods. Additionally, the ST approach can be applied in either white-box or
+black-box settings. Extensive experiments are conducted on CelebA-HQ and AFHQ
+datasets, and our framework demonstrates great fidelity, generalizability, and
+transferability compared to other baselines. Our approaches achieve
+approximately 100% attack success rate in multiple settings with the best FID
+as 36.61. Code is available at
+this https URL.
+
+
+
+ 41. 标题:DebCSE: Rethinking Unsupervised Contrastive Sentence Embedding Learning in the Debiasing Perspective
+ 编号:[223]
+ 链接:https://arxiv.org/abs/2309.07396
+ 作者:Pu Miao, Zeyao Du, Junlin Zhang
+ 备注:
+ 关键词:word frequency biases, prior studies, studies have suggested, suggested that word, word frequency
+
+ 点击查看摘要
+ Several prior studies have suggested that word frequency biases can cause the
+Bert model to learn indistinguishable sentence embeddings. Contrastive learning
+schemes such as SimCSE and ConSERT have already been adopted successfully in
+unsupervised sentence embedding to improve the quality of embeddings by
+reducing this bias. However, these methods still introduce new biases such as
+sentence length bias and false negative sample bias, that hinders model's
+ability to learn more fine-grained semantics. In this paper, we reexamine the
+challenges of contrastive sentence embedding learning from a debiasing
+perspective and argue that effectively eliminating the influence of various
+biases is crucial for learning high-quality sentence embeddings. We think all
+those biases are introduced by simple rules for constructing training data in
+contrastive learning and the key for contrastive learning sentence embedding is
+to mimic the distribution of training data in supervised machine learning in
+unsupervised way. We propose a novel contrastive framework for sentence
+embedding, termed DebCSE, which can eliminate the impact of these biases by an
+inverse propensity weighted sampling method to select high-quality positive and
+negative pairs according to both the surface and semantic similarity between
+sentences. Extensive experiments on semantic textual similarity (STS)
+benchmarks reveal that DebCSE significantly outperforms the latest
+state-of-the-art models with an average Spearman's correlation coefficient of
+80.33% on BERTbase.
+
+
+
+ 42. 标题:Unleashing the Power of Depth and Pose Estimation Neural Networks by Designing Compatible Endoscopic Images
+ 编号:[226]
+ 链接:https://arxiv.org/abs/2309.07390
+ 作者:Junyang Wu, Yun Gu
+ 备注:
+ 关键词:Deep learning models, pose estimation framework, neural networks, neural, Deep learning
+
+ 点击查看摘要
+ Deep learning models have witnessed depth and pose estimation framework on
+unannotated datasets as a effective pathway to succeed in endoscopic
+navigation. Most current techniques are dedicated to developing more advanced
+neural networks to improve the accuracy. However, existing methods ignore the
+special properties of endoscopic images, resulting in an inability to fully
+unleash the power of neural networks. In this study, we conduct a detail
+analysis of the properties of endoscopic images and improve the compatibility
+of images and neural networks, to unleash the power of current neural networks.
+First, we introcude the Mask Image Modelling (MIM) module, which inputs partial
+image information instead of complete image information, allowing the network
+to recover global information from partial pixel information. This enhances the
+network' s ability to perceive global information and alleviates the phenomenon
+of local overfitting in convolutional neural networks due to local artifacts.
+Second, we propose a lightweight neural network to enhance the endoscopic
+images, to explicitly improve the compatibility between images and neural
+networks. Extensive experiments are conducted on the three public datasets and
+one inhouse dataset, and the proposed modules improve baselines by a large
+margin. Furthermore, the enhanced images we proposed, which have higher network
+compatibility, can serve as an effective data augmentation method and they are
+able to extract more stable feature points in traditional feature point
+matching tasks and achieve outstanding performance.
+
+
+
+ 43. 标题:Hodge-Aware Contrastive Learning
+ 编号:[236]
+ 链接:https://arxiv.org/abs/2309.07364
+ 作者:Alexander Möllers, Alexander Immer, Vincent Fortuin, Elvin Isufi
+ 备注:4 pages, 2 figures
+ 关键词:complexes prove effective, Simplicial complexes prove, multiway dependencies, complexes prove, prove effective
+
+ 点击查看摘要
+ Simplicial complexes prove effective in modeling data with multiway
+dependencies, such as data defined along the edges of networks or within other
+higher-order structures. Their spectrum can be decomposed into three
+interpretable subspaces via the Hodge decomposition, resulting foundational in
+numerous applications. We leverage this decomposition to develop a contrastive
+self-supervised learning approach for processing simplicial data and generating
+embeddings that encapsulate specific spectral information.Specifically, we
+encode the pertinent data invariances through simplicial neural networks and
+devise augmentations that yield positive contrastive examples with suitable
+spectral properties for downstream tasks. Additionally, we reweight the
+significance of negative examples in the contrastive loss, considering the
+similarity of their Hodge components to the anchor. By encouraging a stronger
+separation among less similar instances, we obtain an embedding space that
+reflects the spectral properties of the data. The numerical results on two
+standard edge flow classification tasks show a superior performance even when
+compared to supervised learning techniques. Our findings underscore the
+importance of adopting a spectral perspective for contrastive learning with
+higher-order data.
+
+
+
+ 44. 标题:Learning from Auxiliary Sources in Argumentative Revision Classification
+ 编号:[247]
+ 链接:https://arxiv.org/abs/2309.07334
+ 作者:Tazin Afrin, Diane Litman
+ 备注:
+ 关键词:classify desirable reasoning, desirable reasoning revisions, argumentative writing, develop models, models to classify
+
+ 点击查看摘要
+ We develop models to classify desirable reasoning revisions in argumentative
+writing. We explore two approaches -- multi-task learning and transfer learning
+-- to take advantage of auxiliary sources of revision data for similar tasks.
+Results of intrinsic and extrinsic evaluations show that both approaches can
+indeed improve classifier performance over baselines. While multi-task learning
+shows that training on different sources of data at the same time may improve
+performance, transfer-learning better represents the relationship between the
+data.
+
+
+
+ 45. 标题:Reliability-based cleaning of noisy training labels with inductive conformal prediction in multi-modal biomedical data mining
+ 编号:[249]
+ 链接:https://arxiv.org/abs/2309.07332
+ 作者:Xianghao Zhan, Qinmei Xu, Yuanning Zheng, Guangming Lu, Olivier Gevaert
+ 备注:
+ 关键词:presents a challenge, data, training data, biomedical data presents, labeling biomedical data
+
+ 点击查看摘要
+ Accurately labeling biomedical data presents a challenge. Traditional
+semi-supervised learning methods often under-utilize available unlabeled data.
+To address this, we propose a novel reliability-based training data cleaning
+method employing inductive conformal prediction (ICP). This method capitalizes
+on a small set of accurately labeled training data and leverages ICP-calculated
+reliability metrics to rectify mislabeled data and outliers within vast
+quantities of noisy training data. The efficacy of the method is validated
+across three classification tasks within distinct modalities: filtering
+drug-induced-liver-injury (DILI) literature with title and abstract, predicting
+ICU admission of COVID-19 patients through CT radiomics and electronic health
+records, and subtyping breast cancer using RNA-sequencing data. Varying levels
+of noise to the training labels were introduced through label permutation.
+Results show significant enhancements in classification performance: accuracy
+enhancement in 86 out of 96 DILI experiments (up to 11.4%), AUROC and AUPRC
+enhancements in all 48 COVID-19 experiments (up to 23.8% and 69.8%), and
+accuracy and macro-average F1 score improvements in 47 out of 48 RNA-sequencing
+experiments (up to 74.6% and 89.0%). Our method offers the potential to
+substantially boost classification performance in multi-modal biomedical
+machine learning tasks. Importantly, it accomplishes this without necessitating
+an excessive volume of meticulously curated training data.
+
+
+
+ 46. 标题:Traveling Words: A Geometric Interpretation of Transformers
+ 编号:[254]
+ 链接:https://arxiv.org/abs/2309.07315
+ 作者:Raul Molina
+ 备注:
+ 关键词:natural language processing, internal mechanisms remains, language processing, remains a challenge, significantly advanced
+
+ 点击查看摘要
+ Transformers have significantly advanced the field of natural language
+processing, but comprehending their internal mechanisms remains a challenge. In
+this paper, we introduce a novel geometric perspective that elucidates the
+inner mechanisms of transformer operations. Our primary contribution is
+illustrating how layer normalization confines the latent features to a
+hyper-sphere, subsequently enabling attention to mold the semantic
+representation of words on this surface. This geometric viewpoint seamlessly
+connects established properties such as iterative refinement and contextual
+embeddings. We validate our insights by probing a pre-trained 124M parameter
+GPT-2 model. Our findings reveal clear query-key attention patterns in early
+layers and build upon prior observations regarding the subject-specific nature
+of attention heads at deeper layers. Harnessing these geometric insights, we
+present an intuitive understanding of transformers, depicting them as processes
+that model the trajectory of word particles along the hyper-sphere.
+
+
+
+ 47. 标题:AudioSR: Versatile Audio Super-resolution at Scale
+ 编号:[255]
+ 链接:https://arxiv.org/abs/2309.07314
+ 作者:Haohe Liu, Ke Chen, Qiao Tian, Wenwu Wang, Mark D. Plumbley
+ 备注:Under review. Demo and code: this https URL
+ 关键词:predicts high-frequency components, digital applications, Audio, fundamental task, task that predicts
+
+ 点击查看摘要
+ Audio super-resolution is a fundamental task that predicts high-frequency
+components for low-resolution audio, enhancing audio quality in digital
+applications. Previous methods have limitations such as the limited scope of
+audio types (e.g., music, speech) and specific bandwidth settings they can
+handle (e.g., 4kHz to 8kHz). In this paper, we introduce a diffusion-based
+generative model, AudioSR, that is capable of performing robust audio
+super-resolution on versatile audio types, including sound effects, music, and
+speech. Specifically, AudioSR can upsample any input audio signal within the
+bandwidth range of 2kHz to 16kHz to a high-resolution audio signal at 24kHz
+bandwidth with a sampling rate of 48kHz. Extensive objective evaluation on
+various audio super-resolution benchmarks demonstrates the strong result
+achieved by the proposed model. In addition, our subjective evaluation shows
+that AudioSR can acts as a plug-and-play module to enhance the generation
+quality of a wide range of audio generative models, including AudioLDM,
+Fastspeech2, and MusicGen. Our code and demo are available at
+this https URL.
+
+
+
+ 48. 标题:Language-Conditioned Observation Models for Visual Object Search
+ 编号:[273]
+ 链接:https://arxiv.org/abs/2309.07276
+ 作者:Thao Nguyen, Vladislav Hrosinkov, Eric Rosen, Stefanie Tellex
+ 备注:
+ 关键词:Object, Object search, white cup, move its camera, complex language descriptions
+
+ 点击查看摘要
+ Object search is a challenging task because when given complex language
+descriptions (e.g., "find the white cup on the table"), the robot must move its
+camera through the environment and recognize the described object. Previous
+works map language descriptions to a set of fixed object detectors with
+predetermined noise models, but these approaches are challenging to scale
+because new detectors need to be made for each object. In this work, we bridge
+the gap in realistic object search by posing the search problem as a partially
+observable Markov decision process (POMDP) where the object detector and visual
+sensor noise in the observation model is determined by a single Deep Neural
+Network conditioned on complex language descriptions. We incorporate the neural
+network's outputs into our language-conditioned observation model (LCOM) to
+represent dynamically changing sensor noise. With an LCOM, any language
+description of an object can be used to generate an appropriate object detector
+and noise model, and training an LCOM only requires readily available
+supervised image-caption datasets. We empirically evaluate our method by
+comparing against a state-of-the-art object search algorithm in simulation, and
+demonstrate that planning with our observation model yields a significantly
+higher average task completion rate (from 0.46 to 0.66) and more efficient and
+quicker object search than with a fixed-noise model. We demonstrate our method
+on a Boston Dynamics Spot robot, enabling it to handle complex natural language
+object descriptions and efficiently find objects in a room-scale environment.
+
+
+
+ 49. 标题:Safe and Accelerated Deep Reinforcement Learning-based O-RAN Slicing: A Hybrid Transfer Learning Approach
+ 编号:[277]
+ 链接:https://arxiv.org/abs/2309.07265
+ 作者:Ahmad M. Nagib, Hatem Abou-Zeid, Hossam S. Hassanein
+ 备注:This paper has been accepted for publication in a future issue of IEEE Journal on Selected Areas in Communications (JSAC)
+ 关键词:architecture supports intelligent, radio access network, open radio access, supports intelligent network, RAN intelligent controllers
+
+ 点击查看摘要
+ The open radio access network (O-RAN) architecture supports intelligent
+network control algorithms as one of its core capabilities. Data-driven
+applications incorporate such algorithms to optimize radio access network (RAN)
+functions via RAN intelligent controllers (RICs). Deep reinforcement learning
+(DRL) algorithms are among the main approaches adopted in the O-RAN literature
+to solve dynamic radio resource management problems. However, despite the
+benefits introduced by the O-RAN RICs, the practical adoption of DRL algorithms
+in real network deployments falls behind. This is primarily due to the slow
+convergence and unstable performance exhibited by DRL agents upon deployment
+and when facing previously unseen network conditions. In this paper, we address
+these challenges by proposing transfer learning (TL) as a core component of the
+training and deployment workflows for the DRL-based closed-loop control of
+O-RAN functionalities. To this end, we propose and design a hybrid TL-aided
+approach that leverages the advantages of both policy reuse and distillation TL
+methods to provide safe and accelerated convergence in DRL-based O-RAN slicing.
+We conduct a thorough experiment that accommodates multiple services, including
+real VR gaming traffic to reflect practical scenarios of O-RAN slicing. We also
+propose and implement policy reuse and distillation-aided DRL and non-TL-aided
+DRL as three separate baselines. The proposed hybrid approach shows at least:
+7.7% and 20.7% improvements in the average initial reward value and the
+percentage of converged scenarios, and a 64.6% decrease in reward variance
+while maintaining fast convergence and enhancing the generalizability compared
+with the baselines.
+
+
+
+ 50. 标题:Autotuning Apache TVM-based Scientific Applications Using Bayesian Optimization
+ 编号:[287]
+ 链接:https://arxiv.org/abs/2309.07235
+ 作者:Xingfu Wu, Praveen Paramasivam, Valerie Taylor
+ 备注:
+ 关键词:Tensor Virtual Machine, Lower Upper, Artificial Intelligence, open source machine, source machine learning
+
+ 点击查看摘要
+ Apache TVM (Tensor Virtual Machine), an open source machine learning compiler
+framework designed to optimize computations across various hardware platforms,
+provides an opportunity to improve the performance of dense matrix
+factorizations such as LU (Lower Upper) decomposition and Cholesky
+decomposition on GPUs and AI (Artificial Intelligence) accelerators. In this
+paper, we propose a new TVM autotuning framework using Bayesian Optimization
+and use the TVM tensor expression language to implement linear algebra kernels
+such as LU, Cholesky, and 3mm. We use these scientific computation kernels to
+evaluate the effectiveness of our methods on a GPU cluster, called Swing, at
+Argonne National Laboratory. We compare the proposed autotuning framework with
+the TVM autotuning framework AutoTVM with four tuners and find that our
+framework outperforms AutoTVM in most cases.
