@@ -70,9 +57,11 @@ int main(void)
}
```
-Check the common binary sections and symbols. Use the usual coomands (`readelf -S`, `nm`).
+Check the common binary sections and symbols.
+Use the usual coomands (`readelf -S`, `nm`).
Observe in which section each variable is located and the section flags.
-
+
+```console
$ readelf -S buffers
...
[16] .rodata PROGBITS 0000000000402000 00002000
@@ -98,9 +87,10 @@ Key to Flags:
B (symbol in BSS data section)
A lowercase flag means variable is not visible local (not visible outside the object)
-
+```
You can also inspect these programmatically using pwntools and the ELF class:
+
```python
from pwn import *
@@ -138,6 +128,7 @@ print("g_buf_const: 0x{:08x}".format(elf.symbols.g_buf_const))
```
Another handy utility is the `vmmap` command in `pwndbg` which shows all memory maps of the process at runtime:
+
```gdb
pwndbg> b main
pwngdb> run
@@ -154,25 +145,30 @@ LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA
0xffffffffff600000 0xffffffffff601000 --xp 1000 0 [vsyscall]
```
-Non-static local variables and dynamically allocated buffers cannot be seen in the executable (they have meaning only at runtime, because they are allocated on the stack or heap in a function scope). The symbol names aren't found anywhere in the binary, except if debug symbols are enabled (`-g` flag).
+Non-static local variables and dynamically allocated buffers cannot be seen in the executable (they have meaning only at runtime, because they are allocated on the stack or heap in a function scope).
+The symbol names aren't found anywhere in the binary, except if debug symbols are enabled (`-g` flag).
-## Stack buffer overflow
+## Stack Buffer Overflow
- +
-> Note that this is the stack for a 64bit system and the first couple of function arguments are stored in registers (rdi, rsi, rdx, rcx, r8, and r9) and that's why the images has `arg_6` as the first argument.
+Note that this is the stack for a 64bit system and the first couple of function arguments are stored in registers (rdi, rsi, rdx, rcx, r8, and r9) and that's why the images has `arg_6` as the first argument.
We should know by now that the stack serves multiple purposes:
+
- Passing function arguments from the caller to the callee
- Storing local variables for functions
- Temporarily saving register values before a call
- Saving the return address and old frame pointer
-Even though, in an abstract sense, different buffers are separate from one another, ultimately they are just some regions of memory which do not have any intrinsic identification or associated size. To avoid this, most hight level languages use size metadata and bound checks to detect out of bounds accesses to the memory.
+Even though, in an abstract sense, different buffers are separate from one another, ultimately they are just some regions of memory which do not have any intrinsic identification or associated size.
+To avoid this, most hight level languages use size metadata and bound checks to detect out of bounds accesses to the memory.
-But in our case, bounds are unchecked, therefore it is up to the programmer to code carefully. This includes checking for any overflows and using **safe functions**. Unfortunately, many functions in the standard C library, particularly those which work with strings and read user input, are unsafe - nowadays, the compiler will issue warnings when encountering them.
+But in our case, bounds are unchecked, therefore it is up to the programmer to code carefully.
+This includes checking for any overflows and using **safe functions**.
+Unfortunately, many functions in the standard C library, particularly those which work with strings and read user input, are unsafe - nowadays, the compiler will issue warnings when encountering them.
-### Buffer size and offset identification
+### Buffer Size and Offset Identification
When trying to overflow a buffer on the stack we need to know the size and where the buffer is in memory relative to the saved return address (or some other control flow altering value/pointer).
@@ -181,6 +177,7 @@ When trying to overflow a buffer on the stack we need to know the size and where
One way, for simple programs, you can do **static analysis** and check some key points in the diassembled code.
For example, this simple program (`00-tutorial/simple_read`, run `make simple_read` to compile):
+
```c
#include
@@ -191,8 +188,9 @@ int main(void) {
}
```
-generates the following assembly:
-```nasm
+generates the following assembly code:
+
+```asm
push rbp
mov rbp,rsp
sub rsp,0x90
@@ -226,21 +224,22 @@ leave
ret
```
-Looking at the `fread` arguments we can see the buffer start relative to `RBP` and the number of bytes read. `RBP-0x80+0x100*0x1 = RBP+0x80`, so the fread function can read 128 bytes after `RBP` -> return address stored at 136 bytes after `RBP`.
-
-
-
+
-> Note that this is the stack for a 64bit system and the first couple of function arguments are stored in registers (rdi, rsi, rdx, rcx, r8, and r9) and that's why the images has `arg_6` as the first argument.
+Note that this is the stack for a 64bit system and the first couple of function arguments are stored in registers (rdi, rsi, rdx, rcx, r8, and r9) and that's why the images has `arg_6` as the first argument.
We should know by now that the stack serves multiple purposes:
+
- Passing function arguments from the caller to the callee
- Storing local variables for functions
- Temporarily saving register values before a call
- Saving the return address and old frame pointer
-Even though, in an abstract sense, different buffers are separate from one another, ultimately they are just some regions of memory which do not have any intrinsic identification or associated size. To avoid this, most hight level languages use size metadata and bound checks to detect out of bounds accesses to the memory.
+Even though, in an abstract sense, different buffers are separate from one another, ultimately they are just some regions of memory which do not have any intrinsic identification or associated size.
+To avoid this, most hight level languages use size metadata and bound checks to detect out of bounds accesses to the memory.
-But in our case, bounds are unchecked, therefore it is up to the programmer to code carefully. This includes checking for any overflows and using **safe functions**. Unfortunately, many functions in the standard C library, particularly those which work with strings and read user input, are unsafe - nowadays, the compiler will issue warnings when encountering them.
+But in our case, bounds are unchecked, therefore it is up to the programmer to code carefully.
+This includes checking for any overflows and using **safe functions**.
+Unfortunately, many functions in the standard C library, particularly those which work with strings and read user input, are unsafe - nowadays, the compiler will issue warnings when encountering them.
-### Buffer size and offset identification
+### Buffer Size and Offset Identification
When trying to overflow a buffer on the stack we need to know the size and where the buffer is in memory relative to the saved return address (or some other control flow altering value/pointer).
@@ -181,6 +177,7 @@ When trying to overflow a buffer on the stack we need to know the size and where
One way, for simple programs, you can do **static analysis** and check some key points in the diassembled code.
For example, this simple program (`00-tutorial/simple_read`, run `make simple_read` to compile):
+
```c
#include
@@ -191,8 +188,9 @@ int main(void) {
}
```
-generates the following assembly:
-```nasm
+generates the following assembly code:
+
+```asm
push rbp
mov rbp,rsp
sub rsp,0x90
@@ -226,21 +224,22 @@ leave
ret
```
-Looking at the `fread` arguments we can see the buffer start relative to `RBP` and the number of bytes read. `RBP-0x80+0x100*0x1 = RBP+0x80`, so the fread function can read 128 bytes after `RBP` -> return address stored at 136 bytes after `RBP`.
-
-
- +Looking at the `fread` arguments we can see the buffer start relative to `RBP` and the number of bytes read.
+`RBP-0x80+0x100*0x1 = RBP+0x80`, so the fread function can read 128 bytes after `RBP` -> return address stored at 136 bytes after `RBP`.
+
-#### Dynamic analysis
+#### Dynamic Analysis
-You can determine offsets at runtime in a more automated way with pwndbg using an [De Bruijin sequences](https://en.wikipedia.org/wiki/De_Bruijn_sequence) which produces strings where every substring of length N appears only once in the sequence; in our case it helps us identify the offset of an exploitable memory value relative to the buffer.
+You can determine offsets at runtime in a more automated way with pwndbg using an [De Bruijin sequences](https://en.wikipedia.org/wiki/De_Bruijn_sequence) which produces strings where every substring of length N appears only once in the sequence;
+in our case it helps us identify the offset of an exploitable memory value relative to the buffer.
For a simple buffer overflow the worflow is:
+
1. generate an long enough sequence to guarantee a buffer overflow
-2. feed the generated sequence to the input function in the program
-3. the program will produce a segmentation fault when reaching the invalid return address on the stack
-4. search the offset of the faulty address in the generated pattern to get an offset
+1. feed the generated sequence to the input function in the program
+1. the program will produce a segmentation fault when reaching the invalid return address on the stack
+1. search the offset of the faulty address in the generated pattern to get an offset
In pwndbg this works as such:
@@ -268,9 +267,10 @@ pwndbg> cyclic -n 8 -c 64 -l 0x6161616161616172
136
```
-Note: We get the same 136 offset computed manually with the static analysis method
+**Note**:
+We get the same 136 offset computed manually with the static analysis method.
-## Input-Output functions
+## Input-Output Functions
Most programs aren't a straight forward single input buffer overflow so we need to deal with things like:
@@ -278,7 +278,7 @@ Most programs aren't a straight forward single input buffer overflow so we need
- parsing program output - to use potential leaked information
- understand the mechanics of the IO methods used - what kind of data they accept and possible constraints
-_Pwntools_ offers a large area of [IO functions](https://docs.pwntools.com/en/stable/tubes.html) to communicate with a program (either local or remote).
+`pwntools` offers a large area of [IO functions](https://docs.pwntools.com/en/stable/tubes.html) to communicate with a program (either local or remote).
The basic and usual ones are:
- `send(data)` - sends the `data` byte string to the process
@@ -288,31 +288,44 @@ The basic and usual ones are:
- `recvuntil(str)` - receives data until `str` is found (will not contain `str`)
- `recvall()` - receives the full program ouptut (until EOF)
-> Check the documentation for more complex IO functions that might come in handy (like `recvregex`, `sendafter`).
+Check the documentation for more complex IO functions that might come in handy (like `recvregex`, `sendafter`).
+
+It is also important to understand the functionality of the different IO functions the program itself uses.
+For C programs, in our case, you can always
+find useful information in the man pages of specific functions:
-It is also important to understand the functionality of the different IO functions the program itself uses. For C programs, in our case, you can always
-find useful information in the man pages of specific functions, TL;DR:
-- `size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream)` - reads *nmemb* items of data, each *size* bytes long,
- simple and straightforward
-- `char *gets(char *s)` - reads until either a terminating newline or EOF, which it replaces with a null byte ('\0')
- the problem here is that you won't be able to have a newline in the middle of your payload; note that it doesn't have a size argument to it will read indefinetely as long as it doesn't reach a newline or EOF
-- `char *fgets(char *s, int size, FILE *stream)` - reads in **at most** one less than *size* characters from stream and stores them into the buffer pointed to by s. Reading stops after an **EOF** or a **newline**. If a **newline** is read, it is stored into the buffer. A terminating null byte ('\0') is stored after the last character in the buffer.
- this one adds the size limit argument, but also note that it **stores** the newline in the string and **adds** the null byte after (in contrast to `gets`)
-- `int scanf(const char *format, ...)` - as opposed the other funcions `scanf` reads **text** based on the format string and parses it
- don't do the common mistake of **sending binary data to scanf**, for example `"%d"` expects a string representation of a numer like `"16"`, not the binary data like `"\x00\x00\x00\x10"`
+- `size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream)`:
+ Reads *nmemb* items of data, each *size* bytes long, simple and straightforward.
+- `char *gets(char *s)`:
+ Reads until either a terminating newline or EOF, which it replaces with a null byte ('\0').
+ The problem here is that you won't be able to have a newline in the middle of your payload;
+ note that it doesn't have a size argument to it will read indefinetely as long as it doesn't reach a newline or `EOF`.
+- `char *fgets(char *s, int size, FILE *stream)`:
+ Reads in **at most** one less than *size* characters from stream and stores them into the buffer pointed to by s.
+ Reading stops after an **EOF** or a **newline**.
+ If a **newline** is read, it is stored into the buffer.
+ A terminating null byte ('\0') is stored after the last character in the buffer.
+ This one adds the size limit argument, but also note that it **stores** the newline in the string and **adds** the null byte after (in contrast to `gets`)
+- `int scanf(const char *format, ...)`:
+ As opposed the other funcions `scanf` reads **text** based on the format string and parses it
+ Don't do the common mistake of **sending binary data to scanf**, for example `"%d"` expects a string representation of a numer like `"16"`, not the binary data like `"\x00\x00\x00\x10"`
-> Every time you encounter a new input function check the documentation to find it's limitations
+Every time you encounter a new input function check the documentation to find it's limitations
-# Challenges
-## 01. Challenge: Parrot
+## Challenges
-Some programs feature a stack _smashing protection_ in the form of stack canaries, that is, values kept on the stack which are checked before returning from a function. If the value has changed, then the “canary” can conclude that stack data has been corrupted throughout the execution of the current function.
+### 01. Challenge: Parrot
-We have implemented our very own `parrot`. Can you avoid it somehow?
+Some programs feature a stack smashing protection in the form of stack canaries, that is, values kept on the stack which are checked before returning from a function.
+If the value has changed, then the “canary” can conclude that stack data has been corrupted throughout the execution of the current function.
-## 02. Challenge: Indexing
+We have implemented our very own `parrot`.
+Can you avoid it somehow?
-More complex programs require some form of protocol or user interaction. This is where _pwntools_ shines.
+### 02. Challenge: Indexing
+
+More complex programs require some form of protocol or user interaction.
+This is where `pwntools` shines.
Here's an interactive script to get you started:
```python
@@ -330,37 +343,39 @@ Here's an interactive script to get you started:
p.interactive()
```
-> Go through GDB when aiming to solve this challenge. As all input values are strings, you can input them at the keyboard and follow their effect in GDB.
+Go through GDB when aiming to solve this challenge.
+As all input values are strings, you can input them at the keyboard and follow their effect in GDB.
-## 03. Challenge: Smashthestack Level7
+### 03. Challenge: Smashthestack Level7
-Now you can tackle a real challenge. See if you can figure out how you can get a shell from this one.
+Now you can tackle a real challenge.
+See if you can figure out how you can get a shell from this one.
Hints:
- There's an integer overflow + buffer overflow in the program.
-
-- How does integer multiplication work at a low level? Can you get get a positive number by multiplying a negative number by 4?
-
+- How does integer multiplication work at a low level?
+ Can you get get a positive number by multiplying a negative number by 4?
- To pass command line arguments in gdb use `run arg1 arg2 ...` or `set args arg1 arg2 ...` before a `run` command
+- In `pwntools` you can pass a list to `process` (`process(['./level07', arg1, arg2]`)
-- In _pwntools_ you can pass a list to `process` (`process(['./level07', arg1, arg2]`)
+### 04. Challenge: Neighbourly
-## 04. Challenge: Neighbourly
+Let's overwrite a structure's function pointer using a buffer overflow in its vicinity.
+The principle is the same.
-Let's overwrite a structure's function pointer using a buffer overflow in its vicinity. The principle is the same.
+### 05. Challenge: Input Functions
-## 05. Challenge: Input Functions
+On the same idea as the "Indexing" challenge but much harder.
+Carefully check what input functions are used and parse the input accordingly.
-On the same idea as the _Indexing_ challenge but much harder. Carefully check what input functions are used and parse the input accordingly.
+### 06. Challenge: Bonus: Birds
-## 06. Challenge: Bonus: Birds
+Time for a more complex challenge.
+Be patient and don't speed through it.
-Time for a more complex challenge. Be patient and don't speed through it.
-
-# Further Reading
+## Further Reading
- [De Bruijin sequences](https://en.wikipedia.org/wiki/De_Bruijn_sequence)
- [PwnTools ELF Module](https://docs.pwntools.com/en/latest/elf/elf.html) (which internally uses [PyElftoools](https://github.com/eliben/pyelftools) and may expose such objects)
- [PwnTools IO](https://docs.pwntools.com/en/stable/tubes.html)
-
diff --git a/chapters/exploitation-techniques/return-oriented-programming-advanced/reading/README.md b/chapters/exploitation-techniques/return-oriented-programming-advanced/reading/README.md
index 7c54270..198a177 100644
--- a/chapters/exploitation-techniques/return-oriented-programming-advanced/reading/README.md
+++ b/chapters/exploitation-techniques/return-oriented-programming-advanced/reading/README.md
@@ -1,20 +1,6 @@
# Return-Oriented Programming Advanced
-## Table of Contents
-
-- [Return-Oriented Programming Advanced](#return-oriented-programming-advanced)
- * [Calling Conventions in the ROP Context](#calling-conventions-in-the-rop-context)
- * [ROP gadgets on x86_64](#rop-gadgets-on-x86_64)
- * [Libc leaks](#libc-leaks)
- * [Challenges](#challenges)
- * [01. Challenge - Using ROP to Leak and Call system](#01-challenge---using-rop-to-leak-and-call-system)
- * [02. Challenge - Handling Low Stack Space](#02-challenge---handling-low-stack-space)
- * [03. Challenge - Stack Pivoting](#03-challenge---stack-pivoting)
- * [04. Challenge - mprotect](#04-challenge---mprotect)
- * [Further Reading](#further-reading)
-
-
-In this session we are going to dive deeper into *Return-Oriented Programming* and setbacks that appear in modern exploitation.
+In this session we are going to dive deeper into Return-Oriented Programming and setbacks that appear in modern exploitation.
Topics covered:
- ROP for syscalls and 64 bits
@@ -22,7 +8,7 @@ Topics covered:
- Dealing with low space in the overflown buffer
- Combining ROP and shellcodes
-As the basis of the lab we will use a program based on a classical CTF challenge called *ropasaurusrex* and gradually make exploitation harder.
