An on-premises, OCR-free document information extraction tool powered by vision-language models.

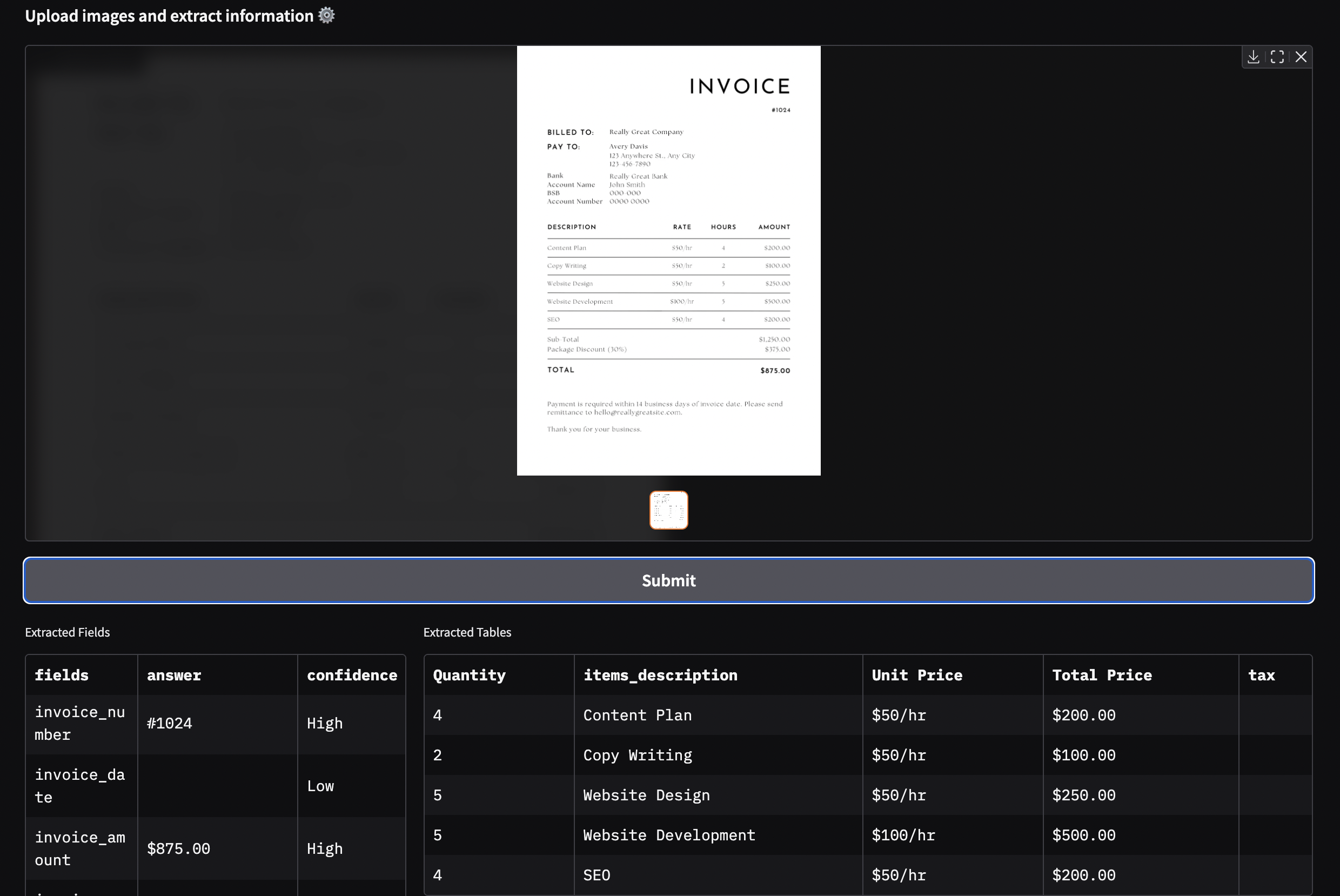
docext is an OCR-free tool for extracting structured information from documents such as invoices, passports, and other documents. It leverages vision-language models (VLMs) to accurately identify and extract both field data and tabular information from document images.
- Flexible extraction: Define custom fields or use pre-built templates
- Table extraction: Extract structured tabular data from documents
- Confidence scoring: Get confidence levels for extracted information
- On-premises deployment: Run entirely on your own infrastructure (Linux, MacOS)
- Multi-page support: Process documents with multiple pages
- REST API: Programmatic access for integration with your applications
- Pre-built templates: Ready-to-use templates for common document types:
- Invoices
- Passports
- Add/delete new fields/columns for other templates.
- Colab notebook for onprem deployment
- Colab notebook for vendor-hosted models (openai, anthropic, openrouter)
- Docker
# create a virtual environment
## install uv if not installed
curl -LsSf https://astral.sh/uv/install.sh | sh
## create a virtual environment with python 3.11
uv venv --python=3.11
source .venv/bin/activate
# Install from PyPI
uv pip install docext
# Or install from source
git clone https://github.com/nanonets/docext.git
cd docext
uv pip install -e .Check Supported Models section for more options.
docext includes a Gradio-based web interface for easy document processing:
# Start the web interface with default configs
python -m docext.app.app
# Start the web interface with custom configs
python -m docext.app.app --model_name "hosted_vllm/Qwen/Qwen2.5-VL-7B-Instruct-AWQ" --max_img_size 1024 # `--help` for more optionsThe interface will be available at http://localhost:7860 with default credentials: (You can change the port by using --ui_port flag)
- Username:
admin - Password:
admin
docext also provides a REST API for programmatic access to the document extraction functionality.
- start the API server
# increase the concurrency limit to process more requests in parallel, default is 1
python -m docext.app.app --concurrency_limit 10- use the API to extract information from a document
import pandas as pd
import concurrent.futures
from gradio_client import Client, handle_file
def dataframe_to_custom_dict(df: pd.DataFrame) -> dict:
return {
"headers": df.columns.tolist(),
"data": df.values.tolist(),
"metadata": None # Modify if metadata is needed
}
def dict_to_dataframe(d: dict) -> pd.DataFrame:
return pd.DataFrame(d["data"], columns=d["headers"])
def get_extracted_fields_and_tables(
client_url: str,
username: str,
password: str,
model_name: str,
fields_and_tables: dict,
file_inputs: list[dict]
):
client = Client(client_url, auth=(username, password))
result = client.predict(
file_inputs=file_inputs,
model_name=model_name,
fields_and_tables=fields_and_tables,
api_name="/extract_information"
)
fields_results, tables_results = result
fields_df = dict_to_dataframe(fields_results)
tables_df = dict_to_dataframe(tables_results)
return fields_df, tables_df
fields_and_tables = dataframe_to_custom_dict(pd.DataFrame([
{"name": "invoice_number", "type": "field", "description": "Invoice number"},
{"name": "item_description", "type": "table", "description": "Item/Product description"}
# add more fields and table columns as needed
]))
file_inputs = [
{
# "image": handle_file("https://your_image_url/invoice.jpg") # incase the image is hosted on the internet
"image": handle_file("assets/invoice_test.jpeg") # incase the image is hosted on the local machine
}
]
## send single request
### client url can be the local host or the public url like `https://6986bdd23daef6f7eb.gradio.live/`
fields_df, tables_df = get_extracted_fields_and_tables(
"http://localhost:7860", "admin", "admin", "hosted_vllm/Qwen/Qwen2.5-VL-7B-Instruct-AWQ", fields_and_tables, file_inputs
)
print("========Fields:=========")
print(fields_df)
print("========Tables:=========")
print(tables_df)
## send multiple requests in parallel
# Define a wrapper function for parallel execution
def run_request():
return get_extracted_fields_and_tables(
"http://localhost:7860", "admin", "admin", "hosted_vllm/Qwen/Qwen2.5-VL-7B-Instruct-AWQ", fields_and_tables, file_inputs
)
# Use ThreadPoolExecutor to send 10 requests in parallel
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
future_results = [executor.submit(run_request) for _ in range(10)]
for future in concurrent.futures.as_completed(future_results):
fields_df, tables_df = future.result()
print("========Fields:=========")
print(fields_df)
print("========Tables:=========")
print(tables_df)- Python 3.11+
- CUDA-compatible GPU (for optimal performance). Use Google Colab for free GPU access.
- Dependencies listed in requirements.txt
docext uses vision-language models for document understanding. By default, it uses: Qwen/Qwen2.5-VL-7B-Instruct-AWQ but you can use any other models supported by vLLM.