+
+
+
+ 51. 标题:Latent Representation and Simulation of Markov Processes via Time-Lagged Information Bottleneck
+ 编号:[292]
+ 链接:https://arxiv.org/abs/2309.07200
+ 作者:Marco Federici, Patrick Forré, Ryota Tomioka, Bastiaan S. Veeling
+ 备注:10 pages, 14 figures
+ 关键词:Markov processes, processes are widely, widely used mathematical, describing dynamic systems, mathematical models
+
+ 点击查看摘要
+ Markov processes are widely used mathematical models for describing dynamic
+systems in various fields. However, accurately simulating large-scale systems
+at long time scales is computationally expensive due to the short time steps
+required for accurate integration. In this paper, we introduce an inference
+process that maps complex systems into a simplified representational space and
+models large jumps in time. To achieve this, we propose Time-lagged Information
+Bottleneck (T-IB), a principled objective rooted in information theory, which
+aims to capture relevant temporal features while discarding high-frequency
+information to simplify the simulation task and minimize the inference error.
+Our experiments demonstrate that T-IB learns information-optimal
+representations for accurately modeling the statistical properties and dynamics
+of the original process at a selected time lag, outperforming existing
+time-lagged dimensionality reduction methods.
+
+
+
+ 52. 标题:Attention-based Dynamic Graph Convolutional Recurrent Neural Network for Traffic Flow Prediction in Highway Transportation
+ 编号:[294]
+ 链接:https://arxiv.org/abs/2309.07196
+ 作者:Tianpu Zhang, Weilong Ding, Mengda Xing
+ 备注:
+ 关键词:spatial feature extraction, feature extraction, important tools, tools for spatial, spatial feature
+
+ 点击查看摘要
+ As one of the important tools for spatial feature extraction, graph
+convolution has been applied in a wide range of fields such as traffic flow
+prediction. However, current popular works of graph convolution cannot
+guarantee spatio-temporal consistency in a long period. The ignorance of
+correlational dynamics, convolutional locality and temporal comprehensiveness
+would limit predictive accuracy. In this paper, a novel Attention-based Dynamic
+Graph Convolutional Recurrent Neural Network (ADGCRNN) is proposed to improve
+traffic flow prediction in highway transportation. Three temporal resolutions
+of data sequence are effectively integrated by self-attention to extract
+characteristics; multi-dynamic graphs and their weights are dynamically created
+to compliantly combine the varying characteristics; a dedicated gated kernel
+emphasizing highly relative nodes is introduced on these complete graphs to
+reduce overfitting for graph convolution operations. Experiments on two public
+datasets show our work better than state-of-the-art baselines, and case studies
+of a real Web system prove practical benefit in highway transportation.
+
+
+
+ 53. 标题:HurriCast: An Automatic Framework Using Machine Learning and Statistical Modeling for Hurricane Forecasting
+ 编号:[301]
+ 链接:https://arxiv.org/abs/2309.07174
+ 作者:Shouwei Gao, Meiyan Gao, Yuepeng Li, Wenqian Dong
+ 备注:This paper includes 7 pages and 8 figures. And we submitted it up to the SC23 workshop. This is only a preprinting
+ 关键词:present major challenges, Hurricanes present major, devastating impacts, present major, major challenges
+
+ 点击查看摘要
+ Hurricanes present major challenges in the U.S. due to their devastating
+impacts. Mitigating these risks is important, and the insurance industry is
+central in this effort, using intricate statistical models for risk assessment.
+However, these models often neglect key temporal and spatial hurricane patterns
+and are limited by data scarcity. This study introduces a refined approach
+combining the ARIMA model and K-MEANS to better capture hurricane trends, and
+an Autoencoder for enhanced hurricane simulations. Our experiments show that
+this hybrid methodology effectively simulate historical hurricane behaviors
+while providing detailed projections of potential future trajectories and
+intensities. Moreover, by leveraging a comprehensive yet selective dataset, our
+simulations enrich the current understanding of hurricane patterns and offer
+actionable insights for risk management strategies.
+
+
+
+ 54. 标题:Exploring Large Language Models for Ontology Alignment
+ 编号:[303]
+ 链接:https://arxiv.org/abs/2309.07172
+ 作者:Yuan He, Jiaoyan Chen, Hang Dong, Ian Horrocks
+ 备注:Accepted at ISWC 2023 (Posters and Demos)
+ 关键词:generative Large Language, recent generative Large, Large Language, generative Large, work investigates
+
+ 点击查看摘要
+ This work investigates the applicability of recent generative Large Language
+Models (LLMs), such as the GPT series and Flan-T5, to ontology alignment for
+identifying concept equivalence mappings across ontologies. To test the
+zero-shot performance of Flan-T5-XXL and GPT-3.5-turbo, we leverage challenging
+subsets from two equivalence matching datasets of the OAEI Bio-ML track, taking
+into account concept labels and structural contexts. Preliminary findings
+suggest that LLMs have the potential to outperform existing ontology alignment
+systems like BERTMap, given careful framework and prompt design.
+
+
+
+ 55. 标题:Goal Space Abstraction in Hierarchical Reinforcement Learning via Reachability Analysis
+ 编号:[304]
+ 链接:https://arxiv.org/abs/2309.07168
+ 作者:Mehdi Zadem (LIX, U2IS), Sergio Mover (LIX), Sao Mai Nguyen (U2IS, Flowers, IMT Atlantique - INFO, Lab-STICC_RAMBO)
+ 备注:
+ 关键词:Open-ended learning benefits, learning benefits immensely, existing Hierarchical Reinforcement, benefits immensely, structure knowledge
+
+ 点击查看摘要
+ Open-ended learning benefits immensely from the use of symbolic methods for
+goal representation as they offer ways to structure knowledge for efficient and
+transferable learning. However, the existing Hierarchical Reinforcement
+Learning (HRL) approaches relying on symbolic reasoning are often limited as
+they require a manual goal representation. The challenge in autonomously
+discovering a symbolic goal representation is that it must preserve critical
+information, such as the environment dynamics. In this work, we propose a
+developmental mechanism for subgoal discovery via an emergent representation
+that abstracts (i.e., groups together) sets of environment states that have
+similar roles in the task. We create a HRL algorithm that gradually learns this
+representation along with the policies and evaluate it on navigation tasks to
+show the learned representation is interpretable and results in data
+efficiency.
+
+
+
+ 56. 标题:Finding Influencers in Complex Networks: An Effective Deep Reinforcement Learning Approach
+ 编号:[309]
+ 链接:https://arxiv.org/abs/2309.07153
+ 作者:Changan Liu, Changjun Fan, Zhongzhi Zhang
+ 备注:
+ 关键词:computationally challenging task, hard nature, social network analysis, practically important, important but computationally
+
+ 点击查看摘要
+ Maximizing influences in complex networks is a practically important but
+computationally challenging task for social network analysis, due to its NP-
+hard nature. Most current approximation or heuristic methods either require
+tremendous human design efforts or achieve unsatisfying balances between
+effectiveness and efficiency. Recent machine learning attempts only focus on
+speed but lack performance enhancement. In this paper, different from previous
+attempts, we propose an effective deep reinforcement learning model that
+achieves superior performances over traditional best influence maximization
+algorithms. Specifically, we design an end-to-end learning framework that
+combines graph neural network as the encoder and reinforcement learning as the
+decoder, named DREIM. Trough extensive training on small synthetic graphs,
+DREIM outperforms the state-of-the-art baseline methods on very large synthetic
+and real-world networks on solution quality, and we also empirically show its
+linear scalability with regard to the network size, which demonstrates its
+superiority in solving this problem.
