diff --git a/doc/content/squeezed/_index.md b/doc/content/squeezed/_index.md
new file mode 100644
index 00000000000..45985d6499f
--- /dev/null
+++ b/doc/content/squeezed/_index.md
@@ -0,0 +1,17 @@
++++
+title = "Squeezed"
+weight = 50
++++
+
+Squeezed is the XAPI Toolstack's host memory manager (aka balloon driver).
+Squeezed uses ballooning to move memory between running VMs, to avoid wasting
+host memory.
+
+Principles
+----------
+
+1. Avoid wasting host memory: unused memory should be put to use by returning
+ it to VMs.
+2. Memory should be shared in proportion to the configured policy.
+3. Operate entirely at the level of domains (not VMs), and be independent of
+ Xen toolstack.
diff --git a/doc/content/squeezed/architecture/index.md b/doc/content/squeezed/architecture/index.md
new file mode 100644
index 00000000000..6d85730ae30
--- /dev/null
+++ b/doc/content/squeezed/architecture/index.md
@@ -0,0 +1,42 @@
++++
+title = "Architecture"
++++
+
+Squeezed is responsible for managing the memory on a single host. Squeezed
+"balances" memory between VMs according to a policy written to Xenstore.
+
+The following diagram shows the internals of Squeezed:
+
+
+
+At the center of squeezed is an abstract model of a Xen host. The model
+includes:
+
+- The amount of already-used host memory (used by fixed overheads such as Xen
+ and the crash kernel).
+- Per-domain memory policy specifically `dynamic-min` and `dynamic-max` which
+ together describe a range, within which the domain's actual used memory
+ should remain.
+- Per-domain calibration data which allows us to compute the necessary balloon
+ target value to achive a particular memory usage value.
+
+Squeezed is a single-threaded program which receives commands from xenopsd over
+a Unix domain socket. When Xenopsd wishes to start a new VM, squeezed will be
+asked to create a "reservation". Note this is different to the Xen notion of a
+reservation. A squeezed reservation consists of an amount of memory squeezed
+will guarantee to keep free labelled with an id. When Xenopsd later creates the
+domain to notionally use the reservation, the reservation is "transferred" to
+the domain before the domain is built.
+
+Squeezed will also wake up every 30s and attempt to rebalance the memory on a
+host. This is useful to correct imbalances caused by balloon drivers
+temporarily failing to reach their targets. Note that ballooning is
+fundamentally a co-operative process, so squeezed must handle cases where the
+domains refuse to obey commands.
+
+The "output" of squeezed is a list of "actions" which include:
+
+- Set domain x's `memory/target` to a new value.
+- Set the `maxmem` of a domain to a new value (as a hard limit beyond which the
+ domain cannot allocate).
+
diff --git a/doc/content/squeezed/architecture/squeezed.png b/doc/content/squeezed/architecture/squeezed.png
new file mode 100644
index 00000000000..eb26f3eba46
Binary files /dev/null and b/doc/content/squeezed/architecture/squeezed.png differ
diff --git a/doc/content/squeezed/design/calculation.svg b/doc/content/squeezed/design/calculation.svg
new file mode 100644
index 00000000000..0b24ce7beeb
--- /dev/null
+++ b/doc/content/squeezed/design/calculation.svg
@@ -0,0 +1,892 @@
+
+
+
+
diff --git a/ocaml/squeezed/doc/design/figs/fraction.latex b/doc/content/squeezed/design/figs/fraction.latex
similarity index 100%
rename from ocaml/squeezed/doc/design/figs/fraction.latex
rename to doc/content/squeezed/design/figs/fraction.latex
diff --git a/ocaml/squeezed/doc/design/figs/g.latex b/doc/content/squeezed/design/figs/g.latex
similarity index 100%
rename from ocaml/squeezed/doc/design/figs/g.latex
rename to doc/content/squeezed/design/figs/g.latex
diff --git a/ocaml/squeezed/doc/design/figs/hostfreemem.latex b/doc/content/squeezed/design/figs/hostfreemem.latex
similarity index 100%
rename from ocaml/squeezed/doc/design/figs/hostfreemem.latex
rename to doc/content/squeezed/design/figs/hostfreemem.latex
diff --git a/ocaml/squeezed/doc/design/figs/reservation.latex b/doc/content/squeezed/design/figs/reservation.latex
similarity index 100%
rename from ocaml/squeezed/doc/design/figs/reservation.latex
rename to doc/content/squeezed/design/figs/reservation.latex
diff --git a/ocaml/squeezed/doc/design/figs/unused.latex b/doc/content/squeezed/design/figs/unused.latex
similarity index 100%
rename from ocaml/squeezed/doc/design/figs/unused.latex
rename to doc/content/squeezed/design/figs/unused.latex
diff --git a/ocaml/squeezed/doc/design/figs/x.latex b/doc/content/squeezed/design/figs/x.latex
similarity index 100%
rename from ocaml/squeezed/doc/design/figs/x.latex
rename to doc/content/squeezed/design/figs/x.latex
diff --git a/ocaml/squeezed/doc/design/figs/xtotpages.latex b/doc/content/squeezed/design/figs/xtotpages.latex
similarity index 100%
rename from ocaml/squeezed/doc/design/figs/xtotpages.latex
rename to doc/content/squeezed/design/figs/xtotpages.latex
diff --git a/doc/content/squeezed/design/fraction.svg b/doc/content/squeezed/design/fraction.svg
new file mode 100644
index 00000000000..92fbce499f4
--- /dev/null
+++ b/doc/content/squeezed/design/fraction.svg
@@ -0,0 +1,265 @@
+
+
diff --git a/doc/content/squeezed/design/g.svg b/doc/content/squeezed/design/g.svg
new file mode 100644
index 00000000000..5136128f6bd
--- /dev/null
+++ b/doc/content/squeezed/design/g.svg
@@ -0,0 +1,92 @@
+
+
diff --git a/doc/content/squeezed/design/hostfreemem.svg b/doc/content/squeezed/design/hostfreemem.svg
new file mode 100644
index 00000000000..c97fd91ae90
--- /dev/null
+++ b/doc/content/squeezed/design/hostfreemem.svg
@@ -0,0 +1,162 @@
+
+
diff --git a/ocaml/squeezed/doc/design/README.md b/doc/content/squeezed/design/index.md
similarity index 90%
rename from ocaml/squeezed/doc/design/README.md
rename to doc/content/squeezed/design/index.md
index 8b46a0c0009..b1ef3a4cb30 100644
--- a/ocaml/squeezed/doc/design/README.md
+++ b/doc/content/squeezed/design/index.md
@@ -1,40 +1,34 @@
-Squeezed: a host memory ballooning daemon for Xen
-=================================================
++++
+title = "Design"
++++
Squeezed is a single host memory ballooning daemon. It helps by:
-1. allowing VM memory to be adjusted dynamically without having to reboot;
+1. Allowing VM memory to be adjusted dynamically without having to reboot;
and
-
-2. avoiding wasting memory by keeping everything fully utilised, while retaining
+2. Avoiding wasting memory by keeping everything fully utilised, while retaining
the ability to take memory back to start new VMs.
-Squeezed currently includes a simple
-[Ballooning policy](#ballooning-policy)
-which serves as a useful default.
-The policy is written with respect to an abstract
-[Xen memory model](#the-memory-model), which is based
-on a number of
-[assumptions about the environment](#environmental-assumptions),
-for example that most domains have co-operative balloon drivers.
-In theory the policy could be replaced later with something more sophisticated
-(for example see
-[xenballoond](https://github.com/avsm/xen-unstable/blob/master/tools/xenballoon/xenballoond.README)).
-
-The [Toolstack interface](#toolstack-interface) is used by
-[Xenopsd](https://github.com/xapi-project/xenopsd) to free memory
-for starting new VMs.
-Although the only known client is Xenopsd,
-the interface can in theory be used by other clients. Multiple clients
-can safely use the interface at the same time.
-
-The [internal structure](#the-structure-of-the-daemon) consists of
-a single-thread event loop. To see how it works end-to-end, consult
-the [example](#example-operation).
-
-No software is ever perfect; to understand the flaws in Squeezed,
-please consult the
-[list of issues](#issues).
+Squeezed currently includes a simple [Ballooning policy](#ballooning-policy)
+which serves as a useful default. The policy is written with respect to an
+abstract [Xen memory model](#the-memory-model), which is based on a number of
+[assumptions about the environment](#environmental-assumptions), for example
+that most domains have co-operative balloon drivers. In theory the policy could
+be replaced later with something more sophisticated (for example see
+[xenballoond](https://github.com/avsm/xen-unstable/blob/master/tools/xenballoon/
+xenballoond.README)).
+
+The [Toolstack interface](#toolstack-interface) is used by Xenopsd to free
+memory for starting new VMs. Although the only known client is Xenopsd, the
+interface can in theory be used by other clients. Multiple clients can safely
+use the interface at the same time.
+
+The [internal structure](#the-structure-of-the-daemon) consists of a
+single-thread event loop. To see how it works end-to-end, consult the
+[example](#example-operation).
+
+No software is ever perfect; to understand the flaws in Squeezed, please
+consult the [list of issues](#issues).
Environmental assumptions
=========================
@@ -45,11 +39,10 @@ Environmental assumptions
is granted full access to xenstore, enabling it to modify every
domain’s `memory/target`.
-2. The Squeezed daemon calls
- `setmaxmem` in order to cap the amount of memory a domain can use.
- This relies on a patch to
- [xen which allows `maxmem` to be set lower than `totpages`](http://xenbits.xen.org/xapi/xen-3.4.pq.hg?file/c01d38e7092a/max-pages-below-tot-pages).
- See Section [maxmem](#use-of-maxmem) for more information.
+2. The Squeezed daemon calls `setmaxmem` in order to cap the amount of memory
+ a domain can use. This relies on a patch to xen which allows `maxmem` to
+ be set lower than `totpages` See Section [maxmem](#use-of-maxmem) for more
+ information.
3. The Squeezed daemon
assumes that only domains which write `control/feature-balloon` into
@@ -101,7 +94,7 @@ Environmental assumptions
guests from allocating *all* host memory (even
transiently) we guarantee that memory from within these special
ranges is always available. Squeezed operates in
- [two phases](#twophase-section): first causing memory to be freed; and
+ [two phases](#two-phase-target-setting): first causing memory to be freed; and
second causing memory to be allocated.
8. The Squeezed daemon
@@ -126,10 +119,10 @@ internal Squeezed concept and Xen is
completely unaware of it. When the daemon is moving memory between
domains, it always aims to keep
-
+
where *s* is the size of the “slush fund” (currently 9MiB) and
-
+
is the amount corresponding to the *i*th
reservation.
@@ -226,7 +219,7 @@ meanings:
If all balloon drivers are responsive then Squeezed daemon allocates
memory proportionally, so that each domain has the same value of:
-
+
So:
@@ -311,7 +304,7 @@ Note that non-ballooning aware domains will always have
since the domain will not be
instructed to balloon. Since a domain which is being built will have
0 <= `totpages` <= `reservation`, Squeezed computes
-
+
and subtracts this from its model of the host’s free memory, ensuring
that it doesn’t accidentally reallocate this memory for some other
purpose.
@@ -361,7 +354,7 @@ Each iteration of the main loop generates the following actions:
1. Domains which were active but have failed to make progress towards
their target in 5s are declared *inactive*. These
domains then have:
- `maxmem` set to the minimum of `target` and `totpages.
+ `maxmem` set to the minimum of `target` and `totpages`.
2. Domains which were inactive but have started to make progress
towards their target are declared *active*. These
@@ -429,7 +422,7 @@ domain 2) and a host. For a domain, the square box shows its
memory. Note the highlighted state where the host’s free memory is
temporarily exhausted
-
+
In the
initial state (at the top of the diagram), there are two domains, one
@@ -470,7 +463,7 @@ domain `maxmem` value is used to limit memory allocations by the domain.
The rules are:
1. if the domain has never been run and is paused then
- `maxmem` is set to `reservation (reservations were described
+ `maxmem` is set to `reservation` (reservations were described
in the [Toolstack interface](#toolstack-interface) section above);
- these domains are probably still being built and we must let
@@ -513,7 +506,7 @@ computing ideal target values and the third diagram shows the result
after targets have been set and the balloon drivers have
responded.
-
+
The scenario above includes 3 domains (domain 1,
domain 2, domain 3) on a host. Each of the domains has a non-ideal
@@ -532,12 +525,12 @@ which would be freed if we set each of the 3 domain’s
situation we would now have
`x` + `s` + `d1` + `d2` + `d3` free on the host where
`s` is the host slush fund and `x` is completely unallocated. Since we
-always want to keep the host free memory above $s$, we are free to
+always want to keep the host free memory above `s`, we are free to
return `x` + `d1` + `d2` + `d3` to guests. If we
use the default built-in proportional policy then, since all domains
have the same `dynamic-min` and `dynamic-max`, each gets the same
fraction of this free memory which we call `g`:
-
+
For each domain, the ideal balloon target is now
`target` = `dynamic-min` + `g`.
Squeezed does not set all the targets at once: this would allow the
@@ -601,7 +594,7 @@ Issues
removed.
- It seems unnecessarily evil to modify an *inactive*
- domain’s `maxmem` leaving `maxmem` less than `target}``, causing
+ domain’s `maxmem` leaving `maxmem` less than `target`, causing
the guest to attempt allocations forwever. It’s probably neater to
move the `target` at the same time.
diff --git a/doc/content/squeezed/design/reservation.svg b/doc/content/squeezed/design/reservation.svg
new file mode 100644
index 00000000000..d7ac27e4639
--- /dev/null
+++ b/doc/content/squeezed/design/reservation.svg
@@ -0,0 +1,75 @@
+
+
diff --git a/doc/content/squeezed/design/twophase.svg b/doc/content/squeezed/design/twophase.svg
new file mode 100644
index 00000000000..b009fa686c0
--- /dev/null
+++ b/doc/content/squeezed/design/twophase.svg
@@ -0,0 +1,540 @@
+
+
+
+
diff --git a/doc/content/squeezed/design/unused.svg b/doc/content/squeezed/design/unused.svg
new file mode 100644
index 00000000000..e85445d7e0b
--- /dev/null
+++ b/doc/content/squeezed/design/unused.svg
@@ -0,0 +1,199 @@
+
+
diff --git a/doc/content/squeezed/squeezer.md b/doc/content/squeezed/squeezer.md
new file mode 100644
index 00000000000..059d295a532
--- /dev/null
+++ b/doc/content/squeezed/squeezer.md
@@ -0,0 +1,263 @@
+---
+title: Overview of the memory squeezer
+hidden: true
+---
+
+{{% notice warning %}}
+This was converted to markdown from squeezer.tex. It is not clear how much
+of this document is still relevant and/or already present in the other docs.
+{{% /notice %}}
+
+summary
+-------
+
+- ballooning is a per-domain operation; not a per-VM operation. A VM
+ may be represented by multiple domains (currently localhost migrate,
+ in the future stubdomains)
+
+- most free host memory is divided up between running domains
+ proportionally, so they all end up with the same value of
+ ratio
+
+
+
+ where ratio(domain) =
+ if domain.dynamic_max - domain.dynamic_min = 0
+ then 0
+ else (domain.target - domain.dynamic_min)
+ / (domain.dynamic_max - domain.dynamic_min)
+
+Assumptions
+-----------
+
+- all memory values are stored and processed in units of KiB
+
+- the squeezing algorithm doesn’t know about host or VM overheads but
+ this doesn’t matter because
+
+- the squeezer assumes that any free host memory can be allocated to
+ running domains and this will be directly reflected in their
+ memory\_actual i.e. if x KiB is free on the host we can tell a guest
+ to use x KiB and see the host memory goes to 0 and the guest’s
+ memory\_actual increase by x KiB. We assume that no-extra ’overhead’
+ is required in this operation (all overheads are functions of
+ static\_max only)
+
+Definitions
+-----------
+
+- domain: an object representing a xen domain
+
+- domain.domid: unique identifier of the domain on the host
+
+- domaininfo(domain): a function which returns live per-domain
+ information from xen (in real-life a hypercall)
+
+- a domain is said to “have never run” if never\_been\_run(domain)
+
+ where never_been_run(domain) = domaininfo(domain).paused
+ and not domaininfo(domain).shutdown
+ and domaininfo(domain).cpu_time = 0
+
+- xenstore-read(path): a function which returns the value associated
+ with ’path’ in xenstore
+
+- domain.initial\_reservation: used to associate freshly freed memory
+ with a new domain which is being built or restored
+
+ domain.initial_reservation =
+ xenstore-read(/local/domain//memory/initial-reservation)
+
+- domain.target: represents what we think the balloon target currently
+ is
+
+ domain.target =
+ if never_been_run(domain)
+ then xenstore-read(/local/domain//memory/target)
+ else domain.initial_reservation
+
+- domain.dynamic\_min: represents what we think the dynamic\_min
+ currently is
+
+ domain.dynamic_min =
+ if never_been_run(domain)
+ then xenstore-read(/local/domain//memory/dynamic_min)
+ else domain.initial_reservation
+
+- domain.dynamic\_max: represents what we think the dynamic\_max
+ currently is
+
+ domain.dynamic_max =
+ if never_been_run(domain)
+ then xenstore-read(/local/domain//memory/dynamic_max)
+ else domain.initial_reservation
+
+- domain.memory\_actual: represents the memory we think the guest is
+ using (doesn’t take overheads like shadow into account)
+
+ domain.memory_actual =
+ if never_been_run(domain)
+ max domaininfo(domain).total_memory_pages domain.initial_reservation
+ else domaininfo(domain).total_memory_pages
+
+- domain.memory\_actual\_last\_update\_time: time when we saw the last
+ change in memory\_actual
+
+- domain.unaccounted\_for: a fresh domain has memory reserved for it
+ but xen doesn’t know about it. We subtract this from the host memory
+ xen thinks is free.
+
+ domain.unaccounted_for =
+ if never_been_run(domain)
+ then max 0 (domain.initial_reservation - domaininfo(domain).total_memory_pages)
+
+- domain.max\_mem: an upper-limit on the amount of memory a domain
+ can allocate. Initially static\_max.
+
+ domain.max_mem = domaininfo(domain).max_mem
+
+- assume\_balloon\_driver\_stuck\_after: a constant number of seconds
+ after which we conclude that the balloon driver has stopped working
+
+ assume_balloon_driver_stuck_after = 2
+
+- domain.active: a boolean value which is true when we think the
+ balloon driver is functioning
+
+ domain.active = has_hit_target(domain)
+ or (now - domain.memory_actual_last_update_time)
+ > assume_balloon_driver_stuck_after
+
+- a domain is said to “have hit its target”
+ if has\_hit\_target(domain)
+
+ where has_hit_target(domain) = floor(memory_actual / 4) = floor(target / 4)
+
+ NB this definition might have to be loosened if it turns out that
+ some drivers are less accurate than this.
+
+- a domain is said to “be capable of ballooning” if
+ can\_balloon(domain) where can\_balloon(domain) = not
+ domaininfo(domain).paused
+
+- host: an object representing a XenServer host
+
+- host.domains: a list of domains present on the host
+
+- physinfo(host): a function which returns live per-host information
+ from xen (in real-life a hypercall)
+
+- host.free\_mem: amount of memory we consider to be free on the host
+
+ host.free_mem = physinfo(host).free_pages + physinfo(host).scrub_pages
+ - \sigma d\in host.domains. d.unaccounted_for
+
+Squeezer APIs
+-------------
+
+The squeezer has 2 APIs:
+
+1. allocate-memory-for-domain(host, domain, amount): frees “amount” and
+ “reserves” (as best it can) it for a particular domain
+
+2. rebalance-memory: called after e.g. domain destruction to rebalance
+ memory between the running domains
+
+allocate-memory-for-domain keeps contains the main loop which performs
+the actual target and max\_mem adjustments:
+
+ function allocate-memory-for-domain(host, domain, amount):
+ \forall d\in host.domains. d.max_mem <- d.target
+ while true do
+ -- call change-host-free-memory with a "success condition" set to
+ -- "when the host memory is >= amount"
+ declared_active, declared_inactive, result =
+ change-host-free-memory(host, amount, \lambda m >= amount)
+ if result == Success:
+ domain.initial_reservation <- amount
+ return Success
+ elif result == DynamicMinsTooHigh:
+ return DynamicMinsTooHigh
+ elif result == DomainsRefusedToCooperate:
+ return DomainsRefusedToCooperate
+ elif result == AdjustTargets(adjustments):
+ \forall (domain, target)\in adjustments:
+ domain.max_mem <- target
+ domain.target <- target
+
+ \forall d\in declared_inactive:
+ domain.max_mem <- min domain.target domain.memory_actual
+ \forall d\in declared_active:
+ domain.max_mem <- domain.target
+ done
+
+The helper function change-host-free-memory(host, amount) does the
+“thinking”:
+
+1. it keeps track of whether domains are active or inactive (only for
+ the duration of the squeezer API call – when the next call comes in
+ we assume that all domains are active and capable of ballooning... a
+ kind of “innocent until proven guilty” approaxh)
+
+2. it computes what the balloon targets should be
+
+
+
+ function change-host-free-memory(host, amount, success_condition):
+ \forall d\in host.domains. recalculate domain.active
+ active_domains <- d\in host.domains where d.active = true
+ inactive_domains <- d\in host.domains where d.active = false
+ -- since the last time we were called compute the lists of domains
+ -- which have become active and inactive
+ declared_active, declared_inactive <- ...
+ -- compute how much memory we could free or allocate given only the
+ -- active domains
+ maximum_freeable_memory =
+ sum(d\in active_domains)(d.memory_actual - d.dynamic_min)
+ maximum_allocatable_memory =
+ sum(d\in active_domains)(d.dynamic_max - d.memory_actual)
+ -- hypothetically consider freeing the maximum memory possible.
+ -- How much would we have to give back after we've taken as much as we want?
+ give_back = max 0 (maximum_freeable_memory - amount)
+ -- compute a list of target changes to 'give this memory back' to active_domains
+ -- NB this code is careful to allocate *all* memory, not just most
+ -- of it because of a rounding error.
+ adjustments = ...
+ -- decide whether every VM has reached its target (a good thing)
+ all_targets_reached = true if \forall d\in active_domains.has_hit_target(d)
+
+ -- If we're happy with the amount of free memory we've got and the active
+ -- guests have finished ballooning
+ if success_condition host.free_mem = true
+ and all_targets_reached and adjustments = []
+ then return declared_active, declared_inactive, Success
+
+ -- If we're happy with the amount of free memory and the running domains
+ -- can't absorb any more of the surplus
+ if host.free_mem >= amount and host.free_mem - maximum_allocatable_memory = 0
+ then return declared_active, declared_inactive, Success
+
+ -- If the target is too aggressive because of some non-active domains
+ if maximum_freeable_memory < amount and inactive_domains <> []
+ then return declared_active, declared_inactive,
+ DomainsRefusedToCooperate inactive_domains
+
+ -- If the target is too aggressive not because of the domains themselves
+ -- but because of the dynamic_mins
+ return declared_active, declared_inactive, DynamicMinsTooHigh
+
+The API rebalance-memory aims to use up as much host memory as possible
+EXCEPT it is necessary to keep some around for xen to use to create
+empty domains with.
+
+ Currently we have:
+ -- 10 MiB
+ target_host_free_mem = 10204
+ -- it's not always possible to allocate everything so a bit of slop has
+ -- been added here:
+ free_mem_tolerance = 1024
+
+ function rebalance-memory(host):
+ change-host-free-memory(host, target_host_free_mem,
+ \lambda m. m - target_host_free_mem < free_mem_tolerance)
+ -- and then wait for the xen page scrubber
diff --git a/doc/content/toolstack/features/events/index.md b/doc/content/toolstack/features/events/index.md
new file mode 100644
index 00000000000..3da4b6a35f7
--- /dev/null
+++ b/doc/content/toolstack/features/events/index.md
@@ -0,0 +1,256 @@
++++
+title = "Event handling in the Control Plane - Xapi, Xenopsd and Xenstore"
+menuTitle = "Event handling"
++++
+
+Introduction
+------------
+
+Xapi, xenopsd and xenstore use a number of different events to obtain
+indications that some state changed in dom0 or in the guests. The events
+are used as an efficient alternative to polling all these states
+periodically.
