forked from huggingface/blog
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
AI Apps in a Flash with Gradio's Reload Mode (huggingface#1980)
* blog * Edit * Add section * Resolve comments * comment * python -> Python
- Loading branch information
1 parent
a14a6d0
commit b8e5ceb
Showing
3 changed files
with
151 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,140 @@ | ||
| --- | ||
| title: "AI Apps in a Flash with Gradio's Reload Mode" | ||
| thumbnail: /blog/assets/gradio-reload/thumbnail_compressed.png | ||
| authors: | ||
| - user: freddyaboulton | ||
| --- | ||
|
|
||
| # AI Apps in a Flash with Gradio's Reload Mode | ||
|
|
||
| In this post, I will show you how you can build a functional AI application quickly with Gradio's reload mode. But before we get to that, I want to explain what reload mode does and why Gradio implements its own auto-reloading logic. If you are already familiar with Gradio and want to get to building, please skip to the third [section](#building-a-document-analyzer-application). | ||
|
|
||
| ## What Does Reload Mode Do? | ||
|
|
||
| To put it simply, it pulls in the latest changes from your source files without restarting the Gradio server. If that does not make sense yet, please continue reading. | ||
|
|
||
| Gradio is a popular Python library for creating interactive machine learning apps. | ||
| Gradio developers declare their UI layout entirely in Python and add some Python logic that triggers whenever a UI event happens. It's easy to learn if you know basic Python. Check out this [quickstart](https://www.gradio.app/guides/quickstart) if you are not familiar with Gradio yet. | ||
|
|
||
| Gradio applications are launched like any other Python script, just run `python app.py` (the file with the Gradio code can be called anything). This will start an HTTP server that renders your app's UI and responds to user actions. If you want to make changes to your app, you stop the server (typically with `Ctrl + C`), edit your source file, and then re-run the script. | ||
|
|
||
| Having to stop and relaunch the server can introduce a lot of latency while you are developing your app. It would be better if there was a way to pull in the latest code changes automatically so you can test new ideas instantly. | ||
|
|
||
