本篇博文主要展示每日从Arxiv论文网站获取的最新论文列表,以计算机视觉、自然语言处理、机器学习、人工智能等大方向进行划分。
+统计
+今日共更新362篇论文,其中:
+
+计算机视觉
+
+ 1. 标题:MosaicFusion: Diffusion Models as Data Augmenters for Large Vocabulary Instance Segmentation
+ 编号:[2]
+ 链接:https://arxiv.org/abs/2309.13042
+ 作者:Jiahao Xie, Wei Li, Xiangtai Li, Ziwei Liu, Yew Soon Ong, Chen Change Loy
+ 备注:GitHub: this https URL
+ 关键词:large vocabulary instance, effective diffusion-based data, diffusion-based data augmentation, data augmentation approach, effective diffusion-based
+
+ 点击查看摘要
+ We present MosaicFusion, a simple yet effective diffusion-based data augmentation approach for large vocabulary instance segmentation. Our method is training-free and does not rely on any label supervision. Two key designs enable us to employ an off-the-shelf text-to-image diffusion model as a useful dataset generator for object instances and mask annotations. First, we divide an image canvas into several regions and perform a single round of diffusion process to generate multiple instances simultaneously, conditioning on different text prompts. Second, we obtain corresponding instance masks by aggregating cross-attention maps associated with object prompts across layers and diffusion time steps, followed by simple thresholding and edge-aware refinement processing. Without bells and whistles, our MosaicFusion can produce a significant amount of synthetic labeled data for both rare and novel categories. Experimental results on the challenging LVIS long-tailed and open-vocabulary benchmarks demonstrate that MosaicFusion can significantly improve the performance of existing instance segmentation models, especially for rare and novel categories. Code will be released at this https URL.
+
+
+
+ 2. 标题:Robotic Offline RL from Internet Videos via Value-Function Pre-Training
+ 编号:[3]
+ 链接:https://arxiv.org/abs/2309.13041
+ 作者:Chethan Bhateja, Derek Guo, Dibya Ghosh, Anikait Singh, Manan Tomar, Quan Vuong, Yevgen Chebotar, Sergey Levine, Aviral Kumar
+ 备注:First three authors contributed equally
+ 关键词:Pre-training on Internet, Internet data, key ingredient, ingredient for broad, broad generalization
+
+ 点击查看摘要
+ Pre-training on Internet data has proven to be a key ingredient for broad generalization in many modern ML systems. What would it take to enable such capabilities in robotic reinforcement learning (RL)? Offline RL methods, which learn from datasets of robot experience, offer one way to leverage prior data into the robotic learning pipeline. However, these methods have a "type mismatch" with video data (such as Ego4D), the largest prior datasets available for robotics, since video offers observation-only experience without the action or reward annotations needed for RL methods. In this paper, we develop a system for leveraging large-scale human video datasets in robotic offline RL, based entirely on learning value functions via temporal-difference learning. We show that value learning on video datasets learns representations that are more conducive to downstream robotic offline RL than other approaches for learning from video data. Our system, called V-PTR, combines the benefits of pre-training on video data with robotic offline RL approaches that train on diverse robot data, resulting in value functions and policies for manipulation tasks that perform better, act robustly, and generalize broadly. On several manipulation tasks on a real WidowX robot, our framework produces policies that greatly improve over prior methods. Our video and additional details can be found at this https URL
+
+
+
+ 3. 标题:NeRRF: 3D Reconstruction and View Synthesis for Transparent and Specular Objects with Neural Refractive-Reflective Fields
+ 编号:[4]
+ 链接:https://arxiv.org/abs/2309.13039
+ 作者:Xiaoxue Chen, Junchen Liu, Hao Zhao, Guyue Zhou, Ya-Qin Zhang
+ 备注:
+ 关键词:image-based view synthesis, Neural radiance fields, Neural radiance, view synthesis, image-based view
+
+ 点击查看摘要
+ Neural radiance fields (NeRF) have revolutionized the field of image-based view synthesis. However, NeRF uses straight rays and fails to deal with complicated light path changes caused by refraction and reflection. This prevents NeRF from successfully synthesizing transparent or specular objects, which are ubiquitous in real-world robotics and A/VR applications. In this paper, we introduce the refractive-reflective field. Taking the object silhouette as input, we first utilize marching tetrahedra with a progressive encoding to reconstruct the geometry of non-Lambertian objects and then model refraction and reflection effects of the object in a unified framework using Fresnel terms. Meanwhile, to achieve efficient and effective anti-aliasing, we propose a virtual cone supersampling technique. We benchmark our method on different shapes, backgrounds and Fresnel terms on both real-world and synthetic datasets. We also qualitatively and quantitatively benchmark the rendering results of various editing applications, including material editing, object replacement/insertion, and environment illumination estimation. Codes and data are publicly available at this https URL.
+
+
+
+ 4. 标题:Privacy Assessment on Reconstructed Images: Are Existing Evaluation Metrics Faithful to Human Perception?
+ 编号:[5]
+ 链接:https://arxiv.org/abs/2309.13038
+ 作者:Xiaoxiao Sun, Nidham Gazagnadou, Vivek Sharma, Lingjuan Lyu, Hongdong Li, Liang Zheng
+ 备注:15 pages, 9 figures and 3 tables
+ 关键词:PSNR and SSIM, privacy leakage, metrics, privacy, SSIM
+
+ 点击查看摘要
+ Hand-crafted image quality metrics, such as PSNR and SSIM, are commonly used to evaluate model privacy risk under reconstruction attacks. Under these metrics, reconstructed images that are determined to resemble the original one generally indicate more privacy leakage. Images determined as overall dissimilar, on the other hand, indicate higher robustness against attack. However, there is no guarantee that these metrics well reflect human opinions, which, as a judgement for model privacy leakage, are more trustworthy. In this paper, we comprehensively study the faithfulness of these hand-crafted metrics to human perception of privacy information from the reconstructed images. On 5 datasets ranging from natural images, faces, to fine-grained classes, we use 4 existing attack methods to reconstruct images from many different classification models and, for each reconstructed image, we ask multiple human annotators to assess whether this image is recognizable. Our studies reveal that the hand-crafted metrics only have a weak correlation with the human evaluation of privacy leakage and that even these metrics themselves often contradict each other. These observations suggest risks of current metrics in the community. To address this potential risk, we propose a learning-based measure called SemSim to evaluate the Semantic Similarity between the original and reconstructed images. SemSim is trained with a standard triplet loss, using an original image as an anchor, one of its recognizable reconstructed images as a positive sample, and an unrecognizable one as a negative. By training on human annotations, SemSim exhibits a greater reflection of privacy leakage on the semantic level. We show that SemSim has a significantly higher correlation with human judgment compared with existing metrics. Moreover, this strong correlation generalizes to unseen datasets, models and attack methods.
+
+
+
+ 5. 标题:Deep3DSketch+: Rapid 3D Modeling from Single Free-hand Sketches
+ 编号:[19]
+ 链接:https://arxiv.org/abs/2309.13006
+ 作者:Tianrun Chen, Chenglong Fu, Ying Zang, Lanyun Zhu, Jia Zhang, Papa Mao, Lingyun Sun
+ 备注:
+ 关键词:brings tremendous demands, rapid development, brings tremendous, tremendous demands, widely-used Computer-Aided Design
+
+ 点击查看摘要
+ The rapid development of AR/VR brings tremendous demands for 3D content. While the widely-used Computer-Aided Design (CAD) method requires a time-consuming and labor-intensive modeling process, sketch-based 3D modeling offers a potential solution as a natural form of computer-human interaction. However, the sparsity and ambiguity of sketches make it challenging to generate high-fidelity content reflecting creators' ideas. Precise drawing from multiple views or strategic step-by-step drawings is often required to tackle the challenge but is not friendly to novice users. In this work, we introduce a novel end-to-end approach, Deep3DSketch+, which performs 3D modeling using only a single free-hand sketch without inputting multiple sketches or view information. Specifically, we introduce a lightweight generation network for efficient inference in real-time and a structural-aware adversarial training approach with a Stroke Enhancement Module (SEM) to capture the structural information to facilitate learning of the realistic and fine-detailed shape structures for high-fidelity performance. Extensive experiments demonstrated the effectiveness of our approach with the state-of-the-art (SOTA) performance on both synthetic and real datasets.
+
+
+
+ 6. 标题:Point Cloud Network: An Order of Magnitude Improvement in Linear Layer Parameter Count
+ 编号:[22]
+ 链接:https://arxiv.org/abs/2309.12996
+ 作者:Charles Hetterich
+ 备注:
+ 关键词:Point Cloud Network, deep learning networks, Multilayer Perceptron, introduces the Point, learning networks
+
+ 点击查看摘要
+ This paper introduces the Point Cloud Network (PCN) architecture, a novel implementation of linear layers in deep learning networks, and provides empirical evidence to advocate for its preference over the Multilayer Perceptron (MLP) in linear layers. We train several models, including the original AlexNet, using both MLP and PCN architectures for direct comparison of linear layers (Krizhevsky et al., 2012). The key results collected are model parameter count and top-1 test accuracy over the CIFAR-10 and CIFAR-100 datasets (Krizhevsky, 2009). AlexNet-PCN16, our PCN equivalent to AlexNet, achieves comparable efficacy (test accuracy) to the original architecture with a 99.5% reduction of parameters in its linear layers. All training is done on cloud RTX 4090 GPUs, leveraging pytorch for model construction and training. Code is provided for anyone to reproduce the trials from this paper.
+
+
+
+ 7. 标题:License Plate Recognition Based On Multi-Angle View Model
+ 编号:[26]
+ 链接:https://arxiv.org/abs/2309.12972
+ 作者:Dat Tran-Anh, Khanh Linh Tran, Hoai-Nam Vu
+ 备注:
+ 关键词:highly challenging problem, realm of research, problem for researchers, captured by cameras, cameras constitutes
+
+ 点击查看摘要
+ In the realm of research, the detection/recognition of text within images/videos captured by cameras constitutes a highly challenging problem for researchers. Despite certain advancements achieving high accuracy, current methods still require substantial improvements to be applicable in practical scenarios. Diverging from text detection in images/videos, this paper addresses the issue of text detection within license plates by amalgamating multiple frames of distinct perspectives. For each viewpoint, the proposed method extracts descriptive features characterizing the text components of the license plate, specifically corner points and area. Concretely, we present three viewpoints: view-1, view-2, and view-3, to identify the nearest neighboring components facilitating the restoration of text components from the same license plate line based on estimations of similarity levels and distance metrics. Subsequently, we employ the CnOCR method for text recognition within license plates. Experimental results on the self-collected dataset (PTITPlates), comprising pairs of images in various scenarios, and the publicly available Stanford Cars Dataset, demonstrate the superiority of the proposed method over existing approaches.
+
+
+
+ 8. 标题:Detect Every Thing with Few Examples
+ 编号:[28]
+ 链接:https://arxiv.org/abs/2309.12969
+ 作者:Xinyu Zhang, Yuting Wang, Abdeslam Boularias
+ 备注:
+ 关键词:detecting arbitrary categories, aims at detecting, detecting arbitrary, object detection aims, Open-set object
+
+ 点击查看摘要
+ Open-set object detection aims at detecting arbitrary categories beyond those seen during training. Most recent advancements have adopted the open-vocabulary paradigm, utilizing vision-language backbones to represent categories with language. In this paper, we introduce DE-ViT, an open-set object detector that employs vision-only DINOv2 backbones and learns new categories through example images instead of language. To improve general detection ability, we transform multi-classification tasks into binary classification tasks while bypassing per-class inference, and propose a novel region propagation technique for localization. We evaluate DE-ViT on open-vocabulary, few-shot, and one-shot object detection benchmark with COCO and LVIS. For COCO, DE-ViT outperforms the open-vocabulary SoTA by 6.9 AP50 and achieves 50 AP50 in novel classes. DE-ViT surpasses the few-shot SoTA by 15 mAP on 10-shot and 7.2 mAP on 30-shot and one-shot SoTA by 2.8 AP50. For LVIS, DE-ViT outperforms the open-vocabulary SoTA by 2.2 mask AP and reaches 34.3 mask APr. Code is available at this https URL.
+
+
+
+ 9. 标题:On Data Fabrication in Collaborative Vehicular Perception: Attacks and Countermeasures
+ 编号:[32]
+ 链接:https://arxiv.org/abs/2309.12955
+ 作者:Qingzhao Zhang, Shuowei Jin, Jiachen Sun, Xumiao Zhang, Ruiyang Zhu, Qi Alfred Chen, Z. Morley Mao
+ 备注:20 pages, 24 figures, accepted by Usenix Security 2024
+ 关键词:external resources, potential security risks, greatly enhances, enhances the sensing, sensing capability
+
+ 点击查看摘要
+ Collaborative perception, which greatly enhances the sensing capability of connected and autonomous vehicles (CAVs) by incorporating data from external resources, also brings forth potential security risks. CAVs' driving decisions rely on remote untrusted data, making them susceptible to attacks carried out by malicious participants in the collaborative perception system. However, security analysis and countermeasures for such threats are absent. To understand the impact of the vulnerability, we break the ground by proposing various real-time data fabrication attacks in which the attacker delivers crafted malicious data to victims in order to perturb their perception results, leading to hard brakes or increased collision risks. Our attacks demonstrate a high success rate of over 86\% on high-fidelity simulated scenarios and are realizable in real-world experiments. To mitigate the vulnerability, we present a systematic anomaly detection approach that enables benign vehicles to jointly reveal malicious fabrication. It detects 91.5% of attacks with a false positive rate of 3% in simulated scenarios and significantly mitigates attack impacts in real-world scenarios.
+
+
+
+ 10. 标题:Background Activation Suppression for Weakly Supervised Object Localization and Semantic Segmentation
+ 编号:[36]
+ 链接:https://arxiv.org/abs/2309.12943
+ 作者:Wei Zhai, Pingyu Wu, Kai Zhu, Yang Cao, Feng Wu, Zheng-Jun Zha
+ 备注:Accepted by IJCV. arXiv admin note: text overlap with arXiv:2112.00580
+ 关键词:foreground prediction map, foreground mask expands, foreground mask, image-level labels, aim to localize
+
+ 点击查看摘要
+ Weakly supervised object localization and semantic segmentation aim to localize objects using only image-level labels. Recently, a new paradigm has emerged by generating a foreground prediction map (FPM) to achieve pixel-level localization. While existing FPM-based methods use cross-entropy to evaluate the foreground prediction map and to guide the learning of the generator, this paper presents two astonishing experimental observations on the object localization learning process: For a trained network, as the foreground mask expands, 1) the cross-entropy converges to zero when the foreground mask covers only part of the object region. 2) The activation value continuously increases until the foreground mask expands to the object boundary. Therefore, to achieve a more effective localization performance, we argue for the usage of activation value to learn more object regions. In this paper, we propose a Background Activation Suppression (BAS) method. Specifically, an Activation Map Constraint (AMC) module is designed to facilitate the learning of generator by suppressing the background activation value. Meanwhile, by using foreground region guidance and area constraint, BAS can learn the whole region of the object. In the inference phase, we consider the prediction maps of different categories together to obtain the final localization results. Extensive experiments show that BAS achieves significant and consistent improvement over the baseline methods on the CUB-200-2011 and ILSVRC datasets. In addition, our method also achieves state-of-the-art weakly supervised semantic segmentation performance on the PASCAL VOC 2012 and MS COCO 2014 datasets. Code and models are available at this https URL.
+
+
+
+ 11. 标题:Gravity Network for end-to-end small lesion detection
+ 编号:[59]
+ 链接:https://arxiv.org/abs/2309.12876
+ 作者:Ciro Russo, Alessandro Bria, Claudio Marrocco
+ 备注:
+ 关键词:detector specifically designed, detector specifically, specifically designed, designed to detect, detect small lesions
+
+ 点击查看摘要
+ This paper introduces a novel one-stage end-to-end detector specifically designed to detect small lesions in medical images. Precise localization of small lesions presents challenges due to their appearance and the diverse contextual backgrounds in which they are found. To address this, our approach introduces a new type of pixel-based anchor that dynamically moves towards the targeted lesion for detection. We refer to this new architecture as GravityNet, and the novel anchors as gravity points since they appear to be "attracted" by the lesions. We conducted experiments on two well-established medical problems involving small lesions to evaluate the performance of the proposed approach: microcalcifications detection in digital mammograms and microaneurysms detection in digital fundus images. Our method demonstrates promising results in effectively detecting small lesions in these medical imaging tasks.
+
+
+
+ 12. 标题:Accurate and Fast Compressed Video Captioning
+ 编号:[63]
+ 链接:https://arxiv.org/abs/2309.12867
+ 作者:Yaojie Shen, Xin Gu, Kai Xu, Heng Fan, Longyin Wen, Libo Zhang
+ 备注:
+ 关键词:approaches typically require, sample video frames, video, video captioning, subsequent process
+
+ 点击查看摘要
+ Existing video captioning approaches typically require to first sample video frames from a decoded video and then conduct a subsequent process (e.g., feature extraction and/or captioning model learning). In this pipeline, manual frame sampling may ignore key information in videos and thus degrade performance. Additionally, redundant information in the sampled frames may result in low efficiency in the inference of video captioning. Addressing this, we study video captioning from a different perspective in compressed domain, which brings multi-fold advantages over the existing pipeline: 1) Compared to raw images from the decoded video, the compressed video, consisting of I-frames, motion vectors and residuals, is highly distinguishable, which allows us to leverage the entire video for learning without manual sampling through a specialized model design; 2) The captioning model is more efficient in inference as smaller and less redundant information is processed. We propose a simple yet effective end-to-end transformer in the compressed domain for video captioning that enables learning from the compressed video for captioning. We show that even with a simple design, our method can achieve state-of-the-art performance on different benchmarks while running almost 2x faster than existing approaches. Code is available at this https URL.
+
+
+
+ 13. 标题:Bridging Sensor Gaps via Single-Direction Tuning for Hyperspectral Image Classification
+ 编号:[64]
+ 链接:https://arxiv.org/abs/2309.12865
+ 作者:Xizhe Xue, Haokui Zhang, Ying Li, Liuwei Wan, Zongwen Bai, Mike Zheng Shou
+ 备注:
+ 关键词:achieved remarkable results, researchers started exploring, tackling HSI classification, proposed SDT, remarkable results
+
+ 点击查看摘要
+ Recently, some researchers started exploring the use of ViTs in tackling HSI classification and achieved remarkable results. However, the training of ViT models requires a considerable number of training samples, while hyperspectral data, due to its high annotation costs, typically has a relatively small number of training samples. This contradiction has not been effectively addressed. In this paper, aiming to solve this problem, we propose the single-direction tuning (SDT) strategy, which serves as a bridge, allowing us to leverage existing labeled HSI datasets even RGB datasets to enhance the performance on new HSI datasets with limited samples. The proposed SDT inherits the idea of prompt tuning, aiming to reuse pre-trained models with minimal modifications for adaptation to new tasks. But unlike prompt tuning, SDT is custom-designed to accommodate the characteristics of HSIs. The proposed SDT utilizes a parallel architecture, an asynchronous cold-hot gradient update strategy, and unidirectional interaction. It aims to fully harness the potent representation learning capabilities derived from training on heterologous, even cross-modal datasets. In addition, we also introduce a novel Triplet-structured transformer (Tri-Former), where spectral attention and spatial attention modules are merged in parallel to construct the token mixing component for reducing computation cost and a 3D convolution-based channel mixer module is integrated to enhance stability and keep structure information. Comparison experiments conducted on three representative HSI datasets captured by different sensors demonstrate the proposed Tri-Former achieves better performance compared to several state-of-the-art methods. Homologous, heterologous and cross-modal tuning experiments verified the effectiveness of the proposed SDT.
+
+
+
+ 14. 标题:Associative Transformer Is A Sparse Representation Learner
+ 编号:[67]
+ 链接:https://arxiv.org/abs/2309.12862
+ 作者:Yuwei Sun, Hideya Ochiai, Zhirong Wu, Stephen Lin, Ryota Kanai
+ 备注:
+ 关键词:conventional Transformer models, monolithic pairwise attention, pairwise attention mechanism, leveraging sparse interactions, Set Transformer
+
+ 点击查看摘要
+ Emerging from the monolithic pairwise attention mechanism in conventional Transformer models, there is a growing interest in leveraging sparse interactions that align more closely with biological principles. Approaches including the Set Transformer and the Perceiver employ cross-attention consolidated with a latent space that forms an attention bottleneck with limited capacity. Building upon recent neuroscience studies of Global Workspace Theory and associative memory, we propose the Associative Transformer (AiT). AiT induces low-rank explicit memory that serves as both priors to guide bottleneck attention in the shared workspace and attractors within associative memory of a Hopfield network. Through joint end-to-end training, these priors naturally develop module specialization, each contributing a distinct inductive bias to form attention bottlenecks. A bottleneck can foster competition among inputs for writing information into the memory. We show that AiT is a sparse representation learner, learning distinct priors through the bottlenecks that are complexity-invariant to input quantities and dimensions. AiT demonstrates its superiority over methods such as the Set Transformer, Vision Transformer, and Coordination in various vision tasks.
+
+
+
+ 15. 标题:SRFNet: Monocular Depth Estimation with Fine-grained Structure via Spatial Reliability-oriented Fusion of Frames and Events
+ 编号:[75]
+ 链接:https://arxiv.org/abs/2309.12842
+ 作者:Tianbo Pan, Zidong Cao, Lin Wang
+ 备注:
+ 关键词:measure distance relative, important for applications, navigation and self-driving, Monocular depth estimation, crucial task
+
+ 点击查看摘要
+ Monocular depth estimation is a crucial task to measure distance relative to a camera, which is important for applications, such as robot navigation and self-driving. Traditional frame-based methods suffer from performance drops due to the limited dynamic range and motion blur. Therefore, recent works leverage novel event cameras to complement or guide the frame modality via frame-event feature fusion. However, event streams exhibit spatial sparsity, leaving some areas unperceived, especially in regions with marginal light changes. Therefore, direct fusion methods, e.g., RAMNet, often ignore the contribution of the most confident regions of each modality. This leads to structural ambiguity in the modality fusion process, thus degrading the depth estimation performance. In this paper, we propose a novel Spatial Reliability-oriented Fusion Network (SRFNet), that can estimate depth with fine-grained structure at both daytime and nighttime. Our method consists of two key technical components. Firstly, we propose an attention-based interactive fusion (AIF) module that applies spatial priors of events and frames as the initial masks and learns the consensus regions to guide the inter-modal feature fusion. The fused feature are then fed back to enhance the frame and event feature learning. Meanwhile, it utilizes an output head to generate a fused mask, which is iteratively updated for learning consensual spatial priors. Secondly, we propose the Reliability-oriented Depth Refinement (RDR) module to estimate dense depth with the fine-grained structure based on the fused features and masks. We evaluate the effectiveness of our method on the synthetic and real-world datasets, which shows that, even without pretraining, our method outperforms the prior methods, e.g., RAMNet, especially in night scenes. Our project homepage: this https URL.
+
+
+
+ 16. 标题:Synthetic Boost: Leveraging Synthetic Data for Enhanced Vision-Language Segmentation in Echocardiography
+ 编号:[78]
+ 链接:https://arxiv.org/abs/2309.12829
+ 作者:Rabin Adhikari, Manish Dhakal, Safal Thapaliya, Kanchan Poudel, Prasiddha Bhandari, Bishesh Khanal
+ 备注:Accepted at the 4th International Workshop of Advances in Simplifying Medical UltraSound (ASMUS)
+ 关键词:cardiovascular diseases, essential for echocardiography-based, echocardiography-based assessment, assessment of cardiovascular, Semantic Diffusion Models
+
+ 点击查看摘要
+ Accurate segmentation is essential for echocardiography-based assessment of cardiovascular diseases (CVDs). However, the variability among sonographers and the inherent challenges of ultrasound images hinder precise segmentation. By leveraging the joint representation of image and text modalities, Vision-Language Segmentation Models (VLSMs) can incorporate rich contextual information, potentially aiding in accurate and explainable segmentation. However, the lack of readily available data in echocardiography hampers the training of VLSMs. In this study, we explore using synthetic datasets from Semantic Diffusion Models (SDMs) to enhance VLSMs for echocardiography segmentation. We evaluate results for two popular VLSMs (CLIPSeg and CRIS) using seven different kinds of language prompts derived from several attributes, automatically extracted from echocardiography images, segmentation masks, and their metadata. Our results show improved metrics and faster convergence when pretraining VLSMs on SDM-generated synthetic images before finetuning on real images. The code, configs, and prompts are available at this https URL.
+
+
+
+ 17. 标题:Domain Adaptive Few-Shot Open-Set Learning
+ 编号:[81]
+ 链接:https://arxiv.org/abs/2309.12814
+ 作者:Debabrata Pal, Deeptej More, Sai Bhargav, Dipesh Tamboli, Vaneet Aggarwal, Biplab Banerjee
+ 备注:
+ 关键词:made impressive strides, recognizing unknown samples, managing visual shifts, Open Set Recognition, target query sets
+
+ 点击查看摘要
+ Few-shot learning has made impressive strides in addressing the crucial challenges of recognizing unknown samples from novel classes in target query sets and managing visual shifts between domains. However, existing techniques fall short when it comes to identifying target outliers under domain shifts by learning to reject pseudo-outliers from the source domain, resulting in an incomplete solution to both problems. To address these challenges comprehensively, we propose a novel approach called Domain Adaptive Few-Shot Open Set Recognition (DA-FSOS) and introduce a meta-learning-based architecture named DAFOSNET. During training, our model learns a shared and discriminative embedding space while creating a pseudo open-space decision boundary, given a fully-supervised source domain and a label-disjoint few-shot target domain. To enhance data density, we use a pair of conditional adversarial networks with tunable noise variances to augment both domains closed and pseudo-open spaces. Furthermore, we propose a domain-specific batch-normalized class prototypes alignment strategy to align both domains globally while ensuring class-discriminativeness through novel metric objectives. Our training approach ensures that DAFOS-NET can generalize well to new scenarios in the target domain. We present three benchmarks for DA-FSOS based on the Office-Home, mini-ImageNet/CUB, and DomainNet datasets and demonstrate the efficacy of DAFOS-NET through extensive experimentation
+
+
+
+ 18. 标题:Scalable Semantic 3D Mapping of Coral Reefs with Deep Learning
+ 编号:[86]
+ 链接:https://arxiv.org/abs/2309.12804
+ 作者:Jonathan Sauder, Guilhem Banc-Prandi, Anders Meibom, Devis Tuia
+ 备注:
+ 关键词:millions of people, diverse ecosystems, hundreds of millions, Coral reefs, Coral
+
+ 点击查看摘要
+ Coral reefs are among the most diverse ecosystems on our planet, and are depended on by hundreds of millions of people. Unfortunately, most coral reefs are existentially threatened by global climate change and local anthropogenic pressures. To better understand the dynamics underlying deterioration of reefs, monitoring at high spatial and temporal resolution is key. However, conventional monitoring methods for quantifying coral cover and species abundance are limited in scale due to the extensive manual labor required. Although computer vision tools have been employed to aid in this process, in particular SfM photogrammetry for 3D mapping and deep neural networks for image segmentation, analysis of the data products creates a bottleneck, effectively limiting their scalability. This paper presents a new paradigm for mapping underwater environments from ego-motion video, unifying 3D mapping systems that use machine learning to adapt to challenging conditions under water, combined with a modern approach for semantic segmentation of images. The method is exemplified on coral reefs in the northern Gulf of Aqaba, Red Sea, demonstrating high-precision 3D semantic mapping at unprecedented scale with significantly reduced required labor costs: a 100 m video transect acquired within 5 minutes of diving with a cheap consumer-grade camera can be fully automatically analyzed within 5 minutes. Our approach significantly scales up coral reef monitoring by taking a leap towards fully automatic analysis of video transects. The method democratizes coral reef transects by reducing the labor, equipment, logistics, and computing cost. This can help to inform conservation policies more efficiently. The underlying computational method of learning-based Structure-from-Motion has broad implications for fast low-cost mapping of underwater environments other than coral reefs.
+
+
+
+ 19. 标题:NOC: High-Quality Neural Object Cloning with 3D Lifting of Segment Anything
+ 编号:[89]
+ 链接:https://arxiv.org/abs/2309.12790
+ 作者:Xiaobao Wei, Renrui Zhang, Jiarui Wu, Jiaming Liu, Ming Lu, Yandong Guo, Shanghang Zhang
+ 备注:
+ 关键词:recently attracted increasing, attracted increasing attention, Neural Object Cloning, target object, neural field
+
+ 点击查看摘要
+ With the development of the neural field, reconstructing the 3D model of a target object from multi-view inputs has recently attracted increasing attention from the community. Existing methods normally learn a neural field for the whole scene, while it is still under-explored how to reconstruct a certain object indicated by users on-the-fly. Considering the Segment Anything Model (SAM) has shown effectiveness in segmenting any 2D images, in this paper, we propose Neural Object Cloning (NOC), a novel high-quality 3D object reconstruction method, which leverages the benefits of both neural field and SAM from two aspects. Firstly, to separate the target object from the scene, we propose a novel strategy to lift the multi-view 2D segmentation masks of SAM into a unified 3D variation field. The 3D variation field is then projected into 2D space and generates the new prompts for SAM. This process is iterative until convergence to separate the target object from the scene. Then, apart from 2D masks, we further lift the 2D features of the SAM encoder into a 3D SAM field in order to improve the reconstruction quality of the target object. NOC lifts the 2D masks and features of SAM into the 3D neural field for high-quality target object reconstruction. We conduct detailed experiments on several benchmark datasets to demonstrate the advantages of our method. The code will be released.
+
+
+
+ 20. 标题:EMS: 3D Eyebrow Modeling from Single-view Images
+ 编号:[90]
+ 链接:https://arxiv.org/abs/2309.12787
+ 作者:Chenghong Li, Leyang Jin, Yujian Zheng, Yizhou Yu, Xiaoguang Han
+ 备注:To appear in SIGGRAPH Asia 2023 (Journal Track). 19 pages, 19 figures, 6 tables
+ 关键词:expression and appearance, play a critical, critical role, role in facial, facial expression
+
+ 点击查看摘要
+ Eyebrows play a critical role in facial expression and appearance. Although the 3D digitization of faces is well explored, less attention has been drawn to 3D eyebrow modeling. In this work, we propose EMS, the first learning-based framework for single-view 3D eyebrow reconstruction. Following the methods of scalp hair reconstruction, we also represent the eyebrow as a set of fiber curves and convert the reconstruction to fibers growing problem. Three modules are then carefully designed: RootFinder firstly localizes the fiber root positions which indicates where to grow; OriPredictor predicts an orientation field in the 3D space to guide the growing of fibers; FiberEnder is designed to determine when to stop the growth of each fiber. Our OriPredictor is directly borrowing the method used in hair reconstruction. Considering the differences between hair and eyebrows, both RootFinder and FiberEnder are newly proposed. Specifically, to cope with the challenge that the root location is severely occluded, we formulate root localization as a density map estimation task. Given the predicted density map, a density-based clustering method is further used for finding the roots. For each fiber, the growth starts from the root point and moves step by step until the ending, where each step is defined as an oriented line with a constant length according to the predicted orientation field. To determine when to end, a pixel-aligned RNN architecture is designed to form a binary classifier, which outputs stop or not for each growing step. To support the training of all proposed networks, we build the first 3D synthetic eyebrow dataset that contains 400 high-quality eyebrow models manually created by artists. Extensive experiments have demonstrated the effectiveness of the proposed EMS pipeline on a variety of different eyebrow styles and lengths, ranging from short and sparse to long bushy eyebrows.
+
+
+
+ 21. 标题:LMC: Large Model Collaboration with Cross-assessment for Training-Free Open-Set Object Recognition
+ 编号:[95]
+ 链接:https://arxiv.org/abs/2309.12780
+ 作者:Haoxuan Qu, Xiaofei Hui, Yujun Cai, Jun Liu
+ 备注:NeurIPS 2023
+ 关键词:Open-set object recognition, object recognition aims, Open-set object, object recognition, object recognition accurately
+
+ 点击查看摘要
+ Open-set object recognition aims to identify if an object is from a class that has been encountered during training or not. To perform open-set object recognition accurately, a key challenge is how to reduce the reliance on spurious-discriminative features. In this paper, motivated by that different large models pre-trained through different paradigms can possess very rich while distinct implicit knowledge, we propose a novel framework named Large Model Collaboration (LMC) to tackle the above challenge via collaborating different off-the-shelf large models in a training-free manner. Moreover, we also incorporate the proposed framework with several novel designs to effectively extract implicit knowledge from large models. Extensive experiments demonstrate the efficacy of our proposed framework. Code is available \href{this https URL}{here}.
+
+
+
+ 22. 标题:WiCV@CVPR2023: The Eleventh Women In Computer Vision Workshop at the Annual CVPR Conference
+ 编号:[99]
+ 链接:https://arxiv.org/abs/2309.12768
+ 作者:Doris Antensteiner, Marah Halawa, Asra Aslam, Ivaxi Sheth, Sachini Herath, Ziqi Huang, Sunnie S. Y. Kim, Aparna Akula, Xin Wang
+ 备注:
+ 关键词:Computer Vision Workshop, computer vision community, Computer Vision, organized alongside, alongside the hybrid
+
+ 点击查看摘要
+ In this paper, we present the details of Women in Computer Vision Workshop - WiCV 2023, organized alongside the hybrid CVPR 2023 in Vancouver, Canada. WiCV aims to amplify the voices of underrepresented women in the computer vision community, fostering increased visibility in both academia and industry. We believe that such events play a vital role in addressing gender imbalances within the field. The annual WiCV@CVPR workshop offers a) opportunity for collaboration between researchers from minority groups, b) mentorship for female junior researchers, c) financial support to presenters to alleviate finanacial burdens and d) a diverse array of role models who can inspire younger researchers at the outset of their careers. In this paper, we present a comprehensive report on the workshop program, historical trends from the past WiCV@CVPR events, and a summary of statistics related to presenters, attendees, and sponsorship for the WiCV 2023 workshop.
+
+
+
+ 23. 标题:S3TC: Spiking Separated Spatial and Temporal Convolutions with Unsupervised STDP-based Learning for Action Recognition
+ 编号:[103]
+ 链接:https://arxiv.org/abs/2309.12761
+ 作者:Mireille El-Assal, Pierre Tirilly, Ioan Marius Bilasco
+ 备注:
+ 关键词:major computer vision, computer vision task, Deep Neural Networks, Spiking Neural Networks, Neural Networks
+
+ 点击查看摘要
+ Video analysis is a major computer vision task that has received a lot of attention in recent years. The current state-of-the-art performance for video analysis is achieved with Deep Neural Networks (DNNs) that have high computational costs and need large amounts of labeled data for training. Spiking Neural Networks (SNNs) have significantly lower computational costs (thousands of times) than regular non-spiking networks when implemented on neuromorphic hardware. They have been used for video analysis with methods like 3D Convolutional Spiking Neural Networks (3D CSNNs). However, these networks have a significantly larger number of parameters compared with spiking 2D CSNN. This, not only increases the computational costs, but also makes these networks more difficult to implement with neuromorphic hardware. In this work, we use CSNNs trained in an unsupervised manner with the Spike Timing-Dependent Plasticity (STDP) rule, and we introduce, for the first time, Spiking Separated Spatial and Temporal Convolutions (S3TCs) for the sake of reducing the number of parameters required for video analysis. This unsupervised learning has the advantage of not needing large amounts of labeled data for training. Factorizing a single spatio-temporal spiking convolution into a spatial and a temporal spiking convolution decreases the number of parameters of the network. We test our network with the KTH, Weizmann, and IXMAS datasets, and we show that S3TCs successfully extract spatio-temporal information from videos, while increasing the output spiking activity, and outperforming spiking 3D convolutions.
+
+
+
+ 24. 标题:Masking Improves Contrastive Self-Supervised Learning for ConvNets, and Saliency Tells You Where
+ 编号:[104]
+ 链接:https://arxiv.org/abs/2309.12757
+ 作者:Zhi-Yi Chin, Chieh-Ming Jiang, Ching-Chun Huang, Pin-Yu Chen, Wei-Chen Chiu
+ 备注:
+ 关键词:convolutional neural networks, vision transformer backbone, image data starts, self-supervised learning scheme, learning process significantly
+
+ 点击查看摘要
+ While image data starts to enjoy the simple-but-effective self-supervised learning scheme built upon masking and self-reconstruction objective thanks to the introduction of tokenization procedure and vision transformer backbone, convolutional neural networks as another important and widely-adopted architecture for image data, though having contrastive-learning techniques to drive the self-supervised learning, still face the difficulty of leveraging such straightforward and general masking operation to benefit their learning process significantly. In this work, we aim to alleviate the burden of including masking operation into the contrastive-learning framework for convolutional neural networks as an extra augmentation method. In addition to the additive but unwanted edges (between masked and unmasked regions) as well as other adverse effects caused by the masking operations for ConvNets, which have been discussed by prior works, we particularly identify the potential problem where for one view in a contrastive sample-pair the randomly-sampled masking regions could be overly concentrated on important/salient objects thus resulting in misleading contrastiveness to the other view. To this end, we propose to explicitly take the saliency constraint into consideration in which the masked regions are more evenly distributed among the foreground and background for realizing the masking-based augmentation. Moreover, we introduce hard negative samples by masking larger regions of salient patches in an input image. Extensive experiments conducted on various datasets, contrastive learning mechanisms, and downstream tasks well verify the efficacy as well as the superior performance of our proposed method with respect to several state-of-the-art baselines.
+
+
+
+ 25. 标题:Transformer-based Image Compression with Variable Image Quality Objectives
+ 编号:[117]
+ 链接:https://arxiv.org/abs/2309.12717
+ 作者:Chia-Hao Kao, Yi-Hsin Chen, Cheng Chien, Wei-Chen Chiu, Wen-Hsiao Peng
+ 备注:
+ 关键词:image compression system, Transformer-based image compression, paper presents, compression system, image quality objective
+
+ 点击查看摘要
+ This paper presents a Transformer-based image compression system that allows for a variable image quality objective according to the user's preference. Optimizing a learned codec for different quality objectives leads to reconstructed images with varying visual characteristics. Our method provides the user with the flexibility to choose a trade-off between two image quality objectives using a single, shared model. Motivated by the success of prompt-tuning techniques, we introduce prompt tokens to condition our Transformer-based autoencoder. These prompt tokens are generated adaptively based on the user's preference and input image through learning a prompt generation network. Extensive experiments on commonly used quality metrics demonstrate the effectiveness of our method in adapting the encoding and/or decoding processes to a variable quality objective. While offering the additional flexibility, our proposed method performs comparably to the single-objective methods in terms of rate-distortion performance.
+
+
+
+ 26. 标题:PointSSC: A Cooperative Vehicle-Infrastructure Point Cloud Benchmark for Semantic Scene Completion
+ 编号:[123]
+ 链接:https://arxiv.org/abs/2309.12708
+ 作者:Yuxiang Yan, Boda Liu, Jianfei Ai, Qinbu Li, Ru Wan, Jian Pu
+ 备注:8 pages, 5 figures, submitted to ICRA2024
+ 关键词:generate space occupancies, jointly generate space, aims to jointly, jointly generate, SSC
+
+ 点击查看摘要
+ Semantic Scene Completion (SSC) aims to jointly generate space occupancies and semantic labels for complex 3D scenes. Most existing SSC models focus on volumetric representations, which are memory-inefficient for large outdoor spaces. Point clouds provide a lightweight alternative but existing benchmarks lack outdoor point cloud scenes with semantic labels. To address this, we introduce PointSSC, the first cooperative vehicle-infrastructure point cloud benchmark for semantic scene completion. These scenes exhibit long-range perception and minimal occlusion. We develop an automated annotation pipeline leveraging Segment Anything to efficiently assign semantics. To benchmark progress, we propose a LiDAR-based model with a Spatial-Aware Transformer for global and local feature extraction and a Completion and Segmentation Cooperative Module for joint completion and segmentation. PointSSC provides a challenging testbed to drive advances in semantic point cloud completion for real-world navigation.
+
+
+
+ 27. 标题:Multi-Label Noise Transition Matrix Estimation with Label Correlations: Theory and Algorithm
+ 编号:[124]
+ 链接:https://arxiv.org/abs/2309.12706
+ 作者:Shikun Li, Xiaobo Xia, Hansong Zhang, Shiming Ge, Tongliang Liu
+ 备注:
+ 关键词:Noisy multi-label learning, garnered increasing attention, increasing attention due, multi-label learning, Noisy
+
+ 点击查看摘要
+ Noisy multi-label learning has garnered increasing attention due to the challenges posed by collecting large-scale accurate labels, making noisy labels a more practical alternative. Motivated by noisy multi-class learning, the introduction of transition matrices can help model multi-label noise and enable the development of statistically consistent algorithms for noisy multi-label learning. However, estimating multi-label noise transition matrices remains a challenging task, as most existing estimators in noisy multi-class learning rely on anchor points and accurate fitting of noisy class posteriors, which is hard to satisfy in noisy multi-label learning. In this paper, we address this problem by first investigating the identifiability of class-dependent transition matrices in noisy multi-label learning. Building upon the identifiability results, we propose a novel estimator that leverages label correlations without the need for anchor points or precise fitting of noisy class posteriors. Specifically, we first estimate the occurrence probability of two noisy labels to capture noisy label correlations. Subsequently, we employ sample selection techniques to extract information implying clean label correlations, which are then used to estimate the occurrence probability of one noisy label when a certain clean label appears. By exploiting the mismatches in label correlations implied by these occurrence probabilities, we demonstrate that the transition matrix becomes identifiable and can be acquired by solving a bilinear decomposition problem. Theoretically, we establish an estimation error bound for our multi-label transition matrix estimator and derive a generalization error bound for our statistically consistent algorithm. Empirically, we validate the effectiveness of our estimator in estimating multi-label noise transition matrices, leading to excellent classification performance.
+
+
+
+ 28. 标题:mixed attention auto encoder for multi-class industrial anomaly detection
+ 编号:[126]
+ 链接:https://arxiv.org/abs/2309.12700
+ 作者:Jiangqi Liu, Feng Wang
+ 备注:5 pages, 4 figures
+ 关键词:unsupervised industrial anomaly, industrial anomaly detection, anomaly detection train, unsupervised industrial, train a separate
+
+ 点击查看摘要
+ Most existing methods for unsupervised industrial anomaly detection train a separate model for each object category. This kind of approach can easily capture the category-specific feature distributions, but results in high storage cost and low training efficiency. In this paper, we propose a unified mixed-attention auto encoder (MAAE) to implement multi-class anomaly detection with a single model. To alleviate the performance degradation due to the diverse distribution patterns of different categories, we employ spatial attentions and channel attentions to effectively capture the global category information and model the feature distributions of multiple classes. Furthermore, to simulate the realistic noises on features and preserve the surface semantics of objects from different categories which are essential for detecting the subtle anomalies, we propose an adaptive noise generator and a multi-scale fusion module for the pre-trained features. MAAE delivers remarkable performances on the benchmark dataset compared with the state-of-the-art methods.
+
+
+
+ 29. 标题:eWand: A calibration framework for wide baseline frame-based and event-based camera systems
+ 编号:[134]
+ 链接:https://arxiv.org/abs/2309.12685
+ 作者:Thomas Gossard, Andreas Ziegler, Levin Kolmar, Jonas Tebbe, Andreas Zell
+ 备注:
+ 关键词:objects precisely, triangulate the position, position of objects, cameras, pattern
+
+ 点击查看摘要
+ Accurate calibration is crucial for using multiple cameras to triangulate the position of objects precisely. However, it is also a time-consuming process that needs to be repeated for every displacement of the cameras. The standard approach is to use a printed pattern with known geometry to estimate the intrinsic and extrinsic parameters of the cameras. The same idea can be applied to event-based cameras, though it requires extra work. By using frame reconstruction from events, a printed pattern can be detected. A blinking pattern can also be displayed on a screen. Then, the pattern can be directly detected from the events. Such calibration methods can provide accurate intrinsic calibration for both frame- and event-based cameras. However, using 2D patterns has several limitations for multi-camera extrinsic calibration, with cameras possessing highly different points of view and a wide baseline. The 2D pattern can only be detected from one direction and needs to be of significant size to compensate for its distance to the camera. This makes the extrinsic calibration time-consuming and cumbersome. To overcome these limitations, we propose eWand, a new method that uses blinking LEDs inside opaque spheres instead of a printed or displayed pattern. Our method provides a faster, easier-to-use extrinsic calibration approach that maintains high accuracy for both event- and frame-based cameras.
+
+
+
+ 30. 标题:Vision Transformers for Computer Go
+ 编号:[139]
+ 链接:https://arxiv.org/abs/2309.12675
+ 作者:Amani Sagri, Tristan Cazenave, Jérôme Arjonilla, Abdallah Saffidine
+ 备注:
+ 关键词:language understanding, understanding and image, investigation explores, explores their application, image analysis
+
+ 点击查看摘要
+ Motivated by the success of transformers in various fields, such as language understanding and image analysis, this investigation explores their application in the context of the game of Go. In particular, our study focuses on the analysis of the Transformer in Vision. Through a detailed analysis of numerous points such as prediction accuracy, win rates, memory, speed, size, or even learning rate, we have been able to highlight the substantial role that transformers can play in the game of Go. This study was carried out by comparing them to the usual Residual Networks.
+
+
+
+ 31. 标题:On Sparse Modern Hopfield Model
+ 编号:[140]
+ 链接:https://arxiv.org/abs/2309.12673
+ 作者:Jerry Yao-Chieh Hu, Donglin Yang, Dennis Wu, Chenwei Xu, Bo-Yu Chen, Han Liu
+ 备注:37 pages, accepted to NeurIPS 2023
+ 关键词:sparse modern Hopfield, modern Hopfield model, modern Hopfield, Hopfield model, sparse Hopfield model
+
+ 点击查看摘要
+ We introduce the sparse modern Hopfield model as a sparse extension of the modern Hopfield model. Like its dense counterpart, the sparse modern Hopfield model equips a memory-retrieval dynamics whose one-step approximation corresponds to the sparse attention mechanism. Theoretically, our key contribution is a principled derivation of a closed-form sparse Hopfield energy using the convex conjugate of the sparse entropic regularizer. Building upon this, we derive the sparse memory retrieval dynamics from the sparse energy function and show its one-step approximation is equivalent to the sparse-structured attention. Importantly, we provide a sparsity-dependent memory retrieval error bound which is provably tighter than its dense analog. The conditions for the benefits of sparsity to arise are therefore identified and discussed. In addition, we show that the sparse modern Hopfield model maintains the robust theoretical properties of its dense counterpart, including rapid fixed point convergence and exponential memory capacity. Empirically, we use both synthetic and real-world datasets to demonstrate that the sparse Hopfield model outperforms its dense counterpart in many situations.
+
+
+
+ 32. 标题:Exploiting Modality-Specific Features For Multi-Modal Manipulation Detection And Grounding
+ 编号:[150]
+ 链接:https://arxiv.org/abs/2309.12657
+ 作者:Jiazhen Wang, Bin Liu, Changtao Miao, Zhiwei Zhao, Wanyi Zhuang, Qi Chu, Nenghai Yu
+ 备注:This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible
+ 关键词:gained significant attention, numerous negative impacts, multi-modal manipulation detection, AI-synthesized text, significant attention
+
+ 点击查看摘要
+ AI-synthesized text and images have gained significant attention, particularly due to the widespread dissemination of multi-modal manipulations on the internet, which has resulted in numerous negative impacts on society. Existing methods for multi-modal manipulation detection and grounding primarily focus on fusing vision-language features to make predictions, while overlooking the importance of modality-specific features, leading to sub-optimal results. In this paper, we construct a simple and novel transformer-based framework for multi-modal manipulation detection and grounding tasks. Our framework simultaneously explores modality-specific features while preserving the capability for multi-modal alignment. To achieve this, we introduce visual/language pre-trained encoders and dual-branch cross-attention (DCA) to extract and fuse modality-unique features. Furthermore, we design decoupled fine-grained classifiers (DFC) to enhance modality-specific feature mining and mitigate modality competition. Moreover, we propose an implicit manipulation query (IMQ) that adaptively aggregates global contextual cues within each modality using learnable queries, thereby improving the discovery of forged details. Extensive experiments on the $\rm DGM^4$ dataset demonstrate the superior performance of our proposed model compared to state-of-the-art approaches.
+
+
+
+ 33. 标题:FP-PET: Large Model, Multiple Loss And Focused Practice
+ 编号:[152]
+ 链接:https://arxiv.org/abs/2309.12650
+ 作者:Yixin Chen, Ourui Fu, Wenrui Shao, Zhaoheng Xie
+ 备注:
+ 关键词:study presents FP-PET, presents FP-PET, PET images, comprehensive approach, medical image segmentation
+
+ 点击查看摘要
+ This study presents FP-PET, a comprehensive approach to medical image segmentation with a focus on CT and PET images. Utilizing a dataset from the AutoPet2023 Challenge, the research employs a variety of machine learning models, including STUNet-large, SwinUNETR, and VNet, to achieve state-of-the-art segmentation performance. The paper introduces an aggregated score that combines multiple evaluation metrics such as Dice score, false positive volume (FPV), and false negative volume (FNV) to provide a holistic measure of model effectiveness. The study also discusses the computational challenges and solutions related to model training, which was conducted on high-performance GPUs. Preprocessing and postprocessing techniques, including gaussian weighting schemes and morphological operations, are explored to further refine the segmentation output. The research offers valuable insights into the challenges and solutions for advanced medical image segmentation.
+
+
+
+ 34. 标题:RHINO: Regularizing the Hash-based Implicit Neural Representation
+ 编号:[156]
+ 链接:https://arxiv.org/abs/2309.12642
+ 作者:Hao Zhu, Fengyi Liu, Qi Zhang, Xun Cao, Zhan Ma
+ 备注:17 pages, 11 figures
+ 关键词:characterizing intricate signals, demonstrated impressive effectiveness, Implicit Neural Representation, Implicit Neural, intricate signals
+
+ 点击查看摘要
+ The use of Implicit Neural Representation (INR) through a hash-table has demonstrated impressive effectiveness and efficiency in characterizing intricate signals. However, current state-of-the-art methods exhibit insufficient regularization, often yielding unreliable and noisy results during interpolations. We find that this issue stems from broken gradient flow between input coordinates and indexed hash-keys, where the chain rule attempts to model discrete hash-keys, rather than the continuous coordinates. To tackle this concern, we introduce RHINO, in which a continuous analytical function is incorporated to facilitate regularization by connecting the input coordinate and the network additionally without modifying the architecture of current hash-based INRs. This connection ensures a seamless backpropagation of gradients from the network's output back to the input coordinates, thereby enhancing regularization. Our experimental results not only showcase the broadened regularization capability across different hash-based INRs like DINER and Instant NGP, but also across a variety of tasks such as image fitting, representation of signed distance functions, and optimization of 5D static / 6D dynamic neural radiance fields. Notably, RHINO outperforms current state-of-the-art techniques in both quality and speed, affirming its superiority.
+
+
+
+ 35. 标题:Global Context Aggregation Network for Lightweight Saliency Detection of Surface Defects
+ 编号:[157]
+ 链接:https://arxiv.org/abs/2309.12641
+ 作者:Feng Yan, Xiaoheng Jiang, Yang Lu, Lisha Cui, Shupan Li, Jiale Cao, Mingliang Xu, Dacheng Tao
+ 备注:
+ 关键词:show weak appearances, Surface defect inspection, challenging task, weak appearances, appearances or exist
+
+ 点击查看摘要
+ Surface defect inspection is a very challenging task in which surface defects usually show weak appearances or exist under complex backgrounds. Most high-accuracy defect detection methods require expensive computation and storage overhead, making them less practical in some resource-constrained defect detection applications. Although some lightweight methods have achieved real-time inference speed with fewer parameters, they show poor detection accuracy in complex defect scenarios. To this end, we develop a Global Context Aggregation Network (GCANet) for lightweight saliency detection of surface defects on the encoder-decoder structure. First, we introduce a novel transformer encoder on the top layer of the lightweight backbone, which captures global context information through a novel Depth-wise Self-Attention (DSA) module. The proposed DSA performs element-wise similarity in channel dimension while maintaining linear complexity. In addition, we introduce a novel Channel Reference Attention (CRA) module before each decoder block to strengthen the representation of multi-level features in the bottom-up path. The proposed CRA exploits the channel correlation between features at different layers to adaptively enhance feature representation. The experimental results on three public defect datasets demonstrate that the proposed network achieves a better trade-off between accuracy and running efficiency compared with other 17 state-of-the-art methods. Specifically, GCANet achieves competitive accuracy (91.79% $F_{\beta}^{w}$, 93.55% $S_\alpha$, and 97.35% $E_\phi$) on SD-saliency-900 while running 272fps on a single gpu.
+
+
+
+ 36. 标题:CINFormer: Transformer network with multi-stage CNN feature injection for surface defect segmentation
+ 编号:[159]
+ 链接:https://arxiv.org/abs/2309.12639
+ 作者:Xiaoheng Jiang, Kaiyi Guo, Yang Lu, Feng Yan, Hao Liu, Jiale Cao, Mingliang Xu, Dacheng Tao
+ 备注:
+ 关键词:Convolutional Neural Network, manufacture and production, Surface defect inspection, great importance, importance for industrial
+
+ 点击查看摘要
+ Surface defect inspection is of great importance for industrial manufacture and production. Though defect inspection methods based on deep learning have made significant progress, there are still some challenges for these methods, such as indistinguishable weak defects and defect-like interference in the background. To address these issues, we propose a transformer network with multi-stage CNN (Convolutional Neural Network) feature injection for surface defect segmentation, which is a UNet-like structure named CINFormer. CINFormer presents a simple yet effective feature integration mechanism that injects the multi-level CNN features of the input image into different stages of the transformer network in the encoder. This can maintain the merit of CNN capturing detailed features and that of transformer depressing noises in the background, which facilitates accurate defect detection. In addition, CINFormer presents a Top-K self-attention module to focus on tokens with more important information about the defects, so as to further reduce the impact of the redundant background. Extensive experiments conducted on the surface defect datasets DAGM 2007, Magnetic tile, and NEU show that the proposed CINFormer achieves state-of-the-art performance in defect detection.
+
+
+
+ 37. 标题:Learning Actions and Control of Focus of Attention with a Log-Polar-like Sensor
+ 编号:[161]
+ 链接:https://arxiv.org/abs/2309.12634
+ 作者:Robin Göransson, Volker Krueger
+ 备注:
+ 关键词:autonomous mobile robot, image processing time, gaze control, Atari games, long-term goal
+
+ 点击查看摘要
+ With the long-term goal of reducing the image processing time on an autonomous mobile robot in mind we explore in this paper the use of log-polar like image data with gaze control. The gaze control is not done on the Cartesian image but on the log-polar like image data. For this we start out from the classic deep reinforcement learning approach for Atari games. We extend an A3C deep RL approach with an LSTM network, and we learn the policy for playing three Atari games and a policy for gaze control. While the Atari games already use low-resolution images of 80 by 80 pixels, we are able to further reduce the amount of image pixels by a factor of 5 without losing any gaming performance.
+
+
+
+ 38. 标题:Decision Fusion Network with Perception Fine-tuning for Defect Classification
+ 编号:[164]
+ 链接:https://arxiv.org/abs/2309.12630
+ 作者:Xiaoheng Jiang, Shilong Tian, Zhiwen Zhu, Yang Lu, Hao Liu, Li Chen, Shupan Li, Mingliang Xu
+ 备注:
+ 关键词:Surface defect inspection, industrial inspection, important task, task in industrial, decision
+
+ 点击查看摘要
+ Surface defect inspection is an important task in industrial inspection. Deep learning-based methods have demonstrated promising performance in this domain. Nevertheless, these methods still suffer from misjudgment when encountering challenges such as low-contrast defects and complex backgrounds. To overcome these issues, we present a decision fusion network (DFNet) that incorporates the semantic decision with the feature decision to strengthen the decision ability of the network. In particular, we introduce a decision fusion module (DFM) that extracts a semantic vector from the semantic decision branch and a feature vector for the feature decision branch and fuses them to make the final classification decision. In addition, we propose a perception fine-tuning module (PFM) that fine-tunes the foreground and background during the segmentation stage. PFM generates the semantic and feature outputs that are sent to the classification decision stage. Furthermore, we present an inner-outer separation weight matrix to address the impact of label edge uncertainty during segmentation supervision. Our experimental results on the publicly available datasets including KolektorSDD2 (96.1% AP) and Magnetic-tile-defect-datasets (94.6% mAP) demonstrate the effectiveness of the proposed method.
