+ +## II. How to run this tutorial (without TLC and locally as a simulation): +### 0. If you haven't done so already, create a virtual environment, install OpenFL, and upgrade pip: + - For help with this step, visit the "Install the Package" section of the [OpenFL installation instructions](https://openfl.readthedocs.io/en/latest/install.html#install-the-package). +
+ +### 1. Split terminal into 3 (1 terminal for the director, 1 for the envoy, and 1 for the experiment) +
+ +### 2. Do the following in each terminal: + - Activate the virtual environment from step 0: + + ```sh + source venv/bin/activate + ``` + - If you are in a network environment with a proxy, ensure proxy environment variables are set in each of your terminals. + - Navigate to the tutorial: + + ```sh + cd openfl/openfl-tutorials/interactive_api/PyTorch_FedProx_MedMNIST + ``` +
+ +### 3. In the first terminal, run the director: + +```sh +cd director +./start_director.sh +``` +
+ +### 4. In the second terminal, install requirements and run the envoy: + +```sh +cd envoy +pip install -r requirements.txt +./start_envoy.sh env_one envoy_config.yaml +``` + +Optional: Run a second envoy in an additional terminal: + - Ensure step 2 is complete for this terminal as well. + - Run the second envoy: +```sh +cd envoy +./start_envoy.sh env_two envoy_config.yaml +``` +
+ +### 5. In the third terminal (or forth terminal, if you chose to do two envoys) run the Jupyter Notebook: + +```sh +cd workspace +jupyter lab Pytorch_FedProx_MedMNIST_2D.ipynb +``` +- A Jupyter Server URL will appear in your terminal. In your browser, proceed to that link. Once the webpage loads, click on the Pytorch_FedProx_MedMNIST_2D.ipynb file. +- To run the experiment, select the icon that looks like two triangles to "Restart Kernel and Run All Cells". +- You will notice activity in your terminals as the experiments runs, and when the experiment is finished the director terminal will display a message that the experiment was finished successfully. diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/director/director_config.yaml new file mode 100644 index 0000000..e51c9c8 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/director/director_config.yaml @@ -0,0 +1,6 @@ +settings: + listen_host: localhost + listen_port: 50051 + sample_shape: ['28', '28', '3'] + target_shape: ['1','1'] + diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/director/start_director.sh new file mode 100755 index 0000000..5806a6c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/director/start_director.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx director start --disable-tls -c director_config.yaml \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/envoy/envoy_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/envoy/envoy_config.yaml new file mode 100644 index 0000000..05ee5ce --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/envoy/envoy_config.yaml @@ -0,0 +1,11 @@ +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: medmnist_shard_descriptor.MedMNISTShardDescriptor + params: + rank_worldsize: 1, 1 + datapath: data/. + dataname: bloodmnist diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/envoy/medmnist_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/envoy/medmnist_shard_descriptor.py new file mode 100644 index 0000000..d5e639f --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/envoy/medmnist_shard_descriptor.py @@ -0,0 +1,129 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""MedMNIST Shard Descriptor.""" + +import logging +import os +from typing import Any, List, Tuple +from medmnist.info import INFO, HOMEPAGE + +import numpy as np + +from openfl.interface.interactive_api.shard_descriptor import ShardDataset +from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor + +logger = logging.getLogger(__name__) + + +class MedMNISTShardDataset(ShardDataset): + """MedMNIST Shard dataset class.""" + + def __init__(self, x, y, data_type: str = 'train', rank: int = 1, worldsize: int = 1) -> None: + """Initialize MedMNISTDataset.""" + self.data_type = data_type + self.rank = rank + self.worldsize = worldsize + self.x = x[self.rank - 1::self.worldsize] + self.y = y[self.rank - 1::self.worldsize] + + def __getitem__(self, index: int) -> Tuple[Any, Any]: + """Return an item by the index.""" + return self.x[index], self.y[index] + + def __len__(self) -> int: + """Return the len of the dataset.""" + return len(self.x) + + +class MedMNISTShardDescriptor(ShardDescriptor): + """MedMNIST Shard descriptor class.""" + + def __init__( + self, + rank_worldsize: str = '1, 1', + datapath: str = '', + dataname: str = 'bloodmnist', + **kwargs + ) -> None: + """Initialize MedMNISTShardDescriptor.""" + self.rank, self.worldsize = tuple(int(num) for num in rank_worldsize.split(',')) + + self.datapath = datapath + self.dataset_name = dataname + self.info = INFO[self.dataset_name] + + (x_train, y_train), (x_test, y_test) = self.load_data() + self.data_by_type = { + 'train': (x_train, y_train), + 'val': (x_test, y_test) + } + + def get_shard_dataset_types(self) -> List[str]: + """Get available shard dataset types.""" + return list(self.data_by_type) + + def get_dataset(self, dataset_type='train') -> MedMNISTShardDataset: + """Return a shard dataset by type.""" + if dataset_type not in self.data_by_type: + raise Exception(f'Wrong dataset type: {dataset_type}') + return MedMNISTShardDataset( + *self.data_by_type[dataset_type], + data_type=dataset_type, + rank=self.rank, + worldsize=self.worldsize + ) + + @property + def sample_shape(self) -> List[str]: + """Return the sample shape info.""" + return ['28', '28', '3'] + + @property + def target_shape(self) -> List[str]: + """Return the target shape info.""" + return ['1', '1'] + + @property + def dataset_description(self) -> str: + """Return the dataset description.""" + return (f'MedMNIST dataset, shard number {self.rank}' + f' out of {self.worldsize}') + + @staticmethod + def download_data(datapath: str = 'data/', + dataname: str = 'bloodmnist', + info: dict = {}) -> None: + + logger.info(f"{datapath}\n{dataname}\n{info}") + try: + from torchvision.datasets.utils import download_url + download_url(url=info["url"], + root=datapath, + filename=dataname, + md5=info["MD5"]) + except Exception: + raise RuntimeError('Something went wrong when downloading! ' + + 'Go to the homepage to download manually. ' + + HOMEPAGE) + + def load_data(self) -> Tuple[Tuple[Any, Any], Tuple[Any, Any]]: + """Download prepared dataset.""" + + dataname = self.dataset_name + '.npz' + dataset = os.path.join(self.datapath, dataname) + + if not os.path.isfile(dataset): + logger.info(f"Dataset {dataname} not found at:{self.datapath}.\n\tDownloading...") + MedMNISTShardDescriptor.download_data(self.datapath, dataname, self.info) + logger.info("DONE!") + + data = np.load(dataset) + + x_train = data["train_images"] + x_test = data["test_images"] + + y_train = data["train_labels"] + y_test = data["test_labels"] + logger.info('MedMNIST data was loaded!') + return (x_train, y_train), (x_test, y_test) diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/envoy/requirements.txt b/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/envoy/requirements.txt new file mode 100644 index 0000000..363c0d6 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/envoy/requirements.txt @@ -0,0 +1,3 @@ +medmnist +setuptools>=65.5.1 # not directly required, pinned by Snyk to avoid a vulnerability +wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/envoy/start_envoy.sh new file mode 100755 index 0000000..cdd84e7 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/envoy/start_envoy.sh @@ -0,0 +1,6 @@ +#!/bin/bash +set -e +ENVOY_NAME=$1 +ENVOY_CONF=$2 + +fx envoy start -n "$ENVOY_NAME" --disable-tls --envoy-config-path "$ENVOY_CONF" -dh localhost -dp 50051 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/workspace/Pytorch_FedProx_MedMNIST_2D.ipynb b/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/workspace/Pytorch_FedProx_MedMNIST_2D.ipynb new file mode 100644 index 0000000..3bae96e --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_FedProx_MNIST/workspace/Pytorch_FedProx_MedMNIST_2D.ipynb @@ -0,0 +1,628 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "26fdd9ed", + "metadata": {}, + "source": [ + "# Federated MedMNIST2D Using FedProx Aggregation Algorithm" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "5504ab79", + "metadata": {}, + "outputs": [], + "source": [ + "!pip install medmnist" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d0570122", + "metadata": {}, + "outputs": [], + "source": [ + "# Install dependencies if not already installed\n", + "import tqdm\n", + "import numpy as np\n", + "import torch\n", + "import torch.nn as nn\n", + "import torch.optim as optim\n", + "from torch.utils.data import Dataset, DataLoader\n", + "from torchvision import transforms as T\n", + "import torch.nn.functional as F\n", + "\n", + "import medmnist\n", + "import openfl.utilities.optimizers.torch.fedprox as FP" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "22ba64da", + "metadata": {}, + "outputs": [], + "source": [ + "from medmnist import INFO, Evaluator\n", + "\n", + "## Change dataflag here to reflect the ones defined in the envoy_conifg_xxx.yaml\n", + "dataname = 'bloodmnist'\n" + ] + }, + { + "cell_type": "markdown", + "id": "246f9c98", + "metadata": {}, + "source": [ + "## Connect to the Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d657e463", + "metadata": {}, + "outputs": [], + "source": [ + "# Create a federation\n", + "from openfl.interface.interactive_api.federation import Federation\n", + "\n", + "# please use the same identificator that was used in signed certificate\n", + "client_id = 'api'\n", + "director_node_fqdn = 'localhost'\n", + "director_port=50051\n", + "\n", + "# 2) Run with TLS disabled (trusted environment)\n", + "# Federation can also determine local fqdn automatically\n", + "federation = Federation(\n", + " client_id=client_id,\n", + " director_node_fqdn=director_node_fqdn,\n", + " director_port=director_port, \n", + " tls=False\n", + ")\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "47dcfab3", + "metadata": {}, + "outputs": [], + "source": [ + "shard_registry = federation.get_shard_registry()\n", + "shard_registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "a2a6c237", + "metadata": {}, + "outputs": [], + "source": [ + "# First, request a dummy_shard_desc that holds information about the federated dataset \n", + "dummy_shard_desc = federation.get_dummy_shard_descriptor(size=10)\n", + "dummy_shard_dataset = dummy_shard_desc.get_dataset('train')\n", + "sample, target = dummy_shard_dataset[0]\n", + "f\"Sample shape: {sample.shape}, target shape: {target.shape}\"" + ] + }, + { + "cell_type": "markdown", + "id": "cc0dbdbd", + "metadata": {}, + "source": [ + "## Describing FL experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "fc88700a", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment" + ] + }, + { + "cell_type": "markdown", + "id": "9b3081a6", + "metadata": {}, + "source": [ + "## Load MedMNIST INFO" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "e0377d3a", + "metadata": {}, + "outputs": [], + "source": [ + "num_epochs = 3\n", + "TRAIN_BS, VALID_BS = 64, 128\n", + "\n", + "lr = 0.001\n", + "gamma=0.1\n", + "milestones = [0.5 * num_epochs, 0.75 * num_epochs]\n", + "\n", + "info = INFO[dataname]\n", + "task = info['task']\n", + "n_channels = info['n_channels']\n", + "n_classes = len(info['label'])" + ] + }, + { + "cell_type": "markdown", + "id": "b0979470", + "metadata": {}, + "source": [ + "### Register dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "f0dc457e", + "metadata": {}, + "outputs": [], + "source": [ + "## Data transformations\n", + "data_transform = T.Compose([T.ToTensor(), \n", + " T.Normalize(mean=[.5], std=[.5])]\n", + " )" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "09ba2f64", + "metadata": {}, + "outputs": [], + "source": [ + "from PIL import Image\n", + "\n", + "class TransformedDataset(Dataset):\n", + " \"\"\"Image Person ReID Dataset.\"\"\"\n", + "\n", + "\n", + " def __init__(self, dataset, transform=None, target_transform=None):\n", + " \"\"\"Initialize Dataset.\"\"\"\n", + " self.dataset = dataset\n", + " self.transform = transform\n", + " self.target_transform = target_transform\n", + "\n", + " def __len__(self):\n", + " \"\"\"Length of dataset.\"\"\"\n", + " return len(self.dataset)\n", + "\n", + " def __getitem__(self, index):\n", + " \n", + " img, label = self.dataset[index]\n", + " \n", + " if self.target_transform:\n", + " label = self.target_transform(label) \n", + " else:\n", + " label = label.astype(int)\n", + " \n", + " if self.transform:\n", + " img = Image.fromarray(img)\n", + " img = self.transform(img)\n", + " else:\n", + " base_transform = T.PILToTensor()\n", + " img = Image.fromarray(img)\n", + " img = base_transform(img) \n", + "\n", + " return img, label\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "db2d563e", + "metadata": {}, + "outputs": [], + "source": [ + "class MedMnistFedDataset(DataInterface):\n", + " def __init__(self, **kwargs):\n", + " self.kwargs = kwargs\n", + " \n", + " @property\n", + " def shard_descriptor(self):\n", + " return self._shard_descriptor\n", + " \n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + "\n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + "\n", + " self.train_set = TransformedDataset(\n", + " self._shard_descriptor.get_dataset('train'),\n", + " transform=data_transform\n", + " ) \n", + " \n", + " self.valid_set = TransformedDataset(\n", + " self._shard_descriptor.get_dataset('val'),\n", + " transform=data_transform\n", + " )\n", + " \n", + " def get_train_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks with optimizer in contract\n", + " \"\"\"\n", + " return DataLoader(\n", + " self.train_set, num_workers=8, batch_size=self.kwargs['train_bs'], shuffle=True)\n", + "\n", + " def get_valid_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks without optimizer in contract\n", + " \"\"\"\n", + " return DataLoader(self.valid_set, num_workers=8, batch_size=self.kwargs['valid_bs'])\n", + "\n", + " def get_train_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.train_set)\n", + "\n", + " def get_valid_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.valid_set)\n", + " " + ] + }, + { + "cell_type": "markdown", + "id": "b0dfb459", + "metadata": {}, + "source": [ + "### Create Mnist federated dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4af5c4c2", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = MedMnistFedDataset(train_bs=TRAIN_BS, valid_bs=VALID_BS)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "7f63908e", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset.shard_descriptor = dummy_shard_desc\n", + "for i, (sample, target) in enumerate(fed_dataset.get_train_loader()):\n", + " print(sample.shape, target.shape)" + ] + }, + { + "cell_type": "markdown", + "id": "075d1d6c", + "metadata": {}, + "source": [ + "### Describe the model and optimizer" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "8477a001", + "metadata": {}, + "outputs": [], + "source": [ + "# define a simple CNN model\n", + "class Net(nn.Module):\n", + " def __init__(self, in_channels, num_classes):\n", + " super(Net, self).__init__()\n", + "\n", + " self.layer1 = nn.Sequential(\n", + " nn.Conv2d(in_channels, 16, kernel_size=3),\n", + " nn.BatchNorm2d(16),\n", + " nn.ReLU())\n", + "\n", + " self.layer2 = nn.Sequential(\n", + " nn.Conv2d(16, 16, kernel_size=3),\n", + " nn.BatchNorm2d(16),\n", + " nn.ReLU(),\n", + " nn.MaxPool2d(kernel_size=2, stride=2))\n", + "\n", + " self.layer3 = nn.Sequential(\n", + " nn.Conv2d(16, 64, kernel_size=3),\n", + " nn.BatchNorm2d(64),\n", + " nn.ReLU())\n", + " \n", + " self.layer4 = nn.Sequential(\n", + " nn.Conv2d(64, 64, kernel_size=3),\n", + " nn.BatchNorm2d(64),\n", + " nn.ReLU())\n", + "\n", + " self.layer5 = nn.Sequential(\n", + " nn.Conv2d(64, 64, kernel_size=3, padding=1),\n", + " nn.BatchNorm2d(64),\n", + " nn.ReLU(),\n", + " nn.MaxPool2d(kernel_size=2, stride=2))\n", + "\n", + " self.fc = nn.Sequential(\n", + " nn.Linear(64 * 4 * 4, 128),\n", + " nn.ReLU(),\n", + " nn.Linear(128, 128),\n", + " nn.ReLU(),\n", + " nn.Linear(128, num_classes))\n", + "\n", + " def forward(self, x):\n", + " x = self.layer1(x)\n", + " x = self.layer2(x)\n", + " x = self.layer3(x)\n", + " x = self.layer4(x)\n", + " x = self.layer5(x)\n", + " x = x.view(x.size(0), -1)\n", + " x = self.fc(x)\n", + " return x\n", + "\n", + "model = Net(in_channels=n_channels, num_classes=n_classes)\n", + " \n", + "# define loss function and optimizer\n", + "if task == \"multi-label, binary-class\":\n", + " criterion = nn.BCEWithLogitsLoss()\n", + "else:\n", + " criterion = nn.CrossEntropyLoss()\n", + " \n", + "optimizer = FP.FedProxOptimizer(params = model.parameters(), lr=lr, momentum=0.9)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "f2154486", + "metadata": {}, + "outputs": [], + "source": [ + "print(model)" + ] + }, + { + "cell_type": "markdown", + "id": "8d1c78ee", + "metadata": {}, + "source": [ + "### Register model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "59831bcd", + "metadata": {}, + "outputs": [], + "source": [ + "from copy import deepcopy\n", + "\n", + "framework_adapter = 'openfl.plugins.frameworks_adapters.pytorch_adapter.FrameworkAdapterPlugin'\n", + "MI = ModelInterface(model=model, optimizer=optimizer, framework_plugin=framework_adapter)\n", + "\n", + "# Save the initial model state\n", + "initial_model = deepcopy(model)" + ] + }, + { + "cell_type": "markdown", + "id": "849c165b", + "metadata": {}, + "source": [ + "## Define and register FL tasks" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4ff463bd", + "metadata": {}, + "outputs": [], + "source": [ + "TI = TaskInterface()\n", + "\n", + "train_custom_params={'criterion':criterion,'task':task}\n", + "\n", + "# Task interface currently supports only standalone functions.\n", + "@TI.add_kwargs(**train_custom_params)\n", + "@TI.register_fl_task(model='model', data_loader='train_loader',\n", + " device='device', optimizer='optimizer')\n", + "def train(model, train_loader, device, optimizer, criterion, task):\n", + " total_loss = []\n", + " \n", + " train_loader = tqdm.tqdm(train_loader, desc=\"train\")\n", + " model.train()\n", + " model.to(device)\n", + " \n", + " for inputs, targets in train_loader:\n", + " \n", + " optimizer.set_old_weights(list(model.parameters()))\n", + " optimizer.zero_grad()\n", + " \n", + " outputs = model(inputs.to(device))\n", + " \n", + " if task == 'multi-label, binary-class':\n", + " targets = targets.to(torch.float32).to(device)\n", + " loss = criterion(outputs, targets)\n", + " else:\n", + " targets = torch.squeeze(targets, 1).long().to(device)\n", + " loss = criterion(outputs, targets)\n", + " \n", + " total_loss.append(loss.item())\n", + " \n", + " loss.backward()\n", + " optimizer.step()\n", + "\n", + " return {'train_loss': np.mean(total_loss),}\n", + "\n", + "\n", + "val_custom_params={'criterion':criterion, \n", + " 'task':task}\n", + "\n", + "@TI.add_kwargs(**val_custom_params)\n", + "@TI.register_fl_task(model='model', data_loader='val_loader', device='device')\n", + "def validate(model, val_loader, device, criterion, task):\n", + "\n", + " val_loader = tqdm.tqdm(val_loader, desc=\"validate\")\n", + " model.eval()\n", + " model.to(device)\n", + "\n", + " val_score = 0\n", + " total_samples = 0\n", + " total_loss = []\n", + " y_score = torch.tensor([]).to(device)\n", + "\n", + " with torch.no_grad():\n", + " for inputs, targets in val_loader:\n", + " outputs = model(inputs.to(device))\n", + " \n", + " if task == 'multi-label, binary-class':\n", + " targets = targets.to(torch.float32).to(device)\n", + " loss = criterion(outputs, targets)\n", + " m = nn.Sigmoid()\n", + " outputs = m(outputs).to(device)\n", + " else:\n", + " targets = torch.squeeze(targets, 1).long().to(device)\n", + " loss = criterion(outputs, targets)\n", + " m = nn.Softmax(dim=1)\n", + " outputs = m(outputs).to(device)\n", + " targets = targets.float().resize_(len(targets), 1)\n", + "\n", + " total_loss.append(loss.item())\n", + " \n", + " total_samples += targets.shape[0]\n", + " pred = outputs.argmax(dim=1)\n", + " val_score += pred.eq(targets).sum().cpu().numpy()\n", + " \n", + " acc = val_score / total_samples \n", + " test_loss = sum(total_loss) / len(total_loss)\n", + "\n", + " return {'acc': acc,\n", + " 'test_loss': test_loss,\n", + " }" + ] + }, + { + "cell_type": "markdown", + "id": "8f0ebf2d", + "metadata": {}, + "source": [ + "## Time to start a federated learning experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d41b7896", + "metadata": {}, + "outputs": [], + "source": [ + "# create an experimnet in federation\n", + "experiment_name = 'medmnist_exp'\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "41b44de9", + "metadata": { + "scrolled": true + }, + "outputs": [], + "source": [ + "# The following command zips the workspace and python requirements to be transfered to collaborator nodes\n", + "fl_experiment.start(model_provider=MI, \n", + " task_keeper=TI,\n", + " data_loader=fed_dataset,\n", + " rounds_to_train=3,\n", + " opt_treatment='RESET',\n", + " device_assignment_policy='CUDA_PREFERRED')" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "01fa7cea", + "metadata": { + "scrolled": true + }, + "outputs": [], + "source": [ + "# If user want to stop IPython session, then reconnect and check how experiment is going\n", + "# fl_experiment.restore_experiment_state(model_interface)\n", + "\n", + "fl_experiment.stream_metrics(tensorboard_logs=False)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "92940763", + "metadata": {}, + "outputs": [], + "source": [ + "\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "1690ea49", + "metadata": {}, + "outputs": [], + "source": [] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "10d7d5a2", + "metadata": {}, + "outputs": [], + "source": [] + } + ], + "metadata": { + "kernelspec": { + "display_name": "Python 3 (ipykernel)", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.10" + }, + "vscode": { + "interpreter": { + "hash": "916dbcbb3f70747c44a77c7bcd40155683ae19c65e1c03b4aa3499c5328201f1" + } + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/README.md b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/README.md new file mode 100644 index 0000000..54ff74b --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/README.md @@ -0,0 +1,66 @@ +# PyTorch_Histology + +## **How to run this tutorial (without TLC and locally as a simulation):** +
+ +### 0. If you haven't done so already, create a virtual environment, install OpenFL, and upgrade pip: + - For help with this step, visit the "Install the Package" section of the [OpenFL installation instructions](https://openfl.readthedocs.io/en/latest/install.html#install-the-package). + +
+ +### 1. Split terminal into 3 (1 terminal for the director, 1 for the envoy, and 1 for the experiment) + +
+ +### 2. Do the following in each terminal: + - Activate the virtual environment from step 0: + + ```sh + source venv/bin/activate + ``` + - If you are in a network environment with a proxy, ensure proxy environment variables are set in each of your terminals. + - Navigate to the tutorial: + + ```sh + cd openfl/openfl-tutorials/interactive_api/PyTorch_Histology + ``` + +
+ +### 3. In the first terminal, run the director: + +```sh +cd director +./start_director.sh +``` + +
+ +### 4. In the second terminal, install requirements and run the envoy: + +```sh +cd envoy +pip install -r requirements.txt +./start_envoy.sh env_one envoy_config.yaml +``` + +Optional: Run a second envoy in an additional terminal: + - Ensure step 2 is complete for this terminal as well. + - Run the second envoy: +```sh +cd envoy +./start_envoy.sh env_two envoy_config.yaml +``` + +
+ +### 5. Now that your director and envoy terminals are set up, run the Jupyter Notebook in your experiment terminal: + +```sh +cd workspace +jupyter lab pytorch_histology.ipynb +``` +- A Jupyter Server URL will appear in your terminal. In your browser, proceed to that link. Once the webpage loads, click on the pytorch_histology.ipynb file. +- To run the experiment, select the icon that looks like two triangles to "Restart Kernel and Run All Cells". +- You will notice activity in your terminals as the experiment runs, and when the experiment is finished the director terminal will display a message that the experiment has finished successfully. + diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/director/director_config.yaml new file mode 100644 index 0000000..14f3868 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/director/director_config.yaml @@ -0,0 +1,5 @@ +settings: + listen_host: localhost + listen_port: 50051 + sample_shape: ['150', '150'] + target_shape: ['1'] diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/director/director_config_review_exp.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/director/director_config_review_exp.yaml new file mode 100644 index 0000000..4bbfccc --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/director/director_config_review_exp.yaml @@ -0,0 +1,6 @@ +settings: + listen_host: localhost + listen_port: 50051 + sample_shape: ['150', '150'] + target_shape: ['1'] + review_experiment: True diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/director/start_director.sh new file mode 100755 index 0000000..5806a6c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/director/start_director.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx director start --disable-tls -c director_config.yaml \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/director/start_director_with_tls.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/director/start_director_with_tls.sh new file mode 100755 index 0000000..5d6d46a --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/director/start_director_with_tls.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e +FQDN=$1 +fx director start -c director_config.yaml -rc cert/root_ca.crt -pk cert/"${FQDN}".key -oc cert/"${FQDN}".crt \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/.gitignore b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/.gitignore new file mode 100644 index 0000000..ad818ec --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/.gitignore @@ -0,0 +1 @@ +histology_data \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/__pycache__/histology_shard_descriptor.cpython-38.pyc b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/__pycache__/histology_shard_descriptor.cpython-38.pyc new file mode 100644 index 0000000..83b4002 Binary files /dev/null and b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/__pycache__/histology_shard_descriptor.cpython-38.pyc differ diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/envoy_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/envoy_config.yaml new file mode 100644 index 0000000..b51c0db --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/envoy_config.yaml @@ -0,0 +1,10 @@ +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: histology_shard_descriptor.HistologyShardDescriptor + params: + data_folder: histology_data + rank_worldsize: 1,2 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/envoy_config_review_exp.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/envoy_config_review_exp.yaml new file mode 100644 index 0000000..d8341b2 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/envoy_config_review_exp.yaml @@ -0,0 +1,11 @@ +params: + cuda_devices: [] + review_experiment: True + +optional_plugin_components: {} + +shard_descriptor: + template: histology_shard_descriptor.HistologyShardDescriptor + params: + data_folder: histology_data + rank_worldsize: 1,2 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/histology_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/histology_shard_descriptor.py new file mode 100644 index 0000000..7baed8c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/histology_shard_descriptor.py @@ -0,0 +1,130 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""Histology Shard Descriptor.""" + +import logging +import os +from pathlib import Path +from typing import Tuple +from urllib.request import urlretrieve +from zipfile import ZipFile + +import numpy as np +from PIL import Image + +from openfl.interface.interactive_api.shard_descriptor import ShardDataset +from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor +from openfl.utilities import tqdm_report_hook +from openfl.utilities import validate_file_hash + + +logger = logging.getLogger(__name__) + + +class HistologyShardDataset(ShardDataset): + """Histology shard dataset class.""" + + TRAIN_SPLIT_RATIO = 0.8 + + def __init__(self, data_folder: Path, data_type='train', rank=1, worldsize=1): + """Histology shard dataset class.""" + self.data_type = data_type + root = Path(data_folder) / 'Kather_texture_2016_image_tiles_5000' + classes = [d.name for d in root.iterdir() if d.is_dir()] + class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)} + self.samples = [] + root = root.expanduser() + for target_class in sorted(class_to_idx.keys()): + class_index = class_to_idx[target_class] + target_dir = os.path.join(root, target_class) + for class_root, _, fnames in sorted(os.walk(target_dir, followlinks=True)): + for fname in sorted(fnames): + path = os.path.join(class_root, fname) + item = path, class_index + self.samples.append(item) + + idx_range = list(range(len(self.samples))) + idx_sep = int(len(idx_range) * HistologyShardDataset.TRAIN_SPLIT_RATIO) + train_idx, test_idx = np.split(idx_range, [idx_sep]) + if data_type == 'train': + self.idx = train_idx[rank - 1::worldsize] + else: + self.idx = test_idx[rank - 1::worldsize] + + def __len__(self) -> int: + """Return the len of the shard dataset.""" + return len(self.idx) + + def load_pil(self, path): + """Load image.""" + with open(path, 'rb') as f: + img = Image.open(f) + return img.convert('RGB') + + def __getitem__(self, index: int) -> Tuple['Image', int]: + """Return an item by the index.""" + path, target = self.samples[self.idx[index]] + sample = self.load_pil(path) + return sample, target + + +class HistologyShardDescriptor(ShardDescriptor): + """Shard descriptor class.""" + + URL = ('https://zenodo.org/record/53169/files/Kather_' + 'texture_2016_image_tiles_5000.zip?download=1') + FILENAME = 'Kather_texture_2016_image_tiles_5000.zip' + ZIP_SHA384 = ('7d86abe1d04e68b77c055820c2a4c582a1d25d2983e38ab724e' + 'ac75affce8b7cb2cbf5ba68848dcfd9d84005d87d6790') + DEFAULT_PATH = Path.home() / '.openfl' / 'data' + + def __init__( + self, + data_folder: Path = DEFAULT_PATH, + rank_worldsize: str = '1,1', + **kwargs + ): + """Initialize HistologyShardDescriptor.""" + self.data_folder = Path.cwd() / data_folder + self.download_data() + self.rank, self.worldsize = tuple(int(num) for num in rank_worldsize.split(',')) + + def download_data(self): + """Download prepared shard dataset.""" + os.makedirs(self.data_folder, exist_ok=True) + filepath = self.data_folder / HistologyShardDescriptor.FILENAME + if not filepath.exists(): + reporthook = tqdm_report_hook() + urlretrieve(HistologyShardDescriptor.URL, filepath, reporthook) # nosec + validate_file_hash(filepath, HistologyShardDescriptor.ZIP_SHA384) + with ZipFile(filepath, 'r') as f: + f.extractall(self.data_folder) + + def get_dataset(self, dataset_type): + """Return a shard dataset by type.""" + return HistologyShardDataset( + data_folder=self.data_folder, + data_type=dataset_type, + rank=self.rank, + worldsize=self.worldsize + ) + + @property + def sample_shape(self): + """Return the sample shape info.""" + shape = self.get_dataset('train')[0][0].size + return [str(dim) for dim in shape] + + @property + def target_shape(self): + """Return the target shape info.""" + target = self.get_dataset('train')[0][1] + shape = np.array([target]).shape + return [str(dim) for dim in shape] + + @property + def dataset_description(self) -> str: + """Return the shard dataset description.""" + return (f'Histology dataset, shard number {self.rank}' + f' out of {self.worldsize}') diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/requirements.txt b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/requirements.txt new file mode 100644 index 0000000..069a960 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/requirements.txt @@ -0,0 +1,3 @@ +numpy==1.22.2 +Pillow==10.3.0 +tqdm==4.66.3 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/start_envoy.sh new file mode 100755 index 0000000..1dfda52 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/start_envoy.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx envoy start -n env_one --disable-tls --envoy-config-path envoy_config.yaml -dh localhost -dp 50051 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/start_envoy_with_tls.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/start_envoy_with_tls.sh new file mode 100755 index 0000000..06b2916 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/envoy/start_envoy_with_tls.sh @@ -0,0 +1,6 @@ +#!/bin/bash +set -e +ENVOY_NAME=$1 +DIRECTOR_FQDN=$2 + +fx envoy start -n "$ENVOY_NAME" --envoy-config-path envoy_config.yaml -dh "$DIRECTOR_FQDN" -dp 50051 -rc cert/root_ca.crt -pk cert/"$ENVOY_NAME".key -oc cert/"$ENVOY_NAME".crt \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/.ipynb_checkpoints/pytorch_histology-checkpoint.ipynb b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/.ipynb_checkpoints/pytorch_histology-checkpoint.ipynb new file mode 100644 index 0000000..cf0eb46 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/.ipynb_checkpoints/pytorch_histology-checkpoint.ipynb @@ -0,0 +1,531 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "26fdd9ed", + "metadata": {}, + "source": [ + "# Federated PyTorch Histology Tutorial" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "895288d0", + "metadata": {}, + "outputs": [], + "source": [ + "!pip install torchvision==0.8.2" + ] + }, + { + "cell_type": "markdown", + "id": "246f9c98", + "metadata": {}, + "source": [ + "## Connect to the Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d657e463", + "metadata": {}, + "outputs": [], + "source": [ + "# Create a federation\n", + "from openfl.interface.interactive_api.federation import Federation\n", + "\n", + "# please use the same identificator that was used in signed certificate\n", + "client_id = 'api'\n", + "cert_dir = 'cert'\n", + "director_node_fqdn = 'localhost'\n", + "# 1) Run with API layer - Director mTLS \n", + "# If the user wants to enable mTLS their must provide CA root chain, and signed key pair to the federation interface\n", + "# cert_chain = f'{cert_dir}/root_ca.crt'\n", + "# api_certificate = f'{cert_dir}/{client_id}.crt'\n", + "# api_private_key = f'{cert_dir}/{client_id}.key'\n", + "\n", + "# federation = Federation(client_id=client_id, director_node_fqdn=director_node_fqdn, director_port='50051',\n", + "# cert_chain=cert_chain, api_cert=api_certificate, api_private_key=api_private_key)\n", + "\n", + "# --------------------------------------------------------------------------------------------------------------------\n", + "\n", + "# 2) Run with TLS disabled (trusted environment)\n", + "# Federation can also determine local fqdn automatically\n", + "federation = Federation(client_id=client_id, director_node_fqdn=director_node_fqdn, director_port='50051', tls=False)\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "1abebd90", + "metadata": {}, + "outputs": [], + "source": [ + "federation.target_shape" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "47dcfab3", + "metadata": {}, + "outputs": [], + "source": [ + "shard_registry = federation.get_shard_registry()\n", + "shard_registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "a2a6c237", + "metadata": {}, + "outputs": [], + "source": [ + "# First, request a dummy_shard_desc that holds information about the federated dataset \n", + "dummy_shard_desc = federation.get_dummy_shard_descriptor(size=10)\n", + "sample, target = dummy_shard_desc.get_dataset('train')[0]" + ] + }, + { + "cell_type": "markdown", + "id": "cc0dbdbd", + "metadata": {}, + "source": [ + "## Creating a FL experiment using Interactive API" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "fc88700a", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment" + ] + }, + { + "cell_type": "markdown", + "id": "b0979470", + "metadata": {}, + "source": [ + "### Register dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "7dda1680", + "metadata": {}, + "outputs": [], + "source": [ + "import torchvision\n", + "from torchvision import transforms as T\n", + "\n", + "normalize = T.Normalize(mean=[0.485, 0.456, 0.406],\n", + " std=[0.229, 0.224, 0.225])\n", + "\n", + "augmentation = T.RandomApply(\n", + " [T.RandomHorizontalFlip(),\n", + " T.RandomRotation(10),\n", + " T.RandomResizedCrop(64)], \n", + " p=.8\n", + ")\n", + "\n", + "training_transform = T.ToTensor()\n", + "\n", + "valid_transform = T.ToTensor()\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "0314d5bf", + "metadata": {}, + "outputs": [], + "source": [ + "from torch.utils.data import Dataset\n", + "\n", + "\n", + "class TransformedDataset(Dataset):\n", + " \"\"\"Image Person ReID Dataset.\"\"\"\n", + "\n", + " def __init__(self, dataset, transform=None, target_transform=None):\n", + " \"\"\"Initialize Dataset.\"\"\"\n", + " self.dataset = dataset\n", + " self.transform = transform\n", + " self.target_transform = target_transform\n", + "\n", + " def __len__(self):\n", + " \"\"\"Length of dataset.\"\"\"\n", + " return len(self.dataset)\n", + "\n", + " def __getitem__(self, index):\n", + " img, label = self.dataset[index]\n", + " label = self.target_transform(label) if self.target_transform else label\n", + " img = self.transform(img) if self.transform else img\n", + " return img, label\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "01369e3b", + "metadata": {}, + "outputs": [], + "source": [ + "class HistologyDataset(DataInterface):\n", + " def __init__(self, **kwargs):\n", + " self.kwargs = kwargs\n", + " \n", + " @property\n", + " def shard_descriptor(self):\n", + " return self._shard_descriptor\n", + " \n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + "\n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + " \n", + " self.train_set = TransformedDataset(\n", + " self._shard_descriptor.get_dataset('train'),\n", + " transform=training_transform\n", + " )\n", + " self.valid_set = TransformedDataset(\n", + " self._shard_descriptor.get_dataset('val'),\n", + " transform=valid_transform\n", + " )\n", + " \n", + " def get_train_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks with optimizer in contract\n", + " \"\"\"\n", + " return DataLoader(\n", + " self.train_set, num_workers=8, batch_size=self.kwargs['train_bs'], shuffle=True\n", + " )\n", + "\n", + " def get_valid_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks without optimizer in contract\n", + " \"\"\"\n", + " return DataLoader(self.valid_set, num_workers=8, batch_size=self.kwargs['valid_bs'])\n", + "\n", + " def get_train_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.train_set)\n", + "\n", + " def get_valid_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.valid_set)\n", + " " + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4a6cedef", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = HistologyDataset(train_bs=64, valid_bs=64)" + ] + }, + { + "cell_type": "markdown", + "id": "74cac654", + "metadata": {}, + "source": [ + "### Describe the model and optimizer" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4949e16d", + "metadata": {}, + "outputs": [], + "source": [ + "import os\n", + "import glob\n", + "from torch.utils.data import Dataset, DataLoader\n", + "from PIL import Image\n", + "\n", + "import numpy as np\n", + "import torch\n", + "import torch.nn as nn\n", + "import torch.nn.functional as F\n", + "import torch.optim as optim" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "43e25fe3", + "metadata": {}, + "outputs": [], + "source": [ + "\"\"\"\n", + "MobileNetV2 model\n", + "\"\"\"\n", + "\n", + "class Net(nn.Module):\n", + " def __init__(self):\n", + " super(Net, self).__init__()\n", + " conv_kwargs = {'kernel_size': 3, 'stride': 1, 'padding': 1}\n", + " self.conv1 = nn.Conv2d(3, 16, **conv_kwargs)\n", + " self.conv2 = nn.Conv2d(16, 32, **conv_kwargs)\n", + " self.conv3 = nn.Conv2d(32, 64, **conv_kwargs)\n", + " self.conv4 = nn.Conv2d(64, 128, **conv_kwargs)\n", + " self.conv5 = nn.Conv2d(128 + 32, 256, **conv_kwargs)\n", + " self.conv6 = nn.Conv2d(256, 512, **conv_kwargs)\n", + " self.conv7 = nn.Conv2d(512 + 128 + 32, 256, **conv_kwargs)\n", + " self.conv8 = nn.Conv2d(256, 512, **conv_kwargs)\n", + " self.fc1 = nn.Linear(1184 * 9 * 9, 128)\n", + " self.fc2 = nn.Linear(128, 8)\n", + "\n", + "\n", + " def forward(self, x):\n", + " x = F.relu(self.conv1(x))\n", + " x = F.relu(self.conv2(x))\n", + " maxpool = F.max_pool2d(x, 2, 2)\n", + "\n", + " x = F.relu(self.conv3(maxpool))\n", + " x = F.relu(self.conv4(x))\n", + " concat = torch.cat([maxpool, x], dim=1)\n", + " maxpool = F.max_pool2d(concat, 2, 2)\n", + "\n", + " x = F.relu(self.conv5(maxpool))\n", + " x = F.relu(self.conv6(x))\n", + " concat = torch.cat([maxpool, x], dim=1)\n", + " maxpool = F.max_pool2d(concat, 2, 2)\n", + "\n", + " x = F.relu(self.conv7(maxpool))\n", + " x = F.relu(self.conv8(x))\n", + " concat = torch.cat([maxpool, x], dim=1)\n", + " maxpool = F.max_pool2d(concat, 2, 2)\n", + "\n", + " x = maxpool.flatten(start_dim=1)\n", + " x = F.dropout(self.fc1(x), p=0.5)\n", + " x = self.fc2(x)\n", + " return x\n", + "\n", + "model_net = Net()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d279b4fb", + "metadata": {}, + "outputs": [], + "source": [ + "optimizer_adam = optim.Adam(model_net.parameters(), lr=1e-4)" + ] + }, + { + "cell_type": "markdown", + "id": "f097cdc5", + "metadata": {}, + "source": [ + "### Register model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "06a8cca8", + "metadata": {}, + "outputs": [], + "source": [ + "from copy import deepcopy\n", + "\n", + "framework_adapter = 'openfl.plugins.frameworks_adapters.pytorch_adapter.FrameworkAdapterPlugin'\n", + "model_interface = ModelInterface(model=model_net, optimizer=optimizer_adam, framework_plugin=framework_adapter)\n", + "\n", + "# Save the initial model state\n", + "initial_model = deepcopy(model_net)" + ] + }, + { + "cell_type": "markdown", + "id": "849c165b", + "metadata": {}, + "source": [ + "## Define and register FL tasks" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "b9649385", + "metadata": {}, + "outputs": [], + "source": [ + "task_interface = TaskInterface()\n", + "import torch\n", + "\n", + "import tqdm\n", + "\n", + "# The Interactive API supports registering functions definied in main module or imported.\n", + "def function_defined_in_notebook(some_parameter):\n", + " print(f'Also I accept a parameter and it is {some_parameter}')\n", + "\n", + "# Task interface currently supports only standalone functions.\n", + "@task_interface.add_kwargs(**{'some_parameter': 42})\n", + "@task_interface.register_fl_task(model='net_model', data_loader='train_loader', \\\n", + " device='device', optimizer='optimizer') \n", + "def train(net_model, train_loader, optimizer, device, loss_fn=F.cross_entropy, some_parameter=None):\n", + " device = torch.device('cuda')\n", + " if not torch.cuda.is_available():\n", + " device = 'cpu'\n", + " \n", + " function_defined_in_notebook(some_parameter)\n", + " \n", + " train_loader = tqdm.tqdm(train_loader, desc=\"train\")\n", + " net_model.train()\n", + " net_model.to(device)\n", + "\n", + " losses = []\n", + "\n", + " for data, target in train_loader:\n", + " data, target = torch.tensor(data).to(device), torch.tensor(\n", + " target).to(device) \n", + " optimizer.zero_grad()\n", + " output = net_model(data)\n", + " loss = loss_fn(output, target)\n", + " loss.backward()\n", + " optimizer.step()\n", + " losses.append(loss.detach().cpu().numpy())\n", + " \n", + " return {'train_loss': np.mean(losses),}\n", + "\n", + "\n", + "@task_interface.register_fl_task(model='net_model', data_loader='val_loader', device='device') \n", + "def validate(net_model, val_loader, device):\n", + " device = torch.device('cuda')\n", + " if not torch.cuda.is_available():\n", + " device = 'cpu'\n", + " net_model.eval()\n", + " net_model.to(device)\n", + " \n", + " val_loader = tqdm.tqdm(val_loader, desc=\"validate\")\n", + " val_score = 0\n", + " total_samples = 0\n", + "\n", + " with torch.no_grad():\n", + " for data, target in val_loader:\n", + " samples = target.shape[0]\n", + " total_samples += samples\n", + " data, target = torch.tensor(data).to(device), \\\n", + " torch.tensor(target).to(device)\n", + " output = net_model(data)\n", + " pred = output.argmax(dim=1)\n", + " val_score += pred.eq(target).sum().cpu().numpy()\n", + " \n", + " return {'acc': val_score / total_samples,}" + ] + }, + { + "cell_type": "markdown", + "id": "8f0ebf2d", + "metadata": {}, + "source": [ + "## Time to start a federated learning experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d41b7896", + "metadata": {}, + "outputs": [], + "source": [ + "# create an experimnet in federation\n", + "experiment_name = 'histology_test_experiment'\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "41b44de9", + "metadata": {}, + "outputs": [], + "source": [ + "# The following command zips the workspace and python requirements to be transfered to collaborator nodes\n", + "fl_experiment.start(\n", + " model_provider=model_interface, \n", + " task_keeper=task_interface,\n", + " data_loader=fed_dataset,\n", + " rounds_to_train=5,\n", + " opt_treatment='CONTINUE_GLOBAL'\n", + ")" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "f3efc78f-57cd-42e0-9398-bdebd596fac5", + "metadata": {}, + "outputs": [], + "source": [ + "# Get status of the current experiment\n", + "fl_experiment.get_experiment_status()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "acting-immunology", + "metadata": {}, + "outputs": [], + "source": [ + "# If user want to stop IPython session, then reconnect and check how experiment is going\n", + "# fl_experiment.restore_experiment_state(model_interface)\n", + "\n", + "fl_experiment.stream_metrics(tensorboard_logs=False)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "432afab5-c44b-440a-9d54-1611fb48cf03", + "metadata": {}, + "outputs": [], + "source": [] + } + ], + "metadata": { + "kernelspec": { + "display_name": "Python 3 (ipykernel)", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.13" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/aggregation_function_obj.pkl b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/aggregation_function_obj.pkl new file mode 100644 index 0000000..87a5269 Binary files /dev/null and b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/aggregation_function_obj.pkl differ diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/loader_obj.pkl b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/loader_obj.pkl new file mode 100644 index 0000000..95efaf4 Binary files /dev/null and b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/loader_obj.pkl differ diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/model_obj.pkl b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/model_obj.pkl new file mode 100644 index 0000000..3b1394f Binary files /dev/null and b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/model_obj.pkl differ diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/pytorch_histology.ipynb b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/pytorch_histology.ipynb new file mode 100644 index 0000000..cf0eb46 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/pytorch_histology.ipynb @@ -0,0 +1,531 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "26fdd9ed", + "metadata": {}, + "source": [ + "# Federated PyTorch Histology Tutorial" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "895288d0", + "metadata": {}, + "outputs": [], + "source": [ + "!pip install torchvision==0.8.2" + ] + }, + { + "cell_type": "markdown", + "id": "246f9c98", + "metadata": {}, + "source": [ + "## Connect to the Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d657e463", + "metadata": {}, + "outputs": [], + "source": [ + "# Create a federation\n", + "from openfl.interface.interactive_api.federation import Federation\n", + "\n", + "# please use the same identificator that was used in signed certificate\n", + "client_id = 'api'\n", + "cert_dir = 'cert'\n", + "director_node_fqdn = 'localhost'\n", + "# 1) Run with API layer - Director mTLS \n", + "# If the user wants to enable mTLS their must provide CA root chain, and signed key pair to the federation interface\n", + "# cert_chain = f'{cert_dir}/root_ca.crt'\n", + "# api_certificate = f'{cert_dir}/{client_id}.crt'\n", + "# api_private_key = f'{cert_dir}/{client_id}.key'\n", + "\n", + "# federation = Federation(client_id=client_id, director_node_fqdn=director_node_fqdn, director_port='50051',\n", + "# cert_chain=cert_chain, api_cert=api_certificate, api_private_key=api_private_key)\n", + "\n", + "# --------------------------------------------------------------------------------------------------------------------\n", + "\n", + "# 2) Run with TLS disabled (trusted environment)\n", + "# Federation can also determine local fqdn automatically\n", + "federation = Federation(client_id=client_id, director_node_fqdn=director_node_fqdn, director_port='50051', tls=False)\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "1abebd90", + "metadata": {}, + "outputs": [], + "source": [ + "federation.target_shape" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "47dcfab3", + "metadata": {}, + "outputs": [], + "source": [ + "shard_registry = federation.get_shard_registry()\n", + "shard_registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "a2a6c237", + "metadata": {}, + "outputs": [], + "source": [ + "# First, request a dummy_shard_desc that holds information about the federated dataset \n", + "dummy_shard_desc = federation.get_dummy_shard_descriptor(size=10)\n", + "sample, target = dummy_shard_desc.get_dataset('train')[0]" + ] + }, + { + "cell_type": "markdown", + "id": "cc0dbdbd", + "metadata": {}, + "source": [ + "## Creating a FL experiment using Interactive API" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "fc88700a", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment" + ] + }, + { + "cell_type": "markdown", + "id": "b0979470", + "metadata": {}, + "source": [ + "### Register dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "7dda1680", + "metadata": {}, + "outputs": [], + "source": [ + "import torchvision\n", + "from torchvision import transforms as T\n", + "\n", + "normalize = T.Normalize(mean=[0.485, 0.456, 0.406],\n", + " std=[0.229, 0.224, 0.225])\n", + "\n", + "augmentation = T.RandomApply(\n", + " [T.RandomHorizontalFlip(),\n", + " T.RandomRotation(10),\n", + " T.RandomResizedCrop(64)], \n", + " p=.8\n", + ")\n", + "\n", + "training_transform = T.ToTensor()\n", + "\n", + "valid_transform = T.ToTensor()\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "0314d5bf", + "metadata": {}, + "outputs": [], + "source": [ + "from torch.utils.data import Dataset\n", + "\n", + "\n", + "class TransformedDataset(Dataset):\n", + " \"\"\"Image Person ReID Dataset.\"\"\"\n", + "\n", + " def __init__(self, dataset, transform=None, target_transform=None):\n", + " \"\"\"Initialize Dataset.\"\"\"\n", + " self.dataset = dataset\n", + " self.transform = transform\n", + " self.target_transform = target_transform\n", + "\n", + " def __len__(self):\n", + " \"\"\"Length of dataset.\"\"\"\n", + " return len(self.dataset)\n", + "\n", + " def __getitem__(self, index):\n", + " img, label = self.dataset[index]\n", + " label = self.target_transform(label) if self.target_transform else label\n", + " img = self.transform(img) if self.transform else img\n", + " return img, label\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "01369e3b", + "metadata": {}, + "outputs": [], + "source": [ + "class HistologyDataset(DataInterface):\n", + " def __init__(self, **kwargs):\n", + " self.kwargs = kwargs\n", + " \n", + " @property\n", + " def shard_descriptor(self):\n", + " return self._shard_descriptor\n", + " \n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + "\n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + " \n", + " self.train_set = TransformedDataset(\n", + " self._shard_descriptor.get_dataset('train'),\n", + " transform=training_transform\n", + " )\n", + " self.valid_set = TransformedDataset(\n", + " self._shard_descriptor.get_dataset('val'),\n", + " transform=valid_transform\n", + " )\n", + " \n", + " def get_train_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks with optimizer in contract\n", + " \"\"\"\n", + " return DataLoader(\n", + " self.train_set, num_workers=8, batch_size=self.kwargs['train_bs'], shuffle=True\n", + " )\n", + "\n", + " def get_valid_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks without optimizer in contract\n", + " \"\"\"\n", + " return DataLoader(self.valid_set, num_workers=8, batch_size=self.kwargs['valid_bs'])\n", + "\n", + " def get_train_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.train_set)\n", + "\n", + " def get_valid_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.valid_set)\n", + " " + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4a6cedef", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = HistologyDataset(train_bs=64, valid_bs=64)" + ] + }, + { + "cell_type": "markdown", + "id": "74cac654", + "metadata": {}, + "source": [ + "### Describe the model and optimizer" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4949e16d", + "metadata": {}, + "outputs": [], + "source": [ + "import os\n", + "import glob\n", + "from torch.utils.data import Dataset, DataLoader\n", + "from PIL import Image\n", + "\n", + "import numpy as np\n", + "import torch\n", + "import torch.nn as nn\n", + "import torch.nn.functional as F\n", + "import torch.optim as optim" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "43e25fe3", + "metadata": {}, + "outputs": [], + "source": [ + "\"\"\"\n", + "MobileNetV2 model\n", + "\"\"\"\n", + "\n", + "class Net(nn.Module):\n", + " def __init__(self):\n", + " super(Net, self).__init__()\n", + " conv_kwargs = {'kernel_size': 3, 'stride': 1, 'padding': 1}\n", + " self.conv1 = nn.Conv2d(3, 16, **conv_kwargs)\n", + " self.conv2 = nn.Conv2d(16, 32, **conv_kwargs)\n", + " self.conv3 = nn.Conv2d(32, 64, **conv_kwargs)\n", + " self.conv4 = nn.Conv2d(64, 128, **conv_kwargs)\n", + " self.conv5 = nn.Conv2d(128 + 32, 256, **conv_kwargs)\n", + " self.conv6 = nn.Conv2d(256, 512, **conv_kwargs)\n", + " self.conv7 = nn.Conv2d(512 + 128 + 32, 256, **conv_kwargs)\n", + " self.conv8 = nn.Conv2d(256, 512, **conv_kwargs)\n", + " self.fc1 = nn.Linear(1184 * 9 * 9, 128)\n", + " self.fc2 = nn.Linear(128, 8)\n", + "\n", + "\n", + " def forward(self, x):\n", + " x = F.relu(self.conv1(x))\n", + " x = F.relu(self.conv2(x))\n", + " maxpool = F.max_pool2d(x, 2, 2)\n", + "\n", + " x = F.relu(self.conv3(maxpool))\n", + " x = F.relu(self.conv4(x))\n", + " concat = torch.cat([maxpool, x], dim=1)\n", + " maxpool = F.max_pool2d(concat, 2, 2)\n", + "\n", + " x = F.relu(self.conv5(maxpool))\n", + " x = F.relu(self.conv6(x))\n", + " concat = torch.cat([maxpool, x], dim=1)\n", + " maxpool = F.max_pool2d(concat, 2, 2)\n", + "\n", + " x = F.relu(self.conv7(maxpool))\n", + " x = F.relu(self.conv8(x))\n", + " concat = torch.cat([maxpool, x], dim=1)\n", + " maxpool = F.max_pool2d(concat, 2, 2)\n", + "\n", + " x = maxpool.flatten(start_dim=1)\n", + " x = F.dropout(self.fc1(x), p=0.5)\n", + " x = self.fc2(x)\n", + " return x\n", + "\n", + "model_net = Net()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d279b4fb", + "metadata": {}, + "outputs": [], + "source": [ + "optimizer_adam = optim.Adam(model_net.parameters(), lr=1e-4)" + ] + }, + { + "cell_type": "markdown", + "id": "f097cdc5", + "metadata": {}, + "source": [ + "### Register model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "06a8cca8", + "metadata": {}, + "outputs": [], + "source": [ + "from copy import deepcopy\n", + "\n", + "framework_adapter = 'openfl.plugins.frameworks_adapters.pytorch_adapter.FrameworkAdapterPlugin'\n", + "model_interface = ModelInterface(model=model_net, optimizer=optimizer_adam, framework_plugin=framework_adapter)\n", + "\n", + "# Save the initial model state\n", + "initial_model = deepcopy(model_net)" + ] + }, + { + "cell_type": "markdown", + "id": "849c165b", + "metadata": {}, + "source": [ + "## Define and register FL tasks" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "b9649385", + "metadata": {}, + "outputs": [], + "source": [ + "task_interface = TaskInterface()\n", + "import torch\n", + "\n", + "import tqdm\n", + "\n", + "# The Interactive API supports registering functions definied in main module or imported.\n", + "def function_defined_in_notebook(some_parameter):\n", + " print(f'Also I accept a parameter and it is {some_parameter}')\n", + "\n", + "# Task interface currently supports only standalone functions.\n", + "@task_interface.add_kwargs(**{'some_parameter': 42})\n", + "@task_interface.register_fl_task(model='net_model', data_loader='train_loader', \\\n", + " device='device', optimizer='optimizer') \n", + "def train(net_model, train_loader, optimizer, device, loss_fn=F.cross_entropy, some_parameter=None):\n", + " device = torch.device('cuda')\n", + " if not torch.cuda.is_available():\n", + " device = 'cpu'\n", + " \n", + " function_defined_in_notebook(some_parameter)\n", + " \n", + " train_loader = tqdm.tqdm(train_loader, desc=\"train\")\n", + " net_model.train()\n", + " net_model.to(device)\n", + "\n", + " losses = []\n", + "\n", + " for data, target in train_loader:\n", + " data, target = torch.tensor(data).to(device), torch.tensor(\n", + " target).to(device) \n", + " optimizer.zero_grad()\n", + " output = net_model(data)\n", + " loss = loss_fn(output, target)\n", + " loss.backward()\n", + " optimizer.step()\n", + " losses.append(loss.detach().cpu().numpy())\n", + " \n", + " return {'train_loss': np.mean(losses),}\n", + "\n", + "\n", + "@task_interface.register_fl_task(model='net_model', data_loader='val_loader', device='device') \n", + "def validate(net_model, val_loader, device):\n", + " device = torch.device('cuda')\n", + " if not torch.cuda.is_available():\n", + " device = 'cpu'\n", + " net_model.eval()\n", + " net_model.to(device)\n", + " \n", + " val_loader = tqdm.tqdm(val_loader, desc=\"validate\")\n", + " val_score = 0\n", + " total_samples = 0\n", + "\n", + " with torch.no_grad():\n", + " for data, target in val_loader:\n", + " samples = target.shape[0]\n", + " total_samples += samples\n", + " data, target = torch.tensor(data).to(device), \\\n", + " torch.tensor(target).to(device)\n", + " output = net_model(data)\n", + " pred = output.argmax(dim=1)\n", + " val_score += pred.eq(target).sum().cpu().numpy()\n", + " \n", + " return {'acc': val_score / total_samples,}" + ] + }, + { + "cell_type": "markdown", + "id": "8f0ebf2d", + "metadata": {}, + "source": [ + "## Time to start a federated learning experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d41b7896", + "metadata": {}, + "outputs": [], + "source": [ + "# create an experimnet in federation\n", + "experiment_name = 'histology_test_experiment'\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "41b44de9", + "metadata": {}, + "outputs": [], + "source": [ + "# The following command zips the workspace and python requirements to be transfered to collaborator nodes\n", + "fl_experiment.start(\n", + " model_provider=model_interface, \n", + " task_keeper=task_interface,\n", + " data_loader=fed_dataset,\n", + " rounds_to_train=5,\n", + " opt_treatment='CONTINUE_GLOBAL'\n", + ")" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "f3efc78f-57cd-42e0-9398-bdebd596fac5", + "metadata": {}, + "outputs": [], + "source": [ + "# Get status of the current experiment\n", + "fl_experiment.get_experiment_status()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "acting-immunology", + "metadata": {}, + "outputs": [], + "source": [ + "# If user want to stop IPython session, then reconnect and check how experiment is going\n", + "# fl_experiment.restore_experiment_state(model_interface)\n", + "\n", + "fl_experiment.stream_metrics(tensorboard_logs=False)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "432afab5-c44b-440a-9d54-1611fb48cf03", + "metadata": {}, + "outputs": [], + "source": [] + } + ], + "metadata": { + "kernelspec": { + "display_name": "Python 3 (ipykernel)", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.13" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/task_assigner_obj.pkl b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/task_assigner_obj.pkl new file mode 100644 index 0000000..1c3589d Binary files /dev/null and b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/task_assigner_obj.pkl differ diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/tasks_obj.pkl b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/tasks_obj.pkl new file mode 100644 index 0000000..e51e5c1 Binary files /dev/null and b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology/workspace/tasks_obj.pkl differ diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/README.md b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/README.md new file mode 100644 index 0000000..1f3058e --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/README.md @@ -0,0 +1,28 @@ +# PyTorch tutorial for FedCurv Federated Learning method on Histology dataset + +To show results on non-iid data distribution, this tutorial contains shard descriptor with custom data splitter where data is split log-normally. Federation consists of 8 envoys. + +Your Python environment must have OpenFL installed. + +1. Run Director instance: +``` +cd director +bash start_director.sh +``` + +2. In a separate terminal, execute: +``` +cd envoy +bash populate_envoys.sh # This creates all envoys folders in current directory +bash start_envoys.sh # This launches all envoy instances +``` + +3. In a separate terminal, launch a Jupyter Lab: +``` +cd workspace +jupyter lab +``` + +4. Open your browser at corresponding port and open `pytorch_histology.ipynb` from Jupyter web interface. + +5. Execute all cells in order. diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/director/director_config.yaml new file mode 100644 index 0000000..14f3868 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/director/director_config.yaml @@ -0,0 +1,5 @@ +settings: + listen_host: localhost + listen_port: 50051 + sample_shape: ['150', '150'] + target_shape: ['1'] diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/director/start_director.sh new file mode 100755 index 0000000..5806a6c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/director/start_director.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx director start --disable-tls -c director_config.yaml \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/director/start_director_with_tls.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/director/start_director_with_tls.sh new file mode 100755 index 0000000..5d6d46a --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/director/start_director_with_tls.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e +FQDN=$1 +fx director start -c director_config.yaml -rc cert/root_ca.crt -pk cert/"${FQDN}".key -oc cert/"${FQDN}".crt \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/.gitignore b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/.gitignore new file mode 100644 index 0000000..ad818ec --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/.gitignore @@ -0,0 +1 @@ +histology_data \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/envoy_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/envoy_config.yaml new file mode 100644 index 0000000..24dee18 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/envoy_config.yaml @@ -0,0 +1,10 @@ +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: histology_shard_descriptor.HistologyShardDescriptor + params: + data_folder: histology_data + rank_worldsize: 1,8 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/histology_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/histology_shard_descriptor.py new file mode 100644 index 0000000..7e73f0e --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/histology_shard_descriptor.py @@ -0,0 +1,138 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""Histology Shard Descriptor.""" + +import logging +import os +from pathlib import Path +from typing import Tuple +from urllib.request import urlretrieve +from zipfile import ZipFile + +import numpy as np +from PIL import Image + +from openfl.interface.interactive_api.shard_descriptor import ShardDataset +from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor +from openfl.utilities import tqdm_report_hook +from openfl.utilities import validate_file_hash +from openfl.utilities.data_splitters.numpy import LogNormalNumPyDataSplitter + + +logger = logging.getLogger(__name__) + + +class HistologyShardDataset(ShardDataset): + """Histology shard dataset class.""" + + TRAIN_SPLIT_RATIO = 0.8 + + def __init__(self, data_folder: Path, data_type='train', rank=1, worldsize=1): + """Histology shard dataset class.""" + self.data_type = data_type + root = Path(data_folder) / 'Kather_texture_2016_image_tiles_5000' + classes = [d.name for d in root.iterdir() if d.is_dir()] + class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)} + self.samples = [] + root = root.absolute() + for target_class in sorted(class_to_idx.keys()): + class_index = class_to_idx[target_class] + target_dir = root / target_class + for path in sorted(target_dir.glob('*')): + item = path, class_index + self.samples.append(item) + np.random.seed(0) + np.random.shuffle(self.samples) + idx_range = list(range(len(self.samples))) + idx_sep = int(len(idx_range) * HistologyShardDataset.TRAIN_SPLIT_RATIO) + train_idx, test_idx = np.split(idx_range, [idx_sep]) + data_splitter = LogNormalNumPyDataSplitter( + mu=0, + sigma=2, + num_classes=8, + classes_per_col=2, + min_samples_per_class=5) + if data_type == 'train': + labels = np.array(self.samples)[train_idx][:, 1].astype(int) + self.idx = data_splitter.split(labels, worldsize)[rank - 1] + else: + labels = np.array(self.samples)[test_idx][:, 1].astype(int) + self.idx = data_splitter.split(labels, worldsize)[rank - 1] + + def __len__(self) -> int: + """Return the len of the shard dataset.""" + return len(self.idx) + + def load_pil(self, path): + """Load image.""" + with open(path, 'rb') as f: + img = Image.open(f) + return img.convert('RGB') + + def __getitem__(self, index: int) -> Tuple['Image', int]: + """Return an item by the index.""" + path, target = self.samples[self.idx[index]] + sample = self.load_pil(path) + return sample, target + + +class HistologyShardDescriptor(ShardDescriptor): + """Shard descriptor class.""" + + URL = ('https://zenodo.org/record/53169/files/Kather_' + 'texture_2016_image_tiles_5000.zip?download=1') + FILENAME = 'Kather_texture_2016_image_tiles_5000.zip' + ZIP_SHA384 = ('7d86abe1d04e68b77c055820c2a4c582a1d25d2983e38ab724e' + 'ac75affce8b7cb2cbf5ba68848dcfd9d84005d87d6790') + DEFAULT_PATH = Path('.') / 'data' + + def __init__( + self, + data_folder: Path = DEFAULT_PATH, + rank_worldsize: str = '1,1', + **kwargs + ): + """Initialize HistologyShardDescriptor.""" + self.data_folder = Path.cwd() / data_folder + self.download_data() + self.rank, self.worldsize = tuple(int(num) for num in rank_worldsize.split(',')) + + def download_data(self): + """Download prepared shard dataset.""" + os.makedirs(self.data_folder, exist_ok=True) + filepath = self.data_folder / HistologyShardDescriptor.FILENAME + if not filepath.exists(): + reporthook = tqdm_report_hook() + urlretrieve(HistologyShardDescriptor.URL, filepath, reporthook) # nosec + validate_file_hash(filepath, HistologyShardDescriptor.ZIP_SHA384) + with ZipFile(filepath, 'r') as f: + f.extractall(self.data_folder) + + def get_dataset(self, dataset_type): + """Return a shard dataset by type.""" + return HistologyShardDataset( + data_folder=self.data_folder, + data_type=dataset_type, + rank=self.rank, + worldsize=self.worldsize + ) + + @property + def sample_shape(self): + """Return the sample shape info.""" + shape = self.get_dataset('train')[0][0].size + return [str(dim) for dim in shape] + + @property + def target_shape(self): + """Return the target shape info.""" + target = self.get_dataset('train')[0][1] + shape = np.array([target]).shape + return [str(dim) for dim in shape] + + @property + def dataset_description(self) -> str: + """Return the shard dataset description.""" + return (f'Histology dataset, shard number {self.rank}' + f' out of {self.worldsize}') diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/populate_envoys.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/populate_envoys.sh new file mode 100644 index 0000000..f3e4619 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/populate_envoys.sh @@ -0,0 +1,26 @@ +#!/bin/bash +DIRECTOR_HOST=${1:-'localhost'} +DIRECTOR_PORT=${2:-'50051'} +PYTHON=${3:-'python3.8'} + +for i in {1..8} +do + mkdir $i + cd $i + echo "shard_descriptor: + template: histology_shard_descriptor.HistologyShardDescriptor + params: + data_folder: histology_data + rank_worldsize: $i,8 +" > envoy_config.yaml + + eval ${PYTHON} '-m venv venv' + echo "source venv/bin/activate + pip install ../../../../.. # install OpenFL + pip install -r requirements.txt + fx envoy start -n env_$i --disable-tls --envoy-config-path envoy_config.yaml -dh ${DIRECTOR_HOST} -dp ${DIRECTOR_PORT} + " > start_envoy.sh + cp ../requirements.txt . + cp ../histology_shard_descriptor.py . + cd .. +done diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/requirements.txt b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/requirements.txt new file mode 100644 index 0000000..069a960 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/requirements.txt @@ -0,0 +1,3 @@ +numpy==1.22.2 +Pillow==10.3.0 +tqdm==4.66.3 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/start_envoy.sh new file mode 100755 index 0000000..1dfda52 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/start_envoy.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx envoy start -n env_one --disable-tls --envoy-config-path envoy_config.yaml -dh localhost -dp 50051 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/start_envoy_with_tls.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/start_envoy_with_tls.sh new file mode 100755 index 0000000..06b2916 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/start_envoy_with_tls.sh @@ -0,0 +1,6 @@ +#!/bin/bash +set -e +ENVOY_NAME=$1 +DIRECTOR_FQDN=$2 + +fx envoy start -n "$ENVOY_NAME" --envoy-config-path envoy_config.yaml -dh "$DIRECTOR_FQDN" -dp 50051 -rc cert/root_ca.crt -pk cert/"$ENVOY_NAME".key -oc cert/"$ENVOY_NAME".crt \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/start_envoys.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/start_envoys.sh new file mode 100644 index 0000000..db52671 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/envoy/start_envoys.sh @@ -0,0 +1,11 @@ +#!/bin/bash +set -e + +cd 1 && bash start_envoy.sh & +cd 2 && bash start_envoy.sh & +cd 3 && bash start_envoy.sh & +cd 4 && bash start_envoy.sh & +cd 5 && bash start_envoy.sh & +cd 6 && bash start_envoy.sh & +cd 7 && bash start_envoy.sh & +cd 8 && bash start_envoy.sh diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/workspace/.gitignore b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/workspace/.gitignore new file mode 100644 index 0000000..98d8a5a --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/workspace/.gitignore @@ -0,0 +1 @@ +logs diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/workspace/pytorch_histology.ipynb b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/workspace/pytorch_histology.ipynb new file mode 100644 index 0000000..4a014c9 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Histology_FedCurv/workspace/pytorch_histology.ipynb @@ -0,0 +1,521 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "26fdd9ed", + "metadata": {}, + "source": [ + "# Federated PyTorch Histology Tutorial" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "895288d0", + "metadata": {}, + "outputs": [], + "source": [ + "!pip install torchvision==0.10.0" + ] + }, + { + "cell_type": "markdown", + "id": "246f9c98", + "metadata": {}, + "source": [ + "## Connect to the Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d657e463", + "metadata": {}, + "outputs": [], + "source": [ + "# Create a federation\n", + "from openfl.interface.interactive_api.federation import Federation\n", + "\n", + "# please use the same identificator that was used in signed certificate\n", + "client_id = 'api'\n", + "cert_dir = 'cert'\n", + "director_node_fqdn = 'localhost'\n", + "# 1) Run with API layer - Director mTLS \n", + "# If the user wants to enable mTLS their must provide CA root chain, and signed key pair to the federation interface\n", + "# cert_chain = f'{cert_dir}/root_ca.crt'\n", + "# api_certificate = f'{cert_dir}/{client_id}.crt'\n", + "# api_private_key = f'{cert_dir}/{client_id}.key'\n", + "\n", + "# federation = Federation(client_id=client_id, director_node_fqdn=director_node_fqdn, director_port='50051',\n", + "# cert_chain=cert_chain, api_cert=api_certificate, api_private_key=api_private_key)\n", + "\n", + "# --------------------------------------------------------------------------------------------------------------------\n", + "\n", + "# 2) Run with TLS disabled (trusted environment)\n", + "# Federation can also determine local fqdn automatically\n", + "federation = Federation(client_id=client_id, director_node_fqdn=director_node_fqdn, director_port='50051', tls=False)\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "1abebd90", + "metadata": {}, + "outputs": [], + "source": [ + "federation.target_shape" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "47dcfab3", + "metadata": {}, + "outputs": [], + "source": [ + "shard_registry = federation.get_shard_registry()\n", + "shard_registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "a2a6c237", + "metadata": {}, + "outputs": [], + "source": [ + "# First, request a dummy_shard_desc that holds information about the federated dataset \n", + "dummy_shard_desc = federation.get_dummy_shard_descriptor(size=10)\n", + "sample, target = dummy_shard_desc.get_dataset('train')[0]" + ] + }, + { + "cell_type": "markdown", + "id": "cc0dbdbd", + "metadata": {}, + "source": [ + "## Creating a FL experiment using Interactive API" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "fc88700a", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment" + ] + }, + { + "cell_type": "markdown", + "id": "b0979470", + "metadata": {}, + "source": [ + "### Register dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "7dda1680", + "metadata": {}, + "outputs": [], + "source": [ + "import torchvision\n", + "from torchvision import transforms as T\n", + "\n", + "normalize = T.Normalize(mean=[0.485, 0.456, 0.406],\n", + " std=[0.229, 0.224, 0.225])\n", + "\n", + "augmentation = T.RandomApply(\n", + " [T.RandomHorizontalFlip(),\n", + " T.RandomRotation(10),\n", + " T.RandomResizedCrop(64)], \n", + " p=.8\n", + ")\n", + "\n", + "training_transform = T.ToTensor()\n", + "\n", + "valid_transform = T.ToTensor()\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "0314d5bf", + "metadata": {}, + "outputs": [], + "source": [ + "from torch.utils.data import Dataset\n", + "\n", + "\n", + "class TransformedDataset(Dataset):\n", + " \"\"\"Image Person ReID Dataset.\"\"\"\n", + "\n", + " def __init__(self, dataset, transform=None, target_transform=None):\n", + " \"\"\"Initialize Dataset.\"\"\"\n", + " self.dataset = dataset\n", + " self.transform = transform\n", + " self.target_transform = target_transform\n", + "\n", + " def __len__(self):\n", + " \"\"\"Length of dataset.\"\"\"\n", + " return len(self.dataset)\n", + "\n", + " def __getitem__(self, index):\n", + " img, label = self.dataset[index]\n", + " label = self.target_transform(label) if self.target_transform else label\n", + " img = self.transform(img) if self.transform else img\n", + " return img, label\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "01369e3b", + "metadata": {}, + "outputs": [], + "source": [ + "class HistologyDataset(DataInterface):\n", + " def __init__(self, **kwargs):\n", + " self.kwargs = kwargs\n", + " \n", + " @property\n", + " def shard_descriptor(self):\n", + " return self._shard_descriptor\n", + " \n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + "\n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + " \n", + " self.train_set = TransformedDataset(\n", + " self._shard_descriptor.get_dataset('train'),\n", + " transform=training_transform\n", + " )\n", + " self.valid_set = TransformedDataset(\n", + " self._shard_descriptor.get_dataset('val'),\n", + " transform=valid_transform\n", + " )\n", + " \n", + " def get_train_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks with optimizer in contract\n", + " \"\"\"\n", + " return DataLoader(\n", + " self.train_set, num_workers=8, batch_size=self.kwargs['train_bs'], shuffle=True\n", + " )\n", + "\n", + " def get_valid_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks without optimizer in contract\n", + " \"\"\"\n", + " return DataLoader(self.valid_set, num_workers=8, batch_size=self.kwargs['valid_bs'])\n", + "\n", + " def get_train_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.train_set)\n", + "\n", + " def get_valid_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.valid_set)\n", + " " + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4a6cedef", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = HistologyDataset(train_bs=64, valid_bs=64)" + ] + }, + { + "cell_type": "markdown", + "id": "74cac654", + "metadata": {}, + "source": [ + "### Describe the model and optimizer" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4949e16d", + "metadata": {}, + "outputs": [], + "source": [ + "import os\n", + "import glob\n", + "from torch.utils.data import Dataset, DataLoader\n", + "from PIL import Image\n", + "\n", + "import numpy as np\n", + "import torch\n", + "import torch.nn as nn\n", + "import torch.nn.functional as F\n", + "import torch.optim as optim" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d6158e87", + "metadata": {}, + "outputs": [], + "source": [ + "np.random.seed(0)\n", + "torch.manual_seed(0)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "43e25fe3", + "metadata": {}, + "outputs": [], + "source": [ + "\"\"\"\n", + "MobileNetV2 model\n", + "\"\"\"\n", + "\n", + "class Net(nn.Module):\n", + " def __init__(self):\n", + " super(Net, self).__init__()\n", + " conv_kwargs = {'kernel_size': 3, 'stride': 1, 'padding': 1}\n", + " self.conv1 = nn.Conv2d(3, 16, **conv_kwargs)\n", + " self.conv2 = nn.Conv2d(16, 32, **conv_kwargs)\n", + " self.conv3 = nn.Conv2d(32, 64, **conv_kwargs)\n", + " self.conv4 = nn.Conv2d(64, 128, **conv_kwargs)\n", + " self.conv5 = nn.Conv2d(128 + 32, 256, **conv_kwargs)\n", + " self.conv6 = nn.Conv2d(256, 512, **conv_kwargs)\n", + " self.conv7 = nn.Conv2d(512 + 128 + 32, 256, **conv_kwargs)\n", + " self.conv8 = nn.Conv2d(256, 512, **conv_kwargs)\n", + " self.fc1 = nn.Linear(1184 * 9 * 9, 128)\n", + " self.fc2 = nn.Linear(128, 8)\n", + "\n", + "\n", + " def forward(self, x):\n", + " torch.manual_seed(0)\n", + " x = F.relu(self.conv1(x))\n", + " x = F.relu(self.conv2(x))\n", + " maxpool = F.max_pool2d(x, 2, 2)\n", + "\n", + " x = F.relu(self.conv3(maxpool))\n", + " x = F.relu(self.conv4(x))\n", + " concat = torch.cat([maxpool, x], dim=1)\n", + " maxpool = F.max_pool2d(concat, 2, 2)\n", + "\n", + " x = F.relu(self.conv5(maxpool))\n", + " x = F.relu(self.conv6(x))\n", + " concat = torch.cat([maxpool, x], dim=1)\n", + " maxpool = F.max_pool2d(concat, 2, 2)\n", + "\n", + " x = F.relu(self.conv7(maxpool))\n", + " x = F.relu(self.conv8(x))\n", + " concat = torch.cat([maxpool, x], dim=1)\n", + " maxpool = F.max_pool2d(concat, 2, 2)\n", + "\n", + " x = maxpool.flatten(start_dim=1)\n", + " x = F.dropout(self.fc1(x), p=0.5)\n", + " x = self.fc2(x)\n", + " return x\n", + "\n", + "model_net = Net()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "79021778", + "metadata": {}, + "outputs": [], + "source": [ + "optimizer_adam = optim.Adam(model_net.parameters(), lr=1e-4)" + ] + }, + { + "cell_type": "markdown", + "id": "f097cdc5", + "metadata": {}, + "source": [ + "### Register model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "06a8cca8", + "metadata": {}, + "outputs": [], + "source": [ + "from copy import deepcopy\n", + "\n", + "framework_adapter = 'openfl.plugins.frameworks_adapters.pytorch_adapter.FrameworkAdapterPlugin'\n", + "model_interface = ModelInterface(model=model_net, optimizer=optimizer_adam, framework_plugin=framework_adapter)\n", + "\n", + "# Save the initial model state\n", + "initial_model = deepcopy(model_net)" + ] + }, + { + "cell_type": "markdown", + "id": "849c165b", + "metadata": {}, + "source": [ + "## Define and register FL tasks" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "b9649385", + "metadata": {}, + "outputs": [], + "source": [ + "task_interface = TaskInterface()\n", + "import torch\n", + "\n", + "from openfl.utilities.fedcurv.torch import FedCurv\n", + "from openfl.interface.aggregation_functions import FedCurvWeightedAverage\n", + "import tqdm\n", + "\n", + "fedcurv = FedCurv(model_interface.provide_model(), importance=1e7)\n", + "\n", + "@task_interface.register_fl_task(model='net_model', data_loader='train_loader', \\\n", + " device='device', optimizer='optimizer')\n", + "@task_interface.set_aggregation_function(FedCurvWeightedAverage())\n", + "def train(net_model, train_loader, optimizer, device, loss_fn=F.cross_entropy):\n", + " torch.manual_seed(0)\n", + " fedcurv.on_train_begin(net_model)\n", + " device = 'cpu'\n", + " \n", + " train_loader = tqdm.tqdm(train_loader, desc=\"train\")\n", + " net_model.train()\n", + " net_model.to(device)\n", + "\n", + " losses = []\n", + "\n", + " for data, target in train_loader:\n", + " data, target = torch.tensor(data).to(device), torch.tensor(\n", + " target).to(device) \n", + " optimizer.zero_grad()\n", + " output = net_model(data)\n", + " loss = loss_fn(output, target) + fedcurv.get_penalty(net_model)\n", + " loss.backward()\n", + " optimizer.step()\n", + " losses.append(loss.detach().cpu().numpy())\n", + " \n", + " fedcurv.on_train_end(net_model, train_loader, device)\n", + " \n", + " return {'train_loss': np.mean(losses),}\n", + "\n", + "\n", + "@task_interface.register_fl_task(model='net_model', data_loader='val_loader', device='device') \n", + "def validate(net_model, val_loader, device):\n", + " device = torch.device('cpu')\n", + " net_model.eval()\n", + " net_model.to(device)\n", + " \n", + " val_loader = tqdm.tqdm(val_loader, desc=\"validate\")\n", + " val_score = 0\n", + " total_samples = 0\n", + "\n", + " with torch.no_grad():\n", + " for data, target in val_loader:\n", + " samples = target.shape[0]\n", + " total_samples += samples\n", + " data, target = torch.tensor(data).to(device), \\\n", + " torch.tensor(target).to(device, dtype=torch.int64)\n", + " output = net_model(data)\n", + " pred = output.argmax(dim=1)\n", + " val_score += pred.eq(target).sum().cpu().numpy()\n", + " \n", + " return {'acc': val_score / total_samples,}" + ] + }, + { + "cell_type": "markdown", + "id": "8f0ebf2d", + "metadata": {}, + "source": [ + "## Time to start a federated learning experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d41b7896", + "metadata": {}, + "outputs": [], + "source": [ + "# create an experimnet in federation\n", + "experiment_name = f'histology_test_experiment {fedcurv.importance=}'\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "41b44de9", + "metadata": {}, + "outputs": [], + "source": [ + "# The following command zips the workspace and python requirements to be transfered to collaborator nodes\n", + "fl_experiment.start(\n", + " model_provider=model_interface, \n", + " task_keeper=task_interface,\n", + " data_loader=fed_dataset,\n", + " rounds_to_train=5,\n", + " opt_treatment='CONTINUE_GLOBAL'\n", + ")" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "acting-immunology", + "metadata": {}, + "outputs": [], + "source": [ + "# If user want to stop IPython session, then reconnect and check how experiment is going\n", + "# fl_experiment.restore_experiment_state(model_interface)\n", + "\n", + "fl_experiment.stream_metrics()" + ] + } + ], + "metadata": { + "kernelspec": { + "display_name": "Python 3 (ipykernel)", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.12" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Huggingface_transformers_SUPERB/README.md b/openfl_contrib_tutorials/interactive_api/PyTorch_Huggingface_transformers_SUPERB/README.md new file mode 100644 index 0000000..ac1c94b --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Huggingface_transformers_SUPERB/README.md @@ -0,0 +1,63 @@ +# Federated Hugging face :hugs: transformers tutorial for audio classification using PyTorch + +Transformers have been a driving point for breakthrough developments in the Audio and Speech processing domain. Recently, Hugging Face dropped the State-of-the-art Natural Language Processing library Transformers v4.30 and extended its reach to Speech Recognition by adding one of the leading Automatic Speech Recognition models by Facebook called the Wav2Vec2. + +### About model: Wav2Vec2 + +This tutorial uses [Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2#wav2vec2forsequenceclassification) model which is a speech model checkpoint from the [Model Hub](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&sort=downloads). The Wav2Vec2 model was proposed in [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) which shows that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. We will fine-tune this pretrained speech model for Automatic Speech Recognition in this tutorial. + +### About dataset: Keyword spotting (KS) from SUPERB + +Keyword spotting subset from [SUPERB](https://huggingface.co/datasets/superb) dataset is used. Keyword Spotting (KS) detects preregistered keywords by classifying utterances into a predefined set of words. The dataset consists of ten classes of keywords, a class for silence, and an unknown class to include the false positive. The evaluation metric is accuracy (ACC). + +### Links + +* [Huggingface transformers on Github](https://github.com/huggingface/transformers) +* [Original Huggingface notebook audio classification example on Github](https://github.com/huggingface/notebooks/blob/master/examples/audio_classification.ipynb) + +### How to run this tutorial (without TLS and locally as a simulation): + +Using hugging face models requires you to setup a [cache directory](https://huggingface.co/transformers/v4.0.1/installation.html#caching-models) at every node where the experiment is run, like XDG_CACHE_HOME. + +In addition to this, the Trainer class in huggingface transformers is desgined to use all available GPUs on a node. Hence, to avoid [cuda runtime error](https://forums.developer.nvidia.com/t/cuda-peer-resources-error-when-running-on-more-than-8-k80s-aws-p2-16xlarge/45351/5) on nodes that have more than 8 GPUs, setting up CUDA_VISIBLE_DEVICES limits the number of GPUs participating in the experiment. + +Go to example [folder](./) + +```sh +export PYTORCH_HUGGINGFACE_TRANSFORMERS_SUPERB=