+
+
+
+ 57. 标题:Ontologies for increasing the FAIRness of plant research data
+ 编号:[312]
+ 链接:https://arxiv.org/abs/2309.07129
+ 作者:Kathryn Dumschott, Hannah Dörpholz, Marie-Angélique Laporte, Dominik Brilhaus, Andrea Schrader, Björn Usadel, Steffen Neumann, Elizabeth Arnaud, Angela Kranz
+ 备注:34 pages, 4 figures, 1 table, 1 supplementary table
+ 关键词:improving the FAIRness, face of large, omics technologies, importance of improving, complex datasets
+
+ 点击查看摘要
+ The importance of improving the FAIRness (findability, accessibility,
+interoperability, reusability) of research data is undeniable, especially in
+the face of large, complex datasets currently being produced by omics
+technologies. Facilitating the integration of a dataset with other types of
+data increases the likelihood of reuse, and the potential of answering novel
+research questions. Ontologies are a useful tool for semantically tagging
+datasets as adding relevant metadata increases the understanding of how data
+was produced and increases its interoperability. Ontologies provide concepts
+for a particular domain as well as the relationships between concepts. By
+tagging data with ontology terms, data becomes both human and machine
+interpretable, allowing for increased reuse and interoperability. However, the
+task of identifying ontologies relevant to a particular research domain or
+technology is challenging, especially within the diverse realm of fundamental
+plant research. In this review, we outline the ontologies most relevant to the
+fundamental plant sciences and how they can be used to annotate data related to
+plant-specific experiments within metadata frameworks, such as
+Investigation-Study-Assay (ISA). We also outline repositories and platforms
+most useful for identifying applicable ontologies or finding ontology terms.
+
+
+
+ 58. 标题:Applying Deep Learning to Calibrate Stochastic Volatility Models
+ 编号:[317]
+ 链接:https://arxiv.org/abs/2309.07843
+ 作者:Abir Sridi, Paul Bilokon
+ 备注:
+ 关键词:implied volatility surfaces, Stochastic volatility models, essential stylized facts, Stochastic volatility, implied volatility
+
+ 点击查看摘要
+ Stochastic volatility models, where the volatility is a stochastic process,
+can capture most of the essential stylized facts of implied volatility surfaces
+and give more realistic dynamics of the volatility smile or skew. However, they
+come with the significant issue that they take too long to calibrate.
+Alternative calibration methods based on Deep Learning (DL) techniques have
+been recently used to build fast and accurate solutions to the calibration
+problem. Huge and Savine developed a Differential Deep Learning (DDL) approach,
+where Machine Learning models are trained on samples of not only features and
+labels but also differentials of labels to features. The present work aims to
+apply the DDL technique to price vanilla European options (i.e. the calibration
+instruments), more specifically, puts when the underlying asset follows a
+Heston model and then calibrate the model on the trained network. DDL allows
+for fast training and accurate pricing. The trained neural network dramatically
+reduces Heston calibration's computation time.
+In this work, we also introduce different regularisation techniques, and we
+apply them notably in the case of the DDL. We compare their performance in
+reducing overfitting and improving the generalisation error. The DDL
+performance is also compared to the classical DL (without differentiation) one
+in the case of Feed-Forward Neural Networks. We show that the DDL outperforms
+the DL.
+
+
+
+ 59. 标题:Variational Quantum Linear Solver enhanced Quantum Support Vector Machine
+ 编号:[326]
+ 链接:https://arxiv.org/abs/2309.07770
+ 作者:Jianming Yi, Kalyani Suresh, Ali Moghiseh, Norbert Wehn
+ 备注:
+ 关键词:Support Vector Machines, Quantum Support Vector, machine learning tasks, supervised machine learning, Support Vector
+
+ 点击查看摘要
+ Quantum Support Vector Machines (QSVM) play a vital role in using quantum
+resources for supervised machine learning tasks, such as classification.
+However, current methods are strongly limited in terms of scalability on Noisy
+Intermediate Scale Quantum (NISQ) devices. In this work, we propose a novel
+approach called the Variational Quantum Linear Solver (VQLS) enhanced QSVM.
+This is built upon our idea of utilizing the variational quantum linear solver
+to solve system of linear equations of a least squares-SVM on a NISQ device.
+The implementation of our approach is evaluated by an extensive series of
+numerical experiments with the Iris dataset, which consists of three distinct
+iris plant species. Based on this, we explore the practicality and
+effectiveness of our algorithm by constructing a classifier capable of
+classification in a feature space ranging from one to seven dimensions.
+Furthermore, by strategically exploiting both classical and quantum computing
+for various subroutines of our algorithm, we effectively mitigate practical
+challenges associated with the implementation. These include significant
+improvement in the trainability of the variational ansatz and notable
+reductions in run-time for cost calculations. Based on the numerical
+experiments, our approach exhibits the capability of identifying a separating
+hyperplane in an 8-dimensional feature space. Moreover, it consistently
+demonstrated strong performance across various instances with the same dataset.
+
+
+
+ 60. 标题:The kernel-balanced equation for deep neural networks
+ 编号:[349]
+ 链接:https://arxiv.org/abs/2309.07367
+ 作者:Kenichi Nakazato
+ 备注:
+ 关键词:Deep neural networks, Deep neural, shown many fruitful, fruitful applications, neural networks
+
+ 点击查看摘要
+ Deep neural networks have shown many fruitful applications in this decade. A
+network can get the generalized function through training with a finite
+dataset. The degree of generalization is a realization of the proximity scale
+in the data space. Specifically, the scale is not clear if the dataset is
+complicated. Here we consider a network for the distribution estimation of the
+dataset. We show the estimation is unstable and the instability depends on the
+data density and training duration. We derive the kernel-balanced equation,
+which gives a short phenomenological description of the solution. The equation
+tells us the reason for the instability and the mechanism of the scale. The
+network outputs a local average of the dataset as a prediction and the scale of
+averaging is determined along the equation. The scale gradually decreases along
+training and finally results in instability in our case.
+
+
+
+ 61. 标题:Efficient quantum recurrent reinforcement learning via quantum reservoir computing
+ 编号:[352]
+ 链接:https://arxiv.org/abs/2309.07339
+ 作者:Samuel Yen-Chi Chen
+ 备注:
+ 关键词:solve sequential decision-making, sequential decision-making tasks, showcasing empirical quantum, Quantum reinforcement learning, reinforcement learning
+
+ 点击查看摘要
+ Quantum reinforcement learning (QRL) has emerged as a framework to solve
+sequential decision-making tasks, showcasing empirical quantum advantages. A
+notable development is through quantum recurrent neural networks (QRNNs) for
+memory-intensive tasks such as partially observable environments. However, QRL
+models incorporating QRNN encounter challenges such as inefficient training of
+QRL with QRNN, given that the computation of gradients in QRNN is both
+computationally expensive and time-consuming. This work presents a novel
+approach to address this challenge by constructing QRL agents utilizing
+QRNN-based reservoirs, specifically employing quantum long short-term memory
+(QLSTM). QLSTM parameters are randomly initialized and fixed without training.
+The model is trained using the asynchronous advantage actor-aritic (A3C)
+algorithm. Through numerical simulations, we validate the efficacy of our
+QLSTM-Reservoir RL framework. Its performance is assessed on standard
+benchmarks, demonstrating comparable results to a fully trained QLSTM RL model
+with identical architecture and training settings.
