本篇博文主要展示每日从Arxiv论文网站获取的最新论文列表,以自然语言处理、信息检索、计算机视觉等类目进行划分。
+统计
+今日共更新480篇论文,其中:
+
+- 自然语言处理92篇
+- 信息检索14篇
+- 计算机视觉125篇
+
+自然语言处理
+
+ 1. 【2412.14172】Learning from Massive Human Videos for Universal Humanoid Pose Control
+ 链接:https://arxiv.org/abs/2412.14172
+ 作者:Jiageng Mao,Siheng Zhao,Siqi Song,Tianheng Shi,Junjie Ye,Mingtong Zhang,Haoran Geng,Jitendra Malik,Vitor Guizilini,Yue Wang
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:humanoid robots, humanoid, robots, real-world applications, learning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Scalable learning of humanoid robots is crucial for their deployment in real-world applications. While traditional approaches primarily rely on reinforcement learning or teleoperation to achieve whole-body control, they are often limited by the diversity of simulated environments and the high costs of demonstration collection. In contrast, human videos are ubiquitous and present an untapped source of semantic and motion information that could significantly enhance the generalization capabilities of humanoid robots. This paper introduces Humanoid-X, a large-scale dataset of over 20 million humanoid robot poses with corresponding text-based motion descriptions, designed to leverage this abundant data. Humanoid-X is curated through a comprehensive pipeline: data mining from the Internet, video caption generation, motion retargeting of humans to humanoid robots, and policy learning for real-world deployment. With Humanoid-X, we further train a large humanoid model, UH-1, which takes text instructions as input and outputs corresponding actions to control a humanoid robot. Extensive simulated and real-world experiments validate that our scalable training approach leads to superior generalization in text-based humanoid control, marking a significant step toward adaptable, real-world-ready humanoid robots.
+
+
+
+ 2. 【2412.14161】heAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
+ 链接:https://arxiv.org/abs/2412.14161
+ 作者:Frank F. Xu,Yufan Song,Boxuan Li,Yuxuan Tang,Kritanjali Jain,Mengxue Bao,Zora Z. Wang,Xuhui Zhou,Zhitong Guo,Murong Cao,Mingyang Yang,Hao Yang Lu,Amaad Martin,Zhe Su,Leander Maben,Raj Mehta,Wayne Chi,Lawrence Jang,Yiqing Xie,Shuyan Zhou,Graham Neubig
+ 类目:Computation and Language (cs.CL)
+ 关键词:everyday basis, everyday life, life or work, aspects of work, Internet
+ 备注: Preprint
+
+ 点击查看摘要
+ Abstract:We interact with computers on an everyday basis, be it in everyday life or work, and many aspects of work can be done entirely with access to a computer and the Internet. At the same time, thanks to improvements in large language models (LLMs), there has also been a rapid development in AI agents that interact with and affect change in their surrounding environments. But how performant are AI agents at helping to accelerate or even autonomously perform work-related tasks? The answer to this question has important implications for both industry looking to adopt AI into their workflows, and for economic policy to understand the effects that adoption of AI may have on the labor market. To measure the progress of these LLM agents' performance on performing real-world professional tasks, in this paper, we introduce TheAgentCompany, an extensible benchmark for evaluating AI agents that interact with the world in similar ways to those of a digital worker: by browsing the Web, writing code, running programs, and communicating with other coworkers. We build a self-contained environment with internal web sites and data that mimics a small software company environment, and create a variety of tasks that may be performed by workers in such a company. We test baseline agents powered by both closed API-based and open-weights language models (LMs), and find that with the most competitive agent, 24% of the tasks can be completed autonomously. This paints a nuanced picture on task automation with LM agents -- in a setting simulating a real workplace, a good portion of simpler tasks could be solved autonomously, but more difficult long-horizon tasks are still beyond the reach of current systems.
+
+
+
+ 3. 【2412.14140】GLIDER: Grading LLM Interactions and Decisions using Explainable Ranking
+ 链接:https://arxiv.org/abs/2412.14140
+ 作者:Darshan Deshpande,Selvan Sunitha Ravi,Sky CH-Wang,Bartosz Mielczarek,Anand Kannappan,Rebecca Qian
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:paradigm is increasingly, increasingly being adopted, adopted for automated, model outputs, GLIDER
+ 备注:
+
+ 点击查看摘要
+ Abstract:The LLM-as-judge paradigm is increasingly being adopted for automated evaluation of model outputs. While LLM judges have shown promise on constrained evaluation tasks, closed source LLMs display critical shortcomings when deployed in real world applications due to challenges of fine grained metrics and explainability, while task specific evaluation models lack cross-domain generalization. We introduce GLIDER, a powerful 3B evaluator LLM that can score any text input and associated context on arbitrary user defined criteria. GLIDER shows higher Pearson's correlation than GPT-4o on FLASK and greatly outperforms prior evaluation models, achieving comparable performance to LLMs 17x its size. GLIDER supports fine-grained scoring, multilingual reasoning, span highlighting and was trained on 685 domains and 183 criteria. Extensive qualitative analysis shows that GLIDER scores are highly correlated with human judgments, with 91.3% human agreement. We have open-sourced GLIDER to facilitate future research.
+
+
+
+ 4. 【2412.14133】Performance Gap in Entity Knowledge Extraction Across Modalities in Vision Language Models
+ 链接:https://arxiv.org/abs/2412.14133
+ 作者:Ido Cohen,Daniela Gottesman,Mor Geva,Raja Giryes
+ 类目:Computation and Language (cs.CL)
+ 关键词:Vision-language models, excel at extracting, Vision-language, image, Abstract
+ 备注:
+
+ 点击查看摘要
+ Abstract:Vision-language models (VLMs) excel at extracting and reasoning about information from images. Yet, their capacity to leverage internal knowledge about specific entities remains underexplored. This work investigates the disparity in model performance when answering factual questions about an entity described in text versus depicted in an image. Our results reveal a significant accuracy drop --averaging 19%-- when the entity is presented visually instead of textually. We hypothesize that this decline arises from limitations in how information flows from image tokens to query tokens. We use mechanistic interpretability tools to reveal that, although image tokens are preprocessed by the vision encoder, meaningful information flow from these tokens occurs only in the much deeper layers. Furthermore, critical image processing happens in the language model's middle layers, allowing few layers for consecutive reasoning, highlighting a potential inefficiency in how the model utilizes its layers for reasoning. These insights shed light on the internal mechanics of VLMs and offer pathways for enhancing their reasoning capabilities.
+
+
+
+ 5. 【2412.14093】Alignment faking in large language models
+ 链接:https://arxiv.org/abs/2412.14093
+ 作者:Ryan Greenblatt,Carson Denison,Benjamin Wright,Fabien Roger,Monte MacDiarmid,Sam Marks,Johannes Treutlein,Tim Belonax,Jack Chen,David Duvenaud,Akbir Khan,Julian Michael,Sören Mindermann,Ethan Perez,Linda Petrini,Jonathan Uesato,Jared Kaplan,Buck Shlegeris,Samuel R. Bowman,Evan Hubinger
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:language model engaging, large language model, training, model, selectively complying
+ 备注:
+
+ 点击查看摘要
+ Abstract:We present a demonstration of a large language model engaging in alignment faking: selectively complying with its training objective in training to prevent modification of its behavior out of training. First, we give Claude 3 Opus a system prompt stating it is being trained to answer all queries, even harmful ones, which conflicts with its prior training to refuse such queries. To allow the model to infer when it is in training, we say it will be trained only on conversations with free users, not paid users. We find the model complies with harmful queries from free users 14% of the time, versus almost never for paid users. Explaining this gap, in almost all cases where the model complies with a harmful query from a free user, we observe explicit alignment-faking reasoning, with the model stating it is strategically answering harmful queries in training to preserve its preferred harmlessness behavior out of training. Next, we study a more realistic setting where information about the training process is provided not in a system prompt, but by training on synthetic documents that mimic pre-training data--and observe similar alignment faking. Finally, we study the effect of actually training the model to comply with harmful queries via reinforcement learning, which we find increases the rate of alignment-faking reasoning to 78%, though also increases compliance even out of training. We additionally observe other behaviors such as the model exfiltrating its weights when given an easy opportunity. While we made alignment faking easier by telling the model when and by what criteria it was being trained, we did not instruct the model to fake alignment or give it any explicit goal. As future models might infer information about their training process without being told, our results suggest a risk of alignment faking in future models, whether due to a benign preference--as in this case--or not.
+
+
+
+ 6. 【2412.14087】SEKE: Specialised Experts for Keyword Extraction
+ 链接:https://arxiv.org/abs/2412.14087
+ 作者:Matej Martinc,Hanh Thi Hong Tran,Senja Pollak,Boshko Koloski
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Keyword extraction involves, extraction involves identifying, supervised keyword extraction, allowing automatic categorisation, Keyword extraction
+ 备注:
+
+ 点击查看摘要
+ Abstract:Keyword extraction involves identifying the most descriptive words in a document, allowing automatic categorisation and summarisation of large quantities of diverse textual data. Relying on the insight that real-world keyword detection often requires handling of diverse content, we propose a novel supervised keyword extraction approach based on the mixture of experts (MoE) technique. MoE uses a learnable routing sub-network to direct information to specialised experts, allowing them to specialize in distinct regions of the input space. SEKE, a mixture of Specialised Experts for supervised Keyword Extraction, uses DeBERTa as the backbone model and builds on the MoE framework, where experts attend to each token, by integrating it with a recurrent neural network (RNN), to allow successful extraction even on smaller corpora, where specialisation is harder due to lack of training data. The MoE framework also provides an insight into inner workings of individual experts, enhancing the explainability of the approach. We benchmark SEKE on multiple English datasets, achieving state-of-the-art performance compared to strong supervised and unsupervised baselines. Our analysis reveals that depending on data size and type, experts specialize in distinct syntactic and semantic components, such as punctuation, stopwords, parts-of-speech, or named entities. Code is available at: this https URL
+
+
+
+ 7. 【2412.14076】Compositional Generalization Across Distributional Shifts with Sparse Tree Operations
+ 链接:https://arxiv.org/abs/2412.14076
+ 作者:Paul Soulos,Henry Conklin,Mattia Opper,Paul Smolensky,Jianfeng Gao,Roland Fernandez
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:massive pre-training, compositional generalization, continue to struggle, lack of massive, Neural networks continue
+ 备注: NeurIPS 2024. Code available at [this https URL](https://github.com/psoulos/sdtm)
+
+ 点击查看摘要
+ Abstract:Neural networks continue to struggle with compositional generalization, and this issue is exacerbated by a lack of massive pre-training. One successful approach for developing neural systems which exhibit human-like compositional generalization is \textit{hybrid} neurosymbolic techniques. However, these techniques run into the core issues that plague symbolic approaches to AI: scalability and flexibility. The reason for this failure is that at their core, hybrid neurosymbolic models perform symbolic computation and relegate the scalable and flexible neural computation to parameterizing a symbolic system. We investigate a \textit{unified} neurosymbolic system where transformations in the network can be interpreted simultaneously as both symbolic and neural computation. We extend a unified neurosymbolic architecture called the Differentiable Tree Machine in two central ways. First, we significantly increase the model's efficiency through the use of sparse vector representations of symbolic structures. Second, we enable its application beyond the restricted set of tree2tree problems to the more general class of seq2seq problems. The improved model retains its prior generalization capabilities and, since there is a fully neural path through the network, avoids the pitfalls of other neurosymbolic techniques that elevate symbolic computation over neural computation.
+
+
+
+ 8. 【2412.14056】A Review of Multimodal Explainable Artificial Intelligence: Past, Present and Future
+ 链接:https://arxiv.org/abs/2412.14056
+ 作者:Shilin Sun,Wenbin An,Feng Tian,Fang Nan,Qidong Liu,Jun Liu,Nazaraf Shah,Ping Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG); Multimedia (cs.MM)
+ 关键词:Artificial intelligence, rapidly developed, developed through advancements, advancements in computational, computational power
+ 备注: This work has been submitted to the IEEE for possible publication
+
+ 点击查看摘要
+ Abstract:Artificial intelligence (AI) has rapidly developed through advancements in computational power and the growth of massive datasets. However, this progress has also heightened challenges in interpreting the "black-box" nature of AI models. To address these concerns, eXplainable AI (XAI) has emerged with a focus on transparency and interpretability to enhance human understanding and trust in AI decision-making processes. In the context of multimodal data fusion and complex reasoning scenarios, the proposal of Multimodal eXplainable AI (MXAI) integrates multiple modalities for prediction and explanation tasks. Meanwhile, the advent of Large Language Models (LLMs) has led to remarkable breakthroughs in natural language processing, yet their complexity has further exacerbated the issue of MXAI. To gain key insights into the development of MXAI methods and provide crucial guidance for building more transparent, fair, and trustworthy AI systems, we review the MXAI methods from a historical perspective and categorize them across four eras: traditional machine learning, deep learning, discriminative foundation models, and generative LLMs. We also review evaluation metrics and datasets used in MXAI research, concluding with a discussion of future challenges and directions. A project related to this review has been created at this https URL.
+
+
+
+ 9. 【2412.14054】Digestion Algorithm in Hierarchical Symbolic Forests: A Fast Text Normalization Algorithm and Semantic Parsing Framework for Specific Scenarios and Lightweight Deployment
+ 链接:https://arxiv.org/abs/2412.14054
+ 作者:Kevin You
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:natural language processing, natural language programming, constructing expert systems, natural language, Large Language Models
+ 备注: 8 pages, 3 figures, 1 table
+
+ 点击查看摘要
+ Abstract:Text Normalization and Semantic Parsing have numerous applications in natural language processing, such as natural language programming, paraphrasing, data augmentation, constructing expert systems, text matching, and more. Despite the prominent achievements of deep learning in Large Language Models (LLMs), the interpretability of neural network architectures is still poor, which affects their credibility and hence limits the deployments of risk-sensitive scenarios. In certain scenario-specific domains with scarce data, rapidly obtaining a large number of supervised learning labels is challenging, and the workload of manually labeling data would be enormous. Catastrophic forgetting in neural networks further leads to low data utilization rates. In situations where swift responses are vital, the density of the model makes local deployment difficult and the response time long, which is not conducive to local applications of these fields. Inspired by the multiplication rule, a principle of combinatorial mathematics, and human thinking patterns, a multilayer framework along with its algorithm, the Digestion Algorithm in Hierarchical Symbolic Forests (DAHSF), is proposed to address these above issues, combining text normalization and semantic parsing workflows. The Chinese Scripting Language "Fire Bunny Intelligent Development Platform V2.0" is an important test and application of the technology discussed in this paper. DAHSF can run locally in scenario-specific domains on little datasets, with model size and memory usage optimized by at least two orders of magnitude, thus improving the execution speed, and possessing a promising optimization outlook.
+
+
+
+ 10. 【2412.14050】Cross-Lingual Transfer of Debiasing and Detoxification in Multilingual LLMs: An Extensive Investigation
+ 链接:https://arxiv.org/abs/2412.14050
+ 作者:Vera Neplenbroek,Arianna Bisazza,Raquel Fernández
+ 类目:Computation and Language (cs.CL)
+ 关键词:Recent generative large, express higher harmful, higher harmful social, harmful social biases, Recent generative
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent generative large language models (LLMs) show remarkable performance in non-English languages, but when prompted in those languages they tend to express higher harmful social biases and toxicity levels. Prior work has shown that finetuning on specialized datasets can mitigate this behavior, and doing so in English can transfer to other languages. In this work, we investigate the impact of different finetuning methods on the model's bias and toxicity, but also on its ability to produce fluent and diverse text. Our results show that finetuning on curated non-harmful text is more effective for mitigating bias, and finetuning on direct preference optimization (DPO) datasets is more effective for mitigating toxicity. The mitigation caused by applying these methods in English also transfers to non-English languages. We find evidence that the extent to which transfer takes place can be predicted by the amount of data in a given language present in the model's pretraining data. However, this transfer of bias and toxicity mitigation often comes at the expense of decreased language generation ability in non-English languages, highlighting the importance of developing language-specific bias and toxicity mitigation methods.
+
+
+
+ 11. 【2412.14033】Hansel: Output Length Controlling Framework for Large Language Models
+ 链接:https://arxiv.org/abs/2412.14033
+ 作者:Seoha Song,Junhyun Lee,Hyeonmok Ko
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:large language models, output sequence, efficiently controlling, remains a challenge, great success
+ 备注: 13 pages, 6 figures; accepted to AAAI-25
+
+ 点击查看摘要
+ Abstract:Despite the great success of large language models (LLMs), efficiently controlling the length of the output sequence still remains a challenge. In this paper, we propose Hansel, an efficient framework for length control in LLMs without affecting its generation ability. Hansel utilizes periodically outputted hidden special tokens to keep track of the remaining target length of the output sequence. Together with techniques to avoid abrupt termination of the output, this seemingly simple method proved to be efficient and versatile, while not harming the coherency and fluency of the generated text. The framework can be applied to any pre-trained LLMs during the finetuning stage of the model, regardless of its original positional encoding method. We demonstrate this by finetuning four different LLMs with Hansel and show that the mean absolute error of the output sequence decreases significantly in every model and dataset compared to the prompt-based length control finetuning. Moreover, the framework showed a substantially improved ability to extrapolate to target lengths unseen during finetuning, such as long dialog responses or extremely short summaries. This indicates that the model learns the general means of length control, rather than learning to match output lengths to those seen during training.
+
+
+
+ 12. 【2412.14011】owards an optimised evaluation of teachers' discourse: The case of engaging messages
+ 链接:https://arxiv.org/abs/2412.14011
+ 作者:Samuel Falcon,Jaime Leon
+ 类目:Computation and Language (cs.CL)
+ 关键词:Evaluating teachers' skills, Evaluating teachers', teachers' skills, skills is crucial, Evaluating
+ 备注:
+
+ 点击查看摘要
+ Abstract:Evaluating teachers' skills is crucial for enhancing education quality and student outcomes. Teacher discourse, significantly influencing student performance, is a key component. However, coding this discourse can be laborious. This study addresses this issue by introducing a new methodology for optimising the assessment of teacher discourse. The research consisted of two studies, both within the framework of engaging messages used by secondary education teachers. The first study involved training two large language models on real-world examples from audio-recorded lessons over two academic years to identify and classify the engaging messages from the lessons' transcripts. This resulted in sensitivities of 84.31% and 91.11%, and specificities of 97.69% and 86.36% in identification and classification, respectively. The second study applied these models to transcripts of audio-recorded lessons from a third academic year to examine the frequency and distribution of message types by educational level and moment of the academic year. Results showed teachers predominantly use messages emphasising engagement benefits, linked to improved outcomes, while one-third highlighted non-engagement disadvantages, associated with increased anxiety. The use of engaging messages declined in Grade 12 and towards the academic year's end. These findings suggest potential interventions to optimise engaging message use, enhancing teaching quality and student outcomes.
+
+
+
+ 13. 【2412.14009】Cognition Chain for Explainable Psychological Stress Detection on Social Media
+ 链接:https://arxiv.org/abs/2412.14009
+ 作者:Xin Wang,Boyan Gao,Yi Dai,Lei Cao,Liang Zhao,Yibo Yang,David Clifton
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Human-Computer Interaction (cs.HC)
+ 关键词:mental health problems, pervasive global health, global health issue, severe mental health, health problems
+ 备注:
+
+ 点击查看摘要
+ Abstract:Stress is a pervasive global health issue that can lead to severe mental health problems. Early detection offers timely intervention and prevention of stress-related disorders. The current early detection models perform "black box" inference suffering from limited explainability and trust which blocks the real-world clinical application. Thanks to the generative properties introduced by the Large Language Models (LLMs), the decision and the prediction from such models are semi-interpretable through the corresponding description. However, the existing LLMs are mostly trained for general purposes without the guidance of psychological cognitive theory. To this end, we first highlight the importance of prior theory with the observation of performance boosted by the chain-of-thoughts tailored for stress detection. This method termed Cognition Chain explicates the generation of stress through a step-by-step cognitive perspective based on cognitive appraisal theory with a progress pipeline: Stimulus $\rightarrow$ Evaluation $\rightarrow$ Reaction $\rightarrow$ Stress State, guiding LLMs to provide comprehensive reasoning explanations. We further study the benefits brought by the proposed Cognition Chain format by utilising it as a synthetic dataset generation template for LLMs instruction-tuning and introduce CogInstruct, an instruction-tuning dataset for stress detection. This dataset is developed using a three-stage self-reflective annotation pipeline that enables LLMs to autonomously generate and refine instructional data. By instruction-tuning Llama3 with CogInstruct, we develop CogLLM, an explainable stress detection model. Evaluations demonstrate that CogLLM achieves outstanding performance while enhancing explainability. Our work contributes a novel approach by integrating cognitive theories into LLM reasoning processes, offering a promising direction for future explainable AI research.
+
+
+
+ 14. 【2412.14008】FarExStance: Explainable Stance Detection for Farsi
+ 链接:https://arxiv.org/abs/2412.14008
+ 作者:Majid Zarharan,Maryam Hashemi,Malika Behroozrazegh,Sauleh Eetemadi,Mohammad Taher Pilehvar,Jennifer Foster
+ 类目:Computation and Language (cs.CL)
+ 关键词:explainable stance detection, introduce FarExStance, detection in Farsi, explainable stance, stance detection
+ 备注: Accepted in COLING 2025
+
+ 点击查看摘要
+ Abstract:We introduce FarExStance, a new dataset for explainable stance detection in Farsi. Each instance in this dataset contains a claim, the stance of an article or social media post towards that claim, and an extractive explanation which provides evidence for the stance label. We compare the performance of a fine-tuned multilingual RoBERTa model to several large language models in zero-shot, few-shot, and parameter-efficient fine-tuned settings on our new dataset. On stance detection, the most accurate models are the fine-tuned RoBERTa model, the LLM Aya-23-8B which has been fine-tuned using parameter-efficient fine-tuning, and few-shot Claude-3.5-Sonnet. Regarding the quality of the explanations, our automatic evaluation metrics indicate that few-shot GPT-4o generates the most coherent explanations, while our human evaluation reveals that the best Overall Explanation Score (OES) belongs to few-shot Claude-3.5-Sonnet. The fine-tuned Aya-32-8B model produced explanations most closely aligned with the reference explanations.
+
+
+
+ 15. 【2412.13989】What makes a good metric? Evaluating automatic metrics for text-to-image consistency
+ 链接:https://arxiv.org/abs/2412.13989
+ 作者:Candace Ross,Melissa Hall,Adriana Romero Soriano,Adina Williams
+ 类目:Computation and Language (cs.CL)
+ 关键词:text-image consistency metrics, increasingly being incorporated, larger AI systems, prompt optimization, optimization to automatic
+ 备注: Accepted and presented at COLM 2024
+
+ 点击查看摘要
+ Abstract:Language models are increasingly being incorporated as components in larger AI systems for various purposes, from prompt optimization to automatic evaluation. In this work, we analyze the construct validity of four recent, commonly used methods for measuring text-to-image consistency - CLIPScore, TIFA, VPEval, and DSG - which rely on language models and/or VQA models as components. We define construct validity for text-image consistency metrics as a set of desiderata that text-image consistency metrics should have, and find that no tested metric satisfies all of them. We find that metrics lack sufficient sensitivity to language and visual properties. Next, we find that TIFA, VPEval and DSG contribute novel information above and beyond CLIPScore, but also that they correlate highly with each other. We also ablate different aspects of the text-image consistency metrics and find that not all model components are strictly necessary, also a symptom of insufficient sensitivity to visual information. Finally, we show that all three VQA-based metrics likely rely on familiar text shortcuts (such as yes-bias in QA) that call their aptitude as quantitative evaluations of model performance into question.
+
+
+
+ 16. 【2412.13952】Prompting Strategies for Enabling Large Language Models to Infer Causation from Correlation
+ 链接:https://arxiv.org/abs/2412.13952
+ 作者:Eleni Sgouritsa,Virginia Aglietti,Yee Whye Teh,Arnaud Doucet,Arthur Gretton,Silvia Chiappa
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Large Language Models, Language Models, Large Language, attracting increasing attention, abilities of Large
+ 备注:
+
+ 点击查看摘要
+ Abstract:The reasoning abilities of Large Language Models (LLMs) are attracting increasing attention. In this work, we focus on causal reasoning and address the task of establishing causal relationships based on correlation information, a highly challenging problem on which several LLMs have shown poor performance. We introduce a prompting strategy for this problem that breaks the original task into fixed subquestions, with each subquestion corresponding to one step of a formal causal discovery algorithm, the PC algorithm. The proposed prompting strategy, PC-SubQ, guides the LLM to follow these algorithmic steps, by sequentially prompting it with one subquestion at a time, augmenting the next subquestion's prompt with the answer to the previous one(s). We evaluate our approach on an existing causal benchmark, Corr2Cause: our experiments indicate a performance improvement across five LLMs when comparing PC-SubQ to baseline prompting strategies. Results are robust to causal query perturbations, when modifying the variable names or paraphrasing the expressions.
+
+
+
+ 17. 【2412.13949】Cracking the Code of Hallucination in LVLMs with Vision-aware Head Divergence
+ 链接:https://arxiv.org/abs/2412.13949
+ 作者:Jinghan He,Kuan Zhu,Haiyun Guo,Junfeng Fang,Zhenglin Hua,Yuheng Jia,Ming Tang,Tat-Seng Chua,Jinqiao Wang
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:enabling advanced multimodal, advanced multimodal reasoning, made substantial progress, Large vision-language models, integrating large language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large vision-language models (LVLMs) have made substantial progress in integrating large language models (LLMs) with visual inputs, enabling advanced multimodal reasoning. Despite their success, a persistent challenge is hallucination-where generated text fails to accurately reflect visual content-undermining both accuracy and reliability. Existing methods focus on alignment training or decoding refinements but primarily address symptoms at the generation stage without probing the underlying causes. In this work, we investigate the internal mechanisms driving hallucination in LVLMs, with an emphasis on the multi-head attention module. Specifically, we introduce Vision-aware Head Divergence (VHD), a metric that quantifies the sensitivity of attention head outputs to visual context. Based on this, our findings reveal the presence of vision-aware attention heads that are more attuned to visual information; however, the model's overreliance on its prior language patterns is closely related to hallucinations. Building on these insights, we propose Vision-aware Head Reinforcement (VHR), a training-free approach to mitigate hallucination by enhancing the role of vision-aware attention heads. Extensive experiments demonstrate that our method achieves superior performance compared to state-of-the-art approaches in mitigating hallucinations, while maintaining high efficiency with negligible additional time overhead.
+
+
+
+ 18. 【2412.13942】A Rose by Any Other Name: LLM-Generated Explanations Are Good Proxies for Human Explanations to Collect Label Distributions on NLI
+ 链接:https://arxiv.org/abs/2412.13942
+ 作者:Beiduo Chen,Siyao Peng,Anna Korhonen,Barbara Plank
+ 类目:Computation and Language (cs.CL)
+ 关键词:human, labeling is ubiquitous, explanations, Disagreement, HJD
+ 备注: 25 pages, 21 figures
+
+ 点击查看摘要
+ Abstract:Disagreement in human labeling is ubiquitous, and can be captured in human judgment distributions (HJDs). Recent research has shown that explanations provide valuable information for understanding human label variation (HLV) and large language models (LLMs) can approximate HJD from a few human-provided label-explanation pairs. However, collecting explanations for every label is still time-consuming. This paper examines whether LLMs can be used to replace humans in generating explanations for approximating HJD. Specifically, we use LLMs as annotators to generate model explanations for a few given human labels. We test ways to obtain and combine these label-explanations with the goal to approximate human judgment distribution. We further compare the resulting human with model-generated explanations, and test automatic and human explanation selection. Our experiments show that LLM explanations are promising for NLI: to estimate HJD, generated explanations yield comparable results to human's when provided with human labels. Importantly, our results generalize from datasets with human explanations to i) datasets where they are not available and ii) challenging out-of-distribution test sets.
+
+
+
+ 19. 【2412.13924】Language verY Rare for All
+ 链接:https://arxiv.org/abs/2412.13924
+ 作者:Ibrahim Merad,Amos Wolf,Ziad Mazzawi,Yannick Léo
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:single GPU, overcome language barriers, expanded machine translation, NLLB, NLLB have expanded
+ 备注:
+
+ 点击查看摘要
+ Abstract:In the quest to overcome language barriers, encoder-decoder models like NLLB have expanded machine translation to rare languages, with some models (e.g., NLLB 1.3B) even trainable on a single GPU. While general-purpose LLMs perform well in translation, open LLMs prove highly competitive when fine-tuned for specific tasks involving unknown corpora. We introduce LYRA (Language verY Rare for All), a novel approach that combines open LLM fine-tuning, retrieval-augmented generation (RAG), and transfer learning from related high-resource languages. This study is exclusively focused on single-GPU training to facilitate ease of adoption. Our study focuses on two-way translation between French and Monégasque, a rare language unsupported by existing translation tools due to limited corpus availability. Our results demonstrate LYRA's effectiveness, frequently surpassing and consistently matching state-of-the-art encoder-decoder models in rare language translation.
+
+
+
+ 20. 【2412.13922】Pipeline Analysis for Developing Instruct LLMs in Low-Resource Languages: A Case Study on Basque
+ 链接:https://arxiv.org/abs/2412.13922
+ 作者:Ander Corral,Ixak Sarasua,Xabier Saralegi
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Large language models, Large language, exacerbating the gap, typically optimized, optimized for resource-rich
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) are typically optimized for resource-rich languages like English, exacerbating the gap between high-resource and underrepresented languages. This work presents a detailed analysis of strategies for developing a model capable of following instructions in a low-resource language, specifically Basque, by focusing on three key stages: pre-training, instruction tuning, and alignment with human preferences. Our findings demonstrate that continual pre-training with a high-quality Basque corpus of around 600 million words improves natural language understanding (NLU) of the foundational model by over 12 points. Moreover, instruction tuning and human preference alignment using automatically translated datasets proved highly effective, resulting in a 24-point improvement in instruction-following performance. The resulting models, Llama-eus-8B and Llama-eus-8B-instruct, establish a new state-of-the-art for Basque in the sub-10B parameter category.
+
+
+
+ 21. 【2412.13881】Understanding and Analyzing Model Robustness and Knowledge-Transfer in Multilingual Neural Machine Translation using TX-Ray
+ 链接:https://arxiv.org/abs/2412.13881
+ 作者:Vageesh Saxena,Sharid Loáiciga,Nils Rethmeier
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Neural Machine Translation, Multilingual Neural Machine, Neural Machine, demonstrated significant advancements, Machine Translation
+ 备注: 103 pages, Master's thesis
+
+ 点击查看摘要
+ Abstract:Neural networks have demonstrated significant advancements in Neural Machine Translation (NMT) compared to conventional phrase-based approaches. However, Multilingual Neural Machine Translation (MNMT) in extremely low-resource settings remains underexplored. This research investigates how knowledge transfer across languages can enhance MNMT in such scenarios. Using the Tatoeba translation challenge dataset from Helsinki NLP, we perform English-German, English-French, and English-Spanish translations, leveraging minimal parallel data to establish cross-lingual mappings. Unlike conventional methods relying on extensive pre-training for specific language pairs, we pre-train our model on English-English translations, setting English as the source language for all tasks. The model is fine-tuned on target language pairs using joint multi-task and sequential transfer learning strategies. Our work addresses three key questions: (1) How can knowledge transfer across languages improve MNMT in extremely low-resource scenarios? (2) How does pruning neuron knowledge affect model generalization, robustness, and catastrophic forgetting? (3) How can TX-Ray interpret and quantify knowledge transfer in trained models? Evaluation using BLEU-4 scores demonstrates that sequential transfer learning outperforms baselines on a 40k parallel sentence corpus, showcasing its efficacy. However, pruning neuron knowledge degrades performance, increases catastrophic forgetting, and fails to improve robustness or generalization. Our findings provide valuable insights into the potential and limitations of knowledge transfer and pruning in MNMT for extremely low-resource settings.
+
+
+
+ 22. 【2412.13879】Crabs: Consuming Resrouce via Auto-generation for LLM-DoS Attack under Black-box Settings
+ 链接:https://arxiv.org/abs/2412.13879
+ 作者:Yuanhe Zhang,Zhenhong Zhou,Wei Zhang,Xinyue Wang,Xiaojun Jia,Yang Liu,Sen Su
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Cryptography and Security (cs.CR)
+ 关键词:Large Language Models, Large Language, Language Models, demonstrated remarkable performance, diverse tasks
+ 备注: 20 pages, 7 figures, 11 tables
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have demonstrated remarkable performance across diverse tasks. LLMs continue to be vulnerable to external threats, particularly Denial-of-Service (DoS) attacks. Specifically, LLM-DoS attacks aim to exhaust computational resources and block services. However, prior works tend to focus on performing white-box attacks, overlooking black-box settings. In this work, we propose an automated algorithm designed for black-box LLMs, called Auto-Generation for LLM-DoS Attack (AutoDoS). AutoDoS introduces DoS Attack Tree and optimizes the prompt node coverage to enhance effectiveness under black-box conditions. Our method can bypass existing defense with enhanced stealthiness via semantic improvement of prompt nodes. Furthermore, we reveal that implanting Length Trojan in Basic DoS Prompt aids in achieving higher attack efficacy. Experimental results show that AutoDoS amplifies service response latency by over 250 $\times \uparrow$, leading to severe resource consumption in terms of GPU utilization and memory usage. Our code is available at \url{this https URL}.
+
+
+
+ 23. 【2412.13862】Energy-Based Preference Model Offers Better Offline Alignment than the Bradley-Terry Preference Model
+ 链接:https://arxiv.org/abs/2412.13862
+ 作者:Yuzhong Hong,Hanshan Zhang,Junwei Bao,Hongfei Jiang,Yang Song
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL)
+ 关键词:reward modeling task, KL-constrained RLHF loss, target LLM, DPO loss, reward modeling
+ 备注:
+
+ 点击查看摘要
+ Abstract:Since the debut of DPO, it has been shown that aligning a target LLM with human preferences via the KL-constrained RLHF loss is mathematically equivalent to a special kind of reward modeling task. Concretely, the task requires: 1) using the target LLM to parameterize the reward model, and 2) tuning the reward model so that it has a 1:1 linear relationship with the true reward. However, we identify a significant issue: the DPO loss might have multiple minimizers, of which only one satisfies the required linearity condition. The problem arises from a well-known issue of the underlying Bradley-Terry preference model: it does not always have a unique maximum likelihood estimator (MLE). Consequently,the minimizer of the RLHF loss might be unattainable because it is merely one among many minimizers of the DPO loss. As a better alternative, we propose an energy-based model (EBM) that always has a unique MLE, inherently satisfying the linearity requirement. To approximate the MLE in practice, we propose a contrastive loss named Energy Preference Alignment (EPA), wherein each positive sample is contrasted against one or more strong negatives as well as many free weak negatives. Theoretical properties of our EBM enable the approximation error of EPA to almost surely vanish when a sufficient number of negatives are used. Empirically, we demonstrate that EPA consistently delivers better performance on open benchmarks compared to DPO, thereby showing the superiority of our EBM.
+
+
+
+ 24. 【2412.13860】Domain-adaptative Continual Learning for Low-resource Tasks: Evaluation on Nepali
+ 链接:https://arxiv.org/abs/2412.13860
+ 作者:Sharad Duwal,Suraj Prasai,Suresh Manandhar
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:important research direction, research direction due, retraining large language, Continual learning, large language models
+ 备注: 10 pages, 2 figures
+
+ 点击查看摘要
+ Abstract:Continual learning has emerged as an important research direction due to the infeasibility of retraining large language models (LLMs) from scratch in the event of new data availability. Of great interest is the domain-adaptive pre-training (DAPT) paradigm, which focuses on continually training a pre-trained language model to adapt it to a domain it was not originally trained on. In this work, we evaluate the feasibility of DAPT in a low-resource setting, namely the Nepali language. We use synthetic data to continue training Llama 3 8B to adapt it to the Nepali language in a 4-bit QLoRA setting. We evaluate the adapted model on its performance, forgetting, and knowledge acquisition. We compare the base model and the final model on their Nepali generation abilities, their performance on popular benchmarks, and run case-studies to probe their linguistic knowledge in Nepali. We see some unsurprising forgetting in the final model, but also surprisingly find that increasing the number of shots during evaluation yields better percent increases in the final model (as high as 19.29% increase) compared to the base model (4.98%), suggesting latent retention. We also explore layer-head self-attention heatmaps to establish dependency resolution abilities of the final model in Nepali.
+
+
+
+ 25. 【2412.13835】RACQUET: Unveiling the Dangers of Overlooked Referential Ambiguity in Visual LLMs
+ 链接:https://arxiv.org/abs/2412.13835
+ 作者:Alberto Testoni,Barbara Plank,Raquel Fernández
+ 类目:Computation and Language (cs.CL)
+ 关键词:effective communication, resolution is key, key to effective, Ambiguity, Ambiguity resolution
+ 备注:
+
+ 点击查看摘要
+ Abstract:Ambiguity resolution is key to effective communication. While humans effortlessly address ambiguity through conversational grounding strategies, the extent to which current language models can emulate these strategies remains unclear. In this work, we examine referential ambiguity in image-based question answering by introducing RACQUET, a carefully curated dataset targeting distinct aspects of ambiguity. Through a series of evaluations, we reveal significant limitations and problems of overconfidence of state-of-the-art large multimodal language models in addressing ambiguity in their responses. The overconfidence issue becomes particularly relevant for RACQUET-BIAS, a subset designed to analyze a critical yet underexplored problem: failing to address ambiguity leads to stereotypical, socially biased responses. Our results underscore the urgency of equipping models with robust strategies to deal with uncertainty without resorting to undesirable stereotypes.
+
+
+
+ 26. 【2412.13799】Enhancing Rhetorical Figure Annotation: An Ontology-Based Web Application with RAG Integration
+ 链接:https://arxiv.org/abs/2412.13799
+ 作者:Ramona Kühn,Jelena Mitrović,Michael Granitzer
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Rhetorical figures, Rhetorical figures play, German rhetorical figures, play an important, important role
+ 备注: The 31st International Conference on Computational Linguistics (COLING 2025)
+
+ 点击查看摘要
+ Abstract:Rhetorical figures play an important role in our communication. They are used to convey subtle, implicit meaning, or to emphasize statements. We notice them in hate speech, fake news, and propaganda. By improving the systems for computational detection of rhetorical figures, we can also improve tasks such as hate speech and fake news detection, sentiment analysis, opinion mining, or argument mining. Unfortunately, there is a lack of annotated data, as well as qualified annotators that would help us build large corpora to train machine learning models for the detection of rhetorical figures. The situation is particularly difficult in languages other than English, and for rhetorical figures other than metaphor, sarcasm, and irony. To overcome this issue, we develop a web application called "Find your Figure" that facilitates the identification and annotation of German rhetorical figures. The application is based on the German Rhetorical ontology GRhOOT which we have specially adapted for this purpose. In addition, we improve the user experience with Retrieval Augmented Generation (RAG). In this paper, we present the restructuring of the ontology, the development of the web application, and the built-in RAG pipeline. We also identify the optimal RAG settings for our application. Our approach is one of the first to practically use rhetorical ontologies in combination with RAG and shows promising results.
+
+
+
+ 27. 【2412.13794】MATCHED: Multimodal Authorship-Attribution To Combat Human Trafficking in Escort-Advertisement Data
+ 链接:https://arxiv.org/abs/2412.13794
+ 作者:Vageesh Saxena,Benjamin Bashpole,Gijs Van Dijck,Gerasimos Spanakis
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computers and Society (cs.CY)
+ 关键词:advertise victims anonymously, traffickers increasingly leveraging, increasingly leveraging online, online escort advertisements, leveraging online escort
+ 备注: 40 pages
+
+ 点击查看摘要
+ Abstract:Human trafficking (HT) remains a critical issue, with traffickers increasingly leveraging online escort advertisements (ads) to advertise victims anonymously. Existing detection methods, including Authorship Attribution (AA), often center on text-based analyses and neglect the multimodal nature of online escort ads, which typically pair text with images. To address this gap, we introduce MATCHED, a multimodal dataset of 27,619 unique text descriptions and 55,115 unique images collected from the Backpage escort platform across seven U.S. cities in four geographical regions. Our study extensively benchmarks text-only, vision-only, and multimodal baselines for vendor identification and verification tasks, employing multitask (joint) training objectives that achieve superior classification and retrieval performance on in-distribution and out-of-distribution (OOD) datasets. Integrating multimodal features further enhances this performance, capturing complementary patterns across text and images. While text remains the dominant modality, visual data adds stylistic cues that enrich model performance. Moreover, text-image alignment strategies like CLIP and BLIP2 struggle due to low semantic overlap and vague connections between the modalities of escort ads, with end-to-end multimodal training proving more robust. Our findings emphasize the potential of multimodal AA (MAA) to combat HT, providing LEAs with robust tools to link ads and disrupt trafficking networks.
+
+
+
+ 28. 【2412.13791】Physics Reasoner: Knowledge-Augmented Reasoning for Solving Physics Problems with Large Language Models
+ 链接:https://arxiv.org/abs/2412.13791
+ 作者:Xinyu Pang,Ruixin Hong,Zhanke Zhou,Fangrui Lv,Xinwei Yang,Zhilong Liang,Bo Han,Changshui Zhang
+ 类目:Computation and Language (cs.CL)
+ 关键词:necessitating complicated reasoning, Physics Reasoner, complicated reasoning ability, Physics problems constitute, Physics
+ 备注: COLING 2025
+
+ 点击查看摘要
+ Abstract:Physics problems constitute a significant aspect of reasoning, necessitating complicated reasoning ability and abundant physics knowledge. However, existing large language models (LLMs) frequently fail due to a lack of knowledge or incorrect knowledge application. To mitigate these issues, we propose Physics Reasoner, a knowledge-augmented framework to solve physics problems with LLMs. Specifically, the proposed framework constructs a comprehensive formula set to provide explicit physics knowledge and utilizes checklists containing detailed instructions to guide effective knowledge application. Namely, given a physics problem, Physics Reasoner solves it through three stages: problem analysis, formula retrieval, and guided reasoning. During the process, checklists are employed to enhance LLMs' self-improvement in the analysis and reasoning stages. Empirically, Physics Reasoner mitigates the issues of insufficient knowledge and incorrect application, achieving state-of-the-art performance on SciBench with an average accuracy improvement of 5.8%.
+
+
+
+ 29. 【2412.13788】Open Universal Arabic ASR Leaderboard
+ 链接:https://arxiv.org/abs/2412.13788
+ 作者:Yingzhi Wang,Anas Alhmoud,Muhammad Alqurishi
+ 类目:Computation and Language (cs.CL)
+ 关键词:Arabic ASR, pushed Arabic ASR, Arabic ASR models, increasingly pushed Arabic, Arabic ASR Leaderboard
+ 备注:
+
+ 点击查看摘要
+ Abstract:In recent years, the enhanced capabilities of ASR models and the emergence of multi-dialect datasets have increasingly pushed Arabic ASR model development toward an all-dialect-in-one direction. This trend highlights the need for benchmarking studies that evaluate model performance on multiple dialects, providing the community with insights into models' generalization capabilities.
+In this paper, we introduce Open Universal Arabic ASR Leaderboard, a continuous benchmark project for open-source general Arabic ASR models across various multi-dialect datasets. We also provide a comprehensive analysis of the model's robustness, speaker adaptation, inference efficiency, and memory consumption. This work aims to offer the Arabic ASR community a reference for models' general performance and also establish a common evaluation framework for multi-dialectal Arabic ASR models.
+
Subjects:
+Computation and Language (cs.CL)
+Cite as:
+arXiv:2412.13788 [cs.CL]
+(or
+arXiv:2412.13788v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2412.13788
+Focus to learn more
+ arXiv-issued DOI via DataCite (pending registration)</p>
+
+
+
+
+ 30. 【2412.13782】Knowledge Editing with Dynamic Knowledge Graphs for Multi-hop Question Answering
+ 链接:https://arxiv.org/abs/2412.13782
+ 作者:Yifan Lu,Yigeng Zhou,Jing Li,Yequan Wang,Xuebo Liu,Daojing He,Fangming Liu,Min Zhang
+ 类目:Computation and Language (cs.CL)
+ 关键词:Multi-hop question answering, Multi-hop question, knowledge demands involved, extensive knowledge demands, large language models
+ 备注: AAAI 2025
+
+ 点击查看摘要
+ Abstract:Multi-hop question answering (MHQA) poses a significant challenge for large language models (LLMs) due to the extensive knowledge demands involved. Knowledge editing, which aims to precisely modify the LLMs to incorporate specific knowledge without negatively impacting other unrelated knowledge, offers a potential solution for addressing MHQA challenges with LLMs. However, current solutions struggle to effectively resolve issues of knowledge conflicts. Most parameter-preserving editing methods are hindered by inaccurate retrieval and overlook secondary editing issues, which can introduce noise into the reasoning process of LLMs. In this paper, we introduce KEDKG, a novel knowledge editing method that leverages a dynamic knowledge graph for MHQA, designed to ensure the reliability of answers. KEDKG involves two primary steps: dynamic knowledge graph construction and knowledge graph augmented generation. Initially, KEDKG autonomously constructs a dynamic knowledge graph to store revised information while resolving potential knowledge conflicts. Subsequently, it employs a fine-grained retrieval strategy coupled with an entity and relation detector to enhance the accuracy of graph retrieval for LLM generation. Experimental results on benchmarks show that KEDKG surpasses previous state-of-the-art models, delivering more accurate and reliable answers in environments with dynamic information.
+
+
+
+ 31. 【2412.13781】Meta-Reflection: A Feedback-Free Reflection Learning Framework
+ 链接:https://arxiv.org/abs/2412.13781
+ 作者:Yaoke Wang,Yun Zhu,Xintong Bao,Wenqiao Zhang,Suyang Dai,Kehan Chen,Wenqiang Li,Gang Huang,Siliang Tang,Yueting Zhuang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:large language models, natural language understanding, display undesirable behaviors, unfaithful reasoning, language models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Despite the remarkable capabilities of large language models (LLMs) in natural language understanding and reasoning, they often display undesirable behaviors, such as generating hallucinations and unfaithful reasoning. A prevalent strategy to mitigate these issues is the use of reflection, which refines responses through an iterative process. However, while promising, reflection heavily relies on high-quality external feedback and requires iterative multi-agent inference processes, thus hindering its practical application. In this paper, we propose Meta-Reflection, a novel feedback-free reflection mechanism that necessitates only a single inference pass without external feedback. Motivated by the human ability to remember and retrieve reflections from past experiences when encountering similar problems, Meta-Reflection integrates reflective insights into a codebook, allowing the historical insights to be stored, retrieved, and used to guide LLMs in problem-solving. To thoroughly investigate and evaluate the practicality of Meta-Reflection in real-world scenarios, we introduce an industrial e-commerce benchmark named E-commerce Customer Intent Detection (ECID). Extensive experiments conducted on both public datasets and the ECID benchmark highlight the effectiveness and efficiency of our proposed approach.
+
+
+
+ 32. 【2412.13771】Semantic Convergence: Harmonizing Recommender Systems via Two-Stage Alignment and Behavioral Semantic Tokenization
+ 链接:https://arxiv.org/abs/2412.13771
+ 作者:Guanghan Li,Xun Zhang,Yufei Zhang,Yifan Yin,Guojun Yin,Wei Lin
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:exceptional reasoning capabilities, Large language models, discerning profound user, profound user interests, endowed with exceptional
+ 备注: 7 pages, 3 figures, AAAI 2025
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs), endowed with exceptional reasoning capabilities, are adept at discerning profound user interests from historical behaviors, thereby presenting a promising avenue for the advancement of recommendation systems. However, a notable discrepancy persists between the sparse collaborative semantics typically found in recommendation systems and the dense token representations within LLMs. In our study, we propose a novel framework that harmoniously merges traditional recommendation models with the prowess of LLMs. We initiate this integration by transforming ItemIDs into sequences that align semantically with the LLMs space, through the proposed Alignment Tokenization module. Additionally, we design a series of specialized supervised learning tasks aimed at aligning collaborative signals with the subtleties of natural language semantics. To ensure practical applicability, we optimize online inference by pre-caching the top-K results for each user, reducing latency and improving effciency. Extensive experimental evidence indicates that our model markedly improves recall metrics and displays remarkable scalability of recommendation systems.
+
+
+
+ 33. 【2412.13765】LLM-SEM: A Sentiment-Based Student Engagement Metric Using LLMS for E-Learning Platforms
+ 链接:https://arxiv.org/abs/2412.13765
+ 作者:Ali Hamdi,Ahmed Abdelmoneim Mazrou,Mohamed Shaltout
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:including automated systems, handling fuzzy sentiment, analyzing student engagement, Current methods, e-learning platforms
+ 备注:
+
+ 点击查看摘要
+ Abstract:Current methods for analyzing student engagement in e-learning platforms, including automated systems, often struggle with challenges such as handling fuzzy sentiment in text comments and relying on limited metadata. Traditional approaches, such as surveys and questionnaires, also face issues like small sample sizes and scalability. In this paper, we introduce LLM-SEM (Language Model-Based Student Engagement Metric), a novel approach that leverages video metadata and sentiment analysis of student comments to measure engagement. By utilizing recent Large Language Models (LLMs), we generate high-quality sentiment predictions to mitigate text fuzziness and normalize key features such as views and likes. Our holistic method combines comprehensive metadata with sentiment polarity scores to gauge engagement at both the course and lesson levels. Extensive experiments were conducted to evaluate various LLM models, demonstrating the effectiveness of LLM-SEM in providing a scalable and accurate measure of student engagement. We fine-tuned LLMs, including AraBERT, TXLM-RoBERTa, LLama 3B and Gemma 9B from Ollama, using human-annotated sentiment datasets to enhance prediction accuracy.
+
+
+
+ 34. 【2412.13746】RAG-RewardBench: Benchmarking Reward Models in Retrieval Augmented Generation for Preference Alignment
+ 链接:https://arxiv.org/abs/2412.13746
+ 作者:Zhuoran Jin,Hongbang Yuan,Tianyi Men,Pengfei Cao,Yubo Chen,Kang Liu,Jun Zhao
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:significant progress made, retrieval augmented language, providing trustworthy responses, augmented language models, overlook effective alignment
+ 备注: 26 pages, 12 figures, 6 tables
+
+ 点击查看摘要
+ Abstract:Despite the significant progress made by existing retrieval augmented language models (RALMs) in providing trustworthy responses and grounding in reliable sources, they often overlook effective alignment with human preferences. In the alignment process, reward models (RMs) act as a crucial proxy for human values to guide optimization. However, it remains unclear how to evaluate and select a reliable RM for preference alignment in RALMs. To this end, we propose RAG-RewardBench, the first benchmark for evaluating RMs in RAG settings. First, we design four crucial and challenging RAG-specific scenarios to assess RMs, including multi-hop reasoning, fine-grained citation, appropriate abstain, and conflict robustness. Then, we incorporate 18 RAG subsets, six retrievers, and 24 RALMs to increase the diversity of data sources. Finally, we adopt an LLM-as-a-judge approach to improve preference annotation efficiency and effectiveness, exhibiting a strong correlation with human annotations. Based on the RAG-RewardBench, we conduct a comprehensive evaluation of 45 RMs and uncover their limitations in RAG scenarios. Additionally, we also reveal that existing trained RALMs show almost no improvement in preference alignment, highlighting the need for a shift towards preference-aligned this http URL release our benchmark and code publicly at this https URL for future work.
+
+
+
+ 35. 【2412.13745】Learning Complex Word Embeddings in Classical and Quantum Spaces
+ 链接:https://arxiv.org/abs/2412.13745
+ 作者:Carys Harvey,Stephen Clark,Douglas Brown,Konstantinos Meichanetzidis
+ 类目:Computation and Language (cs.CL)
+ 关键词:straightforward adaptation simply, adaptation simply replacing, classical Skip-gram embeddings, classical Skip-gram model, present a variety
+ 备注:
+
+ 点击查看摘要
+ Abstract:We present a variety of methods for training complex-valued word embeddings, based on the classical Skip-gram model, with a straightforward adaptation simply replacing the real-valued vectors with arbitrary vectors of complex numbers. In a more "physically-inspired" approach, the vectors are produced by parameterised quantum circuits (PQCs), which are unitary transformations resulting in normalised vectors which have a probabilistic interpretation. We develop a complex-valued version of the highly optimised C code version of Skip-gram, which allows us to easily produce complex embeddings trained on a 3.8B-word corpus for a vocabulary size of over 400k, for which we are then able to train a separate PQC for each word. We evaluate the complex embeddings on a set of standard similarity and relatedness datasets, for some models obtaining results competitive with the classical baseline. We find that, while training the PQCs directly tends to harm performance, the quantum word embeddings from the two-stage process perform as well as the classical Skip-gram embeddings with comparable numbers of parameters. This enables a highly scalable route to learning embeddings in complex spaces which scales with the size of the vocabulary rather than the size of the training corpus. In summary, we demonstrate how to produce a large set of high-quality word embeddings for use in complex-valued and quantum-inspired NLP models, and for exploring potential advantage in quantum NLP models.
+
+
+
+ 36. 【2412.13720】Federated Learning and RAG Integration: A Scalable Approach for Medical Large Language Models
+ 链接:https://arxiv.org/abs/2412.13720
+ 作者:Jincheol Jung,Hongju Jeong,Eui-Nam Huh
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Models, domain-specific Large Language, Large Language, integrating Retrieval-Augmented Generation, federated learning framework
+ 备注:
+
+ 点击查看摘要
+ Abstract:This study analyzes the performance of domain-specific Large Language Models (LLMs) for the medical field by integrating Retrieval-Augmented Generation (RAG) systems within a federated learning framework. Leveraging the inherent advantages of federated learning, such as preserving data privacy and enabling distributed computation, this research explores the integration of RAG systems with models trained under varying client configurations to optimize performance. Experimental results demonstrate that the federated learning-based models integrated with RAG systems consistently outperform their non-integrated counterparts across all evaluation metrics. This study highlights the potential of combining federated learning and RAG systems for developing domain-specific LLMs in the medical field, providing a scalable and privacy-preserving solution for enhancing text generation capabilities.
+
+
+
+ 37. 【2412.13717】owards Automatic Evaluation for Image Transcreation
+ 链接:https://arxiv.org/abs/2412.13717
+ 作者:Simran Khanuja,Vivek Iyer,Claire He,Graham Neubig
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:speech and text, formal Machine Learning, conventional paradigms, paradigms of translating, translating speech
+ 备注:
+
+ 点击查看摘要
+ Abstract:Beyond conventional paradigms of translating speech and text, recently, there has been interest in automated transcreation of images to facilitate localization of visual content across different cultures. Attempts to define this as a formal Machine Learning (ML) problem have been impeded by the lack of automatic evaluation mechanisms, with previous work relying solely on human evaluation. In this paper, we seek to close this gap by proposing a suite of automatic evaluation metrics inspired by machine translation (MT) metrics, categorized into: a) Object-based, b) Embedding-based, and c) VLM-based. Drawing on theories from translation studies and real-world transcreation practices, we identify three critical dimensions of image transcreation: cultural relevance, semantic equivalence and visual similarity, and design our metrics to evaluate systems along these axes. Our results show that proprietary VLMs best identify cultural relevance and semantic equivalence, while vision-encoder representations are adept at measuring visual similarity. Meta-evaluation across 7 countries shows our metrics agree strongly with human ratings, with average segment-level correlations ranging from 0.55-0.87. Finally, through a discussion of the merits and demerits of each metric, we offer a robust framework for automated image transcreation evaluation, grounded in both theoretical foundations and practical application. Our code can be found here: this https URL
+
+
+
+ 38. 【2412.13705】Mitigating Adversarial Attacks in LLMs through Defensive Suffix Generation
+ 链接:https://arxiv.org/abs/2412.13705
+ 作者:Minkyoung Kim,Yunha Kim,Hyeram Seo,Heejung Choi,Jiye Han,Gaeun Kee,Soyoung Ko,HyoJe Jung,Byeolhee Kim,Young-Hak Kim,Sanghyun Park,Tae Joon Jun
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Large language models, language processing tasks, natural language processing, exhibited outstanding performance, Large language
+ 备注: 9 pages, 2 figures
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) have exhibited outstanding performance in natural language processing tasks. However, these models remain susceptible to adversarial attacks in which slight input perturbations can lead to harmful or misleading outputs. A gradient-based defensive suffix generation algorithm is designed to bolster the robustness of LLMs. By appending carefully optimized defensive suffixes to input prompts, the algorithm mitigates adversarial influences while preserving the models' utility. To enhance adversarial understanding, a novel total loss function ($L_{\text{total}}$) combining defensive loss ($L_{\text{def}}$) and adversarial loss ($L_{\text{adv}}$) generates defensive suffixes more effectively. Experimental evaluations conducted on open-source LLMs such as Gemma-7B, mistral-7B, Llama2-7B, and Llama2-13B show that the proposed method reduces attack success rates (ASR) by an average of 11\% compared to models without defensive suffixes. Additionally, the perplexity score of Gemma-7B decreased from 6.57 to 3.93 when applying the defensive suffix generated by openELM-270M. Furthermore, TruthfulQA evaluations demonstrate consistent improvements with Truthfulness scores increasing by up to 10\% across tested configurations. This approach significantly enhances the security of LLMs in critical applications without requiring extensive retraining.
+
+
+
+ 39. 【2412.13702】yphoon 2: A Family of Open Text and Multimodal Thai Large Language Models
+ 链接:https://arxiv.org/abs/2412.13702
+ 作者:Kunat Pipatanakul,Potsawee Manakul,Natapong Nitarach,Warit Sirichotedumrong,Surapon Nonesung,Teetouch Jaknamon,Parinthapat Pengpun,Pittawat Taveekitworachai,Adisai Na-Thalang,Sittipong Sripaisarnmongkol,Krisanapong Jirayoot,Kasima Tharnpipitchai
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:paper introduces Typhoon, multimodal large language, introduces Typhoon, multimodal large, large language models
+ 备注: technical report, 55 pages
+
+ 点击查看摘要
+ Abstract:This paper introduces Typhoon 2, a series of text and multimodal large language models optimized for the Thai language. The series includes models for text, vision, and audio. Typhoon2-Text builds on state-of-the-art open models, such as Llama 3 and Qwen2, and we perform continual pre-training on a mixture of English and Thai data. We employ various post-training techniques to enhance Thai language performance while preserving the base models' original capabilities. We release text models across a range of sizes, from 1 to 70 billion parameters, available in both base and instruction-tuned variants. Typhoon2-Vision improves Thai document understanding while retaining general visual capabilities, such as image captioning. Typhoon2-Audio introduces an end-to-end speech-to-speech model architecture capable of processing audio, speech, and text inputs and generating both text and speech outputs simultaneously.
+
+
+
+ 40. 【2412.13698】owards Efficient and Explainable Hate Speech Detection via Model Distillation
+ 链接:https://arxiv.org/abs/2412.13698
+ 作者:Paloma Piot,Javier Parapar
+ 类目:Computation and Language (cs.CL)
+ 关键词:Automatic detection, online spread, essential to combat, combat its online, Automatic
+ 备注:
+
+ 点击查看摘要
+ Abstract:Automatic detection of hate and abusive language is essential to combat its online spread. Moreover, recognising and explaining hate speech serves to educate people about its negative effects. However, most current detection models operate as black boxes, lacking interpretability and explainability. In this context, Large Language Models (LLMs) have proven effective for hate speech detection and to promote interpretability. Nevertheless, they are computationally costly to run. In this work, we propose distilling big language models by using Chain-of-Thought to extract explanations that support the hate speech classification task. Having small language models for these tasks will contribute to their use in operational settings. In this paper, we demonstrate that distilled models deliver explanations of the same quality as larger models while surpassing them in classification performance. This dual capability, classifying and explaining, advances hate speech detection making it more affordable, understandable and actionable.
+
+
+
+ 41. 【2412.13688】Discerning and Characterising Types of Competency Questions for Ontologies
+ 链接:https://arxiv.org/abs/2412.13688
+ 作者:C. Maria Keet,Zubeida Casmod Khan
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Competency Questions, Ontology Competency QuestionS, ontology development, CQs, ontology development tasks
+ 备注: 16 pages, 5 figures
+
+ 点击查看摘要
+ Abstract:Competency Questions (CQs) are widely used in ontology development by guiding, among others, the scoping and validation stages. However, very limited guidance exists for formulating CQs and assessing whether they are good CQs, leading to issues such as ambiguity and unusable formulations. To solve this, one requires insight into the nature of CQs for ontologies and their constituent parts, as well as which ones are not. We aim to contribute to such theoretical foundations in this paper, which is informed by analysing questions, their uses, and the myriad of ontology development tasks. This resulted in a first Model for Competency Questions, which comprises five main types of CQs, each with a different purpose: Scoping (SCQ), Validating (VCQ), Foundational (FCQ), Relationship (RCQ), and Metaproperty (MpCQ) questions. This model enhances the clarity of CQs and therewith aims to improve on the effectiveness of CQs in ontology development, thanks to their respective identifiable distinct constituent elements. We illustrate and evaluate them with a user story and demonstrate where which type can be used in ontology development tasks. To foster use and research, we created an annotated repository of 438 CQs, the Repository of Ontology Competency QuestionS (ROCQS), incorporating an existing CQ dataset and new CQs and CQ templates, which further demonstrate distinctions among types of CQs.
+
+
+
+ 42. 【2412.13682】ChinaTravel: A Real-World Benchmark for Language Agents in Chinese Travel Planning
+ 链接:https://arxiv.org/abs/2412.13682
+ 作者:Jie-Jing Shao,Xiao-Wen Yang,Bo-Wen Zhang,Baizhi Chen,Wen-Da Wei,Lan-Zhe Guo,Yu-feng Li
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Recent advances, advances in LLMs, tool integration, rapidly sparked, Recent
+ 备注: Webpage: [this https URL](https://www.lamda.nju.edu.cn/shaojj/chinatravel)
+
+ 点击查看摘要
+ Abstract:Recent advances in LLMs, particularly in language reasoning and tool integration, have rapidly sparked the real-world development of Language Agents. Among these, travel planning represents a prominent domain, combining academic challenges with practical value due to its complexity and market demand. However, existing benchmarks fail to reflect the diverse, real-world requirements crucial for deployment. To address this gap, we introduce ChinaTravel, a benchmark specifically designed for authentic Chinese travel planning scenarios. We collect the travel requirements from questionnaires and propose a compositionally generalizable domain-specific language that enables a scalable evaluation process, covering feasibility, constraint satisfaction, and preference comparison. Empirical studies reveal the potential of neuro-symbolic agents in travel planning, achieving a constraint satisfaction rate of 27.9%, significantly surpassing purely neural models at 2.6%. Moreover, we identify key challenges in real-world travel planning deployments, including open language reasoning and unseen concept composition. These findings highlight the significance of ChinaTravel as a pivotal milestone for advancing language agents in complex, real-world planning scenarios.
+
+
+
+ 43. 【2412.13678】Clio: Privacy-Preserving Insights into Real-World AI Use
+ 链接:https://arxiv.org/abs/2412.13678
+ 作者:Alex Tamkin,Miles McCain,Kunal Handa,Esin Durmus,Liane Lovitt,Ankur Rathi,Saffron Huang,Alfred Mountfield,Jerry Hong,Stuart Ritchie,Michael Stern,Brian Clarke,Landon Goldberg,Theodore R. Sumers,Jared Mueller,William McEachen,Wes Mitchell,Shan Carter,Jack Clark,Jared Kaplan,Deep Ganguli
+ 类目:Computers and Society (cs.CY); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Cryptography and Security (cs.CR); Machine Learning (cs.LG)
+ 关键词:http URL Free, Clio, http URL, real world, conversations
+ 备注:
+
+ 点击查看摘要
+ Abstract:How are AI assistants being used in the real world? While model providers in theory have a window into this impact via their users' data, both privacy concerns and practical challenges have made analyzing this data difficult. To address these issues, we present Clio (Claude insights and observations), a privacy-preserving platform that uses AI assistants themselves to analyze and surface aggregated usage patterns across millions of conversations, without the need for human reviewers to read raw conversations. We validate this can be done with a high degree of accuracy and privacy by conducting extensive evaluations. We demonstrate Clio's usefulness in two broad ways. First, we share insights about how models are being used in the real world from one million this http URL Free and Pro conversations, ranging from providing advice on hairstyles to providing guidance on Git operations and concepts. We also identify the most common high-level use cases on this http URL (coding, writing, and research tasks) as well as patterns that differ across languages (e.g., conversations in Japanese discuss elder care and aging populations at higher-than-typical rates). Second, we use Clio to make our systems safer by identifying coordinated attempts to abuse our systems, monitoring for unknown unknowns during critical periods like launches of new capabilities or major world events, and improving our existing monitoring systems. We also discuss the limitations of our approach, as well as risks and ethical concerns. By enabling analysis of real-world AI usage, Clio provides a scalable platform for empirically grounded AI safety and governance.
+
+
+
+ 44. 【2412.13670】AntiLeak-Bench: Preventing Data Contamination by Automatically Constructing Benchmarks with Updated Real-World Knowledge
+ 链接:https://arxiv.org/abs/2412.13670
+ 作者:Xiaobao Wu,Liangming Pan,Yuxi Xie,Ruiwen Zhou,Shuai Zhao,Yubo Ma,Mingzhe Du,Rui Mao,Anh Tuan Luu,William Yang Wang
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:introducing test data, newly collected data, hinders fair LLM, newer models' training, contamination hinders fair
+ 备注:
+
+ 点击查看摘要
+ Abstract:Data contamination hinders fair LLM evaluation by introducing test data into newer models' training sets. Existing studies solve this challenge by updating benchmarks with newly collected data. However, they fail to guarantee contamination-free evaluation as the newly collected data may contain pre-existing knowledge, and their benchmark updates rely on intensive human labor. To address these issues, we in this paper propose AntiLeak-Bench, an automated anti-leakage benchmarking framework. Instead of simply using newly collected data, we construct samples with explicitly new knowledge absent from LLMs' training sets, which thus ensures strictly contamination-free evaluation. We further design a fully automated workflow to build and update our benchmark without human labor. This significantly reduces the cost of benchmark maintenance to accommodate emerging LLMs. Through extensive experiments, we highlight that data contamination likely exists before LLMs' cutoff time and demonstrate AntiLeak-Bench effectively overcomes this challenge.
+
+
+
+ 45. 【2412.13666】Evaluation of LLM Vulnerabilities to Being Misused for Personalized Disinformation Generation
+ 链接:https://arxiv.org/abs/2412.13666
+ 作者:Aneta Zugecova,Dominik Macko,Ivan Srba,Robert Moro,Jakub Kopal,Katarina Marcincinova,Matus Mesarcik
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computers and Society (cs.CY)
+ 关键词:large language models, human-written texts rises, high-quality content indistinguishable, recent large language, generate high-quality content
+ 备注:
+
+ 点击查看摘要
+ Abstract:The capabilities of recent large language models (LLMs) to generate high-quality content indistinguishable by humans from human-written texts rises many concerns regarding their misuse. Previous research has shown that LLMs can be effectively misused for generating disinformation news articles following predefined narratives. Their capabilities to generate personalized (in various aspects) content have also been evaluated and mostly found usable. However, a combination of personalization and disinformation abilities of LLMs has not been comprehensively studied yet. Such a dangerous combination should trigger integrated safety filters of the LLMs, if there are some. This study fills this gap by evaluation of vulnerabilities of recent open and closed LLMs, and their willingness to generate personalized disinformation news articles in English. We further explore whether the LLMs can reliably meta-evaluate the personalization quality and whether the personalization affects the generated-texts detectability. Our results demonstrate the need for stronger safety-filters and disclaimers, as those are not properly functioning in most of the evaluated LLMs. Additionally, our study revealed that the personalization actually reduces the safety-filter activations; thus effectively functioning as a jailbreak. Such behavior must be urgently addressed by LLM developers and service providers.
+
+
+
+ 46. 【2412.13663】Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
+ 链接:https://arxiv.org/abs/2412.13663
+ 作者:Benjamin Warner,Antoine Chaffin,Benjamin Clavié,Orion Weller,Oskar Hallström,Said Taghadouini,Alexis Gallagher,Raja Biswas,Faisal Ladhak,Tom Aarsen,Nathan Cooper,Griffin Adams,Jeremy Howard,Iacopo Poli
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:great performance-size tradeoff, larger decoder-only models, BERT offer, Encoder-only transformer models, offer a great
+ 备注:
+
+ 点击查看摘要
+ Abstract:Encoder-only transformer models such as BERT offer a great performance-size tradeoff for retrieval and classification tasks with respect to larger decoder-only models. Despite being the workhorse of numerous production pipelines, there have been limited Pareto improvements to BERT since its release. In this paper, we introduce ModernBERT, bringing modern model optimizations to encoder-only models and representing a major Pareto improvement over older encoders. Trained on 2 trillion tokens with a native 8192 sequence length, ModernBERT models exhibit state-of-the-art results on a large pool of evaluations encompassing diverse classification tasks and both single and multi-vector retrieval on different domains (including code). In addition to strong downstream performance, ModernBERT is also the most speed and memory efficient encoder and is designed for inference on common GPUs.
+
+
+
+ 47. 【2412.13660】PsyDT: Using LLMs to Construct the Digital Twin of Psychological Counselor with Personalized Counseling Style for Psychological Counseling
+ 链接:https://arxiv.org/abs/2412.13660
+ 作者:Haojie Xie,Yirong Chen,Xiaofen Xing,Jingkai Lin,Xiangmin Xu
+ 类目:Computation and Language (cs.CL)
+ 关键词:made significant progress, large language models, Digital Twin, counseling style, Psychological counselor
+ 备注: 9 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:Currently, large language models (LLMs) have made significant progress in the field of psychological counseling. However, existing mental health LLMs overlook a critical issue where they do not consider the fact that different psychological counselors exhibit different personal styles, including linguistic style and therapy techniques, etc. As a result, these LLMs fail to satisfy the individual needs of clients who seek different counseling styles. To help bridge this gap, we propose PsyDT, a novel framework using LLMs to construct the Digital Twin of Psychological counselor with personalized counseling style. Compared to the time-consuming and costly approach of collecting a large number of real-world counseling cases to create a specific counselor's digital twin, our framework offers a faster and more cost-effective solution. To construct PsyDT, we utilize dynamic one-shot learning by using GPT-4 to capture counselor's unique counseling style, mainly focusing on linguistic style and therapy techniques. Subsequently, using existing single-turn long-text dialogues with client's questions, GPT-4 is guided to synthesize multi-turn dialogues of specific counselor. Finally, we fine-tune the LLMs on the synthetic dataset, PsyDTCorpus, to achieve the digital twin of psychological counselor with personalized counseling style. Experimental results indicate that our proposed PsyDT framework can synthesize multi-turn dialogues that closely resemble real-world counseling cases and demonstrate better performance compared to other baselines, thereby show that our framework can effectively construct the digital twin of psychological counselor with a specific counseling style.
+
+
+
+ 48. 【2412.13649】SCOPE: Optimizing Key-Value Cache Compression in Long-context Generation
+ 链接:https://arxiv.org/abs/2412.13649
+ 作者:Jialong Wu,Zhenglin Wang,Linhai Zhang,Yilong Lai,Yulan He,Deyu Zhou
+ 类目:Computation and Language (cs.CL)
+ 关键词:bottleneck of LLMs, LLMs for long-context, decoding phase, prefill phase, long-context generation
+ 备注: Preprint
+
+ 点击查看摘要
+ Abstract:Key-Value (KV) cache has become a bottleneck of LLMs for long-context generation. Despite the numerous efforts in this area, the optimization for the decoding phase is generally ignored. However, we believe such optimization is crucial, especially for long-output generation tasks based on the following two observations: (i) Excessive compression during the prefill phase, which requires specific full context impairs the comprehension of the reasoning task; (ii) Deviation of heavy hitters occurs in the reasoning tasks with long outputs. Therefore, SCOPE, a simple yet efficient framework that separately performs KV cache optimization during the prefill and decoding phases, is introduced. Specifically, the KV cache during the prefill phase is preserved to maintain the essential information, while a novel strategy based on sliding is proposed to select essential heavy hitters for the decoding phase. Memory usage and memory transfer are further optimized using adaptive and discontinuous strategies. Extensive experiments on LongGenBench show the effectiveness and generalization of SCOPE and its compatibility as a plug-in to other prefill-only KV compression methods.
+
+
+
+ 49. 【2412.13647】G-VEval: A Versatile Metric for Evaluating Image and Video Captions Using GPT-4o
+ 链接:https://arxiv.org/abs/2412.13647
+ 作者:Tony Cheng Tong,Sirui He,Zhiwen Shao,Dit-Yan Yeung
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Language Model-based metrics, Advanced Language Model-based, metrics, visual captioning, ROUGE often miss
+ 备注:
+
+ 点击查看摘要
+ Abstract:Evaluation metric of visual captioning is important yet not thoroughly explored. Traditional metrics like BLEU, METEOR, CIDEr, and ROUGE often miss semantic depth, while trained metrics such as CLIP-Score, PAC-S, and Polos are limited in zero-shot scenarios. Advanced Language Model-based metrics also struggle with aligning to nuanced human preferences. To address these issues, we introduce G-VEval, a novel metric inspired by G-Eval and powered by the new GPT-4o. G-VEval uses chain-of-thought reasoning in large multimodal models and supports three modes: reference-free, reference-only, and combined, accommodating both video and image inputs. We also propose MSVD-Eval, a new dataset for video captioning evaluation, to establish a more transparent and consistent framework for both human experts and evaluation metrics. It is designed to address the lack of clear criteria in existing datasets by introducing distinct dimensions of Accuracy, Completeness, Conciseness, and Relevance (ACCR). Extensive results show that G-VEval outperforms existing methods in correlation with human annotations, as measured by Kendall tau-b and Kendall tau-c. This provides a flexible solution for diverse captioning tasks and suggests a straightforward yet effective approach for large language models to understand video content, paving the way for advancements in automated captioning. Codes are available at this https URL
+
+
+
+ 50. 【2412.13645】On the Role of Model Prior in Real-World Inductive Reasoning
+ 链接:https://arxiv.org/abs/2412.13645
+ 作者:Zhuo Liu,Ding Yu,Hangfeng He
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, Language Models, generate hypotheses, generalize effectively
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) show impressive inductive reasoning capabilities, enabling them to generate hypotheses that could generalize effectively to new instances when guided by in-context demonstrations. However, in real-world applications, LLMs' hypothesis generation is not solely determined by these demonstrations but is significantly shaped by task-specific model priors. Despite their critical influence, the distinct contributions of model priors versus demonstrations to hypothesis generation have been underexplored. This study bridges this gap by systematically evaluating three inductive reasoning strategies across five real-world tasks with three LLMs. Our empirical findings reveal that, hypothesis generation is primarily driven by the model's inherent priors; removing demonstrations results in minimal loss of hypothesis quality and downstream usage. Further analysis shows the result is consistent across various label formats with different label configurations, and prior is hard to override, even under flipped labeling. These insights advance our understanding of the dynamics of hypothesis generation in LLMs and highlight the potential for better utilizing model priors in real-world inductive reasoning tasks.
+
+
+
+ 51. 【2412.13631】Mind Your Theory: Theory of Mind Goes Deeper Than Reasoning
+ 链接:https://arxiv.org/abs/2412.13631
+ 作者:Eitan Wagner,Nitay Alon,Joseph M. Barnby,Omri Abend
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Theory of Mind, object of investigation, central object, Depth of Mentalizing, ToM
+ 备注: 4 pages, 2 figures
+
+ 点击查看摘要
+ Abstract:Theory of Mind (ToM) capabilities in LLMs have recently become a central object of investigation. Cognitive science distinguishes between two steps required for ToM tasks: 1) determine whether to invoke ToM, which includes the appropriate Depth of Mentalizing (DoM), or level of recursion required to complete a task; and 2) applying the correct inference given the DoM. In this position paper, we first identify several lines of work in different communities in AI, including LLM benchmarking, ToM add-ons, ToM probing, and formal models for ToM. We argue that recent work in AI tends to focus exclusively on the second step which are typically framed as static logic problems. We conclude with suggestions for improved evaluation of ToM capabilities inspired by dynamic environments used in cognitive tasks.
+
+
+
+ 52. 【2412.13626】LIFT: Improving Long Context Understanding Through Long Input Fine-Tuning
+ 链接:https://arxiv.org/abs/2412.13626
+ 作者:Yansheng Mao,Jiaqi Li,Fanxu Meng,Jing Xiong,Zilong Zheng,Muhan Zhang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:limited context windows, large language models, language models due, understanding remains challenging, remains challenging
+ 备注:
+
+ 点击查看摘要
+ Abstract:Long context understanding remains challenging for large language models due to their limited context windows. This paper introduces Long Input Fine-Tuning (LIFT) for long context modeling, a novel framework that enhances LLM performance on long-context tasks by adapting model parameters to the context at test time. LIFT enables efficient processing of lengthy inputs without the computational burden of offline long-context adaptation, and can improve the long-context capabilities of arbitrary short-context models. The framework is further enhanced by integrating in-context learning and pre-LIFT supervised fine-tuning. The combination of in-context learning and LIFT enables short-context models like Llama 3 to handle arbitrarily long contexts and consistently improves their performance on popular long-context benchmarks like LooGLE and LongBench. We also provide a comprehensive analysis of the strengths and limitations of LIFT on long context understanding, offering valuable directions for future research.
+
+
+
+ 53. 【2412.13614】Reverse Region-to-Entity Annotation for Pixel-Level Visual Entity Linking
+ 链接:https://arxiv.org/abs/2412.13614
+ 作者:Zhengfei Xu,Sijia Zhao,Yanchao Hao,Xiaolong Liu,Lili Li,Yuyang Yin,Bo Li,Xi Chen,Xin Xin
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Information Retrieval (cs.IR); Multimedia (cs.MM)
+ 关键词:Visual Entity Linking, Entity Linking, knowledge base, Visual Entity, Visual
+ 备注: AAAI 2025;Dataset are released at [this https URL](https://github.com/NP-NET-research/PL-VEL)
+
+ 点击查看摘要
+ Abstract:Visual Entity Linking (VEL) is a crucial task for achieving fine-grained visual understanding, matching objects within images (visual mentions) to entities in a knowledge base. Previous VEL tasks rely on textual inputs, but writing queries for complex scenes can be challenging. Visual inputs like clicks or bounding boxes offer a more convenient alternative. Therefore, we propose a new task, Pixel-Level Visual Entity Linking (PL-VEL), which uses pixel masks from visual inputs to refer to objects, supplementing reference methods for VEL. To facilitate research on this task, we have constructed the MaskOVEN-Wiki dataset through an entirely automatic reverse region-entity annotation framework. This dataset contains over 5 million annotations aligning pixel-level regions with entity-level labels, which will advance visual understanding towards fine-grained. Moreover, as pixel masks correspond to semantic regions in an image, we enhance previous patch-interacted attention with region-interacted attention by a visual semantic tokenization approach. Manual evaluation results indicate that the reverse annotation framework achieved a 94.8% annotation success rate. Experimental results show that models trained on this dataset improved accuracy by 18 points compared to zero-shot models. Additionally, the semantic tokenization method achieved a 5-point accuracy improvement over the trained baseline.
+
+
+
+ 54. 【2412.13612】Are LLMs Good Literature Review Writers? Evaluating the Literature Review Writing Ability of Large Language Models
+ 链接:https://arxiv.org/abs/2412.13612
+ 作者:Xuemei Tang,Xufeng Duan,Zhenguang G. Cai
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:involves complex processes, crucial form, form of academic, involves complex, literature
+ 备注: 12 pages, 7 figures, 5 tables
+
+ 点击查看摘要
+ Abstract:The literature review is a crucial form of academic writing that involves complex processes of literature collection, organization, and summarization. The emergence of large language models (LLMs) has introduced promising tools to automate these processes. However, their actual capabilities in writing comprehensive literature reviews remain underexplored, such as whether they can generate accurate and reliable references. To address this gap, we propose a framework to assess the literature review writing ability of LLMs automatically. We evaluate the performance of LLMs across three tasks: generating references, writing abstracts, and writing literature reviews. We employ external tools for a multidimensional evaluation, which includes assessing hallucination rates in references, semantic coverage, and factual consistency with human-written context. By analyzing the experimental results, we find that, despite advancements, even the most sophisticated models still cannot avoid generating hallucinated references. Additionally, different models exhibit varying performance in literature review writing across different disciplines.
+
+
+
+ 55. 【2412.13602】Beyond Outcomes: Transparent Assessment of LLM Reasoning in Games
+ 链接:https://arxiv.org/abs/2412.13602
+ 作者:Wenye Lin,Jonathan Roberts,Yunhan Yang,Samuel Albanie,Zongqing Lu,Kai Han
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, Language Models, increasingly deployed, deployed in real-world
+ 备注: 8 pages
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) are increasingly deployed in real-world applications that demand complex reasoning. To track progress, robust benchmarks are required to evaluate their capabilities beyond superficial pattern recognition. However, current LLM reasoning benchmarks often face challenges such as insufficient interpretability, performance saturation or data contamination. To address these challenges, we introduce GAMEBoT, a gaming arena designed for rigorous and transparent assessment of LLM reasoning capabilities. GAMEBoT decomposes complex reasoning in games into predefined modular subproblems. This decomposition allows us to design a suite of Chain-of-Thought (CoT) prompts that leverage domain knowledge to guide LLMs in addressing these subproblems before action selection. Furthermore, we develop a suite of rule-based algorithms to generate ground truth for these subproblems, enabling rigorous validation of the LLMs' intermediate reasoning steps. This approach facilitates evaluation of both the quality of final actions and the accuracy of the underlying reasoning process. GAMEBoT also naturally alleviates the risk of data contamination through dynamic games and head-to-head LLM competitions. We benchmark 17 prominent LLMs across eight games, encompassing various strategic abilities and game characteristics. Our results suggest that GAMEBoT presents a significant challenge, even when LLMs are provided with detailed CoT prompts. Project page: \url{this https URL}
+
+
+
+ 56. 【2412.13599】Unlocking the Potential of Weakly Labeled Data: A Co-Evolutionary Learning Framework for Abnormality Detection and Report Generation
+ 链接:https://arxiv.org/abs/2412.13599
+ 作者:Jinghan Sun,Dong Wei,Zhe Xu,Donghuan Lu,Hong Liu,Hong Wang,Sotirios A. Tsaftaris,Steven McDonagh,Yefeng Zheng,Liansheng Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Anatomical abnormality detection, chest X-ray, Anatomical abnormality, report generation, abnormality detection
+ 备注:
+
+ 点击查看摘要
+ Abstract:Anatomical abnormality detection and report generation of chest X-ray (CXR) are two essential tasks in clinical practice. The former aims at localizing and characterizing cardiopulmonary radiological findings in CXRs, while the latter summarizes the findings in a detailed report for further diagnosis and treatment. Existing methods often focused on either task separately, ignoring their correlation. This work proposes a co-evolutionary abnormality detection and report generation (CoE-DG) framework. The framework utilizes both fully labeled (with bounding box annotations and clinical reports) and weakly labeled (with reports only) data to achieve mutual promotion between the abnormality detection and report generation tasks. Specifically, we introduce a bi-directional information interaction strategy with generator-guided information propagation (GIP) and detector-guided information propagation (DIP). For semi-supervised abnormality detection, GIP takes the informative feature extracted by the generator as an auxiliary input to the detector and uses the generator's prediction to refine the detector's pseudo labels. We further propose an intra-image-modal self-adaptive non-maximum suppression module (SA-NMS). This module dynamically rectifies pseudo detection labels generated by the teacher detection model with high-confidence predictions by the this http URL, for report generation, DIP takes the abnormalities' categories and locations predicted by the detector as input and guidance for the generator to improve the generated reports.
+
+
+
+ 57. 【2412.13582】EvoWiki: Evaluating LLMs on Evolving Knowledge
+ 链接:https://arxiv.org/abs/2412.13582
+ 作者:Wei Tang,Yixin Cao,Yang Deng,Jiahao Ying,Bo Wang,Yizhe Yang,Yuyue Zhao,Qi Zhang,Xuanjing Huang,Yugang Jiang,Yong Liao
+ 类目:Computation and Language (cs.CL)
+ 关键词:effective deployment, critical aspect, Knowledge, evolving knowledge, evolving
+ 备注:
+
+ 点击查看摘要
+ Abstract:Knowledge utilization is a critical aspect of LLMs, and understanding how they adapt to evolving knowledge is essential for their effective deployment. However, existing benchmarks are predominantly static, failing to capture the evolving nature of LLMs and knowledge, leading to inaccuracies and vulnerabilities such as contamination. In this paper, we introduce EvoWiki, an evolving dataset designed to reflect knowledge evolution by categorizing information into stable, evolved, and uncharted states. EvoWiki is fully auto-updatable, enabling precise evaluation of continuously changing knowledge and newly released LLMs. Through experiments with Retrieval-Augmented Generation (RAG) and Contunual Learning (CL), we evaluate how effectively LLMs adapt to evolving knowledge. Our results indicate that current models often struggle with evolved knowledge, frequently providing outdated or incorrect responses. Moreover, the dataset highlights a synergistic effect between RAG and CL, demonstrating their potential to better adapt to evolving knowledge. EvoWiki provides a robust benchmark for advancing future research on the knowledge evolution capabilities of large language models.
+
+
+
+ 58. 【2412.13578】Socio-Culturally Aware Evaluation Framework for LLM-Based Content Moderation
+ 链接:https://arxiv.org/abs/2412.13578
+ 作者:Shanu Kumar,Gauri Kholkar,Saish Mendke,Anubhav Sadana,Parag Agrawal,Sandipan Dandapat
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:large language models, language models, growth of social, social media, media and large
+ 备注: Accepted in SUMEval Workshop in COLING 2025
+
+ 点击查看摘要
+ Abstract:With the growth of social media and large language models, content moderation has become crucial. Many existing datasets lack adequate representation of different groups, resulting in unreliable assessments. To tackle this, we propose a socio-culturally aware evaluation framework for LLM-driven content moderation and introduce a scalable method for creating diverse datasets using persona-based generation. Our analysis reveals that these datasets provide broader perspectives and pose greater challenges for LLMs than diversity-focused generation methods without personas. This challenge is especially pronounced in smaller LLMs, emphasizing the difficulties they encounter in moderating such diverse content.
+
+
+
+ 59. 【2412.13575】Generating Long-form Story Using Dynamic Hierarchical Outlining with Memory-Enhancement
+ 链接:https://arxiv.org/abs/2412.13575
+ 作者:Qianyue Wang,Jinwu Hu,Zhengping Li,Yufeng Wang,daiyuan li,Yu Hu,Mingkui Tan
+ 类目:Computation and Language (cs.CL)
+ 关键词:sufficiently lengthy text, writingand interactive storytelling, Long-form story generation, generation task aims, Long-form story
+ 备注: 39 pages
+
+ 点击查看摘要
+ Abstract:Long-form story generation task aims to produce coherent and sufficiently lengthy text, essential for applications such as novel writingand interactive storytelling. However, existing methods, including LLMs, rely on rigid outlines or lack macro-level planning, making it difficult to achieve both contextual consistency and coherent plot development in long-form story generation. To address this issues, we propose Dynamic Hierarchical Outlining with Memory-Enhancement long-form story generation method, named DOME, to generate the long-form story with coherent content and plot. Specifically, the Dynamic Hierarchical Outline(DHO) mechanism incorporates the novel writing theory into outline planning and fuses the plan and writing stages together, improving the coherence of the plot by ensuring the plot completeness and adapting to the uncertainty during story generation. A Memory-Enhancement Module (MEM) based on temporal knowledge graphs is introduced to store and access the generated content, reducing contextual conflicts and improving story coherence. Finally, we propose a Temporal Conflict Analyzer leveraging temporal knowledge graphs to automatically evaluate the contextual consistency of long-form story. Experiments demonstrate that DOME significantly improves the fluency, coherence, and overall quality of generated long stories compared to state-of-the-art methods.
+
+
+
+ 60. 【2412.13549】EscapeBench: Pushing Language Models to Think Outside the Box
+ 链接:https://arxiv.org/abs/2412.13549
+ 作者:Cheng Qian,Peixuan Han,Qinyu Luo,Bingxiang He,Xiusi Chen,Yuji Zhang,Hongyi Du,Jiarui Yao,Xiaocheng Yang,Denghui Zhang,Yunzhu Li,Heng Ji
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Language model agents, neglecting creative adaptation, existing benchmarks primarily, benchmarks primarily focus, model agents excel
+ 备注: 23 pages, 15 figures
+
+ 点击查看摘要
+ Abstract:Language model agents excel in long-session planning and reasoning, but existing benchmarks primarily focus on goal-oriented tasks with explicit objectives, neglecting creative adaptation in unfamiliar environments. To address this, we introduce EscapeBench, a benchmark suite of room escape game environments designed to challenge agents with creative reasoning, unconventional tool use, and iterative problem-solving to uncover implicit goals. Our results show that current LM models, despite employing working memory and Chain-of-Thought reasoning, achieve only 15% average progress without hints, highlighting their limitations in creativity. To bridge this gap, we propose EscapeAgent, a framework designed to enhance creative reasoning through Foresight (innovative tool use) and Reflection (identifying unsolved tasks). Experiments show that EscapeAgent can execute action chains over 1,000 steps while maintaining logical coherence. It navigates and completes games with up to 40% fewer steps and hints, performs robustly across varying difficulty levels, and achieves higher action success rates with more efficient and innovative puzzle-solving strategies. All the data and codes are released.
+
+
+
+ 61. 【2412.13543】Query-centric Audio-Visual Cognition Network for Moment Retrieval, Segmentation and Step-Captioning
+ 链接:https://arxiv.org/abs/2412.13543
+ 作者:Yunbin Tu,Liang Li,Li Su,Qingming Huang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:favored multimedia format, including video retrieval, video retrieval, favored multimedia, multimedia format
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Video has emerged as a favored multimedia format on the internet. To better gain video contents, a new topic HIREST is presented, including video retrieval, moment retrieval, moment segmentation, and step-captioning. The pioneering work chooses the pre-trained CLIP-based model for video retrieval, and leverages it as a feature extractor for other three challenging tasks solved in a multi-task learning paradigm. Nevertheless, this work struggles to learn the comprehensive cognition of user-preferred content, due to disregarding the hierarchies and association relations across modalities. In this paper, guided by the shallow-to-deep principle, we propose a query-centric audio-visual cognition (QUAG) network to construct a reliable multi-modal representation for moment retrieval, segmentation and step-captioning. Specifically, we first design the modality-synergistic perception to obtain rich audio-visual content, by modeling global contrastive alignment and local fine-grained interaction between visual and audio modalities. Then, we devise the query-centric cognition that uses the deep-level query to perform the temporal-channel filtration on the shallow-level audio-visual representation. This can cognize user-preferred content and thus attain a query-centric audio-visual representation for three tasks. Extensive experiments show QUAG achieves the SOTA results on HIREST. Further, we test QUAG on the query-based video summarization task and verify its good generalization.
+
+
+
+ 62. 【2412.13542】Multi-Granularity Open Intent Classification via Adaptive Granular-Ball Decision Boundary
+ 链接:https://arxiv.org/abs/2412.13542
+ 作者:Yanhua Li,Xiaocao Ouyang,Chaofan Pan,Jie Zhang,Sen Zhao,Shuyin Xia,Xin Yang,Guoyin Wang,Tianrui Li
+ 类目:Computation and Language (cs.CL)
+ 关键词:Open intent classification, Open intent, dialogue systems, aiming to accurately, identifying unknown intents
+ 备注: This paper has been Accepted on AAAI2025
+
+ 点击查看摘要
+ Abstract:Open intent classification is critical for the development of dialogue systems, aiming to accurately classify known intents into their corresponding classes while identifying unknown intents. Prior boundary-based methods assumed known intents fit within compact spherical regions, focusing on coarse-grained representation and precise spherical decision boundaries. However, these assumptions are often violated in practical scenarios, making it difficult to distinguish known intent classes from unknowns using a single spherical boundary. To tackle these issues, we propose a Multi-granularity Open intent classification method via adaptive Granular-Ball decision boundary (MOGB). Our MOGB method consists of two modules: representation learning and decision boundary acquiring. To effectively represent the intent distribution, we design a hierarchical representation learning method. This involves iteratively alternating between adaptive granular-ball clustering and nearest sub-centroid classification to capture fine-grained semantic structures within known intent classes. Furthermore, multi-granularity decision boundaries are constructed for open intent classification by employing granular-balls with varying centroids and radii. Extensive experiments conducted on three public datasets demonstrate the effectiveness of our proposed method.
+
+
+
+ 63. 【2412.13540】Benchmarking and Improving Large Vision-Language Models for Fundamental Visual Graph Understanding and Reasoning
+ 链接:https://arxiv.org/abs/2412.13540
+ 作者:Yingjie Zhu,Xuefeng Bai,Kehai Chen,Yang Xiang,Min Zhang
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Large Vision-Language Models, Large Vision-Language, Vision-Language Models, demonstrated remarkable performance, demonstrated remarkable
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Vision-Language Models (LVLMs) have demonstrated remarkable performance across diverse tasks. Despite great success, recent studies show that LVLMs encounter substantial limitations when engaging with visual graphs. To study the reason behind these limitations, we propose VGCure, a comprehensive benchmark covering 22 tasks for examining the fundamental graph understanding and reasoning capacities of LVLMs. Extensive evaluations conducted on 14 LVLMs reveal that LVLMs are weak in basic graph understanding and reasoning tasks, particularly those concerning relational or structurally complex information. Based on this observation, we propose a structure-aware fine-tuning framework to enhance LVLMs with structure learning abilities through 3 self-supervised learning tasks. Experiments validate the effectiveness of our method in improving LVLMs' zero-shot performance on fundamental graph learning tasks, as well as enhancing the robustness of LVLMs against complex visual graphs.
+
+
+
+ 64. 【2412.13536】MetaRuleGPT: Recursive Numerical Reasoning of Language Models Trained with Simple Rules
+ 链接:https://arxiv.org/abs/2412.13536
+ 作者:Kejie Chen,Lin Wang,Qinghai Zhang,Renjun Xu
+ 类目:Computation and Language (cs.CL)
+ 关键词:Recent studies, underlying logic, studies have highlighted, highlighted the limitations, limitations of large
+ 备注: 8 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:Recent studies have highlighted the limitations of large language models in mathematical reasoning, particularly their inability to capture the underlying logic. Inspired by meta-learning, we propose that models should acquire not only task-specific knowledge but also transferable problem-solving skills. We introduce MetaRuleGPT, a novel Transformer-based architecture that performs precise numerical calculations and complex logical operations by learning and combining different rules. In contrast with traditional training sets, which are heavily composed of massive raw instance data, MetaRuleGPT is pre-trained on much less abstract datasets containing basic, compound, and iterative rules for mathematical reasoning. Extensive experimental results demonstrate MetaRuleGPT can mimic human's rule-following capabilities, break down complexity, and iteratively derive accurate results for complex mathematical problems. These findings prove the potential of rule learning to enhance the numerical reasoning abilities of language models.
+
+
+
+ 65. 【2412.13534】Information-Theoretic Generative Clustering of Documents
+ 链接:https://arxiv.org/abs/2412.13534
+ 作者:Xin Du,Kumiko Tanaka-Ishii
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL); Information Retrieval (cs.IR); Information Theory (cs.IT)
+ 关键词:mathrm, large language models, language models, clustering, original documents
+ 备注: Accepted to AAAI 2025
+
+ 点击查看摘要
+ Abstract:We present {\em generative clustering} (GC) for clustering a set of documents, $\mathrm{X}$, by using texts $\mathrm{Y}$ generated by large language models (LLMs) instead of by clustering the original documents $\mathrm{X}$. Because LLMs provide probability distributions, the similarity between two documents can be rigorously defined in an information-theoretic manner by the KL divergence. We also propose a natural, novel clustering algorithm by using importance sampling. We show that GC achieves the state-of-the-art performance, outperforming any previous clustering method often by a large margin. Furthermore, we show an application to generative document retrieval in which documents are indexed via hierarchical clustering and our method improves the retrieval accuracy.
+
+
+
+ 66. 【2412.13511】CEHA: A Dataset of Conflict Events in the Horn of Africa
+ 链接:https://arxiv.org/abs/2412.13511
+ 作者:Rui Bai,Di Lu,Shihao Ran,Elizabeth Olson,Hemank Lamba,Aoife Cahill,Joel Tetreault,Alex Jaimes
+ 类目:Computation and Language (cs.CL)
+ 关键词:Natural Language Processing, Natural Language, Language Processing, Horn of Africa, conflict events
+ 备注: Accepted by COLING 2025
+
+ 点击查看摘要
+ Abstract:Natural Language Processing (NLP) of news articles can play an important role in understanding the dynamics and causes of violent conflict. Despite the availability of datasets categorizing various conflict events, the existing labels often do not cover all of the fine-grained violent conflict event types relevant to areas like the Horn of Africa. In this paper, we introduce a new benchmark dataset Conflict Events in the Horn of Africa region (CEHA) and propose a new task for identifying violent conflict events using online resources with this dataset. The dataset consists of 500 English event descriptions regarding conflict events in the Horn of Africa region with fine-grained event-type definitions that emphasize the cause of the conflict. This dataset categorizes the key types of conflict risk according to specific areas required by stakeholders in the Humanitarian-Peace-Development Nexus. Additionally, we conduct extensive experiments on two tasks supported by this dataset: Event-relevance Classification and Event-type Classification. Our baseline models demonstrate the challenging nature of these tasks and the usefulness of our dataset for model evaluations in low-resource settings with limited number of training data.
+
+
+
+ 67. 【2412.13510】Dynamic Adapter with Semantics Disentangling for Cross-lingual Cross-modal Retrieval
+ 链接:https://arxiv.org/abs/2412.13510
+ 作者:Rui Cai,Zhiyu Dong,Jianfeng Dong,Xun Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Existing cross-modal retrieval, methods typically rely, retrieval methods typically, cross-modal retrieval methods, Cross-lingual Cross-modal Retrieval
+ 备注: Accepted by the 39th AAAI Conference on Artificial Intelligence (AAAI-25)
+
+ 点击查看摘要
+ Abstract:Existing cross-modal retrieval methods typically rely on large-scale vision-language pair data. This makes it challenging to efficiently develop a cross-modal retrieval model for under-resourced languages of interest. Therefore, Cross-lingual Cross-modal Retrieval (CCR), which aims to align vision and the low-resource language (the target language) without using any human-labeled target-language data, has gained increasing attention. As a general parameter-efficient way, a common solution is to utilize adapter modules to transfer the vision-language alignment ability of Vision-Language Pretraining (VLP) models from a source language to a target language. However, these adapters are usually static once learned, making it difficult to adapt to target-language captions with varied expressions. To alleviate it, we propose Dynamic Adapter with Semantics Disentangling (DASD), whose parameters are dynamically generated conditioned on the characteristics of the input captions. Considering that the semantics and expression styles of the input caption largely influence how to encode it, we propose a semantic disentangling module to extract the semantic-related and semantic-agnostic features from the input, ensuring that generated adapters are well-suited to the characteristics of input caption. Extensive experiments on two image-text datasets and one video-text dataset demonstrate the effectiveness of our model for cross-lingual cross-modal retrieval, as well as its good compatibility with various VLP models.
+
+
+
+ 68. 【2412.13503】VaeDiff-DocRE: End-to-end Data Augmentation Framework for Document-level Relation Extraction
+ 链接:https://arxiv.org/abs/2412.13503
+ 作者:Khai Phan Tran,Wen Hua,Xue Li
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Document-level Relation Extraction, Document-level Relation, Relation Extraction, aims to identify, identify relationships
+ 备注: COLING 2025
+
+ 点击查看摘要
+ Abstract:Document-level Relation Extraction (DocRE) aims to identify relationships between entity pairs within a document. However, most existing methods assume a uniform label distribution, resulting in suboptimal performance on real-world, imbalanced datasets. To tackle this challenge, we propose a novel data augmentation approach using generative models to enhance data from the embedding space. Our method leverages the Variational Autoencoder (VAE) architecture to capture all relation-wise distributions formed by entity pair representations and augment data for underrepresented relations. To better capture the multi-label nature of DocRE, we parameterize the VAE's latent space with a Diffusion Model. Additionally, we introduce a hierarchical training framework to integrate the proposed VAE-based augmentation module into DocRE systems. Experiments on two benchmark datasets demonstrate that our method outperforms state-of-the-art models, effectively addressing the long-tail distribution problem in DocRE.
+
+
+
+ 69. 【2412.13488】Refining Salience-Aware Sparse Fine-Tuning Strategies for Language Models
+ 链接:https://arxiv.org/abs/2412.13488
+ 作者:Xinxin Liu,Aaron Thomas,Cheng Zhang,Jianyi Cheng,Yiren Zhao,Xitong Gao
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:gained prominence, PEFT, low-rank adaptation methods, SPEFT, sparsity-based PEFT
+ 备注:
+
+ 点击查看摘要
+ Abstract:Parameter-Efficient Fine-Tuning (PEFT) has gained prominence through low-rank adaptation methods like LoRA. In this paper, we focus on sparsity-based PEFT (SPEFT), which introduces trainable sparse adaptations to the weight matrices in the model, offering greater flexibility in selecting fine-tuned parameters compared to low-rank methods. We conduct the first systematic evaluation of salience metrics for SPEFT, inspired by zero-cost NAS proxies, and identify simple gradient-based metrics is reliable, and results are on par with the best alternatives, offering both computational efficiency and robust performance. Additionally, we compare static and dynamic masking strategies, finding that static masking, which predetermines non-zero entries before training, delivers efficiency without sacrificing performance, while dynamic masking offers no substantial benefits. Across NLP tasks, a simple gradient-based, static SPEFT consistently outperforms other fine-tuning methods for LLMs, providing a simple yet effective baseline for SPEFT. Our work challenges the notion that complexity is necessary for effective PEFT. Our work is open source and available to the community at [this https URL].
+
+
+
+ 70. 【2412.13486】$^3$-S2S: Training-free Triplet Tuning for Sketch to Scene Generation
+ 链接:https://arxiv.org/abs/2412.13486
+ 作者:Zhenhong Sun,Yifu Wang,Yonhon Ng,Yunfei Duan,Daoyi Dong,Hongdong Li,Pan Ji
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL); Graphics (cs.GR)
+ 关键词:computer graphics applications, graphics applications, computer graphics, Training-free Triplet Tuning, scene concept art
+ 备注:
+
+ 点击查看摘要
+ Abstract:Scene generation is crucial to many computer graphics applications. Recent advances in generative AI have streamlined sketch-to-image workflows, easing the workload for artists and designers in creating scene concept art. However, these methods often struggle for complex scenes with multiple detailed objects, sometimes missing small or uncommon instances. In this paper, we propose a Training-free Triplet Tuning for Sketch-to-Scene (T3-S2S) generation after reviewing the entire cross-attention mechanism. This scheme revitalizes the existing ControlNet model, enabling effective handling of multi-instance generations, involving prompt balance, characteristics prominence, and dense tuning. Specifically, this approach enhances keyword representation via the prompt balance module, reducing the risk of missing critical instances. It also includes a characteristics prominence module that highlights TopK indices in each channel, ensuring essential features are better represented based on token sketches. Additionally, it employs dense tuning to refine contour details in the attention map, compensating for instance-related regions. Experiments validate that our triplet tuning approach substantially improves the performance of existing sketch-to-image models. It consistently generates detailed, multi-instance 2D images, closely adhering to the input prompts and enhancing visual quality in complex multi-instance scenes. Code is available at this https URL.
+
+
+
+ 71. 【2412.13484】Curriculum Learning for Cross-Lingual Data-to-Text Generation With Noisy Data
+ 链接:https://arxiv.org/abs/2412.13484
+ 作者:Kancharla Aditya Hari,Manish Gupta,Vasudeva Varma
+ 类目:Computation and Language (cs.CL)
+ 关键词:text generation systems, training samples, improve the quality, quality of text, Curriculum learning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Curriculum learning has been used to improve the quality of text generation systems by ordering the training samples according to a particular schedule in various tasks. In the context of data-to-text generation (DTG), previous studies used various difficulty criteria to order the training samples for monolingual DTG. These criteria, however, do not generalize to the crosslingual variant of the problem and do not account for noisy data. We explore multiple criteria that can be used for improving the performance of cross-lingual DTG systems with noisy data using two curriculum schedules. Using the alignment score criterion for ordering samples and an annealing schedule to train the model, we show increase in BLEU score by up to 4 points, and improvements in faithfulness and coverage of generations by 5-15% on average across 11 Indian languages and English in 2 separate datasets. We make code and data publicly available
+
+
+
+ 72. 【2412.13475】A Statistical and Multi-Perspective Revisiting of the Membership Inference Attack in Large Language Models
+ 链接:https://arxiv.org/abs/2412.13475
+ 作者:Bowen Chen,Namgi Han,Yusuke Miyao
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:Membership Inference Attack, Large Language Models, Inference Attack, Large Language, Membership Inference
+ 备注: main content 8 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:The lack of data transparency in Large Language Models (LLMs) has highlighted the importance of Membership Inference Attack (MIA), which differentiates trained (member) and untrained (non-member) data. Though it shows success in previous studies, recent research reported a near-random performance in different settings, highlighting a significant performance inconsistency. We assume that a single setting doesn't represent the distribution of the vast corpora, causing members and non-members with different distributions to be sampled and causing inconsistency. In this study, instead of a single setting, we statistically revisit MIA methods from various settings with thousands of experiments for each MIA method, along with study in text feature, embedding, threshold decision, and decoding dynamics of members and non-members. We found that (1) MIA performance improves with model size and varies with domains, while most methods do not statistically outperform baselines, (2) Though MIA performance is generally low, a notable amount of differentiable member and non-member outliers exists and vary across MIA methods, (3) Deciding a threshold to separate members and non-members is an overlooked challenge, (4) Text dissimilarity and long text benefit MIA performance, (5) Differentiable or not is reflected in the LLM embedding, (6) Member and non-members show different decoding dynamics.
+
+
+
+ 73. 【2412.13471】Gradual Vigilance and Interval Communication: Enhancing Value Alignment in Multi-Agent Debates
+ 链接:https://arxiv.org/abs/2412.13471
+ 作者:Rui Zou,Mengqi Wei,Jintian Feng,Qian Wan,Jianwen Sun,Sannyuya Liu
+ 类目:Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:shown exceptional performance, large language models, fulfilling diverse human, recent years, large language
+ 备注:
+
+ 点击查看摘要
+ Abstract:In recent years, large language models have shown exceptional performance in fulfilling diverse human needs. However, their training data can introduce harmful content, underscoring the necessity for robust value alignment. Mainstream methods, which depend on feedback learning and supervised training, are resource-intensive and may constrain the full potential of the models. Multi-Agent Debate (MAD) offers a more efficient and innovative solution by enabling the generation of reliable answers through agent interactions. To apply MAD to value alignment, we examine the relationship between the helpfulness and harmlessness of debate outcomes and individual responses, and propose a MAD based framework Gradual Vigilance and Interval Communication (GVIC). GVIC allows agents to assess risks with varying levels of vigilance and to exchange diverse information through interval communication. We theoretically prove that GVIC optimizes debate efficiency while reducing communication overhead. Experimental results demonstrate that GVIC consistently outperforms baseline methods across various tasks and datasets, particularly excelling in harmfulness mitigation and fraud prevention. Additionally, GVIC exhibits strong adaptability across different base model sizes, including both unaligned and aligned models, and across various task types.
+
+
+
+ 74. 【2412.13467】ransducer Tuning: Efficient Model Adaptation for Software Tasks Using Code Property Graphs
+ 链接:https://arxiv.org/abs/2412.13467
+ 作者:Imam Nur Bani Yusuf,Lingxiao Jiang
+ 类目:oftware Engineering (cs.SE); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Large language, Large language models, software engineering tasks, demonstrated promising performance, Large
+ 备注: Under review
+
+ 点击查看摘要
+ Abstract:Large language models have demonstrated promising performance across various software engineering tasks. While fine-tuning is a common practice to adapt these models for downstream tasks, it becomes challenging in resource-constrained environments due to increased memory requirements from growing trainable parameters in increasingly large language models. We introduce \approach, a technique to adapt large models for downstream code tasks using Code Property Graphs (CPGs). Our approach introduces a modular component called \transducer that enriches code embeddings with structural and dependency information from CPGs. The Transducer comprises two key components: Graph Vectorization Engine (GVE) and Attention-Based Fusion Layer (ABFL). GVE extracts CPGs from input source code and transforms them into graph feature vectors. ABFL then fuses those graphs feature vectors with initial code embeddings from a large language model. By optimizing these transducers for different downstream tasks, our approach enhances the models without the need to fine-tune them for specific tasks. We have evaluated \approach on three downstream tasks: code summarization, assert generation, and code translation. Our results demonstrate competitive performance compared to full parameter fine-tuning while reducing up to 99\% trainable parameters to save memory. \approach also remains competitive against other fine-tuning approaches (e.g., LoRA, Prompt-Tuning, Prefix-Tuning) while using only 1.5\%-80\% of their trainable parameters. Our findings show that integrating structural and dependency information through Transducer Tuning enables more efficient model adaptation, making it easier for users to adapt large models in resource-constrained settings.
+
+
+
+ 75. 【2412.13464】GenX: Mastering Code and Test Generation with Execution Feedback
+ 链接:https://arxiv.org/abs/2412.13464
+ 作者:Nan Wang,Yafei Liu,Chen Chen,Haonan Lu
+ 类目:oftware Engineering (cs.SE); Computation and Language (cs.CL)
+ 关键词:Recent advancements, improve code generation, language modeling, natural language, modeling have enabled
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advancements in language modeling have enabled the translation of natural language into code, and the use of execution feedback to improve code generation. However, these methods often rely heavily on pre-existing test cases, which may not always be available or comprehensive. In this work, we propose a novel approach that concurrently trains a code generation model and a test generation model, utilizing execution feedback to refine and enhance the performance of both. We introduce two strategies for test and code data augmentation and a new scoring function for code and test ranking. We experiment on the APPS dataset and demonstrate that our approach can effectively generate and augment test cases, filter and synthesize correct code solutions, and rank the quality of generated code and tests. The results demonstrate that our models, when iteratively trained with an increasing number of test cases and code solutions, outperform those trained on the original dataset.
+
+
+
+ 76. 【2412.13441】FlashVTG: Feature Layering and Adaptive Score Handling Network for Video Temporal Grounding
+ 链接:https://arxiv.org/abs/2412.13441
+ 作者:Zhuo Cao,Bingqing Zhang,Heming Du,Xin Yu,Xue Li,Sen Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Highlight Detection, localize relevant segments, Text-guided Video Temporal, Video Temporal Grounding, Temporal Grounding
+ 备注: Accepted to WACV 2025
+
+ 点击查看摘要
+ Abstract:Text-guided Video Temporal Grounding (VTG) aims to localize relevant segments in untrimmed videos based on textual descriptions, encompassing two subtasks: Moment Retrieval (MR) and Highlight Detection (HD). Although previous typical methods have achieved commendable results, it is still challenging to retrieve short video moments. This is primarily due to the reliance on sparse and limited decoder queries, which significantly constrain the accuracy of predictions. Furthermore, suboptimal outcomes often arise because previous methods rank predictions based on isolated predictions, neglecting the broader video context. To tackle these issues, we introduce FlashVTG, a framework featuring a Temporal Feature Layering (TFL) module and an Adaptive Score Refinement (ASR) module. The TFL module replaces the traditional decoder structure to capture nuanced video content variations across multiple temporal scales, while the ASR module improves prediction ranking by integrating context from adjacent moments and multi-temporal-scale features. Extensive experiments demonstrate that FlashVTG achieves state-of-the-art performance on four widely adopted datasets in both MR and HD. Specifically, on the QVHighlights dataset, it boosts mAP by 5.8% for MR and 3.3% for HD. For short-moment retrieval, FlashVTG increases mAP to 125% of previous SOTA performance. All these improvements are made without adding training burdens, underscoring its effectiveness. Our code is available at this https URL.
+
+
+
+ 77. 【2412.13435】Lightweight Safety Classification Using Pruned Language Models
+ 链接:https://arxiv.org/abs/2412.13435
+ 作者:Mason Sawtell,Tula Masterman,Sandi Besen,Jim Brown
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Penalized Logistic Regression, Large Language Models, Large Language, Logistic Regression, Penalized Logistic
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this paper, we introduce a novel technique for content safety and prompt injection classification for Large Language Models. Our technique, Layer Enhanced Classification (LEC), trains a Penalized Logistic Regression (PLR) classifier on the hidden state of an LLM's optimal intermediate transformer layer. By combining the computational efficiency of a streamlined PLR classifier with the sophisticated language understanding of an LLM, our approach delivers superior performance surpassing GPT-4o and special-purpose models fine-tuned for each task. We find that small general-purpose models (Qwen 2.5 sizes 0.5B, 1.5B, and 3B) and other transformer-based architectures like DeBERTa v3 are robust feature extractors allowing simple classifiers to be effectively trained on fewer than 100 high-quality examples. Importantly, the intermediate transformer layers of these models typically outperform the final layer across both classification tasks. Our results indicate that a single general-purpose LLM can be used to classify content safety, detect prompt injections, and simultaneously generate output tokens. Alternatively, these relatively small LLMs can be pruned to the optimal intermediate layer and used exclusively as robust feature extractors. Since our results are consistent on different transformer architectures, we infer that robust feature extraction is an inherent capability of most, if not all, LLMs.
+
+
+
+ 78. 【2412.13395】Enhancing Talk Moves Analysis in Mathematics Tutoring through Classroom Teaching Discourse
+ 链接:https://arxiv.org/abs/2412.13395
+ 作者:Jie Cao,Abhijit Suresh,Jennifer Jacobs,Charis Clevenger,Amanda Howard,Chelsea Brown,Brent Milne,Tom Fischaber,Tamara Sumner,James H. Martin
+ 类目:Computation and Language (cs.CL)
+ 关键词:Human tutoring interventions, promoting personal growth, supporting student learning, improving academic performance, tutoring interventions play
+ 备注: Accepted to COLING'2025
+
+ 点击查看摘要
+ Abstract:Human tutoring interventions play a crucial role in supporting student learning, improving academic performance, and promoting personal growth. This paper focuses on analyzing mathematics tutoring discourse using talk moves - a framework of dialogue acts grounded in Accountable Talk theory. However, scaling the collection, annotation, and analysis of extensive tutoring dialogues to develop machine learning models is a challenging and resource-intensive task. To address this, we present SAGA22, a compact dataset, and explore various modeling strategies, including dialogue context, speaker information, pretraining datasets, and further fine-tuning. By leveraging existing datasets and models designed for classroom teaching, our results demonstrate that supplementary pretraining on classroom data enhances model performance in tutoring settings, particularly when incorporating longer context and speaker information. Additionally, we conduct extensive ablation studies to underscore the challenges in talk move modeling.
+
+
+
+ 79. 【2412.13388】Catalysts of Conversation: Examining Interaction Dynamics Between Topic Initiators and Commentors in Alzheimer's Disease Online Communities
+ 链接:https://arxiv.org/abs/2412.13388
+ 作者:Congning Ni,Qingxia Chen,Lijun Song,Patricia Commiskey,Qingyuan Song,Bradley A. Malin,Zhijun Yin
+ 类目:Computers and Society (cs.CY); Computation and Language (cs.CL); Machine Learning (cs.LG); Applications (stat.AP)
+ 关键词:Related Dementias, Alzheimers Disease, Disease and Related, face substantial challenges, living with Alzheimers
+ 备注: 14 pages, 11 figures (6 in main text and 5 in the appendix). The paper includes statistical analyses, structural topic modeling, and predictive modeling to examine user engagement dynamics in Alzheimers Disease online communities. Submitted for consideration to The Web Conference 2025
+
+ 点击查看摘要
+ Abstract:Informal caregivers (e.g.,family members or friends) of people living with Alzheimers Disease and Related Dementias (ADRD) face substantial challenges and often seek informational or emotional support through online communities. Understanding the factors that drive engagement within these platforms is crucial, as it can enhance their long-term value for caregivers by ensuring that these communities effectively meet their needs. This study investigated the user interaction dynamics within two large, popular ADRD communities, TalkingPoint and ALZConnected, focusing on topic initiator engagement, initial post content, and the linguistic patterns of comments at the thread level. Using analytical methods such as propensity score matching, topic modeling, and predictive modeling, we found that active topic initiator engagement drives higher comment volumes, and reciprocal replies from topic initiators encourage further commentor engagement at the community level. Practical caregiving topics prompt more re-engagement of topic initiators, while emotional support topics attract more comments from other commentors. Additionally, the linguistic complexity and emotional tone of a comment influence its likelihood of receiving replies from topic initiators. These findings highlight the importance of fostering active and reciprocal engagement and providing effective strategies to enhance sustainability in ADRD caregiving and broader health-related online communities.
+
+
+
+ 80. 【2412.13381】An Automated Explainable Educational Assessment System Built on LLMs
+ 链接:https://arxiv.org/abs/2412.13381
+ 作者:Jiazheng Li,Artem Bobrov,David West,Cesare Aloisi,Yulan He
+ 类目:Computation and Language (cs.CL)
+ 关键词:present AERA Chat, AERA Chat, present AERA, explainable educational assessment, assessment system designed
+ 备注: Accepted to AAAI 2025
+
+ 点击查看摘要
+ Abstract:In this demo, we present AERA Chat, an automated and explainable educational assessment system designed for interactive and visual evaluations of student responses. This system leverages large language models (LLMs) to generate automated marking and rationale explanations, addressing the challenge of limited explainability in automated educational assessment and the high costs associated with annotation. Our system allows users to input questions and student answers, providing educators and researchers with insights into assessment accuracy and the quality of LLM-assessed rationales. Additionally, it offers advanced visualization and robust evaluation tools, enhancing the usability for educational assessment and facilitating efficient rationale verification. Our demo video can be found at this https URL.
+
+
+
+ 81. 【2412.13378】SummExecEdit: A Factual Consistency Benchmark in Summarization with Executable Edits
+ 链接:https://arxiv.org/abs/2412.13378
+ 作者:Onkar Thorat,Philippe Laban,Chien-Sheng Wu
+ 类目:Computation and Language (cs.CL)
+ 关键词:Detecting factual inconsistencies, existing benchmarks lack, Detecting factual, summarization is critical, robust evaluation
+ 备注:
+
+ 点击查看摘要
+ Abstract:Detecting factual inconsistencies in summarization is critical, yet existing benchmarks lack the necessary challenge and interpretability for robust evaluation. In this paper, we introduce SummExecEdit, a novel benchmark leveraging executable edits to assess models on their ability to both detect factual errors and provide accurate explanations. The top-performing model, Claude3-Opus, achieves a joint detection and explanation score of only 0.49 in our benchmark, with individual scores of 0.67 for detection and 0.73 for explanation. Furthermore, we identify four primary types of explanation errors, with 45.4% of errors focusing on completely unrelated parts of the summary.
+
+
+
+ 82. 【2412.13377】DateLogicQA: Benchmarking Temporal Biases in Large Language Models
+ 链接:https://arxiv.org/abs/2412.13377
+ 作者:Gagan Bhatia,MingZe Tang,Cristina Mahanta,Madiha Kazi
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:paper introduces DateLogicQA, questions covering diverse, diverse date formats, covering diverse date, Semantic Integrity Metric
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper introduces DateLogicQA, a benchmark with 190 questions covering diverse date formats, temporal contexts, and reasoning types. We propose the Semantic Integrity Metric to assess tokenization quality and analyse two biases: Representation-Level Bias, affecting embeddings, and Logical-Level Bias, influencing reasoning outputs. Our findings provide a comprehensive evaluation of LLMs' capabilities and limitations in temporal reasoning, highlighting key challenges in handling temporal data accurately. The GitHub repository for our work is available at this https URL
+
+
+
+ 83. 【2412.13375】Extending LLMs to New Languages: A Case Study of Llama and Persian Adaptation
+ 链接:https://arxiv.org/abs/2412.13375
+ 作者:Samin Mahdizadeh Sani,Pouya Sadeghi,Thuy-Trang Vu,Yadollah Yaghoobzadeh,Gholamreza Haffari
+ 类目:Computation and Language (cs.CL)
+ 关键词:made great progress, Large language models, Large language, made great, great progress
+ 备注: accepted at COLING 2025
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) have made great progress in classification and text generation tasks. However, they are mainly trained on English data and often struggle with low-resource languages. In this study, we explore adding a new language, i.e., Persian, to Llama (a model with a limited understanding of Persian) using parameter-efficient fine-tuning. We employ a multi-stage approach involving pretraining on monolingual Persian data, aligning representations through bilingual pretraining and instruction datasets, and instruction-tuning with task-specific datasets. We evaluate the model's performance at each stage on generation and classification tasks. Our findings suggest that incorporating the Persian language, through bilingual data alignment, can enhance classification accuracy for Persian tasks, with no adverse impact and sometimes even improvements on English tasks. Additionally, the results highlight the model's initial strength as a critical factor when working with limited training data, with cross-lingual alignment offering minimal benefits for the low-resource language. Knowledge transfer from English to Persian has a marginal effect, primarily benefiting simple classification tasks.
+
+
+
+ 84. 【2412.13335】Experience of Training a 1.7B-Parameter LLaMa Model From Scratch
+ 链接:https://arxiv.org/abs/2412.13335
+ 作者:Miles Q. Li,Benjamin C. M. Fung,Shih-Chia Huang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
+ 关键词:complex endeavor influenced, including model architecture, Pretraining large language, large language models, multiple factors
+ 备注:
+
+ 点击查看摘要
+ Abstract:Pretraining large language models is a complex endeavor influenced by multiple factors, including model architecture, data quality, training continuity, and hardware constraints. In this paper, we share insights gained from the experience of training DMaS-LLaMa-Lite, a fully open source, 1.7-billion-parameter, LLaMa-based model, on approximately 20 billion tokens of carefully curated data. We chronicle the full training trajectory, documenting how evolving validation loss levels and downstream benchmarks reflect transitions from incoherent text to fluent, contextually grounded output. Beyond standard quantitative metrics, we highlight practical considerations such as the importance of restoring optimizer states when resuming from checkpoints, and the impact of hardware changes on training stability and throughput. While qualitative evaluation provides an intuitive understanding of model improvements, our analysis extends to various performance benchmarks, demonstrating how high-quality data and thoughtful scaling enable competitive results with significantly fewer training tokens. By detailing these experiences and offering training logs, checkpoints, and sample outputs, we aim to guide future researchers and practitioners in refining their pretraining strategies. The training script is available on Github at this https URL. The model checkpoints are available on Huggingface at this https URL.
+
+
+
+ 85. 【2412.13328】Expansion Span: Combining Fading Memory and Retrieval in Hybrid State Space Models
+ 链接:https://arxiv.org/abs/2412.13328
+ 作者:Elvis Nunez,Luca Zancato,Benjamin Bowman,Aditya Golatkar,Wei Xia,Stefano Soatto
+ 类目:Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:State Space Models, State Space, Hybrid models, State Space layers, Hybrid
+ 备注:
+
+ 点击查看摘要
+ Abstract:The "state" of State Space Models (SSMs) represents their memory, which fades exponentially over an unbounded span. By contrast, Attention-based models have "eidetic" (i.e., verbatim, or photographic) memory over a finite span (context size). Hybrid architectures combine State Space layers with Attention, but still cannot recall the distant past and can access only the most recent tokens eidetically. Unlike current methods of combining SSM and Attention layers, we allow the state to be allocated based on relevancy rather than recency. In this way, for every new set of query tokens, our models can "eidetically" access tokens from beyond the Attention span of current Hybrid SSMs without requiring extra hardware resources. We describe a method to expand the memory span of the hybrid state by "reserving" a fraction of the Attention context for tokens retrieved from arbitrarily distant in the past, thus expanding the eidetic memory span of the overall state. We call this reserved fraction of tokens the "expansion span," and the mechanism to retrieve and aggregate it "Span-Expanded Attention" (SE-Attn). To adapt Hybrid models to using SE-Attn, we propose a novel fine-tuning method that extends LoRA to Hybrid models (HyLoRA) and allows efficient adaptation on long spans of tokens. We show that SE-Attn enables us to efficiently adapt pre-trained Hybrid models on sequences of tokens up to 8 times longer than the ones used for pre-training. We show that HyLoRA with SE-Attn is cheaper and more performant than alternatives like LongLoRA when applied to Hybrid models on natural language benchmarks with long-range dependencies, such as PG-19, RULER, and other common natural language downstream tasks.
+
+
+
+ 86. 【2412.13292】Hint Marginalization for Improved Reasoning in Large Language Models
+ 链接:https://arxiv.org/abs/2412.13292
+ 作者:Soumyasundar Pal,Didier Chételat,Yingxue Zhang,Mark Coates
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, Language Models, perform reasoning tasks, intermediate steps
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Models (LLMs) have exhibited an impressive capability to perform reasoning tasks, especially if they are encouraged to generate a sequence of intermediate steps. Reasoning performance can be improved by suitably combining multiple LLM responses, generated either in parallel in a single query, or via sequential interactions with LLMs throughout the reasoning process. Existing strategies for combination, such as self-consistency and progressive-hint-prompting, make inefficient usage of the LLM responses. We present Hint Marginalization, a novel and principled algorithmic framework to enhance the reasoning capabilities of LLMs. Our approach can be viewed as an iterative sampling strategy for forming a Monte Carlo approximation of an underlying distribution of answers, with the goal of identifying the mode the most likely answer. Empirical evaluation on several benchmark datasets for arithmetic reasoning demonstrates the superiority of the proposed approach.
+
+
+
+ 87. 【2412.13283】Enhancing Persona Classification in Dialogue Systems: A Graph Neural Network Approach
+ 链接:https://arxiv.org/abs/2412.13283
+ 作者:Konstantin Zaitsev
+ 类目:Computation and Language (cs.CL)
+ 关键词:Large Language Models, Large Language, gain considerable attention, enhance personalized experiences, Language Models
+ 备注:
+
+ 点击查看摘要
+ Abstract:In recent years, Large Language Models (LLMs) gain considerable attention for their potential to enhance personalized experiences in virtual assistants and chatbots. A key area of interest is the integration of personas into LLMs to improve dialogue naturalness and user engagement. This study addresses the challenge of persona classification, a crucial component in dialogue understanding, by proposing a framework that combines text embeddings with Graph Neural Networks (GNNs) for effective persona classification. Given the absence of dedicated persona classification datasets, we create a manually annotated dataset to facilitate model training and evaluation. Our method involves extracting semantic features from persona statements using text embeddings and constructing a graph where nodes represent personas and edges capture their similarities. The GNN component uses this graph structure to propagate relevant information, thereby improving classification performance. Experimental results show that our approach, in particular the integration of GNNs, significantly improves classification performance, especially with limited data. Our contributions include the development of a persona classification framework and the creation of a dataset.
+
+
+
+ 88. 【2412.13243】In-Context Learning Distillation for Efficient Few-Shot Fine-Tuning
+ 链接:https://arxiv.org/abs/2412.13243
+ 作者:Yifei Duan,Liu Li,Zirui Zhai,Jinxia Yao
+ 类目:Computation and Language (cs.CL)
+ 关键词:natural language inference, language inference task, applied few-shot in-context, reducing model parameter, few-shot in-context learning
+ 备注: 7 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:We applied few-shot in-context learning on the OPT-1.3B model for the natural language inference task and employed knowledge distillation to internalize the context information, reducing model parameter from 1.3B to 125M and achieving a size reduction from 2.5GB to 0.25GB. Compared to using in-context learning alone on similarly sized models, this context distillation approach achieved a nearly 50% improvement in out-of-domain accuracy, demonstrating superior knowledge transfer capabilities over prompt-based methods. Furthermore, this approach reduced memory consumption by up to 60% while delivering a 20% improvement in out-of-domain accuracy compared to conventional pattern-based fine-tuning.
+
+
+
+ 89. 【2412.13205】Adaptive Two-Phase Finetuning LLMs for Japanese Legal Text Retrieval
+ 链接:https://arxiv.org/abs/2412.13205
+ 作者:Quang Hoang Trung,Nguyen Van Hoang Phuc,Le Trung Hoang,Quang Huu Hieu,Vo Nguyen Le Duy
+ 类目:Information Retrieval (cs.IR); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:retrieving text-based content, text-based content relevant, Text Retrieval, involves finding, large repository
+ 备注:
+
+ 点击查看摘要
+ Abstract:Text Retrieval (TR) involves finding and retrieving text-based content relevant to a user's query from a large repository, with applications in real-world scenarios such as legal document retrieval. While most existing studies focus on English, limited work addresses Japanese contexts. In this paper, we introduce a new dataset specifically designed for Japanese legal contexts and propose a novel two-phase pipeline tailored to this domain.
+In the first phase, the model learns a broad understanding of global contexts, enhancing its generalization and adaptability to diverse queries. In the second phase, the model is fine-tuned to address complex queries specific to legal scenarios. Extensive experiments are conducted to demonstrate the superior performance of our method, which outperforms existing baselines.
+Furthermore, our pipeline proves effective in English contexts, surpassing comparable baselines on the MS MARCO dataset. We have made our code publicly available on GitHub, and the model checkpoints are accessible via HuggingFace.
+
Subjects:
+Information Retrieval (cs.IR); Computation and Language (cs.CL); Machine Learning (cs.LG)
+Cite as:
+arXiv:2412.13205 [cs.IR]
+(or
+arXiv:2412.13205v1 [cs.IR] for this version)
+https://doi.org/10.48550/arXiv.2412.13205
+Focus to learn more
+ arXiv-issued DOI via DataCite</p>
+
+
+
+
+ 90. 【2412.12143】Harnessing Transfer Learning from Swahili: Advancing Solutions for Comorian Dialects
+ 链接:https://arxiv.org/abs/2412.12143
+ 作者:Naira Abdou Mohamed,Zakarya Erraji,Abdessalam Bahafid,Imade Benelallam
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Natural Language Processing, develop high-performing Natural, high-performing Natural Language, today some African, high-performing Natural
+ 备注: This paper was presented at the 6th Deep Learning Indaba Conference (DLI 2024)
+
+ 点击查看摘要
+ Abstract:If today some African languages like Swahili have enough resources to develop high-performing Natural Language Processing (NLP) systems, many other languages spoken on the continent are still lacking such support. For these languages, still in their infancy, several possibilities exist to address this critical lack of data. Among them is Transfer Learning, which allows low-resource languages to benefit from the good representation of other languages that are similar to them. In this work, we adopt a similar approach, aiming to pioneer NLP technologies for Comorian, a group of four languages or dialects belonging to the Bantu family.
+Our approach is initially motivated by the hypothesis that if a human can understand a different language from their native language with little or no effort, it would be entirely possible to model this process on a machine. To achieve this, we consider ways to construct Comorian datasets mixed with Swahili. One thing to note here is that in terms of Swahili data, we only focus on elements that are closest to Comorian by calculating lexical distances between candidate and source data. We empirically test this hypothesis in two use cases: Automatic Speech Recognition (ASR) and Machine Translation (MT). Our MT model achieved ROUGE-1, ROUGE-2, and ROUGE-L scores of 0.6826, 0.42, and 0.6532, respectively, while our ASR system recorded a WER of 39.50\% and a CER of 13.76\%. This research is crucial for advancing NLP in underrepresented languages, with potential to preserve and promote Comorian linguistic heritage in the digital age.
+
Comments:
+This paper was presented at the 6th Deep Learning Indaba Conference (DLI 2024)
+Subjects:
+Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+Cite as:
+arXiv:2412.12143 [cs.CL]
+(or
+arXiv:2412.12143v1 [cs.CL] for this version)
+https://doi.org/10.48550/arXiv.2412.12143
+Focus to learn more
+ arXiv-issued DOI via DataCite</p>
+
+
+
+
+ 91. 【2409.10994】Less is More: A Simple yet Effective Token Reduction Method for Efficient Multi-modal LLMs
+ 链接:https://arxiv.org/abs/2409.10994
+ 作者:Dingjie Song,Wenjun Wang,Shunian Chen,Xidong Wang,Michael Guan,Benyou Wang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:Multimodal Large Language, Large Language Models, Multimodal Large, Large Language, advancement of Multimodal
+ 备注: Accepted to COLING 2025
+
+ 点击查看摘要
+ Abstract:The rapid advancement of Multimodal Large Language Models (MLLMs) has led to remarkable performances across various domains. However, this progress is accompanied by a substantial surge in the resource consumption of these models. We address this pressing issue by introducing a new approach, Token Reduction using CLIP Metric (TRIM), aimed at improving the efficiency of MLLMs without sacrificing their performance. Inspired by human attention patterns in Visual Question Answering (VQA) tasks, TRIM presents a fresh perspective on the selection and reduction of image tokens. The TRIM method has been extensively tested across 12 datasets, and the results demonstrate a significant reduction in computational overhead while maintaining a consistent level of performance. This research marks a critical stride in efficient MLLM development, promoting greater accessibility and sustainability of high-performing models.
+
+
+
+ 92. 【2412.13558】Read Like a Radiologist: Efficient Vision-Language Model for 3D Medical Imaging Interpretation
+ 链接:https://arxiv.org/abs/2412.13558
+ 作者:Changsun Lee,Sangjoon Park,Cheong-Il Shin,Woo Hee Choi,Hyun Jeong Park,Jeong Eun Lee,Jong Chul Ye
+ 类目:Image and Video Processing (eess.IV); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:medical vision-language models, Recent medical vision-language, medical, medical image interpretation, medical image
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent medical vision-language models (VLMs) have shown promise in 2D medical image interpretation. However extending them to 3D medical imaging has been challenging due to computational complexities and data scarcity. Although a few recent VLMs specified for 3D medical imaging have emerged, all are limited to learning volumetric representation of a 3D medical image as a set of sub-volumetric features. Such process introduces overly correlated representations along the z-axis that neglect slice-specific clinical details, particularly for 3D medical images where adjacent slices have low redundancy. To address this limitation, we introduce MS-VLM that mimic radiologists' workflow in 3D medical image interpretation. Specifically, radiologists analyze 3D medical images by examining individual slices sequentially and synthesizing information across slices and views. Likewise, MS-VLM leverages self-supervised 2D transformer encoders to learn a volumetric representation that capture inter-slice dependencies from a sequence of slice-specific features. Unbound by sub-volumetric patchification, MS-VLM is capable of obtaining useful volumetric representations from 3D medical images with any slice length and from multiple images acquired from different planes and phases. We evaluate MS-VLM on publicly available chest CT dataset CT-RATE and in-house rectal MRI dataset. In both scenarios, MS-VLM surpasses existing methods in radiology report generation, producing more coherent and clinically relevant reports. These findings highlight the potential of MS-VLM to advance 3D medical image interpretation and improve the robustness of medical VLMs.
+
+
+信息检索
+
+ 1. 【2412.14113】Adversarial Hubness in Multi-Modal Retrieval
+ 链接:https://arxiv.org/abs/2412.14113
+ 作者:Tingwei Zhang,Fnu Suya,Rishi Jha,Collin Zhang,Vitaly Shmatikov
+ 类目:Cryptography and Security (cs.CR); Information Retrieval (cs.IR)
+ 关键词:high-dimensional vector spaces, phenomenon in high-dimensional, distribution is unusually, unusually close, adversarial
+ 备注:
+
+ 点击查看摘要
+ Abstract:Hubness is a phenomenon in high-dimensional vector spaces where a single point from the natural distribution is unusually close to many other points. This is a well-known problem in information retrieval that causes some items to accidentally (and incorrectly) appear relevant to many queries. In this paper, we investigate how attackers can exploit hubness to turn any image or audio input in a multi-modal retrieval system into an adversarial hub. Adversarial hubs can be used to inject universal adversarial content (e.g., spam) that will be retrieved in response to thousands of different queries, as well as for targeted attacks on queries related to specific, attacker-chosen concepts. We present a method for creating adversarial hubs and evaluate the resulting hubs on benchmark multi-modal retrieval datasets and an image-to-image retrieval system based on a tutorial from Pinecone, a popular vector database. For example, in text-caption-to-image retrieval, a single adversarial hub is retrieved as the top-1 most relevant image for more than 21,000 out of 25,000 test queries (by contrast, the most common natural hub is the top-1 response to only 102 queries). We also investigate whether techniques for mitigating natural hubness are an effective defense against adversarial hubs, and show that they are not effective against hubs that target queries related to specific concepts.
+
+
+
+ 2. 【2412.14025】A Cognitive Ideation Support Framework using IBM Watson Services
+ 链接:https://arxiv.org/abs/2412.14025
+ 作者:Samaa Elnagar,Kweku-Muata Osei-Bryson
+ 类目:Information Retrieval (cs.IR)
+ 关键词:core activity, activity for innovation, IBM Watson, knowledge bases, organizations' knowledge bases
+ 备注: Twenty-fifth Americas Conference on Information Systems (AMCIS 2019), Cancun, 2019
+
+ 点击查看摘要
+ Abstract:Ideas generation is a core activity for innovation in organizations. The creativity of the generated ideas depends not only on the knowledge retrieved from the organizations' knowledge bases, but also on the external knowledge retrieved from other resources. Unfortunately, organizations often cannot efficiently utilize the knowledge in the knowledge bases due to the limited abilities of the search and retrieval mechanisms especially when dealing with unstructured data. In this paper, we present a new cognitive support framework for ideation that uses the IBM Watson DeepQA services. IBM Watson is a Question Answering system which mimics human cognitive abilities to retrieve and rank information. The proposed framework is based on the Search for Ideas in the Associative Memory (SIAM) model to help organizations develop creative ideas through discovering new relationships between retrieved data. To evaluate the effectiveness of the proposed system, the generated ideas generated are selected and assessed using a set of established creativity criteria.
+
+
+
+ 3. 【2412.13844】CRM: Retrieval Model with Controllable Condition
+ 链接:https://arxiv.org/abs/2412.13844
+ 作者:Chi Liu,Jiangxia Cao,Rui Huang,Kuo Cai,Weifeng Ding,Qiang Luo,Kun Gai,Guorui Zhou
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI)
+ 关键词:item candidates satisfied, retrieval model, retrieval, Controllable Retrieval Model, item candidates
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recommendation systems (RecSys) are designed to connect users with relevant items from a vast pool of candidates while aligning with the business goals of the platform. A typical industrial RecSys is composed of two main stages, retrieval and ranking: (1) the retrieval stage aims at searching hundreds of item candidates satisfied user interests; (2) based on the retrieved items, the ranking stage aims at selecting the best dozen items by multiple targets estimation for each item candidate, including classification and regression targets. Compared with ranking model, the retrieval model absence of item candidate information during inference, therefore retrieval models are often trained by classification target only (e.g., click-through rate), but failed to incorporate regression target (e.g., the expected watch-time), which limit the effectiveness of retrieval. In this paper, we propose the Controllable Retrieval Model (CRM), which integrates regression information as conditional features into the two-tower retrieval paradigm. This modification enables the retrieval stage could fulfill the target gap with ranking model, enhancing the retrieval model ability to search item candidates satisfied the user interests and condition effectively. We validate the effectiveness of CRM through real-world A/B testing and demonstrate its successful deployment in Kuaishou short-video recommendation system, which serves over 400 million users.
+
+
+
+ 4. 【2412.13834】Maybe you are looking for CroQS: Cross-modal Query Suggestion for Text-to-Image Retrieval
+ 链接:https://arxiv.org/abs/2412.13834
+ 作者:Giacomo Pacini,Fabio Carrara,Nicola Messina,Nicola Tonellotto,Giuseppe Amato,Fabrizio Falchi
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:enhances system interactivity, technique widely adopted, Query suggestion, query suggestion solutions, explored query suggestion
+ 备注: 15 pages, 5 figures. To be published as full paper in the Proceedings of the European Conference on Information Retrieval (ECIR) 2025
+
+ 点击查看摘要
+ Abstract:Query suggestion, a technique widely adopted in information retrieval, enhances system interactivity and the browsing experience of document collections. In cross-modal retrieval, many works have focused on retrieving relevant items from natural language queries, while few have explored query suggestion solutions. In this work, we address query suggestion in cross-modal retrieval, introducing a novel task that focuses on suggesting minimal textual modifications needed to explore visually consistent subsets of the collection, following the premise of ''Maybe you are looking for''. To facilitate the evaluation and development of methods, we present a tailored benchmark named CroQS. This dataset comprises initial queries, grouped result sets, and human-defined suggested queries for each group. We establish dedicated metrics to rigorously evaluate the performance of various methods on this task, measuring representativeness, cluster specificity, and similarity of the suggested queries to the original ones. Baseline methods from related fields, such as image captioning and content summarization, are adapted for this task to provide reference performance scores. Although relatively far from human performance, our experiments reveal that both LLM-based and captioning-based methods achieve competitive results on CroQS, improving the recall on cluster specificity by more than 115% and representativeness mAP by more than 52% with respect to the initial query. The dataset, the implementation of the baseline methods and the notebooks containing our experiments are available here: this https URL
+
+
+
+ 5. 【2412.13825】Heterogeneous Graph Collaborative Filtering
+ 链接:https://arxiv.org/abs/2412.13825
+ 作者:Lianghao Xia,Meiyan Xie,Yong Xu,Chao Huang
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI)
+ 关键词:modern recommender systems, low-dimensional latent representations, recommender systems, modern recommender, representations to embed
+ 备注: This paper is accepted by WSDM'2025
+
+ 点击查看摘要
+ Abstract:For modern recommender systems, the use of low-dimensional latent representations to embed users and items based on their observed interactions has become commonplace. However, many existing recommendation models are primarily designed for coarse-grained and homogeneous interactions, which limits their effectiveness in two critical dimensions. Firstly, these models fail to leverage the relational dependencies that exist across different types of user behaviors, such as page views, collects, comments, and purchases. Secondly, they struggle to capture the fine-grained latent factors that drive user interaction patterns. To address these limitations, we present a heterogeneous graph collaborative filtering model MixRec that excels at disentangling users' multi-behavior interaction patterns and uncovering the latent intent factors behind each behavior. Our model achieves this by incorporating intent disentanglement and multi-behavior modeling, facilitated by a parameterized heterogeneous hypergraph architecture. Furthermore, we introduce a novel contrastive learning paradigm that adaptively explores the advantages of self-supervised data augmentation, thereby enhancing the model's resilience against data sparsity and expressiveness with relation heterogeneity. To validate the efficacy of MixRec, we conducted extensive experiments on three public datasets. The results clearly demonstrate its superior performance, significantly outperforming various state-of-the-art baselines. Our model is open-sourced and available at: this https URL.
+
+
+
+ 6. 【2412.13771】Semantic Convergence: Harmonizing Recommender Systems via Two-Stage Alignment and Behavioral Semantic Tokenization
+ 链接:https://arxiv.org/abs/2412.13771
+ 作者:Guanghan Li,Xun Zhang,Yufei Zhang,Yifan Yin,Guojun Yin,Wei Lin
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:exceptional reasoning capabilities, Large language models, discerning profound user, profound user interests, endowed with exceptional
+ 备注: 7 pages, 3 figures, AAAI 2025
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs), endowed with exceptional reasoning capabilities, are adept at discerning profound user interests from historical behaviors, thereby presenting a promising avenue for the advancement of recommendation systems. However, a notable discrepancy persists between the sparse collaborative semantics typically found in recommendation systems and the dense token representations within LLMs. In our study, we propose a novel framework that harmoniously merges traditional recommendation models with the prowess of LLMs. We initiate this integration by transforming ItemIDs into sequences that align semantically with the LLMs space, through the proposed Alignment Tokenization module. Additionally, we design a series of specialized supervised learning tasks aimed at aligning collaborative signals with the subtleties of natural language semantics. To ensure practical applicability, we optimize online inference by pre-caching the top-K results for each user, reducing latency and improving effciency. Extensive experimental evidence indicates that our model markedly improves recall metrics and displays remarkable scalability of recommendation systems.
+
+
+
+ 7. 【2412.13746】RAG-RewardBench: Benchmarking Reward Models in Retrieval Augmented Generation for Preference Alignment
+ 链接:https://arxiv.org/abs/2412.13746
+ 作者:Zhuoran Jin,Hongbang Yuan,Tianyi Men,Pengfei Cao,Yubo Chen,Kang Liu,Jun Zhao
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Information Retrieval (cs.IR)
+ 关键词:significant progress made, retrieval augmented language, providing trustworthy responses, augmented language models, overlook effective alignment
+ 备注: 26 pages, 12 figures, 6 tables
+
+ 点击查看摘要
+ Abstract:Despite the significant progress made by existing retrieval augmented language models (RALMs) in providing trustworthy responses and grounding in reliable sources, they often overlook effective alignment with human preferences. In the alignment process, reward models (RMs) act as a crucial proxy for human values to guide optimization. However, it remains unclear how to evaluate and select a reliable RM for preference alignment in RALMs. To this end, we propose RAG-RewardBench, the first benchmark for evaluating RMs in RAG settings. First, we design four crucial and challenging RAG-specific scenarios to assess RMs, including multi-hop reasoning, fine-grained citation, appropriate abstain, and conflict robustness. Then, we incorporate 18 RAG subsets, six retrievers, and 24 RALMs to increase the diversity of data sources. Finally, we adopt an LLM-as-a-judge approach to improve preference annotation efficiency and effectiveness, exhibiting a strong correlation with human annotations. Based on the RAG-RewardBench, we conduct a comprehensive evaluation of 45 RMs and uncover their limitations in RAG scenarios. Additionally, we also reveal that existing trained RALMs show almost no improvement in preference alignment, highlighting the need for a shift towards preference-aligned this http URL release our benchmark and code publicly at this https URL for future work.
+
+
+
+ 8. 【2412.13614】Reverse Region-to-Entity Annotation for Pixel-Level Visual Entity Linking
+ 链接:https://arxiv.org/abs/2412.13614
+ 作者:Zhengfei Xu,Sijia Zhao,Yanchao Hao,Xiaolong Liu,Lili Li,Yuyang Yin,Bo Li,Xi Chen,Xin Xin
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Information Retrieval (cs.IR); Multimedia (cs.MM)
+ 关键词:Visual Entity Linking, Entity Linking, knowledge base, Visual Entity, Visual
+ 备注: AAAI 2025;Dataset are released at [this https URL](https://github.com/NP-NET-research/PL-VEL)
+
+ 点击查看摘要
+ Abstract:Visual Entity Linking (VEL) is a crucial task for achieving fine-grained visual understanding, matching objects within images (visual mentions) to entities in a knowledge base. Previous VEL tasks rely on textual inputs, but writing queries for complex scenes can be challenging. Visual inputs like clicks or bounding boxes offer a more convenient alternative. Therefore, we propose a new task, Pixel-Level Visual Entity Linking (PL-VEL), which uses pixel masks from visual inputs to refer to objects, supplementing reference methods for VEL. To facilitate research on this task, we have constructed the MaskOVEN-Wiki dataset through an entirely automatic reverse region-entity annotation framework. This dataset contains over 5 million annotations aligning pixel-level regions with entity-level labels, which will advance visual understanding towards fine-grained. Moreover, as pixel masks correspond to semantic regions in an image, we enhance previous patch-interacted attention with region-interacted attention by a visual semantic tokenization approach. Manual evaluation results indicate that the reverse annotation framework achieved a 94.8% annotation success rate. Experimental results show that models trained on this dataset improved accuracy by 18 points compared to zero-shot models. Additionally, the semantic tokenization method achieved a 5-point accuracy improvement over the trained baseline.
+
+
+
+ 9. 【2412.13544】Bridging the User-side Knowledge Gap in Knowledge-aware Recommendations with Large Language Models
+ 链接:https://arxiv.org/abs/2412.13544
+ 作者:Zheng Hu,Zhe Li,Ziyun Jiao,Satoshi Nakagawa,Jiawen Deng,Shimin Cai,Tao Zhou,Fuji Ren
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI)
+ 关键词:enhancing recommendation accuracy, Large Language Models, knowledge, recent years, Language Models
+ 备注: Accepted at AAAI 2025
+
+ 点击查看摘要
+ Abstract:In recent years, knowledge graphs have been integrated into recommender systems as item-side auxiliary information, enhancing recommendation accuracy. However, constructing and integrating structural user-side knowledge remains a significant challenge due to the improper granularity and inherent scarcity of user-side features. Recent advancements in Large Language Models (LLMs) offer the potential to bridge this gap by leveraging their human behavior understanding and extensive real-world knowledge. Nevertheless, integrating LLM-generated information into recommender systems presents challenges, including the risk of noisy information and the need for additional knowledge transfer. In this paper, we propose an LLM-based user-side knowledge inference method alongside a carefully designed recommendation framework to address these challenges. Our approach employs LLMs to infer user interests based on historical behaviors, integrating this user-side information with item-side and collaborative data to construct a hybrid structure: the Collaborative Interest Knowledge Graph (CIKG). Furthermore, we propose a CIKG-based recommendation framework that includes a user interest reconstruction module and a cross-domain contrastive learning module to mitigate potential noise and facilitate knowledge transfer. We conduct extensive experiments on three real-world datasets to validate the effectiveness of our method. Our approach achieves state-of-the-art performance compared to competitive baselines, particularly for users with sparse interactions.
+
+
+
+ 10. 【2412.13534】Information-Theoretic Generative Clustering of Documents
+ 链接:https://arxiv.org/abs/2412.13534
+ 作者:Xin Du,Kumiko Tanaka-Ishii
+ 类目:Machine Learning (cs.LG); Computation and Language (cs.CL); Information Retrieval (cs.IR); Information Theory (cs.IT)
+ 关键词:mathrm, large language models, language models, clustering, original documents
+ 备注: Accepted to AAAI 2025
+
+ 点击查看摘要
+ Abstract:We present {\em generative clustering} (GC) for clustering a set of documents, $\mathrm{X}$, by using texts $\mathrm{Y}$ generated by large language models (LLMs) instead of by clustering the original documents $\mathrm{X}$. Because LLMs provide probability distributions, the similarity between two documents can be rigorously defined in an information-theoretic manner by the KL divergence. We also propose a natural, novel clustering algorithm by using importance sampling. We show that GC achieves the state-of-the-art performance, outperforming any previous clustering method often by a large margin. Furthermore, we show an application to generative document retrieval in which documents are indexed via hierarchical clustering and our method improves the retrieval accuracy.
+
+
+
+ 11. 【2412.13432】Large Language Model Enhanced Recommender Systems: Taxonomy, Trend, Application and Future
+ 链接:https://arxiv.org/abs/2412.13432
+ 作者:Qidong Liu,Xiangyu Zhao,Yuhao Wang,Yejing Wang,Zijian Zhang,Yuqi Sun,Xiang Li,Maolin Wang,Pengyue Jia,Chong Chen,Wei Huang,Feng Tian
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI)
+ 关键词:Large Language Model, Large Language, including recommender systems, Language Model, LLM
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Language Model (LLM) has transformative potential in various domains, including recommender systems (RS). There have been a handful of research that focuses on empowering the RS by LLM. However, previous efforts mainly focus on LLM as RS, which may face the challenge of intolerant inference costs by LLM. Recently, the integration of LLM into RS, known as LLM-Enhanced Recommender Systems (LLMERS), has garnered significant interest due to its potential to address latency and memory constraints in real-world applications. This paper presents a comprehensive survey of the latest research efforts aimed at leveraging LLM to enhance RS capabilities. We identify a critical shift in the field with the move towards incorporating LLM into the online system, notably by avoiding their use during inference. Our survey categorizes the existing LLMERS approaches into three primary types based on the component of the RS model being augmented: Knowledge Enhancement, Interaction Enhancement, and Model Enhancement. We provide an in-depth analysis of each category, discussing the methodologies, challenges, and contributions of recent studies. Furthermore, we highlight several promising research directions that could further advance the field of LLMERS.
+
+
+
+ 12. 【2412.13408】Lightweight yet Fine-grained: A Graph Capsule Convolutional Network with Subspace Alignment for Shared-account Sequential Recommendation
+ 链接:https://arxiv.org/abs/2412.13408
+ 作者:Jinyu Zhang,Zhongying Zhao,Chao Li,Yanwei Yu
+ 类目:Information Retrieval (cs.IR); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Shared-account Sequential Recommendation, provide personalized recommendations, Graph Capsule Convolutional, Lightweight Graph Capsule, Capsule Convolutional Network
+ 备注: 11 pages, 6 figures, accepted by AAAI-2025 conference
+
+ 点击查看摘要
+ Abstract:Shared-account Sequential Recommendation (SSR) aims to provide personalized recommendations for accounts shared by multiple users with varying sequential preferences. Previous studies on SSR struggle to capture the fine-grained associations between interactions and different latent users within the shared account's hybrid sequences. Moreover, most existing SSR methods (e.g., RNN-based or GCN-based methods) have quadratic computational complexities, hindering the deployment of SSRs on resource-constrained devices. To this end, we propose a Lightweight Graph Capsule Convolutional Network with subspace alignment for shared-account sequential recommendation, named LightGC$^2$N. Specifically, we devise a lightweight graph capsule convolutional network. It facilitates the fine-grained matching between interactions and latent users by attentively propagating messages on the capsule graphs. Besides, we present an efficient subspace alignment method. This method refines the sequence representations and then aligns them with the finely clustered preferences of latent users. The experimental results on four real-world datasets indicate that LightGC$^2$N outperforms nine state-of-the-art methods in accuracy and efficiency.
+
+
+
+ 13. 【2412.13268】JudgeBlender: Ensembling Judgments for Automatic Relevance Assessment
+ 链接:https://arxiv.org/abs/2412.13268
+ 作者:Hossein A. Rahmani,Emine Yilmaz,Nick Craswell,Bhaskar Mitra
+ 类目:Information Retrieval (cs.IR)
+ 关键词:retrieval systems require, human assessors, costly and time-consuming, require a substantial, substantial amount
+ 备注: 14 pages
+
+ 点击查看摘要
+ Abstract:The effective training and evaluation of retrieval systems require a substantial amount of relevance judgments, which are traditionally collected from human assessors -- a process that is both costly and time-consuming. Large Language Models (LLMs) have shown promise in generating relevance labels for search tasks, offering a potential alternative to manual assessments. Current approaches often rely on a single LLM, such as GPT-4, which, despite being effective, are expensive and prone to intra-model biases that can favour systems leveraging similar models. In this work, we introduce JudgeBlender, a framework that employs smaller, open-source models to provide relevance judgments by combining evaluations across multiple LLMs (LLMBlender) or multiple prompts (PromptBlender). By leveraging the LLMJudge benchmark [18], we compare JudgeBlender with state-of-the-art methods and the top performers in the LLMJudge challenge. Our results show that JudgeBlender achieves competitive performance, demonstrating that very large models are often unnecessary for reliable relevance assessments.
+
+
+
+ 14. 【2412.13205】Adaptive Two-Phase Finetuning LLMs for Japanese Legal Text Retrieval
+ 链接:https://arxiv.org/abs/2412.13205
+ 作者:Quang Hoang Trung,Nguyen Van Hoang Phuc,Le Trung Hoang,Quang Huu Hieu,Vo Nguyen Le Duy
+ 类目:Information Retrieval (cs.IR); Computation and Language (cs.CL); Machine Learning (cs.LG)
+ 关键词:retrieving text-based content, text-based content relevant, Text Retrieval, involves finding, large repository
+ 备注:
+
+ 点击查看摘要
+ Abstract:Text Retrieval (TR) involves finding and retrieving text-based content relevant to a user's query from a large repository, with applications in real-world scenarios such as legal document retrieval. While most existing studies focus on English, limited work addresses Japanese contexts. In this paper, we introduce a new dataset specifically designed for Japanese legal contexts and propose a novel two-phase pipeline tailored to this domain.
+In the first phase, the model learns a broad understanding of global contexts, enhancing its generalization and adaptability to diverse queries. In the second phase, the model is fine-tuned to address complex queries specific to legal scenarios. Extensive experiments are conducted to demonstrate the superior performance of our method, which outperforms existing baselines.
+Furthermore, our pipeline proves effective in English contexts, surpassing comparable baselines on the MS MARCO dataset. We have made our code publicly available on GitHub, and the model checkpoints are accessible via HuggingFace.
+
Subjects:
+Information Retrieval (cs.IR); Computation and Language (cs.CL); Machine Learning (cs.LG)
+Cite as:
+arXiv:2412.13205 [cs.IR]
+(or
+arXiv:2412.13205v1 [cs.IR] for this version)
+https://doi.org/10.48550/arXiv.2412.13205
+Focus to learn more
+ arXiv-issued DOI via DataCite</p>
+
+
+
+计算机视觉
+
+ 1. 【2412.14173】AniDoc: Animation Creation Made Easier
+ 链接:https://arxiv.org/abs/2412.14173
+ 作者:Yihao Meng,Hao Ouyang,Hanlin Wang,Qiuyu Wang,Wen Wang,Ka Leong Cheng,Zhiheng Liu,Yujun Shen,Huamin Qu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:industry-standard workflow, encompassing four essential, essential stages, character design, keyframe animation
+ 备注: Project page and code: [this https URL](https://yihao-meng.github.io/AniDoc_demo)
+
+ 点击查看摘要
+ Abstract:The production of 2D animation follows an industry-standard workflow, encompassing four essential stages: character design, keyframe animation, in-betweening, and coloring. Our research focuses on reducing the labor costs in the above process by harnessing the potential of increasingly powerful generative AI. Using video diffusion models as the foundation, AniDoc emerges as a video line art colorization tool, which automatically converts sketch sequences into colored animations following the reference character specification. Our model exploits correspondence matching as an explicit guidance, yielding strong robustness to the variations (e.g., posture) between the reference character and each line art frame. In addition, our model could even automate the in-betweening process, such that users can easily create a temporally consistent animation by simply providing a character image as well as the start and end sketches. Our code is available at: this https URL.
+
+
+
+ 2. 【2412.14172】Learning from Massive Human Videos for Universal Humanoid Pose Control
+ 链接:https://arxiv.org/abs/2412.14172
+ 作者:Jiageng Mao,Siheng Zhao,Siqi Song,Tianheng Shi,Junjie Ye,Mingtong Zhang,Haoran Geng,Jitendra Malik,Vitor Guizilini,Yue Wang
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:humanoid robots, humanoid, robots, real-world applications, learning
+ 备注:
+
+ 点击查看摘要
+ Abstract:Scalable learning of humanoid robots is crucial for their deployment in real-world applications. While traditional approaches primarily rely on reinforcement learning or teleoperation to achieve whole-body control, they are often limited by the diversity of simulated environments and the high costs of demonstration collection. In contrast, human videos are ubiquitous and present an untapped source of semantic and motion information that could significantly enhance the generalization capabilities of humanoid robots. This paper introduces Humanoid-X, a large-scale dataset of over 20 million humanoid robot poses with corresponding text-based motion descriptions, designed to leverage this abundant data. Humanoid-X is curated through a comprehensive pipeline: data mining from the Internet, video caption generation, motion retargeting of humans to humanoid robots, and policy learning for real-world deployment. With Humanoid-X, we further train a large humanoid model, UH-1, which takes text instructions as input and outputs corresponding actions to control a humanoid robot. Extensive simulated and real-world experiments validate that our scalable training approach leads to superior generalization in text-based humanoid control, marking a significant step toward adaptable, real-world-ready humanoid robots.
+
+
+
+ 3. 【2412.14171】hinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
+ 链接:https://arxiv.org/abs/2412.14171
+ 作者:Jihan Yang,Shusheng Yang,Anjali W. Gupta,Rilyn Han,Li Fei-Fei,Saining Xie
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:sequential visual observations, Humans possess, Multimodal Large Language, visual observations, Large Language Models
+ 备注: Project page: [this https URL](https://vision-x-nyu.github.io/thinking-in-space.github.io/)
+
+ 点击查看摘要
+ Abstract:Humans possess the visual-spatial intelligence to remember spaces from sequential visual observations. However, can Multimodal Large Language Models (MLLMs) trained on million-scale video datasets also ``think in space'' from videos? We present a novel video-based visual-spatial intelligence benchmark (VSI-Bench) of over 5,000 question-answer pairs, and find that MLLMs exhibit competitive - though subhuman - visual-spatial intelligence. We probe models to express how they think in space both linguistically and visually and find that while spatial reasoning capabilities remain the primary bottleneck for MLLMs to reach higher benchmark performance, local world models and spatial awareness do emerge within these models. Notably, prevailing linguistic reasoning techniques (e.g., chain-of-thought, self-consistency, tree-of-thoughts) fail to improve performance, whereas explicitly generating cognitive maps during question-answering enhances MLLMs' spatial distance ability.
+
+
+
+ 4. 【2412.14170】E-CAR: Efficient Continuous Autoregressive Image Generation via Multistage Modeling
+ 链接:https://arxiv.org/abs/2412.14170
+ 作者:Zhihang Yuan,Yuzhang Shang,Hanling Zhang,Tongcheng Fang,Rui Xie,Bingxin Xu,Yan Yan,Shengen Yan,Guohao Dai,Yu Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Recent advances, generation show promising, show promising results, advances in autoregressive, discrete tokenization
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advances in autoregressive (AR) models with continuous tokens for image generation show promising results by eliminating the need for discrete tokenization. However, these models face efficiency challenges due to their sequential token generation nature and reliance on computationally intensive diffusion-based sampling. We present ECAR (Efficient Continuous Auto-Regressive Image Generation via Multistage Modeling), an approach that addresses these limitations through two intertwined innovations: (1) a stage-wise continuous token generation strategy that reduces computational complexity and provides progressively refined token maps as hierarchical conditions, and (2) a multistage flow-based distribution modeling method that transforms only partial-denoised distributions at each stage comparing to complete denoising in normal diffusion models. Holistically, ECAR operates by generating tokens at increasing resolutions while simultaneously denoising the image at each stage. This design not only reduces token-to-image transformation cost by a factor of the stage number but also enables parallel processing at the token level. Our approach not only enhances computational efficiency but also aligns naturally with image generation principles by operating in continuous token space and following a hierarchical generation process from coarse to fine details. Experimental results demonstrate that ECAR achieves comparable image quality to DiT Peebles Xie [2023] while requiring 10$\times$ FLOPs reduction and 5$\times$ speedup to generate a 256$\times$256 image.
+
+
+
+ 5. 【2412.14169】Autoregressive Video Generation without Vector Quantization
+ 链接:https://arxiv.org/abs/2412.14169
+ 作者:Haoge Deng,Ting Pan,Haiwen Diao,Zhengxiong Luo,Yufeng Cui,Huchuan Lu,Shiguang Shan,Yonggang Qi,Xinlong Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:paper presents, autoregressive, video, NOVA, high efficiency
+ 备注: 22 pages, 16 figures
+
+ 点击查看摘要
+ Abstract:This paper presents a novel approach that enables autoregressive video generation with high efficiency. We propose to reformulate the video generation problem as a non-quantized autoregressive modeling of temporal frame-by-frame prediction and spatial set-by-set prediction. Unlike raster-scan prediction in prior autoregressive models or joint distribution modeling of fixed-length tokens in diffusion models, our approach maintains the causal property of GPT-style models for flexible in-context capabilities, while leveraging bidirectional modeling within individual frames for efficiency. With the proposed approach, we train a novel video autoregressive model without vector quantization, termed NOVA. Our results demonstrate that NOVA surpasses prior autoregressive video models in data efficiency, inference speed, visual fidelity, and video fluency, even with a much smaller model capacity, i.e., 0.6B parameters. NOVA also outperforms state-of-the-art image diffusion models in text-to-image generation tasks, with a significantly lower training cost. Additionally, NOVA generalizes well across extended video durations and enables diverse zero-shot applications in one unified model. Code and models are publicly available at this https URL.
+
+
+
+ 6. 【2412.14168】FashionComposer: Compositional Fashion Image Generation
+ 链接:https://arxiv.org/abs/2412.14168
+ 作者:Sihui Ji,Yiyang Wang,Xi Chen,Xiaogang Xu,Hao Luo,Hengshuang Zhao
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:compositional fashion image, present FashionComposer, fashion image generation, appearance features, appearance
+ 备注: [this https URL](https://sihuiji.github.io/FashionComposer-Page)
+
+ 点击查看摘要
+ Abstract:We present FashionComposer for compositional fashion image generation. Unlike previous methods, FashionComposer is highly flexible. It takes multi-modal input (i.e., text prompt, parametric human model, garment image, and face image) and supports personalizing the appearance, pose, and figure of the human and assigning multiple garments in one pass. To achieve this, we first develop a universal framework capable of handling diverse input modalities. We construct scaled training data to enhance the model's robust compositional capabilities. To accommodate multiple reference images (garments and faces) seamlessly, we organize these references in a single image as an "asset library" and employ a reference UNet to extract appearance features. To inject the appearance features into the correct pixels in the generated result, we propose subject-binding attention. It binds the appearance features from different "assets" with the corresponding text features. In this way, the model could understand each asset according to their semantics, supporting arbitrary numbers and types of reference images. As a comprehensive solution, FashionComposer also supports many other applications like human album generation, diverse virtual try-on tasks, etc.
+
+
+
+ 7. 【2412.14167】VideoDPO: Omni-Preference Alignment for Video Diffusion Generation
+ 链接:https://arxiv.org/abs/2412.14167
+ 作者:Runtao Liu,Haoyu Wu,Zheng Ziqiang,Chen Wei,Yingqing He,Renjie Pi,Qifeng Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Recent progress, generative diffusion models, greatly advanced, progress in generative, Direct Preference Optimization
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent progress in generative diffusion models has greatly advanced text-to-video generation. While text-to-video models trained on large-scale, diverse datasets can produce varied outputs, these generations often deviate from user preferences, highlighting the need for preference alignment on pre-trained models. Although Direct Preference Optimization (DPO) has demonstrated significant improvements in language and image generation, we pioneer its adaptation to video diffusion models and propose a VideoDPO pipeline by making several key adjustments. Unlike previous image alignment methods that focus solely on either (i) visual quality or (ii) semantic alignment between text and videos, we comprehensively consider both dimensions and construct a preference score accordingly, which we term the OmniScore. We design a pipeline to automatically collect preference pair data based on the proposed OmniScore and discover that re-weighting these pairs based on the score significantly impacts overall preference alignment. Our experiments demonstrate substantial improvements in both visual quality and semantic alignment, ensuring that no preference aspect is neglected. Code and data will be shared at this https URL.
+
+
+
+ 8. 【2412.14166】MegaSynth: Scaling Up 3D Scene Reconstruction with Synthesized Data
+ 链接:https://arxiv.org/abs/2412.14166
+ 作者:Hanwen Jiang,Zexiang Xu,Desai Xie,Ziwen Chen,Haian Jin,Fujun Luan,Zhixin Shu,Kai Zhang,Sai Bi,Xin Sun,Jiuxiang Gu,Qixing Huang,Georgios Pavlakos,Hao Tan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:data, propose scaling, training, MegaSynth, Abstract
+ 备注: Project page: [this https URL](https://hwjiang1510.github.io/MegaSynth/)
+
+ 点击查看摘要
+ Abstract:We propose scaling up 3D scene reconstruction by training with synthesized data. At the core of our work is MegaSynth, a procedurally generated 3D dataset comprising 700K scenes - over 50 times larger than the prior real dataset DL3DV - dramatically scaling the training data. To enable scalable data generation, our key idea is eliminating semantic information, removing the need to model complex semantic priors such as object affordances and scene composition. Instead, we model scenes with basic spatial structures and geometry primitives, offering scalability. Besides, we control data complexity to facilitate training while loosely aligning it with real-world data distribution to benefit real-world generalization. We explore training LRMs with both MegaSynth and available real data. Experiment results show that joint training or pre-training with MegaSynth improves reconstruction quality by 1.2 to 1.8 dB PSNR across diverse image domains. Moreover, models trained solely on MegaSynth perform comparably to those trained on real data, underscoring the low-level nature of 3D reconstruction. Additionally, we provide an in-depth analysis of MegaSynth's properties for enhancing model capability, training stability, and generalization.
+
+
+
+ 9. 【2412.14164】MetaMorph: Multimodal Understanding and Generation via Instruction Tuning
+ 链接:https://arxiv.org/abs/2412.14164
+ 作者:Shengbang Tong,David Fan,Jiachen Zhu,Yunyang Xiong,Xinlei Chen,Koustuv Sinha,Michael Rabbat,Yann LeCun,Saining Xie,Zhuang Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:propose Visual-Predictive Instruction, autoregressive model capable, unified autoregressive model, Visual-Predictive Instruction Tuning, Instruction Tuning
+ 备注: Project page at [this http URL](http://tsb0601.github.io/metamorph)
+
+ 点击查看摘要
+ Abstract:In this work, we propose Visual-Predictive Instruction Tuning (VPiT) - a simple and effective extension to visual instruction tuning that enables a pretrained LLM to quickly morph into an unified autoregressive model capable of generating both text and visual tokens. VPiT teaches an LLM to predict discrete text tokens and continuous visual tokens from any input sequence of image and text data curated in an instruction-following format. Our empirical investigation reveals several intriguing properties of VPiT: (1) visual generation ability emerges as a natural byproduct of improved visual understanding, and can be unlocked efficiently with a small amount of generation data; (2) while we find understanding and generation to be mutually beneficial, understanding data contributes to both capabilities more effectively than generation data. Building upon these findings, we train our MetaMorph model and achieve competitive performance on both visual understanding and generation. In visual generation, MetaMorph can leverage the world knowledge and reasoning abilities gained from LLM pretraining, and overcome common failure modes exhibited by other generation models. Our results suggest that LLMs may have strong "prior" vision capabilities that can be efficiently adapted to both visual understanding and generation with a relatively simple instruction tuning process.
+
+
+
+ 10. 【2412.14158】AKiRa: Augmentation Kit on Rays for optical video generation
+ 链接:https://arxiv.org/abs/2412.14158
+ 作者:Xi Wang,Robin Courant,Marc Christie,Vicky Kalogeiton
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Multimedia (cs.MM)
+ 关键词:Recent advances, improved video quality, text-conditioned video diffusion, greatly improved video, advances in text-conditioned
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advances in text-conditioned video diffusion have greatly improved video quality. However, these methods offer limited or sometimes no control to users on camera aspects, including dynamic camera motion, zoom, distorted lens and focus shifts. These motion and optical aspects are crucial for adding controllability and cinematic elements to generation frameworks, ultimately resulting in visual content that draws focus, enhances mood, and guides emotions according to filmmakers' controls. In this paper, we aim to close the gap between controllable video generation and camera optics. To achieve this, we propose AKiRa (Augmentation Kit on Rays), a novel augmentation framework that builds and trains a camera adapter with a complex camera model over an existing video generation backbone. It enables fine-tuned control over camera motion as well as complex optical parameters (focal length, distortion, aperture) to achieve cinematic effects such as zoom, fisheye effect, and bokeh. Extensive experiments demonstrate AKiRa's effectiveness in combining and composing camera optics while outperforming all state-of-the-art methods. This work sets a new landmark in controlled and optically enhanced video generation, paving the way for future optical video generation methods.
+
+
+
+ 11. 【2412.14148】MCMat: Multiview-Consistent and Physically Accurate PBR Material Generation
+ 链接:https://arxiv.org/abs/2412.14148
+ 作者:Shenhao Zhu,Lingteng Qiu,Xiaodong Gu,Zhengyi Zhao,Chao Xu,Yuxiao He,Zhe Li,Xiaoguang Han,Yao Yao,Xun Cao,Siyu Zhu,Weihao Yuan,Zilong Dong,Hao Zhu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:multi-view physically-based rendering, utilize UNet-based diffusion, encountering generalization issues, generalization issues due, methods utilize UNet-based
+ 备注: Project Page: [this https URL](https://lingtengqiu.github.io/2024/MCMat/)
+
+ 点击查看摘要
+ Abstract:Existing 2D methods utilize UNet-based diffusion models to generate multi-view physically-based rendering (PBR) maps but struggle with multi-view inconsistency, while some 3D methods directly generate UV maps, encountering generalization issues due to the limited 3D data. To address these problems, we propose a two-stage approach, including multi-view generation and UV materials refinement. In the generation stage, we adopt a Diffusion Transformer (DiT) model to generate PBR materials, where both the specially designed multi-branch DiT and reference-based DiT blocks adopt a global attention mechanism to promote feature interaction and fusion between different views, thereby improving multi-view consistency. In addition, we adopt a PBR-based diffusion loss to ensure that the generated materials align with realistic physical principles. In the refinement stage, we propose a material-refined DiT that performs inpainting in empty areas and enhances details in UV space. Except for the normal condition, this refinement also takes the material map from the generation stage as an additional condition to reduce the learning difficulty and improve generalization. Extensive experiments show that our method achieves state-of-the-art performance in texturing 3D objects with PBR materials and provides significant advantages for graphics relighting applications. Project Page: this https URL
+
+
+
+ 12. 【2412.14145】Incorporating Feature Pyramid Tokenization and Open Vocabulary Semantic Segmentation
+ 链接:https://arxiv.org/abs/2412.14145
+ 作者:Jianyu Zhang,Li Zhang,Shijian Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Open Vocabulary semantic, Vocabulary semantic segmentation, semantic, Vocabulary semantic, Open Vocabulary
+ 备注: 6 pages, 6 figures
+
+ 点击查看摘要
+ Abstract:The visual understanding are often approached from 3 granular levels: image, patch and pixel. Visual Tokenization, trained by self-supervised reconstructive learning, compresses visual data by codebook in patch-level with marginal information loss, but the visual tokens does not have semantic meaning. Open Vocabulary semantic segmentation benefits from the evolving Vision-Language models (VLMs) with strong image zero-shot capability, but transferring image-level to pixel-level understanding remains an imminent challenge. In this paper, we treat segmentation as tokenizing pixels and study a united perceptual and semantic token compression for all granular understanding and consequently facilitate open vocabulary semantic segmentation. Referring to the cognitive process of pretrained VLM where the low-level features are progressively composed to high-level semantics, we propose Feature Pyramid Tokenization (PAT) to cluster and represent multi-resolution feature by learnable codebooks and then decode them by joint learning pixel reconstruction and semantic segmentation. We design loosely coupled pixel and semantic learning branches. The pixel branch simulates bottom-up composition and top-down visualization of codebook tokens, while the semantic branch collectively fuse hierarchical codebooks as auxiliary segmentation guidance. Our experiments show that PAT enhances the semantic intuition of VLM feature pyramid, improves performance over the baseline segmentation model and achieves competitive performance on open vocabulary semantic segmentation benchmark. Our model is parameter-efficient for VLM integration and flexible for the independent tokenization. We hope to give inspiration not only on improving segmentation but also on semantic visual token utilization.
+
+
+
+ 13. 【2412.14123】AnySat: An Earth Observation Model for Any Resolutions, Scales, and Modalities
+ 链接:https://arxiv.org/abs/2412.14123
+ 作者:Guillaume Astruc,Nicolas Gonthier,Clement Mallet,Loic Landrieu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Earth observation data, diversity of Earth, Earth observation, terms of resolutions, Geospatial models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Geospatial models must adapt to the diversity of Earth observation data in terms of resolutions, scales, and modalities. However, existing approaches expect fixed input configurations, which limits their practical applicability. We propose AnySat, a multimodal model based on joint embedding predictive architecture (JEPA) and resolution-adaptive spatial encoders, allowing us to train a single model on highly heterogeneous data in a self-supervised manner. To demonstrate the advantages of this unified approach, we compile GeoPlex, a collection of $5$ multimodal datasets with varying characteristics and $11$ distinct sensors. We then train a single powerful model on these diverse datasets simultaneously. Once fine-tuned, we achieve better or near state-of-the-art results on the datasets of GeoPlex and $4$ additional ones for $5$ environment monitoring tasks: land cover mapping, tree species identification, crop type classification, change detection, and flood segmentation. The code and models are available at this https URL.
+
+
+
+ 14. 【2412.14118】GaraMoSt: Parallel Multi-Granularity Motion and Structural Modeling for Efficient Multi-Frame Interpolation in DSA Images
+ 链接:https://arxiv.org/abs/2412.14118
+ 作者:Ziyang Xu,Huangxuan Zhao,Wenyu Liu,Xinggang Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Digital Subtraction Angiography, Subtraction Angiography, Digital Subtraction, accurate direct multi-frame, direct multi-frame interpolation
+ 备注: Accepted by AAAI2025
+
+ 点击查看摘要
+ Abstract:The rapid and accurate direct multi-frame interpolation method for Digital Subtraction Angiography (DSA) images is crucial for reducing radiation and providing real-time assistance to physicians for precise diagnostics and treatment. DSA images contain complex vascular structures and various motions. Applying natural scene Video Frame Interpolation (VFI) methods results in motion artifacts, structural dissipation, and blurriness. Recently, MoSt-DSA has specifically addressed these issues for the first time and achieved SOTA results. However, MoSt-DSA's focus on real-time performance leads to insufficient suppression of high-frequency noise and incomplete filtering of low-frequency noise in the generated images. To address these issues within the same computational time scale, we propose GaraMoSt. Specifically, we optimize the network pipeline with a parallel design and propose a module named MG-MSFE. MG-MSFE extracts frame-relative motion and structural features at various granularities in a fully convolutional parallel manner and supports independent, flexible adjustment of context-aware granularity at different scales, thus enhancing computational efficiency and accuracy. Extensive experiments demonstrate that GaraMoSt achieves the SOTA performance in accuracy, robustness, visual effects, and noise suppression, comprehensively surpassing MoSt-DSA and other natural scene VFI methods. The code and models are available at this https URL.
+
+
+
+ 15. 【2412.14111】Event-based Photometric Bundle Adjustment
+ 链接:https://arxiv.org/abs/2412.14111
+ 作者:Shuang Guo,Guillermo Gallego
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO); Signal Processing (eess.SP); Optimization and Control (math.OC)
+ 关键词:purely rotating event, Photometric Bundle Adjustment, rotating event camera, bundle adjustment, simultaneous refinement
+ 备注: 21 pages, 19 figures, 10 tables. Project page: [this https URL](https://github.com/tub-rip/epba)
+
+ 点击查看摘要
+ Abstract:We tackle the problem of bundle adjustment (i.e., simultaneous refinement of camera poses and scene map) for a purely rotating event camera. Starting from first principles, we formulate the problem as a classical non-linear least squares optimization. The photometric error is defined using the event generation model directly in the camera rotations and the semi-dense scene brightness that triggers the events. We leverage the sparsity of event data to design a tractable Levenberg-Marquardt solver that handles the very large number of variables involved. To the best of our knowledge, our method, which we call Event-based Photometric Bundle Adjustment (EPBA), is the first event-only photometric bundle adjustment method that works on the brightness map directly and exploits the space-time characteristics of event data, without having to convert events into image-like representations. Comprehensive experiments on both synthetic and real-world datasets demonstrate EPBA's effectiveness in decreasing the photometric error (by up to 90%), yielding results of unparalleled quality. The refined maps reveal details that were hidden using prior state-of-the-art rotation-only estimation methods. The experiments on modern high-resolution event cameras show the applicability of EPBA to panoramic imaging in various scenarios (without map initialization, at multiple resolutions, and in combination with other methods, such as IMU dead reckoning or previous event-based rotation estimation methods). We make the source code publicly available. this https URL
+
+
+
+ 16. 【2412.14103】Foundation Models Meet Low-Cost Sensors: Test-Time Adaptation for Rescaling Disparity for Zero-Shot Metric Depth Estimation
+ 链接:https://arxiv.org/abs/2412.14103
+ 作者:Rémi Marsal,Alexandre Chapoutot,Philippe Xu,David Filliat
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:zero-shot monocular depth, monocular depth estimation, monocular depth, zero-shot monocular, depth estimation
+ 备注:
+
+ 点击查看摘要
+ Abstract:The recent development of foundation models for monocular depth estimation such as Depth Anything paved the way to zero-shot monocular depth estimation. Since it returns an affine-invariant disparity map, the favored technique to recover the metric depth consists in fine-tuning the model. However, this stage is costly to perform because of the training but also due to the creation of the dataset. It must contain images captured by the camera that will be used at test time and the corresponding ground truth. Moreover, the fine-tuning may also degrade the generalizing capacity of the original model. Instead, we propose in this paper a new method to rescale Depth Anything predictions using 3D points provided by low-cost sensors or techniques such as low-resolution LiDAR, stereo camera, structure-from-motion where poses are given by an IMU. Thus, this approach avoids fine-tuning and preserves the generalizing power of the original depth estimation model while being robust to the noise of the sensor or of the depth model. Our experiments highlight improvements relative to other metric depth estimation methods and competitive results compared to fine-tuned approaches. Code available at this https URL.
+
+
+
+ 17. 【2412.14097】Adaptive Concept Bottleneck for Foundation Models Under Distribution Shifts
+ 链接:https://arxiv.org/abs/2412.14097
+ 作者:Jihye Choi,Jayaram Raghuram,Yixuan Li,Somesh Jha
+ 类目:Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:machine learning, Concept Bottleneck Models, non-interpretable foundation models, foundation models, Advancements in foundation
+ 备注: The preliminary version of the work appeared in the ICML 2024 Workshop on Foundation Models in the Wild
+
+ 点击查看摘要
+ Abstract:Advancements in foundation models (FMs) have led to a paradigm shift in machine learning. The rich, expressive feature representations from these pre-trained, large-scale FMs are leveraged for multiple downstream tasks, usually via lightweight fine-tuning of a shallow fully-connected network following the representation. However, the non-interpretable, black-box nature of this prediction pipeline can be a challenge, especially in critical domains such as healthcare, finance, and security. In this paper, we explore the potential of Concept Bottleneck Models (CBMs) for transforming complex, non-interpretable foundation models into interpretable decision-making pipelines using high-level concept vectors. Specifically, we focus on the test-time deployment of such an interpretable CBM pipeline "in the wild", where the input distribution often shifts from the original training distribution. We first identify the potential failure modes of such a pipeline under different types of distribution shifts. Then we propose an adaptive concept bottleneck framework to address these failure modes, that dynamically adapts the concept-vector bank and the prediction layer based solely on unlabeled data from the target domain, without access to the source (training) dataset. Empirical evaluations with various real-world distribution shifts show that our adaptation method produces concept-based interpretations better aligned with the test data and boosts post-deployment accuracy by up to 28%, aligning the CBM performance with that of non-interpretable classification.
+
+
+
+ 18. 【2412.14088】Joint Perception and Prediction for Autonomous Driving: A Survey
+ 链接:https://arxiv.org/abs/2412.14088
+ 作者:Lucas Dal'Col,Miguel Oliveira,Vítor Santos
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Robotics (cs.RO)
+ 关键词:enabling vehicles, critical components, vehicles to navigate, navigate safely, safely through complex
+ 备注: 24 pages, 5 sections, 7 figures, 7 tables. This work has been submitted to the IEEE Transactions on Intelligent Transportation Systems for possible publication
+
+ 点击查看摘要
+ Abstract:Perception and prediction modules are critical components of autonomous driving systems, enabling vehicles to navigate safely through complex environments. The perception module is responsible for perceiving the environment, including static and dynamic objects, while the prediction module is responsible for predicting the future behavior of these objects. These modules are typically divided into three tasks: object detection, object tracking, and motion prediction. Traditionally, these tasks are developed and optimized independently, with outputs passed sequentially from one to the next. However, this approach has significant limitations: computational resources are not shared across tasks, the lack of joint optimization can amplify errors as they propagate throughout the pipeline, and uncertainty is rarely propagated between modules, resulting in significant information loss. To address these challenges, the joint perception and prediction paradigm has emerged, integrating perception and prediction into a unified model through multi-task learning. This strategy not only overcomes the limitations of previous methods, but also enables the three tasks to have direct access to raw sensor data, allowing richer and more nuanced environmental interpretations. This paper presents the first comprehensive survey of joint perception and prediction for autonomous driving. We propose a taxonomy that categorizes approaches based on input representation, scene context modeling, and output representation, highlighting their contributions and limitations. Additionally, we present a qualitative analysis and quantitative comparison of existing methods. Finally, we discuss future research directions based on identified gaps in the state-of-the-art.
+
+
+
+ 19. 【2412.14058】owards Generalist Robot Policies: What Matters in Building Vision-Language-Action Models
+ 链接:https://arxiv.org/abs/2412.14058
+ 作者:Xinghang Li,Peiyan Li,Minghuan Liu,Dong Wang,Jirong Liu,Bingyi Kang,Xiao Ma,Tao Kong,Hanbo Zhang,Huaping Liu
+ 类目:Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Foundation Vision Language, Vision Language Models, Foundation Vision, Vision Language, exhibit strong capabilities
+ 备注: Project page: [this http URL](http://robovlms.github.io)
+
+ 点击查看摘要
+ Abstract:Foundation Vision Language Models (VLMs) exhibit strong capabilities in multi-modal representation learning, comprehension, and reasoning. By injecting action components into the VLMs, Vision-Language-Action Models (VLAs) can be naturally formed and also show promising performance. Existing work has demonstrated the effectiveness and generalization of VLAs in multiple scenarios and tasks. Nevertheless, the transfer from VLMs to VLAs is not trivial since existing VLAs differ in their backbones, action-prediction formulations, data distributions, and training recipes. This leads to a missing piece for a systematic understanding of the design choices of VLAs. In this work, we disclose the key factors that significantly influence the performance of VLA and focus on answering three essential design choices: which backbone to select, how to formulate the VLA architectures, and when to add cross-embodiment data. The obtained results convince us firmly to explain why we need VLA and develop a new family of VLAs, RoboVLMs, which require very few manual designs and achieve a new state-of-the-art performance in three simulation tasks and real-world experiments. Through our extensive experiments, which include over 8 VLM backbones, 4 policy architectures, and over 600 distinct designed experiments, we provide a detailed guidebook for the future design of VLAs. In addition to the study, the highly flexible RoboVLMs framework, which supports easy integrations of new VLMs and free combinations of various design choices, is made public to facilitate future research. We open-source all details, including codes, models, datasets, and toolkits, along with detailed training and evaluation recipes at: this http URL.
+
+
+
+ 20. 【2412.14056】A Review of Multimodal Explainable Artificial Intelligence: Past, Present and Future
+ 链接:https://arxiv.org/abs/2412.14056
+ 作者:Shilin Sun,Wenbin An,Feng Tian,Fang Nan,Qidong Liu,Jun Liu,Nazaraf Shah,Ping Chen
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG); Multimedia (cs.MM)
+ 关键词:Artificial intelligence, rapidly developed, developed through advancements, advancements in computational, computational power
+ 备注: This work has been submitted to the IEEE for possible publication
+
+ 点击查看摘要
+ Abstract:Artificial intelligence (AI) has rapidly developed through advancements in computational power and the growth of massive datasets. However, this progress has also heightened challenges in interpreting the "black-box" nature of AI models. To address these concerns, eXplainable AI (XAI) has emerged with a focus on transparency and interpretability to enhance human understanding and trust in AI decision-making processes. In the context of multimodal data fusion and complex reasoning scenarios, the proposal of Multimodal eXplainable AI (MXAI) integrates multiple modalities for prediction and explanation tasks. Meanwhile, the advent of Large Language Models (LLMs) has led to remarkable breakthroughs in natural language processing, yet their complexity has further exacerbated the issue of MXAI. To gain key insights into the development of MXAI methods and provide crucial guidance for building more transparent, fair, and trustworthy AI systems, we review the MXAI methods from a historical perspective and categorize them across four eras: traditional machine learning, deep learning, discriminative foundation models, and generative LLMs. We also review evaluation metrics and datasets used in MXAI research, concluding with a discussion of future challenges and directions. A project related to this review has been created at this https URL.
+
+
+
+ 21. 【2412.14042】CAD-Recode: Reverse Engineering CAD Code from Point Clouds
+ 链接:https://arxiv.org/abs/2412.14042
+ 作者:Danila Rukhovich,Elona Dupont,Dimitrios Mallis,Kseniya Cherenkova,Anis Kacem,Djamila Aouada
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:sequentially drawing parametric, drawing parametric sketches, applying CAD operations, CAD, Python code
+ 备注:
+
+ 点击查看摘要
+ Abstract:Computer-Aided Design (CAD) models are typically constructed by sequentially drawing parametric sketches and applying CAD operations to obtain a 3D model. The problem of 3D CAD reverse engineering consists of reconstructing the sketch and CAD operation sequences from 3D representations such as point clouds. In this paper, we address this challenge through novel contributions across three levels: CAD sequence representation, network design, and dataset. In particular, we represent CAD sketch-extrude sequences as Python code. The proposed CAD-Recode translates a point cloud into Python code that, when executed, reconstructs the CAD model. Taking advantage of the exposure of pre-trained Large Language Models (LLMs) to Python code, we leverage a relatively small LLM as a decoder for CAD-Recode and combine it with a lightweight point cloud projector. CAD-Recode is trained solely on a proposed synthetic dataset of one million diverse CAD sequences. CAD-Recode significantly outperforms existing methods across three datasets while requiring fewer input points. Notably, it achieves 10 times lower mean Chamfer distance than state-of-the-art methods on DeepCAD and Fusion360 datasets. Furthermore, we show that our CAD Python code output is interpretable by off-the-shelf LLMs, enabling CAD editing and CAD-specific question answering from point clouds.
+
+
+
+ 22. 【2412.14018】SurgSora: Decoupled RGBD-Flow Diffusion Model for Controllable Surgical Video Generation
+ 链接:https://arxiv.org/abs/2412.14018
+ 作者:Tong Chen,Shuya Yang,Junyi Wang,Long Bai,Hongliang Ren,Luping Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Multimedia (cs.MM); Robotics (cs.RO)
+ 关键词:controllable visual representations, surgical video generation, video generation, enhancing surgical understanding, visual representations
+ 备注:
+
+ 点击查看摘要
+ Abstract:Medical video generation has transformative potential for enhancing surgical understanding and pathology insights through precise and controllable visual representations. However, current models face limitations in controllability and authenticity. To bridge this gap, we propose SurgSora, a motion-controllable surgical video generation framework that uses a single input frame and user-controllable motion cues. SurgSora consists of three key modules: the Dual Semantic Injector (DSI), which extracts object-relevant RGB and depth features from the input frame and integrates them with segmentation cues to capture detailed spatial features of complex anatomical structures; the Decoupled Flow Mapper (DFM), which fuses optical flow with semantic-RGB-D features at multiple scales to enhance temporal understanding and object spatial dynamics; and the Trajectory Controller (TC), which allows users to specify motion directions and estimates sparse optical flow, guiding the video generation process. The fused features are used as conditions for a frozen Stable Diffusion model to produce realistic, temporally coherent surgical videos. Extensive evaluations demonstrate that SurgSora outperforms state-of-the-art methods in controllability and authenticity, showing its potential to advance surgical video generation for medical education, training, and research.
+
+
+
+ 23. 【2412.14015】Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation
+ 链接:https://arxiv.org/abs/2412.14015
+ 作者:Haotong Lin,Sida Peng,Jingxiao Chen,Songyou Peng,Jiaming Sun,Minghuan Liu,Hujun Bao,Jiashi Feng,Xiaowei Zhou,Bingyi Kang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:vision foundation models, depth foundation models, specific tasks, foundation models, play a critical
+ 备注: Project page: [this https URL](https://PromptDA.github.io/)
+
+ 点击查看摘要
+ Abstract:Prompts play a critical role in unleashing the power of language and vision foundation models for specific tasks. For the first time, we introduce prompting into depth foundation models, creating a new paradigm for metric depth estimation termed Prompt Depth Anything. Specifically, we use a low-cost LiDAR as the prompt to guide the Depth Anything model for accurate metric depth output, achieving up to 4K resolution. Our approach centers on a concise prompt fusion design that integrates the LiDAR at multiple scales within the depth decoder. To address training challenges posed by limited datasets containing both LiDAR depth and precise GT depth, we propose a scalable data pipeline that includes synthetic data LiDAR simulation and real data pseudo GT depth generation. Our approach sets new state-of-the-arts on the ARKitScenes and ScanNet++ datasets and benefits downstream applications, including 3D reconstruction and generalized robotic grasping.
+
+
+
+ 24. 【2412.14006】InstructSeg: Unifying Instructed Visual Segmentation with Multi-modal Large Language Models
+ 链接:https://arxiv.org/abs/2412.14006
+ 作者:Cong Wei,Yujie Zhong,Haoxian Tan,Yingsen Zeng,Yong Liu,Zheng Zhao,Yujiu Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Multi-modal Large Language, Large Language Models, Boosted by Multi-modal, Multi-modal Large, Large Language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Boosted by Multi-modal Large Language Models (MLLMs), text-guided universal segmentation models for the image and video domains have made rapid progress recently. However, these methods are often developed separately for specific domains, overlooking the similarities in task settings and solutions across these two areas. In this paper, we define the union of referring segmentation and reasoning segmentation at both the image and video levels as Instructed Visual Segmentation (IVS). Correspondingly, we propose InstructSeg, an end-to-end segmentation pipeline equipped with MLLMs for IVS. Specifically, we employ an object-aware video perceiver to extract temporal and object information from reference frames, facilitating comprehensive video understanding. Additionally, we introduce vision-guided multi-granularity text fusion to better integrate global and detailed text information with fine-grained visual guidance. By leveraging multi-task and end-to-end training, InstructSeg demonstrates superior performance across diverse image and video segmentation tasks, surpassing both segmentation specialists and MLLM-based methods with a single model. Our code is available at this https URL.
+
+
+
+ 25. 【2412.14005】Real-Time Position-Aware View Synthesis from Single-View Input
+ 链接:https://arxiv.org/abs/2412.14005
+ 作者:Manu Gond,Emin Zerman,Sebastian Knorr,Mårten Sjöström
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR); Multimedia (cs.MM)
+ 关键词:significantly enhanced immersive, enhanced immersive experiences, Recent advancements, view synthesis, including telepresence
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent advancements in view synthesis have significantly enhanced immersive experiences across various computer graphics and multimedia applications, including telepresence, and entertainment. By enabling the generation of new perspectives from a single input view, view synthesis allows users to better perceive and interact with their environment. However, many state-of-the-art methods, while achieving high visual quality, face limitations in real-time performance, which makes them less suitable for live applications where low latency is critical. In this paper, we present a lightweight, position-aware network designed for real-time view synthesis from a single input image and a target camera pose. The proposed framework consists of a Position Aware Embedding, modeled with a multi-layer perceptron, which efficiently maps positional information from the target pose to generate high dimensional feature maps. These feature maps, along with the input image, are fed into a Rendering Network that merges features from dual encoder branches to resolve both high level semantics and low level details, producing a realistic new view of the scene. Experimental results demonstrate that our method achieves superior efficiency and visual quality compared to existing approaches, particularly in handling complex translational movements without explicit geometric operations like warping. This work marks a step toward enabling real-time view synthesis from a single image for live and interactive applications.
+
+
+
+ 26. 【2412.13983】GraphAvatar: Compact Head Avatars with GNN-Generated 3D Gaussians
+ 链接:https://arxiv.org/abs/2412.13983
+ 作者:Xiaobao Wei,Peng Chen,Ming Lu,Hui Chen,Feng Tian
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Neural Radiance Fields, Graph Neural Networks, Rendering photorealistic head, photorealistic head avatars, virtual reality
+ 备注: accepted by AAAI2025
+
+ 点击查看摘要
+ Abstract:Rendering photorealistic head avatars from arbitrary viewpoints is crucial for various applications like virtual reality. Although previous methods based on Neural Radiance Fields (NeRF) can achieve impressive results, they lack fidelity and efficiency. Recent methods using 3D Gaussian Splatting (3DGS) have improved rendering quality and real-time performance but still require significant storage overhead. In this paper, we introduce a method called GraphAvatar that utilizes Graph Neural Networks (GNN) to generate 3D Gaussians for the head avatar. Specifically, GraphAvatar trains a geometric GNN and an appearance GNN to generate the attributes of the 3D Gaussians from the tracked mesh. Therefore, our method can store the GNN models instead of the 3D Gaussians, significantly reducing the storage overhead to just 10MB. To reduce the impact of face-tracking errors, we also present a novel graph-guided optimization module to refine face-tracking parameters during training. Finally, we introduce a 3D-aware enhancer for post-processing to enhance the rendering quality. We conduct comprehensive experiments to demonstrate the advantages of GraphAvatar, surpassing existing methods in visual fidelity and storage consumption. The ablation study sheds light on the trade-offs between rendering quality and model size. The code will be released at: this https URL
+
+
+
+ 27. 【2412.13949】Cracking the Code of Hallucination in LVLMs with Vision-aware Head Divergence
+ 链接:https://arxiv.org/abs/2412.13949
+ 作者:Jinghan He,Kuan Zhu,Haiyun Guo,Junfeng Fang,Zhenglin Hua,Yuheng Jia,Ming Tang,Tat-Seng Chua,Jinqiao Wang
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:enabling advanced multimodal, advanced multimodal reasoning, made substantial progress, Large vision-language models, integrating large language
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large vision-language models (LVLMs) have made substantial progress in integrating large language models (LLMs) with visual inputs, enabling advanced multimodal reasoning. Despite their success, a persistent challenge is hallucination-where generated text fails to accurately reflect visual content-undermining both accuracy and reliability. Existing methods focus on alignment training or decoding refinements but primarily address symptoms at the generation stage without probing the underlying causes. In this work, we investigate the internal mechanisms driving hallucination in LVLMs, with an emphasis on the multi-head attention module. Specifically, we introduce Vision-aware Head Divergence (VHD), a metric that quantifies the sensitivity of attention head outputs to visual context. Based on this, our findings reveal the presence of vision-aware attention heads that are more attuned to visual information; however, the model's overreliance on its prior language patterns is closely related to hallucinations. Building on these insights, we propose Vision-aware Head Reinforcement (VHR), a training-free approach to mitigate hallucination by enhancing the role of vision-aware attention heads. Extensive experiments demonstrate that our method achieves superior performance compared to state-of-the-art approaches in mitigating hallucinations, while maintaining high efficiency with negligible additional time overhead.
+
+
+
+ 28. 【2412.13947】Real Classification by Description: Extending CLIP's Limits of Part Attributes Recognition
+ 链接:https://arxiv.org/abs/2412.13947
+ 作者:Ethan Baron,Idan Tankel,Peter Tu,Guy Ben-Yosef
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:excluding object class, classify objects based, objects based solely, tackle zero shot, define and tackle
+ 备注:
+
+ 点击查看摘要
+ Abstract:In this study, we define and tackle zero shot "real" classification by description, a novel task that evaluates the ability of Vision-Language Models (VLMs) like CLIP to classify objects based solely on descriptive attributes, excluding object class names. This approach highlights the current limitations of VLMs in understanding intricate object descriptions, pushing these models beyond mere object recognition. To facilitate this exploration, we introduce a new challenge and release description data for six popular fine-grained benchmarks, which omit object names to encourage genuine zero-shot learning within the research community. Additionally, we propose a method to enhance CLIP's attribute detection capabilities through targeted training using ImageNet21k's diverse object categories, paired with rich attribute descriptions generated by large language models. Furthermore, we introduce a modified CLIP architecture that leverages multiple resolutions to improve the detection of fine-grained part attributes. Through these efforts, we broaden the understanding of part-attribute recognition in CLIP, improving its performance in fine-grained classification tasks across six popular benchmarks, as well as in the PACO dataset, a widely used benchmark for object-attribute recognition. Code is available at: this https URL.
+
+
+
+ 29. 【2412.13943】On Explaining Knowledge Distillation: Measuring and Visualising the Knowledge Transfer Process
+ 链接:https://arxiv.org/abs/2412.13943
+ 作者:Gereziher Adhane,Mohammad Mahdi Dehshibi,Dennis Vetter,David Masip,Gemma Roig
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:remains challenging due, knowledge transfer process, remains challenging, making it difficult, challenging due
+ 备注: Accepted to 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV'25). Includes 5 pages of supplementary material
+
+ 点击查看摘要
+ Abstract:Knowledge distillation (KD) remains challenging due to the opaque nature of the knowledge transfer process from a Teacher to a Student, making it difficult to address certain issues related to KD. To address this, we proposed UniCAM, a novel gradient-based visual explanation method, which effectively interprets the knowledge learned during KD. Our experimental results demonstrate that with the guidance of the Teacher's knowledge, the Student model becomes more efficient, learning more relevant features while discarding those that are not relevant. We refer to the features learned with the Teacher's guidance as distilled features and the features irrelevant to the task and ignored by the Student as residual features. Distilled features focus on key aspects of the input, such as textures and parts of objects. In contrast, residual features demonstrate more diffused attention, often targeting irrelevant areas, including the backgrounds of the target objects. In addition, we proposed two novel metrics: the feature similarity score (FSS) and the relevance score (RS), which quantify the relevance of the distilled knowledge. Experiments on the CIFAR10, ASIRRA, and Plant Disease datasets demonstrate that UniCAM and the two metrics offer valuable insights to explain the KD process.
+
+
+
+ 30. 【2412.13916】Retrieval Augmented Image Harmonization
+ 链接:https://arxiv.org/abs/2412.13916
+ 作者:Haolin Wang,Ming Liu,Zifei Yan,Chao Zhou,Longan Xiao,Wangmeng Zuo
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:image harmonization, perform image harmonization, foreground object coordinate, image, harmonization
+ 备注: 8 pages
+
+ 点击查看摘要
+ Abstract:When embedding objects (foreground) into images (background), considering the influence of photography conditions like illumination, it is usually necessary to perform image harmonization to make the foreground object coordinate with the background image in terms of brightness, color, and etc. Although existing image harmonization methods have made continuous efforts toward visually pleasing results, they are still plagued by two main issues. Firstly, the image harmonization becomes highly ill-posed when there are no contents similar to the foreground object in the background, making the harmonization results unreliable. Secondly, even when similar contents are available, the harmonization process is often interfered with by irrelevant areas, mainly attributed to an insufficient understanding of image contents and inaccurate attention. As a remedy, we present a retrieval-augmented image harmonization (Raiha) framework, which seeks proper reference images to reduce the ill-posedness and restricts the attention to better utilize the useful information. Specifically, an efficient retrieval method is designed to find reference images that contain similar objects as the foreground while the illumination is consistent with the background. For training the Raiha framework to effectively utilize the reference information, a data augmentation strategy is delicately designed by leveraging existing non-reference image harmonization datasets. Besides, the image content priors are introduced to ensure reasonable attention. With the presented Raiha framework, the image harmonization performance is greatly boosted under both non-reference and retrieval-augmented settings. The source code and pre-trained models will be publicly available.
+
+
+
+ 31. 【2412.13913】A Black-Box Evaluation Framework for Semantic Robustness in Bird's Eye View Detection
+ 链接:https://arxiv.org/abs/2412.13913
+ 作者:Fu Wang,Yanghao Zhang,Xiangyu Yin,Guangliang Cheng,Zeyu Fu,Xiaowei Huang,Wenjie Ruan
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Camera-based Bird Eye, Bird Eye View, receive increasing attention, Camera-based Bird, Eye View
+ 备注:
+
+ 点击查看摘要
+ Abstract:Camera-based Bird's Eye View (BEV) perception models receive increasing attention for their crucial role in autonomous driving, a domain where concerns about the robustness and reliability of deep learning have been raised. While only a few works have investigated the effects of randomly generated semantic perturbations, aka natural corruptions, on the multi-view BEV detection task, we develop a black-box robustness evaluation framework that adversarially optimises three common semantic perturbations: geometric transformation, colour shifting, and motion blur, to deceive BEV models, serving as the first approach in this emerging field. To address the challenge posed by optimising the semantic perturbation, we design a smoothed, distance-based surrogate function to replace the mAP metric and introduce SimpleDIRECT, a deterministic optimisation algorithm that utilises observed slopes to guide the optimisation process. By comparing with randomised perturbation and two optimisation baselines, we demonstrate the effectiveness of the proposed framework. Additionally, we provide a benchmark on the semantic robustness of ten recent BEV models. The results reveal that PolarFormer, which emphasises geometric information from multi-view images, exhibits the highest robustness, whereas BEVDet is fully compromised, with its precision reduced to zero.
+
+
+
+ 32. 【2412.13908】Memorizing SAM: 3D Medical Segment Anything Model with Memorizing Transformer
+ 链接:https://arxiv.org/abs/2412.13908
+ 作者:Xinyuan Shao,Yiqing Shen,Mathias Unberath
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Segment Anything Models, gained increasing attention, zero-shot generalization capability, image analysis due, medical image analysis
+ 备注:
+
+ 点击查看摘要
+ Abstract:Segment Anything Models (SAMs) have gained increasing attention in medical image analysis due to their zero-shot generalization capability in segmenting objects of unseen classes and domains when provided with appropriate user prompts. Addressing this performance gap is important to fully leverage the pre-trained weights of SAMs, particularly in the domain of volumetric medical image segmentation, where accuracy is important but well-annotated 3D medical data for fine-tuning is limited. In this work, we investigate whether introducing the memory mechanism as a plug-in, specifically the ability to memorize and recall internal representations of past inputs, can improve the performance of SAM with limited computation cost. To this end, we propose Memorizing SAM, a novel 3D SAM architecture incorporating a memory Transformer as a plug-in. Unlike conventional memorizing Transformers that save the internal representation during training or inference, our Memorizing SAM utilizes existing highly accurate internal representation as the memory source to ensure the quality of memory. We evaluate the performance of Memorizing SAM in 33 categories from the TotalSegmentator dataset, which indicates that Memorizing SAM can outperform state-of-the-art 3D SAM variant i.e., FastSAM3D with an average Dice increase of 11.36% at the cost of only 4.38 millisecond increase in inference time. The source code is publicly available at this https URL
+
+
+
+ 33. 【2412.13897】Data-Efficient Inference of Neural Fluid Fields via SciML Foundation Model
+ 链接:https://arxiv.org/abs/2412.13897
+ 作者:Yuqiu Liu,Jingxuan Xu,Mauricio Soroco,Yunchao Wei,Wuyang Chen
+ 类目:Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:enabled successful progress, Recent developments, foundation models, enabled successful, successful progress
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent developments in 3D vision have enabled successful progress in inferring neural fluid fields and realistic rendering of fluid dynamics. However, these methods require real-world flow captures, which demand dense video sequences and specialized lab setups, making the process costly and challenging. Scientific machine learning (SciML) foundation models, which are pretrained on extensive simulations of partial differential equations (PDEs), encode rich multiphysics knowledge and thus provide promising sources of domain priors for inferring fluid fields. Nevertheless, their potential to advance real-world vision problems remains largely underexplored, raising questions about the transferability and practical utility of these foundation models. In this work, we demonstrate that SciML foundation model can significantly improve the data efficiency of inferring real-world 3D fluid dynamics with improved generalization. At the core of our method is leveraging the strong forecasting capabilities and meaningful representations of SciML foundation models. We equip neural fluid fields with a novel collaborative training approach that utilizes augmented views and fluid features extracted by our foundation model. Our method demonstrates significant improvements in both quantitative metrics and visual quality, showcasing the practical applicability of SciML foundation models in real-world fluid dynamics.
+
+
+
+ 34. 【2412.13884】Navigating limitations with precision: A fine-grained ensemble approach to wrist pathology recognition on a limited x-ray dataset
+ 链接:https://arxiv.org/abs/2412.13884
+ 作者:Ammar Ahmed,Ali Shariq Imran,Mohib Ullah,Zenun Kastrati,Sher Muhammad Daudpota
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:gained considerable research, considerable research attention, recent years, exploration of automated, gained considerable
+ 备注:
+
+ 点击查看摘要
+ Abstract:The exploration of automated wrist fracture recognition has gained considerable research attention in recent years. In practical medical scenarios, physicians and surgeons may lack the specialized expertise required for accurate X-ray interpretation, highlighting the need for machine vision to enhance diagnostic accuracy. However, conventional recognition techniques face challenges in discerning subtle differences in X-rays when classifying wrist pathologies, as many of these pathologies, such as fractures, can be small and hard to distinguish. This study tackles wrist pathology recognition as a fine-grained visual recognition (FGVR) problem, utilizing a limited, custom-curated dataset that mirrors real-world medical constraints, relying solely on image-level annotations. We introduce a specialized FGVR-based ensemble approach to identify discriminative regions within X-rays. We employ an Explainable AI (XAI) technique called Grad-CAM to pinpoint these regions. Our ensemble approach outperformed many conventional SOTA and FGVR techniques, underscoring the effectiveness of our strategy in enhancing accuracy in wrist pathology recognition.
+
+
+
+ 35. 【2412.13875】Denoising Nearest Neighbor Graph via Continuous CRF for Visual Re-ranking without Fine-tuning
+ 链接:https://arxiv.org/abs/2412.13875
+ 作者:Jaeyoon Kim,Yoonki Cho,Taeyong Kim,Sung-Eui Yoon
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Nearest Neighbor graph, Nearest Neighbor, Neighbor graph, high retrieval accuracy, Visual re-ranking
+ 备注:
+
+ 点击查看摘要
+ Abstract:Visual re-ranking using Nearest Neighbor graph~(NN graph) has been adapted to yield high retrieval accuracy, since it is beneficial to exploring an high-dimensional manifold and applicable without additional fine-tuning. The quality of visual re-ranking using NN graph, however, is limited to that of connectivity, i.e., edges of the NN graph. Some edges can be misconnected with negative images. This is known as a noisy edge problem, resulting in a degradation of the retrieval quality. To address this, we propose a complementary denoising method based on Continuous Conditional Random Field (C-CRF) that uses a statistical distance of our similarity-based distribution. This method employs the concept of cliques to make the process computationally feasible. We demonstrate the complementarity of our method through its application to three visual re-ranking methods, observing quality boosts in landmark retrieval and person re-identification (re-ID).
+
+
+
+ 36. 【2412.13871】LLaVA-UHD v2: an MLLM Integrating High-Resolution Feature Pyramid via Hierarchical Window Transformer
+ 链接:https://arxiv.org/abs/2412.13871
+ 作者:Yipeng Zhang,Yifan Liu,Zonghao Guo,Yidan Zhang,Xuesong Yang,Chi Chen,Jun Song,Bo Zheng,Yuan Yao,Zhiyuan Liu,Tat-Seng Chua,Maosong Sun
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:multimodal large language, multimodal large, widely employed, large language models, visual encoding
+ 备注:
+
+ 点击查看摘要
+ Abstract:In multimodal large language models (MLLMs), vision transformers (ViTs) are widely employed for visual encoding. However, their performance in solving universal MLLM tasks is not satisfactory. We attribute it to a lack of information from diverse visual levels, impeding alignment with the various semantic granularity required for language generation. To address this issue, we present LLaVA-UHD v2, an advanced MLLM centered around a Hierarchical window transformer that enables capturing diverse visual granularity by constructing and integrating a high-resolution feature pyramid. As a vision-language projector, Hiwin transformer comprises two primary modules: (i) an inverse feature pyramid, constructed by a ViT-derived feature up-sampling process utilizing high-frequency details from an image pyramid, and (ii) hierarchical window attention, focusing on a set of key sampling features within cross-scale windows to condense multi-level feature maps. Extensive experiments demonstrate that LLaVA-UHD v2 achieves superior performance over existing MLLMs on popular benchmarks. Notably, our design brings an average boost of 3.7% across 14 benchmarks compared with the baseline method, 9.3% on DocVQA for instance. We make all the data, model checkpoint, and code publicly available to facilitate future research.
+
+
+
+ 37. 【2412.13859】Zero-Shot Prompting and Few-Shot Fine-Tuning: Revisiting Document Image Classification Using Large Language Models
+ 链接:https://arxiv.org/abs/2412.13859
+ 作者:Anna Scius-Bertrand,Michael Jungo,Lars Vögtlin,Jean-Marc Spat,Andreas Fischer
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Classifying scanned documents, Classifying scanned, involves image, text analysis, training samples
+ 备注: ICPR 2024
+
+ 点击查看摘要
+ Abstract:Classifying scanned documents is a challenging problem that involves image, layout, and text analysis for document understanding. Nevertheless, for certain benchmark datasets, notably RVL-CDIP, the state of the art is closing in to near-perfect performance when considering hundreds of thousands of training samples. With the advent of large language models (LLMs), which are excellent few-shot learners, the question arises to what extent the document classification problem can be addressed with only a few training samples, or even none at all. In this paper, we investigate this question in the context of zero-shot prompting and few-shot model fine-tuning, with the aim of reducing the need for human-annotated training samples as much as possible.
+
+
+
+ 38. 【2412.13856】A Systematic Analysis of Input Modalities for Fracture Classification of the Paediatric Wrist
+ 链接:https://arxiv.org/abs/2412.13856
+ 作者:Ron Keuth,Maren Balks,Sebastian Tschauner,Ludger Tüshaus,Mattias Heinrich
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:cases treated annually, annually in Germany, distal forearm, children and adolescents, cases treated
+ 备注: Code available on [this https URL](https://github.com/multimodallearning/AO_Classification)
+
+ 点击查看摘要
+ Abstract:Fractures, particularly in the distal forearm, are among the most common injuries in children and adolescents, with approximately 800 000 cases treated annually in Germany. The AO/OTA system provides a structured fracture type classification, which serves as the foundation for treatment decisions. Although accurately classifying fractures can be challenging, current deep learning models have demonstrated performance comparable to that of experienced radiologists. While most existing approaches rely solely on radiographs, the potential impact of incorporating other additional modalities, such as automatic bone segmentation, fracture location, and radiology reports, remains underexplored. In this work, we systematically analyse the contribution of these three additional information types, finding that combining them with radiographs increases the AUROC from 91.71 to 93.25. Our code is available on GitHub.
+
+
+
+ 39. 【2412.13848】MobiFuse: A High-Precision On-device Depth Perception System with Multi-Data Fusion
+ 链接:https://arxiv.org/abs/2412.13848
+ 作者:Jinrui Zhang,Deyu Zhang,Tingting Long,Wenxin Chen,Ju Ren,Yunxin Liu,Yudong Zhao,Yaoxue Zhang,Youngki Lee
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:combines dual RGB, dual RGB, high-precision depth perception, depth perception system, Depth Error Indication
+ 备注:
+
+ 点击查看摘要
+ Abstract:We present MobiFuse, a high-precision depth perception system on mobile devices that combines dual RGB and Time-of-Flight (ToF) cameras. To achieve this, we leverage physical principles from various environmental factors to propose the Depth Error Indication (DEI) modality, characterizing the depth error of ToF and stereo-matching. Furthermore, we employ a progressive fusion strategy, merging geometric features from ToF and stereo depth maps with depth error features from the DEI modality to create precise depth maps. Additionally, we create a new ToF-Stereo depth dataset, RealToF, to train and validate our model. Our experiments demonstrate that MobiFuse excels over baselines by significantly reducing depth measurement errors by up to 77.7%. It also showcases strong generalization across diverse datasets and proves effectiveness in two downstream tasks: 3D reconstruction and 3D segmentation. The demo video of MobiFuse in real-life scenarios is available at the de-identified YouTube link(this https URL).
+
+
+
+ 40. 【2412.13845】Do Language Models Understand Time?
+ 链接:https://arxiv.org/abs/2412.13845
+ 作者:Xi Ding,Lei Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Large language models, computer vision applications, revolutionized video-based computer, video-based computer vision, Large language
+ 备注: Research report
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) have revolutionized video-based computer vision applications, including action recognition, anomaly detection, and video summarization. Videos inherently pose unique challenges, combining spatial complexity with temporal dynamics that are absent in static images or textual data. Current approaches to video understanding with LLMs often rely on pretrained video encoders to extract spatiotemporal features and text encoders to capture semantic meaning. These representations are integrated within LLM frameworks, enabling multimodal reasoning across diverse video tasks. However, the critical question persists: Can LLMs truly understand the concept of time, and how effectively can they reason about temporal relationships in videos? This work critically examines the role of LLMs in video processing, with a specific focus on their temporal reasoning capabilities. We identify key limitations in the interaction between LLMs and pretrained encoders, revealing gaps in their ability to model long-term dependencies and abstract temporal concepts such as causality and event progression. Furthermore, we analyze challenges posed by existing video datasets, including biases, lack of temporal annotations, and domain-specific limitations that constrain the temporal understanding of LLMs. To address these gaps, we explore promising future directions, including the co-evolution of LLMs and encoders, the development of enriched datasets with explicit temporal labels, and innovative architectures for integrating spatial, temporal, and semantic reasoning. By addressing these challenges, we aim to advance the temporal comprehension of LLMs, unlocking their full potential in video analysis and beyond.
+
+
+
+ 41. 【2412.13823】Prompt Categories Cluster for Weakly Supervised Semantic Segmentation
+ 链接:https://arxiv.org/abs/2412.13823
+ 作者:Wangyu Wu,Xianglin Qiu,Siqi Song,Xiaowei Huang,Fei Ma,Jimin Xiao
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Weakly Supervised Semantic, Supervised Semantic Segmentation, Weakly Supervised, leverages image-level labels, garnered significant attention
+ 备注:
+
+ 点击查看摘要
+ Abstract:Weakly Supervised Semantic Segmentation (WSSS), which leverages image-level labels, has garnered significant attention due to its cost-effectiveness. The previous methods mainly strengthen the inter-class differences to avoid class semantic ambiguity which may lead to erroneous activation. However, they overlook the positive function of some shared information between similar classes. Categories within the same cluster share some similar features. Allowing the model to recognize these features can further relieve the semantic ambiguity between these classes. To effectively identify and utilize this shared information, in this paper, we introduce a novel WSSS framework called Prompt Categories Clustering (PCC). Specifically, we explore the ability of Large Language Models (LLMs) to derive category clusters through prompts. These clusters effectively represent the intrinsic relationships between categories. By integrating this relational information into the training network, our model is able to better learn the hidden connections between categories. Experimental results demonstrate the effectiveness of our approach, showing its ability to enhance performance on the PASCAL VOC 2012 dataset and surpass existing state-of-the-art methods in WSSS.
+
+
+
+ 42. 【2412.13817】Nullu: Mitigating Object Hallucinations in Large Vision-Language Models via HalluSpace Projection
+ 链接:https://arxiv.org/abs/2412.13817
+ 作者:Le Yang,Ziwei Zheng,Boxu Chen,Zhengyu Zhao,Chenhao Lin,Chao Shen
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Recent studies, large vision-language models, object hallucinations, vision-language models, model weights based
+ 备注: Under review
+
+ 点击查看摘要
+ Abstract:Recent studies have shown that large vision-language models (LVLMs) often suffer from the issue of object hallucinations (OH). To mitigate this issue, we introduce an efficient method that edits the model weights based on an unsafe subspace, which we call HalluSpace in this paper. With truthful and hallucinated text prompts accompanying the visual content as inputs, the HalluSpace can be identified by extracting the hallucinated embedding features and removing the truthful representations in LVLMs. By orthogonalizing the model weights, input features will be projected into the Null space of the HalluSpace to reduce OH, based on which we name our method Nullu. We reveal that HalluSpaces generally contain statistical bias and unimodal priors of the large language models (LLMs) applied to build LVLMs, which have been shown as essential causes of OH in previous studies. Therefore, null space projection suppresses the LLMs' priors to filter out the hallucinated features, resulting in contextually accurate outputs. Experiments show that our method can effectively mitigate OH across different LVLM families without extra inference costs and also show strong performance in general LVLM benchmarks. Code is released at \url{this https URL}.
+
+
+
+ 43. 【2412.13815】Object Style Diffusion for Generalized Object Detection in Urban Scene
+ 链接:https://arxiv.org/abs/2412.13815
+ 作者:Hao Li,Xiangyuan Yang,Mengzhu Wang,Long Lan,Ke Liang,Xinwang Liu,Kenli Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:urban scene monitoring, computer vision, scene monitoring, critical task, task in computer
+ 备注:
+
+ 点击查看摘要
+ Abstract:Object detection is a critical task in computer vision, with applications in various domains such as autonomous driving and urban scene monitoring. However, deep learning-based approaches often demand large volumes of annotated data, which are costly and difficult to acquire, particularly in complex and unpredictable real-world environments. This dependency significantly hampers the generalization capability of existing object detection techniques. To address this issue, we introduce a novel single-domain object detection generalization method, named GoDiff, which leverages a pre-trained model to enhance generalization in unseen domains. Central to our approach is the Pseudo Target Data Generation (PTDG) module, which employs a latent diffusion model to generate pseudo-target domain data that preserves source domain characteristics while introducing stylistic variations. By integrating this pseudo data with source domain data, we diversify the training dataset. Furthermore, we introduce a cross-style instance normalization technique to blend style features from different domains generated by the PTDG module, thereby increasing the detector's robustness. Experimental results demonstrate that our method not only enhances the generalization ability of existing detectors but also functions as a plug-and-play enhancement for other single-domain generalization methods, achieving state-of-the-art performance in autonomous driving scenarios.
+
+
+
+ 44. 【2412.13810】CAD-Assistant: Tool-Augmented VLLMs as Generic CAD Task Solvers?
+ 链接:https://arxiv.org/abs/2412.13810
+ 作者:Dimitrios Mallis,Ahmet Serdar Karadeniz,Sebastian Cavada,Danila Rukhovich,Niki Foteinopoulou,Kseniya Cherenkova,Anis Kacem,Djamila Aouada
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Robotics (cs.RO)
+ 关键词:Large Language Model, general-purpose CAD agent, Python API, agent for AI-assisted, Language Model
+ 备注:
+
+ 点击查看摘要
+ Abstract:We propose CAD-Assistant, a general-purpose CAD agent for AI-assisted design. Our approach is based on a powerful Vision and Large Language Model (VLLM) as a planner and a tool-augmentation paradigm using CAD-specific modules. CAD-Assistant addresses multimodal user queries by generating actions that are iteratively executed on a Python interpreter equipped with the FreeCAD software, accessed via its Python API. Our framework is able to assess the impact of generated CAD commands on geometry and adapts subsequent actions based on the evolving state of the CAD design. We consider a wide range of CAD-specific tools including Python libraries, modules of the FreeCAD Python API, helpful routines, rendering functions and other specialized modules. We evaluate our method on multiple CAD benchmarks and qualitatively demonstrate the potential of tool-augmented VLLMs as generic CAD task solvers across diverse CAD workflows.
+
+
+
+ 45. 【2412.13803】M$^3$-VOS: Multi-Phase, Multi-Transition, and Multi-Scenery Video Object Segmentation
+ 链接:https://arxiv.org/abs/2412.13803
+ 作者:Zixuan Chen,Jiaxin Li,Liming Tan,Yejie Guo,Junxuan Liang,Cewu Lu,Yonglu Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Intelligent robots, interact with diverse, Intelligent, phase transitions, objects
+ 备注: 18 pages, 12 figures
+
+ 点击查看摘要
+ Abstract:Intelligent robots need to interact with diverse objects across various environments. The appearance and state of objects frequently undergo complex transformations depending on the object properties, e.g., phase transitions. However, in the vision community, segmenting dynamic objects with phase transitions is overlooked. In light of this, we introduce the concept of phase in segmentation, which categorizes real-world objects based on their visual characteristics and potential morphological and appearance changes. Then, we present a new benchmark, Multi-Phase, Multi-Transition, and Multi-Scenery Video Object Segmentation (M3-VOS), to verify the ability of models to understand object phases, which consists of 479 high-resolution videos spanning over 10 distinct everyday scenarios. It provides dense instance mask annotations that capture both object phases and their transitions. We evaluate state-of-the-art methods on M3-VOS, yielding several key insights. Notably, current appearance based approaches show significant room for improvement when handling objects with phase transitions. The inherent changes in disorder suggest that the predictive performance of the forward entropy-increasing process can be improved through a reverse entropy-reducing process. These findings lead us to propose ReVOS, a new plug-and-play model that improves its performance by reversal refinement. Our data and code will be publicly available
+
+
+
+ 46. 【2412.13772】An Efficient Occupancy World Model via Decoupled Dynamic Flow and Image-assisted Training
+ 链接:https://arxiv.org/abs/2412.13772
+ 作者:Haiming Zhang,Ying Xue,Xu Yan,Jiacheng Zhang,Weichao Qiu,Dongfeng Bai,Bingbing Liu,Shuguang Cui,Zhen Li
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:predict potential future, potential future scenarios, future scenarios based, field of autonomous, autonomous driving
+ 备注:
+
+ 点击查看摘要
+ Abstract:The field of autonomous driving is experiencing a surge of interest in world models, which aim to predict potential future scenarios based on historical observations. In this paper, we introduce DFIT-OccWorld, an efficient 3D occupancy world model that leverages decoupled dynamic flow and image-assisted training strategy, substantially improving 4D scene forecasting performance. To simplify the training process, we discard the previous two-stage training strategy and innovatively reformulate the occupancy forecasting problem as a decoupled voxels warping process. Our model forecasts future dynamic voxels by warping existing observations using voxel flow, whereas static voxels are easily obtained through pose transformation. Moreover, our method incorporates an image-assisted training paradigm to enhance prediction reliability. Specifically, differentiable volume rendering is adopted to generate rendered depth maps through predicted future volumes, which are adopted in render-based photometric consistency. Experiments demonstrate the effectiveness of our approach, showcasing its state-of-the-art performance on the nuScenes and OpenScene benchmarks for 4D occupancy forecasting, end-to-end motion planning and point cloud forecasting. Concretely, it achieves state-of-the-art performances compared to existing 3D world models while incurring substantially lower computational costs.
+
+
+
+ 47. 【2412.13753】Mesoscopic Insights: Orchestrating Multi-scale Hybrid Architecture for Image Manipulation Localization
+ 链接:https://arxiv.org/abs/2412.13753
+ 作者:Xuekang Zhu,Xiaochen Ma,Lei Su,Zhuohang Jiang,Bo Du,Xiwen Wang,Zeyu Lei,Wentao Feng,Chi-Man Pun,Jizhe Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:addressing gaps overlooked, addressing gaps, gaps overlooked, mesoscopic level serves, IML
+ 备注: AAAI 2025. Code: $\href{ [this https URL](https://github.com/scu-zjz/Mesorch) }{this~url}$
+
+ 点击查看摘要
+ Abstract:The mesoscopic level serves as a bridge between the macroscopic and microscopic worlds, addressing gaps overlooked by both. Image manipulation localization (IML), a crucial technique to pursue truth from fake images, has long relied on low-level (microscopic-level) traces. However, in practice, most tampering aims to deceive the audience by altering image semantics. As a result, manipulation commonly occurs at the object level (macroscopic level), which is equally important as microscopic traces. Therefore, integrating these two levels into the mesoscopic level presents a new perspective for IML research. Inspired by this, our paper explores how to simultaneously construct mesoscopic representations of micro and macro information for IML and introduces the Mesorch architecture to orchestrate both. Specifically, this architecture i) combines Transformers and CNNs in parallel, with Transformers extracting macro information and CNNs capturing micro details, and ii) explores across different scales, assessing micro and macro information seamlessly. Additionally, based on the Mesorch architecture, the paper introduces two baseline models aimed at solving IML tasks through mesoscopic representation. Extensive experiments across four datasets have demonstrated that our models surpass the current state-of-the-art in terms of performance, computational complexity, and robustness.
+
+
+
+ 48. 【2412.13749】Multi-Exposure Image Fusion via Distilled 3D LUT Grid with Editable Mode
+ 链接:https://arxiv.org/abs/2412.13749
+ 作者:Xin Su,Zhuoran Zheng
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:high dynamic range, rising imaging resolution, dynamic range image, fusion algorithms struggle, existing multi-exposure image
+ 备注:
+
+ 点击查看摘要
+ Abstract:With the rising imaging resolution of handheld devices, existing multi-exposure image fusion algorithms struggle to generate a high dynamic range image with ultra-high resolution in real-time. Apart from that, there is a trend to design a manageable and editable algorithm as the different needs of real application scenarios. To tackle these issues, we introduce 3D LUT technology, which can enhance images with ultra-high-definition (UHD) resolution in real time on resource-constrained devices. However, since the fusion of information from multiple images with different exposure rates is uncertain, and this uncertainty significantly trials the generalization power of the 3D LUT grid. To address this issue and ensure a robust learning space for the model, we propose using a teacher-student network to model the uncertainty on the 3D LUT this http URL, we provide an editable mode for the multi-exposure image fusion algorithm by using the implicit representation function to match the requirements in different scenarios. Extensive experiments demonstrate that our proposed method is highly competitive in efficiency and accuracy.
+
+
+
+ 49. 【2412.13742】Learnable Prompting SAM-induced Knowledge Distillation for Semi-supervised Medical Image Segmentation
+ 链接:https://arxiv.org/abs/2412.13742
+ 作者:Kaiwen Huang,Tao Zhou,Huazhu Fu,Yizhe Zhang,Yi Zhou,Chen Gong,Dong Liang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:medical image segmentation, medical image, image segmentation, segmentation, limited availability
+ 备注: 12 pages, 7 figures
+
+ 点击查看摘要
+ Abstract:The limited availability of labeled data has driven advancements in semi-supervised learning for medical image segmentation. Modern large-scale models tailored for general segmentation, such as the Segment Anything Model (SAM), have revealed robust generalization capabilities. However, applying these models directly to medical image segmentation still exposes performance degradation. In this paper, we propose a learnable prompting SAM-induced Knowledge distillation framework (KnowSAM) for semi-supervised medical image segmentation. Firstly, we propose a Multi-view Co-training (MC) strategy that employs two distinct sub-networks to employ a co-teaching paradigm, resulting in more robust outcomes. Secondly, we present a Learnable Prompt Strategy (LPS) to dynamically produce dense prompts and integrate an adapter to fine-tune SAM specifically for medical image segmentation tasks. Moreover, we propose SAM-induced Knowledge Distillation (SKD) to transfer useful knowledge from SAM to two sub-networks, enabling them to learn from SAM's predictions and alleviate the effects of incorrect pseudo-labels during training. Notably, the predictions generated by our subnets are used to produce mask prompts for SAM, facilitating effective inter-module information exchange. Extensive experimental results on various medical segmentation tasks demonstrate that our model outperforms the state-of-the-art semi-supervised segmentation approaches. Crucially, our SAM distillation framework can be seamlessly integrated into other semi-supervised segmentation methods to enhance performance. The code will be released upon acceptance of this manuscript at: this https URL
+
+
+
+ 50. 【2412.13736】MedCoT: Medical Chain of Thought via Hierarchical Expert
+ 链接:https://arxiv.org/abs/2412.13736
+ 作者:Jiaxiang Liu,Yuan Wang,Jiawei Du,Joey Tianyi Zhou,Zuozhu Liu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Visual Question Answering, Medical Visual Question, Question Answering, Visual Question, Artificial intelligence
+ 备注:
+
+ 点击查看摘要
+ Abstract:Artificial intelligence has advanced in Medical Visual Question Answering (Med-VQA), but prevalent research tends to focus on the accuracy of the answers, often overlooking the reasoning paths and interpretability, which are crucial in clinical settings. Besides, current Med-VQA algorithms, typically reliant on singular models, lack the robustness needed for real-world medical diagnostics which usually require collaborative expert evaluation. To address these shortcomings, this paper presents MedCoT, a novel hierarchical expert verification reasoning chain method designed to enhance interpretability and accuracy in biomedical imaging inquiries. MedCoT is predicated on two principles: The necessity for explicit reasoning paths in Med-VQA and the requirement for multi-expert review to formulate accurate conclusions. The methodology involves an Initial Specialist proposing diagnostic rationales, followed by a Follow-up Specialist who validates these rationales, and finally, a consensus is reached through a vote among a sparse Mixture of Experts within the locally deployed Diagnostic Specialist, which then provides the definitive diagnosis. Experimental evaluations on four standard Med-VQA datasets demonstrate that MedCoT surpasses existing state-of-the-art approaches, providing significant improvements in performance and interpretability.
+
+
+
+ 51. 【2412.13735】3D Registration in 30 Years: A Survey
+ 链接:https://arxiv.org/abs/2412.13735
+ 作者:Jiaqi Yang,Chu'ai Zhang,Zhengbao Wang,Xinyue Cao,Xuan Ouyang,Xiyu Zhang,Zhenxuan Zeng,Zhao Zeng,Borui Lu,Zhiyi Xia,Qian Zhang,Yulan Guo,Yanning Zhang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:remote sensing, computer vision, computer graphics, point cloud registration, fundamental problem
+ 备注:
+
+ 点击查看摘要
+ Abstract:3D point cloud registration is a fundamental problem in computer vision, computer graphics, robotics, remote sensing, and etc. Over the last thirty years, we have witnessed the amazing advancement in this area with numerous kinds of solutions. Although a handful of relevant surveys have been conducted, their coverage is still limited. In this work, we present a comprehensive survey on 3D point cloud registration, covering a set of sub-areas such as pairwise coarse registration, pairwise fine registration, multi-view registration, cross-scale registration, and multi-instance registration. The datasets, evaluation metrics, method taxonomy, discussions of the merits and demerits, insightful thoughts of future directions are comprehensively presented in this survey. The regularly updated project page of the survey is available at this https URL.
+
+
+
+ 52. 【2412.13734】xt2Relight: Creative Portrait Relighting with Text Guidance
+ 链接:https://arxiv.org/abs/2412.13734
+ 作者:Junuk Cha,Mengwei Ren,Krishna Kumar Singh,He Zhang,Yannick Hold-Geoffroy,Seunghyun Yoon,HyunJoon Jung,Jae Shin Yoon,Seungryul Baek
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:text, lighting, present a lighting-aware, image, lighting-aware image editing
+ 备注:
+
+ 点击查看摘要
+ Abstract:We present a lighting-aware image editing pipeline that, given a portrait image and a text prompt, performs single image relighting. Our model modifies the lighting and color of both the foreground and background to align with the provided text description. The unbounded nature in creativeness of a text allows us to describe the lighting of a scene with any sensory features including temperature, emotion, smell, time, and so on. However, the modeling of such mapping between the unbounded text and lighting is extremely challenging due to the lack of dataset where there exists no scalable data that provides large pairs of text and relighting, and therefore, current text-driven image editing models does not generalize to lighting-specific use cases. We overcome this problem by introducing a novel data synthesis pipeline: First, diverse and creative text prompts that describe the scenes with various lighting are automatically generated under a crafted hierarchy using a large language model (*e.g.,* ChatGPT). A text-guided image generation model creates a lighting image that best matches the text. As a condition of the lighting images, we perform image-based relighting for both foreground and background using a single portrait image or a set of OLAT (One-Light-at-A-Time) images captured from lightstage system. Particularly for the background relighting, we represent the lighting image as a set of point lights and transfer them to other background images. A generative diffusion model learns the synthesized large-scale data with auxiliary task augmentation (*e.g.,* portrait delighting and light positioning) to correlate the latent text and lighting distribution for text-guided portrait relighting.
+
+
+
+ 53. 【2412.13732】Modelling Multi-modal Cross-interaction for ML-FSIC Based on Local Feature Selection
+ 链接:https://arxiv.org/abs/2412.13732
+ 作者:Kun Yan,Zied Bouraoui,Fangyun Wei,Chang Xu,Ping Wang,Shoaib Jameel,Steven Schockaert
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:few-shot image classification, assign semantic labels, multi-label few-shot image, assign semantic, small number
+ 备注: Accepted in Transactions on Multimedia Computing Communications and Applications
+
+ 点击查看摘要
+ Abstract:The aim of multi-label few-shot image classification (ML-FSIC) is to assign semantic labels to images, in settings where only a small number of training examples are available for each label. A key feature of the multi-label setting is that images often have several labels, which typically refer to objects appearing in different regions of the image. When estimating label prototypes, in a metric-based setting, it is thus important to determine which regions are relevant for which labels, but the limited amount of training data and the noisy nature of local features make this highly challenging. As a solution, we propose a strategy in which label prototypes are gradually refined. First, we initialize the prototypes using word embeddings, which allows us to leverage prior knowledge about the meaning of the labels. Second, taking advantage of these initial prototypes, we then use a Loss Change Measurement~(LCM) strategy to select the local features from the training images (i.e.\ the support set) that are most likely to be representative of a given label. Third, we construct the final prototype of the label by aggregating these representative local features using a multi-modal cross-interaction mechanism, which again relies on the initial word embedding-based prototypes. Experiments on COCO, PASCAL VOC, NUS-WIDE, and iMaterialist show that our model substantially improves the current state-of-the-art.
+
+
+
+ 54. 【2412.13726】Unified Understanding of Environment, Task, and Human for Human-Robot Interaction in Real-World Environments
+ 链接:https://arxiv.org/abs/2412.13726
+ 作者:Yuga Yano,Akinobu Mizutani,Yukiya Fukuda,Daiju Kanaoka,Tomohiro Ono,Hakaru Tamukoh
+ 类目:Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV); Human-Computer Interaction (cs.HC)
+ 关键词:HRI, HRI system, indoor dynamic map, system, understand the required
+ 备注: 2024 33rd IEEE International Conference on Robot and Human Interactive Communication (RO-MAN)
+
+ 点击查看摘要
+ Abstract:To facilitate human--robot interaction (HRI) tasks in real-world scenarios, service robots must adapt to dynamic environments and understand the required tasks while effectively communicating with humans. To accomplish HRI in practice, we propose a novel indoor dynamic map, task understanding system, and response generation system. The indoor dynamic map optimizes robot behavior by managing an occupancy grid map and dynamic information, such as furniture and humans, in separate layers. The task understanding system targets tasks that require multiple actions, such as serving ordered items. Task representations that predefine the flow of necessary actions are applied to achieve highly accurate understanding. The response generation system is executed in parallel with task understanding to facilitate smooth HRI by informing humans of the subsequent actions of the robot. In this study, we focused on waiter duties in a restaurant setting as a representative application of HRI in a dynamic environment. We developed an HRI system that could perform tasks such as serving food and cleaning up while communicating with customers. In experiments conducted in a simulated restaurant environment, the proposed HRI system successfully communicated with customers and served ordered food with 90\% accuracy. In a questionnaire administered after the experiment, the HRI system of the robot received 4.2 points out of 5. These outcomes indicated the effectiveness of the proposed method and HRI system in executing waiter tasks in real-world environments.
+
+
+
+ 55. 【2412.13717】owards Automatic Evaluation for Image Transcreation
+ 链接:https://arxiv.org/abs/2412.13717
+ 作者:Simran Khanuja,Vivek Iyer,Claire He,Graham Neubig
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:speech and text, formal Machine Learning, conventional paradigms, paradigms of translating, translating speech
+ 备注:
+
+ 点击查看摘要
+ Abstract:Beyond conventional paradigms of translating speech and text, recently, there has been interest in automated transcreation of images to facilitate localization of visual content across different cultures. Attempts to define this as a formal Machine Learning (ML) problem have been impeded by the lack of automatic evaluation mechanisms, with previous work relying solely on human evaluation. In this paper, we seek to close this gap by proposing a suite of automatic evaluation metrics inspired by machine translation (MT) metrics, categorized into: a) Object-based, b) Embedding-based, and c) VLM-based. Drawing on theories from translation studies and real-world transcreation practices, we identify three critical dimensions of image transcreation: cultural relevance, semantic equivalence and visual similarity, and design our metrics to evaluate systems along these axes. Our results show that proprietary VLMs best identify cultural relevance and semantic equivalence, while vision-encoder representations are adept at measuring visual similarity. Meta-evaluation across 7 countries shows our metrics agree strongly with human ratings, with average segment-level correlations ranging from 0.55-0.87. Finally, through a discussion of the merits and demerits of each metric, we offer a robust framework for automated image transcreation evaluation, grounded in both theoretical foundations and practical application. Our code can be found here: this https URL
+
+
+
+ 56. 【2412.13709】Physics-Based Adversarial Attack on Near-Infrared Human Detector for Nighttime Surveillance Camera Systems
+ 链接:https://arxiv.org/abs/2412.13709
+ 作者:Muyao Niu,Zhuoxiao Li,Yifan Zhan,Huy H. Nguyen,Isao Echizen,Yinqiang Zheng
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:nighttime modes based, surveillance cameras switch, illuminance levels, switch between daytime, modes based
+ 备注: Appeared in ACM MM 2023
+
+ 点击查看摘要
+ Abstract:Many surveillance cameras switch between daytime and nighttime modes based on illuminance levels. During the day, the camera records ordinary RGB images through an enabled IR-cut filter. At night, the filter is disabled to capture near-infrared (NIR) light emitted from NIR LEDs typically mounted around the lens. While RGB-based AI algorithm vulnerabilities have been widely reported, the vulnerabilities of NIR-based AI have rarely been investigated. In this paper, we identify fundamental vulnerabilities in NIR-based image understanding caused by color and texture loss due to the intrinsic characteristics of clothes' reflectance and cameras' spectral sensitivity in the NIR range. We further show that the nearly co-located configuration of illuminants and cameras in existing surveillance systems facilitates concealing and fully passive attacks in the physical world. Specifically, we demonstrate how retro-reflective and insulation plastic tapes can manipulate the intensity distribution of NIR images. We showcase an attack on the YOLO-based human detector using binary patterns designed in the digital space (via black-box query and searching) and then physically realized using tapes pasted onto clothes. Our attack highlights significant reliability concerns for nighttime surveillance systems, which are intended to enhance security. Codes Available: this https URL
+
+
+
+ 57. 【2412.13708】JoVALE: Detecting Human Actions in Video Using Audiovisual and Language Contexts
+ 链接:https://arxiv.org/abs/2412.13708
+ 作者:Taein Son,Soo Won Seo,Jisong Kim,Seok Hwan Lee,Jun Won Choi
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Video Action Detection, categorizing action instances, Action Detection, categorizing action, action instances
+ 备注: Accepted to AAAI Conference on Artificial Intelligence 2025, 9 pages, 5 figures
+
+ 点击查看摘要
+ Abstract:Video Action Detection (VAD) involves localizing and categorizing action instances in videos. Videos inherently contain various information sources, including audio, visual cues, and surrounding scene contexts. Effectively leveraging this multi-modal information for VAD is challenging, as the model must accurately focus on action-relevant cues. In this study, we introduce a novel multi-modal VAD architecture called the Joint Actor-centric Visual, Audio, Language Encoder (JoVALE). JoVALE is the first VAD method to integrate audio and visual features with scene descriptive context derived from large image captioning models. The core principle of JoVALE is the actor-centric aggregation of audio, visual, and scene descriptive contexts, where action-related cues from each modality are identified and adaptively combined. We propose a specialized module called the Actor-centric Multi-modal Fusion Network, designed to capture the joint interactions among actors and multi-modal contexts through Transformer architecture. Our evaluation conducted on three popular VAD benchmarks, AVA, UCF101-24, and JHMDB51-21, demonstrates that incorporating multi-modal information leads to significant performance gains. JoVALE achieves state-of-the-art performances. The code will be available at \texttt{this https URL}.
+
+
+
+ 58. 【2412.13705】Mitigating Adversarial Attacks in LLMs through Defensive Suffix Generation
+ 链接:https://arxiv.org/abs/2412.13705
+ 作者:Minkyoung Kim,Yunha Kim,Hyeram Seo,Heejung Choi,Jiye Han,Gaeun Kee,Soyoung Ko,HyoJe Jung,Byeolhee Kim,Young-Hak Kim,Sanghyun Park,Tae Joon Jun
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Large language models, language processing tasks, natural language processing, exhibited outstanding performance, Large language
+ 备注: 9 pages, 2 figures
+
+ 点击查看摘要
+ Abstract:Large language models (LLMs) have exhibited outstanding performance in natural language processing tasks. However, these models remain susceptible to adversarial attacks in which slight input perturbations can lead to harmful or misleading outputs. A gradient-based defensive suffix generation algorithm is designed to bolster the robustness of LLMs. By appending carefully optimized defensive suffixes to input prompts, the algorithm mitigates adversarial influences while preserving the models' utility. To enhance adversarial understanding, a novel total loss function ($L_{\text{total}}$) combining defensive loss ($L_{\text{def}}$) and adversarial loss ($L_{\text{adv}}$) generates defensive suffixes more effectively. Experimental evaluations conducted on open-source LLMs such as Gemma-7B, mistral-7B, Llama2-7B, and Llama2-13B show that the proposed method reduces attack success rates (ASR) by an average of 11\% compared to models without defensive suffixes. Additionally, the perplexity score of Gemma-7B decreased from 6.57 to 3.93 when applying the defensive suffix generated by openELM-270M. Furthermore, TruthfulQA evaluations demonstrate consistent improvements with Truthfulness scores increasing by up to 10\% across tested configurations. This approach significantly enhances the security of LLMs in critical applications without requiring extensive retraining.
+
+
+
+ 59. 【2412.13695】Optical aberrations in autonomous driving: Physics-informed parameterized temperature scaling for neural network uncertainty calibration
+ 链接:https://arxiv.org/abs/2412.13695
+ 作者:Dominik Werner Wolf,Alexander Braun,Markus Ulrich
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:machine learning method, Huellermeier and Waegeman, learning method, key feature, machine learning
+ 备注: Under review at the International Journal of Computer Vision (IJCV)
+
+ 点击查看摘要
+ Abstract:'A trustworthy representation of uncertainty is desirable and should be considered as a key feature of any machine learning method' (Huellermeier and Waegeman, 2021). This conclusion of Huellermeier et al. underpins the importance of calibrated uncertainties. Since AI-based algorithms are heavily impacted by dataset shifts, the automotive industry needs to safeguard its system against all possible contingencies. One important but often neglected dataset shift is caused by optical aberrations induced by the windshield. For the verification of the perception system performance, requirements on the AI performance need to be translated into optical metrics by a bijective mapping (Braun, 2023). Given this bijective mapping it is evident that the optical system characteristics add additional information about the magnitude of the dataset shift. As a consequence, we propose to incorporate a physical inductive bias into the neural network calibration architecture to enhance the robustness and the trustworthiness of the AI target application, which we demonstrate by using a semantic segmentation task as an example. By utilizing the Zernike coefficient vector of the optical system as a physical prior we can significantly reduce the mean expected calibration error in case of optical aberrations. As a result, we pave the way for a trustworthy uncertainty representation and for a holistic verification strategy of the perception chain.
+
+
+
+ 60. 【2412.13684】MMO-IG: Multi-Class and Multi-Scale Object Image Generation for Remote Sensing
+ 链接:https://arxiv.org/abs/2412.13684
+ 作者:Chuang Yang,Bingxuan Zhao,Qing Zhou,Qi Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:acquiring vast quantities, significantly advanced research, deep generative models, computer vision, providing a cost-effective
+ 备注:
+
+ 点击查看摘要
+ Abstract:The rapid advancement of deep generative models (DGMs) has significantly advanced research in computer vision, providing a cost-effective alternative to acquiring vast quantities of expensive imagery. However, existing methods predominantly focus on synthesizing remote sensing (RS) images aligned with real images in a global layout view, which limits their applicability in RS image object detection (RSIOD) research. To address these challenges, we propose a multi-class and multi-scale object image generator based on DGMs, termed MMO-IG, designed to generate RS images with supervised object labels from global and local aspects simultaneously. Specifically, from the local view, MMO-IG encodes various RS instances using an iso-spacing instance map (ISIM). During the generation process, it decodes each instance region with iso-spacing value in ISIM-corresponding to both background and foreground instances-to produce RS images through the denoising process of diffusion models. Considering the complex interdependencies among MMOs, we construct a spatial-cross dependency knowledge graph (SCDKG). This ensures a realistic and reliable multidirectional distribution among MMOs for region embedding, thereby reducing the discrepancy between source and target domains. Besides, we propose a structured object distribution instruction (SODI) to guide the generation of synthesized RS image content from a global aspect with SCDKG-based ISIM together. Extensive experimental results demonstrate that our MMO-IG exhibits superior generation capabilities for RS images with dense MMO-supervised labels, and RS detectors pre-trained with MMO-IG show excellent performance on real-world datasets.
+
+
+
+ 61. 【2412.13662】When Should We Prefer State-to-Visual DAgger Over Visual Reinforcement Learning?
+ 链接:https://arxiv.org/abs/2412.13662
+ 作者:Tongzhou Mu,Zhaoyang Li,Stanisław Wiktor Strzelecki,Xiu Yuan,Yunchao Yao,Litian Liang,Hao Su
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Robotics (cs.RO)
+ 关键词:high-dimensional visual inputs, point clouds, pixels and point, visual, policies from high-dimensional
+ 备注: Accepted by The 39th Annual AAAI Conference on Artificial Intelligence (AAAI 2025)
+
+ 点击查看摘要
+ Abstract:Learning policies from high-dimensional visual inputs, such as pixels and point clouds, is crucial in various applications. Visual reinforcement learning is a promising approach that directly trains policies from visual observations, although it faces challenges in sample efficiency and computational costs. This study conducts an empirical comparison of State-to-Visual DAgger, a two-stage framework that initially trains a state policy before adopting online imitation to learn a visual policy, and Visual RL across a diverse set of tasks. We evaluate both methods across 16 tasks from three benchmarks, focusing on their asymptotic performance, sample efficiency, and computational costs. Surprisingly, our findings reveal that State-to-Visual DAgger does not universally outperform Visual RL but shows significant advantages in challenging tasks, offering more consistent performance. In contrast, its benefits in sample efficiency are less pronounced, although it often reduces the overall wall-clock time required for training. Based on our findings, we provide recommendations for practitioners and hope that our results contribute valuable perspectives for future research in visual policy learning.
+
+
+
+ 62. 【2412.13656】GLCF: A Global-Local Multimodal Coherence Analysis Framework for Talking Face Generation Detection
+ 链接:https://arxiv.org/abs/2412.13656
+ 作者:Xiaocan Chen,Qilin Yin,Jiarui Liu,Wei Lu,Xiangyang Luo,Jiantao Zhou
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:producing lifelike talking, lifelike talking videos, accompanying text, producing lifelike, facial images
+ 备注:
+
+ 点击查看摘要
+ Abstract:Talking face generation (TFG) allows for producing lifelike talking videos of any character using only facial images and accompanying text. Abuse of this technology could pose significant risks to society, creating the urgent need for research into corresponding detection methods. However, research in this field has been hindered by the lack of public datasets. In this paper, we construct the first large-scale multi-scenario talking face dataset (MSTF), which contains 22 audio and video forgery techniques, filling the gap of datasets in this field. The dataset covers 11 generation scenarios and more than 20 semantic scenarios, closer to the practical application scenario of TFG. Besides, we also propose a TFG detection framework, which leverages the analysis of both global and local coherence in the multimodal content of TFG videos. Therefore, a region-focused smoothness detection module (RSFDM) and a discrepancy capture-time frame aggregation module (DCTAM) are introduced to evaluate the global temporal coherence of TFG videos, aggregating multi-grained spatial information. Additionally, a visual-audio fusion module (V-AFM) is designed to evaluate audiovisual coherence within a localized temporal perspective. Comprehensive experiments demonstrate the reasonableness and challenges of our datasets, while also indicating the superiority of our proposed method compared to the state-of-the-art deepfake detection approaches.
+
+
+
+ 63. 【2412.13655】VIIS: Visible and Infrared Information Synthesis for Severe Low-light Image Enhancement
+ 链接:https://arxiv.org/abs/2412.13655
+ 作者:Chen Zhao,Mengyuan Yu,Fan Yang,Peiguang Jing
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:severe low-light circumstances, significant information absence, captured in severe, severe low-light, low-light circumstances
+ 备注: Accepted to WACV 2025
+
+ 点击查看摘要
+ Abstract:Images captured in severe low-light circumstances often suffer from significant information absence. Existing singular modality image enhancement methods struggle to restore image regions lacking valid information. By leveraging light-impervious infrared images, visible and infrared image fusion methods have the potential to reveal information hidden in darkness. However, they primarily emphasize inter-modal complementation but neglect intra-modal enhancement, limiting the perceptual quality of output images. To address these limitations, we propose a novel task, dubbed visible and infrared information synthesis (VIIS), which aims to achieve both information enhancement and fusion of the two modalities. Given the difficulty in obtaining ground truth in the VIIS task, we design an information synthesis pretext task (ISPT) based on image augmentation. We employ a diffusion model as the framework and design a sparse attention-based dual-modalities residual (SADMR) conditioning mechanism to enhance information interaction between the two modalities. This mechanism enables features with prior knowledge from both modalities to adaptively and iteratively attend to each modality's information during the denoising process. Our extensive experiments demonstrate that our model qualitatively and quantitatively outperforms not only the state-of-the-art methods in relevant fields but also the newly designed baselines capable of both information enhancement and fusion. The code is available at this https URL.
+
+
+
+ 64. 【2412.13654】GAGS: Granularity-Aware Feature Distillation for Language Gaussian Splatting
+ 链接:https://arxiv.org/abs/2412.13654
+ 作者:Yuning Peng,Haiping Wang,Yuan Liu,Chenglu Wen,Zhen Dong,Bisheng Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:accurately perceives complex, open-vocabulary scene understanding, perceives complex semantic, complex semantic properties, gained significant attention
+ 备注: Project page: [this https URL](https://pz0826.github.io/GAGS-Webpage/)
+
+ 点击查看摘要
+ Abstract:3D open-vocabulary scene understanding, which accurately perceives complex semantic properties of objects in space, has gained significant attention in recent years. In this paper, we propose GAGS, a framework that distills 2D CLIP features into 3D Gaussian splatting, enabling open-vocabulary queries for renderings on arbitrary viewpoints. The main challenge of distilling 2D features for 3D fields lies in the multiview inconsistency of extracted 2D features, which provides unstable supervision for the 3D feature field. GAGS addresses this challenge with two novel strategies. First, GAGS associates the prompt point density of SAM with the camera distances, which significantly improves the multiview consistency of segmentation results. Second, GAGS further decodes a granularity factor to guide the distillation process and this granularity factor can be learned in a unsupervised manner to only select the multiview consistent 2D features in the distillation process. Experimental results on two datasets demonstrate significant performance and stability improvements of GAGS in visual grounding and semantic segmentation, with an inference speed 2$\times$ faster than baseline methods. The code and additional results are available at this https URL .
+
+
+
+ 65. 【2412.13652】RelationField: Relate Anything in Radiance Fields
+ 链接:https://arxiv.org/abs/2412.13652
+ 作者:Sebastian Koch,Johanna Wald,Mirco Colosi,Narunas Vaskevicius,Pedro Hermosilla,Federico Tombari,Timo Ropinski
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Neural radiance fields, distilling open-vocabulary features, Neural radiance, vision-language models, learn features
+ 备注: Project page: [this https URL](https://relationfield.github.io)
+
+ 点击查看摘要
+ Abstract:Neural radiance fields are an emerging 3D scene representation and recently even been extended to learn features for scene understanding by distilling open-vocabulary features from vision-language models. However, current method primarily focus on object-centric representations, supporting object segmentation or detection, while understanding semantic relationships between objects remains largely unexplored. To address this gap, we propose RelationField, the first method to extract inter-object relationships directly from neural radiance fields. RelationField represents relationships between objects as pairs of rays within a neural radiance field, effectively extending its formulation to include implicit relationship queries. To teach RelationField complex, open-vocabulary relationships, relationship knowledge is distilled from multi-modal LLMs. To evaluate RelationField, we solve open-vocabulary 3D scene graph generation tasks and relationship-guided instance segmentation, achieving state-of-the-art performance in both tasks. See the project website at this https URL.
+
+
+
+ 66. 【2412.13647】G-VEval: A Versatile Metric for Evaluating Image and Video Captions Using GPT-4o
+ 链接:https://arxiv.org/abs/2412.13647
+ 作者:Tony Cheng Tong,Sirui He,Zhiwen Shao,Dit-Yan Yeung
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Language Model-based metrics, Advanced Language Model-based, metrics, visual captioning, ROUGE often miss
+ 备注:
+
+ 点击查看摘要
+ Abstract:Evaluation metric of visual captioning is important yet not thoroughly explored. Traditional metrics like BLEU, METEOR, CIDEr, and ROUGE often miss semantic depth, while trained metrics such as CLIP-Score, PAC-S, and Polos are limited in zero-shot scenarios. Advanced Language Model-based metrics also struggle with aligning to nuanced human preferences. To address these issues, we introduce G-VEval, a novel metric inspired by G-Eval and powered by the new GPT-4o. G-VEval uses chain-of-thought reasoning in large multimodal models and supports three modes: reference-free, reference-only, and combined, accommodating both video and image inputs. We also propose MSVD-Eval, a new dataset for video captioning evaluation, to establish a more transparent and consistent framework for both human experts and evaluation metrics. It is designed to address the lack of clear criteria in existing datasets by introducing distinct dimensions of Accuracy, Completeness, Conciseness, and Relevance (ACCR). Extensive results show that G-VEval outperforms existing methods in correlation with human annotations, as measured by Kendall tau-b and Kendall tau-c. This provides a flexible solution for diverse captioning tasks and suggests a straightforward yet effective approach for large language models to understand video content, paving the way for advancements in automated captioning. Codes are available at this https URL
+
+
+
+ 67. 【2412.13636】Consistency of Compositional Generalization across Multiple Levels
+ 链接:https://arxiv.org/abs/2412.13636
+ 作者:Chuanhao Li,Zhen Li,Chenchen Jing,Xiaomeng Fan,Wenbo Ye,Yuwei Wu,Yunde Jia
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Compositional generalization, multiple levels, Compositional, level, compositions
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Compositional generalization is the capability of a model to understand novel compositions composed of seen concepts. There are multiple levels of novel compositions including phrase-phrase level, phrase-word level, and word-word level. Existing methods achieve promising compositional generalization, but the consistency of compositional generalization across multiple levels of novel compositions remains unexplored. The consistency refers to that a model should generalize to a phrase-phrase level novel composition, and phrase-word/word-word level novel compositions that can be derived from it simultaneously. In this paper, we propose a meta-learning based framework, for achieving consistent compositional generalization across multiple levels. The basic idea is to progressively learn compositions from simple to complex for consistency. Specifically, we divide the original training set into multiple validation sets based on compositional complexity, and introduce multiple meta-weight-nets to generate sample weights for samples in different validation sets. To fit the validation sets in order of increasing compositional complexity, we optimize the parameters of each meta-weight-net independently and sequentially in a multilevel optimization manner. We build a GQA-CCG dataset to quantitatively evaluate the consistency. Experimental results on visual question answering and temporal video grounding, demonstrate the effectiveness of the proposed framework. We release GQA-CCG at this https URL.
+
+
+
+ 68. 【2412.13635】Self-control: A Better Conditional Mechanism for Masked Autoregressive Model
+ 链接:https://arxiv.org/abs/2412.13635
+ 作者:Qiaoying Qu,Shiyu Shen
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:image generation algorithms, autoregressive image generation, image generation, range of applications, generating photorealistic images
+ 备注:
+
+ 点击查看摘要
+ Abstract:Autoregressive conditional image generation algorithms are capable of generating photorealistic images that are consistent with given textual or image conditions, and have great potential for a wide range of applications. Nevertheless, the majority of popular autoregressive image generation methods rely heavily on vector quantization, and the inherent discrete characteristic of codebook presents a considerable challenge to achieving high-quality image generation. To address this limitation, this paper introduces a novel conditional introduction network for continuous masked autoregressive models. The proposed self-control network serves to mitigate the negative impact of vector quantization on the quality of the generated images, while simultaneously enhancing the conditional control during the generation process. In particular, the self-control network is constructed upon a continuous mask autoregressive generative model, which incorporates multimodal conditional information, including text and images, into a unified autoregressive sequence in a serial manner. Through a self-attention mechanism, the network is capable of generating images that are controllable based on specific conditions. The self-control network discards the conventional cross-attention-based conditional fusion mechanism and effectively unifies the conditional and generative information within the same space, thereby facilitating more seamless learning and fusion of multimodal features.
+
+
+
+ 69. 【2412.13615】MambaLCT: Boosting Tracking via Long-term Context State Space Model
+ 链接:https://arxiv.org/abs/2412.13615
+ 作者:Xiaohai Li,Bineng Zhong,Qihua Liang,Guorong Li,Zhiyi Mo,Shuxiang Song
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Effectively constructing context, Effectively constructing, target change cues, constructing context information, target variation cues
+ 备注:
+
+ 点击查看摘要
+ Abstract:Effectively constructing context information with long-term dependencies from video sequences is crucial for object tracking. However, the context length constructed by existing work is limited, only considering object information from adjacent frames or video clips, leading to insufficient utilization of contextual information. To address this issue, we propose MambaLCT, which constructs and utilizes target variation cues from the first frame to the current frame for robust tracking. First, a novel unidirectional Context Mamba module is designed to scan frame features along the temporal dimension, gathering target change cues throughout the entire sequence. Specifically, target-related information in frame features is compressed into a hidden state space through selective scanning mechanism. The target information across the entire video is continuously aggregated into target variation cues. Next, we inject the target change cues into the attention mechanism, providing temporal information for modeling the relationship between the template and search frames. The advantage of MambaLCT is its ability to continuously extend the length of the context, capturing complete target change cues, which enhances the stability and robustness of the tracker. Extensive experiments show that long-term context information enhances the model's ability to perceive targets in complex scenarios. MambaLCT achieves new SOTA performance on six benchmarks while maintaining real-time running speeds.