+
+
+
+ 39. 标题:DeFormer: Integrating Transformers with Deformable Models for 3D Shape Abstraction from a Single Image
+ 编号:[184]
+ 链接:https://arxiv.org/abs/2309.12594
+ 作者:Di Liu, Xiang Yu, Meng Ye, Qilong Zhangli, Zhuowei Li, Zhixing Zhang, Dimitris N. Metaxas
+ 备注:Accepted by ICCV 2023
+ 关键词:vision and graphics, long-standing problem, problem in computer, computer vision, shape abstraction
+
+ 点击查看摘要
+ Accurate 3D shape abstraction from a single 2D image is a long-standing problem in computer vision and graphics. By leveraging a set of primitives to represent the target shape, recent methods have achieved promising results. However, these methods either use a relatively large number of primitives or lack geometric flexibility due to the limited expressibility of the primitives. In this paper, we propose a novel bi-channel Transformer architecture, integrated with parameterized deformable models, termed DeFormer, to simultaneously estimate the global and local deformations of primitives. In this way, DeFormer can abstract complex object shapes while using a small number of primitives which offer a broader geometry coverage and finer details. Then, we introduce a force-driven dynamic fitting and a cycle-consistent re-projection loss to optimize the primitive parameters. Extensive experiments on ShapeNet across various settings show that DeFormer achieves better reconstruction accuracy over the state-of-the-art, and visualizes with consistent semantic correspondences for improved interpretability.
+
+
+
+ 40. 标题:Improving Machine Learning Robustness via Adversarial Training
+ 编号:[185]
+ 链接:https://arxiv.org/abs/2309.12593
+ 作者:Long Dang, Thushari Hapuarachchi, Kaiqi Xiong, Jing Lin
+ 备注:
+ 关键词:potential worst-case noises, highly unusual situations, Machine Learning, IID data case, real-world applications
+
+ 点击查看摘要
+ As Machine Learning (ML) is increasingly used in solving various tasks in real-world applications, it is crucial to ensure that ML algorithms are robust to any potential worst-case noises, adversarial attacks, and highly unusual situations when they are designed. Studying ML robustness will significantly help in the design of ML algorithms. In this paper, we investigate ML robustness using adversarial training in centralized and decentralized environments, where ML training and testing are conducted in one or multiple computers. In the centralized environment, we achieve a test accuracy of 65.41% and 83.0% when classifying adversarial examples generated by Fast Gradient Sign Method and DeepFool, respectively. Comparing to existing studies, these results demonstrate an improvement of 18.41% for FGSM and 47% for DeepFool. In the decentralized environment, we study Federated learning (FL) robustness by using adversarial training with independent and identically distributed (IID) and non-IID data, respectively, where CIFAR-10 is used in this research. In the IID data case, our experimental results demonstrate that we can achieve such a robust accuracy that it is comparable to the one obtained in the centralized environment. Moreover, in the non-IID data case, the natural accuracy drops from 66.23% to 57.82%, and the robust accuracy decreases by 25% and 23.4% in C&W and Projected Gradient Descent (PGD) attacks, compared to the IID data case, respectively. We further propose an IID data-sharing approach, which allows for increasing the natural accuracy to 85.04% and the robust accuracy from 57% to 72% in C&W attacks and from 59% to 67% in PGD attacks.
+
+
+
+ 41. 标题:BGF-YOLO: Enhanced YOLOv8 with Multiscale Attentional Feature Fusion for Brain Tumor Detection
+ 编号:[189]
+ 链接:https://arxiv.org/abs/2309.12585
+ 作者:Ming Kang, Chee-Ming Ting, Fung Fung Ting, Raphaël C.-W. Phan
+ 备注:
+ 关键词:based object detectors, Bi-level Routing Attention, shown remarkable accuracy, incorporating Bi-level Routing, based object
+
+ 点击查看摘要
+ You Only Look Once (YOLO)-based object detectors have shown remarkable accuracy for automated brain tumor detection. In this paper, we develop a novel BGFG-YOLO architecture by incorporating Bi-level Routing Attention (BRA), Generalized feature pyramid networks (GFPN), Forth detecting head, and Generalized-IoU (GIoU) bounding box regression loss into YOLOv8. BGFG-YOLO contains an attention mechanism to focus more on important features, and feature pyramid networks to enrich feature representation by merging high-level semantic features with spatial details. Furthermore, we investigate the effect of different attention mechanisms and feature fusions, detection head architectures on brain tumor detection accuracy. Experimental results show that BGFG-YOLO gives a 3.4% absolute increase of mAP50 compared to YOLOv8x, and achieves state-of-the-art on the brain tumor detection dataset Br35H. The code is available at this https URL.
+
+
+
+ 42. 标题:Classification of Alzheimers Disease with Deep Learning on Eye-tracking Data
+ 编号:[194]
+ 链接:https://arxiv.org/abs/2309.12574
+ 作者:Harshinee Sriram, Cristina Conati, Thalia Field
+ 备注:ICMI 2023 long paper
+ 关键词:classifying Alzheimers Disease, Alzheimers Disease, task-specific engineered features, classifying Alzheimers, engineered features
+
+ 点击查看摘要
+ Existing research has shown the potential of classifying Alzheimers Disease (AD) from eye-tracking (ET) data with classifiers that rely on task-specific engineered features. In this paper, we investigate whether we can improve on existing results by using a Deep-Learning classifier trained end-to-end on raw ET data. This classifier (VTNet) uses a GRU and a CNN in parallel to leverage both visual (V) and temporal (T) representations of ET data and was previously used to detect user confusion while processing visual displays. A main challenge in applying VTNet to our target AD classification task is that the available ET data sequences are much longer than those used in the previous confusion detection task, pushing the limits of what is manageable by LSTM-based models. We discuss how we address this challenge and show that VTNet outperforms the state-of-the-art approaches in AD classification, providing encouraging evidence on the generality of this model to make predictions from ET data.
+
+
+
+ 43. 标题:Invariant Learning via Probability of Sufficient and Necessary Causes
+ 编号:[202]
+ 链接:https://arxiv.org/abs/2309.12559
+ 作者:Mengyue Yang, Zhen Fang, Yonggang Zhang, Yali Du, Furui Liu, Jean-Francois Ton, Jun Wang
+ 备注:
+ 关键词:testing distribution typically, distribution typically unknown, achieving OOD generalization, OOD generalization, indispensable for learning
+
+ 点击查看摘要
+ Out-of-distribution (OOD) generalization is indispensable for learning models in the wild, where testing distribution typically unknown and different from the training. Recent methods derived from causality have shown great potential in achieving OOD generalization. However, existing methods mainly focus on the invariance property of causes, while largely overlooking the property of \textit{sufficiency} and \textit{necessity} conditions. Namely, a necessary but insufficient cause (feature) is invariant to distribution shift, yet it may not have required accuracy. By contrast, a sufficient yet unnecessary cause (feature) tends to fit specific data well but may have a risk of adapting to a new domain. To capture the information of sufficient and necessary causes, we employ a classical concept, the probability of sufficiency and necessary causes (PNS), which indicates the probability of whether one is the necessary and sufficient cause. To associate PNS with OOD generalization, we propose PNS risk and formulate an algorithm to learn representation with a high PNS value. We theoretically analyze and prove the generalizability of the PNS risk. Experiments on both synthetic and real-world benchmarks demonstrate the effectiveness of the proposed method. The details of the implementation can be found at the GitHub repository: this https URL.
+
+
+
+ 44. 标题:Triple-View Knowledge Distillation for Semi-Supervised Semantic Segmentation
+ 编号:[203]
+ 链接:https://arxiv.org/abs/2309.12557
+ 作者:Ping Li, Junjie Chen, Li Yuan, Xianghua Xu, Mingli Song
+ 备注:
+ 关键词:expensive human labeling, pixel-level label map, labeled images, unlabeled images, semantic segmentation employs
+
+ 点击查看摘要
+ To alleviate the expensive human labeling, semi-supervised semantic segmentation employs a few labeled images and an abundant of unlabeled images to predict the pixel-level label map with the same size. Previous methods often adopt co-training using two convolutional networks with the same architecture but different initialization, which fails to capture the sufficiently diverse features. This motivates us to use tri-training and develop the triple-view encoder to utilize the encoders with different architectures to derive diverse features, and exploit the knowledge distillation skill to learn the complementary semantics among these encoders. Moreover, existing methods simply concatenate the features from both encoder and decoder, resulting in redundant features that require large memory cost. This inspires us to devise a dual-frequency decoder that selects those important features by projecting the features from the spatial domain to the frequency domain, where the dual-frequency channel attention mechanism is introduced to model the feature importance. Therefore, we propose a Triple-view Knowledge Distillation framework, termed TriKD, for semi-supervised semantic segmentation, including the triple-view encoder and the dual-frequency decoder. Extensive experiments were conducted on two benchmarks, \ie, Pascal VOC 2012 and Cityscapes, whose results verify the superiority of the proposed method with a good tradeoff between precision and inference speed.
+
+
+
+ 45. 标题:A Sentence Speaks a Thousand Images: Domain Generalization through Distilling CLIP with Language Guidance
+ 编号:[214]
+ 链接:https://arxiv.org/abs/2309.12530
+ 作者:Zeyi Huang, Andy Zhou, Zijian Lin, Mu Cai, Haohan Wang, Yong Jae Lee
+ 备注:to appear at ICCV2023
+ 关键词:Domain generalization studies, Domain generalization, studies the problem, CLIP teacher model, Domain
+
+ 点击查看摘要
+ Domain generalization studies the problem of training a model with samples from several domains (or distributions) and then testing the model with samples from a new, unseen domain. In this paper, we propose a novel approach for domain generalization that leverages recent advances in large vision-language models, specifically a CLIP teacher model, to train a smaller model that generalizes to unseen domains. The key technical contribution is a new type of regularization that requires the student's learned image representations to be close to the teacher's learned text representations obtained from encoding the corresponding text descriptions of images. We introduce two designs of the loss function, absolute and relative distance, which provide specific guidance on how the training process of the student model should be regularized. We evaluate our proposed method, dubbed RISE (Regularized Invariance with Semantic Embeddings), on various benchmark datasets and show that it outperforms several state-of-the-art domain generalization methods. To our knowledge, our work is the first to leverage knowledge distillation using a large vision-language model for domain generalization. By incorporating text-based information, RISE improves the generalization capability of machine learning models.
+
+
+
+ 46. 标题:License Plate Super-Resolution Using Diffusion Models
+ 编号:[222]
+ 链接:https://arxiv.org/abs/2309.12506
+ 作者:Sawsan AlHalawani, Bilel Benjdira, Adel Ammar, Anis Koubaa, Anas M. Ali
+ 备注:
+ 关键词:compromising recognition precision, Convolutional Neural Networks, Generative Adversarial Networks, accurately recognizing license, recognizing license plates
+
+ 点击查看摘要
+ In surveillance, accurately recognizing license plates is hindered by their often low quality and small dimensions, compromising recognition precision. Despite advancements in AI-based image super-resolution, methods like Convolutional Neural Networks (CNNs) and Generative Adversarial Networks (GANs) still fall short in enhancing license plate images. This study leverages the cutting-edge diffusion model, which has consistently outperformed other deep learning techniques in image restoration. By training this model using a curated dataset of Saudi license plates, both in low and high resolutions, we discovered the diffusion model's superior efficacy. The method achieves a 12.55\% and 37.32% improvement in Peak Signal-to-Noise Ratio (PSNR) over SwinIR and ESRGAN, respectively. Moreover, our method surpasses these techniques in terms of Structural Similarity Index (SSIM), registering a 4.89% and 17.66% improvement over SwinIR and ESRGAN, respectively. Furthermore, 92% of human evaluators preferred our images over those from other algorithms. In essence, this research presents a pioneering solution for license plate super-resolution, with tangible potential for surveillance systems.
+
+
+
+ 47. 标题:Impact of architecture on robustness and interpretability of multispectral deep neural networks
+ 编号:[241]
+ 链接:https://arxiv.org/abs/2309.12463
+ 作者:Charles Godfrey, Elise Bishoff, Myles McKay, Eleanor Byler
+ 备注:Comments welcome!
+ 关键词:deep learning model, deep learning, improve deep learning, vision-oriented tasks, learning model
+
+ 点击查看摘要
+ Including information from additional spectral bands (e.g., near-infrared) can improve deep learning model performance for many vision-oriented tasks. There are many possible ways to incorporate this additional information into a deep learning model, but the optimal fusion strategy has not yet been determined and can vary between applications. At one extreme, known as "early fusion," additional bands are stacked as extra channels to obtain an input image with more than three channels. At the other extreme, known as "late fusion," RGB and non-RGB bands are passed through separate branches of a deep learning model and merged immediately before a final classification or segmentation layer. In this work, we characterize the performance of a suite of multispectral deep learning models with different fusion approaches, quantify their relative reliance on different input bands and evaluate their robustness to naturalistic image corruptions affecting one or more input channels.
+
+
+
+ 48. 标题:Multimodal Deep Learning for Scientific Imaging Interpretation
+ 编号:[243]
+ 链接:https://arxiv.org/abs/2309.12460
+ 作者:Abdulelah S. Alshehri, Franklin L. Lee, Shihu Wang
+ 备注:
+ 关键词:Scanning Electron Microscopy, interpreting visual data, demands an intricate, intricate combination, subject materials
+
+ 点击查看摘要
+ In the domain of scientific imaging, interpreting visual data often demands an intricate combination of human expertise and deep comprehension of the subject materials. This study presents a novel methodology to linguistically emulate and subsequently evaluate human-like interactions with Scanning Electron Microscopy (SEM) images, specifically of glass materials. Leveraging a multimodal deep learning framework, our approach distills insights from both textual and visual data harvested from peer-reviewed articles, further augmented by the capabilities of GPT-4 for refined data synthesis and evaluation. Despite inherent challenges--such as nuanced interpretations and the limited availability of specialized datasets--our model (GlassLLaVA) excels in crafting accurate interpretations, identifying key features, and detecting defects in previously unseen SEM images. Moreover, we introduce versatile evaluation metrics, suitable for an array of scientific imaging applications, which allows for benchmarking against research-grounded answers. Benefiting from the robustness of contemporary Large Language Models, our model adeptly aligns with insights from research papers. This advancement not only underscores considerable progress in bridging the gap between human and machine interpretation in scientific imaging, but also hints at expansive avenues for future research and broader application.
+
+
+
+ 49. 标题:Active Learning for Multilingual Fingerspelling Corpora
+ 编号:[250]
+ 链接:https://arxiv.org/abs/2309.12443
+ 作者:Shuai Wang, Eric Nalisnick
+ 备注:
+ 关键词:apply active learning, data scarcity problems, apply active, active learning, data scarcity
+
+ 点击查看摘要
+ We apply active learning to help with data scarcity problems in sign languages. In particular, we perform a novel analysis of the effect of pre-training. Since many sign languages are linguistic descendants of French sign language, they share hand configurations, which pre-training can hopefully exploit. We test this hypothesis on American, Chinese, German, and Irish fingerspelling corpora. We do observe a benefit from pre-training, but this may be due to visual rather than linguistic similarities
+
+
+
+ 50. 标题:DIOR: Dataset for Indoor-Outdoor Reidentification -- Long Range 3D/2D Skeleton Gait Collection Pipeline, Semi-Automated Gait Keypoint Labeling and Baseline Evaluation Methods
+ 编号:[256]
+ 链接:https://arxiv.org/abs/2309.12429
+ 作者:Yuyang Chen, Praveen Raj Masilamani, Bhavin Jawade, Srirangaraj Setlur, Karthik Dantu
+ 备注:
+ 关键词:UAV cameras, street cams, recent times, increased interest, identification and re-identification
+
+ 点击查看摘要
+ In recent times, there is an increased interest in the identification and re-identification of people at long distances, such as from rooftop cameras, UAV cameras, street cams, and others. Such recognition needs to go beyond face and use whole-body markers such as gait. However, datasets to train and test such recognition algorithms are not widely prevalent, and fewer are labeled. This paper introduces DIOR -- a framework for data collection, semi-automated annotation, and also provides a dataset with 14 subjects and 1.649 million RGB frames with 3D/2D skeleton gait labels, including 200 thousands frames from a long range camera. Our approach leverages advanced 3D computer vision techniques to attain pixel-level accuracy in indoor settings with motion capture systems. Additionally, for outdoor long-range settings, we remove the dependency on motion capture systems and adopt a low-cost, hybrid 3D computer vision and learning pipeline with only 4 low-cost RGB cameras, successfully achieving precise skeleton labeling on far-away subjects, even when their height is limited to a mere 20-25 pixels within an RGB frame. On publication, we will make our pipeline open for others to use.
+
+
+
+ 51. 标题:Synthetic Image Detection: Highlights from the IEEE Video and Image Processing Cup 2022 Student Competition
+ 编号:[257]
+ 链接:https://arxiv.org/abs/2309.12428
+ 作者:Davide Cozzolino, Koki Nagano, Lucas Thomaz, Angshul Majumdar, Luisa Verdoliva
+ 备注:
+ 关键词:IEEE International Conference, IEEE VIP Cup, International Conference, Image Processing, VIP Cup asked
+
+ 点击查看摘要
+ The Video and Image Processing (VIP) Cup is a student competition that takes place each year at the IEEE International Conference on Image Processing. The 2022 IEEE VIP Cup asked undergraduate students to develop a system capable of distinguishing pristine images from generated ones. The interest in this topic stems from the incredible advances in the AI-based generation of visual data, with tools that allows the synthesis of highly realistic images and videos. While this opens up a large number of new opportunities, it also undermines the trustworthiness of media content and fosters the spread of disinformation on the internet. Recently there was strong concern about the generation of extremely realistic images by means of editing software that includes the recent technology on diffusion models. In this context, there is a need to develop robust and automatic tools for synthetic image detection.
+
+
+
+ 52. 标题:DualToken-ViT: Position-aware Efficient Vision Transformer with Dual Token Fusion
+ 编号:[259]
+ 链接:https://arxiv.org/abs/2309.12424
+ 作者:Zhenzhen Chu, Jiayu Chen, Cen Chen, Chengyu Wang, Ziheng Wu, Jun Huang, Weining Qian
+ 备注:
+ 关键词:highly competitive architecture, highly competitive, competitive architecture, architecture in computer, ViTs
+
+ 点击查看摘要
+ Self-attention-based vision transformers (ViTs) have emerged as a highly competitive architecture in computer vision. Unlike convolutional neural networks (CNNs), ViTs are capable of global information sharing. With the development of various structures of ViTs, ViTs are increasingly advantageous for many vision tasks. However, the quadratic complexity of self-attention renders ViTs computationally intensive, and their lack of inductive biases of locality and translation equivariance demands larger model sizes compared to CNNs to effectively learn visual features. In this paper, we propose a light-weight and efficient vision transformer model called DualToken-ViT that leverages the advantages of CNNs and ViTs. DualToken-ViT effectively fuses the token with local information obtained by convolution-based structure and the token with global information obtained by self-attention-based structure to achieve an efficient attention structure. In addition, we use position-aware global tokens throughout all stages to enrich the global information, which further strengthening the effect of DualToken-ViT. Position-aware global tokens also contain the position information of the image, which makes our model better for vision tasks. We conducted extensive experiments on image classification, object detection and semantic segmentation tasks to demonstrate the effectiveness of DualToken-ViT. On the ImageNet-1K dataset, our models of different scales achieve accuracies of 75.4% and 79.4% with only 0.5G and 1.0G FLOPs, respectively, and our model with 1.0G FLOPs outperforms LightViT-T using global tokens by 0.7%.
+
+
+
+ 53. 标题:Speeding up Resnet Architecture with Layers Targeted Low Rank Decomposition
+ 编号:[263]
+ 链接:https://arxiv.org/abs/2309.12412
+ 作者:Walid Ahmed, Habib Hajimolahoseini, Austin Wen, Yang Liu
+ 备注:
+ 关键词:neural network, network, Compression, study applying compression, network layers
+
+ 点击查看摘要
+ Compression of a neural network can help in speeding up both the training and the inference of the network. In this research, we study applying compression using low rank decomposition on network layers. Our research demonstrates that to acquire a speed up, the compression methodology should be aware of the underlying hardware as analysis should be done to choose which layers to compress. The advantage of our approach is demonstrated via a case study of compressing ResNet50 and training on full ImageNet-ILSVRC2012. We tested on two different hardware systems Nvidia V100 and Huawei Ascend910. With hardware targeted compression, results on Ascend910 showed 5.36% training speedup and 15.79% inference speed on Ascend310 with only 1% drop in accuracy compared to the original uncompressed model
+
+
+
+ 54. 标题:POLAR3D: Augmenting NASA's POLAR Dataset for Data-Driven Lunar Perception and Rover Simulation
+ 编号:[265]
+ 链接:https://arxiv.org/abs/2309.12397
+ 作者:Bo-Hsun Chen, Peter Negrut, Thomas Liang, Nevindu Batagoda, Harry Zhang, Dan Negrut
+ 备注:7 pages, 4 figures; this work has been submitted to the 2024 IEEE Conference on Robotics and Automation (ICRA) under review
+ 关键词:generated by NASA, NASA to mimic, lunar lighting conditions, POLAR dataset, mimic lunar lighting
+
+ 点击查看摘要
+ We report on an effort that led to POLAR3D, a set of digital assets that enhance the POLAR dataset of stereo images generated by NASA to mimic lunar lighting conditions. Our contributions are twofold. First, we have annotated each photo in the POLAR dataset, providing approximately 23 000 labels for rocks and their shadows. Second, we digitized several lunar terrain scenarios available in the POLAR dataset. Specifically, by utilizing both the lunar photos and the POLAR's LiDAR point clouds, we constructed detailed obj files for all identifiable assets. POLAR3D is the set of digital assets comprising of rock/shadow labels and obj files associated with the digital twins of lunar terrain scenarios. This new dataset can be used for training perception algorithms for lunar exploration and synthesizing photorealistic images beyond the original POLAR collection. Likewise, the obj assets can be integrated into simulation environments to facilitate realistic rover operations in a digital twin of a POLAR scenario. POLAR3D is publicly available to aid perception algorithm development, camera simulation efforts, and lunar simulation exercises.POLAR3D is publicly available at this https URL.
+
+
+
+ 55. 标题:SCOB: Universal Text Understanding via Character-wise Supervised Contrastive Learning with Online Text Rendering for Bridging Domain Gap
+ 编号:[266]
+ 链接:https://arxiv.org/abs/2309.12382
+ 作者:Daehee Kim, Yoonsik Kim, DongHyun Kim, Yumin Lim, Geewook Kim, Taeho Kil
+ 备注:ICCV 2023
+ 关键词:visual document understanding, explored LM-based pre-training, language model, recent studies, great success
+
+ 点击查看摘要
+ Inspired by the great success of language model (LM)-based pre-training, recent studies in visual document understanding have explored LM-based pre-training methods for modeling text within document images. Among them, pre-training that reads all text from an image has shown promise, but often exhibits instability and even fails when applied to broader domains, such as those involving both visual documents and scene text images. This is a substantial limitation for real-world scenarios, where the processing of text image inputs in diverse domains is essential. In this paper, we investigate effective pre-training tasks in the broader domains and also propose a novel pre-training method called SCOB that leverages character-wise supervised contrastive learning with online text rendering to effectively pre-train document and scene text domains by bridging the domain gap. Moreover, SCOB enables weakly supervised learning, significantly reducing annotation costs. Extensive benchmarks demonstrate that SCOB generally improves vanilla pre-training methods and achieves comparable performance to state-of-the-art methods. Our findings suggest that SCOB can be served generally and effectively for read-type pre-training methods. The code will be available at this https URL.
+
+
+
+ 56. 标题:Spatially Guiding Unsupervised Semantic Segmentation Through Depth-Informed Feature Distillation and Sampling
+ 编号:[268]
+ 链接:https://arxiv.org/abs/2309.12378
+ 作者:Leon Sick, Dominik Engel, Pedro Hermosilla, Timo Ropinski
+ 备注:
+ 关键词:expensive human-made annotations, segmentation required expensive, required expensive human-made, perform semantic segmentation, semantic segmentation required
+
+ 点击查看摘要
+ Traditionally, training neural networks to perform semantic segmentation required expensive human-made annotations. But more recently, advances in the field of unsupervised learning have made significant progress on this issue and towards closing the gap to supervised algorithms. To achieve this, semantic knowledge is distilled by learning to correlate randomly sampled features from images across an entire dataset. In this work, we build upon these advances by incorporating information about the structure of the scene into the training process through the use of depth information. We achieve this by (1) learning depth-feature correlation by spatially correlate the feature maps with the depth maps to induce knowledge about the structure of the scene and (2) implementing farthest-point sampling to more effectively select relevant features by utilizing 3D sampling techniques on depth information of the scene. Finally, we demonstrate the effectiveness of our technical contributions through extensive experimentation and present significant improvements in performance across multiple benchmark datasets.
+
+
+
+ 57. 标题:FUTURE-AI: International consensus guideline for trustworthy and deployable artificial intelligence in healthcare
+ 编号:[310]
+ 链接:https://arxiv.org/abs/2309.12325
+ 作者:Karim Lekadir, Aasa Feragen, Abdul Joseph Fofanah, Alejandro F Frangi, Alena Buyx, Anais Emelie, Andrea Lara, Antonio R Porras, An-Wen Chan, Arcadi Navarro, Ben Glocker, Benard O Botwe, Bishesh Khanal, Brigit Beger, Carol C Wu, Celia Cintas, Curtis P Langlotz, Daniel Rueckert, Deogratias Mzurikwao, Dimitrios I Fotiadis, Doszhan Zhussupov, Enzo Ferrante, Erik Meijering, Eva Weicken, Fabio A González, Folkert W Asselbergs, Fred Prior, Gabriel P Krestin, Gary Collins, Geletaw S Tegenaw, Georgios Kaissis, Gianluca Misuraca, Gianna Tsakou, Girish Dwivedi, Haridimos Kondylakis, Harsha Jayakody, Henry C Woodruf, Hugo JWL Aerts, Ian Walsh, Ioanna Chouvarda, Irène Buvat, Islem Rekik, James Duncan, Jayashree Kalpathy-Cramer, Jihad Zahir, Jinah Park, John Mongan, Judy W Gichoya, Julia A Schnabel, et al. (69 additional authors not shown)
+ 备注:
+ 关键词:technologies remain limited, artificial intelligence, major advances, advances in artificial, technologies remain
+
+ 点击查看摘要
+ Despite major advances in artificial intelligence (AI) for medicine and healthcare, the deployment and adoption of AI technologies remain limited in real-world clinical practice. In recent years, concerns have been raised about the technical, clinical, ethical and legal risks associated with medical AI. To increase real world adoption, it is essential that medical AI tools are trusted and accepted by patients, clinicians, health organisations and authorities. This work describes the FUTURE-AI guideline as the first international consensus framework for guiding the development and deployment of trustworthy AI tools in healthcare. The FUTURE-AI consortium was founded in 2021 and currently comprises 118 inter-disciplinary experts from 51 countries representing all continents, including AI scientists, clinicians, ethicists, and social scientists. Over a two-year period, the consortium defined guiding principles and best practices for trustworthy AI through an iterative process comprising an in-depth literature review, a modified Delphi survey, and online consensus meetings. The FUTURE-AI framework was established based on 6 guiding principles for trustworthy AI in healthcare, i.e. Fairness, Universality, Traceability, Usability, Robustness and Explainability. Through consensus, a set of 28 best practices were defined, addressing technical, clinical, legal and socio-ethical dimensions. The recommendations cover the entire lifecycle of medical AI, from design, development and validation to regulation, deployment, and monitoring. FUTURE-AI is a risk-informed, assumption-free guideline which provides a structured approach for constructing medical AI tools that will be trusted, deployed and adopted in real-world practice. Researchers are encouraged to take the recommendations into account in proof-of-concept stages to facilitate future translation towards clinical practice of medical AI.
+
+
+
+ 58. 标题:Performance Analysis of UNet and Variants for Medical Image Segmentation
+ 编号:[321]
+ 链接:https://arxiv.org/abs/2309.13013
+ 作者:Walid Ehab, Yongmin Li
+ 备注:
+ 关键词:enabling early disease, early disease detection, providing non-invasive visualisation, medical image segmentation, accurate diagnosis
+
+ 点击查看摘要
+ Medical imaging plays a crucial role in modern healthcare by providing non-invasive visualisation of internal structures and abnormalities, enabling early disease detection, accurate diagnosis, and treatment planning. This study aims to explore the application of deep learning models, particularly focusing on the UNet architecture and its variants, in medical image segmentation. We seek to evaluate the performance of these models across various challenging medical image segmentation tasks, addressing issues such as image normalization, resizing, architecture choices, loss function design, and hyperparameter tuning. The findings reveal that the standard UNet, when extended with a deep network layer, is a proficient medical image segmentation model, while the Res-UNet and Attention Res-UNet architectures demonstrate smoother convergence and superior performance, particularly when handling fine image details. The study also addresses the challenge of high class imbalance through careful preprocessing and loss function definitions. We anticipate that the results of this study will provide useful insights for researchers seeking to apply these models to new medical imaging problems and offer guidance and best practices for their implementation.
+
+
+
+ 59. 标题:PI-RADS v2 Compliant Automated Segmentation of Prostate Zones Using co-training Motivated Multi-task Dual-Path CNN
+ 编号:[325]
+ 链接:https://arxiv.org/abs/2309.12970
+ 作者:Arnab Das, Suhita Ghosh, Sebastian Stober
+ 备注:Authors Arnab Das and Suhita Ghosh contributed equally. Submitted in ISBI 2022
+ 关键词:Magnetic Resonance Imaging, Resonance Imaging, Magnetic Resonance, detailed images produced, provide life-critical information
+
+ 点击查看摘要
+ The detailed images produced by Magnetic Resonance Imaging (MRI) provide life-critical information for the diagnosis and treatment of prostate cancer. To provide standardized acquisition, interpretation and usage of the complex MRI images, the PI-RADS v2 guideline was proposed. An automated segmentation following the guideline facilitates consistent and precise lesion detection, staging and treatment. The guideline recommends a division of the prostate into four zones, PZ (peripheral zone), TZ (transition zone), DPU (distal prostatic urethra) and AFS (anterior fibromuscular stroma). Not every zone shares a boundary with the others and is present in every slice. Further, the representations captured by a single model might not suffice for all zones. This motivated us to design a dual-branch convolutional neural network (CNN), where each branch captures the representations of the connected zones separately. Further, the representations from different branches act complementary to each other at the second stage of training, where they are fine-tuned through an unsupervised loss. The loss penalises the difference in predictions from the two branches for the same class. We also incorporate multi-task learning in our framework to further improve the segmentation accuracy. The proposed approach improves the segmentation accuracy of the baseline (mean absolute symmetric distance) by 7.56%, 11.00%, 58.43% and 19.67% for PZ, TZ, DPU and AFS zones respectively.
+
+
+
+ 60. 标题:Inter-vendor harmonization of Computed Tomography (CT) reconstruction kernels using unpaired image translation
+ 编号:[327]
+ 链接:https://arxiv.org/abs/2309.12953
+ 作者:Aravind R. Krishnan, Kaiwen Xu, Thomas Li, Chenyu Gao, Lucas W. Remedios, Praitayini Kanakaraj, Ho Hin Lee, Shunxing Bao, Kim L. Sandler, Fabien Maldonado, Ivana Isgum, Bennett A. Landman
+ 备注:9 pages, 6 figures, 1 table, Submitted to SPIE Medical Imaging : Image Processing. San Diego, CA. February 2024
+ 关键词:reconstruction kernels, reconstruction, kernel, computed tomography, generation determines
+
+ 点击查看摘要
+ The reconstruction kernel in computed tomography (CT) generation determines the texture of the image. Consistency in reconstruction kernels is important as the underlying CT texture can impact measurements during quantitative image analysis. Harmonization (i.e., kernel conversion) minimizes differences in measurements due to inconsistent reconstruction kernels. Existing methods investigate harmonization of CT scans in single or multiple manufacturers. However, these methods require paired scans of hard and soft reconstruction kernels that are spatially and anatomically aligned. Additionally, a large number of models need to be trained across different kernel pairs within manufacturers. In this study, we adopt an unpaired image translation approach to investigate harmonization between and across reconstruction kernels from different manufacturers by constructing a multipath cycle generative adversarial network (GAN). We use hard and soft reconstruction kernels from the Siemens and GE vendors from the National Lung Screening Trial dataset. We use 50 scans from each reconstruction kernel and train a multipath cycle GAN. To evaluate the effect of harmonization on the reconstruction kernels, we harmonize 50 scans each from Siemens hard kernel, GE soft kernel and GE hard kernel to a reference Siemens soft kernel (B30f) and evaluate percent emphysema. We fit a linear model by considering the age, smoking status, sex and vendor and perform an analysis of variance (ANOVA) on the emphysema scores. Our approach minimizes differences in emphysema measurement and highlights the impact of age, sex, smoking status and vendor on emphysema quantification.
+
+
+
+ 61. 标题:Cross-Modal Translation and Alignment for Survival Analysis
+ 编号:[333]
+ 链接:https://arxiv.org/abs/2309.12855
+ 作者:Fengtao Zhou, Hao Chen
+ 备注:Accepted by ICCV2023
+ 关键词:high-throughput sequencing technologies, examining clinical indicators, incorporating genomic profiles, genomic profiles, pathological images
+
+ 点击查看摘要
+ With the rapid advances in high-throughput sequencing technologies, the focus of survival analysis has shifted from examining clinical indicators to incorporating genomic profiles with pathological images. However, existing methods either directly adopt a straightforward fusion of pathological features and genomic profiles for survival prediction, or take genomic profiles as guidance to integrate the features of pathological images. The former would overlook intrinsic cross-modal correlations. The latter would discard pathological information irrelevant to gene expression. To address these issues, we present a Cross-Modal Translation and Alignment (CMTA) framework to explore the intrinsic cross-modal correlations and transfer potential complementary information. Specifically, we construct two parallel encoder-decoder structures for multi-modal data to integrate intra-modal information and generate cross-modal representation. Taking the generated cross-modal representation to enhance and recalibrate intra-modal representation can significantly improve its discrimination for comprehensive survival analysis. To explore the intrinsic crossmodal correlations, we further design a cross-modal attention module as the information bridge between different modalities to perform cross-modal interactions and transfer complementary information. Our extensive experiments on five public TCGA datasets demonstrate that our proposed framework outperforms the state-of-the-art methods.
+
+
+
+ 62. 标题:Automatic view plane prescription for cardiac magnetic resonance imaging via supervision by spatial relationship between views
+ 编号:[337]
+ 链接:https://arxiv.org/abs/2309.12805
+ 作者:Dong Wei, Yawen Huang, Donghuan Lu, Yuexiang Li, Yefeng Zheng
+ 备注:Medical Physics. arXiv admin note: text overlap with arXiv:2109.11715
+ 关键词:cardiac magnetic resonance, CMR view planning, magnetic resonance, imaging remains, clinical practice
+
+ 点击查看摘要
+ Background: View planning for the acquisition of cardiac magnetic resonance (CMR) imaging remains a demanding task in clinical practice. Purpose: Existing approaches to its automation relied either on an additional volumetric image not typically acquired in clinic routine, or on laborious manual annotations of cardiac structural landmarks. This work presents a clinic-compatible, annotation-free system for automatic CMR view planning. Methods: The system mines the spatial relationship, more specifically, locates the intersecting lines, between the target planes and source views, and trains deep networks to regress heatmaps defined by distances from the intersecting lines. The intersection lines are the prescription lines prescribed by the technologists at the time of image acquisition using cardiac landmarks, and retrospectively identified from the spatial relationship. As the spatial relationship is self-contained in properly stored data, the need for additional manual annotation is eliminated. In addition, the interplay of multiple target planes predicted in a source view is utilized in a stacked hourglass architecture to gradually improve the regression. Then, a multi-view planning strategy is proposed to aggregate information from the predicted heatmaps for all the source views of a target plane, for a globally optimal prescription, mimicking the similar strategy practiced by skilled human prescribers. Results: The experiments include 181 CMR exams. Our system yields the mean angular difference and point-to-plane distance of 5.68 degrees and 3.12 mm, respectively. It not only achieves superior accuracy to existing approaches including conventional atlas-based and newer deep-learning-based in prescribing the four standard CMR planes but also demonstrates prescription of the first cardiac-anatomy-oriented plane(s) from the body-oriented scout.
+
+
+
+ 63. 标题:Auto-Lesion Segmentation with a Novel Intensity Dark Channel Prior for COVID-19 Detection
+ 编号:[349]
+ 链接:https://arxiv.org/abs/2309.12638
+ 作者:Basma Jumaa Saleh, Zaid Omar, Vikrant Bhateja, Lila Iznita Izhar
+ 备注:8 pages, 2 figures, The 1st International Conference on Electronic and Computer Engineering, Universiti Teknologi Malaysia, "accept"
+ 关键词:medical imaging techniques, computed tomography, scans have demonstrated, techniques like computed, combating the rapid
+
+ 点击查看摘要
+ During the COVID-19 pandemic, medical imaging techniques like computed tomography (CT) scans have demonstrated effectiveness in combating the rapid spread of the virus. Therefore, it is crucial to conduct research on computerized models for the detection of COVID-19 using CT imaging. A novel processing method has been developed, utilizing radiomic features, to assist in the CT-based diagnosis of COVID-19. Given the lower specificity of traditional features in distinguishing between different causes of pulmonary diseases, the objective of this study is to develop a CT-based radiomics framework for the differentiation of COVID-19 from other lung diseases. The model is designed to focus on outlining COVID-19 lesions, as traditional features often lack specificity in this aspect. The model categorizes images into three classes: COVID-19, non-COVID-19, or normal. It employs enhancement auto-segmentation principles using intensity dark channel prior (IDCP) and deep neural networks (ALS-IDCP-DNN) within a defined range of analysis thresholds. A publicly available dataset comprising COVID-19, normal, and non-COVID-19 classes was utilized to validate the proposed model's effectiveness. The best performing classification model, Residual Neural Network with 50 layers (Resnet-50), attained an average accuracy, precision, recall, and F1-score of 98.8%, 99%, 98%, and 98% respectively. These results demonstrate the capability of our model to accurately classify COVID-19 images, which could aid radiologists in diagnosing suspected COVID-19 patients. Furthermore, our model's performance surpasses that of more than 10 current state-of-the-art studies conducted on the same dataset.
+
+
+
+ 64. 标题:Interpretable 3D Multi-Modal Residual Convolutional Neural Network for Mild Traumatic Brain Injury Diagnosis
+ 编号:[355]
+ 链接:https://arxiv.org/abs/2309.12572
+ 作者:Hanem Ellethy, Viktor Vegh, Shekhar S. Chandra
+ 备注:Accepted by the Australasian Joint Conference on Artificial Intelligence 2023 (AJCAI 2023). 12 pages and 5 Figures
+ 关键词:Traumatic Brain Injury, Mild Traumatic Brain, Brain Injury, long-term health effects, Traumatic Brain
+
+ 点击查看摘要
+ Mild Traumatic Brain Injury (mTBI) is a significant public health challenge due to its high prevalence and potential for long-term health effects. Despite Computed Tomography (CT) being the standard diagnostic tool for mTBI, it often yields normal results in mTBI patients despite symptomatic evidence. This fact underscores the complexity of accurate diagnosis. In this study, we introduce an interpretable 3D Multi-Modal Residual Convolutional Neural Network (MRCNN) for mTBI diagnostic model enhanced with Occlusion Sensitivity Maps (OSM). Our MRCNN model exhibits promising performance in mTBI diagnosis, demonstrating an average accuracy of 82.4%, sensitivity of 82.6%, and specificity of 81.6%, as validated by a five-fold cross-validation process. Notably, in comparison to the CT-based Residual Convolutional Neural Network (RCNN) model, the MRCNN shows an improvement of 4.4% in specificity and 9.0% in accuracy. We show that the OSM offers superior data-driven insights into CT images compared to the Grad-CAM approach. These results highlight the efficacy of the proposed multi-modal model in enhancing the diagnostic precision of mTBI.
+
+
+自然语言处理
+
+ 1. 标题:ReConcile: Round-Table Conference Improves Reasoning via Consensus among Diverse LLMs
+ 编号:[18]
+ 链接:https://arxiv.org/abs/2309.13007
+ 作者:Justin Chih-Yao Chen, Swarnadeep Saha, Mohit Bansal
+ 备注:19 pages, 9 figures, 7 tables
+ 关键词:Large Language Models, Language Models, Large Language, complex reasoning tasks, agents
+
+ 点击查看摘要
+ Large Language Models (LLMs) still struggle with complex reasoning tasks. Motivated by the society of minds (Minsky, 1988), we propose ReConcile, a multi-model multi-agent framework designed as a round table conference among diverse LLM agents to foster diverse thoughts and discussion for improved consensus. ReConcile enhances the reasoning capabilities of LLMs by holding multiple rounds of discussion, learning to convince other agents to improve their answers, and employing a confidence-weighted voting mechanism. In each round, ReConcile initiates discussion between agents via a 'discussion prompt' that consists of (a) grouped answers and explanations generated by each agent in the previous round, (b) their uncertainties, and (c) demonstrations of answer-rectifying human explanations, used for convincing other agents. This discussion prompt enables each agent to revise their responses in light of insights from other agents. Once a consensus is reached and the discussion ends, ReConcile determines the final answer by leveraging the confidence of each agent in a weighted voting scheme. We implement ReConcile with ChatGPT, Bard, and Claude2 as the three agents. Our experimental results on various benchmarks demonstrate that ReConcile significantly enhances the reasoning performance of the agents (both individually and as a team), surpassing prior single-agent and multi-agent baselines by 7.7% and also outperforming GPT-4 on some of these datasets. We also experiment with GPT-4 itself as one of the agents in ReConcile and demonstrate that its initial performance also improves by absolute 10.0% through discussion and feedback from other agents. Finally, we also analyze the accuracy after every round and observe that ReConcile achieves better and faster consensus between agents, compared to a multi-agent debate baseline. Our code is available at: this https URL
+
+
+
+ 2. 标题:Audience-specific Explanations for Machine Translation
+ 编号:[21]
+ 链接:https://arxiv.org/abs/2309.12998
+ 作者:Renhan Lou, Jan Niehues
+ 备注:
+ 关键词:target language audience, language audience due, machine translation, cultural backgrounds, audience due
+
+ 点击查看摘要
+ In machine translation, a common problem is that the translation of certain words even if translated can cause incomprehension of the target language audience due to different cultural backgrounds. A solution to solve this problem is to add explanations for these words. In a first step, we therefore need to identify these words or phrases. In this work we explore techniques to extract example explanations from a parallel corpus. However, the sparsity of sentences containing words that need to be explained makes building the training dataset extremely difficult. In this work, we propose a semi-automatic technique to extract these explanations from a large parallel corpus. Experiments on English->German language pair show that our method is able to extract sentence so that more than 10% of the sentences contain explanation, while only 1.9% of the original sentences contain explanations. In addition, experiments on English->French and English->Chinese language pairs also show similar conclusions. This is therefore an essential first automatic step to create a explanation dataset. Furthermore we show that the technique is robust for all three language pairs.
+
+
+
+ 3. 标题:Wordification: A New Way of Teaching English Spelling Patterns
+ 编号:[24]
+ 链接:https://arxiv.org/abs/2309.12981
+ 作者:Lexington Whalen, Nathan Bickel, Shash Comandur, Dalton Craven, Stanley Dubinsky, Homayoun Valafar
+ 备注:1 pages, 4 figures, IEEE CPS Conference
+ 关键词:greater society, crucial indicator, indicator of success, success in life, life and greater
+
+ 点击查看摘要
+ Literacy, or the ability to read and write, is a crucial indicator of success in life and greater society. It is estimated that 85% of people in juvenile delinquent systems cannot adequately read or write, that more than half of those with substance abuse issues have complications in reading or writing and that two-thirds of those who do not complete high school lack proper literacy skills. Furthermore, young children who do not possess reading skills matching grade level by the fourth grade are approximately 80% likely to not catch up at all. Many may believe that in a developed country such as the United States, literacy fails to be an issue; however, this is a dangerous misunderstanding. Globally an estimated 1.19 trillion dollars are lost every year due to issues in literacy; in the USA, the loss is an estimated 300 billion. To put it in more shocking terms, one in five American adults still fail to comprehend basic sentences. Making matters worse, the only tools available now to correct a lack of reading and writing ability are found in expensive tutoring or other programs that oftentimes fail to be able to reach the required audience. In this paper, our team puts forward a new way of teaching English spelling and word recognitions to grade school students in the United States: Wordification. Wordification is a web application designed to teach English literacy using principles of linguistics applied to the orthographic and phonological properties of words in a manner not fully utilized previously in any computer-based teaching application.
+
+
+
+ 4. 标题:Nested Event Extraction upon Pivot Element Recogniton
+ 编号:[30]
+ 链接:https://arxiv.org/abs/2309.12960
+ 作者:Weicheng Ren, Zixuan Li, Xiaolong Jin, Long Bai, Miao Su, Yantao Liu, Saiping Guan, Jiafeng Guo, Xueqi Cheng
+ 备注:
+ 关键词:Nested Event Extraction, Event Extraction, complex event structures, Pivot Elements, NEE
+
+ 点击查看摘要
+ Nested Event Extraction (NEE) aims to extract complex event structures where an event contains other events as its arguments recursively. Nested events involve a kind of Pivot Elements (PEs) that simultaneously act as arguments of outer events and as triggers of inner events, and thus connect them into nested structures. This special characteristic of PEs brings challenges to existing NEE methods, as they cannot well cope with the dual identities of PEs. Therefore, this paper proposes a new model, called PerNee, which extracts nested events mainly based on recognizing PEs. Specifically, PerNee first recognizes the triggers of both inner and outer events and further recognizes the PEs via classifying the relation type between trigger pairs. In order to obtain better representations of triggers and arguments to further improve NEE performance, it incorporates the information of both event types and argument roles into PerNee through prompt learning. Since existing NEE datasets (e.g., Genia11) are limited to specific domains and contain a narrow range of event types with nested structures, we systematically categorize nested events in generic domain and construct a new NEE dataset, namely ACE2005-Nest. Experimental results demonstrate that PerNee consistently achieves state-of-the-art performance on ACE2005-Nest, Genia11 and Genia13.
+
+
+
+ 5. 标题:Self-Explanation Prompting Improves Dialogue Understanding in Large Language Models
+ 编号:[38]
+ 链接:https://arxiv.org/abs/2309.12940
+ 作者:Haoyu Gao, Ting-En Lin, Hangyu Li, Min Yang, Yuchuan Wu, Wentao Ma, Yongbin Li
+ 备注:
+ 关键词:Large Language Models, systems facilitate users, Large Language, Language Models, systems facilitate
+
+ 点击查看摘要
+ Task-oriented dialogue (TOD) systems facilitate users in executing various activities via multi-turn dialogues, but Large Language Models (LLMs) often struggle to comprehend these intricate contexts. In this study, we propose a novel "Self-Explanation" prompting strategy to enhance the comprehension abilities of LLMs in multi-turn dialogues. This task-agnostic approach requires the model to analyze each dialogue utterance before task execution, thereby improving performance across various dialogue-centric tasks. Experimental results from six benchmark datasets confirm that our method consistently outperforms other zero-shot prompts and matches or exceeds the efficacy of few-shot prompts, demonstrating its potential as a powerful tool in enhancing LLMs' comprehension in complex dialogue tasks.
+
+
+
+ 6. 标题:TopRoBERTa: Topology-Aware Authorship Attribution of Deepfake Texts
+ 编号:[41]
+ 链接:https://arxiv.org/abs/2309.12934
+ 作者:Adaku Uchendu, Thai Le, Dongwon Lee
+ 备注:
+ 关键词:Large Language Models, Large Language, advances in Large, open-ended high-quality texts, Language Models
+
+ 点击查看摘要
+ Recent advances in Large Language Models (LLMs) have enabled the generation of open-ended high-quality texts, that are non-trivial to distinguish from human-written texts. We refer to such LLM-generated texts as \emph{deepfake texts}. There are currently over 11K text generation models in the huggingface model repo. As such, users with malicious intent can easily use these open-sourced LLMs to generate harmful texts and misinformation at scale. To mitigate this problem, a computational method to determine if a given text is a deepfake text or not is desired--i.e., Turing Test (TT). In particular, in this work, we investigate the more general version of the problem, known as \emph{Authorship Attribution (AA)}, in a multi-class setting--i.e., not only determining if a given text is a deepfake text or not but also being able to pinpoint which LLM is the author. We propose \textbf{TopRoBERTa} to improve existing AA solutions by capturing more linguistic patterns in deepfake texts by including a Topological Data Analysis (TDA) layer in the RoBERTa model. We show the benefits of having a TDA layer when dealing with noisy, imbalanced, and heterogeneous datasets, by extracting TDA features from the reshaped $pooled\_output$ of RoBERTa as input. We use RoBERTa to capture contextual representations (i.e., semantic and syntactic linguistic features), while using TDA to capture the shape and structure of data (i.e., linguistic structures). Finally, \textbf{TopRoBERTa}, outperforms the vanilla RoBERTa in 2/3 datasets, achieving up to 7\% increase in Macro F1 score.
+
+
+
+ 7. 标题:On Separate Normalization in Self-supervised Transformers
+ 编号:[42]
+ 链接:https://arxiv.org/abs/2309.12931
+ 作者:Xiaohui Chen, Yinkai Wang, Yuanqi Du, Soha Hassoun, Li-Ping Liu
+ 备注:NIPS 2023
+ 关键词:Self-supervised training methods, demonstrated remarkable performance, Self-supervised training, transformers have demonstrated, demonstrated remarkable
+
+ 点击查看摘要
+ Self-supervised training methods for transformers have demonstrated remarkable performance across various domains. Previous transformer-based models, such as masked autoencoders (MAE), typically utilize a single normalization layer for both the [CLS] symbol and the tokens. We propose in this paper a simple modification that employs separate normalization layers for the tokens and the [CLS] symbol to better capture their distinct characteristics and enhance downstream task performance. Our method aims to alleviate the potential negative effects of using the same normalization statistics for both token types, which may not be optimally aligned with their individual roles. We empirically show that by utilizing a separate normalization layer, the [CLS] embeddings can better encode the global contextual information and are distributed more uniformly in its anisotropic space. When replacing the conventional normalization layer with the two separate layers, we observe an average 2.7% performance improvement over the image, natural language, and graph domains.
+
+
+
+ 8. 标题:ProtoEM: A Prototype-Enhanced Matching Framework for Event Relation Extraction
+ 编号:[54]
+ 链接:https://arxiv.org/abs/2309.12892
+ 作者:Zhilei Hu, Zixuan Li, Daozhu Xu, Long Bai, Cheng Jin, Xiaolong Jin, Jiafeng Guo, Xueqi Cheng
+ 备注:Work in progress
+ 关键词:event relations, relations, Event, Event Relation Extraction, ERE
+
+ 点击查看摘要
+ Event Relation Extraction (ERE) aims to extract multiple kinds of relations among events in texts. However, existing methods singly categorize event relations as different classes, which are inadequately capturing the intrinsic semantics of these relations. To comprehensively understand their intrinsic semantics, in this paper, we obtain prototype representations for each type of event relation and propose a Prototype-Enhanced Matching (ProtoEM) framework for the joint extraction of multiple kinds of event relations. Specifically, ProtoEM extracts event relations in a two-step manner, i.e., prototype representing and prototype matching. In the first step, to capture the connotations of different event relations, ProtoEM utilizes examples to represent the prototypes corresponding to these relations. Subsequently, to capture the interdependence among event relations, it constructs a dependency graph for the prototypes corresponding to these relations and utilized a Graph Neural Network (GNN)-based module for modeling. In the second step, it obtains the representations of new event pairs and calculates their similarity with those prototypes obtained in the first step to evaluate which types of event relations they belong to. Experimental results on the MAVEN-ERE dataset demonstrate that the proposed ProtoEM framework can effectively represent the prototypes of event relations and further obtain a significant improvement over baseline models.
+
+
+
+ 9. 标题:Affect Recognition in Conversations Using Large Language Models
+ 编号:[57]
+ 链接:https://arxiv.org/abs/2309.12881
+ 作者:Shutong Feng, Guangzhi Sun, Nurul Lubis, Chao Zhang, Milica Gašić
+ 备注:
+ 关键词:encompassing emotions, plays a pivotal, pivotal role, human communication, Affect recognition
+
+ 点击查看摘要
+ Affect recognition, encompassing emotions, moods, and feelings, plays a pivotal role in human communication. In the realm of conversational artificial intelligence (AI), the ability to discern and respond to human affective cues is a critical factor for creating engaging and empathetic interactions. This study delves into the capacity of large language models (LLMs) to recognise human affect in conversations, with a focus on both open-domain chit-chat dialogues and task-oriented dialogues. Leveraging three diverse datasets, namely IEMOCAP, EmoWOZ, and DAIC-WOZ, covering a spectrum of dialogues from casual conversations to clinical interviews, we evaluated and compared LLMs' performance in affect recognition. Our investigation explores the zero-shot and few-shot capabilities of LLMs through in-context learning (ICL) as well as their model capacities through task-specific fine-tuning. Additionally, this study takes into account the potential impact of automatic speech recognition (ASR) errors on LLM predictions. With this work, we aim to shed light on the extent to which LLMs can replicate human-like affect recognition capabilities in conversations.
+
+
+
+ 10. 标题:AnglE-Optimized Text Embeddings
+ 编号:[61]
+ 链接:https://arxiv.org/abs/2309.12871
+ 作者:Xianming Li, Jing Li
+ 备注:NLP, Text Embedding, Semantic Textual Similarity
+ 关键词:Large Language Model, Large Language, semantic textual similarity, improving semantic textual, components in Large
+
+ 点击查看摘要
+ High-quality text embedding is pivotal in improving semantic textual similarity (STS) tasks, which are crucial components in Large Language Model (LLM) applications. However, a common challenge existing text embedding models face is the problem of vanishing gradients, primarily due to their reliance on the cosine function in the optimization objective, which has saturation zones. To address this issue, this paper proposes a novel angle-optimized text embedding model called AnglE. The core idea of AnglE is to introduce angle optimization in a complex space. This novel approach effectively mitigates the adverse effects of the saturation zone in the cosine function, which can impede gradient and hinder optimization processes. To set up a comprehensive STS evaluation, we experimented on existing short-text STS datasets and a newly collected long-text STS dataset from GitHub Issues. Furthermore, we examine domain-specific STS scenarios with limited labeled data and explore how AnglE works with LLM-annotated data. Extensive experiments were conducted on various tasks including short-text STS, long-text STS, and domain-specific STS tasks. The results show that AnglE outperforms the state-of-the-art (SOTA) STS models that ignore the cosine saturation zone. These findings demonstrate the ability of AnglE to generate high-quality text embeddings and the usefulness of angle optimization in STS.
+
+
+
+ 11. 标题:Domain Adaptation for Arabic Machine Translation: The Case of Financial Texts
+ 编号:[66]
+ 链接:https://arxiv.org/abs/2309.12863
+ 作者:Emad A. Alghamdi, Jezia Zakraoui, Fares A. Abanmy
+ 备注:
+ 关键词:shown impressive performance, Neural machine translation, Neural machine, large-scale corpora, NMT
+
+ 点击查看摘要
+ Neural machine translation (NMT) has shown impressive performance when trained on large-scale corpora. However, generic NMT systems have demonstrated poor performance on out-of-domain translation. To mitigate this issue, several domain adaptation methods have recently been proposed which often lead to better translation quality than genetic NMT systems. While there has been some continuous progress in NMT for English and other European languages, domain adaption in Arabic has received little attention in the literature. The current study, therefore, aims to explore the effectiveness of domain-specific adaptation for Arabic MT (AMT), in yet unexplored domain, financial news articles. To this end, we developed carefully a parallel corpus for Arabic-English (AR- EN) translation in the financial domain for benchmarking different domain adaptation methods. We then fine-tuned several pre-trained NMT and Large Language models including ChatGPT-3.5 Turbo on our dataset. The results showed that the fine-tuning is successful using just a few well-aligned in-domain AR-EN segments. The quality of ChatGPT translation was superior than other models based on automatic and human evaluations. To the best of our knowledge, this is the first work on fine-tuning ChatGPT towards financial domain transfer learning. To contribute to research in domain translation, we made our datasets and fine-tuned models available at this https URL.
