This project delves into enhancing Question Answering systems using Knowledge Graphs (KGs). By integrating these graphs with advanced machine learning models, we aim to improve the accuracy and efficiency of systems that answer complex questions.
- Medhasweta Sen
- Nina Ebensperger
- Nayaeun Kwon
- Dr. Amir Jafari
Abstract: This project investigates the impact of negative sampling on Knowledge Graph Embeddings (KGEs) for Knowledge Graph Question Answering (KGQA) systems. We explore various negative sampling techniques and KGE models like DistMult and ComplEx, assessing their effects across several knowledge graph benchmarks.
- Introduction
- Related Work
- Knowledge Graphs and Knowledge Graph Embeddings
- EmbedKGQA: The Question Answering Pipeline
- Experiment
- Results and Discussion
- Conclusion and Future Research Directions
Challenges Addressed:
- Complex Queries: Enhancing the ability of systems to understand and process complex queries by leveraging the structured relationships stored in Knowledge Graphs.
- Sparse Data: Improving system robustness in handling sparse data areas within databases, which are typically challenging for traditional methods.
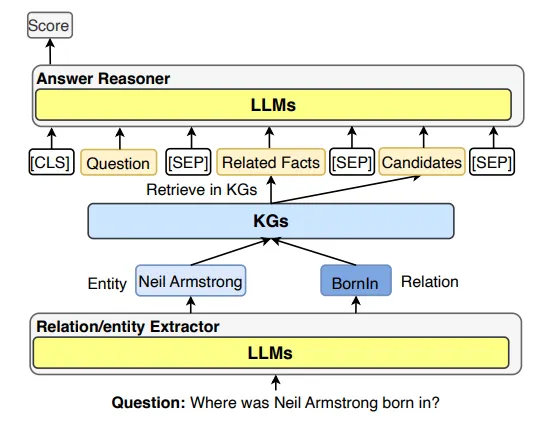
Figure: General Framework of LLMs for KGQA - adapted from Pan, S., Luo, L., Wang, Y., Chen, C., Wang, J., & Wu, X. (2023). "Unifying Large Language Models and Knowledge Graphs: A Roadmap." arXiv preprint arXiv:2306.08302. [Access here](https://arxiv.org/abs/2306.08302
The development of Knowledge Graph Question Answering (KGQA) systems has significantly advanced with the integration of Knowledge Graph Embeddings (KGEs) and Large Language Models (LLMs). This section reviews notable methodologies and models that have shaped the current landscape of KGQA, particularly focusing on their application in enhancing the effectiveness and accuracy of question answering over knowledge graphs.
Introduced by Trouillon et al. (2016), the ComplEx model employs complex-valued embeddings to handle both symmetric and antisymmetric relations effectively within knowledge graphs. This model is renowned for its use of complex numbers to enrich the representation of entities and relations, thereby allowing for the effective capture of intricate relational patterns. The ComplEx model is distinguished by its use of the Hermitian dot product to calculate the interaction between embeddings, offering a robust method for link prediction that has shown superior performance on benchmarks like FB15K and WN18 (Trouillon et al., 2016).
The DistMult model from Yang et al. (2015) simplifies the embedding process by utilizing real-valued vectors to represent entities and relations, making it highly efficient for large-scale knowledge bases. DistMult applies a diagonal matrix to model relations within its bilinear scoring function, which has been effective in tasks such as link prediction and rule mining. This model's ability to generalize several existing embedding models highlights its utility in enhancing scalability and interpretability within KGQA systems (Yang et al., 2015).
The evolution of KGQA has been marked by a shift from basic embedding models to more sophisticated, multi-dimensional approaches that accommodate complex, multi-hop queries. Early systems relied on models like TransE, which, while effective in simplifying entities and relations, often struggled with the complexity of multi-hop question answering due to their limited relational path encapsulation capabilities.
Significant enhancements in KGQA include the integration of complex vector space embeddings like ComplEx, which enable dynamic interpretation and linking of relational entities. Further advancements have incorporated methods for extracting sub-graphs from knowledge graphs, reducing computational overhead and improving accuracy by focusing on relevant graph sections.
The Embed-KGQA model, as detailed by Saxena et al. (2020), represents a synthesis of these advancements, incorporating complex embeddings and neural techniques to enhance question answering capabilities. This model employs a structured pipeline consisting of a KG Embedding Module, a Question Embedding Module, and an Answer Selection Module, each designed to optimize the accuracy and efficiency of KGQA systems on extensive knowledge bases.
