Welcome to Smol Models, a family of efficient and lightweight AI models from Hugging Face. Our mission is to create powerful yet compact models, for text and vision, that can run effectively on-device while maintaining strong performance.
News 📰
- Introducing FineMath, the best public math pretraining dataset 🚀
- Added continual pretraining code for Llama 3.2 3B on FineMath & FineWeb-Edu with
nanotron
SmolLM2 is our family of compact language models available in three sizes:
- SmolLM2-135M: Ultra-lightweight model for basic text tasks
- SmolLM2-360M: Balanced model for general use
- SmolLM2-1.7B: Our most capable language model, available at 🤏 SmolLM2-1.7B-Instruct here.
All models have instruction-tuned versions optimized for assistant-like interactions. Find them in our SmolLM2 collection.
SmolVLM is our compact multimodal model that can:
- Process both images and text and perform tasks like visual QA, image description, and visual storytelling
- Handle multiple images in a single conversation
- Run efficiently on-device
smollm/
├── text/ # SmolLM2 related code and resources
├── vision/ # SmolVLM related code and resources
└── tools/ # Shared utilities and inference tools
├── smol_tools/ # Lightweight AI-powered tools
├── smollm_local_inference/
└── smolvlm_local_inference/
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceTB/SmolLM2-1.7B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
messages = [{"role": "user", "content": "Write a 100-word article on 'Benefits of Open-Source in AI research"}]
input_text = tokenizer.apply_chat_template(messages, tokenize=False)from transformers import AutoProcessor, AutoModelForVision2Seq
processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")
model = AutoModelForVision2Seq.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "What's in this image?"}
]
}
]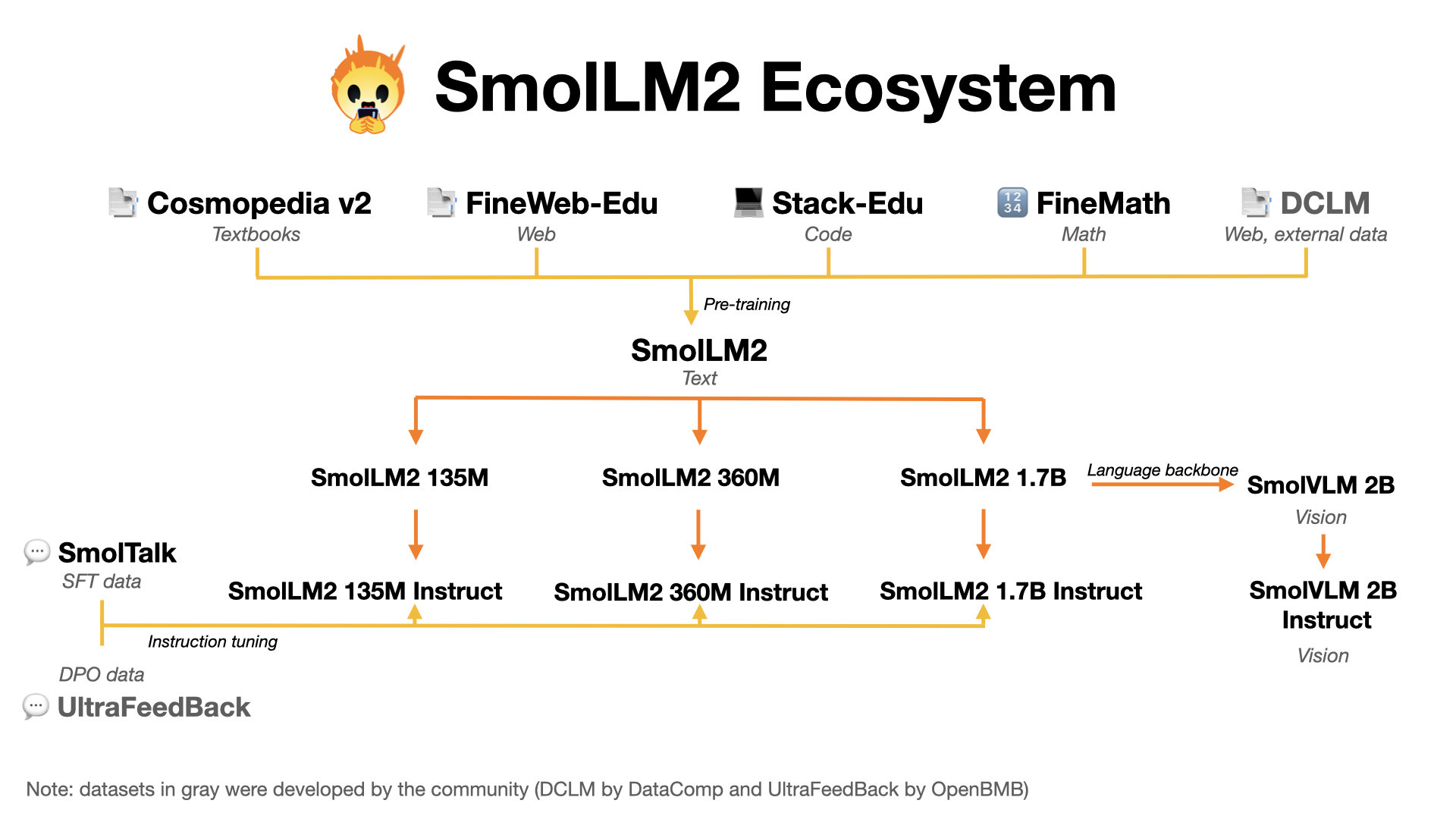
- SmolTalk - Our instruction-tuning dataset
- FineMath - Mathematics pretraining dataset
- FineWeb-Edu - Educational content pretraining dataset