Map之后、Reduce之前的数据处理过程统称为Shuffle机制
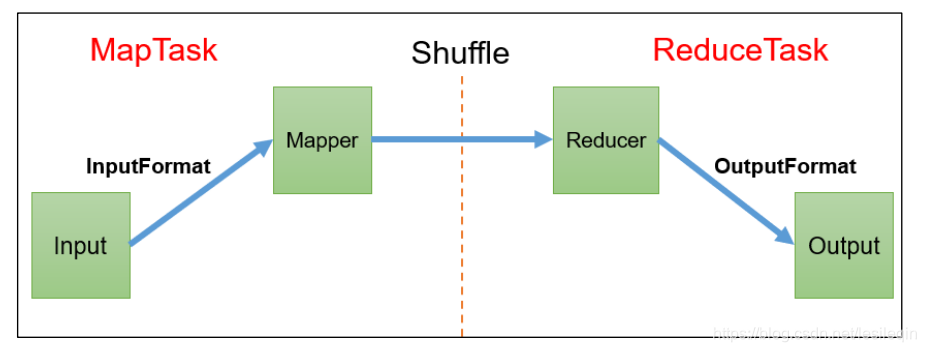
WritableComparable排序是Shuffle的一部分功能,它的作用是==如果自定义数据类型做为key,则实现该接口,对所需要的字段进行排序。==
MapReduce规定必须对key进行排序,如果key的数据类型是自定义类型,而且没有实现WritableComparable接口的compartTo方法,那么就会报错!
默认排序是按照==字典顺序==排序的,且实现该排序的方法是==快速排序==
看一下WritableComparable接口:

既然该接口继承了两个接口:
-
Writable:是实现序列化的接口,这个在之前的博客中有解释及对应的案例,感兴趣的读者可以看一下 -
Comparable:实现比较的接口,隶属于java.util.*包 -


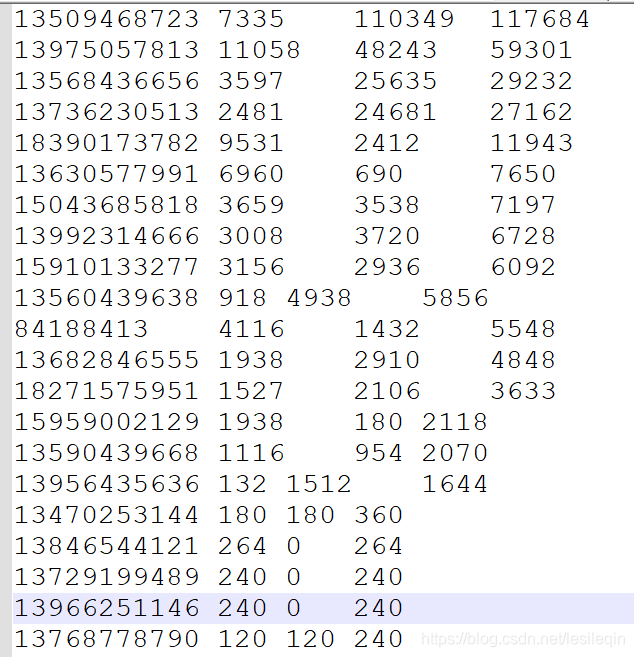
根据前几篇博客(序列化)中的案例再进一步:对总流量进行倒叙排序,如果总流量相等,则按照上行流量倒叙排序
输入数据为:序列化案例处理后的数据:
手机号 上行 下行 总流量
13590439668 1116 954 2070
13630577991 6960 690 7650输出数据为对总流量从大到小排序后的数据

MapReduce默认对key进行排序,那么在Mapper中输出的泛型就可以调换一下位置:
public class FlowMapper extends Mapper<LongWritable, Text, FlowBean, Text>同样的,Reducer中作为输入的泛型要与Mapper的输出类型保持一致,最终输出的泛型还希望是手机号->数据:
public class FlowReducer extends Reducer<FlowBean, Text, Text, FlowBean>同样也需要重写map()和reduce()方法逻辑,也需要在Driver类中重新指定Map的输出类型
FlowBean类需要实现WritableComparable接口,重写实现序列化(本文不涉及,请参考前文)的操作与比较compartTo()方法
FlowBean类添加compartTo()方法:
@Override
public int compareTo(FlowBean o) {
//对总流量进行排序
if (this.sumFlow > o.sumFlow) {
return -1;
} else if (this.sumFlow < o.sumFlow) {
return 1;
} else {
//如果相等,对上行流量进行排序
if (this.upFlow > o.upFlow) {
return -1;
} else if (this.upFlow < o.upFlow) {
return 1;
} else {
return 0;
}
}
}因为替换了泛型,所以重写Mapper:
package com.wzq.mapreduce.writableComparable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowMapper extends Mapper<LongWritable, Text, FlowBean, Text> {
private FlowBean outK = new FlowBean();
private Text outV = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行数据,分割字符串
String[] split = value.toString().split("\t");
//封装
outV.set(split[0]);
outK.setUpFlow(Long.parseLong(split[1]));
outK.setDownFlow(Long.parseLong(split[2]));
outK.setSumFlow();
//写输出
context.write(outK, outV);
}
}Reducer:
package com.wzq.mapreduce.writableComparable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReducer extends Reducer<FlowBean, Text, Text, FlowBean> {
@Override
protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(value, key);
}
}
}Driver类,需要指定Map的输出类型,替换输入输出路径,这里只贴出这两部分代码,其他保持不变:
//设置Mapper输出的K-V类型
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class);
//设置输入输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\BigData_workspace\\output\\output2"));
FileOutputFormat.setOutputPath(job, new Path("D:\\BigData_workspace\\output\\output5"));执行之后的输出结果:
现在对上面的案例,再进一步要求:把排序输出的结果按照不同的手机号前缀输出到不同的文件中
基于前一个需求分析,增加自定义分区类,因为分区也属于Shuffle机制,所以它的泛型对应的也是Mapper输出的泛型:(分区详解请点击我)
public class FlowPartition extends Partitioner<FlowBean, Text>然后重写getPartition()方法即可
FlowPartitioner类:
package com.wzq.mapreduce.writableComparable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class FlowPartition extends Partitioner<FlowBean, Text> {
@Override
public int getPartition(FlowBean flowBean, Text text, int numPartitions) {
//1、截取手机号前三位
String prePhone = text.toString().substring(0, 3);
//2、设置标记变量,标记最后输出到哪个分区
int partition;
//3、对比手机号,给标记变量赋值
if ("136".equals(prePhone)) {
partition = 0;
} else if ("137".equals(prePhone)) {
partition = 1;
} else if ("138".equals(prePhone)) {
partition = 2;
} else if ("139".equals(prePhone)) {
partition = 3;
} else {
partition = 4;
}
return partition;
}
}在Driver类中也需要指定使用Partitioner类,设置ReduceTask个数,替换输入输出文件路径:
job.setPartitionerClass(FlowPartition.class);
job.setNumReduceTasks(5);
//设置输入输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\BigData_workspace\\output\\output5"));
FileOutputFormat.setOutputPath(job, new Path("D:\\BigData_workspace\\output\\output6"));最终运行测试:
