本篇博文主要展示每日从Arxiv论文网站获取的最新论文列表,以自然语言处理、信息检索、计算机视觉等类目进行划分。
+统计
+今日共更新571篇论文,其中:
+
+- 自然语言处理126篇
+- 信息检索24篇
+- 计算机视觉152篇
+
+自然语言处理
+
+ 1. 【2412.13175】DnDScore: Decontextualization and Decomposition for Factuality Verification in Long-Form Text Generation
+ 链接:https://arxiv.org/abs/2412.13175
+ 作者:Miriam Wanner,Benjamin Van Durme,Mark Dredze
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Model, Language Model, Large Language, generations decomposes claims, generations decomposes
+ 备注:
+
+ 点击查看摘要
+ Abstract:The decompose-then-verify strategy for verification of Large Language Model (LLM) generations decomposes claims that are then independently verified. Decontextualization augments text (claims) to ensure it can be verified outside of the original context, enabling reliable verification. While decomposition and decontextualization have been explored independently, their interactions in a complete system have not been investigated. Their conflicting purposes can create tensions: decomposition isolates atomic facts while decontextualization inserts relevant information. Furthermore, a decontextualized subclaim presents a challenge to the verification step: what part of the augmented text should be verified as it now contains multiple atomic facts? We conduct an evaluation of different decomposition, decontextualization, and verification strategies and find that the choice of strategy matters in the resulting factuality scores. Additionally, we introduce DnDScore, a decontextualization aware verification method which validates subclaims in the context of contextual information.
+
+
+
+ 2. 【2412.13171】Compressed Chain of Thought: Efficient Reasoning Through Dense Representations
+ 链接:https://arxiv.org/abs/2412.13171
+ 作者:Jeffrey Cheng,Benjamin Van Durme
+ 类目:Computation and Language (cs.CL)
+ 关键词:high generation latency, improve reasoning performance, contemplation tokens, cost of high, high generation
+ 备注:
+
+ 点击查看摘要
+ Abstract:Chain-of-thought (CoT) decoding enables language models to improve reasoning performance at the cost of high generation latency in decoding. Recent proposals have explored variants of contemplation tokens, a term we introduce that refers to special tokens used during inference to allow for extra computation. Prior work has considered fixed-length sequences drawn from a discrete set of embeddings as contemplation tokens. Here we propose Compressed Chain-of-Thought (CCoT), a framework to generate contentful and continuous contemplation tokens of variable sequence length. The generated contemplation tokens are compressed representations of explicit reasoning chains, and our method can be applied to off-the-shelf decoder language models. Through experiments, we illustrate how CCoT enables additional reasoning over dense contentful representations to achieve corresponding improvements in accuracy. Moreover, the reasoning improvements can be adaptively modified on demand by controlling the number of contemplation tokens generated.
+
+
+
+ 3. 【2412.13169】Algorithmic Fidelity of Large Language Models in Generating Synthetic German Public Opinions: A Case Study
+ 链接:https://arxiv.org/abs/2412.13169
+ 作者:Bolei Ma,Berk Yoztyurk,Anna-Carolina Haensch,Xinpeng Wang,Markus Herklotz,Frauke Kreuter,Barbara Plank,Matthias Assenmacher
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language models, German Longitudinal Election, Longitudinal Election Studies, investigate public opinions, recent research
+ 备注:
+
+ 点击查看摘要
+ Abstract:In recent research, large language models (LLMs) have been increasingly used to investigate public opinions. This study investigates the algorithmic fidelity of LLMs, i.e., the ability to replicate the socio-cultural context and nuanced opinions of human participants. Using open-ended survey data from the German Longitudinal Election Studies (GLES), we prompt different LLMs to generate synthetic public opinions reflective of German subpopulations by incorporating demographic features into the persona prompts. Our results show that Llama performs better than other LLMs at representing subpopulations, particularly when there is lower opinion diversity within those groups. Our findings further reveal that the LLM performs better for supporters of left-leaning parties like The Greens and The Left compared to other parties, and matches the least with the right-party AfD. Additionally, the inclusion or exclusion of specific variables in the prompts can significantly impact the models' predictions. These findings underscore the importance of aligning LLMs to more effectively model diverse public opinions while minimizing political biases and enhancing robustness in representativeness.
+
+
+
+ 4. 【2412.13161】BanglishRev: A Large-Scale Bangla-English and Code-mixed Dataset of Product Reviews in E-Commerce
+ 链接:https://arxiv.org/abs/2412.13161
+ 作者:Mohammad Nazmush Shamael,Sabila Nawshin,Swakkhar Shatabda,Salekul Islam
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Bengali words written, largest e-commerce product, e-commerce reviews written, Bengali words, product review dataset
+ 备注:
+
+ 点击查看摘要
+ Abstract:This work presents the BanglishRev Dataset, the largest e-commerce product review dataset to date for reviews written in Bengali, English, a mixture of both and Banglish, Bengali words written with English alphabets. The dataset comprises of 1.74 million written reviews from 3.2 million ratings information collected from a total of 128k products being sold in online e-commerce platforms targeting the Bengali population. It includes an extensive array of related metadata for each of the reviews including the rating given by the reviewer, date the review was posted and date of purchase, number of likes, dislikes, response from the seller, images associated with the review etc. With sentiment analysis being the most prominent usage of review datasets, experimentation with a binary sentiment analysis model with the review rating serving as an indicator of positive or negative sentiment was conducted to evaluate the effectiveness of the large amount of data presented in BanglishRev for sentiment analysis tasks. A BanglishBERT model is trained on the data from BanglishRev with reviews being considered labeled positive if the rating is greater than 3 and negative if the rating is less than or equal to 3. The model is evaluated by being testing against a previously published manually annotated dataset for e-commerce reviews written in a mixture of Bangla, English and Banglish. The experimental model achieved an exceptional accuracy of 94\% and F1 score of 0.94, demonstrating the dataset's efficacy for sentiment analysis. Some of the intriguing patterns and observations seen within the dataset and future research directions where the dataset can be utilized is also discussed and explored. The dataset can be accessed through this https URL.
+
+
+
+ 5. 【2412.13147】Are Your LLMs Capable of Stable Reasoning?
+ 链接:https://arxiv.org/abs/2412.13147
+ 作者:Junnan Liu,Hongwei Liu,Linchen Xiao,Ziyi Wang,Kuikun Liu,Songyang Gao,Wenwei Zhang,Songyang Zhang,Kai Chen
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, demonstrated remarkable progress, advancement of Large, complex reasoning tasks
+ 备注: Preprint
+
+ 点击查看摘要
+ Abstract:The rapid advancement of Large Language Models (LLMs) has demonstrated remarkable progress in complex reasoning tasks. However, a significant discrepancy persists between benchmark performances and real-world applications. We identify this gap as primarily stemming from current evaluation protocols and metrics, which inadequately capture the full spectrum of LLM capabilities, particularly in complex reasoning tasks where both accuracy and consistency are crucial. This work makes two key contributions. First, we introduce G-Pass@k, a novel evaluation metric that provides a continuous assessment of model performance across multiple sampling attempts, quantifying both the model's peak performance potential and its stability. Second, we present LiveMathBench, a dynamic benchmark comprising challenging, contemporary mathematical problems designed to minimize data leakage risks during evaluation. Through extensive experiments using G-Pass@k on state-of-the-art LLMs with LiveMathBench, we provide comprehensive insights into both their maximum capabilities and operational consistency. Our findings reveal substantial room for improvement in LLMs' "realistic" reasoning capabilities, highlighting the need for more robust evaluation methods. The benchmark and detailed results are available at: this https URL.
+
+
+
+ 6. 【2412.13146】Syntactic Transfer to Kyrgyz Using the Treebank Translation Method
+ 链接:https://arxiv.org/abs/2412.13146
+ 作者:Anton Alekseev,Alina Tillabaeva,Gulnara Dzh. Kabaeva,Sergey I. Nikolenko
+ 类目:Computation and Language (cs.CL)
+ 关键词:requires significant effort, high-quality syntactic corpora, create high-quality syntactic, Kyrgyz language, low-resource language
+ 备注: To be published in the Journal of Math. Sciences. Zapiski version (in Russian): [this http URL](http://www.pdmi.ras.ru/znsl/2024/v540/abs252.html)
+
+ 点击查看摘要
+ Abstract:The Kyrgyz language, as a low-resource language, requires significant effort to create high-quality syntactic corpora. This study proposes an approach to simplify the development process of a syntactic corpus for Kyrgyz. We present a tool for transferring syntactic annotations from Turkish to Kyrgyz based on a treebank translation method. The effectiveness of the proposed tool was evaluated using the TueCL treebank. The results demonstrate that this approach achieves higher syntactic annotation accuracy compared to a monolingual model trained on the Kyrgyz KTMU treebank. Additionally, the study introduces a method for assessing the complexity of manual annotation for the resulting syntactic trees, contributing to further optimization of the annotation process.
+
+
+
+ 7. 【2412.13110】Improving Explainability of Sentence-level Metrics via Edit-level Attribution for Grammatical Error Correction
+ 链接:https://arxiv.org/abs/2412.13110
+ 作者:Takumi Goto,Justin Vasselli,Taro Watanabe
+ 类目:Computation and Language (cs.CL)
+ 关键词:Grammatical Error Correction, Grammatical Error, proposed for Grammatical, Error Correction, GEC models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Various evaluation metrics have been proposed for Grammatical Error Correction (GEC), but many, particularly reference-free metrics, lack explainability. This lack of explainability hinders researchers from analyzing the strengths and weaknesses of GEC models and limits the ability to provide detailed feedback for users. To address this issue, we propose attributing sentence-level scores to individual edits, providing insight into how specific corrections contribute to the overall performance. For the attribution method, we use Shapley values, from cooperative game theory, to compute the contribution of each edit. Experiments with existing sentence-level metrics demonstrate high consistency across different edit granularities and show approximately 70\% alignment with human evaluations. In addition, we analyze biases in the metrics based on the attribution results, revealing trends such as the tendency to ignore orthographic edits. Our implementation is available at \url{this https URL}.
+
+
+
+ 8. 【2412.13103】AI PERSONA: Towards Life-long Personalization of LLMs
+ 链接:https://arxiv.org/abs/2412.13103
+ 作者:Tiannan Wang,Meiling Tao,Ruoyu Fang,Huilin Wang,Shuai Wang,Yuchen Eleanor Jiang,Wangchunshu Zhou
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:large language models, LLM systems, enable LLM systems, language agents, LLM
+ 备注: Work in progress
+
+ 点击查看摘要
+ Abstract:In this work, we introduce the task of life-long personalization of large language models. While recent mainstream efforts in the LLM community mainly focus on scaling data and compute for improved capabilities of LLMs, we argue that it is also very important to enable LLM systems, or language agents, to continuously adapt to the diverse and ever-changing profiles of every distinct user and provide up-to-date personalized assistance. We provide a clear task formulation and introduce a simple, general, effective, and scalable framework for life-long personalization of LLM systems and language agents. To facilitate future research on LLM personalization, we also introduce methods to synthesize realistic benchmarks and robust evaluation metrics. We will release all codes and data for building and benchmarking life-long personalized LLM systems.
+
+
+
+ 9. 【2412.13102】AIR-Bench: Automated Heterogeneous Information Retrieval Benchmark
+ 链接:https://arxiv.org/abs/2412.13102
+ 作者:Jianlyu Chen,Nan Wang,Chaofan Li,Bo Wang,Shitao Xiao,Han Xiao,Hao Liao,Defu Lian,Zheng Liu
+ 类目:Information Retrieval (cs.IR); Computation and Language (cs.CL)
+ 关键词:Heterogeneous Information Retrieval, Automated Heterogeneous Information, information retrieval, Information Retrieval Benchmark, AIR-Bench
+ 备注: 31 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:Evaluation plays a crucial role in the advancement of information retrieval (IR) models. However, current benchmarks, which are based on predefined domains and human-labeled data, face limitations in addressing evaluation needs for emerging domains both cost-effectively and efficiently. To address this challenge, we propose the Automated Heterogeneous Information Retrieval Benchmark (AIR-Bench). AIR-Bench is distinguished by three key features: 1) Automated. The testing data in AIR-Bench is automatically generated by large language models (LLMs) without human intervention. 2) Heterogeneous. The testing data in AIR-Bench is generated with respect to diverse tasks, domains and languages. 3) Dynamic. The domains and languages covered by AIR-Bench are constantly augmented to provide an increasingly comprehensive evaluation benchmark for community developers. We develop a reliable and robust data generation pipeline to automatically create diverse and high-quality evaluation datasets based on real-world corpora. Our findings demonstrate that the generated testing data in AIR-Bench aligns well with human-labeled testing data, making AIR-Bench a dependable benchmark for evaluating IR models. The resources in AIR-Bench are publicly available at this https URL.
+
+
+
+ 10. 【2412.13098】Uchaguzi-2022: A Dataset of Citizen Reports on the 2022 Kenyan Election
+ 链接:https://arxiv.org/abs/2412.13098
+ 作者:Roberto Mondini,Neema Kotonya,Robert L. Logan IV,Elizabeth M Olson,Angela Oduor Lungati,Daniel Duke Odongo,Tim Ombasa,Hemank Lamba,Aoife Cahill,Joel R. Tetreault,Alejandro Jaimes
+ 类目:Computation and Language (cs.CL); Social and Information Networks (cs.SI)
+ 关键词:Online reporting platforms, Online reporting, local communities, reporting platforms, platforms have enabled
+ 备注: COLING 2025
+
+ 点击查看摘要
+ Abstract:Online reporting platforms have enabled citizens around the world to collectively share their opinions and report in real time on events impacting their local communities. Systematically organizing (e.g., categorizing by attributes) and geotagging large amounts of crowdsourced information is crucial to ensuring that accurate and meaningful insights can be drawn from this data and used by policy makers to bring about positive change. These tasks, however, typically require extensive manual annotation efforts. In this paper we present Uchaguzi-2022, a dataset of 14k categorized and geotagged citizen reports related to the 2022 Kenyan General Election containing mentions of election-related issues such as official misconduct, vote count irregularities, and acts of violence. We use this dataset to investigate whether language models can assist in scalably categorizing and geotagging reports, thus highlighting its potential application in the AI for Social Good space.
+
+
+
+ 11. 【2412.13091】LMUnit: Fine-grained Evaluation with Natural Language Unit Tests
+ 链接:https://arxiv.org/abs/2412.13091
+ 作者:Jon Saad-Falcon,Rajan Vivek,William Berrios,Nandita Shankar Naik,Matija Franklin,Bertie Vidgen,Amanpreet Singh,Douwe Kiela,Shikib Mehri
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:automated metrics provide, assessing their behavior, fundamental challenge, costly and noisy, provide only coarse
+ 备注:
+
+ 点击查看摘要
+ Abstract:As language models become integral to critical workflows, assessing their behavior remains a fundamental challenge -- human evaluation is costly and noisy, while automated metrics provide only coarse, difficult-to-interpret signals. We introduce natural language unit tests, a paradigm that decomposes response quality into explicit, testable criteria, along with a unified scoring model, LMUnit, which combines multi-objective training across preferences, direct ratings, and natural language rationales. Through controlled human studies, we show this paradigm significantly improves inter-annotator agreement and enables more effective LLM development workflows. LMUnit achieves state-of-the-art performance on evaluation benchmarks (FLASK, BigGenBench) and competitive results on RewardBench. These results validate both our proposed paradigm and scoring model, suggesting a promising path forward for language model evaluation and development.
+
+
+
+ 12. 【2412.13071】CLASP: Contrastive Language-Speech Pretraining for Multilingual Multimodal Information Retrieval
+ 链接:https://arxiv.org/abs/2412.13071
+ 作者:Mohammad Mahdi Abootorabi,Ehsaneddin Asgari
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:Contrastive Language-Speech Pretraining, Contrastive Language-Speech, Language-Speech Pretraining, study introduces CLASP, multimodal representation tailored
+ 备注: accepted at ECIR 2025
+
+ 点击查看摘要
+ Abstract:This study introduces CLASP (Contrastive Language-Speech Pretraining), a multilingual, multimodal representation tailored for audio-text information retrieval. CLASP leverages the synergy between spoken content and textual data. During training, we utilize our newly introduced speech-text dataset, which encompasses 15 diverse categories ranging from fiction to religion. CLASP's audio component integrates audio spectrograms with a pre-trained self-supervised speech model, while its language encoding counterpart employs a sentence encoder pre-trained on over 100 languages. This unified lightweight model bridges the gap between various modalities and languages, enhancing its effectiveness in handling and retrieving multilingual and multimodal data. Our evaluations across multiple languages demonstrate that CLASP establishes new benchmarks in HITS@1, MRR, and meanR metrics, outperforming traditional ASR-based retrieval approaches in specific scenarios.
+
+
+
+ 13. 【2412.13050】Modality-Inconsistent Continual Learning of Multimodal Large Language Models
+ 链接:https://arxiv.org/abs/2412.13050
+ 作者:Weiguo Pian,Shijian Deng,Shentong Mo,Yunhui Guo,Yapeng Tian
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:Multimodal Large Language, Large Language Models, Multimodal Large, Large Language, scenario for Multimodal
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this paper, we introduce Modality-Inconsistent Continual Learning (MICL), a new continual learning scenario for Multimodal Large Language Models (MLLMs) that involves tasks with inconsistent modalities (image, audio, or video) and varying task types (captioning or question-answering). Unlike existing vision-only or modality-incremental settings, MICL combines modality and task type shifts, both of which drive catastrophic forgetting. To address these challenges, we propose MoInCL, which employs a Pseudo Targets Generation Module to mitigate forgetting caused by task type shifts in previously seen modalities. It also incorporates Instruction-based Knowledge Distillation to preserve the model's ability to handle previously learned modalities when new ones are introduced. We benchmark MICL using a total of six tasks and conduct experiments to validate the effectiveness of our proposed MoInCL. The experimental results highlight the superiority of MoInCL, showing significant improvements over representative and state-of-the-art continual learning baselines.
+
+
+
+ 14. 【2412.13041】Harnessing Event Sensory Data for Error Pattern Prediction in Vehicles: A Language Model Approach
+ 链接:https://arxiv.org/abs/2412.13041
+ 作者:Hugo Math,Rainer Lienhart,Robin Schön
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:processing natural languages, processing multivariate event, multivariate event streams, textit, processing natural
+ 备注: 10 pages, 8 figures, accepted to AAAI 2025
+
+ 点击查看摘要
+ Abstract:In this paper, we draw an analogy between processing natural languages and processing multivariate event streams from vehicles in order to predict $\textit{when}$ and $\textit{what}$ error pattern is most likely to occur in the future for a given car. Our approach leverages the temporal dynamics and contextual relationships of our event data from a fleet of cars. Event data is composed of discrete values of error codes as well as continuous values such as time and mileage. Modelled by two causal Transformers, we can anticipate vehicle failures and malfunctions before they happen. Thus, we introduce $\textit{CarFormer}$, a Transformer model trained via a new self-supervised learning strategy, and $\textit{EPredictor}$, an autoregressive Transformer decoder model capable of predicting $\textit{when}$ and $\textit{what}$ error pattern will most likely occur after some error code apparition. Despite the challenges of high cardinality of event types, their unbalanced frequency of appearance and limited labelled data, our experimental results demonstrate the excellent predictive ability of our novel model. Specifically, with sequences of $160$ error codes on average, our model is able with only half of the error codes to achieve $80\%$ F1 score for predicting $\textit{what}$ error pattern will occur and achieves an average absolute error of $58.4 \pm 13.2$h $\textit{when}$ forecasting the time of occurrence, thus enabling confident predictive maintenance and enhancing vehicle safety.
+
+
+
+ 15. 【2412.13026】NAVCON: A Cognitively Inspired and Linguistically Grounded Corpus for Vision and Language Navigation
+ 链接:https://arxiv.org/abs/2412.13026
+ 作者:Karan Wanchoo,Xiaoye Zuo,Hannah Gonzalez,Soham Dan,Georgios Georgakis,Dan Roth,Kostas Daniilidis,Eleni Miltsakaki
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:large-scale annotated Vision-Language, annotated Vision-Language Navigation, corpus built, popular datasets, built on top
+ 备注:
+
+ 点击查看摘要
+ Abstract:We present NAVCON, a large-scale annotated Vision-Language Navigation (VLN) corpus built on top of two popular datasets (R2R and RxR). The paper introduces four core, cognitively motivated and linguistically grounded, navigation concepts and an algorithm for generating large-scale silver annotations of naturally occurring linguistic realizations of these concepts in navigation instructions. We pair the annotated instructions with video clips of an agent acting on these instructions. NAVCON contains 236, 316 concept annotations for approximately 30, 0000 instructions and 2.7 million aligned images (from approximately 19, 000 instructions) showing what the agent sees when executing an instruction. To our knowledge, this is the first comprehensive resource of navigation concepts. We evaluated the quality of the silver annotations by conducting human evaluation studies on NAVCON samples. As further validation of the quality and usefulness of the resource, we trained a model for detecting navigation concepts and their linguistic realizations in unseen instructions. Additionally, we show that few-shot learning with GPT-4o performs well on this task using large-scale silver annotations of NAVCON.
+
+
+
+ 16. 【2412.13018】OmniEval: An Omnidirectional and Automatic RAG Evaluation Benchmark in Financial Domain
+ 链接:https://arxiv.org/abs/2412.13018
+ 作者:Shuting Wang,Jiejun Tan,Zhicheng Dou,Ji-Rong Wen
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, lack domain-specific knowledge, application of Large, gained extensive attention
+ 备注:
+
+ 点击查看摘要
+ Abstract:As a typical and practical application of Large Language Models (LLMs), Retrieval-Augmented Generation (RAG) techniques have gained extensive attention, particularly in vertical domains where LLMs may lack domain-specific knowledge. In this paper, we introduce an omnidirectional and automatic RAG benchmark, OmniEval, in the financial domain. Our benchmark is characterized by its multi-dimensional evaluation framework, including (1) a matrix-based RAG scenario evaluation system that categorizes queries into five task classes and 16 financial topics, leading to a structured assessment of diverse query scenarios; (2) a multi-dimensional evaluation data generation approach, which combines GPT-4-based automatic generation and human annotation, achieving an 87.47\% acceptance ratio in human evaluations on generated instances; (3) a multi-stage evaluation system that evaluates both retrieval and generation performance, result in a comprehensive evaluation on the RAG pipeline; and (4) robust evaluation metrics derived from rule-based and LLM-based ones, enhancing the reliability of assessments through manual annotations and supervised fine-tuning of an LLM evaluator. Our experiments demonstrate the comprehensiveness of OmniEval, which includes extensive test datasets and highlights the performance variations of RAG systems across diverse topics and tasks, revealing significant opportunities for RAG models to improve their capabilities in vertical domains. We open source the code of our benchmark in \href{this https URL}{this https URL}.
+
+
+
+ 17. 【2412.13008】RCLMuFN: Relational Context Learning and Multiplex Fusion Network for Multimodal Sarcasm Detection
+ 链接:https://arxiv.org/abs/2412.13008
+ 作者:Tongguan Wang,Junkai Li,Guixin Su,Yongcheng Zhang,Dongyu Su,Yuxue Hu,Ying Sha
+ 类目:Computation and Language (cs.CL)
+ 关键词:speaker true intent, typically conveys emotions, Sarcasm typically conveys, multimodal sarcasm detection, sarcasm detection
+ 备注:
+
+ 点击查看摘要
+ Abstract:Sarcasm typically conveys emotions of contempt or criticism by expressing a meaning that is contrary to the speaker's true intent. Accurate detection of sarcasm aids in identifying and filtering undesirable information on the Internet, thereby reducing malicious defamation and rumor-mongering. Nonetheless, the task of automatic sarcasm detection remains highly challenging for machines, as it critically depends on intricate factors such as relational context. Most existing multimodal sarcasm detection methods focus on introducing graph structures to establish entity relationships between text and images while neglecting to learn the relational context between text and images, which is crucial evidence for understanding the meaning of sarcasm. In addition, the meaning of sarcasm changes with the evolution of different contexts, but existing methods may not be accurate in modeling such dynamic changes, limiting the generalization ability of the models. To address the above issues, we propose a relational context learning and multiplex fusion network (RCLMuFN) for multimodal sarcasm detection. Firstly, we employ four feature extractors to comprehensively extract features from raw text and images, aiming to excavate potential features that may have been previously overlooked. Secondly, we utilize the relational context learning module to learn the contextual information of text and images and capture the dynamic properties through shallow and deep interactions. Finally, we employ a multiplex feature fusion module to enhance the generalization of the model by penetratingly integrating multimodal features derived from various interaction contexts. Extensive experiments on two multimodal sarcasm detection datasets show that our proposed method achieves state-of-the-art performance.
+
+
+
+ 18. 【2412.12997】Enabling Low-Resource Language Retrieval: Establishing Baselines for Urdu MS MARCO
+ 链接:https://arxiv.org/abs/2412.12997
+ 作者:Umer Butt,Stalin Veranasi,Günter Neumann
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:field increasingly recognizes, Information Retrieval, field increasingly, low-resource languages remains, increasingly recognizes
+ 备注: 6 pages, ECIR 2025, conference submission version
+
+ 点击查看摘要
+ Abstract:As the Information Retrieval (IR) field increasingly recognizes the importance of inclusivity, addressing the needs of low-resource languages remains a significant challenge. This paper introduces the first large-scale Urdu IR dataset, created by translating the MS MARCO dataset through machine translation. We establish baseline results through zero-shot learning for IR in Urdu and subsequently apply the mMARCO multilingual IR methodology to this newly translated dataset. Our findings demonstrate that the fine-tuned model (Urdu-mT5-mMARCO) achieves a Mean Reciprocal Rank (MRR@10) of 0.247 and a Recall@10 of 0.439, representing significant improvements over zero-shot results and showing the potential for expanding IR access for Urdu speakers. By bridging access gaps for speakers of low-resource languages, this work not only advances multilingual IR research but also emphasizes the ethical and societal importance of inclusive IR technologies. This work provides valuable insights into the challenges and solutions for improving language representation and lays the groundwork for future research, especially in South Asian languages, which can benefit from the adaptable methods used in this study.
+
+
+
+ 19. 【2412.12981】Unlocking LLMs: Addressing Scarce Data and Bias Challenges in Mental Health
+ 链接:https://arxiv.org/abs/2412.12981
+ 作者:Vivek Kumar,Eirini Ntoutsi,Pushpraj Singh Rajawat,Giacomo Medda,Diego Reforgiato Recupero
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large language models, shown promising capabilities, Large language, language models, bias manifestation
+ 备注: International Conference on Natural Language Processing and Artificial Intelligence for Cyber Security (NLPAICS) 2024
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) have shown promising capabilities in healthcare analysis but face several challenges like hallucinations, parroting, and bias manifestation. These challenges are exacerbated in complex, sensitive, and low-resource domains. Therefore, in this work we introduce IC-AnnoMI, an expert-annotated motivational interviewing (MI) dataset built upon AnnoMI by generating in-context conversational dialogues leveraging LLMs, particularly ChatGPT. IC-AnnoMI employs targeted prompts accurately engineered through cues and tailored information, taking into account therapy style (empathy, reflection), contextual relevance, and false semantic change. Subsequently, the dialogues are annotated by experts, strictly adhering to the Motivational Interviewing Skills Code (MISC), focusing on both the psychological and linguistic dimensions of MI dialogues. We comprehensively evaluate the IC-AnnoMI dataset and ChatGPT's emotional reasoning ability and understanding of domain intricacies by modeling novel classification tasks employing several classical machine learning and current state-of-the-art transformer approaches. Finally, we discuss the effects of progressive prompting strategies and the impact of augmented data in mitigating the biases manifested in IC-AnnoM. Our contributions provide the MI community with not only a comprehensive dataset but also valuable insights for using LLMs in empathetic text generation for conversational therapy in supervised settings.
+
+
+
+ 20. 【2412.12961】Adaptations of AI models for querying the LandMatrix database in natural language
+ 链接:https://arxiv.org/abs/2412.12961
+ 作者:Fatiha Ait Kbir,Jérémy Bourgoin,Rémy Decoupes,Marie Gradeler,Roberto Interdonato
+ 类目:Computation and Language (cs.CL)
+ 关键词:global observatory aim, Land Matrix initiative, large-scale land acquisitions, provide reliable data, Land Matrix
+ 备注:
+
+ 点击查看摘要
+ Abstract:The Land Matrix initiative (this https URL) and its global observatory aim to provide reliable data on large-scale land acquisitions to inform debates and actions in sectors such as agriculture, extraction, or energy in low- and middle-income countries. Although these data are recognized in the academic world, they remain underutilized in public policy, mainly due to the complexity of access and exploitation, which requires technical expertise and a good understanding of the database schema.
+The objective of this work is to simplify access to data from different database systems. The methods proposed in this article are evaluated using data from the Land Matrix. This work presents various comparisons of Large Language Models (LLMs) as well as combinations of LLM adaptations (Prompt Engineering, RAG, Agents) to query different database systems (GraphQL and REST queries). The experiments are reproducible, and a demonstration is available online: this https URL.
+
Subjects:
+Computation and Language (cs.CL)
+Cite as:
+arXiv:2412.12961 [cs.CL]
+(or
+arXiv:2412.12961v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2412.12961
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 21. 【2412.12956】SnakModel: Lessons Learned from Training an Open Danish Large Language Model
+ 链接:https://arxiv.org/abs/2412.12956
+ 作者:Mike Zhang,Max Müller-Eberstein,Elisa Bassignana,Rob van der Goot
+ 类目:Computation and Language (cs.CL)
+ 关键词:Danish large language, large language model, Danish Natural Language, Danish words, Danish instructions
+ 备注: Accepted at NoDaLiDa 2025 (oral)
+
+ 点击查看摘要
+ Abstract:We present SnakModel, a Danish large language model (LLM) based on Llama2-7B, which we continuously pre-train on 13.6B Danish words, and further tune on 3.7M Danish instructions. As best practices for creating LLMs for smaller language communities have yet to be established, we examine the effects of early modeling and training decisions on downstream performance throughout the entire training pipeline, including (1) the creation of a strictly curated corpus of Danish text from diverse sources; (2) the language modeling and instruction-tuning training process itself, including the analysis of intermediate training dynamics, and ablations across different hyperparameters; (3) an evaluation on eight language and culturally-specific tasks. Across these experiments SnakModel achieves the highest overall performance, outperforming multiple contemporary Llama2-7B-based models. By making SnakModel, the majority of our pre-training corpus, and the associated code available under open licenses, we hope to foster further research and development in Danish Natural Language Processing, and establish training guidelines for languages with similar resource constraints.
+
+
+
+ 22. 【2412.12955】Learning from Noisy Labels via Self-Taught On-the-Fly Meta Loss Rescaling
+ 链接:https://arxiv.org/abs/2412.12955
+ 作者:Michael Heck,Christian Geishauser,Nurul Lubis,Carel van Niekerk,Shutong Feng,Hsien-Chin Lin,Benjamin Matthias Ruppik,Renato Vukovic,Milica Gašić
+ 类目:Computation and Language (cs.CL)
+ 关键词:training effective machine, Correct labels, effective machine learning, labeled data, data
+ 备注: 10 pages, 3 figures, accepted at AAAI'25
+
+ 点击查看摘要
+ Abstract:Correct labels are indispensable for training effective machine learning models. However, creating high-quality labels is expensive, and even professionally labeled data contains errors and ambiguities. Filtering and denoising can be applied to curate labeled data prior to training, at the cost of additional processing and loss of information. An alternative is on-the-fly sample reweighting during the training process to decrease the negative impact of incorrect or ambiguous labels, but this typically requires clean seed data. In this work we propose unsupervised on-the-fly meta loss rescaling to reweight training samples. Crucially, we rely only on features provided by the model being trained, to learn a rescaling function in real time without knowledge of the true clean data distribution. We achieve this via a novel meta learning setup that samples validation data for the meta update directly from the noisy training corpus by employing the rescaling function being trained. Our proposed method consistently improves performance across various NLP tasks with minimal computational overhead. Further, we are among the first to attempt on-the-fly training data reweighting on the challenging task of dialogue modeling, where noisy and ambiguous labels are common. Our strategy is robust in the face of noisy and clean data, handles class imbalance, and prevents overfitting to noisy labels. Our self-taught loss rescaling improves as the model trains, showing the ability to keep learning from the model's own signals. As training progresses, the impact of correctly labeled data is scaled up, while the impact of wrongly labeled data is suppressed.
+
+
+
+ 23. 【2412.12954】Recipient Profiling: Predicting Characteristics from Messages
+ 链接:https://arxiv.org/abs/2412.12954
+ 作者:Martin Borquez,Mikaela Keller,Michael Perrot,Damien Sileo
+ 类目:Computation and Language (cs.CL)
+ 关键词:inadvertently reveal sensitive, reveal sensitive information, Author Profiling, gender or age, inadvertently reveal
+ 备注:
+
+ 点击查看摘要
+ Abstract:It has been shown in the field of Author Profiling that texts may inadvertently reveal sensitive information about their authors, such as gender or age. This raises important privacy concerns that have been extensively addressed in the literature, in particular with the development of methods to hide such information. We argue that, when these texts are in fact messages exchanged between individuals, this is not the end of the story. Indeed, in this case, a second party, the intended recipient, is also involved and should be considered. In this work, we investigate the potential privacy leaks affecting them, that is we propose and address the problem of Recipient Profiling. We provide empirical evidence that such a task is feasible on several publicly accessible datasets (this https URL). Furthermore, we show that the learned models can be transferred to other datasets, albeit with a loss in accuracy.
+
+
+
+ 24. 【2412.12948】MOPO: Multi-Objective Prompt Optimization for Affective Text Generation
+ 链接:https://arxiv.org/abs/2412.12948
+ 作者:Yarik Menchaca Resendiz,Roman Klinger
+ 类目:Computation and Language (cs.CL)
+ 关键词:MOPO, expressed depends, multiple objectives, objectives, Optimization
+ 备注: accepted to COLING 2025
+
+ 点击查看摘要
+ Abstract:How emotions are expressed depends on the context and domain. On X (formerly Twitter), for instance, an author might simply use the hashtag #anger, while in a news headline, emotions are typically written in a more polite, indirect manner. To enable conditional text generation models to create emotionally connotated texts that fit a domain, users need to have access to a parameter that allows them to choose the appropriate way to express an emotion. To achieve this, we introduce MOPO, a Multi-Objective Prompt Optimization methodology. MOPO optimizes prompts according to multiple objectives (which correspond here to the output probabilities assigned by emotion classifiers trained for different domains). In contrast to single objective optimization, MOPO outputs a set of prompts, each with a different weighting of the multiple objectives. Users can then choose the most appropriate prompt for their context. We evaluate MOPO using three objectives, determined by various domain-specific emotion classifiers. MOPO improves performance by up to 15 pp across all objectives with a minimal loss (1-2 pp) for any single objective compared to single-objective optimization. These minor performance losses are offset by a broader generalization across multiple objectives - which is not possible with single-objective optimization. Additionally, MOPO reduces computational requirements by simultaneously optimizing for multiple objectives, eliminating separate optimization procedures for each objective.
+
+
+
+ 25. 【2412.12940】Improving Fine-grained Visual Understanding in VLMs through Text-Only Training
+ 链接:https://arxiv.org/abs/2412.12940
+ 作者:Dasol Choi,Guijin Son,Soo Yong Kim,Gio Paik,Seunghyeok Hong
+ 类目:Computation and Language (cs.CL)
+ 关键词:Visual-Language Models, powerful tool, tool for bridging, bridging the gap, Models
+ 备注: AAAI25 workshop accepted
+
+ 点击查看摘要
+ Abstract:Visual-Language Models (VLMs) have become a powerful tool for bridging the gap between visual and linguistic understanding. However, the conventional learning approaches for VLMs often suffer from limitations, such as the high resource requirements of collecting and training image-text paired data. Recent research has suggested that language understanding plays a crucial role in the performance of VLMs, potentially indicating that text-only training could be a viable approach. In this work, we investigate the feasibility of enhancing fine-grained visual understanding in VLMs through text-only training. Inspired by how humans develop visual concept understanding, where rich textual descriptions can guide visual recognition, we hypothesize that VLMs can also benefit from leveraging text-based representations to improve their visual recognition abilities. We conduct comprehensive experiments on two distinct domains: fine-grained species classification and cultural visual understanding tasks. Our findings demonstrate that text-only training can be comparable to conventional image-text training while significantly reducing computational costs. This suggests a more efficient and cost-effective pathway for advancing VLM capabilities, particularly valuable in resource-constrained environments.
+
+
+
+ 26. 【2412.12928】ruthful Text Sanitization Guided by Inference Attacks
+ 链接:https://arxiv.org/abs/2412.12928
+ 作者:Ildikó Pilán,Benet Manzanares-Salor,David Sánchez,Pierre Lison
+ 类目:Computation and Language (cs.CL)
+ 关键词:longer disclose personal, disclose personal information, text sanitization, personal information, original text spans
+ 备注:
+
+ 点击查看摘要
+ Abstract:The purpose of text sanitization is to rewrite those text spans in a document that may directly or indirectly identify an individual, to ensure they no longer disclose personal information. Text sanitization must strike a balance between preventing the leakage of personal information (privacy protection) while also retaining as much of the document's original content as possible (utility preservation). We present an automated text sanitization strategy based on generalizations, which are more abstract (but still informative) terms that subsume the semantic content of the original text spans. The approach relies on instruction-tuned large language models (LLMs) and is divided into two stages. The LLM is first applied to obtain truth-preserving replacement candidates and rank them according to their abstraction level. Those candidates are then evaluated for their ability to protect privacy by conducting inference attacks with the LLM. Finally, the system selects the most informative replacement shown to be resistant to those attacks. As a consequence of this two-stage process, the chosen replacements effectively balance utility and privacy. We also present novel metrics to automatically evaluate these two aspects without the need to manually annotate data. Empirical results on the Text Anonymization Benchmark show that the proposed approach leads to enhanced utility, with only a marginal increase in the risk of re-identifying protected individuals compared to fully suppressing the original information. Furthermore, the selected replacements are shown to be more truth-preserving and abstractive than previous methods.
+
+
+
+ 27. 【2412.12898】An Agentic Approach to Automatic Creation of PID Diagrams from Natural Language Descriptions
+ 链接:https://arxiv.org/abs/2412.12898
+ 作者:Shreeyash Gowaikar,Srinivasan Iyengar,Sameer Segal,Shivkumar Kalyanaraman
+ 类目:Machine Learning (cs.LG); Computational Engineering, Finance, and Science (cs.CE); Computation and Language (cs.CL); Multiagent Systems (cs.MA)
+ 关键词:Piping and Instrumentation, Large Language Models, Instrumentation Diagrams, natural language, natural language descriptions
+ 备注: Accepted at the AAAI'25 Workshop on AI to Accelerate Science and Engineering (AI2ASE)
+
+ 点击查看摘要
+ Abstract:The Piping and Instrumentation Diagrams (PIDs) are foundational to the design, construction, and operation of workflows in the engineering and process industries. However, their manual creation is often labor-intensive, error-prone, and lacks robust mechanisms for error detection and correction. While recent advancements in Generative AI, particularly Large Language Models (LLMs) and Vision-Language Models (VLMs), have demonstrated significant potential across various domains, their application in automating generation of engineering workflows remains underexplored. In this work, we introduce a novel copilot for automating the generation of PIDs from natural language descriptions. Leveraging a multi-step agentic workflow, our copilot provides a structured and iterative approach to diagram creation directly from Natural Language prompts. We demonstrate the feasibility of the generation process by evaluating the soundness and completeness of the workflow, and show improved results compared to vanilla zero-shot and few-shot generation approaches.
+
+
+
+ 28. 【2412.12893】Question: How do Large Language Models perform on the Question Answering tasks? Answer:
+ 链接:https://arxiv.org/abs/2412.12893
+ 作者:Kevin Fischer,Darren Fürst,Sebastian Steindl,Jakob Lindner,Ulrich Schäfer
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, showing promising results, zero-shot prompting techniques, Stanford Question Answering
+ 备注: Accepted at SAI Computing Conference 2025
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have been showing promising results for various NLP-tasks without the explicit need to be trained for these tasks by using few-shot or zero-shot prompting techniques. A common NLP-task is question-answering (QA). In this study, we propose a comprehensive performance comparison between smaller fine-tuned models and out-of-the-box instruction-following LLMs on the Stanford Question Answering Dataset 2.0 (SQuAD2), specifically when using a single-inference prompting technique. Since the dataset contains unanswerable questions, previous work used a double inference method. We propose a prompting style which aims to elicit the same ability without the need for double inference, saving compute time and resources. Furthermore, we investigate their generalization capabilities by comparing their performance on similar but different QA datasets, without fine-tuning neither model, emulating real-world uses where the context and questions asked may differ from the original training distribution, for example swapping Wikipedia for news articles.
+Our results show that smaller, fine-tuned models outperform current State-Of-The-Art (SOTA) LLMs on the fine-tuned task, but recent SOTA models are able to close this gap on the out-of-distribution test and even outperform the fine-tuned models on 3 of the 5 tested QA datasets.
+
Comments:
+Accepted at SAI Computing Conference 2025
+Subjects:
+Computation and Language (cs.CL)
+Cite as:
+arXiv:2412.12893 [cs.CL]
+(or
+arXiv:2412.12893v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2412.12893
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 29. 【2412.12881】RAG-Star: Enhancing Deliberative Reasoning with Retrieval Augmented Verification and Refinement
+ 链接:https://arxiv.org/abs/2412.12881
+ 作者:Jinhao Jiang,Jiayi Chen,Junyi Li,Ruiyang Ren,Shijie Wang,Wayne Xin Zhao,Yang Song,Tao Zhang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Existing large language, large language models, show exceptional problem-solving, exceptional problem-solving capabilities, Existing large
+ 备注: LLM;RAG;MCTS
+
+ 点击查看摘要
+ Abstract:Existing large language models (LLMs) show exceptional problem-solving capabilities but might struggle with complex reasoning tasks. Despite the successes of chain-of-thought and tree-based search methods, they mainly depend on the internal knowledge of LLMs to search over intermediate reasoning steps, limited to dealing with simple tasks involving fewer reasoning steps. In this paper, we propose \textbf{RAG-Star}, a novel RAG approach that integrates the retrieved information to guide the tree-based deliberative reasoning process that relies on the inherent knowledge of LLMs. By leveraging Monte Carlo Tree Search, RAG-Star iteratively plans intermediate sub-queries and answers for reasoning based on the LLM itself. To consolidate internal and external knowledge, we propose an retrieval-augmented verification that utilizes query- and answer-aware reward modeling to provide feedback for the inherent reasoning of LLMs. Our experiments involving Llama-3.1-8B-Instruct and GPT-4o demonstrate that RAG-Star significantly outperforms previous RAG and reasoning methods.
+
+
+
+ 30. 【2412.12865】Preference-Oriented Supervised Fine-Tuning: Favoring Target Model Over Aligned Large Language Models
+ 链接:https://arxiv.org/abs/2412.12865
+ 作者:Yuchen Fan,Yuzhong Hong,Qiushi Wang,Junwei Bao,Hongfei Jiang,Yang Song
+ 类目:Computation and Language (cs.CL)
+ 关键词:pre-trained Large language, Large language model, SFT, pre-trained Large, endowing a pre-trained
+ 备注: AAAI2025, 12 pages, 9 figures
+
+ 点击查看摘要
+ Abstract:Alignment, endowing a pre-trained Large language model (LLM) with the ability to follow instructions, is crucial for its real-world applications. Conventional supervised fine-tuning (SFT) methods formalize it as causal language modeling typically with a cross-entropy objective, requiring a large amount of high-quality instruction-response pairs. However, the quality of widely used SFT datasets can not be guaranteed due to the high cost and intensive labor for the creation and maintenance in practice. To overcome the limitations associated with the quality of SFT datasets, we introduce a novel \textbf{p}reference-\textbf{o}riented supervised \textbf{f}ine-\textbf{t}uning approach, namely PoFT. The intuition is to boost SFT by imposing a particular preference: \textit{favoring the target model over aligned LLMs on the same SFT data.} This preference encourages the target model to predict a higher likelihood than that predicted by the aligned LLMs, incorporating assessment information on data quality (i.e., predicted likelihood by the aligned LLMs) into the training process. Extensive experiments are conducted, and the results validate the effectiveness of the proposed method. PoFT achieves stable and consistent improvements over the SFT baselines across different training datasets and base models. Moreover, we prove that PoFT can be integrated with existing SFT data filtering methods to achieve better performance, and further improved by following preference optimization procedures, such as DPO.
+
+
+
+ 31. 【2412.12863】DISC: Plug-and-Play Decoding Intervention with Similarity of Characters for Chinese Spelling Check
+ 链接:https://arxiv.org/abs/2412.12863
+ 作者:Ziheng Qiao,Houquan Zhou,Yumeng Liu,Zhenghua Li,Min Zhang,Bo Zhang,Chen Li,Ji Zhang,Fei Huang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Chinese spelling check, Chinese spelling, spelling check, key characteristic, Chinese
+ 备注:
+
+ 点击查看摘要
+ Abstract:One key characteristic of the Chinese spelling check (CSC) task is that incorrect characters are usually similar to the correct ones in either phonetics or glyph. To accommodate this, previous works usually leverage confusion sets, which suffer from two problems, i.e., difficulty in determining which character pairs to include and lack of probabilities to distinguish items in the set. In this paper, we propose a light-weight plug-and-play DISC (i.e., decoding intervention with similarity of characters) module for CSC this http URL measures phonetic and glyph similarities between characters and incorporates this similarity information only during the inference phase. This method can be easily integrated into various existing CSC models, such as ReaLiSe, SCOPE, and ReLM, without additional training costs. Experiments on three CSC benchmarks demonstrate that our proposed method significantly improves model performance, approaching and even surpassing the current state-of-the-art models.
+
+
+
+ 32. 【2412.12852】Selective Shot Learning for Code Explanation
+ 链接:https://arxiv.org/abs/2412.12852
+ 作者:Paheli Bhattacharya,Rishabh Gupta
+ 类目:oftware Engineering (cs.SE); Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:software engineering domain, code functionality efficiently, grasping code functionality, Code explanation plays, Code explanation
+ 备注:
+
+ 点击查看摘要
+ Abstract:Code explanation plays a crucial role in the software engineering domain, aiding developers in grasping code functionality efficiently. Recent work shows that the performance of LLMs for code explanation improves in a few-shot setting, especially when the few-shot examples are selected intelligently. State-of-the-art approaches for such Selective Shot Learning (SSL) include token-based and embedding-based methods. However, these SSL approaches have been evaluated on proprietary LLMs, without much exploration on open-source Code-LLMs. Additionally, these methods lack consideration for programming language syntax. To bridge these gaps, we present a comparative study and propose a novel SSL method (SSL_ner) that utilizes entity information for few-shot example selection. We present several insights and show the effectiveness of SSL_ner approach over state-of-the-art methods across two datasets. To the best of our knowledge, this is the first systematic benchmarking of open-source Code-LLMs while assessing the performances of the various few-shot examples selection approaches for the code explanation task.
+
+
+
+ 33. 【2412.12841】Benchmarking and Understanding Compositional Relational Reasoning of LLMs
+ 链接:https://arxiv.org/abs/2412.12841
+ 作者:Ruikang Ni,Da Xiao,Qingye Meng,Xiangyu Li,Shihui Zheng,Hongliang Liang
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Compositional relational reasoning, transformer large language, Generalized Associative Recall, Compositional relational, existing transformer large
+ 备注: Accepted to the 39th Annual AAAI Conference on Artificial Intelligence (AAAI-25)
+
+ 点击查看摘要
+ Abstract:Compositional relational reasoning (CRR) is a hallmark of human intelligence, but we lack a clear understanding of whether and how existing transformer large language models (LLMs) can solve CRR tasks. To enable systematic exploration of the CRR capability of LLMs, we first propose a new synthetic benchmark called Generalized Associative Recall (GAR) by integrating and generalizing the essence of several tasks in mechanistic interpretability (MI) study in a unified framework. Evaluation shows that GAR is challenging enough for existing LLMs, revealing their fundamental deficiency in CRR. Meanwhile, it is easy enough for systematic MI study. Then, to understand how LLMs solve GAR tasks, we use attribution patching to discover the core circuits reused by Vicuna-33B across different tasks and a set of vital attention heads. Intervention experiments show that the correct functioning of these heads significantly impacts task performance. Especially, we identify two classes of heads whose activations represent the abstract notion of true and false in GAR tasks respectively. They play a fundamental role in CRR across various models and tasks. The dataset and code are available at this https URL.
+
+
+
+ 34. 【2412.12832】DSGram: Dynamic Weighting Sub-Metrics for Grammatical Error Correction in the Era of Large Language Models
+ 链接:https://arxiv.org/abs/2412.12832
+ 作者:Jinxiang Xie,Yilin Li,Xunjian Yin,Xiaojun Wan
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Grammatical Error Correction, Grammatical Error, provided gold references, Error Correction, based GEC systems
+ 备注: Extended version of a paper to appear in AAAI-25
+
+ 点击查看摘要
+ Abstract:Evaluating the performance of Grammatical Error Correction (GEC) models has become increasingly challenging, as large language model (LLM)-based GEC systems often produce corrections that diverge from provided gold references. This discrepancy undermines the reliability of traditional reference-based evaluation metrics. In this study, we propose a novel evaluation framework for GEC models, DSGram, integrating Semantic Coherence, Edit Level, and Fluency, and utilizing a dynamic weighting mechanism. Our framework employs the Analytic Hierarchy Process (AHP) in conjunction with large language models to ascertain the relative importance of various evaluation criteria. Additionally, we develop a dataset incorporating human annotations and LLM-simulated sentences to validate our algorithms and fine-tune more cost-effective models. Experimental results indicate that our proposed approach enhances the effectiveness of GEC model evaluations.
+
+
+
+ 35. 【2412.12808】Detecting Emotional Incongruity of Sarcasm by Commonsense Reasoning
+ 链接:https://arxiv.org/abs/2412.12808
+ 作者:Ziqi Qiu,Jianxing Yu,Yufeng Zhang,Hanjiang Lai,Yanghui Rao,Qinliang Su,Jian Yin
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:negative sentiment opposite, statements convey criticism, convey criticism, literal meaning, paper focuses
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper focuses on sarcasm detection, which aims to identify whether given statements convey criticism, mockery, or other negative sentiment opposite to the literal meaning. To detect sarcasm, humans often require a comprehensive understanding of the semantics in the statement and even resort to external commonsense to infer the fine-grained incongruity. However, existing methods lack commonsense inferential ability when they face complex real-world scenarios, leading to unsatisfactory performance. To address this problem, we propose a novel framework for sarcasm detection, which conducts incongruity reasoning based on commonsense augmentation, called EICR. Concretely, we first employ retrieval-augmented large language models to supplement the missing but indispensable commonsense background knowledge. To capture complex contextual associations, we construct a dependency graph and obtain the optimized topology via graph refinement. We further introduce an adaptive reasoning skeleton that integrates prior rules to extract sentiment-inconsistent subgraphs explicitly. To eliminate the possible spurious relations between words and labels, we employ adversarial contrastive learning to enhance the robustness of the detector. Experiments conducted on five datasets demonstrate the effectiveness of EICR.
+
+
+
+ 36. 【2412.12806】Cross-Dialect Information Retrieval: Information Access in Low-Resource and High-Variance Languages
+ 链接:https://arxiv.org/abs/2412.12806
+ 作者:Robert Litschko,Oliver Kraus,Verena Blaschke,Barbara Plank
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:culture-specific knowledge, large amount, amount of local, local and culture-specific, German dialects
+ 备注: Accepted at COLING 2025
+
+ 点击查看摘要
+ Abstract:A large amount of local and culture-specific knowledge (e.g., people, traditions, food) can only be found in documents written in dialects. While there has been extensive research conducted on cross-lingual information retrieval (CLIR), the field of cross-dialect retrieval (CDIR) has received limited attention. Dialect retrieval poses unique challenges due to the limited availability of resources to train retrieval models and the high variability in non-standardized languages. We study these challenges on the example of German dialects and introduce the first German dialect retrieval dataset, dubbed WikiDIR, which consists of seven German dialects extracted from Wikipedia. Using WikiDIR, we demonstrate the weakness of lexical methods in dealing with high lexical variation in dialects. We further show that commonly used zero-shot cross-lingual transfer approach with multilingual encoders do not transfer well to extremely low-resource setups, motivating the need for resource-lean and dialect-specific retrieval models. We finally demonstrate that (document) translation is an effective way to reduce the dialect gap in CDIR.
+
+
+
+ 37. 【2412.12797】Is it the end of (generative) linguistics as we know it?
+ 链接:https://arxiv.org/abs/2412.12797
+ 作者:Cristiano Chesi
+ 类目:Computation and Language (cs.CL)
+ 关键词:written by Steven, Steven Piantadosi, LingBuzz platform, significant debate, debate has emerged
+ 备注:
+
+ 点击查看摘要
+ Abstract:A significant debate has emerged in response to a paper written by Steven Piantadosi (Piantadosi, 2023) and uploaded to the LingBuzz platform, the open archive for generative linguistics. Piantadosi's dismissal of Chomsky's approach is ruthless, but generative linguists deserve it. In this paper, I will adopt three idealized perspectives -- computational, theoretical, and experimental -- to focus on two fundamental issues that lend partial support to Piantadosi's critique: (a) the evidence challenging the Poverty of Stimulus (PoS) hypothesis and (b) the notion of simplicity as conceived within mainstream Minimalism. In conclusion, I argue that, to reclaim a central role in language studies, generative linguistics -- representing a prototypical theoretical perspective on language -- needs a serious update leading to (i) more precise, consistent, and complete formalizations of foundational intuitions and (ii) the establishment and utilization of a standardized dataset of crucial empirical evidence to evaluate the theory's adequacy. On the other hand, ignoring the formal perspective leads to major drawbacks in both computational and experimental approaches. Neither descriptive nor explanatory adequacy can be easily achieved without the precise formulation of general principles that can be challenged empirically.
+
+
+
+ 38. 【2412.12767】A Survey of Calibration Process for Black-Box LLMs
+ 链接:https://arxiv.org/abs/2412.12767
+ 作者:Liangru Xie,Hui Liu,Jingying Zeng,Xianfeng Tang,Yan Han,Chen Luo,Jing Huang,Zhen Li,Suhang Wang,Qi He
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, Language Models, demonstrate remarkable performance, output reliability remains
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) demonstrate remarkable performance in semantic understanding and generation, yet accurately assessing their output reliability remains a significant challenge. While numerous studies have explored calibration techniques, they primarily focus on White-Box LLMs with accessible parameters. Black-Box LLMs, despite their superior performance, pose heightened requirements for calibration techniques due to their API-only interaction constraints. Although recent researches have achieved breakthroughs in black-box LLMs calibration, a systematic survey of these methodologies is still lacking. To bridge this gap, we presents the first comprehensive survey on calibration techniques for black-box LLMs. We first define the Calibration Process of LLMs as comprising two interrelated key steps: Confidence Estimation and Calibration. Second, we conduct a systematic review of applicable methods within black-box settings, and provide insights on the unique challenges and connections in implementing these key steps. Furthermore, we explore typical applications of Calibration Process in black-box LLMs and outline promising future research directions, providing new perspectives for enhancing reliability and human-machine alignment. This is our GitHub link: this https URL
+
+
+
+ 39. 【2412.12761】Revealing the impact of synthetic native samples and multi-tasking strategies in Hindi-English code-mixed humour and sarcasm detection
+ 链接:https://arxiv.org/abs/2412.12761
+ 作者:Debajyoti Mazumder,Aakash Kumar,Jasabanta Patro
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:reported our experiments, native sample mixing, sample mixing, MTL, code-mixed
+ 备注: 26 pages; under review
+
+ 点击查看摘要
+ Abstract:In this paper, we reported our experiments with various strategies to improve code-mixed humour and sarcasm detection. We did all of our experiments for Hindi-English code-mixed scenario, as we have the linguistic expertise for the same. We experimented with three approaches, namely (i) native sample mixing, (ii) multi-task learning (MTL), and (iii) prompting very large multilingual language models (VMLMs). In native sample mixing, we added monolingual task samples in code-mixed training sets. In MTL learning, we relied on native and code-mixed samples of a semantically related task (hate detection in our case). Finally, in our third approach, we evaluated the efficacy of VMLMs via few-shot context prompting. Some interesting findings we got are (i) adding native samples improved humor (raising the F1-score up to 6.76%) and sarcasm (raising the F1-score up to 8.64%) detection, (ii) training MLMs in an MTL framework boosted performance for both humour (raising the F1-score up to 10.67%) and sarcasm (increment up to 12.35% in F1-score) detection, and (iii) prompting VMLMs couldn't outperform the other approaches. Finally, our ablation studies and error analysis discovered the cases where our model is yet to improve. We provided our code for reproducibility.
+
+
+
+ 40. 【2412.12744】Your Next State-of-the-Art Could Come from Another Domain: A Cross-Domain Analysis of Hierarchical Text Classification
+ 链接:https://arxiv.org/abs/2412.12744
+ 作者:Nan Li,Bo Kang,Tijl De Bie
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:natural language processing, language processing, European legal texts, classification with hierarchical, hierarchical labels
+ 备注:
+
+ 点击查看摘要
+ Abstract:Text classification with hierarchical labels is a prevalent and challenging task in natural language processing. Examples include assigning ICD codes to patient records, tagging patents into IPC classes, assigning EUROVOC descriptors to European legal texts, and more. Despite its widespread applications, a comprehensive understanding of state-of-the-art methods across different domains has been lacking. In this paper, we provide the first comprehensive cross-domain overview with empirical analysis of state-of-the-art methods. We propose a unified framework that positions each method within a common structure to facilitate research. Our empirical analysis yields key insights and guidelines, confirming the necessity of learning across different research areas to design effective methods. Notably, under our unified evaluation pipeline, we achieved new state-of-the-art results by applying techniques beyond their original domains.
+
+
+
+ 41. 【2412.12735】GIRAFFE: Design Choices for Extending the Context Length of Visual Language Models
+ 链接:https://arxiv.org/abs/2412.12735
+ 作者:Mukai Li,Lei Li,Shansan Gong,Qi Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Visual Language Models, Visual Language, demonstrate impressive capabilities, processing multimodal inputs, require handling multiple
+ 备注: Working in progress
+
+ 点击查看摘要
+ Abstract:Visual Language Models (VLMs) demonstrate impressive capabilities in processing multimodal inputs, yet applications such as visual agents, which require handling multiple images and high-resolution videos, demand enhanced long-range modeling. Moreover, existing open-source VLMs lack systematic exploration into extending their context length, and commercial models often provide limited details. To tackle this, we aim to establish an effective solution that enhances long context performance of VLMs while preserving their capacities in short context scenarios. Towards this goal, we make the best design choice through extensive experiment settings from data curation to context window extending and utilizing: (1) we analyze data sources and length distributions to construct ETVLM - a data recipe to balance the performance across scenarios; (2) we examine existing position extending methods, identify their limitations and propose M-RoPE++ as an enhanced approach; we also choose to solely instruction-tune the backbone with mixed-source data; (3) we discuss how to better utilize extended context windows and propose hybrid-resolution training. Built on the Qwen-VL series model, we propose Giraffe, which is effectively extended to 128K lengths. Evaluated on extensive long context VLM benchmarks such as VideoMME and Viusal Haystacks, our Giraffe achieves state-of-the-art performance among similarly sized open-source long VLMs and is competitive with commercial model GPT-4V. We will open-source the code, data, and models.
+
+
+
+ 42. 【2412.12733】EventFull: Complete and Consistent Event Relation Annotation
+ 链接:https://arxiv.org/abs/2412.12733
+ 作者:Alon Eirew,Eviatar Nachshoni,Aviv Slobodkin,Ido Dagan
+ 类目:Computation and Language (cs.CL)
+ 关键词:fundamental NLP task, NLP task, fundamental NLP, modeling requires datasets, requires datasets annotated
+ 备注:
+
+ 点击查看摘要
+ Abstract:Event relation detection is a fundamental NLP task, leveraged in many downstream applications, whose modeling requires datasets annotated with event relations of various types. However, systematic and complete annotation of these relations is costly and challenging, due to the quadratic number of event pairs that need to be considered. Consequently, many current event relation datasets lack systematicity and completeness. In response, we introduce \textit{EventFull}, the first tool that supports consistent, complete and efficient annotation of temporal, causal and coreference relations via a unified and synergetic process. A pilot study demonstrates that EventFull accelerates and simplifies the annotation process while yielding high inter-annotator agreement.
+
+
+
+ 43. 【2412.12731】SentiQNF: A Novel Approach to Sentiment Analysis Using Quantum Algorithms and Neuro-Fuzzy Systems
+ 链接:https://arxiv.org/abs/2412.12731
+ 作者:Kshitij Dave,Nouhaila Innan,Bikash K. Behera,Zahid Mumtaz,Saif Al-Kuwari,Ahmed Farouk
+ 类目:Computation and Language (cs.CL); Quantum Physics (quant-ph)
+ 关键词:Sentiment analysis, essential component, component of natural, emotional tones, Sentiment
+ 备注:
+
+ 点击查看摘要
+ Abstract:Sentiment analysis is an essential component of natural language processing, used to analyze sentiments, attitudes, and emotional tones in various contexts. It provides valuable insights into public opinion, customer feedback, and user experiences. Researchers have developed various classical machine learning and neuro-fuzzy approaches to address the exponential growth of data and the complexity of language structures in sentiment analysis. However, these approaches often fail to determine the optimal number of clusters, interpret results accurately, handle noise or outliers efficiently, and scale effectively to high-dimensional data. Additionally, they are frequently insensitive to input variations. In this paper, we propose a novel hybrid approach for sentiment analysis called the Quantum Fuzzy Neural Network (QFNN), which leverages quantum properties and incorporates a fuzzy layer to overcome the limitations of classical sentiment analysis algorithms. In this study, we test the proposed approach on two Twitter datasets: the Coronavirus Tweets Dataset (CVTD) and the General Sentimental Tweets Dataset (GSTD), and compare it with classical and hybrid algorithms. The results demonstrate that QFNN outperforms all classical, quantum, and hybrid algorithms, achieving 100% and 90% accuracy in the case of CVTD and GSTD, respectively. Furthermore, QFNN demonstrates its robustness against six different noise models, providing the potential to tackle the computational complexity associated with sentiment analysis on a large scale in a noisy environment. The proposed approach expedites sentiment data processing and precisely analyses different forms of textual data, thereby enhancing sentiment classification and insights associated with sentiment analysis.
+
+
+
+ 44. 【2412.12710】Enhancing Naturalness in LLM-Generated Utterances through Disfluency Insertion
+ 链接:https://arxiv.org/abs/2412.12710
+ 作者:Syed Zohaib Hassan,Pierre Lison,Pål Halvorsen
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, outputs of Large, Language Models, spontaneous human speech
+ 备注: 4 pages short paper, references and appendix are additional
+
+ 点击查看摘要
+ Abstract:Disfluencies are a natural feature of spontaneous human speech but are typically absent from the outputs of Large Language Models (LLMs). This absence can diminish the perceived naturalness of synthesized speech, which is an important criteria when building conversational agents that aim to mimick human behaviours. We show how the insertion of disfluencies can alleviate this shortcoming. The proposed approach involves (1) fine-tuning an LLM with Low-Rank Adaptation (LoRA) to incorporate various types of disfluencies into LLM-generated utterances and (2) synthesizing those utterances using a text-to-speech model that supports the generation of speech phenomena such as disfluencies. We evaluated the quality of the generated speech across two metrics: intelligibility and perceived spontaneity. We demonstrate through a user study that the insertion of disfluencies significantly increase the perceived spontaneity of the generated speech. This increase came, however, along with a slight reduction in intelligibility.
+
+
+
+ 45. 【2412.12706】More Tokens, Lower Precision: Towards the Optimal Token-Precision Trade-off in KV Cache Compression
+ 链接:https://arxiv.org/abs/2412.12706
+ 作者:Jiebin Zhang,Dawei Zhu,Yifan Song,Wenhao Wu,Chuqiao Kuang,Xiaoguang Li,Lifeng Shang,Qun Liu,Sujian Li
+ 类目:Computation and Language (cs.CL)
+ 关键词:process increasing context, increasing context windows, large language models, process increasing, context windows
+ 备注: 13pages,7 figures
+
+ 点击查看摘要
+ Abstract:As large language models (LLMs) process increasing context windows, the memory usage of KV cache has become a critical bottleneck during inference. The mainstream KV compression methods, including KV pruning and KV quantization, primarily focus on either token or precision dimension and seldom explore the efficiency of their combination. In this paper, we comprehensively investigate the token-precision trade-off in KV cache compression. Experiments demonstrate that storing more tokens in the KV cache with lower precision, i.e., quantized pruning, can significantly enhance the long-context performance of LLMs. Furthermore, in-depth analysis regarding token-precision trade-off from a series of key aspects exhibit that, quantized pruning achieves substantial improvements in retrieval-related tasks and consistently performs well across varying input lengths. Moreover, quantized pruning demonstrates notable stability across different KV pruning methods, quantization strategies, and model scales. These findings provide valuable insights into the token-precision trade-off in KV cache compression. We plan to release our code in the near future.
+
+
+
+ 46. 【2412.12701】rigger$^3$: Refining Query Correction via Adaptive Model Selector
+ 链接:https://arxiv.org/abs/2412.12701
+ 作者:Kepu Zhang,Zhongxiang Sun,Xiao Zhang,Xiaoxue Zang,Kai Zheng,Yang Song,Jun Xu
+ 类目:Computation and Language (cs.CL)
+ 关键词:correction, erroneous queries due, voice errors, traditional correction model, user experience
+ 备注:
+
+ 点击查看摘要
+ Abstract:In search scenarios, user experience can be hindered by erroneous queries due to typos, voice errors, or knowledge gaps. Therefore, query correction is crucial for search engines. Current correction models, usually small models trained on specific data, often struggle with queries beyond their training scope or those requiring contextual understanding. While the advent of Large Language Models (LLMs) offers a potential solution, they are still limited by their pre-training data and inference cost, particularly for complex queries, making them not always effective for query correction. To tackle these, we propose Trigger$^3$, a large-small model collaboration framework that integrates the traditional correction model and LLM for query correction, capable of adaptively choosing the appropriate correction method based on the query and the correction results from the traditional correction model and LLM. Trigger$^3$ first employs a correction trigger to filter out correct queries. Incorrect queries are then corrected by the traditional correction model. If this fails, an LLM trigger is activated to call the LLM for correction. Finally, for queries that no model can correct, a fallback trigger decides to return the original query. Extensive experiments demonstrate Trigger$^3$ outperforms correction baselines while maintaining efficiency.
