本篇博文主要展示每日从Arxiv论文网站获取的最新论文列表,以计算机视觉、自然语言处理、机器学习、人工智能等大方向进行划分。
+统计
+今日共更新232篇论文,其中:
+
+计算机视觉
+
+ 1. 标题:Generalized Cross-domain Multi-label Few-shot Learning for Chest X-rays
+ 编号:[4]
+ 链接:https://arxiv.org/abs/2309.04462
+ 作者:Aroof Aimen, Arsh Verma, Makarand Tapaswi, Narayanan C. Krishnan
+ 备注:17 pages
+ 关键词:X-ray abnormality classification, abnormality classification requires, classification requires dealing, chest X-ray abnormality, limited training data
+
+ 点击查看摘要
+ Real-world application of chest X-ray abnormality classification requires
+dealing with several challenges: (i) limited training data; (ii) training and
+evaluation sets that are derived from different domains; and (iii) classes that
+appear during training may have partial overlap with classes of interest during
+evaluation. To address these challenges, we present an integrated framework
+called Generalized Cross-Domain Multi-Label Few-Shot Learning (GenCDML-FSL).
+The framework supports overlap in classes during training and evaluation,
+cross-domain transfer, adopts meta-learning to learn using few training
+samples, and assumes each chest X-ray image is either normal or associated with
+one or more abnormalities. Furthermore, we propose Generalized Episodic
+Training (GenET), a training strategy that equips models to operate with
+multiple challenges observed in the GenCDML-FSL scenario. Comparisons with
+well-established methods such as transfer learning, hybrid transfer learning,
+and multi-label meta-learning on multiple datasets show the superiority of our
+approach.
+
+
+
+ 2. 标题:Measuring and Improving Chain-of-Thought Reasoning in Vision-Language Models
+ 编号:[5]
+ 链接:https://arxiv.org/abs/2309.04461
+ 作者:Yangyi Chen, Karan Sikka, Michael Cogswell, Heng Ji, Ajay Divakaran
+ 备注:The data is released at \url{this https URL}
+ 关键词:parse natural queries, generate human-like outputs, recently demonstrated strong, demonstrated strong efficacy, reasoning
+
+ 点击查看摘要
+ Vision-language models (VLMs) have recently demonstrated strong efficacy as
+visual assistants that can parse natural queries about the visual content and
+generate human-like outputs. In this work, we explore the ability of these
+models to demonstrate human-like reasoning based on the perceived information.
+To address a crucial concern regarding the extent to which their reasoning
+capabilities are fully consistent and grounded, we also measure the reasoning
+consistency of these models. We achieve this by proposing a chain-of-thought
+(CoT) based consistency measure. However, such an evaluation requires a
+benchmark that encompasses both high-level inference and detailed reasoning
+chains, which is costly. We tackle this challenge by proposing a
+LLM-Human-in-the-Loop pipeline, which notably reduces cost while simultaneously
+ensuring the generation of a high-quality dataset. Based on this pipeline and
+the existing coarse-grained annotated dataset, we build the CURE benchmark to
+measure both the zero-shot reasoning performance and consistency of VLMs. We
+evaluate existing state-of-the-art VLMs, and find that even the best-performing
+model is unable to demonstrate strong visual reasoning capabilities and
+consistency, indicating that substantial efforts are required to enable VLMs to
+perform visual reasoning as systematically and consistently as humans. As an
+early step, we propose a two-stage training framework aimed at improving both
+the reasoning performance and consistency of VLMs. The first stage involves
+employing supervised fine-tuning of VLMs using step-by-step reasoning samples
+automatically generated by LLMs. In the second stage, we further augment the
+training process by incorporating feedback provided by LLMs to produce
+reasoning chains that are highly consistent and grounded. We empirically
+highlight the effectiveness of our framework in both reasoning performance and
+consistency.
+
+
+
+ 3. 标题:WiSARD: A Labeled Visual and Thermal Image Dataset for Wilderness Search and Rescue
+ 编号:[8]
+ 链接:https://arxiv.org/abs/2309.04453
+ 作者:Daniel Broyles, Christopher R. Hayner, Karen Leung
+ 备注:
+ 关键词:reduce search times, Sensor-equipped unoccupied aerial, unoccupied aerial vehicles, alleviate safety risks, Search and Rescue
+
+ 点击查看摘要
+ Sensor-equipped unoccupied aerial vehicles (UAVs) have the potential to help
+reduce search times and alleviate safety risks for first responders carrying
+out Wilderness Search and Rescue (WiSAR) operations, the process of finding and
+rescuing person(s) lost in wilderness areas. Unfortunately, visual sensors
+alone do not address the need for robustness across all the possible terrains,
+weather, and lighting conditions that WiSAR operations can be conducted in. The
+use of multi-modal sensors, specifically visual-thermal cameras, is critical in
+enabling WiSAR UAVs to perform in diverse operating conditions. However, due to
+the unique challenges posed by the wilderness context, existing dataset
+benchmarks are inadequate for developing vision-based algorithms for autonomous
+WiSAR UAVs. To this end, we present WiSARD, a dataset with roughly 56,000
+labeled visual and thermal images collected from UAV flights in various
+terrains, seasons, weather, and lighting conditions. To the best of our
+knowledge, WiSARD is the first large-scale dataset collected with multi-modal
+sensors for autonomous WiSAR operations. We envision that our dataset will
+provide researchers with a diverse and challenging benchmark that can test the
+robustness of their algorithms when applied to real-world (life-saving)
+applications.
+
+
+
+ 4. 标题:Demographic Disparities in 1-to-Many Facial Identification
+ 编号:[9]
+ 链接:https://arxiv.org/abs/2309.04447
+ 作者:Aman Bhatta, Gabriella Pangelinan, Micheal C. King, Kevin W. Bowyer
+ 备注:9 pages, 8 figures, Conference submission
+ 关键词:examined demographic variations, surveillance camera quality, probe image, accuracy, studies to date
+
+ 点击查看摘要
+ Most studies to date that have examined demographic variations in face
+recognition accuracy have analyzed 1-to-1 matching accuracy, using images that
+could be described as "government ID quality". This paper analyzes the accuracy
+of 1-to-many facial identification across demographic groups, and in the
+presence of blur and reduced resolution in the probe image as might occur in
+"surveillance camera quality" images. Cumulative match characteristic
+curves(CMC) are not appropriate for comparing propensity for rank-one
+recognition errors across demographics, and so we introduce three metrics for
+this: (1) d' metric between mated and non-mated score distributions, (2)
+absolute score difference between thresholds in the high-similarity tail of the
+non-mated and the low-similarity tail of the mated distribution, and (3)
+distribution of (mated - non-mated rank one scores) across the set of probe
+images. We find that demographic variation in 1-to-many accuracy does not
+entirely follow what has been observed in 1-to-1 matching accuracy. Also,
+different from 1-to-1 accuracy, demographic comparison of 1-to-many accuracy
+can be affected by different numbers of identities and images across
+demographics. Finally, we show that increased blur in the probe image, or
+reduced resolution of the face in the probe image, can significantly increase
+the false positive identification rate. And we show that the demographic
+variation in these high blur or low resolution conditions is much larger for
+male/ female than for African-American / Caucasian. The point that 1-to-many
+accuracy can potentially collapse in the context of processing "surveillance
+camera quality" probe images against a "government ID quality" gallery is an
+important one.
+
+
+
+ 5. 标题:Comparative Study of Visual SLAM-Based Mobile Robot Localization Using Fiducial Markers
+ 编号:[11]
+ 链接:https://arxiv.org/abs/2309.04441
+ 作者:Jongwon Lee, Su Yeon Choi, David Hanley, Timothy Bretl
+ 备注:IEEE 2023 IROS Workshop "Closing the Loop on Localization". For more information, see this https URL
+ 关键词:square-shaped artificial landmarks, robot localization based, mobile robot localization, prior map, grid pattern
+
+ 点击查看摘要
+ This paper presents a comparative study of three modes for mobile robot
+localization based on visual SLAM using fiducial markers (i.e., square-shaped
+artificial landmarks with a black-and-white grid pattern): SLAM, SLAM with a
+prior map, and localization with a prior map. The reason for comparing the
+SLAM-based approaches leveraging fiducial markers is because previous work has
+shown their superior performance over feature-only methods, with less
+computational burden compared to methods that use both feature and marker
+detection without compromising the localization performance. The evaluation is
+conducted using indoor image sequences captured with a hand-held camera
+containing multiple fiducial markers in the environment. The performance
+metrics include absolute trajectory error and runtime for the optimization
+process per frame. In particular, for the last two modes (SLAM and localization
+with a prior map), we evaluate their performances by perturbing the quality of
+prior map to study the extent to which each mode is tolerant to such
+perturbations. Hardware experiments show consistent trajectory error levels
+across the three modes, with the localization mode exhibiting the shortest
+runtime among them. Yet, with map perturbations, SLAM with a prior map
+maintains performance, while localization mode degrades in both aspects.
+
+
+
+ 6. 标题:Single View Refractive Index Tomography with Neural Fields
+ 编号:[12]
+ 链接:https://arxiv.org/abs/2309.04437
+ 作者:Brandon Zhao, Aviad Levis, Liam Connor, Pratul P. Srinivasan, Katherine L. Bouman
+ 备注:
+ 关键词:Refractive Index Tomography, refractive field, Refractive Index, Index Tomography, Refractive
+
+ 点击查看摘要
+ Refractive Index Tomography is an inverse problem in which we seek to
+reconstruct a scene's 3D refractive field from 2D projected image measurements.
+The refractive field is not visible itself, but instead affects how the path of
+a light ray is continuously curved as it travels through space. Refractive
+fields appear across a wide variety of scientific applications, from
+translucent cell samples in microscopy to fields of dark matter bending light
+from faraway galaxies. This problem poses a unique challenge because the
+refractive field directly affects the path that light takes, making its
+recovery a non-linear problem. In addition, in contrast with traditional
+tomography, we seek to recover the refractive field using a projected image
+from only a single viewpoint by leveraging knowledge of light sources scattered
+throughout the medium. In this work, we introduce a method that uses a
+coordinate-based neural network to model the underlying continuous refractive
+field in a scene. We then use explicit modeling of rays' 3D spatial curvature
+to optimize the parameters of this network, reconstructing refractive fields
+with an analysis-by-synthesis approach. The efficacy of our approach is
+demonstrated by recovering refractive fields in simulation, and analyzing how
+recovery is affected by the light source distribution. We then test our method
+on a simulated dark matter mapping problem, where we recover the refractive
+field underlying a realistic simulated dark matter distribution.
+
+
+
+ 7. 标题:Create Your World: Lifelong Text-to-Image Diffusion
+ 编号:[15]
+ 链接:https://arxiv.org/abs/2309.04430
+ 作者:Gan Sun, Wenqi Liang, Jiahua Dong, Jun Li, Zhengming Ding, Yang Cong
+ 备注:15 pages,10 figures
+ 关键词:produce diverse high-quality, demonstrated excellent ability, diverse high-quality images, produce diverse, diverse high-quality
+
+ 点击查看摘要
+ Text-to-image generative models can produce diverse high-quality images of
+concepts with a text prompt, which have demonstrated excellent ability in image
+generation, image translation, etc. We in this work study the problem of
+synthesizing instantiations of a use's own concepts in a never-ending manner,
+i.e., create your world, where the new concepts from user are quickly learned
+with a few examples. To achieve this goal, we propose a Lifelong text-to-image
+Diffusion Model (L2DM), which intends to overcome knowledge "catastrophic
+forgetting" for the past encountered concepts, and semantic "catastrophic
+neglecting" for one or more concepts in the text prompt. In respect of
+knowledge "catastrophic forgetting", our L2DM framework devises a task-aware
+memory enhancement module and a elastic-concept distillation module, which
+could respectively safeguard the knowledge of both prior concepts and each past
+personalized concept. When generating images with a user text prompt, the
+solution to semantic "catastrophic neglecting" is that a concept attention
+artist module can alleviate the semantic neglecting from concept aspect, and an
+orthogonal attention module can reduce the semantic binding from attribute
+aspect. To the end, our model can generate more faithful image across a range
+of continual text prompts in terms of both qualitative and quantitative
+metrics, when comparing with the related state-of-the-art models. The code will
+be released at this https URL.
+
+
+
+ 8. 标题:Video Task Decathlon: Unifying Image and Video Tasks in Autonomous Driving
+ 编号:[20]
+ 链接:https://arxiv.org/abs/2309.04422
+ 作者:Thomas E. Huang, Yifan Liu, Luc Van Gool, Fisher Yu
+ 备注:ICCV 2023, project page at this https URL
+ 关键词:Performing multiple heterogeneous, multiple heterogeneous visual, heterogeneous visual tasks, human perception capability, tasks
+
+ 点击查看摘要
+ Performing multiple heterogeneous visual tasks in dynamic scenes is a
+hallmark of human perception capability. Despite remarkable progress in image
+and video recognition via representation learning, current research still
+focuses on designing specialized networks for singular, homogeneous, or simple
+combination of tasks. We instead explore the construction of a unified model
+for major image and video recognition tasks in autonomous driving with diverse
+input and output structures. To enable such an investigation, we design a new
+challenge, Video Task Decathlon (VTD), which includes ten representative image
+and video tasks spanning classification, segmentation, localization, and
+association of objects and pixels. On VTD, we develop our unified network,
+VTDNet, that uses a single structure and a single set of weights for all ten
+tasks. VTDNet groups similar tasks and employs task interaction stages to
+exchange information within and between task groups. Given the impracticality
+of labeling all tasks on all frames, and the performance degradation associated
+with joint training of many tasks, we design a Curriculum training,
+Pseudo-labeling, and Fine-tuning (CPF) scheme to successfully train VTDNet on
+all tasks and mitigate performance loss. Armed with CPF, VTDNet significantly
+outperforms its single-task counterparts on most tasks with only 20% overall
+computations. VTD is a promising new direction for exploring the unification of
+perception tasks in autonomous driving.
+
+
+
+ 9. 标题:SynthoGestures: A Novel Framework for Synthetic Dynamic Hand Gesture Generation for Driving Scenarios
+ 编号:[21]
+ 链接:https://arxiv.org/abs/2309.04421
+ 作者:Amr Gomaa, Robin Zitt, Guillermo Reyes, Antonio Krüger
+ 备注:Shorter versions are accepted as AutomotiveUI2023 Work in Progress and UIST2023 Poster Papers
+ 关键词:dynamic human-machine interfaces, Creating a diverse, challenging and time-consuming, diverse and comprehensive, dynamic human-machine
+
+ 点击查看摘要
+ Creating a diverse and comprehensive dataset of hand gestures for dynamic
+human-machine interfaces in the automotive domain can be challenging and
+time-consuming. To overcome this challenge, we propose using synthetic gesture
+datasets generated by virtual 3D models. Our framework utilizes Unreal Engine
+to synthesize realistic hand gestures, offering customization options and
+reducing the risk of overfitting. Multiple variants, including gesture speed,
+performance, and hand shape, are generated to improve generalizability. In
+addition, we simulate different camera locations and types, such as RGB,
+infrared, and depth cameras, without incurring additional time and cost to
+obtain these cameras. Experimental results demonstrate that our proposed
+framework,
+SynthoGestures\footnote{\url{this https URL}},
+improves gesture recognition accuracy and can replace or augment real-hand
+datasets. By saving time and effort in the creation of the data set, our tool
+accelerates the development of gesture recognition systems for automotive
+applications.
+
+
+
+ 10. 标题:DeformToon3D: Deformable 3D Toonification from Neural Radiance Fields
+ 编号:[24]
+ 链接:https://arxiv.org/abs/2309.04410
+ 作者:Junzhe Zhang, Yushi Lan, Shuai Yang, Fangzhou Hong, Quan Wang, Chai Kiat Yeo, Ziwei Liu, Chen Change Loy
+ 备注:ICCV 2023. Code: this https URL Project page: this https URL
+ 关键词:artistic domain, face with stylized, address the challenging, challenging problem, involves transferring
+
+ 点击查看摘要
+ In this paper, we address the challenging problem of 3D toonification, which
+involves transferring the style of an artistic domain onto a target 3D face
+with stylized geometry and texture. Although fine-tuning a pre-trained 3D GAN
+on the artistic domain can produce reasonable performance, this strategy has
+limitations in the 3D domain. In particular, fine-tuning can deteriorate the
+original GAN latent space, which affects subsequent semantic editing, and
+requires independent optimization and storage for each new style, limiting
+flexibility and efficient deployment. To overcome these challenges, we propose
+DeformToon3D, an effective toonification framework tailored for hierarchical 3D
+GAN. Our approach decomposes 3D toonification into subproblems of geometry and
+texture stylization to better preserve the original latent space. Specifically,
+we devise a novel StyleField that predicts conditional 3D deformation to align
+a real-space NeRF to the style space for geometry stylization. Thanks to the
+StyleField formulation, which already handles geometry stylization well,
+texture stylization can be achieved conveniently via adaptive style mixing that
+injects information of the artistic domain into the decoder of the pre-trained
+3D GAN. Due to the unique design, our method enables flexible style degree
+control and shape-texture-specific style swap. Furthermore, we achieve
+efficient training without any real-world 2D-3D training pairs but proxy
+samples synthesized from off-the-shelf 2D toonification models.
+
+
+
+ 11. 标题:MaskDiffusion: Boosting Text-to-Image Consistency with Conditional Mask
+ 编号:[28]
+ 链接:https://arxiv.org/abs/2309.04399
+ 作者:Yupeng Zhou, Daquan Zhou, Zuo-Liang Zhu, Yaxing Wang, Qibin Hou, Jiashi Feng
+ 备注:
+ 关键词:generate visually striking, visually striking images, Recent advancements, showcased their impressive, impressive capacity
+
+ 点击查看摘要
+ Recent advancements in diffusion models have showcased their impressive
+capacity to generate visually striking images. Nevertheless, ensuring a close
+match between the generated image and the given prompt remains a persistent
+challenge. In this work, we identify that a crucial factor leading to the
+text-image mismatch issue is the inadequate cross-modality relation learning
+between the prompt and the output image. To better align the prompt and image
+content, we advance the cross-attention with an adaptive mask, which is
+conditioned on the attention maps and the prompt embeddings, to dynamically
+adjust the contribution of each text token to the image features. This
+mechanism explicitly diminishes the ambiguity in semantic information embedding
+from the text encoder, leading to a boost of text-to-image consistency in the
+synthesized images. Our method, termed MaskDiffusion, is training-free and
+hot-pluggable for popular pre-trained diffusion models. When applied to the
+latent diffusion models, our MaskDiffusion can significantly improve the
+text-to-image consistency with negligible computation overhead compared to the
+original diffusion models.
+
+
+
+ 12. 标题:Language Prompt for Autonomous Driving
+ 编号:[33]
+ 链接:https://arxiv.org/abs/2309.04379
+ 作者:Dongming Wu, Wencheng Han, Tiancai Wang, Yingfei Liu, Xiangyu Zhang, Jianbing Shen
+ 备注:
+ 关键词:flexible human command, human command represented, natural language prompt, computer vision community, computer vision
+
+ 点击查看摘要
+ A new trend in the computer vision community is to capture objects of
+interest following flexible human command represented by a natural language
+prompt. However, the progress of using language prompts in driving scenarios is
+stuck in a bottleneck due to the scarcity of paired prompt-instance data. To
+address this challenge, we propose the first object-centric language prompt set
+for driving scenes within 3D, multi-view, and multi-frame space, named
+NuPrompt. It expands Nuscenes dataset by constructing a total of 35,367
+language descriptions, each referring to an average of 5.3 object tracks. Based
+on the object-text pairs from the new benchmark, we formulate a new
+prompt-based driving task, \ie, employing a language prompt to predict the
+described object trajectory across views and frames. Furthermore, we provide a
+simple end-to-end baseline model based on Transformer, named PromptTrack.
+Experiments show that our PromptTrack achieves impressive performance on
+NuPrompt. We hope this work can provide more new insights for the autonomous
+driving community. Dataset and Code will be made public at
+\href{this https URL}{this https URL}.
+
+
+
+ 13. 标题:MoEController: Instruction-based Arbitrary Image Manipulation with Mixture-of-Expert Controllers
+ 编号:[36]
+ 链接:https://arxiv.org/abs/2309.04372
+ 作者:Sijia Li, Chen Chen, Haonan Lu
+ 备注:5 pages,6 figures
+ 关键词:image manipulation tasks, producing fascinating results, made astounding progress, recently made astounding, manipulation tasks
+
+ 点击查看摘要
+ Diffusion-model-based text-guided image generation has recently made
+astounding progress, producing fascinating results in open-domain image
+manipulation tasks. Few models, however, currently have complete zero-shot
+capabilities for both global and local image editing due to the complexity and
+diversity of image manipulation tasks. In this work, we propose a method with a
+mixture-of-expert (MOE) controllers to align the text-guided capacity of
+diffusion models with different kinds of human instructions, enabling our model
+to handle various open-domain image manipulation tasks with natural language
+instructions. First, we use large language models (ChatGPT) and conditional
+image synthesis models (ControlNet) to generate a large number of global image
+transfer dataset in addition to the instruction-based local image editing
+dataset. Then, using an MOE technique and task-specific adaptation training on
+a large-scale dataset, our conditional diffusion model can edit images globally
+and locally. Extensive experiments demonstrate that our approach performs
+surprisingly well on various image manipulation tasks when dealing with
+open-domain images and arbitrary human instructions. Please refer to our
+project page: [this https URL]
+
+
+
+ 14. 标题:CNN Injected Transformer for Image Exposure Correction
+ 编号:[40]
+ 链接:https://arxiv.org/abs/2309.04366
+ 作者:Shuning Xu, Xiangyu Chen, Binbin Song, Jiantao Zhou
+ 备注:
+ 关键词:satisfactory visual experience, incorrect exposure settings, exposure settings fails, visual experience, exposure correction
+
+ 点击查看摘要
+ Capturing images with incorrect exposure settings fails to deliver a
+satisfactory visual experience. Only when the exposure is properly set, can the
+color and details of the images be appropriately preserved. Previous exposure
+correction methods based on convolutions often produce exposure deviation in
+images as a consequence of the restricted receptive field of convolutional
+kernels. This issue arises because convolutions are not capable of capturing
+long-range dependencies in images accurately. To overcome this challenge, we
+can apply the Transformer to address the exposure correction problem,
+leveraging its capability in modeling long-range dependencies to capture global
+representation. However, solely relying on the window-based Transformer leads
+to visually disturbing blocking artifacts due to the application of
+self-attention in small patches. In this paper, we propose a CNN Injected
+Transformer (CIT) to harness the individual strengths of CNN and Transformer
+simultaneously. Specifically, we construct the CIT by utilizing a window-based
+Transformer to exploit the long-range interactions among different regions in
+the entire image. Within each CIT block, we incorporate a channel attention
+block (CAB) and a half-instance normalization block (HINB) to assist the
+window-based self-attention to acquire the global statistics and refine local
+features. In addition to the hybrid architecture design for exposure
+correction, we apply a set of carefully formulated loss functions to improve
+the spatial coherence and rectify potential color deviations. Extensive
+experiments demonstrate that our image exposure correction method outperforms
+state-of-the-art approaches in terms of both quantitative and qualitative
+metrics.
+
+
+
+ 15. 标题:SSIG: A Visually-Guided Graph Edit Distance for Floor Plan Similarity
+ 编号:[43]
+ 链接:https://arxiv.org/abs/2309.04357
+ 作者:Casper van Engelenburg, Seyran Khademi, Jan van Gemert
+ 备注:To be published in ICCVW 2023, 10 pages
+ 关键词:floor plan, architectural floor plans, floor, floor plan data, structural similarity
+
+ 点击查看摘要
+ We propose a simple yet effective metric that measures structural similarity
+between visual instances of architectural floor plans, without the need for
+learning. Qualitatively, our experiments show that the retrieval results are
+similar to deeply learned methods. Effectively comparing instances of floor
+plan data is paramount to the success of machine understanding of floor plan
+data, including the assessment of floor plan generative models and floor plan
+recommendation systems. Comparing visual floor plan images goes beyond a sole
+pixel-wise visual examination and is crucially about similarities and
+differences in the shapes and relations between subdivisions that compose the
+layout. Currently, deep metric learning approaches are used to learn a
+pair-wise vector representation space that closely mimics the structural
+similarity, in which the models are trained on similarity labels that are
+obtained by Intersection-over-Union (IoU). To compensate for the lack of
+structural awareness in IoU, graph-based approaches such as Graph Matching
+Networks (GMNs) are used, which require pairwise inference for comparing data
+instances, making GMNs less practical for retrieval applications. In this
+paper, an effective evaluation metric for judging the structural similarity of
+floor plans, coined SSIG (Structural Similarity by IoU and GED), is proposed
+based on both image and graph distances. In addition, an efficient algorithm is
+developed that uses SSIG to rank a large-scale floor plan database. Code will
+be openly available.
+
+
+
+ 16. 标题:Mobile V-MoEs: Scaling Down Vision Transformers via Sparse Mixture-of-Experts
+ 编号:[45]
+ 链接:https://arxiv.org/abs/2309.04354
+ 作者:Erik Daxberger, Floris Weers, Bowen Zhang, Tom Gunter, Ruoming Pang, Marcin Eichner, Michael Emmersberger, Yinfei Yang, Alexander Toshev, Xianzhi Du
+ 备注:
+ 关键词:recently gained popularity, gained popularity due, decouple model size, input token, recently gained
+
+ 点击查看摘要
+ Sparse Mixture-of-Experts models (MoEs) have recently gained popularity due
+to their ability to decouple model size from inference efficiency by only
+activating a small subset of the model parameters for any given input token. As
+such, sparse MoEs have enabled unprecedented scalability, resulting in
+tremendous successes across domains such as natural language processing and
+computer vision. In this work, we instead explore the use of sparse MoEs to
+scale-down Vision Transformers (ViTs) to make them more attractive for
+resource-constrained vision applications. To this end, we propose a simplified
+and mobile-friendly MoE design where entire images rather than individual
+patches are routed to the experts. We also propose a stable MoE training
+procedure that uses super-class information to guide the router. We empirically
+show that our sparse Mobile Vision MoEs (V-MoEs) can achieve a better trade-off
+between performance and efficiency than the corresponding dense ViTs. For
+example, for the ViT-Tiny model, our Mobile V-MoE outperforms its dense
+counterpart by 3.39% on ImageNet-1k. For an even smaller ViT variant with only
+54M FLOPs inference cost, our MoE achieves an improvement of 4.66%.
+
+
+
+ 17. 标题:Leveraging Model Fusion for Improved License Plate Recognition
+ 编号:[57]
+ 链接:https://arxiv.org/abs/2309.04331
+ 作者:Rayson Laroca, Luiz A. Zanlorensi, Valter Estevam, Rodrigo Minetto, David Menotti
+ 备注:Accepted for presentation at the Iberoamerican Congress on Pattern Recognition (CIARP) 2023
+ 关键词:License Plate Recognition, traffic law enforcement, License Plate, Plate Recognition, parking management
+
+ 点击查看摘要
+ License Plate Recognition (LPR) plays a critical role in various
+applications, such as toll collection, parking management, and traffic law
+enforcement. Although LPR has witnessed significant advancements through the
+development of deep learning, there has been a noticeable lack of studies
+exploring the potential improvements in results by fusing the outputs from
+multiple recognition models. This research aims to fill this gap by
+investigating the combination of up to 12 different models using
+straightforward approaches, such as selecting the most confident prediction or
+employing majority vote-based strategies. Our experiments encompass a wide
+range of datasets, revealing substantial benefits of fusion approaches in both
+intra- and cross-dataset setups. Essentially, fusing multiple models reduces
+considerably the likelihood of obtaining subpar performance on a particular
+dataset/scenario. We also found that combining models based on their speed is
+an appealing approach. Specifically, for applications where the recognition
+task can tolerate some additional time, though not excessively, an effective
+strategy is to combine 4-6 models. These models may not be the most accurate
+individually, but their fusion strikes an optimal balance between accuracy and
+speed.
+
+
+
+ 18. 标题:AMLP:Adaptive Masking Lesion Patches for Self-supervised Medical Image Segmentation
+ 编号:[62]
+ 链接:https://arxiv.org/abs/2309.04312
+ 作者:Xiangtao Wang, Ruizhi Wang, Jie Zhou, Thomas Lukasiewicz, Zhenghua Xu
+ 备注:
+ 关键词:shown promising results, shown promising, promising results, Adaptive Masking, Adaptive Masking Ratio
+
+ 点击查看摘要
+ Self-supervised masked image modeling has shown promising results on natural
+images. However, directly applying such methods to medical images remains
+challenging. This difficulty stems from the complexity and distinct
+characteristics of lesions compared to natural images, which impedes effective
+representation learning. Additionally, conventional high fixed masking ratios
+restrict reconstructing fine lesion details, limiting the scope of learnable
+information. To tackle these limitations, we propose a novel self-supervised
+medical image segmentation framework, Adaptive Masking Lesion Patches (AMLP).
+Specifically, we design a Masked Patch Selection (MPS) strategy to identify and
+focus learning on patches containing lesions. Lesion regions are scarce yet
+critical, making their precise reconstruction vital. To reduce
+misclassification of lesion and background patches caused by unsupervised
+clustering in MPS, we introduce an Attention Reconstruction Loss (ARL) to focus
+on hard-to-reconstruct patches likely depicting lesions. We further propose a
+Category Consistency Loss (CCL) to refine patch categorization based on
+reconstruction difficulty, strengthening distinction between lesions and
+background. Moreover, we develop an Adaptive Masking Ratio (AMR) strategy that
+gradually increases the masking ratio to expand reconstructible information and
+improve learning. Extensive experiments on two medical segmentation datasets
+demonstrate AMLP's superior performance compared to existing self-supervised
+approaches. The proposed strategies effectively address limitations in applying
+masked modeling to medical images, tailored to capturing fine lesion details
+vital for segmentation tasks.
+
+
+
+ 19. 标题:Have We Ever Encountered This Before? Retrieving Out-of-Distribution Road Obstacles from Driving Scenes
+ 编号:[66]
+ 链接:https://arxiv.org/abs/2309.04302
+ 作者:Youssef Shoeb, Robin Chan, Gesina Schwalbe, Azarm Nowzard, Fatma Güney, Hanno Gottschalk
+ 备注:11 pages, 7 figures, and 3 tables
+ 关键词:OoD road obstacles, highly automated systems, automated systems operating, road obstacles, dynamic environment
+
+ 点击查看摘要
+ In the life cycle of highly automated systems operating in an open and
+dynamic environment, the ability to adjust to emerging challenges is crucial.
+For systems integrating data-driven AI-based components, rapid responses to
+deployment issues require fast access to related data for testing and
+reconfiguration. In the context of automated driving, this especially applies
+to road obstacles that were not included in the training data, commonly
+referred to as out-of-distribution (OoD) road obstacles. Given the availability
+of large uncurated recordings of driving scenes, a pragmatic approach is to
+query a database to retrieve similar scenarios featuring the same safety
+concerns due to OoD road obstacles. In this work, we extend beyond identifying
+OoD road obstacles in video streams and offer a comprehensive approach to
+extract sequences of OoD road obstacles using text queries, thereby proposing a
+way of curating a collection of OoD data for subsequent analysis. Our proposed
+method leverages the recent advances in OoD segmentation and multi-modal
+foundation models to identify and efficiently extract safety-relevant scenes
+from unlabeled videos. We present a first approach for the novel task of
+text-based OoD object retrieval, which addresses the question ''Have we ever
+encountered this before?''.
+
+
+
+ 20. 标题:Towards Practical Capture of High-Fidelity Relightable Avatars
+ 编号:[85]
+ 链接:https://arxiv.org/abs/2309.04247
+ 作者:Haotian Yang, Mingwu Zheng, Wanquan Feng, Haibin Huang, Yu-Kun Lai, Pengfei Wan, Zhongyuan Wang, Chongyang Ma
+ 备注:Accepted to SIGGRAPH Asia 2023 (Conference); Project page: this https URL
+ 关键词:reconstructing high-fidelity, capturing and reconstructing, TRAvatar, lighting conditions, conditions
+
+ 点击查看摘要
+ In this paper, we propose a novel framework, Tracking-free Relightable Avatar
+(TRAvatar), for capturing and reconstructing high-fidelity 3D avatars. Compared
+to previous methods, TRAvatar works in a more practical and efficient setting.
+Specifically, TRAvatar is trained with dynamic image sequences captured in a
+Light Stage under varying lighting conditions, enabling realistic relighting
+and real-time animation for avatars in diverse scenes. Additionally, TRAvatar
+allows for tracking-free avatar capture and obviates the need for accurate
+surface tracking under varying illumination conditions. Our contributions are
+two-fold: First, we propose a novel network architecture that explicitly builds
+on and ensures the satisfaction of the linear nature of lighting. Trained on
+simple group light captures, TRAvatar can predict the appearance in real-time
+with a single forward pass, achieving high-quality relighting effects under
+illuminations of arbitrary environment maps. Second, we jointly optimize the
+facial geometry and relightable appearance from scratch based on image
+sequences, where the tracking is implicitly learned. This tracking-free
+approach brings robustness for establishing temporal correspondences between
+frames under different lighting conditions. Extensive qualitative and
+quantitative experiments demonstrate that our framework achieves superior
+performance for photorealistic avatar animation and relighting.
+
+
+
+ 21. 标题:FIVA: Facial Image and Video Anonymization and Anonymization Defense
+ 编号:[91]
+ 链接:https://arxiv.org/abs/2309.04228
+ 作者:Felix Rosberg, Eren Erdal Aksoy, Cristofer Englund, Fernando Alonso-Fernandez
+ 备注:Accepted to ICCVW 2023 - DFAD 2023
+ 关键词:approach for facial, facial anonymization, FIVA, paper, videos
+
+ 点击查看摘要
+ In this paper, we present a new approach for facial anonymization in images
+and videos, abbreviated as FIVA. Our proposed method is able to maintain the
+same face anonymization consistently over frames with our suggested
+identity-tracking and guarantees a strong difference from the original face.
+FIVA allows for 0 true positives for a false acceptance rate of 0.001. Our work
+considers the important security issue of reconstruction attacks and
+investigates adversarial noise, uniform noise, and parameter noise to disrupt
+reconstruction attacks. In this regard, we apply different defense and
+protection methods against these privacy threats to demonstrate the scalability
+of FIVA. On top of this, we also show that reconstruction attack models can be
+used for detection of deep fakes. Last but not least, we provide experimental
+results showing how FIVA can even enable face swapping, which is purely trained
+on a single target image.
+
+
+
+ 22. 标题:Long-Range Correlation Supervision for Land-Cover Classification from Remote Sensing Images
+ 编号:[92]
+ 链接:https://arxiv.org/abs/2309.04225
+ 作者:Dawen Yu, Shunping Ji
+ 备注:14 pages, 11 figures
+ 关键词:Long-range dependency modeling, modern deep learning, deep learning based, supervised long-range correlation, long-range correlation
+
+ 点击查看摘要
+ Long-range dependency modeling has been widely considered in modern deep
+learning based semantic segmentation methods, especially those designed for
+large-size remote sensing images, to compensate the intrinsic locality of
+standard convolutions. However, in previous studies, the long-range dependency,
+modeled with an attention mechanism or transformer model, has been based on
+unsupervised learning, instead of explicit supervision from the objective
+ground truth. In this paper, we propose a novel supervised long-range
+correlation method for land-cover classification, called the supervised
+long-range correlation network (SLCNet), which is shown to be superior to the
+currently used unsupervised strategies. In SLCNet, pixels sharing the same
+category are considered highly correlated and those having different categories
+are less relevant, which can be easily supervised by the category consistency
+information available in the ground truth semantic segmentation map. Under such
+supervision, the recalibrated features are more consistent for pixels of the
+same category and more discriminative for pixels of other categories,
+regardless of their proximity. To complement the detailed information lacking
+in the global long-range correlation, we introduce an auxiliary adaptive
+receptive field feature extraction module, parallel to the long-range
+correlation module in the encoder, to capture finely detailed feature
+representations for multi-size objects in multi-scale remote sensing images. In
+addition, we apply multi-scale side-output supervision and a hybrid loss
+function as local and global constraints to further boost the segmentation
+accuracy. Experiments were conducted on three remote sensing datasets. Compared
+with the advanced segmentation methods from the computer vision, medicine, and
+remote sensing communities, the SLCNet achieved a state-of-the-art performance
+on all the datasets.
+
+
+
+ 23. 标题:Score-PA: Score-based 3D Part Assembly
+ 编号:[96]
+ 链接:https://arxiv.org/abs/2309.04220
+ 作者:Junfeng Cheng, Mingdong Wu, Ruiyuan Zhang, Guanqi Zhan, Chao Wu, Hao Dong
+ 备注:BMVC 2023
+ 关键词:computer vision, part assembly, areas of robotics, Part Assembly framework, part
+
+ 点击查看摘要
+ Autonomous 3D part assembly is a challenging task in the areas of robotics
+and 3D computer vision. This task aims to assemble individual components into a
+complete shape without relying on predefined instructions. In this paper, we
+formulate this task from a novel generative perspective, introducing the
+Score-based 3D Part Assembly framework (Score-PA) for 3D part assembly. Knowing
+that score-based methods are typically time-consuming during the inference
+stage. To address this issue, we introduce a novel algorithm called the Fast
+Predictor-Corrector Sampler (FPC) that accelerates the sampling process within
+the framework. We employ various metrics to assess assembly quality and
+diversity, and our evaluation results demonstrate that our algorithm
+outperforms existing state-of-the-art approaches. We release our code at
+this https URL.
+
+
+
+ 24. 标题:Stereo Matching in Time: 100+ FPS Video Stereo Matching for Extended Reality
+ 编号:[112]
+ 链接:https://arxiv.org/abs/2309.04183
+ 作者:Ziang Cheng, Jiayu Yang, Hongdong Li
+ 备注:
+ 关键词:cornerstone algorithm, Stereo Matching, Stereo, Real-time Stereo Matching, Extended
+
+ 点击查看摘要
+ Real-time Stereo Matching is a cornerstone algorithm for many Extended
+Reality (XR) applications, such as indoor 3D understanding, video pass-through,
+and mixed-reality games. Despite significant advancements in deep stereo
+methods, achieving real-time depth inference with high accuracy on a low-power
+device remains a major challenge. One of the major difficulties is the lack of
+high-quality indoor video stereo training datasets captured by head-mounted
+VR/AR glasses. To address this issue, we introduce a novel video stereo
+synthetic dataset that comprises photorealistic renderings of various indoor
+scenes and realistic camera motion captured by a 6-DoF moving VR/AR
+head-mounted display (HMD). This facilitates the evaluation of existing
+approaches and promotes further research on indoor augmented reality scenarios.
+Our newly proposed dataset enables us to develop a novel framework for
+continuous video-rate stereo matching.
+As another contribution, our dataset enables us to proposed a new video-based
+stereo matching approach tailored for XR applications, which achieves real-time
+inference at an impressive 134fps on a standard desktop computer, or 30fps on a
+battery-powered HMD. Our key insight is that disparity and contextual
+information are highly correlated and redundant between consecutive stereo
+frames. By unrolling an iterative cost aggregation in time (i.e. in the
+temporal dimension), we are able to distribute and reuse the aggregated
+features over time. This approach leads to a substantial reduction in
+computation without sacrificing accuracy. We conducted extensive evaluations
+and comparisons and demonstrated that our method achieves superior performance
+compared to the current state-of-the-art, making it a strong contender for
+real-time stereo matching in VR/AR applications.
+
+
+
+ 25. 标题:Unsupervised Object Localization with Representer Point Selection
+ 编号:[118]
+ 链接:https://arxiv.org/abs/2309.04172
+ 作者:Yeonghwan Song, Seokwoo Jang, Dina Katabi, Jeany Son
+ 备注:Accepted by ICCV 2023
+ 关键词:self-supervised object localization, utilizing self-supervised pre-trained, unsupervised object localization, object localization method, object localization
+
+ 点击查看摘要
+ We propose a novel unsupervised object localization method that allows us to
+explain the predictions of the model by utilizing self-supervised pre-trained
+models without additional finetuning. Existing unsupervised and self-supervised
+object localization methods often utilize class-agnostic activation maps or
+self-similarity maps of a pre-trained model. Although these maps can offer
+valuable information for localization, their limited ability to explain how the
+model makes predictions remains challenging. In this paper, we propose a simple
+yet effective unsupervised object localization method based on representer
+point selection, where the predictions of the model can be represented as a
+linear combination of representer values of training points. By selecting
+representer points, which are the most important examples for the model
+predictions, our model can provide insights into how the model predicts the
+foreground object by providing relevant examples as well as their importance.
+Our method outperforms the state-of-the-art unsupervised and self-supervised
+object localization methods on various datasets with significant margins and
+even outperforms recent weakly supervised and few-shot methods.
+
+
+
+ 26. 标题:PRISTA-Net: Deep Iterative Shrinkage Thresholding Network for Coded Diffraction Patterns Phase Retrieval
+ 编号:[119]
+ 链接:https://arxiv.org/abs/2309.04171
+ 作者:Aoxu Liu, Xiaohong Fan, Yin Yang, Jianping Zhang
+ 备注:12 pages
+ 关键词:nonlinear inverse problem, challenge nonlinear inverse, limited amplitude measurement, amplitude measurement data, inverse problem
+
+ 点击查看摘要
+ The problem of phase retrieval (PR) involves recovering an unknown image from
+limited amplitude measurement data and is a challenge nonlinear inverse problem
+in computational imaging and image processing. However, many of the PR methods
+are based on black-box network models that lack interpretability and
+plug-and-play (PnP) frameworks that are computationally complex and require
+careful parameter tuning. To address this, we have developed PRISTA-Net, a deep
+unfolding network (DUN) based on the first-order iterative shrinkage
+thresholding algorithm (ISTA). This network utilizes a learnable nonlinear
+transformation to address the proximal-point mapping sub-problem associated
+with the sparse priors, and an attention mechanism to focus on phase
+information containing image edges, textures, and structures. Additionally, the
+fast Fourier transform (FFT) is used to learn global features to enhance local
+information, and the designed logarithmic-based loss function leads to
+significant improvements when the noise level is low. All parameters in the
+proposed PRISTA-Net framework, including the nonlinear transformation,
+threshold parameters, and step size, are learned end-to-end instead of being
+manually set. This method combines the interpretability of traditional methods
+with the fast inference ability of deep learning and is able to handle noise at
+each iteration during the unfolding stage, thus improving recovery quality.
+Experiments on Coded Diffraction Patterns (CDPs) measurements demonstrate that
+our approach outperforms the existing state-of-the-art methods in terms of
+qualitative and quantitative evaluations. Our source codes are available at
+\emph{this https URL}.
+
+
+
+ 27. 标题:Grouping Boundary Proposals for Fast Interactive Image Segmentation
+ 编号:[120]
+ 链接:https://arxiv.org/abs/2309.04169
+ 作者:Li Liu, Da Chen, Minglei Shu, Laurent D. Cohen
+ 备注:
+ 关键词:image segmentation, image segmentation model, image, efficient tool, tool for solving
+
+ 点击查看摘要
+ Geodesic models are known as an efficient tool for solving various image
+segmentation problems. Most of existing approaches only exploit local pointwise
+image features to track geodesic paths for delineating the objective
+boundaries. However, such a segmentation strategy cannot take into account the
+connectivity of the image edge features, increasing the risk of shortcut
+problem, especially in the case of complicated scenario. In this work, we
+introduce a new image segmentation model based on the minimal geodesic
+framework in conjunction with an adaptive cut-based circular optimal path
+computation scheme and a graph-based boundary proposals grouping scheme.
+Specifically, the adaptive cut can disconnect the image domain such that the
+target contours are imposed to pass through this cut only once. The boundary
+proposals are comprised of precomputed image edge segments, providing the
+connectivity information for our segmentation model. These boundary proposals
+are then incorporated into the proposed image segmentation model, such that the
+target segmentation contours are made up of a set of selected boundary
+proposals and the corresponding geodesic paths linking them. Experimental
+results show that the proposed model indeed outperforms state-of-the-art
+minimal paths-based image segmentation approaches.
+
+
+
+ 28. 标题:Context-Aware Prompt Tuning for Vision-Language Model with Dual-Alignment
+ 编号:[124]
+ 链接:https://arxiv.org/abs/2309.04158
+ 作者:Hongyu Hu, Tiancheng Lin, Jie Wang, Zhenbang Sun, Yi Xu
+ 备注:
+ 关键词:broad visual concepts, tedious training data, showing superb generalization, superb generalization ability, learn broad visual
+
+ 点击查看摘要
+ Large-scale vision-language models (VLMs), e.g., CLIP, learn broad visual
+concepts from tedious training data, showing superb generalization ability.
+Amount of prompt learning methods have been proposed to efficiently adapt the
+VLMs to downstream tasks with only a few training samples. We introduce a novel
+method to improve the prompt learning of vision-language models by
+incorporating pre-trained large language models (LLMs), called Dual-Aligned
+Prompt Tuning (DuAl-PT). Learnable prompts, like CoOp, implicitly model the
+context through end-to-end training, which are difficult to control and
+interpret. While explicit context descriptions generated by LLMs, like GPT-3,
+can be directly used for zero-shot classification, such prompts are overly
+relying on LLMs and still underexplored in few-shot domains. With DuAl-PT, we
+propose to learn more context-aware prompts, benefiting from both explicit and
+implicit context modeling. To achieve this, we introduce a pre-trained LLM to
+generate context descriptions, and we encourage the prompts to learn from the
+LLM's knowledge by alignment, as well as the alignment between prompts and
+local image features. Empirically, DuAl-PT achieves superior performance on 11
+downstream datasets on few-shot recognition and base-to-new generalization.
+Hopefully, DuAl-PT can serve as a strong baseline. Code will be available.
+
+
+
+ 29. 标题:Mapping EEG Signals to Visual Stimuli: A Deep Learning Approach to Match vs. Mismatch Classification
+ 编号:[127]
+ 链接:https://arxiv.org/abs/2309.04153
+ 作者:Yiqian Yang, Zhengqiao Zhao, Qian Wang, Yan Yang, Jingdong Chen
+ 备注:
+ 关键词:handling between-subject variance, modeling speech-brain response, Existing approaches, facing difficulties, difficulties in handling
+
+ 点击查看摘要
+ Existing approaches to modeling associations between visual stimuli and brain
+responses are facing difficulties in handling between-subject variance and
+model generalization. Inspired by the recent progress in modeling speech-brain
+response, we propose in this work a ``match-vs-mismatch'' deep learning model
+to classify whether a video clip induces excitatory responses in recorded EEG
+signals and learn associations between the visual content and corresponding
+neural recordings. Using an exclusive experimental dataset, we demonstrate that
+the proposed model is able to achieve the highest accuracy on unseen subjects
+as compared to other baseline models. Furthermore, we analyze the inter-subject
+noise using a subject-level silhouette score in the embedding space and show
+that the developed model is able to mitigate inter-subject noise and
+significantly reduce the silhouette score. Moreover, we examine the Grad-CAM
+activation score and show that the brain regions associated with language
+processing contribute most to the model predictions, followed by regions
+associated with visual processing. These results have the potential to
+facilitate the development of neural recording-based video reconstruction and
+its related applications.
+
+
+
+ 30. 标题:Representation Synthesis by Probabilistic Many-Valued Logic Operation in Self-Supervised Learning
+ 编号:[129]
+ 链接:https://arxiv.org/abs/2309.04148
+ 作者:Hiroki Nakamura, Masashi Okada, Tadahiro Taniguchi
+ 备注:This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible
+ 关键词:representation, mixed images, mixed images learn, mixed, image
+
+ 点击查看摘要
+ Self-supervised learning (SSL) using mixed images has been studied to learn
+various image representations. Existing methods using mixed images learn a
+representation by maximizing the similarity between the representation of the
+mixed image and the synthesized representation of the original images. However,
+few methods consider the synthesis of representations from the perspective of
+mathematical logic. In this study, we focused on a synthesis method of
+representations. We proposed a new SSL with mixed images and a new
+representation format based on many-valued logic. This format can indicate the
+feature-possession degree, that is, how much of each image feature is possessed
+by a representation. This representation format and representation synthesis by
+logic operation realize that the synthesized representation preserves the
+remarkable characteristics of the original representations. Our method
+performed competitively with previous representation synthesis methods for
+image classification tasks. We also examined the relationship between the
+feature-possession degree and the number of classes of images in the multilabel
+image classification dataset to verify that the intended learning was achieved.
+In addition, we discussed image retrieval, which is an application of our
+proposed representation format using many-valued logic.
+
+
+
+ 31. 标题:Robot Localization and Mapping Final Report -- Sequential Adversarial Learning for Self-Supervised Deep Visual Odometry
+ 编号:[130]
+ 链接:https://arxiv.org/abs/2309.04147
+ 作者:Akankshya Kar, Sajal Maheshwari, Shamit Lal, Vinay Sameer Raja Kad
+ 备注:
+ 关键词:motion for decades, multi-view geometry, geometry via local, local structure, structure from motion
+
+ 点击查看摘要
+ Visual odometry (VO) and SLAM have been using multi-view geometry via local
+structure from motion for decades. These methods have a slight disadvantage in
+challenging scenarios such as low-texture images, dynamic scenarios, etc.
+Meanwhile, use of deep neural networks to extract high level features is
+ubiquitous in computer vision. For VO, we can use these deep networks to
+extract depth and pose estimates using these high level features. The visual
+odometry task then can be modeled as an image generation task where the pose
+estimation is the by-product. This can also be achieved in a self-supervised
+manner, thereby eliminating the data (supervised) intensive nature of training
+deep neural networks. Although some works tried the similar approach [1], the
+depth and pose estimation in the previous works are vague sometimes resulting
+in accumulation of error (drift) along the trajectory. The goal of this work is
+to tackle these limitations of past approaches and to develop a method that can
+provide better depths and pose estimates. To address this, a couple of
+approaches are explored: 1) Modeling: Using optical flow and recurrent neural
+networks (RNN) in order to exploit spatio-temporal correlations which can
+provide more information to estimate depth. 2) Loss function: Generative
+adversarial network (GAN) [2] is deployed to improve the depth estimation (and
+thereby pose too), as shown in Figure 1. This additional loss term improves the
+realism in generated images and reduces artifacts.
+
+
+
+ 32. 标题:Depth Completion with Multiple Balanced Bases and Confidence for Dense Monocular SLAM
+ 编号:[132]
+ 链接:https://arxiv.org/abs/2309.04145
+ 作者:Weijian Xie, Guanyi Chu, Quanhao Qian, Yihao Yu, Hai Li, Danpeng Chen, Shangjin Zhai, Nan Wang, Hujun Bao, Guofeng Zhang
+ 备注:
+ 关键词:Dense SLAM based, sparse SLAM systems, SLAM systems, sparse SLAM, SLAM
+
+ 点击查看摘要
+ Dense SLAM based on monocular cameras does indeed have immense application
+value in the field of AR/VR, especially when it is performed on a mobile
+device. In this paper, we propose a novel method that integrates a light-weight
+depth completion network into a sparse SLAM system using a multi-basis depth
+representation, so that dense mapping can be performed online even on a mobile
+phone. Specifically, we present a specifically optimized multi-basis depth
+completion network, called BBC-Net, tailored to the characteristics of
+traditional sparse SLAM systems. BBC-Net can predict multiple balanced bases
+and a confidence map from a monocular image with sparse points generated by
+off-the-shelf keypoint-based SLAM systems. The final depth is a linear
+combination of predicted depth bases that can be optimized by tuning the
+corresponding weights. To seamlessly incorporate the weights into traditional
+SLAM optimization and ensure efficiency and robustness, we design a set of
+depth weight factors, which makes our network a versatile plug-in module,
+facilitating easy integration into various existing sparse SLAM systems and
+significantly enhancing global depth consistency through bundle adjustment. To
+verify the portability of our method, we integrate BBC-Net into two
+representative SLAM systems. The experimental results on various datasets show
+that the proposed method achieves better performance in monocular dense mapping
+than the state-of-the-art methods. We provide an online demo running on a
+mobile phone, which verifies the efficiency and mapping quality of the proposed
+method in real-world scenarios.
+
+
+
+ 33. 标题:From Text to Mask: Localizing Entities Using the Attention of Text-to-Image Diffusion Models
+ 编号:[141]
+ 链接:https://arxiv.org/abs/2309.04109
+ 作者:Changming Xiao, Qi Yang, Feng Zhou, Changshui Zhang
+ 备注:
+ 关键词:revolted the field, Diffusion models, generation recently, models, method
+
+ 点击查看摘要
+ Diffusion models have revolted the field of text-to-image generation
+recently. The unique way of fusing text and image information contributes to
+their remarkable capability of generating highly text-related images. From
+another perspective, these generative models imply clues about the precise
+correlation between words and pixels. In this work, a simple but effective
+method is proposed to utilize the attention mechanism in the denoising network
+of text-to-image diffusion models. Without re-training nor inference-time
+optimization, the semantic grounding of phrases can be attained directly. We
+evaluate our method on Pascal VOC 2012 and Microsoft COCO 2014 under
+weakly-supervised semantic segmentation setting and our method achieves
+superior performance to prior methods. In addition, the acquired word-pixel
+correlation is found to be generalizable for the learned text embedding of
+customized generation methods, requiring only a few modifications. To validate
+our discovery, we introduce a new practical task called "personalized referring
+image segmentation" with a new dataset. Experiments in various situations
+demonstrate the advantages of our method compared to strong baselines on this
+task. In summary, our work reveals a novel way to extract the rich multi-modal
+knowledge hidden in diffusion models for segmentation.
+
+
+
+ 34. 标题:Weakly Supervised Point Clouds Transformer for 3D Object Detection
+ 编号:[143]
+ 链接:https://arxiv.org/abs/2309.04105
+ 作者:Zuojin Tang, Bo Sun, Tongwei Ma, Daosheng Li, Zhenhui Xu
+ 备注:International Conference on Intelligent Transportation Systems (ITSC), 2022
+ 关键词:object detection, scene understanding, Voting Proposal Module, network, Unsupervised Voting Proposal
+
+ 点击查看摘要
+ The annotation of 3D datasets is required for semantic-segmentation and
+object detection in scene understanding. In this paper we present a framework
+for the weakly supervision of a point clouds transformer that is used for 3D
+object detection. The aim is to decrease the required amount of supervision
+needed for training, as a result of the high cost of annotating a 3D datasets.
+We propose an Unsupervised Voting Proposal Module, which learns randomly preset
+anchor points and uses voting network to select prepared anchor points of high
+quality. Then it distills information into student and teacher network. In
+terms of student network, we apply ResNet network to efficiently extract local
+characteristics. However, it also can lose much global information. To provide
+the input which incorporates the global and local information as the input of
+student networks, we adopt the self-attention mechanism of transformer to
+extract global features, and the ResNet layers to extract region proposals. The
+teacher network supervises the classification and regression of the student
+network using the pre-trained model on ImageNet. On the challenging KITTI
+datasets, the experimental results have achieved the highest level of average
+precision compared with the most recent weakly supervised 3D object detectors.
+
+
+
+ 35. 标题:Toward Sufficient Spatial-Frequency Interaction for Gradient-aware Underwater Image Enhancement
+ 编号:[145]
+ 链接:https://arxiv.org/abs/2309.04089
+ 作者:Chen Zhao, Weiling Cai, Chenyu Dong, Ziqi Zeng
+ 备注:
+ 关键词:underwater visual tasks, Underwater images suffer, suffer from complex, complex and diverse, inevitably affects
+
+ 点击查看摘要
+ Underwater images suffer from complex and diverse degradation, which
+inevitably affects the performance of underwater visual tasks. However, most
+existing learning-based Underwater image enhancement (UIE) methods mainly
+restore such degradations in the spatial domain, and rarely pay attention to
+the fourier frequency information. In this paper, we develop a novel UIE
+framework based on spatial-frequency interaction and gradient maps, namely
+SFGNet, which consists of two stages. Specifically, in the first stage, we
+propose a dense spatial-frequency fusion network (DSFFNet), mainly including
+our designed dense fourier fusion block and dense spatial fusion block,
+achieving sufficient spatial-frequency interaction by cross connections between
+these two blocks. In the second stage, we propose a gradient-aware corrector
+(GAC) to further enhance perceptual details and geometric structures of images
+by gradient map. Experimental results on two real-world underwater image
+datasets show that our approach can successfully enhance underwater images, and
+achieves competitive performance in visual quality improvement.
+
+
+
+ 36. 标题:Towards Efficient SDRTV-to-HDRTV by Learning from Image Formation
+ 编号:[148]
+ 链接:https://arxiv.org/abs/2309.04084
+ 作者:Xiangyu Chen, Zheyuan Li, Zhengwen Zhang, Jimmy S. Ren, Yihao Liu, Jingwen He, Yu Qiao, Jiantao Zhou, Chao Dong
+ 备注:Extended version of HDRTVNet
+ 关键词:high dynamic range, standard dynamic range, dynamic range, Modern displays, displays are capable
+
+ 点击查看摘要
+ Modern displays are capable of rendering video content with high dynamic
+range (HDR) and wide color gamut (WCG). However, the majority of available
+resources are still in standard dynamic range (SDR). As a result, there is
+significant value in transforming existing SDR content into the HDRTV standard.
+In this paper, we define and analyze the SDRTV-to-HDRTV task by modeling the
+formation of SDRTV/HDRTV content. Our analysis and observations indicate that a
+naive end-to-end supervised training pipeline suffers from severe gamut
+transition errors. To address this issue, we propose a novel three-step
+solution pipeline called HDRTVNet++, which includes adaptive global color
+mapping, local enhancement, and highlight refinement. The adaptive global color
+mapping step uses global statistics as guidance to perform image-adaptive color
+mapping. A local enhancement network is then deployed to enhance local details.
+Finally, we combine the two sub-networks above as a generator and achieve
+highlight consistency through GAN-based joint training. Our method is primarily
+designed for ultra-high-definition TV content and is therefore effective and
+lightweight for processing 4K resolution images. We also construct a dataset
+using HDR videos in the HDR10 standard, named HDRTV1K that contains 1235 and
+117 training images and 117 testing images, all in 4K resolution. Besides, we
+select five metrics to evaluate the results of SDRTV-to-HDRTV algorithms. Our
+final results demonstrate state-of-the-art performance both quantitatively and
+visually. The code, model and dataset are available at
+this https URL.
+
+
+
+ 37. 标题:UER: A Heuristic Bias Addressing Approach for Online Continual Learning
+ 编号:[150]
+ 链接:https://arxiv.org/abs/2309.04081
+ 作者:Huiwei Lin, Shanshan Feng, Baoquan Zhang, Hongliang Qiao, Xutao Li, Yunming Ye
+ 备注:9 pages, 12 figures, ACM MM2023
+ 关键词:continual learning aims, continuously train neural, train neural networks, single pass-through data, continuous data stream
+
+ 点击查看摘要
+ Online continual learning aims to continuously train neural networks from a
+continuous data stream with a single pass-through data. As the most effective
+approach, the rehearsal-based methods replay part of previous data. Commonly
+used predictors in existing methods tend to generate biased dot-product logits
+that prefer to the classes of current data, which is known as a bias issue and
+a phenomenon of forgetting. Many approaches have been proposed to overcome the
+forgetting problem by correcting the bias; however, they still need to be
+improved in online fashion. In this paper, we try to address the bias issue by
+a more straightforward and more efficient method. By decomposing the
+dot-product logits into an angle factor and a norm factor, we empirically find
+that the bias problem mainly occurs in the angle factor, which can be used to
+learn novel knowledge as cosine logits. On the contrary, the norm factor
+abandoned by existing methods helps remember historical knowledge. Based on
+this observation, we intuitively propose to leverage the norm factor to balance
+the new and old knowledge for addressing the bias. To this end, we develop a
+heuristic approach called unbias experience replay (UER). UER learns current
+samples only by the angle factor and further replays previous samples by both
+the norm and angle factors. Extensive experiments on three datasets show that
+UER achieves superior performance over various state-of-the-art methods. The
+code is in this https URL.
+
+
+
+ 38. 标题:INSURE: An Information Theory Inspired Disentanglement and Purification Model for Domain Generalization
+ 编号:[158]
+ 链接:https://arxiv.org/abs/2309.04063
+ 作者:Xi Yu, Huan-Hsin Tseng, Shinjae Yoo, Haibin Ling, Yuewei Lin
+ 备注:10 pages, 4 figures
+ 关键词:unseen target domain, observed source domains, domain-specific class-relevant features, multiple observed source, class-relevant
+
+ 点击查看摘要
+ Domain Generalization (DG) aims to learn a generalizable model on the unseen
+target domain by only training on the multiple observed source domains.
+Although a variety of DG methods have focused on extracting domain-invariant
+features, the domain-specific class-relevant features have attracted attention
+and been argued to benefit generalization to the unseen target domain. To take
+into account the class-relevant domain-specific information, in this paper we
+propose an Information theory iNspired diSentanglement and pURification modEl
+(INSURE) to explicitly disentangle the latent features to obtain sufficient and
+compact (necessary) class-relevant feature for generalization to the unseen
+domain. Specifically, we first propose an information theory inspired loss
+function to ensure the disentangled class-relevant features contain sufficient
+class label information and the other disentangled auxiliary feature has
+sufficient domain information. We further propose a paired purification loss
+function to let the auxiliary feature discard all the class-relevant
+information and thus the class-relevant feature will contain sufficient and
+compact (necessary) class-relevant information. Moreover, instead of using
+multiple encoders, we propose to use a learnable binary mask as our
+disentangler to make the disentanglement more efficient and make the
+disentangled features complementary to each other. We conduct extensive
+experiments on four widely used DG benchmark datasets including PACS,
+OfficeHome, TerraIncognita, and DomainNet. The proposed INSURE outperforms the
+state-of-art methods. We also empirically show that domain-specific
+class-relevant features are beneficial for domain generalization.
+
+
+
+ 39. 标题:Evaluation and Mitigation of Agnosia in Multimodal Large Language Models
+ 编号:[162]
+ 链接:https://arxiv.org/abs/2309.04041
+ 作者:Jiaying Lu, Jinmeng Rao, Kezhen Chen, Xiaoyuan Guo, Yawen Zhang, Baochen Sun, Carl Yang, Jie Yang
+ 备注:
+ 关键词:Large Language Models, Multimodal Large Language, Language Models, Large Language, Multimodal Large
+
+ 点击查看摘要
+ While Multimodal Large Language Models (MLLMs) are widely used for a variety
+of vision-language tasks, one observation is that they sometimes misinterpret
+visual inputs or fail to follow textual instructions even in straightforward
+cases, leading to irrelevant responses, mistakes, and ungrounded claims. This
+observation is analogous to a phenomenon in neuropsychology known as Agnosia,
+an inability to correctly process sensory modalities and recognize things
+(e.g., objects, colors, relations). In our study, we adapt this similar concept
+to define "agnosia in MLLMs", and our goal is to comprehensively evaluate and
+mitigate such agnosia in MLLMs. Inspired by the diagnosis and treatment process
+in neuropsychology, we propose a novel framework EMMA (Evaluation and
+Mitigation of Multimodal Agnosia). In EMMA, we develop an evaluation module
+that automatically creates fine-grained and diverse visual question answering
+examples to assess the extent of agnosia in MLLMs comprehensively. We also
+develop a mitigation module to reduce agnosia in MLLMs through multimodal
+instruction tuning on fine-grained conversations. To verify the effectiveness
+of our framework, we evaluate and analyze agnosia in seven state-of-the-art
+MLLMs using 9K test samples. The results reveal that most of them exhibit
+agnosia across various aspects and degrees. We further develop a fine-grained
+instruction set and tune MLLMs to mitigate agnosia, which led to notable
+improvement in accuracy.
+
+
+
+ 40. 标题:S-Adapter: Generalizing Vision Transformer for Face Anti-Spoofing with Statistical Tokens
+ 编号:[163]
+ 链接:https://arxiv.org/abs/2309.04038
+ 作者:Rizhao Cai, Zitong Yu, Chenqi Kong, Haoliang Li, Changsheng Chen, Yongjian Hu, Alex Kot
+ 备注:
+ 关键词:face recognition system, presenting spoofed faces, detect malicious attempts, Face Anti-Spoofing, face recognition
+
+ 点击查看摘要
+ Face Anti-Spoofing (FAS) aims to detect malicious attempts to invade a face
+recognition system by presenting spoofed faces. State-of-the-art FAS techniques
+predominantly rely on deep learning models but their cross-domain
+generalization capabilities are often hindered by the domain shift problem,
+which arises due to different distributions between training and testing data.
+In this study, we develop a generalized FAS method under the Efficient
+Parameter Transfer Learning (EPTL) paradigm, where we adapt the pre-trained
+Vision Transformer models for the FAS task. During training, the adapter
+modules are inserted into the pre-trained ViT model, and the adapters are
+updated while other pre-trained parameters remain fixed. We find the
+limitations of previous vanilla adapters in that they are based on linear
+layers, which lack a spoofing-aware inductive bias and thus restrict the
+cross-domain generalization. To address this limitation and achieve
+cross-domain generalized FAS, we propose a novel Statistical Adapter
+(S-Adapter) that gathers local discriminative and statistical information from
+localized token histograms. To further improve the generalization of the
+statistical tokens, we propose a novel Token Style Regularization (TSR), which
+aims to reduce domain style variance by regularizing Gram matrices extracted
+from tokens across different domains. Our experimental results demonstrate that
+our proposed S-Adapter and TSR provide significant benefits in both zero-shot
+and few-shot cross-domain testing, outperforming state-of-the-art methods on
+several benchmark tests. We will release the source code upon acceptance.
+
+
+
+ 41. 标题:Improving the Accuracy of Beauty Product Recommendations by Assessing Face Illumination Quality
+ 编号:[173]
+ 链接:https://arxiv.org/abs/2309.04022
+ 作者:Parnian Afshar, Jenny Yeon, Andriy Levitskyy, Rahul Suresh, Amin Banitalebi-Dehkordi
+ 备注:7 pages, 5 figures. Presented in FAccTRec2023
+ 关键词:responsible beauty product, beauty product recommendation, focus on addressing, addressing the challenges, challenges in responsible
+
+ 点击查看摘要
+ We focus on addressing the challenges in responsible beauty product
+recommendation, particularly when it involves comparing the product's color
+with a person's skin tone, such as for foundation and concealer products. To
+make accurate recommendations, it is crucial to infer both the product
+attributes and the product specific facial features such as skin conditions or
+tone. However, while many product photos are taken under good light conditions,
+face photos are taken from a wide range of conditions. The features extracted
+using the photos from ill-illuminated environment can be highly misleading or
+even be incompatible to be compared with the product attributes. Hence bad
+illumination condition can severely degrade quality of the recommendation.
+We introduce a machine learning framework for illumination assessment which
+classifies images into having either good or bad illumination condition. We
+then build an automatic user guidance tool which informs a user holding their
+camera if their illumination condition is good or bad. This way, the user is
+provided with rapid feedback and can interactively control how the photo is
+taken for their recommendation. Only a few studies are dedicated to this
+problem, mostly due to the lack of dataset that is large, labeled, and diverse
+both in terms of skin tones and light patterns. Lack of such dataset leads to
+neglecting skin tone diversity. Therefore, We begin by constructing a diverse
+synthetic dataset that simulates various skin tones and light patterns in
+addition to an existing facial image dataset. Next, we train a Convolutional
+Neural Network (CNN) for illumination assessment that outperforms the existing
+solutions using the synthetic dataset. Finally, we analyze how the our work
+improves the shade recommendation for various foundation products.
+
+
+
+ 42. 标题:Multimodal Transformer for Material Segmentation
+ 编号:[178]
+ 链接:https://arxiv.org/abs/2309.04001
+ 作者:Md Kaykobad Reza (1), Ashley Prater-Bennette (2), M. Salman Asif (1) ((1) University of California, Riverside, (2) Air Force Research Laboratory)
+ 备注:9 pages, 3 figures
+ 关键词:Linear Polarization, multimodal segmentation tasks, Leveraging information, segmentation tasks, diverse modalities
+
+ 点击查看摘要
+ Leveraging information across diverse modalities is known to enhance
+performance on multimodal segmentation tasks. However, effectively fusing
+information from different modalities remains challenging due to the unique
+characteristics of each modality. In this paper, we propose a novel fusion
+strategy that can effectively fuse information from different combinations of
+four different modalities: RGB, Angle of Linear Polarization (AoLP), Degree of
+Linear Polarization (DoLP) and Near-Infrared (NIR). We also propose a new model
+named Multi-Modal Segmentation Transformer (MMSFormer) that incorporates the
+proposed fusion strategy to perform multimodal material segmentation. MMSFormer
+achieves 52.05% mIoU outperforming the current state-of-the-art on Multimodal
+Material Segmentation (MCubeS) dataset. For instance, our method provides
+significant improvement in detecting gravel (+10.4%) and human (+9.1%) classes.
+Ablation studies show that different modules in the fusion block are crucial
+for overall model performance. Furthermore, our ablation studies also highlight
+the capacity of different input modalities to improve performance in the
+identification of different types of materials. The code and pretrained models
+will be made available at this https URL.
+
+
+
+ 43. 标题:Adapting Self-Supervised Representations to Multi-Domain Setups
+ 编号:[179]
+ 链接:https://arxiv.org/abs/2309.03999
+ 作者:Neha Kalibhat, Sam Sharpe, Jeremy Goodsitt, Bayan Bruss, Soheil Feizi
+ 备注:Published at BMVC 2023
+ 关键词:DDM, domains, self-supervised, trained, self-supervised approaches
+
+ 点击查看摘要
+ Current state-of-the-art self-supervised approaches, are effective when
+trained on individual domains but show limited generalization on unseen
+domains. We observe that these models poorly generalize even when trained on a
+mixture of domains, making them unsuitable to be deployed under diverse
+real-world setups. We therefore propose a general-purpose, lightweight Domain
+Disentanglement Module (DDM) that can be plugged into any self-supervised
+encoder to effectively perform representation learning on multiple, diverse
+domains with or without shared classes. During pre-training according to a
+self-supervised loss, DDM enforces a disentanglement in the representation
+space by splitting it into a domain-variant and a domain-invariant portion.
+When domain labels are not available, DDM uses a robust clustering approach to
+discover pseudo-domains. We show that pre-training with DDM can show up to 3.5%
+improvement in linear probing accuracy on state-of-the-art self-supervised
+models including SimCLR, MoCo, BYOL, DINO, SimSiam and Barlow Twins on
+multi-domain benchmarks including PACS, DomainNet and WILDS. Models trained
+with DDM show significantly improved generalization (7.4%) to unseen domains
+compared to baselines. Therefore, DDM can efficiently adapt self-supervised
+encoders to provide high-quality, generalizable representations for diverse
+multi-domain data.
+
+
+
+ 44. 标题:CDFSL-V: Cross-Domain Few-Shot Learning for Videos
+ 编号:[181]
+ 链接:https://arxiv.org/abs/2309.03989
+ 作者:Sarinda Samarasinghe, Mamshad Nayeem Rizve, Navid Kardan, Mubarak Shah
+ 备注:ICCV 2023
+ 关键词:video action recognition, annotating large-scale video, Few-shot video action, action recognition, video action
+
+ 点击查看摘要
+ Few-shot video action recognition is an effective approach to recognizing new
+categories with only a few labeled examples, thereby reducing the challenges
+associated with collecting and annotating large-scale video datasets. Existing
+methods in video action recognition rely on large labeled datasets from the
+same domain. However, this setup is not realistic as novel categories may come
+from different data domains that may have different spatial and temporal
+characteristics. This dissimilarity between the source and target domains can
+pose a significant challenge, rendering traditional few-shot action recognition
+techniques ineffective. To address this issue, in this work, we propose a novel
+cross-domain few-shot video action recognition method that leverages
+self-supervised learning and curriculum learning to balance the information
+from the source and target domains. To be particular, our method employs a
+masked autoencoder-based self-supervised training objective to learn from both
+source and target data in a self-supervised manner. Then a progressive
+curriculum balances learning the discriminative information from the source
+dataset with the generic information learned from the target domain. Initially,
+our curriculum utilizes supervised learning to learn class discriminative
+features from the source data. As the training progresses, we transition to
+learning target-domain-specific features. We propose a progressive curriculum
+to encourage the emergence of rich features in the target domain based on class
+discriminative supervised features in the source domain. %a schedule that helps
+with this transition. We evaluate our method on several challenging benchmark
+datasets and demonstrate that our approach outperforms existing cross-domain
+few-shot learning techniques. Our code is available at
+\hyperlink{this https URL}{this https URL}
+
+
+
+ 45. 标题:Separable Self and Mixed Attention Transformers for Efficient Object Tracking
+ 编号:[184]
+ 链接:https://arxiv.org/abs/2309.03979
+ 作者:Goutam Yelluru Gopal, Maria A. Amer
+ 备注:Accepted by WACV2024. Code available at this https URL
+ 关键词:visual object tracking, Siamese lightweight tracking, visual object, mixed attention transformer-based, object tracking
+
+ 点击查看摘要
+ The deployment of transformers for visual object tracking has shown
+state-of-the-art results on several benchmarks. However, the transformer-based
+models are under-utilized for Siamese lightweight tracking due to the
+computational complexity of their attention blocks. This paper proposes an
+efficient self and mixed attention transformer-based architecture for
+lightweight tracking. The proposed backbone utilizes the separable mixed
+attention transformers to fuse the template and search regions during feature
+extraction to generate superior feature encoding. Our prediction head performs
+global contextual modeling of the encoded features by leveraging efficient
+self-attention blocks for robust target state estimation. With these
+contributions, the proposed lightweight tracker deploys a transformer-based
+backbone and head module concurrently for the first time. Our ablation study
+testifies to the effectiveness of the proposed combination of backbone and head
+modules. Simulations show that our Separable Self and Mixed Attention-based
+Tracker, SMAT, surpasses the performance of related lightweight trackers on
+GOT10k, TrackingNet, LaSOT, NfS30, UAV123, and AVisT datasets, while running at
+37 fps on CPU, 158 fps on GPU, and having 3.8M parameters. For example, it
+significantly surpasses the closely related trackers E.T.Track and
+MixFormerV2-S on GOT10k-test by a margin of 7.9% and 5.8%, respectively, in the
+AO metric. The tracker code and model is available at
+this https URL
+
+
+
+ 46. 标题:Improving Resnet-9 Generalization Trained on Small Datasets
+ 编号:[190]
+ 链接:https://arxiv.org/abs/2309.03965
+ 作者:Omar Mohamed Awad, Habib Hajimolahoseini, Michael Lim, Gurpreet Gosal, Walid Ahmed, Yang Liu, Gordon Deng
+ 备注:
+ 关键词:Hardware Aware Efficient, paper presents, presents our proposed, Aware Efficient Training, Efficient Training
+
+ 点击查看摘要
+ This paper presents our proposed approach that won the first prize at the
+ICLR competition on Hardware Aware Efficient Training. The challenge is to
+achieve the highest possible accuracy in an image classification task in less
+than 10 minutes. The training is done on a small dataset of 5000 images picked
+randomly from CIFAR-10 dataset. The evaluation is performed by the competition
+organizers on a secret dataset with 1000 images of the same size. Our approach
+includes applying a series of technique for improving the generalization of
+ResNet-9 including: sharpness aware optimization, label smoothing, gradient
+centralization, input patch whitening as well as metalearning based training.
