{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
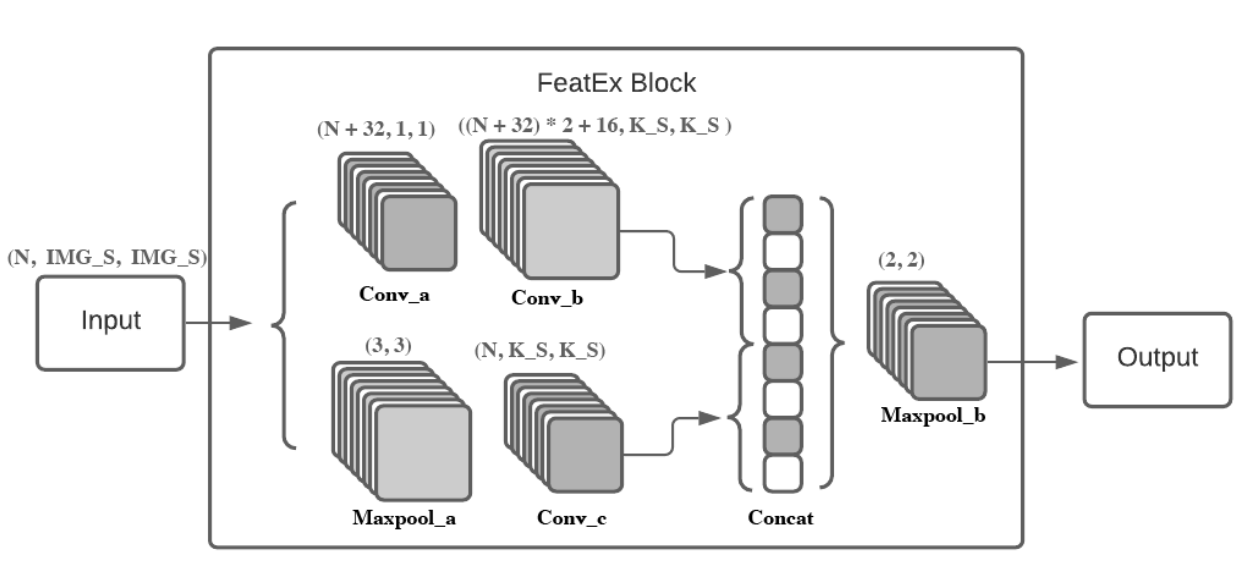
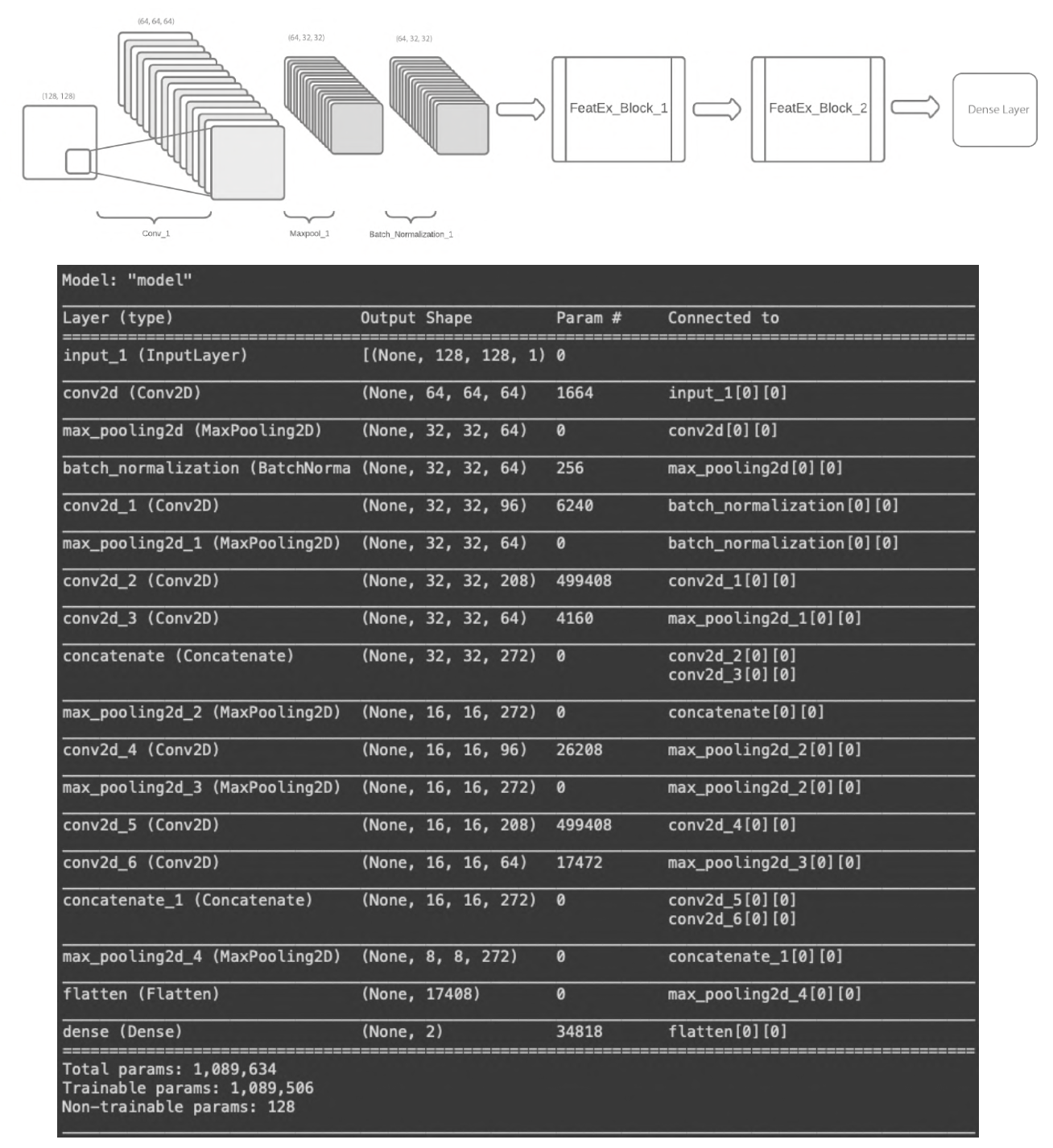
The objective of this project is to develop a robust gender classification model capable of accurately determining the gender of individuals depicted in images, particularly in regions of Asia where distinguishing gender can be challenging due to the diverse range of religious items worn. To achieve this, a custom dataset was curated by collecting images from public accounts on Instagram. The model employed for this task utilizes a convolutional neural network (CNN) architecture, leveraging a parallel feature extraction pipeline. This approach effectively optimizes the model by reducing the number of trainable parameters, while still achieving a commendable F1 score comparable to larger and more complex models. By harnessing the power of this streamlined architecture, we aim to provide a reliable and efficient solution for gender classification, addressing the unique challenges prevalent in the Asian context.
The dataset preparation process plays a critical role in the performance and accuracy of any machine learning model. In the context of image classification tasks, it is important to ensure that the dataset contains only relevant and useful images to prevent the model from being trained on irrelevant or misleading information.
To this end, a face detection layer has been implemented to filter out images that do not contain faces. Additionally, duplicate images have been removed using a hash check mechanism to avoid training the model on the same image multiple times, which can lead to overfitting.
Furthermore, to improve the diversity of the dataset, the images have been converted to grayscale and data augmentation techniques have been applied. These techniques can help increase the variability of the images by adjusting the contrast and rotation of the images, which can help the model learn to recognize different variations of the same object.