+ +### 0. If you haven't done so already, create a virtual environment, install OpenFL, and upgrade pip: + - For help with this step, visit the "Install the Package" section of the [OpenFL installation instructions](https://openfl.readthedocs.io/en/latest/install.html#install-the-package). + +
+ +### 1. Split terminal into 3 (1 terminal for the director, 1 for the envoy, and 1 for the experiment) + +
+ +### 2. Do the following in each terminal: + - Activate the virtual environment from step 0: + + ```sh + source venv/bin/activate + ``` + - If you are in a network environment with a proxy, ensure proxy environment variables are set in each of your terminals. + - Navigate to the tutorial: + + ```sh + cd openfl/openfl-tutorials/interactive_api/PyTorch_Kvasir_UNet + ``` + +
+ +### 3. In the first terminal, run the director: + +```sh +cd director +./start_director.sh +``` + +
+ +### 4. In the second terminal, install requirements and run the envoy: + +```sh +cd envoy +pip install -r sd_requirements.txt +``` + - If you have GPUs: +```sh +./start_envoy.sh env_one envoy_config.yaml +``` + - For no GPUs, use: +```sh +./start_envoy.sh env_one envoy_config_no_gpu.yaml +``` + + +Optional: Run a second envoy in an additional terminal: + - Ensure step 2 is complete for this terminal as well. + - Repeat step 4 instructions above but change "env_one" name to "env_two" (or another name of your choice). + +
+ +### 5. Now that your director and envoy terminals are set up, run the Jupyter Notebook in your experiment terminal: + +```sh +cd workspace +jupyter lab PyTorch_Kvasir_UNet.ipynb +``` +- A Jupyter Server URL will appear in your terminal. In your browser, proceed to that link. Once the webpage loads, click on the PyTorch_Kvasir_UNet.ipynb file. +- To run the experiment, select the icon that looks like two triangles to "Restart Kernel and Run All Cells". +- You will notice activity in your terminals as the experiment runs, and when the experiment is finished the director terminal will display a message that the experiment has finished successfully. + diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/director/director_config.yaml new file mode 100644 index 0000000..860e043 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/director/director_config.yaml @@ -0,0 +1,6 @@ +settings: + listen_host: localhost + listen_port: 50050 + sample_shape: ['300', '400', '3'] + target_shape: ['300', '400'] + envoy_health_check_period: 5 # in seconds diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/director/start_director.sh new file mode 100755 index 0000000..5806a6c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/director/start_director.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx director start --disable-tls -c director_config.yaml \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/director/start_director_with_tls.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/director/start_director_with_tls.sh new file mode 100755 index 0000000..5d6d46a --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/director/start_director_with_tls.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e +FQDN=$1 +fx director start -c director_config.yaml -rc cert/root_ca.crt -pk cert/"${FQDN}".key -oc cert/"${FQDN}".crt \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/envoy_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/envoy_config.yaml new file mode 100644 index 0000000..aae095f --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/envoy_config.yaml @@ -0,0 +1,14 @@ +params: + cuda_devices: [0,2] + +optional_plugin_components: + cuda_device_monitor: + template: openfl.plugins.processing_units_monitor.pynvml_monitor.PynvmlCUDADeviceMonitor + settings: [] + +shard_descriptor: + template: kvasir_shard_descriptor.KvasirShardDescriptor + params: + data_folder: kvasir_data + rank_worldsize: 1,10 + enforce_image_hw: '300,400' diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/envoy_config_no_gpu.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/envoy_config_no_gpu.yaml new file mode 100644 index 0000000..1c121e5 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/envoy_config_no_gpu.yaml @@ -0,0 +1,12 @@ +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: kvasir_shard_descriptor.KvasirShardDescriptor + params: + data_folder: kvasir_data + rank_worldsize: 2,10 + enforce_image_hw: '300,400' + \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/kvasir_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/kvasir_shard_descriptor.py new file mode 100644 index 0000000..2a83543 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/kvasir_shard_descriptor.py @@ -0,0 +1,160 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 +"""Kvasir shard descriptor.""" + +import os +from pathlib import Path + +import numpy as np +from PIL import Image + +from openfl.interface.interactive_api.shard_descriptor import ShardDataset +from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor +from openfl.utilities import validate_file_hash + + +class KvasirShardDataset(ShardDataset): + """Kvasir Shard dataset class.""" + + def __init__(self, dataset_dir: Path, rank=1, worldsize=1, enforce_image_hw=None): + """Initialize KvasirShardDataset.""" + self.rank = rank + self.worldsize = worldsize + self.dataset_dir = dataset_dir + self.enforce_image_hw = enforce_image_hw + self.images_path = self.dataset_dir / 'segmented-images' / 'images' + self.masks_path = self.dataset_dir / 'segmented-images' / 'masks' + + self.images_names = [ + img_name + for img_name in sorted(os.listdir(self.images_path)) + if len(img_name) > 3 and img_name[-3:] == 'jpg' + ] + # Sharding + self.images_names = self.images_names[self.rank - 1::self.worldsize] + + def __getitem__(self, index): + """Return a item by the index.""" + name = self.images_names[index] + # Reading data + img = Image.open(self.images_path / name) + mask = Image.open(self.masks_path / name) + if self.enforce_image_hw is not None: + # If we need to resize data + # PIL accepts (w,h) tuple, not (h,w) + img = img.resize(self.enforce_image_hw[::-1]) + mask = mask.resize(self.enforce_image_hw[::-1]) + img = np.asarray(img) + mask = np.asarray(mask) + assert img.shape[2] == 3 + + return img, mask[:, :, 0].astype(np.uint8) + + def __len__(self): + """Return the len of the dataset.""" + return len(self.images_names) + + +class KvasirShardDescriptor(ShardDescriptor): + """Shard descriptor class.""" + + def __init__(self, data_folder: str = 'kvasir_data', + rank_worldsize: str = '1,1', + enforce_image_hw: str = None) -> None: + """Initialize KvasirShardDescriptor.""" + super().__init__() + # Settings for sharding the dataset + self.rank, self.worldsize = tuple(int(num) for num in rank_worldsize.split(',')) + + self.data_folder = Path.cwd() / data_folder + self.download_data(self.data_folder) + + # Settings for resizing data + self.enforce_image_hw = None + if enforce_image_hw is not None: + self.enforce_image_hw = tuple(int(size) for size in enforce_image_hw.split(',')) + + # Calculating data and target shapes + ds = self.get_dataset() + sample, target = ds[0] + self._sample_shape = [str(dim) for dim in sample.shape] + self._target_shape = [str(dim) for dim in target.shape] + + def get_dataset(self, dataset_type='train'): + """Return a shard dataset by type.""" + return KvasirShardDataset( + dataset_dir=self.data_folder, + rank=self.rank, + worldsize=self.worldsize, + enforce_image_hw=self.enforce_image_hw + ) + + @staticmethod + def download_data(data_folder): + """Download data.""" + zip_file_path = data_folder / 'kvasir.zip' + os.makedirs(data_folder, exist_ok=True) + os.system( + 'wget -nc' + " 'https://datasets.simula.no/downloads/" + "hyper-kvasir/hyper-kvasir-segmented-images.zip'" + f' -O {zip_file_path.relative_to(Path.cwd())}' + ) + zip_sha384 = ('66cd659d0e8afd8c83408174' + '1ade2b75dada8d4648b816f2533c8748b1658efa3d49e205415d4116faade2c5810e241e') + validate_file_hash(zip_file_path, zip_sha384) + os.system(f'unzip -n {zip_file_path.relative_to(Path.cwd())}' + f' -d {data_folder.relative_to(Path.cwd())}') + + @property + def sample_shape(self): + """Return the sample shape info.""" + return self._sample_shape + + @property + def target_shape(self): + """Return the target shape info.""" + return self._target_shape + + @property + def dataset_description(self) -> str: + """Return the dataset description.""" + return (f'Kvasir dataset, shard number {self.rank} ' + f'out of {self.worldsize}') + + +if __name__ == '__main__': + from openfl.interface.cli import setup_logging + + setup_logging() + + data_folder = 'data' + rank_worldsize = '1,100' + enforce_image_hw = '529,622' + + kvasir_sd = KvasirShardDescriptor( + data_folder, + rank_worldsize=rank_worldsize, + enforce_image_hw=enforce_image_hw) + + print(kvasir_sd.dataset_description) + print(kvasir_sd.sample_shape, kvasir_sd.target_shape) + + from openfl.component.envoy.envoy import Envoy + + shard_name = 'one' + director_host = 'localhost' + director_port = 50051 + + keeper = Envoy( + shard_name=shard_name, + director_host=director_host, + director_port=director_port, + shard_descriptor=kvasir_sd, + tls=True, + root_certificate='./cert/root_ca.crt', + private_key='./cert/one.key', + certificate='./cert/one.crt', + ) + + keeper.start() diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/kvasir_shard_descriptor_with_data_splitter.py b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/kvasir_shard_descriptor_with_data_splitter.py new file mode 100644 index 0000000..09bcde8 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/kvasir_shard_descriptor_with_data_splitter.py @@ -0,0 +1,119 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 +"""Kvasir shard descriptor.""" + + +import os +from pathlib import Path + +import numpy as np +from PIL import Image + +from openfl.interface.interactive_api.shard_descriptor import ShardDataset +from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor +from openfl.utilities import validate_file_hash +from openfl.utilities.data_splitters import RandomNumPyDataSplitter + + +class KvasirShardDataset(ShardDataset): + """Kvasir Shard dataset class.""" + + def __init__(self, dataset_dir: Path, rank=1, worldsize=1, enforce_image_hw=None): + """Initialize KvasirShardDataset.""" + self.rank = rank + self.worldsize = worldsize + self.dataset_dir = dataset_dir + self.enforce_image_hw = enforce_image_hw + + self.images_path = self.dataset_dir / 'segmented-images' / 'images' + self.masks_path = self.dataset_dir / 'segmented-images' / 'masks' + + self.images_names = [ + img_name + for img_name in sorted(os.listdir(self.images_path)) + if len(img_name) > 3 and img_name[-3:] == 'jpg' + ] + # Sharding + data_splitter = RandomNumPyDataSplitter() + shard_idx = data_splitter.split(self.images_names, self.worldsize)[self.rank] + self.images_names = [self.images_names[i] for i in shard_idx] + + def __getitem__(self, index): + """Return a item by the index.""" + name = self.images_names[index] + # Reading data + img = Image.open(self.images_path / name) + mask = Image.open(self.masks_path / name) + if self.enforce_image_hw is not None: + # If we need to resize data + # PIL accepts (w,h) tuple, not (h,w) + img = img.resize(self.enforce_image_hw[::-1]) + mask = mask.resize(self.enforce_image_hw[::-1]) + img = np.asarray(img) + mask = np.asarray(mask) + assert img.shape[2] == 3 + + return img, mask[:, :, 0].astype(np.uint8) + + def __len__(self): + """Return the len of the dataset.""" + return len(self.images_names) + + +class KvasirShardDescriptor(ShardDescriptor): + """Shard descriptor class.""" + + def __init__(self, data_folder: str = 'kvasir_data', + rank_worldsize: str = '1,1', + enforce_image_hw: str = None) -> None: + """Initialize KvasirShardDescriptor.""" + super().__init__() + # Settings for sharding the dataset + self.rank, self.worldsize = tuple(int(num) for num in rank_worldsize.split(',')) + + self.data_folder = Path.cwd() / data_folder + self.download_data(self.data_folder) + + # Settings for resizing data + self.enforce_image_hw = None + if enforce_image_hw is not None: + self.enforce_image_hw = tuple(int(size) for size in enforce_image_hw.split(',')) + + def get_dataset(self, dataset_type='train'): + """Return a shard dataset by type.""" + return KvasirShardDataset( + dataset_dir=self.data_folder, + rank=self.rank, + worldsize=self.worldsize, + enforce_image_hw=self.enforce_image_hw + ) + + @staticmethod + def download_data(data_folder): + """Download data.""" + zip_file_path = data_folder / 'kvasir.zip' + os.makedirs(data_folder, exist_ok=True) + os.system('wget -nc' + " 'https://datasets.simula.no/downloads/hyper-kvasir/" + "hyper-kvasir-segmented-images.zip'" + f' -O {zip_file_path.relative_to(Path.cwd())}') + zip_sha384 = ('66cd659d0e8afd8c83408174' + '1ade2b75dada8d4648b816f2533c8748b1658efa3d49e205415d4116faade2c5810e241e') + validate_file_hash(zip_file_path, zip_sha384) + os.system(f'unzip -n {zip_file_path.relative_to(Path.cwd())}' + f' -d {data_folder.relative_to(Path.cwd())}') + + @property + def sample_shape(self): + """Return the sample shape info.""" + return ['300', '400', '3'] + + @property + def target_shape(self): + """Return the target shape info.""" + return ['300', '400'] + + @property + def dataset_description(self) -> str: + """Return the dataset description.""" + return f'Kvasir dataset, shard number {self.rank} out of {self.worldsize}' diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/sd_requirements.txt b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/sd_requirements.txt new file mode 100644 index 0000000..772cf9f --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/sd_requirements.txt @@ -0,0 +1,3 @@ +numpy +pillow +pynvml diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/start_envoy.sh new file mode 100755 index 0000000..ae9b4c2 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/start_envoy.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx envoy start -n env_one --disable-tls --envoy-config-path envoy_config.yaml -dh localhost -dp 50050 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/start_envoy_with_tls.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/start_envoy_with_tls.sh new file mode 100755 index 0000000..97e3f4d --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/envoy/start_envoy_with_tls.sh @@ -0,0 +1,6 @@ +#!/bin/bash +set -e +ENVOY_NAME=$1 +DIRECTOR_FQDN=$2 + +fx envoy start -n "$ENVOY_NAME" --envoy-config-path envoy_config.yaml -dh "$DIRECTOR_FQDN" -dp 50050 -rc cert/root_ca.crt -pk cert/"$ENVOY_NAME".key -oc cert/"$ENVOY_NAME".crt diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/workspace/PyTorch_Kvasir_UNet.ipynb b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/workspace/PyTorch_Kvasir_UNet.ipynb new file mode 100644 index 0000000..ed583e3 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/workspace/PyTorch_Kvasir_UNet.ipynb @@ -0,0 +1,610 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "liquid-jacket", + "metadata": {}, + "source": [ + "# Federated Kvasir with Director example" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "alike-sharing", + "metadata": {}, + "outputs": [], + "source": [ + "# Install dependencies if not already installed\n", + "!pip install torchvision==0.8.1" + ] + }, + { + "cell_type": "markdown", + "id": "16986f22", + "metadata": {}, + "source": [ + "# Connect to the Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4485ac79", + "metadata": {}, + "outputs": [], + "source": [ + "# Create a federation\n", + "from openfl.interface.interactive_api.federation import Federation\n", + "\n", + "# please use the same identificator that was used in signed certificate\n", + "client_id = 'frontend'\n", + "director_node_fqdn = 'localhost'\n", + "director_port = 50050\n", + "\n", + "# 1) Run with API layer - Director mTLS \n", + "# If the user wants to enable mTLS their must provide CA root chain, and signed key pair to the federation interface\n", + "# cert_chain = 'cert/root_ca.crt'\n", + "# API_certificate = 'cert/frontend.crt'\n", + "# API_private_key = 'cert/frontend.key'\n", + "\n", + "# federation = Federation(\n", + "# client_id=client_id,\n", + "# director_node_fqdn=director_node_fqdn,\n", + "# director_port=director_port,\n", + "# tls=True,\n", + "# cert_chain=cert_chain,\n", + "# api_cert=api_certificate,\n", + "# api_private_key=api_private_key\n", + "# )\n", + "\n", + "# --------------------------------------------------------------------------------------------------------------------\n", + "\n", + "# 2) Run with TLS disabled (trusted environment)\n", + "# Federation can also determine local fqdn automatically\n", + "federation = Federation(\n", + " client_id=client_id,\n", + " director_node_fqdn=director_node_fqdn,\n", + " director_port=director_port,\n", + " tls=False\n", + ")\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "e35802d5", + "metadata": {}, + "outputs": [], + "source": [ + "# import time\n", + "# while True:\n", + "# shard_registry = federation.get_shard_registry()\n", + "# print(shard_registry)\n", + "# time.sleep(5)\n", + "shard_registry = federation.get_shard_registry()\n", + "shard_registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "67ae50de", + "metadata": {}, + "outputs": [], + "source": [ + "federation.target_shape" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "920216d3", + "metadata": {}, + "outputs": [], + "source": [ + "# First, request a dummy_shard_desc that holds information about the federated dataset \n", + "dummy_shard_desc = federation.get_dummy_shard_descriptor(size=10)\n", + "dummy_shard_dataset = dummy_shard_desc.get_dataset('train')\n", + "sample, target = dummy_shard_dataset[0]\n", + "f\"Sample shape: {sample.shape}, target shape: {target.shape}\"" + ] + }, + { + "cell_type": "markdown", + "id": "obvious-tyler", + "metadata": {}, + "source": [ + "## Creating a FL experiment using Interactive API" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "rubber-address", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment" + ] + }, + { + "cell_type": "markdown", + "id": "sustainable-public", + "metadata": {}, + "source": [ + "### Register dataset" + ] + }, + { + "cell_type": "markdown", + "id": "unlike-texas", + "metadata": {}, + "source": [ + "We extract User dataset class implementation.\n", + "Is it convinient?\n", + "What if the dataset is not a class?" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "64f37dcf", + "metadata": {}, + "outputs": [], + "source": [ + "import os\n", + "import PIL\n", + "import numpy as np\n", + "from torch.utils.data import Dataset, DataLoader, SubsetRandomSampler\n", + "from torchvision import transforms as tsf\n", + "\n", + "\n", + "class KvasirShardDataset(Dataset):\n", + " \n", + " def __init__(self, dataset):\n", + " self._dataset = dataset\n", + " \n", + " # Prepare transforms\n", + " self.img_trans = tsf.Compose([\n", + " tsf.ToPILImage(),\n", + " tsf.Resize((332, 332)),\n", + " tsf.ToTensor(),\n", + " tsf.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])\n", + " self.mask_trans = tsf.Compose([\n", + " tsf.ToPILImage(),\n", + " tsf.Resize((332, 332), interpolation=PIL.Image.NEAREST),\n", + " tsf.ToTensor()])\n", + " \n", + " def __getitem__(self, index):\n", + " img, mask = self._dataset[index]\n", + " img = self.img_trans(img).numpy()\n", + " mask = self.mask_trans(mask).numpy()\n", + " return img, mask\n", + " \n", + " def __len__(self):\n", + " return len(self._dataset)\n", + "\n", + " \n", + "\n", + "# Now you can implement you data loaders using dummy_shard_desc\n", + "class KvasirSD(DataInterface):\n", + "\n", + " def __init__(self, validation_fraction=1/8, **kwargs):\n", + " super().__init__(**kwargs)\n", + " \n", + " self.validation_fraction = validation_fraction\n", + " \n", + " @property\n", + " def shard_descriptor(self):\n", + " return self._shard_descriptor\n", + " \n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + "\n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + " self._shard_dataset = KvasirShardDataset(shard_descriptor.get_dataset('train'))\n", + " \n", + " validation_size = max(1, int(len(self._shard_dataset) * self.validation_fraction))\n", + " \n", + " self.train_indeces = np.arange(len(self._shard_dataset) - validation_size)\n", + " self.val_indeces = np.arange(len(self._shard_dataset) - validation_size, len(self._shard_dataset))\n", + " \n", + " def get_train_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks with optimizer in contract\n", + " \"\"\"\n", + " train_sampler = SubsetRandomSampler(self.train_indeces)\n", + " return DataLoader(\n", + " self._shard_dataset,\n", + " num_workers=8,\n", + " batch_size=self.kwargs['train_bs'],\n", + " sampler=train_sampler\n", + " )\n", + "\n", + " def get_valid_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks without optimizer in contract\n", + " \"\"\"\n", + " val_sampler = SubsetRandomSampler(self.val_indeces)\n", + " return DataLoader(\n", + " self._shard_dataset,\n", + " num_workers=8,\n", + " batch_size=self.kwargs['valid_bs'],\n", + " sampler=val_sampler\n", + " )\n", + "\n", + " def get_train_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.train_indeces)\n", + "\n", + " def get_valid_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.val_indeces)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d8df35f5", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = KvasirSD(train_bs=4, valid_bs=8)\n", + "fed_dataset.shard_descriptor = dummy_shard_desc\n", + "for i, (sample, target) in enumerate(fed_dataset.get_train_loader()):\n", + " print(sample.shape)" + ] + }, + { + "cell_type": "markdown", + "id": "caring-distinction", + "metadata": {}, + "source": [ + "### Describe a model and optimizer" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "visible-victor", + "metadata": {}, + "outputs": [], + "source": [ + "import torch\n", + "import torch.nn as nn\n", + "import torch.optim as optim" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "foreign-gospel", + "metadata": {}, + "outputs": [], + "source": [ + "\"\"\"\n", + "UNet model definition\n", + "\"\"\"\n", + "from layers import soft_dice_coef, soft_dice_loss, DoubleConv, Down, Up\n", + "\n", + "\n", + "class UNet(nn.Module):\n", + " def __init__(self, n_channels=3, n_classes=1):\n", + " super().__init__()\n", + " self.inc = DoubleConv(n_channels, 64)\n", + " self.down1 = Down(64, 128)\n", + " self.down2 = Down(128, 256)\n", + " self.down3 = Down(256, 512)\n", + " self.up1 = Up(512, 256)\n", + " self.up2 = Up(256, 128)\n", + " self.up3 = Up(128, 64)\n", + " self.outc = nn.Conv2d(64, n_classes, 1)\n", + "\n", + " def forward(self, x):\n", + " x1 = self.inc(x)\n", + " x2 = self.down1(x1)\n", + " x3 = self.down2(x2)\n", + " x4 = self.down3(x3)\n", + " x = self.up1(x4, x3)\n", + " x = self.up2(x, x2)\n", + " x = self.up3(x, x1)\n", + " x = self.outc(x)\n", + " x = torch.sigmoid(x)\n", + " return x\n", + " \n", + "model_unet = UNet()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "greater-activation", + "metadata": {}, + "outputs": [], + "source": [ + "optimizer_adam = optim.Adam(model_unet.parameters(), lr=1e-4)" + ] + }, + { + "cell_type": "markdown", + "id": "caroline-passion", + "metadata": {}, + "source": [ + "#### Register model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "handled-teens", + "metadata": {}, + "outputs": [], + "source": [ + "from copy import deepcopy\n", + "\n", + "framework_adapter = 'openfl.plugins.frameworks_adapters.pytorch_adapter.FrameworkAdapterPlugin'\n", + "MI = ModelInterface(model=model_unet, optimizer=optimizer_adam, framework_plugin=framework_adapter)\n", + "\n", + "# Save the initial model state\n", + "initial_model = deepcopy(model_unet)" + ] + }, + { + "cell_type": "markdown", + "id": "portuguese-groove", + "metadata": {}, + "source": [ + "### Define and register FL tasks" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "increasing-builder", + "metadata": {}, + "outputs": [], + "source": [ + "TI = TaskInterface()\n", + "import torch\n", + "\n", + "import tqdm\n", + "from openfl.interface.aggregation_functions import Median\n", + "\n", + "# The Interactive API supports registering functions definied in main module or imported.\n", + "def function_defined_in_notebook(some_parameter):\n", + " print(f'Also I accept a parameter and it is {some_parameter}')\n", + "\n", + "#The Interactive API supports overriding of the aggregation function\n", + "aggregation_function = Median()\n", + "\n", + "# Task interface currently supports only standalone functions.\n", + "@TI.add_kwargs(**{'some_parameter': 42})\n", + "@TI.register_fl_task(model='unet_model', data_loader='train_loader', \\\n", + " device='device', optimizer='optimizer') \n", + "@TI.set_aggregation_function(aggregation_function)\n", + "def train(unet_model, train_loader, optimizer, device, loss_fn=soft_dice_loss, some_parameter=None):\n", + " \n", + " \"\"\" \n", + " The following constructions, that may lead to resource race\n", + " is no longer needed:\n", + " \n", + " if not torch.cuda.is_available():\n", + " device = 'cpu'\n", + " else:\n", + " device = 'cuda'\n", + " \n", + " \"\"\"\n", + "\n", + " print(f'\\n\\n TASK TRAIN GOT DEVICE {device}\\n\\n')\n", + " \n", + " function_defined_in_notebook(some_parameter)\n", + " \n", + " train_loader = tqdm.tqdm(train_loader, desc=\"train\")\n", + " \n", + " unet_model.train()\n", + " unet_model.to(device)\n", + "\n", + " losses = []\n", + "\n", + " for data, target in train_loader:\n", + " data, target = torch.tensor(data).to(device), torch.tensor(\n", + " target).to(device, dtype=torch.float32)\n", + " optimizer.zero_grad()\n", + " output = unet_model(data)\n", + " loss = loss_fn(output=output, target=target)\n", + " loss.backward()\n", + " optimizer.step()\n", + " losses.append(loss.detach().cpu().numpy())\n", + " \n", + " return {'train_loss': np.mean(losses),}\n", + "\n", + "\n", + "@TI.register_fl_task(model='unet_model', data_loader='val_loader', device='device') \n", + "def validate(unet_model, val_loader, device):\n", + " print(f'\\n\\n TASK VALIDATE GOT DEVICE {device}\\n\\n')\n", + " \n", + " unet_model.eval()\n", + " unet_model.to(device)\n", + " \n", + " val_loader = tqdm.tqdm(val_loader, desc=\"validate\")\n", + "\n", + " val_score = 0\n", + " total_samples = 0\n", + "\n", + " with torch.no_grad():\n", + " for data, target in val_loader:\n", + " samples = target.shape[0]\n", + " total_samples += samples\n", + " data, target = torch.tensor(data).to(device), \\\n", + " torch.tensor(target).to(device, dtype=torch.int64)\n", + " output = unet_model(data)\n", + " val = soft_dice_coef(output, target)\n", + " val_score += val.sum().cpu().numpy()\n", + " \n", + " return {'dice_coef': val_score / total_samples,}" + ] + }, + { + "cell_type": "markdown", + "id": "derived-bride", + "metadata": {}, + "source": [ + "## Time to start a federated learning experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "mature-renewal", + "metadata": {}, + "outputs": [], + "source": [ + "# create an experimnet in federation\n", + "experiment_name = 'kvasir_test_experiment'\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "lightweight-causing", + "metadata": {}, + "outputs": [], + "source": [ + "# If I use autoreload I got a pickling error\n", + "\n", + "# The following command zips the workspace and python requirements to be transfered to collaborator nodes\n", + "fl_experiment.start(model_provider=MI, \n", + " task_keeper=TI,\n", + " data_loader=fed_dataset,\n", + " rounds_to_train=2,\n", + " opt_treatment='CONTINUE_GLOBAL',\n", + " device_assignment_policy='CUDA_PREFERRED')\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "f1543a36", + "metadata": {}, + "outputs": [], + "source": [ + "# If user want to stop IPython session, then reconnect and check how experiment is going \n", + "# fl_experiment.restore_experiment_state(MI)\n", + "\n", + "fl_experiment.stream_metrics()" + ] + }, + { + "cell_type": "markdown", + "id": "8c30b301", + "metadata": {}, + "source": [ + "## Now we validate the best model!" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "55acff59", + "metadata": {}, + "outputs": [], + "source": [ + "best_model = fl_experiment.get_best_model()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "9479fb7f", + "metadata": {}, + "outputs": [], + "source": [ + "# We remove exremove_experiment_datamove_experiment_datamove_experiment_datariment data from director\n", + "fl_experiment.remove_experiment_data()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "75c8aeab", + "metadata": {}, + "outputs": [], + "source": [ + "best_model.inc.conv[0].weight\n", + "# model_unet.inc.conv[0].weight" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "a2acb7e6", + "metadata": {}, + "outputs": [], + "source": [ + "# Validating initial model\n", + "validate(initial_model, fed_dataset.get_valid_loader(), 'cpu')" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "c12ca93f", + "metadata": {}, + "outputs": [], + "source": [ + "# Validating trained model\n", + "validate(best_model, fed_dataset.get_valid_loader(), 'cpu')" + ] + }, + { + "cell_type": "markdown", + "id": "1e6734f6", + "metadata": {}, + "source": [ + "## We can tune model further!" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "3940e75e", + "metadata": {}, + "outputs": [], + "source": [ + "MI = ModelInterface(model=best_model, optimizer=optimizer_adam, framework_plugin=framework_adapter)\n", + "fl_experiment.start(model_provider=MI, task_keeper=TI, data_loader=fed_dataset, rounds_to_train=4, \\\n", + " opt_treatment='CONTINUE_GLOBAL')" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "1bd786d2", + "metadata": {}, + "outputs": [], + "source": [ + "best_model = fl_experiment.get_best_model()\n", + "# Validating trained model\n", + "validate(best_model, fed_dataset.get_valid_loader(), 'cpu')" + ] + } + ], + "metadata": { + "language_info": { + "name": "python" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/workspace/layers.py b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/workspace/layers.py new file mode 100644 index 0000000..12d913c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Kvasir_UNet/workspace/layers.py @@ -0,0 +1,103 @@ +# Copyright (C) 2021-2022 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""Layers for Unet model.""" + +import torch +import torch.nn as nn +import torch.nn.functional as F + + +def soft_dice_loss(output, target): + """Calculate loss.""" + num = target.size(0) + m1 = output.view(num, -1) + m2 = target.view(num, -1) + intersection = m1 * m2 + score = 2.0 * (intersection.sum(1) + 1) / (m1.sum(1) + m2.sum(1) + 1) + score = 1 - score.sum() / num + return score + + +def soft_dice_coef(output, target): + """Calculate soft DICE coefficient.""" + num = target.size(0) + m1 = output.view(num, -1) + m2 = target.view(num, -1) + intersection = m1 * m2 + score = 2.0 * (intersection.sum(1) + 1) / (m1.sum(1) + m2.sum(1) + 1) + return score.sum() + + +class DoubleConv(nn.Module): + """Pytorch double conv class.""" + + def __init__(self, in_ch, out_ch): + """Initialize layer.""" + super(DoubleConv, self).__init__() + self.in_ch = in_ch + self.out_ch = out_ch + self.conv = nn.Sequential( + nn.Conv2d(in_ch, out_ch, 3, padding=1), + nn.BatchNorm2d(out_ch), + nn.ReLU(inplace=True), + nn.Conv2d(out_ch, out_ch, 3, padding=1), + nn.BatchNorm2d(out_ch), + nn.ReLU(inplace=True), + ) + + def forward(self, x): + """Do forward pass.""" + x = self.conv(x) + return x + + +class Down(nn.Module): + """Pytorch nn module subclass.""" + + def __init__(self, in_ch, out_ch): + """Initialize layer.""" + super(Down, self).__init__() + self.mpconv = nn.Sequential( + nn.MaxPool2d(2), + DoubleConv(in_ch, out_ch) + ) + + def forward(self, x): + """Do forward pass.""" + x = self.mpconv(x) + return x + + +class Up(nn.Module): + """Pytorch nn module subclass.""" + + def __init__(self, in_ch, out_ch, bilinear=False): + """Initialize layer.""" + super(Up, self).__init__() + self.in_ch = in_ch + self.out_ch = out_ch + if bilinear: + self.up = nn.Upsample( + scale_factor=2, + mode='bilinear', + align_corners=True + ) + else: + self.up = nn.ConvTranspose2d(in_ch, in_ch // 2, 2, stride=2) + self.conv = DoubleConv(in_ch, out_ch) + + def forward(self, x1, x2): + """Do forward pass.""" + x1 = self.up(x1) + diff_y = x2.size()[2] - x1.size()[2] + diff_x = x2.size()[3] - x1.size()[3] + + x1 = F.pad( + x1, + (diff_x // 2, diff_x - diff_x // 2, diff_y // 2, diff_y - diff_y // 2) + ) + + x = torch.cat([x2, x1], dim=1) + x = self.conv(x) + return x diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/README.md b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/README.md new file mode 100755 index 0000000..f5c53d8 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/README.md @@ -0,0 +1,129 @@ +# PyTorch Lightining tutorial for Generative Adverserial Network (GAN) Dataset + +## **I. About model: Generative Adverserial Networks (GANs)** + +[Generative Adverserial Networks](https://arxiv.org/abs/1406.2661) or GANs were introduced to the +machine learning community by Ian J. Goodfellow in 2014. The idea is to generate real-looking +samples or images that resemble the training data. A GAN has three primary components: a Generator +model for generating new data from random data (noise), a discriminator model for classifying +whether generated data is real or fake, and the adversarial network that pits them against each +other. The fundamental nature of these dual networks is to outplay each other until the generator +starts generating real looking samples that the discriminator fails to differentiate. + +
+
+ +## **II. About framework: PyTorch Lightning** + +[Pytorch Lightning](https://www.pytorchlightning.ai/) is a framework built on top of PyTorch that +allows the models to be scaled without the boilerplate. + +
+
+ +## **III. About dataset: MNIST** + +[MNIST](http://yann.lecun.com/exdb/mnist/) database is a database of handwritten digits that has a +training set of 60,000 examples, and a test set of 10,000 examples. It is a subset of a larger set +available from NIST. The digits have been size-normalized and centered in a fixed-size image. + +
+
+ +## **IV. Using multiple optimizers** + +The example uses two different optimizers: one for discriminator and one for generator. +The [plugin](workspace/plugin_for_multiple_optimizers.py) to support multiple optimizers with +OpenFL has been added. Note that in order to use PyTorch Lightning framework with a single +optimizer, this plugin is NOT required. + +
+
+ +## **V. Training Generator and Discriminator models separately** + +Cuurently, the tutorial shows how to train both the generator and the discriminator models +parallely. Individual models can be trained as well. To train only the generator, the flag ' +train_gen_only' should be set to 1 and to train only the discriminator, 'train_disc_only' should be +set to 1. + +
+
+ +## **VI. Links** + +* [Original GAN paper](https://arxiv.org/abs/1406.2661) +* [Original PyTorch Lightning code](https://pytorch-lightning.readthedocs.io/en/stable/notebooks/lightning_examples/basic-gan.html) + +
+
+ +## **VII. How to run this tutorial (without TLS and locally as a simulation):** + +
+ +### 0. If you haven't done so already, create a virtual environment, install OpenFL, and upgrade pip: + - For help with this step, visit the "Install the Package" section of the [OpenFL installation instructions](https://openfl.readthedocs.io/en/latest/install.html#install-the-package). + +
+ +### 1. Split terminal into 3 (1 terminal for the director, 1 for the envoy, and 1 for the experiment) + +
+ +### 2. Do the following in each terminal: + - Activate the virtual environment from step 0: + + ```sh + source venv/bin/activate + ``` + - If you are in a network environment with a proxy, ensure proxy environment variables are set in each of your terminals. + - Navigate to the tutorial: + + ```sh + cd openfl/openfl-tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN + ``` + +
+ +### 3. In the first terminal, run the director: + +```sh +cd director +./start_director.sh +``` + +
+ +### 4. In the second terminal, install requirements and run the envoy: + +```sh +cd envoy +pip install -r sd_requirements.txt +``` + - If you have GPUs: +```sh +./start_envoy.sh env_one envoy_config.yaml +``` + - For no GPUs, use: +```sh +./start_envoy.sh env_one envoy_config_no_gpu.yaml +``` + + +Optional: Run a second envoy in an additional terminal: + - Ensure step 2 is complete for this terminal as well. + - Repeat step 4 instructions above but change "env_one" name to "env_two" (or another name of your choice). + +
+ +### 5. Now that your director and envoy terminals are set up, run the Jupyter Notebook in your experiment terminal: + +```sh +cd workspace +jupyter lab PyTorch_Lightning_GAN.ipynb +``` +- A Jupyter Server URL will appear in your terminal. In your browser, proceed to that link. Once the webpage loads, click on the PyTorch_Lightning_GAN.ipynb file. +- To run the experiment, select the icon that looks like two triangles to "Restart Kernel and Run All Cells". +- You will notice activity in your terminals as the experiment runs, and when the experiment is finished the director terminal will display a message that the experiment has finished successfully. + diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/director/director_config.yaml new file mode 100644 index 0000000..91a33c3 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/director/director_config.yaml @@ -0,0 +1,5 @@ +settings: + listen_host: localhost + listen_port: 50050 + sample_shape: ['28','28'] + target_shape: ['1'] diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/director/start_director.sh new file mode 100755 index 0000000..5806a6c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/director/start_director.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx director start --disable-tls -c director_config.yaml \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/envoy/envoy_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/envoy/envoy_config.yaml new file mode 100644 index 0000000..bcc1953 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/envoy/envoy_config.yaml @@ -0,0 +1,12 @@ +params: + cuda_devices: [0,2] + +optional_plugin_components: + cuda_device_monitor: + template: openfl.plugins.processing_units_monitor.pynvml_monitor.PynvmlCUDADeviceMonitor + settings: [] + +shard_descriptor: + template: mnist_shard_descriptor.MnistShardDescriptor + params: + rank_worldsize: 1, 2 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/envoy/envoy_config_no_gpu.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/envoy/envoy_config_no_gpu.yaml new file mode 100644 index 0000000..0923271 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/envoy/envoy_config_no_gpu.yaml @@ -0,0 +1,7 @@ +params: + cuda_devices: [] + +shard_descriptor: + template: mnist_shard_descriptor.MnistShardDescriptor + params: + rank_worldsize: 1,2 \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/envoy/mnist_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/envoy/mnist_shard_descriptor.py new file mode 100644 index 0000000..bf298bb --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/envoy/mnist_shard_descriptor.py @@ -0,0 +1,98 @@ +# Copyright (C) 2021-2022 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""Mnist Shard Descriptor.""" + +import logging +from typing import Any +from typing import Dict +from typing import List +from typing import Tuple + +from torchvision import datasets + +from openfl.interface.interactive_api.shard_descriptor import ShardDataset +from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor + +logger = logging.getLogger(__name__) + + +class MnistShardDataset(ShardDataset): + """Mnist Shard dataset class.""" + + def __init__(self, x, y, data_type, rank: int = 1, worldsize: int = 1) -> None: + """Initialize Mnist shard Dataset.""" + self.data_type = data_type + self.rank = rank + self.worldsize = worldsize + + self.x = x[self.rank - 1::self.worldsize] + self.y = y[self.rank - 1::self.worldsize] + + def __getitem__(self, index: int) -> Tuple[Any, Any]: + """Return an item by the index.""" + return self.x[index], self.y[index] + + def __len__(self) -> int: + """Return the len of the dataset.""" + return len(self.x) + + +class MnistShardDescriptor(ShardDescriptor): + """Mnist Shard descriptor class.""" + + def __init__( + self, + rank_worldsize: str = '1, 1', + **kwargs + ) -> None: + """Initialize MnistShardDescriptor.""" + self.rank, self.worldsize = tuple(int(num) for num in rank_worldsize.split(',')) + (x_train, y_train), (x_val, y_val) = self.download_data() + self.data_by_type = { + 'train': (x_train, y_train), + 'val': (x_val, y_val) + } + + def get_shard_dataset_types(self) -> List[Dict[str, Any]]: + """Get available shard dataset types.""" + return list(self.data_by_type) + + def get_dataset(self, dataset_type: str = 'train') -> MnistShardDataset: + """Return a shard dataset by type.""" + if dataset_type not in self.data_by_type: + raise Exception(f'Wrong dataset type: {dataset_type}') + return MnistShardDataset( + *self.data_by_type[dataset_type], + data_type=dataset_type, + rank=self.rank, + worldsize=self.worldsize + ) + + @property + def sample_shape(self) -> List[str]: + """Return the sample shape info.""" + return ['28', '28'] + + @property + def target_shape(self) -> List[str]: + """Return the target shape info.""" + return ['1'] + + @property + def dataset_description(self) -> str: + """Return the dataset description.""" + return (f'Mnist dataset, shard number {self.rank}' + f' out of {self.worldsize}') + + def download_data(self) -> Tuple[Tuple[Any, Any], Tuple[Any, Any]]: + """Download prepared dataset.""" + train_data, val_data = ( + datasets.MNIST('data', train=train, download=True) + for train in (True, False) + ) + x_train, y_train = train_data.train_data, train_data.train_labels + x_val, y_val = val_data.test_data, val_data.test_labels + + print('Mnist data was loaded!') + return (x_train, y_train), (x_val, y_val) diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/envoy/sd_requirements.txt b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/envoy/sd_requirements.txt new file mode 100644 index 0000000..278e0f5 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/envoy/sd_requirements.txt @@ -0,0 +1,7 @@ +numpy +pillow +pynvml==11.4.1 +setuptools>=65.5.1 # not directly required, pinned by Snyk to avoid a vulnerability +torch==2.3.1 +torchvision==0.18.1 +wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/envoy/start_envoy.sh new file mode 100755 index 0000000..ae9b4c2 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/envoy/start_envoy.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx envoy start -n env_one --disable-tls --envoy-config-path envoy_config.yaml -dh localhost -dp 50050 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/workspace/PyTorch_Lightning_GAN.ipynb b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/workspace/PyTorch_Lightning_GAN.ipynb new file mode 100644 index 0000000..95dbeb7 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/workspace/PyTorch_Lightning_GAN.ipynb @@ -0,0 +1,699 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "liquid-jacket", + "metadata": {}, + "source": [ + "# Federated GAN tutorial with PyTorch Lightning" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "alike-sharing", + "metadata": {}, + "outputs": [], + "source": [ + "!pip install \"pytorch-lightning>=1.3\" \"torch==2.3.1\" \"torchvision==0.18.1\" \"torchmetrics>=0.3\" \"scikit-image\" \"matplotlib\"" + ] + }, + { + "cell_type": "markdown", + "id": "16986f22", + "metadata": {}, + "source": [ + "# Connect to the Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4485ac79", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.federation import Federation\n", + "\n", + "client_id = \"frontend\"\n", + "director_node_fqdn = \"localhost\"\n", + "director_port = 50050\n", + "\n", + "#Run with TLS disabled (trusted environment)\n", + "federation = Federation(\n", + " client_id=client_id,\n", + " director_node_fqdn=director_node_fqdn,\n", + " director_port=director_port,\n", + " tls=False,\n", + ")" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "e35802d5", + "metadata": {}, + "outputs": [], + "source": [ + "shard_registry = federation.get_shard_registry()\n", + "shard_registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "67ae50de", + "metadata": {}, + "outputs": [], + "source": [ + "federation.target_shape" + ] + }, + { + "cell_type": "markdown", + "id": "obvious-tyler", + "metadata": {}, + "source": [ + "## Creating a FL experiment using Interactive API" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "rubber-address", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.experiment import (\n", + " DataInterface,\n", + " FLExperiment,\n", + " ModelInterface,\n", + " TaskInterface,\n", + ")" + ] + }, + { + "cell_type": "markdown", + "id": "sustainable-public", + "metadata": {}, + "source": [ + "### Register dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "8d9acb53", + "metadata": {}, + "outputs": [], + "source": [ + "import copy\n", + "import os\n", + "import shutil\n", + "import PIL\n", + "from collections import OrderedDict\n", + "\n", + "import numpy as np\n", + "import torch\n", + "import torch.nn as nn\n", + "import torch.nn.functional as F\n", + "import torch.optim as optim\n", + "import torchvision\n", + "import torchvision.transforms as transforms\n", + "from pytorch_lightning import LightningDataModule, LightningModule, Trainer\n", + "from torch.utils.data import DataLoader, Dataset, random_split\n", + "from torchvision.datasets import MNIST" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "64f37dcf", + "metadata": {}, + "outputs": [], + "source": [ + "mnist_transform = transforms.Compose(\n", + " [\n", + " transforms.ToPILImage(),\n", + " transforms.Resize((28, 28)),\n", + " transforms.ToTensor(),\n", + " transforms.Normalize((0.1307,), (0.3081,)),\n", + " ]\n", + ")\n", + "\n", + "\n", + "class MnistShardDataset(Dataset):\n", + " def __init__(self, x, y, transform=None):\n", + " self.x, self.y = x, y\n", + " self.transform = transform\n", + "\n", + " def __getitem__(self, index):\n", + " x, y = self.x[index], self.y[index]\n", + " x = self.transform(x).numpy()\n", + " y = y.numpy()\n", + " return x, y\n", + "\n", + " def __len__(self):\n", + " return len(self.x)\n", + "\n", + "\n", + "class MnistFedDataset(DataInterface):\n", + " def __init__(self, **kwargs):\n", + " super().__init__(**kwargs)\n", + "\n", + " @property\n", + " def shard_descriptor(self):\n", + " return self._shard_descriptor\n", + "\n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + "\n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + " self.train_set = MnistShardDataset(\n", + " self._shard_descriptor.get_dataset(\"train\")[:][0],\n", + " self._shard_descriptor.get_dataset(\"train\")[:][1],\n", + " transform=mnist_transform,\n", + " )\n", + " self.valid_set = MnistShardDataset(\n", + " self._shard_descriptor.get_dataset(\"val\")[:][0],\n", + " self._shard_descriptor.get_dataset(\"val\")[:][1],\n", + " transform=mnist_transform,\n", + " )\n", + "\n", + " def __getitem__(self, index):\n", + " return self.shard_descriptor[index]\n", + "\n", + " def __len__(self):\n", + " return len(self.shard_descriptor)\n", + "\n", + " def get_train_loader(self):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks with optimizer in contract\n", + " \"\"\"\n", + " if self.kwargs[\"train_bs\"]:\n", + " batch_size = self.kwargs[\"train_bs\"]\n", + " else:\n", + " batch_size = 256\n", + " return DataLoader(self.train_set, batch_size=batch_size, num_workers=4)\n", + "\n", + " def get_valid_loader(self):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks without optimizer in contract\n", + " \"\"\"\n", + " if self.kwargs[\"valid_bs\"]:\n", + " batch_size = self.kwargs[\"valid_bs\"]\n", + " else:\n", + " batch_size = 64\n", + " return DataLoader(self.valid_set, batch_size=batch_size)\n", + "\n", + " def get_train_data_size(self):\n", + " \"\"\"\n", + " train data size\n", + " \"\"\"\n", + "\n", + " return len(self.train_set)\n", + "\n", + " def get_valid_data_size(self):\n", + " \"\"\"\n", + " val data size\n", + " \"\"\"\n", + " return len(self.valid_set)\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d8df35f5", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = MnistFedDataset(train_bs=256, valid_bs=64)" + ] + }, + { + "cell_type": "markdown", + "id": "caring-distinction", + "metadata": {}, + "source": [ + "### Describe a model and optimizer" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "foreign-gospel", + "metadata": {}, + "outputs": [], + "source": [ + "\"\"\"\n", + "Generator and discriminator model definition\n", + "\"\"\"\n", + "\n", + "\n", + "class Generator(nn.Module):\n", + " def __init__(self, latent_dim, img_shape):\n", + " super().__init__()\n", + " self.img_shape = img_shape\n", + "\n", + " def block(in_feat, out_feat, normalize=True):\n", + " layers = [nn.Linear(in_feat, out_feat)]\n", + " if normalize:\n", + " layers.append(nn.BatchNorm1d(out_feat, 0.8))\n", + " layers.append(nn.LeakyReLU(0.2, inplace=True))\n", + " return layers\n", + "\n", + " self.model = nn.Sequential(\n", + " *block(latent_dim, 128, normalize=False),\n", + " *block(128, 256),\n", + " *block(256, 512),\n", + " *block(512, 1024),\n", + " nn.Linear(1024, int(np.prod(img_shape))),\n", + " nn.Tanh(),\n", + " )\n", + "\n", + " def forward(self, z):\n", + " z = z.float()\n", + " img = self.model(z)\n", + " img = img.view(img.size(0), *self.img_shape)\n", + " return img" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "981b810c", + "metadata": {}, + "outputs": [], + "source": [ + "class Discriminator(nn.Module):\n", + " def __init__(self, img_shape):\n", + " super().__init__()\n", + "\n", + " self.model = nn.Sequential(\n", + " nn.Linear(int(np.prod(img_shape)), 512),\n", + " nn.LeakyReLU(0.2, inplace=True),\n", + " nn.Linear(512, 256),\n", + " nn.LeakyReLU(0.2, inplace=True),\n", + " nn.Linear(256, 1),\n", + " nn.Sigmoid(),\n", + " )\n", + "\n", + " def forward(self, img):\n", + " img_flat = img.view(img.size(0), -1)\n", + " img_flat = img_flat.float()\n", + " validity = self.model(img_flat)\n", + "\n", + " return validity" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "6cc92e98", + "metadata": {}, + "outputs": [], + "source": [ + "class GAN(LightningModule):\n", + " def __init__(\n", + " self,\n", + " channels,\n", + " width,\n", + " height,\n", + " train_disc_only,\n", + " train_gen_only,\n", + " latent_dim: int = 100,\n", + " lr: float = 0.0002,\n", + " b1: float = 0.5,\n", + " b2: float = 0.999,\n", + " batch_size: int = 256,\n", + " **kwargs\n", + " ):\n", + " super().__init__()\n", + " self.save_hyperparameters()\n", + "\n", + " data_shape = (channels, width, height)\n", + " self.generator = Generator(\n", + " latent_dim=self.hparams.latent_dim, img_shape=data_shape\n", + " )\n", + " self.discriminator = Discriminator(img_shape=data_shape)\n", + "\n", + " self.validation_z = torch.randn(8, self.hparams.latent_dim)\n", + " self.example_input_array = torch.zeros(2, self.hparams.latent_dim)\n", + " self.train_disc_only = train_disc_only\n", + " self.train_gen_only = train_gen_only\n", + "\n", + " def forward(self, z):\n", + " return self.generator(z)\n", + "\n", + " def adversarial_loss(self, y_hat, y):\n", + " return F.binary_cross_entropy(y_hat, y)\n", + "\n", + " def training_step(self, batch, batch_idx, optimizer_idx):\n", + " imgs, _ = batch\n", + "\n", + " # sample noise\n", + " z = torch.randn(imgs.shape[0], self.hparams.latent_dim)\n", + " z = z.type_as(imgs)\n", + "\n", + " if optimizer_idx == 0 and self.train_disc_only == 0:\n", + " return self.train_generator(imgs, z, display_images=0)\n", + "\n", + " elif optimizer_idx == 1 and self.train_gen_only == 0:\n", + " return self.train_discriminator(imgs, z)\n", + "\n", + " def train_generator(self, imgs, z, display_images=0):\n", + " self.generated_imgs = self(z)\n", + " sample_imgs = self.generated_imgs[:10]\n", + " sample_imgs = np.reshape(sample_imgs.detach().cpu().numpy(), (10, 28, 28, 1))\n", + " \n", + " if display_images:\n", + " from skimage import data, io\n", + " from matplotlib import pyplot as plt\n", + " for img in sample_imgs:\n", + " io.imshow(img.reshape((28, 28)), cmap='gray_r')\n", + " plt.axis('off')\n", + " plt.show()\n", + "\n", + " valid = torch.ones(imgs.size(0), 1)\n", + " valid = valid.type_as(imgs).float()\n", + "\n", + " g_loss = self.adversarial_loss(self.discriminator(self(z)), valid)\n", + " tqdm_dict = {\"g_loss\": g_loss}\n", + " output = OrderedDict(\n", + " {\"loss\": g_loss, \"progress_bar\": tqdm_dict, \"log\": tqdm_dict}\n", + " )\n", + " self.log(name=\"Generator training loss\", value=g_loss, on_epoch=True)\n", + " return output\n", + "\n", + " def train_discriminator(self, imgs, z):\n", + " valid = torch.ones(imgs.size(0), 1)\n", + " valid = valid.type_as(imgs).float()\n", + "\n", + " real_loss = self.adversarial_loss(self.discriminator(imgs), valid)\n", + "\n", + " fake = torch.zeros(imgs.size(0), 1)\n", + " fake = fake.type_as(imgs).float()\n", + "\n", + " fake_loss = self.adversarial_loss(self.discriminator(self(z).detach()), fake)\n", + "\n", + " d_loss = (real_loss + fake_loss) / 2\n", + " tqdm_dict = {\"d_loss\": d_loss}\n", + " output = OrderedDict(\n", + " {\"loss\": d_loss, \"progress_bar\": tqdm_dict, \"log\": tqdm_dict}\n", + " )\n", + " self.log(name=\"Discriminator training loss\", value=d_loss, on_epoch=True)\n", + " return output\n", + "\n", + " def configure_optimizers(self):\n", + " lr = self.hparams.lr\n", + " b1 = self.hparams.b1\n", + " b2 = self.hparams.b2\n", + "\n", + " opt_g = torch.optim.Adam(self.generator.parameters(), lr=lr, betas=(b1, b2))\n", + " opt_d = torch.optim.Adam(self.discriminator.parameters(), lr=lr, betas=(b1, b2))\n", + "\n", + " return [opt_g, opt_d]\n", + "\n", + " def validation_step(self, batch, batch_idx, optimizer_idx=1):\n", + " imgs, _ = batch\n", + "\n", + " valid = torch.ones(imgs.size(0), 1)\n", + " valid = valid.type_as(imgs).float()\n", + "\n", + " val_real_loss = self.adversarial_loss(self.discriminator(imgs), valid)\n", + " self.log(name=\"Discriminator val loss\", value=val_real_loss, on_epoch=True)\n", + " return {\"val_loss\": val_real_loss}\n", + "\n", + " def on_val_epoch_end(self):\n", + " z = self.validation_z.type_as(self.generator.model[0].weight)\n", + "\n", + " sample_imgs = self(z)\n", + " grid = torchvision.utils.make_grid(sample_imgs)\n", + " self.logger.experiment.add_image(\"generated_images\", grid, self.current_epoch)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "5719fa50", + "metadata": {}, + "outputs": [], + "source": [ + "from pytorch_lightning.callbacks import Callback\n", + "\n", + "\n", + "class MetricsCallback(Callback):\n", + " \"\"\"PyTorch Lightning metric callback.\"\"\"\n", + "\n", + " def __init__(self):\n", + " super().__init__()\n", + " self.metrics = []\n", + "\n", + " def on_val_epoch_end(self, trainer, pl_module):\n", + " met = copy.deepcopy(trainer.callback_metrics)\n", + " self.metrics.append(met)\n", + "\n", + " def __call__(self):\n", + " return self.get_callbacks()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "46692b08", + "metadata": {}, + "outputs": [], + "source": [ + "model = GAN(channels=1, width=28, height=28, train_disc_only=0, train_gen_only=0)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "greater-activation", + "metadata": {}, + "outputs": [], + "source": [ + "optimizer = model.configure_optimizers()" + ] + }, + { + "cell_type": "markdown", + "id": "caroline-passion", + "metadata": {}, + "source": [ + "#### Register model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "handled-teens", + "metadata": {}, + "outputs": [], + "source": [ + "from copy import deepcopy\n", + "\n", + "# Need this plugin only if multiple optimizers are used. Not required for PyTorch Lightning with a single optimizer.\n", + "framework_adapter = (\n", + " \"plugin_for_multiple_optimizers.FrameworkAdapterPluginforMultipleOpt\"\n", + ")\n", + "MI = ModelInterface(\n", + " model=model, optimizer=optimizer, framework_plugin=framework_adapter\n", + ")\n", + "\n", + "initial_model = deepcopy(model)" + ] + }, + { + "cell_type": "markdown", + "id": "portuguese-groove", + "metadata": {}, + "source": [ + "### Define and register FL tasks" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "increasing-builder", + "metadata": {}, + "outputs": [], + "source": [ + "TI = TaskInterface()\n", + "\n", + "import tqdm\n", + "\n", + "@TI.register_fl_task(\n", + " model=\"model\", data_loader=\"train_loader\", device=\"device\", optimizer=\"optimizer\"\n", + ")\n", + "def train(model, train_loader, optimizer, device, some_parameter=None):\n", + "\n", + " print(f\"\\n\\n TASK TRAIN GOT DEVICE {device}\\n\\n\")\n", + "\n", + " AVAIL_GPUS = 1 if \"cuda\" in device else 0\n", + "\n", + " trainer = Trainer(gpus=AVAIL_GPUS, max_epochs=1, callbacks=[MetricsCallback()])\n", + " trainer.fit(model=model, train_dataloaders=train_loader)\n", + " print(\"training logged metrics\", trainer.logged_metrics)\n", + "\n", + " if \"Discriminator training loss_epoch\" in trainer.logged_metrics:\n", + " train_loss = trainer.logged_metrics[\"Discriminator training loss_epoch\"]\n", + " else:\n", + " train_loss = trainer.logged_metrics[\"Generator training loss_epoch\"]\n", + " return {\"train_loss\": train_loss}\n", + "\n", + "\n", + "@TI.register_fl_task(model=\"model\", data_loader=\"val_loader\", device=\"device\")\n", + "def validate(model, val_loader, device):\n", + "\n", + " print(f\"\\n\\n TASK VALIDATE GOT DEVICE {device}\\n\\n\")\n", + "\n", + " model.eval()\n", + " model.to(device)\n", + "\n", + " AVAIL_GPUS = 1 if \"cuda\" in device else 0\n", + "\n", + " trainer = Trainer(gpus=AVAIL_GPUS, max_epochs=1, callbacks=[MetricsCallback()])\n", + "\n", + " trainer.validate(model=model, dataloaders=val_loader)\n", + " print(\"validation logged metrics\", trainer.logged_metrics)\n", + "\n", + " val_loss = trainer.logged_metrics[\"Discriminator val loss\"]\n", + "\n", + " return {\"val_loss\": val_loss}" + ] + }, + { + "cell_type": "markdown", + "id": "derived-bride", + "metadata": {}, + "source": [ + "## Time to start a federated learning experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "mature-renewal", + "metadata": {}, + "outputs": [], + "source": [ + "# create an experimnet in federation\n", + "experiment_name = \"PL_MNIST_test_experiment\"\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "lightweight-causing", + "metadata": {}, + "outputs": [], + "source": [ + "fl_experiment.start(\n", + " model_provider=MI,\n", + " task_keeper=TI,\n", + " data_loader=fed_dataset,\n", + " rounds_to_train=10,\n", + " opt_treatment=\"CONTINUE_GLOBAL\",\n", + " device_assignment_policy=\"CUDA_PREFERRED\",\n", + ")" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "f1543a36", + "metadata": {}, + "outputs": [], + "source": [ + "fl_experiment.stream_metrics()" + ] + }, + { + "cell_type": "markdown", + "id": "f987d2c4", + "metadata": {}, + "source": [ + "## Check the images generated by the model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "fec7a708", + "metadata": {}, + "outputs": [], + "source": [ + "!pip install -r ../envoy/sd_requirements.txt\n", + "import sys\n", + "\n", + "sys.path.insert(1, \"../envoy\")\n", + "from mnist_shard_descriptor import MnistShardDescriptor" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "2bc77cd8", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = MnistFedDataset(train_bs=256, valid_bs=64)\n", + "fed_dataset.shard_descriptor = MnistShardDescriptor(rank_worldsize=\"1,1\")\n", + "\n", + "last_model = fl_experiment.get_last_model()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "5f821972", + "metadata": {}, + "outputs": [], + "source": [ + "val_imgs, _ = next(iter(fed_dataset.get_valid_loader()))\n", + "\n", + "z = torch.randn(val_imgs.shape[0], 100)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "9549d1ab", + "metadata": {}, + "outputs": [], + "source": [ + "last_model.train_generator(val_imgs, z, display_images=1)\n", + "pass" + ] + } + ], + "metadata": { + "kernelspec": { + "display_name": "Python 3 (ipykernel)", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.9" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/workspace/plugin_for_multiple_optimizers.py b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/workspace/plugin_for_multiple_optimizers.py new file mode 100644 index 0000000..d47c13b --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Lightning_MNIST_GAN/workspace/plugin_for_multiple_optimizers.py @@ -0,0 +1,37 @@ +# Copyright (C) 2021-2022 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""Pytorch Framework Adapter plugin for multiple optimizers.""" + + +from openfl.plugins.frameworks_adapters.pytorch_adapter import _get_optimizer_state +from openfl.plugins.frameworks_adapters.pytorch_adapter import FrameworkAdapterPlugin +from openfl.plugins.frameworks_adapters.pytorch_adapter import to_cpu_numpy + + +class FrameworkAdapterPluginforMultipleOpt(FrameworkAdapterPlugin): + """Framework adapter plugin class for multiple optimizers.""" + + def __init__(self): + """Initialize framework adapter.""" + super().__init__() + + @staticmethod + def get_tensor_dict(model, optimizers=None): + """ + Extract tensor dict from a model and a list of optimizers. + + Returns: + dict {weight name: numpy ndarray} + """ + state = to_cpu_numpy(model.state_dict()) + if optimizers is not None: + for opt in optimizers: + if isinstance(opt, dict): + opt_state = _get_optimizer_state(opt['optimizer']) + else: + opt_state = _get_optimizer_state(opt) + + state = {**state, **opt_state} + + return state diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/README.md b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/README.md new file mode 100644 index 0000000..84c75e5 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/README.md @@ -0,0 +1,56 @@ +# PyTorch based Linear Regression Tutorial + +### 1. About dataset + +Generate a random regression problem using `make_regression` from sklearn.datasets with pre-defined parameters. + +Define the below param in envoy.yaml config to shard the dataset across participants/envoy. +- rank_worldsize + + +### 2. About model + +Simple Regression Model based on PyTorch. + + +### 3. How to run this tutorial (without TLC and locally as a simulation): + +1. Run director: + +```sh +cd director_folder +./start_director.sh +``` + +2. Run envoy: + +Step 1: Activate virtual environment and install packages +``` +cd envoy_folder +pip install -r requirements.txt +``` +Step 2: start the envoy +```sh +./start_envoy.sh env_instance_1 envoy_config.yaml +``` + +Optional: start second envoy: + +- Copy `envoy_folder` to another place and follow the same process as above: + +```sh +./start_envoy.sh env_instance_2 envoy_config.yaml +``` + +3. Run `torch_linear_regression.ipynb` jupyter notebook: + +```sh +cd workspace +jupyter lab torch_linear_regression.ipynb +``` + +4. Visualization + +``` +tensorboard --logdir logs/ +``` diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/director/director_config.yaml new file mode 100644 index 0000000..d22b4b7 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/director/director_config.yaml @@ -0,0 +1,6 @@ +settings: + listen_host: localhost + listen_port: 50050 + sample_shape: ['1'] # Modify this param if experimenting with `n_features` of shard_descriptor. + target_shape: ['1'] + envoy_health_check_period: 5 # in seconds diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/director/start_director.sh new file mode 100755 index 0000000..5806a6c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/director/start_director.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx director start --disable-tls -c director_config.yaml \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/envoy/envoy_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/envoy/envoy_config.yaml new file mode 100644 index 0000000..8f35387 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/envoy/envoy_config.yaml @@ -0,0 +1,9 @@ +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: regression_shard_descriptor.RegressionShardDescriptor + params: + rank_worldsize: 1, 2 \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/envoy/regression_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/envoy/regression_shard_descriptor.py new file mode 100644 index 0000000..467307f --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/envoy/regression_shard_descriptor.py @@ -0,0 +1,74 @@ +# Copyright (C) 2020-2022 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 +"""Noisy-Sin Shard Descriptor.""" + +from typing import List + +import numpy as np +import torch +from sklearn.datasets import make_regression +from sklearn.model_selection import train_test_split + +from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor + + +class RegressionShardDescriptor(ShardDescriptor): + """Regression Shard descriptor class.""" + + def __init__(self, rank_worldsize: str = '1, 1', **kwargs) -> None: + """ + Initialize Regression Data Shard Descriptor. + + This Shard Descriptor generate random regression data with some gaussian centered noise + using make_regression method from sklearn.datasets. + Shards data across participants using rank and world size. + """ + + self.rank, self.worldsize = tuple(int(num) for num in rank_worldsize.split(',')) + X_train, y_train, X_test, y_test = self.generate_data() + self.data_by_type = { + 'train': np.concatenate((X_train, y_train[:, None]), axis=1), + 'val': np.concatenate((X_test, y_test[:, None]), axis=1) + } + + def generate_data(self): + """Generate regression dataset with predefined params.""" + x, y = make_regression(n_samples=1000, n_features=1, noise=14, random_state=24) + X_train, X_test, y_train, y_test = train_test_split(x, y, random_state=24) + self.data = np.concatenate((x, y[:, None]), axis=1) + return X_train, y_train, X_test, y_test + + def get_shard_dataset_types(self) -> List[str]: + """Get available shard dataset types.""" + return list(self.data_by_type) + + def get_dataset(self, dataset_type='train'): + """Return a shard dataset by type.""" + if dataset_type not in self.data_by_type: + raise Exception(f'Incorrect dataset type: {dataset_type}') + + if dataset_type in ['train', 'val']: + return torch.tensor( + self.data_by_type[dataset_type][self.rank - 1::self.worldsize], + dtype=torch.float32 + ) + else: + raise ValueError + + @property + def sample_shape(self) -> List[str]: + """Return the sample shape info.""" + (*x, _) = self.data[0] + return [str(i) for i in np.array(x, ndmin=1).shape] + + @property + def target_shape(self) -> List[str]: + """Return the target shape info.""" + (*_, y) = self.data[0] + return [str(i) for i in np.array(y, ndmin=1).shape] + + @property + def dataset_description(self) -> str: + """Return the dataset description.""" + return (f'Regression dataset, shard number {self.rank}' + f' out of {self.worldsize}') diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/envoy/requirements.txt b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/envoy/requirements.txt new file mode 100644 index 0000000..acfef16 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/envoy/requirements.txt @@ -0,0 +1,7 @@ +mistune>=2.0.3 # not directly required, pinned by Snyk to avoid a vulnerability +numpy>=1.13.3 +openfl>=1.2.1 +scikit-learn>=0.24.1 +setuptools>=65.5.1 # not directly required, pinned by Snyk to avoid a vulnerability +torch>=1.13.1 +wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/envoy/start_envoy.sh new file mode 100755 index 0000000..4da0782 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/envoy/start_envoy.sh @@ -0,0 +1,6 @@ +#!/bin/bash +set -e +ENVOY_NAME=$1 +ENVOY_CONF=$2 + +fx envoy start -n "$ENVOY_NAME" --disable-tls --envoy-config-path "$ENVOY_CONF" -dh localhost -dp 50050 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/workspace/requirements.txt b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/workspace/requirements.txt new file mode 100644 index 0000000..fbeabbc --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/workspace/requirements.txt @@ -0,0 +1,7 @@ +jupyterlab +numpy>=1.13.3 +openfl>=1.2.1 +scikit-learn>=0.24.1 +setuptools>=65.5.1 # not directly required, pinned by Snyk to avoid a vulnerability +torch>=1.13.1 +wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/workspace/torch_linear_regression.ipynb b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/workspace/torch_linear_regression.ipynb new file mode 100644 index 0000000..d7ad3e3 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_LinearRegression/workspace/torch_linear_regression.ipynb @@ -0,0 +1,388 @@ +{ + "cells": [ + { + "attachments": {}, + "cell_type": "markdown", + "metadata": {}, + "source": [ + "# Torch Regression Example - Interactive API" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "import numpy as np\n", + "import torch\n", + "import torch.nn as nn\n", + "import torch.optim as optim" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "NUM_FEATURES = 1\n", + "LEARNING_RATE = 0.5" + ] + }, + { + "attachments": {}, + "cell_type": "markdown", + "metadata": {}, + "source": [ + "## Torch Definitions" + ] + }, + { + "attachments": {}, + "cell_type": "markdown", + "metadata": {}, + "source": [ + "### Model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "class LRModel(nn.Module):\n", + "\n", + " def __init__(self, in_features: int, out_features: int) -> None:\n", + " super().__init__()\n", + " self.fc = torch.nn.Linear(in_features, out_features)\n", + " \n", + " def forward(self, x: torch.Tensor) -> torch.Tensor:\n", + " return self.fc(x)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "model = LRModel(NUM_FEATURES, 1)" + ] + }, + { + "attachments": {}, + "cell_type": "markdown", + "metadata": {}, + "source": [ + "### Optimizer" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "optimizer = optim.SGD(model.parameters(), lr=LEARNING_RATE)" + ] + }, + { + "attachments": {}, + "cell_type": "markdown", + "metadata": {}, + "source": [ + "### Loss function" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "loss_fn = nn.MSELoss()" + ] + }, + { + "attachments": {}, + "cell_type": "markdown", + "metadata": {}, + "source": [ + "## Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "import copy" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment" + ] + }, + { + "attachments": {}, + "cell_type": "markdown", + "metadata": {}, + "source": [ + "### Dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "class LRDataset(DataInterface):\n", + " def __init__(self, train_bs: int = 1024, val_bs: int = 1024, **kwargs):\n", + " super().__init__(**kwargs)\n", + " self._train_bs = train_bs\n", + " self._val_bs = val_bs\n", + " self._train_data = None\n", + " self._val_data = None\n", + "\n", + " @property\n", + " def shard_descriptor(self):\n", + " return self._shard_descriptor\n", + "\n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + "\n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + " self._train_data = self._shard_descriptor.get_dataset('train')\n", + " self._val_data = self._shard_descriptor.get_dataset('val')\n", + " \n", + " def get_train_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks with optimizer in contract\n", + " \"\"\"\n", + " if self._train_data is None:\n", + " raise ValueError(\"train data is not set\")\n", + " return torch.utils.data.DataLoader(self._train_data, batch_size=self._train_bs, shuffle=True)\n", + "\n", + " def get_valid_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks without optimizer in contract\n", + " \"\"\"\n", + " if self._val_data is None:\n", + " raise ValueError(\"validation data is not set\")\n", + " return torch.utils.data.DataLoader(self._val_data, batch_size=self._val_bs)\n", + "\n", + " def get_train_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " if self._train_data is None:\n", + " raise ValueError(\"train data is not set\")\n", + " return len(self._train_data)\n", + "\n", + " def get_valid_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " if self._val_data is None:\n", + " raise ValueError(\"validation data is not set\")\n", + " return len(self._val_data)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "fl_dataset = LRDataset()" + ] + }, + { + "attachments": {}, + "cell_type": "markdown", + "metadata": {}, + "source": [ + "### Register model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "framework_adapter = 'openfl.plugins.frameworks_adapters.pytorch_adapter.FrameworkAdapterPlugin'\n", + "model_interface = ModelInterface(model=model, optimizer=optimizer, framework_plugin=framework_adapter)\n", + "\n", + "# Save the initial model state\n", + "initial_model = copy.deepcopy(model)" + ] + }, + { + "attachments": {}, + "cell_type": "markdown", + "metadata": {}, + "source": [ + "### Register tasks" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "task_interface = TaskInterface()\n", + "\n", + "# Task interface currently supports only standalone functions.\n", + "@task_interface.add_kwargs(**{'loss_fn': loss_fn})\n", + "@task_interface.register_fl_task(model='model', data_loader='train_loader', device='device', optimizer='optimizer') \n", + "def train(model, train_loader, optimizer, device, loss_fn): \n", + " model.to(device)\n", + " model.train()\n", + "\n", + " losses = []\n", + " for data in train_loader:\n", + " data = data.to(device)\n", + " optimizer.zero_grad()\n", + " loss = loss_fn(model(data[:,:NUM_FEATURES]), data[:,NUM_FEATURES:])\n", + " loss.backward()\n", + " optimizer.step()\n", + " losses.append(loss.detach().cpu().numpy())\n", + "\n", + " return {'train_mse': np.mean(losses)}\n", + "\n", + "\n", + "@task_interface.add_kwargs(**{'loss_fn': loss_fn})\n", + "@task_interface.register_fl_task(model='model', data_loader='val_loader', device='device') \n", + "def validate(model, val_loader, device, loss_fn):\n", + " model.to(device)\n", + " model.eval()\n", + " \n", + " losses = []\n", + " with torch.no_grad():\n", + " for data in val_loader:\n", + " data = data.to(device)\n", + " loss = loss_fn(model(data[:,:NUM_FEATURES]), data[:,NUM_FEATURES:])\n", + " losses.append(loss.detach().cpu().numpy())\n", + "\n", + " return {'val_mse': np.mean(losses)}" + ] + }, + { + "attachments": {}, + "cell_type": "markdown", + "metadata": {}, + "source": [ + "### Create Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.federation import Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "# please use the same identificator that was used in signed certificate\n", + "client_id = 'frontend'\n", + "director_node_fqdn = 'localhost'\n", + "director_port = 50050\n", + "\n", + "federation = Federation(\n", + " client_id=client_id,\n", + " director_node_fqdn=director_node_fqdn,\n", + " director_port=director_port,\n", + " tls=False\n", + ")" + ] + }, + { + "attachments": {}, + "cell_type": "markdown", + "metadata": {}, + "source": [ + "### Run Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "# create an experimnet in federation\n", + "experiment_name = 'torch_linear_regression_experiment'\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "# The following command zips the workspace and python requirements to be transfered to collaborator nodes\n", + "fl_experiment.start(\n", + " model_provider=model_interface, \n", + " task_keeper=task_interface,\n", + " data_loader=fl_dataset,\n", + " rounds_to_train=10\n", + ")" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "fl_experiment.stream_metrics()" + ] + } + ], + "metadata": { + "kernelspec": { + "display_name": "osh", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.16" + }, + "orig_nbformat": 4 + }, + "nbformat": 4, + "nbformat_minor": 2 +} diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/README.md b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/README.md new file mode 100755 index 0000000..3e538db --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/README.md @@ -0,0 +1,105 @@ +# Anomaly Detection with PatchSVDD for MVTec Dataset + + + +## **I. About the Dataset** + +MVTec AD is a dataset for benchmarking anomaly detection methods with a focus on industrial +inspection. It contains over 5000 high-resolution images divided into fifteen different object and +texture categories. Each class contains 60 to 390 normal train images (defect free) and 40 to 167 +test images (with various kinds of defects as well as images without defects). More info +at [MVTec dataset](https://www.mvtec.com/company/research/datasets/mvtec-ad). For each object, the +data is divided into 3 folders - 'train' (containing defect free training images), 'test'( +containing test images, both good and bad), 'ground_truth' (containing the masks of defected +images). + +
+
+ +## **II. About the Model** + +Two neural networks are used: an encoder and a classifier. The encoder is composed of convolutional +layers only. The classifier is a two layered MLP model having 128 hidden units per layer, and the +input to the classifier is a subtraction of the features of the two patches. The activation +function for both networks is a LeakyReLU with a α = 0.1. The encoder has a hierarchical structure. +The receptive field of the encoder is K = 64, and that of the embedded smaller encoder is K = 32. +Patch SVDD divides the images into patches with a size K and a stride S. The values for the strides +are S = 16 and S = 4 for the encoders with K = 64 and K = 32, respectively. + +
+
+ +## **III. Links** + +* [Original paper](https://arxiv.org/abs/2006.16067) +* [Original Github code](https://github.com/nuclearboy95/Anomaly-Detection-PatchSVDD-PyTorch/tree/934d6238e5e0ad511e2a0e7fc4f4899010e7d892) +* [MVTec ad dataset download link](https://www.mydrive.ch/shares/38536/3830184030e49fe74747669442f0f282/download/420938113-1629952094/mvtec_anomaly_detection.tar.xz) + +
+
+ +## **IV. How to run this tutorial (without TLS and locally as a simulation):** + +
+ +### **Note: An NVIDIA driver and GPUs are needed to run this tutorial unless configured otherwise.** + +
+ +### 0. If you haven't done so already, create a virtual environment, install OpenFL, and upgrade pip: + - For help with this step, visit the "Install the Package" section of the [OpenFL installation instructions](https://openfl.readthedocs.io/en/latest/install.html#install-the-package). + +
+ +### 1. Split terminal into 3 (1 terminal for the director, 1 for the envoy, and 1 for the experiment) + +
+ +### 2. Do the following in each terminal: + - Activate the virtual environment from step 0: + + ```sh + source venv/bin/activate + ``` + - If you are in a network environment with a proxy, ensure proxy environment variables are set in each of your terminals. + - Navigate to the tutorial: + + ```sh + cd openfl/openfl-tutorials/interactive_api/PyTorch_MVTec_PatchSVDD + ``` + +
+ +### 3. In the first terminal, run the director: + +```sh +cd director +./start_director.sh +``` + +
+ +### 4. In the second terminal, install requirements and run the envoy: + +```sh +cd envoy +pip install -r sd_requirements.txt +./start_envoy.sh env_one envoy_config.yaml +``` + +Optional: Run a second envoy in an additional terminal: + - Ensure step 2 is complete for this terminal as well. + - Repeat step 4 instructions above but change "env_one" name to "env_two" (or another name of your choice). + +
+ +### 5. Now that your director and envoy terminals are set up, run the Jupyter Notebook in your experiment terminal: + +```sh +cd workspace +jupyter lab PatchSVDD_with_Director.ipynb +``` +- A Jupyter Server URL will appear in your terminal. In your browser, proceed to that link. Once the webpage loads, click on the PatchSVDD_with_Director.ipynb file. +- To run the experiment, select the icon that looks like two triangles to "Restart Kernel and Run All Cells". +- You will notice activity in your terminals as the experiment runs, and when the experiment is finished the director terminal will display a message that the experiment has finished successfully. + diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/director/director_config.yaml new file mode 100644 index 0000000..abe05b0 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/director/director_config.yaml @@ -0,0 +1,5 @@ +settings: + listen_host: localhost + listen_port: 50050 + sample_shape: ['256', '256', '3'] + target_shape: ['256', '256'] diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/director/start_director.sh new file mode 100755 index 0000000..5806a6c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/director/start_director.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx director start --disable-tls -c director_config.yaml \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/director/start_director_with_tls.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/director/start_director_with_tls.sh new file mode 100755 index 0000000..5d6d46a --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/director/start_director_with_tls.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e +FQDN=$1 +fx director start -c director_config.yaml -rc cert/root_ca.crt -pk cert/"${FQDN}".key -oc cert/"${FQDN}".crt \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/envoy/envoy_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/envoy/envoy_config.yaml new file mode 100644 index 0000000..02d3853 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/envoy/envoy_config.yaml @@ -0,0 +1,11 @@ +params: + cuda_devices: [0,2] + +optional_plugin_components: {} + +shard_descriptor: + template: mvtec_shard_descriptor.MVTecShardDescriptor + params: + data_folder: MVTec_data + rank_worldsize: 1,1 + obj: bottle \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/envoy/mvtec_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/envoy/mvtec_shard_descriptor.py new file mode 100644 index 0000000..e1e7df9 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/envoy/mvtec_shard_descriptor.py @@ -0,0 +1,159 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 +"""MVTec shard descriptor.""" + +import os +from glob import glob +from pathlib import Path + +import numpy as np +from imageio import imread +from PIL import Image + +from openfl.interface.interactive_api.shard_descriptor import ShardDataset +from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor + + +class MVTecShardDataset(ShardDataset): + """MVTec Shard dataset class.""" + + def __init__(self, images_path, + mask_path, labels, + rank=1, + worldsize=1): + """Initialize MVTecShardDataset.""" + self.rank = rank + self.worldsize = worldsize + self.images_path = images_path[self.rank - 1::self.worldsize] + self.mask_path = mask_path[self.rank - 1::self.worldsize] + self.labels = labels[self.rank - 1::self.worldsize] + + def __getitem__(self, index): + """Return a item by the index.""" + img = np.asarray(imread(self.images_path[index])) + if img.shape[-1] != 3: + img = self.gray2rgb(img) + + img = self.resize(img) + img = np.asarray(img) + label = self.labels[index] + if self.mask_path[index]: + mask = np.asarray(imread(self.mask_path[index])) + mask = self.resize(mask) + mask = np.asarray(mask) + else: + mask = np.zeros(img.shape)[:, :, 0] + return img, mask, label + + def __len__(self): + """Return the len of the dataset.""" + return len(self.images_path) + + def resize(self, image, shape=(256, 256)): + """Resize image.""" + return np.array(Image.fromarray(image).resize(shape)) + + def gray2rgb(self, images): + """Change image from gray to rgb.""" + tile_shape = tuple(np.ones(len(images.shape), dtype=int)) + tile_shape += (3,) + + images = np.tile(np.expand_dims(images, axis=-1), tile_shape) + return images + + +class MVTecShardDescriptor(ShardDescriptor): + """MVTec Shard descriptor class.""" + + def __init__(self, data_folder: str = 'MVTec_data', + rank_worldsize: str = '1,1', + obj: str = 'bottle'): + """Initialize MVTecShardDescriptor.""" + super().__init__() + + self.dataset_path = Path.cwd() / data_folder + self.download_data() + self.rank, self.worldsize = tuple(int(num) for num in rank_worldsize.split(',')) + self.obj = obj + + # Calculating data and target shapes + ds = self.get_dataset() + sample, masks, target = ds[0] + self._sample_shape = [str(dim) for dim in sample.shape] + self._target_shape = [str(dim) for dim in target.shape] + + def download_data(self): + """Download data.""" + zip_file_path = self.dataset_path / 'mvtec_anomaly_detection.tar.xz' + if not Path(zip_file_path).exists(): + os.makedirs(self.dataset_path, exist_ok=True) + print('Downloading MVTec Dataset...this might take a while') + os.system('wget -nc' + " 'https://www.mydrive.ch/shares/38536/3830184030e49fe74747669442f0f282/download/420938113-1629952094/mvtec_anomaly_detection.tar.xz'" # noqa + f' -O {zip_file_path.relative_to(Path.cwd())}') + print('Downloaded MVTec dataset, untar-ring now') + os.system(f'tar -xvf {zip_file_path.relative_to(Path.cwd())}' + f' -C {self.dataset_path.relative_to(Path.cwd())}') + # change to write permissions + self.change_permissions(self.dataset_path, 0o764) + + def change_permissions(self, folder, code): + """Change permissions after data is downloaded.""" + for root, dirs, files in os.walk(folder): + for d in dirs: + os.chmod(os.path.join(root, d), code) + for f in files: + os.chmod(os.path.join(root, f), code) + + def get_dataset(self, dataset_type='train'): + """Return a shard dataset by type.""" + # Train dataset + if dataset_type == 'train': + fpattern = os.path.join(self.dataset_path, f'{self.obj}/train/*/*.png') + fpaths = sorted(glob(fpattern)) + self.images_path = list(fpaths) + self.labels = np.zeros(len(fpaths), dtype=np.int32) + # Masks + self.mask_path = np.full(self.labels.shape, None) + # Test dataset + elif dataset_type == 'test': + fpattern = os.path.join(self.dataset_path, f'{self.obj}/test/*/*.png') + fpaths = sorted(glob(fpattern)) + fpaths_anom = list( + filter(lambda fpath: os.path.basename(os.path.dirname(fpath)) != 'good', fpaths)) + fpaths_good = list( + filter(lambda fpath: os.path.basename(os.path.dirname(fpath)) == 'good', fpaths)) + fpaths = fpaths_anom + fpaths_good + self.images_path = fpaths + self.labels = np.zeros(len(fpaths_anom) + len(fpaths_good), dtype=np.int32) + self.labels[:len(fpaths_anom)] = 1 # anomalies + # Masks + fpattern_mask = os.path.join(self.dataset_path, f'{self.obj}/ground_truth/*/*.png') + self.mask_path = sorted(glob(fpattern_mask)) + [None] * len(fpaths_good) + else: + raise Exception(f'Wrong dataset type: {dataset_type}.' + f'Choose from the list: [train, test]') + + return MVTecShardDataset( + images_path=self.images_path, + mask_path=self.mask_path, + labels=self.labels, + rank=self.rank, + worldsize=self.worldsize, + ) + + @property + def sample_shape(self): + """Return the sample shape info.""" + return ['256', '256', '3'] + + @property + def target_shape(self): + """Return the target shape info.""" + return ['256', '256'] + + @property + def dataset_description(self) -> str: + """Return the shard dataset description.""" + return (f'MVTec dataset, shard number {self.rank}' + f' out of {self.worldsize}') diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/envoy/sd_requirements.txt b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/envoy/sd_requirements.txt new file mode 100644 index 0000000..a1e73bf --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/envoy/sd_requirements.txt @@ -0,0 +1,3 @@ +imageio +numpy +pillow diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/envoy/start_envoy.sh new file mode 100755 index 0000000..ae9b4c2 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/envoy/start_envoy.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx envoy start -n env_one --disable-tls --envoy-config-path envoy_config.yaml -dh localhost -dp 50050 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/envoy/start_envoy_with_tls.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/envoy/start_envoy_with_tls.sh new file mode 100755 index 0000000..d4e0960 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/envoy/start_envoy_with_tls.sh @@ -0,0 +1,6 @@ +#!/bin/bash +set -e +ENVOY_NAME=$1 +DIRECTOR_FQDN=$2 + +fx envoy start -n "$ENVOY_NAME" --envoy-config-path envoy_config.yaml -dh"$DIRECTOR_FQDN" -dp 50050 -rc cert/root_ca.crt -pk cert/"$ENVOY_NAME".key -oc cert/"$ENVOY_NAME".crt \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/workspace/PatchSVDD_with_Director.ipynb b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/workspace/PatchSVDD_with_Director.ipynb new file mode 100644 index 0000000..3519347 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/workspace/PatchSVDD_with_Director.ipynb @@ -0,0 +1,1120 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "liquid-jacket", + "metadata": {}, + "source": [ + "# Federated PatchSVDD algorithm with Director example" + ] + }, + { + "cell_type": "markdown", + "id": "83e6aae2", + "metadata": {}, + "source": [ + "# PatchSVDD algorithm\n", + "Anomaly detection involves making a binary decision as to whether an input image contains an anomaly, and anomaly segmentation aims to locate the anomaly on the pixel level. The deep learning variant of Support vector data description (SVDD: a long-standing algorithm used for anomaly detection) is used to the patch-based method using self-supervised learning. This extension enables anomaly segmentation and improves detection performances which are measured in AUROC on MVTec AD dataset.\n", + "\n", + "\n", + "\n", + "* Original paper: https://arxiv.org/abs/2006.16067\n", + "* Original Github code: https://github.com/nuclearboy95/Anomaly-Detection-PatchSVDD-PyTorch/tree/934d6238e5e0ad511e2a0e7fc4f4899010e7d892\n", + "* MVTec ad dataset download link: https://www.mydrive.ch/shares/38536/3830184030e49fe74747669442f0f282/download/420938113-1629952094/mvtec_anomaly_detection.tar.xz" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "alike-sharing", + "metadata": { + "scrolled": true + }, + "outputs": [], + "source": [ + "# Install dependencies if not already installed\n", + "!pip install torchvision==0.8.1 matplotlib numpy scikit-image scikit-learn torch tqdm Pillow imageio opencv-python ngt" + ] + }, + { + "cell_type": "markdown", + "id": "16986f22", + "metadata": {}, + "source": [ + "# Connect to the Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4485ac79", + "metadata": {}, + "outputs": [], + "source": [ + "# Create a federation\n", + "from openfl.interface.interactive_api.federation import Federation\n", + "\n", + "# 1) Run with API layer - Director mTLS \n", + "# If the user wants to enable mTLS their must provide CA root chain, and signed key pair to the federation interface\n", + "# cert_chain = 'cert/root_ca.crt'\n", + "# API_certificate = 'cert/frontend.crt'\n", + "# API_private_key = 'cert/frontend.key'\n", + "\n", + "# federation = Federation(client_id='frontend', director_node_fqdn='localhost', director_port='50051',\n", + "# cert_chain=cert_chain, api_cert=API_certificate, api_private_key=API_private_key)\n", + "\n", + "# --------------------------------------------------------------------------------------------------------------------\n", + "\n", + "# 2) Run with TLS disabled (trusted environment)\n", + "# Federation can also determine local fqdn automatically\n", + "federation = Federation(client_id='frontend', director_node_fqdn='localhost', director_port='50050', tls=False)\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "e35802d5", + "metadata": { + "scrolled": true + }, + "outputs": [], + "source": [ + "shard_registry = federation.get_shard_registry()\n", + "shard_registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "67ae50de", + "metadata": {}, + "outputs": [], + "source": [ + "federation.target_shape" + ] + }, + { + "cell_type": "markdown", + "id": "obvious-tyler", + "metadata": {}, + "source": [ + "## Creating a FL experiment using Interactive API" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "rubber-address", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment" + ] + }, + { + "cell_type": "markdown", + "id": "sustainable-public", + "metadata": {}, + "source": [ + "### Register dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "dd2407cf", + "metadata": { + "scrolled": true + }, + "outputs": [], + "source": [ + "#Arguments\n", + "args = {\n", + "'obj' : 'bottle',\n", + "'lambda_value': '1e-3',\n", + "'D' : 64,\n", + "'lr' : '1e-4',\n", + "}" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "8669bc63", + "metadata": {}, + "outputs": [], + "source": [ + "import argparse\n", + "import torch\n", + "from functools import reduce\n", + "from torch.utils.data import DataLoader,Dataset\n", + "import torch.nn as nn\n", + "import torch.nn.functional as F\n", + "import math\n", + "import numpy as np\n", + "from PIL import Image\n", + "from imageio import imread\n", + "from glob import glob\n", + "from sklearn.metrics import roc_auc_score\n", + "import os, shutil\n", + "import _pickle as p\n", + "from contextlib import contextmanager\n", + "import PIL\n", + "from torch.utils.data import Dataset, DataLoader, SubsetRandomSampler\n", + "from torchvision import transforms as tsf\n", + "from utils import to_device, task, DictionaryConcatDataset, crop_chw, cnn_output_size, crop_image_chw\n", + "from functools import reduce" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "64f37dcf", + "metadata": { + "scrolled": true + }, + "outputs": [], + "source": [ + "def generate_coords(H, W, K):\n", + " h = np.random.randint(0, H - K + 1)\n", + " w = np.random.randint(0, W - K + 1)\n", + " return h, w\n", + "\n", + "\n", + "def generate_coords_position(H, W, K):\n", + " with task('P1'):\n", + " p1 = generate_coords(H, W, K)\n", + " h1, w1 = p1\n", + "\n", + " pos = np.random.randint(8)\n", + "\n", + " with task('P2'):\n", + " J = K // 4\n", + "\n", + " K3_4 = 3 * K // 4\n", + " h_dir, w_dir = pos_to_diff[pos]\n", + " h_del, w_del = np.random.randint(J, size=2)\n", + "\n", + " h_diff = h_dir * (h_del + K3_4)\n", + " w_diff = w_dir * (w_del + K3_4)\n", + "\n", + " h2 = h1 + h_diff\n", + " w2 = w1 + w_diff\n", + "\n", + " h2 = np.clip(h2, 0, H - K)\n", + " w2 = np.clip(w2, 0, W - K)\n", + "\n", + " p2 = (h2, w2)\n", + "\n", + " return p1, p2, pos\n", + "\n", + "\n", + "def generate_coords_svdd(H, W, K):\n", + " with task('P1'):\n", + " p1 = generate_coords(H, W, K)\n", + " h1, w1 = p1\n", + "\n", + " with task('P2'):\n", + " J = K // 32\n", + "\n", + " h_jit, w_jit = 0, 0\n", + "\n", + " while h_jit == 0 and w_jit == 0:\n", + " h_jit = np.random.randint(-J, J + 1)\n", + " w_jit = np.random.randint(-J, J + 1)\n", + "\n", + " h2 = h1 + h_jit\n", + " w2 = w1 + w_jit\n", + "\n", + " h2 = np.clip(h2, 0, H - K)\n", + " w2 = np.clip(w2, 0, W - K)\n", + "\n", + " p2 = (h2, w2)\n", + "\n", + " return p1, p2\n", + "\n", + "\n", + "pos_to_diff = {\n", + " 0: (-1, -1),\n", + " 1: (-1, 0),\n", + " 2: (-1, 1),\n", + " 3: (0, -1),\n", + " 4: (0, 1),\n", + " 5: (1, -1),\n", + " 6: (1, 0),\n", + " 7: (1, 1)\n", + "}\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "242e3109", + "metadata": {}, + "outputs": [], + "source": [ + "class SVDD_Dataset(Dataset):\n", + " def __init__(self, memmap, K=64, repeat=1):\n", + " super().__init__()\n", + " self.arr = np.asarray(memmap)\n", + " self.K = K\n", + " self.repeat = repeat\n", + " \n", + "\n", + " def __len__(self):\n", + " N = self.arr.shape[0]\n", + " return N * self.repeat\n", + "\n", + " def __getitem__(self, idx):\n", + " N = self.arr.shape[0]\n", + " K = self.K\n", + " n = idx % N\n", + "\n", + " p1, p2 = generate_coords_svdd(256, 256, K)\n", + "\n", + " image = self.arr[n]\n", + "\n", + " patch1 = crop_image_chw(image, p1, K)\n", + " patch2 = crop_image_chw(image, p2, K)\n", + "\n", + " return patch1, patch2" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "cea3ee13", + "metadata": {}, + "outputs": [], + "source": [ + "class PositionDataset(Dataset):\n", + " def __init__(self, x, K=64, repeat=1):\n", + " super(PositionDataset, self).__init__()\n", + " self.x = np.asarray(x)\n", + " self.K = K\n", + " self.repeat = repeat\n", + "\n", + " def __len__(self):\n", + " N = self.x.shape[0]\n", + " return N * self.repeat\n", + "\n", + " def __getitem__(self, idx):\n", + " N = self.x.shape[0]\n", + " K = self.K\n", + " n = idx % N\n", + "\n", + " image = self.x[n]\n", + " p1, p2, pos = generate_coords_position(256, 256, K)\n", + "\n", + " patch1 = crop_image_chw(image, p1, K).copy()\n", + " patch2 = crop_image_chw(image, p2, K).copy()\n", + "\n", + " # perturb RGB\n", + " rgbshift1 = np.random.normal(scale=0.02, size=(3, 1, 1))\n", + " rgbshift2 = np.random.normal(scale=0.02, size=(3, 1, 1))\n", + "\n", + " patch1 += rgbshift1\n", + " patch2 += rgbshift2\n", + "\n", + " # additive noise\n", + " noise1 = np.random.normal(scale=0.02, size=(3, K, K))\n", + " noise2 = np.random.normal(scale=0.02, size=(3, K, K))\n", + "\n", + " patch1 += noise1\n", + " patch2 += noise2\n", + "\n", + " return patch1, patch2, pos\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "6efc53ee", + "metadata": {}, + "outputs": [], + "source": [ + "class PatchDataset_NCHW(Dataset):\n", + " def __init__(self, memmap, tfs=None, K=32, S=1):\n", + " super().__init__()\n", + " self.arr = memmap\n", + " self.tfs = tfs\n", + " self.S = S\n", + " self.K = K\n", + " self.N = self.arr.shape[0]\n", + " \n", + " def __len__(self):\n", + " return self.N * self.row_num * self.col_num\n", + "\n", + " @property\n", + " def row_num(self):\n", + " N, C, H, W = self.arr.shape\n", + " K = self.K\n", + " S = self.S\n", + " I = cnn_output_size(H, k=K, s=S)\n", + " return I\n", + "\n", + " @property\n", + " def col_num(self):\n", + " N, C, H, W = self.arr.shape\n", + " K = self.K\n", + " S = self.S\n", + " J = cnn_output_size(W, k=K, s=S)\n", + " return J\n", + "\n", + " def __getitem__(self, idx):\n", + " N = self.N\n", + " n, i, j = np.unravel_index(idx, (N, self.row_num, self.col_num))\n", + " K = self.K\n", + " S = self.S\n", + " image = self.arr[n]\n", + " patch = crop_chw(image, i, j, K, S)\n", + "\n", + " if self.tfs:\n", + " patch = self.tfs(patch)\n", + "\n", + " return patch, n, i, j\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "fd781c21", + "metadata": {}, + "outputs": [], + "source": [ + "\"\"\"\n", + "ShardDataset class\n", + "\"\"\"\n", + "class MVTecShardDataset(Dataset):\n", + " \n", + " def __init__(self, dataset):\n", + " self._dataset = dataset\n", + " \n", + " def __getitem__(self, index):\n", + " img, mask, label = self._dataset[index]\n", + " return img, mask, label\n", + " \n", + " def __len__(self):\n", + " return len(self._dataset)\n", + " \n", + "class MVTecSD(DataInterface):\n", + "\n", + " def __init__(self, **kwargs):\n", + " super().__init__(**kwargs)\n", + " \n", + " @property\n", + " def shard_descriptor(self):\n", + " return self._shard_descriptor\n", + " \n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + "\n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + " \n", + " self.train_set = MVTecShardDataset(shard_descriptor.get_dataset('train'))\n", + "\n", + " self.test_set = MVTecShardDataset(shard_descriptor.get_dataset('test')) \n", + " \n", + " def get_train_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks with optimizer in contract\n", + " \"\"\"\n", + " train_x = np.stack([image for image, mask, label in self.train_set]).astype(np.float32)\n", + " mean = train_x.astype(np.float32).mean(axis=0)\n", + " train_x = (train_x.astype(np.float32) - mean) / 255\n", + " train_x = np.transpose(train_x, [0, 3, 1, 2])\n", + " \n", + " if self.kwargs['train_bs']:\n", + " batch_size = self.kwargs['train_bs']\n", + " else:\n", + " batch_size = 64\n", + " \n", + " loader = DataLoader(self.get_train_dataset_dict(train_x), batch_size=batch_size, shuffle=True, num_workers=2, pin_memory=True)\n", + " return loader\n", + "\n", + " def get_valid_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks without optimizer in contract\n", + " \"\"\"\n", + " # We need both train and test data for obtaining embeddings\n", + " train_x = np.stack([image for image, mask, label in self.train_set]).astype(np.float32)\n", + " mean = train_x.astype(np.float32).mean(axis=0)\n", + " train_x = (train_x.astype(np.float32) - mean) / 255\n", + " train_x = np.transpose(train_x, [0, 3, 1, 2])\n", + " \n", + " #getting val loader\n", + " test_x = np.stack([image for image, mask, label in self.test_set]).astype(np.float32)\n", + " mean = test_x.astype(np.float32).mean(axis=0)\n", + " test_x = (test_x.astype(np.float32) - mean) / 255\n", + " test_x = np.transpose(test_x, [0, 3, 1, 2])\n", + " \n", + " masks = np.stack([mask for image, mask, label in self.test_set]).astype(np.int32)\n", + " masks[masks <= 128] = 0\n", + " masks[masks > 128] = 255\n", + " labels = np.stack([label for image, mask, label in self.test_set]).astype(np.int32)\n", + "\n", + " return (train_x, test_x, masks, labels, mean)\n", + "\n", + "\n", + " def get_train_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.train_set)\n", + " \n", + "\n", + " def get_valid_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.test_set)\n", + " \n", + " def get_train_dataset_dict(self,inp_x):\n", + " rep = 100\n", + " datasets = dict()\n", + " datasets[f'pos_64'] = PositionDataset(inp_x, K=64, repeat=rep)\n", + " datasets[f'pos_32'] = PositionDataset(inp_x, K=32, repeat=rep)\n", + "\n", + " datasets[f'svdd_64'] = SVDD_Dataset(inp_x, K=64, repeat=rep)\n", + " datasets[f'svdd_32'] = SVDD_Dataset(inp_x, K=32, repeat=rep)\n", + " dataset = DictionaryConcatDataset(datasets)\n", + " return dataset\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d8df35f5", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = MVTecSD(train_bs=64, val_bs=64)" + ] + }, + { + "cell_type": "markdown", + "id": "8f786b8b", + "metadata": {}, + "source": [ + "### Describe a model and optimizer" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "visible-victor", + "metadata": {}, + "outputs": [], + "source": [ + "import torch.optim as optim\n", + "import torch.nn as nn\n", + "import torch\n", + "import torch.nn.functional as F\n", + "import math\n", + "from utils import makedirpath" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "138e1493", + "metadata": {}, + "outputs": [], + "source": [ + "class Encoder(nn.Module):\n", + " def __init__(self, K, D=64, bias=True):\n", + " super().__init__()\n", + "\n", + " self.conv1 = nn.Conv2d(3, 64, 5, 2, 0, bias=bias)\n", + " self.conv2 = nn.Conv2d(64, 64, 5, 2, 0, bias=bias)\n", + " self.conv3 = nn.Conv2d(64, 128, 5, 2, 0, bias=bias)\n", + " self.conv4 = nn.Conv2d(128, D, 5, 1, 0, bias=bias)\n", + "\n", + " self.K = K\n", + " self.D = D\n", + " self.bias = bias\n", + "\n", + " def forward(self, x):\n", + " h = self.conv1(x)\n", + " h = F.leaky_relu(h, 0.1)\n", + "\n", + " h = self.conv2(h)\n", + " h = F.leaky_relu(h, 0.1)\n", + "\n", + " h = self.conv3(h)\n", + "\n", + " if self.K == 64:\n", + " h = F.leaky_relu(h, 0.1)\n", + " h = self.conv4(h)\n", + "\n", + " h = torch.tanh(h)\n", + "\n", + " return h\n", + "\n", + "def forward_hier(x, emb_small, K):\n", + " K_2 = K // 2\n", + " n = x.size(0)\n", + " x1 = x[..., :K_2, :K_2]\n", + " x2 = x[..., :K_2, K_2:]\n", + " x3 = x[..., K_2:, :K_2]\n", + " x4 = x[..., K_2:, K_2:]\n", + " xx = torch.cat([x1, x2, x3, x4], dim=0)\n", + " hh = emb_small(xx)\n", + "\n", + " h1 = hh[:n]\n", + " h2 = hh[n: 2 * n]\n", + " h3 = hh[2 * n: 3 * n]\n", + " h4 = hh[3 * n:]\n", + "\n", + " h12 = torch.cat([h1, h2], dim=3)\n", + " h34 = torch.cat([h3, h4], dim=3)\n", + " h = torch.cat([h12, h34], dim=2)\n", + " return h\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "113f5a73", + "metadata": {}, + "outputs": [], + "source": [ + "class EncoderDeep(nn.Module):\n", + " def __init__(self, K, D=64, bias=True):\n", + " super().__init__()\n", + "\n", + " self.conv1 = nn.Conv2d(3, 32, 3, 2, 0, bias=bias)\n", + " self.conv2 = nn.Conv2d(32, 64, 3, 1, 0, bias=bias)\n", + " self.conv3 = nn.Conv2d(64, 128, 3, 1, 0, bias=bias)\n", + " self.conv4 = nn.Conv2d(128, 128, 3, 1, 0, bias=bias)\n", + " self.conv5 = nn.Conv2d(128, 64, 3, 1, 0, bias=bias)\n", + " self.conv6 = nn.Conv2d(64, 32, 3, 1, 0, bias=bias)\n", + " self.conv7 = nn.Conv2d(32, 32, 3, 1, 0, bias=bias)\n", + " self.conv8 = nn.Conv2d(32, D, 3, 1, 0, bias=bias)\n", + "\n", + " self.K = K\n", + " self.D = D\n", + "\n", + " def forward(self, x):\n", + " h = self.conv1(x)\n", + " h = F.leaky_relu(h, 0.1)\n", + "\n", + " h = self.conv2(h)\n", + " h = F.leaky_relu(h, 0.1)\n", + "\n", + " h = self.conv3(h)\n", + " h = F.leaky_relu(h, 0.1)\n", + "\n", + " h = self.conv4(h)\n", + " h = F.leaky_relu(h, 0.1)\n", + "\n", + " h = self.conv5(h)\n", + " h = F.leaky_relu(h, 0.1)\n", + "\n", + " h = self.conv6(h)\n", + " h = F.leaky_relu(h, 0.1)\n", + "\n", + " h = self.conv7(h)\n", + " h = F.leaky_relu(h, 0.1)\n", + "\n", + " h = self.conv8(h)\n", + " h = torch.tanh(h)\n", + "\n", + " return h\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "70ccf01d", + "metadata": {}, + "outputs": [], + "source": [ + "class EncoderHier(nn.Module):\n", + " def __init__(self, K, D=64, bias=True):\n", + " super().__init__()\n", + "\n", + " if K > 64:\n", + " self.enc = EncoderHier(K // 2, D, bias=bias)\n", + "\n", + " elif K == 64:\n", + " self.enc = EncoderDeep(K // 2, D, bias=bias)\n", + "\n", + " else:\n", + " raise ValueError()\n", + "\n", + " self.conv1 = nn.Conv2d(D, 128, 2, 1, 0, bias=bias)\n", + " self.conv2 = nn.Conv2d(128, D, 1, 1, 0, bias=bias)\n", + "\n", + " self.K = K\n", + " self.D = D\n", + "\n", + " def forward(self, x):\n", + " h = forward_hier(x, self.enc, K=self.K)\n", + "\n", + " h = self.conv1(h)\n", + " h = F.leaky_relu(h, 0.1)\n", + "\n", + " h = self.conv2(h)\n", + " h = torch.tanh(h)\n", + "\n", + " return h\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "6e7688de", + "metadata": {}, + "outputs": [], + "source": [ + "xent = nn.CrossEntropyLoss()\n", + "\n", + "class NormalizedLinear(nn.Module):\n", + " __constants__ = ['bias', 'in_features', 'out_features']\n", + "\n", + " def __init__(self, in_features, out_features, bias=True):\n", + " super(NormalizedLinear, self).__init__()\n", + " self.in_features = in_features\n", + " self.out_features = out_features\n", + " self.weight = nn.Parameter(torch.Tensor(out_features, in_features))\n", + " if bias:\n", + " self.bias = nn.Parameter(torch.Tensor(out_features))\n", + " else:\n", + " self.register_parameter('bias', None)\n", + " self.reset_parameters()\n", + "\n", + " def reset_parameters(self):\n", + " nn.init.kaiming_uniform_(self.weight, a=math.sqrt(5))\n", + " if self.bias is not None:\n", + " fan_in, _ = nn.init._calculate_fan_in_and_fan_out(self.weight)\n", + " bound = 1 / math.sqrt(fan_in)\n", + " nn.init.uniform_(self.bias, -bound, bound)\n", + "\n", + " def forward(self, x):\n", + " with torch.no_grad():\n", + " w = self.weight / self.weight.data.norm(keepdim=True, dim=0)\n", + " return F.linear(x, w, self.bias)\n", + "\n", + " def extra_repr(self):\n", + " return 'in_features={}, out_features={}, bias={}'.format(\n", + " self.in_features, self.out_features, self.bias is not None\n", + " )\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "foreign-gospel", + "metadata": {}, + "outputs": [], + "source": [ + "class PositionClassifier(nn.Module):\n", + " def __init__(self, K, D, class_num=8):\n", + " super().__init__()\n", + " self.D = D\n", + "\n", + " self.fc1 = nn.Linear(D, 128)\n", + " self.act1 = nn.LeakyReLU(0.1)\n", + "\n", + " self.fc2 = nn.Linear(128, 128)\n", + " self.act2 = nn.LeakyReLU(0.1)\n", + "\n", + " self.fc3 = NormalizedLinear(128, class_num)\n", + " self.fc3.requires_grad_(False)\n", + "\n", + " self.K = K\n", + "\n", + " def forward(self, h1, h2):\n", + " h1 = h1.view(-1, self.D)\n", + " h2 = h2.view(-1, self.D)\n", + "\n", + " h = h1 - h2\n", + "\n", + " h = self.fc1(h)\n", + " h = self.act1(h)\n", + "\n", + " h = self.fc2(h)\n", + " h = self.act2(h)\n", + "\n", + " h = self.fc3(h)\n", + " return h\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "db853fe0", + "metadata": {}, + "outputs": [], + "source": [ + "\"\"\"\n", + "Model definition (ensembled)\n", + "\"\"\"\n", + "class MyEnsembledModel(nn.Module):\n", + " def __init__(self, enc, cls_64, cls_32):\n", + " super().__init__()\n", + " self._enc = enc\n", + " self._cls_64 = cls_64\n", + " self._cls_32 = cls_32\n", + " \n", + " def forward(self):\n", + " pass\n", + "\n", + "\n", + "enc = EncoderHier(64, args['D'])\n", + "cls_64 = PositionClassifier(64, args['D'])\n", + "cls_32 = PositionClassifier(32, args['D'])\n", + "\n", + "model = MyEnsembledModel(enc, cls_64, cls_32)\n", + "\n", + "params_to_update = []\n", + "for p in model.parameters():\n", + " if p.requires_grad:\n", + " params_to_update.append(p)\n", + "optimizer_adam = torch.optim.Adam(params=params_to_update , lr=float(args['lr']))\n" + ] + }, + { + "cell_type": "markdown", + "id": "caroline-passion", + "metadata": {}, + "source": [ + "#### Register model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "handled-teens", + "metadata": {}, + "outputs": [], + "source": [ + "from copy import deepcopy\n", + "\n", + "framework_adapter = 'openfl.plugins.frameworks_adapters.pytorch_adapter.FrameworkAdapterPlugin'\n", + "MI = ModelInterface(model=model, optimizer=optimizer_adam, framework_plugin=framework_adapter)\n", + "\n", + "# Save the initial model state\n", + "initial_model = deepcopy(model)" + ] + }, + { + "cell_type": "markdown", + "id": "portuguese-groove", + "metadata": {}, + "source": [ + "### Define and register FL tasks" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "increasing-builder", + "metadata": {}, + "outputs": [], + "source": [ + "TI = TaskInterface()\n", + "import torch\n", + "import tqdm\n", + "from utils import cnn_output_size\n", + "from inspection import eval_embeddings_nn_multik\n", + "\n", + "# The Interactive API supports registering functions definied in main module or imported.\n", + "def function_defined_in_notebook(some_parameter):\n", + " print(f'Also I accept a parameter and it is {some_parameter}')\n", + "\n", + "# Task interface currently supports only standalone functions.\n", + "@TI.add_kwargs(**{'some_parameter': 42})\n", + "@TI.register_fl_task(model='model', data_loader='train_loader', \\\n", + " device='device', optimizer='optimizer') \n", + "\n", + "def train(model, train_loader, optimizer, device, some_parameter=None):\n", + " print(f'\\n\\n TASK TRAIN GOT DEVICE {device}\\n\\n')\n", + " \n", + " function_defined_in_notebook(some_parameter)\n", + " \n", + " train_loader = tqdm.tqdm(train_loader, desc=\"train\")\n", + "\n", + " model.train()\n", + " model.to(device)\n", + " losses = []\n", + "\n", + " for d in train_loader:\n", + " d = to_device(d, device, non_blocking=True)\n", + " optimizer.zero_grad()\n", + " loss_pos_64 = PositionClassifier_infer(model._cls_64, model._enc, d['pos_64'])\n", + " loss_pos_32 = PositionClassifier_infer(model._cls_32, model._enc.enc, d['pos_32'])\n", + " loss_svdd_64 = SVDD_Dataset_infer(model._enc, d['svdd_64'])\n", + " loss_svdd_32 = SVDD_Dataset_infer(model._enc.enc, d['svdd_32'])\n", + "\n", + " loss = loss_pos_64 + loss_pos_32 + float(args['lambda_value']) * (loss_svdd_64 + loss_svdd_32)\n", + " loss.backward()\n", + " optimizer.step()\n", + " losses.append(loss.detach().cpu().numpy())\n", + " return {'train_loss': np.mean(losses),}\n", + " \n", + "\n", + "@TI.register_fl_task(model='model', data_loader='val_loader', device='device') \n", + "def validate(model, val_loader, device):\n", + " print(f'\\n\\n TASK VALIDATE GOT DEVICE {device}\\n\\n')\n", + " \n", + " model._enc.eval()\n", + " model._enc.to(device)\n", + " \n", + " x_tr, x_te, masks, labels, mean = val_loader\n", + "\n", + " embs64_tr = infer_(x_tr, model._enc, K=64, S=16, device=device)\n", + " embs64_te = infer_(x_te, model._enc, K=64, S=16, device=device)\n", + " embs32_tr = infer_(x_tr, model._enc.enc, K=32, S=4, device=device)\n", + " embs32_te = infer_(x_te, model._enc.enc, K=32, S=4, device=device)\n", + "\n", + " embs64 = embs64_tr, embs64_te\n", + " embs32 = embs32_tr, embs32_te\n", + "\n", + " results = eval_embeddings_nn_multik(args['obj'], embs64, embs32, masks, labels)\n", + " \n", + " maps = results['maps_mult']\n", + " obj = args['obj']\n", + "\n", + " print(\"| K64 | Det: {:.3f} Seg:{:.3f} BA: {:.3f}\".format(results['det_64'],results['seg_64'],results['bal_acc_64']))\n", + " print(\"| K32 | Det: {:.3f} Seg:{:.3f} BA: {:.3f}\".format(results['det_32'],results['seg_32'],results['bal_acc_32']))\n", + " print(\"| sum | Det: {:.3f} Seg:{:.3f} BA: {:.3f}\".format(results['det_sum'],results['seg_sum'],results['bal_acc_sum']))\n", + " print(\"| mult | Det: {:.3f} Seg:{:.3f} BA: {:.3f}\".format(results['det_mult'],results['seg_mult'],results['bal_acc_mult']))\n", + "\n", + " return {'detection_score_sum': results['det_sum'], 'segmentation_score_sum': results['seg_sum'], 'balanced_accuracy_score_sum': results['bal_acc_sum'], 'detection_score_mult': results['det_mult'], 'segmentation_score_mult': results['seg_mult'], 'balanced_accuracy_score_mult': results['bal_acc_mult']}\n", + "\n", + " " + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "17d53d96", + "metadata": {}, + "outputs": [], + "source": [ + "# Infer functions\n", + "def PositionClassifier_infer(c, enc, batch):\n", + " x1s, x2s, ys = batch\n", + " h1 = enc(x1s)\n", + " h2 = enc(x2s)\n", + " logits = c(h1, h2)\n", + " loss = xent(logits, ys)\n", + " return loss\n", + "\n", + "def SVDD_Dataset_infer(enc, batch):\n", + " x1s, x2s, = batch\n", + " h1s = enc(x1s)\n", + " h2s = enc(x2s)\n", + " diff = h1s - h2s\n", + " l2 = diff.norm(dim=1)\n", + " loss = l2.mean()\n", + " return loss\n", + "\n", + "def infer_(x, enc, K, S, device):\n", + " dataset = PatchDataset_NCHW(x, K=K, S=S)\n", + " loader = DataLoader(dataset, batch_size=64, shuffle=False, pin_memory=True)\n", + " embs = np.empty((dataset.N, dataset.row_num, dataset.col_num, args['D']), dtype=np.float32) # [-1, I, J, D]\n", + " enc = enc.eval()\n", + " with torch.no_grad():\n", + " for xs, ns, iis, js in loader:\n", + " xs = xs.to(device)\n", + " embedding = enc(xs)\n", + " embedding = embedding.detach().cpu().numpy()\n", + "\n", + " for embed, n, i, j in zip(embedding, ns, iis, js):\n", + " embs[n, i, j] = np.squeeze(embed)\n", + " return embs" + ] + }, + { + "cell_type": "markdown", + "id": "derived-bride", + "metadata": {}, + "source": [ + "## Time to start a federated learning experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "mature-renewal", + "metadata": {}, + "outputs": [], + "source": [ + "# create an experimnet in federation\n", + "experiment_name = 'MVTec_test_experiment'\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "lightweight-causing", + "metadata": { + "scrolled": true + }, + "outputs": [], + "source": [ + "# If I use autoreload I got a pickling error\n", + "\n", + "# The following command zips the workspace and python requirements to be transfered to collaborator nodes\n", + "fl_experiment.start(model_provider=MI, \n", + " task_keeper=TI,\n", + " data_loader=fed_dataset,\n", + " rounds_to_train=10,\n", + " opt_treatment='CONTINUE_GLOBAL',\n", + " device_assignment_policy='CUDA_PREFERRED')\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "f1543a36", + "metadata": {}, + "outputs": [], + "source": [ + "# If user wants to stop IPython session, then reconnect and check how experiment is going \n", + "# fl_experiment.restore_experiment_state(MI)\n", + "\n", + "fl_experiment.stream_metrics()" + ] + }, + { + "cell_type": "markdown", + "id": "8c30b301", + "metadata": {}, + "source": [ + "## Now we validate the best model and print anomaly maps!" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "12186086", + "metadata": {}, + "outputs": [], + "source": [ + "!pip install -r ../envoy/sd_requirements.txt\n", + "import sys\n", + "sys.path.insert(1, '../envoy')\n", + "from mvtec_shard_descriptor import MVTecShardDescriptor\n", + "from inspection import measure_emb_nn, eval_embeddings_nn_maps\n", + "import matplotlib.pyplot as plt\n", + "from PIL import Image\n", + "from skimage.segmentation import mark_boundaries\n", + "from utils import makedirpath, distribute_scores\n", + "import pickle" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "439049e1", + "metadata": {}, + "outputs": [], + "source": [ + "def obtain_maps(model, val_loader, device):\n", + " print(f'\\n\\n OBTAIN MAPS GOT DEVICE {device}\\n\\n')\n", + " \n", + " model._enc.eval()\n", + " model._enc.to(device)\n", + " \n", + " x_tr, x_te, masks, labels, mean = val_loader\n", + "\n", + " embs64_tr = infer_(x_tr, model._enc, K=64, S=16, device=device)\n", + " embs64_te = infer_(x_te, model._enc, K=64, S=16, device=device)\n", + " embs32_tr = infer_(x_tr, model._enc.enc, K=32, S=4, device=device)\n", + " embs32_te = infer_(x_te, model._enc.enc, K=32, S=4, device=device)\n", + "\n", + " embs64 = embs64_tr, embs64_te\n", + " embs32 = embs32_tr, embs32_te\n", + "\n", + " maps = eval_embeddings_nn_maps(args['obj'], embs64, embs32, masks, labels) \n", + " print_anomaly_maps(args['obj'], maps, x_te, masks, mean)\n", + " \n", + "\n", + "def infer_(x, enc, K, S, device):\n", + " dataset = PatchDataset_NCHW(x, K=K, S=S)\n", + " loader = DataLoader(dataset, batch_size=64, shuffle=False, pin_memory=True)\n", + " embs = np.empty((dataset.N, dataset.row_num, dataset.col_num, args['D']), dtype=np.float32) # [-1, I, J, D]\n", + " enc = enc.eval()\n", + " with torch.no_grad():\n", + " for xs, ns, iis, js in loader:\n", + " xs = xs.to(device)\n", + " embedding = enc(xs)\n", + " embedding = embedding.detach().cpu().numpy()\n", + "\n", + " for embed, n, i, j in zip(embedding, ns, iis, js):\n", + " embs[n, i, j] = np.squeeze(embed)\n", + " return embs\n", + "\n", + "def print_anomaly_maps(obj, maps, images, masks, mean):\n", + " \"\"\"Print generated anomaly maps.\"\"\"\n", + " mshape = maps.shape[0]\n", + " images = np.transpose(images, [0, 3, 2, 1])\n", + " images = (images.astype(np.float32) * 255 + mean)\n", + "\n", + " for n in range(10):\n", + " fig, axes = plt.subplots(ncols=2)\n", + " fig.set_size_inches(6, 3)\n", + "\n", + " shape = (128, 128)\n", + " image = np.array(Image.fromarray((images[n] * 255).astype(np.uint8)).resize(shape[::-1]))\n", + " mask = np.array(Image.fromarray(masks[n]).resize(shape[::-1]))\n", + " image = mark_boundaries(image, mask, color=(1, 0, 0), mode='thick')\n", + "\n", + " axes[0].imshow(image)\n", + " axes[0].set_axis_off()\n", + "\n", + " axes[1].imshow(maps[n], vmax=maps[n].max(), cmap='Reds')\n", + " axes[1].set_axis_off()\n", + "\n", + " plt.tight_layout()\n", + " plt.show()\n", + " plt.close()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "52ba543f", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = MVTecSD(train_bs=64, val_bs=64)\n", + "fed_dataset.shard_descriptor = MVTecShardDescriptor(obj=args['obj'], data_folder='MVTec_data',rank_worldsize='1,1')\n", + "\n", + "last_model = fl_experiment.get_last_model()\n", + "obtain_maps(last_model, fed_dataset.get_valid_loader(), 'cuda')" + ] + } + ], + "metadata": { + "kernelspec": { + "display_name": "Python 3 (ipykernel)", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.5" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/workspace/data_transf.py b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/workspace/data_transf.py new file mode 100644 index 0000000..878dcb3 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/workspace/data_transf.py @@ -0,0 +1,48 @@ +# Copyright (C) 2021-2022 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""Data transform functions.""" + +import numpy as np +from sklearn.metrics import balanced_accuracy_score +from sklearn.metrics import precision_recall_curve +from sklearn.metrics import roc_auc_score + + +def bilinears(images, shape) -> np.ndarray: + """Generate binlinears.""" + import cv2 + n = images.shape[0] + new_shape = (n,) + shape + ret = np.zeros(new_shape, dtype=images.dtype) + for i in range(n): + ret[i] = cv2.resize(images[i], dsize=shape[::-1], interpolation=cv2.INTER_LINEAR) + return ret + + +def bal_acc_score(obj, predictions, labels): + """Calculate balanced accuracy score.""" + precision, recall, thresholds = precision_recall_curve(labels.flatten(), predictions.flatten()) + f1_score = (2 * precision * recall) / (precision + recall) + threshold = thresholds[np.argmax(f1_score)] + prediction_result = predictions > threshold + ba_score = balanced_accuracy_score(labels, prediction_result) + return ba_score + + +def detection_auroc(obj, anomaly_scores, labels): + """Calculate detection auroc.""" + # 1: anomaly 0: normal + auroc = roc_auc_score(labels, anomaly_scores) + return auroc + + +def segmentation_auroc(obj, anomaly_maps, masks): + """Calculate segmentation auroc.""" + gt = masks + gt = gt.astype(np.int32) + gt[gt == 255] = 1 # 1: anomaly + + anomaly_maps = bilinears(anomaly_maps, (256, 256)) + auroc = roc_auc_score(gt.flatten(), anomaly_maps.flatten()) + return auroc diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/workspace/inspection.py b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/workspace/inspection.py new file mode 100644 index 0000000..c815159 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/workspace/inspection.py @@ -0,0 +1,139 @@ +# Copyright (C) 2021-2022 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""Inspection of images and patches.""" + +import os +import shutil + +import ngtpy +import numpy as np +from data_transf import bal_acc_score +from data_transf import detection_auroc +from data_transf import segmentation_auroc +from sklearn.neighbors import KDTree +from utils import distribute_scores + + +def search_nn(test_emb, train_emb_flat, nn=1, method='kdt'): + """Seach nearest neighbors.""" + if method == 'ngt': + return search_nn_ngt(test_emb, train_emb_flat, nn=nn) + + kdt = KDTree(train_emb_flat) + + ntest, i, j, d = test_emb.shape + closest_inds = np.empty((ntest, i, j, nn), dtype=np.int32) + l2_maps = np.empty((ntest, i, j, nn), dtype=np.float32) + + for n_ in range(ntest): + for i_ in range(i): + dists, inds = kdt.query(test_emb[n_, i_, :, :], return_distance=True, k=nn) + closest_inds[n_, i_, :, :] = inds[:, :] + l2_maps[n_, i_, :, :] = dists[:, :] + + return l2_maps, closest_inds + + +def search_nn_ngt(test_emb, train_emb_flat, nn=1): + """Search nearest neighbors.""" + ntest, i, j, d = test_emb.shape + closest_inds = np.empty((ntest, i, j, nn), dtype=np.int32) + l2_maps = np.empty((ntest, i, j, nn), dtype=np.float32) + + dpath = f'/tmp/{os.getpid()}' + ngtpy.create(dpath, d) + index = ngtpy.Index(dpath) + index.batch_insert(train_emb_flat) + + for n_ in range(ntest): + for i_ in range(i): + for j_ in range(j): + query = test_emb[n_, i_, j_, :] + results = index.search(query, nn) + inds = [result[0] for result in results] + + closest_inds[n_, i_, j_, :] = inds + vecs = np.asarray([index.get_object(inds[nn_]) for nn_ in range(nn)]) + dists = np.linalg.norm(query - vecs, axis=-1) + l2_maps[n_, i_, j_, :] = dists + shutil.rmtree(dpath) + + return l2_maps, closest_inds + + +def assess_anomaly_maps(obj, anomaly_maps, masks, labels): + """Assess anomaly maps.""" + auroc_seg = segmentation_auroc(obj, anomaly_maps, masks) + + anomaly_scores = anomaly_maps.max(axis=-1).max(axis=-1) + auroc_det = detection_auroc(obj, anomaly_scores, labels) + ba_score = bal_acc_score(obj, anomaly_scores, labels) + return auroc_det, auroc_seg, ba_score + + +def eval_embeddings_nn_multik(obj, embs64, embs32, masks, labels, nn=1): + """Evaluate embeddings.""" + emb_tr, emb_te = embs64 + maps_64 = measure_emb_nn(emb_te, emb_tr, method='kdt', nn=nn) + maps_64 = distribute_scores(maps_64, (256, 256), k=64, s=16) + det_64, seg_64, ba_64 = assess_anomaly_maps(obj, maps_64, masks, labels) + + emb_tr, emb_te = embs32 + maps_32 = measure_emb_nn(emb_te, emb_tr, method='ngt', nn=nn) + maps_32 = distribute_scores(maps_32, (256, 256), k=32, s=4) + det_32, seg_32, ba_32 = assess_anomaly_maps(obj, maps_32, masks, labels) + + maps_sum = maps_64 + maps_32 + det_sum, seg_sum, ba_sum = assess_anomaly_maps(obj, maps_sum, masks, labels) + + maps_mult = maps_64 * maps_32 + det_mult, seg_mult, ba_mult = assess_anomaly_maps(obj, maps_mult, masks, labels) + + return { + 'det_64': det_64, + 'seg_64': seg_64, + 'bal_acc_64': ba_64, + + 'det_32': det_32, + 'seg_32': seg_32, + 'bal_acc_32': ba_32, + + 'det_sum': det_sum, + 'seg_sum': seg_sum, + 'bal_acc_sum': ba_sum, + + 'det_mult': det_mult, + 'seg_mult': seg_mult, + 'bal_acc_mult': ba_mult, + + 'maps_64': maps_64, + 'maps_32': maps_32, + 'maps_sum': maps_sum, + 'maps_mult': maps_mult, + } + + +def eval_embeddings_nn_maps(obj, embs64, embs32, masks, labels, nn=1): + """Evaluate embeddings.""" + emb_tr, emb_te = embs64 + maps_64 = measure_emb_nn(emb_te, emb_tr, method='kdt', nn=nn) + maps_64 = distribute_scores(maps_64, (256, 256), k=64, s=16) + + emb_tr, emb_te = embs32 + maps_32 = measure_emb_nn(emb_te, emb_tr, method='ngt', nn=nn) + maps_32 = distribute_scores(maps_32, (256, 256), k=32, s=4) + + maps_mult = maps_64 * maps_32 + return maps_mult + + +def measure_emb_nn(emb_te, emb_tr, method='kdt', nn=1): + """Measure embeddings.""" + d = emb_tr.shape[-1] + train_emb_all = emb_tr.reshape(-1, d) + + l2_maps, _ = search_nn(emb_te, train_emb_all, method=method, nn=nn) + anomaly_maps = np.mean(l2_maps, axis=-1) + + return anomaly_maps diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/workspace/utils.py b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/workspace/utils.py new file mode 100644 index 0000000..bd8569c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MVTec_PatchSVDD/workspace/utils.py @@ -0,0 +1,133 @@ +# Copyright (C) 2021-2022 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""Utilities.""" + +import os +from contextlib import contextmanager + +import _pickle as p +import numpy as np +import torch +from torch.utils.data import Dataset + + +def to_device(obj, device, non_blocking=False): + """Copy to device.""" + if isinstance(obj, torch.Tensor): + return obj.to(device, non_blocking=non_blocking) + + if isinstance(obj, dict): + return {k: to_device(v, device, non_blocking=non_blocking) + for k, v in obj.items()} + + if isinstance(obj, list): + return [to_device(v, device, non_blocking=non_blocking) + for v in obj] + + if isinstance(obj, tuple): + return tuple([to_device(v, device, non_blocking=non_blocking) + for v in obj]) + + +@contextmanager +def task(_): + """Yield.""" + yield + + +class DictionaryConcatDataset(Dataset): + """Concate dictionaries.""" + + def __init__(self, d_of_datasets): + """Initialize.""" + self.d_of_datasets = d_of_datasets + lengths = [len(d) for d in d_of_datasets.values()] + self._length = min(lengths) + self.keys = self.d_of_datasets.keys() + assert min(lengths) == max(lengths), 'Length of the datasets should be the same' + + def __getitem__(self, idx): + """Get item.""" + return { + key: self.d_of_datasets[key][idx] + for key in self.keys + } + + def __len__(self): + """Get length.""" + return self._length + + +def crop_chw(image, i, j, k, s=1): + """Crop func.""" + if s == 1: + h, w = i, j + else: + h = s * i + w = s * j + return image[:, h: h + k, w: w + k] + + +def cnn_output_size(h, k, s=1, p=0) -> int: + """Output size. + + :param int H: input_size + :param int K: filter_size + :param int S: stride + :param int P: padding + :return:. + + """ + return 1 + (h - k + 2 * p) // s + + +def crop_image_chw(image, coord, k): + """Crop func.""" + h, w = coord + return image[:, h: h + k, w: w + k] + + +def load_binary(fpath, encoding='ASCII'): + """Load binaries.""" + with open(fpath, 'rb') as f: + return p.load(f, encoding=encoding) + + +def save_binary(d, fpath): + """Save binary.""" + with open(fpath, 'wb') as f: + p.dump(d, f) + + +def makedirpath(fpath: str): + """Make path.""" + dpath = os.path.dirname(fpath) + if dpath: + os.makedirs(dpath, exist_ok=True) + + +def distribute_scores(score_masks, output_shape, k: int, s: int) -> np.ndarray: + """Distribute scores.""" + n_all = score_masks.shape[0] + results = [distribute_score(score_masks[n], output_shape, k, s) for n in range(n_all)] + return np.asarray(results) + + +def distribute_score(score_mask, output_shape, k: int, s: int) -> np.ndarray: + """Distribute scores.""" + h, w = output_shape + mask = np.zeros([h, w], dtype=np.float32) + cnt = np.zeros([h, w], dtype=np.int32) + + i, j = score_mask.shape[:2] + for i_ in range(i): + for j_ in range(j): + h_, w_ = i_ * s, j_ * s + + mask[h_: h_ + k, w_: w_ + k] += score_mask[i_, j_] + cnt[h_: h_ + k, w_: w_ + k] += 1 + + cnt[cnt == 0] = 1 + + return mask / cnt diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/README.md b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/README.md new file mode 100644 index 0000000..247a979 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/README.md @@ -0,0 +1,66 @@ +# PyTorch_Market_Re-ID + +## **How to run this tutorial (without TLC and locally as a simulation):** +
+ +### 0. If you haven't done so already, create a virtual environment, install OpenFL, and upgrade pip: + - For help with this step, visit the "Install the Package" section of the [OpenFL installation instructions](https://openfl.readthedocs.io/en/latest/install.html#install-the-package). + +
+ +### 1. Split terminal into 3 (1 terminal for the director, 1 for the envoy, and 1 for the experiment) + +
+ +### 2. Do the following in each terminal: + - Activate the virtual environment from step 0: + + ```sh + source venv/bin/activate + ``` + - If you are in a network environment with a proxy, ensure proxy environment variables are set in each of your terminals. + - Navigate to the tutorial: + + ```sh + cd openfl/openfl-tutorials/interactive_api/PyTorch_Market_Re-ID + ``` + +
+ +### 3. In the first terminal, run the director: + +```sh +cd director +./start_director.sh +``` + +
+ +### 4. In the second terminal, install requirements and run the envoy: + +```sh +cd envoy +pip install -r requirements.txt +./start_envoy.sh env_one envoy_config_one.yaml +``` + +Optional: Run a second envoy in an additional terminal: + - Ensure step 2 is complete for this terminal as well. + - Run the second envoy: +```sh +cd envoy +./start_envoy.sh env_two envoy_config_two.yaml +``` + +
+ +### 5. Now that your director and envoy terminals are set up, run the Jupyter Notebook in your experiment terminal: + +```sh +cd workspace +jupyter lab PyTorch_Market_Re-ID.ipynb +``` +- A Jupyter Server URL will appear in your terminal. In your browser, proceed to that link. Once the webpage loads, click on the PyTorch_Market_Re-ID.ipynb file. +- To run the experiment, select the icon that looks like two triangles to "Restart Kernel and Run All Cells". +- You will notice activity in your terminals as the experiment runs, and when the experiment is finished the director terminal will display a message that the experiment has finished successfully. + diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/director/director_config.yaml new file mode 100644 index 0000000..c3aa1d5 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/director/director_config.yaml @@ -0,0 +1,4 @@ +settings: + listen_ip: localhost + sample_shape: ['64', '128', '3'] + target_shape: ['2'] diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/director/start_director.sh new file mode 100755 index 0000000..5806a6c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/director/start_director.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx director start --disable-tls -c director_config.yaml \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/director/start_director_with_tls.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/director/start_director_with_tls.sh new file mode 100755 index 0000000..5d6d46a --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/director/start_director_with_tls.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e +FQDN=$1 +fx director start -c director_config.yaml -rc cert/root_ca.crt -pk cert/"${FQDN}".key -oc cert/"${FQDN}".crt \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/envoy_config_one.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/envoy_config_one.yaml new file mode 100644 index 0000000..04afb45 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/envoy_config_one.yaml @@ -0,0 +1,10 @@ +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: market_shard_descriptor.MarketShardDescriptor + params: + data_folder_name: Market-1501-v15.09.15 + rank_worldsize: 1,2 \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/envoy_config_two.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/envoy_config_two.yaml new file mode 100644 index 0000000..2da3304 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/envoy_config_two.yaml @@ -0,0 +1,10 @@ +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: market_shard_descriptor.MarketShardDescriptor + params: + data_folder_name: Market-1501-v15.09.15 + rank_worldsize: 2,2 \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/market_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/market_shard_descriptor.py new file mode 100644 index 0000000..463aa50 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/market_shard_descriptor.py @@ -0,0 +1,136 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""Market shard descriptor.""" + +import logging +import re +import zipfile +from pathlib import Path +from typing import List + +import gdown +from PIL import Image + +from openfl.interface.interactive_api.shard_descriptor import ShardDataset +from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor + +logger = logging.getLogger(__name__) + + +class MarketShardDataset(ShardDataset): + """Market shard dataset.""" + + def __init__(self, dataset_dir: Path, dataset_type: str, rank=1, worldsize=1): + """Initialize MarketShardDataset.""" + self.dataset_dir = dataset_dir + self.dataset_type = dataset_type + self.rank = rank + self.worldsize = worldsize + + self.imgs_path = list(dataset_dir.glob('*.jpg'))[self.rank - 1::self.worldsize] + self.pattern = re.compile(r'([-\d]+)_c(\d)') + + def __len__(self): + """Length of shard.""" + return len(self.imgs_path) + + def __getitem__(self, index: int): + """Return an item by the index.""" + img_path = self.imgs_path[index] + pid, camid = map(int, self.pattern.search(img_path.name).groups()) + + img = Image.open(img_path) + return img, (pid, camid) + + +class MarketShardDescriptor(ShardDescriptor): + """ + Market1501 Shard descriptor class. + + Reference: + Zheng et al. Scalable Person Re-identification: A Benchmark. ICCV 2015. + URL: http://www.liangzheng.org/Project/project_reid.html + + Dataset statistics: + identities: 1501 (+1 for background) + images: 12936 (train) + 3368 (query) + 15913 (gallery) + """ + + def __init__(self, data_folder_name: str = 'Market-1501-v15.09.15', + rank_worldsize: str = '1,1') -> None: + """Initialize MarketShardDescriptor.""" + super().__init__() + + # Settings for sharding the dataset + self.rank, self.worldsize = tuple(int(num) for num in rank_worldsize.split(',')) + + self.data_folder_name = data_folder_name + self.dataset_dir = Path.cwd() / data_folder_name + self.download() + + self.path_by_type = { + 'train': self.dataset_dir / 'bounding_box_train', + 'query': self.dataset_dir / 'query', + 'gallery': self.dataset_dir / 'bounding_box_test' + } + self._check_before_run() + + def get_shard_dataset_types(self) -> List[str]: + """Get available shard dataset types.""" + return list(self.path_by_type) + + def get_dataset(self, dataset_type='train'): + """Return a dataset by type.""" + if dataset_type not in self.path_by_type: + raise Exception(f'Wrong dataset type: {dataset_type}.' + f'Choose from the list: {", ".join(self.path_by_type)}') + return MarketShardDataset( + dataset_dir=self.path_by_type[dataset_type], + dataset_type=dataset_type, + rank=self.rank, + worldsize=self.worldsize + ) + + @property + def sample_shape(self): + """Return the sample shape info.""" + return ['64', '128', '3'] + + @property + def target_shape(self): + """Return the target shape info.""" + return ['2'] + + @property + def dataset_description(self) -> str: + """Return the dataset description.""" + return (f'Market dataset, shard number {self.rank} ' + f'out of {self.worldsize}') + + def download(self): + """Download Market1501 dataset.""" + logger.info('Download Market1501 dataset.') + if self.dataset_dir.exists(): + return None + + logger.info('Try to download.') + output = f'{self.data_folder_name}.zip' + + if not Path(output).exists(): + url = 'https://drive.google.com/u/1/uc?id=0B8-rUzbwVRk0c054eEozWG9COHM' + gdown.download(url, output, quiet=False) + logger.info(f'{output} is downloaded.') + + with zipfile.ZipFile(output, 'r') as zip_ref: + zip_ref.extractall(Path.cwd()) + + Path(output).unlink() # remove zip + + def _check_before_run(self): + """Check if all files are available before going deeper.""" + if not self.dataset_dir.exists(): + raise RuntimeError(f'{self.dataset_dir} does not exist') + for dataset_path in self.path_by_type.values(): + if not dataset_path.exists(): + raise RuntimeError(f'{dataset_path} does not exist') diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/requirements.txt b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/requirements.txt new file mode 100644 index 0000000..1c1bf94 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/requirements.txt @@ -0,0 +1,2 @@ +gdown==3.13.0 +Pillow==10.3.0 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/start_envoy.sh new file mode 100755 index 0000000..ff20adf --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/start_envoy.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx envoy start -n env_one --disable-tls -dh localhost -dp 50051 -ec envoy_config_one.yaml diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/start_envoy_with_tls.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/start_envoy_with_tls.sh new file mode 100755 index 0000000..9e10f43 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/envoy/start_envoy_with_tls.sh @@ -0,0 +1,7 @@ +#!/bin/bash +set -e +ENVOY_NAME=$1 +DIRECTOR_FQDN=$2 +ENVOY_CONFIG=$3 + +fx envoy start -n "$ENVOY_NAME" -dh "$DIRECTOR_FQDN" -dp 50051 -ec "$ENVOY_CONFIG" -rc cert/root_ca.crt -pk cert/"$ENVOY_NAME".key -oc cert/"$ENVOY_NAME".crt diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/workspace/PyTorch_Market_Re-ID.ipynb b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/workspace/PyTorch_Market_Re-ID.ipynb new file mode 100644 index 0000000..0a50d68 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/workspace/PyTorch_Market_Re-ID.ipynb @@ -0,0 +1,593 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "liquid-jacket", + "metadata": {}, + "source": [ + "# Federated Market with Director example" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "db949008", + "metadata": { + "pycharm": { + "name": "#%%\n" + } + }, + "outputs": [], + "source": [ + "# Install dependencies if not already installed\n", + "!pip install -r requirements.txt" + ] + }, + { + "cell_type": "markdown", + "id": "16986f22", + "metadata": {}, + "source": [ + "# Connect to the Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4485ac79", + "metadata": {}, + "outputs": [], + "source": [ + "# Create a federation\n", + "from openfl.interface.interactive_api.federation import Federation\n", + "\n", + "# please use the same identificator that was used in signed certificate\n", + "client_id = 'frontend'\n", + "director_node_fqdn = 'localhost'\n", + "director_port = 50051\n", + "\n", + "# 1) Run with API layer - Director mTLS \n", + "# If the user wants to enable mTLS their must provide CA root chain, and signed key pair to the federation interface\n", + "# cert_chain = 'cert/root_ca.crt'\n", + "# api_certificate = 'cert/frontend.crt'\n", + "# api_private_key = 'cert/frontend.key'\n", + "\n", + "# federation = Federation(\n", + "# client_id=client_id,\n", + "# director_node_fqdn=director_node_fqdn,\n", + "# director_port=director_port,\n", + "# tls=True,\n", + "# cert_chain=cert_chain,\n", + "# api_cert=api_certificate,\n", + "# api_private_key=api_private_key\n", + "# )\n", + "\n", + "# --------------------------------------------------------------------------------------------------------------------\n", + "\n", + "# 2) Run with TLS disabled (trusted environment)\n", + "# Federation can also determine local fqdn automatically\n", + "federation = Federation(\n", + " client_id=client_id,\n", + " director_node_fqdn=director_node_fqdn,\n", + " director_port=director_port,\n", + " tls=False\n", + ")" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "e35802d5", + "metadata": { + "pycharm": { + "is_executing": true + }, + "scrolled": true + }, + "outputs": [], + "source": [ + "shard_registry = federation.get_shard_registry()\n", + "shard_registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "67ae50de", + "metadata": { + "pycharm": { + "is_executing": true + } + }, + "outputs": [], + "source": [ + "federation.target_shape" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "b42efc49", + "metadata": {}, + "outputs": [], + "source": [ + "# First, request a dummy_shard_desc that holds information about the federated dataset \n", + "dummy_shard_desc = federation.get_dummy_shard_descriptor(size=10)\n", + "dummy_shard_dataset = dummy_shard_desc.get_dataset('train')\n", + "sample, target = dummy_shard_dataset[0]\n", + "print(sample.shape)\n", + "print(target.shape)" + ] + }, + { + "cell_type": "markdown", + "id": "obvious-tyler", + "metadata": {}, + "source": [ + "## Creating a FL experiment using Interactive API" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "rubber-address", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment" + ] + }, + { + "cell_type": "markdown", + "id": "sustainable-public", + "metadata": {}, + "source": [ + "### Register dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "64f37dcf", + "metadata": { + "scrolled": true + }, + "outputs": [], + "source": [ + "from copy import deepcopy\n", + "\n", + "from torch.utils.data import DataLoader, Dataset\n", + "from torchvision.transforms import Compose, Normalize, RandomHorizontalFlip, Resize, ToTensor\n", + "\n", + "from tools import RandomIdentitySampler\n", + "import transforms as T\n", + "\n", + "\n", + "# Now you can implement you data loaders using dummy_shard_desc\n", + "class ImageDataset(Dataset):\n", + " \"\"\"Image Person ReID Dataset.\"\"\"\n", + "\n", + " def __init__(self, dataset, transform=None):\n", + " \"\"\"Initialize Dataset.\"\"\"\n", + " self.dataset = dataset\n", + " self.transform = transform\n", + "\n", + " def __len__(self):\n", + " \"\"\"Length of dataset.\"\"\"\n", + " return len(self.dataset)\n", + "\n", + " def __getitem__(self, index):\n", + " \"\"\"Get item from dataset.\"\"\"\n", + " img, (pid, camid) = self.dataset[index]\n", + " if self.transform is not None:\n", + " img = self.transform(img)\n", + " return img, (pid, camid)\n", + "\n", + "\n", + "class MarketFLDataloader(DataInterface):\n", + " \"\"\"Market Dataset.\"\"\"\n", + "\n", + " def __init__(self, **kwargs):\n", + " super().__init__(**kwargs)\n", + "\n", + " # Prepare transforms\n", + " self.transform_train = Compose([\n", + " T.ResizeRandomCropping(256, 128, p=0.5),\n", + " RandomHorizontalFlip(),\n", + " ToTensor(),\n", + " Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n", + " T.RandomErasing(probability=0.5)\n", + " ])\n", + " self.transform_test = Compose([\n", + " Resize((265, 128)),\n", + " ToTensor(),\n", + " Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n", + " ])\n", + "\n", + " @property\n", + " def shard_descriptor(self):\n", + " return self._shard_descriptor\n", + "\n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + "\n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + "\n", + " def get_train_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks with optimizer in contract.\n", + " \"\"\"\n", + " if self.kwargs['train_bs']:\n", + " batch_size = self.kwargs['train_bs']\n", + " else:\n", + " batch_size = 64\n", + "\n", + " self.train_ds = self.shard_descriptor.get_dataset('train')\n", + " return DataLoader(\n", + " # ImageDataset make transform\n", + " ImageDataset(self.train_ds, transform=self.transform_train),\n", + " sampler=RandomIdentitySampler(self.train_ds, num_instances=4),\n", + " batch_size=batch_size,\n", + " num_workers=4,\n", + " pin_memory=True,\n", + " drop_last=True\n", + " )\n", + "\n", + " def get_valid_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks without optimizer in contract.\n", + " \"\"\"\n", + " if self.kwargs['valid_bs']:\n", + " batch_size = self.kwargs['valid_bs']\n", + " else:\n", + " batch_size = 512\n", + "\n", + " query_sd = self.shard_descriptor.get_dataset('query')\n", + " query_loader = DataLoader(\n", + " ImageDataset(query_sd, transform=self.transform_test),\n", + " batch_size=batch_size,\n", + " num_workers=4,\n", + " pin_memory=True,\n", + " drop_last=False,\n", + " shuffle=False\n", + " )\n", + "\n", + " self.gallery_sd = self.shard_descriptor.get_dataset('gallery')\n", + " gallery_loader = DataLoader(\n", + " ImageDataset(self.gallery_sd, transform=self.transform_test),\n", + " batch_size=batch_size,\n", + " num_workers=4,\n", + " pin_memory=True,\n", + " drop_last=False,\n", + " shuffle=False\n", + " )\n", + "\n", + " return query_loader, gallery_loader\n", + "\n", + " def get_train_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation.\n", + " \"\"\"\n", + " return len(self.train_ds)\n", + "\n", + " def get_valid_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation.\n", + " \"\"\"\n", + " return len(self.gallery_sd)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "8cb6c73c", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = MarketFLDataloader(train_bs=64, valid_bs=512)" + ] + }, + { + "cell_type": "markdown", + "id": "caring-distinction", + "metadata": {}, + "source": [ + "### Describe a model and optimizer" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "visible-victor", + "metadata": {}, + "outputs": [], + "source": [ + "import torch\n", + "import torch.nn as nn\n", + "import torch.optim as optim\n", + "import torchvision" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "foreign-gospel", + "metadata": {}, + "outputs": [], + "source": [ + "\"\"\"\n", + "ResNet and Classifier definition\n", + "\"\"\"\n", + "\n", + "class ResNet50(nn.Module):\n", + " \"Pretrained ResNet50.\"\n", + "\n", + " def __init__(self, **kwargs):\n", + " super().__init__()\n", + " \n", + " self.classifier = NormalizedClassifier()\n", + "\n", + " resnet50 = torchvision.models.resnet50(pretrained=True)\n", + " resnet50.layer4[0].conv2.stride = (1, 1)\n", + " resnet50.layer4[0].downsample[0].stride = (1, 1)\n", + " self.base = nn.Sequential(*list(resnet50.children())[:-2])\n", + "\n", + " self.bn = nn.BatchNorm1d(2048)\n", + " nn.init.normal_(self.bn.weight.data, 1.0, 0.02)\n", + " nn.init.constant_(self.bn.bias.data, 0.0)\n", + "\n", + " def forward(self, x):\n", + " x = self.base(x)\n", + " x = nn.functional.avg_pool2d(x, x.size()[2:])\n", + " x = x.view(x.size(0), -1)\n", + " f = self.bn(x)\n", + "\n", + " return f\n", + "\n", + "\n", + "class NormalizedClassifier(nn.Module):\n", + " \"\"\"Classifier.\"\"\"\n", + "\n", + " def __init__(self):\n", + " super().__init__()\n", + " self.weight = nn.Parameter(torch.Tensor(1501, 2048))\n", + " self.weight.data.uniform_(-1, 1).renorm_(2,0,1e-5).mul_(1e5)\n", + "\n", + " def forward(self, x):\n", + " w = self.weight\n", + "\n", + " x = nn.functional.normalize(x, p=2, dim=1)\n", + " w = nn.functional.normalize(w, p=2, dim=1)\n", + "\n", + " return nn.functional.linear(x, w)\n", + "\n", + "\n", + "resnet = ResNet50()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "greater-activation", + "metadata": { + "pycharm": { + "is_executing": true + } + }, + "outputs": [], + "source": [ + "parameters = list(resnet.parameters()) + list(resnet.classifier.parameters())\n", + "optimizer_adam = optim.Adam(parameters, lr=1e-4)" + ] + }, + { + "cell_type": "markdown", + "id": "caroline-passion", + "metadata": {}, + "source": [ + "#### Register model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "handled-teens", + "metadata": {}, + "outputs": [], + "source": [ + "framework_adapter = 'openfl.plugins.frameworks_adapters.pytorch_adapter.FrameworkAdapterPlugin'\n", + "MI = ModelInterface(model=resnet, optimizer=optimizer_adam, framework_plugin=framework_adapter)\n", + "# Save the initial model state\n", + "initial_model = deepcopy(resnet)" + ] + }, + { + "cell_type": "markdown", + "id": "portuguese-groove", + "metadata": {}, + "source": [ + "### Define and register FL tasks" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "increasing-builder", + "metadata": {}, + "outputs": [], + "source": [ + "TI = TaskInterface()\n", + "\n", + "from logging import getLogger\n", + "\n", + "import torch\n", + "import tqdm\n", + "\n", + "from losses import ArcFaceLoss, TripletLoss\n", + "from tools import AverageMeter, evaluate, extract_feature\n", + "\n", + "logger = getLogger(__name__)\n", + "\n", + "# Task interface currently supports only standalone functions.\n", + "@TI.register_fl_task(model='model', data_loader='train_loader',\n", + " device='device', optimizer='optimizer')\n", + "def train(model, train_loader, optimizer, device):\n", + " device = torch.device('cuda')\n", + " \n", + " criterion_cla = ArcFaceLoss(scale=16., margin=0.1)\n", + " criterion_pair = TripletLoss(margin=0.3, distance='cosine')\n", + "\n", + " batch_cla_loss = AverageMeter()\n", + " batch_pair_loss = AverageMeter()\n", + " corrects = AverageMeter()\n", + " \n", + " model.train()\n", + " model.to(device)\n", + " model.classifier.train()\n", + " model.classifier.to(device)\n", + " \n", + " logger.info('==> Start training')\n", + " train_loader = tqdm.tqdm(train_loader, desc='train')\n", + "\n", + " for imgs, (pids, _) in train_loader:\n", + " imgs, pids = torch.tensor(imgs).to(device), torch.tensor(pids).to(device)\n", + " # Zero the parameter gradients\n", + " optimizer.zero_grad()\n", + " # Forward\n", + " features = model(imgs)\n", + " outputs = model.classifier(features)\n", + " _, preds = torch.max(outputs.data, 1)\n", + " # Compute loss\n", + " cla_loss = criterion_cla(outputs, pids)\n", + " pair_loss = criterion_pair(features, pids)\n", + " loss = cla_loss + pair_loss\n", + " # Backward + Optimize\n", + " loss.backward()\n", + " optimizer.step()\n", + " # statistics\n", + " corrects.update(torch.sum(preds == pids.data).float() / pids.size(0), pids.size(0))\n", + " batch_cla_loss.update(cla_loss.item(), pids.size(0))\n", + " batch_pair_loss.update(pair_loss.item(), pids.size(0))\n", + "\n", + " return {'ArcFaceLoss': batch_cla_loss.avg,\n", + " 'TripletLoss': batch_pair_loss.avg,\n", + " 'Accuracy': corrects.avg.cpu()}\n", + "\n", + "\n", + "@TI.register_fl_task(model='model', data_loader='val_loader', device='device')\n", + "def validate(model, val_loader, device):\n", + " queryloader, galleryloader = val_loader\n", + " device = torch.device('cuda')\n", + " \n", + " logger.info('==> Start validating')\n", + " model.eval()\n", + " model.to(device)\n", + " \n", + " # Extract features for query set\n", + " qf, q_pids, q_camids = extract_feature(model, queryloader)\n", + " logger.info(f'Extracted features for query set, obtained {qf.shape} matrix')\n", + " # Extract features for gallery set\n", + " gf, g_pids, g_camids = extract_feature(model, galleryloader)\n", + " logger.info(f'Extracted features for gallery set, obtained {gf.shape} matrix')\n", + " # Compute distance matrix between query and gallery\n", + " m, n = qf.size(0), gf.size(0)\n", + " distmat = torch.zeros((m,n))\n", + " # Cosine similarity\n", + " qf = nn.functional.normalize(qf, p=2, dim=1)\n", + " gf = nn.functional.normalize(gf, p=2, dim=1)\n", + " for i in range(m):\n", + " distmat[i] = - torch.mm(qf[i:i+1], gf.t())\n", + " distmat = distmat.numpy()\n", + "\n", + " cmc, mAP = evaluate(distmat, q_pids, g_pids, q_camids, g_camids)\n", + " return {'top1': cmc[0], 'top5': cmc[4], 'top10': cmc[9], 'mAP': mAP}" + ] + }, + { + "cell_type": "markdown", + "id": "derived-bride", + "metadata": {}, + "source": [ + "## Time to start a federated learning experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "mature-renewal", + "metadata": {}, + "outputs": [], + "source": [ + "# create an experimnet in federation\n", + "experiment_name = 'market_test_experiment'\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "lightweight-causing", + "metadata": { + "pycharm": { + "is_executing": true + }, + "scrolled": false + }, + "outputs": [], + "source": [ + "# If I use autoreload I got a pickling error\n", + "\n", + "# The following command zips the workspace and python requirements to be transfered to collaborator nodes\n", + "fl_experiment.start(model_provider=MI, \n", + " task_keeper=TI,\n", + " data_loader=fed_dataset,\n", + " rounds_to_train=3,\n", + " opt_treatment='RESET')" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "bfc4f89c", + "metadata": { + "pycharm": { + "is_executing": true, + "name": "#%%\n" + } + }, + "outputs": [], + "source": [ + "# If user want to stop IPython session, then reconnect and check how experiment is going \n", + "# fl_experiment.restore_experiment_state(MI)\n", + "\n", + "fl_experiment.stream_metrics(tensorboard_logs=False)" + ] + } + ], + "metadata": { + "kernelspec": { + "display_name": "Python 3", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.0" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/workspace/losses.py b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/workspace/losses.py new file mode 100644 index 0000000..be266a4 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/workspace/losses.py @@ -0,0 +1,98 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""Compute ArcFace loss and Triplet loss.""" + +import math + +import torch +import torch.nn.functional as F +from torch import nn + + +class ArcFaceLoss(nn.Module): + """ArcFace loss.""" + + def __init__(self, margin=0.1, scale=16, easy_margin=False): + """Initialize ArcFace loss.""" + super(ArcFaceLoss, self).