

Makes it easy to parallelize your calculations in pandas on all your CPUs.
pip install --upgrade parallel-pandasimport pandas as pd
import numpy as np
from parallel_pandas import ParallelPandas
#initialize parallel-pandas
ParallelPandas.initialize(n_cpu=16, split_factor=4, disable_pr_bar=True)
# create big DataFrame
df = pd.DataFrame(np.random.random((1_000_000, 100)))
# calculate multiple quantiles. Pandas only uses one core of CPU
%%timeit
res = df.quantile(q=[.25, .5, .95], axis=1)3.66 s ± 31.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
#p_quantile is parallel analogue of quantile methods. Can use all cores of your CPU.
%%timeit
res = df.p_quantile(q=[.25, .5, .95], axis=1)679 ms ± 10.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
As you can see the p_quantile method is 5 times faster!
Under the hood, parallel-pandas works very simply. The Dataframe or Series is split into chunks along the first or second axis. Then these chunks are passed to a pool of processes or threads where the desired method is executed on each part. At the end, the parts are concatenated to get the final result.
When initializing parallel-pandas you can specify the following options:
n_cpu- the number of cores of your CPU that you want to use (defaultNone- use all cores of CPU)split_factor- Affects the number of chunks into which the DataFrame/Series is split according to the formulachunks_number = split_factor*n_cpu(default 1).show_vmem- Shows a progress bar with available RAM (defaultFalse)disable_pr_bar- Disable the progress bar for parallel tasks (defaultFalse)
For example
import pandas as pd
import numpy as np
from parallel_pandas import ParallelPandas
#initialize parallel-pandas
ParallelPandas.initialize(n_cpu=16, split_factor=4, disable_pr_bar=False)
# create big DataFrame
df = pd.DataFrame(np.random.random((1_000_000, 100)))
During initialization, we specified split_factor=4 and n_cpu = 16, so the DataFrame will be split into 64 chunks (in the case of the describe method, axis = 1) and the progress bar shows the progress for each chunk
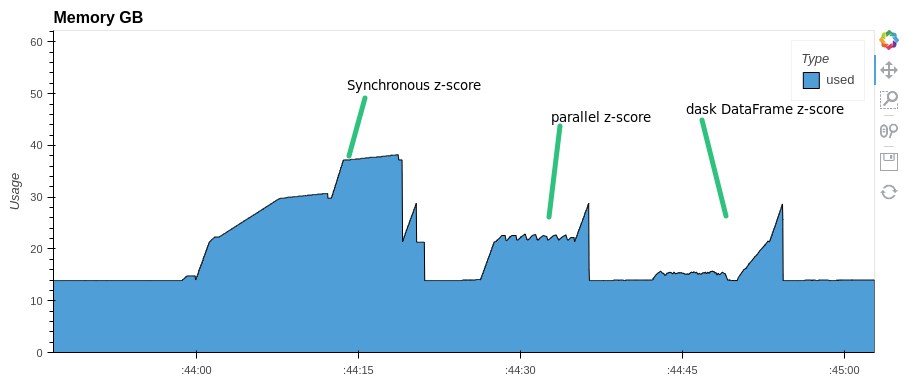
You can parallelize any expression with pandas Dataframe. For example, let's do a z-score normalization of columns in a dataframe. Let's look at the execution time and memory consumption. Compare with synchronous execution and with Dask.DataFrame
import pandas as pd
import numpy as np
from parallel_pandas import ParallelPandas
import dask.dataframe as dd
from time import monotonic
#initialize parallel-pandas
ParallelPandas.initialize(n_cpu=16, split_factor=8, disable_pr_bar=True)
# create big DataFrame
df = pd.DataFrame(np.random.random((1_000_000, 1000)))
# create dask DataFrame
ddf = dd.from_pandas(df, npartitions=128)
start = monotonic()
res=(df-df.mean())/df.std()
print(f'synchronous z-score normalization time took: {monotonic()-start:.1f} s.')synchronous z-score normalization time took: 21.7 s.#parallel-pandas
start = monotonic()
res=(df-df.p_mean())/df.p_std()
print(f'parallel z-score normalization time took: {monotonic()-start:.1f} s.')parallel z-score normalization time took: 11.7 s.#dask dataframe
start = monotonic()
res=((ddf-ddf.mean())/ddf.std()).compute()