+Our experiments show that the ResNet-9 can achieve the accuracy of 88% while
+trained only on a 10% subset of CIFAR-10 dataset in less than 10 minuets
+
+
+
+ 47. 标题:REALM: Robust Entropy Adaptive Loss Minimization for Improved Single-Sample Test-Time Adaptation
+ 编号:[191]
+ 链接:https://arxiv.org/abs/2309.03964
+ 作者:Skyler Seto, Barry-John Theobald, Federico Danieli, Navdeep Jaitly, Dan Busbridge
+ 备注:Accepted at WACV 2024, 17 pages, 7 figures, 11 tables
+ 关键词:training data, mitigate performance loss, performance loss due, test data, model training procedure
+
+ 点击查看摘要
+ Fully-test-time adaptation (F-TTA) can mitigate performance loss due to
+distribution shifts between train and test data (1) without access to the
+training data, and (2) without knowledge of the model training procedure. In
+online F-TTA, a pre-trained model is adapted using a stream of test samples by
+minimizing a self-supervised objective, such as entropy minimization. However,
+models adapted with online using entropy minimization, are unstable especially
+in single sample settings, leading to degenerate solutions, and limiting the
+adoption of TTA inference strategies. Prior works identify noisy, or
+unreliable, samples as a cause of failure in online F-TTA. One solution is to
+ignore these samples, which can lead to bias in the update procedure, slow
+adaptation, and poor generalization. In this work, we present a general
+framework for improving robustness of F-TTA to these noisy samples, inspired by
+self-paced learning and robust loss functions. Our proposed approach, Robust
+Entropy Adaptive Loss Minimization (REALM), achieves better adaptation accuracy
+than previous approaches throughout the adaptation process on corruptions of
+CIFAR-10 and ImageNet-1K, demonstrating its effectiveness.
+
+
+
+ 48. 标题:SimpleNeRF: Regularizing Sparse Input Neural Radiance Fields with Simpler Solutions
+ 编号:[192]
+ 链接:https://arxiv.org/abs/2309.03955
+ 作者:Nagabhushan Somraj, Adithyan Karanayil, Rajiv Soundararajan
+ 备注:SIGGRAPH Asia 2023
+ 关键词:photorealistic free-view rendering, Neural Radiance Fields, show impressive performance, Radiance Fields, show impressive
+
+ 点击查看摘要
+ Neural Radiance Fields (NeRF) show impressive performance for the
+photorealistic free-view rendering of scenes. However, NeRFs require dense
+sampling of images in the given scene, and their performance degrades
+significantly when only a sparse set of views are available. Researchers have
+found that supervising the depth estimated by the NeRF helps train it
+effectively with fewer views. The depth supervision is obtained either using
+classical approaches or neural networks pre-trained on a large dataset. While
+the former may provide only sparse supervision, the latter may suffer from
+generalization issues. As opposed to the earlier approaches, we seek to learn
+the depth supervision by designing augmented models and training them along
+with the NeRF. We design augmented models that encourage simpler solutions by
+exploring the role of positional encoding and view-dependent radiance in
+training the few-shot NeRF. The depth estimated by these simpler models is used
+to supervise the NeRF depth estimates. Since the augmented models can be
+inaccurate in certain regions, we design a mechanism to choose only reliable
+depth estimates for supervision. Finally, we add a consistency loss between the
+coarse and fine multi-layer perceptrons of the NeRF to ensure better
+utilization of hierarchical sampling. We achieve state-of-the-art
+view-synthesis performance on two popular datasets by employing the above
+regularizations. The source code for our model can be found on our project
+page: this https URL
+
+
+
+ 49. 标题:BluNF: Blueprint Neural Field
+ 编号:[193]
+ 链接:https://arxiv.org/abs/2309.03933
+ 作者:Robin Courant, Xi Wang, Marc Christie, Vicky Kalogeiton
+ 备注:ICCV-W (AI3DCC) 2023. Project page with videos and code: this https URL
+ 关键词:offering visually realistic, Neural Radiance Fields, Radiance Fields, Neural Radiance, view synthesis
+
+ 点击查看摘要
+ Neural Radiance Fields (NeRFs) have revolutionized scene novel view
+synthesis, offering visually realistic, precise, and robust implicit
+reconstructions. While recent approaches enable NeRF editing, such as object
+removal, 3D shape modification, or material property manipulation, the manual
+annotation prior to such edits makes the process tedious. Additionally,
+traditional 2D interaction tools lack an accurate sense of 3D space, preventing
+precise manipulation and editing of scenes. In this paper, we introduce a novel
+approach, called Blueprint Neural Field (BluNF), to address these editing
+issues. BluNF provides a robust and user-friendly 2D blueprint, enabling
+intuitive scene editing. By leveraging implicit neural representation, BluNF
+constructs a blueprint of a scene using prior semantic and depth information.
+The generated blueprint allows effortless editing and manipulation of NeRF
+representations. We demonstrate BluNF's editability through an intuitive
+click-and-change mechanism, enabling 3D manipulations, such as masking,
+appearance modification, and object removal. Our approach significantly
+contributes to visual content creation, paving the way for further research in
+this area.
+
+
+
+ 50. 标题:Random Expert Sampling for Deep Learning Segmentation of Acute Ischemic Stroke on Non-contrast CT
+ 编号:[195]
+ 链接:https://arxiv.org/abs/2309.03930
+ 作者:Sophie Ostmeier, Brian Axelrod, Benjamin Pulli, Benjamin F.J. Verhaaren, Abdelkader Mahammedi, Yongkai Liu, Christian Federau, Greg Zaharchuk, Jeremy J. Heit
+ 备注:
+ 关键词:Multi-expert deep learning, ischemic brain tissue, automatically quantify ischemic, quantify ischemic brain, deep learning training
+
+ 点击查看摘要
+ Purpose: Multi-expert deep learning training methods to automatically
+quantify ischemic brain tissue on Non-Contrast CT Materials and Methods: The
+data set consisted of 260 Non-Contrast CTs from 233 patients of acute ischemic
+stroke patients recruited in the DEFUSE 3 trial. A benchmark U-Net was trained
+on the reference annotations of three experienced neuroradiologists to segment
+ischemic brain tissue using majority vote and random expert sampling training
+schemes. We used a one-sided Wilcoxon signed-rank test on a set of segmentation
+metrics to compare bootstrapped point estimates of the training schemes with
+the inter-expert agreement and ratio of variance for consistency analysis. We
+further compare volumes with the 24h-follow-up DWI (final infarct core) in the
+patient subgroup with full reperfusion and we test volumes for correlation to
+the clinical outcome (mRS after 30 and 90 days) with the Spearman method.
+Results: Random expert sampling leads to a model that shows better agreement
+with experts than experts agree among themselves and better agreement than the
+agreement between experts and a majority-vote model performance (Surface Dice
+at Tolerance 5mm improvement of 61% to 0.70 +- 0.03 and Dice improvement of 25%
+to 0.50 +- 0.04). The model-based predicted volume similarly estimated the
+final infarct volume and correlated better to the clinical outcome than CT
+perfusion. Conclusion: A model trained on random expert sampling can identify
+the presence and location of acute ischemic brain tissue on Non-Contrast CT
+similar to CT perfusion and with better consistency than experts. This may
+further secure the selection of patients eligible for endovascular treatment in
+less specialized hospitals.
+
+
+
+ 51. 标题:C-CLIP: Contrastive Image-Text Encoders to Close the Descriptive-Commentative Gap
+ 编号:[198]
+ 链接:https://arxiv.org/abs/2309.03921
+ 作者:William Theisen, Walter Scheirer
+ 备注:11 Pages, 5 Figures
+ 关键词:social media post, social media, high importance, importance for understanding, CLIP models
+
+ 点击查看摘要
+ The interplay between the image and comment on a social media post is one of
+high importance for understanding its overall message. Recent strides in
+multimodal embedding models, namely CLIP, have provided an avenue forward in
+relating image and text. However the current training regime for CLIP models is
+insufficient for matching content found on social media, regardless of site or
+language. Current CLIP training data is based on what we call ``descriptive''
+text: text in which an image is merely described. This is something rarely seen
+on social media, where the vast majority of text content is ``commentative'' in
+nature. The captions provide commentary and broader context related to the
+image, rather than describing what is in it. Current CLIP models perform poorly
+on retrieval tasks where image-caption pairs display a commentative
+relationship. Closing this gap would be beneficial for several important
+application areas related to social media. For instance, it would allow groups
+focused on Open-Source Intelligence Operations (OSINT) to further aid efforts
+during disaster events, such as the ongoing Russian invasion of Ukraine, by
+easily exposing data to non-technical users for discovery and analysis. In
+order to close this gap we demonstrate that training contrastive image-text
+encoders on explicitly commentative pairs results in large improvements in
+retrieval results, with the results extending across a variety of non-English
+languages.
+
+
+
+ 52. 标题:Revealing the preference for correcting separated aberrations in joint optic-image design
+ 编号:[209]
+ 链接:https://arxiv.org/abs/2309.04342
+ 作者:Jingwen Zhou, Shiqi Chen, Zheng Ren, Wenguan Zhang, Jiapu Yan, Huajun Feng, Qi Li, Yueting Chen
+ 备注:
+ 关键词:joint design, promising task, challenging and promising, efficient joint design, design
+
+ 点击查看摘要
+ The joint design of the optical system and the downstream algorithm is a
+challenging and promising task. Due to the demand for balancing the global
+optimal of imaging systems and the computational cost of physical simulation,
+existing methods cannot achieve efficient joint design of complex systems such
+as smartphones and drones. In this work, starting from the perspective of the
+optical design, we characterize the optics with separated aberrations.
+Additionally, to bridge the hardware and software without gradients, an image
+simulation system is presented to reproduce the genuine imaging procedure of
+lenses with large field-of-views. As for aberration correction, we propose a
+network to perceive and correct the spatially varying aberrations and validate
+its superiority over state-of-the-art methods. Comprehensive experiments reveal
+that the preference for correcting separated aberrations in joint design is as
+follows: longitudinal chromatic aberration, lateral chromatic aberration,
+spherical aberration, field curvature, and coma, with astigmatism coming last.
+Drawing from the preference, a 10% reduction in the total track length of the
+consumer-level mobile phone lens module is accomplished. Moreover, this
+procedure spares more space for manufacturing deviations, realizing
+extreme-quality enhancement of computational photography. The optimization
+paradigm provides innovative insight into the practical joint design of
+sophisticated optical systems and post-processing algorithms.
+
+
+
+ 53. 标题:How Can We Tame the Long-Tail of Chest X-ray Datasets?
+ 编号:[211]
+ 链接:https://arxiv.org/abs/2309.04293
+ 作者:Arsh Verma
+ 备注:Extended Abstract presented at Computer Vision for Automated Medical Diagnosis Workshop at the International Conference on Computer Vision 2023, October 2nd 2023, Paris, France, & Virtual, this https URL, 7 pages
+ 关键词:medical imaging modality, Chest X-rays, medical imaging, imaging modality, infer a large
+
+ 点击查看摘要
+ Chest X-rays (CXRs) are a medical imaging modality that is used to infer a
+large number of abnormalities. While it is hard to define an exhaustive list of
+these abnormalities, which may co-occur on a chest X-ray, few of them are quite
+commonly observed and are abundantly represented in CXR datasets used to train
+deep learning models for automated inference. However, it is challenging for
+current models to learn independent discriminatory features for labels that are
+rare but may be of high significance. Prior works focus on the combination of
+multi-label and long tail problems by introducing novel loss functions or some
+mechanism of re-sampling or re-weighting the data. Instead, we propose that it
+is possible to achieve significant performance gains merely by choosing an
+initialization for a model that is closer to the domain of the target dataset.
+This method can complement the techniques proposed in existing literature, and
+can easily be scaled to new labels. Finally, we also examine the veracity of
+synthetically generated data to augment the tail labels and analyse its
+contribution to improving model performance.
+
+
+
+ 54. 标题:SegmentAnything helps microscopy images based automatic and quantitative organoid detection and analysis
+ 编号:[215]
+ 链接:https://arxiv.org/abs/2309.04190
+ 作者:Xiaodan Xing, Chunling Tang, Yunzhe Guo, Nicholas Kurniawan, Guang Yang
+ 备注:submitted to SPIE: Medical Imaging 2024
+ 关键词:mimic the architecture, architecture and function, vivo tissues, studying organ development, organoid morphology
+
+ 点击查看摘要
+ Organoids are self-organized 3D cell clusters that closely mimic the
+architecture and function of in vivo tissues and organs. Quantification of
+organoid morphology helps in studying organ development, drug discovery, and
+toxicity assessment. Recent microscopy techniques provide a potent tool to
+acquire organoid morphology features, but manual image analysis remains a labor
+and time-intensive process. Thus, this paper proposes a comprehensive pipeline
+for microscopy analysis that leverages the SegmentAnything to precisely
+demarcate individual organoids. Additionally, we introduce a set of
+morphological properties, including perimeter, area, radius, non-smoothness,
+and non-circularity, allowing researchers to analyze the organoid structures
+quantitatively and automatically. To validate the effectiveness of our
+approach, we conducted tests on bright-field images of human induced
+pluripotent stem cells (iPSCs) derived neural-epithelial (NE) organoids. The
+results obtained from our automatic pipeline closely align with manual organoid
+detection and measurement, showcasing the capability of our proposed method in
+accelerating organoids morphology analysis.
+
+
+
+ 55. 标题:Enhancing Hierarchical Transformers for Whole Brain Segmentation with Intracranial Measurements Integration
+ 编号:[219]
+ 链接:https://arxiv.org/abs/2309.04071
+ 作者:Xin Yu, Yucheng Tang, Qi Yang, Ho Hin Lee, Shunxing Bao, Yuankai Huo, Bennett A. Landman
+ 备注:
+ 关键词:including total intracranial, magnetic resonance imaging, TICV, PFV, PFV labels
+
+ 点击查看摘要
+ Whole brain segmentation with magnetic resonance imaging (MRI) enables the
+non-invasive measurement of brain regions, including total intracranial volume
+(TICV) and posterior fossa volume (PFV). Enhancing the existing whole brain
+segmentation methodology to incorporate intracranial measurements offers a
+heightened level of comprehensiveness in the analysis of brain structures.
+Despite its potential, the task of generalizing deep learning techniques for
+intracranial measurements faces data availability constraints due to limited
+manually annotated atlases encompassing whole brain and TICV/PFV labels. In
+this paper, we enhancing the hierarchical transformer UNesT for whole brain
+segmentation to achieve segmenting whole brain with 133 classes and TICV/PFV
+simultaneously. To address the problem of data scarcity, the model is first
+pretrained on 4859 T1-weighted (T1w) 3D volumes sourced from 8 different sites.
+These volumes are processed through a multi-atlas segmentation pipeline for
+label generation, while TICV/PFV labels are unavailable. Subsequently, the
+model is finetuned with 45 T1w 3D volumes from Open Access Series Imaging
+Studies (OASIS) where both 133 whole brain classes and TICV/PFV labels are
+available. We evaluate our method with Dice similarity coefficients(DSC). We
+show that our model is able to conduct precise TICV/PFV estimation while
+maintaining the 132 brain regions performance at a comparable level. Code and
+trained model are available at: this https URL.
+
+
+
+ 56. 标题:Algebra and Geometry of Camera Resectioning
+ 编号:[220]
+ 链接:https://arxiv.org/abs/2309.04028
+ 作者:Erin Connelly, Timothy Duff, Jessie Loucks-Tavitas
+ 备注:27 pages
+ 关键词:study algebraic varieties, study algebraic, algebraic varieties, Gröbner basis techniques, camera resectioning problem
+
+ 点击查看摘要
+ We study algebraic varieties associated with the camera resectioning problem.
+We characterize these resectioning varieties' multigraded vanishing ideals
+using Gröbner basis techniques. As an application, we derive and re-interpret
+celebrated results in geometric computer vision related to camera-point
+duality. We also clarify some relationships between the classical problems of
+optimal resectioning and triangulation, state a conjectural formula for the
+Euclidean distance degree of the resectioning variety, and discuss how this
+conjecture relates to the recently-resolved multiview conjecture.
+
+
+
+ 57. 标题:A-Eval: A Benchmark for Cross-Dataset Evaluation of Abdominal Multi-Organ Segmentation
+ 编号:[229]
+ 链接:https://arxiv.org/abs/2309.03906
+ 作者:Ziyan Huang, Zhongying Deng, Jin Ye, Haoyu Wang, Yanzhou Su, Tianbin Li, Hui Sun, Junlong Cheng, Jianpin Chen, Junjun He, Yun Gu, Shaoting Zhang, Lixu Gu, Yu Qiao
+ 备注:
+ 关键词:abdominal multi-organ segmentation, revolutionized abdominal multi-organ, multi-organ segmentation, deep learning, learning have revolutionized
+
+ 点击查看摘要
+ Although deep learning have revolutionized abdominal multi-organ
+segmentation, models often struggle with generalization due to training on
+small, specific datasets. With the recent emergence of large-scale datasets,
+some important questions arise: \textbf{Can models trained on these datasets
+generalize well on different ones? If yes/no, how to further improve their
+generalizability?} To address these questions, we introduce A-Eval, a benchmark
+for the cross-dataset Evaluation ('Eval') of Abdominal ('A') multi-organ
+segmentation. We employ training sets from four large-scale public datasets:
+FLARE22, AMOS, WORD, and TotalSegmentator, each providing extensive labels for
+abdominal multi-organ segmentation. For evaluation, we incorporate the
+validation sets from these datasets along with the training set from the BTCV
+dataset, forming a robust benchmark comprising five distinct datasets. We
+evaluate the generalizability of various models using the A-Eval benchmark,
+with a focus on diverse data usage scenarios: training on individual datasets
+independently, utilizing unlabeled data via pseudo-labeling, mixing different
+modalities, and joint training across all available datasets. Additionally, we
+explore the impact of model sizes on cross-dataset generalizability. Through
+these analyses, we underline the importance of effective data usage in
+enhancing models' generalization capabilities, offering valuable insights for
+assembling large-scale datasets and improving training strategies. The code and
+pre-trained models are available at
+\href{this https URL}{this https URL}.
+
+
+自然语言处理
+
+ 1. 标题:Measuring and Improving Chain-of-Thought Reasoning in Vision-Language Models
+ 编号:[5]
+ 链接:https://arxiv.org/abs/2309.04461
+ 作者:Yangyi Chen, Karan Sikka, Michael Cogswell, Heng Ji, Ajay Divakaran
+ 备注:The data is released at \url{this https URL}
+ 关键词:parse natural queries, generate human-like outputs, recently demonstrated strong, demonstrated strong efficacy, reasoning
+
+ 点击查看摘要
+ Vision-language models (VLMs) have recently demonstrated strong efficacy as
+visual assistants that can parse natural queries about the visual content and
+generate human-like outputs. In this work, we explore the ability of these
+models to demonstrate human-like reasoning based on the perceived information.
+To address a crucial concern regarding the extent to which their reasoning
+capabilities are fully consistent and grounded, we also measure the reasoning
+consistency of these models. We achieve this by proposing a chain-of-thought
+(CoT) based consistency measure. However, such an evaluation requires a
+benchmark that encompasses both high-level inference and detailed reasoning
+chains, which is costly. We tackle this challenge by proposing a
+LLM-Human-in-the-Loop pipeline, which notably reduces cost while simultaneously
+ensuring the generation of a high-quality dataset. Based on this pipeline and
+the existing coarse-grained annotated dataset, we build the CURE benchmark to
+measure both the zero-shot reasoning performance and consistency of VLMs. We
+evaluate existing state-of-the-art VLMs, and find that even the best-performing
+model is unable to demonstrate strong visual reasoning capabilities and
+consistency, indicating that substantial efforts are required to enable VLMs to
+perform visual reasoning as systematically and consistently as humans. As an
+early step, we propose a two-stage training framework aimed at improving both
+the reasoning performance and consistency of VLMs. The first stage involves
+employing supervised fine-tuning of VLMs using step-by-step reasoning samples
+automatically generated by LLMs. In the second stage, we further augment the
+training process by incorporating feedback provided by LLMs to produce
+reasoning chains that are highly consistent and grounded. We empirically
+highlight the effectiveness of our framework in both reasoning performance and
+consistency.
+
+
+
+ 2. 标题:CSPRD: A Financial Policy Retrieval Dataset for Chinese Stock Market
+ 编号:[30]
+ 链接:https://arxiv.org/abs/2309.04389
+ 作者:Jinyuan Wang, Hai Zhao, Zhong Wang, Zeyang Zhu, Jinhao Xie, Yong Yu, Yongjian Fei, Yue Huang, Dawei Cheng
+ 备注:
+ 关键词:sparked considerable research, considerable research focus, achieved promising performance, pre-trained language models, retrieving relative passages
+
+ 点击查看摘要
+ In recent years, great advances in pre-trained language models (PLMs) have
+sparked considerable research focus and achieved promising performance on the
+approach of dense passage retrieval, which aims at retrieving relative passages
+from massive corpus with given questions. However, most of existing datasets
+mainly benchmark the models with factoid queries of general commonsense, while
+specialised fields such as finance and economics remain unexplored due to the
+deficiency of large-scale and high-quality datasets with expert annotations. In
+this work, we propose a new task, policy retrieval, by introducing the Chinese
+Stock Policy Retrieval Dataset (CSPRD), which provides 700+ prospectus passages
+labeled by experienced experts with relevant articles from 10k+ entries in our
+collected Chinese policy corpus. Experiments on lexical, embedding and
+fine-tuned bi-encoder models show the effectiveness of our proposed CSPRD yet
+also suggests ample potential for improvement. Our best performing baseline
+achieves 56.1% MRR@10, 28.5% NDCG@10, 37.5% Recall@10 and 80.6% Precision@10 on
+dev set.
+
+
+
+ 3. 标题:MoEController: Instruction-based Arbitrary Image Manipulation with Mixture-of-Expert Controllers
+ 编号:[36]
+ 链接:https://arxiv.org/abs/2309.04372
+ 作者:Sijia Li, Chen Chen, Haonan Lu
+ 备注:5 pages,6 figures
+ 关键词:image manipulation tasks, producing fascinating results, made astounding progress, recently made astounding, manipulation tasks
+
+ 点击查看摘要
+ Diffusion-model-based text-guided image generation has recently made
+astounding progress, producing fascinating results in open-domain image
+manipulation tasks. Few models, however, currently have complete zero-shot
+capabilities for both global and local image editing due to the complexity and
+diversity of image manipulation tasks. In this work, we propose a method with a
+mixture-of-expert (MOE) controllers to align the text-guided capacity of
+diffusion models with different kinds of human instructions, enabling our model
+to handle various open-domain image manipulation tasks with natural language
+instructions. First, we use large language models (ChatGPT) and conditional
+image synthesis models (ControlNet) to generate a large number of global image
+transfer dataset in addition to the instruction-based local image editing
+dataset. Then, using an MOE technique and task-specific adaptation training on
+a large-scale dataset, our conditional diffusion model can edit images globally
+and locally. Extensive experiments demonstrate that our approach performs
+surprisingly well on various image manipulation tasks when dealing with
+open-domain images and arbitrary human instructions. Please refer to our
+project page: [this https URL]
+
+
+
+ 4. 标题:Beyond Static Datasets: A Deep Interaction Approach to LLM Evaluation
+ 编号:[38]
+ 链接:https://arxiv.org/abs/2309.04369
+ 作者:Jiatong Li, Rui Li, Qi Liu
+ 备注:
+ 关键词:Large Language Models, Language Models, Large Language, LLMs, LLM evaluation methods
+
+ 点击查看摘要
+ Large Language Models (LLMs) have made progress in various real-world tasks,
+which stimulates requirements for the evaluation of LLMs. Existing LLM
+evaluation methods are mainly supervised signal-based which depends on static
+datasets and cannot evaluate the ability of LLMs in dynamic real-world
+scenarios where deep interaction widely exists. Other LLM evaluation methods
+are human-based which are costly and time-consuming and are incapable of
+large-scale evaluation of LLMs. To address the issues above, we propose a novel
+Deep Interaction-based LLM-evaluation framework. In our proposed framework,
+LLMs' performances in real-world domains can be evaluated from their deep
+interaction with other LLMs in elaborately designed evaluation tasks.
+Furthermore, our proposed framework is a general evaluation method that can be
+applied to a host of real-world tasks such as machine translation and code
+generation. We demonstrate the effectiveness of our proposed method through
+extensive experiments on four elaborately designed evaluation tasks.
+
+
+
+ 5. 标题:Encoding Multi-Domain Scientific Papers by Ensembling Multiple CLS Tokens
+ 编号:[55]
+ 链接:https://arxiv.org/abs/2309.04333
+ 作者:Ronald Seoh, Haw-Shiuan Chang, Andrew McCallum
+ 备注:
+ 关键词:multiple CLS tokens, Transformer single CLS, involve corpora, multiple scientific domains, topic classification
+
+ 点击查看摘要
+ Many useful tasks on scientific documents, such as topic classification and
+citation prediction, involve corpora that span multiple scientific domains.
+Typically, such tasks are accomplished by representing the text with a vector
+embedding obtained from a Transformer's single CLS token. In this paper, we
+argue that using multiple CLS tokens could make a Transformer better specialize
+to multiple scientific domains. We present Multi2SPE: it encourages each of
+multiple CLS tokens to learn diverse ways of aggregating token embeddings, then
+sums them up together to create a single vector representation. We also propose
+our new multi-domain benchmark, Multi-SciDocs, to test scientific paper vector
+encoders under multi-domain settings. We show that Multi2SPE reduces error by
+up to 25 percent in multi-domain citation prediction, while requiring only a
+negligible amount of computation in addition to one BERT forward pass.
+
+
+
+ 6. 标题:Fuzzy Fingerprinting Transformer Language-Models for Emotion Recognition in Conversations
+ 编号:[70]
+ 链接:https://arxiv.org/abs/2309.04292
+ 作者:Patrícia Pereira, Rui Ribeiro, Helena Moniz, Luisa Coheur, Joao Paulo Carvalho
+ 备注:FUZZ-IEEE 2023
+ 关键词:text classification technique, largely surpassed, surpassed in performance, Large Language Models-based, Large Pre-trained Language
+
+ 点击查看摘要
+ Fuzzy Fingerprints have been successfully used as an interpretable text
+classification technique, but, like most other techniques, have been largely
+surpassed in performance by Large Pre-trained Language Models, such as BERT or
+RoBERTa. These models deliver state-of-the-art results in several Natural
+Language Processing tasks, namely Emotion Recognition in Conversations (ERC),
+but suffer from the lack of interpretability and explainability. In this paper,
+we propose to combine the two approaches to perform ERC, as a means to obtain
+simpler and more interpretable Large Language Models-based classifiers. We
+propose to feed the utterances and their previous conversational turns to a
+pre-trained RoBERTa, obtaining contextual embedding utterance representations,
+that are then supplied to an adapted Fuzzy Fingerprint classification module.
+We validate our approach on the widely used DailyDialog ERC benchmark dataset,
+in which we obtain state-of-the-art level results using a much lighter model.
+
+
+
+ 7. 标题:From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting
+ 编号:[77]
+ 链接:https://arxiv.org/abs/2309.04269
+ 作者:Griffin Adams, Alexander Fabbri, Faisal Ladhak, Eric Lehman, Noémie Elhadad
+ 备注:preprint
+ 关键词:difficult task, amount of information, information to include, Chain of Density, summaries
+
+ 点击查看摘要
+ Selecting the ``right'' amount of information to include in a summary is a
+difficult task. A good summary should be detailed and entity-centric without
+being overly dense and hard to follow. To better understand this tradeoff, we
+solicit increasingly dense GPT-4 summaries with what we refer to as a ``Chain
+of Density'' (CoD) prompt. Specifically, GPT-4 generates an initial
+entity-sparse summary before iteratively incorporating missing salient entities
+without increasing the length. Summaries generated by CoD are more abstractive,
+exhibit more fusion, and have less of a lead bias than GPT-4 summaries
+generated by a vanilla prompt. We conduct a human preference study on 100 CNN
+DailyMail articles and find that that humans prefer GPT-4 summaries that are
+more dense than those generated by a vanilla prompt and almost as dense as
+human written summaries. Qualitative analysis supports the notion that there
+exists a tradeoff between informativeness and readability. 500 annotated CoD
+summaries, as well as an extra 5,000 unannotated summaries, are freely
+available on HuggingFace
+(this https URL).
+
+
+
+ 8. 标题:UQ at #SMM4H 2023: ALEX for Public Health Analysis with Social Media
+ 编号:[98]
+ 链接:https://arxiv.org/abs/2309.04213
+ 作者:Yan Jiang, Ruihong Qiu, Yi Zhang, Zi Huang
+ 备注:
+ 关键词:public health emerge, public health, public health analysis, activities related, health
+
+ 点击查看摘要
+ As social media becomes increasingly popular, more and more activities
+related to public health emerge. Current techniques for public health analysis
+involve popular models such as BERT and large language models (LLMs). However,
+the costs of training in-domain LLMs for public health are especially
+expensive. Furthermore, such kinds of in-domain datasets from social media are
+generally imbalanced. To tackle these challenges, the data imbalance issue can
+be overcome by data augmentation and balanced training. Moreover, the ability
+of the LLMs can be effectively utilized by prompting the model properly. In
+this paper, a novel ALEX framework is proposed to improve the performance of
+public health analysis on social media by adopting an LLMs explanation
+mechanism. Results show that our ALEX model got the best performance among all
+submissions in both Task 2 and Task 4 with a high score in Task 1 in Social
+Media Mining for Health 2023 (SMM4H)[1]. Our code has been released at https://
+this http URL.
+
+
+
+ 9. 标题:The CALLA Dataset: Probing LLMs' Interactive Knowledge Acquisition from Chinese Medical Literature
+ 编号:[104]
+ 链接:https://arxiv.org/abs/2309.04198
+ 作者:Yanrui Du, Sendong Zhao, Yuhan Chen, Rai Bai, Jing Liu, Hua Wu, Haifeng Wang, Bing Qin
+ 备注:
+ 关键词:Large Language Models, Language Models, Large Language, medical knowledge, medical
+
+ 点击查看摘要
+ The application of Large Language Models (LLMs) to the medical domain has
+stimulated the interest of researchers. Recent studies have focused on
+constructing Instruction Fine-Tuning (IFT) data through medical knowledge
+graphs to enrich the interactive medical knowledge of LLMs. However, the
+medical literature serving as a rich source of medical knowledge remains
+unexplored. Our work introduces the CALLA dataset to probe LLMs' interactive
+knowledge acquisition from Chinese medical literature. It assesses the
+proficiency of LLMs in mastering medical knowledge through a free-dialogue
+fact-checking task. We identify a phenomenon called the ``fact-following
+response``, where LLMs tend to affirm facts mentioned in questions and display
+a reluctance to challenge them. To eliminate the inaccurate evaluation caused
+by this phenomenon, for the golden fact, we artificially construct test data
+from two perspectives: one consistent with the fact and one inconsistent with
+the fact. Drawing from the probing experiment on the CALLA dataset, we conclude
+that IFT data highly correlated with the medical literature corpus serves as a
+potent catalyst for LLMs, enabling themselves to skillfully employ the medical
+knowledge acquired during the pre-training phase within interactive scenarios,
+enhancing accuracy. Furthermore, we design a framework for automatically
+constructing IFT data based on medical literature and discuss some real-world
+applications.
+
+
+
+ 10. 标题:Knowledge-tuning Large Language Models with Structured Medical Knowledge Bases for Reliable Response Generation in Chinese
+ 编号:[116]
+ 链接:https://arxiv.org/abs/2309.04175
+ 作者:Haochun Wang, Sendong Zhao, Zewen Qiang, Zijian Li, Nuwa Xi, Yanrui Du, MuZhen Cai, Haoqiang Guo, Yuhan Chen, Haoming Xu, Bing Qin, Ting Liu
+ 备注:11 pages, 5 figures
+ 关键词:Large Language Models, natural language processing, diverse natural language, Language Models, demonstrated remarkable success
+
+ 点击查看摘要
+ Large Language Models (LLMs) have demonstrated remarkable success in diverse
+natural language processing (NLP) tasks in general domains. However, LLMs
+sometimes generate responses with the hallucination about medical facts due to
+limited domain knowledge. Such shortcomings pose potential risks in the
+utilization of LLMs within medical contexts. To address this challenge, we
+propose knowledge-tuning, which leverages structured medical knowledge bases
+for the LLMs to grasp domain knowledge efficiently and facilitate reliable
+response generation. We also release cMedKnowQA, a Chinese medical knowledge
+question-answering dataset constructed from medical knowledge bases to assess
+the medical knowledge proficiency of LLMs. Experimental results show that the
+LLMs which are knowledge-tuned with cMedKnowQA, can exhibit higher levels of
+accuracy in response generation compared with vanilla instruction-tuning and
+offer a new reliable way for the domain adaptation of LLMs.
+
+
+
+ 11. 标题:Manifold-based Verbalizer Space Re-embedding for Tuning-free Prompt-based Classification
+ 编号:[117]
+ 链接:https://arxiv.org/abs/2309.04174
+ 作者:Haochun Wang, Sendong Zhao, Chi Liu, Nuwa Xi, Muzhen Cai, Bing Qin, Ting Liu
+ 备注:11 pages, 3 figures
+ 关键词:cloze question format, question format utilizing, classification adapts tasks, filled tokens, adapts tasks
+
+ 点击查看摘要
+ Prompt-based classification adapts tasks to a cloze question format utilizing
+the [MASK] token and the filled tokens are then mapped to labels through
+pre-defined verbalizers. Recent studies have explored the use of verbalizer
+embeddings to reduce labor in this process. However, all existing studies
+require a tuning process for either the pre-trained models or additional
+trainable embeddings. Meanwhile, the distance between high-dimensional
+verbalizer embeddings should not be measured by Euclidean distance due to the
+potential for non-linear manifolds in the representation space. In this study,
+we propose a tuning-free manifold-based space re-embedding method called
+Locally Linear Embedding with Intra-class Neighborhood Constraint (LLE-INC) for
+verbalizer embeddings, which preserves local properties within the same class
+as guidance for classification. Experimental results indicate that even without
+tuning any parameters, our LLE-INC is on par with automated verbalizers with
+parameter tuning. And with the parameter updating, our approach further
+enhances prompt-based tuning by up to 3.2%. Furthermore, experiments with the
+LLaMA-7B&13B indicate that LLE-INC is an efficient tuning-free classification
+approach for the hyper-scale language models.
+
+
+
+ 12. 标题:GLS-CSC: A Simple but Effective Strategy to Mitigate Chinese STM Models' Over-Reliance on Superficial Clue
+ 编号:[121]
+ 链接:https://arxiv.org/abs/2309.04162
+ 作者:Yanrui Du, Sendong Zhao, Yuhan Chen, Rai Bai, Jing Liu, Hua Wu, Haifeng Wang, Bing Qin
+ 备注:
+ 关键词:Short Text Matching, Chinese Short Text, Text Matching, Chinese Short, Short Text
+
+ 点击查看摘要
+ Pre-trained models have achieved success in Chinese Short Text Matching (STM)
+tasks, but they often rely on superficial clues, leading to a lack of robust
+predictions. To address this issue, it is crucial to analyze and mitigate the
+influence of superficial clues on STM models. Our study aims to investigate
+their over-reliance on the edit distance feature, commonly used to measure the
+semantic similarity of Chinese text pairs, which can be considered a
+superficial clue. To mitigate STM models' over-reliance on superficial clues,
+we propose a novel resampling training strategy called Gradually Learn Samples
+Containing Superficial Clue (GLS-CSC). Through comprehensive evaluations of
+In-Domain (I.D.), Robustness (Rob.), and Out-Of-Domain (O.O.D.) test sets, we
+demonstrate that GLS-CSC outperforms existing methods in terms of enhancing the
+robustness and generalization of Chinese STM models. Moreover, we conduct a
+detailed analysis of existing methods and reveal their commonality.
+
+
+
+ 13. 标题:Cross-Utterance Conditioned VAE for Speech Generation
+ 编号:[125]
+ 链接:https://arxiv.org/abs/2309.04156
+ 作者:Yang Li, Cheng Yu, Guangzhi Sun, Weiqin Zu, Zheng Tian, Ying Wen, Wei Pan, Chao Zhang, Jun Wang, Yang Yang, Fanglei Sun
+ 备注:13 pages;
+ 关键词:neural networks hold, networks hold promise, frequently face issues, synthesis systems powered, multimedia production
+
+ 点击查看摘要
+ Speech synthesis systems powered by neural networks hold promise for
+multimedia production, but frequently face issues with producing expressive
+speech and seamless editing. In response, we present the Cross-Utterance
+Conditioned Variational Autoencoder speech synthesis (CUC-VAE S2) framework to
+enhance prosody and ensure natural speech generation. This framework leverages
+the powerful representational capabilities of pre-trained language models and
+the re-expression abilities of variational autoencoders (VAEs). The core
+component of the CUC-VAE S2 framework is the cross-utterance CVAE, which
+extracts acoustic, speaker, and textual features from surrounding sentences to
+generate context-sensitive prosodic features, more accurately emulating human
+prosody generation. We further propose two practical algorithms tailored for
+distinct speech synthesis applications: CUC-VAE TTS for text-to-speech and
+CUC-VAE SE for speech editing. The CUC-VAE TTS is a direct application of the
+framework, designed to generate audio with contextual prosody derived from
+surrounding texts. On the other hand, the CUC-VAE SE algorithm leverages real
+mel spectrogram sampling conditioned on contextual information, producing audio
+that closely mirrors real sound and thereby facilitating flexible speech
+editing based on text such as deletion, insertion, and replacement.
+Experimental results on the LibriTTS datasets demonstrate that our proposed
+models significantly enhance speech synthesis and editing, producing more
+natural and expressive speech.
