A curated list of recent diffusion models for video generation, editing, restoration, understanding, nerf, etc.


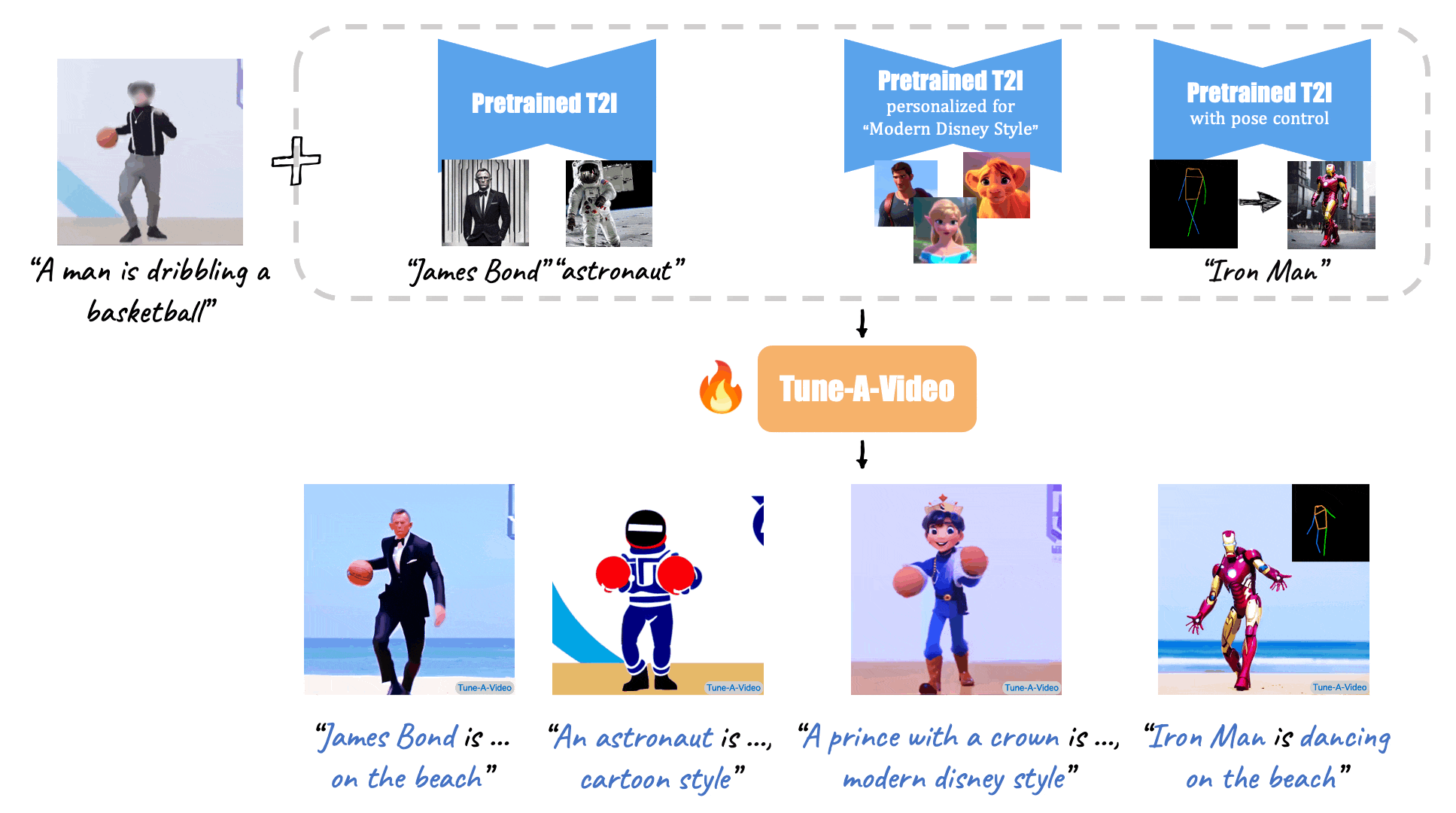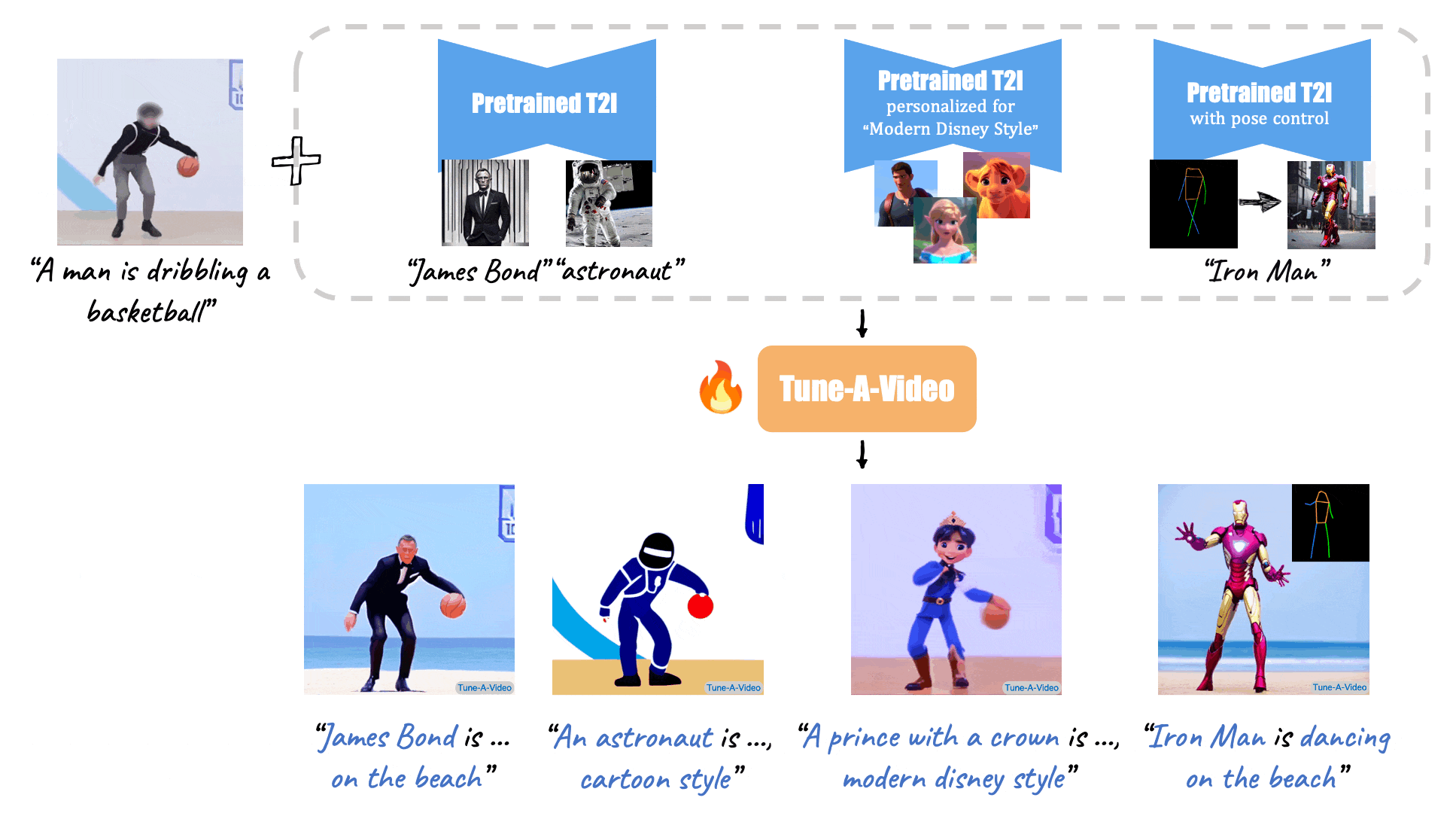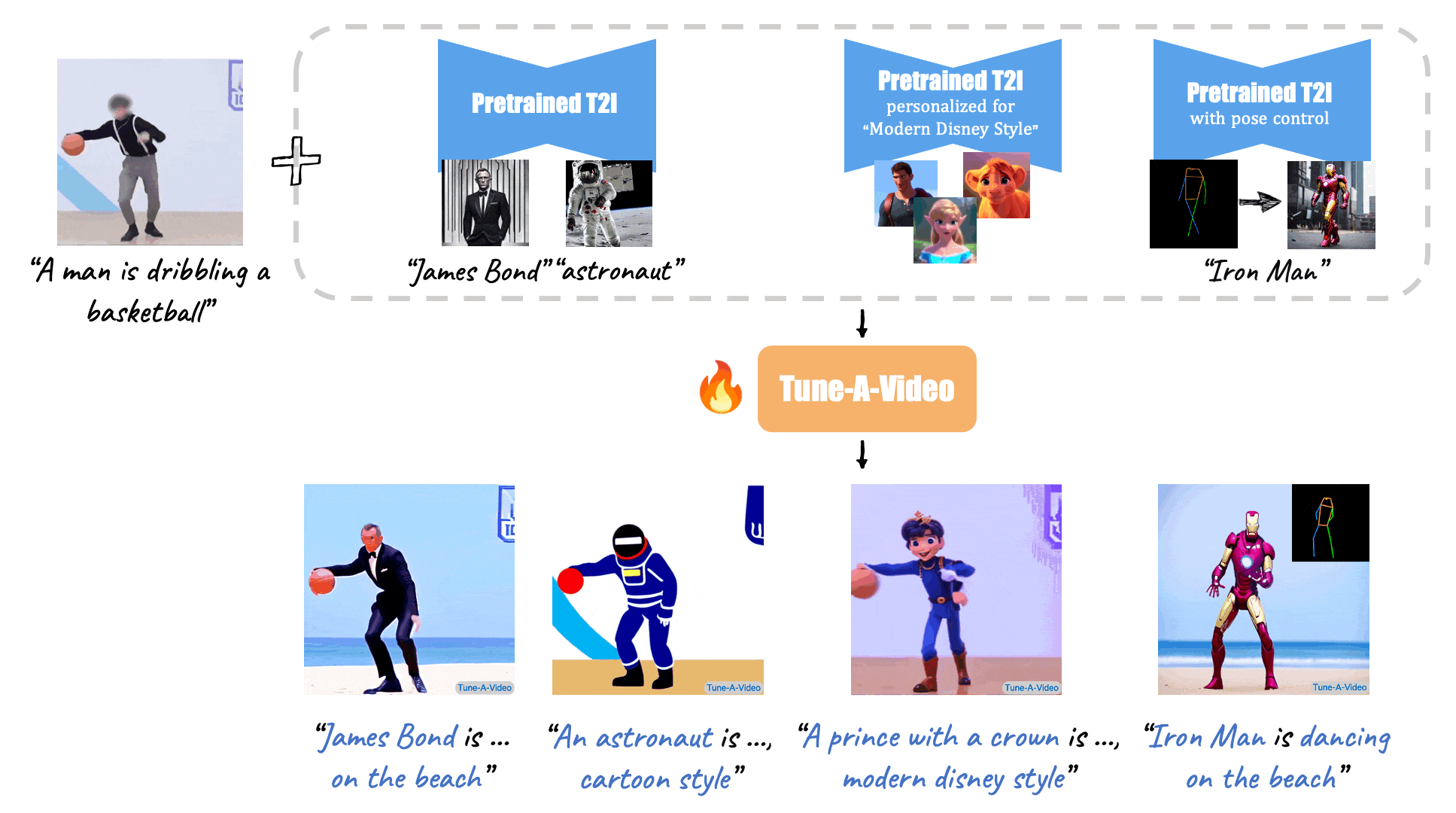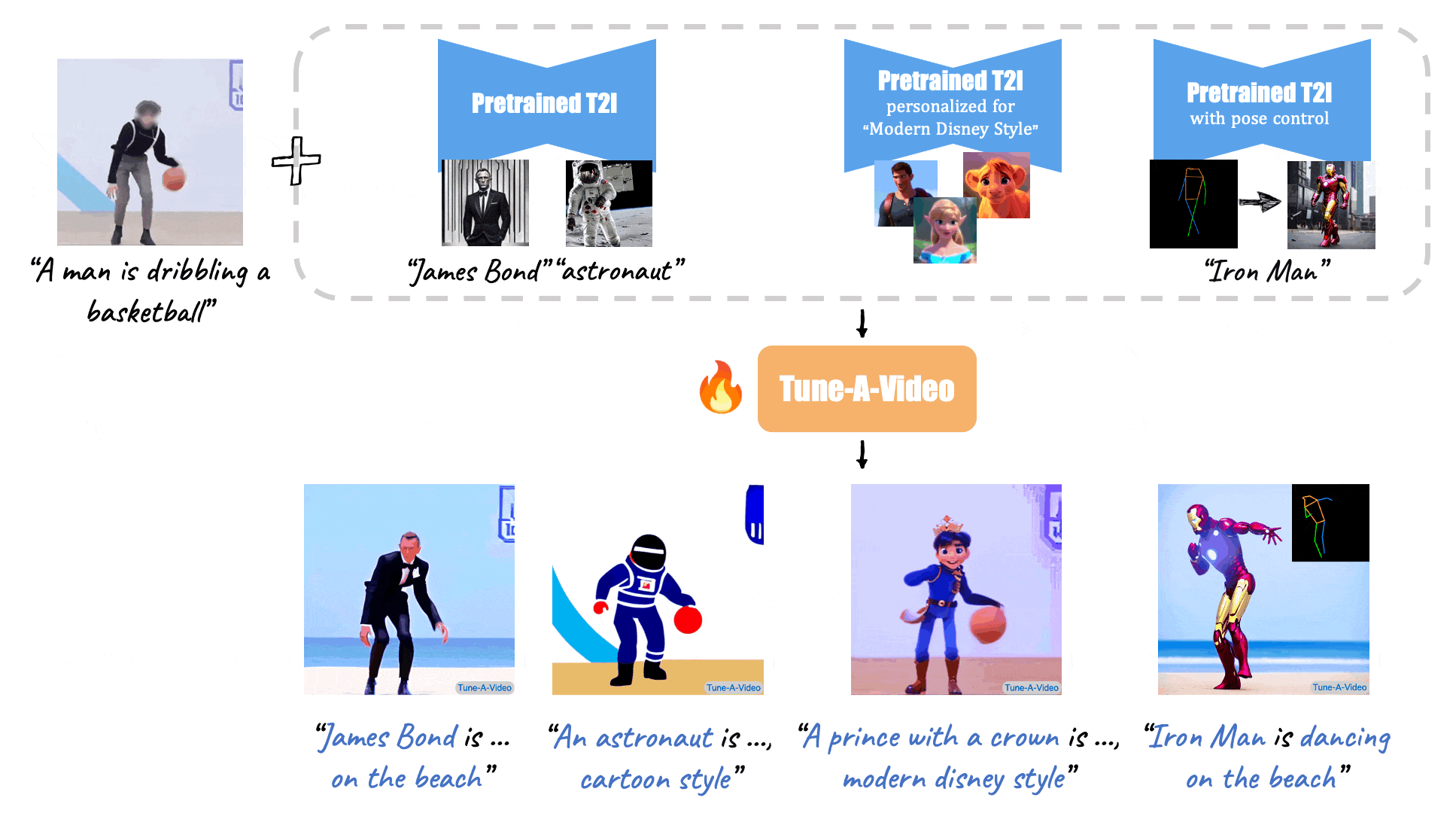


(Source: Make-A-Video, Tune-A-Video, and Fate/Zero.)
- Open-source Toolboxes and Foundation Models
- Video Generation
- Video Editing
- Long-form Video Generation and Completion
- Human or Subject Motion
- Video Enhancement and Restoration
- 3D / NeRF
- Video Understanding
- Healthcare and Biology




-
VideoComposer: Compositional Video Synthesis with Motion Controllability (May, 2023)
-
Probabilistic Adaptation of Text-to-Video Models (May, 2023)
-
Make-Your-Video: Customized Video Generation Using Textual and Structural Guidance (May, 2023)
-
Gen-L-Video: Multi-Text to Long Video Generation via Temporal Co-Denoising (May, 2023)
-
Control-A-Video: Controllable Text-to-Video Generation with Diffusion Models (May, 2023)
-
ControlVideo: Training-free Controllable Text-to-Video Generation (May, 2023)
-
Cinematic Mindscapes: High-quality Video Reconstruction from Brain Activity (May, 2023)
-
Any-to-Any Generation via Composable Diffusion (May, 2023)
-
VideoFactory: Swap Attention in Spatiotemporal Diffusions for Text-to-Video Generation (May, 2023)
-
Preserve Your Own Correlation: A Noise Prior for Video Diffusion Models (May, 2023)
-
Motion-Conditioned Diffusion Model for Controllable Video Synthesis (Apr., 2023)
-
LaMD: Latent Motion Diffusion for Video Generation (Apr., 2023)
-
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models (CVPR 2023)
-
Text2Performer: Text-Driven Human Video Generation (Apr., 2023)
-
Generative Disco: Text-to-Video Generation for Music Visualization (Apr., 2023)
-
Latent-Shift: Latent Diffusion with Temporal Shift (Apr., 2023)
-
DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion (Apr., 2023)
-
Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos (Apr., 2023)
-
Physics-Driven Diffusion Models for Impact Sound Synthesis from Videos (CVPR 2023)
-
Seer: Language Instructed Video Prediction with Latent Diffusion Models (Mar., 2023)
-
Text2video-Zero: Text-to-Image Diffusion Models Are Zero-Shot Video Generators (Mar., 2023)
-
Conditional Image-to-Video Generation with Latent Flow Diffusion Models (CVPR 2023)
-
Decomposed Diffusion Models for High-Quality Video Generation (CVPR 2023)
-
Video Probabilistic Diffusion Models in Projected Latent Space (CVPR 2023)
-
Learning 3D Photography Videos via Self-supervised Diffusion on Single Images (Feb., 2023)
-
Structure and Content-Guided Video Synthesis With Diffusion Models (Feb., 2023)
-
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation (Dec., 2022)
-
Mm-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation (CVPR 2023)
-
Magvit: Masked Generative Video Transformer (Dec., 2022)
-
VIDM: Video Implicit Diffusion Models (AAAI 2023)
-
Latent Video Diffusion Models for High-Fidelity Video Generation With Arbitrary Lengths (Nov., 2022)
-
SinFusion: Training Diffusion Models on a Single Image or Video (Nov., 2022)
-
MagicVideo: Efficient Video Generation With Latent Diffusion Models (Nov., 2022)
-
Imagen Video: High Definition Video Generation With Diffusion Models (Oct., 2022)
-
Make-A-Video: Text-to-Video Generation without Text-Video Data (ICLR 2023)
-
Diffusion Models for Video Prediction and Infilling (TMLR 2022)
-
McVd: Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation (NeurIPS 2022)
-
Video Diffusion Models (Apr., 2022)
-
Diffusion Probabilistic Modeling for Video Generation (Mar., 2022)





















-
VidEdit: Zero-Shot and Spatially Aware Text-Driven Video Editing (Jun., 2023)
-
Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation (Jun., 2023)
-
ControlVideo: Adding Conditional Control for One Shot Text-to-Video Editing (May, 2023)
-
Make-A-Protagonist: Generic Video Editing with An Ensemble of Experts (May, 2023)
-
Soundini: Sound-Guided Diffusion for Natural Video Editing (Apr., 2023)
-
Zero-Shot Video Editing Using Off-the-Shelf Image Diffusion Models (Mar., 2023)
-
Edit-A-Video: Single Video Editing with Object-Aware Consistency (Mar., 2023)
-
FateZero: Fusing Attentions for Zero-shot Text-based Video Editing (Mar., 2023)
-
Pix2video: Video Editing Using Image Diffusion (Mar., 2023)
-
Video-P2P: Video Editing with Cross-attention Control (Mar., 2023)
-
Dreamix: Video Diffusion Models Are General Video Editors (Feb., 2023)
-
Shape-Aware Text-Driven Layered Video Editing (Jan., 2023)
-
Speech Driven Video Editing via an Audio-Conditioned Diffusion Model (Jan., 2023)








-
MCVD: Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation (NeurIPS 2022)
-
NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation (Mar., 2023)
-
Flexible Diffusion Modeling of Long Videos (May, 2022)


-
Avatars Grow Legs: Generating Smooth Human Motion from Sparse Tracking Inputs with Diffusion Model (CVPR 2023)
-
InterGen: Diffusion-based Multi-human Motion Generation under Complex Interactions (Apr., 2023)
-
ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model (Apr., 2023)
-
Human Motion Diffusion as a Generative Prior (Mar., 2023)
-
Can We Use Diffusion Probabilistic Models for 3d Motion Prediction? (Feb., 2023)
-
Single Motion Diffusion (Feb., 2023)
-
HumanMAC: Masked Motion Completion for Human Motion Prediction (Feb., 2023)
-
DiffMotion: Speech-Driven Gesture Synthesis Using Denoising Diffusion Model (Jan., 2023)
-
Modiff: Action-Conditioned 3d Motion Generation With Denoising Diffusion Probabilistic Models (Jan., 2023)
-
Unifying Human Motion Synthesis and Style Transfer With Denoising Diffusion Probabilistic Models (GRAPP 2023)
-
Executing Your Commands via Motion Diffusion in Latent Space (CVPR 2023)
-
Pretrained Diffusion Models for Unified Human Motion Synthesis (Dec., 2022)
-
PhysDiff: Physics-Guided Human Motion Diffusion Model (Dec., 2022)
-
BeLFusion: Latent Diffusion for Behavior-Driven Human Motion Prediction (Dec., 2022)
-
Listen, Denoise, Action! Audio-Driven Motion Synthesis With Diffusion Models (Nov. 2022)
-
Diffusion Motion: Generate Text-Guided 3d Human Motion by Diffusion Model (ICASSP 2023)
-
Human Joint Kinematics Diffusion-Refinement for Stochastic Motion Prediction (Oct., 2022)
-
Human Motion Diffusion Model (ICLR 2023)
-
FLAME: Free-form Language-based Motion Synthesis & Editing (AAAI 2023)
-
MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model (Aug., 2022)
-
Stochastic Trajectory Prediction via Motion Indeterminacy Diffusion (CVPR 2022)














-
LDMVFI: Video Frame Interpolation with Latent Diffusion Models (Mar., 2023)
-
CaDM: Codec-aware Diffusion Modeling for Neural-enhanced Video Streaming (Nov., 2022)
-
Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields (May, 2023)
-
RoomDreamer: Text-Driven 3D Indoor Scene Synthesis with Coherent Geometry and Texture (May, 2023)
-
NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models (CVPR 2023)
-
Single-Stage Diffusion NeRF: A Unified Approach to 3D Generation and Reconstruction (Apr., 2023)
-
Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions (Mar., 2023)
-
DiffusioNeRF: Regularizing Neural Radiance Fields with Denoising Diffusion Models (Feb., 2023)
-
NerfDiff: Single-image View Synthesis with NeRF-guided Distillation from 3D-aware Diffusion (Feb., 2023)
-
DiffRF: Rendering-guided 3D Radiance Field Diffusion (CVPR 2023)



-
Exploring Diffusion Models for Unsupervised Video Anomaly Detection (Apr., 2023)
-
PDPP:Projected Diffusion for Procedure Planning in Instructional Videos (CVPR 2023)
-
DiffTAD: Temporal Action Detection with Proposal Denoising Diffusion (Mar., 2023)
-
DiffusionRet: Generative Text-Video Retrieval with Diffusion Model (Mar., 2023)
-
Refined Semantic Enhancement Towards Frequency Diffusion for Video Captioning (Nov., 2022)
-
A Generalist Framework for Panoptic Segmentation of Images and Videos (Oct., 2022)




-
Annealed Score-Based Diffusion Model for Mr Motion Artifact Reduction (Jan., 2023)
-
Feature-Conditioned Cascaded Video Diffusion Models for Precise Echocardiogram Synthesis (Mar., 2023)
-
Neural Cell Video Synthesis via Optical-Flow Diffusion (Dec., 2022)
A paper list of recent diffusion models Text-to-video generation, text guidede video editing, personality video generation, video prediction, etc.
(Source: Make-A-Video, SimDA, PYoCo, Video LDM and Tune-A-Video)
-
CelebV-Text: A Large-Scale Facial Text-Video Dataset (CVPR, 2023)
-
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation (Jul., 2023)
-
VideoFactory: Swap Attention in Spatiotemporal Diffusions for Text-to-Video Generation (May, 2023)
-
Advancing High-Resolution Video-Language Representation with Large-Scale Video Transcriptions (Nov, 2021)
-
Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval (ICCV, 2021)
-
MSR-VTT: A Large Video Description Dataset for Bridging Video and Language (CVPR, 2016)


-
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild (Dec., 2012)
-
First Order Motion Model for Image Animation (NeurIPS, 2019)
-
Learning to Generate Time-Lapse Videos Using Multi-Stage Dynamic Generative Adversarial Networks (CVPR, 2018)
-
Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation (Sep., 2023)
-
LaVie: High-Quality Video Generation with Cascaded Latent Diffusion Models (Sep., 2023)
-
Reuse and Diffuse: Iterative Denoising for Text-to-Video Generation (Sep., 2023)
-
VideoGen: A Reference-Guided Latent Diffusion Approach for High Definition Text-to-Video Generation (Sep., 2023)
-
Dysen-VDM: Empowering Dynamics-aware Text-to-Video Diffusion with Large Language Models (Aug., 2023)
-
SimDA: Simple Diffusion Adapter for Efficient Video Generation (Aug., 2023)
-
Dual-Stream Diffusion Net for Text-to-Video Generation (Aug., 2023)
-
ModelScope Text-to-Video Technical Report (Aug., 2023)
-
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation (Jul., 2023)
-
VideoFactory: Swap Attention in Spatiotemporal Diffusions for Text-to-Video Generation (May, 2023)
-
Preserve Your Own Correlation: A Noise Prior for Video Diffusion Models (May, 2023)
-
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models (CVPR 2023)
-
Latent-Shift: Latent Diffusion with Temporal Shift (Apr., 2023)
-
ED-T2V: An Efficient Training Framework for Diffusion-based Text-to-Video Generation (IJCNN, 2023)
-
MagicVideo: Efficient Video Generation With Latent Diffusion Models (Nov., 2022)
-
Imagen Video: High Definition Video Generation With Diffusion Models (Oct., 2022)
-
VideoFusion:Decomposed Diffusion Models for High-Quality Video Generation (CVPR 2023)
-
Make-A-Video: Text-to-Video Generation without Text-Video Data (ICLR 2023)
-
Latent Video Diffusion Models for High-Fidelity Video Generation With Arbitrary Lengths (Nov., 2022)
-
Video Diffusion Models (Apr., 2022)

-
Free-Bloom: Zero-Shot Text-to-Video Generator with LLM Director and LDM Animator (NeurIPS, 2023)
-
Large Language Models are Frame-level Directors for Zero-shot Text-to-Video Generation (May, 2023)
-
Text2video-Zero: Text-to-Image Diffusion Models Are Zero-Shot Video Generators (Mar., 2023)


-
Feature-Conditioned Cascaded Video Diffusion Models for Precise Echocardiogram Synthesis (May. 2023)
-
GD-VDM: Generated Depth for better Diffusion-based Video Generation (Jun. 2023)
-
VDT: An Empirical Study on Video Diffusion with Transformers (May 2023)
-
Video Probabilistic Diffusion Models in Projected Latent Space (CVPR 2023)
-
VIDM: Video Implicit Diffusion Models (AAAI 2023)


-
Animate-A-Story: Storytelling with Retrieval-Augmented Video Generation (Jul., 2023)
-
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning (Jul., 2023)
-
Make-Your-Video: Customized Video Generation Using Textual and Structural Guidance (Jun., 2023)
-
SinFusion: Training Diffusion Models on a Single Image or Video (Nov., 2022)


-
LEO: Generative Latent Image Animator for Human Video Synthesis (May., 2023)
-
DisCo: Disentangled Control for Referring Human Dance Generation in Real World (Jul., 2023)
-
Text2Performer: Text-Driven Human Video Generation (Apr., 2023)
-
Conditional Image-to-Video Generation with Latent Flow Diffusion Models (CVPR 2023)


- Generative Image Dynamics (Sep., 2023)
-
Dancing Avatar: Pose and Text-Guided Human Motion Videos Synthesis with Image Diffusion Model (Aug., 2023)
-
DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion (Apr., 2023)
-
Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos (Apr., 2023)
-
Motion-Conditioned Diffusion Model for Controllable Video Synthesis (Apr., 2023)
-
LaMD: Latent Motion Diffusion for Video Generation (Apr., 2023)
-
The Power of Sound (TPoS): Audio Reactive Video Generation with Stable Diffusion (ICCV, 2023)
-
Generative Disco: Text-to-Video Generation for Music Visualization (Apr., 2023)
-
VideoComposer: Compositional Video Synthesis with Motion Controllability (Jun., 2023)
-
Probabilistic Adaptation of Text-to-Video Models (Jun., 2023)
-
Control-A-Video: Controllable Text-to-Video Generation with Diffusion Models (May, 2023)
-
PDPP:Projected Diffusion for Procedure Planning in Instructional Videos (CVPR 2023)
-
LDMVFI: Video Frame Interpolation with Latent Diffusion Models (Mar., 2023)
-
CaDM: Codec-aware Diffusion Modeling for Neural-enhanced Video Streaming (Nov., 2022)
-
Gen-L-Video: Multi-Text to Long Video Generation via Temporal Co-Denoising (May, 2023)
-
NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation (Mar., 2023)
-
Flexible Diffusion Modeling of Long Videos (May, 2022)
-
Video Diffusion Models with Local-Global Context Guidance (IJCAI, 2023)
-
Seer: Language Instructed Video Prediction with Latent Diffusion Models (Mar., 2023)
-
Diffusion Models for Video Prediction and Infilling (TMLR 2022)
-
McVd: Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation (NeurIPS 2022)
-
Diffusion Probabilistic Modeling for Video Generation (Mar., 2022)

-
NExT-GPT: Any-to-Any Multimodal LLM (Sep, 2023)
-
MovieFactory: Automatic Movie Creation from Text using LargeGenerative Models for Language and Images (Jun, 2023)
-
Any-to-Any Generation via Composable Diffusion (May, 2023)
-
Mm-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation (CVPR 2023)
-
CCEdit: Creative and Controllable Video Editing via Diffusion Models (Sep, 2023)
-
MagicProp: Diffusion-based Video Editing via Motion-aware Appearance Propagation (Sep, 2023)
-
MagicEdit: High-Fidelity and Temporally Coherent Video Editing (Aug, 2023)
-
Edit Temporal-Consistent Videos with Image Diffusion Model (Aug, 2023)
-
Structure and Content-Guided Video Synthesis With Diffusion Models (Feb., 2023)
-
Dreamix: Video Diffusion Models Are General Video Editors (Feb., 2023)
-
StableVideo: Text-driven Consistency-aware Diffusion Video Editing (ICCV, 2023)
-
Shape-aware Text-driven Layered Video Editing (CVPR, 2023)
-
SAVE: Spectral-Shift-Aware Adaptation of Image Diffusion Models for Text-guided Video Editing (May., 2023)
-
Towards Consistent Video Editing with Text-to-Image Diffusion Models (Mar., 2023)
-
Edit-A-Video: Single Video Editing with Object-Aware Consistency (Mar., 2023)
-
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation (Dec., 2022)
-
ControlVideo: Adding Conditional Control for One Shot Text-to-Video Editing (May, 2023)
-
Video-P2P: Video Editing with Cross-attention Control (Mar., 2023)

