{kind=link}
{kind=link}
{kind=link}
This is the official PyTorch implementation of our work: "Modeling the Background for Incremental Learning in Semantic Segmentation" accepted at CVPR 2020.
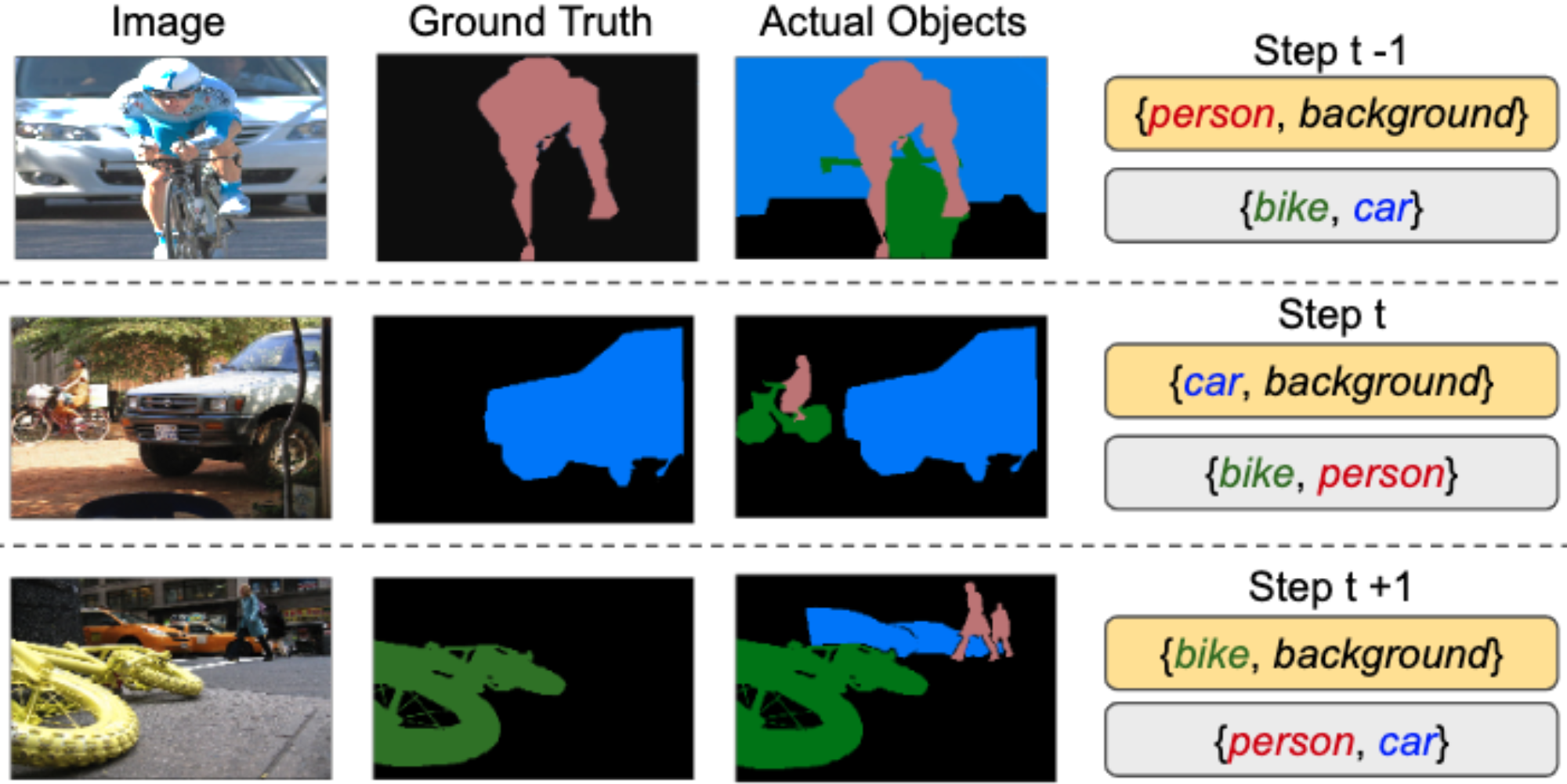
In this paper, we present a novel approach and we define a new evaluation benchmark for incremental learning in semantic segmentation. We asses the performance of our method and previous state-of-the-art methods on Pascal-VOC 2012 and ADE20K datasets.