+
+
+
+ 70. 【2412.13614】Reverse Region-to-Entity Annotation for Pixel-Level Visual Entity Linking
+ 链接:https://arxiv.org/abs/2412.13614
+ 作者:Zhengfei Xu,Sijia Zhao,Yanchao Hao,Xiaolong Liu,Lili Li,Yuyang Yin,Bo Li,Xi Chen,Xin Xin
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Information Retrieval (cs.IR); Multimedia (cs.MM)
+ 关键词:Visual Entity Linking, Entity Linking, knowledge base, Visual Entity, Visual
+ 备注: AAAI 2025;Dataset are released at [this https URL](https://github.com/NP-NET-research/PL-VEL)
+
+ 点击查看摘要
+ Abstract:Visual Entity Linking (VEL) is a crucial task for achieving fine-grained visual understanding, matching objects within images (visual mentions) to entities in a knowledge base. Previous VEL tasks rely on textual inputs, but writing queries for complex scenes can be challenging. Visual inputs like clicks or bounding boxes offer a more convenient alternative. Therefore, we propose a new task, Pixel-Level Visual Entity Linking (PL-VEL), which uses pixel masks from visual inputs to refer to objects, supplementing reference methods for VEL. To facilitate research on this task, we have constructed the MaskOVEN-Wiki dataset through an entirely automatic reverse region-entity annotation framework. This dataset contains over 5 million annotations aligning pixel-level regions with entity-level labels, which will advance visual understanding towards fine-grained. Moreover, as pixel masks correspond to semantic regions in an image, we enhance previous patch-interacted attention with region-interacted attention by a visual semantic tokenization approach. Manual evaluation results indicate that the reverse annotation framework achieved a 94.8% annotation success rate. Experimental results show that models trained on this dataset improved accuracy by 18 points compared to zero-shot models. Additionally, the semantic tokenization method achieved a 5-point accuracy improvement over the trained baseline.
+
+
+
+ 71. 【2412.13611】Robust Tracking via Mamba-based Context-aware Token Learning
+ 链接:https://arxiv.org/abs/2412.13611
+ 作者:Jinxia Xie,Bineng Zhong,Qihua Liang,Ning Li,Zhiyi Mo,Shuxiang Song
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:make a good, good trade-off, cost is crucial, track tokens, track
+ 备注: AAAI2025
+
+ 点击查看摘要
+ Abstract:How to make a good trade-off between performance and computational cost is crucial for a tracker. However, current famous methods typically focus on complicated and time-consuming learning that combining temporal and appearance information by input more and more images (or features). Consequently, these methods not only increase the model's computational source and learning burden but also introduce much useless and potentially interfering information. To alleviate the above issues, we propose a simple yet robust tracker that separates temporal information learning from appearance modeling and extracts temporal relations from a set of representative tokens rather than several images (or features). Specifically, we introduce one track token for each frame to collect the target's appearance information in the backbone. Then, we design a mamba-based Temporal Module for track tokens to be aware of context by interacting with other track tokens within a sliding window. This module consists of a mamba layer with autoregressive characteristic and a cross-attention layer with strong global perception ability, ensuring sufficient interaction for track tokens to perceive the appearance changes and movement trends of the target. Finally, track tokens serve as a guidance to adjust the appearance feature for the final prediction in the head. Experiments show our method is effective and achieves competitive performance on multiple benchmarks at a real-time speed. Code and trained models will be available at this https URL.
+
+
+
+ 72. 【2412.13610】Faster and Stronger: When ANN-SNN Conversion Meets Parallel Spiking Calculation
+ 链接:https://arxiv.org/abs/2412.13610
+ 作者:Zecheng Hao,Zhaofei Yu,Tiejun Huang
+ 类目:Neural and Evolutionary Computing (cs.NE); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Spiking Neural Network, Neural Network, Spiking Neural, brain-inspired and energy-efficient, facing the pivotal
+ 备注:
+
+ 点击查看摘要
+ Abstract:Spiking Neural Network (SNN), as a brain-inspired and energy-efficient network, is currently facing the pivotal challenge of exploring a suitable and efficient learning framework. The predominant training methodologies, namely Spatial-Temporal Back-propagation (STBP) and ANN-SNN Conversion, are encumbered by substantial training overhead or pronounced inference latency, which impedes the advancement of SNNs in scaling to larger networks and navigating intricate application domains. In this work, we propose a novel parallel conversion learning framework, which establishes a mathematical mapping relationship between each time-step of the parallel spiking neurons and the cumulative spike firing rate. We theoretically validate the lossless and sorting properties of the conversion process, as well as pointing out the optimal shifting distance for each step. Furthermore, by integrating the above framework with the distribution-aware error calibration technique, we can achieve efficient conversion towards more general activation functions or training-free circumstance. Extensive experiments have confirmed the significant performance advantages of our method for various conversion cases under ultra-low time latency. To our best knowledge, this is the first work which jointly utilizes parallel spiking calculation and ANN-SNN Conversion, providing a highly promising approach for SNN supervised training.
+
+
+
+ 73. 【2412.13609】Sign-IDD: Iconicity Disentangled Diffusion for Sign Language Production
+ 链接:https://arxiv.org/abs/2412.13609
+ 作者:Shengeng Tang,Jiayi He,Dan Guo,Yanyan Wei,Feng Li,Richang Hong
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:Sign Language Production, Language Production, semantically consistent sign, consistent sign videos, Sign Language
+ 备注: 9 pages, 5 figures
+
+ 点击查看摘要
+ Abstract:Sign Language Production (SLP) aims to generate semantically consistent sign videos from textual statements, where the conversion from textual glosses to sign poses (G2P) is a crucial step. Existing G2P methods typically treat sign poses as discrete three-dimensional coordinates and directly fit them, which overlooks the relative positional relationships among joints. To this end, we provide a new perspective, constraining joint associations and gesture details by modeling the limb bones to improve the accuracy and naturalness of the generated poses. In this work, we propose a pioneering iconicity disentangled diffusion framework, termed Sign-IDD, specifically designed for SLP. Sign-IDD incorporates a novel Iconicity Disentanglement (ID) module to bridge the gap between relative positions among joints. The ID module disentangles the conventional 3D joint representation into a 4D bone representation, comprising the 3D spatial direction vector and 1D spatial distance vector between adjacent joints. Additionally, an Attribute Controllable Diffusion (ACD) module is introduced to further constrain joint associations, in which the attribute separation layer aims to separate the bone direction and length attributes, and the attribute control layer is designed to guide the pose generation by leveraging the above attributes. The ACD module utilizes the gloss embeddings as semantic conditions and finally generates sign poses from noise embeddings. Extensive experiments on PHOENIX14T and USTC-CSL datasets validate the effectiveness of our method. The code is available at: this https URL.
+
+
+
+ 74. 【2412.13601】Hybrid CNN-LSTM based Indoor Pedestrian Localization with CSI Fingerprint Maps
+ 链接:https://arxiv.org/abs/2412.13601
+ 作者:Muhammad Emad-ud-din
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:CSI Fingerprint Map, Channel State Information, CSI data, Channel State, CSI Fingerprint
+ 备注: 12 pages, 14 figures and 3 tables
+
+ 点击查看摘要
+ Abstract:The paper presents a novel Wi-Fi fingerprinting system that uses Channel State Information (CSI) data for fine-grained pedestrian localization. The proposed system exploits the frequency diversity and spatial diversity of the features extracted from CSI data to generate a 2D+channel image termed as a CSI Fingerprint Map. We then use this CSI Fingerprint Map representation of CSI data to generate a pedestrian trajectory hypothesis using a hybrid architecture that combines a Convolutional Neural Network and a Long Short-Term Memory Recurrent Neural Network model. The proposed architecture exploits the temporal and spatial relationship information among the CSI data observations gathered at neighboring locations. A particle filter is then employed to separate out the most likely hypothesis matching a human walk model. The experimental performance of our method is compared to existing deep learning localization methods such ConFi, DeepFi and to a self-developed temporal-feature based LSTM based location classifier. The experimental results show marked improvement with an average RMSE of 0.36 m in a moderately dynamic and 0.17 m in a static environment. Our method is essentially a proof of concept that with (1) sparse availability of observations, (2) limited infrastructure requirements, (3) moderate level of short-term and long-term noise in the training and testing environment, reliable fine-grained Wi-Fi based pedestrian localization is a potential option.
+
+
+
+ 75. 【2412.13599】Unlocking the Potential of Weakly Labeled Data: A Co-Evolutionary Learning Framework for Abnormality Detection and Report Generation
+ 链接:https://arxiv.org/abs/2412.13599
+ 作者:Jinghan Sun,Dong Wei,Zhe Xu,Donghuan Lu,Hong Liu,Hong Wang,Sotirios A. Tsaftaris,Steven McDonagh,Yefeng Zheng,Liansheng Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Anatomical abnormality detection, chest X-ray, Anatomical abnormality, report generation, abnormality detection
+ 备注:
+
+ 点击查看摘要
+ Abstract:Anatomical abnormality detection and report generation of chest X-ray (CXR) are two essential tasks in clinical practice. The former aims at localizing and characterizing cardiopulmonary radiological findings in CXRs, while the latter summarizes the findings in a detailed report for further diagnosis and treatment. Existing methods often focused on either task separately, ignoring their correlation. This work proposes a co-evolutionary abnormality detection and report generation (CoE-DG) framework. The framework utilizes both fully labeled (with bounding box annotations and clinical reports) and weakly labeled (with reports only) data to achieve mutual promotion between the abnormality detection and report generation tasks. Specifically, we introduce a bi-directional information interaction strategy with generator-guided information propagation (GIP) and detector-guided information propagation (DIP). For semi-supervised abnormality detection, GIP takes the informative feature extracted by the generator as an auxiliary input to the detector and uses the generator's prediction to refine the detector's pseudo labels. We further propose an intra-image-modal self-adaptive non-maximum suppression module (SA-NMS). This module dynamically rectifies pseudo detection labels generated by the teacher detection model with high-confidence predictions by the this http URL, for report generation, DIP takes the abnormalities' categories and locations predicted by the detector as input and guidance for the generator to improve the generated reports.
+
+
+
+ 76. 【2412.13594】Generalizable Sensor-Based Activity Recognition via Categorical Concept Invariant Learning
+ 链接:https://arxiv.org/abs/2412.13594
+ 作者:Di Xiong,Shuoyuan Wang,Lei Zhang,Wenbo Huang,Chaolei Han
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:massive sensor data, Human Activity Recognition, Human Activity, aims to recognize, sensor data
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Human Activity Recognition (HAR) aims to recognize activities by training models on massive sensor data. In real-world deployment, a crucial aspect of HAR that has been largely overlooked is that the test sets may have different distributions from training sets due to inter-subject variability including age, gender, behavioral habits, etc., which leads to poor generalization performance. One promising solution is to learn domain-invariant representations to enable a model to generalize on an unseen distribution. However, most existing methods only consider the feature-invariance of the penultimate layer for domain-invariant learning, which leads to suboptimal results. In this paper, we propose a Categorical Concept Invariant Learning (CCIL) framework for generalizable activity recognition, which introduces a concept matrix to regularize the model in the training stage by simultaneously concentrating on feature-invariance and logit-invariance. Our key idea is that the concept matrix for samples belonging to the same activity category should be similar. Extensive experiments on four public HAR benchmarks demonstrate that our CCIL substantially outperforms the state-of-the-art approaches under cross-person, cross-dataset, cross-position, and one-person-to-another settings.
+
+
+
+ 77. 【2412.13577】Bridge then Begin Anew: Generating Target-relevant Intermediate Model for Source-free Visual Emotion Adaptation
+ 链接:https://arxiv.org/abs/2412.13577
+ 作者:Jiankun Zhu,Sicheng Zhao,Jing Jiang,Wenbo Tang,Zhaopan Xu,Tingting Han,Pengfei Xu,Hongxun Yao
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Visual emotion recognition, attracted increasing attention, visual stimuli, understanding humans' emotional, humans' emotional reactions
+ 备注: Accepted by AAAI2025
+
+ 点击查看摘要
+ Abstract:Visual emotion recognition (VER), which aims at understanding humans' emotional reactions toward different visual stimuli, has attracted increasing attention. Given the subjective and ambiguous characteristics of emotion, annotating a reliable large-scale dataset is hard. For reducing reliance on data labeling, domain adaptation offers an alternative solution by adapting models trained on labeled source data to unlabeled target data. Conventional domain adaptation methods require access to source data. However, due to privacy concerns, source emotional data may be inaccessible. To address this issue, we propose an unexplored task: source-free domain adaptation (SFDA) for VER, which does not have access to source data during the adaptation process. To achieve this, we propose a novel framework termed Bridge then Begin Anew (BBA), which consists of two steps: domain-bridged model generation (DMG) and target-related model adaptation (TMA). First, the DMG bridges cross-domain gaps by generating an intermediate model, avoiding direct alignment between two VER datasets with significant differences. Then, the TMA begins training the target model anew to fit the target structure, avoiding the influence of source-specific knowledge. Extensive experiments are conducted on six SFDA settings for VER. The results demonstrate the effectiveness of BBA, which achieves remarkable performance gains compared with state-of-the-art SFDA methods and outperforms representative unsupervised domain adaptation approaches.
+
+
+
+ 78. 【2412.13573】Seeking Consistent Flat Minima for Better Domain Generalization via Refining Loss Landscapes
+ 链接:https://arxiv.org/abs/2412.13573
+ 作者:Aodi Li,Liansheng Zhuang,Xiao Long,Minghong Yao,Shafei Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:unseen test domains, loss landscapes, multiple training domains, flat minima, Domain generalization aims
+ 备注:
+
+ 点击查看摘要
+ Abstract:Domain generalization aims to learn a model from multiple training domains and generalize it to unseen test domains. Recent theory has shown that seeking the deep models, whose parameters lie in the flat minima of the loss landscape, can significantly reduce the out-of-domain generalization error. However, existing methods often neglect the consistency of loss landscapes in different domains, resulting in models that are not simultaneously in the optimal flat minima in all domains, which limits their generalization ability. To address this issue, this paper proposes an iterative Self-Feedback Training (SFT) framework to seek consistent flat minima that are shared across different domains by progressively refining loss landscapes during training. It alternatively generates a feedback signal by measuring the inconsistency of loss landscapes in different domains and refines these loss landscapes for greater consistency using this feedback signal. Benefiting from the consistency of the flat minima within these refined loss landscapes, our SFT helps achieve better out-of-domain generalization. Extensive experiments on DomainBed demonstrate superior performances of SFT when compared to state-of-the-art sharpness-aware methods and other prevalent DG baselines. On average across five DG benchmarks, SFT surpasses the sharpness-aware minimization by 2.6% with ResNet-50 and 1.5% with ViT-B/16, respectively. The code will be available soon.
+
+
+
+ 79. 【2412.13569】Multi-View Pedestrian Occupancy Prediction with a Novel Synthetic Dataset
+ 链接:https://arxiv.org/abs/2412.13569
+ 作者:Sithu Aung,Min-Cheol Sagong,Junghyun Cho
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:urban traffic, address an advanced, advanced challenge, detection in urban, multi-view pedestrian detection
+ 备注: AAAI 2025
+
+ 点击查看摘要
+ Abstract:We address an advanced challenge of predicting pedestrian occupancy as an extension of multi-view pedestrian detection in urban traffic. To support this, we have created a new synthetic dataset called MVP-Occ, designed for dense pedestrian scenarios in large-scale scenes. Our dataset provides detailed representations of pedestrians using voxel structures, accompanied by rich semantic scene understanding labels, facilitating visual navigation and insights into pedestrian spatial information. Furthermore, we present a robust baseline model, termed OmniOcc, capable of predicting both the voxel occupancy state and panoptic labels for the entire scene from multi-view images. Through in-depth analysis, we identify and evaluate the key elements of our proposed model, highlighting their specific contributions and importance.
+
+
+
+ 80. 【2412.13565】CA-Edit: Causality-Aware Condition Adapter for High-Fidelity Local Facial Attribute Editing
+ 链接:https://arxiv.org/abs/2412.13565
+ 作者:Xiaole Xian,Xilin He,Zenghao Niu,Junliang Zhang,Weicheng Xie,Siyang Song,Zitong Yu,Linlin Shen
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:require additional fine-tuning, high-fidelity local facial, existing editing methods, efficient and high-fidelity, require additional
+ 备注: accepted by aaai
+
+ 点击查看摘要
+ Abstract:For efficient and high-fidelity local facial attribute editing, most existing editing methods either require additional fine-tuning for different editing effects or tend to affect beyond the editing regions. Alternatively, inpainting methods can edit the target image region while preserving external areas. However, current inpainting methods still suffer from the generation misalignment with facial attributes description and the loss of facial skin details. To address these challenges, (i) a novel data utilization strategy is introduced to construct datasets consisting of attribute-text-image triples from a data-driven perspective, (ii) a Causality-Aware Condition Adapter is proposed to enhance the contextual causality modeling of specific details, which encodes the skin details from the original image while preventing conflicts between these cues and textual conditions. In addition, a Skin Transition Frequency Guidance technique is introduced for the local modeling of contextual causality via sampling guidance driven by low-frequency alignment. Extensive quantitative and qualitative experiments demonstrate the effectiveness of our method in boosting both fidelity and editability for localized attribute editing. The code is available at this https URL.
+
+
+
+ 81. 【2412.13552】DragScene: Interactive 3D Scene Editing with Single-view Drag Instructions
+ 链接:https://arxiv.org/abs/2412.13552
+ 作者:Chenghao Gu,Zhenzhe Li,Zhengqi Zhang,Yunpeng Bai,Shuzhao Xie,Zhi Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:shown remarkable capability, editing, shown remarkable, Drag-style editing, remarkable capability
+ 备注:
+
+ 点击查看摘要
+ Abstract:3D editing has shown remarkable capability in editing scenes based on various instructions. However, existing methods struggle with achieving intuitive, localized editing, such as selectively making flowers blossom. Drag-style editing has shown exceptional capability to edit images with direct manipulation instead of ambiguous text commands. Nevertheless, extending drag-based editing to 3D scenes presents substantial challenges due to multi-view inconsistency. To this end, we introduce DragScene, a framework that integrates drag-style editing with diverse 3D representations. First, latent optimization is performed on a reference view to generate 2D edits based on user instructions. Subsequently, coarse 3D clues are reconstructed from the reference view using a point-based representation to capture the geometric details of the edits. The latent representation of the edited view is then mapped to these 3D clues, guiding the latent optimization of other views. This process ensures that edits are propagated seamlessly across multiple views, maintaining multi-view consistency. Finally, the target 3D scene is reconstructed from the edited multi-view images. Extensive experiments demonstrate that DragScene facilitates precise and flexible drag-style editing of 3D scenes, supporting broad applicability across diverse 3D representations.
+
+
+
+ 82. 【2412.13547】urbo-GS: Accelerating 3D Gaussian Fitting for High-Quality Radiance Fields
+ 链接:https://arxiv.org/abs/2412.13547
+ 作者:Tao Lu,Ankit Dhiman,R Srinath,Emre Arslan,Angela Xing,Yuanbo Xiangli,R Venkatesh Babu,Srinath Sridhar
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Novel-view synthesis, mixed reality, important problem, problem in computer, computer vision
+ 备注: Project page: [this https URL](https://ivl.cs.brown.edu/research/turbo-gs)
+
+ 点击查看摘要
+ Abstract:Novel-view synthesis is an important problem in computer vision with applications in 3D reconstruction, mixed reality, and robotics. Recent methods like 3D Gaussian Splatting (3DGS) have become the preferred method for this task, providing high-quality novel views in real time. However, the training time of a 3DGS model is slow, often taking 30 minutes for a scene with 200 views. In contrast, our goal is to reduce the optimization time by training for fewer steps while maintaining high rendering quality. Specifically, we combine the guidance from both the position error and the appearance error to achieve a more effective densification. To balance the rate between adding new Gaussians and fitting old Gaussians, we develop a convergence-aware budget control mechanism. Moreover, to make the densification process more reliable, we selectively add new Gaussians from mostly visited regions. With these designs, we reduce the Gaussian optimization steps to one-third of the previous approach while achieving a comparable or even better novel view rendering quality. To further facilitate the rapid fitting of 4K resolution images, we introduce a dilation-based rendering technique. Our method, Turbo-GS, speeds up optimization for typical scenes and scales well to high-resolution (4K) scenarios on standard datasets. Through extensive experiments, we show that our method is significantly faster in optimization than other methods while retaining quality. Project page: this https URL.
+
+
+
+ 83. 【2412.13543】Query-centric Audio-Visual Cognition Network for Moment Retrieval, Segmentation and Step-Captioning
+ 链接:https://arxiv.org/abs/2412.13543
+ 作者:Yunbin Tu,Liang Li,Li Su,Qingming Huang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:favored multimedia format, including video retrieval, video retrieval, favored multimedia, multimedia format
+ 备注: Accepted by AAAI 2025
+
+ 点击查看摘要
+ Abstract:Video has emerged as a favored multimedia format on the internet. To better gain video contents, a new topic HIREST is presented, including video retrieval, moment retrieval, moment segmentation, and step-captioning. The pioneering work chooses the pre-trained CLIP-based model for video retrieval, and leverages it as a feature extractor for other three challenging tasks solved in a multi-task learning paradigm. Nevertheless, this work struggles to learn the comprehensive cognition of user-preferred content, due to disregarding the hierarchies and association relations across modalities. In this paper, guided by the shallow-to-deep principle, we propose a query-centric audio-visual cognition (QUAG) network to construct a reliable multi-modal representation for moment retrieval, segmentation and step-captioning. Specifically, we first design the modality-synergistic perception to obtain rich audio-visual content, by modeling global contrastive alignment and local fine-grained interaction between visual and audio modalities. Then, we devise the query-centric cognition that uses the deep-level query to perform the temporal-channel filtration on the shallow-level audio-visual representation. This can cognize user-preferred content and thus attain a query-centric audio-visual representation for three tasks. Extensive experiments show QUAG achieves the SOTA results on HIREST. Further, we test QUAG on the query-based video summarization task and verify its good generalization.
+
+
+
+ 84. 【2412.13541】Spatio-Temporal Fuzzy-oriented Multi-Modal Meta-Learning for Fine-grained Emotion Recognition
+ 链接:https://arxiv.org/abs/2412.13541
+ 作者:Jingyao Wang,Yuxuan Yang,Wenwen Qiang,Changwen Zheng,Hui Xiong
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Neural and Evolutionary Computing (cs.NE)
+ 关键词:personalized recommendations, plays a vital, disease diagnosis, multimedia mining, Fuzzy-oriented Multi-modal Meta-learning
+ 备注: 13 pages, Submitted to TMM in 30-May-2024
+
+ 点击查看摘要
+ Abstract:Fine-grained emotion recognition (FER) plays a vital role in various fields, such as disease diagnosis, personalized recommendations, and multimedia mining. However, existing FER methods face three key challenges in real-world applications: (i) they rely on large amounts of continuously annotated data to ensure accuracy since emotions are complex and ambiguous in reality, which is costly and time-consuming; (ii) they cannot capture the temporal heterogeneity caused by changing emotion patterns, because they usually assume that the temporal correlation within sampling periods is the same; (iii) they do not consider the spatial heterogeneity of different FER scenarios, that is, the distribution of emotion information in different data may have bias or interference. To address these challenges, we propose a Spatio-Temporal Fuzzy-oriented Multi-modal Meta-learning framework (ST-F2M). Specifically, ST-F2M first divides the multi-modal videos into multiple views, and each view corresponds to one modality of one emotion. Multiple randomly selected views for the same emotion form a meta-training task. Next, ST-F2M uses an integrated module with spatial and temporal convolutions to encode the data of each task, reflecting the spatial and temporal heterogeneity. Then it adds fuzzy semantic information to each task based on generalized fuzzy rules, which helps handle the complexity and ambiguity of emotions. Finally, ST-F2M learns emotion-related general meta-knowledge through meta-recurrent neural networks to achieve fast and robust fine-grained emotion recognition. Extensive experiments show that ST-F2M outperforms various state-of-the-art methods in terms of accuracy and model efficiency. In addition, we construct ablation studies and further analysis to explore why ST-F2M performs well.
+
+
+
+ 85. 【2412.13540】Benchmarking and Improving Large Vision-Language Models for Fundamental Visual Graph Understanding and Reasoning
+ 链接:https://arxiv.org/abs/2412.13540
+ 作者:Yingjie Zhu,Xuefeng Bai,Kehai Chen,Yang Xiang,Min Zhang
+ 类目:Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Large Vision-Language Models, Large Vision-Language, Vision-Language Models, demonstrated remarkable performance, demonstrated remarkable
+ 备注:
+
+ 点击查看摘要
+ Abstract:Large Vision-Language Models (LVLMs) have demonstrated remarkable performance across diverse tasks. Despite great success, recent studies show that LVLMs encounter substantial limitations when engaging with visual graphs. To study the reason behind these limitations, we propose VGCure, a comprehensive benchmark covering 22 tasks for examining the fundamental graph understanding and reasoning capacities of LVLMs. Extensive evaluations conducted on 14 LVLMs reveal that LVLMs are weak in basic graph understanding and reasoning tasks, particularly those concerning relational or structurally complex information. Based on this observation, we propose a structure-aware fine-tuning framework to enhance LVLMs with structure learning abilities through 3 self-supervised learning tasks. Experiments validate the effectiveness of our method in improving LVLMs' zero-shot performance on fundamental graph learning tasks, as well as enhancing the robustness of LVLMs against complex visual graphs.
+
+
+
+ 86. 【2412.13533】Language-guided Medical Image Segmentation with Target-informed Multi-level Contrastive Alignments
+ 链接:https://arxiv.org/abs/2412.13533
+ 作者:Mingjian Li,Mingyuan Meng,Shuchang Ye,David Dagan Feng,Lei Bi,Jinman Kim
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:language-guided segmentation, crucial in modern, aid into diagnosis, image, segmentation
+ 备注:
+
+ 点击查看摘要
+ Abstract:Medical image segmentation is crucial in modern medical image analysis, which can aid into diagnosis of various disease conditions. Recently, language-guided segmentation methods have shown promising results in automating image segmentation where text reports are incorporated as guidance. These text reports, containing image impressions and insights given by clinicians, provides auxiliary guidance. However, these methods neglect the inherent pattern gaps between the two distinct modalities, which leads to sub-optimal image-text feature fusion without proper cross-modality feature alignments. Contrastive alignments are widely used to associate image-text semantics in representation learning; however, it has not been exploited to bridge the pattern gaps in language-guided segmentation that relies on subtle low level image details to represent diseases. Existing contrastive alignment methods typically algin high-level global image semantics without involving low-level, localized target information, and therefore fails to explore fine-grained text guidance for language-guided segmentation. In this study, we propose a language-guided segmentation network with Target-informed Multi-level Contrastive Alignments (TMCA). TMCA enables target-informed cross-modality alignments and fine-grained text guidance to bridge the pattern gaps in language-guided segmentation. Specifically, we introduce: 1) a target-sensitive semantic distance module that enables granular image-text alignment modelling, and 2) a multi-level alignment strategy that directs text guidance on low-level image features. In addition, a language-guided target enhancement module is proposed to leverage the aligned text to redirect attention to focus on critical localized image features. Extensive experiments on 4 image-text datasets, involving 3 medical imaging modalities, demonstrated that our TMCA achieved superior performances.
+
+
+
+ 87. 【2412.13525】Hybrid Data-Free Knowledge Distillation
+ 链接:https://arxiv.org/abs/2412.13525
+ 作者:Jialiang Tang,Shuo Chen,Chen Gong
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Data-free knowledge distillation, Data-free knowledge, pre-trained large teacher, teacher network, knowledge distillation aims
+ 备注:
+
+ 点击查看摘要
+ Abstract:Data-free knowledge distillation aims to learn a compact student network from a pre-trained large teacher network without using the original training data of the teacher network. Existing collection-based and generation-based methods train student networks by collecting massive real examples and generating synthetic examples, respectively. However, they inevitably become weak in practical scenarios due to the difficulties in gathering or emulating sufficient real-world data. To solve this problem, we propose a novel method called \textbf{H}ybr\textbf{i}d \textbf{D}ata-\textbf{F}ree \textbf{D}istillation (HiDFD), which leverages only a small amount of collected data as well as generates sufficient examples for training student networks. Our HiDFD comprises two primary modules, \textit{i.e.}, the teacher-guided generation and student distillation. The teacher-guided generation module guides a Generative Adversarial Network (GAN) by the teacher network to produce high-quality synthetic examples from very few real-world collected examples. Specifically, we design a feature integration mechanism to prevent the GAN from overfitting and facilitate the reliable representation learning from the teacher network. Meanwhile, we drive a category frequency smoothing technique via the teacher network to balance the generative training of each category. In the student distillation module, we explore a data inflation strategy to properly utilize a blend of real and synthetic data to train the student network via a classifier-sharing-based feature alignment technique. Intensive experiments across multiple benchmarks demonstrate that our HiDFD can achieve state-of-the-art performance using 120 times less collected data than existing methods. Code is available at this https URL.
+
+
+
+ 88. 【2412.13510】Dynamic Adapter with Semantics Disentangling for Cross-lingual Cross-modal Retrieval
+ 链接:https://arxiv.org/abs/2412.13510
+ 作者:Rui Cai,Zhiyu Dong,Jianfeng Dong,Xun Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL)
+ 关键词:Existing cross-modal retrieval, methods typically rely, retrieval methods typically, cross-modal retrieval methods, Cross-lingual Cross-modal Retrieval
+ 备注: Accepted by the 39th AAAI Conference on Artificial Intelligence (AAAI-25)
+
+ 点击查看摘要
+ Abstract:Existing cross-modal retrieval methods typically rely on large-scale vision-language pair data. This makes it challenging to efficiently develop a cross-modal retrieval model for under-resourced languages of interest. Therefore, Cross-lingual Cross-modal Retrieval (CCR), which aims to align vision and the low-resource language (the target language) without using any human-labeled target-language data, has gained increasing attention. As a general parameter-efficient way, a common solution is to utilize adapter modules to transfer the vision-language alignment ability of Vision-Language Pretraining (VLP) models from a source language to a target language. However, these adapters are usually static once learned, making it difficult to adapt to target-language captions with varied expressions. To alleviate it, we propose Dynamic Adapter with Semantics Disentangling (DASD), whose parameters are dynamically generated conditioned on the characteristics of the input captions. Considering that the semantics and expression styles of the input caption largely influence how to encode it, we propose a semantic disentangling module to extract the semantic-related and semantic-agnostic features from the input, ensuring that generated adapters are well-suited to the characteristics of input caption. Extensive experiments on two image-text datasets and one video-text dataset demonstrate the effectiveness of our model for cross-lingual cross-modal retrieval, as well as its good compatibility with various VLP models.
+
+
+
+ 89. 【2412.13507】Novel AI Camera Camouflage: Face Cloaking Without Full Disguise
+ 链接:https://arxiv.org/abs/2412.13507
+ 作者:David Noever,Forrest McKee
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:combines targeted cosmetic, targeted cosmetic perturbations, evade modern facial, modern facial recognition, Microsoft Bing Visual
+ 备注:
+
+ 点击查看摘要
+ Abstract:This study demonstrates a novel approach to facial camouflage that combines targeted cosmetic perturbations and alpha transparency layer manipulation to evade modern facial recognition systems. Unlike previous methods -- such as CV dazzle, adversarial patches, and theatrical disguises -- this work achieves effective obfuscation through subtle modifications to key-point regions, particularly the brow, nose bridge, and jawline. Empirical testing with Haar cascade classifiers and commercial systems like BetaFaceAPI and Microsoft Bing Visual Search reveals that vertical perturbations near dense facial key points significantly disrupt detection without relying on overt disguises. Additionally, leveraging alpha transparency attacks in PNG images creates a dual-layer effect: faces remain visible to human observers but disappear in machine-readable RGB layers, rendering them unidentifiable during reverse image searches. The results highlight the potential for creating scalable, low-visibility facial obfuscation strategies that balance effectiveness and subtlety, opening pathways for defeating surveillance while maintaining plausible anonymity.
+
+
+
+ 90. 【2412.13504】Urban Air Temperature Prediction using Conditional Diffusion Models
+ 链接:https://arxiv.org/abs/2412.13504
+ 作者:Siyang Dai,Jun Liu,Ngai-Man Cheung
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:urban heat island, environmental challenges, heat island, global trend, trend has led
+ 备注:
+
+ 点击查看摘要
+ Abstract:Urbanization as a global trend has led to many environmental challenges, including the urban heat island (UHI) effect. The increase in temperature has a significant impact on the well-being of urban residents. Air temperature ($T_a$) at 2m above the surface is a key indicator of the UHI effect. How land use land cover (LULC) affects $T_a$ is a critical research question which requires high-resolution (HR) $T_a$ data at neighborhood scale. However, weather stations providing $T_a$ measurements are sparsely distributed e.g. more than 10km apart; and numerical models are impractically slow and computationally expensive. In this work, we propose a novel method to predict HR $T_a$ at 100m ground separation distance (gsd) using land surface temperature (LST) and other LULC related features which can be easily obtained from satellite imagery. Our method leverages diffusion models for the first time to generate accurate and visually realistic HR $T_a$ maps, which outperforms prior methods. We pave the way for meteorological research using computer vision techniques by providing a dataset of an extended spatial and temporal coverage, and a high spatial resolution as a benchmark for future research. Furthermore, we show that our model can be applied to urban planning by simulating the impact of different urban designs on $T_a$.
+
+
+
+ 91. 【2412.13502】Level-Set Parameters: Novel Representation for 3D Shape Analysis
+ 链接:https://arxiv.org/abs/2412.13502
+ 作者:Huan Lei,Hongdong Li,Andreas Geiger,Anthony Dick
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:input resolutions, largely focused, discrete nature, susceptible to variations, variations in input
+ 备注:
+
+ 点击查看摘要
+ Abstract:3D shape analysis has been largely focused on traditional 3D representations of point clouds and meshes, but the discrete nature of these data makes the analysis susceptible to variations in input resolutions. Recent development of neural fields brings in level-set parameters from signed distance functions as a novel, continuous, and numerical representation of 3D shapes, where the shape surfaces are defined as zero-level-sets of those functions. This motivates us to extend shape analysis from the traditional 3D data to these novel parameter data. Since the level-set parameters are not Euclidean like point clouds, we establish correlations across different shapes by formulating them as a pseudo-normal distribution, and learn the distribution prior from the respective dataset. To further explore the level-set parameters with shape transformations, we propose to condition a subset of these parameters on rotations and translations, and generate them with a hypernetwork. This simplifies the pose-related shape analysis compared to using traditional data. We demonstrate the promise of the novel representations through applications in shape classification (arbitrary poses), retrieval, and 6D object pose estimation. Code and data in this research are provided at this https URL.
+
+
+
+ 92. 【2412.13496】QueryCDR: Query-based Controllable Distortion Rectification Network for Fisheye Images
+ 链接:https://arxiv.org/abs/2412.13496
+ 作者:Pengbo Guo,Chengxu Liu,Xingsong Hou,Xueming Qian
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:distortion, aims to correct, image rectification aims, Controllable Distortion Rectification, varying degrees
+ 备注: ECCV2024
+
+ 点击查看摘要
+ Abstract:Fisheye image rectification aims to correct distortions in images taken with fisheye cameras. Although current models show promising results on images with a similar degree of distortion as the training data, they will produce sub-optimal results when the degree of distortion changes and without retraining. The lack of generalization ability for dealing with varying degrees of distortion limits their practical application. In this paper, we take one step further to enable effective distortion rectification for images with varying degrees of distortion without retraining. We propose a novel Query-based Controllable Distortion Rectification network for fisheye images (QueryCDR). In particular, we first present the Distortion-aware Learnable Query Mechanism (DLQM), which defines the latent spatial relationships for different distortion degrees as a series of learnable queries. Each query can be learned to obtain position-dependent rectification control conditions, providing control over the rectification process. Then, we propose two kinds of controllable modulating blocks to enable the control conditions to guide the modulation of the distortion features better. These core components cooperate with each other to effectively boost the generalization ability of the model at varying degrees of distortion. Extensive experiments on fisheye image datasets with different distortion degrees demonstrate our approach achieves high-quality and controllable distortion rectification.
+
+
+
+ 93. 【2412.13490】Comparative Analysis of YOLOv9, YOLOv10 and RT-DETR for Real-Time Weed Detection
+ 链接:https://arxiv.org/abs/2412.13490
+ 作者:Ahmet Oğuz Saltık,Alicia Allmendinger,Anthony Stein
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:smart-spraying applications focusing, object detection models, paper presents, presents a comprehensive, comprehensive evaluation
+ 备注:
+
+ 点击查看摘要
+ Abstract:This paper presents a comprehensive evaluation of state-of-the-art object detection models, including YOLOv9, YOLOv10, and RT-DETR, for the task of weed detection in smart-spraying applications focusing on three classes: Sugarbeet, Monocot, and Dicot. The performance of these models is compared based on mean Average Precision (mAP) scores and inference times on different GPU devices. We consider various model variations, such as nano, small, medium, large alongside different image resolutions (320px, 480px, 640px, 800px, 960px). The results highlight the trade-offs between inference time and detection accuracy, providing valuable insights for selecting the most suitable model for real-time weed detection. This study aims to guide the development of efficient and effective smart spraying systems, enhancing agricultural productivity through precise weed management.
+
+
+
+ 94. 【2412.13486】$^3$-S2S: Training-free Triplet Tuning for Sketch to Scene Generation
+ 链接:https://arxiv.org/abs/2412.13486
+ 作者:Zhenhong Sun,Yifu Wang,Yonhon Ng,Yunfei Duan,Daoyi Dong,Hongdong Li,Pan Ji
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL); Graphics (cs.GR)
+ 关键词:computer graphics applications, graphics applications, computer graphics, Training-free Triplet Tuning, scene concept art
+ 备注:
+
+ 点击查看摘要
+ Abstract:Scene generation is crucial to many computer graphics applications. Recent advances in generative AI have streamlined sketch-to-image workflows, easing the workload for artists and designers in creating scene concept art. However, these methods often struggle for complex scenes with multiple detailed objects, sometimes missing small or uncommon instances. In this paper, we propose a Training-free Triplet Tuning for Sketch-to-Scene (T3-S2S) generation after reviewing the entire cross-attention mechanism. This scheme revitalizes the existing ControlNet model, enabling effective handling of multi-instance generations, involving prompt balance, characteristics prominence, and dense tuning. Specifically, this approach enhances keyword representation via the prompt balance module, reducing the risk of missing critical instances. It also includes a characteristics prominence module that highlights TopK indices in each channel, ensuring essential features are better represented based on token sketches. Additionally, it employs dense tuning to refine contour details in the attention map, compensating for instance-related regions. Experiments validate that our triplet tuning approach substantially improves the performance of existing sketch-to-image models. It consistently generates detailed, multi-instance 2D images, closely adhering to the input prompts and enhancing visual quality in complex multi-instance scenes. Code is available at this https URL.
+
+
+
+ 95. 【2412.13479】Real-time One-Step Diffusion-based Expressive Portrait Videos Generation
+ 链接:https://arxiv.org/abs/2412.13479
+ 作者:Hanzhong Guo,Hongwei Yi,Daquan Zhou,Alexander William Bergman,Michael Lingelbach,Yizhou Yu
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:made great strides, Latent diffusion models, generating expressive portrait, single reference image, audio input
+ 备注: 14 pages
+
+ 点击查看摘要
+ Abstract:Latent diffusion models have made great strides in generating expressive portrait videos with accurate lip-sync and natural motion from a single reference image and audio input. However, these models are far from real-time, often requiring many sampling steps that take minutes to generate even one second of video-significantly limiting practical use. We introduce OSA-LCM (One-Step Avatar Latent Consistency Model), paving the way for real-time diffusion-based avatars. Our method achieves comparable video quality to existing methods but requires only one sampling step, making it more than 10x faster. To accomplish this, we propose a novel avatar discriminator design that guides lip-audio consistency and motion expressiveness to enhance video quality in limited sampling steps. Additionally, we employ a second-stage training architecture using an editing fine-tuned method (EFT), transforming video generation into an editing task during training to effectively address the temporal gap challenge in single-step generation. Experiments demonstrate that OSA-LCM outperforms existing open-source portrait video generation models while operating more efficiently with a single sampling step.
+
+
+
+ 96. 【2412.13469】Enabling Region-Specific Control via Lassos in Point-Based Colorization
+ 链接:https://arxiv.org/abs/2412.13469
+ 作者:Sanghyeon Lee,Jooyeol Yun,Jaegul Choo
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
+ 关键词:Point-based interactive colorization, interactive colorization techniques, effortlessly colorize grayscale, colorize grayscale images, Point-based interactive
+ 备注: Accepted to AAAI2025
+
+ 点击查看摘要
+ Abstract:Point-based interactive colorization techniques allow users to effortlessly colorize grayscale images using user-provided color hints. However, point-based methods often face challenges when different colors are given to semantically similar areas, leading to color intermingling and unsatisfactory results-an issue we refer to as color collapse. The fundamental cause of color collapse is the inadequacy of points for defining the boundaries for each color. To mitigate color collapse, we introduce a lasso tool that can control the scope of each color hint. Additionally, we design a framework that leverages the user-provided lassos to localize the attention masks. The experimental results show that using a single lasso is as effective as applying 4.18 individual color hints and can achieve the desired outcomes in 30% less time than using points alone.
+
+
+
+ 97. 【2412.13463】FlexPose: Pose Distribution Adaptation with Limited Guidance
+ 链接:https://arxiv.org/abs/2412.13463
+ 作者:Zixiao Wang,Junwu Weng,Mengyuan Liu,Bei Yu
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Numerous well-annotated human, Numerous well-annotated, well-annotated human key-point, human key-point datasets, Pose
+ 备注: Accepted by AAAI25, 12 pages, 10 figures
+
+ 点击查看摘要
+ Abstract:Numerous well-annotated human key-point datasets are publicly available to date. However, annotating human poses for newly collected images is still a costly and time-consuming progress. Pose distributions from different datasets share similar pose hinge-structure priors with different geometric transformations, such as pivot orientation, joint rotation, and bone length ratio. The difference between Pose distributions is essentially the difference between the transformation distributions. Inspired by this fact, we propose a method to calibrate a pre-trained pose generator in which the pose prior has already been learned to an adapted one following a new pose distribution. We treat the representation of human pose joint coordinates as skeleton image and transfer a pre-trained pose annotation generator with only a few annotation guidance. By fine-tuning a limited number of linear layers that closely related to the pose transformation, the adapted generator is able to produce any number of pose annotations that are similar to the target poses. We evaluate our proposed method, FlexPose, on several cross-dataset settings both qualitatively and quantitatively, which demonstrates that our approach achieves state-of-the-art performance compared to the existing generative-model-based transfer learning methods when given limited annotation guidance.
+
+
+
+ 98. 【2412.13461】Look Inside for More: Internal Spatial Modality Perception for 3D Anomaly Detection
+ 链接:https://arxiv.org/abs/2412.13461
+ 作者:Hanzhe Liang,Guoyang Xie,Chengbin Hou,Bingshu Wang,Can Gao,Jinbao Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Image and Video Processing (eess.IV)
+ 关键词:computer vision, anomaly detection, anomaly detection performance, significant focus, focus in computer
+ 备注: AAAI2025 Accepted
+
+ 点击查看摘要
+ Abstract:3D anomaly detection has recently become a significant focus in computer vision. Several advanced methods have achieved satisfying anomaly detection performance. However, they typically concentrate on the external structure of 3D samples and struggle to leverage the internal information embedded within samples. Inspired by the basic intuition of why not look inside for more, we introduce a straightforward method named Internal Spatial Modality Perception (ISMP) to explore the feature representation from internal views fully. Specifically, our proposed ISMP consists of a critical perception module, Spatial Insight Engine (SIE), which abstracts complex internal information of point clouds into essential global features. Besides, to better align structural information with point data, we propose an enhanced key point feature extraction module for amplifying spatial structure feature representation. Simultaneously, a novel feature filtering module is incorporated to reduce noise and redundant features for further aligning precise spatial structure. Extensive experiments validate the effectiveness of our proposed method, achieving object-level and pixel-level AUROC improvements of 4.2% and 13.1%, respectively, on the Real3D-AD benchmarks. Note that the strong generalization ability of SIE has been theoretically proven and is verified in both classification and segmentation tasks.
+
+
+
+ 99. 【2412.13454】Pre-training a Density-Aware Pose Transformer for Robust LiDAR-based 3D Human Pose Estimation
+ 链接:https://arxiv.org/abs/2412.13454
+ 作者:Xiaoqi An,Lin Zhao,Chen Gong,Jun Li,Jian Yang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:Human Pose Estimation, Pose Estimation, pose estimation remains, point clouds, autonomous driving
+ 备注: Accepted to AAAI 2025
+
+ 点击查看摘要
+ Abstract:With the rapid development of autonomous driving, LiDAR-based 3D Human Pose Estimation (3D HPE) is becoming a research focus. However, due to the noise and sparsity of LiDAR-captured point clouds, robust human pose estimation remains challenging. Most of the existing methods use temporal information, multi-modal fusion, or SMPL optimization to correct biased results. In this work, we try to obtain sufficient information for 3D HPE only by modeling the intrinsic properties of low-quality point clouds. Hence, a simple yet powerful method is proposed, which provides insights both on modeling and augmentation of point clouds. Specifically, we first propose a concise and effective density-aware pose transformer (DAPT) to get stable keypoint representations. By using a set of joint anchors and a carefully designed exchange module, valid information is extracted from point clouds with different densities. Then 1D heatmaps are utilized to represent the precise locations of the keypoints. Secondly, a comprehensive LiDAR human synthesis and augmentation method is proposed to pre-train the model, enabling it to acquire a better human body prior. We increase the diversity of point clouds by randomly sampling human positions and orientations and by simulating occlusions through the addition of laser-level masks. Extensive experiments have been conducted on multiple datasets, including IMU-annotated LidarHuman26M, SLOPER4D, and manually annotated Waymo Open Dataset v2.0 (Waymo), HumanM3. Our method demonstrates SOTA performance in all scenarios. In particular, compared with LPFormer on Waymo, we reduce the average MPJPE by $10.0mm$. Compared with PRN on SLOPER4D, we notably reduce the average MPJPE by $20.7mm$.
+
+
+
+ 100. 【2412.13452】ConDo: Continual Domain Expansion for Absolute Pose Regression
+ 链接:https://arxiv.org/abs/2412.13452
+ 作者:Zijun Li,Zhipeng Cai,Bochun Yang,Xuelun Shen,Siqi Shen,Xiaoliang Fan,Michael Paulitsch,Cheng Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
+ 关键词:machine learning problem, fundamental machine learning, Visual localization, Absolute Pose Regression, learning problem
+ 备注: AAAI2025
+
+ 点击查看摘要
+ Abstract:Visual localization is a fundamental machine learning problem. Absolute Pose Regression (APR) trains a scene-dependent model to efficiently map an input image to the camera pose in a pre-defined scene. However, many applications have continually changing environments, where inference data at novel poses or scene conditions (weather, geometry) appear after deployment. Training APR on a fixed dataset leads to overfitting, making it fail catastrophically on challenging novel data. This work proposes Continual Domain Expansion (ConDo), which continually collects unlabeled inference data to update the deployed APR. Instead of applying standard unsupervised domain adaptation methods which are ineffective for APR, ConDo effectively learns from unlabeled data by distilling knowledge from scene-agnostic localization methods. By sampling data uniformly from historical and newly collected data, ConDo can effectively expand the generalization domain of APR. Large-scale benchmarks with various scene types are constructed to evaluate models under practical (long-term) data changes. ConDo consistently and significantly outperforms baselines across architectures, scene types, and data changes. On challenging scenes (Fig.1), it reduces the localization error by 7x (14.8m vs 1.7m). Analysis shows the robustness of ConDo against compute budgets, replay buffer sizes and teacher prediction noise. Comparing to model re-training, ConDo achieves similar performance up to 25x faster.
+
+
+
+ 101. 【2412.13443】DarkIR: Robust Low-Light Image Restoration
+ 链接:https://arxiv.org/abs/2412.13443
+ 作者:Daniel Feijoo,Juan C. Benito,Alvaro Garcia,Marcos V. Conde
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV)
+ 关键词:blurring issues due, conditions typically suffers, Low-light Image Enhancement, dark conditions typically, suffers from noise
+ 备注: Technical Report
+
+ 点击查看摘要
+ Abstract:Photography during night or in dark conditions typically suffers from noise, low light and blurring issues due to the dim environment and the common use of long exposure. Although Deblurring and Low-light Image Enhancement (LLIE) are related under these conditions, most approaches in image restoration solve these tasks separately. In this paper, we present an efficient and robust neural network for multi-task low-light image restoration. Instead of following the current tendency of Transformer-based models, we propose new attention mechanisms to enhance the receptive field of efficient CNNs. Our method reduces the computational costs in terms of parameters and MAC operations compared to previous methods. Our model, DarkIR, achieves new state-of-the-art results on the popular LOLBlur, LOLv2 and Real-LOLBlur datasets, being able to generalize on real-world night and dark images. Code and models at this https URL
+
+
+
+ 102. 【2412.13441】FlashVTG: Feature Layering and Adaptive Score Handling Network for Video Temporal Grounding
+ 链接:https://arxiv.org/abs/2412.13441
+ 作者:Zhuo Cao,Bingqing Zhang,Heming Du,Xin Yu,Xue Li,Sen Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL)
+ 关键词:Highlight Detection, localize relevant segments, Text-guided Video Temporal, Video Temporal Grounding, Temporal Grounding
+ 备注: Accepted to WACV 2025
+
+ 点击查看摘要
+ Abstract:Text-guided Video Temporal Grounding (VTG) aims to localize relevant segments in untrimmed videos based on textual descriptions, encompassing two subtasks: Moment Retrieval (MR) and Highlight Detection (HD). Although previous typical methods have achieved commendable results, it is still challenging to retrieve short video moments. This is primarily due to the reliance on sparse and limited decoder queries, which significantly constrain the accuracy of predictions. Furthermore, suboptimal outcomes often arise because previous methods rank predictions based on isolated predictions, neglecting the broader video context. To tackle these issues, we introduce FlashVTG, a framework featuring a Temporal Feature Layering (TFL) module and an Adaptive Score Refinement (ASR) module. The TFL module replaces the traditional decoder structure to capture nuanced video content variations across multiple temporal scales, while the ASR module improves prediction ranking by integrating context from adjacent moments and multi-temporal-scale features. Extensive experiments demonstrate that FlashVTG achieves state-of-the-art performance on four widely adopted datasets in both MR and HD. Specifically, on the QVHighlights dataset, it boosts mAP by 5.8% for MR and 3.3% for HD. For short-moment retrieval, FlashVTG increases mAP to 125% of previous SOTA performance. All these improvements are made without adding training burdens, underscoring its effectiveness. Our code is available at this https URL.
+
+
+
+ 103. 【2412.13419】Exploring Transformer-Augmented LSTM for Temporal and Spatial Feature Learning in Trajectory Prediction
+ 链接:https://arxiv.org/abs/2412.13419
+ 作者:Chandra Raskoti,Weizi Li
+ 类目:Robotics (cs.RO); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:efficient autonomous driving, Accurate vehicle trajectory, Long Short-Term Memory, Accurate vehicle, trajectory prediction
+ 备注:
+
+ 点击查看摘要
+ Abstract:Accurate vehicle trajectory prediction is crucial for ensuring safe and efficient autonomous driving. This work explores the integration of Transformer based model with Long Short-Term Memory (LSTM) based technique to enhance spatial and temporal feature learning in vehicle trajectory prediction. Here, a hybrid model that combines LSTMs for temporal encoding with a Transformer encoder for capturing complex interactions between vehicles is proposed. Spatial trajectory features of the neighboring vehicles are processed and goes through a masked scatter mechanism in a grid based environment, which is then combined with temporal trajectory of the vehicles. This combined trajectory data are learned by sequential LSTM encoding and Transformer based attention layers. The proposed model is benchmarked against predecessor LSTM based methods, including STA-LSTM, SA-LSTM, CS-LSTM, and NaiveLSTM. Our results, while not outperforming it's predecessor, demonstrate the potential of integrating Transformers with LSTM based technique to build interpretable trajectory prediction model. Future work will explore alternative architectures using Transformer applications to further enhance performance. This study provides a promising direction for improving trajectory prediction models by leveraging transformer based architectures, paving the way for more robust and interpretable vehicle trajectory prediction system.
+
+
+
+ 104. 【2412.13401】Zero-Shot Low Light Image Enhancement with Diffusion Prior
+ 链接:https://arxiv.org/abs/2412.13401
+ 作者:Joshua Cho,Sara Aghajanzadeh,Zhen Zhu,D. A. Forsyth
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:Balancing aesthetic quality, Balancing aesthetic, degraded sources, computational photography, aesthetic quality
+ 备注:
+
+ 点击查看摘要
+ Abstract:Balancing aesthetic quality with fidelity when enhancing images from challenging, degraded sources is a core objective in computational photography. In this paper, we address low light image enhancement (LLIE), a task in which dark images often contain limited visible information. Diffusion models, known for their powerful image enhancement capacities, are a natural choice for this problem. However, their deep generative priors can also lead to hallucinations, introducing non-existent elements or substantially altering the visual semantics of the original scene. In this work, we introduce a novel zero-shot method for controlling and refining the generative behavior of diffusion models for dark-to-light image conversion tasks. Our method demonstrates superior performance over existing state-of-the-art methods in the task of low-light image enhancement, as evidenced by both quantitative metrics and qualitative analysis.
+
+
+
+ 105. 【2412.13394】Distribution Shifts at Scale: Out-of-distribution Detection in Earth Observation
+ 链接:https://arxiv.org/abs/2412.13394
+ 作者:Burak Ekim,Girmaw Abebe Tadesse,Caleb Robinson,Gilles Hacheme,Michael Schmitt,Rahul Dodhia,Juan M. Lavista Ferres
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Training robust deep, Earth Observation, robust deep learning, Training robust, critical in Earth
+ 备注:
+
+ 点击查看摘要
+ Abstract:Training robust deep learning models is critical in Earth Observation, where globally deployed models often face distribution shifts that degrade performance, especially in low-data regions. Out-of-distribution (OOD) detection addresses this challenge by identifying inputs that differ from in-distribution (ID) data. However, existing methods either assume access to OOD data or compromise primary task performance, making them unsuitable for real-world deployment. We propose TARDIS, a post-hoc OOD detection method for scalable geospatial deployments. The core novelty lies in generating surrogate labels by integrating information from ID data and unknown distributions, enabling OOD detection at scale. Our method takes a pre-trained model, ID data, and WILD samples, disentangling the latter into surrogate ID and surrogate OOD labels based on internal activations, and fits a binary classifier as an OOD detector. We validate TARDIS on EuroSAT and xBD datasets, across 17 experimental setups covering covariate and semantic shifts, showing that it performs close to the theoretical upper bound in assigning surrogate ID and OOD samples in 13 cases. To demonstrate scalability, we deploy TARDIS on the Fields of the World dataset, offering actionable insights into pre-trained model behavior for large-scale deployments. The code is publicly available at this https URL.
+
+
+
+ 106. 【2412.13393】MMHMR: Generative Masked Modeling for Hand Mesh Recovery
+ 链接:https://arxiv.org/abs/2412.13393
+ 作者:Muhammad Usama Saleem,Ekkasit Pinyoanuntapong,Mayur Jagdishbhai Patel,Hongfei Xue,Ahmed Helmy,Srijan Das,Pu Wang
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:single RGB image, single RGB, RGB image, challenging due, due to complex
+ 备注:
+
+ 点击查看摘要
+ Abstract:Reconstructing a 3D hand mesh from a single RGB image is challenging due to complex articulations, self-occlusions, and depth ambiguities. Traditional discriminative methods, which learn a deterministic mapping from a 2D image to a single 3D mesh, often struggle with the inherent ambiguities in 2D-to-3D mapping. To address this challenge, we propose MMHMR, a novel generative masked model for hand mesh recovery that synthesizes plausible 3D hand meshes by learning and sampling from the probabilistic distribution of the ambiguous 2D-to-3D mapping process. MMHMR consists of two key components: (1) a VQ-MANO, which encodes 3D hand articulations as discrete pose tokens in a latent space, and (2) a Context-Guided Masked Transformer that randomly masks out pose tokens and learns their joint distribution, conditioned on corrupted token sequences, image context, and 2D pose cues. This learned distribution facilitates confidence-guided sampling during inference, producing mesh reconstructions with low uncertainty and high precision. Extensive evaluations on benchmark and real-world datasets demonstrate that MMHMR achieves state-of-the-art accuracy, robustness, and realism in 3D hand mesh reconstruction. Project website: this https URL
+
+
+
+ 107. 【2412.13389】Marigold-DC: Zero-Shot Monocular Depth Completion with Guided Diffusion
+ 链接:https://arxiv.org/abs/2412.13389
+ 作者:Massimiliano Viola,Kevin Qu,Nando Metzger,Bingxin Ke,Alexander Becker,Konrad Schindler,Anton Obukhov
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Depth, upgrades sparse depth, Depth completion upgrades, completion upgrades sparse, sparse depth measurements
+ 备注:
+
+ 点击查看摘要
+ Abstract:Depth completion upgrades sparse depth measurements into dense depth maps guided by a conventional image. Existing methods for this highly ill-posed task operate in tightly constrained settings and tend to struggle when applied to images outside the training domain or when the available depth measurements are sparse, irregularly distributed, or of varying density. Inspired by recent advances in monocular depth estimation, we reframe depth completion as an image-conditional depth map generation guided by sparse measurements. Our method, Marigold-DC, builds on a pretrained latent diffusion model for monocular depth estimation and injects the depth observations as test-time guidance via an optimization scheme that runs in tandem with the iterative inference of denoising diffusion. The method exhibits excellent zero-shot generalization across a diverse range of environments and handles even extremely sparse guidance effectively. Our results suggest that contemporary monocular depth priors greatly robustify depth completion: it may be better to view the task as recovering dense depth from (dense) image pixels, guided by sparse depth; rather than as inpainting (sparse) depth, guided by an image. Project website: this https URL
+
+
+
+ 108. 【2412.13376】argeted View-Invariant Adversarial Perturbations for 3D Object Recognition
+ 链接:https://arxiv.org/abs/2412.13376
+ 作者:Christian Green,Mehmet Ergezer,Abdurrahman Zeybey
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Cryptography and Security (cs.CR); Image and Video Processing (eess.IV)
+ 关键词:pose significant challenges, scenarios involving multi-view, involving multi-view analysis, attacks pose significant, varying angles
+ 备注: Accepted to AAAI-25 Workshop on Artificial Intelligence for Cyber Security (AICS): [this http URL](http://aics.site/AICS2025/index.html)
+
+ 点击查看摘要
+ Abstract:Adversarial attacks pose significant challenges in 3D object recognition, especially in scenarios involving multi-view analysis where objects can be observed from varying angles. This paper introduces View-Invariant Adversarial Perturbations (VIAP), a novel method for crafting robust adversarial examples that remain effective across multiple viewpoints. Unlike traditional methods, VIAP enables targeted attacks capable of manipulating recognition systems to classify objects as specific, pre-determined labels, all while using a single universal perturbation. Leveraging a dataset of 1,210 images across 121 diverse rendered 3D objects, we demonstrate the effectiveness of VIAP in both targeted and untargeted settings. Our untargeted perturbations successfully generate a singular adversarial noise robust to 3D transformations, while targeted attacks achieve exceptional results, with top-1 accuracies exceeding 95% across various epsilon values. These findings highlight VIAPs potential for real-world applications, such as testing the robustness of 3D recognition systems. The proposed method sets a new benchmark for view-invariant adversarial robustness, advancing the field of adversarial machine learning for 3D object recognition.
+
+
+
+ 109. 【2412.13364】Bringing Multimodality to Amazon Visual Search System
+ 链接:https://arxiv.org/abs/2412.13364
+ 作者:Xinliang Zhu,Michael Huang,Han Ding,Jinyu Yang,Kelvin Chen,Tao Zhou,Tal Neiman,Ouye Xie,Son Tran,Benjamin Yao,Doug Gray,Anuj Bindal,Arnab Dhua
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:computer vision community, vision community, computer vision, Image, matching
+ 备注:
+
+ 点击查看摘要
+ Abstract:Image to image matching has been well studied in the computer vision community. Previous studies mainly focus on training a deep metric learning model matching visual patterns between the query image and gallery images. In this study, we show that pure image-to-image matching suffers from false positives caused by matching to local visual patterns. To alleviate this issue, we propose to leverage recent advances in vision-language pretraining research. Specifically, we introduce additional image-text alignment losses into deep metric learning, which serve as constraints to the image-to-image matching loss. With additional alignments between the text (e.g., product title) and image pairs, the model can learn concepts from both modalities explicitly, which avoids matching low-level visual features. We progressively develop two variants, a 3-tower and a 4-tower model, where the latter takes one more short text query input. Through extensive experiments, we show that this change leads to a substantial improvement to the image to image matching problem. We further leveraged this model for multimodal search, which takes both image and reformulation text queries to improve search quality. Both offline and online experiments show strong improvements on the main metrics. Specifically, we see 4.95% relative improvement on image matching click through rate with the 3-tower model and 1.13% further improvement from the 4-tower model.
+
+
+
+ 110. 【2412.13324】BadSAD: Clean-Label Backdoor Attacks against Deep Semi-Supervised Anomaly Detection
+ 链接:https://arxiv.org/abs/2412.13324
+ 作者:He Cheng,Depeng Xu,Shuhan Yuan
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Cryptography and Security (cs.CR)
+ 关键词:anomaly detection, medical imaging, industrial inspection, Image anomaly detection, Semi-Supervised Anomaly Detection
+ 备注:
+
+ 点击查看摘要
+ Abstract:Image anomaly detection (IAD) is essential in applications such as industrial inspection, medical imaging, and security. Despite the progress achieved with deep learning models like Deep Semi-Supervised Anomaly Detection (DeepSAD), these models remain susceptible to backdoor attacks, presenting significant security challenges. In this paper, we introduce BadSAD, a novel backdoor attack framework specifically designed to target DeepSAD models. Our approach involves two key phases: trigger injection, where subtle triggers are embedded into normal images, and latent space manipulation, which positions and clusters the poisoned images near normal images to make the triggers appear benign. Extensive experiments on benchmark datasets validate the effectiveness of our attack strategy, highlighting the severe risks that backdoor attacks pose to deep learning-based anomaly detection systems.
+
+
+
+ 111. 【2412.13303】FastVLM: Efficient Vision Encoding for Vision Language Models
+ 链接:https://arxiv.org/abs/2412.13303
+ 作者:Pavan Kumar Anasosalu Vasu,Fartash Faghri,Chun-Liang Li,Cem Koc,Nate True,Albert Antony,Gokul Santhanam,James Gabriel,Peter Grasch,Oncel Tuzel,Hadi Pouransari
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
+ 关键词:Vision Language Models, image understanding tasks, text-rich image understanding, Vision Language, Language Models
+ 备注:
+
+ 点击查看摘要
+ Abstract:Scaling the input image resolution is essential for enhancing the performance of Vision Language Models (VLMs), particularly in text-rich image understanding tasks. However, popular visual encoders such as ViTs become inefficient at high resolutions due to the large number of tokens and high encoding latency caused by stacked self-attention layers. At different operational resolutions, the vision encoder of a VLM can be optimized along two axes: reducing encoding latency and minimizing the number of visual tokens passed to the LLM, thereby lowering overall latency. Based on a comprehensive efficiency analysis of the interplay between image resolution, vision latency, token count, and LLM size, we introduce FastVLM, a model that achieves an optimized trade-off between latency, model size and accuracy. FastVLM incorporates FastViTHD, a novel hybrid vision encoder designed to output fewer tokens and significantly reduce encoding time for high-resolution images. Unlike previous methods, FastVLM achieves the optimal balance between visual token count and image resolution solely by scaling the input image, eliminating the need for additional token pruning and simplifying the model design. In the LLaVA-1.5 setup, FastVLM achieves 3.2$\times$ improvement in time-to-first-token (TTFT) while maintaining similar performance on VLM benchmarks compared to prior works. Compared to LLaVa-OneVision at the highest resolution (1152$\times$1152), FastVLM achieves comparable performance on key benchmarks like SeedBench and MMMU, using the same 0.5B LLM, but with 85$\times$ faster TTFT and a vision encoder that is 3.4$\times$ smaller.
+
+
+
+ 112. 【2412.13294】Image registration is a geometric deep learning task
+ 链接:https://arxiv.org/abs/2412.13294
+ 作者:Vasiliki Sideri-Lampretsa,Nil Stolt-Ansó,Martin Menten,Huaqi Qiu,Julian McGinnis,Daniel Rueckert
+ 类目:Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:process grid-like inputs, methods predominantly rely, grid-like inputs, predominantly rely, Data-driven deformable image
+ 备注: 22 Pages
+
+ 点击查看摘要
+ Abstract:Data-driven deformable image registration methods predominantly rely on operations that process grid-like inputs. However, applying deformable transformations to an image results in a warped space that deviates from a rigid grid structure. Consequently, data-driven approaches with sequential deformations have to apply grid resampling operations between each deformation step. While artifacts caused by resampling are negligible in high-resolution images, the resampling of sparse, high-dimensional feature grids introduces errors that affect the deformation modeling process. Taking inspiration from Lagrangian reference frames of deformation fields, our work introduces a novel paradigm for data-driven deformable image registration that utilizes geometric deep-learning principles to model deformations without grid requirements. Specifically, we model image features as a set of nodes that freely move in Euclidean space, update their coordinates under graph operations, and dynamically readjust their local neighborhoods. We employ this formulation to construct a multi-resolution deformable registration model, where deformation layers iteratively refine the overall transformation at each resolution without intermediate resampling operations on the feature grids. We investigate our method's ability to fully deformably capture large deformations across a number of medical imaging registration tasks. In particular, we apply our approach (GeoReg) to the registration of inter-subject brain MR images and inhale-exhale lung CT images, showing on par performance with the current state-of-the-art methods. We believe our contribution open up avenues of research to reduce the black-box nature of current learned registration paradigms by explicitly modeling the transformation within the architecture.
+
+
+
+ 113. 【2412.13273】CompactFlowNet: Efficient Real-time Optical Flow Estimation on Mobile Devices
+ 链接:https://arxiv.org/abs/2412.13273
+ 作者:Andrei Znobishchev,Valerii Filev,Oleg Kudashev,Nikita Orlov,Humphrey Shi
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:initial frame relative, optical flow prediction, mobile neural network, optical flow, initial frame
+ 备注:
+
+ 点击查看摘要
+ Abstract:We present CompactFlowNet, the first real-time mobile neural network for optical flow prediction, which involves determining the displacement of each pixel in an initial frame relative to the corresponding pixel in a subsequent frame. Optical flow serves as a fundamental building block for various video-related tasks, such as video restoration, motion estimation, video stabilization, object tracking, action recognition, and video generation. While current state-of-the-art methods prioritize accuracy, they often overlook constraints regarding speed and memory usage. Existing light models typically focus on reducing size but still exhibit high latency, compromise significantly on quality, or are optimized for high-performance GPUs, resulting in sub-optimal performance on mobile devices. This study aims to develop a mobile-optimized optical flow model by proposing a novel mobile device-compatible architecture, as well as enhancements to the training pipeline, which optimize the model for reduced weight, low memory utilization, and increased speed while maintaining minimal error. Our approach demonstrates superior or comparable performance to the state-of-the-art lightweight models on the challenging KITTI and Sintel benchmarks. Furthermore, it attains a significantly accelerated inference speed, thereby yielding real-time operational efficiency on the iPhone 8, while surpassing real-time performance levels on more advanced mobile devices.
+
+
+
+ 114. 【2412.13244】RBSM: A Deep Implicit 3D Breast Shape Model
+ 链接:https://arxiv.org/abs/2412.13244
+ 作者:Maximilian Weiherer,Antonia von Riedheim,Vanessa Brébant,Bernhard Egger,Christoph Palm
+ 类目:Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:recently proposed Regensburg, proposed Regensburg Breast, Regensburg Breast Shape, proposed Regensburg, Regensburg Breast
+ 备注: 6 pages, 5 figures
+
+ 点击查看摘要
+ Abstract:We present the first deep implicit 3D shape model of the female breast, building upon and improving the recently proposed Regensburg Breast Shape Model (RBSM). Compared to its PCA-based predecessor, our model employs implicit neural representations; hence, it can be trained on raw 3D breast scans and eliminates the need for computationally demanding non-rigid registration -- a task that is particularly difficult for feature-less breast shapes. The resulting model, dubbed iRBSM, captures detailed surface geometry including fine structures such as nipples and belly buttons, is highly expressive, and outperforms the RBSM on different surface reconstruction tasks. Finally, leveraging the iRBSM, we present a prototype application to 3D reconstruct breast shapes from just a single image. Model and code publicly available at this https URL.
+
+
+
+ 115. 【2412.13211】ManiSkill-HAB: A Benchmark for Low-Level Manipulation in Home Rearrangement Tasks
+ 链接:https://arxiv.org/abs/2412.13211
+ 作者:Arth Shukla,Stone Tao,Hao Su
+ 类目:Robotics (cs.RO); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:enabling significant advancements, High-quality benchmarks, embodied AI research, enabling significant, long-horizon navigation
+ 备注:
+
+ 点击查看摘要
+ Abstract:High-quality benchmarks are the foundation for embodied AI research, enabling significant advancements in long-horizon navigation, manipulation and rearrangement tasks. However, as frontier tasks in robotics get more advanced, they require faster simulation speed, more intricate test environments, and larger demonstration datasets. To this end, we present MS-HAB, a holistic benchmark for low-level manipulation and in-home object rearrangement. First, we provide a GPU-accelerated implementation of the Home Assistant Benchmark (HAB). We support realistic low-level control and achieve over 3x the speed of previous magical grasp implementations at similar GPU memory usage. Second, we train extensive reinforcement learning (RL) and imitation learning (IL) baselines for future work to compare against. Finally, we develop a rule-based trajectory filtering system to sample specific demonstrations from our RL policies which match predefined criteria for robot behavior and safety. Combining demonstration filtering with our fast environments enables efficient, controlled data generation at scale.
+
+
+
+ 116. 【2409.10994】Less is More: A Simple yet Effective Token Reduction Method for Efficient Multi-modal LLMs
+ 链接:https://arxiv.org/abs/2409.10994
+ 作者:Dingjie Song,Wenjun Wang,Shunian Chen,Xidong Wang,Michael Guan,Benyou Wang
+ 类目:Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
+ 关键词:Multimodal Large Language, Large Language Models, Multimodal Large, Large Language, advancement of Multimodal
+ 备注: Accepted to COLING 2025
+
+ 点击查看摘要
+ Abstract:The rapid advancement of Multimodal Large Language Models (MLLMs) has led to remarkable performances across various domains. However, this progress is accompanied by a substantial surge in the resource consumption of these models. We address this pressing issue by introducing a new approach, Token Reduction using CLIP Metric (TRIM), aimed at improving the efficiency of MLLMs without sacrificing their performance. Inspired by human attention patterns in Visual Question Answering (VQA) tasks, TRIM presents a fresh perspective on the selection and reduction of image tokens. The TRIM method has been extensively tested across 12 datasets, and the results demonstrate a significant reduction in computational overhead while maintaining a consistent level of performance. This research marks a critical stride in efficient MLLM development, promoting greater accessibility and sustainability of high-performing models.
+
+
+
+ 117. 【2412.14100】Parameter-efficient Fine-tuning for improved Convolutional Baseline for Brain Tumor Segmentation in Sub-Saharan Africa Adult Glioma Dataset
+ 链接:https://arxiv.org/abs/2412.14100
+ 作者:Bijay Adhikari,Pratibha Kulung,Jakesh Bohaju,Laxmi Kanta Poudel,Confidence Raymond,Dong Zhang,Udunna C Anazodo,Bishesh Khanal,Mahesh Shakya
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Automating brain tumor, brain tumor segmentation, Automating brain, deep learning methods, medical imaging
+ 备注: Accepted to "The International Brain Tumor Segmentation (BraTS) challenge organized at MICCAI 2024 conference"
+
+ 点击查看摘要
+ Abstract:Automating brain tumor segmentation using deep learning methods is an ongoing challenge in medical imaging. Multiple lingering issues exist including domain-shift and applications in low-resource settings which brings a unique set of challenges including scarcity of data. As a step towards solving these specific problems, we propose Convolutional adapter-inspired Parameter-efficient Fine-tuning (PEFT) of MedNeXt architecture. To validate our idea, we show our method performs comparable to full fine-tuning with the added benefit of reduced training compute using BraTS-2021 as pre-training dataset and BraTS-Africa as the fine-tuning dataset. BraTS-Africa consists of a small dataset (60 train / 35 validation) from the Sub-Saharan African population with marked shift in the MRI quality compared to BraTS-2021 (1251 train samples). We first show that models trained on BraTS-2021 dataset do not generalize well to BraTS-Africa as shown by 20% reduction in mean dice on BraTS-Africa validation samples. Then, we show that PEFT can leverage both the BraTS-2021 and BraTS-Africa dataset to obtain mean dice of 0.8 compared to 0.72 when trained only on BraTS-Africa. Finally, We show that PEFT (0.80 mean dice) results in comparable performance to full fine-tuning (0.77 mean dice) which may show PEFT to be better on average but the boxplots show that full finetuning results is much lesser variance in performance. Nevertheless, on disaggregation of the dice metrics, we find that the model has tendency to oversegment as shown by high specificity (0.99) compared to relatively low sensitivity(0.75). The source code is available at this https URL
+
+
+
+ 118. 【2412.13857】Diagnosising Helicobacter pylori using AutoEncoders and Limited Annotations through Anomalous Staining Patterns in IHC Whole Slide Images
+ 链接:https://arxiv.org/abs/2412.13857
+ 作者:Pau Cano,Eva Musulen,Debora Gil
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:Helicobacter pylori, detection of Helicobacter, work addresses, histological images, Purpose
+ 备注:
+
+ 点击查看摘要
+ Abstract:Purpose: This work addresses the detection of Helicobacter pylori (H. pylori) in histological images with immunohistochemical staining. This analysis is a time demanding task, currently done by an expert pathologist that visually inspects the samples. Given the effort required to localise the pathogen in images, a limited number of annotations might be available in an initial setting. Our goal is to design an approach that, using a limited set of annotations, is capable of obtaining results good enough to be used as a support tool. Methods: We propose to use autoencoders to learn the latent patterns of healthy patches and formulate a specific measure of the reconstruction error of the image in HSV space. ROC analysis is used to set the optimal threshold of this measure and the percentage of positive patches in a sample that determines the presence of H. pylori. Results: Our method has been tested on an own database of 245 Whole Slide Images (WSI) having 117 cases without H. pylori and different density of the bacteria in the remaining ones. The database has 1211 annotated patches, with only 163 positive patches. This dataset of positive annotations was used to train a baseline thresholding and an SVM using the features of a pre-trained RedNet18 and ViT models. A 10-fold cross-validation shows that our method has better performance with 91% accuracy, 86% sensitivity, 96% specificity and 0.97 AUC in the diagnosis of H. pylori. Conclusion: Unlike classification approaches, our shallow autoencoder with threshold adaptation for the detection of anomalous staining is able to achieve competitive results with a limited set of annotated data. This initial approach is good enough to be used as a guide for fast annotation of infected patches.
+
+
+
+ 119. 【2412.13811】Spatial Brain Tumor Concentration Estimation for Individualized Radiotherapy Planning
+ 链接:https://arxiv.org/abs/2412.13811
+ 作者:Jonas Weidner,Michal Balcerak,Ivan Ezhov,André Datchev,Laurin Lux,Lucas Zimmerand Daniel Rueckert,Björn Menze,Benedikt Wiestler
+ 类目:Medical Physics (physics.med-ph); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:personalizing radiotherapy planning, Biophysical modeling, promising strategy, strategy for personalizing, personalizing radiotherapy
+ 备注:
+
+ 点击查看摘要
+ Abstract:Biophysical modeling of brain tumors has emerged as a promising strategy for personalizing radiotherapy planning by estimating the otherwise hidden distribution of tumor cells within the brain. However, many existing state-of-the-art methods are computationally intensive, limiting their widespread translation into clinical practice. In this work, we propose an efficient and direct method that utilizes soft physical constraints to estimate the tumor cell concentration from preoperative MRI of brain tumor patients. Our approach optimizes a 3D tumor concentration field by simultaneously minimizing the difference between the observed MRI and a physically informed loss function. Compared to existing state-of-the-art techniques, our method significantly improves predicting tumor recurrence on two public datasets with a total of 192 patients while maintaining a clinically viable runtime of under one minute - a substantial reduction from the 30 minutes required by the current best approach. Furthermore, we showcase the generalizability of our framework by incorporating additional imaging information and physical constraints, highlighting its potential to translate to various medical diffusion phenomena with imperfect data.
+
+
+
+ 120. 【2412.13703】MBInception: A new Multi-Block Inception Model for Enhancing Image Processing Efficiency
+ 链接:https://arxiv.org/abs/2412.13703
+ 作者:Fatemeh Froughirad,Reza Bakhoda Eshtivani,Hamed Khajavi,Amir Rastgoo
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Numerical Analysis (math.NA)
+ 关键词:Deep learning models, raw pixel data, convolutional neural networks, autonomously extracting features, extracting features directly
+ 备注: 26 pages, 10 figures
+
+ 点击查看摘要
+ Abstract:Deep learning models, specifically convolutional neural networks, have transformed the landscape of image classification by autonomously extracting features directly from raw pixel data. This article introduces an innovative image classification model that employs three consecutive inception blocks within a convolutional neural networks framework, providing a comprehensive comparative analysis with well-established architectures such as Visual Geometry Group, Residual Network, and MobileNet. Through the utilization of benchmark datasets, including Canadian Institute for Advanced Researc, Modified National Institute of Standards and Technology database, and Fashion Modified National Institute of Standards and Technology database, we assess the performance of our proposed model in comparison to these benchmarks. The outcomes reveal that our novel model consistently outperforms its counterparts across diverse datasets, underscoring its effectiveness and potential for advancing the current state-of-the-art in image classification. Evaluation metrics further emphasize that the proposed model surpasses the other compared architectures, thereby enhancing the efficiency of image classification on standard datasets.
+
+
+
+ 121. 【2412.13558】Read Like a Radiologist: Efficient Vision-Language Model for 3D Medical Imaging Interpretation
+ 链接:https://arxiv.org/abs/2412.13558
+ 作者:Changsun Lee,Sangjoon Park,Cheong-Il Shin,Woo Hee Choi,Hyun Jeong Park,Jeong Eun Lee,Jong Chul Ye
+ 类目:Image and Video Processing (eess.IV); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
+ 关键词:medical vision-language models, Recent medical vision-language, medical, medical image interpretation, medical image
+ 备注:
+
+ 点击查看摘要
+ Abstract:Recent medical vision-language models (VLMs) have shown promise in 2D medical image interpretation. However extending them to 3D medical imaging has been challenging due to computational complexities and data scarcity. Although a few recent VLMs specified for 3D medical imaging have emerged, all are limited to learning volumetric representation of a 3D medical image as a set of sub-volumetric features. Such process introduces overly correlated representations along the z-axis that neglect slice-specific clinical details, particularly for 3D medical images where adjacent slices have low redundancy. To address this limitation, we introduce MS-VLM that mimic radiologists' workflow in 3D medical image interpretation. Specifically, radiologists analyze 3D medical images by examining individual slices sequentially and synthesizing information across slices and views. Likewise, MS-VLM leverages self-supervised 2D transformer encoders to learn a volumetric representation that capture inter-slice dependencies from a sequence of slice-specific features. Unbound by sub-volumetric patchification, MS-VLM is capable of obtaining useful volumetric representations from 3D medical images with any slice length and from multiple images acquired from different planes and phases. We evaluate MS-VLM on publicly available chest CT dataset CT-RATE and in-house rectal MRI dataset. In both scenarios, MS-VLM surpasses existing methods in radiology report generation, producing more coherent and clinically relevant reports. These findings highlight the potential of MS-VLM to advance 3D medical image interpretation and improve the robustness of medical VLMs.
+
+
+
+ 122. 【2412.13508】Plug-and-Play Tri-Branch Invertible Block for Image Rescaling
+ 链接:https://arxiv.org/abs/2412.13508
+ 作者:Jingwei Bao,Jinhua Hao,Pengcheng Xu,Ming Sun,Chao Zhou,Shuyuan Zhu
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:downscaled to low-resolution, reduce bandwidth, original details, commonly downscaled, restore their original
+ 备注: Accepted by AAAI 2025. Code is available at [this https URL](https://github.com/Jingwei-Bao/T-InvBlocks)
+
+ 点击查看摘要
+ Abstract:High-resolution (HR) images are commonly downscaled to low-resolution (LR) to reduce bandwidth, followed by upscaling to restore their original details. Recent advancements in image rescaling algorithms have employed invertible neural networks (INNs) to create a unified framework for downscaling and upscaling, ensuring a one-to-one mapping between LR and HR images. Traditional methods, utilizing dual-branch based vanilla invertible blocks, process high-frequency and low-frequency information separately, often relying on specific distributions to model high-frequency components. However, processing the low-frequency component directly in the RGB domain introduces channel redundancy, limiting the efficiency of image reconstruction. To address these challenges, we propose a plug-and-play tri-branch invertible block (T-InvBlocks) that decomposes the low-frequency branch into luminance (Y) and chrominance (CbCr) components, reducing redundancy and enhancing feature processing. Additionally, we adopt an all-zero mapping strategy for high-frequency components during upscaling, focusing essential rescaling information within the LR image. Our T-InvBlocks can be seamlessly integrated into existing rescaling models, improving performance in both general rescaling tasks and scenarios involving lossy compression. Extensive experiments confirm that our method advances the state of the art in HR image reconstruction.
+
+
+
+ 123. 【2412.13477】Generating Unseen Nonlinear Evolution in Sea Surface Temperature Using a Deep Learning-Based Latent Space Data Assimilation Framework
+ 链接:https://arxiv.org/abs/2412.13477
+ 作者:Qingyu Zheng,Guijun Han,Wei Li,Lige Cao,Gongfu Zhou,Haowen Wu,Qi Shao,Ru Wang,Xiaobo Wu,Xudong Cui,Hong Li,Xuan Wang
+ 类目:Atmospheric and Oceanic Physics (physics.ao-ph); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Geophysics (physics.geo-ph)
+ 关键词:Earth system predictions, accuracy of Earth, Earth system, system predictions, greatly improved
+ 备注: 31 pages, 14 figures
+
+ 点击查看摘要
+ Abstract:Advances in data assimilation (DA) methods have greatly improved the accuracy of Earth system predictions. To fuse multi-source data and reconstruct the nonlinear evolution missing from observations, geoscientists are developing future-oriented DA methods. In this paper, we redesign a purely data-driven latent space DA framework (DeepDA) that employs a generative artificial intelligence model to capture the nonlinear evolution in sea surface temperature. Under variational constraints, DeepDA embedded with nonlinear features can effectively fuse heterogeneous data. The results show that DeepDA remains highly stable in capturing and generating nonlinear evolutions even when a large amount of observational information is missing. It can be found that when only 10% of the observation information is available, the error increase of DeepDA does not exceed 40%. Furthermore, DeepDA has been shown to be robust in the fusion of real observations and ensemble simulations. In particular, this paper provides a mechanism analysis of the nonlinear evolution generated by DeepDA from the perspective of physical patterns, which reveals the inherent explainability of our DL model in capturing multi-scale ocean signals.
+
+
+
+ 124. 【2412.13299】In-context learning for medical image segmentation
+ 链接:https://arxiv.org/abs/2412.13299
+ 作者:Eichi Takaya,Shinnosuke Yamamoto
+ 类目:Image and Video Processing (eess.IV); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
+ 关键词:evaluating treatment efficacy, planning radiotherapy, crucial for evaluating, evaluating treatment, treatment efficacy
+ 备注:
+
+ 点击查看摘要
+ Abstract:Annotation of medical images, such as MRI and CT scans, is crucial for evaluating treatment efficacy and planning radiotherapy. However, the extensive workload of medical professionals limits their ability to annotate large image datasets, posing a bottleneck for AI applications in medical imaging. To address this, we propose In-context Cascade Segmentation (ICS), a novel method that minimizes annotation requirements while achieving high segmentation accuracy for sequential medical images. ICS builds on the UniverSeg framework, which performs few-shot segmentation using support images without additional training. By iteratively adding the inference results of each slice to the support set, ICS propagates information forward and backward through the sequence, ensuring inter-slice consistency. We evaluate the proposed method on the HVSMR dataset, which includes segmentation tasks for eight cardiac regions. Experimental results demonstrate that ICS significantly improves segmentation performance in complex anatomical regions, particularly in maintaining boundary consistency across slices, compared to baseline methods. The study also highlights the impact of the number and position of initial support slices on segmentation accuracy. ICS offers a promising solution for reducing annotation burdens while delivering robust segmentation results, paving the way for its broader adoption in clinical and research applications.
+
+
+
+ 125. 【2412.13237】Optimized two-stage AI-based Neural Decoding for Enhanced Visual Stimulus Reconstruction from fMRI Data
+ 链接:https://arxiv.org/abs/2412.13237
+ 作者:Lorenzo Veronese,Andrea Moglia,Luca Mainardi,Pietro Cerveri
+ 类目:Image and Video Processing (eess.IV); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Neurons and Cognition (q-bio.NC)
+ 关键词:AI-based neural decoding, map brain activity, neural decoding reconstructs, decoding reconstructs visual, reconstructs visual perception
+ 备注: 14 pages, 5 figures
+
+ 点击查看摘要
+ Abstract:AI-based neural decoding reconstructs visual perception by leveraging generative models to map brain activity, measured through functional MRI (fMRI), into latent hierarchical representations. Traditionally, ridge linear models transform fMRI into a latent space, which is then decoded using latent diffusion models (LDM) via a pre-trained variational autoencoder (VAE). Due to the complexity and noisiness of fMRI data, newer approaches split the reconstruction into two sequential steps, the first one providing a rough visual approximation, the second on improving the stimulus prediction via LDM endowed by CLIP embeddings. This work proposes a non-linear deep network to improve fMRI latent space representation, optimizing the dimensionality alike. Experiments on the Natural Scenes Dataset showed that the proposed architecture improved the structural similarity of the reconstructed image by about 2\% with respect to the state-of-the-art model, based on ridge linear transform. The reconstructed image's semantics improved by about 4\%, measured by perceptual similarity, with respect to the state-of-the-art. The noise sensitivity analysis of the LDM showed that the role of the first stage was fundamental to predict the stimulus featuring high structural similarity. Conversely, providing a large noise stimulus affected less the semantics of the predicted stimulus, while the structural similarity between the ground truth and predicted stimulus was very poor. The findings underscore the importance of leveraging non-linear relationships between BOLD signal and the latent representation and two-stage generative AI for optimizing the fidelity of reconstructed visual stimuli from noisy fMRI data.
+
+
+