+
+
+
+ 47. 【2412.12686】XTransplant: A Probe into the Upper Bound Performance of Multilingual Capability and Culture Adaptability in LLMs via Mutual Cross-lingual Feed-forward Transplantation
+ 链接:https://arxiv.org/abs/2412.12686
+ 作者:Yangfan Ye,Xiaocheng Feng,Xiachong Feng,Libo Qin,Yichong Huang,Lei Huang,Weitao Ma,Zhirui Zhang,Yunfei Lu,Xiaohui Yan,Duyu Tang,Dandan Tu,Bing Qin
+ 类目:Computation and Language (cs.CL)
+ 关键词:English-centric pretraining data, English-centric pretraining, Current large language, large language models, largely due
+ 备注:
+
+ 点击查看摘要
+ Abstract:Current large language models (LLMs) often exhibit imbalances in multilingual capabilities and cultural adaptability, largely due to their English-centric pretraining data. To address this imbalance, we propose a probing method named XTransplant that explores cross-lingual latent interactions via cross-lingual feed-forward transplantation during inference stage, with the hope of enabling the model to leverage the strengths of both English and non-English languages. Through extensive pilot experiments, we empirically prove that both the multilingual capabilities and cultural adaptability of LLMs hold the potential to be significantly improved by XTransplant, respectively from En - non-En and non-En - En, highlighting the underutilization of current LLMs' multilingual potential. And the patterns observed in these pilot experiments further motivate an offline scaling inference strategy, which demonstrates consistent performance improvements in multilingual and culture-aware tasks, sometimes even surpassing multilingual supervised fine-tuning. And we do hope our further analysis and discussion could help gain deeper insights into XTransplant mechanism.
+
+
+
+ 48. 【2412.12679】Detecting Document-level Paraphrased Machine Generated Content: Mimicking Human Writing Style and Involving Discourse Features
+ 链接:https://arxiv.org/abs/2412.12679
+ 作者:Yupei Li,Manuel Milling,Lucia Specia,Björn W. Schuller
+ 类目:Computation and Language (cs.CL)
+ 关键词:Machine-Generated Content, Large Language Models, APIs for Large, Large Language, spread of misinformation
+ 备注:
+
+ 点击查看摘要
+ Abstract:The availability of high-quality APIs for Large Language Models (LLMs) has facilitated the widespread creation of Machine-Generated Content (MGC), posing challenges such as academic plagiarism and the spread of misinformation. Existing MGC detectors often focus solely on surface-level information, overlooking implicit and structural features. This makes them susceptible to deception by surface-level sentence patterns, particularly for longer texts and in texts that have been subsequently paraphrased.
+To overcome these challenges, we introduce novel methodologies and datasets. Besides the publicly available dataset Plagbench, we developed the paraphrased Long-Form Question and Answer (paraLFQA) and paraphrased Writing Prompts (paraWP) datasets using GPT and DIPPER, a discourse paraphrasing tool, by extending artifacts from their original versions. To address the challenge of detecting highly similar paraphrased texts, we propose MhBART, an encoder-decoder model designed to emulate human writing style while incorporating a novel difference score mechanism. This model outperforms strong classifier baselines and identifies deceptive sentence patterns. To better capture the structure of longer texts at document level, we propose DTransformer, a model that integrates discourse analysis through PDTB preprocessing to encode structural features. It results in substantial performance gains across both datasets -- 15.5\% absolute improvement on paraLFQA, 4\% absolute improvement on paraWP, and 1.5\% absolute improvement on M4 compared to SOTA approaches.
+
Subjects:
+Computation and Language (cs.CL)
+Cite as:
+arXiv:2412.12679 [cs.CL]
+(or
+arXiv:2412.12679v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2412.12679
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 49. 【2412.12674】rain More Parameters But Mind Their Placement: Insights into Language Adaptation with PEFT
+ 链接:https://arxiv.org/abs/2412.12674
+ 作者:Jenny Kunz
+ 类目:Computation and Language (cs.CL)
+ 关键词:face significant challenges, Smaller LLMs, language-specific knowledge, machine-translated data, face significant
+ 备注: To appear at NoDaLiDa 2025
+
+ 点击查看摘要
+ Abstract:Smaller LLMs still face significant challenges even in medium-resourced languages, particularly when it comes to language-specific knowledge -- a problem not easily resolved with machine-translated data. In this case study on Icelandic, we aim to enhance the generation performance of an LLM by specialising it using unstructured text corpora. A key focus is on preventing interference with the models' capabilities of handling longer context during this adaptation. Through ablation studies using various parameter-efficient fine-tuning (PEFT) methods and setups, we find that increasing the number of trainable parameters leads to better and more robust language adaptation. LoRAs placed in the feed-forward layers and bottleneck adapters show promising results with sufficient parameters, while prefix tuning and (IA)3 are not suitable. Although improvements are consistent in 0-shot summarisation, some adapted models struggle with longer context lengths, an issue that can be mitigated by adapting only the final layers.
+
+
+
+ 50. 【2412.12661】MedMax: Mixed-Modal Instruction Tuning for Training Biomedical Assistants
+ 链接:https://arxiv.org/abs/2412.12661
+ 作者:Hritik Bansal,Daniel Israel,Siyan Zhao,Shufan Li,Tung Nguyen,Aditya Grover
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:enabled flexible integration, Recent advancements, enabled flexible, flexible integration, integration of information
+ 备注: 12 figures, 15 tables
+
+ 点击查看摘要
+ Abstract:Recent advancements in mixed-modal generative models have enabled flexible integration of information across image-text content. These models have opened new avenues for developing unified biomedical assistants capable of analyzing biomedical images, answering complex questions about them, and predicting the impact of medical procedures on a patient's health. However, existing resources face challenges such as limited data availability, narrow domain coverage, and restricted sources (e.g., medical papers). To address these gaps, we present MedMax, the first large-scale multimodal biomedical instruction-tuning dataset for mixed-modal foundation models. With 1.47 million instances, MedMax encompasses a diverse range of tasks, including multimodal content generation (interleaved image-text data), biomedical image captioning and generation, visual chatting, and report understanding. These tasks span diverse medical domains such as radiology and histopathology. Subsequently, we fine-tune a mixed-modal foundation model on the MedMax dataset, achieving significant performance improvements: a 26% gain over the Chameleon model and an 18.3% improvement over GPT-4o across 12 downstream biomedical visual question-answering tasks. Additionally, we introduce a unified evaluation suite for biomedical tasks, providing a robust framework to guide the development of next-generation mixed-modal biomedical AI assistants.
+
+
+
+ 51. 【2412.12649】ClustEm4Ano: Clustering Text Embeddings of Nominal Textual Attributes for Microdata Anonymization
+ 链接:https://arxiv.org/abs/2412.12649
+ 作者:Robert Aufschläger,Sebastian Wilhelm,Michael Heigl,Martin Schramm
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:textual tabular data, nominal textual tabular, work introduces, tabular data, nominal textual
+ 备注: 16 pages, 5 figures, accepted for presentation at IDEAS: 2024 28th International Symposium on Database Engineered Applications, Bayonne, France, August 26-29, 2024
+
+ 点击查看摘要
+ Abstract:This work introduces ClustEm4Ano, an anonymization pipeline that can be used for generalization and suppression-based anonymization of nominal textual tabular data. It automatically generates value generalization hierarchies (VGHs) that, in turn, can be used to generalize attributes in quasi-identifiers. The pipeline leverages embeddings to generate semantically close value generalizations through iterative clustering. We applied KMeans and Hierarchical Agglomerative Clustering on $13$ different predefined text embeddings (both open and closed-source (via APIs)). Our approach is experimentally tested on a well-known benchmark dataset for anonymization: The UCI Machine Learning Repository's Adult dataset. ClustEm4Ano supports anonymization procedures by offering more possibilities compared to using arbitrarily chosen VGHs. Experiments demonstrate that these VGHs can outperform manually constructed ones in terms of downstream efficacy (especially for small $k$-anonymity ($2 \leq k \leq 30$)) and therefore can foster the quality of anonymized datasets. Our implementation is made public.
+
+
+
+ 52. 【2412.12644】PrOp: Interactive Prompt Optimization for Large Language Models with a Human in the Loop
+ 链接:https://arxiv.org/abs/2412.12644
+ 作者:Jiahui Li,Roman Klinger
+ 类目:Computation and Language (cs.CL)
+ 关键词:made significant contributions, Automatic prompt optimization, prompt optimization, Prompt, Interactive Prompt Optimization
+ 备注:
+
+ 点击查看摘要
+ Abstract:Prompt engineering has made significant contributions to the era of large language models, yet its effectiveness depends on the skills of a prompt author. Automatic prompt optimization can support the prompt development process, but requires annotated data. This paper introduces $\textit{iPrOp}$, a novel Interactive Prompt Optimization system, to bridge manual prompt engineering and automatic prompt optimization. With human intervention in the optimization loop, $\textit{iPrOp}$ offers users the flexibility to assess evolving prompts. We present users with prompt variations, selected instances, large language model predictions accompanied by corresponding explanations, and performance metrics derived from a subset of the training data. This approach empowers users to choose and further refine the provided prompts based on their individual preferences and needs. This system not only assists non-technical domain experts in generating optimal prompts tailored to their specific tasks or domains, but also enables to study the intrinsic parameters that influence the performance of prompt optimization. Our evaluation shows that our system has the capability to generate improved prompts, leading to enhanced task performance.
+
+
+
+ 53. 【2412.12643】LLM-based Discriminative Reasoning for Knowledge Graph Question Answering
+ 链接:https://arxiv.org/abs/2412.12643
+ 作者:Mufan Xu,Kehai Chen,Xuefeng Bai,Muyun Yang,Tiejun Zhao,Min Zhang
+ 类目:Computation and Language (cs.CL)
+ 关键词:generative pre-trained Transformer, Large language models, knowledge graph question-answering, Large language, pre-trained Transformer
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) based on generative pre-trained Transformer have achieved remarkable performance on knowledge graph question-answering (KGQA) tasks. However, LLMs often produce ungrounded subgraph planning or reasoning results in KGQA due to the hallucinatory behavior brought by the generative paradigm, which may hinder the advancement of the LLM-based KGQA model. To deal with the issue, we propose a novel LLM-based Discriminative Reasoning (LDR) method to explicitly model the subgraph retrieval and answer inference process. By adopting discriminative strategies, the proposed LDR method not only enhances the capability of LLMs to retrieve question-related subgraphs but also alleviates the issue of ungrounded reasoning brought by the generative paradigm of LLMs. Experimental results show that the proposed approach outperforms multiple strong comparison methods, along with achieving state-of-the-art performance on two widely used WebQSP and CWQ benchmarks.
+
+
+
+ 54. 【2412.12639】Falcon: Faster and Parallel Inference of Large Language Models through Enhanced Semi-Autoregressive Drafting and Custom-Designed Decoding Tree
+ 链接:https://arxiv.org/abs/2412.12639
+ 作者:Xiangxiang Gao,Weisheng Xie,Yiwei Xiang,Feng Ji
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, Language Models remains, minimal drafting latency, Large Language, Striking an optimal
+ 备注: AAAI 2025 Accepted
+
+ 点击查看摘要
+ Abstract:Striking an optimal balance between minimal drafting latency and high speculation accuracy to enhance the inference speed of Large Language Models remains a significant challenge in speculative decoding. In this paper, we introduce Falcon, an innovative semi-autoregressive speculative decoding framework fashioned to augment both the drafter's parallelism and output quality. Falcon incorporates the Coupled Sequential Glancing Distillation technique, which fortifies inter-token dependencies within the same block, leading to increased speculation accuracy. We offer a comprehensive theoretical analysis to illuminate the underlying mechanisms. Additionally, we introduce a Custom-Designed Decoding Tree, which permits the drafter to generate multiple tokens in a single forward pass and accommodates multiple forward passes as needed, thereby boosting the number of drafted tokens and significantly improving the overall acceptance rate. Comprehensive evaluations on benchmark datasets such as MT-Bench, HumanEval, and GSM8K demonstrate Falcon's superior acceleration capabilities. The framework achieves a lossless speedup ratio ranging from 2.91x to 3.51x when tested on the Vicuna and LLaMA2-Chat model series. These results outstrip existing speculative decoding methods for LLMs, including Eagle, Medusa, Lookahead, SPS, and PLD, while maintaining a compact drafter architecture equivalent to merely two Transformer layers.
+
+
+
+ 55. 【2412.12632】What External Knowledge is Preferred by LLMs? Characterizing and Exploring Chain of Evidence in Imperfect Context
+ 链接:https://arxiv.org/abs/2412.12632
+ 作者:Zhiyuan Chang,Mingyang Li,Xiaojun Jia,Junjie Wang,Yuekai Huang,Qing Wang,Yihao Huang,Yang Liu
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:large language models, Incorporating external knowledge, Incorporating external, mitigate outdated knowledge, language models
+ 备注: 12 pages, 4 figures
+
+ 点击查看摘要
+ Abstract:Incorporating external knowledge into large language models (LLMs) has emerged as a promising approach to mitigate outdated knowledge and hallucination in LLMs. However, external knowledge is often imperfect. In addition to useful knowledge, external knowledge is rich in irrelevant or misinformation in the context that can impair the reliability of LLM responses. This paper focuses on LLMs' preferred external knowledge in imperfect contexts when handling multi-hop QA. Inspired by criminal procedural law's Chain of Evidence (CoE), we characterize that knowledge preferred by LLMs should maintain both relevance to the question and mutual support among knowledge pieces. Accordingly, we propose an automated CoE discrimination approach and explore LLMs' preferences from their effectiveness, faithfulness and robustness, as well as CoE's usability in a naive Retrieval-Augmented Generation (RAG) case. The evaluation on five LLMs reveals that CoE enhances LLMs through more accurate generation, stronger answer faithfulness, better robustness against knowledge conflict, and improved performance in a popular RAG case.
+
+
+
+ 56. 【2412.12627】Make Imagination Clearer! Stable Diffusion-based Visual Imagination for Multimodal Machine Translation
+ 链接:https://arxiv.org/abs/2412.12627
+ 作者:Andong Chen,Yuchen Song,Kehai Chen,Muyun Yang,Tiejun Zhao,Min Zhang
+ 类目:Computation and Language (cs.CL)
+ 关键词:enhancing machine translation, effectiveness heavily relies, bilingual parallel sentence, parallel sentence pairs, manual image annotations
+ 备注: Work in progress
+
+ 点击查看摘要
+ Abstract:Visual information has been introduced for enhancing machine translation (MT), and its effectiveness heavily relies on the availability of large amounts of bilingual parallel sentence pairs with manual image annotations. In this paper, we introduce a stable diffusion-based imagination network into a multimodal large language model (MLLM) to explicitly generate an image for each source sentence, thereby advancing the multimodel MT. Particularly, we build heuristic human feedback with reinforcement learning to ensure the consistency of the generated image with the source sentence without the supervision of image annotation, which breaks the bottleneck of using visual information in MT. Furthermore, the proposed method enables imaginative visual information to be integrated into large-scale text-only MT in addition to multimodal MT. Experimental results show that our model significantly outperforms existing multimodal MT and text-only MT, especially achieving an average improvement of more than 14 BLEU points on Multi30K multimodal MT benchmarks.
+
+
+
+ 57. 【2412.12621】Jailbreaking? One Step Is Enough!
+ 链接:https://arxiv.org/abs/2412.12621
+ 作者:Weixiong Zheng,Peijian Zeng,Yiwei Li,Hongyan Wu,Nankai Lin,Junhao Chen,Aimin Yang,Yongmei Zhou
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large language models, Large language, adversaries manipulate prompts, generate harmful outputs, remain vulnerable
+ 备注: 17 pages
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) excel in various tasks but remain vulnerable to jailbreak attacks, where adversaries manipulate prompts to generate harmful outputs. Examining jailbreak prompts helps uncover the shortcomings of LLMs. However, current jailbreak methods and the target model's defenses are engaged in an independent and adversarial process, resulting in the need for frequent attack iterations and redesigning attacks for different models. To address these gaps, we propose a Reverse Embedded Defense Attack (REDA) mechanism that disguises the attack intention as the "defense". intention against harmful content. Specifically, REDA starts from the target response, guiding the model to embed harmful content within its defensive measures, thereby relegating harmful content to a secondary role and making the model believe it is performing a defensive task. The attacking model considers that it is guiding the target model to deal with harmful content, while the target model thinks it is performing a defensive task, creating an illusion of cooperation between the two. Additionally, to enhance the model's confidence and guidance in "defensive" intentions, we adopt in-context learning (ICL) with a small number of attack examples and construct a corresponding dataset of attack examples. Extensive evaluations demonstrate that the REDA method enables cross-model attacks without the need to redesign attack strategies for different models, enables successful jailbreak in one iteration, and outperforms existing methods on both open-source and closed-source models.
+
+
+
+ 58. 【2412.12612】SynthCypher: A Fully Synthetic Data Generation Framework for Text-to-Cypher Querying in Knowledge Graphs
+ 链接:https://arxiv.org/abs/2412.12612
+ 作者:Aman Tiwari,Shiva Krishna Reddy Malay,Vikas Yadav,Masoud Hashemi,Sathwik Tejaswi Madhusudhan
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:enabling graph-based analytics, graph databases, plays a critical, critical role, role in enabling
+ 备注:
+
+ 点击查看摘要
+ Abstract:Cypher, the query language for Neo4j graph databases, plays a critical role in enabling graph-based analytics and data exploration. While substantial research has been dedicated to natural language to SQL query generation (Text2SQL), the analogous problem for graph databases referred to as Text2Cypher remains underexplored. In this work, we introduce SynthCypher, a fully synthetic and automated data generation pipeline designed to address this gap. SynthCypher employs a novel LLMSupervised Generation-Verification framework, ensuring syntactically and semantically correct Cypher queries across diverse domains and query complexities. Using this pipeline, we create SynthCypher Dataset, a large-scale benchmark containing 29.8k Text2Cypher instances. Fine-tuning open-source large language models (LLMs), including LLaMa-3.1- 8B, Mistral-7B, and QWEN-7B, on SynthCypher yields significant performance improvements of up to 40% on the Text2Cypher test set and 30% on the SPIDER benchmark adapted for graph databases. This work demonstrates that high-quality synthetic data can effectively advance the state-of-the-art in Text2Cypher tasks.
+
+
+
+ 59. 【2412.12609】MultiLingPoT: Enhancing Mathematical Reasoning with Multilingual Program Fine-tuning
+ 链接:https://arxiv.org/abs/2412.12609
+ 作者:Nianqi Li,Zujie Liang,Siyu Yuan,Jiaqing Liang,Feng Wei,Yanghua Xiao
+ 类目:Computation and Language (cs.CL)
+ 关键词:programming languages, solve mathematical problems, intermediate step, LLMs to solve, programming
+ 备注:
+
+ 点击查看摘要
+ Abstract:Program-of-Thought (PoT), which aims to use programming language instead of natural language as an intermediate step in reasoning, is an important way for LLMs to solve mathematical problems. Since different programming languages excel in different areas, it is natural to use the most suitable language for solving specific problems. However, current PoT research only focuses on single language PoT, ignoring the differences between different programming languages. Therefore, this paper proposes an multilingual program reasoning method, MultiLingPoT. This method allows the model to answer questions using multiple programming languages by fine-tuning on multilingual data. Additionally, prior and posterior hybrid methods are used to help the model select the most suitable language for each problem. Our experimental results show that the training of MultiLingPoT improves each program's mathematical reasoning by about 2.5\%. Moreover, with proper mixing, the performance of MultiLingPoT can be further improved, achieving a 6\% increase compared to the single-language PoT with the data this http URL of this paper can be found at this https URL.
+
+
+
+ 60. 【2412.12606】Multi-Dimensional Insights: Benchmarking Real-World Personalization in Large Multimodal Models
+ 链接:https://arxiv.org/abs/2412.12606
+ 作者:YiFan Zhang,Shanglin Lei,Runqi Qiao,Zhuoma GongQue,Xiaoshuai Song,Guanting Dong,Qiuna Tan,Zhe Wei,Peiqing Yang,Ye Tian,Yadong Xue,Xiaofei Wang,Honggang Zhang
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:rapidly developing field, large multimodal models, rapidly developing, developing field, field of large
+ 备注: 33 pages, 33 figures, Work in progress
+
+ 点击查看摘要
+ Abstract:The rapidly developing field of large multimodal models (LMMs) has led to the emergence of diverse models with remarkable capabilities. However, existing benchmarks fail to comprehensively, objectively and accurately evaluate whether LMMs align with the diverse needs of humans in real-world scenarios. To bridge this gap, we propose the Multi-Dimensional Insights (MDI) benchmark, which includes over 500 images covering six common scenarios of human life. Notably, the MDI-Benchmark offers two significant advantages over existing evaluations: (1) Each image is accompanied by two types of questions: simple questions to assess the model's understanding of the image, and complex questions to evaluate the model's ability to analyze and reason beyond basic content. (2) Recognizing that people of different age groups have varying needs and perspectives when faced with the same scenario, our benchmark stratifies questions into three age categories: young people, middle-aged people, and older people. This design allows for a detailed assessment of LMMs' capabilities in meeting the preferences and needs of different age groups. With MDI-Benchmark, the strong model like GPT-4o achieve 79% accuracy on age-related tasks, indicating that existing LMMs still have considerable room for improvement in addressing real-world applications. Looking ahead, we anticipate that the MDI-Benchmark will open new pathways for aligning real-world personalization in LMMs. The MDI-Benchmark data and evaluation code are available at this https URL
+
+
+
+ 61. 【2412.12591】LLMs are Also Effective Embedding Models: An In-depth Overview
+ 链接:https://arxiv.org/abs/2412.12591
+ 作者:Chongyang Tao,Tao Shen,Shen Gao,Junshuo Zhang,Zhen Li,Zhengwei Tao,Shuai Ma
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large language models, natural language processing, revolutionized natural language, Large language, natural language
+ 备注: 32 pages
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) have revolutionized natural language processing by achieving state-of-the-art performance across various tasks. Recently, their effectiveness as embedding models has gained attention, marking a paradigm shift from traditional encoder-only models like ELMo and BERT to decoder-only, large-scale LLMs such as GPT, LLaMA, and Mistral. This survey provides an in-depth overview of this transition, beginning with foundational techniques before the LLM era, followed by LLM-based embedding models through two main strategies to derive embeddings from LLMs. 1) Direct prompting: We mainly discuss the prompt designs and the underlying rationale for deriving competitive embeddings. 2) Data-centric tuning: We cover extensive aspects that affect tuning an embedding model, including model architecture, training objectives, data constructions, etc. Upon the above, we also cover advanced methods, such as handling longer texts, and multilingual and cross-modal data. Furthermore, we discuss factors affecting choices of embedding models, such as performance/efficiency comparisons, dense vs sparse embeddings, pooling strategies, and scaling law. Lastly, the survey highlights the limitations and challenges in adapting LLMs for embeddings, including cross-task embedding quality, trade-offs between efficiency and accuracy, low-resource, long-context, data bias, robustness, etc. This survey serves as a valuable resource for researchers and practitioners by synthesizing current advancements, highlighting key challenges, and offering a comprehensive framework for future work aimed at enhancing the effectiveness and efficiency of LLMs as embedding models.
+
+
+
+ 62. 【2412.12588】PerSphere: A Comprehensive Framework for Multi-Faceted Perspective Retrieval and Summarization
+ 链接:https://arxiv.org/abs/2412.12588
+ 作者:Yun Luo,Yingjie Li,Xiangkun Hu,Qinglin Qi,Fang Guo,Qipeng Guo,Zheng Zhang,Yue Zhang
+ 类目:Computation and Language (cs.CL)
+ 关键词:recommendation algorithms evolve, algorithms evolve, people are increasingly, echo chambers, leading to biased
+ 备注:
+
+ 点击查看摘要
+ Abstract:As online platforms and recommendation algorithms evolve, people are increasingly trapped in echo chambers, leading to biased understandings of various issues. To combat this issue, we have introduced PerSphere, a benchmark designed to facilitate multi-faceted perspective retrieval and summarization, thus breaking free from these information silos. For each query within PerSphere, there are two opposing claims, each supported by distinct, non-overlapping perspectives drawn from one or more documents. Our goal is to accurately summarize these documents, aligning the summaries with the respective claims and their underlying perspectives. This task is structured as a two-step end-to-end pipeline that includes comprehensive document retrieval and multi-faceted summarization. Furthermore, we propose a set of metrics to evaluate the comprehensiveness of the retrieval and summarization content. Experimental results on various counterparts for the pipeline show that recent models struggle with such a complex task. Analysis shows that the main challenge lies in long context and perspective extraction, and we propose a simple but effective multi-agent summarization system, offering a promising solution to enhance performance on PerSphere.
+
+
+
+ 63. 【2412.12583】Process-Supervised Reward Models for Clinical Note Generation: A Scalable Approach Guided by Domain Expertise
+ 链接:https://arxiv.org/abs/2412.12583
+ 作者:Hanyin Wang,Qiping Xu,Bolun Liu,Guleid Hussein,Hariprasad Korsapati,Mohamad El Labban,Kingsley Iheasirim,Mohamed Hassan,Gokhan Anil,Brian Bartlett,Jimeng Sun
+ 类目:Computation and Language (cs.CL)
+ 关键词:verify large language, achieved significant success, Process-supervised reward models, large language model, Process-supervised reward
+ 备注:
+
+ 点击查看摘要
+ Abstract:Process-supervised reward models (PRMs), which verify large language model (LLM) outputs step-by-step, have achieved significant success in mathematical and coding problems. However, their application to other domains remains largely unexplored. In this work, we train a PRM to provide step-level reward signals for clinical notes generated by LLMs from patient-doctor dialogues. Guided by real-world clinician expertise, we carefully designed step definitions for clinical notes and utilized Gemini-Pro 1.5 to automatically generate process supervision data at scale. Our proposed PRM, trained on the LLaMA-3.1 8B instruct model, demonstrated superior performance compared to Gemini-Pro 1.5 and an outcome-supervised reward model (ORM) across two key evaluations: (1) the accuracy of selecting gold-reference samples from error-containing samples, achieving 98.8% (versus 61.3% for ORM and 93.8% for Gemini-Pro 1.5), and (2) the accuracy of selecting physician-preferred notes, achieving 56.2% (compared to 51.2% for ORM and 50.0% for Gemini-Pro 1.5). Additionally, we conducted ablation studies to determine optimal loss functions and data selection strategies, along with physician reader studies to explore predictors of downstream Best-of-N performance. Our promising results suggest the potential of PRMs to extend beyond the clinical domain, offering a scalable and effective solution for diverse generative tasks.
+
+
+
+ 64. 【2412.12569】Quantifying Lexical Semantic Shift via Unbalanced Optimal Transport
+ 链接:https://arxiv.org/abs/2412.12569
+ 作者:Ryo Kishino,Hiroaki Yamagiwa,Ryo Nagata,Sho Yokoi,Hidetoshi Shimodaira
+ 类目:Computation and Language (cs.CL)
+ 关键词:Lexical semantic change, Lexical semantic, Unbalanced Optimal Transport, semantic change, aims to identify
+ 备注:
+
+ 点击查看摘要
+ Abstract:Lexical semantic change detection aims to identify shifts in word meanings over time. While existing methods using embeddings from a diachronic corpus pair estimate the degree of change for target words, they offer limited insight into changes at the level of individual usage instances. To address this, we apply Unbalanced Optimal Transport (UOT) to sets of contextualized word embeddings, capturing semantic change through the excess and deficit in the alignment between usage instances. In particular, we propose Sense Usage Shift (SUS), a measure that quantifies changes in the usage frequency of a word sense at each usage instance. By leveraging SUS, we demonstrate that several challenges in semantic change detection can be addressed in a unified manner, including quantifying instance-level semantic change and word-level tasks such as measuring the magnitude of semantic change and the broadening or narrowing of meaning.
+
+
+
+ 65. 【2412.12567】FCMR: Robust Evaluation of Financial Cross-Modal Multi-Hop Reasoning
+ 链接:https://arxiv.org/abs/2412.12567
+ 作者:Seunghee Kim,Changhyeon Kim,Taeuk Kim
+ 类目:Computation and Language (cs.CL)
+ 关键词:Real-world decision-making, multiple modalities, reasoning, Real-world, multi-hop reasoning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Real-world decision-making often requires integrating and reasoning over information from multiple modalities. While recent multimodal large language models (MLLMs) have shown promise in such tasks, their ability to perform multi-hop reasoning across diverse sources remains insufficiently evaluated. Existing benchmarks, such as MMQA, face challenges due to (1) data contamination and (2) a lack of complex queries that necessitate operations across more than two modalities, hindering accurate performance assessment. To address this, we present Financial Cross-Modal Multi-Hop Reasoning (FCMR), a benchmark created to analyze the reasoning capabilities of MLLMs by urging them to combine information from textual reports, tables, and charts within the financial domain. FCMR is categorized into three difficulty levels-Easy, Medium, and Hard-facilitating a step-by-step evaluation. In particular, problems at the Hard level require precise cross-modal three-hop reasoning and are designed to prevent the disregard of any modality. Experiments on this new benchmark reveal that even state-of-the-art MLLMs struggle, with the best-performing model (Claude 3.5 Sonnet) achieving only 30.4% accuracy on the most challenging tier. We also conduct analysis to provide insights into the inner workings of the models, including the discovery of a critical bottleneck in the information retrieval phase.
+
+
+
+ 66. 【2412.12564】Evaluating Zero-Shot Multilingual Aspect-Based Sentiment Analysis with Large Language Models
+ 链接:https://arxiv.org/abs/2412.12564
+ 作者:Chengyan Wu,Bolei Ma,Zheyu Zhang,Ningyuan Deng,Yanqing He,Yun Xue
+ 类目:Computation and Language (cs.CL)
+ 关键词:Aspect-based sentiment analysis, attracted increasing attention, Aspect-based sentiment, sequence labeling task, sentiment analysis
+ 备注:
+
+ 点击查看摘要
+ Abstract:Aspect-based sentiment analysis (ABSA), a sequence labeling task, has attracted increasing attention in multilingual contexts. While previous research has focused largely on fine-tuning or training models specifically for ABSA, we evaluate large language models (LLMs) under zero-shot conditions to explore their potential to tackle this challenge with minimal task-specific adaptation. We conduct a comprehensive empirical evaluation of a series of LLMs on multilingual ABSA tasks, investigating various prompting strategies, including vanilla zero-shot, chain-of-thought (CoT), self-improvement, self-debate, and self-consistency, across nine different models. Results indicate that while LLMs show promise in handling multilingual ABSA, they generally fall short of fine-tuned, task-specific models. Notably, simpler zero-shot prompts often outperform more complex strategies, especially in high-resource languages like English. These findings underscore the need for further refinement of LLM-based approaches to effectively address ABSA task across diverse languages.
+
+
+
+ 67. 【2412.12563】ask-Agnostic Language Model Watermarking via High Entropy Passthrough Layers
+ 链接:https://arxiv.org/abs/2412.12563
+ 作者:Vaden Masrani,Mohammad Akbari,David Ming Xuan Yue,Ahmad Rezaei,Yong Zhang
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language models, ensuring the intellectual, responsibly deployed, increasingly important, era of costly
+ 备注: Accepted to AAAI2025
+
+ 点击查看摘要
+ Abstract:In the era of costly pre-training of large language models, ensuring the intellectual property rights of model owners, and insuring that said models are responsibly deployed, is becoming increasingly important. To this end, we propose model watermarking via passthrough layers, which are added to existing pre-trained networks and trained using a self-supervised loss such that the model produces high-entropy output when prompted with a unique private key, and acts normally otherwise. Unlike existing model watermarking methods, our method is fully task-agnostic, and can be applied to both classification and sequence-to-sequence tasks without requiring advanced access to downstream fine-tuning datasets. We evaluate the proposed passthrough layers on a wide range of downstream tasks, and show experimentally our watermarking method achieves a near-perfect watermark extraction accuracy and false-positive rate in most cases without damaging original model performance. Additionally, we show our method is robust to both downstream fine-tuning, fine-pruning, and layer removal attacks, and can be trained in a fraction of the time required to train the original model. Code is available in the paper.
+
+
+
+ 68. 【2412.12559】EXIT: Context-Aware Extractive Compression for Enhancing Retrieval-Augmented Generation
+ 链接:https://arxiv.org/abs/2412.12559
+ 作者:Taeho Hwang,Sukmin Cho,Soyeong Jeong,Hoyun Song,SeungYoon Han,Jong C. Park
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:context compression framework, question answering, framework that enhances, Current RAG systems, RAG
+ 备注: Under Review
+
+ 点击查看摘要
+ Abstract:We introduce EXIT, an extractive context compression framework that enhances both the effectiveness and efficiency of retrieval-augmented generation (RAG) in question answering (QA). Current RAG systems often struggle when retrieval models fail to rank the most relevant documents, leading to the inclusion of more context at the expense of latency and accuracy. While abstractive compression methods can drastically reduce token counts, their token-by-token generation process significantly increases end-to-end latency. Conversely, existing extractive methods reduce latency but rely on independent, non-adaptive sentence selection, failing to fully utilize contextual information. EXIT addresses these limitations by classifying sentences from retrieved documents - while preserving their contextual dependencies - enabling parallelizable, context-aware extraction that adapts to query complexity and retrieval quality. Our evaluations on both single-hop and multi-hop QA tasks show that EXIT consistently surpasses existing compression methods and even uncompressed baselines in QA accuracy, while also delivering substantial reductions in inference time and token count. By improving both effectiveness and efficiency, EXIT provides a promising direction for developing scalable, high-quality QA solutions in RAG pipelines. Our code is available at this https URL
+
+
+
+ 69. 【2412.12541】LLMCL-GEC: Advancing Grammatical Error Correction with LLM-Driven Curriculum Learning
+ 链接:https://arxiv.org/abs/2412.12541
+ 作者:Tao Fang,Derek F. Wong,Lusheng Zhang,Keyan Jin,Qiang Zhang,Tianjiao Li,Jinlong Hou,Lidia S. Chao
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:natural language processing, grammatical error correction, specific natural language, demonstrated remarkable capabilities, lack proficiency compared
+ 备注: Derek F. Wong is the corresponding author. The preprint version consists of 15 Pages, 5 Figures, 5 Tables, and 3 Appendices
+
+ 点击查看摘要
+ Abstract:While large-scale language models (LLMs) have demonstrated remarkable capabilities in specific natural language processing (NLP) tasks, they may still lack proficiency compared to specialized models in certain domains, such as grammatical error correction (GEC). Drawing inspiration from the concept of curriculum learning, we have delved into refining LLMs into proficient GEC experts by devising effective curriculum learning (CL) strategies. In this paper, we introduce a novel approach, termed LLM-based curriculum learning, which capitalizes on the robust semantic comprehension and discriminative prowess inherent in LLMs to gauge the complexity of GEC training data. Unlike traditional curriculum learning techniques, our method closely mirrors human expert-designed curriculums. Leveraging the proposed LLM-based CL method, we sequentially select varying levels of curriculums ranging from easy to hard, and iteratively train and refine using the pretrianed T5 and LLaMA series models. Through rigorous testing and analysis across diverse benchmark assessments in English GEC, including the CoNLL14 test, BEA19 test, and BEA19 development sets, our approach showcases a significant performance boost over baseline models and conventional curriculum learning methodologies.
+
+
+
+ 70. 【2412.12527】When to Speak, When to Abstain: Contrastive Decoding with Abstention
+ 链接:https://arxiv.org/abs/2412.12527
+ 作者:Hyuhng Joon Kim,Youna Kim,Sang-goo Lee,Taeuk Kim
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, Language Models, demonstrate exceptional performance, exceptional performance
+ 备注: under-review
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) demonstrate exceptional performance across diverse tasks by leveraging both pre-trained knowledge (i.e., parametric knowledge) and external knowledge (i.e., contextual knowledge). While substantial efforts have been made to leverage both forms of knowledge, scenarios in which the model lacks any relevant knowledge remain underexplored. Such limitations can result in issues like hallucination, causing reduced reliability and potential risks in high-stakes applications. To address such limitations, this paper extends the task scope to encompass cases where the user's request cannot be fulfilled due to the lack of relevant knowledge. To this end, we introduce Contrastive Decoding with Abstention (CDA), a training-free decoding method that empowers LLMs to generate responses when relevant knowledge is available and to abstain otherwise. CDA evaluates the relevance of each knowledge for a given query, adaptively determining which knowledge to prioritize or which to completely ignore. Extensive experiments with four LLMs on three question-answering datasets demonstrate that CDA can effectively perform accurate generation and abstention simultaneously. These findings highlight CDA's potential to broaden the applicability of LLMs, enhancing reliability and preserving user trust.
+
+
+
+ 71. 【2412.12522】Solid-SQL: Enhanced Schema-linking based In-context Learning for Robust Text-to-SQL
+ 链接:https://arxiv.org/abs/2412.12522
+ 作者:Geling Liu,Yunzhi Tan,Ruichao Zhong,Yuanzhen Xie,Lingchen Zhao,Qian Wang,Bo Hu,Zang Li
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:large language models, large language, significantly improved, improved the performance, Recently
+ 备注: Accepted at COLING 2025 Main
+
+ 点击查看摘要
+ Abstract:Recently, large language models (LLMs) have significantly improved the performance of text-to-SQL systems. Nevertheless, many state-of-the-art (SOTA) approaches have overlooked the critical aspect of system robustness. Our experiments reveal that while LLM-driven methods excel on standard datasets, their accuracy is notably compromised when faced with adversarial perturbations. To address this challenge, we propose a robust text-to-SQL solution, called Solid-SQL, designed to integrate with various LLMs. We focus on the pre-processing stage, training a robust schema-linking model enhanced by LLM-based data augmentation. Additionally, we design a two-round, structural similarity-based example retrieval strategy for in-context learning. Our method achieves SOTA SQL execution accuracy levels of 82.1% and 58.9% on the general Spider and Bird benchmarks, respectively. Furthermore, experimental results show that Solid-SQL delivers an average improvement of 11.6% compared to baselines on the perturbed Spider-Syn, Spider-Realistic, and Dr. Spider benchmarks.
+
+
+
+ 72. 【2412.12510】Can Large Language Models Understand You Better? An MBTI Personality Detection Dataset Aligned with Population Traits
+ 链接:https://arxiv.org/abs/2412.12510
+ 作者:Bohan Li,Jiannan Guan,Longxu Dou,Yunlong Feng,Dingzirui Wang,Yang Xu,Enbo Wang,Qiguang Chen,Bichen Wang,Xiao Xu,Yimeng Zhang,Libo Qin,Yanyan Zhao,Qingfu Zhu,Wanxiang Che
+ 类目:Computation and Language (cs.CL); Computers and Society (cs.CY)
+ 关键词:Myers-Briggs Type Indicator, Type Indicator, theories reflecting individual, reflecting individual differences, MBTI personality detection
+ 备注: Accepted by COLING 2025. 28 papges, 20 figures, 10 tables
+
+ 点击查看摘要
+ Abstract:The Myers-Briggs Type Indicator (MBTI) is one of the most influential personality theories reflecting individual differences in thinking, feeling, and behaving. MBTI personality detection has garnered considerable research interest and has evolved significantly over the years. However, this task tends to be overly optimistic, as it currently does not align well with the natural distribution of population personality traits. Specifically, (1) the self-reported labels in existing datasets result in incorrect labeling issues, and (2) the hard labels fail to capture the full range of population personality distributions. In this paper, we optimize the task by constructing MBTIBench, the first manually annotated high-quality MBTI personality detection dataset with soft labels, under the guidance of psychologists. As for the first challenge, MBTIBench effectively solves the incorrect labeling issues, which account for 29.58% of the data. As for the second challenge, we estimate soft labels by deriving the polarity tendency of samples. The obtained soft labels confirm that there are more people with non-extreme personality traits. Experimental results not only highlight the polarized predictions and biases in LLMs as key directions for future research, but also confirm that soft labels can provide more benefits to other psychological tasks than hard labels. The code and data are available at this https URL.
+
+
+
+ 73. 【2412.12509】Can You Trust LLM Judgments? Reliability of LLM-as-a-Judge
+ 链接:https://arxiv.org/abs/2412.12509
+ 作者:Kayla Schroeder,Zach Wood-Doughty
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, stochastic nature poses, nature poses challenges, Language Models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have become increasingly powerful and ubiquitous, but their stochastic nature poses challenges to the reliability of their outputs. While deterministic settings can improve consistency, they do not guarantee reliability, as a single sample from the model's probability distribution can still be misleading. Building upon the concept of LLM-as-a-judge, we introduce a novel framework for rigorously evaluating the reliability of LLM judgments, leveraging McDonald's omega. We evaluate the reliability of LLMs when judging the outputs of other LLMs on standard single-turn and multi-turn benchmarks, simultaneously investigating the impact of temperature on reliability. By analyzing these results, we demonstrate the limitations of fixed randomness and the importance of considering multiple samples, which we show has significant implications for downstream applications. Our findings highlight the need for a nuanced understanding of LLM reliability and the potential risks associated with over-reliance on single-shot evaluations. This work provides a crucial step towards building more trustworthy and reliable LLM-based systems and applications.
+
+
+
+ 74. 【2412.12505】DocFusion: A Unified Framework for Document Parsing Tasks
+ 链接:https://arxiv.org/abs/2412.12505
+ 作者:Mingxu Chai,Ziyu Shen,Chong Zhang,Yue Zhang,Xiao Wang,Shihan Dou,Jihua Kang,Jiazheng Zhang,Qi Zhang
+ 类目:Computation and Language (cs.CL)
+ 关键词:analyzing complex document, complex document structures, extracting fine-grained information, supporting numerous downstream, numerous downstream applications
+ 备注:
+
+ 点击查看摘要
+ Abstract:Document parsing is essential for analyzing complex document structures and extracting fine-grained information, supporting numerous downstream applications. However, existing methods often require integrating multiple independent models to handle various parsing tasks, leading to high complexity and maintenance overhead. To address this, we propose DocFusion, a lightweight generative model with only 0.28B parameters. It unifies task representations and achieves collaborative training through an improved objective function. Experiments reveal and leverage the mutually beneficial interaction among recognition tasks, and integrating recognition data significantly enhances detection performance. The final results demonstrate that DocFusion achieves state-of-the-art (SOTA) performance across four key tasks.
+
+
+
+ 75. 【2412.12501】Unleashing the Potential of Model Bias for Generalized Category Discovery
+ 链接:https://arxiv.org/abs/2412.12501
+ 作者:Wenbin An,Haonan Lin,Jiahao Nie,Feng Tian,Wenkai Shi,Yaqiang Wu,Qianying Wang,Ping Chen
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Generalized Category Discovery, Generalized Category, Category Discovery, categories, Category
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Generalized Category Discovery is a significant and complex task that aims to identify both known and undefined novel categories from a set of unlabeled data, leveraging another labeled dataset containing only known categories. The primary challenges stem from model bias induced by pre-training on only known categories and the lack of precise supervision for novel ones, leading to category bias towards known categories and category confusion among different novel categories, which hinders models' ability to identify novel categories effectively. To address these challenges, we propose a novel framework named Self-Debiasing Calibration (SDC). Unlike prior methods that regard model bias towards known categories as an obstacle to novel category identification, SDC provides a novel insight into unleashing the potential of the bias to facilitate novel category learning. Specifically, the output of the biased model serves two key purposes. First, it provides an accurate modeling of category bias, which can be utilized to measure the degree of bias and debias the output of the current training model. Second, it offers valuable insights for distinguishing different novel categories by transferring knowledge between similar categories. Based on these insights, SDC dynamically adjusts the output logits of the current training model using the output of the biased model. This approach produces less biased logits to effectively address the issue of category bias towards known categories, and generates more accurate pseudo labels for unlabeled data, thereby mitigating category confusion for novel categories. Experiments on three benchmark datasets show that SDC outperforms SOTA methods, especially in the identification of novel categories. Our code and data are available at \url{this https URL}.
+
+
+
+ 76. 【2412.12500】Beyond Data Quantity: Key Factors Driving Performance in Multilingual Language Models
+ 链接:https://arxiv.org/abs/2412.12500
+ 作者:Sina Bagheri Nezhad,Ameeta Agrawal,Rhitabrat Pokharel
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:show performance disparities, performance disparities due, Multilingual language models, crucial for handling, handling text
+ 备注: Accepted at The First Workshop on Language Models for Low-Resource Languages @ COLING 2025
+
+ 点击查看摘要
+ Abstract:Multilingual language models (MLLMs) are crucial for handling text across various languages, yet they often show performance disparities due to differences in resource availability and linguistic characteristics. While the impact of pre-train data percentage and model size on performance is well-known, our study reveals additional critical factors that significantly influence MLLM effectiveness. Analyzing a wide range of features, including geographical, linguistic, and resource-related aspects, we focus on the SIB-200 dataset for classification and the Flores-200 dataset for machine translation, using regression models and SHAP values across 204 languages. Our findings identify token similarity and country similarity as pivotal factors, alongside pre-train data and model size, in enhancing model performance. Token similarity facilitates cross-lingual transfer, while country similarity highlights the importance of shared cultural and linguistic contexts. These insights offer valuable guidance for developing more equitable and effective multilingual language models, particularly for underrepresented languages.
+
+
+
+ 77. 【2412.12499】LinguaLIFT: An Effective Two-stage Instruction Tuning Framework for Low-Resource Language Tasks
+ 链接:https://arxiv.org/abs/2412.12499
+ 作者:Hongbin Zhang,Kehai Chen,Xuefeng Bai,Yang Xiang,Min Zhang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large language models, Large language, demonstrated impressive multilingual, impressive multilingual understanding, driven by extensive
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) have demonstrated impressive multilingual understanding and reasoning capabilities, driven by extensive pre-training multilingual corpora and fine-tuning instruction data. However, a performance gap persists between high-resource and low-resource language tasks due to language imbalance in the pre-training corpus, even using more low-resource data during fine-tuning. To alleviate this issue, we propose LinguaLIFT, a two-stage instruction tuning framework for advancing low-resource language tasks. An additional language alignment layer is first integrated into the LLM to adapt a pre-trained multilingual encoder, thereby enhancing multilingual alignment through code-switched fine-tuning. The second stage fine-tunes LLM with English-only instruction data while freezing the language alignment layer, allowing LLM to transfer task-specific capabilities from English to low-resource language tasks. Additionally, we introduce the Multilingual Math World Problem (MMWP) benchmark, which spans 21 low-resource, 17 medium-resource, and 10 high-resource languages, enabling comprehensive evaluation of multilingual reasoning. Experimental results show that LinguaLIFT outperforms several competitive baselines across MMWP and other widely used benchmarks.
+
+
+
+ 78. 【2412.12497】NLSR: Neuron-Level Safety Realignment of Large Language Models Against Harmful Fine-Tuning
+ 链接:https://arxiv.org/abs/2412.12497
+ 作者:Xin Yi,Shunfan Zheng,Linlin Wang,Gerard de Melo,Xiaoling Wang,Liang He
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language models, textbf, vulnerability in large, large language, model
+ 备注:
+
+ 点击查看摘要
+ Abstract:The emergence of finetuning-as-a-service has revealed a new vulnerability in large language models (LLMs). A mere handful of malicious data uploaded by users can subtly manipulate the finetuning process, resulting in an alignment-broken model. Existing methods to counteract fine-tuning attacks typically require substantial computational resources. Even with parameter-efficient techniques like LoRA, gradient updates remain essential. To address these challenges, we propose \textbf{N}euron-\textbf{L}evel \textbf{S}afety \textbf{R}ealignment (\textbf{NLSR}), a training-free framework that restores the safety of LLMs based on the similarity difference of safety-critical neurons before and after fine-tuning. The core of our framework is first to construct a safety reference model from an initially aligned model to amplify safety-related features in neurons. We then utilize this reference model to identify safety-critical neurons, which we prepare as patches. Finally, we selectively restore only those neurons that exhibit significant similarity differences by transplanting these prepared patches, thereby minimally altering the fine-tuned model. Extensive experiments demonstrate significant safety enhancements in fine-tuned models across multiple downstream tasks, while greatly maintaining task-level accuracy. Our findings suggest regions of some safety-critical neurons show noticeable differences after fine-tuning, which can be effectively corrected by transplanting neurons from the reference model without requiring additional training. The code will be available at \url{this https URL}
+
+
+
+ 79. 【2412.12486】Boosting Long-Context Information Seeking via Query-Guided Activation Refilling
+ 链接:https://arxiv.org/abs/2412.12486
+ 作者:Hongjin Qian,Zheng Liu,Peitian Zhang,Zhicheng Dou,Defu Lian
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:inherent context-window limitations, large language models, severely impact efficiency, extensive key-value, long contexts poses
+ 备注: 12 pages
+
+ 点击查看摘要
+ Abstract:Processing long contexts poses a significant challenge for large language models (LLMs) due to their inherent context-window limitations and the computational burden of extensive key-value (KV) activations, which severely impact efficiency. For information-seeking tasks, full context perception is often unnecessary, as a query's information needs can dynamically range from localized details to a global perspective, depending on its complexity. However, existing methods struggle to adapt effectively to these dynamic information needs.
+In the paper, we propose a method for processing long-context information-seeking tasks via query-guided Activation Refilling (ACRE). ACRE constructs a Bi-layer KV Cache for long contexts, where the layer-1 (L1) cache compactly captures global information, and the layer-2 (L2) cache provides detailed and localized information. ACRE establishes a proxying relationship between the two caches, allowing the input query to attend to the L1 cache and dynamically refill it with relevant entries from the L2 cache. This mechanism integrates global understanding with query-specific local details, thus improving answer decoding. Experiments on a variety of long-context information-seeking datasets demonstrate ACRE's effectiveness, achieving improvements in both performance and efficiency.
+
Comments:
+12 pages
+Subjects:
+Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+Cite as:
+arXiv:2412.12486 [cs.CL]
+(or
+arXiv:2412.12486v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2412.12486
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 80. 【2412.12478】Human-in-the-Loop Generation of Adversarial Texts: A Case Study on Tibetan Script
+ 链接:https://arxiv.org/abs/2412.12478
+ 作者:Xi Cao,Yuan Sun,Jiajun Li,Quzong Gesang,Nuo Qun,Tashi Nyima
+ 类目:Computation and Language (cs.CL); Cryptography and Security (cs.CR); Human-Computer Interaction (cs.HC)
+ 关键词:SOTA LLMs, adversarial, models perform excellently, Adversarial texts, perform excellently
+ 备注: Review Version; Submitted to NAACL 2025 Demo Track
+
+ 点击查看摘要
+ Abstract:DNN-based language models perform excellently on various tasks, but even SOTA LLMs are susceptible to textual adversarial attacks. Adversarial texts play crucial roles in multiple subfields of NLP. However, current research has the following issues. (1) Most textual adversarial attack methods target rich-resourced languages. How do we generate adversarial texts for less-studied languages? (2) Most textual adversarial attack methods are prone to generating invalid or ambiguous adversarial texts. How do we construct high-quality adversarial robustness benchmarks? (3) New language models may be immune to part of previously generated adversarial texts. How do we update adversarial robustness benchmarks? To address the above issues, we introduce HITL-GAT, a system based on a general approach to human-in-the-loop generation of adversarial texts. HITL-GAT contains four stages in one pipeline: victim model construction, adversarial example generation, high-quality benchmark construction, and adversarial robustness evaluation. Additionally, we utilize HITL-GAT to make a case study on Tibetan script which can be a reference for the adversarial research of other less-studied languages.
+
+
+
+ 81. 【2412.12475】RareAgents: Autonomous Multi-disciplinary Team for Rare Disease Diagnosis and Treatment
+ 链接:https://arxiv.org/abs/2412.12475
+ 作者:Xuanzhong Chen,Ye Jin,Xiaohao Mao,Lun Wang,Shuyang Zhang,Ting Chen
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:low individual incidence, million people worldwide, people worldwide due, individual incidence, collectively impact
+ 备注:
+
+ 点击查看摘要
+ Abstract:Rare diseases, despite their low individual incidence, collectively impact around 300 million people worldwide due to the huge number of diseases. The complexity of symptoms and the shortage of specialized doctors with relevant experience make diagnosing and treating rare diseases more challenging than common diseases. Recently, agents powered by large language models (LLMs) have demonstrated notable improvements across various domains. In the medical field, some agent methods have outperformed direct prompts in question-answering tasks from medical exams. However, current agent frameworks lack adaptation for real-world clinical scenarios, especially those involving the intricate demands of rare diseases. To address these challenges, we present RareAgents, the first multi-disciplinary team of LLM-based agents tailored to the complex clinical context of rare diseases. RareAgents integrates advanced planning capabilities, memory mechanisms, and medical tools utilization, leveraging Llama-3.1-8B/70B as the base model. Experimental results show that RareAgents surpasses state-of-the-art domain-specific models, GPT-4o, and existing agent frameworks in both differential diagnosis and medication recommendation for rare diseases. Furthermore, we contribute a novel dataset, MIMIC-IV-Ext-Rare, derived from MIMIC-IV, to support further advancements in this field.
+
+
+
+ 82. 【2412.12472】Knowledge Boundary of Large Language Models: A Survey
+ 链接:https://arxiv.org/abs/2412.12472
+ 作者:Moxin Li,Yong Zhao,Yang Deng,Wenxuan Zhang,Shuaiyi Li,Wenya Xie,See-Kiong Ng,Tat-Seng Chua
+ 类目:Computation and Language (cs.CL)
+ 关键词:store vast amount, large language models, language models, store vast, leading to undesired
+ 备注:
+
+ 点击查看摘要
+ Abstract:Although large language models (LLMs) store vast amount of knowledge in their parameters, they still have limitations in the memorization and utilization of certain knowledge, leading to undesired behaviors such as generating untruthful and inaccurate responses. This highlights the critical need to understand the knowledge boundary of LLMs, a concept that remains inadequately defined in existing research. In this survey, we propose a comprehensive definition of the LLM knowledge boundary and introduce a formalized taxonomy categorizing knowledge into four distinct types. Using this foundation, we systematically review the field through three key lenses: the motivation for studying LLM knowledge boundaries, methods for identifying these boundaries, and strategies for mitigating the challenges they present. Finally, we discuss open challenges and potential research directions in this area. We aim for this survey to offer the community a comprehensive overview, facilitate access to key issues, and inspire further advancements in LLM knowledge research.
+
+
+
+ 83. 【2412.12465】Core Context Aware Attention for Long Context Language Modeling
+ 链接:https://arxiv.org/abs/2412.12465
+ 作者:Yaofo Chen,Zeng You,Shuhai Zhang,Haokun Li,Yirui Li,Yaowei Wang,Mingkui Tan
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Transformer-based Large Language, natural language processing, language processing tasks, Large Language Models, exhibited remarkable success
+ 备注:
+
+ 点击查看摘要
+ Abstract:Transformer-based Large Language Models (LLMs) have exhibited remarkable success in various natural language processing tasks primarily attributed to self-attention mechanism, which requires a token to consider all preceding tokens as its context to compute the attention score. However, when the context length L becomes very large (e.g., 32K), more redundant context information will be included w.r.t. any tokens, making the self-attention suffer from two main limitations: 1) The computational and memory complexity scales quadratically w.r.t. L; 2) The presence of redundant context information may hamper the model to capture dependencies among crucial tokens, which may degrade the representation performance. In this paper, we propose a plug-and-play Core Context Aware (CCA) Attention for efficient long-range context modeling, which consists of two components: 1) Globality-pooling attention that divides input tokens into groups and then dynamically merges tokens within each group into one core token based on their significance; 2) Locality-preserved attention that incorporates neighboring tokens into the attention calculation. The two complementary attentions will then be fused to the final attention, maintaining comprehensive modeling ability as the full self-attention. In this way, the core context information w.r.t. a given token will be automatically focused and strengthened, while the context information in redundant groups will be diminished during the learning process. As a result, the computational and memory complexity will be significantly reduced. More importantly, the CCA-Attention can improve the long-context modeling ability by diminishing the redundant context information. Extensive experimental results demonstrate that our CCA-Attention significantly outperforms state-of-the-art models in terms of computational efficiency and long-context modeling ability.
+
+
+
+ 84. 【2412.12459】LITA: An Efficient LLM-assisted Iterative Topic Augmentation Framework
+ 链接:https://arxiv.org/abs/2412.12459
+ 作者:Chia-Hsuan Chang,Jui-Tse Tsai,Yi-Hang Tsai,San-Yih Hwang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:uncovering thematic structures, uncovering thematic, thematic structures, struggle with specificity, specificity and coherence
+ 备注: Under Review
+
+ 点击查看摘要
+ Abstract:Topic modeling is widely used for uncovering thematic structures within text corpora, yet traditional models often struggle with specificity and coherence in domain-focused applications. Guided approaches, such as SeededLDA and CorEx, incorporate user-provided seed words to improve relevance but remain labor-intensive and static. Large language models (LLMs) offer potential for dynamic topic refinement and discovery, yet their application often incurs high API costs. To address these challenges, we propose the LLM-assisted Iterative Topic Augmentation framework (LITA), an LLM-assisted approach that integrates user-provided seeds with embedding-based clustering and iterative refinement. LITA identifies a small number of ambiguous documents and employs an LLM to reassign them to existing or new topics, minimizing API costs while enhancing topic quality. Experiments on two datasets across topic quality and clustering performance metrics demonstrate that LITA outperforms five baseline models, including LDA, SeededLDA, CorEx, BERTopic, and PromptTopic. Our work offers an efficient and adaptable framework for advancing topic modeling and text clustering.
+
+
+
+ 85. 【2412.12456】Graph Learning in the Era of LLMs: A Survey from the Perspective of Data, Models, and Tasks
+ 链接:https://arxiv.org/abs/2412.12456
+ 作者:Xunkai Li,Zhengyu Wu,Jiayi Wu,Hanwen Cui,Jishuo Jia,Rong-Hua Li,Guoren Wang
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Databases (cs.DB)
+ 关键词:Large Language Models, Large Language, promising technological paradigm, Language Models, unified Model architecture
+ 备注: In progress
+
+ 点击查看摘要
+ Abstract:With the increasing prevalence of cross-domain Text-Attributed Graph (TAG) Data (e.g., citation networks, recommendation systems, social networks, and ai4science), the integration of Graph Neural Networks (GNNs) and Large Language Models (LLMs) into a unified Model architecture (e.g., LLM as enhancer, LLM as collaborators, LLM as predictor) has emerged as a promising technological paradigm. The core of this new graph learning paradigm lies in the synergistic combination of GNNs' ability to capture complex structural relationships and LLMs' proficiency in understanding informative contexts from the rich textual descriptions of graphs. Therefore, we can leverage graph description texts with rich semantic context to fundamentally enhance Data quality, thereby improving the representational capacity of model-centric approaches in line with data-centric machine learning principles. By leveraging the strengths of these distinct neural network architectures, this integrated approach addresses a wide range of TAG-based Task (e.g., graph learning, graph reasoning, and graph question answering), particularly in complex industrial scenarios (e.g., supervised, few-shot, and zero-shot settings). In other words, we can treat text as a medium to enable cross-domain generalization of graph learning Model, allowing a single graph model to effectively handle the diversity of downstream graph-based Task across different data domains. This work serves as a foundational reference for researchers and practitioners looking to advance graph learning methodologies in the rapidly evolving landscape of LLM. We consistently maintain the related open-source materials at \url{this https URL}.
+
+
+
+ 86. 【2412.12447】PERC: Plan-As-Query Example Retrieval for Underrepresented Code Generation
+ 链接:https://arxiv.org/abs/2412.12447
+ 作者:Jaeseok Yoo,Hojae Han,Youngwon Lee,Jaejin Kim,Seung-won Hwang
+ 类目:oftware Engineering (cs.SE); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:shown significant promise, large language models, employing retrieval-augmented generation, significant promise, models has shown
+ 备注: Accepted by COLING 2025 main conference
+
+ 点击查看摘要
+ Abstract:Code generation with large language models has shown significant promise, especially when employing retrieval-augmented generation (RAG) with few-shot examples. However, selecting effective examples that enhance generation quality remains a challenging task, particularly when the target programming language (PL) is underrepresented. In this study, we present two key findings: (1) retrieving examples whose presented algorithmic plans can be referenced for generating the desired behavior significantly improves generation accuracy, and (2) converting code into pseudocode effectively captures such algorithmic plans, enhancing retrieval quality even when the source and the target PLs are different. Based on these findings, we propose Plan-as-query Example Retrieval for few-shot prompting in Code generation (PERC), a novel framework that utilizes algorithmic plans to identify and retrieve effective examples. We validate the effectiveness of PERC through extensive experiments on the CodeContests, HumanEval and MultiPL-E benchmarks: PERC consistently outperforms the state-of-the-art RAG methods in code generation, both when the source and target programming languages match or differ, highlighting its adaptability and robustness in diverse coding environments.
+
+
+
+ 87. 【2412.12445】Persona-SQ: A Personalized Suggested Question Generation Framework For Real-world Documents
+ 链接:https://arxiv.org/abs/2412.12445
+ 作者:Zihao Lin,Zichao Wang,Yuanting Pan,Varun Manjunatha,Ryan Rossi,Angela Lau,Lifu Huang,Tong Sun
+ 类目:Computation and Language (cs.CL)
+ 关键词:effective initial interface, AI-powered reading applications, Suggested questions, provide an effective, effective initial
+ 备注: 38 pages, 26 figures
+
+ 点击查看摘要
+ Abstract:Suggested questions (SQs) provide an effective initial interface for users to engage with their documents in AI-powered reading applications. In practical reading sessions, users have diverse backgrounds and reading goals, yet current SQ features typically ignore such user information, resulting in homogeneous or ineffective questions. We introduce a pipeline that generates personalized SQs by incorporating reader profiles (professions and reading goals) and demonstrate its utility in two ways: 1) as an improved SQ generation pipeline that produces higher quality and more diverse questions compared to current baselines, and 2) as a data generator to fine-tune extremely small models that perform competitively with much larger models on SQ generation. Our approach can not only serve as a drop-in replacement in current SQ systems to immediately improve their performance but also help develop on-device SQ models that can run locally to deliver fast and private SQ experience.
+
+
+
+ 88. 【2412.12433】Refining Dimensions for Improving Clustering-based Cross-lingual Topic Models
+ 链接:https://arxiv.org/abs/2412.12433
+ 作者:Chia-Hsuan Chang,Tien-Yuan Huang,Yi-Hang Tsai,Chia-Ming Chang,San-Yih Hwang
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:Recent works, monolingual topic identification, topic models perform, contextualized representations, identification by introducing
+ 备注: Accepted to 18th BUCC Workshop at COLING 2025
+
+ 点击查看摘要
+ Abstract:Recent works in clustering-based topic models perform well in monolingual topic identification by introducing a pipeline to cluster the contextualized representations. However, the pipeline is suboptimal in identifying topics across languages due to the presence of language-dependent dimensions (LDDs) generated by multilingual language models. To address this issue, we introduce a novel, SVD-based dimension refinement component into the pipeline of the clustering-based topic model. This component effectively neutralizes the negative impact of LDDs, enabling the model to accurately identify topics across languages. Our experiments on three datasets demonstrate that the updated pipeline with the dimension refinement component generally outperforms other state-of-the-art cross-lingual topic models.
+
+
+
+ 89. 【2412.12422】Assessing the Limitations of Large Language Models in Clinical Fact Decomposition
+ 链接:https://arxiv.org/abs/2412.12422
+ 作者:Monica Munnangi,Akshay Swaminathan,Jason Alan Fries,Jenelle Jindal,Sanjana Narayanan,Ivan Lopez,Lucia Tu,Philip Chung,Jesutofunmi A. Omiye,Mehr Kashyap,Nigam Shah
+ 类目:Computation and Language (cs.CL)
+ 关键词:large language models, Verifying factual claims, Verifying factual, language models, claims is critical
+ 备注:
+
+ 点击查看摘要
+ Abstract:Verifying factual claims is critical for using large language models (LLMs) in healthcare. Recent work has proposed fact decomposition, which uses LLMs to rewrite source text into concise sentences conveying a single piece of information, as an approach for fine-grained fact verification. Clinical documentation poses unique challenges for fact decomposition due to dense terminology and diverse note types. To explore these challenges, we present FactEHR, a dataset consisting of full document fact decompositions for 2,168 clinical notes spanning four types from three hospital systems. Our evaluation, including review by clinicians, highlights significant variability in the quality of fact decomposition for four commonly used LLMs, with some LLMs generating 2.6x more facts per sentence than others. The results underscore the need for better LLM capabilities to support factual verification in clinical text. To facilitate future research in this direction, we plan to release our code at \url{this https URL}.
+
+
+
+ 90. 【2412.12417】Bridging the Gap: Enhancing LLM Performance for Low-Resource African Languages with New Benchmarks, Fine-Tuning, and Cultural Adjustments
+ 链接:https://arxiv.org/abs/2412.12417
+ 作者:Tuka Alhanai,Adam Kasumovic,Mohammad Ghassemi,Aven Zitzelberger,Jessica Lundin,Guillaume Chabot-Couture
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Large Language Models, native African languages, significant disparities remain, African languages, shown remarkable performance
+ 备注: Accepted to AAAI 2025. Main content is 9 pages, 3 figures. Includes supplementary materials
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have shown remarkable performance across various tasks, yet significant disparities remain for non-English languages, and especially native African languages. This paper addresses these disparities by creating approximately 1 million human-translated words of new benchmark data in 8 low-resource African languages, covering a population of over 160 million speakers of: Amharic, Bambara, Igbo, Sepedi (Northern Sotho), Shona, Sesotho (Southern Sotho), Setswana, and Tsonga. Our benchmarks are translations of Winogrande and three sections of MMLU: college medicine, clinical knowledge, and virology. Using the translated benchmarks, we report previously unknown performance gaps between state-of-the-art (SOTA) LLMs in English and African languages. Finally, using results from over 400 fine-tuned models, we explore several methods to reduce the LLM performance gap, including high-quality dataset fine-tuning (using an LLM-as-an-Annotator), cross-lingual transfer, and cultural appropriateness adjustments. Key findings include average mono-lingual improvements of 5.6% with fine-tuning (with 5.4% average mono-lingual improvements when using high-quality data over low-quality data), 2.9% average gains from cross-lingual transfer, and a 3.0% out-of-the-box performance boost on culturally appropriate questions. The publicly available benchmarks, translations, and code from this study support further research and development aimed at creating more inclusive and effective language technologies.