| That's exactly what Gradio's reload mode does. Simply run `gradio app.py` instead of `python app.py` to launch your app in reload mode! | ||
|
|
||
| ## Why Did Gradio Build Its Own Reloader? | ||
|
|
||
| Gradio applications are run with [uvicorn](https://www.uvicorn.org/), an asynchronous server for Python web frameworks. Uvicorn already offers [auto-reloading](https://www.uvicorn.org/) but Gradio implements its own logic for the following reasons: | ||
|
|
||
| 1. **Faster Reloading**: Uvicorn's auto-reload will shut down the server and spin it back up. This is faster than doing it by hand, but it's too slow for developing a Gradio app. Gradio developers build their UI in Python so they should see how ther UI looks as soon as a change is made. This is standard in the Javascript ecosystem but it's new to Python. | ||
| 2. **Selective Reloading**: Gradio applications are AI applications. This means they typically load an AI model into memory or connect to a datastore like a vector database. Relaunching the server during development will mean reloading that model or reconnecting to that database, which introduces too much latency between development cycles. To fix this issue, Gradio introduces an `if gr.NO_RELOAD:` code-block that you can use to mark code that should not be reloaded. This is only possible because Gradio implements its own reloading logic. | ||
|
|
||
| I will now show you how you can use Gradio reload mode to quickly build an AI App. | ||
|
|
||
| ## Building a Document Analyzer Application | ||
|
|
||
| Our application will allow users to upload pictures of documents and ask questions about them. They will receive answers in natural language. We will use the free [Hugging Face Inference API](https://huggingface.co/docs/huggingface_hub/guides/inference) so you should be able to follow along from your computer. No GPU required! | ||
|
|
||
| To get started, let's create a barebones `gr.Interface`. Enter the following code in a file called `app.py` and launch it in reload mode with `gradio app.py`: | ||
|
|
||
| ```python | ||
| import gradio as gr | ||
|
|
||
| demo = gr.Interface(lambda x: x, "text", "text") | ||
|
|
||
| if __name__ == "__main__": | ||
| demo.launch() | ||
| ``` | ||
|
|
||
| This creates the following simple UI. | ||
|
|
||
|  | ||
|
|
||