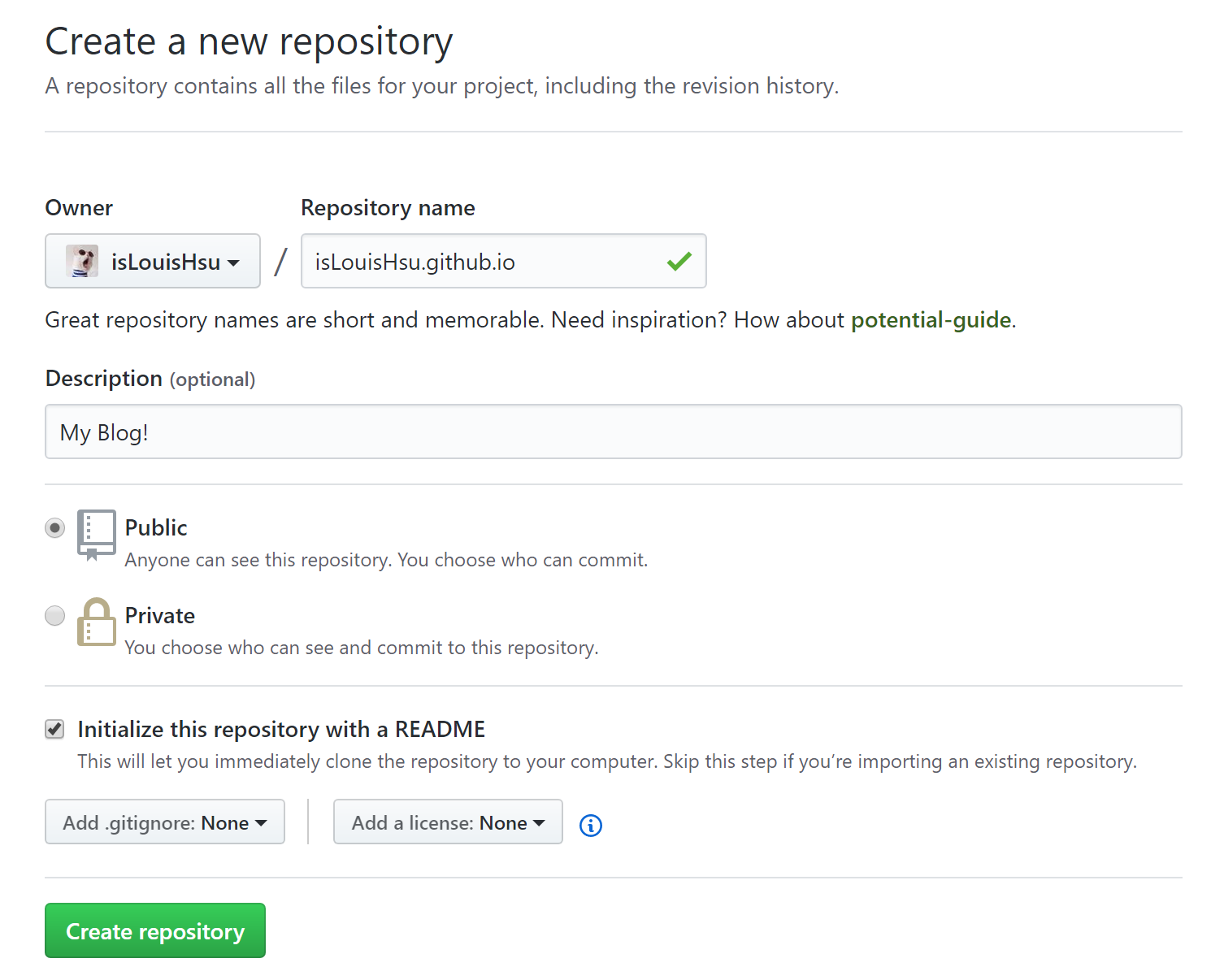
/Fig1_pretrain_finetune.png)
/Fig2_eda1.png)
/Fig2_eda2.png)
/Fig2_eda3.png)
/Fig3_reweight.png)
/Fig5_model1.png)
/Fig5_attention_mask.png)
/Fig4_wwm.png)
/Fig5_model2.png)
/Fig5_model3.png)
/Fig7_ensemble1.png)
/Fig6_res1.png)
/Fig6_res2.png)