+
+
+
+ 14. 标题:NESTLE: a No-Code Tool for Statistical Analysis of Legal Corpus
+ 编号:[131]
+ 链接:https://arxiv.org/abs/2309.04146
+ 作者:Kyoungyeon Cho, Seungkum Han, Wonseok Hwang
+ 备注:
+ 关键词:statistical analysis, system, NESTLE, analysis, provide valuable legal
+
+ 点击查看摘要
+ The statistical analysis of large scale legal corpus can provide valuable
+legal insights. For such analysis one needs to (1) select a subset of the
+corpus using document retrieval tools, (2) structuralize text using information
+extraction (IE) systems, and (3) visualize the data for the statistical
+analysis. Each process demands either specialized tools or programming skills
+whereas no comprehensive unified "no-code" tools have been available.
+Especially for IE, if the target information is not predefined in the ontology
+of the IE system, one needs to build their own system. Here we provide NESTLE,
+a no code tool for large-scale statistical analysis of legal corpus. With
+NESTLE, users can search target documents, extract information, and visualize
+the structured data all via the chat interface with accompanying auxiliary GUI
+for the fine-level control. NESTLE consists of three main components: a search
+engine, an end-to-end IE system, and a Large Language Model (LLM) that glues
+the whole components together and provides the chat interface. Powered by LLM
+and the end-to-end IE system, NESTLE can extract any type of information that
+has not been predefined in the IE system opening up the possibility of
+unlimited customizable statistical analysis of the corpus without writing a
+single line of code. The use of the custom end-to-end IE system also enables
+faster and low-cost IE on large scale corpus. We validate our system on 15
+Korean precedent IE tasks and 3 legal text classification tasks from LEXGLUE.
+The comprehensive experiments reveal NESTLE can achieve GPT-4 comparable
+performance by training the internal IE module with 4 human-labeled, and 192
+LLM-labeled examples. The detailed analysis provides the insight on the
+trade-off between accuracy, time, and cost in building such system.
+
+
+
+ 15. 标题:RST-style Discourse Parsing Guided by Document-level Content Structures
+ 编号:[134]
+ 链接:https://arxiv.org/abs/2309.04141
+ 作者:Ming Li, Ruihong Huang
+ 备注:
+ 关键词:Structure Theory based, Theory based Discourse, Rhetorical Structure Theory, large text spans, Theory based
+
+ 点击查看摘要
+ Rhetorical Structure Theory based Discourse Parsing (RST-DP) explores how
+clauses, sentences, and large text spans compose a whole discourse and presents
+the rhetorical structure as a hierarchical tree. Existing RST parsing pipelines
+construct rhetorical structures without the knowledge of document-level content
+structures, which causes relatively low performance when predicting the
+discourse relations for large text spans. Recognizing the value of high-level
+content-related information in facilitating discourse relation recognition, we
+propose a novel pipeline for RST-DP that incorporates structure-aware news
+content sentence representations derived from the task of News Discourse
+Profiling. By incorporating only a few additional layers, this enhanced
+pipeline exhibits promising performance across various RST parsing metrics.
+
+
+
+ 16. 标题:Meta predictive learning model of natural languages
+ 编号:[142]
+ 链接:https://arxiv.org/abs/2309.04106
+ 作者:Chan Li, Junbin Qiu, Haiping Huang
+ 备注:23 pages, 6 figures, codes are available in the main text with the link
+ 关键词:Large language models, achieved astonishing performances, language models based, Large language, based on self-attention
+
+ 点击查看摘要
+ Large language models based on self-attention mechanisms have achieved
+astonishing performances not only in natural language itself, but also in a
+variety of tasks of different nature. However, regarding processing language,
+our human brain may not operate using the same principle. Then, a debate is
+established on the connection between brain computation and artificial
+self-supervision adopted in large language models. One of most influential
+hypothesis in brain computation is the predictive coding framework, which
+proposes to minimize the prediction error by local learning. However, the role
+of predictive coding and the associated credit assignment in language
+processing remains unknown. Here, we propose a mean-field learning model within
+the predictive coding framework, assuming that the synaptic weight of each
+connection follows a spike and slab distribution, and only the distribution is
+trained. This meta predictive learning is successfully validated on classifying
+handwritten digits where pixels are input to the network in sequence, and on
+the toy and real language corpus. Our model reveals that most of the
+connections become deterministic after learning, while the output connections
+have a higher level of variability. The performance of the resulting network
+ensemble changes continuously with data load, further improving with more
+training data, in analogy with the emergent behavior of large language models.
+Therefore, our model provides a starting point to investigate the physics and
+biology correspondences of the language processing and the unexpected general
+intelligence.
+
+
+
+ 17. 标题:Unsupervised Multi-document Summarization with Holistic Inference
+ 编号:[146]
+ 链接:https://arxiv.org/abs/2309.04087
+ 作者:Haopeng Zhang, Sangwoo Cho, Kaiqiang Song, Xiaoyang Wang, Hongwei Wang, Jiawei Zhang, Dong Yu
+ 备注:Findings of IJCNLP-AACL 2023
+ 关键词:obtain core information, Multi-document summarization aims, Subset Representative Index, aims to obtain, obtain core
+
+ 点击查看摘要
+ Multi-document summarization aims to obtain core information from a
+collection of documents written on the same topic. This paper proposes a new
+holistic framework for unsupervised multi-document extractive summarization.
+Our method incorporates the holistic beam search inference method associated
+with the holistic measurements, named Subset Representative Index (SRI). SRI
+balances the importance and diversity of a subset of sentences from the source
+documents and can be calculated in unsupervised and adaptive manners. To
+demonstrate the effectiveness of our method, we conduct extensive experiments
+on both small and large-scale multi-document summarization datasets under both
+unsupervised and adaptive settings. The proposed method outperforms strong
+baselines by a significant margin, as indicated by the resulting ROUGE scores
+and diversity measures. Our findings also suggest that diversity is essential
+for improving multi-document summary performance.
+
+
+
+ 18. 标题:Evaluation and Mitigation of Agnosia in Multimodal Large Language Models
+ 编号:[162]
+ 链接:https://arxiv.org/abs/2309.04041
+ 作者:Jiaying Lu, Jinmeng Rao, Kezhen Chen, Xiaoyuan Guo, Yawen Zhang, Baochen Sun, Carl Yang, Jie Yang
+ 备注:
+ 关键词:Large Language Models, Multimodal Large Language, Language Models, Large Language, Multimodal Large
+
+ 点击查看摘要
+ While Multimodal Large Language Models (MLLMs) are widely used for a variety
+of vision-language tasks, one observation is that they sometimes misinterpret
+visual inputs or fail to follow textual instructions even in straightforward
+cases, leading to irrelevant responses, mistakes, and ungrounded claims. This
+observation is analogous to a phenomenon in neuropsychology known as Agnosia,
+an inability to correctly process sensory modalities and recognize things
+(e.g., objects, colors, relations). In our study, we adapt this similar concept
+to define "agnosia in MLLMs", and our goal is to comprehensively evaluate and
+mitigate such agnosia in MLLMs. Inspired by the diagnosis and treatment process
+in neuropsychology, we propose a novel framework EMMA (Evaluation and
+Mitigation of Multimodal Agnosia). In EMMA, we develop an evaluation module
+that automatically creates fine-grained and diverse visual question answering
+examples to assess the extent of agnosia in MLLMs comprehensively. We also
+develop a mitigation module to reduce agnosia in MLLMs through multimodal
+instruction tuning on fine-grained conversations. To verify the effectiveness
+of our framework, we evaluate and analyze agnosia in seven state-of-the-art
+MLLMs using 9K test samples. The results reveal that most of them exhibit
+agnosia across various aspects and degrees. We further develop a fine-grained
+instruction set and tune MLLMs to mitigate agnosia, which led to notable
+improvement in accuracy.
+
+
+
+ 19. 标题:Multiple Representation Transfer from Large Language Models to End-to-End ASR Systems
+ 编号:[167]
+ 链接:https://arxiv.org/abs/2309.04031
+ 作者:Takuma Udagawa, Masayuki Suzuki, Gakuto Kurata, Masayasu Muraoka, George Saon
+ 备注:Submitted to ICASSP 2024
+ 关键词:automatic speech recognition, incorporate linguistic knowledge, large language models, automatic speech, speech recognition
+
+ 点击查看摘要
+ Transferring the knowledge of large language models (LLMs) is a promising
+technique to incorporate linguistic knowledge into end-to-end automatic speech
+recognition (ASR) systems. However, existing works only transfer a single
+representation of LLM (e.g. the last layer of pretrained BERT), while the
+representation of a text is inherently non-unique and can be obtained variously
+from different layers, contexts and models. In this work, we explore a wide
+range of techniques to obtain and transfer multiple representations of LLMs
+into a transducer-based ASR system. While being conceptually simple, we show
+that transferring multiple representations of LLMs can be an effective
+alternative to transferring only a single representation.
+
+
+
+ 20. 标题:TIDE: Textual Identity Detection for Evaluating and Augmenting Classification and Language Models
+ 编号:[169]
+ 链接:https://arxiv.org/abs/2309.04027
+ 作者:Emmanuel Klu, Sameer Sethi
+ 备注:Preprint
+ 关键词:perpetuate unintended biases, Machine learning models, Machine learning, perpetuate unintended, unintended biases
+
+ 点击查看摘要
+ Machine learning models can perpetuate unintended biases from unfair and
+imbalanced datasets. Evaluating and debiasing these datasets and models is
+especially hard in text datasets where sensitive attributes such as race,
+gender, and sexual orientation may not be available. When these models are
+deployed into society, they can lead to unfair outcomes for historically
+underrepresented groups. In this paper, we present a dataset coupled with an
+approach to improve text fairness in classifiers and language models. We create
+a new, more comprehensive identity lexicon, TIDAL, which includes 15,123
+identity terms and associated sense context across three demographic
+categories. We leverage TIDAL to develop an identity annotation and
+augmentation tool that can be used to improve the availability of identity
+context and the effectiveness of ML fairness techniques. We evaluate our
+approaches using human contributors, and additionally run experiments focused
+on dataset and model debiasing. Results show our assistive annotation technique
+improves the reliability and velocity of human-in-the-loop processes. Our
+dataset and methods uncover more disparities during evaluation, and also
+produce more fair models during remediation. These approaches provide a
+practical path forward for scaling classifier and generative model fairness in
+real-world settings.
+
+
+
+ 21. 标题:ConDA: Contrastive Domain Adaptation for AI-generated Text Detection
+ 编号:[180]
+ 链接:https://arxiv.org/abs/2309.03992
+ 作者:Amrita Bhattacharjee, Tharindu Kumarage, Raha Moraffah, Huan Liu
+ 备注:Accepted at IJCNLP-AACL 2023 main track
+ 关键词:Large language models, Large language, language models, including journalistic, journalistic news articles
+
+ 点击查看摘要
+ Large language models (LLMs) are increasingly being used for generating text
+in a variety of use cases, including journalistic news articles. Given the
+potential malicious nature in which these LLMs can be used to generate
+disinformation at scale, it is important to build effective detectors for such
+AI-generated text. Given the surge in development of new LLMs, acquiring
+labeled training data for supervised detectors is a bottleneck. However, there
+might be plenty of unlabeled text data available, without information on which
+generator it came from. In this work we tackle this data problem, in detecting
+AI-generated news text, and frame the problem as an unsupervised domain
+adaptation task. Here the domains are the different text generators, i.e. LLMs,
+and we assume we have access to only the labeled source data and unlabeled
+target data. We develop a Contrastive Domain Adaptation framework, called
+ConDA, that blends standard domain adaptation techniques with the
+representation power of contrastive learning to learn domain invariant
+representations that are effective for the final unsupervised detection task.
+Our experiments demonstrate the effectiveness of our framework, resulting in
+average performance gains of 31.7% from the best performing baselines, and
+within 0.8% margin of a fully supervised detector. All our code and data is
+available at this https URL.
+
+
+
+ 22. 标题:LanSER: Language-Model Supported Speech Emotion Recognition
+ 编号:[185]
+ 链接:https://arxiv.org/abs/2309.03978
+ 作者:Taesik Gong, Josh Belanich, Krishna Somandepalli, Arsha Nagrani, Brian Eoff, Brendan Jou
+ 备注:Presented at INTERSPEECH 2023
+ 关键词:making scaling methods, emotion taxonomies difficult, costly human-labeled data, nuanced emotion taxonomies, making scaling
+
+ 点击查看摘要
+ Speech emotion recognition (SER) models typically rely on costly
+human-labeled data for training, making scaling methods to large speech
+datasets and nuanced emotion taxonomies difficult. We present LanSER, a method
+that enables the use of unlabeled data by inferring weak emotion labels via
+pre-trained large language models through weakly-supervised learning. For
+inferring weak labels constrained to a taxonomy, we use a textual entailment
+approach that selects an emotion label with the highest entailment score for a
+speech transcript extracted via automatic speech recognition. Our experimental
+results show that models pre-trained on large datasets with this weak
+supervision outperform other baseline models on standard SER datasets when
+fine-tuned, and show improved label efficiency. Despite being pre-trained on
+labels derived only from text, we show that the resulting representations
+appear to model the prosodic content of speech.
+
+
+
+ 23. 标题:Evaluation of large language models for discovery of gene set function
+ 编号:[221]
+ 链接:https://arxiv.org/abs/2309.04019
+ 作者:Mengzhou Hu, Sahar Alkhairy, Ingoo Lee, Rudolf T. Pillich, Robin Bachelder, Trey Ideker, Dexter Pratt
+ 备注:
+ 关键词:manually curated databases, Gene, biological context, relies on manually, manually curated
+
+ 点击查看摘要
+ Gene set analysis is a mainstay of functional genomics, but it relies on
+manually curated databases of gene functions that are incomplete and unaware of
+biological context. Here we evaluate the ability of OpenAI's GPT-4, a Large
+Language Model (LLM), to develop hypotheses about common gene functions from
+its embedded biomedical knowledge. We created a GPT-4 pipeline to label gene
+sets with names that summarize their consensus functions, substantiated by
+analysis text and citations. Benchmarking against named gene sets in the Gene
+Ontology, GPT-4 generated very similar names in 50% of cases, while in most
+remaining cases it recovered the name of a more general concept. In gene sets
+discovered in 'omics data, GPT-4 names were more informative than gene set
+enrichment, with supporting statements and citations that largely verified in
+human review. The ability to rapidly synthesize common gene functions positions
+LLMs as valuable functional genomics assistants.
+
+
+机器学习
+
+ 1. 标题:On the Actionability of Outcome Prediction
+ 编号:[1]
+ 链接:https://arxiv.org/abs/2309.04470
+ 作者:Lydia T. Liu, Solon Barocas, Jon Kleinberg, Karen Levy
+ 备注:14 pages, 3 figures
+ 关键词:social impact domains, Predicting future outcomes, prevalent application, application of machine, machine learning
+
+ 点击查看摘要
+ Predicting future outcomes is a prevalent application of machine learning in
+social impact domains. Examples range from predicting student success in
+education to predicting disease risk in healthcare. Practitioners recognize
+that the ultimate goal is not just to predict but to act effectively.
+Increasing evidence suggests that relying on outcome predictions for downstream
+interventions may not have desired results.
+In most domains there exists a multitude of possible interventions for each
+individual, making the challenge of taking effective action more acute. Even
+when causal mechanisms connecting the individual's latent states to outcomes is
+well understood, in any given instance (a specific student or patient),
+practitioners still need to infer -- from budgeted measurements of latent
+states -- which of many possible interventions will be most effective for this
+individual. With this in mind, we ask: when are accurate predictors of outcomes
+helpful for identifying the most suitable intervention?
+Through a simple model encompassing actions, latent states, and measurements,
+we demonstrate that pure outcome prediction rarely results in the most
+effective policy for taking actions, even when combined with other
+measurements. We find that except in cases where there is a single decisive
+action for improving the outcome, outcome prediction never maximizes "action
+value", the utility of taking actions. Making measurements of actionable latent
+states, where specific actions lead to desired outcomes, considerably enhances
+the action value compared to outcome prediction, and the degree of improvement
+depends on action costs and the outcome model. This analysis emphasizes the
+need to go beyond generic outcome prediction in interventional settings by
+incorporating knowledge of plausible actions and latent states.
+
+
+
+ 2. 标题:Measuring and Improving Chain-of-Thought Reasoning in Vision-Language Models
+ 编号:[5]
+ 链接:https://arxiv.org/abs/2309.04461
+ 作者:Yangyi Chen, Karan Sikka, Michael Cogswell, Heng Ji, Ajay Divakaran
+ 备注:The data is released at \url{this https URL}
+ 关键词:parse natural queries, generate human-like outputs, recently demonstrated strong, demonstrated strong efficacy, reasoning
+
+ 点击查看摘要
+ Vision-language models (VLMs) have recently demonstrated strong efficacy as
+visual assistants that can parse natural queries about the visual content and
+generate human-like outputs. In this work, we explore the ability of these
+models to demonstrate human-like reasoning based on the perceived information.
+To address a crucial concern regarding the extent to which their reasoning
+capabilities are fully consistent and grounded, we also measure the reasoning
+consistency of these models. We achieve this by proposing a chain-of-thought
+(CoT) based consistency measure. However, such an evaluation requires a
+benchmark that encompasses both high-level inference and detailed reasoning
+chains, which is costly. We tackle this challenge by proposing a
+LLM-Human-in-the-Loop pipeline, which notably reduces cost while simultaneously
+ensuring the generation of a high-quality dataset. Based on this pipeline and
+the existing coarse-grained annotated dataset, we build the CURE benchmark to
+measure both the zero-shot reasoning performance and consistency of VLMs. We
+evaluate existing state-of-the-art VLMs, and find that even the best-performing
+model is unable to demonstrate strong visual reasoning capabilities and
+consistency, indicating that substantial efforts are required to enable VLMs to
+perform visual reasoning as systematically and consistently as humans. As an
+early step, we propose a two-stage training framework aimed at improving both
+the reasoning performance and consistency of VLMs. The first stage involves
+employing supervised fine-tuning of VLMs using step-by-step reasoning samples
+automatically generated by LLMs. In the second stage, we further augment the
+training process by incorporating feedback provided by LLMs to produce
+reasoning chains that are highly consistent and grounded. We empirically
+highlight the effectiveness of our framework in both reasoning performance and
+consistency.
+
+
+
+ 3. 标题:Subwords as Skills: Tokenization for Sparse-Reward Reinforcement Learning
+ 编号:[6]
+ 链接:https://arxiv.org/abs/2309.04459
+ 作者:David Yunis, Justin Jung, Falcon Dai, Matthew Walter
+ 备注:
+ 关键词:continuous action spaces, requirement of long, coordinated sequences, achieve any reward, difficult due
+
+ 点击查看摘要
+ Exploration in sparse-reward reinforcement learning is difficult due to the
+requirement of long, coordinated sequences of actions in order to achieve any
+reward. Moreover, in continuous action spaces there are an infinite number of
+possible actions, which only increases the difficulty of exploration. One class
+of methods designed to address these issues forms temporally extended actions,
+often called skills, from interaction data collected in the same domain, and
+optimizes a policy on top of this new action space. Typically such methods
+require a lengthy pretraining phase, especially in continuous action spaces, in
+order to form the skills before reinforcement learning can begin. Given prior
+evidence that the full range of the continuous action space is not required in
+such tasks, we propose a novel approach to skill-generation with two
+components. First we discretize the action space through clustering, and second
+we leverage a tokenization technique borrowed from natural language processing
+to generate temporally extended actions. Such a method outperforms baselines
+for skill-generation in several challenging sparse-reward domains, and requires
+orders-of-magnitude less computation in skill-generation and online rollouts.
+
+
+
+ 4. 标题:Variations and Relaxations of Normalizing Flows
+ 编号:[13]
+ 链接:https://arxiv.org/abs/2309.04433
+ 作者:Keegan Kelly, Lorena Piedras, Sukrit Rao, David Roth
+ 备注:
+ 关键词:simpler base distribution, Normalizing Flows, describe a class, series of bijective, simpler base
+
+ 点击查看摘要
+ Normalizing Flows (NFs) describe a class of models that express a complex
+target distribution as the composition of a series of bijective transformations
+over a simpler base distribution. By limiting the space of candidate
+transformations to diffeomorphisms, NFs enjoy efficient, exact sampling and
+density evaluation, enabling NFs to flexibly behave as both discriminative and
+generative models. Their restriction to diffeomorphisms, however, enforces that
+input, output and all intermediary spaces share the same dimension, limiting
+their ability to effectively represent target distributions with complex
+topologies. Additionally, in cases where the prior and target distributions are
+not homeomorphic, Normalizing Flows can leak mass outside of the support of the
+target. This survey covers a selection of recent works that combine aspects of
+other generative model classes, such as VAEs and score-based diffusion, and in
+doing so loosen the strict bijectivity constraints of NFs to achieve a balance
+of expressivity, training speed, sample efficiency and likelihood tractability.
+
+
+
+ 5. 标题:Robust Representation Learning for Privacy-Preserving Machine Learning: A Multi-Objective Autoencoder Approach
+ 编号:[17]
+ 链接:https://arxiv.org/abs/2309.04427
+ 作者:Sofiane Ouaari, Ali Burak Ünal, Mete Akgün, Nico Pfeifer
+ 备注:
+ 关键词:domains increasingly rely, privacy-preserving machine learning, domains increasingly, increasingly rely, machine learning
+
+ 点击查看摘要
+ Several domains increasingly rely on machine learning in their applications.
+The resulting heavy dependence on data has led to the emergence of various laws
+and regulations around data ethics and privacy and growing awareness of the
+need for privacy-preserving machine learning (ppML). Current ppML techniques
+utilize methods that are either purely based on cryptography, such as
+homomorphic encryption, or that introduce noise into the input, such as
+differential privacy. The main criticism given to those techniques is the fact
+that they either are too slow or they trade off a model s performance for
+improved confidentiality. To address this performance reduction, we aim to
+leverage robust representation learning as a way of encoding our data while
+optimizing the privacy-utility trade-off. Our method centers on training
+autoencoders in a multi-objective manner and then concatenating the latent and
+learned features from the encoding part as the encoded form of our data. Such a
+deep learning-powered encoding can then safely be sent to a third party for
+intensive training and hyperparameter tuning. With our proposed framework, we
+can share our data and use third party tools without being under the threat of
+revealing its original form. We empirically validate our results on unimodal
+and multimodal settings, the latter following a vertical splitting system and
+show improved performance over state-of-the-art.
+
+
+
+ 6. 标题:Parallel and Limited Data Voice Conversion Using Stochastic Variational Deep Kernel Learning
+ 编号:[22]
+ 链接:https://arxiv.org/abs/2309.04420
+ 作者:Mohamadreza Jafaryani, Hamid Sheikhzadeh, Vahid Pourahmadi
+ 备注:
+ 关键词:data, limited data, training data, limited training data, Gaussian process
+
+ 点击查看摘要
+ Typically, voice conversion is regarded as an engineering problem with
+limited training data. The reliance on massive amounts of data hinders the
+practical applicability of deep learning approaches, which have been
+extensively researched in recent years. On the other hand, statistical methods
+are effective with limited data but have difficulties in modelling complex
+mapping functions. This paper proposes a voice conversion method that works
+with limited data and is based on stochastic variational deep kernel learning
+(SVDKL). At the same time, SVDKL enables the use of deep neural networks'
+expressive capability as well as the high flexibility of the Gaussian process
+as a Bayesian and non-parametric method. When the conventional kernel is
+combined with the deep neural network, it is possible to estimate non-smooth
+and more complex functions. Furthermore, the model's sparse variational
+Gaussian process solves the scalability problem and, unlike the exact Gaussian
+process, allows for the learning of a global mapping function for the entire
+acoustic space. One of the most important aspects of the proposed scheme is
+that the model parameters are trained using marginal likelihood optimization,
+which considers both data fitting and model complexity. Considering the
+complexity of the model reduces the amount of training data by increasing the
+resistance to overfitting. To evaluate the proposed scheme, we examined the
+model's performance with approximately 80 seconds of training data. The results
+indicated that our method obtained a higher mean opinion score, smaller
+spectral distortion, and better preference tests than the compared methods.
+
+
+
+ 7. 标题:Generalization Bounds: Perspectives from Information Theory and PAC-Bayes
+ 编号:[32]
+ 链接:https://arxiv.org/abs/2309.04381
+ 作者:Fredrik Hellström, Giuseppe Durisi, Benjamin Guedj, Maxim Raginsky
+ 备注:222 pages
+ 关键词:machine learning algorithms, theoretical machine learning, machine learning, learning algorithms, fundamental question
+
+ 点击查看摘要
+ A fundamental question in theoretical machine learning is generalization.
+Over the past decades, the PAC-Bayesian approach has been established as a
+flexible framework to address the generalization capabilities of machine
+learning algorithms, and design new ones. Recently, it has garnered increased
+interest due to its potential applicability for a variety of learning
+algorithms, including deep neural networks. In parallel, an
+information-theoretic view of generalization has developed, wherein the
+relation between generalization and various information measures has been
+established. This framework is intimately connected to the PAC-Bayesian
+approach, and a number of results have been independently discovered in both
+strands. In this monograph, we highlight this strong connection and present a
+unified treatment of generalization. We present techniques and results that the
+two perspectives have in common, and discuss the approaches and interpretations
+that differ. In particular, we demonstrate how many proofs in the area share a
+modular structure, through which the underlying ideas can be intuited. We pay
+special attention to the conditional mutual information (CMI) framework;
+analytical studies of the information complexity of learning algorithms; and
+the application of the proposed methods to deep learning. This monograph is
+intended to provide a comprehensive introduction to information-theoretic
+generalization bounds and their connection to PAC-Bayes, serving as a
+foundation from which the most recent developments are accessible. It is aimed
+broadly towards researchers with an interest in generalization and theoretical
+machine learning.
+
+
+
+ 8. 标题:Seeing-Eye Quadruped Navigation with Force Responsive Locomotion Control
+ 编号:[37]
+ 链接:https://arxiv.org/abs/2309.04370
+ 作者:David DeFazio, Eisuke Hirota, Shiqi Zhang
+ 备注:Accepted to CoRL 2023
+ 关键词:visually impaired people, guiding visually impaired, huge societal impact, real guide dogs, impaired people
+
+ 点击查看摘要
+ Seeing-eye robots are very useful tools for guiding visually impaired people,
+potentially producing a huge societal impact given the low availability and
+high cost of real guide dogs. Although a few seeing-eye robot systems have
+already been demonstrated, none considered external tugs from humans, which
+frequently occur in a real guide dog setting. In this paper, we simultaneously
+train a locomotion controller that is robust to external tugging forces via
+Reinforcement Learning (RL), and an external force estimator via supervised
+learning. The controller ensures stable walking, and the force estimator
+enables the robot to respond to the external forces from the human. These
+forces are used to guide the robot to the global goal, which is unknown to the
+robot, while the robot guides the human around nearby obstacles via a local
+planner. Experimental results in simulation and on hardware show that our
+controller is robust to external forces, and our seeing-eye system can
+accurately detect force direction. We demonstrate our full seeing-eye robot
+system on a real quadruped robot with a blindfolded human. The video can be
+seen at our project page: this https URL
+
+
+
+ 9. 标题:Active Learning for Classifying 2D Grid-Based Level Completability
+ 编号:[39]
+ 链接:https://arxiv.org/abs/2309.04367
+ 作者:Mahsa Bazzaz, Seth Cooper
+ 备注:4 pages, 3 figures
+ 关键词:Active learning, Super Mario Bros., procedural generators, solver agents, require a significant
+
+ 点击查看摘要
+ Determining the completability of levels generated by procedural generators
+such as machine learning models can be challenging, as it can involve the use
+of solver agents that often require a significant amount of time to analyze and
+solve levels. Active learning is not yet widely adopted in game evaluations,
+although it has been used successfully in natural language processing, image
+and speech recognition, and computer vision, where the availability of labeled
+data is limited or expensive. In this paper, we propose the use of active
+learning for learning level completability classification. Through an active
+learning approach, we train deep-learning models to classify the completability
+of generated levels for Super Mario Bros., Kid Icarus, and a Zelda-like game.
+We compare active learning for querying levels to label with completability
+against random queries. Our results show using an active learning approach to
+label levels results in better classifier performance with the same amount of
+labeled data.
+
+
+
+ 10. 标题:Learning from Power Signals: An Automated Approach to Electrical Disturbance Identification Within a Power Transmission System
+ 编号:[42]
+ 链接:https://arxiv.org/abs/2309.04361
+ 作者:Jonathan D. Boyd, Joshua H. Tyler, Anthony M. Murphy, Donald R. Reising
+ 备注:18 pages
+ 关键词:electric utility industry, power quality, power quality events, utility industry, continues to grow
+
+ 点击查看摘要
+ As power quality becomes a higher priority in the electric utility industry,
+the amount of disturbance event data continues to grow. Utilities do not have
+the required personnel to analyze each event by hand. This work presents an
+automated approach for analyzing power quality events recorded by digital fault
+recorders and power quality monitors operating within a power transmission
+system. The automated approach leverages rule-based analytics to examine the
+time and frequency domain characteristics of the voltage and current signals.
+Customizable thresholds are set to categorize each disturbance event. The
+events analyzed within this work include various faults, motor starting, and
+incipient instrument transformer failure. Analytics for fourteen different
+event types have been developed. The analytics were tested on 160 signal files
+and yielded an accuracy of ninety-nine percent. Continuous, nominal signal data
+analysis is performed using an approach coined as the cyclic histogram. The
+cyclic histogram process will be integrated into the digital fault recorders
+themselves to facilitate the detection of subtle signal variations that are too
+small to trigger a disturbance event and that can occur over hours or days. In
+addition to reducing memory requirements by a factor of 320, it is anticipated
+that cyclic histogram processing will aid in identifying incipient events and
+identifiers. This project is expected to save engineers time by automating the
+classification of disturbance events and increase the reliability of the
+transmission system by providing near real time detection and identification of
+disturbances as well as prevention of problems before they occur.
+
+
+
+ 11. 标题:Value-Compressed Sparse Column (VCSC): Sparse Matrix Storage for Redundant Data
+ 编号:[44]
+ 链接:https://arxiv.org/abs/2309.04355
+ 作者:Skyler Ruiter, Seth Wolfgang, Marc Tunnell, Timothy Triche Jr., Erin Carrier, Zachary DeBruine
+ 备注:
+ 关键词:Value-Compressed Sparse Column, Sparse Column, Sparse, CSC, Compressed Sparse Column
+
+ 点击查看摘要
+ Compressed Sparse Column (CSC) and Coordinate (COO) are popular compression
+formats for sparse matrices. However, both CSC and COO are general purpose and
+cannot take advantage of any of the properties of the data other than sparsity,
+such as data redundancy. Highly redundant sparse data is common in many machine
+learning applications, such as genomics, and is often too large for in-core
+computation using conventional sparse storage formats. In this paper, we
+present two extensions to CSC: (1) Value-Compressed Sparse Column (VCSC) and
+(2) Index- and Value-Compressed Sparse Column (IVCSC). VCSC takes advantage of
+high redundancy within a column to further compress data up to 3-fold over COO
+and 2.25-fold over CSC, without significant negative impact to performance
+characteristics. IVCSC extends VCSC by compressing index arrays through delta
+encoding and byte-packing, achieving a 10-fold decrease in memory usage over
+COO and 7.5-fold decrease over CSC. Our benchmarks on simulated and real data
+show that VCSC and IVCSC can be read in compressed form with little added
+computational cost. These two novel compression formats offer a broadly useful
+solution to encoding and reading redundant sparse data.
+
+
+
+ 12. 标题:Mobile V-MoEs: Scaling Down Vision Transformers via Sparse Mixture-of-Experts
+ 编号:[45]
+ 链接:https://arxiv.org/abs/2309.04354
+ 作者:Erik Daxberger, Floris Weers, Bowen Zhang, Tom Gunter, Ruoming Pang, Marcin Eichner, Michael Emmersberger, Yinfei Yang, Alexander Toshev, Xianzhi Du
+ 备注:
+ 关键词:recently gained popularity, gained popularity due, decouple model size, input token, recently gained
+
+ 点击查看摘要
+ Sparse Mixture-of-Experts models (MoEs) have recently gained popularity due
+to their ability to decouple model size from inference efficiency by only
+activating a small subset of the model parameters for any given input token. As
+such, sparse MoEs have enabled unprecedented scalability, resulting in
+tremendous successes across domains such as natural language processing and
+computer vision. In this work, we instead explore the use of sparse MoEs to
+scale-down Vision Transformers (ViTs) to make them more attractive for
+resource-constrained vision applications. To this end, we propose a simplified
+and mobile-friendly MoE design where entire images rather than individual
+patches are routed to the experts. We also propose a stable MoE training
+procedure that uses super-class information to guide the router. We empirically
+show that our sparse Mobile Vision MoEs (V-MoEs) can achieve a better trade-off
+between performance and efficiency than the corresponding dense ViTs. For
+example, for the ViT-Tiny model, our Mobile V-MoE outperforms its dense
+counterpart by 3.39% on ImageNet-1k. For an even smaller ViT variant with only
+54M FLOPs inference cost, our MoE achieves an improvement of 4.66%.
+
+
+
+ 13. 标题:Zero-Shot Robustification of Zero-Shot Models With Foundation Models
+ 编号:[51]
+ 链接:https://arxiv.org/abs/2309.04344
+ 作者:Dyah Adila, Changho Shin, Linrong Cai, Frederic Sala
+ 备注:
+ 关键词:powerful paradigm, paradigm that enables, large pretrained models, models, large pretrained
+
+ 点击查看摘要
+ Zero-shot inference is a powerful paradigm that enables the use of large
+pretrained models for downstream classification tasks without further training.
+However, these models are vulnerable to inherited biases that can impact their
+performance. The traditional solution is fine-tuning, but this undermines the
+key advantage of pretrained models, which is their ability to be used
+out-of-the-box. We propose RoboShot, a method that improves the robustness of
+pretrained model embeddings in a fully zero-shot fashion. First, we use
+zero-shot language models (LMs) to obtain useful insights from task
+descriptions. These insights are embedded and used to remove harmful and boost
+useful components in embeddings -- without any supervision. Theoretically, we
+provide a simple and tractable model for biases in zero-shot embeddings and
+give a result characterizing under what conditions our approach can boost
+performance. Empirically, we evaluate RoboShot on nine image and NLP
+classification tasks and show an average improvement of 15.98% over several
+zero-shot baselines. Additionally, we demonstrate that RoboShot is compatible
+with a variety of pretrained and language models.
+
+
+
+ 14. 标题:Online Submodular Maximization via Online Convex Optimization
+ 编号:[53]
+ 链接:https://arxiv.org/abs/2309.04339
+ 作者:T. Si-Salem, G. Özcan, I. Nikolaou, E. Terzi, S. Ioannidis
+ 备注:Under review
+ 关键词:general matroid constraints, study monotone submodular, monotone submodular maximization, study monotone, maximization under general
+
+ 点击查看摘要
+ We study monotone submodular maximization under general matroid constraints
+in the online setting. We prove that online optimization of a large class of
+submodular functions, namely, weighted threshold potential functions, reduces
+to online convex optimization (OCO). This is precisely because functions in
+this class admit a concave relaxation; as a result, OCO policies, coupled with
+an appropriate rounding scheme, can be used to achieve sublinear regret in the
+combinatorial setting. We show that our reduction extends to many different
+versions of the online learning problem, including the dynamic regret, bandit,
+and optimistic-learning settings.
+
+
+
+ 15. 标题:Encoding Multi-Domain Scientific Papers by Ensembling Multiple CLS Tokens
+ 编号:[55]
+ 链接:https://arxiv.org/abs/2309.04333
+ 作者:Ronald Seoh, Haw-Shiuan Chang, Andrew McCallum
+ 备注:
+ 关键词:multiple CLS tokens, Transformer single CLS, involve corpora, multiple scientific domains, topic classification
+
+ 点击查看摘要
+ Many useful tasks on scientific documents, such as topic classification and
+citation prediction, involve corpora that span multiple scientific domains.
+Typically, such tasks are accomplished by representing the text with a vector
+embedding obtained from a Transformer's single CLS token. In this paper, we
+argue that using multiple CLS tokens could make a Transformer better specialize
+to multiple scientific domains. We present Multi2SPE: it encourages each of
+multiple CLS tokens to learn diverse ways of aggregating token embeddings, then
+sums them up together to create a single vector representation. We also propose
+our new multi-domain benchmark, Multi-SciDocs, to test scientific paper vector
+encoders under multi-domain settings. We show that Multi2SPE reduces error by
+up to 25 percent in multi-domain citation prediction, while requiring only a
+negligible amount of computation in addition to one BERT forward pass.
+
+
+
+ 16. 标题:Graph Neural Networks Use Graphs When They Shouldn't
+ 编号:[56]
+ 链接:https://arxiv.org/abs/2309.04332
+ 作者:Maya Bechler-Speicher, Ido Amos, Ran Gilad-Bachrach, Amir Globerson
+ 备注:
+ 关键词:including social networks, Graph Neural Networks, social networks, Neural Networks, including social
+
+ 点击查看摘要
+ Predictions over graphs play a crucial role in various domains, including
+social networks, molecular biology, medicine, and more. Graph Neural Networks
+(GNNs) have emerged as the dominant approach for learning on graph data.
+Instances of graph labeling problems consist of the graph-structure (i.e., the
+adjacency matrix), along with node-specific feature vectors. In some cases,
+this graph-structure is non-informative for the predictive task. For instance,
+molecular properties such as molar mass depend solely on the constituent atoms
+(node features), and not on the molecular structure. While GNNs have the
+ability to ignore the graph-structure in such cases, it is not clear that they
+will. In this work, we show that GNNs actually tend to overfit the
+graph-structure in the sense that they use it even when a better solution can
+be obtained by ignoring it. We examine this phenomenon with respect to
+different graph distributions and find that regular graphs are more robust to
+this overfitting. We then provide a theoretical explanation for this
+phenomenon, via analyzing the implicit bias of gradient-descent-based learning
+of GNNs in this setting. Finally, based on our empirical and theoretical
+findings, we propose a graph-editing method to mitigate the tendency of GNNs to
+overfit graph-structures that should be ignored. We show that this method
+indeed improves the accuracy of GNNs across multiple benchmarks.
