Machine Learning Overview
Important
Please feel free to update and revise this page.
Below are extracts from https://medium.com/@dimas.wrdntx/machine-learning-for-dummies-a-beginners-guide-dee643f983b8
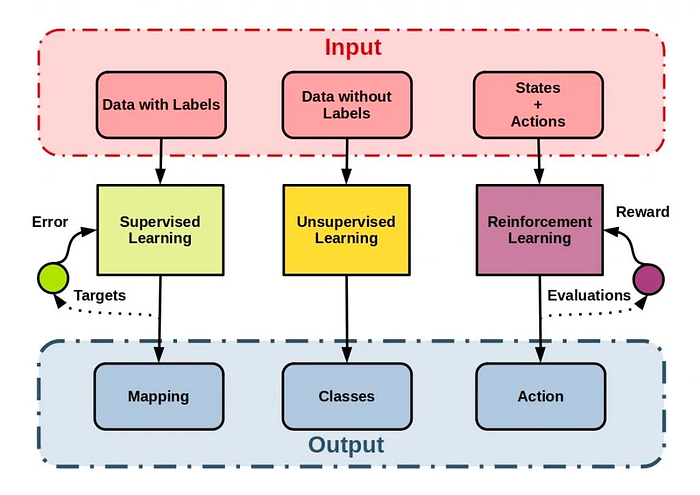
- Supervised Learning: In supervised learning, the intended output directs the learning of an algorithm using labelled training data. It entails creating an algorithm to figure out how to translate an input to a certain output. Because an algorithm learns from the training dataset is analogous to a teacher monitoring the learning process, this technique is known as “supervised” learning.
Tip
Predicting the cost of a property based on its location, size, etc. On a dataset with predetermined prices (outputs), the model is “trained” on a dataset where the prices (output) are already known
- Unsupervised Learning: In unsupervised learning, an algorithm is trained using zero labels. The system makes an effort to recognise patterns and connections in the data on its own. Consider database customer segmentation as an example. The algorithm classifies clients into categories based on traits and behaviours without knowing beforehand who belongs where.
- Reinforcement learning: It is a sort of machine learning in which an agent learns how to respond in a given environment by taking actions and observing the outcomes. Correct input/output pairings are never offered, and suboptimal behaviours are never explicitly corrected, which is how it differs from supervised learning.
Tip
Training a machine to play a video game. The machine gets better over time based on the rewards and penalties it receives as it navigates the game.
In Supervised Learning, we have a dataset consisting of both features and labels. The objective is to build an estimator that can forecast an object’s label given a collection of characteristics. A dataset of patients is a typical illustration of this. Age, blood pressure, cholesterol levels, and other characteristics may be featured in this case, and the labels may indicate whether or not the individual has heart disease.
- Data Collection: Gather a labeled dataset which will be used for training and testing.
- Preprocessing: Clean the data and maybe extract features.
- Model Selection: Choose a suitable model based on the problem at hand.
- Training: Feed the training data (features and labels) to the model.
- Evaluation: Test the model using the testing dataset and evaluate its performance using relevant metrics (accuracy, precision, recall, etc.).
There are two major types of Supervised Learning methods:
- Classification: In classification, the output variable is a category, such as “spam” or “not spam”.
- Regression: In regression, the output variable is a real or continuous value, such as “salary” or “weight”.