%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_text_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/eda_entity_length.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/model.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/dont_stop_pretraining.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/a.png)
%EF%BC%9A%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96(Rank2)/b.png)

%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/lengths_histplot.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_entity_lengths.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/train_label_dist.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/%E6%80%BB%E4%BD%93%E6%96%B9%E6%A1%88.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/pretrain_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/finetune_model.png)
%EF%BC%9A%E5%95%86%E5%93%81%E6%A0%87%E9%A2%98%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB(%E4%BA%8C%E7%AD%89%E5%A5%96)/rdrop.png)

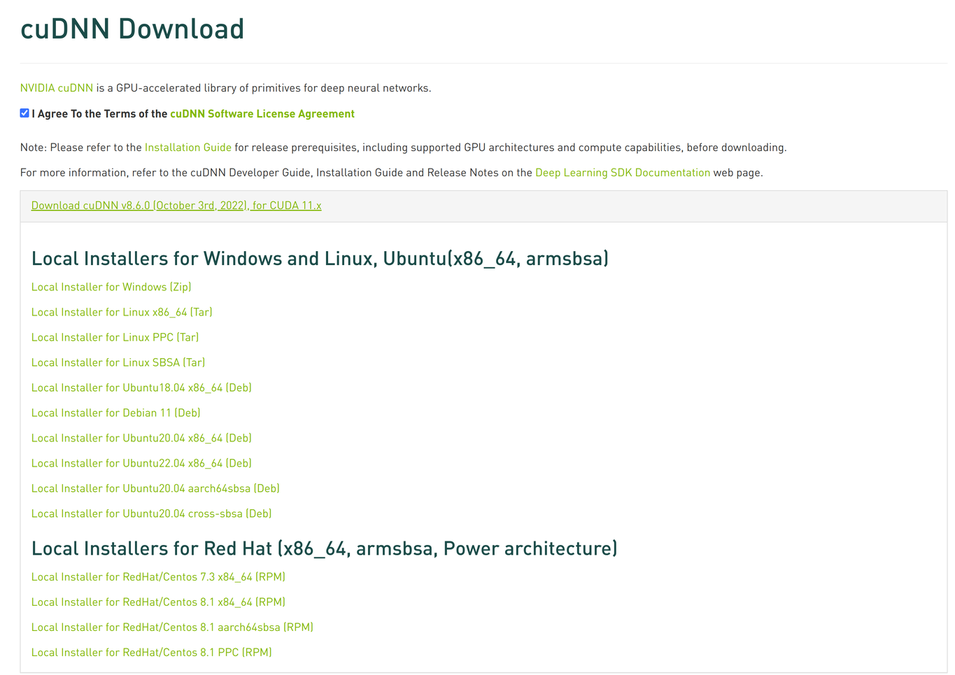
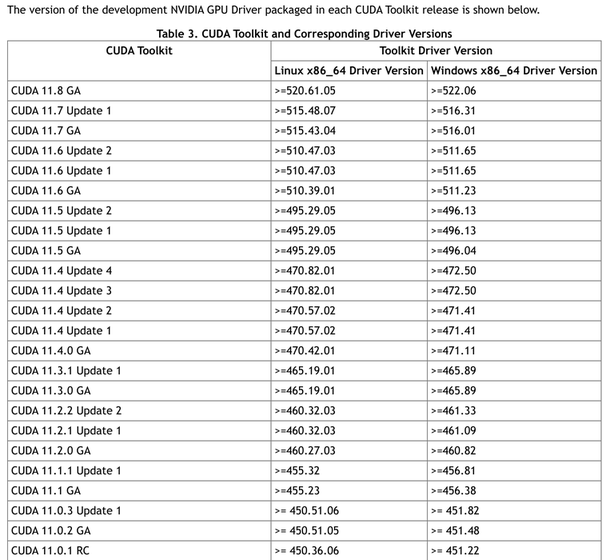