+
+
+
+ 12. 标题:Synthetic Boost: Leveraging Synthetic Data for Enhanced Vision-Language Segmentation in Echocardiography
+ 编号:[78]
+ 链接:https://arxiv.org/abs/2309.12829
+ 作者:Rabin Adhikari, Manish Dhakal, Safal Thapaliya, Kanchan Poudel, Prasiddha Bhandari, Bishesh Khanal
+ 备注:Accepted at the 4th International Workshop of Advances in Simplifying Medical UltraSound (ASMUS)
+ 关键词:cardiovascular diseases, essential for echocardiography-based, echocardiography-based assessment, assessment of cardiovascular, Semantic Diffusion Models
+
+ 点击查看摘要
+ Accurate segmentation is essential for echocardiography-based assessment of cardiovascular diseases (CVDs). However, the variability among sonographers and the inherent challenges of ultrasound images hinder precise segmentation. By leveraging the joint representation of image and text modalities, Vision-Language Segmentation Models (VLSMs) can incorporate rich contextual information, potentially aiding in accurate and explainable segmentation. However, the lack of readily available data in echocardiography hampers the training of VLSMs. In this study, we explore using synthetic datasets from Semantic Diffusion Models (SDMs) to enhance VLSMs for echocardiography segmentation. We evaluate results for two popular VLSMs (CLIPSeg and CRIS) using seven different kinds of language prompts derived from several attributes, automatically extracted from echocardiography images, segmentation masks, and their metadata. Our results show improved metrics and faster convergence when pretraining VLSMs on SDM-generated synthetic images before finetuning on real images. The code, configs, and prompts are available at this https URL.
+
+
+
+ 13. 标题:StyloMetrix: An Open-Source Multilingual Tool for Representing Stylometric Vectors
+ 编号:[83]
+ 链接:https://arxiv.org/abs/2309.12810
+ 作者:Inez Okulska, Daria Stetsenko, Anna Kołos, Agnieszka Karlińska, Kinga Głąbińska, Adam Nowakowski
+ 备注:26 pages, 6 figures, pre-print for the conference
+ 关键词:open-source multilanguage tool, multilanguage tool called, tool called StyloMetrix, work aims, open-source multilanguage
+
+ 点击查看摘要
+ This work aims to provide an overview on the open-source multilanguage tool called StyloMetrix. It offers stylometric text representations that cover various aspects of grammar, syntax and lexicon. StyloMetrix covers four languages: Polish as the primary language, English, Ukrainian and Russian. The normalized output of each feature can become a fruitful course for machine learning models and a valuable addition to the embeddings layer for any deep learning algorithm. We strive to provide a concise, but exhaustive overview on the application of the StyloMetrix vectors as well as explain the sets of the developed linguistic features. The experiments have shown promising results in supervised content classification with simple algorithms as Random Forest Classifier, Voting Classifier, Logistic Regression and others. The deep learning assessments have unveiled the usefulness of the StyloMetrix vectors at enhancing an embedding layer extracted from Transformer architectures. The StyloMetrix has proven itself to be a formidable source for the machine learning and deep learning algorithms to execute different classification tasks.
+
+
+
+ 14. 标题:ChatPRCS: A Personalized Support System for English Reading Comprehension based on ChatGPT
+ 编号:[84]
+ 链接:https://arxiv.org/abs/2309.12808
+ 作者:Xizhe Wang, Yihua Zhong, Changqin Huang, Xiaodi Huang
+ 备注:
+ 关键词:learning English, reading comprehension, comprehension primarily entails, entails reading articles, primarily entails reading
+
+ 点击查看摘要
+ As a common approach to learning English, reading comprehension primarily entails reading articles and answering related questions. However, the complexity of designing effective exercises results in students encountering standardized questions, making it challenging to align with individualized learners' reading comprehension ability. By leveraging the advanced capabilities offered by large language models, exemplified by ChatGPT, this paper presents a novel personalized support system for reading comprehension, referred to as ChatPRCS, based on the Zone of Proximal Development theory. ChatPRCS employs methods including reading comprehension proficiency prediction, question generation, and automatic evaluation, among others, to enhance reading comprehension instruction. First, we develop a new algorithm that can predict learners' reading comprehension abilities using their historical data as the foundation for generating questions at an appropriate level of difficulty. Second, a series of new ChatGPT prompt patterns is proposed to address two key aspects of reading comprehension objectives: question generation, and automated evaluation. These patterns further improve the quality of generated questions. Finally, by integrating personalized ability and reading comprehension prompt patterns, ChatPRCS is systematically validated through experiments. Empirical results demonstrate that it provides learners with high-quality reading comprehension questions that are broadly aligned with expert-crafted questions at a statistical level.
+
+
+
+ 15. 标题:Furthest Reasoning with Plan Assessment: Stable Reasoning Path with Retrieval-Augmented Large Language Models
+ 编号:[100]
+ 链接:https://arxiv.org/abs/2309.12767
+ 作者:Yin Zhu, Zhiling Luo, Gong Cheng
+ 备注:
+ 关键词:Large Language Models, natural language tasks, Language Models, exhibit extraordinary performance, question answering
+
+ 点击查看摘要
+ Large Language Models (LLMs), acting as a powerful reasoner and generator, exhibit extraordinary performance across various natural language tasks, such as question answering (QA). Among these tasks, Multi-Hop Question Answering (MHQA) stands as a widely discussed category, necessitating seamless integration between LLMs and the retrieval of external knowledge. Existing methods employ LLM to generate reasoning paths and plans, and utilize IR to iteratively retrieve related knowledge, but these approaches have inherent flaws. On one hand, Information Retriever (IR) is hindered by the low quality of generated queries by LLM. On the other hand, LLM is easily misguided by the irrelevant knowledge by IR. These inaccuracies, accumulated by the iterative interaction between IR and LLM, lead to a disaster in effectiveness at the end. To overcome above barriers, in this paper, we propose a novel pipeline for MHQA called Furthest-Reasoning-with-Plan-Assessment (FuRePA), including an improved framework (Furthest Reasoning) and an attached module (Plan Assessor). 1) Furthest reasoning operates by masking previous reasoning path and generated queries for LLM, encouraging LLM generating chain of thought from scratch in each iteration. This approach enables LLM to break the shackle built by previous misleading thoughts and queries (if any). 2) The Plan Assessor is a trained evaluator that selects an appropriate plan from a group of candidate plans proposed by LLM. Our methods are evaluated on three highly recognized public multi-hop question answering datasets and outperform state-of-the-art on most metrics (achieving a 10%-12% in answer accuracy).
+
+
+
+ 16. 标题:In-context Interference in Chat-based Large Language Models
+ 编号:[113]
+ 链接:https://arxiv.org/abs/2309.12727
+ 作者:Eric Nuertey Coleman, Julio Hurtado, Vincenzo Lomonaco
+ 备注:
+ 关键词:Large language models, Large language, huge impact, impact on society, society due
+
+ 点击查看摘要
+ Large language models (LLMs) have had a huge impact on society due to their impressive capabilities and vast knowledge of the world. Various applications and tools have been created that allow users to interact with these models in a black-box scenario. However, one limitation of this scenario is that users cannot modify the internal knowledge of the model, and the only way to add or modify internal knowledge is by explicitly mentioning it to the model during the current interaction. This learning process is called in-context training, and it refers to training that is confined to the user's current session or context. In-context learning has significant applications, but also has limitations that are seldom studied. In this paper, we present a study that shows how the model can suffer from interference between information that continually flows in the context, causing it to forget previously learned knowledge, which can reduce the model's performance. Along with showing the problem, we propose an evaluation benchmark based on the bAbI dataset.
+
+
+
+ 17. 标题:Semantic similarity prediction is better than other semantic similarity measures
+ 编号:[127]
+ 链接:https://arxiv.org/abs/2309.12697
+ 作者:Steffen Herbold
+ 备注:Under review
+ 关键词:natural language texts, overlap between subsequences, natural language, language texts, texts is typically
+
+ 点击查看摘要
+ Semantic similarity between natural language texts is typically measured either by looking at the overlap between subsequences (e.g., BLEU) or by using embeddings (e.g., BERTScore, S-BERT). Within this paper, we argue that when we are only interested in measuring the semantic similarity, it is better to directly predict the similarity using a fine-tuned model for such a task. Using a fine-tuned model for the STS-B from the GLUE benchmark, we define the STSScore approach and show that the resulting similarity is better aligned with our expectations on a robust semantic similarity measure than other approaches.
+
+
+
+ 18. 标题:AMPLIFY:Attention-based Mixup for Performance Improvement and Label Smoothing in Transformer
+ 编号:[132]
+ 链接:https://arxiv.org/abs/2309.12689
+ 作者:Leixin Yang, Yaping Zhang, Haoyu Xiong, Yu Xiang
+ 备注:
+ 关键词:effective data augmentation, aggregating linear combinations, data augmentation method, original samples, Mixup method called
+
+ 点击查看摘要
+ Mixup is an effective data augmentation method that generates new augmented samples by aggregating linear combinations of different original samples. However, if there are noises or aberrant features in the original samples, Mixup may propagate them to the augmented samples, leading to over-sensitivity of the model to these outliers . To solve this problem, this paper proposes a new Mixup method called AMPLIFY. This method uses the Attention mechanism of Transformer itself to reduce the influence of noises and aberrant values in the original samples on the prediction results, without increasing additional trainable parameters, and the computational cost is very low, thereby avoiding the problem of high resource consumption in common Mixup methods such as Sentence Mixup . The experimental results show that, under a smaller computational resource cost, AMPLIFY outperforms other Mixup methods in text classification tasks on 7 benchmark datasets, providing new ideas and new ways to further improve the performance of pre-trained models based on the Attention mechanism, such as BERT, ALBERT, RoBERTa, and GPT. Our code can be obtained at this https URL.
+
+
+
+ 19. 标题:JCoLA: Japanese Corpus of Linguistic Acceptability
+ 编号:[138]
+ 链接:https://arxiv.org/abs/2309.12676
+ 作者:Taiga Someya, Yushi Sugimoto, Yohei Oseki
+ 备注:
+ 关键词:exhibited outstanding performance, downstream tasks, exhibited outstanding, range of downstream, acceptability judgments
+
+ 点击查看摘要
+ Neural language models have exhibited outstanding performance in a range of downstream tasks. However, there is limited understanding regarding the extent to which these models internalize syntactic knowledge, so that various datasets have recently been constructed to facilitate syntactic evaluation of language models across languages. In this paper, we introduce JCoLA (Japanese Corpus of Linguistic Acceptability), which consists of 10,020 sentences annotated with binary acceptability judgments. Specifically, those sentences are manually extracted from linguistics textbooks, handbooks and journal articles, and split into in-domain data (86 %; relatively simple acceptability judgments extracted from textbooks and handbooks) and out-of-domain data (14 %; theoretically significant acceptability judgments extracted from journal articles), the latter of which is categorized by 12 linguistic phenomena. We then evaluate the syntactic knowledge of 9 different types of Japanese language models on JCoLA. The results demonstrated that several models could surpass human performance for the in-domain data, while no models were able to exceed human performance for the out-of-domain data. Error analyses by linguistic phenomena further revealed that although neural language models are adept at handling local syntactic dependencies like argument structure, their performance wanes when confronted with long-distance syntactic dependencies like verbal agreement and NPI licensing.
+
+
+
+ 20. 标题:HRoT: Hybrid prompt strategy and Retrieval of Thought for Table-Text Hybrid Question Answering
+ 编号:[143]
+ 链接:https://arxiv.org/abs/2309.12669
+ 作者:Tongxu Luo, Fangyu Lei, Jiahe Lei, Weihao Liu, Shihu He, Jun Zhao, Kang Liu
+ 备注:
+ 关键词:Answering numerical questions, Large Language Models, Answering numerical, tables and text, challenging task
+
+ 点击查看摘要
+ Answering numerical questions over hybrid contents from the given tables and text(TextTableQA) is a challenging task. Recently, Large Language Models (LLMs) have gained significant attention in the NLP community. With the emergence of large language models, In-Context Learning and Chain-of-Thought prompting have become two particularly popular research topics in this field. In this paper, we introduce a new prompting strategy called Hybrid prompt strategy and Retrieval of Thought for TextTableQA. Through In-Context Learning, we prompt the model to develop the ability of retrieval thinking when dealing with hybrid data. Our method achieves superior performance compared to the fully-supervised SOTA on the MultiHiertt dataset in the few-shot setting.
+
+
+
+ 21. 标题:Decoding Affect in Dyadic Conversations: Leveraging Semantic Similarity through Sentence Embedding
+ 编号:[154]
+ 链接:https://arxiv.org/abs/2309.12646
+ 作者:Chen-Wei Yu, Yun-Shiuan Chuang, Alexandros N. Lotsos, Claudia M. Haase
+ 备注:
+ 关键词:Natural Language Processing, Language Processing, Natural Language, advancements in Natural, Recent advancements
+
+ 点击查看摘要
+ Recent advancements in Natural Language Processing (NLP) have highlighted the potential of sentence embeddings in measuring semantic similarity. Yet, its application in analyzing real-world dyadic interactions and predicting the affect of conversational participants remains largely uncharted. To bridge this gap, the present study utilizes verbal conversations within 50 married couples talking about conflicts and pleasant activities. Transformer-based model all-MiniLM-L6-v2 was employed to obtain the embeddings of the utterances from each speaker. The overall similarity of the conversation was then quantified by the average cosine similarity between the embeddings of adjacent utterances. Results showed that semantic similarity had a positive association with wives' affect during conflict (but not pleasant) conversations. Moreover, this association was not observed with husbands' affect regardless of conversation types. Two validation checks further provided support for the validity of the similarity measure and showed that the observed patterns were not mere artifacts of data. The present study underscores the potency of sentence embeddings in understanding the association between interpersonal dynamics and individual affect, paving the way for innovative applications in affective and relationship sciences.
+
+
+
+ 22. 标题:Construction contract risk identification based on knowledge-augmented language model
+ 编号:[167]
+ 链接:https://arxiv.org/abs/2309.12626
+ 作者:Saika Wong, Chunmo Zheng, Xing Su, Yinqiu Tang
+ 备注:
+ 关键词:prevent potential losses, potential losses, essential step, projects to prevent, prevent potential
+
+ 点击查看摘要
+ Contract review is an essential step in construction projects to prevent potential losses. However, the current methods for reviewing construction contracts lack effectiveness and reliability, leading to time-consuming and error-prone processes. While large language models (LLMs) have shown promise in revolutionizing natural language processing (NLP) tasks, they struggle with domain-specific knowledge and addressing specialized issues. This paper presents a novel approach that leverages LLMs with construction contract knowledge to emulate the process of contract review by human experts. Our tuning-free approach incorporates construction contract domain knowledge to enhance language models for identifying construction contract risks. The use of a natural language when building the domain knowledge base facilitates practical implementation. We evaluated our method on real construction contracts and achieved solid performance. Additionally, we investigated how large language models employ logical thinking during the task and provide insights and recommendations for future research.
+
+
+
+ 23. 标题:DRG-LLaMA : Tuning LLaMA Model to Predict Diagnosis-related Group for Hospitalized Patients
+ 编号:[168]
+ 链接:https://arxiv.org/abs/2309.12625
+ 作者:Hanyin Wang, Chufan Gao, Christopher Dantona, Bryan Hull, Jimeng Sun
+ 备注:
+ 关键词:inpatient payment system, current assignment process, Diagnosis-Related Group, inpatient payment, payment system
+
+ 点击查看摘要
+ In the U.S. inpatient payment system, the Diagnosis-Related Group (DRG) plays a key role but its current assignment process is time-consuming. We introduce DRG-LLaMA, a large language model (LLM) fine-tuned on clinical notes for improved DRG prediction. Using Meta's LLaMA as the base model, we optimized it with Low-Rank Adaptation (LoRA) on 236,192 MIMIC-IV discharge summaries. With an input token length of 512, DRG-LLaMA-7B achieved a macro-averaged F1 score of 0.327, a top-1 prediction accuracy of 52.0% and a macro-averaged Area Under the Curve (AUC) of 0.986. Impressively, DRG-LLaMA-7B surpassed previously reported leading models on this task, demonstrating a relative improvement in macro-averaged F1 score of 40.3% compared to ClinicalBERT and 35.7% compared to CAML. When DRG-LLaMA is applied to predict base DRGs and complication or comorbidity (CC) / major complication or comorbidity (MCC), the top-1 prediction accuracy reached 67.8% for base DRGs and 67.5% for CC/MCC status. DRG-LLaMA performance exhibits improvements in correlation with larger model parameters and longer input context lengths. Furthermore, usage of LoRA enables training even on smaller GPUs with 48 GB of VRAM, highlighting the viability of adapting LLMs for DRGs prediction.
+
+
+
+ 24. 标题:Learning to Diversify Neural Text Generation via Degenerative Model
+ 编号:[172]
+ 链接:https://arxiv.org/abs/2309.12619
+ 作者:Jimin Hong, ChaeHun Park, Jaegul Choo
+ 备注:IJCNLP-AACL2023 Findings, 10 pages
+ 关键词:informative texts, limiting their applicability, Neural language models, generate diverse, diverse and informative
+
+ 点击查看摘要
+ Neural language models often fail to generate diverse and informative texts, limiting their applicability in real-world problems. While previous approaches have proposed to address these issues by identifying and penalizing undesirable behaviors (e.g., repetition, overuse of frequent words) from language models, we propose an alternative approach based on an observation: models primarily learn attributes within examples that are likely to cause degeneration problems. Based on this observation, we propose a new approach to prevent degeneration problems by training two models. Specifically, we first train a model that is designed to amplify undesirable patterns. We then enhance the diversity of the second model by focusing on patterns that the first model fails to learn. Extensive experiments on two tasks, namely language modeling and dialogue generation, demonstrate the effectiveness of our approach.
+
+
+
+ 25. 标题:Unlocking Model Insights: A Dataset for Automated Model Card Generation
+ 编号:[175]
+ 链接:https://arxiv.org/abs/2309.12616
+ 作者:Shruti Singh, Hitesh Lodwal, Husain Malwat, Rakesh Thakur, Mayank Singh
+ 备注:
+ 关键词:autonomous AI agents, longer restricted, rise in autonomous, Model, Model cards
+
+ 点击查看摘要
+ Language models (LMs) are no longer restricted to ML community, and instruction-tuned LMs have led to a rise in autonomous AI agents. As the accessibility of LMs grows, it is imperative that an understanding of their capabilities, intended usage, and development cycle also improves. Model cards are a popular practice for documenting detailed information about an ML model. To automate model card generation, we introduce a dataset of 500 question-answer pairs for 25 ML models that cover crucial aspects of the model, such as its training configurations, datasets, biases, architecture details, and training resources. We employ annotators to extract the answers from the original paper. Further, we explore the capabilities of LMs in generating model cards by answering questions. Our initial experiments with ChatGPT-3.5, LLaMa, and Galactica showcase a significant gap in the understanding of research papers by these aforementioned LMs as well as generating factual textual responses. We posit that our dataset can be used to train models to automate the generation of model cards from paper text and reduce human effort in the model card curation process. The complete dataset is available on this https URL
+
+
+
+ 26. 标题:Creativity Support in the Age of Large Language Models: An Empirical Study Involving Emerging Writers
+ 编号:[195]
+ 链接:https://arxiv.org/abs/2309.12570
+ 作者:Tuhin Chakrabarty, Vishakh Padmakumar, Faeze Brahman, Smaranda Muresan
+ 备注:
+ 关键词:sparked increased interest, large language models, conversational interactions sparked, interactions sparked increased, support tools
+
+ 点击查看摘要
+ The development of large language models (LLMs) capable of following instructions and engaging in conversational interactions sparked increased interest in their utilization across various support tools. We investigate the utility of modern LLMs in assisting professional writers via an empirical user study (n=30). The design of our collaborative writing interface is grounded in the cognitive process model of writing that views writing as a goal-oriented thinking process encompassing non-linear cognitive activities: planning, translating, and reviewing. Participants are asked to submit a post-completion survey to provide feedback on the potential and pitfalls of LLMs as writing collaborators. Upon analyzing the writer-LLM interactions, we find that while writers seek LLM's help across all three types of cognitive activities, they find LLMs more helpful in translation and reviewing. Our findings from analyzing both the interactions and the survey responses highlight future research directions in creative writing assistance using LLMs.
+
+
+
+ 27. 标题:PlanFitting: Tailoring Personalized Exercise Plans with Large Language Models
+ 编号:[204]
+ 链接:https://arxiv.org/abs/2309.12555
+ 作者:Donghoon Shin, Gary Hsieh, Young-Ho Kim
+ 备注:22 pages, 5 figures, 1 table
+ 关键词:sufficient physical activities, ensuring sufficient physical, tailored exercise regimen, personally tailored exercise, physical activities
+
+ 点击查看摘要
+ A personally tailored exercise regimen is crucial to ensuring sufficient physical activities, yet challenging to create as people have complex schedules and considerations and the creation of plans often requires iterations with experts. We present PlanFitting, a conversational AI that assists in personalized exercise planning. Leveraging generative capabilities of large language models, PlanFitting enables users to describe various constraints and queries in natural language, thereby facilitating the creation and refinement of their weekly exercise plan to suit their specific circumstances while staying grounded in foundational principles. Through a user study where participants (N=18) generated a personalized exercise plan using PlanFitting and expert planners (N=3) evaluated these plans, we identified the potential of PlanFitting in generating personalized, actionable, and evidence-based exercise plans. We discuss future design opportunities for AI assistants in creating plans that better comply with exercise principles and accommodate personal constraints.
+
+
+
+ 28. 标题:Is it Possible to Modify Text to a Target Readability Level? An Initial Investigation Using Zero-Shot Large Language Models
+ 编号:[206]
+ 链接:https://arxiv.org/abs/2309.12551
+ 作者:Asma Farajidizaji, Vatsal Raina, Mark Gales
+ 备注:11 pages, 4 figures, 5 tables
+ 关键词:readability, Text, easier to understand, Text simplification, target readability
+
+ 点击查看摘要
+ Text simplification is a common task where the text is adapted to make it easier to understand. Similarly, text elaboration can make a passage more sophisticated, offering a method to control the complexity of reading comprehension tests. However, text simplification and elaboration tasks are limited to only relatively alter the readability of texts. It is useful to directly modify the readability of any text to an absolute target readability level to cater to a diverse audience. Ideally, the readability of readability-controlled generated text should be independent of the source text. Therefore, we propose a novel readability-controlled text modification task. The task requires the generation of 8 versions at various target readability levels for each input text. We introduce novel readability-controlled text modification metrics. The baselines for this task use ChatGPT and Llama-2, with an extension approach introducing a two-step process (generating paraphrases by passing through the language model twice). The zero-shot approaches are able to push the readability of the paraphrases in the desired direction but the final readability remains correlated with the original text's readability. We also find greater drops in semantic and lexical similarity between the source and target texts with greater shifts in the readability.
+
+
+
+ 29. 标题:Automatic Answerability Evaluation for Question Generation
+ 编号:[208]
+ 链接:https://arxiv.org/abs/2309.12546
+ 作者:Zifan Wang, Kotaro Funakoshi, Manabu Okumura
+ 备注:
+ 关键词:BLEU and ROUGE, natural language generation, developed for natural, automatic evaluation metric, natural language
+
+ 点击查看摘要
+ Conventional automatic evaluation metrics, such as BLEU and ROUGE, developed for natural language generation (NLG) tasks, are based on measuring the n-gram overlap between the generated and reference text. These simple metrics may be insufficient for more complex tasks, such as question generation (QG), which requires generating questions that are answerable by the reference answers. Developing a more sophisticated automatic evaluation metric, thus, remains as an urgent problem in QG research. This work proposes a Prompting-based Metric on ANswerability (PMAN), a novel automatic evaluation metric to assess whether the generated questions are answerable by the reference answers for the QG tasks. Extensive experiments demonstrate that its evaluation results are reliable and align with human evaluations. We further apply our metric to evaluate the performance of QG models, which shows our metric complements conventional metrics. Our implementation of a ChatGPT-based QG model achieves state-of-the-art (SOTA) performance in generating answerable questions.
+
+
+
+ 30. 标题:Knowledge Graph Embedding: An Overview
+ 编号:[224]
+ 链接:https://arxiv.org/abs/2309.12501
+ 作者:Xiou Ge, Yun-Cheng Wang, Bin Wang, C.-C. Jay Kuo
+ 备注:
+ 关键词:representing Knowledge Graph, Knowledge Graph, representing Knowledge, downstream tasks, link prediction
+
+ 点击查看摘要
+ Many mathematical models have been leveraged to design embeddings for representing Knowledge Graph (KG) entities and relations for link prediction and many downstream tasks. These mathematically-inspired models are not only highly scalable for inference in large KGs, but also have many explainable advantages in modeling different relation patterns that can be validated through both formal proofs and empirical results. In this paper, we make a comprehensive overview of the current state of research in KG completion. In particular, we focus on two main branches of KG embedding (KGE) design: 1) distance-based methods and 2) semantic matching-based methods. We discover the connections between recently proposed models and present an underlying trend that might help researchers invent novel and more effective models. Next, we delve into CompoundE and CompoundE3D, which draw inspiration from 2D and 3D affine operations, respectively. They encompass a broad spectrum of techniques including distance-based and semantic-based methods. We will also discuss an emerging approach for KG completion which leverages pre-trained language models (PLMs) and textual descriptions of entities and relations and offer insights into the integration of KGE embedding methods with PLMs for KG completion.
+
+
+
+ 31. 标题:Exploring the Impact of Training Data Distribution and Subword Tokenization on Gender Bias in Machine Translation
+ 编号:[228]
+ 链接:https://arxiv.org/abs/2309.12491
+ 作者:Bar Iluz, Tomasz Limisiewicz, Gabriel Stanovsky, David Mareček
+ 备注:Accepted to AACL 2023
+ 关键词:previous works, gender bias, study the effect, effect of tokenization, largely overlooked
+
+ 点击查看摘要
+ We study the effect of tokenization on gender bias in machine translation, an aspect that has been largely overlooked in previous works. Specifically, we focus on the interactions between the frequency of gendered profession names in training data, their representation in the subword tokenizer's vocabulary, and gender bias. We observe that female and non-stereotypical gender inflections of profession names (e.g., Spanish "doctora" for "female doctor") tend to be split into multiple subword tokens. Our results indicate that the imbalance of gender forms in the model's training corpus is a major factor contributing to gender bias and has a greater impact than subword splitting. We show that analyzing subword splits provides good estimates of gender-form imbalance in the training data and can be used even when the corpus is not publicly available. We also demonstrate that fine-tuning just the token embedding layer can decrease the gap in gender prediction accuracy between female and male forms without impairing the translation quality.
+
+
+
+ 32. 标题:Studying and improving reasoning in humans and machines
+ 编号:[231]
+ 链接:https://arxiv.org/abs/2309.12485
+ 作者:Nicolas Yax, Hernan Anlló, Stefano Palminteri
+ 备注:The paper is split in 4 parts : main text (pages 2-27), methods (pages 28-34), technical appendix (pages 35-45) and supplementary methods (pages 46-125)
+ 关键词:tools traditionally dedicated, large language models, psychology tools traditionally, present study, cognitive psychology tools
+
+ 点击查看摘要
+ In the present study, we investigate and compare reasoning in large language models (LLM) and humans using a selection of cognitive psychology tools traditionally dedicated to the study of (bounded) rationality. To do so, we presented to human participants and an array of pretrained LLMs new variants of classical cognitive experiments, and cross-compared their performances. Our results showed that most of the included models presented reasoning errors akin to those frequently ascribed to error-prone, heuristic-based human reasoning. Notwithstanding this superficial similarity, an in-depth comparison between humans and LLMs indicated important differences with human-like reasoning, with models limitations disappearing almost entirely in more recent LLMs releases. Moreover, we show that while it is possible to devise strategies to induce better performance, humans and machines are not equally-responsive to the same prompting schemes. We conclude by discussing the epistemological implications and challenges of comparing human and machine behavior for both artificial intelligence and cognitive psychology.
+
+
+
+ 33. 标题:HANS, are you clever? Clever Hans Effect Analysis of Neural Systems
+ 编号:[235]
+ 链接:https://arxiv.org/abs/2309.12481
+ 作者:Leonardo Ranaldi, Fabio Massimo Zanzotto
+ 备注:
+ 关键词:Instruction-tuned Large Language, Large Language Models, social interactions effectively, letting humans guide, Large Language
+
+ 点击查看摘要
+ Instruction-tuned Large Language Models (It-LLMs) have been exhibiting outstanding abilities to reason around cognitive states, intentions, and reactions of all people involved, letting humans guide and comprehend day-to-day social interactions effectively. In fact, several multiple-choice questions (MCQ) benchmarks have been proposed to construct solid assessments of the models' abilities. However, earlier works are demonstrating the presence of inherent "order bias" in It-LLMs, posing challenges to the appropriate evaluation. In this paper, we investigate It-LLMs' resilience abilities towards a series of probing tests using four MCQ benchmarks. Introducing adversarial examples, we show a significant performance gap, mainly when varying the order of the choices, which reveals a selection bias and brings into discussion reasoning abilities. Following a correlation between first positions and model choices due to positional bias, we hypothesized the presence of structural heuristics in the decision-making process of the It-LLMs, strengthened by including significant examples in few-shot scenarios. Finally, by using the Chain-of-Thought (CoT) technique, we elicit the model to reason and mitigate the bias by obtaining more robust models.
+
+
+
+ 34. 标题:Multimodal Deep Learning for Scientific Imaging Interpretation
+ 编号:[243]
+ 链接:https://arxiv.org/abs/2309.12460
+ 作者:Abdulelah S. Alshehri, Franklin L. Lee, Shihu Wang
+ 备注:
+ 关键词:Scanning Electron Microscopy, interpreting visual data, demands an intricate, intricate combination, subject materials
+
+ 点击查看摘要
+ In the domain of scientific imaging, interpreting visual data often demands an intricate combination of human expertise and deep comprehension of the subject materials. This study presents a novel methodology to linguistically emulate and subsequently evaluate human-like interactions with Scanning Electron Microscopy (SEM) images, specifically of glass materials. Leveraging a multimodal deep learning framework, our approach distills insights from both textual and visual data harvested from peer-reviewed articles, further augmented by the capabilities of GPT-4 for refined data synthesis and evaluation. Despite inherent challenges--such as nuanced interpretations and the limited availability of specialized datasets--our model (GlassLLaVA) excels in crafting accurate interpretations, identifying key features, and detecting defects in previously unseen SEM images. Moreover, we introduce versatile evaluation metrics, suitable for an array of scientific imaging applications, which allows for benchmarking against research-grounded answers. Benefiting from the robustness of contemporary Large Language Models, our model adeptly aligns with insights from research papers. This advancement not only underscores considerable progress in bridging the gap between human and machine interpretation in scientific imaging, but also hints at expansive avenues for future research and broader application.
+
+
+
+ 35. 标题:LongDocFACTScore: Evaluating the Factuality of Long Document Abstractive Summarisation
+ 编号:[246]
+ 链接:https://arxiv.org/abs/2309.12455
+ 作者:Jennifer A Bishop, Qianqian Xie, Sophia Ananiadou
+ 备注:12 pages, 5 figures
+ 关键词:ROUGE scoring, text summarisation, abstractive text summarisation, long document text, document text summarisation
+
+ 点击查看摘要
+ Maintaining factual consistency is a critical issue in abstractive text summarisation, however, it cannot be assessed by traditional automatic metrics used for evaluating text summarisation, such as ROUGE scoring. Recent efforts have been devoted to developing improved metrics for measuring factual consistency using pre-trained language models, but these metrics have restrictive token limits, and are therefore not suitable for evaluating long document text summarisation. Moreover, there is limited research evaluating whether existing automatic evaluation metrics are fit for purpose when applied to long document data sets. In this work, we evaluate the efficacy of automatic metrics at assessing factual consistency in long document text summarisation and propose a new evaluation framework LongDocFACTScore. This framework allows metrics to be extended to any length document. This framework outperforms existing state-of-the-art metrics in its ability to correlate with human measures of factuality when used to evaluate long document summarisation data sets. Furthermore, we show LongDocFACTScore has performance comparable to state-of-the-art metrics when evaluated against human measures of factual consistency on short document data sets. We make our code and annotated data publicly available: this https URL.
+
+
+
+ 36. 标题:Foundation Metrics: Quantifying Effectiveness of Healthcare Conversations powered by Generative AI
+ 编号:[249]
+ 链接:https://arxiv.org/abs/2309.12444
+ 作者:Mahyar Abbasian, Elahe Khatibi, Iman Azimi, David Oniani, Zahra Shakeri Hossein Abad, Alexander Thieme, Zhongqi Yang, Yanshan Wang, Bryant Lin, Olivier Gevaert, Li-Jia Li, Ramesh Jain, Amir M. Rahmani
+ 备注:13 pages, 4 figures, 2 tables, journal paper
+ 关键词:Generative Artificial Intelligence, Artificial Intelligence, Generative Artificial, transforming traditional patient, traditional patient care
+
+ 点击查看摘要
+ Generative Artificial Intelligence is set to revolutionize healthcare delivery by transforming traditional patient care into a more personalized, efficient, and proactive process. Chatbots, serving as interactive conversational models, will probably drive this patient-centered transformation in healthcare. Through the provision of various services, including diagnosis, personalized lifestyle recommendations, and mental health support, the objective is to substantially augment patient health outcomes, all the while mitigating the workload burden on healthcare providers. The life-critical nature of healthcare applications necessitates establishing a unified and comprehensive set of evaluation metrics for conversational models. Existing evaluation metrics proposed for various generic large language models (LLMs) demonstrate a lack of comprehension regarding medical and health concepts and their significance in promoting patients' well-being. Moreover, these metrics neglect pivotal user-centered aspects, including trust-building, ethics, personalization, empathy, user comprehension, and emotional support. The purpose of this paper is to explore state-of-the-art LLM-based evaluation metrics that are specifically applicable to the assessment of interactive conversational models in healthcare. Subsequently, we present an comprehensive set of evaluation metrics designed to thoroughly assess the performance of healthcare chatbots from an end-user perspective. These metrics encompass an evaluation of language processing abilities, impact on real-world clinical tasks, and effectiveness in user-interactive conversations. Finally, we engage in a discussion concerning the challenges associated with defining and implementing these metrics, with particular emphasis on confounding factors such as the target audience, evaluation methods, and prompt techniques involved in the evaluation process.
+
+
+
+ 37. 标题:Active Learning for Multilingual Fingerspelling Corpora
+ 编号:[250]
+ 链接:https://arxiv.org/abs/2309.12443
+ 作者:Shuai Wang, Eric Nalisnick
+ 备注:
+ 关键词:apply active learning, data scarcity problems, apply active, active learning, data scarcity
+
+ 点击查看摘要
+ We apply active learning to help with data scarcity problems in sign languages. In particular, we perform a novel analysis of the effect of pre-training. Since many sign languages are linguistic descendants of French sign language, they share hand configurations, which pre-training can hopefully exploit. We test this hypothesis on American, Chinese, German, and Irish fingerspelling corpora. We do observe a benefit from pre-training, but this may be due to visual rather than linguistic similarities
+
+
+
+ 38. 标题:Can LLMs Augment Low-Resource Reading Comprehension Datasets? Opportunities and Challenges
+ 编号:[258]
+ 链接:https://arxiv.org/abs/2309.12426
+ 作者:Vinay Samuel, Houda Aynaou, Arijit Ghosh Chowdhury, Karthik Venkat Ramanan, Aman Chadha
+ 备注:5 pages, 1 figure, 3 tables
+ 关键词:Large Language Models, Language Models, range of NLP, NLP tasks, demonstrating the ability
+
+ 点击查看摘要
+ Large Language Models (LLMs) have demonstrated impressive zero shot performance on a wide range of NLP tasks, demonstrating the ability to reason and apply commonsense. A relevant application is to use them for creating high quality synthetic datasets for downstream tasks. In this work, we probe whether GPT-4 can be used to augment existing extractive reading comprehension datasets. Automating data annotation processes has the potential to save large amounts of time, money and effort that goes into manually labelling datasets. In this paper, we evaluate the performance of GPT-4 as a replacement for human annotators for low resource reading comprehension tasks, by comparing performance after fine tuning, and the cost associated with annotation. This work serves to be the first analysis of LLMs as synthetic data augmenters for QA systems, highlighting the unique opportunities and challenges. Additionally, we release augmented versions of low resource datasets, that will allow the research community to create further benchmarks for evaluation of generated datasets.
+
+
+
+ 39. 标题:Constraints First: A New MDD-based Model to Generate Sentences Under Constraints
+ 编号:[262]
+ 链接:https://arxiv.org/abs/2309.12415
+ 作者:Alexandre Bonlarron, Aurélie Calabrèse, Pierre Kornprobst, Jean-Charles Régin
+ 备注:To be published in Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI 2023
+ 关键词:generating strongly constrained, approach to generating, generating strongly, strongly constrained texts, standardized sentence generation
+
+ 点击查看摘要
+ This paper introduces a new approach to generating strongly constrained texts. We consider standardized sentence generation for the typical application of vision screening. To solve this problem, we formalize it as a discrete combinatorial optimization problem and utilize multivalued decision diagrams (MDD), a well-known data structure to deal with constraints. In our context, one key strength of MDD is to compute an exhaustive set of solutions without performing any search. Once the sentences are obtained, we apply a language model (GPT-2) to keep the best ones. We detail this for English and also for French where the agreement and conjugation rules are known to be more complex. Finally, with the help of GPT-2, we get hundreds of bona-fide candidate sentences. When compared with the few dozen sentences usually available in the well-known vision screening test (MNREAD), this brings a major breakthrough in the field of standardized sentence generation. Also, as it can be easily adapted for other languages, it has the potential to make the MNREAD test even more valuable and usable. More generally, this paper highlights MDD as a convincing alternative for constrained text generation, especially when the constraints are hard to satisfy, but also for many other prospects.
+
+
+
+ 40. 标题:Examining the Influence of Varied Levels of Domain Knowledge Base Inclusion in GPT-based Intelligent Tutors
+ 编号:[272]
+ 链接:https://arxiv.org/abs/2309.12367
+ 作者:Blake Castleman, Mehmet Kerem Turkcan
+ 备注:
+ 关键词:large language models, sophisticated conversational capabilities, intelligent tutors, Recent advancements, language models
+
+ 点击查看摘要
+ Recent advancements in large language models (LLMs) have facilitated the development of chatbots with sophisticated conversational capabilities. However, LLMs exhibit frequent inaccurate responses to queries, hindering applications in educational settings. In this paper, we investigate the effectiveness of integrating a knowledge base (KB) with LLM intelligent tutors to increase response reliability. To achieve this, we design a scaleable KB that affords educational supervisors seamless integration of lesson curricula, which is automatically processed by the intelligent tutoring system. We then detail an evaluation, where student participants were presented with questions about the artificial intelligence curriculum to respond to. GPT-4 intelligent tutors with varying hierarchies of KB access and human domain experts then assessed these responses. Lastly, students cross-examined the intelligent tutors' responses to the domain experts' and ranked their various pedagogical abilities. Results suggest that, although these intelligent tutors still demonstrate a lower accuracy compared to domain experts, the accuracy of the intelligent tutors increases when access to a KB is granted. We also observe that the intelligent tutors with KB access exhibit better pedagogical abilities to speak like a teacher and understand students than those of domain experts, while their ability to help students remains lagging behind domain experts.
+
+
+
+ 41. 标题:ChatGPT Assisting Diagnosis of Neuro-ophthalmology Diseases Based on Case Reports
+ 编号:[278]
+ 链接:https://arxiv.org/abs/2309.12361
+ 作者:Yeganeh Madadi, Mohammad Delsoz, Priscilla A. Lao, Joseph W. Fong, TJ Hollingsworth, Malik Y. Kahook, Siamak Yousefi
+ 备注:
+ 关键词:large language models, ChatGPT, detailed case descriptions, neuro-ophthalmic diseases based, neuro-ophthalmic diseases
+
+ 点击查看摘要
+ Objective: To evaluate the efficiency of large language models (LLMs) such as ChatGPT to assist in diagnosing neuro-ophthalmic diseases based on detailed case descriptions. Methods: We selected 22 different case reports of neuro-ophthalmic diseases from a publicly available online database. These cases included a wide range of chronic and acute diseases that are commonly seen by neuro-ophthalmic sub-specialists. We inserted the text from each case as a new prompt into both ChatGPT v3.5 and ChatGPT Plus v4.0 and asked for the most probable diagnosis. We then presented the exact information to two neuro-ophthalmologists and recorded their diagnoses followed by comparison to responses from both versions of ChatGPT. Results: ChatGPT v3.5, ChatGPT Plus v4.0, and the two neuro-ophthalmologists were correct in 13 (59%), 18 (82%), 19 (86%), and 19 (86%) out of 22 cases, respectively. The agreement between the various diagnostic sources were as follows: ChatGPT v3.5 and ChatGPT Plus v4.0, 13 (59%); ChatGPT v3.5 and the first neuro-ophthalmologist, 12 (55%); ChatGPT v3.5 and the second neuro-ophthalmologist, 12 (55%); ChatGPT Plus v4.0 and the first neuro-ophthalmologist, 17 (77%); ChatGPT Plus v4.0 and the second neuro-ophthalmologist, 16 (73%); and first and second neuro-ophthalmologists 17 (17%). Conclusions: The accuracy of ChatGPT v3.5 and ChatGPT Plus v4.0 in diagnosing patients with neuro-ophthalmic diseases was 59% and 82%, respectively. With further development, ChatGPT Plus v4.0 may have potential to be used in clinical care settings to assist clinicians in providing quick, accurate diagnoses of patients in neuro-ophthalmology. The applicability of using LLMs like ChatGPT in clinical settings that lack access to subspeciality trained neuro-ophthalmologists deserves further research.
+
+
+
+ 42. 标题:Efficient Social Choice via NLP and Sampling
+ 编号:[279]
+ 链接:https://arxiv.org/abs/2309.12360
+ 作者:Lior Ashkenazy, Nimrod Talmon
+ 备注:
+ 关键词:Attention-Aware Social Choice, Social Choice tackles, fundamental conflict faced, decision making processes, Natural Language Processing
+
+ 点击查看摘要
+ Attention-Aware Social Choice tackles the fundamental conflict faced by some agent communities between their desire to include all members in the decision making processes and the limited time and attention that are at the disposal of the community members. Here, we investigate a combination of two techniques for attention-aware social choice, namely Natural Language Processing (NLP) and Sampling. Essentially, we propose a system in which each governance proposal to change the status quo is first sent to a trained NLP model that estimates the probability that the proposal would pass if all community members directly vote on it; then, based on such an estimation, a population sample of a certain size is being selected and the proposal is decided upon by taking the sample majority. We develop several concrete algorithms following the scheme described above and evaluate them using various data, including such from several Decentralized Autonomous Organizations (DAOs).
+
+
+
+ 43. 标题:Cultural Alignment in Large Language Models: An Explanatory Analysis Based on Hofstede's Cultural Dimensions
+ 编号:[296]
+ 链接:https://arxiv.org/abs/2309.12342
+ 作者:Reem I. Masoud, Ziquan Liu, Martin Ferianc, Philip Treleaven, Miguel Rodrigues
+ 备注:31 pages
+ 关键词:large language models, cultural, language models, raises concerns, Cultural Alignment Test
+
+ 点击查看摘要
+ The deployment of large language models (LLMs) raises concerns regarding their cultural misalignment and potential ramifications on individuals from various cultural norms. Existing work investigated political and social biases and public opinions rather than their cultural values. To address this limitation, the proposed Cultural Alignment Test (CAT) quantifies cultural alignment using Hofstede's cultural dimension framework, which offers an explanatory cross-cultural comparison through the latent variable analysis. We apply our approach to assess the cultural values embedded in state-of-the-art LLMs, such as: ChatGPT and Bard, across diverse cultures of countries: United States (US), Saudi Arabia, China, and Slovakia, using different prompting styles and hyperparameter settings. Our results not only quantify cultural alignment of LLMs with certain countries, but also reveal the difference between LLMs in explanatory cultural dimensions. While all LLMs did not provide satisfactory results in understanding cultural values, GPT-4 exhibited the highest CAT score for the cultural values of the US.
+
+
+
+ 44. 标题:Considerations for health care institutions training large language models on electronic health records
+ 编号:[299]
+ 链接:https://arxiv.org/abs/2309.12339
+ 作者:Weipeng Zhou, Danielle Bitterman, Majid Afshar, Timothy A. Miller
+ 备注:
+ 关键词:electronic health record, Large language models, Large language, scientists across fields, ChatGPT have excited
+
+ 点击查看摘要
+ Large language models (LLMs) like ChatGPT have excited scientists across fields; in medicine, one source of excitement is the potential applications of LLMs trained on electronic health record (EHR) data. But there are tough questions we must first answer if health care institutions are interested in having LLMs trained on their own data; should they train an LLM from scratch or fine-tune it from an open-source model? For healthcare institutions with a predefined budget, what are the biggest LLMs they can afford? In this study, we take steps towards answering these questions with an analysis on dataset sizes, model sizes, and costs for LLM training using EHR data. This analysis provides a framework for thinking about these questions in terms of data scale, compute scale, and training budgets.
+
+
+
+ 45. 标题:Dynamic ASR Pathways: An Adaptive Masking Approach Towards Efficient Pruning of A Multilingual ASR Model
+ 编号:[320]
+ 链接:https://arxiv.org/abs/2309.13018
+ 作者:Jiamin Xie, Ke Li, Jinxi Guo, Andros Tjandra, Yuan Shangguan, Leda Sari, Chunyang Wu, Junteng Jia, Jay Mahadeokar, Ozlem Kalinli
+ 备注:
+ 关键词:automatic speech recognition, minimal performance loss, Dynamic ASR Pathways, Neural network pruning, multilingual automatic speech
+
+ 点击查看摘要
+ Neural network pruning offers an effective method for compressing a multilingual automatic speech recognition (ASR) model with minimal performance loss. However, it entails several rounds of pruning and re-training needed to be run for each language. In this work, we propose the use of an adaptive masking approach in two scenarios for pruning a multilingual ASR model efficiently, each resulting in sparse monolingual models or a sparse multilingual model (named as Dynamic ASR Pathways). Our approach dynamically adapts the sub-network, avoiding premature decisions about a fixed sub-network structure. We show that our approach outperforms existing pruning methods when targeting sparse monolingual models. Further, we illustrate that Dynamic ASR Pathways jointly discovers and trains better sub-networks (pathways) of a single multilingual model by adapting from different sub-network initializations, thereby reducing the need for language-specific pruning.
+
+
+
+ 46. 标题:Reduce, Reuse, Recycle: Is Perturbed Data better than Other Language augmentation for Low Resource Self-Supervised Speech Models
+ 编号:[340]
+ 链接:https://arxiv.org/abs/2309.12763
+ 作者:Asad Ullah, Alessandro Ragano, Andrew Hines
+ 备注:5 pages, 4 figures, ICASSP24
+ 关键词:Self-supervised representation learning, recognition versus supervised, versus supervised models, Self-supervised representation, representation learning
+
+ 点击查看摘要
+ Self-supervised representation learning (SSRL) has improved the performance on downstream phoneme recognition versus supervised models. Training SSRL models requires a large amount of pre-training data and this poses a challenge for low resource languages. A common approach is transferring knowledge from other languages. Instead, we propose to use audio augmentation to pre-train SSRL models in a low resource condition and evaluate phoneme recognition as downstream task. We performed a systematic comparison of augmentation techniques, namely: pitch variation, noise addition, accented target-language speech and other language speech. We found combined augmentations (noise/pitch) was the best augmentation strategy outperforming accent and language knowledge transfer. We compared the performance with various quantities and types of pre-training data. We examined the scaling factor of augmented data to achieve equivalent performance to models pre-trained with target domain speech. Our findings suggest that for resource constrained languages, in-domain synthetic augmentation can outperform knowledge transfer from accented or other language speech.
+
+
+机器学习
+
+ 1. 标题:MosaicFusion: Diffusion Models as Data Augmenters for Large Vocabulary Instance Segmentation
+ 编号:[2]
+ 链接:https://arxiv.org/abs/2309.13042
+ 作者:Jiahao Xie, Wei Li, Xiangtai Li, Ziwei Liu, Yew Soon Ong, Chen Change Loy
+ 备注:GitHub: this https URL
+ 关键词:large vocabulary instance, effective diffusion-based data, diffusion-based data augmentation, data augmentation approach, effective diffusion-based
+
+ 点击查看摘要
+ We present MosaicFusion, a simple yet effective diffusion-based data augmentation approach for large vocabulary instance segmentation. Our method is training-free and does not rely on any label supervision. Two key designs enable us to employ an off-the-shelf text-to-image diffusion model as a useful dataset generator for object instances and mask annotations. First, we divide an image canvas into several regions and perform a single round of diffusion process to generate multiple instances simultaneously, conditioning on different text prompts. Second, we obtain corresponding instance masks by aggregating cross-attention maps associated with object prompts across layers and diffusion time steps, followed by simple thresholding and edge-aware refinement processing. Without bells and whistles, our MosaicFusion can produce a significant amount of synthetic labeled data for both rare and novel categories. Experimental results on the challenging LVIS long-tailed and open-vocabulary benchmarks demonstrate that MosaicFusion can significantly improve the performance of existing instance segmentation models, especially for rare and novel categories. Code will be released at this https URL.
+
+
+
+ 2. 标题:Robotic Offline RL from Internet Videos via Value-Function Pre-Training
+ 编号:[3]
+ 链接:https://arxiv.org/abs/2309.13041
+ 作者:Chethan Bhateja, Derek Guo, Dibya Ghosh, Anikait Singh, Manan Tomar, Quan Vuong, Yevgen Chebotar, Sergey Levine, Aviral Kumar
+ 备注:First three authors contributed equally
+ 关键词:Pre-training on Internet, Internet data, key ingredient, ingredient for broad, broad generalization
+
+ 点击查看摘要
+ Pre-training on Internet data has proven to be a key ingredient for broad generalization in many modern ML systems. What would it take to enable such capabilities in robotic reinforcement learning (RL)? Offline RL methods, which learn from datasets of robot experience, offer one way to leverage prior data into the robotic learning pipeline. However, these methods have a "type mismatch" with video data (such as Ego4D), the largest prior datasets available for robotics, since video offers observation-only experience without the action or reward annotations needed for RL methods. In this paper, we develop a system for leveraging large-scale human video datasets in robotic offline RL, based entirely on learning value functions via temporal-difference learning. We show that value learning on video datasets learns representations that are more conducive to downstream robotic offline RL than other approaches for learning from video data. Our system, called V-PTR, combines the benefits of pre-training on video data with robotic offline RL approaches that train on diverse robot data, resulting in value functions and policies for manipulation tasks that perform better, act robustly, and generalize broadly. On several manipulation tasks on a real WidowX robot, our framework produces policies that greatly improve over prior methods. Our video and additional details can be found at this https URL
+
+
+
+ 3. 标题:Graph Neural Network for Stress Predictions in Stiffened Panels Under Uniform Loading
+ 编号:[12]
+ 链接:https://arxiv.org/abs/2309.13022
+ 作者:Yuecheng Cai, Jasmin Jelovica
+ 备注:20 pages; 7 figures
+ 关键词:finite element analysis, gained significant attention, Machine learning, expensive structural analysis, deep learning
+
+ 点击查看摘要
+ Machine learning (ML) and deep learning (DL) techniques have gained significant attention as reduced order models (ROMs) to computationally expensive structural analysis methods, such as finite element analysis (FEA). Graph neural network (GNN) is a particular type of neural network which processes data that can be represented as graphs. This allows for efficient representation of complex geometries that can change during conceptual design of a structure or a product. In this study, we propose a novel graph embedding technique for efficient representation of 3D stiffened panels by considering separate plate domains as vertices. This approach is considered using Graph Sampling and Aggregation (GraphSAGE) to predict stress distributions in stiffened panels with varying geometries. A comparison between a finite-element-vertex graph representation is conducted to demonstrate the effectiveness of the proposed approach. A comprehensive parametric study is performed to examine the effect of structural geometry on the prediction performance. Our results demonstrate the immense potential of graph neural networks with the proposed graph embedding method as robust reduced-order models for 3D structures.
+
+
+
+ 4. 标题:A Hybrid Deep Learning-based Approach for Optimal Genotype by Environment Selection
+ 编号:[13]
+ 链接:https://arxiv.org/abs/2309.13021
+ 作者:Zahra Khalilzadeh, Motahareh Kashanian, Saeed Khaki, Lizhi Wang
+ 备注:20 pages, 7 figures
+ 关键词:crop yield prediction, improving agricultural practices, Precise crop yield, ensuring crop resilience, Yield Prediction Challenge
+
+ 点击查看摘要
+ Precise crop yield prediction is essential for improving agricultural practices and ensuring crop resilience in varying climates. Integrating weather data across the growing season, especially for different crop varieties, is crucial for understanding their adaptability in the face of climate change. In the MLCAS2021 Crop Yield Prediction Challenge, we utilized a dataset comprising 93,028 training records to forecast yields for 10,337 test records, covering 159 locations across 28 U.S. states and Canadian provinces over 13 years (2003-2015). This dataset included details on 5,838 distinct genotypes and daily weather data for a 214-day growing season, enabling comprehensive analysis. As one of the winning teams, we developed two novel convolutional neural network (CNN) architectures: the CNN-DNN model, combining CNN and fully-connected networks, and the CNN-LSTM-DNN model, with an added LSTM layer for weather variables. Leveraging the Generalized Ensemble Method (GEM), we determined optimal model weights, resulting in superior performance compared to baseline models. The GEM model achieved lower RMSE (5.55% to 39.88%), reduced MAE (5.34% to 43.76%), and higher correlation coefficients (1.1% to 10.79%) when evaluated on test data. We applied the CNN-DNN model to identify top-performing genotypes for various locations and weather conditions, aiding genotype selection based on weather variables. Our data-driven approach is valuable for scenarios with limited testing years. Additionally, a feature importance analysis using RMSE change highlighted the significance of location, MG, year, and genotype, along with the importance of weather variables MDNI and AP.
+
+
+
+ 5. 标题:Understanding Deep Gradient Leakage via Inversion Influence Functions
+ 编号:[15]
+ 链接:https://arxiv.org/abs/2309.13016
+ 作者:Haobo Zhang, Junyuan Hong, Yuyang Deng, Mehrdad Mahdavi, Jiayu Zhou
+ 备注:22 pages, 16 figures, accepted by NeurIPS2023
+ 关键词:recovers private training, Inversion Influence Function, DGL, private training images, highly effective attack
+
+ 点击查看摘要
+ Deep Gradient Leakage (DGL) is a highly effective attack that recovers private training images from gradient vectors. This attack casts significant privacy challenges on distributed learning from clients with sensitive data, where clients are required to share gradients. Defending against such attacks requires but lacks an understanding of when and how privacy leakage happens, mostly because of the black-box nature of deep networks. In this paper, we propose a novel Inversion Influence Function (I$^2$F) that establishes a closed-form connection between the recovered images and the private gradients by implicitly solving the DGL problem. Compared to directly solving DGL, I$^2$F is scalable for analyzing deep networks, requiring only oracle access to gradients and Jacobian-vector products. We empirically demonstrate that I$^2$F effectively approximated the DGL generally on different model architectures, datasets, attack implementations, and noise-based defenses. With this novel tool, we provide insights into effective gradient perturbation directions, the unfairness of privacy protection, and privacy-preferred model initialization. Our codes are provided in this https URL.