+As the basis of the lab we will use a program based on a classical CTF challenge called `ropasaurusrex` and gradually make exploitation harder.
## Calling Conventions in the ROP Context
@@ -60,7 +46,7 @@ syscall
On `x86_64` the ROP payloads will have to be built differently than on `x86` because of the different calling convention.
Having the function arguments stored in registers means that you don't need to do stack cleanup anymore, but you will need gadgets with **specific registers** to pop the arguments into.
-For example to do the `read(0, buf, size)` *libc call* to do this call your payload will need to look like:
+For example to do the `read(0, buf, size)` libc call to do this call your payload will need to look like:
```text
pop rdi; ret
@@ -75,7 +61,8 @@ call read@plt
## Libc leaks
You might have already encountered in other tasks the need to leak values or addresses.
-Most of the time, if you want to get a shell, you won't have a convenient `system@plt` symbol present in your binary, and ASLR will most often be activated; so you will have to compute it relative to another libc symbol at runtime.
+Most of the time, if you want to get a shell, you won't have a convenient `system@plt` symbol present in your binary, and `ASLR` will most often be activated;
+so you will have to compute it relative to another libc symbol at runtime.
For this we will need to know what libc library the program is loading.
For a local executable we can just run `ldd`:
@@ -110,14 +97,16 @@ payload = ... + p64(libc.symbols['system'])
## Challenges
-**NOTE**: All tasks from this session are 64 bit binaries, so take that into consideration when you build the ROP chains.
+**Note**: All tasks from this session are 64 bit binaries, so take that into consideration when you build the ROP chains.
### 01. Challenge - Using ROP to Leak and Call system
Use the `01-leak-call-system/src` executable file in order to spawn a shell.
You can now call the functions in the binary but `system` or any other appropriate function is missing and ASLR is enabled.
-How do you get past this? You need an information leak! To leak information we want to print it to standard output and process it.
+How do you get past this?
+You need an information leak!
+To leak information we want to print it to standard output and process it.
We use calls to `printf`, `puts` or `write` for this.
In our case we can use the `write` function call.
@@ -197,7 +186,8 @@ Call `system`.
### 03. Challenge - Stack Pivoting
Let's assume that `main` function had additional constraints that made it impossible to repeat the overflow.
-How can we still solve it? The method is called stack pivoting.
+How can we still solve it?
+The method is called stack pivoting.
In short, this means making the stack pointer refer another (writable) memory area that has enough space, a memory area that we will populate with the actual ROP chain.
Read more about stack pivoting [here](http://neilscomputerblog.blogspot.ro/2012/06/stack-pivoting.html).
@@ -205,7 +195,8 @@ Read more about stack pivoting [here](http://neilscomputerblog.blogspot.ro/2012/
Tour goal is to fill the actual ROP chain to a large enough memory area.
We need a two stage exploit:
-- In the first stage, prepare the memory area where to fill the second stage ROP chain; then fill the memory area with the second stage ROP chain.
+- In the first stage, prepare the memory area where to fill the second stage ROP chain;
+then fill the memory area with the second stage ROP chain.
- In the second stage, create the actual ROP chain and feed it to the program and profit.
Follow the steps below.
@@ -214,7 +205,8 @@ Use pmap or vmmap in `pwndbg` to discover the writable data section of the proce
Select an address in that section (**don't** use the start address).
This is where you fill the 2nd stage data (the actual ROP chain).
-Who not use the start address? Because `pop` instructions (which decrease the `rsp`) will go outside the memory region.
+Who not use the start address?
+Because `pop` instructions (which decrease the `rsp`) will go outside the memory region.
Create a first stage payload that calls `read` to store the 2nd stage data to the newly found memory area.
After that pivot the stack pointer to the memory area address.
@@ -233,18 +225,18 @@ pop rbp
Write the actual ROP chain as a second stage payload like when we didn't have space constraints.
The 2nd stage will be stored to the memory area and the stack pointer will point to that.
-**Important!** Be careful when and where the stack pivoting takes place.
+**Important!**
+Be careful when and where the stack pivoting takes place.
After the `mov rsp, rbp` part of the `leave` instruction happens your stack will be pivoted, so the following `pop rbp` will happen **on the new stack**.
Take this offset into account when building the payload.
### 04. Challenge - mprotect
-Combine everything you've learned until now and develop a complex payload to call `mprotect` to change the permissions on a memory region to read+write+execute and then instert a *shellcode* to call `system("/bin/sh")`.
+Combine everything you've learned until now and develop a complex payload to call `mprotect` to change the permissions on a memory region to read+write+execute and then instert a shellcode to call `system("/bin/sh")`.
## Further Reading
-- https://syscalls.kernelgrok.com/
-- http://articles.manugarg.com/systemcallinlinux2_6.html
-- https://eli.thegreenplace.net/2011/11/03/position-independent-code-pic-in-shared-libraries#the-procedure-linkage-table-plt
-- https://github.com/Gallopsled/pwntools-tutorial/tree/master/walkthrough
-
+-
+-
+-
+-
diff --git a/chapters/exploitation-techniques/return-oriented-programming/reading/README.md b/chapters/exploitation-techniques/return-oriented-programming/reading/README.md
index 9b7fee9..bd94bb5 100644
--- a/chapters/exploitation-techniques/return-oriented-programming/reading/README.md
+++ b/chapters/exploitation-techniques/return-oriented-programming/reading/README.md
@@ -1,41 +1,5 @@
# Return-Oriented Programming
-## Table of Contents
-* [Prerequisites](#prerequisites)
-* [Recap - ASLR](#recap---aslr)
-* [Solution - `GOT` and `PLT`](#solution---got-and-plt)
- * [Further Inspection](#further-inspection)
-* [Return Oriented Programming (`ROP`)](#return-oriented-programming-rop)
- * [Motivation](#motivation)
- * [NOP Analogy](#nop-analogy)
-* [Gadgets and `ROP` Chains](#gadgets-and-rop-chains)
- * [Code Execution](#code-execution)
- * [Changing Register Values](#changing-register-values)
- * [Clearing the Stack](#clearing-the-stack)
-* [Some Useful Tricks](#some-useful-tricks)
- * [Memory Spraying](#memory-spraying)
- * [`checksec` in `Pwndbg`](#checksec-in-pwndbg)
- * [Finding Gadgets in Pwndbg](#finding-gadgets-in-pwndbg)
-* [Further Reading](#further-reading)
- * [Linux x86 Program Start Up](#linux-x86-program-start-up)
- * [The `.plt.sec` Schema](#the-pltsec-schema)
- * [More about `CET` and r`endbr`](#more-about-cet-and-endbr)
- * [TLDR](#tldr)
-* [Putting it all Together: Demo](#putting-it-all-together-demo)
- * [Calling a Function](#calling-a-function)
- * [Calling a Function with Parameters](#calling-a-function-with-parameters)
- * [Calling Multiple Functions](#calling-multiple-functions)
- * [Finding Gadgets - `ROPgadgetr`](#finding-gadgets---ropgadget)
-* [Challenges](#challenges)
- * [01. Tutorial - Bypass NX Stack with return-to-libc](#01-tutorial---bypass-nx-stack-with-return-to-libc)
- * [02. Challenge - ret-to-libc](#02-challenge---ret-to-libc)
- * [03. Challenge - no-ret-control](#03-challenge---no-ret-control)
- * [04. Challenge - ret-to-plt](#04-challenge---ret-to-plt)
- * [05. Challenge - gadget tutorial](#05-challenge---gadget-tutorial)
- * [06. Bonus Challenge - Echo service](#06-bonus-challenge---echo-service)
-* [Conclusions](#conclusions)
-
-
## Prerequisites
In order to fully grasp the content of this session, you should have a good
@@ -51,7 +15,6 @@ If you are unfamiliar with any of the above concepts or if your understanding of
them is fuzzy, go over their corresponding sessions once again, before you
proceed with the current session.
-
## Recap - ASLR
ASLR is not the only feature that prevents the compiler and the linker from solving some relocations before the binary is actually running.
@@ -215,7 +178,9 @@ The offset to the return address is 24.
So `DOWRD`s from offset 24 onwards will be popped from the stack and executed.
Remember the `NOP` sled concept from previous sessions?
These were long chains of `NOP` instructions (`\x90`) used to pad a payload for alignment purposes.
-Since we can't add any new code to the program (_NX_ is enabled) how could we simulate the effect of a `NOP` sled? Easy! Using return instructions!
+Since we can't add any new code to the program (`NX` is enabled) how could we simulate the effect of a `NOP` sled?
+Easy!
+Using return instructions!
Let's find the `ret` instructions in a would-be binary:
@@ -363,7 +328,8 @@ Thus, the offsets between the values in the payload are 8, instead of 4 (as they
### Clearing the Stack
The second use of gadgets is to clear the stack.
-Remember the issue we had in the [Motivation](#motivation) section? Let's solve it using gadgets.
+Remember the issue we had in the [Motivation](#motivation) section?
+Let's solve it using gadgets.
We need to call `f1(0xAB, 0xCD)` and then `f2(0xEF, 0x42)`.
Our initial solution was:
@@ -426,7 +392,7 @@ int main()
It's a fairly simple overflow, but just how fast can you figure out the offset to the return address?
How much padding do you need?
-There is a shortcut that you can use to figure this out in under 30 seconds without looking at the *Assembly* code.
+There is a shortcut that you can use to figure this out in under 30 seconds without looking at the assembly code.
A [De Bruijn sequence](https://en.wikipedia.org/wiki/De_Bruijn_sequence) is a string of symbols out of a given alphabet in which each consecutive K symbols only appear once in the whole string.
If we can construct such a string out of printable characters then we only need to know the Segmentation Fault address.
@@ -602,7 +568,8 @@ Contents of section .got.plt:
Similarly to what we did previously, we now see that `0x804c00c` points to
address `0x08049040`, which is this code inside the `.plt` section:
-```
+
+```text
8049040: f3 0f 1e fb endbr32
8049044: 68 00 00 00 00 push 0x0
8049049: e9 e2 ff ff ff jmp 8049030 <.plt>
@@ -692,7 +659,7 @@ $ objdump -M intel -d vuln
Our vulnerable buffer is the first parameter of `fgets`, which is at offset `ebp - 0x40` i.e. `ebp - 64`.
Which means that the offset of the return address is `64 + 4 = 68` bytes into this buffer (remember how a stack frame looks like).
-So, in order to call the `warcraft` function, we'll give our binary a payload made up of a padding of 68 bytes, followed by the address of `warcraft`, written in _little endian_ representation, which can be written like this:
+So, in order to call the `warcraft` function, we'll give our binary a payload made up of a padding of 68 bytes, followed by the address of `warcraft`, written in little endian representation, which can be written like this:
```python
offset = 0x40 + 4
@@ -734,7 +701,8 @@ Take a look at those 4 `B`'s in the payload above.
We agreed that they are `overwatch`'s expected return address.
So if we wanted to call another function, we would only need to replace them with that function's address.
Pretty simple, right?
-But what if we wanted to call a third function? Well, then we would need to overwrite the next 4 bytes in our payload with a third address.
+But what if we wanted to call a third function?
+Well, then we would need to overwrite the next 4 bytes in our payload with a third address.
Easy!
But now we have actually run into trouble: the next 4 bytes are `overwatch`'s parameter.
In this situation it looks like we **either** call `overwatch` or we call a third function.
@@ -810,13 +778,13 @@ Go to the [01-tutorial-ret-to-libc/](activities/01-tutorial-ret-to-libc/src/) fo
In the previous sessions we used stack overflow vulnerabilities to inject new code into a running process (on its stack) and redirect execution to it.
This attack is easily defeated by making the stack, together with any other memory page that can be modified, non-executable.
-This is achieved by setting the **NX** bit in the page table of the current process.
+This is achieved by setting the `NX` bit in the page table of the current process.
We will try to bypass this protection for the `01-tutorial-ret-to-libc/src/auth` binary in the lab archive.
For now, disable ASLR in the a new shell:
```console
-$ setarch $(uname -m) -R /bin/bash
+setarch $(uname -m) -R /bin/bash
```
Let's take a look at the program headers and confirm that the stack is no longer executable.
@@ -824,7 +792,7 @@ We only have read and write (RW) permissions for the stack area.
The auth binary requires the `libssl1.0.0:i386` Debian package to work.
You can find `libssl1.0.0:i386` Debian package [here](https://packages.debian.org/jessie/i386/libssl1.0.0/download).
-First, let's check that *NX* bit we mentioned earlier:
+First, let's check that `NX` bit we mentioned earlier:
```console
$ checksec auth
@@ -836,8 +804,7 @@ $ checksec auth
For completeness, lets check that there is indeed a buffer (stack) overflow vulnerability.
```console
-$ python2.7 -c 'print "A" * 1357' | ltrace -i ./auth
-TODO
+python2.7 -c 'print "A" * 1357' | ltrace -i ./auth
```
Check the source file - the buffer length is 1337 bytes.
@@ -902,15 +869,17 @@ $ python2.7 -c 'print "A" * 1353 + "\x0f\x86\x04\x08"' | ltrace -i -e puts ./aut
### 02. Challenge - ret-to-libc
-So far, so good! Now let's get serious and do something useful with this.
+So far, so good!
+Now let's get serious and do something useful with this.
Continue working in the `01-tutorial-ret-to-libc/` folder in the activities archive.
The final goal of this task is to bypass the NX stack protection and call `system("/bin/sh")`.
-We will start with a simple ret-to-plt:
+We will start with a simple `ret-to-plt`:
1. Display all libc functions linked with the auth binary.
-1. Return to `puts()`. Use ltrace to show that the call is actually being made.
+1. Return to `puts()`.
+ Use ltrace to show that the call is actually being made.
1. Find the offset of the `"malloc failed"` static string in the binary.
1. Make the binary print `"failed"` the second time `puts()` is called.
1. **(bonus)** The process should SEGFAULT after printing `Enter password:` again.
@@ -923,13 +892,11 @@ We will start with a simple ret-to-plt:
1. Where is libc linked in the auth binary?
Compute the final addresses and call `system("/bin/sh")` just like you did with `puts()`.
-**Hint 1**
-
+**Hint 1**:
Use `LD_TRACE_LOADED_OBJECTS=1 ./auth` instead of `ldd`.
The latter is not always reliable, because the order in which it loads the libraries might be different than when you actually run the binary.
-**Hint 2**
-
+**Hint 2**:
When you finally attack this, `stdin` will get closed and the new shell will have nothing to read.
Use `cat` to concatenate your attack string with `stdin` like this:
diff --git a/chapters/exploitation-techniques/shellcodes-advanced/reading/README.md b/chapters/exploitation-techniques/shellcodes-advanced/reading/README.md
index 6c09150..71a2eda 100644
--- a/chapters/exploitation-techniques/shellcodes-advanced/reading/README.md
+++ b/chapters/exploitation-techniques/shellcodes-advanced/reading/README.md
@@ -1,25 +1,5 @@
# Shellcodes (Advanced)
-
+Looking at the `fread` arguments we can see the buffer start relative to `RBP` and the number of bytes read.
+`RBP-0x80+0x100*0x1 = RBP+0x80`, so the fread function can read 128 bytes after `RBP` -> return address stored at 136 bytes after `RBP`.
+
-#### Dynamic analysis
+#### Dynamic Analysis
-You can determine offsets at runtime in a more automated way with pwndbg using an [De Bruijin sequences](https://en.wikipedia.org/wiki/De_Bruijn_sequence) which produces strings where every substring of length N appears only once in the sequence; in our case it helps us identify the offset of an exploitable memory value relative to the buffer.
+You can determine offsets at runtime in a more automated way with pwndbg using an [De Bruijin sequences](https://en.wikipedia.org/wiki/De_Bruijn_sequence) which produces strings where every substring of length N appears only once in the sequence;
+in our case it helps us identify the offset of an exploitable memory value relative to the buffer.
For a simple buffer overflow the worflow is:
+
1. generate an long enough sequence to guarantee a buffer overflow
-2. feed the generated sequence to the input function in the program
-3. the program will produce a segmentation fault when reaching the invalid return address on the stack
-4. search the offset of the faulty address in the generated pattern to get an offset
+1. feed the generated sequence to the input function in the program
+1. the program will produce a segmentation fault when reaching the invalid return address on the stack
+1. search the offset of the faulty address in the generated pattern to get an offset
In pwndbg this works as such:
@@ -268,9 +267,10 @@ pwndbg> cyclic -n 8 -c 64 -l 0x6161616161616172
136
```
-Note: We get the same 136 offset computed manually with the static analysis method
+**Note**:
+We get the same 136 offset computed manually with the static analysis method.
-## Input-Output functions
+## Input-Output Functions
Most programs aren't a straight forward single input buffer overflow so we need to deal with things like:
@@ -278,7 +278,7 @@ Most programs aren't a straight forward single input buffer overflow so we need
- parsing program output - to use potential leaked information
- understand the mechanics of the IO methods used - what kind of data they accept and possible constraints
-_Pwntools_ offers a large area of [IO functions](https://docs.pwntools.com/en/stable/tubes.html) to communicate with a program (either local or remote).