+
+
+
+ 62. 标题:Predicting Survival Time of Ball Bearings in the Presence of Censoring
+ 编号:[362]
+ 链接:https://arxiv.org/abs/2309.07188
+ 作者:Christian Marius Lillelund, Fernando Pannullo, Morten Opprud Jakobsen, Christian Fischer Pedersen
+ 备注:Accepted at AAAI Fall Symposium 2023 on Survival Prediction
+ 关键词:bearings find widespread, Ball bearings find, find widespread, manufacturing and mechanical, machine learning
+
+ 点击查看摘要
+ Ball bearings find widespread use in various manufacturing and mechanical
+domains, and methods based on machine learning have been widely adopted in the
+field to monitor wear and spot defects before they lead to failures. Few
+studies, however, have addressed the problem of censored data, in which failure
+is not observed. In this paper, we propose a novel approach to predict the time
+to failure in ball bearings using survival analysis. First, we analyze bearing
+data in the frequency domain and annotate when a bearing fails by comparing the
+Kullback-Leibler divergence and the standard deviation between its break-in
+frequency bins and its break-out frequency bins. Second, we train several
+survival models to estimate the time to failure based on the annotated data and
+covariates extracted from the time domain, such as skewness, kurtosis and
+entropy. The models give a probabilistic prediction of risk over time and allow
+us to compare the survival function between groups of bearings. We demonstrate
+our approach on the XJTU and PRONOSTIA datasets. On XJTU, the best result is a
+0.70 concordance-index and 0.21 integrated Brier score. On PRONOSTIA, the best
+is a 0.76 concordance-index and 0.19 integrated Brier score. Our work motivates
+further work on incorporating censored data in models for predictive
+maintenance.
+
+
+
+ 63. 标题:A Health Monitoring System Based on Flexible Triboelectric Sensors for Intelligence Medical Internet of Things and its Applications in Virtual Reality
+ 编号:[363]
+ 链接:https://arxiv.org/abs/2309.07185
+ 作者:Junqi Mao, Puen Zhou, Xiaoyao Wang, Hongbo Yao, Liuyang Liang, Yiqiao Zhao, Jiawei Zhang, Dayan Ban, Haiwu Zheng
+ 备注:
+ 关键词:combines Internet, Internet of Medical, Medical Things, Internet, platform that combines
+
+ 点击查看摘要
+ The Internet of Medical Things (IoMT) is a platform that combines Internet of
+Things (IoT) technology with medical applications, enabling the realization of
+precision medicine, intelligent healthcare, and telemedicine in the era of
+digitalization and intelligence. However, the IoMT faces various challenges,
+including sustainable power supply, human adaptability of sensors and the
+intelligence of sensors. In this study, we designed a robust and intelligent
+IoMT system through the synergistic integration of flexible wearable
+triboelectric sensors and deep learning-assisted data analytics. We embedded
+four triboelectric sensors into a wristband to detect and analyze limb
+movements in patients suffering from Parkinson's Disease (PD). By further
+integrating deep learning-assisted data analytics, we actualized an intelligent
+healthcare monitoring system for the surveillance and interaction of PD
+patients, which includes location/trajectory tracking, heart monitoring and
+identity recognition. This innovative approach enabled us to accurately capture
+and scrutinize the subtle movements and fine motor of PD patients, thus
+providing insightful feedback and comprehensive assessment of the patients
+conditions. This monitoring system is cost-effective, easily fabricated, highly
+sensitive, and intelligent, consequently underscores the immense potential of
+human body sensing technology in a Health 4.0 society.
+
+
+
+ 64. 标题:CloudBrain-NMR: An Intelligent Cloud Computing Platform for NMR Spectroscopy Processing, Reconstruction and Analysis
+ 编号:[366]
+ 链接:https://arxiv.org/abs/2309.07178
+ 作者:Di Guo, Sijin Li, Jun Liu, Zhangren Tu, Tianyu Qiu, Jingjing Xu, Liubin Feng, Donghai Lin, Qing Hong, Meijin Lin, Yanqin Lin, Xiaobo Qu
+ 备注:11 pages, 13 figures
+ 关键词:Nuclear Magnetic Resonance, Magnetic Resonance, studying molecular structure, Nuclear Magnetic, powerful analytical tool
+
+ 点击查看摘要
+ Nuclear Magnetic Resonance (NMR) spectroscopy has served as a powerful
+analytical tool for studying molecular structure and dynamics in chemistry and
+biology. However, the processing of raw data acquired from NMR spectrometers
+and subsequent quantitative analysis involves various specialized tools, which
+necessitates comprehensive knowledge in programming and NMR. Particularly, the
+emerging deep learning tools is hard to be widely used in NMR due to the
+sophisticated setup of computation. Thus, NMR processing is not an easy task
+for chemist and biologists. In this work, we present CloudBrain-NMR, an
+intelligent online cloud computing platform designed for NMR data reading,
+processing, reconstruction, and quantitative analysis. The platform is
+conveniently accessed through a web browser, eliminating the need for any
+program installation on the user side. CloudBrain-NMR uses parallel computing
+with graphics processing units and central processing units, resulting in
+significantly shortened computation time. Furthermore, it incorporates
+state-of-the-art deep learning-based algorithms offering comprehensive
+functionalities that allow users to complete the entire processing procedure
+without relying on additional software. This platform has empowered NMR
+applications with advanced artificial intelligence processing. CloudBrain-NMR
+is openly accessible for free usage at this https URL
+
+
+
+ 65. 标题:Hybrid ASR for Resource-Constrained Robots: HMM - Deep Learning Fusion
+ 编号:[370]
+ 链接:https://arxiv.org/abs/2309.07164
+ 作者:Anshul Ranjan, Kaushik Jegadeesan
+ 备注:To be published in IEEE Access, 9 pages, 14 figures, Received valuable support from CCBD PESU, for associated code, see this https URL
+ 关键词:Automatic Speech Recognition, Hidden Markov Models, hybrid Automatic Speech, Automatic Speech, deep learning models
+
+ 点击查看摘要
+ This paper presents a novel hybrid Automatic Speech Recognition (ASR) system
+designed specifically for resource-constrained robots. The proposed approach
+combines Hidden Markov Models (HMMs) with deep learning models and leverages
+socket programming to distribute processing tasks effectively. In this
+architecture, the HMM-based processing takes place within the robot, while a
+separate PC handles the deep learning model. This synergy between HMMs and deep
+learning enhances speech recognition accuracy significantly. We conducted
+experiments across various robotic platforms, demonstrating real-time and
+precise speech recognition capabilities. Notably, the system exhibits
+adaptability to changing acoustic conditions and compatibility with low-power
+hardware, making it highly effective in environments with limited computational
+resources. This hybrid ASR paradigm opens up promising possibilities for
+seamless human-robot interaction. In conclusion, our research introduces a
+pioneering dimension to ASR techniques tailored for robotics. By employing
+socket programming to distribute processing tasks across distinct devices and
+strategically combining HMMs with deep learning models, our hybrid ASR system
+showcases its potential to enable robots to comprehend and respond to spoken
+language adeptly, even in environments with restricted computational resources.
+This paradigm sets a innovative course for enhancing human-robot interaction
+across a wide range of real-world scenarios.
+
+
+
+ 66. 标题:Recall-driven Precision Refinement: Unveiling Accurate Fall Detection using LSTM
+ 编号:[374]
+ 链接:https://arxiv.org/abs/2309.07154
+ 作者:Rishabh Mondal, Prasun Ghosal
+ 备注:8 pages, 9 figures, 6th IFIP IoT 2023 Conference
+ 关键词:paper presents, presents an innovative, innovative approach, approach to address, address the pressing
+
+ 点击查看摘要
+ This paper presents an innovative approach to address the pressing concern of
+fall incidents among the elderly by developing an accurate fall detection
+system. Our proposed system combines state-of-the-art technologies, including
+accelerometer and gyroscope sensors, with deep learning models, specifically
+Long Short-Term Memory (LSTM) networks. Real-time execution capabilities are
+achieved through the integration of Raspberry Pi hardware. We introduce pruning
+techniques that strategically fine-tune the LSTM model's architecture and
+parameters to optimize the system's performance. We prioritize recall over
+precision, aiming to accurately identify falls and minimize false negatives for
+timely intervention. Extensive experimentation and meticulous evaluation
+demonstrate remarkable performance metrics, emphasizing a high recall rate
+while maintaining a specificity of 96\%. Our research culminates in a
+state-of-the-art fall detection system that promptly sends notifications,
+ensuring vulnerable individuals receive timely assistance and improve their
+overall well-being. Applying LSTM models and incorporating pruning techniques
+represent a significant advancement in fall detection technology, offering an
+effective and reliable fall prevention and intervention solution.
+
+
+
+ 67. 标题:Decoding visual brain representations from electroencephalography through Knowledge Distillation and latent diffusion models
+ 编号:[376]
+ 链接:https://arxiv.org/abs/2309.07149
+ 作者:Matteo Ferrante, Tommaso Boccato, Stefano Bargione, Nicola Toschi
+ 备注:
+ 关键词:thriving research domain, brain-computer interfaces, representations from human, context of brain-computer, Decoding visual representations
+
+ 点击查看摘要
+ Decoding visual representations from human brain activity has emerged as a
+thriving research domain, particularly in the context of brain-computer
+interfaces. Our study presents an innovative method that employs to classify
+and reconstruct images from the ImageNet dataset using electroencephalography
+(EEG) data from subjects that had viewed the images themselves (i.e. "brain
+decoding"). We analyzed EEG recordings from 6 participants, each exposed to 50
+images spanning 40 unique semantic categories. These EEG readings were
+converted into spectrograms, which were then used to train a convolutional
+neural network (CNN), integrated with a knowledge distillation procedure based
+on a pre-trained Contrastive Language-Image Pre-Training (CLIP)-based image
+classification teacher network. This strategy allowed our model to attain a
+top-5 accuracy of 80%, significantly outperforming a standard CNN and various
+RNN-based benchmarks. Additionally, we incorporated an image reconstruction
+mechanism based on pre-trained latent diffusion models, which allowed us to
+generate an estimate of the images which had elicited EEG activity. Therefore,
+our architecture not only decodes images from neural activity but also offers a
+credible image reconstruction from EEG only, paving the way for e.g. swift,
+individualized feedback experiments. Our research represents a significant step
+forward in connecting neural signals with visual cognition.
+
+
+
+ 68. 标题:ETP: Learning Transferable ECG Representations via ECG-Text Pre-training
+ 编号:[378]
+ 链接:https://arxiv.org/abs/2309.07145
+ 作者:Che Liu, Zhongwei Wan, Sibo Cheng, Mi Zhang, Rossella Arcucci
+ 备注:under review
+ 关键词:non-invasive diagnostic tool, cardiovascular healthcare, non-invasive diagnostic, diagnostic tool, ECG
+
+ 点击查看摘要
+ In the domain of cardiovascular healthcare, the Electrocardiogram (ECG)
+serves as a critical, non-invasive diagnostic tool. Although recent strides in
+self-supervised learning (SSL) have been promising for ECG representation
+learning, these techniques often require annotated samples and struggle with
+classes not present in the fine-tuning stages. To address these limitations, we
+introduce ECG-Text Pre-training (ETP), an innovative framework designed to
+learn cross-modal representations that link ECG signals with textual reports.
+For the first time, this framework leverages the zero-shot classification task
+in the ECG domain. ETP employs an ECG encoder along with a pre-trained language
+model to align ECG signals with their corresponding textual reports. The
+proposed framework excels in both linear evaluation and zero-shot
+classification tasks, as demonstrated on the PTB-XL and CPSC2018 datasets,
+showcasing its ability for robust and generalizable cross-modal ECG feature
+learning.
+
+
+
+ 69. 标题:Design of Recognition and Evaluation System for Table Tennis Players' Motor Skills Based on Artificial Intelligence
+ 编号:[379]
+ 链接:https://arxiv.org/abs/2309.07141
+ 作者:Zhuo-yong Shi, Ye-tao Jia, Ke-xin Zhang, Ding-han Wang, Long-meng Ji, Yong Wu
+ 备注:34pages, 16figures
+ 关键词:table tennis, wearable devices, table tennis sport, table tennis players', improves wearable devices
+
+ 点击查看摘要
+ With the rapid development of electronic science and technology, the research
+on wearable devices is constantly updated, but for now, it is not comprehensive
+for wearable devices to recognize and analyze the movement of specific sports.
+Based on this, this paper improves wearable devices of table tennis sport, and
+realizes the pattern recognition and evaluation of table tennis players' motor
+skills through artificial intelligence. Firstly, a device is designed to
+collect the movement information of table tennis players and the actual
+movement data is processed. Secondly, a sliding window is made to divide the
+collected motion data into a characteristic database of six table tennis
+benchmark movements. Thirdly, motion features were constructed based on feature
+engineering, and motor skills were identified for different models after
+dimensionality reduction. Finally, the hierarchical evaluation system of motor
+skills is established with the loss functions of different evaluation indexes.
+The results show that in the recognition of table tennis players' motor skills,
+the feature-based BP neural network proposed in this paper has higher
+recognition accuracy and stronger generalization ability than the traditional
+convolutional neural network.
+
+
+
+ 70. 标题:Masked Transformer for Electrocardiogram Classification
+ 编号:[382]
+ 链接:https://arxiv.org/abs/2309.07136
+ 作者:Ya Zhou, Xiaolin Diao, Yanni Huo, Yang Liu, Xiaohan Fan, Wei Zhao
+ 备注:
+ 关键词:important diagnostic tools, ECG, important diagnostic, diagnostic tools, tools in clinical
+
+ 点击查看摘要
+ Electrocardiogram (ECG) is one of the most important diagnostic tools in
+clinical applications. With the advent of advanced algorithms, various deep
+learning models have been adopted for ECG tasks. However, the potential of
+Transformers for ECG data is not yet realized, despite their widespread success
+in computer vision and natural language processing. In this work, we present a
+useful masked Transformer method for ECG classification referred to as MTECG,
+which expands the application of masked autoencoders to ECG time series. We
+construct a dataset comprising 220,251 ECG recordings with a broad range of
+diagnoses annoated by medical experts to explore the properties of MTECG. Under
+the proposed training strategies, a lightweight model with 5.7M parameters
+performs stably well on a broad range of masking ratios (5%-75%). The ablation
+studies highlight the importance of fluctuated reconstruction targets, training
+schedule length, layer-wise LR decay and DropPath rate. The experiments on both
+private and public ECG datasets demonstrate that MTECG-T significantly
+outperforms the recent state-of-the-art algorithms in ECG classification.