-
MeDM: Mediating Image Diffusion Models for Video-to-Video Translation with Temporal Correspondence Guidance (Aug., 2023)
-
EVE: Efficient zero-shot text-based Video Editing with Depth Map Guidance and Temporal Consistency Constraints (Aug., 2023)
-
ControlVideo: Training-free Controllable Text-to-Video Generation (May, 2023)
-
TokenFlow: Consistent Diffusion Features for Consistent Video Editing (Jul., 2023)
-
VidEdit: Zero-Shot and Spatially Aware Text-Driven Video Editing (Jun., 2023)
-
Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation (Jun., 2023)
-
Zero-Shot Video Editing Using Off-the-Shelf Image Diffusion Models (Mar., 2023)
-
FateZero: Fusing Attentions for Zero-shot Text-based Video Editing (Mar., 2023)
-
Pix2video: Video Editing Using Image Diffusion (Mar., 2023)
-
InFusion: Inject and Attention Fusion for Multi Concept Zero Shot Text based Video Editing (Aug., 2023)

-
InstructVid2Vid: Controllable Video Editing with Natural Language Instructions (May, 2023)
-
Collaborative Score Distillation for Consistent Visual Synthesis (July, 2023)
-
Speech Driven Video Editing via an Audio-Conditioned Diffusion Model (May., 2023)
-
Soundini: Sound-Guided Diffusion for Natural Video Editing (Apr., 2023)
-
VideoControlNet: A Motion-Guided Video-to-Video Translation Framework by Using Diffusion Model with ControlNet (July, 2023)
-
Make-A-Protagonist: Generic Video Editing with An Ensemble of Experts (May, 2023)
-
Multimodal-driven Talking Face Generation via a Unified Diffusion-based Generator (May, 2023)
-
DiffSynth: Latent In-Iteration Deflickering for Realistic Video Synthesis (Aug, 2023)
-
Style-A-Video: Agile Diffusion for Arbitrary Text-based Video Style Transfer (May, 2023)
-
Instruct-Video2Avatar: Video-to-Avatar Generation with Instructions (Jun, 2023)
-
Video Colorization with Pre-trained Text-to-Image Diffusion Models (Jun, 2023)


-
INVE: Interactive Neural Video Editing (Jul., 2023)
-
Shape-Aware Text-Driven Layered Video Editing (Jan., 2023)
-
DiffusionVMR: Diffusion Model for Video Moment Retrieval (Aug., 2023)
-
DiffPose: SpatioTemporal Diffusion Model for Video-Based Human Pose Estimation (Aug., 2023)
-
Unsupervised Video Anomaly Detection with Diffusion Models Conditioned on Compact Motion Representations (ICIAP, 2023)
-
Exploring Diffusion Models for Unsupervised Video Anomaly Detection (Apr., 2023)
-
Multimodal Motion Conditioned Diffusion Model for Skeleton-based Video Anomaly Detection (ICCV, 2023)
-
Diffusion Action Segmentation (Mar., 2023)
-
DiffTAD: Temporal Action Detection with Proposal Denoising Diffusion (Mar., 2023)
-
DiffusionRet: Generative Text-Video Retrieval with Diffusion Model (Mar., 2023)
-
MomentDiff: Generative Video Moment Retrieval from Random to Real (Jul., 2023)
-
Refined Semantic Enhancement Towards Frequency Diffusion for Video Captioning (Nov., 2022)
-
A Generalist Framework for Panoptic Segmentation of Images and Videos (Oct., 2022)
-
DAVIS: High-Quality Audio-Visual Separation with Generative Diffusion Models (Jul., 2023)
-
Look Ma, No Hands! Agent-Environment Factorization of Egocentric Videos (May., 2023)
-
CaDM: Codec-aware Diffusion Modeling for Neural-enhanced Video Streaming (Mar., 2023)
-
Spatial-temporal Transformer-guided Diffusion based Data Augmentation for Efficient Skeleton-based Action Recognition (Jul., 2023)