+
+- **xenstore** provides a very configurable approach in which each and
+ any key can be watched individually by a xenstore client. Once the
+ value of a watched key changes, xenstore will indicate to the client
+ that the value for that key has changed. An ocaml xenstore client
+ library provides a way for ocaml programs such as xenopsd,
+ message-cli and rrdd to provide high-level ocaml callback functions
+ to watch specific key. It's very common, for instance, for xenopsd
+ to watch specific keys in the xenstore keyspace of a guest and then
+ after receiving events for some or all of them, read other keys or
+ subkeys in xenstored to update its internal state mirroring the
+ state of guests and its devices (for instance, if the guest has pv
+ drivers and specific frontend devices have established connections
+ with the backend devices in dom0).
+- **xapi** also provides a very configurable event mechanism in which
+ the xenapi can be used to provide events whenever a xapi object (for
+ instance, a VM, a VBD etc) changes state. This event mechanism is
+ very reliable and is extensively used by XenCenter to provide
+ real-time update on the XenCenter GUI.
+- **xenopsd** provides a somewhat less configurable event mechanism,
+ where it always provides signals for all objects (VBDs, VMs
+ etc) whose state changed (so it's not possible to select a subset of
+ objects to watch for as in xenstore or in xapi). It's up to the
+ xenopsd client (eg. xapi) to receive these events and then filter
+ out or act on each received signal by calling back xenopsd and
+ asking it information for the specific signalled object. The main
+ use in xapi for the xenopsd signals is to update xapi's database of
+ the current state of each object controlled by xenopsd (VBDs,
+ VMs etc).
+
+Given a choice between polling states and receiving events when the
+state change, we should in general opt for receiving events in the code
+in order to avoid adding bottlenecks in dom0 that will prevent the
+scalability of XenServer to many VMs and virtual devices.
+
+
+
+Xapi
+----
+
+### Sending events from the xenapi
+
+A xenapi user client, such as XenCenter, the xe-cli or a python script,
+can register to receive events from XAPI for specific objects in the
+XAPI DB. XAPI will generate events for those registered clients whenever
+the corresponding XAPI DB object changes.
+
+
+
+This small python scripts shows how to register a simple event watch
+loop for XAPI:
+
+```python
+import XenAPI
+session = XenAPI.Session("http://xshost")
+session.login_with_password("username","password")
+session.xenapi.event.register(["VM","pool"]) # register for events in the pool and VM objects
+while True:
+ try:
+ events = session.xenapi.event.next() # block until a xapi event on a xapi DB object is available
+ for event in events:
+ print "received event op=%s class=%s ref=%s" % (event['operation'], event['class'], event['ref'])
+ if event['class'] == 'vm' and event['operatoin'] == 'mod':
+ vm = event['snapshot']
+ print "xapi-event on vm: vm_uuid=%s, power_state=%s, current_operation=%s" % (vm['uuid'],vm['name_label'],vm['power_state'],vm['current_operations'].values())
+ except XenAPI.Failure, e:
+ if len(e.details) > 0 and e.details[0] == 'EVENTS_LOST':
+ session.xenapi.event.unregister(["VM","pool"])
+ session.xenapi.event.register(["VM","pool"])
+```
+
+
+
+### Receiving events from xenopsd
+
+Xapi receives all events from xenopsd via the function
+xapi\_xenops.events\_watch() in its own independent thread. This is a
+single-threaded function that is responsible for handling all of the
+signals sent by xenopsd. In some situations with lots of VMs and virtual
+devices such as VBDs, this loop may saturate a single dom0 vcpu, which
+will slow down handling all of the xenopsd events and may cause the
+xenopsd signals to accumulate unboundedly in the worst case in the
+updates queue in xenopsd (see Figure 1).
+
+The function xapi\_xenops.events\_watch() calls
+xenops\_client.UPDATES.get() to obtain a list of (barrier,
+barrier\_events), and then it process each one of the barrier\_event,
+which can be one of the following events:
+
+- **Vm id:** something changed in this VM,
+ run xapi\_xenops.update\_vm() to query xenopsd about its state. The
+ function update\_vm() will update power\_state, allowed\_operations,
+ console and guest\_agent state in the xapi DB.
+- **Vbd id:** something changed in this VM,
+ run xapi\_xenops.update\_vbd() to query xenopsd about its state. The
+ function update\_vbd() will update currently\_attached and connected
+ in the xapi DB.
+- **Vif id:** something changed in this VM,
+ run xapi\_xenops.update\_vif() to query xenopsd about its state. The
+ function update\_vif() will update activate and plugged state of in
+ the xapi DB.
+- **Pci id:** something changed in this VM,
+ run xapi\_xenops.update\_pci() to query xenopsd about its state.
+- **Vgpu id:** something changed in this VM,
+ run xapi\_xenops.update\_vgpu() to query xenopsd about its state.
+- **Task id:** something changed in this VM,
+ run xapi\_xenops.update\_task() to query xenopsd about its state.
+ The function update\_task() will update the progress of the task in
+ the xapi DB using the information of the task in xenopsd.
+
+
+
+All the xapi\_xenops.update\_X() functions above will call
+Xenopsd\_client.X.stat() functions to obtain the current state of X from
+xenopsd:
+
+
+
+There are a couple of optimisations while processing the events in
+xapi\_xenops.events\_watch():
+
+- if an event X=(vm\_id,dev\_id) (eg. Vbd dev\_id) has already been
+ processed in a barrier\_events, it's not processed again. A typical
+ value for X is eg. "<vm\_uuid>.xvda" for a VBD.
+- if Events\_from\_xenopsd.are\_supressed X, then this event
+ is ignored. Events are supressed if VM X.vm\_id is migrating away
+ from the host
+
+#### Barriers
+
+When xapi needs to execute (and to wait for events indicating completion
+of) a xapi operation (such as VM.start and VM.shutdown) containing many
+xenopsd sub-operations (such as VM.start – to force xenopsd to change
+the VM power\_state, and VM.stat, VBD.stat, VIF.stat etc – to force the
+xapi DB to catch up with the xenopsd new state for these objects), xapi
+sends to the xenopsd input queue a barrier, indicating that xapi will
+then block and only continue execution of the barred operation when
+xenopsd returns the barrier. The barrier should only be returned when
+xenopsd has finished the execution of all the operations requested by
+xapi (such as VBD.stat and VM.stat in order to update the state of the
+VM in the xapi database after a VM.start has been issued to xenopsd).
+
+A recent problem has been detected in the xapi\_xenops.events\_watch()
+function: when it needs to process many VM\_check\_state events, this
+may push for later the processing of barriers associated with a
+VM.start, delaying xapi in reporting (via a xapi event) that the VM
+state in the xapi DB has reached the running power\_state. This needs
+further debugging, and is probably one of the reasons in CA-87377 why in
+some conditions a xapi event reporting that the VM power\_state is
+running (causing it to go from yellow to green state in XenCenter) is
+taking so long to be returned, way after the VM is already running.
+
+Xenopsd
+-------
+
+Xenopsd has a few queues that are used by xapi to store commands to be
+executed (eg. VBD.stat) and update events to be picked up by xapi. The
+main ones, easily seen at runtime by running the following command in
+dom0, are:
+
+```bash
+# xenops-cli diagnostics --queue=org.xen.xapi.xenops.classic
+{
+ queues: [ # XENOPSD INPUT QUEUE
+ ... stuff that still needs to be processed by xenopsd
+ VM.stat
+ VBD.stat
+ VM.start
+ VM.shutdown
+ VIF.plug
+ etc
+ ]
+ workers: [ # XENOPSD WORKER THREADS
+ ... which stuff each worker thread is processing
+ ]
+ updates: {
+ updates: [ # XENOPSD OUTPUT QUEUE
+ ... signals from xenopsd that need to be picked up by xapi
+ VM_check_state
+ VBD_check_state
+ etc
+ ]
+ } tasks: [ # XENOPSD TASKS
+ ... state of each known task, before they are manually deleted after completion of the task
+ ]
+}
+```
+
+### Sending events to xapi
+
+Whenever xenopsd changes the state of a XenServer object such as a VBD
+or VM, or when it receives an event from xenstore indicating that the
+states of these objects have changed (perhaps because either a guest or
+the dom0 backend changed the state of a virtual device), it creates a
+signal for the corresponding object (VM\_check\_state, VBD\_check\_state
+etc) and send it up to xapi. Xapi will then process this event in its
+xapi\_xenops.events\_watch() function.
+
+
+
+These signals may need to wait a long time to be processed if the
+single-threaded xapi\_xenops.events\_watch() function is having
+difficulties (ie taking a long time) to process previous signals in the
+UPDATES queue from xenopsd.
+
+### Receiving events from xenstore
+
+Xenopsd watches a number of keys in xenstore, both in dom0 and in each
+guest. Xenstore is responsible to send watch events to xenopsd whenever
+the watched keys change state. Xenopsd uses a xenstore client library to
+make it easier to create a callback function that is called whenever
+xenstore sends these events.
+
+
+
+Xenopsd also needs to complement sometimes these watch events with
+polling of some values. An example is the @introduceDomain event in
+xenstore (handled in xenopsd/xc/xenstore\_watch.ml), which indicates
+that a new VM has been created. This event unfortunately does not
+indicate the domid of the VM, and xenopsd needs to query Xen (via libxc)
+which domains are now available in the host and compare with the
+previous list of known domains, in order to figure out the domid of the
+newly introduced domain.
+
+ It is not good practice to poll xenstore for changes of values. This
+will add a large overhead to both xenstore and xenopsd, and decrease the
+scalability of XenServer in terms of number of VMs/host and virtual
+devices per VM. A much better approach is to rely on the watch events of
+xenstore to indicate when a specific value has changed in xenstore.
+
+Xenstore
+--------
+
+### Sending events to xenstore clients
+
+If a xenstore client has created watch events for a key, then xenstore
+will send events to this client whenever this key changes state.
+
+### Receiving events from xenstore clients
+
+Xenstore clients indicate to xenstore that something state changed by
+writing to some xenstore key. This may or may not cause xenstore to
+create watch events for the corresponding key, depending on if other
+xenstore clients have watches on this key.
diff --git a/doc/content/toolstack/features/events/obtaining-current-state.png b/doc/content/toolstack/features/events/obtaining-current-state.png
new file mode 100644
index 00000000000..3bf2c15bc2a
Binary files /dev/null and b/doc/content/toolstack/features/events/obtaining-current-state.png differ
diff --git a/doc/content/toolstack/features/events/receiving-events-from-xenopsd.png b/doc/content/toolstack/features/events/receiving-events-from-xenopsd.png
new file mode 100644
index 00000000000..52afdcca8c3
Binary files /dev/null and b/doc/content/toolstack/features/events/receiving-events-from-xenopsd.png differ
diff --git a/doc/content/toolstack/features/events/receiving-events-from-xenstore.png b/doc/content/toolstack/features/events/receiving-events-from-xenstore.png
new file mode 100644
index 00000000000..022ba4c1097
Binary files /dev/null and b/doc/content/toolstack/features/events/receiving-events-from-xenstore.png differ
diff --git a/doc/content/toolstack/features/events/sending-events-from-xapi.png b/doc/content/toolstack/features/events/sending-events-from-xapi.png
new file mode 100644
index 00000000000..cfbb4e8b572
Binary files /dev/null and b/doc/content/toolstack/features/events/sending-events-from-xapi.png differ
diff --git a/doc/content/toolstack/features/events/sending-events-to-xapi.png b/doc/content/toolstack/features/events/sending-events-to-xapi.png
new file mode 100644
index 00000000000..e7a9da8caff
Binary files /dev/null and b/doc/content/toolstack/features/events/sending-events-to-xapi.png differ
diff --git a/doc/content/toolstack/features/events/xapi-xenopsd-events.png b/doc/content/toolstack/features/events/xapi-xenopsd-events.png
new file mode 100644
index 00000000000..1adf6d50c43
Binary files /dev/null and b/doc/content/toolstack/features/events/xapi-xenopsd-events.png differ
diff --git a/doc/content/xapi/cli/_index.md b/doc/content/xapi/cli/_index.md
new file mode 100644
index 00000000000..a4ae338390a
--- /dev/null
+++ b/doc/content/xapi/cli/_index.md
@@ -0,0 +1,183 @@
++++
+title = "XE CLI architecture"
+menuTitle = "CLI"
++++
+
+{{% notice info %}}
+The links in this page point to the source files of xapi
+[v1.132.0](https://github.com/xapi-project/xen-api/tree/v1.132.0), not to the
+latest source code. Meanwhile, the CLI server code in xapi has been moved to a
+library separate from the main xapi binary, and has its own subdirectory
+`ocaml/xapi-cli-server`.
+{{% /notice %}}
+
+## Architecture
+
+- **The actual CLI** is a very lightweight binary in
+ [ocaml/xe-cli](https://github.com/xapi-project/xen-api/tree/v1.132.0/ocaml/xe-cli)
+ - It is just a dumb client, that does everything that xapi tells
+ it to do
+ - This is a security issue
+ - We must trust the xenserver that we connect to, because it
+ can tell xe to read local files, download files, ...
+ - When it is first called, it takes the few command-line arguments
+ it needs, and then passes the rest to xapi in a HTTP PUT request
+ - Each argument is in a separate line
+ - Then it loops doing what xapi tells it to do, in a loop, until
+ xapi tells it to exit or an exception happens
+
+- **The protocol** description is in
+ [ocaml/xapi-cli-protocol/cli_protocol.ml](https://github.com/xapi-project/xen-api/blob/v1.132.0/ocaml/xapi-cli-protocol/cli_protocol.ml)
+ - The CLI has such a protocol that one binary can talk to multiple
+ versions of xapi as long as their CLI protocol versions are
+ compatible
+ - and the CLI can be changed without updating the xe binary
+ - and also for performance reasons, it is more efficient this way
+ than by having a CLI that makes XenAPI calls
+
+- **Xapi**
+ - The HTTP POST request is sent to the `/cli` URL
+ - In `Xapi.server_init`, xapi [registers the appropriate function
+ to handle these
+ requests](https://github.com/xapi-project/xen-api/blob/v1.132.0/ocaml/xapi/xapi.ml#L804),
+ defined in [common_http_handlers in the same
+ file](https://github.com/xapi-project/xen-api/blob/v1.132.0/ocaml/xapi/xapi.ml#L589):
+ `Xapi_cli.handler`
+ - The relevant code is in `ocaml/xapi/records.ml`,
+ `ocaml/xapi/cli_*.ml`
+ - CLI object definitions are in `records.ml`, command
+ definitions in `cli_frontend.ml` (in
+ [cmdtable_data](https://github.com/xapi-project/xen-api/blob/v1.132.0/ocaml/xapi/cli_frontend.ml#L72)),
+ implementations of commands in `cli_operations.ml`
+ - When a command is received, it is parsed into a command name and
+ a parameter list of key-value pairs
+ - and the command table
+ [is](https://github.com/xapi-project/xen-api/blob/v1.132.0/ocaml/xapi/xapi_cli.ml#L157)
+ [populated
+ lazily](https://github.com/xapi-project/xen-api/blob/v1.132.0/ocaml/xapi/cli_frontend.ml#L3005)
+ from the commands defined in `cmdtable_data` in
+ `cli_frontend.ml`, and [automatically
+ generated](https://github.com/xapi-project/xen-api/blob/v1.132.0/ocaml/xapi/cli_operations.ml#L740)
+ low-level parameter commands (the ones defined in [section
+ A.3.2 of the XenServer Administrator's
+ Guide](http://docs.citrix.com/content/dam/docs/en-us/xenserver/xenserver-7-0/downloads/xenserver-7-0-administrators-guide.pdf))
+ are also added for a list of standard classes
+ - the command table maps command names to records that contain
+ the implementation of the command, among other things
+ - Then the command name [is looked
+ up](https://github.com/xapi-project/xen-api/blob/v1.132.0/ocaml/xapi/xapi_cli.ml#L86)
+ in the command table, and the corresponding operation is
+ executed with the parsed key-value parameter list passed to it
+
+## Walk-through: CLI handler in xapi (external calls)
+
+### Definitions for the HTTP handler
+
+ Constants.cli_uri = "/cli"
+
+ Datamodel.http_actions = [...;
+ ("post_cli", (Post, Constants.cli_uri, false, [], _R_READ_ONLY, []));
+ ...]
+
+ (* these public http actions will NOT be checked by RBAC *)
+ (* they are meant to be used in exceptional cases where RBAC is already *)
+ (* checked inside them, such as in the XMLRPC (API) calls *)
+ Datamodel.public_http_actions_with_no_rbac_check` = [...
+ "post_cli"; (* CLI commands -> calls XMLRPC *)
+ ...]
+
+ Xapi.common_http_handlers = [...;
+ ("post_cli", (Http_svr.BufIO Xapi_cli.handler));
+ ...]
+
+ Xapi.server_init () =
+ ...
+ "Registering http handlers", [], (fun () -> List.iter Xapi_http.add_handler common_http_handlers);
+ ...
+
+Due to there definitions, `Xapi_http.add_handler` does not perform RBAC checks for `post_cli`. This means that the CLI handler does not use `Xapi_http.assert_credentials_ok` when a request comes in, as most other handlers do. The reason is that RBAC checking is delegated to the actual XenAPI calls that are being done by the commands in `Cli_operations`.
+
+This means that the `Xapi_http.add_handler call` so resolves to simply:
+
+ Http_svr.Server.add_handler server Http.Post "/cli" (Http_svr.BufIO Xapi_cli.handler))
+
+...which means that the function `Xapi_cli.handler` is called directly when an HTTP POST request with path `/cli` comes in.
+
+### High-level request processing
+
+`Xapi_cli.handler`:
+
+- Reads the body of the HTTP request, limitted to `Xapi_globs.http_limit_max_cli_size = 200 * 1024` characters.
+- Sends a protocol version string to the client: `"XenSource thin CLI protocol"` plus binary encoded major (0) and (2) minor numbers.
+- Reads the protocol version from the client and exits with an error if it does not match the above.
+- Calls `Xapi_cli.parse_session_and_args` with the request's body to extract the session ref, if there.
+- Calls `Cli_frontend.parse_commandline` to parse the rest of the command line from the body.
+- Calls `Xapi_cli.exec_command` to execute the command.
+- On error, calls `exception_handler`.
+
+`Xapi_cli.parse_session_and_args`:
+
+- Is passed the request body and reads it line by line. Each line is considered an argument.
+- Removes any CR chars from the end of each argument.
+- If the first arg starts with `session_id=`, the the bit after this prefix is considered to be a session reference.
+- Returns the session ref (if there) and (remaining) list of args.
+
+`Cli_frontend.parse_commandline`:
+
+- Returns the command name and assoc list of param names and values. It handles `--name` and `-flag` arguments by turning them into key/value string pairs.
+
+`Xapi_cli.exec_command`:
+
+- Finds username/password params.
+- Get the rpc function: this is the so-called "`fake_rpc` callback", which does not use the network or HTTP at all, but goes straight to `Api_server.callback1` (the XenAPI RPC entry point). This function is used by the CLI handler to do loopback XenAPI calls.
+- Logs the parsed xe command, omitting sensitive data.
+- Continues as `Xapi_cli.do_rpcs`
+- Looks up the command name in the command table from `Cli_frontend` (raises an error if not found).
+- Checks if all required params have been supplied (raises an error if not).
+- Checks that the host is a pool master (raises an error if not).
+- Depending on the command, a `session.login_with_password` or `session.slave_local_login_with_password` XenAPI call is made with the supplied username and password. If the authentication passes, then a session reference is returned for the RBAC role that belongs to the user. This session is used to do further XenAPI calls.
+- Next, the implementation of the command in `Cli_operations` is executed.
+
+### Command implementations
+
+The various commands are implemented in `cli_operations.ml`. These functions are only called after user authentication has passed (see above). However, RBAC restrictions are only enforced inside any XenAPI calls that are made, and _not_ on any of the other code in `cli_operations.ml`.
+
+The type of each command implementation function is as follows (see `cli_cmdtable.ml`):
+
+ type op =
+ Cli_printer.print_fn ->
+ (Rpc.call -> Rpc.response) ->
+ API.ref_session -> ((string*string) list) -> unit
+
+So each function receives a printer for sending text output to the xe client, and rpc function and session reference for doing XenAPI calls, and a key/value pair param list. Here is a typical example:
+
+ let bond_create printer rpc session_id params =
+ let network = List.assoc "network-uuid" params in
+ let mac = List.assoc_default "mac" params "" in
+ let network = Client.Network.get_by_uuid rpc session_id network in
+ let pifs = List.assoc "pif-uuids" params in
+ let uuids = String.split ',' pifs in
+ let pifs = List.map (fun uuid -> Client.PIF.get_by_uuid rpc session_id uuid) uuids in
+ let mode = Record_util.bond_mode_of_string (List.assoc_default "mode" params "") in
+ let properties = read_map_params "properties" params in
+ let bond = Client.Bond.create rpc session_id network pifs mac mode properties in
+ let uuid = Client.Bond.get_uuid rpc session_id bond in
+ printer (Cli_printer.PList [ uuid])
+
+- The necessary parameters are looked up in `params` using `List.assoc` or similar.
+- UUIDs are translated into reference by `get_by_uuid` XenAPI calls (note that the `Client` module is the XenAPI client, and functions in there require the rpc function and session reference).
+- Then the main API call is made (`Client.Bond.create` in this case).
+- Further API calls may be made to output data for the client, and passed to the `printer`.
+
+This is the common case for CLI operations: they do API calls based on the parameters that were passed in.
+
+However, other commands are more complicated, for example `vm_import/export` and `vm_migrate`. These contain a lot more logic in the CLI commands, and also send commands to the client to instruct it to read or write files and/or do HTTP calls.
+
+Yet other commands do not actually do any XenAPI calls, but instead get "helpful" information from other places. Example: `diagnostic_gc_stats`, which displays statistics from xapi's OCaml GC.
+
+## Tutorials
+
+The following tutorials show how to extend the CLI (and XenAPI):
+
+- [Adding a field]({{< relref "../guides/howtos/add-field.md" >}})
+- [Adding an operation]({{< relref "../guides/howtos/add-function.md" >}})
diff --git a/doc/content/xapi/database/_index.md b/doc/content/xapi/database/_index.md
new file mode 100644
index 00000000000..1928f8afac2
--- /dev/null
+++ b/doc/content/xapi/database/_index.md
@@ -0,0 +1,4 @@
++++
+title = "Database"
++++
+
diff --git a/doc/content/xapi/database/redo-log/index.md b/doc/content/xapi/database/redo-log/index.md
new file mode 100644
index 00000000000..8f8ac202f6c
--- /dev/null
+++ b/doc/content/xapi/database/redo-log/index.md
@@ -0,0 +1,395 @@
++++
+title = "Metadata-on-LUN"
++++
+
+In the present version of XenServer, metadata changes resulting in
+writes to the database are not persisted in non-volatile storage. Hence,
+in case of failure, up to five minutes’ worth of metadata changes could
+be lost. The Metadata-on-LUN feature addresses the issue by
+ensuring that all database writes are retained. This will be used to
+improve recovery from failure by storing incremental *deltas* which can
+be re-applied to an old version of the database to bring it more
+up-to-date. An implication of this is that clients will no longer be
+required to perform a ‘pool-sync-database’ to protect critical writes,
+because all writes will be implicitly protected.
+
+This is implemented by saving descriptions of all persistent database
+writes to a LUN when HA is active. Upon xapi restart after failure, such
+as on master fail-over, these descriptions are read and parsed to
+restore the latest version of the database.
+
+Layout on block device
+======================
+
+It is useful to store the database on the block device as well as the
+deltas, so that it is unambiguous on recovery which version of the
+database the deltas apply to.
+
+The content of the block device will be structured as shown in
+the table below. It consists of a header; the rest of the
+device is split into two halves.
+
+| | Length (bytes) | Description
+|-----------------------|------------------:|----------------------------------------------
+| Header | 16 | Magic identifier
+| | 1 | ASCII NUL
+| | 1 | Validity byte
+| First half database | 36 | UUID as ASCII string
+| | 16 | Length of database as decimal ASCII
+| | *(as specified)* | Database (binary data)
+| | 16 | Generation count as decimal ASCII
+| | 36 | UUID as ASCII string
+| First half deltas | 16 | Length of database delta as decimal ASCII
+| | *(as specified)* | Database delta (binary data)
+| | 16 | Generation count as decimal ASCII
+| | 36 | UUID as ASCII string
+| Second half database | 36 | UUID as ASCII string
+| | 16 | Length of database as decimal ASCII
+| | *(as specified)* | Database (binary data)
+| | 16 | Generation count as decimal ASCII
+| | 36 | UUID as ASCII string
+| Second half deltas | 16 | Length of database delta as decimal ASCII
+| | *(as specified)* | Database delta (binary data)
+| | 16 | Generation count as decimal ASCII
+| | 36 | UUID as ASCII string
+
+After the header, one or both halves may be devoid of content. In a half
+which contains a database, there may be zero or more deltas (repetitions
+of the last three entries in each half).