This repository uses the following libraries:
- Python (3.6)
- Pytorch (1.2)
- torchvision (0.4.0)
- tensorboardX (1.8)
- apex (0.1)
- matplotlib (3.3.1)
- numpy (1.17.2)
- inplace-abn (1.0.7)
We also assume to have installed pytorch.distributed package.
To facilitate your work in installing all dependencies, we provide you the requirement (requirements.txt) file.
In this project we use two dataset, ADE20K and Pascal-VOC 2012. We provide the scripts to download them in 'data/download_<dataset_name>.sh'. The script takes no inputs but use it in the target directory (where you want to download data).
The most important file is run.py, that is in charge to start the training or test procedure. To run it, simpy use the following command:
python -m torch.distributed.launch --nproc_per_node=<num_GPUs> run.py --data_root <data_folder> --name <exp_name> .. other args ..
The default is to use a pretraining for the backbone used, that is searched in the pretrained folder of the project. We used the pretrained model released by the authors of In-place ABN (as said in the paper), that can be found here: link. Since the pretrained are made on multiple-gpus, they contain a prefix "module." in each key of the network. Please, be sure to remove them to be compatible with this code (simply rename them using key = key[7:]). If you don't want to use pretrained, please use --no-pretrained.
There are many options (you can see them all by using --help option), but we arranged the code to being straightforward to test the reported methods. Leaving all the default parameters, you can replicate the experiments by setting the following options.
- please specify the data folder using: --data_root <data_root>
- dataset: --dataset voc (Pascal-VOC 2012) | ade (ADE20K)
- task: --task <task>, where tasks are
- 15-5, 15-5s, 19-1 (VOC), 100-50, 100-10, 50, 100-50b, 100-10b, 50b (ADE, b indicates the order)
- step (each step is run separately): --step <N>, where N is the step number, starting from 0
- (only for Pascal-VOC) disjoint is default setup, to enable overlapped: --overlapped
- learning rate: --lr 0.01 (for step 0) | 0.001 (for step > 0)
- batch size: --batch_size <24/num_GPUs>
- epochs: --epochs 30 (Pascal-VOC 2012) | 60 (ADE20K)
- method: --method <method name>, where names are
- FT, LWF, LWF-MC, ILT, EWC, RW, PI, MIB
For all details please follow the information provided using the help option.
LwF on the 100-50 setting of ADE20K, step 0:
python -m torch.distributed.launch --nproc_per_node=2 run.py --data_root data --batch_size 12 --dataset ade --name LWF --task 100-50 --step 0 --lr 0.01 --epochs 60 --method LWF
MIB on the 50b setting of ADE20K, step 2:
python -m torch.distributed.launch --nproc_per_node=2 run.py --data_root data --batch_size 12 --dataset ade --name MIB --task 100-50 --step 2 --lr 0.001 --epochs 60 --method MIB
LWF-MC on 15-5 disjoint setting of VOC, step 1:
python -m torch.distributed.launch --nproc_per_node=2 run.py --data_root data --batch_size 12 --dataset voc --name LWF-MC --task 15-5 --step 1 --lr 0.001 --epochs 30 --method LWF-MC
RW on 15-1 overlapped setting of VOC, step 1:
python -m torch.distributed.launch --nproc_per_node=2 run.py --data_root data --batch_size 12 --dataset voc --name LWF-MC --task 15-5s --overlapped --step 1 --lr 0.001 --epochs 30 --method RW
Once you trained the model, you can see the result on tensorboard (we perform the test after the whole training) or you can test it by using the same script and parameters but using the command
--test
that will skip all the training procedure and test the model on test data.
If you use this repository, please consider to cite
@inProceedings{cermelli2020modeling,
author = {Cermelli, Fabio and Mancini, Massimiliano and Rota Bul\`o, Samuel and Ricci, Elisa and Caputo, Barbara},
title = {Modeling the Background for Incremental Learning in Semantic Segmentation},
booktitle = {Computer Vision and Pattern Recognition (CVPR)},
year = {2020},
month = {June}
}