Recommended models based on GPU memory:
| Model | GPU Memory | --model_name |
|---|---|---|
| Qwen/Qwen2.5-VL-7B-Instruct-AWQ | 16GB | hosted_vllm/Qwen/Qwen2.5-VL-7B-Instruct-AWQ |
| Qwen/Qwen2.5-VL-7B-Instruct | 24GB | hosted_vllm/Qwen/Qwen2.5-VL-7B-Instruct |
| Qwen/Qwen2.5-VL-32B-Instruct-AWQ | 48GB | hosted_vllm/Qwen/Qwen2.5-VL-32B-Instruct-AWQ |
| Qwen/Qwen2.5-VL-32B-Instruct | 80 GB | hosted_vllm/Qwen/Qwen2.5-VL-32B-Instruct |
# will download the default model (Qwen/Qwen2.5-VL-7B-Instruct-AWQ) and host it on your local machine with vLLM on port 8000
python -m docext.app.app
# will download the model (Qwen/Qwen2.5-VL-32B-Instruct-AWQ) and host it on your local machine with vLLM on port 9000
python -m docext.app.app --model_name hosted_vllm/Qwen/Qwen2.5-VL-32B-Instruct-AWQ --vlm_server_port 9000
# If you already have a vLLM server running on ip <your_ip> and port <your_port>, you can use the following command:
export API_KEY=<your_api_key> # incase you have used a API key to host the model
python -m docext.app.app --model_name hosted_vllm/Qwen/Qwen2.5-VL-7B-Instruct-AWQ --vlm_server_host <your_ip> --vlm_server_port <your_port>Ollama is supported on Windows. But I have not tested it.
- Install ollama in your machine.
- Download the checkpoint
ollama pull llama3.2-vision. - Run the following command to start the ollama server.
# You can use the ollama server running on your local machine
python -m docext.app.app --model_name ollama/llama3.2-vision --max_img_size 1024
# incase you have a ollama server running on ip <your_ip> and port <your_port>
python -m docext.app.app --model_name ollama/llama3.2-vision --max_img_size 1024 --vlm_server_host <your_ip> --vlm_server_port <your_port>If you have a machine with GPU >= 16GB, change the --max_img_size to 2048.
docext supports integration with various cloud-based vision-language models.
Important: Please review each provider's data privacy policy before using their services. We recommend using local models for sensitive data.
| Provider | Model Examples | Environment Variable | Usage Example |
|---|---|---|---|
| OpenAI | gpt-4o | OPENAI_API_KEY |
--model_name gpt-4o |
| Anthropic | Claude 3 Sonnet | ANTHROPIC_API_KEY |
--model_name claude-3-sonnet-20240229 |
| OpenRouter | Meta Llama models | OPENROUTER_API_KEY |
--model_name openrouter/meta-llama/llama-4-maverick:free |
| gemini-2.0-flash | GEMINI_API_KEY |
--model_name gemini/gemini-2.0-flash |
Example usage:
export OPENROUTER_API_KEY=sk-...
python -m docext.app.app --model_name "openrouter/meta-llama/llama-4-maverick:free"- Add your huggingface token to the environment variable. Not needed if you are using the default model.
- Utilize all available GPUs or specify a particular one as needed (e.g., --gpus '"device=0"'). CPU mode is not supported; for trying out the app, we recommend using Google Colab, which offers free GPU access.
docker run --rm \
--env "HUGGING_FACE_HUB_TOKEN=<secret>" \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--network host \
--shm-size=20.24gb \
--gpus all \
nanonetsopensource/docext:v0.1.11 --model_name "hosted_vllm/Qwen/Qwen2.5-VL-7B-Instruct-AWQ"- If you are using vendor-hosted models, you can use the following command:
docker run --rm \
--env "OPENROUTER_API_KEY=<secret>" \
--network host \
nanonetsopensource/docext:v0.1.11 --model_name "openrouter/meta-llama/llama-4-maverick:free"docext is developed by Nanonets, a leader in document AI and intelligent document processing solutions. Nanonets is committed to advancing the field of document understanding through open-source contributions and innovative AI technologies. If you are looking for information extraction solutions for your business, please visit our website to learn more.
We welcome contributions! Please see contribution.md for guidelines. If you have a feature request or need support for a new model, feel free to open an issue—we'd love to discuss it further!
If you encounter any issues while using docext, please refer to our Troubleshooting guide for common problems and solutions.
This project is licensed under the Apache License 2.0 - see the LICENSE file for details.