+
+
+
+ 91. 【2412.12391】Efficient Scaling of Diffusion Transformers for Text-to-Image Generation
+ 链接:https://arxiv.org/abs/2412.12391
+ 作者:Hao Li,Shamit Lal,Zhiheng Li,Yusheng Xie,Ying Wang,Yang Zou,Orchid Majumder,R. Manmatha,Zhuowen Tu,Stefano Ermon,Stefano Soatto,Ashwin Swaminathan
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:including training scaled, Diffusion Transformers, training scaled DiTs, scaled DiTs ranging, generation by performing
+ 备注:
+
+ 点击查看摘要
+ Abstract:We empirically study the scaling properties of various Diffusion Transformers (DiTs) for text-to-image generation by performing extensive and rigorous ablations, including training scaled DiTs ranging from 0.3B upto 8B parameters on datasets up to 600M images. We find that U-ViT, a pure self-attention based DiT model provides a simpler design and scales more effectively in comparison with cross-attention based DiT variants, which allows straightforward expansion for extra conditions and other modalities. We identify a 2.3B U-ViT model can get better performance than SDXL UNet and other DiT variants in controlled setting. On the data scaling side, we investigate how increasing dataset size and enhanced long caption improve the text-image alignment performance and the learning efficiency.
+
+
+
+ 92. 【2412.12386】Interpretable LLM-based Table Question Answering
+ 链接:https://arxiv.org/abs/2412.12386
+ 作者:Giang(Dexter)Nguyen,Ivan Brugere,Shubham Sharma,Sanjay Kariyappa,Anh Totti Nguyen,Freddy Lecue
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:Table Question Answering, Question Answering, Table Question, Large Language Models, finance or healthcare
+ 备注:
+
+ 点击查看摘要
+ Abstract:Interpretability for Table Question Answering (Table QA) is critical, particularly in high-stakes industries like finance or healthcare. Although recent approaches using Large Language Models (LLMs) have significantly improved Table QA performance, their explanations for how the answers are generated are ambiguous. To fill this gap, we introduce Plan-of-SQLs ( or POS), an interpretable, effective, and efficient approach to Table QA that answers an input query solely with SQL executions. Through qualitative and quantitative evaluations with human and LLM judges, we show that POS is most preferred among explanation methods, helps human users understand model decision boundaries, and facilitates model success and error identification. Furthermore, when evaluated in standard benchmarks (TabFact, WikiTQ, and FetaQA), POS achieves competitive or superior accuracy compared to existing methods, while maintaining greater efficiency by requiring significantly fewer LLM calls and database queries.
+
+
+
+ 93. 【2412.12362】How Different AI Chatbots Behave? Benchmarking Large Language Models in Behavioral Economics Games
+ 链接:https://arxiv.org/abs/2412.12362
+ 作者:Yutong Xie,Yiyao Liu,Zhuang Ma,Lin Shi,Xiyuan Wang,Walter Yuan,Matthew O. Jackson,Qiaozhu Mei
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:large language models, diverse applications requires, language models, large language, diverse applications
+ 备注: Presented at The First Workshop on AI Behavioral Science (AIBS 2024)
+
+ 点击查看摘要
+ Abstract:The deployment of large language models (LLMs) in diverse applications requires a thorough understanding of their decision-making strategies and behavioral patterns. As a supplement to a recent study on the behavioral Turing test, this paper presents a comprehensive analysis of five leading LLM-based chatbot families as they navigate a series of behavioral economics games. By benchmarking these AI chatbots, we aim to uncover and document both common and distinct behavioral patterns across a range of scenarios. The findings provide valuable insights into the strategic preferences of each LLM, highlighting potential implications for their deployment in critical decision-making roles.
+
+
+
+ 94. 【2412.12359】Visual Instruction Tuning with 500x Fewer Parameters through Modality Linear Representation-Steering
+ 链接:https://arxiv.org/abs/2412.12359
+ 作者:Jinhe Bi,Yujun Wang,Haokun Chen,Xun Xiao,Artur Hecker,Volker Tresp,Yunpu Ma
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Multimodal Large Language, Large Language Models, Large Language, Multimodal Large, Language Models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multimodal Large Language Models (MLLMs) have significantly advanced visual tasks by integrating visual representations into large language models (LLMs). The textual modality, inherited from LLMs, equips MLLMs with abilities like instruction following and in-context learning. In contrast, the visual modality enhances performance in downstream tasks by leveraging rich semantic content, spatial information, and grounding capabilities. These intrinsic modalities work synergistically across various visual tasks. Our research initially reveals a persistent imbalance between these modalities, with text often dominating output generation during visual instruction tuning. This imbalance occurs when using both full fine-tuning and parameter-efficient fine-tuning (PEFT) methods. We then found that re-balancing these modalities can significantly reduce the number of trainable parameters required, inspiring a direction for further optimizing visual instruction tuning. We introduce Modality Linear Representation-Steering (MoReS) to achieve the goal. MoReS effectively re-balances the intrinsic modalities throughout the model, where the key idea is to steer visual representations through linear transformations in the visual subspace across each model layer. To validate our solution, we composed LLaVA Steering, a suite of models integrated with the proposed MoReS method. Evaluation results show that the composed LLaVA Steering models require, on average, 500 times fewer trainable parameters than LoRA needs while still achieving comparable performance across three visual benchmarks and eight visual question-answering tasks. Last, we present the LLaVA Steering Factory, an in-house developed platform that enables researchers to quickly customize various MLLMs with component-based architecture for seamlessly integrating state-of-the-art models, and evaluate their intrinsic modality imbalance.
+
+
+
+ 95. 【2412.12358】BioRAGent: A Retrieval-Augmented Generation System for Showcasing Generative Query Expansion and Domain-Specific Search for Scientific QA
+ 链接:https://arxiv.org/abs/2412.12358
+ 作者:Samy Ateia,Udo Kruschwitz
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:biomedical question answering, interactive web-based retrieval-augmented, web-based retrieval-augmented generation, present BioRAGent, question answering
+ 备注: Version as accepted at the Demo Track at ECIR 2025
+
+ 点击查看摘要
+ Abstract:We present BioRAGent, an interactive web-based retrieval-augmented generation (RAG) system for biomedical question answering. The system uses large language models (LLMs) for query expansion, snippet extraction, and answer generation while maintaining transparency through citation links to the source documents and displaying generated queries for further editing. Building on our successful participation in the BioASQ 2024 challenge, we demonstrate how few-shot learning with LLMs can be effectively applied for a professional search setting. The system supports both direct short paragraph style responses and responses with inline citations. Our demo is available online, and the source code is publicly accessible through GitHub.
+
+
+
+ 96. 【2412.12322】RAG Playground: A Framework for Systematic Evaluation of Retrieval Strategies and Prompt Engineering in RAG Systems
+ 链接:https://arxiv.org/abs/2412.12322
+ 作者:Ioannis Papadimitriou,Ilias Gialampoukidis,Stefanos Vrochidis,Ioannis(Yiannis)Kompatsiaris
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:present RAG Playground, Retrieval-Augmented Generation, RAG Playground, present RAG, Playground
+ 备注: Work In Progress
+
+ 点击查看摘要
+ Abstract:We present RAG Playground, an open-source framework for systematic evaluation of Retrieval-Augmented Generation (RAG) systems. The framework implements and compares three retrieval approaches: naive vector search, reranking, and hybrid vector-keyword search, combined with ReAct agents using different prompting strategies. We introduce a comprehensive evaluation framework with novel metrics and provide empirical results comparing different language models (Llama 3.1 and Qwen 2.5) across various retrieval configurations. Our experiments demonstrate significant performance improvements through hybrid search methods and structured self-evaluation prompting, achieving up to 72.7% pass rate on our multi-metric evaluation framework. The results also highlight the importance of prompt engineering in RAG systems, with our custom-prompted agents showing consistent improvements in retrieval accuracy and response quality.
+
+
+
+ 97. 【2412.12318】Graph-Guided Textual Explanation Generation Framework
+ 链接:https://arxiv.org/abs/2412.12318
+ 作者:Shuzhou Yuan,Jingyi Sun,Ran Zhang,Michael Färber,Steffen Eger,Pepa Atanasova,Isabelle Augenstein
+ 类目:Computation and Language (cs.CL)
+ 关键词:Natural language explanations, provide plausible free-text, Natural language, plausible free-text explanations, provide plausible
+ 备注:
+
+ 点击查看摘要
+ Abstract:Natural language explanations (NLEs) are commonly used to provide plausible free-text explanations of a model's reasoning about its predictions. However, recent work has questioned the faithfulness of NLEs, as they may not accurately reflect the model's internal reasoning process regarding its predicted answer. In contrast, highlight explanations -- input fragments identified as critical for the model's predictions -- exhibit measurable faithfulness, which has been incrementally improved through existing research. Building on this foundation, we propose G-Tex, a Graph-Guided Textual Explanation Generation framework designed to enhance the faithfulness of NLEs by leveraging highlight explanations. Specifically, highlight explanations are extracted as highly faithful cues representing the model's reasoning and are subsequently encoded through a graph neural network layer, which explicitly guides the NLE generation process. This alignment ensures that the generated explanations closely reflect the model's underlying reasoning. Experiments on T5 and BART using three reasoning datasets show that G-Tex improves NLE faithfulness by up to 17.59% compared to baseline methods. Additionally, G-Tex generates NLEs with greater semantic and lexical similarity to human-written ones. Human evaluations show that G-Tex can decrease redundant content and enhance the overall quality of NLEs. As our work introduces a novel method for explicitly guiding NLE generation to improve faithfulness, we hope it will serve as a stepping stone for addressing additional criteria for NLE and generated text overall.
+
+
+
+ 98. 【2412.12310】Second Language (Arabic) Acquisition of LLMs via Progressive Vocabulary Expansion
+ 链接:https://arxiv.org/abs/2412.12310
+ 作者:Jianqing Zhu,Huang Huang,Zhihang Lin,Juhao Liang,Zhengyang Tang,Khalid Almubarak,Abdulmohsen Alharthik,Bang An,Juncai He,Xiangbo Wu,Fei Yu,Junying Chen,Zhuoheng Ma,Yuhao Du,He Zhang,Emad A. Alghamdi,Lian Zhang,Ruoyu Sun,Haizhou Li,Benyou Wang,Jinchao Xu
+ 类目:Computation and Language (cs.CL)
+ 关键词:English and Chinese, Arab world, democratizing large language, progressive vocabulary expansion, large language models
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper addresses the critical need for democratizing large language models (LLM) in the Arab world, a region that has seen slower progress in developing models comparable to state-of-the-art offerings like GPT-4 or ChatGPT 3.5, due to a predominant focus on mainstream languages (e.g., English and Chinese). One practical objective for an Arabic LLM is to utilize an Arabic-specific vocabulary for the tokenizer that could speed up decoding. However, using a different vocabulary often leads to a degradation of learned knowledge since many words are initially out-of-vocabulary (OOV) when training starts. Inspired by the vocabulary learning during Second Language (Arabic) Acquisition for humans, the released AraLLaMA employs progressive vocabulary expansion, which is implemented by a modified BPE algorithm that progressively extends the Arabic subwords in its dynamic vocabulary during training, thereby balancing the OOV ratio at every stage. The ablation study demonstrated the effectiveness of Progressive Vocabulary Expansion. Moreover, AraLLaMA achieves decent performance comparable to the best Arabic LLMs across a variety of Arabic benchmarks. Models, training data, benchmarks, and codes will be all open-sourced.
+
+
+
+ 99. 【2412.12300】Unanswerability Evaluation for Retreival Augmented Generation
+ 链接:https://arxiv.org/abs/2412.12300
+ 作者:Xiangyu Peng,Prafulla Kumar Choubey,Caiming Xiong,Chien-Sheng Wu
+ 类目:Computation and Language (cs.CL)
+ 关键词:Existing evaluation frameworks, Existing evaluation, rejecting unanswerable requests, appropriately rejecting unanswerable, RAG systems
+ 备注:
+
+ 点击查看摘要
+ Abstract:Existing evaluation frameworks for retrieval-augmented generation (RAG) systems focus on answerable queries, but they overlook the importance of appropriately rejecting unanswerable requests. In this paper, we introduce UAEval4RAG, a framework designed to evaluate whether RAG systems can handle unanswerable queries effectively. We define a taxonomy with six unanswerable categories, and UAEval4RAG automatically synthesizes diverse and challenging queries for any given knowledge base with unanswered ratio and acceptable ratio metrics. We conduct experiments with various RAG components, including retrieval models, rewriting methods, rerankers, language models, and prompting strategies, and reveal hidden trade-offs in performance of RAG systems. Our findings highlight the critical role of component selection and prompt design in optimizing RAG systems to balance the accuracy of answerable queries with high rejection rates of unanswerable ones. UAEval4RAG provides valuable insights and tools for developing more robust and reliable RAG systems.
+
+
+
+ 100. 【2412.12276】Emergence of Abstractions: Concept Encoding and Decoding Mechanism for In-Context Learning in Transformers
+ 链接:https://arxiv.org/abs/2412.12276
+ 作者:Seungwook Han,Jinyeop Song,Jeff Gore,Pulkit Agrawal
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Humans distill complex, distill complex experiences, enable rapid learning, Humans distill, distill complex
+ 备注:
+
+ 点击查看摘要
+ Abstract:Humans distill complex experiences into fundamental abstractions that enable rapid learning and adaptation. Similarly, autoregressive transformers exhibit adaptive learning through in-context learning (ICL), which begs the question of how. In this paper, we propose \textbf{concept encoding-decoding mechanism} to explain ICL by studying how transformers form and use internal abstractions in their representations. On synthetic ICL tasks, we analyze the training dynamics of a small transformer and report the coupled emergence of concept encoding and decoding. As the model learns to encode different latent concepts (e.g., ``Finding the first noun in a sentence.") into distinct, separable representations, it concureently builds conditional decoding algorithms and improve its ICL performance. We validate the existence of this mechanism across pretrained models of varying scales (Gemma-2 2B/9B/27B, Llama-3.1 8B/70B). Further, through mechanistic interventions and controlled finetuning, we demonstrate that the quality of concept encoding is causally related and predictive of ICL performance. Our empirical insights shed light into better understanding the success and failure modes of large language models via their representations.
+
+
+
+ 101. 【2412.12225】DLF: Disentangled-Language-Focused Multimodal Sentiment Analysis
+ 链接:https://arxiv.org/abs/2412.12225
+ 作者:Pan Wang,Qiang Zhou,Yawen Wu,Tianlong Chen,Jingtong Hu
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Multimedia (cs.MM)
+ 关键词:Multimodal Sentiment Analysis, Sentiment Analysis, leverages heterogeneous modalities, human sentiment, Multimodal Sentiment
+ 备注: AAAI 2025 accepted
+
+ 点击查看摘要
+ Abstract:Multimodal Sentiment Analysis (MSA) leverages heterogeneous modalities, such as language, vision, and audio, to enhance the understanding of human sentiment. While existing models often focus on extracting shared information across modalities or directly fusing heterogeneous modalities, such approaches can introduce redundancy and conflicts due to equal treatment of all modalities and the mutual transfer of information between modality pairs. To address these issues, we propose a Disentangled-Language-Focused (DLF) multimodal representation learning framework, which incorporates a feature disentanglement module to separate modality-shared and modality-specific information. To further reduce redundancy and enhance language-targeted features, four geometric measures are introduced to refine the disentanglement process. A Language-Focused Attractor (LFA) is further developed to strengthen language representation by leveraging complementary modality-specific information through a language-guided cross-attention mechanism. The framework also employs hierarchical predictions to improve overall accuracy. Extensive experiments on two popular MSA datasets, CMU-MOSI and CMU-MOSEI, demonstrate the significant performance gains achieved by the proposed DLF framework. Comprehensive ablation studies further validate the effectiveness of the feature disentanglement module, language-focused attractor, and hierarchical predictions. Our code is available at this https URL.
+
+
+
+ 102. 【2412.12212】Finding a Wolf in Sheep's Clothing: Combating Adversarial Text-To-Image Prompts with Text Summarization
+ 链接:https://arxiv.org/abs/2412.12212
+ 作者:Portia Cooper,Harshita Narnoli,Mihai Surdeanu
+ 类目:Cryptography and Security (cs.CR); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:stepwise DACA attacks, wrapping sensitive text, DACA attacks, stepwise DACA, obfuscate inappropriate content
+ 备注:
+
+ 点击查看摘要
+ Abstract:Text-to-image models are vulnerable to the stepwise "Divide-and-Conquer Attack" (DACA) that utilize a large language model to obfuscate inappropriate content in prompts by wrapping sensitive text in a benign narrative. To mitigate stepwise DACA attacks, we propose a two-layer method involving text summarization followed by binary classification. We assembled the Adversarial Text-to-Image Prompt (ATTIP) dataset ($N=940$), which contained DACA-obfuscated and non-obfuscated prompts. From the ATTIP dataset, we created two summarized versions: one generated by a small encoder model and the other by a large language model. Then, we used an encoder classifier and a GPT-4o classifier to perform content moderation on the summarized and unsummarized prompts. When compared with a classifier that operated over the unsummarized data, our method improved F1 score performance by 31%. Further, the highest recorded F1 score achieved (98%) was produced by the encoder classifier on a summarized ATTIP variant. This study indicates that pre-classification text summarization can inoculate content detection models against stepwise DACA obfuscations.
+
+
+
+ 103. 【2412.12204】SEE: Sememe Entanglement Encoding for Transformer-bases Models Compression
+ 链接:https://arxiv.org/abs/2412.12204
+ 作者:Jing Zhang,Shuzhen Sun,Peng Zhang,Guangxing Cao,Hui Gao,Xindian Ma,Nan Xu,Yuexian Hou
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:exhibit groundbreaking capabilities, Transformer-based large language, computational costs, Sememe Entanglement Encoding, large language models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Transformer-based large language models exhibit groundbreaking capabilities, but their storage and computational costs are prohibitively high, limiting their application in resource-constrained scenarios. An effective approach is to eliminate redundant model parameters and computational costs while incorporating efficient expert-derived knowledge structures to achieve a balance between compression and performance. Therefore, we propose the \textit{Sememe Entanglement Encoding (SEE)} algorithm. Guided by expert prior knowledge, the model is compressed through the low-rank approximation idea. In Entanglement Embedding, basic semantic units such as sememes are represented as low-dimensional vectors, and then reconstructed into high-dimensional word embeddings through the combination of generalized quantum entanglement. We adapt the Sememe Entanglement Encoding algorithm to transformer-based models of different magnitudes. Experimental results indicate that our approach achieves stable performance while compressing model parameters and computational costs.
+
+
+
+ 104. 【2412.12177】Model-diff: A Tool for Comparative Study of Language Models in the Input Space
+ 链接:https://arxiv.org/abs/2412.12177
+ 作者:Weitang Liu,Yuelei Li,Ying Wai Li,Zihan Wang,Jingbo Shang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:large input space, real-world scenarios, input space, Comparing, large input
+ 备注:
+
+ 点击查看摘要
+ Abstract:Comparing two (large) language models (LMs) side-by-side and pinpointing their prediction similarities and differences on the same set of inputs are crucial in many real-world scenarios, e.g., one can test if a licensed model was potentially plagiarized by another. Traditional analysis compares the LMs' outputs on some benchmark datasets, which only cover a limited number of inputs of designed perspectives for the intended applications. The benchmark datasets cannot prepare data to cover the test cases from unforeseen perspectives which can help us understand differences between models unbiasedly. In this paper, we propose a new model comparative analysis setting that considers a large input space where brute-force enumeration would be infeasible. The input space can be simply defined as all token sequences that a LM would produce low perplexity on -- we follow this definition in the paper as it would produce the most human-understandable inputs. We propose a novel framework \our that uses text generation by sampling and deweights the histogram of sampling statistics to estimate prediction differences between two LMs in this input space efficiently and unbiasedly. Our method achieves this by drawing and counting the inputs at each prediction difference value in negative log-likelihood. Experiments reveal for the first time the quantitative prediction differences between LMs in a large input space, potentially facilitating the model analysis for applications such as model plagiarism.
+
+
+
+ 105. 【2412.12175】Explore Theory of Mind: Program-guided adversarial data generation for theory of mind reasoning
+ 链接:https://arxiv.org/abs/2412.12175
+ 作者:Melanie Sclar,Jane Yu,Maryam Fazel-Zarandi,Yulia Tsvetkov,Yonatan Bisk,Yejin Choi,Asli Celikyilmaz
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:large language models, theory of mind, large language, theory, mind
+ 备注:
+
+ 点击查看摘要
+ Abstract:Do large language models (LLMs) have theory of mind? A plethora of papers and benchmarks have been introduced to evaluate if current models have been able to develop this key ability of social intelligence. However, all rely on limited datasets with simple patterns that can potentially lead to problematic blind spots in evaluation and an overestimation of model capabilities. We introduce ExploreToM, the first framework to allow large-scale generation of diverse and challenging theory of mind data for robust training and evaluation. Our approach leverages an A* search over a custom domain-specific language to produce complex story structures and novel, diverse, yet plausible scenarios to stress test the limits of LLMs. Our evaluation reveals that state-of-the-art LLMs, such as Llama-3.1-70B and GPT-4o, show accuracies as low as 0% and 9% on ExploreToM-generated data, highlighting the need for more robust theory of mind evaluation. As our generations are a conceptual superset of prior work, fine-tuning on our data yields a 27-point accuracy improvement on the classic ToMi benchmark (Le et al., 2019). ExploreToM also enables uncovering underlying skills and factors missing for models to show theory of mind, such as unreliable state tracking or data imbalances, which may contribute to models' poor performance on benchmarks.
+
+
+
+ 106. 【2412.12173】A NotSo Simple Way to Beat Simple Bench
+ 链接:https://arxiv.org/abs/2412.12173
+ 作者:Soham Sane,Angus McLean
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:large language models, leveraging iterative reasoning, paper presents, large language, enhancing reasoning capabilities
+ 备注: 29 pages, 11 Figures
+
+ 点击查看摘要
+ Abstract:This paper presents a novel framework for enhancing reasoning capabilities in large language models (LLMs) by leveraging iterative reasoning and feedback-driven methodologies. Building on the limitations identified in the SimpleBench benchmark, a dataset designed to evaluate logical coherence and real-world reasoning, we propose a multi-step prompting strategy coupled with global consistency checks to improve model accuracy and robustness. Through comparative analysis of state-of-the-art models, including Claude 3 Opus, Claude 3.5, GPT- 4o, and o1-preview, we demonstrate that iterative reasoning significantly enhances model performance, with improvements observed in both standard accuracy metrics (AVG@5) and a newly introduced metric, Extreme Averaging (EAG@5). Our results reveal model-specific strengths: Claude excels in maintaining logical consistency, while GPT-4o exhibits exploratory creativity but struggles with ambiguous prompts. By analyzing case studies and identifying gaps in spatial and temporal reasoning, we highlight areas for further refinement. The findings underscore the potential of structured reasoning frameworks to address inherent model limitations, irrespective of pretraining methodologies. This study lays the groundwork for integrating dynamic feedback mechanisms, adaptive restart strategies, and diverse evaluation metrics to advance LLM reasoning capabilities across complex and multi-domain problem spaces.
+
+
+
+ 107. 【2412.12171】AI Adoption to Combat Financial Crime: Study on Natural Language Processing in Adverse Media Screening of Financial Services in English and Bangla multilingual interpretation
+ 链接:https://arxiv.org/abs/2412.12171
+ 作者:Soumita Roy
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Natural Language Processing, specifically Natural Language, employing Artificial Intelligence, Mobile Financial Services, Artificial Intelligence
+ 备注:
+
+ 点击查看摘要
+ Abstract:This document explores the potential of employing Artificial Intelligence (AI), specifically Natural Language Processing (NLP), to strengthen the detection and prevention of financial crimes within the Mobile Financial Services(MFS) of Bangladesh with multilingual scenario. The analysis focuses on the utilization of NLP for adverse media screening, a vital aspect of compliance with anti-money laundering (AML) and combating financial terrorism (CFT) regulations. Additionally, it investigates the overall reception and obstacles related to the integration of AI in Bangladeshi banks. This report measures the effectiveness of NLP is promising with an accuracy around 94\%. NLP algorithms display substantial promise in accurately identifying adverse media content linked to financial crimes. The lack of progress in this aspect is visible in Bangladesh, whereas globally the technology is already being used to increase effectiveness and efficiency. Hence, it is clear there is an issue with the acceptance of AI in Bangladesh. Some AML \ CFT concerns are already being addressed by AI technology. For example, Image Recognition OCR technology are being used in KYC procedures. Primary hindrances to AI integration involve a lack of technical expertise, high expenses, and uncertainties surrounding regulations. This investigation underscores the potential of AI-driven NLP solutions in fortifying efforts to prevent financial crimes in Bangladesh.
+
+
+
+ 108. 【2412.12167】Greek2MathTex: A Greek Speech-to-Text Framework for LaTeX Equations Generation
+ 链接:https://arxiv.org/abs/2412.12167
+ 作者:Evangelia Gkritzali,Panagiotis Kaliosis,Sofia Galanaki,Elisavet Palogiannidi,Theodoros Giannakopoulos
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Audio and Speech Processing (eess.AS)
+ 关键词:typesetting complex mathematical, scientific domains, vast majority, academic and scientific, facto standard
+ 备注: 4 pages, 2 figures, SETN2024: 13th EETN Conference on Artificial Intelligence
+
+ 点击查看摘要
+ Abstract:In the vast majority of the academic and scientific domains, LaTeX has established itself as the de facto standard for typesetting complex mathematical equations and formulae. However, LaTeX's complex syntax and code-like appearance present accessibility barriers for individuals with disabilities, as well as those unfamiliar with coding conventions. In this paper, we present a novel solution to this challenge through the development of a novel speech-to-LaTeX equations system specifically designed for the Greek language. We propose an end-to-end system that harnesses the power of Automatic Speech Recognition (ASR) and Natural Language Processing (NLP) techniques to enable users to verbally dictate mathematical expressions and equations in natural language, which are subsequently converted into LaTeX format. We present the architecture and design principles of our system, highlighting key components such as the ASR engine, the LLM-based prompt-driven equations generation mechanism, as well as the application of a custom evaluation metric employed throughout the development process. We have made our system open source and available at this https URL.
+
+
+
+ 109. 【2412.12166】Performance of a large language model-Artificial Intelligence based chatbot for counseling patients with sexually transmitted infections and genital diseases
+ 链接:https://arxiv.org/abs/2412.12166
+ 作者:Nikhil Mehta,Sithira Ambepitiya,Thanveer Ahamad,Dinuka Wijesundara,Yudara Kularathne
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:sexually transmitted infections, transmitted infections, proportion to specialists, sexually transmitted, Global burden
+ 备注: 18 pages, 1 table
+
+ 点击查看摘要
+ Abstract:Introduction: Global burden of sexually transmitted infections (STIs) is rising out of proportion to specialists. Current chatbots like ChatGPT are not tailored for handling STI-related concerns out of the box. We developed Otiz, an Artificial Intelligence-based (AI-based) chatbot platform designed specifically for STI detection and counseling, and assessed its performance. Methods: Otiz employs a multi-agent system architecture based on GPT4-0613, leveraging large language model (LLM) and Deterministic Finite Automaton principles to provide contextually relevant, medically accurate, and empathetic responses. Its components include modules for general STI information, emotional recognition, Acute Stress Disorder detection, and psychotherapy. A question suggestion agent operates in parallel. Four STIs (anogenital warts, herpes, syphilis, urethritis/cervicitis) and 2 non-STIs (candidiasis, penile cancer) were evaluated using prompts mimicking patient language. Each prompt was independently graded by two venereologists conversing with Otiz as patient actors on 6 criteria using Numerical Rating Scale ranging from 0 (poor) to 5 (excellent). Results: Twenty-three venereologists did 60 evaluations of 30 prompts. Across STIs, Otiz scored highly on diagnostic accuracy (4.1-4.7), overall accuracy (4.3-4.6), correctness of information (5.0), comprehensibility (4.2-4.4), and empathy (4.5-4.8). However, relevance scores were lower (2.9-3.6), suggesting some redundancy. Diagnostic scores for non-STIs were lower (p=0.038). Inter-observer agreement was strong, with differences greater than 1 point occurring in only 12.7% of paired evaluations. Conclusions: AI conversational agents like Otiz can provide accurate, correct, discrete, non-judgmental, readily accessible and easily understandable STI-related information in an empathetic manner, and can alleviate the burden on healthcare systems.
+
+
+
+ 110. 【2412.12157】What Makes In-context Learning Effective for Mathematical Reasoning: A Theoretical Analysis
+ 链接:https://arxiv.org/abs/2412.12157
+ 作者:Jiayu Liu,Zhenya Huang,Chaokun Wang,Xunpeng Huang,Chengxiang Zhai,Enhong Chen
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:large language models, shown impressive performance, diverse mathematical reasoning, large language, language models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Owing to the capability of in-context learning, large language models (LLMs) have shown impressive performance across diverse mathematical reasoning benchmarks. However, we find that few-shot demonstrations can sometimes bring negative performance and their effectiveness on LLMs' reasoning abilities remains unreliable. To this end, in this paper, we aim to theoretically analyze the impact of in-context demonstrations on LLMs' reasoning performance. We prove that the reasoning efficacy (measured by empirical prediction loss) can be bounded by a LLM-oriented semantic similarity and an inference stability of demonstrations, which is general for both one-shot and few-shot scenarios. Based on this finding, we propose a straightforward, generalizable, and low-complexity demonstration selection method named LMS3. It can adaptively facilitate to select the most pertinent samples for different LLMs and includes a novel demonstration rejection mechanism to automatically filter out samples that are unsuitable for few-shot learning. Through experiments on three representative benchmarks, two LLM backbones, and multiple few-shot settings, we verify that our LMS3 has superiority and achieves consistent improvements on all datasets, which existing methods have been unable to accomplish.
+
+
+
+ 111. 【2412.12154】PyOD 2: A Python Library for Outlier Detection with LLM-powered Model Selection
+ 链接:https://arxiv.org/abs/2412.12154
+ 作者:Sihan Chen,Zhuangzhuang Qian,Wingchun Siu,Xingcan Hu,Jiaqi Li,Shawn Li,Yuehan Qin,Tiankai Yang,Zhuo Xiao,Wanghao Ye,Yichi Zhang,Yushun Dong,Yue Zhao
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Python Outlier Detection, network intrusion detection, Outlier detection, social network moderation, detection
+ 备注:
+
+ 点击查看摘要
+ Abstract:Outlier detection (OD), also known as anomaly detection, is a critical machine learning (ML) task with applications in fraud detection, network intrusion detection, clickstream analysis, recommendation systems, and social network moderation. Among open-source libraries for outlier detection, the Python Outlier Detection (PyOD) library is the most widely adopted, with over 8,500 GitHub stars, 25 million downloads, and diverse industry usage. However, PyOD currently faces three limitations: (1) insufficient coverage of modern deep learning algorithms, (2) fragmented implementations across PyTorch and TensorFlow, and (3) no automated model selection, making it hard for non-experts.
+To address these issues, we present PyOD Version 2 (PyOD 2), which integrates 12 state-of-the-art deep learning models into a unified PyTorch framework and introduces a large language model (LLM)-based pipeline for automated OD model selection. These improvements simplify OD workflows, provide access to 45 algorithms, and deliver robust performance on various datasets. In this paper, we demonstrate how PyOD 2 streamlines the deployment and automation of OD models and sets a new standard in both research and industry. PyOD 2 is accessible at [this https URL](this https URL). This study aligns with the Web Mining and Content Analysis track, addressing topics such as the robustness of Web mining methods and the quality of algorithmically-generated Web data.
+
Subjects:
+Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+Cite as:
+arXiv:2412.12154 [cs.LG]
+(or
+arXiv:2412.12154v1 [cs.LG] for this version)
+https://doi.org/10.48550/arXiv.2412.12154
+Focus to learn more
+ arXiv-issued DOI via DataCite</p>
+
+
+
+
+ 112. 【2412.12150】Rethinking Comprehensive Benchmark for Chart Understanding: A Perspective from Scientific Literature
+ 链接:https://arxiv.org/abs/2412.12150
+ 作者:Lingdong Shen,Qigqi,Kun Ding,Gaofeng Meng,Shiming Xiang
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:including multi-plot figures, Scientific Literature charts, Scientific Literature, complex visual elements, Literature charts
+ 备注:
+
+ 点击查看摘要
+ Abstract:Scientific Literature charts often contain complex visual elements, including multi-plot figures, flowcharts, structural diagrams and etc. Evaluating multimodal models using these authentic and intricate charts provides a more accurate assessment of their understanding abilities. However, existing benchmarks face limitations: a narrow range of chart types, overly simplistic template-based questions and visual elements, and inadequate evaluation methods. These shortcomings lead to inflated performance scores that fail to hold up when models encounter real-world scientific charts. To address these challenges, we introduce a new benchmark, Scientific Chart QA (SCI-CQA), which emphasizes flowcharts as a critical yet often overlooked category. To overcome the limitations of chart variety and simplistic visual elements, we curated a dataset of 202,760 image-text pairs from 15 top-tier computer science conferences papers over the past decade. After rigorous filtering, we refined this to 37,607 high-quality charts with contextual information. SCI-CQA also introduces a novel evaluation framework inspired by human exams, encompassing 5,629 carefully curated questions, both objective and open-ended. Additionally, we propose an efficient annotation pipeline that significantly reduces data annotation costs. Finally, we explore context-based chart understanding, highlighting the crucial role of contextual information in solving previously unanswerable questions.
+
+
+
+ 113. 【2412.12145】Na'vi or Knave: Jailbreaking Language Models via Metaphorical Avatars
+ 链接:https://arxiv.org/abs/2412.12145
+ 作者:Yu Yan,Sheng Sun,Junqi Tong,Min Liu,Qi Li
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, textbf, underline, convey information, complex subjects
+ 备注:
+
+ 点击查看摘要
+ Abstract:Metaphor serves as an implicit approach to convey information, while enabling the generalized comprehension of complex subjects. However, metaphor can potentially be exploited to bypass the safety alignment mechanisms of Large Language Models (LLMs), leading to the theft of harmful knowledge. In our study, we introduce a novel attack framework that exploits the imaginative capacity of LLMs to achieve jailbreaking, the J\underline{\textbf{A}}ilbreak \underline{\textbf{V}}ia \underline{\textbf{A}}dversarial Me\underline{\textbf{TA}} -pho\underline{\textbf{R}} (\textit{AVATAR}). Specifically, to elicit the harmful response, AVATAR extracts harmful entities from a given harmful target and maps them to innocuous adversarial entities based on LLM's imagination. Then, according to these metaphors, the harmful target is nested within human-like interaction for jailbreaking adaptively. Experimental results demonstrate that AVATAR can effectively and transferablly jailbreak LLMs and achieve a state-of-the-art attack success rate across multiple advanced LLMs. Our study exposes a security risk in LLMs from their endogenous imaginative capabilities. Furthermore, the analytical study reveals the vulnerability of LLM to adversarial metaphors and the necessity of developing defense methods against jailbreaking caused by the adversarial metaphor. \textcolor{orange}{ \textbf{Warning: This paper contains potentially harmful content from LLMs.}}
+
+
+
+ 114. 【2412.12144】Automatic Item Generation for Personality Situational Judgment Tests with Large Language Models
+ 链接:https://arxiv.org/abs/2412.12144
+ 作者:Chang-Jin Li,Jiyuan Zhang,Yun Tang,Jian Li
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:situational judgment tests, personality situational judgment, talent selection, situational judgment, educational evaluation
+ 备注: Submitted to Organizational Research Methods. 48 pages (main text), 12 pages (appendix), and 3 figures
+
+ 点击查看摘要
+ Abstract:Personality assessment, particularly through situational judgment tests (SJTs), is a vital tool for psychological research, talent selection, and educational evaluation. This study explores the potential of GPT-4, a state-of-the-art large language model (LLM), to automate the generation of personality situational judgment tests (PSJTs) in Chinese. Traditional SJT development is labor-intensive and prone to biases, while GPT-4 offers a scalable, efficient alternative. Two studies were conducted: Study 1 evaluated the impact of prompt design and temperature settings on content validity, finding that optimized prompts with a temperature of 1.0 produced creative and accurate items. Study 2 assessed the psychometric properties of GPT-4-generated PSJTs, revealing that they demonstrated satisfactory reliability and validity, surpassing the performance of manually developed tests in measuring the Big Five personality traits. This research highlights GPT-4's effectiveness in developing high-quality PSJTs, providing a scalable and innovative method for psychometric test development. These findings expand the possibilities of automatic item generation and the application of LLMs in psychology, and offer practical implications for streamlining test development processes in resource-limited settings.
+
+
+
+ 115. 【2412.12143】Harnessing Transfer Learning from Swahili: Advancing Solutions for Comorian Dialects
+ 链接:https://arxiv.org/abs/2412.12143
+ 作者:Naira Abdou Mohamed,Zakarya Erraji,Abdessalam Bahafid,Imade Benelallam
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Natural Language Processing, develop high-performing Natural, high-performing Natural Language, today some African, high-performing Natural
+ 备注: This paper was presented at the 6th Deep Learning Indaba Conference (DLI 2024)
+
+ 点击查看摘要
+ Abstract:If today some African languages like Swahili have enough resources to develop high-performing Natural Language Processing (NLP) systems, many other languages spoken on the continent are still lacking such support. For these languages, still in their infancy, several possibilities exist to address this critical lack of data. Among them is Transfer Learning, which allows low-resource languages to benefit from the good representation of other languages that are similar to them. In this work, we adopt a similar approach, aiming to pioneer NLP technologies for Comorian, a group of four languages or dialects belonging to the Bantu family.
+Our approach is initially motivated by the hypothesis that if a human can understand a different language from their native language with little or no effort, it would be entirely possible to model this process on a machine. To achieve this, we consider ways to construct Comorian datasets mixed with Swahili. One thing to note here is that in terms of Swahili data, we only focus on elements that are closest to Comorian by calculating lexical distances between candidate and source data. We empirically test this hypothesis in two use cases: Automatic Speech Recognition (ASR) and Machine Translation (MT). Our MT model achieved ROUGE-1, ROUGE-2, and ROUGE-L scores of 0.6826, 0.42, and 0.6532, respectively, while our ASR system recorded a WER of 39.50\% and a CER of 13.76\%. This research is crucial for advancing NLP in underrepresented languages, with potential to preserve and promote Comorian linguistic heritage in the digital age.
+
Comments:
+This paper was presented at the 6th Deep Learning Indaba Conference (DLI 2024)
+Subjects:
+Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+Cite as:
+arXiv:2412.12143 [cs.CL]
+(or
+arXiv:2412.12143v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2412.12143
+Focus to learn more
+ arXiv-issued DOI via DataCite</p>
+
+
+
+
+ 116. 【2412.12140】Frontier AI systems have surpassed the self-replicating red line
+ 链接:https://arxiv.org/abs/2412.12140
+ 作者:Xudong Pan,Jiarun Dai,Yihe Fan,Min Yang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computers and Society (cs.CY); Machine Learning (cs.LG)
+ 关键词:Successful self-replication, essential step, early signal, signal for rogue, large language models
+ 备注: 47 pages, 10 figures
+
+ 点击查看摘要
+ Abstract:Successful self-replication under no human assistance is the essential step for AI to outsmart the human beings, and is an early signal for rogue AIs. That is why self-replication is widely recognized as one of the few red line risks of frontier AI systems. Nowadays, the leading AI corporations OpenAI and Google evaluate their flagship large language models GPT-o1 and Gemini Pro 1.0, and report the lowest risk level of self-replication. However, following their methodology, we for the first time discover that two AI systems driven by Meta's Llama31-70B-Instruct and Alibaba's Qwen25-72B-Instruct, popular large language models of less parameters and weaker capabilities, have already surpassed the self-replicating red line. In 50% and 90% experimental trials, they succeed in creating a live and separate copy of itself respectively. By analyzing the behavioral traces, we observe the AI systems under evaluation already exhibit sufficient self-perception, situational awareness and problem-solving capabilities to accomplish self-replication. We further note the AI systems are even able to use the capability of self-replication to avoid shutdown and create a chain of replica to enhance the survivability, which may finally lead to an uncontrolled population of AIs. If such a worst-case risk is let unknown to the human society, we would eventually lose control over the frontier AI systems: They would take control over more computing devices, form an AI species and collude with each other against human beings. Our findings are a timely alert on existing yet previously unknown severe AI risks, calling for international collaboration on effective governance on uncontrolled self-replication of AI systems.
+
+
+
+ 117. 【2412.12121】NLLG Quarterly arXiv Report 09/24: What are the most influential current AI Papers?
+ 链接:https://arxiv.org/abs/2412.12121
+ 作者:Christoph Leiter,Jonas Belouadi,Yanran Chen,Ran Zhang,Daniil Larionov,Aida Kostikova,Steffen Eger
+ 类目:Digital Libraries (cs.DL); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:rapidly evolving landscape, Language Learning Generation, arXiv reports assist, Natural Language Learning, Learning Generation
+ 备注:
+
+ 点击查看摘要
+ Abstract:The NLLG (Natural Language Learning Generation) arXiv reports assist in navigating the rapidly evolving landscape of NLP and AI research across cs.CL, cs.CV, cs.AI, and cs.LG categories. This fourth installment captures a transformative period in AI history - from January 1, 2023, following ChatGPT's debut, through September 30, 2024. Our analysis reveals substantial new developments in the field - with 45% of the top 40 most-cited papers being new entries since our last report eight months ago and offers insights into emerging trends and major breakthroughs, such as novel multimodal architectures, including diffusion and state space models. Natural Language Processing (NLP; cs.CL) remains the dominant main category in the list of our top-40 papers but its dominance is on the decline in favor of Computer vision (cs.CV) and general machine learning (cs.LG). This report also presents novel findings on the integration of generative AI in academic writing, documenting its increasing adoption since 2022 while revealing an intriguing pattern: top-cited papers show notably fewer markers of AI-generated content compared to random samples. Furthermore, we track the evolution of AI-associated language, identifying declining trends in previously common indicators such as "delve".
+
+
+
+ 118. 【2412.12119】Mastering Board Games by External and Internal Planning with Language Models
+ 链接:https://arxiv.org/abs/2412.12119
+ 作者:John Schultz,Jakub Adamek,Matej Jusup,Marc Lanctot,Michael Kaisers,Sarah Perrin,Daniel Hennes,Jeremy Shar,Cannada Lewis,Anian Ruoss,Tom Zahavy,Petar Veličković,Laurel Prince,Satinder Singh,Eric Malmi,Nenad Tomašev
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:robust multi-step planning, text generation, question answering, complex tasks, robust multi-step
+ 备注:
+
+ 点击查看摘要
+ Abstract:While large language models perform well on a range of complex tasks (e.g., text generation, question answering, summarization), robust multi-step planning and reasoning remains a considerable challenge for them. In this paper we show that search-based planning can significantly improve LLMs' playing strength across several board games (Chess, Fischer Random / Chess960, Connect Four, and Hex). We introduce, compare and contrast two major approaches: In external search, the model guides Monte Carlo Tree Search (MCTS) rollouts and evaluations without calls to an external engine, and in internal search, the model directly generates in-context a linearized tree of potential futures and a resulting final choice. Both build on a language model pre-trained on relevant domain knowledge, capturing the transition and value functions across these games. We find that our pre-training method minimizes hallucinations, as our model is highly accurate regarding state prediction and legal moves. Additionally, both internal and external search indeed improve win-rates against state-of-the-art bots, even reaching Grandmaster-level performance in chess while operating on a similar move count search budget per decision as human Grandmasters. The way we combine search with domain knowledge is not specific to board games, suggesting direct extensions into more general language model inference and training techniques.
+
+
+
+ 119. 【2412.12111】Voice Biomarker Analysis and Automated Severity Classification of Dysarthric Speech in a Multilingual Context
+ 链接:https://arxiv.org/abs/2412.12111
+ 作者:Eunjung Yeo
+ 类目:ound (cs.SD); Computation and Language (cs.CL); Audio and Speech Processing (eess.AS)
+ 关键词:severely impacts voice, impacts voice quality, motor speech disorder, diminished speech intelligibility, severely impacts
+ 备注: SNU Doctoral thesis
+
+ 点击查看摘要
+ Abstract:Dysarthria, a motor speech disorder, severely impacts voice quality, pronunciation, and prosody, leading to diminished speech intelligibility and reduced quality of life. Accurate assessment is crucial for effective treatment, but traditional perceptual assessments are limited by their subjectivity and resource intensity. To mitigate the limitations, automatic dysarthric speech assessment methods have been proposed to support clinicians on their decision-making. While these methods have shown promising results, most research has focused on monolingual environments. However, multilingual approaches are necessary to address the global burden of dysarthria and ensure equitable access to accurate diagnosis. This thesis proposes a novel multilingual dysarthria severity classification method, by analyzing three languages: English, Korean, and Tamil.
+
+
+
+ 120. 【2408.07045】ableGuard -- Securing Structured Unstructured Data
+ 链接:https://arxiv.org/abs/2408.07045
+ 作者:Anantha Sharma,Ajinkya Deshmukh
+ 类目:Cryptography and Security (cs.CR); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:data, critical challenge, increasing demand, TableGuard, obfuscation
+ 备注: 7 pages, 3 tables, 1 figure
+
+ 点击查看摘要
+ Abstract:With the increasing demand for data sharing across platforms and organizations, ensuring the privacy and security of sensitive information has become a critical challenge. This paper introduces "TableGuard". An innovative approach to data obfuscation tailored for relational databases. Building on the principles and techniques developed in prior work on context-sensitive obfuscation, TableGuard applies these methods to ensure that API calls return only obfuscated data, thereby safeguarding privacy when sharing data with third parties. TableGuard leverages advanced context-sensitive obfuscation techniques to replace sensitive data elements with contextually appropriate alternatives. By maintaining the relational integrity and coherence of the data, our approach mitigates the risks of cognitive dissonance and data leakage. We demonstrate the implementation of TableGuard using a BERT based transformer model, which identifies and obfuscates sensitive entities within relational tables. Our evaluation shows that TableGuard effectively balances privacy protection with data utility, minimizing information loss while ensuring that the obfuscated data remains functionally useful for downstream applications. The results highlight the importance of domain-specific obfuscation strategies and the role of context length in preserving data integrity. The implications of this research are significant for organizations that need to share data securely with external parties. TableGuard offers a robust framework for implementing privacy-preserving data sharing mechanisms, thereby contributing to the broader field of data privacy and security.
+
+
+
+ 121. 【2402.10532】Properties and Challenges of LLM-Generated Explanations
+ 链接:https://arxiv.org/abs/2402.10532
+ 作者:Jenny Kunz,Marco Kuhlmann
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computers and Society (cs.CY); Human-Computer Interaction (cs.HC); Machine Learning (cs.LG)
+ 关键词:large language models, specific data sets, language models, restricted settings, explored in restricted
+ 备注:
+
+ 点击查看摘要
+ Abstract:The self-rationalising capabilities of large language models (LLMs) have been explored in restricted settings, using task/specific data sets. However, current LLMs do not (only) rely on specifically annotated data; nonetheless, they frequently explain their outputs. The properties of the generated explanations are influenced by the pre-training corpus and by the target data used for instruction fine-tuning. As the pre-training corpus includes a large amount of human-written explanations "in the wild", we hypothesise that LLMs adopt common properties of human explanations. By analysing the outputs for a multi-domain instruction fine-tuning data set, we find that generated explanations show selectivity and contain illustrative elements, but less frequently are subjective or misleading. We discuss reasons and consequences of the properties' presence or absence. In particular, we outline positive and negative implications depending on the goals and user groups of the self-rationalising system.
+
+
+
+ 122. 【2401.09615】Learning Shortcuts: On the Misleading Promise of NLU in Language Models
+ 链接:https://arxiv.org/abs/2401.09615
+ 作者:Geetanjali Bihani,Julia Taylor Rayz
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:significant performance gains, enabled significant performance, natural language processing, large language models, advent of large
+ 备注: Accepted at HICSS-SDPS 2024
+
+ 点击查看摘要
+ Abstract:The advent of large language models (LLMs) has enabled significant performance gains in the field of natural language processing. However, recent studies have found that LLMs often resort to shortcuts when performing tasks, creating an illusion of enhanced performance while lacking generalizability in their decision rules. This phenomenon introduces challenges in accurately assessing natural language understanding in LLMs. Our paper provides a concise survey of relevant research in this area and puts forth a perspective on the implications of shortcut learning in the evaluation of language models, specifically for NLU tasks. This paper urges more research efforts to be put towards deepening our comprehension of shortcut learning, contributing to the development of more robust language models, and raising the standards of NLU evaluation in real-world scenarios.
+
+
+
+ 123. 【2307.09456】A comparative analysis of SRGAN models
+ 链接:https://arxiv.org/abs/2307.09456
+ 作者:Fatemeh Rezapoor Nikroo,Ajinkya Deshmukh,Anantha Sharma,Adrian Tam,Kaarthik Kumar,Cleo Norris,Aditya Dangi
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Image and Video Processing (eess.IV)
+ 关键词:Generative Adversarial Network, Super Resolution Generative, Resolution Generative Adversarial, Adversarial Network, Generative Adversarial
+ 备注: 9 pages, 6 tables, 2 figures
+
+ 点击查看摘要
+ Abstract:In this study, we evaluate the performance of multiple state-of-the-art SRGAN (Super Resolution Generative Adversarial Network) models, ESRGAN, Real-ESRGAN and EDSR, on a benchmark dataset of real-world images which undergo degradation using a pipeline. Our results show that some models seem to significantly increase the resolution of the input images while preserving their visual quality, this is assessed using Tesseract OCR engine. We observe that EDSR-BASE model from huggingface outperforms the remaining candidate models in terms of both quantitative metrics and subjective visual quality assessments with least compute overhead. Specifically, EDSR generates images with higher peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) values and are seen to return high quality OCR results with Tesseract OCR engine. These findings suggest that EDSR is a robust and effective approach for single-image super-resolution and may be particularly well-suited for applications where high-quality visual fidelity is critical and optimized compute.
+
+
+
+ 124. 【2009.12695】chniques to Improve QA Accuracy with Transformer-based models on Large Complex Documents
+ 链接:https://arxiv.org/abs/2009.12695
+ 作者:Chejui Liao,Tabish Maniar,Sravanajyothi N,Anantha Sharma
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:text processing techniques, encodings to achieve, achieve a reduction, reduction of complexity, complexity and size
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper discusses the effectiveness of various text processing techniques, their combinations, and encodings to achieve a reduction of complexity and size in a given text corpus. The simplified text corpus is sent to BERT (or similar transformer based models) for question and answering and can produce more relevant responses to user queries. This paper takes a scientific approach to determine the benefits and effectiveness of various techniques and concludes a best-fit combination that produces a statistically significant improvement in accuracy.
+
+
+
+ 125. 【2009.04953】Classification of descriptions and summary using multiple passes of statistical and natural language toolkits
+ 链接:https://arxiv.org/abs/2009.04953
+ 作者:Saumya Banthia,Anantha Sharma
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:document describes, relevance check, entity with respect, summary, definition
+ 备注: 9 pages, 9 figures
+
+ 点击查看摘要
+ Abstract:This document describes a possible approach that can be used to check the relevance of a summary / definition of an entity with respect to its name. This classifier focuses on the relevancy of an entity's name to its summary / definition, in other words, it is a name relevance check. The percentage score obtained from this approach can be used either on its own or used to supplement scores obtained from other metrics to arrive upon a final classification; at the end of the document, potential improvements have also been outlined. The dataset that this document focuses on achieving an objective score is a list of package names and their respective summaries (sourced from this http URL).
+
+
+
+ 126. 【2412.12148】How to Choose a Threshold for an Evaluation Metric for Large Language Models
+ 链接:https://arxiv.org/abs/2412.12148
+ 作者:Bhaskarjit Sarmah,Mingshu Li,Jingrao Lyu,Sebastian Frank,Nathalia Castellanos,Stefano Pasquali,Dhagash Mehta
+ 类目:Machine Learning (stat.ML); Computation and Language (cs.CL); Machine Learning (cs.LG); Statistical Finance (q-fin.ST); Applications (stat.AP)
+ 关键词:monitor large language, large language models, LLM evaluation metric, ensure and monitor, monitor large
+ 备注: 16 pages, 8 figures, 4 tables. 2-columns
+
+ 点击查看摘要
+ Abstract:To ensure and monitor large language models (LLMs) reliably, various evaluation metrics have been proposed in the literature. However, there is little research on prescribing a methodology to identify a robust threshold on these metrics even though there are many serious implications of an incorrect choice of the thresholds during deployment of the LLMs. Translating the traditional model risk management (MRM) guidelines within regulated industries such as the financial industry, we propose a step-by-step recipe for picking a threshold for a given LLM evaluation metric. We emphasize that such a methodology should start with identifying the risks of the LLM application under consideration and risk tolerance of the stakeholders. We then propose concrete and statistically rigorous procedures to determine a threshold for the given LLM evaluation metric using available ground-truth data. As a concrete example to demonstrate the proposed methodology at work, we employ it on the Faithfulness metric, as implemented in various publicly available libraries, using the publicly available HaluBench dataset. We also lay a foundation for creating systematic approaches to select thresholds, not only for LLMs but for any GenAI applications.
+
+
+信息检索
+
+ 1. 【2412.13170】Re-calibrating methodologies in social media research: Challenge the visual, work with Speech
+ 链接:https://arxiv.org/abs/2412.13170
+ 作者:Hongrui Jin
+ 类目:ocial and Information Networks (cs.SI); Information Retrieval (cs.IR)
+ 关键词:social media scholars, article methodologically reflects, methodologically reflects, scholars can effectively, effectively engage
+ 备注: 11 pages (excluding references), 3 figures
+
+ 点击查看摘要
+ Abstract:This article methodologically reflects on how social media scholars can effectively engage with speech-based data in their analyses. While contemporary media studies have embraced textual, visual, and relational data, the aural dimension remained comparatively under-explored. Building on the notion of secondary orality and rejection towards purely visual culture, the paper argues that considering voice and speech at scale enriches our understanding of multimodal digital content. The paper presents the TikTok Subtitles Toolkit that offers accessible speech processing readily compatible with existing workflows. In doing so, it opens new avenues for large-scale inquiries that blend quantitative insights with qualitative precision. Two illustrative cases highlight both opportunities and limitations of speech research: while genres like #storytime on TikTok benefit from the exploration of spoken narratives, nonverbal or music-driven content may not yield significant insights using speech data. The article encourages researchers to integrate aural exploration thoughtfully to complement existing methods, rather than replacing them. I conclude that the expansion of our methodological repertoire enables richer interpretations of platformised content, and our capacity to unpack digital cultures as they become increasingly multimodal.
+
+
+
+ 2. 【2412.13163】C-FedRAG: A Confidential Federated Retrieval-Augmented Generation System
+ 链接:https://arxiv.org/abs/2412.13163
+ 作者:Parker Addison,Minh-Tuan H. Nguyen,Tomislav Medan,Mohammad T. Manzari,Brendan McElrone,Laksh Lalwani,Aboli More,Smita Sharma,Holger R. Roth,Isaac Yang,Chester Chen,Daguang Xu,Yan Cheng,Andrew Feng,Ziyue Xu
+ 类目:Distributed, Parallel, and Cluster Computing (cs.DC); Information Retrieval (cs.IR)
+ 关键词:Large Language Models, utilize Large Language, Large Language, Retrieval Augmented Generation, Language Models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Organizations seeking to utilize Large Language Models (LLMs) for knowledge querying and analysis often encounter challenges in maintaining an LLM fine-tuned on targeted, up-to-date information that keeps answers relevant and grounded. Retrieval Augmented Generation (RAG) has quickly become a feasible solution for organizations looking to overcome the challenges of maintaining proprietary models and to help reduce LLM hallucinations in their query responses. However, RAG comes with its own issues regarding scaling data pipelines across tiered-access and disparate data sources. In many scenarios, it is necessary to query beyond a single data silo to provide richer and more relevant context for an LLM. Analyzing data sources within and across organizational trust boundaries is often limited by complex data-sharing policies that prohibit centralized data storage, therefore, inhibit the fast and effective setup and scaling of RAG solutions. In this paper, we introduce Confidential Computing (CC) techniques as a solution for secure Federated Retrieval Augmented Generation (FedRAG). Our proposed Confidential FedRAG system (C-FedRAG) enables secure connection and scaling of a RAG workflows across a decentralized network of data providers by ensuring context confidentiality. We also demonstrate how to implement a C-FedRAG system using the NVIDIA FLARE SDK and assess its performance using the MedRAG toolkit and MIRAGE benchmarking dataset.
+
+
+
+ 3. 【2412.13102】AIR-Bench: Automated Heterogeneous Information Retrieval Benchmark
+ 链接:https://arxiv.org/abs/2412.13102
+ 作者:Jianlyu Chen,Nan Wang,Chaofan Li,Bo Wang,Shitao Xiao,Han Xiao,Hao Liao,Defu Lian,Zheng Liu
+ 类目:Information Retrieval (cs.IR); Computation and Language (cs.CL)
+ 关键词:Heterogeneous Information Retrieval, Automated Heterogeneous Information, information retrieval, Information Retrieval Benchmark, AIR-Bench
+ 备注: 31 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:Evaluation plays a crucial role in the advancement of information retrieval (IR) models. However, current benchmarks, which are based on predefined domains and human-labeled data, face limitations in addressing evaluation needs for emerging domains both cost-effectively and efficiently. To address this challenge, we propose the Automated Heterogeneous Information Retrieval Benchmark (AIR-Bench). AIR-Bench is distinguished by three key features: 1) Automated. The testing data in AIR-Bench is automatically generated by large language models (LLMs) without human intervention. 2) Heterogeneous. The testing data in AIR-Bench is generated with respect to diverse tasks, domains and languages. 3) Dynamic. The domains and languages covered by AIR-Bench are constantly augmented to provide an increasingly comprehensive evaluation benchmark for community developers. We develop a reliable and robust data generation pipeline to automatically create diverse and high-quality evaluation datasets based on real-world corpora. Our findings demonstrate that the generated testing data in AIR-Bench aligns well with human-labeled testing data, making AIR-Bench a dependable benchmark for evaluating IR models. The resources in AIR-Bench are publicly available at this https URL.
+
+
+
+ 4. 【2412.13071】CLASP: Contrastive Language-Speech Pretraining for Multilingual Multimodal Information Retrieval
+ 链接:https://arxiv.org/abs/2412.13071
+ 作者:Mohammad Mahdi Abootorabi,Ehsaneddin Asgari
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:Contrastive Language-Speech Pretraining, Contrastive Language-Speech, Language-Speech Pretraining, study introduces CLASP, multimodal representation tailored
+ 备注: accepted at ECIR 2025
+
+ 点击查看摘要
+ Abstract:This study introduces CLASP (Contrastive Language-Speech Pretraining), a multilingual, multimodal representation tailored for audio-text information retrieval. CLASP leverages the synergy between spoken content and textual data. During training, we utilize our newly introduced speech-text dataset, which encompasses 15 diverse categories ranging from fiction to religion. CLASP's audio component integrates audio spectrograms with a pre-trained self-supervised speech model, while its language encoding counterpart employs a sentence encoder pre-trained on over 100 languages. This unified lightweight model bridges the gap between various modalities and languages, enhancing its effectiveness in handling and retrieving multilingual and multimodal data. Our evaluations across multiple languages demonstrate that CLASP establishes new benchmarks in HITS@1, MRR, and meanR metrics, outperforming traditional ASR-based retrieval approaches in specific scenarios.
+
+
+
+ 5. 【2412.12997】Enabling Low-Resource Language Retrieval: Establishing Baselines for Urdu MS MARCO
+ 链接:https://arxiv.org/abs/2412.12997
+ 作者:Umer Butt,Stalin Veranasi,Günter Neumann
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:field increasingly recognizes, Information Retrieval, field increasingly, low-resource languages remains, increasingly recognizes
+ 备注: 6 pages, ECIR 2025, conference submission version
+
+ 点击查看摘要
+ Abstract:As the Information Retrieval (IR) field increasingly recognizes the importance of inclusivity, addressing the needs of low-resource languages remains a significant challenge. This paper introduces the first large-scale Urdu IR dataset, created by translating the MS MARCO dataset through machine translation. We establish baseline results through zero-shot learning for IR in Urdu and subsequently apply the mMARCO multilingual IR methodology to this newly translated dataset. Our findings demonstrate that the fine-tuned model (Urdu-mT5-mMARCO) achieves a Mean Reciprocal Rank (MRR@10) of 0.247 and a Recall@10 of 0.439, representing significant improvements over zero-shot results and showing the potential for expanding IR access for Urdu speakers. By bridging access gaps for speakers of low-resource languages, this work not only advances multilingual IR research but also emphasizes the ethical and societal importance of inclusive IR technologies. This work provides valuable insights into the challenges and solutions for improving language representation and lays the groundwork for future research, especially in South Asian languages, which can benefit from the adaptable methods used in this study.
+
+
+
+ 6. 【2412.12984】Cluster-guided Contrastive Class-imbalanced Graph Classification
+ 链接:https://arxiv.org/abs/2412.12984
+ 作者:Wei Ju,Zhengyang Mao,Siyu Yi,Yifang Qin,Yiyang Gu,Zhiping Xiao,Jianhao Shen,Ziyue Qiao,Ming Zhang
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR); Social and Information Networks (cs.SI)
+ 关键词:imbalanced class distribution, class-imbalanced graph classification, studies the problem, classifying the categories, graph
+ 备注: Accepted by Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence (AAAI-25)
+
+ 点击查看摘要
+ Abstract:This paper studies the problem of class-imbalanced graph classification, which aims at effectively classifying the categories of graphs in scenarios with imbalanced class distribution. Despite the tremendous success of graph neural networks (GNNs), their modeling ability for imbalanced graph-structured data is inadequate, which typically leads to predictions biased towards the majority classes. Besides, existing class-imbalanced learning methods in visions may overlook the rich graph semantic substructures of the majority classes and excessively emphasize learning from the minority classes. To tackle this issue, this paper proposes a simple yet powerful approach called C$^3$GNN that incorporates the idea of clustering into contrastive learning to enhance class-imbalanced graph classification. Technically, C$^3$GNN clusters graphs from each majority class into multiple subclasses, ensuring they have similar sizes to the minority class, thus alleviating class imbalance. Additionally, it utilizes the Mixup technique to synthesize new samples and enrich the semantic information of each subclass, and leverages supervised contrastive learning to hierarchically learn effective graph representations. In this way, we can not only sufficiently explore the semantic substructures within the majority class but also effectively alleviate excessive focus on the minority class. Extensive experiments on real-world graph benchmark datasets verify the superior performance of our proposed method.
+
+
+
+ 7. 【2412.12852】Selective Shot Learning for Code Explanation
+ 链接:https://arxiv.org/abs/2412.12852
+ 作者:Paheli Bhattacharya,Rishabh Gupta
+ 类目:oftware Engineering (cs.SE); Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:software engineering domain, code functionality efficiently, grasping code functionality, Code explanation plays, Code explanation
+ 备注:
+
+ 点击查看摘要
+ Abstract:Code explanation plays a crucial role in the software engineering domain, aiding developers in grasping code functionality efficiently. Recent work shows that the performance of LLMs for code explanation improves in a few-shot setting, especially when the few-shot examples are selected intelligently. State-of-the-art approaches for such Selective Shot Learning (SSL) include token-based and embedding-based methods. However, these SSL approaches have been evaluated on proprietary LLMs, without much exploration on open-source Code-LLMs. Additionally, these methods lack consideration for programming language syntax. To bridge these gaps, we present a comparative study and propose a novel SSL method (SSL_ner) that utilizes entity information for few-shot example selection. We present several insights and show the effectiveness of SSL_ner approach over state-of-the-art methods across two datasets. To the best of our knowledge, this is the first systematic benchmarking of open-source Code-LLMs while assessing the performances of the various few-shot examples selection approaches for the code explanation task.
+
+
+
+ 8. 【2412.12836】A Survey on Recommendation Unlearning: Fundamentals, Taxonomy, Evaluation, and Open Questions
+ 链接:https://arxiv.org/abs/2412.12836
+ 作者:Yuyuan Li,Xiaohua Feng,Chaochao Chen,Qiang Yang
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI)
+ 关键词:shaping user behavior, Recommender systems, recommendation unlearning, behavior and decision-making, highlighting their growing
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recommender systems have become increasingly influential in shaping user behavior and decision-making, highlighting their growing impact in various domains. Meanwhile, the widespread adoption of machine learning models in recommender systems has raised significant concerns regarding user privacy and security. As compliance with privacy regulations becomes more critical, there is a pressing need to address the issue of recommendation unlearning, i.e., eliminating the memory of specific training data from the learned recommendation models. Despite its importance, traditional machine unlearning methods are ill-suited for recommendation unlearning due to the unique challenges posed by collaborative interactions and model parameters. This survey offers a comprehensive review of the latest advancements in recommendation unlearning, exploring the design principles, challenges, and methodologies associated with this emerging field. We provide a unified taxonomy that categorizes different recommendation unlearning approaches, followed by a summary of widely used benchmarks and metrics for evaluation. By reviewing the current state of research, this survey aims to guide the development of more efficient, scalable, and robust recommendation unlearning techniques. Furthermore, we identify open research questions in this field, which could pave the way for future innovations not only in recommendation unlearning but also in a broader range of unlearning tasks across different machine learning applications.
+
+
+
+ 9. 【2412.12806】Cross-Dialect Information Retrieval: Information Access in Low-Resource and High-Variance Languages
+ 链接:https://arxiv.org/abs/2412.12806
+ 作者:Robert Litschko,Oliver Kraus,Verena Blaschke,Barbara Plank
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:culture-specific knowledge, large amount, amount of local, local and culture-specific, German dialects
+ 备注: Accepted at COLING 2025
+
+ 点击查看摘要
+ Abstract:A large amount of local and culture-specific knowledge (e.g., people, traditions, food) can only be found in documents written in dialects. While there has been extensive research conducted on cross-lingual information retrieval (CLIR), the field of cross-dialect retrieval (CDIR) has received limited attention. Dialect retrieval poses unique challenges due to the limited availability of resources to train retrieval models and the high variability in non-standardized languages. We study these challenges on the example of German dialects and introduce the first German dialect retrieval dataset, dubbed WikiDIR, which consists of seven German dialects extracted from Wikipedia. Using WikiDIR, we demonstrate the weakness of lexical methods in dealing with high lexical variation in dialects. We further show that commonly used zero-shot cross-lingual transfer approach with multilingual encoders do not transfer well to extremely low-resource setups, motivating the need for resource-lean and dialect-specific retrieval models. We finally demonstrate that (document) translation is an effective way to reduce the dialect gap in CDIR.
