
These tutorials showcase how GPDB can address day-to-day tasks performed in typical DW/BI environments. It is designed to be used with the Greenplum Database Sandbox VM that is available for download from the Pivotal Network. Both a Virtual Box, and a VMware version are available. The Virtual Box VM is in OVA format and can be IMPORTED into Virtual Box, while the VMware VM is a ZIP file that can be opened directly.
-
4.3.6.1 Greenplum Database Sandbox Virtual Machines
Note: These VMs contain the commercially supported versions of Greenplum Database and Greenplum Command Center
The scripts/data for this tutorial are in the gpdb-sandbox virtual machine at /home/gpadmin. The repository is pre-cloned, but will update as the VM boots in order to provide the most recent version of these instructions.
- Import the GPDB Sandbox Virtual Machine into VMware Fusion or Virutal Box.
- Start the GPDB Sandbox Virtual Machine. Once the machine starts, you will see the following screen
 This screen provides you all the information you need to interact with the VM.
This screen provides you all the information you need to interact with the VM.
- Username/Password combinations
- Managment URLs
- IP address for SSH Connection
Interacting with the Sandbox via a new terminal is preferable, as it makes many of the operations simpler.
To introduce Greenplum Database, we use a public data set, the Airline On-Time Statistics and Delay Causes data set, published by the United States Department of Transportation at http://www.transtats.bts.gov/. The On-Time Performance dataset records flights by date, airline, originating airport, destination airport, and many other flight details. Data is available for flights since 1987. The exercises in this guide use data for about a million flights in 2009 and 2010. The FAA uses the data to calculate statistics such as the percent of flights that depart or arrive on time by origin, destination, and airline.
You are encouraged to review the SQL scripts in the faa directory as you work through this introduction. You can run most of the exercises by entering the commands yourself or by executing a script in the faa directory.
- Introduction to the Greenplum Database Architecture
- Lesson 1: Create Users and Roles
- Lesson 2: Create and Prepare Database
- Lesson 3: Create Tables
- Lesson 4: Data Loading
- Lesson 5: Queries and Performance Tuning
- Lesson 6: Introduction to Greenplum In-Database Analytics
Pivotal Greenplum Database is a massively parallel processing (MPP) database server with an architecture specially designed to manage large-scale analytic data warehouses and business intelligence workloads.
MPP (also known as a shared nothing architecture) refers to systems with two or more processors that cooperate to carry out an operation, each processor with its own memory, operating system and disks. Greenplum uses this high-performance system architecture to distribute the load of multi-terabyte data warehouses, and can use all of a system's resources in parallel to process a query.
Greenplum Database is based on PostgreSQL open-source technology. It is essentially several PostgreSQL database instances acting together as one cohesive database management system (DBMS). It is based on PostgreSQL 8.2.15, and in most cases is very similar to PostgreSQL with regard to SQL support, features, configuration options, and end-user functionality. Database users interact with Greenplum Database as they would a regular PostgreSQL DBMS.
The internals of PostgreSQL have been modified or supplemented to support the parallel structure of Greenplum Database. For example, the system catalog, optimizer, query executor, and transaction manager components have been modified and enhanced to be able to execute queries simultaneously across all of the parallel PostgreSQL database instances. The Greenplum interconnect (the networking layer) enables communication between the distinct PostgreSQL instances and allows the system to behave as one logical database.
Greenplum Database also includes features designed to optimize PostgreSQL for business intelligence (BI) workloads. For example, Greenplum has added parallel data loading (external tables), resource management, query optimizations, and storage enhancements, which are not found in standard PostgreSQL. Many features and optimizations developed by Greenplum make their way into the PostgreSQL community. For example, table partitioning is a feature first developed by Greenplum, and it is now in standard PostgreSQL.
Greenplum Database stores and processes large amounts of data by distributing the data and processing workload across several servers or hosts. Greenplum Database is an array of individual databases based upon PostgreSQL 8.2 working together to present a single database image. The master is the entry point to the Greenplum Database system. It is the database instance to which clients connect and submit SQL statements. The master coordinates its work with the other database instances in the system, called segments, which store and process the data.
Figure 1. High-Level Greenplum Database Architecture
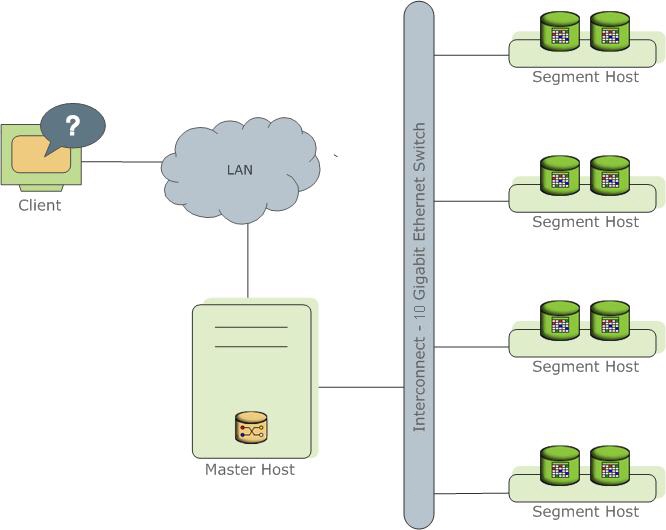
The following topics describe the components that make up a Greenplum Database system and how they work together.
###Greenplum Master The Greenplum Database master is the entry to the Greenplum Database system, accepting client connections and SQL queries, and distributing work to the segment instances.
Greenplum Database end-users interact with Greenplum Database (through the master) as they would with a typical PostgreSQL database. They connect to the database using client programs such as psql or application programming interfaces (APIs) such as JDBC or ODBC.
The master is where the global system catalog resides. The global system catalog is the set of system tables that contain metadata about the Greenplum Database system itself. The master does not contain any user data; data resides only on the segments. The master authenticates client connections, processes incoming SQL commands, distributes workloads among segments, coordinates the results returned by each segment, and presents the final results to the client program.
###Greenplum Segments
Greenplum Database segment instances are independent PostgreSQL databases that each store a portion of the data and perform the majority of query processing.
When a user connects to the database via the Greenplum master and issues a query, processes are created in each segment database to handle the work of that query. For more information about query processes, see About Greenplum Query Processing.
User-defined tables and their indexes are distributed across the available segments in a Greenplum Database system; each segment contains a distinct portion of data. The database server processes that serve segment data run under the corresponding segment instances. Users interact with segments in a Greenplum Database system through the master.
Segments run on a servers called segment hosts. A segment host typically executes from two to eight Greenplum segments, depending on the CPU cores, RAM, storage, network interfaces, and workloads. Segment hosts are expected to be identically configured. The key to obtaining the best performance from Greenplum Database is to distribute data and workloads evenly across a large number of equally capable segments so that all segments begin working on a task simultaneously and complete their work at the same time.
###Greenplum Interconnect The interconect is the networking layer of the Greenplum Database architecture.
The interconnect refers to the inter-process communication between segments and the network infrastructure on which this communication relies. The Greenplum interconnect uses a standard 10-Gigabit Ethernet switching fabric.
By default, the interconnect uses User Datagram Protocol (UDP) to send messages over the network. The Greenplum software performs packet verification beyond what is provided by UDP. This means the reliability is equivalent to Transmission Control Protocol (TCP), and the performance and scalability exceeds TCP. If the interconnect used TCP, Greenplum Database would have a scalability limit of 1000 segment instances. With UDP as the current default protocol for the interconnect, this limit is not applicable.
###Pivotal Query Optimizer The Pivotal Query Optimizer brings a state of the art query optimization framework to Greenplum Database that is distinguished from other optimizers in several ways:
-
Modularity. Pivotal Query Optimizer is not confined inside a single RDBMS. It is currently leveraged in both Greenplum Database and Pivotal HAWQ, but it can also be run as a standalone component to allow greater flexibility in adopting new backend systems and using the optimizer as a service. This also enables elaborate testing of the optimizer without going through the other components of the database stack.
-
Extensibility. The Pivotal Query Optimizer has been designed as a collection of independent components that can be replaced, configured, or extended separately. This significantly reduces the development costs of adding new features, and also allows rapid adoption of emerging technologies. Within the Query Optimizer, the representation of the elements of a query has been separated from how the query is optimized. This lets the optimizer treat all elements equally and avoids the issues with the imposed order of optimizations steps of multi-phase optimizers.
-
Performance. The Pivotal Query Optimizer leverages a multi-core scheduler that can distribute individual optimization tasks across multiple cores to speed up the optimization process. This allows the Query Optimizer to apply all possible optimizations as the same time, which results in many more plan alternatives and a wider range of queries that can be optimized. For instance, when the Pivotal Query Optimizer was used with TPC-H Query 21 it generated 1.2 Billion possible plans in 250 ms. This is especially important in Big Data Analytics where performance challenges are magnified by the volume of data that needs to be processed. A suboptimal optimization choice could very well lead to a query that just runs forever.
Greenplum Database manages database access using roles. Initially, there is one superuser role—the role associated with the OS user who initialized the database instance, usually gpadmin. This user owns all of the Greenplum Database files and OS processes, so it is important to reserve the gpadmin role for system tasks only.
A role can be a user or a group. A user role can log in to a database; that is, it has the LOGIN attribute. A user or group role can become a member of a group.
Permissions can be granted to users or groups. Initially, of course, only the gpadmin role is able to create roles. You can add roles with the createuser utility command, CREATE ROLE SQL command, or the CREATE USER SQL command. The CREATE USER command is the same as the CREATE ROLE command except that it automatically assigns the role the LOGIN attribute.
####Create a user with the createuser utility command
-
Login to the GPDB Sandbox as the gpadmin user.
-
Enter the createuser command and reply to the prompts:
$ createuser -P user1Enter password for new role: Enter it again: Shall the new role be a superuser? (y/n) n Shall the new role be allowed to create databases? (y/n) y Shall the new role be allowed to create more new roles? (y/n) n NOTICE: resource queue required -- using default resource queue "pg_default"
####Create a user with the CREATE USER command
- Connect to the template1 database as gpadmin:
$ psql template1
- Create a user with the name user2:
template1=# CREATE USER user2 WITH PASSWORD 'pivotal' NOSUPERUSER;
- Display a list of roles:
```
template1=# \du
List of roles
Role name | Attributes | Member of
-----------+-----------------------------------+-----------
gpadmin | Superuser, Create role, Create DB |
gpmon | Superuser, Create DB |
user1 | Create DB |
user2 | |
```
####Create a users group and add the users to it
- While connected to the template1 database as gpadmin enter the following SQL commands:
```
template1=# CREATE ROLE users;
template1=# GRANT users TO user1, user2;
```
- Display the list of roles again:
```
template1=# \du
List of roles
Role name | Attributes | Member of
-----------+-----------------------------------+-----------
gpadmin | Superuser, Create role, Create DB |
gpmon | Superuser, Create DB |
user1 | Create DB | {users}
user2 | | {users}
users | Cannot login |
```
- Exit out of the psql shell:
template1=# \q
Create a new database with the CREATE DATABASE SQL command in psql or the createdb utility command in a terminal. The new database is a copy of the template1 database, unless you specify a different template. To use the CREATE DATABASE command, you must be connected to a database. With a newly installed Greenplum Database system, you can connect to the template1 database to create your first user database. The createdb utility, entered at a shell prompt, is a wrapper around the CREATE DATABASE command. In this exercise you will drop the tutorial database if it exists and then create it new with the createdb utility.
####Create Database
- Enter these commands to drop the tutorial database if it exists:
$ dropdb tutorial
- Enter the createdb command to create the tutorial database, with the defaults:
$ createdb tutorial
- Verify that the database was created using the psql -l command:
```
[gpadmin@gpdb-sandbox ~]$ psql -l
List of databases
Name | Owner | Encoding | Access privileges
-----------+---------+----------+---------------------
gpadmin | gpadmin | UTF8 |
gpperfmon | gpadmin | UTF8 | gpadmin=CTc/gpadmin
: =c/gpadmin
postgres | gpadmin | UTF8 |
template0 | gpadmin | UTF8 | =c/gpadmin
: gpadmin=CTc/gpadmin
template1 | gpadmin | UTF8 | =c/gpadmin
: gpadmin=CTc/gpadmin
tutorial | gpadmin | UTF8 |
(6 rows)
```
- Connect to the tutorial database as user1, entering the password you created for user1 when prompted:
psql -U user1 tutorial
- Exit out of the psql shell:
tutorial=# \q
####Grant database privileges to users
In a production database, you should grant users the minimum permissions required to do their work. For example, a user may need SELECT permissions on a table to view data, but not UPDATE, INSERT, or DELETE to modify the data. To complete the exercises in this guide, the database users will require permissions to create and manipulate objects in the tutorial database.
- Connect to the tutorial database as gpadmin.
$ psql -U gpadmin tutorial
- Grant user1 and user2 all privileges on the tutorial database.
tutorial=# GRANT ALL PRIVILEGES ON DATABASE tutorial TO user1, user2;
- Log out of psql and perform the next steps as the user1 role.
tutorial=# \q
####Create a schema and set a search path
A database schema is a named container for a set of database objects, including tables, data types, and functions. A database can have multiple schemas. Objects within the schema are referenced by prefixing the object name with the schema name, separated with a period. For example, the person table in the employee schema is written employee.person.
The schema provides a namespace for the objects it contains. If the database is used for multiple applications, each with its own schema, the same table name can be used in each schema employee.person is a different table than customer.person. Both tables could be accessed in the same query as long as they are qualified with the schema name.
The database contains a schema search path, which is a list of schemas to search for objects names that are not qualified with a schema name. The first schema in the search path is also the schema where new objects are created when no schema is specified. The default search path is user,public, so by default, each object you create belongs to a schema associated with your login name. In this exercise, you create an faa schema and set the search path so that it is the default schema.
- Change to the directory containing the FAA data and scripts:
$ cd ~/gpdb-sandbox-tutorials/faa
- Connect to the tutorial database with psql:
$ psql -U gpadmin tutorial
- Create the faa schema:
```
tutorial=# DROP SCHEMA IF EXISTS faa CASCADE;
tutorial=# CREATE SCHEMA faa;
```
- Add the faa schema to the search path:
tutorial=# SET SEARCH_PATH TO faa, public, pg_catalog, gp_toolkit;
- View the search path:
```
tutorial=# SHOW search_path;
search_path
-------------------------------------
faa, public, pg_catalog, gp_toolkit
(1 row)
```
- The search path you set above is not persistent; you have to set it each time you connect to the database. You can associate a search path with the user role by using the ALTER ROLE command, so that each time you connect to the database with that role, the search path is restored:
tutorial=# ALTER ROLE gpadmin SET search_path TO faa, public, pg_catalog, gp_toolkit;
- Exit out of the psql shell:
tutorial=# \q
The CREATE TABLE SQL statement creates a table in the database.
####About the distribution policy
The definition of a table includes the distribution policy for the data, which has great bearing on system performance. The goals for the distribution policy are to:
- distribute the volume of data and query execution work evenly among the segments, and to
- enable segments to accomplish the most expensive query processing steps locally.
The distribution policy determines how data is distributed among the segments. Defining an effective distribution policy requires an understanding of the data’s characteristics, the kinds of queries that will be run once the data is loaded into the database, and what distribution strategies best utilize the parallel execution capacity of the segments.
Use the DISTRIBUTED clause of the CREATE TABLE statement to define the distribution policy for a table. Ideally, each segment will store an equal volume of data and perform an equal share of work when processing queries. There are two kinds of distribution policies:
- DISTRIBUTED BY (column, ...) defines a distribution key from one or more columns. A hash function applied to the distribution key determines which segment stores the row. Rows that have the same distribution key are stored on the same segment. If the distribution keys are unique, the hash function ensures the data is distributed evenly. The default distribution policy is a hash on the primary key of the table, or the first column if no primary key is specified.
- DISTRIBUTED RANDOMLY distributes rows in round-robin fashion among the segments.
When different tables are joined on the same columns that comprise the distribution key, the join can be accomplished at the segments, which is much faster than joining rows across segments. The random distribution policy makes this impossible, so it is best practice to define a distribution key that will optimize joins.
####Execute the CREATE TABLE script in psql
The CREATE TABLE statements for the faa database are in the faa create_dim_tables.sql script.
- Change to the directory containing the FAA data and scripts:
$ cd ~/gpdb-sandbox-tutorials/faa
- Open the script in a text editor to see the text of the commands that will be executed when you run the script.
```
gpadmin@gpdb-sandbox faa]$ more create_dim_tables.sql
create table faa.d_airports (airport_code text, airport_desc text) distributed by (airport_code);
create table faa.d_wac (wac smallint, area_desc text) distributed by (wac);
create table faa.d_airlines (airlineid integer, airline_desc text) distributed by (airlineid);
create table faa.d_cancellation_codes (cancel_code text, cancel_desc text) distributed by (cancel_code);
create table faa.d_delay_groups (delay_group_code text, delay_group_desc text) distributed by (delay_group_code);
create table faa.d_distance_groups (distance_group_code text, distance_group_desc text) distributed by (distance_group_code)
```
- Execute the create_dim_tables.sql script. The psql \i command executes a script:
$ psql -U gpadmin tutorialtutorial=# \i create_dim_tables.sql
- List the tables that were created, using the psql \dt command.
tutorial=# \dt
- Exit the psql shell:
tutorial=# \q
Loading external data into Greenplum Database tables can be accomplished in different ways. We will use three methods to load the FAA data:
- The simplest data loading method is the SQL INSERT statement. You can execute INSERT statements directly with psql or another interactive client, run a script containing INSERT statements, or run a client application with a database connection. This is the least efficient method for loading large volumes of data and should be used only for small amounts of data.
- You can use the COPY command to load the data into a table when the data is in external text files. The COPY command syntax allows you to define the format of the text file so the data can be parsed into rows and columns. This is faster than INSERT statements but, like INSERT statements, it is not a parallel process.
The SQL COPY command requires that external files be accessible to the host where the master process is running. On a multi-node Greenplum Database system, the data files may be on a file system that is not accessible to the master process. In this case, you can use the psql \copy meta-command, which streams the data to the server over the psql connection. The scripts in this tutorial use the \copy meta-command. - You can use a pair of Greenplum utilities, gpfdist and gpload, to load external data into tables at high data transfer rates. In a large scale, multi-terabyte data warehouse, large amounts of data must be loaded within a relatively small maintenance window. Greenplum supports fast, parallel data loading with its external tables feature. Administrators can also load external tables in single row error isolation mode to filter bad rows into a separate error table while continuing to load properly formatted rows. Administrators can specify an error threshold for a load operation to control how many improperly formatted rows cause Greenplum to abort the load operation.
By using external tables in conjunction with Greenplum Database's parallel file server (gpfdist), administrators can achieve maximum parallelism and load bandwidth from their Greenplum Database system.
Figure 1. External Tables Using Greenplum Parallel File Server (gpfdist)
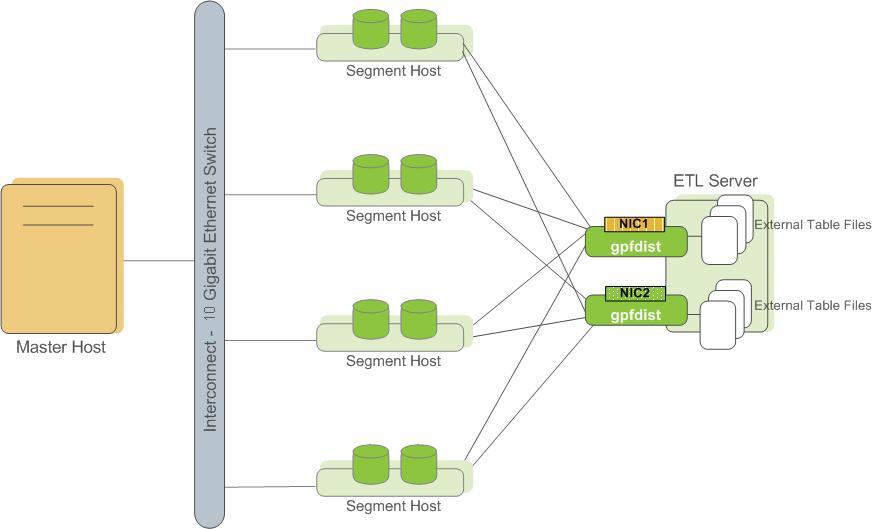
Another Greenplum utility, gpload, runs a load task that you specify in a YAML-formatted control file. You describe the source data locations, format, transformations required, participating hosts, database destinations, and other particulars in the control file and gpload executes the load. This allows you to describe a complex task and execute it in a controlled, repeatable fashion.
In the following exercises, you load data into the tutorial database using each of these methods.
####Load data with the INSERT statement The faa.d_cancellation_codes table is a simple two-column look-up table, easily loaded with an INSERT statement.
- Change to the directory containing the FAA data and scripts:
$ cd ~/gpdb-sandbox-tutorials/faa
- Connect to the tutorial database with psql:
$ psql -U gpadmin tutorial
- Use the \d psql meta-command to describe the faa.d_cancellation_codes table:
```
tutorial=# \d d_cancellation_codes
Table "faa.d_cancellation_codes"
Column | Type | Modifiers
-------------+------+-----------
cancel_code | text |
cancel_desc | text |
Distributed by: (cancel_code)
```
- Load the data into the table with a multirow INSERT statement (alternatively issue \i insert_into_cancellation_codes.sql):
```
tutorial=# INSERT INTO faa.d_cancellation_codes
VALUES ('A', 'Carrier'),('B', 'Weather'),('C', 'NAS'),
('D', 'Security'),('', 'none');
INSERT 0 5
```
####Load data with the COPY statement The COPY statement moves data between the file system and database tables. Data for five of the FAA tables is in the following CSV-formatted text files:
-
In a text editor, review the .csv data files.
- L_AIRLINE_ID.csv
- L_AIRPORTS.csv
- L_DISTANCE_GROUP_250.csv
- L_ONTIME_DELAY_GROUPS.csv
- L_WORLD_AREA_CODES.csv
Notice that the first line of each file contains the column names and that the last line of the file contains the characters “.”, which signals the end of the input data.
-
In a text editor, review the following scripts:
- copy_into_airlines.sql
- copy_into_airports.sql
- copy_into_delay_groups.sql
- copy_into_distance_groups.sql
- copy_into_wac.sql
The HEADER keyword prevents the \copy command from interpreting the column names as data.
-
Run the following scripts to load the data:
```
tutorial-# =# \i copy_into_airlines.sql
tutorial-# =# \i copy_into_airports.sql
tutorial-# =# \i copy_into_delay_groups.sql
tutorial-# =# \i copy_into_distance_groups.sql
tutorial-# =# \i copy_into_wac.sql
```
- Exit the psql shell:
tutorial=# \q
####Load data with gpdist
For the FAA fact table, we will use an ETL (Extract, Transform, Load) process to load data from the source gzip files into a loading table, and then insert the data into a query and reporting table. For the best load speed, use the gpfdist Greenplum utility to distribute the rows to the segments. In a production system, gpfdist runs on the servers where the data is located. With a single-node Greenplum Database instance, there is only one host, and you run gpdist on it. Starting gpfdist is like starting a file server; there is no data movement until a request is made on the process.
Note: This exercise loads data using the Greenplum Database external table feature to move data from external data files into the database. Moving data between the database and external tables is a security consideration, so only superusers are permitted to use the feature. Therefore, you will run this exercise as the gpadmin database user.
- Execute gpfdist. Use the –d switch to set the “home” directory used to search for files in the faa directory. Use the –p switch to set the port and background the process.
$ gpfdist -d ~/gpdb-sandbox-tutorials/faa -p 8081 > /tmp/gpfdist.log 2>&1 &
- Check that gpfdist is running with the ps command:
$ ps -A | grep gpfdist
- View the contents of the gpfdist log.
more /tmp/gpfdist.log
- Start a psql session as gpadmin and execute the create_load_tables.sql script. This script creates two tables: the faa_otp_load table, into which gpdist will load the data, and the faa_load_errors table, where load errors will be logged. (The faa_load_errors table may already exist. Ignore the error message.) The faa_otp_load table is structured to match the format of the input data from the FAA Web site.
$ psql -U gpadmin tutorial
```
tutorial=# \i create_load_tables.sql
CREATE TABLE
CREATE TABLE
```
- Create an external table definition with the same structure as the faa_otp_load table.
```
tutorial=# \i create_ext_table.sql
psql:create_ext_table.sql:5: NOTICE: HEADER means that each one
of the data files has a header row.
CREATE EXTERNAL TABLE
```
This is a pure metadata operation. No data has moved from the data files on the host to the database yet. The external table definition references files in the faa directory that match the pattern otp*.gz. There are two matching files, one containing data for December 2009, the other for January 2010.
- Move data from the external table to the faa_otp_load table.
```
tutorial=# INSERT INTO faa.faa_otp_load SELECT * FROM faa.ext_load_otp;
NOTICE: Found 26526 data formatting errors (26526 or more input rows).
Rejected related input data.
INSERT 0 1024552
```
Greenplum moves data from the gzip files into the load table in the database. In a production environment, you could have many gpfdist processes running, one on each host or several on one host, each on a separate port number.
- Examine the errors briefly. (The \x on psql meta-command changes the display of the results to one line per column, which is easier to read for some result sets.)
```
tutorial=# \x
Expanded display is on.
tutorial=# SELECT DISTINCT relname, errmsg, count(*)
FROM faa.faa_load_errors GROUP BY 1,2;
-[ RECORD 1 ]-------------------------------------------------
relname | ext_load_otp
errmsg | invalid input syntax for integer: "", column deptime
count | 26526
```
- Exit the psql shell:
tutorial=# \q
####Load data with gpload
Greenplum provides a wrapper program for gpfdist called gpload that does much of the work of setting up the external table and the data movement. In this exercise, you reload the faa_otp_load table using the gpload utility.
- Since gpload executes gpfdist, you must first kill the gpfdist process you started in the previous exercise.
```
$ ps -A | grep gpfdist
4035 pts/0 00:00:02 gpfdist
```
Your process id will not be the same, so kill the appropriate one with the kill command, or just use the simpler killall command:
```
$ killall gpfdist
[1]+ Exit 1 gpfdist -d $HOME/gpdb-sandbox-tutorials/faa -p 8081 > /tmp/ gpfdist.log 2>&1
```
- Edit and customize the gpload.yaml input file. Be sure to set the correct path to the faa directory. Notice the TRUNCATE: true preload instruction ensures that the data loaded in the previous exercise will be removed before the load in this exercise starts.
vi gpload.yaml
```
---
VERSION: 1.0.0.1
# describe the Greenplum database parameters
DATABASE: tutorial
USER: gpadmin
HOST: localhost
PORT: 5432
# describe the location of the source files
# in this example, the database master lives on the same host as the source files
GPLOAD:
INPUT:
- SOURCE:
LOCAL_HOSTNAME:
- gpdb-sandbox
PORT: 8081
FILE:
- /home/gpadmin/gpdb-sandbox-tutorials/faa/otp*.gz
- FORMAT: csv
- QUOTE: '"'
- ERROR_LIMIT: 50000
- ERROR_TABLE: faa.faa_load_errors
OUTPUT:
- TABLE: faa.faa_otp_load
- MODE: INSERT
PRELOAD:
- TRUNCATE: true
```
- Execute gpload with the gpload.yaml input file. (Include the -v flag if you want to see details of the loading process.)
$ gpload -f gpload.yaml -l gpload.log
```
2015-10-21 15:05:39|INFO|gpload session started 2015-10-21 15:05:39
2015-10-21 15:05:39|INFO|started gpfdist -p 8081 -P 8082 -f "/home/gpadmin/gpdb-sandbox-tutorials/faa/otp*.gz" -t 30
2015-10-21 15:05:58|WARN|26528 bad rows
2015-10-21 15:05:58|INFO|running time: 18.64 seconds
2015-10-21 15:05:58|INFO|rows Inserted = 1024552
2015-10-21 15:05:58|INFO|rows Updated = 0
2015-10-21 15:05:58|INFO|data formatting errors = 0
2015-10-21 15:05:58|INFO|gpload succeeded with warnings
```
####Create and Load fact tables The final step of the ELT process is to move data from the load table to the fact table. For the FAA example, you create two fact tables. The faa.otp_r table is a row-oriented table, which will be loaded with data from the faa.faa_otp_load table. The faa.otp_c table has the same structure as the faa.otp_r table, but is column-oriented and partitioned. You will load it with data from the faa.otp_r table. The two tables will contain identical data and allow you to experiment with a column-oriented and partioned table in addition to a traditional row-oriented table.
- Create the faa.otp_r and faa.otp_c tables by executing the create_fact_tables.sql script.
$ psql -U gpadmin tutorial
tutorial=# \i create_fact_tables.sql
Review the create_fact_tables.sql script and note that some columns are excluded from the fact table and the data types of some columns are cast to a different datatype. The MADlib routines usually require float8 values, so the numeric columns are cast to float8 as part of the transform step.
- Load the data from the faa_otp_load table into the faa.otp_r table using the SQL INSERT FROM statement. Load the faa.otp_c table from the faa.otp_r table. Both of these loads can be accomplished by running the load_into_fact_table.sql script.
tutorial=# load_into_fact_table.sql
###Data loading summary The ability to load billions of rows quickly into the Greenplum database is one of its key features. Using “Extract, Load and Transform” (ELT) allows load processes to make use of the massive parallelism of the Greenplum system by staging the data (perhaps just the use of external tables) and then applying data transformations within Greenplum Database. Set-based operations can be done in parallel, maximizing performance.
With other loading mechanisms such as COPY, data is loaded through the master in a single process. This does not take advantage of the parallel processing power of the Greenplum segments. External tables provide a means of leveraging the parallel processing power of the segments for data loading. Also, unlike other loading mechanisms, you can access multiple data sources with one SELECT of an external table.
External tables make static data available inside the database. External tables can be defined with file:// or gpfdist:// protocols. gpfdist is a file server program that loads files in parallel. Since the data is static, external tables can be rescanned during a query execution.
External Web tables allow http:// protocol or an EXECUTE clause to execute an operating system command or script. That data is assumed to be dynamic—query plans involving Web tables do not allow rescanning because the data could change during query execution. Execution plans may be slower, as data must be materialized (I/O) if it cannot fit in memory.
The script or process to populate a table with external Web tables may be executed on every segment host. It is possible, therefore, to have duplication of data. This is something to be aware of and check for when using Web tables, particularly with SQL extract calls to another database.
This lesson provides an overview of how Greenplum Database processes queries. Understanding this process can be useful when writing and tuning queries.
Users issue queries to Greenplum Database as they would to any database management system. They connect to the database instance on the Greenplum master host using a client application such as psql and submit SQL statements.
####Understanding Query Planning and Dispatch
The master receives, parses, and optimizes the query. The resulting query plan is either parallel or targeted. The master dispatches parallel query plans to all segments, as shown in Figure 1. Each segment is responsible for executing local database operations on its own set of data.query plans.
Most database operations—such as table scans, joins, aggregations, and sorts—execute across all segments in parallel. Each operation is performed on a segment database independent of the data stored in the other segment databases.
Figure 1. Dispatching the Parallel Query Plan
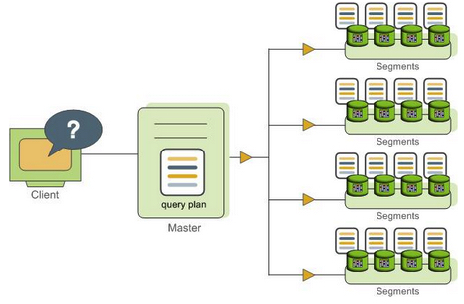
####Understanding Greenplum Query Plans
A query plan is the set of operations Greenplum Database will perform to produce the answer to a query. Each node or step in the plan represents a database operation such as a table scan, join, aggregation, or sort. Plans are read and executed from bottom to top.
In addition to common database operations such as tables scans, joins, and so on, Greenplum Database has an additional operation type called motion. A motion operation involves moving tuples between the segments during query processing.
To achieve maximum parallelism during query execution, Greenplum divides the work of the query plan into slices. A slice is a portion of the plan that segments can work on independently. A query plan is sliced wherever a motion operation occurs in the plan, with one slice on each side of the motion.
####Understanding Parallel Query Execution Greenplum creates a number of database processes to handle the work of a query. On the master, the query worker process is called the query dispatcher (QD). The QD is responsible for creating and dispatching the query plan. It also accumulates and presents the final results. On the segments, a query worker process is called a query executor (QE). A QE is responsible for completing its portion of work and communicating its intermediate results to the other worker processes.
There is at least one worker process assigned to each slice of the query plan. A worker process works on its assigned portion of the query plan independently. During query execution, each segment will have a number of processes working on the query in parallel.
Related processes that are working on the same slice of the query plan but on different segments are called gangs. As a portion of work is completed, tuples flow up the query plan from one gang of processes to the next. This inter-process communication between the segments is referred to as the interconnect component of Greenplum Database.
This section introduces some of the basic principles of query and performance tuning in a Greenplum database.
Some items to consider in performance tuning:
- VACUUM and ANALYZE
- Explain plans
- Indexing
- Column or row orientation
- Set based vs. row based
- Distribution and partitioning
###Exercises
####Analyze the tables
Greenplum uses Multiversion Concurrency Control (MVCC) to guarantee isolation, one of the ACID properties of relational databases. MVCC enables multiple users of the database to obtain consistent results for a query, even if the data is changing as the query is being executed. There can be multiple versions of rows in the database, but a query sees a snapshot of the database at a single point in time, containing only the versions of rows that were valid at that point in time. When a row is updated or deleted and no active transactions continue to reference it, it can be removed. The VACUUM command removes older versions that are no longer needed, leaving free space that can be reused.
In a Greenplum database, normal OLTP operations do not create the need for vacuuming out old rows, but loading data while tables are in use may. It is a best practice to VACUUM a table after a load. If the table is partitioned, and only a single partition is being altered, then a VACUUM on that partition may suffice.
The VACUUM FULL command behaves much differently than VACUUM, and its use is not recommended in Greenplum databases. It can be expensive in CPU and I/O, cause bloat in indexes, and lock data for long periods of time.
The ANALYZE command generates statistics about the distribution of data in a table. In particular it stores histograms about the values in each of the columns. The query optimizer depends on these statistics to select the best plan for executing a query. For example, the optimizer can use distribution data to decide on join orders. One of the optimizer’s goals in a join is to minimize the volume of data that must be analyzed and potententially moved between segments by using the statistics to choose the smallest result set to work with first.
-
Run the ANALYZE command on each of the tables:
$ psql -U gpadmin tutorial``` tutorial=# ANALYZE faa.d_airports; ANALYZE tutorial=# ANALYZE faa.d_airlines; ANALYZE tutorial=# ANALYZE faa.d_wac; ANALYZE tutorial=# ANALYZE faa.d_cancellation_codes; ANALYZE tutorial=# ANALYZE faa.faa_otp_load; ANALYZE tutorial=# ANALYZE faa.otp_r; ANALYZE tutorial=# ANALYZE faa.otp_c; ANALYZE ```
####View explain plans
An explain plan explains the method the optimizer has chosen to produce a result set. Depending on the query, there can be a variety of methods to produce a result set. The optimizer calculates the cost for each method and chooses the one with the lowest cost. In large queries, cost is generally measured by the amount of I/O to be performed.
An explain plan does not do any actual query processing work. Explain plans use statistics generated by the ANALYZE command, so plans generated before and after running ANALYZE can be quite different. This is especially true for queries with multiple joins, because the order of the joins can have a tremendous impact on performance.
In the following exercise, you will generate some small tables that you can query and view some explain plans.
- Enable timing so that you can see the effects of different performance tuning measures.
tutorial=# \timing on
- View the create_sample_table.sql script, and then run it.
tutorial=# \i create_sample_table.sql
```
DROP TABLE
Time: 15.901 ms
SET
Time: 3.174 ms
psql:create_sample_table.sql:3: NOTICE: CREATE TABLE will create implicit
sequence "sample_id_seq" for serial column "sample.id"
CREATE TABLE
Time: 24.421 ms
INSERT 0 1000000
Time: 14624.516 ms
UPDATE 1000000
Time: 1241.156 ms
UPDATE 50000
Time: 190.210 ms
UPDATE 1000000
Time: 1111.454 ms
```
- Request the explain plan for the COUNT() aggregate.
tutorial=# EXPLAIN SELECT COUNT(*) FROM sample WHERE id > 100;
```
QUERY PLAN
Aggregate (cost=0.00..462.77 rows=1 width=8)
-> Gather Motion 2:1 (slice1; segments: 2) (cost=0.00..462.77
rows=1 width=8)
-> Aggregate (cost=0.00..462.76 rows=1 width=8)
-> Table Scan on sample (cost=0.00..462.76 rows=500687 width=1)
Filter: id > 100
Settings: optimizer=on
Optimizer status: PQO version 1.597
(7 rows)
```
Query plans are read from bottom to top. In this example, there are four steps. First there is a sequential scan on each segment server to access the rows. Then there is an aggregation on each segment server to produce a count of the number of rows from that segment. Then there is a gathering of the count value to a single location. Finally, the counts from each segment are aggregated to produce the final result.
The cost number on each step has a start and stop value. For the sequential scan, this begins at time zero and goes until 13863.80. This is a fictional number created by the optimizer—it is not a number of seconds or I/O operations.
The cost numbers are cumulative, so the cost for the second operation includes the cost for the first operation. Notice that nearly all the time to process this query is in the sequential scan.
- The EXPLAIN ANALYZE command actually runs the query (without returning te result set). The cost numbers reflect the actual timings. It also produces some memory and I/O statistics.
tutorial=# EXPLAIN ANALYZE SELECT COUNT(*) FROM sample WHERE id > 100;
```
QUERY PLAN
-----------------------------------------------------------------------------
Aggregate (cost=0.00..462.77 rows=1 width=8)
Rows out: 1 rows with 446 ms to end, start offset by 7.846 ms.
-> Gather Motion 2:1 (slice1; segments: 2) (cost=0.00..462.77
rows=1 width=8) Rows out: 2 rows at destination with 443 ms to first row, 446 ms to end, start offset by 7.860 ms. -> Aggregate (cost=0.00..462.76 rows=1 width=8) Rows out: Avg 1.0 rows x 2 workers. Max 1 rows (seg0) with 442 ms to end, start offset by 9.000 ms. -> Table Scan on sample (cost=0.00..462.76 rows=500687 width=1) Filter: id > 100 Rows out: Avg 499950.0 rows x 2 workers. Max 499951 rows (seg0) with 88 ms to first row, 169 ms to end, start offset by 9.007 ms. Slice statistics: (slice0) Executor memory: 159K bytes. (slice1) Executor memory: 177K bytes avg x 2 workers, 177K bytes max (seg0). Statement statistics: Memory used: 128000K bytes Settings: optimizer=on Optimizer status: PQO version 1.597 Total runtime: 453.855 ms (17 rows) ```
####Indexes and performance Greenplum Database does not depend upon indexes to the same degree as conventional data warehouse systems. Because the segments execute table scans in parallel, each segment scanning a small segment of the table, the traditional performance advantage from indexes is diminished. Indexes consume large amounts of space and require considerable CPU time to compute during data loads. There are, however, times when indexes are useful, especially for highly selective queries. When a query looks up a single row, an index can dramatically improve performance.
In this exercise, you first run a single row lookup on the sample table without an index, then rerun the query after creating an index.
- Select a single row and note the time to execute the query.
tutorial=# SELECT * from sample WHERE big = 12345;
```
id | big | wee | stuff
-------+-------+-----+-------
12345 | 12345 | 0 |
(1 row)
Time: 197.640 ms
```
- View the explain plan for the previous query:
tutorial=# EXPLAIN SELECT * from sample WHERE big = 12345;
```
QUERY PLAN
-----------------------------------------------------------------------
Gather Motion 2:1 (slice1; segments: 2) (cost=0.00..459.04 rows=2 width=12) -> Table Scan on sample (cost=0.00..459.04 rows=1 width=12) Filter: big = 12345 Settings: optimizer=on Optimizer status: PQO version 1.597 (5 rows) Time: 19.719 ms ```
- Create an index on the sample table.
tutorial=# CREATE INDEX sample_big_index ON sample(big);
```
CREATE INDEX
Time: 1106.467 ms
```
- View the explain plan for the single-row select query with the new index in place:
tutorial=# EXPLAIN SELECT * FROM sample WHERE big = 12345;
```
QUERY PLAN
--------------------------------------------------------------------------
Gather Motion 2:1 (slice1; segments: 2) (cost=0.00..3.00 rows=2
width=12) -> Index Scan using sample_big_index on sample (cost=0.00..3.00 rows=1 width=12) Index Cond: big = 12345 Settings: optimizer=on Optimizer status: PQO version 1.597 (5 rows)
Time: 23.674 ms
```
- Run the single-row SELECT query with the index in place and note the time.
tutorial=# SELECT * FROM sample WHERE big = 12345;
```
id | big | wee | stuff
-------+-------+-----+-------
12345 | 12345 | 0 |
(1 row)
Time: 29.421 ms
```
Notice the difference in timing between the single-row SELECT with and without the index. The difference would have been much greater for a larger table. Not that even when there is a index, the optimizer can choose not to use it if it calculates a more efficient plan.
- View the following explain plans to compare plans for some other common types of queries.
```
tutorial=# EXPLAIN SELECT * FROM sample WHERE big = 12345;
tutorial=# EXPLAIN SELECT * FROM sample WHERE big > 12345;
tutorial=# EXPLAIN SELECT * FROM sample WHERE big = 12345 OR big = 12355;
tutorial=# DROP INDEX sample_big_index;
tutorial=# EXPLAIN SELECT * FROM sample WHERE big = 12345 OR big = 12355;
```
####Row vs. column orientation
Greenplum Database offers the ability to store a table in either row or column orientation. Both storage options have advantages, depending upon data compression characteristics, the kinds of queries executed, the row length, and the complexity and number of join columns.
As a general rule, very wide tables are better stored in row orientation, especially if there are joins on many columns. Column orientation works well to save space with compression and to reduce I/O when there is much duplicated data in columns.
In this exercise, you will create a column-oriented version of the fact table and compare it with the row-oriented version.
- Create a column-oriented version of the FAA On Time Performance fact table and insert the data from the row-oriented version.
```
tutorial=# CREATE TABLE FAA.OTP_C (LIKE faa.otp_r) WITH (appendonly=true,
orientation=column)
DISTRIBUTED BY (UniqueCarrier, FlightNum) PARTITION BY RANGE(FlightDate)
( PARTITION mth START('2009-06-01'::date) END ('2010-10-31'::date)
EVERY ('1 mon'::interval));
```
```
tutorial=# INSERT INTO faa.otp_c SELECT * FROM faa.otp_r;
```
- Compare the definitions of the row and the column versions of the table.
tutorial=# \d faa.otp_r
```
Table "faa.otp_r"
Column | Type | Modifiers
----------------------+------------------+-----------
flt_year | smallint |
flt_quarter | smallint |
flt_month | smallint |
flt_dayofmonth | smallint |
flt_dayofweek | smallint |
flightdate | date |
uniquecarrier | text |
airlineid | integer |
carrier | text |
flightnum | text |
origin | text |
origincityname | text |
originstate | text |
originstatename | text |
dest | text |
destcityname | text |
deststate | text |
deststatename | text |
crsdeptime | text |
deptime | integer |
depdelay | double precision |
depdelayminutes | double precision |
departuredelaygroups | smallint |
taxiout | smallint |
wheelsoff | text |
wheelson | text |
taxiin | smallint |
crsarrtime | text |
arrtime | text |
arrdelay | double precision |
arrdelayminutes | double precision |
arrivaldelaygroups | smallint |
cancelled | smallint |
cancellationcode | text |
diverted | smallint |
crselapsedtime | integer |
actualelapsedtime | double precision |
airtime | double precision |
flights | smallint |
distance | double precision |
distancegroup | smallint |
carrierdelay | smallint |
weatherdelay | smallint |
nasdelay | smallint |
securitydelay | smallint |
lateaircraftdelay | smallint |
Distributed by: (uniquecarrier, flightnum)
```
Notice that the column-oriented version is append-only and partitioned. It has seventeen child files for the partitions, one for each month from June 2009 through October 2010.
tutorial=# \d faa.otp_c
```
Append-Only Columnar Table "faa.otp_c"
Column | Type | Modifiers
----------------------+------------------+-----------
flt_year | smallint |
flt_quarter | smallint |
flt_month | smallint |
flt_dayofmonth | smallint |
flt_dayofweek | smallint |
flightdate | date |
uniquecarrier | text |
airlineid | integer |
carrier | text |
flightnum | text |
origin | text |
origincityname | text |
originstate | text |
originstatename | text |
dest | text |
destcityname | text |
deststate | text |
deststatename | text |
crsdeptime | text |
deptime | integer |
depdelay | double precision |
depdelayminutes | double precision |
departuredelaygroups | smallint |
taxiout | smallint |
wheelsoff | text |
wheelson | text |
taxiin | smallint |
crsarrtime | text |
arrtime | text |
arrdelay | double precision |
arrdelayminutes | double precision |
arrivaldelaygroups | smallint |
cancelled | smallint |
cancellationcode | text |
diverted | smallint |
crselapsedtime | integer |
actualelapsedtime | double precision |
airtime | double precision |
flights | smallint |
distance | double precision |
distancegroup | smallint |
carrierdelay | smallint |
weatherdelay | smallint |
nasdelay | smallint |
securitydelay | smallint |
lateaircraftdelay | smallint |
Checksum: t
Number of child tables: 17 (Use \d+ to list them.)
Distributed by: (uniquecarrier, flightnum)
```
- Compare the sizes of the tables using the pg_relation_size() and pg_total_relation_size() functions. The pg_size_pretty() function converts the size in bytes to human-readable units.
tutorial=# SELECT pg_size_pretty(pg_relation_size('faa.otp_r'));
```
pg_size_pretty
----------------
256 MB
(1 row)
```
tutorial=# SELECT pg_size_pretty(pg_total_relation_size('faa.otp_r'));
```
pg_size_pretty
----------------
256 MB
(1 row)
```
tutorial=# SELECT pg_size_pretty(pg_relation_size('faa.otp_c'));
```
pg_size_pretty
----------------
0 bytes
(1 row)
```
tutorial=# SELECT pg_size_pretty(pg_total_relation_size('faa.otp_c'));
```
pg_size_pretty
----------------
288 kB
(1 row)
```
####Check for even data distribution on segments The faa.otp_r and faa.otp_c tables are distributed with a hash function on UniqueCarrier and FlightNum. These two columns were selected because they produce an even distribution of the data onto the segments. Also, with frequent joins expected on the fact table and dimension tables on these two columns, less data moves between segments, reducing query execution time. When there is no advantage to co-locating data from different tables on the segments, a distribution based on a unique column ensures even distribution. Distributing on a column with low cardinality, such as Diverted, which has only two values, will yield a poor distribution.
-
One of the goals of distribution is to ensure that there is approximately the same amount of data in each segment. The query below shows one way of determining this. Since the column-oriented and row-oriented tables are distributed by the same columns, the counts should be the same for each.
tutorial=# SELECT gp_segment_id, COUNT(*) FROM faa.otp_c GROUP BY gp_segment_id ORDER BY gp_segment_id;gp_segment_id | count ---------------+--------- 0 | 1028144 1 | 1020960 (2 rows)
####About partitioning Partitioning a table can improve query performance and simplify data administration. The table is divided into smaller child files using a range or a list value, such as a date range or a country code.
Partitions can improve query performance dramatically. When a query predicate filters on the same criteria used to define partitions, the optimizer can avoid searching partitions that do not contain relevant data.
A common application for partitioning is to maintain a rolling window of data based on date, for example, a fact table containing the most recent 12 months of data. Using the ALTER TABLE statement, an existing partition can be dropped by removing its child file. This is much more efficient than scanning the entire table and removing rows with a DELETE statement.
Partitions may also be subpartitioned. For example, a table could be partitioned by month, and the month partitions could be subpartitioned by week. Greenplum Database creates child files for the months and weeks. The actual data, however, is stored in the child files created for the week subpartitions—only child files at the leaf level hold data.
When a new partition is added, you can run ANALYZE on just the data in that partition. ANALYZE can run on the root partition (the name of the table in the CREATE TABLE statement) or on a child file created for a leaf partition. If ANALYZE has already run on the other partitions and the data is static, it is not necessary to run it again on those partitions.
Greenplum Database supports:
- Range partitioning: division of data based on a numerical range, such as date or price.
- List partitioning: division of data based on a list of values, such as sales territory or product line.
- A combination of both types.

The following exercise compares SELECT statements with WHERE clauses that do and do not use a partitioned column.
-
The column-oriented version of the fact table you created is partitioned by date. First, execute a query that filters on a non-partitioned column and note the execution time.
tutorial=# \timing on
```
Timing is on.
```
>`tutorial=# SELECT MAX(depdelay) FROM faa.otp_c WHERE UniqueCarrier = 'UA';`
```
max
------
1360
(1 row)
Time: 641.574 ms
```
- Execute a query that filters on flightdate, the partitioned column.
tutorial=# SELECT MAX(depdelay) FROM faa.otp_c WHERE flightdate ='2009-11-01';
```
max
-----
'
(1 row)
Time: 30.658 ms
```
The query on the partitioned column takes much less time to execute. If you compare the explain plans for the queries in this exercise, you will see that the first query scans each of the seventeen child files, while the second scans just one child file. The reduction in I/O and CPU time explains the improved execution time.
Running analytics directly in Greenplum Database, rather than exporting data to a separate analytics engine, allows greater agility when exploring large data sets and much better performance due to parallelizing the analytic processes across all the segments.
A variety of power analytic tools is available for use with Greenplum Database:
- MADlib, an open-source, MPP implementation of many analytic algorithms, available at http://madlib.incubator.apache.org/
- R statistical language
- SAS, in many forms, but especially with the SAS Accelerator for Greenplum
- PMML, Predictive Modeling Markup Language
The exercises in this chapter introduce using MADlib with Greenplum Database, using the FAA on-time data example dataset. You will examine scenarios comparing airlines and airports to learn whether there are significant relationships to be found. In this lesson, you will use Apache Zeppelin (incubating) to submit SQL statements to the Greenplum Database. Apache Zeppelin is a web-based notebook that enables interactive data analytics. A PostgeSQL interpreter has been added to Zeppelin, so that it can now work directly with products such as Pivotal Greenplum Database and Pivotal HDB.
####Prepare Apache Zeppelin
-
Open a browser on your desktop and browse to
http://X.X.X.X:8080using the same IP address that you used for the ssh step. You will see the Apache Zepplin Welcome page.
-
Click Interpreter at the top of the Screen and scroll down to the psql section and press edit.
-
Edit the postgresql.url entry by adding tutorial to the end, so that it will connect to the tutorial database.
-
Click Save and then Hit OK to restart the Interpreter
-
Click on Create new note underneath the Notebook heading and type:
tutorial
-
Click "tutorial" to open the newly created notebook.
-
You should now see the the open notebook with a "paragraph" ready for input. Click in the the empty white rectangle (called paragraph) and type:
%psql.sql select count(*) from faa.otp.c;
Then press the play button.

The result should look like the graphic below.

####Run PostgreSQL built-in aggregates PostgreSQL has built-in aggregate functions to get standard statistics on database columns—minimum, maximum, average, and standard deviation, for example. The functions take advantage of the Greenplum Database MPP architecture, aggregating data on the segments and then assembling results on the master.
First, gather simple descriptive statistics on some of the data you will analyze with MADlib. The commands in this exercise are in the stats.sql script in the sample data directory.
-
Get average delay, standard deviation, and number of flights for USAir and Delta airlines. Click a new white rectangle and enter:
%psql.sql SELECT carrier, AVG(arrdelayminutes),STDDEV(arrdelayminutes),
COUNT(*) FROM faa.otp_c WHERE carrier = 'US' OR carrier = 'DL'
GROUP BY carrier;
```
Then press the Play button to execute the query.
-
Get average delay, standard deviation, and number of flights originating from Chicago O’Hare or Atlanta Hartsfield airports. Click a new white rectangle and enter:
%psql.sql SELECT origin, AVG(arrdelayminutes),STDDEV(arrdelayminutes),
COUNT(*) FROM faa.otp_c WHERE origin = 'ORD' OR origin = 'ATL'
GROUP BY origin;
```
Then press the Play button to execute the query.
-
Get average delay, standard deviation, and number of flights originating from Chicago O’Hare or Atlanta Hartsfield airports. Click a new white rectangle and enter:
%psql.sql SELECT origin, AVG(arrdelayminutes),STDDEV(arrdelayminutes),
COUNT(*) FROM faa.otp_c WHERE carrier = 'DL' AND origin IN ('ATL', 'MSP',
'DTW') GROUP BY origin;
```
Then press the Play button to execute the query.
-
Get average delay, standard deviation, and number of flights for Delta and USAir flights originating from Atlanta Harsfield. Click a new white rectangle and enter:
%psql.sql SELECT carrier, AVG(arrdelayminutes),STDDEV(arrdelayminutes),
COUNT(*) FROM faa.otp_c WHERE carrier IN ('DL', 'UA') AND origin = 'ATL'
GROUP BY carrier;
```
Then press the Play button to execute the query.
####Run Apache MADlib ANOVA
ANOVA (Analysis of Variance) shows whether groups of samples are significantly different from each other. The MADlib ANOVA function uses an integer value to distinguish between the groups to compare and a column for the data. The groups we want to analyze in the FAA fact table are text in the data, so we use a PostgreSQL CASE statement to assign the samples to integer values based on the text values. The ANOVA module then divides the rows into groups and performs the test.
ANOVA is a general linear model. To determine whether statistical data samples are significantly different from one another, you compare the total variability of the group by the variability between the groups. This is tempered by the number of observations, which is summarized by the degrees of freedom within the groups. The relevant statistic that measures the degree to which the difference between groups is significant is the ratio of the variance between groups divided by the variance within groups, called the F statistic. If it is close to zero, the groups do not differ by much. If it is far from zero, they do.
From statistical theory you can determine the probability distribution of the F statistic if the groups were identical given sampling error. This is given by the p-value. A p-value close to zero indicates it is very likely that the groups are different. A p-value close to one indicates that it is very likely the groups are the same.
- As gpadmin, install the MADlib packages into the tutorial database.
$ $GPHOME/madlib/bin/madpack -p greenplum -c gpadmin@localhost/tutorial install
-
Run an ANOVA analysis on the average delay minutes between USAir and Delta airlines. The CASE clause assigns USAir flights to group 1 and Delta flights to group 2.
Click a new white rectangle and enter:
%psql.sql SELECT (MADlib.one_way_anova ( CASE WHEN carrier = 'US' THEN 1 WHEN carrier = 'DL' THEN 2 ELSE NULL END, arrdelayminutes )).* FROM faa.otp_r;Then press the Play button to execute the query.
-
Run an ANOVA analysis to determine if the average delays for flights from Chicago and Atlanta are statistically different.
Click a new white rectangle and enter:
%psql.sql SELECT (MADlib.one_way_anova ( CASE WHEN origin = 'ORD' THEN 1 WHEN origin = 'ATL' THEN 2 ELSE NULL END, arrdelayminutes )).* FROM faa.otp_r;Then press the Play button to execute the query.
-
Run an ANOVA analysis to determine if the differences in average delay minutes from three Delta hubs are significant.
Click a new white rectangle and enter:
%psql.sql SELECT (MADlib.one_way_anova ( CASE WHEN carrier = 'DL' AND origin = 'ATL' THEN 1 WHEN carrier = 'DL' AND origin = 'MSP' THEN 2 WHEN carrier = 'DL' AND origin = 'DTW' THEN 3 ELSE NULL END, arrdelayminutes )).* FROM faa.otp_r;Then press the Play button to execute the query.
-
Run an ANOVA analysis to determine if the differences in average delay minutes between Delta and USAir flights from Atlanta are significant.
Click a new white rectangle and enter:
%psql.sql SELECT (MADlib.one_way_anova ( CASE WHEN carrier = 'DL' AND origin = 'ATL' THEN 1 WHEN carrier = 'UA' AND origin = 'ATL' THEN 2 ELSE NULL END, arrdelayminutes )).* FROM faa.otp_r;Then press the Play button to execute the query. From these ANOVA analyses we have learned the following:
- There is a fairly certain difference between delays for USAir and Delta, but the difference is not great
- Delays from O’Hare seem to be significantly different than from Atlanta
- There is a large difference between delays at the three Delta hubs
- There is no significant difference in delays from Atlanta between United and Delta.
####Perform Linear Regression Linear regression shows the relationship between variables. A classic example is the linear relationship between height and weight of adult males in a particular country or ethnic group. MADlib includes modules to perform linear regression with one or multiple independent variables.
The r2 statistic measures the proportion of the total variability in the dependent variable that can be explained by the independent variable.
-
Perform a linear regression to see if there is any relationship between distance and arrival delay. This tests the hypothesis that longer flights are more likely to be on time because the flight crew can make up delays by flying faster over longer periods of time. Test this by running a regression on arrival time as the dependent variable and distance as the independent variable.
Click a new white rectangle and enter:
%psql.sql SELECT ( madlib.linregr(arrdelayminutes,
ARRAY[1,distance])).* FROM faa.otp_c; ```
Then press the Play button to execute the query.
The regression shows that r2 is close to zero, which means that distance is not a good predictor for arrival delay time.
-
Run a regression with departure delay time as the independent variable and arrival delay time as the dependent variable. This tests the hypothesis that if a flight departs late, it is unlikely that the crew can make up the time.
Click a new white rectangle and enter:
%psql.sql SELECT ( madlib.linregr(arrdelayminutes,
ARRAY[1,depdelayminutes])).* FROM faa.otp_c; ```
Then press the Play button to execute the query.
The r2 statistic is very high, especially with 1.5 million samples. The linear relationship can be written as
Arrival_delay = 1.2502729312843388 + 0.96360804792526189 * departure_delay
If you scroll over in the results, the condition_no result is a measure of the mathematical stability of the solution. In computer arithmetic, numbers do not have infinite precision, and round-off error in calculations can be significant, especially if there are a large number of independent variables and they are highly correlated. This is very common in econometric data and techniques have evolved to deal with it.
####Learn more about Apache MADlib MADlib is an Apache Incubator open source project on GitHub. You can find source code for the latest release and information about participating in the project in the GitHub repository. Access the MADlib user documentation on the MADlib Web site at http://madlib.incubator.apache.org/.
###Other Resources White Paper: PivotalR: A Package for Machine Learning on Big Data
The Greenplum Database parallel dump utility gpcrondump backs up the Greenplum master instance and each active segment instance at the same time.
By default, gpcrondump creates dump files in the gp_dump subdirectory.
Several dump files are created for the master, containing database information such as DDL statements, the Greenplum system catalog tables, and metadata files. gpcrondump creates one dump file for each segment, which contains commands to recreate the data on that segment.
You can perform full or incremental backups. To restore a database to its state when an incremental backup was made, you will need to restore the previous full backup and all subsequent incremental backups.

Each file created for a backup begins with a 14-digit timestamp key that identifies the backup set the file belongs to.
gpcrondump can be run directly in a terminal on the master host, or you can add it to crontab on the master host to schedule regular backups.
The Greenplum Database parallel restore utility gpdbrestore takes the timestamp key generated by gpcrondump, validates the backup set, and restores the database objects and data into a distributed database in parallel. Parallel restore operations require a complete backup set created by gpcrondump, a full backup and any required incremental backups.

The Greenplum Database gpdbrestore utility provides flexibility and verification options for use with the automated backup files produced by gpcrondump or with backup files moved from the Greenplum array to an alternate location.
Exercises
These exercises will walk through how to create a full backup of your database and then restore a table.
- To run a full backup, use "gpcrondump -x database -u /path/for/backup -a". This will backup the entire database to the directory given without prompting the user.
$ gpcrondump -x tutorial -u /tmp -a -r
```
20151021:18:15:08:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Starting gpcrondump with args: -x tutorial -u /tmp -a -r
20151021:18:15:09:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Directory /tmp/db_dumps/20151021 exists
20151021:18:15:09:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Checked /tmp on master
20151021:18:15:10:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Configuring for single database dump
20151021:18:15:10:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Validating disk space
20151021:18:15:10:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Adding compression parameter
20151021:18:15:10:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Adding --no-expand-children
20151021:18:15:10:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Dump process command line gp_dump -p 5432 -U gpadmin --gp-d=/tmp/db_dumps/20151021 --gp-r=/tmp/db_dumps/20151021 --gp-s=p --gp-k=20151021181509 --no-lock --gp-c --no-expand-children tutorial
20151021:18:15:10:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Starting Dump process
20151021:18:15:14:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Releasing pg_class lock
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Dump process returned exit code 0
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Timestamp key = 20151021181509
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Checked master status file and master dump file.
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Dump status report
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:----------------------------------------------------
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Target database = tutorial
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Dump subdirectory = 20151021
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Dump type = Full database
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Clear old dump directories = Off
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Dump start time = 18:15:09
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Dump end time = 18:15:30
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Status = COMPLETED
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Dump key = 20151021181509
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Dump file compression = On
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Vacuum mode type = Off
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-Exit code zero, no warnings generated
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:----------------------------------------------------
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[WARNING]:-Found neither /usr/local/greenplum-db/./bin/mail_contacts nor /home/gpadmin/mail_contacts
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[WARNING]:-Unable to send dump email notification
20151021:18:15:30:068072 gpcrondump:gpdb-sandbox:gpadmin-[INFO]:-To enable email notification, create /usr/local/greenplum-db/./bin/mail_contacts or /home/gpadmin/mail_contacts containing required email addresses
```
This runs a full backup of the database created during the previous exercises.
- To view the backups:
ls -al /tmp/db_dumps
- Now, that we have a full backup let's remove data from a table to simulate a failure.
$ psql -U gpadmin tutorial
tutorial=# select count(*) from otp_r;
This should return 2049104 rows in the table. Let's truncate the table and then check the row count:
tutorial=# truncate table otp_r; tutorial=# select count(*) from otp_r;
The report should now show 0 rows in the table.
- Let's restore the data that was lost. First, exit from the psql shell by typing
\qthen issue the gpdbrestore command:
$ gpdbrestore -T faa.otp_r -s tutorial -u /tmp -a
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Starting gpdbrestore with args: -T faa.otp_r -s tutorial -u /tmp -a
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Scanning Master host for latest dump file set for database tutorial
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Located dump file gp_cdatabase_1_1_20151021181325 for database tutorial, adding to list
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Located dump file gp_cdatabase_1_1_20151021181509 for database tutorial, adding to list
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Located dump file gp_cdatabase_1_1_20151021181404 for database tutorial, adding to list
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Located dump file gp_cdatabase_1_1_20151021181423 for database tutorial, adding to list
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Identified latest dump timestamp for tutorial as 20151021181509
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-------------------------------------------
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Greenplum database restore parameters
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-------------------------------------------
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Restore type = Table Restore
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Database name = tutorial
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-------------------------------------------
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Table restore list
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-------------------------------------------
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Table = faa.otp_r
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Restore method = Specific table restore
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Restore timestamp = 20151021181509
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Restore compressed dump = On
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Restore global objects = Off
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Array fault tolerance = n
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-------------------------------------------
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Running metadata restore
20151021:18:21:14:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Invoking commandline: gp_restore -i -h gpdb-sandbox.localdomain -p 5432 -U gpadmin --gp-i --gp-k=20151021181509 --gp-l=p -s /tmp/db_dumps/20151021/gp_dump_1_1_20151021181509.gz -P --gp-r=/tmp/db_dumps/20151021 --status=/tmp/db_dumps/20151021 --gp-d=/tmp/db_dumps/20151021 --gp-f=/tmp/table_list_wXAV1W --gp-c -d tutorial
20151021:18:21:16:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Expanding parent partitions if any in table filter
20151021:18:21:17:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-gp_restore commandline: gp_restore -i -h gpdb-sandbox.localdomain -p 5432 -U gpadmin --gp-i --gp-k=20151021181509 --gp-l=p --gp-d=/tmp/db_dumps/20151021 --gp-r=/tmp/db_dumps/20151021 --status=/tmp/db_dumps/20151021 --gp-f=/tmp/table_list_BsvLQg --gp-c -d tutorial -a:
20151021:18:21:27:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Running post data restore
20151021:18:21:27:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-gp_restore commandline: gp_restore -i -h gpdb-sandbox.localdomain -p 5432 -U gpadmin --gp-d=/tmp/db_dumps/20151021 --gp-i --gp-k=20151021181509 --gp-l=p -P --gp-r=/tmp/db_dumps/20151021 --status=/tmp/db_dumps/20151021 --gp-f=/tmp/table_list_BsvLQg --gp-c -d tutorial:
20151021:18:21:29:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-Commencing analyze of restored tables in 'tutorial' database, please wait
20151021:18:21:39:069135 gpdbrestore:gpdb-sandbox:gpadmin-[INFO]:-'Analyze' of restored tables in 'tutorial' database completed without error
- Finally, verify the row count
$ psql -U gpadmin tutorial
tutorial=# select count(*) from otp_r;
The table should show 2049104 rows again as it was prior to the truncate call.