print(f'dask parallel z-score normalization time took: {monotonic()-start:.1f} s.')dask parallel z-score normalization time took: 12.5 s.Pay attention to memory consumption. parallel-pandas and dask use almost half as much RAM as pandas
For some methods parallel-pandas is faster than dask.DataFrame:
#dask
%%time
res = ddf.nunique().compute()
Wall time: 42.9 s
%%time
res = ddf.rolling(10).mean().compute()
Wall time: 19.1 s
#parallel-pandas
%%time
res = df.p_nunique()
Wall time: 12.9 s
%%time
res = df.rolling(10).p_mean()
Wall time: 12.5 s| methods | parallel analogue | executor |
|---|---|---|
| pd.Series.apply() | pd.Series.p_apply() | threads / processes |
| pd.Series.map() | pd.Series.p_map() | threads / processes |
| methods | parallel analogue | executor |
|---|---|---|
| pd.SeriesGroupBy.apply() | pd.SeriesGroupBy.p_apply() | threads / processes |
| methods | parallel analogue | executor |
|---|---|---|
| df.mean() | df.p_mean() | threads |
| df.min() | df.p_min() | threads |
| df.max() | df.p_max() | threads |
| df.median() | df.p_max() | threads |
| df.kurt() | df.p_kurt() | threads |
| df.skew() | df.p_skew() | threads |
| df.sum() | df.p_sum() | threads |
| df.prod() | df.p_prod() | threads |
| df.var() | df.p_var() | threads |
| df.sem() | df.p_sem() | threads |
| df.std() | df.p_std() | threads |
| df.cummin() | df.p_cummin() | threads |
| df.cumsum() | df.p_cumsum() | threads |
| df.cummax() | df.p_cummax() | threads |
| df.cumprod() | df.p_cumprod() | threads |
| df.apply() | df.p_apply() | threads / processes |
| df.applymap() | df.p_applymap() | processes |
| df.replace() | df.p_replace() | threads |
| df.describe() | df.p_describe() | threads |
| df.nunique() | df.p_nunique() | threads / processes |
| df.mad() | df.p_mad() | threads |
| df.idxmin() | df.p_idxmin() | threads |
| df.idxmax() | df.p_idxmax() | threads |
| df.rank() | df.p_rank() | threads |
| df.mode() | df.p_mode() | threads/processes |
| df.agg() | df.p_agg() | threads/processes |
| df.aggregate() | df.p_aggregate() | threads/processes |
| df.quantile() | df.p_quantile() | threads/processes |
| df.corr() | df.p_corr() | threads/processes |
| methods | parallel analogue | executor |
|---|---|---|
| DataFrameGroupBy.apply() | DataFrameGroupBy.p_apply() | threads / processes |
| methods | parallel analogue | executor |
|---|---|---|
| pd.core.window.Rolling.apply() | pd.core.window.Rolling.p_apply() | threads / processes |
| pd.core.window.Rolling.min() | pd.core.window.Rolling.p_min() | threads / processes |
| pd.core.window.Rolling.max() | pd.core.window.Rolling.p_max() | threads / processes |
| pd.core.window.Rolling.mean() | pd.core.window.Rolling.p_mean() | threads / processes |
| pd.core.window.Rolling.sum() | pd.core.window.Rolling.p_sum() | threads / processes |
| pd.core.window.Rolling.var() | pd.core.window.Rolling.p_var() | threads / processes |
| pd.core.window.Rolling.sem() | pd.core.window.Rolling.p_sem() | threads / processes |
| pd.core.window.Rolling.skew() | pd.core.window.Rolling.p_skew() | threads / processes |
| pd.core.window.Rolling.kurt() | pd.core.window.Rolling.p_kurt() | threads / processes |
| pd.core.window.Rolling.median() | pd.core.window.Rolling.p_median() | threads / processes |