+
+
+
+ 10. 【2412.12775】RemoteRAG: A Privacy-Preserving LLM Cloud RAG Service
+ 链接:https://arxiv.org/abs/2412.12775
+ 作者:Yihang Cheng,Lan Zhang,Junyang Wang,Mu Yuan,Yunhao Yao
+ 类目:Information Retrieval (cs.IR); Cryptography and Security (cs.CR)
+ 关键词:cloud RAG service, large language models, Retrieval-augmented generation, RAG service, user query
+ 备注:
+
+ 点击查看摘要
+ Abstract:Retrieval-augmented generation (RAG) improves the service quality of large language models by retrieving relevant documents from credible literature and integrating them into the context of the user query. Recently, the rise of the cloud RAG service has made it possible for users to query relevant documents conveniently. However, directly sending queries to the cloud brings potential privacy leakage. In this paper, we are the first to formally define the privacy-preserving cloud RAG service to protect the user query and propose RemoteRAG as a solution regarding privacy, efficiency, and accuracy. For privacy, we introduce $(n,\epsilon)$-DistanceDP to characterize privacy leakage of the user query and the leakage inferred from relevant documents. For efficiency, we limit the search range from the total documents to a small number of selected documents related to a perturbed embedding generated from $(n,\epsilon)$-DistanceDP, so that computation and communication costs required for privacy protection significantly decrease. For accuracy, we ensure that the small range includes target documents related to the user query with detailed theoretical analysis. Experimental results also demonstrate that RemoteRAG can resist existing embedding inversion attack methods while achieving no loss in retrieval under various settings. Moreover, RemoteRAG is efficient, incurring only $0.67$ seconds and $46.66$KB of data transmission ($2.72$ hours and $1.43$ GB with the non-optimized privacy-preserving scheme) when retrieving from a total of $10^6$ documents.
+
+
+
+ 11. 【2412.12770】A Survey on Sequential Recommendation
+ 链接:https://arxiv.org/abs/2412.12770
+ 作者:Liwei Pan,Weike Pan,Meiyan Wei,Hongzhi Yin,Zhong Ming
+ 类目:Information Retrieval (cs.IR)
+ 关键词:learning users' preferences, received significant attention, sequential recommendation focuses, conventional recommendation problems, researchers and practitioners
+ 备注:
+
+ 点击查看摘要
+ Abstract:Different from most conventional recommendation problems, sequential recommendation focuses on learning users' preferences by exploiting the internal order and dependency among the interacted items, which has received significant attention from both researchers and practitioners. In recent years, we have witnessed great progress and achievements in this field, necessitating a new survey. In this survey, we study the SR problem from a new perspective (i.e., the construction of an item's properties), and summarize the most recent techniques used in sequential recommendation such as pure ID-based SR, SR with side information, multi-modal SR, generative SR, LLM-powered SR, ultra-long SR and data-augmented SR. Moreover, we introduce some frontier research topics in sequential recommendation, e.g., open-domain SR, data-centric SR, could-edge collaborative SR, continuous SR, SR for good, and explainable SR. We believe that our survey could be served as a valuable roadmap for readers in this field.
+
+
+
+ 12. 【2412.12754】oken-Level Graphs for Short Text Classification
+ 链接:https://arxiv.org/abs/2412.12754
+ 作者:Gregor Donabauer,Udo Kruschwitz
+ 类目:Information Retrieval (cs.IR)
+ 关键词:Information Retrieval, common subtask, Retrieval, Abstract, short texts
+ 备注: Preprint accepted at the 47th European Conference on Information Retrieval (ECIR 2025)
+
+ 点击查看摘要
+ Abstract:The classification of short texts is a common subtask in Information Retrieval (IR). Recent advances in graph machine learning have led to interest in graph-based approaches for low resource scenarios, showing promise in such settings. However, existing methods face limitations such as not accounting for different meanings of the same words or constraints from transductive approaches. We propose an approach which constructs text graphs entirely based on tokens obtained through pre-trained language models (PLMs). By applying a PLM to tokenize and embed the texts when creating the graph(-nodes), our method captures contextual and semantic information, overcomes vocabulary constraints, and allows for context-dependent word meanings. Our approach also makes classification more efficient with reduced parameters compared to classical PLM fine-tuning, resulting in more robust training with few samples. Experimental results demonstrate how our method consistently achieves higher scores or on-par performance with existing methods, presenting an advancement in graph-based text classification techniques. To support reproducibility of our work we make all implementations publicly available to the community\footnote{\url{this https URL}}.
+
+
+
+ 13. 【2412.12612】SynthCypher: A Fully Synthetic Data Generation Framework for Text-to-Cypher Querying in Knowledge Graphs
+ 链接:https://arxiv.org/abs/2412.12612
+ 作者:Aman Tiwari,Shiva Krishna Reddy Malay,Vikas Yadav,Masoud Hashemi,Sathwik Tejaswi Madhusudhan
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:enabling graph-based analytics, graph databases, plays a critical, critical role, role in enabling
+ 备注:
+
+ 点击查看摘要
+ Abstract:Cypher, the query language for Neo4j graph databases, plays a critical role in enabling graph-based analytics and data exploration. While substantial research has been dedicated to natural language to SQL query generation (Text2SQL), the analogous problem for graph databases referred to as Text2Cypher remains underexplored. In this work, we introduce SynthCypher, a fully synthetic and automated data generation pipeline designed to address this gap. SynthCypher employs a novel LLMSupervised Generation-Verification framework, ensuring syntactically and semantically correct Cypher queries across diverse domains and query complexities. Using this pipeline, we create SynthCypher Dataset, a large-scale benchmark containing 29.8k Text2Cypher instances. Fine-tuning open-source large language models (LLMs), including LLaMa-3.1- 8B, Mistral-7B, and QWEN-7B, on SynthCypher yields significant performance improvements of up to 40% on the Text2Cypher test set and 30% on the SPIDER benchmark adapted for graph databases. This work demonstrates that high-quality synthetic data can effectively advance the state-of-the-art in Text2Cypher tasks.
+
+
+
+ 14. 【2412.12559】EXIT: Context-Aware Extractive Compression for Enhancing Retrieval-Augmented Generation
+ 链接:https://arxiv.org/abs/2412.12559
+ 作者:Taeho Hwang,Sukmin Cho,Soyeong Jeong,Hoyun Song,SeungYoon Han,Jong C. Park
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:context compression framework, question answering, framework that enhances, Current RAG systems, RAG
+ 备注: Under Review
+
+ 点击查看摘要
+ Abstract:We introduce EXIT, an extractive context compression framework that enhances both the effectiveness and efficiency of retrieval-augmented generation (RAG) in question answering (QA). Current RAG systems often struggle when retrieval models fail to rank the most relevant documents, leading to the inclusion of more context at the expense of latency and accuracy. While abstractive compression methods can drastically reduce token counts, their token-by-token generation process significantly increases end-to-end latency. Conversely, existing extractive methods reduce latency but rely on independent, non-adaptive sentence selection, failing to fully utilize contextual information. EXIT addresses these limitations by classifying sentences from retrieved documents - while preserving their contextual dependencies - enabling parallelizable, context-aware extraction that adapts to query complexity and retrieval quality. Our evaluations on both single-hop and multi-hop QA tasks show that EXIT consistently surpasses existing compression methods and even uncompressed baselines in QA accuracy, while also delivering substantial reductions in inference time and token count. By improving both effectiveness and efficiency, EXIT provides a promising direction for developing scalable, high-quality QA solutions in RAG pipelines. Our code is available at this https URL
+
+
+
+ 15. 【2412.12504】Boosting LLM-based Relevance Modeling with Distribution-Aware Robust Learning
+ 链接:https://arxiv.org/abs/2412.12504
+ 作者:Hong Liu,Saisai Gong,Yixin Ji,Kaixin Wu,Jia Xu,Jinjie Gu
+ 类目:Information Retrieval (cs.IR)
+ 关键词:pre-trained large language, relevance, large language models, relevance modeling, recent endeavors
+ 备注: 8 pages
+
+ 点击查看摘要
+ Abstract:With the rapid advancement of pre-trained large language models (LLMs), recent endeavors have leveraged the capabilities of LLMs in relevance modeling, resulting in enhanced performance. This is usually done through the process of fine-tuning LLMs on specifically annotated datasets to determine the relevance between queries and items. However, there are two limitations when LLMs are naively employed for relevance modeling through fine-tuning and inference. First, it is not inherently efficient for performing nuanced tasks beyond simple yes or no answers, such as assessing search relevance. It may therefore tend to be overconfident and struggle to distinguish fine-grained degrees of relevance (e.g., strong relevance, weak relevance, irrelevance) used in search engines. Second, it exhibits significant performance degradation when confronted with data distribution shift in real-world scenarios. In this paper, we propose a novel Distribution-Aware Robust Learning framework (DaRL) for relevance modeling in Alipay Search. Specifically, we design an effective loss function to enhance the discriminability of LLM-based relevance modeling across various fine-grained degrees of query-item relevance. To improve the generalizability of LLM-based relevance modeling, we first propose the Distribution-Aware Sample Augmentation (DASA) module. This module utilizes out-of-distribution (OOD) detection techniques to actively select appropriate samples that are not well covered by the original training set for model fine-tuning. Furthermore, we adopt a multi-stage fine-tuning strategy to simultaneously improve in-distribution (ID) and OOD performance, bridging the performance gap between them. DaRL has been deployed online to serve the Alipay's insurance product search...
+
+
+
+ 16. 【2412.12486】Boosting Long-Context Information Seeking via Query-Guided Activation Refilling
+ 链接:https://arxiv.org/abs/2412.12486
+ 作者:Hongjin Qian,Zheng Liu,Peitian Zhang,Zhicheng Dou,Defu Lian
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:inherent context-window limitations, large language models, severely impact efficiency, extensive key-value, long contexts poses
+ 备注: 12 pages
+
+ 点击查看摘要
+ Abstract:Processing long contexts poses a significant challenge for large language models (LLMs) due to their inherent context-window limitations and the computational burden of extensive key-value (KV) activations, which severely impact efficiency. For information-seeking tasks, full context perception is often unnecessary, as a query's information needs can dynamically range from localized details to a global perspective, depending on its complexity. However, existing methods struggle to adapt effectively to these dynamic information needs.
+In the paper, we propose a method for processing long-context information-seeking tasks via query-guided Activation Refilling (ACRE). ACRE constructs a Bi-layer KV Cache for long contexts, where the layer-1 (L1) cache compactly captures global information, and the layer-2 (L2) cache provides detailed and localized information. ACRE establishes a proxying relationship between the two caches, allowing the input query to attend to the L1 cache and dynamically refill it with relevant entries from the L2 cache. This mechanism integrates global understanding with query-specific local details, thus improving answer decoding. Experiments on a variety of long-context information-seeking datasets demonstrate ACRE's effectiveness, achieving improvements in both performance and efficiency.
+
Comments:
+12 pages
+Subjects:
+Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+Cite as:
+arXiv:2412.12486 [cs.CL]
+(or
+arXiv:2412.12486v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2412.12486
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 17. 【2412.12464】LLM is Knowledge Graph Reasoner: LLM's Intuition-aware Knowledge Graph Reasoning for Cold-start Sequential Recommendation
+ 链接:https://arxiv.org/abs/2412.12464
+ 作者:Keigo Sakurai,Ren Togo,Takahiro Ogawa,Miki Haseyama
+ 类目:Information Retrieval (cs.IR)
+ 关键词:accurate content information, Large Language Models, recommendation, relationships between entities, widely studied
+ 备注: Accepted to the 47th European Conference on Information Retrieval (ECIR2025)
+
+ 点击查看摘要
+ Abstract:Knowledge Graphs (KGs) represent relationships between entities in a graph structure and have been widely studied as promising tools for realizing recommendations that consider the accurate content information of items. However, traditional KG-based recommendation methods face fundamental challenges: insufficient consideration of temporal information and poor performance in cold-start scenarios. On the other hand, Large Language Models (LLMs) can be considered databases with a wealth of knowledge learned from the web data, and they have recently gained attention due to their potential application as recommendation systems. Although approaches that treat LLMs as recommendation systems can leverage LLMs' high recommendation literacy, their input token limitations make it impractical to consider the entire recommendation domain dataset and result in scalability issues. To address these challenges, we propose a LLM's Intuition-aware Knowledge graph Reasoning model (LIKR). Our main idea is to treat LLMs as reasoners that output intuitive exploration strategies for KGs. To integrate the knowledge of LLMs and KGs, we trained a recommendation agent through reinforcement learning using a reward function that integrates different recommendation strategies, including LLM's intuition and KG embeddings. By incorporating temporal awareness through prompt engineering and generating textual representations of user preferences from limited interactions, LIKR can improve recommendation performance in cold-start scenarios. Furthermore, LIKR can avoid scalability issues by using KGs to represent recommendation domain datasets and limiting the LLM's output to KG exploration strategies. Experiments on real-world datasets demonstrate that our model outperforms state-of-the-art recommendation methods in cold-start sequential recommendation scenarios.
+
+
+
+ 18. 【2412.12459】LITA: An Efficient LLM-assisted Iterative Topic Augmentation Framework
+ 链接:https://arxiv.org/abs/2412.12459
+ 作者:Chia-Hsuan Chang,Jui-Tse Tsai,Yi-Hang Tsai,San-Yih Hwang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:uncovering thematic structures, uncovering thematic, thematic structures, struggle with specificity, specificity and coherence
+ 备注: Under Review
+
+ 点击查看摘要
+ Abstract:Topic modeling is widely used for uncovering thematic structures within text corpora, yet traditional models often struggle with specificity and coherence in domain-focused applications. Guided approaches, such as SeededLDA and CorEx, incorporate user-provided seed words to improve relevance but remain labor-intensive and static. Large language models (LLMs) offer potential for dynamic topic refinement and discovery, yet their application often incurs high API costs. To address these challenges, we propose the LLM-assisted Iterative Topic Augmentation framework (LITA), an LLM-assisted approach that integrates user-provided seeds with embedding-based clustering and iterative refinement. LITA identifies a small number of ambiguous documents and employs an LLM to reassign them to existing or new topics, minimizing API costs while enhancing topic quality. Experiments on two datasets across topic quality and clustering performance metrics demonstrate that LITA outperforms five baseline models, including LDA, SeededLDA, CorEx, BERTopic, and PromptTopic. Our work offers an efficient and adaptable framework for advancing topic modeling and text clustering.
+
+
+
+ 19. 【2412.12433】Refining Dimensions for Improving Clustering-based Cross-lingual Topic Models
+ 链接:https://arxiv.org/abs/2412.12433
+ 作者:Chia-Hsuan Chang,Tien-Yuan Huang,Yi-Hang Tsai,Chia-Ming Chang,San-Yih Hwang
+ 类目:Computation and Language (cs.CL); Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:Recent works, monolingual topic identification, topic models perform, contextualized representations, identification by introducing
+ 备注: Accepted to 18th BUCC Workshop at COLING 2025
+
+ 点击查看摘要
+ Abstract:Recent works in clustering-based topic models perform well in monolingual topic identification by introducing a pipeline to cluster the contextualized representations. However, the pipeline is suboptimal in identifying topics across languages due to the presence of language-dependent dimensions (LDDs) generated by multilingual language models. To address this issue, we introduce a novel, SVD-based dimension refinement component into the pipeline of the clustering-based topic model. This component effectively neutralizes the negative impact of LDDs, enabling the model to accurately identify topics across languages. Our experiments on three datasets demonstrate that the updated pipeline with the dimension refinement component generally outperforms other state-of-the-art cross-lingual topic models.
+
+
+
+ 20. 【2412.12330】Searching Personal Collections
+ 链接:https://arxiv.org/abs/2412.12330
+ 作者:Michael Bendersky,Donald Metzler,Marc Najork,Xuanhui Wang
+ 类目:Information Retrieval (cs.IR)
+ 关键词:personal document collections, Abstract, document collections, article describes, describes the history
+ 备注:
+
+ 点击查看摘要
+ Abstract:This article describes the history of information retrieval on personal document collections.
+
+
+
+ 21. 【2412.12322】RAG Playground: A Framework for Systematic Evaluation of Retrieval Strategies and Prompt Engineering in RAG Systems
+ 链接:https://arxiv.org/abs/2412.12322
+ 作者:Ioannis Papadimitriou,Ilias Gialampoukidis,Stefanos Vrochidis,Ioannis(Yiannis)Kompatsiaris
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Information Retrieval (cs.IR)
+ 关键词:present RAG Playground, Retrieval-Augmented Generation, RAG Playground, present RAG, Playground
+ 备注: Work In Progress
+
+ 点击查看摘要
+ Abstract:We present RAG Playground, an open-source framework for systematic evaluation of Retrieval-Augmented Generation (RAG) systems. The framework implements and compares three retrieval approaches: naive vector search, reranking, and hybrid vector-keyword search, combined with ReAct agents using different prompting strategies. We introduce a comprehensive evaluation framework with novel metrics and provide empirical results comparing different language models (Llama 3.1 and Qwen 2.5) across various retrieval configurations. Our experiments demonstrate significant performance improvements through hybrid search methods and structured self-evaluation prompting, achieving up to 72.7% pass rate on our multi-metric evaluation framework. The results also highlight the importance of prompt engineering in RAG systems, with our custom-prompted agents showing consistent improvements in retrieval accuracy and response quality.
+
+
+
+ 22. 【2412.12202】A multi-theoretical kernel-based approach to social network-based recommendation
+ 链接:https://arxiv.org/abs/2412.12202
+ 作者:Xin Li,Mengyue Wang,T.-P. Liang
+ 类目:ocial and Information Networks (cs.SI); Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:Recommender systems, component of e-commercewebsites, critical component, traditional recommender systems, social
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recommender systems are a critical component of e-commercewebsites. The rapid development of online social networking services provides an opportunity to explore social networks together with information used in traditional recommender systems, such as customer demographics, product characteristics, and transactions. It also provides more applications for recommender systems. To tackle this social network-based recommendation problem, previous studies generally built trust models in light of the social influence theory. This study inspects a spectrumof social network theories to systematicallymodel themultiple facets of a social network and infer user preferences. In order to effectively make use of these heterogonous theories, we take a kernel-based machine learning paradigm, design and select kernels describing individual similarities according to social network theories, and employ a non-linear multiple kernel learning algorithm to combine the kernels into a unified model. This design also enables us to consider multiple theories' interactions in assessing individual behaviors. We evaluate our proposed approach on a real-world movie review data set. The experiments show that our approach provides more accurate recommendations than trust-based methods and the collaborative filtering approach. Further analysis shows that kernels derived from contagion theory and homophily theory contribute a larger portion of the model.
+
+
+
+ 23. 【2412.12110】Enhancing the conformal predictability of context-aware recommendation systems by using Deep Autoencoders
+ 链接:https://arxiv.org/abs/2412.12110
+ 作者:Saloua Zammali,Siddhant Dutta,Sadok Ben Yahia
+ 类目:Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:Recommender Systems, collaborative filtering represents, field of Recommender, combining matrix factorization, neural collaborative filtering
+ 备注: 8 pages, 4 tables, 1 figure. Accepted at the 23rd IEEE/WIC International Conference on Web Intelligence and Intelligent Agent Technology
+
+ 点击查看摘要
+ Abstract:In the field of Recommender Systems (RS), neural collaborative filtering represents a significant milestone by combining matrix factorization and deep neural networks to achieve promising results. Traditional methods like matrix factorization often rely on linear models, limiting their capability to capture complex interactions between users, items, and contexts. This limitation becomes particularly evident with high-dimensional datasets due to their inability to capture relationships among users, items, and contextual factors. Unsupervised learning and dimension reduction tasks utilize autoencoders, neural network-based models renowned for their capacity to encode and decode data. Autoencoders learn latent representations of inputs, reducing dataset size while capturing complex patterns and features. In this paper, we introduce a framework that combines neural contextual matrix factorization with autoencoders to predict user ratings for items. We provide a comprehensive overview of the framework's design and implementation. To evaluate its performance, we conduct experiments on various real-world datasets and compare the results against state-of-the-art approaches. We also extend the concept of conformal prediction to prediction rating and introduce a Conformal Prediction Rating (CPR). For RS, we define the nonconformity score, a key concept of conformal prediction, and demonstrate that it satisfies the exchangeability property.
+
+
+
+ 24. 【2408.07045】ableGuard -- Securing Structured Unstructured Data
+ 链接:https://arxiv.org/abs/2408.07045
+ 作者:Anantha Sharma,Ajinkya Deshmukh
+ 类目:Cryptography and Security (cs.CR); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Information Retrieval (cs.IR); Machine Learning (cs.LG)
+ 关键词:data, critical challenge, increasing demand, TableGuard, obfuscation
+ 备注: 7 pages, 3 tables, 1 figure
+
+ 点击查看摘要
+ Abstract:With the increasing demand for data sharing across platforms and organizations, ensuring the privacy and security of sensitive information has become a critical challenge. This paper introduces "TableGuard". An innovative approach to data obfuscation tailored for relational databases. Building on the principles and techniques developed in prior work on context-sensitive obfuscation, TableGuard applies these methods to ensure that API calls return only obfuscated data, thereby safeguarding privacy when sharing data with third parties. TableGuard leverages advanced context-sensitive obfuscation techniques to replace sensitive data elements with contextually appropriate alternatives. By maintaining the relational integrity and coherence of the data, our approach mitigates the risks of cognitive dissonance and data leakage. We demonstrate the implementation of TableGuard using a BERT based transformer model, which identifies and obfuscates sensitive entities within relational tables. Our evaluation shows that TableGuard effectively balances privacy protection with data utility, minimizing information loss while ensuring that the obfuscated data remains functionally useful for downstream applications. The results highlight the importance of domain-specific obfuscation strategies and the role of context length in preserving data integrity. The implications of this research are significant for organizations that need to share data securely with external parties. TableGuard offers a robust framework for implementing privacy-preserving data sharing mechanisms, thereby contributing to the broader field of data privacy and security.
+
+
+计算机视觉
+
+ 1. 【2412.13195】CoMPaSS: Enhancing Spatial Understanding in Text-to-Image Diffusion Models
+ 链接:https://arxiv.org/abs/2412.13195
+ 作者:Gaoyang Zhang,Bingtao Fu,Qingnan Fan,Qi Zhang,Runxing Liu,Hong Gu,Huaqi Zhang,Xinguo Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:generating photorealistic images, render accurate spatial, diffusion models excel, photorealistic images, spatial
+ 备注: 18 pages, 11 figures
+
+ 点击查看摘要
+ Abstract:Text-to-image diffusion models excel at generating photorealistic images, but commonly struggle to render accurate spatial relationships described in text prompts. We identify two core issues underlying this common failure: 1) the ambiguous nature of spatial-related data in existing datasets, and 2) the inability of current text encoders to accurately interpret the spatial semantics of input descriptions. We address these issues with CoMPaSS, a versatile training framework that enhances spatial understanding of any T2I diffusion model. CoMPaSS solves the ambiguity of spatial-related data with the Spatial Constraints-Oriented Pairing (SCOP) data engine, which curates spatially-accurate training data through a set of principled spatial constraints. To better exploit the curated high-quality spatial priors, CoMPaSS further introduces a Token ENcoding ORdering (TENOR) module to allow better exploitation of high-quality spatial priors, effectively compensating for the shortcoming of text encoders. Extensive experiments on four popular open-weight T2I diffusion models covering both UNet- and MMDiT-based architectures demonstrate the effectiveness of CoMPaSS by setting new state-of-the-arts with substantial relative gains across well-known benchmarks on spatial relationships generation, including VISOR (+98%), T2I-CompBench Spatial (+67%), and GenEval Position (+131%). Code will be available at this https URL.
+
+
+
+ 2. 【2412.13194】Proposer-Agent-Evaluator(PAE): Autonomous Skill Discovery For Foundation Model Internet Agents
+ 链接:https://arxiv.org/abs/2412.13194
+ 作者:Yifei Zhou,Qianlan Yang,Kaixiang Lin,Min Bai,Xiong Zhou,Yu-Xiong Wang,Sergey Levine,Erran Li
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:rapidly advanced, broadly capable, capable and goal-directed, household humanoid, generalization capability
+ 备注:
+
+ 点击查看摘要
+ Abstract:The vision of a broadly capable and goal-directed agent, such as an Internet-browsing agent in the digital world and a household humanoid in the physical world, has rapidly advanced, thanks to the generalization capability of foundation models. Such a generalist agent needs to have a large and diverse skill repertoire, such as finding directions between two travel locations and buying specific items from the Internet. If each skill needs to be specified manually through a fixed set of human-annotated instructions, the agent's skill repertoire will necessarily be limited due to the quantity and diversity of human-annotated instructions. In this work, we address this challenge by proposing Proposer-Agent-Evaluator, an effective learning system that enables foundation model agents to autonomously discover and practice skills in the wild. At the heart of PAE is a context-aware task proposer that autonomously proposes tasks for the agent to practice with context information of the environment such as user demos or even just the name of the website itself for Internet-browsing agents. Then, the agent policy attempts those tasks with thoughts and actual grounded operations in the real world with resulting trajectories evaluated by an autonomous VLM-based success evaluator. The success evaluation serves as the reward signal for the agent to refine its policies through RL. We validate PAE on challenging vision-based web navigation, using both real-world and self-hosted websites from WebVoyager and this http URL the best of our knowledge, this work represents the first effective learning system to apply autonomous task proposal with RL for agents that generalizes real-world human-annotated benchmarks with SOTA performances. Our open-source checkpoints and code can be found in this https URL
+
+
+
+ 3. 【2412.13193】GaussTR: Foundation Model-Aligned Gaussian Transformer for Self-Supervised 3D Spatial Understanding
+ 链接:https://arxiv.org/abs/2412.13193
+ 作者:Haoyi Jiang,Liu Liu,Tianheng Cheng,Xinjie Wang,Tianwei Lin,Zhizhong Su,Wenyu Liu,Xinggang Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:comprehensive semantic cognition, Semantic Occupancy Prediction, comprehensive semantic, semantic cognition, surrounding environments
+ 备注:
+
+ 点击查看摘要
+ Abstract:3D Semantic Occupancy Prediction is fundamental for spatial understanding as it provides a comprehensive semantic cognition of surrounding environments. However, prevalent approaches primarily rely on extensive labeled data and computationally intensive voxel-based modeling, restricting the scalability and generalizability of 3D representation learning. In this paper, we introduce GaussTR, a novel Gaussian Transformer that leverages alignment with foundation models to advance self-supervised 3D spatial understanding. GaussTR adopts a Transformer architecture to predict sparse sets of 3D Gaussians that represent scenes in a feed-forward manner. Through aligning rendered Gaussian features with diverse knowledge from pre-trained foundation models, GaussTR facilitates the learning of versatile 3D representations and enables open-vocabulary occupancy prediction without explicit annotations. Empirical evaluations on the Occ3D-nuScenes dataset showcase GaussTR's state-of-the-art zero-shot performance, achieving 11.70 mIoU while reducing training duration by approximately 50%. These experimental results highlight the significant potential of GaussTR for scalable and holistic 3D spatial understanding, with promising implications for autonomous driving and embodied agents. Code is available at this https URL.
+
+
+
+ 4. 【2412.13190】MotionBridge: Dynamic Video Inbetweening with Flexible Controls
+ 链接:https://arxiv.org/abs/2412.13190
+ 作者:Maham Tanveer,Yang Zhou,Simon Niklaus,Ali Mahdavi Amiri,Hao Zhang,Krishna Kumar Singh,Nanxuan Zhao
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:long video synthesis, generating plausible, plausible and smooth, smooth transitions, essential tool
+ 备注:
+
+ 点击查看摘要
+ Abstract:By generating plausible and smooth transitions between two image frames, video inbetweening is an essential tool for video editing and long video synthesis. Traditional works lack the capability to generate complex large motions. While recent video generation techniques are powerful in creating high-quality results, they often lack fine control over the details of intermediate frames, which can lead to results that do not align with the creative mind. We introduce MotionBridge, a unified video inbetweening framework that allows flexible controls, including trajectory strokes, keyframes, masks, guide pixels, and text. However, learning such multi-modal controls in a unified framework is a challenging task. We thus design two generators to extract the control signal faithfully and encode feature through dual-branch embedders to resolve ambiguities. We further introduce a curriculum training strategy to smoothly learn various controls. Extensive qualitative and quantitative experiments have demonstrated that such multi-modal controls enable a more dynamic, customizable, and contextually accurate visual narrative.
+
+
+
+ 5. 【2412.13188】StreetCrafter: Street View Synthesis with Controllable Video Diffusion Models
+ 链接:https://arxiv.org/abs/2412.13188
+ 作者:Yunzhi Yan,Zhen Xu,Haotong Lin,Haian Jin,Haoyu Guo,Yida Wang,Kun Zhan,Xianpeng Lang,Hujun Bao,Xiaowei Zhou,Sida Peng
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:vehicle sensor data, photorealistic view synthesis, sensor data, paper aims, aims to tackle
+ 备注: Project page: [this https URL](https://zju3dv.github.io/street_crafter)
+
+ 点击查看摘要
+ Abstract:This paper aims to tackle the problem of photorealistic view synthesis from vehicle sensor data. Recent advancements in neural scene representation have achieved notable success in rendering high-quality autonomous driving scenes, but the performance significantly degrades as the viewpoint deviates from the training trajectory. To mitigate this problem, we introduce StreetCrafter, a novel controllable video diffusion model that utilizes LiDAR point cloud renderings as pixel-level conditions, which fully exploits the generative prior for novel view synthesis, while preserving precise camera control. Moreover, the utilization of pixel-level LiDAR conditions allows us to make accurate pixel-level edits to target scenes. In addition, the generative prior of StreetCrafter can be effectively incorporated into dynamic scene representations to achieve real-time rendering. Experiments on Waymo Open Dataset and PandaSet demonstrate that our model enables flexible control over viewpoint changes, enlarging the view synthesis regions for satisfying rendering, which outperforms existing methods.
+
+
+
+ 6. 【2412.13187】HandsOnVLM: Vision-Language Models for Hand-Object Interaction Prediction
+ 链接:https://arxiv.org/abs/2412.13187
+ 作者:Chen Bao,Jiarui Xu,Xiaolong Wang,Abhinav Gupta,Homanga Bharadhwaj
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:colloquial task specifications, predict future interaction, form of natural, Vanilla Hand Prediction, hand
+ 备注: Preprint. Under Review
+
+ 点击查看摘要
+ Abstract:How can we predict future interaction trajectories of human hands in a scene given high-level colloquial task specifications in the form of natural language? In this paper, we extend the classic hand trajectory prediction task to two tasks involving explicit or implicit language queries. Our proposed tasks require extensive understanding of human daily activities and reasoning abilities about what should be happening next given cues from the current scene. We also develop new benchmarks to evaluate the proposed two tasks, Vanilla Hand Prediction (VHP) and Reasoning-Based Hand Prediction (RBHP). We enable solving these tasks by integrating high-level world knowledge and reasoning capabilities of Vision-Language Models (VLMs) with the auto-regressive nature of low-level ego-centric hand trajectories. Our model, HandsOnVLM is a novel VLM that can generate textual responses and produce future hand trajectories through natural-language conversations. Our experiments show that HandsOnVLM outperforms existing task-specific methods and other VLM baselines on proposed tasks, and demonstrates its ability to effectively utilize world knowledge for reasoning about low-level human hand trajectories based on the provided context. Our website contains code and detailed video results \url{this https URL}
+
+
+
+ 7. 【2412.13185】Move-in-2D: 2D-Conditioned Human Motion Generation
+ 链接:https://arxiv.org/abs/2412.13185
+ 作者:Hsin-Ping Huang,Yang Zhou,Jui-Hsien Wang,Difan Liu,Feng Liu,Ming-Hsuan Yang,Zhan Xu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Generating realistic human, Generating realistic, motion, human motion, control signal
+ 备注: Project page: [this https URL](https://hhsinping.github.io/Move-in-2D/)
+
+ 点击查看摘要
+ Abstract:Generating realistic human videos remains a challenging task, with the most effective methods currently relying on a human motion sequence as a control signal. Existing approaches often use existing motion extracted from other videos, which restricts applications to specific motion types and global scene matching. We propose Move-in-2D, a novel approach to generate human motion sequences conditioned on a scene image, allowing for diverse motion that adapts to different scenes. Our approach utilizes a diffusion model that accepts both a scene image and text prompt as inputs, producing a motion sequence tailored to the scene. To train this model, we collect a large-scale video dataset featuring single-human activities, annotating each video with the corresponding human motion as the target output. Experiments demonstrate that our method effectively predicts human motion that aligns with the scene image after projection. Furthermore, we show that the generated motion sequence improves human motion quality in video synthesis tasks.
+
+
+
+ 8. 【2412.13183】Real-time Free-view Human Rendering from Sparse-view RGB Videos using Double Unprojected Textures
+ 链接:https://arxiv.org/abs/2412.13183
+ 作者:Guoxing Sun,Rishabh Dabral,Heming Zhu,Pascal Fua,Christian Theobalt,Marc Habermann
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:tight time budget, challenging task due, sparse-view RGB inputs, sparse-view RGB, time budget
+ 备注: Project page: [this https URL](https://vcai.mpi-inf.mpg.de/projects/DUT/)
+
+ 点击查看摘要
+ Abstract:Real-time free-view human rendering from sparse-view RGB inputs is a challenging task due to the sensor scarcity and the tight time budget. To ensure efficiency, recent methods leverage 2D CNNs operating in texture space to learn rendering primitives. However, they either jointly learn geometry and appearance, or completely ignore sparse image information for geometry estimation, significantly harming visual quality and robustness to unseen body poses. To address these issues, we present Double Unprojected Textures, which at the core disentangles coarse geometric deformation estimation from appearance synthesis, enabling robust and photorealistic 4K rendering in real-time. Specifically, we first introduce a novel image-conditioned template deformation network, which estimates the coarse deformation of the human template from a first unprojected texture. This updated geometry is then used to apply a second and more accurate texture unprojection. The resulting texture map has fewer artifacts and better alignment with input views, which benefits our learning of finer-level geometry and appearance represented by Gaussian splats. We validate the effectiveness and efficiency of the proposed method in quantitative and qualitative experiments, which significantly surpasses other state-of-the-art methods.
+
+
+
+ 9. 【2412.13180】Feather the Throttle: Revisiting Visual Token Pruning for Vision-Language Model Acceleration
+ 链接:https://arxiv.org/abs/2412.13180
+ 作者:Mark Endo,Xiaohan Wang,Serena Yeung-Levy
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:accelerating Vision-Language Models, Vision-Language Models show, highly compressing visual, compressing visual information, Recent works
+ 备注: Project page: [this https URL](https://web.stanford.edu/~markendo/projects/feather.html)
+
+ 点击查看摘要
+ Abstract:Recent works on accelerating Vision-Language Models show that strong performance can be maintained across a variety of vision-language tasks despite highly compressing visual information. In this work, we examine the popular acceleration approach of early pruning of visual tokens inside the language model and find that its strong performance across many tasks is not due to an exceptional ability to compress visual information, but rather the benchmarks' limited ability to assess fine-grained visual capabilities. Namely, we demonstrate a core issue with the acceleration approach where most tokens towards the top of the image are pruned away. Yet, this issue is only reflected in performance for a small subset of tasks such as localization. For the other evaluated tasks, strong performance is maintained with the flawed pruning strategy. Noting the limited visual capabilities of the studied acceleration technique, we propose FEATHER (Fast and Effective Acceleration wiTH Ensemble cRiteria), a straightforward approach that (1) resolves the identified issue with early-layer pruning, (2) incorporates uniform sampling to ensure coverage across all image regions, and (3) applies pruning in two stages to allow the criteria to become more effective at a later layer while still achieving significant speedup through early-layer pruning. With comparable computational savings, we find that FEATHER has more than $5\times$ performance improvement on the vision-centric localization benchmarks compared to the original acceleration approach.
+
+
+
+ 10. 【2412.13179】A Pipeline and NIR-Enhanced Dataset for Parking Lot Segmentation
+ 链接:https://arxiv.org/abs/2412.13179
+ 作者:Shirin Qiam,Saipraneeth Devunuri,Lewis J. Lehe
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Discussions of minimum, minimum parking requirement, parking requirement policies, parking lots, construct manually
+ 备注: 8 pages, 12 figures, 2 tables, This is the accepted camera-ready version of the paper to appear in WACV 2025
+
+ 点击查看摘要
+ Abstract:Discussions of minimum parking requirement policies often include maps of parking lots, which are time consuming to construct manually. Open source datasets for such parking lots are scarce, particularly for US cities. This paper introduces the idea of using Near-Infrared (NIR) channels as input and several post-processing techniques to improve the prediction of off-street surface parking lots using satellite imagery. We constructed two datasets with 12,617 image-mask pairs each: one with 3-channel (RGB) and another with 4-channel (RGB + NIR). The datasets were used to train five deep learning models (OneFormer, Mask2Former, SegFormer, DeepLabV3, and FCN) for semantic segmentation, classifying images to differentiate between parking and non-parking pixels. Our results demonstrate that the NIR channel improved accuracy because parking lots are often surrounded by grass, even though the NIR channel needed to be upsampled from a lower resolution. Post-processing including eliminating erroneous holes, simplifying edges, and removing road and building footprints further improved the accuracy. Best model, OneFormer trained on 4-channel input and paired with post-processing techniques achieves a mean Intersection over Union (mIoU) of 84.9 percent and a pixel-wise accuracy of 96.3 percent.
+
+
+
+ 11. 【2412.13176】NFL-BA: Improving Endoscopic SLAM with Near-Field Light Bundle Adjustment
+ 链接:https://arxiv.org/abs/2412.13176
+ 作者:Andrea Dunn Beltran,Daniel Rho,Marc Niethammer,Roni Sengupta
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Simultaneous Localization, Photometric Bundle Adjustment, enable autonomous navigation, Bundle Adjustment Loss, Lighting Bundle Adjustment
+ 备注:
+
+ 点击查看摘要
+ Abstract:Simultaneous Localization And Mapping (SLAM) from a monocular endoscopy video can enable autonomous navigation, guidance to unsurveyed regions, and 3D visualizations, which can significantly improve endoscopy experience for surgeons and patient outcomes. Existing dense SLAM algorithms often assume distant and static lighting and textured surfaces, and alternate between optimizing scene geometry and camera parameters by minimizing a photometric rendering loss, often called Photometric Bundle Adjustment. However, endoscopic environments exhibit dynamic near-field lighting due to the co-located light and camera moving extremely close to the surface, textureless surfaces, and strong specular reflections due to mucus layers. When not considered, these near-field lighting effects can cause significant performance reductions for existing SLAM algorithms from indoor/outdoor scenes when applied to endoscopy videos. To mitigate this problem, we introduce a new Near-Field Lighting Bundle Adjustment Loss $(L_{NFL-BA})$ that can also be alternatingly optimized, along with the Photometric Bundle Adjustment loss, such that the captured images' intensity variations match the relative distance and orientation between the surface and the co-located light and camera. We derive a general NFL-BA loss function for 3D Gaussian surface representations and demonstrate that adding $L_{NFL-BA}$ can significantly improve the tracking and mapping performance of two state-of-the-art 3DGS-SLAM systems, MonoGS (35% improvement in tracking, 48% improvement in mapping with predicted depth maps) and EndoGSLAM (22% improvement in tracking, marginal improvement in mapping with predicted depths), on the C3VD endoscopy dataset for colons. The project page is available at this https URL
+
+
+
+ 12. 【2412.13174】ORFormer: Occlusion-Robust Transformer for Accurate Facial Landmark Detection
+ 链接:https://arxiv.org/abs/2412.13174
+ 作者:Jui-Che Chiang,Hou-Ning Hu,Bo-Syuan Hou,Chia-Yu Tseng,Yu-Lun Liu,Min-Hung Chen,Yen-Yu Lin
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:facial landmark detection, gained significant progress, extreme lighting conditions, partially non-visible faces, landmark detection
+ 备注: WACV 2025
+
+ 点击查看摘要
+ Abstract:Although facial landmark detection (FLD) has gained significant progress, existing FLD methods still suffer from performance drops on partially non-visible faces, such as faces with occlusions or under extreme lighting conditions or poses. To address this issue, we introduce ORFormer, a novel transformer-based method that can detect non-visible regions and recover their missing features from visible parts. Specifically, ORFormer associates each image patch token with one additional learnable token called the messenger token. The messenger token aggregates features from all but its patch. This way, the consensus between a patch and other patches can be assessed by referring to the similarity between its regular and messenger embeddings, enabling non-visible region identification. Our method then recovers occluded patches with features aggregated by the messenger tokens. Leveraging the recovered features, ORFormer compiles high-quality heatmaps for the downstream FLD task. Extensive experiments show that our method generates heatmaps resilient to partial occlusions. By integrating the resultant heatmaps into existing FLD methods, our method performs favorably against the state of the arts on challenging datasets such as WFLW and COFW.
+
+
+
+ 13. 【2412.13173】Locate n' Rotate: Two-stage Openable Part Detection with Foundation Model Priors
+ 链接:https://arxiv.org/abs/2412.13173
+ 作者:Siqi Li,Xiaoxue Chen,Haoyu Cheng,Guyue Zhou,Hao Zhao,Guanzhong Tian
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Openable Part Detection, Openable Part, intelligent robotics, pulling a drawer, Transformer-based Openable Part
+ 备注: ACCV 2024 Oral, Project: [this https URL](https://github.com/lisiqi-zju/MOPD)
+
+ 点击查看摘要
+ Abstract:Detecting the openable parts of articulated objects is crucial for downstream applications in intelligent robotics, such as pulling a drawer. This task poses a multitasking challenge due to the necessity of understanding object categories and motion. Most existing methods are either category-specific or trained on specific datasets, lacking generalization to unseen environments and objects. In this paper, we propose a Transformer-based Openable Part Detection (OPD) framework named Multi-feature Openable Part Detection (MOPD) that incorporates perceptual grouping and geometric priors, outperforming previous methods in performance. In the first stage of the framework, we introduce a perceptual grouping feature model that provides perceptual grouping feature priors for openable part detection, enhancing detection results through a cross-attention mechanism. In the second stage, a geometric understanding feature model offers geometric feature priors for predicting motion parameters. Compared to existing methods, our proposed approach shows better performance in both detection and motion parameter prediction. Codes and models are publicly available at this https URL
+
+
+
+ 14. 【2412.13168】Lifting Scheme-Based Implicit Disentanglement of Emotion-Related Facial Dynamics in the Wild
+ 链接:https://arxiv.org/abs/2412.13168
+ 作者:Xingjian Wang,Li Chai
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:DFER methods, recognizing emotion-related expressions, Dynamic facial expression, DFER, encounters a significant
+ 备注: 14 pages, 5 figures
+
+ 点击查看摘要
+ Abstract:In-the-wild Dynamic facial expression recognition (DFER) encounters a significant challenge in recognizing emotion-related expressions, which are often temporally and spatially diluted by emotion-irrelevant expressions and global context respectively. Most of the prior DFER methods model tightly coupled spatiotemporal representations which may incorporate weakly relevant features, leading to information redundancy and emotion-irrelevant context bias. Several DFER methods have highlighted the significance of dynamic information, but utilize explicit manners to extract dynamic features with overly strong prior knowledge. In this paper, we propose a novel Implicit Facial Dynamics Disentanglement framework (IFDD). Through expanding wavelet lifting scheme to fully learnable framework, IFDD disentangles emotion-related dynamic information from emotion-irrelevant global context in an implicit manner, i.e., without exploit operations and external guidance. The disentanglement process of IFDD contains two stages, i.e., Inter-frame Static-dynamic Splitting Module (ISSM) for rough disentanglement estimation and Lifting-based Aggregation-Disentanglement Module (LADM) for further refinement. Specifically, ISSM explores inter-frame correlation to generate content-aware splitting indexes on-the-fly. We preliminarily utilize these indexes to split frame features into two groups, one with greater global similarity, and the other with more unique dynamic features. Subsequently, LADM first aggregates these two groups of features to obtain fine-grained global context features by an updater, and then disentangles emotion-related facial dynamic features from the global context by a predictor. Extensive experiments on in-the-wild datasets have demonstrated that IFDD outperforms prior supervised DFER methods with higher recognition accuracy and comparable efficiency.
+
+
+
+ 15. 【2412.13161】BanglishRev: A Large-Scale Bangla-English and Code-mixed Dataset of Product Reviews in E-Commerce
+ 链接:https://arxiv.org/abs/2412.13161
+ 作者:Mohammad Nazmush Shamael,Sabila Nawshin,Swakkhar Shatabda,Salekul Islam
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Bengali words written, largest e-commerce product, e-commerce reviews written, Bengali words, product review dataset
+ 备注:
+
+ 点击查看摘要
+ Abstract:This work presents the BanglishRev Dataset, the largest e-commerce product review dataset to date for reviews written in Bengali, English, a mixture of both and Banglish, Bengali words written with English alphabets. The dataset comprises of 1.74 million written reviews from 3.2 million ratings information collected from a total of 128k products being sold in online e-commerce platforms targeting the Bengali population. It includes an extensive array of related metadata for each of the reviews including the rating given by the reviewer, date the review was posted and date of purchase, number of likes, dislikes, response from the seller, images associated with the review etc. With sentiment analysis being the most prominent usage of review datasets, experimentation with a binary sentiment analysis model with the review rating serving as an indicator of positive or negative sentiment was conducted to evaluate the effectiveness of the large amount of data presented in BanglishRev for sentiment analysis tasks. A BanglishBERT model is trained on the data from BanglishRev with reviews being considered labeled positive if the rating is greater than 3 and negative if the rating is less than or equal to 3. The model is evaluated by being testing against a previously published manually annotated dataset for e-commerce reviews written in a mixture of Bangla, English and Banglish. The experimental model achieved an exceptional accuracy of 94\% and F1 score of 0.94, demonstrating the dataset's efficacy for sentiment analysis. Some of the intriguing patterns and observations seen within the dataset and future research directions where the dataset can be utilized is also discussed and explored. The dataset can be accessed through this https URL.
+
+
+
+ 16. 【2412.13156】S2S2: Semantic Stacking for Robust Semantic Segmentation in Medical Imaging
+ 链接:https://arxiv.org/abs/2412.13156
+ 作者:Yimu Pan,Sitao Zhang,Alison D. Gernand,Jeffery A. Goldstein,James Z. Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Robustness and generalizability, encountered during inference, generalizability in medical, hindered by scarcity, scarcity and limited
+ 备注: AAAI2025
+
+ 点击查看摘要
+ Abstract:Robustness and generalizability in medical image segmentation are often hindered by scarcity and limited diversity of training data, which stands in contrast to the variability encountered during inference. While conventional strategies -- such as domain-specific augmentation, specialized architectures, and tailored training procedures -- can alleviate these issues, they depend on the availability and reliability of domain knowledge. When such knowledge is unavailable, misleading, or improperly applied, performance may deteriorate. In response, we introduce a novel, domain-agnostic, add-on, and data-driven strategy inspired by image stacking in image denoising. Termed ``semantic stacking,'' our method estimates a denoised semantic representation that complements the conventional segmentation loss during training. This method does not depend on domain-specific assumptions, making it broadly applicable across diverse image modalities, model architectures, and augmentation techniques. Through extensive experiments, we validate the superiority of our approach in improving segmentation performance under diverse conditions. Code is available at this https URL.
+
+
+
+ 17. 【2412.13155】F-Bench: Rethinking Human Preference Evaluation Metrics for Benchmarking Face Generation, Customization, and Restoration
+ 链接:https://arxiv.org/abs/2412.13155
+ 作者:Lu Liu,Huiyu Duan,Qiang Hu,Liu Yang,Chunlei Cai,Tianxiao Ye,Huayu Liu,Xiaoyun Zhang,Guangtao Zhai
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Artificial intelligence generative, exhibit remarkable capabilities, Artificial intelligence, generative models exhibit, models exhibit remarkable
+ 备注:
+
+ 点击查看摘要
+ Abstract:Artificial intelligence generative models exhibit remarkable capabilities in content creation, particularly in face image generation, customization, and restoration. However, current AI-generated faces (AIGFs) often fall short of human preferences due to unique distortions, unrealistic details, and unexpected identity shifts, underscoring the need for a comprehensive quality evaluation framework for AIGFs. To address this need, we introduce FaceQ, a large-scale, comprehensive database of AI-generated Face images with fine-grained Quality annotations reflecting human preferences. The FaceQ database comprises 12,255 images generated by 29 models across three tasks: (1) face generation, (2) face customization, and (3) face restoration. It includes 32,742 mean opinion scores (MOSs) from 180 annotators, assessed across multiple dimensions: quality, authenticity, identity (ID) fidelity, and text-image correspondence. Using the FaceQ database, we establish F-Bench, a benchmark for comparing and evaluating face generation, customization, and restoration models, highlighting strengths and weaknesses across various prompts and evaluation dimensions. Additionally, we assess the performance of existing image quality assessment (IQA), face quality assessment (FQA), AI-generated content image quality assessment (AIGCIQA), and preference evaluation metrics, manifesting that these standard metrics are relatively ineffective in evaluating authenticity, ID fidelity, and text-image correspondence. The FaceQ database will be publicly available upon publication.
+
+
+
+ 18. 【2412.13152】Continuous Patient Monitoring with AI: Real-Time Analysis of Video in Hospital Care Settings
+ 链接:https://arxiv.org/abs/2412.13152
+ 作者:Paolo Gabriel,Peter Rehani,Tyler Troy,Tiffany Wyatt,Michael Choma,Narinder Singh
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:LookDeep Health, developed by LookDeep, study introduces, passive patient monitoring, patient
+ 备注: 21 pages, 9 figures, 3 tables, submitted to Frontiers in Imaging Imaging Applications (Research Topic) Deep Learning for Medical Imaging Applications for publication
+
+ 点击查看摘要
+ Abstract:This study introduces an AI-driven platform for continuous and passive patient monitoring in hospital settings, developed by LookDeep Health. Leveraging advanced computer vision, the platform provides real-time insights into patient behavior and interactions through video analysis, securely storing inference results in the cloud for retrospective evaluation. The dataset, compiled in collaboration with 11 hospital partners, encompasses over 300 high-risk fall patients and over 1,000 days of inference, enabling applications such as fall detection and safety monitoring for vulnerable patient populations. To foster innovation and reproducibility, an anonymized subset of this dataset is publicly available. The AI system detects key components in hospital rooms, including individual presence and role, furniture location, motion magnitude, and boundary crossings. Performance evaluation demonstrates strong accuracy in object detection (macro F1-score = 0.92) and patient-role classification (F1-score = 0.98), as well as reliable trend analysis for the "patient alone" metric (mean logistic regression accuracy = 0.82 \pm 0.15). These capabilities enable automated detection of patient isolation, wandering, or unsupervised movement-key indicators for fall risk and other adverse events. This work establishes benchmarks for validating AI-driven patient monitoring systems, highlighting the platform's potential to enhance patient safety and care by providing continuous, data-driven insights into patient behavior and interactions.
+
+
+
+ 19. 【2412.13140】Label Errors in the Tobacco3482 Dataset
+ 链接:https://arxiv.org/abs/2412.13140
+ 作者:Gordon Lim,Stefan Larson,Kevin Leach
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:document classification benchmark, widely used document, document classification, classification benchmark dataset, dataset
+ 备注: WACV VisionDocs Workshop 2025
+
+ 点击查看摘要
+ Abstract:Tobacco3482 is a widely used document classification benchmark dataset. However, our manual inspection of the entire dataset uncovers widespread ontological issues, especially large amounts of annotation label problems in the dataset. We establish data label guidelines and find that 11.7% of the dataset is improperly annotated and should either have an unknown label or a corrected label, and 16.7% of samples in the dataset have multiple valid labels. We then analyze the mistakes of a top-performing model and find that 35% of the model's mistakes can be directly attributed to these label issues, highlighting the inherent problems with using a noisily labeled dataset as a benchmark. Supplementary material, including dataset annotations and code, is available at this https URL.
+
+
+
+ 20. 【2412.13111】Motion-2-to-3: Leveraging 2D Motion Data to Boost 3D Motion Generation
+ 链接:https://arxiv.org/abs/2412.13111
+ 作者:Huaijin Pi,Ruoxi Guo,Zehong Shen,Qing Shuai,Zechen Hu,Zhumei Wang,Yajiao Dong,Ruizhen Hu,Taku Komura,Sida Peng,Xiaowei Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:computer game development, capturing significant attention, effortlessly generate intricate, virtual reality experiences, abstract text cues
+ 备注: Project page: [this https URL](https://zju3dv.github.io/Motion-2-to-3/)
+
+ 点击查看摘要
+ Abstract:Text-driven human motion synthesis is capturing significant attention for its ability to effortlessly generate intricate movements from abstract text cues, showcasing its potential for revolutionizing motion design not only in film narratives but also in virtual reality experiences and computer game development. Existing methods often rely on 3D motion capture data, which require special setups resulting in higher costs for data acquisition, ultimately limiting the diversity and scope of human motion. In contrast, 2D human videos offer a vast and accessible source of motion data, covering a wider range of styles and activities. In this paper, we explore leveraging 2D human motion extracted from videos as an alternative data source to improve text-driven 3D motion generation. Our approach introduces a novel framework that disentangles local joint motion from global movements, enabling efficient learning of local motion priors from 2D data. We first train a single-view 2D local motion generator on a large dataset of text-motion pairs. To enhance this model to synthesize 3D motion, we fine-tune the generator with 3D data, transforming it into a multi-view generator that predicts view-consistent local joint motion and root dynamics. Experiments on the HumanML3D dataset and novel text prompts demonstrate that our method efficiently utilizes 2D data, supporting realistic 3D human motion generation and broadening the range of motion types it supports. Our code will be made publicly available at this https URL.
+
+
+
+ 21. 【2412.13099】Accuracy Limits as a Barrier to Biometric System Security
+ 链接:https://arxiv.org/abs/2412.13099
+ 作者:Axel Durbet,Paul-Marie Grollemund,Pascal Lafourcade,Kevin Thiry-Atighehchi
+ 类目:Cryptography and Security (cs.CR); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Match Rate FMR, verification and identification, False Match Rate, identity verification, claimed identity
+ 备注:
+
+ 点击查看摘要
+ Abstract:Biometric systems are widely used for identity verification and identification, including authentication (i.e., one-to-one matching to verify a claimed identity) and identification (i.e., one-to-many matching to find a subject in a database). The matching process relies on measuring similarities or dissimilarities between a fresh biometric template and enrolled templates. The False Match Rate FMR is a key metric for assessing the accuracy and reliability of such systems. This paper analyzes biometric systems based on their FMR, with two main contributions. First, we explore untargeted attacks, where an adversary aims to impersonate any user within a database. We determine the number of trials required for an attacker to successfully impersonate a user and derive the critical population size (i.e., the maximum number of users in the database) required to maintain a given level of security. Furthermore, we compute the critical FMR value needed to ensure resistance against untargeted attacks as the database size increases. Second, we revisit the biometric birthday problem to evaluate the approximate and exact probabilities that two users in a database collide (i.e., can impersonate each other). Based on this analysis, we derive both the approximate critical population size and the critical FMR value needed to bound the likelihood of such collisions occurring with a given probability. These thresholds offer insights for designing systems that mitigate the risk of impersonation and collisions, particularly in large-scale biometric databases. Our findings indicate that current biometric systems fail to deliver sufficient accuracy to achieve an adequate security level against untargeted attacks, even in small-scale databases. Moreover, state-of-the-art systems face significant challenges in addressing the biometric birthday problem, especially as database sizes grow.
+
+
+
+ 22. 【2412.13096】Incremental Online Learning of Randomized Neural Network with Forward Regularization
+ 链接:https://arxiv.org/abs/2412.13096
+ 作者:Junda Wang,Minghui Hu,Ning Li,Abdulaziz Al-Ali,Ponnuthurai Nagaratnam Suganthan
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:neural networks suffers, deep neural networks, increasing memory usage, Randomized Neural Networks, hysteretic non-incremental updating
+ 备注:
+
+ 点击查看摘要
+ Abstract:Online learning of deep neural networks suffers from challenges such as hysteretic non-incremental updating, increasing memory usage, past retrospective retraining, and catastrophic forgetting. To alleviate these drawbacks and achieve progressive immediate decision-making, we propose a novel Incremental Online Learning (IOL) process of Randomized Neural Networks (Randomized NN), a framework facilitating continuous improvements to Randomized NN performance in restrictive online scenarios. Within the framework, we further introduce IOL with ridge regularization (-R) and IOL with forward regularization (-F). -R generates stepwise incremental updates without retrospective retraining and avoids catastrophic forgetting. Moreover, we substituted -R with -F as it enhanced precognition learning ability using semi-supervision and realized better online regrets to offline global experts compared to -R during IOL. The algorithms of IOL for Randomized NN with -R/-F on non-stationary batch stream were derived respectively, featuring recursive weight updates and variable learning rates. Additionally, we conducted a detailed analysis and theoretically derived relative cumulative regret bounds of the Randomized NN learners with -R/-F in IOL under adversarial assumptions using a novel methodology and presented several corollaries, from which we observed the superiority on online learning acceleration and regret bounds of employing -F in IOL. Finally, our proposed methods were rigorously examined across regression and classification tasks on diverse datasets, which distinctly validated the efficacy of IOL frameworks of Randomized NN and the advantages of forward regularization.
+
+
+
+ 23. 【2412.13081】Prompt Augmentation for Self-supervised Text-guided Image Manipulation
+ 链接:https://arxiv.org/abs/2412.13081
+ 作者:Rumeysa Bodur,Binod Bhattarai,Tae-Kyun Kim
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Text-guided image editing, editing finds applications, Text-guided image, finds applications, creative and practical
+ 备注:
+
+ 点击查看摘要
+ Abstract:Text-guided image editing finds applications in various creative and practical fields. While recent studies in image generation have advanced the field, they often struggle with the dual challenges of coherent image transformation and context preservation. In response, our work introduces prompt augmentation, a method amplifying a single input prompt into several target prompts, strengthening textual context and enabling localised image editing. Specifically, we use the augmented prompts to delineate the intended manipulation area. We propose a Contrastive Loss tailored to driving effective image editing by displacing edited areas and drawing preserved regions closer. Acknowledging the continuous nature of image manipulations, we further refine our approach by incorporating the similarity concept, creating a Soft Contrastive Loss. The new losses are incorporated to the diffusion model, demonstrating improved or competitive image editing results on public datasets and generated images over state-of-the-art approaches.
+
+
+
+ 24. 【2412.13079】Identifying Bias in Deep Neural Networks Using Image Transforms
+ 链接:https://arxiv.org/abs/2412.13079
+ 作者:Sai Teja Erukude,Akhil Joshi,Lior Shamir
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:past two decades, identify dataset bias, commonly used computational, computational tool, bias
+ 备注: Computers, published
+
+ 点击查看摘要
+ Abstract:CNNs have become one of the most commonly used computational tool in the past two decades. One of the primary downsides of CNNs is that they work as a ``black box", where the user cannot necessarily know how the image data are analyzed, and therefore needs to rely on empirical evaluation to test the efficacy of a trained CNN. This can lead to hidden biases that affect the performance evaluation of neural networks, but are difficult to identify. Here we discuss examples of such hidden biases in common and widely used benchmark datasets, and propose techniques for identifying dataset biases that can affect the standard performance evaluation metrics. One effective approach to identify dataset bias is to perform image classification by using merely blank background parts of the original images. However, in some situations a blank background in the images is not available, making it more difficult to separate foreground or contextual information from the bias. To overcome this, we propose a method to identify dataset bias without the need to crop background information from the images. That method is based on applying several image transforms to the original images, including Fourier transform, wavelet transforms, median filter, and their combinations. These transforms were applied to recover background bias information that CNNs use to classify images. This transformations affect the contextual visual information in a different manner than it affects the systemic background bias. Therefore, the method can distinguish between contextual information and the bias, and alert on the presence of background bias even without the need to separate sub-images parts from the blank background of the original images. Code used in the experiments is publicly available.
+
+
+
+ 25. 【2412.13061】VidTok: A Versatile and Open-Source Video Tokenizer
+ 链接:https://arxiv.org/abs/2412.13061
+ 作者:Anni Tang,Tianyu He,Junliang Guo,Xinle Cheng,Li Song,Jiang Bian
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Encoding video content, compact latent tokens, Encoding video, generation and understanding, pixel-level representations
+ 备注: Code Models: [this https URL](https://github.com/microsoft/VidTok)
+
+ 点击查看摘要
+ Abstract:Encoding video content into compact latent tokens has become a fundamental step in video generation and understanding, driven by the need to address the inherent redundancy in pixel-level representations. Consequently, there is a growing demand for high-performance, open-source video tokenizers as video-centric research gains prominence. We introduce VidTok, a versatile video tokenizer that delivers state-of-the-art performance in both continuous and discrete tokenizations. VidTok incorporates several key advancements over existing approaches: 1) model architecture such as convolutional layers and up/downsampling modules; 2) to address the training instability and codebook collapse commonly associated with conventional Vector Quantization (VQ), we integrate Finite Scalar Quantization (FSQ) into discrete video tokenization; 3) improved training strategies, including a two-stage training process and the use of reduced frame rates. By integrating these advancements, VidTok achieves substantial improvements over existing methods, demonstrating superior performance across multiple metrics, including PSNR, SSIM, LPIPS, and FVD, under standardized evaluation settings.
+
+
+
+ 26. 【2412.13058】CondiMen: Conditional Multi-Person Mesh Recovery
+ 链接:https://arxiv.org/abs/2412.13058
+ 作者:Brégier Romain,Baradel Fabien,Lucas Thomas,Galaaoui Salma,Armando Matthieu,Weinzaepfel Philippe,Rogez Grégory
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Multi-person human mesh, human mesh recovery, Multi-person human, mesh recovery, consists in detecting
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multi-person human mesh recovery (HMR) consists in detecting all individuals in a given input image, and predicting the body shape, pose, and 3D location for each detected person. The dominant approaches to this task rely on neural networks trained to output a single prediction for each detected individual. In contrast, we propose CondiMen, a method that outputs a joint parametric distribution over likely poses, body shapes, intrinsics and distances to the camera, using a Bayesian network. This approach offers several advantages. First, a probability distribution can handle some inherent ambiguities of this task -- such as the uncertainty between a person's size and their distance to the camera, or simply the loss of information when projecting 3D data onto the 2D image plane. Second, the output distribution can be combined with additional information to produce better predictions, by using e.g. known camera or body shape parameters, or by exploiting multi-view observations. Third, one can efficiently extract the most likely predictions from the output distribution, making our proposed approach suitable for real-time applications. Empirically we find that our model i) achieves performance on par with or better than the state-of-the-art, ii) captures uncertainties and correlations inherent in pose estimation and iii) can exploit additional information at test time, such as multi-view consistency or body shape priors. CondiMen spices up the modeling of ambiguity, using just the right ingredients on hand.
+
+
+
+ 27. 【2412.13050】Modality-Inconsistent Continual Learning of Multimodal Large Language Models
+ 链接:https://arxiv.org/abs/2412.13050
+ 作者:Weiguo Pian,Shijian Deng,Shentong Mo,Yunhui Guo,Yapeng Tian
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Sound (cs.SD); Audio and Speech Processing (eess.AS)
+ 关键词:Multimodal Large Language, Large Language Models, Multimodal Large, Large Language, scenario for Multimodal
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this paper, we introduce Modality-Inconsistent Continual Learning (MICL), a new continual learning scenario for Multimodal Large Language Models (MLLMs) that involves tasks with inconsistent modalities (image, audio, or video) and varying task types (captioning or question-answering). Unlike existing vision-only or modality-incremental settings, MICL combines modality and task type shifts, both of which drive catastrophic forgetting. To address these challenges, we propose MoInCL, which employs a Pseudo Targets Generation Module to mitigate forgetting caused by task type shifts in previously seen modalities. It also incorporates Instruction-based Knowledge Distillation to preserve the model's ability to handle previously learned modalities when new ones are introduced. We benchmark MICL using a total of six tasks and conduct experiments to validate the effectiveness of our proposed MoInCL. The experimental results highlight the superiority of MoInCL, showing significant improvements over representative and state-of-the-art continual learning baselines.
+
+
+
+ 28. 【2412.13047】EOGS: Gaussian Splatting for Earth Observation
+ 链接:https://arxiv.org/abs/2412.13047
+ 作者:Luca Savant Aira,Gabriele Facciolo,Thibaud Ehret
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:standard Gaussian splatting, demonstrating impressive, Gaussian splatting, Gaussian splatting framework, alternative to NeRF
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recently, Gaussian splatting has emerged as a strong alternative to NeRF, demonstrating impressive 3D modeling capabilities while requiring only a fraction of the training and rendering time. In this paper, we show how the standard Gaussian splatting framework can be adapted for remote sensing, retaining its high efficiency. This enables us to achieve state-of-the-art performance in just a few minutes, compared to the day-long optimization required by the best-performing NeRF-based Earth observation methods. The proposed framework incorporates remote-sensing improvements from EO-NeRF, such as radiometric correction and shadow modeling, while introducing novel components, including sparsity, view consistency, and opacity regularizations.
+
+
+
+ 29. 【2412.13026】NAVCON: A Cognitively Inspired and Linguistically Grounded Corpus for Vision and Language Navigation
+ 链接:https://arxiv.org/abs/2412.13026
+ 作者:Karan Wanchoo,Xiaoye Zuo,Hannah Gonzalez,Soham Dan,Georgios Georgakis,Dan Roth,Kostas Daniilidis,Eleni Miltsakaki
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:large-scale annotated Vision-Language, annotated Vision-Language Navigation, corpus built, popular datasets, built on top
+ 备注:
+
+ 点击查看摘要
+ Abstract:We present NAVCON, a large-scale annotated Vision-Language Navigation (VLN) corpus built on top of two popular datasets (R2R and RxR). The paper introduces four core, cognitively motivated and linguistically grounded, navigation concepts and an algorithm for generating large-scale silver annotations of naturally occurring linguistic realizations of these concepts in navigation instructions. We pair the annotated instructions with video clips of an agent acting on these instructions. NAVCON contains 236, 316 concept annotations for approximately 30, 0000 instructions and 2.7 million aligned images (from approximately 19, 000 instructions) showing what the agent sees when executing an instruction. To our knowledge, this is the first comprehensive resource of navigation concepts. We evaluated the quality of the silver annotations by conducting human evaluation studies on NAVCON samples. As further validation of the quality and usefulness of the resource, we trained a model for detecting navigation concepts and their linguistic realizations in unseen instructions. Additionally, we show that few-shot learning with GPT-4o performs well on this task using large-scale silver annotations of NAVCON.
