
LibreQoS is a Quality of Experience (QoE) Smart Queue Management (SQM) system designed for Internet Service Providers to optimize the flow of their network traffic and thus reduce bufferbloat, keep the network responsive, and improve the end-user experience.
Servers running LibreQoS can shape traffic for many thousands of customers.
Learn more at LibreQoS.io!
Special thanks to Equinix for providing server resources to support the development of LibreQoS. Learn more about Equinix Metal here.
Please support the continued development of LibreQoS by visiting our GitHub Sponsors page.

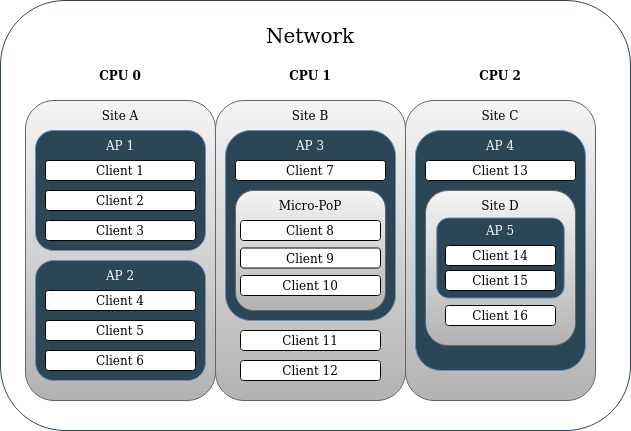
Starting in version v1.1+, operators can map their network hierarchy in LibreQoS. This enables both simple network hierarchies (Site>AP>Client) as well as much more complex ones (Site>Site>Micro-PoP>AP>Site>AP>Client). This can be used to ensure that a given site’s peak bandwidth will not exceed the capacity of its back-haul links (back-haul congestion control). Operators can support more users on the same network equipment with LibreQoS than with competing QoE solutions which only shape by AP and Client.
CAKE is the product of nearly a decade of development efforts to improve on fq_codel. With the diffserv_4 parameter enabled – CAKE groups traffic in to Bulk, Best Effort, Video, and Voice. This means that without having to fine-tune traffic priorities as you would with DPI products – CAKE automatically ensures your clients’ OS update downloads will not disrupt their zoom calls. It allows for multiple video conferences to operate on the same connection which might otherwise “fight” for upload bandwidth causing call disruptions. With work-from-home, remote learning, and tele-medicine becoming increasingly common – minimizing video call disruptions can save jobs, keep students engaged, and help ensure equitable access to medical care.
Fast, multi-CPU queueing leveraging xdp-cpumap-tc and cpumap-pping. Currently tested in the real world past 11 Gbps (so far) with just 30% CPU use on a 16 core Intel Xeon Gold 6254. It's likely capable of 30Gbps or more.
You can graph bandwidth and TCP RTT by client and node (Site, AP, etc), using InfluxDB.
- UISP
- Splynx
- For VMs, NIC passthrough is required for optimal throughput and latency (XDP vs generic XDP). Using Virtio / bridging is much slower than NIC passthrough. Virtio / bridging should not be used for large amounts of traffic.
- 2 or more CPU cores
- A CPU with solid single-thread performance within your budget. Queuing is very CPU-intensive, and requires high single-thread performance.
Single-thread CPU performance will determine the max throughput of a single HTB (cpu core), and in turn, what max speed plan you can offer customers.
| Customer Max Plan | Passmark Single-Thread |
|---|---|
| 100 Mbps | 1000 |
| 250 Mbps | 1500 |
| 500 Mbps | 2000 |
| 1 Gbps | 2500 |
| 2 Gbps | 3000 |
Below is a table of approximate aggregate throughput capacity, assuming a a CPU with a single thread performance of 2700 or greater:
| Aggregate Throughput | CPU Cores |
|---|---|
| 500 Mbps | 2 |
| 1 Gbps | 4 |
| 5 Gbps | 6 |
| 10 Gbps | 8 |
| 20 Gbps | 16 |
| 50 Gbps* | 32 |
(* Estimated)
So for example, an ISP delivering 1Gbps service plans with 10Gbps aggregate throughput would choose a CPU with a 2500+ single-thread score and 8 cores, such as the Intel Xeon E-2388G @ 3.20GHz.
- Minimum RAM = 2 + (0.002 x Subscriber Count) GB
- Recommended RAM:
| Subscribers | RAM |
|---|---|
| 100 | 4 GB |
| 1,000 | 8 GB |
| 5,000 | 16 GB |
| 10,000* | 18 GB |
| 50,000* | 24 GB |
(* Estimated)
- One management network interface completely separate from the traffic shaping interfaces. Usually this would be the Ethernet interface built in to the motherboard.
- Dedicated Network Interface Card for Shaping Interfaces
- NIC must have 2 or more interfaces for traffic shaping.
- NIC must have multiple TX/RX transmit queues. Here's how to check from the command line.
- Known supported cards:
- NVIDIA Mellanox MCX512A-ACAT
- NVIDIA Mellanox MCX416A-CCAT
- Intel X710
- Intel X520