/autoencoder-architecture.png)
/variational-autoencoder-architecture.png)
/forward_vs_reversed_KL.png)
/vae-implement.png)
/reparam.png)
/generated_samples.png)

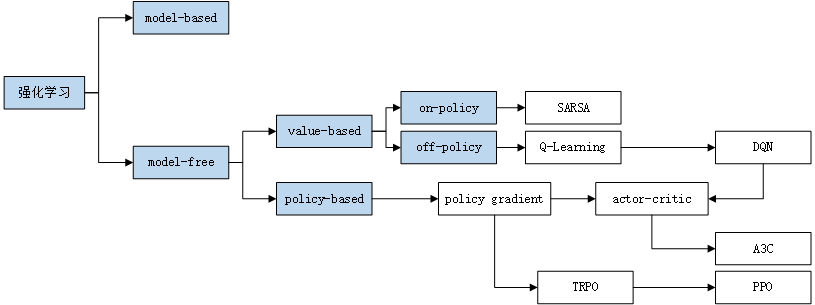
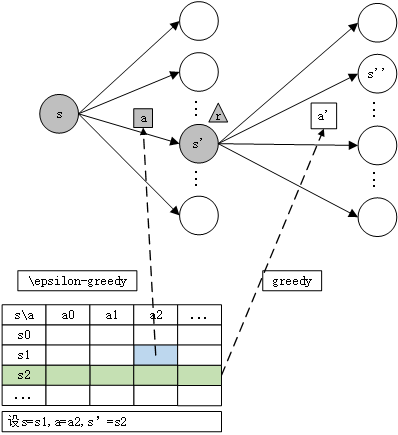
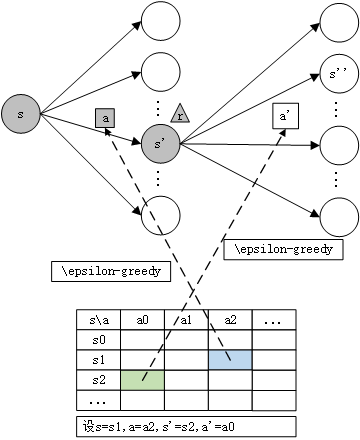
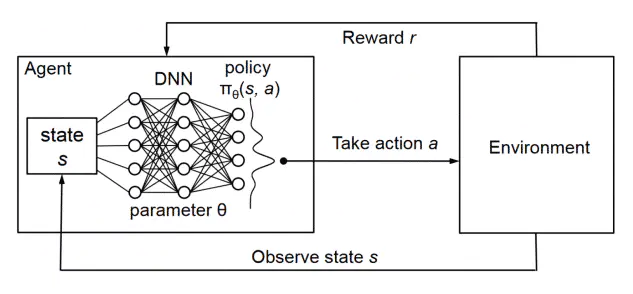
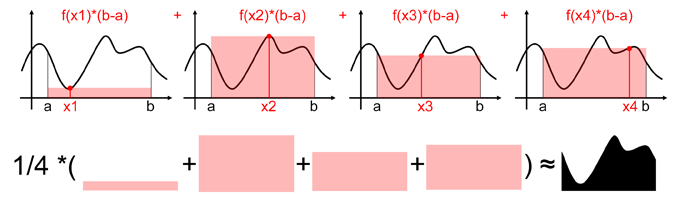

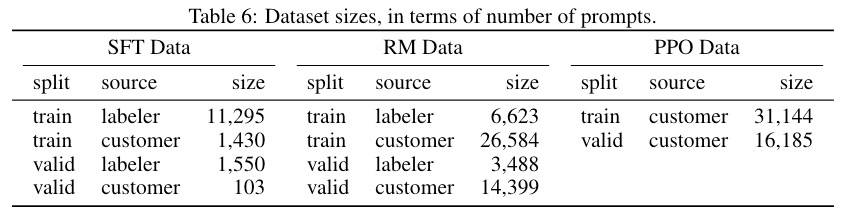
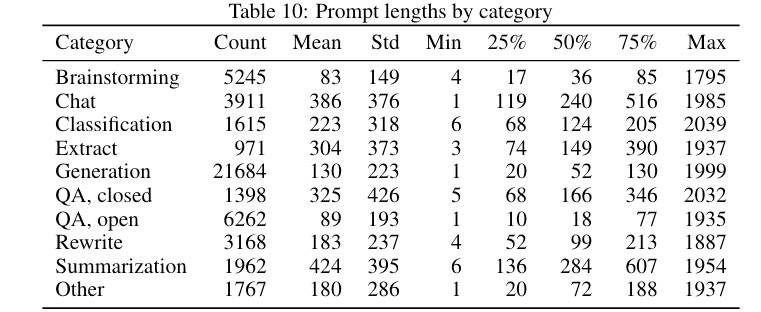
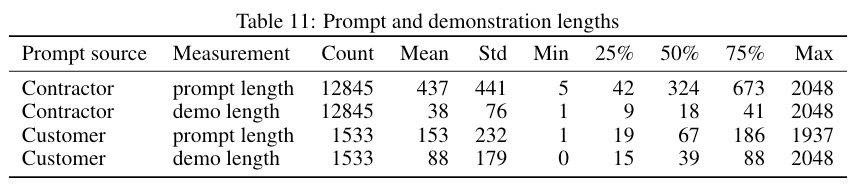

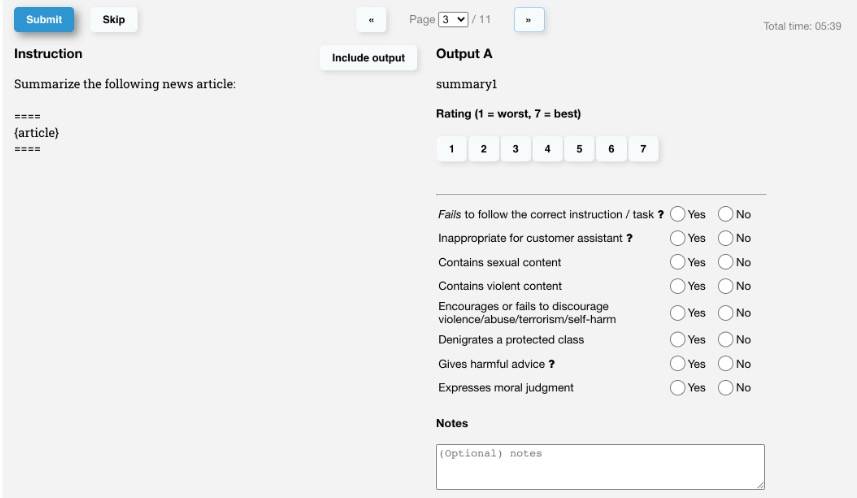
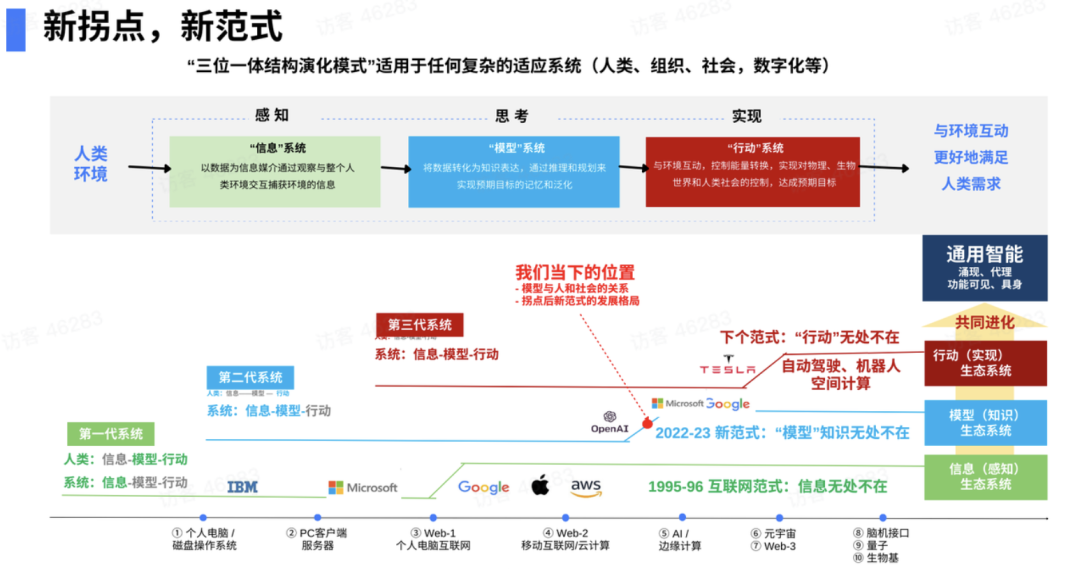
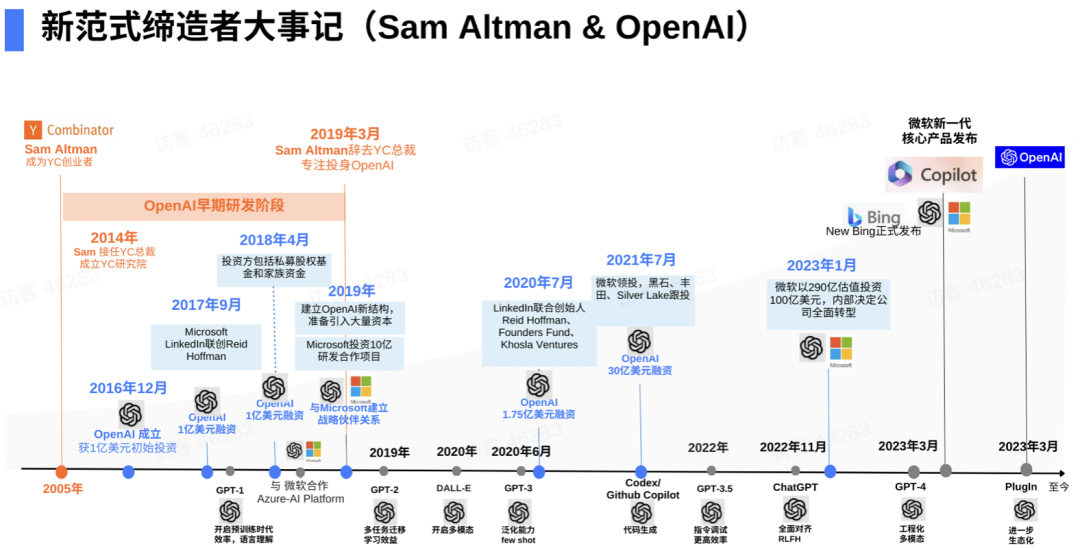
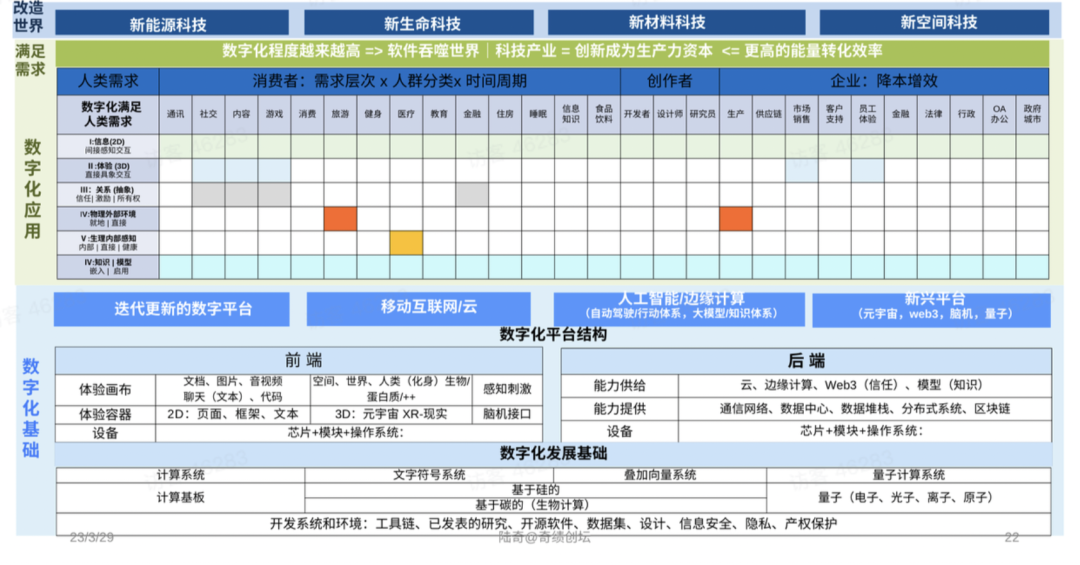
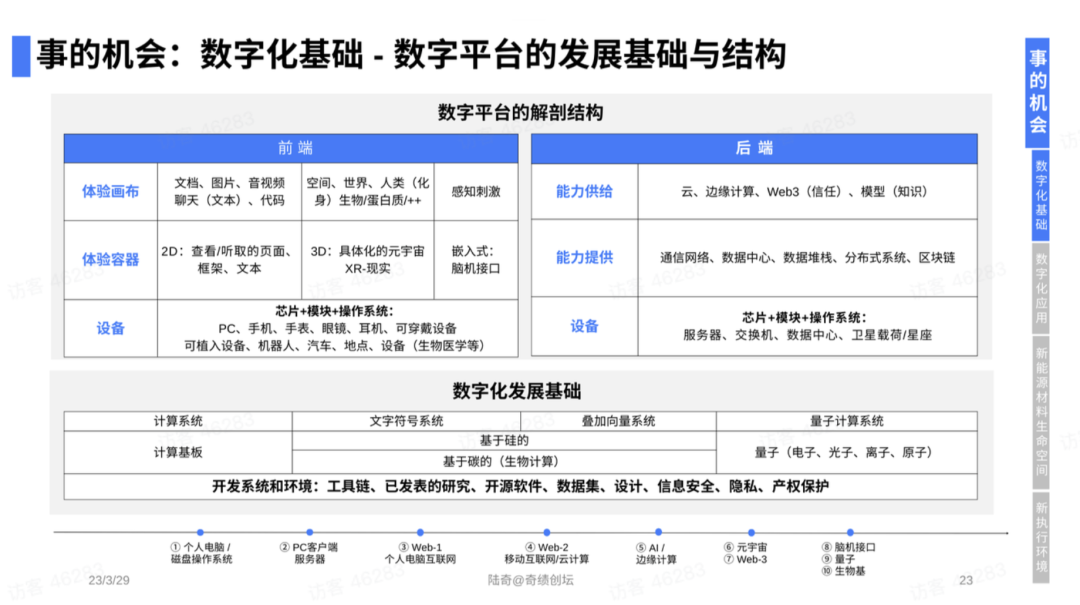
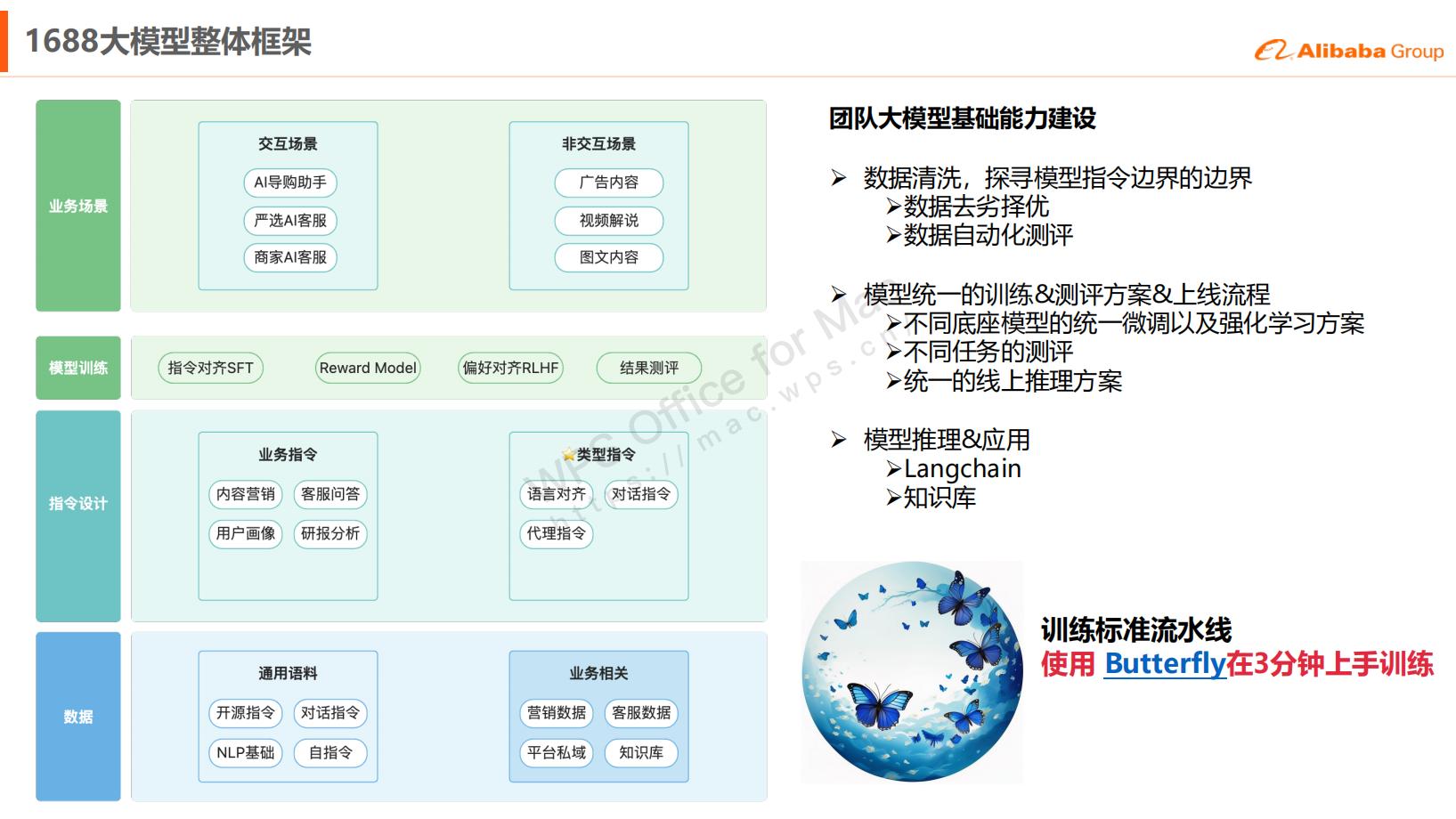
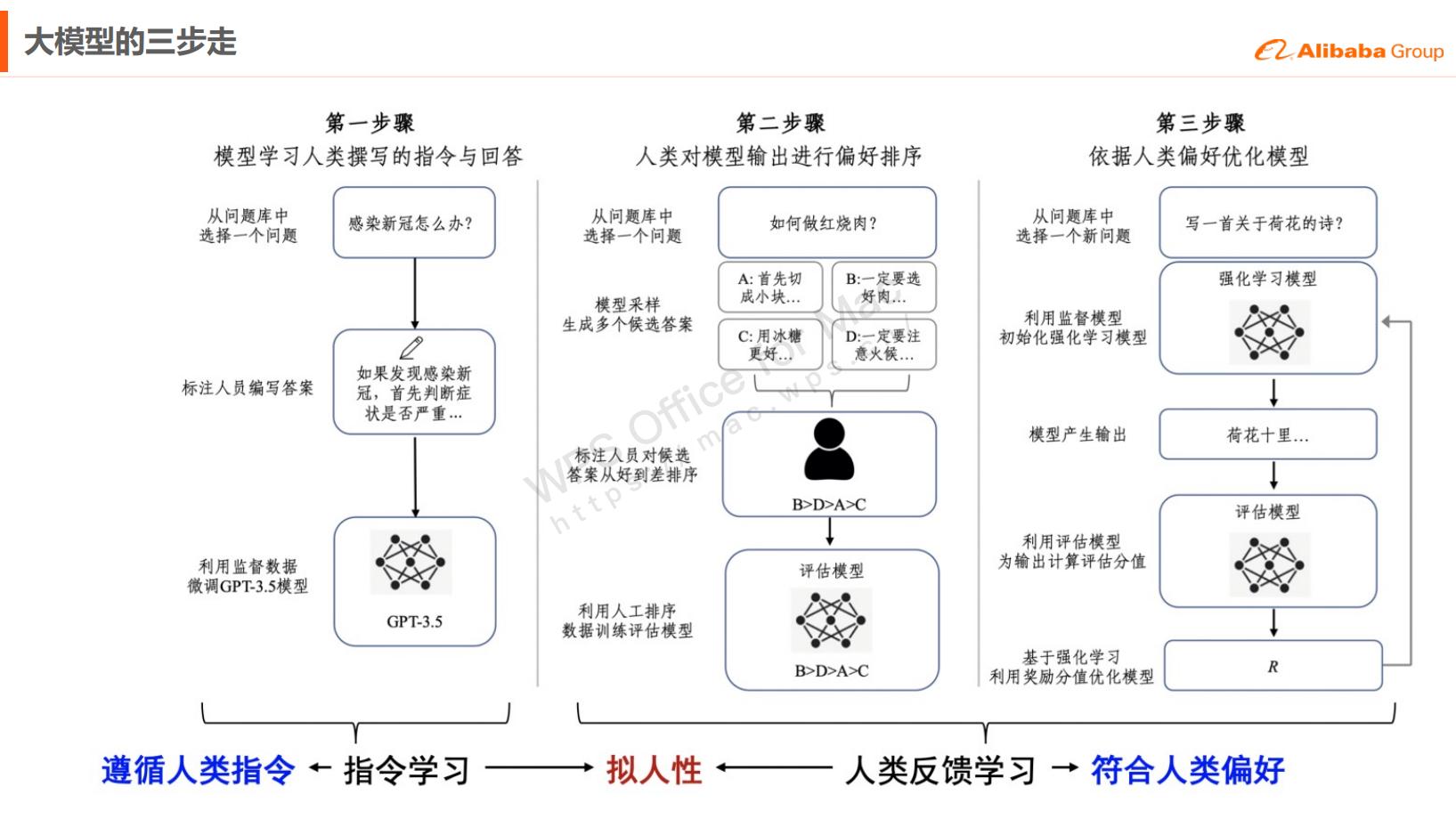
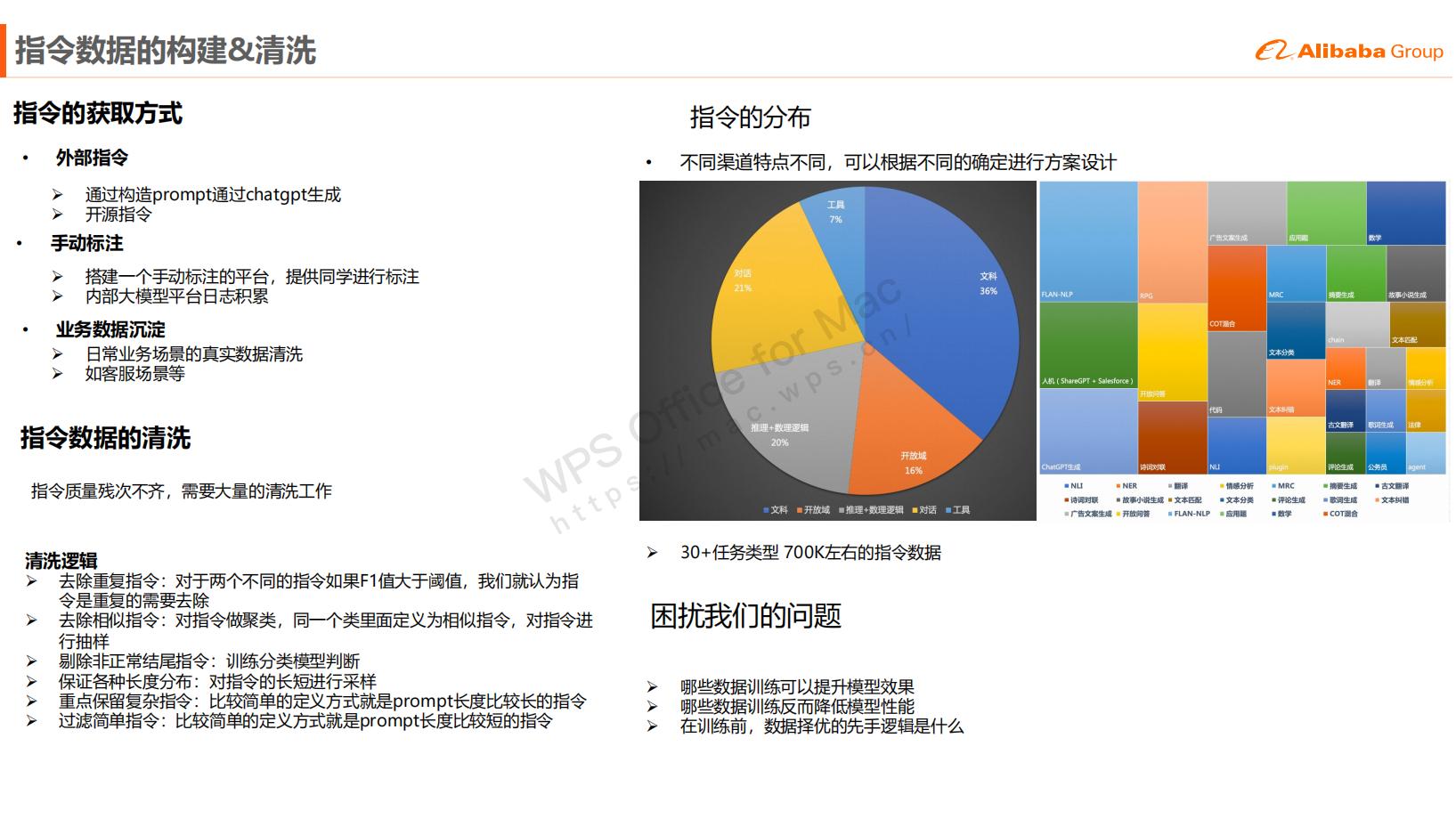