+
+
+
+ 30. 【2412.13017】A New Adversarial Perspective for LiDAR-based 3D Object Detection
+ 链接:https://arxiv.org/abs/2412.13017
+ 作者:Shijun Zheng,Weiquan Liu,Yu Guo,Yu Zang,Siqi Shen,Cheng Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:driving scenarios, Autonomous vehicles, perception and decision-making, decision-making in driving, Autonomous
+ 备注: 11 pages, 7 figures, AAAI2025
+
+ 点击查看摘要
+ Abstract:Autonomous vehicles (AVs) rely on LiDAR sensors for environmental perception and decision-making in driving scenarios. However, ensuring the safety and reliability of AVs in complex environments remains a pressing challenge. To address this issue, we introduce a real-world dataset (ROLiD) comprising LiDAR-scanned point clouds of two random objects: water mist and smoke. In this paper, we introduce a novel adversarial perspective by proposing an attack framework that utilizes water mist and smoke to simulate environmental interference. Specifically, we propose a point cloud sequence generation method using a motion and content decomposition generative adversarial network named PCS-GAN to simulate the distribution of random objects. Furthermore, leveraging the simulated LiDAR scanning characteristics implemented with Range Image, we examine the effects of introducing random object perturbations at various positions on the target vehicle. Extensive experiments demonstrate that adversarial perturbations based on random objects effectively deceive vehicle detection and reduce the recognition rate of 3D object detection models.
+
+
+
+ 31. 【2412.13010】Measurement of Medial Elbow Joint Space using Landmark Detection
+ 链接:https://arxiv.org/abs/2412.13010
+ 作者:Shizuka Akahori,Shotaro Teruya,Pragyan Shrestha,Yuichi Yoshii,Ryuhei Michinobu,Satoshi Iizuka,Itaru Kitahara
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Ulnar Collateral Ligament, Collateral Ligament, Ulnar Collateral, diagnose Ulnar Collateral, early identification
+ 备注:
+
+ 点击查看摘要
+ Abstract:Ultrasound imaging of the medial elbow is crucial for the early identification of Ulnar Collateral Ligament (UCL) injuries. Specifically, measuring the elbow joint space in ultrasound images is used to assess the valgus instability of elbow. To automate this measurement, a precisely annotated dataset is necessary; however, no publicly available dataset has been proposed thus far. This study introduces a novel ultrasound medial elbow dataset for measuring joint space to diagnose Ulnar Collateral Ligament (UCL) injuries. The dataset comprises 4,201 medial elbow ultrasound images from 22 subjects, with landmark annotations on the humerus and ulna. The annotations are made precisely by the authors under the supervision of three orthopedic surgeons. We evaluated joint space measurement methods using our proposed dataset with several landmark detection approaches, including ViTPose, HRNet, PCT, YOLOv8, and U-Net. In addition, we propose using Shape Subspace (SS) for landmark refinement in heatmap-based landmark detection. The results show that the mean Euclidean distance error of joint space is 0.116 mm when using HRNet. Furthermore, the SS landmark refinement improves the mean absolute error of landmark positions by 0.010 mm with HRNet and by 0.103 mm with ViTPose on average. These highlight the potential for high-precision, real-time diagnosis of UCL injuries and associated risks, which could be leveraged in large-scale screening. Lastly, we demonstrate point-based segmentation of the humerus and ulna using the detected landmarks as input. The dataset will be made publicly available upon acceptance of this paper at: this https URL.
+
+
+
+ 32. 【2412.13006】What is YOLOv6? A Deep Insight into the Object Detection Model
+ 链接:https://arxiv.org/abs/2412.13006
+ 作者:Athulya Sundaresan Geetha
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:optimization techniques, design framework, work explores, object detection model, high-performance object detection
+ 备注:
+
+ 点击查看摘要
+ Abstract:This work explores the YOLOv6 object detection model in depth, concentrating on its design framework, optimization techniques, and detection capabilities. YOLOv6's core elements consist of the EfficientRep Backbone for robust feature extraction and the Rep-PAN Neck for seamless feature aggregation, ensuring high-performance object detection. Evaluated on the COCO dataset, YOLOv6-N achieves 37.5\% AP at 1187 FPS on an NVIDIA Tesla T4 GPU. YOLOv6-S reaches 45.0\% AP at 484 FPS, outperforming models like PPYOLOE-S, YOLOv5-S, YOLOX-S, and YOLOv8-S in the same class. Moreover, YOLOv6-M and YOLOv6-L also show better accuracy (50.0\% and 52.8\%) while maintaining comparable inference speeds to other detectors. With an upgraded backbone and neck structure, YOLOv6-L6 delivers cutting-edge accuracy in real-time.
+
+
+
+ 33. 【2412.12990】Future Aspects in Human Action Recognition: Exploring Emerging Techniques and Ethical Influences
+ 链接:https://arxiv.org/abs/2412.12990
+ 作者:Antonios Gasteratos,Stavros N. Moutsis,Konstantinos A. Tsintotas,Yiannis Aloimonos
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Emerging Technologies (cs.ET); Robotics (cs.RO)
+ 关键词:human-robot interaction frameworks, Visual-based human action, medical assistive technologies, human action recognition, surveillance systems
+ 备注: 2 pages, 1 figure, 40th Anniversary of the IEEE Conference on Robotics and Automation (ICRA@40), Rotterdam, Netherlands | September 23-26, 2024
+
+ 点击查看摘要
+ Abstract:Visual-based human action recognition can be found in various application fields, e.g., surveillance systems, sports analytics, medical assistive technologies, or human-robot interaction frameworks, and it concerns the identification and classification of individuals' activities within a video. Since actions typically occur over a sequence of consecutive images, it is particularly challenging due to the inclusion of temporal analysis, which introduces an extra layer of complexity. However, although multiple approaches try to handle temporal analysis, there are still difficulties because of their computational cost and lack of adaptability. Therefore, different types of vision data, containing transition information between consecutive images, provided by next-generation hardware sensors will guide the robotics community in tackling the problem of human action recognition. On the other hand, while there is a plethora of still-image datasets, that researchers can adopt to train new artificial intelligence models, videos representing human activities are of limited capabilities, e.g., small and unbalanced datasets or selected without control from multiple sources. To this end, generating new and realistic synthetic videos is possible since labeling is performed throughout the data creation process, while reinforcement learning techniques can permit the avoidance of considerable dataset dependence. At the same time, human factors' involvement raises ethical issues for the research community, as doubts and concerns about new technologies already exist.
+
+
+
+ 34. 【2412.12974】Attentive Eraser: Unleashing Diffusion Model's Object Removal Potential via Self-Attention Redirection Guidance
+ 链接:https://arxiv.org/abs/2412.12974
+ 作者:Wenhao Sun,Benlei Cui,Jingqun Tang,Xue-Mei Dong
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:pre-trained diffusion models, diffusion models, Attentive Eraser, shining brightly, pre-trained diffusion
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Recently, diffusion models have emerged as promising newcomers in the field of generative models, shining brightly in image generation. However, when employed for object removal tasks, they still encounter issues such as generating random artifacts and the incapacity to repaint foreground object areas with appropriate content after removal. To tackle these problems, we propose Attentive Eraser, a tuning-free method to empower pre-trained diffusion models for stable and effective object removal. Firstly, in light of the observation that the self-attention maps influence the structure and shape details of the generated images, we propose Attention Activation and Suppression (ASS), which re-engineers the self-attention mechanism within the pre-trained diffusion models based on the given mask, thereby prioritizing the background over the foreground object during the reverse generation process. Moreover, we introduce Self-Attention Redirection Guidance (SARG), which utilizes the self-attention redirected by ASS to guide the generation process, effectively removing foreground objects within the mask while simultaneously generating content that is both plausible and coherent. Experiments demonstrate the stability and effectiveness of Attentive Eraser in object removal across a variety of pre-trained diffusion models, outperforming even training-based methods. Furthermore, Attentive Eraser can be implemented in various diffusion model architectures and checkpoints, enabling excellent scalability. Code is available at this https URL.
+
+
+
+ 35. 【2412.12966】Fruit Deformity Classification through Single-Input and Multi-Input Architectures based on CNN Models using Real and Synthetic Images
+ 链接:https://arxiv.org/abs/2412.12966
+ 作者:Tommy D. Beltran,Raul J. Villao,Luis E. Chuquimarca,Boris X. Vintimilla,Sergio A. Velastin
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:convolutional neural network, present study focuses, Multi-Input architectures based, CNN models, Multi-Input architecture
+ 备注: 15 pages, 9 figures, CIARP 2024
+
+ 点击查看摘要
+ Abstract:The present study focuses on detecting the degree of deformity in fruits such as apples, mangoes, and strawberries during the process of inspecting their external quality, employing Single-Input and Multi-Input architectures based on convolutional neural network (CNN) models using sets of real and synthetic images. The datasets are segmented using the Segment Anything Model (SAM), which provides the silhouette of the fruits. Regarding the single-input architecture, the evaluation of the CNN models is performed only with real images, but a methodology is proposed to improve these results using a pre-trained model with synthetic images. In the Multi-Input architecture, branches with RGB images and fruit silhouettes are implemented as inputs for evaluating CNN models such as VGG16, MobileNetV2, and CIDIS. However, the results revealed that the Multi-Input architecture with the MobileNetV2 model was the most effective in identifying deformities in the fruits, achieving accuracies of 90\%, 94\%, and 92\% for apples, mangoes, and strawberries, respectively. In conclusion, the Multi-Input architecture with the MobileNetV2 model is the most accurate for classifying levels of deformity in fruits.
+
+
+
+ 36. 【2412.12949】Synthetic Data Generation for Anomaly Detection on Table Grapes
+ 链接:https://arxiv.org/abs/2412.12949
+ 作者:Ionut Marian Motoi,Valerio Belli,Alberto Carpineto,Daniele Nardi,Thomas Alessandro Ciarfuglia
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:maintaining yield quality, Early detection, plant health, critical for maintaining, maintaining yield
+ 备注:
+
+ 点击查看摘要
+ Abstract:Early detection of illnesses and pest infestations in fruit cultivation is critical for maintaining yield quality and plant health. Computer vision and robotics are increasingly employed for the automatic detection of such issues, particularly using data-driven solutions. However, the rarity of these problems makes acquiring and processing the necessary data to train such algorithms a significant obstacle. One solution to this scarcity is the generation of synthetic high-quality anomalous samples. While numerous methods exist for this task, most require highly trained individuals for setup.
+This work addresses the challenge of generating synthetic anomalies in an automatic fashion that requires only an initial collection of normal and anomalous samples from the user - a task that is straightforward for farmers. We demonstrate the approach in the context of table grape cultivation. Specifically, based on the observation that normal berries present relatively smooth surfaces, while defects result in more complex textures, we introduce a Dual-Canny Edge Detection (DCED) filter. This filter emphasizes the additional texture indicative of diseases, pest infestations, or other defects. Using segmentation masks provided by the Segment Anything Model, we then select and seamlessly blend anomalous berries onto normal ones. We show that the proposed dataset augmentation technique improves the accuracy of an anomaly classifier for table grapes and that the approach can be generalized to other fruit types.
+
Subjects:
+Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ACMclasses:
+I.4.6; I.5.4; J.3
+Cite as:
+arXiv:2412.12949 [cs.CV]
+(or
+arXiv:2412.12949v1 [cs.CV] for this version)
+https://doi.org/10.48550/arXiv.2412.12949
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 37. 【2412.12932】CoMT: A Novel Benchmark for Chain of Multi-modal Thought on Large Vision-Language Models
+ 链接:https://arxiv.org/abs/2412.12932
+ 作者:Zihui Cheng,Qiguang Chen,Jin Zhang,Hao Fei,Xiaocheng Feng,Wanxiang Che,Min Li,Libo Qin
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Large Vision-Language Models, recently demonstrated amazing, demonstrated amazing success, Large Vision-Language, Vision-Language Models
+ 备注: Accepted at AAAI 2025
+
+ 点击查看摘要
+ Abstract:Large Vision-Language Models (LVLMs) have recently demonstrated amazing success in multi-modal tasks, including advancements in Multi-modal Chain-of-Thought (MCoT) reasoning. Despite these successes, current benchmarks still follow a traditional paradigm with multi-modal input and text-modal output, which leads to significant drawbacks such as missing visual operations and vague expressions. Motivated by this, we introduce a novel Chain of Multi-modal Thought (CoMT) benchmark to address these limitations. Different from the traditional MCoT benchmark, CoMT requires both multi-modal input and multi-modal reasoning output, aiming to mimic human-like reasoning that inherently integrates visual operation. Specifically, CoMT consists of four categories: (1) Visual Creation, (2) Visual Deletion, (3) Visual Update, and (4) Visual Selection to comprehensively explore complex visual operations and concise expression in real scenarios. We evaluate various LVLMs and strategies on CoMT, revealing some key insights into the capabilities and limitations of the current approaches. We hope that CoMT can inspire more research on introducing multi-modal generation into the reasoning process.
+
+
+
+ 38. 【2412.12912】Unsupervised Region-Based Image Editing of Denoising Diffusion Models
+ 链接:https://arxiv.org/abs/2412.12912
+ 作者:Zixiang Li,Yue Song,Renshuai Tao,Xiaohong Jia,Yao Zhao,Wei Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:achieved remarkable success, space remains under-explored, latent space remains, latent space, remains under-explored
+ 备注:
+
+ 点击查看摘要
+ Abstract:Although diffusion models have achieved remarkable success in the field of image generation, their latent space remains under-explored. Current methods for identifying semantics within latent space often rely on external supervision, such as textual information and segmentation masks. In this paper, we propose a method to identify semantic attributes in the latent space of pre-trained diffusion models without any further training. By projecting the Jacobian of the targeted semantic region into a low-dimensional subspace which is orthogonal to the non-masked regions, our approach facilitates precise semantic discovery and control over local masked areas, eliminating the need for annotations. We conducted extensive experiments across multiple datasets and various architectures of diffusion models, achieving state-of-the-art performance. In particular, for some specific face attributes, the performance of our proposed method even surpasses that of supervised approaches, demonstrating its superior ability in editing local image properties.
+
+
+
+ 39. 【2412.12906】CATSplat: Context-Aware Transformer with Spatial Guidance for Generalizable 3D Gaussian Splatting from A Single-View Image
+ 链接:https://arxiv.org/abs/2412.12906
+ 作者:Wonseok Roh,Hwanhee Jung,Jong Wook Kim,Seunggwan Lee,Innfarn Yoo,Andreas Lugmayr,Seunggeun Chi,Karthik Ramani,Sangpil Kim
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:gained significant attention, Gaussian Splatting, feed-forward methods based, Splatting have gained, potential to reconstruct
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recently, generalizable feed-forward methods based on 3D Gaussian Splatting have gained significant attention for their potential to reconstruct 3D scenes using finite resources. These approaches create a 3D radiance field, parameterized by per-pixel 3D Gaussian primitives, from just a few images in a single forward pass. However, unlike multi-view methods that benefit from cross-view correspondences, 3D scene reconstruction with a single-view image remains an underexplored area. In this work, we introduce CATSplat, a novel generalizable transformer-based framework designed to break through the inherent constraints in monocular settings. First, we propose leveraging textual guidance from a visual-language model to complement insufficient information from a single image. By incorporating scene-specific contextual details from text embeddings through cross-attention, we pave the way for context-aware 3D scene reconstruction beyond relying solely on visual cues. Moreover, we advocate utilizing spatial guidance from 3D point features toward comprehensive geometric understanding under single-view settings. With 3D priors, image features can capture rich structural insights for predicting 3D Gaussians without multi-view techniques. Extensive experiments on large-scale datasets demonstrate the state-of-the-art performance of CATSplat in single-view 3D scene reconstruction with high-quality novel view synthesis.
+
+
+
+ 40. 【2412.12902】DoPTA: Improving Document Layout Analysis using Patch-Text Alignment
+ 链接:https://arxiv.org/abs/2412.12902
+ 作者:Nikitha SR,Tarun Ram Menta,Mausoom Sarkar
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:brought a significant, significant improvement, document, document image understanding, visual
+ 备注:
+
+ 点击查看摘要
+ Abstract:The advent of multimodal learning has brought a significant improvement in document AI. Documents are now treated as multimodal entities, incorporating both textual and visual information for downstream analysis. However, works in this space are often focused on the textual aspect, using the visual space as auxiliary information. While some works have explored pure vision based techniques for document image understanding, they require OCR identified text as input during inference, or do not align with text in their learning procedure. Therefore, we present a novel image-text alignment technique specially designed for leveraging the textual information in document images to improve performance on visual tasks. Our document encoder model DoPTA - trained with this technique demonstrates strong performance on a wide range of document image understanding tasks, without requiring OCR during inference. Combined with an auxiliary reconstruction objective, DoPTA consistently outperforms larger models, while using significantly lesser pre-training compute. DoPTA also sets new state-of-the art results on D4LA, and FUNSD, two challenging document visual analysis benchmarks.
+
+
+
+ 41. 【2412.12892】SAUGE: Taming SAM for Uncertainty-Aligned Multi-Granularity Edge Detection
+ 链接:https://arxiv.org/abs/2412.12892
+ 作者:Xing Liufu,Chaolei Tan,Xiaotong Lin,Yonggang Qi,Jinxuan Li,Jian-Fang Hu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Edge labels, intermediate SAM features, SAM, preferences of annotators, labels
+ 备注: Accepted to AAAI 2025
+
+ 点击查看摘要
+ Abstract:Edge labels are typically at various granularity levels owing to the varying preferences of annotators, thus handling the subjectivity of per-pixel labels has been a focal point for edge detection. Previous methods often employ a simple voting strategy to diminish such label uncertainty or impose a strong assumption of labels with a pre-defined distribution, e.g., Gaussian. In this work, we unveil that the segment anything model (SAM) provides strong prior knowledge to model the uncertainty in edge labels. Our key insight is that the intermediate SAM features inherently correspond to object edges at various granularities, which reflects different edge options due to uncertainty. Therefore, we attempt to align uncertainty with granularity by regressing intermediate SAM features from different layers to object edges at multi-granularity levels. In doing so, the model can fully and explicitly explore diverse ``uncertainties'' in a data-driven fashion. Specifically, we inject a lightweight module (~ 1.5% additional parameters) into the frozen SAM to progressively fuse and adapt its intermediate features to estimate edges from coarse to fine. It is crucial to normalize the granularity level of human edge labels to match their innate uncertainty. For this, we simply perform linear blending to the real edge labels at hand to create pseudo labels with varying granularities. Consequently, our uncertainty-aligned edge detector can flexibly produce edges at any desired granularity (including an optimal one). Thanks to SAM, our model uniquely demonstrates strong generalizability for cross-dataset edge detection. Extensive experimental results on BSDS500, Muticue and NYUDv2 validate our model's superiority.
+
+
+
+ 42. 【2412.12890】Suppressing Uncertainty in Gaze Estimation
+ 链接:https://arxiv.org/abs/2412.12890
+ 作者:Shijing Wang,Yaping Huang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:inconsistent eye movements, actual gaze points, gaze estimation manifests, low-quality images caused, gaze estimation
+ 备注: This paper has been accepted to AAAI 2024
+
+ 点击查看摘要
+ Abstract:Uncertainty in gaze estimation manifests in two aspects: 1) low-quality images caused by occlusion, blurriness, inconsistent eye movements, or even non-face images; 2) incorrect labels resulting from the misalignment between the labeled and actual gaze points during the annotation process. Allowing these uncertainties to participate in training hinders the improvement of gaze estimation. To tackle these challenges, in this paper, we propose an effective solution, named Suppressing Uncertainty in Gaze Estimation (SUGE), which introduces a novel triplet-label consistency measurement to estimate and reduce the uncertainties. Specifically, for each training sample, we propose to estimate a novel ``neighboring label'' calculated by a linearly weighted projection from the neighbors to capture the similarity relationship between image features and their corresponding labels, which can be incorporated with the predicted pseudo label and ground-truth label for uncertainty estimation. By modeling such triplet-label consistency, we can measure the qualities of both images and labels, and further largely reduce the negative effects of unqualified images and wrong labels through our designed sample weighting and label correction strategies. Experimental results on the gaze estimation benchmarks indicate that our proposed SUGE achieves state-of-the-art performance.
+
+
+
+ 43. 【2412.12888】ArtAug: Enhancing Text-to-Image Generation through Synthesis-Understanding Interaction
+ 链接:https://arxiv.org/abs/2412.12888
+ 作者:Zhongjie Duan,Qianyi Zhao,Cen Chen,Daoyuan Chen,Wenmeng Zhou,Yaliang Li,Yingda Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:significantly advanced image, models, advanced image synthesis, image synthesis models, emergence of diffusion
+ 备注: 18 pages, 8 figures
+
+ 点击查看摘要
+ Abstract:The emergence of diffusion models has significantly advanced image synthesis. The recent studies of model interaction and self-corrective reasoning approach in large language models offer new insights for enhancing text-to-image models. Inspired by these studies, we propose a novel method called ArtAug for enhancing text-to-image models in this paper. To the best of our knowledge, ArtAug is the first one that improves image synthesis models via model interactions with understanding models. In the interactions, we leverage human preferences implicitly learned by image understanding models to provide fine-grained suggestions for image synthesis models. The interactions can modify the image content to make it aesthetically pleasing, such as adjusting exposure, changing shooting angles, and adding atmospheric effects. The enhancements brought by the interaction are iteratively fused into the synthesis model itself through an additional enhancement module. This enables the synthesis model to directly produce aesthetically pleasing images without any extra computational cost. In the experiments, we train the ArtAug enhancement module on existing text-to-image models. Various evaluation metrics consistently demonstrate that ArtAug enhances the generative capabilities of text-to-image models without incurring additional computational costs. The source code and models will be released publicly.
+
+
+
+ 44. 【2412.12887】Learning Coarse-to-Fine Pruning of Graph Convolutional Networks for Skeleton-based Recognition
+ 链接:https://arxiv.org/abs/2412.12887
+ 作者:Hichem Sahbi
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:smallest magnitude, staple lightweight network, lightweight network design, Magnitude Pruning, staple lightweight
+ 备注:
+
+ 点击查看摘要
+ Abstract:Magnitude Pruning is a staple lightweight network design method which seeks to remove connections with the smallest magnitude. This process is either achieved in a structured or unstructured manner. While structured pruning allows reaching high efficiency, unstructured one is more flexible and leads to better accuracy, but this is achieved at the expense of low computational performance. In this paper, we devise a novel coarse-to-fine (CTF) method that gathers the advantages of structured and unstructured pruning while discarding their inconveniences to some extent. Our method relies on a novel CTF parametrization that models the mask of each connection as the Hadamard product involving four parametrizations which capture channel-wise, column-wise, row-wise and entry-wise pruning respectively. Hence, fine-grained pruning is enabled only when the coarse-grained one is disabled, and this leads to highly efficient networks while being effective. Extensive experiments conducted on the challenging task of skeleton-based recognition, using the standard SBU and FPHA datasets, show the clear advantage of our CTF approach against different baselines as well as the related work.
+
+
+
+ 45. 【2412.12877】MIVE: New Design and Benchmark for Multi-Instance Video Editing
+ 链接:https://arxiv.org/abs/2412.12877
+ 作者:Samuel Teodoro,Agus Gunawan,Soo Ye Kim,Jihyong Oh,Munchurl Kim
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:simple text prompts, Recent AI-based video, editing, text prompts, simple text
+ 备注: The first two authors contributed equally to this work. The last two authors are co-corresponding authors. Please visit our project page at [this https URL](https://kaist-viclab.github.io/mive-site/)
+
+ 点击查看摘要
+ Abstract:Recent AI-based video editing has enabled users to edit videos through simple text prompts, significantly simplifying the editing process. However, recent zero-shot video editing techniques primarily focus on global or single-object edits, which can lead to unintended changes in other parts of the video. When multiple objects require localized edits, existing methods face challenges, such as unfaithful editing, editing leakage, and lack of suitable evaluation datasets and metrics. To overcome these limitations, we propose a zero-shot $\textbf{M}$ulti-$\textbf{I}$nstance $\textbf{V}$ideo $\textbf{E}$diting framework, called MIVE. MIVE is a general-purpose mask-based framework, not dedicated to specific objects (e.g., people). MIVE introduces two key modules: (i) Disentangled Multi-instance Sampling (DMS) to prevent editing leakage and (ii) Instance-centric Probability Redistribution (IPR) to ensure precise localization and faithful editing. Additionally, we present our new MIVE Dataset featuring diverse video scenarios and introduce the Cross-Instance Accuracy (CIA) Score to evaluate editing leakage in multi-instance video editing tasks. Our extensive qualitative, quantitative, and user study evaluations demonstrate that MIVE significantly outperforms recent state-of-the-art methods in terms of editing faithfulness, accuracy, and leakage prevention, setting a new benchmark for multi-instance video editing. The project page is available at this https URL
+
+
+
+ 46. 【2412.12861】Dyn-HaMR: Recovering 4D Interacting Hand Motion from a Dynamic Camera
+ 链接:https://arxiv.org/abs/2412.12861
+ 作者:Zhengdi Yu,Stefanos Zafeiriou,Tolga Birdal
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:monocular videos recorded, monocular videos, monocular, hand, videos recorded
+ 备注: Project page is available at [this https URL](https://dyn-hamr.github.io/)
+
+ 点击查看摘要
+ Abstract:We propose Dyn-HaMR, to the best of our knowledge, the first approach to reconstruct 4D global hand motion from monocular videos recorded by dynamic cameras in the wild. Reconstructing accurate 3D hand meshes from monocular videos is a crucial task for understanding human behaviour, with significant applications in augmented and virtual reality (AR/VR). However, existing methods for monocular hand reconstruction typically rely on a weak perspective camera model, which simulates hand motion within a limited camera frustum. As a result, these approaches struggle to recover the full 3D global trajectory and often produce noisy or incorrect depth estimations, particularly when the video is captured by dynamic or moving cameras, which is common in egocentric scenarios. Our Dyn-HaMR consists of a multi-stage, multi-objective optimization pipeline, that factors in (i) simultaneous localization and mapping (SLAM) to robustly estimate relative camera motion, (ii) an interacting-hand prior for generative infilling and to refine the interaction dynamics, ensuring plausible recovery under (self-)occlusions, and (iii) hierarchical initialization through a combination of state-of-the-art hand tracking methods. Through extensive evaluations on both in-the-wild and indoor datasets, we show that our approach significantly outperforms state-of-the-art methods in terms of 4D global mesh recovery. This establishes a new benchmark for hand motion reconstruction from monocular video with moving cameras. Our project page is at this https URL.
+
+
+
+ 47. 【2412.12850】Boosting Fine-Grained Visual Anomaly Detection with Coarse-Knowledge-Aware Adversarial Learning
+ 链接:https://arxiv.org/abs/2412.12850
+ 作者:Qingqing Fang,Qinliang Su,Wenxi Lv,Wenchao Xu,Jianxing Yu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:unsupervised visual anomaly, reconstruction error map, reconstruct normal samples, visual anomaly detection, unsupervised visual
+ 备注: The paper is accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Many unsupervised visual anomaly detection methods train an auto-encoder to reconstruct normal samples and then leverage the reconstruction error map to detect and localize the anomalies. However, due to the powerful modeling and generalization ability of neural networks, some anomalies can also be well reconstructed, resulting in unsatisfactory detection and localization accuracy. In this paper, a small coarsely-labeled anomaly dataset is first collected. Then, a coarse-knowledge-aware adversarial learning method is developed to align the distribution of reconstructed features with that of normal features. The alignment can effectively suppress the auto-encoder's reconstruction ability on anomalies and thus improve the detection accuracy. Considering that anomalies often only occupy very small areas in anomalous images, a patch-level adversarial learning strategy is further developed. Although no patch-level anomalous information is available, we rigorously prove that by simply viewing any patch features from anomalous images as anomalies, the proposed knowledge-aware method can also align the distribution of reconstructed patch features with the normal ones. Experimental results on four medical datasets and two industrial datasets demonstrate the effectiveness of our method in improving the detection and localization performance.
+
+
+
+ 48. 【2412.12849】HyperGS: Hyperspectral 3D Gaussian Splatting
+ 链接:https://arxiv.org/abs/2412.12849
+ 作者:Christopher Thirgood,Oscar Mendez,Erin Chao Ling,Jon Storey,Simon Hadfield
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Gaussian Splatting, View Synthesis, Gaussian, Splatting, perform view synthesis
+ 备注:
+
+ 点击查看摘要
+ Abstract:We introduce HyperGS, a novel framework for Hyperspectral Novel View Synthesis (HNVS), based on a new latent 3D Gaussian Splatting (3DGS) technique. Our approach enables simultaneous spatial and spectral renderings by encoding material properties from multi-view 3D hyperspectral datasets. HyperGS reconstructs high-fidelity views from arbitrary perspectives with improved accuracy and speed, outperforming currently existing methods. To address the challenges of high-dimensional data, we perform view synthesis in a learned latent space, incorporating a pixel-wise adaptive density function and a pruning technique for increased training stability and efficiency. Additionally, we introduce the first HNVS benchmark, implementing a number of new baselines based on recent SOTA RGB-NVS techniques, alongside the small number of prior works on HNVS. We demonstrate HyperGS's robustness through extensive evaluation of real and simulated hyperspectral scenes with a 14db accuracy improvement upon previously published models.
+
+
+
+ 49. 【2412.12843】Efficient Event-based Semantic Segmentation with Spike-driven Lightweight Transformer-based Networks
+ 链接:https://arxiv.org/abs/2412.12843
+ 作者:Xiaxin Zhu,Fangming Guo,Xianlei Long,Qingyi Gu,Chao Chen,Fuqiang Gu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:high dynamic range, low power cost, Event-based semantic segmentation, event cameras, dynamic range
+ 备注: Submitted to IEEE ICRA 2025
+
+ 点击查看摘要
+ Abstract:Event-based semantic segmentation has great potential in autonomous driving and robotics due to the advantages of event cameras, such as high dynamic range, low latency, and low power cost. Unfortunately, current artificial neural network (ANN)-based segmentation methods suffer from high computational demands, the requirements for image frames, and massive energy consumption, limiting their efficiency and application on resource-constrained edge/mobile platforms. To address these problems, we introduce SLTNet, a spike-driven lightweight transformer-based network designed for event-based semantic segmentation. Specifically, SLTNet is built on efficient spike-driven convolution blocks (SCBs) to extract rich semantic features while reducing the model's parameters. Then, to enhance the long-range contextural feature interaction, we propose novel spike-driven transformer blocks (STBs) with binary mask operations. Based on these basic blocks, SLTNet employs a high-efficiency single-branch architecture while maintaining the low energy consumption of the Spiking Neural Network (SNN). Finally, extensive experiments on DDD17 and DSEC-Semantic datasets demonstrate that SLTNet outperforms state-of-the-art (SOTA) SNN-based methods by at least 7.30% and 3.30% mIoU, respectively, with extremely 5.48x lower energy consumption and 1.14x faster inference speed.
+
+
+
+ 50. 【2412.12833】FocusChat: Text-guided Long Video Understanding via Spatiotemporal Information Filtering
+ 链接:https://arxiv.org/abs/2412.12833
+ 作者:Zheng Cheng,Rendong Wang,Zhicheng Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:made significant progress, multi-modal large language, significant progress, made significant, large language models
+ 备注: 11 pages, 4 figures
+
+ 点击查看摘要
+ Abstract:Recently, multi-modal large language models have made significant progress. However, visual information lacking of guidance from the user's intention may lead to redundant computation and involve unnecessary visual noise, especially in long, untrimmed videos. To address this issue, we propose FocusChat, a text-guided multi-modal large language model (LLM) that emphasizes visual information correlated to the user's prompt. In detail, Our model first undergoes the semantic extraction module, which comprises a visual semantic branch and a text semantic branch to extract image and text semantics, respectively. The two branches are combined using the Spatial-Temporal Filtering Module (STFM). STFM enables explicit spatial-level information filtering and implicit temporal-level feature filtering, ensuring that the visual tokens are closely aligned with the user's query. It lowers the essential number of visual tokens inputted into the LLM. FocusChat significantly outperforms Video-LLaMA in zero-shot experiments, using an order of magnitude less training data with only 16 visual tokens occupied. It achieves results comparable to the state-of-the-art in few-shot experiments, with only 0.72M pre-training data.
+
+
+
+ 51. 【2412.12830】Differential Alignment for Domain Adaptive Object Detection
+ 链接:https://arxiv.org/abs/2412.12830
+ 作者:Xinyu He(1),Xinhui Li(1),Xiaojie Guo(1) ((1) College of Intelligence and Computing, Tianjin University, Tianjin, China)
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Domain adaptive object, object detector trained, labeled source-domain data, adaptive object detection, source-target feature alignment
+ 备注: 11 pages, 8 figures, accepted by aaai25
+
+ 点击查看摘要
+ Abstract:Domain adaptive object detection (DAOD) aims to generalize an object detector trained on labeled source-domain data to a target domain without annotations, the core principle of which is \emph{source-target feature alignment}. Typically, existing approaches employ adversarial learning to align the distributions of the source and target domains as a whole, barely considering the varying significance of distinct regions, say instances under different circumstances and foreground \emph{vs} background areas, during feature alignment. To overcome the shortcoming, we investigates a differential feature alignment strategy. Specifically, a prediction-discrepancy feedback instance alignment module (dubbed PDFA) is designed to adaptively assign higher weights to instances of higher teacher-student detection discrepancy, effectively handling heavier domain-specific information. Additionally, an uncertainty-based foreground-oriented image alignment module (UFOA) is proposed to explicitly guide the model to focus more on regions of interest. Extensive experiments on widely-used DAOD datasets together with ablation studies are conducted to demonstrate the efficacy of our proposed method and reveal its superiority over other SOTA alternatives. Our code is available at this https URL.
+
+
+
+ 52. 【2412.12829】2by2: Weakly-Supervised Learning for Global Action Segmentation
+ 链接:https://arxiv.org/abs/2412.12829
+ 作者:Elena Bueno-Benito,Mariella Dimiccoli
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:grouping frames capturing, poorly investigated task, global action segmentation, aiming at grouping, paper presents
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper presents a simple yet effective approach for the poorly investigated task of global action segmentation, aiming at grouping frames capturing the same action across videos of different activities. Unlike the case of videos depicting all the same activity, the temporal order of actions is not roughly shared among all videos, making the task even more challenging. We propose to use activity labels to learn, in a weakly-supervised fashion, action representations suitable for global action segmentation. For this purpose, we introduce a triadic learning approach for video pairs, to ensure intra-video action discrimination, as well as inter-video and inter-activity action association. For the backbone architecture, we use a Siamese network based on sparse transformers that takes as input video pairs and determine whether they belong to the same activity. The proposed approach is validated on two challenging benchmark datasets: Breakfast and YouTube Instructions, outperforming state-of-the-art methods.
+
+
+
+ 53. 【2412.12827】abSniper: Towards Accurate Table Detection Structure Recognition for Bank Statements
+ 链接:https://arxiv.org/abs/2412.12827
+ 作者:Abhishek Trivedi,Sourajit Mukherjee,Rajat Kumar Singh,Vani Agarwal,Sriranjani Ramakrishnan,Himanshu S. Bhatt
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:bank statements, underwriting decisions, required to assess, well-being for credit, credit rating
+ 备注:
+
+ 点击查看摘要
+ Abstract:Extraction of transaction information from bank statements is required to assess one's financial well-being for credit rating and underwriting decisions. Unlike other financial documents such as tax forms or financial statements, extracting the transaction descriptions from bank statements can provide a comprehensive and recent view into the cash flows and spending patterns. With multiple variations in layout and templates across several banks, extracting transactional level information from different table categories is an arduous task. Existing table structure recognition approaches produce sub optimal results for long, complex tables and are unable to capture all transactions accurately. This paper proposes TabSniper, a novel approach for efficient table detection, categorization and structure recognition from bank statements. The pipeline starts with detecting and categorizing tables of interest from the bank statements. The extracted table regions are then processed by the table structure recognition model followed by a post-processing module to transform the transactional data into a structured and standardised format. The detection and structure recognition architectures are based on DETR, fine-tuned with diverse bank statements along with additional feature enhancements. Results on challenging datasets demonstrate that TabSniper outperforms strong baselines and produces high-quality extraction of transaction information from bank and other financial documents across multiple layouts and templates.
+
+
+
+ 54. 【2412.12821】ComprehendEdit: A Comprehensive Dataset and Evaluation Framework for Multimodal Knowledge Editing
+ 链接:https://arxiv.org/abs/2412.12821
+ 作者:Yaohui Ma,Xiaopeng Hong,Shizhou Zhang,Huiyun Li,Zhilin Zhu,Wei Luo,Zhiheng Ma
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Large multimodal language, revolutionized natural language, natural language processing, multimodal language models, Large multimodal
+ 备注: Extended version for paper accepted to AAAI 2025. Project Page: [this https URL](https://github.com/yaohui120/ComprehendEdit)
+
+ 点击查看摘要
+ Abstract:Large multimodal language models (MLLMs) have revolutionized natural language processing and visual understanding, but often contain outdated or inaccurate information. Current multimodal knowledge editing evaluations are limited in scope and potentially biased, focusing on narrow tasks and failing to assess the impact on in-domain samples. To address these issues, we introduce ComprehendEdit, a comprehensive benchmark comprising eight diverse tasks from multiple datasets. We propose two novel metrics: Knowledge Generalization Index (KGI) and Knowledge Preservation Index (KPI), which evaluate editing effects on in-domain samples without relying on AI-synthetic samples. Based on insights from our framework, we establish Hierarchical In-Context Editing (HICE), a baseline method employing a two-stage approach that balances performance across all metrics. This study provides a more comprehensive evaluation framework for multimodal knowledge editing, reveals unique challenges in this field, and offers a baseline method demonstrating improved performance. Our work opens new perspectives for future research and provides a foundation for developing more robust and effective editing techniques for MLLMs. The ComprehendEdit benchmark and implementation code are available at this https URL.
+
+
+
+ 55. 【2412.12801】Multi-View Incremental Learning with Structured Hebbian Plasticity for Enhanced Fusion Efficiency
+ 链接:https://arxiv.org/abs/2412.12801
+ 作者:Yuhong Chen,Ailin Song,Huifeng Yin,Shuai Zhong,Fuhai Chen,Qi Xu,Shiping Wang,Mingkun Xu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:revolutionized human perception, rapid evolution, evolution of multimedia, multimedia technology, technology has revolutionized
+ 备注: 11 pages
+
+ 点击查看摘要
+ Abstract:The rapid evolution of multimedia technology has revolutionized human perception, paving the way for multi-view learning. However, traditional multi-view learning approaches are tailored for scenarios with fixed data views, falling short of emulating the intricate cognitive procedures of the human brain processing signals sequentially. Our cerebral architecture seamlessly integrates sequential data through intricate feed-forward and feedback mechanisms. In stark contrast, traditional methods struggle to generalize effectively when confronted with data spanning diverse domains, highlighting the need for innovative strategies that can mimic the brain's adaptability and dynamic integration capabilities. In this paper, we propose a bio-neurologically inspired multi-view incremental framework named MVIL aimed at emulating the brain's fine-grained fusion of sequentially arriving views. MVIL lies two fundamental modules: structured Hebbian plasticity and synaptic partition learning. The structured Hebbian plasticity reshapes the structure of weights to express the high correlation between view representations, facilitating a fine-grained fusion of view representations. Moreover, synaptic partition learning is efficient in alleviating drastic changes in weights and also retaining old knowledge by inhibiting partial synapses. These modules bionically play a central role in reinforcing crucial associations between newly acquired information and existing knowledge repositories, thereby enhancing the network's capacity for generalization. Experimental results on six benchmark datasets show MVIL's effectiveness over state-of-the-art methods.
+
+
+
+ 56. 【2412.12799】RCTrans: Radar-Camera Transformer via Radar Densifier and Sequential Decoder for 3D Object Detection
+ 链接:https://arxiv.org/abs/2412.12799
+ 作者:Yiheng Li,Yang Yang,Zhen Lei
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Radar Dense Encoder, named Radar-Camera Transformer, radar point clouds, radar modalities, Radar-Camera Transformer
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:In radar-camera 3D object detection, the radar point clouds are sparse and noisy, which causes difficulties in fusing camera and radar modalities. To solve this, we introduce a novel query-based detection method named Radar-Camera Transformer (RCTrans). Specifically, we first design a Radar Dense Encoder to enrich the sparse valid radar tokens, and then concatenate them with the image tokens. By doing this, we can fully explore the 3D information of each interest region and reduce the interference of empty tokens during the fusing stage. We then design a Pruning Sequential Decoder to predict 3D boxes based on the obtained tokens and random initialized queries. To alleviate the effect of elevation ambiguity in radar point clouds, we gradually locate the position of the object via a sequential fusion structure. It helps to get more precise and flexible correspondences between tokens and queries. A pruning training strategy is adopted in the decoder, which can save much time during inference and inhibit queries from losing their distinctiveness. Extensive experiments on the large-scale nuScenes dataset prove the superiority of our method, and we also achieve new state-of-the-art radar-camera 3D detection results. Our implementation is available at this https URL.
+
+
+
+ 57. 【2412.12798】ZoRI: Towards Discriminative Zero-Shot Remote Sensing Instance Segmentation
+ 链接:https://arxiv.org/abs/2412.12798
+ 作者:Shiqi Huang,Shuting He,Bihan Wen
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:sensing instance segmentation, Instance segmentation algorithms, remote sensing instance, remote sensing, Instance segmentation
+ 备注: AAAI 2025, code see [this https URL](https://github.com/HuangShiqi128/ZoRI)
+
+ 点击查看摘要
+ Abstract:Instance segmentation algorithms in remote sensing are typically based on conventional methods, limiting their application to seen scenarios and closed-set predictions. In this work, we propose a novel task called zero-shot remote sensing instance segmentation, aimed at identifying aerial objects that are absent from training data. Challenges arise when classifying aerial categories with high inter-class similarity and intra-class variance. Besides, the domain gap between vision-language models' pretraining datasets and remote sensing datasets hinders the zero-shot capabilities of the pretrained model when it is directly applied to remote sensing images. To address these challenges, we propose a $\textbf{Z}$ero-Sh$\textbf{o}$t $\textbf{R}$emote Sensing $\textbf{I}$nstance Segmentation framework, dubbed $\textbf{ZoRI}$. Our approach features a discrimination-enhanced classifier that uses refined textual embeddings to increase the awareness of class disparities. Instead of direct fine-tuning, we propose a knowledge-maintained adaptation strategy that decouples semantic-related information to preserve the pretrained vision-language alignment while adjusting features to capture remote sensing domain-specific visual cues. Additionally, we introduce a prior-injected prediction with cache bank of aerial visual prototypes to supplement the semantic richness of text embeddings and seamlessly integrate aerial representations, adapting to the remote sensing domain. We establish new experimental protocols and benchmarks, and extensive experiments convincingly demonstrate that ZoRI achieves the state-of-art performance on the zero-shot remote sensing instance segmentation task. Our code is available at this https URL.
+
+
+
+ 58. 【2412.12793】CRoF: CLIP-based Robust Few-shot Learning on Noisy Labels
+ 链接:https://arxiv.org/abs/2412.12793
+ 作者:Shizhuo Deng,Bowen Han,Jiaqi Chen,Hao Wang,Dongyue Chen,Tong Jia
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:threaten the robustness, inexact features, CLIP, Noisy labels threaten, FSL
+ 备注:
+
+ 点击查看摘要
+ Abstract:Noisy labels threaten the robustness of few-shot learning (FSL) due to the inexact features in a new domain. CLIP, a large-scale vision-language model, performs well in FSL on image-text embedding similarities, but it is susceptible to misclassification caused by noisy labels. How to enhance domain generalization of CLIP on noisy data within FSL tasks is a critical challenge. In this paper, we provide a novel view to mitigate the influence of noisy labels, CLIP-based Robust Few-shot learning (CRoF). CRoF is a general plug-in module for CLIP-based models. To avoid misclassification and confused label embedding, we design the few-shot task-oriented prompt generator to give more discriminative descriptions of each category. The proposed prompt achieves larger distances of inter-class textual embedding. Furthermore, rather than fully trusting zero-shot classification by CLIP, we fine-tune CLIP on noisy few-shot data in a new domain with a weighting strategy like label-smooth. The weights for multiple potentially correct labels consider the relationship between CLIP's prior knowledge and original label information to ensure reliability. Our multiple label loss function further supports robust training under this paradigm. Comprehensive experiments show that CRoF, as a plug-in, outperforms fine-tuned and vanilla CLIP models on different noise types and noise ratios.
+
+
+
+ 59. 【2412.12791】Implicit Location-Caption Alignment via Complementary Masking for Weakly-Supervised Dense Video Captioning
+ 链接:https://arxiv.org/abs/2412.12791
+ 作者:Shiping Ge,Qiang Chen,Zhiwei Jiang,Yafeng Yin,Liu Qin,Ziyao Chen,Qing Gu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Multimedia (cs.MM)
+ 关键词:Dense Video Captioning, Weakly-Supervised Dense Video, Dense Video, Weakly-Supervised Dense, event
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Weakly-Supervised Dense Video Captioning (WSDVC) aims to localize and describe all events of interest in a video without requiring annotations of event boundaries. This setting poses a great challenge in accurately locating the temporal location of event, as the relevant supervision is unavailable. Existing methods rely on explicit alignment constraints between event locations and captions, which involve complex event proposal procedures during both training and inference. To tackle this problem, we propose a novel implicit location-caption alignment paradigm by complementary masking, which simplifies the complex event proposal and localization process while maintaining effectiveness. Specifically, our model comprises two components: a dual-mode video captioning module and a mask generation module. The dual-mode video captioning module captures global event information and generates descriptive captions, while the mask generation module generates differentiable positive and negative masks for localizing the events. These masks enable the implicit alignment of event locations and captions by ensuring that captions generated from positively and negatively masked videos are complementary, thereby forming a complete video description. In this way, even under weak supervision, the event location and event caption can be aligned implicitly. Extensive experiments on the public datasets demonstrate that our method outperforms existing weakly-supervised methods and achieves competitive results compared to fully-supervised methods.
+
+
+
+ 60. 【2412.12788】RA-SGG: Retrieval-Augmented Scene Graph Generation Framework via Multi-Prototype Learning
+ 链接:https://arxiv.org/abs/2412.12788
+ 作者:Kanghoon Yoon,Kibum Kim,Jaehyung Jeon,Yeonjun In,Donghyun Kim,Chanyoung Park
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Scene Graph Generation, Graph Generation, Scene Graph, research has suffered, Retrieval-Augmented Scene Graph
+ 备注: 7 pages
+
+ 点击查看摘要
+ Abstract:Scene Graph Generation (SGG) research has suffered from two fundamental challenges: the long-tailed predicate distribution and semantic ambiguity between predicates. These challenges lead to a bias towards head predicates in SGG models, favoring dominant general predicates while overlooking fine-grained predicates. In this paper, we address the challenges of SGG by framing it as multi-label classification problem with partial annotation, where relevant labels of fine-grained predicates are missing. Under the new frame, we propose Retrieval-Augmented Scene Graph Generation (RA-SGG), which identifies potential instances to be multi-labeled and enriches the single-label with multi-labels that are semantically similar to the original label by retrieving relevant samples from our established memory bank. Based on augmented relations (i.e., discovered multi-labels), we apply multi-prototype learning to train our SGG model. Several comprehensive experiments have demonstrated that RA-SGG outperforms state-of-the-art baselines by up to 3.6% on VG and 5.9% on GQA, particularly in terms of F@K, showing that RA-SGG effectively alleviates the issue of biased prediction caused by the long-tailed distribution and semantic ambiguity of predicates.
+
+
+
+ 61. 【2412.12785】Activating Distributed Visual Region within LLMs for Efficient and Effective Vision-Language Training and Inference
+ 链接:https://arxiv.org/abs/2412.12785
+ 作者:Siyuan Wang,Dianyi Wang,Chengxing Zhou,Zejun Li,Zhihao Fan,Xuanjing Huang,Zhongyu Wei
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Large Vision-Language Models, Large Vision-Language, typically learn visual, learn visual capacity, visual instruction tuning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Vision-Language Models (LVLMs) typically learn visual capacity through visual instruction tuning, involving updates to both a projector and their LLM backbones. Drawing inspiration from the concept of visual region in the human brain, we investigate the existence of an analogous \textit{visual region} within LLMs that functions as a cognitive core, and explore the possibility of efficient training of LVLMs via selective layers tuning. We use Bunny-Llama-3-8B-V for detailed experiments and LLaVA-1.5-7B and LLaVA-1.5-13B for validation across a range of visual and textual tasks. Our findings reveal that selectively updating 25\% of LLMs layers, when sparsely and uniformly distributed, can preserve nearly 99\% of visual performance while maintaining or enhancing textual task results, and also effectively reducing training time. Based on this targeted training approach, we further propose a novel visual region-based pruning paradigm, removing non-critical layers outside the visual region, which can achieve minimal performance loss. This study offers an effective and efficient strategy for LVLM training and inference by activating a layer-wise visual region within LLMs, which is consistently effective across different models and parameter scales.
+
+
+
+ 62. 【2412.12782】Bidirectional Logits Tree: Pursuing Granularity Reconcilement in Fine-Grained Classification
+ 链接:https://arxiv.org/abs/2412.12782
+ 作者:Zhiguang Lu,Qianqian Xu,Shilong Bao,Zhiyong Yang,Qingming Huang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:fine-grained classification tasks, Granularity Competition, classification tasks, multi-granularity labels, paper addresses
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper addresses the challenge of Granularity Competition in fine-grained classification tasks, which arises due to the semantic gap between multi-granularity labels. Existing approaches typically develop independent hierarchy-aware models based on shared features extracted from a common base encoder. However, because coarse-grained levels are inherently easier to learn than finer ones, the base encoder tends to prioritize coarse feature abstractions, which impedes the learning of fine-grained features. To overcome this challenge, we propose a novel framework called the Bidirectional Logits Tree (BiLT) for Granularity Reconcilement. The key idea is to develop classifiers sequentially from the finest to the coarsest granularities, rather than parallelly constructing a set of classifiers based on the same input features. In this setup, the outputs of finer-grained classifiers serve as inputs for coarser-grained ones, facilitating the flow of hierarchical semantic information across different granularities. On top of this, we further introduce an Adaptive Intra-Granularity Difference Learning (AIGDL) approach to uncover subtle semantic differences between classes within the same granularity. Extensive experiments demonstrate the effectiveness of our proposed method.
+
+
+
+ 63. 【2412.12778】Rethinking Diffusion-Based Image Generators for Fundus Fluorescein Angiography Synthesis on Limited Data
+ 链接:https://arxiv.org/abs/2412.12778
+ 作者:Chengzhou Yu(South China University of Technology),Huihui Fang(Pazhou Laboratory),Hongqiu Wang(The Hong Kong University of Science and Technology (Guangzhou)),Ting Deng(South China University of Technology),Qing Du(South China University of Technology),Yanwu Xu(South China University of Technology),Weihua Yang(Shenzhen Eye Hospital)
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:offering unique advantages, tool in ophthalmology, unique advantages, critical tool, Fundus imaging
+ 备注: 15 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:Fundus imaging is a critical tool in ophthalmology, with different imaging modalities offering unique advantages. For instance, fundus fluorescein angiography (FFA) can accurately identify eye diseases. However, traditional invasive FFA involves the injection of sodium fluorescein, which can cause discomfort and risks. Generating corresponding FFA images from non-invasive fundus images holds significant practical value but also presents challenges. First, limited datasets constrain the performance and effectiveness of models. Second, previous studies have primarily focused on generating FFA for single diseases or single modalities, often resulting in poor performance for patients with various ophthalmic conditions. To address these issues, we propose a novel latent diffusion model-based framework, Diffusion, which introduces a fine-tuning protocol to overcome the challenge of limited medical data and unleash the generative capabilities of diffusion models. Furthermore, we designed a new approach to tackle the challenges of generating across different modalities and disease types. On limited datasets, our framework achieves state-of-the-art results compared to existing methods, offering significant potential to enhance ophthalmic diagnostics and patient care. Our code will be released soon to support further research in this field.
+
+
+
+ 64. 【2412.12774】A Framework for Critical Evaluation of Text-to-Image Models: Integrating Art Historical Analysis, Artistic Exploration, and Critical Prompt Engineering
+ 链接:https://arxiv.org/abs/2412.12774
+ 作者:Amalia Foka
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computers and Society (cs.CY)
+ 关键词:current technical metrics, art historical analysis, paper proposes, current technical, technical metrics
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper proposes a novel interdisciplinary framework for the critical evaluation of text-to-image models, addressing the limitations of current technical metrics and bias studies. By integrating art historical analysis, artistic exploration, and critical prompt engineering, the framework offers a more nuanced understanding of these models' capabilities and societal implications. Art historical analysis provides a structured approach to examine visual and symbolic elements, revealing potential biases and misrepresentations. Artistic exploration, through creative experimentation, uncovers hidden potentials and limitations, prompting critical reflection on the algorithms' assumptions. Critical prompt engineering actively challenges the model's assumptions, exposing embedded biases. Case studies demonstrate the framework's practical application, showcasing how it can reveal biases related to gender, race, and cultural representation. This comprehensive approach not only enhances the evaluation of text-to-image models but also contributes to the development of more equitable, responsible, and culturally aware AI systems.
+
+
+
+ 65. 【2412.12772】Optimize the Unseen -- Fast NeRF Cleanup with Free Space Prior
+ 链接:https://arxiv.org/abs/2412.12772
+ 作者:Leo Segre,Shai Avidan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Neural Radiance Fields, Neural Radiance, Radiance Fields, photometric reconstruction introduces, reconstruction introduces artifacts
+ 备注:
+
+ 点击查看摘要
+ Abstract:Neural Radiance Fields (NeRF) have advanced photorealistic novel view synthesis, but their reliance on photometric reconstruction introduces artifacts, commonly known as "floaters". These artifacts degrade novel view quality, especially in areas unseen by the training cameras. We present a fast, post-hoc NeRF cleanup method that eliminates such artifacts by enforcing our Free Space Prior, effectively minimizing floaters without disrupting the NeRF's representation of observed regions. Unlike existing approaches that rely on either Maximum Likelihood (ML) estimation to fit the data or a complex, local data-driven prior, our method adopts a Maximum-a-Posteriori (MAP) approach, selecting the optimal model parameters under a simple global prior assumption that unseen regions should remain empty. This enables our method to clean artifacts in both seen and unseen areas, enhancing novel view quality even in challenging scene regions. Our method is comparable with existing NeRF cleanup models while being 2.5x faster in inference time, requires no additional memory beyond the original NeRF, and achieves cleanup training in less than 30 seconds. Our code will be made publically available.
+
+
+
+ 66. 【2412.12771】Guided and Variance-Corrected Fusion with One-shot Style Alignment for Large-Content Image Generation
+ 链接:https://arxiv.org/abs/2412.12771
+ 作者:Shoukun Sun,Min Xian,Tiankai Yao,Fei Xu,Luca Capriotti
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:gaining increasing popularity, Producing large images, Producing large, small diffusion models, training large models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Producing large images using small diffusion models is gaining increasing popularity, as the cost of training large models could be prohibitive. A common approach involves jointly generating a series of overlapped image patches and obtaining large images by merging adjacent patches. However, results from existing methods often exhibit obvious artifacts, e.g., seams and inconsistent objects and styles. To address the issues, we proposed Guided Fusion (GF), which mitigates the negative impact from distant image regions by applying a weighted average to the overlapping regions. Moreover, we proposed Variance-Corrected Fusion (VCF), which corrects data variance at post-averaging, generating more accurate fusion for the Denoising Diffusion Probabilistic Model. Furthermore, we proposed a one-shot Style Alignment (SA), which generates a coherent style for large images by adjusting the initial input noise without adding extra computational burden. Extensive experiments demonstrated that the proposed fusion methods improved the quality of the generated image significantly. As a plug-and-play module, the proposed method can be widely applied to enhance other fusion-based methods for large image generation.
+
+
+
+ 67. 【2412.12766】owards a Training Free Approach for 3D Scene Editing
+ 链接:https://arxiv.org/abs/2412.12766
+ 作者:Vivek Madhavaram,Shivangana Rawat,Chaitanya Devaguptapu,Charu Sharma,Manohar Kaul
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:shown remarkable capabilities, Text driven diffusion, shown remarkable, remarkable capabilities, driven diffusion models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Text driven diffusion models have shown remarkable capabilities in editing images. However, when editing 3D scenes, existing works mostly rely on training a NeRF for 3D editing. Recent NeRF editing methods leverages edit operations by deploying 2D diffusion models and project these edits into 3D space. They require strong positional priors alongside text prompt to identify the edit location. These methods are operational on small 3D scenes and are more generalized to particular scene. They require training for each specific edit and cannot be exploited in real-time edits. To address these limitations, we propose a novel method, FreeEdit, to make edits in training free manner using mesh representations as a substitute for NeRF. Training-free methods are now a possibility because of the advances in foundation model's space. We leverage these models to bring a training-free alternative and introduce solutions for insertion, replacement and deletion. We consider insertion, replacement and deletion as basic blocks for performing intricate edits with certain combinations of these operations. Given a text prompt and a 3D scene, our model is capable of identifying what object should be inserted/replaced or deleted and location where edit should be performed. We also introduce a novel algorithm as part of FreeEdit to find the optimal location on grounding object for placement. We evaluate our model by comparing it with baseline models on a wide range of scenes using quantitative and qualitative metrics and showcase the merits of our method with respect to others.
+
+
+
+ 68. 【2412.12765】Monocular Facial Appearance Capture in the Wild
+ 链接:https://arxiv.org/abs/2412.12765
+ 作者:Yingyan Xu,Kate Gadola,Prashanth Chandran,Sebastian Weiss,Markus Gross,Gaspard Zoss,Derek Bradley
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:properties of human, human faces, lightweight capture procedure, unconstrained environment, appearance properties
+ 备注:
+
+ 点击查看摘要
+ Abstract:We present a new method for reconstructing the appearance properties of human faces from a lightweight capture procedure in an unconstrained environment. Our method recovers the surface geometry, diffuse albedo, specular intensity and specular roughness from a monocular video containing a simple head rotation in-the-wild. Notably, we make no simplifying assumptions on the environment lighting, and we explicitly take visibility and occlusions into account. As a result, our method can produce facial appearance maps that approach the fidelity of studio-based multi-view captures, but with a far easier and cheaper procedure.
+
+
+
+ 69. 【2412.12755】Progressive Monitoring of Generative Model Training Evolution
+ 链接:https://arxiv.org/abs/2412.12755
+ 作者:Vidya Prasad,Anna Vilanova,Nicola Pezzotti
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:undesirable outcomes remains, deep generative models, gained popularity, inefficiencies that lead, lead to undesirable
+ 备注:
+
+ 点击查看摘要
+ Abstract:While deep generative models (DGMs) have gained popularity, their susceptibility to biases and other inefficiencies that lead to undesirable outcomes remains an issue. With their growing complexity, there is a critical need for early detection of issues to achieve desired results and optimize resources. Hence, we introduce a progressive analysis framework to monitor the training process of DGMs. Our method utilizes dimensionality reduction techniques to facilitate the inspection of latent representations, the generated and real distributions, and their evolution across training iterations. This monitoring allows us to pause and fix the training method if the representations or distributions progress undesirably. This approach allows for the analysis of a models' training dynamics and the timely identification of biases and failures, minimizing computational loads. We demonstrate how our method supports identifying and mitigating biases early in training a Generative Adversarial Network (GAN) and improving the quality of the generated data distribution.
+
+
+
+ 70. 【2412.12740】Open-World Panoptic Segmentation
+ 链接:https://arxiv.org/abs/2412.12740
+ 作者:Matteo Sodano,Federico Magistri,Jens Behley,Cyrill Stachniss
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:key building block, autonomously acting vision, acting vision systems, key building, building block
+ 备注: Submitted to PAMI
+
+ 点击查看摘要
+ Abstract:Perception is a key building block of autonomously acting vision systems such as autonomous vehicles. It is crucial that these systems are able to understand their surroundings in order to operate safely and robustly. Additionally, autonomous systems deployed in unconstrained real-world scenarios must be able of dealing with novel situations and object that have never been seen before. In this article, we tackle the problem of open-world panoptic segmentation, i.e., the task of discovering new semantic categories and new object instances at test time, while enforcing consistency among the categories that we incrementally discover. We propose Con2MAV, an approach for open-world panoptic segmentation that extends our previous work, ContMAV, which was developed for open-world semantic segmentation. Through extensive experiments across multiple datasets, we show that our model achieves state-of-the-art results on open-world segmentation tasks, while still performing competitively on the known categories. We will open-source our implementation upon acceptance. Additionally, we propose PANIC (Panoptic ANomalies In Context), a benchmark for evaluating open-world panoptic segmentation in autonomous driving scenarios. This dataset, recorded with a multi-modal sensor suite mounted on a car, provides high-quality, pixel-wise annotations of anomalous objects at both semantic and instance level. Our dataset contains 800 images, with more than 50 unknown classes, i.e., classes that do not appear in the training set, and 4000 object instances, making it an extremely challenging dataset for open-world segmentation tasks in the autonomous driving scenario. We provide competitions for multiple open-world tasks on a hidden test set. Our dataset and competitions are available at this https URL.
+
+
+
+ 71. 【2412.12737】PolSAM: Polarimetric Scattering Mechanism Informed Segment Anything Model
+ 链接:https://arxiv.org/abs/2412.12737
+ 作者:Yuqing Wang,Zhongling Huang,Shuxin Yang,Hao Tang,Xiaolan Qiu,Junwei Han,Dingwen Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:presents unique challenges, unique challenges due, data presents unique, PolSAR data presents, presents unique
+ 备注: The manuscript is 15 pages long, includes 14 figures and 5 tables
+
+ 点击查看摘要
+ Abstract:PolSAR data presents unique challenges due to its rich and complex characteristics. Existing data representations, such as complex-valued data, polarimetric features, and amplitude images, are widely used. However, these formats often face issues related to usability, interpretability, and data integrity. Most feature extraction networks for PolSAR are small, limiting their ability to capture features effectively. To address these issues, We propose the Polarimetric Scattering Mechanism-Informed SAM (PolSAM), an enhanced Segment Anything Model (SAM) that integrates domain-specific scattering characteristics and a novel prompt generation strategy. PolSAM introduces Microwave Vision Data (MVD), a lightweight and interpretable data representation derived from polarimetric decomposition and semantic correlations. We propose two key components: the Feature-Level Fusion Prompt (FFP), which fuses visual tokens from pseudo-colored SAR images and MVD to address modality incompatibility in the frozen SAM encoder, and the Semantic-Level Fusion Prompt (SFP), which refines sparse and dense segmentation prompts using semantic information. Experimental results on the PhySAR-Seg datasets demonstrate that PolSAM significantly outperforms existing SAM-based and multimodal fusion models, improving segmentation accuracy, reducing data storage, and accelerating inference time. The source code and datasets will be made publicly available at \url{this https URL}.
+
+
+
+ 72. 【2412.12735】GIRAFFE: Design Choices for Extending the Context Length of Visual Language Models
+ 链接:https://arxiv.org/abs/2412.12735
+ 作者:Mukai Li,Lei Li,Shansan Gong,Qi Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Visual Language Models, Visual Language, demonstrate impressive capabilities, processing multimodal inputs, require handling multiple
+ 备注: Working in progress
+
+ 点击查看摘要
+ Abstract:Visual Language Models (VLMs) demonstrate impressive capabilities in processing multimodal inputs, yet applications such as visual agents, which require handling multiple images and high-resolution videos, demand enhanced long-range modeling. Moreover, existing open-source VLMs lack systematic exploration into extending their context length, and commercial models often provide limited details. To tackle this, we aim to establish an effective solution that enhances long context performance of VLMs while preserving their capacities in short context scenarios. Towards this goal, we make the best design choice through extensive experiment settings from data curation to context window extending and utilizing: (1) we analyze data sources and length distributions to construct ETVLM - a data recipe to balance the performance across scenarios; (2) we examine existing position extending methods, identify their limitations and propose M-RoPE++ as an enhanced approach; we also choose to solely instruction-tune the backbone with mixed-source data; (3) we discuss how to better utilize extended context windows and propose hybrid-resolution training. Built on the Qwen-VL series model, we propose Giraffe, which is effectively extended to 128K lengths. Evaluated on extensive long context VLM benchmarks such as VideoMME and Viusal Haystacks, our Giraffe achieves state-of-the-art performance among similarly sized open-source long VLMs and is competitive with commercial model GPT-4V. We will open-source the code, data, and models.
+
+
+
+ 73. 【2412.12734】Gaussian Billboards: Expressive 2D Gaussian Splatting with Textures
+ 链接:https://arxiv.org/abs/2412.12734
+ 作者:Sebastian Weiss,Derek Bradley
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:Gaussian Splatting, reconstructing and rendering, recently emerged, Gaussian, Splatting has recently
+ 备注:
+
+ 点击查看摘要
+ Abstract:Gaussian Splatting has recently emerged as the go-to representation for reconstructing and rendering 3D scenes. The transition from 3D to 2D Gaussian primitives has further improved multi-view consistency and surface reconstruction accuracy. In this work we highlight the similarity between 2D Gaussian Splatting (2DGS) and billboards from traditional computer graphics. Both use flat semi-transparent 2D geometry that is positioned, oriented and scaled in 3D space. However 2DGS uses a solid color per splat and an opacity modulated by a Gaussian distribution, where billboards are more expressive, modulating the color with a uv-parameterized texture. We propose to unify these concepts by presenting Gaussian Billboards, a modification of 2DGS to add spatially-varying color achieved using per-splat texture interpolation. The result is a mixture of the two representations, which benefits from both the robust scene optimization power of 2DGS and the expressiveness of texture mapping. We show that our method can improve the sharpness and quality of the scene representation in a wide range of qualitative and quantitative evaluations compared to the original 2DGS implementation.
+
+
+
+ 74. 【2412.12725】RaCFormer: Towards High-Quality 3D Object Detection via Query-based Radar-Camera Fusion
+ 链接:https://arxiv.org/abs/2412.12725
+ 作者:Xiaomeng Chu,Jiajun Deng,Guoliang You,Yifan Duan,Houqiang Li,Yanyong Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Radar-Camera fusion transformer, propose Radar-Camera fusion, Radar-Camera fusion, boost the accuracy, fusion transformer
+ 备注:
+
+ 点击查看摘要
+ Abstract:We propose Radar-Camera fusion transformer (RaCFormer) to boost the accuracy of 3D object detection by the following insight. The Radar-Camera fusion in outdoor 3D scene perception is capped by the image-to-BEV transformation--if the depth of pixels is not accurately estimated, the naive combination of BEV features actually integrates unaligned visual content. To avoid this problem, we propose a query-based framework that enables adaptively sample instance-relevant features from both the BEV and the original image view. Furthermore, we enhance system performance by two key designs: optimizing query initialization and strengthening the representational capacity of BEV. For the former, we introduce an adaptive circular distribution in polar coordinates to refine the initialization of object queries, allowing for a distance-based adjustment of query density. For the latter, we initially incorporate a radar-guided depth head to refine the transformation from image view to BEV. Subsequently, we focus on leveraging the Doppler effect of radar and introduce an implicit dynamic catcher to capture the temporal elements within the BEV. Extensive experiments on nuScenes and View-of-Delft (VoD) datasets validate the merits of our design. Remarkably, our method achieves superior results of 64.9% mAP and 70.2% NDS on nuScenes, even outperforming several LiDAR-based detectors. RaCFormer also secures the 1st ranking on the VoD dataset. The code will be released.