Overall, this dataset preparation process has been designed to ensure that the model is trained on a high-quality dataset that contains only relevant and diverse images. This, in turn, can lead to better model performance and accuracy in real-world scenarios. A subset of the filtered dataset is shown below

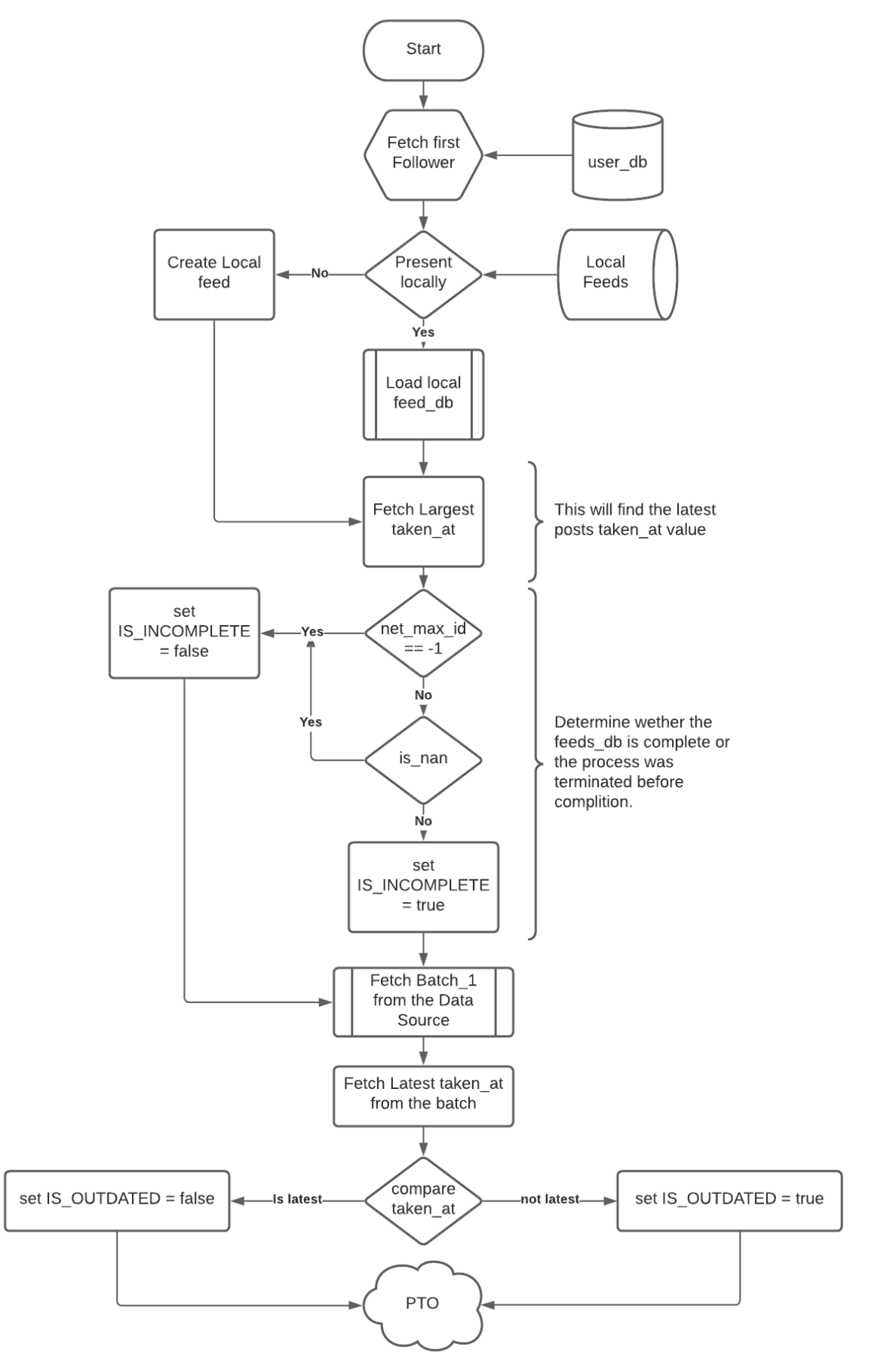