| pd.core.window.Rolling.quantile() | pd.core.window.Rolling.p_quantile() | threads / processes |
| pd.core.window.Rolling.rank() | pd.core.window.Rolling.p_rank() | threads / processes |
| pd.core.window.Rolling.agg() | pd.core.window.Rolling.p_agg() | threads / processes |
| pd.core.window.Rolling.aggregate() | pd.core.window.Rolling.p_aggregate() | threads / processes |
| methods | parallel analogue | executor |
|---|---|---|
| pd.core.window.Window.mean() | pd.core.window.Window.p_mean() | threads / processes |
| pd.core.window.Window.sum() | pd.core.window.Window.p_sum() | threads / processes |
| pd.core.window.Window.var() | pd.core.window.Window.p_var() | threads / processes |
| pd.core.window.Window.std() | pd.core.window.Window.p_std() | threads / processes |
| methods | parallel analogue | executor |
|---|---|---|
| pd.core.window.RollingGroupby.apply() | pd.core.window.RollingGroupby.p_apply() | threads / processes |
| pd.core.window.RollingGroupby.min() | pd.core.window.RollingGroupby.p_min() | threads / processes |
| pd.core.window.RollingGroupby.max() | pd.core.window.RollingGroupby.p_max() | threads / processes |
| pd.core.window.RollingGroupby.mean() | pd.core.window.RollingGroupby.p_mean() | threads / processes |
| pd.core.window.RollingGroupby.sum() | pd.core.window.RollingGroupby.p_sum() | threads / processes |
| pd.core.window.RollingGroupby.var() | pd.core.window.RollingGroupby.p_var() | threads / processes |
| pd.core.window.RollingGroupby.sem() | pd.core.window.RollingGroupby.p_sem() | threads / processes |
| pd.core.window.RollingGroupby.skew() | pd.core.window.RollingGroupby.p_skew() | threads / processes |
| pd.core.window.RollingGroupby.kurt() | pd.core.window.RollingGroupby.p_kurt() | threads / processes |
| pd.core.window.RollingGroupby.median() | pd.core.window.RollingGroupby.p_median() | threads / processes |
| pd.core.window.RollingGroupby.quantile() | pd.core.window.RollingGroupby.p_quantile() | threads / processes |
| pd.core.window.RollingGroupby.rank() | pd.core.window.RollingGroupby.p_rank() | threads / processes |
| pd.core.window.RollingGroupby.agg() | pd.core.window.RollingGroupby.p_agg() | threads / processes |
| pd.core.window.RollingGroupby.aggregate() | pd.core.window.RollingGroupby.p_aggregate() | threads / processes |
| methods | parallel analogue | executor |
|---|---|---|
| pd.core.window.Expanding.apply() | pd.core.window.Expanding.p_apply() | threads / processes |
| pd.core.window.Expanding.min() | pd.core.window.Expanding.p_min() | threads / processes |
| pd.core.window.Expanding.max() | pd.core.window.Expanding.p_max() | threads / processes |
| pd.core.window.Expanding.mean() | pd.core.window.Expanding.p_mean() | threads / processes |
| pd.core.window.Expanding.sum() | pd.core.window.Expanding.p_sum() | threads / processes |
| pd.core.window.Expanding.var() | pd.core.window.Expanding.p_var() | threads / processes |
| pd.core.window.Expanding.sem() | pd.core.window.Expanding.p_sem() | threads / processes |
| pd.core.window.Expanding.skew() | pd.core.window.Expanding.p_skew() | threads / processes |
| pd.core.window.Expanding.kurt() | pd.core.window.Expanding.p_kurt() | threads / processes |
| pd.core.window.Expanding.median() | pd.core.window.Expanding.p_median() | threads / processes |
| pd.core.window.Expanding.quantile() | pd.core.window.Expanding.p_quantile() | threads / processes |
| pd.core.window.Expanding.rank() | pd.core.window.Expanding.p_rank() | threads / processes |
| pd.core.window.Expanding.agg() | pd.core.window.Expanding.p_agg() | threads / processes |
| pd.core.window.Expanding.aggregate() | pd.core.window.Expanding.p_aggregate() | threads / processes |
| methods | parallel analogue | executor |
|---|---|---|
| pd.core.window.ExpandingGroupby.apply() | pd.core.window.ExpandingGroupby.p_apply() | threads / processes |
| pd.core.window.ExpandingGroupby.min() | pd.core.window.ExpandingGroupby.p_min() | threads / processes |
| pd.core.window.ExpandingGroupby.max() | pd.core.window.ExpandingGroupby.p_max() | threads / processes |
| pd.core.window.ExpandingGroupby.mean() | pd.core.window.ExpandingGroupby.p_mean() | threads / processes |
| pd.core.window.ExpandingGroupby.sum() | pd.core.window.ExpandingGroupby.p_sum() | threads / processes |
| pd.core.window.ExpandingGroupby.var() | pd.core.window.ExpandingGroupby.p_var() | threads / processes |
| pd.core.window.ExpandingGroupby.sem() | pd.core.window.ExpandingGroupby.p_sem() | threads / processes |
| pd.core.window.ExpandingGroupby.skew() | pd.core.window.ExpandingGroupby.p_skew() | threads / processes |
| pd.core.window.ExpandingGroupby.kurt() | pd.core.window.ExpandingGroupby.p_kurt() | threads / processes |
| pd.core.window.ExpandingGroupby.median() | pd.core.window.ExpandingGroupby.p_median() | threads / processes |
| pd.core.window.ExpandingGroupby.quantile() | pd.core.window.ExpandingGroupby.p_quantile() | threads / processes |
| pd.core.window.ExpandingGroupby.rank() | pd.core.window.ExpandingGroupby.p_rank() | threads / processes |
| pd.core.window.ExpandingGroupby.agg() | pd.core.window.ExpandingGroupby.p_agg() | threads / processes |
| pd.core.window.ExpandingGroupby.aggregate() | pd.core.window.ExpandingGroupby.p_aggregate() | threads / processes |
| methods | parallel analogue | executor |
|---|---|---|
| pd.core.window.ExponentialMovingWindow.mean() | pd.core.window.ExponentialMovingWindow.p_mean() | threads / processes |
| pd.core.window.ExponentialMovingWindow.sum() | pd.core.window.ExponentialMovingWindow.p_sum() | threads / processes |
| pd.core.window.ExponentialMovingWindow.var() | pd.core.window.ExponentialMovingWindow.p_var() | threads / processes |
| pd.core.window.ExponentialMovingWindow.std() | pd.core.window.ExponentialMovingWindow.p_std() | threads / processes |
| methods | parallel analogue | executor |
|---|---|---|
| pd.core.window.ExponentialMovingWindowGroupby.mean() | pd.core.window.ExponentialMovingWindowGroupby.p_mean() | threads / processes |
| pd.core.window.ExponentialMovingWindowGroupby.sum() | pd.core.window.ExponentialMovingWindowGroupby.p_sum() | threads / processes |
| pd.core.window.ExponentialMovingWindowGroupby.var() | pd.core.window.ExponentialMovingWindowGroupby.p_var() | threads / processes |
| pd.core.window.ExponentialMovingWindowGroupby.std() | pd.core.window.ExponentialMovingWindowGroupby.p_std() | threads / processes |