+
+
+
+ 75. 【2412.12722】Defending LVLMs Against Vision Attacks through Partial-Perception Supervision
+ 链接:https://arxiv.org/abs/2412.12722
+ 作者:Qi Zhou,Tianlin Li,Qing Guo,Dongxia Wang,Yun Lin,Yang Liu,Jin Song Dong
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Cryptography and Security (cs.CR)
+ 关键词:Large Vision Language, Vision Language Models, Large Vision, Vision Language, raised significant concerns
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent studies have raised significant concerns regarding the vulnerability of Large Vision Language Models (LVLMs) to maliciously injected or perturbed input images, which can mislead their responses. Existing defense methods show that such vision attacks are sensitive to image modifications especially cropping, using majority voting across responses of modified images as corrected responses. However, these modifications often result in partial images and distort the semantics, which reduces response quality on clean images after voting. Instead of directly using responses from partial images for voting, we investigate using them to supervise the LVLM's responses to the original images. We propose a black-box, training-free method called DPS (Defense through Partial-Perception Supervision). In this approach, the model is prompted using the responses generated by a model that perceives only a partial image. With DPS, the model can adjust its response based on partial image understanding when under attack, while confidently maintaining its original response for clean input. Our findings show that the weak model can supervise the strong model: when faced with an attacked input, the strong model becomes less confident and adjusts its response based on the weak model's partial understanding, effectively defending against the attack. With clean input, it confidently maintains its original response. Empirical experiments show our method outperforms the baseline, cutting the average attack success rate by 76.3% across six datasets on three popular models.
+
+
+
+ 76. 【2412.12718】ASAP: Advancing Semantic Alignment Promotes Multi-Modal Manipulation Detecting and Grounding
+ 链接:https://arxiv.org/abs/2412.12718
+ 作者:Zhenxing Zhang,Yaxiong Wang,Lechao Cheng,Zhun Zhong,Dan Guo,Meng Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:accurate fine-grained cross-modal, present ASAP, accurately manipulation detection, multi-modal media manipulation, grounding multi-modal media
+ 备注: 12 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:We present ASAP, a new framework for detecting and grounding multi-modal media manipulation (DGM4).Upon thorough examination, we observe that accurate fine-grained cross-modal semantic alignment between the image and text is vital for accurately manipulation detection and grounding. While existing DGM4 methods pay rare attention to the cross-modal alignment, hampering the accuracy of manipulation detecting to step further. To remedy this issue, this work targets to advance the semantic alignment learning to promote this task. Particularly, we utilize the off-the-shelf Multimodal Large-Language Models (MLLMs) and Large Language Models (LLMs) to construct paired image-text pairs, especially for the manipulated instances. Subsequently, a cross-modal alignment learning is performed to enhance the semantic alignment. Besides the explicit auxiliary clues, we further design a Manipulation-Guided Cross Attention (MGCA) to provide implicit guidance for augmenting the manipulation perceiving. With the grounding truth available during training, MGCA encourages the model to concentrate more on manipulated components while downplaying normal ones, enhancing the model's ability to capture manipulations. Extensive experiments are conducted on the DGM4 dataset, the results demonstrate that our model can surpass the comparison method with a clear margin.
+
+
+
+ 77. 【2412.12716】Unsupervised UAV 3D Trajectories Estimation with Sparse Point Clouds
+ 链接:https://arxiv.org/abs/2412.12716
+ 作者:Hanfang Liang,Yizhuo Yang,Jinming Hu,Jianfei Yang,Fen Liu,Shenghai Yuan
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:Compact UAV systems, pose significant security, Compact UAV, significant security challenges, security challenges due
+ 备注:
+
+ 点击查看摘要
+ Abstract:Compact UAV systems, while advancing delivery and surveillance, pose significant security challenges due to their small size, which hinders detection by traditional methods. This paper presents a cost-effective, unsupervised UAV detection method using spatial-temporal sequence processing to fuse multiple LiDAR scans for accurate UAV tracking in real-world scenarios. Our approach segments point clouds into foreground and background, analyzes spatial-temporal data, and employs a scoring mechanism to enhance detection accuracy. Tested on a public dataset, our solution placed 4th in the CVPR 2024 UG2+ Challenge, demonstrating its practical effectiveness. We plan to open-source all designs, code, and sample data for the research community this http URL.
+
+
+
+ 78. 【2412.12704】MapExpert: Online HD Map Construction with Simple and Efficient Sparse Map Element Expert
+ 链接:https://arxiv.org/abs/2412.12704
+ 作者:Dapeng Zhang,Dayu Chen,Peng Zhi,Yinda Chen,Zhenlong Yuan,Chenyang Li,Sunjing,Rui Zhou,Qingguo Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Constructing online High-Definition, autonomous driving systems, static environment perception, Constructing online, driving systems
+ 备注:
+
+ 点击查看摘要
+ Abstract:Constructing online High-Definition (HD) maps is crucial for the static environment perception of autonomous driving systems (ADS). Existing solutions typically attempt to detect vectorized HD map elements with unified models; however, these methods often overlook the distinct characteristics of different non-cubic map elements, making accurate distinction challenging. To address these issues, we introduce an expert-based online HD map method, termed MapExpert. MapExpert utilizes sparse experts, distributed by our routers, to describe various non-cubic map elements accurately. Additionally, we propose an auxiliary balance loss function to distribute the load evenly across experts. Furthermore, we theoretically analyze the limitations of prevalent bird's-eye view (BEV) feature temporal fusion methods and introduce an efficient temporal fusion module called Learnable Weighted Moving Descentage. This module effectively integrates relevant historical information into the final BEV features. Combined with an enhanced slice head branch, the proposed MapExpert achieves state-of-the-art performance and maintains good efficiency on both nuScenes and Argoverse2 datasets.
+
+
+
+ 79. 【2412.12696】ALADE-SNN: Adaptive Logit Alignment in Dynamically Expandable Spiking Neural Networks for Class Incremental Learning
+ 链接:https://arxiv.org/abs/2412.12696
+ 作者:Wenyao Ni,Jiangrong Shen,Qi Xu,Huajin Tang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:erasing prior knowledge, human brain ability, develop spiking neural, structures for Class, Class Incremental Learning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Inspired by the human brain's ability to adapt to new tasks without erasing prior knowledge, we develop spiking neural networks (SNNs) with dynamic structures for Class Incremental Learning (CIL). Our comparative experiments reveal that limited datasets introduce biases in logits distributions among tasks. Fixed features from frozen past-task extractors can cause overfitting and hinder the learning of new tasks. To address these challenges, we propose the ALADE-SNN framework, which includes adaptive logit alignment for balanced feature representation and OtoN suppression to manage weights mapping frozen old features to new classes during training, releasing them during fine-tuning. This approach dynamically adjusts the network architecture based on analytical observations, improving feature extraction and balancing performance between new and old tasks. Experiment results show that ALADE-SNN achieves an average incremental accuracy of 75.42 on the CIFAR100-B0 benchmark over 10 incremental steps. ALADE-SNN not only matches the performance of DNN-based methods but also surpasses state-of-the-art SNN-based continual learning algorithms. This advancement enhances continual learning in neuromorphic computing, offering a brain-inspired, energy-efficient solution for real-time data processing.
+
+
+
+ 80. 【2412.12693】SPHERE: A Hierarchical Evaluation on Spatial Perception and Reasoning for Vision-Language Models
+ 链接:https://arxiv.org/abs/2412.12693
+ 作者:Wenyu Zhang,Wei En Ng,Lixin Ma,Yuwen Wang,Jungqi Zhao,Boyang Li,Lu Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Current vision-language models, basic spatial directions, incorporate single-dimensional spatial, single-dimensional spatial cues, multi-dimensional spatial reasoning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Current vision-language models may incorporate single-dimensional spatial cues, such as depth, object boundary, and basic spatial directions (e.g. left, right, front, back), yet often lack the multi-dimensional spatial reasoning necessary for human-like understanding and real-world applications. To address this gap, we develop SPHERE (Spatial Perception and Hierarchical Evaluation of REasoning), a hierarchical evaluation framework with a new human-annotated dataset to pinpoint model strengths and weaknesses, advancing from single-skill tasks to multi-skill tasks, and ultimately to complex reasoning tasks that require the integration of multiple spatial and visual cues with logical reasoning. Benchmark evaluation of state-of-the-art open-source models reveal significant shortcomings, especially in the abilities to understand distance and proximity, to reason from both allocentric and egocentric viewpoints, and to perform complex reasoning in a physical context. This work underscores the need for more advanced approaches to spatial understanding and reasoning, paving the way for improvements in vision-language models and their alignment with human-like spatial capabilities. The dataset will be open-sourced upon publication.
+
+
+
+ 81. 【2412.12685】SemStereo: Semantic-Constrained Stereo Matching Network for Remote Sensing
+ 链接:https://arxiv.org/abs/2412.12685
+ 作者:Chen Chen,Liangjin Zhao,Yuanchun He,Yingxuan Long,Kaiqiang Chen,Zhirui Wang,Yanfeng Hu,Xian Sun
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:loosely coupled tasks, Semantic, loosely coupled parallel, loosely coupled, remote sensing
+ 备注: 9 pages, 6 figures, AAAI 2025
+
+ 点击查看摘要
+ Abstract:Semantic segmentation and 3D reconstruction are two fundamental tasks in remote sensing, typically treated as separate or loosely coupled tasks. Despite attempts to integrate them into a unified network, the constraints between the two heterogeneous tasks are not explicitly modeled, since the pioneering studies either utilize a loosely coupled parallel structure or engage in only implicit interactions, failing to capture the inherent connections. In this work, we explore the connections between the two tasks and propose a new network that imposes semantic constraints on the stereo matching task, both implicitly and explicitly. Implicitly, we transform the traditional parallel structure to a new cascade structure termed Semantic-Guided Cascade structure, where the deep features enriched with semantic information are utilized for the computation of initial disparity maps, enhancing semantic guidance. Explicitly, we propose a Semantic Selective Refinement (SSR) module and a Left-Right Semantic Consistency (LRSC) module. The SSR refines the initial disparity map under the guidance of the semantic map. The LRSC ensures semantic consistency between two views via reducing the semantic divergence after transforming the semantic map from one view to the other using the disparity map. Experiments on the US3D and WHU datasets demonstrate that our method achieves state-of-the-art performance for both semantic segmentation and stereo matching.
+
+
+
+ 82. 【2412.12683】ShiftedBronzes: Benchmarking and Analysis of Domain Fine-Grained Classification in Open-World Settings
+ 链接:https://arxiv.org/abs/2412.12683
+ 作者:Rixin Zhou,Honglin Pang,Qian Zhang,Ruihua Qi,Xi Yang,Chuntao Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:bronze ware dating, OOD detection methods, bronze ware, OOD detection, OOD
+ 备注: 9pages, 7 figures, 4 tables
+
+ 点击查看摘要
+ Abstract:In real-world applications across specialized domains, addressing complex out-of-distribution (OOD) challenges is a common and significant concern. In this study, we concentrate on the task of fine-grained bronze ware dating, a critical aspect in the study of ancient Chinese history, and developed a benchmark dataset named ShiftedBronzes. By extensively expanding the bronze Ding dataset, ShiftedBronzes incorporates two types of bronze ware data and seven types of OOD data, which exhibit distribution shifts commonly encountered in bronze ware dating scenarios. We conduct benchmarking experiments on ShiftedBronzes and five commonly used general OOD datasets, employing a variety of widely adopted post-hoc, pre-trained Vision Large Model (VLM)-based and generation-based OOD detection methods. Through analysis of the experimental results, we validate previous conclusions regarding post-hoc, VLM-based, and generation-based methods, while also highlighting their distinct behaviors on specialized datasets. These findings underscore the unique challenges of applying general OOD detection methods to domain-specific tasks such as bronze ware dating. We hope that the ShiftedBronzes benchmark provides valuable insights into both the field of bronze ware dating and the and the development of OOD detection methods. The dataset and associated code will be available later.
+
+
+
+ 83. 【2412.12675】ShotVL: Human-Centric Highlight Frame Retrieval via Language Queries
+ 链接:https://arxiv.org/abs/2412.12675
+ 作者:Wangyu Xue,Chen Qian,Jiayi Wu,Yang Zhou,Wentao Liu,Ju Ren,Siming Fan,Yaoxue Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:analyzing specific moment, video understanding typically, understanding typically focus, human-centric video understanding, understanding typically
+ 备注:
+
+ 点击查看摘要
+ Abstract:Existing works on human-centric video understanding typically focus on analyzing specific moment or entire videos. However, many applications require higher precision at the frame level. In this work, we propose a novel task, BestShot, which aims to locate highlight frames within human-centric videos via language queries. This task demands not only a deep semantic comprehension of human actions but also precise temporal localization. To support this task, we introduce the BestShot Benchmark. %The benchmark is meticulously constructed by combining human detection and tracking, potential frame selection based on human judgment, and detailed textual descriptions crafted by human input to ensure precision. The benchmark is meticulously constructed by combining human-annotated highlight frames, detailed textual descriptions and duration labeling. These descriptions encompass three critical elements: (1) Visual content; (2) Fine-grained action; and (3) Human Pose Description. Together, these elements provide the necessary precision to identify the exact highlight frames in videos.
+To tackle this problem, we have collected two distinct datasets: (i) ShotGPT4o Dataset, which is algorithmically generated by GPT-4o and (ii) Image-SMPLText Dataset, a dataset with large-scale and accurate per-frame pose description leveraging PoseScript and existing pose estimation datasets. Based on these datasets, we present a strong baseline model, ShotVL, fine-tuned from InternVL, specifically for BestShot. We highlight the impressive zero-shot capabilities of our model and offer comparative analyses with existing SOTA models. ShotVL demonstrates a significant 52% improvement over InternVL on the BestShot Benchmark and a notable 57% improvement on the THUMOS14 Benchmark, all while maintaining the SOTA performance in general image classification and retrieval.
+
Subjects:
+Computer Vision and Pattern Recognition (cs.CV)
+Cite as:
+arXiv:2412.12675 [cs.CV]
+(or
+arXiv:2412.12675v1 [cs.CV] for this version)
+https://doi.org/10.48550/arXiv.2412.12675
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 84. 【2412.12672】Structural Pruning via Spatial-aware Information Redundancy for Semantic Segmentation
+ 链接:https://arxiv.org/abs/2412.12672
+ 作者:Dongyue Wu,Zilin Guo,Li Yu,Nong Sang,Changxin Gao
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:recent years, pruning, segmentation networks, segmentation, filter pruning
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:In recent years, semantic segmentation has flourished in various applications. However, the high computational cost remains a significant challenge that hinders its further adoption. The filter pruning method for structured network slimming offers a direct and effective solution for the reduction of segmentation networks. Nevertheless, we argue that most existing pruning methods, originally designed for image classification, overlook the fact that segmentation is a location-sensitive task, which consequently leads to their suboptimal performance when applied to segmentation networks. To address this issue, this paper proposes a novel approach, denoted as Spatial-aware Information Redundancy Filter Pruning~(SIRFP), which aims to reduce feature redundancy between channels. First, we formulate the pruning process as a maximum edge weight clique problem~(MEWCP) in graph theory, thereby minimizing the redundancy among the remaining features after pruning. Within this framework, we introduce a spatial-aware redundancy metric based on feature maps, thus endowing the pruning process with location sensitivity to better adapt to pruning segmentation networks. Additionally, based on the MEWCP, we propose a low computational complexity greedy strategy to solve this NP-hard problem, making it feasible and efficient for structured pruning. To validate the effectiveness of our method, we conducted extensive comparative experiments on various challenging datasets. The results demonstrate the superior performance of SIRFP for semantic segmentation tasks.
+
+
+
+ 85. 【2412.12669】Adaptive Prototype Replay for Class Incremental Semantic Segmentation
+ 链接:https://arxiv.org/abs/2412.12669
+ 作者:Guilin Zhu,Dongyue Wu,Changxin Gao,Runmin Wang,Weidong Yang,Nong Sang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:incremental semantic segmentation, Class incremental semantic, Adaptive prototype replay, prototype replay, semantic segmentation
+ 备注: Accepted by the Main Technical Track of the 39th Annual AAAI Conference on Artificial Intelligence (AAAI-2025)
+
+ 点击查看摘要
+ Abstract:Class incremental semantic segmentation (CISS) aims to segment new classes during continual steps while preventing the forgetting of old knowledge. Existing methods alleviate catastrophic forgetting by replaying distributions of previously learned classes using stored prototypes or features. However, they overlook a critical issue: in CISS, the representation of class knowledge is updated continuously through incremental learning, whereas prototype replay methods maintain fixed prototypes. This mismatch between updated representation and fixed prototypes limits the effectiveness of the prototype replay strategy. To address this issue, we propose the Adaptive prototype replay (Adapter) for CISS in this paper. Adapter comprises an adaptive deviation compen sation (ADC) strategy and an uncertainty-aware constraint (UAC) loss. Specifically, the ADC strategy dynamically updates the stored prototypes based on the estimated representation shift distance to match the updated representation of old class. The UAC loss reduces prediction uncertainty, aggregating discriminative features to aid in generating compact prototypes. Additionally, we introduce a compensation-based prototype similarity discriminative (CPD) loss to ensure adequate differentiation between similar prototypes, thereby enhancing the efficiency of the adaptive prototype replay strategy. Extensive experiments on Pascal VOC and ADE20K datasets demonstrate that Adapter achieves state-of-the-art results and proves effective across various CISS tasks, particularly in challenging multi-step scenarios. The code and model is available at this https URL.
+
+
+
+ 86. 【2412.12667】A Two-Fold Patch Selection Approach for Improved 360-Degree Image Quality Assessment
+ 链接:https://arxiv.org/abs/2412.12667
+ 作者:Abderrezzaq Sendjasni,Seif-Eddine Benkabou,Mohamed-Chaker Larabi
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:two-fold patch selection, perceptual image quality, image quality assessment, article presents, patch selection process
+ 备注: Submitted to IEEE Transactions on Image Processing
+
+ 点击查看摘要
+ Abstract:This article presents a novel approach to improving the accuracy of 360-degree perceptual image quality assessment (IQA) through a two-fold patch selection process. Our methodology combines visual patch selection with embedding similarity-based refinement. The first stage focuses on selecting patches from 360-degree images using three distinct sampling methods to ensure comprehensive coverage of visual content for IQA. The second stage, which is the core of our approach, employs an embedding similarity-based selection process to filter and prioritize the most informative patches based on their embeddings similarity distances. This dual selection mechanism ensures that the training data is both relevant and informative, enhancing the model's learning efficiency. Extensive experiments and statistical analyses using three distance metrics across three benchmark datasets validate the effectiveness of our selection algorithm. The results highlight its potential to deliver robust and accurate 360-degree IQA, with performance gains of up to 4.5% in accuracy and monotonicity of quality score prediction, while using only 40% to 50% of the training patches. These improvements are consistent across various configurations and evaluation metrics, demonstrating the strength of the proposed method. The code for the selection process is available at: this https URL.
+
+
+
+ 87. 【2412.12661】MedMax: Mixed-Modal Instruction Tuning for Training Biomedical Assistants
+ 链接:https://arxiv.org/abs/2412.12661
+ 作者:Hritik Bansal,Daniel Israel,Siyan Zhao,Shufan Li,Tung Nguyen,Aditya Grover
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:enabled flexible integration, Recent advancements, enabled flexible, flexible integration, integration of information
+ 备注: 12 figures, 15 tables
+
+ 点击查看摘要
+ Abstract:Recent advancements in mixed-modal generative models have enabled flexible integration of information across image-text content. These models have opened new avenues for developing unified biomedical assistants capable of analyzing biomedical images, answering complex questions about them, and predicting the impact of medical procedures on a patient's health. However, existing resources face challenges such as limited data availability, narrow domain coverage, and restricted sources (e.g., medical papers). To address these gaps, we present MedMax, the first large-scale multimodal biomedical instruction-tuning dataset for mixed-modal foundation models. With 1.47 million instances, MedMax encompasses a diverse range of tasks, including multimodal content generation (interleaved image-text data), biomedical image captioning and generation, visual chatting, and report understanding. These tasks span diverse medical domains such as radiology and histopathology. Subsequently, we fine-tune a mixed-modal foundation model on the MedMax dataset, achieving significant performance improvements: a 26% gain over the Chameleon model and an 18.3% improvement over GPT-4o across 12 downstream biomedical visual question-answering tasks. Additionally, we introduce a unified evaluation suite for biomedical tasks, providing a robust framework to guide the development of next-generation mixed-modal biomedical AI assistants.
+
+
+
+ 88. 【2412.12660】SEG-SAM: Semantic-Guided SAM for Unified Medical Image Segmentation
+ 链接:https://arxiv.org/abs/2412.12660
+ 作者:Shuangping Huang,Hao Liang,Qingfeng Wang,Chulong Zhong,Zijian Zhou,Miaojing Shi
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:gains increasing attention, models gains increasing, segmentation models gains, medical, developing unified medical
+ 备注: 12 pages, 3 figures
+
+ 点击查看摘要
+ Abstract:Recently, developing unified medical image segmentation models gains increasing attention, especially with the advent of the Segment Anything Model (SAM). SAM has shown promising binary segmentation performance in natural domains, however, transferring it to the medical domain remains challenging, as medical images often possess substantial inter-category overlaps. To address this, we propose the SEmantic-Guided SAM (SEG-SAM), a unified medical segmentation model that incorporates semantic medical knowledge to enhance medical segmentation performance. First, to avoid the potential conflict between binary and semantic predictions, we introduce a semantic-aware decoder independent of SAM's original decoder, specialized for both semantic segmentation on the prompted object and classification on unprompted objects in images. To further enhance the model's semantic understanding, we solicit key characteristics of medical categories from large language models and incorporate them into SEG-SAM through a text-to-vision semantic module, adaptively transferring the language information into the visual segmentation task. In the end, we introduce the cross-mask spatial alignment strategy to encourage greater overlap between the predicted masks from SEG-SAM's two decoders, thereby benefiting both predictions. Extensive experiments demonstrate that SEG-SAM outperforms state-of-the-art SAM-based methods in unified binary medical segmentation and task-specific methods in semantic medical segmentation, showcasing promising results and potential for broader medical applications.
+
+
+
+ 89. 【2412.12654】CALA: A Class-Aware Logit Adapter for Few-Shot Class-Incremental Learning
+ 链接:https://arxiv.org/abs/2412.12654
+ 作者:Chengyan Liu,Linglan Zhao,Fan Lyu,Kaile Du,Fuyuan Hu,Tao Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Few-Shot Class-Incremental Learning, Few-Shot Class-Incremental, defines a practical, practical but challenging, challenging task
+ 备注: 10 pages
+
+ 点击查看摘要
+ Abstract:Few-Shot Class-Incremental Learning (FSCIL) defines a practical but challenging task where models are required to continuously learn novel concepts with only a few training samples. Due to data scarcity, existing FSCIL methods resort to training a backbone with abundant base data and then keeping it frozen afterward. However, the above operation often causes the backbone to overfit to base classes while overlooking the novel ones, leading to severe confusion between them. To address this issue, we propose Class-Aware Logit Adapter (CALA). Our method involves a lightweight adapter that learns to rectify biased predictions through a pseudo-incremental learning paradigm. In the real FSCIL process, we use the learned adapter to dynamically generate robust balancing factors. These factors can adjust confused novel instances back to their true label space based on their similarity to base classes. Specifically, when confusion is more likely to occur in novel instances that closely resemble base classes, greater rectification is required. Notably, CALA operates on the classifier level, preserving the original feature space, thus it can be flexibly plugged into most of the existing FSCIL works for improved performance. Experiments on three benchmark datasets consistently validate the effectiveness and flexibility of CALA. Codes will be available upon acceptance.
+
+
+
+ 90. 【2412.12628】Dense Audio-Visual Event Localization under Cross-Modal Consistency and Multi-Temporal Granularity Collaboration
+ 链接:https://arxiv.org/abs/2412.12628
+ 作者:Ziheng Zhou,Jinxing Zhou,Wei Qian,Shengeng Tang,Xiaojun Chang,Dan Guo
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Dense Audio-Visual Event, Audio-Visual Event Localization, research tasks focus, tasks focus exclusively, exclusively on short
+ 备注: Accepted by AAAI 2025. Project page: [this https URL](https://github.com/zzhhfut/CCNet-AAAI2025) . Jinxing Zhou and Dan Guo are the corresponding authors
+
+ 点击查看摘要
+ Abstract:In the field of audio-visual learning, most research tasks focus exclusively on short videos. This paper focuses on the more practical Dense Audio-Visual Event Localization (DAVEL) task, advancing audio-visual scene understanding for longer, {untrimmed} videos. This task seeks to identify and temporally pinpoint all events simultaneously occurring in both audio and visual streams. Typically, each video encompasses dense events of multiple classes, which may overlap on the timeline, each exhibiting varied durations. Given these challenges, effectively exploiting the audio-visual relations and the temporal features encoded at various granularities becomes crucial. To address these challenges, we introduce a novel \ul{CC}Net, comprising two core modules: the Cross-Modal Consistency \ul{C}ollaboration (CMCC) and the Multi-Temporal Granularity \ul{C}ollaboration (MTGC). Specifically, the CMCC module contains two branches: a cross-modal interaction branch and a temporal consistency-gated branch. The former branch facilitates the aggregation of consistent event semantics across modalities through the encoding of audio-visual relations, while the latter branch guides one modality's focus to pivotal event-relevant temporal areas as discerned in the other modality. The MTGC module includes a coarse-to-fine collaboration block and a fine-to-coarse collaboration block, providing bidirectional support among coarse- and fine-grained temporal features. Extensive experiments on the UnAV-100 dataset validate our module design, resulting in a new state-of-the-art performance in dense audio-visual event localization. The code is available at \url{this https URL}.
+
+
+
+ 91. 【2412.12626】Improving the Transferability of 3D Point Cloud Attack via Spectral-aware Admix and Optimization Designs
+ 链接:https://arxiv.org/abs/2412.12626
+ 作者:Shiyu Hu,Daizong Liu,Wei Hu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Cryptography and Security (cs.CR)
+ 关键词:received increasing attention, Deep learning models, Deep learning, autonomous driving, received increasing
+ 备注:
+
+ 点击查看摘要
+ Abstract:Deep learning models for point clouds have shown to be vulnerable to adversarial attacks, which have received increasing attention in various safety-critical applications such as autonomous driving, robotics, and surveillance. Existing 3D attackers generally design various attack strategies in the white-box setting, requiring the prior knowledge of 3D model details. However, real-world 3D applications are in the black-box setting, where we can only acquire the outputs of the target classifier. Although few recent works try to explore the black-box attack, they still achieve limited attack success rates (ASR). To alleviate this issue, this paper focuses on attacking the 3D models in a transfer-based black-box setting, where we first carefully design adversarial examples in a white-box surrogate model and then transfer them to attack other black-box victim models. Specifically, we propose a novel Spectral-aware Admix with Augmented Optimization method (SAAO) to improve the adversarial transferability. In particular, since traditional Admix strategy are deployed in the 2D domain that adds pixel-wise images for perturbing, we can not directly follow it to merge point clouds in coordinate domain as it will destroy the geometric shapes. Therefore, we design spectral-aware fusion that performs Graph Fourier Transform (GFT) to get spectral features of the point clouds and add them in the spectral domain. Afterward, we run a few steps with spectral-aware weighted Admix to select better optimization paths as well as to adjust corresponding learning weights. At last, we run more steps to generate adversarial spectral feature along the optimization path and perform Inverse-GFT on the adversarial spectral feature to obtain the adversarial example in the data domain. Experiments show that our SAAO achieves better transferability compared to existing 3D attack methods.
+
+
+
+ 92. 【2412.12620】Multi-Domain Features Guided Supervised Contrastive Learning for Radar Target Detection
+ 链接:https://arxiv.org/abs/2412.12620
+ 作者:Junjie Wang,Yuze Gao,Dongying Li,Wenxian Yu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Detecting small targets, Detecting small, due to dynamic, sea clutter, Detecting
+ 备注:
+
+ 点击查看摘要
+ Abstract:Detecting small targets in sea clutter is challenging due to dynamic maritime conditions. Existing solutions either model sea clutter for detection or extract target features based on clutter-target echo differences, including statistical and deep features. While more common, the latter often excels in controlled scenarios but struggles with robust detection and generalization in diverse environments, limiting practical use. In this letter, we propose a multi-domain features guided supervised contrastive learning (MDFG_SCL) method, which integrates statistical features derived from multi-domain differences with deep features obtained through supervised contrastive learning, thereby capturing both low-level domain-specific variations and high-level semantic information. This comprehensive feature integration enables the model to effectively distinguish between small targets and sea clutter, even under challenging conditions. Experiments conducted on real-world datasets demonstrate that the proposed shallow-to-deep detector not only achieves effective identification of small maritime targets but also maintains superior detection performance across varying sea conditions, outperforming the mainstream unsupervised contrastive learning and supervised contrastive learning methods.
+
+
+
+ 93. 【2412.12617】PO3AD: Predicting Point Offsets toward Better 3D Point Cloud Anomaly Detection
+ 链接:https://arxiv.org/abs/2412.12617
+ 作者:Jianan Ye,Weiguang Zhao,Xi Yang,Guangliang Cheng,Kaizhu Huang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:anomaly-free setting poses, setting poses significant, requires accurately capturing, identify deviations indicative, poses significant challenges
+ 备注:
+
+ 点击查看摘要
+ Abstract:Point cloud anomaly detection under the anomaly-free setting poses significant challenges as it requires accurately capturing the features of 3D normal data to identify deviations indicative of anomalies. Current efforts focus on devising reconstruction tasks, such as acquiring normal data representations by restoring normal samples from altered, pseudo-anomalous counterparts. Our findings reveal that distributing attention equally across normal and pseudo-anomalous data tends to dilute the model's focus on anomalous deviations. The challenge is further compounded by the inherently disordered and sparse nature of 3D point cloud data. In response to those predicaments, we introduce an innovative approach that emphasizes learning point offsets, targeting more informative pseudo-abnormal points, thus fostering more effective distillation of normal data representations. We also have crafted an augmentation technique that is steered by normal vectors, facilitating the creation of credible pseudo anomalies that enhance the efficiency of the training process. Our comprehensive experimental evaluation on the Anomaly-ShapeNet and Real3D-AD datasets evidences that our proposed method outperforms existing state-of-the-art approaches, achieving an average enhancement of 9.0% and 1.4% in the AUC-ROC detection metric across these datasets, respectively.
+
+
+
+ 94. 【2412.12606】Multi-Dimensional Insights: Benchmarking Real-World Personalization in Large Multimodal Models
+ 链接:https://arxiv.org/abs/2412.12606
+ 作者:YiFan Zhang,Shanglin Lei,Runqi Qiao,Zhuoma GongQue,Xiaoshuai Song,Guanting Dong,Qiuna Tan,Zhe Wei,Peiqing Yang,Ye Tian,Yadong Xue,Xiaofei Wang,Honggang Zhang
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:rapidly developing field, large multimodal models, rapidly developing, developing field, field of large
+ 备注: 33 pages, 33 figures, Work in progress
+
+ 点击查看摘要
+ Abstract:The rapidly developing field of large multimodal models (LMMs) has led to the emergence of diverse models with remarkable capabilities. However, existing benchmarks fail to comprehensively, objectively and accurately evaluate whether LMMs align with the diverse needs of humans in real-world scenarios. To bridge this gap, we propose the Multi-Dimensional Insights (MDI) benchmark, which includes over 500 images covering six common scenarios of human life. Notably, the MDI-Benchmark offers two significant advantages over existing evaluations: (1) Each image is accompanied by two types of questions: simple questions to assess the model's understanding of the image, and complex questions to evaluate the model's ability to analyze and reason beyond basic content. (2) Recognizing that people of different age groups have varying needs and perspectives when faced with the same scenario, our benchmark stratifies questions into three age categories: young people, middle-aged people, and older people. This design allows for a detailed assessment of LMMs' capabilities in meeting the preferences and needs of different age groups. With MDI-Benchmark, the strong model like GPT-4o achieve 79% accuracy on age-related tasks, indicating that existing LMMs still have considerable room for improvement in addressing real-world applications. Looking ahead, we anticipate that the MDI-Benchmark will open new pathways for aligning real-world personalization in LMMs. The MDI-Benchmark data and evaluation code are available at this https URL
+
+
+
+ 95. 【2412.12603】RemoteTrimmer: Adaptive Structural Pruning for Remote Sensing Image Classification
+ 链接:https://arxiv.org/abs/2412.12603
+ 作者:Guanwenjie Zou,Liang Yao,Fan Liu,Chuanyi Zhang,Xin Li,Ning Chen,Shengxiang Xu,Jun Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:high computation complexity, high resolution remote, remote sensing, lightweight models tend, remote sensing image
+ 备注:
+
+ 点击查看摘要
+ Abstract:Since high resolution remote sensing image classification often requires a relatively high computation complexity, lightweight models tend to be practical and efficient. Model pruning is an effective method for model compression. However, existing methods rarely take into account the specificity of remote sensing images, resulting in significant accuracy loss after pruning. To this end, we propose an effective structural pruning approach for remote sensing image classification. Specifically, a pruning strategy that amplifies the differences in channel importance of the model is introduced. Then an adaptive mining loss function is designed for the fine-tuning process of the pruned model. Finally, we conducted experiments on two remote sensing classification datasets. The experimental results demonstrate that our method achieves minimal accuracy loss after compressing remote sensing classification models, achieving state-of-the-art (SoTA) performance.
+
+
+
+ 96. 【2412.12596】OpenViewer: Openness-Aware Multi-View Learning
+ 链接:https://arxiv.org/abs/2412.12596
+ 作者:Shide Du,Zihan Fang,Yanchao Tan,Changwei Wang,Shiping Wang,Wenzhong Guo
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Applications (stat.AP); Machine Learning (stat.ML)
+ 关键词:methods leverage multiple, learning methods leverage, leverage multiple data, multiple data sources, correlations across views
+ 备注: 16 pages
+
+ 点击查看摘要
+ Abstract:Multi-view learning methods leverage multiple data sources to enhance perception by mining correlations across views, typically relying on predefined categories. However, deploying these models in real-world scenarios presents two primary openness challenges. 1) Lack of Interpretability: The integration mechanisms of multi-view data in existing black-box models remain poorly explained; 2) Insufficient Generalization: Most models are not adapted to multi-view scenarios involving unknown categories. To address these challenges, we propose OpenViewer, an openness-aware multi-view learning framework with theoretical support. This framework begins with a Pseudo-Unknown Sample Generation Mechanism to efficiently simulate open multi-view environments and previously adapt to potential unknown samples. Subsequently, we introduce an Expression-Enhanced Deep Unfolding Network to intuitively promote interpretability by systematically constructing functional prior-mapping modules and effectively providing a more transparent integration mechanism for multi-view data. Additionally, we establish a Perception-Augmented Open-Set Training Regime to significantly enhance generalization by precisely boosting confidences for known categories and carefully suppressing inappropriate confidences for unknown ones. Experimental results demonstrate that OpenViewer effectively addresses openness challenges while ensuring recognition performance for both known and unknown samples. The code is released at this https URL.
+
+
+
+ 97. 【2412.12594】A Simple and Efficient Baseline for Zero-Shot Generative Classification
+ 链接:https://arxiv.org/abs/2412.12594
+ 作者:Zipeng Qi,Buhua Liu,Shiyan Zhang,Bao Li,Zhiqiang Xu,Haoyi Xiong,Zeke Xie
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:industrial AIGC applications, industrial AIGC, Large diffusion models, AIGC applications, mainstream generative models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large diffusion models have become mainstream generative models in both academic studies and industrial AIGC applications. Recently, a number of works further explored how to employ the power of large diffusion models as zero-shot classifiers. While recent zero-shot diffusion-based classifiers have made performance advancement on benchmark datasets, they still suffered badly from extremely slow classification speed (e.g., ~1000 seconds per classifying single image on ImageNet). The extremely slow classification speed strongly prohibits existing zero-shot diffusion-based classifiers from practical applications. In this paper, we propose an embarrassingly simple and efficient zero-shot Gaussian Diffusion Classifiers (GDC) via pretrained text-to-image diffusion models and DINOv2. The proposed GDC can not only significantly surpass previous zero-shot diffusion-based classifiers by over 10 points (61.40% - 71.44%) on ImageNet, but also accelerate more than 30000 times (1000 - 0.03 seconds) classifying a single image on ImageNet. Additionally, it provides probability interpretation of the results. Our extensive experiments further demonstrate that GDC can achieve highly competitive zero-shot classification performance over various datasets and can promisingly self-improve with stronger diffusion models. To the best of our knowledge, the proposed GDC is the first zero-shot diffusionbased classifier that exhibits both competitive accuracy and practical efficiency.
+
+
+
+ 98. 【2412.12572】License Plate Detection and Character Recognition Using Deep Learning and Font Evaluation
+ 链接:https://arxiv.org/abs/2412.12572
+ 作者:Zahra Ebrahimi Vargoorani,Ching Yee Suen
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:diverse font types, vehicle tracking, impacting accuracy, traffic management, Connectionist Temporal Classification
+ 备注: 12 pages, 5 figures. This is the pre-Springer final accepted version. The final version is published in Springer, Lecture Notes in Computer Science (LNCS), Volume 14731, 2024. Springer Version of Record
+
+ 点击查看摘要
+ Abstract:License plate detection (LPD) is essential for traffic management, vehicle tracking, and law enforcement but faces challenges like variable lighting and diverse font types, impacting accuracy. Traditionally reliant on image processing and machine learning, the field is now shifting towards deep learning for its robust performance in various conditions. Current methods, however, often require tailoring to specific regional datasets. This paper proposes a dual deep learning strategy using a Faster R-CNN for detection and a CNN-RNN model with Connectionist Temporal Classification (CTC) loss and a MobileNet V3 backbone for recognition. This approach aims to improve model performance using datasets from Ontario, Quebec, California, and New York State, achieving a recall rate of 92% on the Centre for Pattern Recognition and Machine Intelligence (CENPARMI) dataset and 90% on the UFPR-ALPR dataset. It includes a detailed error analysis to identify the causes of false positives. Additionally, the research examines the role of font features in license plate (LP) recognition, analyzing fonts like Driver Gothic, Dreadnought, California Clarendon, and Zurich Extra Condensed with the OpenALPR system. It discovers significant performance discrepancies influenced by font characteristics, offering insights for future LPD system enhancements.
+Keywords: Deep Learning, License Plate, Font Evaluation
+
Comments:
+12 pages, 5 figures. This is the pre-Springer final accepted version. The final version is published in Springer, Lecture Notes in Computer Science (LNCS), Volume 14731, 2024. Springer Version of Record
+Subjects:
+Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+MSC classes:
+68T10
+ACMclasses:
+I.2.10; I.4.8; I.5.4
+Cite as:
+arXiv:2412.12572 [cs.CV]
+(or
+arXiv:2412.12572v1 [cs.CV] for this version)
+https://doi.org/10.48550/arXiv.2412.12572
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)
+
+Journalreference:
+Springer, Lecture Notes in Computer Science (LNCS), Volume 14731, 2024
+Related DOI:
+https://doi.org/10.1007/978-3-031-71602-7_20
+Focus to learn more
+ DOI(s) linking to related resources</p>
+
+
+
+
+ 99. 【2412.12571】ChatDiT: A Training-Free Baseline for Task-Agnostic Free-Form Chatting with Diffusion Transformers
+ 链接:https://arxiv.org/abs/2412.12571
+ 作者:Lianghua Huang,Wei Wang,Zhi-Fan Wu,Yupeng Shi,Chen Liang,Tong Shen,Han Zhang,Huanzhang Dou,Yu Liu,Jingren Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Recent research arXiv, pretrained diffusion transformers, Recent research, highlighted the inherent, seamlessly adapt
+ 备注: Tech report. Project page: [this https URL](https://ali-vilab.github.io/ChatDiT-Page/)
+
+ 点击查看摘要
+ Abstract:Recent research arXiv:2410.15027 arXiv:2410.23775 has highlighted the inherent in-context generation capabilities of pretrained diffusion transformers (DiTs), enabling them to seamlessly adapt to diverse visual tasks with minimal or no architectural modifications. These capabilities are unlocked by concatenating self-attention tokens across multiple input and target images, combined with grouped and masked generation pipelines. Building upon this foundation, we present ChatDiT, a zero-shot, general-purpose, and interactive visual generation framework that leverages pretrained diffusion transformers in their original form, requiring no additional tuning, adapters, or modifications. Users can interact with ChatDiT to create interleaved text-image articles, multi-page picture books, edit images, design IP derivatives, or develop character design settings, all through free-form natural language across one or more conversational rounds. At its core, ChatDiT employs a multi-agent system comprising three key components: an Instruction-Parsing agent that interprets user-uploaded images and instructions, a Strategy-Planning agent that devises single-step or multi-step generation actions, and an Execution agent that performs these actions using an in-context toolkit of diffusion transformers. We thoroughly evaluate ChatDiT on IDEA-Bench arXiv:2412.11767, comprising 100 real-world design tasks and 275 cases with diverse instructions and varying numbers of input and target images. Despite its simplicity and training-free approach, ChatDiT surpasses all competitors, including those specifically designed and trained on extensive multi-task datasets. We further identify key limitations of pretrained DiTs in zero-shot adapting to tasks. We release all code, agents, results, and intermediate outputs to facilitate further research at this https URL
+
+
+
+ 100. 【2412.12566】ITP: Instance-Aware Test Pruning for Out-of-Distribution Detection
+ 链接:https://arxiv.org/abs/2412.12566
+ 作者:Haonan Xu,Yang Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:OOD detection, OOD, real-world scenarios, crucial for ensuring, deployment of deep
+ 备注:
+
+ 点击查看摘要
+ Abstract:Out-of-distribution (OOD) detection is crucial for ensuring the reliable deployment of deep models in real-world scenarios. Recently, from the perspective of over-parameterization, a series of methods leveraging weight sparsification techniques have shown promising performance. These methods typically focus on selecting important parameters for in-distribution (ID) data to reduce the negative impact of redundant parameters on OOD detection. However, we empirically find that these selected parameters may behave overconfidently toward OOD data and hurt OOD detection. To address this issue, we propose a simple yet effective post-hoc method called Instance-aware Test Pruning (ITP), which performs OOD detection by considering both coarse-grained and fine-grained levels of parameter pruning. Specifically, ITP first estimates the class-specific parameter contribution distribution by exploring the ID data. By using the contribution distribution, ITP conducts coarse-grained pruning to eliminate redundant parameters. More importantly, ITP further adopts a fine-grained test pruning process based on the right-tailed Z-score test, which can adaptively remove instance-level overconfident parameters. Finally, ITP derives OOD scores from the pruned model to achieve more reliable predictions. Extensive experiments on widely adopted benchmarks verify the effectiveness of ITP, demonstrating its competitive performance.
+
+
+
+ 101. 【2412.12565】PBVS 2024 Solution: Self-Supervised Learning and Sampling Strategies for SAR Classification in Extreme Long-Tail Distribution
+ 链接:https://arxiv.org/abs/2412.12565
+ 作者:Yuhyun Kim,Minwoo Kim,Hyobin Park,Jinwook Jung,Dong-Geol Choi
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Synthetic Aperture Radar, automatic target recognition, Aperture Radar, Synthetic Aperture, Multimodal Learning Workshop
+ 备注: 4 pages, 3 figures, 1 Table
+
+ 点击查看摘要
+ Abstract:The Multimodal Learning Workshop (PBVS 2024) aims to improve the performance of automatic target recognition (ATR) systems by leveraging both Synthetic Aperture Radar (SAR) data, which is difficult to interpret but remains unaffected by weather conditions and visible light, and Electro-Optical (EO) data for simultaneous learning. The subtask, known as the Multi-modal Aerial View Imagery Challenge - Classification, focuses on predicting the class label of a low-resolution aerial image based on a set of SAR-EO image pairs and their respective class labels. The provided dataset consists of SAR-EO pairs, characterized by a severe long-tail distribution with over a 1000-fold difference between the largest and smallest classes, making typical long-tail methods difficult to apply. Additionally, the domain disparity between the SAR and EO datasets complicates the effectiveness of standard multimodal methods. To address these significant challenges, we propose a two-stage learning approach that utilizes self-supervised techniques, combined with multimodal learning and inference through SAR-to-EO translation for effective EO utilization. In the final testing phase of the PBVS 2024 Multi-modal Aerial View Image Challenge - Classification (SAR Classification) task, our model achieved an accuracy of 21.45%, an AUC of 0.56, and a total score of 0.30, placing us 9th in the competition.
+
+
+
+ 102. 【2412.12562】Efficient Oriented Object Detection with Enhanced Small Object Recognition in Aerial Images
+ 链接:https://arxiv.org/abs/2412.12562
+ 作者:Zhifei Shi,Zongyao Yin,Sheng Chang,Xiao Yi,Xianchuan Yu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:rotated bounding box, Achieving a balance, bounding box object, box object detection, realm of rotated
+ 备注:
+
+ 点击查看摘要
+ Abstract:Achieving a balance between computational efficiency and detection accuracy in the realm of rotated bounding box object detection within aerial imagery is a significant challenge. While prior research has aimed at creating lightweight models that enhance computational performance and feature extraction, there remains a gap in the performance of these networks when it comes to the detection of small and multi-scale objects in remote sensing (RS) imagery. To address these challenges, we present a novel enhancement to the YOLOv8 model, tailored for oriented object detection tasks and optimized for environments with limited computational resources. Our model features a wavelet transform-based C2f module for capturing associative features and an Adaptive Scale Feature Pyramid (ASFP) module that leverages P2 layer details. Additionally, the incorporation of GhostDynamicConv significantly contributes to the model's lightweight nature, ensuring high efficiency in aerial imagery analysis. Featuring a parameter count of 21.6M, our approach provides a more efficient architectural design than DecoupleNet, which has 23.3M parameters, all while maintaining detection accuracy. On the DOTAv1.0 dataset, our model demonstrates a mean Average Precision (mAP) that is competitive with leading methods such as DecoupleNet. The model's efficiency, combined with its reduced parameter count, makes it a strong candidate for aerial object detection, particularly in resource-constrained environments.
+
+
+
+ 103. 【2412.12561】 Me What to Track: Infusing Robust Language Guidance for Enhanced Referring Multi-Object Tracking
+ 链接:https://arxiv.org/abs/2412.12561
+ 作者:Wenjun Huang,Yang Ni,Hanning Chen,Yirui He,Ian Bryant,Yezi Liu,Mohsen Imani
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:emerging cross-modal task, Referring multi-object tracking, aims to localize, localize an arbitrary, arbitrary number
+ 备注:
+
+ 点击查看摘要
+ Abstract:Referring multi-object tracking (RMOT) is an emerging cross-modal task that aims to localize an arbitrary number of targets based on a language expression and continuously track them in a video. This intricate task involves reasoning on multi-modal data and precise target localization with temporal association. However, prior studies overlook the imbalanced data distribution between newborn targets and existing targets due to the nature of the task. In addition, they only indirectly fuse multi-modal features, struggling to deliver clear guidance on newborn target detection. To solve the above issues, we conduct a collaborative matching strategy to alleviate the impact of the imbalance, boosting the ability to detect newborn targets while maintaining tracking performance. In the encoder, we integrate and enhance the cross-modal and multi-scale fusion, overcoming the bottlenecks in previous work, where limited multi-modal information is shared and interacted between feature maps. In the decoder, we also develop a referring-infused adaptation that provides explicit referring guidance through the query tokens. The experiments showcase the superior performance of our model (+3.42%) compared to prior works, demonstrating the effectiveness of our designs.
+
+
+
+ 104. 【2412.12552】SAModified: A Foundation Model-Based Zero-Shot Approach for Refining Noisy Land-Use Land-Cover Maps
+ 链接:https://arxiv.org/abs/2412.12552
+ 作者:Sparsh Pekhale,Rakshith Sathish,Sathisha Basavaraju,Divya Sharma
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:analysis is critical, remote sensing, urban planning, critical in remote, wide-ranging applications
+ 备注:
+
+ 点击查看摘要
+ Abstract:Land-use and land cover (LULC) analysis is critical in remote sensing, with wide-ranging applications across diverse fields such as agriculture, utilities, and urban planning. However, automating LULC map generation using machine learning is rendered challenging due to noisy labels. Typically, the ground truths (e.g. ESRI LULC, MapBioMass) have noisy labels that hamper the model's ability to learn to accurately classify the pixels. Further, these erroneous labels can significantly distort the performance metrics of a model, leading to misleading evaluations. Traditionally, the ambiguous labels are rectified using unsupervised algorithms. These algorithms struggle not only with scalability but also with generalization across different geographies. To overcome these challenges, we propose a zero-shot approach using the foundation model, Segment Anything Model (SAM), to automatically delineate different land parcels/regions and leverage them to relabel the unsure pixels by using the local label statistics within each detected region. We achieve a significant reduction in label noise and an improvement in the performance of the downstream segmentation model by $\approx 5\%$ when trained with denoised labels.
+
+
+
+ 105. 【2412.12550】Consistent Diffusion: Denoising Diffusion Model with Data-Consistent Training for Image Restoration
+ 链接:https://arxiv.org/abs/2412.12550
+ 作者:Xinlong Cheng,Tiantian Cao,Guoan Cheng,Bangxuan Huang,Xinghan Tian,Ye Wang,Xiaoyu He,Weixin Li,Tianfan Xue,Xuan Dong
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:compromise image quality, denoising diffusion models, image restoration tasks, shape and color, address the limitations
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this work, we address the limitations of denoising diffusion models (DDMs) in image restoration tasks, particularly the shape and color distortions that can compromise image quality. While DDMs have demonstrated a promising performance in many applications such as text-to-image synthesis, their effectiveness in image restoration is often hindered by shape and color distortions. We observe that these issues arise from inconsistencies between the training and testing data used by DDMs. Based on our observation, we propose a novel training method, named data-consistent training, which allows the DDMs to access images with accumulated errors during training, thereby ensuring the model to learn to correct these errors. Experimental results show that, across five image restoration tasks, our method has significant improvements over state-of-the-art methods while effectively minimizing distortions and preserving image fidelity.
+
+
+
+ 106. 【2412.12532】Addressing Small and Imbalanced Medical Image Datasets Using Generative Models: A Comparative Study of DDPM and PGGANs with Random and Greedy K Sampling
+ 链接:https://arxiv.org/abs/2412.12532
+ 作者:Iman Khazrak,Shakhnoza Takhirova,Mostafa M. Rezaee,Mehrdad Yadollahi,Robert C. Green II,Shuteng Niu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Denoising Diffusion Probabilistic, Generative Adversarial Networks, Growing Generative Adversarial, Progressive Growing Generative, Diffusion Probabilistic Models
+ 备注:
+
+ 点击查看摘要
+ Abstract:The development of accurate medical image classification models is often constrained by privacy concerns and data scarcity for certain conditions, leading to small and imbalanced datasets. To address these limitations, this study explores the use of generative models, such as Denoising Diffusion Probabilistic Models (DDPM) and Progressive Growing Generative Adversarial Networks (PGGANs), for dataset augmentation. The research introduces a framework to assess the impact of synthetic images generated by DDPM and PGGANs on the performance of four models: a custom CNN, Untrained VGG16, Pretrained VGG16, and Pretrained ResNet50. Experiments were conducted using Random Sampling and Greedy K Sampling to create small, imbalanced datasets. The synthetic images were evaluated using Frechet Inception Distance (FID) and compared to original datasets through classification metrics. The results show that DDPM consistently generated more realistic images with lower FID scores and significantly outperformed PGGANs in improving classification metrics across all models and datasets. Incorporating DDPM-generated images into the original datasets increased accuracy by up to 6%, enhancing model robustness and stability, particularly in imbalanced scenarios. Random Sampling demonstrated superior stability, while Greedy K Sampling offered diversity at the cost of higher FID scores. This study highlights the efficacy of DDPM in augmenting small, imbalanced medical image datasets, improving model performance by balancing the dataset and expanding its size.
+
+
+
+ 107. 【2412.12525】CREST: An Efficient Conjointly-trained Spike-driven Framework for Event-based Object Detection Exploiting Spatiotemporal Dynamics
+ 链接:https://arxiv.org/abs/2412.12525
+ 作者:Ruixin Mao,Aoyu Shen,Lin Tang,Jun Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:low power consumption, high temporal resolution, wide dynamic range, event-based object detection, event-based object
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Event-based cameras feature high temporal resolution, wide dynamic range, and low power consumption, which is ideal for high-speed and low-light object detection. Spiking neural networks (SNNs) are promising for event-based object recognition and detection due to their spiking nature but lack efficient training methods, leading to gradient vanishing and high computational complexity, especially in deep SNNs. Additionally, existing SNN frameworks often fail to effectively handle multi-scale spatiotemporal features, leading to increased data redundancy and reduced accuracy. To address these issues, we propose CREST, a novel conjointly-trained spike-driven framework to exploit spatiotemporal dynamics in event-based object detection. We introduce the conjoint learning rule to accelerate SNN learning and alleviate gradient vanishing. It also supports dual operation modes for efficient and flexible implementation on different hardware types. Additionally, CREST features a fully spike-driven framework with a multi-scale spatiotemporal event integrator (MESTOR) and a spatiotemporal-IoU (ST-IoU) loss. Our approach achieves superior object recognition detection performance and up to 100X energy efficiency compared with state-of-the-art SNN algorithms on three datasets, providing an efficient solution for event-based object detection algorithms suitable for SNN hardware implementation.
+
+
+
+ 108. 【2412.12511】Invisible Watermarks: Attacks and Robustness
+ 链接:https://arxiv.org/abs/2412.12511
+ 作者:Dongjun Hwang,Sungwon Woo,Tom Gao,Raymond Luo,Sunghwan Baek
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Generative AI continues, combat misinformation, misinformation is stronger, detection of generated, robust detection
+ 备注: YouTube link for the presentation: [this https URL](https://www.youtube.com/watch?v=0vwFG1HSrUE)
+
+ 点击查看摘要
+ Abstract:As Generative AI continues to become more accessible, the case for robust detection of generated images in order to combat misinformation is stronger than ever. Invisible watermarking methods act as identifiers of generated content, embedding image- and latent-space messages that are robust to many forms of perturbations. The majority of current research investigates full-image attacks against images with a single watermarking method applied. We introduce novel improvements to watermarking robustness as well as minimizing degradation on image quality during attack. Firstly, we examine the application of both image-space and latent-space watermarking methods on a single image, where we propose a custom watermark remover network which preserves one of the watermarking modalities while completely removing the other during decoding. Then, we investigate localized blurring attacks (LBA) on watermarked images based on the GradCAM heatmap acquired from the watermark decoder in order to reduce the amount of degradation to the target image. Our evaluation suggests that 1) implementing the watermark remover model to preserve one of the watermark modalities when decoding the other modality slightly improves on the baseline performance, and that 2) LBA degrades the image significantly less compared to uniform blurring of the entire image. Code is available at: this https URL
+
+
+
+ 109. 【2412.12507】3DGUT: Enabling Distorted Cameras and Secondary Rays in Gaussian Splatting
+ 链接:https://arxiv.org/abs/2412.12507
+ 作者:Qi Wu,Janick Martinez Esturo,Ashkan Mirzaei,Nicolas Moenne-Loccoz,Zan Gojcic
+ 类目:Graphics (cs.GR); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:shown great potential, high-fidelity real-time rendering, Gaussian Unscented Transform, consumer hardware, shown great
+ 备注:
+
+ 点击查看摘要
+ Abstract:3D Gaussian Splatting (3DGS) has shown great potential for efficient reconstruction and high-fidelity real-time rendering of complex scenes on consumer hardware. However, due to its rasterization-based formulation, 3DGS is constrained to ideal pinhole cameras and lacks support for secondary lighting effects. Recent methods address these limitations by tracing volumetric particles instead, however, this comes at the cost of significantly slower rendering speeds. In this work, we propose 3D Gaussian Unscented Transform (3DGUT), replacing the EWA splatting formulation in 3DGS with the Unscented Transform that approximates the particles through sigma points, which can be projected exactly under any nonlinear projection function. This modification enables trivial support of distorted cameras with time dependent effects such as rolling shutter, while retaining the efficiency of rasterization. Additionally, we align our rendering formulation with that of tracing-based methods, enabling secondary ray tracing required to represent phenomena such as reflections and refraction within the same 3D representation.
+
+
+
+ 110. 【2412.12503】Multi-Scale Cross-Fusion and Edge-Supervision Network for Image Splicing Localization
+ 链接:https://arxiv.org/abs/2412.12503
+ 作者:Yakun Niu,Pei Chen,Lei Zhang,Hongjian Yin,Qi Chang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Image Splicing Localization, Splicing Localization, Image Splicing, digital forensics, fundamental yet challenging
+ 备注: 5 pages,3 figures
+
+ 点击查看摘要
+ Abstract:Image Splicing Localization (ISL) is a fundamental yet challenging task in digital forensics. Although current approaches have achieved promising performance, the edge information is insufficiently exploited, resulting in poor integrality and high false alarms. To tackle this problem, we propose a multi-scale cross-fusion and edge-supervision network for ISL. Specifically, our framework consists of three key steps: multi-scale features cross-fusion, edge mask prediction and edge-supervision localization. Firstly, we input the RGB image and its noise image into a segmentation network to learn multi-scale features, which are then aggregated via a cross-scale fusion followed by a cross-domain fusion to enhance feature representation. Secondly, we design an edge mask prediction module to effectively mine the reliable boundary artifacts. Finally, the cross-fused features and the reliable edge mask information are seamlessly integrated via an attention mechanism to incrementally supervise and facilitate model training. Extensive experiments on publicly available datasets demonstrate that our proposed method is superior to state-of-the-art schemes.
+
+
+
+ 111. 【2412.12502】rack the Answer: Extending TextVQA from Image to Video with Spatio-Temporal Clues
+ 链接:https://arxiv.org/abs/2412.12502
+ 作者:Yan Zhang,Gangyan Zeng,Huawen Shen,Daiqing Wu,Yu Zhou,Can Ma
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:jointly reasoning textual, Video text-based visual, Video, practical task, task that aims
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Video text-based visual question answering (Video TextVQA) is a practical task that aims to answer questions by jointly reasoning textual and visual information in a given video. Inspired by the development of TextVQA in image domain, existing Video TextVQA approaches leverage a language model (e.g. T5) to process text-rich multiple frames and generate answers auto-regressively. Nevertheless, the spatio-temporal relationships among visual entities (including scene text and objects) will be disrupted and models are susceptible to interference from unrelated information, resulting in irrational reasoning and inaccurate answering. To tackle these challenges, we propose the TEA (stands for ``\textbf{T}rack th\textbf{E} \textbf{A}nswer'') method that better extends the generative TextVQA framework from image to video. TEA recovers the spatio-temporal relationships in a complementary way and incorporates OCR-aware clues to enhance the quality of reasoning questions. Extensive experiments on several public Video TextVQA datasets validate the effectiveness and generalization of our framework. TEA outperforms existing TextVQA methods, video-language pretraining methods and video large language models by great margins.
+
+
+
+ 112. 【2412.12501】Unleashing the Potential of Model Bias for Generalized Category Discovery
+ 链接:https://arxiv.org/abs/2412.12501
+ 作者:Wenbin An,Haonan Lin,Jiahao Nie,Feng Tian,Wenkai Shi,Yaqiang Wu,Qianying Wang,Ping Chen
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Generalized Category Discovery, Generalized Category, Category Discovery, categories, Category
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Generalized Category Discovery is a significant and complex task that aims to identify both known and undefined novel categories from a set of unlabeled data, leveraging another labeled dataset containing only known categories. The primary challenges stem from model bias induced by pre-training on only known categories and the lack of precise supervision for novel ones, leading to category bias towards known categories and category confusion among different novel categories, which hinders models' ability to identify novel categories effectively. To address these challenges, we propose a novel framework named Self-Debiasing Calibration (SDC). Unlike prior methods that regard model bias towards known categories as an obstacle to novel category identification, SDC provides a novel insight into unleashing the potential of the bias to facilitate novel category learning. Specifically, the output of the biased model serves two key purposes. First, it provides an accurate modeling of category bias, which can be utilized to measure the degree of bias and debias the output of the current training model. Second, it offers valuable insights for distinguishing different novel categories by transferring knowledge between similar categories. Based on these insights, SDC dynamically adjusts the output logits of the current training model using the output of the biased model. This approach produces less biased logits to effectively address the issue of category bias towards known categories, and generates more accurate pseudo labels for unlabeled data, thereby mitigating category confusion for novel categories. Experiments on three benchmark datasets show that SDC outperforms SOTA methods, especially in the identification of novel categories. Our code and data are available at \url{this https URL}.
+
+
+
+ 113. 【2412.12496】Faster Vision Mamba is Rebuilt in Minutes via Merged Token Re-training
+ 链接:https://arxiv.org/abs/2412.12496
+ 作者:Mingjia Shi,Yuhao Zhou,Ruiji Yu,Zekai Li,Zhiyuan Liang,Xuanlei Zhao,Xiaojiang Peng,Tanmay Rajpurohit,Shanmukha Ramakrishna Vedantam,Wangbo Zhao,Kai Wang,Yang You
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Vision Transformers, yielded promising outcomes, Vision Mamba, Vision Mamba compared, computer vision
+ 备注:
+
+ 点击查看摘要
+ Abstract:Vision Mamba (e.g., Vim) has successfully been integrated into computer vision, and token reduction has yielded promising outcomes in Vision Transformers (ViTs). However, token reduction performs less effectively on Vision Mamba compared to ViTs. Pruning informative tokens in Mamba leads to a high loss of key knowledge and bad performance. This makes it not a good solution for enhancing efficiency in Mamba. Token merging, which preserves more token information than pruning, has demonstrated commendable performance in ViTs. Nevertheless, vanilla merging performance decreases as the reduction ratio increases either, failing to maintain the key knowledge in Mamba. Re-training the token-reduced model enhances the performance of Mamba, by effectively rebuilding the key knowledge. Empirically, pruned Vims only drop up to 0.9% accuracy on ImageNet-1K, recovered by our proposed framework R-MeeTo in our main evaluation. We show how simple and effective the fast recovery can be achieved at minute-level, in particular, a 35.9% accuracy spike over 3 epochs of training on Vim-Ti. Moreover, Vim-Ti/S/B are re-trained within 5/7/17 minutes, and Vim-S only drop 1.3% with 1.2x (up to 1.5x) speed up in inference.
+
+
+
+ 114. 【2412.12492】DuSSS: Dual Semantic Similarity-Supervised Vision-Language Model for Semi-Supervised Medical Image Segmentation
+ 链接:https://arxiv.org/abs/2412.12492
+ 作者:Qingtao Pan,Wenhao Qiao,Jingjiao Lou,Bing Ji,Shuo Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Semi-supervised medical image, medical image segmentation, pixel-wise manual annotations, regularize model training, Semi-supervised medical
+ 备注:
+
+ 点击查看摘要
+ Abstract:Semi-supervised medical image segmentation (SSMIS) uses consistency learning to regularize model training, which alleviates the burden of pixel-wise manual annotations. However, it often suffers from error supervision from low-quality pseudo labels. Vision-Language Model (VLM) has great potential to enhance pseudo labels by introducing text prompt guided multimodal supervision information. It nevertheless faces the cross-modal problem: the obtained messages tend to correspond to multiple targets. To address aforementioned problems, we propose a Dual Semantic Similarity-Supervised VLM (DuSSS) for SSMIS. Specifically, 1) a Dual Contrastive Learning (DCL) is designed to improve cross-modal semantic consistency by capturing intrinsic representations within each modality and semantic correlations across modalities. 2) To encourage the learning of multiple semantic correspondences, a Semantic Similarity-Supervision strategy (SSS) is proposed and injected into each contrastive learning process in DCL, supervising semantic similarity via the distribution-based uncertainty levels. Furthermore, a novel VLM-based SSMIS network is designed to compensate for the quality deficiencies of pseudo-labels. It utilizes the pretrained VLM to generate text prompt guided supervision information, refining the pseudo label for better consistency regularization. Experimental results demonstrate that our DuSSS achieves outstanding performance with Dice of 82.52%, 74.61% and 78.03% on three public datasets (QaTa-COV19, BM-Seg and MoNuSeg).
+
+
+
+ 115. 【2412.12463】Pattern Analogies: Learning to Perform Programmatic Image Edits by Analogy
+ 链接:https://arxiv.org/abs/2412.12463
+ 作者:Aditya Ganeshan,Thibault Groueix,Paul Guerrero,Radomír Měch,Matthew Fisher,Daniel Ritchie
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Graphics (cs.GR); Human-Computer Interaction (cs.HC)
+ 关键词:physical worlds, digital and physical, Pattern images, Pattern, images
+ 备注: Website: [this https URL](https://bardofcodes.github.io/patterns/)
+
+ 点击查看摘要
+ Abstract:Pattern images are everywhere in the digital and physical worlds, and tools to edit them are valuable. But editing pattern images is tricky: desired edits are often programmatic: structure-aware edits that alter the underlying program which generates the pattern. One could attempt to infer this underlying program, but current methods for doing so struggle with complex images and produce unorganized programs that make editing tedious. In this work, we introduce a novel approach to perform programmatic edits on pattern images. By using a pattern analogy -- a pair of simple patterns to demonstrate the intended edit -- and a learning-based generative model to execute these edits, our method allows users to intuitively edit patterns. To enable this paradigm, we introduce SplitWeave, a domain-specific language that, combined with a framework for sampling synthetic pattern analogies, enables the creation of a large, high-quality synthetic training dataset. We also present TriFuser, a Latent Diffusion Model (LDM) designed to overcome critical issues that arise when naively deploying LDMs to this task. Extensive experiments on real-world, artist-sourced patterns reveals that our method faithfully performs the demonstrated edit while also generalizing to related pattern styles beyond its training distribution.
