Loss of performance in Crocoddyl parallelization #1182
Comments
|
Hi @TheoMF, thanks for sharing these plots! At the moment, I can't claim that there is an issue. For instance, I could explain the computation increase in the second plot with thread synchronization. Could you provide more explanatory details on why you believe there is an issue? I am also keen to hear more about what your findings are regarding the On another note, improvements in the As part of our research work, we are extending Crocoddyl features, which I can't talk about now. However, these new features required us to revisit Crocoddyl API. In short, some classes will be deprecated when realising this code. |
|
Btw, |
|
We clearly see that the thread parallelization does not allow to linearly divide the computational cost of calcdiff. There is no sync between the tasks, so no reason for that beyond a minimal loss. Here, it is much more significant. First, we would like to agree on the loss. If it is not evident, we can provide more analysis. Second, we would like to fix it. @TheoMF obtained better results with replacing the map of CostSum by a vector. Once we agree on the initial observation, we can share the results of improvement. |
I understand this, but my question is the follows: have you observed the same increase in the computation cost per thread when the number of OC nodes is increased? If I understand correctly these results, you have a bench with 100 nodes, right? Could it be possible to analyse this for a different number of nodes? It would be also useful to do it for different systems: quadrotors, manipulators and quadrupeds. For instance, the parallelization in quadrotors (or low-dimensional systems) is much more expensive than the non-parallelization case. In short, a few extra results will show a better picture of what is happening, I believe.
I am with you on looking to fix this issue if exists. When replacing the map with a vector internally, are you planning to have an internal mechanism to identify cost functions? That would be important for having the flexibility to specialise references or activate/deactivate costs. This is something quite used in our MPC. |
Crocoddyl parallelization seems to face issues.
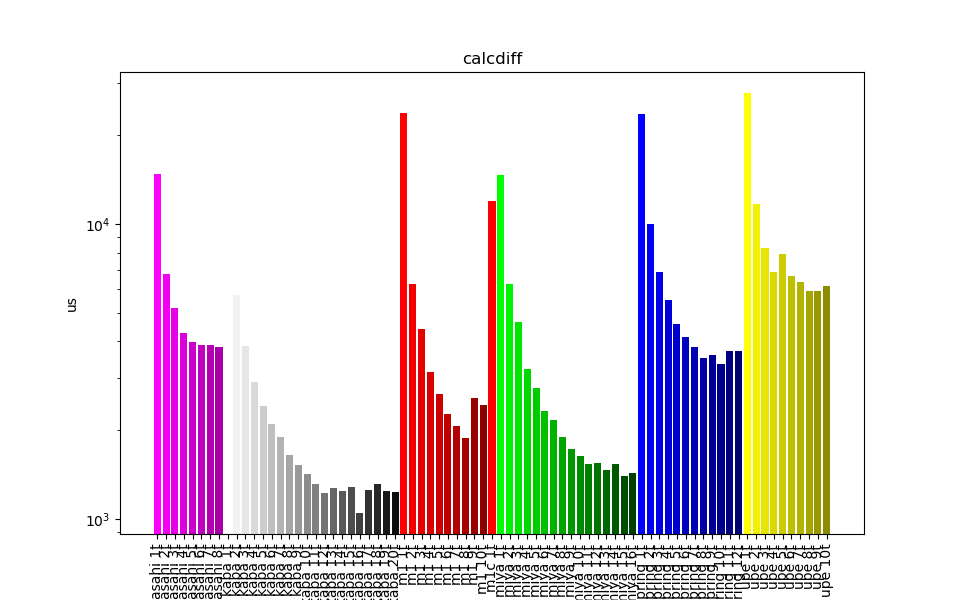
When measuring execution time while parallelizing the function
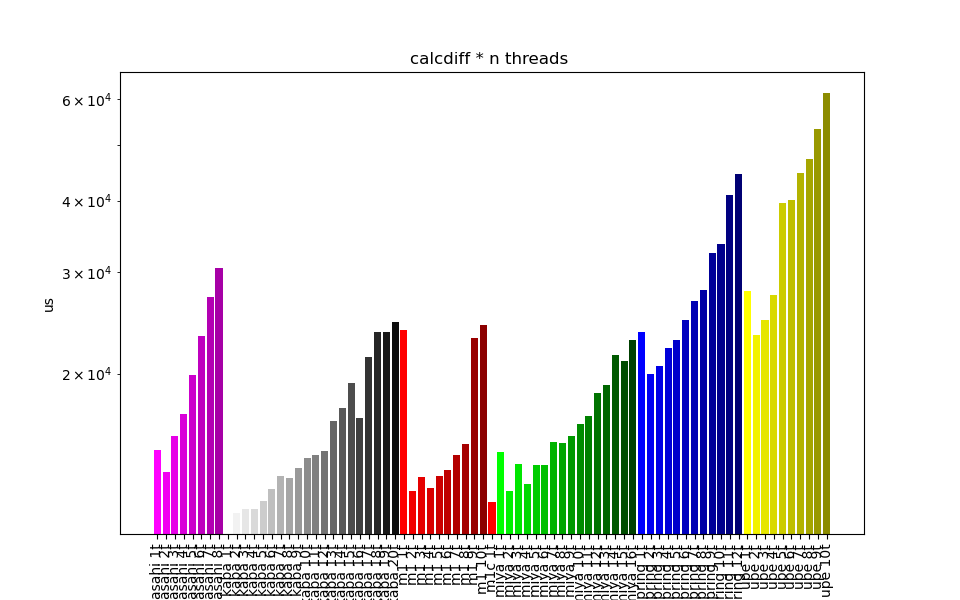
calcdiffof the classIntegratedActionModelEuleron the robot Talos, we can observe a decrease in performance. On the repository https://gitlab.laas.fr/gsaurel/croco-benchs, we have plots of it that shows the results on multiple computers :This is what the execution time looks like on multiple machines as we increase the number of cores. Now if we plot the execution time multiplied by the number of cores, if the parallelization was successfull, we would have something constant when using more cores. Actually, the more we use cores, the higher the multiplication is :
The increase of this multiplication shows the loss of performance.
I am writing this issue in the prospect of solving this problem. I am currently investigating the causes of it.
I think I have found one of the cause of this issue : the function
calcdiffin the classCostModelSum. I can open a PR to discuss about it. If we agree, I could open a PR to discuss this first step with more details.I'm also looking at the
calcdiffin the classIntegratedActionModelEuler, there may be a problem of aliasing that also decrease the performance.The text was updated successfully, but these errors were encountered: