Fake news has become a major problem. A Pew Research Center survey conducted in 2016 found that nearly two-thirds of U.S. adults say that fake news has caused a great deal of confusion about basic facts of current events and nearly a quarter have said that they have either knowingly or unknowingly shared fake news online1. Due to the widespread nature of social media, the spread of misinformation is fast and can have significant consequences for individuals, communities, and societies. For example, fake news can lead to distrust of the media, undermining of the democratic process/contribute to political divisiveness, and influence erroneous decision-making2.
By developing accurate and effective methods to predict fake news, social scientists can: 1. understand how people consume information (specifically cognitive biases, social homophily and inattention) which can shed light on the psychological, social, and technological factors that contribute to the viral spread of misinformation
2. assess the impact of fake news on society on the most vulnerable communities/individuals most susceptible of sharing misinformation without proper verification and develop interventions to mitigate the harmful effects
3. understand the specifics of fake news that lead to manipulation of populations exposed and how to combat this phenomenon
- Text processing, that is, the act of turning text into a numeric input that a machine learning model can take in, would benefit largely from parallelization. Namely, tokenization, the act of breaking down chunks of text into smaller subunits (e.g., words) is a necessary step that can be computationally expensive, especially when dealing with large documents.
- Feature extraction such as obtaining n-grams from text can lead to extremely wide dataframes (high dimensions - count vectorizers increase in folds of the length of the vocabulary size, which can be in the tens of thousands), requiring substantial memory resources.
- Large language models (not used in this project, but can be applied to increase accuracy), have millions of parameters leading to the need for more compute-intensive resources.
- Model fine-tuning often involve computationally expensive and time consuming procedures such as hyperparameter tuning via grid search.
- Can fake news be predicted and if so, how well?
- What are the biggest differences between articles from reliable and unreliable sources and are there topics that are more susceptible to being faked?
Data come from this Kaggle competition. The key file is train.csv, which is a labeled dataset of 20,800 news articles. The test.csv file does not contain labels so I excluded it from this project.
The project is divided into two main parts and used PySpark:
-
Build a text cleaning and preprocessing pipeline
- Data cleaning
- Tokenize text
- Clean & normalize tokens: remove stop words, punctuation, make all text lowercase and lemmatize words (extracting base words--for example "running" --> "run")
- Text processing: convert preprocessed tokens to a numerical format models can take in using a count vectorizer which takes in n-grams from the corpus and counts the number of instances that n-gram is seen in the example
- Data cleaning
-
Build a machine learning pipeline to obtain predictions (each notebook also performs text cleaning and preprocessing)
- Build and tune models (logistic regression and gradient boosted trees) to predict whether an article is from an unreliable source (fake)
- Perform LDA topic modeling to analyze which topics are more likely to be manipulated into fake news.
- Code: lda.ipynb
-
Fake News Prediction: data for both models were split into an 80/20 train-test split
-
Logistic Regression: I chose a logistic regression model since logistic regression is relatively simple and interpretable and provides a probabilistic interpretation of classification results. I performed hyperparameter tuning via 5-fold grid search cross validation of the regularization parameter and elastic net parameter. The evaluator used was the BinaryClassificationEvaluator from PySpark with AUC-ROC as the evaluation metric. The test AUC and test accuracy came out to 0.9732 and 0.9217, respectively, indicating that fake news can be predicted well using a matrix of n-gram token counts from the count vectorizer and logistic regression.
-
Gradient Boosted Tree Classifier: The second model I chose to use was a gradient boosted tree since they are generally considered accurate, stable, and highly interpretable. Additionally, contrary to linear models such as logistic regression, tree-based models don’t assume our data have linear boundaries. I performed hyperparameter tuning via 5-fold grid search cross validation of maximum depth of the tree and maximum number of iterations. The evaluator used was the BinaryClassificationEvaluator from PySpark with AUC-ROC as the evaluation metric. The test AUC and test accuracy came out to 0.9724 and 0.9071, respectively. The test AUC is similar to the one from the logistic regression model, but test accuracy was slightly lower here.
-
-
LDA Topic Modeling
-
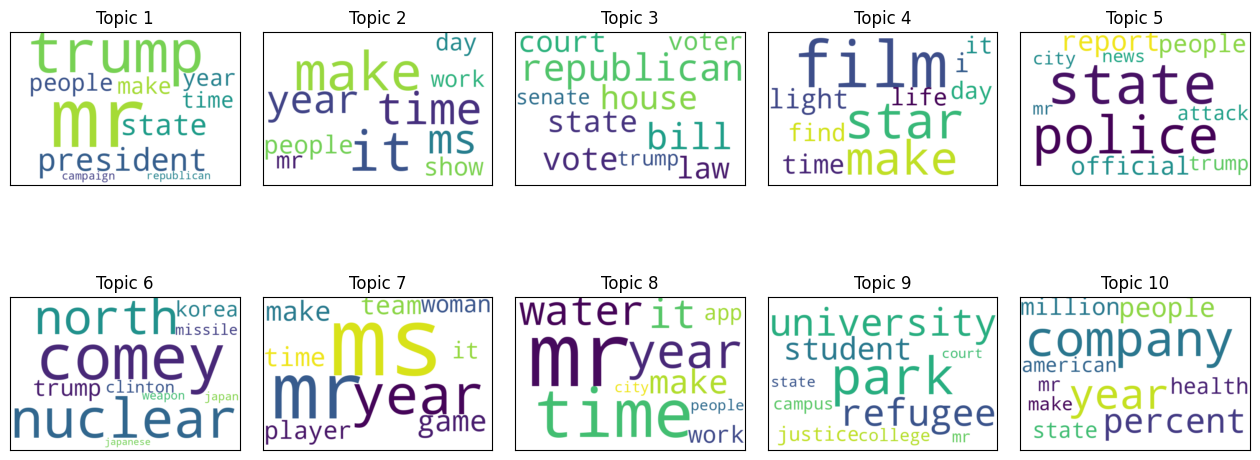
Results from the top 10 words from 10 topics
- Unreliable (fake) articles:

- Reliable (real) articles:

From the images above, we can see that topics and frequent words from fake news articles tend to be polarizing and controversial (i.e., 2016 Presidential Election in Topics 2 and 3). While topics and frequent words from real news articles overlap with the ones from fake news articles (Topics 1 and 3), we can see from the wordclouds in Topics 1, 7, and 8 that honorifics are commonly used. I used an arbitrary number of topics (10), but for future work, it would be a good idea to determine the number of topics less arbitrarily and examine the differences in frequently used words and topics from LDA more analytically.
-