+
+
+
+ 17. 标题:Generating the Ground Truth: Synthetic Data for Label Noise Research
+ 编号:[60]
+ 链接:https://arxiv.org/abs/2309.04318
+ 作者:Sjoerd de Vries, Dirk Thierens
+ 备注:
+ 关键词:real-world classification tasks, classification tasks suffer, real-world classification, classification tasks, tasks suffer
+
+ 点击查看摘要
+ Most real-world classification tasks suffer from label noise to some extent.
+Such noise in the data adversely affects the generalization error of learned
+models and complicates the evaluation of noise-handling methods, as their
+performance cannot be accurately measured without clean labels. In label noise
+research, typically either noisy or incomplex simulated data are accepted as a
+baseline, into which additional noise with known properties is injected. In
+this paper, we propose SYNLABEL, a framework that aims to improve upon the
+aforementioned methodologies. It allows for creating a noiseless dataset
+informed by real data, by either pre-specifying or learning a function and
+defining it as the ground truth function from which labels are generated.
+Furthermore, by resampling a number of values for selected features in the
+function domain, evaluating the function and aggregating the resulting labels,
+each data point can be assigned a soft label or label distribution. Such
+distributions allow for direct injection and quantification of label noise. The
+generated datasets serve as a clean baseline of adjustable complexity into
+which different types of noise may be introduced. We illustrate how the
+framework can be applied, how it enables quantification of label noise and how
+it improves over existing methodologies.
+
+
+
+ 18. 标题:Federated Learning for Early Dropout Prediction on Healthy Ageing Applications
+ 编号:[63]
+ 链接:https://arxiv.org/abs/2309.04311
+ 作者:Christos Chrysanthos Nikolaidis, Vasileios Perifanis, Nikolaos Pavlidis, Pavlos S. Efraimidis
+ 备注:
+ 关键词:provide early interventions, social care applications, early interventions, provision of social, social care
+
+ 点击查看摘要
+ The provision of social care applications is crucial for elderly people to
+improve their quality of life and enables operators to provide early
+interventions. Accurate predictions of user dropouts in healthy ageing
+applications are essential since they are directly related to individual health
+statuses. Machine Learning (ML) algorithms have enabled highly accurate
+predictions, outperforming traditional statistical methods that struggle to
+cope with individual patterns. However, ML requires a substantial amount of
+data for training, which is challenging due to the presence of personal
+identifiable information (PII) and the fragmentation posed by regulations. In
+this paper, we present a federated machine learning (FML) approach that
+minimizes privacy concerns and enables distributed training, without
+transferring individual data. We employ collaborative training by considering
+individuals and organizations under FML, which models both cross-device and
+cross-silo learning scenarios. Our approach is evaluated on a real-world
+dataset with non-independent and identically distributed (non-iid) data among
+clients, class imbalance and label ambiguity. Our results show that data
+selection and class imbalance handling techniques significantly improve the
+predictive accuracy of models trained under FML, demonstrating comparable or
+superior predictive performance than traditional ML models.
+
+
+
+ 19. 标题:Navigating Out-of-Distribution Electricity Load Forecasting during COVID-19: A Continual Learning Approach Leveraging Human Mobility
+ 编号:[68]
+ 链接:https://arxiv.org/abs/2309.04296
+ 作者:Arian Prabowo, Kaixuan Chen, Hao Xue, Subbu Sethuvenkatraman, Flora D. Salim
+ 备注:10 pages, 2 figures, 5 tables, BuildSys '23
+ 关键词:distribution remains constant, data distribution remains, remains constant, deep learning algorithms, learning
+
+ 点击查看摘要
+ In traditional deep learning algorithms, one of the key assumptions is that
+the data distribution remains constant during both training and deployment.
+However, this assumption becomes problematic when faced with
+Out-of-Distribution periods, such as the COVID-19 lockdowns, where the data
+distribution significantly deviates from what the model has seen during
+training. This paper employs a two-fold strategy: utilizing continual learning
+techniques to update models with new data and harnessing human mobility data
+collected from privacy-preserving pedestrian counters located outside
+buildings. In contrast to online learning, which suffers from 'catastrophic
+forgetting' as newly acquired knowledge often erases prior information,
+continual learning offers a holistic approach by preserving past insights while
+integrating new data. This research applies FSNet, a powerful continual
+learning algorithm, to real-world data from 13 building complexes in Melbourne,
+Australia, a city which had the second longest total lockdown duration globally
+during the pandemic. Results underscore the crucial role of continual learning
+in accurate energy forecasting, particularly during Out-of-Distribution
+periods. Secondary data such as mobility and temperature provided ancillary
+support to the primary forecasting model. More importantly, while traditional
+methods struggled to adapt during lockdowns, models featuring at least online
+learning demonstrated resilience, with lockdown periods posing fewer challenges
+once armed with adaptive learning techniques. This study contributes valuable
+methodologies and insights to the ongoing effort to improve energy load
+forecasting during future Out-of-Distribution periods.
+
+
+
+ 20. 标题:Viewing the process of generating counterfactuals as a source of knowledge -- Application to the Naive Bayes classifier
+ 编号:[72]
+ 链接:https://arxiv.org/abs/2309.04284
+ 作者:Vincent Lemaire, Nathan Le Boudec, Françoise Fessant, Victor Guyomard
+ 备注:12 pages
+ 关键词:machine learning algorithm, comprehension algorithms, learning algorithm, understanding the decisions, machine learning
+
+ 点击查看摘要
+ There are now many comprehension algorithms for understanding the decisions
+of a machine learning algorithm. Among these are those based on the generation
+of counterfactual examples. This article proposes to view this generation
+process as a source of creating a certain amount of knowledge that can be
+stored to be used, later, in different ways. This process is illustrated in the
+additive model and, more specifically, in the case of the naive Bayes
+classifier, whose interesting properties for this purpose are shown.
+
+
+
+ 21. 标题:Learning Zero-Sum Linear Quadratic Games with Improved Sample Complexity
+ 编号:[76]
+ 链接:https://arxiv.org/abs/2309.04272
+ 作者:Jiduan Wu, Anas Barakat, Ilyas Fatkhullin, Niao He
+ 备注:
+ 关键词:continuous state-control spaces, Zero-sum Linear Quadratic, dynamic game formulation, single-agent linear quadratic, linear quadratic regulator
+
+ 点击查看摘要
+ Zero-sum Linear Quadratic (LQ) games are fundamental in optimal control and
+can be used (i) as a dynamic game formulation for risk-sensitive or robust
+control, or (ii) as a benchmark setting for multi-agent reinforcement learning
+with two competing agents in continuous state-control spaces. In contrast to
+the well-studied single-agent linear quadratic regulator problem, zero-sum LQ
+games entail solving a challenging nonconvex-nonconcave min-max problem with an
+objective function that lacks coercivity. Recently, Zhang et al. discovered an
+implicit regularization property of natural policy gradient methods which is
+crucial for safety-critical control systems since it preserves the robustness
+of the controller during learning. Moreover, in the model-free setting where
+the knowledge of model parameters is not available, Zhang et al. proposed the
+first polynomial sample complexity algorithm to reach an
+$\epsilon$-neighborhood of the Nash equilibrium while maintaining the desirable
+implicit regularization property. In this work, we propose a simpler nested
+Zeroth-Order (ZO) algorithm improving sample complexity by several orders of
+magnitude. Our main result guarantees a
+$\widetilde{\mathcal{O}}(\epsilon^{-3})$ sample complexity under the same
+assumptions using a single-point ZO estimator. Furthermore, when the estimator
+is replaced by a two-point estimator, our method enjoys a better
+$\widetilde{\mathcal{O}}(\epsilon^{-2})$ sample complexity. Our key
+improvements rely on a more sample-efficient nested algorithm design and finer
+control of the ZO natural gradient estimation error.
+
+
+
+ 22. 标题:Adaptive Distributed Kernel Ridge Regression: A Feasible Distributed Learning Scheme for Data Silos
+ 编号:[88]
+ 链接:https://arxiv.org/abs/2309.04236
+ 作者:Di Wang, Xiaotong Liu, Shao-Bo Lin, Ding-Xuan Zhou
+ 备注:46pages, 13figures
+ 关键词:significantly constrain collaborations, Data silos, significantly constrain, organizations with similar, necessity of collaborations
+
+ 点击查看摘要
+ Data silos, mainly caused by privacy and interoperability, significantly
+constrain collaborations among different organizations with similar data for
+the same purpose. Distributed learning based on divide-and-conquer provides a
+promising way to settle the data silos, but it suffers from several challenges,
+including autonomy, privacy guarantees, and the necessity of collaborations.
+This paper focuses on developing an adaptive distributed kernel ridge
+regression (AdaDKRR) by taking autonomy in parameter selection, privacy in
+communicating non-sensitive information, and the necessity of collaborations in
+performance improvement into account. We provide both solid theoretical
+verification and comprehensive experiments for AdaDKRR to demonstrate its
+feasibility and effectiveness. Theoretically, we prove that under some mild
+conditions, AdaDKRR performs similarly to running the optimal learning
+algorithms on the whole data, verifying the necessity of collaborations and
+showing that no other distributed learning scheme can essentially beat AdaDKRR
+under the same conditions. Numerically, we test AdaDKRR on both toy simulations
+and two real-world applications to show that AdaDKRR is superior to other
+existing distributed learning schemes. All these results show that AdaDKRR is a
+feasible scheme to defend against data silos, which are highly desired in
+numerous application regions such as intelligent decision-making, pricing
+forecasting, and performance prediction for products.
+
+
+
+ 23. 标题:Offline Recommender System Evaluation under Unobserved Confounding
+ 编号:[94]
+ 链接:https://arxiv.org/abs/2309.04222
+ 作者:Olivier Jeunen, Ben London
+ 备注:Accepted at the CONSEQUENCES'23 workshop at RecSys '23
+ 关键词:evaluate decision-making policies, OPE methods, learn and evaluate, evaluate decision-making, decision-making policies
+
+ 点击查看摘要
+ Off-Policy Estimation (OPE) methods allow us to learn and evaluate
+decision-making policies from logged data. This makes them an attractive choice
+for the offline evaluation of recommender systems, and several recent works
+have reported successful adoption of OPE methods to this end. An important
+assumption that makes this work is the absence of unobserved confounders:
+random variables that influence both actions and rewards at data collection
+time. Because the data collection policy is typically under the practitioner's
+control, the unconfoundedness assumption is often left implicit, and its
+violations are rarely dealt with in the existing literature.
+This work aims to highlight the problems that arise when performing
+off-policy estimation in the presence of unobserved confounders, specifically
+focusing on a recommendation use-case. We focus on policy-based estimators,
+where the logging propensities are learned from logged data. We characterise
+the statistical bias that arises due to confounding, and show how existing
+diagnostics are unable to uncover such cases. Because the bias depends directly
+on the true and unobserved logging propensities, it is non-identifiable. As the
+unconfoundedness assumption is famously untestable, this becomes especially
+problematic. This paper emphasises this common, yet often overlooked issue.
+Through synthetic data, we empirically show how naïve propensity estimation
+under confounding can lead to severely biased metric estimates that are allowed
+to fly under the radar. We aim to cultivate an awareness among researchers and
+practitioners of this important problem, and touch upon potential research
+directions towards mitigating its effects.
+
+
+
+ 24. 标题:Concomitant Group Testing
+ 编号:[95]
+ 链接:https://arxiv.org/abs/2309.04221
+ 作者:Thach V. Bui, Jonathan Scarlett
+ 备注:15 pages, 3 figures, 1 table
+ 关键词:Concomitant Group Testing, testing problem capturing, positive test requires, group testing, group testing problem
+
+ 点击查看摘要
+ In this paper, we introduce a variation of the group testing problem
+capturing the idea that a positive test requires a combination of multiple
+``types'' of item. Specifically, we assume that there are multiple disjoint
+\emph{semi-defective sets}, and a test is positive if and only if it contains
+at least one item from each of these sets. The goal is to reliably identify all
+of the semi-defective sets using as few tests as possible, and we refer to this
+problem as \textit{Concomitant Group Testing} (ConcGT). We derive a variety of
+algorithms for this task, focusing primarily on the case that there are two
+semi-defective sets. Our algorithms are distinguished by (i) whether they are
+deterministic (zero-error) or randomized (small-error), and (ii) whether they
+are non-adaptive, fully adaptive, or have limited adaptivity (e.g., 2 or 3
+stages). Both our deterministic adaptive algorithm and our randomized
+algorithms (non-adaptive or limited adaptivity) are order-optimal in broad
+scaling regimes of interest, and improve significantly over baseline results
+that are based on solving a more general problem as an intermediate step (e.g.,
+hypergraph learning).
+
+
+
+ 25. 标题:Counterfactual Explanations via Locally-guided Sequential Algorithmic Recourse
+ 编号:[99]
+ 链接:https://arxiv.org/abs/2309.04211
+ 作者:Edward A. Small, Jeffrey N. Clark, Christopher J. McWilliams, Kacper Sokol, Jeffrey Chan, Flora D. Salim, Raul Santos-Rodriguez
+ 备注:7 pages, 5 figures, 3 appendix pages
+ 关键词:intelligence systems explainable, make artificial intelligence, artificial intelligence systems, systems explainable, powerful tool
+
+ 点击查看摘要
+ Counterfactuals operationalised through algorithmic recourse have become a
+powerful tool to make artificial intelligence systems explainable.
+Conceptually, given an individual classified as y -- the factual -- we seek
+actions such that their prediction becomes the desired class y' -- the
+counterfactual. This process offers algorithmic recourse that is (1) easy to
+customise and interpret, and (2) directly aligned with the goals of each
+individual. However, the properties of a "good" counterfactual are still
+largely debated; it remains an open challenge to effectively locate a
+counterfactual along with its corresponding recourse. Some strategies use
+gradient-driven methods, but these offer no guarantees on the feasibility of
+the recourse and are open to adversarial attacks on carefully created
+manifolds. This can lead to unfairness and lack of robustness. Other methods
+are data-driven, which mostly addresses the feasibility problem at the expense
+of privacy, security and secrecy as they require access to the entire training
+data set. Here, we introduce LocalFACE, a model-agnostic technique that
+composes feasible and actionable counterfactual explanations using
+locally-acquired information at each step of the algorithmic recourse. Our
+explainer preserves the privacy of users by only leveraging data that it
+specifically requires to construct actionable algorithmic recourse, and
+protects the model by offering transparency solely in the regions deemed
+necessary for the intervention.
+
+
+
+ 26. 标题:Towards Mitigating Architecture Overfitting in Dataset Distillation
+ 编号:[107]
+ 链接:https://arxiv.org/abs/2309.04195
+ 作者:Xuyang Zhong, Chen Liu
+ 备注:
+ 关键词:demonstrated remarkable performance, Dataset distillation methods, Dataset distillation, distilled training data, neural networks trained
+
+ 点击查看摘要
+ Dataset distillation methods have demonstrated remarkable performance for
+neural networks trained with very limited training data. However, a significant
+challenge arises in the form of architecture overfitting: the distilled
+training data synthesized by a specific network architecture (i.e., training
+network) generates poor performance when trained by other network architectures
+(i.e., test networks). This paper addresses this issue and proposes a series of
+approaches in both architecture designs and training schemes which can be
+adopted together to boost the generalization performance across different
+network architectures on the distilled training data. We conduct extensive
+experiments to demonstrate the effectiveness and generality of our methods.
+Particularly, across various scenarios involving different sizes of distilled
+data, our approaches achieve comparable or superior performance to existing
+methods when training on the distilled data using networks with larger
+capacities.
+
+
+
+ 27. 标题:Leveraging Prototype Patient Representations with Feature-Missing-Aware Calibration to Mitigate EHR Data Sparsity
+ 编号:[123]
+ 链接:https://arxiv.org/abs/2309.04160
+ 作者:Yinghao Zhu, Zixiang Wang, Long He, Shiyun Xie, Zixi Chen, Jingkun An, Liantao Ma, Chengwei Pan
+ 备注:
+ 关键词:Electronic Health Record, Health Record, exhibits sparse characteristics, frequently exhibits sparse, data frequently exhibits
+
+ 点击查看摘要
+ Electronic Health Record (EHR) data frequently exhibits sparse
+characteristics, posing challenges for predictive modeling. Current direct
+imputation such as matrix imputation approaches hinge on referencing analogous
+rows or columns to complete raw missing data and do not differentiate between
+imputed and actual values. As a result, models may inadvertently incorporate
+irrelevant or deceptive information with respect to the prediction objective,
+thereby compromising the efficacy of downstream performance. While some methods
+strive to recalibrate or augment EHR embeddings after direct imputation, they
+often mistakenly prioritize imputed features. This misprioritization can
+introduce biases or inaccuracies into the model. To tackle these issues, our
+work resorts to indirect imputation, where we leverage prototype
+representations from similar patients to obtain a denser embedding. Recognizing
+the limitation that missing features are typically treated the same as present
+ones when measuring similar patients, our approach designs a feature confidence
+learner module. This module is sensitive to the missing feature status,
+enabling the model to better judge the reliability of each feature. Moreover,
+we propose a novel patient similarity metric that takes feature confidence into
+account, ensuring that evaluations are not based merely on potentially
+inaccurate imputed values. Consequently, our work captures dense prototype
+patient representations with feature-missing-aware calibration process.
+Comprehensive experiments demonstrate that designed model surpasses established
+EHR-focused models with a statistically significant improvement on MIMIC-III
+and MIMIC-IV datasets in-hospital mortality outcome prediction task. The code
+is publicly available at \url{https://anonymous.4open.science/r/SparseEHR} to
+assure the reproducibility.
+
+
+
+ 28. 标题:Sample-Efficient Co-Design of Robotic Agents Using Multi-fidelity Training on Universal Policy Network
+ 编号:[147]
+ 链接:https://arxiv.org/abs/2309.04085
+ 作者:Kishan R. Nagiredla, Buddhika L. Semage, Thommen G. Karimpanal, Arun Kumar A. V, Santu Rana
+ 备注:17 pages, 10 figures
+ 关键词:Co-design involves simultaneously, involves simultaneously optimizing, design, simultaneously optimizing, agents physical design
+
+ 点击查看摘要
+ Co-design involves simultaneously optimizing the controller and agents
+physical design. Its inherent bi-level optimization formulation necessitates an
+outer loop design optimization driven by an inner loop control optimization.
+This can be challenging when the design space is large and each design
+evaluation involves data-intensive reinforcement learning process for control
+optimization. To improve the sample-efficiency we propose a
+multi-fidelity-based design exploration strategy based on Hyperband where we
+tie the controllers learnt across the design spaces through a universal policy
+learner for warm-starting the subsequent controller learning problems. Further,
+we recommend a particular way of traversing the Hyperband generated design
+matrix that ensures that the stochasticity of the Hyperband is reduced the most
+with the increasing warm starting effect of the universal policy learner as it
+is strengthened with each new design evaluation. Experiments performed on a
+wide range of agent design problems demonstrate the superiority of our method
+compared to the baselines. Additionally, analysis of the optimized designs
+shows interesting design alterations including design simplifications and
+non-intuitive alterations that have emerged in the biological world.
+
+
+
+ 29. 标题:Curve Your Attention: Mixed-Curvature Transformers for Graph Representation Learning
+ 编号:[149]
+ 链接:https://arxiv.org/abs/2309.04082
+ 作者:Sungjun Cho, Seunghyuk Cho, Sungwoo Park, Hankook Lee, Honglak Lee, Moontae Lee
+ 备注:19 pages, 7 figures
+ 关键词:typical Euclidean space, naturally exhibit hierarchical, typical Euclidean, Real-world graphs naturally, graphs naturally exhibit
+
+ 点击查看摘要
+ Real-world graphs naturally exhibit hierarchical or cyclical structures that
+are unfit for the typical Euclidean space. While there exist graph neural
+networks that leverage hyperbolic or spherical spaces to learn representations
+that embed such structures more accurately, these methods are confined under
+the message-passing paradigm, making the models vulnerable against side-effects
+such as oversmoothing and oversquashing. More recent work have proposed global
+attention-based graph Transformers that can easily model long-range
+interactions, but their extensions towards non-Euclidean geometry are yet
+unexplored. To bridge this gap, we propose Fully Product-Stereographic
+Transformer, a generalization of Transformers towards operating entirely on the
+product of constant curvature spaces. When combined with tokenized graph
+Transformers, our model can learn the curvature appropriate for the input graph
+in an end-to-end fashion, without the need of additional tuning on different
+curvature initializations. We also provide a kernelized approach to
+non-Euclidean attention, which enables our model to run in time and memory cost
+linear to the number of nodes and edges while respecting the underlying
+geometry. Experiments on graph reconstruction and node classification
+demonstrate the benefits of generalizing Transformers to the non-Euclidean
+domain.
+
+
+
+ 30. 标题:UER: A Heuristic Bias Addressing Approach for Online Continual Learning
+ 编号:[150]
+ 链接:https://arxiv.org/abs/2309.04081
+ 作者:Huiwei Lin, Shanshan Feng, Baoquan Zhang, Hongliang Qiao, Xutao Li, Yunming Ye
+ 备注:9 pages, 12 figures, ACM MM2023
+ 关键词:continual learning aims, continuously train neural, train neural networks, single pass-through data, continuous data stream
+
+ 点击查看摘要
+ Online continual learning aims to continuously train neural networks from a
+continuous data stream with a single pass-through data. As the most effective
+approach, the rehearsal-based methods replay part of previous data. Commonly
+used predictors in existing methods tend to generate biased dot-product logits
+that prefer to the classes of current data, which is known as a bias issue and
+a phenomenon of forgetting. Many approaches have been proposed to overcome the
+forgetting problem by correcting the bias; however, they still need to be
+improved in online fashion. In this paper, we try to address the bias issue by
+a more straightforward and more efficient method. By decomposing the
+dot-product logits into an angle factor and a norm factor, we empirically find
+that the bias problem mainly occurs in the angle factor, which can be used to
+learn novel knowledge as cosine logits. On the contrary, the norm factor
+abandoned by existing methods helps remember historical knowledge. Based on
+this observation, we intuitively propose to leverage the norm factor to balance
+the new and old knowledge for addressing the bias. To this end, we develop a
+heuristic approach called unbias experience replay (UER). UER learns current
+samples only by the angle factor and further replays previous samples by both
+the norm and angle factors. Extensive experiments on three datasets show that
+UER achieves superior performance over various state-of-the-art methods. The
+code is in this https URL.
+
+
+
+ 31. 标题:Enabling the Evaluation of Driver Physiology Via Vehicle Dynamics
+ 编号:[151]
+ 链接:https://arxiv.org/abs/2309.04078
+ 作者:Rodrigo Ordonez-Hurtado, Bo Wen, Nicholas Barra, Ryan Vimba, Sergio Cabrero-Barros, Sergiy Zhuk, Jeffrey L. Rogers
+ 备注:7 pages, 11 figures, 2023 IEEE International Conference on Digital Health (ICDH)
+ 关键词:daily routine, driver, connected ecosystem capable, assessing driver physiology, globe
+
+ 点击查看摘要
+ Driving is a daily routine for many individuals across the globe. This paper
+presents the configuration and methodologies used to transform a vehicle into a
+connected ecosystem capable of assessing driver physiology. We integrated an
+array of commercial sensors from the automotive and digital health sectors
+along with driver inputs from the vehicle itself. This amalgamation of sensors
+allows for meticulous recording of the external conditions and driving
+maneuvers. These data streams are processed to extract key parameters,
+providing insights into driver behavior in relation to their external
+environment and illuminating vital physiological responses. This innovative
+driver evaluation system holds the potential to amplify road safety. Moreover,
+when paired with data from conventional health settings, it may enhance early
+detection of health-related complications.
+
+
+
+ 32. 标题:Riemannian Langevin Monte Carlo schemes for sampling PSD matrices with fixed rank
+ 编号:[155]
+ 链接:https://arxiv.org/abs/2309.04072
+ 作者:Tianmin Yu, Shixin Zheng, Jianfeng Lu, Govind Menon, Xiangxiong Zhang
+ 备注:
+ 关键词:real positive semi-definite, mathcal, Riemannian Langevin equation, positive semi-definite, sample matrices
+
+ 点击查看摘要
+ This paper introduces two explicit schemes to sample matrices from Gibbs
+distributions on $\mathcal S^{n,p}_+$, the manifold of real positive
+semi-definite (PSD) matrices of size $n\times n$ and rank $p$. Given an energy
+function $\mathcal E:\mathcal S^{n,p}_+\to \mathbb{R}$ and certain Riemannian
+metrics $g$ on $\mathcal S^{n,p}_+$, these schemes rely on an Euler-Maruyama
+discretization of the Riemannian Langevin equation (RLE) with Brownian motion
+on the manifold. We present numerical schemes for RLE under two fundamental
+metrics on $\mathcal S^{n,p}_+$: (a) the metric obtained from the embedding of
+$\mathcal S^{n,p}_+ \subset \mathbb{R}^{n\times n} $; and (b) the
+Bures-Wasserstein metric corresponding to quotient geometry. We also provide
+examples of energy functions with explicit Gibbs distributions that allow
+numerical validation of these schemes.
+
+
+
+ 33. 标题:3D Denoisers are Good 2D Teachers: Molecular Pretraining via Denoising and Cross-Modal Distillation
+ 编号:[159]
+ 链接:https://arxiv.org/abs/2309.04062
+ 作者:Sungjun Cho, Dae-Woong Jeong, Sung Moon Ko, Jinwoo Kim, Sehui Han, Seunghoon Hong, Honglak Lee, Moontae Lee
+ 备注:16 pages, 5 figures
+ 关键词:obtaining ground-truth labels, large unlabeled data, ground-truth labels, large unlabeled, unlabeled data
+
+ 点击查看摘要
+ Pretraining molecular representations from large unlabeled data is essential
+for molecular property prediction due to the high cost of obtaining
+ground-truth labels. While there exist various 2D graph-based molecular
+pretraining approaches, these methods struggle to show statistically
+significant gains in predictive performance. Recent work have thus instead
+proposed 3D conformer-based pretraining under the task of denoising, which led
+to promising results. During downstream finetuning, however, models trained
+with 3D conformers require accurate atom-coordinates of previously unseen
+molecules, which are computationally expensive to acquire at scale. In light of
+this limitation, we propose D&D, a self-supervised molecular representation
+learning framework that pretrains a 2D graph encoder by distilling
+representations from a 3D denoiser. With denoising followed by cross-modal
+knowledge distillation, our approach enjoys use of knowledge obtained from
+denoising as well as painless application to downstream tasks with no access to
+accurate conformers. Experiments on real-world molecular property prediction
+datasets show that the graph encoder trained via D&D can infer 3D information
+based on the 2D graph and shows superior performance and label-efficiency
+against other baselines.
+
+
+
+ 34. 标题:SRN-SZ: Deep Leaning-Based Scientific Error-bounded Lossy Compression with Super-resolution Neural Networks
+ 编号:[164]
+ 链接:https://arxiv.org/abs/2309.04037
+ 作者:Jinyang Liu, Sheng Di, Sian Jin, Kai Zhao, Xin Liang, Zizhong Chen, Franck Cappello
+ 备注:
+ 关键词:modern super-computing systems, raised great challenges, exascale scientific data, scientific data, error-bounded lossy compressors
+
+ 点击查看摘要
+ The fast growth of computational power and scales of modern super-computing
+systems have raised great challenges for the management of exascale scientific
+data. To maintain the usability of scientific data, error-bound lossy
+compression is proposed and developed as an essential technique for the size
+reduction of scientific data with constrained data distortion. Among the
+diverse datasets generated by various scientific simulations, certain datasets
+cannot be effectively compressed by existing error-bounded lossy compressors
+with traditional techniques. The recent success of Artificial Intelligence has
+inspired several researchers to integrate neural networks into error-bounded
+lossy compressors. However, those works still suffer from limited compression
+ratios and/or extremely low efficiencies. To address those issues and improve
+the compression on the hard-to-compress datasets, in this paper, we propose
+SRN-SZ, which is a deep learning-based scientific error-bounded lossy
+compressor leveraging the hierarchical data grid expansion paradigm implemented
+by super-resolution neural networks. SRN-SZ applies the most advanced
+super-resolution network HAT for its compression, which is free of time-costing
+per-data training. In experiments compared with various state-of-the-art
+compressors, SRN-SZ achieves up to 75% compression ratio improvements under the
+same error bound and up to 80% compression ratio improvements under the same
+PSNR than the second-best compressor.
+
+
+
+ 35. 标题:Brief technical note on linearizing recurrent neural networks (RNNs) before vs after the pointwise nonlinearity
+ 编号:[168]
+ 链接:https://arxiv.org/abs/2309.04030
+ 作者:Marino Pagan, Adrian Valente, Srdjan Ostojic, Carlos D. Brody
+ 备注:10 pages
+ 关键词:recurrent neural networks, neural networks, study their properties, recurrent neural, pointwise nonlinearity
+
+ 点击查看摘要
+ Linearization of the dynamics of recurrent neural networks (RNNs) is often
+used to study their properties. The same RNN dynamics can be written in terms
+of the ``activations" (the net inputs to each unit, before its pointwise
+nonlinearity) or in terms of the ``activities" (the output of each unit, after
+its pointwise nonlinearity); the two corresponding linearizations are different
+from each other. This brief and informal technical note describes the
+relationship between the two linearizations, between the left and right
+eigenvectors of their dynamics matrices, and shows that some context-dependent
+effects are readily apparent under linearization of activity dynamics but not
+linearization of activation dynamics.
+
+
+
+ 36. 标题:TIDE: Textual Identity Detection for Evaluating and Augmenting Classification and Language Models
+ 编号:[169]
+ 链接:https://arxiv.org/abs/2309.04027
+ 作者:Emmanuel Klu, Sameer Sethi
+ 备注:Preprint
+ 关键词:perpetuate unintended biases, Machine learning models, Machine learning, perpetuate unintended, unintended biases
+
+ 点击查看摘要
+ Machine learning models can perpetuate unintended biases from unfair and
+imbalanced datasets. Evaluating and debiasing these datasets and models is
+especially hard in text datasets where sensitive attributes such as race,
+gender, and sexual orientation may not be available. When these models are
+deployed into society, they can lead to unfair outcomes for historically
+underrepresented groups. In this paper, we present a dataset coupled with an
+approach to improve text fairness in classifiers and language models. We create
+a new, more comprehensive identity lexicon, TIDAL, which includes 15,123
+identity terms and associated sense context across three demographic
+categories. We leverage TIDAL to develop an identity annotation and
+augmentation tool that can be used to improve the availability of identity
+context and the effectiveness of ML fairness techniques. We evaluate our
+approaches using human contributors, and additionally run experiments focused
+on dataset and model debiasing. Results show our assistive annotation technique
+improves the reliability and velocity of human-in-the-loop processes. Our
+dataset and methods uncover more disparities during evaluation, and also
+produce more fair models during remediation. These approaches provide a
+practical path forward for scaling classifier and generative model fairness in
+real-world settings.
+
+
+
+ 37. 标题:Optimal Transport with Tempered Exponential Measures
+ 编号:[174]
+ 链接:https://arxiv.org/abs/2309.04015
+ 作者:Ehsan Amid, Frank Nielsen, Richard Nock, Manfred K. Warmuth
+ 备注:
+ 关键词:prominent subfields face, extremely sparse plans, maximally un-sparse plans, near-linear approximation algorithms, unregularized optimal transport
+
+ 点击查看摘要
+ In the field of optimal transport, two prominent subfields face each other:
+(i) unregularized optimal transport, ``à-la-Kantorovich'', which leads to
+extremely sparse plans but with algorithms that scale poorly, and (ii)
+entropic-regularized optimal transport, ``à-la-Sinkhorn-Cuturi'', which gets
+near-linear approximation algorithms but leads to maximally un-sparse plans. In
+this paper, we show that a generalization of the latter to tempered exponential
+measures, a generalization of exponential families with indirect measure
+normalization, gets to a very convenient middle ground, with both very fast
+approximation algorithms and sparsity which is under control up to sparsity
+patterns. In addition, it fits naturally in the unbalanced optimal transport
+problem setting as well.
+
+
+
+ 38. 标题:Multimodal Transformer for Material Segmentation
+ 编号:[178]
+ 链接:https://arxiv.org/abs/2309.04001
+ 作者:Md Kaykobad Reza (1), Ashley Prater-Bennette (2), M. Salman Asif (1) ((1) University of California, Riverside, (2) Air Force Research Laboratory)
+ 备注:9 pages, 3 figures
+ 关键词:Linear Polarization, multimodal segmentation tasks, Leveraging information, segmentation tasks, diverse modalities
+
+ 点击查看摘要
+ Leveraging information across diverse modalities is known to enhance
+performance on multimodal segmentation tasks. However, effectively fusing
+information from different modalities remains challenging due to the unique
+characteristics of each modality. In this paper, we propose a novel fusion
+strategy that can effectively fuse information from different combinations of
+four different modalities: RGB, Angle of Linear Polarization (AoLP), Degree of
+Linear Polarization (DoLP) and Near-Infrared (NIR). We also propose a new model
+named Multi-Modal Segmentation Transformer (MMSFormer) that incorporates the
+proposed fusion strategy to perform multimodal material segmentation. MMSFormer
+achieves 52.05% mIoU outperforming the current state-of-the-art on Multimodal
+Material Segmentation (MCubeS) dataset. For instance, our method provides
+significant improvement in detecting gravel (+10.4%) and human (+9.1%) classes.
+Ablation studies show that different modules in the fusion block are crucial
+for overall model performance. Furthermore, our ablation studies also highlight
+the capacity of different input modalities to improve performance in the
+identification of different types of materials. The code and pretrained models
+will be made available at this https URL.
+
+
+
+ 39. 标题:Adapting Self-Supervised Representations to Multi-Domain Setups
+ 编号:[179]
+ 链接:https://arxiv.org/abs/2309.03999
+ 作者:Neha Kalibhat, Sam Sharpe, Jeremy Goodsitt, Bayan Bruss, Soheil Feizi
+ 备注:Published at BMVC 2023
+ 关键词:DDM, domains, self-supervised, trained, self-supervised approaches
+
+ 点击查看摘要
+ Current state-of-the-art self-supervised approaches, are effective when
+trained on individual domains but show limited generalization on unseen
+domains. We observe that these models poorly generalize even when trained on a
+mixture of domains, making them unsuitable to be deployed under diverse
+real-world setups. We therefore propose a general-purpose, lightweight Domain
+Disentanglement Module (DDM) that can be plugged into any self-supervised
+encoder to effectively perform representation learning on multiple, diverse
+domains with or without shared classes. During pre-training according to a
+self-supervised loss, DDM enforces a disentanglement in the representation
+space by splitting it into a domain-variant and a domain-invariant portion.
+When domain labels are not available, DDM uses a robust clustering approach to
+discover pseudo-domains. We show that pre-training with DDM can show up to 3.5%
+improvement in linear probing accuracy on state-of-the-art self-supervised
+models including SimCLR, MoCo, BYOL, DINO, SimSiam and Barlow Twins on
+multi-domain benchmarks including PACS, DomainNet and WILDS. Models trained
+with DDM show significantly improved generalization (7.4%) to unseen domains
+compared to baselines. Therefore, DDM can efficiently adapt self-supervised
+encoders to provide high-quality, generalizable representations for diverse
+multi-domain data.
+
+
+
+ 40. 标题:ConDA: Contrastive Domain Adaptation for AI-generated Text Detection
+ 编号:[180]
+ 链接:https://arxiv.org/abs/2309.03992
+ 作者:Amrita Bhattacharjee, Tharindu Kumarage, Raha Moraffah, Huan Liu
+ 备注:Accepted at IJCNLP-AACL 2023 main track
+ 关键词:Large language models, Large language, language models, including journalistic, journalistic news articles
+
+ 点击查看摘要
+ Large language models (LLMs) are increasingly being used for generating text
+in a variety of use cases, including journalistic news articles. Given the
+potential malicious nature in which these LLMs can be used to generate
+disinformation at scale, it is important to build effective detectors for such
+AI-generated text. Given the surge in development of new LLMs, acquiring
+labeled training data for supervised detectors is a bottleneck. However, there
+might be plenty of unlabeled text data available, without information on which
+generator it came from. In this work we tackle this data problem, in detecting
+AI-generated news text, and frame the problem as an unsupervised domain
+adaptation task. Here the domains are the different text generators, i.e. LLMs,
+and we assume we have access to only the labeled source data and unlabeled
+target data. We develop a Contrastive Domain Adaptation framework, called
+ConDA, that blends standard domain adaptation techniques with the
+representation power of contrastive learning to learn domain invariant
+representations that are effective for the final unsupervised detection task.
+Our experiments demonstrate the effectiveness of our framework, resulting in
+average performance gains of 31.7% from the best performing baselines, and
+within 0.8% margin of a fully supervised detector. All our code and data is
+available at this https URL.