__init__() + self.m = margin + self.s = scale + self.easy_margin = easy_margin + + def forward(self, pred, target): + """Compute forward.""" + # make a one-hot index + index = pred.data * 0.0 # size = (B, Classnum) + index.scatter_(1, target.data.view(-1, 1), 1) + index = index.bool() + + cos_m = math.cos(self.m) + sin_m = math.sin(self.m) + cos_t = pred[index] + sin_t = torch.sqrt(1.0 - cos_t * cos_t) + cos_t_add_m = cos_t * cos_m - sin_t * sin_m + + cond_v = cos_t - math.cos(math.pi - self.m) + cond = F.relu(cond_v) + keep = cos_t - math.sin(math.pi - self.m) * self.m + + cos_t_add_m = torch.where(cond.bool(), cos_t_add_m, keep) + + output = pred * 1.0 # size = (B, Classnum) + output[index] = cos_t_add_m + output = self.s * output + + return F.cross_entropy(output, target) + + +class TripletLoss(nn.Module): + """ + Triplet loss with hard positive/negative mining. + + Reference: + Hermans et al. In Defense of the Triplet Loss for Person Re-Identification. arXiv:1703.07737. + + Code imported from https://github.com/Cysu/open-reid/blob/master/reid/loss/triplet.py. + + Args: + margin (float): margin for triplet. + distance (str): distance for triplet. + """ + + def __init__(self, margin=0.3, distance='cosine'): + """Initialize Triplet loss.""" + super(TripletLoss, self).__init__() + + self.distance = distance + self.margin = margin + self.ranking_loss = nn.MarginRankingLoss(margin=margin) + + def forward(self, inputs, targets): + """ + Compute forward. + + Args: + inputs: feature matrix with shape (batch_size, feat_dim) + targets: ground truth labels with shape (num_classes) + """ + n = inputs.size(0) + + # Compute pairwise distance, replace by the official when merged + inputs = F.normalize(inputs, p=2, dim=1) + dist = - torch.mm(inputs, inputs.t()) + + # For each anchor, find the hardest positive and negative + mask = targets.expand(n, n).eq(targets.expand(n, n).t()) + dist_ap, dist_an = [], [] + for i in range(n): + dist_ap.append(dist[i][mask[i]].max().unsqueeze(0)) + dist_an.append(dist[i][mask[i] == 0].min().unsqueeze(0)) + dist_ap = torch.cat(dist_ap) + dist_an = torch.cat(dist_an) + + # Compute ranking hinge loss + y = torch.ones_like(dist_an) + loss = self.ranking_loss(dist_an, dist_ap, y) + + return loss diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/workspace/requirements.txt b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/workspace/requirements.txt new file mode 100644 index 0000000..62c8356 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/workspace/requirements.txt @@ -0,0 +1,2 @@ +torch==2.3.1 +torchvision==0.18.1 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/workspace/tools.py b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/workspace/tools.py new file mode 100644 index 0000000..75c4374 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/workspace/tools.py @@ -0,0 +1,190 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""Tools for metric computation and Dataloader.""" + +import copy +import random +from collections import defaultdict +from logging import getLogger + +import numpy as np +import torch +from torch.utils.data.sampler import Sampler + +logger = getLogger(__name__) + + +class AverageMeter: + """ + Computes and stores the average and current value. + + Code imported from https://github.com/pytorch/examples/blob/master/imagenet/main.py#L247-L262 + """ + + def __init__(self): + """Initialize Average Meter.""" + self.reset() + + def reset(self): + """Reset values.""" + self.val = 0 + self.avg = 0 + self.sum = 0 + self.count = 0 + + def update(self, val, n=1): + """Update values.""" + self.val = val + self.sum += val * n + self.count += n + self.avg = self.sum / self.count + + +def compute_ap_cmc(index, good_index, junk_index): + """Compute validation metrics.""" + ap = 0 + cmc = np.zeros(len(index)) + + # remove junk_index + mask = np.in1d(index, junk_index, invert=True) + index = index[mask] + + # find good_index index + ngood = len(good_index) + mask = np.in1d(index, good_index) + rows_good = np.argwhere(mask) + rows_good = rows_good.flatten() + + cmc[rows_good[0]:] = 1.0 + for i in range(ngood): + d_recall = 1.0 / ngood + precision = (i + 1) * 1.0 / (rows_good[i] + 1) + ap = ap + d_recall * precision + + return ap, cmc + + +def evaluate(distmat, q_pids, g_pids, q_camids, g_camids): + """Evaluate model.""" + num_q, num_g = distmat.shape + index = np.argsort(distmat, axis=1) # from small to large + + num_no_gt = 0 # num of query imgs without groundtruth + num_r1 = 0 + cmc = np.zeros(len(g_pids)) + ap = 0 + + for i in range(num_q): + # groundtruth index + query_index = np.argwhere(g_pids == q_pids[i]) + camera_index = np.argwhere(g_camids == q_camids[i]) + good_index = np.setdiff1d(query_index, camera_index, assume_unique=True) + if good_index.size == 0: + num_no_gt += 1 + continue + # remove gallery samples that have the same pid and camid with query + junk_index = np.intersect1d(query_index, camera_index) + + ap_tmp, cmc_tmp = compute_ap_cmc(index[i], good_index, junk_index) + if cmc_tmp[0] == 1: + num_r1 += 1 + cmc = cmc + cmc_tmp + ap += ap_tmp + + if num_no_gt > 0: + logger.error(f'{num_no_gt} query imgs do not have groundtruth.') + + cmc = cmc / (num_q - num_no_gt) + mean_ap = ap / (num_q - num_no_gt) + + return cmc, mean_ap + + +@torch.no_grad() +def extract_feature(model, dataloader): + """Extract features for validation.""" + features, pids, camids = [], [], [] + for imgs, (batch_pids, batch_camids) in dataloader: + flip_imgs = fliplr(imgs) + imgs, flip_imgs = imgs.cuda(), flip_imgs.cuda() + batch_features = model(imgs).data + batch_features_flip = model(flip_imgs).data + batch_features += batch_features_flip + + features.append(batch_features) + pids.append(batch_pids) + camids.append(batch_camids) + features = torch.cat(features, 0) + pids = torch.cat(pids, 0).numpy() + camids = torch.cat(camids, 0).numpy() + + return features, pids, camids + + +def fliplr(img): + """Flip horizontal.""" + inv_idx = torch.arange(img.size(3) - 1, -1, -1).long() # N x C x H x W + img_flip = img.index_select(3, inv_idx) + + return img_flip + + +class RandomIdentitySampler(Sampler): + """ + Random Sampler. + + Randomly sample N identities, then for each identity, + randomly sample K instances, therefore batch size is N*K. + + Args: + - data_source (Dataset): dataset to sample from. + - num_instances (int): number of instances per identity. + """ + + def __init__(self, data_source, num_instances=4): + """Initialize Sampler.""" + self.data_source = data_source + self.num_instances = num_instances + self.index_dic = defaultdict(list) + for index, (_, (pid, _)) in enumerate(data_source): + self.index_dic[pid].append(index) + self.pids = list(self.index_dic.keys()) + self.num_identities = len(self.pids) + + # compute number of examples in an epoch + self.length = 0 + for pid in self.pids: + idxs = self.index_dic[pid] + num = len(idxs) + if num < self.num_instances: + num = self.num_instances + self.length += num - num % self.num_instances + + def __iter__(self): + """Iterate over Sampler.""" + list_container = [] + + for pid in self.pids: + idxs = copy.deepcopy(self.index_dic[pid]) + if len(idxs) < self.num_instances: + idxs = np.random.choice(idxs, size=self.num_instances, replace=True) + random.shuffle(idxs) + batch_idxs = [] + for idx in idxs: + batch_idxs.append(idx) + if len(batch_idxs) == self.num_instances: + list_container.append(batch_idxs) + batch_idxs = [] + + random.shuffle(list_container) + + ret = [] + for batch_idxs in list_container: + ret.extend(batch_idxs) + + return iter(ret) + + def __len__(self): + """Return number of examples in an epoch.""" + return self.length diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/workspace/transforms.py b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/workspace/transforms.py new file mode 100644 index 0000000..5ffa435 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_Market_Re-ID/workspace/transforms.py @@ -0,0 +1,103 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""Image transform tools.""" + +import math +import random + +from PIL import Image + + +class ResizeRandomCropping: + """ + With a probability, first increase image size to (1 + 1/8), and then perform random crop. + + Args: + height (int): target height. + width (int): target width. + p (float): probability of performing this transformation. Default: 0.5. + """ + + def __init__(self, height, width, p=0.5, interpolation=Image.BILINEAR): + """Initialize cropping.""" + self.height = height + self.width = width + self.p = p + self.interpolation = interpolation + + def __call__(self, img): + """ + Call of cropping. + + Args: + img (PIL Image): Image to be cropped. + Returns: + PIL Image: Cropped image. + """ + if random.uniform(0, 1) >= self.p: + return img.resize((self.width, self.height), self.interpolation) + + new_width, new_height = int(round(self.width * 1.125)), int(round(self.height * 1.125)) + resized_img = img.resize((new_width, new_height), self.interpolation) + x_maxrange = new_width - self.width + y_maxrange = new_height - self.height + x1 = int(round(random.uniform(0, x_maxrange))) + y1 = int(round(random.uniform(0, y_maxrange))) + cropped_img = resized_img.crop((x1, y1, x1 + self.width, y1 + self.height)) + + return cropped_img + + +class RandomErasing: + """ + Randomly selects a rectangle region in an image and erases its pixels. + + 'Random Erasing Data Augmentation' by Zhong et al. + See https://arxiv.org/pdf/1708.04896.pdf + + Args: + probability: The probability that the Random Erasing operation will be performed. + sl: Minimum proportion of erased area against input image. + sh: Maximum proportion of erased area against input image. + r1: Minimum aspect ratio of erased area. + mean: Erasing value. + """ + + def __init__(self, probability=0.5, sl=0.02, sh=0.4, r1=0.3, mean=None): + """Initialize Erasing.""" + if not mean: + mean = [0.4914, 0.4822, 0.4465] + + self.probability = probability + self.mean = mean + self.sl = sl + self.sh = sh + self.r1 = r1 + + def __call__(self, img): + """Call of Erasing.""" + if random.uniform(0, 1) >= self.probability: + return img + + for _attempt in range(100): + area = img.size()[1] * img.size()[2] + + target_area = random.uniform(self.sl, self.sh) * area + aspect_ratio = random.uniform(self.r1, 1 / self.r1) + + h = int(round(math.sqrt(target_area * aspect_ratio))) + w = int(round(math.sqrt(target_area / aspect_ratio))) + + if w < img.size()[2] and h < img.size()[1]: + x1 = random.randint(0, img.size()[1] - h) + y1 = random.randint(0, img.size()[2] - w) + if img.size()[0] == 3: + img[0, x1:x1 + h, y1:y1 + w] = self.mean[0] + img[1, x1:x1 + h, y1:y1 + w] = self.mean[1] + img[2, x1:x1 + h, y1:y1 + w] = self.mean[2] + else: + img[0, x1:x1 + h, y1:y1 + w] = self.mean[0] + return img + + return img diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/README.md b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/README.md new file mode 100644 index 0000000..40afb0b --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/README.md @@ -0,0 +1,70 @@ +# MedMNIST 2D Classification Tutorial + + + +For more details, please refer to the original paper: +**MedMNIST v2: A Large-Scale Lightweight Benchmark for 2D and 3D Biomedical Image Classification** ([arXiv](https://arxiv.org/abs/2110.14795)), and [PyPI](https://pypi.org/project/medmnist/). + + +## I. About model and experiments + +We use a simple convolutional neural network and settings coming from [the experiments](https://github.com/MedMNIST/experiments) repository. +
+ +## II. How to run this tutorial (without TLC and locally as a simulation): +### 0. If you haven't done so already, create a virtual environment, install OpenFL, and upgrade pip: + - For help with this step, visit the "Install the Package" section of the [OpenFL installation instructions](https://openfl.readthedocs.io/en/latest/install.html#install-the-package). +
+ +### 1. Split terminal into 3 (1 terminal for the director, 1 for the envoy, and 1 for the experiment) +
+ +### 2. Do the following in each terminal: + - Activate the virtual environment from step 0: + + ```sh + source venv/bin/activate + ``` + - If you are in a network environment with a proxy, ensure proxy environment variables are set in each of your terminals. + - Navigate to the tutorial: + + ```sh + cd openfl/openfl-tutorials/interactive_api/PyTorch_MedMNIST_2D + ``` +
+ +### 3. In the first terminal, run the director: + +```sh +cd director +./start_director.sh +``` +
+ +### 4. In the second terminal, install requirements and run the envoy: + +```sh +cd envoy +pip install -r requirements.txt +./start_envoy.sh env_one envoy_config.yaml +``` + +Optional: Run a second envoy in an additional terminal: + - Ensure step 2 is complete for this terminal as well. + - Run the second envoy: +```sh +cd envoy +./start_envoy.sh env_two envoy_config.yaml +``` +
+ +### 5. In the third terminal (or forth terminal, if you chose to do two envoys) run the Jupyter Notebook: + +```sh +cd workspace +jupyter lab Pytorch_MedMNIST_2D.ipynb +``` +- A Jupyter Server URL will appear in your terminal. In your browser, proceed to that link. Once the webpage loads, click on the Pytorch_MedMNIST_2D.ipynb file. +- To run the experiment, select the icon that looks like two triangles to "Restart Kernel and Run All Cells". +- You will notice activity in your terminals as the experiments runs, and when the experiment is finished the director terminal will display a message that the experiment was finished successfully. + \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/director/director_config.yaml new file mode 100644 index 0000000..f7d3847 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/director/director_config.yaml @@ -0,0 +1,5 @@ +settings: + listen_host: localhost + listen_port: 50051 + sample_shape: ['28', '28', '3'] + target_shape: ['1','1'] diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/director/start_director.sh new file mode 100755 index 0000000..5806a6c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/director/start_director.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx director start --disable-tls -c director_config.yaml \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/envoy/envoy_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/envoy/envoy_config.yaml new file mode 100644 index 0000000..05ee5ce --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/envoy/envoy_config.yaml @@ -0,0 +1,11 @@ +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: medmnist_shard_descriptor.MedMNISTShardDescriptor + params: + rank_worldsize: 1, 1 + datapath: data/. + dataname: bloodmnist diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/envoy/medmnist_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/envoy/medmnist_shard_descriptor.py new file mode 100644 index 0000000..d5e639f --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/envoy/medmnist_shard_descriptor.py @@ -0,0 +1,129 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""MedMNIST Shard Descriptor.""" + +import logging +import os +from typing import Any, List, Tuple +from medmnist.info import INFO, HOMEPAGE + +import numpy as np + +from openfl.interface.interactive_api.shard_descriptor import ShardDataset +from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor + +logger = logging.getLogger(__name__) + + +class MedMNISTShardDataset(ShardDataset): + """MedMNIST Shard dataset class.""" + + def __init__(self, x, y, data_type: str = 'train', rank: int = 1, worldsize: int = 1) -> None: + """Initialize MedMNISTDataset.""" + self.data_type = data_type + self.rank = rank + self.worldsize = worldsize + self.x = x[self.rank - 1::self.worldsize] + self.y = y[self.rank - 1::self.worldsize] + + def __getitem__(self, index: int) -> Tuple[Any, Any]: + """Return an item by the index.""" + return self.x[index], self.y[index] + + def __len__(self) -> int: + """Return the len of the dataset.""" + return len(self.x) + + +class MedMNISTShardDescriptor(ShardDescriptor): + """MedMNIST Shard descriptor class.""" + + def __init__( + self, + rank_worldsize: str = '1, 1', + datapath: str = '', + dataname: str = 'bloodmnist', + **kwargs + ) -> None: + """Initialize MedMNISTShardDescriptor.""" + self.rank, self.worldsize = tuple(int(num) for num in rank_worldsize.split(',')) + + self.datapath = datapath + self.dataset_name = dataname + self.info = INFO[self.dataset_name] + + (x_train, y_train), (x_test, y_test) = self.load_data() + self.data_by_type = { + 'train': (x_train, y_train), + 'val': (x_test, y_test) + } + + def get_shard_dataset_types(self) -> List[str]: + """Get available shard dataset types.""" + return list(self.data_by_type) + + def get_dataset(self, dataset_type='train') -> MedMNISTShardDataset: + """Return a shard dataset by type.""" + if dataset_type not in self.data_by_type: + raise Exception(f'Wrong dataset type: {dataset_type}') + return MedMNISTShardDataset( + *self.data_by_type[dataset_type], + data_type=dataset_type, + rank=self.rank, + worldsize=self.worldsize + ) + + @property + def sample_shape(self) -> List[str]: + """Return the sample shape info.""" + return ['28', '28', '3'] + + @property + def target_shape(self) -> List[str]: + """Return the target shape info.""" + return ['1', '1'] + + @property + def dataset_description(self) -> str: + """Return the dataset description.""" + return (f'MedMNIST dataset, shard number {self.rank}' + f' out of {self.worldsize}') + + @staticmethod + def download_data(datapath: str = 'data/', + dataname: str = 'bloodmnist', + info: dict = {}) -> None: + + logger.info(f"{datapath}\n{dataname}\n{info}") + try: + from torchvision.datasets.utils import download_url + download_url(url=info["url"], + root=datapath, + filename=dataname, + md5=info["MD5"]) + except Exception: + raise RuntimeError('Something went wrong when downloading! ' + + 'Go to the homepage to download manually. ' + + HOMEPAGE) + + def load_data(self) -> Tuple[Tuple[Any, Any], Tuple[Any, Any]]: + """Download prepared dataset.""" + + dataname = self.dataset_name + '.npz' + dataset = os.path.join(self.datapath, dataname) + + if not os.path.isfile(dataset): + logger.info(f"Dataset {dataname} not found at:{self.datapath}.\n\tDownloading...") + MedMNISTShardDescriptor.download_data(self.datapath, dataname, self.info) + logger.info("DONE!") + + data = np.load(dataset) + + x_train = data["train_images"] + x_test = data["test_images"] + + y_train = data["train_labels"] + y_test = data["test_labels"] + logger.info('MedMNIST data was loaded!') + return (x_train, y_train), (x_test, y_test) diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/envoy/requirements.txt b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/envoy/requirements.txt new file mode 100644 index 0000000..363c0d6 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/envoy/requirements.txt @@ -0,0 +1,3 @@ +medmnist +setuptools>=65.5.1 # not directly required, pinned by Snyk to avoid a vulnerability +wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/envoy/start_envoy.sh new file mode 100755 index 0000000..cdd84e7 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/envoy/start_envoy.sh @@ -0,0 +1,6 @@ +#!/bin/bash +set -e +ENVOY_NAME=$1 +ENVOY_CONF=$2 + +fx envoy start -n "$ENVOY_NAME" --disable-tls --envoy-config-path "$ENVOY_CONF" -dh localhost -dp 50051 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/workspace/Pytorch_MedMNIST_2D.ipynb b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/workspace/Pytorch_MedMNIST_2D.ipynb new file mode 100644 index 0000000..4cdcd36 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_2D/workspace/Pytorch_MedMNIST_2D.ipynb @@ -0,0 +1,614 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "26fdd9ed", + "metadata": {}, + "source": [ + "# Federated MedMNIST2D " + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "5504ab79", + "metadata": {}, + "outputs": [], + "source": [ + "!pip install medmnist" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d0570122", + "metadata": {}, + "outputs": [], + "source": [ + "# Install dependencies if not already installed\n", + "import tqdm\n", + "import numpy as np\n", + "import torch\n", + "import torch.nn as nn\n", + "import torch.optim as optim\n", + "from torch.utils.data import Dataset, DataLoader\n", + "from torchvision import transforms as T\n", + "import torch.nn.functional as F\n", + "\n", + "import medmnist" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "22ba64da", + "metadata": {}, + "outputs": [], + "source": [ + "from medmnist import INFO, Evaluator\n", + "\n", + "## Change dataflag here to reflect the ones defined in the envoy_conifg_xxx.yaml\n", + "dataname = 'bloodmnist'\n" + ] + }, + { + "cell_type": "markdown", + "id": "246f9c98", + "metadata": {}, + "source": [ + "## Connect to the Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d657e463", + "metadata": {}, + "outputs": [], + "source": [ + "# Create a federation\n", + "from openfl.interface.interactive_api.federation import Federation\n", + "\n", + "# please use the same identificator that was used in signed certificate\n", + "client_id = 'api'\n", + "director_node_fqdn = 'localhost'\n", + "director_port=50051\n", + "\n", + "# 2) Run with TLS disabled (trusted environment)\n", + "# Federation can also determine local fqdn automatically\n", + "federation = Federation(\n", + " client_id=client_id,\n", + " director_node_fqdn=director_node_fqdn,\n", + " director_port=director_port, \n", + " tls=False\n", + ")\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "47dcfab3", + "metadata": {}, + "outputs": [], + "source": [ + "shard_registry = federation.get_shard_registry()\n", + "shard_registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "a2a6c237", + "metadata": {}, + "outputs": [], + "source": [ + "# First, request a dummy_shard_desc that holds information about the federated dataset \n", + "dummy_shard_desc = federation.get_dummy_shard_descriptor(size=10)\n", + "dummy_shard_dataset = dummy_shard_desc.get_dataset('train')\n", + "sample, target = dummy_shard_dataset[0]\n", + "f\"Sample shape: {sample.shape}, target shape: {target.shape}\"" + ] + }, + { + "cell_type": "markdown", + "id": "cc0dbdbd", + "metadata": {}, + "source": [ + "## Describing FL experimen" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "fc88700a", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment" + ] + }, + { + "cell_type": "markdown", + "id": "9b3081a6", + "metadata": {}, + "source": [ + "## Load MedMNIST INFO" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "e0377d3a", + "metadata": {}, + "outputs": [], + "source": [ + "num_epochs = 3\n", + "TRAIN_BS, VALID_BS = 64, 128\n", + "\n", + "lr = 0.001\n", + "gamma=0.1\n", + "milestones = [0.5 * num_epochs, 0.75 * num_epochs]\n", + "\n", + "info = INFO[dataname]\n", + "task = info['task']\n", + "n_channels = info['n_channels']\n", + "n_classes = len(info['label'])" + ] + }, + { + "cell_type": "markdown", + "id": "b0979470", + "metadata": {}, + "source": [ + "### Register dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "f0dc457e", + "metadata": {}, + "outputs": [], + "source": [ + "## Data transformations\n", + "data_transform = T.Compose([T.ToTensor(), \n", + " T.Normalize(mean=[.5], std=[.5])]\n", + " )" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "09ba2f64", + "metadata": {}, + "outputs": [], + "source": [ + "from PIL import Image\n", + "\n", + "class TransformedDataset(Dataset):\n", + " \"\"\"Image Person ReID Dataset.\"\"\"\n", + "\n", + "\n", + " def __init__(self, dataset, transform=None, target_transform=None):\n", + " \"\"\"Initialize Dataset.\"\"\"\n", + " self.dataset = dataset\n", + " self.transform = transform\n", + " self.target_transform = target_transform\n", + "\n", + " def __len__(self):\n", + " \"\"\"Length of dataset.\"\"\"\n", + " return len(self.dataset)\n", + "\n", + " def __getitem__(self, index):\n", + " \n", + " img, label = self.dataset[index]\n", + " \n", + " if self.target_transform:\n", + " label = self.target_transform(label) \n", + " else:\n", + " label = label.astype(int)\n", + " \n", + " if self.transform:\n", + " img = Image.fromarray(img)\n", + " img = self.transform(img)\n", + " else:\n", + " base_transform = T.PILToTensor()\n", + " img = Image.fromarray(img)\n", + " img = base_transform(img) \n", + "\n", + " return img, label\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "db2d563e", + "metadata": {}, + "outputs": [], + "source": [ + "class MedMnistFedDataset(DataInterface):\n", + " def __init__(self, **kwargs):\n", + " self.kwargs = kwargs\n", + " \n", + " @property\n", + " def shard_descriptor(self):\n", + " return self._shard_descriptor\n", + " \n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + "\n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + "\n", + " self.train_set = TransformedDataset(\n", + " self._shard_descriptor.get_dataset('train'),\n", + " transform=data_transform\n", + " ) \n", + " \n", + " self.valid_set = TransformedDataset(\n", + " self._shard_descriptor.get_dataset('val'),\n", + " transform=data_transform\n", + " )\n", + " \n", + " def get_train_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks with optimizer in contract\n", + " \"\"\"\n", + " return DataLoader(\n", + " self.train_set, num_workers=8, batch_size=self.kwargs['train_bs'], shuffle=True)\n", + "\n", + " def get_valid_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks without optimizer in contract\n", + " \"\"\"\n", + " return DataLoader(self.valid_set, num_workers=8, batch_size=self.kwargs['valid_bs'])\n", + "\n", + " def get_train_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.train_set)\n", + "\n", + " def get_valid_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.valid_set)\n", + " " + ] + }, + { + "cell_type": "markdown", + "id": "b0dfb459", + "metadata": {}, + "source": [ + "### Create Mnist federated dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4af5c4c2", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = MedMnistFedDataset(train_bs=TRAIN_BS, valid_bs=VALID_BS)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "7f63908e", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset.shard_descriptor = dummy_shard_desc\n", + "for i, (sample, target) in enumerate(fed_dataset.get_train_loader()):\n", + " print(sample.shape, target.shape)" + ] + }, + { + "cell_type": "markdown", + "id": "075d1d6c", + "metadata": {}, + "source": [ + "### Describe the model and optimizer" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "8477a001", + "metadata": {}, + "outputs": [], + "source": [ + "# define a simple CNN model\n", + "class Net(nn.Module):\n", + " def __init__(self, in_channels, num_classes):\n", + " super(Net, self).__init__()\n", + "\n", + " self.layer1 = nn.Sequential(\n", + " nn.Conv2d(in_channels, 16, kernel_size=3),\n", + " nn.BatchNorm2d(16),\n", + " nn.ReLU())\n", + "\n", + " self.layer2 = nn.Sequential(\n", + " nn.Conv2d(16, 16, kernel_size=3),\n", + " nn.BatchNorm2d(16),\n", + " nn.ReLU(),\n", + " nn.MaxPool2d(kernel_size=2, stride=2))\n", + "\n", + " self.layer3 = nn.Sequential(\n", + " nn.Conv2d(16, 64, kernel_size=3),\n", + " nn.BatchNorm2d(64),\n", + " nn.ReLU())\n", + " \n", + " self.layer4 = nn.Sequential(\n", + " nn.Conv2d(64, 64, kernel_size=3),\n", + " nn.BatchNorm2d(64),\n", + " nn.ReLU())\n", + "\n", + " self.layer5 = nn.Sequential(\n", + " nn.Conv2d(64, 64, kernel_size=3, padding=1),\n", + " nn.BatchNorm2d(64),\n", + " nn.ReLU(),\n", + " nn.MaxPool2d(kernel_size=2, stride=2))\n", + "\n", + " self.fc = nn.Sequential(\n", + " nn.Linear(64 * 4 * 4, 128),\n", + " nn.ReLU(),\n", + " nn.Linear(128, 128),\n", + " nn.ReLU(),\n", + " nn.Linear(128, num_classes))\n", + "\n", + " def forward(self, x):\n", + " x = self.layer1(x)\n", + " x = self.layer2(x)\n", + " x = self.layer3(x)\n", + " x = self.layer4(x)\n", + " x = self.layer5(x)\n", + " x = x.view(x.size(0), -1)\n", + " x = self.fc(x)\n", + " return x\n", + "\n", + "model = Net(in_channels=n_channels, num_classes=n_classes)\n", + " \n", + "# define loss function and optimizer\n", + "if task == \"multi-label, binary-class\":\n", + " criterion = nn.BCEWithLogitsLoss()\n", + "else:\n", + " criterion = nn.CrossEntropyLoss()\n", + " \n", + "optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.9)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "f2154486", + "metadata": {}, + "outputs": [], + "source": [ + "print(model)" + ] + }, + { + "cell_type": "markdown", + "id": "8d1c78ee", + "metadata": {}, + "source": [ + "### Register model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "59831bcd", + "metadata": {}, + "outputs": [], + "source": [ + "from copy import deepcopy\n", + "\n", + "framework_adapter = 'openfl.plugins.frameworks_adapters.pytorch_adapter.FrameworkAdapterPlugin'\n", + "MI = ModelInterface(model=model, optimizer=optimizer, framework_plugin=framework_adapter)\n", + "\n", + "# Save the initial model state\n", + "initial_model = deepcopy(model)" + ] + }, + { + "cell_type": "markdown", + "id": "849c165b", + "metadata": {}, + "source": [ + "## Define and register FL tasks" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4ff463bd", + "metadata": {}, + "outputs": [], + "source": [ + "TI = TaskInterface()\n", + "\n", + "train_custom_params={'criterion':criterion,'task':task}\n", + "\n", + "# Task interface currently supports only standalone functions.\n", + "@TI.add_kwargs(**train_custom_params)\n", + "@TI.register_fl_task(model='model', data_loader='train_loader',\n", + " device='device', optimizer='optimizer')\n", + "def train(model, train_loader, device, optimizer, criterion, task):\n", + " total_loss = []\n", + " \n", + " train_loader = tqdm.tqdm(train_loader, desc=\"train\")\n", + " model.train()\n", + " model.to(device)\n", + " \n", + " for inputs, targets in train_loader:\n", + " \n", + " optimizer.zero_grad()\n", + " outputs = model(inputs.to(device))\n", + " \n", + " if task == 'multi-label, binary-class':\n", + " targets = targets.to(torch.float32).to(device)\n", + " loss = criterion(outputs, targets)\n", + " else:\n", + " targets = torch.squeeze(targets, 1).long().to(device)\n", + " loss = criterion(outputs, targets)\n", + " \n", + " total_loss.append(loss.item())\n", + " \n", + " loss.backward()\n", + " optimizer.step()\n", + "\n", + " return {'train_loss': np.mean(total_loss),}\n", + "\n", + "\n", + "\n", + "val_custom_params={'criterion':criterion, \n", + " 'task':task}\n", + "\n", + "@TI.add_kwargs(**val_custom_params)\n", + "@TI.register_fl_task(model='model', data_loader='val_loader', device='device')\n", + "def validate(model, val_loader, device, criterion, task):\n", + "\n", + " val_loader = tqdm.tqdm(val_loader, desc=\"validate\")\n", + " model.eval()\n", + " model.to(device)\n", + "\n", + " val_score = 0\n", + " total_samples = 0\n", + " total_loss = []\n", + " y_score = torch.tensor([]).to(device)\n", + "\n", + " with torch.no_grad():\n", + " for inputs, targets in val_loader:\n", + " outputs = model(inputs.to(device))\n", + " \n", + " if task == 'multi-label, binary-class':\n", + " targets = targets.to(torch.float32).to(device)\n", + " loss = criterion(outputs, targets)\n", + " m = nn.Sigmoid()\n", + " outputs = m(outputs).to(device)\n", + " else:\n", + " targets = torch.squeeze(targets, 1).long().to(device)\n", + " loss = criterion(outputs, targets)\n", + " m = nn.Softmax(dim=1)\n", + " outputs = m(outputs).to(device)\n", + " targets = targets.float().resize_(len(targets), 1)\n", + "\n", + " total_loss.append(loss.item())\n", + " \n", + " total_samples += targets.shape[0]\n", + " pred = outputs.argmax(dim=1)\n", + " val_score += pred.eq(targets).sum().cpu().numpy()\n", + " \n", + " acc = val_score / total_samples \n", + " test_loss = sum(total_loss) / len(total_loss)\n", + "\n", + " return {'acc': acc,\n", + " 'test_loss': test_loss,\n", + " }" + ] + }, + { + "cell_type": "markdown", + "id": "8f0ebf2d", + "metadata": {}, + "source": [ + "## Time to start a federated learning experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d41b7896", + "metadata": {}, + "outputs": [], + "source": [ + "# create an experimnet in federation\n", + "experiment_name = 'medmnist_exp'\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "41b44de9", + "metadata": {}, + "outputs": [], + "source": [ + "# The following command zips the workspace and python requirements to be transfered to collaborator nodes\n", + "fl_experiment.start(model_provider=MI, \n", + " task_keeper=TI,\n", + " data_loader=fed_dataset,\n", + " rounds_to_train=3,\n", + " opt_treatment='RESET',\n", + " device_assignment_policy='CUDA_PREFERRED')" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "01fa7cea", + "metadata": {}, + "outputs": [], + "source": [ + "# If user want to stop IPython session, then reconnect and check how experiment is going\n", + "# fl_experiment.restore_experiment_state(model_interface)\n", + "\n", + "fl_experiment.stream_metrics(tensorboard_logs=False)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "92940763", + "metadata": {}, + "outputs": [], + "source": [ + "\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "1690ea49", + "metadata": {}, + "outputs": [], + "source": [] + } + ], + "metadata": { + "kernelspec": { + "display_name": "Python 3.8.10 64-bit", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.10" + }, + "vscode": { + "interpreter": { + "hash": "916dbcbb3f70747c44a77c7bcd40155683ae19c65e1c03b4aa3499c5328201f1" + } + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/README.md b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/README.md new file mode 100644 index 0000000..6c5c516 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/README.md @@ -0,0 +1,78 @@ +# MedMNIST 3D Classification Tutorial + + + +For more details, please refer to the original paper: +**MedMNIST v2: A Large-Scale Lightweight Benchmark for 2D and 3D Biomedical Image Classification** ([arXiv](https://arxiv.org/abs/2110.14795)) +or visit the MedMNIST [PyPI](https://pypi.org/project/medmnist/). + +## **I. About model and experiments** + +We use a simple convolutional neural network and settings coming from [the experiments](https://github.com/MedMNIST/experiments) repository. +
+
+ +## **II. How to run this tutorial (without TLC and locally as a simulation):** +
+ +### 0. If you haven't done so already, create a virtual environment, install OpenFL, and upgrade pip: + - For help with this step, visit the "Install the Package" section of the [OpenFL installation instructions](https://openfl.readthedocs.io/en/latest/install.html#install-the-package). + +
+ +### 1. Split terminal into 3 (1 terminal for the director, 1 for the envoy, and 1 for the experiment) + +
+ +### 2. Do the following in each terminal: + - Activate the virtual environment from step 0: + + ```sh + source venv/bin/activate + ``` + - If you are in a network environment with a proxy, ensure proxy environment variables are set in each of your terminals. + - Navigate to the tutorial: + + ```sh + cd openfl/openfl-tutorials/interactive_api/PyTorch_MedMNIST_3D + ``` + +
+ +### 3. In the first terminal, run the director: + +```sh +cd director +./start_director.sh +``` + +
+ +### 4. In the second terminal, install requirements and run the envoy: + +```sh +cd envoy +pip install -r requirements.txt +./start_envoy.sh env_one envoy_config.yaml +``` + +Optional: Run a second envoy in an additional terminal: + - Ensure step 2 is complete for this terminal as well. + - Run the second envoy: +```sh +cd envoy +./start_envoy.sh env_two envoy_config.yaml +``` + +
+ +### 5. Now that your director and envoy terminals are set up, run the Jupyter Notebook in your experiment terminal: + +```sh +cd workspace +jupyter lab Pytorch_MedMNIST_3D.ipynb +``` +- A Jupyter Server URL will appear in your terminal. In your browser, proceed to that link. Once the webpage loads, click on the Pytorch_MedMNIST_3D.ipynb file. +- To run the experiment, select the icon that looks like two triangles to "Restart Kernel and Run All Cells". +- You will notice activity in your terminals as the experiment runs, and when the experiment is finished the director terminal will display a message that the experiment has finished successfully. + diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/director/director_config.yaml new file mode 100644 index 0000000..14c8152 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/director/director_config.yaml @@ -0,0 +1,5 @@ +settings: + listen_host: localhost + listen_port: 50051 + sample_shape: ['28', '28', '28'] + target_shape: ['1','1'] diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/director/start_director.sh new file mode 100755 index 0000000..5806a6c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/director/start_director.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx director start --disable-tls -c director_config.yaml \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/envoy/envoy_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/envoy/envoy_config.yaml new file mode 100644 index 0000000..7eea1a6 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/envoy/envoy_config.yaml @@ -0,0 +1,11 @@ +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: medmnist_shard_descriptor.MedMNISTShardDescriptor + params: + rank_worldsize: 1, 1 + datapath: data/. + dataname: synapsemnist3d diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/envoy/medmnist_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/envoy/medmnist_shard_descriptor.py new file mode 100644 index 0000000..5f490a6 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/envoy/medmnist_shard_descriptor.py @@ -0,0 +1,129 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""MedMNIST Shard Descriptor.""" + +import logging +import os +from typing import Any, List, Tuple +from medmnist.info import INFO, HOMEPAGE + +import numpy as np + +from openfl.interface.interactive_api.shard_descriptor import ShardDataset +from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor + +logger = logging.getLogger(__name__) + + +class MedMNISTShardDataset(ShardDataset): + """MedMNIST Shard dataset class.""" + + def __init__(self, x, y, data_type: str = 'train', rank: int = 1, worldsize: int = 1) -> None: + """Initialize MedMNISTDataset.""" + self.data_type = data_type + self.rank = rank + self.worldsize = worldsize + self.x = x[self.rank - 1::self.worldsize] + self.y = y[self.rank - 1::self.worldsize] + + def __getitem__(self, index: int) -> Tuple[Any, Any]: + """Return an item by the index.""" + return self.x[index], self.y[index] + + def __len__(self) -> int: + """Return the len of the dataset.""" + return len(self.x) + + +class MedMNISTShardDescriptor(ShardDescriptor): + """MedMNIST Shard descriptor class.""" + + def __init__( + self, + rank_worldsize: str = '1, 1', + datapath: str = '', + dataname: str = 'bloodmnist', + **kwargs + ) -> None: + """Initialize MedMNISTShardDescriptor.""" + self.rank, self.worldsize = tuple(int(num) for num in rank_worldsize.split(',')) + + self.datapath = datapath + self.dataset_name = dataname + self.info = INFO[self.dataset_name] + + (x_train, y_train), (x_test, y_test) = self.load_data() + self.data_by_type = { + 'train': (x_train, y_train), + 'val': (x_test, y_test) + } + + def get_shard_dataset_types(self) -> List[str]: + """Get available shard dataset types.""" + return list(self.data_by_type) + + def get_dataset(self, dataset_type='train') -> MedMNISTShardDataset: + """Return a shard dataset by type.""" + if dataset_type not in self.data_by_type: + raise Exception(f'Wrong dataset type: {dataset_type}') + return MedMNISTShardDataset( + *self.data_by_type[dataset_type], + data_type=dataset_type, + rank=self.rank, + worldsize=self.worldsize + ) + + @property + def sample_shape(self) -> List[str]: + """Return the sample shape info.""" + return ['28', '28', '28'] + + @property + def target_shape(self) -> List[str]: + """Return the target shape info.""" + return ['1', '1'] + + @property + def dataset_description(self) -> str: + """Return the dataset description.""" + return (f'MedMNIST dataset, shard number {self.rank}' + f' out of {self.worldsize}') + + @staticmethod + def download_data(datapath: str = 'data/', + dataname: str = 'bloodmnist', + info: dict = {}) -> None: + + logger.info(f"{datapath}\n{dataname}\n{info}") + try: + from torchvision.datasets.utils import download_url + download_url(url=info["url"], + root=datapath, + filename=dataname, + md5=info["MD5"]) + except Exception: + raise RuntimeError('Something went wrong when downloading! ' + + 'Go to the homepage to download manually. ' + + HOMEPAGE) + + def load_data(self) -> Tuple[Tuple[Any, Any], Tuple[Any, Any]]: + """Download prepared dataset.""" + + dataname = self.dataset_name + '.npz' + dataset = os.path.join(self.datapath, dataname) + + if not os.path.isfile(dataset): + logger.info(f"Dataset {dataname} not found at:{self.datapath}.\n\tDownloading...") + MedMNISTShardDescriptor.download_data(self.datapath, dataname, self.info) + logger.info("DONE!") + + data = np.load(dataset) + + x_train = data["train_images"] + x_test = data["test_images"] + + y_train = data["train_labels"] + y_test = data["test_labels"] + logger.info('MedMNIST data was loaded!') + return (x_train, y_train), (x_test, y_test) diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/envoy/requirements.txt b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/envoy/requirements.txt new file mode 100644 index 0000000..8244055 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/envoy/requirements.txt @@ -0,0 +1,5 @@ +ACSConv +medmnist +protobuf>=3.20.2 # not directly required, pinned by Snyk to avoid a vulnerability +setuptools>=65.5.1 # not directly required, pinned by Snyk to avoid a vulnerability +wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/envoy/start_envoy.sh new file mode 100755 index 0000000..cdd84e7 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/envoy/start_envoy.sh @@ -0,0 +1,6 @@ +#!/bin/bash +set -e +ENVOY_NAME=$1 +ENVOY_CONF=$2 + +fx envoy start -n "$ENVOY_NAME" --disable-tls --envoy-config-path "$ENVOY_CONF" -dh localhost -dp 50051 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/Pytorch_MedMNIST_3D.ipynb b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/Pytorch_MedMNIST_3D.ipynb new file mode 100644 index 0000000..a400b6f --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/Pytorch_MedMNIST_3D.ipynb @@ -0,0 +1,739 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "26fdd9ed", + "metadata": {}, + "source": [ + "# Federated MedMNIST3D " + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "f9d99476", + "metadata": {}, + "outputs": [], + "source": [ + "!pip install medmnist\n", + "!pip install ACSConv" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d0570122", + "metadata": {}, + "outputs": [], + "source": [ + "# Install dependencies if not already installed\n", + "import tqdm\n", + "import numpy as np\n", + "import torch\n", + "import torch.nn as nn\n", + "import torch.optim as optim\n", + "from torch.utils.data import Dataset, DataLoader\n", + "from torchvision import transforms as T\n", + "import torch.nn.functional as F\n", + "\n", + "import medmnist" + ] + }, + { + "cell_type": "markdown", + "id": "246f9c98", + "metadata": {}, + "source": [ + "## Connect to the Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d657e463", + "metadata": {}, + "outputs": [], + "source": [ + "# Create a federation\n", + "from openfl.interface.interactive_api.federation import Federation\n", + "\n", + "# please use the same identificator that was used in signed certificate\n", + "client_id = 'api'\n", + "director_node_fqdn = 'localhost'\n", + "director_port=50051\n", + "\n", + "# 2) Run with TLS disabled (trusted environment)\n", + "# Federation can also determine local fqdn automatically\n", + "federation = Federation(\n", + " client_id=client_id,\n", + " director_node_fqdn=director_node_fqdn,\n", + " director_port=director_port, \n", + " tls=False\n", + ")\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "47dcfab3", + "metadata": {}, + "outputs": [], + "source": [ + "shard_registry = federation.get_shard_registry()\n", + "shard_registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "a2a6c237", + "metadata": {}, + "outputs": [], + "source": [ + "# First, request a dummy_shard_desc that holds information about the federated dataset \n", + "dummy_shard_desc = federation.get_dummy_shard_descriptor(size=10)\n", + "dummy_shard_dataset = dummy_shard_desc.get_dataset('train')\n", + "sample, target = dummy_shard_dataset[0]\n", + "f\"Sample shape: {sample.shape}, target shape: {target.shape}\"" + ] + }, + { + "cell_type": "markdown", + "id": "cc0dbdbd", + "metadata": {}, + "source": [ + "## Describing FL experimen" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "fc88700a", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment" + ] + }, + { + "cell_type": "markdown", + "id": "9b3081a6", + "metadata": {}, + "source": [ + "## Load MedMNIST INFO" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "e0377d3a", + "metadata": {}, + "outputs": [], + "source": [ + "from medmnist import INFO, Evaluator\n", + "\n", + "data_flag = 'synapsemnist3d'\n", + "num_epochs = 1\n", + "batch_size = 128\n", + "\n", + "lr = 0.001\n", + "\n", + "info = INFO[data_flag]\n", + "task = info['task']\n", + "n_channels = info['n_channels']\n", + "n_classes = len(info['label'])\n", + "\n", + "print(info)" + ] + }, + { + "cell_type": "markdown", + "id": "b0979470", + "metadata": {}, + "source": [ + "### Register dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "f0dc457e", + "metadata": {}, + "outputs": [], + "source": [ + "from wspace_utils.utils import Transform3D, model_to_syncbn\n", + "shape_transform = False\n", + "\n", + "train_transform = Transform3D(mul='random') if shape_transform else Transform3D()\n", + "eval_transform = Transform3D(mul='0.5') if shape_transform else Transform3D()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "09ba2f64", + "metadata": {}, + "outputs": [], + "source": [ + "from PIL import Image\n", + "\n", + "class TransformedDataset(Dataset):\n", + " \"\"\"Image Person ReID Dataset.\"\"\"\n", + "\n", + "\n", + " def __init__(self, dataset, transform=None, target_transform=None, as_rgb=False):\n", + " \"\"\"Initialize Dataset.\"\"\"\n", + " self.dataset = dataset\n", + " self.transform = transform\n", + " self.target_transform = target_transform\n", + " self.as_rgb = as_rgb\n", + "\n", + " def __len__(self):\n", + " \"\"\"Length of dataset.\"\"\"\n", + " return len(self.dataset)\n", + "\n", + " def __getitem__(self, index):\n", + " \n", + " img, label = self.dataset[index]\n", + " \n", + " if self.target_transform:\n", + " label = self.target_transform(label) \n", + " else:\n", + " label = label.astype(int)\n", + " \n", + " img = np.stack([img/255.]*(3 if self.as_rgb else 1), axis=0) \n", + " if self.transform is not None:\n", + " img = self.transform(img)\n", + "\n", + " if self.target_transform is not None:\n", + " target = self.target_transform(target)\n", + "\n", + " return img, label\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "db2d563e", + "metadata": {}, + "outputs": [], + "source": [ + "class MedMnistFedDataset(DataInterface):\n", + " def __init__(self, **kwargs):\n", + " self.kwargs = kwargs\n", + " \n", + " @property\n", + " def shard_descriptor(self):\n", + " return self._shard_descriptor\n", + " \n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + "\n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + "\n", + " self.train_set = TransformedDataset(\n", + " self._shard_descriptor.get_dataset('train'),\n", + " transform=train_transform, as_rgb=False\n", + " ) \n", + " \n", + " self.valid_set = TransformedDataset(\n", + " self._shard_descriptor.get_dataset('val'),\n", + " transform=eval_transform, as_rgb=False\n", + " )\n", + " \n", + " def get_train_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks with optimizer in contract\n", + " \"\"\"\n", + " return DataLoader(\n", + " self.train_set, num_workers=8, batch_size=self.kwargs['train_bs'], shuffle=True)\n", + "\n", + " def get_valid_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks without optimizer in contract\n", + " \"\"\"\n", + " return DataLoader(self.valid_set, num_workers=8, batch_size=self.kwargs['valid_bs'])\n", + "\n", + " def get_train_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.train_set)\n", + "\n", + " def get_valid_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.valid_set)\n", + " " + ] + }, + { + "cell_type": "markdown", + "id": "b0dfb459", + "metadata": {}, + "source": [ + "### Create Mnist federated dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4af5c4c2", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = MedMnistFedDataset(train_bs=64, valid_bs=512)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "7f63908e", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset.shard_descriptor = dummy_shard_desc\n", + "for i, (sample, target) in enumerate(fed_dataset.get_train_loader()):\n", + " sample = (np.array(sample))\n", + " print(sample.shape, target.shape)\n", + " \n", + "print(f\"dtype = {sample.dtype}, type = {type(sample)}\")" + ] + }, + { + "cell_type": "markdown", + "id": "f005760c", + "metadata": {}, + "source": [ + "## Describe the model and optimizer" + ] + }, + { + "cell_type": "markdown", + "id": "12e343b3", + "metadata": {}, + "source": [ + "## ResNet (compute intensive)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d47f74d2", + "metadata": {}, + "outputs": [], + "source": [ + "class BasicBlock(nn.Module):\n", + " expansion = 1\n", + "\n", + " def __init__(self, in_planes, planes, stride=1):\n", + " super(BasicBlock, self).__init__()\n", + " self.conv1 = nn.Conv2d(\n", + " in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)\n", + " self.bn1 = nn.BatchNorm2d(planes)\n", + " \n", + " self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,\n", + " stride=1, padding=1, bias=False)\n", + " self.bn2 = nn.BatchNorm2d(planes)\n", + "\n", + " self.shortcut = nn.Sequential()\n", + " if stride != 1 or in_planes != self.expansion*planes:\n", + " self.shortcut = nn.Sequential(\n", + " nn.Conv2d(in_planes, self.expansion*planes,\n", + " kernel_size=1, stride=stride, bias=False),\n", + " nn.BatchNorm2d(self.expansion*planes)\n", + " \n", + " )\n", + "\n", + " def forward(self, x):\n", + " out = F.relu(self.bn1(self.conv1(x)))\n", + " out = self.bn2(self.conv2(out))\n", + " out += self.shortcut(x)\n", + " out = F.relu(out)\n", + " return out\n", + "\n", + "\n", + "class Bottleneck(nn.Module):\n", + " expansion = 4\n", + "\n", + " def __init__(self, in_planes, planes, stride=1):\n", + " super(Bottleneck, self).__init__()\n", + " self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)\n", + " self.bn1 = nn.BatchNorm2d(planes)\n", + " self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,\n", + " stride=stride, padding=1, bias=False)\n", + " self.bn2 = nn.BatchNorm2d(planes)\n", + " self.conv3 = nn.Conv2d(planes, self.expansion *\n", + " planes, kernel_size=1, bias=False)\n", + " self.bn3 = nn.BatchNorm2d(self.expansion*planes)\n", + "\n", + " self.shortcut = nn.Sequential()\n", + " if stride != 1 or in_planes != self.expansion*planes:\n", + " self.shortcut = nn.Sequential(\n", + " nn.Conv2d(in_planes, self.expansion*planes,\n", + " kernel_size=1, stride=stride, bias=False),\n", + " nn.BatchNorm2d(self.expansion*planes)\n", + " )\n", + "\n", + " def forward(self, x):\n", + " out = F.relu(self.bn1(self.conv1(x)))\n", + " out = F.relu(self.bn2(self.conv2(out)))\n", + " out = self.bn3(self.conv3(out))\n", + " out += self.shortcut(x)\n", + " out = F.relu(out)\n", + " return out\n", + "\n", + "\n", + "class ResNet(nn.Module):\n", + " def __init__(self, block, num_blocks, in_channels=1, num_classes=2):\n", + " super(ResNet, self).__init__()\n", + " self.in_planes = 64\n", + "\n", + " self.conv1 = nn.Conv2d(in_channels, 64, kernel_size=3,\n", + " stride=1, padding=1, bias=False)\n", + " self.bn1 = nn.BatchNorm2d(64)\n", + " self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)\n", + " self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)\n", + " self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)\n", + " self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)\n", + " self.avgpool = nn.AdaptiveAvgPool2d((1, 1))\n", + " self.linear = nn.Linear(512 * block.expansion, num_classes)\n", + "\n", + " def _make_layer(self, block, planes, num_blocks, stride):\n", + " strides = [stride] + [1]*(num_blocks-1)\n", + " layers = []\n", + " for stride in strides:\n", + " layers.append(block(self.in_planes, planes, stride))\n", + " self.in_planes = planes * block.expansion\n", + " return nn.Sequential(*layers)\n", + "\n", + " def forward(self, x):\n", + " out = F.relu(self.bn1(self.conv1(x)))\n", + " out = self.layer1(out)\n", + " out = self.layer2(out)\n", + " out = self.layer3(out)\n", + " out = self.layer4(out)\n", + " out = self.avgpool(out)\n", + " out = out.view(out.size(0), -1)\n", + " out = self.linear(out)\n", + " return out\n", + "\n", + "\n", + "def ResNet18(in_channels, num_classes):\n", + " return ResNet(BasicBlock, [2, 2, 2, 2], in_channels=in_channels, num_classes=num_classes)\n", + "\n", + "\n", + "def ResNet50(in_channels, num_classes):\n", + " return ResNet(Bottleneck, [3, 4, 6, 3], in_channels=in_channels, num_classes=num_classes)" + ] + }, + { + "cell_type": "markdown", + "id": "073ae903", + "metadata": {}, + "source": [ + "## Simple 3D Net - Demo example" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "7423423a", + "metadata": {}, + "outputs": [], + "source": [ + "# define a simple CNN model\n", + "class Net(nn.Module):\n", + " def __init__(self, in_channels, num_classes):\n", + " super(Net, self).__init__()\n", + "\n", + " self.layer1 = nn.Sequential(\n", + " nn.Conv2d(in_channels, 16, kernel_size=3),\n", + " nn.BatchNorm2d(16),\n", + " nn.ReLU())\n", + "\n", + " self.layer2 = nn.Sequential(\n", + " nn.Conv2d(16, 16, kernel_size=3),\n", + " nn.BatchNorm2d(16),\n", + " nn.ReLU(),\n", + " nn.MaxPool2d(kernel_size=2, stride=2))\n", + "\n", + " self.layer3 = nn.Sequential(\n", + " nn.Conv2d(16, 64, kernel_size=3),\n", + " nn.BatchNorm2d(64),\n", + " nn.ReLU())\n", + " \n", + " self.layer4 = nn.Sequential(\n", + " nn.Conv2d(64, 64, kernel_size=3),\n", + " nn.BatchNorm2d(64),\n", + " nn.ReLU())\n", + "\n", + " self.layer5 = nn.Sequential(\n", + " nn.Conv2d(64, 64, kernel_size=3, padding=1),\n", + " nn.BatchNorm2d(64),\n", + " nn.ReLU(),\n", + " nn.MaxPool2d(kernel_size=2, stride=2))\n", + "\n", + " self.fc = nn.Sequential(\n", + " nn.Linear(64 * 4 * 4 * 4, 128),\n", + " nn.ReLU(),\n", + " nn.Linear(128, 128),\n", + " nn.ReLU(),\n", + " nn.Linear(128, num_classes))\n", + "\n", + " def forward(self, x):\n", + " x = self.layer1(x)\n", + " x = self.layer2(x)\n", + " x = self.layer3(x)\n", + " x = self.layer4(x)\n", + " x = self.layer5(x)\n", + " x = x.view(x.size(0), -1)\n", + " x = self.fc(x)\n", + " return x" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "15e0294b", + "metadata": {}, + "outputs": [], + "source": [ + "from acsconv.converters import ACSConverter, Conv3dConverter, Conv2_5dConverter\n", + "\n", + "#model = ResNet18(in_channels=n_channels, num_classes=n_classes)\n", + "model = Net(in_channels=n_channels, num_classes=n_classes)\n", + "model = model_to_syncbn(Conv3dConverter(model, i3d_repeat_axis=None))\n", + "\n", + "criterion = nn.CrossEntropyLoss()\n", + "optimizer = torch.optim.Adam(model.parameters(), lr=lr)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "f2154486", + "metadata": {}, + "outputs": [], + "source": [ + "print(model)" + ] + }, + { + "cell_type": "markdown", + "id": "8d1c78ee", + "metadata": {}, + "source": [ + "### Register model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "59831bcd", + "metadata": {}, + "outputs": [], + "source": [ + "from copy import deepcopy\n", + "\n", + "framework_adapter = 'openfl.plugins.frameworks_adapters.pytorch_adapter.FrameworkAdapterPlugin'\n", + "MI = ModelInterface(model=model.model, optimizer=optimizer, framework_plugin=framework_adapter)\n", + "\n", + "# Save the initial model state\n", + "initial_model = deepcopy(model.model)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "06a84be2", + "metadata": {}, + "outputs": [], + "source": [ + "from medmnist.evaluator import getACC" + ] + }, + { + "cell_type": "markdown", + "id": "849c165b", + "metadata": {}, + "source": [ + "## Define and register FL tasks" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4ff463bd", + "metadata": {}, + "outputs": [], + "source": [ + "TI = TaskInterface()\n", + "\n", + "train_custom_params={'criterion':criterion,'task':task}\n", + "\n", + "# Task interface currently supports only standalone functions.\n", + "@TI.add_kwargs(**train_custom_params)\n", + "@TI.register_fl_task(model='model', data_loader='train_loader',\n", + " device='device', optimizer='optimizer')\n", + "def train(model, train_loader, device, optimizer, criterion, task):\n", + " total_loss = []\n", + " \n", + " train_loader = tqdm.tqdm(train_loader, desc=\"train\")\n", + " model.train()\n", + " model.to(device)\n", + " for inputs, targets in train_loader:\n", + " \n", + " inputs, targets = inputs.to(device), targets.to(device)\n", + " \n", + " optimizer.zero_grad()\n", + " outputs = model(inputs.to(device))\n", + " \n", + " if task == 'multi-label, binary-class':\n", + " targets = targets.to(torch.float32).to(device)\n", + " loss = criterion(outputs, targets)\n", + " else:\n", + " targets = torch.squeeze(targets, 1).long().to(device)\n", + " loss = criterion(outputs, targets)\n", + " \n", + " total_loss.append(loss.item())\n", + " \n", + " loss.backward()\n", + " optimizer.step()\n", + " \n", + " return {'train_loss': np.mean(total_loss),}\n", + "\n", + "\n", + "val_custom_params={'criterion':criterion,'task':task, 'acc_fn':getACC}\n", + "\n", + "@TI.add_kwargs(**val_custom_params)\n", + "@TI.register_fl_task(model='model', data_loader='val_loader', device='device')\n", + "def validate(model, val_loader, device, criterion, task, acc_fn):\n", + "\n", + " val_loader = tqdm.tqdm(val_loader, desc=\"validate\")\n", + " model.eval()\n", + " model.to(device)\n", + "\n", + " val_score = 0\n", + " total_samples = 0\n", + " total_loss = []\n", + " y_score = torch.tensor([]).to(device)\n", + "\n", + " with torch.no_grad():\n", + " for inputs, targets in val_loader:\n", + " outputs = model(inputs.to(device))\n", + " \n", + " targets = torch.squeeze(targets, 1).long().to(device)\n", + " loss = criterion(outputs, targets)\n", + " m = nn.Softmax(dim=1)\n", + " outputs = m(outputs).to(device)\n", + " targets = targets.float().resize_(len(targets), 1)\n", + "\n", + " total_loss.append(loss.item())\n", + "\n", + " y_score = torch.cat((y_score, outputs), 0)\n", + "\n", + " y_score = y_score.detach().cpu().numpy()\n", + " acc = acc_fn(targets, y_score, task)\n", + "\n", + " test_loss = sum(total_loss) / len(total_loss)\n", + "\n", + " return {'acc': acc,\n", + " 'test_loss': test_loss,\n", + " }" + ] + }, + { + "cell_type": "markdown", + "id": "8f0ebf2d", + "metadata": {}, + "source": [ + "## Time to start a federated learning experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d41b7896", + "metadata": {}, + "outputs": [], + "source": [ + "# create an experimnet in federation\n", + "experiment_name = 'medmnist_exp'\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "41b44de9", + "metadata": {}, + "outputs": [], + "source": [ + "# The following command zips the workspace and python requirements to be transfered to collaborator nodes\n", + "fl_experiment.start(model_provider=MI, \n", + " task_keeper=TI,\n", + " data_loader=fed_dataset,\n", + " rounds_to_train=3,\n", + " opt_treatment='RESET',\n", + " device_assignment_policy='CUDA_PREFERRED')" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "01fa7cea", + "metadata": {}, + "outputs": [], + "source": [ + "# If user want to stop IPython session, then reconnect and check how experiment is going\n", + "# fl_experiment.restore_experiment_state(model_interface)\n", + "\n", + "fl_experiment.stream_metrics(tensorboard_logs=False)" + ] + }, + { + "cell_type": "markdown", + "id": "ef600100", + "metadata": {}, + "source": [ + "### " + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "bd975242", + "metadata": {}, + "outputs": [], + "source": [] + } + ], + "metadata": { + "kernelspec": { + "display_name": "openfl", + "language": "python", + "name": "openfl" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.10" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/wspace_utils/__init__.py b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/wspace_utils/__init__.py new file mode 100644 index 0000000..fbe97a0 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/wspace_utils/__init__.py @@ -0,0 +1,7 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +from .utils import Transform3D +from .utils import model_to_syncbn + +__all__ = ["Transform3D", "model_to_syncbn"] diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/wspace_utils/batchnorm.py b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/wspace_utils/batchnorm.py new file mode 100644 index 0000000..29ab79e --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/wspace_utils/batchnorm.py @@ -0,0 +1,412 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + + +# -*- coding: utf-8 -*- +# File batchnorm.py +# Author Jiayuan Mao +# Email maojiayuan@gmail.com +# Date 27/01/2018 +# +# This file is part of Synchronized-BatchNorm-PyTorch. +# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch +# Distributed under MIT License. + +import collections +import contextlib + +import torch +import torch.nn.functional as F + +from torch.nn.modules.batchnorm import _BatchNorm + +try: + from torch.nn.parallel._functions import ReduceAddCoalesced, Broadcast +except ImportError: + ReduceAddCoalesced = Broadcast = None + +try: + from jactorch.parallel.comm import SyncMaster + from jactorch.parallel.data_parallel import JacDataParallel as DataParallelWithCallback +except ImportError: + from .comm import SyncMaster + from .replicate import DataParallelWithCallback + +__all__ = [ + 'SynchronizedBatchNorm1d', 'SynchronizedBatchNorm2d', 'SynchronizedBatchNorm3d', + 'patch_sync_batchnorm', 'convert_model' +] + + +def _sum_ft(tensor): + """sum over the first and last dimention""" + return tensor.sum(dim=0).sum(dim=-1) + + +def _unsqueeze_ft(tensor): + """add new dimensions at the front and the tail""" + return tensor.unsqueeze(0).unsqueeze(-1) + + +_ChildMessage = collections.namedtuple('_ChildMessage', ['sum', 'ssum', 'sum_size']) +_MasterMessage = collections.namedtuple('_MasterMessage', ['sum', 'inv_std']) + + +class _SynchronizedBatchNorm(_BatchNorm): + def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True): + # TODO: remove assert + error_text = 'Can not use Synchronized Batch Normalization without CUDA support.' + assert ReduceAddCoalesced is not None, error_text + + super(_SynchronizedBatchNorm, self).__init__( + num_features, + eps=eps, + momentum=momentum, + affine=affine + ) + + self._sync_master = SyncMaster(self._data_parallel_master) + + self._is_parallel = False + self._parallel_id = None + self._slave_pipe = None + + def forward(self, input): + # If it is not parallel computation or is in evaluation mode, use PyTorch's implementation. + if not (self._is_parallel and self.training): + return F.batch_norm( + input, self.running_mean, self.running_var, self.weight, self.bias, + self.training, self.momentum, self.eps) + + # Resize the input to (B, C, -1). + input_shape = input.size() + input = input.view(input.size(0), self.num_features, -1) + + # Compute the sum and square-sum. + sum_size = input.size(0) * input.size(2) + input_sum = _sum_ft(input) + input_ssum = _sum_ft(input ** 2) + child_message = _ChildMessage(input_sum, input_ssum, sum_size) + + # Reduce-and-broadcast the statistics. + if self._parallel_id == 0: + mean, inv_std = self._sync_master.run_master(child_message) + else: + mean, inv_std = self._slave_pipe.run_slave(child_message) + + # Compute the output. + if self.affine: + # MJY:: Fuse the multiplication for speed. + output = (input - _unsqueeze_ft(mean)) * _unsqueeze_ft( + inv_std * self.weight + ) + _unsqueeze_ft(self.bias) + else: + output = (input - _unsqueeze_ft(mean)) * _unsqueeze_ft(inv_std) + + # Reshape it. + return output.view(input_shape) + + def __data_parallel_replicate__(self, ctx, copy_id): + self._is_parallel = True + self._parallel_id = copy_id + + # parallel_id == 0 means master device. + if self._parallel_id == 0: + ctx.sync_master = self._sync_master + else: + self._slave_pipe = ctx.sync_master.register_slave(copy_id) + + def _data_parallel_master(self, intermediates): + """Reduce the sum and square-sum, compute the statistics, and broadcast it.""" + + # Always using same "device order" makes the ReduceAdd operation faster. + # Thanks to:: Tete Xiao (http://tetexiao.com/) + intermediates = sorted(intermediates, key=lambda i: i[1].sum.get_device()) + + to_reduce = [i[1][:2] for i in intermediates] + to_reduce = [j for i in to_reduce for j in i] # flatten + target_gpus = [i[1].sum.get_device() for i in intermediates] + + sum_size = sum([i[1].sum_size for i in intermediates]) + sum_, ssum = ReduceAddCoalesced.apply(target_gpus[0], 2, *to_reduce) + mean, inv_std = self._compute_mean_std(sum_, ssum, sum_size) + + broadcasted = Broadcast.apply(target_gpus, mean, inv_std) + + outputs = [] + for i, rec in enumerate(intermediates): + outputs.append((rec[0], _MasterMessage(*broadcasted[i * 2:i * 2 + 2]))) + + return outputs + + def _compute_mean_std(self, sum_, ssum, size): + """Compute the mean and standard-deviation with sum and square-sum. This method + also maintains the moving average on the master device.""" + assert size > 1, 'BatchNorm computes unbiased standard-deviation, which requires size > 1.' + mean = sum_ / size + sumvar = ssum - sum_ * mean + unbias_var = sumvar / (size - 1) + bias_var = sumvar / size + + if hasattr(torch, 'no_grad'): + with torch.no_grad(): + self.running_mean = (1 - self.momentum) * self.running_mean + self.running_mean += self.momentum * mean.data + self.running_var = (1 - self.momentum) * self.running_var + self.running_var += self.momentum * unbias_var.data + else: + self.running_mean = (1 - self.momentum) * self.running_mean + self.running_mean += self.momentum * mean.data + self.running_var = (1 - self.momentum) * self.running_var + self.running_var += self.momentum * unbias_var.data + + return mean, bias_var.clamp(self.eps) ** -0.5 + + +class SynchronizedBatchNorm1d(_SynchronizedBatchNorm): + r"""Applies Synchronized Batch Normalization over a 2d or 3d input that is seen as a + mini-batch. + + .. math:: + + y = \frac{x - mean[x]}{ \sqrt{Var[x] + \epsilon}} * gamma + beta + + This module differs from the built-in PyTorch BatchNorm1d as the mean and + standard-deviation are reduced across all devices during training. + + For example, when one uses `nn.DataParallel` to wrap the network during + training, PyTorch's implementation normalize the tensor on each device using + the statistics only on that device, which accelerated the computation and + is also easy to implement, but the statistics might be inaccurate. + Instead, in this synchronized version, the statistics will be computed + over all training samples distributed on multiple devices. + + Note that, for one-GPU or CPU-only case, this module behaves exactly same + as the built-in PyTorch implementation. + + The mean and standard-deviation are calculated per-dimension over + the mini-batches and gamma and beta are learnable parameter vectors + of size C (where C is the input size). + + During training, this layer keeps a running estimate of its computed mean + and variance. The running sum is kept with a default momentum of 0.1. + + During evaluation, this running mean/variance is used for normalization. + + Because the BatchNorm is done over the `C` dimension, computing statistics + on `(N, L)` slices, it's common terminology to call this Temporal BatchNorm + + Args: + num_features: num_features from an expected input of size + `batch_size x num_features [x width]` + eps: a value added to the denominator for numerical stability. + Default: 1e-5 + momentum: the value used for the running_mean and running_var + computation. Default: 0.1 + affine: a boolean value that when set to ``True``, gives the layer learnable + affine parameters. Default: ``True`` + + Shape:: + - Input: :math:`(N, C)` or :math:`(N, C, L)` + - Output: :math:`(N, C)` or :math:`(N, C, L)` (same shape as input) + + Examples: + >>> # With Learnable Parameters + >>> m = SynchronizedBatchNorm1d(100) + >>> # Without Learnable Parameters + >>> m = SynchronizedBatchNorm1d(100, affine=False) + >>> input = torch.autograd.Variable(torch.randn(20, 100)) + >>> output = m(input) + """ + + def _check_input_dim(self, input): + if input.dim() != 2 and input.dim() != 3: + raise ValueError('expected 2D or 3D input (got {}D input)' + .format(input.dim())) + super(SynchronizedBatchNorm1d, self)._check_input_dim(input) + + +class SynchronizedBatchNorm2d(_SynchronizedBatchNorm): + r"""Applies Batch Normalization over a 4d input that is seen as a mini-batch + of 3d inputs + + .. math:: + + y = \frac{x - mean[x]}{ \sqrt{Var[x] + \epsilon}} * gamma + beta + + This module differs from the built-in PyTorch BatchNorm2d as the mean and + standard-deviation are reduced across all devices during training. + + For example, when one uses `nn.DataParallel` to wrap the network during + training, PyTorch's implementation normalize the tensor on each device using + the statistics only on that device, which accelerated the computation and + is also easy to implement, but the statistics might be inaccurate. + Instead, in this synchronized version, the statistics will be computed + over all training samples distributed on multiple devices. + + Note that, for one-GPU or CPU-only case, this module behaves exactly same + as the built-in PyTorch implementation. + + The mean and standard-deviation are calculated per-dimension over + the mini-batches and gamma and beta are learnable parameter vectors + of size C (where C is the input size). + + During training, this layer keeps a running estimate of its computed mean + and variance. The running sum is kept with a default momentum of 0.1. + + During evaluation, this running mean/variance is used for normalization. + + Because the BatchNorm is done over the `C` dimension, computing statistics + on `(N, H, W)` slices, it's common terminology to call this Spatial BatchNorm + + Args: + num_features: num_features from an expected input of + size batch_size x num_features x height x width + eps: a value added to the denominator for numerical stability. + Default: 1e-5 + momentum: the value used for the running_mean and running_var + computation. Default: 0.1 + affine: a boolean value that when set to ``True``, gives the layer learnable + affine parameters. Default: ``True`` + + Shape:: + - Input: :math:`(N, C, H, W)` + - Output: :math:`(N, C, H, W)` (same shape as input) + + Examples: + >>> # With Learnable Parameters + >>> m = SynchronizedBatchNorm2d(100) + >>> # Without Learnable Parameters + >>> m = SynchronizedBatchNorm2d(100, affine=False) + >>> input = torch.autograd.Variable(torch.randn(20, 100, 35, 45)) + >>> output = m(input) + """ + + def _check_input_dim(self, input): + if input.dim() != 4: + raise ValueError('expected 4D input (got {}D input)' + .format(input.dim())) + super(SynchronizedBatchNorm2d, self)._check_input_dim(input) + + +class SynchronizedBatchNorm3d(_SynchronizedBatchNorm): + r"""Applies Batch Normalization over a 5d input that is seen as a mini-batch + of 4d inputs + + .. math:: + + y = \frac{x - mean[x]}{ \sqrt{Var[x] + \epsilon}} * gamma + beta + + This module differs from the built-in PyTorch BatchNorm3d as the mean and + standard-deviation are reduced across all devices during training. + + For example, when one uses `nn.DataParallel` to wrap the network during + training, PyTorch's implementation normalize the tensor on each device using + the statistics only on that device, which accelerated the computation and + is also easy to implement, but the statistics might be inaccurate. + Instead, in this synchronized version, the statistics will be computed + over all training samples distributed on multiple devices. + + Note that, for one-GPU or CPU-only case, this module behaves exactly same + as the built-in PyTorch implementation. + + The mean and standard-deviation are calculated per-dimension over + the mini-batches and gamma and beta are learnable parameter vectors + of size C (where C is the input size). + + During training, this layer keeps a running estimate of its computed mean + and variance. The running sum is kept with a default momentum of 0.1. + + During evaluation, this running mean/variance is used for normalization. + + Because the BatchNorm is done over the `C` dimension, computing statistics + on `(N, D, H, W)` slices, it's common terminology to call this Volumetric BatchNorm + or Spatio-temporal BatchNorm + + Args: + num_features: num_features from an expected input of + size batch_size x num_features x depth x height x width + eps: a value added to the denominator for numerical stability. + Default: 1e-5 + momentum: the value used for the running_mean and running_var + computation. Default: 0.1 + affine: a boolean value that when set to ``True``, gives the layer learnable + affine parameters. Default: ``True`` + + Shape:: + - Input: :math:`(N, C, D, H, W)` + - Output: :math:`(N, C, D, H, W)` (same shape as input) + + Examples: + >>> # With Learnable Parameters + >>> m = SynchronizedBatchNorm3d(100) + >>> # Without Learnable Parameters + >>> m = SynchronizedBatchNorm3d(100, affine=False) + >>> input = torch.autograd.Variable(torch.randn(20, 100, 35, 45, 10)) + >>> output = m(input) + """ + + def _check_input_dim(self, input): + if input.dim() != 5: + raise ValueError('expected 5D input (got {}D input)' + .format(input.dim())) + super(SynchronizedBatchNorm3d, self)._check_input_dim(input) + + +@contextlib.contextmanager +def patch_sync_batchnorm(): + import torch.nn as nn + + backup = nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d + + nn.BatchNorm1d = SynchronizedBatchNorm1d + nn.BatchNorm2d = SynchronizedBatchNorm2d + nn.BatchNorm3d = SynchronizedBatchNorm3d + + yield + + nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d = backup + + +def convert_model(module): + """Traverse the input module and its child recursively + and replace all instance of torch.nn.modules.batchnorm.BatchNorm*N*d + to SynchronizedBatchNorm*N*d + + Args: + module: the input module needs to be convert to SyncBN model + + Examples: + >>> import torch.nn as nn + >>> import torchvision + >>> # m is a standard pytorch model + >>> m = torchvision.models.resnet18(True) + >>> m = nn.DataParallel(m) + >>> # after convert, m is using SyncBN + >>> m = convert_model(m) + """ + if isinstance(module, torch.nn.DataParallel): + mod = module.module + mod = convert_model(mod) + mod = DataParallelWithCallback(mod) + return mod + + mod = module + for pth_module, sync_module in zip([torch.nn.modules.batchnorm.BatchNorm1d, + torch.nn.modules.batchnorm.BatchNorm2d, + torch.nn.modules.batchnorm.BatchNorm3d], + [SynchronizedBatchNorm1d, + SynchronizedBatchNorm2d, + SynchronizedBatchNorm3d]): + if isinstance(module, pth_module): + mod = sync_module(module.num_features, module.eps, module.momentum, module.affine) + mod.running_mean = module.running_mean + mod.running_var = module.running_var + if module.affine: + mod.weight.data = module.weight.data.clone().detach() + mod.bias.data = module.bias.data.clone().detach() + + for name, child in module.named_children(): + mod.add_module(name, convert_model(child)) + + return mod diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/wspace_utils/comm.py b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/wspace_utils/comm.py new file mode 100644 index 0000000..1f5ceca --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/wspace_utils/comm.py @@ -0,0 +1,143 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +# -*- coding: utf-8 -*- +# File comm.py +# Author Jiayuan Mao +# Email maojiayuan@gmail.com +# Date 27/01/2018 +# +# This file is part of Synchronized-BatchNorm-PyTorch. +# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch +# Distributed under MIT License. + +import queue +import collections +import threading + +__all__ = ['FutureResult', 'SlavePipe', 'SyncMaster'] + + +class FutureResult(object): + """A thread-safe future implementation. Used only as one-to-one pipe.""" + + def __init__(self): + self._result = None + self._lock = threading.Lock() + self._cond = threading.Condition(self._lock) + + def put(self, result): + with self._lock: + assert self._result is None, 'Previous result has\'t been fetched.' + self._result = result + self._cond.notify() + + def get(self): + with self._lock: + if self._result is None: + self._cond.wait() + + res = self._result + self._result = None + return res + + +_MasterRegistry = collections.namedtuple('MasterRegistry', ['result']) +_SlavePipeBase = collections.namedtuple('_SlavePipeBase', ['identifier', 'queue', 'result']) + + +class SlavePipe(_SlavePipeBase): + """Pipe for master-slave communication.""" + + def run_slave(self, msg): + self.queue.put((self.identifier, msg)) + ret = self.result.get() + self.queue.put(True) + return ret + + +class SyncMaster(object): + """An abstract `SyncMaster` object. + + - During the replication, as the data parallel will trigger an callback of each module, + all slave devices should call `register(id)` and obtain an `SlavePipe` + to communicate with the master. + - During the forward pass, master device invokes `run_master`, + all messages from slave devices will be collected, and passed to a registered callback. + - After receiving the messages, the master device should gather the information + and determine to message passed back to each slave devices. + """ + + def __init__(self, master_callback): + """ + + Args: + master_callback: a callback to be invoked + after having collected messages from slave devices. + """ + self._master_callback = master_callback + self._queue = queue.Queue() + self._registry = collections.OrderedDict() + self._activated = False + + def __getstate__(self): + return {'master_callback': self._master_callback} + + def __setstate__(self, state): + self.__init__(state['master_callback']) + + def register_slave(self, identifier): + """ + Register an slave device. + + Args: + identifier: an identifier, usually is the device id. + + Returns: a `SlavePipe` object which can be used to communicate with the master device. + + """ + if self._activated: + assert self._queue.empty(), 'Queue is not clean before next initialization.' + self._activated = False + self._registry.clear() + future = FutureResult() + self._registry[identifier] = _MasterRegistry(future) + return SlavePipe(identifier, self._queue, future) + + def run_master(self, master_msg): + """ + Main entry for the master device in each forward pass. + The messages were first collected from each devices (including the master device), and then + an callback will be invoked to compute the message to be sent back to each devices + (including the master device). + + Args: + master_msg: the message that the master want to send to itself. + This will be placed as the first message when calling `master_callback`. + For detailed usage, see `_SynchronizedBatchNorm` for an example. + + Returns: the message to be sent back to the master device. + + """ + self._activated = True + + intermediates = [(0, master_msg)] + for i in range(self.nr_slaves): + intermediates.append(self._queue.get()) + + results = self._master_callback(intermediates) + assert results[0][0] == 0, 'The first result should belongs to the master.' + + for i, res in results: + if i == 0: + continue + self._registry[i].result.put(res) + + for i in range(self.nr_slaves): + assert self._queue.get() is True + + return results[0][1] + + @property + def nr_slaves(self): + return len(self._registry) diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/wspace_utils/replicate.py b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/wspace_utils/replicate.py new file mode 100644 index 0000000..6edc8ab --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/wspace_utils/replicate.py @@ -0,0 +1,98 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +# -*- coding: utf-8 -*- +# File replicate.py +# Author Jiayuan Mao +# Email maojiayuan@gmail.com +# Date 27/01/2018 +# +# This file is part of Synchronized-BatchNorm-PyTorch. +# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch +# Distributed under MIT License. + +import functools + +from torch.nn.parallel.data_parallel import DataParallel + +__all__ = [ + 'CallbackContext', + 'execute_replication_callbacks', + 'DataParallelWithCallback', + 'patch_replication_callback' +] + + +class CallbackContext(object): + pass + + +def execute_replication_callbacks(modules): + """ + Execute an replication callback `__data_parallel_replicate__` + on each module created by original replication. + + The callback will be invoked with arguments `__data_parallel_replicate__(ctx, copy_id)` + + Note that, as all modules are isomorphism, we assign each sub-module with a context + (shared among multiple copies of this module on different devices). + Through this context, different copies can share some information. + + We guarantee that the callback on the master copy (the first copy) + will be called ahead of calling the callback of any slave copies. + """ + master_copy = modules[0] + nr_modules = len(list(master_copy.modules())) + ctxs = [CallbackContext() for _ in range(nr_modules)] + + for i, module in enumerate(modules): + for j, m in enumerate(module.modules()): + if hasattr(m, '__data_parallel_replicate__'): + m.__data_parallel_replicate__(ctxs[j], i) + + +class DataParallelWithCallback(DataParallel): + """ + Data Parallel with a replication callback. + + An replication callback `__data_parallel_replicate__` of each module + will be invoked after being created by original `replicate` function. + The callback will be invoked with arguments `__data_parallel_replicate__(ctx, copy_id)` + + Examples: + > sync_bn = SynchronizedBatchNorm1d(10, eps=1e-5, affine=False) + > sync_bn = DataParallelWithCallback(sync_bn, device_ids=[0, 1]) + # sync_bn.__data_parallel_replicate__ will be invoked. + """ + + def replicate(self, module, device_ids): + modules = super(DataParallelWithCallback, self).replicate(module, device_ids) + execute_replication_callbacks(modules) + return modules + + +def patch_replication_callback(data_parallel): + """ + Monkey-patch an existing `DataParallel` object. Add the replication callback. + Useful when you have customized `DataParallel` implementation. + + Examples: + > sync_bn = SynchronizedBatchNorm1d(10, eps=1e-5, affine=False) + > sync_bn = DataParallel(sync_bn, device_ids=[0, 1]) + > patch_replication_callback(sync_bn) + # this is equivalent to + > sync_bn = SynchronizedBatchNorm1d(10, eps=1e-5, affine=False) + > sync_bn = DataParallelWithCallback(sync_bn, device_ids=[0, 1]) + """ + + assert isinstance(data_parallel, DataParallel) + + old_replicate = data_parallel.replicate + + @functools.wraps(old_replicate) + def new_replicate(module, device_ids): + modules = old_replicate(module, device_ids) + execute_replication_callbacks(modules) + return modules + + data_parallel.replicate = new_replicate diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/wspace_utils/utils.py b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/wspace_utils/utils.py new file mode 100644 index 0000000..91ffa9c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_MedMNIST_3D/workspace/wspace_utils/utils.py @@ -0,0 +1,41 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +import torch.nn as nn +import numpy as np + + +class Transform3D: + + def __init__(self, mul=None): + self.mul = mul + + def __call__(self, voxel): + + if self.mul == '0.5': + voxel = voxel * 0.5 + elif self.mul == 'random': + voxel = voxel * np.random.uniform() + + return voxel.astype(np.float32) + + +def model_to_syncbn(model): + preserve_state_dict = model.state_dict() + _convert_module_from_bn_to_syncbn(model) + model.load_state_dict(preserve_state_dict) + return model + + +def _convert_module_from_bn_to_syncbn(module): + for child_name, child in module.named_children(): + if ( + hasattr(nn, child.__class__.__name__) + and 'batchnorm' in child.__class__.__name__.lower() + ): + TargetClass = globals()['Synchronized' + child.__class__.__name__] # noqa: N806 + arguments = TargetClass.__init__.__code__.co_varnames[1:] + kwargs = {k: getattr(child, k) for k in arguments} + setattr(module, child_name, TargetClass(**kwargs)) + else: + _convert_module_from_bn_to_syncbn(child) diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/README.md b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/README.md new file mode 100644 index 0000000..5e066ba --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/README.md @@ -0,0 +1,66 @@ +# PyTorch_TinyImageNet + +## **How to run this tutorial (without TLC and locally as a simulation):** +