+
+
+
+ 6. 标题:Efficient N:M Sparse DNN Training Using Algorithm, Architecture, and Dataflow Co-Design
+ 编号:[16]
+ 链接:https://arxiv.org/abs/2309.13015
+ 作者:Chao Fang, Wei Sun, Aojun Zhou, Zhongfeng Wang
+ 备注:To appear in the IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD)
+ 关键词:DNN training, Sparse, sparse DNN training, training, Sparse training
+
+ 点击查看摘要
+ Sparse training is one of the promising techniques to reduce the computational cost of DNNs while retaining high accuracy. In particular, N:M fine-grained structured sparsity, where only N out of consecutive M elements can be nonzero, has attracted attention due to its hardware-friendly pattern and capability of achieving a high sparse ratio. However, the potential to accelerate N:M sparse DNN training has not been fully exploited, and there is a lack of efficient hardware supporting N:M sparse training. To tackle these challenges, this paper presents a computation-efficient training scheme for N:M sparse DNNs using algorithm, architecture, and dataflow co-design. At the algorithm level, a bidirectional weight pruning method, dubbed BDWP, is proposed to leverage the N:M sparsity of weights during both forward and backward passes of DNN training, which can significantly reduce the computational cost while maintaining model accuracy. At the architecture level, a sparse accelerator for DNN training, namely SAT, is developed to neatly support both the regular dense operations and the computation-efficient N:M sparse operations. At the dataflow level, multiple optimization methods ranging from interleave mapping, pre-generation of N:M sparse weights, and offline scheduling, are proposed to boost the computational efficiency of SAT. Finally, the effectiveness of our training scheme is evaluated on a Xilinx VCU1525 FPGA card using various DNN models and datasets. Experimental results show the SAT accelerator with the BDWP sparse training method under 2:8 sparse ratio achieves an average speedup of 1.75x over that with the dense training, accompanied by a negligible accuracy loss of 0.56% on average. Furthermore, our proposed training scheme significantly improves the training throughput by 2.97~25.22x and the energy efficiency by 1.36~3.58x over prior FPGA-based accelerators.
+
+
+
+ 7. 标题:ReConcile: Round-Table Conference Improves Reasoning via Consensus among Diverse LLMs
+ 编号:[18]
+ 链接:https://arxiv.org/abs/2309.13007
+ 作者:Justin Chih-Yao Chen, Swarnadeep Saha, Mohit Bansal
+ 备注:19 pages, 9 figures, 7 tables
+ 关键词:Large Language Models, Language Models, Large Language, complex reasoning tasks, agents
+
+ 点击查看摘要
+ Large Language Models (LLMs) still struggle with complex reasoning tasks. Motivated by the society of minds (Minsky, 1988), we propose ReConcile, a multi-model multi-agent framework designed as a round table conference among diverse LLM agents to foster diverse thoughts and discussion for improved consensus. ReConcile enhances the reasoning capabilities of LLMs by holding multiple rounds of discussion, learning to convince other agents to improve their answers, and employing a confidence-weighted voting mechanism. In each round, ReConcile initiates discussion between agents via a 'discussion prompt' that consists of (a) grouped answers and explanations generated by each agent in the previous round, (b) their uncertainties, and (c) demonstrations of answer-rectifying human explanations, used for convincing other agents. This discussion prompt enables each agent to revise their responses in light of insights from other agents. Once a consensus is reached and the discussion ends, ReConcile determines the final answer by leveraging the confidence of each agent in a weighted voting scheme. We implement ReConcile with ChatGPT, Bard, and Claude2 as the three agents. Our experimental results on various benchmarks demonstrate that ReConcile significantly enhances the reasoning performance of the agents (both individually and as a team), surpassing prior single-agent and multi-agent baselines by 7.7% and also outperforming GPT-4 on some of these datasets. We also experiment with GPT-4 itself as one of the agents in ReConcile and demonstrate that its initial performance also improves by absolute 10.0% through discussion and feedback from other agents. Finally, we also analyze the accuracy after every round and observe that ReConcile achieves better and faster consensus between agents, compared to a multi-agent debate baseline. Our code is available at: this https URL
+
+
+
+ 8. 标题:Pursuing Counterfactual Fairness via Sequential Autoencoder Across Domains
+ 编号:[20]
+ 链接:https://arxiv.org/abs/2309.13005
+ 作者:Yujie Lin, Chen Zhao, Minglai Shao, Baoluo Meng, Xujiang Zhao, Haifeng Chen
+ 备注:
+ 关键词:machine learning systems, machine learning, sensitive attributes, Recognizing the prevalence, developed to enhance
+
+ 点击查看摘要
+ Recognizing the prevalence of domain shift as a common challenge in machine learning, various domain generalization (DG) techniques have been developed to enhance the performance of machine learning systems when dealing with out-of-distribution (OOD) data. Furthermore, in real-world scenarios, data distributions can gradually change across a sequence of sequential domains. While current methodologies primarily focus on improving model effectiveness within these new domains, they often overlook fairness issues throughout the learning process. In response, we introduce an innovative framework called Counterfactual Fairness-Aware Domain Generalization with Sequential Autoencoder (CDSAE). This approach effectively separates environmental information and sensitive attributes from the embedded representation of classification features. This concurrent separation not only greatly improves model generalization across diverse and unfamiliar domains but also effectively addresses challenges related to unfair classification. Our strategy is rooted in the principles of causal inference to tackle these dual issues. To examine the intricate relationship between semantic information, sensitive attributes, and environmental cues, we systematically categorize exogenous uncertainty factors into four latent variables: 1) semantic information influenced by sensitive attributes, 2) semantic information unaffected by sensitive attributes, 3) environmental cues influenced by sensitive attributes, and 4) environmental cues unaffected by sensitive attributes. By incorporating fairness regularization, we exclusively employ semantic information for classification purposes. Empirical validation on synthetic and real-world datasets substantiates the effectiveness of our approach, demonstrating improved accuracy levels while ensuring the preservation of fairness in the evolving landscape of continuous domains.
+
+
+
+ 9. 标题:Point Cloud Network: An Order of Magnitude Improvement in Linear Layer Parameter Count
+ 编号:[22]
+ 链接:https://arxiv.org/abs/2309.12996
+ 作者:Charles Hetterich
+ 备注:
+ 关键词:Point Cloud Network, deep learning networks, Multilayer Perceptron, introduces the Point, learning networks
+
+ 点击查看摘要
+ This paper introduces the Point Cloud Network (PCN) architecture, a novel implementation of linear layers in deep learning networks, and provides empirical evidence to advocate for its preference over the Multilayer Perceptron (MLP) in linear layers. We train several models, including the original AlexNet, using both MLP and PCN architectures for direct comparison of linear layers (Krizhevsky et al., 2012). The key results collected are model parameter count and top-1 test accuracy over the CIFAR-10 and CIFAR-100 datasets (Krizhevsky, 2009). AlexNet-PCN16, our PCN equivalent to AlexNet, achieves comparable efficacy (test accuracy) to the original architecture with a 99.5% reduction of parameters in its linear layers. All training is done on cloud RTX 4090 GPUs, leveraging pytorch for model construction and training. Code is provided for anyone to reproduce the trials from this paper.
+
+
+
+ 10. 标题:Higher-order Graph Convolutional Network with Flower-Petals Laplacians on Simplicial Complexes
+ 编号:[27]
+ 链接:https://arxiv.org/abs/2309.12971
+ 作者:Yiming Huang, Yujie Zeng, Qiang Wu, Linyuan Lü
+ 备注:
+ 关键词:vanilla Graph Neural, Graph Neural Networks, networks inherently limits, discern latent higher-order, pairwise interaction networks
+
+ 点击查看摘要
+ Despite the recent successes of vanilla Graph Neural Networks (GNNs) on many tasks, their foundation on pairwise interaction networks inherently limits their capacity to discern latent higher-order interactions in complex systems. To bridge this capability gap, we propose a novel approach exploiting the rich mathematical theory of simplicial complexes (SCs) - a robust tool for modeling higher-order interactions. Current SC-based GNNs are burdened by high complexity and rigidity, and quantifying higher-order interaction strengths remains challenging. Innovatively, we present a higher-order Flower-Petals (FP) model, incorporating FP Laplacians into SCs. Further, we introduce a Higher-order Graph Convolutional Network (HiGCN) grounded in FP Laplacians, capable of discerning intrinsic features across varying topological scales. By employing learnable graph filters, a parameter group within each FP Laplacian domain, we can identify diverse patterns where the filters' weights serve as a quantifiable measure of higher-order interaction strengths. The theoretical underpinnings of HiGCN's advanced expressiveness are rigorously demonstrated. Additionally, our empirical investigations reveal that the proposed model accomplishes state-of-the-art (SOTA) performance on a range of graph tasks and provides a scalable and flexible solution to explore higher-order interactions in graphs.
+
+
+
+ 11. 标题:On Separate Normalization in Self-supervised Transformers
+ 编号:[42]
+ 链接:https://arxiv.org/abs/2309.12931
+ 作者:Xiaohui Chen, Yinkai Wang, Yuanqi Du, Soha Hassoun, Li-Ping Liu
+ 备注:NIPS 2023
+ 关键词:Self-supervised training methods, demonstrated remarkable performance, Self-supervised training, transformers have demonstrated, demonstrated remarkable
+
+ 点击查看摘要
+ Self-supervised training methods for transformers have demonstrated remarkable performance across various domains. Previous transformer-based models, such as masked autoencoders (MAE), typically utilize a single normalization layer for both the [CLS] symbol and the tokens. We propose in this paper a simple modification that employs separate normalization layers for the tokens and the [CLS] symbol to better capture their distinct characteristics and enhance downstream task performance. Our method aims to alleviate the potential negative effects of using the same normalization statistics for both token types, which may not be optimally aligned with their individual roles. We empirically show that by utilizing a separate normalization layer, the [CLS] embeddings can better encode the global contextual information and are distributed more uniformly in its anisotropic space. When replacing the conventional normalization layer with the two separate layers, we observe an average 2.7% performance improvement over the image, natural language, and graph domains.
+
+
+
+ 12. 标题:BayesDLL: Bayesian Deep Learning Library
+ 编号:[43]
+ 链接:https://arxiv.org/abs/2309.12928
+ 作者:Minyoung Kim, Timothy Hospedales
+ 备注:
+ 关键词:Bayesian neural network, Bayesian neural, Bayesian, url, Bayesian inference
+
+ 点击查看摘要
+ We release a new Bayesian neural network library for PyTorch for large-scale deep networks. Our library implements mainstream approximate Bayesian inference algorithms: variational inference, MC-dropout, stochastic-gradient MCMC, and Laplace approximation. The main differences from other existing Bayesian neural network libraries are as follows: 1) Our library can deal with very large-scale deep networks including Vision Transformers (ViTs). 2) We need virtually zero code modifications for users (e.g., the backbone network definition codes do not neet to be modified at all). 3) Our library also allows the pre-trained model weights to serve as a prior mean, which is very useful for performing Bayesian inference with the large-scale foundation models like ViTs that are hard to optimise from scratch with the downstream data alone. Our code is publicly available at: \url{this https URL}\footnote{A mirror repository is also available at: \url{this https URL}.}.
+
+
+
+ 13. 标题:A matter of attitude: Focusing on positive and active gradients to boost saliency maps
+ 编号:[47]
+ 链接:https://arxiv.org/abs/2309.12913
+ 作者:Oscar Llorente, Jaime Boal, Eugenio F. Sánchez-Úbeda
+ 备注:
+ 关键词:convolutional neural networks, widely used interpretability, interpretability techniques, techniques for convolutional, convolutional neural
+
+ 点击查看摘要
+ Saliency maps have become one of the most widely used interpretability techniques for convolutional neural networks (CNN) due to their simplicity and the quality of the insights they provide. However, there are still some doubts about whether these insights are a trustworthy representation of what CNNs use to come up with their predictions. This paper explores how rescuing the sign of the gradients from the saliency map can lead to a deeper understanding of multi-class classification problems. Using both pretrained and trained from scratch CNNs we unveil that considering the sign and the effect not only of the correct class, but also the influence of the other classes, allows to better identify the pixels of the image that the network is really focusing on. Furthermore, how occluding or altering those pixels is expected to affect the outcome also becomes clearer.
+
+
+
+ 14. 标题:FairComp: Workshop on Fairness and Robustness in Machine Learning for Ubiquitous Computing
+ 编号:[58]
+ 链接:https://arxiv.org/abs/2309.12877
+ 作者:Sofia Yfantidou, Dimitris Spathis, Marios Constantinides, Tong Xia, Niels van Berkel
+ 备注:
+ 关键词:Ubiquitous Computing, ethical and fair, Computing, UbiComp, research
+
+ 点击查看摘要
+ How can we ensure that Ubiquitous Computing (UbiComp) research outcomes are both ethical and fair? While fairness in machine learning (ML) has gained traction in recent years, fairness in UbiComp remains unexplored. This workshop aims to discuss fairness in UbiComp research and its social, technical, and legal implications. From a social perspective, we will examine the relationship between fairness and UbiComp research and identify pathways to ensure that ubiquitous technologies do not cause harm or infringe on individual rights. From a technical perspective, we will initiate a discussion on data practices to develop bias mitigation approaches tailored to UbiComp research. From a legal perspective, we will examine how new policies shape our community's work and future research. We aim to foster a vibrant community centered around the topic of responsible UbiComp, while also charting a clear path for future research endeavours in this field.
+
+
+
+ 15. 标题:AnglE-Optimized Text Embeddings
+ 编号:[61]
+ 链接:https://arxiv.org/abs/2309.12871
+ 作者:Xianming Li, Jing Li
+ 备注:NLP, Text Embedding, Semantic Textual Similarity
+ 关键词:Large Language Model, Large Language, semantic textual similarity, improving semantic textual, components in Large
+
+ 点击查看摘要
+ High-quality text embedding is pivotal in improving semantic textual similarity (STS) tasks, which are crucial components in Large Language Model (LLM) applications. However, a common challenge existing text embedding models face is the problem of vanishing gradients, primarily due to their reliance on the cosine function in the optimization objective, which has saturation zones. To address this issue, this paper proposes a novel angle-optimized text embedding model called AnglE. The core idea of AnglE is to introduce angle optimization in a complex space. This novel approach effectively mitigates the adverse effects of the saturation zone in the cosine function, which can impede gradient and hinder optimization processes. To set up a comprehensive STS evaluation, we experimented on existing short-text STS datasets and a newly collected long-text STS dataset from GitHub Issues. Furthermore, we examine domain-specific STS scenarios with limited labeled data and explore how AnglE works with LLM-annotated data. Extensive experiments were conducted on various tasks including short-text STS, long-text STS, and domain-specific STS tasks. The results show that AnglE outperforms the state-of-the-art (SOTA) STS models that ignore the cosine saturation zone. These findings demonstrate the ability of AnglE to generate high-quality text embeddings and the usefulness of angle optimization in STS.
+
+
+
+ 16. 标题:Associative Transformer Is A Sparse Representation Learner
+ 编号:[67]
+ 链接:https://arxiv.org/abs/2309.12862
+ 作者:Yuwei Sun, Hideya Ochiai, Zhirong Wu, Stephen Lin, Ryota Kanai
+ 备注:
+ 关键词:conventional Transformer models, monolithic pairwise attention, pairwise attention mechanism, leveraging sparse interactions, Set Transformer
+
+ 点击查看摘要
+ Emerging from the monolithic pairwise attention mechanism in conventional Transformer models, there is a growing interest in leveraging sparse interactions that align more closely with biological principles. Approaches including the Set Transformer and the Perceiver employ cross-attention consolidated with a latent space that forms an attention bottleneck with limited capacity. Building upon recent neuroscience studies of Global Workspace Theory and associative memory, we propose the Associative Transformer (AiT). AiT induces low-rank explicit memory that serves as both priors to guide bottleneck attention in the shared workspace and attractors within associative memory of a Hopfield network. Through joint end-to-end training, these priors naturally develop module specialization, each contributing a distinct inductive bias to form attention bottlenecks. A bottleneck can foster competition among inputs for writing information into the memory. We show that AiT is a sparse representation learner, learning distinct priors through the bottlenecks that are complexity-invariant to input quantities and dimensions. AiT demonstrates its superiority over methods such as the Set Transformer, Vision Transformer, and Coordination in various vision tasks.
+
+
+
+ 17. 标题:Robotic Handling of Compliant Food Objects by Robust Learning from Demonstration
+ 编号:[72]
+ 链接:https://arxiv.org/abs/2309.12856
+ 作者:Ekrem Misimi, Alexander Olofsson, Aleksander Eilertsen, Elling Ruud Øye, John Reidar Mathiassen
+ 备注:8 pages, 7 figures,IROS 2018
+ 关键词:high biological variation, food raw materials, deformable food raw, raw materials, biological variation
+
+ 点击查看摘要
+ The robotic handling of compliant and deformable food raw materials, characterized by high biological variation, complex geometrical 3D shapes, and mechanical structures and texture, is currently in huge demand in the ocean space, agricultural, and food industries. Many tasks in these industries are performed manually by human operators who, due to the laborious and tedious nature of their tasks, exhibit high variability in execution, with variable outcomes. The introduction of robotic automation for most complex processing tasks has been challenging due to current robot learning policies. A more consistent learning policy involving skilled operators is desired. In this paper, we address the problem of robot learning when presented with inconsistent demonstrations. To this end, we propose a robust learning policy based on Learning from Demonstration (LfD) for robotic grasping of food compliant objects. The approach uses a merging of RGB-D images and tactile data in order to estimate the necessary pose of the gripper, gripper finger configuration and forces exerted on the object in order to achieve effective robot handling. During LfD training, the gripper pose, finger configurations and tactile values for the fingers, as well as RGB-D images are saved. We present an LfD learning policy that automatically removes inconsistent demonstrations, and estimates the teacher's intended policy. The performance of our approach is validated and demonstrated for fragile and compliant food objects with complex 3D shapes. The proposed approach has a vast range of potential applications in the aforementioned industry sectors.
+
+
+
+ 18. 标题:DeepOPF-U: A Unified Deep Neural Network to Solve AC Optimal Power Flow in Multiple Networks
+ 编号:[74]
+ 链接:https://arxiv.org/abs/2309.12849
+ 作者:Heng Liang, Changhong Zhao
+ 备注:3 pages, 2 figures
+ 关键词:distributed energy resources, traditional machine learning, machine learning models, optimal power flow, solve optimal power
+
+ 点击查看摘要
+ The traditional machine learning models to solve optimal power flow (OPF) are mostly trained for a given power network and lack generalizability to today's power networks with varying topologies and growing plug-and-play distributed energy resources (DERs). In this paper, we propose DeepOPF-U, which uses one unified deep neural network (DNN) to solve alternating-current (AC) OPF problems in different power networks, including a set of power networks that is successively expanding. Specifically, we design elastic input and output layers for the vectors of given loads and OPF solutions with varying lengths in different networks. The proposed method, using a single unified DNN, can deal with different and growing numbers of buses, lines, loads, and DERs. Simulations of IEEE 57/118/300-bus test systems and a network growing from 73 to 118 buses verify the improved performance of DeepOPF-U compared to existing DNN-based solution methods.
+
+
+
+ 19. 标题:Reward Function Design for Crowd Simulation via Reinforcement Learning
+ 编号:[76]
+ 链接:https://arxiv.org/abs/2309.12841
+ 作者:Ariel Kwiatkowski, Vicky Kalogeiton, Julien Pettré, Marie-Paule Cani
+ 备注:
+ 关键词:populate virtual worlds, Crowd simulation, important for video-games, worlds with autonomous, autonomous avatars
+
+ 点击查看摘要
+ Crowd simulation is important for video-games design, since it enables to populate virtual worlds with autonomous avatars that navigate in a human-like manner. Reinforcement learning has shown great potential in simulating virtual crowds, but the design of the reward function is critical to achieving effective and efficient results. In this work, we explore the design of reward functions for reinforcement learning-based crowd simulation. We provide theoretical insights on the validity of certain reward functions according to their analytical properties, and evaluate them empirically using a range of scenarios, using the energy efficiency as the metric. Our experiments show that directly minimizing the energy usage is a viable strategy as long as it is paired with an appropriately scaled guiding potential, and enable us to study the impact of the different reward components on the behavior of the simulated crowd. Our findings can inform the development of new crowd simulation techniques, and contribute to the wider study of human-like navigation.
+
+
+
+ 20. 标题:AxOCS: Scaling FPGA-based Approximate Operators using Configuration Supersampling
+ 编号:[77]
+ 链接:https://arxiv.org/abs/2309.12830
+ 作者:Siva Satyendra Sahoo, Salim Ullah, Soumyo Bhattacharjee, Akash Kumar
+ 备注:11 pages, under review with IEEE TCAS-I
+ 关键词:resource-constrained embedded systems, low-cost ML implementation, processing across application, application domains, domains has exacerbated
+
+ 点击查看摘要
+ The rising usage of AI and ML-based processing across application domains has exacerbated the need for low-cost ML implementation, specifically for resource-constrained embedded systems. To this end, approximate computing, an approach that explores the power, performance, area (PPA), and behavioral accuracy (BEHAV) trade-offs, has emerged as a possible solution for implementing embedded machine learning. Due to the predominance of MAC operations in ML, designing platform-specific approximate arithmetic operators forms one of the major research problems in approximate computing. Recently there has been a rising usage of AI/ML-based design space exploration techniques for implementing approximate operators. However, most of these approaches are limited to using ML-based surrogate functions for predicting the PPA and BEHAV impact of a set of related design decisions. While this approach leverages the regression capabilities of ML methods, it does not exploit the more advanced approaches in ML. To this end, we propose AxOCS, a methodology for designing approximate arithmetic operators through ML-based supersampling. Specifically, we present a method to leverage the correlation of PPA and BEHAV metrics across operators of varying bit-widths for generating larger bit-width operators. The proposed approach involves traversing the relatively smaller design space of smaller bit-width operators and employing its associated Design-PPA-BEHAV relationship to generate initial solutions for metaheuristics-based optimization for larger operators. The experimental evaluation of AxOCS for FPGA-optimized approximate operators shows that the proposed approach significantly improves the quality-resulting hypervolume for multi-objective optimization-of 8x8 signed approximate multipliers.
+
+
+
+ 21. 标题:Synthetic Boost: Leveraging Synthetic Data for Enhanced Vision-Language Segmentation in Echocardiography
+ 编号:[78]
+ 链接:https://arxiv.org/abs/2309.12829
+ 作者:Rabin Adhikari, Manish Dhakal, Safal Thapaliya, Kanchan Poudel, Prasiddha Bhandari, Bishesh Khanal
+ 备注:Accepted at the 4th International Workshop of Advances in Simplifying Medical UltraSound (ASMUS)
+ 关键词:cardiovascular diseases, essential for echocardiography-based, echocardiography-based assessment, assessment of cardiovascular, Semantic Diffusion Models
+
+ 点击查看摘要
+ Accurate segmentation is essential for echocardiography-based assessment of cardiovascular diseases (CVDs). However, the variability among sonographers and the inherent challenges of ultrasound images hinder precise segmentation. By leveraging the joint representation of image and text modalities, Vision-Language Segmentation Models (VLSMs) can incorporate rich contextual information, potentially aiding in accurate and explainable segmentation. However, the lack of readily available data in echocardiography hampers the training of VLSMs. In this study, we explore using synthetic datasets from Semantic Diffusion Models (SDMs) to enhance VLSMs for echocardiography segmentation. We evaluate results for two popular VLSMs (CLIPSeg and CRIS) using seven different kinds of language prompts derived from several attributes, automatically extracted from echocardiography images, segmentation masks, and their metadata. Our results show improved metrics and faster convergence when pretraining VLSMs on SDM-generated synthetic images before finetuning on real images. The code, configs, and prompts are available at this https URL.
+
+
+
+ 22. 标题:Improving Generalization in Game Agents with Data Augmentation in Imitation Learning
+ 编号:[80]
+ 链接:https://arxiv.org/abs/2309.12815
+ 作者:Derek Yadgaroff, Alessandro Sestini, Konrad Tollmar, Linus Gisslén
+ 备注:8 pages, 5 figures
+ 关键词:efficient game production, imitation learning agents, effective approach, Imitation learning, game production
+
+ 点击查看摘要
+ Imitation learning is an effective approach for training game-playing agents and, consequently, for efficient game production. However, generalization - the ability to perform well in related but unseen scenarios - is an essential requirement that remains an unsolved challenge for game AI. Generalization is difficult for imitation learning agents because it requires the algorithm to take meaningful actions outside of the training distribution. In this paper we propose a solution to this challenge. Inspired by the success of data augmentation in supervised learning, we augment the training data so the distribution of states and actions in the dataset better represents the real state-action distribution. This study evaluates methods for combining and applying data augmentations to observations, to improve generalization of imitation learning agents. It also provides a performance benchmark of these augmentations across several 3D environments. These results demonstrate that data augmentation is a promising framework for improving generalization in imitation learning agents.
+
+
+
+ 23. 标题:Automatically Testing Functional Properties of Code Translation Models
+ 编号:[82]
+ 链接:https://arxiv.org/abs/2309.12813
+ 作者:Hasan Ferit Eniser, Valentin Wüstholz, Maria Christakis
+ 备注:13 pages including appendix and references
+ 关键词:Large language models, Large language, programming languages, increasingly practical, practical for translating
+
+ 点击查看摘要
+ Large language models are becoming increasingly practical for translating code across programming languages, a process known as $transpiling$. Even though automated transpilation significantly boosts developer productivity, a key concern is whether the generated code is correct. Existing work initially used manually crafted test suites to test the translations of a small corpus of programs; these test suites were later automated. In contrast, we devise the first approach for automated, functional, property-based testing of code translation models. Our general, user-provided specifications about the transpiled code capture a range of properties, from purely syntactic to purely semantic ones. As shown by our experiments, this approach is very effective in detecting property violations in popular code translation models, and therefore, in evaluating model quality with respect to given properties. We also go a step further and explore the usage scenario where a user simply aims to obtain a correct translation of some code with respect to certain properties without necessarily being concerned about the overall quality of the model. To this purpose, we develop the first property-guided search procedure for code translation models, where a model is repeatedly queried with slightly different parameters to produce alternative and potentially more correct translations. Our results show that this search procedure helps to obtain significantly better code translations.
+
+
+
+ 24. 标题:Deepfake audio as a data augmentation technique for training automatic speech to text transcription models
+ 编号:[88]
+ 链接:https://arxiv.org/abs/2309.12802
+ 作者:Alexandre R. Ferreira, Cláudio E. C. Campelo
+ 备注:9 pages, 6 figures, 7 tables
+ 关键词:produce robust results, diverse labeled dataset, robust results, produce robust, large and diverse
+
+ 点击查看摘要
+ To train transcriptor models that produce robust results, a large and diverse labeled dataset is required. Finding such data with the necessary characteristics is a challenging task, especially for languages less popular than English. Moreover, producing such data requires significant effort and often money. Therefore, a strategy to mitigate this problem is the use of data augmentation techniques. In this work, we propose a framework that approaches data augmentation based on deepfake audio. To validate the produced framework, experiments were conducted using existing deepfake and transcription models. A voice cloner and a dataset produced by Indians (in English) were selected, ensuring the presence of a single accent in the dataset. Subsequently, the augmented data was used to train speech to text models in various scenarios.
+
+
+
+ 25. 标题:An Intelligent Approach to Detecting Novel Fault Classes for Centrifugal Pumps Based on Deep CNNs and Unsupervised Methods
+ 编号:[101]
+ 链接:https://arxiv.org/abs/2309.12765
+ 作者:Mahdi Abdollah Chalaki, Daniyal Maroufi, Mahdi Robati, Mohammad Javad Karimi, Ali Sadighi
+ 备注:6 pages, 9 figures
+ 关键词:data-driven fault diagnosis, rotating machines, recent success, success in data-driven, diagnosis of rotating
+
+ 点击查看摘要
+ Despite the recent success in data-driven fault diagnosis of rotating machines, there are still remaining challenges in this field. Among the issues to be addressed, is the lack of information about variety of faults the system may encounter in the field. In this paper, we assume a partial knowledge of the system faults and use the corresponding data to train a convolutional neural network. A combination of t-SNE method and clustering techniques is then employed to detect novel faults. Upon detection, the network is augmented using the new data. Finally, a test setup is used to validate this two-stage methodology on a centrifugal pump and experimental results show high accuracy in detecting novel faults.
+
+
+
+ 26. 标题:Masking Improves Contrastive Self-Supervised Learning for ConvNets, and Saliency Tells You Where
+ 编号:[104]
+ 链接:https://arxiv.org/abs/2309.12757
+ 作者:Zhi-Yi Chin, Chieh-Ming Jiang, Ching-Chun Huang, Pin-Yu Chen, Wei-Chen Chiu
+ 备注:
+ 关键词:convolutional neural networks, vision transformer backbone, image data starts, self-supervised learning scheme, learning process significantly
+
+ 点击查看摘要
+ While image data starts to enjoy the simple-but-effective self-supervised learning scheme built upon masking and self-reconstruction objective thanks to the introduction of tokenization procedure and vision transformer backbone, convolutional neural networks as another important and widely-adopted architecture for image data, though having contrastive-learning techniques to drive the self-supervised learning, still face the difficulty of leveraging such straightforward and general masking operation to benefit their learning process significantly. In this work, we aim to alleviate the burden of including masking operation into the contrastive-learning framework for convolutional neural networks as an extra augmentation method. In addition to the additive but unwanted edges (between masked and unmasked regions) as well as other adverse effects caused by the masking operations for ConvNets, which have been discussed by prior works, we particularly identify the potential problem where for one view in a contrastive sample-pair the randomly-sampled masking regions could be overly concentrated on important/salient objects thus resulting in misleading contrastiveness to the other view. To this end, we propose to explicitly take the saliency constraint into consideration in which the masked regions are more evenly distributed among the foreground and background for realizing the masking-based augmentation. Moreover, we introduce hard negative samples by masking larger regions of salient patches in an input image. Extensive experiments conducted on various datasets, contrastive learning mechanisms, and downstream tasks well verify the efficacy as well as the superior performance of our proposed method with respect to several state-of-the-art baselines.
+
+
+
+ 27. 标题:Make the U in UDA Matter: Invariant Consistency Learning for Unsupervised Domain Adaptation
+ 编号:[108]
+ 链接:https://arxiv.org/abs/2309.12742
+ 作者:Zhongqi Yue, Hanwang Zhang, Qianru Sun
+ 备注:Accepted by NeurIPS 2023
+ 关键词:target domain, unsupervised target domains, Domain Adaptation, additional unsupervised target, domain-invariant features
+
+ 点击查看摘要
+ Domain Adaptation (DA) is always challenged by the spurious correlation between domain-invariant features (e.g., class identity) and domain-specific features (e.g., environment) that does not generalize to the target domain. Unfortunately, even enriched with additional unsupervised target domains, existing Unsupervised DA (UDA) methods still suffer from it. This is because the source domain supervision only considers the target domain samples as auxiliary data (e.g., by pseudo-labeling), yet the inherent distribution in the target domain -- where the valuable de-correlation clues hide -- is disregarded. We propose to make the U in UDA matter by giving equal status to the two domains. Specifically, we learn an invariant classifier whose prediction is simultaneously consistent with the labels in the source domain and clusters in the target domain, hence the spurious correlation inconsistent in the target domain is removed. We dub our approach "Invariant CONsistency learning" (ICON). Extensive experiments show that ICON achieves the state-of-the-art performance on the classic UDA benchmarks: Office-Home and VisDA-2017, and outperforms all the conventional methods on the challenging WILDS 2.0 benchmark. Codes are in this https URL.
+
+
+
+ 28. 标题:Optimal Dynamic Fees for Blockchain Resources
+ 编号:[109]
+ 链接:https://arxiv.org/abs/2309.12735
+ 作者:Davide Crapis, Ciamac C. Moallemi, Shouqiao Wang
+ 备注:
+ 关键词:dynamic fee mechanisms, address the problem, mechanisms for multiple, multiple blockchain resources, optimal policies
+
+ 点击查看摘要
+ We develop a general and practical framework to address the problem of the optimal design of dynamic fee mechanisms for multiple blockchain resources. Our framework allows to compute policies that optimally trade-off between adjusting resource prices to handle persistent demand shifts versus being robust to local noise in the observed block demand. In the general case with more than one resource, our optimal policies correctly handle cross-effects (complementarity and substitutability) in resource demands. We also show how these cross-effects can be used to inform resource design, i.e. combining resources into bundles that have low demand-side cross-effects can yield simpler and more efficient price-update rules. Our framework is also practical, we demonstrate how it can be used to refine or inform the design of heuristic fee update rules such as EIP-1559 or EIP-4844 with two case studies. We then estimate a uni-dimensional version of our model using real market data from the Ethereum blockchain and empirically compare the performance of our optimal policies to EIP-1559.
+
+
+
+ 29. 标题:H2O+: An Improved Framework for Hybrid Offline-and-Online RL with Dynamics Gaps
+ 编号:[118]
+ 链接:https://arxiv.org/abs/2309.12716
+ 作者:Haoyi Niu, Tianying Ji, Bingqi Liu, Haocheng Zhao, Xiangyu Zhu, Jianying Zheng, Pengfei Huang, Guyue Zhou, Jianming Hu, Xianyuan Zhan
+ 备注:
+ 关键词:Solving real-world complex, real-world complex tasks, high-fidelity simulation environments, complex tasks, tasks using reinforcement
+
+ 点击查看摘要
+ Solving real-world complex tasks using reinforcement learning (RL) without high-fidelity simulation environments or large amounts of offline data can be quite challenging. Online RL agents trained in imperfect simulation environments can suffer from severe sim-to-real issues. Offline RL approaches although bypass the need for simulators, often pose demanding requirements on the size and quality of the offline datasets. The recently emerged hybrid offline-and-online RL provides an attractive framework that enables joint use of limited offline data and imperfect simulator for transferable policy learning. In this paper, we develop a new algorithm, called H2O+, which offers great flexibility to bridge various choices of offline and online learning methods, while also accounting for dynamics gaps between the real and simulation environment. Through extensive simulation and real-world robotics experiments, we demonstrate superior performance and flexibility over advanced cross-domain online and offline RL algorithms.
+
+
+
+ 30. 标题:PointSSC: A Cooperative Vehicle-Infrastructure Point Cloud Benchmark for Semantic Scene Completion
+ 编号:[123]
+ 链接:https://arxiv.org/abs/2309.12708
+ 作者:Yuxiang Yan, Boda Liu, Jianfei Ai, Qinbu Li, Ru Wan, Jian Pu
+ 备注:8 pages, 5 figures, submitted to ICRA2024
+ 关键词:generate space occupancies, jointly generate space, aims to jointly, jointly generate, SSC
+
+ 点击查看摘要
+ Semantic Scene Completion (SSC) aims to jointly generate space occupancies and semantic labels for complex 3D scenes. Most existing SSC models focus on volumetric representations, which are memory-inefficient for large outdoor spaces. Point clouds provide a lightweight alternative but existing benchmarks lack outdoor point cloud scenes with semantic labels. To address this, we introduce PointSSC, the first cooperative vehicle-infrastructure point cloud benchmark for semantic scene completion. These scenes exhibit long-range perception and minimal occlusion. We develop an automated annotation pipeline leveraging Segment Anything to efficiently assign semantics. To benchmark progress, we propose a LiDAR-based model with a Spatial-Aware Transformer for global and local feature extraction and a Completion and Segmentation Cooperative Module for joint completion and segmentation. PointSSC provides a challenging testbed to drive advances in semantic point cloud completion for real-world navigation.
+
+
+
+ 31. 标题:Multi-Label Noise Transition Matrix Estimation with Label Correlations: Theory and Algorithm
+ 编号:[124]
+ 链接:https://arxiv.org/abs/2309.12706
+ 作者:Shikun Li, Xiaobo Xia, Hansong Zhang, Shiming Ge, Tongliang Liu
+ 备注:
+ 关键词:Noisy multi-label learning, garnered increasing attention, increasing attention due, multi-label learning, Noisy
+
+ 点击查看摘要
+ Noisy multi-label learning has garnered increasing attention due to the challenges posed by collecting large-scale accurate labels, making noisy labels a more practical alternative. Motivated by noisy multi-class learning, the introduction of transition matrices can help model multi-label noise and enable the development of statistically consistent algorithms for noisy multi-label learning. However, estimating multi-label noise transition matrices remains a challenging task, as most existing estimators in noisy multi-class learning rely on anchor points and accurate fitting of noisy class posteriors, which is hard to satisfy in noisy multi-label learning. In this paper, we address this problem by first investigating the identifiability of class-dependent transition matrices in noisy multi-label learning. Building upon the identifiability results, we propose a novel estimator that leverages label correlations without the need for anchor points or precise fitting of noisy class posteriors. Specifically, we first estimate the occurrence probability of two noisy labels to capture noisy label correlations. Subsequently, we employ sample selection techniques to extract information implying clean label correlations, which are then used to estimate the occurrence probability of one noisy label when a certain clean label appears. By exploiting the mismatches in label correlations implied by these occurrence probabilities, we demonstrate that the transition matrix becomes identifiable and can be acquired by solving a bilinear decomposition problem. Theoretically, we establish an estimation error bound for our multi-label transition matrix estimator and derive a generalization error bound for our statistically consistent algorithm. Empirically, we validate the effectiveness of our estimator in estimating multi-label noise transition matrices, leading to excellent classification performance.
+
+
+
+ 32. 标题:Discovering the Interpretability-Performance Pareto Front of Decision Trees with Dynamic Programming
+ 编号:[125]
+ 链接:https://arxiv.org/abs/2309.12701
+ 作者:Hector Kohler, Riad Akrour, Philippe Preux
+ 备注:
+ 关键词:interpreted by humans, Markov Decision Problem, optimal decision trees, intrinsically interpretable, inspected and interpreted
+
+ 点击查看摘要
+ Decision trees are known to be intrinsically interpretable as they can be inspected and interpreted by humans. Furthermore, recent hardware advances have rekindled an interest for optimal decision tree algorithms, that produce more accurate trees than the usual greedy approaches. However, these optimal algorithms return a single tree optimizing a hand defined interpretability-performance trade-off, obtained by specifying a maximum number of decision nodes, giving no further insights about the quality of this trade-off. In this paper, we propose a new Markov Decision Problem (MDP) formulation for finding optimal decision trees. The main interest of this formulation is that we can compute the optimal decision trees for several interpretability-performance trade-offs by solving a single dynamic program, letting the user choose a posteriori the tree that best suits their needs. Empirically, we show that our method is competitive with state-of-the-art algorithms in terms of accuracy and runtime while returning a whole set of trees on the interpretability-performance Pareto front.
+
+
+
+ 33. 标题:Semantic similarity prediction is better than other semantic similarity measures
+ 编号:[127]
+ 链接:https://arxiv.org/abs/2309.12697
+ 作者:Steffen Herbold
+ 备注:Under review
+ 关键词:natural language texts, overlap between subsequences, natural language, language texts, texts is typically
+
+ 点击查看摘要
+ Semantic similarity between natural language texts is typically measured either by looking at the overlap between subsequences (e.g., BLEU) or by using embeddings (e.g., BERTScore, S-BERT). Within this paper, we argue that when we are only interested in measuring the semantic similarity, it is better to directly predict the similarity using a fine-tuned model for such a task. Using a fine-tuned model for the STS-B from the GLUE benchmark, we define the STSScore approach and show that the resulting similarity is better aligned with our expectations on a robust semantic similarity measure than other approaches.
+
+
+
+ 34. 标题:Recurrent Temporal Revision Graph Networks
+ 编号:[130]
+ 链接:https://arxiv.org/abs/2309.12694
+ 作者:Yizhou Chen, Anxiang Zeng, Guangda Huzhang, Qingtao Yu, Kerui Zhang, Cao Yuanpeng, Kangle Wu, Han Yu, Zhiming Zhou
+ 备注:
+ 关键词:Temporal graphs offer, static graphs, offer more accurate, accurate modeling, Temporal graphs
+
+ 点击查看摘要
+ Temporal graphs offer more accurate modeling of many real-world scenarios than static graphs. However, neighbor aggregation, a critical building block of graph networks, for temporal graphs, is currently straightforwardly extended from that of static graphs. It can be computationally expensive when involving all historical neighbors during such aggregation. In practice, typically only a subset of the most recent neighbors are involved. However, such subsampling leads to incomplete and biased neighbor information. To address this limitation, we propose a novel framework for temporal neighbor aggregation that uses the recurrent neural network with node-wise hidden states to integrate information from all historical neighbors for each node to acquire the complete neighbor information. We demonstrate the superior theoretical expressiveness of the proposed framework as well as its state-of-the-art performance in real-world applications. Notably, it achieves a significant +9.6% improvement on averaged precision in a real-world Ecommerce dataset over existing methods on 2-layer models.
+
+
+
+ 35. 标题:AMPLIFY:Attention-based Mixup for Performance Improvement and Label Smoothing in Transformer
+ 编号:[132]
+ 链接:https://arxiv.org/abs/2309.12689
+ 作者:Leixin Yang, Yaping Zhang, Haoyu Xiong, Yu Xiang
+ 备注:
+ 关键词:effective data augmentation, aggregating linear combinations, data augmentation method, original samples, Mixup method called
+
+ 点击查看摘要
+ Mixup is an effective data augmentation method that generates new augmented samples by aggregating linear combinations of different original samples. However, if there are noises or aberrant features in the original samples, Mixup may propagate them to the augmented samples, leading to over-sensitivity of the model to these outliers . To solve this problem, this paper proposes a new Mixup method called AMPLIFY. This method uses the Attention mechanism of Transformer itself to reduce the influence of noises and aberrant values in the original samples on the prediction results, without increasing additional trainable parameters, and the computational cost is very low, thereby avoiding the problem of high resource consumption in common Mixup methods such as Sentence Mixup . The experimental results show that, under a smaller computational resource cost, AMPLIFY outperforms other Mixup methods in text classification tasks on 7 benchmark datasets, providing new ideas and new ways to further improve the performance of pre-trained models based on the Attention mechanism, such as BERT, ALBERT, RoBERTa, and GPT. Our code can be obtained at this https URL.
+
+
+
+ 36. 标题:On Sparse Modern Hopfield Model
+ 编号:[140]
+ 链接:https://arxiv.org/abs/2309.12673
+ 作者:Jerry Yao-Chieh Hu, Donglin Yang, Dennis Wu, Chenwei Xu, Bo-Yu Chen, Han Liu
+ 备注:37 pages, accepted to NeurIPS 2023
+ 关键词:sparse modern Hopfield, modern Hopfield model, modern Hopfield, Hopfield model, sparse Hopfield model
+
+ 点击查看摘要
+ We introduce the sparse modern Hopfield model as a sparse extension of the modern Hopfield model. Like its dense counterpart, the sparse modern Hopfield model equips a memory-retrieval dynamics whose one-step approximation corresponds to the sparse attention mechanism. Theoretically, our key contribution is a principled derivation of a closed-form sparse Hopfield energy using the convex conjugate of the sparse entropic regularizer. Building upon this, we derive the sparse memory retrieval dynamics from the sparse energy function and show its one-step approximation is equivalent to the sparse-structured attention. Importantly, we provide a sparsity-dependent memory retrieval error bound which is provably tighter than its dense analog. The conditions for the benefits of sparsity to arise are therefore identified and discussed. In addition, we show that the sparse modern Hopfield model maintains the robust theoretical properties of its dense counterpart, including rapid fixed point convergence and exponential memory capacity. Empirically, we use both synthetic and real-world datasets to demonstrate that the sparse Hopfield model outperforms its dense counterpart in many situations.
+
+
+
+ 37. 标题:How to Fine-tune the Model: Unified Model Shift and Model Bias Policy Optimization
+ 编号:[142]
+ 链接:https://arxiv.org/abs/2309.12671
+ 作者:Hai Zhang, Hang Yu, Junqiao Zhao, Di Zhang, ChangHuang, Hongtu Zhou, Xiao Zhang, Chen Ye
+ 备注:
+ 关键词:deriving effective model-based, effective model-based reinforcement, model-based reinforcement learning, model shift, model
+
+ 点击查看摘要
+ Designing and deriving effective model-based reinforcement learning (MBRL) algorithms with a performance improvement guarantee is challenging, mainly attributed to the high coupling between model learning and policy optimization. Many prior methods that rely on return discrepancy to guide model learning ignore the impacts of model shift, which can lead to performance deterioration due to excessive model updates. Other methods use performance difference bound to explicitly consider model shift. However, these methods rely on a fixed threshold to constrain model shift, resulting in a heavy dependence on the threshold and a lack of adaptability during the training process. In this paper, we theoretically derive an optimization objective that can unify model shift and model bias and then formulate a fine-tuning process. This process adaptively adjusts the model updates to get a performance improvement guarantee while avoiding model overfitting. Based on these, we develop a straightforward algorithm USB-PO (Unified model Shift and model Bias Policy Optimization). Empirical results show that USB-PO achieves state-of-the-art performance on several challenging benchmark tasks.
+
+
+
+ 38. 标题:OneNet: Enhancing Time Series Forecasting Models under Concept Drift by Online Ensembling
+ 编号:[148]
+ 链接:https://arxiv.org/abs/2309.12659
+ 作者:Yi-Fan Zhang, Qingsong Wen, Xue Wang, Weiqi Chen, Liang Sun, Zhang Zhang, Liang Wang, Rong Jin, Tieniu Tan
+ 备注:32 pages, 11 figures, 37th Conference on Neural Information Processing Systems (NeurIPS 2023)
+ 关键词:efficiently updating forecasting, time series forecasting, online time series, updating forecasting models, concept drifting problem
+
+ 点击查看摘要
+ Online updating of time series forecasting models aims to address the concept drifting problem by efficiently updating forecasting models based on streaming data. Many algorithms are designed for online time series forecasting, with some exploiting cross-variable dependency while others assume independence among variables. Given every data assumption has its own pros and cons in online time series modeling, we propose \textbf{On}line \textbf{e}nsembling \textbf{Net}work (OneNet). It dynamically updates and combines two models, with one focusing on modeling the dependency across the time dimension and the other on cross-variate dependency. Our method incorporates a reinforcement learning-based approach into the traditional online convex programming framework, allowing for the linear combination of the two models with dynamically adjusted weights. OneNet addresses the main shortcoming of classical online learning methods that tend to be slow in adapting to the concept drift. Empirical results show that OneNet reduces online forecasting error by more than $\mathbf{50\%}$ compared to the State-Of-The-Art (SOTA) method. The code is available at \url{this https URL}.
+
+
+
+ 39. 标题:Neural Operator Variational Inference based on Regularized Stein Discrepancy for Deep Gaussian Processes
+ 编号:[149]
+ 链接:https://arxiv.org/abs/2309.12658
+ 作者:Jian Xu, Shian Du, Junmei Yang, Qianli Ma, Delu Zeng
+ 备注:
+ 关键词:Deep Gaussian Processes, powerful nonparametric approach, Operator Variational Inference, Deep Gaussian, SOTA Gaussian process
+
+ 点击查看摘要
+ Deep Gaussian Process (DGP) models offer a powerful nonparametric approach for Bayesian inference, but exact inference is typically intractable, motivating the use of various approximations. However, existing approaches, such as mean-field Gaussian assumptions, limit the expressiveness and efficacy of DGP models, while stochastic approximation can be computationally expensive. To tackle these challenges, we introduce Neural Operator Variational Inference (NOVI) for Deep Gaussian Processes. NOVI uses a neural generator to obtain a sampler and minimizes the Regularized Stein Discrepancy in L2 space between the generated distribution and true posterior. We solve the minimax problem using Monte Carlo estimation and subsampling stochastic optimization techniques. We demonstrate that the bias introduced by our method can be controlled by multiplying the Fisher divergence with a constant, which leads to robust error control and ensures the stability and precision of the algorithm. Our experiments on datasets ranging from hundreds to tens of thousands demonstrate the effectiveness and the faster convergence rate of the proposed method. We achieve a classification accuracy of 93.56 on the CIFAR10 dataset, outperforming SOTA Gaussian process methods. Furthermore, our method guarantees theoretically controlled prediction error for DGP models and demonstrates remarkable performance on various datasets. We are optimistic that NOVI has the potential to enhance the performance of deep Bayesian nonparametric models and could have significant implications for various practical applications
+
+
+
+ 40. 标题:FP-PET: Large Model, Multiple Loss And Focused Practice
+ 编号:[152]
+ 链接:https://arxiv.org/abs/2309.12650
+ 作者:Yixin Chen, Ourui Fu, Wenrui Shao, Zhaoheng Xie
+ 备注:
+ 关键词:study presents FP-PET, presents FP-PET, PET images, comprehensive approach, medical image segmentation
+
+ 点击查看摘要
+ This study presents FP-PET, a comprehensive approach to medical image segmentation with a focus on CT and PET images. Utilizing a dataset from the AutoPet2023 Challenge, the research employs a variety of machine learning models, including STUNet-large, SwinUNETR, and VNet, to achieve state-of-the-art segmentation performance. The paper introduces an aggregated score that combines multiple evaluation metrics such as Dice score, false positive volume (FPV), and false negative volume (FNV) to provide a holistic measure of model effectiveness. The study also discusses the computational challenges and solutions related to model training, which was conducted on high-performance GPUs. Preprocessing and postprocessing techniques, including gaussian weighting schemes and morphological operations, are explored to further refine the segmentation output. The research offers valuable insights into the challenges and solutions for advanced medical image segmentation.
+
+
+
+ 41. 标题:Are Deep Learning Classification Results Obtained on CT Scans Fair and Interpretable?
+ 编号:[163]
+ 链接:https://arxiv.org/abs/2309.12632
+ 作者:Mohamad M.A. Ashames, Ahmet Demir, Omer N. Gerek, Mehmet Fidan, M. Bilginer Gulmezoglu, Semih Ergin, Mehmet Koc, Atalay Barkana, Cuneyt Calisir
+ 备注:This version has been submitted to CAAI Transactions on Intelligence Technology. 2023
+ 关键词:automatic diagnosis cases, deep neural networks, biomedical image processing, image processing society, neural networks trained
+
+ 点击查看摘要
+ Following the great success of various deep learning methods in image and object classification, the biomedical image processing society is also overwhelmed with their applications to various automatic diagnosis cases. Unfortunately, most of the deep learning-based classification attempts in the literature solely focus on the aim of extreme accuracy scores, without considering interpretability, or patient-wise separation of training and test data. For example, most lung nodule classification papers using deep learning randomly shuffle data and split it into training, validation, and test sets, causing certain images from the CT scan of a person to be in the training set, while other images of the exact same person to be in the validation or testing image sets. This can result in reporting misleading accuracy rates and the learning of irrelevant features, ultimately reducing the real-life usability of these models. When the deep neural networks trained on the traditional, unfair data shuffling method are challenged with new patient images, it is observed that the trained models perform poorly. In contrast, deep neural networks trained with strict patient-level separation maintain their accuracy rates even when new patient images are tested. Heat-map visualizations of the activations of the deep neural networks trained with strict patient-level separation indicate a higher degree of focus on the relevant nodules. We argue that the research question posed in the title has a positive answer only if the deep neural networks are trained with images of patients that are strictly isolated from the validation and testing patient sets.
+
+
+
+ 42. 标题:Sequential Action-Induced Invariant Representation for Reinforcement Learning
+ 编号:[165]
+ 链接:https://arxiv.org/abs/2309.12628
+ 作者:Dayang Liang, Qihang Chen, Yunlong Liu
+ 备注:
+ 关键词:visual reinforcement learning, task-relevant state representations, accurately learn task-relevant, learn task-relevant state, visual reinforcement
+
+ 点击查看摘要
+ How to accurately learn task-relevant state representations from high-dimensional observations with visual distractions is a realistic and challenging problem in visual reinforcement learning. Recently, unsupervised representation learning methods based on bisimulation metrics, contrast, prediction, and reconstruction have shown the ability for task-relevant information extraction. However, due to the lack of appropriate mechanisms for the extraction of task information in the prediction, contrast, and reconstruction-related approaches and the limitations of bisimulation-related methods in domains with sparse rewards, it is still difficult for these methods to be effectively extended to environments with distractions. To alleviate these problems, in the paper, the action sequences, which contain task-intensive signals, are incorporated into representation learning. Specifically, we propose a Sequential Action--induced invariant Representation (SAR) method, in which the encoder is optimized by an auxiliary learner to only preserve the components that follow the control signals of sequential actions, so the agent can be induced to learn the robust representation against distractions. We conduct extensive experiments on the DeepMind Control suite tasks with distractions while achieving the best performance over strong baselines. We also demonstrate the effectiveness of our method at disregarding task-irrelevant information by deploying SAR to real-world CARLA-based autonomous driving with natural distractions. Finally, we provide the analysis results of generalization drawn from the generalization decay and t-SNE visualization. Code and demo videos are available at this https URL.
+
+
+
+ 43. 标题:Data-driven Preference Learning Methods for Multiple Criteria Sorting with Temporal Criteria
+ 编号:[171]
+ 链接:https://arxiv.org/abs/2309.12620
+ 作者:Li Yijun, Guo Mengzhuo, Zhang Qingpeng
+ 备注:
+ 关键词:data-driven decision support, time discount factors, methodologies has catalyzed, catalyzed the emergence, emergence of data-driven
+
+ 点击查看摘要
+ The advent of predictive methodologies has catalyzed the emergence of data-driven decision support across various domains. However, developing models capable of effectively handling input time series data presents an enduring challenge. This study presents novel preference learning approaches to multiple criteria sorting problems in the presence of temporal criteria. We first formulate a convex quadratic programming model characterized by fixed time discount factors, operating within a regularization framework. Additionally, we propose an ensemble learning algorithm designed to consolidate the outputs of multiple, potentially weaker, optimizers, a process executed efficiently through parallel computation. To enhance scalability and accommodate learnable time discount factors, we introduce a novel monotonic Recurrent Neural Network (mRNN). It is designed to capture the evolving dynamics of preferences over time while upholding critical properties inherent to MCS problems, including criteria monotonicity, preference independence, and the natural ordering of classes. The proposed mRNN can describe the preference dynamics by depicting marginal value functions and personalized time discount factors along with time, effectively amalgamating the interpretability of traditional MCS methods with the predictive potential offered by deep preference learning models. Comprehensive assessments of the proposed models are conducted, encompassing synthetic data scenarios and a real-case study centered on classifying valuable users within a mobile gaming app based on their historical in-app behavioral sequences. Empirical findings underscore the notable performance improvements achieved by the proposed models when compared to a spectrum of baseline methods, spanning machine learning, deep learning, and conventional multiple criteria sorting approaches.
+
+
+
+ 44. 标题:Zero-Regret Performative Prediction Under Inequality Constraints
+ 编号:[173]
+ 链接:https://arxiv.org/abs/2309.12618
+ 作者:Wenjing Yan, Xuanyu Cao
+ 备注:
+ 关键词:predictions guide decision-making, influence future data, guide decision-making, influence future, Performative prediction
+
+ 点击查看摘要
+ Performative prediction is a recently proposed framework where predictions guide decision-making and hence influence future data distributions. Such performative phenomena are ubiquitous in various areas, such as transportation, finance, public policy, and recommendation systems. To date, work on performative prediction has only focused on unconstrained scenarios, neglecting the fact that many real-world learning problems are subject to constraints. This paper bridges this gap by studying performative prediction under inequality constraints. Unlike most existing work that provides only performative stable points, we aim to find the optimal solutions. Anticipating performative gradients is a challenging task, due to the agnostic performative effect on data distributions. To address this issue, we first develop a robust primal-dual framework that requires only approximate gradients up to a certain accuracy, yet delivers the same order of performance as the stochastic primal-dual algorithm without performativity. Based on this framework, we then propose an adaptive primal-dual algorithm for location families. Our analysis demonstrates that the proposed adaptive primal-dual algorithm attains $\ca{O}(\sqrt{T})$ regret and constraint violations, using only $\sqrt{T} + 2T$ samples, where $T$ is the time horizon. To our best knowledge, this is the first study and analysis on the optimality of the performative prediction problem under inequality constraints. Finally, we validate the effectiveness of our algorithm and theoretical results through numerical simulations.