+
+
+









/Fig1_pretrain_finetune.png)
/Fig2_eda1.png)
/Fig2_eda2.png)
/Fig2_eda3.png)
/Fig3_reweight.png)
/Fig5_model1.png)
/Fig5_attention_mask.png)
/Fig4_wwm.png)
/Fig5_model2.png)
/Fig5_model3.png)
/Fig7_ensemble1.png)
/Fig6_res1.png)
/Fig6_res2.png)












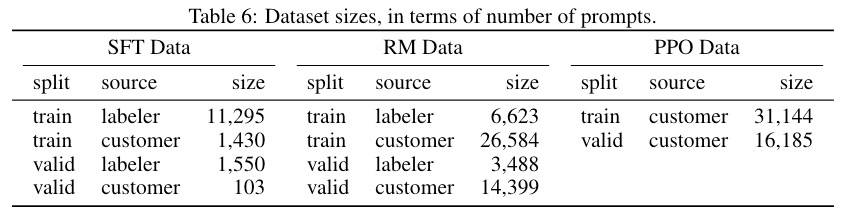
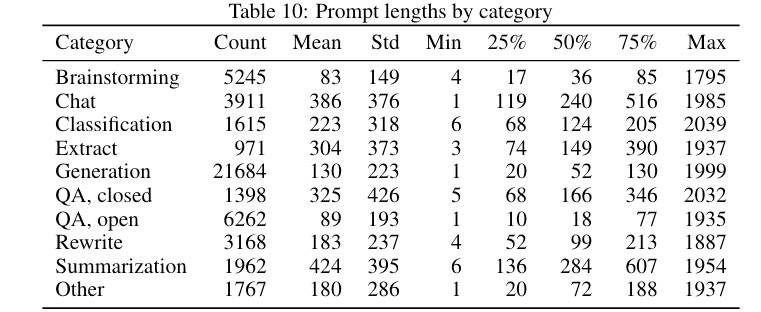
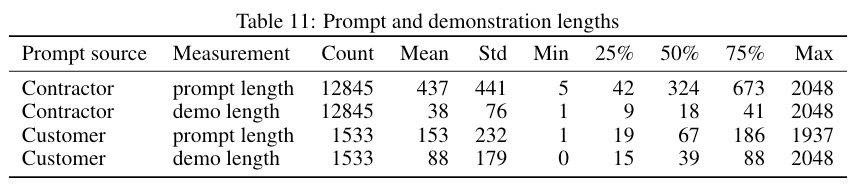

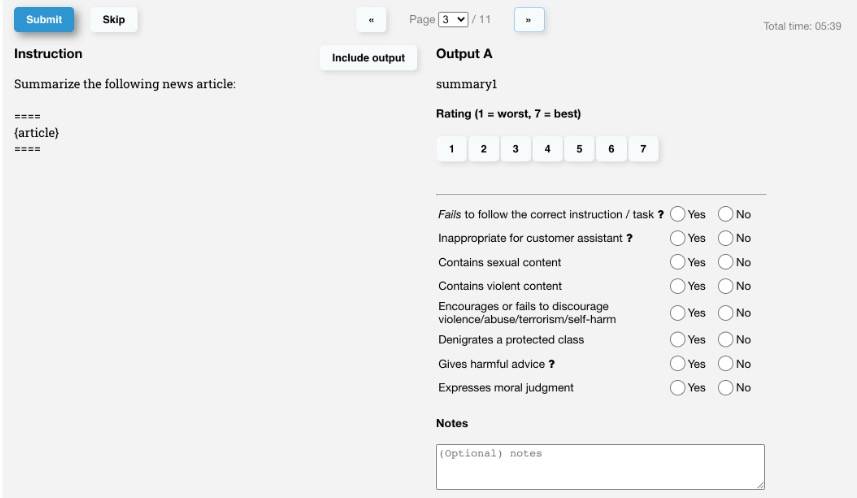