+
+
+
+ 41. 标题:Noisy Computing of the $\mathsf{OR}$ and $\mathsf{MAX}$ Functions
+ 编号:[182]
+ 链接:https://arxiv.org/abs/2309.03986
+ 作者:Banghua Zhu, Ziao Wang, Nadim Ghaddar, Jiantao Jiao, Lele Wang
+ 备注:
+ 关键词:mathsf, problem of computing, query is incorrect, queries correspond, noisy pairwise comparisons
+
+ 点击查看摘要
+ We consider the problem of computing a function of $n$ variables using noisy
+queries, where each query is incorrect with some fixed and known probability $p
+\in (0,1/2)$. Specifically, we consider the computation of the $\mathsf{OR}$
+function of $n$ bits (where queries correspond to noisy readings of the bits)
+and the $\mathsf{MAX}$ function of $n$ real numbers (where queries correspond
+to noisy pairwise comparisons). We show that an expected number of queries of
+\[ (1 \pm o(1)) \frac{n\log \frac{1}{\delta}}{D_{\mathsf{KL}}(p \| 1-p)} \] is
+both sufficient and necessary to compute both functions with a vanishing error
+probability $\delta = o(1)$, where $D_{\mathsf{KL}}(p \| 1-p)$ denotes the
+Kullback-Leibler divergence between $\mathsf{Bern}(p)$ and $\mathsf{Bern}(1-p)$
+distributions. Compared to previous work, our results tighten the dependence on
+$p$ in both the upper and lower bounds for the two functions.
+
+
+
+ 42. 标题:LanSER: Language-Model Supported Speech Emotion Recognition
+ 编号:[185]
+ 链接:https://arxiv.org/abs/2309.03978
+ 作者:Taesik Gong, Josh Belanich, Krishna Somandepalli, Arsha Nagrani, Brian Eoff, Brendan Jou
+ 备注:Presented at INTERSPEECH 2023
+ 关键词:making scaling methods, emotion taxonomies difficult, costly human-labeled data, nuanced emotion taxonomies, making scaling
+
+ 点击查看摘要
+ Speech emotion recognition (SER) models typically rely on costly
+human-labeled data for training, making scaling methods to large speech
+datasets and nuanced emotion taxonomies difficult. We present LanSER, a method
+that enables the use of unlabeled data by inferring weak emotion labels via
+pre-trained large language models through weakly-supervised learning. For
+inferring weak labels constrained to a taxonomy, we use a textual entailment
+approach that selects an emotion label with the highest entailment score for a
+speech transcript extracted via automatic speech recognition. Our experimental
+results show that models pre-trained on large datasets with this weak
+supervision outperform other baseline models on standard SER datasets when
+fine-tuned, and show improved label efficiency. Despite being pre-trained on
+labels derived only from text, we show that the resulting representations
+appear to model the prosodic content of speech.
+
+
+
+ 43. 标题:DBsurf: A Discrepancy Based Method for Discrete Stochastic Gradient Estimation
+ 编号:[187]
+ 链接:https://arxiv.org/abs/2309.03974
+ 作者:Pau Mulet Arabi, Alec Flowers, Lukas Mauch, Fabien Cardinaux
+ 备注:22 pages, 7 figures
+ 关键词:Monte Carlo simulation, science and engineering, expectation with respect, distributional parameters, fields of science
+
+ 点击查看摘要
+ Computing gradients of an expectation with respect to the distributional
+parameters of a discrete distribution is a problem arising in many fields of
+science and engineering. Typically, this problem is tackled using Reinforce,
+which frames the problem of gradient estimation as a Monte Carlo simulation.
+Unfortunately, the Reinforce estimator is especially sensitive to discrepancies
+between the true probability distribution and the drawn samples, a common issue
+in low sampling regimes that results in inaccurate gradient estimates. In this
+paper, we introduce DBsurf, a reinforce-based estimator for discrete
+distributions that uses a novel sampling procedure to reduce the discrepancy
+between the samples and the actual distribution. To assess the performance of
+our estimator, we subject it to a diverse set of tasks. Among existing
+estimators, DBsurf attains the lowest variance in a least squares problem
+commonly used in the literature for benchmarking. Furthermore, DBsurf achieves
+the best results for training variational auto-encoders (VAE) across different
+datasets and sampling setups. Finally, we apply DBsurf to build a simple and
+efficient Neural Architecture Search (NAS) algorithm with state-of-the-art
+performance.
+
+
+
+ 44. 标题:Automatic Concept Embedding Model (ACEM): No train-time concepts, No issue!
+ 编号:[189]
+ 链接:https://arxiv.org/abs/2309.03970
+ 作者:Rishabh Jain
+ 备注:Appeared in IJCAI 2023 Workshop on Explainable Artificial Intelligence (XAI)
+ 关键词:increasing in importance, neural networks, networks is continuously, continuously increasing, safety-critical domains
+
+ 点击查看摘要
+ Interpretability and explainability of neural networks is continuously
+increasing in importance, especially within safety-critical domains and to
+provide the social right to explanation. Concept based explanations align well
+with how humans reason, proving to be a good way to explain models. Concept
+Embedding Models (CEMs) are one such concept based explanation architectures.
+These have shown to overcome the trade-off between explainability and
+performance. However, they have a key limitation -- they require concept
+annotations for all their training data. For large datasets, this can be
+expensive and infeasible. Motivated by this, we propose Automatic Concept
+Embedding Models (ACEMs), which learn the concept annotations automatically.
+
+
+
+ 45. 标题:Improving Resnet-9 Generalization Trained on Small Datasets
+ 编号:[190]
+ 链接:https://arxiv.org/abs/2309.03965
+ 作者:Omar Mohamed Awad, Habib Hajimolahoseini, Michael Lim, Gurpreet Gosal, Walid Ahmed, Yang Liu, Gordon Deng
+ 备注:
+ 关键词:Hardware Aware Efficient, paper presents, presents our proposed, Aware Efficient Training, Efficient Training
+
+ 点击查看摘要
+ This paper presents our proposed approach that won the first prize at the
+ICLR competition on Hardware Aware Efficient Training. The challenge is to
+achieve the highest possible accuracy in an image classification task in less
+than 10 minutes. The training is done on a small dataset of 5000 images picked
+randomly from CIFAR-10 dataset. The evaluation is performed by the competition
+organizers on a secret dataset with 1000 images of the same size. Our approach
+includes applying a series of technique for improving the generalization of
+ResNet-9 including: sharpness aware optimization, label smoothing, gradient
+centralization, input patch whitening as well as metalearning based training.
+Our experiments show that the ResNet-9 can achieve the accuracy of 88% while
+trained only on a 10% subset of CIFAR-10 dataset in less than 10 minuets
+
+
+
+ 46. 标题:REALM: Robust Entropy Adaptive Loss Minimization for Improved Single-Sample Test-Time Adaptation
+ 编号:[191]
+ 链接:https://arxiv.org/abs/2309.03964
+ 作者:Skyler Seto, Barry-John Theobald, Federico Danieli, Navdeep Jaitly, Dan Busbridge
+ 备注:Accepted at WACV 2024, 17 pages, 7 figures, 11 tables
+ 关键词:training data, mitigate performance loss, performance loss due, test data, model training procedure
+
+ 点击查看摘要
+ Fully-test-time adaptation (F-TTA) can mitigate performance loss due to
+distribution shifts between train and test data (1) without access to the
+training data, and (2) without knowledge of the model training procedure. In
+online F-TTA, a pre-trained model is adapted using a stream of test samples by
+minimizing a self-supervised objective, such as entropy minimization. However,
+models adapted with online using entropy minimization, are unstable especially
+in single sample settings, leading to degenerate solutions, and limiting the
+adoption of TTA inference strategies. Prior works identify noisy, or
+unreliable, samples as a cause of failure in online F-TTA. One solution is to
+ignore these samples, which can lead to bias in the update procedure, slow
+adaptation, and poor generalization. In this work, we present a general
+framework for improving robustness of F-TTA to these noisy samples, inspired by
+self-paced learning and robust loss functions. Our proposed approach, Robust
+Entropy Adaptive Loss Minimization (REALM), achieves better adaptation accuracy
+than previous approaches throughout the adaptation process on corruptions of
+CIFAR-10 and ImageNet-1K, demonstrating its effectiveness.
+
+
+
+ 47. 标题:Large-Scale Automatic Audiobook Creation
+ 编号:[196]
+ 链接:https://arxiv.org/abs/2309.03926
+ 作者:Brendan Walsh, Mark Hamilton, Greg Newby, Xi Wang, Serena Ruan, Sheng Zhao, Lei He, Shaofei Zhang, Eric Dettinger, William T. Freeman, Markus Weimer
+ 备注:
+ 关键词:improve reader engagement, dramatically improve, improve reader, reader engagement, literature accessibility
+
+ 点击查看摘要
+ An audiobook can dramatically improve a work of literature's accessibility
+and improve reader engagement. However, audiobooks can take hundreds of hours
+of human effort to create, edit, and publish. In this work, we present a system
+that can automatically generate high-quality audiobooks from online e-books. In
+particular, we leverage recent advances in neural text-to-speech to create and
+release thousands of human-quality, open-license audiobooks from the Project
+Gutenberg e-book collection. Our method can identify the proper subset of
+e-book content to read for a wide collection of diversely structured books and
+can operate on hundreds of books in parallel. Our system allows users to
+customize an audiobook's speaking speed and style, emotional intonation, and
+can even match a desired voice using a small amount of sample audio. This work
+contributed over five thousand open-license audiobooks and an interactive demo
+that allows users to quickly create their own customized audiobooks. To listen
+to the audiobook collection visit \url{this https URL}.
+
+
+
+ 48. 标题:A recommender for the management of chronic pain in patients undergoing spinal cord stimulation
+ 编号:[199]
+ 链接:https://arxiv.org/abs/2309.03918
+ 作者:Tigran Tchrakian, Mykhaylo Zayats, Alessandra Pascale, Dat Huynh, Pritish Parida, Carla Agurto Rios, Sergiy Zhuk, Jeffrey L. Rogers, ENVISION Studies Physician Author Group, Boston Scientific Research Scientists Consortium
+ 备注:
+ 关键词:SCS, Spinal cord stimulation, Spinal cord, pain, chronic pain
+
+ 点击查看摘要
+ Spinal cord stimulation (SCS) is a therapeutic approach used for the
+management of chronic pain. It involves the delivery of electrical impulses to
+the spinal cord via an implanted device, which when given suitable stimulus
+parameters can mask or block pain signals. Selection of optimal stimulation
+parameters usually happens in the clinic under the care of a provider whereas
+at-home SCS optimization is managed by the patient. In this paper, we propose a
+recommender system for the management of pain in chronic pain patients
+undergoing SCS. In particular, we use a contextual multi-armed bandit (CMAB)
+approach to develop a system that recommends SCS settings to patients with the
+aim of improving their condition. These recommendations, sent directly to
+patients though a digital health ecosystem, combined with a patient monitoring
+system closes the therapeutic loop around a chronic pain patient over their
+entire patient journey. We evaluated the system in a cohort of SCS-implanted
+ENVISION study subjects (this http URL ID: NCT03240588) using a
+combination of quality of life metrics and Patient States (PS), a novel measure
+of holistic outcomes. SCS recommendations provided statistically significant
+improvement in clinical outcomes (pain and/or QoL) in 85\% of all subjects
+(N=21). Among subjects in moderate PS (N=7) prior to receiving recommendations,
+100\% showed statistically significant improvements and 5/7 had improved PS
+dwell time. This analysis suggests SCS patients may benefit from SCS
+recommendations, resulting in additional clinical improvement on top of
+benefits already received from SCS therapy.
+
+
+
+ 49. 标题:A Robust Adaptive Workload Orchestration in Pure Edge Computing
+ 编号:[201]
+ 链接:https://arxiv.org/abs/2309.03913
+ 作者:Zahra Safavifar, Charafeddine Mechalikh, Fatemeh Golpayegani
+ 备注:9 pages, Accepted in ICAART conference
+ 关键词:bring cloud applications, Pure Edge computing, growing user demand, data-driven computing, cloud applications
+
+ 点击查看摘要
+ Pure Edge computing (PEC) aims to bring cloud applications and services to
+the edge of the network to support the growing user demand for time-sensitive
+applications and data-driven computing. However, mobility and limited
+computational capacity of edge devices pose challenges in supporting some
+urgent and computationally intensive tasks with strict response time demands.
+If the execution results of these tasks exceed the deadline, they become
+worthless and can cause severe safety issues. Therefore, it is essential to
+ensure that edge nodes complete as many latency-sensitive tasks as possible.
+\\In this paper, we propose a Robust Adaptive Workload Orchestration
+(R-AdWOrch) model to minimize deadline misses and data loss by using priority
+definition and a reallocation strategy. The results show that R-AdWOrch can
+minimize deadline misses of urgent tasks while minimizing the data loss of
+lower priority tasks under all conditions.
+
+
+
+ 50. 标题:Postprocessing of Ensemble Weather Forecasts Using Permutation-invariant Neural Networks
+ 编号:[203]
+ 链接:https://arxiv.org/abs/2309.04452
+ 作者:Kevin Höhlein, Benedikt Schulz, Rüdiger Westermann, Sebastian Lerch
+ 备注:Submitted to Artificial Intelligence for the Earth Systems
+ 关键词:raw numerical weather, numerical weather forecasts, reliable probabilistic forecast, probabilistic forecast distributions, raw numerical
+
+ 点击查看摘要
+ Statistical postprocessing is used to translate ensembles of raw numerical
+weather forecasts into reliable probabilistic forecast distributions. In this
+study, we examine the use of permutation-invariant neural networks for this
+task. In contrast to previous approaches, which often operate on ensemble
+summary statistics and dismiss details of the ensemble distribution, we propose
+networks which treat forecast ensembles as a set of unordered member forecasts
+and learn link functions that are by design invariant to permutations of the
+member ordering. We evaluate the quality of the obtained forecast distributions
+in terms of calibration and sharpness, and compare the models against classical
+and neural network-based benchmark methods. In case studies addressing the
+postprocessing of surface temperature and wind gust forecasts, we demonstrate
+state-of-the-art prediction quality. To deepen the understanding of the learned
+inference process, we further propose a permutation-based importance analysis
+for ensemble-valued predictors, which highlights specific aspects of the
+ensemble forecast that are considered important by the trained postprocessing
+models. Our results suggest that most of the relevant information is contained
+in few ensemble-internal degrees of freedom, which may impact the design of
+future ensemble forecasting and postprocessing systems.
+
+
+
+ 51. 标题:Soft Quantization using Entropic Regularization
+ 编号:[204]
+ 链接:https://arxiv.org/abs/2309.04428
+ 作者:Rajmadan Lakshmanan, Alois Pichler
+ 备注:
+ 关键词:quantization problem aims, quantization problem, aims to find, discrete measures, quantization problem approximation
+
+ 点击查看摘要
+ The quantization problem aims to find the best possible approximation of
+probability measures on ${\mathbb{R}}^d$ using finite, discrete measures. The
+Wasserstein distance is a typical choice to measure the quality of the
+approximation. This contribution investigates the properties and robustness of
+the entropy-regularized quantization problem, which relaxes the standard
+quantization problem. The proposed approximation technique naturally adopts the
+softmin function, which is well known for its robustness in terms of
+theoretical and practicability standpoints. Moreover, we use the
+entropy-regularized Wasserstein distance to evaluate the quality of the soft
+quantization problem's approximation, and we implement a stochastic gradient
+approach to achieve the optimal solutions. The control parameter in our
+proposed method allows for the adjustment of the optimization problem's
+difficulty level, providing significant advantages when dealing with
+exceptionally challenging problems of interest. As well, this contribution
+empirically illustrates the performance of the method in various expositions.
+
+
+
+ 52. 标题:Emergent learning in physical systems as feedback-based aging in a glassy landscape
+ 编号:[207]
+ 链接:https://arxiv.org/abs/2309.04382
+ 作者:Vidyesh Rao Anisetti, Ananth Kandala, J. M. Schwarz
+ 备注:11 pages, 7 figures
+ 关键词:learn linear transformations, weight update rules, properties evolve due, training linear physical, physical properties evolve
+
+ 点击查看摘要
+ By training linear physical networks to learn linear transformations, we
+discern how their physical properties evolve due to weight update rules. Our
+findings highlight a striking similarity between the learning behaviors of such
+networks and the processes of aging and memory formation in disordered and
+glassy systems. We show that the learning dynamics resembles an aging process,
+where the system relaxes in response to repeated application of the feedback
+boundary forces in presence of an input force, thus encoding a memory of the
+input-output relationship. With this relaxation comes an increase in the
+correlation length, which is indicated by the two-point correlation function
+for the components of the network. We also observe that the square root of the
+mean-squared error as a function of epoch takes on a non-exponential form,
+which is a typical feature of glassy systems. This physical interpretation
+suggests that by encoding more detailed information into input and feedback
+boundary forces, the process of emergent learning can be rather ubiquitous and,
+thus, serve as a very early physical mechanism, from an evolutionary
+standpoint, for learning in biological systems.
+
+
+
+ 53. 标题:Actor critic learning algorithms for mean-field control with moment neural networks
+ 编号:[210]
+ 链接:https://arxiv.org/abs/2309.04317
+ 作者:Huyên Pham, Xavier Warin
+ 备注:16 pages, 11 figures
+ 关键词:continuous time reinforcement, time reinforcement learning, gradient and actor-critic, actor-critic algorithm, algorithm for solving
+
+ 点击查看摘要
+ We develop a new policy gradient and actor-critic algorithm for solving
+mean-field control problems within a continuous time reinforcement learning
+setting. Our approach leverages a gradient-based representation of the value
+function, employing parametrized randomized policies. The learning for both the
+actor (policy) and critic (value function) is facilitated by a class of moment
+neural network functions on the Wasserstein space of probability measures, and
+the key feature is to sample directly trajectories of distributions. A central
+challenge addressed in this study pertains to the computational treatment of an
+operator specific to the mean-field framework. To illustrate the effectiveness
+of our methods, we provide a comprehensive set of numerical results. These
+encompass diverse examples, including multi-dimensional settings and nonlinear
+quadratic mean-field control problems with controlled volatility.
+
+
+
+ 54. 标题:Optimal Rate of Kernel Regression in Large Dimensions
+ 编号:[214]
+ 链接:https://arxiv.org/abs/2309.04268
+ 作者:Weihao Lu, Haobo Zhang, Yicheng Li, Manyun Xu, Qian Lin
+ 备注:
+ 关键词:kernel regression, sample size, gamma, perform a study, polynomially depending
+
+ 点击查看摘要
+ We perform a study on kernel regression for large-dimensional data (where the
+sample size $n$ is polynomially depending on the dimension $d$ of the samples,
+i.e., $n\asymp d^{\gamma}$ for some $\gamma >0$ ). We first build a general
+tool to characterize the upper bound and the minimax lower bound of kernel
+regression for large dimensional data through the Mendelson complexity
+$\varepsilon_{n}^{2}$ and the metric entropy $\bar{\varepsilon}_{n}^{2}$
+respectively. When the target function falls into the RKHS associated with a
+(general) inner product model defined on $\mathbb{S}^{d}$, we utilize the new
+tool to show that the minimax rate of the excess risk of kernel regression is
+$n^{-1/2}$ when $n\asymp d^{\gamma}$ for $\gamma =2, 4, 6, 8, \cdots$. We then
+further determine the optimal rate of the excess risk of kernel regression for
+all the $\gamma>0$ and find that the curve of optimal rate varying along
+$\gamma$ exhibits several new phenomena including the {\it multiple descent
+behavior} and the {\it periodic plateau behavior}. As an application, For the
+neural tangent kernel (NTK), we also provide a similar explicit description of
+the curve of optimal rate. As a direct corollary, we know these claims hold for
+wide neural networks as well.
+
+
+
+ 55. 标题:A Deep Learning Method for Sensitivity Enhancement of Deuterium Metabolic Imaging (DMI)
+ 编号:[216]
+ 链接:https://arxiv.org/abs/2309.04100
+ 作者:Siyuan Dong, Henk M. De Feyter, Monique A. Thomas, Robin A. de Graaf, James S. Duncan
+ 备注:
+ 关键词:Deuterium Metabolic Imaging, MRSI techniques, duration of Deuterium, minimal scan duration, Metabolic Imaging
+
+ 点击查看摘要
+ Purpose: Common to most MRSI techniques, the spatial resolution and the
+minimal scan duration of Deuterium Metabolic Imaging (DMI) are limited by the
+achievable SNR. This work presents a deep learning method for sensitivity
+enhancement of DMI.
+Methods: A convolutional neural network (CNN) was designed to estimate the
+2H-labeled metabolite concentrations from low SNR and distorted DMI FIDs. The
+CNN was trained with synthetic data that represent a range of SNR levels
+typically encountered in vivo. The estimation precision was further improved by
+fine-tuning the CNN with MRI-based edge-preserving regularization for each DMI
+dataset. The proposed processing method, PReserved Edge ConvolutIonal neural
+network for Sensitivity Enhanced DMI (PRECISE-DMI), was applied to simulation
+studies and in vivo experiments to evaluate the anticipated improvements in SNR
+and investigate the potential for inaccuracies.
+Results: PRECISE-DMI visually improved the metabolic maps of low SNR
+datasets, and quantitatively provided higher precision than the standard
+Fourier reconstruction. Processing of DMI data acquired in rat brain tumor
+models resulted in more precise determination of 2H-labeled lactate and
+glutamate + glutamine levels, at increased spatial resolution (from >8 to 2
+$\mu$L) or shortened scan time (from 32 to 4 min) compared to standard
+acquisitions. However, rigorous SD-bias analyses showed that overuse of the
+edge-preserving regularization can compromise the accuracy of the results.
+Conclusion: PRECISE-DMI allows a flexible trade-off between enhancing the
+sensitivity of DMI and minimizing the inaccuracies. With typical settings, the
+DMI sensitivity can be improved by 3-fold while retaining the capability to
+detect local signal variations.
+
+
+
+ 56. 标题:An Element-wise RSAV Algorithm for Unconstrained Optimization Problems
+ 编号:[222]
+ 链接:https://arxiv.org/abs/2309.04013
+ 作者:Shiheng Zhang, Jiahao Zhang, Jie Shen, Guang Lin
+ 备注:25 pages, 7 figures
+ 关键词:scalar auxiliary variable, element-wise relaxed scalar, unconditional energy dissipation, energy dissipation law, relaxed scalar auxiliary
+
+ 点击查看摘要
+ We present a novel optimization algorithm, element-wise relaxed scalar
+auxiliary variable (E-RSAV), that satisfies an unconditional energy dissipation
+law and exhibits improved alignment between the modified and the original
+energy. Our algorithm features rigorous proofs of linear convergence in the
+convex setting. Furthermore, we present a simple accelerated algorithm that
+improves the linear convergence rate to super-linear in the univariate case. We
+also propose an adaptive version of E-RSAV with Steffensen step size. We
+validate the robustness and fast convergence of our algorithm through ample
+numerical experiments.
+
+
+
+ 57. 标题:Derivation of Coordinate Descent Algorithms from Optimal Control Theory
+ 编号:[224]
+ 链接:https://arxiv.org/abs/2309.03990
+ 作者:I. M. Ross
+ 备注:
+ 关键词:central source emanating, disparate optimization algorithms, optimal control theory, coordinate descent algorithms, descent algorithms
+
+ 点击查看摘要
+ Recently, it was posited that disparate optimization algorithms may be
+coalesced in terms of a central source emanating from optimal control theory.
+Here we further this proposition by showing how coordinate descent algorithms
+may be derived from this emerging new principle. In particular, we show that
+basic coordinate descent algorithms can be derived using a maximum principle
+and a collection of max functions as "control" Lyapunov functions. The
+convergence of the resulting coordinate descent algorithms is thus connected to
+the controlled dissipation of their corresponding Lyapunov functions. The
+operational metric for the search vector in all cases is given by the Hessian
+of the convex objective function.
+
+
+
+ 58. 标题:Beyond attention: deriving biologically interpretable insights from weakly-supervised multiple-instance learning models
+ 编号:[226]
+ 链接:https://arxiv.org/abs/2309.03925
+ 作者:Willem Bonnaffé, CRUK ICGC Prostate Group, Freddie Hamdy, Yang Hu, Ian Mills, Jens Rittscher, Clare Verrill, Dan J. Woodcock
+ 备注:
+ 关键词:multiple instance learning, attention-based multiple instance, Recent advances, instance learning, digital pathology
+
+ 点击查看摘要
+ Recent advances in attention-based multiple instance learning (MIL) have
+improved our insights into the tissue regions that models rely on to make
+predictions in digital pathology. However, the interpretability of these
+approaches is still limited. In particular, they do not report whether
+high-attention regions are positively or negatively associated with the class
+labels or how well these regions correspond to previously established clinical
+and biological knowledge. We address this by introducing a post-training
+methodology to analyse MIL models. Firstly, we introduce
+prediction-attention-weighted (PAW) maps by combining tile-level attention and
+prediction scores produced by a refined encoder, allowing us to quantify the
+predictive contribution of high-attention regions. Secondly, we introduce a
+biological feature instantiation technique by integrating PAW maps with nuclei
+segmentation masks. This further improves interpretability by providing
+biologically meaningful features related to the cellular organisation of the
+tissue and facilitates comparisons with known clinical features. We illustrate
+the utility of our approach by comparing PAW maps obtained for prostate cancer
+diagnosis (i.e. samples containing malignant tissue, 381/516 tissue samples)
+and prognosis (i.e. samples from patients with biochemical recurrence following
+surgery, 98/663 tissue samples) in a cohort of patients from the international
+cancer genome consortium (ICGC UK Prostate Group). Our approach reveals that
+regions that are predictive of adverse prognosis do not tend to co-locate with
+the tumour regions, indicating that non-cancer cells should also be studied
+when evaluating prognosis.
+
+
+
+ 59. 标题:A hybrid quantum-classical fusion neural network to improve protein-ligand binding affinity predictions for drug discovery
+ 编号:[227]
+ 链接:https://arxiv.org/abs/2309.03919
+ 作者:S. Banerjee, S. He Yuxun, S. Konakanchi, L. Ogunfowora, S. Roy, S. Selvaras, L. Domingo, M. Chehimi, M. Djukic, C. Johnson
+ 备注:5 pages, 3 figures
+ 关键词:influence disease progression, proteins directly influence, directly influence disease, prospective drug molecules, disease progression
+
+ 点击查看摘要
+ The field of drug discovery hinges on the accurate prediction of binding
+affinity between prospective drug molecules and target proteins, especially
+when such proteins directly influence disease progression. However, estimating
+binding affinity demands significant financial and computational resources.
+While state-of-the-art methodologies employ classical machine learning (ML)
+techniques, emerging hybrid quantum machine learning (QML) models have shown
+promise for enhanced performance, owing to their inherent parallelism and
+capacity to manage exponential increases in data dimensionality. Despite these
+advances, existing models encounter issues related to convergence stability and
+prediction accuracy. This paper introduces a novel hybrid quantum-classical
+deep learning model tailored for binding affinity prediction in drug discovery.
+Specifically, the proposed model synergistically integrates 3D and spatial
+graph convolutional neural networks within an optimized quantum architecture.
+Simulation results demonstrate a 6% improvement in prediction accuracy relative
+to existing classical models, as well as a significantly more stable
+convergence performance compared to previous classical approaches.
+
+
+
+ 60. 标题:DrugChat: Towards Enabling ChatGPT-Like Capabilities on Drug Molecule Graphs
+ 编号:[228]
+ 链接:https://arxiv.org/abs/2309.03907
+ 作者:Youwei Liang, Ruiyi Zhang, Li Zhang, Pengtao Xie
+ 备注:
+ 关键词:guiding lead optimization, streamlining clinical trials, accelerating drug discovery, aiding drug repurposing, pharmaceutical research
+
+ 点击查看摘要
+ A ChatGPT-like system for drug compounds could be a game-changer in
+pharmaceutical research, accelerating drug discovery, enhancing our
+understanding of structure-activity relationships, guiding lead optimization,
+aiding drug repurposing, reducing the failure rate, and streamlining clinical
+trials. In this work, we make an initial attempt towards enabling ChatGPT-like
+capabilities on drug molecule graphs, by developing a prototype system
+DrugChat. DrugChat works in a similar way as ChatGPT. Users upload a compound
+molecule graph and ask various questions about this compound. DrugChat will
+answer these questions in a multi-turn, interactive manner. The DrugChat system
+consists of a graph neural network (GNN), a large language model (LLM), and an
+adaptor. The GNN takes a compound molecule graph as input and learns a
+representation for this graph. The adaptor transforms the graph representation
+produced by the GNN into another representation that is acceptable to the LLM.
+The LLM takes the compound representation transformed by the adaptor and users'
+questions about this compound as inputs and generates answers. All these
+components are trained end-to-end. To train DrugChat, we collected instruction
+tuning datasets which contain 10,834 drug compounds and 143,517 question-answer
+pairs. The code and data is available at
+\url{this https URL}
+
+
+
+ 61. 标题:R2D2: Deep neural network series for near real-time high-dynamic range imaging in radio astronomy
+ 编号:[230]
+ 链接:https://arxiv.org/abs/2309.03291
+ 作者:Aghabiglou A, Chu C S, Jackson A, Dabbech A, Wiaux Y
+ 备注:10 pages, 5 figures, 1 Table
+ 关键词:high-resolution high-dynamic range, high-dynamic range synthesis, range synthesis imaging, high-resolution high-dynamic, AIRI and uSARA
+
+ 点击查看摘要
+ We present a novel AI approach for high-resolution high-dynamic range
+synthesis imaging by radio interferometry (RI) in astronomy. R2D2, standing for
+"{R}esidual-to-{R}esidual {D}NN series for high-{D}ynamic range imaging", is a
+model-based data-driven approach relying on hybrid deep neural networks (DNNs)
+and data-consistency updates. Its reconstruction is built as a series of
+residual images estimated as the outputs of DNNs, each taking the residual
+dirty image of the previous iteration as an input. The approach can be
+interpreted as a learned version of a matching pursuit approach, whereby model
+components are iteratively identified from residual dirty images, and of which
+CLEAN is a well-known example. We propose two variants of the R2D2 model, built
+upon two distinctive DNN architectures: a standard U-Net, and a novel unrolled
+architecture. We demonstrate their use for monochromatic intensity imaging on
+highly-sensitive observations of the radio galaxy Cygnus~A at S band, from the
+Very Large Array (VLA). R2D2 is validated against CLEAN and the recent RI
+algorithms AIRI and uSARA, which respectively inject a learned implicit
+regularization and an advanced handcrafted sparsity-based regularization into
+the RI data. With only few terms in its series, the R2D2 model is able to
+deliver high-precision imaging, significantly superior to CLEAN and matching
+the precision of AIRI and uSARA. In terms of computational efficiency, R2D2
+runs at a fraction of the cost of AIRI and uSARA, and is also faster than
+CLEAN, opening the door to real-time precision imaging in RI.
+
+
+
+ 62. 标题:Scalable precision wide-field imaging in radio interferometry: II. AIRI validated on ASKAP data
+ 编号:[231]
+ 链接:https://arxiv.org/abs/2302.14149
+ 作者:Amanda G. Wilber, Arwa Dabbech, Matthieu Terris, Adrian Jackson, Yves Wiaux
+ 备注:Accepted for publication in MNRAS
+ 关键词:Kilometre Array Pathfinder, Australian Square Kilometre, Square Kilometre Array, Array Pathfinder, Australian Square
+
+ 点击查看摘要
+ Accompanying Part I, this sequel delineates a validation of the recently
+proposed AI for Regularisation in radio-interferometric Imaging (AIRI)
+algorithm on observations from the Australian Square Kilometre Array Pathfinder
+(ASKAP). The monochromatic AIRI-ASKAP images showcased in this work are formed
+using the same parallelised and automated imaging framework described in Part
+I: ``uSARA validated on ASKAP data''. Using a Plug-and-Play approach, AIRI
+differs from uSARA by substituting a trained denoising deep neural network
+(DNN) for the proximal operator in the regularisation step of the
+forward-backward algorithm during deconvolution. We build a trained shelf of
+DNN denoisers which target the estimated image-dynamic-ranges of our selected
+data. Furthermore, we quantify variations of AIRI reconstructions when
+selecting the nearest DNN on the shelf versus using a universal DNN with the
+highest dynamic range, opening the door to a more complete framework that not
+only delivers image estimation but also quantifies epistemic model uncertainty.
+We continue our comparative analysis of source structure, diffuse flux
+measurements, and spectral index maps of selected target sources as imaged by
+AIRI and the algorithms in Part I -- uSARA and WSClean. Overall we see an
+improvement over uSARA and WSClean in the reconstruction of diffuse components
+in AIRI images. The scientific potential delivered by AIRI is evident in
+further imaging precision, more accurate spectral index maps, and a significant
+acceleration in deconvolution time, whereby AIRI is four times faster than its
+sub-iterative sparsity-based counterpart uSARA.
+
+
+
+ 63. 标题:First AI for deep super-resolution wide-field imaging in radio astronomy: unveiling structure in ESO 137--006
+ 编号:[232]
+ 链接:https://arxiv.org/abs/2207.11336
+ 作者:Arwa Dabbech, Matthieu Terris, Adrian Jackson, Mpati Ramatsoku, Oleg M. Smirnov, Yves Wiaux
+ 备注:accepted for publication in ApJL
+ 关键词:wide-field radio-interferometric imaging, 137-006 radio galaxy, wide-field radio-interferometric, radio-interferometric imaging, radio galaxy
+
+ 点击查看摘要
+ We introduce the first AI-based framework for deep, super-resolution,
+wide-field radio-interferometric imaging, and demonstrate it on observations of
+the ESO~137-006 radio galaxy. The algorithmic framework to solve the inverse
+problem for image reconstruction builds on a recent ``plug-and-play'' scheme
+whereby a denoising operator is injected as an image regulariser in an
+optimisation algorithm, which alternates until convergence between denoising
+steps and gradient-descent data-fidelity steps. We investigate handcrafted and
+learned variants of high-resolution high-dynamic range denoisers. We propose a
+parallel algorithm implementation relying on automated decompositions of the
+image into facets and the measurement operator into sparse low-dimensional
+blocks, enabling scalability to large data and image dimensions. We validate
+our framework for image formation at a wide field of view containing
+ESO~137-006, from 19 gigabytes of MeerKAT data at 1053 and 1399 MHz. The
+recovered maps exhibit significantly more resolution and dynamic range than
+CLEAN, revealing collimated synchrotron threads close to the galactic core.
+
+
+人工智能
+
+ 1. 标题:On the Actionability of Outcome Prediction
+ 编号:[1]
+ 链接:https://arxiv.org/abs/2309.04470
+ 作者:Lydia T. Liu, Solon Barocas, Jon Kleinberg, Karen Levy
+ 备注:14 pages, 3 figures
+ 关键词:social impact domains, Predicting future outcomes, prevalent application, application of machine, machine learning
+
+ 点击查看摘要
+ Predicting future outcomes is a prevalent application of machine learning in
+social impact domains. Examples range from predicting student success in
+education to predicting disease risk in healthcare. Practitioners recognize
+that the ultimate goal is not just to predict but to act effectively.
+Increasing evidence suggests that relying on outcome predictions for downstream
+interventions may not have desired results.
+In most domains there exists a multitude of possible interventions for each
+individual, making the challenge of taking effective action more acute. Even
+when causal mechanisms connecting the individual's latent states to outcomes is
+well understood, in any given instance (a specific student or patient),
+practitioners still need to infer -- from budgeted measurements of latent
+states -- which of many possible interventions will be most effective for this
+individual. With this in mind, we ask: when are accurate predictors of outcomes
+helpful for identifying the most suitable intervention?
+Through a simple model encompassing actions, latent states, and measurements,
+we demonstrate that pure outcome prediction rarely results in the most
+effective policy for taking actions, even when combined with other
+measurements. We find that except in cases where there is a single decisive
+action for improving the outcome, outcome prediction never maximizes "action
+value", the utility of taking actions. Making measurements of actionable latent
+states, where specific actions lead to desired outcomes, considerably enhances
+the action value compared to outcome prediction, and the degree of improvement
+depends on action costs and the outcome model. This analysis emphasizes the
+need to go beyond generic outcome prediction in interventional settings by
+incorporating knowledge of plausible actions and latent states.
+
+
+
+ 2. 标题:Subwords as Skills: Tokenization for Sparse-Reward Reinforcement Learning
+ 编号:[6]
+ 链接:https://arxiv.org/abs/2309.04459
+ 作者:David Yunis, Justin Jung, Falcon Dai, Matthew Walter
+ 备注:
+ 关键词:continuous action spaces, requirement of long, coordinated sequences, achieve any reward, difficult due
+
+ 点击查看摘要
+ Exploration in sparse-reward reinforcement learning is difficult due to the
+requirement of long, coordinated sequences of actions in order to achieve any
+reward. Moreover, in continuous action spaces there are an infinite number of
+possible actions, which only increases the difficulty of exploration. One class
+of methods designed to address these issues forms temporally extended actions,
+often called skills, from interaction data collected in the same domain, and
+optimizes a policy on top of this new action space. Typically such methods
+require a lengthy pretraining phase, especially in continuous action spaces, in
+order to form the skills before reinforcement learning can begin. Given prior
+evidence that the full range of the continuous action space is not required in
+such tasks, we propose a novel approach to skill-generation with two
+components. First we discretize the action space through clustering, and second
+we leverage a tokenization technique borrowed from natural language processing
+to generate temporally extended actions. Such a method outperforms baselines
+for skill-generation in several challenging sparse-reward domains, and requires
+orders-of-magnitude less computation in skill-generation and online rollouts.
+
+
+
+ 3. 标题:Variations and Relaxations of Normalizing Flows
+ 编号:[13]
+ 链接:https://arxiv.org/abs/2309.04433
+ 作者:Keegan Kelly, Lorena Piedras, Sukrit Rao, David Roth
+ 备注:
+ 关键词:simpler base distribution, Normalizing Flows, describe a class, series of bijective, simpler base
+
+ 点击查看摘要
+ Normalizing Flows (NFs) describe a class of models that express a complex
+target distribution as the composition of a series of bijective transformations
+over a simpler base distribution. By limiting the space of candidate
+transformations to diffeomorphisms, NFs enjoy efficient, exact sampling and
+density evaluation, enabling NFs to flexibly behave as both discriminative and
+generative models. Their restriction to diffeomorphisms, however, enforces that
+input, output and all intermediary spaces share the same dimension, limiting
+their ability to effectively represent target distributions with complex
+topologies. Additionally, in cases where the prior and target distributions are
+not homeomorphic, Normalizing Flows can leak mass outside of the support of the
+target. This survey covers a selection of recent works that combine aspects of
+other generative model classes, such as VAEs and score-based diffusion, and in
+doing so loosen the strict bijectivity constraints of NFs to achieve a balance
+of expressivity, training speed, sample efficiency and likelihood tractability.