+`pwntools` offers a large area of [IO functions](https://docs.pwntools.com/en/stable/tubes.html) to communicate with a program (either local or remote).
The basic and usual ones are:
- `send(data)` - sends the `data` byte string to the process
@@ -288,31 +288,44 @@ The basic and usual ones are:
- `recvuntil(str)` - receives data until `str` is found (will not contain `str`)
- `recvall()` - receives the full program ouptut (until EOF)
-> Check the documentation for more complex IO functions that might come in handy (like `recvregex`, `sendafter`).
+Check the documentation for more complex IO functions that might come in handy (like `recvregex`, `sendafter`).
+
+It is also important to understand the functionality of the different IO functions the program itself uses.
+For C programs, in our case, you can always
+find useful information in the man pages of specific functions:
-It is also important to understand the functionality of the different IO functions the program itself uses. For C programs, in our case, you can always
-find useful information in the man pages of specific functions, TL;DR:
-- `size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream)` - reads *nmemb* items of data, each *size* bytes long,
- simple and straightforward
-- `char *gets(char *s)` - reads until either a terminating newline or EOF, which it replaces with a null byte ('\0')
- the problem here is that you won't be able to have a newline in the middle of your payload; note that it doesn't have a size argument to it will read indefinetely as long as it doesn't reach a newline or EOF
-- `char *fgets(char *s, int size, FILE *stream)` - reads in **at most** one less than *size* characters from stream and stores them into the buffer pointed to by s. Reading stops after an **EOF** or a **newline**. If a **newline** is read, it is stored into the buffer. A terminating null byte ('\0') is stored after the last character in the buffer.
- this one adds the size limit argument, but also note that it **stores** the newline in the string and **adds** the null byte after (in contrast to `gets`)
-- `int scanf(const char *format, ...)` - as opposed the other funcions `scanf` reads **text** based on the format string and parses it
- don't do the common mistake of **sending binary data to scanf**, for example `"%d"` expects a string representation of a numer like `"16"`, not the binary data like `"\x00\x00\x00\x10"`
+- `size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream)`:
+ Reads *nmemb* items of data, each *size* bytes long, simple and straightforward.
+- `char *gets(char *s)`:
+ Reads until either a terminating newline or EOF, which it replaces with a null byte ('\0').
+ The problem here is that you won't be able to have a newline in the middle of your payload;
+ note that it doesn't have a size argument to it will read indefinetely as long as it doesn't reach a newline or `EOF`.
+- `char *fgets(char *s, int size, FILE *stream)`:
+ Reads in **at most** one less than *size* characters from stream and stores them into the buffer pointed to by s.
+ Reading stops after an **EOF** or a **newline**.
+ If a **newline** is read, it is stored into the buffer.
+ A terminating null byte ('\0') is stored after the last character in the buffer.
+ This one adds the size limit argument, but also note that it **stores** the newline in the string and **adds** the null byte after (in contrast to `gets`)
+- `int scanf(const char *format, ...)`:
+ As opposed the other funcions `scanf` reads **text** based on the format string and parses it
+ Don't do the common mistake of **sending binary data to scanf**, for example `"%d"` expects a string representation of a numer like `"16"`, not the binary data like `"\x00\x00\x00\x10"`
-> Every time you encounter a new input function check the documentation to find it's limitations
+Every time you encounter a new input function check the documentation to find it's limitations
-# Challenges
-## 01. Challenge: Parrot
+## Challenges
-Some programs feature a stack _smashing protection_ in the form of stack canaries, that is, values kept on the stack which are checked before returning from a function. If the value has changed, then the “canary” can conclude that stack data has been corrupted throughout the execution of the current function.
+### 01. Challenge: Parrot
-We have implemented our very own `parrot`. Can you avoid it somehow?
+Some programs feature a stack smashing protection in the form of stack canaries, that is, values kept on the stack which are checked before returning from a function.
+If the value has changed, then the “canary” can conclude that stack data has been corrupted throughout the execution of the current function.
-## 02. Challenge: Indexing
+We have implemented our very own `parrot`.
+Can you avoid it somehow?
-More complex programs require some form of protocol or user interaction. This is where _pwntools_ shines.
+### 02. Challenge: Indexing
+
+More complex programs require some form of protocol or user interaction.
+This is where `pwntools` shines.
Here's an interactive script to get you started:
```python
@@ -330,37 +343,39 @@ Here's an interactive script to get you started:
p.interactive()
```
-> Go through GDB when aiming to solve this challenge. As all input values are strings, you can input them at the keyboard and follow their effect in GDB.
+Go through GDB when aiming to solve this challenge.
+As all input values are strings, you can input them at the keyboard and follow their effect in GDB.
-## 03. Challenge: Smashthestack Level7
+### 03. Challenge: Smashthestack Level7
-Now you can tackle a real challenge. See if you can figure out how you can get a shell from this one.
+Now you can tackle a real challenge.
+See if you can figure out how you can get a shell from this one.
Hints:
- There's an integer overflow + buffer overflow in the program.
-
-- How does integer multiplication work at a low level? Can you get get a positive number by multiplying a negative number by 4?
-
+- How does integer multiplication work at a low level?
+ Can you get get a positive number by multiplying a negative number by 4?
- To pass command line arguments in gdb use `run arg1 arg2 ...` or `set args arg1 arg2 ...` before a `run` command
+- In `pwntools` you can pass a list to `process` (`process(['./level07', arg1, arg2]`)
-- In _pwntools_ you can pass a list to `process` (`process(['./level07', arg1, arg2]`)
+### 04. Challenge: Neighbourly
-## 04. Challenge: Neighbourly
+Let's overwrite a structure's function pointer using a buffer overflow in its vicinity.
+The principle is the same.
-Let's overwrite a structure's function pointer using a buffer overflow in its vicinity. The principle is the same.
+### 05. Challenge: Input Functions
-## 05. Challenge: Input Functions
+On the same idea as the "Indexing" challenge but much harder.
+Carefully check what input functions are used and parse the input accordingly.
-On the same idea as the _Indexing_ challenge but much harder. Carefully check what input functions are used and parse the input accordingly.
+### 06. Challenge: Bonus: Birds
-## 06. Challenge: Bonus: Birds
+Time for a more complex challenge.
+Be patient and don't speed through it.
-Time for a more complex challenge. Be patient and don't speed through it.
-
-# Further Reading
+## Further Reading
- [De Bruijin sequences](https://en.wikipedia.org/wiki/De_Bruijn_sequence)
- [PwnTools ELF Module](https://docs.pwntools.com/en/latest/elf/elf.html) (which internally uses [PyElftoools](https://github.com/eliben/pyelftools) and may expose such objects)
- [PwnTools IO](https://docs.pwntools.com/en/stable/tubes.html)
-
diff --git a/chapters/exploitation-techniques/return-oriented-programming-advanced/reading/README.md b/chapters/exploitation-techniques/return-oriented-programming-advanced/reading/README.md
index 7c54270..198a177 100644
--- a/chapters/exploitation-techniques/return-oriented-programming-advanced/reading/README.md
+++ b/chapters/exploitation-techniques/return-oriented-programming-advanced/reading/README.md
@@ -1,20 +1,6 @@
# Return-Oriented Programming Advanced
-## Table of Contents
-
-- [Return-Oriented Programming Advanced](#return-oriented-programming-advanced)
- * [Calling Conventions in the ROP Context](#calling-conventions-in-the-rop-context)
- * [ROP gadgets on x86_64](#rop-gadgets-on-x86_64)
- * [Libc leaks](#libc-leaks)
- * [Challenges](#challenges)
- * [01. Challenge - Using ROP to Leak and Call system](#01-challenge---using-rop-to-leak-and-call-system)
- * [02. Challenge - Handling Low Stack Space](#02-challenge---handling-low-stack-space)
- * [03. Challenge - Stack Pivoting](#03-challenge---stack-pivoting)
- * [04. Challenge - mprotect](#04-challenge---mprotect)
- * [Further Reading](#further-reading)
-
-
-In this session we are going to dive deeper into *Return-Oriented Programming* and setbacks that appear in modern exploitation.
+In this session we are going to dive deeper into Return-Oriented Programming and setbacks that appear in modern exploitation.
Topics covered:
- ROP for syscalls and 64 bits
@@ -22,7 +8,7 @@ Topics covered:
- Dealing with low space in the overflown buffer
- Combining ROP and shellcodes
-As the basis of the lab we will use a program based on a classical CTF challenge called *ropasaurusrex* and gradually make exploitation harder.
+As the basis of the lab we will use a program based on a classical CTF challenge called `ropasaurusrex` and gradually make exploitation harder.
## Calling Conventions in the ROP Context
@@ -60,7 +46,7 @@ syscall
On `x86_64` the ROP payloads will have to be built differently than on `x86` because of the different calling convention.
Having the function arguments stored in registers means that you don't need to do stack cleanup anymore, but you will need gadgets with **specific registers** to pop the arguments into.
-For example to do the `read(0, buf, size)` *libc call* to do this call your payload will need to look like:
+For example to do the `read(0, buf, size)` libc call to do this call your payload will need to look like:
```text
pop rdi; ret
@@ -75,7 +61,8 @@ call read@plt
## Libc leaks
You might have already encountered in other tasks the need to leak values or addresses.
-Most of the time, if you want to get a shell, you won't have a convenient `system@plt` symbol present in your binary, and ASLR will most often be activated; so you will have to compute it relative to another libc symbol at runtime.
+Most of the time, if you want to get a shell, you won't have a convenient `system@plt` symbol present in your binary, and `ASLR` will most often be activated;
+so you will have to compute it relative to another libc symbol at runtime.
For this we will need to know what libc library the program is loading.
For a local executable we can just run `ldd`:
@@ -110,14 +97,16 @@ payload = ... + p64(libc.symbols['system'])
## Challenges
-**NOTE**: All tasks from this session are 64 bit binaries, so take that into consideration when you build the ROP chains.
+**Note**: All tasks from this session are 64 bit binaries, so take that into consideration when you build the ROP chains.
### 01. Challenge - Using ROP to Leak and Call system
Use the `01-leak-call-system/src` executable file in order to spawn a shell.
You can now call the functions in the binary but `system` or any other appropriate function is missing and ASLR is enabled.
-How do you get past this? You need an information leak! To leak information we want to print it to standard output and process it.
+How do you get past this?
+You need an information leak!
+To leak information we want to print it to standard output and process it.
We use calls to `printf`, `puts` or `write` for this.
In our case we can use the `write` function call.
@@ -197,7 +186,8 @@ Call `system`.
### 03. Challenge - Stack Pivoting
Let's assume that `main` function had additional constraints that made it impossible to repeat the overflow.
-How can we still solve it? The method is called stack pivoting.
+How can we still solve it?
+The method is called stack pivoting.
In short, this means making the stack pointer refer another (writable) memory area that has enough space, a memory area that we will populate with the actual ROP chain.
Read more about stack pivoting [here](http://neilscomputerblog.blogspot.ro/2012/06/stack-pivoting.html).
@@ -205,7 +195,8 @@ Read more about stack pivoting [here](http://neilscomputerblog.blogspot.ro/2012/
Tour goal is to fill the actual ROP chain to a large enough memory area.
We need a two stage exploit:
-- In the first stage, prepare the memory area where to fill the second stage ROP chain; then fill the memory area with the second stage ROP chain.
+- In the first stage, prepare the memory area where to fill the second stage ROP chain;
+then fill the memory area with the second stage ROP chain.
- In the second stage, create the actual ROP chain and feed it to the program and profit.
Follow the steps below.
@@ -214,7 +205,8 @@ Use pmap or vmmap in `pwndbg` to discover the writable data section of the proce
Select an address in that section (**don't** use the start address).
This is where you fill the 2nd stage data (the actual ROP chain).
-Who not use the start address? Because `pop` instructions (which decrease the `rsp`) will go outside the memory region.
+Who not use the start address?
+Because `pop` instructions (which decrease the `rsp`) will go outside the memory region.
Create a first stage payload that calls `read` to store the 2nd stage data to the newly found memory area.
After that pivot the stack pointer to the memory area address.
@@ -233,18 +225,18 @@ pop rbp
Write the actual ROP chain as a second stage payload like when we didn't have space constraints.
The 2nd stage will be stored to the memory area and the stack pointer will point to that.
-**Important!** Be careful when and where the stack pivoting takes place.
+**Important!**
+Be careful when and where the stack pivoting takes place.
After the `mov rsp, rbp` part of the `leave` instruction happens your stack will be pivoted, so the following `pop rbp` will happen **on the new stack**.
Take this offset into account when building the payload.
### 04. Challenge - mprotect
-Combine everything you've learned until now and develop a complex payload to call `mprotect` to change the permissions on a memory region to read+write+execute and then instert a *shellcode* to call `system("/bin/sh")`.
+Combine everything you've learned until now and develop a complex payload to call `mprotect` to change the permissions on a memory region to read+write+execute and then instert a shellcode to call `system("/bin/sh")`.
## Further Reading
-- https://syscalls.kernelgrok.com/
-- http://articles.manugarg.com/systemcallinlinux2_6.html
-- https://eli.thegreenplace.net/2011/11/03/position-independent-code-pic-in-shared-libraries#the-procedure-linkage-table-plt
-- https://github.com/Gallopsled/pwntools-tutorial/tree/master/walkthrough
-
+-
+-
+-
+-
diff --git a/chapters/exploitation-techniques/return-oriented-programming/reading/README.md b/chapters/exploitation-techniques/return-oriented-programming/reading/README.md
index 9b7fee9..bd94bb5 100644
--- a/chapters/exploitation-techniques/return-oriented-programming/reading/README.md
+++ b/chapters/exploitation-techniques/return-oriented-programming/reading/README.md
@@ -1,41 +1,5 @@
# Return-Oriented Programming
-## Table of Contents
-* [Prerequisites](#prerequisites)
-* [Recap - ASLR](#recap---aslr)
-* [Solution - `GOT` and `PLT`](#solution---got-and-plt)
- * [Further Inspection](#further-inspection)
-* [Return Oriented Programming (`ROP`)](#return-oriented-programming-rop)
- * [Motivation](#motivation)
- * [NOP Analogy](#nop-analogy)
-* [Gadgets and `ROP` Chains](#gadgets-and-rop-chains)
- * [Code Execution](#code-execution)
- * [Changing Register Values](#changing-register-values)
- * [Clearing the Stack](#clearing-the-stack)
-* [Some Useful Tricks](#some-useful-tricks)
- * [Memory Spraying](#memory-spraying)
- * [`checksec` in `Pwndbg`](#checksec-in-pwndbg)
- * [Finding Gadgets in Pwndbg](#finding-gadgets-in-pwndbg)
-* [Further Reading](#further-reading)
- * [Linux x86 Program Start Up](#linux-x86-program-start-up)
- * [The `.plt.sec` Schema](#the-pltsec-schema)
- * [More about `CET` and r`endbr`](#more-about-cet-and-endbr)
- * [TLDR](#tldr)
-* [Putting it all Together: Demo](#putting-it-all-together-demo)
- * [Calling a Function](#calling-a-function)
- * [Calling a Function with Parameters](#calling-a-function-with-parameters)
- * [Calling Multiple Functions](#calling-multiple-functions)
- * [Finding Gadgets - `ROPgadgetr`](#finding-gadgets---ropgadget)
-* [Challenges](#challenges)
- * [01. Tutorial - Bypass NX Stack with return-to-libc](#01-tutorial---bypass-nx-stack-with-return-to-libc)
- * [02. Challenge - ret-to-libc](#02-challenge---ret-to-libc)
- * [03. Challenge - no-ret-control](#03-challenge---no-ret-control)
- * [04. Challenge - ret-to-plt](#04-challenge---ret-to-plt)
- * [05. Challenge - gadget tutorial](#05-challenge---gadget-tutorial)
- * [06. Bonus Challenge - Echo service](#06-bonus-challenge---echo-service)
-* [Conclusions](#conclusions)
-
-
## Prerequisites
In order to fully grasp the content of this session, you should have a good
@@ -51,7 +15,6 @@ If you are unfamiliar with any of the above concepts or if your understanding of
them is fuzzy, go over their corresponding sessions once again, before you
proceed with the current session.
-
## Recap - ASLR
ASLR is not the only feature that prevents the compiler and the linker from solving some relocations before the binary is actually running.
@@ -215,7 +178,9 @@ The offset to the return address is 24.
So `DOWRD`s from offset 24 onwards will be popped from the stack and executed.
Remember the `NOP` sled concept from previous sessions?
These were long chains of `NOP` instructions (`\x90`) used to pad a payload for alignment purposes.
-Since we can't add any new code to the program (_NX_ is enabled) how could we simulate the effect of a `NOP` sled? Easy! Using return instructions!
+Since we can't add any new code to the program (`NX` is enabled) how could we simulate the effect of a `NOP` sled?
+Easy!
+Using return instructions!
Let's find the `ret` instructions in a would-be binary:
@@ -363,7 +328,8 @@ Thus, the offsets between the values in the payload are 8, instead of 4 (as they
### Clearing the Stack
The second use of gadgets is to clear the stack.
-Remember the issue we had in the [Motivation](#motivation) section? Let's solve it using gadgets.
+Remember the issue we had in the [Motivation](#motivation) section?
+Let's solve it using gadgets.
We need to call `f1(0xAB, 0xCD)` and then `f2(0xEF, 0x42)`.