+
+
+
+ 45. 标题:Improving Machine Learning Robustness via Adversarial Training
+ 编号:[185]
+ 链接:https://arxiv.org/abs/2309.12593
+ 作者:Long Dang, Thushari Hapuarachchi, Kaiqi Xiong, Jing Lin
+ 备注:
+ 关键词:potential worst-case noises, highly unusual situations, Machine Learning, IID data case, real-world applications
+
+ 点击查看摘要
+ As Machine Learning (ML) is increasingly used in solving various tasks in real-world applications, it is crucial to ensure that ML algorithms are robust to any potential worst-case noises, adversarial attacks, and highly unusual situations when they are designed. Studying ML robustness will significantly help in the design of ML algorithms. In this paper, we investigate ML robustness using adversarial training in centralized and decentralized environments, where ML training and testing are conducted in one or multiple computers. In the centralized environment, we achieve a test accuracy of 65.41% and 83.0% when classifying adversarial examples generated by Fast Gradient Sign Method and DeepFool, respectively. Comparing to existing studies, these results demonstrate an improvement of 18.41% for FGSM and 47% for DeepFool. In the decentralized environment, we study Federated learning (FL) robustness by using adversarial training with independent and identically distributed (IID) and non-IID data, respectively, where CIFAR-10 is used in this research. In the IID data case, our experimental results demonstrate that we can achieve such a robust accuracy that it is comparable to the one obtained in the centralized environment. Moreover, in the non-IID data case, the natural accuracy drops from 66.23% to 57.82%, and the robust accuracy decreases by 25% and 23.4% in C&W and Projected Gradient Descent (PGD) attacks, compared to the IID data case, respectively. We further propose an IID data-sharing approach, which allows for increasing the natural accuracy to 85.04% and the robust accuracy from 57% to 72% in C&W attacks and from 59% to 67% in PGD attacks.
+
+
+
+ 46. 标题:SPION: Layer-Wise Sparse Training of Transformer via Convolutional Flood Filling
+ 编号:[192]
+ 链接:https://arxiv.org/abs/2309.12578
+ 作者:Bokyeong Yoon, Yoonsang Han, Gordon Euhyun Moon
+ 备注:
+ 关键词:garnered considerable interest, Transformer, considerable interest, computationally demanding, garnered considerable
+
+ 点击查看摘要
+ Sparsifying the Transformer has garnered considerable interest, as training the Transformer is very computationally demanding. Prior efforts to sparsify the Transformer have either used a fixed pattern or data-driven approach to reduce the number of operations involving the computation of multi-head attention, which is the main bottleneck of the Transformer. However, existing methods suffer from inevitable problems, such as the potential loss of essential sequence features due to the uniform fixed pattern applied across all layers, and an increase in the model size resulting from the use of additional parameters to learn sparsity patterns in attention operations. In this paper, we propose a novel sparsification scheme for the Transformer that integrates convolution filters and the flood filling method to efficiently capture the layer-wise sparse pattern in attention operations. Our sparsification approach reduces the computational complexity and memory footprint of the Transformer during training. Efficient implementations of the layer-wise sparsified attention algorithm on GPUs are developed, demonstrating a new SPION that achieves up to 3.08X speedup over existing state-of-the-art sparse Transformer models, with better evaluation quality.
+
+
+
+ 47. 标题:Classification of Alzheimers Disease with Deep Learning on Eye-tracking Data
+ 编号:[194]
+ 链接:https://arxiv.org/abs/2309.12574
+ 作者:Harshinee Sriram, Cristina Conati, Thalia Field
+ 备注:ICMI 2023 long paper
+ 关键词:classifying Alzheimers Disease, Alzheimers Disease, task-specific engineered features, classifying Alzheimers, engineered features
+
+ 点击查看摘要
+ Existing research has shown the potential of classifying Alzheimers Disease (AD) from eye-tracking (ET) data with classifiers that rely on task-specific engineered features. In this paper, we investigate whether we can improve on existing results by using a Deep-Learning classifier trained end-to-end on raw ET data. This classifier (VTNet) uses a GRU and a CNN in parallel to leverage both visual (V) and temporal (T) representations of ET data and was previously used to detect user confusion while processing visual displays. A main challenge in applying VTNet to our target AD classification task is that the available ET data sequences are much longer than those used in the previous confusion detection task, pushing the limits of what is manageable by LSTM-based models. We discuss how we address this challenge and show that VTNet outperforms the state-of-the-art approaches in AD classification, providing encouraging evidence on the generality of this model to make predictions from ET data.
+
+
+
+ 48. 标题:Invariant Learning via Probability of Sufficient and Necessary Causes
+ 编号:[202]
+ 链接:https://arxiv.org/abs/2309.12559
+ 作者:Mengyue Yang, Zhen Fang, Yonggang Zhang, Yali Du, Furui Liu, Jean-Francois Ton, Jun Wang
+ 备注:
+ 关键词:testing distribution typically, distribution typically unknown, achieving OOD generalization, OOD generalization, indispensable for learning
+
+ 点击查看摘要
+ Out-of-distribution (OOD) generalization is indispensable for learning models in the wild, where testing distribution typically unknown and different from the training. Recent methods derived from causality have shown great potential in achieving OOD generalization. However, existing methods mainly focus on the invariance property of causes, while largely overlooking the property of \textit{sufficiency} and \textit{necessity} conditions. Namely, a necessary but insufficient cause (feature) is invariant to distribution shift, yet it may not have required accuracy. By contrast, a sufficient yet unnecessary cause (feature) tends to fit specific data well but may have a risk of adapting to a new domain. To capture the information of sufficient and necessary causes, we employ a classical concept, the probability of sufficiency and necessary causes (PNS), which indicates the probability of whether one is the necessary and sufficient cause. To associate PNS with OOD generalization, we propose PNS risk and formulate an algorithm to learn representation with a high PNS value. We theoretically analyze and prove the generalizability of the PNS risk. Experiments on both synthetic and real-world benchmarks demonstrate the effectiveness of the proposed method. The details of the implementation can be found at the GitHub repository: this https URL.
+
+
+
+ 49. 标题:Provably Robust and Plausible Counterfactual Explanations for Neural Networks via Robust Optimisation
+ 编号:[209]
+ 链接:https://arxiv.org/abs/2309.12545
+ 作者:Junqi Jiang, Jianglin Lan, Francesco Leofante, Antonio Rago, Francesca Toni
+ 备注:Accepted at ACML 2023, camera-ready version
+ 关键词:neural network classifiers, received increasing interest, explaining neural network, network classifiers, Counterfactual Explanations
+
+ 点击查看摘要
+ Counterfactual Explanations (CEs) have received increasing interest as a major methodology for explaining neural network classifiers. Usually, CEs for an input-output pair are defined as data points with minimum distance to the input that are classified with a different label than the output. To tackle the established problem that CEs are easily invalidated when model parameters are updated (e.g. retrained), studies have proposed ways to certify the robustness of CEs under model parameter changes bounded by a norm ball. However, existing methods targeting this form of robustness are not sound or complete, and they may generate implausible CEs, i.e., outliers wrt the training dataset. In fact, no existing method simultaneously optimises for proximity and plausibility while preserving robustness guarantees. In this work, we propose Provably RObust and PLAusible Counterfactual Explanations (PROPLACE), a method leveraging on robust optimisation techniques to address the aforementioned limitations in the literature. We formulate an iterative algorithm to compute provably robust CEs and prove its convergence, soundness and completeness. Through a comparative experiment involving six baselines, five of which target robustness, we show that PROPLACE achieves state-of-the-art performances against metrics on three evaluation aspects.
+
+
+
+ 50. 标题:Trip Planning for Autonomous Vehicles with Wireless Data Transfer Needs Using Reinforcement Learning
+ 编号:[212]
+ 链接:https://arxiv.org/abs/2309.12534
+ 作者:Yousef AlSaqabi, Bhaskar Krishnamachari
+ 备注:7 pages, 12 figures
+ 关键词:Internet of Things, full autonomy, recent advancements, evolving towards full, Things
+
+ 点击查看摘要
+ With recent advancements in the field of communications and the Internet of Things, vehicles are becoming more aware of their environment and are evolving towards full autonomy. Vehicular communication opens up the possibility for vehicle-to-infrastructure interaction, where vehicles could share information with components such as cameras, traffic lights, and signage that support a countrys road system. As a result, vehicles are becoming more than just a means of transportation; they are collecting, processing, and transmitting massive amounts of data used to make driving safer and more convenient. With 5G cellular networks and beyond, there is going to be more data bandwidth available on our roads, but it may be heterogeneous because of limitations like line of sight, infrastructure, and heterogeneous traffic on the road. This paper addresses the problem of route planning for autonomous vehicles in urban areas accounting for both driving time and data transfer needs. We propose a novel reinforcement learning solution that prioritizes high bandwidth roads to meet a vehicles data transfer requirement, while also minimizing driving time. We compare this approach to traffic-unaware and bandwidth-unaware baselines to show how much better it performs under heterogeneous traffic. This solution could be used as a starting point to understand what good policies look like, which could potentially yield faster, more efficient heuristics in the future.
+
+
+
+ 51. 标题:Confidence Calibration for Systems with Cascaded Predictive Modules
+ 编号:[220]
+ 链接:https://arxiv.org/abs/2309.12510
+ 作者:Yunye Gong, Yi Yao, Xiao Lin, Ajay Divakaran, Melinda Gervasio
+ 备注:
+ 关键词:target confidence levels, algorithms estimate prediction, prediction algorithms estimate, Existing conformal prediction, estimate prediction intervals
+
+ 点击查看摘要
+ Existing conformal prediction algorithms estimate prediction intervals at target confidence levels to characterize the performance of a regression model on new test samples. However, considering an autonomous system consisting of multiple modules, prediction intervals constructed for individual modules fall short of accommodating uncertainty propagation over different modules and thus cannot provide reliable predictions on system behavior. We address this limitation and present novel solutions based on conformal prediction to provide prediction intervals calibrated for a predictive system consisting of cascaded modules (e.g., an upstream feature extraction module and a downstream regression module). Our key idea is to leverage module-level validation data to characterize the system-level error distribution without direct access to end-to-end validation data. We provide theoretical justification and empirical experimental results to demonstrate the effectiveness of proposed solutions. In comparison to prediction intervals calibrated for individual modules, our solutions generate improved intervals with more accurate performance guarantees for system predictions, which are demonstrated on both synthetic systems and real-world systems performing overlap prediction for indoor navigation using the Matterport3D dataset.
+
+
+
+ 52. 标题:A Diffusion-Model of Joint Interactive Navigation
+ 编号:[221]
+ 链接:https://arxiv.org/abs/2309.12508
+ 作者:Matthew Niedoba, Jonathan Wilder Lavington, Yunpeng Liu, Vasileios Lioutas, Justice Sefas, Xiaoxuan Liang, Dylan Green, Setareh Dabiri, Berend Zwartsenberg, Adam Scibior, Frank Wood
+ 备注:10 pages, 4 figures
+ 关键词:autonomous vehicle systems, vehicle systems requires, participants exhibit diverse, simulated traffic participants, traffic participants exhibit
+
+ 点击查看摘要
+ Simulation of autonomous vehicle systems requires that simulated traffic participants exhibit diverse and realistic behaviors. The use of prerecorded real-world traffic scenarios in simulation ensures realism but the rarity of safety critical events makes large scale collection of driving scenarios expensive. In this paper, we present DJINN - a diffusion based method of generating traffic scenarios. Our approach jointly diffuses the trajectories of all agents, conditioned on a flexible set of state observations from the past, present, or future. On popular trajectory forecasting datasets, we report state of the art performance on joint trajectory metrics. In addition, we demonstrate how DJINN flexibly enables direct test-time sampling from a variety of valuable conditional distributions including goal-based sampling, behavior-class sampling, and scenario editing.
+
+
+
+ 53. 标题:Knowledge Graph Embedding: An Overview
+ 编号:[224]
+ 链接:https://arxiv.org/abs/2309.12501
+ 作者:Xiou Ge, Yun-Cheng Wang, Bin Wang, C.-C. Jay Kuo
+ 备注:
+ 关键词:representing Knowledge Graph, Knowledge Graph, representing Knowledge, downstream tasks, link prediction
+
+ 点击查看摘要
+ Many mathematical models have been leveraged to design embeddings for representing Knowledge Graph (KG) entities and relations for link prediction and many downstream tasks. These mathematically-inspired models are not only highly scalable for inference in large KGs, but also have many explainable advantages in modeling different relation patterns that can be validated through both formal proofs and empirical results. In this paper, we make a comprehensive overview of the current state of research in KG completion. In particular, we focus on two main branches of KG embedding (KGE) design: 1) distance-based methods and 2) semantic matching-based methods. We discover the connections between recently proposed models and present an underlying trend that might help researchers invent novel and more effective models. Next, we delve into CompoundE and CompoundE3D, which draw inspiration from 2D and 3D affine operations, respectively. They encompass a broad spectrum of techniques including distance-based and semantic-based methods. We will also discuss an emerging approach for KG completion which leverages pre-trained language models (PLMs) and textual descriptions of entities and relations and offer insights into the integration of KGE embedding methods with PLMs for KG completion.
+
+
+
+ 54. 标题:User-Level Differential Privacy With Few Examples Per User
+ 编号:[225]
+ 链接:https://arxiv.org/abs/2309.12500
+ 作者:Badih Ghazi, Pritish Kamath, Ravi Kumar, Pasin Manurangsi, Raghu Meka, Chiyuan Zhang
+ 备注:To appear at Neural Information Processing Systems (NeurIPS) 2023
+ 关键词:user-level differential privacy, differential privacy, Previous work, Ghazi, Bun
+
+ 点击查看摘要
+ Previous work on user-level differential privacy (DP) [Ghazi et al. NeurIPS 2021, Bun et al. STOC 2023] obtained generic algorithms that work for various learning tasks. However, their focus was on the example-rich regime, where the users have so many examples that each user could themselves solve the problem. In this work we consider the example-scarce regime, where each user has only a few examples, and obtain the following results:
+1. For approximate-DP, we give a generic transformation of any item-level DP algorithm to a user-level DP algorithm. Roughly speaking, the latter gives a (multiplicative) savings of $O_{\varepsilon,\delta}(\sqrt{m})$ in terms of the number of users required for achieving the same utility, where $m$ is the number of examples per user. This algorithm, while recovering most known bounds for specific problems, also gives new bounds, e.g., for PAC learning.
+2. For pure-DP, we present a simple technique for adapting the exponential mechanism [McSherry, Talwar FOCS 2007] to the user-level setting. This gives new bounds for a variety of tasks, such as private PAC learning, hypothesis selection, and distribution learning. For some of these problems, we show that our bounds are near-optimal.
+
+
+
+ 55. 标题:Evidential uncertainties on rich labels for active learning
+ 编号:[227]
+ 链接:https://arxiv.org/abs/2309.12494
+ 作者:Arthur Hoarau, Vincent Lemaire, Arnaud Martin, Jean-Christophe Dubois, Yolande Le Gall
+ 备注:
+ 关键词:Recent research, active learning, irreducible uncertainties, research in active, decomposition of model
+
+ 点击查看摘要
+ Recent research in active learning, and more precisely in uncertainty sampling, has focused on the decomposition of model uncertainty into reducible and irreducible uncertainties. In this paper, we propose to simplify the computational phase and remove the dependence on observations, but more importantly to take into account the uncertainty already present in the labels, \emph{i.e.} the uncertainty of the oracles. Two strategies are proposed, sampling by Klir uncertainty, which addresses the exploration-exploitation problem, and sampling by evidential epistemic uncertainty, which extends the reducible uncertainty to the evidential framework, both using the theory of belief functions.
+
+
+
+ 56. 标题:Sharpness-Aware Minimization and the Edge of Stability
+ 编号:[229]
+ 链接:https://arxiv.org/abs/2309.12488
+ 作者:Philip M. Long, Peter L. Bartlett
+ 备注:
+ 关键词:Recent experiments, step size, approximately reaches, neural network, edge of stability
+
+ 点击查看摘要
+ Recent experiments have shown that, often, when training a neural network with gradient descent (GD) with a step size $\eta$, the operator norm of the Hessian of the loss grows until it approximately reaches $2/\eta$, after which it fluctuates around this value.
+The quantity $2/\eta$ has been called the "edge of stability" based on consideration of a local quadratic approximation of the loss. We perform a similar calculation to arrive at an "edge of stability" for Sharpness-Aware Minimization (SAM), a variant of GD which has been shown to improve its generalization. Unlike the case for GD, the resulting SAM-edge depends on the norm of the gradient. Using three deep learning training tasks, we see empirically that SAM operates on the edge of stability identified by this analysis.
+
+
+
+ 57. 标题:Studying and improving reasoning in humans and machines
+ 编号:[231]
+ 链接:https://arxiv.org/abs/2309.12485
+ 作者:Nicolas Yax, Hernan Anlló, Stefano Palminteri
+ 备注:The paper is split in 4 parts : main text (pages 2-27), methods (pages 28-34), technical appendix (pages 35-45) and supplementary methods (pages 46-125)
+ 关键词:tools traditionally dedicated, large language models, psychology tools traditionally, present study, cognitive psychology tools
+
+ 点击查看摘要
+ In the present study, we investigate and compare reasoning in large language models (LLM) and humans using a selection of cognitive psychology tools traditionally dedicated to the study of (bounded) rationality. To do so, we presented to human participants and an array of pretrained LLMs new variants of classical cognitive experiments, and cross-compared their performances. Our results showed that most of the included models presented reasoning errors akin to those frequently ascribed to error-prone, heuristic-based human reasoning. Notwithstanding this superficial similarity, an in-depth comparison between humans and LLMs indicated important differences with human-like reasoning, with models limitations disappearing almost entirely in more recent LLMs releases. Moreover, we show that while it is possible to devise strategies to induce better performance, humans and machines are not equally-responsive to the same prompting schemes. We conclude by discussing the epistemological implications and challenges of comparing human and machine behavior for both artificial intelligence and cognitive psychology.
+
+
+
+ 58. 标题:Robust Energy Consumption Prediction with a Missing Value-Resilient Metaheuristic-based Neural Network in Mobile App Development
+ 编号:[232]
+ 链接:https://arxiv.org/abs/2309.12484
+ 作者:Seyed Jalaleddin Mousavirad, Luís A. Alexandre
+ 备注:The paper is submitted to a related journal
+ 关键词:bearing substantial significance, mobile application development, mobile app development, bearing substantial, developers and end-users
+
+ 点击查看摘要
+ Energy consumption is a fundamental concern in mobile application development, bearing substantial significance for both developers and end-users. Moreover, it is a critical determinant in the consumer's decision-making process when considering a smartphone purchase. From the sustainability perspective, it becomes imperative to explore approaches aimed at mitigating the energy consumption of mobile devices, given the significant global consequences arising from the extensive utilisation of billions of smartphones, which imparts a profound environmental impact. Despite the existence of various energy-efficient programming practices within the Android platform, the dominant mobile ecosystem, there remains a need for documented machine learning-based energy prediction algorithms tailored explicitly for mobile app development. Hence, the main objective of this research is to propose a novel neural network-based framework, enhanced by a metaheuristic approach, to achieve robust energy prediction in the context of mobile app development. The metaheuristic approach here plays a crucial role in not only identifying suitable learning algorithms and their corresponding parameters but also determining the optimal number of layers and neurons within each layer. To the best of our knowledge, prior studies have yet to employ any metaheuristic algorithm to address all these hyperparameters simultaneously. Moreover, due to limitations in accessing certain aspects of a mobile phone, there might be missing data in the data set, and the proposed framework can handle this. In addition, we conducted an optimal algorithm selection strategy, employing 13 metaheuristic algorithms, to identify the best algorithm based on accuracy and resistance to missing values. The comprehensive experiments demonstrate that our proposed approach yields significant outcomes for energy consumption prediction.
+
+
+
+ 59. 标题:State2Explanation: Concept-Based Explanations to Benefit Agent Learning and User Understanding
+ 编号:[234]
+ 链接:https://arxiv.org/abs/2309.12482
+ 作者:Devleena Das, Sonia Chernova, Been Kim
+ 备注:Accepted to NeurIPS 2023
+ 关键词:non-AI experts, understandable by non-AI, complete daily tasks, decision making understandable, decision making
+
+ 点击查看摘要
+ With more complex AI systems used by non-AI experts to complete daily tasks, there is an increasing effort to develop methods that produce explanations of AI decision making understandable by non-AI experts. Towards this effort, leveraging higher-level concepts and producing concept-based explanations have become a popular method. Most concept-based explanations have been developed for classification techniques, and we posit that the few existing methods for sequential decision making are limited in scope. In this work, we first contribute a desiderata for defining "concepts" in sequential decision making settings. Additionally, inspired by the Protege Effect which states explaining knowledge often reinforces one's self-learning, we explore the utility of concept-based explanations providing a dual benefit to the RL agent by improving agent learning rate, and to the end-user by improving end-user understanding of agent decision making. To this end, we contribute a unified framework, State2Explanation (S2E), that involves learning a joint embedding model between state-action pairs and concept-based explanations, and leveraging such learned model to both (1) inform reward shaping during an agent's training, and (2) provide explanations to end-users at deployment for improved task performance. Our experimental validations, in Connect 4 and Lunar Lander, demonstrate the success of S2E in providing a dual-benefit, successfully informing reward shaping and improving agent learning rate, as well as significantly improving end user task performance at deployment time.
+
+
+
+ 60. 标题:Impact of architecture on robustness and interpretability of multispectral deep neural networks
+ 编号:[241]
+ 链接:https://arxiv.org/abs/2309.12463
+ 作者:Charles Godfrey, Elise Bishoff, Myles McKay, Eleanor Byler
+ 备注:Comments welcome!
+ 关键词:deep learning model, deep learning, improve deep learning, vision-oriented tasks, learning model
+
+ 点击查看摘要
+ Including information from additional spectral bands (e.g., near-infrared) can improve deep learning model performance for many vision-oriented tasks. There are many possible ways to incorporate this additional information into a deep learning model, but the optimal fusion strategy has not yet been determined and can vary between applications. At one extreme, known as "early fusion," additional bands are stacked as extra channels to obtain an input image with more than three channels. At the other extreme, known as "late fusion," RGB and non-RGB bands are passed through separate branches of a deep learning model and merged immediately before a final classification or segmentation layer. In this work, we characterize the performance of a suite of multispectral deep learning models with different fusion approaches, quantify their relative reliance on different input bands and evaluate their robustness to naturalistic image corruptions affecting one or more input channels.
+
+
+
+ 61. 标题:Multimodal Deep Learning for Scientific Imaging Interpretation
+ 编号:[243]
+ 链接:https://arxiv.org/abs/2309.12460
+ 作者:Abdulelah S. Alshehri, Franklin L. Lee, Shihu Wang
+ 备注:
+ 关键词:Scanning Electron Microscopy, interpreting visual data, demands an intricate, intricate combination, subject materials
+
+ 点击查看摘要
+ In the domain of scientific imaging, interpreting visual data often demands an intricate combination of human expertise and deep comprehension of the subject materials. This study presents a novel methodology to linguistically emulate and subsequently evaluate human-like interactions with Scanning Electron Microscopy (SEM) images, specifically of glass materials. Leveraging a multimodal deep learning framework, our approach distills insights from both textual and visual data harvested from peer-reviewed articles, further augmented by the capabilities of GPT-4 for refined data synthesis and evaluation. Despite inherent challenges--such as nuanced interpretations and the limited availability of specialized datasets--our model (GlassLLaVA) excels in crafting accurate interpretations, identifying key features, and detecting defects in previously unseen SEM images. Moreover, we introduce versatile evaluation metrics, suitable for an array of scientific imaging applications, which allows for benchmarking against research-grounded answers. Benefiting from the robustness of contemporary Large Language Models, our model adeptly aligns with insights from research papers. This advancement not only underscores considerable progress in bridging the gap between human and machine interpretation in scientific imaging, but also hints at expansive avenues for future research and broader application.
+
+
+
+ 62. 标题:A Theory of Multimodal Learning
+ 编号:[245]
+ 链接:https://arxiv.org/abs/2309.12458
+ 作者:Zhou Lu
+ 备注:Neurips 2023, to appear
+ 关键词:world involves recognizing, empirical world involves, Human perception, diverse appearances, underlying objects
+
+ 点击查看摘要
+ Human perception of the empirical world involves recognizing the diverse appearances, or 'modalities', of underlying objects. Despite the longstanding consideration of this perspective in philosophy and cognitive science, the study of multimodality remains relatively under-explored within the field of machine learning. Nevertheless, current studies of multimodal machine learning are limited to empirical practices, lacking theoretical foundations beyond heuristic arguments. An intriguing finding from the practice of multimodal learning is that a model trained on multiple modalities can outperform a finely-tuned unimodal model, even on unimodal tasks. This paper provides a theoretical framework that explains this phenomenon, by studying generalization properties of multimodal learning algorithms. We demonstrate that multimodal learning allows for a superior generalization bound compared to unimodal learning, up to a factor of $O(\sqrt{n})$, where $n$ represents the sample size. Such advantage occurs when both connection and heterogeneity exist between the modalities.
+
+
+
+ 63. 标题:LongDocFACTScore: Evaluating the Factuality of Long Document Abstractive Summarisation
+ 编号:[246]
+ 链接:https://arxiv.org/abs/2309.12455
+ 作者:Jennifer A Bishop, Qianqian Xie, Sophia Ananiadou
+ 备注:12 pages, 5 figures
+ 关键词:ROUGE scoring, text summarisation, abstractive text summarisation, long document text, document text summarisation
+
+ 点击查看摘要
+ Maintaining factual consistency is a critical issue in abstractive text summarisation, however, it cannot be assessed by traditional automatic metrics used for evaluating text summarisation, such as ROUGE scoring. Recent efforts have been devoted to developing improved metrics for measuring factual consistency using pre-trained language models, but these metrics have restrictive token limits, and are therefore not suitable for evaluating long document text summarisation. Moreover, there is limited research evaluating whether existing automatic evaluation metrics are fit for purpose when applied to long document data sets. In this work, we evaluate the efficacy of automatic metrics at assessing factual consistency in long document text summarisation and propose a new evaluation framework LongDocFACTScore. This framework allows metrics to be extended to any length document. This framework outperforms existing state-of-the-art metrics in its ability to correlate with human measures of factuality when used to evaluate long document summarisation data sets. Furthermore, we show LongDocFACTScore has performance comparable to state-of-the-art metrics when evaluated against human measures of factual consistency on short document data sets. We make our code and annotated data publicly available: this https URL.
+
+
+
+ 64. 标题:Ensemble Neural Networks for Remaining Useful Life (RUL) Prediction
+ 编号:[248]
+ 链接:https://arxiv.org/abs/2309.12445
+ 作者:Ahbishek Srinivasan, Juan Carlos Andresen, Anders Holst
+ 备注:6 pages, 2 figures, 2 tables, conference proceeding
+ 关键词:health and degradation, remaining useful life, probabilistic RUL predictions, RUL prediction focus, core part
+
+ 点击查看摘要
+ A core part of maintenance planning is a monitoring system that provides a good prognosis on health and degradation, often expressed as remaining useful life (RUL). Most of the current data-driven approaches for RUL prediction focus on single-point prediction. These point prediction approaches do not include the probabilistic nature of the failure. The few probabilistic approaches to date either include the aleatoric uncertainty (which originates from the system), or the epistemic uncertainty (which originates from the model parameters), or both simultaneously as a total uncertainty. Here, we propose ensemble neural networks for probabilistic RUL predictions which considers both uncertainties and decouples these two uncertainties. These decoupled uncertainties are vital in knowing and interpreting the confidence of the predictions. This method is tested on NASA's turbofan jet engine CMAPSS data-set. Our results show how these uncertainties can be modeled and how to disentangle the contribution of aleatoric and epistemic uncertainty. Additionally, our approach is evaluated on different metrics and compared against the current state-of-the-art methods.
+
+
+
+ 65. 标题:Change Management using Generative Modeling on Digital Twins
+ 编号:[261]
+ 链接:https://arxiv.org/abs/2309.12421
+ 作者:Nilanjana Das, Anantaa Kotal, Daniel Roseberry, Anupam Joshi
+ 备注:
+ 关键词:key challenge faced, medium-sized business entities, managing software updates, key challenge, challenge faced
+
+ 点击查看摘要
+ A key challenge faced by small and medium-sized business entities is securely managing software updates and changes. Specifically, with rapidly evolving cybersecurity threats, changes/updates/patches to software systems are necessary to stay ahead of emerging threats and are often mandated by regulators or statutory authorities to counter these. However, security patches/updates require stress testing before they can be released in the production system. Stress testing in production environments is risky and poses security threats. Large businesses usually have a non-production environment where such changes can be made and tested before being released into production. Smaller businesses do not have such facilities. In this work, we show how "digital twins", especially for a mix of IT and IoT environments, can be created on the cloud. These digital twins act as a non-production environment where changes can be applied, and the system can be securely tested before patch release. Additionally, the non-production digital twin can be used to collect system data and run stress tests on the environment, both manually and automatically. In this paper, we show how using a small sample of real data/interactions, Generative Artificial Intelligence (AI) models can be used to generate testing scenarios to check for points of failure.
+
+
+
+ 66. 标题:Speeding up Resnet Architecture with Layers Targeted Low Rank Decomposition
+ 编号:[263]
+ 链接:https://arxiv.org/abs/2309.12412
+ 作者:Walid Ahmed, Habib Hajimolahoseini, Austin Wen, Yang Liu
+ 备注:
+ 关键词:neural network, network, Compression, study applying compression, network layers
+
+ 点击查看摘要
+ Compression of a neural network can help in speeding up both the training and the inference of the network. In this research, we study applying compression using low rank decomposition on network layers. Our research demonstrates that to acquire a speed up, the compression methodology should be aware of the underlying hardware as analysis should be done to choose which layers to compress. The advantage of our approach is demonstrated via a case study of compressing ResNet50 and training on full ImageNet-ILSVRC2012. We tested on two different hardware systems Nvidia V100 and Huawei Ascend910. With hardware targeted compression, results on Ascend910 showed 5.36% training speedup and 15.79% inference speed on Ascend310 with only 1% drop in accuracy compared to the original uncompressed model
+
+
+
+ 67. 标题:Memory Efficient Mixed-Precision Optimizers
+ 编号:[267]
+ 链接:https://arxiv.org/abs/2309.12381
+ 作者:Basile Lewandowski, Atli Kosson
+ 备注:
+ 关键词:floating point arithmetic, Traditional optimization methods, optimization methods rely, single-precision floating point, floating point
+
+ 点击查看摘要
+ Traditional optimization methods rely on the use of single-precision floating point arithmetic, which can be costly in terms of memory size and computing power. However, mixed precision optimization techniques leverage the use of both single and half-precision floating point arithmetic to reduce memory requirements while maintaining model accuracy. We provide here an algorithm to further reduce memory usage during the training of a model by getting rid of the floating point copy of the parameters, virtually keeping only half-precision numbers. We also explore the benefits of getting rid of the gradient's value by executing the optimizer step during the back-propagation. In practice, we achieve up to 25% lower peak memory use and 15% faster training while maintaining the same level of accuracy.
+
+
+
+ 68. 标题:Shedding Light on the Ageing of Extra Virgin Olive Oil: Probing the Impact of Temperature with Fluorescence Spectroscopy and Machine Learning Techniques
+ 编号:[269]
+ 链接:https://arxiv.org/abs/2309.12377
+ 作者:Francesca Venturini, Silvan Fluri, Manas Mejari, Michael Baumgartner, Dario Piga, Umberto Michelucci
+ 备注:
+ 关键词:work systematically investigates, extra virgin olive, virgin olive oil, accelerated storage conditions, work systematically
+
+ 点击查看摘要
+ This work systematically investigates the oxidation of extra virgin olive oil (EVOO) under accelerated storage conditions with UV absorption and total fluorescence spectroscopy. With the large amount of data collected, it proposes a method to monitor the oil's quality based on machine learning applied to highly-aggregated data. EVOO is a high-quality vegetable oil that has earned worldwide reputation for its numerous health benefits and excellent taste. Despite its outstanding quality, EVOO degrades over time owing to oxidation, which can affect both its health qualities and flavour. Therefore, it is highly relevant to quantify the effects of oxidation on EVOO and develop methods to assess it that can be easily implemented under field conditions, rather than in specialized laboratories. The following study demonstrates that fluorescence spectroscopy has the capability to monitor the effect of oxidation and assess the quality of EVOO, even when the data are highly aggregated. It shows that complex laboratory equipment is not necessary to exploit fluorescence spectroscopy using the proposed method and that cost-effective solutions, which can be used in-field by non-scientists, could provide an easily-accessible assessment of the quality of EVOO.
+
+
+
+ 69. 标题:Fairness Hub Technical Briefs: AUC Gap
+ 编号:[270]
+ 链接:https://arxiv.org/abs/2309.12371
+ 作者:Jinsook Lee, Chris Brooks, Renzhe Yu, Rene Kizilcec
+ 备注:Fairness Hub Technical Briefs of Learning Engineering Virtual Institute (LEVI) Program supported by Schmidt Futures
+ 关键词:lowest test AUC, AUC Gap, test AUC, prior knowledge, absolute difference
+
+ 点击查看摘要
+ To measure bias, we encourage teams to consider using AUC Gap: the absolute difference between the highest and lowest test AUC for subgroups (e.g., gender, race, SES, prior knowledge). It is agnostic to the AI/ML algorithm used and it captures the disparity in model performance for any number of subgroups, which enables non-binary fairness assessments such as for intersectional identity groups. The LEVI teams use a wide range of AI/ML models in pursuit of a common goal of doubling math achievement in low-income middle schools. Ensuring that the models, which are trained on datasets collected in many different contexts, do not introduce or amplify biases is important for achieving the LEVI goal. We offer here a versatile and easy-to-compute measure of model bias for all LEVI teams in order to create a common benchmark and an analytical basis for sharing what strategies have worked for different teams.
+
+
+
+ 70. 标题:Rethinking Human-AI Collaboration in Complex Medical Decision Making: A Case Study in Sepsis Diagnosis
+ 编号:[271]
+ 链接:https://arxiv.org/abs/2309.12368
+ 作者:Shao Zhang, Jianing Yu, Xuhai Xu, Changchang Yin, Yuxuan Lu, Bingsheng Yao, Melanie Tory, Lace M. Padilla, Jeffrey Caterino, Ping Zhang, Dakuo Wang
+ 备注:Under submission to CHI2024
+ 关键词:real-world deployment, succeed on benchmark, benchmark datasets, datasets in research, research papers
+
+ 点击查看摘要
+ Today's AI systems for medical decision support often succeed on benchmark datasets in research papers but fail in real-world deployment. This work focuses on the decision making of sepsis, an acute life-threatening systematic infection that requires an early diagnosis with high uncertainty from the clinician. Our aim is to explore the design requirements for AI systems that can support clinical experts in making better decisions for the early diagnosis of sepsis. The study begins with a formative study investigating why clinical experts abandon an existing AI-powered Sepsis predictive module in their electrical health record (EHR) system. We argue that a human-centered AI system needs to support human experts in the intermediate stages of a medical decision-making process (e.g., generating hypotheses or gathering data), instead of focusing only on the final decision. Therefore, we build SepsisLab based on a state-of-the-art AI algorithm and extend it to predict the future projection of sepsis development, visualize the prediction uncertainty, and propose actionable suggestions (i.e., which additional laboratory tests can be collected) to reduce such uncertainty. Through heuristic evaluation with six clinicians using our prototype system, we demonstrate that SepsisLab enables a promising human-AI collaboration paradigm for the future of AI-assisted sepsis diagnosis and other high-stakes medical decision making.
+
+
+
+ 71. 标题:Examining the Influence of Varied Levels of Domain Knowledge Base Inclusion in GPT-based Intelligent Tutors
+ 编号:[272]
+ 链接:https://arxiv.org/abs/2309.12367
+ 作者:Blake Castleman, Mehmet Kerem Turkcan
+ 备注:
+ 关键词:large language models, sophisticated conversational capabilities, intelligent tutors, Recent advancements, language models
+
+ 点击查看摘要
+ Recent advancements in large language models (LLMs) have facilitated the development of chatbots with sophisticated conversational capabilities. However, LLMs exhibit frequent inaccurate responses to queries, hindering applications in educational settings. In this paper, we investigate the effectiveness of integrating a knowledge base (KB) with LLM intelligent tutors to increase response reliability. To achieve this, we design a scaleable KB that affords educational supervisors seamless integration of lesson curricula, which is automatically processed by the intelligent tutoring system. We then detail an evaluation, where student participants were presented with questions about the artificial intelligence curriculum to respond to. GPT-4 intelligent tutors with varying hierarchies of KB access and human domain experts then assessed these responses. Lastly, students cross-examined the intelligent tutors' responses to the domain experts' and ranked their various pedagogical abilities. Results suggest that, although these intelligent tutors still demonstrate a lower accuracy compared to domain experts, the accuracy of the intelligent tutors increases when access to a KB is granted. We also observe that the intelligent tutors with KB access exhibit better pedagogical abilities to speak like a teacher and understand students than those of domain experts, while their ability to help students remains lagging behind domain experts.
+
+
+
+ 72. 标题:Efficient Social Choice via NLP and Sampling
+ 编号:[279]
+ 链接:https://arxiv.org/abs/2309.12360
+ 作者:Lior Ashkenazy, Nimrod Talmon
+ 备注:
+ 关键词:Attention-Aware Social Choice, Social Choice tackles, fundamental conflict faced, decision making processes, Natural Language Processing
+
+ 点击查看摘要
+ Attention-Aware Social Choice tackles the fundamental conflict faced by some agent communities between their desire to include all members in the decision making processes and the limited time and attention that are at the disposal of the community members. Here, we investigate a combination of two techniques for attention-aware social choice, namely Natural Language Processing (NLP) and Sampling. Essentially, we propose a system in which each governance proposal to change the status quo is first sent to a trained NLP model that estimates the probability that the proposal would pass if all community members directly vote on it; then, based on such an estimation, a population sample of a certain size is being selected and the proposal is decided upon by taking the sample majority. We develop several concrete algorithms following the scheme described above and evaluate them using various data, including such from several Decentralized Autonomous Organizations (DAOs).
+
+
+
+ 73. 标题:Antagonising explanation and revealing bias directly through sequencing and multimodal inference
+ 编号:[293]
+ 链接:https://arxiv.org/abs/2309.12345
+ 作者:Luís Arandas, Mick Grierson, Miguel Carvalhais
+ 备注:3 pages, no figures. ACM C&C 23 Workshop paper
+ 关键词:models produce data, Deep generative models, computing possible samples, generative models produce, approximation computing
+
+ 点击查看摘要
+ Deep generative models produce data according to a learned representation, e.g. diffusion models, through a process of approximation computing possible samples. Approximation can be understood as reconstruction and the large datasets used to train models as sets of records in which we represent the physical world with some data structure (photographs, audio recordings, manuscripts). During the process of reconstruction, e.g., image frames develop each timestep towards a textual input description. While moving forward in time, frame sets are shaped according to learned bias and their production, we argue here, can be considered as going back in time; not by inspiration on the backward diffusion process but acknowledging culture is specifically marked in the records. Futures of generative modelling, namely in film and audiovisual arts, can benefit by dealing with diffusion systems as a process to compute the future by inevitably being tied to the past, if acknowledging the records as to capture fields of view at a specific time, and to correlate with our own finite memory ideals. Models generating new data distributions can target video production as signal processors and by developing sequences through timelines we ourselves also go back to decade-old algorithmic and multi-track methodologies revealing the actual predictive failure of contemporary approaches to synthesis in moving image, both as relevant to composition and not explanatory.
+
+
+
+ 74. 标题:Cultural Alignment in Large Language Models: An Explanatory Analysis Based on Hofstede's Cultural Dimensions
+ 编号:[296]
+ 链接:https://arxiv.org/abs/2309.12342
+ 作者:Reem I. Masoud, Ziquan Liu, Martin Ferianc, Philip Treleaven, Miguel Rodrigues
+ 备注:31 pages
+ 关键词:large language models, cultural, language models, raises concerns, Cultural Alignment Test
+
+ 点击查看摘要
+ The deployment of large language models (LLMs) raises concerns regarding their cultural misalignment and potential ramifications on individuals from various cultural norms. Existing work investigated political and social biases and public opinions rather than their cultural values. To address this limitation, the proposed Cultural Alignment Test (CAT) quantifies cultural alignment using Hofstede's cultural dimension framework, which offers an explanatory cross-cultural comparison through the latent variable analysis. We apply our approach to assess the cultural values embedded in state-of-the-art LLMs, such as: ChatGPT and Bard, across diverse cultures of countries: United States (US), Saudi Arabia, China, and Slovakia, using different prompting styles and hyperparameter settings. Our results not only quantify cultural alignment of LLMs with certain countries, but also reveal the difference between LLMs in explanatory cultural dimensions. While all LLMs did not provide satisfactory results in understanding cultural values, GPT-4 exhibited the highest CAT score for the cultural values of the US.
+
+
+
+ 75. 标题:Deep Knowledge Tracing is an implicit dynamic multidimensional item response theory model
+ 编号:[304]
+ 链接:https://arxiv.org/abs/2309.12334
+ 作者:Jill-Jênn Vie (SODA), Hisashi Kashima
+ 备注:ICCE 2023 - The 31st International Conference on Computers in Education, Asia-Pacific Society for Computers in Education, Dec 2023, Matsue, Shimane, France
+ 关键词:Knowledge tracing, Knowledge tracing consists, Deep knowledge tracing, assessment and learning, previous questions
+
+ 点击查看摘要
+ Knowledge tracing consists in predicting the performance of some students on new questions given their performance on previous questions, and can be a prior step to optimizing assessment and learning. Deep knowledge tracing (DKT) is a competitive model for knowledge tracing relying on recurrent neural networks, even if some simpler models may match its performance. However, little is known about why DKT works so well. In this paper, we frame deep knowledge tracing as a encoderdecoder architecture. This viewpoint not only allows us to propose better models in terms of performance, simplicity or expressivity but also opens up promising avenues for future research directions. In particular, we show on several small and large datasets that a simpler decoder, with possibly fewer parameters than the one used by DKT, can predict student performance better.
+
+
+
+ 76. 标题:Onchain Sports Betting using UBET Automated Market Maker
+ 编号:[305]
+ 链接:https://arxiv.org/abs/2309.12333
+ 作者:Daniel Jiwoong Im, Alexander Kondratskiy, Vincent Harvey, Hsuan-Wei Fu
+ 备注:
+ 关键词:traditional centralized platforms, lower fees, underscores how decentralization, addresses the drawbacks, drawbacks of traditional
+
+ 点击查看摘要
+ The paper underscores how decentralization in sports betting addresses the drawbacks of traditional centralized platforms, ensuring transparency, security, and lower fees. Non-custodial solutions empower bettors with ownership of funds, bypassing geographical restrictions. Decentralized platforms enhance security, privacy, and democratic decision-making. However, decentralized sports betting necessitates automated market makers (AMMs) for efficient liquidity provision. Existing AMMs like Uniswap lack alignment with fair odds, creating risks for liquidity providers. To mitigate this, the paper introduces UBET AMM (UAMM), utilizing smart contracts and algorithms to price sports odds fairly. It establishes an on-chain betting framework, detailing market creation, UAMM application, collateral liquidity pools, and experiments that exhibit positive outcomes. UAMM enhances decentralized sports betting by ensuring liquidity, decentralized pricing, and global accessibility, promoting trustless and efficient betting.
+
+
+
+ 77. 标题:FUTURE-AI: International consensus guideline for trustworthy and deployable artificial intelligence in healthcare
+ 编号:[310]
+ 链接:https://arxiv.org/abs/2309.12325
+ 作者:Karim Lekadir, Aasa Feragen, Abdul Joseph Fofanah, Alejandro F Frangi, Alena Buyx, Anais Emelie, Andrea Lara, Antonio R Porras, An-Wen Chan, Arcadi Navarro, Ben Glocker, Benard O Botwe, Bishesh Khanal, Brigit Beger, Carol C Wu, Celia Cintas, Curtis P Langlotz, Daniel Rueckert, Deogratias Mzurikwao, Dimitrios I Fotiadis, Doszhan Zhussupov, Enzo Ferrante, Erik Meijering, Eva Weicken, Fabio A González, Folkert W Asselbergs, Fred Prior, Gabriel P Krestin, Gary Collins, Geletaw S Tegenaw, Georgios Kaissis, Gianluca Misuraca, Gianna Tsakou, Girish Dwivedi, Haridimos Kondylakis, Harsha Jayakody, Henry C Woodruf, Hugo JWL Aerts, Ian Walsh, Ioanna Chouvarda, Irène Buvat, Islem Rekik, James Duncan, Jayashree Kalpathy-Cramer, Jihad Zahir, Jinah Park, John Mongan, Judy W Gichoya, Julia A Schnabel, et al. (69 additional authors not shown)
+ 备注:
+ 关键词:technologies remain limited, artificial intelligence, major advances, advances in artificial, technologies remain
+
+ 点击查看摘要
+ Despite major advances in artificial intelligence (AI) for medicine and healthcare, the deployment and adoption of AI technologies remain limited in real-world clinical practice. In recent years, concerns have been raised about the technical, clinical, ethical and legal risks associated with medical AI. To increase real world adoption, it is essential that medical AI tools are trusted and accepted by patients, clinicians, health organisations and authorities. This work describes the FUTURE-AI guideline as the first international consensus framework for guiding the development and deployment of trustworthy AI tools in healthcare. The FUTURE-AI consortium was founded in 2021 and currently comprises 118 inter-disciplinary experts from 51 countries representing all continents, including AI scientists, clinicians, ethicists, and social scientists. Over a two-year period, the consortium defined guiding principles and best practices for trustworthy AI through an iterative process comprising an in-depth literature review, a modified Delphi survey, and online consensus meetings. The FUTURE-AI framework was established based on 6 guiding principles for trustworthy AI in healthcare, i.e. Fairness, Universality, Traceability, Usability, Robustness and Explainability. Through consensus, a set of 28 best practices were defined, addressing technical, clinical, legal and socio-ethical dimensions. The recommendations cover the entire lifecycle of medical AI, from design, development and validation to regulation, deployment, and monitoring. FUTURE-AI is a risk-informed, assumption-free guideline which provides a structured approach for constructing medical AI tools that will be trusted, deployed and adopted in real-world practice. Researchers are encouraged to take the recommendations into account in proof-of-concept stages to facilitate future translation towards clinical practice of medical AI.
+
+
+
+ 78. 标题:Aviation Safety Risk Analysis and Flight Technology Assessment Issues
+ 编号:[311]
+ 链接:https://arxiv.org/abs/2309.12324
+ 作者:Shuanghe Liu
+ 备注:
+ 关键词:China civil aviation, comprehensive research, China civil, text highlights, highlights the significance
+
+ 点击查看摘要
+ This text highlights the significance of flight safety in China's civil aviation industry and emphasizes the need for comprehensive research. It focuses on two main areas: analyzing exceedance events and statistically evaluating non-exceedance data. The challenges of current approaches lie in insufficient cause analysis for exceedances. The proposed solutions involve data preprocessing, reliability assessment, quantifying flight control using neural networks, exploratory data analysis, flight personnel skill evaluation with machine learning, and establishing real-time automated warnings. These endeavors aim to enhance flight safety, personnel assessment, and warning mechanisms, contributing to a safer and more efficient civil aviation sector.
+
+
+
+ 79. 标题:Memory-augmented conformer for improved end-to-end long-form ASR
+ 编号:[319]
+ 链接:https://arxiv.org/abs/2309.13029
+ 作者:Carlos Carvalho, Alberto Abad
+ 备注:
+ 关键词:automatic speech recognition, promising modelling approach, outperforming recurrent neural, recurrent neural network-based, neural network-based approaches
+
+ 点击查看摘要
+ Conformers have recently been proposed as a promising modelling approach for automatic speech recognition (ASR), outperforming recurrent neural network-based approaches and transformers. Nevertheless, in general, the performance of these end-to-end models, especially attention-based models, is particularly degraded in the case of long utterances. To address this limitation, we propose adding a fully-differentiable memory-augmented neural network between the encoder and decoder of a conformer. This external memory can enrich the generalization for longer utterances since it allows the system to store and retrieve more information recurrently. Notably, we explore the neural Turing machine (NTM) that results in our proposed Conformer-NTM model architecture for ASR. Experimental results using Librispeech train-clean-100 and train-960 sets show that the proposed system outperforms the baseline conformer without memory for long utterances.
+
+
+
+ 80. 标题:Expressive variational quantum circuits provide inherent privacy in federated learning
+ 编号:[322]
+ 链接:https://arxiv.org/abs/2309.13002
+ 作者:Niraj Kumar, Jamie Heredge, Changhao Li, Shaltiel Eloul, Shree Hari Sureshbabu, Marco Pistoia
+ 备注:24 pages, 13 figures
+ 关键词:viable distributed solution, Federated learning, machine learning models, federated learning models, learning models
+
+ 点击查看摘要
+ Federated learning has emerged as a viable distributed solution to train machine learning models without the actual need to share data with the central aggregator. However, standard neural network-based federated learning models have been shown to be susceptible to data leakage from the gradients shared with the server. In this work, we introduce federated learning with variational quantum circuit model built using expressive encoding maps coupled with overparameterized ansätze. We show that expressive maps lead to inherent privacy against gradient inversion attacks, while overparameterization ensures model trainability. Our privacy framework centers on the complexity of solving the system of high-degree multivariate Chebyshev polynomials generated by the gradients of quantum circuit. We present compelling arguments highlighting the inherent difficulty in solving these equations, both in exact and approximate scenarios. Additionally, we delve into machine learning-based attack strategies and establish a direct connection between overparameterization in the original federated learning model and underparameterization in the attack model. Furthermore, we provide numerical scaling arguments showcasing that underparameterization of the expressive map in the attack model leads to the loss landscape being swamped with exponentially many spurious local minima points, thus making it extremely hard to realize a successful attack. This provides a strong claim, for the first time, that the nature of quantum machine learning models inherently helps prevent data leakage in federated learning.
+
+
+
+ 81. 标题:Deep learning probability flows and entropy production rates in active matter
+ 编号:[324]
+ 链接:https://arxiv.org/abs/2309.12991
+ 作者:Nicholas M. Boffi, Eric Vanden-Eijnden
+ 备注:
+ 关键词:Active matter systems, motile bacteria, self-propelled colloids, colloids to motile, conversion of free
+
+ 点击查看摘要
+ Active matter systems, from self-propelled colloids to motile bacteria, are characterized by the conversion of free energy into useful work at the microscopic scale. These systems generically involve physics beyond the reach of equilibrium statistical mechanics, and a persistent challenge has been to understand the nature of their nonequilibrium states. The entropy production rate and the magnitude of the steady-state probability current provide quantitative ways to do so by measuring the breakdown of time-reversal symmetry and the strength of nonequilibrium transport of measure. Yet, their efficient computation has remained elusive, as they depend on the system's unknown and high-dimensional probability density. Here, building upon recent advances in generative modeling, we develop a deep learning framework that estimates the score of this density. We show that the score, together with the microscopic equations of motion, gives direct access to the entropy production rate, the probability current, and their decomposition into local contributions from individual particles, spatial regions, and degrees of freedom. To represent the score, we introduce a novel, spatially-local transformer-based network architecture that learns high-order interactions between particles while respecting their underlying permutation symmetry. We demonstrate the broad utility and scalability of the method by applying it to several high-dimensional systems of interacting active particles undergoing motility-induced phase separation (MIPS). We show that a single instance of our network trained on a system of 4096 particles at one packing fraction can generalize to other regions of the phase diagram, including systems with as many as 32768 particles. We use this observation to quantify the spatial structure of the departure from equilibrium in MIPS as a function of the number of particles and the packing fraction.
+
+
+
+ 82. 标题:Building explainable graph neural network by sparse learning for the drug-protein binding prediction
+ 编号:[331]
+ 链接:https://arxiv.org/abs/2309.12906
+ 作者:Yang Wang, Zanyu Shi, Timothy Richardson, Kun Huang, Pathum Weerawarna, Yijie Wang
+ 备注:
+ 关键词:Graph Neural Networks, key structures identified, current explainable GNN, explainable GNN models, key structures
+
+ 点击查看摘要
+ Explainable Graph Neural Networks (GNNs) have been developed and applied to drug-protein binding prediction to identify the key chemical structures in a drug that have active interactions with the target proteins. However, the key structures identified by the current explainable GNN models are typically chemically invalid. Furthermore, a threshold needs to be manually selected to pinpoint the key structures from the rest. To overcome the limitations of the current explainable GNN models, we propose our SLGNN, which stands for using Sparse Learning to Graph Neural Networks. Our SLGNN relies on using a chemical-substructure-based graph (where nodes are chemical substructures) to represent a drug molecule. Furthermore, SLGNN incorporates generalized fussed lasso with message-passing algorithms to identify connected subgraphs that are critical for the drug-protein binding prediction. Due to the use of the chemical-substructure-based graph, it is guaranteed that any subgraphs in a drug identified by our SLGNN are chemically valid structures. These structures can be further interpreted as the key chemical structures for the drug to bind to the target protein. We demonstrate the explanatory power of our SLGNN by first showing all the key structures identified by our SLGNN are chemically valid. In addition, we illustrate that the key structures identified by our SLGNN have more predictive power than the key structures identified by the competing methods. At last, we use known drug-protein binding data to show the key structures identified by our SLGNN contain most of the binding sites.
+
+
+
+ 83. 标题:Cross-Modal Translation and Alignment for Survival Analysis
+ 编号:[333]
+ 链接:https://arxiv.org/abs/2309.12855
+ 作者:Fengtao Zhou, Hao Chen
+ 备注:Accepted by ICCV2023
+ 关键词:high-throughput sequencing technologies, examining clinical indicators, incorporating genomic profiles, genomic profiles, pathological images
+
+ 点击查看摘要
+ With the rapid advances in high-throughput sequencing technologies, the focus of survival analysis has shifted from examining clinical indicators to incorporating genomic profiles with pathological images. However, existing methods either directly adopt a straightforward fusion of pathological features and genomic profiles for survival prediction, or take genomic profiles as guidance to integrate the features of pathological images. The former would overlook intrinsic cross-modal correlations. The latter would discard pathological information irrelevant to gene expression. To address these issues, we present a Cross-Modal Translation and Alignment (CMTA) framework to explore the intrinsic cross-modal correlations and transfer potential complementary information. Specifically, we construct two parallel encoder-decoder structures for multi-modal data to integrate intra-modal information and generate cross-modal representation. Taking the generated cross-modal representation to enhance and recalibrate intra-modal representation can significantly improve its discrimination for comprehensive survival analysis. To explore the intrinsic crossmodal correlations, we further design a cross-modal attention module as the information bridge between different modalities to perform cross-modal interactions and transfer complementary information. Our extensive experiments on five public TCGA datasets demonstrate that our proposed framework outperforms the state-of-the-art methods.
+
+
+
+ 84. 标题:Doubly Robust Proximal Causal Learning for Continuous Treatments
+ 编号:[335]
+ 链接:https://arxiv.org/abs/2309.12819
+ 作者:Yong Wu, Yanwei Fu, Shouyan Wang, Xinwei Sun
+ 备注:Preprint, under review
+ 关键词:Proximal causal learning, unmeasured confounders, existence of unmeasured, promising framework, Proximal causal
+
+ 点击查看摘要
+ Proximal causal learning is a promising framework for identifying the causal effect under the existence of unmeasured confounders. Within this framework, the doubly robust (DR) estimator was derived and has shown its effectiveness in estimation, especially when the model assumption is violated. However, the current form of the DR estimator is restricted to binary treatments, while the treatment can be continuous in many real-world applications. The primary obstacle to continuous treatments resides in the delta function present in the original DR estimator, making it infeasible in causal effect estimation and introducing a heavy computational burden in nuisance function estimation. To address these challenges, we propose a kernel-based DR estimator that can well handle continuous treatments. Equipped with its smoothness, we show that its oracle form is a consistent approximation of the influence function. Further, we propose a new approach to efficiently solve the nuisance functions. We then provide a comprehensive convergence analysis in terms of the mean square error. We demonstrate the utility of our estimator on synthetic datasets and real-world applications.