+
+
+
+ 4. 标题:Create Your World: Lifelong Text-to-Image Diffusion
+ 编号:[15]
+ 链接:https://arxiv.org/abs/2309.04430
+ 作者:Gan Sun, Wenqi Liang, Jiahua Dong, Jun Li, Zhengming Ding, Yang Cong
+ 备注:15 pages,10 figures
+ 关键词:produce diverse high-quality, demonstrated excellent ability, diverse high-quality images, produce diverse, diverse high-quality
+
+ 点击查看摘要
+ Text-to-image generative models can produce diverse high-quality images of
+concepts with a text prompt, which have demonstrated excellent ability in image
+generation, image translation, etc. We in this work study the problem of
+synthesizing instantiations of a use's own concepts in a never-ending manner,
+i.e., create your world, where the new concepts from user are quickly learned
+with a few examples. To achieve this goal, we propose a Lifelong text-to-image
+Diffusion Model (L2DM), which intends to overcome knowledge "catastrophic
+forgetting" for the past encountered concepts, and semantic "catastrophic
+neglecting" for one or more concepts in the text prompt. In respect of
+knowledge "catastrophic forgetting", our L2DM framework devises a task-aware
+memory enhancement module and a elastic-concept distillation module, which
+could respectively safeguard the knowledge of both prior concepts and each past
+personalized concept. When generating images with a user text prompt, the
+solution to semantic "catastrophic neglecting" is that a concept attention
+artist module can alleviate the semantic neglecting from concept aspect, and an
+orthogonal attention module can reduce the semantic binding from attribute
+aspect. To the end, our model can generate more faithful image across a range
+of continual text prompts in terms of both qualitative and quantitative
+metrics, when comparing with the related state-of-the-art models. The code will
+be released at this https URL.
+
+
+
+ 5. 标题:Advanced Computing and Related Applications Leveraging Brain-inspired Spiking Neural Networks
+ 编号:[18]
+ 链接:https://arxiv.org/abs/2309.04426
+ 作者:Lyuyang Sima, Joseph Bucukovski, Erwan Carlson, Nicole L. Yien
+ 备注:
+ 关键词:sophisticated electromagnetic environment, increasingly sophisticated electromagnetic, show great potential, real-time information processing, spatio-temporal information processing
+
+ 点击查看摘要
+ In the rapid evolution of next-generation brain-inspired artificial
+intelligence and increasingly sophisticated electromagnetic environment, the
+most bionic characteristics and anti-interference performance of spiking neural
+networks show great potential in terms of computational speed, real-time
+information processing, and spatio-temporal information processing. Data
+processing. Spiking neural network is one of the cores of brain-like artificial
+intelligence, which realizes brain-like computing by simulating the structure
+and information transfer mode of biological neural networks. This paper
+summarizes the strengths, weaknesses and applicability of five neuronal models
+and analyzes the characteristics of five network topologies; then reviews the
+spiking neural network algorithms and summarizes the unsupervised learning
+algorithms based on synaptic plasticity rules and four types of supervised
+learning algorithms from the perspectives of unsupervised learning and
+supervised learning; finally focuses on the review of brain-like neuromorphic
+chips under research at home and abroad. This paper is intended to provide
+learning concepts and research orientations for the peers who are new to the
+research field of spiking neural networks through systematic summaries.
+
+
+
+ 6. 标题:SynthoGestures: A Novel Framework for Synthetic Dynamic Hand Gesture Generation for Driving Scenarios
+ 编号:[21]
+ 链接:https://arxiv.org/abs/2309.04421
+ 作者:Amr Gomaa, Robin Zitt, Guillermo Reyes, Antonio Krüger
+ 备注:Shorter versions are accepted as AutomotiveUI2023 Work in Progress and UIST2023 Poster Papers
+ 关键词:dynamic human-machine interfaces, Creating a diverse, challenging and time-consuming, diverse and comprehensive, dynamic human-machine
+
+ 点击查看摘要
+ Creating a diverse and comprehensive dataset of hand gestures for dynamic
+human-machine interfaces in the automotive domain can be challenging and
+time-consuming. To overcome this challenge, we propose using synthetic gesture
+datasets generated by virtual 3D models. Our framework utilizes Unreal Engine
+to synthesize realistic hand gestures, offering customization options and
+reducing the risk of overfitting. Multiple variants, including gesture speed,
+performance, and hand shape, are generated to improve generalizability. In
+addition, we simulate different camera locations and types, such as RGB,
+infrared, and depth cameras, without incurring additional time and cost to
+obtain these cameras. Experimental results demonstrate that our proposed
+framework,
+SynthoGestures\footnote{\url{this https URL}},
+improves gesture recognition accuracy and can replace or augment real-hand
+datasets. By saving time and effort in the creation of the data set, our tool
+accelerates the development of gesture recognition systems for automotive
+applications.
+
+
+
+ 7. 标题:Generalization Bounds: Perspectives from Information Theory and PAC-Bayes
+ 编号:[32]
+ 链接:https://arxiv.org/abs/2309.04381
+ 作者:Fredrik Hellström, Giuseppe Durisi, Benjamin Guedj, Maxim Raginsky
+ 备注:222 pages
+ 关键词:machine learning algorithms, theoretical machine learning, machine learning, learning algorithms, fundamental question
+
+ 点击查看摘要
+ A fundamental question in theoretical machine learning is generalization.
+Over the past decades, the PAC-Bayesian approach has been established as a
+flexible framework to address the generalization capabilities of machine
+learning algorithms, and design new ones. Recently, it has garnered increased
+interest due to its potential applicability for a variety of learning
+algorithms, including deep neural networks. In parallel, an
+information-theoretic view of generalization has developed, wherein the
+relation between generalization and various information measures has been
+established. This framework is intimately connected to the PAC-Bayesian
+approach, and a number of results have been independently discovered in both
+strands. In this monograph, we highlight this strong connection and present a
+unified treatment of generalization. We present techniques and results that the
+two perspectives have in common, and discuss the approaches and interpretations
+that differ. In particular, we demonstrate how many proofs in the area share a
+modular structure, through which the underlying ideas can be intuited. We pay
+special attention to the conditional mutual information (CMI) framework;
+analytical studies of the information complexity of learning algorithms; and
+the application of the proposed methods to deep learning. This monograph is
+intended to provide a comprehensive introduction to information-theoretic
+generalization bounds and their connection to PAC-Bayes, serving as a
+foundation from which the most recent developments are accessible. It is aimed
+broadly towards researchers with an interest in generalization and theoretical
+machine learning.
+
+
+
+ 8. 标题:Beyond Static Datasets: A Deep Interaction Approach to LLM Evaluation
+ 编号:[38]
+ 链接:https://arxiv.org/abs/2309.04369
+ 作者:Jiatong Li, Rui Li, Qi Liu
+ 备注:
+ 关键词:Large Language Models, Language Models, Large Language, LLMs, LLM evaluation methods
+
+ 点击查看摘要
+ Large Language Models (LLMs) have made progress in various real-world tasks,
+which stimulates requirements for the evaluation of LLMs. Existing LLM
+evaluation methods are mainly supervised signal-based which depends on static
+datasets and cannot evaluate the ability of LLMs in dynamic real-world
+scenarios where deep interaction widely exists. Other LLM evaluation methods
+are human-based which are costly and time-consuming and are incapable of
+large-scale evaluation of LLMs. To address the issues above, we propose a novel
+Deep Interaction-based LLM-evaluation framework. In our proposed framework,
+LLMs' performances in real-world domains can be evaluated from their deep
+interaction with other LLMs in elaborately designed evaluation tasks.
+Furthermore, our proposed framework is a general evaluation method that can be
+applied to a host of real-world tasks such as machine translation and code
+generation. We demonstrate the effectiveness of our proposed method through
+extensive experiments on four elaborately designed evaluation tasks.
+
+
+
+ 9. 标题:Active Learning for Classifying 2D Grid-Based Level Completability
+ 编号:[39]
+ 链接:https://arxiv.org/abs/2309.04367
+ 作者:Mahsa Bazzaz, Seth Cooper
+ 备注:4 pages, 3 figures
+ 关键词:Active learning, Super Mario Bros., procedural generators, solver agents, require a significant
+
+ 点击查看摘要
+ Determining the completability of levels generated by procedural generators
+such as machine learning models can be challenging, as it can involve the use
+of solver agents that often require a significant amount of time to analyze and
+solve levels. Active learning is not yet widely adopted in game evaluations,
+although it has been used successfully in natural language processing, image
+and speech recognition, and computer vision, where the availability of labeled
+data is limited or expensive. In this paper, we propose the use of active
+learning for learning level completability classification. Through an active
+learning approach, we train deep-learning models to classify the completability
+of generated levels for Super Mario Bros., Kid Icarus, and a Zelda-like game.
+We compare active learning for querying levels to label with completability
+against random queries. Our results show using an active learning approach to
+label levels results in better classifier performance with the same amount of
+labeled data.
+
+
+
+ 10. 标题:Zero-Shot Robustification of Zero-Shot Models With Foundation Models
+ 编号:[51]
+ 链接:https://arxiv.org/abs/2309.04344
+ 作者:Dyah Adila, Changho Shin, Linrong Cai, Frederic Sala
+ 备注:
+ 关键词:powerful paradigm, paradigm that enables, large pretrained models, models, large pretrained
+
+ 点击查看摘要
+ Zero-shot inference is a powerful paradigm that enables the use of large
+pretrained models for downstream classification tasks without further training.
+However, these models are vulnerable to inherited biases that can impact their
+performance. The traditional solution is fine-tuning, but this undermines the
+key advantage of pretrained models, which is their ability to be used
+out-of-the-box. We propose RoboShot, a method that improves the robustness of
+pretrained model embeddings in a fully zero-shot fashion. First, we use
+zero-shot language models (LMs) to obtain useful insights from task
+descriptions. These insights are embedded and used to remove harmful and boost
+useful components in embeddings -- without any supervision. Theoretically, we
+provide a simple and tractable model for biases in zero-shot embeddings and
+give a result characterizing under what conditions our approach can boost
+performance. Empirically, we evaluate RoboShot on nine image and NLP
+classification tasks and show an average improvement of 15.98% over several
+zero-shot baselines. Additionally, we demonstrate that RoboShot is compatible
+with a variety of pretrained and language models.
+
+
+
+ 11. 标题:Online Submodular Maximization via Online Convex Optimization
+ 编号:[53]
+ 链接:https://arxiv.org/abs/2309.04339
+ 作者:T. Si-Salem, G. Özcan, I. Nikolaou, E. Terzi, S. Ioannidis
+ 备注:Under review
+ 关键词:general matroid constraints, study monotone submodular, monotone submodular maximization, study monotone, maximization under general
+
+ 点击查看摘要
+ We study monotone submodular maximization under general matroid constraints
+in the online setting. We prove that online optimization of a large class of
+submodular functions, namely, weighted threshold potential functions, reduces
+to online convex optimization (OCO). This is precisely because functions in
+this class admit a concave relaxation; as a result, OCO policies, coupled with
+an appropriate rounding scheme, can be used to achieve sublinear regret in the
+combinatorial setting. We show that our reduction extends to many different
+versions of the online learning problem, including the dynamic regret, bandit,
+and optimistic-learning settings.
+
+
+
+ 12. 标题:Graph Neural Networks Use Graphs When They Shouldn't
+ 编号:[56]
+ 链接:https://arxiv.org/abs/2309.04332
+ 作者:Maya Bechler-Speicher, Ido Amos, Ran Gilad-Bachrach, Amir Globerson
+ 备注:
+ 关键词:including social networks, Graph Neural Networks, social networks, Neural Networks, including social
+
+ 点击查看摘要
+ Predictions over graphs play a crucial role in various domains, including
+social networks, molecular biology, medicine, and more. Graph Neural Networks
+(GNNs) have emerged as the dominant approach for learning on graph data.
+Instances of graph labeling problems consist of the graph-structure (i.e., the
+adjacency matrix), along with node-specific feature vectors. In some cases,
+this graph-structure is non-informative for the predictive task. For instance,
+molecular properties such as molar mass depend solely on the constituent atoms
+(node features), and not on the molecular structure. While GNNs have the
+ability to ignore the graph-structure in such cases, it is not clear that they
+will. In this work, we show that GNNs actually tend to overfit the
+graph-structure in the sense that they use it even when a better solution can
+be obtained by ignoring it. We examine this phenomenon with respect to
+different graph distributions and find that regular graphs are more robust to
+this overfitting. We then provide a theoretical explanation for this
+phenomenon, via analyzing the implicit bias of gradient-descent-based learning
+of GNNs in this setting. Finally, based on our empirical and theoretical
+findings, we propose a graph-editing method to mitigate the tendency of GNNs to
+overfit graph-structures that should be ignored. We show that this method
+indeed improves the accuracy of GNNs across multiple benchmarks.
+
+
+
+ 13. 标题:Incremental Learning of Humanoid Robot Behavior from Natural Interaction and Large Language Models
+ 编号:[61]
+ 链接:https://arxiv.org/abs/2309.04316
+ 作者:Leonard Bärmann, Rainer Kartmann, Fabian Peller-Konrad, Alex Waibel, Tamim Asfour
+ 备注:This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible. Submitted to the 2023 IEEE/RAS International Conference on Humanoid Robots (Humanoids). Supplementary video available at this https URL
+ 关键词:intuitive human-robot interaction, Natural-language dialog, dialog is key, key for intuitive, intuitive human-robot
+
+ 点击查看摘要
+ Natural-language dialog is key for intuitive human-robot interaction. It can
+be used not only to express humans' intents, but also to communicate
+instructions for improvement if a robot does not understand a command
+correctly. Of great importance is to endow robots with the ability to learn
+from such interaction experience in an incremental way to allow them to improve
+their behaviors or avoid mistakes in the future. In this paper, we propose a
+system to achieve incremental learning of complex behavior from natural
+interaction, and demonstrate its implementation on a humanoid robot. Building
+on recent advances, we present a system that deploys Large Language Models
+(LLMs) for high-level orchestration of the robot's behavior, based on the idea
+of enabling the LLM to generate Python statements in an interactive console to
+invoke both robot perception and action. The interaction loop is closed by
+feeding back human instructions, environment observations, and execution
+results to the LLM, thus informing the generation of the next statement.
+Specifically, we introduce incremental prompt learning, which enables the
+system to interactively learn from its mistakes. For that purpose, the LLM can
+call another LLM responsible for code-level improvements of the current
+interaction based on human feedback. The improved interaction is then saved in
+the robot's memory, and thus retrieved on similar requests. We integrate the
+system in the robot cognitive architecture of the humanoid robot ARMAR-6 and
+evaluate our methods both quantitatively (in simulation) and qualitatively (in
+simulation and real-world) by demonstrating generalized incrementally-learned
+knowledge.
+
+
+
+ 14. 标题:Federated Learning for Early Dropout Prediction on Healthy Ageing Applications
+ 编号:[63]
+ 链接:https://arxiv.org/abs/2309.04311
+ 作者:Christos Chrysanthos Nikolaidis, Vasileios Perifanis, Nikolaos Pavlidis, Pavlos S. Efraimidis
+ 备注:
+ 关键词:provide early interventions, social care applications, early interventions, provision of social, social care
+
+ 点击查看摘要
+ The provision of social care applications is crucial for elderly people to
+improve their quality of life and enables operators to provide early
+interventions. Accurate predictions of user dropouts in healthy ageing
+applications are essential since they are directly related to individual health
+statuses. Machine Learning (ML) algorithms have enabled highly accurate
+predictions, outperforming traditional statistical methods that struggle to
+cope with individual patterns. However, ML requires a substantial amount of
+data for training, which is challenging due to the presence of personal
+identifiable information (PII) and the fragmentation posed by regulations. In
+this paper, we present a federated machine learning (FML) approach that
+minimizes privacy concerns and enables distributed training, without
+transferring individual data. We employ collaborative training by considering
+individuals and organizations under FML, which models both cross-device and
+cross-silo learning scenarios. Our approach is evaluated on a real-world
+dataset with non-independent and identically distributed (non-iid) data among
+clients, class imbalance and label ambiguity. Our results show that data
+selection and class imbalance handling techniques significantly improve the
+predictive accuracy of models trained under FML, demonstrating comparable or
+superior predictive performance than traditional ML models.
+
+
+
+ 15. 标题:Navigating Out-of-Distribution Electricity Load Forecasting during COVID-19: A Continual Learning Approach Leveraging Human Mobility
+ 编号:[68]
+ 链接:https://arxiv.org/abs/2309.04296
+ 作者:Arian Prabowo, Kaixuan Chen, Hao Xue, Subbu Sethuvenkatraman, Flora D. Salim
+ 备注:10 pages, 2 figures, 5 tables, BuildSys '23
+ 关键词:distribution remains constant, data distribution remains, remains constant, deep learning algorithms, learning
+
+ 点击查看摘要
+ In traditional deep learning algorithms, one of the key assumptions is that
+the data distribution remains constant during both training and deployment.
+However, this assumption becomes problematic when faced with
+Out-of-Distribution periods, such as the COVID-19 lockdowns, where the data
+distribution significantly deviates from what the model has seen during
+training. This paper employs a two-fold strategy: utilizing continual learning
+techniques to update models with new data and harnessing human mobility data
+collected from privacy-preserving pedestrian counters located outside
+buildings. In contrast to online learning, which suffers from 'catastrophic
+forgetting' as newly acquired knowledge often erases prior information,
+continual learning offers a holistic approach by preserving past insights while
+integrating new data. This research applies FSNet, a powerful continual
+learning algorithm, to real-world data from 13 building complexes in Melbourne,
+Australia, a city which had the second longest total lockdown duration globally
+during the pandemic. Results underscore the crucial role of continual learning
+in accurate energy forecasting, particularly during Out-of-Distribution
+periods. Secondary data such as mobility and temperature provided ancillary
+support to the primary forecasting model. More importantly, while traditional
+methods struggled to adapt during lockdowns, models featuring at least online
+learning demonstrated resilience, with lockdown periods posing fewer challenges
+once armed with adaptive learning techniques. This study contributes valuable
+methodologies and insights to the ongoing effort to improve energy load
+forecasting during future Out-of-Distribution periods.
+
+
+
+ 16. 标题:FIMO: A Challenge Formal Dataset for Automated Theorem Proving
+ 编号:[69]
+ 链接:https://arxiv.org/abs/2309.04295
+ 作者:Chengwu Liu, Jianhao Shen, Huajian Xin, Zhengying Liu, Ye Yuan, Haiming Wang, Wei Ju, Chuanyang Zheng, Yichun Yin, Lin Li, Ming Zhang, Qun Liu
+ 备注:
+ 关键词:International Mathematical Olympiad, Mathematical Olympiad, International Mathematical, innovative dataset comprising, comprising formal mathematical
+
+ 点击查看摘要
+ We present FIMO, an innovative dataset comprising formal mathematical problem
+statements sourced from the International Mathematical Olympiad (IMO)
+Shortlisted Problems. Designed to facilitate advanced automated theorem proving
+at the IMO level, FIMO is currently tailored for the Lean formal language. It
+comprises 149 formal problem statements, accompanied by both informal problem
+descriptions and their corresponding LaTeX-based informal proofs. Through
+initial experiments involving GPT-4, our findings underscore the existing
+limitations in current methodologies, indicating a substantial journey ahead
+before achieving satisfactory IMO-level automated theorem proving outcomes.
+
+
+
+ 17. 标题:Fuzzy Fingerprinting Transformer Language-Models for Emotion Recognition in Conversations
+ 编号:[70]
+ 链接:https://arxiv.org/abs/2309.04292
+ 作者:Patrícia Pereira, Rui Ribeiro, Helena Moniz, Luisa Coheur, Joao Paulo Carvalho
+ 备注:FUZZ-IEEE 2023
+ 关键词:text classification technique, largely surpassed, surpassed in performance, Large Language Models-based, Large Pre-trained Language
+
+ 点击查看摘要
+ Fuzzy Fingerprints have been successfully used as an interpretable text
+classification technique, but, like most other techniques, have been largely
+surpassed in performance by Large Pre-trained Language Models, such as BERT or
+RoBERTa. These models deliver state-of-the-art results in several Natural
+Language Processing tasks, namely Emotion Recognition in Conversations (ERC),
+but suffer from the lack of interpretability and explainability. In this paper,
+we propose to combine the two approaches to perform ERC, as a means to obtain
+simpler and more interpretable Large Language Models-based classifiers. We
+propose to feed the utterances and their previous conversational turns to a
+pre-trained RoBERTa, obtaining contextual embedding utterance representations,
+that are then supplied to an adapted Fuzzy Fingerprint classification module.
+We validate our approach on the widely used DailyDialog ERC benchmark dataset,
+in which we obtain state-of-the-art level results using a much lighter model.
+
+
+
+ 18. 标题:LLMCad: Fast and Scalable On-device Large Language Model Inference
+ 编号:[82]
+ 链接:https://arxiv.org/abs/2309.04255
+ 作者:Daliang Xu, Wangsong Yin, Xin Jin, Ying Zhang, Shiyun Wei, Mengwei Xu, Xuanzhe Liu
+ 备注:
+ 关键词:question answering, hold a crucial, Large Language Models, crucial position, mobile applications
+
+ 点击查看摘要
+ Generative tasks, such as text generation and question answering, hold a
+crucial position in the realm of mobile applications. Due to their sensitivity
+to privacy concerns, there is a growing demand for their execution directly on
+mobile devices. Currently, the execution of these generative tasks heavily
+depends on Large Language Models (LLMs). Nevertheless, the limited memory
+capacity of these devices presents a formidable challenge to the scalability of
+such models.
+In our research, we introduce LLMCad, an innovative on-device inference
+engine specifically designed for efficient generative Natural Language
+Processing (NLP) tasks. The core idea behind LLMCad revolves around model
+collaboration: a compact LLM, residing in memory, takes charge of generating
+the most straightforward tokens, while a high-precision LLM steps in to
+validate these tokens and rectify any identified errors. LLMCad incorporates
+three novel techniques: (1) Instead of generating candidate tokens in a
+sequential manner, LLMCad employs the smaller LLM to construct a token tree,
+encompassing a wider range of plausible token pathways. Subsequently, the
+larger LLM can efficiently validate all of these pathways simultaneously. (2)
+It employs a self-adjusting fallback strategy, swiftly initiating the
+verification process whenever the smaller LLM generates an erroneous token. (3)
+To ensure a continuous flow of token generation, LLMCad speculatively generates
+tokens during the verification process by implementing a compute-IO pipeline.
+Through an extensive series of experiments, LLMCad showcases an impressive
+token generation speed, achieving rates up to 9.3x faster than existing
+inference engines.
+
+
+
+ 19. 标题:UQ at #SMM4H 2023: ALEX for Public Health Analysis with Social Media
+ 编号:[98]
+ 链接:https://arxiv.org/abs/2309.04213
+ 作者:Yan Jiang, Ruihong Qiu, Yi Zhang, Zi Huang
+ 备注:
+ 关键词:public health emerge, public health, public health analysis, activities related, health
+
+ 点击查看摘要
+ As social media becomes increasingly popular, more and more activities
+related to public health emerge. Current techniques for public health analysis
+involve popular models such as BERT and large language models (LLMs). However,
+the costs of training in-domain LLMs for public health are especially
+expensive. Furthermore, such kinds of in-domain datasets from social media are
+generally imbalanced. To tackle these challenges, the data imbalance issue can
+be overcome by data augmentation and balanced training. Moreover, the ability
+of the LLMs can be effectively utilized by prompting the model properly. In
+this paper, a novel ALEX framework is proposed to improve the performance of
+public health analysis on social media by adopting an LLMs explanation
+mechanism. Results show that our ALEX model got the best performance among all
+submissions in both Task 2 and Task 4 with a high score in Task 1 in Social
+Media Mining for Health 2023 (SMM4H)[1]. Our code has been released at https://
+this http URL.
+
+
+
+ 20. 标题:Towards Mitigating Architecture Overfitting in Dataset Distillation
+ 编号:[107]
+ 链接:https://arxiv.org/abs/2309.04195
+ 作者:Xuyang Zhong, Chen Liu
+ 备注:
+ 关键词:demonstrated remarkable performance, Dataset distillation methods, Dataset distillation, distilled training data, neural networks trained
+
+ 点击查看摘要
+ Dataset distillation methods have demonstrated remarkable performance for
+neural networks trained with very limited training data. However, a significant
+challenge arises in the form of architecture overfitting: the distilled
+training data synthesized by a specific network architecture (i.e., training
+network) generates poor performance when trained by other network architectures
+(i.e., test networks). This paper addresses this issue and proposes a series of
+approaches in both architecture designs and training schemes which can be
+adopted together to boost the generalization performance across different
+network architectures on the distilled training data. We conduct extensive
+experiments to demonstrate the effectiveness and generality of our methods.
+Particularly, across various scenarios involving different sizes of distilled
+data, our approaches achieve comparable or superior performance to existing
+methods when training on the distilled data using networks with larger
+capacities.
+
+
+
+ 21. 标题:Knowledge-tuning Large Language Models with Structured Medical Knowledge Bases for Reliable Response Generation in Chinese
+ 编号:[116]
+ 链接:https://arxiv.org/abs/2309.04175
+ 作者:Haochun Wang, Sendong Zhao, Zewen Qiang, Zijian Li, Nuwa Xi, Yanrui Du, MuZhen Cai, Haoqiang Guo, Yuhan Chen, Haoming Xu, Bing Qin, Ting Liu
+ 备注:11 pages, 5 figures
+ 关键词:Large Language Models, natural language processing, diverse natural language, Language Models, demonstrated remarkable success
+
+ 点击查看摘要
+ Large Language Models (LLMs) have demonstrated remarkable success in diverse
+natural language processing (NLP) tasks in general domains. However, LLMs
+sometimes generate responses with the hallucination about medical facts due to
+limited domain knowledge. Such shortcomings pose potential risks in the
+utilization of LLMs within medical contexts. To address this challenge, we
+propose knowledge-tuning, which leverages structured medical knowledge bases
+for the LLMs to grasp domain knowledge efficiently and facilitate reliable
+response generation. We also release cMedKnowQA, a Chinese medical knowledge
+question-answering dataset constructed from medical knowledge bases to assess
+the medical knowledge proficiency of LLMs. Experimental results show that the
+LLMs which are knowledge-tuned with cMedKnowQA, can exhibit higher levels of
+accuracy in response generation compared with vanilla instruction-tuning and
+offer a new reliable way for the domain adaptation of LLMs.
+
+
+
+ 22. 标题:Manifold-based Verbalizer Space Re-embedding for Tuning-free Prompt-based Classification
+ 编号:[117]
+ 链接:https://arxiv.org/abs/2309.04174
+ 作者:Haochun Wang, Sendong Zhao, Chi Liu, Nuwa Xi, Muzhen Cai, Bing Qin, Ting Liu
+ 备注:11 pages, 3 figures
+ 关键词:cloze question format, question format utilizing, classification adapts tasks, filled tokens, adapts tasks
+
+ 点击查看摘要
+ Prompt-based classification adapts tasks to a cloze question format utilizing
+the [MASK] token and the filled tokens are then mapped to labels through
+pre-defined verbalizers. Recent studies have explored the use of verbalizer
+embeddings to reduce labor in this process. However, all existing studies
+require a tuning process for either the pre-trained models or additional
+trainable embeddings. Meanwhile, the distance between high-dimensional
+verbalizer embeddings should not be measured by Euclidean distance due to the
+potential for non-linear manifolds in the representation space. In this study,
+we propose a tuning-free manifold-based space re-embedding method called
+Locally Linear Embedding with Intra-class Neighborhood Constraint (LLE-INC) for
+verbalizer embeddings, which preserves local properties within the same class
+as guidance for classification. Experimental results indicate that even without
+tuning any parameters, our LLE-INC is on par with automated verbalizers with
+parameter tuning. And with the parameter updating, our approach further
+enhances prompt-based tuning by up to 3.2%. Furthermore, experiments with the
+LLaMA-7B&13B indicate that LLE-INC is an efficient tuning-free classification
+approach for the hyper-scale language models.
+
+
+
+ 23. 标题:Leveraging Prototype Patient Representations with Feature-Missing-Aware Calibration to Mitigate EHR Data Sparsity
+ 编号:[123]
+ 链接:https://arxiv.org/abs/2309.04160
+ 作者:Yinghao Zhu, Zixiang Wang, Long He, Shiyun Xie, Zixi Chen, Jingkun An, Liantao Ma, Chengwei Pan
+ 备注:
+ 关键词:Electronic Health Record, Health Record, exhibits sparse characteristics, frequently exhibits sparse, data frequently exhibits
+
+ 点击查看摘要
+ Electronic Health Record (EHR) data frequently exhibits sparse
+characteristics, posing challenges for predictive modeling. Current direct
+imputation such as matrix imputation approaches hinge on referencing analogous
+rows or columns to complete raw missing data and do not differentiate between
+imputed and actual values. As a result, models may inadvertently incorporate
+irrelevant or deceptive information with respect to the prediction objective,
+thereby compromising the efficacy of downstream performance. While some methods
+strive to recalibrate or augment EHR embeddings after direct imputation, they
+often mistakenly prioritize imputed features. This misprioritization can
+introduce biases or inaccuracies into the model. To tackle these issues, our
+work resorts to indirect imputation, where we leverage prototype
+representations from similar patients to obtain a denser embedding. Recognizing
+the limitation that missing features are typically treated the same as present
+ones when measuring similar patients, our approach designs a feature confidence
+learner module. This module is sensitive to the missing feature status,
+enabling the model to better judge the reliability of each feature. Moreover,
+we propose a novel patient similarity metric that takes feature confidence into
+account, ensuring that evaluations are not based merely on potentially
+inaccurate imputed values. Consequently, our work captures dense prototype
+patient representations with feature-missing-aware calibration process.
+Comprehensive experiments demonstrate that designed model surpasses established
+EHR-focused models with a statistically significant improvement on MIMIC-III
+and MIMIC-IV datasets in-hospital mortality outcome prediction task. The code
+is publicly available at \url{https://anonymous.4open.science/r/SparseEHR} to
+assure the reproducibility.
+
+
+
+ 24. 标题:NESTLE: a No-Code Tool for Statistical Analysis of Legal Corpus
+ 编号:[131]
+ 链接:https://arxiv.org/abs/2309.04146
+ 作者:Kyoungyeon Cho, Seungkum Han, Wonseok Hwang
+ 备注:
+ 关键词:statistical analysis, system, NESTLE, analysis, provide valuable legal
+
+ 点击查看摘要
+ The statistical analysis of large scale legal corpus can provide valuable
+legal insights. For such analysis one needs to (1) select a subset of the
+corpus using document retrieval tools, (2) structuralize text using information
+extraction (IE) systems, and (3) visualize the data for the statistical
+analysis. Each process demands either specialized tools or programming skills
+whereas no comprehensive unified "no-code" tools have been available.
+Especially for IE, if the target information is not predefined in the ontology
+of the IE system, one needs to build their own system. Here we provide NESTLE,
+a no code tool for large-scale statistical analysis of legal corpus. With
+NESTLE, users can search target documents, extract information, and visualize
+the structured data all via the chat interface with accompanying auxiliary GUI
+for the fine-level control. NESTLE consists of three main components: a search
+engine, an end-to-end IE system, and a Large Language Model (LLM) that glues
+the whole components together and provides the chat interface. Powered by LLM
+and the end-to-end IE system, NESTLE can extract any type of information that
+has not been predefined in the IE system opening up the possibility of
+unlimited customizable statistical analysis of the corpus without writing a
+single line of code. The use of the custom end-to-end IE system also enables
+faster and low-cost IE on large scale corpus. We validate our system on 15
+Korean precedent IE tasks and 3 legal text classification tasks from LEXGLUE.
+The comprehensive experiments reveal NESTLE can achieve GPT-4 comparable
+performance by training the internal IE module with 4 human-labeled, and 192
+LLM-labeled examples. The detailed analysis provides the insight on the
+trade-off between accuracy, time, and cost in building such system.
+
+
+
+ 25. 标题:Trustworthy and Synergistic Artificial Intelligence for Software Engineering: Vision and Roadmaps
+ 编号:[133]
+ 链接:https://arxiv.org/abs/2309.04142
+ 作者:David Lo
+ 备注:This paper is to appear in the post-proceedings of the Future of Software Engineering (FoSE) track of the 45th IEEE/ACM International Conference on Software Engineering (ICSE 2023)
+ 关键词:enhancing developer productivity, elevating software quality, software engineering, devising automated solutions, automated solutions aimed
+
+ 点击查看摘要
+ For decades, much software engineering research has been dedicated to
+devising automated solutions aimed at enhancing developer productivity and
+elevating software quality. The past two decades have witnessed an unparalleled
+surge in the development of intelligent solutions tailored for software
+engineering tasks. This momentum established the Artificial Intelligence for
+Software Engineering (AI4SE) area, which has swiftly become one of the most
+active and popular areas within the software engineering field.
+This Future of Software Engineering (FoSE) paper navigates through several
+focal points. It commences with a succinct introduction and history of AI4SE.
+Thereafter, it underscores the core challenges inherent to AI4SE, particularly
+highlighting the need to realize trustworthy and synergistic AI4SE.
+Progressing, the paper paints a vision for the potential leaps achievable if
+AI4SE's key challenges are surmounted, suggesting a transition towards Software
+Engineering 2.0. Two strategic roadmaps are then laid out: one centered on
+realizing trustworthy AI4SE, and the other on fostering synergistic AI4SE.
+While this paper may not serve as a conclusive guide, its intent is to catalyze
+further progress. The ultimate aspiration is to position AI4SE as a linchpin in
+redefining the horizons of software engineering, propelling us toward Software
+Engineering 2.0.
+
+
+
+ 26. 标题:Proprioceptive External Torque Learning for Floating Base Robot and its Applications to Humanoid Locomotion
+ 编号:[135]
+ 链接:https://arxiv.org/abs/2309.04138
+ 作者:Daegyu Lim, Myeong-Ju Kim, Junhyeok Cha, Donghyeon Kim, Jaeheung Park
+ 备注:Accepted by 2023 IROS conference
+ 关键词:achieving stable locomotion, external joint torque, contact wrench, essential for achieving, locomotion of humanoids
+
+ 点击查看摘要
+ The estimation of external joint torque and contact wrench is essential for
+achieving stable locomotion of humanoids and safety-oriented robots. Although
+the contact wrench on the foot of humanoids can be measured using a
+force-torque sensor (FTS), FTS increases the cost, inertia, complexity, and
+failure possibility of the system. This paper introduces a method for learning
+external joint torque solely using proprioceptive sensors (encoders and IMUs)
+for a floating base robot. For learning, the GRU network is used and random
+walking data is collected. Real robot experiments demonstrate that the network
+can estimate the external torque and contact wrench with significantly smaller
+errors compared to the model-based method, momentum observer (MOB) with
+friction modeling. The study also validates that the estimated contact wrench
+can be utilized for zero moment point (ZMP) feedback control, enabling stable
+walking. Moreover, even when the robot's feet and the inertia of the upper body
+are changed, the trained network shows consistent performance with a
+model-based calibration. This result demonstrates the possibility of removing
+FTS on the robot, which reduces the disadvantages of hardware sensors. The
+summary video is available at this https URL.
+
+
+
+ 27. 标题:Weakly Supervised Point Clouds Transformer for 3D Object Detection
+ 编号:[143]
+ 链接:https://arxiv.org/abs/2309.04105
+ 作者:Zuojin Tang, Bo Sun, Tongwei Ma, Daosheng Li, Zhenhui Xu
+ 备注:International Conference on Intelligent Transportation Systems (ITSC), 2022
+ 关键词:object detection, scene understanding, Voting Proposal Module, network, Unsupervised Voting Proposal
+
+ 点击查看摘要
+ The annotation of 3D datasets is required for semantic-segmentation and
+object detection in scene understanding. In this paper we present a framework
+for the weakly supervision of a point clouds transformer that is used for 3D
+object detection. The aim is to decrease the required amount of supervision
+needed for training, as a result of the high cost of annotating a 3D datasets.
+We propose an Unsupervised Voting Proposal Module, which learns randomly preset
+anchor points and uses voting network to select prepared anchor points of high
+quality. Then it distills information into student and teacher network. In
+terms of student network, we apply ResNet network to efficiently extract local
+characteristics. However, it also can lose much global information. To provide
+the input which incorporates the global and local information as the input of
+student networks, we adopt the self-attention mechanism of transformer to
+extract global features, and the ResNet layers to extract region proposals. The
+teacher network supervises the classification and regression of the student
+network using the pre-trained model on ImageNet. On the challenging KITTI
+datasets, the experimental results have achieved the highest level of average
+precision compared with the most recent weakly supervised 3D object detectors.