Our initial solution was:
@@ -426,7 +392,7 @@ int main()
It's a fairly simple overflow, but just how fast can you figure out the offset to the return address?
How much padding do you need?
-There is a shortcut that you can use to figure this out in under 30 seconds without looking at the *Assembly* code.
+There is a shortcut that you can use to figure this out in under 30 seconds without looking at the assembly code.
A [De Bruijn sequence](https://en.wikipedia.org/wiki/De_Bruijn_sequence) is a string of symbols out of a given alphabet in which each consecutive K symbols only appear once in the whole string.
If we can construct such a string out of printable characters then we only need to know the Segmentation Fault address.
@@ -602,7 +568,8 @@ Contents of section .got.plt:
Similarly to what we did previously, we now see that `0x804c00c` points to
address `0x08049040`, which is this code inside the `.plt` section:
-```
+
+```text
8049040: f3 0f 1e fb endbr32
8049044: 68 00 00 00 00 push 0x0
8049049: e9 e2 ff ff ff jmp 8049030 <.plt>
@@ -692,7 +659,7 @@ $ objdump -M intel -d vuln
Our vulnerable buffer is the first parameter of `fgets`, which is at offset `ebp - 0x40` i.e. `ebp - 64`.
Which means that the offset of the return address is `64 + 4 = 68` bytes into this buffer (remember how a stack frame looks like).
-So, in order to call the `warcraft` function, we'll give our binary a payload made up of a padding of 68 bytes, followed by the address of `warcraft`, written in _little endian_ representation, which can be written like this:
+So, in order to call the `warcraft` function, we'll give our binary a payload made up of a padding of 68 bytes, followed by the address of `warcraft`, written in little endian representation, which can be written like this:
```python
offset = 0x40 + 4
@@ -734,7 +701,8 @@ Take a look at those 4 `B`'s in the payload above.
We agreed that they are `overwatch`'s expected return address.
So if we wanted to call another function, we would only need to replace them with that function's address.
Pretty simple, right?
-But what if we wanted to call a third function? Well, then we would need to overwrite the next 4 bytes in our payload with a third address.
+But what if we wanted to call a third function?
+Well, then we would need to overwrite the next 4 bytes in our payload with a third address.
Easy!
But now we have actually run into trouble: the next 4 bytes are `overwatch`'s parameter.
In this situation it looks like we **either** call `overwatch` or we call a third function.
@@ -810,13 +778,13 @@ Go to the [01-tutorial-ret-to-libc/](activities/01-tutorial-ret-to-libc/src/) fo
In the previous sessions we used stack overflow vulnerabilities to inject new code into a running process (on its stack) and redirect execution to it.
This attack is easily defeated by making the stack, together with any other memory page that can be modified, non-executable.
-This is achieved by setting the **NX** bit in the page table of the current process.
+This is achieved by setting the `NX` bit in the page table of the current process.
We will try to bypass this protection for the `01-tutorial-ret-to-libc/src/auth` binary in the lab archive.
For now, disable ASLR in the a new shell:
```console
-$ setarch $(uname -m) -R /bin/bash
+setarch $(uname -m) -R /bin/bash
```
Let's take a look at the program headers and confirm that the stack is no longer executable.
@@ -824,7 +792,7 @@ We only have read and write (RW) permissions for the stack area.
The auth binary requires the `libssl1.0.0:i386` Debian package to work.
You can find `libssl1.0.0:i386` Debian package [here](https://packages.debian.org/jessie/i386/libssl1.0.0/download).
-First, let's check that *NX* bit we mentioned earlier:
+First, let's check that `NX` bit we mentioned earlier:
```console
$ checksec auth
@@ -836,8 +804,7 @@ $ checksec auth
For completeness, lets check that there is indeed a buffer (stack) overflow vulnerability.
```console
-$ python2.7 -c 'print "A" * 1357' | ltrace -i ./auth
-TODO
+python2.7 -c 'print "A" * 1357' | ltrace -i ./auth
```
Check the source file - the buffer length is 1337 bytes.
@@ -902,15 +869,17 @@ $ python2.7 -c 'print "A" * 1353 + "\x0f\x86\x04\x08"' | ltrace -i -e puts ./aut
### 02. Challenge - ret-to-libc
-So far, so good! Now let's get serious and do something useful with this.
+So far, so good!
+Now let's get serious and do something useful with this.
Continue working in the `01-tutorial-ret-to-libc/` folder in the activities archive.
The final goal of this task is to bypass the NX stack protection and call `system("/bin/sh")`.
-We will start with a simple ret-to-plt:
+We will start with a simple `ret-to-plt`:
1. Display all libc functions linked with the auth binary.
-1. Return to `puts()`. Use ltrace to show that the call is actually being made.
+1. Return to `puts()`.
+ Use ltrace to show that the call is actually being made.
1. Find the offset of the `"malloc failed"` static string in the binary.
1. Make the binary print `"failed"` the second time `puts()` is called.
1. **(bonus)** The process should SEGFAULT after printing `Enter password:` again.
@@ -923,13 +892,11 @@ We will start with a simple ret-to-plt:
1. Where is libc linked in the auth binary?
Compute the final addresses and call `system("/bin/sh")` just like you did with `puts()`.
-**Hint 1**
-
+**Hint 1**:
Use `LD_TRACE_LOADED_OBJECTS=1 ./auth` instead of `ldd`.
The latter is not always reliable, because the order in which it loads the libraries might be different than when you actually run the binary.
-**Hint 2**
-
+**Hint 2**:
When you finally attack this, `stdin` will get closed and the new shell will have nothing to read.
Use `cat` to concatenate your attack string with `stdin` like this:
diff --git a/chapters/exploitation-techniques/shellcodes-advanced/reading/README.md b/chapters/exploitation-techniques/shellcodes-advanced/reading/README.md
index 6c09150..71a2eda 100644
--- a/chapters/exploitation-techniques/shellcodes-advanced/reading/README.md
+++ b/chapters/exploitation-techniques/shellcodes-advanced/reading/README.md
@@ -1,25 +1,5 @@
# Shellcodes (Advanced)
-
- Table of contents
-
- * [Introduction](#introduction)
- * [Tutorials](#tutorials)
- * [01. Tutorial: preventing stack operations from overwriting the shellcode](#01-tutorial-preventing-stack-operations-from-overwriting-the-shellcode)
- * [02. Tutorial: NOP sleds](#02-tutorial-nop-sleds)
- * [03. Tutorial: null-free shellcodes](#03-tutorial-null-free-shellcodes)
- * [04. Tutorial: shellcodes in pwntools](#04-tutorial-shellcodes-in-pwntools)
- * [05. Tutorial: alphanumeric shellcode](#05-tutorial-alphanumeric-shellcode)
- * [Challenges](#challenges)
- * [06. Challenge: NOP sled redo](#06-challenge-nop-sled-redo)
- * [07. Challenge: No NOPs allowed!](#07-challenge-no-nops-allowed)
- * [08. Challenge: multiline output](#08-challenge-multiline-output)
- * [09: Challenge: execve blocking attempt](#09-challenge-execve-blocking-attempt)
- * [Further Reading](#further-reading)
- * [Input restrictions](#input-restrictions)
-
-
-
In [the "Shellcodes" session](../../shellcodes/reading), we learned about **shellcodes**, a form of **code injection** which allowed us to hijack the control flow of a process and make it do our bidding.
## Introduction
@@ -31,7 +11,8 @@ The three steps for a successful shellcode attack are:
- **trigger**: divert control flow to the beginning of our shellcode
The first step seems pretty straightforward, but there are a lot of things that could go wrong with the last two.
-For example, we cannot inject a shellcode in a process that doesn't read input or reads very little (though remember that if we can launch the target program we can place the shellcode inside its environment or command line arguments); we cannot trigger our shellcode if we cannot overwrite some code-pointer (e.g.
+For example, we cannot inject a shellcode in a process that doesn't read input or reads very little (though remember that if we can launch the target program we can place the shellcode inside its environment or command line arguments);
+we cannot trigger our shellcode if we cannot overwrite some code-pointer (e.g.
a saved return) or if we do not know the precise address at which it ends up in the process' memory and we cannot use such an attack if there isn't some memory region where we have both write and execute permissions.
Some of these hurdles can occur naturally, while others are intentionally created as preventive measures (e.g.
@@ -65,21 +46,25 @@ plus, `push`-ing has the side effect of placing our address in the `rsp` registe
In cases where our shellcode is also injected on the stack this leads to the complicated situation in which the stack serves as both a code and data region.
If we aren't careful, our data pushes might end up overwriting the injected code and ruining our attack.
-Run `make` then use the `exploit.py` script (don't bother with how it works, for now); it will create a shellcode, pad it and feed it to the program, then open a new terminal window with a `gdb` instance breaked at the end of the `main` function.
+Run `make` then use the `exploit.py` script (don't bother with how it works, for now);
+it will create a shellcode, pad it and feed it to the program, then open a new terminal window with a `gdb` instance breaked at the end of the `main` function.
You can then explore what happens step by step and you will notice that, as the shellcode pushes the data it needs onto the stack it eventually comes to overwrite itself, resulting in some garbage.
The problem is that, after executing `ret` at the end of `main` and getting hijacked to jump to the beginning of our shellcode, `rip` ends up at `0x7ffca44f2280`, while `rsp` ends up at `0x7ffca44f22c0` (addresses on your machine will probably differ).
The instruction pointer is only 64 bytes **below** the stack pointer.
-- as instructions get executed, the instruction pointer is *incremented*
-- as values are pushed onto the stack, the stack pointer is *decremented*
+- as instructions get executed, the instruction pointer is incremented
+- as values are pushed onto the stack, the stack pointer is decremented
Thus the difference will shrink more and more with each instruction executed.
The total length of the shellcode is 48 bytes so that means that after pushing 16 bytes onto the stack (64 - 48) any `push` will overwrite the end of our shellcode!
-One obvious solution is to try and modify our shellcode to make it shorter, or to make it push less data onto the stack; this might work in some situations, but it's not a general fix.
+One obvious solution is to try and modify our shellcode to make it shorter, or to make it push less data onto the stack;
+this might work in some situations, but it's not a general fix.
-Remember that after the vulnerable function returns, we control the execution of the program; so we can control what happens to the stack! Then we'll simply move the top of the stack to give us some space by adding this as the first instruction to our shellcode:
+Remember that after the vulnerable function returns, we control the execution of the program;
+so we can control what happens to the stack!
+Then we'll simply move the top of the stack to give us some space by adding this as the first instruction to our shellcode:
```asm
sub rsp, 64
@@ -88,17 +73,19 @@ Remember that after the vulnerable function returns, we control the execution of
Now, right after jumping to our shellcode, `rip` and `rsp` will be the same, but they'll go on in opposite directions and everything will be well.
Uncomment line 64 in `exploit.py`, run it again and see what happens.
-If we're at the very low-edge of the stack and can't access memory below, we can use `add` to move the stack pointer way up, so that even if the pushed data comes towards our injected code, it will not reach it; after all, our shellcode is short and we're not pushing much.
+If we're at the very low-edge of the stack and can't access memory below, we can use `add` to move the stack pointer way up, so that even if the pushed data comes towards our injected code, it will not reach it;
+after all, our shellcode is short and we're not pushing much.
### 02. Tutorial: NOP sleds
In the previous session, you probably had some difficulties with the 9th task in [the "Shellcodes" section](../../shellcodes/reading), which asked you to perform a shellcode-on-stack attack without having a leak of the overflown buffer's address.
-You can determine it using `gdb` but, as you've seen, things differ between `gdb` and non-`gdb` environments; the problem is even worse if the target binary is running on a remote machine.
+You can determine it using `gdb` but, as you've seen, things differ between `gdb` and non-`gdb` environments;
+the problem is even worse if the target binary is running on a remote machine.
The crux of the issue is the fact that we have to precisely guess **one** exact address where our shellcode begins.
For example, our shellcode might end up looking like this in memory:
-```
+```text
0x7fffffffce28: rex.WX adc QWORD PTR [rax+0x0],rax
0x7fffffffce2c: add BYTE PTR [rax],al
0x7fffffffce2e: add BYTE PTR [rax],al
@@ -111,10 +98,11 @@ For example, our shellcode might end up looking like this in memory:
The first instruction of our shellcode is the `push 0x68` at address `0x7fffffffce30`:
-- if we jump before it, we'll execute some garbage interpreted as code; in the above example, missing it by two bytes would execute `add BYTE PTR [rax],al` which might SEGFAULT if `rax` doesn't happen to hold a valid writable address
+- if we jump before it, we'll execute some garbage interpreted as code;
+in the above example, missing it by two bytes would execute `add BYTE PTR [rax],al` which might SEGFAULT if `rax` doesn't happen to hold a valid writable address
- if we jump after it, we'll have a malformed `"/bin/sh"` string on the stack, so the later `execve` call will not work.
-Fortunately, we don't have to consider the entire address space, so our chances are better than 1 in 264:
+Fortunately, we don't have to consider the entire address space, so our chances are better than 1 in $2^64$.
- the stack is usually placed at a fixed address (e.g.
0x7fffffffdd000), so we have a known-prefix several octets wide
@@ -122,7 +110,9 @@ Fortunately, we don't have to consider the entire address space, so our chances
On your local machine, using `gdb` to look at the buffer's address will then allow you to use just a bit of bruteforce search to determine the address outside of `gdb`.
-But what if we could increase our chances to jump to the beginning of our shellcode? So that we don't have to guess **one** exact address, but just hit some address range? This is where "NOP sleds" come in.
+But what if we could increase our chances to jump to the beginning of our shellcode?
+So that we don't have to guess **one** exact address, but just hit some address range?
+This is where "NOP sleds" come in.
A "NOP sled" is simply a string of `NOP` instructions added as a prefix to a shellcode.
The salient features of a `NOP` instruction that make it useful for us are:
@@ -134,7 +124,7 @@ Thus if we chain a bunch of these together and prepend them to our shellcode, we
Our shellcode will end up looking like this in the process memory:
-```
+```text
0x7fffffffd427: mov BYTE PTR [rax], al
0x7fffffffd429: nop
0x7fffffffd42a: nop
@@ -150,10 +140,12 @@ Our shellcode will end up looking like this in the process memory:
Again, our first "useful" instruction is the `push 0x68` at `0x7fffffffd430`.
Jumping after it and skipping its execution is still problematic, but notice that we can now jump **before** it, missing it by several bytes with no issue.
-If we jump to `0x7fffffffd42c` for example, we'll reach a `nop`, then execution will pass on to the next `nop` and so on; after executing 4 nops, our shellcode will be reached and everything will be as if we had jumped directly to `0x7fffffffd430` in the first place.
+If we jump to `0x7fffffffd42c` for example, we'll reach a `nop`, then execution will pass on to the next `nop` and so on;
+after executing 4 nops, our shellcode will be reached and everything will be as if we had jumped directly to `0x7fffffffd430` in the first place.
There is now a continuous range of 8 addresses where it's ok to jump to.
-But 8 is such a small number; the longer the NOP sled, the better our chances.
+But 8 is such a small number;
+the longer the NOP sled, the better our chances.
The only limit is how much data we can feed into the program when we inject our shellcode.
- Run `make`, then inspect the `vuln` binary in `gdb` and determine the location of the vulnerable buffer.
@@ -162,18 +154,20 @@ Most likely, it will not work: the address outside of `gdb` is different.
- Uncomment line 17 of the script, then run it again.
- You should now have a shell!
-If this doesn't work, play a bit with the address left on line 14; increment it by 256, then decrement it by 256.
+If this doesn't work, play a bit with the address left on line 14;
+increment it by 256, then decrement it by 256.
You're aiming to get **below** the actual address at some offset smaller than the NOP sled length which, in this example, is 1536.
### 03. Tutorial: null-free shellcodes
Up until now, all the vulnerable programs attacked used `read` as a method of getting the input.
This allows us to feed them any string of arbitrary bytes.
-In practice, however, there are many cases in which the input is treated as a 0-terminated *string* and processed by functions like `strcpy`.
+In practice, however, there are many cases in which the input is treated as a 0-terminated string and processed by functions like `strcpy`.
This means that our shellcode cannot contain a 0 byte because, as far as functions like `strcpy` are concerned, that signals the end of the input.
However, shellcodes are likely to contain 0 bytes.
-For example, remember that we need to set `rax` to a value indicating the syscall we want; if we wish to `execve` a new shell, we'll have to place the value `59` in `rax`:
+For example, remember that we need to set `rax` to a value indicating the syscall we want;
+if we wish to `execve` a new shell, we'll have to place the value `59` in `rax`:
```asm
mov rax, 0x3b
@@ -182,10 +176,12 @@ For example, remember that we need to set `rax` to a value indicating the syscal
Due to the nature of x86 instructions and the size of the `rax` register, that `0x3b` might be considered an 8-byte wide constant, yielding the following machine code: `48 b8 59 00 00 00 00 00 00 00`.
As you can see, there are quite a lot of zeroes.
-We could get rid of them if we considered `0x3b` to be a 1-byte wide constant; unfortunately there's no instruction to place into `rax` an immediate 1-byte value.
+We could get rid of them if we considered `0x3b` to be a 1-byte wide constant;
+unfortunately there's no instruction to place into `rax` an immediate 1-byte value.