While current advancements have significantly improved KGQA systems, challenges in scalability and adaptability remain. Future research may explore more adaptive models that update embeddings in real-time and integrate more detailed linguistic features to refine accuracy further.
For detailed insights and references, please consult the works of Trouillon et al., 2016, Yang et al., 2015, and Saxena et al., 2020.
Knowledge Graphs (KGs) play a pivotal role in structuring and harnessing complex data across diverse domains. Defined as a collection of triples, KG = {(h, r, t) ⊆ E × R × E}, where E represents entities and R denotes relations, these graphs store knowledge in a structured, semantically rich format. This structure not only supports advanced data integration and querying but also enhances analysis capabilities crucial for intelligent systems.
Knowledge graphs can be categorized based on the nature of the stored information:
- Encyclopedic KGs: Such as Wikidata, Freebase, and Dbpedia, which provide broad informational coverage by compiling general knowledge from extensive sources.
- Commonsense KGs: Like ConceptNet and ATOMIC, encode everyday knowledge about objects and interactions, aiding machines in understanding human concepts.
- Domain-Specific KGs: Focus on specialized fields like medicine or finance, emphasizing precision and relevance over breadth.
- Multimodal KGs: Such as IMGpedia and MMKG, integrate data across various modalities—text, images, videos—to enhance data richness and support complex applications like visual question answering.
While KGs are effective for direct queries, their structural form can limit applications requiring inferential reasoning, such as link prediction or similarity assessment. KGEs transform these entities and relationships into continuous vector spaces, enabling the use of mathematical tools to measure similarities and predict relationships. This transformation is crucial for tasks like recommendation systems or social network analysis and aids in integrating KGs with other machine learning models for enhanced NLP system performance.
Negative sampling is essential in KGE training, helping models learn to distinguish between true and potential but unobserved relationships. This process involves:
- Discriminative Learning: Learning to preferentially score true relationships higher than false ones.
- Handling Sparse Data: Addressing the sparsity of KGs by teaching models about potential non-existing relations.
- Improving Generalization: Encouraging models to generalize well by providing a variety of counterexamples.
Static Random Negative Sampling, a prevalent approach, applies the closed-world assumption, considering any triple not present in the KG as negative. However, this method faces challenges due to the inherent incompleteness of KGs and might generate incorrect negative instances, leading to errors in model training.
For a deeper understanding, refer to the works of Pan et al., 2023, Madushanka and Ichise, 2024, and other leading researchers in the field.