/autoencoder-architecture.png)
/variational-autoencoder-architecture.png)
/forward_vs_reversed_KL.png)
/vae-implement.png)
/reparam.png)
/generated_samples.png)
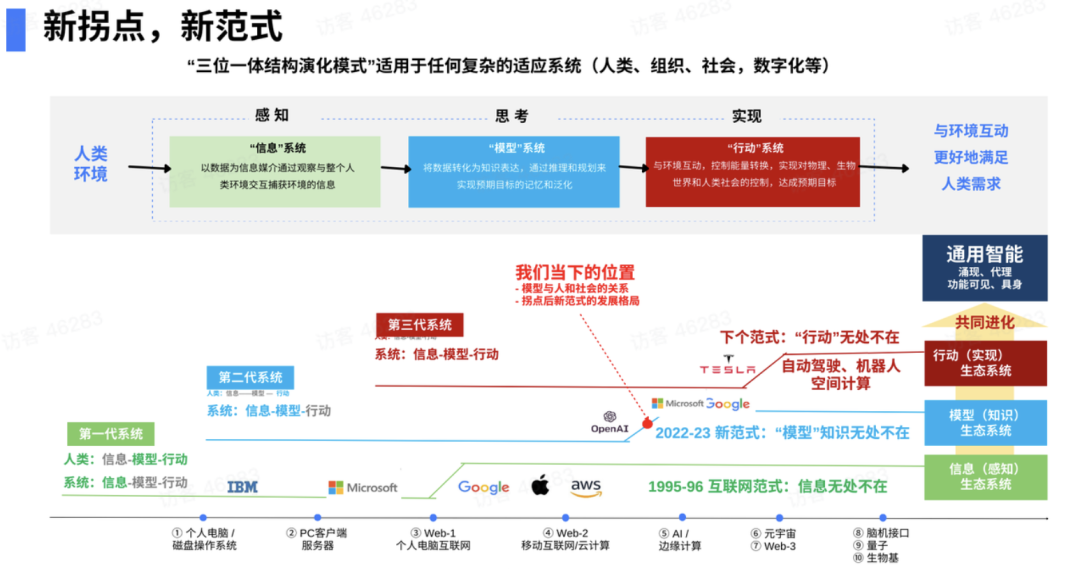
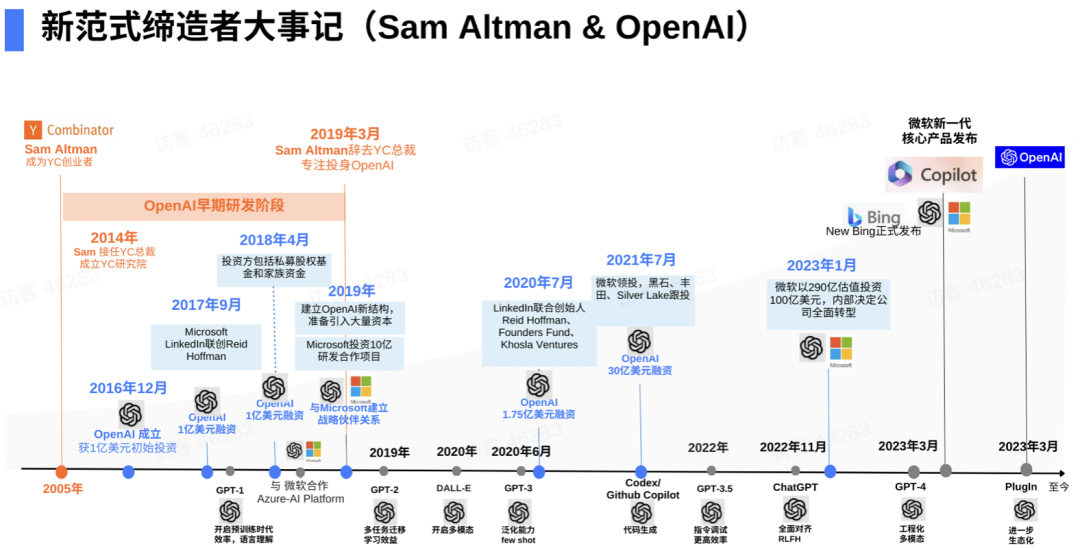
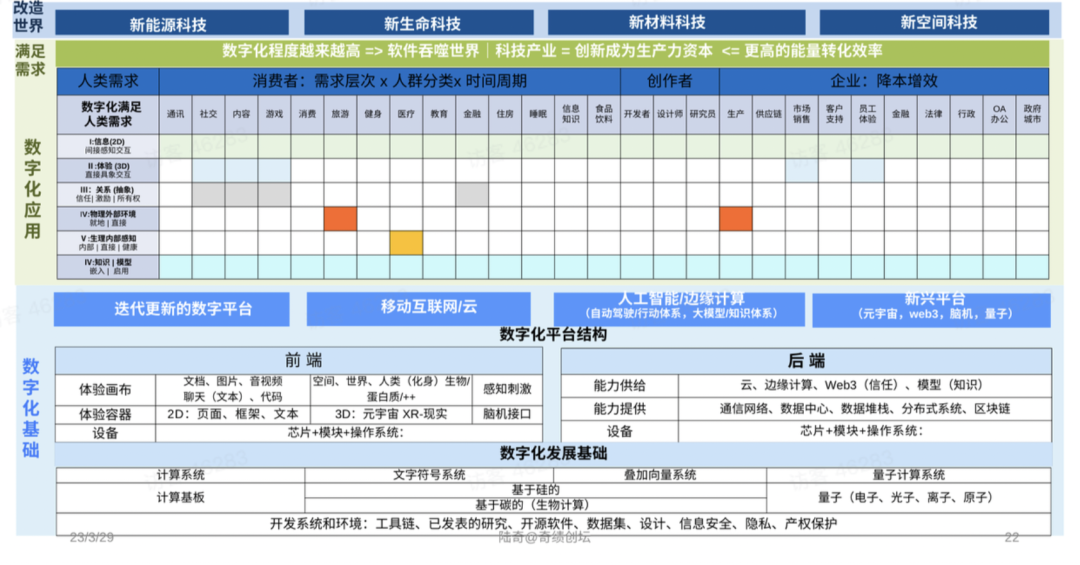
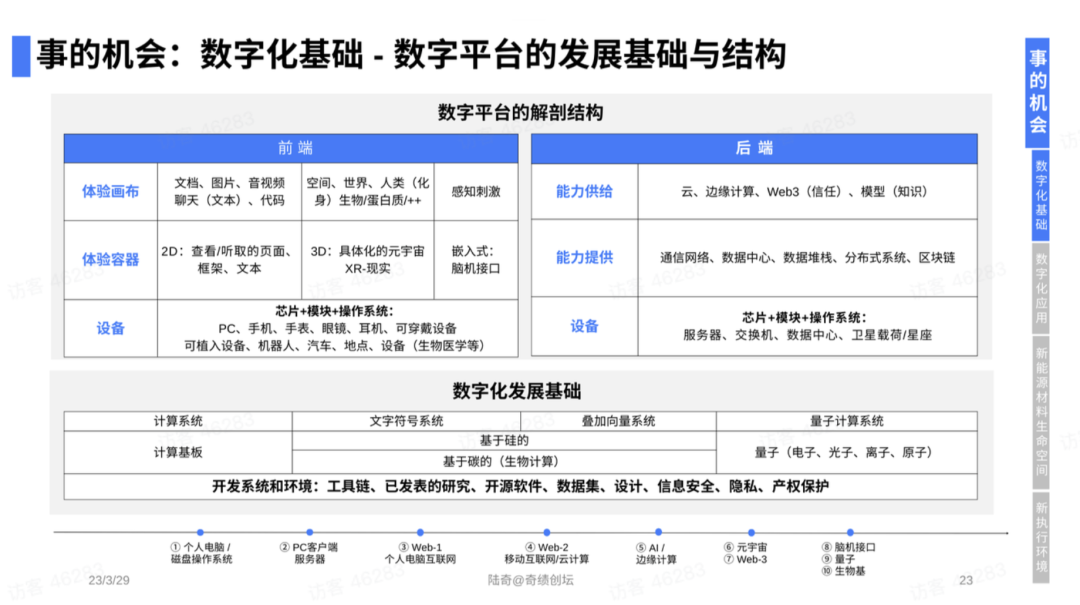





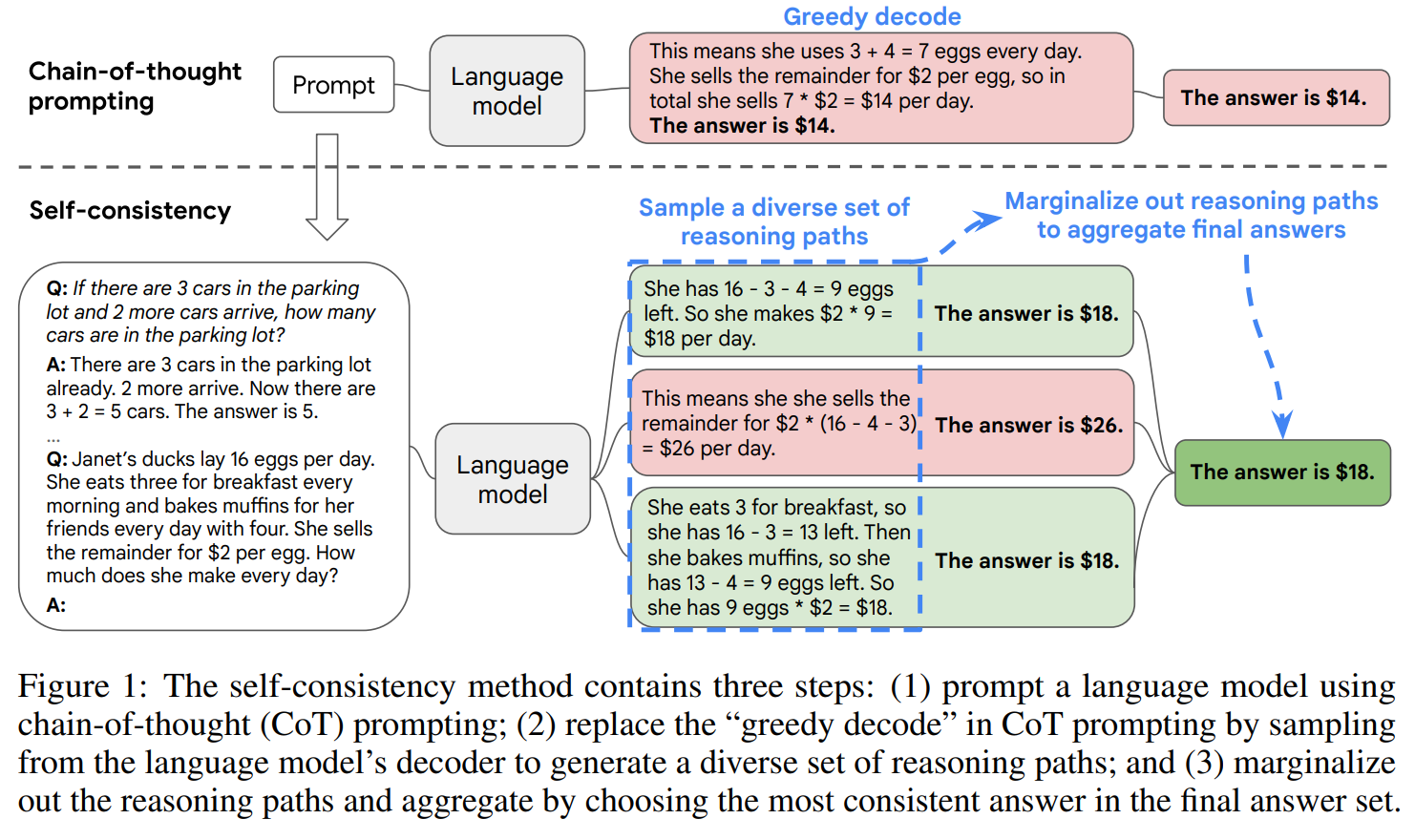













 ' +
+ '
' +
+ '