However, there is an instruction to place an immediate 1-byte value in `al`, the lowest octet of `rax`.
But we need the other seven octets to be 0...
-Fortunately, we can do a trick by xor-ing the register with itself! This will make every bit 0, plus the `xor` instruction itself doesn't contain 0 bytes.
+Fortunately, we can do a trick by xor-ing the register with itself!
+This will make every bit 0, plus the `xor` instruction itself doesn't contain 0 bytes.
So we can replace the code above with:
```asm
@@ -221,7 +217,8 @@ We can write:
Note that extra-slashes in a path don't make any difference.
The `vuln.c` program reads data properly into a buffer, then uses `strcpy` to move data into a smaller buffer, resulting in an overflow.
-Run `make`, then the `exploit.py` script; just like before, it will start a new terminal window with a `gdb` instance in which you can explore what happens.
+Run `make`, then the `exploit.py` script;
+just like before, it will start a new terminal window with a `gdb` instance in which you can explore what happens.
The attack will fail because the injected shellcode contains 0 bytes so `strcpy` will only stop copying well before the end of the shellcode.
Comment line 55 and uncomment line 56, replacing the shellcode with a null-free version.
@@ -239,13 +236,15 @@ For example, to obtain a shellcode which performs `execve("/bin/sh", {"/bin/sh",
shellcraft.amd64.linux.sh()
```
-Note that this will give you back text representing *assembly code* and **not** *machine code* bytes.
+Note that this will give you back text representing assembly code and **not** machine code bytes.
You can then use the `asm` function to assemble it:
```python
asm(shellcraft.amd64.linux.sh(), arch="amd64", os="linux"))
```
-Remember the friendly features of pwntools! Instead of always specifying the OS and the architecture, we can set them in the global context, like this:
+
+Remember the friendly features of pwntools!
+Instead of always specifying the OS and the architecture, we can set them in the global context, like this:
```python
context.arch="amd64"
@@ -262,14 +261,16 @@ You'll notice that all these shellcodes are free of zero bytes and newlines!
### 05. Tutorial: alphanumeric shellcode
It is commonly the case that user input is filtered to make sure it matches certain conditions.
-Most user input expected from a keyboard should not contain non-printable characters; a "name" should contain only letters, a PIN should contain only digits, etc.
+Most user input expected from a keyboard should not contain non-printable characters;
+a "name" should contain only letters, a PIN should contain only digits, etc.
The program might check its input against some conditions and, if rejected, bail in such a way so as to not trigger our injected code.
This places the burden on us to develop shellcode that doesn't contain certain bytes.
We've seen how we can avoid newlines and zero bytes to work around some input-reading functions.
This concept can be pushed even further, heavily restricting our character set: on 32-bit platforms, we can write **alphanumeric shellcodes**!
-But can we really? It's plausible that there are some clever tricks on the level of replacing `mov eax, 0x3b` with `xor eax, eax; mov al, 0x3b` that could make use of only alphanumeric characters, but all our shellcodes so far need to perform a syscall.
+But can we really?
+It's plausible that there are some clever tricks on the level of replacing `mov eax, 0x3b` with `xor eax, eax; mov al, 0x3b` that could make use of only alphanumeric characters, but all our shellcodes so far need to perform a syscall.
Looking at the encoding of the `int 0x80` instruction seems pretty grim: `\xcd\x80`.
Those are not even printable characters.
So how can we perform a syscall?
@@ -279,7 +280,9 @@ Here it's important to step back and carefully consider our assumptions:
- There is some memory region to which we have both write and execute access (otherwise we wouldn't attempt a code injection attack)
- After our input is read, there is some check on it to make sure it doesn't contain certain characters.
-Aha! We cannot **inject** some bytes, but nothing's stopping us from injecting something that **generates** those bytes! Generating is just an alternative way of *writing*, so instead of **injecting** our shellcode, we'll inject some code which **generates** the shellcode, then executes it!
+Aha!
+We cannot **inject** some bytes, but nothing's stopping us from injecting something that **generates** those bytes!
+Generating is just an alternative way of writing, so instead of **injecting** our shellcode, we'll inject some code which **generates** the shellcode, then executes it!
This is, in fact, as complicated as it sounds, so we won't do it ourselves.
We'll just observe how such a shellcode, produced by a specialized tool (`msfvenom`) works.
@@ -289,9 +292,10 @@ So invoke the following command, which should give you a python-syntax buffer co
- `-a x86`: specifies the architecture as 32-bit x86
- `--platform linux`: specifies OS
-- `-p linux/x86/exec`: specifies a preset program (you can use `-` or `STDIN` for a custom initial shellcode, to be transformed)
+- `-p linux/x86/exec`: specifies a preset program (you can use `-` or `stdin` for a custom initial shellcode, to be transformed)
- `-e x86/alpha_mixed`: specifies encoding to be alphanumeric
-- `BufferRegister=ECX`: specifies an initial register which holds the address of the buffer; this is needed in order to have some way to refer to the region in which we're unpacking our code.
+- `BufferRegister=ECX`: specifies an initial register which holds the address of the buffer;
+this is needed in order to have some way to refer to the region in which we're unpacking our code.
Without this, a short non-alphanumeric preamble is added instead to automatically extract the buffer address
- `-f python`: formats output using python syntax
@@ -299,18 +303,18 @@ Without this, a short non-alphanumeric preamble is added instead to automaticall
## Challenges
-### 06. Challenge: NOP sled redo
+### 06. Challenge: NOP-sled Redo
Redo the last three challenges (9, 10, 11) from [the "Shellcodes" session](../../shellcodes/reading) using NOP-sleds.
-### 07. Challenge: No NOPs allowed!
+### 07. Challenge: No NOPs Allowed
This is similar to the previous tasks: you are left to guess a stack address.
However, the `\x90` byte is filtered from input so you cannot use a NOP sled.
But you should be able to adapt the concept.
Remember the relevant features of the "NOP" instruction!
-### 08. Challenge: multiline output
+### 08. Challenge: Multiline Output
While perfectly ok with the byte 0, some functions (e.g.
`fgets`) will stop reading when they encounter a newline character (`\n`).
@@ -318,7 +322,7 @@ Thus, if our input is read by such a function, we need to make sure our shellcod
For this challenge, the input will be read using the `gets` function, but you will need to craft a shellcode which prints to `stdout` the exact string:
-```
+```text
first
second
third
@@ -326,15 +330,18 @@ third
### 09: Challenge: `execve` blocking attempt
-If shellcodes are such a powerful threat, what if we attempted to block some shellcode-sepcific characters? Such as the bytes that encode a `syscall` function.
-Or the slash needed in a path; maybe it's not such a big loss to avoid these in legitimate inputs.
+If shellcodes are such a powerful threat, what if we attempted to block some shellcode-sepcific characters?
+Such as the bytes that encode a `syscall` function.
+Or the slash needed in a path;
+maybe it's not such a big loss to avoid these in legitimate inputs.
-Can you still get a shell? For this task, **don't use** an existing encoder, but rather apply the encoding principles yourself.
+Can you still get a shell?
+For this task, **don't use** an existing encoder, but rather apply the encoding principles yourself.
## Further Reading
["Smashing The Stack For Fun And Profit", Aleph One](http://phrack.org/issues/49/14.html) - a legendary attack paper documenting SBOs and shellcodes.
-As it is written in '96, the examples in it will probably _not_ work (either out-of-the-box or with some tweaks).
+As it is written in '96, the examples in it will probably **not** work (either out-of-the-box or with some tweaks).
We recommend perusing it for its historical/cultural significance, but don't waste much time on the technical details of the examples.
### Input restrictions
@@ -344,8 +351,8 @@ The examples presented will most likely not work as-they-are in a modern environ
[*Writing ia32 alphanumeric shellcodes*, 2001 - rix](http://phrack.org/issues/57/15.html) - probably the first comprehensive presentation of how to automatically convert generic shellcodes to alphanumeric ones.
-[*Building IA32 'Unicode-Proof' Shellcodes*, 2003 - obscou](http://phrack.org/issues/61/11.html) - rather than being concerned with input *restrictions*, this addresses ulterior transformations on input, namely converting an ASCII string to a UTF-16 one (as mentioned in the article's introduction, you could also imagine other possible transformations, such as case normalization).
+[*Building IA32 'Unicode-Proof' Shellcodes*, 2003 - obscou](http://phrack.org/issues/61/11.html) - rather than being concerned with input restrictions, this addresses ulterior transformations on input, namely converting an ASCII string to a UTF-16 one (as mentioned in the article's introduction, you could also imagine other possible transformations, such as case normalization).
[*Writing UTF-8 compatible shellcodes*, 2004 - Wana](http://phrack.org/issues/62/9.html)
-[*English shellcode*, 2009 - Mason, Small, Monrose, MacManus](https://www.cs.jhu.edu/~sam/ccs243-mason.pdf) - delves into automatically generating shellcode which has the same statistical properties as English text.
+[*English shellcode*, 2009 - Mason, Small, Monrose, MacManus](https://www.cs.jhu.edu/~sam/ccs243-mason.pdf) delves into automatically generating shellcode which has the same statistical properties as English text.
diff --git a/chapters/exploitation-techniques/shellcodes/reading/README.md b/chapters/exploitation-techniques/shellcodes/reading/README.md
index 09d29a2..805a541 100644
--- a/chapters/exploitation-techniques/shellcodes/reading/README.md
+++ b/chapters/exploitation-techniques/shellcodes/reading/README.md
@@ -1,62 +1,39 @@
# Shellcodes
-
- Table of contents
-
- * [Introduction](#introduction)
- * [Stack-buffer-overflow recap](#stack-buffer-overflow-recap)
- * [Code injection](#code-injection)
- * [Develop](#develop)
- * [Inject](#inject)
- * [Trigger](#trigger)
- * ["Shellcodes"](#shellcodes)
- * [Tutorials](#tutorials)
- * [01. Tutorial: generating machine code](#01-tutorial-generating-machine-code)
- * [02. Tutorial: inspecting machine code](#02-tutorial-inspecting-machine-code)
- * [03. Tutorial: feeding machine code to a program](#03-tutorial-feeding-machine-code-to-a-program)
- * [04. Tutorial: "Hello, world!" shellcode](#04-tutorial-hello-world-shellcode)
- * [05. Tutorial: Debugging shellcodes](#05-tutorial-debugging-shellcodes)
- * [Challenges](#challenges)
- * [06. Challenge: /bin/sh shellcode](#06-challenge-binsh-shellcode)
- * [07. Challenge: shellcode on stack](#07-challenge-shellcode-on-stack)
- * [08. Challenge: shellcode after saved ret](#08-challenge-shellcode-after-saved-ret)
- * [09. Challenge: shellcode after saved ret - no leak](#09-challenge-shellcode-after-saved-ret---no-leak)
- * [10. Challenge: shellcode as command line arg](#10-challenge-shellcode-as-command-line-arg)
- * [11. Challenge: shellcode in the environment](#11-challenge-shellcode-in-the-environment)
- * [Further Reading](#further-reading)
- * [Resources](#resources)
-
-
-
## Introduction
-### Stack-buffer-overflow recap
+### Stack Buffer Overflow Recap
In the last session, we studied what an attacker can do to a program with a stack-buffer-overflow vulnerability: fill up the legitimately reserved space with junk, then overwrite the saved-return value with an address of their choosing.
After the vulnerable function's execution ends, its final `ret` will place the attacker's chosen address into the `eip`/`rip` and execution will continue from there.
-
+
The above scenario limits the attacker to the functionality already present in the vulnerable program.
-If an attacker desires to spawn a shell, but no shell-spawning code is already present - tough luck! In this session we will start studying a method of overcoming this limitation: code injection.
+If an attacker desires to spawn a shell, but no shell-spawning code is already present - tough luck!
+In this session we will start studying a method of overcoming this limitation: code injection.
-### Code injection
+### Code Injection
-If the code we want to execute is not present in the target program, we'll simply add it ourselves! We will implement our desired functionality in machine code, inject (which is just a fancy word for "write") it into the target process' memory, then force execution to jump to the beginning of our code.
+If the code we want to execute is not present in the target program, we'll simply add it ourselves!
+We will implement our desired functionality in machine code, inject (which is just a fancy word for "write") it into the target process' memory, then force execution to jump to the beginning of our code.
These steps can be succinctly summarized as: develop, inject, trigger.
#### Develop
First, we need to implement our desired functionality.
-Our goal is to obtain _something_ that can be placed directly into the memory space of a running process and be executed; so it cannot be text representing code in C, Python, Java etc.
+Our goal is to obtain _something_ that can be placed directly into the memory space of a running process and be executed;
+so it cannot be text representing code in C, Python, Java etc.
It must be _machine code_.
-This might seem a very difficult task, but we'll simply use the tools we usually employ when writing code that we intend to run; in particular, we will rely on the assembler: we write ASM code to do what we want, then assemble it to obtain a string of machine code bytes.
+This might seem a very difficult task, but we'll simply use the tools we usually employ when writing code that we intend to run;
+in particular, we will rely on the assembler: we write ASM code to do what we want, then assemble it to obtain a string of machine code bytes.
#### Inject
Once we have our string of machine code bytes, we need it to be present in the memory space of the target process.
This means the program must read some input (with a `gets`, `fgets`, `fscanf`, `read` etc.).
-However, if we can _launch_ the program, we can also place our code in the environment or inside a command line argument; even if a program doesn't use these, the loader still places them in its address space.
+However, if we can _launch_ the program, we can also place our code in the environment or inside a command line argument;
+even if a program doesn't use these, the loader still places them in its address space.
#### Trigger
@@ -71,7 +48,7 @@ However, this label is also used for any piece of injected code, even if it does
## Tutorials
-### 01. Tutorial: generating machine code
+### 01. Tutorial: Generating Machine Code
To address the first step of our code injection technique, we will start with a simple example: we want to force the program to end cleanly with an exit code of 42;
more precisely we want to execute an `exit(42)` system call.
@@ -101,12 +78,12 @@ exit_shellcode.bin: data
It is not an executable file at all, but simply contains a raw string of machine code bytes.
You can see that it is very, very small:
-```
+```console
$ wc --bytes exit_shellcode.bin
12 exit_shellcode.bin
```
-### 02. Tutorial: inspecting machine code
+### 02. Tutorial: Inspecting Machine Code
We would also like to be able to do the reverse of this: given a file that contains a raw string of machine code bytes, translate it back into readable assembly.
This is useful to check that our assembly process was correct, as well as for analyzing files that we did not create.
@@ -150,13 +127,13 @@ $ xxd exit_shellcode.bin
00000010: 000f 05 ...
```
-### 03. Tutorial: feeding machine code to a program
+### 03. Tutorial: Feeding Machine Code to a Program
Now that we know how to obtain a bytestring of machine code from an assembly program, it's time to move on to the next step: injection.
The simplest way is to redirect the `stdin` of the target program to the file containing our raw machine code.
```console
-$ ./vuln < exit_shellcode.bin
+./vuln < exit_shellcode.bin
```
However, we might want to freely edit the payload directly on the command line (for example, if the program reads some other stuff).
@@ -184,13 +161,13 @@ $ hexdump -v -e '"\\" 1/1 "x%02x"' exit_shellcode.bin
Which we can then combine with some other input
```console
-$ printf '1\x48\xc7\xc0\xff\xff\xff\xff\xbf\x2a\x00\x00\x00\xb8\x3c\x00\x00\x00\x0f\x05' | ./vuln2
+printf '1\x48\xc7\xc0\xff\xff\xff\xff\xbf\x2a\x00\x00\x00\xb8\x3c\x00\x00\x00\x0f\x05' | ./vuln2
```
Or we can do this directly:
```console
-$ printf '1'$(hexdump -v -e '"\\" 1/1 "x%02x"' exit_shellcode.bin) | ./vuln2
+printf '1'$(hexdump -v -e '"\\" 1/1 "x%02x"' exit_shellcode.bin) | ./vuln2
```
We can then verify that the program did indeed exit with code 42:
@@ -200,9 +177,9 @@ $ echo $?
42
```
-### 04. Tutorial: "Hello, world!" shellcode
+### 04. Tutorial: "Hello, world!" Shellcode
-Our aim now is to develop a shellcode that prints `"Hello, world!\n"` to stdout, then inject it into `vuln` and trigger its execution.
+Our aim now is to develop a shellcode that prints `"Hello, world!\n"` to standard output, then inject it into `vuln` and trigger its execution.
We start by writing a shellcode that does a `write(1, "Hello, world!\n", 14)` system call, by writing the string on to the stack such that the stack pointer points to the beginning of the string.
@@ -226,10 +203,11 @@ This is just one way to do it and there are other possible approaches to it.
We then assemble our snippet to get a string of machine code bytes (the `Makefile` provided already does this).
```console
-$ nasm hello_shellcode.nasm -o hello_shellcode.bin
+nasm hello_shellcode.nasm -o hello_shellcode.bin
```
Our vulnerable program first reads 128 bytes into a global buffer (line 8):
+
```c
read(0, machine_code, 128);
```
@@ -287,16 +265,18 @@ As you can see, even with simple exploits, payloads quickly become unwieldy.
Our advice is to make use of a script in a language like python.
There is one such script example in the task directory.
-Even though we succeeded in printing our message, the program then ended abruptly with a _Segmentation fault_.