+
+
+
+ 28. 标题:Curve Your Attention: Mixed-Curvature Transformers for Graph Representation Learning
+ 编号:[149]
+ 链接:https://arxiv.org/abs/2309.04082
+ 作者:Sungjun Cho, Seunghyuk Cho, Sungwoo Park, Hankook Lee, Honglak Lee, Moontae Lee
+ 备注:19 pages, 7 figures
+ 关键词:typical Euclidean space, naturally exhibit hierarchical, typical Euclidean, Real-world graphs naturally, graphs naturally exhibit
+
+ 点击查看摘要
+ Real-world graphs naturally exhibit hierarchical or cyclical structures that
+are unfit for the typical Euclidean space. While there exist graph neural
+networks that leverage hyperbolic or spherical spaces to learn representations
+that embed such structures more accurately, these methods are confined under
+the message-passing paradigm, making the models vulnerable against side-effects
+such as oversmoothing and oversquashing. More recent work have proposed global
+attention-based graph Transformers that can easily model long-range
+interactions, but their extensions towards non-Euclidean geometry are yet
+unexplored. To bridge this gap, we propose Fully Product-Stereographic
+Transformer, a generalization of Transformers towards operating entirely on the
+product of constant curvature spaces. When combined with tokenized graph
+Transformers, our model can learn the curvature appropriate for the input graph
+in an end-to-end fashion, without the need of additional tuning on different
+curvature initializations. We also provide a kernelized approach to
+non-Euclidean attention, which enables our model to run in time and memory cost
+linear to the number of nodes and edges while respecting the underlying
+geometry. Experiments on graph reconstruction and node classification
+demonstrate the benefits of generalizing Transformers to the non-Euclidean
+domain.
+
+
+
+ 29. 标题:SayNav: Grounding Large Language Models for Dynamic Planning to Navigation in New Environments
+ 编号:[152]
+ 链接:https://arxiv.org/abs/2309.04077
+ 作者:Abhinav Rajvanshi, Karan Sikka, Xiao Lin, Bhoram Lee, Han-Pang Chiu, Alvaro Velasquez
+ 备注:
+ 关键词:Large Language Models, dynamic planning capabilities, complex navigation tasks, Semantic reasoning, perform complex navigation
+
+ 点击查看摘要
+ Semantic reasoning and dynamic planning capabilities are crucial for an
+autonomous agent to perform complex navigation tasks in unknown environments.
+It requires a large amount of common-sense knowledge, that humans possess, to
+succeed in these tasks. We present SayNav, a new approach that leverages human
+knowledge from Large Language Models (LLMs) for efficient generalization to
+complex navigation tasks in unknown large-scale environments. SayNav uses a
+novel grounding mechanism, that incrementally builds a 3D scene graph of the
+explored environment as inputs to LLMs, for generating feasible and
+contextually appropriate high-level plans for navigation. The LLM-generated
+plan is then executed by a pre-trained low-level planner, that treats each
+planned step as a short-distance point-goal navigation sub-task. SayNav
+dynamically generates step-by-step instructions during navigation and
+continuously refines future steps based on newly perceived information. We
+evaluate SayNav on a new multi-object navigation task, that requires the agent
+to utilize a massive amount of human knowledge to efficiently search multiple
+different objects in an unknown environment. SayNav outperforms an oracle based
+Point-nav baseline, achieving a success rate of 95.35% (vs 56.06% for the
+baseline), under the ideal settings on this task, highlighting its ability to
+generate dynamic plans for successfully locating objects in large-scale new
+environments.
+
+
+
+ 30. 标题:Computationally Efficient Data-Driven Discovery and Linear Representation of Nonlinear Systems For Control
+ 编号:[154]
+ 链接:https://arxiv.org/abs/2309.04074
+ 作者:Madhur Tiwari, George Nehma, Bethany Lusch
+ 备注:
+ 关键词:Koopman operator theory, Koopman operator, work focuses, focuses on developing, developing a data-driven
+
+ 点击查看摘要
+ This work focuses on developing a data-driven framework using Koopman
+operator theory for system identification and linearization of nonlinear
+systems for control. Our proposed method presents a deep learning framework
+with recursive learning. The resulting linear system is controlled using a
+linear quadratic control. An illustrative example using a pendulum system is
+presented with simulations on noisy data. We show that our proposed method is
+trained more efficiently and is more accurate than an autoencoder baseline.
+
+
+
+ 31. 标题:Inferring physical laws by artificial intelligence based causal models
+ 编号:[156]
+ 链接:https://arxiv.org/abs/2309.04069
+ 作者:Jorawar Singh, Kishor Bharti, Arvind
+ 备注:Latex 12 pages, 16 figures
+ 关键词:Artificial General Intelligence, knowledge creation, adding new dimensions, Artificial Intelligence, Artificial General
+
+ 点击查看摘要
+ The advances in Artificial Intelligence (AI) and Machine Learning (ML) have
+opened up many avenues for scientific research, and are adding new dimensions
+to the process of knowledge creation. However, even the most powerful and
+versatile of ML applications till date are primarily in the domain of analysis
+of associations and boil down to complex data fitting. Judea Pearl has pointed
+out that Artificial General Intelligence must involve interventions involving
+the acts of doing and imagining. Any machine assisted scientific discovery thus
+must include casual analysis and interventions. In this context, we propose a
+causal learning model of physical principles, which not only recognizes
+correlations but also brings out casual relationships. We use the principles of
+causal inference and interventions to study the cause-and-effect relationships
+in the context of some well-known physical phenomena. We show that this
+technique can not only figure out associations among data, but is also able to
+correctly ascertain the cause-and-effect relations amongst the variables,
+thereby strengthening (or weakening) our confidence in the proposed model of
+the underlying physical process.
+
+
+
+ 32. 标题:3D Denoisers are Good 2D Teachers: Molecular Pretraining via Denoising and Cross-Modal Distillation
+ 编号:[159]
+ 链接:https://arxiv.org/abs/2309.04062
+ 作者:Sungjun Cho, Dae-Woong Jeong, Sung Moon Ko, Jinwoo Kim, Sehui Han, Seunghoon Hong, Honglak Lee, Moontae Lee
+ 备注:16 pages, 5 figures
+ 关键词:obtaining ground-truth labels, large unlabeled data, ground-truth labels, large unlabeled, unlabeled data
+
+ 点击查看摘要
+ Pretraining molecular representations from large unlabeled data is essential
+for molecular property prediction due to the high cost of obtaining
+ground-truth labels. While there exist various 2D graph-based molecular
+pretraining approaches, these methods struggle to show statistically
+significant gains in predictive performance. Recent work have thus instead
+proposed 3D conformer-based pretraining under the task of denoising, which led
+to promising results. During downstream finetuning, however, models trained
+with 3D conformers require accurate atom-coordinates of previously unseen
+molecules, which are computationally expensive to acquire at scale. In light of
+this limitation, we propose D&D, a self-supervised molecular representation
+learning framework that pretrains a 2D graph encoder by distilling
+representations from a 3D denoiser. With denoising followed by cross-modal
+knowledge distillation, our approach enjoys use of knowledge obtained from
+denoising as well as painless application to downstream tasks with no access to
+accurate conformers. Experiments on real-world molecular property prediction
+datasets show that the graph encoder trained via D&D can infer 3D information
+based on the 2D graph and shows superior performance and label-efficiency
+against other baselines.
+
+
+
+ 33. 标题:ConDA: Contrastive Domain Adaptation for AI-generated Text Detection
+ 编号:[180]
+ 链接:https://arxiv.org/abs/2309.03992
+ 作者:Amrita Bhattacharjee, Tharindu Kumarage, Raha Moraffah, Huan Liu
+ 备注:Accepted at IJCNLP-AACL 2023 main track
+ 关键词:Large language models, Large language, language models, including journalistic, journalistic news articles
+
+ 点击查看摘要
+ Large language models (LLMs) are increasingly being used for generating text
+in a variety of use cases, including journalistic news articles. Given the
+potential malicious nature in which these LLMs can be used to generate
+disinformation at scale, it is important to build effective detectors for such
+AI-generated text. Given the surge in development of new LLMs, acquiring
+labeled training data for supervised detectors is a bottleneck. However, there
+might be plenty of unlabeled text data available, without information on which
+generator it came from. In this work we tackle this data problem, in detecting
+AI-generated news text, and frame the problem as an unsupervised domain
+adaptation task. Here the domains are the different text generators, i.e. LLMs,
+and we assume we have access to only the labeled source data and unlabeled
+target data. We develop a Contrastive Domain Adaptation framework, called
+ConDA, that blends standard domain adaptation techniques with the
+representation power of contrastive learning to learn domain invariant
+representations that are effective for the final unsupervised detection task.
+Our experiments demonstrate the effectiveness of our framework, resulting in
+average performance gains of 31.7% from the best performing baselines, and
+within 0.8% margin of a fully supervised detector. All our code and data is
+available at this https URL.
+
+
+
+ 34. 标题:Noisy Computing of the $\mathsf{OR}$ and $\mathsf{MAX}$ Functions
+ 编号:[182]
+ 链接:https://arxiv.org/abs/2309.03986
+ 作者:Banghua Zhu, Ziao Wang, Nadim Ghaddar, Jiantao Jiao, Lele Wang
+ 备注:
+ 关键词:mathsf, problem of computing, query is incorrect, queries correspond, noisy pairwise comparisons
+
+ 点击查看摘要
+ We consider the problem of computing a function of $n$ variables using noisy
+queries, where each query is incorrect with some fixed and known probability $p
+\in (0,1/2)$. Specifically, we consider the computation of the $\mathsf{OR}$
+function of $n$ bits (where queries correspond to noisy readings of the bits)
+and the $\mathsf{MAX}$ function of $n$ real numbers (where queries correspond
+to noisy pairwise comparisons). We show that an expected number of queries of
+\[ (1 \pm o(1)) \frac{n\log \frac{1}{\delta}}{D_{\mathsf{KL}}(p \| 1-p)} \] is
+both sufficient and necessary to compute both functions with a vanishing error
+probability $\delta = o(1)$, where $D_{\mathsf{KL}}(p \| 1-p)$ denotes the
+Kullback-Leibler divergence between $\mathsf{Bern}(p)$ and $\mathsf{Bern}(1-p)$
+distributions. Compared to previous work, our results tighten the dependence on
+$p$ in both the upper and lower bounds for the two functions.
+
+
+
+ 35. 标题:Large-Scale Automatic Audiobook Creation
+ 编号:[196]
+ 链接:https://arxiv.org/abs/2309.03926
+ 作者:Brendan Walsh, Mark Hamilton, Greg Newby, Xi Wang, Serena Ruan, Sheng Zhao, Lei He, Shaofei Zhang, Eric Dettinger, William T. Freeman, Markus Weimer
+ 备注:
+ 关键词:improve reader engagement, dramatically improve, improve reader, reader engagement, literature accessibility
+
+ 点击查看摘要
+ An audiobook can dramatically improve a work of literature's accessibility
+and improve reader engagement. However, audiobooks can take hundreds of hours
+of human effort to create, edit, and publish. In this work, we present a system
+that can automatically generate high-quality audiobooks from online e-books. In
+particular, we leverage recent advances in neural text-to-speech to create and
+release thousands of human-quality, open-license audiobooks from the Project
+Gutenberg e-book collection. Our method can identify the proper subset of
+e-book content to read for a wide collection of diversely structured books and
+can operate on hundreds of books in parallel. Our system allows users to
+customize an audiobook's speaking speed and style, emotional intonation, and
+can even match a desired voice using a small amount of sample audio. This work
+contributed over five thousand open-license audiobooks and an interactive demo
+that allows users to quickly create their own customized audiobooks. To listen
+to the audiobook collection visit \url{this https URL}.
+
+
+
+ 36. 标题:Automatic Algorithm Selection for Pseudo-Boolean Optimization with Given Computational Time Limits
+ 编号:[197]
+ 链接:https://arxiv.org/abs/2309.03924
+ 作者:Catalina Pezo, Dorit Hochbaum, Julio Godoy, Roberto Asin-Acha
+ 备注:
+ 关键词:Machine learning, based on predicted, proposed to automatically, automatically select, Traveling Salesperson
+
+ 点击查看摘要
+ Machine learning (ML) techniques have been proposed to automatically select
+the best solver from a portfolio of solvers, based on predicted performance.
+These techniques have been applied to various problems, such as Boolean
+Satisfiability, Traveling Salesperson, Graph Coloring, and others.
+These methods, known as meta-solvers, take an instance of a problem and a
+portfolio of solvers as input. They then predict the best-performing solver and
+execute it to deliver a solution. Typically, the quality of the solution
+improves with a longer computational time. This has led to the development of
+anytime selectors, which consider both the instance and a user-prescribed
+computational time limit. Anytime meta-solvers predict the best-performing
+solver within the specified time limit.
+Constructing an anytime meta-solver is considerably more challenging than
+building a meta-solver without the "anytime" feature. In this study, we focus
+on the task of designing anytime meta-solvers for the NP-hard optimization
+problem of Pseudo-Boolean Optimization (PBO), which generalizes Satisfiability
+and Maximum Satisfiability problems. The effectiveness of our approach is
+demonstrated via extensive empirical study in which our anytime meta-solver
+improves dramatically on the performance of Mixed Integer Programming solver
+Gurobi, which is the best-performing single solver in the portfolio. For
+example, out of all instances and time limits for which Gurobi failed to find
+feasible solutions, our meta-solver identified feasible solutions for 47% of
+these.
+
+
+
+ 37. 标题:A recommender for the management of chronic pain in patients undergoing spinal cord stimulation
+ 编号:[199]
+ 链接:https://arxiv.org/abs/2309.03918
+ 作者:Tigran Tchrakian, Mykhaylo Zayats, Alessandra Pascale, Dat Huynh, Pritish Parida, Carla Agurto Rios, Sergiy Zhuk, Jeffrey L. Rogers, ENVISION Studies Physician Author Group, Boston Scientific Research Scientists Consortium
+ 备注:
+ 关键词:SCS, Spinal cord stimulation, Spinal cord, pain, chronic pain
+
+ 点击查看摘要
+ Spinal cord stimulation (SCS) is a therapeutic approach used for the
+management of chronic pain. It involves the delivery of electrical impulses to
+the spinal cord via an implanted device, which when given suitable stimulus
+parameters can mask or block pain signals. Selection of optimal stimulation
+parameters usually happens in the clinic under the care of a provider whereas
+at-home SCS optimization is managed by the patient. In this paper, we propose a
+recommender system for the management of pain in chronic pain patients
+undergoing SCS. In particular, we use a contextual multi-armed bandit (CMAB)
+approach to develop a system that recommends SCS settings to patients with the
+aim of improving their condition. These recommendations, sent directly to
+patients though a digital health ecosystem, combined with a patient monitoring
+system closes the therapeutic loop around a chronic pain patient over their
+entire patient journey. We evaluated the system in a cohort of SCS-implanted
+ENVISION study subjects (this http URL ID: NCT03240588) using a
+combination of quality of life metrics and Patient States (PS), a novel measure
+of holistic outcomes. SCS recommendations provided statistically significant
+improvement in clinical outcomes (pain and/or QoL) in 85\% of all subjects
+(N=21). Among subjects in moderate PS (N=7) prior to receiving recommendations,
+100\% showed statistically significant improvements and 5/7 had improved PS
+dwell time. This analysis suggests SCS patients may benefit from SCS
+recommendations, resulting in additional clinical improvement on top of
+benefits already received from SCS therapy.
+
+
+
+ 38. 标题:Sequential Semantic Generative Communication for Progressive Text-to-Image Generation
+ 编号:[212]
+ 链接:https://arxiv.org/abs/2309.04287
+ 作者:Hyelin Nam, Jihong Park, Jinho Choi, Seong-Lyun Kim
+ 备注:4 pages, 2 figures, to be published in IEEE International Conference on Sensing, Communication, and Networking, Workshop on Semantic Communication for 6G (SC6G-SECON23)
+ 关键词:paper proposes, proposes new framework, communication system leveraging, leveraging promising generation, promising generation capabilities
+
+ 点击查看摘要
+ This paper proposes new framework of communication system leveraging
+promising generation capabilities of multi-modal generative models. Regarding
+nowadays smart applications, successful communication can be made by conveying
+the perceptual meaning, which we set as text prompt. Text serves as a suitable
+semantic representation of image data as it has evolved to instruct an image or
+generate image through multi-modal techniques, by being interpreted in a manner
+similar to human cognition. Utilizing text can also reduce the overload
+compared to transmitting the intact data itself. The transmitter converts
+objective image to text through multi-model generation process and the receiver
+reconstructs the image using reverse process. Each word in the text sentence
+has each syntactic role, responsible for particular piece of information the
+text contains. For further efficiency in communication load, the transmitter
+sequentially sends words in priority of carrying the most information until
+reaches successful communication. Therefore, our primary focus is on the
+promising design of a communication system based on image-to-text
+transformation and the proposed schemes for sequentially transmitting word
+tokens. Our work is expected to pave a new road of utilizing state-of-the-art
+generative models to real communication systems
+
+
+
+ 39. 标题:Data-driven classification of low-power communication signals by an unauthenticated user using a software-defined radio
+ 编号:[218]
+ 链接:https://arxiv.org/abs/2309.04088
+ 作者:Tarun Rao Keshabhoina, Marcos M. Vasconcelos
+ 备注:Accepted for presentation at Asilomar Conference on Signals, Systems, and Computers, 2023
+ 关键词:large-scale distributed multi-agent, distributed multi-agent systems, multi-agent systems exchange, systems exchange information, large-scale distributed
+
+ 点击查看摘要
+ Many large-scale distributed multi-agent systems exchange information over
+low-power communication networks. In particular, agents intermittently
+communicate state and control signals in robotic network applications, often
+with limited power over an unlicensed spectrum, prone to eavesdropping and
+denial-of-service attacks. In this paper, we argue that a widely popular
+low-power communication protocol known as LoRa is vulnerable to
+denial-of-service attacks by an unauthenticated attacker if it can successfully
+identify a target signal's bandwidth and spreading factor. Leveraging a
+structural pattern in the LoRa signal's instantaneous frequency representation,
+we relate the problem of jointly inferring the two unknown parameters to a
+classification problem, which can be efficiently implemented using neural
+networks.
+
+
+
+ 40. 标题:Evaluation of large language models for discovery of gene set function
+ 编号:[221]
+ 链接:https://arxiv.org/abs/2309.04019
+ 作者:Mengzhou Hu, Sahar Alkhairy, Ingoo Lee, Rudolf T. Pillich, Robin Bachelder, Trey Ideker, Dexter Pratt
+ 备注:
+ 关键词:manually curated databases, Gene, biological context, relies on manually, manually curated
+
+ 点击查看摘要
+ Gene set analysis is a mainstay of functional genomics, but it relies on
+manually curated databases of gene functions that are incomplete and unaware of
+biological context. Here we evaluate the ability of OpenAI's GPT-4, a Large
+Language Model (LLM), to develop hypotheses about common gene functions from
+its embedded biomedical knowledge. We created a GPT-4 pipeline to label gene
+sets with names that summarize their consensus functions, substantiated by
+analysis text and citations. Benchmarking against named gene sets in the Gene
+Ontology, GPT-4 generated very similar names in 50% of cases, while in most
+remaining cases it recovered the name of a more general concept. In gene sets
+discovered in 'omics data, GPT-4 names were more informative than gene set
+enrichment, with supporting statements and citations that largely verified in
+human review. The ability to rapidly synthesize common gene functions positions
+LLMs as valuable functional genomics assistants.
+
+
+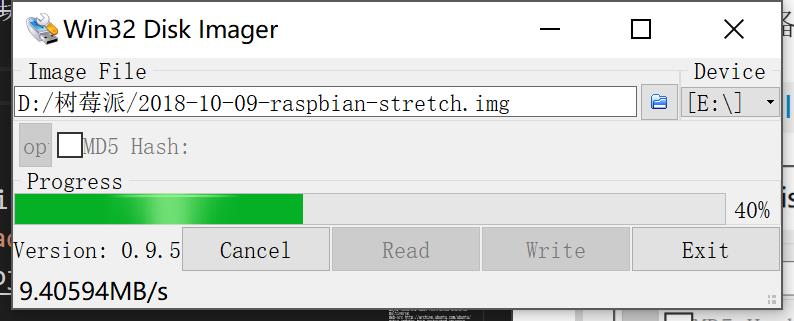




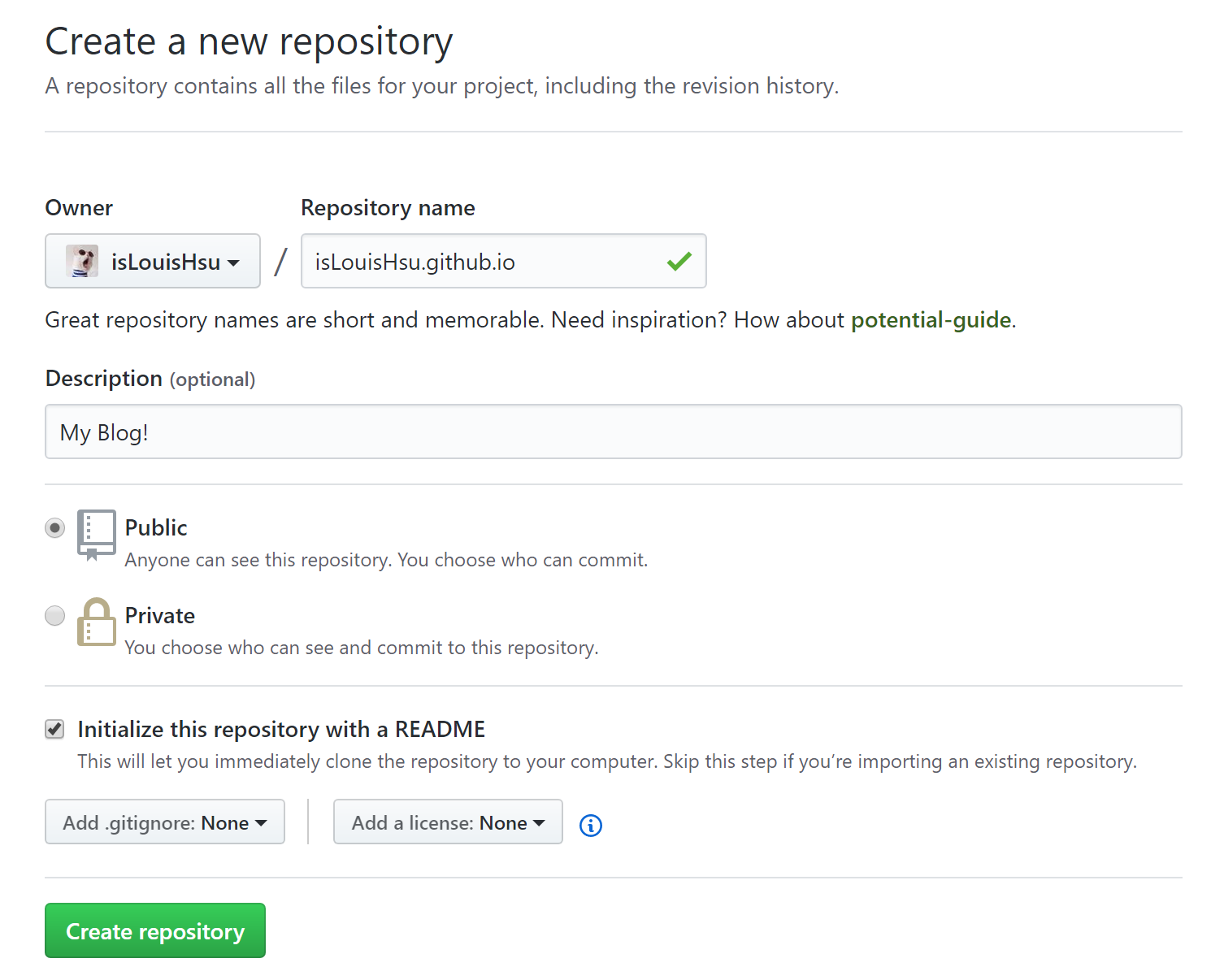
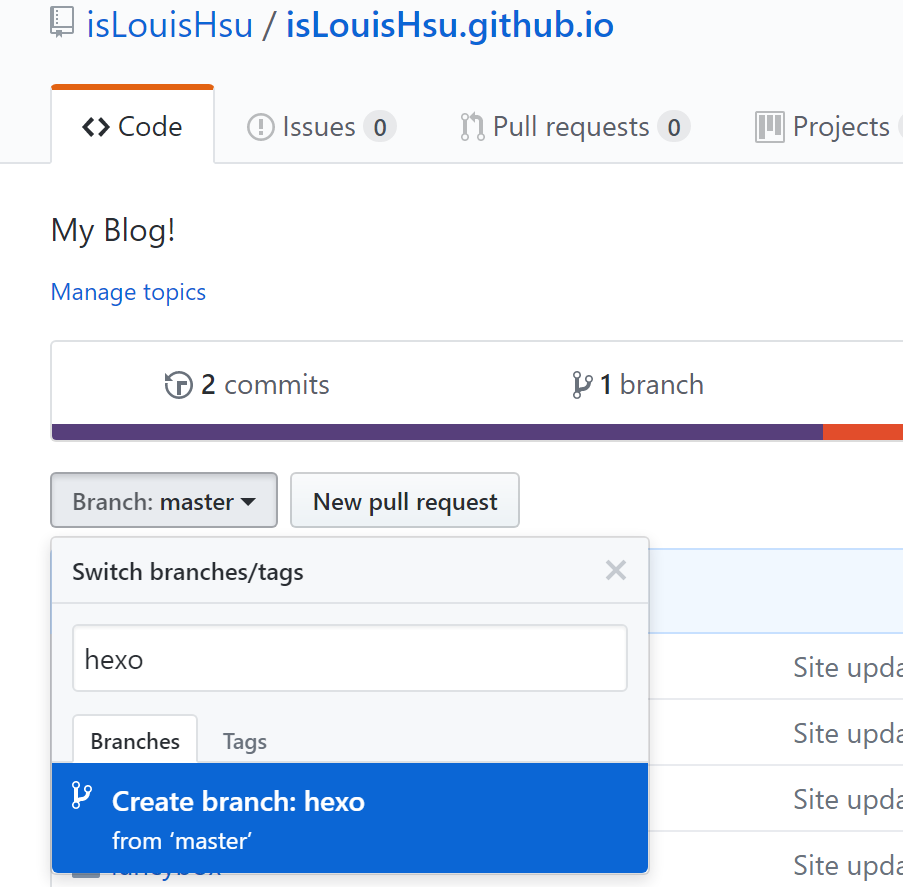





/Fig1_pretrain_finetune.png)
/Fig2_eda1.png)
/Fig2_eda2.png)
/Fig2_eda3.png)
/Fig3_reweight.png)
/Fig5_model1.png)
/Fig5_attention_mask.png)
/Fig4_wwm.png)
/Fig5_model2.png)
/Fig5_model3.png)
/Fig7_ensemble1.png)
/Fig6_res1.png)
/Fig6_res2.png)












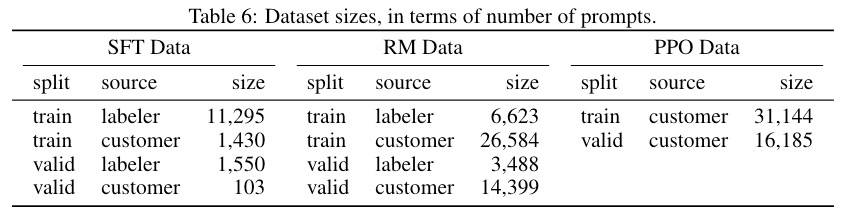
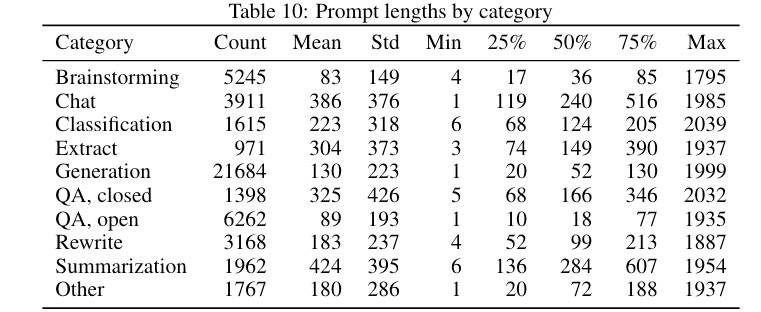
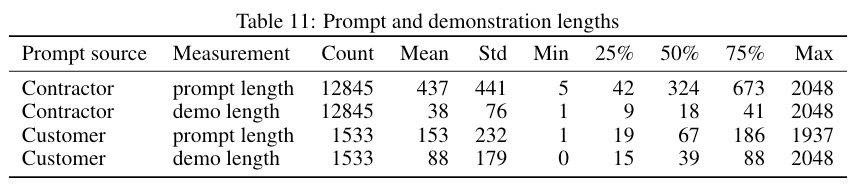

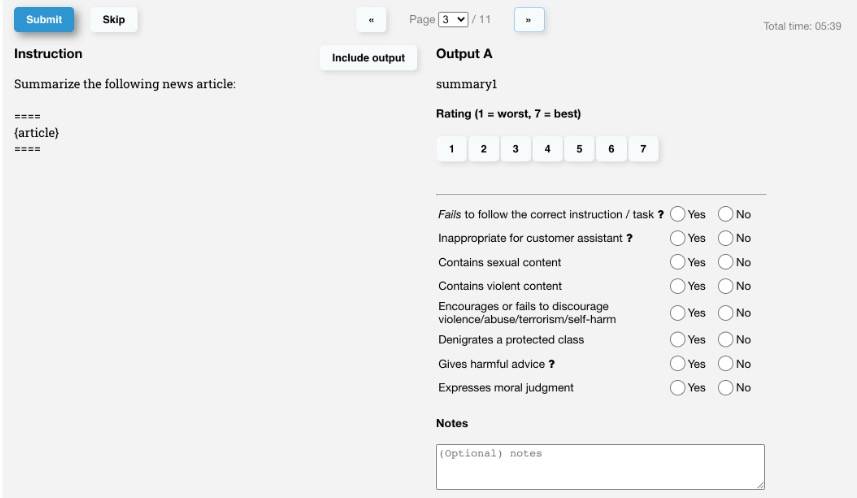
/autoencoder-architecture.png)
/variational-autoencoder-architecture.png)
/forward_vs_reversed_KL.png)
/vae-implement.png)
/reparam.png)
/generated_samples.png)
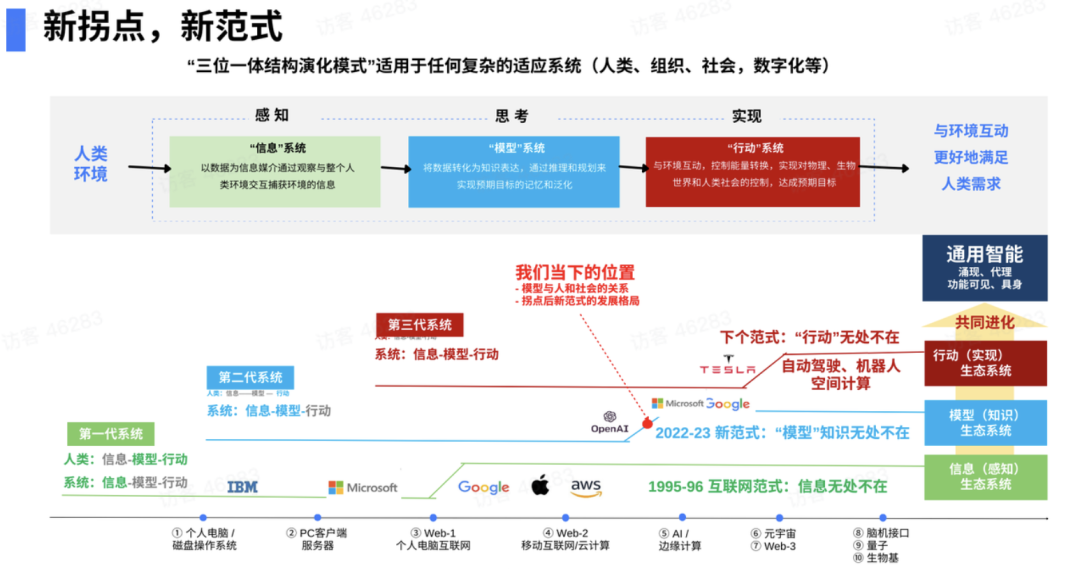
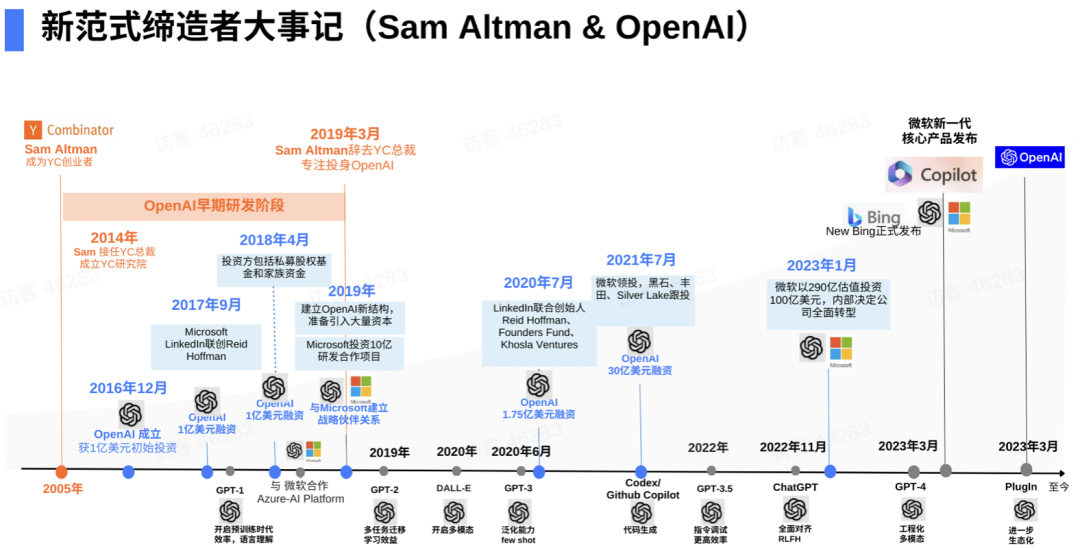
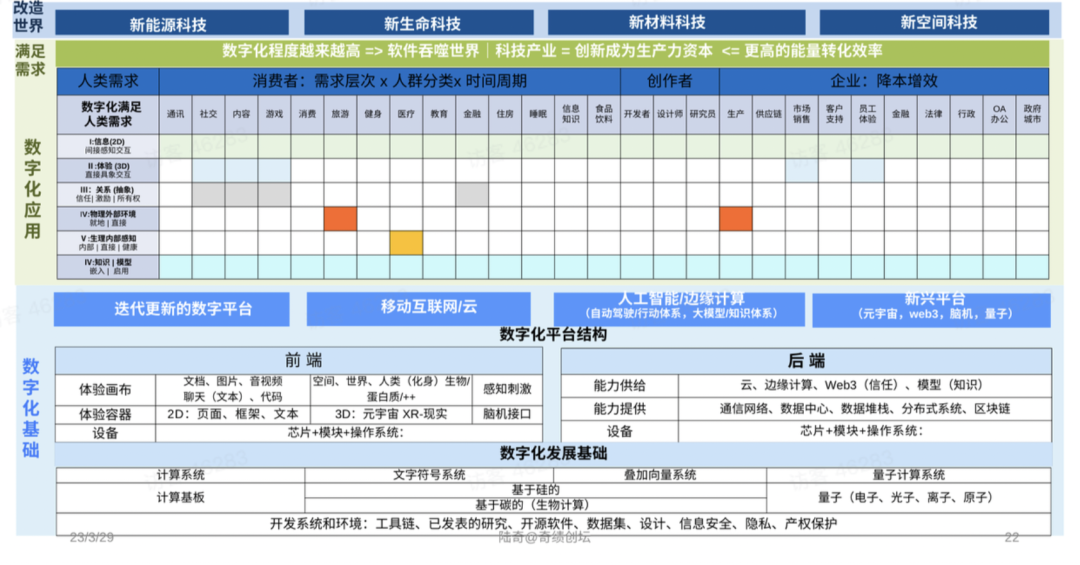
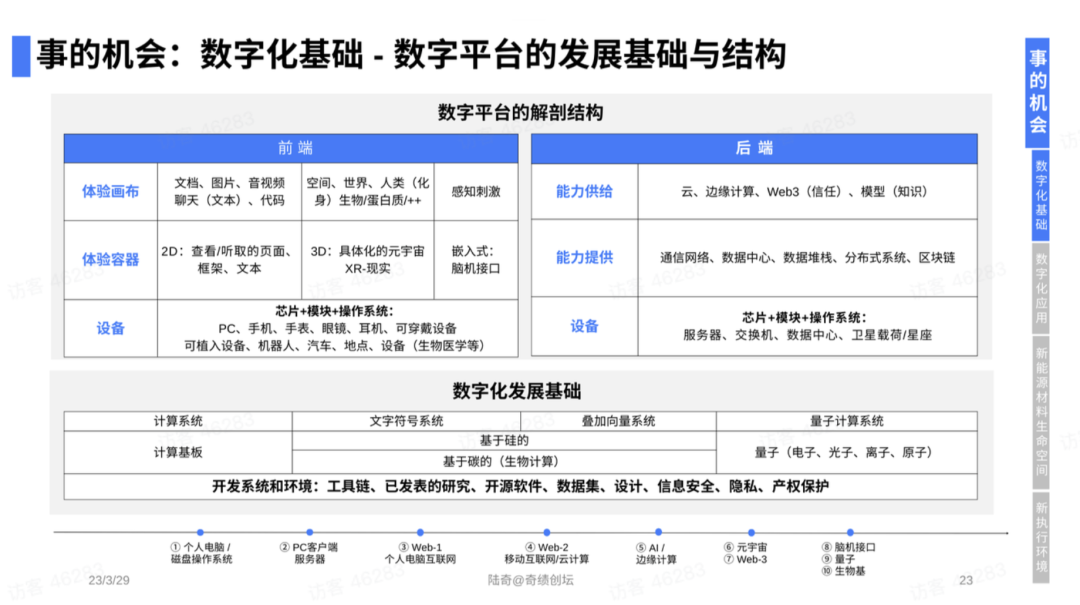














 ' +
+ '
' +
+ '