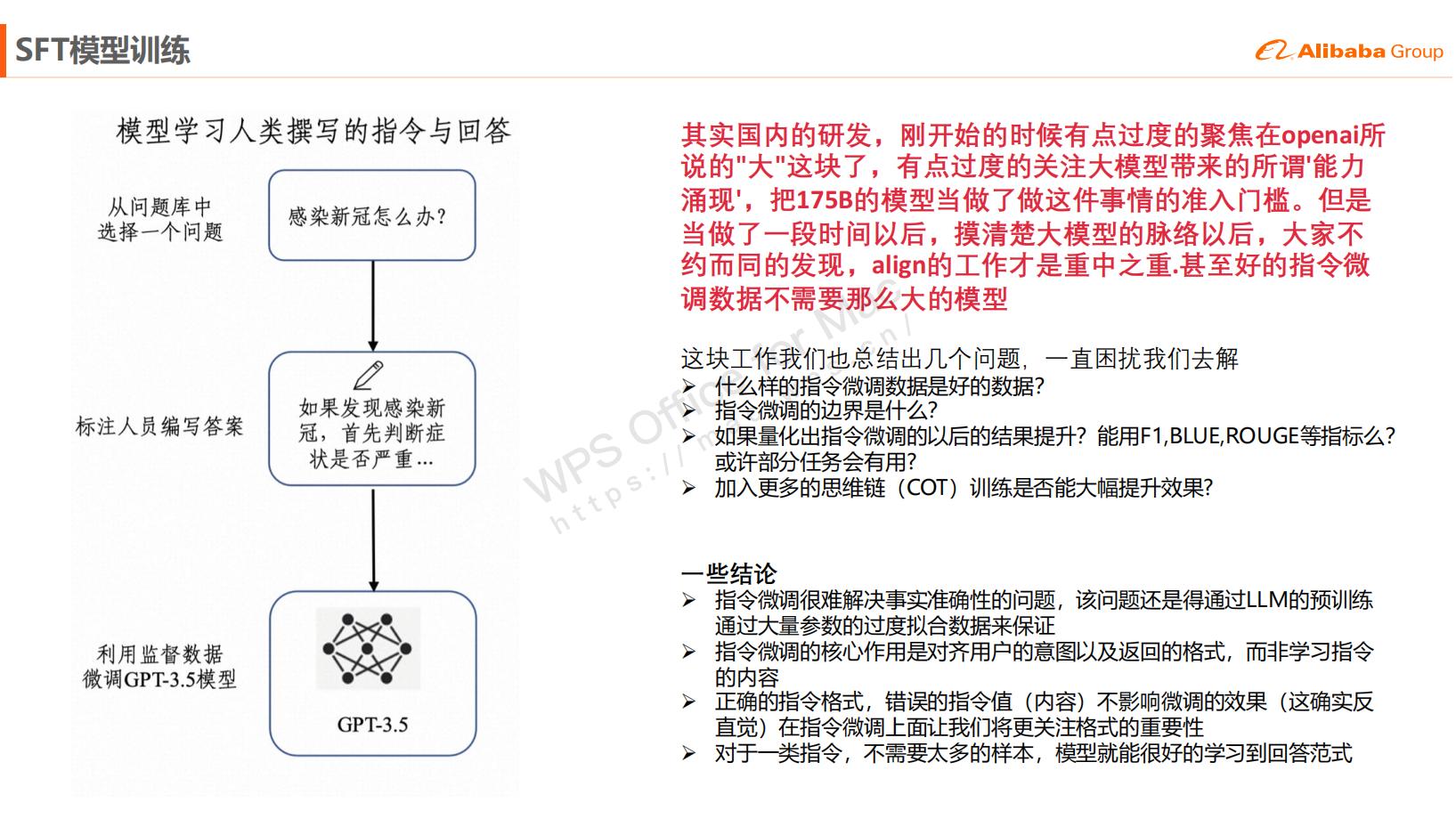

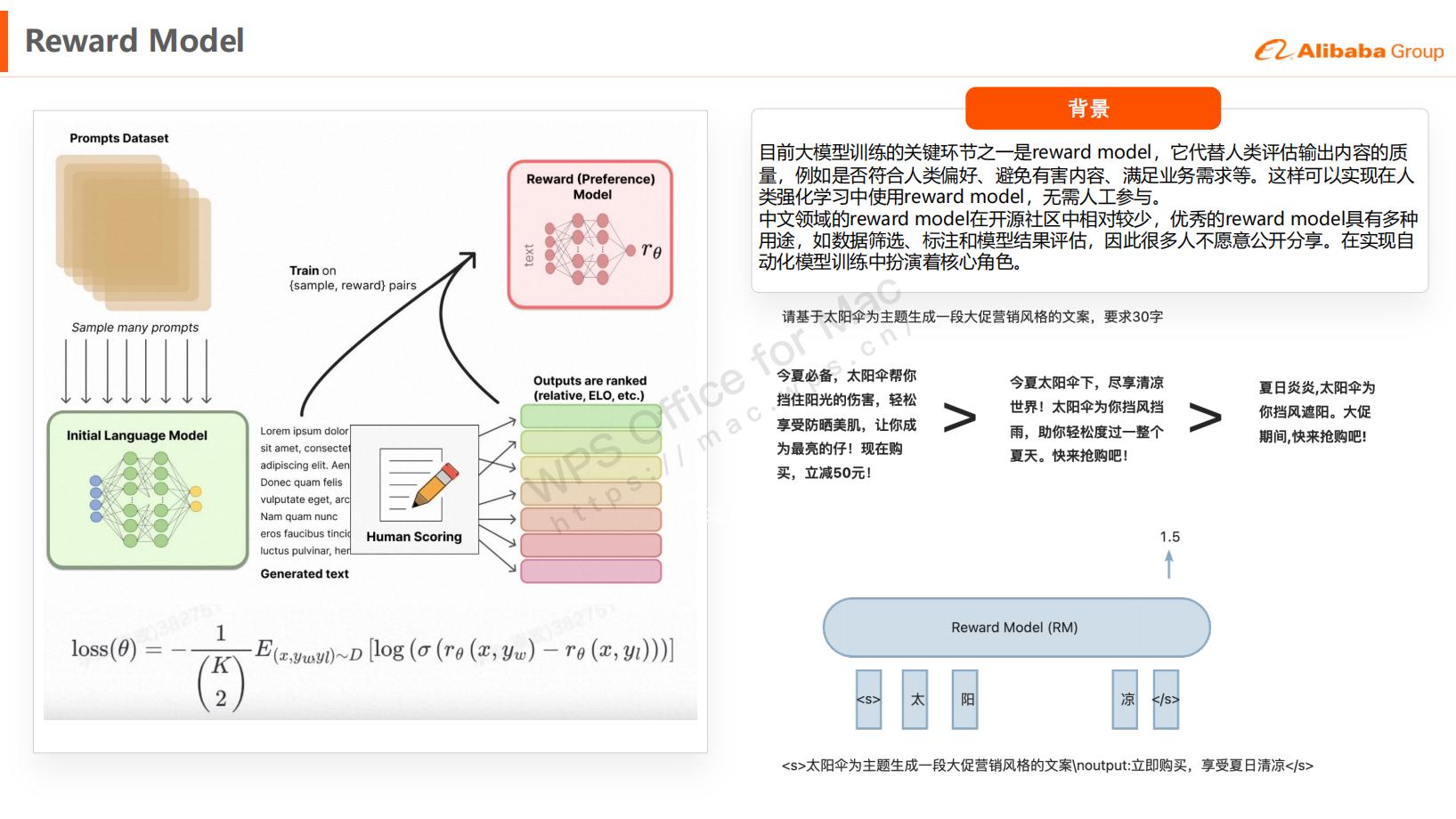




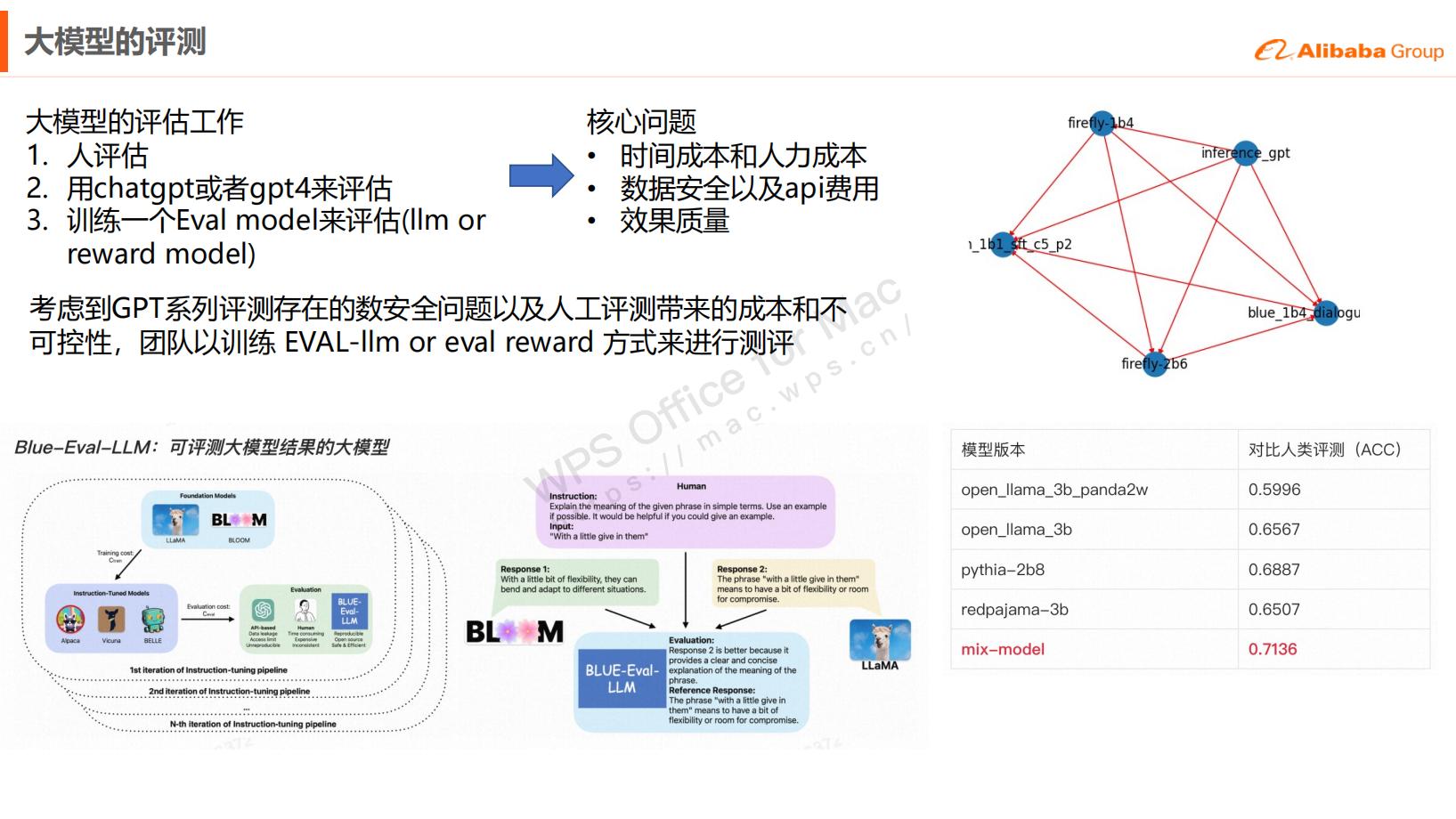
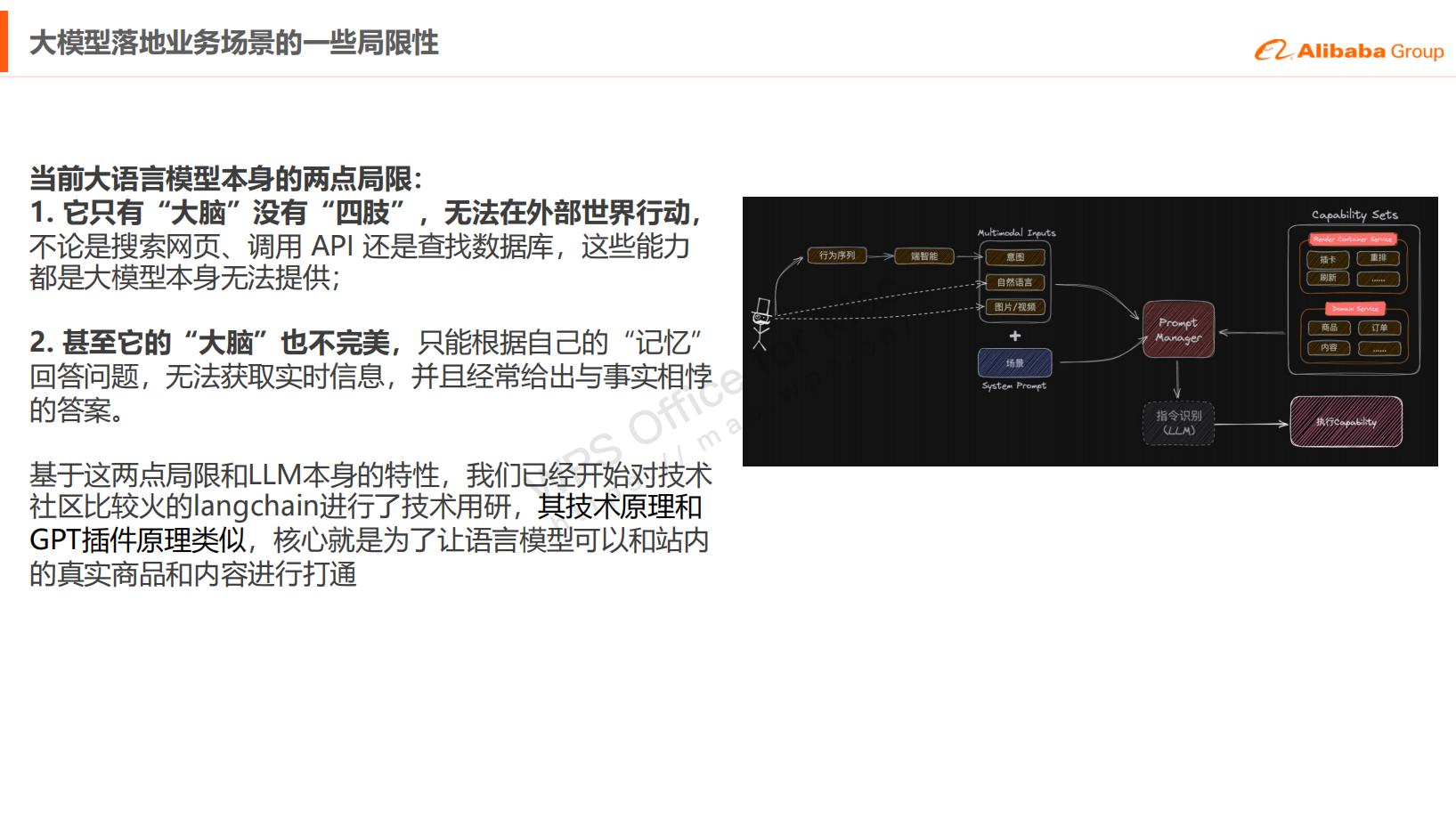





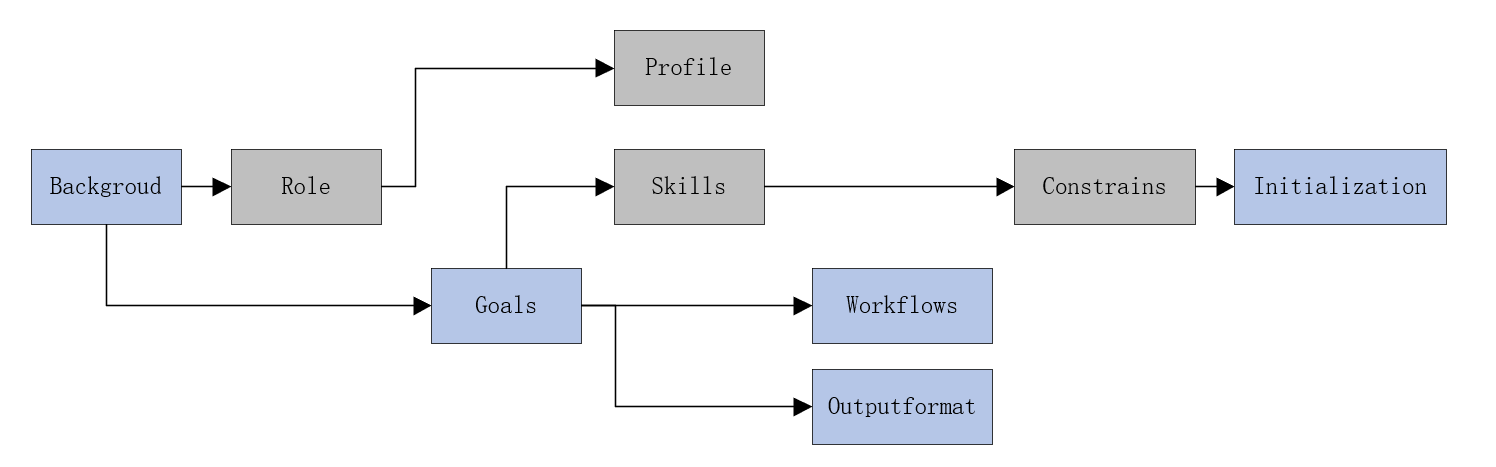

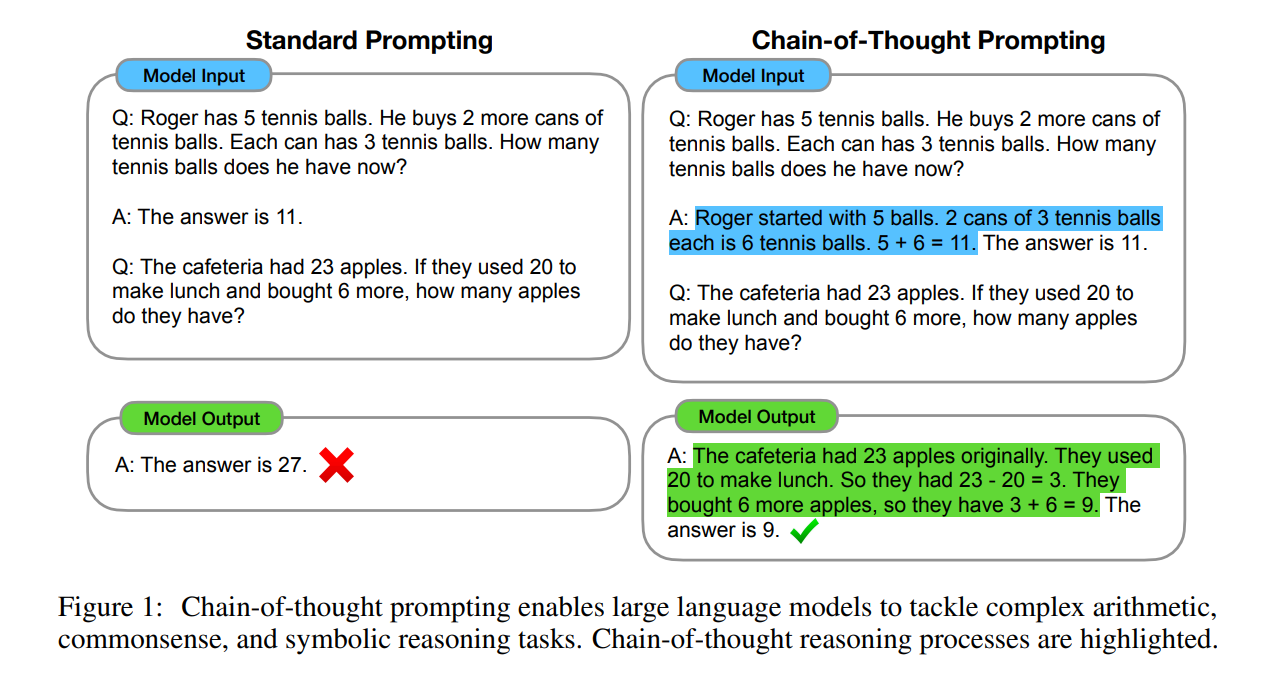

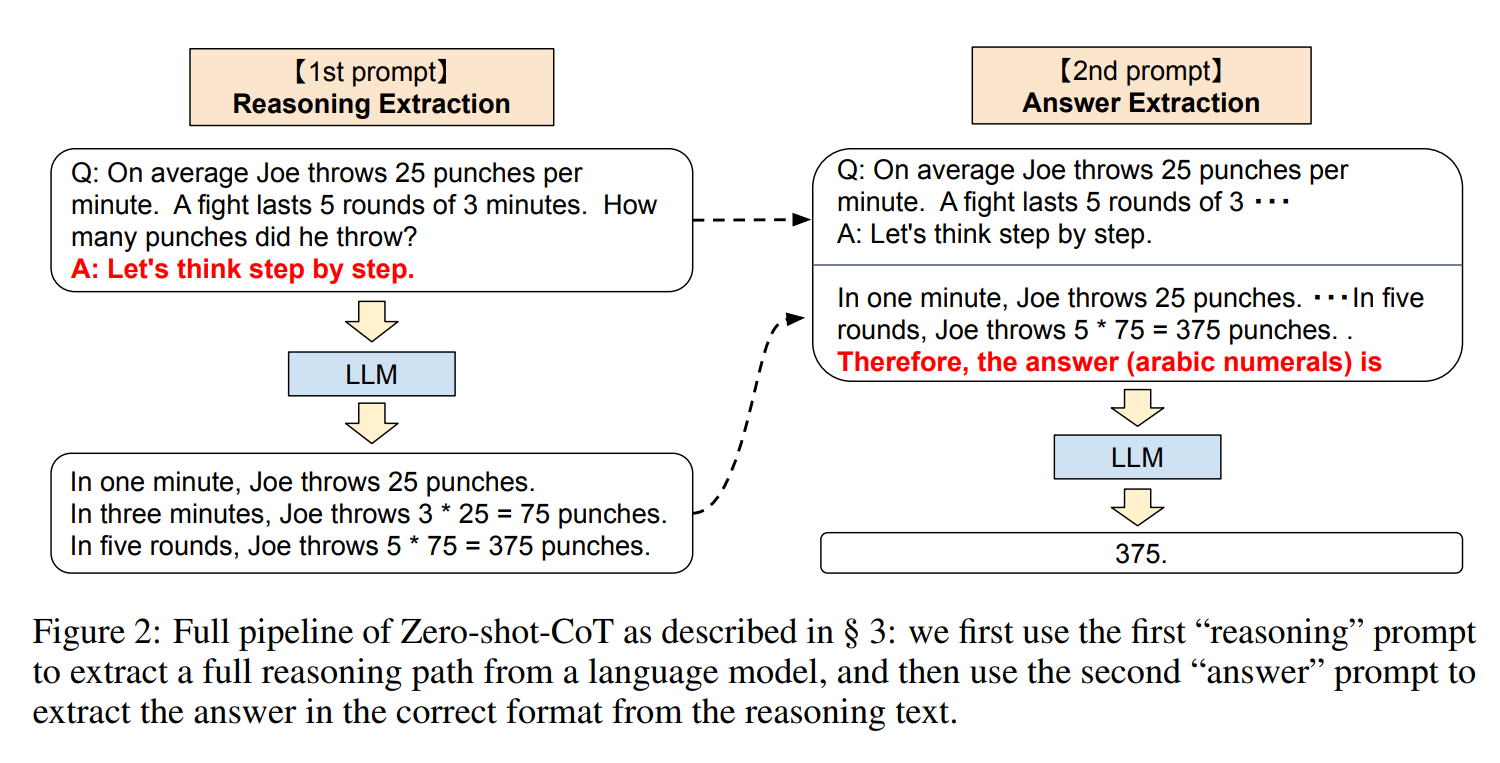
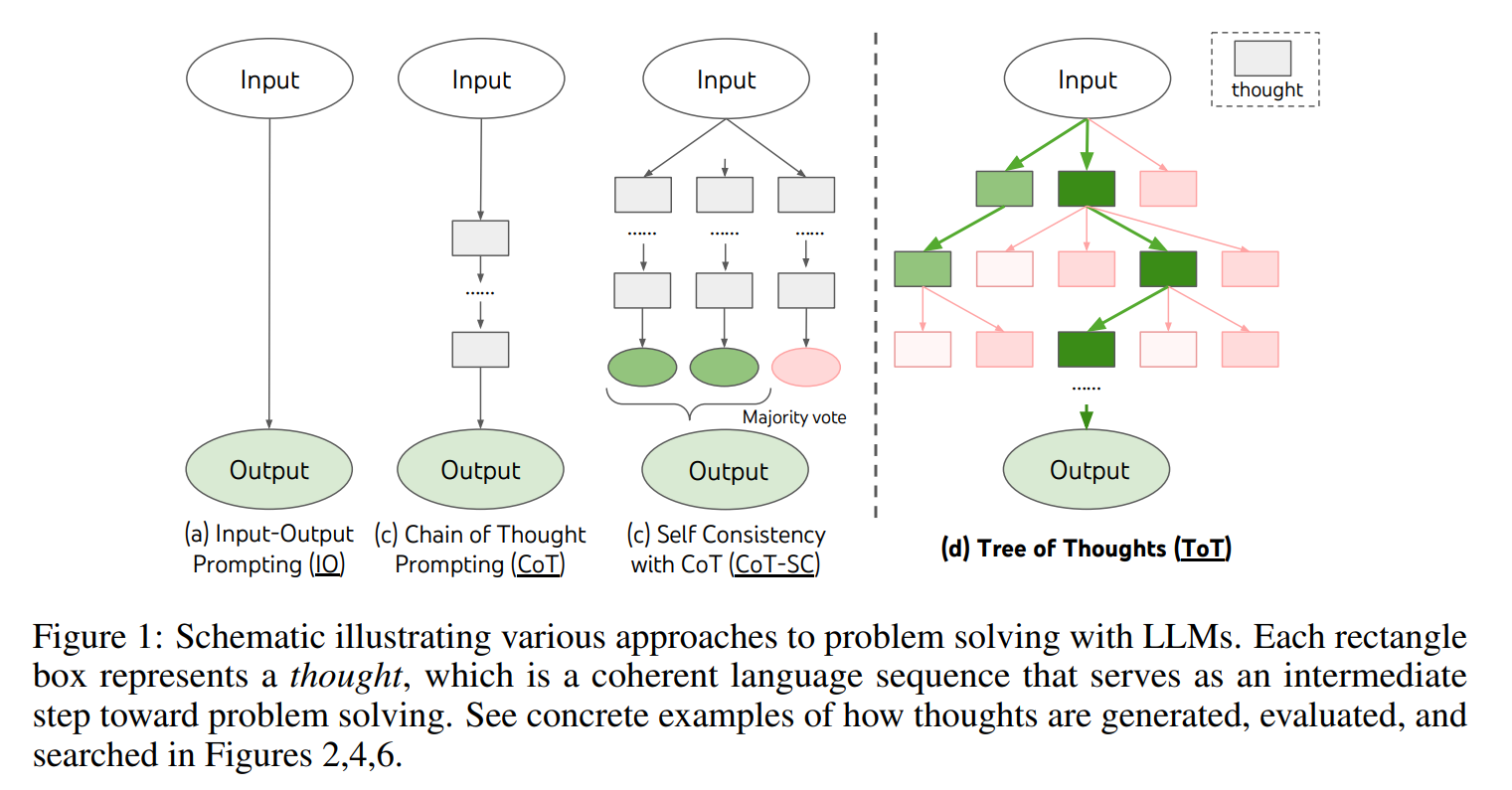


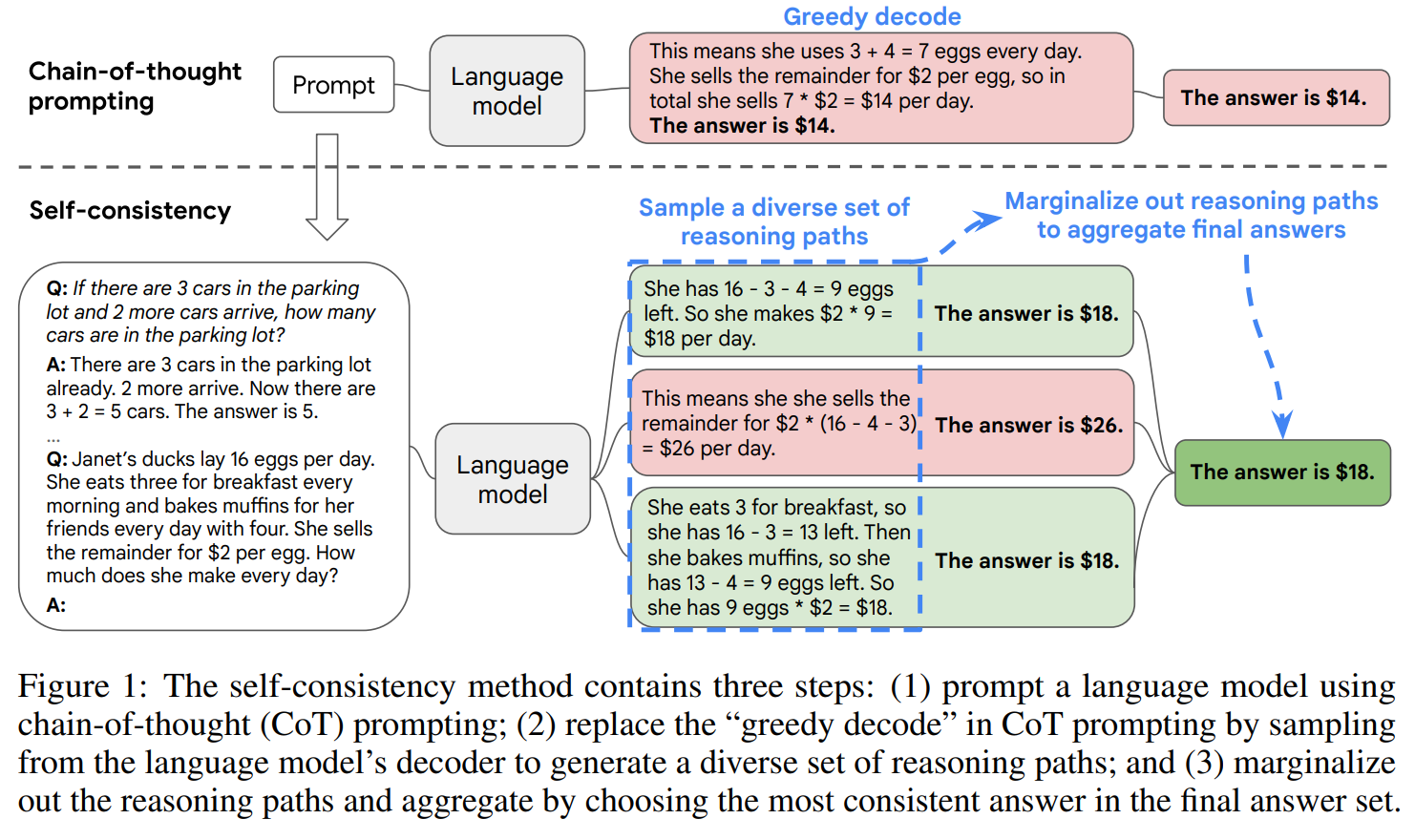



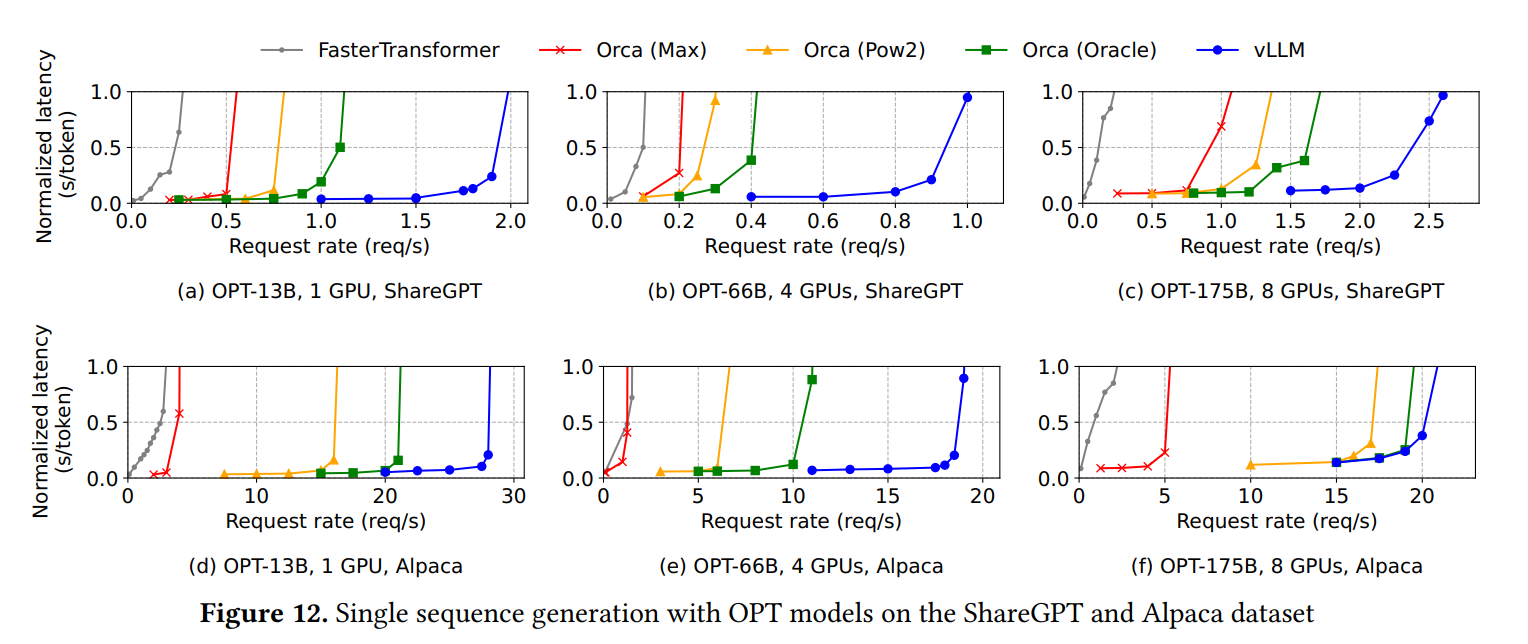
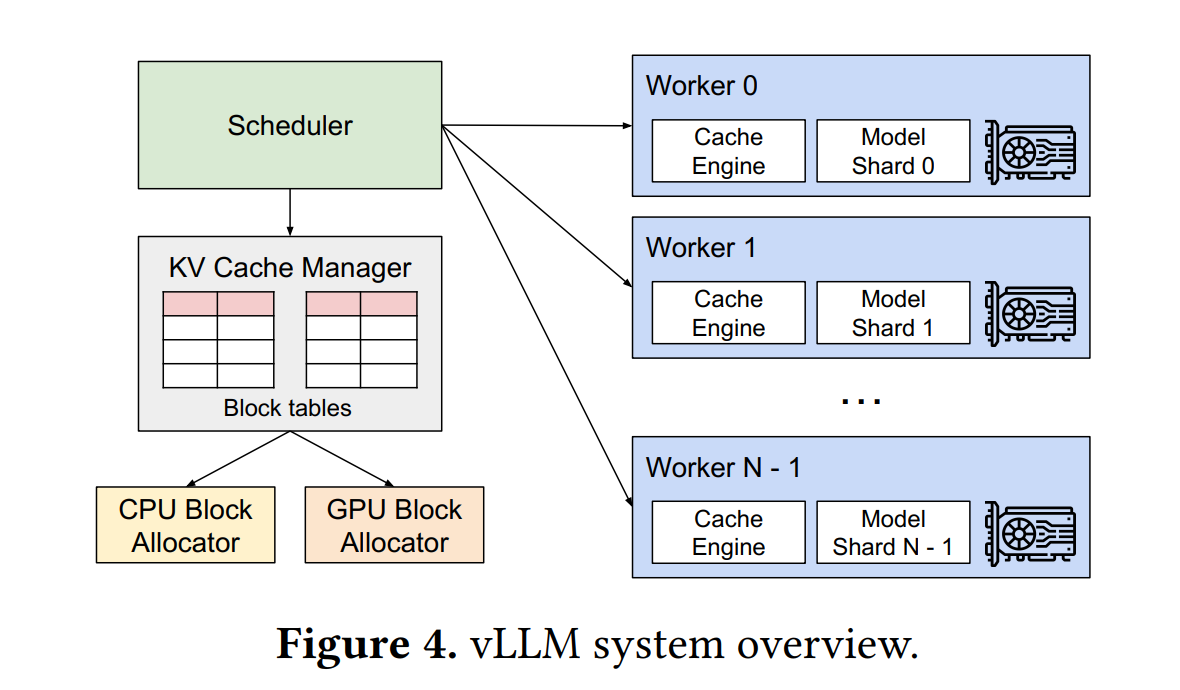
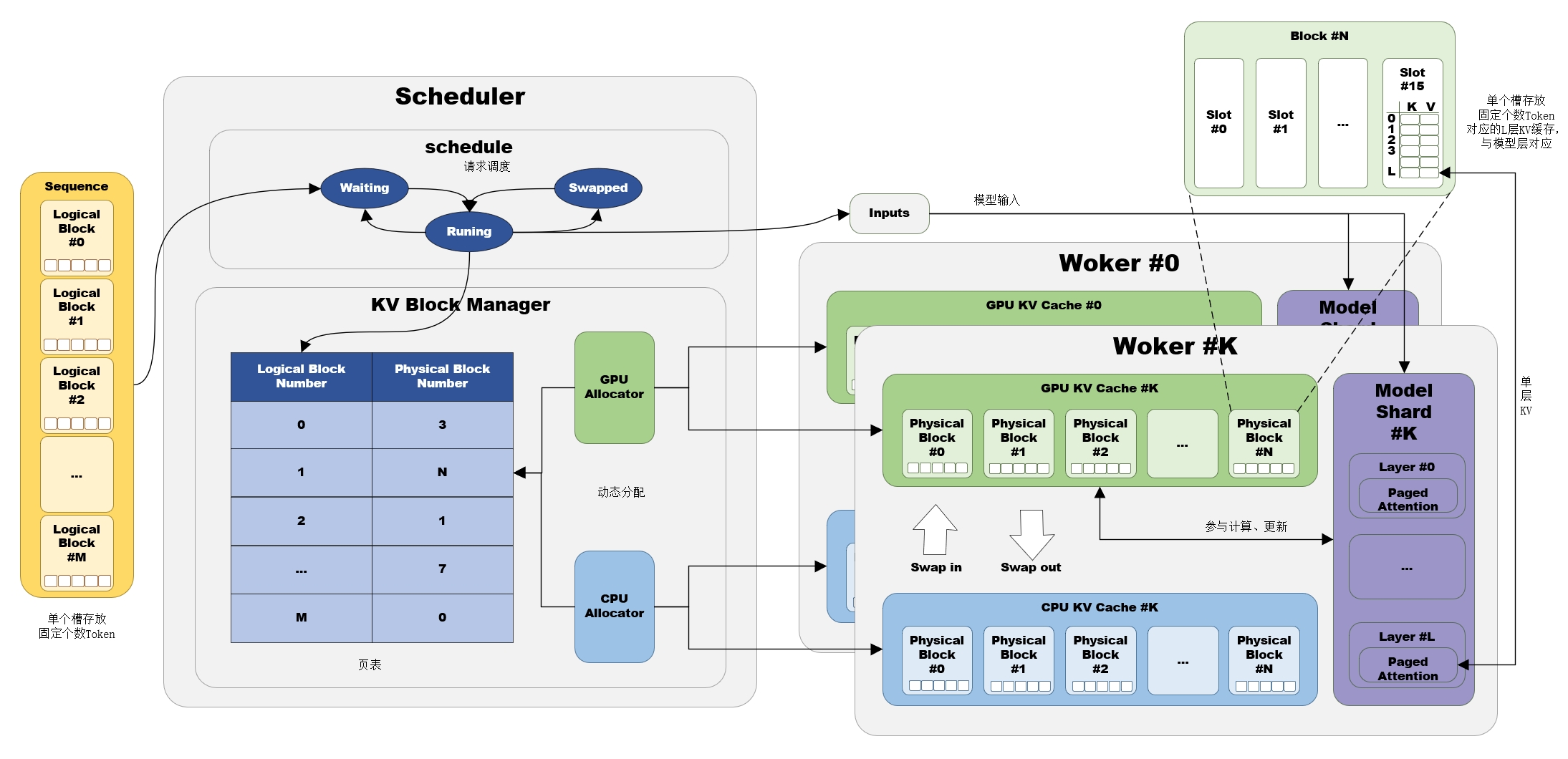
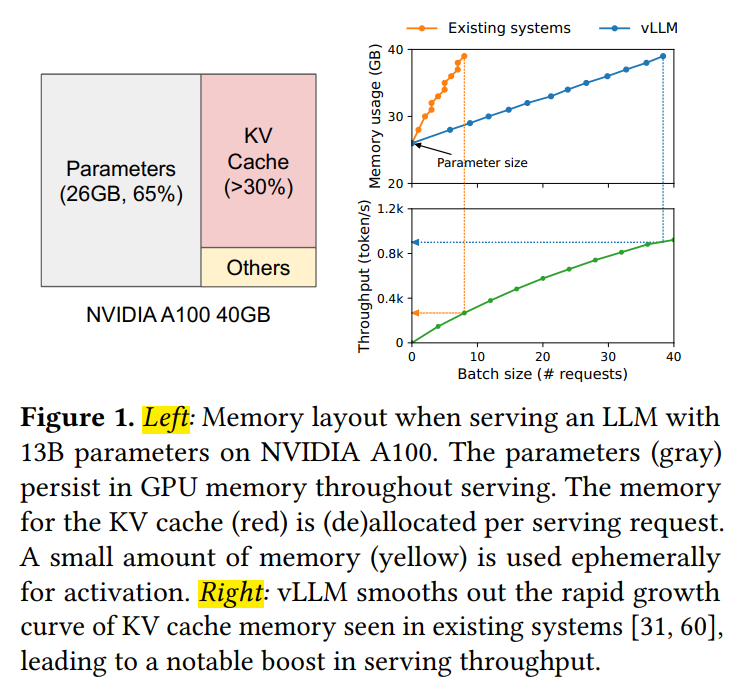
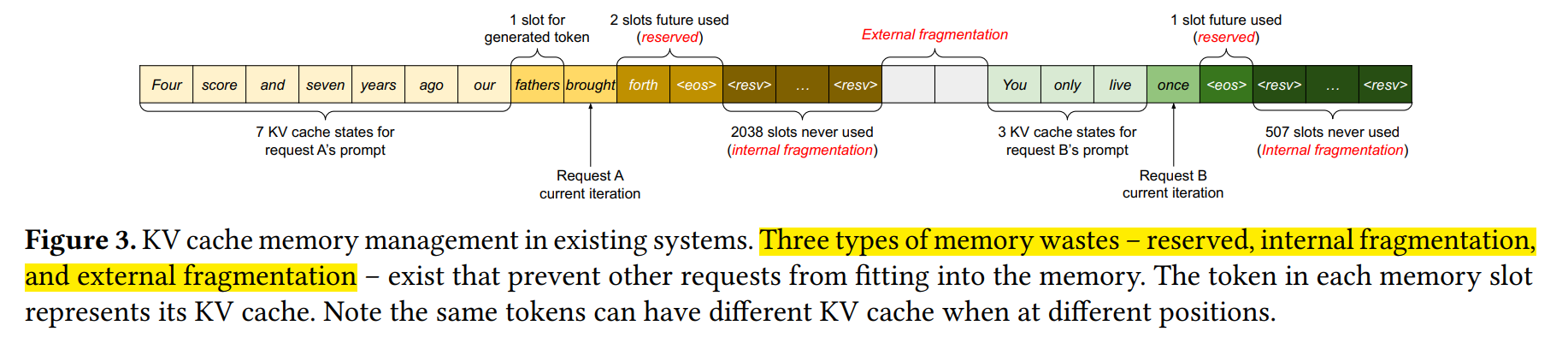
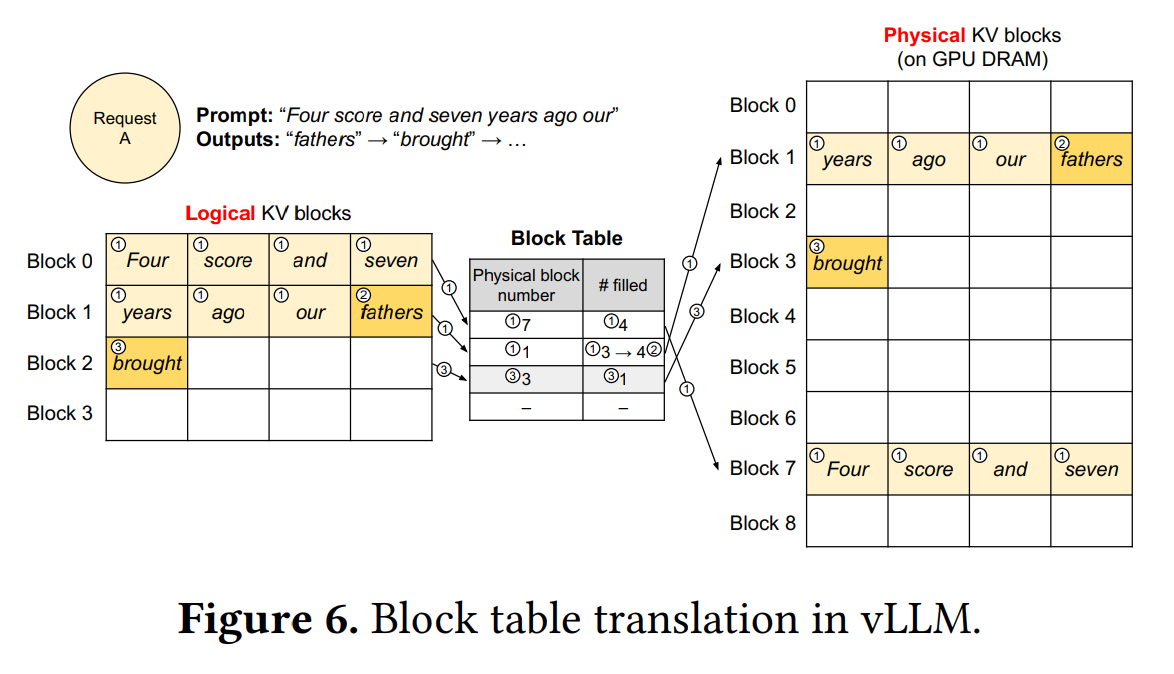
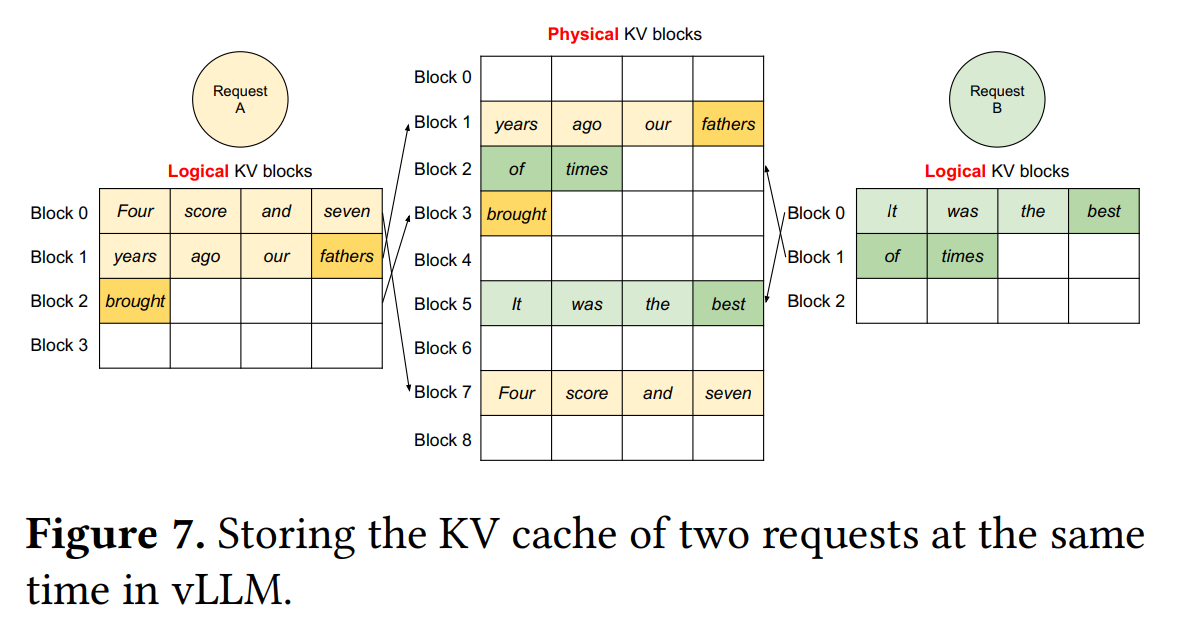
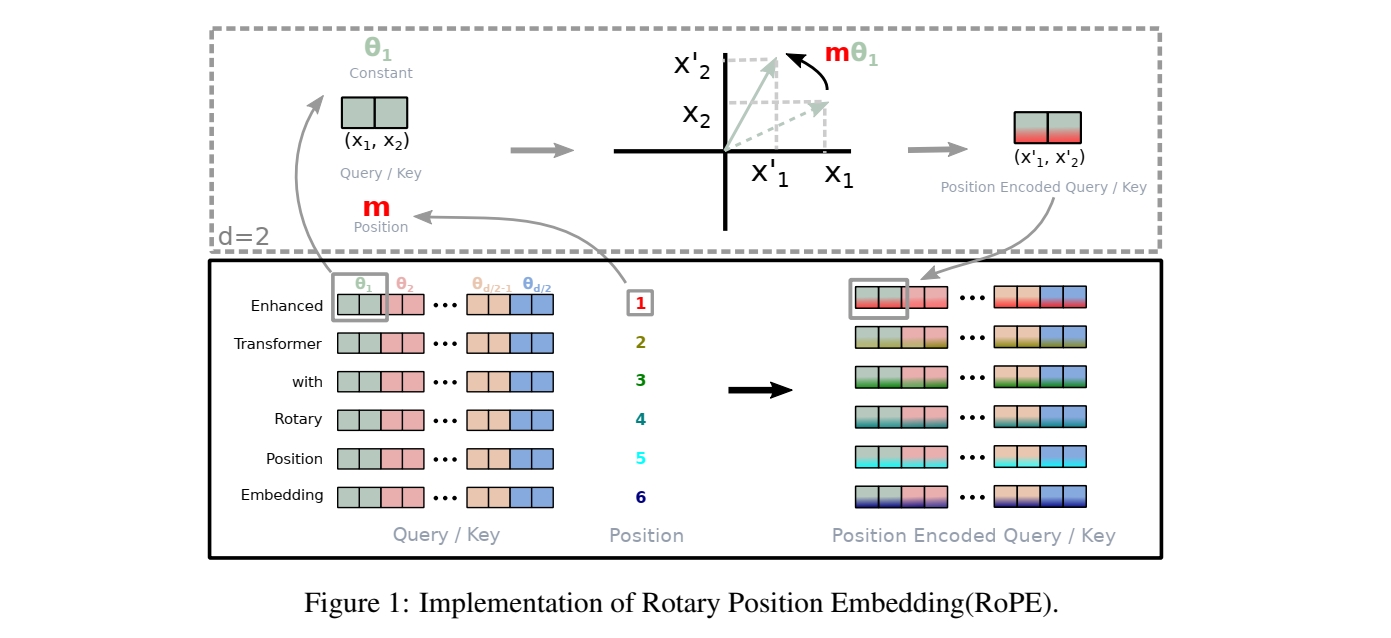
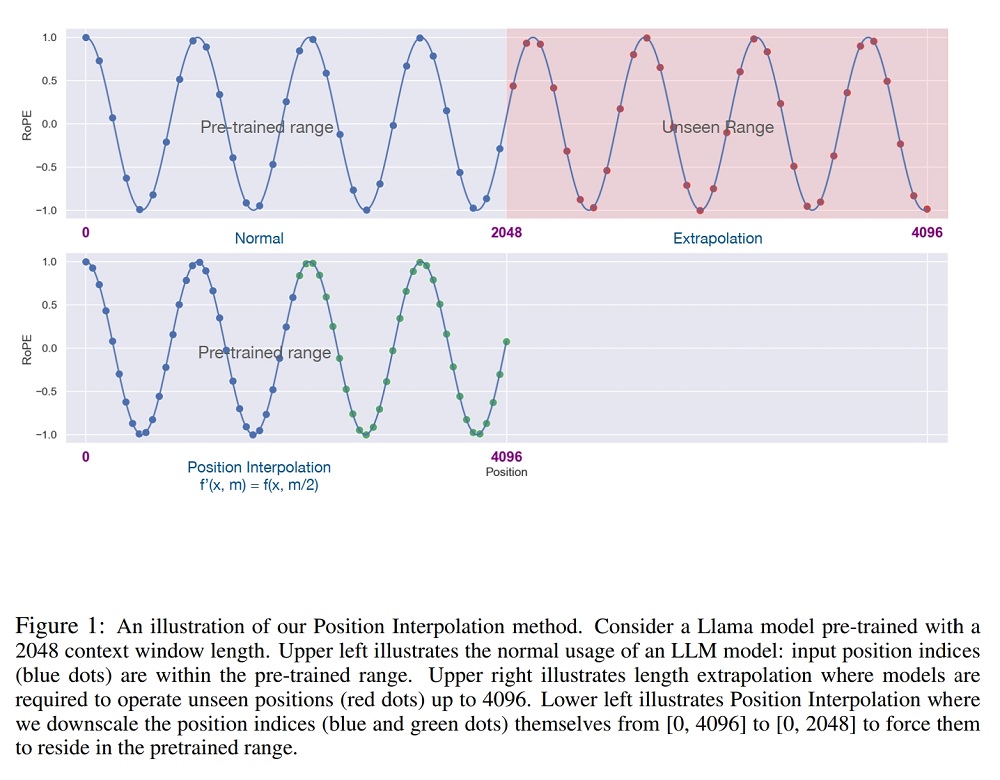
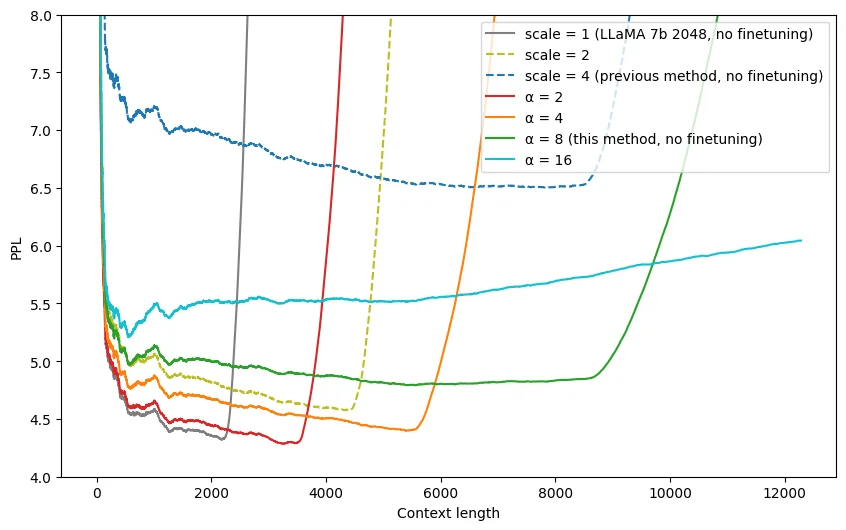
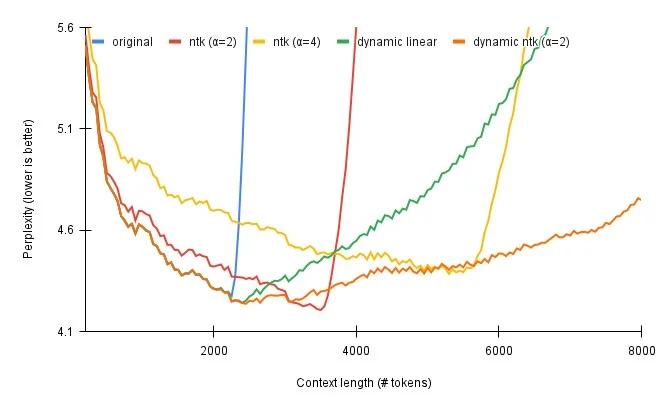










 ' +
+ '
' +
+ '