+Even though we succeeded in printing our message, the program then ended abruptly with a "Segmentation fault" message.
Pause for a second to figure out why that is.
Because we hijacked normal control flow, the program does not reach the end of the `main` function to terminate gracefully, but instead continues to attempt to execute instructions from the `machine_code` global var.
We can help the program exit gracefully by extending our shellcode to also perform an `exit(0)` syscall after the `write`.
Remember to check the size of the new shellcode and update the padding accordingly!
-### 05. Tutorial: Debugging shellcodes
+### 05. Tutorial: Debugging Shellcodes
-How can we **know** that our shellcode worked properly? Sometimes its external effects are not immediately visible; if it involves any system calls, we can make use of `strace`:
+How can we **know** that our shellcode worked properly?
+Sometimes its external effects are not immediately visible;
+if it involves any system calls, we can make use of `strace`:
```console
$ printf '1'$(hexdump -v -e '"\\" 1/1 "x%02x"' exit_shellcode.bin) | strace ./vuln2
@@ -309,8 +289,6 @@ exit(42) = ?
A more productive approach is to use `gdb` to inspect the execution of the shellcode step by step.
Load the program, break on the shellcode address, feed it the input and run:
-**GDB output**
-
```console
$ gdb ./vuln
Reading symbols from ./vuln...
@@ -406,20 +384,20 @@ gdb-peda$
## Challenges
-### 06. Challenge: /bin/sh shellcode
+### 06. Challenge: /bin/sh Shellcode
You are given a piece of assembly code that attempts to spawn a shell with the aid of the `execve` syscall.
However, the given code is buggy and it will not work.
Your task is to figure out what's wrong with it and fix it.
-### 07. Challenge: shellcode on stack
+### 07. Challenge: Shellcode on Stack
Up until now we have injected code into some memory area, then used a stack-buffer-overflow vulnerability to overwrite a saved return address and hijack control flow.
If we think about it, the legitimately reserved buffer space on the stack _is_ a memory area and we could perform our attack using a single read: the overflowing one.
So our payload will consist of the bytes in our shellcode, then some junk to pad the rest of the space to the saved return, then the address of the buffer itself:
- +
Now that our shellcode is written on the stack, things become a little harder.
Due to several factors (such as the fact that environment variables and command line arguments are placed by the loader on the stack), it is difficult to predict the address at which any value will be placed on the stack.
@@ -444,42 +422,42 @@ $ FOO=bar ./vuln
0x7fffffffd5c0
```
-### 08. Challenge: shellcode after saved ret
+### 08. Challenge: Shellcode after Saved Return Address
In the previous challenge, we placed our shellcode on the stack, in the space between the overflown buffer's beginning and the saved return address.
-However, we could switch things up and place the shellcode in the area _after_ the saved return address.
+However, we could switch things up and place the shellcode in the area **after** the saved return address.
This might be useful when the stack buffer is too short to hold our payload.
So our payload will consist of padding junk from the beginning of the buffer to the saved return, the address of the next stack portion, then the bytes of our shellcode.
-
+
Now that our shellcode is written on the stack, things become a little harder.
Due to several factors (such as the fact that environment variables and command line arguments are placed by the loader on the stack), it is difficult to predict the address at which any value will be placed on the stack.
@@ -444,42 +422,42 @@ $ FOO=bar ./vuln
0x7fffffffd5c0
```
-### 08. Challenge: shellcode after saved ret
+### 08. Challenge: Shellcode after Saved Return Address
In the previous challenge, we placed our shellcode on the stack, in the space between the overflown buffer's beginning and the saved return address.
-However, we could switch things up and place the shellcode in the area _after_ the saved return address.
+However, we could switch things up and place the shellcode in the area **after** the saved return address.
This might be useful when the stack buffer is too short to hold our payload.
So our payload will consist of padding junk from the beginning of the buffer to the saved return, the address of the next stack portion, then the bytes of our shellcode.
- +
To recap: given a stack-buffer-overflow vulnerability we can not only hijack control flow, but also place a shellcode on the stack using the buggy read.
There are two regions where we can do this:
-- between the buffer start and the saved return.
-The number of bytes we can write here is determined by _how much space was allocated on the stack_.
-- after the saved return.
-The number of bytes we can write here is determined by _how many bytes are read_.
+- between the buffer start and the saved return address:
+ The number of bytes we can write here is determined by **how much space was allocated on the stack**.
+- after the saved return address:
+ The number of bytes we can write here is determined by **how many bytes are read**.
If any of these regions is too small, we can try the other one.
If both of them are too small, that's a problem.
However, note that shellcodes are usually tiny.
-### 09. Challenge: shellcode after saved ret - no leak
+### 09. Challenge: Shellcode after Saved Return Address - No Leak
This is the same as the previous challenge, only this time the executable does not conveniently leak the buffer's address.
So you will have to deal with the differences between running a binary inside and outside of `gdb` to precisely determine the necessary address, then jump to it.
-### 10. Challenge: shellcode as command line arg
+### 10. Challenge: Shellcode as Command Line Argument
-As mentioned in the introduction, reading from stdin or from a file isn't the only way to place content inside the memory space of a process.
+As mentioned in the introduction, reading from standard input or from a file isn't the only way to place content inside the memory space of a process.
If we can launch the executable, we can modify its environment or command line arguments.
The fact that a program might not use its arguments or environment is irrelevant, the loader can't know this, so it places them in the address space anyway.
Take the `/bin/sh` shellcode and feed it to the program as a command-line argument, then exploit the SBO to actually run it.
-### 11. Challenge: shellcode in the environment
+### 11. Challenge: Shellcode in the Environment
Take the `/bin/sh` shellcode and place it in the environment, then exploit the SBO to actually run it.
diff --git a/chapters/extra/pwntools-intro/reading/README.md b/chapters/extra/pwntools-intro/reading/README.md
index f0503f1..3a389ab 100644
--- a/chapters/extra/pwntools-intro/reading/README.md
+++ b/chapters/extra/pwntools-intro/reading/README.md
@@ -6,8 +6,8 @@ Pwntools comes to level the playing field and bring together developers to creat
## Installation
-```bash
-$ pip install -U pwntools
+```console
+pip install -U pwntools
```
## Local and Remote I/O
@@ -72,7 +72,7 @@ io.interactive()
If we run the previous script, we get the following output:
-```
+```text
[+] Starting local process './leaky': Done
Got: Okay, here you go: 0xffe947d8 S
@@ -152,7 +152,7 @@ def leak_char(offset):
Now the output should be much more verbose:
-```
+```text
[+] Starting local process './leaky': Done
[*] Sending request for offset: -10
[*] Got back raw response: Okay, here you go: 0xffb14948 S
@@ -206,7 +206,8 @@ log.info("Main at: " + hex(main_addr))
log.info(disasm(leaky_elf.read(main_addr, 14), arch='x86'))
```
-We can also write ELF files from raw assembly; this is very useful for testing shellcodes.
+We can also write ELF files from raw assembly;
+this is very useful for testing shellcodes.
```python
#!/usr/bin/env python
@@ -229,10 +230,11 @@ with open('test_shell', 'wb') as f:
f.write(e.get_data())
```
-This will result in a binary named test_shell which executes the necessary assembly code to spawn a shell.
-```bash
-$ chmod u+x test_shell
-$ ./test_shell
+This will result in a binary named `test_shell` which executes the necessary assembly code to spawn a shell:
+
+```console
+chmod u+x test_shell
+./test_shell
```
## Shellcode generation
@@ -285,9 +287,9 @@ These shellcodes can be directly assembled using asm inside your script, and giv
''', arch = 'amd64')
```
-
Most of the time you'll be working with as specific vulnerable program.
To avoid specifying architecture for the asm function or to shellcraft you can define the context at the start of the script which will imply the architecture from the binary header.
+
```python
context.binary = './vuln_program'
@@ -331,8 +333,8 @@ main:
Compile it with:
```console
-$ nasm vuln.asm -felf64
-$ gcc -no-pie -fno-pic -fno-stack-protector -z execstack vuln.o -o vuln
+nasm vuln.asm -felf64
+gcc -no-pie -fno-pic -fno-stack-protector -z execstack vuln.o -o vuln
```
Use this script to exploit the program:
@@ -412,7 +414,7 @@ Continuing.
The continue command will return control to the terminal in which we're running the pwntools script.
This is where the `raw_input()` function comes in handy, because it will wait for you to say`“go` before proceeding further.
-Now if you hit `` at the Send payload? prompt, you will notice that GDB has reached the breakpoint you've previously set.
+Now if you hit `` at the `Send payload?` prompt, you will notice that GDB has reached the breakpoint you've previously set.
You can now single-step each instruction of the shellcode inside GDB to see that everything is working properly.
Once you reach int `0x80`, you can continue again (or close GDB altogether) and interact with the newly spawned shell in the pwntools session.
diff --git a/chapters/mitigations-and-defensive-strategies/defense-mechanisms/reading/README.md b/chapters/mitigations-and-defensive-strategies/defense-mechanisms/reading/README.md
index 5d3551e..12ff211 100644
--- a/chapters/mitigations-and-defensive-strategies/defense-mechanisms/reading/README.md
+++ b/chapters/mitigations-and-defensive-strategies/defense-mechanisms/reading/README.md
@@ -158,7 +158,7 @@ Program Headers:
```
Check the `Flg` column.
-For example, the first `LOAD` segment contains `.text` and is marked `R E`, while the `GNU_STACK` segment is marked `RW `.
+For example, the first `LOAD` segment contains `.text` and is marked `R E`, while the `GNU_STACK` segment is marked `RW`.
Next we are interested in seeing calls to `mmap2()` and `mprotect()` made by the loader.
We are going to use the `strace` tool for this, and directly execute the loader.
@@ -228,13 +228,16 @@ fffdd000-ffffe000 rw-p 00000000 00:00 0 [stack]
Below are a few methods of exploiting a binary that has **NX** enabled:
-- **ret-to-plt/libc**. You can return to the `.plt` section and call library function already linked.
+- **ret-to-plt/libc**:
+ You can return to the `.plt` section and call library function already linked.
You can also call other library functions based on their known offsets.
The latter approach assumes no ASLR (see next section), or the possibility of an information leak.
-- **mprotect()**. If the application is using `mprotect()` you can easily call it to modify the permissions and include `PROT_EXEC` for the stack.
+- **mprotect()**:
+ If the application is using `mprotect()` you can easily call it to modify the permissions and include `PROT_EXEC` for the stack.
You can also call this in a `ret-to-libc` attack.
You can also `mmap` a completely new memory region and dump the shellcode there.
-- **Return Oriented Programming (ROP)**. This is a generalization of the `ret-to-*` approach that makes use of existing code to execute almost anything.
+- **Return Oriented Programming (ROP)**:
+ This is a generalization of the `ret-to-*` approach that makes use of existing code to execute almost anything.
As this is probably one of the most common types of attacks, it will be discussed in depth in a future section.
### Address Space Layout Randomization
@@ -248,7 +251,9 @@ Linux allows 3 options for its ASLR implementation that can be configured using
Writing **0**, **1** or **2** to this will results in the following behaviors:
- **0**: deactivated;
-- **1**: random stack, vdso, libraries; heap is after code section; random code section (only for PIE-linked binaries);
+- **1**: random stack, vdso, libraries;
+ heap is after code section;
+ random code section (only for PIE-linked binaries);
- **2**: random heap too.
Make sure you reactivate ASLR after the previous section of the tutorial, by one of the two options below.
@@ -275,23 +280,28 @@ pwndbg> set disable-randomization off
Below are a few methods of exploiting a binary that has **ASLR** enabled:
-- **Bruteforce**. If you are able to inject payloads multiple times without crashing the application, you can bruteforce the address you are interested in (e.g., a target in libc).
+- **Bruteforce**:
+ If you are able to inject payloads multiple times without crashing the application, you can bruteforce the address you are interested in (e.g., a target in libc).
Otherwise, you can just run the exploit multiple times.
Another thing to keep in mind is that, as addresses are randomized at load-time, child processes spawned with fork inherit the memory layout of the parent.
Take the following scenario: we interact with a vulnerable sever that handles connections by forking to another process.
We manage to obtain a leak from a child process but we are not able to create an exploit chain that leads to arbitrary code execution.
However, we may still be able to use this leak in another connection, since the new process will have the same address space as the previous.
-- **NOP sled**. In the case of shellcodes, a longer NOP sled will maximize the chances of jumping inside it and eventually reaching the exploit code even if the stack address is randomized.
+- **NOP sled**:
+ In the case of shellcodes, a longer NOP sled will maximize the chances of jumping inside it and eventually reaching the exploit code even if the stack address is randomized.
This is not very useful when we are interested in jumping to libc or other functions, which is usually the case if the executable space protection is also active.
-- **jmp esp**. This will basically jump into the stack, no matter where it is mapped.
+- **jmp esp**:
+ This will basically jump into the stack, no matter where it is mapped.
It's actually a very rudimentary form of Return Oriented Programming which was discussed in the previous session.
-- **Restrict entropy**. There are various ways of reducing the entropy of the randomized address.
+- **Restrict entropy**:
+ There are various ways of reducing the entropy of the randomized address.
For example, you can decrease the initial stack size by setting a huge amount of dummy environment variables.
-- **Partial overwrite**. This technique is useful when we are able to overwrite only the least significant byte(s) of an address (e.g. a GOT entry).
+- **Partial overwrite**:
+ This technique is useful when we are able to overwrite only the least significant byte(s) of an address (e.g. a GOT entry).
We must take into account the offsets of the original and final addresses from the beginning of the mapping.
If these offsets only differ in the last 8 bits, the exploit is deterministic, as the base of the mapping is aligned to 0x1000.
The offsets of `read` and `write` in `libc6_2.27-3ubuntu1.2_i386` are suitable for a partial overwrite:
@@ -305,7 +315,8 @@ Below are a few methods of exploiting a binary that has **ASLR** enabled:
However, since bits 12-16 of the offsets differ, the corresponding bits in the full addresses would have to be bruteforced (probability 1/4).
-- **Information leak**. The most effective way of bypassing ASLR is by using an information leak vulnerability that exposes randomized address, or at least parts of them.
+- **Information leak**:
+ The most effective way of bypassing ASLR is by using an information leak vulnerability that exposes randomized address, or at least parts of them.
You can also dump parts of libraries (e.g. `libc`) if you are able to create an exploit that reads them.
This is useful in remote attacks to infer the version of the library, downloading it from the web, and thus knowing the right offsets for other functions (not originally linked with the binary).
@@ -434,8 +445,10 @@ p.interactive()
It comes in two flavors:
-- **Partial**. Protects the `.init_array`, `.fini_array`, `.dynamic` and `.got` sections (but NOT `.got.plt`);
-- **Full**. Additionally protects `.got.plt`, rendering the **GOT overwrite** attack infeasible.
+- **Partial**:
+ Protects the `.init_array`, `.fini_array`, `.dynamic` and `.got` sections (but NOT `.got.plt`).
+- **Full**:
+ Additionally protects `.got.plt`, rendering the **GOT overwrite** attack infeasible.
In a previous session we explained how the addresses of dynamically linked functions are resolved using lazy binding.
When Full RELRO is in effect, the addresses are resolved at load-time and then marked as read-only.
@@ -461,7 +474,7 @@ The [seccomp-tools](https://github.com/david942j/seccomp-tools) suite provides t
The `dump` subcommand may be used to extract the filter from a binary at runtime and display it in a pseudocode format:
```console
-silvia@imladris:/sss/demo$ seccomp-tools dump ./seccomp_example
+$ seccomp-tools dump ./seccomp_example
line CODE JT JF K
=================================
0000: 0x20 0x00 0x00 0x00000004 A = arch
@@ -483,7 +496,7 @@ In the example above we see a filter operating on the whitelist model: it specif
To install `seccomp-tools` on the Kali VM, use the the `gem` package manager:
```console
-$ gem install seccomp-tools
+gem install seccomp-tools
```
## Challenges
@@ -503,7 +516,8 @@ They are numbered in the suggested solving order.
**Tips**:
-- Do not waste time on reverse engineering `rwslotmachine3`! It is very similar to `rwslotmachine2`, but operates on the client/server model.
+- Do not waste time on reverse engineering `rwslotmachine3`!
+ It is very similar to `rwslotmachine2`, but operates on the client/server model.
- To set `LD_LIBRARY_PATH` from within a pwntools script, use `p = process('./rwslotmachineX', env={'LD_LIBRARY_PATH' : '.'})`.
- In the case of `rwslotmachine4`, you will need the shared library `libint.so` (found inside of the github repo).
diff --git a/chapters/mitigations-and-defensive-strategies/information-leaks/reading/README.md b/chapters/mitigations-and-defensive-strategies/information-leaks/reading/README.md
index 2cb45aa..15a3076 100644
--- a/chapters/mitigations-and-defensive-strategies/information-leaks/reading/README.md
+++ b/chapters/mitigations-and-defensive-strategies/information-leaks/reading/README.md
@@ -2,14 +2,14 @@
## Introduction
-#### Objectives & Rationale
+### Objectives & Rationale
This is a tutorial based lab.
Throughout this lab you will learn about frequent errors that occur when handling strings.
This tutorial is focused on the C language.