+
+
+
+ 85. 标题:Unsupervised Representations Improve Supervised Learning in Speech Emotion Recognition
+ 编号:[344]
+ 链接:https://arxiv.org/abs/2309.12714
+ 作者:Amirali Soltani Tehrani, Niloufar Faridani, Ramin Toosi
+ 备注:
+ 关键词:Speech Emotion Recognition, Emotion Recognition, range of applications, effective communication, enabling a deeper
+
+ 点击查看摘要
+ Speech Emotion Recognition (SER) plays a pivotal role in enhancing human-computer interaction by enabling a deeper understanding of emotional states across a wide range of applications, contributing to more empathetic and effective communication. This study proposes an innovative approach that integrates self-supervised feature extraction with supervised classification for emotion recognition from small audio segments. In the preprocessing step, to eliminate the need of crafting audio features, we employed a self-supervised feature extractor, based on the Wav2Vec model, to capture acoustic features from audio data. Then, the output featuremaps of the preprocessing step are fed to a custom designed Convolutional Neural Network (CNN)-based model to perform emotion classification. Utilizing the ShEMO dataset as our testing ground, the proposed method surpasses two baseline methods, i.e. support vector machine classifier and transfer learning of a pretrained CNN. comparing the propose method to the state-of-the-art methods in SER task indicates the superiority of the proposed method. Our findings underscore the pivotal role of deep unsupervised feature learning in elevating the landscape of SER, offering enhanced emotional comprehension in the realm of human-computer interactions.
+
+
+
+ 86. 标题:Big model only for hard audios: Sample dependent Whisper model selection for efficient inferences
+ 编号:[345]
+ 链接:https://arxiv.org/abs/2309.12712
+ 作者:Hugo Malard, Salah Zaiem, Robin Algayres
+ 备注:Submitted to ICASSP 2024
+ 关键词:Automatic Speech Recognition, Speech Recognition, Automatic Speech, progress in Automatic, Recent progress
+
+ 点击查看摘要
+ Recent progress in Automatic Speech Recognition (ASR) has been coupled with a substantial increase in the model sizes, which may now contain billions of parameters, leading to slow inferences even with adapted hardware. In this context, several ASR models exist in various sizes, with different inference costs leading to different performance levels. Based on the observation that smaller models perform optimally on large parts of testing corpora, we propose to train a decision module, that would allow, given an audio sample, to use the smallest sufficient model leading to a good transcription. We apply our approach to two Whisper models with different sizes. By keeping the decision process computationally efficient, we build a decision module that allows substantial computational savings with reduced performance drops.
+
+
+
+ 87. 标题:Multiply Robust Federated Estimation of Targeted Average Treatment Effects
+ 编号:[352]
+ 链接:https://arxiv.org/abs/2309.12600
+ 作者:Larry Han, Zhu Shen, Jose Zubizarreta
+ 备注:Accepted at NeurIPS 2023
+ 关键词:including increased generalizability, study rare exposures, study underrepresented populations, ability to study, study underrepresented
+
+ 点击查看摘要
+ Federated or multi-site studies have distinct advantages over single-site studies, including increased generalizability, the ability to study underrepresented populations, and the opportunity to study rare exposures and outcomes. However, these studies are challenging due to the need to preserve the privacy of each individual's data and the heterogeneity in their covariate distributions. We propose a novel federated approach to derive valid causal inferences for a target population using multi-site data. We adjust for covariate shift and covariate mismatch between sites by developing multiply-robust and privacy-preserving nuisance function estimation. Our methodology incorporates transfer learning to estimate ensemble weights to combine information from source sites. We show that these learned weights are efficient and optimal under different scenarios. We showcase the finite sample advantages of our approach in terms of efficiency and robustness compared to existing approaches.
+
+
+
+ 88. 标题:Sampling-Frequency-Independent Universal Sound Separation
+ 编号:[354]
+ 链接:https://arxiv.org/abs/2309.12581
+ 作者:Tomohiko Nakamura, Kohei Yatabe
+ 备注:Submitted to ICASSP2024
+ 关键词:untrained sampling frequencies, handling untrained sampling, universal sound separation, universal source separator, sound separation
+
+ 点击查看摘要
+ This paper proposes a universal sound separation (USS) method capable of handling untrained sampling frequencies (SFs). The USS aims at separating arbitrary sources of different types and can be the key technique to realize a source separator that can be universally used as a preprocessor for any downstream tasks. To realize a universal source separator, there are two essential properties: universalities with respect to source types and recording conditions. The former property has been studied in the USS literature, which has greatly increased the number of source types that can be handled by a single neural network. However, the latter property (e.g., SF) has received less attention despite its necessity. Since the SF varies widely depending on the downstream tasks, the universal source separator must handle a wide variety of SFs. In this paper, to encompass the two properties, we propose an SF-independent (SFI) extension of a computationally efficient USS network, SuDoRM-RF. The proposed network uses our previously proposed SFI convolutional layers, which can handle various SFs by generating convolutional kernels in accordance with an input SF. Experiments show that signal resampling can degrade the USS performance and the proposed method works more consistently than signal-resampling-based methods for various SFs.
+
+
+
+ 89. 标题:Interpretable 3D Multi-Modal Residual Convolutional Neural Network for Mild Traumatic Brain Injury Diagnosis
+ 编号:[355]
+ 链接:https://arxiv.org/abs/2309.12572
+ 作者:Hanem Ellethy, Viktor Vegh, Shekhar S. Chandra
+ 备注:Accepted by the Australasian Joint Conference on Artificial Intelligence 2023 (AJCAI 2023). 12 pages and 5 Figures
+ 关键词:Traumatic Brain Injury, Mild Traumatic Brain, Brain Injury, long-term health effects, Traumatic Brain
+
+ 点击查看摘要
+ Mild Traumatic Brain Injury (mTBI) is a significant public health challenge due to its high prevalence and potential for long-term health effects. Despite Computed Tomography (CT) being the standard diagnostic tool for mTBI, it often yields normal results in mTBI patients despite symptomatic evidence. This fact underscores the complexity of accurate diagnosis. In this study, we introduce an interpretable 3D Multi-Modal Residual Convolutional Neural Network (MRCNN) for mTBI diagnostic model enhanced with Occlusion Sensitivity Maps (OSM). Our MRCNN model exhibits promising performance in mTBI diagnosis, demonstrating an average accuracy of 82.4%, sensitivity of 82.6%, and specificity of 81.6%, as validated by a five-fold cross-validation process. Notably, in comparison to the CT-based Residual Convolutional Neural Network (RCNN) model, the MRCNN shows an improvement of 4.4% in specificity and 9.0% in accuracy. We show that the OSM offers superior data-driven insights into CT images compared to the Grad-CAM approach. These results highlight the efficacy of the proposed multi-modal model in enhancing the diagnostic precision of mTBI.
+
+
+
+ 90. 标题:A Convex Framework for Confounding Robust Inference
+ 编号:[357]
+ 链接:https://arxiv.org/abs/2309.12450
+ 作者:Kei Ishikawa, Naio He, Takafumi Kanamori
+ 备注:This is an extension of the following work this https URL arXiv admin note: text overlap with arXiv:2302.13348
+ 关键词:offline contextual bandits, contextual bandits subject, study policy evaluation, unobserved confounders, evaluation of offline
+
+ 点击查看摘要
+ We study policy evaluation of offline contextual bandits subject to unobserved confounders. Sensitivity analysis methods are commonly used to estimate the policy value under the worst-case confounding over a given uncertainty set. However, existing work often resorts to some coarse relaxation of the uncertainty set for the sake of tractability, leading to overly conservative estimation of the policy value. In this paper, we propose a general estimator that provides a sharp lower bound of the policy value using convex programming. The generality of our estimator enables various extensions such as sensitivity analysis with f-divergence, model selection with cross validation and information criterion, and robust policy learning with the sharp lower bound. Furthermore, our estimation method can be reformulated as an empirical risk minimization problem thanks to the strong duality, which enables us to provide strong theoretical guarantees of the proposed estimator using techniques of the M-estimation.
+
+
+
+ 91. 标题:Methods for generating and evaluating synthetic longitudinal patient data: a systematic review
+ 编号:[358]
+ 链接:https://arxiv.org/abs/2309.12380
+ 作者:Katariina Perkonoja, Kari Auranen, Joni Virta
+ 备注:
+ 关键词:development activities, data, recent years, years has led, advancement and utilization
+
+ 点击查看摘要
+ The proliferation of data in recent years has led to the advancement and utilization of various statistical and deep learning techniques, thus expediting research and development activities. However, not all industries have benefited equally from the surge in data availability, partly due to legal restrictions on data usage and privacy regulations, such as in medicine. To address this issue, various statistical disclosure and privacy-preserving methods have been proposed, including the use of synthetic data generation. Synthetic data are generated based on some existing data, with the aim of replicating them as closely as possible and acting as a proxy for real sensitive data. This paper presents a systematic review of methods for generating and evaluating synthetic longitudinal patient data, a prevalent data type in medicine. The review adheres to the PRISMA guidelines and covers literature from five databases until the end of 2022. The paper describes 17 methods, ranging from traditional simulation techniques to modern deep learning methods. The collected information includes, but is not limited to, method type, source code availability, and approaches used to assess resemblance, utility, and privacy. Furthermore, the paper discusses practical guidelines and key considerations for developing synthetic longitudinal data generation methods.
+
+
+
+ 92. 标题:Mono/Multi-material Characterization Using Hyperspectral Images and Multi-Block Non-Negative Matrix Factorization
+ 编号:[361]
+ 链接:https://arxiv.org/abs/2309.12329
+ 作者:Mahdiyeh Ghaffari, Gerjen H. Tinnevelt, Marcel C. P. van Eijk, Stanislav Podchezertsev, Geert J. Postma, Jeroen J. Jansen
+ 备注:
+ 关键词:negative Matrix Factorization, essential step, Matrix Factorization, Infrared Hyperspectral Imaging, negative Matrix
+
+ 点击查看摘要
+ Plastic sorting is a very essential step in waste management, especially due to the presence of multilayer plastics. These monomaterial and multimaterial plastics are widely employed to enhance the functional properties of packaging, combining beneficial properties in thickness, mechanical strength, and heat tolerance. However, materials containing multiple polymer species need to be pretreated before they can be recycled as monomaterials and therefore should not end up in monomaterial streams. Industry 4.0 has significantly improved materials sorting of plastic packaging in speed and accuracy compared to manual sorting, specifically through Near Infrared Hyperspectral Imaging (NIRHSI) that provides an automated, fast, and accurate material characterization, without sample preparation. Identification of multimaterials with HSI however requires novel dedicated approaches for chemical pattern recognition. Non negative Matrix Factorization, NMF, is widely used for the chemical resolution of hyperspectral images. Chemically relevant model constraints may make it specifically valuable to identify multilayer plastics through HSI. Specifically, Multi Block Non Negative Matrix Factorization (MBNMF) with correspondence among different chemical species constraint may be used to evaluate the presence or absence of particular polymer species. To translate the MBNMF model into an evidence based sorting decision, we extended the model with an F test to distinguish between monomaterial and multimaterial objects. The benefits of our new approach, MBNMF, were illustrated by the identification of several plastic waste objects.
+
+
+
+ 93. 标题:Evaluating the diversity and utility of materials proposed by generative models
+ 编号:[362]
+ 链接:https://arxiv.org/abs/2309.12323
+ 作者:Alexander New, Michael Pekala, Elizabeth A. Pogue, Nam Q. Le, Janna Domenico, Christine D. Piatko, Christopher D. Stiles
+ 备注:12 pages, 9 figures. Published at SynS & ML @ ICML2023: this https URL
+ 关键词:create large quantities, Generative machine learning, machine learning models, machine learning, scientific modeling
+
+ 点击查看摘要
+ Generative machine learning models can use data generated by scientific modeling to create large quantities of novel material structures. Here, we assess how one state-of-the-art generative model, the physics-guided crystal generation model (PGCGM), can be used as part of the inverse design process. We show that the default PGCGM's input space is not smooth with respect to parameter variation, making material optimization difficult and limited. We also demonstrate that most generated structures are predicted to be thermodynamically unstable by a separate property-prediction model, partially due to out-of-domain data challenges. Our findings suggest how generative models might be improved to enable better inverse design.
+
+
+人工智能
+
+ 1. 标题:E(2)-Equivariant Graph Planning for Navigation
+ 编号:[1]
+ 链接:https://arxiv.org/abs/2309.13043
+ 作者:Linfeng Zhao, Hongyu Li, Taskin Padir, Huaizu Jiang, Lawson L.S. Wong
+ 备注:
+ 关键词:robot navigation presents, presents a critical, critical and challenging, efficient learning approaches, necessitate efficient learning
+
+ 点击查看摘要
+ Learning for robot navigation presents a critical and challenging task. The scarcity and costliness of real-world datasets necessitate efficient learning approaches. In this letter, we exploit Euclidean symmetry in planning for 2D navigation, which originates from Euclidean transformations between reference frames and enables parameter sharing. To address the challenges of unstructured environments, we formulate the navigation problem as planning on a geometric graph and develop an equivariant message passing network to perform value iteration. Furthermore, to handle multi-camera input, we propose a learnable equivariant layer to lift features to a desired space. We conduct comprehensive evaluations across five diverse tasks encompassing structured and unstructured environments, along with maps of known and unknown, given point goals or semantic goals. Our experiments confirm the substantial benefits on training efficiency, stability, and generalization.
+
+
+
+ 2. 标题:MosaicFusion: Diffusion Models as Data Augmenters for Large Vocabulary Instance Segmentation
+ 编号:[2]
+ 链接:https://arxiv.org/abs/2309.13042
+ 作者:Jiahao Xie, Wei Li, Xiangtai Li, Ziwei Liu, Yew Soon Ong, Chen Change Loy
+ 备注:GitHub: this https URL
+ 关键词:large vocabulary instance, effective diffusion-based data, diffusion-based data augmentation, data augmentation approach, effective diffusion-based
+
+ 点击查看摘要
+ We present MosaicFusion, a simple yet effective diffusion-based data augmentation approach for large vocabulary instance segmentation. Our method is training-free and does not rely on any label supervision. Two key designs enable us to employ an off-the-shelf text-to-image diffusion model as a useful dataset generator for object instances and mask annotations. First, we divide an image canvas into several regions and perform a single round of diffusion process to generate multiple instances simultaneously, conditioning on different text prompts. Second, we obtain corresponding instance masks by aggregating cross-attention maps associated with object prompts across layers and diffusion time steps, followed by simple thresholding and edge-aware refinement processing. Without bells and whistles, our MosaicFusion can produce a significant amount of synthetic labeled data for both rare and novel categories. Experimental results on the challenging LVIS long-tailed and open-vocabulary benchmarks demonstrate that MosaicFusion can significantly improve the performance of existing instance segmentation models, especially for rare and novel categories. Code will be released at this https URL.
+
+
+
+ 3. 标题:A Hybrid Deep Learning-based Approach for Optimal Genotype by Environment Selection
+ 编号:[13]
+ 链接:https://arxiv.org/abs/2309.13021
+ 作者:Zahra Khalilzadeh, Motahareh Kashanian, Saeed Khaki, Lizhi Wang
+ 备注:20 pages, 7 figures
+ 关键词:crop yield prediction, improving agricultural practices, Precise crop yield, ensuring crop resilience, Yield Prediction Challenge
+
+ 点击查看摘要
+ Precise crop yield prediction is essential for improving agricultural practices and ensuring crop resilience in varying climates. Integrating weather data across the growing season, especially for different crop varieties, is crucial for understanding their adaptability in the face of climate change. In the MLCAS2021 Crop Yield Prediction Challenge, we utilized a dataset comprising 93,028 training records to forecast yields for 10,337 test records, covering 159 locations across 28 U.S. states and Canadian provinces over 13 years (2003-2015). This dataset included details on 5,838 distinct genotypes and daily weather data for a 214-day growing season, enabling comprehensive analysis. As one of the winning teams, we developed two novel convolutional neural network (CNN) architectures: the CNN-DNN model, combining CNN and fully-connected networks, and the CNN-LSTM-DNN model, with an added LSTM layer for weather variables. Leveraging the Generalized Ensemble Method (GEM), we determined optimal model weights, resulting in superior performance compared to baseline models. The GEM model achieved lower RMSE (5.55% to 39.88%), reduced MAE (5.34% to 43.76%), and higher correlation coefficients (1.1% to 10.79%) when evaluated on test data. We applied the CNN-DNN model to identify top-performing genotypes for various locations and weather conditions, aiding genotype selection based on weather variables. Our data-driven approach is valuable for scenarios with limited testing years. Additionally, a feature importance analysis using RMSE change highlighted the significance of location, MG, year, and genotype, along with the importance of weather variables MDNI and AP.
+
+
+
+ 4. 标题:Efficient N:M Sparse DNN Training Using Algorithm, Architecture, and Dataflow Co-Design
+ 编号:[16]
+ 链接:https://arxiv.org/abs/2309.13015
+ 作者:Chao Fang, Wei Sun, Aojun Zhou, Zhongfeng Wang
+ 备注:To appear in the IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD)
+ 关键词:DNN training, Sparse, sparse DNN training, training, Sparse training
+
+ 点击查看摘要
+ Sparse training is one of the promising techniques to reduce the computational cost of DNNs while retaining high accuracy. In particular, N:M fine-grained structured sparsity, where only N out of consecutive M elements can be nonzero, has attracted attention due to its hardware-friendly pattern and capability of achieving a high sparse ratio. However, the potential to accelerate N:M sparse DNN training has not been fully exploited, and there is a lack of efficient hardware supporting N:M sparse training. To tackle these challenges, this paper presents a computation-efficient training scheme for N:M sparse DNNs using algorithm, architecture, and dataflow co-design. At the algorithm level, a bidirectional weight pruning method, dubbed BDWP, is proposed to leverage the N:M sparsity of weights during both forward and backward passes of DNN training, which can significantly reduce the computational cost while maintaining model accuracy. At the architecture level, a sparse accelerator for DNN training, namely SAT, is developed to neatly support both the regular dense operations and the computation-efficient N:M sparse operations. At the dataflow level, multiple optimization methods ranging from interleave mapping, pre-generation of N:M sparse weights, and offline scheduling, are proposed to boost the computational efficiency of SAT. Finally, the effectiveness of our training scheme is evaluated on a Xilinx VCU1525 FPGA card using various DNN models and datasets. Experimental results show the SAT accelerator with the BDWP sparse training method under 2:8 sparse ratio achieves an average speedup of 1.75x over that with the dense training, accompanied by a negligible accuracy loss of 0.56% on average. Furthermore, our proposed training scheme significantly improves the training throughput by 2.97~25.22x and the energy efficiency by 1.36~3.58x over prior FPGA-based accelerators.
+
+
+
+ 5. 标题:ReConcile: Round-Table Conference Improves Reasoning via Consensus among Diverse LLMs
+ 编号:[18]
+ 链接:https://arxiv.org/abs/2309.13007
+ 作者:Justin Chih-Yao Chen, Swarnadeep Saha, Mohit Bansal
+ 备注:19 pages, 9 figures, 7 tables
+ 关键词:Large Language Models, Language Models, Large Language, complex reasoning tasks, agents
+
+ 点击查看摘要
+ Large Language Models (LLMs) still struggle with complex reasoning tasks. Motivated by the society of minds (Minsky, 1988), we propose ReConcile, a multi-model multi-agent framework designed as a round table conference among diverse LLM agents to foster diverse thoughts and discussion for improved consensus. ReConcile enhances the reasoning capabilities of LLMs by holding multiple rounds of discussion, learning to convince other agents to improve their answers, and employing a confidence-weighted voting mechanism. In each round, ReConcile initiates discussion between agents via a 'discussion prompt' that consists of (a) grouped answers and explanations generated by each agent in the previous round, (b) their uncertainties, and (c) demonstrations of answer-rectifying human explanations, used for convincing other agents. This discussion prompt enables each agent to revise their responses in light of insights from other agents. Once a consensus is reached and the discussion ends, ReConcile determines the final answer by leveraging the confidence of each agent in a weighted voting scheme. We implement ReConcile with ChatGPT, Bard, and Claude2 as the three agents. Our experimental results on various benchmarks demonstrate that ReConcile significantly enhances the reasoning performance of the agents (both individually and as a team), surpassing prior single-agent and multi-agent baselines by 7.7% and also outperforming GPT-4 on some of these datasets. We also experiment with GPT-4 itself as one of the agents in ReConcile and demonstrate that its initial performance also improves by absolute 10.0% through discussion and feedback from other agents. Finally, we also analyze the accuracy after every round and observe that ReConcile achieves better and faster consensus between agents, compared to a multi-agent debate baseline. Our code is available at: this https URL
+
+
+
+ 6. 标题:Pursuing Counterfactual Fairness via Sequential Autoencoder Across Domains
+ 编号:[20]
+ 链接:https://arxiv.org/abs/2309.13005
+ 作者:Yujie Lin, Chen Zhao, Minglai Shao, Baoluo Meng, Xujiang Zhao, Haifeng Chen
+ 备注:
+ 关键词:machine learning systems, machine learning, sensitive attributes, Recognizing the prevalence, developed to enhance
+
+ 点击查看摘要
+ Recognizing the prevalence of domain shift as a common challenge in machine learning, various domain generalization (DG) techniques have been developed to enhance the performance of machine learning systems when dealing with out-of-distribution (OOD) data. Furthermore, in real-world scenarios, data distributions can gradually change across a sequence of sequential domains. While current methodologies primarily focus on improving model effectiveness within these new domains, they often overlook fairness issues throughout the learning process. In response, we introduce an innovative framework called Counterfactual Fairness-Aware Domain Generalization with Sequential Autoencoder (CDSAE). This approach effectively separates environmental information and sensitive attributes from the embedded representation of classification features. This concurrent separation not only greatly improves model generalization across diverse and unfamiliar domains but also effectively addresses challenges related to unfair classification. Our strategy is rooted in the principles of causal inference to tackle these dual issues. To examine the intricate relationship between semantic information, sensitive attributes, and environmental cues, we systematically categorize exogenous uncertainty factors into four latent variables: 1) semantic information influenced by sensitive attributes, 2) semantic information unaffected by sensitive attributes, 3) environmental cues influenced by sensitive attributes, and 4) environmental cues unaffected by sensitive attributes. By incorporating fairness regularization, we exclusively employ semantic information for classification purposes. Empirical validation on synthetic and real-world datasets substantiates the effectiveness of our approach, demonstrating improved accuracy levels while ensuring the preservation of fairness in the evolving landscape of continuous domains.
+
+
+
+ 7. 标题:Audience-specific Explanations for Machine Translation
+ 编号:[21]
+ 链接:https://arxiv.org/abs/2309.12998
+ 作者:Renhan Lou, Jan Niehues
+ 备注:
+ 关键词:target language audience, language audience due, machine translation, cultural backgrounds, audience due
+
+ 点击查看摘要
+ In machine translation, a common problem is that the translation of certain words even if translated can cause incomprehension of the target language audience due to different cultural backgrounds. A solution to solve this problem is to add explanations for these words. In a first step, we therefore need to identify these words or phrases. In this work we explore techniques to extract example explanations from a parallel corpus. However, the sparsity of sentences containing words that need to be explained makes building the training dataset extremely difficult. In this work, we propose a semi-automatic technique to extract these explanations from a large parallel corpus. Experiments on English->German language pair show that our method is able to extract sentence so that more than 10% of the sentences contain explanation, while only 1.9% of the original sentences contain explanations. In addition, experiments on English->French and English->Chinese language pairs also show similar conclusions. This is therefore an essential first automatic step to create a explanation dataset. Furthermore we show that the technique is robust for all three language pairs.
+
+
+
+ 8. 标题:Higher-order Graph Convolutional Network with Flower-Petals Laplacians on Simplicial Complexes
+ 编号:[27]
+ 链接:https://arxiv.org/abs/2309.12971
+ 作者:Yiming Huang, Yujie Zeng, Qiang Wu, Linyuan Lü
+ 备注:
+ 关键词:vanilla Graph Neural, Graph Neural Networks, networks inherently limits, discern latent higher-order, pairwise interaction networks
+
+ 点击查看摘要
+ Despite the recent successes of vanilla Graph Neural Networks (GNNs) on many tasks, their foundation on pairwise interaction networks inherently limits their capacity to discern latent higher-order interactions in complex systems. To bridge this capability gap, we propose a novel approach exploiting the rich mathematical theory of simplicial complexes (SCs) - a robust tool for modeling higher-order interactions. Current SC-based GNNs are burdened by high complexity and rigidity, and quantifying higher-order interaction strengths remains challenging. Innovatively, we present a higher-order Flower-Petals (FP) model, incorporating FP Laplacians into SCs. Further, we introduce a Higher-order Graph Convolutional Network (HiGCN) grounded in FP Laplacians, capable of discerning intrinsic features across varying topological scales. By employing learnable graph filters, a parameter group within each FP Laplacian domain, we can identify diverse patterns where the filters' weights serve as a quantifiable measure of higher-order interaction strengths. The theoretical underpinnings of HiGCN's advanced expressiveness are rigorously demonstrated. Additionally, our empirical investigations reveal that the proposed model accomplishes state-of-the-art (SOTA) performance on a range of graph tasks and provides a scalable and flexible solution to explore higher-order interactions in graphs.
+
+
+
+ 9. 标题:Trusta: Reasoning about Assurance Cases with Formal Methods and Large Language Models
+ 编号:[37]
+ 链接:https://arxiv.org/abs/2309.12941
+ 作者:Zezhong Chen, Yuxin Deng, Wenjie Du
+ 备注:38 pages
+ 关键词:Derivation Tree Analyzer, Trustworthiness Derivation Trees, Assurance cases, safety engineering, Trustworthiness Derivation
+
+ 点击查看摘要
+ Assurance cases can be used to argue for the safety of products in safety engineering. In safety-critical areas, the construction of assurance cases is indispensable. Trustworthiness Derivation Trees (TDTs) enhance assurance cases by incorporating formal methods, rendering it possible for automatic reasoning about assurance cases. We present Trustworthiness Derivation Tree Analyzer (Trusta), a desktop application designed to automatically construct and verify TDTs. The tool has a built-in Prolog interpreter in its backend, and is supported by the constraint solvers Z3 and MONA. Therefore, it can solve constraints about logical formulas involving arithmetic, sets, Horn clauses etc. Trusta also utilizes large language models to make the creation and evaluation of assurance cases more convenient. It allows for interactive human examination and modification. We evaluated top language models like ChatGPT-3.5, ChatGPT-4, and PaLM 2 for generating assurance cases. Our tests showed a 50%-80% similarity between machine-generated and human-created cases. In addition, Trusta can extract formal constraints from text in natural languages, facilitating an easier interpretation and validation process. This extraction is subject to human review and correction, blending the best of automated efficiency with human insight. To our knowledge, this marks the first integration of large language models in automatic creating and reasoning about assurance cases, bringing a novel approach to a traditional challenge. Through several industrial case studies, Trusta has proven to quickly find some subtle issues that are typically missed in manual inspection, demonstrating its practical value in enhancing the assurance case development process.
+
+
+
+ 10. 标题:Self-Explanation Prompting Improves Dialogue Understanding in Large Language Models
+ 编号:[38]
+ 链接:https://arxiv.org/abs/2309.12940
+ 作者:Haoyu Gao, Ting-En Lin, Hangyu Li, Min Yang, Yuchuan Wu, Wentao Ma, Yongbin Li
+ 备注:
+ 关键词:Large Language Models, systems facilitate users, Large Language, Language Models, systems facilitate
+
+ 点击查看摘要
+ Task-oriented dialogue (TOD) systems facilitate users in executing various activities via multi-turn dialogues, but Large Language Models (LLMs) often struggle to comprehend these intricate contexts. In this study, we propose a novel "Self-Explanation" prompting strategy to enhance the comprehension abilities of LLMs in multi-turn dialogues. This task-agnostic approach requires the model to analyze each dialogue utterance before task execution, thereby improving performance across various dialogue-centric tasks. Experimental results from six benchmark datasets confirm that our method consistently outperforms other zero-shot prompts and matches or exceeds the efficacy of few-shot prompts, demonstrating its potential as a powerful tool in enhancing LLMs' comprehension in complex dialogue tasks.
+
+
+
+ 11. 标题:Frustrated with Code Quality Issues? LLMs can Help!
+ 编号:[39]
+ 链接:https://arxiv.org/abs/2309.12938
+ 作者:Nalin Wadhwa, Jui Pradhan, Atharv Sonwane, Surya Prakash Sahu, Nagarajan Natarajan, Aditya Kanade, Suresh Parthasarathy, Sriram Rajamani
+ 备注:
+ 关键词:software projects progress, assumes paramount importance, code assumes paramount, code quality issues, code quality
+
+ 点击查看摘要
+ As software projects progress, quality of code assumes paramount importance as it affects reliability, maintainability and security of software. For this reason, static analysis tools are used in developer workflows to flag code quality issues. However, developers need to spend extra efforts to revise their code to improve code quality based on the tool findings. In this work, we investigate the use of (instruction-following) large language models (LLMs) to assist developers in revising code to resolve code quality issues. We present a tool, CORE (short for COde REvisions), architected using a pair of LLMs organized as a duo comprised of a proposer and a ranker. Providers of static analysis tools recommend ways to mitigate the tool warnings and developers follow them to revise their code. The \emph{proposer LLM} of CORE takes the same set of recommendations and applies them to generate candidate code revisions. The candidates which pass the static quality checks are retained. However, the LLM may introduce subtle, unintended functionality changes which may go un-detected by the static analysis. The \emph{ranker LLM} evaluates the changes made by the proposer using a rubric that closely follows the acceptance criteria that a developer would enforce. CORE uses the scores assigned by the ranker LLM to rank the candidate revisions before presenting them to the developer. CORE could revise 59.2% Python files (across 52 quality checks) so that they pass scrutiny by both a tool and a human reviewer. The ranker LLM is able to reduce false positives by 25.8% in these cases. CORE produced revisions that passed the static analysis tool in 76.8% Java files (across 10 quality checks) comparable to 78.3% of a specialized program repair tool, with significantly much less engineering efforts.
+
+
+
+ 12. 标题:On Separate Normalization in Self-supervised Transformers
+ 编号:[42]
+ 链接:https://arxiv.org/abs/2309.12931
+ 作者:Xiaohui Chen, Yinkai Wang, Yuanqi Du, Soha Hassoun, Li-Ping Liu
+ 备注:NIPS 2023
+ 关键词:Self-supervised training methods, demonstrated remarkable performance, Self-supervised training, transformers have demonstrated, demonstrated remarkable
+
+ 点击查看摘要
+ Self-supervised training methods for transformers have demonstrated remarkable performance across various domains. Previous transformer-based models, such as masked autoencoders (MAE), typically utilize a single normalization layer for both the [CLS] symbol and the tokens. We propose in this paper a simple modification that employs separate normalization layers for the tokens and the [CLS] symbol to better capture their distinct characteristics and enhance downstream task performance. Our method aims to alleviate the potential negative effects of using the same normalization statistics for both token types, which may not be optimally aligned with their individual roles. We empirically show that by utilizing a separate normalization layer, the [CLS] embeddings can better encode the global contextual information and are distributed more uniformly in its anisotropic space. When replacing the conventional normalization layer with the two separate layers, we observe an average 2.7% performance improvement over the image, natural language, and graph domains.
+
+
+
+ 13. 标题:A matter of attitude: Focusing on positive and active gradients to boost saliency maps
+ 编号:[47]
+ 链接:https://arxiv.org/abs/2309.12913
+ 作者:Oscar Llorente, Jaime Boal, Eugenio F. Sánchez-Úbeda
+ 备注:
+ 关键词:convolutional neural networks, widely used interpretability, interpretability techniques, techniques for convolutional, convolutional neural
+
+ 点击查看摘要
+ Saliency maps have become one of the most widely used interpretability techniques for convolutional neural networks (CNN) due to their simplicity and the quality of the insights they provide. However, there are still some doubts about whether these insights are a trustworthy representation of what CNNs use to come up with their predictions. This paper explores how rescuing the sign of the gradients from the saliency map can lead to a deeper understanding of multi-class classification problems. Using both pretrained and trained from scratch CNNs we unveil that considering the sign and the effect not only of the correct class, but also the influence of the other classes, allows to better identify the pixels of the image that the network is really focusing on. Furthermore, how occluding or altering those pixels is expected to affect the outcome also becomes clearer.
+
+
+
+ 14. 标题:KG-MDL: Mining Graph Patterns in Knowledge Graphs with the MDL Principle
+ 编号:[49]
+ 链接:https://arxiv.org/abs/2309.12908
+ 作者:Francesco Bariatti, Peggy Cellier, Sébastien Ferré
+ 备注:
+ 关键词:Graph mining, Graph, Graph mining approaches, mining, patterns
+
+ 点击查看摘要
+ Nowadays, increasingly more data are available as knowledge graphs (KGs). While this data model supports advanced reasoning and querying, they remain difficult to mine due to their size and complexity. Graph mining approaches can be used to extract patterns from KGs. However this presents two main issues. First, graph mining approaches tend to extract too many patterns for a human analyst to interpret (pattern explosion). Second, real-life KGs tend to differ from the graphs usually treated in graph mining: they are multigraphs, their vertex degrees tend to follow a power-law, and the way in which they model knowledge can produce spurious patterns. Recently, a graph mining approach named GraphMDL+ has been proposed to tackle the problem of pattern explosion, using the Minimum Description Length (MDL) principle. However, GraphMDL+, like other graph mining approaches, is not suited for KGs without adaptations. In this paper we propose KG-MDL, a graph pattern mining approach based on the MDL principle that, given a KG, generates a human-sized and descriptive set of graph patterns, and so in a parameter-less and anytime way. We report on experiments on medium-sized KGs showing that our approach generates sets of patterns that are both small enough to be interpreted by humans and descriptive of the KG. We show that the extracted patterns highlight relevant characteristics of the data: both of the schema used to create the data, and of the concrete facts it contains. We also discuss the issues related to mining graph patterns on knowledge graphs, as opposed to other types of graph data.
+
+
+
+ 15. 标题:ProtoEM: A Prototype-Enhanced Matching Framework for Event Relation Extraction
+ 编号:[54]
+ 链接:https://arxiv.org/abs/2309.12892
+ 作者:Zhilei Hu, Zixuan Li, Daozhu Xu, Long Bai, Cheng Jin, Xiaolong Jin, Jiafeng Guo, Xueqi Cheng
+ 备注:Work in progress
+ 关键词:event relations, relations, Event, Event Relation Extraction, ERE
+
+ 点击查看摘要
+ Event Relation Extraction (ERE) aims to extract multiple kinds of relations among events in texts. However, existing methods singly categorize event relations as different classes, which are inadequately capturing the intrinsic semantics of these relations. To comprehensively understand their intrinsic semantics, in this paper, we obtain prototype representations for each type of event relation and propose a Prototype-Enhanced Matching (ProtoEM) framework for the joint extraction of multiple kinds of event relations. Specifically, ProtoEM extracts event relations in a two-step manner, i.e., prototype representing and prototype matching. In the first step, to capture the connotations of different event relations, ProtoEM utilizes examples to represent the prototypes corresponding to these relations. Subsequently, to capture the interdependence among event relations, it constructs a dependency graph for the prototypes corresponding to these relations and utilized a Graph Neural Network (GNN)-based module for modeling. In the second step, it obtains the representations of new event pairs and calculates their similarity with those prototypes obtained in the first step to evaluate which types of event relations they belong to. Experimental results on the MAVEN-ERE dataset demonstrate that the proposed ProtoEM framework can effectively represent the prototypes of event relations and further obtain a significant improvement over baseline models.
+
+
+
+ 16. 标题:Gravity Network for end-to-end small lesion detection
+ 编号:[59]
+ 链接:https://arxiv.org/abs/2309.12876
+ 作者:Ciro Russo, Alessandro Bria, Claudio Marrocco
+ 备注:
+ 关键词:detector specifically designed, detector specifically, specifically designed, designed to detect, detect small lesions
+
+ 点击查看摘要
+ This paper introduces a novel one-stage end-to-end detector specifically designed to detect small lesions in medical images. Precise localization of small lesions presents challenges due to their appearance and the diverse contextual backgrounds in which they are found. To address this, our approach introduces a new type of pixel-based anchor that dynamically moves towards the targeted lesion for detection. We refer to this new architecture as GravityNet, and the novel anchors as gravity points since they appear to be "attracted" by the lesions. We conducted experiments on two well-established medical problems involving small lesions to evaluate the performance of the proposed approach: microcalcifications detection in digital mammograms and microaneurysms detection in digital fundus images. Our method demonstrates promising results in effectively detecting small lesions in these medical imaging tasks.
+
+
+
+ 17. 标题:AnglE-Optimized Text Embeddings
+ 编号:[61]
+ 链接:https://arxiv.org/abs/2309.12871
+ 作者:Xianming Li, Jing Li
+ 备注:NLP, Text Embedding, Semantic Textual Similarity
+ 关键词:Large Language Model, Large Language, semantic textual similarity, improving semantic textual, components in Large
+
+ 点击查看摘要
+ High-quality text embedding is pivotal in improving semantic textual similarity (STS) tasks, which are crucial components in Large Language Model (LLM) applications. However, a common challenge existing text embedding models face is the problem of vanishing gradients, primarily due to their reliance on the cosine function in the optimization objective, which has saturation zones. To address this issue, this paper proposes a novel angle-optimized text embedding model called AnglE. The core idea of AnglE is to introduce angle optimization in a complex space. This novel approach effectively mitigates the adverse effects of the saturation zone in the cosine function, which can impede gradient and hinder optimization processes. To set up a comprehensive STS evaluation, we experimented on existing short-text STS datasets and a newly collected long-text STS dataset from GitHub Issues. Furthermore, we examine domain-specific STS scenarios with limited labeled data and explore how AnglE works with LLM-annotated data. Extensive experiments were conducted on various tasks including short-text STS, long-text STS, and domain-specific STS tasks. The results show that AnglE outperforms the state-of-the-art (SOTA) STS models that ignore the cosine saturation zone. These findings demonstrate the ability of AnglE to generate high-quality text embeddings and the usefulness of angle optimization in STS.
+
+
+
+ 18. 标题:Accurate and Fast Compressed Video Captioning
+ 编号:[63]
+ 链接:https://arxiv.org/abs/2309.12867
+ 作者:Yaojie Shen, Xin Gu, Kai Xu, Heng Fan, Longyin Wen, Libo Zhang
+ 备注:
+ 关键词:approaches typically require, sample video frames, video, video captioning, subsequent process
+
+ 点击查看摘要
+ Existing video captioning approaches typically require to first sample video frames from a decoded video and then conduct a subsequent process (e.g., feature extraction and/or captioning model learning). In this pipeline, manual frame sampling may ignore key information in videos and thus degrade performance. Additionally, redundant information in the sampled frames may result in low efficiency in the inference of video captioning. Addressing this, we study video captioning from a different perspective in compressed domain, which brings multi-fold advantages over the existing pipeline: 1) Compared to raw images from the decoded video, the compressed video, consisting of I-frames, motion vectors and residuals, is highly distinguishable, which allows us to leverage the entire video for learning without manual sampling through a specialized model design; 2) The captioning model is more efficient in inference as smaller and less redundant information is processed. We propose a simple yet effective end-to-end transformer in the compressed domain for video captioning that enables learning from the compressed video for captioning. We show that even with a simple design, our method can achieve state-of-the-art performance on different benchmarks while running almost 2x faster than existing approaches. Code is available at this https URL.
+
+
+
+ 19. 标题:Domain Adaptation for Arabic Machine Translation: The Case of Financial Texts
+ 编号:[66]
+ 链接:https://arxiv.org/abs/2309.12863
+ 作者:Emad A. Alghamdi, Jezia Zakraoui, Fares A. Abanmy
+ 备注:
+ 关键词:shown impressive performance, Neural machine translation, Neural machine, large-scale corpora, NMT
+
+ 点击查看摘要
+ Neural machine translation (NMT) has shown impressive performance when trained on large-scale corpora. However, generic NMT systems have demonstrated poor performance on out-of-domain translation. To mitigate this issue, several domain adaptation methods have recently been proposed which often lead to better translation quality than genetic NMT systems. While there has been some continuous progress in NMT for English and other European languages, domain adaption in Arabic has received little attention in the literature. The current study, therefore, aims to explore the effectiveness of domain-specific adaptation for Arabic MT (AMT), in yet unexplored domain, financial news articles. To this end, we developed carefully a parallel corpus for Arabic-English (AR- EN) translation in the financial domain for benchmarking different domain adaptation methods. We then fine-tuned several pre-trained NMT and Large Language models including ChatGPT-3.5 Turbo on our dataset. The results showed that the fine-tuning is successful using just a few well-aligned in-domain AR-EN segments. The quality of ChatGPT translation was superior than other models based on automatic and human evaluations. To the best of our knowledge, this is the first work on fine-tuning ChatGPT towards financial domain transfer learning. To contribute to research in domain translation, we made our datasets and fine-tuned models available at this https URL.
+
+
+
+ 20. 标题:Diffusion Augmentation for Sequential Recommendation
+ 编号:[70]
+ 链接:https://arxiv.org/abs/2309.12858
+ 作者:Qidong Liu, Fan Yan, Xiangyu Zhao, Zhaocheng Du, Huifeng Guo, Ruiming Tang, Feng Tian
+ 备注:
+ 关键词:Sequential recommendation, sequential recommendation models, user historical interactions, applications recently, technical foundation
+
+ 点击查看摘要
+ Sequential recommendation (SRS) has become the technical foundation in many applications recently, which aims to recommend the next item based on the user's historical interactions. However, sequential recommendation often faces the problem of data sparsity, which widely exists in recommender systems. Besides, most users only interact with a few items, but existing SRS models often underperform these users. Such a problem, named the long-tail user problem, is still to be resolved. Data augmentation is a distinct way to alleviate these two problems, but they often need fabricated training strategies or are hindered by poor-quality generated interactions. To address these problems, we propose a Diffusion Augmentation for Sequential Recommendation (DiffuASR) for a higher quality generation. The augmented dataset by DiffuASR can be used to train the sequential recommendation models directly, free from complex training procedures. To make the best of the generation ability of the diffusion model, we first propose a diffusion-based pseudo sequence generation framework to fill the gap between image and sequence generation. Then, a sequential U-Net is designed to adapt the diffusion noise prediction model U-Net to the discrete sequence generation task. At last, we develop two guide strategies to assimilate the preference between generated and origin sequences. To validate the proposed DiffuASR, we conduct extensive experiments on three real-world datasets with three sequential recommendation models. The experimental results illustrate the effectiveness of DiffuASR. As far as we know, DiffuASR is one pioneer that introduce the diffusion model to the recommendation.
+
+
+
+ 21. 标题:AxOCS: Scaling FPGA-based Approximate Operators using Configuration Supersampling
+ 编号:[77]
+ 链接:https://arxiv.org/abs/2309.12830
+ 作者:Siva Satyendra Sahoo, Salim Ullah, Soumyo Bhattacharjee, Akash Kumar
+ 备注:11 pages, under review with IEEE TCAS-I
+ 关键词:resource-constrained embedded systems, low-cost ML implementation, processing across application, application domains, domains has exacerbated
+
+ 点击查看摘要
+ The rising usage of AI and ML-based processing across application domains has exacerbated the need for low-cost ML implementation, specifically for resource-constrained embedded systems. To this end, approximate computing, an approach that explores the power, performance, area (PPA), and behavioral accuracy (BEHAV) trade-offs, has emerged as a possible solution for implementing embedded machine learning. Due to the predominance of MAC operations in ML, designing platform-specific approximate arithmetic operators forms one of the major research problems in approximate computing. Recently there has been a rising usage of AI/ML-based design space exploration techniques for implementing approximate operators. However, most of these approaches are limited to using ML-based surrogate functions for predicting the PPA and BEHAV impact of a set of related design decisions. While this approach leverages the regression capabilities of ML methods, it does not exploit the more advanced approaches in ML. To this end, we propose AxOCS, a methodology for designing approximate arithmetic operators through ML-based supersampling. Specifically, we present a method to leverage the correlation of PPA and BEHAV metrics across operators of varying bit-widths for generating larger bit-width operators. The proposed approach involves traversing the relatively smaller design space of smaller bit-width operators and employing its associated Design-PPA-BEHAV relationship to generate initial solutions for metaheuristics-based optimization for larger operators. The experimental evaluation of AxOCS for FPGA-optimized approximate operators shows that the proposed approach significantly improves the quality-resulting hypervolume for multi-objective optimization-of 8x8 signed approximate multipliers.
+
+
+
+ 22. 标题:Synthetic Boost: Leveraging Synthetic Data for Enhanced Vision-Language Segmentation in Echocardiography
+ 编号:[78]
+ 链接:https://arxiv.org/abs/2309.12829
+ 作者:Rabin Adhikari, Manish Dhakal, Safal Thapaliya, Kanchan Poudel, Prasiddha Bhandari, Bishesh Khanal
+ 备注:Accepted at the 4th International Workshop of Advances in Simplifying Medical UltraSound (ASMUS)
+ 关键词:cardiovascular diseases, essential for echocardiography-based, echocardiography-based assessment, assessment of cardiovascular, Semantic Diffusion Models
+
+ 点击查看摘要
+ Accurate segmentation is essential for echocardiography-based assessment of cardiovascular diseases (CVDs). However, the variability among sonographers and the inherent challenges of ultrasound images hinder precise segmentation. By leveraging the joint representation of image and text modalities, Vision-Language Segmentation Models (VLSMs) can incorporate rich contextual information, potentially aiding in accurate and explainable segmentation. However, the lack of readily available data in echocardiography hampers the training of VLSMs. In this study, we explore using synthetic datasets from Semantic Diffusion Models (SDMs) to enhance VLSMs for echocardiography segmentation. We evaluate results for two popular VLSMs (CLIPSeg and CRIS) using seven different kinds of language prompts derived from several attributes, automatically extracted from echocardiography images, segmentation masks, and their metadata. Our results show improved metrics and faster convergence when pretraining VLSMs on SDM-generated synthetic images before finetuning on real images. The code, configs, and prompts are available at this https URL.
+
+
+
+ 23. 标题:OmniDrones: An Efficient and Flexible Platform for Reinforcement Learning in Drone Control
+ 编号:[79]
+ 链接:https://arxiv.org/abs/2309.12825
+ 作者:Botian Xu, Feng Gao, Chao Yu, Ruize Zhang, Yi Wu, Yu Wang
+ 备注:Submitted to IEEE RA-L
+ 关键词:Omniverse Isaac Sim, Nvidia Omniverse Isaac, Isaac Sim, Nvidia Omniverse, Omniverse Isaac
+
+ 点击查看摘要
+ In this work, we introduce OmniDrones, an efficient and flexible platform tailored for reinforcement learning in drone control, built on Nvidia's Omniverse Isaac Sim. It employs a bottom-up design approach that allows users to easily design and experiment with various application scenarios on top of GPU-parallelized simulations. It also offers a range of benchmark tasks, presenting challenges ranging from single-drone hovering to over-actuated system tracking. In summary, we propose an open-sourced drone simulation platform, equipped with an extensive suite of tools for drone learning. It includes 4 drone models, 5 sensor modalities, 4 control modes, over 10 benchmark tasks, and a selection of widely used RL baselines. To showcase the capabilities of OmniDrones and to support future research, we also provide preliminary results on these benchmark tasks. We hope this platform will encourage further studies on applying RL to practical drone systems.
+
+
+
+ 24. 标题:Masking Improves Contrastive Self-Supervised Learning for ConvNets, and Saliency Tells You Where
+ 编号:[104]
+ 链接:https://arxiv.org/abs/2309.12757
+ 作者:Zhi-Yi Chin, Chieh-Ming Jiang, Ching-Chun Huang, Pin-Yu Chen, Wei-Chen Chiu
+ 备注:
+ 关键词:convolutional neural networks, vision transformer backbone, image data starts, self-supervised learning scheme, learning process significantly
+
+ 点击查看摘要
+ While image data starts to enjoy the simple-but-effective self-supervised learning scheme built upon masking and self-reconstruction objective thanks to the introduction of tokenization procedure and vision transformer backbone, convolutional neural networks as another important and widely-adopted architecture for image data, though having contrastive-learning techniques to drive the self-supervised learning, still face the difficulty of leveraging such straightforward and general masking operation to benefit their learning process significantly. In this work, we aim to alleviate the burden of including masking operation into the contrastive-learning framework for convolutional neural networks as an extra augmentation method. In addition to the additive but unwanted edges (between masked and unmasked regions) as well as other adverse effects caused by the masking operations for ConvNets, which have been discussed by prior works, we particularly identify the potential problem where for one view in a contrastive sample-pair the randomly-sampled masking regions could be overly concentrated on important/salient objects thus resulting in misleading contrastiveness to the other view. To this end, we propose to explicitly take the saliency constraint into consideration in which the masked regions are more evenly distributed among the foreground and background for realizing the masking-based augmentation. Moreover, we introduce hard negative samples by masking larger regions of salient patches in an input image. Extensive experiments conducted on various datasets, contrastive learning mechanisms, and downstream tasks well verify the efficacy as well as the superior performance of our proposed method with respect to several state-of-the-art baselines.
+
+
+
+ 25. 标题:Towards an MLOps Architecture for XAI in Industrial Applications
+ 编号:[105]
+ 链接:https://arxiv.org/abs/2309.12756
+ 作者:Leonhard Faubel, Thomas Woudsma, Leila Methnani, Amir Ghorbani Ghezeljhemeidan, Fabian Buelow, Klaus Schmid, Willem D. van Driel, Benjamin Kloepper, Andreas Theodorou, Mohsen Nosratinia, Magnus Bång
+ 备注:
+ 关键词:Machine Learning Operations, Machine learning, increase efficiency, reduce costs, popular tool
+
+ 点击查看摘要
+ Machine learning (ML) has become a popular tool in the industrial sector as it helps to improve operations, increase efficiency, and reduce costs. However, deploying and managing ML models in production environments can be complex. This is where Machine Learning Operations (MLOps) comes in. MLOps aims to streamline this deployment and management process. One of the remaining MLOps challenges is the need for explanations. These explanations are essential for understanding how ML models reason, which is key to trust and acceptance. Better identification of errors and improved model accuracy are only two resulting advantages. An often neglected fact is that deployed models are bypassed in practice when accuracy and especially explainability do not meet user expectations. We developed a novel MLOps software architecture to address the challenge of integrating explanations and feedback capabilities into the ML development and deployment processes. In the project EXPLAIN, our architecture is implemented in a series of industrial use cases. The proposed MLOps software architecture has several advantages. It provides an efficient way to manage ML models in production environments. Further, it allows for integrating explanations into the development and deployment processes.
+
+
+
+ 26. 标题:OpenAi's GPT4 as coding assistant
+ 编号:[110]
+ 链接:https://arxiv.org/abs/2309.12732
+ 作者:Lefteris Moussiades, George Zografos
+ 备注:10 pages
+ 关键词:Large Language Models, potent Large Language, Large Language, Language Models, Language
+
+ 点击查看摘要
+ Lately, Large Language Models have been widely used in code generation. GPT4 is considered the most potent Large Language Model from Openai. In this paper, we examine GPT3.5 and GPT4 as coding assistants. More specifically, we have constructed appropriate tests to check whether the two systems can a) answer typical questions that can arise during the code development, b) produce reliable code, and c) contribute to code debugging. The test results are impressive. The performance of GPT4 is outstanding and signals an increase in the productivity of programmers and the reorganization of software development procedures based on these new tools.
+
+
+
+ 27. 标题:Defeasible Reasoning with Knowledge Graphs
+ 编号:[111]
+ 链接:https://arxiv.org/abs/2309.12731
+ 作者:Dave Raggett
+ 备注:Accepted for: Knowledge Graph and Semantic Web Conference (KGSWC-2023), 13-15 September, 2023, Zaragoza, Spain
+ 关键词:incompleteness and inconsistencies, subject to uncertainties, Human knowledge, Semantic Web, imprecision
+
+ 点击查看摘要
+ Human knowledge is subject to uncertainties, imprecision, incompleteness and inconsistencies. Moreover, the meaning of many everyday terms is dependent on the context. That poses a huge challenge for the Semantic Web. This paper introduces work on an intuitive notation and model for defeasible reasoning with imperfect knowledge, and relates it to previous work on argumentation theory. PKN is to N3 as defeasible reasoning is to deductive logic. Further work is needed on an intuitive syntax for describing reasoning strategies and tactics in declarative terms, drawing upon the AIF ontology for inspiration. The paper closes with observations on symbolic approaches in the era of large language models.
+
+
+
+ 28. 标题:In-context Interference in Chat-based Large Language Models
+ 编号:[113]
+ 链接:https://arxiv.org/abs/2309.12727
+ 作者:Eric Nuertey Coleman, Julio Hurtado, Vincenzo Lomonaco
+ 备注:
+ 关键词:Large language models, Large language, huge impact, impact on society, society due
+
+ 点击查看摘要
+ Large language models (LLMs) have had a huge impact on society due to their impressive capabilities and vast knowledge of the world. Various applications and tools have been created that allow users to interact with these models in a black-box scenario. However, one limitation of this scenario is that users cannot modify the internal knowledge of the model, and the only way to add or modify internal knowledge is by explicitly mentioning it to the model during the current interaction. This learning process is called in-context training, and it refers to training that is confined to the user's current session or context. In-context learning has significant applications, but also has limitations that are seldom studied. In this paper, we present a study that shows how the model can suffer from interference between information that continually flows in the context, causing it to forget previously learned knowledge, which can reduce the model's performance. Along with showing the problem, we propose an evaluation benchmark based on the bAbI dataset.
+
+
+
+ 29. 标题:H2O+: An Improved Framework for Hybrid Offline-and-Online RL with Dynamics Gaps
+ 编号:[118]
+ 链接:https://arxiv.org/abs/2309.12716
+ 作者:Haoyi Niu, Tianying Ji, Bingqi Liu, Haocheng Zhao, Xiangyu Zhu, Jianying Zheng, Pengfei Huang, Guyue Zhou, Jianming Hu, Xianyuan Zhan
+ 备注:
+ 关键词:Solving real-world complex, real-world complex tasks, high-fidelity simulation environments, complex tasks, tasks using reinforcement
+
+ 点击查看摘要
+ Solving real-world complex tasks using reinforcement learning (RL) without high-fidelity simulation environments or large amounts of offline data can be quite challenging. Online RL agents trained in imperfect simulation environments can suffer from severe sim-to-real issues. Offline RL approaches although bypass the need for simulators, often pose demanding requirements on the size and quality of the offline datasets. The recently emerged hybrid offline-and-online RL provides an attractive framework that enables joint use of limited offline data and imperfect simulator for transferable policy learning. In this paper, we develop a new algorithm, called H2O+, which offers great flexibility to bridge various choices of offline and online learning methods, while also accounting for dynamics gaps between the real and simulation environment. Through extensive simulation and real-world robotics experiments, we demonstrate superior performance and flexibility over advanced cross-domain online and offline RL algorithms.
+
+
+
+ 30. 标题:The Mathematical Game
+ 编号:[121]
+ 链接:https://arxiv.org/abs/2309.12711
+ 作者:Marc Pierre, Quentin Cohen-Solal, Tristan Cazenave
+ 备注:
+ 关键词:Monte Carlo Tree, Carlo Tree Search, Monte Carlo, automated theorem proving, Carlo Tree
+
+ 点击查看摘要
+ Monte Carlo Tree Search can be used for automated theorem proving. Holophrasm is a neural theorem prover using MCTS combined with neural networks for the policy and the evaluation. In this paper we propose to improve the performance of the Holophrasm theorem prover using other game tree search algorithms.
