反相器
+COMS电路
-
-
- 递归的思想 +
- CMOS的输出特性,CMOS受负载的输出高低电平变化 +
- \(V_{OH}\quad V_{OL}...\)的取法(噪声容限) +
- CMOS门不允许悬空,和地面的电阻相接不影响 +
- CMOS电路的输入端不允许悬空,因为悬空会使电位不定,破坏正常的逻辑关系。另外,悬空时输入阻抗高,易受外界噪声干扰,使电路产生误动作,而且也极易造成栅极感应静电而击穿。 +
TTL电路
-
-
- 要求第n项,先求n-1和n-2项,若n-1和n-2项为1,2则都令为1 -
- Fobonacci -Sequence复杂度比较高,不适合大数据计算,例如当n=100时,计算起来就十分的慢 -
扇出系数的概念,计算
\(T_{cd}和T_{pd}\),为什么\(T_{cd}=0\)的时候,将无法信任电平?
+因为\(T_{cd}=0\),表面一旦高电平降低,那么电路进入无效区,这时候就需要重新,\(T_{cd}可以变大点\)
交流噪声容限(是指噪声信号是高频吗?)
TTL电源不允许大幅调整,不允许超过10%
TTL电路输入端通过电阻接地,电阻值R的大小直接影响电路所处的状态。
def fibo(n): |
-既然Fibonacci数列的递归计算如此复杂,那么,我们应该想什么办法来优化整个算法呢,我们考虑到,Fibonacci之所以复杂,是因为递归的存在,导致整个程序的时间复杂度都十分的高那么我们有没有简单一点的方法呢,对了,我们可以采用记录的方式,将每一个点之前的Fibonacci的数值都保存下来
-def Fibo(n): |
-我们调用了相关的带有memo的Fibo函数之后,明显发现,整个速度提升了很多,整个计算没有超过一秒钟,显然,这种方法是很有效的,我们称这个memo为DP数组
-House-robber
+-
-
- 你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。给定一个代表每个房屋存放金额的非负整数数组,计算你 -不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。 -
- 输入:[1,2,3,1] -
输出:4
-解释:偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。
-偷窃到的最高金额 = 1 + 3 = 4 。
-对于小偷问题,我们可以这么去思考,就是我们新建一个DP数组,用来储存小偷走到这个点时之前可以得到的最大的收益,如果按照这种思路,然后去整个数组的最大值
-def steal(): |
Maximum value of gifts
-在一个 m*n -的棋盘的每一格都放有一个礼物,每个礼物都有一定的价值(价值大于 -0)。你可以从棋盘的左上角开始拿格子里的礼物,并每次向右或者向下移动一格、直到到达棋盘的右下角。给定一个棋盘及其上面的礼物的价值,请计算你最多能拿到多少价值的礼物?
-输入:
-[
-[1,3,1],
-[1,5,1],
-[4,2,1]
-]
-输出: 12
-解释: 路径 1→3→5→2→1 可以拿到最多价值的礼物
-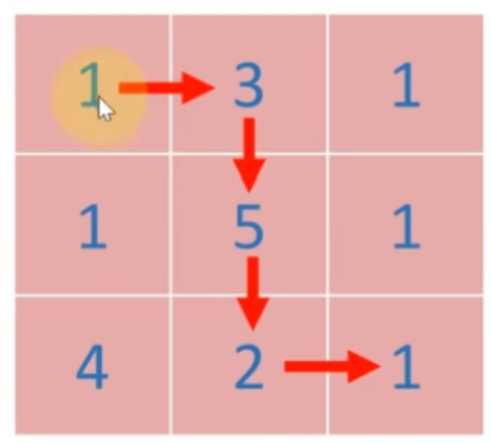
-我们要计算从左上角到右下角最大的礼物价值,我们不妨这么思考,我们还是新建一个DP数组,这个DP数组应该是二维的,然后考虑DP数组是左上角到达每个点的最大价值,又因为路线只能右走或者下走。所以当其为横向、纵向的边界时,我们只要考虑左边、上面
-def gift(): |
Coins exchange
-给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount -,表示总金额。计算并返回可以凑成总金额所需的 最少的硬币个数 -。如果没有任何一种硬币组合能组成总金额,返回 -1 -。你可以认为每种硬币的数量是无限的。
-输入:coins = [1, 2, 5], S = 11
-输出:3
-解释:11 = 5 + 5 + 1
-输入:coins = [2], S = 3
-输出:-1
-
\[ -f(x)=min\{f(x-c_1),f(x-c_2),...f(x-c_m)\}+1 -\]
-如果\(x-c_i<0\),则令\(f(x-c_i)=\infty\)这样就不会选这个\(f(x-c_i)\)了
-如果\(x-c_i=0\),那么\(f(x-c_i)=0\)即\(f(0)=0\)
-def change_coins(): |
现在我们已经知道硬币的最少组合为3,那我们如何得到是哪些硬币的组合
-思路: -我们可以将S=11的最小硬币数是3分解一下,例如,硬币数是3,说明[1,2,5]中的三个可以组成,于是我们可以一个一个的遍历,看当11减去其中的一些数之后判断一下剩余的需要的最小硬币数是不是2,例如:11-1,然后:凑成10元的所需硬币数最小是2吗,是的话,跳出遍历,选择这一10继续分解,不是的话,继续遍历下面的,直到S=0说明已经遍历到0了,可以结束
-如何得到硬币的组合呢(5,5,1)
-def find_coins(S): |
Knapsack Problem
- -有10件货物要从甲地运送到乙地,每件货物的重量(单位:吨)和利润(单位:元)
-如下表所示:
-
-由于只有--辆最大载重为30t的货车能用来运送货物,所以只能选择部分货物配送,要求确定运送哪些货物,使得运送这些货物的总利润最大。
-思路:
- 有m件物品,第i件物品的利润为\(v_i\)重量为\(w_i\)背包的总重量为W.
-原问题:在满足重量约束的条件下,将这m个物品选择性放入容量为W的背包所能获得的最大利润
-子问题:在满足重量的约束条件下,将i(\(i\le
-m\))件物品选择性放入容量为j(\(j \le
-W\))的背包所获得的最大利润
状态分析:
- -我们要讲m件商品装进容量为W的背包,我们可以假设背包是从1,2,3,4...增大的容量,物品从第一次只装第一个产品,然后慢慢推广到前i个产品,所以DP表格其实是在背包容量为i的情况下,能装的礼物的最大价值
- -对于第一行来说,装的物品为第一个物品,所以只需要判断背包容量是否大于第一件物品的重量,若大于,则最大价值为第一件物品的价值
- -对于第一列来说,背包容量为1,装进前i件物品的最大价值,由于物品的重量始终为整数,所以在前i件物品里,我们要看有没有总量为1的物品,若没有,则什么也装不进去,那么最大价值为0,若有(可能有几个),则去前i个产品中重量为1的所有物品中价值最大的那个为该点dp表的值
- 对于其它的列来说,需要用到状态转移方程,对于要求前\(i\)件物品装进容量为\(j\)的背包,在\(i-1\)的基础上只需要考虑到底装不装第\(i\)件物品,那么怎么考虑呢?要装第\(i\)件物品首先,第\(i\)件物品的重量必须小于背包的容量所以有: -\(j-weight(i)>=0\)才去判断: \[ -max(dp[i-1][j],dp[i-1][j-weight[i]]+value[i]) -\]
-它的意思是如果第i件物品装的下,那么就去判断不装这件物品和在没装这件物品,也就是dp[i-1][j-weight[i]]的最大价值,然后加上这件物品的价值。这样就可推出整个dp数组,而数组的最后一个元素,就是我们要求的最大价值
-items=[(1,6,540),(2,3,200),(3,4,180),(4,5,350),(5,1,60),(6,2,150),(7,3,280),(8,5,450),(9,4,320),(10,2,120)] |
.png)
.png)
.png)
.png)