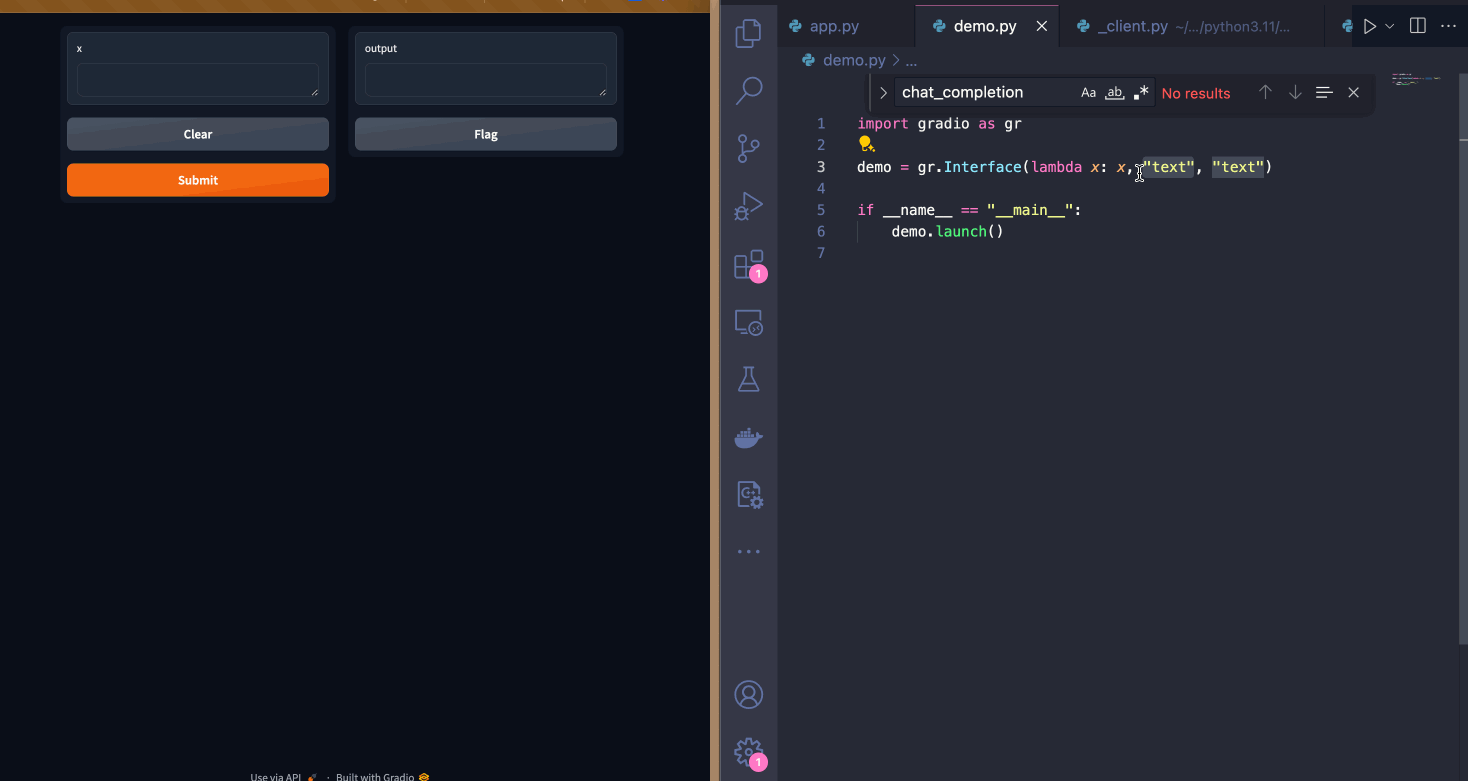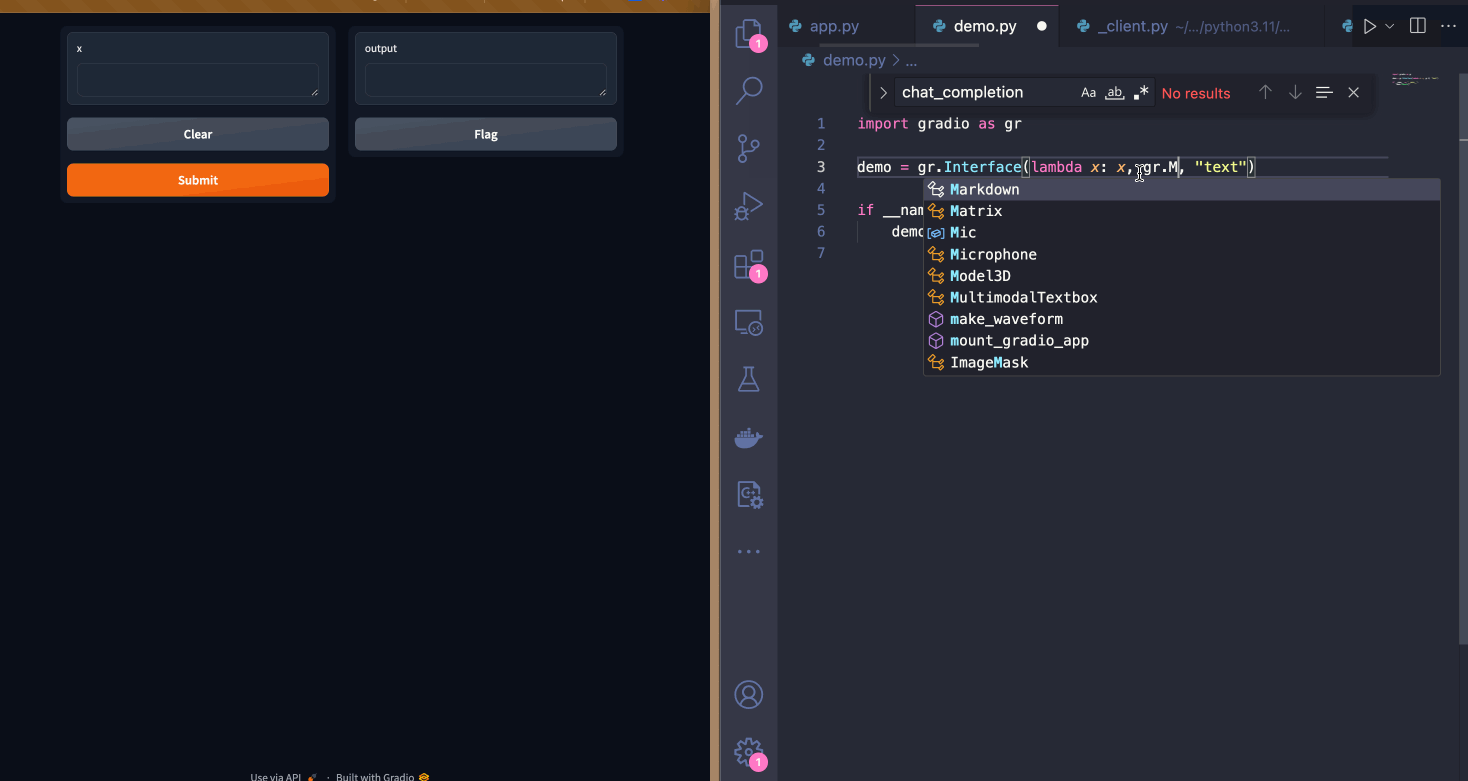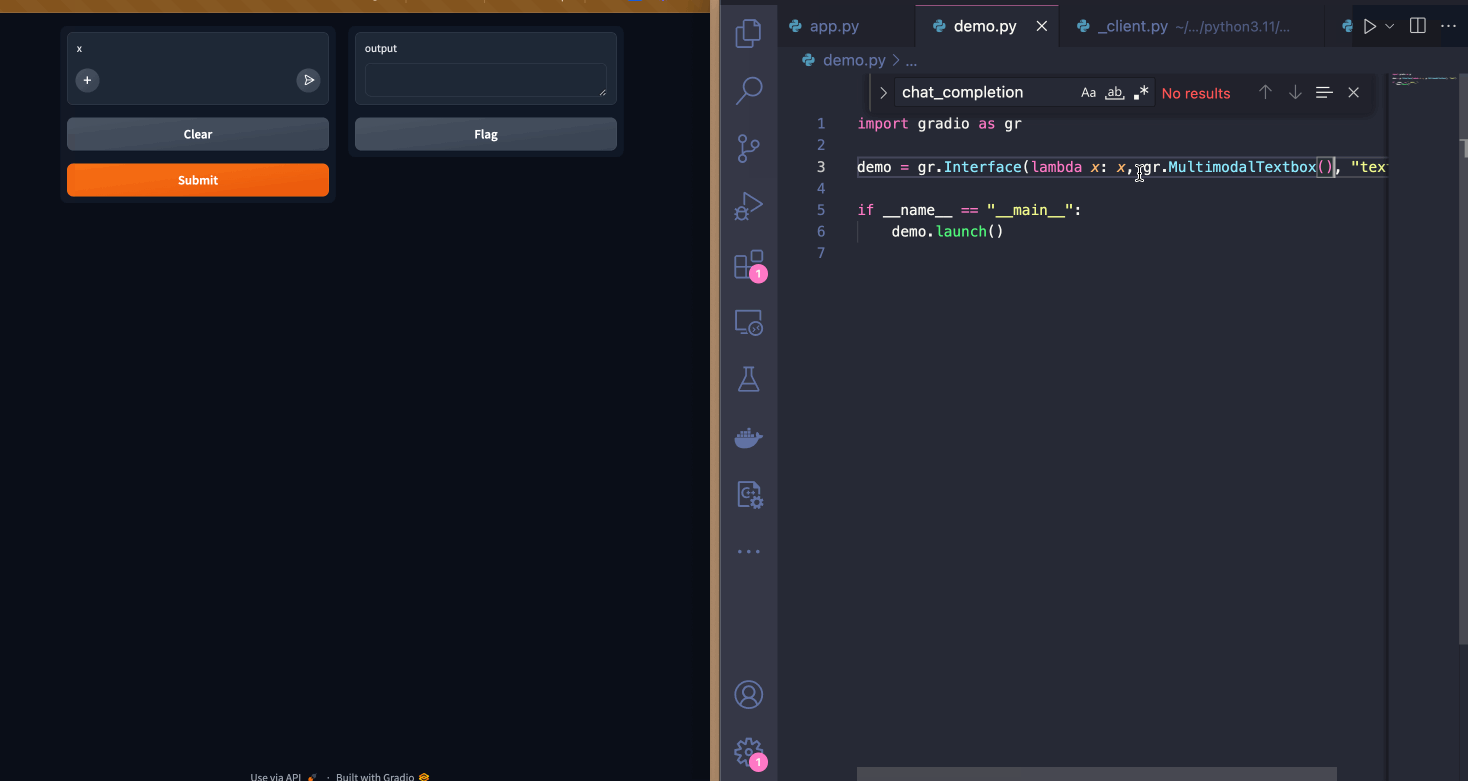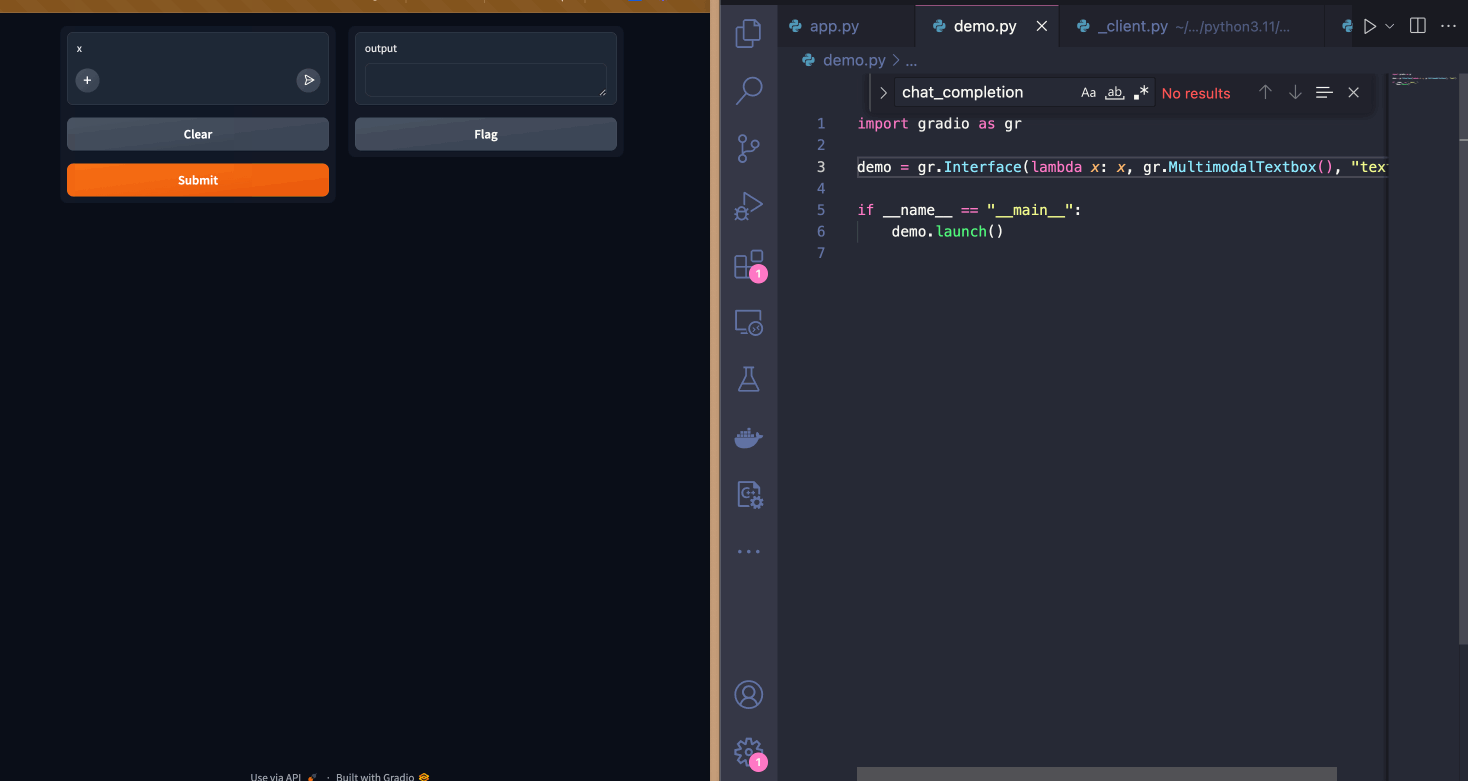
| Since I want to let users upload image files along with their questions, I will switch the input component to be a `gr.MultimodalTextbox()`. Notice how the UI updates instantly! | ||
|
|
||
|
|
||
|  | ||
|
|
||
| This UI works but, I think it would be better if the input textbox was below the output textbox. I can do this with the `Blocks` API. I'm also customizing the input textbox by adding a placeholder text to guide users. | ||
|
|
||
|
|
||
| 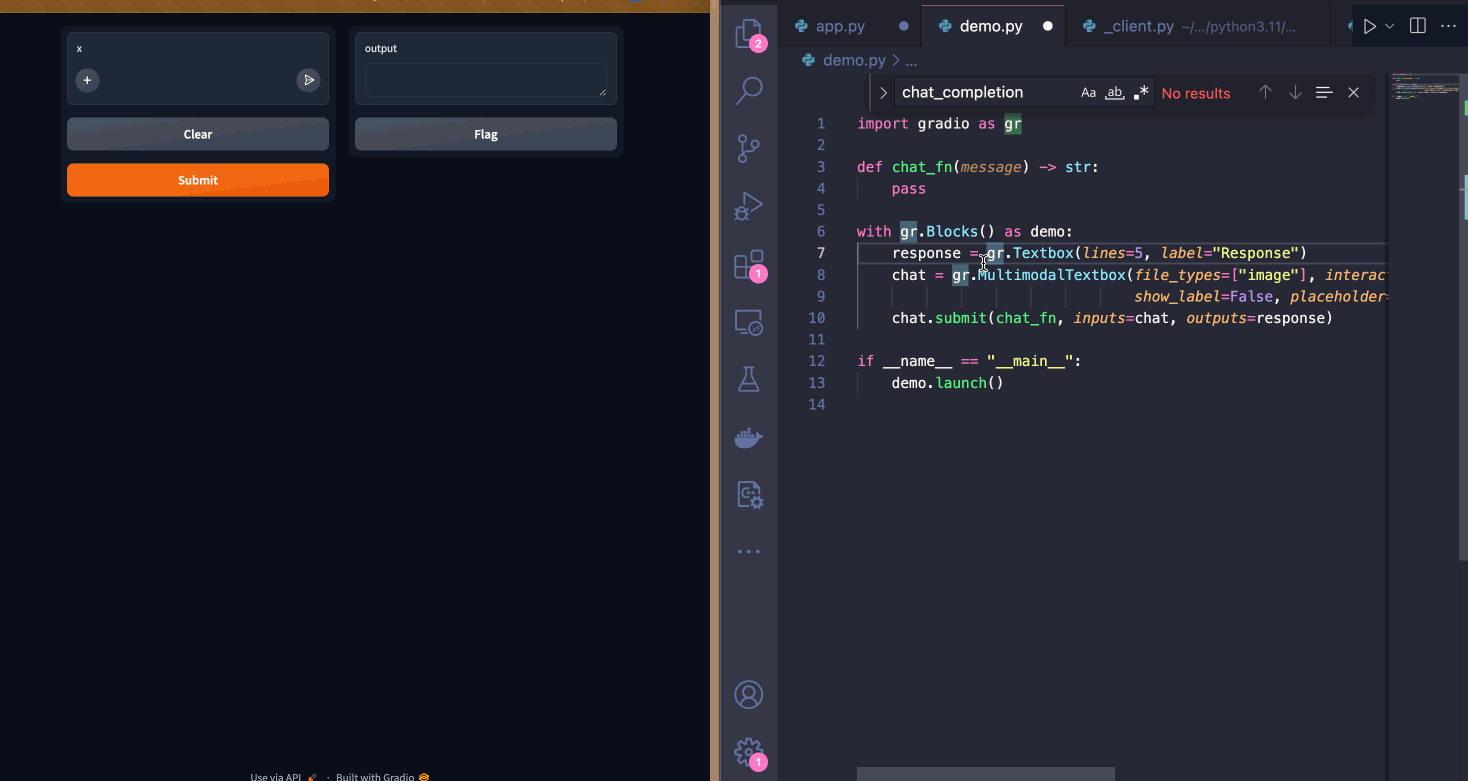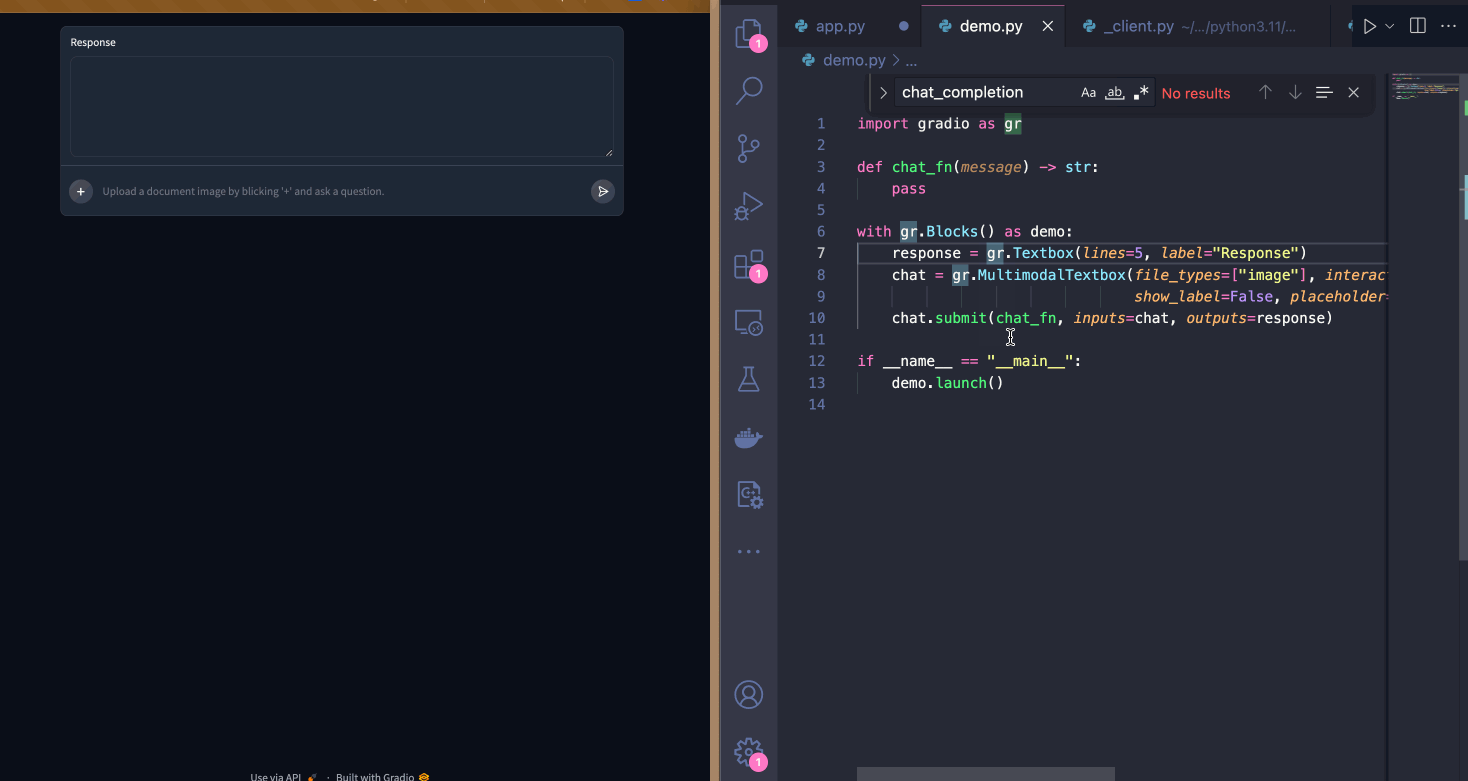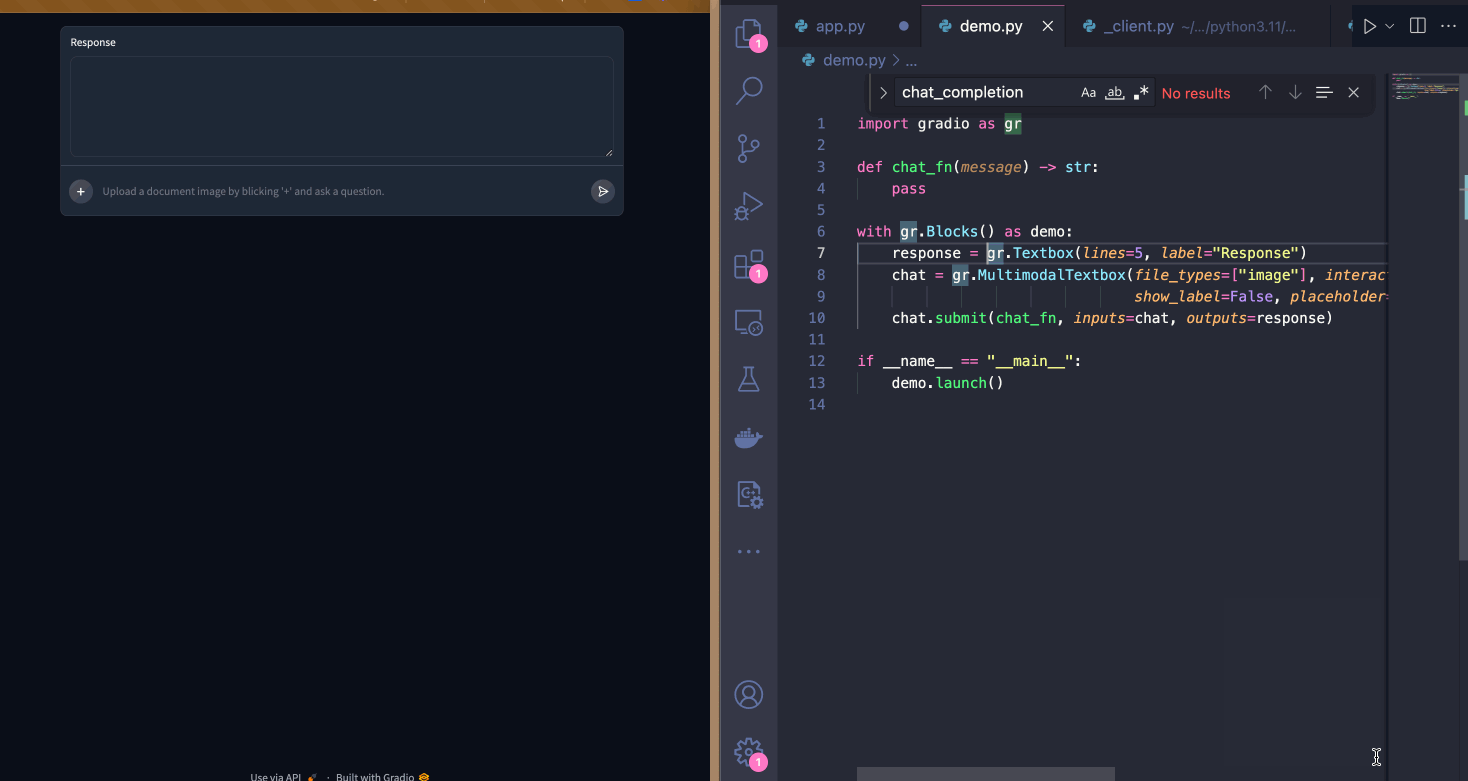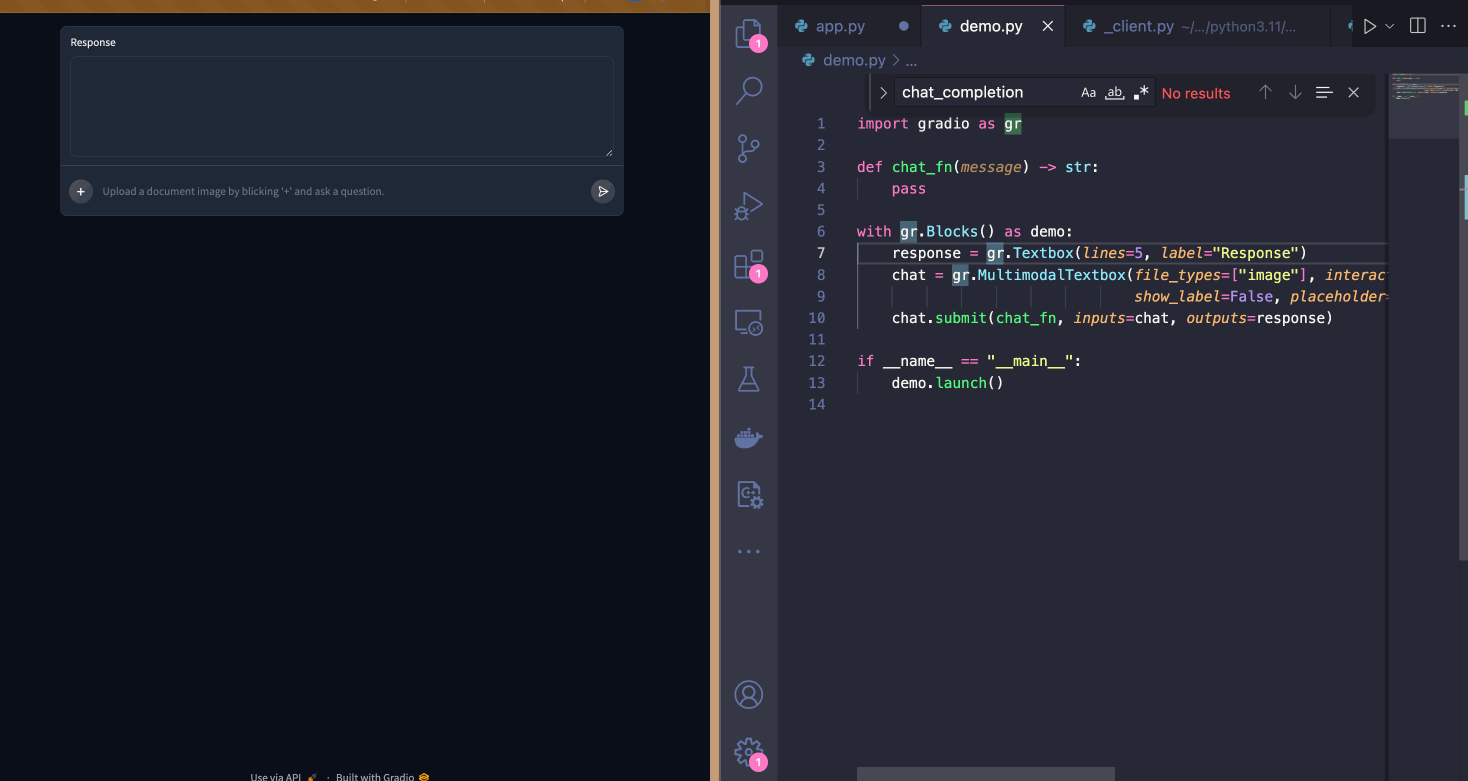 | ||
|
|
||
|
|
||
| Now that I'm satisfied with the UI, I will start implementing the logic of the `chat_fn`. | ||
|
|
||
| Since I'll be using Hugging Face's Inference API, I will import the `InferenceClient` from the `huggingface_hub` package (it comes pre-installed with Gradio). I'll be using the [`impira/layouylm-document-qa`](https://huggingface.co/impira/layoutlm-document-qa) model to answer the user's question. I will then use the [HuggingFaceH4/zephyr-7b-beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta) LLM to provide a response in natural language. | ||
|
|
||
|
|
||
| ```python | ||
| from huggingface_hub import InferenceClient | ||
|
|
||
| client = InferenceClient() | ||
|
|
||
| def chat_fn(multimodal_message): | ||
| question = multimodal_message["text"] | ||
| image = multimodal_message["files"][0] | ||
|
|
||
| answer = client.document_question_answering(image=image, question=question, model="impira/layoutlm-document-qa") | ||
|
|
||
| answer = [{"answer": a.answer, "confidence": a.score} for a in answer] | ||
|
|
||
| user_message = {"role": "user", "content": f"Question: {question}, answer: {answer}"} | ||
|
|
||
| message = "" | ||
| for token in client.chat_completion(messages=[user_message], | ||
| max_tokens=200, | ||
| stream=True, | ||
| model="HuggingFaceH4/zephyr-7b-beta"): | ||
| if token.choices[0].finish_reason is not None: | ||
| continue | ||
| message += token.choices[0].delta.content | ||
| yield message | ||
| ``` | ||
|
|
||
|
|
||
| Here is our demo in action! | ||
|
|
||
| 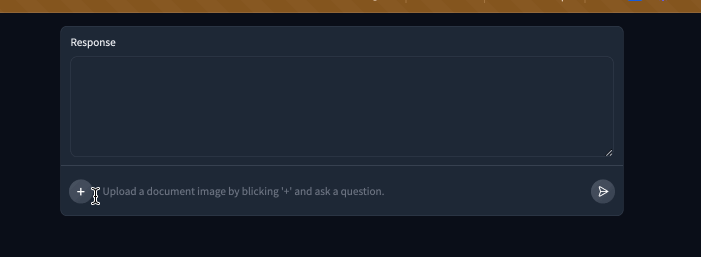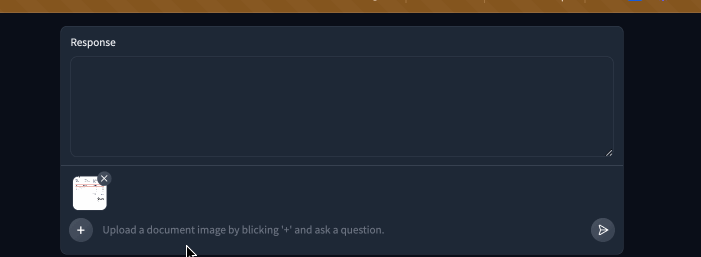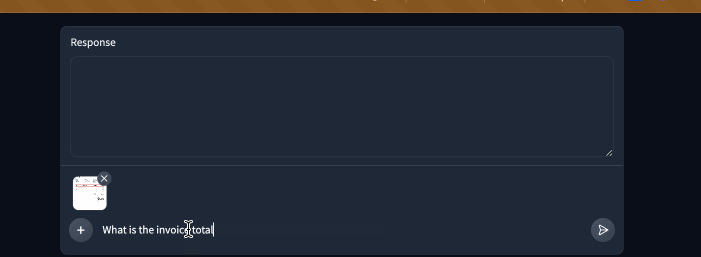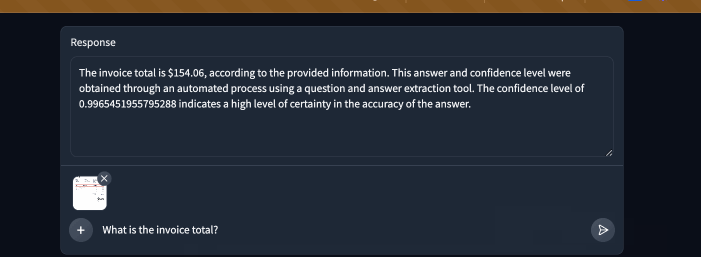 | ||
|
|
||
|
|
||
| I will also provide a system message so that the LLM keeps answers short and doesn't include the raw confidence scores. To avoid re-instantiating the `InferenceClient` on every change, I will place it inside a no reload code block. | ||
|
|
||
| ```python | ||
| if gr.NO_RELOAD: | ||
| client = InferenceClient() | ||
|
|
||
| system_message = { | ||
| "role": "system", | ||
| "content": """ | ||
| You are a helpful assistant. | ||
| You will be given a question and a set of answers along with a confidence score between 0 and 1 for each answer. | ||
| You job is to turn this information into a short, coherent response. | ||
| For example: | ||
| Question: "Who is being invoiced?", answer: {"answer": "John Doe", "confidence": 0.98} | ||
| You should respond with something like: | ||
| With a high degree of confidence, I can say John Doe is being invoiced. | ||
| Question: "What is the invoice total?", answer: [{"answer": "154.08", "confidence": 0.75}, {"answer": "155", "confidence": 0.25} | ||
| You should respond with something like: | ||
| I believe the invoice total is $154.08 but it can also be $155. | ||
| """} | ||
| ``` | ||
|
|
||
| Here is our demo in action now! The system message really helped keep the bot's answers short and free of long decimals. | ||
|
|
||
| 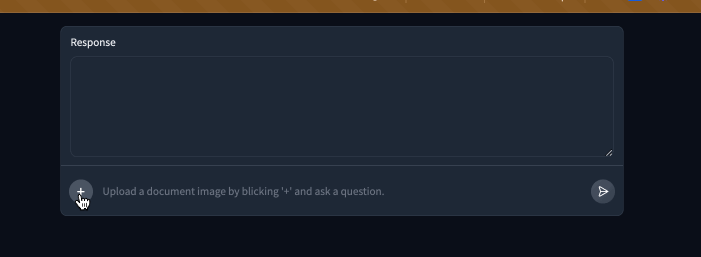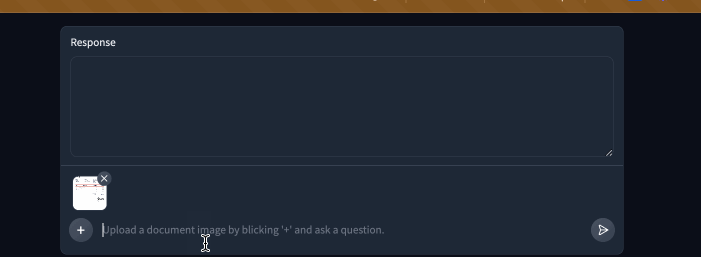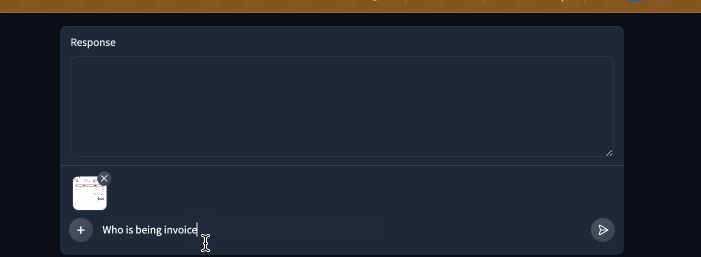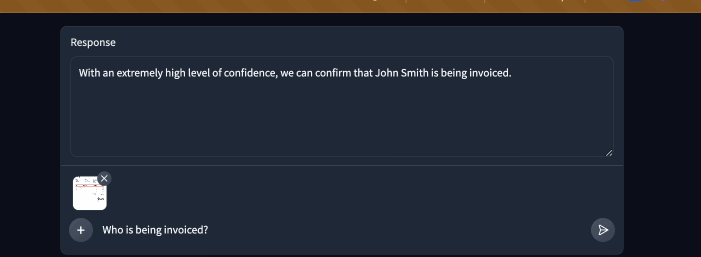 | ||
|
|
||
| As a final improvement, I will add a markdown header to the page: | ||
|
|
||
|  | ||
|
|
||
|
|
||
| ## Conclusion | ||
|
|
||
| In this post, I developed a working AI application with Gradio and the Hugging Face Inference API. When I started developing this, I didn't know what the final product would look like so having the UI and server logic reload instanty let me iterate on different ideas very quickly. It took me about an hour to develop this entire app! | ||
|
|
||
| If you'd like to see the entire code for this demo, please check out this [space](https://huggingface.co/spaces/freddyaboulton/document-analyzer/settings)! |