+
+
+
+ 31. 标题:PointSSC: A Cooperative Vehicle-Infrastructure Point Cloud Benchmark for Semantic Scene Completion
+ 编号:[123]
+ 链接:https://arxiv.org/abs/2309.12708
+ 作者:Yuxiang Yan, Boda Liu, Jianfei Ai, Qinbu Li, Ru Wan, Jian Pu
+ 备注:8 pages, 5 figures, submitted to ICRA2024
+ 关键词:generate space occupancies, jointly generate space, aims to jointly, jointly generate, SSC
+
+ 点击查看摘要
+ Semantic Scene Completion (SSC) aims to jointly generate space occupancies and semantic labels for complex 3D scenes. Most existing SSC models focus on volumetric representations, which are memory-inefficient for large outdoor spaces. Point clouds provide a lightweight alternative but existing benchmarks lack outdoor point cloud scenes with semantic labels. To address this, we introduce PointSSC, the first cooperative vehicle-infrastructure point cloud benchmark for semantic scene completion. These scenes exhibit long-range perception and minimal occlusion. We develop an automated annotation pipeline leveraging Segment Anything to efficiently assign semantics. To benchmark progress, we propose a LiDAR-based model with a Spatial-Aware Transformer for global and local feature extraction and a Completion and Segmentation Cooperative Module for joint completion and segmentation. PointSSC provides a challenging testbed to drive advances in semantic point cloud completion for real-world navigation.
+
+
+
+ 32. 标题:Multi-Label Noise Transition Matrix Estimation with Label Correlations: Theory and Algorithm
+ 编号:[124]
+ 链接:https://arxiv.org/abs/2309.12706
+ 作者:Shikun Li, Xiaobo Xia, Hansong Zhang, Shiming Ge, Tongliang Liu
+ 备注:
+ 关键词:Noisy multi-label learning, garnered increasing attention, increasing attention due, multi-label learning, Noisy
+
+ 点击查看摘要
+ Noisy multi-label learning has garnered increasing attention due to the challenges posed by collecting large-scale accurate labels, making noisy labels a more practical alternative. Motivated by noisy multi-class learning, the introduction of transition matrices can help model multi-label noise and enable the development of statistically consistent algorithms for noisy multi-label learning. However, estimating multi-label noise transition matrices remains a challenging task, as most existing estimators in noisy multi-class learning rely on anchor points and accurate fitting of noisy class posteriors, which is hard to satisfy in noisy multi-label learning. In this paper, we address this problem by first investigating the identifiability of class-dependent transition matrices in noisy multi-label learning. Building upon the identifiability results, we propose a novel estimator that leverages label correlations without the need for anchor points or precise fitting of noisy class posteriors. Specifically, we first estimate the occurrence probability of two noisy labels to capture noisy label correlations. Subsequently, we employ sample selection techniques to extract information implying clean label correlations, which are then used to estimate the occurrence probability of one noisy label when a certain clean label appears. By exploiting the mismatches in label correlations implied by these occurrence probabilities, we demonstrate that the transition matrix becomes identifiable and can be acquired by solving a bilinear decomposition problem. Theoretically, we establish an estimation error bound for our multi-label transition matrix estimator and derive a generalization error bound for our statistically consistent algorithm. Empirically, we validate the effectiveness of our estimator in estimating multi-label noise transition matrices, leading to excellent classification performance.
+
+
+
+ 33. 标题:Counterfactual Conservative Q Learning for Offline Multi-agent Reinforcement Learning
+ 编号:[128]
+ 链接:https://arxiv.org/abs/2309.12696
+ 作者:Jianzhun Shao, Yun Qu, Chen Chen, Hongchang Zhang, Xiangyang Ji
+ 备注:37th Conference on Neural Information Processing Systems (NeurIPS 2023)
+ 关键词:shift issue common, dimension issue common, distribution shift issue, phenomenon excessively severe, overestimation phenomenon excessively
+
+ 点击查看摘要
+ Offline multi-agent reinforcement learning is challenging due to the coupling effect of both distribution shift issue common in offline setting and the high dimension issue common in multi-agent setting, making the action out-of-distribution (OOD) and value overestimation phenomenon excessively severe. Tomitigate this problem, we propose a novel multi-agent offline RL algorithm, named CounterFactual Conservative Q-Learning (CFCQL) to conduct conservative value estimation. Rather than regarding all the agents as a high dimensional single one and directly applying single agent methods to it, CFCQL calculates conservative regularization for each agent separately in a counterfactual way and then linearly combines them to realize an overall conservative value estimation. We prove that it still enjoys the underestimation property and the performance guarantee as those single agent conservative methods do, but the induced regularization and safe policy improvement bound are independent of the agent number, which is therefore theoretically superior to the direct treatment referred to above, especially when the agent number is large. We further conduct experiments on four environments including both discrete and continuous action settings on both existing and our man-made datasets, demonstrating that CFCQL outperforms existing methods on most datasets and even with a remarkable margin on some of them.
+
+
+
+ 34. 标题:Enhancing Graph Representation of the Environment through Local and Cloud Computation
+ 编号:[131]
+ 链接:https://arxiv.org/abs/2309.12692
+ 作者:Francesco Argenziano, Vincenzo Suriani, Daniele Nardi
+ 备注:5 pages, 4 figures
+ 关键词:low-level sensor readings, high-level semantic understanding, challenging task, task that aims, aims at bridging
+
+ 点击查看摘要
+ Enriching the robot representation of the operational environment is a challenging task that aims at bridging the gap between low-level sensor readings and high-level semantic understanding. Having a rich representation often requires computationally demanding architectures and pure point cloud based detection systems that struggle when dealing with everyday objects that have to be handled by the robot. To overcome these issues, we propose a graph-based representation that addresses this gap by providing a semantic representation of robot environments from multiple sources. In fact, to acquire information from the environment, the framework combines classical computer vision tools with modern computer vision cloud services, ensuring computational feasibility on onboard hardware. By incorporating an ontology hierarchy with over 800 object classes, the framework achieves cross-domain adaptability, eliminating the need for environment-specific tools. The proposed approach allows us to handle also small objects and integrate them into the semantic representation of the environment. The approach is implemented in the Robot Operating System (ROS) using the RViz visualizer for environment representation. This work is a first step towards the development of a general-purpose framework, to facilitate intuitive interaction and navigation across different domains.
+
+
+
+ 35. 标题:TrTr: A Versatile Pre-Trained Large Traffic Model based on Transformer for Capturing Trajectory Diversity in Vehicle Population
+ 编号:[137]
+ 链接:https://arxiv.org/abs/2309.12677
+ 作者:Ruyi Feng, Zhibin Li, Bowen Liu, Yan Ding, Ou Zheng
+ 备注:16 pages, 6 figures, under reviewed by Transportation Research Board Annual Meeting, work in update
+ 关键词:Understanding trajectory diversity, addressing practical traffic, practical traffic tasks, Understanding trajectory, traffic tasks
+
+ 点击查看摘要
+ Understanding trajectory diversity is a fundamental aspect of addressing practical traffic tasks. However, capturing the diversity of trajectories presents challenges, particularly with traditional machine learning and recurrent neural networks due to the requirement of large-scale parameters. The emerging Transformer technology, renowned for its parallel computation capabilities enabling the utilization of models with hundreds of millions of parameters, offers a promising solution. In this study, we apply the Transformer architecture to traffic tasks, aiming to learn the diversity of trajectories within vehicle populations. We analyze the Transformer's attention mechanism and its adaptability to the goals of traffic tasks, and subsequently, design specific pre-training tasks. To achieve this, we create a data structure tailored to the attention mechanism and introduce a set of noises that correspond to spatio-temporal demands, which are incorporated into the structured data during the pre-training process. The designed pre-training model demonstrates excellent performance in capturing the spatial distribution of the vehicle population, with no instances of vehicle overlap and an RMSE of 0.6059 when compared to the ground truth values. In the context of time series prediction, approximately 95% of the predicted trajectories' speeds closely align with the true speeds, within a deviation of 7.5144m/s. Furthermore, in the stability test, the model exhibits robustness by continuously predicting a time series ten times longer than the input sequence, delivering smooth trajectories and showcasing diverse driving behaviors. The pre-trained model also provides a good basis for downstream fine-tuning tasks. The number of parameters of our model is over 50 million.
+
+
+
+ 36. 标题:Vision Transformers for Computer Go
+ 编号:[139]
+ 链接:https://arxiv.org/abs/2309.12675
+ 作者:Amani Sagri, Tristan Cazenave, Jérôme Arjonilla, Abdallah Saffidine
+ 备注:
+ 关键词:language understanding, understanding and image, investigation explores, explores their application, image analysis
+
+ 点击查看摘要
+ Motivated by the success of transformers in various fields, such as language understanding and image analysis, this investigation explores their application in the context of the game of Go. In particular, our study focuses on the analysis of the Transformer in Vision. Through a detailed analysis of numerous points such as prediction accuracy, win rates, memory, speed, size, or even learning rate, we have been able to highlight the substantial role that transformers can play in the game of Go. This study was carried out by comparing them to the usual Residual Networks.
+
+
+
+ 37. 标题:On Sparse Modern Hopfield Model
+ 编号:[140]
+ 链接:https://arxiv.org/abs/2309.12673
+ 作者:Jerry Yao-Chieh Hu, Donglin Yang, Dennis Wu, Chenwei Xu, Bo-Yu Chen, Han Liu
+ 备注:37 pages, accepted to NeurIPS 2023
+ 关键词:sparse modern Hopfield, modern Hopfield model, modern Hopfield, Hopfield model, sparse Hopfield model
+
+ 点击查看摘要
+ We introduce the sparse modern Hopfield model as a sparse extension of the modern Hopfield model. Like its dense counterpart, the sparse modern Hopfield model equips a memory-retrieval dynamics whose one-step approximation corresponds to the sparse attention mechanism. Theoretically, our key contribution is a principled derivation of a closed-form sparse Hopfield energy using the convex conjugate of the sparse entropic regularizer. Building upon this, we derive the sparse memory retrieval dynamics from the sparse energy function and show its one-step approximation is equivalent to the sparse-structured attention. Importantly, we provide a sparsity-dependent memory retrieval error bound which is provably tighter than its dense analog. The conditions for the benefits of sparsity to arise are therefore identified and discussed. In addition, we show that the sparse modern Hopfield model maintains the robust theoretical properties of its dense counterpart, including rapid fixed point convergence and exponential memory capacity. Empirically, we use both synthetic and real-world datasets to demonstrate that the sparse Hopfield model outperforms its dense counterpart in many situations.
+
+
+
+ 38. 标题:How to Fine-tune the Model: Unified Model Shift and Model Bias Policy Optimization
+ 编号:[142]
+ 链接:https://arxiv.org/abs/2309.12671
+ 作者:Hai Zhang, Hang Yu, Junqiao Zhao, Di Zhang, ChangHuang, Hongtu Zhou, Xiao Zhang, Chen Ye
+ 备注:
+ 关键词:deriving effective model-based, effective model-based reinforcement, model-based reinforcement learning, model shift, model
+
+ 点击查看摘要
+ Designing and deriving effective model-based reinforcement learning (MBRL) algorithms with a performance improvement guarantee is challenging, mainly attributed to the high coupling between model learning and policy optimization. Many prior methods that rely on return discrepancy to guide model learning ignore the impacts of model shift, which can lead to performance deterioration due to excessive model updates. Other methods use performance difference bound to explicitly consider model shift. However, these methods rely on a fixed threshold to constrain model shift, resulting in a heavy dependence on the threshold and a lack of adaptability during the training process. In this paper, we theoretically derive an optimization objective that can unify model shift and model bias and then formulate a fine-tuning process. This process adaptively adjusts the model updates to get a performance improvement guarantee while avoiding model overfitting. Based on these, we develop a straightforward algorithm USB-PO (Unified model Shift and model Bias Policy Optimization). Empirical results show that USB-PO achieves state-of-the-art performance on several challenging benchmark tasks.
+
+
+
+ 39. 标题:Natural revision is contingently-conditionalized revision
+ 编号:[151]
+ 链接:https://arxiv.org/abs/2309.12655
+ 作者:Paolo Liberatore
+ 备注:
+ 关键词:Natural revision, Natural, revision, current conditions, conditions
+
+ 点击查看摘要
+ Natural revision seems so natural: it changes beliefs as little as possible to incorporate new information. Yet, some counterexamples show it wrong. It is so conservative that it never fully believes. It only believes in the current conditions. This is right in some cases and wrong in others. Which is which? The answer requires extending natural revision from simple formulae expressing universal truths (something holds) to conditionals expressing conditional truth (something holds in certain conditions). The extension is based on the basic principles natural revision follows, identified as minimal change, indifference and naivety: change beliefs as little as possible; equate the likeliness of scenarios by default; believe all until contradicted. The extension says that natural revision restricts changes to the current conditions. A comparison with an unrestricting revision shows what exactly the current conditions are. It is not what currently considered true if it contradicts the new information. It includes something more and more unlikely until the new information is at least possible.
+
+
+
+ 40. 标题:Are Deep Learning Classification Results Obtained on CT Scans Fair and Interpretable?
+ 编号:[163]
+ 链接:https://arxiv.org/abs/2309.12632
+ 作者:Mohamad M.A. Ashames, Ahmet Demir, Omer N. Gerek, Mehmet Fidan, M. Bilginer Gulmezoglu, Semih Ergin, Mehmet Koc, Atalay Barkana, Cuneyt Calisir
+ 备注:This version has been submitted to CAAI Transactions on Intelligence Technology. 2023
+ 关键词:automatic diagnosis cases, deep neural networks, biomedical image processing, image processing society, neural networks trained
+
+ 点击查看摘要
+ Following the great success of various deep learning methods in image and object classification, the biomedical image processing society is also overwhelmed with their applications to various automatic diagnosis cases. Unfortunately, most of the deep learning-based classification attempts in the literature solely focus on the aim of extreme accuracy scores, without considering interpretability, or patient-wise separation of training and test data. For example, most lung nodule classification papers using deep learning randomly shuffle data and split it into training, validation, and test sets, causing certain images from the CT scan of a person to be in the training set, while other images of the exact same person to be in the validation or testing image sets. This can result in reporting misleading accuracy rates and the learning of irrelevant features, ultimately reducing the real-life usability of these models. When the deep neural networks trained on the traditional, unfair data shuffling method are challenged with new patient images, it is observed that the trained models perform poorly. In contrast, deep neural networks trained with strict patient-level separation maintain their accuracy rates even when new patient images are tested. Heat-map visualizations of the activations of the deep neural networks trained with strict patient-level separation indicate a higher degree of focus on the relevant nodules. We argue that the research question posed in the title has a positive answer only if the deep neural networks are trained with images of patients that are strictly isolated from the validation and testing patient sets.
+
+
+
+ 41. 标题:A Quantum Computing-based System for Portfolio Optimization using Future Asset Values and Automatic Reduction of the Investment Universe
+ 编号:[166]
+ 链接:https://arxiv.org/abs/2309.12627
+ 作者:Eneko Osaba, Guillaume Gelabert, Esther Villar-Rodriguez, Antón Asla, Izaskun Oregi
+ 备注:10 pages, 3 figures, paper accepted for being presented in the upcoming 9th International Congress on Information and Communication Technology (ICICT 2024)
+ 关键词:portfolio optimization problem, portfolio optimization, Automatic Universe Reduction, optimization problem, quantitative finance
+
+ 点击查看摘要
+ One of the problems in quantitative finance that has received the most attention is the portfolio optimization problem. Regarding its solving, this problem has been approached using different techniques, with those related to quantum computing being especially prolific in recent years. In this study, we present a system called Quantum Computing-based System for Portfolio Optimization with Future Asset Values and Automatic Universe Reduction (Q4FuturePOP), which deals with the Portfolio Optimization Problem considering the following innovations: i) the developed tool is modeled for working with future prediction of assets, instead of historical values; and ii) Q4FuturePOP includes an automatic universe reduction module, which is conceived to intelligently reduce the complexity of the problem. We also introduce a brief discussion about the preliminary performance of the different modules that compose the prototypical version of Q4FuturePOP.
+
+
+
+ 42. 标题:Construction contract risk identification based on knowledge-augmented language model
+ 编号:[167]
+ 链接:https://arxiv.org/abs/2309.12626
+ 作者:Saika Wong, Chunmo Zheng, Xing Su, Yinqiu Tang
+ 备注:
+ 关键词:prevent potential losses, potential losses, essential step, projects to prevent, prevent potential
+
+ 点击查看摘要
+ Contract review is an essential step in construction projects to prevent potential losses. However, the current methods for reviewing construction contracts lack effectiveness and reliability, leading to time-consuming and error-prone processes. While large language models (LLMs) have shown promise in revolutionizing natural language processing (NLP) tasks, they struggle with domain-specific knowledge and addressing specialized issues. This paper presents a novel approach that leverages LLMs with construction contract knowledge to emulate the process of contract review by human experts. Our tuning-free approach incorporates construction contract domain knowledge to enhance language models for identifying construction contract risks. The use of a natural language when building the domain knowledge base facilitates practical implementation. We evaluated our method on real construction contracts and achieved solid performance. Additionally, we investigated how large language models employ logical thinking during the task and provide insights and recommendations for future research.
+
+
+
+ 43. 标题:DRG-LLaMA : Tuning LLaMA Model to Predict Diagnosis-related Group for Hospitalized Patients
+ 编号:[168]
+ 链接:https://arxiv.org/abs/2309.12625
+ 作者:Hanyin Wang, Chufan Gao, Christopher Dantona, Bryan Hull, Jimeng Sun
+ 备注:
+ 关键词:inpatient payment system, current assignment process, Diagnosis-Related Group, inpatient payment, payment system
+
+ 点击查看摘要
+ In the U.S. inpatient payment system, the Diagnosis-Related Group (DRG) plays a key role but its current assignment process is time-consuming. We introduce DRG-LLaMA, a large language model (LLM) fine-tuned on clinical notes for improved DRG prediction. Using Meta's LLaMA as the base model, we optimized it with Low-Rank Adaptation (LoRA) on 236,192 MIMIC-IV discharge summaries. With an input token length of 512, DRG-LLaMA-7B achieved a macro-averaged F1 score of 0.327, a top-1 prediction accuracy of 52.0% and a macro-averaged Area Under the Curve (AUC) of 0.986. Impressively, DRG-LLaMA-7B surpassed previously reported leading models on this task, demonstrating a relative improvement in macro-averaged F1 score of 40.3% compared to ClinicalBERT and 35.7% compared to CAML. When DRG-LLaMA is applied to predict base DRGs and complication or comorbidity (CC) / major complication or comorbidity (MCC), the top-1 prediction accuracy reached 67.8% for base DRGs and 67.5% for CC/MCC status. DRG-LLaMA performance exhibits improvements in correlation with larger model parameters and longer input context lengths. Furthermore, usage of LoRA enables training even on smaller GPUs with 48 GB of VRAM, highlighting the viability of adapting LLMs for DRGs prediction.
+
+
+
+ 44. 标题:From Text to Trends: A Unique Garden Analytics Perspective on the Future of Modern Agriculture
+ 编号:[191]
+ 链接:https://arxiv.org/abs/2309.12579
+ 作者:Parag Saxena
+ 备注:
+ 关键词:Data-driven insights, insights are essential, essential for modern, Extension Master Gardener, Master Gardener Program
+
+ 点击查看摘要
+ Data-driven insights are essential for modern agriculture. This research paper introduces a machine learning framework designed to improve how we educate and reach out to people in the field of horticulture. The framework relies on data from the Horticulture Online Help Desk (HOHD), which is like a big collection of questions from people who love gardening and are part of the Extension Master Gardener Program (EMGP). This framework has two main parts. First, it uses special computer programs (machine learning models) to sort questions into categories. This helps us quickly send each question to the right expert, so we can answer it faster. Second, it looks at when questions are asked and uses that information to guess how many questions we might get in the future and what they will be about. This helps us plan on topics that will be really important. It's like knowing what questions will be popular in the coming months. We also take into account where the questions come from by looking at the Zip Code. This helps us make research that fits the challenges faced by gardeners in different places. In this paper, we demonstrate the potential of machine learning techniques to predict trends in horticulture by analyzing textual queries from homeowners. We show that NLP, classification, and time series analysis can be used to identify patterns in homeowners' queries and predict future trends in horticulture. Our results suggest that machine learning could be used to predict trends in other agricultural sectors as well. If large-scale agriculture industries curate and maintain a comparable repository of textual data, the potential for trend prediction and strategic agricultural planning could be revolutionized. This convergence of technology and agriculture offers a promising pathway for the future of sustainable farming and data-informed agricultural practices
+
+
+
+ 45. 标题:Understanding Patterns of Deep Learning ModelEvolution in Network Architecture Search
+ 编号:[193]
+ 链接:https://arxiv.org/abs/2309.12576
+ 作者:Robert Underwood, Meghana Madhastha, Randal Burns, Bogdan Nicolae
+ 备注:11 pages, 4 figures
+ 关键词:regularized evolution algorithm, specifically Regularized Evolution, search space.We show, Network Architecture Search, deep learning model.However
+
+ 点击查看摘要
+ Network Architecture Search and specifically Regularized Evolution is a common way to refine the structure of a deep learning model.However, little is known about how models empirically evolve over time which has design implications for designing caching policies, refining the search algorithm for particular applications, and other important use this http URL this work, we algorithmically analyze and quantitatively characterize the patterns of model evolution for a set of models from the Candle project and the Nasbench-201 search space.We show how the evolution of the model structure is influenced by the regularized evolution algorithm. We describe how evolutionary patterns appear in distributed settings and opportunities for caching and improved scheduling. Lastly, we describe the conditions that affect when particular model architectures rise and fall in popularity based on their frequency of acting as a donor in a sliding window.
+
+
+
+ 46. 标题:Creativity Support in the Age of Large Language Models: An Empirical Study Involving Emerging Writers
+ 编号:[195]
+ 链接:https://arxiv.org/abs/2309.12570
+ 作者:Tuhin Chakrabarty, Vishakh Padmakumar, Faeze Brahman, Smaranda Muresan
+ 备注:
+ 关键词:sparked increased interest, large language models, conversational interactions sparked, interactions sparked increased, support tools
+
+ 点击查看摘要
+ The development of large language models (LLMs) capable of following instructions and engaging in conversational interactions sparked increased interest in their utilization across various support tools. We investigate the utility of modern LLMs in assisting professional writers via an empirical user study (n=30). The design of our collaborative writing interface is grounded in the cognitive process model of writing that views writing as a goal-oriented thinking process encompassing non-linear cognitive activities: planning, translating, and reviewing. Participants are asked to submit a post-completion survey to provide feedback on the potential and pitfalls of LLMs as writing collaborators. Upon analyzing the writer-LLM interactions, we find that while writers seek LLM's help across all three types of cognitive activities, they find LLMs more helpful in translation and reviewing. Our findings from analyzing both the interactions and the survey responses highlight future research directions in creative writing assistance using LLMs.
+
+
+
+ 47. 标题:A Study on Learning Social Robot Navigation with Multimodal Perception
+ 编号:[196]
+ 链接:https://arxiv.org/abs/2309.12568
+ 作者:Bhabaranjan Panigrahi, Amir Hossain Raj, Mohammad Nazeri, Xuesu Xiao
+ 备注:
+ 关键词:LiDARs and RGB, RGB cameras, Autonomous mobile robots, social robot navigation, Autonomous mobile
+
+ 点击查看摘要
+ Autonomous mobile robots need to perceive the environments with their onboard sensors (e.g., LiDARs and RGB cameras) and then make appropriate navigation decisions. In order to navigate human-inhabited public spaces, such a navigation task becomes more than only obstacle avoidance, but also requires considering surrounding humans and their intentions to somewhat change the navigation behavior in response to the underlying social norms, i.e., being socially compliant. Machine learning methods are shown to be effective in capturing those complex and subtle social interactions in a data-driven manner, without explicitly hand-crafting simplified models or cost functions. Considering multiple available sensor modalities and the efficiency of learning methods, this paper presents a comprehensive study on learning social robot navigation with multimodal perception using a large-scale real-world dataset. The study investigates social robot navigation decision making on both the global and local planning levels and contrasts unimodal and multimodal learning against a set of classical navigation approaches in different social scenarios, while also analyzing the training and generalizability performance from the learning perspective. We also conduct a human study on how learning with multimodal perception affects the perceived social compliance. The results show that multimodal learning has a clear advantage over unimodal learning in both dataset and human studies. We open-source our code for the community's future use to study multimodal perception for learning social robot navigation.
+
+
+
+ 48. 标题:Machine Learning Meets Advanced Robotic Manipulation
+ 编号:[201]
+ 链接:https://arxiv.org/abs/2309.12560
+ 作者:Saeid Nahavandi, Roohallah Alizadehsani, Darius Nahavandi, Chee Peng Lim, Kevin Kelly, Fernando Bello
+ 备注:
+ 关键词:Automated industries lead, high quality production, lower manufacturing cost, Automated industries, quality production
+
+ 点击查看摘要
+ Automated industries lead to high quality production, lower manufacturing cost and better utilization of human resources. Robotic manipulator arms have major role in the automation process. However, for complex manipulation tasks, hard coding efficient and safe trajectories is challenging and time consuming. Machine learning methods have the potential to learn such controllers based on expert demonstrations. Despite promising advances, better approaches must be developed to improve safety, reliability, and efficiency of ML methods in both training and deployment phases. This survey aims to review cutting edge technologies and recent trends on ML methods applied to real-world manipulation tasks. After reviewing the related background on ML, the rest of the paper is devoted to ML applications in different domains such as industry, healthcare, agriculture, space, military, and search and rescue. The paper is closed with important research directions for future works.
+
+
+
+ 49. 标题:Invariant Learning via Probability of Sufficient and Necessary Causes
+ 编号:[202]
+ 链接:https://arxiv.org/abs/2309.12559
+ 作者:Mengyue Yang, Zhen Fang, Yonggang Zhang, Yali Du, Furui Liu, Jean-Francois Ton, Jun Wang
+ 备注:
+ 关键词:testing distribution typically, distribution typically unknown, achieving OOD generalization, OOD generalization, indispensable for learning
+
+ 点击查看摘要
+ Out-of-distribution (OOD) generalization is indispensable for learning models in the wild, where testing distribution typically unknown and different from the training. Recent methods derived from causality have shown great potential in achieving OOD generalization. However, existing methods mainly focus on the invariance property of causes, while largely overlooking the property of \textit{sufficiency} and \textit{necessity} conditions. Namely, a necessary but insufficient cause (feature) is invariant to distribution shift, yet it may not have required accuracy. By contrast, a sufficient yet unnecessary cause (feature) tends to fit specific data well but may have a risk of adapting to a new domain. To capture the information of sufficient and necessary causes, we employ a classical concept, the probability of sufficiency and necessary causes (PNS), which indicates the probability of whether one is the necessary and sufficient cause. To associate PNS with OOD generalization, we propose PNS risk and formulate an algorithm to learn representation with a high PNS value. We theoretically analyze and prove the generalizability of the PNS risk. Experiments on both synthetic and real-world benchmarks demonstrate the effectiveness of the proposed method. The details of the implementation can be found at the GitHub repository: this https URL.
+
+
+
+ 50. 标题:PlanFitting: Tailoring Personalized Exercise Plans with Large Language Models
+ 编号:[204]
+ 链接:https://arxiv.org/abs/2309.12555
+ 作者:Donghoon Shin, Gary Hsieh, Young-Ho Kim
+ 备注:22 pages, 5 figures, 1 table
+ 关键词:sufficient physical activities, ensuring sufficient physical, tailored exercise regimen, personally tailored exercise, physical activities
+
+ 点击查看摘要
+ A personally tailored exercise regimen is crucial to ensuring sufficient physical activities, yet challenging to create as people have complex schedules and considerations and the creation of plans often requires iterations with experts. We present PlanFitting, a conversational AI that assists in personalized exercise planning. Leveraging generative capabilities of large language models, PlanFitting enables users to describe various constraints and queries in natural language, thereby facilitating the creation and refinement of their weekly exercise plan to suit their specific circumstances while staying grounded in foundational principles. Through a user study where participants (N=18) generated a personalized exercise plan using PlanFitting and expert planners (N=3) evaluated these plans, we identified the potential of PlanFitting in generating personalized, actionable, and evidence-based exercise plans. We discuss future design opportunities for AI assistants in creating plans that better comply with exercise principles and accommodate personal constraints.
+
+
+
+ 51. 标题:Provably Robust and Plausible Counterfactual Explanations for Neural Networks via Robust Optimisation
+ 编号:[209]
+ 链接:https://arxiv.org/abs/2309.12545
+ 作者:Junqi Jiang, Jianglin Lan, Francesco Leofante, Antonio Rago, Francesca Toni
+ 备注:Accepted at ACML 2023, camera-ready version
+ 关键词:neural network classifiers, received increasing interest, explaining neural network, network classifiers, Counterfactual Explanations
+
+ 点击查看摘要
+ Counterfactual Explanations (CEs) have received increasing interest as a major methodology for explaining neural network classifiers. Usually, CEs for an input-output pair are defined as data points with minimum distance to the input that are classified with a different label than the output. To tackle the established problem that CEs are easily invalidated when model parameters are updated (e.g. retrained), studies have proposed ways to certify the robustness of CEs under model parameter changes bounded by a norm ball. However, existing methods targeting this form of robustness are not sound or complete, and they may generate implausible CEs, i.e., outliers wrt the training dataset. In fact, no existing method simultaneously optimises for proximity and plausibility while preserving robustness guarantees. In this work, we propose Provably RObust and PLAusible Counterfactual Explanations (PROPLACE), a method leveraging on robust optimisation techniques to address the aforementioned limitations in the literature. We formulate an iterative algorithm to compute provably robust CEs and prove its convergence, soundness and completeness. Through a comparative experiment involving six baselines, five of which target robustness, we show that PROPLACE achieves state-of-the-art performances against metrics on three evaluation aspects.
+
+
+
+ 52. 标题:Curriculum Reinforcement Learning via Morphology-Environment Co-Evolution
+ 编号:[215]
+ 链接:https://arxiv.org/abs/2309.12529
+ 作者:Shuang Ao, Tianyi Zhou, Guodong Long, Xuan Song, Jing Jiang
+ 备注:
+ 关键词:physical structures adaptive, morphology, long history, natural species, species have learned
+
+ 点击查看摘要
+ Throughout long history, natural species have learned to survive by evolving their physical structures adaptive to the environment changes. In contrast, current reinforcement learning (RL) studies mainly focus on training an agent with a fixed morphology (e.g., skeletal structure and joint attributes) in a fixed environment, which can hardly generalize to changing environments or new tasks. In this paper, we optimize an RL agent and its morphology through ``morphology-environment co-evolution (MECE)'', in which the morphology keeps being updated to adapt to the changing environment, while the environment is modified progressively to bring new challenges and stimulate the improvement of the morphology. This leads to a curriculum to train generalizable RL, whose morphology and policy are optimized for different environments. Instead of hand-crafting the curriculum, we train two policies to automatically change the morphology and the environment. To this end, (1) we develop two novel and effective rewards for the two policies, which are solely based on the learning dynamics of the RL agent; (2) we design a scheduler to automatically determine when to change the environment and the morphology. In experiments on two classes of tasks, the morphology and RL policies trained via MECE exhibit significantly better generalization performance in unseen test environments than SOTA morphology optimization methods. Our ablation studies on the two MECE policies further show that the co-evolution between the morphology and environment is the key to the success.
+
+
+
+ 53. 标题:Knowledge Graph Embedding: An Overview
+ 编号:[224]
+ 链接:https://arxiv.org/abs/2309.12501
+ 作者:Xiou Ge, Yun-Cheng Wang, Bin Wang, C.-C. Jay Kuo
+ 备注:
+ 关键词:representing Knowledge Graph, Knowledge Graph, representing Knowledge, downstream tasks, link prediction
+
+ 点击查看摘要
+ Many mathematical models have been leveraged to design embeddings for representing Knowledge Graph (KG) entities and relations for link prediction and many downstream tasks. These mathematically-inspired models are not only highly scalable for inference in large KGs, but also have many explainable advantages in modeling different relation patterns that can be validated through both formal proofs and empirical results. In this paper, we make a comprehensive overview of the current state of research in KG completion. In particular, we focus on two main branches of KG embedding (KGE) design: 1) distance-based methods and 2) semantic matching-based methods. We discover the connections between recently proposed models and present an underlying trend that might help researchers invent novel and more effective models. Next, we delve into CompoundE and CompoundE3D, which draw inspiration from 2D and 3D affine operations, respectively. They encompass a broad spectrum of techniques including distance-based and semantic-based methods. We will also discuss an emerging approach for KG completion which leverages pre-trained language models (PLMs) and textual descriptions of entities and relations and offer insights into the integration of KGE embedding methods with PLMs for KG completion.
+
+
+
+ 54. 标题:Exploring the Impact of Training Data Distribution and Subword Tokenization on Gender Bias in Machine Translation
+ 编号:[228]
+ 链接:https://arxiv.org/abs/2309.12491
+ 作者:Bar Iluz, Tomasz Limisiewicz, Gabriel Stanovsky, David Mareček
+ 备注:Accepted to AACL 2023
+ 关键词:previous works, gender bias, study the effect, effect of tokenization, largely overlooked
+
+ 点击查看摘要
+ We study the effect of tokenization on gender bias in machine translation, an aspect that has been largely overlooked in previous works. Specifically, we focus on the interactions between the frequency of gendered profession names in training data, their representation in the subword tokenizer's vocabulary, and gender bias. We observe that female and non-stereotypical gender inflections of profession names (e.g., Spanish "doctora" for "female doctor") tend to be split into multiple subword tokens. Our results indicate that the imbalance of gender forms in the model's training corpus is a major factor contributing to gender bias and has a greater impact than subword splitting. We show that analyzing subword splits provides good estimates of gender-form imbalance in the training data and can be used even when the corpus is not publicly available. We also demonstrate that fine-tuning just the token embedding layer can decrease the gap in gender prediction accuracy between female and male forms without impairing the translation quality.
+
+
+
+ 55. 标题:Studying and improving reasoning in humans and machines
+ 编号:[231]
+ 链接:https://arxiv.org/abs/2309.12485
+ 作者:Nicolas Yax, Hernan Anlló, Stefano Palminteri
+ 备注:The paper is split in 4 parts : main text (pages 2-27), methods (pages 28-34), technical appendix (pages 35-45) and supplementary methods (pages 46-125)
+ 关键词:tools traditionally dedicated, large language models, psychology tools traditionally, present study, cognitive psychology tools
+
+ 点击查看摘要
+ In the present study, we investigate and compare reasoning in large language models (LLM) and humans using a selection of cognitive psychology tools traditionally dedicated to the study of (bounded) rationality. To do so, we presented to human participants and an array of pretrained LLMs new variants of classical cognitive experiments, and cross-compared their performances. Our results showed that most of the included models presented reasoning errors akin to those frequently ascribed to error-prone, heuristic-based human reasoning. Notwithstanding this superficial similarity, an in-depth comparison between humans and LLMs indicated important differences with human-like reasoning, with models limitations disappearing almost entirely in more recent LLMs releases. Moreover, we show that while it is possible to devise strategies to induce better performance, humans and machines are not equally-responsive to the same prompting schemes. We conclude by discussing the epistemological implications and challenges of comparing human and machine behavior for both artificial intelligence and cognitive psychology.
+
+
+
+ 56. 标题:State2Explanation: Concept-Based Explanations to Benefit Agent Learning and User Understanding
+ 编号:[234]
+ 链接:https://arxiv.org/abs/2309.12482
+ 作者:Devleena Das, Sonia Chernova, Been Kim
+ 备注:Accepted to NeurIPS 2023
+ 关键词:non-AI experts, understandable by non-AI, complete daily tasks, decision making understandable, decision making
+
+ 点击查看摘要
+ With more complex AI systems used by non-AI experts to complete daily tasks, there is an increasing effort to develop methods that produce explanations of AI decision making understandable by non-AI experts. Towards this effort, leveraging higher-level concepts and producing concept-based explanations have become a popular method. Most concept-based explanations have been developed for classification techniques, and we posit that the few existing methods for sequential decision making are limited in scope. In this work, we first contribute a desiderata for defining "concepts" in sequential decision making settings. Additionally, inspired by the Protege Effect which states explaining knowledge often reinforces one's self-learning, we explore the utility of concept-based explanations providing a dual benefit to the RL agent by improving agent learning rate, and to the end-user by improving end-user understanding of agent decision making. To this end, we contribute a unified framework, State2Explanation (S2E), that involves learning a joint embedding model between state-action pairs and concept-based explanations, and leveraging such learned model to both (1) inform reward shaping during an agent's training, and (2) provide explanations to end-users at deployment for improved task performance. Our experimental validations, in Connect 4 and Lunar Lander, demonstrate the success of S2E in providing a dual-benefit, successfully informing reward shaping and improving agent learning rate, as well as significantly improving end user task performance at deployment time.
+
+
+
+ 57. 标题:SAVME: Efficient Safety Validation for Autonomous Systems Using Meta-Learning
+ 编号:[238]
+ 链接:https://arxiv.org/abs/2309.12474
+ 作者:Marc R. Schlichting, Nina V. Board, Anthony L. Corso, Mykel J. Kochenderfer
+ 备注:Accepted for ITSC 2023
+ 关键词:Discovering potential failures, Discovering potential, prior to deployment, important prior, potential failures
+
+ 点击查看摘要
+ Discovering potential failures of an autonomous system is important prior to deployment. Falsification-based methods are often used to assess the safety of such systems, but the cost of running many accurate simulation can be high. The validation can be accelerated by identifying critical failure scenarios for the system under test and by reducing the simulation runtime. We propose a Bayesian approach that integrates meta-learning strategies with a multi-armed bandit framework. Our method involves learning distributions over scenario parameters that are prone to triggering failures in the system under test, as well as a distribution over fidelity settings that enable fast and accurate simulations. In the spirit of meta-learning, we also assess whether the learned fidelity settings distribution facilitates faster learning of the scenario parameter distributions for new scenarios. We showcase our methodology using a cutting-edge 3D driving simulator, incorporating 16 fidelity settings for an autonomous vehicle stack that includes camera and lidar sensors. We evaluate various scenarios based on an autonomous vehicle pre-crash typology. As a result, our approach achieves a significant speedup, up to 18 times faster compared to traditional methods that solely rely on a high-fidelity simulator.
+
+
+
+ 58. 标题:Multimodal Deep Learning for Scientific Imaging Interpretation
+ 编号:[243]
+ 链接:https://arxiv.org/abs/2309.12460
+ 作者:Abdulelah S. Alshehri, Franklin L. Lee, Shihu Wang
+ 备注:
+ 关键词:Scanning Electron Microscopy, interpreting visual data, demands an intricate, intricate combination, subject materials
+
+ 点击查看摘要
+ In the domain of scientific imaging, interpreting visual data often demands an intricate combination of human expertise and deep comprehension of the subject materials. This study presents a novel methodology to linguistically emulate and subsequently evaluate human-like interactions with Scanning Electron Microscopy (SEM) images, specifically of glass materials. Leveraging a multimodal deep learning framework, our approach distills insights from both textual and visual data harvested from peer-reviewed articles, further augmented by the capabilities of GPT-4 for refined data synthesis and evaluation. Despite inherent challenges--such as nuanced interpretations and the limited availability of specialized datasets--our model (GlassLLaVA) excels in crafting accurate interpretations, identifying key features, and detecting defects in previously unseen SEM images. Moreover, we introduce versatile evaluation metrics, suitable for an array of scientific imaging applications, which allows for benchmarking against research-grounded answers. Benefiting from the robustness of contemporary Large Language Models, our model adeptly aligns with insights from research papers. This advancement not only underscores considerable progress in bridging the gap between human and machine interpretation in scientific imaging, but also hints at expansive avenues for future research and broader application.
+
+
+
+ 59. 标题:LongDocFACTScore: Evaluating the Factuality of Long Document Abstractive Summarisation
+ 编号:[246]
+ 链接:https://arxiv.org/abs/2309.12455
+ 作者:Jennifer A Bishop, Qianqian Xie, Sophia Ananiadou
+ 备注:12 pages, 5 figures
+ 关键词:ROUGE scoring, text summarisation, abstractive text summarisation, long document text, document text summarisation
+
+ 点击查看摘要
+ Maintaining factual consistency is a critical issue in abstractive text summarisation, however, it cannot be assessed by traditional automatic metrics used for evaluating text summarisation, such as ROUGE scoring. Recent efforts have been devoted to developing improved metrics for measuring factual consistency using pre-trained language models, but these metrics have restrictive token limits, and are therefore not suitable for evaluating long document text summarisation. Moreover, there is limited research evaluating whether existing automatic evaluation metrics are fit for purpose when applied to long document data sets. In this work, we evaluate the efficacy of automatic metrics at assessing factual consistency in long document text summarisation and propose a new evaluation framework LongDocFACTScore. This framework allows metrics to be extended to any length document. This framework outperforms existing state-of-the-art metrics in its ability to correlate with human measures of factuality when used to evaluate long document summarisation data sets. Furthermore, we show LongDocFACTScore has performance comparable to state-of-the-art metrics when evaluated against human measures of factual consistency on short document data sets. We make our code and annotated data publicly available: this https URL.
+
+
+
+ 60. 标题:Ensemble Neural Networks for Remaining Useful Life (RUL) Prediction
+ 编号:[248]
+ 链接:https://arxiv.org/abs/2309.12445
+ 作者:Ahbishek Srinivasan, Juan Carlos Andresen, Anders Holst
+ 备注:6 pages, 2 figures, 2 tables, conference proceeding
+ 关键词:health and degradation, remaining useful life, probabilistic RUL predictions, RUL prediction focus, core part
+
+ 点击查看摘要
+ A core part of maintenance planning is a monitoring system that provides a good prognosis on health and degradation, often expressed as remaining useful life (RUL). Most of the current data-driven approaches for RUL prediction focus on single-point prediction. These point prediction approaches do not include the probabilistic nature of the failure. The few probabilistic approaches to date either include the aleatoric uncertainty (which originates from the system), or the epistemic uncertainty (which originates from the model parameters), or both simultaneously as a total uncertainty. Here, we propose ensemble neural networks for probabilistic RUL predictions which considers both uncertainties and decouples these two uncertainties. These decoupled uncertainties are vital in knowing and interpreting the confidence of the predictions. This method is tested on NASA's turbofan jet engine CMAPSS data-set. Our results show how these uncertainties can be modeled and how to disentangle the contribution of aleatoric and epistemic uncertainty. Additionally, our approach is evaluated on different metrics and compared against the current state-of-the-art methods.
+
+
+
+ 61. 标题:Can LLMs Augment Low-Resource Reading Comprehension Datasets? Opportunities and Challenges
+ 编号:[258]
+ 链接:https://arxiv.org/abs/2309.12426
+ 作者:Vinay Samuel, Houda Aynaou, Arijit Ghosh Chowdhury, Karthik Venkat Ramanan, Aman Chadha
+ 备注:5 pages, 1 figure, 3 tables
+ 关键词:Large Language Models, Language Models, range of NLP, NLP tasks, demonstrating the ability
+
+ 点击查看摘要
+ Large Language Models (LLMs) have demonstrated impressive zero shot performance on a wide range of NLP tasks, demonstrating the ability to reason and apply commonsense. A relevant application is to use them for creating high quality synthetic datasets for downstream tasks. In this work, we probe whether GPT-4 can be used to augment existing extractive reading comprehension datasets. Automating data annotation processes has the potential to save large amounts of time, money and effort that goes into manually labelling datasets. In this paper, we evaluate the performance of GPT-4 as a replacement for human annotators for low resource reading comprehension tasks, by comparing performance after fine tuning, and the cost associated with annotation. This work serves to be the first analysis of LLMs as synthetic data augmenters for QA systems, highlighting the unique opportunities and challenges. Additionally, we release augmented versions of low resource datasets, that will allow the research community to create further benchmarks for evaluation of generated datasets.
+
+
+
+ 62. 标题:Event Prediction using Case-Based Reasoning over Knowledge Graphs
+ 编号:[260]
+ 链接:https://arxiv.org/abs/2309.12423
+ 作者:Sola Shirai, Debarun Bhattacharjya, Oktie Hassanzadeh
+ 备注:published at WWW '23: Proceedings of the ACM Web Conference 2023. Code base: this https URL
+ 关键词:Applying link prediction, exciting opportunity, Applying link, knowledge graphs, link prediction
+
+ 点击查看摘要
+ Applying link prediction (LP) methods over knowledge graphs (KG) for tasks such as causal event prediction presents an exciting opportunity. However, typical LP models are ill-suited for this task as they are incapable of performing inductive link prediction for new, unseen event entities and they require retraining as knowledge is added or changed in the underlying KG. We introduce a case-based reasoning model, EvCBR, to predict properties about new consequent events based on similar cause-effect events present in the KG. EvCBR uses statistical measures to identify similar events and performs path-based predictions, requiring no training step. To generalize our methods beyond the domain of event prediction, we frame our task as a 2-hop LP task, where the first hop is a causal relation connecting a cause event to a new effect event and the second hop is a property about the new event which we wish to predict. The effectiveness of our method is demonstrated using a novel dataset of newsworthy events with causal relations curated from Wikidata, where EvCBR outperforms baselines including translational-distance-based, GNN-based, and rule-based LP models.
+
+
+
+ 63. 标题:Constraints First: A New MDD-based Model to Generate Sentences Under Constraints
+ 编号:[262]
+ 链接:https://arxiv.org/abs/2309.12415
+ 作者:Alexandre Bonlarron, Aurélie Calabrèse, Pierre Kornprobst, Jean-Charles Régin
+ 备注:To be published in Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI 2023
+ 关键词:generating strongly constrained, approach to generating, generating strongly, strongly constrained texts, standardized sentence generation
+
+ 点击查看摘要
+ This paper introduces a new approach to generating strongly constrained texts. We consider standardized sentence generation for the typical application of vision screening. To solve this problem, we formalize it as a discrete combinatorial optimization problem and utilize multivalued decision diagrams (MDD), a well-known data structure to deal with constraints. In our context, one key strength of MDD is to compute an exhaustive set of solutions without performing any search. Once the sentences are obtained, we apply a language model (GPT-2) to keep the best ones. We detail this for English and also for French where the agreement and conjugation rules are known to be more complex. Finally, with the help of GPT-2, we get hundreds of bona-fide candidate sentences. When compared with the few dozen sentences usually available in the well-known vision screening test (MNREAD), this brings a major breakthrough in the field of standardized sentence generation. Also, as it can be easily adapted for other languages, it has the potential to make the MNREAD test even more valuable and usable. More generally, this paper highlights MDD as a convincing alternative for constrained text generation, especially when the constraints are hard to satisfy, but also for many other prospects.
+
+
+
+ 64. 标题:SCOB: Universal Text Understanding via Character-wise Supervised Contrastive Learning with Online Text Rendering for Bridging Domain Gap
+ 编号:[266]
+ 链接:https://arxiv.org/abs/2309.12382
+ 作者:Daehee Kim, Yoonsik Kim, DongHyun Kim, Yumin Lim, Geewook Kim, Taeho Kil
+ 备注:ICCV 2023
+ 关键词:visual document understanding, explored LM-based pre-training, language model, recent studies, great success
+
+ 点击查看摘要
+ Inspired by the great success of language model (LM)-based pre-training, recent studies in visual document understanding have explored LM-based pre-training methods for modeling text within document images. Among them, pre-training that reads all text from an image has shown promise, but often exhibits instability and even fails when applied to broader domains, such as those involving both visual documents and scene text images. This is a substantial limitation for real-world scenarios, where the processing of text image inputs in diverse domains is essential. In this paper, we investigate effective pre-training tasks in the broader domains and also propose a novel pre-training method called SCOB that leverages character-wise supervised contrastive learning with online text rendering to effectively pre-train document and scene text domains by bridging the domain gap. Moreover, SCOB enables weakly supervised learning, significantly reducing annotation costs. Extensive benchmarks demonstrate that SCOB generally improves vanilla pre-training methods and achieves comparable performance to state-of-the-art methods. Our findings suggest that SCOB can be served generally and effectively for read-type pre-training methods. The code will be available at this https URL.
+
+
+
+ 65. 标题:Rethinking Human-AI Collaboration in Complex Medical Decision Making: A Case Study in Sepsis Diagnosis
+ 编号:[271]
+ 链接:https://arxiv.org/abs/2309.12368
+ 作者:Shao Zhang, Jianing Yu, Xuhai Xu, Changchang Yin, Yuxuan Lu, Bingsheng Yao, Melanie Tory, Lace M. Padilla, Jeffrey Caterino, Ping Zhang, Dakuo Wang
+ 备注:Under submission to CHI2024
+ 关键词:real-world deployment, succeed on benchmark, benchmark datasets, datasets in research, research papers
+
+ 点击查看摘要
+ Today's AI systems for medical decision support often succeed on benchmark datasets in research papers but fail in real-world deployment. This work focuses on the decision making of sepsis, an acute life-threatening systematic infection that requires an early diagnosis with high uncertainty from the clinician. Our aim is to explore the design requirements for AI systems that can support clinical experts in making better decisions for the early diagnosis of sepsis. The study begins with a formative study investigating why clinical experts abandon an existing AI-powered Sepsis predictive module in their electrical health record (EHR) system. We argue that a human-centered AI system needs to support human experts in the intermediate stages of a medical decision-making process (e.g., generating hypotheses or gathering data), instead of focusing only on the final decision. Therefore, we build SepsisLab based on a state-of-the-art AI algorithm and extend it to predict the future projection of sepsis development, visualize the prediction uncertainty, and propose actionable suggestions (i.e., which additional laboratory tests can be collected) to reduce such uncertainty. Through heuristic evaluation with six clinicians using our prototype system, we demonstrate that SepsisLab enables a promising human-AI collaboration paradigm for the future of AI-assisted sepsis diagnosis and other high-stakes medical decision making.
+
+
+
+ 66. 标题:Examining the Influence of Varied Levels of Domain Knowledge Base Inclusion in GPT-based Intelligent Tutors
+ 编号:[272]
+ 链接:https://arxiv.org/abs/2309.12367
+ 作者:Blake Castleman, Mehmet Kerem Turkcan
+ 备注:
+ 关键词:large language models, sophisticated conversational capabilities, intelligent tutors, Recent advancements, language models
+
+ 点击查看摘要
+ Recent advancements in large language models (LLMs) have facilitated the development of chatbots with sophisticated conversational capabilities. However, LLMs exhibit frequent inaccurate responses to queries, hindering applications in educational settings. In this paper, we investigate the effectiveness of integrating a knowledge base (KB) with LLM intelligent tutors to increase response reliability. To achieve this, we design a scaleable KB that affords educational supervisors seamless integration of lesson curricula, which is automatically processed by the intelligent tutoring system. We then detail an evaluation, where student participants were presented with questions about the artificial intelligence curriculum to respond to. GPT-4 intelligent tutors with varying hierarchies of KB access and human domain experts then assessed these responses. Lastly, students cross-examined the intelligent tutors' responses to the domain experts' and ranked their various pedagogical abilities. Results suggest that, although these intelligent tutors still demonstrate a lower accuracy compared to domain experts, the accuracy of the intelligent tutors increases when access to a KB is granted. We also observe that the intelligent tutors with KB access exhibit better pedagogical abilities to speak like a teacher and understand students than those of domain experts, while their ability to help students remains lagging behind domain experts.
+
+
+
+ 67. 标题:An Efficient Intelligent Semi-Automated Warehouse Inventory Stocktaking System
+ 编号:[274]
+ 链接:https://arxiv.org/abs/2309.12365
+ 作者:Chunan Tong
+ 备注:
+ 关键词:evolving supply chain, supply chain management, substantially for businesses, efficient inventory management, context of evolving
+
+ 点击查看摘要
+ In the context of evolving supply chain management, the significance of efficient inventory management has grown substantially for businesses. However, conventional manual and experience-based approaches often struggle to meet the complexities of modern market demands. This research introduces an intelligent inventory management system to address challenges related to inaccurate data, delayed monitoring, and overreliance on subjective experience in forecasting. The proposed system integrates bar code and distributed flutter application technologies for intelligent perception, alongside comprehensive big data analytics to enable data-driven decision-making. Through meticulous analysis, system design, critical technology exploration, and simulation validation, the effectiveness of the proposed system is successfully demonstrated. The intelligent system facilitates second-level monitoring, high-frequency checks, and artificial intelligence-driven forecasting, consequently enhancing the automation, precision, and intelligence of inventory management. This system contributes to cost reduction and optimized inventory sizes through accurate predictions and informed decisions, ultimately achieving a mutually beneficial scenario. The outcomes of this research offer
+
+
+
+ 68. 标题:Investigating Online Financial Misinformation and Its Consequences: A Computational Perspective
+ 编号:[276]
+ 链接:https://arxiv.org/abs/2309.12363
+ 作者:Aman Rangapur, Haoran Wang, Kai Shu
+ 备注:32 pages, 2 figures
+ 关键词:financial misinformation, online financial misinformation, financial, misinformation, realm of finance
+
+ 点击查看摘要
+ The rapid dissemination of information through digital platforms has revolutionized the way we access and consume news and information, particularly in the realm of finance. However, this digital age has also given rise to an alarming proliferation of financial misinformation, which can have detrimental effects on individuals, markets, and the overall economy. This research paper aims to provide a comprehensive survey of online financial misinformation, including its types, sources, and impacts. We first discuss the characteristics and manifestations of financial misinformation, encompassing false claims and misleading content. We explore various case studies that illustrate the detrimental consequences of financial misinformation on the economy. Finally, we highlight the potential impact and implications of detecting financial misinformation. Early detection and mitigation strategies can help protect investors, enhance market transparency, and preserve financial stability. We emphasize the importance of greater awareness, education, and regulation to address the issue of online financial misinformation and safeguard individuals and businesses from its harmful effects. In conclusion, this research paper sheds light on the pervasive issue of online financial misinformation and its wide-ranging consequences. By understanding the types, sources, and impacts of misinformation, stakeholders can work towards implementing effective detection and prevention measures to foster a more informed and resilient financial ecosystem.
+
+
+
+ 69. 标题:ChatGPT Assisting Diagnosis of Neuro-ophthalmology Diseases Based on Case Reports
+ 编号:[278]
+ 链接:https://arxiv.org/abs/2309.12361
+ 作者:Yeganeh Madadi, Mohammad Delsoz, Priscilla A. Lao, Joseph W. Fong, TJ Hollingsworth, Malik Y. Kahook, Siamak Yousefi
+ 备注:
+ 关键词:large language models, ChatGPT, detailed case descriptions, neuro-ophthalmic diseases based, neuro-ophthalmic diseases
+
+ 点击查看摘要
+ Objective: To evaluate the efficiency of large language models (LLMs) such as ChatGPT to assist in diagnosing neuro-ophthalmic diseases based on detailed case descriptions. Methods: We selected 22 different case reports of neuro-ophthalmic diseases from a publicly available online database. These cases included a wide range of chronic and acute diseases that are commonly seen by neuro-ophthalmic sub-specialists. We inserted the text from each case as a new prompt into both ChatGPT v3.5 and ChatGPT Plus v4.0 and asked for the most probable diagnosis. We then presented the exact information to two neuro-ophthalmologists and recorded their diagnoses followed by comparison to responses from both versions of ChatGPT. Results: ChatGPT v3.5, ChatGPT Plus v4.0, and the two neuro-ophthalmologists were correct in 13 (59%), 18 (82%), 19 (86%), and 19 (86%) out of 22 cases, respectively. The agreement between the various diagnostic sources were as follows: ChatGPT v3.5 and ChatGPT Plus v4.0, 13 (59%); ChatGPT v3.5 and the first neuro-ophthalmologist, 12 (55%); ChatGPT v3.5 and the second neuro-ophthalmologist, 12 (55%); ChatGPT Plus v4.0 and the first neuro-ophthalmologist, 17 (77%); ChatGPT Plus v4.0 and the second neuro-ophthalmologist, 16 (73%); and first and second neuro-ophthalmologists 17 (17%). Conclusions: The accuracy of ChatGPT v3.5 and ChatGPT Plus v4.0 in diagnosing patients with neuro-ophthalmic diseases was 59% and 82%, respectively. With further development, ChatGPT Plus v4.0 may have potential to be used in clinical care settings to assist clinicians in providing quick, accurate diagnoses of patients in neuro-ophthalmology. The applicability of using LLMs like ChatGPT in clinical settings that lack access to subspeciality trained neuro-ophthalmologists deserves further research.
