The official implementation of the paper "Vision Transformer Adapter for Dense Predictions".
(2022/06/09) ViT-Adapter-L yields 60.4 box AP and 52.5 mask AP on COCO test-dev.
(2022/06/04) Code and models are released.
(2022/05/17) ViT-Adapter-L yields 60.1 box AP and 52.1 mask AP on COCO test-dev.
(2022/05/12) ViT-Adapter-L reaches 85.2 mIoU on Cityscapes test set without coarse data.
(2022/05/05) ViT-Adapter-L achieves the SOTA on ADE20K val set with 60.5 mIoU!
This work investigates a simple yet powerful adapter for Vision Transformer (ViT). Unlike recent visual transformers that introduce vision-specific inductive biases into their architectures, ViT achieves inferior performance on dense prediction tasks due to lacking prior information of images. To solve this issue, we propose a Vision Transformer Adapter (ViT-Adapter), which can remedy the defects of ViT and achieve comparable performance to vision-specific models by introducing inductive biases via an additional architecture. Specifically, the backbone in our framework is a vanilla transformer that can be pre-trained with multi-modal data. When fine-tuning on downstream tasks, a modality-specific adapter is used to introduce the data and tasks' prior information into the model, making it suitable for these tasks. We verify the effectiveness of our ViT-Adapter on multiple downstream tasks, including object detection, instance segmentation, and semantic segmentation. Notably, when using HTC++, our ViT-Adapter-L yields 60.1 box AP and 52.1 mask AP on COCO test-dev, surpassing Swin-L by 1.4 box AP and 1.0 mask AP. For semantic segmentation, our ViT-Adapter-L establishes a new state-of-the-art of 60.5 mIoU on ADE20K val. We hope that the proposed ViT-Adapter could serve as an alternative for vision-specific transformers and facilitate future research.
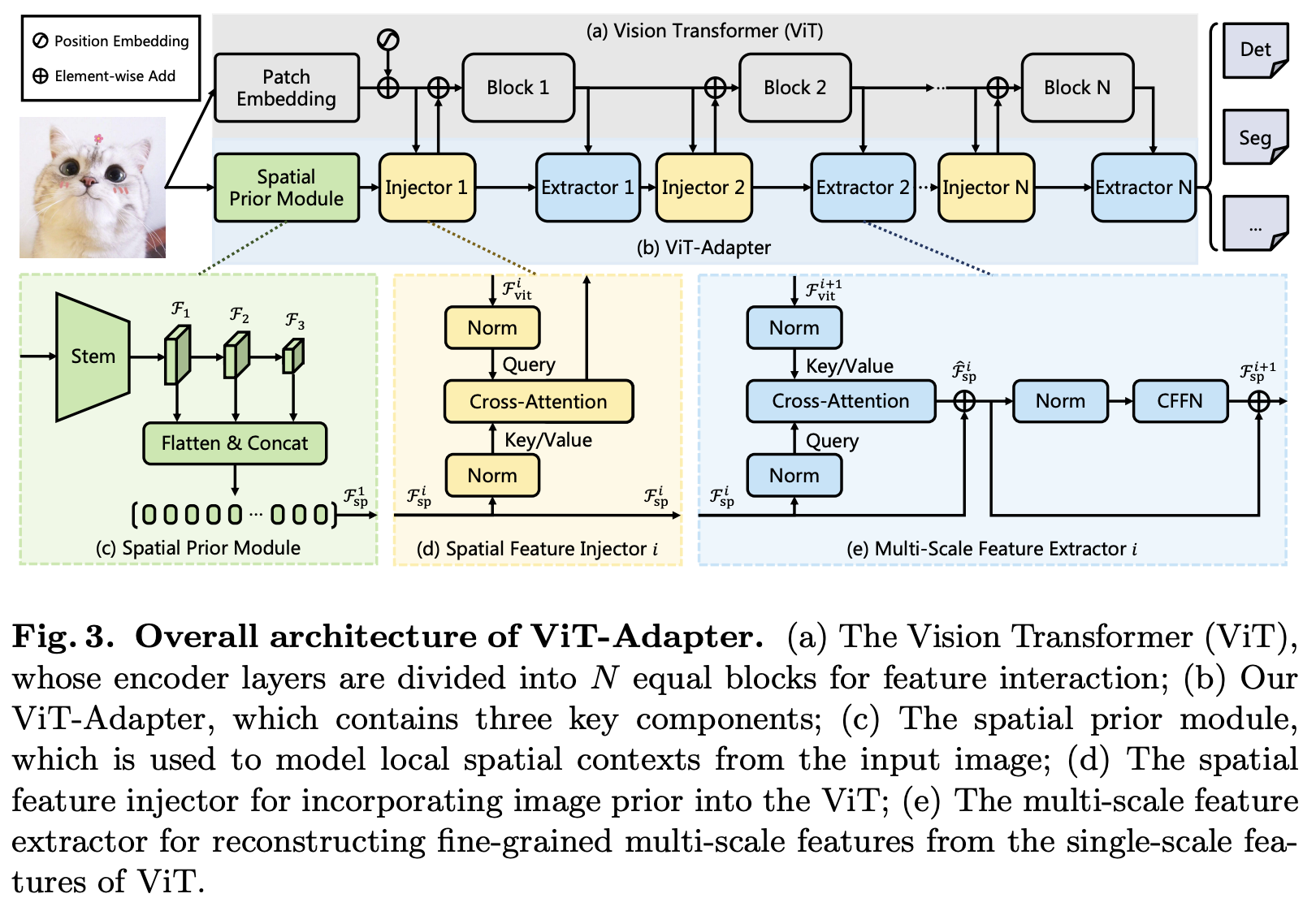

- Segmentation checkpoints
- Segmentation code
- Detection checkpoints
- Detection code
- Initialization
If this work is helpful for your research, please consider citing the following BibTeX entry.
@article{chen2022vitadapter,
title={Vision Transformer Adapter for Dense Predictions},
author={Chen, Zhe and Duan, Yuchen and Wang, Wenhai and He, Junjun and Lu, Tong and Dai, Jifeng and Qiao, Yu},
journal={arXiv preprint arXiv:2205.08534},
year={2022}
}
This repository is released under the Apache 2.0 license as found in the LICENSE file.