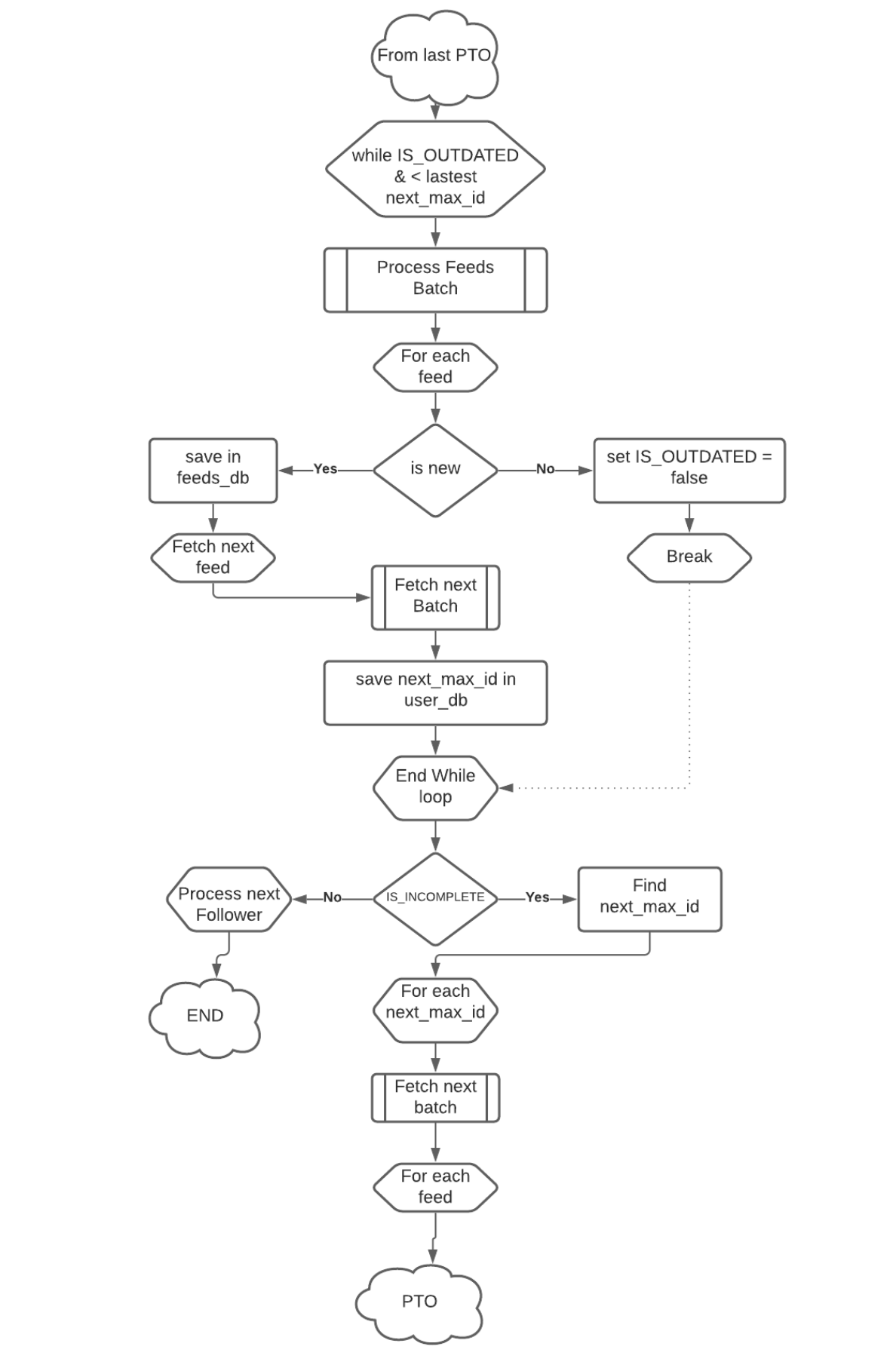
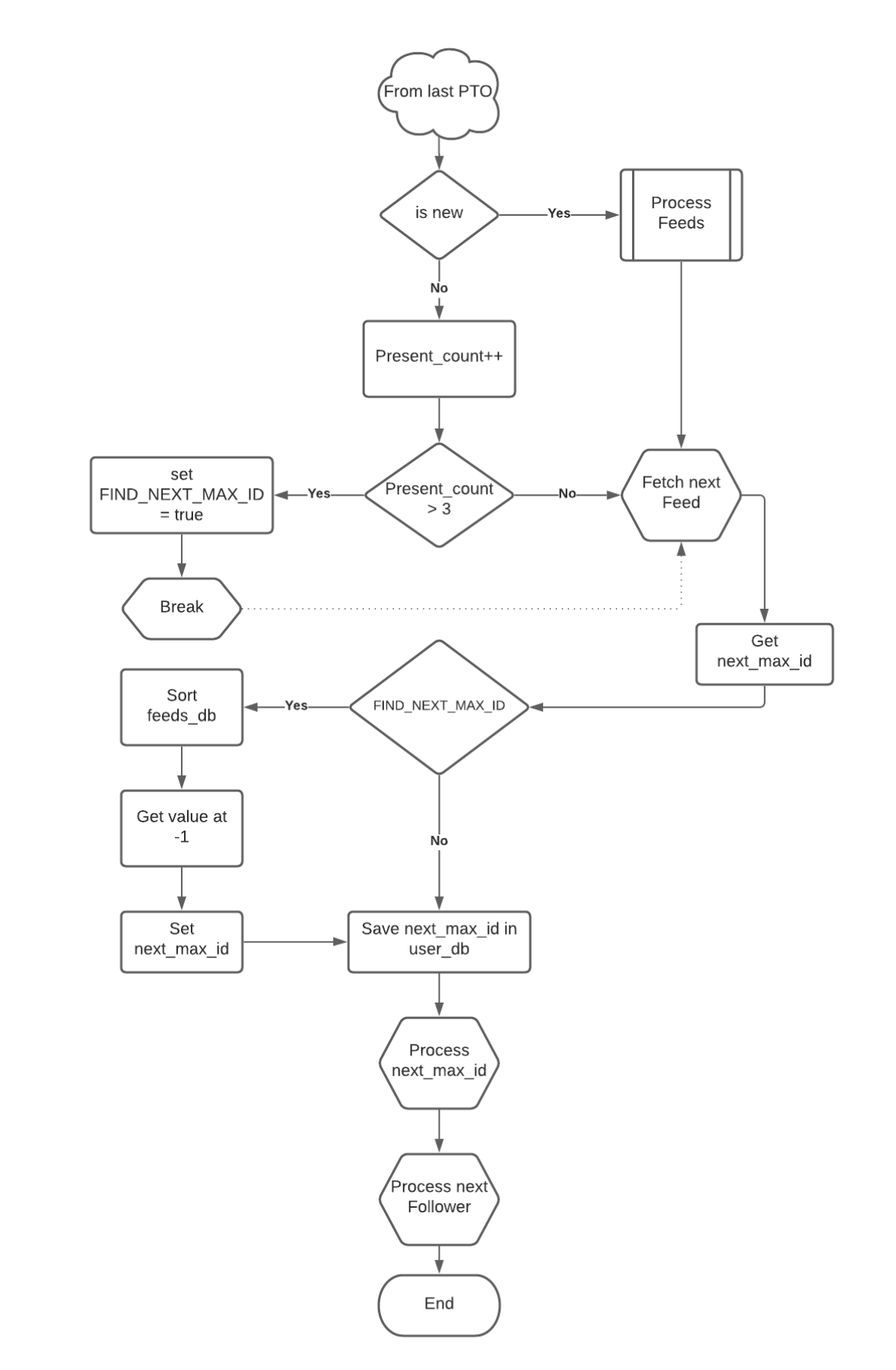
The projexct uses a complex algorithm designed for the sole purpose of constructing the new dataset. The