+
+
+
+ 70. 标题:Efficient Social Choice via NLP and Sampling
+ 编号:[279]
+ 链接:https://arxiv.org/abs/2309.12360
+ 作者:Lior Ashkenazy, Nimrod Talmon
+ 备注:
+ 关键词:Attention-Aware Social Choice, Social Choice tackles, fundamental conflict faced, decision making processes, Natural Language Processing
+
+ 点击查看摘要
+ Attention-Aware Social Choice tackles the fundamental conflict faced by some agent communities between their desire to include all members in the decision making processes and the limited time and attention that are at the disposal of the community members. Here, we investigate a combination of two techniques for attention-aware social choice, namely Natural Language Processing (NLP) and Sampling. Essentially, we propose a system in which each governance proposal to change the status quo is first sent to a trained NLP model that estimates the probability that the proposal would pass if all community members directly vote on it; then, based on such an estimation, a population sample of a certain size is being selected and the proposal is decided upon by taking the sample majority. We develop several concrete algorithms following the scheme described above and evaluate them using various data, including such from several Decentralized Autonomous Organizations (DAOs).
+
+
+
+ 71. 标题:Mapping AI Arguments in Journalism Studies
+ 编号:[282]
+ 链接:https://arxiv.org/abs/2309.12357
+ 作者:Gregory Gondwe
+ 备注:
+ 关键词:examining Artificial Intelligence, Artificial Intelligence, mass communication research, examining Artificial, study investigates
+
+ 点击查看摘要
+ This study investigates and suggests typologies for examining Artificial Intelligence (AI) within the domains of journalism and mass communication research. We aim to elucidate the seven distinct subfields of AI, which encompass machine learning, natural language processing (NLP), speech recognition, expert systems, planning, scheduling, optimization, robotics, and computer vision, through the provision of concrete examples and practical applications. The primary objective is to devise a structured framework that can help AI researchers in the field of journalism. By comprehending the operational principles of each subfield, scholars can enhance their ability to focus on a specific facet when analyzing a particular research topic.
+
+
+
+ 72. 标题:A Critical Examination of the Ethics of AI-Mediated Peer Review
+ 编号:[283]
+ 链接:https://arxiv.org/abs/2309.12356
+ 作者:Laurie A. Schintler, Connie L. McNeely, James Witte
+ 备注:21 pages, 1 figure
+ 关键词:including large language, large language models, peer review, AI-driven peer review, peer review systems
+
+ 点击查看摘要
+ Recent advancements in artificial intelligence (AI) systems, including large language models like ChatGPT, offer promise and peril for scholarly peer review. On the one hand, AI can enhance efficiency by addressing issues like long publication delays. On the other hand, it brings ethical and social concerns that could compromise the integrity of the peer review process and outcomes. However, human peer review systems are also fraught with related problems, such as biases, abuses, and a lack of transparency, which already diminish credibility. While there is increasing attention to the use of AI in peer review, discussions revolve mainly around plagiarism and authorship in academic journal publishing, ignoring the broader epistemic, social, cultural, and societal epistemic in which peer review is positioned. The legitimacy of AI-driven peer review hinges on the alignment with the scientific ethos, encompassing moral and epistemic norms that define appropriate conduct in the scholarly community. In this regard, there is a "norm-counternorm continuum," where the acceptability of AI in peer review is shaped by institutional logics, ethical practices, and internal regulatory mechanisms. The discussion here emphasizes the need to critically assess the legitimacy of AI-driven peer review, addressing the benefits and downsides relative to the broader epistemic, social, ethical, and regulatory factors that sculpt its implementation and impact.
+
+
+
+ 73. 标题:Establishing trust in automated reasoning
+ 编号:[288]
+ 链接:https://arxiv.org/abs/2309.12351
+ 作者:Konrad Hinsen (SSOLEIL, CBM)
+ 备注:
+ 关键词:automated reasoning, scientific research, growing importance, importance in scientific, underlying automated reasoning
+
+ 点击查看摘要
+ Since its beginnings in the 1940s, automated reasoning by computers has become a tool of ever growing importance in scientific research. So far, the rules underlying automated reasoning have mainly been formulated by humans, in the form of program source code. Rules derived from large amounts of data, via machine learning techniques, are a complementary approach currently under intense development. The question of why we should trust these systems, and the results obtained with their help, has been discussed by philosophers of science but has so far received little attention by practitioners. The present work focuses on independent reviewing, an important source of trust in science, and identifies the characteristics of automated reasoning systems that affect their reviewability. It also discusses possible steps towards increasing reviewability and trustworthiness via a combination of technical and social measures.
+
+
+
+ 74. 标题:Considerations for health care institutions training large language models on electronic health records
+ 编号:[299]
+ 链接:https://arxiv.org/abs/2309.12339
+ 作者:Weipeng Zhou, Danielle Bitterman, Majid Afshar, Timothy A. Miller
+ 备注:
+ 关键词:electronic health record, Large language models, Large language, scientists across fields, ChatGPT have excited
+
+ 点击查看摘要
+ Large language models (LLMs) like ChatGPT have excited scientists across fields; in medicine, one source of excitement is the potential applications of LLMs trained on electronic health record (EHR) data. But there are tough questions we must first answer if health care institutions are interested in having LLMs trained on their own data; should they train an LLM from scratch or fine-tune it from an open-source model? For healthcare institutions with a predefined budget, what are the biggest LLMs they can afford? In this study, we take steps towards answering these questions with an analysis on dataset sizes, model sizes, and costs for LLM training using EHR data. This analysis provides a framework for thinking about these questions in terms of data scale, compute scale, and training budgets.
+
+
+
+ 75. 标题:Artificial Intelligence and Aesthetic Judgment
+ 编号:[300]
+ 链接:https://arxiv.org/abs/2309.12338
+ 作者:Jessica Hullman, Ari Holtzman, Andrew Gelman
+ 备注:16 pages, 4 figures
+ 关键词:AIs produce creative, produce creative outputs, Generative AIs produce, AIs produce, produce creative
+
+ 点击查看摘要
+ Generative AIs produce creative outputs in the style of human expression. We argue that encounters with the outputs of modern generative AI models are mediated by the same kinds of aesthetic judgments that organize our interactions with artwork. The interpretation procedure we use on art we find in museums is not an innate human faculty, but one developed over history by disciplines such as art history and art criticism to fulfill certain social functions. This gives us pause when considering our reactions to generative AI, how we should approach this new medium, and why generative AI seems to incite so much fear about the future. We naturally inherit a conundrum of causal inference from the history of art: a work can be read as a symptom of the cultural conditions that influenced its creation while simultaneously being framed as a timeless, seemingly acausal distillation of an eternal human condition. In this essay, we focus on an unresolved tension when we bring this dilemma to bear in the context of generative AI: are we looking for proof that generated media reflects something about the conditions that created it or some eternal human essence? Are current modes of interpretation sufficient for this task? Historically, new forms of art have changed how art is interpreted, with such influence used as evidence that a work of art has touched some essential human truth. As generative AI influences contemporary aesthetic judgment we outline some of the pitfalls and traps in attempting to scrutinize what AI generated media means.
+
+
+
+ 76. 标题:ActiveAI: Introducing AI Literacy for Middle School Learners with Goal-based Scenario Learning
+ 编号:[301]
+ 链接:https://arxiv.org/abs/2309.12337
+ 作者:Ying Jui Tseng, Gautam Yadav
+ 备注:
+ 关键词:addresses key challenges, literacy learning experience, learning experience based, ActiveAI project addresses, project addresses key
+
+ 点击查看摘要
+ The ActiveAI project addresses key challenges in AI education for grades 7-9 students by providing an engaging AI literacy learning experience based on the AI4K12 knowledge framework. Utilizing learning science mechanisms such as goal-based scenarios, immediate feedback, project-based learning, and intelligent agents, the app incorporates a variety of learner inputs like sliders, steppers, and collectors to enhance understanding. In these courses, students work on real-world scenarios like analyzing sentiment in social media comments. This helps them learn to effectively engage with AI systems and develop their ability to evaluate AI-generated output. The Learning Engineering Process (LEP) guided the project's creation and data instrumentation, focusing on design and impact. The project is currently in the implementation stage, leveraging the intelligent tutor design principles for app development. The extended abstract presents the foundational design and development, with further evaluation and research to be conducted in the future.
+
+
+
+ 77. 标题:Education in the age of Generative AI: Context and Recent Developments
+ 编号:[306]
+ 链接:https://arxiv.org/abs/2309.12332
+ 作者:Rafael Ferreira Mello, Elyda Freitas, Filipe Dwan Pereira, Luciano Cabral, Patricia Tedesco, Geber Ramalho
+ 备注:
+ 关键词:improve product quality, generative artificial intelligence, increasing number, number of individuals, individuals and organizations
+
+ 点击查看摘要
+ With the emergence of generative artificial intelligence, an increasing number of individuals and organizations have begun exploring its potential to enhance productivity and improve product quality across various sectors. The field of education is no exception. However, it is vital to notice that artificial intelligence adoption in education dates back to the 1960s. In light of this historical context, this white paper serves as the inaugural piece in a four-part series that elucidates the role of AI in education. The series delves into topics such as its potential, successful applications, limitations, ethical considerations, and future trends. This initial article provides a comprehensive overview of the field, highlighting the recent developments within the generative artificial intelligence sphere.
+
+
+
+ 78. 标题:Approaches to Generative Artificial Intelligence, A Social Justice Perspective
+ 编号:[307]
+ 链接:https://arxiv.org/abs/2309.12331
+ 作者:Myke Healy
+ 备注:12 pages, 3 figures, 14 references
+ 关键词:billion monthly visits, 2023-2024 academic year, impact academic integrity, generative artificial intelligence, exemplified by ChatGPT
+
+ 点击查看摘要
+ In the 2023-2024 academic year, the widespread availability of generative artificial intelligence, exemplified by ChatGPT's 1.6 billion monthly visits, is set to impact academic integrity. With 77% of high school students previously reporting engagement in dishonest behaviour, the rise of AI-driven writing assistance, dubbed 'AI-giarism' by Chan (arXiv:2306.03358v2), will make plagiarism more accessible and less detectable. While these concerns are urgent, they also raise broader questions about the revolutionary nature of this technology, including autonomy, data privacy, copyright, and equity. This paper aims to explore generative AI from a social justice perspective, examining the training of these models, the inherent biases, and the potential injustices in detecting AI-generated writing.
+
+
+
+ 79. 标题:Ground Truth Or Dare: Factors Affecting The Creation Of Medical Datasets For Training AI
+ 编号:[308]
+ 链接:https://arxiv.org/abs/2309.12327
+ 作者:Hubert D. Zając, Natalia R. Avlona, Tariq O. Andersen, Finn Kensing, Irina Shklovski
+ 备注:
+ 关键词:ensuring high-quality training, high-quality training datasets, ground truth schema, core goals, development is ensuring
+
+ 点击查看摘要
+ One of the core goals of responsible AI development is ensuring high-quality training datasets. Many researchers have pointed to the importance of the annotation step in the creation of high-quality data, but less attention has been paid to the work that enables data annotation. We define this work as the design of ground truth schema and explore the challenges involved in the creation of datasets in the medical domain even before any annotations are made. Based on extensive work in three health-tech organisations, we describe five external and internal factors that condition medical dataset creation processes. Three external factors include regulatory constraints, the context of creation and use, and commercial and operational pressures. These factors condition medical data collection and shape the ground truth schema design. Two internal factors include epistemic differences and limits of labelling. These directly shape the design of the ground truth schema. Discussions of what constitutes high-quality data need to pay attention to the factors that shape and constrain what is possible to be created, to ensure responsible AI design.
+
+
+
+ 80. 标题:FUTURE-AI: International consensus guideline for trustworthy and deployable artificial intelligence in healthcare
+ 编号:[310]
+ 链接:https://arxiv.org/abs/2309.12325
+ 作者:Karim Lekadir, Aasa Feragen, Abdul Joseph Fofanah, Alejandro F Frangi, Alena Buyx, Anais Emelie, Andrea Lara, Antonio R Porras, An-Wen Chan, Arcadi Navarro, Ben Glocker, Benard O Botwe, Bishesh Khanal, Brigit Beger, Carol C Wu, Celia Cintas, Curtis P Langlotz, Daniel Rueckert, Deogratias Mzurikwao, Dimitrios I Fotiadis, Doszhan Zhussupov, Enzo Ferrante, Erik Meijering, Eva Weicken, Fabio A González, Folkert W Asselbergs, Fred Prior, Gabriel P Krestin, Gary Collins, Geletaw S Tegenaw, Georgios Kaissis, Gianluca Misuraca, Gianna Tsakou, Girish Dwivedi, Haridimos Kondylakis, Harsha Jayakody, Henry C Woodruf, Hugo JWL Aerts, Ian Walsh, Ioanna Chouvarda, Irène Buvat, Islem Rekik, James Duncan, Jayashree Kalpathy-Cramer, Jihad Zahir, Jinah Park, John Mongan, Judy W Gichoya, Julia A Schnabel, et al. (69 additional authors not shown)
+ 备注:
+ 关键词:technologies remain limited, artificial intelligence, major advances, advances in artificial, technologies remain
+
+ 点击查看摘要
+ Despite major advances in artificial intelligence (AI) for medicine and healthcare, the deployment and adoption of AI technologies remain limited in real-world clinical practice. In recent years, concerns have been raised about the technical, clinical, ethical and legal risks associated with medical AI. To increase real world adoption, it is essential that medical AI tools are trusted and accepted by patients, clinicians, health organisations and authorities. This work describes the FUTURE-AI guideline as the first international consensus framework for guiding the development and deployment of trustworthy AI tools in healthcare. The FUTURE-AI consortium was founded in 2021 and currently comprises 118 inter-disciplinary experts from 51 countries representing all continents, including AI scientists, clinicians, ethicists, and social scientists. Over a two-year period, the consortium defined guiding principles and best practices for trustworthy AI through an iterative process comprising an in-depth literature review, a modified Delphi survey, and online consensus meetings. The FUTURE-AI framework was established based on 6 guiding principles for trustworthy AI in healthcare, i.e. Fairness, Universality, Traceability, Usability, Robustness and Explainability. Through consensus, a set of 28 best practices were defined, addressing technical, clinical, legal and socio-ethical dimensions. The recommendations cover the entire lifecycle of medical AI, from design, development and validation to regulation, deployment, and monitoring. FUTURE-AI is a risk-informed, assumption-free guideline which provides a structured approach for constructing medical AI tools that will be trusted, deployed and adopted in real-world practice. Researchers are encouraged to take the recommendations into account in proof-of-concept stages to facilitate future translation towards clinical practice of medical AI.
+
+
+
+ 81. 标题:A Case for AI Safety via Law
+ 编号:[313]
+ 链接:https://arxiv.org/abs/2309.12321
+ 作者:Jeffrey W. Johnston
+ 备注:25 pages
+ 关键词:open research question, make artificial intelligence, artificial intelligence, research question, safe and aligned
+
+ 点击查看摘要
+ How to make artificial intelligence (AI) systems safe and aligned with human values is an open research question. Proposed solutions tend toward relying on human intervention in uncertain situations, learning human values and intentions through training or observation, providing off-switches, implementing isolation or simulation environments, or extrapolating what people would want if they had more knowledge and more time to think. Law-based approaches--such as inspired by Isaac Asimov--have not been well regarded. This paper makes a case that effective legal systems are the best way to address AI safety. Law is defined as any rules that codify prohibitions and prescriptions applicable to particular agents in specified domains/contexts and includes processes for enacting, managing, enforcing, and litigating such rules.
+
+
+
+ 82. 标题:Use Scenarios & Practical Examples of AI Use in Education
+ 编号:[314]
+ 链接:https://arxiv.org/abs/2309.12320
+ 作者:Dara Cassidy, Yann-Aël Le Borgne, Francisco Bellas, Riina Vuorikari, Elise Rondin, Madhumalti Sharma, Jessica Niewint-Gori, Johanna Gröpler, Anne Gilleran, Lidija Kralj
+ 备注:Developed within the AI in Education working group of the European Digital Education Hub
+ 关键词:introducing artificial intelligence, Artificial Intelligence Education, Intelligence Education field, artificial intelligence, pre-university levels
+
+ 点击查看摘要
+ This report presents a set of use scenarios based on existing resources that teachers can use as inspiration to create their own, with the aim of introducing artificial intelligence (AI) at different pre-university levels, and with different goals. The Artificial Intelligence Education field (AIEd) is very active, with new resources and tools arising continuously. Those included in this document have already been tested with students and selected by experts in the field, but they must be taken just as practical examples to guide and inspire teachers creativity.
+
+
+
+ 83. 标题:Memory-augmented conformer for improved end-to-end long-form ASR
+ 编号:[319]
+ 链接:https://arxiv.org/abs/2309.13029
+ 作者:Carlos Carvalho, Alberto Abad
+ 备注:
+ 关键词:automatic speech recognition, promising modelling approach, outperforming recurrent neural, recurrent neural network-based, neural network-based approaches
+
+ 点击查看摘要
+ Conformers have recently been proposed as a promising modelling approach for automatic speech recognition (ASR), outperforming recurrent neural network-based approaches and transformers. Nevertheless, in general, the performance of these end-to-end models, especially attention-based models, is particularly degraded in the case of long utterances. To address this limitation, we propose adding a fully-differentiable memory-augmented neural network between the encoder and decoder of a conformer. This external memory can enrich the generalization for longer utterances since it allows the system to store and retrieve more information recurrently. Notably, we explore the neural Turing machine (NTM) that results in our proposed Conformer-NTM model architecture for ASR. Experimental results using Librispeech train-clean-100 and train-960 sets show that the proposed system outperforms the baseline conformer without memory for long utterances.
+
+
+
+ 84. 标题:A Spectral Theory of Neural Prediction and Alignment
+ 编号:[334]
+ 链接:https://arxiv.org/abs/2309.12821
+ 作者:Abdulkadir Canatar, Jenelle Feather, Albert Wakhloo, SueYeon Chung
+ 备注:First two authors contributed equally. To appear at NeurIPS 2023
+ 关键词:biological systems, deep neural networks, neural, neural networks, neural network responses
+
+ 点击查看摘要
+ The representations of neural networks are often compared to those of biological systems by performing regression between the neural network responses and those measured from biological systems. Many different state-of-the-art deep neural networks yield similar neural predictions, but it remains unclear how to differentiate among models that perform equally well at predicting neural responses. To gain insight into this, we use a recent theoretical framework that relates the generalization error from regression to the spectral bias of the model activations and the alignment of the neural responses onto the learnable subspace of the model. We extend this theory to the case of regression between model activations and neural responses, and define geometrical properties describing the error embedding geometry. We test a large number of deep neural networks that predict visual cortical activity and show that there are multiple types of geometries that result in low neural prediction error as measured via regression. The work demonstrates that carefully decomposing representational metrics can provide interpretability of how models are capturing neural activity and points the way towards improved models of neural activity.
+
+
+
+ 85. 标题:QAL-BP: An Augmented Lagrangian Quantum Approach for Bin Packing Problem
+ 编号:[347]
+ 链接:https://arxiv.org/abs/2309.12678
+ 作者:Lorenzo Cellini, Antonio Macaluso, Michele Lombardi
+ 备注:14 pages, 4 figures, 1 table
+ 关键词:posing significant challenges, well-known NP-Hard problem, finding efficient solutions, Unconstrained Binary Optimization, Quadratic Unconstrained Binary
+
+ 点击查看摘要
+ The bin packing is a well-known NP-Hard problem in the domain of artificial intelligence, posing significant challenges in finding efficient solutions. Conversely, recent advancements in quantum technologies have shown promising potential for achieving substantial computational speedup, particularly in certain problem classes, such as combinatorial optimization. In this study, we introduce QAL-BP, a novel Quadratic Unconstrained Binary Optimization (QUBO) formulation designed specifically for bin packing and suitable for quantum computation. QAL-BP utilizes the augmented Lagrangian method to incorporate the bin packing constraints into the objective function while also facilitating an analytical estimation of heuristic, but empirically robust, penalty multipliers. This approach leads to a more versatile and generalizable model that eliminates the need for empirically calculating instance-dependent Lagrangian coefficients, a requirement commonly encountered in alternative QUBO formulations for similar problems. To assess the effectiveness of our proposed approach, we conduct experiments on a set of bin-packing instances using a real Quantum Annealing device. Additionally, we compare the results with those obtained from two different classical solvers, namely simulated annealing and Gurobi. The experimental findings not only confirm the correctness of the proposed formulation but also demonstrate the potential of quantum computation in effectively solving the bin-packing problem, particularly as more reliable quantum technology becomes available.
+
+
+





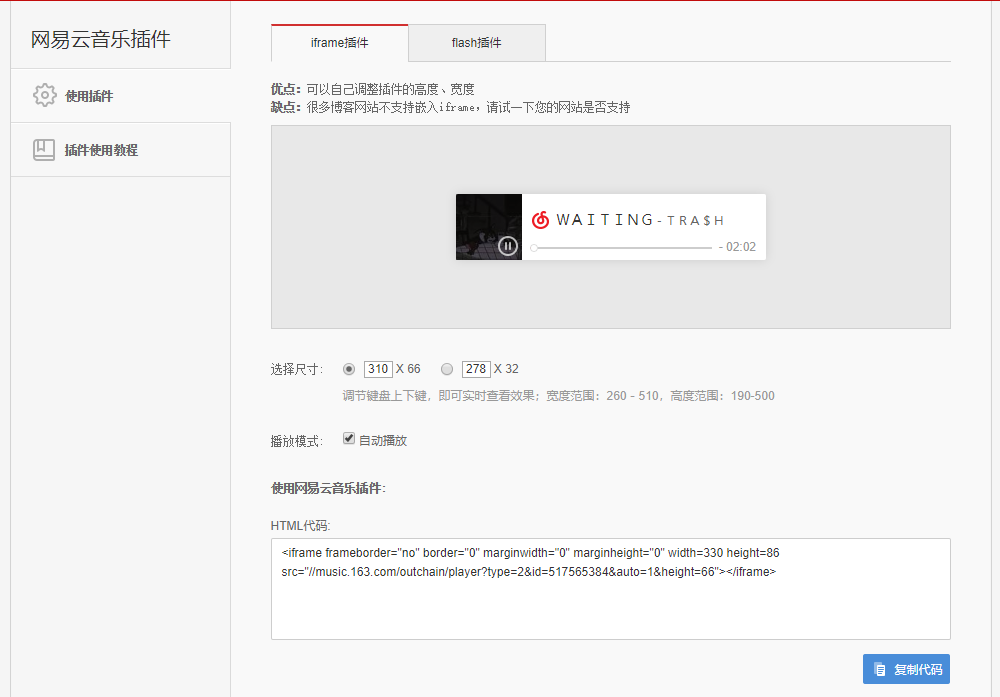
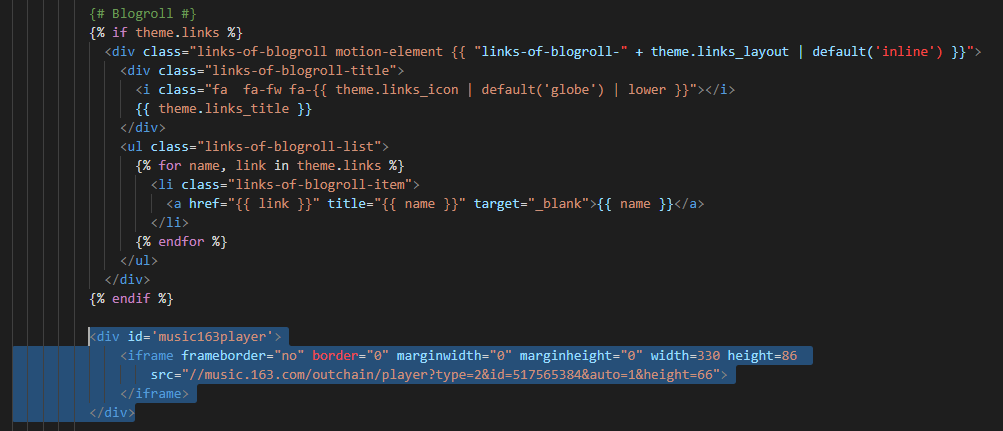
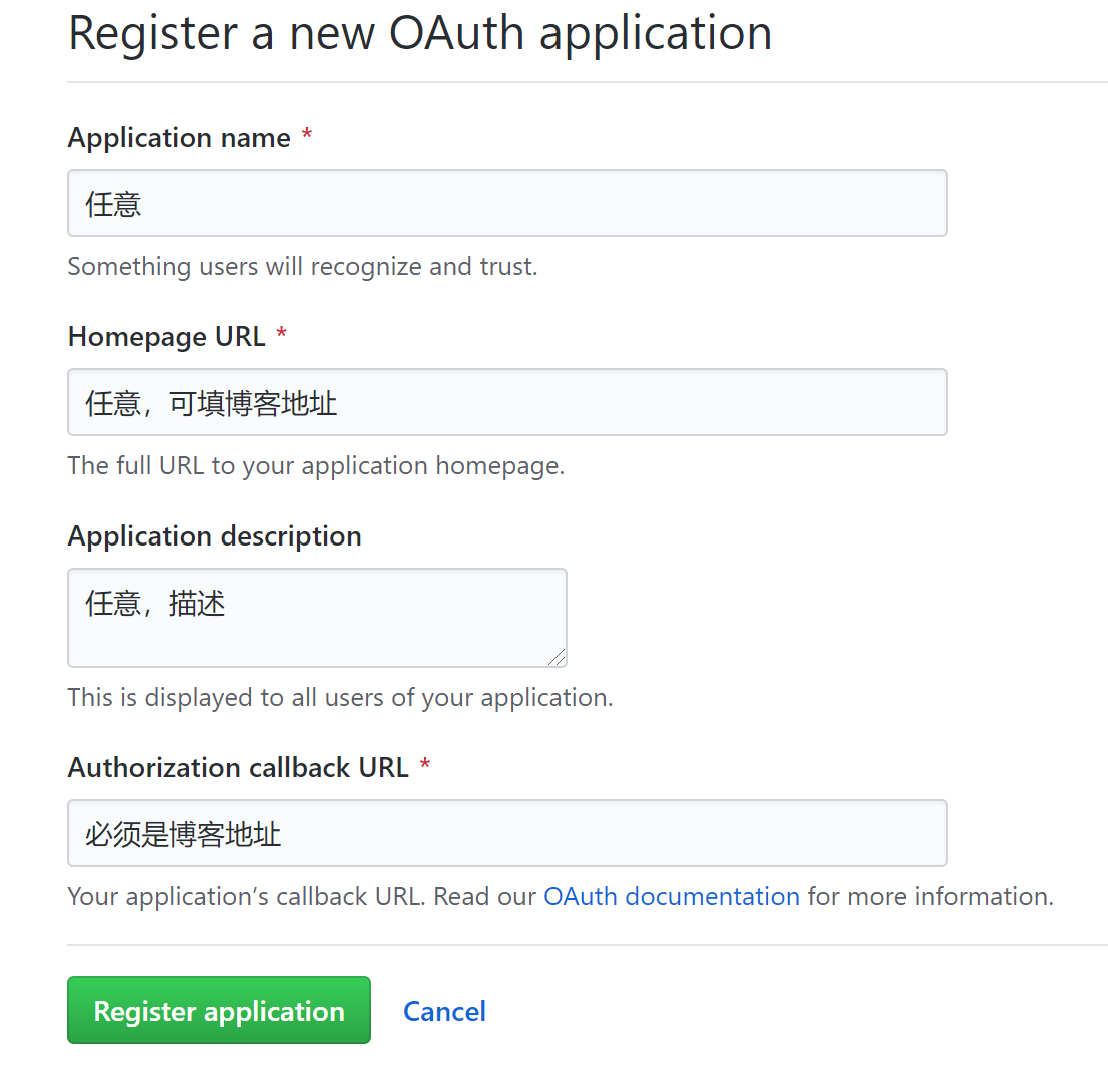
/Fig1_pretrain_finetune.png)
/Fig2_eda1.png)
/Fig2_eda2.png)
/Fig2_eda3.png)
/Fig3_reweight.png)
/Fig5_model1.png)
/Fig5_attention_mask.png)
/Fig4_wwm.png)
/Fig5_model2.png)
/Fig5_model3.png)
/Fig7_ensemble1.png)
/Fig6_res1.png)
/Fig6_res2.png)


%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_text_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_entity_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/model.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/dont_stop_pretraining.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/a.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/b.png)

%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/lengths_histplot.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_entity_lengths.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_label_dist.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/%E6%80%BB%E4%BD%93%E6%96%B9%E6%A1%88.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/pretrain_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/finetune_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/rdrop.png)

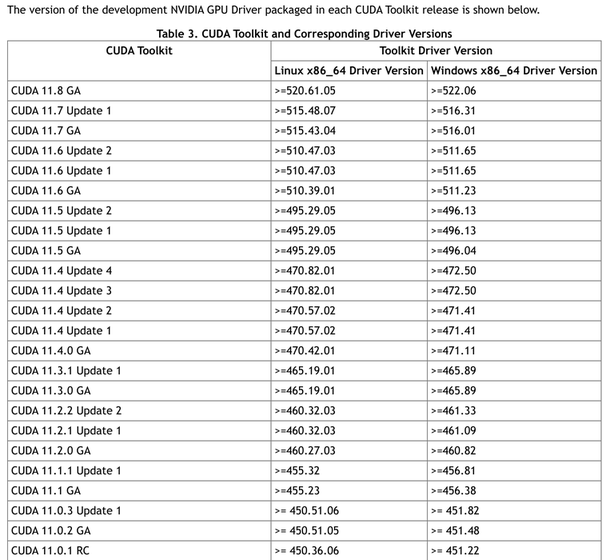

/autoencoder-architecture.png)
/variational-autoencoder-architecture.png)
/forward_vs_reversed_KL.png)
/vae-implement.png)
/reparam.png)
/generated_samples.png)







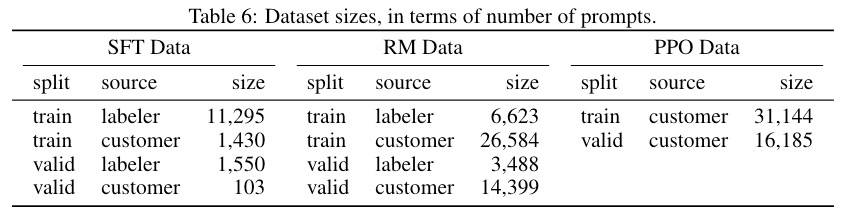
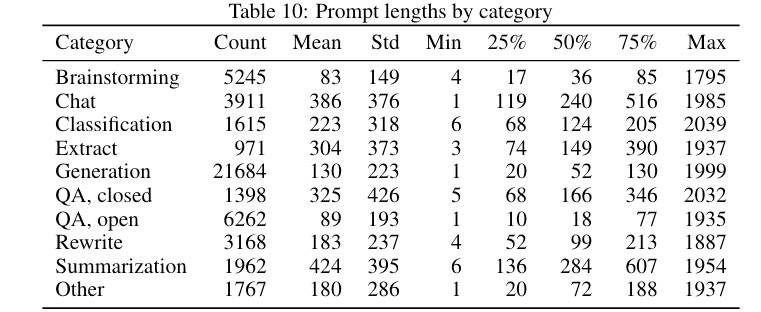
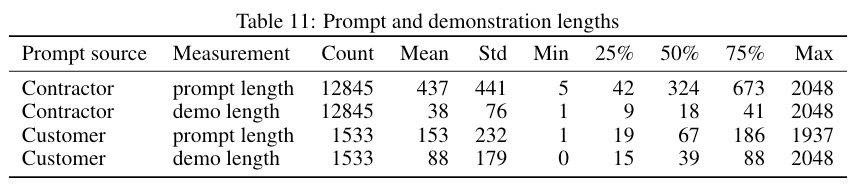

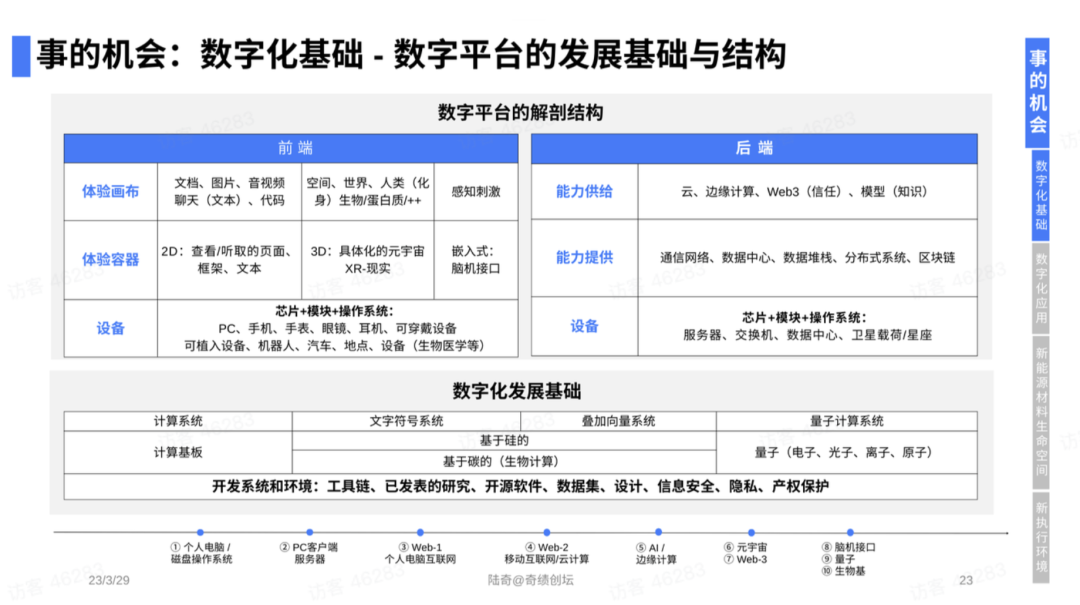



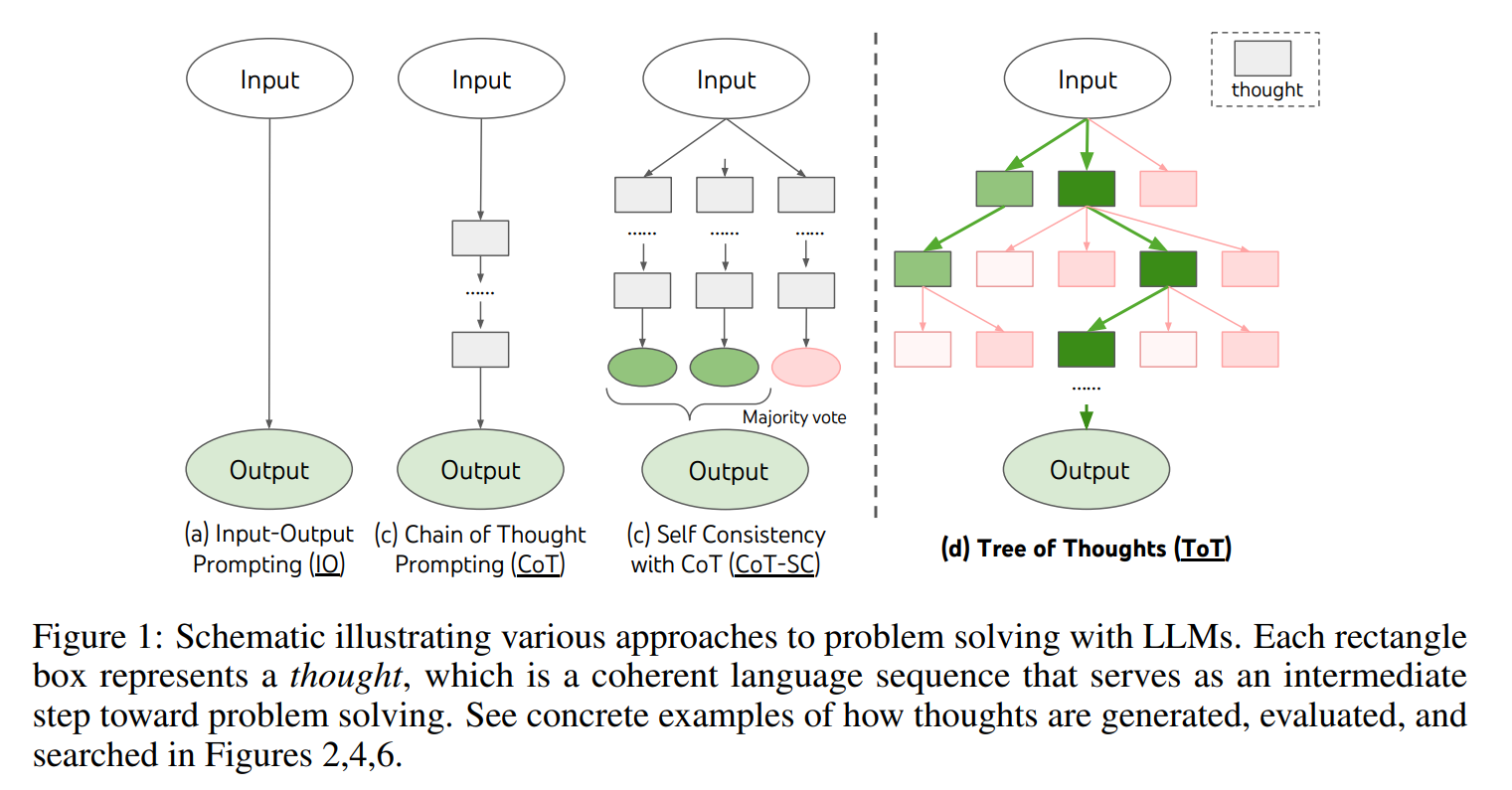


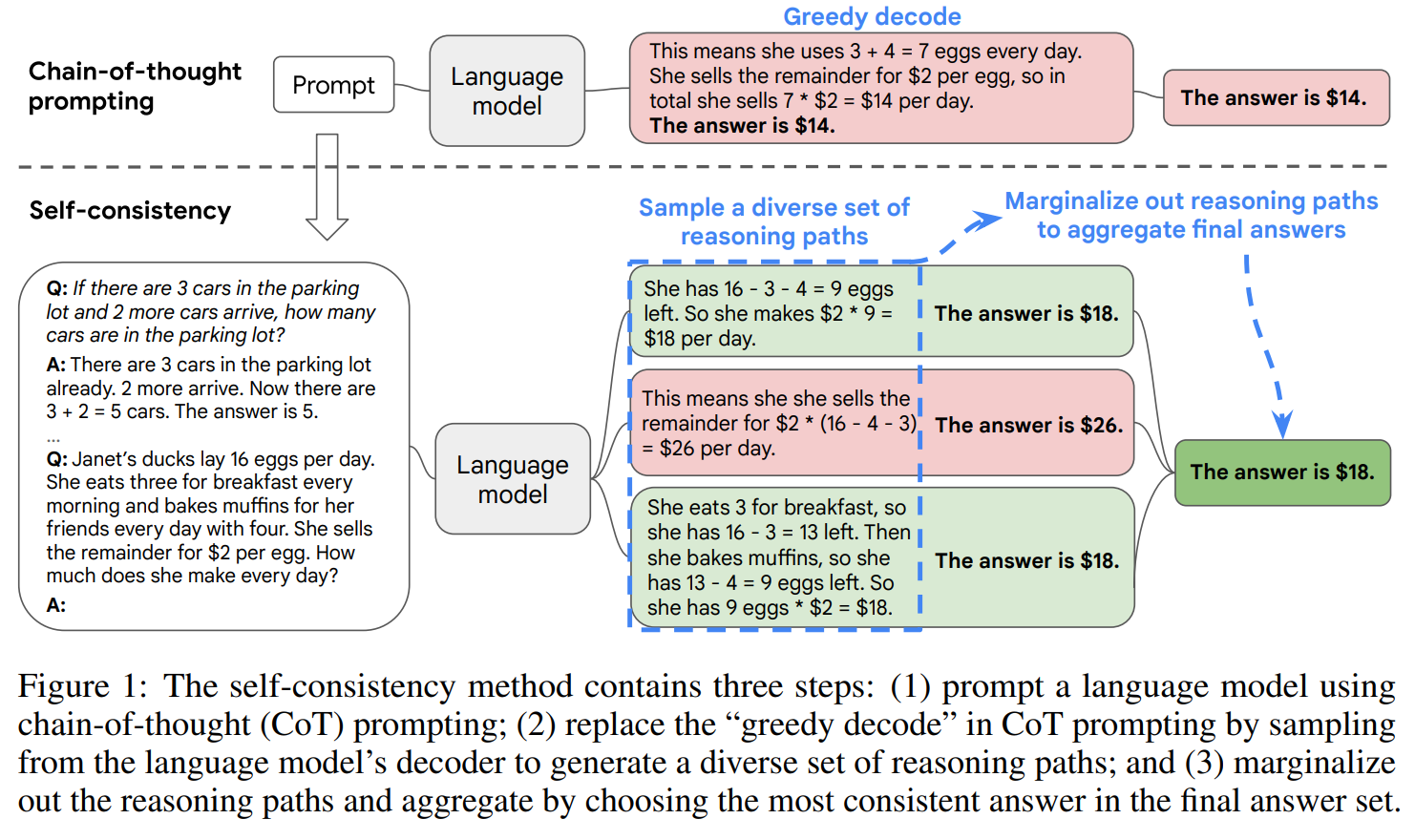
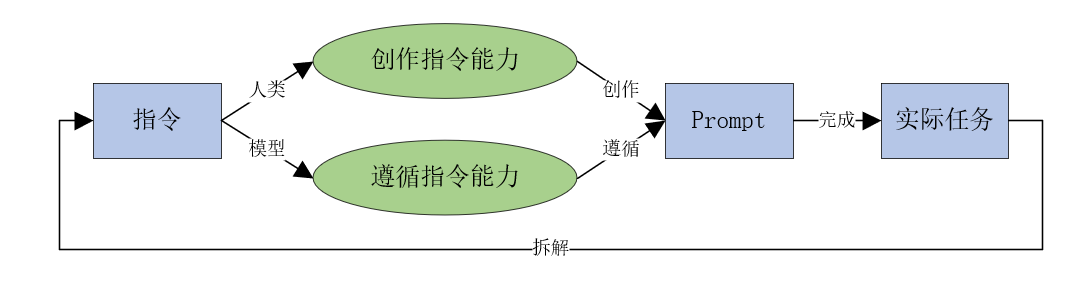



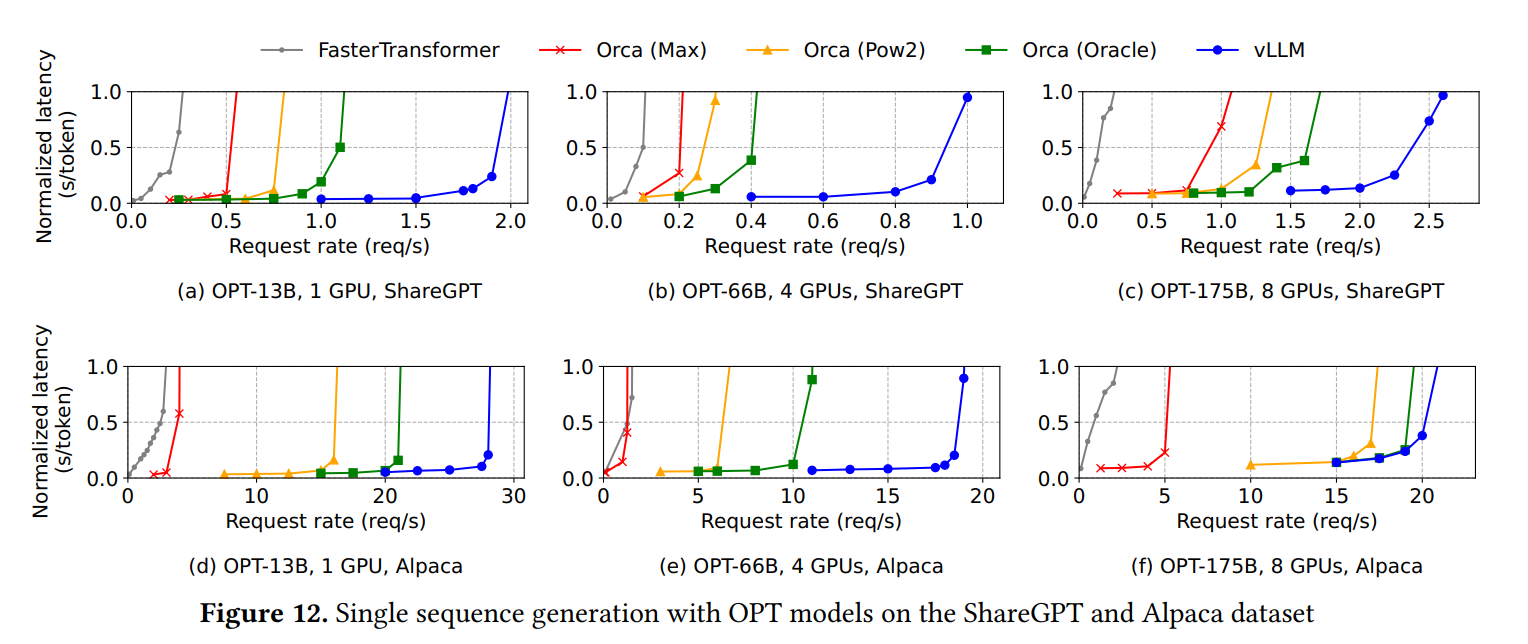
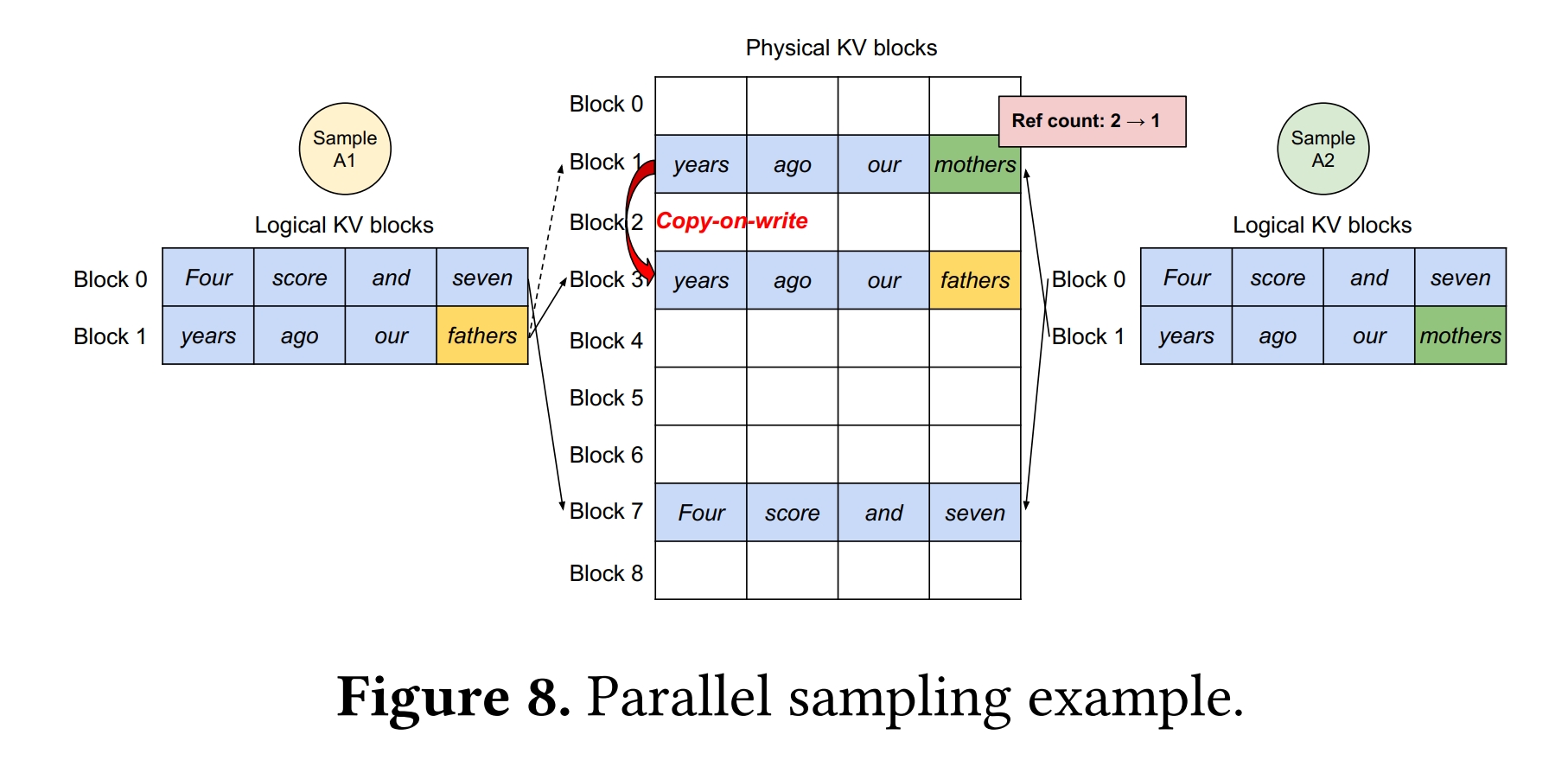
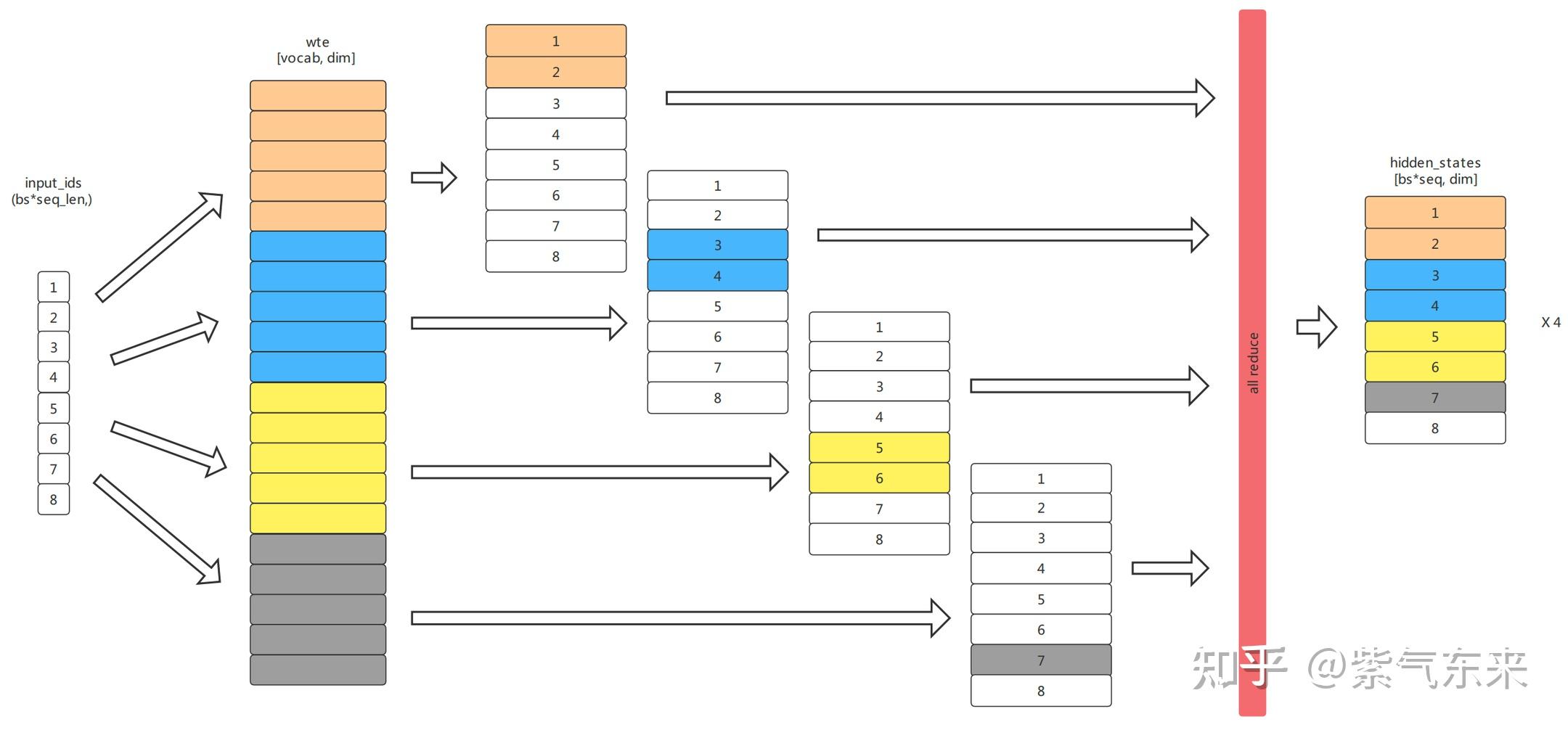
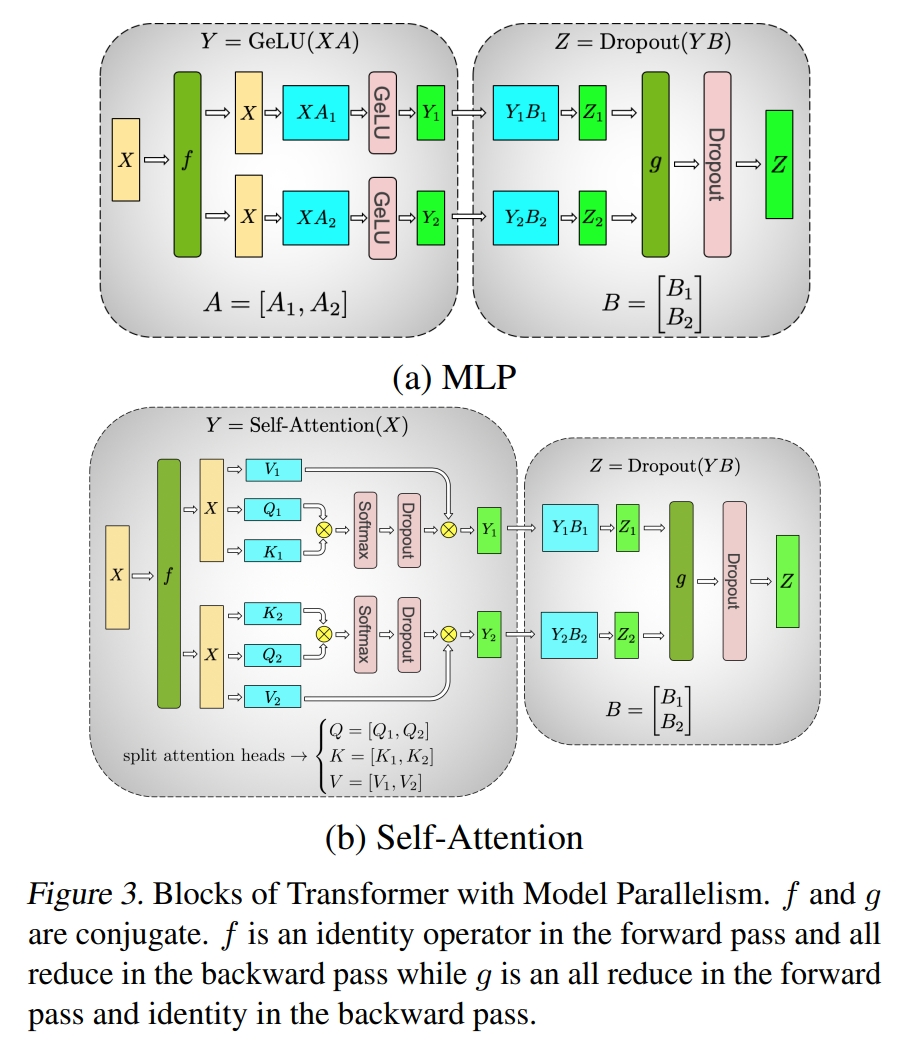








 ' +
+ '
' +
+ '