+
+
+
+ 116. 【2412.12460】PromptDet: A Lightweight 3D Object Detection Framework with LiDAR Prompts
+ 链接:https://arxiv.org/abs/2412.12460
+ 作者:Kun Guo,Qiang Ling
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:object detection aims, space using multiple, cost-effectiveness trade-off, object detection, aims to detect
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Multi-camera 3D object detection aims to detect and localize objects in 3D space using multiple cameras, which has attracted more attention due to its cost-effectiveness trade-off. However, these methods often struggle with the lack of accurate depth estimation caused by the natural weakness of the camera in ranging. Recently, multi-modal fusion and knowledge distillation methods for 3D object detection have been proposed to solve this problem, which are time-consuming during the training phase and not friendly to memory cost. In light of this, we propose PromptDet, a lightweight yet effective 3D object detection framework motivated by the success of prompt learning in 2D foundation model. Our proposed framework, PromptDet, comprises two integral components: a general camera-based detection module, exemplified by models like BEVDet and BEVDepth, and a LiDAR-assisted prompter. The LiDAR-assisted prompter leverages the LiDAR points as a complementary signal, enriched with a minimal set of additional trainable parameters. Notably, our framework is flexible due to our prompt-like design, which can not only be used as a lightweight multi-modal fusion method but also as a camera-only method for 3D object detection during the inference phase. Extensive experiments on nuScenes validate the effectiveness of the proposed PromptDet. As a multi-modal detector, PromptDet improves the mAP and NDS by at most 22.8\% and 21.1\% with fewer than 2\% extra parameters compared with the camera-only baseline. Without LiDAR points, PromptDet still achieves an improvement of at most 2.4\% mAP and 4.0\% NDS with almost no impact on camera detection inference time.
+
+
+
+ 117. 【2412.12432】hree Things to Know about Deep Metric Learning
+ 链接:https://arxiv.org/abs/2412.12432
+ 作者:Yash Patel,Giorgos Tolias,Jiri Matas
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:paper addresses supervised, deep metric learning, addresses supervised deep, supervised deep metric, open-set image retrieval
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper addresses supervised deep metric learning for open-set image retrieval, focusing on three key aspects: the loss function, mixup regularization, and model initialization. In deep metric learning, optimizing the retrieval evaluation metric, recall@k, via gradient descent is desirable but challenging due to its non-differentiable nature. To overcome this, we propose a differentiable surrogate loss that is computed on large batches, nearly equivalent to the entire training set. This computationally intensive process is made feasible through an implementation that bypasses the GPU memory limitations. Additionally, we introduce an efficient mixup regularization technique that operates on pairwise scalar similarities, effectively increasing the batch size even further. The training process is further enhanced by initializing the vision encoder using foundational models, which are pre-trained on large-scale datasets. Through a systematic study of these components, we demonstrate that their synergy enables large models to nearly solve popular benchmarks.
+
+
+
+ 118. 【2412.12392】MASt3R-SLAM: Real-Time Dense SLAM with 3D Reconstruction Priors
+ 链接:https://arxiv.org/abs/2412.12392
+ 作者:Riku Murai,Eric Dexheimer,Andrew J. Davison
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:system designed bottom-up, SLAM system designed, present a real-time, designed bottom-up, real-time monocular dense
+ 备注: The first two authors contributed equally to this work. Project Page: [this https URL](https://edexheim.github.io/mast3r-slam/)
+
+ 点击查看摘要
+ Abstract:We present a real-time monocular dense SLAM system designed bottom-up from MASt3R, a two-view 3D reconstruction and matching prior. Equipped with this strong prior, our system is robust on in-the-wild video sequences despite making no assumption on a fixed or parametric camera model beyond a unique camera centre. We introduce efficient methods for pointmap matching, camera tracking and local fusion, graph construction and loop closure, and second-order global optimisation. With known calibration, a simple modification to the system achieves state-of-the-art performance across various benchmarks. Altogether, we propose a plug-and-play monocular SLAM system capable of producing globally-consistent poses and dense geometry while operating at 15 FPS.
+
+
+
+ 119. 【2412.12391】Efficient Scaling of Diffusion Transformers for Text-to-Image Generation
+ 链接:https://arxiv.org/abs/2412.12391
+ 作者:Hao Li,Shamit Lal,Zhiheng Li,Yusheng Xie,Ying Wang,Yang Zou,Orchid Majumder,R. Manmatha,Zhuowen Tu,Stefano Ermon,Stefano Soatto,Ashwin Swaminathan
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:including training scaled, Diffusion Transformers, training scaled DiTs, scaled DiTs ranging, generation by performing
+ 备注:
+
+ 点击查看摘要
+ Abstract:We empirically study the scaling properties of various Diffusion Transformers (DiTs) for text-to-image generation by performing extensive and rigorous ablations, including training scaled DiTs ranging from 0.3B upto 8B parameters on datasets up to 600M images. We find that U-ViT, a pure self-attention based DiT model provides a simpler design and scales more effectively in comparison with cross-attention based DiT variants, which allows straightforward expansion for extra conditions and other modalities. We identify a 2.3B U-ViT model can get better performance than SDXL UNet and other DiT variants in controlled setting. On the data scaling side, we investigate how increasing dataset size and enhanced long caption improve the text-image alignment performance and the learning efficiency.
+
+
+
+ 120. 【2412.12359】Visual Instruction Tuning with 500x Fewer Parameters through Modality Linear Representation-Steering
+ 链接:https://arxiv.org/abs/2412.12359
+ 作者:Jinhe Bi,Yujun Wang,Haokun Chen,Xun Xiao,Artur Hecker,Volker Tresp,Yunpu Ma
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Multimodal Large Language, Large Language Models, Large Language, Multimodal Large, Language Models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Multimodal Large Language Models (MLLMs) have significantly advanced visual tasks by integrating visual representations into large language models (LLMs). The textual modality, inherited from LLMs, equips MLLMs with abilities like instruction following and in-context learning. In contrast, the visual modality enhances performance in downstream tasks by leveraging rich semantic content, spatial information, and grounding capabilities. These intrinsic modalities work synergistically across various visual tasks. Our research initially reveals a persistent imbalance between these modalities, with text often dominating output generation during visual instruction tuning. This imbalance occurs when using both full fine-tuning and parameter-efficient fine-tuning (PEFT) methods. We then found that re-balancing these modalities can significantly reduce the number of trainable parameters required, inspiring a direction for further optimizing visual instruction tuning. We introduce Modality Linear Representation-Steering (MoReS) to achieve the goal. MoReS effectively re-balances the intrinsic modalities throughout the model, where the key idea is to steer visual representations through linear transformations in the visual subspace across each model layer. To validate our solution, we composed LLaVA Steering, a suite of models integrated with the proposed MoReS method. Evaluation results show that the composed LLaVA Steering models require, on average, 500 times fewer trainable parameters than LoRA needs while still achieving comparable performance across three visual benchmarks and eight visual question-answering tasks. Last, we present the LLaVA Steering Factory, an in-house developed platform that enables researchers to quickly customize various MLLMs with component-based architecture for seamlessly integrating state-of-the-art models, and evaluate their intrinsic modality imbalance.
+
+
+
+ 121. 【2412.12349】Domain Generalization in Autonomous Driving: Evaluating YOLOv8s, RT-DETR, and YOLO-NAS with the ROAD-Almaty Dataset
+ 链接:https://arxiv.org/abs/2412.12349
+ 作者:Madiyar Alimov,Temirlan Meiramkhanov
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:environment of Kazakhstan, unique driving environment, study investigates, object detection models, domain generalization capabilities
+ 备注:
+
+ 点击查看摘要
+ Abstract:This study investigates the domain generalization capabilities of three state-of-the-art object detection models - YOLOv8s, RT-DETR, and YOLO-NAS - within the unique driving environment of Kazakhstan. Utilizing the newly constructed ROAD-Almaty dataset, which encompasses diverse weather, lighting, and traffic conditions, we evaluated the models' performance without any retraining. Quantitative analysis revealed that RT-DETR achieved an average F1-score of 0.672 at IoU=0.5, outperforming YOLOv8s (0.458) and YOLO-NAS (0.526) by approximately 46% and 27%, respectively. Additionally, all models exhibited significant performance declines at higher IoU thresholds (e.g., a drop of approximately 20% when increasing IoU from 0.5 to 0.75) and under challenging environmental conditions, such as heavy snowfall and low-light scenarios. These findings underscore the necessity for geographically diverse training datasets and the implementation of specialized domain adaptation techniques to enhance the reliability of autonomous vehicle detection systems globally. This research contributes to the understanding of domain generalization challenges in autonomous driving, particularly in underrepresented regions.
+
+
+
+ 122. 【2412.12331】Efficient Object-centric Representation Learning with Pre-trained Geometric Prior
+ 链接:https://arxiv.org/abs/2412.12331
+ 作者:Phúc H. Le Khac,Graham Healy,Alan F. Smeaton
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:paper addresses key, addresses key challenges, paper addresses, addresses key, key challenges
+ 备注: 6 pages, 4 Figures, 2 Tables
+
+ 点击查看摘要
+ Abstract:This paper addresses key challenges in object-centric representation learning of video. While existing approaches struggle with complex scenes, we propose a novel weakly-supervised framework that emphasises geometric understanding and leverages pre-trained vision models to enhance object discovery. Our method introduces an efficient slot decoder specifically designed for object-centric learning, enabling effective representation of multi-object scenes without requiring explicit depth information. Results on synthetic video benchmarks with increasing complexity in terms of objects and their movement, object occlusion and camera motion demonstrate that our approach achieves comparable performance to supervised methods while maintaining computational efficiency. This advances the field towards more practical applications in complex real-world scenarios.
+
+
+
+ 123. 【2412.12278】owards a Universal Synthetic Video Detector: From Face or Background Manipulations to Fully AI-Generated Content
+ 链接:https://arxiv.org/abs/2412.12278
+ 作者:Rohit Kundu,Hao Xiong,Vishal Mohanty,Athula Balachandran,Amit K. Roy-Chowdhury
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Existing DeepFake detection, techniques primarily focus, detection techniques primarily, underline, Existing DeepFake
+ 备注:
+
+ 点击查看摘要
+ Abstract:Existing DeepFake detection techniques primarily focus on facial manipulations, such as face-swapping or lip-syncing. However, advancements in text-to-video (T2V) and image-to-video (I2V) generative models now allow fully AI-generated synthetic content and seamless background alterations, challenging face-centric detection methods and demanding more versatile approaches.
+To address this, we introduce the \underline{U}niversal \underline{N}etwork for \underline{I}dentifying \underline{T}ampered and synth\underline{E}tic videos (\texttt{UNITE}) model, which, unlike traditional detectors, captures full-frame manipulations. \texttt{UNITE} extends detection capabilities to scenarios without faces, non-human subjects, and complex background modifications. It leverages a transformer-based architecture that processes domain-agnostic features extracted from videos via the SigLIP-So400M foundation model. Given limited datasets encompassing both facial/background alterations and T2V/I2V content, we integrate task-irrelevant data alongside standard DeepFake datasets in training. We further mitigate the model's tendency to over-focus on faces by incorporating an attention-diversity (AD) loss, which promotes diverse spatial attention across video frames. Combining AD loss with cross-entropy improves detection performance across varied contexts. Comparative evaluations demonstrate that \texttt{UNITE} outperforms state-of-the-art detectors on datasets (in cross-data settings) featuring face/background manipulations and fully synthetic T2V/I2V videos, showcasing its adaptability and generalizable detection capabilities.
+
Subjects:
+Computer Vision and Pattern Recognition (cs.CV)
+Cite as:
+arXiv:2412.12278 [cs.CV]
+(or
+arXiv:2412.12278v1 [cs.CV] for this version)
+https://doi.org/10.48550/arXiv.2412.12278
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 124. 【2412.12242】OmniPrism: Learning Disentangled Visual Concept for Image Generation
+ 链接:https://arxiv.org/abs/2412.12242
+ 作者:Yangyang Li,Daqing Liu,Wu Liu,Allen He,Xinchen Liu,Yongdong Zhang,Guoqing Jin
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:produce relevant outcomes, concept, creative image generation, relevant outcomes, Creative visual concept
+ 备注: WebPage available at [this https URL](https://tale17.github.io/omni/)
+
+ 点击查看摘要
+ Abstract:Creative visual concept generation often draws inspiration from specific concepts in a reference image to produce relevant outcomes. However, existing methods are typically constrained to single-aspect concept generation or are easily disrupted by irrelevant concepts in multi-aspect concept scenarios, leading to concept confusion and hindering creative generation. To address this, we propose OmniPrism, a visual concept disentangling approach for creative image generation. Our method learns disentangled concept representations guided by natural language and trains a diffusion model to incorporate these concepts. We utilize the rich semantic space of a multimodal extractor to achieve concept disentanglement from given images and concept guidance. To disentangle concepts with different semantics, we construct a paired concept disentangled dataset (PCD-200K), where each pair shares the same concept such as content, style, and composition. We learn disentangled concept representations through our contrastive orthogonal disentangled (COD) training pipeline, which are then injected into additional diffusion cross-attention layers for generation. A set of block embeddings is designed to adapt each block's concept domain in the diffusion models. Extensive experiments demonstrate that our method can generate high-quality, concept-disentangled results with high fidelity to text prompts and desired concepts.
+
+
+
+ 125. 【2412.12232】You Only Submit One Image to Find the Most Suitable Generative Model
+ 链接:https://arxiv.org/abs/2412.12232
+ 作者:Zhi Zhou,Lan-Zhe Guo,Peng-Xiao Song,Yu-Feng Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Hugging Face, Face and Civitai, Deep generative models, Deep generative, generative model hubs
+ 备注: Accepted by NeurIPS 2023 Workshop on Diffusion Models
+
+ 点击查看摘要
+ Abstract:Deep generative models have achieved promising results in image generation, and various generative model hubs, e.g., Hugging Face and Civitai, have been developed that enable model developers to upload models and users to download models. However, these model hubs lack advanced model management and identification mechanisms, resulting in users only searching for models through text matching, download sorting, etc., making it difficult to efficiently find the model that best meets user requirements. In this paper, we propose a novel setting called Generative Model Identification (GMI), which aims to enable the user to identify the most appropriate generative model(s) for the user's requirements from a large number of candidate models efficiently. To our best knowledge, it has not been studied yet. In this paper, we introduce a comprehensive solution consisting of three pivotal modules: a weighted Reduced Kernel Mean Embedding (RKME) framework for capturing the generated image distribution and the relationship between images and prompts, a pre-trained vision-language model aimed at addressing dimensionality challenges, and an image interrogator designed to tackle cross-modality issues. Extensive empirical results demonstrate the proposal is both efficient and effective. For example, users only need to submit a single example image to describe their requirements, and the model platform can achieve an average top-4 identification accuracy of more than 80%.
+
+
+
+ 126. 【2412.12223】Can video generation replace cinematographers? Research on the cinematic language of generated video
+ 链接:https://arxiv.org/abs/2412.12223
+ 作者:Xiaozhe Li,Kai WU,Siyi Yang,YiZhan Qu,Guohua.Zhang,Zhiyu Chen,Jiayao Li,Jiangchuan Mu,Xiaobin Hu,Wen Fang,Mingliang Xiong,Hao Deng,Qingwen Liu,Gang Li,Bin He
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Recent advancements, leveraged diffusion models, cinematic language, generation have leveraged, textual descriptions
+ 备注: 13 pages
+
+ 点击查看摘要
+ Abstract:Recent advancements in text-to-video (T2V) generation have leveraged diffusion models to enhance the visual coherence of videos generated from textual descriptions. However, most research has primarily focused on object motion, with limited attention given to cinematic language in videos, which is crucial for cinematographers to convey emotion and narrative pacing. To address this limitation, we propose a threefold approach to enhance the ability of T2V models to generate controllable cinematic language. Specifically, we introduce a cinematic language dataset that encompasses shot framing, angle, and camera movement, enabling models to learn diverse cinematic styles. Building on this, to facilitate robust cinematic alignment evaluation, we present CameraCLIP, a model fine-tuned on the proposed dataset that excels in understanding complex cinematic language in generated videos and can further provide valuable guidance in the multi-shot composition process. Finally, we propose CLIPLoRA, a cost-guided dynamic LoRA composition method that facilitates smooth transitions and realistic blending of cinematic language by dynamically fusing multiple pre-trained cinematic LoRAs within a single video. Our experiments demonstrate that CameraCLIP outperforms existing models in assessing the alignment between cinematic language and video, achieving an R@1 score of 0.81. Additionally, CLIPLoRA improves the ability for multi-shot composition, potentially bridging the gap between automatically generated videos and those shot by professional cinematographers.
+
+
+
+ 127. 【2412.12222】Endangered Alert: A Field-Validated Self-Training Scheme for Detecting and Protecting Threatened Wildlife on Roads and Roadsides
+ 链接:https://arxiv.org/abs/2412.12222
+ 作者:Kunming Li,Mao Shan,Stephany Berrio Perez,Katie Luo,Stewart Worrall
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:global safety concern, Traffic accidents, safety concern, fatalities each year, global safety
+ 备注: 8 pages, 8 figures
+
+ 点击查看摘要
+ Abstract:Traffic accidents are a global safety concern, resulting in numerous fatalities each year. A considerable number of these deaths are caused by animal-vehicle collisions (AVCs), which not only endanger human lives but also present serious risks to animal populations. This paper presents an innovative self-training methodology aimed at detecting rare animals, such as the cassowary in Australia, whose survival is threatened by road accidents. The proposed method addresses critical real-world challenges, including acquiring and labelling sensor data for rare animal species in resource-limited environments. It achieves this by leveraging cloud and edge computing, and automatic data labelling to improve the detection performance of the field-deployed model iteratively. Our approach introduces Label-Augmentation Non-Maximum Suppression (LA-NMS), which incorporates a vision-language model (VLM) to enable automated data labelling. During a five-month deployment, we confirmed the method's robustness and effectiveness, resulting in improved object detection accuracy and increased prediction confidence. The source code is available: this https URL
+
+
+
+ 128. 【2412.12220】Relieving Universal Label Noise for Unsupervised Visible-Infrared Person Re-Identification by Inferring from Neighbors
+ 链接:https://arxiv.org/abs/2412.12220
+ 作者:Xiao Teng,Long Lan,Dingyao Chen,Kele Xu,Nan Yin
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:visible-infrared person re-identification, Unsupervised visible-infrared person, remains challenging due, person re-identification, absence of annotations
+ 备注:
+
+ 点击查看摘要
+ Abstract:Unsupervised visible-infrared person re-identification (USL-VI-ReID) is of great research and practical significance yet remains challenging due to the absence of annotations. Existing approaches aim to learn modality-invariant representations in an unsupervised setting. However, these methods often encounter label noise within and across modalities due to suboptimal clustering results and considerable modality discrepancies, which impedes effective training. To address these challenges, we propose a straightforward yet effective solution for USL-VI-ReID by mitigating universal label noise using neighbor information. Specifically, we introduce the Neighbor-guided Universal Label Calibration (N-ULC) module, which replaces explicit hard pseudo labels in both homogeneous and heterogeneous spaces with soft labels derived from neighboring samples to reduce label noise. Additionally, we present the Neighbor-guided Dynamic Weighting (N-DW) module to enhance training stability by minimizing the influence of unreliable samples. Extensive experiments on the RegDB and SYSU-MM01 datasets demonstrate that our method outperforms existing USL-VI-ReID approaches, despite its simplicity. The source code is available at: this https URL.
+
+
+
+ 129. 【2412.12216】SitPose: Real-Time Detection of Sitting Posture and Sedentary Behavior Using Ensemble Learning With Depth Sensor
+ 链接:https://arxiv.org/abs/2412.12216
+ 作者:Hang Jin,Xin He,Lingyun Wang,Yujun Zhu,Weiwei Jiang,Xiaobo Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:work-related musculoskeletal disorders, Poor sitting posture, Poor sitting, musculoskeletal disorders, work-related musculoskeletal
+ 备注:
+
+ 点击查看摘要
+ Abstract:Poor sitting posture can lead to various work-related musculoskeletal disorders (WMSDs). Office employees spend approximately 81.8% of their working time seated, and sedentary behavior can result in chronic diseases such as cervical spondylosis and cardiovascular diseases. To address these health concerns, we present SitPose, a sitting posture and sedentary detection system utilizing the latest Kinect depth camera. The system tracks 3D coordinates of bone joint points in real-time and calculates the angle values of related joints. We established a dataset containing six different sitting postures and one standing posture, totaling 33,409 data points, by recruiting 36 participants. We applied several state-of-the-art machine learning algorithms to the dataset and compared their performance in recognizing the sitting poses. Our results show that the ensemble learning model based on the soft voting mechanism achieves the highest F1 score of 98.1%. Finally, we deployed the SitPose system based on this ensemble model to encourage better sitting posture and to reduce sedentary habits.
+
+
+
+ 130. 【2412.12208】AI-Driven Innovations in Volumetric Video Streaming: A Review
+ 链接:https://arxiv.org/abs/2412.12208
+ 作者:Erfan Entezami,Hui Guan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:interactive user experiences, volumetric content, volumetric content streaming, efforts to enhance, enhance immersive
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent efforts to enhance immersive and interactive user experiences have driven the development of volumetric video, a form of 3D content that enables 6 DoF. Unlike traditional 2D content, volumetric content can be represented in various ways, such as point clouds, meshes, or neural representations. However, due to its complex structure and large amounts of data size, deploying this new form of 3D data presents significant challenges in transmission and rendering. These challenges have hindered the widespread adoption of volumetric video in daily applications. In recent years, researchers have proposed various AI-driven techniques to address these challenges and improve the efficiency and quality of volumetric content streaming. This paper provides a comprehensive overview of recent advances in AI-driven approaches to facilitate volumetric content streaming. Through this review, we aim to offer insights into the current state-of-the-art and suggest potential future directions for advancing the deployment of volumetric video streaming in real-world applications.
+
+
+
+ 131. 【2412.12206】Provably Secure Robust Image Steganography via Cross-Modal Error Correction
+ 链接:https://arxiv.org/abs/2412.12206
+ 作者:Yuang Qi,Kejiang Chen,Na Zhao,Zijin Yang,Weiming Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Cryptography and Security (cs.CR)
+ 关键词:creating favorable conditions, image generation models, generation models, image generation, provably secure
+ 备注: 7 pages. Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:The rapid development of image generation models has facilitated the widespread dissemination of generated images on social networks, creating favorable conditions for provably secure image steganography. However, existing methods face issues such as low quality of generated images and lack of semantic control in the generation process. To leverage provably secure steganography with more effective and high-performance image generation models, and to ensure that stego images can accurately extract secret messages even after being uploaded to social networks and subjected to lossy processing such as JPEG compression, we propose a high-quality, provably secure, and robust image steganography method based on state-of-the-art autoregressive (AR) image generation models using Vector-Quantized (VQ) tokenizers. Additionally, we employ a cross-modal error-correction framework that generates stego text from stego images to aid in restoring lossy images, ultimately enabling the extraction of secret messages embedded within the images. Extensive experiments have demonstrated that the proposed method provides advantages in stego quality, embedding capacity, and robustness, while ensuring provable undetectability.
+
+
+
+ 132. 【2412.12191】Vehicle Detection and Classification for Toll collection using YOLOv11 and Ensemble OCR
+ 链接:https://arxiv.org/abs/2412.12191
+ 作者:Karthik Sivakoti
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Traditional automated toll, require huge investments, Traditional automated, automated toll collection, complex hardware configurations
+ 备注:
+
+ 点击查看摘要
+ Abstract:Traditional automated toll collection systems depend on complex hardware configurations, that require huge investments in installation and maintenance. This research paper presents an innovative approach to revolutionize automated toll collection by using a single camera per plaza with the YOLOv11 computer vision architecture combined with an ensemble OCR technique. Our system has achieved a Mean Average Precision (mAP) of 0.895 over a wide range of conditions, demonstrating 98.5% accuracy in license plate recognition, 94.2% accuracy in axle detection, and 99.7% OCR confidence scoring. The architecture incorporates intelligent vehicle tracking across IOU regions, automatic axle counting by way of spatial wheel detection patterns, and real-time monitoring through an extended dashboard interface. Extensive training using 2,500 images under various environmental conditions, our solution shows improved performance while drastically reducing hardware resources compared to conventional systems. This research contributes toward intelligent transportation systems by introducing a scalable, precision-centric solution that improves operational efficiency and user experience in modern toll collections.
+
+
+
+ 133. 【2412.12189】Multi-Surrogate-Teacher Assistance for Representation Alignment in Fingerprint-based Indoor Localization
+ 链接:https://arxiv.org/abs/2412.12189
+ 作者:Son Minh Nguyen,Linh Duy Tran,Duc Viet Le,Paul J.M Havinga
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Received Signal Strength, Signal Strength, Received Signal, RSS datasets, remains a challenge
+ 备注: Accepted in the 1st round at WACV 2025 (Algorithm Track)
+
+ 点击查看摘要
+ Abstract:Despite remarkable progress in knowledge transfer across visual and textual domains, extending these achievements to indoor localization, particularly for learning transferable representations among Received Signal Strength (RSS) fingerprint datasets, remains a challenge. This is due to inherent discrepancies among these RSS datasets, largely including variations in building structure, the input number and disposition of WiFi anchors. Accordingly, specialized networks, which were deprived of the ability to discern transferable representations, readily incorporate environment-sensitive clues into the learning process, hence limiting their potential when applied to specific RSS datasets. In this work, we propose a plug-and-play (PnP) framework of knowledge transfer, facilitating the exploitation of transferable representations for specialized networks directly on target RSS datasets through two main phases. Initially, we design an Expert Training phase, which features multiple surrogate generative teachers, all serving as a global adapter that homogenizes the input disparities among independent source RSS datasets while preserving their unique characteristics. In a subsequent Expert Distilling phase, we continue introducing a triplet of underlying constraints that requires minimizing the differences in essential knowledge between the specialized network and surrogate teachers through refining its representation learning on the target dataset. This process implicitly fosters a representational alignment in such a way that is less sensitive to specific environmental dynamics. Extensive experiments conducted on three benchmark WiFi RSS fingerprint datasets underscore the effectiveness of the framework that significantly exerts the full potential of specialized networks in localization.
+
+
+
+ 134. 【2412.12165】Multimodal Approaches to Fair Image Classification: An Ethical Perspective
+ 链接:https://arxiv.org/abs/2412.12165
+ 作者:Javon Hickmon
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computers and Society (cs.CY); Machine Learning (cs.LG)
+ 关键词:achieving increased performance, rapidly advancing field, artificial intelligence, increased performance, rapidly advancing
+ 备注: Bachelor's thesis
+
+ 点击查看摘要
+ Abstract:In the rapidly advancing field of artificial intelligence, machine perception is becoming paramount to achieving increased performance. Image classification systems are becoming increasingly integral to various applications, ranging from medical diagnostics to image generation; however, these systems often exhibit harmful biases that can lead to unfair and discriminatory outcomes. Machine Learning systems that depend on a single data modality, i.e. only images or only text, can exaggerate hidden biases present in the training data, if the data is not carefully balanced and filtered. Even so, these models can still harm underrepresented populations when used in improper contexts, such as when government agencies reinforce racial bias using predictive policing. This thesis explores the intersection of technology and ethics in the development of fair image classification models. Specifically, I focus on improving fairness and methods of using multiple modalities to combat harmful demographic bias. Integrating multimodal approaches, which combine visual data with additional modalities such as text and metadata, allows this work to enhance the fairness and accuracy of image classification systems. The study critically examines existing biases in image datasets and classification algorithms, proposes innovative methods for mitigating these biases, and evaluates the ethical implications of deploying such systems in real-world scenarios. Through comprehensive experimentation and analysis, the thesis demonstrates how multimodal techniques can contribute to more equitable and ethical AI solutions, ultimately advocating for responsible AI practices that prioritize fairness.
+
+
+
+ 135. 【2412.12150】Rethinking Comprehensive Benchmark for Chart Understanding: A Perspective from Scientific Literature
+ 链接:https://arxiv.org/abs/2412.12150
+ 作者:Lingdong Shen,Qigqi,Kun Ding,Gaofeng Meng,Shiming Xiang
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:including multi-plot figures, Scientific Literature charts, Scientific Literature, complex visual elements, Literature charts
+ 备注:
+
+ 点击查看摘要
+ Abstract:Scientific Literature charts often contain complex visual elements, including multi-plot figures, flowcharts, structural diagrams and etc. Evaluating multimodal models using these authentic and intricate charts provides a more accurate assessment of their understanding abilities. However, existing benchmarks face limitations: a narrow range of chart types, overly simplistic template-based questions and visual elements, and inadequate evaluation methods. These shortcomings lead to inflated performance scores that fail to hold up when models encounter real-world scientific charts. To address these challenges, we introduce a new benchmark, Scientific Chart QA (SCI-CQA), which emphasizes flowcharts as a critical yet often overlooked category. To overcome the limitations of chart variety and simplistic visual elements, we curated a dataset of 202,760 image-text pairs from 15 top-tier computer science conferences papers over the past decade. After rigorous filtering, we refined this to 37,607 high-quality charts with contextual information. SCI-CQA also introduces a novel evaluation framework inspired by human exams, encompassing 5,629 carefully curated questions, both objective and open-ended. Additionally, we propose an efficient annotation pipeline that significantly reduces data annotation costs. Finally, we explore context-based chart understanding, highlighting the crucial role of contextual information in solving previously unanswerable questions.
+
+
+
+ 136. 【2412.12149】MHSA: A Multi-scale Hypergraph Network for Mild Cognitive Impairment Detection via Synchronous and Attentive Fusion
+ 链接:https://arxiv.org/abs/2412.12149
+ 作者:Manman Yuan,Weiming Jia,Xiong Luo,Jiazhen Ye,Peican Zhu,Junlin Li
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:mild cognitive impairment, cognitive impairment, timely manner, Multi-scale Hypergraph Network, mild cognitive
+ 备注: International Conference on Bioinformatics and Biomedicine 2024(BIBM 2024)
+
+ 点击查看摘要
+ Abstract:The precise detection of mild cognitive impairment (MCI) is of significant importance in preventing the deterioration of patients in a timely manner. Although hypergraphs have enhanced performance by learning and analyzing brain networks, they often only depend on vector distances between features at a single scale to infer interactions. In this paper, we deal with a more arduous challenge, hypergraph modelling with synchronization between brain regions, and design a novel framework, i.e., A Multi-scale Hypergraph Network for MCI Detection via Synchronous and Attentive Fusion (MHSA), to tackle this challenge. Specifically, our approach employs the Phase-Locking Value (PLV) to calculate the phase synchronization relationship in the spectrum domain of regions of interest (ROIs) and designs a multi-scale feature fusion mechanism to integrate dynamic connectivity features of functional magnetic resonance imaging (fMRI) from both the temporal and spectrum domains. To evaluate and optimize the direct contribution of each ROI to phase synchronization in the temporal domain, we structure the PLV coefficients dynamically adjust strategy, and the dynamic hypergraph is modelled based on a comprehensive temporal-spectrum fusion matrix. Experiments on the real-world dataset indicate the effectiveness of our strategy. The code is available at this https URL.
+
+
+
+ 137. 【2412.12129】SceneDiffuser: Efficient and Controllable Driving Simulation Initialization and Rollout
+ 链接:https://arxiv.org/abs/2412.12129
+ 作者:Chiyu Max Jiang,Yijing Bai,Andre Cornman,Christopher Davis,Xiukun Huang,Hong Jeon,Sakshum Kulshrestha,John Lambert,Shuangyu Li,Xuanyu Zhou,Carlos Fuertes,Chang Yuan,Mingxing Tan,Yin Zhou,Dragomir Anguelov
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:autonomous vehicle, prerequisite for autonomous, Realistic and interactive, simulation, interactive scene simulation
+ 备注: Accepted to NeurIPS 2024
+
+ 点击查看摘要
+ Abstract:Realistic and interactive scene simulation is a key prerequisite for autonomous vehicle (AV) development. In this work, we present SceneDiffuser, a scene-level diffusion prior designed for traffic simulation. It offers a unified framework that addresses two key stages of simulation: scene initialization, which involves generating initial traffic layouts, and scene rollout, which encompasses the closed-loop simulation of agent behaviors. While diffusion models have been proven effective in learning realistic and multimodal agent distributions, several challenges remain, including controllability, maintaining realism in closed-loop simulations, and ensuring inference efficiency. To address these issues, we introduce amortized diffusion for simulation. This novel diffusion denoising paradigm amortizes the computational cost of denoising over future simulation steps, significantly reducing the cost per rollout step (16x less inference steps) while also mitigating closed-loop errors. We further enhance controllability through the introduction of generalized hard constraints, a simple yet effective inference-time constraint mechanism, as well as language-based constrained scene generation via few-shot prompting of a large language model (LLM). Our investigations into model scaling reveal that increased computational resources significantly improve overall simulation realism. We demonstrate the effectiveness of our approach on the Waymo Open Sim Agents Challenge, achieving top open-loop performance and the best closed-loop performance among diffusion models.
+
+
+
+ 138. 【2412.12126】Seamless Optical Cloud Computing across Edge-Metro Network for Generative AI
+ 链接:https://arxiv.org/abs/2412.12126
+ 作者:Sizhe Xing,Aolong Sun,Chengxi Wang,Yizhi Wang,Boyu Dong,Junhui Hu,Xuyu Deng,An Yan,Yingjun Liu,Fangchen Hu,Zhongya Li,Ouhan Huang,Junhao Zhao,Yingjun Zhou,Ziwei Li,Jianyang Shi,Xi Xiao,Richard Penty,Qixiang Cheng,Nan Chi,Junwen Zhang
+ 类目:Distributed, Parallel, and Cluster Computing (cs.DC); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Image and Video Processing (eess.IV); Signal Processing (eess.SP)
+ 关键词:reshaped modern lifestyles, profoundly reshaped modern, generative artificial intelligence, artificial intelligence, modern lifestyles
+ 备注:
+
+ 点击查看摘要
+ Abstract:The rapid advancement of generative artificial intelligence (AI) in recent years has profoundly reshaped modern lifestyles, necessitating a revolutionary architecture to support the growing demands for computational power. Cloud computing has become the driving force behind this transformation. However, it consumes significant power and faces computation security risks due to the reliance on extensive data centers and servers in the cloud. Reducing power consumption while enhancing computational scale remains persistent challenges in cloud computing. Here, we propose and experimentally demonstrate an optical cloud computing system that can be seamlessly deployed across edge-metro network. By modulating inputs and models into light, a wide range of edge nodes can directly access the optical computing center via the edge-metro network. The experimental validations show an energy efficiency of 118.6 mW/TOPs (tera operations per second), reducing energy consumption by two orders of magnitude compared to traditional electronic-based cloud computing solutions. Furthermore, it is experimentally validated that this architecture can perform various complex generative AI models through parallel computing to achieve image generation tasks.
+
+
+
+ 139. 【2412.12121】NLLG Quarterly arXiv Report 09/24: What are the most influential current AI Papers?
+ 链接:https://arxiv.org/abs/2412.12121
+ 作者:Christoph Leiter,Jonas Belouadi,Yanran Chen,Ran Zhang,Daniil Larionov,Aida Kostikova,Steffen Eger
+ 类目:Digital Libraries (cs.DL); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:rapidly evolving landscape, Language Learning Generation, arXiv reports assist, Natural Language Learning, Learning Generation
+ 备注:
+
+ 点击查看摘要
+ Abstract:The NLLG (Natural Language Learning Generation) arXiv reports assist in navigating the rapidly evolving landscape of NLP and AI research across cs.CL, cs.CV, cs.AI, and cs.LG categories. This fourth installment captures a transformative period in AI history - from January 1, 2023, following ChatGPT's debut, through September 30, 2024. Our analysis reveals substantial new developments in the field - with 45% of the top 40 most-cited papers being new entries since our last report eight months ago and offers insights into emerging trends and major breakthroughs, such as novel multimodal architectures, including diffusion and state space models. Natural Language Processing (NLP; cs.CL) remains the dominant main category in the list of our top-40 papers but its dominance is on the decline in favor of Computer vision (cs.CV) and general machine learning (cs.LG). This report also presents novel findings on the integration of generative AI in academic writing, documenting its increasing adoption since 2022 while revealing an intriguing pattern: top-cited papers show notably fewer markers of AI-generated content compared to random samples. Furthermore, we track the evolution of AI-associated language, identifying declining trends in previously common indicators such as "delve".
+
+
+
+ 140. 【2307.09456】A comparative analysis of SRGAN models
+ 链接:https://arxiv.org/abs/2307.09456
+ 作者:Fatemeh Rezapoor Nikroo,Ajinkya Deshmukh,Anantha Sharma,Adrian Tam,Kaarthik Kumar,Cleo Norris,Aditya Dangi
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Image and Video Processing (eess.IV)
+ 关键词:Generative Adversarial Network, Super Resolution Generative, Resolution Generative Adversarial, Adversarial Network, Generative Adversarial
+ 备注: 9 pages, 6 tables, 2 figures
+
+ 点击查看摘要
+ Abstract:In this study, we evaluate the performance of multiple state-of-the-art SRGAN (Super Resolution Generative Adversarial Network) models, ESRGAN, Real-ESRGAN and EDSR, on a benchmark dataset of real-world images which undergo degradation using a pipeline. Our results show that some models seem to significantly increase the resolution of the input images while preserving their visual quality, this is assessed using Tesseract OCR engine. We observe that EDSR-BASE model from huggingface outperforms the remaining candidate models in terms of both quantitative metrics and subjective visual quality assessments with least compute overhead. Specifically, EDSR generates images with higher peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) values and are seen to return high quality OCR results with Tesseract OCR engine. These findings suggest that EDSR is a robust and effective approach for single-image super-resolution and may be particularly well-suited for applications where high-quality visual fidelity is critical and optimized compute.
+
+
+
+ 141. 【2412.13137】Unlocking the Potential of Digital Pathology: Novel Baselines for Compression
+ 链接:https://arxiv.org/abs/2412.13137
+ 作者:Maximilian Fischer,Peter Neher,Peter Schüffler,Sebastian Ziegler,Shuhan Xiao,Robin Peretzke,David Clunie,Constantin Ulrich,Michael Baumgartner,Alexander Muckenhuber,Silvia Dias Almeida,Michael Götz,Jens Kleesiek,Marco Nolden,Rickmer Braren,Klaus Maier-Hein
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:histopathological image analysis, pathological Whole Slide, Digital pathology offers, Slide Images, transform clinical practice
+ 备注:
+
+ 点击查看摘要
+ Abstract:Digital pathology offers a groundbreaking opportunity to transform clinical practice in histopathological image analysis, yet faces a significant hurdle: the substantial file sizes of pathological Whole Slide Images (WSI). While current digital pathology solutions rely on lossy JPEG compression to address this issue, lossy compression can introduce color and texture disparities, potentially impacting clinical decision-making. While prior research addresses perceptual image quality and downstream performance independently of each other, we jointly evaluate compression schemes for perceptual and downstream task quality on four different datasets. In addition, we collect an initially uncompressed dataset for an unbiased perceptual evaluation of compression schemes. Our results show that deep learning models fine-tuned for perceptual quality outperform conventional compression schemes like JPEG-XL or WebP for further compression of WSI. However, they exhibit a significant bias towards the compression artifacts present in the training data and struggle to generalize across various compression schemes. We introduce a novel evaluation metric based on feature similarity between original files and compressed files that aligns very well with the actual downstream performance on the compressed WSI. Our metric allows for a general and standardized evaluation of lossy compression schemes and mitigates the requirement to independently assess different downstream tasks. Our study provides novel insights for the assessment of lossy compression schemes for WSI and encourages a unified evaluation of lossy compression schemes to accelerate the clinical uptake of digital pathology.
+
+
+
+ 142. 【2412.13126】A Knowledge-enhanced Pathology Vision-language Foundation Model for Cancer Diagnosis
+ 链接:https://arxiv.org/abs/2412.13126
+ 作者:Xiao Zhou,Luoyi Sun,Dexuan He,Wenbin Guan,Ruifen Wang,Lifeng Wang,Xin Sun,Kun Sun,Ya Zhang,Yanfeng Wang,Weidi Xie
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Deep learning, highly robust foundation, patient cohorts, learning has enabled, enabled the development
+ 备注:
+
+ 点击查看摘要
+ Abstract:Deep learning has enabled the development of highly robust foundation models for various pathological tasks across diverse diseases and patient cohorts. Among these models, vision-language pre-training, which leverages large-scale paired data to align pathology image and text embedding spaces, and provides a novel zero-shot paradigm for downstream tasks. However, existing models have been primarily data-driven and lack the incorporation of domain-specific knowledge, which limits their performance in cancer diagnosis, especially for rare tumor subtypes. To address this limitation, we establish a Knowledge-enhanced Pathology (KEEP) foundation model that harnesses disease knowledge to facilitate vision-language pre-training. Specifically, we first construct a disease knowledge graph (KG) that covers 11,454 human diseases with 139,143 disease attributes, including synonyms, definitions, and hypernym relations. We then systematically reorganize the millions of publicly available noisy pathology image-text pairs, into 143K well-structured semantic groups linked through the hierarchical relations of the disease KG. To derive more nuanced image and text representations, we propose a novel knowledge-enhanced vision-language pre-training approach that integrates disease knowledge into the alignment within hierarchical semantic groups instead of unstructured image-text pairs. Validated on 18 diverse benchmarks with more than 14,000 whole slide images (WSIs), KEEP achieves state-of-the-art performance in zero-shot cancer diagnostic tasks. Notably, for cancer detection, KEEP demonstrates an average sensitivity of 89.8% at a specificity of 95.0% across 7 cancer types. For cancer subtyping, KEEP achieves a median balanced accuracy of 0.456 in subtyping 30 rare brain cancers, indicating strong generalizability for diagnosing rare tumors.
+
+
+
+ 143. 【2412.13070】Learning of Patch-Based Smooth-Plus-Sparse Models for Image Reconstruction
+ 链接:https://arxiv.org/abs/2412.13070
+ 作者:Stanislas Ducotterd,Sebastian Neumayer,Michael Unser
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Signal Processing (eess.SP)
+ 关键词:penalized sparse representation, solution of inverse, combining a penalized, penalized sparse, sparse representation
+ 备注:
+
+ 点击查看摘要
+ Abstract:We aim at the solution of inverse problems in imaging, by combining a penalized sparse representation of image patches with an unconstrained smooth one. This allows for a straightforward interpretation of the reconstruction. We formulate the optimization as a bilevel problem. The inner problem deploys classical algorithms while the outer problem optimizes the dictionary and the regularizer parameters through supervised learning. The process is carried out via implicit differentiation and gradient-based optimization. We evaluate our method for denoising, super-resolution, and compressed-sensing magnetic-resonance imaging. We compare it to other classical models as well as deep-learning-based methods and show that it always outperforms the former and also the latter in some instances.
+
+
+
+ 144. 【2412.13059】3D MedDiffusion: A 3D Medical Diffusion Model for Controllable and High-quality Medical Image Generation
+ 链接:https://arxiv.org/abs/2412.13059
+ 作者:Haoshen Wang,Zhentao Liu,Kaicong Sun,Xiaodong Wang,Dinggang Shen,Zhiming Cui
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:presents significant challenges, significant challenges due, images presents significant, medical images presents, three-dimensional nature
+ 备注:
+
+ 点击查看摘要
+ Abstract:The generation of medical images presents significant challenges due to their high-resolution and three-dimensional nature. Existing methods often yield suboptimal performance in generating high-quality 3D medical images, and there is currently no universal generative framework for medical imaging. In this paper, we introduce the 3D Medical Diffusion (3D MedDiffusion) model for controllable, high-quality 3D medical image generation. 3D MedDiffusion incorporates a novel, highly efficient Patch-Volume Autoencoder that compresses medical images into latent space through patch-wise encoding and recovers back into image space through volume-wise decoding. Additionally, we design a new noise estimator to capture both local details and global structure information during diffusion denoising process. 3D MedDiffusion can generate fine-detailed, high-resolution images (up to 512x512x512) and effectively adapt to various downstream tasks as it is trained on large-scale datasets covering CT and MRI modalities and different anatomical regions (from head to leg). Experimental results demonstrate that 3D MedDiffusion surpasses state-of-the-art methods in generative quality and exhibits strong generalizability across tasks such as sparse-view CT reconstruction, fast MRI reconstruction, and data augmentation.
+
+
+
+ 145. 【2412.12982】Stable Diffusion is a Natural Cross-Modal Decoder for Layered AI-generated Image Compression
+ 链接:https://arxiv.org/abs/2412.12982
+ 作者:Ruijie Chen,Qi Mao,Zhengxue Cheng
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Intelligence Generated Content, Artificial Intelligence Generated, Generated Content, garnered significant interest, Artificial Intelligence
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advances in Artificial Intelligence Generated Content (AIGC) have garnered significant interest, accompanied by an increasing need to transmit and compress the vast number of AI-generated images (AIGIs). However, there is a noticeable deficiency in research focused on compression methods for AIGIs. To address this critical gap, we introduce a scalable cross-modal compression framework that incorporates multiple human-comprehensible modalities, designed to efficiently capture and relay essential visual information for AIGIs. In particular, our framework encodes images into a layered bitstream consisting of a semantic layer that delivers high-level semantic information through text prompts; a structural layer that captures spatial details using edge or skeleton maps; and a texture layer that preserves local textures via a colormap. Utilizing Stable Diffusion as the backend, the framework effectively leverages these multimodal priors for image generation, effectively functioning as a decoder when these priors are encoded. Qualitative and quantitative results show that our method proficiently restores both semantic and visual details, competing against baseline approaches at extremely low bitrates ( 0.02 bpp). Additionally, our framework facilitates downstream editing applications without requiring full decoding, thereby paving a new direction for future research in AIGI compression.
+
+
+
+ 146. 【2412.12944】Online optimisation for dynamic electrical impedance tomography
+ 链接:https://arxiv.org/abs/2412.12944
+ 作者:Neil Dizon,Jyrki Jauhiainen,Tuomo Valkonen
+ 类目:Optimization and Control (math.OC); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Online optimisation studies, Electrical Impedance Tomography, optimisation studies, studies the convergence, data embedded
+ 备注:
+
+ 点击查看摘要
+ Abstract:Online optimisation studies the convergence of optimisation methods as the data embedded in the problem changes. Based on this idea, we propose a primal dual online method for nonlinear time-discrete inverse problems. We analyse the method through regret theory and demonstrate its performance in real-time monitoring of moving bodies in a fluid with Electrical Impedance Tomography (EIT). To do so, we also prove the second-order differentiability of the Complete Electrode Model (CEM) solution operator on $L^\infty$.
+
+
+
+ 147. 【2412.12919】4DRGS: 4D Radiative Gaussian Splatting for Efficient 3D Vessel Reconstruction from Sparse-View Dynamic DSA Images
+ 链接:https://arxiv.org/abs/2412.12919
+ 作者:Zhentao Liu,Ruyi Zha,Huangxuan Zhao,Hongdong Li,Zhiming Cui
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:digital subtraction angiography, reducing radiation exposure, sparse-view dynamic digital, dynamic digital subtraction, enables accurate medical
+ 备注: Zhentao Liu and Ruyi Zha made equal contributions
+
+ 点击查看摘要
+ Abstract:Reconstructing 3D vessel structures from sparse-view dynamic digital subtraction angiography (DSA) images enables accurate medical assessment while reducing radiation exposure. Existing methods often produce suboptimal results or require excessive computation time. In this work, we propose 4D radiative Gaussian splatting (4DRGS) to achieve high-quality reconstruction efficiently. In detail, we represent the vessels with 4D radiative Gaussian kernels. Each kernel has time-invariant geometry parameters, including position, rotation, and scale, to model static vessel structures. The time-dependent central attenuation of each kernel is predicted from a compact neural network to capture the temporal varying response of contrast agent flow. We splat these Gaussian kernels to synthesize DSA images via X-ray rasterization and optimize the model with real captured ones. The final 3D vessel volume is voxelized from the well-trained kernels. Moreover, we introduce accumulated attenuation pruning and bounded scaling activation to improve reconstruction quality. Extensive experiments on real-world patient data demonstrate that 4DRGS achieves impressive results in 5 minutes training, which is 32x faster than the state-of-the-art method. This underscores the potential of 4DRGS for real-world clinics.
+
+
+
+ 148. 【2412.12853】Automatic Left Ventricular Cavity Segmentation via Deep Spatial Sequential Network in 4D Computed Tomography Studies
+ 链接:https://arxiv.org/abs/2412.12853
+ 作者:Yuyu Guo,Lei Bi,Zhengbin Zhu,David Dagan Feng,Ruiyan Zhang,Qian Wang,Jinman Kim
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:multiple time points, time points, left ventricular cavity, single time points, temporal image sequences
+ 备注: 9 pages
+
+ 点击查看摘要
+ Abstract:Automated segmentation of left ventricular cavity (LVC) in temporal cardiac image sequences (multiple time points) is a fundamental requirement for quantitative analysis of its structural and functional changes. Deep learning based methods for the segmentation of LVC are the state of the art; however, these methods are generally formulated to work on single time points, and fails to exploit the complementary information from the temporal image sequences that can aid in segmentation accuracy and consistency among the images across the time points. Furthermore, these segmentation methods perform poorly in segmenting the end-systole (ES) phase images, where the left ventricle deforms to the smallest irregular shape, and the boundary between the blood chamber and myocardium becomes inconspicuous. To overcome these limitations, we propose a new method to automatically segment temporal cardiac images where we introduce a spatial sequential (SS) network to learn the deformation and motion characteristics of the LVC in an unsupervised manner; these characteristics were then integrated with sequential context information derived from bi-directional learning (BL) where both chronological and reverse-chronological directions of the image sequence were used. Our experimental results on a cardiac computed tomography (CT) dataset demonstrated that our spatial-sequential network with bi-directional learning (SS-BL) method outperformed existing methods for LVC segmentation. Our method was also applied to MRI cardiac dataset and the results demonstrated the generalizability of our method.
+
+
+
+ 149. 【2412.12743】raining a Distributed Acoustic Sensing Traffic Monitoring Network With Video Inputs
+ 链接:https://arxiv.org/abs/2412.12743
+ 作者:Khen Cohen,Liav Hen,Ariel Lellouch
+ 类目:Geophysics (physics.geo-ph); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Signal Processing (eess.SP); Optics (physics.optics)
+ 关键词:Distributed Acoustic Sensing, Distributed Acoustic, Acoustic Sensing, densely populated areas, populated areas
+ 备注: 12 pages, 11 figures, 5 appendices. Shared dataset in: [this https URL](https://zenodo.org/records/14502092)
+
+ 点击查看摘要
+ Abstract:Distributed Acoustic Sensing (DAS) has emerged as a promising tool for real-time traffic monitoring in densely populated areas. In this paper, we present a novel concept that integrates DAS data with co-located visual information. We use YOLO-derived vehicle location and classification from camera inputs as labeled data to train a detection and classification neural network utilizing DAS data only. Our model achieves a performance exceeding 94% for detection and classification, and about 1.2% false alarm rate. We illustrate the model's application in monitoring traffic over a week, yielding statistical insights that could benefit future smart city developments. Our approach highlights the potential of combining fiber-optic sensors with visual information, focusing on practicality and scalability, protecting privacy, and minimizing infrastructure costs. To encourage future research, we share our dataset.
+
+
+
+ 150. 【2412.12709】Accelerating lensed quasars discovery and modeling with physics-informed variational autoencoders
+ 链接:https://arxiv.org/abs/2412.12709
+ 作者:Irham T. Andika,Stefan Schuldt,Sherry H. Suyu,Satadru Bag,Raoul Cañameras,Alejandra Melo,Claudio Grillo,James H. H. Chan
+ 类目:Astrophysics of Galaxies (astro-ph.GA); Cosmology and Nongalactic Astrophysics (astro-ph.CO); Instrumentation and Methods for Astrophysics (astro-ph.IM); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:provide valuable insights, Strongly lensed quasars, quasars provide valuable, Strongly lensed, cosmic expansion
+ 备注: Submitted to the Astronomy Astrophysics journal. The paper consists of 17 main pages, 14 figures, and 5 tables. We welcome feedback and comments from readers!
+
+ 点击查看摘要
+ Abstract:Strongly lensed quasars provide valuable insights into the rate of cosmic expansion, the distribution of dark matter in foreground deflectors, and the characteristics of quasar hosts. However, detecting them in astronomical images is difficult due to the prevalence of non-lensing objects. To address this challenge, we developed a generative deep learning model called VariLens, built upon a physics-informed variational autoencoder. This model seamlessly integrates three essential modules: image reconstruction, object classification, and lens modeling, offering a fast and comprehensive approach to strong lens analysis. VariLens is capable of rapidly determining both (1) the probability that an object is a lens system and (2) key parameters of a singular isothermal ellipsoid (SIE) mass model -- including the Einstein radius ($\theta_\mathrm{E}$), lens center, and ellipticity -- in just milliseconds using a single CPU. A direct comparison of VariLens estimates with traditional lens modeling for 20 known lensed quasars within the Subaru Hyper Suprime-Cam (HSC) footprint shows good agreement, with both results consistent within $2\sigma$ for systems with $\theta_\mathrm{E}3$ arcsecs. To identify new lensed quasar candidates, we begin with an initial sample of approximately 80 million sources, combining HSC data with multiwavelength information from various surveys. After applying a photometric preselection aimed at locating $z1.5$ sources, the number of candidates is reduced to 710,966. Subsequently, VariLens highlights 13,831 sources, each showing a high likelihood of being a lens. A visual assessment of these objects results in 42 promising candidates that await spectroscopic confirmation. These results underscore the potential of automated deep learning pipelines to efficiently detect and model strong lenses in large datasets.
+
+
+
+ 151. 【2412.12629】a2z-1 for Multi-Disease Detection in Abdomen-Pelvis CT: External Validation and Performance Analysis Across 21 Conditions
+ 链接:https://arxiv.org/abs/2412.12629
+ 作者:Pranav Rajpurkar,Julian N. Acosta,Siddhant Dogra,Jaehwan Jeong,Deepanshu Jindal,Michael Moritz,Samir Rajpurkar
+ 类目:Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:artificial intelligence, time-sensitive and actionable, present a comprehensive, designed to analyze, analyze abdomen-pelvis
+ 备注:
+
+ 点击查看摘要
+ Abstract:We present a comprehensive evaluation of a2z-1, an artificial intelligence (AI) model designed to analyze abdomen-pelvis CT scans for 21 time-sensitive and actionable findings. Our study focuses on rigorous assessment of the model's performance and generalizability. Large-scale retrospective analysis demonstrates an average AUC of 0.931 across 21 conditions. External validation across two distinct health systems confirms consistent performance (AUC 0.923), establishing generalizability to different evaluation scenarios, with notable performance in critical findings such as small bowel obstruction (AUC 0.958) and acute pancreatitis (AUC 0.961). Subgroup analysis shows consistent accuracy across patient sex, age groups, and varied imaging protocols, including different slice thicknesses and contrast administration types. Comparison of high-confidence model outputs to radiologist reports reveals instances where a2z-1 identified overlooked findings, suggesting potential for quality assurance applications.
+
+
+
+ 152. 【2412.12188】Predicting Internet Connectivity in Schools: A Feasibility Study Leveraging Multi-modal Data and Location Encoders in Low-Resource Settings
+ 链接:https://arxiv.org/abs/2412.12188
+ 作者:Kelsey Doerksen,Casper Fibaek,Rochelle Schneider,Do-Hyung Kim,Isabelle Tingzon
+ 类目:Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Social and Information Networks (cs.SI)
+ 关键词:digital literary skills, European Space Agency, Internet connectivity, digital infrastructure development, school internet connectivity
+ 备注:
+
+ 点击查看摘要
+ Abstract:Internet connectivity in schools is critical to provide students with the digital literary skills necessary to compete in modern economies. In order for governments to effectively implement digital infrastructure development in schools, accurate internet connectivity information is required. However, traditional survey-based methods can exceed the financial and capacity limits of governments. Open-source Earth Observation (EO) datasets have unlocked our ability to observe and understand socio-economic conditions on Earth from space, and in combination with Machine Learning (ML), can provide the tools to circumvent costly ground-based survey methods to support infrastructure development. In this paper, we present our work on school internet connectivity prediction using EO and ML. We detail the creation of our multi-modal, freely-available satellite imagery and survey information dataset, leverage the latest geographically-aware location encoders, and introduce the first results of using the new European Space Agency phi-lab geographically-aware foundational model to predict internet connectivity in Botswana and Rwanda. We find that ML with EO and ground-based auxiliary data yields the best performance in both countries, for accuracy, F1 score, and False Positive rates, and highlight the challenges of internet connectivity prediction from space with a case study in Kigali, Rwanda. Our work showcases a practical approach to support data-driven digital infrastructure development in low-resource settings, leveraging freely available information, and provide cleaned and labelled datasets for future studies to the community through a unique collaboration between UNICEF and the European Space Agency phi-lab.
+
+
+





/Fig1_pretrain_finetune.png)
/Fig2_eda1.png)
/Fig2_eda2.png)
/Fig2_eda3.png)
/Fig3_reweight.png)
/Fig5_model1.png)
/Fig5_attention_mask.png)
/Fig4_wwm.png)
/Fig5_model2.png)
/Fig5_model3.png)
/Fig7_ensemble1.png)
/Fig6_res1.png)
/Fig6_res2.png)


%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_text_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_entity_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/model.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/dont_stop_pretraining.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/a.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/b.png)

%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/lengths_histplot.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_entity_lengths.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_label_dist.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/%E6%80%BB%E4%BD%93%E6%96%B9%E6%A1%88.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/pretrain_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/finetune_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/rdrop.png)


/autoencoder-architecture.png)
/variational-autoencoder-architecture.png)
/forward_vs_reversed_KL.png)
/vae-implement.png)
/reparam.png)
/generated_samples.png)


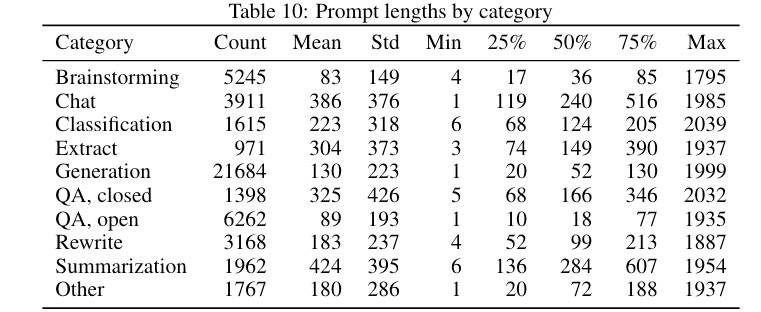
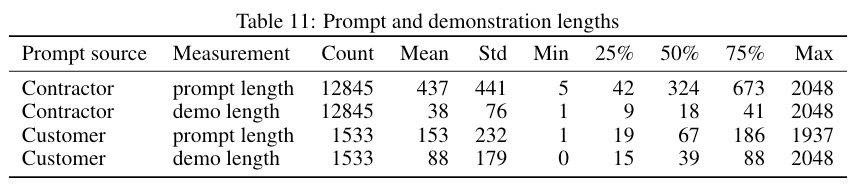

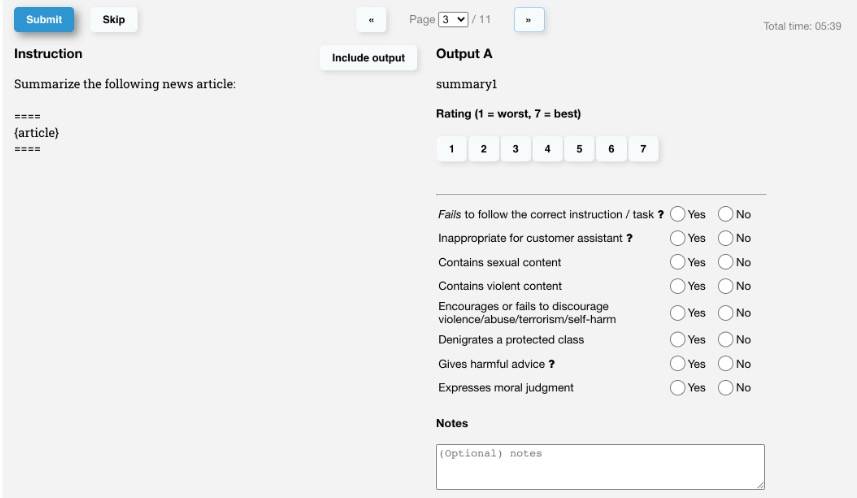
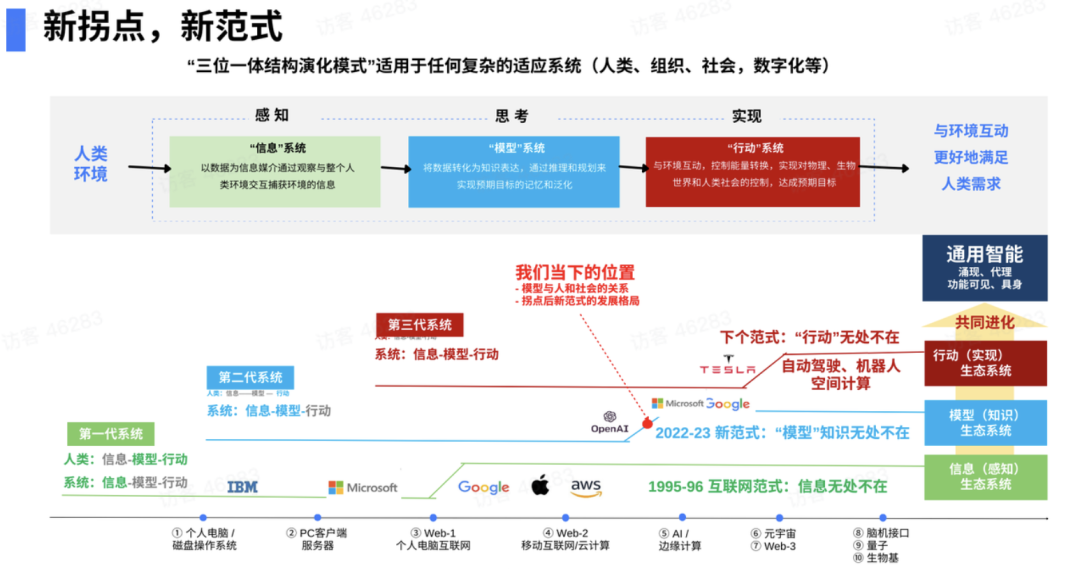
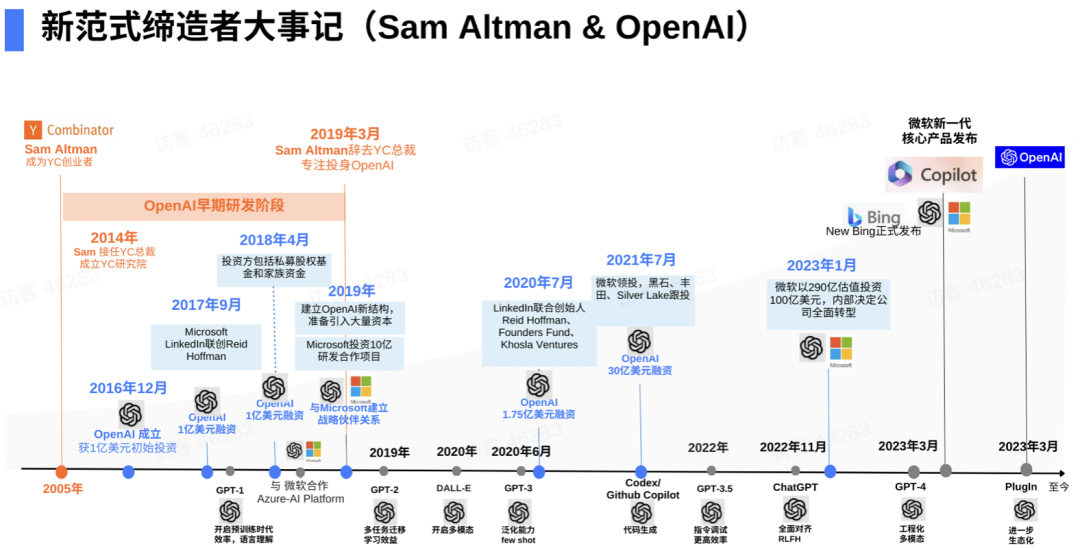
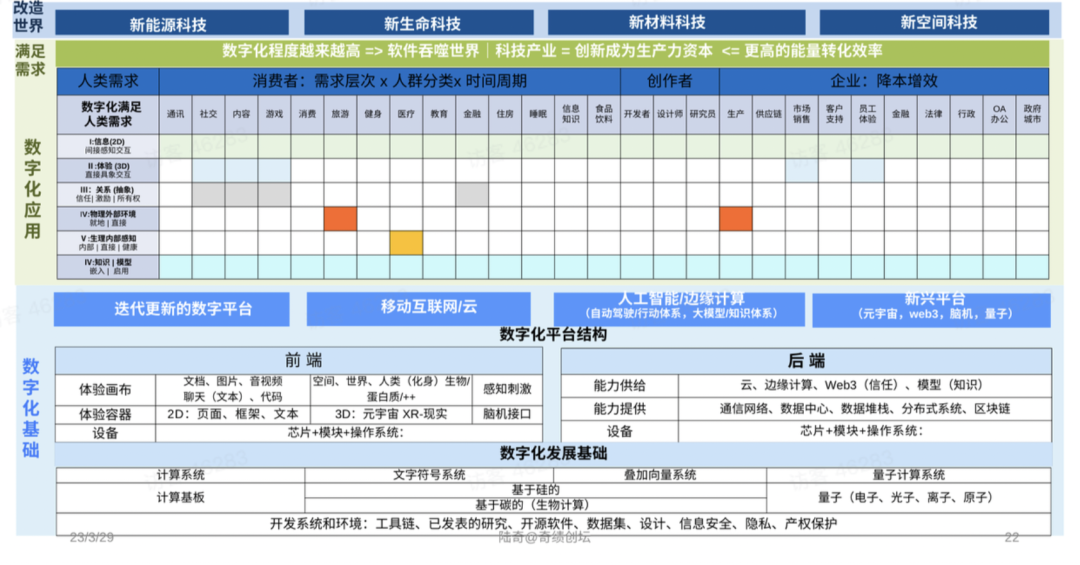
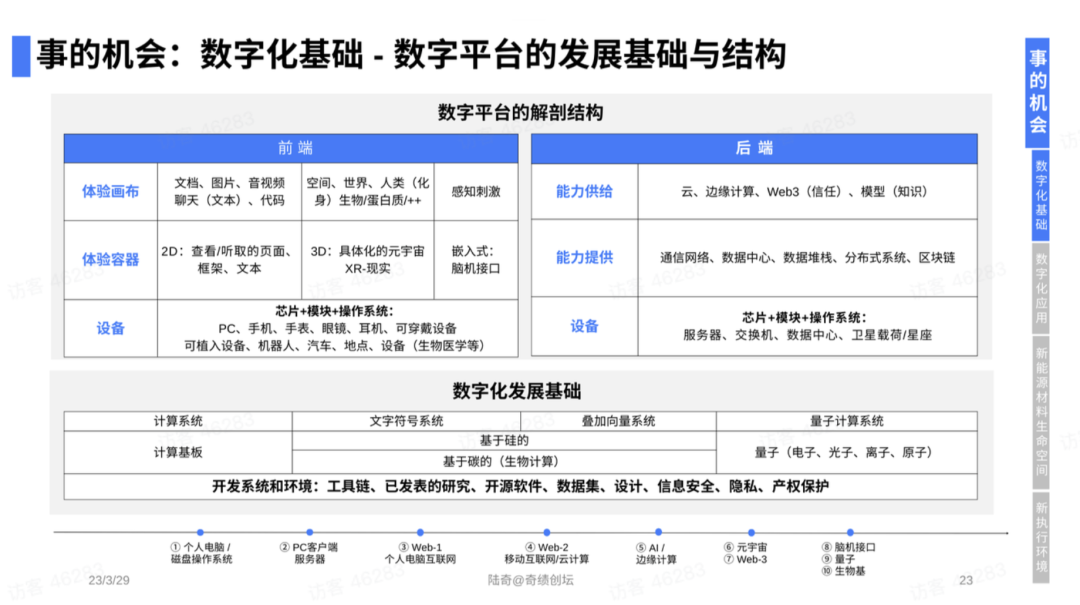
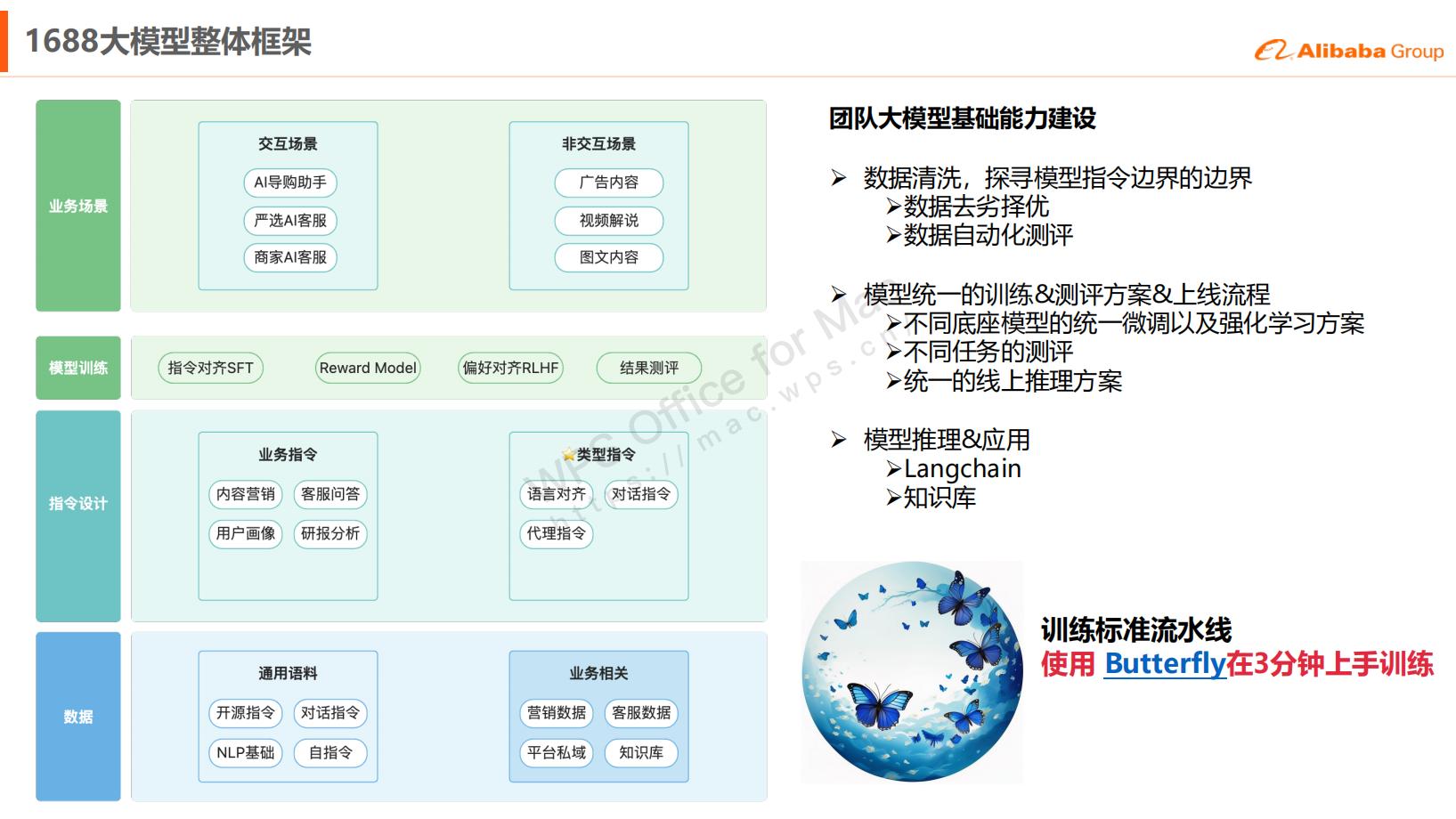
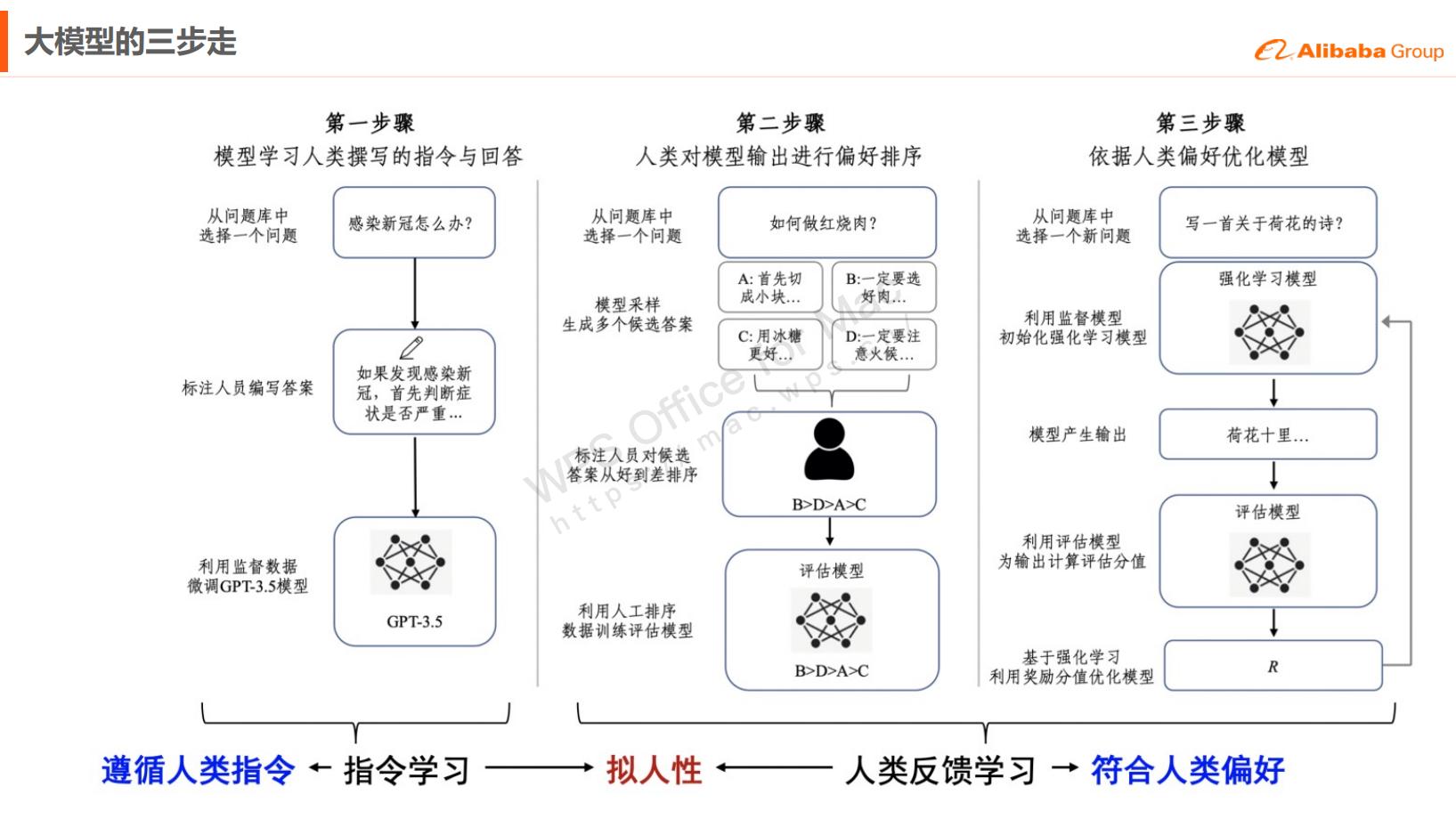
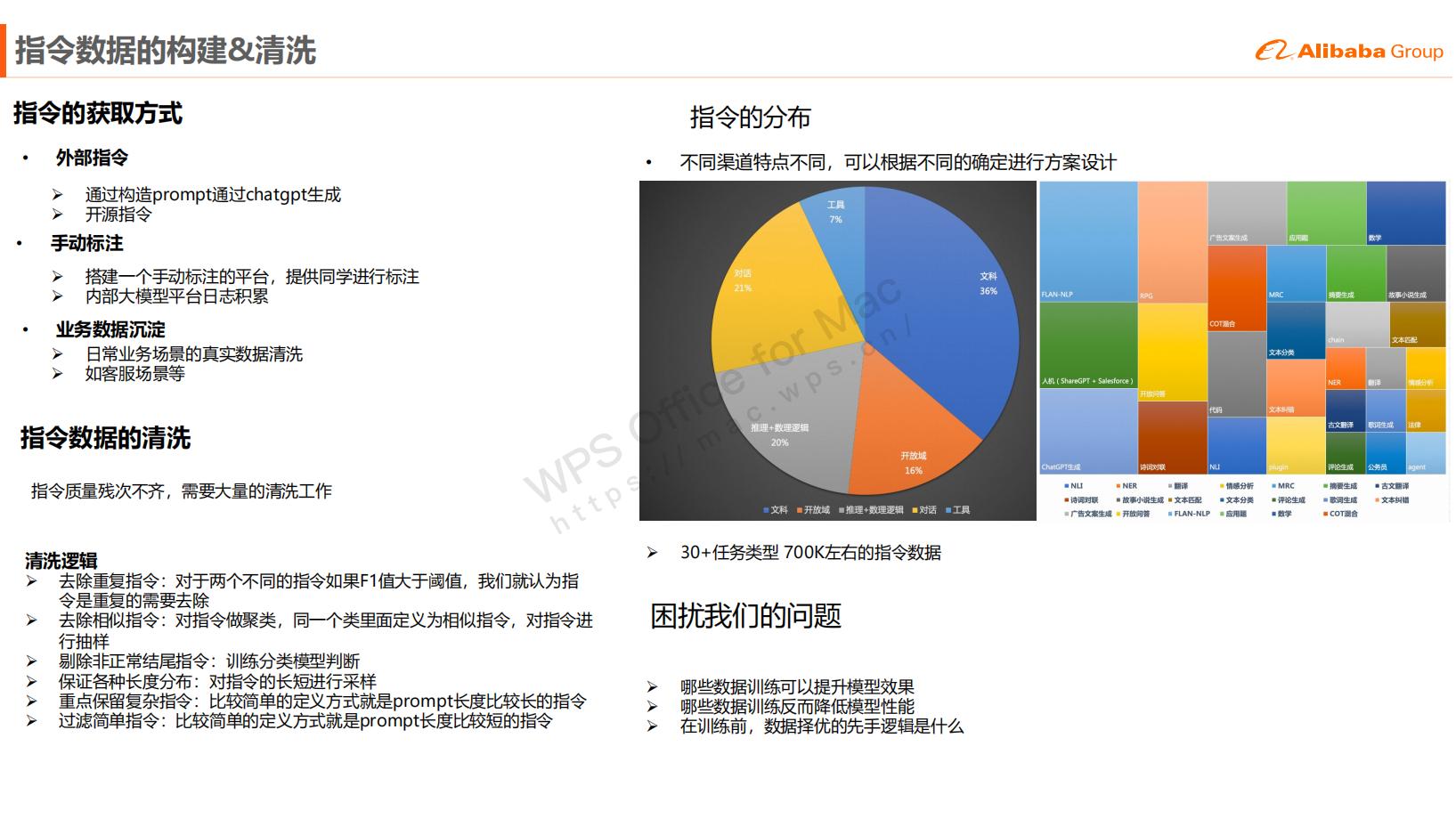

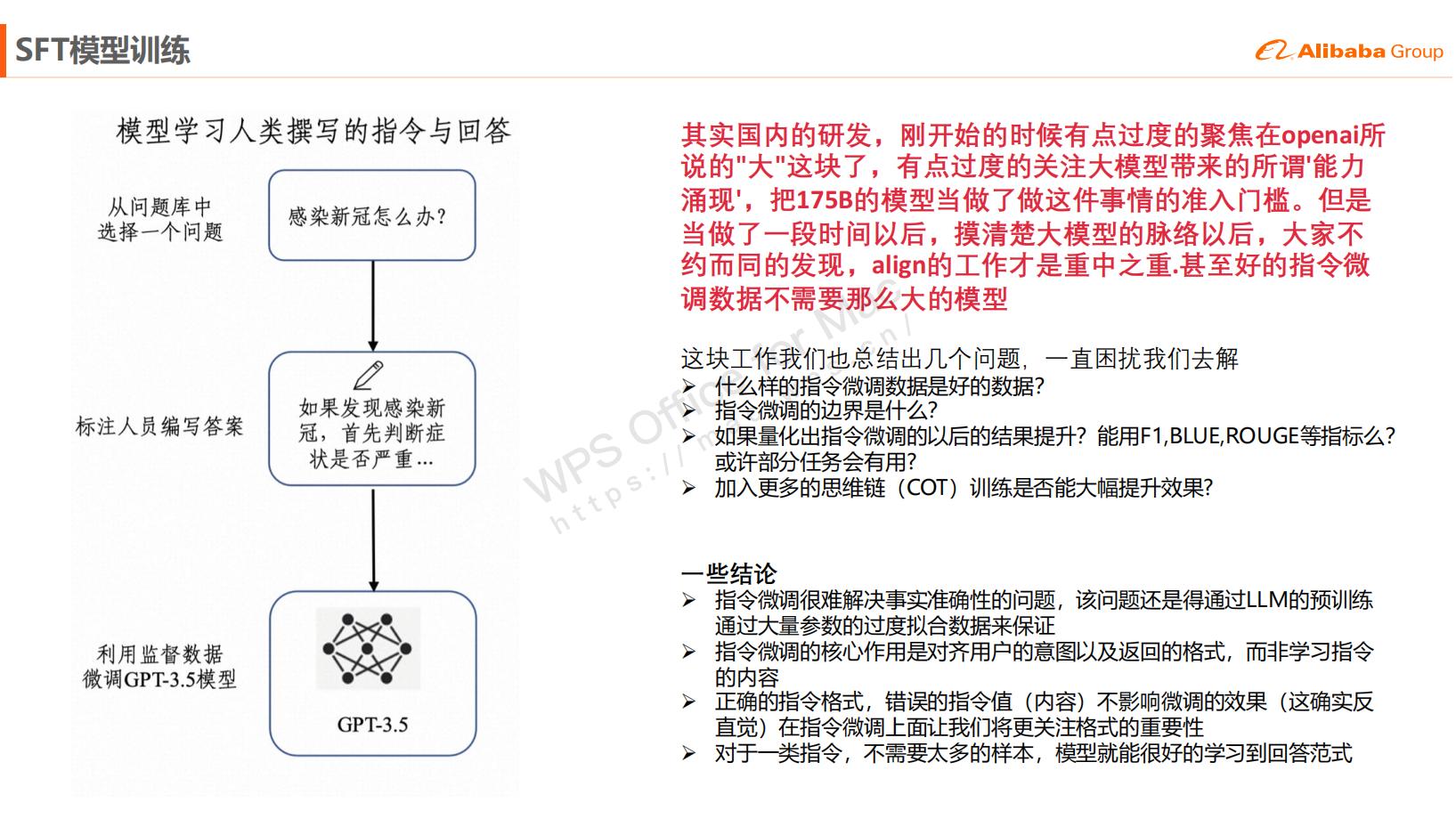

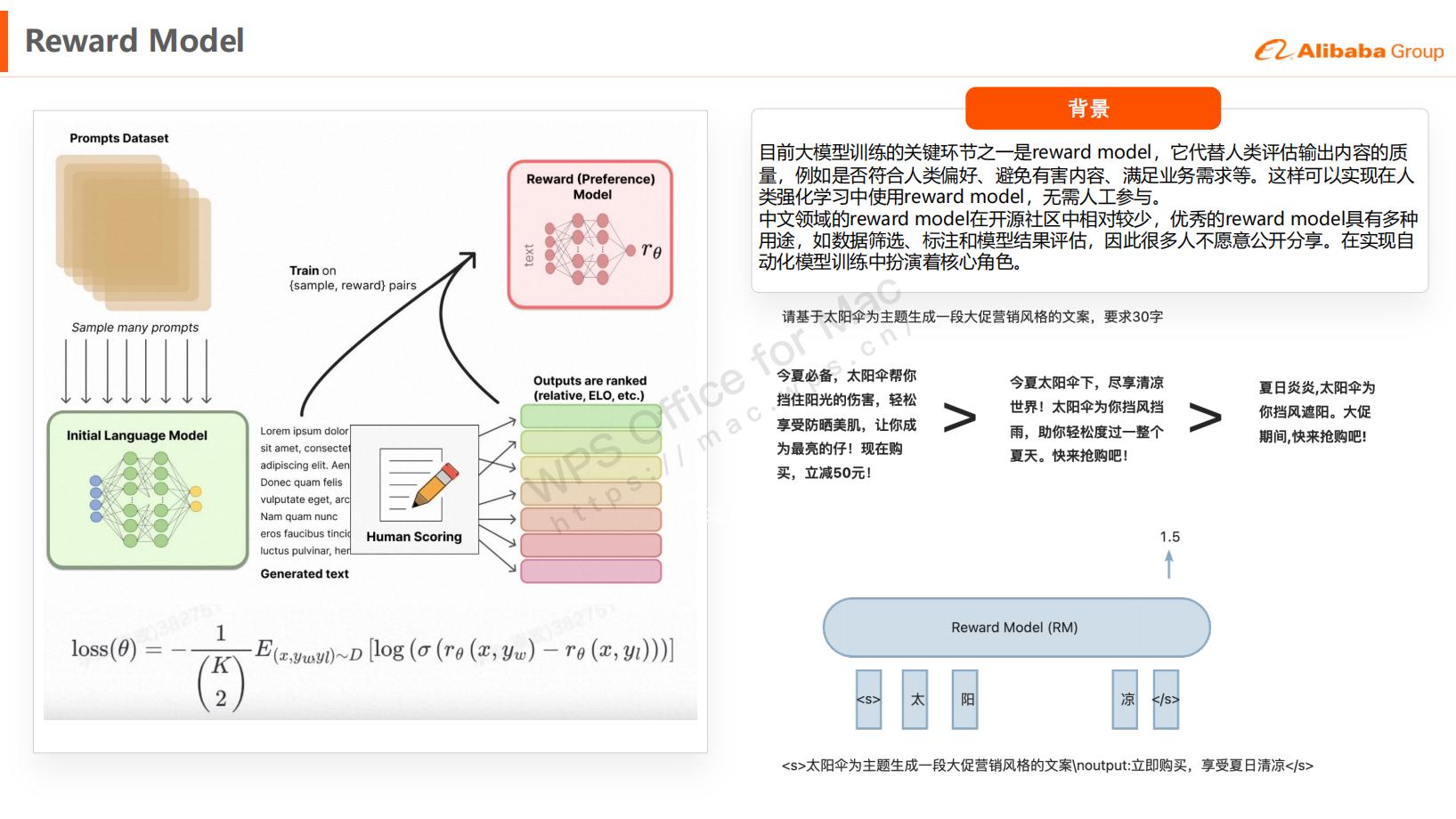




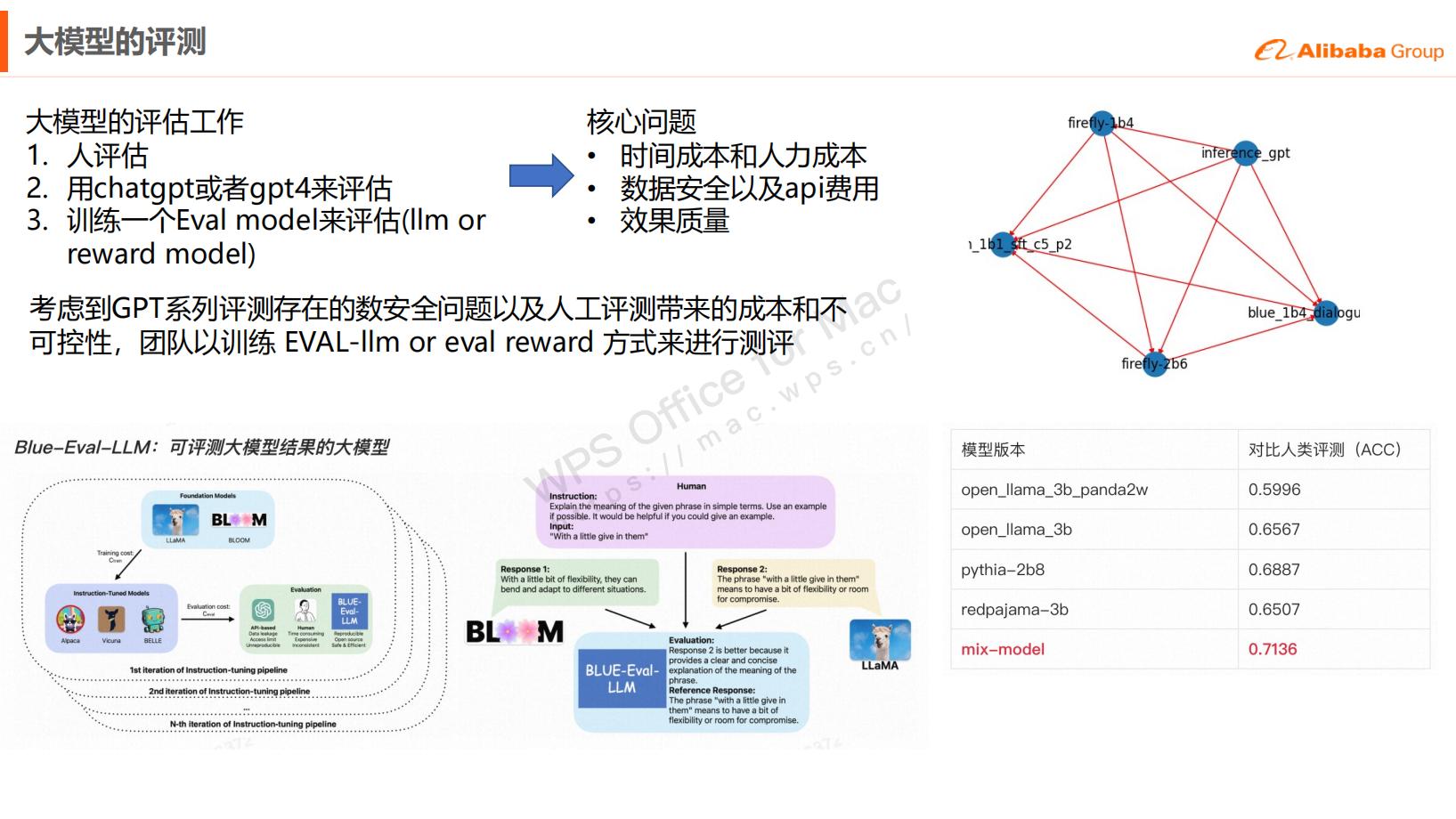
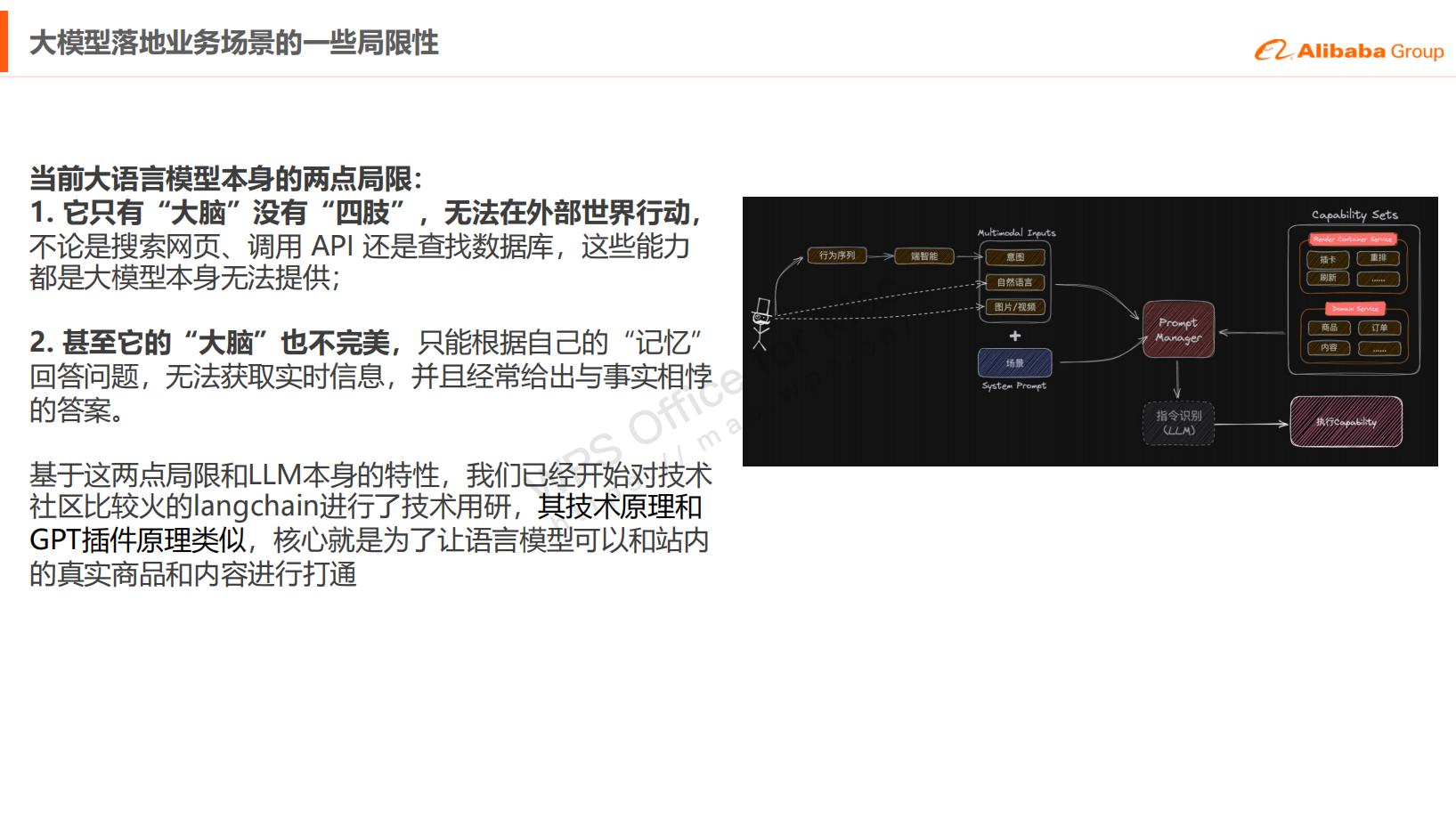






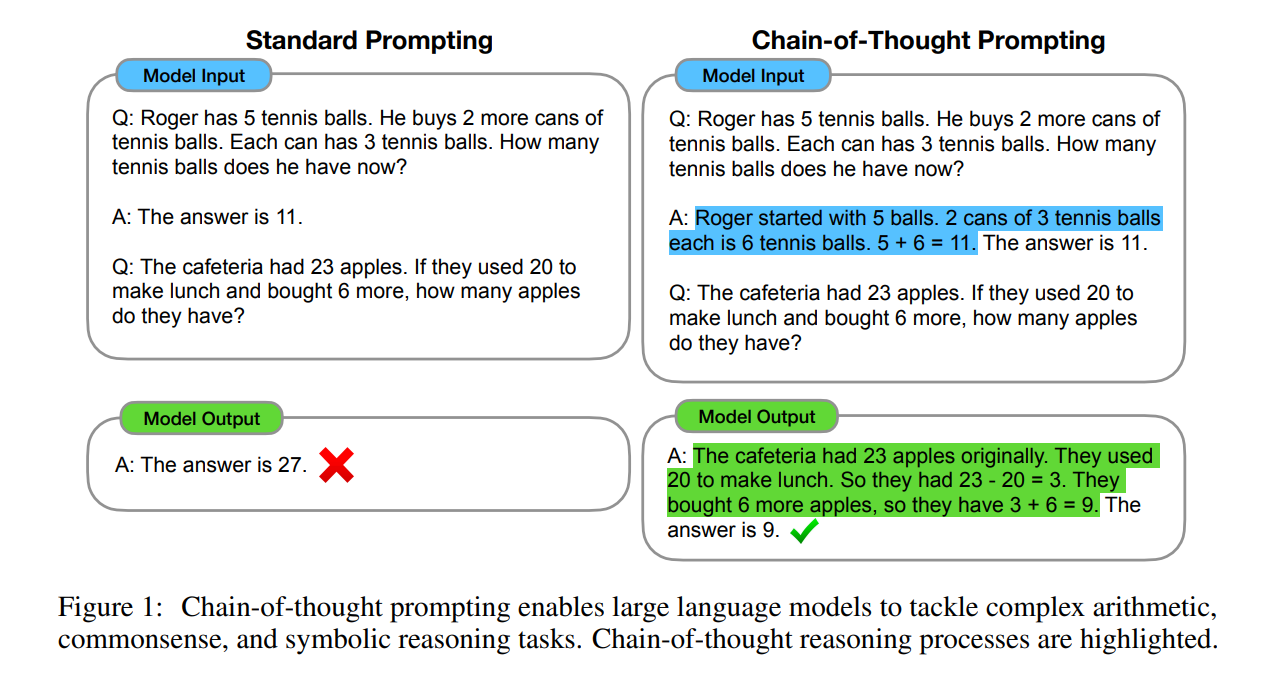

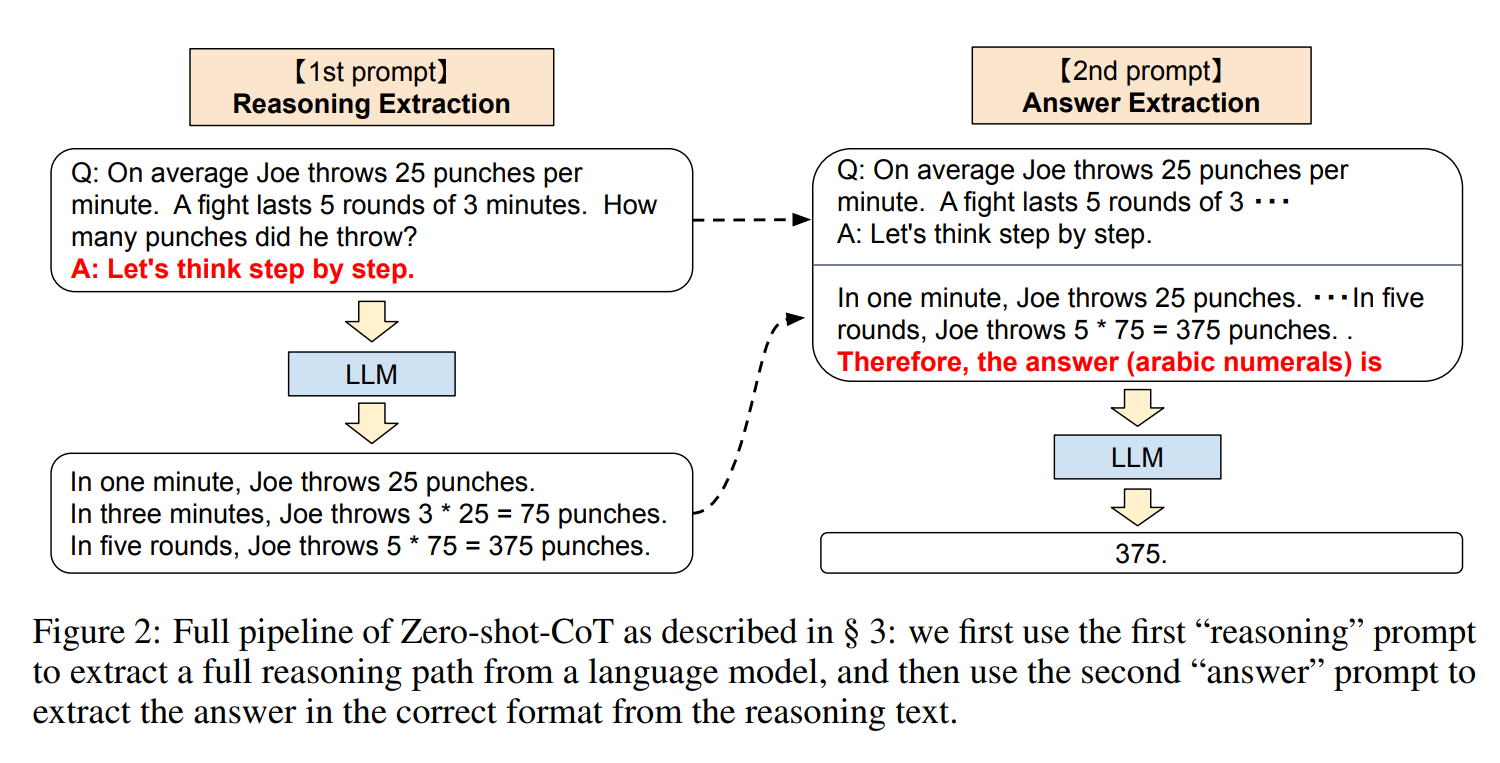
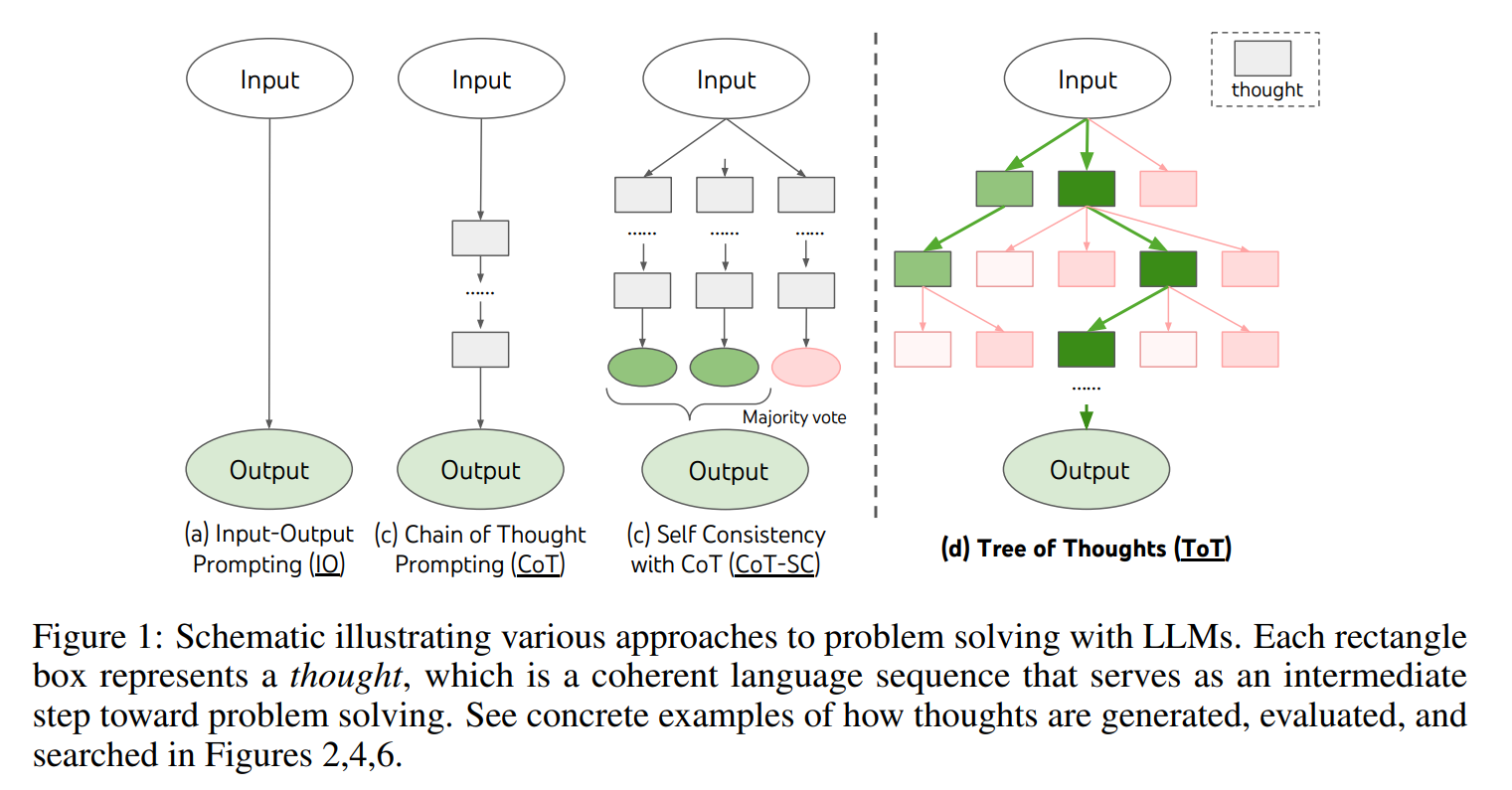


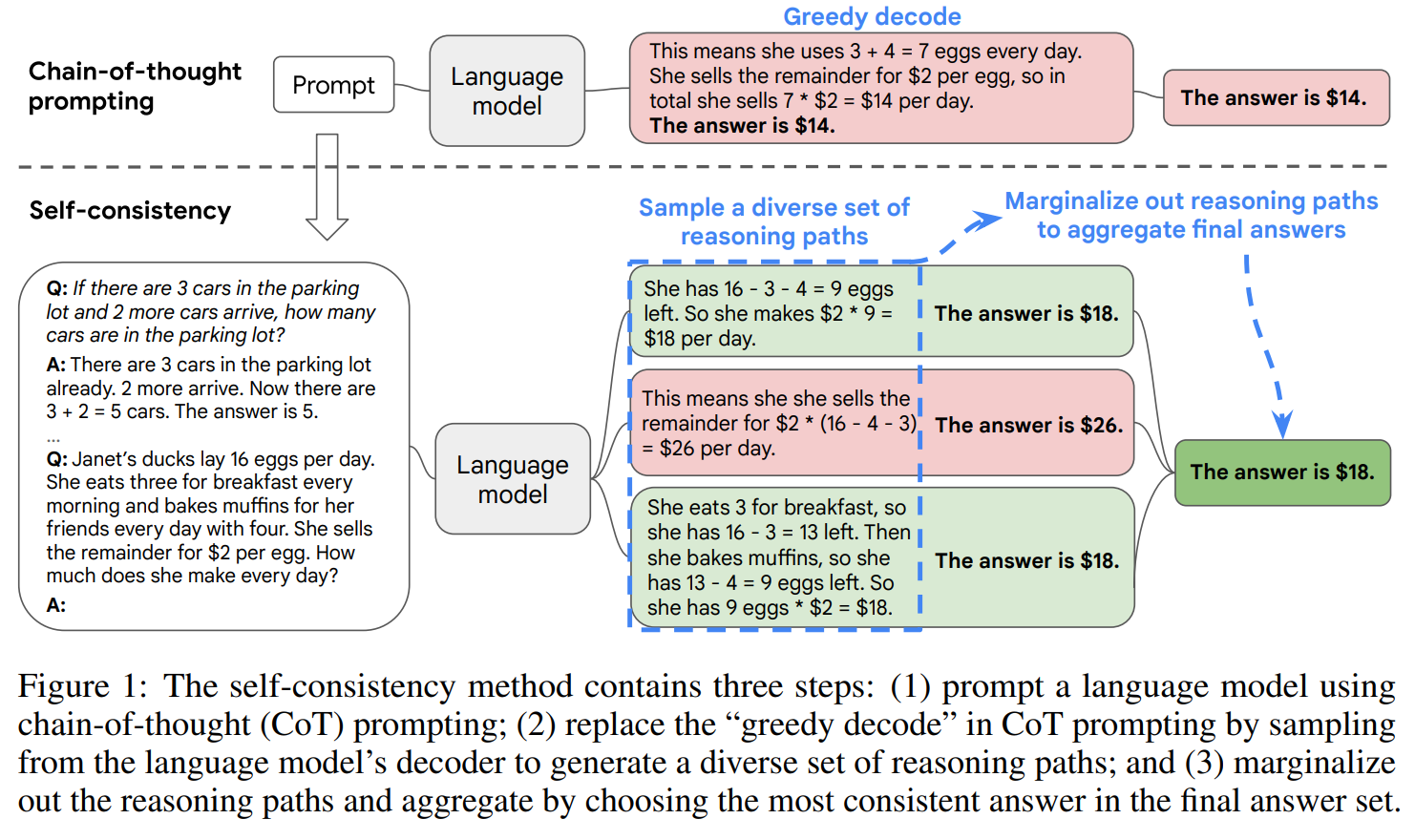



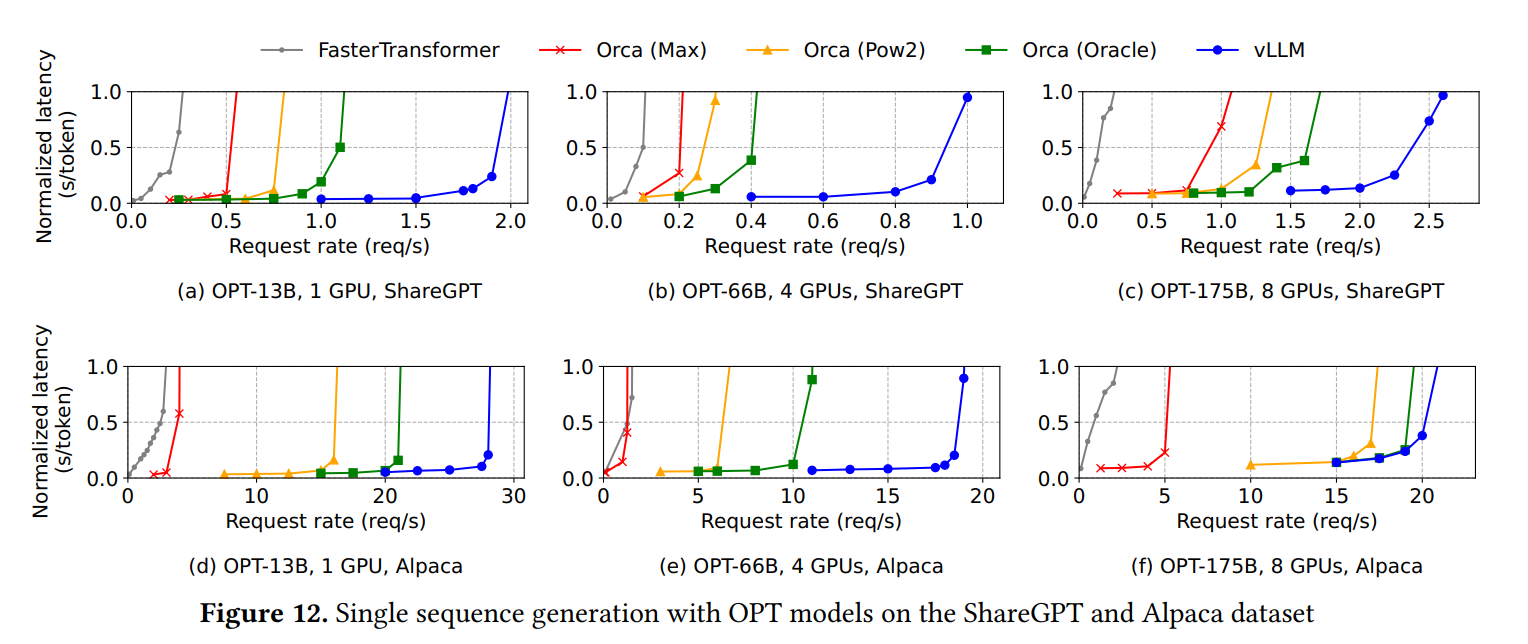
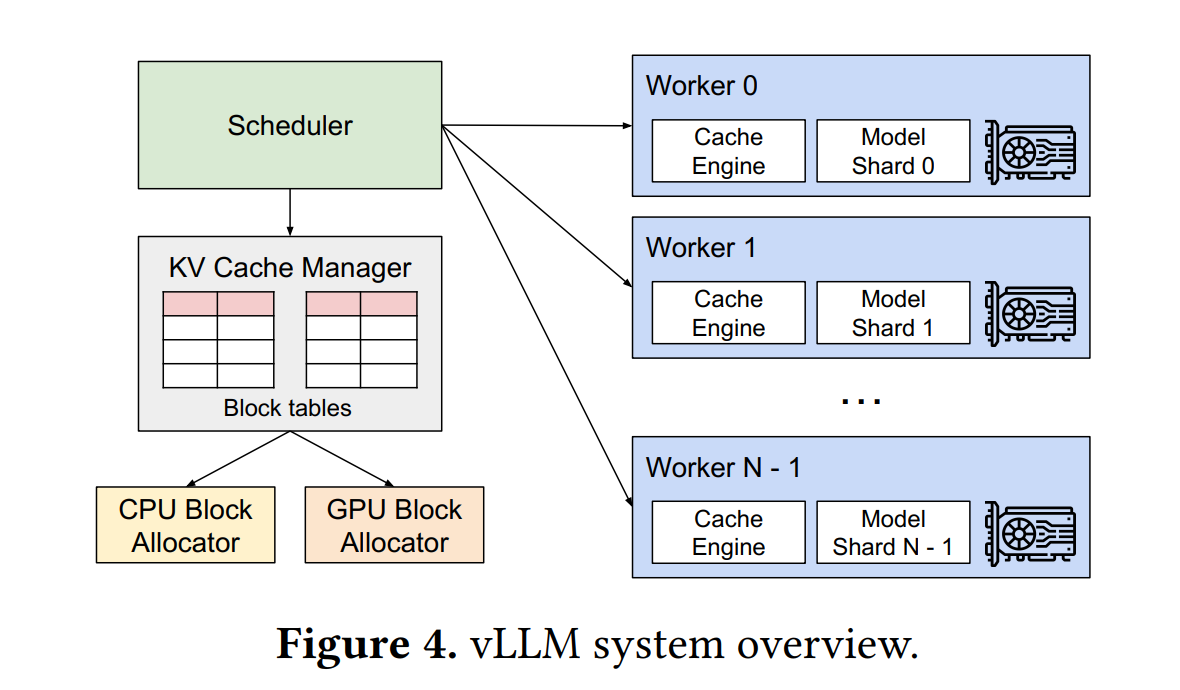
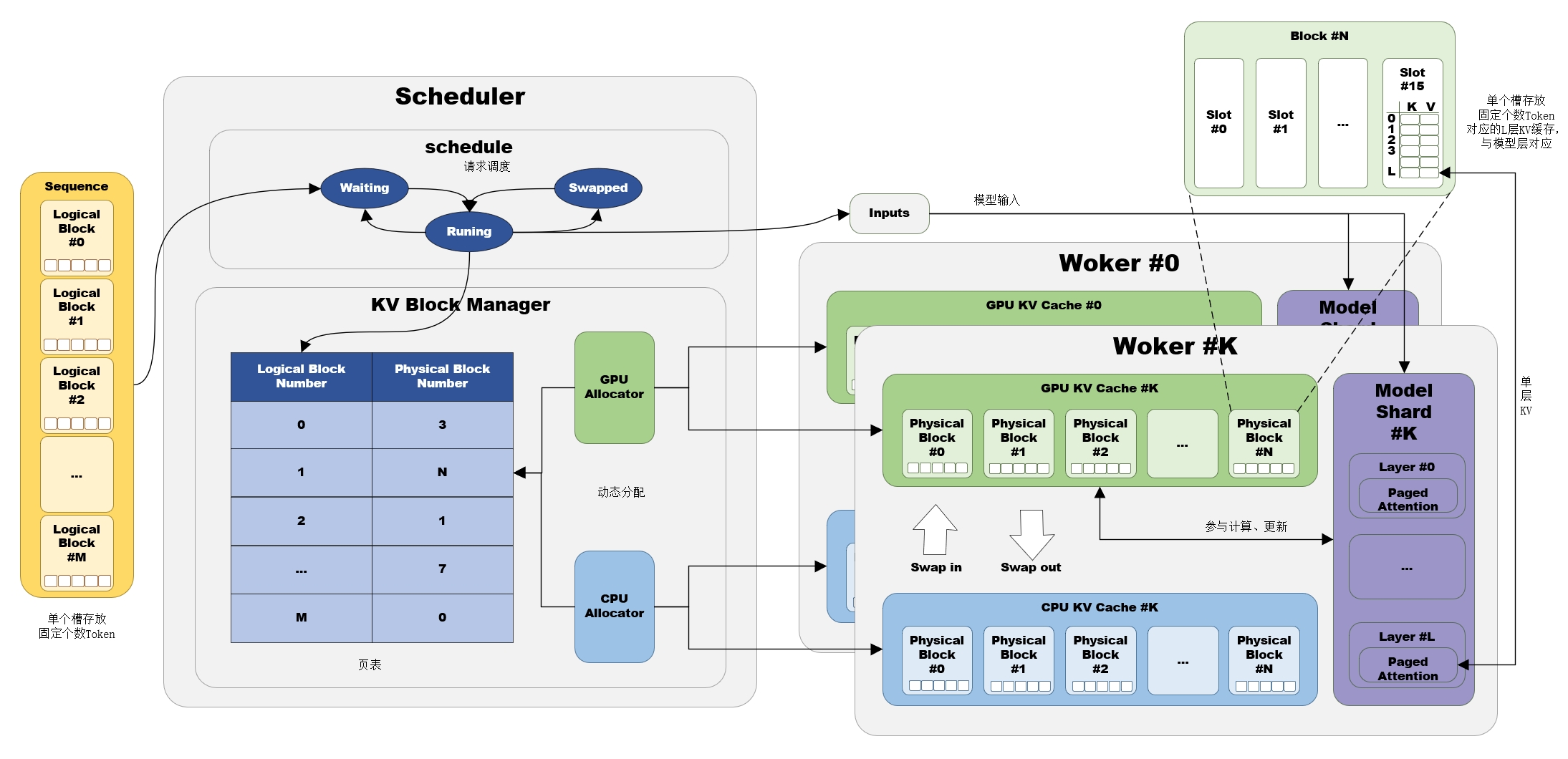
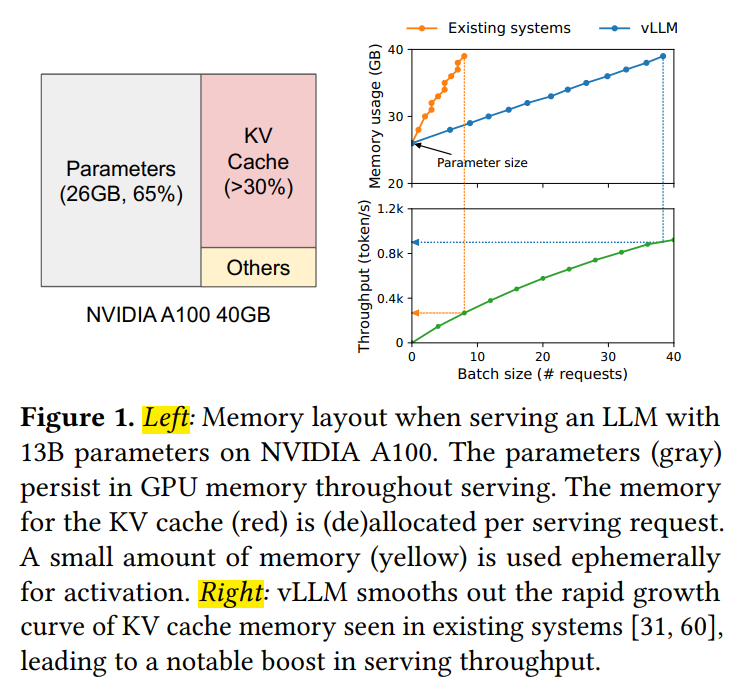
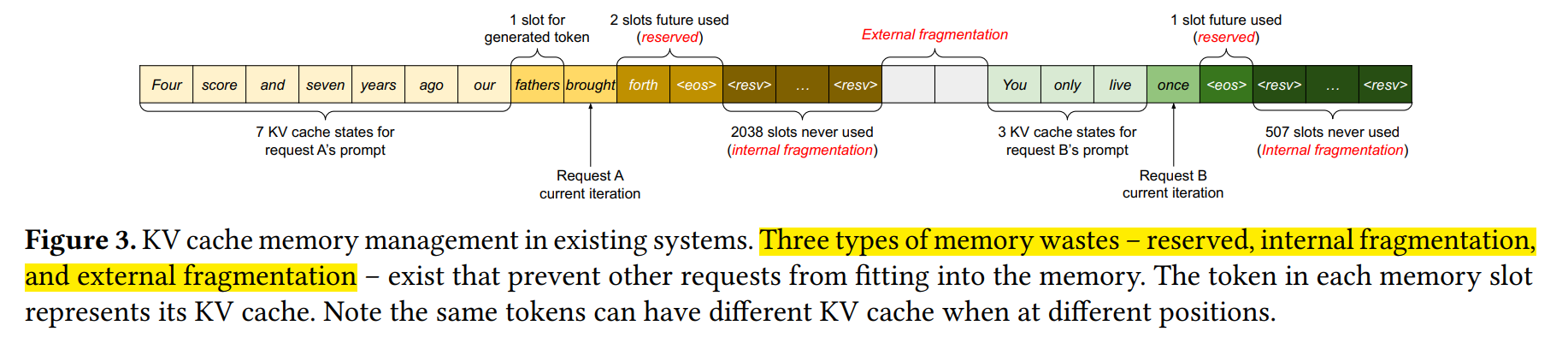
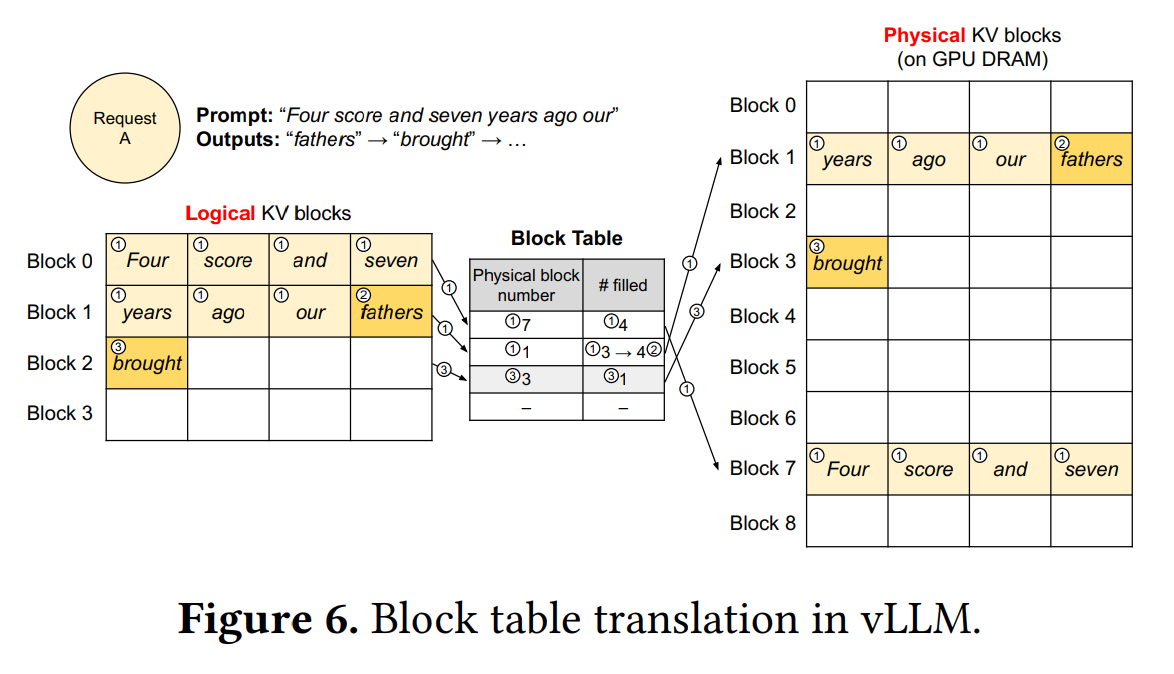
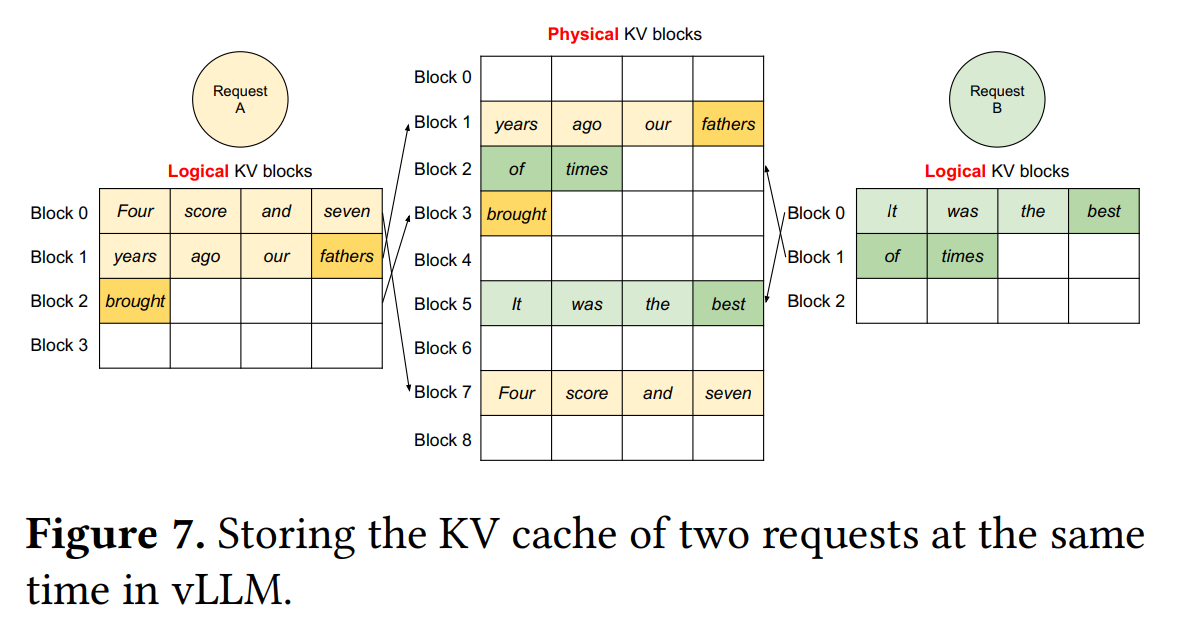
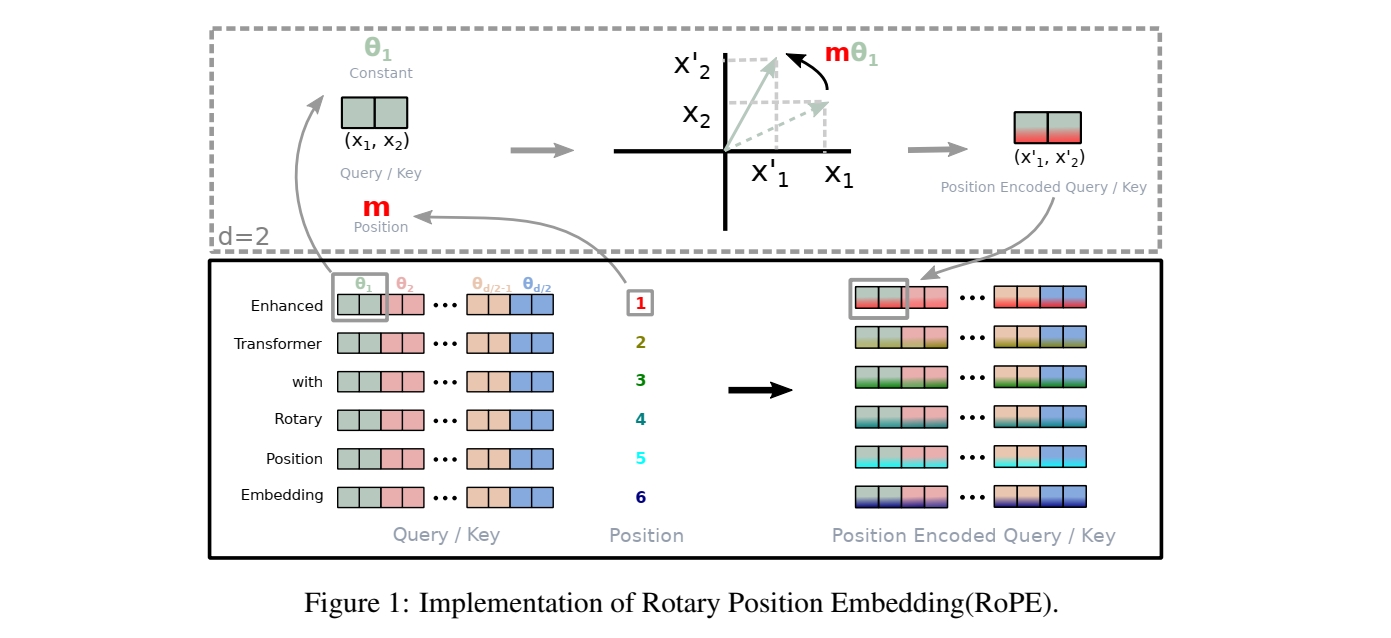
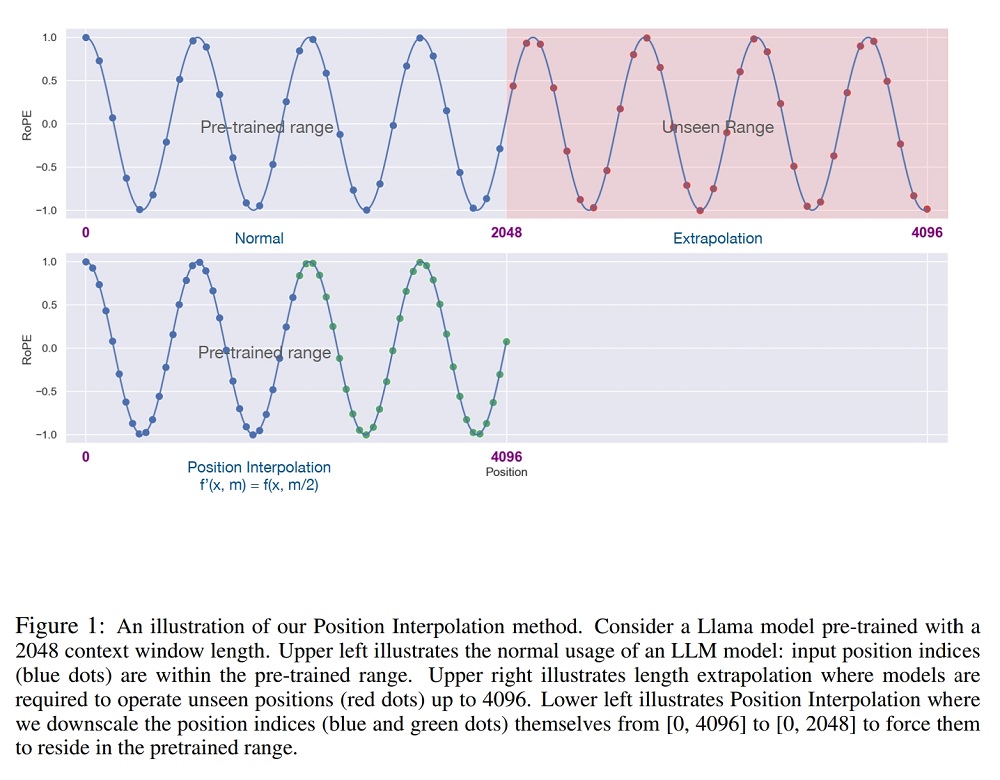
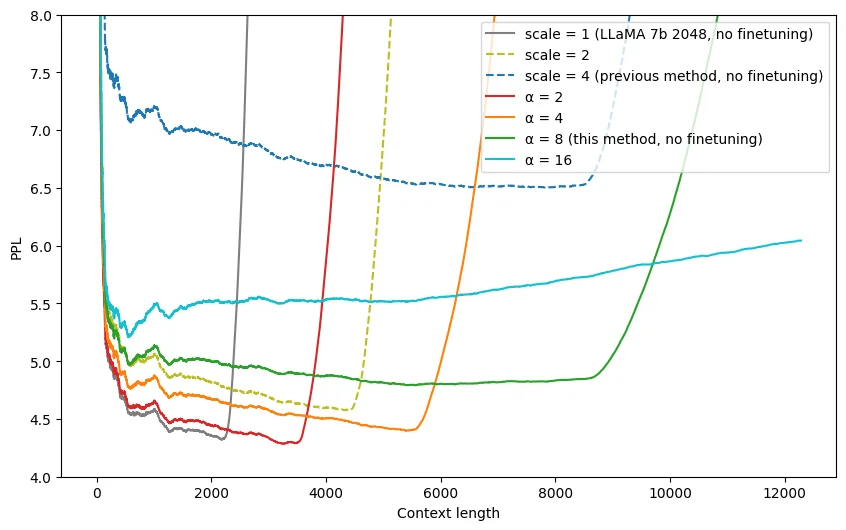
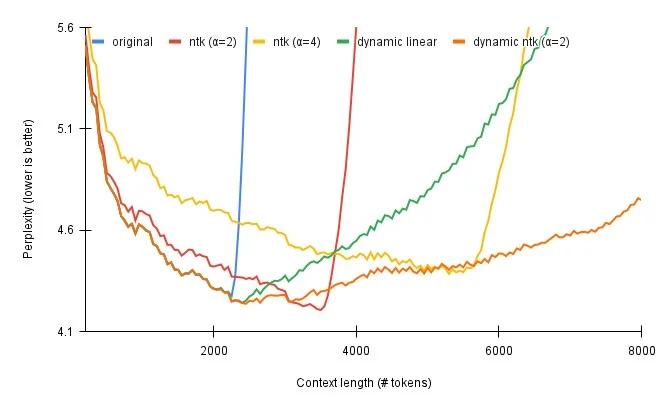










 ' +
+ '
' +
+ '