complete algorithm is explain the provided Flow charts. A simpler version is displayed here:
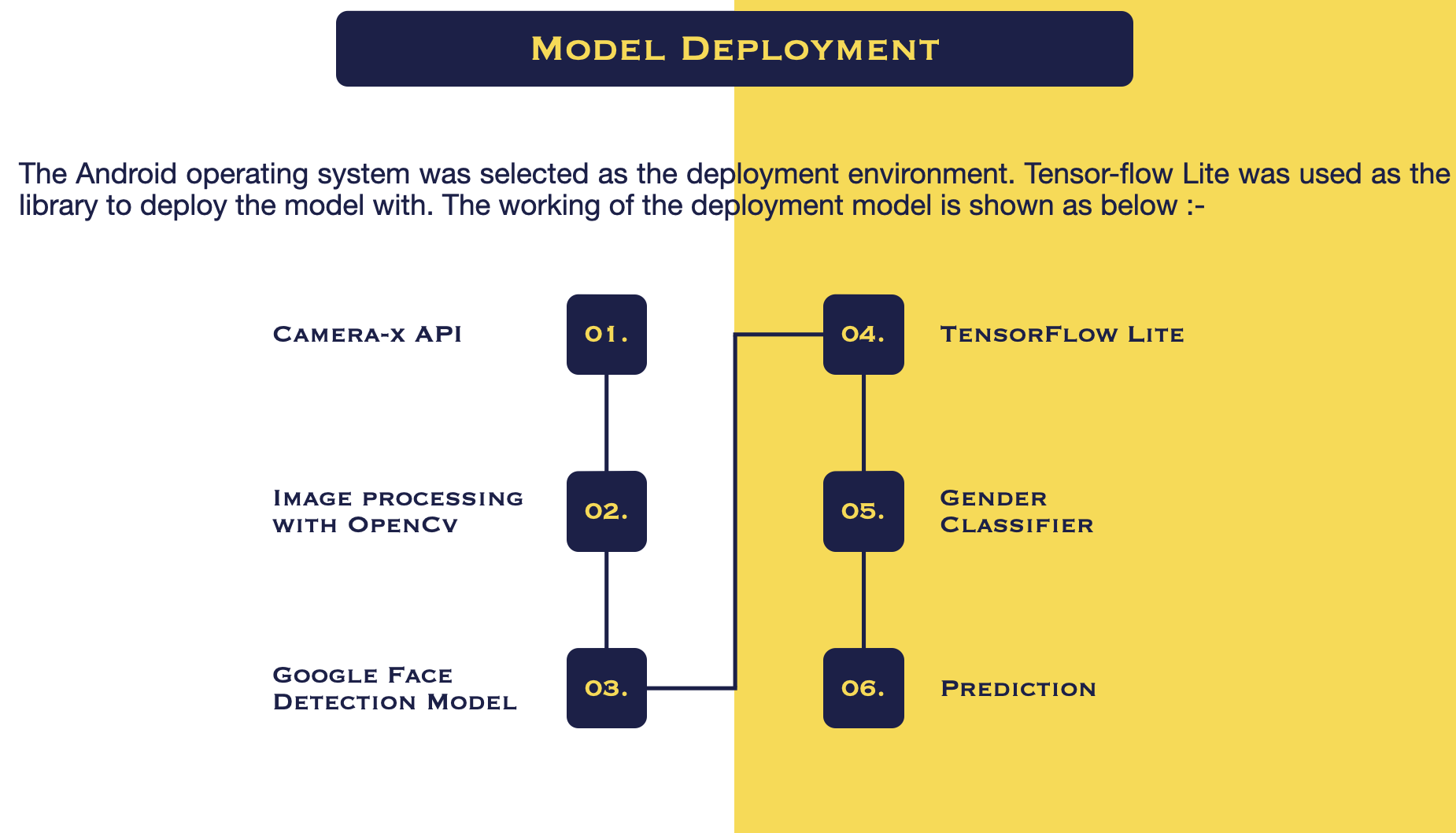
for more detailed information check out:-