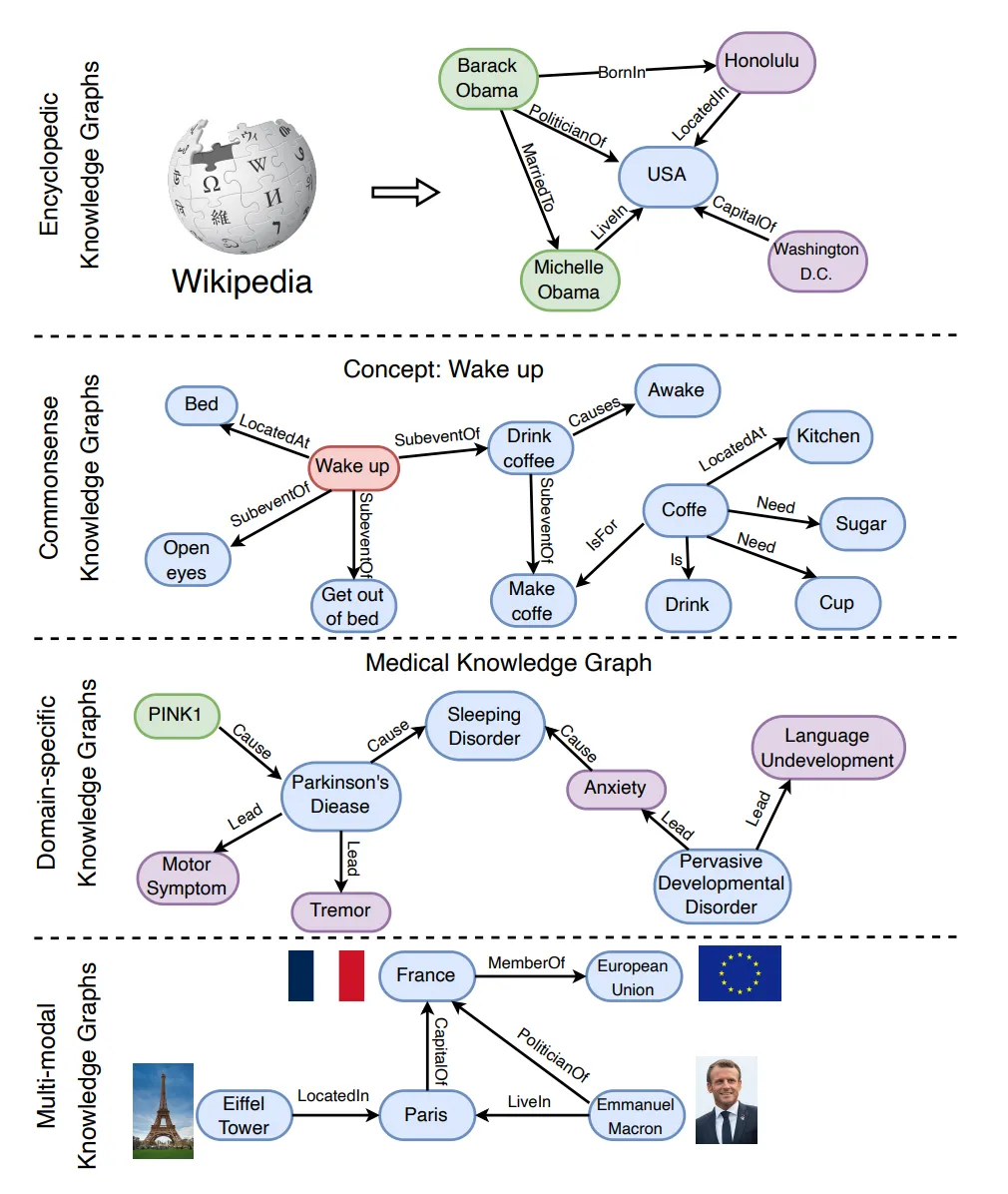
Figure: Examples of Knowledge Graph Categories - adapted from Pan, S., Luo, L., Wang, Y., Chen, C., Wang, J., & Wu, X. (2023). "Unifying Large Language Models and Knowledge Graphs: A Roadmap." arXiv preprint arXiv:2306.08302. Access here.
EmbedKGQA methodically answers complex questions using KGs through its three main modules: KG Embedding, Question Embedding, and Answer Selection. This pipeline optimizes the question answering process with advanced embedding techniques.

Figure: Overview of EmbedKGQA - adapted from Saxena, A., Tripathi, A., & Talukdar, P. (2020). "Improving Multi-hop Question Answering over Knowledge Graphs using Knowledge Base Embeddings." Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Access here.
We utilize the MetaQA dataset, a multi-hop KGQA dataset focused on the movie domain, to evaluate our KGQA system. This dataset includes extensive queries connected to a comprehensive movie knowledge graph.
This method measures the effectiveness of the EmbedKGQA system by comparing it to traditional cosine similarity approaches in text analysis.
The experiment investigates various negative sampling techniques and their impact on KGEs by employing models like ComplEx and DistMult and assessing their performance through different metrics.
The effectiveness of different KGE models under various negative sampling techniques was assessed using three key performance metrics:
- Mean Rank: Measures the average position of the correct entity in a list ranked by the model. A lower mean rank indicates better performance, as the correct entities are ranked closer to the top (Bordes et al., 2013).
- Mean Reciprocal Rank (MRR): This metric evaluates the average inverse rank of the correct entities, with higher values indicating superior model performance in ranking correct entities near the top of the list (Yang et al., 2015).
- Hits@k: Measures the percentage of correct entities that appear within the top k ranks, with higher values suggesting better retrieval performance (Yang et al., 2015).
The comparative analysis revealed that ComplEx, particularly with Random Corrupt Negative Sampling, outperformed other configurations, including DistMult. The table below summarizes the key metrics for different sampling and embedding methods:
| KGE Model | Sampling Method | Mean Rank | MRR | Hits@10 |
|---|---|---|---|---|
| ComplEx | Uniform | 397.48 | 0.2742 | 0.3664 |
| ComplEx | Random Corrupt | 357.62 | 0.2849 | 0.3886 |
| ComplEx | Batch NS | 463.07 | 0.2668 | 0.3459 |
| DistMult | Uniform | 528.17 | 0.2386 | 0.3360 |
| DistMult | Random Corrupt | 477.78 | 0.2554 | 0.3400 |
| DistMult | Batch NS | 660.01 | 0.1922 | 0.2756 |
The superior performance of ComplEx can be attributed to its ability to effectively model both symmetric and antisymmetric relations, thanks to its complex-valued embeddings. These embeddings enhance the model’s capability to distinguish between different types of relational structures, a critical factor in accurately processing complex KGQA tasks.