+ +### 0. If you haven't done so already, create a virtual environment, install OpenFL, and upgrade pip: + - For help with this step, visit the "Install the Package" section of the [OpenFL installation instructions](https://openfl.readthedocs.io/en/latest/install.html#install-the-package). + +
+ +### 1. Split terminal into 3 (1 terminal for the director, 1 for the envoy, and 1 for the experiment) + +
+ +### 2. Do the following in each terminal: + - Activate the virtual environment from step 0: + + ```sh + source venv/bin/activate + ``` + - If you are in a network environment with a proxy, ensure proxy environment variables are set in each of your terminals. + - Navigate to the tutorial: + + ```sh + cd openfl/openfl-tutorials/interactive_api/PyTorch_TinyImageNet + ``` + +
+ +### 3. In the first terminal, run the director: + +```sh +cd director +./start_director.sh +``` + +
+ +### 4. In the second terminal, install requirements and run the envoy: + +```sh +cd envoy +pip install -r requirements.txt +./start_envoy.sh env_one envoy_config.yaml +``` + +Optional: Run a second envoy in an additional terminal: + - Ensure step 2 is complete for this terminal as well. + - Run the second envoy: +```sh +cd envoy +./start_envoy.sh env_two envoy_config.yaml +``` + +
+ +### 5. Now that your director and envoy terminals are set up, run the Jupyter Notebook in your experiment terminal: + +```sh +cd workspace +jupyter lab pytorch_tinyimagenet.ipynb +``` +- A Jupyter Server URL will appear in your terminal. In your browser, proceed to that link. Once the webpage loads, click on the pytorch_tinyimagenet.ipynb file. +- To run the experiment, select the icon that looks like two triangles to "Restart Kernel and Run All Cells". +- You will notice activity in your terminals as the experiment runs, and when the experiment is finished the director terminal will display a message that the experiment has finished successfully. + diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/director/director_config.yaml new file mode 100644 index 0000000..3fc4137 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/director/director_config.yaml @@ -0,0 +1,5 @@ +settings: + listen_host: localhost + listen_port: 50051 + sample_shape: ['64', '64', '3'] + target_shape: ['64', '64'] diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/director/start_director.sh new file mode 100755 index 0000000..5806a6c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/director/start_director.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx director start --disable-tls -c director_config.yaml \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/director/start_director_with_tls.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/director/start_director_with_tls.sh new file mode 100755 index 0000000..5d6d46a --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/director/start_director_with_tls.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e +FQDN=$1 +fx director start -c director_config.yaml -rc cert/root_ca.crt -pk cert/"${FQDN}".key -oc cert/"${FQDN}".crt \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/envoy/envoy_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/envoy/envoy_config.yaml new file mode 100644 index 0000000..cb04056 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/envoy/envoy_config.yaml @@ -0,0 +1,10 @@ +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: tinyimagenet_shard_descriptor.TinyImageNetShardDescriptor + params: + data_folder: tinyimagenet_data + rank_worldsize: 1,1 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/envoy/requirements.txt b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/envoy/requirements.txt new file mode 100644 index 0000000..7f361a8 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/envoy/requirements.txt @@ -0,0 +1 @@ +Pillow==10.3.0 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/envoy/start_envoy.sh new file mode 100755 index 0000000..1dd6591 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/envoy/start_envoy.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx envoy start -n env_one --disable-tls --envoy-config-path envoy_config.yaml -dh localhost -dp 50051 \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/envoy/start_envoy_with_tls.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/envoy/start_envoy_with_tls.sh new file mode 100755 index 0000000..06b2916 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/envoy/start_envoy_with_tls.sh @@ -0,0 +1,6 @@ +#!/bin/bash +set -e +ENVOY_NAME=$1 +DIRECTOR_FQDN=$2 + +fx envoy start -n "$ENVOY_NAME" --envoy-config-path envoy_config.yaml -dh "$DIRECTOR_FQDN" -dp 50051 -rc cert/root_ca.crt -pk cert/"$ENVOY_NAME".key -oc cert/"$ENVOY_NAME".crt \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/envoy/tinyimagenet_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/envoy/tinyimagenet_shard_descriptor.py new file mode 100644 index 0000000..7101642 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/envoy/tinyimagenet_shard_descriptor.py @@ -0,0 +1,120 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""TinyImageNet Shard Descriptor.""" + +import glob +import logging +import os +import shutil +from pathlib import Path +from typing import Tuple + +from PIL import Image + +from openfl.interface.interactive_api.shard_descriptor import ShardDataset +from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor + +logger = logging.getLogger(__name__) + + +class TinyImageNetDataset(ShardDataset): + """TinyImageNet shard dataset class.""" + + NUM_IMAGES_PER_CLASS = 500 + + def __init__(self, data_folder: Path, data_type='train', rank=1, worldsize=1): + """Initialize TinyImageNetDataset.""" + self.data_type = data_type + self._common_data_folder = data_folder + self._data_folder = os.path.join(data_folder, data_type) + self.labels = {} # fname - label number mapping + self.image_paths = sorted( + glob.iglob( + os.path.join(self._data_folder, '**', '*.JPEG'), + recursive=True + ) + )[rank - 1::worldsize] + wnids_path = os.path.join(self._common_data_folder, 'wnids.txt') + with open(wnids_path, 'r', encoding='utf-8') as fp: + self.label_texts = sorted([text.strip() for text in fp.readlines()]) + self.label_text_to_number = {text: i for i, text in enumerate(self.label_texts)} + self.fill_labels() + + def __len__(self) -> int: + """Return the len of the shard dataset.""" + return len(self.image_paths) + + def __getitem__(self, index: int) -> Tuple['Image', int]: + """Return an item by the index.""" + file_path = self.image_paths[index] + label = self.labels[os.path.basename(file_path)] + return self.read_image(file_path), label + + def read_image(self, path: Path) -> Image: + """Read the image.""" + img = Image.open(path) + return img + + def fill_labels(self) -> None: + """Fill labels.""" + if self.data_type == 'train': + for label_text, i in self.label_text_to_number.items(): + for cnt in range(self.NUM_IMAGES_PER_CLASS): + self.labels[f'{label_text}_{cnt}.JPEG'] = i + elif self.data_type == 'val': + val_annotations_path = os.path.join(self._data_folder, 'val_annotations.txt') + with open(val_annotations_path, 'r', encoding='utf-8') as fp: + for line in fp.readlines(): + terms = line.split('\t') + file_name, label_text = terms[0], terms[1] + self.labels[file_name] = self.label_text_to_number[label_text] + + +class TinyImageNetShardDescriptor(ShardDescriptor): + """Shard descriptor class.""" + + def __init__( + self, + data_folder: str = 'data', + rank_worldsize: str = '1,1', + **kwargs + ): + """Initialize TinyImageNetShardDescriptor.""" + self.common_data_folder = Path.cwd() / data_folder + self.data_folder = Path.cwd() / data_folder / 'tiny-imagenet-200' + self.download_data() + self.rank, self.worldsize = tuple(int(num) for num in rank_worldsize.split(',')) + + def download_data(self): + """Download prepared shard dataset.""" + zip_file_path = self.common_data_folder / 'tiny-imagenet-200.zip' + os.makedirs(self.common_data_folder, exist_ok=True) + os.system(f'wget --no-clobber http://cs231n.stanford.edu/tiny-imagenet-200.zip' + f' -O {zip_file_path}') + shutil.unpack_archive(str(zip_file_path), str(self.common_data_folder)) + + def get_dataset(self, dataset_type): + """Return a shard dataset by type.""" + return TinyImageNetDataset( + data_folder=self.data_folder, + data_type=dataset_type, + rank=self.rank, + worldsize=self.worldsize + ) + + @property + def sample_shape(self): + """Return the sample shape info.""" + return ['64', '64', '3'] + + @property + def target_shape(self): + """Return the target shape info.""" + return ['64', '64'] + + @property + def dataset_description(self) -> str: + """Return the shard dataset description.""" + return (f'TinyImageNetDataset dataset, shard number {self.rank}' + f' out of {self.worldsize}') diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/workspace/non-federated_case.ipynb b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/workspace/non-federated_case.ipynb new file mode 100644 index 0000000..0d7a329 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/workspace/non-federated_case.ipynb @@ -0,0 +1,305 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "source": [ + "## Vanilla PyTorch training on TinyImageNet dataset" + ], + "metadata": {} + }, + { + "cell_type": "markdown", + "source": [ + "This notebook is intended to show that fixing random seeds leads to the same result in both federated and non-federated cases." + ], + "metadata": {} + }, + { + "cell_type": "code", + "execution_count": null, + "source": [ + "!pip install -r requirements.txt" + ], + "outputs": [], + "metadata": {} + }, + { + "cell_type": "code", + "execution_count": null, + "source": [ + "from pathlib import Path\n", + "import os\n", + "import shutil\n", + "from torch.utils.data import Dataset\n", + "from torch.utils.data import DataLoader\n", + "from torch import nn\n", + "from torch import optim\n", + "import torch.nn.functional as F\n", + "import torch\n", + "import torchvision.transforms as T\n", + "import torchvision\n", + "import glob\n", + "import tqdm\n", + "from PIL import Image\n", + "import numpy as np" + ], + "outputs": [], + "metadata": {} + }, + { + "cell_type": "markdown", + "source": [ + "## Download data" + ], + "metadata": {} + }, + { + "cell_type": "code", + "execution_count": null, + "source": [ + "common_data_folder = Path.cwd() / 'data'\n", + "zip_file_path = common_data_folder / 'tiny-imagenet-200.zip'\n", + "os.makedirs(common_data_folder, exist_ok=True)\n", + "os.system(f'wget --no-clobber http://cs231n.stanford.edu/tiny-imagenet-200.zip'\n", + " f' -O {zip_file_path}')\n", + "shutil.unpack_archive(str(zip_file_path), str(common_data_folder))" + ], + "outputs": [], + "metadata": {} + }, + { + "cell_type": "code", + "execution_count": null, + "source": [ + "class TinyImageNetDataset(Dataset):\n", + " \"\"\"TinyImageNet shard dataset class.\"\"\"\n", + "\n", + " NUM_IMAGES_PER_CLASS = 500\n", + "\n", + " def __init__(self, data_folder: Path, data_type='train', transform=None):\n", + " \"\"\"Initialize TinyImageNetDataset.\"\"\"\n", + " self.data_type = data_type\n", + " self._common_data_folder = data_folder\n", + " self._data_folder = os.path.join(data_folder, data_type)\n", + " self.labels = {} # fname - label number mapping\n", + " self.image_paths = sorted(\n", + " glob.iglob(\n", + " os.path.join(self._data_folder, '**', '*.JPEG'),\n", + " recursive=True\n", + " )\n", + " )\n", + " with open(os.path.join(self._common_data_folder, 'wnids.txt'), 'r') as fp:\n", + " self.label_texts = sorted([text.strip() for text in fp.readlines()])\n", + " self.label_text_to_number = {text: i for i, text in enumerate(self.label_texts)}\n", + " self.fill_labels()\n", + " self.transform = transform\n", + "\n", + " def __len__(self) -> int:\n", + " \"\"\"Return the len of the shard dataset.\"\"\"\n", + " return len(self.image_paths)\n", + "\n", + " def __getitem__(self, index: int):\n", + " \"\"\"Return an item by the index.\"\"\"\n", + " file_path = self.image_paths[index]\n", + " sample = self.read_image(file_path)\n", + " if self.transform:\n", + " sample = self.transform(sample)\n", + " label = self.labels[os.path.basename(file_path)]\n", + " return sample, label\n", + "\n", + " def read_image(self, path: Path):\n", + " \"\"\"Read the image.\"\"\"\n", + " img = Image.open(path)\n", + " return img\n", + "\n", + " def fill_labels(self) -> None:\n", + " \"\"\"Fill labels.\"\"\"\n", + " if self.data_type == 'train':\n", + " for label_text, i in self.label_text_to_number.items():\n", + " for cnt in range(self.NUM_IMAGES_PER_CLASS):\n", + " self.labels[f'{label_text}_{cnt}.JPEG'] = i\n", + " elif self.data_type == 'val':\n", + " with open(os.path.join(self._data_folder, 'val_annotations.txt'), 'r') as fp:\n", + " for line in fp.readlines():\n", + " terms = line.split('\\t')\n", + " file_name, label_text = terms[0], terms[1]\n", + " self.labels[file_name] = self.label_text_to_number[label_text]" + ], + "outputs": [], + "metadata": {} + }, + { + "cell_type": "code", + "execution_count": null, + "source": [ + "normalize = T.Normalize(\n", + " mean=[0.485, 0.456, 0.406],\n", + " std=[0.229, 0.224, 0.225]\n", + ")\n", + "\n", + "augmentation = T.RandomApply(\n", + " [T.RandomHorizontalFlip(),\n", + " T.RandomRotation(10),\n", + " T.RandomResizedCrop(64)], \n", + " p=.8\n", + ")\n", + "\n", + "training_transform = T.Compose(\n", + " [T.Lambda(lambda x: x.convert(\"RGB\")),\n", + " T.ToTensor(),\n", + " augmentation,\n", + " normalize]\n", + ")\n", + "\n", + "valid_transform = T.Compose(\n", + " [T.Lambda(lambda x: x.convert(\"RGB\")),\n", + " T.ToTensor(),\n", + " normalize]\n", + ")" + ], + "outputs": [], + "metadata": {} + }, + { + "cell_type": "code", + "execution_count": null, + "id": "dense-commerce", + "metadata": {}, + "outputs": [], + "source": [ + "def get_train_loader():\n", + " generator=torch.Generator()\n", + " generator.manual_seed(0)\n", + " train_set = TinyImageNetDataset(common_data_folder / 'tiny-imagenet-200', transform=training_transform)\n", + " return DataLoader(train_set, batch_size=64, shuffle=True, generator=generator)\n", + "\n", + "def get_valid_loader():\n", + " valid_set = TinyImageNetDataset(common_data_folder / 'tiny-imagenet-200', data_type='val', transform=valid_transform)\n", + " return DataLoader(valid_set, batch_size=64)" + ] + }, + { + "cell_type": "markdown", + "source": [ + "## Describe the model and optimizer" + ], + "metadata": {} + }, + { + "cell_type": "code", + "execution_count": null, + "source": [ + "class Net(nn.Module):\n", + " def __init__(self):\n", + " torch.manual_seed(0)\n", + " super(Net, self).__init__()\n", + " self.model = torchvision.models.mobilenet_v2(pretrained=True)\n", + " self.model.requires_grad_(False)\n", + " self.model.classifier[1] = torch.nn.Linear(in_features=1280, \\\n", + " out_features=200, bias=True)\n", + "\n", + " def forward(self, x):\n", + " x = self.model.forward(x)\n", + " return x\n", + "\n", + "model = Net()" + ], + "outputs": [], + "metadata": {} + }, + { + "cell_type": "code", + "execution_count": null, + "source": [ + "optimizer = optim.Adam([x for x in model.parameters() if x.requires_grad], lr=1e-4)" + ], + "outputs": [], + "metadata": {} + }, + { + "cell_type": "code", + "execution_count": null, + "source": [ + "loss_fn = F.cross_entropy" + ], + "outputs": [], + "metadata": {} + }, + { + "cell_type": "code", + "execution_count": null, + "source": [ + "def train():\n", + " torch.manual_seed(0)\n", + " device='cpu'\n", + " \n", + " data_loader = tqdm.tqdm(get_train_loader(), desc=\"train\")\n", + " model.train()\n", + " model.to(device)\n", + "\n", + " losses = []\n", + "\n", + " for data, target in data_loader:\n", + " data, target = torch.tensor(data).to(device), torch.tensor(\n", + " target).to(device)\n", + " optimizer.zero_grad()\n", + " output = model(data)\n", + " loss = loss_fn(output, target)\n", + " loss.backward()\n", + " optimizer.step()\n", + " losses.append(loss.detach().cpu().numpy())\n", + " \n", + " return {'train_loss': np.mean(losses),}\n", + "\n", + "def validate():\n", + " torch.manual_seed(0)\n", + " device = torch.device('cpu')\n", + " model.eval()\n", + " model.to(device)\n", + " \n", + " data_loader = tqdm.tqdm(get_valid_loader(), desc=\"validate\")\n", + " val_score = 0\n", + " total_samples = 0\n", + "\n", + " with torch.no_grad():\n", + " for data, target in data_loader:\n", + " samples = target.shape[0]\n", + " total_samples += samples\n", + " data, target = torch.tensor(data).to(device), \\\n", + " torch.tensor(target).to(device, dtype=torch.int64)\n", + " output = model(data)\n", + " pred = output.argmax(dim=1,keepdim=True)\n", + " val_score += pred.eq(target).sum().cpu().numpy()\n", + " \n", + " return {'acc': val_score / total_samples,}" + ], + "outputs": [], + "metadata": {} + }, + { + "cell_type": "code", + "execution_count": null, + "source": [ + "for i in range(5):\n", + " if i == 0:\n", + " name, value = next(iter(validate().items()))\n", + " print(f'{name}: {value:f}')\n", + " \n", + " name, value = next(iter(train().items()))\n", + " print(f'{name}: {value:f}')\n", + " \n", + " name, value = next(iter(validate().items()))\n", + " print(f'{name}: {value:f}')" + ], + "outputs": [], + "metadata": {} + } + ], + "metadata": { + "language_info": { + "name": "python" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/workspace/pytorch_tinyimagenet.ipynb b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/workspace/pytorch_tinyimagenet.ipynb new file mode 100644 index 0000000..bbfadfd --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/workspace/pytorch_tinyimagenet.ipynb @@ -0,0 +1,483 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "26fdd9ed", + "metadata": {}, + "source": [ + "# Federated PyTorch TinyImageNet Tutorial" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "895288d0", + "metadata": {}, + "outputs": [], + "source": [ + "!pip install -r requirements.txt" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "billion-drunk", + "metadata": {}, + "outputs": [], + "source": [ + "import os\n", + "import glob\n", + "\n", + "from PIL import Image\n", + "\n", + "import numpy as np\n", + "import torch\n", + "import torch.nn as nn\n", + "import torch.nn.functional as F\n", + "import torch.optim as optim\n", + "from openfl.interface.interactive_api.federation import Federation\n", + "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment\n", + "from copy import deepcopy\n", + "import torchvision\n", + "from torchvision import transforms as T\n", + "from torch.utils.data import Dataset\n", + "from torch.utils.data import DataLoader\n", + "import tqdm\n", + "\n", + "torch.manual_seed(0)\n", + "np.random.seed(0)" + ] + }, + { + "cell_type": "markdown", + "id": "246f9c98", + "metadata": {}, + "source": [ + "## Connect to the Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d657e463", + "metadata": {}, + "outputs": [], + "source": [ + "# Create a federation\n", + "\n", + "# please use the same identificator that was used in signed certificate\n", + "client_id = 'api'\n", + "cert_dir = 'cert'\n", + "director_node_fqdn = 'localhost'\n", + "# 1) Run with API layer - Director mTLS \n", + "# If the user wants to enable mTLS their must provide CA root chain, and signed key pair to the federation interface\n", + "# cert_chain = f'{cert_dir}/root_ca.crt'\n", + "# api_certificate = f'{cert_dir}/{client_id}.crt'\n", + "# api_private_key = f'{cert_dir}/{client_id}.key'\n", + "\n", + "# federation = Federation(client_id=client_id, director_node_fqdn=director_node_fqdn, director_port='50051',\n", + "# cert_chain=cert_chain, api_cert=api_certificate, api_private_key=api_private_key)\n", + "\n", + "# --------------------------------------------------------------------------------------------------------------------\n", + "\n", + "# 2) Run with TLS disabled (trusted environment)\n", + "# Federation can also determine local fqdn automatically\n", + "federation = Federation(client_id=client_id, director_node_fqdn=director_node_fqdn, director_port='50051', tls=False)\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "1abebd90", + "metadata": {}, + "outputs": [], + "source": [ + "federation.target_shape" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "47dcfab3", + "metadata": {}, + "outputs": [], + "source": [ + "shard_registry = federation.get_shard_registry()\n", + "shard_registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "a2a6c237", + "metadata": {}, + "outputs": [], + "source": [ + "# First, request a dummy_shard_desc that holds information about the federated dataset \n", + "dummy_shard_desc = federation.get_dummy_shard_descriptor(size=10)\n", + "dummy_shard_dataset = dummy_shard_desc.get_dataset('train')\n", + "sample, target = dummy_shard_dataset[0]\n", + "print(sample.shape)\n", + "print(target.shape)" + ] + }, + { + "cell_type": "markdown", + "id": "cc0dbdbd", + "metadata": {}, + "source": [ + "## Creating a FL experiment using Interactive API" + ] + }, + { + "cell_type": "markdown", + "id": "b0979470", + "metadata": {}, + "source": [ + "### Register dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "7dda1680", + "metadata": {}, + "outputs": [], + "source": [ + "normalize = T.Normalize(\n", + " mean=[0.485, 0.456, 0.406],\n", + " std=[0.229, 0.224, 0.225]\n", + ")\n", + "\n", + "augmentation = T.RandomApply(\n", + " [T.RandomHorizontalFlip(),\n", + " T.RandomRotation(10),\n", + " T.RandomResizedCrop(64)], \n", + " p=.8\n", + ")\n", + "\n", + "training_transform = T.Compose(\n", + " [T.Lambda(lambda x: x.convert(\"RGB\")),\n", + " T.ToTensor(),\n", + " augmentation,\n", + " normalize]\n", + ")\n", + "\n", + "valid_transform = T.Compose(\n", + " [T.Lambda(lambda x: x.convert(\"RGB\")),\n", + " T.ToTensor(),\n", + " normalize]\n", + ")\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "0314d5bf", + "metadata": {}, + "outputs": [], + "source": [ + "class TransformedDataset(Dataset):\n", + " \"\"\"Image Person ReID Dataset.\"\"\"\n", + "\n", + " def __init__(self, dataset, transform=None, target_transform=None):\n", + " \"\"\"Initialize Dataset.\"\"\"\n", + " self.dataset = dataset\n", + " self.transform = transform\n", + " self.target_transform = target_transform\n", + "\n", + " def __len__(self):\n", + " \"\"\"Length of dataset.\"\"\"\n", + " return len(self.dataset)\n", + "\n", + " def __getitem__(self, index):\n", + " img, label = self.dataset[index]\n", + " label = self.target_transform(label) if self.target_transform else label\n", + " img = self.transform(img) if self.transform else img\n", + " return img, label\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "01369e3b", + "metadata": {}, + "outputs": [], + "source": [ + "class TinyImageNetDataset(DataInterface):\n", + " def __init__(self, **kwargs):\n", + " self.kwargs = kwargs\n", + " \n", + " @property\n", + " def shard_descriptor(self):\n", + " return self._shard_descriptor\n", + " \n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + "\n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + " \n", + " self.train_set = TransformedDataset(\n", + " self._shard_descriptor.get_dataset('train'),\n", + " transform=training_transform\n", + " )\n", + " self.valid_set = TransformedDataset(\n", + " self._shard_descriptor.get_dataset('val'),\n", + " transform=valid_transform\n", + " )\n", + " \n", + " def get_train_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks with optimizer in contract\n", + " \"\"\"\n", + " generator=torch.Generator()\n", + " generator.manual_seed(0)\n", + " return DataLoader(\n", + " self.train_set, batch_size=self.kwargs['train_bs'], shuffle=True, generator=generator\n", + " )\n", + "\n", + " def get_valid_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks without optimizer in contract\n", + " \"\"\"\n", + " return DataLoader(self.valid_set, batch_size=self.kwargs['valid_bs'])\n", + "\n", + " def get_train_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.train_set)\n", + "\n", + " def get_valid_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.valid_set)\n", + " " + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4a6cedef", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = TinyImageNetDataset(train_bs=64, valid_bs=64)" + ] + }, + { + "cell_type": "markdown", + "id": "74cac654", + "metadata": {}, + "source": [ + "### Describe the model and optimizer" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "43e25fe3", + "metadata": {}, + "outputs": [], + "source": [ + "\"\"\"\n", + "MobileNetV2 model\n", + "\"\"\"\n", + "\n", + "class Net(nn.Module):\n", + " def __init__(self):\n", + " torch.manual_seed(0)\n", + " super(Net, self).__init__()\n", + " self.model = torchvision.models.mobilenet_v2(pretrained=True)\n", + " self.model.requires_grad_(False)\n", + " self.model.classifier[1] = torch.nn.Linear(in_features=1280, \\\n", + " out_features=200, bias=True)\n", + "\n", + " def forward(self, x):\n", + " x = self.model.forward(x)\n", + " return x\n", + "\n", + "model_net = Net()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "79021778", + "metadata": {}, + "outputs": [], + "source": [ + "params_to_update = []\n", + "for param in model_net.parameters():\n", + " if param.requires_grad == True:\n", + " params_to_update.append(param)\n", + " \n", + "optimizer_adam = optim.Adam(params_to_update, lr=1e-4)\n", + "\n", + "def cross_entropy(output, target):\n", + " \"\"\"Binary cross-entropy metric\n", + " \"\"\"\n", + " return F.cross_entropy(input=output,target=target)" + ] + }, + { + "cell_type": "markdown", + "id": "f097cdc5", + "metadata": {}, + "source": [ + "### Register model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "06a8cca8", + "metadata": {}, + "outputs": [], + "source": [ + "framework_adapter = 'openfl.plugins.frameworks_adapters.pytorch_adapter.FrameworkAdapterPlugin'\n", + "model_interface = ModelInterface(model=model_net, optimizer=optimizer_adam, framework_plugin=framework_adapter)\n", + "\n", + "# Save the initial model state\n", + "initial_model = deepcopy(model_net)" + ] + }, + { + "cell_type": "markdown", + "id": "849c165b", + "metadata": {}, + "source": [ + "## Define and register FL tasks" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "b9649385", + "metadata": {}, + "outputs": [], + "source": [ + "task_interface = TaskInterface()\n", + "\n", + "\n", + "# The Interactive API supports registering functions definied in main module or imported.\n", + "def function_defined_in_notebook(some_parameter):\n", + " print(f'Also I accept a parameter and it is {some_parameter}')\n", + "\n", + "# Task interface currently supports only standalone functions.\n", + "@task_interface.add_kwargs(**{'some_parameter': 42})\n", + "@task_interface.register_fl_task(model='net_model', data_loader='train_loader', \\\n", + " device='device', optimizer='optimizer') \n", + "def train(net_model, train_loader, optimizer, device, loss_fn=cross_entropy, some_parameter=None):\n", + " torch.manual_seed(0)\n", + " device='cpu'\n", + " function_defined_in_notebook(some_parameter)\n", + " \n", + " train_loader = tqdm.tqdm(train_loader, desc=\"train\")\n", + " net_model.train()\n", + " net_model.to(device)\n", + "\n", + " losses = []\n", + "\n", + " for data, target in train_loader:\n", + " data, target = torch.tensor(data).to(device), torch.tensor(\n", + " target).to(device)\n", + " optimizer.zero_grad()\n", + " output = net_model(data)\n", + " loss = loss_fn(output=output, target=target)\n", + " loss.backward()\n", + " optimizer.step()\n", + " losses.append(loss.detach().cpu().numpy())\n", + " \n", + " return {'train_loss': np.mean(losses),}\n", + "\n", + "\n", + "@task_interface.register_fl_task(model='net_model', data_loader='val_loader', device='device') \n", + "def validate(net_model, val_loader, device):\n", + " torch.manual_seed(0)\n", + " device = torch.device('cpu')\n", + " net_model.eval()\n", + " net_model.to(device)\n", + " \n", + " val_loader = tqdm.tqdm(val_loader, desc=\"validate\")\n", + " val_score = 0\n", + " total_samples = 0\n", + "\n", + " with torch.no_grad():\n", + " for data, target in val_loader:\n", + " samples = target.shape[0]\n", + " total_samples += samples\n", + " data, target = torch.tensor(data).to(device), \\\n", + " torch.tensor(target).to(device, dtype=torch.int64)\n", + " output = net_model(data)\n", + " pred = output.argmax(dim=1,keepdim=True)\n", + " val_score += pred.eq(target).sum().cpu().numpy()\n", + " \n", + " return {'acc': val_score / total_samples,}" + ] + }, + { + "cell_type": "markdown", + "id": "8f0ebf2d", + "metadata": {}, + "source": [ + "## Time to start a federated learning experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d41b7896", + "metadata": {}, + "outputs": [], + "source": [ + "# create an experimnet in federation\n", + "experiment_name = 'tinyimagenet_test_experiment'\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "41b44de9", + "metadata": {}, + "outputs": [], + "source": [ + "# The following command zips the workspace and python requirements to be transfered to collaborator nodes\n", + "fl_experiment.start(\n", + " model_provider=model_interface, \n", + " task_keeper=task_interface,\n", + " data_loader=fed_dataset,\n", + " rounds_to_train=5,\n", + " opt_treatment='CONTINUE_GLOBAL'\n", + ")" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "83edd88f", + "metadata": {}, + "outputs": [], + "source": [ + "# If user want to stop IPython session, then reconnect and check how experiment is going\n", + "# fl_experiment.restore_experiment_state(model_interface)\n", + "\n", + "fl_experiment.stream_metrics(tensorboard_logs=False)" + ] + } + ], + "metadata": { + "language_info": { + "name": "python" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/workspace/requirements.txt b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/workspace/requirements.txt new file mode 100644 index 0000000..bd0fcb5 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet/workspace/requirements.txt @@ -0,0 +1,4 @@ +setuptools>=65.5.1 # not directly required, pinned by Snyk to avoid a vulnerability +torch==2.3.1 +torchvision==0.18.1 +wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/README.md b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/README.md new file mode 100644 index 0000000..277431c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/README.md @@ -0,0 +1,90 @@ +# PyTorch_TinyImageNet + +## **How to run this tutorial (without TLC and locally as a simulation):** +
+ +Before we dive in, let's clarify some terms. XPU is a term coined by Intel to describe their line of computing devices, which includes CPUs, GPUs, FPGAs, and other accelerators. In this tutorial, we will be focusing on the Intel® Data Center GPU Max Series model, a GPU that is part of Intel's XPU lineup. + +### 0a. If you haven't done so already, create a virtual environment, install OpenFL, and upgrade pip: + - For help with this step, visit the "Install the Package" section of the [OpenFL installation instructions](https://openfl.readthedocs.io/en/latest/install.html#install-the-package). + +
+ +### 0b. Quick XPU Setup + In this tutorial, when we refer to XPU, we are specifically referring to the Intel® Data Center GPU Max Series. When using the Intel® Extension for PyTorch* package, selecting the device as 'xpu' will refer to this Intel® Data Center GPU Max Series. + + For a successful setup, please follow the steps outlined in the [Installation Guide](https://intel.github.io/intel-extension-for-pytorch/xpu/2.1.10+xpu/tutorials/installation.html). This guide provides detailed information on system requirements and the installation process for the Intel® Extension for PyTorch. For a deeper understanding of features, APIs, and technical details, refer to the [Intel® Extension for PyTorch* Documentation](https://intel.github.io/intel-extension-for-pytorch/xpu/2.1.10+xpu/index.html). + +Hardware Prerequisite: Intel® Data Center GPU Max Series. + +This Jupyter Notebook has been tested and confirmed to work with the following versions: + + - intel-extension-for-pytorch==2.0.120 (xpu) + - pytorch==2.0.1 + - torchvision==0.15.2 + +These versions were obtained from official Intel® channels. + +Additionally, the XPU driver version used in testing was: + + - [XPU_Driver==803](https://dgpu-docs.intel.com/driver/installation.html) + + +
+ +### 1. Split terminal into 3 (1 terminal for the director, 1 for the envoy, and 1 for the experiment) + +
+ +### 2. Do the following in each terminal: + - Activate the virtual environment from step 0: + + ```sh + source venv/bin/activate + ``` + - If you are in a network environment with a proxy, ensure proxy environment variables are set in each of your terminals. + - Navigate to the tutorial: + + ```sh + cd openfl/openfl-tutorials/interactive_api/PyTorch_TinyImageNet + ``` + +
+ +### 3. In the first terminal, run the director: + +```sh +cd director +./start_director.sh +``` + +
+ +### 4. In the second terminal, install requirements and run the envoy: + +```sh +cd envoy +pip install -r requirements.txt +./start_envoy.sh env_one envoy_config.yaml +``` + +Optional: Run a second envoy in an additional terminal: + - Ensure step 2 is complete for this terminal as well. + - Run the second envoy: +```sh +cd envoy +./start_envoy.sh env_two envoy_config.yaml +``` + +
+ +### 5. Now that your director and envoy terminals are set up, run the Jupyter Notebook in your experiment terminal: + +```sh +cd workspace +jupyter lab pytorch_tinyimagenet_XPU.ipynb +``` +- A Jupyter Server URL will appear in your terminal. In your browser, proceed to that link. Once the webpage loads, click on the pytorch_tinyimagenet.ipynb file. +- To run the experiment, select the icon that looks like two triangles to "Restart Kernel and Run All Cells". +- You will notice activity in your terminals as the experiment runs, and when the experiment is finished the director terminal will display a message that the experiment has finished successfully. + diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/director/director_config.yaml new file mode 100644 index 0000000..3fc4137 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/director/director_config.yaml @@ -0,0 +1,5 @@ +settings: + listen_host: localhost + listen_port: 50051 + sample_shape: ['64', '64', '3'] + target_shape: ['64', '64'] diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/director/start_director.sh new file mode 100755 index 0000000..5806a6c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/director/start_director.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx director start --disable-tls -c director_config.yaml \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/director/start_director_with_tls.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/director/start_director_with_tls.sh new file mode 100755 index 0000000..5d6d46a --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/director/start_director_with_tls.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e +FQDN=$1 +fx director start -c director_config.yaml -rc cert/root_ca.crt -pk cert/"${FQDN}".key -oc cert/"${FQDN}".crt \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/envoy/envoy_config.yaml b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/envoy/envoy_config.yaml new file mode 100644 index 0000000..cb04056 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/envoy/envoy_config.yaml @@ -0,0 +1,10 @@ +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: tinyimagenet_shard_descriptor.TinyImageNetShardDescriptor + params: + data_folder: tinyimagenet_data + rank_worldsize: 1,1 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/envoy/requirements.txt b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/envoy/requirements.txt new file mode 100644 index 0000000..7f361a8 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/envoy/requirements.txt @@ -0,0 +1 @@ +Pillow==10.3.0 diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/envoy/start_envoy.sh new file mode 100755 index 0000000..1dd6591 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/envoy/start_envoy.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx envoy start -n env_one --disable-tls --envoy-config-path envoy_config.yaml -dh localhost -dp 50051 \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/envoy/start_envoy_with_tls.sh b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/envoy/start_envoy_with_tls.sh new file mode 100755 index 0000000..06b2916 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/envoy/start_envoy_with_tls.sh @@ -0,0 +1,6 @@ +#!/bin/bash +set -e +ENVOY_NAME=$1 +DIRECTOR_FQDN=$2 + +fx envoy start -n "$ENVOY_NAME" --envoy-config-path envoy_config.yaml -dh "$DIRECTOR_FQDN" -dp 50051 -rc cert/root_ca.crt -pk cert/"$ENVOY_NAME".key -oc cert/"$ENVOY_NAME".crt \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/envoy/tinyimagenet_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/envoy/tinyimagenet_shard_descriptor.py new file mode 100644 index 0000000..cb161d9 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/envoy/tinyimagenet_shard_descriptor.py @@ -0,0 +1,120 @@ +# Copyright (C) 2020-2024 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""TinyImageNet Shard Descriptor.""" + +import glob +import logging +import os +import shutil +from pathlib import Path +from typing import Tuple + +from PIL import Image + +from openfl.interface.interactive_api.shard_descriptor import ShardDataset +from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor + +logger = logging.getLogger(__name__) + + +class TinyImageNetDataset(ShardDataset): + """TinyImageNet shard dataset class.""" + + NUM_IMAGES_PER_CLASS = 500 + + def __init__(self, data_folder: Path, data_type='train', rank=1, worldsize=1): + """Initialize TinyImageNetDataset.""" + self.data_type = data_type + self._common_data_folder = data_folder + self._data_folder = os.path.join(data_folder, data_type) + self.labels = {} # fname - label number mapping + self.image_paths = sorted( + glob.iglob( + os.path.join(self._data_folder, '**', '*.JPEG'), + recursive=True + ) + )[rank - 1::worldsize] + wnids_path = os.path.join(self._common_data_folder, 'wnids.txt') + with open(wnids_path, 'r', encoding='utf-8') as fp: + self.label_texts = sorted([text.strip() for text in fp.readlines()]) + self.label_text_to_number = {text: i for i, text in enumerate(self.label_texts)} + self.fill_labels() + + def __len__(self) -> int: + """Return the len of the shard dataset.""" + return len(self.image_paths) + + def __getitem__(self, index: int) -> Tuple['Image', int]: + """Return an item by the index.""" + file_path = self.image_paths[index] + label = self.labels[os.path.basename(file_path)] + return self.read_image(file_path), label + + def read_image(self, path: Path) -> Image: + """Read the image.""" + img = Image.open(path) + return img + + def fill_labels(self) -> None: + """Fill labels.""" + if self.data_type == 'train': + for label_text, i in self.label_text_to_number.items(): + for cnt in range(self.NUM_IMAGES_PER_CLASS): + self.labels[f'{label_text}_{cnt}.JPEG'] = i + elif self.data_type == 'val': + val_annotations_path = os.path.join(self._data_folder, 'val_annotations.txt') + with open(val_annotations_path, 'r', encoding='utf-8') as fp: + for line in fp.readlines(): + terms = line.split('\t') + file_name, label_text = terms[0], terms[1] + self.labels[file_name] = self.label_text_to_number[label_text] + + +class TinyImageNetShardDescriptor(ShardDescriptor): + """Shard descriptor class.""" + + def __init__( + self, + data_folder: str = 'data', + rank_worldsize: str = '1,1', + **kwargs + ): + """Initialize TinyImageNetShardDescriptor.""" + self.common_data_folder = Path.cwd() / data_folder + self.data_folder = Path.cwd() / data_folder / 'tiny-imagenet-200' + self.download_data() + self.rank, self.worldsize = tuple(int(num) for num in rank_worldsize.split(',')) + + def download_data(self): + """Download prepared shard dataset.""" + zip_file_path = self.common_data_folder / 'tiny-imagenet-200.zip' + os.makedirs(self.common_data_folder, exist_ok=True) + os.system(f'wget --no-clobber http://cs231n.stanford.edu/tiny-imagenet-200.zip' + f' -O {zip_file_path}') + shutil.unpack_archive(str(zip_file_path), str(self.common_data_folder)) + + def get_dataset(self, dataset_type): + """Return a shard dataset by type.""" + return TinyImageNetDataset( + data_folder=self.data_folder, + data_type=dataset_type, + rank=self.rank, + worldsize=self.worldsize + ) + + @property + def sample_shape(self): + """Return the sample shape info.""" + return ['64', '64', '3'] + + @property + def target_shape(self): + """Return the target shape info.""" + return ['64', '64'] + + @property + def dataset_description(self) -> str: + """Return the shard dataset description.""" + return (f'TinyImageNetDataset dataset, shard number {self.rank}' + f' out of {self.worldsize}') diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/workspace/pytorch_tinyimagenet_XPU.ipynb b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/workspace/pytorch_tinyimagenet_XPU.ipynb new file mode 100644 index 0000000..02d9008 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/workspace/pytorch_tinyimagenet_XPU.ipynb @@ -0,0 +1,530 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "26fdd9ed", + "metadata": {}, + "source": [ + "# Federated PyTorch TinyImageNet Tutorial XPU Version" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "895288d0", + "metadata": {}, + "outputs": [], + "source": [ + "# For interactive api requirements. For XPU requirements, review Readme Quick XPU Setup section.\n", + "!pip install -r requirements.txt" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "billion-drunk", + "metadata": {}, + "outputs": [], + "source": [ + "import os\n", + "import glob\n", + "\n", + "from PIL import Image\n", + "\n", + "import numpy as np\n", + "import torch\n", + "import torch.nn as nn\n", + "import torch.nn.functional as F\n", + "import torch.optim as optim\n", + "from openfl.interface.interactive_api.federation import Federation\n", + "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment\n", + "from copy import deepcopy\n", + "import torchvision\n", + "from torchvision import transforms as T\n", + "from torch.utils.data import Dataset\n", + "from torch.utils.data import DataLoader\n", + "import tqdm\n", + "\n", + "import intel_extension_for_pytorch as ipex\n", + "device = torch.device(\"xpu\")\n", + "\n", + "torch.manual_seed(0)\n", + "np.random.seed(0)" + ] + }, + { + "cell_type": "markdown", + "id": "246f9c98", + "metadata": {}, + "source": [ + "## Connect to the Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d657e463", + "metadata": {}, + "outputs": [], + "source": [ + "# Create a federation\n", + "\n", + "# please use the same identificator that was used in signed certificate\n", + "client_id = 'api'\n", + "cert_dir = 'cert'\n", + "director_node_fqdn = 'localhost'\n", + "# 1) Run with API layer - Director mTLS \n", + "# If the user wants to enable mTLS their must provide CA root chain, and signed key pair to the federation interface\n", + "# cert_chain = f'{cert_dir}/root_ca.crt'\n", + "# api_certificate = f'{cert_dir}/{client_id}.crt'\n", + "# api_private_key = f'{cert_dir}/{client_id}.key'\n", + "\n", + "# federation = Federation(client_id=client_id, director_node_fqdn=director_node_fqdn, director_port='50051',\n", + "# cert_chain=cert_chain, api_cert=api_certificate, api_private_key=api_private_key)\n", + "\n", + "# --------------------------------------------------------------------------------------------------------------------\n", + "\n", + "# 2) Run with TLS disabled (trusted environment)\n", + "# Federation can also determine local fqdn automatically\n", + "federation = Federation(client_id=client_id, director_node_fqdn=director_node_fqdn, director_port='50051', tls=False)\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "1abebd90", + "metadata": {}, + "outputs": [], + "source": [ + "federation.target_shape" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "47dcfab3", + "metadata": {}, + "outputs": [], + "source": [ + "shard_registry = federation.get_shard_registry()\n", + "shard_registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "a2a6c237", + "metadata": {}, + "outputs": [], + "source": [ + "# First, request a dummy_shard_desc that holds information about the federated dataset \n", + "dummy_shard_desc = federation.get_dummy_shard_descriptor(size=10)\n", + "dummy_shard_dataset = dummy_shard_desc.get_dataset('train')\n", + "sample, target = dummy_shard_dataset[0]\n", + "print(sample.shape)\n", + "print(target.shape)" + ] + }, + { + "cell_type": "markdown", + "id": "cc0dbdbd", + "metadata": {}, + "source": [ + "## Creating a FL experiment using Interactive API" + ] + }, + { + "cell_type": "markdown", + "id": "b0979470", + "metadata": {}, + "source": [ + "### Register dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "7dda1680", + "metadata": {}, + "outputs": [], + "source": [ + "normalize = T.Normalize(\n", + " mean=[0.485, 0.456, 0.406],\n", + " std=[0.229, 0.224, 0.225]\n", + ")\n", + "\n", + "augmentation = T.RandomApply(\n", + " [T.RandomHorizontalFlip(),\n", + " T.RandomRotation(10),\n", + " T.RandomResizedCrop(64)], \n", + " p=.8\n", + ")\n", + "\n", + "training_transform = T.Compose(\n", + " [T.Lambda(lambda x: x.convert(\"RGB\")),\n", + " T.ToTensor(),\n", + " augmentation,\n", + " normalize]\n", + ")\n", + "\n", + "valid_transform = T.Compose(\n", + " [T.Lambda(lambda x: x.convert(\"RGB\")),\n", + " T.ToTensor(),\n", + " normalize]\n", + ")\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "0314d5bf", + "metadata": {}, + "outputs": [], + "source": [ + "class TransformedDataset(Dataset):\n", + " \"\"\"Image Person ReID Dataset.\"\"\"\n", + "\n", + " def __init__(self, dataset, transform=None, target_transform=None):\n", + " \"\"\"Initialize Dataset.\"\"\"\n", + " self.dataset = dataset\n", + " self.transform = transform\n", + " self.target_transform = target_transform\n", + "\n", + " def __len__(self):\n", + " \"\"\"Length of dataset.\"\"\"\n", + " return len(self.dataset)\n", + "\n", + " def __getitem__(self, index):\n", + " img, label = self.dataset[index]\n", + " label = self.target_transform(label) if self.target_transform else label\n", + " img = self.transform(img) if self.transform else img\n", + " return img, label\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "01369e3b", + "metadata": {}, + "outputs": [], + "source": [ + "class TinyImageNetDataset(DataInterface):\n", + " def __init__(self, **kwargs):\n", + " self.kwargs = kwargs\n", + " \n", + " @property\n", + " def shard_descriptor(self):\n", + " return self._shard_descriptor\n", + " \n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + "\n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + " \n", + " self.train_set = TransformedDataset(\n", + " self._shard_descriptor.get_dataset('train'),\n", + " transform=training_transform\n", + " )\n", + " self.valid_set = TransformedDataset(\n", + " self._shard_descriptor.get_dataset('val'),\n", + " transform=valid_transform\n", + " )\n", + " \n", + " def get_train_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks with optimizer in contract\n", + " \"\"\"\n", + " generator=torch.Generator()\n", + " generator.manual_seed(0)\n", + " return DataLoader(\n", + " self.train_set, batch_size=self.kwargs['train_bs'], shuffle=True, generator=generator\n", + " )\n", + "\n", + " def get_valid_loader(self, **kwargs):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks without optimizer in contract\n", + " \"\"\"\n", + " return DataLoader(self.valid_set, batch_size=self.kwargs['valid_bs'])\n", + "\n", + " def get_train_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.train_set)\n", + "\n", + " def get_valid_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.valid_set)\n", + " " + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4a6cedef", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = TinyImageNetDataset(train_bs=64, valid_bs=64)" + ] + }, + { + "cell_type": "markdown", + "id": "74cac654", + "metadata": {}, + "source": [ + "### Describe the model and optimizer" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "43e25fe3", + "metadata": {}, + "outputs": [], + "source": [ + "\"\"\"\n", + "MobileNetV2 model\n", + "\"\"\"\n", + "\n", + "class Net(nn.Module):\n", + " def __init__(self):\n", + " torch.manual_seed(0)\n", + " super(Net, self).__init__()\n", + " self.model = torchvision.models.mobilenet_v2(pretrained=True)\n", + " self.model.requires_grad_(False)\n", + " self.model.classifier[1] = torch.nn.Linear(in_features=1280, \\\n", + " out_features=200, bias=True)\n", + "\n", + " def forward(self, x):\n", + " x = self.model.forward(x)\n", + " return x\n", + "\n", + "model_net = Net()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "79021778", + "metadata": {}, + "outputs": [], + "source": [ + "params_to_update = []\n", + "for param in model_net.parameters():\n", + " if param.requires_grad == True:\n", + " params_to_update.append(param)\n", + " \n", + "optimizer_adam = optim.Adam(params_to_update, lr=1e-4)\n", + "\n", + "def cross_entropy(output, target):\n", + " \"\"\"Binary cross-entropy metric\n", + " \"\"\"\n", + " return F.cross_entropy(input=output,target=target)" + ] + }, + { + "cell_type": "markdown", + "id": "f097cdc5", + "metadata": {}, + "source": [ + "### Register model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "06a8cca8", + "metadata": {}, + "outputs": [], + "source": [ + "framework_adapter = 'openfl.plugins.frameworks_adapters.pytorch_adapter.FrameworkAdapterPlugin'\n", + "model_interface = ModelInterface(model=model_net, optimizer=optimizer_adam, framework_plugin=framework_adapter)\n", + "\n", + "# Save the initial model state\n", + "initial_model = deepcopy(model_net)" + ] + }, + { + "cell_type": "markdown", + "id": "849c165b", + "metadata": {}, + "source": [ + "## Define and register FL tasks" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "1d7e010d-b885-4b77-83d5-e69e239be5a6", + "metadata": {}, + "outputs": [], + "source": [ + "# Counter class for the Rounds\n", + "class Counter:\n", + " def __init__(self):\n", + " self.value = 0\n", + " \n", + " def current(self):\n", + " return self.value\n", + " \n", + " def add(self):\n", + " self.value += 1\n", + "\n", + "counter = Counter()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "b9649385", + "metadata": {}, + "outputs": [], + "source": [ + "task_interface = TaskInterface()\n", + "\n", + "\n", + "# Task interface currently supports only standalone functions.\n", + "@task_interface.add_kwargs(**{ 'device':'xpu'})\n", + "@task_interface.register_fl_task(model='model_net', data_loader='train_loader', \\\n", + " device='device', optimizer='optimizer') \n", + "def train(model_net, train_loader, optimizer, device, loss_fn=cross_entropy, some_parameter=None):\n", + " torch.manual_seed(0)\n", + " \n", + " # Start counter of rounds\n", + " round = counter.current()\n", + " \n", + " model_net.train()\n", + " # On first round move model to device\n", + " if round == 0:\n", + " model_net.to(device)\n", + " model_net, optimizer = ipex.optimize(model_net, optimizer=optimizer_adam)\n", + " \n", + " counter.add()\n", + " \n", + " train_loader = tqdm.tqdm(train_loader, desc=\"train\")\n", + " model_net.train()\n", + " model_net.to(device)\n", + "\n", + " losses = []\n", + "\n", + " for data, target in train_loader:\n", + " data, target = torch.tensor(data).to(device), torch.tensor(\n", + " target).to(device)\n", + " optimizer.zero_grad()\n", + " # Code changes\n", + " with torch.xpu.amp.autocast(enabled=True, dtype=torch.bfloat16):\n", + " output = model_net(data)\n", + " loss = loss_fn(output=output, target=target)\n", + " loss.backward()\n", + " optimizer.step()\n", + " losses.append(loss.detach().cpu().numpy())\n", + " \n", + " return {'train_loss': np.mean(losses),}\n", + "\n", + "@task_interface.add_kwargs(**{ 'device':'xpu'})\n", + "@task_interface.register_fl_task(model='model_net', device='device',data_loader='val_loader') \n", + "def validate(model_net, val_loader, device):\n", + " torch.manual_seed(0)\n", + " model_net.eval()\n", + " model_net.to(device)\n", + " \n", + " val_loader = tqdm.tqdm(val_loader, desc=\"validate\")\n", + " val_score = 0\n", + " total_samples = 0\n", + "\n", + " with torch.no_grad():\n", + " for data, target in val_loader:\n", + " samples = target.shape[0]\n", + " total_samples += samples\n", + " data, target = torch.tensor(data).to(device), \\\n", + " torch.tensor(target).to(device, dtype=torch.int64)\n", + " # Code changes\n", + " with torch.xpu.amp.autocast(enabled=True, dtype=torch.int64):\n", + " output = model_net(data)\n", + " pred = output.argmax(dim=1,keepdim=True)\n", + " val_score += pred.eq(target).sum().cpu().numpy()\n", + " \n", + " return {'acc': val_score / total_samples,}" + ] + }, + { + "cell_type": "markdown", + "id": "8f0ebf2d", + "metadata": {}, + "source": [ + "## Time to start a federated learning experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d41b7896", + "metadata": {}, + "outputs": [], + "source": [ + "# create an experimnet in federation\n", + "experiment_name = 'tinyimagenet_test_experiment'\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "41b44de9", + "metadata": {}, + "outputs": [], + "source": [ + "# The following command zips the workspace and python requirements to be transfered to collaborator nodes\n", + "fl_experiment.start(\n", + " model_provider=model_interface, \n", + " task_keeper=task_interface,\n", + " data_loader=fed_dataset,\n", + " rounds_to_train=5,\n", + " opt_treatment='CONTINUE_GLOBAL'\n", + ")" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "83edd88f", + "metadata": {}, + "outputs": [], + "source": [ + "# If user want to stop IPython session, then reconnect and check how experiment is going\n", + "# fl_experiment.restore_experiment_state(model_interface)\n", + "\n", + "fl_experiment.stream_metrics(tensorboard_logs=False)" + ] + } + ], + "metadata": { + "kernelspec": { + "display_name": "conda_IPEX", + "language": "python", + "name": "conda_ipex" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.18" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/workspace/requirements.txt b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/workspace/requirements.txt new file mode 100644 index 0000000..bd0fcb5 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/PyTorch_TinyImageNet_XPU/workspace/requirements.txt @@ -0,0 +1,4 @@ +setuptools>=65.5.1 # not directly required, pinned by Snyk to avoid a vulnerability +torch==2.3.1 +torchvision==0.18.1 +wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability diff --git a/openfl_contrib_tutorials/interactive_api/README.md b/openfl_contrib_tutorials/interactive_api/README.md new file mode 100644 index 0000000..454bab5 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/README.md @@ -0,0 +1,4 @@ +# **Interactive API (Director Workflow) Tutorials** + +### The Director Workflow tutorials explore a variety of frameworks, models, and datasets. The steps are similar for each tutorial, however each one has its own README with specific instructions and requirements. + diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/README.md b/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/README.md new file mode 100644 index 0000000..527b5db --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/README.md @@ -0,0 +1,75 @@ +# CIFAR10 Federated Classification Tutorial + +## I. About the Dataset + +The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images. +
+ +## II. About the Model + +A simple multi-layer CNN is used. Definition provided in the notebook. +
+ +## III. About the Federation + +Data is equally partitioned between envoys/participants. + +You can write your own splitting schema in the shard descriptor class. +
+ +## IV. How to run this tutorial (without TLC and locally as a simulation): + +### 0. If you haven't done so already, create a virtual environment, install OpenFL, and upgrade pip: + - For help with this step, visit the "Install the Package" section of the [OpenFL installation instructions](https://openfl.readthedocs.io/en/latest/install.html#install-the-package). +
+ +### 1. Split terminal into 3 (1 terminal for the director, 1 for the envoy, and 1 for the experiment) +
+ +### 2. Do the following in each terminal: + - Activate the virtual environment from step 0: + + ```sh + source venv/bin/activate + ``` + - If you are in a network environment with a proxy, ensure proxy environment variables are set in each of your terminals. + - Navigate to the tutorial: + + ```sh + cd openfl/openfl-tutorials/interactive_api/Tensorflow_CIFAR_tfdata + ``` +
+ +### 3. In the first terminal, run the director: + +```sh +cd director +./start_director.sh +``` +
+ +### 4. In the second terminal run the envoy: + +```sh +cd envoy +./start_envoy.sh env_one envoy_config_one.yaml +``` + +Optional: Run a second envoy in an additional terminal: + - Ensure step 2 is complete for this terminal as well. + - Run the second envoy: +```sh +cd envoy +./start_envoy.sh env_two envoy_config_two.yaml +``` +
+ +### 5. In the third terminal (or forth terminal, if you chose to do two envoys) run the Jupyter Notebook: + +```sh +cd workspace +jupyter lab Tensorflow_CIFAR.ipynb +``` +- A Jupyter Server URL will appear in your terminal. In your browser, proceed to that link. Once the webpage loads, click on the Tensorflow_CIFAR.ipynb file. +- To run the experiment, select the icon that looks like two triangles to "Restart Kernel and Run All Cells". +- You will notice activity in your terminals as the experiment runs, and when the experiment is finished the director terminal will display a message that the experiment was finished successfully. \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/director/director_config.yaml new file mode 100644 index 0000000..1d3c067 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/director/director_config.yaml @@ -0,0 +1,5 @@ +settings: + listen_host: localhost + listen_port: 50051 + sample_shape: ['32', '32', '3'] + target_shape: ['1'] diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/director/start_director.sh new file mode 100755 index 0000000..5806a6c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/director/start_director.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx director start --disable-tls -c director_config.yaml \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/envoy/cifar10_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/envoy/cifar10_shard_descriptor.py new file mode 100644 index 0000000..aabaf70 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/envoy/cifar10_shard_descriptor.py @@ -0,0 +1,93 @@ +# Copyright (C) 2022 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""CIFAR10 Shard Descriptor (using `tf.data.Dataset` API)""" +import logging +from typing import List, Tuple + +import tensorflow as tf + +from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor + +logger = logging.getLogger(__name__) + + +class CIFAR10ShardDescriptor(ShardDescriptor): + """ + CIFAR10 Shard Descriptor + + This example is based on `tf.data.Dataset` pipelines. + Note that the ingestion of any model/task requires an iterable dataloader. + Hence, it is possible to utilize these pipelines without explicit need of a + new interface. + """ + + def __init__( + self, + rank_worldsize: str = '1, 1', + **kwargs + ): + """Download/Prepare CIFAR10 dataset""" + self.rank, self.worldsize = tuple(int(num) for num in rank_worldsize.split(',')) + + # Load dataset + train_ds, valid_ds = self._download_and_prepare_dataset( + rank=self.rank, + worldsize=self.worldsize + ) + + # Set attributes + self._sample_shape = train_ds.element_spec[0].shape + self._target_shape = train_ds.element_spec[1].shape + + self.splits = { + 'train': train_ds, + 'valid': valid_ds + } + + @staticmethod + def _download_and_prepare_dataset(rank: int, worldsize: int) -> Tuple[tf.data.Dataset]: + """ + Load CIFAR10 as `tf.data.Dataset`. + + Provide `rank` and `worldsize` to auto-split uniquely for each client + for simulation purposes. + """ + (x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data() + + # Split + x_train, y_train = x_train[rank - 1::worldsize], y_train[rank - 1::worldsize] + x_test, y_test = x_test[rank - 1::worldsize], y_test[rank - 1::worldsize] + + train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)) + test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)) + return train_ds, test_ds + + def get_shard_dataset_types(self) -> List[str]: + """Get available split names""" + return list(self.splits) + + def get_split(self, name: str) -> tf.data.Dataset: + """Return a shard dataset by type.""" + if name not in self.splits: + raise Exception(f'Split name `{name}` not found.' + f' Expected one of {list(self.splits.keys())}') + return self.splits[name] + + @property + def sample_shape(self) -> List[str]: + """Return the sample shape info.""" + return list(map(str, self._sample_shape)) + + @property + def target_shape(self) -> List[str]: + """Return the target shape info.""" + return list(map(str, self._target_shape)) + + @property + def dataset_description(self) -> str: + """Return the dataset description.""" + n_train = len(self.splits['train']) + n_test = len(self.splits['valid']) + return (f'CIFAR10 dataset, shard number {self.rank}/{self.worldsize}.' + f'\nSamples [Train/Valid]: [{n_train}/{n_test}]') diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/envoy/envoy_config_one.yaml b/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/envoy/envoy_config_one.yaml new file mode 100644 index 0000000..bf9f9e5 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/envoy/envoy_config_one.yaml @@ -0,0 +1,9 @@ +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: cifar10_shard_descriptor.CIFAR10ShardDescriptor + params: + rank_worldsize: 1, 2 diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/envoy/envoy_config_two.yaml b/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/envoy/envoy_config_two.yaml new file mode 100644 index 0000000..22d8211 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/envoy/envoy_config_two.yaml @@ -0,0 +1,9 @@ +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: cifar10_shard_descriptor.CIFAR10ShardDescriptor + params: + rank_worldsize: 2, 2 diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/envoy/start_envoy.sh new file mode 100755 index 0000000..cdd84e7 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/envoy/start_envoy.sh @@ -0,0 +1,6 @@ +#!/bin/bash +set -e +ENVOY_NAME=$1 +ENVOY_CONF=$2 + +fx envoy start -n "$ENVOY_NAME" --disable-tls --envoy-config-path "$ENVOY_CONF" -dh localhost -dp 50051 diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/workspace/Tensorflow_CIFAR.ipynb b/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/workspace/Tensorflow_CIFAR.ipynb new file mode 100644 index 0000000..87dee45 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_CIFAR_tfdata/workspace/Tensorflow_CIFAR.ipynb @@ -0,0 +1,375 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "26fdd9ed", + "metadata": {}, + "source": [ + "# Federated Tensorflow CIFAR10 Tutorial\n", + "Using `tf.data` API" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "1329f2e6", + "metadata": {}, + "outputs": [], + "source": [ + "# Install TF if not already. We recommend TF2.13 or greater.\n", + "# !pip install tensorflow==2.13" + ] + }, + { + "cell_type": "markdown", + "id": "e0d30942", + "metadata": {}, + "source": [ + "## Imports" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "0833dfc9", + "metadata": {}, + "outputs": [], + "source": [ + "import tensorflow as tf\n", + "print('TensorFlow', tf.__version__)" + ] + }, + { + "cell_type": "markdown", + "id": "246f9c98", + "metadata": {}, + "source": [ + "## Connect to the Federation\n", + "\n", + "Start `Director` and `Envoy` before proceeding with this cell. \n", + "\n", + "This cell connects this notebook to the Federation." + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d657e463", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.federation import Federation\n", + "\n", + "# please use the same identificator that was used in signed certificate\n", + "client_id = 'api'\n", + "cert_dir = 'cert'\n", + "director_node_fqdn = 'localhost'\n", + "director_port = 50051\n", + "\n", + "# Create a Federation\n", + "federation = Federation(\n", + " client_id=client_id,\n", + " director_node_fqdn=director_node_fqdn,\n", + " director_port=director_port, \n", + " tls=False\n", + ")" + ] + }, + { + "cell_type": "markdown", + "id": "6efe22a8", + "metadata": {}, + "source": [ + "## Query Datasets from Shard Registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "47dcfab3", + "metadata": {}, + "outputs": [], + "source": [ + "shard_registry = federation.get_shard_registry()\n", + "shard_registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "a2a6c237", + "metadata": {}, + "outputs": [], + "source": [ + "# First, request a dummy_shard_desc that holds information about the federated dataset \n", + "dummy_shard_desc = federation.get_dummy_shard_descriptor(size=10)\n", + "dummy_shard_dataset = dummy_shard_desc.get_dataset('train')\n", + "sample, target = dummy_shard_dataset[0]\n", + "f\"Sample shape: {sample.shape}, target shape: {target.shape}\"" + ] + }, + { + "cell_type": "markdown", + "id": "cc0dbdbd", + "metadata": {}, + "source": [ + "## Describing FL experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "fc88700a", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.experiment import TaskInterface\n", + "from openfl.interface.interactive_api.experiment import ModelInterface\n", + "from openfl.interface.interactive_api.experiment import FLExperiment" + ] + }, + { + "cell_type": "markdown", + "id": "3b468ae1", + "metadata": {}, + "source": [ + "### Register model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "06545bbb", + "metadata": {}, + "outputs": [], + "source": [ + "# Define model\n", + "model = tf.keras.Sequential([\n", + " tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),\n", + " tf.keras.layers.MaxPooling2D((2, 2)),\n", + " tf.keras.layers.BatchNormalization(),\n", + " tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),\n", + " tf.keras.layers.MaxPooling2D((2, 2)),\n", + " tf.keras.layers.BatchNormalization(),\n", + " tf.keras.layers.Flatten(),\n", + " tf.keras.layers.Dense(10, activation=None),\n", + "], name='simplecnn')\n", + "model.summary()\n", + "\n", + "# Define optimizer\n", + "optimizer = tf.keras.optimizers.legacy.Adam(learning_rate=1e-4)\n", + "\n", + "# Loss and metrics. These will be used later.\n", + "loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)\n", + "train_acc_metric = tf.keras.metrics.SparseCategoricalAccuracy()\n", + "val_acc_metric = tf.keras.metrics.SparseCategoricalAccuracy()\n", + "\n", + "# Create ModelInterface\n", + "framework_adapter = 'openfl.plugins.frameworks_adapters.keras_adapter.FrameworkAdapterPlugin'\n", + "MI = ModelInterface(model=model, optimizer=optimizer, framework_plugin=framework_adapter)" + ] + }, + { + "cell_type": "markdown", + "id": "b0979470", + "metadata": {}, + "source": [ + "### Register dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d8c9eb50", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.experiment import DataInterface\n", + "\n", + "class CIFAR10FedDataset(DataInterface):\n", + "\n", + " def __init__(self, **kwargs):\n", + " super().__init__(**kwargs)\n", + "\n", + " @property\n", + " def shard_descriptor(self):\n", + " return self._shard_descriptor\n", + "\n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + "\n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + " \n", + " # shard_descriptor.get_split(...) returns a tf.data.Dataset\n", + " # Check cifar10_shard_descriptor.py for details\n", + " self.train_set = shard_descriptor.get_split('train')\n", + " self.valid_set = shard_descriptor.get_split('valid')\n", + "\n", + " def get_train_loader(self):\n", + " \"\"\"Output of this method will be provided to tasks with optimizer in contract\"\"\"\n", + " bs = self.kwargs.get('train_bs', 32)\n", + " return self.train_set.batch(bs)\n", + "\n", + " def get_valid_loader(self):\n", + " \"\"\"Output of this method will be provided to tasks without optimizer in contract\"\"\"\n", + " bs = self.kwargs.get('valid_bs', 32)\n", + " return self.valid_set.batch(bs)\n", + " \n", + " def get_train_data_size(self) -> int:\n", + " \"\"\"Information for aggregation\"\"\"\n", + " return len(self.train_set)\n", + "\n", + " def get_valid_data_size(self) -> int:\n", + " \"\"\"Information for aggregation\"\"\"\n", + " return len(self.valid_set)" + ] + }, + { + "cell_type": "markdown", + "id": "b0dfb459", + "metadata": {}, + "source": [ + "### Create CIFAR10 federated dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4af5c4c2", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = CIFAR10FedDataset(train_bs=64, valid_bs=512)" + ] + }, + { + "cell_type": "markdown", + "id": "849c165b", + "metadata": {}, + "source": [ + "## Define and register FL tasks" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "b9649385", + "metadata": {}, + "outputs": [], + "source": [ + "from tensorflow.keras.utils import Progbar\n", + "\n", + "TI = TaskInterface()\n", + "\n", + "@TI.register_fl_task(model='model', data_loader='dataset', optimizer='optimizer', device='device') \n", + "def train(model, dataset, optimizer, device, loss_fn=loss_fn, warmup=False):\n", + "\n", + " # Iterate over the batches of the dataset.\n", + " pbar = Progbar(len(dataset))\n", + " \n", + " for step, (x, y) in enumerate(dataset):\n", + " \n", + " # Gradient\n", + " with tf.GradientTape() as tape:\n", + " logits = model(x, training=True)\n", + " loss_value = loss_fn(y, logits)\n", + " grads = tape.gradient(loss_value, model.trainable_weights)\n", + " optimizer.apply_gradients(zip(grads, model.trainable_weights))\n", + "\n", + " # Update training metric.\n", + " train_acc_metric.update_state(y, logits)\n", + " pbar.update(step+1, \n", + " values={'loss': loss_value, 'acc': train_acc_metric.result()}.items())\n", + " if warmup: break\n", + " \n", + " # Display metrics at the end of each epoch.\n", + " train_acc = train_acc_metric.result()\n", + " print(\"Training acc over epoch: %.4f\" % (float(train_acc),))\n", + "\n", + " # Reset training metrics at the end of each epoch\n", + " train_acc_metric.reset_states()\n", + " return {'train_acc': train_acc,}\n", + "\n", + "\n", + "@TI.register_fl_task(model='model', data_loader='dataset', device='device') \n", + "def validate(model, dataset, device):\n", + " # Run a validation loop at the end of each epoch.\n", + " for x, y in dataset:\n", + " logits = model(x, training=False)\n", + " # Update val metrics\n", + " val_acc_metric.update_state(y, logits)\n", + " val_acc = val_acc_metric.result()\n", + " val_acc_metric.reset_states()\n", + " print(\"Validation acc: %.4f\" % (float(val_acc),))\n", + " \n", + " return {'validation_accuracy': val_acc,}" + ] + }, + { + "cell_type": "markdown", + "id": "8f0ebf2d", + "metadata": {}, + "source": [ + "## Time to start a federated learning experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d41b7896", + "metadata": {}, + "outputs": [], + "source": [ + "# create an experimnet in federation\n", + "experiment_name = 'cifar10_experiment'\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name,serializer_plugin='openfl.plugins.interface_serializer.keras_serializer.KerasSerializer)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "41b44de9", + "metadata": {}, + "outputs": [], + "source": [ + "# The following command zips the workspace and python requirements to be transfered to collaborator nodes\n", + "ROUNDS_TO_TRAIN = 10\n", + "fl_experiment.start(model_provider=MI, \n", + " task_keeper=TI,\n", + " data_loader=fed_dataset,\n", + " rounds_to_train=ROUNDS_TO_TRAIN,\n", + " opt_treatment='CONTINUE_GLOBAL')\n", + "fl_experiment.stream_metrics()" + ] + } + ], + "metadata": { + "interpreter": { + "hash": "f82a63373a71051274245dbf52f7a790e1979bab025fdff4da684b10eb9978bd" + }, + "kernelspec": { + "display_name": "Python 3 (ipykernel)", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.10" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/README.md b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/README.md new file mode 100644 index 0000000..271ad4e --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/README.md @@ -0,0 +1,68 @@ +# MNIST Classification Tutorial + + + +## I. About the dataset + +It is a dataset of 60,000 small square 28×28 pixel grayscale images of handwritten single digits +between 0 and 9. More info at [wiki](https://en.wikipedia.org/wiki/MNIST_database). + +## II. About the model + +We use a simple fully-connected neural network defined at +[layers.py](./workspace/layers.py) file. + +## III. How to run this tutorial (without TLC and locally as a simulation): +
+ +### 0. If you haven't done so already, create a virtual environment, install OpenFL, and upgrade pip: + - For help with this step, visit the "Install the Package" section of the [OpenFL installation instructions](https://openfl.readthedocs.io/en/latest/install.html#install-the-package). +
+ +### 1. Split terminal into 3 (1 terminal for the director, 1 for the envoy, and 1 for the experiment) and do the following in each terminal: + - Activate the virtual environment from step 0: + + ```sh + source venv/bin/activate + ``` + - If you are in a network environment with a proxy, ensure proxy environment variables are set in each of your terminals. + - Navigate to the tutorial: + + ```sh + cd openfl/openfl-tutorials/interactive_api/Tensorflow_MNIST + ``` + + +
+ +### 2. In the first terminal, run the director: + +```sh +cd director +./start_director.sh +``` +
+ +### 3. In the second terminal, run the envoy: + +```sh +cd envoy +./start_envoy.sh env_one envoy_config_one.yaml +``` + +Optional: Run a second envoy in an additional terminal: + - Ensure steps 0 and 1 are complete for this terminal as well. + - Run the second envoy: +```sh +cd envoy +./start_envoy.sh env_two envoy_config_two.yaml +``` + - Notice that "env_one" was changed to "env_two", and "envoy_config_one.yaml" was changed to "envoy_config_two.yaml" +
+ +### 4. In the third terminal (or forth terminal, if you chose to do two envoys) run the `Tensorflow_MNIST.ipynb` Jupyter Notebook: + +```sh +cd workspace +jupyter lab Tensorflow_MNIST.ipynb +``` diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/director/director_config.yaml new file mode 100644 index 0000000..4621e98 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/director/director_config.yaml @@ -0,0 +1,5 @@ +settings: + listen_host: localhost + listen_port: 50051 + sample_shape: ['28', '28', '1'] + target_shape: ['1'] diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/director/start_director.sh new file mode 100755 index 0000000..5806a6c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/director/start_director.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx director start --disable-tls -c director_config.yaml \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/director/start_director_with_tls.sh b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/director/start_director_with_tls.sh new file mode 100755 index 0000000..5d6d46a --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/director/start_director_with_tls.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e +FQDN=$1 +fx director start -c director_config.yaml -rc cert/root_ca.crt -pk cert/"${FQDN}".key -oc cert/"${FQDN}".crt \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/__pycache__/mnist_shard_descriptor.cpython-38.pyc b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/__pycache__/mnist_shard_descriptor.cpython-38.pyc new file mode 100644 index 0000000..a91e2c7 Binary files /dev/null and b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/__pycache__/mnist_shard_descriptor.cpython-38.pyc differ diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/envoy_config_one.yaml b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/envoy_config_one.yaml new file mode 100644 index 0000000..053d5ef --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/envoy_config_one.yaml @@ -0,0 +1,9 @@ +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: mnist_shard_descriptor.MnistShardDescriptor + params: + rank_worldsize: 1, 2 diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/envoy_config_two.yaml b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/envoy_config_two.yaml new file mode 100644 index 0000000..b8b9685 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/envoy_config_two.yaml @@ -0,0 +1,9 @@ +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: mnist_shard_descriptor.MnistShardDescriptor + params: + rank_worldsize: 2, 2 diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/mnist_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/mnist_shard_descriptor.py new file mode 100644 index 0000000..a8089b1 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/mnist_shard_descriptor.py @@ -0,0 +1,102 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 + +"""Mnist Shard Descriptor.""" + +import logging +import os +from typing import List + +import numpy as np +import requests + +from openfl.interface.interactive_api.shard_descriptor import ShardDataset +from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor + +logger = logging.getLogger(__name__) + + +class MnistShardDataset(ShardDataset): + """Mnist Shard dataset class.""" + + def __init__(self, x, y, data_type, rank=1, worldsize=1): + """Pick rank-specific subset of (x, y)""" + self.data_type = data_type + self.rank = rank + self.worldsize = worldsize + self.x = x[self.rank - 1::self.worldsize] + self.y = y[self.rank - 1::self.worldsize] + + def __getitem__(self, index: int): + """Return an item by the index.""" + return self.x[index], self.y[index] + + def __len__(self): + """Return the len of the dataset.""" + return len(self.x) + + +class MnistShardDescriptor(ShardDescriptor): + """Mnist Shard descriptor class.""" + + def __init__( + self, + rank_worldsize: str = '1, 1', + **kwargs + ): + """Initialize MnistShardDescriptor.""" + self.rank, self.worldsize = tuple(int(num) for num in rank_worldsize.split(',')) + (x_train, y_train), (x_test, y_test) = self.download_data() + self.data_by_type = { + 'train': (x_train, y_train), + 'val': (x_test, y_test) + } + + def get_shard_dataset_types(self) -> List[str]: + """Get available shard dataset types.""" + return list(self.data_by_type) + + def get_dataset(self, dataset_type='train'): + """Return a shard dataset by type.""" + if dataset_type not in self.data_by_type: + raise Exception(f'Wrong dataset type: {dataset_type}') + return MnistShardDataset( + *self.data_by_type[dataset_type], + data_type=dataset_type, + rank=self.rank, + worldsize=self.worldsize + ) + + @property + def sample_shape(self): + """Return the sample shape info.""" + return ['28', '28', '1'] + + @property + def target_shape(self): + """Return the target shape info.""" + return ['1'] + + @property + def dataset_description(self) -> str: + """Return the dataset description.""" + return (f'Mnist dataset, shard number {self.rank}' + f' out of {self.worldsize}') + + def download_data(self): + """Download prepared dataset.""" + local_file_path = 'mnist.npz' + mnist_url = 'https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz' + response = requests.get(mnist_url) + with open(local_file_path, 'wb') as f: + f.write(response.content) + + with np.load(local_file_path) as f: + x_train, y_train = f['x_train'], f['y_train'] + x_test, y_test = f['x_test'], f['y_test'] + x_train = np.reshape(x_train, (-1, 28, 28, 1)) + x_test = np.reshape(x_test, (-1, 28, 28, 1)) + + os.remove(local_file_path) # remove mnist.npz + print('Mnist data was loaded!') + return (x_train, y_train), (x_test, y_test) diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/start_envoy.sh new file mode 100755 index 0000000..cdd84e7 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/start_envoy.sh @@ -0,0 +1,6 @@ +#!/bin/bash +set -e +ENVOY_NAME=$1 +ENVOY_CONF=$2 + +fx envoy start -n "$ENVOY_NAME" --disable-tls --envoy-config-path "$ENVOY_CONF" -dh localhost -dp 50051 diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/start_envoy_with_tls.sh b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/start_envoy_with_tls.sh new file mode 100755 index 0000000..2585cc9 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/envoy/start_envoy_with_tls.sh @@ -0,0 +1,7 @@ +#!/bin/bash +set -e +ENVOY_NAME=$1 +ENVOY_CONF=$2 +DIRECTOR_FQDN=$3 + +fx envoy start -n "$ENVOY_NAME" --envoy-config-path "$ENVOY_CONF" -dh "$DIRECTOR_FQDN" -dp 50051 -rc cert/root_ca.crt -pk cert/"$ENVOY_NAME".key -oc cert/"$ENVOY_NAME".crt diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/workspace/.ipynb_checkpoints/Tensorflow_MNIST-checkpoint.ipynb b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/workspace/.ipynb_checkpoints/Tensorflow_MNIST-checkpoint.ipynb new file mode 100644 index 0000000..accf12f --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/workspace/.ipynb_checkpoints/Tensorflow_MNIST-checkpoint.ipynb @@ -0,0 +1,481 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "26fdd9ed", + "metadata": {}, + "source": [ + "# Federated Tensorflow MNIST Tutorial" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "1329f2e6", + "metadata": {}, + "outputs": [], + "source": [ + "# Install TF if not already. We recommend TF2.7 or greater.\n", + "# !pip install tensorflow==2.8" + ] + }, + { + "cell_type": "markdown", + "id": "e0d30942", + "metadata": {}, + "source": [ + "## Imports" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "0833dfc9", + "metadata": {}, + "outputs": [], + "source": [ + "import tensorflow as tf\n", + "print('TensorFlow', tf.__version__)" + ] + }, + { + "cell_type": "markdown", + "id": "246f9c98", + "metadata": {}, + "source": [ + "## Connect to the Federation\n", + "\n", + "Start `Director` and `Envoy` before proceeding with this cell. \n", + "\n", + "This cell connects this notebook to the Federation." + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d657e463", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.federation import Federation\n", + "\n", + "# please use the same identificator that was used in signed certificate\n", + "client_id = 'api'\n", + "cert_dir = 'cert'\n", + "director_node_fqdn = 'localhost'\n", + "director_port = 50051\n", + "# 1) Run with API layer - Director mTLS \n", + "# If the user wants to enable mTLS their must provide CA root chain, and signed key pair to the federation interface\n", + "# cert_chain = f'{cert_dir}/root_ca.crt'\n", + "# api_certificate = f'{cert_dir}/{client_id}.crt'\n", + "# api_private_key = f'{cert_dir}/{client_id}.key'\n", + "\n", + "# federation = Federation(\n", + "# client_id=client_id,\n", + "# director_node_fqdn=director_node_fqdn,\n", + "# director_port=director_port,\n", + "# cert_chain=cert_chain,\n", + "# api_cert=api_certificate,\n", + "# api_private_key=api_private_key\n", + "# )\n", + "\n", + "# --------------------------------------------------------------------------------------------------------------------\n", + "\n", + "# 2) Run with TLS disabled (trusted environment)\n", + "\n", + "# Create a Federation\n", + "federation = Federation(\n", + " client_id=client_id,\n", + " director_node_fqdn=director_node_fqdn,\n", + " director_port=director_port, \n", + " tls=False\n", + ")" + ] + }, + { + "cell_type": "markdown", + "id": "6efe22a8", + "metadata": {}, + "source": [ + "## Query Datasets from Shard Registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "47dcfab3", + "metadata": {}, + "outputs": [], + "source": [ + "shard_registry = federation.get_shard_registry()\n", + "shard_registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "a2a6c237", + "metadata": {}, + "outputs": [], + "source": [ + "# First, request a dummy_shard_desc that holds information about the federated dataset \n", + "dummy_shard_desc = federation.get_dummy_shard_descriptor(size=10)\n", + "dummy_shard_dataset = dummy_shard_desc.get_dataset('train')\n", + "sample, target = dummy_shard_dataset[0]\n", + "f\"Sample shape: {sample.shape}, target shape: {target.shape}\"" + ] + }, + { + "cell_type": "markdown", + "id": "cc0dbdbd", + "metadata": {}, + "source": [ + "## Describing FL experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "fc88700a", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.experiment import TaskInterface\n", + "from openfl.interface.interactive_api.experiment import ModelInterface\n", + "from openfl.interface.interactive_api.experiment import FLExperiment" + ] + }, + { + "cell_type": "markdown", + "id": "3b468ae1", + "metadata": {}, + "source": [ + "### Register model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "06545bbb", + "metadata": {}, + "outputs": [], + "source": [ + "# Define model\n", + "model = tf.keras.Sequential([\n", + " tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),\n", + " tf.keras.layers.MaxPooling2D((2, 2)),\n", + " tf.keras.layers.BatchNormalization(),\n", + " tf.keras.layers.Conv2D(64, (3, 3), activation='relu', input_shape=(28, 28, 1)),\n", + " tf.keras.layers.MaxPooling2D((2, 2)),\n", + " tf.keras.layers.BatchNormalization(),\n", + " tf.keras.layers.Flatten(),\n", + " tf.keras.layers.Dense(10, activation=None),\n", + "], name='simplecnn')\n", + "model.summary()\n", + "\n", + "# Define optimizer\n", + "optimizer = tf.optimizers.Adam(learning_rate=1e-3)\n", + "\n", + "# Loss and metrics. These will be used later.\n", + "loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)\n", + "train_acc_metric = tf.keras.metrics.SparseCategoricalAccuracy()\n", + "val_acc_metric = tf.keras.metrics.SparseCategoricalAccuracy()\n", + "\n", + "# Create ModelInterface\n", + "framework_adapter = 'openfl.plugins.frameworks_adapters.keras_adapter.FrameworkAdapterPlugin'\n", + "MI = ModelInterface(model=model, optimizer=optimizer, framework_plugin=framework_adapter)" + ] + }, + { + "cell_type": "markdown", + "id": "b0979470", + "metadata": {}, + "source": [ + "### Register dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d8c9eb50", + "metadata": {}, + "outputs": [], + "source": [ + "import numpy as np\n", + "from tensorflow.keras.utils import Sequence\n", + "\n", + "from openfl.interface.interactive_api.experiment import DataInterface\n", + "\n", + "\n", + "class DataGenerator(Sequence):\n", + "\n", + " def __init__(self, shard_descriptor, batch_size):\n", + " self.shard_descriptor = shard_descriptor\n", + " self.batch_size = batch_size\n", + " self.indices = np.arange(len(shard_descriptor))\n", + " self.on_epoch_end()\n", + "\n", + " def __len__(self):\n", + " return len(self.indices) // self.batch_size\n", + "\n", + " def __getitem__(self, index):\n", + " index = self.indices[index * self.batch_size:(index + 1) * self.batch_size]\n", + " batch = [self.indices[k] for k in index]\n", + "\n", + " X, y = self.shard_descriptor[batch]\n", + " return X, y\n", + "\n", + " def on_epoch_end(self):\n", + " np.random.shuffle(self.indices)\n", + "\n", + "\n", + "class MnistFedDataset(DataInterface):\n", + "\n", + " def __init__(self, **kwargs):\n", + " super().__init__(**kwargs)\n", + "\n", + " @property\n", + " def shard_descriptor(self):\n", + " return self._shard_descriptor\n", + "\n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + "\n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + " \n", + " self.train_set = shard_descriptor.get_dataset('train')\n", + " self.valid_set = shard_descriptor.get_dataset('val')\n", + "\n", + " def __getitem__(self, index):\n", + " return self.shard_descriptor[index]\n", + "\n", + " def __len__(self):\n", + " return len(self.shard_descriptor)\n", + "\n", + " def get_train_loader(self):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks with optimizer in contract\n", + " \"\"\"\n", + " if self.kwargs['train_bs']:\n", + " batch_size = self.kwargs['train_bs']\n", + " else:\n", + " batch_size = 32\n", + " return DataGenerator(self.train_set, batch_size=batch_size)\n", + "\n", + " def get_valid_loader(self):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks without optimizer in contract\n", + " \"\"\"\n", + " if self.kwargs['valid_bs']:\n", + " batch_size = self.kwargs['valid_bs']\n", + " else:\n", + " batch_size = 32\n", + " \n", + " return DataGenerator(self.valid_set, batch_size=batch_size)\n", + "\n", + " def get_train_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " \n", + " return len(self.train_set)\n", + "\n", + " def get_valid_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.valid_set)" + ] + }, + { + "cell_type": "markdown", + "id": "b0dfb459", + "metadata": {}, + "source": [ + "### Create Mnist federated dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4af5c4c2", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = MnistFedDataset(train_bs=64, valid_bs=512)" + ] + }, + { + "cell_type": "markdown", + "id": "849c165b", + "metadata": {}, + "source": [ + "## Define and register FL tasks" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "b9649385", + "metadata": {}, + "outputs": [], + "source": [ + "import time\n", + "\n", + "\n", + "\n", + "TI = TaskInterface()\n", + "\n", + "# from openfl.interface.aggregation_functions import AdagradAdaptiveAggregation # Uncomment this lines to use \n", + "# agg_fn = AdagradAdaptiveAggregation(model_interface=MI, learning_rate=0.4) # Adaptive Federated Optimization\n", + "# @TI.set_aggregation_function(agg_fn) # alghorithm!\n", + "# # See details in the:\n", + "# # https://arxiv.org/abs/2003.00295\n", + "\n", + "@TI.register_fl_task(model='model', data_loader='train_dataset', device='device', optimizer='optimizer') \n", + "def train(model, train_dataset, optimizer, device, loss_fn=loss_fn, warmup=False):\n", + " start_time = time.time()\n", + "\n", + " # Iterate over the batches of the dataset.\n", + " for step, (x_batch_train, y_batch_train) in enumerate(train_dataset):\n", + " with tf.GradientTape() as tape:\n", + " logits = model(x_batch_train, training=True)\n", + " loss_value = loss_fn(y_batch_train, logits)\n", + " grads = tape.gradient(loss_value, model.trainable_weights)\n", + " optimizer.apply_gradients(zip(grads, model.trainable_weights))\n", + "\n", + " # Update training metric.\n", + " train_acc_metric.update_state(y_batch_train, logits)\n", + "\n", + " # Log every 200 batches.\n", + " if step % 200 == 0:\n", + " print(\n", + " \"Training loss (for one batch) at step %d: %.4f\"\n", + " % (step, float(loss_value))\n", + " )\n", + " print(\"Seen so far: %d samples\" % ((step + 1) * 64))\n", + " if warmup:\n", + " break\n", + "\n", + " # Display metrics at the end of each epoch.\n", + " train_acc = train_acc_metric.result()\n", + " print(\"Training acc over epoch: %.4f\" % (float(train_acc),))\n", + "\n", + " # Reset training metrics at the end of each epoch\n", + " train_acc_metric.reset_states()\n", + "\n", + " \n", + " return {'train_acc': train_acc,}\n", + "\n", + "\n", + "@TI.register_fl_task(model='model', data_loader='val_dataset', device='device') \n", + "def validate(model, val_dataset, device):\n", + " # Run a validation loop at the end of each epoch.\n", + " for x_batch_val, y_batch_val in val_dataset:\n", + " val_logits = model(x_batch_val, training=False)\n", + " # Update val metrics\n", + " val_acc_metric.update_state(y_batch_val, val_logits)\n", + " val_acc = val_acc_metric.result()\n", + " val_acc_metric.reset_states()\n", + " print(\"Validation acc: %.4f\" % (float(val_acc),))\n", + " \n", + " return {'validation_accuracy': val_acc,}" + ] + }, + { + "cell_type": "markdown", + "id": "8f0ebf2d", + "metadata": {}, + "source": [ + "## Time to start a federated learning experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d41b7896", + "metadata": {}, + "outputs": [], + "source": [ + "# create an experimnet in federation\n", + "experiment_name = 'mnist_experiment'\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name,serializer_plugin='openfl.plugins.interface_serializer.keras_serializer.KerasSerializer)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "480700cc-400b-4073-9daf-71b1f0d60d62", + "metadata": {}, + "outputs": [], + "source": [ + "# print the default federated learning plan\n", + "import openfl.native as fx\n", + "print(fx.get_plan(fl_plan=fl_experiment.plan))" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "41b44de9", + "metadata": {}, + "outputs": [], + "source": [ + "# The following command zips the workspace and python requirements to be transfered to collaborator nodes\n", + "fl_experiment.start(model_provider=MI, \n", + " task_keeper=TI,\n", + " data_loader=fed_dataset,\n", + " rounds_to_train=5,\n", + " opt_treatment='CONTINUE_GLOBAL',\n", + " override_config={'aggregator.settings.db_store_rounds': 1, 'compression_pipeline.template': 'openfl.pipelines.KCPipeline', 'compression_pipeline.settings.n_clusters': 2})" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "01fa7cea", + "metadata": {}, + "outputs": [], + "source": [ + "fl_experiment.stream_metrics()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "98fb4f07-a19f-498d-985d-1b606984fb9f", + "metadata": {}, + "outputs": [], + "source": [] + } + ], + "metadata": { + "interpreter": { + "hash": "f82a63373a71051274245dbf52f7a790e1979bab025fdff4da684b10eb9978bd" + }, + "kernelspec": { + "display_name": "Python 3 (ipykernel)", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.13" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/workspace/Tensorflow_MNIST.ipynb b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/workspace/Tensorflow_MNIST.ipynb new file mode 100644 index 0000000..accf12f --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_MNIST/workspace/Tensorflow_MNIST.ipynb @@ -0,0 +1,481 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "26fdd9ed", + "metadata": {}, + "source": [ + "# Federated Tensorflow MNIST Tutorial" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "1329f2e6", + "metadata": {}, + "outputs": [], + "source": [ + "# Install TF if not already. We recommend TF2.7 or greater.\n", + "# !pip install tensorflow==2.8" + ] + }, + { + "cell_type": "markdown", + "id": "e0d30942", + "metadata": {}, + "source": [ + "## Imports" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "0833dfc9", + "metadata": {}, + "outputs": [], + "source": [ + "import tensorflow as tf\n", + "print('TensorFlow', tf.__version__)" + ] + }, + { + "cell_type": "markdown", + "id": "246f9c98", + "metadata": {}, + "source": [ + "## Connect to the Federation\n", + "\n", + "Start `Director` and `Envoy` before proceeding with this cell. \n", + "\n", + "This cell connects this notebook to the Federation." + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d657e463", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.federation import Federation\n", + "\n", + "# please use the same identificator that was used in signed certificate\n", + "client_id = 'api'\n", + "cert_dir = 'cert'\n", + "director_node_fqdn = 'localhost'\n", + "director_port = 50051\n", + "# 1) Run with API layer - Director mTLS \n", + "# If the user wants to enable mTLS their must provide CA root chain, and signed key pair to the federation interface\n", + "# cert_chain = f'{cert_dir}/root_ca.crt'\n", + "# api_certificate = f'{cert_dir}/{client_id}.crt'\n", + "# api_private_key = f'{cert_dir}/{client_id}.key'\n", + "\n", + "# federation = Federation(\n", + "# client_id=client_id,\n", + "# director_node_fqdn=director_node_fqdn,\n", + "# director_port=director_port,\n", + "# cert_chain=cert_chain,\n", + "# api_cert=api_certificate,\n", + "# api_private_key=api_private_key\n", + "# )\n", + "\n", + "# --------------------------------------------------------------------------------------------------------------------\n", + "\n", + "# 2) Run with TLS disabled (trusted environment)\n", + "\n", + "# Create a Federation\n", + "federation = Federation(\n", + " client_id=client_id,\n", + " director_node_fqdn=director_node_fqdn,\n", + " director_port=director_port, \n", + " tls=False\n", + ")" + ] + }, + { + "cell_type": "markdown", + "id": "6efe22a8", + "metadata": {}, + "source": [ + "## Query Datasets from Shard Registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "47dcfab3", + "metadata": {}, + "outputs": [], + "source": [ + "shard_registry = federation.get_shard_registry()\n", + "shard_registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "a2a6c237", + "metadata": {}, + "outputs": [], + "source": [ + "# First, request a dummy_shard_desc that holds information about the federated dataset \n", + "dummy_shard_desc = federation.get_dummy_shard_descriptor(size=10)\n", + "dummy_shard_dataset = dummy_shard_desc.get_dataset('train')\n", + "sample, target = dummy_shard_dataset[0]\n", + "f\"Sample shape: {sample.shape}, target shape: {target.shape}\"" + ] + }, + { + "cell_type": "markdown", + "id": "cc0dbdbd", + "metadata": {}, + "source": [ + "## Describing FL experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "fc88700a", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.experiment import TaskInterface\n", + "from openfl.interface.interactive_api.experiment import ModelInterface\n", + "from openfl.interface.interactive_api.experiment import FLExperiment" + ] + }, + { + "cell_type": "markdown", + "id": "3b468ae1", + "metadata": {}, + "source": [ + "### Register model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "06545bbb", + "metadata": {}, + "outputs": [], + "source": [ + "# Define model\n", + "model = tf.keras.Sequential([\n", + " tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),\n", + " tf.keras.layers.MaxPooling2D((2, 2)),\n", + " tf.keras.layers.BatchNormalization(),\n", + " tf.keras.layers.Conv2D(64, (3, 3), activation='relu', input_shape=(28, 28, 1)),\n", + " tf.keras.layers.MaxPooling2D((2, 2)),\n", + " tf.keras.layers.BatchNormalization(),\n", + " tf.keras.layers.Flatten(),\n", + " tf.keras.layers.Dense(10, activation=None),\n", + "], name='simplecnn')\n", + "model.summary()\n", + "\n", + "# Define optimizer\n", + "optimizer = tf.optimizers.Adam(learning_rate=1e-3)\n", + "\n", + "# Loss and metrics. These will be used later.\n", + "loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)\n", + "train_acc_metric = tf.keras.metrics.SparseCategoricalAccuracy()\n", + "val_acc_metric = tf.keras.metrics.SparseCategoricalAccuracy()\n", + "\n", + "# Create ModelInterface\n", + "framework_adapter = 'openfl.plugins.frameworks_adapters.keras_adapter.FrameworkAdapterPlugin'\n", + "MI = ModelInterface(model=model, optimizer=optimizer, framework_plugin=framework_adapter)" + ] + }, + { + "cell_type": "markdown", + "id": "b0979470", + "metadata": {}, + "source": [ + "### Register dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d8c9eb50", + "metadata": {}, + "outputs": [], + "source": [ + "import numpy as np\n", + "from tensorflow.keras.utils import Sequence\n", + "\n", + "from openfl.interface.interactive_api.experiment import DataInterface\n", + "\n", + "\n", + "class DataGenerator(Sequence):\n", + "\n", + " def __init__(self, shard_descriptor, batch_size):\n", + " self.shard_descriptor = shard_descriptor\n", + " self.batch_size = batch_size\n", + " self.indices = np.arange(len(shard_descriptor))\n", + " self.on_epoch_end()\n", + "\n", + " def __len__(self):\n", + " return len(self.indices) // self.batch_size\n", + "\n", + " def __getitem__(self, index):\n", + " index = self.indices[index * self.batch_size:(index + 1) * self.batch_size]\n", + " batch = [self.indices[k] for k in index]\n", + "\n", + " X, y = self.shard_descriptor[batch]\n", + " return X, y\n", + "\n", + " def on_epoch_end(self):\n", + " np.random.shuffle(self.indices)\n", + "\n", + "\n", + "class MnistFedDataset(DataInterface):\n", + "\n", + " def __init__(self, **kwargs):\n", + " super().__init__(**kwargs)\n", + "\n", + " @property\n", + " def shard_descriptor(self):\n", + " return self._shard_descriptor\n", + "\n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + "\n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + " \n", + " self.train_set = shard_descriptor.get_dataset('train')\n", + " self.valid_set = shard_descriptor.get_dataset('val')\n", + "\n", + " def __getitem__(self, index):\n", + " return self.shard_descriptor[index]\n", + "\n", + " def __len__(self):\n", + " return len(self.shard_descriptor)\n", + "\n", + " def get_train_loader(self):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks with optimizer in contract\n", + " \"\"\"\n", + " if self.kwargs['train_bs']:\n", + " batch_size = self.kwargs['train_bs']\n", + " else:\n", + " batch_size = 32\n", + " return DataGenerator(self.train_set, batch_size=batch_size)\n", + "\n", + " def get_valid_loader(self):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks without optimizer in contract\n", + " \"\"\"\n", + " if self.kwargs['valid_bs']:\n", + " batch_size = self.kwargs['valid_bs']\n", + " else:\n", + " batch_size = 32\n", + " \n", + " return DataGenerator(self.valid_set, batch_size=batch_size)\n", + "\n", + " def get_train_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " \n", + " return len(self.train_set)\n", + "\n", + " def get_valid_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.valid_set)" + ] + }, + { + "cell_type": "markdown", + "id": "b0dfb459", + "metadata": {}, + "source": [ + "### Create Mnist federated dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "4af5c4c2", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = MnistFedDataset(train_bs=64, valid_bs=512)" + ] + }, + { + "cell_type": "markdown", + "id": "849c165b", + "metadata": {}, + "source": [ + "## Define and register FL tasks" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "b9649385", + "metadata": {}, + "outputs": [], + "source": [ + "import time\n", + "\n", + "\n", + "\n", + "TI = TaskInterface()\n", + "\n", + "# from openfl.interface.aggregation_functions import AdagradAdaptiveAggregation # Uncomment this lines to use \n", + "# agg_fn = AdagradAdaptiveAggregation(model_interface=MI, learning_rate=0.4) # Adaptive Federated Optimization\n", + "# @TI.set_aggregation_function(agg_fn) # alghorithm!\n", + "# # See details in the:\n", + "# # https://arxiv.org/abs/2003.00295\n", + "\n", + "@TI.register_fl_task(model='model', data_loader='train_dataset', device='device', optimizer='optimizer') \n", + "def train(model, train_dataset, optimizer, device, loss_fn=loss_fn, warmup=False):\n", + " start_time = time.time()\n", + "\n", + " # Iterate over the batches of the dataset.\n", + " for step, (x_batch_train, y_batch_train) in enumerate(train_dataset):\n", + " with tf.GradientTape() as tape:\n", + " logits = model(x_batch_train, training=True)\n", + " loss_value = loss_fn(y_batch_train, logits)\n", + " grads = tape.gradient(loss_value, model.trainable_weights)\n", + " optimizer.apply_gradients(zip(grads, model.trainable_weights))\n", + "\n", + " # Update training metric.\n", + " train_acc_metric.update_state(y_batch_train, logits)\n", + "\n", + " # Log every 200 batches.\n", + " if step % 200 == 0:\n", + " print(\n", + " \"Training loss (for one batch) at step %d: %.4f\"\n", + " % (step, float(loss_value))\n", + " )\n", + " print(\"Seen so far: %d samples\" % ((step + 1) * 64))\n", + " if warmup:\n", + " break\n", + "\n", + " # Display metrics at the end of each epoch.\n", + " train_acc = train_acc_metric.result()\n", + " print(\"Training acc over epoch: %.4f\" % (float(train_acc),))\n", + "\n", + " # Reset training metrics at the end of each epoch\n", + " train_acc_metric.reset_states()\n", + "\n", + " \n", + " return {'train_acc': train_acc,}\n", + "\n", + "\n", + "@TI.register_fl_task(model='model', data_loader='val_dataset', device='device') \n", + "def validate(model, val_dataset, device):\n", + " # Run a validation loop at the end of each epoch.\n", + " for x_batch_val, y_batch_val in val_dataset:\n", + " val_logits = model(x_batch_val, training=False)\n", + " # Update val metrics\n", + " val_acc_metric.update_state(y_batch_val, val_logits)\n", + " val_acc = val_acc_metric.result()\n", + " val_acc_metric.reset_states()\n", + " print(\"Validation acc: %.4f\" % (float(val_acc),))\n", + " \n", + " return {'validation_accuracy': val_acc,}" + ] + }, + { + "cell_type": "markdown", + "id": "8f0ebf2d", + "metadata": {}, + "source": [ + "## Time to start a federated learning experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d41b7896", + "metadata": {}, + "outputs": [], + "source": [ + "# create an experimnet in federation\n", + "experiment_name = 'mnist_experiment'\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name,serializer_plugin='openfl.plugins.interface_serializer.keras_serializer.KerasSerializer)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "480700cc-400b-4073-9daf-71b1f0d60d62", + "metadata": {}, + "outputs": [], + "source": [ + "# print the default federated learning plan\n", + "import openfl.native as fx\n", + "print(fx.get_plan(fl_plan=fl_experiment.plan))" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "41b44de9", + "metadata": {}, + "outputs": [], + "source": [ + "# The following command zips the workspace and python requirements to be transfered to collaborator nodes\n", + "fl_experiment.start(model_provider=MI, \n", + " task_keeper=TI,\n", + " data_loader=fed_dataset,\n", + " rounds_to_train=5,\n", + " opt_treatment='CONTINUE_GLOBAL',\n", + " override_config={'aggregator.settings.db_store_rounds': 1, 'compression_pipeline.template': 'openfl.pipelines.KCPipeline', 'compression_pipeline.settings.n_clusters': 2})" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "01fa7cea", + "metadata": {}, + "outputs": [], + "source": [ + "fl_experiment.stream_metrics()" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "98fb4f07-a19f-498d-985d-1b606984fb9f", + "metadata": {}, + "outputs": [], + "source": [] + } + ], + "metadata": { + "interpreter": { + "hash": "f82a63373a71051274245dbf52f7a790e1979bab025fdff4da684b10eb9978bd" + }, + "kernelspec": { + "display_name": "Python 3 (ipykernel)", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.13" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/README.md b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/README.md new file mode 100644 index 0000000..2aa8424 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/README.md @@ -0,0 +1,90 @@ +# Next Word Prediction Tutorial on Keras + +## I. GPU supporting + +Currently GPU (with CUDA 11) is not supported by Tensorflow properly, so we disabled CUDA in the +tutorial. Otherwise, you can use these charms in the first answer of this Stack Overflow question (https://stackoverflow.com/questions/41991101/importerror-libcudnn-when-running-a-tensorflow-program) +to fix your environment and enjoy GPU. Don't forget to +change `os.environ['CUDA_VISIBLE_DEVICES'] = '-1'` to a positive value. + +As an option you can set the CUDA variable for each envoy before starting +it: `export CUDA_VISIBLE_DEVICES=0` +
+
+ +## II. Data + +Different envoys can have different texts, so in this tutorial each envoy uses one of these 3 fairy tale books: + +- Polish Fairy Tales by A. J. Gliński https://www.gutenberg.org/files/36668/36668-h/36668-h.htm +- English Fairy Tales by Joseph Jacobs https://www.gutenberg.org/cache/epub/7439/pg7439-images.html +- American Fairy Tales by L. FRANK BAUM https://www.gutenberg.org/files/4357/4357-h/4357-h.htm +
+
+ +## III. Keras Model + +At this point OpenFL maintains Sequential API and Functional API. Keras Submodel is not supported. +https://github.com/securefederatedai/openfl/issues/185 +
+
+ +## IV. To run this experiment: +
+ +### 0. If you haven't done so already, create a virtual environment, install OpenFL, and upgrade pip: + - For help with this step, visit the "Install the Package" section of the [OpenFL installation instructions](https://openfl.readthedocs.io/en/latest/install.html#install-the-package). +
+ +### 1. Split terminal into 3 (1 terminal for the director, 1 for the envoy, and 1 for the experiment) +
+ +### 2. Do the following in each terminal: + - Activate the virtual environment from step 0: + + ```sh + source venv/bin/activate + ``` + - If you are in a network environment with a proxy, ensure proxy environment variables are set in each of your terminals. + - Navigate to the tutorial: + + ```sh + cd openfl/openfl-tutorials/interactive_api/Tensorflow_Word_Prediction + ``` +
+ +### 3. In the first terminal, run the director: + +```sh +cd director +./start_director.sh +``` +
+ +### 4. In the second terminal, install requirements and run the envoy: + +```sh +cd envoy +pip install -r sd_requirements.txt +./start_envoy.sh env_one envoy_config_one.yaml +``` + +Optional: Run a second or third envoy in additional terminals: + - Ensure step 2 is complete for these terminals as well. + - Follow step 4 for each envoy, changing the envoy name and config file accordingly. For example: + - Envoy two would use: + ```sh + ./start_envoy.sh env_two envoy_config_two.yaml + ``` +
+ +### 5. Now that your director and envoy terminals are set up, run the Jupyter Notebook in your experiment terminal: + +```sh +cd workspace +jupyter lab Tensorflow_Word_Prediction.ipynb +``` +- A Jupyter Server URL will appear in your terminal. In your browser, proceed to that link. Once the webpage loads, click on the Tensorflow_Word_Prediction.ipynb file. +- To run the experiment, select the icon that looks like two triangles to "Restart Kernel and Run All Cells". +- You will notice activity in your terminals as the experiment runs, and when the experiment is finished the director terminal will display a message that the experiment has finished successfully. + diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/director/director_config.yaml new file mode 100644 index 0000000..3183a70 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/director/director_config.yaml @@ -0,0 +1,4 @@ +settings: + listen_ip: localhost + sample_shape: ['3', '96'] + target_shape: ['10719'] \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/director/start_director.sh new file mode 100755 index 0000000..5806a6c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/director/start_director.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx director start --disable-tls -c director_config.yaml \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/director/start_director_with_tls.sh b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/director/start_director_with_tls.sh new file mode 100755 index 0000000..5d6d46a --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/director/start_director_with_tls.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e +FQDN=$1 +fx director start -c director_config.yaml -rc cert/root_ca.crt -pk cert/"${FQDN}".key -oc cert/"${FQDN}".crt \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/envoy_config_one.yaml b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/envoy_config_one.yaml new file mode 100644 index 0000000..3db7be6 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/envoy_config_one.yaml @@ -0,0 +1,11 @@ +# https://www.gutenberg.org/files/36668/36668-h/36668-h.htm +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: shard_descriptor.NextWordShardDescriptor + params: + title: Polish Fairy Tales + author: A. J. Gliński \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/envoy_config_three.yaml b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/envoy_config_three.yaml new file mode 100644 index 0000000..a8ebdd7 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/envoy_config_three.yaml @@ -0,0 +1,11 @@ +# https://www.gutenberg.org/files/4357/4357-h/4357-h.htm +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: shard_descriptor.NextWordShardDescriptor + params: + title: American Fairy Tales + author: L. FRANK BAUM \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/envoy_config_two.yaml b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/envoy_config_two.yaml new file mode 100644 index 0000000..fbdf200 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/envoy_config_two.yaml @@ -0,0 +1,11 @@ +# https://www.gutenberg.org/cache/epub/7439/pg7439-images.html +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: shard_descriptor.NextWordShardDescriptor + params: + title: English Fairy Tales + author: Joseph Jacobs \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/sd_requirements.txt b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/sd_requirements.txt new file mode 100644 index 0000000..5f3956b --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/sd_requirements.txt @@ -0,0 +1,4 @@ +gdown==3.13.0 +numpy==1.22.2 +pandas==1.3.3 +pyarrow==14.0.1 diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/shard_descriptor.py new file mode 100644 index 0000000..b5dba87 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/shard_descriptor.py @@ -0,0 +1,142 @@ +# Copyright (C) 2020-2021 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 +"""Shard descriptor for text.""" + +import re +import urllib.request +import zipfile +from pathlib import Path + +import gdown +import numpy as np +import pandas as pd + +from openfl.interface.interactive_api.shard_descriptor import ShardDataset +from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor + + +class NextWordShardDataset(ShardDataset): + """Shard Dataset for text.""" + + def __init__(self, X, y): + """Initialize NextWordShardDataset.""" + self.X = X + self.y = y + + def __len__(self): + """Count number of sequences.""" + return len(self.X) + + def __getitem__(self, index: int): + """Return an item by the index.""" + return self.X[index], self.y[index] + + +class NextWordShardDescriptor(ShardDescriptor): + """Data is any text.""" + + def __init__(self, title: str = '', author: str = '') -> None: + """Initialize NextWordShardDescriptor.""" + super().__init__() + + self.title = title + self.author = author + + dataset_dir = self.download_data(title) + data = self.load_data(dataset_dir) # list of words + self.X, self.y = self.get_sequences(data) + + def get_dataset(self, dataset_type='train', train_val_split=0.8): + """Return a dataset by type.""" + train_size = round(len(self.X) * train_val_split) + if dataset_type == 'train': + X = self.X[:train_size] + y = self.y[:train_size] + elif dataset_type == 'val': + X = self.X[train_size:] + y = self.y[train_size:] + else: + raise Exception(f'Wrong dataset type: {dataset_type}.' + f'Choose from the list: [train, val]') + return NextWordShardDataset(X, y) + + @property + def sample_shape(self): + """Return the sample shape info.""" + length, n_gram, vector_size = self.X.shape + return [str(n_gram), str(vector_size)] # three vectors + + @property + def target_shape(self): + """Return the target shape info.""" + length, vocab_size = self.y.shape + return [str(vocab_size)] # row at one-hot matrix with n = vocab_size + + @property + def dataset_description(self) -> str: + """Return the dataset description.""" + return f'Dataset from {self.title} by {self.author}' + + @staticmethod + def load_data(path): + """Load text file, return list of words.""" + file = open(path, 'r', encoding='utf8').read() + data = re.findall(r'[a-z]+', file.lower()) + return data + + @staticmethod + def get_sequences(data): + """Transform words to sequences, for X transform to vectors as well.""" + # spacy en_core_web_sm vocab_size = 10719, vector_size = 96 + x_seq = [] + y_seq = [] + + # created with make_vocab.py from + # https://gist.github.com/katerina-merkulova/e351b11c67832034b49652835b14adb0 + NextWordShardDescriptor.download_vectors() + vectors = pd.read_feather('keyed_vectors.feather') + vectors.set_index('index', inplace=True) + + for i in range(len(data) - 3): + x = data[i:i + 3] # make 3-grams + y = data[i + 3] + cur_x = [vectors.vector[word] for word in x if word in vectors.index] + if len(cur_x) == 3 and y in vectors.index: + x_seq.append(cur_x) + y_seq.append(vectors.index.get_loc(y)) + + x_seq = np.array(x_seq) + y_seq = np.array(y_seq) + y = np.zeros((y_seq.size, 10719)) + y[np.arange(y_seq.size), y_seq] = 1 + return x_seq, y + + @staticmethod + def download_data(title): + """Download text by title form Github Gist.""" + url = ('https://gist.githubusercontent.com/katerina-merkulova/e351b11c67832034b49652835b' + '14adb0/raw/5b6667c3a2e1266f3d9125510069d23d8f24dc73/' + title.replace(' ', '_') + + '.txt') + filepath = Path.cwd() / f'{title}.txt' + if not filepath.exists(): + with urllib.request.urlopen(url) as response: + content = response.read().decode('utf-8') + with open(filepath, 'w', encoding='utf-8') as file: + file.write(content) + return filepath + + @staticmethod + def download_vectors(): + """Download vectors.""" + if Path('keyed_vectors.feather').exists(): + return None + + output = 'keyed_vectors.zip' + if not Path(output).exists(): + url = 'https://drive.google.com/uc?id=1QfidtkJ9qxzNLs1pgXoY_hqnBjsDI_2i' + gdown.download(url, output, quiet=False) + + with zipfile.ZipFile(output, 'r') as zip_ref: + zip_ref.extractall(Path.cwd()) + + Path(output).unlink() # remove zip diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/start_envoy.sh new file mode 100755 index 0000000..3ddcc49 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/start_envoy.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx envoy start -n env_one --disable-tls -dh localhost -dp 50051 -ec envoy_config_one.yaml \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/start_envoy_with_tls.sh b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/start_envoy_with_tls.sh new file mode 100755 index 0000000..873ebcb --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/envoy/start_envoy_with_tls.sh @@ -0,0 +1,6 @@ +#!/bin/bash +set -e +ENVOY_NAME=$1 +DIRECTOR_FQDN=$2 + +fx envoy start -n "$ENVOY_NAME" --envoy-config-path envoy_config.yaml -d "$DIRECTOR_FQDN":50051 -rc cert/root_ca.crt -pk cert/"$ENVOY_NAME".key -oc cert/"$ENVOY_NAME".crt \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/workspace/Tensorflow_Word_Prediction.ipynb b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/workspace/Tensorflow_Word_Prediction.ipynb new file mode 100644 index 0000000..85bc5d9 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/workspace/Tensorflow_Word_Prediction.ipynb @@ -0,0 +1,481 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "2390f64a", + "metadata": {}, + "source": [ + "# Federated Next Word Prediction with Director example" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "e3f166dd", + "metadata": {}, + "outputs": [], + "source": [ + "# install requirements\n", + "!pip install -r requirements.txt" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "52a6f355", + "metadata": {}, + "outputs": [], + "source": [ + "import numpy as np\n", + "\n", + "import os\n", + "# disable GPUs due to Tensoflow not supporting CUDA 11\n", + "os.environ['CUDA_VISIBLE_DEVICES'] = '-1'" + ] + }, + { + "cell_type": "markdown", + "id": "1a8e22c1", + "metadata": {}, + "source": [ + "# Connect to the Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "5c479dad", + "metadata": {}, + "outputs": [], + "source": [ + "# Create a federation\n", + "from openfl.interface.interactive_api.federation import Federation\n", + "\n", + "# please use the same identificator that was used in signed certificate\n", + "cliend_id = 'frontend'\n", + "\n", + "# 1) Run with API layer - Director mTLS\n", + "# If the user wants to enable mTLS their must provide CA root chain, and signed key pair to the federation interface\n", + "# cert_chain = 'cert/root_ca.crt'\n", + "# API_certificate = 'cert/frontend.crt'\n", + "# API_private_key = 'cert/frontend.key'\n", + "\n", + "# federation = Federation(client_id='frontend', director_node_fqdn='localhost', director_port='50051', disable_tls=False,\n", + "# cert_chain=cert_chain, api_cert=API_certificate, api_private_key=API_private_key)\n", + "\n", + "# --------------------------------------------------------------------------------------------------------------------\n", + "\n", + "# 2) Run with TLS disabled (trusted environment)\n", + "# Federation can also determine local fqdn automatically\n", + "federation = Federation(client_id='frontend', director_node_fqdn='localhost', director_port='50051', tls=False)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "466edd2c", + "metadata": {}, + "outputs": [], + "source": [ + "shard_registry = federation.get_shard_registry()\n", + "shard_registry" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "381a2e96", + "metadata": {}, + "outputs": [], + "source": [ + "federation.target_shape" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d72d9aef", + "metadata": {}, + "outputs": [], + "source": [ + "# First, request a dummy_shard_desc that holds information about the federated dataset \n", + "dummy_shard_desc = federation.get_dummy_shard_descriptor(size=10)\n", + "sample, target = dummy_shard_desc.get_dataset(dataset_type='')[0]" + ] + }, + { + "cell_type": "markdown", + "id": "obvious-tyler", + "metadata": {}, + "source": [ + "## Creating a FL experiment using Interactive API" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "9001b56e", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment" + ] + }, + { + "cell_type": "markdown", + "id": "sustainable-public", + "metadata": {}, + "source": [ + "### Register dataset" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "41ba9a55", + "metadata": {}, + "outputs": [], + "source": [ + "from tensorflow.keras.utils import Sequence\n", + "\n", + "class DataGenerator(Sequence):\n", + "\n", + " def __init__(self, dataset, batch_size):\n", + " self.dataset = dataset\n", + " self.batch_size = batch_size\n", + " self.on_epoch_end()\n", + "\n", + " def __len__(self):\n", + " return len(self.dataset) // self.batch_size\n", + "\n", + " def __getitem__(self, index):\n", + " return self.dataset[index * self.batch_size:(index + 1) * self.batch_size]\n", + "\n", + "# Now you can implement you data loaders using dummy_shard_desc\n", + "class NextWordSD(DataInterface):\n", + "\n", + " def __init__(self, train_val_split=0.8, **kwargs):\n", + " super().__init__(**kwargs)\n", + " self.train_val_split = train_val_split\n", + "\n", + " @property\n", + " def shard_descriptor(self):\n", + " return self._shard_descriptor\n", + "\n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + "\n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + "\n", + " def __getitem__(self, index):\n", + " return self.shard_descriptor[index]\n", + "\n", + " def __len__(self):\n", + " return len(self.shard_descriptor)\n", + "\n", + " def get_train_loader(self):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks with optimizer in contract\n", + " \"\"\"\n", + " if self.kwargs['train_bs']:\n", + " batch_size = self.kwargs['train_bs']\n", + " else:\n", + " batch_size = 64\n", + "\n", + " self.train_dataset = self.shard_descriptor.get_dataset('train', self.train_val_split)\n", + " return DataGenerator(self.train_dataset, batch_size=batch_size)\n", + "\n", + " def get_valid_loader(self):\n", + " \"\"\"\n", + " Output of this method will be provided to tasks without optimizer in contract\n", + " \"\"\"\n", + " if self.kwargs['valid_bs']:\n", + " batch_size = self.kwargs['valid_bs']\n", + " else:\n", + " batch_size = 512\n", + "\n", + " self.val_dataset = self.shard_descriptor.get_dataset('val', self.train_val_split)\n", + " return DataGenerator(self.val_dataset, batch_size=batch_size)\n", + "\n", + " def get_train_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.train_dataset)\n", + "\n", + " def get_valid_data_size(self):\n", + " \"\"\"\n", + " Information for aggregation\n", + " \"\"\"\n", + " return len(self.val_dataset)\n" + ] + }, + { + "cell_type": "markdown", + "id": "caring-distinction", + "metadata": {}, + "source": [ + "### Describe a model and optimizer\n", + "#### Sequential API" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "3524931d", + "metadata": {}, + "outputs": [], + "source": [ + "import tensorflow as tf\n", + "from tensorflow.keras.layers import LSTM, Dense\n", + "from tensorflow.keras.legacy.optimizers import Adam\n", + "from tensorflow.keras.metrics import TopKCategoricalAccuracy\n", + "from tensorflow.keras.losses import CategoricalCrossentropy\n", + "from tensorflow.keras.models import Sequential\n", + "\n", + "model = Sequential()\n", + "model.add(LSTM(1000, return_sequences=True))\n", + "model.add(LSTM(1000))\n", + "model.add(Dense(1000, activation='tanh'))\n", + "model.add(Dense(10719, activation='softmax'))\n", + "\n", + "optimizer = Adam(learning_rate=0.001)\n", + "loss_fn = CategoricalCrossentropy()\n", + "train_acc_metric = TopKCategoricalAccuracy(k=10)\n", + "val_acc_metric = TopKCategoricalAccuracy(k=10)\n", + "\n", + "batch_size = 64\n", + "model.build(input_shape=[batch_size, 3, 96])" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "9b26d13e", + "metadata": {}, + "outputs": [], + "source": [ + "fed_dataset = NextWordSD(train_bs=64, valid_bs=512)" + ] + }, + { + "cell_type": "markdown", + "id": "portuguese-groove", + "metadata": {}, + "source": [ + "### Define and register FL tasks" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "7e326d8f", + "metadata": {}, + "outputs": [], + "source": [ + "TI = TaskInterface()\n", + "\n", + "# https://www.tensorflow.org/guide/keras/customizing_what_happens_in_fit\n", + "@TI.register_fl_task(model='model', data_loader='train_loader', device='device', optimizer='optimizer')\n", + "def train(model, train_loader, device, optimizer):\n", + "\n", + " # Iterate over the batches of the dataset.\n", + " for step, (x_batch_train, y_batch_train) in enumerate(train_loader):\n", + "\n", + " y = tf.convert_to_tensor(y_batch_train)\n", + " with tf.GradientTape() as tape:\n", + " y_pred = model(x_batch_train, training=True) # Forward pass\n", + " # Compute the loss value\n", + " # (the loss function is configured in `compile()`)\n", + " loss = loss_fn(y, y_pred)\n", + "\n", + " # Compute gradients\n", + " trainable_vars = model.trainable_variables\n", + " gradients = tape.gradient(loss, trainable_vars)\n", + "\n", + " # Update weights\n", + " optimizer.apply_gradients(zip(gradients, trainable_vars))\n", + "\n", + " # Update metrics\n", + " train_acc_metric.update_state(y, y_pred)\n", + " \n", + " # Reset training metrics at the end of each epoch\n", + " train_acc = train_acc_metric.result()\n", + " train_acc_metric.reset_states()\n", + " return {'train_acc': train_acc, 'loss': loss}\n", + "\n", + "\n", + "@TI.register_fl_task(model='model', data_loader='val_loader', device='device')\n", + "def validate(model, val_loader, device=''):\n", + " for x_batch_val, y_batch_val in val_loader:\n", + " y = tf.convert_to_tensor(y_batch_val)\n", + " # Compute predictions\n", + " y_pred = model(x_batch_val, training=False)\n", + " # Update the metrics.\n", + " val_acc_metric.update_state(y, y_pred)\n", + " val_acc = val_acc_metric.result()\n", + " val_acc_metric.reset_states()\n", + " return {'validation_accuracy': val_acc}\n" + ] + }, + { + "cell_type": "markdown", + "id": "caroline-passion", + "metadata": {}, + "source": [ + "#### Register model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "145676d1", + "metadata": {}, + "outputs": [], + "source": [ + "from copy import deepcopy\n", + "\n", + "framework_adapter = 'openfl.plugins.frameworks_adapters.keras_adapter.FrameworkAdapterPlugin'\n", + "MI = ModelInterface(model=model, optimizer=optimizer, framework_plugin=framework_adapter)\n", + "# Save the initial model state\n", + "initial_model = deepcopy(model)" + ] + }, + { + "cell_type": "markdown", + "id": "derived-bride", + "metadata": {}, + "source": [ + "## Time to start a federated learning experiment" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "df9d0e68", + "metadata": {}, + "outputs": [], + "source": [ + "# create an experimnet in federation\n", + "experiment_name = 'word_prediction_test_experiment'\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name,serializer_plugin='openfl.plugins.interface_serializer.keras_serializer.KerasSerializer)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "1fdb59e1", + "metadata": {}, + "outputs": [], + "source": [ + "# If I use autoreload I got a pickling error\n", + "\n", + "# The following command zips the workspace and python requirements to be transfered to collaborator nodes\n", + "fl_experiment.start(model_provider=MI, \n", + " task_keeper=TI,\n", + " data_loader=fed_dataset,\n", + " rounds_to_train=20,\n", + " opt_treatment='RESET')" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "92510227", + "metadata": {}, + "outputs": [], + "source": [ + "# If user want to stop IPython session, then reconnect and check how experiment is going \n", + "# fl_experiment.restore_experiment_state(MI)\n", + "\n", + "fl_experiment.stream_metrics()" + ] + }, + { + "cell_type": "markdown", + "id": "e9e0c0a8", + "metadata": { + "pycharm": { + "name": "#%% md\n" + } + }, + "source": [ + "## Testing the best model" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "0b55ddee", + "metadata": {}, + "outputs": [], + "source": [ + "!pip install -r ../envoy/sd_requirements.txt" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "b23a6ec6", + "metadata": {}, + "outputs": [], + "source": [ + "import sys\n", + "sys.path.insert(1, '../envoy')" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "6bbdfedc", + "metadata": {}, + "outputs": [], + "source": [ + "from shard_descriptor import NextWordShardDescriptor\n", + "\n", + "# https://www.gutenberg.org/files/2892/2892-h/2892-h.htm\n", + "fed_dataset = NextWordSD(train_bs=64, valid_bs=512, train_val_split=0)\n", + "fed_dataset.shard_descriptor = NextWordShardDescriptor(title='Irish Fairy Tales', author='James Stephens')" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "821b69a7", + "metadata": {}, + "outputs": [], + "source": [ + "best_model = fl_experiment.get_best_model()\n", + "\n", + "# We remove data from director\n", + "fl_experiment.remove_experiment_data()\n", + "\n", + "# Validating initial model\n", + "validate(initial_model, fed_dataset.get_valid_loader())" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "5c75b1f5", + "metadata": {}, + "outputs": [], + "source": [ + "# Validating trained model\n", + "validate(best_model, fed_dataset.get_valid_loader())" + ] + } + ], + "metadata": { + "language_info": { + "name": "python" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/workspace/requirements.txt b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/workspace/requirements.txt new file mode 100644 index 0000000..906c897 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/Tensorflow_Word_Prediction/workspace/requirements.txt @@ -0,0 +1,2 @@ +numpy==1.22.2 +tensorflow==2.13 diff --git a/openfl_contrib_tutorials/interactive_api/jax_linear_regression/README.md b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/README.md new file mode 100644 index 0000000..966d810 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/README.md @@ -0,0 +1,72 @@ +# JAX based Linear Regression Tutorial + +### 1. About dataset + +Generate a random regression problem using `make_regression` from sklearn.datasets with pre-defined parameters. + +Define the below param in envoy.yaml config to shard the dataset across participants/envoy. +- rank_worldsize + + +### 2. About model + +Simple Regression Model with XLA compiled and Auto-grad based parameter updates. + + +### 3. How to run this tutorial (without TLC and locally as a simulation): + +1. Run director: + +```sh +cd director_folder +./start_director.sh +``` + +2. Run envoy: + +Step 1: Activate virtual environment and install packages +``` +cd envoy_folder +pip install -r requirements.txt +``` +Step 2: start the envoy +```sh +./start_envoy.sh env_instance_1 envoy_config_1.yaml +``` + +Optional: start second envoy: + +- Copy `envoy_folder` to another place and follow the same process as above: + +```sh +./start_envoy.sh env_instance_2 envoy_config_2.yaml +``` + +3. Run `jax_linear_regression.ipynb` jupyter notebook: + +```sh +cd workspace +jupyter lab jax_linear_regression.ipynb +``` + +4. Visualization + +``` +tensorboard --logdir logs/ +``` + + +### 4. Known issues + +1. ##### CUDA_ERROR_OUT_OF_MEMORY Exception - JAX XLA pre-allocates 90% of the GPU at start + +- Below flag to restrict max GPU allocation to 50% +``` +%env XLA_PYTHON_CLIENT_MEM_FRACTION=.5 +``` +OR + +- set XLA_PYTHON_CLIENT_PREALLOCATE to start with a small footprint. +``` +%env XLA_PYTHON_CLIENT_PREALLOCATE=false +``` \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/jax_linear_regression/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/director/director_config.yaml new file mode 100644 index 0000000..d22b4b7 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/director/director_config.yaml @@ -0,0 +1,6 @@ +settings: + listen_host: localhost + listen_port: 50050 + sample_shape: ['1'] # Modify this param if experimenting with `n_features` of shard_descriptor. + target_shape: ['1'] + envoy_health_check_period: 5 # in seconds diff --git a/openfl_contrib_tutorials/interactive_api/jax_linear_regression/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/director/start_director.sh new file mode 100755 index 0000000..5806a6c --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/director/start_director.sh @@ -0,0 +1,4 @@ +#!/bin/bash +set -e + +fx director start --disable-tls -c director_config.yaml \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/jax_linear_regression/envoy/envoy_config_1.yaml b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/envoy/envoy_config_1.yaml new file mode 100644 index 0000000..8f35387 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/envoy/envoy_config_1.yaml @@ -0,0 +1,9 @@ +params: + cuda_devices: [] + +optional_plugin_components: {} + +shard_descriptor: + template: regression_shard_descriptor.RegressionShardDescriptor + params: + rank_worldsize: 1, 2 \ No newline at end of file diff --git a/openfl_contrib_tutorials/interactive_api/jax_linear_regression/envoy/regression_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/envoy/regression_shard_descriptor.py new file mode 100644 index 0000000..2a9e1f4 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/envoy/regression_shard_descriptor.py @@ -0,0 +1,70 @@ +# Copyright (C) 2020-2022 Intel Corporation +# SPDX-License-Identifier: Apache-2.0 +"""Noisy-Sin Shard Descriptor.""" + +from typing import List + +import jax.numpy as jnp +from sklearn.datasets import make_regression +from sklearn.model_selection import train_test_split + +from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor + + +class RegressionShardDescriptor(ShardDescriptor): + """Regression Shard descriptor class.""" + + def __init__(self, rank_worldsize: str = '1, 1', **kwargs) -> None: + """ + Initialize Regression Data Shard Descriptor. + + This Shard Descriptor generate random regression data with some gaussian centered noise + using make_regression method from sklearn.datasets. + Shards data across participants using rank and world size. + """ + + self.rank, self.worldsize = tuple(int(num) for num in rank_worldsize.split(',')) + X_train, y_train, X_test, y_test = self.generate_data() + self.data_by_type = { + 'train': jnp.concatenate((X_train, y_train[:, None]), axis=1), + 'val': jnp.concatenate((X_test, y_test[:, None]), axis=1) + } + + def generate_data(self): + """Generate regression dataset with predefined params.""" + x, y = make_regression(n_samples=1000, n_features=1, noise=14, random_state=24) + X_train, X_test, y_train, y_test = train_test_split(x, y, random_state=24) + self.data = jnp.concatenate((x, y[:, None]), axis=1) + return X_train, y_train, X_test, y_test + + def get_shard_dataset_types(self) -> List[str]: + """Get available shard dataset types.""" + return list(self.data_by_type) + + def get_dataset(self, dataset_type='train'): + """Return a shard dataset by type.""" + if dataset_type not in self.data_by_type: + raise Exception(f'Incorrect dataset type: {dataset_type}') + + if dataset_type in ['train', 'val']: + return self.data_by_type[dataset_type][self.rank - 1::self.worldsize] + else: + raise ValueError + + @property + def sample_shape(self) -> List[str]: + """Return the sample shape info.""" + (*x, _) = self.data[0] + return [str(i) for i in jnp.array(x, ndmin=1).shape] + + @property + def target_shape(self) -> List[str]: + """Return the target shape info.""" + (*_, y) = self.data[0] + return [str(i) for i in jnp.array(y, ndmin=1).shape] + + @property + def dataset_description(self) -> str: + """Return the dataset description.""" + return (f'Regression dataset, shard number {self.rank}' + f' out of {self.worldsize}') diff --git a/openfl_contrib_tutorials/interactive_api/jax_linear_regression/envoy/requirements.txt b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/envoy/requirements.txt new file mode 100644 index 0000000..9af7b85 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/envoy/requirements.txt @@ -0,0 +1,6 @@ +jax==0.3.13 +jaxlib==0.3.10 +mistune>=2.0.3 # not directly required, pinned by Snyk to avoid a vulnerability +openfl==1.3 +setuptools>=65.5.1 # not directly required, pinned by Snyk to avoid a vulnerability +wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability diff --git a/openfl_contrib_tutorials/interactive_api/jax_linear_regression/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/envoy/start_envoy.sh new file mode 100755 index 0000000..4da0782 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/envoy/start_envoy.sh @@ -0,0 +1,6 @@ +#!/bin/bash +set -e +ENVOY_NAME=$1 +ENVOY_CONF=$2 + +fx envoy start -n "$ENVOY_NAME" --disable-tls --envoy-config-path "$ENVOY_CONF" -dh localhost -dp 50050 diff --git a/openfl_contrib_tutorials/interactive_api/jax_linear_regression/workspace/JAX_linear_regression.ipynb b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/workspace/JAX_linear_regression.ipynb new file mode 100644 index 0000000..e2562e1 --- /dev/null +++ b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/workspace/JAX_linear_regression.ipynb @@ -0,0 +1,536 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "6705776d-d264-493d-9696-7623231e558a", + "metadata": {}, + "source": [ + "# JAX Regression Example - Interactive API" + ] + }, + { + "cell_type": "markdown", + "id": "de0fb48a-e902-4c5a-a7b7-39728f845707", + "metadata": {}, + "source": [ + "Run this jupyter notebook on a virtual environment." + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "cd66b4cd-03c2-4dc6-9113-0c3fc309e5db", + "metadata": {}, + "outputs": [], + "source": [ + "!pip install jax==0.3.13 jaxlib==0.3.10 -q" + ] + }, + { + "cell_type": "markdown", + "id": "8b95eeb4-9a6b-401d-9d35-2deaa4b51860", + "metadata": {}, + "source": [ + "GPU version of JAX. Pick the jax version compatible with the CUDA and cuDNN pre-installed." + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "1e0e9cff-71f9-4710-87ae-cc5c37925008", + "metadata": {}, + "outputs": [], + "source": [ + "# !pip install --upgrade pip # Careful with the pip upgrade, it may cause a package dependency related problems during OpenFL workflow execution.\n", + "\n", + "# Installs the wheel compatible with CUDA 11 and cuDNN 8.2 or newer.\n", + "# Note: wheels only available on linux.\n", + "# !pip install --upgrade \"jax[cuda]\" -f https://storage.googleapis.com/jax-releases/jax_releases.html\n", + "\n", + "# Installs the wheel compatible with Cuda >= 11.4 and cudnn >= 8.2\n", + "# !pip install \"jax[cuda11_cudnn82]\" -f https://storage.googleapis.com/jax-releases/jax_releases.html\n", + "\n", + "# Installs the wheel compatible with Cuda >= 11.1 and cudnn >= 8.0.5\n", + "# !pip install \"jax[cuda11_cudnn805]\" -f https://storage.googleapis.com/jax-releases/jax_releases.html" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "0b3fcc5b-ee99-4ea8-95e8-6ce08db00809", + "metadata": {}, + "outputs": [], + "source": [ + "# Without either of the below flags, JAX XLA raised CUDA_OUT_OF_MEMORY exception.\n", + "# JAX XLA pre-allocates 90% of the GPU at start\n", + "\n", + "# Below flag to restrict max GPU allocation to 50%\n", + "%env XLA_PYTHON_CLIENT_MEM_FRACTION=.5\n", + "\n", + "# OR\n", + "\n", + "# set XLA_PYTHON_CLIENT_PREALLOCATE to false to incrementally allocate GPU memory as and when required. But can take entire GPU by the end.\n", + "# %env XLA_PYTHON_CLIENT_PREALLOCATE=false\n" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "9008000e-fe07-4ff5-91cf-facb2decc560", + "metadata": {}, + "outputs": [], + "source": [ + "# Mandatory imports for Federation\n", + "\n", + "import jax\n", + "import jax.numpy as jnp\n", + "import time" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d292230e-bc1d-423d-836d-b4630a1c4042", + "metadata": {}, + "outputs": [], + "source": [ + "# Both the MSE function are optimal and accurate in terms of correctness.\n", + "\n", + "# Calculate MSE approach 1\n", + "def mse_loss_function1(W, X, y):\n", + " y_pred = jnp.dot(X, W)\n", + " mse_error = y_pred - y\n", + " return jnp.mean(jnp.square(mse_error))\n", + "\n", + "# Calculate MSE approach 2\n", + "def mse_loss_function2(W, X, Y):\n", + " def squared_error(x, y):\n", + " y_pred = jnp.dot(x, W)\n", + " return jnp.inner(y-y_pred, y-y_pred)\n", + " vectorized_square_error = jax.vmap(squared_error)\n", + " return jnp.mean(vectorized_square_error(X, Y), axis=0)\n", + "\n", + "# Weight update, JAX compiled function. Consequent executions are way faster!!!.\n", + "def update(W, x, y, lr):\n", + " W = W - lr * jax.grad(mse_loss_function1)(W, x, y)\n", + " return W" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "2cdf9a57-29c4-4787-bbd4-97553187b354", + "metadata": {}, + "outputs": [], + "source": [ + "class LinearRegression:\n", + " def __init__(self, n_feat: int) -> None:\n", + " self.weights = jnp.ones(n_feat)\n", + " \n", + " def mse(self, X, y) -> float:\n", + " return mse_loss_function1(self.weights, X, y)\n", + " \n", + " def predict(self, X):\n", + " return jnp.dot(X, self.weights)\n", + " \n", + " def fit(self, X, Y, n_epochs : int, learning_rate : int, silent : bool) -> None:\n", + " \n", + " # Speed up weight updates with consecutive calls to jitted `update` function.\n", + " update_weights = jax.jit(update)\n", + " \n", + " start_time = time.time()\n", + " print('Training Loss at start: ', self.mse(X, Y))\n", + " for i in range(n_epochs):\n", + " self.weights = update_weights(self.weights, X, Y, learning_rate)\n", + " if i % int(n_epochs/10) == 0 and not silent:\n", + " print(str(i), 'Training Loss: ', self.mse(X, Y))\n", + "\n", + " print(\"--- %s seconds ---\" % (time.time() - start_time))\n", + "\n", + " " + ] + }, + { + "cell_type": "markdown", + "id": "ffd4d2d7-5537-496a-88c1-301da87d979c", + "metadata": { + "tags": [] + }, + "source": [ + "# JAX Linear Regression with federation" + ] + }, + { + "cell_type": "markdown", + "id": "09cf7090-da51-4f4e-9d28-2a5c6e3bca02", + "metadata": { + "tags": [] + }, + "source": [ + "## Connect to a Federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "1b3c0039-e1f7-4047-b98b-a2d4bd42f015", + "metadata": {}, + "outputs": [], + "source": [ + "# Create a federation\n", + "from openfl.interface.interactive_api.federation import Federation\n", + "\n", + "# please use the same identificator that was used in signed certificate\n", + "client_id = 'frontend'\n", + "director_node_fqdn = 'localhost'\n", + "director_port = 50050\n", + "\n", + "federation = Federation(\n", + " client_id=client_id,\n", + " director_node_fqdn=director_node_fqdn,\n", + " director_port=director_port,\n", + " tls=False\n", + ")" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "7815120e-b704-4a7d-a65a-3c7542023ead", + "metadata": { + "tags": [] + }, + "outputs": [], + "source": [ + "shard_registry = federation.get_shard_registry()\n", + "shard_registry" + ] + }, + { + "cell_type": "markdown", + "id": "b011dd95-64a7-4a8b-91ec-e61cdf885bbb", + "metadata": {}, + "source": [ + "### Initialize Data Interface" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "b1985ac9-a2b1-4561-a962-6adfe35c3b97", + "metadata": {}, + "outputs": [], + "source": [ + "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment\n", + "\n", + "class LinearRegressionDataSet(DataInterface):\n", + " def __init__(self, **kwargs):\n", + " \"\"\"Initialize DataLoader.\"\"\"\n", + " self.kwargs = kwargs\n", + "\n", + " @property\n", + " def shard_descriptor(self):\n", + " \"\"\"Return shard descriptor.\"\"\"\n", + " return self._shard_descriptor\n", + " \n", + " @shard_descriptor.setter\n", + " def shard_descriptor(self, shard_descriptor):\n", + " \"\"\"\n", + " Describe per-collaborator procedures or sharding.\n", + " \n", + " This method will be called during a collaborator initialization.\n", + " Local shard_descriptor will be set by Envoy.\n", + " \"\"\"\n", + " self._shard_descriptor = shard_descriptor\n", + " self.train_set = shard_descriptor.get_dataset('train')\n", + " self.val_set = shard_descriptor.get_dataset('val')\n", + " \n", + " def get_train_loader(self, **kwargs):\n", + " \"\"\"Output of this method will be provided to tasks with optimizer in contract.\"\"\"\n", + " return self.train_set\n", + "\n", + " def get_valid_loader(self, **kwargs):\n", + " \"\"\"Output of this method will be provided to tasks without optimizer in contract.\"\"\"\n", + " return self.val_set\n", + "\n", + " def get_train_data_size(self):\n", + " \"\"\"Information for aggregation.\"\"\"\n", + " return len(self.train_set)\n", + "\n", + " def get_valid_data_size(self):\n", + " \"\"\"Information for aggregation.\"\"\"\n", + " return len(self.val_set)\n", + " \n", + "lin_reg_dataset = LinearRegressionDataSet()" + ] + }, + { + "cell_type": "markdown", + "id": "b8909127-99d1-4dba-86fe-01a1b86585e7", + "metadata": {}, + "source": [ + "### Define Model Interface" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "9523c9a2-a259-461f-937f-1fb054bd2886", + "metadata": {}, + "outputs": [], + "source": [ + "framework_adapter = 'custom_adapter.CustomFrameworkAdapter'\n", + "\n", + "# LinearRegression class accepts a parameter n_features. Should be same as `sample_shape` from `director_config.yaml`\n", + "fed_model = LinearRegression(1)\n", + "MI = ModelInterface(model=fed_model, optimizer=None, framework_plugin=framework_adapter)\n", + "\n", + "# Save the initial model state\n", + "initial_model = LinearRegression(1)" + ] + }, + { + "cell_type": "markdown", + "id": "2e3558bb-b21b-48ac-b07e-43cf75e6907b", + "metadata": {}, + "source": [ + "### Register Tasks\n", + "We need to employ a trick reporting metrics. OpenFL decides which model is the best based on an *increasing* metric." + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "f73e1ff9-d54a-49b5-9ce8-8bc72c6a2c6f", + "metadata": {}, + "outputs": [], + "source": [ + "TI = TaskInterface()\n", + "\n", + "@TI.add_kwargs(**{'lr': 0.01,\n", + " 'epochs': 101})\n", + "@TI.register_fl_task(model='my_model', data_loader='train_data', \\\n", + " device='device', optimizer='optimizer') \n", + "def train(my_model, train_data, optimizer, device, lr, epochs):\n", + " X, Y = train_data[:,:-1], train_data[:,-1]\n", + " my_model.fit(X, Y, epochs, lr, silent=False)\n", + " return {'train_MSE': my_model.mse(X, Y),}\n", + "\n", + "@TI.register_fl_task(model='my_model', data_loader='val_data', device='device')\n", + "def validate(my_model, val_data, device):\n", + " X, Y = val_data[:,:-1], val_data[:,-1] \n", + " return {'validation_MSE': my_model.mse(X, Y),}" + ] + }, + { + "cell_type": "markdown", + "id": "ee7659cc-6e03-43f5-9078-95707fa0e4d5", + "metadata": { + "tags": [] + }, + "source": [ + "### Run the federation" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "749100e8-05ce-418c-a980-545e3beb900b", + "metadata": {}, + "outputs": [], + "source": [ + "experiment_name = 'jax_linear_regression_experiment'\n", + "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "16bf1df7-8ca8-4a5e-a833-47c265c11e05", + "metadata": {}, + "outputs": [], + "source": [ + "fl_experiment.start(model_provider=MI,\n", + " task_keeper=TI,\n", + " data_loader=lin_reg_dataset,\n", + " rounds_to_train=2)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "1178d1ea-05e6-46be-ac07-21620bd6ec76", + "metadata": { + "tags": [] + }, + "outputs": [], + "source": [ + "fl_experiment.stream_metrics()" + ] + }, + { + "cell_type": "markdown", + "id": "6f23cac5-caec-4161-b4b2-dddceb3eab80", + "metadata": { + "tags": [] + }, + "source": [ + "# JAX Linear Regression without federation (Optional Simulation)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "94be17d7-90c9-4e5f-aeb1-102271826370", + "metadata": {}, + "outputs": [], + "source": [ + "!pip install matplotlib scikit-learn -q" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "3f5ced27-a808-4eca-be6e-d8b62929f32b", + "metadata": { + "tags": [] + }, + "outputs": [], + "source": [ + "# Imports for running JAX Linear Regression example without OpenFL.\n", + "\n", + "import matplotlib.pyplot as plt\n", + "\n", + "%matplotlib inline\n", + "from matplotlib.pylab import rcParams\n", + "rcParams['figure.figsize'] = 7, 5\n", + "\n", + "from jax import make_jaxpr\n", + "from sklearn.datasets import make_regression\n", + "from sklearn.model_selection import train_test_split" + ] + }, + { + "cell_type": "markdown", + "id": "58128c30-7865-4412-b4fd-86b0fe53f1a7", + "metadata": { + "tags": [] + }, + "source": [ + "#### Simple Linear Regression\n", + "
 \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "140705fc-4af3-4668-a26b-2ebe2d42575e",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# create a dataset with n_features\n",
+ "X, y = make_regression(n_samples=100, n_features=1, noise=10, random_state=42)\n",
+ "\n",
+ "# Train test split - Default 0.75/0.25\n",
+ "X, X_test, y, y_test = train_test_split(X, y, random_state=42)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a2665d0b-78ce-4caf-a4ca-a9decffaa96f",
+ "metadata": {},
+ "source": [
+ "Visualize data distribution"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "68f5afbf-e010-4d4a-bb92-46de06d39866",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "_ = plt.scatter(X, y)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ebe555dd-9e8d-4e80-bfde-87e3cafac14c",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "_ = plt.scatter(X_test, y_test)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "68a7ddb3-166e-447f-a8f1-881511cfbd9f",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# JAX logical execution plan\n",
+ "print(jax.make_jaxpr(update)(jnp.ones(X.shape[1]), X, y, 0.01))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "574bac29-b5c2-4f41-8655-e98450fdef8d",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# X.shape -> (n_samples, n_features)\n",
+ "\n",
+ "lr_model = LinearRegression(X.shape[1])\n",
+ "lr = 0.01\n",
+ "epochs = 101\n",
+ "\n",
+ "print(f\"Initial Test MSE: {lr_model.mse(X_test,y_test)}\")\n",
+ "\n",
+ "# silent: logging verbosity\n",
+ "lr_model.fit(X,y, epochs, lr, silent=False)\n",
+ "\n",
+ "print(f\"Final Test MSE: {lr_model.mse(X_test,y_test)}\")\n",
+ "\n",
+ "print(f\"Final parameters: {lr_model.weights}\")"
+ ]
+ }
+ ],
+ "metadata": {
+ "interpreter": {
+ "hash": "916dbcbb3f70747c44a77c7bcd40155683ae19c65e1c03b4aa3499c5328201f1"
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/openfl_contrib_tutorials/interactive_api/jax_linear_regression/workspace/custom_adapter.py b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/workspace/custom_adapter.py
new file mode 100644
index 0000000..35345df
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/workspace/custom_adapter.py
@@ -0,0 +1,21 @@
+# Copyright (C) 2020-2022 Intel Corporation
+# SPDX-License-Identifier: Apache-2.0
+"""Custom model numpy adapter."""
+
+from openfl.plugins.frameworks_adapters.framework_adapter_interface import (
+ FrameworkAdapterPluginInterface,
+)
+
+
+class CustomFrameworkAdapter(FrameworkAdapterPluginInterface):
+ """Framework adapter plugin class."""
+
+ @staticmethod
+ def get_tensor_dict(model, optimizer=None):
+ """Extract tensors from a model."""
+ return {'w': model.weights}
+
+ @staticmethod
+ def set_tensor_dict(model, tensor_dict, optimizer=None, device='cpu'):
+ """Load tensors to a model."""
+ model.weights = tensor_dict['w']
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/README.md b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/README.md
new file mode 100644
index 0000000..8a2c360
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/README.md
@@ -0,0 +1,24 @@
+# Linear Regression with Numpy and OpenFL
+
+This example is devoted to demonstrating several techniques of working with OpenFL.
+
+1. Envoy workspace contains a Shard Descriptor designed to generate 1-dimensional noisy data for linear regression of sinusoid. The random seed for generation for a specific Envoy is parametrized by the `rank` argument in shard_config.
+2. The LinReg frontend jupyter notebook (data scientist's entry point) features a simple numpy-based model for linear regression trained with Ridge regularization.
+3. The data scientist's workspace also contains a custom framework adapter allowing extracting and setting weights to the custom model.
+4. The start_federation notebook provides shortcut methods to start a Federation with an arbitrary number of Envoys with different datasets. It may save time for people willing to conduct one-node experiments.
+5. The SingleNotebook jupyter notebook combines two aforementioned notebooks and allows to run the whole pipeline in Google colab. Besides previously mentioned components, it contains scripts for pulling the OpenFL repo with the example workspaces and installing dependencies.
+
+## How to use this example
+### Locally:
+1. Start a Federation
+Distributed experiments:
+Use OpenFL CLI to start the Director and Envoy services from corresponding folders.
+Single-node experiments:
+Users may use the same path or benefit from the start_federation notebook in the workspace folder
+
+2. Submit an experiment
+Follow LinReg jupyter notebook.
+
+### Google Colab:
+
+[](https://colab.research.google.com/github/intel/openfl/blob/develop/openfl-tutorials/interactive_api/numpy_linear_regression/workspace/SingleNotebook.ipynb)
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/director/director_config.yaml
new file mode 100644
index 0000000..478cd5c
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/director/director_config.yaml
@@ -0,0 +1,6 @@
+settings:
+ listen_host: localhost
+ listen_port: 50049
+ sample_shape: ['1']
+ target_shape: ['1']
+ envoy_health_check_period: 5 # in seconds
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/envoy_config.yaml b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/envoy_config.yaml
new file mode 100644
index 0000000..107c566
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/envoy_config.yaml
@@ -0,0 +1,12 @@
+params:
+ cuda_devices: []
+
+optional_plugin_components: {}
+
+shard_descriptor:
+ template: linreg_shard_descriptor.LinRegSD
+ params:
+ rank: 1
+ n_samples: 80
+ noise: 0.15
+
\ No newline at end of file
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/linreg_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/linreg_shard_descriptor.py
new file mode 100644
index 0000000..12bfed9
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/linreg_shard_descriptor.py
@@ -0,0 +1,60 @@
+# Copyright (C) 2020-2021 Intel Corporation
+# SPDX-License-Identifier: Apache-2.0
+"""Noisy-Sin Shard Descriptor."""
+
+from typing import List
+
+import numpy as np
+
+from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor
+
+
+class LinRegSD(ShardDescriptor):
+ """Shard descriptor class."""
+
+ def __init__(self, rank: int, n_samples: int = 10, noise: float = 0.15) -> None:
+ """
+ Initialize LinReg Shard Descriptor.
+
+ This Shard Descriptor generate random data. Sample features are
+ floats between pi/3 and 5*pi/3, and targets are calculated
+ calculated as sin(feature) + normal_noise.
+ """
+ np.random.seed(rank) # Setting seed for reproducibility
+ self.n_samples = max(n_samples, 5)
+ self.interval = 240
+ self.x_start = 60
+ x = np.random.rand(n_samples, 1) * self.interval + self.x_start
+ x *= np.pi / 180
+ y = np.sin(x) + np.random.normal(0, noise, size=(n_samples, 1))
+ self.data = np.concatenate((x, y), axis=1)
+
+ def get_dataset(self, dataset_type: str) -> np.ndarray:
+ """
+ Return a shard dataset by type.
+
+ A simple list with elements (x, y) implemets the Shard Dataset interface.
+ """
+ if dataset_type == 'train':
+ return self.data[:self.n_samples // 2]
+ elif dataset_type == 'val':
+ return self.data[self.n_samples // 2:]
+ else:
+ pass
+
+ @property
+ def sample_shape(self) -> List[str]:
+ """Return the sample shape info."""
+ (*x, _) = self.data[0]
+ return [str(i) for i in np.array(x, ndmin=1).shape]
+
+ @property
+ def target_shape(self) -> List[str]:
+ """Return the target shape info."""
+ (*_, y) = self.data[0]
+ return [str(i) for i in np.array(y, ndmin=1).shape]
+
+ @property
+ def dataset_description(self) -> str:
+ """Return the dataset description."""
+ return 'Allowed dataset types are `train` and `val`'
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/requirements.txt b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/requirements.txt
new file mode 100644
index 0000000..fb452e0
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/requirements.txt
@@ -0,0 +1,5 @@
+mistune>=2.0.3 # not directly required, pinned by Snyk to avoid a vulnerability
+numpy
+openfl==1.2.1
+setuptools>=65.5.1 # not directly required, pinned by Snyk to avoid a vulnerability
+wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/LinReg.ipynb b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/LinReg.ipynb
new file mode 100644
index 0000000..3e4131d
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/LinReg.ipynb
@@ -0,0 +1,485 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "689ee822",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!pip install -r requirements.txt"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d63e64c6-9955-4afc-8d04-d8c85bb28edc",
+ "metadata": {},
+ "source": [
+ "# Linear Regression with Numpy and OpenFL"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6c9eee14-22a1-4d48-a7da-e68d01037cd4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from typing import List, Union\n",
+ "import numpy as np\n",
+ "import random\n",
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline\n",
+ "from matplotlib.pylab import rcParams\n",
+ "rcParams['figure.figsize'] = 7, 5"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c4b334ef-6a72-4b82-b978-1401973d0512",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "# We will use MSE as loss function and Ridge weights regularization\n",
+ "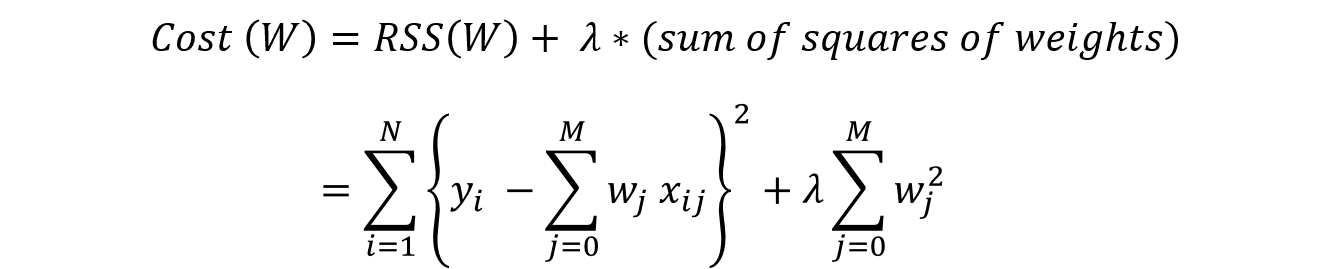"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f4cc8ec2-b818-4db8-8700-39c1a12917df",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class LinRegLasso:\n",
+ " def __init__(self, n_feat: int) -> None:\n",
+ " self.weights = np.ones((n_feat + 1)) # (n_feat + 1,) weights + bias\n",
+ " \n",
+ " def predict(self, feature_vector: Union[np.ndarray, List[int]]) -> float:\n",
+ " '''\n",
+ " feature_vector may be a list or have shape (n_feat,)\n",
+ " or it may be a bunch of vectors (n_vec, nfeat)\n",
+ " '''\n",
+ " feature_vector = np.array(feature_vector)\n",
+ " if len(feature_vector.shape) == 1:\n",
+ " feature_vector = feature_vector[:,np.newaxis]\n",
+ " assert feature_vector.shape[-1] == self.weights.shape[0] - 1, \\\n",
+ " f\"sample shape is {feature_vector.shape} and weights shape is f{self.weights}\"\n",
+ " \n",
+ " return self.weights @ np.concatenate((feature_vector.T, [[1]*feature_vector.shape[0]]))\n",
+ " \n",
+ " def mse(self, X: np.ndarray, Y: np.ndarray) -> float:\n",
+ " Y_hat = self.predict(X)\n",
+ " return np.sum((Y - Y_hat)**2) / Y.shape[0]\n",
+ "\n",
+ " def _update_weights(self, X: np.ndarray, Y: np.ndarray, lr: float, wd: float) -> None:\n",
+ " '''\n",
+ " X: (n_samples, n_features)\n",
+ " Y: (n_samples,)\n",
+ " self.weights: (n_features + 1)\n",
+ " \n",
+ " Cost function is MSE: (y - W*X - b)**2;\n",
+ " its derivative with resp to any x is -2*X*(y - W*X - b),\n",
+ " and with resp to b is -2*(y - W*X - b).\n",
+ " \n",
+ " Regularisation function is L1 |W|;\n",
+ " its derivative is SIGN(w)\n",
+ " '''\n",
+ " predictions = self.predict(X)\n",
+ " error = Y - predictions # (n_samples,)\n",
+ " X_with_bias = np.concatenate((X.T, [[1]*X.shape[0]])).T\n",
+ " updates = -2 * X_with_bias.T @ error / Y.shape[0]\n",
+ " regression_term = np.sign(self.weights)\n",
+ " \n",
+ " self.weights = self.weights - lr * updates + wd * regression_term\n",
+ " \n",
+ " def fit(self, X: np.ndarray, Y: np.ndarray,\n",
+ " n_epochs: int, lr: float, wd: float,\n",
+ " silent: bool=False) -> None:\n",
+ " for i in range(n_epochs):\n",
+ " self._update_weights(X, Y, lr, wd)\n",
+ " mse = self.mse(X, Y)\n",
+ " if not silent:\n",
+ " print(f'epoch: {i}, \\t MSE: {mse}')\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "af89e7e5-6cfc-46bc-acd2-7d5bfb373091",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Define input array with angles from 60deg to 300deg converted to radians\n",
+ "x = np.array([i*np.pi/180 for i in range(60,300,4)])\n",
+ "np.random.seed(10) # Setting seed for reproducibility\n",
+ "y = np.sin(x) + np.random.normal(0,0.15,len(x))\n",
+ "# plt.plot(x,y,'.')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ffefca2b-d7f6-4111-8872-c017c182a2de",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "lr_model = LinRegLasso(1)\n",
+ "wd = 0.0001\n",
+ "lr = 0.08\n",
+ "epochs = 100\n",
+ "\n",
+ "print(f\"Initila MSE: {lr_model.mse(x,y)}\")\n",
+ "lr_model.fit(x[:,np.newaxis],y, epochs, lr, wd, silent=True)\n",
+ "print(f\"Final MSE: {lr_model.mse(x,y)}\")\n",
+ "print(f\"Final parameters: {lr_model.weights}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "410f2d80-989a-43ab-958f-7b68fd8f2e90",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# We can also solve this 1D problem using Numpy\n",
+ "numpy_solution = np.polyfit(x,y,1)\n",
+ "predictor_np = np.poly1d(numpy_solution)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6cb323db-9f3a-42af-94da-4b170adef867",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "y_hat = lr_model.predict(x)\n",
+ "y_np = predictor_np(x)\n",
+ "plt.plot(x,y,'.')\n",
+ "plt.plot(x,y_hat,'.')\n",
+ "plt.plot(x,y_np,'--')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ffd4d2d7-5537-496a-88c1-301da87d979c",
+ "metadata": {},
+ "source": [
+ "# Now we run the same training on federated data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "09cf7090-da51-4f4e-9d28-2a5c6e3bca02",
+ "metadata": {},
+ "source": [
+ "## Connect to a Federation"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1b3c0039-e1f7-4047-b98b-a2d4bd42f015",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Create a federation\n",
+ "from openfl.interface.interactive_api.federation import Federation\n",
+ "\n",
+ "# please use the same identificator that was used in signed certificate\n",
+ "client_id = 'frontend'\n",
+ "director_node_fqdn = 'localhost'\n",
+ "director_port = 50049\n",
+ "\n",
+ "federation = Federation(\n",
+ " client_id=client_id,\n",
+ " director_node_fqdn=director_node_fqdn,\n",
+ " director_port=director_port,\n",
+ " tls=False\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7815120e-b704-4a7d-a65a-3c7542023ead",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "shard_registry = federation.get_shard_registry()\n",
+ "shard_registry"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b011dd95-64a7-4a8b-91ec-e61cdf885bbb",
+ "metadata": {},
+ "source": [
+ "### Data"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b1985ac9-a2b1-4561-a962-6adfe35c3b97",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment\n",
+ "\n",
+ "class LinRegDataSet(DataInterface):\n",
+ " def __init__(self, **kwargs):\n",
+ " \"\"\"Initialize DataLoader.\"\"\"\n",
+ " self.kwargs = kwargs\n",
+ " pass\n",
+ "\n",
+ " @property\n",
+ " def shard_descriptor(self):\n",
+ " \"\"\"Return shard descriptor.\"\"\"\n",
+ " return self._shard_descriptor\n",
+ " \n",
+ " @shard_descriptor.setter\n",
+ " def shard_descriptor(self, shard_descriptor):\n",
+ " \"\"\"\n",
+ " Describe per-collaborator procedures or sharding.\n",
+ "\n",
+ " This method will be called during a collaborator initialization.\n",
+ " Local shard_descriptor will be set by Envoy.\n",
+ " \"\"\"\n",
+ " self._shard_descriptor = shard_descriptor\n",
+ " self.train_set = shard_descriptor.get_dataset(\"train\")\n",
+ " self.val_set = shard_descriptor.get_dataset(\"val\")\n",
+ "\n",
+ " def get_train_loader(self, **kwargs):\n",
+ " \"\"\"Output of this method will be provided to tasks with optimizer in contract.\"\"\"\n",
+ " return self.train_set\n",
+ "\n",
+ " def get_valid_loader(self, **kwargs):\n",
+ " \"\"\"Output of this method will be provided to tasks without optimizer in contract.\"\"\"\n",
+ " return self.val_set\n",
+ "\n",
+ " def get_train_data_size(self):\n",
+ " \"\"\"Information for aggregation.\"\"\"\n",
+ " return len(self.train_set)\n",
+ "\n",
+ " def get_valid_data_size(self):\n",
+ " \"\"\"Information for aggregation.\"\"\"\n",
+ " return len(self.val_set)\n",
+ " \n",
+ "lin_reg_dataset = LinRegDataSet()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b8909127-99d1-4dba-86fe-01a1b86585e7",
+ "metadata": {},
+ "source": [
+ "### Model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9523c9a2-a259-461f-937f-1fb054bd2886",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "framework_adapter = 'custom_adapter.CustomFrameworkAdapter'\n",
+ "fed_model = LinRegLasso(1)\n",
+ "MI = ModelInterface(model=fed_model, optimizer=None, framework_plugin=framework_adapter)\n",
+ "\n",
+ "# Save the initial model state\n",
+ "initial_model = LinRegLasso(1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2e3558bb-b21b-48ac-b07e-43cf75e6907b",
+ "metadata": {},
+ "source": [
+ "### Tasks\n",
+ "We need to employ a trick reporting metrics. OpenFL decides which model is the best based on an *increasing* metric."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f73e1ff9-d54a-49b5-9ce8-8bc72c6a2c6f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "TI = TaskInterface()\n",
+ "\n",
+ "@TI.add_kwargs(**{'lr': 0.001,\n",
+ " 'wd': 0.0001,\n",
+ " 'epoches': 1})\n",
+ "@TI.register_fl_task(model='my_model', data_loader='train_data', \\\n",
+ " device='device', optimizer='optimizer') \n",
+ "def train(my_model, train_data, optimizer, device, lr, wd, epoches):\n",
+ " X, Y = train_data[:,:-1], train_data[:,-1]\n",
+ " my_model.fit(X, Y, epochs, lr, wd, silent=True)\n",
+ " return {'train_MSE': my_model.mse(X, Y),}\n",
+ "\n",
+ "@TI.register_fl_task(model='my_model', data_loader='val_data', device='device') \n",
+ "def validate(my_model, val_data, device):\n",
+ " X, Y = val_data[:,:-1], val_data[:,-1] \n",
+ " return {'validation_MSE': my_model.mse(X, Y),}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ee7659cc-6e03-43f5-9078-95707fa0e4d5",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Run"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "749100e8-05ce-418c-a980-545e3beb900b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "experiment_name = 'linear_regression_experiment'\n",
+ "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name,\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "16bf1df7-8ca8-4a5e-a833-47c265c11e05",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fl_experiment.start(model_provider=MI, \n",
+ " task_keeper=TI,\n",
+ " data_loader=lin_reg_dataset,\n",
+ " rounds_to_train=10,)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1178d1ea-05e6-46be-ac07-21620bd6ec76",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "fl_experiment.stream_metrics()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "af331ccd-66b4-4925-8627-52cf03ceea5e",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Optional: start tensorboard"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fde4ed4d-dda5-4bab-8dd3-e1ac44f5acf9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%script /bin/bash --bg\n",
+ "tensorboard --host $(hostname --all-fqdns | awk '{print $1}') --logdir logs"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7aa78602-b66a-4378-bea9-e915f2a1fdd8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "last_model = fl_experiment.get_last_model()\n",
+ "best_model = fl_experiment.get_best_model()\n",
+ "print(best_model.weights)\n",
+ "print(last_model.weights)\n",
+ "print(f\"last model MSE: {last_model.mse(x,y)}\")\n",
+ "print(f\"best model MSE: {best_model.mse(x,y)}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ae66d688",
+ "metadata": {},
+ "source": [
+ "### Evaluate results"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "573417e0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "n_cols = 20\n",
+ "n_samples = 4\n",
+ "interval = 240\n",
+ "x_start = 60\n",
+ "noise = 0.3\n",
+ "\n",
+ "X = None\n",
+ "\n",
+ "for rank in range(n_cols):\n",
+ " np.random.seed(rank) # Setting seed for reproducibility\n",
+ " x = np.random.rand(n_samples, 1) * interval + x_start\n",
+ " x *= np.pi / 180\n",
+ " X = x if X is None else np.vstack((X,x))\n",
+ " y = np.sin(x) + np.random.normal(0, noise, size=(n_samples, 1))\n",
+ " plt.plot(x,y,'+')\n",
+ " \n",
+ "X.sort() \n",
+ "Y_hat = last_model.predict(X)\n",
+ "plt.plot(X,Y_hat,'--')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "84e927c8",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/SingleNotebook.ipynb b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/SingleNotebook.ipynb
new file mode 100644
index 0000000..d0de783
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/SingleNotebook.ipynb
@@ -0,0 +1,810 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "4dd5da0c-1ae1-43e6-8ad9-360c8974476c",
+ "metadata": {},
+ "source": [
+ "[](https://colab.research.google.com/github/intel/openfl/blob/develop/openfl-tutorials/interactive_api/numpy_linear_regression/workspace/SingleNotebook.ipynb)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1637381d-84d0-4132-92c3-bf1a1e9c7f7a",
+ "metadata": {},
+ "source": [
+ "# Linear Regression with Numpy and OpenFL"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ee73e205-d273-4b6c-878a-5ea958bfe267",
+ "metadata": {},
+ "source": [
+ "### Preparations in colab:\n",
+ "1. Install OpenFL \n",
+ "2. Clone the OpenFL repository, it contains infrastructure configs for this example.\n",
+ "3. Change working directory "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c6fafe9e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!pip install openfl\n",
+ "!git clone https://github.com/securefederatedai/openfl.git"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2698f1da-fa69-4543-bb15-c7c0dcb776b9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "import os\n",
+ "\n",
+ "# Logging fix for Google Colab\n",
+ "log = logging.getLogger()\n",
+ "log.setLevel(logging.INFO)\n",
+ "\n",
+ "os.chdir('./openfl/openfl-tutorials/interactive_api/numpy_linear_regression/workspace')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fde856d8-da4e-4d2f-bee2-85e673050623",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from typing import List, Union\n",
+ "import numpy as np\n",
+ "import random\n",
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline\n",
+ "from matplotlib.pylab import rcParams\n",
+ "rcParams['figure.figsize'] = 7, 5"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "72e76f9d",
+ "metadata": {},
+ "source": [
+ "# Define a linear model and train it locally\n",
+ "We start with training a linear model locally on a synthetic dataset so we have a baseline solution."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5e06d979-c582-4f44-b092-e5d60cce88bf",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## We will use MSE as loss function and Ridge weights regularization\n",
+ "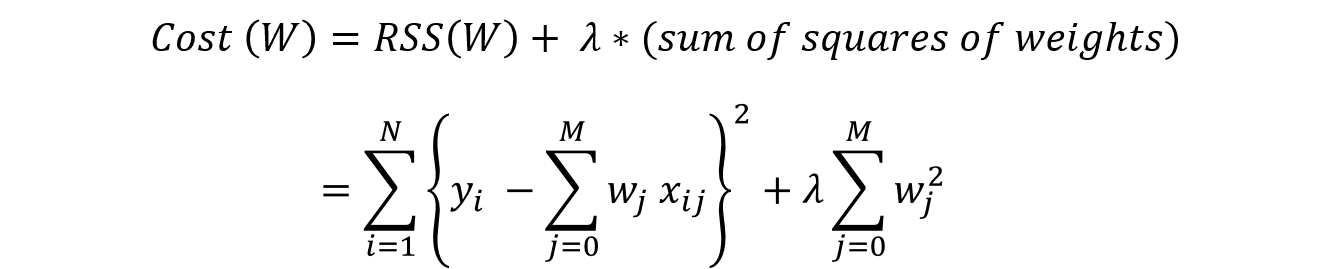"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c9a860ab-91a5-410e-9d1e-4b9bd5a33d70",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class LinRegLasso:\n",
+ " def __init__(self, n_feat: int) -> None:\n",
+ " self.weights = np.ones((n_feat + 1)) # (n_feat + 1,) weights + bias\n",
+ " \n",
+ " def predict(self, feature_vector: Union[np.ndarray, List[int]]) -> float:\n",
+ " '''\n",
+ " feature_vector may be a list or have shape (n_feat,)\n",
+ " or it may be a bunch of vectors (n_vec, nfeat)\n",
+ " '''\n",
+ " feature_vector = np.array(feature_vector)\n",
+ " if len(feature_vector.shape) == 1:\n",
+ " feature_vector = feature_vector[:,np.newaxis]\n",
+ " assert feature_vector.shape[-1] == self.weights.shape[0] - 1, \\\n",
+ " f\"sample shape is {feature_vector.shape} and weights shape is f{self.weights}\"\n",
+ " \n",
+ " return self.weights @ np.concatenate((feature_vector.T, [[1]*feature_vector.shape[0]]))\n",
+ " \n",
+ " def mse(self, X: np.ndarray, Y: np.ndarray) -> float:\n",
+ " Y_hat = self.predict(X)\n",
+ " return np.sum((Y - Y_hat)**2) / Y.shape[0]\n",
+ "\n",
+ " def _update_weights(self, X: np.ndarray, Y: np.ndarray, lr: float, wd: float) -> None:\n",
+ " '''\n",
+ " X: (n_samples, n_features)\n",
+ " Y: (n_samples,)\n",
+ " self.weights: (n_features + 1)\n",
+ " \n",
+ " Cost function is MSE: (y - W*X - b)**2;\n",
+ " its derivative with resp to any x is -2*X*(y - W*X - b),\n",
+ " and with resp to b is -2*(y - W*X - b).\n",
+ " \n",
+ " Regularisation function is L1 |W|;\n",
+ " its derivative is SIGN(w)\n",
+ " '''\n",
+ " predictions = self.predict(X)\n",
+ " error = Y - predictions # (n_samples,)\n",
+ " X_with_bias = np.concatenate((X.T, [[1]*X.shape[0]])).T\n",
+ " updates = -2 * X_with_bias.T @ error / Y.shape[0]\n",
+ " regression_term = np.sign(self.weights)\n",
+ " \n",
+ " self.weights = self.weights - lr * updates + wd * regression_term\n",
+ " \n",
+ " def fit(self, X: np.ndarray, Y: np.ndarray,\n",
+ " n_epochs: int, lr: float, wd: float,\n",
+ " silent: bool=False) -> None:\n",
+ " for i in range(n_epochs):\n",
+ " self._update_weights(X, Y, lr, wd)\n",
+ " mse = self.mse(X, Y)\n",
+ " if not silent:\n",
+ " print(f'epoch: {i}, \\t MSE: {mse}')\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "796b0de6-cb80-4ca6-91e9-503011d6851f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Define input array with angles from 60deg to 300deg converted to radians\n",
+ "noise=0.2\n",
+ "\n",
+ "x = np.array([i*np.pi/180 for i in range(60,300,4)])\n",
+ "np.random.seed(10) # Setting seed for reproducibility\n",
+ "y = np.sin(x) + np.random.normal(0, noise, len(x))\n",
+ "# plt.plot(x,y,'.')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "033a74b4-3bc2-4a19-b734-007ad8a4c037",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "lr_model = LinRegLasso(1)\n",
+ "wd = 0.0001\n",
+ "lr = 0.08\n",
+ "epochs = 100\n",
+ "\n",
+ "print(f\"Initila MSE: {lr_model.mse(x,y)}\")\n",
+ "lr_model.fit(x[:,np.newaxis],y, epochs, lr, wd, silent=True)\n",
+ "print(f\"Final MSE: {lr_model.mse(x,y)}\")\n",
+ "print(f\"Final parameters: {lr_model.weights}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "25873a87-7564-4e4a-8ef5-79a9415b209f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# We can also solve this 1D problem using Numpy\n",
+ "numpy_solution = np.polyfit(x,y,1)\n",
+ "predictor_np = np.poly1d(numpy_solution)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2e5b7a9b-4d4b-4222-8eef-4ef4ba63434a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "y_hat = lr_model.predict(x)\n",
+ "y_np = predictor_np(x)\n",
+ "plt.plot(x,y,'.')\n",
+ "plt.plot(x,y_hat,'.')\n",
+ "plt.plot(x,y_np,'--')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cd2e26a5-9f4e-4011-a999-e428246aa8c1",
+ "metadata": {},
+ "source": [
+ "# Now we run the same training on federated data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "83378ece-9cd5-4d40-a134-24cf68bdb79a",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## 1. Start the Director service and several envoys with generated data"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b0d105a0-04c4-4c26-81c7-a350e14393c2",
+ "metadata": {
+ "tags": [
+ "parameters"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "# Here are the main parameters for our Federation\n",
+ "n_cols=10 # Number of Envoys / Collaborators\n",
+ "n_samples_per_col=10\n",
+ "noise=0.2"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c0c3e78b-6e9d-4efc-9b30-3ddc413c0423",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "from pathlib import Path\n",
+ "from time import sleep\n",
+ "from typing import Dict, List, Union\n",
+ "import yaml"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "463a2821-b657-4e12-90ac-33b7810c5ff4",
+ "metadata": {},
+ "source": [
+ "### Start the Director service"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e736d33f-5df2-4a2f-8210-f1feba9fd367",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "cwd = Path.cwd()\n",
+ "director_workspace_path = Path('../director/').absolute()\n",
+ "director_config_file = director_workspace_path / 'director_config.yaml'\n",
+ "director_logfile = director_workspace_path / 'director.log'\n",
+ "if director_logfile.is_file(): director_logfile.unlink()\n",
+ "\n",
+ "os.environ['main_folder'] = str(cwd)\n",
+ "os.environ['director_workspace_path'] = str(director_workspace_path)\n",
+ "os.environ['director_logfile'] = str(director_logfile)\n",
+ "os.environ['director_config_file'] = str(director_config_file)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bb950328-c1e6-4062-8b36-b42486d60241",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%script /bin/bash --bg\n",
+ "cd $director_workspace_path\n",
+ "fx director start --disable-tls -c $director_config_file > $director_logfile &\n",
+ "cd $main_folder"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "223f0037-c87e-440d-b8df-8fe9211c34dc",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## Start Envoys"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f6deeee4-5dc8-433d-a4ea-c464c74b1b2b",
+ "metadata": {},
+ "source": [
+ "#### First, we create several envoy config files "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c0e65a39-15f7-4cca-90bb-a2970b7be9f0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the original envoy config file content\n",
+ "with open(Path('../envoy/envoy_config.yaml'), \"r\") as stream:\n",
+ " orig_config = yaml.safe_load(stream)\n",
+ "\n",
+ "def generate_envoy_configs(config: Dict,\n",
+ " save_path: Union[str, Path] = '../envoy/',\n",
+ " n_cols: int = 10,\n",
+ " n_samples_per_col: int = 10,\n",
+ " noise: float = 0.15) -> List[Path]:\n",
+ " # Prevent installing requirements by Envoys as they will run in the same environment\n",
+ " config['params']['install_requirements'] = False\n",
+ "\n",
+ " # Pass parameters for Shard Descriptors so they can generate relevant datasets\n",
+ " config['shard_descriptor']['params']['n_samples'] = n_samples_per_col\n",
+ " config['shard_descriptor']['params']['noise'] = noise\n",
+ " \n",
+ " config_paths = [(Path(save_path) / f'{i}_envoy_config.yaml').absolute()\n",
+ " for i in range(1, n_cols + 1)]\n",
+ "\n",
+ " for i, path in enumerate(config_paths):\n",
+ " config['shard_descriptor']['params']['rank'] = i\n",
+ " with open(path, \"w\") as stream:\n",
+ " yaml.safe_dump(config, stream)\n",
+ " \n",
+ " return config_paths\n",
+ " \n",
+ "def remove_configs(config_paths):\n",
+ " for path in config_paths:\n",
+ " path.unlink()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "90109c5b-c785-4af7-ace9-dcd913018dca",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "config_paths = generate_envoy_configs(orig_config,\n",
+ " n_cols=n_cols,\n",
+ " n_samples_per_col=n_samples_per_col,\n",
+ " noise=noise)\n",
+ "# remove_configs(config_paths)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "70c3078a-7beb-47c5-bcee-2de264ef3266",
+ "metadata": {},
+ "source": [
+ "#### Now start Envoy processes in a loop"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "843f698e-5582-4918-828c-cf095988da92",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# envoy_workspace_path = Path('../envoy/').absolute()\n",
+ "def start_envoys(config_paths: List[Path]) -> None:\n",
+ " envoy_workspace_path = config_paths[0].parent\n",
+ " cwd = Path.cwd()\n",
+ " os.chdir(envoy_workspace_path)\n",
+ " for i, path in enumerate(config_paths):\n",
+ " os.system(f'fx envoy start -n env_{i + 1} --disable-tls '\n",
+ " f'--envoy-config-path {path} -dh localhost -dp 50049 '\n",
+ " f'>env_{i + 1}.log &')\n",
+ " os.chdir(cwd)\n",
+ "\n",
+ "sleep(5)\n",
+ "\n",
+ "start_envoys(config_paths)\n",
+ "\n",
+ "sleep(25)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6216f14c-78d8-444c-9144-ee8316d1487b",
+ "metadata": {},
+ "source": [
+ "## 2. Connect to the Director service of out Federation as Data scientist"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b9d3b764-cb86-4eec-ba8e-df119da7a27f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Create a federation\n",
+ "from openfl.interface.interactive_api.federation import Federation\n",
+ "\n",
+ "# please use the same identificator that was used in signed certificate\n",
+ "client_id = 'frontend'\n",
+ "director_node_fqdn = 'localhost'\n",
+ "director_port = 50049\n",
+ "\n",
+ "federation = Federation(\n",
+ " client_id=client_id,\n",
+ " director_node_fqdn=director_node_fqdn,\n",
+ " director_port=director_port,\n",
+ " tls=False\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1bed370b-d0c0-46bc-8114-ea8255b2478b",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Data scientist may request a list of connected envoys\n",
+ "shard_registry = federation.get_shard_registry()\n",
+ "\n",
+ "# WARNING!\n",
+ "\n",
+ "# Make sure shard registry contains all the envoys you started!\n",
+ "# In other case try to run this cell again or reconnect to the Director (the cell above).\n",
+ "shard_registry"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c6401026-795f-491e-90cb-dd59b451df5f",
+ "metadata": {},
+ "source": [
+ "### Now we will prepare an FL experimnet using OpenFL Python API"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8166c689-9dde-4500-b05c-5b1ddf968978",
+ "metadata": {},
+ "source": [
+ "### Data"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "55fb1a98-b44f-47ff-950d-5a40a1cca0d8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment\n",
+ "\n",
+ "class LinRegDataSet(DataInterface):\n",
+ " def __init__(self, **kwargs):\n",
+ " \"\"\"Initialize DataLoader.\"\"\"\n",
+ " self.kwargs = kwargs\n",
+ " pass\n",
+ "\n",
+ " @property\n",
+ " def shard_descriptor(self):\n",
+ " \"\"\"Return shard descriptor.\"\"\"\n",
+ " return self._shard_descriptor\n",
+ " \n",
+ " @shard_descriptor.setter\n",
+ " def shard_descriptor(self, shard_descriptor):\n",
+ " \"\"\"\n",
+ " Describe per-collaborator procedures or sharding.\n",
+ "\n",
+ " This method will be called during a collaborator initialization.\n",
+ " Local shard_descriptor will be set by Envoy.\n",
+ " \"\"\"\n",
+ " self._shard_descriptor = shard_descriptor\n",
+ " self.train_set = shard_descriptor.get_dataset(\"train\")\n",
+ " self.val_set = shard_descriptor.get_dataset(\"val\")\n",
+ "\n",
+ " def get_train_loader(self, **kwargs):\n",
+ " \"\"\"Output of this method will be provided to tasks with optimizer in contract.\"\"\"\n",
+ " return self.train_set\n",
+ "\n",
+ " def get_valid_loader(self, **kwargs):\n",
+ " \"\"\"Output of this method will be provided to tasks without optimizer in contract.\"\"\"\n",
+ " return self.val_set\n",
+ "\n",
+ " def get_train_data_size(self):\n",
+ " \"\"\"Information for aggregation.\"\"\"\n",
+ " return len(self.train_set)\n",
+ "\n",
+ " def get_valid_data_size(self):\n",
+ " \"\"\"Information for aggregation.\"\"\"\n",
+ " return len(self.val_set)\n",
+ " \n",
+ "lin_reg_dataset = LinRegDataSet()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6233e1ed-a2f2-456f-9417-f35a2c27b236",
+ "metadata": {},
+ "source": [
+ "### Model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "885a8530-6248-4060-a30a-45cdc79bc41a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# You can inspect the framework adapter used in this example.\n",
+ "# It is a plug-in component allowing OpenFL to manage model parameters.\n",
+ "framework_adapter = 'custom_adapter.CustomFrameworkAdapter'\n",
+ "fed_model = LinRegLasso(1)\n",
+ "MI = ModelInterface(model=fed_model, optimizer=None, framework_plugin=framework_adapter)\n",
+ "\n",
+ "# Save the initial model state\n",
+ "initial_model = LinRegLasso(1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dc9da235-02a8-4e7a-9455-5fe2462aa317",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Tasks\n",
+ "Using an Optimizer does not make sense for this experiment. Yet it is a required part of a training task contract in the current version of OpenFL, so we just pass None.\n",
+ "We need to employ a trick reporting metrics. OpenFL decides which model is the best based on an *increasing* metric."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7e101689-8a63-4562-98ff-09443b1ab9f2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "TI = TaskInterface()\n",
+ "\n",
+ "@TI.add_kwargs(**{'lr': 0.001,\n",
+ " 'wd': 0.0001,\n",
+ " 'epoches': 1})\n",
+ "@TI.register_fl_task(model='my_model', data_loader='train_data', \\\n",
+ " device='device', optimizer='optimizer') \n",
+ "def train(my_model, train_data, optimizer, device, lr, wd, epoches):\n",
+ " X, Y = train_data[:,:-1], train_data[:,-1]\n",
+ " my_model.fit(X, Y, epochs, lr, wd, silent=True)\n",
+ " return {'train_MSE': my_model.mse(X, Y),}\n",
+ "\n",
+ "@TI.register_fl_task(model='my_model', data_loader='val_data', device='device') \n",
+ "def validate(my_model, val_data, device):\n",
+ " X, Y = val_data[:,:-1], val_data[:,-1] \n",
+ " return {'validation_MSE': my_model.mse(X, Y),}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "40a4623e-6559-4d4c-b199-f9afe16c0bbd",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Run"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fb357a88-7098-45b2-85f4-71fe2f2e0f82",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "experiment_name = 'linear_regression_experiment'\n",
+ "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name,\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "db20124a-949d-4218-abfd-aaf4d0758284",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fl_experiment.start(model_provider=MI, \n",
+ " task_keeper=TI,\n",
+ " data_loader=lin_reg_dataset,\n",
+ " rounds_to_train=10,)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4909be2b-d23b-4356-b2af-10a212382d52",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# This method not only prints messages recieved from the director, \n",
+ "# but also saves logs in the tensorboard format (by default)\n",
+ "fl_experiment.stream_metrics()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dd479019-1579-42c4-a446-f7d0a12596df",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Optional: start tensorboard"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a6faaaea",
+ "metadata": {},
+ "source": [
+ "Running on your own machine locally, start tensorboard in background and open localhost:6006 in your browser:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c5f4b673-e6b1-4bbe-8294-d2b61a65d40b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%script /bin/bash --bg\n",
+ "tensorboard --host $(hostname --all-fqdns | awk '{print $1}') --logdir logs"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "68867a02",
+ "metadata": {},
+ "source": [
+ "In Google Colab you may use the inline extension "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f3684b26",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%load_ext tensorboard\n",
+ "%tensorboard --logdir logs"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b4d27834-ec5b-4290-8c9d-4c3c5589a7e6",
+ "metadata": {},
+ "source": [
+ "### 3. Retrieve the trained model from the Director"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ad915ab3-0032-4a06-b2c0-00710585e24d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "last_model = fl_experiment.get_last_model()\n",
+ "best_model = fl_experiment.get_best_model()\n",
+ "print(best_model.weights)\n",
+ "print(last_model.weights)\n",
+ "print(f\"last model MSE: {last_model.mse(x,y)}\")\n",
+ "print(f\"best model MSE: {best_model.mse(x,y)}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1930789e-b7b5-415e-844d-14ccc3844482",
+ "metadata": {},
+ "source": [
+ "## Lets see what does the unified dataset look like\n",
+ "And see how the trained model performs.\n",
+ "Note: dots of the same colour belong to the same Envoy's dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c51e8a56-d2f1-4758-a5a1-6d6652e4355e",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "n_cols = n_cols\n",
+ "n_samples = n_samples_per_col\n",
+ "interval = 240\n",
+ "x_start = 60\n",
+ "noise = noise\n",
+ "\n",
+ "X = None\n",
+ "\n",
+ "for rank in range(n_cols):\n",
+ " np.random.seed(rank) # Setting seed for reproducibility\n",
+ " x = np.random.rand(n_samples, 1) * interval + x_start\n",
+ " x *= np.pi / 180\n",
+ " X = x if X is None else np.vstack((X,x))\n",
+ " y = np.sin(x) + np.random.normal(0, noise, size=(n_samples, 1))\n",
+ " plt.plot(x,y,'+')\n",
+ " \n",
+ "X.sort() \n",
+ "Y_hat = last_model.predict(X)\n",
+ "plt.plot(X,Y_hat,'--')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9e365766-4ea6-40bc-96ae-a183274e8b8c",
+ "metadata": {},
+ "source": [
+ "## Cleaning"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e5d793be-6c20-4a22-bad7-c082c1ee76ca",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# To stop all services\n",
+ "!pkill fx"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "809b8eb3-4775-43d9-8f96-de84a089a54e",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "remove_configs(config_paths)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d0b28b29-48d3-4f21-bc69-40259b83f93b",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/custom_adapter.py b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/custom_adapter.py
new file mode 100644
index 0000000..e7bb5b3
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/custom_adapter.py
@@ -0,0 +1,21 @@
+# Copyright (C) 2020-2021 Intel Corporation
+# SPDX-License-Identifier: Apache-2.0
+"""Custom model numpy adapter."""
+
+from openfl.plugins.frameworks_adapters.framework_adapter_interface import (
+ FrameworkAdapterPluginInterface,
+)
+
+
+class CustomFrameworkAdapter(FrameworkAdapterPluginInterface):
+ """Framework adapter plugin class."""
+
+ @staticmethod
+ def get_tensor_dict(model, optimizer=None):
+ """Extract tensors from a model."""
+ return {'w': model.weights}
+
+ @staticmethod
+ def set_tensor_dict(model, tensor_dict, optimizer=None, device='cpu'):
+ """Load tensors to a model."""
+ model.weights = tensor_dict['w']
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/requirements.txt b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/requirements.txt
new file mode 100644
index 0000000..ce2479f
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/requirements.txt
@@ -0,0 +1,7 @@
+jupyterlab
+matplotlib
+mistune>=2.0.3 # not directly required, pinned by Snyk to avoid a vulnerability
+numpy
+openfl==1.2.1
+setuptools>=65.5.1 # not directly required, pinned by Snyk to avoid a vulnerability
+wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/start_federation.ipynb b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/start_federation.ipynb
new file mode 100644
index 0000000..9b71200
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/start_federation.ipynb
@@ -0,0 +1,193 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f813b6ae-b082-49bb-b64f-fd619b6de14a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "from pathlib import Path\n",
+ "import yaml\n",
+ "from typing import Dict, List, Union"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d1ee62ab-09e4-4f4c-984f-bdb6909d6106",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the original envoy config file content\n",
+ "with open(Path('../envoy/envoy_config.yaml'), \"r\") as stream:\n",
+ " orig_config = yaml.safe_load(stream)\n",
+ "\n",
+ "def generate_envoy_configs(config: Dict,\n",
+ " save_path: Union[str, Path] = '../envoy/',\n",
+ " n_cols: int = 10,\n",
+ " n_samples_per_col: int = 10,\n",
+ " noise: float = 0.15) -> List[Path]:\n",
+ "\n",
+ " config['shard_descriptor']['params']['n_samples'] = n_samples_per_col\n",
+ " config['shard_descriptor']['params']['noise'] = noise\n",
+ " \n",
+ " config_paths = [(Path(save_path) / f'{i}_envoy_config.yaml').absolute()\n",
+ " for i in range(1, n_cols + 1)]\n",
+ "\n",
+ " for i, path in enumerate(config_paths):\n",
+ " config['shard_descriptor']['params']['rank'] = i\n",
+ " with open(path, \"w\") as stream:\n",
+ " yaml.safe_dump(config, stream)\n",
+ " \n",
+ " return config_paths\n",
+ " \n",
+ "def remove_configs(config_paths):\n",
+ " for path in config_paths:\n",
+ " path.unlink()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0d058340-22d4-4630-b8e3-9c3fc29198ab",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "config_paths = generate_envoy_configs(orig_config, n_cols=20, n_samples_per_col=8, noise=0.3)\n",
+ "# remove_configs(config_paths)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ec065be9-c2c6-4a81-9a2a-ea54794e52ba",
+ "metadata": {},
+ "source": [
+ "## Start the Director service"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "60bcaa49-aabb-42ec-a279-9e32b31ce6ca",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "cwd = Path.cwd()\n",
+ "director_workspace_path = Path('../director/').absolute()\n",
+ "director_config_file = director_workspace_path / 'director_config.yaml'\n",
+ "director_logfile = director_workspace_path / 'director.log'\n",
+ "director_logfile.unlink(missing_ok=True)\n",
+ "# \n",
+ "\n",
+ "os.environ['main_folder'] = str(cwd)\n",
+ "os.environ['director_workspace_path'] = str(director_workspace_path)\n",
+ "os.environ['director_logfile'] = str(director_logfile)\n",
+ "os.environ['director_config_file'] = str(director_config_file)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "72a9268a-ee1e-4dda-a4c4-cfb29428f45e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%script /bin/bash --bg\n",
+ "cd $director_workspace_path\n",
+ "fx director start --disable-tls -c $director_config_file > $director_logfile &\n",
+ "cd $main_folder"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e0a634ea-9c62-4048-bb91-099fe9097b55",
+ "metadata": {},
+ "source": [
+ "## Start Envoys"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "13470bfd-d67e-48dc-b1ff-10c7ff526c0c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# envoy_workspace_path = Path('../envoy/').absolute()\n",
+ "def start_envoys(config_paths: List[Path]) -> None:\n",
+ " envoy_workspace_path = config_paths[0].parent\n",
+ " cwd = Path.cwd()\n",
+ " os.chdir(envoy_workspace_path)\n",
+ " for i, path in enumerate(config_paths):\n",
+ " os.system(f'fx envoy start -n env_{i + 1} --disable-tls '\n",
+ " f'--envoy-config-path {path} -dh localhost -dp 50049 '\n",
+ " f'>env_{i + 1}.log &')\n",
+ " os.chdir(cwd)\n",
+ " \n",
+ "start_envoys(config_paths)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2fc8a569-6978-4c80-88d1-741799407239",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a5fdc3af-63b5-41b5-b9d6-be2aac8626e0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# To stop all services run\n",
+ "!pkill fx"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4e69ae57-bfa3-4047-af7f-3e1cf24ac35e",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "remove_configs(config_paths)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "46095127-f116-4ae3-a3b4-6be24064b49f",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/README.md b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/README.md
new file mode 100644
index 0000000..2485306
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/README.md
@@ -0,0 +1,55 @@
+# Scikit-learn based Linear Regression Tutorial
+
+### 1. About dataset
+
+Generate 1-dimensional noisy data for linear regression of sinusoid.
+
+Define the below pamameter in shard_config in the envoy_config.yaml file as the random seed for the dataset generation for a specific Envoy
+- rank
+
+### 2. About model
+
+Linear Regression Lasso Model based on Scikit-learn.
+
+
+### 3. How to run this tutorial (without TLC and locally as a simulation):
+
+1. Run director:
+
+```sh
+cd director folder
+./start_director.sh
+```
+
+2. Run envoy:
+
+Step 1: Activate virtual environment and install packages
+```
+cd envoy folder
+pip install -r requirements.txt
+```
+Step 2: start the envoy
+```sh
+./start_envoy.sh env_instance_1 envoy_config.yaml
+```
+
+Optional: start second envoy:
+
+- Copy `envoy_folder` to another place and follow the same process as above:
+
+```sh
+./start_envoy.sh env_instance_2 envoy_config_2.yaml
+```
+
+3. Run `scikit_learn_linear_regression.ipynb` jupyter notebook:
+
+```sh
+cd workspace
+jupyter lab scikit_learn_linear_regression.ipynb
+```
+
+4. Visualization
+
+```
+tensorboard --logdir logs/
+```
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/director/director_config.yaml
new file mode 100644
index 0000000..d22b4b7
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/director/director_config.yaml
@@ -0,0 +1,6 @@
+settings:
+ listen_host: localhost
+ listen_port: 50050
+ sample_shape: ['1'] # Modify this param if experimenting with `n_features` of shard_descriptor.
+ target_shape: ['1']
+ envoy_health_check_period: 5 # in seconds
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/director/start_director.sh
new file mode 100755
index 0000000..5806a6c
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/director/start_director.sh
@@ -0,0 +1,4 @@
+#!/bin/bash
+set -e
+
+fx director start --disable-tls -c director_config.yaml
\ No newline at end of file
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/envoy_config.yaml b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/envoy_config.yaml
new file mode 100644
index 0000000..107c566
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/envoy_config.yaml
@@ -0,0 +1,12 @@
+params:
+ cuda_devices: []
+
+optional_plugin_components: {}
+
+shard_descriptor:
+ template: linreg_shard_descriptor.LinRegSD
+ params:
+ rank: 1
+ n_samples: 80
+ noise: 0.15
+
\ No newline at end of file
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/linreg_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/linreg_shard_descriptor.py
new file mode 100644
index 0000000..12bfed9
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/linreg_shard_descriptor.py
@@ -0,0 +1,60 @@
+# Copyright (C) 2020-2021 Intel Corporation
+# SPDX-License-Identifier: Apache-2.0
+"""Noisy-Sin Shard Descriptor."""
+
+from typing import List
+
+import numpy as np
+
+from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor
+
+
+class LinRegSD(ShardDescriptor):
+ """Shard descriptor class."""
+
+ def __init__(self, rank: int, n_samples: int = 10, noise: float = 0.15) -> None:
+ """
+ Initialize LinReg Shard Descriptor.
+
+ This Shard Descriptor generate random data. Sample features are
+ floats between pi/3 and 5*pi/3, and targets are calculated
+ calculated as sin(feature) + normal_noise.
+ """
+ np.random.seed(rank) # Setting seed for reproducibility
+ self.n_samples = max(n_samples, 5)
+ self.interval = 240
+ self.x_start = 60
+ x = np.random.rand(n_samples, 1) * self.interval + self.x_start
+ x *= np.pi / 180
+ y = np.sin(x) + np.random.normal(0, noise, size=(n_samples, 1))
+ self.data = np.concatenate((x, y), axis=1)
+
+ def get_dataset(self, dataset_type: str) -> np.ndarray:
+ """
+ Return a shard dataset by type.
+
+ A simple list with elements (x, y) implemets the Shard Dataset interface.
+ """
+ if dataset_type == 'train':
+ return self.data[:self.n_samples // 2]
+ elif dataset_type == 'val':
+ return self.data[self.n_samples // 2:]
+ else:
+ pass
+
+ @property
+ def sample_shape(self) -> List[str]:
+ """Return the sample shape info."""
+ (*x, _) = self.data[0]
+ return [str(i) for i in np.array(x, ndmin=1).shape]
+
+ @property
+ def target_shape(self) -> List[str]:
+ """Return the target shape info."""
+ (*_, y) = self.data[0]
+ return [str(i) for i in np.array(y, ndmin=1).shape]
+
+ @property
+ def dataset_description(self) -> str:
+ """Return the dataset description."""
+ return 'Allowed dataset types are `train` and `val`'
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/requirements.txt b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/requirements.txt
new file mode 100644
index 0000000..40d18d9
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/requirements.txt
@@ -0,0 +1,7 @@
+matplotlib>=2.0.0
+mistune>=2.0.3 # not directly required, pinned by Snyk to avoid a vulnerability
+numpy>=1.13.3
+openfl>=1.2.1
+scikit-learn>=0.24.1
+setuptools>=65.5.1 # not directly required, pinned by Snyk to avoid a vulnerability
+wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/start_envoy.sh
new file mode 100755
index 0000000..4da0782
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/start_envoy.sh
@@ -0,0 +1,6 @@
+#!/bin/bash
+set -e
+ENVOY_NAME=$1
+ENVOY_CONF=$2
+
+fx envoy start -n "$ENVOY_NAME" --disable-tls --envoy-config-path "$ENVOY_CONF" -dh localhost -dp 50050
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/custom_adapter.py b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/custom_adapter.py
new file mode 100644
index 0000000..6991d2b
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/custom_adapter.py
@@ -0,0 +1,21 @@
+# Copyright (C) 2020-2023 Intel Corporation
+# SPDX-License-Identifier: Apache-2.0
+"""Custom model numpy adapter."""
+
+from openfl.plugins.frameworks_adapters.framework_adapter_interface import (
+ FrameworkAdapterPluginInterface,
+)
+
+
+class CustomFrameworkAdapter(FrameworkAdapterPluginInterface):
+ """Framework adapter plugin class."""
+
+ @staticmethod
+ def get_tensor_dict(model, optimizer=None):
+ """Extract tensors from a model."""
+ return {'w': model.weights}
+
+ @staticmethod
+ def set_tensor_dict(model, tensor_dict, optimizer=None, device='cpu'):
+ """Load tensors to a model."""
+ model.weights = tensor_dict['w']
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/requirements.txt b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/requirements.txt
new file mode 100644
index 0000000..40d18d9
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/requirements.txt
@@ -0,0 +1,7 @@
+matplotlib>=2.0.0
+mistune>=2.0.3 # not directly required, pinned by Snyk to avoid a vulnerability
+numpy>=1.13.3
+openfl>=1.2.1
+scikit-learn>=0.24.1
+setuptools>=65.5.1 # not directly required, pinned by Snyk to avoid a vulnerability
+wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/scikit_learn_linear_regression.ipynb b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/scikit_learn_linear_regression.ipynb
new file mode 100644
index 0000000..4ef7023
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/scikit_learn_linear_regression.ipynb
@@ -0,0 +1,420 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "689ee822",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!pip install -r requirements.txt"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d63e64c6-9955-4afc-8d04-d8c85bb28edc",
+ "metadata": {},
+ "source": [
+ "# Scikit-learn Linear Regression Example - Interactive API"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6c9eee14-22a1-4d48-a7da-e68d01037cd4",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "from typing import List, Union\n",
+ "\n",
+ "from sklearn.linear_model import Lasso\n",
+ "from sklearn.preprocessing import StandardScaler\n",
+ "from sklearn.datasets import make_regression\n",
+ "from sklearn.metrics import mean_squared_error\n",
+ "import numpy as np\n",
+ "import random\n",
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline\n",
+ "from matplotlib.pylab import rcParams\n",
+ "rcParams['figure.figsize'] = 7, 5"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c4b334ef-6a72-4b82-b978-1401973d0512",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "# We will use MSE as loss function and Ridge weights regularization\n",
+ "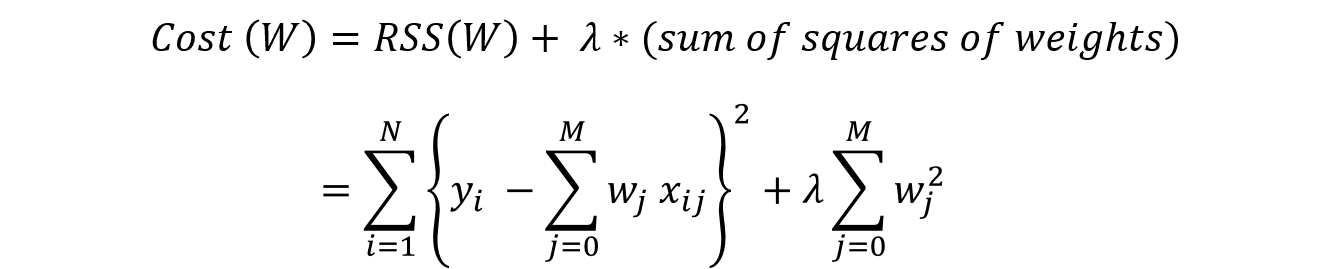"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f4cc8ec2-b818-4db8-8700-39c1a12917df",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "class SklearnLinearRegressionLasso:\n",
+ " def __init__(self, n_feat: int, alpha: float = 1.0) -> None:\n",
+ " self.model = Lasso(alpha=alpha)\n",
+ " self.scaler = StandardScaler()\n",
+ " self.weights = np.ones((n_feat + 1)) \n",
+ " \n",
+ " def predict(self, feature_vector: Union[np.ndarray, List[int]]) -> float:\n",
+ " '''\n",
+ " feature_vector may be a list or have shape (n_feat,)\n",
+ " or it may be a bunch of vectors (n_vec, nfeat)\n",
+ " '''\n",
+ " feature_vector = np.array(feature_vector)\n",
+ " if len(feature_vector.shape) == 1:\n",
+ " feature_vector = feature_vector[:,np.newaxis]\n",
+ " \n",
+ " feature_vector = self.scaler.transform(feature_vector)\n",
+ " return self.model.predict(feature_vector)\n",
+ " \n",
+ " def mse(self, X: np.ndarray, Y: np.ndarray) -> float:\n",
+ " Y_predict = self.predict(X)\n",
+ " return mean_squared_error(Y, Y_predict)\n",
+ " \n",
+ " def fit(self, X: np.ndarray, Y: np.ndarray, silent: bool=False) -> None:\n",
+ " \n",
+ " X = self.scaler.fit_transform(X)\n",
+ " self.model.fit(X, Y)\n",
+ " mse = self.mse(X, Y)\n",
+ " #self.weights[:-1] = self.model.coef_\n",
+ " #self.weights[-1] = self.model.intercept_\n",
+ " if not silent:\n",
+ " print(f'MSE: {mse}')\n",
+ " \n",
+ " def print_parameters(self) -> None:\n",
+ " print('Final parameters: ')\n",
+ " print(f'Weights: {self.model.coef_}')\n",
+ " print(f'Bias: {self.model.intercept_}')\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "af89e7e5-6cfc-46bc-acd2-7d5bfb373091",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Define input array with angles from 60deg to 300deg converted to radians\n",
+ "x = np.array([i*np.pi/180 for i in range(60,300,4)])\n",
+ "np.random.seed(10) # Setting seed for reproducibility\n",
+ "y = np.sin(x) + np.random.normal(0,0.15,len(x))\n",
+ "# plt.plot(x,y,'.')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ffefca2b-d7f6-4111-8872-c017c182a2de",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "lr_model = SklearnLinearRegressionLasso(n_feat=1, alpha=0.1)\n",
+ "\n",
+ "lr_model.fit(x[:,np.newaxis], y)\n",
+ "\n",
+ "#print the final parameters\n",
+ "lr_model.print_parameters()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "410f2d80-989a-43ab-958f-7b68fd8f2e90",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# We can also solve this 1D problem using Numpy\n",
+ "numpy_solution = np.polyfit(x,y,1)\n",
+ "predictor_np = np.poly1d(numpy_solution)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6cb323db-9f3a-42af-94da-4b170adef867",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "y_hat = lr_model.predict(x)\n",
+ "y_np = predictor_np(x)\n",
+ "plt.plot(x,y,'.')\n",
+ "plt.plot(x,y_hat,'.')\n",
+ "plt.plot(x,y_np,'--')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ffd4d2d7-5537-496a-88c1-301da87d979c",
+ "metadata": {},
+ "source": [
+ "# Now we run the same training on federated data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "09cf7090-da51-4f4e-9d28-2a5c6e3bca02",
+ "metadata": {},
+ "source": [
+ "## Connect to a Federation"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1b3c0039-e1f7-4047-b98b-a2d4bd42f015",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Create a federation\n",
+ "from openfl.interface.interactive_api.federation import Federation\n",
+ "\n",
+ "# please use the same identificator that was used in signed certificate\n",
+ "client_id = 'frontend'\n",
+ "director_node_fqdn = 'localhost'\n",
+ "director_port = 50050\n",
+ "\n",
+ "federation = Federation(\n",
+ " client_id=client_id,\n",
+ " director_node_fqdn=director_node_fqdn,\n",
+ " director_port=director_port,\n",
+ " tls=False\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7815120e-b704-4a7d-a65a-3c7542023ead",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "shard_registry = federation.get_shard_registry()\n",
+ "shard_registry"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b011dd95-64a7-4a8b-91ec-e61cdf885bbb",
+ "metadata": {},
+ "source": [
+ "### Data"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b1985ac9-a2b1-4561-a962-6adfe35c3b97",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment\n",
+ "\n",
+ "class LinRegDataSet(DataInterface):\n",
+ " def __init__(self, **kwargs):\n",
+ " \"\"\"Initialize DataLoader.\"\"\"\n",
+ " self.kwargs = kwargs\n",
+ " pass\n",
+ "\n",
+ " @property\n",
+ " def shard_descriptor(self):\n",
+ " \"\"\"Return shard descriptor.\"\"\"\n",
+ " return self._shard_descriptor\n",
+ " \n",
+ " @shard_descriptor.setter\n",
+ " def shard_descriptor(self, shard_descriptor):\n",
+ " \"\"\"\n",
+ " Describe per-collaborator procedures or sharding.\n",
+ "\n",
+ " This method will be called during a collaborator initialization.\n",
+ " Local shard_descriptor will be set by Envoy.\n",
+ " \"\"\"\n",
+ " self._shard_descriptor = shard_descriptor\n",
+ " self.train_set = shard_descriptor.get_dataset(\"train\")\n",
+ " self.val_set = shard_descriptor.get_dataset(\"val\")\n",
+ "\n",
+ " def get_train_loader(self, **kwargs):\n",
+ " \"\"\"Output of this method will be provided to tasks with optimizer in contract.\"\"\"\n",
+ " return self.train_set\n",
+ "\n",
+ " def get_valid_loader(self, **kwargs):\n",
+ " \"\"\"Output of this method will be provided to tasks without optimizer in contract.\"\"\"\n",
+ " return self.val_set\n",
+ "\n",
+ " def get_train_data_size(self):\n",
+ " \"\"\"Information for aggregation.\"\"\"\n",
+ " return len(self.train_set)\n",
+ "\n",
+ " def get_valid_data_size(self):\n",
+ " \"\"\"Information for aggregation.\"\"\"\n",
+ " return len(self.val_set)\n",
+ " \n",
+ "lin_reg_dataset = LinRegDataSet()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b8909127-99d1-4dba-86fe-01a1b86585e7",
+ "metadata": {},
+ "source": [
+ "### Model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9523c9a2-a259-461f-937f-1fb054bd2886",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "framework_adapter = 'custom_adapter.CustomFrameworkAdapter'\n",
+ "fed_model = SklearnLinearRegressionLasso(n_feat=1, alpha=0.1)\n",
+ "MI = ModelInterface(model=fed_model, optimizer=None, framework_plugin=framework_adapter)\n",
+ "\n",
+ "# Save the initial model state\n",
+ "initial_model = SklearnLinearRegressionLasso(n_feat=1, alpha=0.1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2e3558bb-b21b-48ac-b07e-43cf75e6907b",
+ "metadata": {},
+ "source": [
+ "### Tasks\n",
+ "We need to employ a trick reporting metrics. OpenFL decides which model is the best based on an *increasing* metric."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f73e1ff9-d54a-49b5-9ce8-8bc72c6a2c6f",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "TI = TaskInterface()\n",
+ "\n",
+ "@TI.register_fl_task(model='my_model', data_loader='train_data', \\\n",
+ " device='device', optimizer='optimizer') \n",
+ "def train(my_model, train_data, optimizer, device):\n",
+ " X, Y = train_data[:,:-1], train_data[:,-1]\n",
+ " my_model.fit(X, Y, silent=True)\n",
+ " return {'train_MSE': my_model.mse(X, Y),}\n",
+ "\n",
+ "@TI.register_fl_task(model='my_model', data_loader='val_data', device='device') \n",
+ "def validate(my_model, val_data, device):\n",
+ " X, Y = val_data[:,:-1], val_data[:,-1] \n",
+ " return {'validation_MSE': my_model.mse(X, Y),}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ee7659cc-6e03-43f5-9078-95707fa0e4d5",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Run"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "749100e8-05ce-418c-a980-545e3beb900b",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "experiment_name = 'linear_regression_experiment'\n",
+ "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name,\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "16bf1df7-8ca8-4a5e-a833-47c265c11e05",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "fl_experiment.start(model_provider=MI, \n",
+ " task_keeper=TI,\n",
+ " data_loader=lin_reg_dataset,\n",
+ " rounds_to_train=10,)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1178d1ea-05e6-46be-ac07-21620bd6ec76",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "fl_experiment.stream_metrics()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c04b4ab2-1d40-44c7-907b-a6a7d176c959",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.13"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "140705fc-4af3-4668-a26b-2ebe2d42575e",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# create a dataset with n_features\n",
+ "X, y = make_regression(n_samples=100, n_features=1, noise=10, random_state=42)\n",
+ "\n",
+ "# Train test split - Default 0.75/0.25\n",
+ "X, X_test, y, y_test = train_test_split(X, y, random_state=42)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a2665d0b-78ce-4caf-a4ca-a9decffaa96f",
+ "metadata": {},
+ "source": [
+ "Visualize data distribution"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "68f5afbf-e010-4d4a-bb92-46de06d39866",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "_ = plt.scatter(X, y)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ebe555dd-9e8d-4e80-bfde-87e3cafac14c",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "_ = plt.scatter(X_test, y_test)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "68a7ddb3-166e-447f-a8f1-881511cfbd9f",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# JAX logical execution plan\n",
+ "print(jax.make_jaxpr(update)(jnp.ones(X.shape[1]), X, y, 0.01))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "574bac29-b5c2-4f41-8655-e98450fdef8d",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# X.shape -> (n_samples, n_features)\n",
+ "\n",
+ "lr_model = LinearRegression(X.shape[1])\n",
+ "lr = 0.01\n",
+ "epochs = 101\n",
+ "\n",
+ "print(f\"Initial Test MSE: {lr_model.mse(X_test,y_test)}\")\n",
+ "\n",
+ "# silent: logging verbosity\n",
+ "lr_model.fit(X,y, epochs, lr, silent=False)\n",
+ "\n",
+ "print(f\"Final Test MSE: {lr_model.mse(X_test,y_test)}\")\n",
+ "\n",
+ "print(f\"Final parameters: {lr_model.weights}\")"
+ ]
+ }
+ ],
+ "metadata": {
+ "interpreter": {
+ "hash": "916dbcbb3f70747c44a77c7bcd40155683ae19c65e1c03b4aa3499c5328201f1"
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/openfl_contrib_tutorials/interactive_api/jax_linear_regression/workspace/custom_adapter.py b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/workspace/custom_adapter.py
new file mode 100644
index 0000000..35345df
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/jax_linear_regression/workspace/custom_adapter.py
@@ -0,0 +1,21 @@
+# Copyright (C) 2020-2022 Intel Corporation
+# SPDX-License-Identifier: Apache-2.0
+"""Custom model numpy adapter."""
+
+from openfl.plugins.frameworks_adapters.framework_adapter_interface import (
+ FrameworkAdapterPluginInterface,
+)
+
+
+class CustomFrameworkAdapter(FrameworkAdapterPluginInterface):
+ """Framework adapter plugin class."""
+
+ @staticmethod
+ def get_tensor_dict(model, optimizer=None):
+ """Extract tensors from a model."""
+ return {'w': model.weights}
+
+ @staticmethod
+ def set_tensor_dict(model, tensor_dict, optimizer=None, device='cpu'):
+ """Load tensors to a model."""
+ model.weights = tensor_dict['w']
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/README.md b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/README.md
new file mode 100644
index 0000000..8a2c360
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/README.md
@@ -0,0 +1,24 @@
+# Linear Regression with Numpy and OpenFL
+
+This example is devoted to demonstrating several techniques of working with OpenFL.
+
+1. Envoy workspace contains a Shard Descriptor designed to generate 1-dimensional noisy data for linear regression of sinusoid. The random seed for generation for a specific Envoy is parametrized by the `rank` argument in shard_config.
+2. The LinReg frontend jupyter notebook (data scientist's entry point) features a simple numpy-based model for linear regression trained with Ridge regularization.
+3. The data scientist's workspace also contains a custom framework adapter allowing extracting and setting weights to the custom model.
+4. The start_federation notebook provides shortcut methods to start a Federation with an arbitrary number of Envoys with different datasets. It may save time for people willing to conduct one-node experiments.
+5. The SingleNotebook jupyter notebook combines two aforementioned notebooks and allows to run the whole pipeline in Google colab. Besides previously mentioned components, it contains scripts for pulling the OpenFL repo with the example workspaces and installing dependencies.
+
+## How to use this example
+### Locally:
+1. Start a Federation
+Distributed experiments:
+Use OpenFL CLI to start the Director and Envoy services from corresponding folders.
+Single-node experiments:
+Users may use the same path or benefit from the start_federation notebook in the workspace folder
+
+2. Submit an experiment
+Follow LinReg jupyter notebook.
+
+### Google Colab:
+
+[](https://colab.research.google.com/github/intel/openfl/blob/develop/openfl-tutorials/interactive_api/numpy_linear_regression/workspace/SingleNotebook.ipynb)
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/director/director_config.yaml
new file mode 100644
index 0000000..478cd5c
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/director/director_config.yaml
@@ -0,0 +1,6 @@
+settings:
+ listen_host: localhost
+ listen_port: 50049
+ sample_shape: ['1']
+ target_shape: ['1']
+ envoy_health_check_period: 5 # in seconds
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/envoy_config.yaml b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/envoy_config.yaml
new file mode 100644
index 0000000..107c566
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/envoy_config.yaml
@@ -0,0 +1,12 @@
+params:
+ cuda_devices: []
+
+optional_plugin_components: {}
+
+shard_descriptor:
+ template: linreg_shard_descriptor.LinRegSD
+ params:
+ rank: 1
+ n_samples: 80
+ noise: 0.15
+
\ No newline at end of file
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/linreg_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/linreg_shard_descriptor.py
new file mode 100644
index 0000000..12bfed9
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/linreg_shard_descriptor.py
@@ -0,0 +1,60 @@
+# Copyright (C) 2020-2021 Intel Corporation
+# SPDX-License-Identifier: Apache-2.0
+"""Noisy-Sin Shard Descriptor."""
+
+from typing import List
+
+import numpy as np
+
+from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor
+
+
+class LinRegSD(ShardDescriptor):
+ """Shard descriptor class."""
+
+ def __init__(self, rank: int, n_samples: int = 10, noise: float = 0.15) -> None:
+ """
+ Initialize LinReg Shard Descriptor.
+
+ This Shard Descriptor generate random data. Sample features are
+ floats between pi/3 and 5*pi/3, and targets are calculated
+ calculated as sin(feature) + normal_noise.
+ """
+ np.random.seed(rank) # Setting seed for reproducibility
+ self.n_samples = max(n_samples, 5)
+ self.interval = 240
+ self.x_start = 60
+ x = np.random.rand(n_samples, 1) * self.interval + self.x_start
+ x *= np.pi / 180
+ y = np.sin(x) + np.random.normal(0, noise, size=(n_samples, 1))
+ self.data = np.concatenate((x, y), axis=1)
+
+ def get_dataset(self, dataset_type: str) -> np.ndarray:
+ """
+ Return a shard dataset by type.
+
+ A simple list with elements (x, y) implemets the Shard Dataset interface.
+ """
+ if dataset_type == 'train':
+ return self.data[:self.n_samples // 2]
+ elif dataset_type == 'val':
+ return self.data[self.n_samples // 2:]
+ else:
+ pass
+
+ @property
+ def sample_shape(self) -> List[str]:
+ """Return the sample shape info."""
+ (*x, _) = self.data[0]
+ return [str(i) for i in np.array(x, ndmin=1).shape]
+
+ @property
+ def target_shape(self) -> List[str]:
+ """Return the target shape info."""
+ (*_, y) = self.data[0]
+ return [str(i) for i in np.array(y, ndmin=1).shape]
+
+ @property
+ def dataset_description(self) -> str:
+ """Return the dataset description."""
+ return 'Allowed dataset types are `train` and `val`'
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/requirements.txt b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/requirements.txt
new file mode 100644
index 0000000..fb452e0
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/envoy/requirements.txt
@@ -0,0 +1,5 @@
+mistune>=2.0.3 # not directly required, pinned by Snyk to avoid a vulnerability
+numpy
+openfl==1.2.1
+setuptools>=65.5.1 # not directly required, pinned by Snyk to avoid a vulnerability
+wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/LinReg.ipynb b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/LinReg.ipynb
new file mode 100644
index 0000000..3e4131d
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/LinReg.ipynb
@@ -0,0 +1,485 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "689ee822",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!pip install -r requirements.txt"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d63e64c6-9955-4afc-8d04-d8c85bb28edc",
+ "metadata": {},
+ "source": [
+ "# Linear Regression with Numpy and OpenFL"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6c9eee14-22a1-4d48-a7da-e68d01037cd4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from typing import List, Union\n",
+ "import numpy as np\n",
+ "import random\n",
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline\n",
+ "from matplotlib.pylab import rcParams\n",
+ "rcParams['figure.figsize'] = 7, 5"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c4b334ef-6a72-4b82-b978-1401973d0512",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "# We will use MSE as loss function and Ridge weights regularization\n",
+ "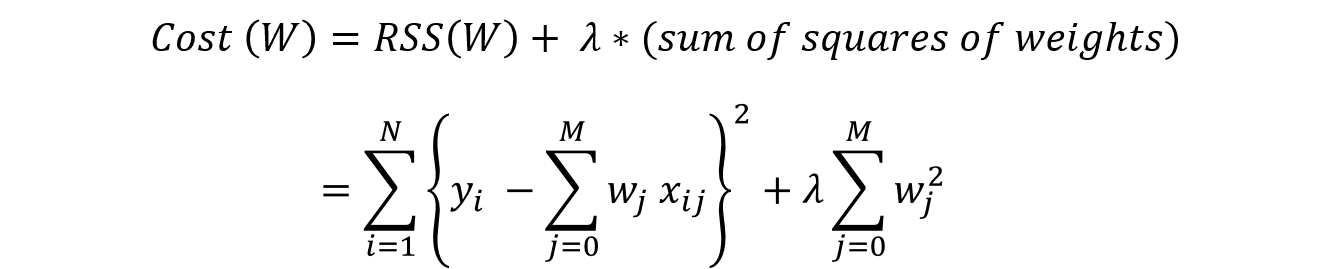"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f4cc8ec2-b818-4db8-8700-39c1a12917df",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class LinRegLasso:\n",
+ " def __init__(self, n_feat: int) -> None:\n",
+ " self.weights = np.ones((n_feat + 1)) # (n_feat + 1,) weights + bias\n",
+ " \n",
+ " def predict(self, feature_vector: Union[np.ndarray, List[int]]) -> float:\n",
+ " '''\n",
+ " feature_vector may be a list or have shape (n_feat,)\n",
+ " or it may be a bunch of vectors (n_vec, nfeat)\n",
+ " '''\n",
+ " feature_vector = np.array(feature_vector)\n",
+ " if len(feature_vector.shape) == 1:\n",
+ " feature_vector = feature_vector[:,np.newaxis]\n",
+ " assert feature_vector.shape[-1] == self.weights.shape[0] - 1, \\\n",
+ " f\"sample shape is {feature_vector.shape} and weights shape is f{self.weights}\"\n",
+ " \n",
+ " return self.weights @ np.concatenate((feature_vector.T, [[1]*feature_vector.shape[0]]))\n",
+ " \n",
+ " def mse(self, X: np.ndarray, Y: np.ndarray) -> float:\n",
+ " Y_hat = self.predict(X)\n",
+ " return np.sum((Y - Y_hat)**2) / Y.shape[0]\n",
+ "\n",
+ " def _update_weights(self, X: np.ndarray, Y: np.ndarray, lr: float, wd: float) -> None:\n",
+ " '''\n",
+ " X: (n_samples, n_features)\n",
+ " Y: (n_samples,)\n",
+ " self.weights: (n_features + 1)\n",
+ " \n",
+ " Cost function is MSE: (y - W*X - b)**2;\n",
+ " its derivative with resp to any x is -2*X*(y - W*X - b),\n",
+ " and with resp to b is -2*(y - W*X - b).\n",
+ " \n",
+ " Regularisation function is L1 |W|;\n",
+ " its derivative is SIGN(w)\n",
+ " '''\n",
+ " predictions = self.predict(X)\n",
+ " error = Y - predictions # (n_samples,)\n",
+ " X_with_bias = np.concatenate((X.T, [[1]*X.shape[0]])).T\n",
+ " updates = -2 * X_with_bias.T @ error / Y.shape[0]\n",
+ " regression_term = np.sign(self.weights)\n",
+ " \n",
+ " self.weights = self.weights - lr * updates + wd * regression_term\n",
+ " \n",
+ " def fit(self, X: np.ndarray, Y: np.ndarray,\n",
+ " n_epochs: int, lr: float, wd: float,\n",
+ " silent: bool=False) -> None:\n",
+ " for i in range(n_epochs):\n",
+ " self._update_weights(X, Y, lr, wd)\n",
+ " mse = self.mse(X, Y)\n",
+ " if not silent:\n",
+ " print(f'epoch: {i}, \\t MSE: {mse}')\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "af89e7e5-6cfc-46bc-acd2-7d5bfb373091",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Define input array with angles from 60deg to 300deg converted to radians\n",
+ "x = np.array([i*np.pi/180 for i in range(60,300,4)])\n",
+ "np.random.seed(10) # Setting seed for reproducibility\n",
+ "y = np.sin(x) + np.random.normal(0,0.15,len(x))\n",
+ "# plt.plot(x,y,'.')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ffefca2b-d7f6-4111-8872-c017c182a2de",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "lr_model = LinRegLasso(1)\n",
+ "wd = 0.0001\n",
+ "lr = 0.08\n",
+ "epochs = 100\n",
+ "\n",
+ "print(f\"Initila MSE: {lr_model.mse(x,y)}\")\n",
+ "lr_model.fit(x[:,np.newaxis],y, epochs, lr, wd, silent=True)\n",
+ "print(f\"Final MSE: {lr_model.mse(x,y)}\")\n",
+ "print(f\"Final parameters: {lr_model.weights}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "410f2d80-989a-43ab-958f-7b68fd8f2e90",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# We can also solve this 1D problem using Numpy\n",
+ "numpy_solution = np.polyfit(x,y,1)\n",
+ "predictor_np = np.poly1d(numpy_solution)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6cb323db-9f3a-42af-94da-4b170adef867",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "y_hat = lr_model.predict(x)\n",
+ "y_np = predictor_np(x)\n",
+ "plt.plot(x,y,'.')\n",
+ "plt.plot(x,y_hat,'.')\n",
+ "plt.plot(x,y_np,'--')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ffd4d2d7-5537-496a-88c1-301da87d979c",
+ "metadata": {},
+ "source": [
+ "# Now we run the same training on federated data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "09cf7090-da51-4f4e-9d28-2a5c6e3bca02",
+ "metadata": {},
+ "source": [
+ "## Connect to a Federation"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1b3c0039-e1f7-4047-b98b-a2d4bd42f015",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Create a federation\n",
+ "from openfl.interface.interactive_api.federation import Federation\n",
+ "\n",
+ "# please use the same identificator that was used in signed certificate\n",
+ "client_id = 'frontend'\n",
+ "director_node_fqdn = 'localhost'\n",
+ "director_port = 50049\n",
+ "\n",
+ "federation = Federation(\n",
+ " client_id=client_id,\n",
+ " director_node_fqdn=director_node_fqdn,\n",
+ " director_port=director_port,\n",
+ " tls=False\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7815120e-b704-4a7d-a65a-3c7542023ead",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "shard_registry = federation.get_shard_registry()\n",
+ "shard_registry"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b011dd95-64a7-4a8b-91ec-e61cdf885bbb",
+ "metadata": {},
+ "source": [
+ "### Data"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b1985ac9-a2b1-4561-a962-6adfe35c3b97",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment\n",
+ "\n",
+ "class LinRegDataSet(DataInterface):\n",
+ " def __init__(self, **kwargs):\n",
+ " \"\"\"Initialize DataLoader.\"\"\"\n",
+ " self.kwargs = kwargs\n",
+ " pass\n",
+ "\n",
+ " @property\n",
+ " def shard_descriptor(self):\n",
+ " \"\"\"Return shard descriptor.\"\"\"\n",
+ " return self._shard_descriptor\n",
+ " \n",
+ " @shard_descriptor.setter\n",
+ " def shard_descriptor(self, shard_descriptor):\n",
+ " \"\"\"\n",
+ " Describe per-collaborator procedures or sharding.\n",
+ "\n",
+ " This method will be called during a collaborator initialization.\n",
+ " Local shard_descriptor will be set by Envoy.\n",
+ " \"\"\"\n",
+ " self._shard_descriptor = shard_descriptor\n",
+ " self.train_set = shard_descriptor.get_dataset(\"train\")\n",
+ " self.val_set = shard_descriptor.get_dataset(\"val\")\n",
+ "\n",
+ " def get_train_loader(self, **kwargs):\n",
+ " \"\"\"Output of this method will be provided to tasks with optimizer in contract.\"\"\"\n",
+ " return self.train_set\n",
+ "\n",
+ " def get_valid_loader(self, **kwargs):\n",
+ " \"\"\"Output of this method will be provided to tasks without optimizer in contract.\"\"\"\n",
+ " return self.val_set\n",
+ "\n",
+ " def get_train_data_size(self):\n",
+ " \"\"\"Information for aggregation.\"\"\"\n",
+ " return len(self.train_set)\n",
+ "\n",
+ " def get_valid_data_size(self):\n",
+ " \"\"\"Information for aggregation.\"\"\"\n",
+ " return len(self.val_set)\n",
+ " \n",
+ "lin_reg_dataset = LinRegDataSet()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b8909127-99d1-4dba-86fe-01a1b86585e7",
+ "metadata": {},
+ "source": [
+ "### Model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9523c9a2-a259-461f-937f-1fb054bd2886",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "framework_adapter = 'custom_adapter.CustomFrameworkAdapter'\n",
+ "fed_model = LinRegLasso(1)\n",
+ "MI = ModelInterface(model=fed_model, optimizer=None, framework_plugin=framework_adapter)\n",
+ "\n",
+ "# Save the initial model state\n",
+ "initial_model = LinRegLasso(1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2e3558bb-b21b-48ac-b07e-43cf75e6907b",
+ "metadata": {},
+ "source": [
+ "### Tasks\n",
+ "We need to employ a trick reporting metrics. OpenFL decides which model is the best based on an *increasing* metric."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f73e1ff9-d54a-49b5-9ce8-8bc72c6a2c6f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "TI = TaskInterface()\n",
+ "\n",
+ "@TI.add_kwargs(**{'lr': 0.001,\n",
+ " 'wd': 0.0001,\n",
+ " 'epoches': 1})\n",
+ "@TI.register_fl_task(model='my_model', data_loader='train_data', \\\n",
+ " device='device', optimizer='optimizer') \n",
+ "def train(my_model, train_data, optimizer, device, lr, wd, epoches):\n",
+ " X, Y = train_data[:,:-1], train_data[:,-1]\n",
+ " my_model.fit(X, Y, epochs, lr, wd, silent=True)\n",
+ " return {'train_MSE': my_model.mse(X, Y),}\n",
+ "\n",
+ "@TI.register_fl_task(model='my_model', data_loader='val_data', device='device') \n",
+ "def validate(my_model, val_data, device):\n",
+ " X, Y = val_data[:,:-1], val_data[:,-1] \n",
+ " return {'validation_MSE': my_model.mse(X, Y),}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ee7659cc-6e03-43f5-9078-95707fa0e4d5",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Run"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "749100e8-05ce-418c-a980-545e3beb900b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "experiment_name = 'linear_regression_experiment'\n",
+ "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name,\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "16bf1df7-8ca8-4a5e-a833-47c265c11e05",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fl_experiment.start(model_provider=MI, \n",
+ " task_keeper=TI,\n",
+ " data_loader=lin_reg_dataset,\n",
+ " rounds_to_train=10,)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1178d1ea-05e6-46be-ac07-21620bd6ec76",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "fl_experiment.stream_metrics()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "af331ccd-66b4-4925-8627-52cf03ceea5e",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Optional: start tensorboard"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fde4ed4d-dda5-4bab-8dd3-e1ac44f5acf9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%script /bin/bash --bg\n",
+ "tensorboard --host $(hostname --all-fqdns | awk '{print $1}') --logdir logs"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7aa78602-b66a-4378-bea9-e915f2a1fdd8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "last_model = fl_experiment.get_last_model()\n",
+ "best_model = fl_experiment.get_best_model()\n",
+ "print(best_model.weights)\n",
+ "print(last_model.weights)\n",
+ "print(f\"last model MSE: {last_model.mse(x,y)}\")\n",
+ "print(f\"best model MSE: {best_model.mse(x,y)}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ae66d688",
+ "metadata": {},
+ "source": [
+ "### Evaluate results"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "573417e0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "n_cols = 20\n",
+ "n_samples = 4\n",
+ "interval = 240\n",
+ "x_start = 60\n",
+ "noise = 0.3\n",
+ "\n",
+ "X = None\n",
+ "\n",
+ "for rank in range(n_cols):\n",
+ " np.random.seed(rank) # Setting seed for reproducibility\n",
+ " x = np.random.rand(n_samples, 1) * interval + x_start\n",
+ " x *= np.pi / 180\n",
+ " X = x if X is None else np.vstack((X,x))\n",
+ " y = np.sin(x) + np.random.normal(0, noise, size=(n_samples, 1))\n",
+ " plt.plot(x,y,'+')\n",
+ " \n",
+ "X.sort() \n",
+ "Y_hat = last_model.predict(X)\n",
+ "plt.plot(X,Y_hat,'--')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "84e927c8",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/SingleNotebook.ipynb b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/SingleNotebook.ipynb
new file mode 100644
index 0000000..d0de783
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/SingleNotebook.ipynb
@@ -0,0 +1,810 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "4dd5da0c-1ae1-43e6-8ad9-360c8974476c",
+ "metadata": {},
+ "source": [
+ "[](https://colab.research.google.com/github/intel/openfl/blob/develop/openfl-tutorials/interactive_api/numpy_linear_regression/workspace/SingleNotebook.ipynb)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1637381d-84d0-4132-92c3-bf1a1e9c7f7a",
+ "metadata": {},
+ "source": [
+ "# Linear Regression with Numpy and OpenFL"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ee73e205-d273-4b6c-878a-5ea958bfe267",
+ "metadata": {},
+ "source": [
+ "### Preparations in colab:\n",
+ "1. Install OpenFL \n",
+ "2. Clone the OpenFL repository, it contains infrastructure configs for this example.\n",
+ "3. Change working directory "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c6fafe9e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!pip install openfl\n",
+ "!git clone https://github.com/securefederatedai/openfl.git"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2698f1da-fa69-4543-bb15-c7c0dcb776b9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "import os\n",
+ "\n",
+ "# Logging fix for Google Colab\n",
+ "log = logging.getLogger()\n",
+ "log.setLevel(logging.INFO)\n",
+ "\n",
+ "os.chdir('./openfl/openfl-tutorials/interactive_api/numpy_linear_regression/workspace')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fde856d8-da4e-4d2f-bee2-85e673050623",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from typing import List, Union\n",
+ "import numpy as np\n",
+ "import random\n",
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline\n",
+ "from matplotlib.pylab import rcParams\n",
+ "rcParams['figure.figsize'] = 7, 5"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "72e76f9d",
+ "metadata": {},
+ "source": [
+ "# Define a linear model and train it locally\n",
+ "We start with training a linear model locally on a synthetic dataset so we have a baseline solution."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5e06d979-c582-4f44-b092-e5d60cce88bf",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## We will use MSE as loss function and Ridge weights regularization\n",
+ "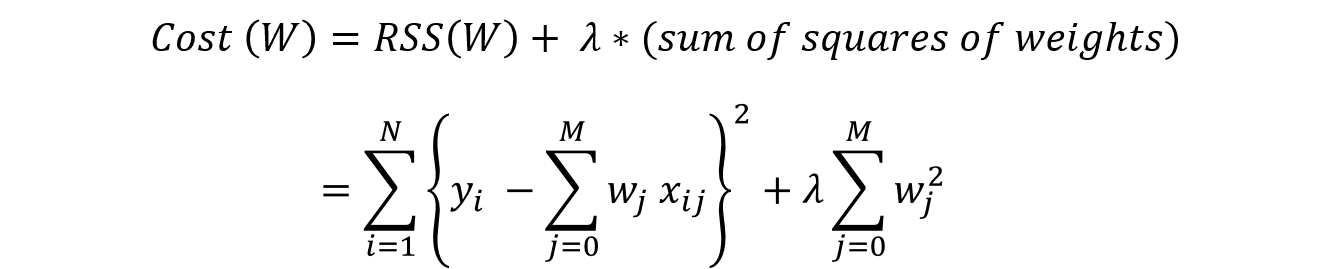"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c9a860ab-91a5-410e-9d1e-4b9bd5a33d70",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class LinRegLasso:\n",
+ " def __init__(self, n_feat: int) -> None:\n",
+ " self.weights = np.ones((n_feat + 1)) # (n_feat + 1,) weights + bias\n",
+ " \n",
+ " def predict(self, feature_vector: Union[np.ndarray, List[int]]) -> float:\n",
+ " '''\n",
+ " feature_vector may be a list or have shape (n_feat,)\n",
+ " or it may be a bunch of vectors (n_vec, nfeat)\n",
+ " '''\n",
+ " feature_vector = np.array(feature_vector)\n",
+ " if len(feature_vector.shape) == 1:\n",
+ " feature_vector = feature_vector[:,np.newaxis]\n",
+ " assert feature_vector.shape[-1] == self.weights.shape[0] - 1, \\\n",
+ " f\"sample shape is {feature_vector.shape} and weights shape is f{self.weights}\"\n",
+ " \n",
+ " return self.weights @ np.concatenate((feature_vector.T, [[1]*feature_vector.shape[0]]))\n",
+ " \n",
+ " def mse(self, X: np.ndarray, Y: np.ndarray) -> float:\n",
+ " Y_hat = self.predict(X)\n",
+ " return np.sum((Y - Y_hat)**2) / Y.shape[0]\n",
+ "\n",
+ " def _update_weights(self, X: np.ndarray, Y: np.ndarray, lr: float, wd: float) -> None:\n",
+ " '''\n",
+ " X: (n_samples, n_features)\n",
+ " Y: (n_samples,)\n",
+ " self.weights: (n_features + 1)\n",
+ " \n",
+ " Cost function is MSE: (y - W*X - b)**2;\n",
+ " its derivative with resp to any x is -2*X*(y - W*X - b),\n",
+ " and with resp to b is -2*(y - W*X - b).\n",
+ " \n",
+ " Regularisation function is L1 |W|;\n",
+ " its derivative is SIGN(w)\n",
+ " '''\n",
+ " predictions = self.predict(X)\n",
+ " error = Y - predictions # (n_samples,)\n",
+ " X_with_bias = np.concatenate((X.T, [[1]*X.shape[0]])).T\n",
+ " updates = -2 * X_with_bias.T @ error / Y.shape[0]\n",
+ " regression_term = np.sign(self.weights)\n",
+ " \n",
+ " self.weights = self.weights - lr * updates + wd * regression_term\n",
+ " \n",
+ " def fit(self, X: np.ndarray, Y: np.ndarray,\n",
+ " n_epochs: int, lr: float, wd: float,\n",
+ " silent: bool=False) -> None:\n",
+ " for i in range(n_epochs):\n",
+ " self._update_weights(X, Y, lr, wd)\n",
+ " mse = self.mse(X, Y)\n",
+ " if not silent:\n",
+ " print(f'epoch: {i}, \\t MSE: {mse}')\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "796b0de6-cb80-4ca6-91e9-503011d6851f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Define input array with angles from 60deg to 300deg converted to radians\n",
+ "noise=0.2\n",
+ "\n",
+ "x = np.array([i*np.pi/180 for i in range(60,300,4)])\n",
+ "np.random.seed(10) # Setting seed for reproducibility\n",
+ "y = np.sin(x) + np.random.normal(0, noise, len(x))\n",
+ "# plt.plot(x,y,'.')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "033a74b4-3bc2-4a19-b734-007ad8a4c037",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "lr_model = LinRegLasso(1)\n",
+ "wd = 0.0001\n",
+ "lr = 0.08\n",
+ "epochs = 100\n",
+ "\n",
+ "print(f\"Initila MSE: {lr_model.mse(x,y)}\")\n",
+ "lr_model.fit(x[:,np.newaxis],y, epochs, lr, wd, silent=True)\n",
+ "print(f\"Final MSE: {lr_model.mse(x,y)}\")\n",
+ "print(f\"Final parameters: {lr_model.weights}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "25873a87-7564-4e4a-8ef5-79a9415b209f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# We can also solve this 1D problem using Numpy\n",
+ "numpy_solution = np.polyfit(x,y,1)\n",
+ "predictor_np = np.poly1d(numpy_solution)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2e5b7a9b-4d4b-4222-8eef-4ef4ba63434a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "y_hat = lr_model.predict(x)\n",
+ "y_np = predictor_np(x)\n",
+ "plt.plot(x,y,'.')\n",
+ "plt.plot(x,y_hat,'.')\n",
+ "plt.plot(x,y_np,'--')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cd2e26a5-9f4e-4011-a999-e428246aa8c1",
+ "metadata": {},
+ "source": [
+ "# Now we run the same training on federated data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "83378ece-9cd5-4d40-a134-24cf68bdb79a",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## 1. Start the Director service and several envoys with generated data"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b0d105a0-04c4-4c26-81c7-a350e14393c2",
+ "metadata": {
+ "tags": [
+ "parameters"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "# Here are the main parameters for our Federation\n",
+ "n_cols=10 # Number of Envoys / Collaborators\n",
+ "n_samples_per_col=10\n",
+ "noise=0.2"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c0c3e78b-6e9d-4efc-9b30-3ddc413c0423",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "from pathlib import Path\n",
+ "from time import sleep\n",
+ "from typing import Dict, List, Union\n",
+ "import yaml"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "463a2821-b657-4e12-90ac-33b7810c5ff4",
+ "metadata": {},
+ "source": [
+ "### Start the Director service"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e736d33f-5df2-4a2f-8210-f1feba9fd367",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "cwd = Path.cwd()\n",
+ "director_workspace_path = Path('../director/').absolute()\n",
+ "director_config_file = director_workspace_path / 'director_config.yaml'\n",
+ "director_logfile = director_workspace_path / 'director.log'\n",
+ "if director_logfile.is_file(): director_logfile.unlink()\n",
+ "\n",
+ "os.environ['main_folder'] = str(cwd)\n",
+ "os.environ['director_workspace_path'] = str(director_workspace_path)\n",
+ "os.environ['director_logfile'] = str(director_logfile)\n",
+ "os.environ['director_config_file'] = str(director_config_file)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bb950328-c1e6-4062-8b36-b42486d60241",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%script /bin/bash --bg\n",
+ "cd $director_workspace_path\n",
+ "fx director start --disable-tls -c $director_config_file > $director_logfile &\n",
+ "cd $main_folder"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "223f0037-c87e-440d-b8df-8fe9211c34dc",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## Start Envoys"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f6deeee4-5dc8-433d-a4ea-c464c74b1b2b",
+ "metadata": {},
+ "source": [
+ "#### First, we create several envoy config files "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c0e65a39-15f7-4cca-90bb-a2970b7be9f0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the original envoy config file content\n",
+ "with open(Path('../envoy/envoy_config.yaml'), \"r\") as stream:\n",
+ " orig_config = yaml.safe_load(stream)\n",
+ "\n",
+ "def generate_envoy_configs(config: Dict,\n",
+ " save_path: Union[str, Path] = '../envoy/',\n",
+ " n_cols: int = 10,\n",
+ " n_samples_per_col: int = 10,\n",
+ " noise: float = 0.15) -> List[Path]:\n",
+ " # Prevent installing requirements by Envoys as they will run in the same environment\n",
+ " config['params']['install_requirements'] = False\n",
+ "\n",
+ " # Pass parameters for Shard Descriptors so they can generate relevant datasets\n",
+ " config['shard_descriptor']['params']['n_samples'] = n_samples_per_col\n",
+ " config['shard_descriptor']['params']['noise'] = noise\n",
+ " \n",
+ " config_paths = [(Path(save_path) / f'{i}_envoy_config.yaml').absolute()\n",
+ " for i in range(1, n_cols + 1)]\n",
+ "\n",
+ " for i, path in enumerate(config_paths):\n",
+ " config['shard_descriptor']['params']['rank'] = i\n",
+ " with open(path, \"w\") as stream:\n",
+ " yaml.safe_dump(config, stream)\n",
+ " \n",
+ " return config_paths\n",
+ " \n",
+ "def remove_configs(config_paths):\n",
+ " for path in config_paths:\n",
+ " path.unlink()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "90109c5b-c785-4af7-ace9-dcd913018dca",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "config_paths = generate_envoy_configs(orig_config,\n",
+ " n_cols=n_cols,\n",
+ " n_samples_per_col=n_samples_per_col,\n",
+ " noise=noise)\n",
+ "# remove_configs(config_paths)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "70c3078a-7beb-47c5-bcee-2de264ef3266",
+ "metadata": {},
+ "source": [
+ "#### Now start Envoy processes in a loop"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "843f698e-5582-4918-828c-cf095988da92",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# envoy_workspace_path = Path('../envoy/').absolute()\n",
+ "def start_envoys(config_paths: List[Path]) -> None:\n",
+ " envoy_workspace_path = config_paths[0].parent\n",
+ " cwd = Path.cwd()\n",
+ " os.chdir(envoy_workspace_path)\n",
+ " for i, path in enumerate(config_paths):\n",
+ " os.system(f'fx envoy start -n env_{i + 1} --disable-tls '\n",
+ " f'--envoy-config-path {path} -dh localhost -dp 50049 '\n",
+ " f'>env_{i + 1}.log &')\n",
+ " os.chdir(cwd)\n",
+ "\n",
+ "sleep(5)\n",
+ "\n",
+ "start_envoys(config_paths)\n",
+ "\n",
+ "sleep(25)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6216f14c-78d8-444c-9144-ee8316d1487b",
+ "metadata": {},
+ "source": [
+ "## 2. Connect to the Director service of out Federation as Data scientist"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b9d3b764-cb86-4eec-ba8e-df119da7a27f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Create a federation\n",
+ "from openfl.interface.interactive_api.federation import Federation\n",
+ "\n",
+ "# please use the same identificator that was used in signed certificate\n",
+ "client_id = 'frontend'\n",
+ "director_node_fqdn = 'localhost'\n",
+ "director_port = 50049\n",
+ "\n",
+ "federation = Federation(\n",
+ " client_id=client_id,\n",
+ " director_node_fqdn=director_node_fqdn,\n",
+ " director_port=director_port,\n",
+ " tls=False\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1bed370b-d0c0-46bc-8114-ea8255b2478b",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Data scientist may request a list of connected envoys\n",
+ "shard_registry = federation.get_shard_registry()\n",
+ "\n",
+ "# WARNING!\n",
+ "\n",
+ "# Make sure shard registry contains all the envoys you started!\n",
+ "# In other case try to run this cell again or reconnect to the Director (the cell above).\n",
+ "shard_registry"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c6401026-795f-491e-90cb-dd59b451df5f",
+ "metadata": {},
+ "source": [
+ "### Now we will prepare an FL experimnet using OpenFL Python API"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8166c689-9dde-4500-b05c-5b1ddf968978",
+ "metadata": {},
+ "source": [
+ "### Data"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "55fb1a98-b44f-47ff-950d-5a40a1cca0d8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment\n",
+ "\n",
+ "class LinRegDataSet(DataInterface):\n",
+ " def __init__(self, **kwargs):\n",
+ " \"\"\"Initialize DataLoader.\"\"\"\n",
+ " self.kwargs = kwargs\n",
+ " pass\n",
+ "\n",
+ " @property\n",
+ " def shard_descriptor(self):\n",
+ " \"\"\"Return shard descriptor.\"\"\"\n",
+ " return self._shard_descriptor\n",
+ " \n",
+ " @shard_descriptor.setter\n",
+ " def shard_descriptor(self, shard_descriptor):\n",
+ " \"\"\"\n",
+ " Describe per-collaborator procedures or sharding.\n",
+ "\n",
+ " This method will be called during a collaborator initialization.\n",
+ " Local shard_descriptor will be set by Envoy.\n",
+ " \"\"\"\n",
+ " self._shard_descriptor = shard_descriptor\n",
+ " self.train_set = shard_descriptor.get_dataset(\"train\")\n",
+ " self.val_set = shard_descriptor.get_dataset(\"val\")\n",
+ "\n",
+ " def get_train_loader(self, **kwargs):\n",
+ " \"\"\"Output of this method will be provided to tasks with optimizer in contract.\"\"\"\n",
+ " return self.train_set\n",
+ "\n",
+ " def get_valid_loader(self, **kwargs):\n",
+ " \"\"\"Output of this method will be provided to tasks without optimizer in contract.\"\"\"\n",
+ " return self.val_set\n",
+ "\n",
+ " def get_train_data_size(self):\n",
+ " \"\"\"Information for aggregation.\"\"\"\n",
+ " return len(self.train_set)\n",
+ "\n",
+ " def get_valid_data_size(self):\n",
+ " \"\"\"Information for aggregation.\"\"\"\n",
+ " return len(self.val_set)\n",
+ " \n",
+ "lin_reg_dataset = LinRegDataSet()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6233e1ed-a2f2-456f-9417-f35a2c27b236",
+ "metadata": {},
+ "source": [
+ "### Model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "885a8530-6248-4060-a30a-45cdc79bc41a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# You can inspect the framework adapter used in this example.\n",
+ "# It is a plug-in component allowing OpenFL to manage model parameters.\n",
+ "framework_adapter = 'custom_adapter.CustomFrameworkAdapter'\n",
+ "fed_model = LinRegLasso(1)\n",
+ "MI = ModelInterface(model=fed_model, optimizer=None, framework_plugin=framework_adapter)\n",
+ "\n",
+ "# Save the initial model state\n",
+ "initial_model = LinRegLasso(1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dc9da235-02a8-4e7a-9455-5fe2462aa317",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Tasks\n",
+ "Using an Optimizer does not make sense for this experiment. Yet it is a required part of a training task contract in the current version of OpenFL, so we just pass None.\n",
+ "We need to employ a trick reporting metrics. OpenFL decides which model is the best based on an *increasing* metric."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7e101689-8a63-4562-98ff-09443b1ab9f2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "TI = TaskInterface()\n",
+ "\n",
+ "@TI.add_kwargs(**{'lr': 0.001,\n",
+ " 'wd': 0.0001,\n",
+ " 'epoches': 1})\n",
+ "@TI.register_fl_task(model='my_model', data_loader='train_data', \\\n",
+ " device='device', optimizer='optimizer') \n",
+ "def train(my_model, train_data, optimizer, device, lr, wd, epoches):\n",
+ " X, Y = train_data[:,:-1], train_data[:,-1]\n",
+ " my_model.fit(X, Y, epochs, lr, wd, silent=True)\n",
+ " return {'train_MSE': my_model.mse(X, Y),}\n",
+ "\n",
+ "@TI.register_fl_task(model='my_model', data_loader='val_data', device='device') \n",
+ "def validate(my_model, val_data, device):\n",
+ " X, Y = val_data[:,:-1], val_data[:,-1] \n",
+ " return {'validation_MSE': my_model.mse(X, Y),}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "40a4623e-6559-4d4c-b199-f9afe16c0bbd",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Run"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fb357a88-7098-45b2-85f4-71fe2f2e0f82",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "experiment_name = 'linear_regression_experiment'\n",
+ "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name,\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "db20124a-949d-4218-abfd-aaf4d0758284",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fl_experiment.start(model_provider=MI, \n",
+ " task_keeper=TI,\n",
+ " data_loader=lin_reg_dataset,\n",
+ " rounds_to_train=10,)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4909be2b-d23b-4356-b2af-10a212382d52",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# This method not only prints messages recieved from the director, \n",
+ "# but also saves logs in the tensorboard format (by default)\n",
+ "fl_experiment.stream_metrics()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dd479019-1579-42c4-a446-f7d0a12596df",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Optional: start tensorboard"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a6faaaea",
+ "metadata": {},
+ "source": [
+ "Running on your own machine locally, start tensorboard in background and open localhost:6006 in your browser:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c5f4b673-e6b1-4bbe-8294-d2b61a65d40b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%script /bin/bash --bg\n",
+ "tensorboard --host $(hostname --all-fqdns | awk '{print $1}') --logdir logs"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "68867a02",
+ "metadata": {},
+ "source": [
+ "In Google Colab you may use the inline extension "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f3684b26",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%load_ext tensorboard\n",
+ "%tensorboard --logdir logs"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b4d27834-ec5b-4290-8c9d-4c3c5589a7e6",
+ "metadata": {},
+ "source": [
+ "### 3. Retrieve the trained model from the Director"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ad915ab3-0032-4a06-b2c0-00710585e24d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "last_model = fl_experiment.get_last_model()\n",
+ "best_model = fl_experiment.get_best_model()\n",
+ "print(best_model.weights)\n",
+ "print(last_model.weights)\n",
+ "print(f\"last model MSE: {last_model.mse(x,y)}\")\n",
+ "print(f\"best model MSE: {best_model.mse(x,y)}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1930789e-b7b5-415e-844d-14ccc3844482",
+ "metadata": {},
+ "source": [
+ "## Lets see what does the unified dataset look like\n",
+ "And see how the trained model performs.\n",
+ "Note: dots of the same colour belong to the same Envoy's dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c51e8a56-d2f1-4758-a5a1-6d6652e4355e",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "n_cols = n_cols\n",
+ "n_samples = n_samples_per_col\n",
+ "interval = 240\n",
+ "x_start = 60\n",
+ "noise = noise\n",
+ "\n",
+ "X = None\n",
+ "\n",
+ "for rank in range(n_cols):\n",
+ " np.random.seed(rank) # Setting seed for reproducibility\n",
+ " x = np.random.rand(n_samples, 1) * interval + x_start\n",
+ " x *= np.pi / 180\n",
+ " X = x if X is None else np.vstack((X,x))\n",
+ " y = np.sin(x) + np.random.normal(0, noise, size=(n_samples, 1))\n",
+ " plt.plot(x,y,'+')\n",
+ " \n",
+ "X.sort() \n",
+ "Y_hat = last_model.predict(X)\n",
+ "plt.plot(X,Y_hat,'--')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9e365766-4ea6-40bc-96ae-a183274e8b8c",
+ "metadata": {},
+ "source": [
+ "## Cleaning"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e5d793be-6c20-4a22-bad7-c082c1ee76ca",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# To stop all services\n",
+ "!pkill fx"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "809b8eb3-4775-43d9-8f96-de84a089a54e",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "remove_configs(config_paths)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d0b28b29-48d3-4f21-bc69-40259b83f93b",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/custom_adapter.py b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/custom_adapter.py
new file mode 100644
index 0000000..e7bb5b3
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/custom_adapter.py
@@ -0,0 +1,21 @@
+# Copyright (C) 2020-2021 Intel Corporation
+# SPDX-License-Identifier: Apache-2.0
+"""Custom model numpy adapter."""
+
+from openfl.plugins.frameworks_adapters.framework_adapter_interface import (
+ FrameworkAdapterPluginInterface,
+)
+
+
+class CustomFrameworkAdapter(FrameworkAdapterPluginInterface):
+ """Framework adapter plugin class."""
+
+ @staticmethod
+ def get_tensor_dict(model, optimizer=None):
+ """Extract tensors from a model."""
+ return {'w': model.weights}
+
+ @staticmethod
+ def set_tensor_dict(model, tensor_dict, optimizer=None, device='cpu'):
+ """Load tensors to a model."""
+ model.weights = tensor_dict['w']
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/requirements.txt b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/requirements.txt
new file mode 100644
index 0000000..ce2479f
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/requirements.txt
@@ -0,0 +1,7 @@
+jupyterlab
+matplotlib
+mistune>=2.0.3 # not directly required, pinned by Snyk to avoid a vulnerability
+numpy
+openfl==1.2.1
+setuptools>=65.5.1 # not directly required, pinned by Snyk to avoid a vulnerability
+wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability
diff --git a/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/start_federation.ipynb b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/start_federation.ipynb
new file mode 100644
index 0000000..9b71200
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/numpy_linear_regression/workspace/start_federation.ipynb
@@ -0,0 +1,193 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f813b6ae-b082-49bb-b64f-fd619b6de14a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "from pathlib import Path\n",
+ "import yaml\n",
+ "from typing import Dict, List, Union"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d1ee62ab-09e4-4f4c-984f-bdb6909d6106",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the original envoy config file content\n",
+ "with open(Path('../envoy/envoy_config.yaml'), \"r\") as stream:\n",
+ " orig_config = yaml.safe_load(stream)\n",
+ "\n",
+ "def generate_envoy_configs(config: Dict,\n",
+ " save_path: Union[str, Path] = '../envoy/',\n",
+ " n_cols: int = 10,\n",
+ " n_samples_per_col: int = 10,\n",
+ " noise: float = 0.15) -> List[Path]:\n",
+ "\n",
+ " config['shard_descriptor']['params']['n_samples'] = n_samples_per_col\n",
+ " config['shard_descriptor']['params']['noise'] = noise\n",
+ " \n",
+ " config_paths = [(Path(save_path) / f'{i}_envoy_config.yaml').absolute()\n",
+ " for i in range(1, n_cols + 1)]\n",
+ "\n",
+ " for i, path in enumerate(config_paths):\n",
+ " config['shard_descriptor']['params']['rank'] = i\n",
+ " with open(path, \"w\") as stream:\n",
+ " yaml.safe_dump(config, stream)\n",
+ " \n",
+ " return config_paths\n",
+ " \n",
+ "def remove_configs(config_paths):\n",
+ " for path in config_paths:\n",
+ " path.unlink()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0d058340-22d4-4630-b8e3-9c3fc29198ab",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "config_paths = generate_envoy_configs(orig_config, n_cols=20, n_samples_per_col=8, noise=0.3)\n",
+ "# remove_configs(config_paths)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ec065be9-c2c6-4a81-9a2a-ea54794e52ba",
+ "metadata": {},
+ "source": [
+ "## Start the Director service"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "60bcaa49-aabb-42ec-a279-9e32b31ce6ca",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "cwd = Path.cwd()\n",
+ "director_workspace_path = Path('../director/').absolute()\n",
+ "director_config_file = director_workspace_path / 'director_config.yaml'\n",
+ "director_logfile = director_workspace_path / 'director.log'\n",
+ "director_logfile.unlink(missing_ok=True)\n",
+ "# \n",
+ "\n",
+ "os.environ['main_folder'] = str(cwd)\n",
+ "os.environ['director_workspace_path'] = str(director_workspace_path)\n",
+ "os.environ['director_logfile'] = str(director_logfile)\n",
+ "os.environ['director_config_file'] = str(director_config_file)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "72a9268a-ee1e-4dda-a4c4-cfb29428f45e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%script /bin/bash --bg\n",
+ "cd $director_workspace_path\n",
+ "fx director start --disable-tls -c $director_config_file > $director_logfile &\n",
+ "cd $main_folder"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e0a634ea-9c62-4048-bb91-099fe9097b55",
+ "metadata": {},
+ "source": [
+ "## Start Envoys"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "13470bfd-d67e-48dc-b1ff-10c7ff526c0c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# envoy_workspace_path = Path('../envoy/').absolute()\n",
+ "def start_envoys(config_paths: List[Path]) -> None:\n",
+ " envoy_workspace_path = config_paths[0].parent\n",
+ " cwd = Path.cwd()\n",
+ " os.chdir(envoy_workspace_path)\n",
+ " for i, path in enumerate(config_paths):\n",
+ " os.system(f'fx envoy start -n env_{i + 1} --disable-tls '\n",
+ " f'--envoy-config-path {path} -dh localhost -dp 50049 '\n",
+ " f'>env_{i + 1}.log &')\n",
+ " os.chdir(cwd)\n",
+ " \n",
+ "start_envoys(config_paths)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2fc8a569-6978-4c80-88d1-741799407239",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a5fdc3af-63b5-41b5-b9d6-be2aac8626e0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# To stop all services run\n",
+ "!pkill fx"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4e69ae57-bfa3-4047-af7f-3e1cf24ac35e",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "remove_configs(config_paths)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "46095127-f116-4ae3-a3b4-6be24064b49f",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/README.md b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/README.md
new file mode 100644
index 0000000..2485306
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/README.md
@@ -0,0 +1,55 @@
+# Scikit-learn based Linear Regression Tutorial
+
+### 1. About dataset
+
+Generate 1-dimensional noisy data for linear regression of sinusoid.
+
+Define the below pamameter in shard_config in the envoy_config.yaml file as the random seed for the dataset generation for a specific Envoy
+- rank
+
+### 2. About model
+
+Linear Regression Lasso Model based on Scikit-learn.
+
+
+### 3. How to run this tutorial (without TLC and locally as a simulation):
+
+1. Run director:
+
+```sh
+cd director folder
+./start_director.sh
+```
+
+2. Run envoy:
+
+Step 1: Activate virtual environment and install packages
+```
+cd envoy folder
+pip install -r requirements.txt
+```
+Step 2: start the envoy
+```sh
+./start_envoy.sh env_instance_1 envoy_config.yaml
+```
+
+Optional: start second envoy:
+
+- Copy `envoy_folder` to another place and follow the same process as above:
+
+```sh
+./start_envoy.sh env_instance_2 envoy_config_2.yaml
+```
+
+3. Run `scikit_learn_linear_regression.ipynb` jupyter notebook:
+
+```sh
+cd workspace
+jupyter lab scikit_learn_linear_regression.ipynb
+```
+
+4. Visualization
+
+```
+tensorboard --logdir logs/
+```
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/director/director_config.yaml b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/director/director_config.yaml
new file mode 100644
index 0000000..d22b4b7
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/director/director_config.yaml
@@ -0,0 +1,6 @@
+settings:
+ listen_host: localhost
+ listen_port: 50050
+ sample_shape: ['1'] # Modify this param if experimenting with `n_features` of shard_descriptor.
+ target_shape: ['1']
+ envoy_health_check_period: 5 # in seconds
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/director/start_director.sh b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/director/start_director.sh
new file mode 100755
index 0000000..5806a6c
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/director/start_director.sh
@@ -0,0 +1,4 @@
+#!/bin/bash
+set -e
+
+fx director start --disable-tls -c director_config.yaml
\ No newline at end of file
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/envoy_config.yaml b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/envoy_config.yaml
new file mode 100644
index 0000000..107c566
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/envoy_config.yaml
@@ -0,0 +1,12 @@
+params:
+ cuda_devices: []
+
+optional_plugin_components: {}
+
+shard_descriptor:
+ template: linreg_shard_descriptor.LinRegSD
+ params:
+ rank: 1
+ n_samples: 80
+ noise: 0.15
+
\ No newline at end of file
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/linreg_shard_descriptor.py b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/linreg_shard_descriptor.py
new file mode 100644
index 0000000..12bfed9
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/linreg_shard_descriptor.py
@@ -0,0 +1,60 @@
+# Copyright (C) 2020-2021 Intel Corporation
+# SPDX-License-Identifier: Apache-2.0
+"""Noisy-Sin Shard Descriptor."""
+
+from typing import List
+
+import numpy as np
+
+from openfl.interface.interactive_api.shard_descriptor import ShardDescriptor
+
+
+class LinRegSD(ShardDescriptor):
+ """Shard descriptor class."""
+
+ def __init__(self, rank: int, n_samples: int = 10, noise: float = 0.15) -> None:
+ """
+ Initialize LinReg Shard Descriptor.
+
+ This Shard Descriptor generate random data. Sample features are
+ floats between pi/3 and 5*pi/3, and targets are calculated
+ calculated as sin(feature) + normal_noise.
+ """
+ np.random.seed(rank) # Setting seed for reproducibility
+ self.n_samples = max(n_samples, 5)
+ self.interval = 240
+ self.x_start = 60
+ x = np.random.rand(n_samples, 1) * self.interval + self.x_start
+ x *= np.pi / 180
+ y = np.sin(x) + np.random.normal(0, noise, size=(n_samples, 1))
+ self.data = np.concatenate((x, y), axis=1)
+
+ def get_dataset(self, dataset_type: str) -> np.ndarray:
+ """
+ Return a shard dataset by type.
+
+ A simple list with elements (x, y) implemets the Shard Dataset interface.
+ """
+ if dataset_type == 'train':
+ return self.data[:self.n_samples // 2]
+ elif dataset_type == 'val':
+ return self.data[self.n_samples // 2:]
+ else:
+ pass
+
+ @property
+ def sample_shape(self) -> List[str]:
+ """Return the sample shape info."""
+ (*x, _) = self.data[0]
+ return [str(i) for i in np.array(x, ndmin=1).shape]
+
+ @property
+ def target_shape(self) -> List[str]:
+ """Return the target shape info."""
+ (*_, y) = self.data[0]
+ return [str(i) for i in np.array(y, ndmin=1).shape]
+
+ @property
+ def dataset_description(self) -> str:
+ """Return the dataset description."""
+ return 'Allowed dataset types are `train` and `val`'
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/requirements.txt b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/requirements.txt
new file mode 100644
index 0000000..40d18d9
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/requirements.txt
@@ -0,0 +1,7 @@
+matplotlib>=2.0.0
+mistune>=2.0.3 # not directly required, pinned by Snyk to avoid a vulnerability
+numpy>=1.13.3
+openfl>=1.2.1
+scikit-learn>=0.24.1
+setuptools>=65.5.1 # not directly required, pinned by Snyk to avoid a vulnerability
+wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/start_envoy.sh b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/start_envoy.sh
new file mode 100755
index 0000000..4da0782
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/envoy/start_envoy.sh
@@ -0,0 +1,6 @@
+#!/bin/bash
+set -e
+ENVOY_NAME=$1
+ENVOY_CONF=$2
+
+fx envoy start -n "$ENVOY_NAME" --disable-tls --envoy-config-path "$ENVOY_CONF" -dh localhost -dp 50050
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/custom_adapter.py b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/custom_adapter.py
new file mode 100644
index 0000000..6991d2b
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/custom_adapter.py
@@ -0,0 +1,21 @@
+# Copyright (C) 2020-2023 Intel Corporation
+# SPDX-License-Identifier: Apache-2.0
+"""Custom model numpy adapter."""
+
+from openfl.plugins.frameworks_adapters.framework_adapter_interface import (
+ FrameworkAdapterPluginInterface,
+)
+
+
+class CustomFrameworkAdapter(FrameworkAdapterPluginInterface):
+ """Framework adapter plugin class."""
+
+ @staticmethod
+ def get_tensor_dict(model, optimizer=None):
+ """Extract tensors from a model."""
+ return {'w': model.weights}
+
+ @staticmethod
+ def set_tensor_dict(model, tensor_dict, optimizer=None, device='cpu'):
+ """Load tensors to a model."""
+ model.weights = tensor_dict['w']
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/requirements.txt b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/requirements.txt
new file mode 100644
index 0000000..40d18d9
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/requirements.txt
@@ -0,0 +1,7 @@
+matplotlib>=2.0.0
+mistune>=2.0.3 # not directly required, pinned by Snyk to avoid a vulnerability
+numpy>=1.13.3
+openfl>=1.2.1
+scikit-learn>=0.24.1
+setuptools>=65.5.1 # not directly required, pinned by Snyk to avoid a vulnerability
+wheel>=0.38.0 # not directly required, pinned by Snyk to avoid a vulnerability
diff --git a/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/scikit_learn_linear_regression.ipynb b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/scikit_learn_linear_regression.ipynb
new file mode 100644
index 0000000..4ef7023
--- /dev/null
+++ b/openfl_contrib_tutorials/interactive_api/scikit_learn_linear_regression/workspace/scikit_learn_linear_regression.ipynb
@@ -0,0 +1,420 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "689ee822",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!pip install -r requirements.txt"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d63e64c6-9955-4afc-8d04-d8c85bb28edc",
+ "metadata": {},
+ "source": [
+ "# Scikit-learn Linear Regression Example - Interactive API"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6c9eee14-22a1-4d48-a7da-e68d01037cd4",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "from typing import List, Union\n",
+ "\n",
+ "from sklearn.linear_model import Lasso\n",
+ "from sklearn.preprocessing import StandardScaler\n",
+ "from sklearn.datasets import make_regression\n",
+ "from sklearn.metrics import mean_squared_error\n",
+ "import numpy as np\n",
+ "import random\n",
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline\n",
+ "from matplotlib.pylab import rcParams\n",
+ "rcParams['figure.figsize'] = 7, 5"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c4b334ef-6a72-4b82-b978-1401973d0512",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "# We will use MSE as loss function and Ridge weights regularization\n",
+ "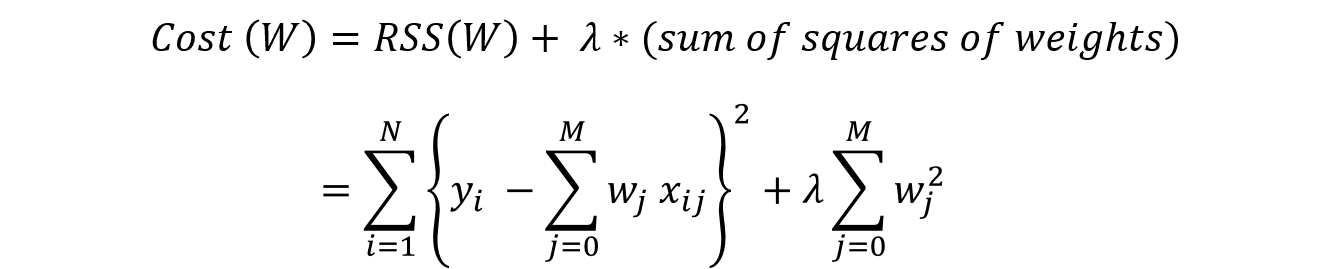"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f4cc8ec2-b818-4db8-8700-39c1a12917df",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "class SklearnLinearRegressionLasso:\n",
+ " def __init__(self, n_feat: int, alpha: float = 1.0) -> None:\n",
+ " self.model = Lasso(alpha=alpha)\n",
+ " self.scaler = StandardScaler()\n",
+ " self.weights = np.ones((n_feat + 1)) \n",
+ " \n",
+ " def predict(self, feature_vector: Union[np.ndarray, List[int]]) -> float:\n",
+ " '''\n",
+ " feature_vector may be a list or have shape (n_feat,)\n",
+ " or it may be a bunch of vectors (n_vec, nfeat)\n",
+ " '''\n",
+ " feature_vector = np.array(feature_vector)\n",
+ " if len(feature_vector.shape) == 1:\n",
+ " feature_vector = feature_vector[:,np.newaxis]\n",
+ " \n",
+ " feature_vector = self.scaler.transform(feature_vector)\n",
+ " return self.model.predict(feature_vector)\n",
+ " \n",
+ " def mse(self, X: np.ndarray, Y: np.ndarray) -> float:\n",
+ " Y_predict = self.predict(X)\n",
+ " return mean_squared_error(Y, Y_predict)\n",
+ " \n",
+ " def fit(self, X: np.ndarray, Y: np.ndarray, silent: bool=False) -> None:\n",
+ " \n",
+ " X = self.scaler.fit_transform(X)\n",
+ " self.model.fit(X, Y)\n",
+ " mse = self.mse(X, Y)\n",
+ " #self.weights[:-1] = self.model.coef_\n",
+ " #self.weights[-1] = self.model.intercept_\n",
+ " if not silent:\n",
+ " print(f'MSE: {mse}')\n",
+ " \n",
+ " def print_parameters(self) -> None:\n",
+ " print('Final parameters: ')\n",
+ " print(f'Weights: {self.model.coef_}')\n",
+ " print(f'Bias: {self.model.intercept_}')\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "af89e7e5-6cfc-46bc-acd2-7d5bfb373091",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Define input array with angles from 60deg to 300deg converted to radians\n",
+ "x = np.array([i*np.pi/180 for i in range(60,300,4)])\n",
+ "np.random.seed(10) # Setting seed for reproducibility\n",
+ "y = np.sin(x) + np.random.normal(0,0.15,len(x))\n",
+ "# plt.plot(x,y,'.')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ffefca2b-d7f6-4111-8872-c017c182a2de",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "lr_model = SklearnLinearRegressionLasso(n_feat=1, alpha=0.1)\n",
+ "\n",
+ "lr_model.fit(x[:,np.newaxis], y)\n",
+ "\n",
+ "#print the final parameters\n",
+ "lr_model.print_parameters()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "410f2d80-989a-43ab-958f-7b68fd8f2e90",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# We can also solve this 1D problem using Numpy\n",
+ "numpy_solution = np.polyfit(x,y,1)\n",
+ "predictor_np = np.poly1d(numpy_solution)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6cb323db-9f3a-42af-94da-4b170adef867",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "y_hat = lr_model.predict(x)\n",
+ "y_np = predictor_np(x)\n",
+ "plt.plot(x,y,'.')\n",
+ "plt.plot(x,y_hat,'.')\n",
+ "plt.plot(x,y_np,'--')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ffd4d2d7-5537-496a-88c1-301da87d979c",
+ "metadata": {},
+ "source": [
+ "# Now we run the same training on federated data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "09cf7090-da51-4f4e-9d28-2a5c6e3bca02",
+ "metadata": {},
+ "source": [
+ "## Connect to a Federation"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1b3c0039-e1f7-4047-b98b-a2d4bd42f015",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Create a federation\n",
+ "from openfl.interface.interactive_api.federation import Federation\n",
+ "\n",
+ "# please use the same identificator that was used in signed certificate\n",
+ "client_id = 'frontend'\n",
+ "director_node_fqdn = 'localhost'\n",
+ "director_port = 50050\n",
+ "\n",
+ "federation = Federation(\n",
+ " client_id=client_id,\n",
+ " director_node_fqdn=director_node_fqdn,\n",
+ " director_port=director_port,\n",
+ " tls=False\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7815120e-b704-4a7d-a65a-3c7542023ead",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "shard_registry = federation.get_shard_registry()\n",
+ "shard_registry"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b011dd95-64a7-4a8b-91ec-e61cdf885bbb",
+ "metadata": {},
+ "source": [
+ "### Data"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b1985ac9-a2b1-4561-a962-6adfe35c3b97",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "from openfl.interface.interactive_api.experiment import TaskInterface, DataInterface, ModelInterface, FLExperiment\n",
+ "\n",
+ "class LinRegDataSet(DataInterface):\n",
+ " def __init__(self, **kwargs):\n",
+ " \"\"\"Initialize DataLoader.\"\"\"\n",
+ " self.kwargs = kwargs\n",
+ " pass\n",
+ "\n",
+ " @property\n",
+ " def shard_descriptor(self):\n",
+ " \"\"\"Return shard descriptor.\"\"\"\n",
+ " return self._shard_descriptor\n",
+ " \n",
+ " @shard_descriptor.setter\n",
+ " def shard_descriptor(self, shard_descriptor):\n",
+ " \"\"\"\n",
+ " Describe per-collaborator procedures or sharding.\n",
+ "\n",
+ " This method will be called during a collaborator initialization.\n",
+ " Local shard_descriptor will be set by Envoy.\n",
+ " \"\"\"\n",
+ " self._shard_descriptor = shard_descriptor\n",
+ " self.train_set = shard_descriptor.get_dataset(\"train\")\n",
+ " self.val_set = shard_descriptor.get_dataset(\"val\")\n",
+ "\n",
+ " def get_train_loader(self, **kwargs):\n",
+ " \"\"\"Output of this method will be provided to tasks with optimizer in contract.\"\"\"\n",
+ " return self.train_set\n",
+ "\n",
+ " def get_valid_loader(self, **kwargs):\n",
+ " \"\"\"Output of this method will be provided to tasks without optimizer in contract.\"\"\"\n",
+ " return self.val_set\n",
+ "\n",
+ " def get_train_data_size(self):\n",
+ " \"\"\"Information for aggregation.\"\"\"\n",
+ " return len(self.train_set)\n",
+ "\n",
+ " def get_valid_data_size(self):\n",
+ " \"\"\"Information for aggregation.\"\"\"\n",
+ " return len(self.val_set)\n",
+ " \n",
+ "lin_reg_dataset = LinRegDataSet()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b8909127-99d1-4dba-86fe-01a1b86585e7",
+ "metadata": {},
+ "source": [
+ "### Model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9523c9a2-a259-461f-937f-1fb054bd2886",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "framework_adapter = 'custom_adapter.CustomFrameworkAdapter'\n",
+ "fed_model = SklearnLinearRegressionLasso(n_feat=1, alpha=0.1)\n",
+ "MI = ModelInterface(model=fed_model, optimizer=None, framework_plugin=framework_adapter)\n",
+ "\n",
+ "# Save the initial model state\n",
+ "initial_model = SklearnLinearRegressionLasso(n_feat=1, alpha=0.1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2e3558bb-b21b-48ac-b07e-43cf75e6907b",
+ "metadata": {},
+ "source": [
+ "### Tasks\n",
+ "We need to employ a trick reporting metrics. OpenFL decides which model is the best based on an *increasing* metric."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f73e1ff9-d54a-49b5-9ce8-8bc72c6a2c6f",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "TI = TaskInterface()\n",
+ "\n",
+ "@TI.register_fl_task(model='my_model', data_loader='train_data', \\\n",
+ " device='device', optimizer='optimizer') \n",
+ "def train(my_model, train_data, optimizer, device):\n",
+ " X, Y = train_data[:,:-1], train_data[:,-1]\n",
+ " my_model.fit(X, Y, silent=True)\n",
+ " return {'train_MSE': my_model.mse(X, Y),}\n",
+ "\n",
+ "@TI.register_fl_task(model='my_model', data_loader='val_data', device='device') \n",
+ "def validate(my_model, val_data, device):\n",
+ " X, Y = val_data[:,:-1], val_data[:,-1] \n",
+ " return {'validation_MSE': my_model.mse(X, Y),}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ee7659cc-6e03-43f5-9078-95707fa0e4d5",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Run"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "749100e8-05ce-418c-a980-545e3beb900b",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "experiment_name = 'linear_regression_experiment'\n",
+ "fl_experiment = FLExperiment(federation=federation, experiment_name=experiment_name,\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "16bf1df7-8ca8-4a5e-a833-47c265c11e05",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "fl_experiment.start(model_provider=MI, \n",
+ " task_keeper=TI,\n",
+ " data_loader=lin_reg_dataset,\n",
+ " rounds_to_train=10,)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1178d1ea-05e6-46be-ac07-21620bd6ec76",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "fl_experiment.stream_metrics()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c04b4ab2-1d40-44c7-907b-a6a7d176c959",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.13"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}