+
+The structure of the device is split into two halves to provide
+double-buffering. In case of failure during write to one half, the other
+half remains intact.
+
+The magic identifier at the start of the file protect against attempting
+to treat a different device as a redo log.
+
+The validity byte is a single `ascii character indicating the
+state of the two halves. It can take the following values:
+
+| Byte | Description
+|-------|------------------------
+| `0` | Neither half is valid
+| `1` | First half is valid
+| `2` | Second half is valid
+
+The use of lengths preceding data sections permit convenient reading.
+The constant repetitions of the UUIDs act as nonces to protect
+against reading in invalid data in the case of an incomplete or corrupt
+write.
+
+Architecture
+============
+
+The I/O to and from the block device may involve long delays. For
+example, if there is a network problem, or the iSCSI device disappears,
+the I/O calls may block indefinitely. It is important to isolate this
+from xapi. Hence, I/O with the block device will occur in a separate
+process.
+
+Xapi will communicate with the I/O process via a UNIX domain socket using a
+simple text-based protocol described below. The I/O process will use to
+ensure that it can always accept xapi’s requests with a guaranteed upper
+limit on the delay. Xapi can therefore communicate with the process
+using blocking I/O.
+
+Xapi will interact with the I/O process in a best-effort fashion. If it
+cannot communicate with the process, or the process indicates that it
+has not carried out the requested command, xapi will continue execution
+regardless. Redo-log entries are idempotent (modulo the raising of
+exceptions in some cases) so it is of little consequence if a particular
+entry cannot be written but others can. If xapi notices that the process
+has died, it will attempt to restart it.
+
+The I/O process keeps track of a pointer for each half indicating the
+position at which the next delta will be written in that half.
+
+Protocol
+--------
+
+Upon connection to the control socket, the I/O process will attempt to
+connect to the block device. Depending on whether this is successful or
+unsuccessful, one of two responses will be sent to the client.
+
+- `connect|ack_` if it is successful; or
+
+- `connect|nack||` if it is unsuccessful, perhaps
+ because the block device does not exist or cannot be read from. The
+ `` is a description of the error; the `` of the message
+ is expressed using 16 digits of decimal ascii.
+
+The former message indicates that the I/O process is ready to receive
+commands. The latter message indicates that commands can not be sent to
+the I/O process.
+
+There are three commands which xapi can send to the I/O
+process. These are described below, with a high level description of the
+operational semantics of the I/O process’ actions, and the corresponding
+responses. For ease of parsing, each command is ten bytes in length.
+
+### Write database
+
+Xapi requests that a new database is written to the block device, and
+sends its content using the data socket.
+
+##### Command:
+
+: `writedb___|||`
+: The UUID is expressed as 36 ASCII
+ characters. The *length* of the data and the *generation-count* are
+ expressed using 16 digits of decimal ASCII.
+
+##### Semantics:
+
+1. Read the validity byte.
+2. If one half is valid, we will use the other half. If no halves
+ are valid, we will use the first half.
+3. Read the data from the data socket and write it into the
+ chosen half.
+4. Set the pointer for the chosen half to point to the position
+ after the data.
+5. Set the validity byte to indicate the chosen half is valid.
+
+##### Response:
+
+: `writedb|ack_` in case of successful write; or
+: `writedb|nack||` otherwise.
+: For error messages, the *length* of the message is expressed using
+ 16 digits of decimal ascii. In particular, the
+ error message for timeouts is the string `Timeout`.
+
+### Write database delta
+
+Xapi sends a description of a database delta to append to the block
+device.
+
+##### Command:
+
+: `writedelta||||`
+: The UUID is expressed as 36 ASCII
+ characters. The *length* of the data and the *generation-count* are
+ expressed using 16 digits of decimal ASCII.
+
+##### Semantics:
+
+1. Read the validity byte to establish which half is valid. If
+ neither half is valid, return with a `nack`.
+2. If the half’s pointer is set, seek to that position. Otherwise,
+ scan through the half and stop at the position after the
+ last write.
+3. Write the entry.
+4. Update the half’s pointer to point to the position after
+ the entry.
+
+##### Response:
+
+: `writedelta|ack_` in case of successful append; or
+: `writedelta|nack||` otherwise.
+: For error messages, the *length* of the message is expressed using
+ 16 digits of decimal ASCII. In particular, the
+ error message for timeouts is the string `Timeout`.
+
+### Read log
+
+Xapi requests the contents of the log.
+
+##### Command:
+
+: `read______`
+
+##### Semantics:
+
+1. Read the validity byte to establish which half is valid. If
+ neither half is valid, return with an `end`.
+2. Attempt to read the database from the current half.
+3. If this is successful, continue in that half reading entries up
+ to the position of the half’s pointer. If the pointer is not
+ set, read until a record of length zero is found or the end of
+ the half is reached. Otherwise—if the attempt to the read the
+ database was not successful—switch to using the other half and
+ try again from step 2.
+4. Finally output an `end`.
+
+##### Response:
+
+: `read|nack_||` in case of error; or
+: `read|db___|||` for a database record, then a
+ sequence of zero or more
+: `read|delta|||` for each delta record, then
+: `read|end__`
+: For each record, and for error messages, the *length* of the data or
+ message is expressed using 16 digits of decimal ascii. In particular, the
+ error message for timeouts is the string `Timeout`.
+
+### Re-initialise log
+
+Xapi requests that the block device is re-initialised with a fresh
+redo-log.
+
+##### Command:
+
+: `empty_____`\
+
+##### Semantics:
+
+: 1. Set the validity byte to indicate that neither half is valid.
+
+##### Response:
+
+: `empty|ack_` in case of successful re-initialisation; or
+ `empty|nack||` otherwise.
+: For error messages, the *length* of the message is expressed using
+ 16 digits of decimal ASCII. In particular, the
+ error message for timeouts is the string `Timeout`.
+
+Impact on xapi performance
+==========================
+
+The implementation of the feature causes a slow-down in xapi of around
+6% in the general case. However, if the LUN becomes inaccessible this
+can cause a slow-down of up to 25% in the worst case.
+
+The figure below shows the result of testing four configurations,
+counting the number of database writes effected through a command-line
+‘xe pool-param-set’ call.
+
+- The first and second configurations are xapi *without* the
+ Metadata-on-LUN feature, with HA disabled and
+ enabled respectively.
+
+- The third configuration shows xapi *with* the
+ Metadata-on-LUN feature using a healthy LUN to which
+ all database writes can be successfully flushed.
+
+- The fourth configuration shows xapi *with* the
+ Metadata-on-LUN feature using an inaccessible LUN for
+ which all database writes fail.
+
+
+
+Testing strategy
+================
+
+The section above shows how xapi performance is affected by this feature. The
+sections below describe the dev-testing which has already been undertaken, and
+propose how this feature will impact on regression testing.
+
+Dev-testing performed
+---------------------
+
+A variety of informal tests have been performed as part of the
+development process:
+
+Enable HA.
+
+: Confirm LUN starts being used to persist database writes.
+
+Enable HA, disable HA.
+
+: Confirm LUN stops being used.
+
+Enable HA, kill xapi on master, restart xapi on master.
+
+: Confirm that last database write before kill is successfully
+ restored on restart.
+
+Repeatedly enable and disable HA.
+
+: Confirm that no file descriptors are leaked (verified by counting
+ the number of descriptors in /proc/*pid*/fd/).
+
+Enable HA, reboot the master.
+
+: Due to HA, a slave becomes the master (or this can be forced using
+ ‘xe pool-emergency-transition-to-master’). Confirm that the new
+ master starts is able to restore the database from the LUN from the
+ point the old master left off, and begins to write new changes to
+ the LUN.
+
+Enable HA, disable the iSCSI volume.
+
+: Confirm that xapi continues to make progress, although database
+ writes are not persisted.
+
+Enable HA, disable and enable the iSCSI volume.
+
+: Confirm that xapi begins to use the LUN when the iSCSI volume is
+ re-enabled and subsequent writes are persisted.
+
+These tests have been undertaken using an iSCSI target VM and a real
+iSCSI volume on lannik. In these scenarios, disabling the iSCSI volume
+consists of stopping the VM and unmapping the LUN, respectively.
+
+Proposed new regression test
+----------------------------
+
+A new regression test is proposed to confirm that all database writes
+are persisted across failure.
+
+There are three types of database modification to test: row creation,
+field-write and row deletion. Although these three kinds of write could
+be tested in separate tests, the means of setting up the pre-conditions
+for a field-write and a row deletion require a row creation, so it is
+convenient to test them all in a single test.
+
+1. Start a pool containing three hosts.
+
+2. Issue a CLI command on the master to create a row in the
+ database, e.g.
+
+ `xe network-create name-label=a`.
+
+3. Forcefully power-cycle the master.
+
+4. On fail-over, issue a CLI command on the new master to check that
+ the row creation persisted:
+
+ `xe network-list name-label=a`,
+
+ confirming that the returned string is non-empty.
+
+5. Issue a CLI command on the master to modify a field in the new row
+ in the database:
+
+ `xe network-param-set uuid= name-description=abcd`,
+
+ where `` is the UUID returned from step 2.
+
+6. Forcefully power-cycle the master.
+
+7. On fail-over, issue a CLI command on the new master to check that
+ the field-write persisted:
+
+ `xe network-param-get uuid= param-name=name-description`,
+
+ where `` is the UUID returned from step 2. The returned string
+ should contain
+
+ `abcd`.
+
+8. Issue a CLI command on the master to delete the row from the
+ database:
+
+ `xe network-destroy uuid=`,
+
+ where `` is the UUID returned from step 2.
+
+9. Forcefully power-cycle the master.
+
+10. On fail-over, issue a CLI command on the new master to check that
+ the row does not exist:
+
+ `xe network-list name-label=a`,
+
+ confirming that the returned string is empty.
+
+Impact on existing regression tests
+-----------------------------------
+
+The Metadata-on-LUN feature should mean that there is no
+need to perform an ‘xe pool-sync-database’ operation in existing HA
+regression tests to ensure that database state persists on xapi failure.
diff --git a/doc/content/xapi/database/redo-log/performance.svg b/doc/content/xapi/database/redo-log/performance.svg
new file mode 100644
index 00000000000..fae19ce0f77
--- /dev/null
+++ b/doc/content/xapi/database/redo-log/performance.svg
@@ -0,0 +1,306 @@
+
+
\ No newline at end of file
diff --git a/doc/content/xapi/storage/_index.md b/doc/content/xapi/storage/_index.md
new file mode 100644
index 00000000000..c265353869a
--- /dev/null
+++ b/doc/content/xapi/storage/_index.md
@@ -0,0 +1,415 @@
++++
+title = "XAPI's Storage Layers"
+menuTitle = "Storage"
++++
+
+{{% notice info %}}
+The links in this page point to the source files of xapi
+[v1.127.0](https://github.com/xapi-project/xen-api/tree/v1.127.0), and xcp-idl
+[v1.62.0](https://github.com/xapi-project/xcp-idl/tree/v1.62.0), not to the
+latest source code.
+
+In the beginning of 2023, significant changes have been made in the layering.
+In particular, the wrapper code from `storage_impl.ml` has been pushed down the
+stack, below the mux, such that it only covers the SMAPIv1 backend and not
+SMAPIv3. Also, all of the code (from xcp-idl etc) is now present in this repo
+(xen-api).
+{{% /notice %}}
+
+Xapi directly communicates only with the SMAPIv2 layer. There are no
+plugins directly implementing the SMAPIv2 interface, but the plugins in
+other layers are accessed through it:
+
+{{}}
+graph TD
+A[xapi] --> B[SMAPIv2 interface]
+B --> C[SMAPIv2 <-> SMAPIv1 translation: storage_access.ml]
+B --> D[SMAPIv2 <-> SMAPIv3 translation: xapi-storage-script]
+C --> E[SMAPIv1 plugins]
+D --> F[SMAPIv3 plugins]
+{{< /mermaid >}}
+
+## SMAPIv1
+
+These are the files related to SMAPIv1 in `xen-api/ocaml/xapi/`:
+
+- [sm.ml](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/sm.ml):
+ OCaml "bindings" for the SMAPIv1 Python "drivers" (SM)
+- [sm_exec.ml](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/sm_exec.ml):
+ support for implementing the above "bindings". The
+ parameters are converted to XML-RPC, passed to the relevant python
+ script ("driver"), and then the standard output of the program is
+ parsed as an XML-RPC response (we use
+ `xen-api-libs-transitional/http-svr/xMLRPC.ml` for parsing XML-RPC).
+ When adding new functionality, we can modify `type call` to add parameters,
+ but when we don't add any common ones, we should just pass the new
+ parameters in the args record.
+- `smint.ml`: Contains types, exceptions, ... for the SMAPIv1 OCaml
+ interface
+
+## SMAPIv2
+
+These are the files related to SMAPIv2, which need to be modified to
+implement new calls:
+
+- [xcp-idl/storage/storage\_interface.ml](https://github.com/xapi-project/xcp-idl/blob/v1.62.0/storage/storage_interface.ml):
+ Contains the SMAPIv2 interface
+- [xcp-idl/storage/storage\_skeleton.ml](https://github.com/xapi-project/xcp-idl/blob/v1.62.0/storage/storage_skeleton.ml):
+ A stub SMAPIv2 storage server implementation that matches the
+ SMAPIv2 storage server interface (this is verified by
+ [storage\_skeleton\_test.ml](https://github.com/xapi-project/xcp-idl/blob/v1.62.0/storage/storage_skeleton_test.ml)),
+ each of its function just raise a `Storage_interface.Unimplemented`
+ error. This skeleton is used to automatically fill the unimplemented
+ methods of the below storage servers to satisfy the interface.
+- [xen-api/ocaml/xapi/storage\_access.ml](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/storage_access.ml):
+ [module SMAPIv1](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/storage_access.ml#L104):
+ a SMAPIv2 server that does SMAPIv2 -> SMAPIv1 translation.
+ It passes the XML-RPC requests as the first command-line argument to the
+ corresponding Python script, which returns an XML-RPC response on standard
+ output.
+- [xen-api/ocaml/xapi/storage\_impl.ml](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/storage_impl.ml):
+ The
+ [Wrapper](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/storage_impl.ml#L302)
+ module wraps a SMAPIv2 server (Server\_impl) and takes care of
+ locking and datapaths (in case of multiple connections (=datapaths)
+ from VMs to the same VDI, it will use the superstate computed by the
+ [Vdi_automaton](https://github.com/xapi-project/xcp-idl/blob/v1.62.0/storage/vdi_automaton.ml)
+ in xcp-idl). It also implements some functionality, like the `DP`
+ module, that is not implemented in lower layers.
+- [xen-api/ocaml/xapi/storage\_mux.ml](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/storage_mux.ml):
+ A SMAPIv2 server, which multiplexes between other servers. A
+ different SMAPIv2 server can be registered for each SR. Then it
+ forwards the calls for each SR to the "storage plugin" registered
+ for that SR.
+
+### How SMAPIv2 works:
+
+We use [message-switch] under the hood for RPC communication between
+[xcp-idl](https://github.com/xapi-project/xcp-idl) components. The
+main `Storage_mux.Server` (basically `Storage_impl.Wrapper(Mux)`) is
+[registered to
+listen](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/storage_access.ml#L1279)
+on the "`org.xen.xapi.storage`" queue [during xapi's
+startup](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/xapi.ml#L801),
+and this is the main entry point for incoming SMAPIv2 function calls.
+`Storage_mux` does not really multiplex between different plugins right
+now: [earlier during xapi's
+startup](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/xapi.ml#L799),
+the same SMAPIv1 storage server module [is
+registered](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/storage_access.ml#L934)
+on the various "`org.xen.xapi.storage.`" queues for each
+supported SR type. (This will change with SMAPIv3, which is accessed via
+a SMAPIv2 plugin outside of xapi that translates between SMAPIv2 and
+SMAPIv3.) Then, in
+[Storage\_access.create\_sr](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/storage_access.ml#L1531),
+which is called
+[during SR.create](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/xapi_sr.ml#L326),
+and also
+[during PBD.plug](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/xapi_pbd.ml#L121),
+the relevant "`org.xen.xapi.storage.`" queue needed for that
+PBD is [registered with Storage_mux in
+Storage\_access.bind](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/storage_access.ml#L1107)
+for the SR of that PBD.\
+So basically what happens is that xapi registers itself as a SMAPIv2
+server, and forwards incoming function calls to itself through
+`message-switch`, using its `Storage_mux` module. These calls are
+forwarded to xapi's `SMAPIv1` module doing SMAPIv2 -> SMAPIv1
+translation.
+
+#### Registration of the various storage servers
+
+{{}}
+sequenceDiagram
+participant q as message-switch
+participant v1 as Storage_access.SMAPIv1
+participant svr as Storage_mux.Server
+
+Note over q, svr: xapi startup, "Starting SMAPIv1 proxies"
+q ->> v1:org.xen.xapi.storage.sr_type_1
+q ->> v1:org.xen.xapi.storage.sr_type_2
+q ->> v1:org.xen.xapi.storage.sr_type_3
+
+Note over q, svr: xapi startup, "Starting SM service"
+q ->> svr:org.xen.xapi.storage
+
+Note over q, svr: SR.create, PBD.plug
+svr ->> q:org.xapi.storage.sr_type_2
+{{< /mermaid >}}
+
+#### What happens when a SMAPIv2 "function" is called
+
+{{}}
+graph TD
+
+call[SMAPIv2 call] --VDI.attach2--> org.xen.xapi.storage
+
+subgraph message-switch
+org.xen.xapi.storage
+org.xen.xapi.storage.SR_type_x
+end
+
+org.xen.xapi.storage --VDI.attach2--> Storage_impl.Wrapper
+
+subgraph xapi
+subgraph Storage_mux.server
+Storage_impl.Wrapper --> Storage_mux.mux
+end
+Storage_access.SMAPIv1
+end
+
+Storage_mux.mux --VDI.attach2--> org.xen.xapi.storage.SR_type_x
+org.xen.xapi.storage.SR_type_x --VDI.attach2--> Storage_access.SMAPIv1
+
+subgraph SMAPIv1
+driver_x[SMAPIv1 driver for SR_type_x]
+end
+
+Storage_access.SMAPIv1 --vdi_attach--> driver_x
+{{< /mermaid >}}
+
+### Interface Changes, Backward Compatibility, & SXM
+
+During SXM, xapi calls SMAPIv2 functions on a remote xapi. Therefore it
+is important to keep all those SMAPIv2 functions backward-compatible
+that we call remotely (e.g. Remote.VDI.attach), otherwise SXM from an
+older to a newer xapi will break.
+
+### Functionality implemented in SMAPIv2 layers
+
+The layer between SMAPIv2 and SMAPIv1 is much fatter than the one between
+SMAPIv2 and SMAPIv3. The latter does not do much, apart from simple
+translation. However, the former has large portions of code in its intermediate
+layers, in addition to the basic SMAPIv2 <-> SMAPIv1 translation in
+`storage_access.ml`.
+
+These are the three files in xapi that implement the SMAPIv2 storage interface,
+from higher to lower level:
+
+- [xen-api/ocaml/xapi/storage\_impl.ml](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/storage_impl.ml):
+- [xen-api/ocaml/xapi/storage\_mux.ml](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/storage_mux.ml):
+- [xen-api/ocaml/xapi/storage\_access.ml](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/storage_access.ml):
+
+Functionality implemented by higher layers is not implemented by the layers below it.
+
+#### Extra functionality in `storage_impl.ml`
+
+In addition to its usual functions, `Storage_impl.Wrapper` also implements the
+`UPDATES` and `TASK` SMAPIv2 APIs, without calling the wrapped module.
+
+These are backed by the `Updates`, `Task_server`, and `Scheduler` modules from
+xcp-idl, instantiated in xapi's `Storage_task` module. Migration code in
+`Storage_mux` will interact with these to update task progress. There is also
+an event loop in xapi that keeps calling `UPDATES.get` to keep the tasks in
+xapi's database in sync with the storage manager's tasks.
+
+`Storage_impl.Wrapper` also implements the legacy `VDI.attach` call by simply
+calling the newer `VDI.attach2` call in the same module. In general, this is a
+good place to implement a compatibility layer for deprecated functionality
+removed from other layers, because this is the first module that intercepts a
+SMAPIv2 call.
+
+#### Extra functionality in `storage_mux.ml`
+
+`Storage_mux` implements storage motion (SXM): it implements the `DATA` and
+`DATA.MIRROR` modules. Migration code will use the `Storage_task` module to run
+the operations and update the task's progress.
+
+It also implements the `Policy` module from the SMAPIv2 interface.
+
+## SMAPIv3
+
+[SMAPIv3](https://xapi-project.github.io/xapi-storage/) has a slightly
+different interface from SMAPIv2.The
+[xapi-storage-script](https://github.com/xapi-project/xapi-storage-script)
+daemon is a SMAPIv2 plugin separate from xapi that is doing the SMAPIv2
+↔ SMAPIv3 translation. It keeps the plugins registered with xcp-idl
+(their message-switch queues) up to date as their files appear or
+disappear from the relevant directory.
+
+### SMAPIv3 Interface
+
+The SMAPIv3 interface is defined using an OCaml-based IDL from the
+[ocaml-rpc](https://github.com/mirage/ocaml-rpc) library, and is in this
+repo:
+
+From this interface we generate
+
+- OCaml RPC client bindings used in
+ [xapi-storage-script](https://github.com/xapi-project/xapi-storage-script)
+- The [SMAPIv3 API
+ reference](https://xapi-project.github.io/xapi-storage)
+- Python bindings, used by the SM scripts that implement the SMAPIv3
+ interface.
+ - These bindings are built by running "`make`" in the root
+ [xapi-storage](https://github.com/xapi-project/xapi-storage),
+ and appear in the` _build/default/python/xapi/storage/api/v5`
+ directory.
+ - On a XenServer host, they are stored in the
+ `/usr/lib/python2.7/site-packages/xapi/storage/api/v5/`
+ directory
+
+### SMAPIv3 Plugins
+
+For [SMAPIv3](https://xapi-project.github.io/xapi-storage/) we have
+volume plugins to manipulate SRs and volumes (=VDIs) in them, and
+datapath plugins for connecting to the volumes. Volume plugins tell us
+which datapath plugins we can use with each volume, and what to pass to
+the plugin. Both volume and datapath plugins implement some common
+functionality: the SMAPIv3 [plugin
+interface](https://xapi-project.github.io/xapi-storage/#plugin).
+
+### How SMAPIv3 works:
+
+The `xapi-storage-script` daemon detects volume and datapath plugins
+stored in subdirectories of the
+`/usr/libexec/xapi-storage-script/volume/` and
+`/usr/libexec/xapi-storage-script/datapath/` directories, respectively.
+When it finds a new datapath plugin, it adds the plugin to a lookup table and
+uses it the next time that datapath is required. When it finds a new volume
+plugin, it binds a new [message-switch] queue named after the plugin's
+subdirectory to a new server instance that uses these volume scripts.
+
+To invoke a SMAPIv3 method, it executes a program named
+`.` in the plugin's directory, for
+example
+`/usr/libexec/xapi-storage-script/volume/org.xen.xapi.storage.gfs2/SR.ls`.
+The inputs to each script can be passed as command-line arguments and
+are type-checked using the generated Python bindings, and so are the
+outputs. The URIs of the SRs that xapi-storage-script knows about are
+stored in the `/var/run/nonpersistent/xapi-storage-script/state.db`
+file, these URIs can be used on the command line when an sr argument is
+expected.` `
+
+#### Registration of the various SMAPIv3 plugins
+
+{{}}
+sequenceDiagram
+participant q as message-switch
+participant v1 as (Storage_access.SMAPIv1)
+participant svr as Storage_mux.Server
+participant vol_dir as /../volume/
+participant dp_dir as /../datapath/
+participant script as xapi-storage-script
+
+Note over script, vol_dir: xapi-storage-script startup
+script ->> vol_dir: new subdir org.xen.xapi.storage.sr_type_4
+q ->> script: org.xen.xapi.storage.sr_type_4
+script ->> dp_dir: new subdir sr_type_4_dp
+
+Note over q, svr: xapi startup, "Starting SMAPIv1 proxies"
+q -->> v1:org.xen.xapi.storage.sr_type_1
+q -->> v1:org.xen.xapi.storage.sr_type_2
+q -->> v1:org.xen.xapi.storage.sr_type_3
+
+Note over q, svr: xapi startup, "Starting SM service"
+q ->> svr:org.xen.xapi.storage
+
+Note over q, svr: SR.create, PBD.plug
+svr ->> q:org.xapi.storage.sr_type_4
+{{< /mermaid >}}
+
+#### What happens when a SMAPIv3 "function" is called
+
+{{}}
+graph TD
+
+call[SMAPIv2 call] --VDI.attach2--> org.xen.xapi.storage
+
+subgraph message-switch
+org.xen.xapi.storage
+org.xen.xapi.storage.SR_type_x
+end
+
+org.xen.xapi.storage --VDI.attach2--> Storage_impl.Wrapper
+
+subgraph xapi
+subgraph Storage_mux.server
+Storage_impl.Wrapper --> Storage_mux.mux
+end
+Storage_access.SMAPIv1
+end
+
+Storage_mux.mux --VDI.attach2--> org.xen.xapi.storage.SR_type_x
+
+org.xen.xapi.storage.SR_type_x -."VDI.attach2".-> Storage_access.SMAPIv1
+
+subgraph SMAPIv1
+driver_x[SMAPIv1 driver for SR_type_x]
+end
+
+Storage_access.SMAPIv1 -.vdi_attach.-> driver_x
+
+subgraph SMAPIv3
+xapi-storage-script --Datapath.attach--> v3_dp_plugin_x
+subgraph SMAPIv3 plugins
+v3_vol_plugin_x[volume plugin for SR_type_x]
+v3_dp_plugin_x[datapath plugin for SR_type_x]
+end
+end
+
+org.xen.xapi.storage.SR_type_x --VDI.attach2-->xapi-storage-script
+{{< /mermaid >}}
+
+## Error reporting
+
+In our SMAPIv1 OCaml "bindings" in xapi
+([xen-api/ocaml/xapi/sm\_exec.ml](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/sm_exec.ml)),
+[when we inspect the error codes returned from a call to
+SM](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/sm_exec.ml#L199),
+we translate some of the SMAPIv1/SM error codes to XenAPI errors, and
+for others, we just [construct an error
+code](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/sm_exec.ml#L214)
+of the form `SR_BACKEND_FAILURE_`.
+
+The file
+[xcp-idl/storage/storage\_interface.ml](https://github.com/xapi-project/xcp-idl/blob/v1.62.0/storage/storage_interface.ml#L362)
+defines a number of SMAPIv2 errors, ultimately all errors from the various
+SMAPIv2 storage servers in xapi will be returned as one of these. Most of the
+errors aren't converted into a specific exception in `Storage_interface`, but
+are simply wrapped with `Storage_interface.Backend_error`.
+
+The
+[Storage\_access.transform\_storage\_exn](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/storage_access.ml#L29)
+function is used by the client code in xapi to translate the SMAPIv2
+errors into XenAPI errors again, this unwraps the errors wrapped with
+`Storage_interface.Backend_error`.
+
+## Message Forwarding
+
+In the message forwarding layer, first we check the validity of VDI
+operations using `mark_vdi` and `mark_sr`. These first check that the
+operation is valid operations,
+using [Xapi\_vdi.check\_operation\_error](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/xapi_vdi.ml#L57),
+for `mark_vdi`, which also inspects the current operations of the VDI,
+and then, if the operation is valid, it is added to the VDI's current
+operations, and update\_allowed\_operations is called. Then we forward
+the VDI operation to a suitable host that has a PBD plugged for the
+VDI's SR.
+
+### Checking that the SR is attached
+
+For the VDI operations, we check at two different places whether the SR
+is attached: first, at the Xapi level, [in
+Xapi\_vdi.check\_operation\_error](https://github.com/xapi-project/xen-api/blob/v1.127.0/ocaml/xapi/xapi_vdi.ml#L98),
+for the resize operation, and then, at the SMAPIv1 level, in
+`Sm.assert_pbd_is_plugged`. `Sm.assert_pbd_is_plugged` performs the
+same checks, plus it checks that the PBD is attached to the localhost,
+unlike Xapi\_vdi.check\_operation\_error. This behaviour is correct,
+because `Xapi_vdi.check_operation_error` is called from the message
+forwarding layer, which forwards the call to a host that has the SR
+attached.
+
+## VDI Identifiers and Storage Motion
+
+- VDI "location": this is the VDI identifier used by the SM backend.
+ It is usually the UUID of the VDI, but for ISO SRs it is the name of
+ the ISO.
+- VDI "content\_id": this is used for storage motion, to reduce the
+ amount of data copied. When we copy over a VDI, the content\_id will
+ initially be the same. However, when we attach a VDI as read-write,
+ and then detach it, then we will blank its content\_id (set it to a
+ random UUID), because we may have written to it, so the content
+ could be different. .
+
+[message-switch]: https://github.com/xapi-project/message-switch
+
diff --git a/doc/content/xapi/storage/sxm.md b/doc/content/xapi/storage/sxm.md
new file mode 100644
index 00000000000..8429f87321c
--- /dev/null
+++ b/doc/content/xapi/storage/sxm.md
@@ -0,0 +1,1767 @@
+---
+Title: Storage migration
+---
+
+## Overview
+
+{{}}
+sequenceDiagram
+participant local_tapdisk as local tapdisk
+participant local_smapiv2 as local SMAPIv2
+participant xapi
+participant remote_xapi as remote xapi
+participant remote_smapiv2 as remote SMAPIv2 (might redirect)
+participant remote_tapdisk as remote tapdisk
+
+Note over xapi: Sort VDIs increasingly by size and then age
+
+loop VM's & snapshots' VDIs & suspend images
+ xapi->>remote_xapi: plug dest SR to dest host and pool master
+ alt VDI is not mirrored
+ Note over xapi: We don't mirror RO VDIs & VDIs of snapshots
+ xapi->>local_smapiv2: DATA.copy remote_sm_url
+
+ activate local_smapiv2
+ local_smapiv2-->>local_smapiv2: SR.scan
+ local_smapiv2-->>local_smapiv2: VDI.similar_content
+ local_smapiv2-->>remote_smapiv2: SR.scan
+ Note over local_smapiv2: Find nearest smaller remote VDI remote_base, if any
+ alt remote_base
+ local_smapiv2-->>remote_smapiv2: VDI.clone
+ local_smapiv2-->>remote_smapiv2: VDI.resize
+ else no remote_base
+ local_smapiv2-->>remote_smapiv2: VDI.create
+ end
+
+ Note over local_smapiv2: call copy'
+ activate local_smapiv2
+ local_smapiv2-->>remote_smapiv2: SR.list
+ local_smapiv2-->>remote_smapiv2: SR.scan
+ Note over local_smapiv2: create new datapaths remote_dp, base_dp, leaf_dp
+ Note over local_smapiv2: find local base_vdi with same content_id as dest, if any
+ local_smapiv2-->>remote_smapiv2: VDI.attach2 remote_dp dest
+ local_smapiv2-->>remote_smapiv2: VDI.activate remote_dp dest
+ opt base_vdi
+ local_smapiv2-->>local_smapiv2: VDI.attach2 base_dp base_vdi
+ local_smapiv2-->>local_smapiv2: VDI.activate base_dp base_vdi
+ end
+ local_smapiv2-->>local_smapiv2: VDI.attach2 leaf_dp vdi
+ local_smapiv2-->>local_smapiv2: VDI.activate leaf_dp vdi
+ local_smapiv2-->>remote_xapi: sparse_dd base_vdi vdi dest [NBD URI for dest & remote_dp]
+ Note over remote_xapi: HTTP handler verifies credentials
+ remote_xapi-->>remote_tapdisk: then passes connection to tapdisk's NBD server
+ local_smapiv2-->>local_smapiv2: VDI.deactivate leaf_dp vdi
+ local_smapiv2-->>local_smapiv2: VDI.detach leaf_dp vdi
+ opt base_vdi
+ local_smapiv2-->>local_smapiv2: VDI.deactivate base_dp base_vdi
+ local_smapiv2-->>local_smapiv2: VDI.detach base_dp base_vdi
+ end
+ local_smapiv2-->>remote_smapiv2: DP.destroy remote_dp
+ deactivate local_smapiv2
+
+ local_smapiv2-->>remote_smapiv2: VDI.snapshot remote_copy
+ local_smapiv2-->>remote_smapiv2: VDI.destroy remote_copy
+ local_smapiv2->>xapi: task(snapshot)
+ deactivate local_smapiv2
+
+ else VDI is mirrored
+ Note over xapi: We mirror RW VDIs of the VM
+ Note over xapi: create new datapath dp
+ xapi->>local_smapiv2: VDI.attach2 dp
+ xapi->>local_smapiv2: VDI.activate dp
+ xapi->>local_smapiv2: DATA.MIRROR.start dp remote_sm_url
+
+ activate local_smapiv2
+ Note over local_smapiv2: copy disk data & mirror local writes
+ local_smapiv2-->>local_smapiv2: SR.scan
+ local_smapiv2-->>local_smapiv2: VDI.similar_content
+ local_smapiv2-->>remote_smapiv2: DATA.MIRROR.receive_start similars
+ activate remote_smapiv2
+ remote_smapiv2-->>local_smapiv2: mirror_vdi,mirror_dp,copy_diffs_from,copy_diffs_to,dummy_vdi
+ deactivate remote_smapiv2
+ local_smapiv2-->>local_smapiv2: DP.attach_info dp
+ local_smapiv2-->>remote_xapi: connect to [NBD URI for mirror_vdi & mirror_dp]
+ Note over remote_xapi: HTTP handler verifies credentials
+ remote_xapi-->>remote_tapdisk: then passes connection to tapdisk's NBD server
+ local_smapiv2-->>local_tapdisk: pass socket & dp to tapdisk of dp
+ local_smapiv2-->>local_smapiv2: VDI.snapshot local_vdi [mirror:dp]
+ local_smapiv2-->>local_tapdisk: [Python] unpause disk, pass dp
+ local_tapdisk-->>remote_tapdisk: mirror new writes via NBD to socket
+ Note over local_smapiv2: call copy' snapshot copy_diffs_to
+ local_smapiv2-->>remote_smapiv2: VDI.compose copy_diffs_to mirror_vdi
+ local_smapiv2-->>remote_smapiv2: VDI.remove_from_sm_config mirror_vdi base_mirror
+ local_smapiv2-->>remote_smapiv2: VDI.destroy dummy_vdi
+ local_smapiv2-->>local_smapiv2: VDI.destroy snapshot
+ local_smapiv2->>xapi: task(mirror ID)
+ deactivate local_smapiv2
+
+ xapi->>local_smapiv2: DATA.MIRROR.stat
+ activate local_smapiv2
+ local_smapiv2->>xapi: dest_vdi
+ deactivate local_smapiv2
+ end
+
+ loop until task finished
+ xapi->>local_smapiv2: UPDATES.get
+ xapi->>local_smapiv2: TASK.stat
+ end
+ xapi->>local_smapiv2: TASK.stat
+ xapi->>local_smapiv2: TASK.destroy
+end
+opt for snapshot VDIs
+ xapi->>local_smapiv2: SR.update_snapshot_info_src remote_sm_url
+ activate local_smapiv2
+ local_smapiv2-->>remote_smapiv2: SR.update_snapshot_info_dest
+ deactivate local_smapiv2
+end
+Note over xapi: ...
+Note over xapi: reserve resources for the new VM in dest host
+loop all VDIs
+ opt VDI is mirrored
+ xapi->>local_smapiv2: DP.destroy dp
+ end
+end
+opt post_detach_hook
+ opt active local mirror
+ local_smapiv2-->>remote_smapiv2: DATA.MIRROR.receive_finalize [mirror ID]
+ Note over remote_smapiv2: destroy mirror dp
+ end
+end
+Note over xapi: memory image migration by xenopsd
+Note over xapi: destroy the VM record
+{{< /mermaid >}}
+
+### Receiving SXM
+
+These are the remote calls in the above diagram sent from the remote host to
+the receiving end of storage motion:
+
+* Remote SMAPIv2 -> local SMAPIv2 RPC calls:
+ * `SR.list`
+ * `SR.scan`
+ * `SR.update_snapshot_info_dest`
+ * `VDI.attach2`
+ * `VDI.activate`
+ * `VDI.snapshot`
+ * `VDI.destroy`
+ * For copying:
+ * For copying from base:
+ * `VDI.clone`
+ * `VDI.resize`
+ * For copying without base:
+ * `VDI.create`
+ * For mirroring:
+ * `DATA.MIRROR.receive_start`
+ * `VDI.compose`
+ * `VDI.remove_from_sm_config`
+ * `DATA.MIRROR.receive_finalize`
+* HTTP requests to xapi:
+ * Connecting to NBD URI via xapi's HTTP handler
+
+---
+
+This is how xapi coordinates storage migration. We'll do it as a code walkthrough through the two layers: xapi and storage-in-xapi (SMAPIv2).
+
+## Xapi code
+
+The entry point is in [xapi_vm_migration.ml](https://github.com/xapi-project/xen-api/blob/f75d51e7a3eff89d952330ec1a739df85a2895e2/ocaml/xapi/xapi_vm_migrate.ml#L786)
+
+The function takes several arguments:
+
+* a vm reference (`vm`)
+* a dictionary of `(string * string)` key-value pairs about the destination (`dest)`. This is the result of a previous call to the destination pool, `Host.migrate_receive`
+* `live`, a boolean of whether we should live-migrate or suspend-resume,
+* `vdi_map`, a mapping of VDI references to destination SR references,
+* `vif_map`, a mapping of VIF references to destination network references,
+* `vgpu_map`, similar for VGPUs
+* `options`, another dictionary of options
+
+```ocaml
+let migrate_send' ~__context ~vm ~dest ~live ~vdi_map ~vif_map ~vgpu_map ~options =
+ SMPERF.debug "vm.migrate_send called vm:%s" (Db.VM.get_uuid ~__context ~self:vm);
+
+ let open Xapi_xenops in
+
+ let localhost = Helpers.get_localhost ~__context in
+ let remote = remote_of_dest dest in
+
+ (* Copy mode means we don't destroy the VM on the source host. We also don't
+ copy over the RRDs/messages *)
+ let copy = try bool_of_string (List.assoc "copy" options) with _ -> false in
+```
+
+It begins by getting the local host reference, deciding whether we're copying or moving, and converting the input `dest` parameter from an untyped string association list to a typed record, `remote`, which is declared further up the file:
+
+```ocaml
+type remote = {
+ rpc : Rpc.call -> Rpc.response;
+ session : API.ref_session;
+ sm_url : string;
+ xenops_url : string;
+ master_url : string;
+ remote_ip : string; (* IP address *)
+ remote_master_ip : string; (* IP address *)
+ dest_host : API.ref_host;
+}
+```
+
+this contains:
+
+* A function, `rpc`, for calling XenAPI RPCs on the destination
+* A `session` valid on the destination
+* A `sm_url` on which SMAPIv2 APIs can be called on the destination
+* A `master_url` on which XenAPI commands can be called (not currently used)
+* The IP address, `remote_ip`, of the destination host
+* The IP address, `remote_master_ip`, of the master of the destination pool
+
+Next, we determine which VDIs to copy:
+
+```ocaml
+ (* The first thing to do is to create mirrors of all the disks on the remote.
+ We look through the VM's VBDs and all of those of the snapshots. We then
+ compile a list of all of the associated VDIs, whether we mirror them or not
+ (mirroring means we believe the VDI to be active and new writes should be
+ mirrored to the destination - otherwise we just copy it)
+ We look at the VDIs of the VM, the VDIs of all of the snapshots, and any
+ suspend-image VDIs. *)
+
+ let vm_uuid = Db.VM.get_uuid ~__context ~self:vm in
+ let vbds = Db.VM.get_VBDs ~__context ~self:vm in
+ let vifs = Db.VM.get_VIFs ~__context ~self:vm in
+ let snapshots = Db.VM.get_snapshots ~__context ~self:vm in
+ let vm_and_snapshots = vm :: snapshots in
+ let snapshots_vbds = List.flatten (List.map (fun self -> Db.VM.get_VBDs ~__context ~self) snapshots) in
+ let snapshot_vifs = List.flatten (List.map (fun self -> Db.VM.get_VIFs ~__context ~self) snapshots) in
+```
+
+we now decide whether we're intra-pool or not, and if we're intra-pool whether we're migrating onto the same host (localhost migrate). Intra-pool is decided by trying to do a lookup of our current host uuid on the destination pool.
+
+```ocaml
+ let is_intra_pool = try ignore(Db.Host.get_uuid ~__context ~self:remote.dest_host); true with _ -> false in
+ let is_same_host = is_intra_pool && remote.dest_host == localhost in
+
+ if copy && is_intra_pool then raise (Api_errors.Server_error(Api_errors.operation_not_allowed, [ "Copy mode is disallowed on intra pool storage migration, try efficient alternatives e.g. VM.copy/clone."]));
+```
+
+Having got all of the VBDs of the VM, we now need to find the associated VDIs, filtering out empty CDs, and decide whether we're going to copy them or mirror them - read-only VDIs can be copied but RW VDIs must be mirrored.
+
+```ocaml
+ let vms_vdis = List.filter_map (vdi_filter __context true) vbds in
+```
+
+where `vdi_filter` is defined earler:
+
+```ocaml
+(* We ignore empty or CD VBDs - nothing to do there. Possible redundancy here:
+ I don't think any VBDs other than CD VBDs can be 'empty' *)
+let vdi_filter __context allow_mirror vbd =
+ if Db.VBD.get_empty ~__context ~self:vbd || Db.VBD.get_type ~__context ~self:vbd = `CD
+ then None
+ else
+ let do_mirror = allow_mirror && (Db.VBD.get_mode ~__context ~self:vbd = `RW) in
+ let vm = Db.VBD.get_VM ~__context ~self:vbd in
+ let vdi = Db.VBD.get_VDI ~__context ~self:vbd in
+ Some (get_vdi_mirror __context vm vdi do_mirror)
+```
+
+This in turn calls `get_vdi_mirror` which gathers together some important info:
+
+```ocaml
+let get_vdi_mirror __context vm vdi do_mirror =
+ let snapshot_of = Db.VDI.get_snapshot_of ~__context ~self:vdi in
+ let size = Db.VDI.get_virtual_size ~__context ~self:vdi in
+ let xenops_locator = Xapi_xenops.xenops_vdi_locator ~__context ~self:vdi in
+ let location = Db.VDI.get_location ~__context ~self:vdi in
+ let dp = Storage_access.presentative_datapath_of_vbd ~__context ~vm ~vdi in
+ let sr = Db.SR.get_uuid ~__context ~self:(Db.VDI.get_SR ~__context ~self:vdi) in
+ {vdi; dp; location; sr; xenops_locator; size; snapshot_of; do_mirror}
+```
+
+The record is helpfully commented above:
+
+```ocaml
+type vdi_mirror = {
+ vdi : [ `VDI ] API.Ref.t; (* The API reference of the local VDI *)
+ dp : string; (* The datapath the VDI will be using if the VM is running *)
+ location : string; (* The location of the VDI in the current SR *)
+ sr : string; (* The VDI's current SR uuid *)
+ xenops_locator : string; (* The 'locator' xenops uses to refer to the VDI on the current host *)
+ size : Int64.t; (* Size of the VDI *)
+ snapshot_of : [ `VDI ] API.Ref.t; (* API's snapshot_of reference *)
+ do_mirror : bool; (* Whether we should mirror or just copy the VDI *)
+}
+```
+
+`xenops_locator` is `/`, and `dp` is `vbd//` if the VM is running and `vbd//` if not.
+
+So now we have a list of these records for all VDIs attached to the VM. For these we check explicitly that they're all defined in the `vdi_map`, the mapping of VDI references to their destination SR references.
+
+```ocaml
+ check_vdi_map ~__context vms_vdis vdi_map;
+```
+
+We then figure out the VIF map:
+
+```ocaml
+ let vif_map =
+ if is_intra_pool then vif_map
+ else infer_vif_map ~__context (vifs @ snapshot_vifs) vif_map
+ in
+```
+
+More sanity checks: We can't do a storage migration if any of the VDIs is a reset-on-boot one - since the state will be lost on the destination when it's attached:
+
+```ocaml
+(* Block SXM when VM has a VDI with on_boot=reset *)
+ List.(iter (fun vconf ->
+ let vdi = vconf.vdi in
+ if (Db.VDI.get_on_boot ~__context ~self:vdi ==`reset) then
+ raise (Api_errors.Server_error(Api_errors.vdi_on_boot_mode_incompatible_with_operation, [Ref.string_of vdi]))) vms_vdis) ;
+```
+
+We now consider all of the VDIs associated with the snapshots. As for the VM's VBDs above, we end up with a `vdi_mirror` list. Note we pass `false` to the `allow_mirror` parameter of the `get_vdi_mirror` function as none of these snapshot VDIs will ever require mirrorring.
+
+```ocaml
+let snapshots_vdis = List.filter_map (vdi_filter __context false)
+```
+
+Finally we get all of the suspend-image VDIs from all snapshots as well as the actual VM, since it might be suspended itself:
+
+```ocaml
+snapshots_vbds in
+ let suspends_vdis =
+ List.fold_left
+ (fun acc vm ->
+ if Db.VM.get_power_state ~__context ~self:vm = `Suspended
+ then
+ let vdi = Db.VM.get_suspend_VDI ~__context ~self:vm in
+ let sr = Db.VDI.get_SR ~__context ~self:vdi in
+ if is_intra_pool && Helpers.host_has_pbd_for_sr ~__context ~host:remote.dest_host ~sr
+ then acc
+ else (get_vdi_mirror __context vm vdi false):: acc
+ else acc)
+ [] vm_and_snapshots in
+```
+
+Sanity check that we can see all of the suspend-image VDIs on this host:
+
+```ocaml
+ (* Double check that all of the suspend VDIs are all visible on the source *)
+ List.iter (fun vdi_mirror ->
+ let sr = Db.VDI.get_SR ~__context ~self:vdi_mirror.vdi in
+ if not (Helpers.host_has_pbd_for_sr ~__context ~host:localhost ~sr)
+ then raise (Api_errors.Server_error (Api_errors.suspend_image_not_accessible, [ Ref.string_of vdi_mirror.vdi ]))) suspends_vdis;
+```
+
+Next is a fairly complex piece that determines the destination SR for all of these VDIs. We don't require API uses to decide destinations for all of the VDIs on snapshots and hence we have to make some decisions here:
+
+```ocaml
+ let dest_pool = List.hd (XenAPI.Pool.get_all remote.rpc remote.session) in
+ let default_sr_ref =
+ XenAPI.Pool.get_default_SR remote.rpc remote.session dest_pool in
+ let suspend_sr_ref =
+ let pool_suspend_SR = XenAPI.Pool.get_suspend_image_SR remote.rpc remote.session dest_pool
+ and host_suspend_SR = XenAPI.Host.get_suspend_image_sr remote.rpc remote.session remote.dest_host in
+ if pool_suspend_SR <> Ref.null then pool_suspend_SR else host_suspend_SR in
+
+ (* Resolve placement of unspecified VDIs here - unspecified VDIs that
+ are 'snapshot_of' a specified VDI go to the same place. suspend VDIs
+ that are unspecified go to the suspend_sr_ref defined above *)
+
+ let extra_vdis = suspends_vdis @ snapshots_vdis in
+
+ let extra_vdi_map =
+ List.map
+ (fun vconf ->
+ let dest_sr_ref =
+ let is_mapped = List.mem_assoc vconf.vdi vdi_map
+ and snapshot_of_is_mapped = List.mem_assoc vconf.snapshot_of vdi_map
+ and is_suspend_vdi = List.mem vconf suspends_vdis
+ and remote_has_suspend_sr = suspend_sr_ref <> Ref.null
+ and remote_has_default_sr = default_sr_ref <> Ref.null in
+ let log_prefix =
+ Printf.sprintf "Resolving VDI->SR map for VDI %s:" (Db.VDI.get_uuid ~__context ~self:vconf.vdi) in
+ if is_mapped then begin
+ debug "%s VDI has been specified in the map" log_prefix;
+ List.assoc vconf.vdi vdi_map
+ end else if snapshot_of_is_mapped then begin
+ debug "%s Snapshot VDI has entry in map for it's snapshot_of link" log_prefix;
+ List.assoc vconf.snapshot_of vdi_map
+ end else if is_suspend_vdi && remote_has_suspend_sr then begin
+ debug "%s Mapping suspend VDI to remote suspend SR" log_prefix;
+ suspend_sr_ref
+ end else if is_suspend_vdi && remote_has_default_sr then begin
+ debug "%s Remote suspend SR not set, mapping suspend VDI to remote default SR" log_prefix;
+ default_sr_ref
+ end else if remote_has_default_sr then begin
+ debug "%s Mapping unspecified VDI to remote default SR" log_prefix;
+ default_sr_ref
+ end else begin
+ error "%s VDI not in VDI->SR map and no remote default SR is set" log_prefix;
+ raise (Api_errors.Server_error(Api_errors.vdi_not_in_map, [ Ref.string_of vconf.vdi ]))
+ end in
+ (vconf.vdi, dest_sr_ref))
+ extra_vdis in
+```
+
+At the end of this we've got all of the VDIs that need to be copied and destinations for all of them:
+
+```ocaml
+ let vdi_map = vdi_map @ extra_vdi_map in
+ let all_vdis = vms_vdis @ extra_vdis in
+
+ (* The vdi_map should be complete at this point - it should include all the
+ VDIs in the all_vdis list. *)
+```
+
+Now we gather some final information together:
+
+```ocaml
+ assert_no_cbt_enabled_vdi_migrated ~__context ~vdi_map;
+
+ let dbg = Context.string_of_task __context in
+ let open Xapi_xenops_queue in
+ let queue_name = queue_of_vm ~__context ~self:vm in
+ let module XenopsAPI = (val make_client queue_name : XENOPS) in
+
+ let remote_vdis = ref [] in
+
+ let ha_always_run_reset = not is_intra_pool && Db.VM.get_ha_always_run ~__context ~self:vm in
+
+ let cd_vbds = find_cds_to_eject __context vdi_map vbds in
+ eject_cds __context cd_vbds;
+```
+
+check there's no CBT (we can't currently migrate the CBT metadata), make our client to talk to Xenopsd, make a mutable list of remote VDIs (which I think is redundant right now), decide whether we need to do anything for HA (we disable HA protection for this VM on the destination until it's fully migrated) and eject any CDs from the VM.
+
+Up until now this has mostly been gathering info (aside from the ejecting CDs bit), but now we'll start to do some actions, so we begin a `try-catch` block:
+
+```ocaml
+try
+```
+
+but we've still got a bit of thinking to do: we sort the VDIs to copy based on age/size:
+
+```ocaml
+ (* Sort VDIs by size in principle and then age secondly. This gives better
+ chances that similar but smaller VDIs would arrive comparatively
+ earlier, which can serve as base for incremental copying the larger
+ ones. *)
+ let compare_fun v1 v2 =
+ let r = Int64.compare v1.size v2.size in
+ if r = 0 then
+ let t1 = Date.to_float (Db.VDI.get_snapshot_time ~__context ~self:v1.vdi) in
+ let t2 = Date.to_float (Db.VDI.get_snapshot_time ~__context ~self:v2.vdi) in
+ compare t1 t2
+ else r in
+ let all_vdis = all_vdis |> List.sort compare_fun in
+
+ let total_size = List.fold_left (fun acc vconf -> Int64.add acc vconf.size) 0L all_vdis in
+ let so_far = ref 0L in
+```
+
+OK, let's copy/mirror:
+
+```ocaml
+ with_many (vdi_copy_fun __context dbg vdi_map remote is_intra_pool remote_vdis so_far total_size copy) all_vdis @@ fun all_map ->
+
+```
+
+The copy functions are written such that they take continuations. This it to make the error handling simpler - each individual component function can perform its setup and execute the continuation. In the event of an exception coming from the continuation it can then unroll its bit of state and rethrow the exception for the next layer to handle.
+
+`with_many` is a simple helper function for nesting invocations of functions that take continuations. It has the delightful type:
+
+```
+('a -> ('b -> 'c) -> 'c) -> 'a list -> ('b list -> 'c) -> 'c
+```
+
+```ocaml
+(* Helper function to apply a 'with_x' function to a list *)
+let rec with_many withfn many fn =
+ let rec inner l acc =
+ match l with
+ | [] -> fn acc
+ | x::xs -> withfn x (fun y -> inner xs (y::acc))
+ in inner many []
+```
+
+As an example of its operation, imagine our withfn is as follows:
+
+```ocaml
+let withfn x c =
+ Printf.printf "Starting withfn: x=%d\n" x;
+ try
+ c (string_of_int x)
+ with e ->
+ Printf.printf "Handling exception for x=%d\n" x;
+ raise e;;
+```
+
+applying this gives the output:
+
+```ocaml
+utop # with_many withfn [1;2;3;4] (String.concat ",");;
+Starting with fn: x=1
+Starting with fn: x=2
+Starting with fn: x=3
+Starting with fn: x=4
+- : string = "4,3,2,1"
+```
+whereas raising an exception in the continutation results in the following:
+
+```ocaml
+utop # with_many with_fn [1;2;3;4] (fun _ -> failwith "error");;
+Starting with fn: x=1
+Starting with fn: x=2
+Starting with fn: x=3
+Starting with fn: x=4
+Handling exception for x=4
+Handling exception for x=3
+Handling exception for x=2
+Handling exception for x=1
+Exception: Failure "error".
+```
+
+All the real action is in `vdi_copy_fun`, which copies or mirrors a single VDI:
+
+```ocaml
+let vdi_copy_fun __context dbg vdi_map remote is_intra_pool remote_vdis so_far total_size copy vconf continuation =
+ TaskHelper.exn_if_cancelling ~__context;
+ let open Storage_access in
+ let dest_sr_ref = List.assoc vconf.vdi vdi_map in
+ let dest_sr_uuid = XenAPI.SR.get_uuid remote.rpc remote.session dest_sr_ref in
+
+ (* Plug the destination shared SR into destination host and pool master if unplugged.
+ Plug the local SR into destination host only if unplugged *)
+ let dest_pool = List.hd (XenAPI.Pool.get_all remote.rpc remote.session) in
+ let master_host = XenAPI.Pool.get_master remote.rpc remote.session dest_pool in
+ let pbds = XenAPI.SR.get_PBDs remote.rpc remote.session dest_sr_ref in
+ let pbd_host_pair = List.map (fun pbd -> (pbd, XenAPI.PBD.get_host remote.rpc remote.session pbd)) pbds in
+ let hosts_to_be_attached = [master_host; remote.dest_host] in
+ let pbds_to_be_plugged = List.filter (fun (_, host) ->
+ (List.mem host hosts_to_be_attached) && (XenAPI.Host.get_enabled remote.rpc remote.session host)) pbd_host_pair in
+ List.iter (fun (pbd, _) ->
+ if not (XenAPI.PBD.get_currently_attached remote.rpc remote.session pbd) then
+ XenAPI.PBD.plug remote.rpc remote.session pbd) pbds_to_be_plugged;
+```
+
+It begins by attempting to ensure the SRs we require are definitely attached on the destination host and on the destination pool master.
+
+There's now a little logic to support the case where we have cross-pool SRs and the VDI is already visible to the destination pool. Since this is outside our normal support envelope there is a key in xapi_globs that has to be set (via xapi.conf) to enable this:
+
+```ocaml
+ let rec dest_vdi_exists_on_sr vdi_uuid sr_ref retry =
+ try
+ let dest_vdi_ref = XenAPI.VDI.get_by_uuid remote.rpc remote.session vdi_uuid in
+ let dest_vdi_sr_ref = XenAPI.VDI.get_SR remote.rpc remote.session dest_vdi_ref in
+ if dest_vdi_sr_ref = sr_ref then
+ true
+ else
+ false
+ with _ ->
+ if retry then
+ begin
+ XenAPI.SR.scan remote.rpc remote.session sr_ref;
+ dest_vdi_exists_on_sr vdi_uuid sr_ref false
+ end
+ else
+ false
+ in
+
+ (* CP-4498 added an unsupported mode to use cross-pool shared SRs - the initial
+ use case is for a shared raw iSCSI SR (same uuid, same VDI uuid) *)
+ let vdi_uuid = Db.VDI.get_uuid ~__context ~self:vconf.vdi in
+ let mirror = if !Xapi_globs.relax_xsm_sr_check then
+ if (dest_sr_uuid = vconf.sr) then
+ begin
+ (* Check if the VDI uuid already exists in the target SR *)
+ if (dest_vdi_exists_on_sr vdi_uuid dest_sr_ref true) then
+ false
+ else
+ failwith ("SR UUID matches on destination but VDI does not exist")
+ end
+ else
+ true
+ else
+ (not is_intra_pool) || (dest_sr_uuid <> vconf.sr)
+ in
+```
+
+The check also covers the case where we're doing an intra-pool migration and not copying all of the disks, in which case we don't need to do anything for that disk.
+
+We now have a wrapper function that creates a new datapath and passes it to a continuation function. On error it handles the destruction of the datapath:
+
+```ocaml
+let with_new_dp cont =
+ let dp = Printf.sprintf (if vconf.do_mirror then "mirror_%s" else "copy_%s") vconf.dp in
+ try cont dp
+ with e ->
+ (try SMAPI.DP.destroy ~dbg ~dp ~allow_leak:false with _ -> info "Failed to cleanup datapath: %s" dp);
+ raise e in
+```
+
+and now a helper that, given a remote VDI uuid, looks up the reference on the remote host and gives it to a continuation function. On failure of the continuation it will destroy the remote VDI:
+
+```ocaml
+ let with_remote_vdi remote_vdi cont =
+ debug "Executing remote scan to ensure VDI is known to xapi";
+ XenAPI.SR.scan remote.rpc remote.session dest_sr_ref;
+ let query = Printf.sprintf "(field \"location\"=\"%s\") and (field \"SR\"=\"%s\")" remote_vdi (Ref.string_of dest_sr_ref) in
+ let vdis = XenAPI.VDI.get_all_records_where remote.rpc remote.session query in
+ let remote_vdi_ref = match vdis with
+ | [] -> raise (Api_errors.Server_error(Api_errors.vdi_location_missing, [Ref.string_of dest_sr_ref; remote_vdi]))
+ | h :: [] -> debug "Found remote vdi reference: %s" (Ref.string_of (fst h)); fst h
+ | _ -> raise (Api_errors.Server_error(Api_errors.location_not_unique, [Ref.string_of dest_sr_ref; remote_vdi])) in
+ try cont remote_vdi_ref
+ with e ->
+ (try XenAPI.VDI.destroy remote.rpc remote.session remote_vdi_ref with _ -> error "Failed to destroy remote VDI");
+ raise e in
+```
+
+another helper to gather together info about a mirrored VDI:
+
+```ocaml
+let get_mirror_record ?new_dp remote_vdi remote_vdi_reference =
+ { mr_dp = new_dp;
+ mr_mirrored = mirror;
+ mr_local_sr = vconf.sr;
+ mr_local_vdi = vconf.location;
+ mr_remote_sr = dest_sr_uuid;
+ mr_remote_vdi = remote_vdi;
+ mr_local_xenops_locator = vconf.xenops_locator;
+ mr_remote_xenops_locator = Xapi_xenops.xenops_vdi_locator_of_strings dest_sr_uuid remote_vdi;
+ mr_local_vdi_reference = vconf.vdi;
+ mr_remote_vdi_reference = remote_vdi_reference } in
+```
+
+and finally the really important function:
+
+```ocaml
+let mirror_to_remote new_dp =
+ let task =
+ if not vconf.do_mirror then
+ SMAPI.DATA.copy ~dbg ~sr:vconf.sr ~vdi:vconf.location ~dp:new_dp ~url:remote.sm_url ~dest:dest_sr_uuid
+ else begin
+ (* Though we have no intention of "write", here we use the same mode as the
+ associated VBD on a mirrored VDIs (i.e. always RW). This avoids problem
+ when we need to start/stop the VM along the migration. *)
+ let read_write = true in
+ (* DP set up is only essential for MIRROR.start/stop due to their open ended pattern.
+ It's not necessary for copy which will take care of that itself. *)
+ ignore(SMAPI.VDI.attach ~dbg ~dp:new_dp ~sr:vconf.sr ~vdi:vconf.location ~read_write);
+ SMAPI.VDI.activate ~dbg ~dp:new_dp ~sr:vconf.sr ~vdi:vconf.location;
+ ignore(Storage_access.register_mirror __context vconf.location);
+ SMAPI.DATA.MIRROR.start ~dbg ~sr:vconf.sr ~vdi:vconf.location ~dp:new_dp ~url:remote.sm_url ~dest:dest_sr_uuid
+ end in
+
+ let mapfn x =
+ let total = Int64.to_float total_size in
+ let done_ = Int64.to_float !so_far /. total in
+ let remaining = Int64.to_float vconf.size /. total in
+ done_ +. x *. remaining in
+
+ let open Storage_access in
+
+ let task_result =
+ task |> register_task __context
+ |> add_to_progress_map mapfn
+ |> wait_for_task dbg
+ |> remove_from_progress_map
+ |> unregister_task __context
+ |> success_task dbg in
+
+ let mirror_id, remote_vdi =
+ if not vconf.do_mirror then
+ let vdi = task_result |> vdi_of_task dbg in
+ remote_vdis := vdi.vdi :: !remote_vdis;
+ None, vdi.vdi
+ else
+ let mirrorid = task_result |> mirror_of_task dbg in
+ let m = SMAPI.DATA.MIRROR.stat ~dbg ~id:mirrorid in
+ Some mirrorid, m.Mirror.dest_vdi in
+
+ so_far := Int64.add !so_far vconf.size;
+ debug "Local VDI %s %s to %s" vconf.location (if vconf.do_mirror then "mirrored" else "copied") remote_vdi;
+ mirror_id, remote_vdi in
+```
+
+This is the bit that actually starts the mirroring or copying. Before the call to mirror we call `VDI.attach` and `VDI.activate` locally to ensure that if the VM is shutdown then the detach/deactivate there doesn't kill the mirroring process.
+
+Note the parameters to the SMAPI call are `sr` and `vdi`, locating the local VDI and SM backend, `new_dp`, the datapath we're using for the mirroring, `url`, which is the remote url on which SMAPI calls work, and `dest`, the destination SR uuid. These are also the arguments to `copy` above too.
+
+There's a little function to calculate the overall progress of the task, and the function waits until the completion of the task before it continues. The function `success_task` will raise an exception if the task failed. For `DATA.mirror`, completion implies both that the disk data has been copied to the destination and that all local writes are being mirrored to the destination. Hence more cleanup must be done on cancellation. In contrast, if the `DATA.copy` path had been taken then the operation at this point has completely finished.
+
+The result of this function is an optional mirror id and the remote VDI uuid.
+
+Next, there is a `post_mirror` function:
+
+```ocaml
+ let post_mirror mirror_id mirror_record =
+ try
+ let result = continuation mirror_record in
+ (match mirror_id with
+ | Some mid -> ignore(Storage_access.unregister_mirror mid);
+ | None -> ());
+ if mirror && not (Xapi_fist.storage_motion_keep_vdi () || copy) then
+ Helpers.call_api_functions ~__context (fun rpc session_id ->
+ XenAPI.VDI.destroy rpc session_id vconf.vdi);
+ result
+ with e ->
+ let mirror_failed =
+ match mirror_id with
+ | Some mid ->
+ ignore(Storage_access.unregister_mirror mid);
+ let m = SMAPI.DATA.MIRROR.stat ~dbg ~id:mid in
+ (try SMAPI.DATA.MIRROR.stop ~dbg ~id:mid with _ -> ());
+ m.Mirror.failed
+ | None -> false in
+ if mirror_failed then raise (Api_errors.Server_error(Api_errors.mirror_failed,[Ref.string_of vconf.vdi]))
+ else raise e in
+```
+
+This is poorly named - it is post mirror _and_ copy. The aim of this function is to destroy the source VDIs on successful completion of the continuation function, which will have migrated the VM to the destination. In its exception handler it will stop the mirroring, but before doing so it will check to see if the mirroring process it was looking after has itself failed, and raise `mirror_failed` if so. This is because a failed mirror can result in a range of actual errors, and we decide here that the failed mirror was probably the root cause.
+
+These functions are assembled together at the end of the `vdi_copy_fun` function:
+
+```
+ if mirror then
+ with_new_dp (fun new_dp ->
+ let mirror_id, remote_vdi = mirror_to_remote new_dp in
+ with_remote_vdi remote_vdi (fun remote_vdi_ref ->
+ let mirror_record = get_mirror_record ~new_dp remote_vdi remote_vdi_ref in
+ post_mirror mirror_id mirror_record))
+ else
+ let mirror_record = get_mirror_record vconf.location (XenAPI.VDI.get_by_uuid remote.rpc remote.session vdi_uuid) in
+ continuation mirror_record
+```
+again, `mirror` here is poorly named, and means mirror _or_ copy.
+
+Once all of the disks have been mirrored or copied, we jump back to the body of `migrate_send`. We split apart the mirror records according to the source of the VDI:
+
+```ocaml
+ let was_from vmap = List.exists (fun vconf -> vconf.vdi = vmap.mr_local_vdi_reference) in
+
+ let suspends_map, snapshots_map, vdi_map = List.fold_left (fun (suspends, snapshots, vdis) vmap ->
+ if was_from vmap suspends_vdis then vmap :: suspends, snapshots, vdis
+ else if was_from vmap snapshots_vdis then suspends, vmap :: snapshots, vdis
+ else suspends, snapshots, vmap :: vdis
+ ) ([],[],[]) all_map in
+```
+
+then we reassemble all_map from this, for some reason:
+
+```ocaml
+ let all_map = List.concat [suspends_map; snapshots_map; vdi_map] in
+```
+
+Now we need to update the snapshot-of links:
+
+```ocaml
+ (* All the disks and snapshots have been created in the remote SR(s),
+ * so update the snapshot links if there are any snapshots. *)
+ if snapshots_map <> [] then
+ update_snapshot_info ~__context ~dbg ~url:remote.sm_url ~vdi_map ~snapshots_map;
+```
+
+I'm not entirely sure why this is done in this layer as opposed to in the storage layer.
+
+A little housekeeping:
+
+```ocaml
+ let xenops_vdi_map = List.map (fun mirror_record -> (mirror_record.mr_local_xenops_locator, mirror_record.mr_remote_xenops_locator)) all_map in
+
+ (* Wait for delay fist to disappear *)
+ wait_for_fist __context Xapi_fist.pause_storage_migrate "pause_storage_migrate";
+
+ TaskHelper.exn_if_cancelling ~__context;
+```
+
+the `fist` thing here simply allows tests to put in a delay at this specific point.
+
+We also check the task to see if we've been cancelled and raise an exception if so.
+
+The VM metadata is now imported into the remote pool, with all the XenAPI level objects remapped:
+
+```ocaml
+let new_vm =
+ if is_intra_pool
+ then vm
+ else
+ (* Make sure HA replaning cycle won't occur right during the import process or immediately after *)
+ let () = if ha_always_run_reset then XenAPI.Pool.ha_prevent_restarts_for ~rpc:remote.rpc ~session_id:remote.session ~seconds:(Int64.of_float !Xapi_globs.ha_monitor_interval) in
+ (* Move the xapi VM metadata to the remote pool. *)
+ let vms =
+ let vdi_map =
+ List.map (fun mirror_record -> {
+ local_vdi_reference = mirror_record.mr_local_vdi_reference;
+ remote_vdi_reference = Some mirror_record.mr_remote_vdi_reference;
+ })
+ all_map in
+ let vif_map =
+ List.map (fun (vif, network) -> {
+ local_vif_reference = vif;
+ remote_network_reference = network;
+ })
+ vif_map in
+ let vgpu_map =
+ List.map (fun (vgpu, gpu_group) -> {
+ local_vgpu_reference = vgpu;
+ remote_gpu_group_reference = gpu_group;
+ })
+ vgpu_map
+ in
+ inter_pool_metadata_transfer ~__context ~remote ~vm ~vdi_map
+ ~vif_map ~vgpu_map ~dry_run:false ~live:true ~copy
+ in
+ let vm = List.hd vms in
+ let () = if ha_always_run_reset then XenAPI.VM.set_ha_always_run ~rpc:remote.rpc ~session_id:remote.session ~self:vm ~value:false in
+ (* Reserve resources for the new VM on the destination pool's host *)
+ let () = XenAPI.Host.allocate_resources_for_vm remote.rpc remote.session remote.dest_host vm true in
+ vm in
+```
+
+More waiting for fist points:
+
+```
+ wait_for_fist __context Xapi_fist.pause_storage_migrate2 "pause_storage_migrate2";
+
+ (* Attach networks on remote *)
+ XenAPI.Network.attach_for_vm ~rpc:remote.rpc ~session_id:remote.session ~host:remote.dest_host ~vm:new_vm;
+```
+
+also make sure all the networks are plugged for the VM on the destination.
+Next we create the xenopsd-level vif map, equivalent to the vdi_map above:
+
+```ocaml
+ (* Create the vif-map for xenops, linking VIF devices to bridge names on the remote *)
+ let xenops_vif_map =
+ let vifs = XenAPI.VM.get_VIFs ~rpc:remote.rpc ~session_id:remote.session ~self:new_vm in
+ List.map (fun vif ->
+ let vifr = XenAPI.VIF.get_record ~rpc:remote.rpc ~session_id:remote.session ~self:vif in
+ let bridge = Xenops_interface.Network.Local
+ (XenAPI.Network.get_bridge ~rpc:remote.rpc ~session_id:remote.session ~self:vifr.API.vIF_network) in
+ vifr.API.vIF_device, bridge
+ ) vifs
+ in
+```
+
+Now we destroy any extra mirror datapaths we set up previously:
+
+```ocaml
+ (* Destroy the local datapaths - this allows the VDIs to properly detach, invoking the migrate_finalize calls *)
+ List.iter (fun mirror_record ->
+ if mirror_record.mr_mirrored
+ then match mirror_record.mr_dp with | Some dp -> SMAPI.DP.destroy ~dbg ~dp ~allow_leak:false | None -> ()) all_map;
+```
+
+More housekeeping:
+
+```ocaml
+ SMPERF.debug "vm.migrate_send: migration initiated vm:%s" vm_uuid;
+
+ (* In case when we do SXM on the same host (mostly likely a VDI
+ migration), the VM's metadata in xenopsd will be in-place updated
+ as soon as the domain migration starts. For these case, there
+ will be no (clean) way back from this point. So we disable task
+ cancellation for them here.
+ *)
+ if is_same_host then (TaskHelper.exn_if_cancelling ~__context; TaskHelper.set_not_cancellable ~__context);
+
+```
+
+Finally we get to the memory-image part of the migration:
+
+```ocaml
+ (* It's acceptable for the VM not to exist at this point; shutdown commutes with storage migrate *)
+ begin
+ try
+ Xapi_xenops.Events_from_xenopsd.with_suppressed queue_name dbg vm_uuid
+ (fun () ->
+ let xenops_vgpu_map = (* can raise VGPU_mapping *)
+ infer_vgpu_map ~__context ~remote new_vm in
+ migrate_with_retry
+ ~__context queue_name dbg vm_uuid xenops_vdi_map
+ xenops_vif_map xenops_vgpu_map remote.xenops_url;
+ Xapi_xenops.Xenopsd_metadata.delete ~__context vm_uuid)
+ with
+ | Xenops_interface.Does_not_exist ("VM",_)
+ | Xenops_interface.Does_not_exist ("extra",_) ->
+ info "%s: VM %s stopped being live during migration"
+ "vm_migrate_send" vm_uuid
+ | VGPU_mapping(msg) ->
+ info "%s: VM %s - can't infer vGPU map: %s"
+ "vm_migrate_send" vm_uuid msg;
+ raise Api_errors.
+ (Server_error
+ (vm_migrate_failed,
+ ([ vm_uuid
+ ; Helpers.get_localhost_uuid ()
+ ; Db.Host.get_uuid ~__context ~self:remote.dest_host
+ ; "The VM changed its power state during migration"
+ ])))
+ end;
+
+ debug "Migration complete";
+ SMPERF.debug "vm.migrate_send: migration complete vm:%s" vm_uuid;
+```
+
+Now we tidy up after ourselves:
+
+```ocaml
+ (* So far the main body of migration is completed, and the rests are
+ updates, config or cleanup on the source and destination. There will
+ be no (clean) way back from this point, due to these destructive
+ changes, so we don't want user intervention e.g. task cancellation.
+ *)
+ TaskHelper.exn_if_cancelling ~__context;
+ TaskHelper.set_not_cancellable ~__context;
+ XenAPI.VM.pool_migrate_complete remote.rpc remote.session new_vm remote.dest_host;
+
+ detach_local_network_for_vm ~__context ~vm ~destination:remote.dest_host;
+ Xapi_xenops.refresh_vm ~__context ~self:vm;
+```
+
+the function `pool_migrate_complete` is called on the destination host, and consists of a few things that ordinarily would be set up during VM.start or the like:
+
+```ocaml
+let pool_migrate_complete ~__context ~vm ~host =
+ let id = Db.VM.get_uuid ~__context ~self:vm in
+ debug "VM.pool_migrate_complete %s" id;
+ let dbg = Context.string_of_task __context in
+ let queue_name = Xapi_xenops_queue.queue_of_vm ~__context ~self:vm in
+ if Xapi_xenops.vm_exists_in_xenopsd queue_name dbg id then begin
+ Cpuid_helpers.update_cpu_flags ~__context ~vm ~host;
+ Xapi_xenops.set_resident_on ~__context ~self:vm;
+ Xapi_xenops.add_caches id;
+ Xapi_xenops.refresh_vm ~__context ~self:vm;
+ Monitor_dbcalls_cache.clear_cache_for_vm ~vm_uuid:id
+ end
+```
+
+More tidying up, remapping some remaining VBDs and clearing state on the sender:
+
+```ocaml
+ (* Those disks that were attached at the point the migration happened will have been
+ remapped by the Events_from_xenopsd logic. We need to remap any other disks at
+ this point here *)
+
+ if is_intra_pool
+ then
+ List.iter
+ (fun vm' ->
+ intra_pool_vdi_remap ~__context vm' all_map;
+ intra_pool_fix_suspend_sr ~__context remote.dest_host vm')
+ vm_and_snapshots;
+
+ (* If it's an inter-pool migrate, the VBDs will still be 'currently-attached=true'
+ because we supressed the events coming from xenopsd. Destroy them, so that the
+ VDIs can be destroyed *)
+ if not is_intra_pool && not copy
+ then List.iter (fun vbd -> Db.VBD.destroy ~__context ~self:vbd) (vbds @ snapshots_vbds);
+
+ new_vm
+ in
+```
+
+The remark about the `Events_from_xenopsd` is that we have a thread watching for events that are emitted by xenopsd, and we resynchronise xapi's state according to xenopsd's state for several fields for which xenopsd is considered the canonical source of truth. One of these is the exact VDI the VBD is associated with.
+
+The suspend_SR field of the VM is set to the source's value, so we reset that.
+
+Now we move the RRDs:
+
+```ocaml
+ if not copy then begin
+ Rrdd_proxy.migrate_rrd ~__context ~remote_address:remote.remote_ip ~session_id:(Ref.string_of remote.session)
+ ~vm_uuid:vm_uuid ~host_uuid:(Ref.string_of remote.dest_host) ()
+ end;
+```
+
+This can be done for intra- and inter- pool migrates in the same way, simplifying the logic.
+
+However, for messages and blobs we have to only migrate them for inter-pool migrations:
+
+```ocaml
+ if not is_intra_pool && not copy then begin
+ (* Replicate HA runtime flag if necessary *)
+ if ha_always_run_reset then XenAPI.VM.set_ha_always_run ~rpc:remote.rpc ~session_id:remote.session ~self:new_vm ~value:true;
+ (* Send non-database metadata *)
+ Xapi_message.send_messages ~__context ~cls:`VM ~obj_uuid:vm_uuid
+ ~session_id:remote.session ~remote_address:remote.remote_master_ip;
+ Xapi_blob.migrate_push ~__context ~rpc:remote.rpc
+ ~remote_address:remote.remote_master_ip ~session_id:remote.session ~old_vm:vm ~new_vm ;
+ (* Signal the remote pool that we're done *)
+ end;
+```
+
+Lastly, we destroy the VM record on the source:
+
+```ocaml
+ Helpers.call_api_functions ~__context (fun rpc session_id ->
+ if not is_intra_pool && not copy then begin
+ info "Destroying VM ref=%s uuid=%s" (Ref.string_of vm) vm_uuid;
+ Xapi_vm_lifecycle.force_state_reset ~__context ~self:vm ~value:`Halted;
+ List.iter (fun self -> Db.VM.destroy ~__context ~self) vm_and_snapshots
+ end);
+ SMPERF.debug "vm.migrate_send exiting vm:%s" vm_uuid;
+ new_vm
+```
+
+The exception handler still has to clean some state, but mostly things are handled in the CPS functions declared above:
+
+```ocaml
+with e ->
+ error "Caught %s: cleaning up" (Printexc.to_string e);
+
+ (* We do our best to tidy up the state left behind *)
+ Events_from_xenopsd.with_suppressed queue_name dbg vm_uuid (fun () ->
+ try
+ let _, state = XenopsAPI.VM.stat dbg vm_uuid in
+ if Xenops_interface.(state.Vm.power_state = Suspended) then begin
+ debug "xenops: %s: shutting down suspended VM" vm_uuid;
+ Xapi_xenops.shutdown ~__context ~self:vm None;
+ end;
+ with _ -> ());
+
+ if not is_intra_pool && Db.is_valid_ref __context vm then begin
+ List.map (fun self -> Db.VM.get_uuid ~__context ~self) vm_and_snapshots
+ |> List.iter (fun self ->
+ try
+ let vm_ref = XenAPI.VM.get_by_uuid remote.rpc remote.session self in
+ info "Destroying stale VM uuid=%s on destination host" self;
+ XenAPI.VM.destroy remote.rpc remote.session vm_ref
+ with e -> error "Caught %s while destroying VM uuid=%s on destination host" (Printexc.to_string e) self)
+ end;
+
+ let task = Context.get_task_id __context in
+ let oc = Db.Task.get_other_config ~__context ~self:task in
+ if List.mem_assoc "mirror_failed" oc then begin
+ let failed_vdi = List.assoc "mirror_failed" oc in
+ let vconf = List.find (fun vconf -> vconf.location=failed_vdi) vms_vdis in
+ debug "Mirror failed for VDI: %s" failed_vdi;
+ raise (Api_errors.Server_error(Api_errors.mirror_failed,[Ref.string_of vconf.vdi]))
+ end;
+ TaskHelper.exn_if_cancelling ~__context;
+ begin match e with
+ | Storage_interface.Backend_error(code, params) -> raise (Api_errors.Server_error(code, params))
+ | Storage_interface.Unimplemented(code) -> raise (Api_errors.Server_error(Api_errors.unimplemented_in_sm_backend, [code]))
+ | Xenops_interface.Cancelled _ -> TaskHelper.raise_cancelled ~__context
+ | _ -> raise e
+ end
+```
+
+Failures during the migration can result in the VM being in a suspended state. There's no point leaving it like this since there's nothing that can be done to resume it, so we force shut it down.
+
+We also try to remove the VM record from the destination if we managed to send it there.
+
+Finally we check for mirror failure in the task - this is set by the events thread watching for events from the storage layer, in [storage_access.ml](https://github.com/xapi-project/xen-api/blob/f75d51e7a3eff89d952330ec1a739df85a2895e2/ocaml/xapi/storage_access.ml#L1169-L1207)
+
+
+## Storage code
+
+The part of the code that is conceptually in the storage layer, but physically in xapi, is located in
+[storage_migrate.ml](https://github.com/xapi-project/xen-api/blob/f75d51e7a3eff89d952330ec1a739df85a2895e2/ocaml/xapi/storage_migrate.ml). There are logically a few separate parts to this file:
+
+* A [stateful module](https://github.com/xapi-project/xen-api/blob/f75d51e7a3eff89d952330ec1a739df85a2895e2/ocaml/xapi/storage_migrate.ml#L34-L204) for persisting state across xapi restarts.
+* Some general [helper functions](https://github.com/xapi-project/xen-api/blob/f75d51e7a3eff89d952330ec1a739df85a2895e2/ocaml/xapi/storage_migrate.ml#L206-L281)
+* Some quite specific [helper](https://github.com/xapi-project/xen-api/blob/f75d51e7a3eff89d952330ec1a739df85a2895e2/ocaml/xapi/storage_migrate.ml#L206-L281) [functions](https://github.com/xapi-project/xen-api/blob/f75d51e7a3eff89d952330ec1a739df85a2895e2/ocaml/xapi/storage_migrate.ml#L738-L791) related to actions to be taken on deactivate/detach
+* An [NBD handler](https://github.com/xapi-project/xen-api/blob/f75d51e7a3eff89d952330ec1a739df85a2895e2/ocaml/xapi/storage_migrate.ml#L793-L818)
+* The implementations of the SMAPIv2 [mirroring APIs](https://github.com/xapi-project/xcp-idl/blob/master/storage/storage_interface.ml#L430-L460)
+
+Let's start by considering the way the storage APIs are intended to be used.
+
+### Copying a VDI
+
+`DATA.copy` takes several parameters:
+
+* `dbg` - a debug string
+* `sr` - the source SR (a uuid)
+* `vdi` - the source VDI (a uuid)
+* `dp` - **unused**
+* `url` - a URL on which SMAPIv2 API calls can be made
+* `sr` - the destination SR in which the VDI should be copied
+
+and returns a parameter of type `Task.id`. The API call is intended to be called in an asynchronous fashion - ie., the caller makes the call, receives the task ID back and polls or uses the event mechanism to wait until the task has completed. The task may be cancelled via the `Task.cancel` API call. The result of the operation is obtained by calling TASK.stat, which returns a record:
+
+```ocaml
+ type t = {
+ id: id;
+ dbg: string;
+ ctime: float;
+ state: state;
+ subtasks: (string * state) list;
+ debug_info: (string * string) list;
+ backtrace: string;
+ }
+```
+
+Where the `state` field contains the result once the task has completed:
+
+```ocaml
+type async_result_t =
+ | Vdi_info of vdi_info
+ | Mirror_id of Mirror.id
+
+type completion_t = {
+ duration : float;
+ result : async_result_t option
+}
+
+type state =
+ | Pending of float
+ | Completed of completion_t
+ | Failed of Rpc.t
+```
+
+Once the result has been obtained from the task, the task should be destroyed via the `TASK.destroy` API call.
+
+The implementation uses the `url` parameter to make SMAPIv2 calls to the destination SR. This is used, for example, to invoke a VDI.create call if necessary. The URL contains an authentication token within it (valid for the duration of the XenAPI call that caused this DATA.copy API call).
+
+The implementation tries to minimize the amount of data copied by looking for related VDIs on the destination SR. See below for more details.
+
+
+### Mirroring a VDI
+
+`DATA.MIRROR.start` takes a similar set of parameters to that of copy:
+
+* `dbg` - a debug string
+* `sr` - the source SR (a uuid)
+* `vdi` - the source VDI (a uuid)
+* `dp` - the datapath on which the VDI has been attached
+* `url` - a URL on which SMAPIv2 API calls can be made
+* `sr` - the destination SR in which the VDI should be copied
+
+Similar to copy above, this returns a task id. The task 'completes' once the mirror has been set up - that is, at any point afterwards we can detach the disk and the destination disk will be identical to the source. Unlike for copy the operation is ongoing after the API call completes, since new writes need to be mirrored to the destination. Therefore the completion type of the mirror operation is `Mirror_id` which contains a handle on which further API calls related to the mirror call can be made. For example [MIRROR.stat](https://github.com/xapi-project/xcp-idl/blob/a999ef6191629c8f68377f7c412ee98fc6a39dea/storage/storage_interface.ml#L446) whose signature is:
+
+```ocaml
+MIRROR.stat: dbg:debug_info -> id:Mirror.id -> Mirror.t
+```
+
+The return type of this call is a record containing information about the mirror:
+
+```ocaml
+type state =
+ | Receiving
+ | Sending
+ | Copying
+
+type t = {
+ source_vdi : vdi;
+ dest_vdi : vdi;
+ state : state list;
+ failed : bool;
+}
+```
+
+Note that state is a list since the initial phase of the operation requires both copying and mirroring.
+
+Additionally the mirror can be cancelled using the `MIRROR.stop` API call.
+
+### Code walkthrough
+
+let's go through the implementation of `copy`:
+
+#### DATA.copy
+
+```ocaml
+let copy ~task ~dbg ~sr ~vdi ~dp ~url ~dest =
+ debug "copy sr:%s vdi:%s url:%s dest:%s" sr vdi url dest;
+ let remote_url = Http.Url.of_string url in
+ let module Remote = Client(struct let rpc = rpc ~srcstr:"smapiv2" ~dststr:"dst_smapiv2" remote_url end) in
+```
+
+Here we are constructing a module `Remote` on which we can do SMAPIv2 calls directly on the destination.
+
+```ocaml
+ try
+```
+
+Wrap the whole function in an exception handler.
+
+```ocaml
+ (* Find the local VDI *)
+ let vdis = Local.SR.scan ~dbg ~sr in
+ let local_vdi =
+ try List.find (fun x -> x.vdi = vdi) vdis
+ with Not_found -> failwith (Printf.sprintf "Local VDI %s not found" vdi) in
+```
+
+We first find the metadata for our source VDI by doing a local SMAPIv2 call `SR.scan`. This returns a list of VDI metadata, out of which we extract the VDI we're interested in.
+
+```ocaml
+ try
+```
+
+Another exception handler. This looks redundant to me right now.
+
+```
+ let similar_vdis = Local.VDI.similar_content ~dbg ~sr ~vdi in
+ let similars = List.map (fun vdi -> vdi.content_id) similar_vdis in
+ debug "Similar VDIs to %s = [ %s ]" vdi (String.concat "; " (List.map (fun x -> Printf.sprintf "(vdi=%s,content_id=%s)" x.vdi x.content_id) similar_vdis));
+```
+
+Here we look for related VDIs locally using the `VDI.similar_content` SMAPIv2 API call. This searches for related VDIs and returns an ordered list where the most similar is first in the list. It returns both clones and snapshots, and hence is more general than simply following `snapshot_of` links.
+
+```
+ let remote_vdis = Remote.SR.scan ~dbg ~sr:dest in
+ (** We drop cbt_metadata VDIs that do not have any actual data *)
+ let remote_vdis = List.filter (fun vdi -> vdi.ty <> "cbt_metadata") remote_vdis in
+
+ let nearest = List.fold_left
+ (fun acc content_id -> match acc with
+ | Some x -> acc
+ | None ->
+ try Some (List.find (fun vdi -> vdi.content_id = content_id && vdi.virtual_size <= local_vdi.virtual_size) remote_vdis)
+ with Not_found -> None) None similars in
+
+ debug "Nearest VDI: content_id=%s vdi=%s"
+ (Opt.default "None" (Opt.map (fun x -> x.content_id) nearest))
+ (Opt.default "None" (Opt.map (fun x -> x.vdi) nearest));
+```
+
+Here we look for VDIs on the destination with the same `content_id` as one of the locally similar VDIs. We will use this as a base image and only copy deltas to the destination. This is done by cloning the VDI on the destination and then using `sparse_dd` to find the deltas from our local disk to our local copy of the content_id disk and streaming these to the destination. Note that we need to ensure the VDI is smaller than the one we want to copy since we can't resize disks downwards in size.
+
+```ocaml
+ let remote_base = match nearest with
+ | Some vdi ->
+ debug "Cloning VDI %s" vdi.vdi;
+ let vdi_clone = Remote.VDI.clone ~dbg ~sr:dest ~vdi_info:vdi in
+ if vdi_clone.virtual_size <> local_vdi.virtual_size then begin
+ let new_size = Remote.VDI.resize ~dbg ~sr:dest ~vdi:vdi_clone.vdi ~new_size:local_vdi.virtual_size in
+ debug "Resize remote VDI %s to %Ld: result %Ld" vdi_clone.vdi local_vdi.virtual_size new_size;
+ end;
+ vdi_clone
+ | None ->
+ debug "Creating a blank remote VDI";
+ Remote.VDI.create ~dbg ~sr:dest ~vdi_info:{ local_vdi with sm_config = [] } in
+```
+
+If we've found a base VDI we clone it and resize it immediately. If there's nothing on the destination already we can use, we just create a new VDI. Note that the calls to create and clone may well fail if the destination host is not the SRmaster. This is [handled purely in the `rpc` function](https://github.com/xapi-project/xen-api/blob/master/ocaml/xapi/storage_migrate.ml#L214-L229):
+
+```ocaml
+let rec rpc ~srcstr ~dststr url call =
+ let result = XMLRPC_protocol.rpc ~transport:(transport_of_url url)
+ ~srcstr ~dststr ~http:(xmlrpc ~version:"1.0" ?auth:(Http.Url.auth_of url) ~query:(Http.Url.get_query_params url) (Http.Url.get_uri url)) call
+ in
+ if not result.Rpc.success then begin
+ debug "Got failure: checking for redirect";
+ debug "Call was: %s" (Rpc.string_of_call call);
+ debug "result.contents: %s" (Jsonrpc.to_string result.Rpc.contents);
+ match Storage_interface.Exception.exnty_of_rpc result.Rpc.contents with
+ | Storage_interface.Exception.Redirect (Some ip) ->
+ let open Http.Url in
+ let newurl =
+ match url with
+ | (Http h, d) ->
+ (Http {h with host=ip}, d)
+ | _ ->
+ remote_url ip in
+ debug "Redirecting to ip: %s" ip;
+ let r = rpc ~srcstr ~dststr newurl call in
+ debug "Successfully redirected. Returning";
+ r
+ | _ ->
+ debug "Not a redirect";
+ result
+ end
+ else result
+```
+
+Back to the copy function:
+
+```ocaml
+ let remote_copy = copy' ~task ~dbg ~sr ~vdi ~url ~dest ~dest_vdi:remote_base.vdi |> vdi_info in
+```
+
+This calls the actual data copy part. See below for more on that.
+
+```ocaml
+ let snapshot = Remote.VDI.snapshot ~dbg ~sr:dest ~vdi_info:remote_copy in
+ Remote.VDI.destroy ~dbg ~sr:dest ~vdi:remote_copy.vdi;
+ Some (Vdi_info snapshot)
+```
+
+Finally we snapshot the remote VDI to ensure we've got a VDI of type 'snapshot' on the destination, and we delete the non-snapshot VDI.
+
+```ocaml
+ with e ->
+ error "Caught %s: copying snapshots vdi" (Printexc.to_string e);
+ raise (Internal_error (Printexc.to_string e))
+ with
+ | Backend_error(code, params)
+ | Api_errors.Server_error(code, params) ->
+ raise (Backend_error(code, params))
+ | e ->
+ raise (Internal_error(Printexc.to_string e))
+```
+
+The exception handler does nothing - so we leak remote VDIs if the exception happens after we've done our cloning :-(
+
+#### DATA.copy_into
+
+Let's now look at the data-copying part. This is common code shared between `VDI.copy`, `VDI.copy_into` and `MIRROR.start` and hence has some duplication of the calls made above.
+
+```ocaml
+let copy_into ~task ~dbg ~sr ~vdi ~url ~dest ~dest_vdi =
+ copy' ~task ~dbg ~sr ~vdi ~url ~dest ~dest_vdi
+```
+
+`copy_into` is a stub and just calls `copy'`
+
+```ocaml
+let copy' ~task ~dbg ~sr ~vdi ~url ~dest ~dest_vdi =
+ let remote_url = Http.Url.of_string url in
+ let module Remote = Client(struct let rpc = rpc ~srcstr:"smapiv2" ~dststr:"dst_smapiv2" remote_url end) in
+ debug "copy local=%s/%s url=%s remote=%s/%s" sr vdi url dest dest_vdi;
+```
+
+This call takes roughly the same parameters as the ``DATA.copy` call above, except it specifies the destination VDI.
+Once again we construct a module to do remote SMAPIv2 calls
+
+```ocaml
+ (* Check the remote SR exists *)
+ let srs = Remote.SR.list ~dbg in
+ if not(List.mem dest srs)
+ then failwith (Printf.sprintf "Remote SR %s not found" dest);
+```
+
+Sanity check.
+
+```ocaml
+ let vdis = Remote.SR.scan ~dbg ~sr:dest in
+ let remote_vdi =
+ try List.find (fun x -> x.vdi = dest_vdi) vdis
+ with Not_found -> failwith (Printf.sprintf "Remote VDI %s not found" dest_vdi)
+ in
+```
+
+Find the metadata of the destination VDI
+
+```ocaml
+ let dest_content_id = remote_vdi.content_id in
+```
+
+If we've got a local VDI with the same content_id as the destination, we only need copy the deltas, so we make a note of the destination content ID here.
+
+```ocaml
+ (* Find the local VDI *)
+ let vdis = Local.SR.scan ~dbg ~sr in
+ let local_vdi =
+ try List.find (fun x -> x.vdi = vdi) vdis
+ with Not_found -> failwith (Printf.sprintf "Local VDI %s not found" vdi) in
+
+ debug "copy local=%s/%s content_id=%s" sr vdi local_vdi.content_id;
+ debug "copy remote=%s/%s content_id=%s" dest dest_vdi remote_vdi.content_id;
+```
+
+Find the source VDI metadata.
+
+```
+ if local_vdi.virtual_size > remote_vdi.virtual_size then begin
+ (* This should never happen provided the higher-level logic is working properly *)
+ error "copy local=%s/%s virtual_size=%Ld > remote=%s/%s virtual_size = %Ld" sr vdi local_vdi.virtual_size dest dest_vdi remote_vdi.virtual_size;
+ failwith "local VDI is larger than the remote VDI";
+ end;
+```
+
+Sanity check - the remote VDI can't be smaller than the source.
+
+```ocaml
+ let on_fail : (unit -> unit) list ref = ref [] in
+```
+
+We do some ugly error handling here by keeping a mutable list of operations to perform in the event of a failure.
+
+```ocaml
+ let base_vdi =
+ try
+ let x = (List.find (fun x -> x.content_id = dest_content_id) vdis).vdi in
+ debug "local VDI %s has content_id = %s; we will perform an incremental copy" x dest_content_id;
+ Some x
+ with _ ->
+ debug "no local VDI has content_id = %s; we will perform a full copy" dest_content_id;
+ None
+ in
+```
+
+See if we can identify a local VDI with the same `content_id` as the destination. If not, no problem.
+
+```ocaml
+ try
+ let remote_dp = Uuid.string_of_uuid (Uuid.make_uuid ()) in
+ let base_dp = Uuid.string_of_uuid (Uuid.make_uuid ()) in
+ let leaf_dp = Uuid.string_of_uuid (Uuid.make_uuid ()) in
+```
+
+Construct some `datapaths` - named reasons why the VDI is attached - that we will pass to `VDI.attach/activate`.
+
+```ocaml
+ let dest_vdi_url = Http.Url.set_uri remote_url (Printf.sprintf "%s/nbd/%s/%s/%s" (Http.Url.get_uri remote_url) dest dest_vdi remote_dp) |> Http.Url.to_string in
+
+ debug "copy remote=%s/%s NBD URL = %s" dest dest_vdi dest_vdi_url;
+```
+
+Here we are constructing a URI that we use to connect to the destination xapi. The handler for this particular path will verify the credentials and then pass the connection on to tapdisk which will behave as a NBD server. The VDI has to be attached and activated for this to work, unlike the new NBD handler in `xapi-nbd` that is smarter. The handler for this URI is declared [in this file](https://github.com/xapi-project/xen-api/blob/master/ocaml/xapi/storage_migrate.ml#L858-L884)
+
+```ocaml
+ let id=State.copy_id_of (sr,vdi) in
+ debug "Persisting state for copy (id=%s)" id;
+ State.add id State.(Copy_op Copy_state.({
+ base_dp; leaf_dp; remote_dp; dest_sr=dest; copy_vdi=remote_vdi.vdi; remote_url=url}));
+```
+
+Since we're about to perform a long-running operation that is stateful, we persist the state here so that if xapi is restarted we can cancel the operation and not leak VDI attaches. Normally in xapi code we would be doing VBD.plug operations to persist the state in the xapi db, but this is storage code so we have to use a different mechanism.
+
+```ocaml
+ SMPERF.debug "mirror.copy: copy initiated local_vdi:%s dest_vdi:%s" vdi dest_vdi;
+
+ Pervasiveext.finally (fun () ->
+ debug "activating RW datapath %s on remote=%s/%s" remote_dp dest dest_vdi;
+ ignore(Remote.VDI.attach ~dbg ~sr:dest ~vdi:dest_vdi ~dp:remote_dp ~read_write:true);
+ Remote.VDI.activate ~dbg ~dp:remote_dp ~sr:dest ~vdi:dest_vdi;
+
+ with_activated_disk ~dbg ~sr ~vdi:base_vdi ~dp:base_dp
+ (fun base_path ->
+ with_activated_disk ~dbg ~sr ~vdi:(Some vdi) ~dp:leaf_dp
+ (fun src ->
+ let dd = Sparse_dd_wrapper.start ~progress_cb:(progress_callback 0.05 0.9 task) ?base:base_path true (Opt.unbox src)
+ dest_vdi_url remote_vdi.virtual_size in
+ Storage_task.with_cancel task
+ (fun () -> Sparse_dd_wrapper.cancel dd)
+ (fun () ->
+ try Sparse_dd_wrapper.wait dd
+ with Sparse_dd_wrapper.Cancelled -> Storage_task.raise_cancelled task)
+ )
+ );
+ )
+ (fun () ->
+ Remote.DP.destroy ~dbg ~dp:remote_dp ~allow_leak:false;
+ State.remove_copy id
+ );
+```
+
+In this chunk of code we attach and activate the disk on the remote SR via the SMAPI, then locally attach and activate both the VDI we're copying and the base image we're copying deltas from (if we've got one). We then call `sparse_dd` to copy the data to the remote NBD URL. There is some logic to update progress indicators and to cancel the operation if the SMAPIv2 call `TASK.cancel` is called.
+
+Once the operation has terminated (either on success, error or cancellation), we remove the local attach and activations in the `with_activated_disk` function and the remote attach and activation by destroying the datapath on the remote SR. We then remove the persistent state relating to the copy.
+
+```ocaml
+ SMPERF.debug "mirror.copy: copy complete local_vdi:%s dest_vdi:%s" vdi dest_vdi;
+
+ debug "setting remote=%s/%s content_id <- %s" dest dest_vdi local_vdi.content_id;
+ Remote.VDI.set_content_id ~dbg ~sr:dest ~vdi:dest_vdi ~content_id:local_vdi.content_id;
+ (* PR-1255: XXX: this is useful because we don't have content_ids by default *)
+ debug "setting local=%s/%s content_id <- %s" sr local_vdi.vdi local_vdi.content_id;
+ Local.VDI.set_content_id ~dbg ~sr ~vdi:local_vdi.vdi ~content_id:local_vdi.content_id;
+ Some (Vdi_info remote_vdi)
+```
+
+The last thing we do is to set the local and remote content_id. The local set_content_id is there because the content_id of the VDI is constructed from the location if it is unset in the [storage_access.ml](https://github.com/xapi-project/xen-api/blob/3bf897b3accfc172f365689c3c6927746e059177/ocaml/xapi/storage_access.ml#L69-L72) module of xapi (still part of the storage layer)
+
+
+```ocaml
+ with e ->
+ error "Caught %s: performing cleanup actions" (Printexc.to_string e);
+ perform_cleanup_actions !on_fail;
+ raise e
+```
+
+Here we perform the list of cleanup operations. Theoretically. It seems we don't ever actually set this to anything, so this is dead code.
+
+
+#### DATA.MIRROR.start
+
+```ocaml
+let start' ~task ~dbg ~sr ~vdi ~dp ~url ~dest =
+ debug "Mirror.start sr:%s vdi:%s url:%s dest:%s" sr vdi url dest;
+ SMPERF.debug "mirror.start called sr:%s vdi:%s url:%s dest:%s" sr vdi url dest;
+ let remote_url = Http.Url.of_string url in
+ let module Remote = Client(struct let rpc = rpc ~srcstr:"smapiv2" ~dststr:"dst_smapiv2" remote_url end) in
+
+ (* Find the local VDI *)
+ let vdis = Local.SR.scan ~dbg ~sr in
+ let local_vdi =
+ try List.find (fun x -> x.vdi = vdi) vdis
+ with Not_found -> failwith (Printf.sprintf "Local VDI %s not found" vdi) in
+```
+
+As with the previous calls, we make a remote module for SMAPIv2 calls on the destination, and we find local VDI metadata via `SR.scan`
+
+```ocaml
+ let id = State.mirror_id_of (sr,local_vdi.vdi) in
+```
+
+Mirror ids are deterministically constructed.
+
+```ocaml
+ (* A list of cleanup actions to perform if the operation should fail. *)
+ let on_fail : (unit -> unit) list ref = ref [] in
+```
+
+This `on_fail` list is actually used.
+
+```ocaml
+ try
+ let similar_vdis = Local.VDI.similar_content ~dbg ~sr ~vdi in
+ let similars = List.filter (fun x -> x <> "") (List.map (fun vdi -> vdi.content_id) similar_vdis) in
+ debug "Similar VDIs to %s = [ %s ]" vdi (String.concat "; " (List.map (fun x -> Printf.sprintf "(vdi=%s,content_id=%s)" x.vdi x.content_id) similar_vdis));
+```
+
+As with copy we look locally for similar VDIs. However, rather than use that here we actually pass this information on to the destination SR via the `receive_start` internal SMAPIv2 call:
+
+```ocaml
+ let result_ty = Remote.DATA.MIRROR.receive_start ~dbg ~sr:dest ~vdi_info:local_vdi ~id ~similar:similars in
+ let result = match result_ty with
+ Mirror.Vhd_mirror x -> x
+ in
+```
+
+This gives the destination SR a chance to say what sort of migration it can support. We only support `Vhd_mirror` style migrations which require the destination to support the `compose` SMAPIv2 operation. The type of `x` is a record:
+
+```ocaml
+type mirror_receive_result_vhd_t = {
+ mirror_vdi : vdi_info;
+ mirror_datapath : dp;
+ copy_diffs_from : content_id option;
+ copy_diffs_to : vdi;
+ dummy_vdi : vdi;
+}
+```
+Field descriptions:
+
+* `mirror_vdi` is the VDI to which new writes should be mirrored.
+* `mirror_datapath` is the remote datapath on which the VDI has been attached and activated. This is required to construct the remote NBD url
+* `copy_diffs_from` represents the source base VDI to be used for the non-mirrored data copy.
+* `copy_diffs_to` is the remote VDI to copy those diffs to
+* `dummy_vdi` exists to prevent leaf-coalesce on the `mirror_vdi`
+
+```ocaml
+ (* Enable mirroring on the local machine *)
+ let mirror_dp = result.Mirror.mirror_datapath in
+
+ let uri = (Printf.sprintf "/services/SM/nbd/%s/%s/%s" dest result.Mirror.mirror_vdi.vdi mirror_dp) in
+ let dest_url = Http.Url.set_uri remote_url uri in
+ let request = Http.Request.make ~query:(Http.Url.get_query_params dest_url) ~version:"1.0" ~user_agent:"smapiv2" Http.Put uri in
+ let transport = Xmlrpc_client.transport_of_url dest_url in
+```
+This is where we connect to the NBD server on the destination.
+
+
+```ocaml
+ debug "Searching for data path: %s" dp;
+ let attach_info = Local.DP.attach_info ~dbg:"nbd" ~sr ~vdi ~dp in
+ debug "Got it!";
+```
+
+we need the local `attach_info` to find the local tapdisk so we can send it the connected NBD socket.
+
+```ocaml
+ on_fail := (fun () -> Remote.DATA.MIRROR.receive_cancel ~dbg ~id) :: !on_fail;
+```
+
+This should probably be set directly after the call to `receive_start`
+
+```ocaml
+ let tapdev = match tapdisk_of_attach_info attach_info with
+ | Some tapdev ->
+ debug "Got tapdev";
+ let pid = Tapctl.get_tapdisk_pid tapdev in
+ let path = Printf.sprintf "/var/run/blktap-control/nbdclient%d" pid in
+ with_transport transport (with_http request (fun (response, s) ->
+ debug "Here inside the with_transport";
+ let control_fd = Unix.socket Unix.PF_UNIX Unix.SOCK_STREAM 0 in
+ finally
+ (fun () ->
+ debug "Connecting to path: %s" path;
+ Unix.connect control_fd (Unix.ADDR_UNIX path);
+ let msg = dp in
+ let len = String.length msg in
+ let written = Unixext.send_fd control_fd msg 0 len [] s in
+ debug "Sent fd";
+ if written <> len then begin
+ error "Failed to transfer fd to %s" path;
+ failwith "foo"
+ end)
+ (fun () ->
+ Unix.close control_fd)));
+ tapdev
+ | None ->
+ failwith "Not attached"
+ in
+```
+Here we connect to the remote NBD server, then pass that connected fd to the local tapdisk that is using the disk. This fd is passed with a name that is later used to tell tapdisk to start using it - we use the datapath name for this.
+
+```ocaml
+ debug "Adding to active local mirrors: id=%s" id;
+ let alm = State.Send_state.({
+ url;
+ dest_sr=dest;
+ remote_dp=mirror_dp;
+ local_dp=dp;
+ mirror_vdi=result.Mirror.mirror_vdi.vdi;
+ remote_url=url;
+ tapdev;
+ failed=false;
+ watchdog=None}) in
+ State.add id (State.Send_op alm);
+ debug "Added";
+```
+
+As for copy we persist some state to disk to say that we're doing a mirror so we can undo any state changes after a toolstack restart.
+
+```ocaml
+ debug "About to snapshot VDI = %s" (string_of_vdi_info local_vdi);
+ let local_vdi = add_to_sm_config local_vdi "mirror" ("nbd:" ^ dp) in
+ let local_vdi = add_to_sm_config local_vdi "base_mirror" id in
+ let snapshot =
+ try
+ Local.VDI.snapshot ~dbg ~sr ~vdi_info:local_vdi
+ with
+ | Storage_interface.Backend_error(code, _) when code = "SR_BACKEND_FAILURE_44" ->
+ raise (Api_errors.Server_error(Api_errors.sr_source_space_insufficient, [ sr ]))
+ | e ->
+ raise e
+ in
+ debug "Done!";
+
+ SMPERF.debug "mirror.start: snapshot created, mirror initiated vdi:%s snapshot_of:%s"
+ snapshot.vdi local_vdi.vdi ;
+
+ on_fail := (fun () -> Local.VDI.destroy ~dbg ~sr ~vdi:snapshot.vdi) :: !on_fail;
+```
+
+This bit inserts into `sm_config` the name of the fd we passed earlier to do mirroring. This is interpreted by the python SM backends and passed on the `tap-ctl` invocation to unpause the disk. This causes all new writes to be mirrored via NBD to the file descriptor passed earlier.
+
+
+```ocaml
+ begin
+ let rec inner () =
+ debug "tapdisk watchdog";
+ let alm_opt = State.find_active_local_mirror id in
+ match alm_opt with
+ | Some alm ->
+ let stats = Tapctl.stats (Tapctl.create ()) tapdev in
+ if stats.Tapctl.Stats.nbd_mirror_failed = 1 then
+ Updates.add (Dynamic.Mirror id) updates;
+ alm.State.Send_state.watchdog <- Some (Scheduler.one_shot scheduler (Scheduler.Delta 5) "tapdisk_watchdog" inner)
+ | None -> ()
+ in inner ()
+ end;
+```
+
+This is the watchdog that runs `tap-ctl stats` every 5 seconds watching `mirror_failed` for evidence of a failure in the mirroring code. If it detects one the only thing it does is to notify that the state of the mirroring has changed. This will be picked up by the thread in xapi that is monitoring the state of the mirror. It will then issue a `MIRROR.stat` call which will return the state of the mirror including the information that it has failed.
+
+```ocaml
+ on_fail := (fun () -> stop ~dbg ~id) :: !on_fail;
+ (* Copy the snapshot to the remote *)
+ let new_parent = Storage_task.with_subtask task "copy" (fun () ->
+ copy' ~task ~dbg ~sr ~vdi:snapshot.vdi ~url ~dest ~dest_vdi:result.Mirror.copy_diffs_to) |> vdi_info in
+ debug "Local VDI %s == remote VDI %s" snapshot.vdi new_parent.vdi;
+```
+
+This is where we copy the VDI returned by the snapshot invocation to the remote VDI called `copy_diffs_to`. We only copy deltas, but we rely on `copy'` to figure out which disk the deltas should be taken from, which it does via the `content_id` field.
+
+```ocaml
+ Remote.VDI.compose ~dbg ~sr:dest ~vdi1:result.Mirror.copy_diffs_to ~vdi2:result.Mirror.mirror_vdi.vdi;
+ Remote.VDI.remove_from_sm_config ~dbg ~sr:dest ~vdi:result.Mirror.mirror_vdi.vdi ~key:"base_mirror";
+ debug "Local VDI %s now mirrored to remote VDI: %s" local_vdi.vdi result.Mirror.mirror_vdi.vdi;
+```
+
+Once the copy has finished we invoke the `compose` SMAPIv2 call that composes the diffs from the mirror with the base image copied from the snapshot.
+
+```ocaml
+ debug "Destroying dummy VDI %s on remote" result.Mirror.dummy_vdi;
+ Remote.VDI.destroy ~dbg ~sr:dest ~vdi:result.Mirror.dummy_vdi;
+ debug "Destroying snapshot %s on src" snapshot.vdi;
+ Local.VDI.destroy ~dbg ~sr ~vdi:snapshot.vdi;
+
+ Some (Mirror_id id)
+```
+
+we can now destroy the dummy vdi on the remote (which will cause a leaf-coalesce in due course), and we destroy the local snapshot here (which will also cause a leaf-coalesce in due course, providing we don't destroy it first). The return value from the function is the mirror_id that we can use to monitor the state or cancel the mirror.
+
+```ocaml
+ with
+ | Sr_not_attached(sr_uuid) ->
+ error " Caught exception %s:%s. Performing cleanup." Api_errors.sr_not_attached sr_uuid;
+ perform_cleanup_actions !on_fail;
+ raise (Api_errors.Server_error(Api_errors.sr_not_attached,[sr_uuid]))
+ | e ->
+ error "Caught %s: performing cleanup actions" (Api_errors.to_string e);
+ perform_cleanup_actions !on_fail;
+ raise e
+```
+
+The exception handler just cleans up afterwards.
+
+This is not the end of the story, since we need to detach the remote datapath being used for mirroring when we detach this end. The hook function is in [storage_migrate.ml](https://github.com/xapi-project/xen-api/blob/master/ocaml/xapi/storage_migrate.ml#L775-L791):
+
+```ocaml
+let post_detach_hook ~sr ~vdi ~dp =
+ let open State.Send_state in
+ let id = State.mirror_id_of (sr,vdi) in
+ State.find_active_local_mirror id |>
+ Opt.iter (fun r ->
+ let remote_url = Http.Url.of_string r.url in
+ let module Remote = Client(struct let rpc = rpc ~srcstr:"smapiv2" ~dststr:"dst_smapiv2" remote_url end) in
+ let t = Thread.create (fun () ->
+ debug "Calling receive_finalize";
+ log_and_ignore_exn
+ (fun () -> Remote.DATA.MIRROR.receive_finalize ~dbg:"Mirror-cleanup" ~id);
+ debug "Finished calling receive_finalize";
+ State.remove_local_mirror id;
+ debug "Removed active local mirror: %s" id
+ ) () in
+ Opt.iter (fun id -> Scheduler.cancel scheduler id) r.watchdog;
+ debug "Created thread %d to call receive finalize and dp destroy" (Thread.id t))
+```
+
+This removes the persistent state and calls `receive_finalize` on the destination. The body of that functions is:
+
+```ocaml
+let receive_finalize ~dbg ~id =
+ let recv_state = State.find_active_receive_mirror id in
+ let open State.Receive_state in Opt.iter (fun r -> Local.DP.destroy ~dbg ~dp:r.leaf_dp ~allow_leak:false) recv_state;
+ State.remove_receive_mirror id
+```
+
+which removes the persistent state on the destination and destroys the datapath associated with the mirror.
+
+Additionally, there is also a pre-deactivate hook. The rationale for this is that we want to detect any failures to write that occur right at the end of the SXM process. So if there is a mirror operation going on, before we deactivate we wait for tapdisk to flush its queue of outstanding requests, then we query whether there has been a mirror failure. The code is just above the detach hook in [storage_migrate.ml](https://github.com/xapi-project/xen-api/blob/master/ocaml/xapi/storage_migrate.ml#L738-L773):
+
+```ocaml
+let pre_deactivate_hook ~dbg ~dp ~sr ~vdi =
+ let open State.Send_state in
+ let id = State.mirror_id_of (sr,vdi) in
+ let start = Mtime_clock.counter () in
+ let get_delta () = Mtime_clock.count start |> Mtime.Span.to_s in
+ State.find_active_local_mirror id |>
+ Opt.iter (fun s ->
+ try
+ (* We used to pause here and then check the nbd_mirror_failed key. Now, we poll
+ until the number of outstanding requests has gone to zero, then check the
+ status. This avoids confusing the backend (CA-128460) *)
+ let open Tapctl in
+ let ctx = create () in
+ let rec wait () =
+ if get_delta () > reqs_outstanding_timeout then raise Timeout;
+ let st = stats ctx s.tapdev in
+ if st.Stats.reqs_outstanding > 0
+ then (Thread.delay 1.0; wait ())
+ else st
+ in
+ let st = wait () in
+ debug "Got final stats after waiting %f seconds" (get_delta ());
+ if st.Stats.nbd_mirror_failed = 1
+ then begin
+ error "tapdisk reports mirroring failed";
+ s.failed <- true
+ end;
+ with
+ | Timeout ->
+ error "Timeout out after %f seconds waiting for tapdisk to complete all outstanding requests" (get_delta ());
+ s.failed <- true
+ | e ->
+ error "Caught exception while finally checking mirror state: %s"
+ (Printexc.to_string e);
+ s.failed <- true
+ )
+```
diff --git a/doc/content/xcp-rrdd/_index.md b/doc/content/xcp-rrdd/_index.md
new file mode 100644
index 00000000000..bb09e7f0c29
--- /dev/null
+++ b/doc/content/xcp-rrdd/_index.md
@@ -0,0 +1,9 @@
++++
+title = "RRDD"
++++
+
+The `xcp-rrdd` daemon (hereafter simply called “rrdd”) is a component in the
+xapi toolstack that is responsible for collecting metrics, storing them as
+"Round-Robin Databases" (RRDs) and exposing these to clients.
+
+The code is in ocaml/xcp-rrdd.
\ No newline at end of file
diff --git a/doc/content/xcp-rrdd/design/plugin-protocol-v2.md b/doc/content/xcp-rrdd/design/plugin-protocol-v2.md
new file mode 100644
index 00000000000..c8581a2aad3
--- /dev/null
+++ b/doc/content/xcp-rrdd/design/plugin-protocol-v2.md
@@ -0,0 +1,162 @@
+---
+title: RRDD plugin protocol v2
+design_doc: true
+revision: 1
+status: released (7.0)
+revision_history:
+- revision_number: 1
+ description: Initial version
+---
+
+Motivation
+----------
+
+rrdd plugins currently report datasources via a shared-memory file, using the
+following format:
+
+```
+DATASOURCES
+000001e4
+dba4bf7a84b6d11d565d19ef91f7906e
+{
+ "timestamp": 1339685573,
+ "data_sources": {
+ "cpu-temp-cpu0": {
+ "description": "Temperature of CPU 0",
+ "type": "absolute",
+ "units": "degC",
+ "value": "64.33"
+ "value_type": "float",
+ },
+ "cpu-temp-cpu1": {
+ "description": "Temperature of CPU 1",
+ "type": "absolute",
+ "units": "degC",
+ "value": "62.14"
+ "value_type": "float",
+ }
+ }
+}
+```
+
+This format contains four main components:
+
+* A constant header string
+
+`DATASOURCES`
+
+This should always be present.
+
+* The JSON data length, encoded as hexadecimal
+
+`000001e4`
+
+* The md5sum of the JSON data
+
+`dba4bf7a84b6d11d565d19ef91f7906e`
+
+* The JSON data itself, encoding the values and metadata associated with the
+reported datasources.
+
+```
+{
+ "timestamp": 1339685573,
+ "data_sources": {
+ "cpu-temp-cpu0": {
+ "description": "Temperature of CPU 0",
+ "type": "absolute",
+ "units": "degC",
+ "value": "64.33"
+ "value_type": "float",
+ },
+ "cpu-temp-cpu1": {
+ "description": "Temperature of CPU 1",
+ "type": "absolute",
+ "units": "degC",
+ "value": "62.14"
+ "value_type": "float",
+ }
+ }
+}
+```
+
+The disadvantage of this protocol is that rrdd has to parse the entire JSON
+structure each tick, even though most of the time only the values will change.
+
+For this reason a new protocol is proposed.
+
+Protocol V2
+-----------
+
+|value|bits|format|notes|
+|-----|----|------|-----|
+|header string |(string length)*8|string|"Datasources" as in the V1 protocol |
+|data checksum |32 |int32 |binary-encoded crc32 of the concatenation of the encoded timestamp and datasource values|
+|metadata checksum |32 |int32 |binary-encoded crc32 of the metadata string (see below) |
+|number of datasources|32 |int32 |only needed if the metadata has changed - otherwise RRDD can use a cached value |
+|timestamp |64 |int64 |Unix epoch |
+|datasource values |n * 64 |int64 |n is the number of datasources exported by the plugin |
+|metadata length |32 |int32 | |
+|metadata |(string length)*8|string| |
+
+All integers are bigendian. The metadata will have the same JSON-based format as
+in the V1 protocol, minus the timestamp and `value` key-value pair for each
+datasource, for example:
+
+```
+{
+ "datasources": {
+ "memory_reclaimed": {
+ "description":"Host memory reclaimed by squeezed",
+ "owner":"host",
+ "value_type":"int64",
+ "type":"absolute",
+ "default":"true",
+ "units":"B",
+ "min":"-inf",
+ "max":"inf"
+ },
+ "memory_reclaimed_max": {
+ "description":"Host memory that could be reclaimed by squeezed",
+ "owner":"host",
+ "value_type":"int64",
+ "type":"absolute",
+ "default":"true",
+ "units":"B",
+ "min":"-inf",
+ "max":"inf"
+ }
+ }
+}
+```
+
+The above formatting is not required, but added here for readability.
+
+Reading algorithm
+-----------------
+
+```
+if header != expected_header:
+ raise InvalidHeader()
+if data_checksum == last_data_checksum:
+ raise NoUpdate()
+if data_checksum != md5sum(encoded_timestamp_and_values):
+ raise InvalidChecksum()
+if metadata_checksum == last_metadata_checksum:
+ for datasource, value in cached_datasources, values:
+ update(datasource, value)
+else:
+ if metadata_checksum != md5sum(metadata):
+ raise InvalidChecksum()
+ cached_datasources = create_datasources(metadata)
+ for datasource, value in cached_datasources, values:
+ update(datasource, value)
+```
+
+This means that for a normal update, RRDD will only have to read the header plus
+the first (16 + 16 + 4 + 8 + 8*n) bytes of data, where n is the number of
+datasources exported by the plugin. If the metadata changes RRDD will have to
+read all the data (and parse the metadata).
+
+n.b. the timestamp reported by plugins is not currently used by RRDD - it uses
+its own global timestamp.
diff --git a/doc/content/xcp-rrdd/futures/archival-redesign.md b/doc/content/xcp-rrdd/futures/archival-redesign.md
new file mode 100644
index 00000000000..a05c6280ef8
--- /dev/null
+++ b/doc/content/xcp-rrdd/futures/archival-redesign.md
@@ -0,0 +1,94 @@
+---
+title: RRDD archival redesign
+design_doc: true
+revision: 1
+status: released (7,0)
+---
+
+## Introduction
+
+Current problems with rrdd:
+
+* rrdd stores knowledge about whether it is running on a master or a slave
+
+This determines the host to which rrdd will archive a VM's rrd when the VM's
+domain disappears - rrdd will always try to archive to the master. However,
+when a host joins a pool as a slave rrdd is not restarted so this knowledge is
+out of date. When a VM shuts down on the slave rrdd will archive the rrd
+locally. When starting this VM again the master xapi will attempt to push any
+locally-existing rrd to the host on which the VM is being started, but since
+no rrd archive exists on the master the slave rrdd will end up creating a new
+rrd and the previous rrd will be lost.
+
+* rrdd handles rebooting VMs unpredictably
+
+When rebooting a VM, there is a chance rrdd will attempt to update that VM's rrd
+during the brief period when there is no domain for that VM. If this happens,
+rrdd will archive the VM's rrd to the master, and then create a new rrd for the
+VM when it sees the new domain. If rrdd doesn't attempt to update that VM's rrd
+during this period, rrdd will continue to add data for the new domain to the old
+rrd.
+
+## Proposal
+
+To solve these problems, we will remove some of the intelligence from rrdd and
+make it into more of a slave process of xapi. This will entail removing all
+knowledge from rrdd of whether it is running on a master or a slave, and also
+modifying rrdd to only start monitoring a VM when it is told to, and only
+archiving an rrd (to a specified address) when it is told to. This matches the
+way xenopsd only manages domains which it has been told to manage.
+
+## Design
+
+For most VM lifecycle operations, xapi and rrdd processes (sometimes across more
+than one host) cooperate to start or stop recording a VM's metrics and/or to
+restore or backup the VM's archived metrics. Below we will describe, for each
+relevant VM operation, how the VM's rrd is currently handled, and how we propose
+it will be handled after the redesign.
+
+#### VM.destroy
+
+The master xapi makes a remove_rrd call to the local rrdd, which causes rrdd to
+to delete the VM's archived rrd from disk. This behaviour will remain unchanged.
+
+#### VM.start(\_on) and VM.resume(\_on)
+
+The master xapi makes a push_rrd call to the local rrdd, which causes rrdd to
+send any locally-archived rrd for the VM in question to the rrdd of the host on
+which the VM is starting. This behaviour will remain unchanged.
+
+#### VM.shutdown and VM.suspend
+
+Every update cycle rrdd compares its list of registered VMs to the list of
+domains actually running on the host. Any registered VMs which do not have a
+corresponding domain have their rrds archived to the rrdd running on the host
+believed to be the master. We will change this behaviour by stopping rrdd from
+doing the archiving itself; instead we will expose a new function in rrdd's
+interface:
+
+```
+val archive_rrd : vm_uuid:string -> remote_address:string -> unit
+```
+
+This will cause rrdd to remove the specified rrd from its table of registered
+VMs, and archive the rrd to the specified host. When a VM has finished shutting
+down or suspending, the xapi process on the host on which the VM was running
+will call archive_rrd to ask the local rrdd to archive back to the master rrdd.
+
+#### VM.reboot
+
+Removing rrdd's ability to automatically archive the rrds for disappeared
+domains will have the bonus effect of fixing how the rrds of rebooting VMs are
+handled, as we don't want the rrds of rebooting VMs to be archived at all.
+
+#### VM.checkpoint
+
+This will be handled automatically, as internally VM.checkpoint carries out a
+VM.suspend followed by a VM.resume.
+
+#### VM.pool_migrate and VM.migrate_send
+
+The source host's xapi makes a migrate_rrd call to the local rrd, with a
+destination address and an optional session ID. The session ID is only required
+for cross-pool migration. The local rrdd sends the rrd for that VM to the
+destination host's rrdd as an HTTP PUT. This behaviour will remain unchanged.
diff --git a/doc/content/xcp-rrdd/futures/sr-level-rrds.md b/doc/content/xcp-rrdd/futures/sr-level-rrds.md
new file mode 100644
index 00000000000..b6e84c9cd3f
--- /dev/null
+++ b/doc/content/xcp-rrdd/futures/sr-level-rrds.md
@@ -0,0 +1,146 @@
+---
+title: SR-Level RRDs
+design_doc: true
+revision: 11
+status: confirmed
+design_review: 139
+revision_history:
+- revision_number: 1
+ description: Initial version
+- revision_number: 2
+ description: Added details about the VDI's binary format and size, and the SR capability name.
+- revision_number: 3
+ description: Tar was not needed after all!
+- revision_number: 4
+ description: Add details about discovering the VDI using a new vdi_type.
+- revision_number: 5
+ description: Add details about the http handlers and interaction with xapi's database
+- revision_number: 6
+ description: Add details about the framing of the data within the VDI
+- revision_number: 7
+ description: Redesign semantics of the rrd_updates handler
+- revision_number: 8
+ description: Redesign semantics of the rrd_updates handler (again)
+- revision_number: 9
+ description: Magic number change in framing format of vdi
+- revision_number: 10
+ description: Add details of new APIs added to xapi and xcp-rrdd
+- revision_number: 11
+ description: Remove unneeded API calls
+
+---
+
+## Introduction
+
+Xapi has RRDs to track VM- and host-level metrics. There is a desire to have SR-level RRDs as a new category, because SR stats are not specific to a certain VM or host. Examples are size and free space on the SR. While recording SR metrics is relatively straightforward within the current RRD system, the main question is where to archive them, which is what this design aims to address.
+
+## Stats Collection
+
+All SR types, including the existing ones, should be able to have RRDs defined for them. Some RRDs, such as a "free space" one, may make sense for multiple (if not all) SR types. However, the way to measure something like free space will be SR specific. Furthermore, it should be possible for each type of SR to have its own specialised RRDs.
+
+It follows that each SR will need its own `xcp-rrdd` plugin, which runs on the SR master and defines and collects the stats. For the new thin-lvhd SR this could be `xenvmd` itself. The plugin registers itself with `xcp-rrdd`, so that the latter records the live stats from the plugin into RRDs.
+
+## Archiving
+
+SR-level RRDs will be archived in the SR itself, in a VDI, rather than in the local filesystem of the SR master. This way, we don't need to worry about master failover.
+
+The VDI will be 4MB in size. This is a little more space than we would need for the RRDs we have in mind at the moment, but will give us enough headroom for the foreseeable future. It will not have a filesystem on it for simplicity and performance. There will only be one RRD archive file for each SR (possibly containing data for multiple metrics), which is gzipped by `xcp-rrdd`, and can be copied onto the VDI.
+
+There will be a simple framing format for the data on the VDI. This will be as follows:
+
+Offset | Type | Name | Comment
+-------|--------------------------|---------|--------------------------
+0 | 32 bit network-order int | magic | Magic number = 0x7ada7ada
+4 | 32 bit network-order int | version | 1
+8 | 32 bit network-order int | length | length of payload
+12 | gzipped data | data |
+
+Xapi will be in charge of the lifecycle of this VDI, not the plugin or `xcp-rrdd`, which will make it a little easier to manage them. Only xapi will attach/detach and read from/write to this VDI. We will keep `xcp-rrdd` as simple as possible, and have it archive to its standard path in the local file system. Xapi will then copy the RRDs in and out of the VDI.
+
+A new value `"rrd"` in the `vdi_type` enum of the datamodel will be defined, and the `VDI.type` of the VDI will be set to that value. The storage backend will write the VDI type to the LVM metadata of the VDI, so that xapi can discover the VDI containing the SR-level RRDs when attaching an SR to a new pool. This means that SR-level RRDs are currently restricted to LVM SRs.
+
+Because we will not write plugins for all SRs at once, and therefore do not need xapi to set up the VDI for all SRs, we will add an SR "capability" for the backends to be able to tell xapi whether it has the ability to record stats and will need storage for them. The capability name will be: `SR_STATS`.
+
+## Management of the SR-stats VDI
+
+The SR-stats VDI will be attached/detached on `PBD.plug`/`unplug` on the SR master.
+
+* On `PBD.plug` on the SR master, if the SR has the stats capability, xapi:
+ * Creates a stats VDI if not already there (search for an existing one based on the VDI type).
+ * Attaches the stats VDI if it did already exist, and copies the RRDs to the local file system (standard location in the filesystem; asks `xcp-rrdd` where to put them).
+ * Informs `xcp-rrdd` about the RRDs so that it will load the RRDs and add newly recorded data to them (needs a function like `push_rrd_local` for VM-level RRDs).
+ * Detaches stats VDI.
+
+* On `PBD.unplug` on the SR master, if the SR has the stats capability xapi:
+ * Tells `xcp-rrdd` to archive the RRDs for the SR, which it will do to the local filesystem.
+ * Attaches the stats VDI, copies the RRDs into it, detaches VDI.
+
+## Periodic Archiving
+
+Xapi's periodic scheduler regularly triggers `xcp-rrdd` to archive the host and VM RRDs. It will need to do this for the SR ones as well. Furthermore, xapi will need to attach the stats VDI and copy the RRD archives into it (as on `PBD.unplug`).
+
+## Exporting
+
+There will be a new handler for downloading an SR RRD:
+
+ http:///sr_rrd?session_id=&uuid=
+
+RRD updates are handled via a single handler for the host, VM and SR UUIDs
+RRD updates for the host, VMs and SRs are handled by a a single handler at
+`/rrd_updates`. Exactly what is returned will be determined by the parameters
+passed to this handler.
+
+Whether the host RRD updates are returned is governed by the presence of
+`host=true` in the parameters. `host=` or the absence of the
+`host` key will mean the host RRD is not returned.
+
+Whether the VM RRD updates are returned is governed by the `vm_uuid` key in the
+URL parameters. `vm_uuid=all` will return RRD updates for all VM RRDs.
+`vm_uuid=xxx` will return the RRD updates for the VM with uuid `xxx` only.
+If `vm_uuid` is `none` (or any other string which is not a valid VM UUID) then
+the handler will return no VM RRD updates. If the `vm_uuid` key is absent, RRD
+updates for all VMs will be returned.
+
+Whether the SR RRD updates are returned is governed by the `sr_uuid` key in the
+URL parameters. `sr_uuid=all` will return RRD updates for all SR RRDs.
+`sr_uuid=xxx` will return the RRD updates for the SR with uuid `xxx` only.
+If `sr_uuid` is `none` (or any other string which is not a valid SR UUID) then
+the handler will return no SR RRD updates. If the `sr_uuid` key is absent, no
+SR RRD updates will be returned.
+
+It will be possible to mix and match these parameters; for example to return
+RRD updates for the host and all VMs, the URL to use would be:
+
+ http:///rrd_updates?session_id=&start=10258122541&host=true&vm_uuid=all&sr_uuid=none
+
+Or, to return RRD updates for all SRs but nothing else, the URL to use would be:
+
+ http:///rrd_updates?session_id=&start=10258122541&host=false&vm_uuid=none&sr_uuid=all
+
+While behaviour is defined if any of the keys `host`, `vm_uuid` and `sr_uuid` is
+missing, this is for backwards compatibility and it is recommended that clients
+specify each parameter explicitly.
+
+## Database updating.
+
+If the SR is presenting a data source called 'physical_utilisation',
+xapi will record this periodically in its database. In order to do
+this, xapi will fork a thread that, every n minutes (2 suggested, but
+open to suggestions here), will query the attached SRs, then query
+RRDD for the latest data source for these, and update the database.
+
+The utilisation of VDIs will _not_ be updated in this way until
+scalability worries for RRDs are addressed.
+
+Xapi will cache whether it is SR master for every attached SR and only
+attempt to update if it is the SR master.
+
+## New APIs.
+
+#### xcp-rrdd:
+
+* Get the filesystem location where sr rrds are archived: `val sr_rrds_path : uid:string -> string`
+
+* Archive the sr rrds to the filesystem: `val archive_sr_rrd : sr_uuid:string -> unit`
+
+* Load the sr rrds from the filesystem: `val push_sr_rrd : sr_uuid:string -> unit`
diff --git a/ocaml/squeezed/doc/Makefile b/ocaml/squeezed/doc/Makefile
deleted file mode 100644
index 827fd9740a7..00000000000
--- a/ocaml/squeezed/doc/Makefile
+++ /dev/null
@@ -1,4 +0,0 @@
-default:
- pdflatex main.tex
- pdflatex main.tex
-
diff --git a/ocaml/squeezed/doc/README.md b/ocaml/squeezed/doc/README.md
deleted file mode 100644
index 7371a4d61b8..00000000000
--- a/ocaml/squeezed/doc/README.md
+++ /dev/null
@@ -1,21 +0,0 @@
-Squeezed: the developer handbook
-===============================
-
-Squeezed is the [xapi-project](http://github.com/xapi-project) host
-memory manager (aka balloon driver driver). Squeezed uses ballooning
-to move memory between running VMs, to avoid wasting host memory.
-
-Principles
-----------
-
-1. avoid wasting host memory: unused memory should be put to use by returning
- it to VMs
-2. memory should be shared in proportion to the configured policy
-3. operate entirely at the level of domains (not VMs), and be independent of
- Xen toolstack
-
-Contents
---------
-- [Architecture](architecture/README.md): a high-level overview of Squeezed.
-- [Design](design/README.md): discover the low-level details, formats, protocols,
- concurrency etc.
diff --git a/ocaml/squeezed/doc/architecture/README.md b/ocaml/squeezed/doc/architecture/README.md
deleted file mode 100644
index 16d3995f2e2..00000000000
--- a/ocaml/squeezed/doc/architecture/README.md
+++ /dev/null
@@ -1,36 +0,0 @@
-Squeezed architecture
-=====================
-
-Squeezed is responsible for managing the memory on a single host. Squeezed
-"balances" memory between VMs according to a policy written to Xenstore.
-
-The following diagram shows the internals of Squeezed:
-
-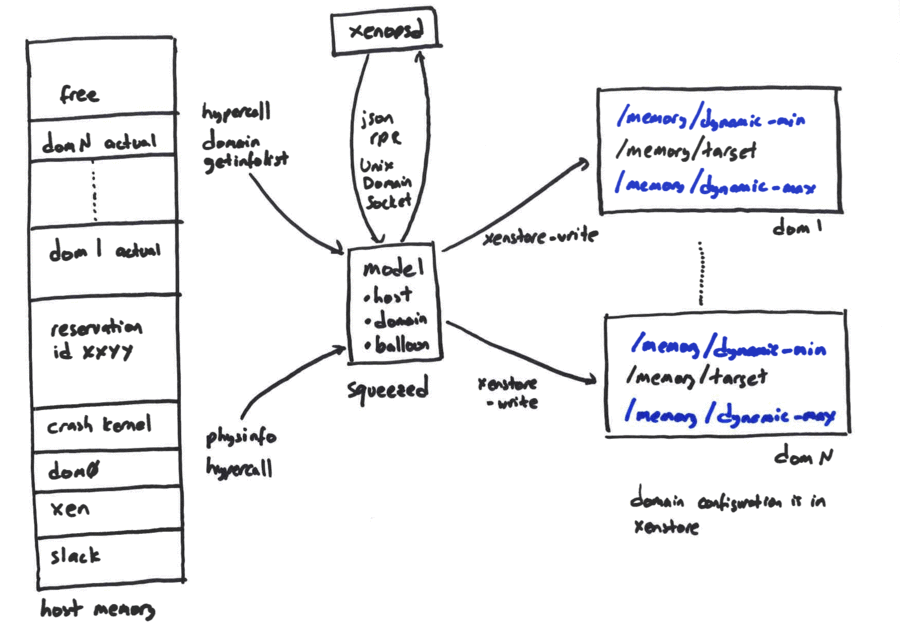
-
-At the center of squeezed is an abstract model of a Xen host. The model includes
-- the amount of already-used host memory (used by fixed overheads such as Xen
- and the crash kernel)
-- per-domain memory policy specifically ```dynamic-min``` and ```dynamic-max``` which
- together describe a range, within which the domain's actual used memory should remain
-- per-domain calibration data which allows us to compute the necessary balloon target
- value to achive a particular memory usage value.
-
-Squeezed is a single-threaded program which receives commands from
-[Xenopsd](https://github.com/xapi-project/xenopsd) over a Unix domain socket.
-When Xenopsd wishes to start a new VM, squeezed will be asked to create a "reservation".
-Note this is different to the Xen notion of a reservation. A squeezed reservation consists
-of an amount of memory squeezed will guarantee to keep free labelled with an id.
-When Xenopsd later creates the domain to notionally use the reservation, the reservation
-is "transferred" to the domain before the domain is built.
-
-Squeezed will also wake up every 30s and attempt to rebalance the memory on a host. This
-is useful to correct imbalances caused by balloon drivers temporarily failing to reach
-their targets. Note that ballooning is fundamentally a co-operative process, so squeezed
-must handle cases where the domains refuse to obey commands.
-
-The "output" of squeezed is a list of "actions" which include:
-- set domain x's ```memory/target``` to a new value
-- set the ```maxmem``` of a domain to a new value (as a hard limit beyond which the domain
- cannot allocate)
-
diff --git a/ocaml/squeezed/doc/squeezer.tex b/ocaml/squeezed/doc/squeezer.tex
deleted file mode 100644
index 9a1dec43d63..00000000000
--- a/ocaml/squeezed/doc/squeezer.tex
+++ /dev/null
@@ -1,212 +0,0 @@
-\chapter{Overview of the memory squeezer}
-\section{summary}
-\begin{itemize}
-\item ballooning is a per-domain operation; not a per-VM operation. A VM may be represented by multiple domains
- (currently localhost migrate, in the future stubdomains)
-\item most free host memory is divided up between running domains proportionally, so they all end up with the same
- value of {\tt ratio}
-\end{itemize}
-
-\begin{verbatim}
- where ratio(domain) =
- if domain.dynamic_max - domain.dynamic_min = 0
- then 0
- else (domain.target - domain.dynamic_min)
- / (domain.dynamic_max - domain.dynamic_min)
-\end{verbatim}
-
-\section{Assumptions}
-\begin{itemize}
-\item all memory values are stored and processed in units of KiB
-\item the squeezing algorithm doesn't know about host or VM overheads but this doesn't matter because
-\item the squeezer assumes that any free host memory can be allocated to running domains and this will be directly reflected in their memory\_actual i.e. if x KiB is free on the host we can tell a guest to use x KiB and see the host memory goes to 0 and the guest's memory\_actual increase by x KiB. We assume that no-extra 'overhead' is required in this operation (all overheads are functions of static\_max only)
-\end{itemize}
-
-\section{Definitions}
-
-\begin{itemize}
-\item domain: an object representing a xen domain
-\item domain.domid: unique identifier of the domain on the host
-\item domaininfo(domain): a function which returns live per-domain information from xen (in real-life a hypercall)
-\item a domain is said to "have never run" if never\_been\_run(domain)
-\begin{verbatim}
- where never_been_run(domain) = domaininfo(domain).paused
- and not domaininfo(domain).shutdown
- and domaininfo(domain).cpu_time = 0
-\end{verbatim}
-\item xenstore-read(path): a function which returns the value associated with 'path' in xenstore
-\item domain.initial\_reservation: used to associate freshly freed memory with a new domain which is being built or restored
-\begin{verbatim}
- domain.initial_reservation =
- xenstore-read(/local/domain//memory/initial-reservation)
-\end{verbatim}
-\item domain.target: represents what we think the balloon target currently is
-\begin{verbatim}
- domain.target =
- if never_been_run(domain)
- then xenstore-read(/local/domain//memory/target)
- else domain.initial_reservation
-\end{verbatim}
-\item domain.dynamic\_min: represents what we think the dynamic\_min currently is
-\begin{verbatim}
- domain.dynamic_min =
- if never_been_run(domain)
- then xenstore-read(/local/domain//memory/dynamic_min)
- else domain.initial_reservation
-\end{verbatim}
-\item domain.dynamic\_max: represents what we think the dynamic\_max currently is
-\begin{verbatim}
- domain.dynamic_max =
- if never_been_run(domain)
- then xenstore-read(/local/domain//memory/dynamic_max)
- else domain.initial_reservation
-\end{verbatim}
-\item domain.memory\_actual: represents the memory we think the guest is using (doesn't take overheads like shadow into account)
-\begin{verbatim}
- domain.memory_actual =
- if never_been_run(domain)
- max domaininfo(domain).total_memory_pages domain.initial_reservation
- else domaininfo(domain).total_memory_pages
-\end{verbatim}
-\item domain.memory\_actual\_last\_update\_time: time when we saw the last change in memory\_actual
-\item domain.unaccounted\_for: a fresh domain has memory reserved for it but xen doesn't know about it. We subtract this from the host memory xen thinks is free.
-\begin{verbatim}
- domain.unaccounted_for =
- if never_been_run(domain)
- then max 0 (domain.initial_reservation - domaininfo(domain).total_memory_pages)
-\end{verbatim}
-\item domain.max\_mem: an upper-limit on the amount of memory a domain can allocate. Initially static\_max.
-\begin{verbatim}
- domain.max_mem = domaininfo(domain).max_mem
-\end{verbatim}
-\item assume\_balloon\_driver\_stuck\_after: a constant number of seconds after which we conclude that the balloon driver has stopped working
-\begin{verbatim}
- assume_balloon_driver_stuck_after = 2
-\end{verbatim}
-\item domain.active: a boolean value which is true when we think the balloon driver is functioning
-\begin{verbatim}
- domain.active = has_hit_target(domain)
- or (now - domain.memory_actual_last_update_time)
- > assume_balloon_driver_stuck_after
-\end{verbatim}
-\item a domain is said to "have hit its target" if has\_hit\_target(domain)
-\begin{verbatim}
- where has_hit_target(domain) = floor(memory_actual / 4) = floor(target / 4)
-\end{verbatim}
- NB this definition might have to be loosened if it turns out that some drivers are less accurate than this.
-\item a domain is said to "be capable of ballooning" if can\_balloon(domain)
- where can\_balloon(domain) = not domaininfo(domain).paused
-
-
-\item host: an object representing a XenServer host
-\item host.domains: a list of domains present on the host
-\item physinfo(host): a function which returns live per-host information from xen (in real-life a hypercall)
-\item host.free\_mem: amount of memory we consider to be free on the host
-\begin{verbatim}
- host.free_mem = physinfo(host).free_pages + physinfo(host).scrub_pages
- - \sigma d\in host.domains. d.unaccounted_for
-\end{verbatim}
-\end{itemize}
-
-\section{Squeezer APIs}
-The squeezer has 2 APIs:
-\begin{enumerate}
-\item allocate-memory-for-domain(host, domain, amount): frees "amount" and "reserves" (as best it can) it for a particular domain
-\item rebalance-memory: called after e.g. domain destruction to rebalance memory between the running domains
-\end{enumerate}
-
-allocate-memory-for-domain keeps contains the main loop which performs the actual target and max\_mem adjustments:
-\begin{verbatim}
-function allocate-memory-for-domain(host, domain, amount):
- \forall d\in host.domains. d.max_mem <- d.target
- while true do
- -- call change-host-free-memory with a "success condition" set to
- -- "when the host memory is >= amount"
- declared_active, declared_inactive, result =
- change-host-free-memory(host, amount, \lambda m >= amount)
- if result == Success:
- domain.initial_reservation <- amount
- return Success
- elif result == DynamicMinsTooHigh:
- return DynamicMinsTooHigh
- elif result == DomainsRefusedToCooperate:
- return DomainsRefusedToCooperate
- elif result == AdjustTargets(adjustments):
- \forall (domain, target)\in adjustments:
- domain.max_mem <- target
- domain.target <- target
-
- \forall d\in declared_inactive:
- domain.max_mem <- min domain.target domain.memory_actual
- \forall d\in declared_active:
- domain.max_mem <- domain.target
- done
-\end{verbatim}
-The helper function change-host-free-memory(host, amount) does the "thinking":
-\begin{enumerate}
-\item it keeps track of whether domains are active or inactive (only for the duration of the squeezer API call -- when the next
- call comes in we assume that all domains are active and capable of ballooning... a kind of "innocent until proven guilty" approaxh)
-\item it computes what the balloon targets should be
-\end{enumerate}
-
-\begin{verbatim}
-function change-host-free-memory(host, amount, success_condition):
- \forall d\in host.domains. recalculate domain.active
- active_domains <- d\in host.domains where d.active = true
- inactive_domains <- d\in host.domains where d.active = false
- -- since the last time we were called compute the lists of domains
- -- which have become active and inactive
- declared_active, declared_inactive <- ...
- -- compute how much memory we could free or allocate given only the
- -- active domains
- maximum_freeable_memory =
- sum(d\in active_domains)(d.memory_actual - d.dynamic_min)
- maximum_allocatable_memory =
- sum(d\in active_domains)(d.dynamic_max - d.memory_actual)
- -- hypothetically consider freeing the maximum memory possible.
- -- How much would we have to give back after we've taken as much as we want?
- give_back = max 0 (maximum_freeable_memory - amount)
- -- compute a list of target changes to 'give this memory back' to active_domains
- -- NB this code is careful to allocate *all* memory, not just most
- -- of it because of a rounding error.
- adjustments = ...
- -- decide whether every VM has reached its target (a good thing)
- all_targets_reached = true if \forall d\in active_domains.has_hit_target(d)
-
- -- If we're happy with the amount of free memory we've got and the active
- -- guests have finished ballooning
- if success_condition host.free_mem = true
- and all_targets_reached and adjustments = []
- then return declared_active, declared_inactive, Success
-
- -- If we're happy with the amount of free memory and the running domains
- -- can't absorb any more of the surplus
- if host.free_mem >= amount and host.free_mem - maximum_allocatable_memory = 0
- then return declared_active, declared_inactive, Success
-
- -- If the target is too aggressive because of some non-active domains
- if maximum_freeable_memory < amount and inactive_domains <> []
- then return declared_active, declared_inactive,
- DomainsRefusedToCooperate inactive_domains
-
- -- If the target is too aggressive not because of the domains themselves
- -- but because of the dynamic_mins
- return declared_active, declared_inactive, DynamicMinsTooHigh
-\end{verbatim}
-
-The API rebalance-memory aims to use up as much host memory as possible EXCEPT it is necessary to keep some around
-for xen to use to create empty domains with.
-
-\begin{verbatim}
-Currently we have:
- -- 10 MiB
- target_host_free_mem = 10204
- -- it's not always possible to allocate everything so a bit of slop has
- -- been added here:
- free_mem_tolerance = 1024
-
-function rebalance-memory(host):
- change-host-free-memory(host, target_host_free_mem,
- \lambda m. m - target_host_free_mem < free_mem_tolerance)
- -- and then wait for the xen page scrubber
-\end{verbatim}