DistMult’s limitations stem from its symmetric scoring function, which cannot differentiate well between relational structures where directionality is crucial, such as antisymmetric relations. This fundamental difference in handling relation types is a key factor in the observed performance disparity between ComplEx and DistMult.
The findings from this study not only highlight the importance of choosing the right negative sampling technique but also underscore the potential of complex embeddings in enhancing the performance of KGQA systems.
For a more detailed exploration of these results and methodologies, refer to the studies by Trouillon et al., 2016 and Yang et al., 2015.
This study highlights the pivotal role of negative sampling in enhancing the performance of KGQA systems and suggests future research areas such as dynamic adaptation of embeddings and the integration of multimodal data.
Video Demonstration: Click here to watch
Dataset: Access the dataset here
References:
- Pan, S., Luo, L., Wang, Y., Chen, C., Wang, J., & Wu, X. (2023). Unifying Large Language Models and Knowledge Graphs: A Roadmap. arXiv preprint arXiv:2306.08302. Access here.
- Saxena, A., Tripathi, A., & Talukdar, P. (2020). Improving Multi-hop Question Answering over Knowledge Graphs using Knowledge Base Embeddings. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Access here.
- Rao, D. J., Mane, S. S., & Paliwal, M. A. (2022). Biomedical Multi-hop Question Answering Using Knowledge Graph Embeddings and Language Models. arXiv preprint arXiv:2211.05351.
- Yang, B., Yih, W., He, X., Gao, J., & Deng, L. (2015). Embedding Entities and Relations for Learning and Inference in Knowledge Bases. arXiv preprint arXiv:1412.6575.
- Bordes, A., Usunier, N., Garcia-Duran, A., Weston, J., & Yakhnenko, O. (2013). Translating Embeddings for Modeling Multi-relational Data. Neural Information Processing Systems.
- Sun, Z., Deng, Z., Nie, J., & Tang, J. (2019). RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space. arXiv preprint arXiv:1902.10197.
- Yang, M., Lee, D., Park, S., & Rim, H. (2015). Knowledge-based Question Answering Using the Semantic Embedding Space. Expert Systems with Applications, 42, 9086-9104. DOI.
- Bao, J., Duan, N., Yan, Z., Zhou, M., & Zhao, T. (2016). Constraint-Based Question Answering with Knowledge Graph. Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, 2503–2514. Access here.
- Trouillon, T., Welbl, J., Riedel, S., Gaussier, É., & Bouchard, G. (2016). Complex Embeddings for Simple Link Prediction. arXiv preprint arXiv:1606.06357.
- Bordes, A., Usunier, N., Garcia-Duran, A., Weston, J., & Yakhnenko, O. (2013). Translating Embeddings for Modeling Multi-relational Data. Advances in Neural Information Processing Systems.
- Sun, H., Dhingra, B., Wang, M., Mazaitis, K., Salakhutdinov, R., & Cohen, W. W. (2018). Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text. arXiv preprint arXiv:1809.00782.
- Sun, H., Bedrax-Weiss, T., & Cohen, W. W. (2019). PullNet: Open Domain Question Answering with Iterative Retrieval on Knowledge Bases and Text. arXiv preprint arXiv:1904.09537.
- Madushanka, T., & Ichise, R. (2024). Negative Sampling in Knowledge Graph Representation Learning: A Review. arXiv preprint arXiv:2402.19195.
- Ganesan, B., Ravikumar, A., Piplani, L., Bhaumurk, R., Padmanaban, D., Narasimhamurthy, S., Adhikary, C., & Deshapogu, S. (2024). Automated Answer Validation using Text Similarity. arXiv preprint arXiv:2401.08688.
- Yih, W., Chang, M., He, X., & Gao, J. (2015). Semantic Parsing for Single-Relation Question Answering. Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, 643–648. Access here.
- Zhang, Y., Dai, H., Kozareva, Z., Smola, A., & Song, L. (2017). Variational Reasoning for Question Answering With Knowledge Graph. Proceedings of the AAAI Conference on Artificial Intelligence, 32(1).
- Murtagh, F., & Legendre, P. (2014). Ward’s Hierarchical Agglomerative Clustering Method: Which Algorithms Implement Ward’s Criterion? Journal of Classification, 31(3), 274–295. DOI.