Generally, OOP languages (like Java, C#,C++) are using classes to represent strings -- this simplifies the way strings are handled and decreases the frequency of programming errors.
-#### What is a String?
+### What is a String?
Conceptually, a string is sequence of characters.
The representation of a string can be done in multiple ways.
@@ -43,8 +43,7 @@ An ASCII string ends with a `0` value byte called the `NUL` byte.
Every `str*` function (i.e. a function with the name starting with `str`, such as `strcpy`, `strcat`, `strdup`, `strstr` etc.) uses this `0` byte to detect where the string ends.
As a result, not ending strings in `0` and using `str*` functions leads to vulnerabilities.
-### 1. Basic Info Leak (tutorial)
-
+## 1. Basic Info Leak (tutorial)
Enter the `01-basic-info-leak/` subfolder.
It's a basic information leak example.
@@ -84,7 +83,7 @@ The return address usually doesn't change (except for executables with PIE, *Pos
But assuming ASLR is enabled, the `rbp` value changes at each run.
If we leak it we have a basic address that we can toy around to leak or overwrite other values.
-### 2. Information Leak
+## 2. Information Leak
We will now show how improper string handling will lead to information leaks from the memory.
For this, please access the `02-info-leak/` subfolder.
@@ -122,7 +121,7 @@ static void my_main(void)
What catches our eye is that the `read()` function call in the `read_name()` function read **exactly** `32` bytes.
If we provide it `32` bytes it won't be null-terminated and will result in an information leak when `printf()` is called in the `my_main()` function.
-#### Exploiting the Memory Write Using the Info Leak
+### Exploiting the Memory Write Using the Info Leak
Let's first try to see how the program works:
@@ -172,7 +171,8 @@ $ python -c 'import sys; sys.stdout.write(32*"A")' | ./info_leak | xxd | grep ',
00000020: 4141 4141 4141 f0dc ffff ff7f 2c20 7768 AAAAAA......, wh
```
-The variable part is related to a stack address (it starts with `0x7f`); it varies because ASLR is enabled.
+The variable part is related to a stack address (it starts with `0x7f`);
+it varies because ASLR is enabled.
We want to look more carefully using GDB and figure out what the variable value represents:
```console
@@ -225,7 +225,7 @@ In the above run the value of `rbp` is `0x00007fffffffdc50`.
We also see that the stored `rbp` value is stored at **address** `0x7fffffffdc40`, which is the address current `rbp`.
We have the situation in the below diagram:
-
+
We marked the stored `rbp` value (i.e. the frame pointer for `main()`: `0x7fffffffdc50`) with the font color red in both places.
@@ -262,7 +262,7 @@ uid=1000(ctf) gid=1000(ctf) groups=1000(ctf)
The rule of thumb is: **Always know your string length.**
-#### Format String Attacks
+### Format String Attacks
We will now see how (im)proper use of `printf` may provide us with ways of extracting information or doing actual attacks.
@@ -282,7 +282,7 @@ Let's recap some of [useful formats](http://www.cplusplus.com/reference/cstdio/p
This format is not widely used but it is in the C standard.
- `%x` and `%n` are enough to have memory read and write and hence, to successfully exploit a vulnerable program that calls printf (or other format string function) directly with a string controlled by the user.
-### Example 2
+## Example 2
```c
printf(my_string);
@@ -299,7 +299,7 @@ Try to think about:
- How matching between format strings (e.g. the one above) and arguments is enforced (*hint*: it's not) and what happens in general when the number of arguments doesn't match the number of format specifiers
- How we could use this to cause information leaks and arbitrary memory writes (*hint*: see the format specifiers at the beginning of the section)
-### Example 3
+## Example 3
We would like to check some of the well known and not so-well known features of [the printf function](http://man7.org/linux/man-pages/man3/printf.3.html "http://man7.org/linux/man-pages/man3/printf.3.html").
Some of them may be used for information leaking and for attacks such as format string attacks.
@@ -320,7 +320,7 @@ and then run the resulting executable file using
Go through the `printf-features.c` file again and check how print, length and conversion specifiers are used by `printf`.
We will make use of the `%n` feature that allows memory writes, a requirement for attacks.
-### Basic Format String Attack
+## Basic Format String Attack
You will now do a basic format string attack using the `03-basic-format-string/` subfolder.
The source code is in `basic_format_string.c` and the executable is in `basic_format_string`.
@@ -331,10 +331,11 @@ You have to do three steps:
1. Determine the address of the `v` variable using `nm`.
1. Determine the `n`-th parameter of `printf()` that you can write to using `%n`.
-The `buffer` variable will have to be that parameter; you will store the address of the `v` variable in the `buffer` variable.
-
-1. Construct a format string that enables the attack; the number of characters processed by `printf()` until `%n` is matched will have to be `0x300`.
+ The `buffer` variable will have to be that parameter;
+ you will store the address of the `v` variable in the `buffer` variable.
+1. Construct a format string that enables the attack;
+ the number of characters processed by `printf()` until `%n` is matched will have to be `0x300`.
For the second step let's run the program multiple times and figure out where the `buffer` address starts.
We fill `buffer` with the `aaaa` string and we expect to discover it using the `printf()` format specifiers.
@@ -388,7 +389,7 @@ $ python exploit64.py
$
```
-### Extra: Format String Attack
+## Extra: Format String Attack
Go to the `04-format-string/` subfolder.
In this task you will be working with a **32-bit binary**.
@@ -405,7 +406,7 @@ int main(int argc, char *argv[])
}
```
-#### Transform Format String Attack to a Memory Write
+### Transform Format String Attack to a Memory Write
Any string that represents a useful format (e.g. `%d`, `%x` etc.) can be used to discover the vulnerability.
@@ -436,7 +437,7 @@ Note the equivalence between formats.
Now, because we are able to select *any* higher address with this function and because the buffer is on the stack, sooner or later we will discover our own buffer.
```console
-$ ./format "$(python -c 'print("%08x\n" * 10000)')"
+./format "$(python -c 'print("%08x\n" * 10000)')"
```
Depending on your setup you should be able to view the hex
@@ -489,7 +490,7 @@ io.interactive()
Then call the `format` using:
```console
-$ python exploit.py
+python exploit.py
```
One idea is to keep things in multiple of 4, like "%08x \\n".
@@ -511,7 +512,7 @@ You can see that the last information is our b"ABCD" string printed with `%08x`
You need to enable core dumps in order to reproduce the steps below:
```console
-$ ulimit -c unlimited
+ulimit -c unlimited
```
The steps below work an a given version of libc and a given system.
@@ -589,11 +590,14 @@ Which means that if we want to print with a padding of 100 (three digits) we sho
You can try this by yourself.
**How far can we go?**
-Probably we can use any integer for specifying the number of bytes which are used for a format, but we don't need this; moreover specifying a very large padding is not always feasible, think what happens when printing with `snprintf`. 255 should be enough.
+Probably we can use any integer for specifying the number of bytes which are used for a format, but we don't need this;
+moreover specifying a very large padding is not always feasible, think what happens when printing with `snprintf`.
+`255` should be enough.
Remember, we want to write a value to a certain address.
So far we control the address, but the value is somewhat limited.
-If we want to write 4 bytes at a time we can make use of the endianness of the machine. **The idea** is to write at the address n and then at the address n+1 and so on.
+If we want to write 4 bytes at a time we can make use of the endianness of the machine.
+**The idea** is to write at the address n and then at the address n+1 and so on.
Lets first display the address.
We are using the address `0x804c014`.
@@ -632,7 +636,7 @@ As `%n` writes how many characters have been printed until it is reached, each `
We use the 4 adjacent adressess to write byte by byte and use overflows to reach a lower value for the next byte.
For example, after writing `0xa6` we can write `0x0191`:
-
+
Also, the `%n` count doesn\'t reset so, if we want to write `0xa6` and then `0x91` the payload should be in the form of `<0xa6 bytes>%n<0x100 - 0xa6 + 0x91 bytes>%n`.
@@ -641,17 +645,17 @@ As mentioned earlier above, instead writing N bytes `“A” * N` you can use ot
**Bonus task** Can you get a shell?
(Assume ASLR is disabled).
-#### Mitigation and Recommendations
+### Mitigation and Recommendations
-1. Manage the string length carefully
+1. Manage the string length carefully.
1. Don't use `gets`.
With `gets` there is no way of knowing how much data was read
-1. Use string functions with `n` parameter, whenever a non constant string is involved. i.e. `strnprintf`, `strncat`.
+1. Use string functions with `n` parameter, whenever a non constant string is involved, i.e. `strnprintf`, `strncat`.
1. Make sure that the `NUL` byte is added, for instance `strncpy` does **not** add a `NUL` byte.
1. Use `wcstr*` functions when dealing with wide char strings.
1. Don't trust the user!
-#### Real life Examples
+### Real life Examples
- [Heartbleed](http://xkcd.com/1354/)
Linux kernel through 3.9.4 [CVE-2013-2851](http://www.cvedetails.com/cve/CVE-2013-2851/)
@@ -663,7 +667,7 @@ As mentioned earlier above, instead writing N bytes `“A” * N` you can use ot
- Pidgin off the record plugin [CVE-2012-2369](http://www.cvedetails.com/cve/CVE-2012-2369).
The fix is [here](https://bugzilla.novell.com/show_bug.cgi?id=762498#c1)
-### Resources
+## Resources
- [Secure Coding in C and C++](http://www.cert.org/books/secure-coding/)
- [String representation in C](http://www.informit.com/articles/article.aspx?p=2036582)
+
To recap: given a stack-buffer-overflow vulnerability we can not only hijack control flow, but also place a shellcode on the stack using the buggy read.
There are two regions where we can do this:
-- between the buffer start and the saved return.
-The number of bytes we can write here is determined by _how much space was allocated on the stack_.
-- after the saved return.
-The number of bytes we can write here is determined by _how many bytes are read_.
+- between the buffer start and the saved return address:
+ The number of bytes we can write here is determined by **how much space was allocated on the stack**.
+- after the saved return address:
+ The number of bytes we can write here is determined by **how many bytes are read**.
If any of these regions is too small, we can try the other one.
If both of them are too small, that's a problem.
However, note that shellcodes are usually tiny.
-### 09. Challenge: shellcode after saved ret - no leak
+### 09. Challenge: Shellcode after Saved Return Address - No Leak
This is the same as the previous challenge, only this time the executable does not conveniently leak the buffer's address.
So you will have to deal with the differences between running a binary inside and outside of `gdb` to precisely determine the necessary address, then jump to it.
-### 10. Challenge: shellcode as command line arg
+### 10. Challenge: Shellcode as Command Line Argument
-As mentioned in the introduction, reading from stdin or from a file isn't the only way to place content inside the memory space of a process.
+As mentioned in the introduction, reading from standard input or from a file isn't the only way to place content inside the memory space of a process.
If we can launch the executable, we can modify its environment or command line arguments.
The fact that a program might not use its arguments or environment is irrelevant, the loader can't know this, so it places them in the address space anyway.
Take the `/bin/sh` shellcode and feed it to the program as a command-line argument, then exploit the SBO to actually run it.
-### 11. Challenge: shellcode in the environment
+### 11. Challenge: Shellcode in the Environment
Take the `/bin/sh` shellcode and place it in the environment, then exploit the SBO to actually run it.
diff --git a/chapters/extra/pwntools-intro/reading/README.md b/chapters/extra/pwntools-intro/reading/README.md
index f0503f1..3a389ab 100644
--- a/chapters/extra/pwntools-intro/reading/README.md
+++ b/chapters/extra/pwntools-intro/reading/README.md
@@ -6,8 +6,8 @@ Pwntools comes to level the playing field and bring together developers to creat
## Installation
-```bash
-$ pip install -U pwntools
+```console
+pip install -U pwntools
```
## Local and Remote I/O
@@ -72,7 +72,7 @@ io.interactive()
If we run the previous script, we get the following output:
-```
+```text
[+] Starting local process './leaky': Done
Got: Okay, here you go: 0xffe947d8 S
@@ -152,7 +152,7 @@ def leak_char(offset):
Now the output should be much more verbose:
-```
+```text
[+] Starting local process './leaky': Done
[*] Sending request for offset: -10
[*] Got back raw response: Okay, here you go: 0xffb14948 S
@@ -206,7 +206,8 @@ log.info("Main at: " + hex(main_addr))
log.info(disasm(leaky_elf.read(main_addr, 14), arch='x86'))
```
-We can also write ELF files from raw assembly; this is very useful for testing shellcodes.
+We can also write ELF files from raw assembly;
+this is very useful for testing shellcodes.
```python
#!/usr/bin/env python
@@ -229,10 +230,11 @@ with open('test_shell', 'wb') as f:
f.write(e.get_data())
```
-This will result in a binary named test_shell which executes the necessary assembly code to spawn a shell.
-```bash
-$ chmod u+x test_shell
-$ ./test_shell
+This will result in a binary named `test_shell` which executes the necessary assembly code to spawn a shell:
+
+```console
+chmod u+x test_shell
+./test_shell
```
## Shellcode generation
@@ -285,9 +287,9 @@ These shellcodes can be directly assembled using asm inside your script, and giv
''', arch = 'amd64')
```
-
Most of the time you'll be working with as specific vulnerable program.
To avoid specifying architecture for the asm function or to shellcraft you can define the context at the start of the script which will imply the architecture from the binary header.
+
```python
context.binary = './vuln_program'
@@ -331,8 +333,8 @@ main:
Compile it with:
```console
-$ nasm vuln.asm -felf64
-$ gcc -no-pie -fno-pic -fno-stack-protector -z execstack vuln.o -o vuln
+nasm vuln.asm -felf64
+gcc -no-pie -fno-pic -fno-stack-protector -z execstack vuln.o -o vuln
```
Use this script to exploit the program:
@@ -412,7 +414,7 @@ Continuing.
The continue command will return control to the terminal in which we're running the pwntools script.
This is where the `raw_input()` function comes in handy, because it will wait for you to say`“go` before proceeding further.
-Now if you hit `` at the Send payload? prompt, you will notice that GDB has reached the breakpoint you've previously set.
+Now if you hit `` at the `Send payload?` prompt, you will notice that GDB has reached the breakpoint you've previously set.
You can now single-step each instruction of the shellcode inside GDB to see that everything is working properly.
Once you reach int `0x80`, you can continue again (or close GDB altogether) and interact with the newly spawned shell in the pwntools session.
diff --git a/chapters/mitigations-and-defensive-strategies/defense-mechanisms/reading/README.md b/chapters/mitigations-and-defensive-strategies/defense-mechanisms/reading/README.md
index 5d3551e..12ff211 100644
--- a/chapters/mitigations-and-defensive-strategies/defense-mechanisms/reading/README.md
+++ b/chapters/mitigations-and-defensive-strategies/defense-mechanisms/reading/README.md
@@ -158,7 +158,7 @@ Program Headers:
```
Check the `Flg` column.
-For example, the first `LOAD` segment contains `.text` and is marked `R E`, while the `GNU_STACK` segment is marked `RW `.
+For example, the first `LOAD` segment contains `.text` and is marked `R E`, while the `GNU_STACK` segment is marked `RW`.
Next we are interested in seeing calls to `mmap2()` and `mprotect()` made by the loader.
We are going to use the `strace` tool for this, and directly execute the loader.
@@ -228,13 +228,16 @@ fffdd000-ffffe000 rw-p 00000000 00:00 0 [stack]
Below are a few methods of exploiting a binary that has **NX** enabled:
-- **ret-to-plt/libc**. You can return to the `.plt` section and call library function already linked.
+- **ret-to-plt/libc**:
+ You can return to the `.plt` section and call library function already linked.
You can also call other library functions based on their known offsets.
The latter approach assumes no ASLR (see next section), or the possibility of an information leak.
-- **mprotect()**. If the application is using `mprotect()` you can easily call it to modify the permissions and include `PROT_EXEC` for the stack.
+- **mprotect()**:
+ If the application is using `mprotect()` you can easily call it to modify the permissions and include `PROT_EXEC` for the stack.
You can also call this in a `ret-to-libc` attack.
You can also `mmap` a completely new memory region and dump the shellcode there.
-- **Return Oriented Programming (ROP)**. This is a generalization of the `ret-to-*` approach that makes use of existing code to execute almost anything.
+- **Return Oriented Programming (ROP)**:
+ This is a generalization of the `ret-to-*` approach that makes use of existing code to execute almost anything.
As this is probably one of the most common types of attacks, it will be discussed in depth in a future section.
### Address Space Layout Randomization
@@ -248,7 +251,9 @@ Linux allows 3 options for its ASLR implementation that can be configured using
Writing **0**, **1** or **2** to this will results in the following behaviors:
- **0**: deactivated;
-- **1**: random stack, vdso, libraries; heap is after code section; random code section (only for PIE-linked binaries);
+- **1**: random stack, vdso, libraries;
+ heap is after code section;
+ random code section (only for PIE-linked binaries);
- **2**: random heap too.
Make sure you reactivate ASLR after the previous section of the tutorial, by one of the two options below.
@@ -275,23 +280,28 @@ pwndbg> set disable-randomization off
Below are a few methods of exploiting a binary that has **ASLR** enabled:
-- **Bruteforce**. If you are able to inject payloads multiple times without crashing the application, you can bruteforce the address you are interested in (e.g., a target in libc).
+- **Bruteforce**:
+ If you are able to inject payloads multiple times without crashing the application, you can bruteforce the address you are interested in (e.g., a target in libc).
Otherwise, you can just run the exploit multiple times.
Another thing to keep in mind is that, as addresses are randomized at load-time, child processes spawned with fork inherit the memory layout of the parent.
Take the following scenario: we interact with a vulnerable sever that handles connections by forking to another process.
We manage to obtain a leak from a child process but we are not able to create an exploit chain that leads to arbitrary code execution.
However, we may still be able to use this leak in another connection, since the new process will have the same address space as the previous.
-- **NOP sled**. In the case of shellcodes, a longer NOP sled will maximize the chances of jumping inside it and eventually reaching the exploit code even if the stack address is randomized.
+- **NOP sled**:
+ In the case of shellcodes, a longer NOP sled will maximize the chances of jumping inside it and eventually reaching the exploit code even if the stack address is randomized.
This is not very useful when we are interested in jumping to libc or other functions, which is usually the case if the executable space protection is also active.
-- **jmp esp**. This will basically jump into the stack, no matter where it is mapped.
+- **jmp esp**:
+ This will basically jump into the stack, no matter where it is mapped.
It's actually a very rudimentary form of Return Oriented Programming which was discussed in the previous session.
-- **Restrict entropy**. There are various ways of reducing the entropy of the randomized address.
+- **Restrict entropy**:
+ There are various ways of reducing the entropy of the randomized address.
For example, you can decrease the initial stack size by setting a huge amount of dummy environment variables.
-- **Partial overwrite**. This technique is useful when we are able to overwrite only the least significant byte(s) of an address (e.g. a GOT entry).
+- **Partial overwrite**:
+ This technique is useful when we are able to overwrite only the least significant byte(s) of an address (e.g. a GOT entry).
We must take into account the offsets of the original and final addresses from the beginning of the mapping.
If these offsets only differ in the last 8 bits, the exploit is deterministic, as the base of the mapping is aligned to 0x1000.
The offsets of `read` and `write` in `libc6_2.27-3ubuntu1.2_i386` are suitable for a partial overwrite:
@@ -305,7 +315,8 @@ Below are a few methods of exploiting a binary that has **ASLR** enabled:
However, since bits 12-16 of the offsets differ, the corresponding bits in the full addresses would have to be bruteforced (probability 1/4).
-- **Information leak**. The most effective way of bypassing ASLR is by using an information leak vulnerability that exposes randomized address, or at least parts of them.
+- **Information leak**:
+ The most effective way of bypassing ASLR is by using an information leak vulnerability that exposes randomized address, or at least parts of them.
You can also dump parts of libraries (e.g. `libc`) if you are able to create an exploit that reads them.
This is useful in remote attacks to infer the version of the library, downloading it from the web, and thus knowing the right offsets for other functions (not originally linked with the binary).
@@ -434,8 +445,10 @@ p.interactive()
It comes in two flavors:
-- **Partial**. Protects the `.init_array`, `.fini_array`, `.dynamic` and `.got` sections (but NOT `.got.plt`);
-- **Full**. Additionally protects `.got.plt`, rendering the **GOT overwrite** attack infeasible.
+- **Partial**:
+ Protects the `.init_array`, `.fini_array`, `.dynamic` and `.got` sections (but NOT `.got.plt`).
+- **Full**:
+ Additionally protects `.got.plt`, rendering the **GOT overwrite** attack infeasible.
In a previous session we explained how the addresses of dynamically linked functions are resolved using lazy binding.
When Full RELRO is in effect, the addresses are resolved at load-time and then marked as read-only.
@@ -461,7 +474,7 @@ The [seccomp-tools](https://github.com/david942j/seccomp-tools) suite provides t
The `dump` subcommand may be used to extract the filter from a binary at runtime and display it in a pseudocode format:
```console
-silvia@imladris:/sss/demo$ seccomp-tools dump ./seccomp_example
+$ seccomp-tools dump ./seccomp_example
line CODE JT JF K
=================================
0000: 0x20 0x00 0x00 0x00000004 A = arch
@@ -483,7 +496,7 @@ In the example above we see a filter operating on the whitelist model: it specif
To install `seccomp-tools` on the Kali VM, use the the `gem` package manager:
```console
-$ gem install seccomp-tools
+gem install seccomp-tools
```
## Challenges
@@ -503,7 +516,8 @@ They are numbered in the suggested solving order.
**Tips**:
-- Do not waste time on reverse engineering `rwslotmachine3`! It is very similar to `rwslotmachine2`, but operates on the client/server model.
+- Do not waste time on reverse engineering `rwslotmachine3`!
+ It is very similar to `rwslotmachine2`, but operates on the client/server model.
- To set `LD_LIBRARY_PATH` from within a pwntools script, use `p = process('./rwslotmachineX', env={'LD_LIBRARY_PATH' : '.'})`.
- In the case of `rwslotmachine4`, you will need the shared library `libint.so` (found inside of the github repo).
diff --git a/chapters/mitigations-and-defensive-strategies/information-leaks/reading/README.md b/chapters/mitigations-and-defensive-strategies/information-leaks/reading/README.md
index 2cb45aa..15a3076 100644
--- a/chapters/mitigations-and-defensive-strategies/information-leaks/reading/README.md
+++ b/chapters/mitigations-and-defensive-strategies/information-leaks/reading/README.md
@@ -2,14 +2,14 @@
## Introduction
-#### Objectives & Rationale
+### Objectives & Rationale
This is a tutorial based lab.
Throughout this lab you will learn about frequent errors that occur when handling strings.
This tutorial is focused on the C language.
Generally, OOP languages (like Java, C#,C++) are using classes to represent strings -- this simplifies the way strings are handled and decreases the frequency of programming errors.
-#### What is a String?
+### What is a String?
Conceptually, a string is sequence of characters.
The representation of a string can be done in multiple ways.
@@ -43,8 +43,7 @@ An ASCII string ends with a `0` value byte called the `NUL` byte.
Every `str*` function (i.e. a function with the name starting with `str`, such as `strcpy`, `strcat`, `strdup`, `strstr` etc.) uses this `0` byte to detect where the string ends.
As a result, not ending strings in `0` and using `str*` functions leads to vulnerabilities.
-### 1. Basic Info Leak (tutorial)
-
+## 1. Basic Info Leak (tutorial)
Enter the `01-basic-info-leak/` subfolder.
It's a basic information leak example.
@@ -84,7 +83,7 @@ The return address usually doesn't change (except for executables with PIE, *Pos
But assuming ASLR is enabled, the `rbp` value changes at each run.
If we leak it we have a basic address that we can toy around to leak or overwrite other values.
-### 2. Information Leak
+## 2. Information Leak
We will now show how improper string handling will lead to information leaks from the memory.
For this, please access the `02-info-leak/` subfolder.
@@ -122,7 +121,7 @@ static void my_main(void)
What catches our eye is that the `read()` function call in the `read_name()` function read **exactly** `32` bytes.
If we provide it `32` bytes it won't be null-terminated and will result in an information leak when `printf()` is called in the `my_main()` function.
-#### Exploiting the Memory Write Using the Info Leak
+### Exploiting the Memory Write Using the Info Leak
Let's first try to see how the program works:
@@ -172,7 +171,8 @@ $ python -c 'import sys; sys.stdout.write(32*"A")' | ./info_leak | xxd | grep ',
00000020: 4141 4141 4141 f0dc ffff ff7f 2c20 7768 AAAAAA......, wh
```
-The variable part is related to a stack address (it starts with `0x7f`); it varies because ASLR is enabled.
+The variable part is related to a stack address (it starts with `0x7f`);
+it varies because ASLR is enabled.
We want to look more carefully using GDB and figure out what the variable value represents:
```console
@@ -225,7 +225,7 @@ In the above run the value of `rbp` is `0x00007fffffffdc50`.
We also see that the stored `rbp` value is stored at **address** `0x7fffffffdc40`, which is the address current `rbp`.
We have the situation in the below diagram:
-
+
We marked the stored `rbp` value (i.e. the frame pointer for `main()`: `0x7fffffffdc50`) with the font color red in both places.
@@ -262,7 +262,7 @@ uid=1000(ctf) gid=1000(ctf) groups=1000(ctf)
The rule of thumb is: **Always know your string length.**
-#### Format String Attacks
+### Format String Attacks
We will now see how (im)proper use of `printf` may provide us with ways of extracting information or doing actual attacks.
@@ -282,7 +282,7 @@ Let's recap some of [useful formats](http://www.cplusplus.com/reference/cstdio/p
This format is not widely used but it is in the C standard.
- `%x` and `%n` are enough to have memory read and write and hence, to successfully exploit a vulnerable program that calls printf (or other format string function) directly with a string controlled by the user.
-### Example 2
+## Example 2
```c
printf(my_string);
@@ -299,7 +299,7 @@ Try to think about:
- How matching between format strings (e.g. the one above) and arguments is enforced (*hint*: it's not) and what happens in general when the number of arguments doesn't match the number of format specifiers
- How we could use this to cause information leaks and arbitrary memory writes (*hint*: see the format specifiers at the beginning of the section)
-### Example 3
+## Example 3
We would like to check some of the well known and not so-well known features of [the printf function](http://man7.org/linux/man-pages/man3/printf.3.html "http://man7.org/linux/man-pages/man3/printf.3.html").
Some of them may be used for information leaking and for attacks such as format string attacks.
@@ -320,7 +320,7 @@ and then run the resulting executable file using
Go through the `printf-features.c` file again and check how print, length and conversion specifiers are used by `printf`.
We will make use of the `%n` feature that allows memory writes, a requirement for attacks.
-### Basic Format String Attack
+## Basic Format String Attack
You will now do a basic format string attack using the `03-basic-format-string/` subfolder.
The source code is in `basic_format_string.c` and the executable is in `basic_format_string`.
@@ -331,10 +331,11 @@ You have to do three steps:
1. Determine the address of the `v` variable using `nm`.
1. Determine the `n`-th parameter of `printf()` that you can write to using `%n`.
-The `buffer` variable will have to be that parameter; you will store the address of the `v` variable in the `buffer` variable.
-
-1. Construct a format string that enables the attack; the number of characters processed by `printf()` until `%n` is matched will have to be `0x300`.
+ The `buffer` variable will have to be that parameter;
+ you will store the address of the `v` variable in the `buffer` variable.
+1. Construct a format string that enables the attack;
+ the number of characters processed by `printf()` until `%n` is matched will have to be `0x300`.
For the second step let's run the program multiple times and figure out where the `buffer` address starts.
We fill `buffer` with the `aaaa` string and we expect to discover it using the `printf()` format specifiers.
@@ -388,7 +389,7 @@ $ python exploit64.py
$
```
-### Extra: Format String Attack
+## Extra: Format String Attack
Go to the `04-format-string/` subfolder.
In this task you will be working with a **32-bit binary**.
@@ -405,7 +406,7 @@ int main(int argc, char *argv[])
}
```
-#### Transform Format String Attack to a Memory Write
+### Transform Format String Attack to a Memory Write
Any string that represents a useful format (e.g. `%d`, `%x` etc.) can be used to discover the vulnerability.
@@ -436,7 +437,7 @@ Note the equivalence between formats.
Now, because we are able to select *any* higher address with this function and because the buffer is on the stack, sooner or later we will discover our own buffer.
```console
-$ ./format "$(python -c 'print("%08x\n" * 10000)')"
+./format "$(python -c 'print("%08x\n" * 10000)')"
```
Depending on your setup you should be able to view the hex
@@ -489,7 +490,7 @@ io.interactive()
Then call the `format` using:
```console
-$ python exploit.py
+python exploit.py
```
One idea is to keep things in multiple of 4, like "%08x \\n".
@@ -511,7 +512,7 @@ You can see that the last information is our b"ABCD" string printed with `%08x`
You need to enable core dumps in order to reproduce the steps below:
```console
-$ ulimit -c unlimited
+ulimit -c unlimited
```
The steps below work an a given version of libc and a given system.
@@ -589,11 +590,14 @@ Which means that if we want to print with a padding of 100 (three digits) we sho
You can try this by yourself.
**How far can we go?**
-Probably we can use any integer for specifying the number of bytes which are used for a format, but we don't need this; moreover specifying a very large padding is not always feasible, think what happens when printing with `snprintf`. 255 should be enough.
+Probably we can use any integer for specifying the number of bytes which are used for a format, but we don't need this;
+moreover specifying a very large padding is not always feasible, think what happens when printing with `snprintf`.
+`255` should be enough.
Remember, we want to write a value to a certain address.
So far we control the address, but the value is somewhat limited.
-If we want to write 4 bytes at a time we can make use of the endianness of the machine. **The idea** is to write at the address n and then at the address n+1 and so on.
+If we want to write 4 bytes at a time we can make use of the endianness of the machine.
+**The idea** is to write at the address n and then at the address n+1 and so on.
Lets first display the address.
We are using the address `0x804c014`.
@@ -632,7 +636,7 @@ As `%n` writes how many characters have been printed until it is reached, each `
We use the 4 adjacent adressess to write byte by byte and use overflows to reach a lower value for the next byte.
For example, after writing `0xa6` we can write `0x0191`:
-
+
Also, the `%n` count doesn\'t reset so, if we want to write `0xa6` and then `0x91` the payload should be in the form of `<0xa6 bytes>%n<0x100 - 0xa6 + 0x91 bytes>%n`.
@@ -641,17 +645,17 @@ As mentioned earlier above, instead writing N bytes `“A” * N` you can use ot
**Bonus task** Can you get a shell?
(Assume ASLR is disabled).
-#### Mitigation and Recommendations
+### Mitigation and Recommendations
-1. Manage the string length carefully
+1. Manage the string length carefully.
1. Don't use `gets`.
With `gets` there is no way of knowing how much data was read
-1. Use string functions with `n` parameter, whenever a non constant string is involved. i.e. `strnprintf`, `strncat`.
+1. Use string functions with `n` parameter, whenever a non constant string is involved, i.e. `strnprintf`, `strncat`.
1. Make sure that the `NUL` byte is added, for instance `strncpy` does **not** add a `NUL` byte.
1. Use `wcstr*` functions when dealing with wide char strings.
1. Don't trust the user!
-#### Real life Examples
+### Real life Examples
- [Heartbleed](http://xkcd.com/1354/)
Linux kernel through 3.9.4 [CVE-2013-2851](http://www.cvedetails.com/cve/CVE-2013-2851/)
@@ -663,7 +667,7 @@ As mentioned earlier above, instead writing N bytes `“A” * N` you can use ot
- Pidgin off the record plugin [CVE-2012-2369](http://www.cvedetails.com/cve/CVE-2012-2369).
The fix is [here](https://bugzilla.novell.com/show_bug.cgi?id=762498#c1)
-### Resources
+## Resources
- [Secure Coding in C and C++](http://www.cert.org/books/secure-coding/)
- [String representation in C](http://www.informit.com/articles/article.aspx?p=2036582)
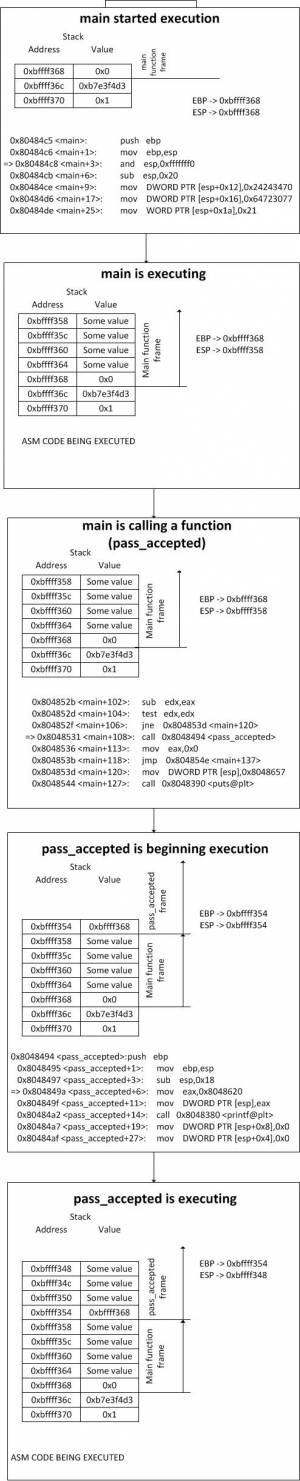 -
-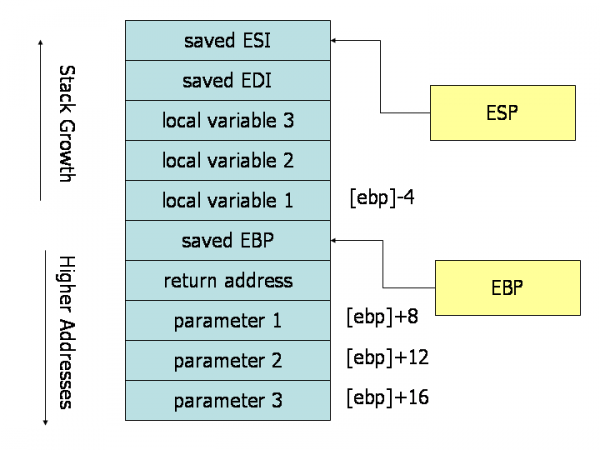 -
- -
-