- The Art of Computer Programming - Donald Knuth
- Clean Code: A Handbook of Agile Software Craftsmanship - Robert C. Martin Series
- The Mythical Man-Month: Essays on Software Engineering
- Eletrônica – Para Autodidatas, Estudantes e Técnicos – 2ª Edição, de Gabriel Torres
- Rob Pike's 5 Rules of Programming
- https://martinfowler.com/
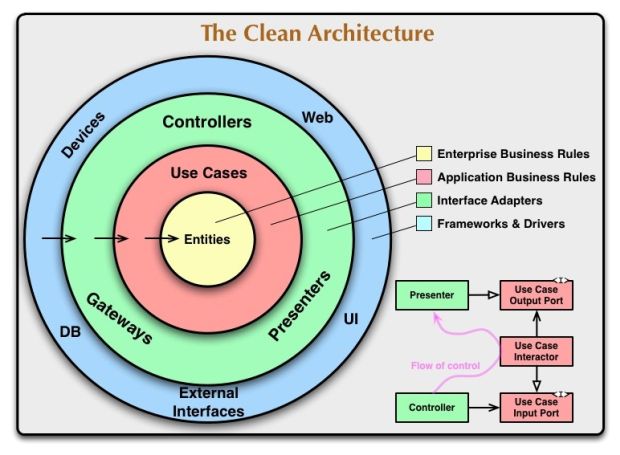
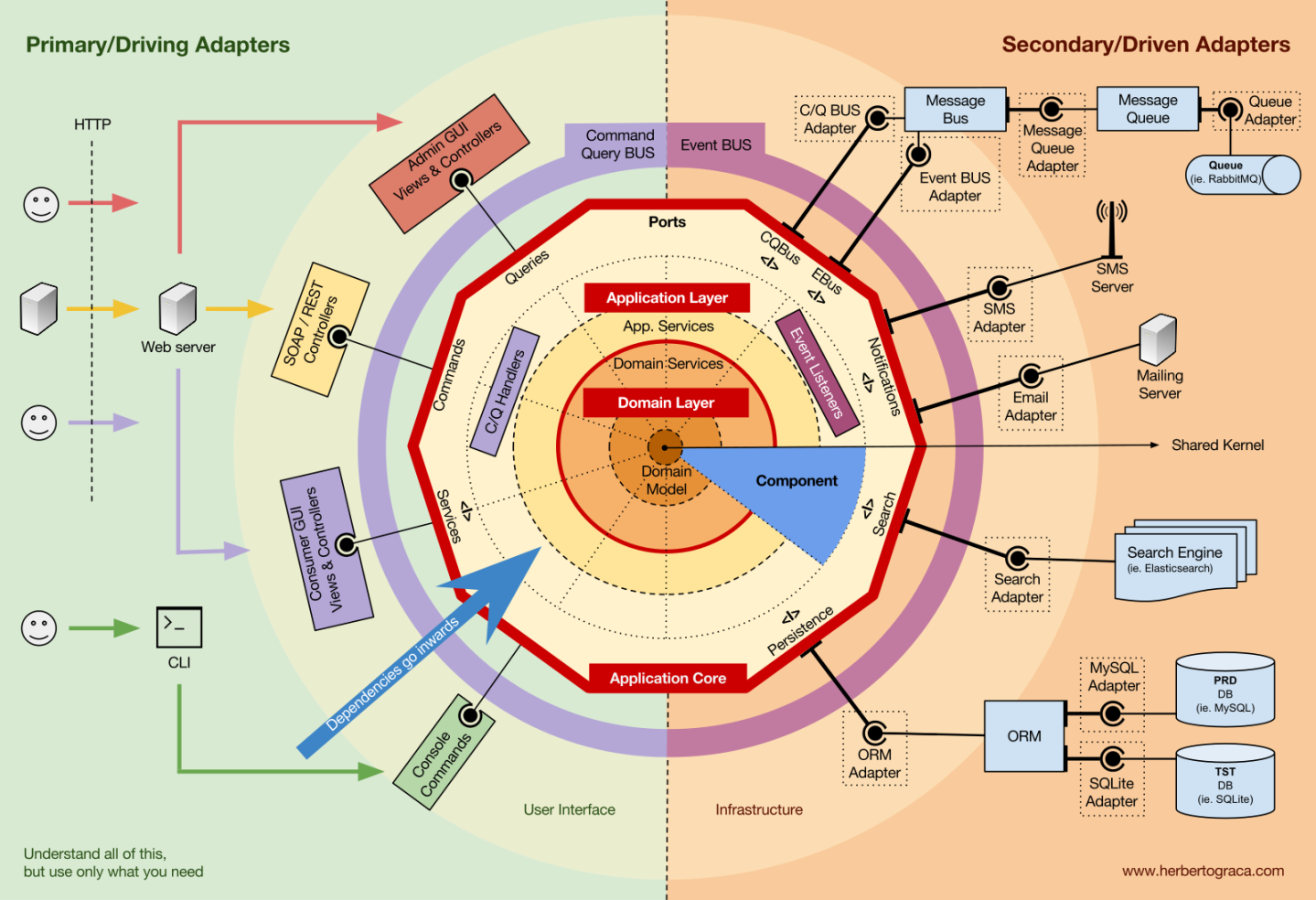
- Livro Clean Architecture - Uncle Bob
- Teach Yourself Programming in Ten Years - Peter Norvig
- Coding Interview University
- Teach Yourself CS
- Web Developer Roadmap
- How Browsers Work: Behind the scenes of modern web browsers
- Roadmap.sh
- https://developer.mozilla.org/en-US/
- https://thewisedev.com.br/
- Software Engineering at Google - SWE BOOK
- Staff Engineering Book
- Book ShapeUp - BaseCamp
- The Stoic Mind: A Visual Exploration Of Stoic Philosophy






- 1 - Inconscientemente incompetente: “você não sabe o quanto você não sabe”
- 2 - Conscientemente incompetente: “você sabe o quanto você não sabe”
- 3 - Conscientemente competente: “você já sabe o quanto você sabe”
- 4 - Sabedoria: “inconscientemente você não sabe o quanto você sabe”
Segundo o economista Milton Friedman, existem 4 maneiras de gastar dinheiro
- 1- Gastar meu dinheiro comigo:
- Nesse caso, tenho o incentivo para procurar o melhor custo benefício
- Um bom serviço, por um preço justo
- 2- Gastar meu dinheiro com outras pessoas:
- Nesse tipo de situação, o objetivo é economizar, o preço é mais importante que a qualidade do serviço
- Um serviço mediano por um bom preço
- 3- Gastar o dinheiro de outra pessoa comigo:
- Nesse caso, o dinheiro é gasto com grande atenção para a qualidade, mas com pouco interesse em buscar o melhor preço
- Um serviço excelente, por um preço elevado
- 4- Gastar o dinheiro de outra pessoa com um terceiro:
- Em uma situação como essa, há pouco incentivo em se preocupar tanto com a qualidade do serviço quanto com o preço
- Serviço ruim por um preço elevado ou serviço bom por um preço extremamente elevado
- “Software ruim que adicionar valor > Software perfeito que não adiciona valor.”
- “Aprenda a dizer: Eu NÃO Sei, e caso necessário, procure aprender.”
- “Otimização prematura: a raiz de todo mal.”
- “Lembre-se que os dinossauros quase sempre são as melhores referências.”
- “Quem pensa pouco, erra muito” - Leonardo da Vinci
- “Em Deus eu confio. Todos os outros devem trazer dados.”
- “Falta de dinheiro é a raíz de todo mal.”
- “Não existe bala de prata.”
- “Fazer funcionar > Fazer de forma correta.”
- “Aumentar receitas > diminuir custos.”
- “SaaS > PaaS > IaaS > In-House”
- “Você != Unicórnio”
- “Sempre tente entender o que está acontecendo debaixo dos panos.”
- “Escrever código != programar != engenharia de software”
- “Manutenção > Perfomance”
- “Sem métricas, sem otimização”
- “Nunca pare de questionar”
- “Engenharia de software é 80% PENSANDO sobre o problema, e 20% COMO resolver o problema.”
- “Quanto mais conhecimento você tiver, menos você sabe. EGO = 1 / conhecimento.”
- “Todo mundo deveria se importar com qualidade”
- “Pelo menos 80% do código de um bom software foi refeito, diminuido ou melhor ainda, deletado. Menos é mais.”
- “2+2 não é 5, não importa quantas pessoas digam isso.”
- “Princípios > Analogia.”
- “Converse e aprenda com pessoas mais inteligentes do que você.”
- “Sempre tente usar a única fonte da verdade.”
- “Não reinvente a roda. É para isso que existe frameworks e bibliotecas prontas.”
- “Sempre é bom estudar uma ferramenta profundamente antes de colocar em produção.”
- “Modularização é tudo.”
- “Bons artistas copiam, grandes artistas roubam.”
- “Inovação só existe em um mundo de restrição, e não abundância.”
- “Sempre vai existir alguma coisa para melhorar. Feito é melhor que perfeito.”
- 😊 Ctrl + P: Abrir arquivo por nome.
- 🖱️ Ctrl + Shift + N: Criar uma nova janela.
- 📝 Ctrl + Shift + P: Abrir a paleta de comandos.
- 🔀 Ctrl + Tab: Alternar entre abas.
- 🔀 Ctrl + Shift + Tab: Alternar entre abas na ordem inversa.
- 📚 Ctrl + \ : Mostrar/esconder o painel lateral.
- 🏢 Ctrl + B: Mostrar/esconder a barra de atividades.
- 🔎 Ctrl + F: Localizar.
- 🔍 Ctrl + H: Substituir.
- 🔁 Ctrl + D: Selecionar a próxima ocorrência da seleção atual.
- ⬅️ Ctrl + U: Desfazer a última seleção.
- 📌 Ctrl + L: Selecionar a linha atual.
- 🗺️ Ctrl + G: Ir para uma linha específica.
- 🗺️ Ctrl + P + Número da Linha + : ir para uma linha específica.
- ↩️ Ctrl + -: voltar para a última posição do cursor.
- ↪️ Ctrl + Shift + -: avançar para a próxima posição do cursor.
- ⬅️ Alt + ←/→: Voltar/avançar para a última posição do cursor.
- ⬅️ Ctrl + Shift + ←/→: selecionar palavra a palavra.
- 📋 Ctrl + C: Copiar linha ou seleção.
- ✂️ Ctrl + X: Recortar linha ou seleção.
- 📥 Ctrl + V: Colar linha ou seleção.
- ❌ Ctrl + Shift + K: Excluir linha.
- ➕ Ctrl + Enter: Inserir linha abaixo.
- ➕ Ctrl + Shift + Enter: Inserir linha acima.
- 🔃 Shift + Alt + ↓/↑: mover linha para cima ou para baixo.
- 🔀 Alt + ↓/↑: mover linha ou bloco de código para cima, ou para baixo.
- 🔑 Ctrl + Shift + : Ir para a chave de abertura ou fechamento correspondente.
- 🔍 F12: ir para definição.
- 💡 Ctrl + F12: ir para definição rápida.
- 🔎 Shift + F12: encontrar todas as referências.
- 🔍 Ctrl + Shift + F: Pesquisar em arquivos.
- 🔍 Ctrl + Shift + H: Substituir em arquivos.
- TheWisePad - NodeJS & Typescript BackEnd REST API Example - Otavio Lemos
- Livro Arquitetura Limpa na Prática, do Otávio Lemos
- https://github.com/khaosdoctor/layered-typescript-bookstore
-



- High Performance Browser Networking
- Hypertext Transfer Protocol Version 2 (HTTP/2)
- HTTP/2 101 (Chrome Dev Summit 2015)
- Introdução a HTTP/2 Google Developers
- https://developer.mozilla.org/pt-BR/docs/Web/HTTP
- Lista de campos de cabeçalho HTTP
- Protocolo HTTP em detalhes #2 - Teoria
- Livro: Desconstruindo a Web - As tecnologias por trás de uma requisição
- Sérgio Lopes - [Web.br 2015] HTTP/2
- Sérgio Lopes - Desafios práticos de performance Web - BrazilJS Conf 2016
- O Que É HTTP/3 – A Verdade Sobre o Novo Protocolo Baseado em UDP
- O que é HTTP/2 – O Guia Final

- POST vs PUT vs PATCH
- Use POST para criação de novos recursos em endpoints de coleção, como api.biblioteca.com/livros.
- Use PUT para atualização de recursos em endpoints de entidade, como api.biblioteca.com/livros/iliada.
- Use PATCH para atualização parcial de recursos, também em endpoints de entidade.
- Resumo
+-----------------------------+-----+------+-----+-------+--------+
| | GET | POST | PUT | PATCH | DELETE |
+-----------------------------+-----+------+-----+-------+--------+
| Requisição aceita body? | Não | Sim | Sim | Sim | Sim |
| Resposta aceita body? | Sim | Sim | Sim | Sim | Sim |
| Altera estado dos recursos? | Não | Sim | Sim | Sim | Sim |
| É idempotente? | Sim | Não | Sim | Não | Sim |
| É cacheável? | Sim | Não* | Não | Não | Não |
+-----------------------------+-----+------+-----+-------+--------+
* depende do que vier nos headers
- Source/Credits: https://github.com/waldemarnt/http-status-codes
- Others: https://httpstatuses.com/
- 100 - Continue - Client should continue with request.
- 101 - Switching Protocols - Server is switching protocols.
- 102 - Processing - Server has received and is processing the request.
- 103 - Processing - Server has received and is processing the request.
- 122 - Request-uri too long - URI is longer than a maximum of 2083 characters.
These codes indicate success. The body section if present is the object returned by the request. It is a MIME format object. It is in MIME format, and may only be in text/plain, text/html or one fo the formats specified as acceptable in the request.
- 200 - Ok - The request was fulfilled.
- 201 - Created - Following a POST command, this indicates success, but the textual part of the response line indicates the URI by which the newly created document should be known.
- 202 - Accepted - The request has been accepted for processing, but the processing has not been completed. The request may or may not eventually be acted upon, as it may be disallowed when processing actually takes place. there is no facility for status returns from asynchronous operations such as this.
- 203 - Partial Information - When received in the response to a GET command, this indicates that the returned metainformation is not a definitive set of the object from a server with a copy of the object, but is from a private overlaid web. This may include annotation information about the object, for example.
- 204 - No Response - Server has received the request but there is no information to send back, and the client should stay in the same document view. This is mainly to allow input for scripts without changing the document at the same time.
- 205 - Reset Content - Request processed, no content returned, reset document view.
- 206 - Partial Content - partial resource return due to request header.
- 207 - Multi-Status - XML, can contain multiple separate responses.
- 208 - Already Reported - results previously returned.
- 226 - Im Used - request fulfilled, reponse is instance-manipulations.
The codes in this section indicate action to be taken (normally automatically) by the client in order to fulfill the request.
- 301 - Moved - The data requested has been assigned a new URI, the change is permanent. (N.B. this is an optimisation, which must, pragmatically, be included in this definition. Browsers with link editing capabiliy should automatically relink to the new reference, where possible)
- 302 - Found - The data requested actually resides under a different URL, however, the redirection may be altered on occasion (when making links to these kinds of document, the browser should default to using the Udi of the redirection document, but have the option of linking to the final document) as for "Forward".
- 303 - Method - Like the found response, this suggests that the client go try another network address. In this case, a different method may be used too, rather than GET.
- 304 - Not Modified - If the client has done a conditional GET and access is allowed, but the document has not been modified since the date and time specified in If-Modified-Since field, the server responds with a 304 status code and does not send the document body to the client.
- 305 - Use Proxy - Content located elsewhere, retrieve from there.
- 306 - Switch Proxy - Subsequent requests should use the specified proxy.
- 307 - Temporary Redirect - Connect again to different URI as provided.
- 308 - Permanent Redirect - Connect again to a different URI using the same method.
The 4xx codes are intended for cases in which the client seems to have erred, and the 5xx codes for the cases in which the server is aware that the server has erred. It is impossible to distinguish these cases in general, so the difference is only informational.
The body section may contain a document describing the error in human readable form. The document is in MIME format, and may only be in text/plain, text/html or one for the formats specified as acceptable in the request.
- 400 - Bad Request - The request had bad syntax or was inherently impossible to be satisfied.
- 401 - Unauthorized - The parameter to this message gives a specification of authorization schemes which are acceptable. The client should retry the request with a suitable Authorization header.
- 402 - Payment Required - The parameter to this message gives a specification of charging schemes acceptable. The client may retry the request with a suitable ChargeTo header.
- 403 - Forbidden - The request is for something forbidden. Authorization will not help.
- 404 - Not Found - The server has not found anything matching the URI given.
- 405 - Method Not Allowed - Request method not supported by that resource.
- 406 - Not Acceptable - Content not acceptable according to the Accept headers.
- 407 - Proxy Authentication Required - Client must first authenticate itself with the proxy.
- 408 - Request Timeout - Server timed out waiting for the request.
- 409 - Conflict - Request could not be processed because of conflict.
- 410 - Gone - Resource is no longer available and will not be available again.
- 411 - Length Required - Request did not specify the length of its content.
- 412 - Precondition Failed - Server does not meet request preconditions.
- 413 - Request Entity Too Large - Request is larger than the server is willing or able to process.
- 414 - Request URI Too Large - URI provided was too long for the server to process.
- 415 - Unsupported Media Type - Server does not support media type.
- 416 - Requested Rage Not Satisfiable - Client has asked for unprovidable portion of the file.
- 417 - Expectation Failed - Server cannot meet requirements of Expect request-header field.
- 418 - I'm a teapot - I'm a teapot.
- 420 - Enhance Your Calm - Twitter rate limiting.
- 421 - Misdirected Request - Server is not able to produce a response.
- 422 - Unprocessable Entity - Request unable to be followed due to semantic errors.
- 423 - Locked - Resource that is being accessed is locked.
- 424 - Failed Dependency - Request failed due to failure of a previous request.
- 426 - Upgrade Required - Client should switch to a different protocol.
- 428 - Precondition Required - Origin server requires the request to be conditional.
- 429 - Too Many Requests - User has sent too many requests in a given amount of time.
- 431 - Request Header Fields Too Large - Server is unwilling to process the request.
- 444 - No Response - Server returns no information and closes the connection.
- 449 - Retry With - Request should be retried after performing action.
- 450 - Blocked By Windows Parental Controls - Windows Parental Controls blocking access to webpage.
- 451 - Wrong Exchange Server - The server cannot reach the client's mailbox.
- 499 - Client Closed Request - Connection closed by client while HTTP server is processing.
This means that even though the request appeared to be valid something went wrong at the server level and it wasn’t able to return anything.
- 500 - Internal Error - The server encountered an unexpected condition which prevented it from fulfilling the request.
- 501 - Not Implemented - The server does not support the facility required.
- 502 - Service temporarily overloaded - The server cannot process the request due to a high load (whether HTTP servicing or other requests). The implication is that this is a temporary condition which maybe alleviated at other times.
- 503 - Gateway timeout - This is equivalent to Internal Error 500, but in the case of a server which is in turn accessing some other service, this indicates that the respose from the other service did not return within a time that the gateway was prepared to wait. As from the point of view of the clientand the HTTP transaction the other service is hidden within the server, this maybe treated identically to Internal error 500, but has more diagnostic value.
- 504 - Gateway Timeout - Gateway did not receive response from upstream server.
- 505 - Http Version Not Supported - Server does not support the HTTP protocol version.
- 506 - Variant Also Negotiates - Content negotiation for the request results in a circular reference.
- 507 - Insufficient Storage - Server is unable to store the representation.
- 508 - Loop Detected - Server detected an infinite loop while processing the request.
- 509 - Bandwidth Limit Exceeded - Bandwidth limit exceeded.
- 510 - Not Extended - Further extensions to the request are required.
- 511 - Network Authentication Required - Client needs to authenticate to gain network access.
- 598 - Network Read Timeout Error - Network read timeout behind the proxy.
- 599 - Network Connect Timeout Error - Network connect timeout behind the proxy.
- YouTube
- Sites
- GitHub Repositories
- Treinamento de Código
- KhanAcademy
- Recursão 💀
- Visualização de Estruturas de Dados 💀
- Big O Notation 💀
- bigocheatsheet.com
- A coffee-break introduction to time complexity of algorithms
- O(1) Constant Time
- Melhor caso possível
- Se um algoritmo possui tempo constante, significa que sempre vai levar o mesmo tempo para produzir o resultado.
- Exemplo: array.pop() -> tirar último item de um array, independente do tamanho, levará sempre o mesmo tempo!
- Logarithms O(log n)
- Preferível na maioria das vezes
- Logaritimos são o inverso da exponenciação.
- Exemplo: Algoritmo de busca binária -> dividir para conquistar
-

- Linear time O(n)
- Preferível na maioria das vezes
- Se um algoritmo possui tempo linear, significa que o tempo de execução aumenta linearmente de acordo com o tamanho do input.
- Exemplo: array.forEach() soma de todos os valores
- Linear Logarithms O(n log n)
- Aceitável
x = n while ( x > 0 ) { y = x while ( y > 0 ) { y = y / 2 } x -= 1 }- Examples: Quicksort, Mergesort and Heapsort -> dividir para conquistar
- Quadratic time O(n²) 💀
- Bom evitar
- O tempo de execução desse algoritmo é diretamente proporcional ao o quadrado do input.
- Ou seja: 2->4 3->9 4->16 5->25 etc
- Exemplo: Soma de matrizes
for (var outer = 0; outer < elements.Count; outer++){ for (var inner = 0; inner < elements.Count; inner++){ ... } } - Exponential Time O(2^n) 💀 💀
- Um dos piores casos, sempre é bom evitar
- Indica um algoritmo cujo crescimento dobra a cada adição ao conjunto de dados de entrada. A curva de crescimento de uma função O (2N) é exponencial - começando muito rasa e depois subindo meteoricamente
- Exemplo: recursive calculation of Fibonacci numbers
int Fibonacci(int number){ if (number <= 1) return number; return Fibonacci(number - 2) + Fibonacci(number - 1); } - Factorial Time O(n!) 💀 💀 💀
- Sempre tente evitar!
- Extremamente não perfomático
- Vai executar em tempo fatorial para cada operação
- Exemplo: Problema do vendedor viajante
- "Dada uma lista de cidades e as distâncias entre cada par de cidades, qual é o caminho mais curto possível que visita cada cidade e retorna à cidade de origem?"
- Resumo
-



- Sites
- YouTube
- Segurança Web
- Banco de dados
- Ferramentas
- Operation Systems
- Virtual Machines for Pentest
- Transport Layer Security/Secure Sockets Layer
- Softwares
- DataBases
- CLI Commands
- Browsers
- https://www.netlify.com/
- https://pages.github.com/
- https://vercel.com/
- https://www.digitalocean.com/products/app-platform/
- https://www.submarinecablemap.com/
- https://www.similartech.com/
- https://w3techs.com/
- https://archive.org/web/
- https://desktop.github.com/
- https://www.gitkraken.com/
- https://hyper.is/
- https://ngrok.com/
- https://www.lastpass.com/pt
- https://w3techs.com/
- https://placeholder.com/
- https://emojipedia.org
- https://www.getrevue.co/
- https://dillinger.io/
- https://choosealicense.com/
- https://enable-cors.org/
- https://schema.org/
Ao definir um nome, precisamos ter em mente dois pontos principais:
- Ser preciso: precisamos passar a ideia central da nossa variável ou método, sem dar voltas, sendo conciso e direto.
- Não ter medo de nomes grandes: um nome bem descritivo, mesmo que seja grande, irá possibilitar uma melhor compreensão e posterior manutenção do código.
Para finalizar, é recomendável que:
- Métodos ou Funções: devem ter nome de verbos, para assim, expressar quais são suas finalidades;
- Classes e Objetos: deve ser utilizado substantivos.
Segundo Robert C. Martin, a primeira regra das funções é a seguinte:
- “Elas precisam ser pequenas.”
Já a segunda regra das funções diz o seguinte:
- “Elas têm de ser ainda menores.”
Testes limpos seguem as regras do acrônimo FIRST (Fast, Indepedent, Repeatable, Self-validation, Timely).
- Rapidez: os testes devem ser rápidos para que possam ser executados diversas vezes;
- Independência: quando testes são dependentes, uma falha pode causar um efeito dominó dificultando a análise individual;
- Repetitividade: deve ser possível repetir o teste em qualquer ambiente;
- Auto validação: bons testes possuem como resultado respostas do tipo “verdadeiro” ou “falso”. Caso contrário, a falha pode se tornar subjetiva;
- Pontualidade: os testes precisam ser escritos antes do código de produção, onde os testes serão aplicados. Caso contrário, o código pode ficar complexo demais para ser testado ou até pode ser que o código não possa ser testado.
DRY é o acrônimo para Don’t repeat yourself (Não repita a si mesmo). É o conceito que diz que cada parte de conhecimento do sistema deve possuir apenas uma representação. Desta forma, evitando a ambiguidade do código. Em outras palavras, não deve existir duas partes do programa que desempenham a mesma função, ou seja, o famoso copiar e colar no código.
Mas porque evitar repetição? Simples!
Quem tem uma segunda casa na praia, ou no campo, sabe o quão complicado é garantir a manutenção das duas. Mesmo que a repetição possa parecer inofensiva em programas mais simples, ela pode vir a ser um problema à medida que o software vai crescendo e as manutenções e desenvolvimentos se tornam cada vez mais complexos.
Uma boa maneira de evitar a duplicidade do código é aplicar corretamente a técnica de responsabilidade única. Para cada função ou método, utilizar apenas uma parte do método (ou função). O correto é abstrair apenas essa parte e criar um novo!
Algumas ambiguidades de condições não são tão destrutivas ao código, mas com o tempo podem ser. Portanto, procure evitá-las o máximo possível.
Melhor prevenir do que remediar. Esse famoso ditado se aplica ao desenvolvimento de software também. Bons desenvolvedores pensam que as coisas podem dar errado, pois isso eventualmente irá acontecer. Desta forma, o código deve estar preparado para lidar com esses problemas que surgirão.
Hoje a maioria das linguagens possuem recursos para tratar erros nos códigos através de Exceptions e blocos try-catch.
Exceptions: mecanismo que sinaliza eventos excepcionais. Por exemplo, tentar inserir o caractere “a” em uma variável do tipo inteiro;
Blocos try-catch: capturam as exceções citadas. Portanto, devem ser utilizados de maneira global. Afinal de contas, os métodos já possuem suas funções (que não é tratar erros).
Para finalizarmos esse tópico, uma dica excelente para não gerar erros em seu código é simplesmente não utilizar “null”, tanto como parâmetro, quanto para retorno em funções. Muitas vezes, esses retornos exigem verificações desnecessárias que, caso não sejam feitas, podem gerar erros.
"You aren't gonna need it" (YAGNI) é um princípio da Extreme Programming (XP) que afirma que o programador não deve adicionar nenhuma funcionalidade até que ela seja realmente necessária.
"Sempre implemente funcionalidades quando você realmente precisar delas, e nunca quando você prever que vai precisar delas".
Parece óbvio não é mesmo, mas pense bem. quantas vezes você implementou uma funcionalidade em um projeto apenas por que achava que o cliente ia adorar, ou que ela iria dar aquele diferencial ao projeto ?
Isso não significa que você deve evitar criar um código flexível.
Significa que você não deve incluir funcionalidades em seu código baseado-se no fato que você pode precisar delas mais tarde.
Há duas razões principais para a prática YAGNI:
Você economiza tempo, porque você evita escrever código que você não vai precisar no momento;
Seu código fica melhor, porque você evita poluir o código com 'palpites' que acabam, na maioria dos casos, sendo palpites errados;
1- Se você não precisa da funcionalidade agora então não implemente. Você não precisa dela.
2- Você acha mesmo que vai economizar tempo global gastando mais tempo agora do que no futuro ?
Dado um número de versão MAJOR.MINOR.PATCH, incremente a:
- versão Maior(MAJOR): quando fizer mudanças incompatíveis na API,
- versão Menor(MINOR): quando adicionar funcionalidades mantendo compatibilidade, e
- versão de Correção(PATCH): quando corrigir falhas mantendo compatibilidade.
Rótulos adicionais para pré-lançamento(pre-release) e metadados de construção(build) estão disponíveis como extensão ao formato MAJOR.MINOR.PATCH.
No mundo de gerenciamento de software existe algo terrível conhecido como inferno das dependências (“dependency hell”). Quanto mais o sistema cresce, e mais pacotes são adicionados a ele, maior será a possibilidade de, um dia, você encontrar-se neste poço de desespero.
Em sistemas com muitas dependências, lançar novos pacotes de versões pode se tornar rapidamente um pesadelo. Se as especificações das dependências são muito amarradas você corre o risco de um bloqueio de versão (A falta de capacidade de atualizar um pacote sem ter de liberar novas versões de cada pacote dependente). Se as dependências são vagamente especificadas, você irá inevitavelmente ser mordido pela ‘promiscuidade da versão’ (assumindo compatibilidade com futuras versões mais do que é razoável). O inferno das dependências é onde você está quando um bloqueio de versão e/ou promiscuidade de versão te impede de seguir em frente com seu projeto de maneira fácil e segura.
Como uma solução para este problema proponho um conjunto simples de regras e requisitos que ditam como os números das versões são atribuídos e incrementados.
Essas regras são baseadas em, mas não necessariamente limitadas às, bem difundidas práticas comumente em uso tanto em softwares fechados como open-source. Para que este sistema funcione, primeiro você precisa declarar uma API pública. Isto pode consistir de documentação ou ser determinada pelo próprio código. De qualquer maneira, é importante que esta API seja clara e precisa. Depois de identificada a API pública, você comunica as mudanças com incrementos específicos para o seu número de versão. Considere o formato de versão X.Y.Z (Maior.Menor.Correção). Correção de falhas (bug fixes) que não afetam a API, incrementa a versão de Correção, adições/alterações compatíveis com as versões anteriores da API incrementa a versão Menor, e alterações incompatíveis com as versões anteriores da API incrementa a versão Maior.
Eu chamo esse sistema de “Versionamento Semântico”. Sob este esquema, os números de versão e a forma como eles mudam transmitem o significado do código subjacente e o que foi modificado de uma versão para a próxima.
As palavras-chaves “DEVE”, “NÃO DEVE”, “OBRIGATÓRIO”, “DEVERÁ”, “NÃO DEVERÁ”, “PODEM”, “NÃO PODEM”, “RECOMENDADO”, “PODE” e “OPCIONAL” no presente documento devem ser interpretados como descrito na [RFC 2119] (http://tools.ietf.org/html/rfc2119).
-
Software usando Versionamento Semântico DEVE declarar uma API pública. Esta API poderá ser declarada no próprio código ou existir estritamente na documentação, desde que seja precisa e compreensiva.
-
Um número de versão normal DEVE ter o formato de X.Y.Z, onde X, Y, e Z são inteiros não negativos, e NÃO DEVE conter zeros à esquerda. X é a versão Maior, Y é a versão Menor, e Z é a versão de Correção. Cada elemento DEVE aumentar numericamente. Por exemplo: 1.9.0 -> 1.10.0 -> 1.11.0.
-
Uma vez que um pacote versionado foi lançado(released), o conteúdo desta versão NÃO DEVE ser modificado. Qualquer modificação DEVE ser lançado como uma nova versão.
-
No início do desenvolvimento, a versão Maior DEVE ser zero (0.y.z). Qualquer coisa pode mudar a qualquer momento. A API pública não deve ser considerada estável.
-
Versão 1.0.0 define a API como pública. A maneira como o número de versão é incrementado após este lançamento é dependente da API pública e como ela muda.
-
Versão de Correção Z (x.y.Z | x > 0) DEVE ser incrementado apenas se mantiver compatibilidade e introduzir correção de bugs. Uma correção de bug é definida como uma mudança interna que corrige um comportamento incorreto.
-
Versão Menor Y (x.Y.z | x > 0) DEVE ser incrementada se uma funcionalidade nova e compatível for introduzida na API pública. DEVE ser incrementada se qualquer funcionalidade da API pública for definida como descontinuada. PODE ser incrementada se uma nova funcionalidade ou melhoria substancial for introduzida dentro do código privado. PODE incluir mudanças a nível de correção. A versão de Correção deve ser redefinida para 0(zero) quando a versão Menor for incrementada.
-
Versão Maior X (X.y.z | X > 0) DEVE ser incrementada se forem introduzidas mudanças incompatíveis na API pública. PODE incluir alterações a nível de versão Menor e de versão de Correção. Versão de Correção e Versão Menor devem ser redefinidas para 0(zero) quando a versão Maior for incrementada.
-
Uma versão de Pré-Lançamento (pre-release) PODE ser identificada adicionando um hífen (dash) e uma série de identificadores separados por ponto (dot) imediatamente após a versão de Correção. Identificador DEVE incluir apenas caracteres alfanuméricos e hífen [0-9A-Za-z-]. Identificador NÃO DEVE ser vazio. Indicador numérico NÃO DEVE incluir zeros à esquerda. Versão de Pré-Lançamento tem precedência inferior à versão normal a que está associada. Uma versão de Pré-Lançamento (pre-release) indica que a versão é instável e pode não satisfazer os requisitos de compatibilidade pretendidos, como indicado por sua versão normal associada. Exemplos: 1.0.0-alpha, 1.0.0-alpha.1, 1.0.0-0.3.7, 1.0.0-x.7.z.92.
-
Metadados de construção(Build) PODE ser identificada por adicionar um sinal de adição (+) e uma série de identificadores separados por ponto imediatamente após a Correção ou Pré-Lançamento. Identificador DEVE ser composto apenas por caracteres alfanuméricos e hífen [0-9A-Za-z-]. Identificador NÃO DEVE ser vazio. Metadados de construção PODEM ser ignorados quando se determina a versão de precedência. Assim, duas versões que diferem apenas nos metadados de construção, têm a mesma precedência. Exemplos: 1.0.0-alpha+001, 1.0.0+20130313144700, 1.0.0-beta+exp.sha.5114f85.
-
A precedência refere como as versões são comparadas com cada outra quando solicitado. A precedência DEVE ser calculada separando identificadores de versão em Maior, Menor, Correção e Pré-lançamento, nesta ordem (Metadados de construção não figuram na precedência). A precedência é determinada pela primeira diferença quando se compara cada identificador da esquerda para direita, como se segue: Versões Maior, Menor e Correção são sempre comparadas numericamente. Example: 1.0.0 < 2.0.0 < 2.1.0 < 2.1.1. Quando Maior, Menor e Correção são iguais, a versão de Pré-Lançamento tem precedência menor que a versão normal. Example: 1.0.0-alpha < 1.0.0. A precedência entre duas versões de Pré-lançamento com mesma versão Maior, Menor e Correção DEVE ser determinada comparando cada identificador separado por ponto da esquerda para direita até que seja encontrada diferença da seguinte forma: identificadores consistindo apenas dígitos são comparados numericamente e identificadores com letras ou hífen são comparados lexicalmente na ordem de classificação ASCII. Identificadores numéricos sempre têm menor precedência do que os não numéricos. Um conjunto maior de campos de pré-lançamento tem uma precedência maior do que um conjunto menor, se todos os identificadores anteriores são iguais. Example: 1.0.0-alpha < 1.0.0-alpha.1 < 1.0.0-alpha.beta < 1.0.0-beta < 1.0.0-beta.2 < 1.0.0-beta.11 < 1.0.0-rc.1 < 1.0.0.
Esta não é uma ideia nova ou revolucionária. De fato, você provavelmente já faz algo próximo a isso. O problema é que “próximo” não é bom o bastante. Sem a aderência a algum tipo de especificação formal, os números de versão são essencialmente inúteis para gerenciamento de dependências. Dando um nome e definições claras às ideias acima, fica fácil comunicar suas intenções aos usuários de seu software. Uma vez que estas intenções estão claras, especificações de dependências flexíveis (mas não tão flexíveis) finalmente podem ser feitas.
Um exemplo simples vai demonstrar como o Versionamento Semântico pode fazer do inferno de dependência uma coisa do passado. Considere uma biblioteca chamada “CaminhaoBombeiros”. Ela requer um pacote versionado dinamicamente chamado “Escada”. Quando CaminhaoBombeiros foi criado, Escada estava na versão 3.1.0. Como CaminhaoBombeiros utiliza algumas funcionalidades que foram inicialmente introduzidas na versão 3.1.0, você pode especificar, com segurança, a dependência da Escada como maior ou igual a 3.1.0 porém menor que 4.0.0. Agora, quando Escada versão 3.1.1 e 3.2.0 estiverem disponíveis, você poderá lança-los ao seu sistema de gerenciamento de pacote e saberá que eles serão compatíveis com os softwares dependentes existentes.
Como um desenvolvedor responsável você irá, é claro, querer certificar-se que qualquer atualização no pacote funcionará como anunciado. O mundo real é um lugar bagunçado; não há nada que possamos fazer quanto a isso senão sermos vigilantes. O que você pode fazer é deixar o Versionamento Semântico lhe fornecer uma maneira sensata de lançar e atualizar pacotes sem precisar atualizar para novas versões de pacotes dependentes, salvando-lhe tempo e aborrecimento.
Se tudo isto soa desejável, tudo que você precisar fazer para começar a usar Versionamento Semântico é declarar que você o esta usando e então, seguir as regras. Adicione um link para este website no seu README para que outros saibam as regras e possam beneficiar-se delas.
- https://martinfowler.com/microservices/
- http://blog.cleancoder.com/uncle-bob/2015/05/28/TheFirstMicroserviceArchitecture.html
- https://martinfowler.com/articles/microservices.html
- https://www.redhat.com/pt-br/topics/microservices
- https://www.redhat.com/pt-br/topics/microservices/what-are-microservices
Microsserviços são uma abordagem de arquitetura para a criação de aplicações. O que diferencia a arquitetura de microsserviços das abordagens monolíticas tradicionais é como ela decompõe a aplicação por funções básicas. Cada função é denominada um serviço e pode ser criada e implantada de maneira independente. Isso significa que cada serviço individual pode funcionar ou falhar sem comprometer os demais.

Pense na última vez em que você acessou o site de uma loja. Provavelmente, você usou a barra de pesquisa do site para procurar produtos. Essa pesquisa representa um serviço. Talvez você também tenha visto recomendações de produtos relacionados, extraídas de um banco de dados das preferências dos compradores. Isso também é um serviço. Você adicionou algum item ao carrinho de compras? Isso mesmo, esse é mais um serviço.

Quais são os benefícios da arquitetura de microsserviços?
Com os microsserviços, suas equipes e tarefas rotineiras podem se tornar mais eficientes por meio do desenvolvimento distribuído. Além disso, é possível desenvolver vários microsserviços ao mesmo tempo. Isso significa que você pode ter mais desenvolvedores trabalhando simultaneamente na mesma aplicação, o que resulta em menos tempo gasto com desenvolvimento.
- Lançamento no mercado com mais rapidez => Como os ciclos de desenvolvimento são reduzidos, a arquitetura de microsserviços é compatível com implantações e atualizações mais ágeis.
- Altamente escalável => À medida que a demanda por determinados serviços aumenta, você pode fazer implantações em vários servidores e infraestruturas para atender às suas necessidades.
- Resiliente => Os serviços independentes, se construídos corretamente, não afetam uns aos outros. Isso significa que, se um elemento falhar, o restante da aplicação permanece em funcionamento, diferentemente do modelo monolítico.
- Fácil de implementar => Como as aplicações baseadas em microsserviços são mais modulares e menores do que as aplicações monolíticas tradicionais, as preocupações resultantes dessas implantações são invalidadas. Isso requer uma coordenação maior, mas as recompensas podem ser extraordinárias.
- Acessível => Como a aplicação maior é decomposta em partes menores, os desenvolvedores têm mais facilidade para entender, atualizar e aprimorar essas partes. Isso resulta em ciclos de desenvolvimento mais rápidos, principalmente quando também são empregadas as tecnologias de desenvolvimento ágil.
- Mais open source => Devido ao uso de APIs poliglotas, os desenvolvedores têm liberdade para escolher a melhor linguagem e tecnologia para a função necessária.
- I. Base de Código -> Uma base de código com rastreamento utilizando controle de revisão, muitos deploys
- II. Dependências -> Declare e isole as dependências
- III. Configurações -> Armazene as configurações no ambiente
- IV. Serviços de Apoio -> Trate os serviços de apoio, como recursos ligados
- V. Build, release, run -> Separe estritamente os builds e execute em estágios
- VI. Processos -> Execute a aplicação como um ou mais processos que não armazenam estado
- VII. Vínculo de porta -> Exporte serviços por ligação de porta
- VIII. Concorrência -> Dimensione por um modelo de processo
- IX. Descartabilidade -> Maximizar a robustez com inicialização e desligamento rápido
- X. Dev/prod semelhantes -> Mantenha o desenvolvimento, teste, produção o mais semelhante possível
- XI. Logs -> Trate logs como fluxo de eventos
- XII. Processos de Admin -> Executar tarefas de administração/gerenciamento como processos pontuais
- https://app.diagrams.net/
- https://www.uml-diagrams.org/
- https://www.ateomomento.com.br/diagramas-uml/
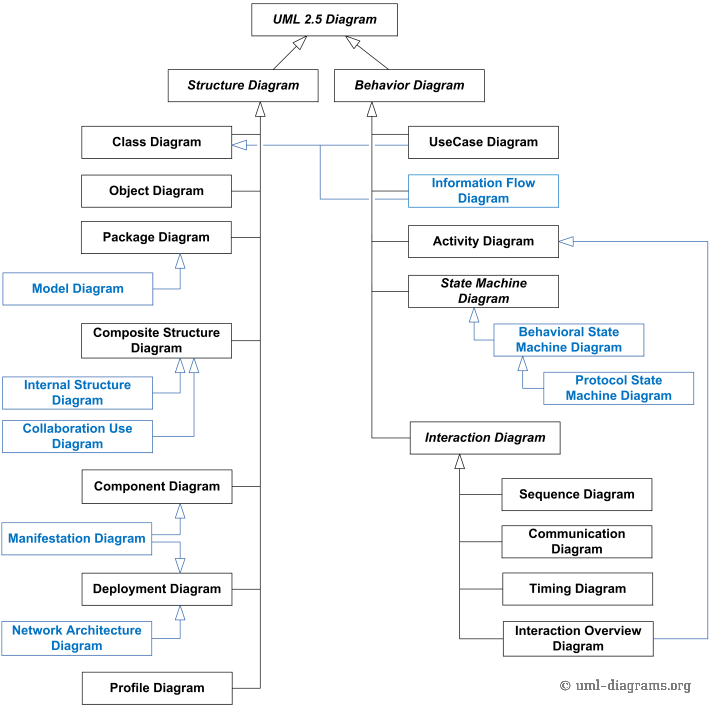
É uma linguagem de notação (um jeito de escrever, ilustrar, comunicar) para uso em projetos de sistemas.
Esta linguagem é expressa através de diagramas. Cada diagrama é composto por elementos (formas gráficas usadas para os desenhos) que possuem relação entre si.
Os diagramas da UML se dividem em dois grandes grupos: diagramas estruturais e diagramas comportamentais.
Diagramas estruturais devem ser utilizados para especificar detalhes da estrutura do sistema (parte estática), por exemplo: classes, métodos, interfaces, namespaces, serviços, como componentes devem ser instalados, como deve ser a arquitetura do sistema etc.
Diagramas comportamentais devem ser utilizados para especificar detalhes do comportamento do sistema (parte dinâmica), por exemplo: como as funcionalidades devem funcionar, como um processo de negócio deve ser tratado pelo sistema, como componentes estruturais trocam mensagens e como respondem às chamadas etc.
"João quer A, explica à equipe algo “parecido” com B. Marcos entende que João quer C, e explica para Claudia que é para fazer D. Claudia faz um “D que mais se parece um E”, e entrega um “meio E” para João. E João queria um A…"
A UML é como uma linguagem universal para profissionais de produção de software, é um “Google Translate” que ajuda muito a comunicação clara e objetiva entre pessoas envolvidas no processo de produção (Analistas de Negócio, Product Onwer, Scrum Master, Arquitetos, Desenvolvedores, Gerentes de Projeto/Produto e demais partes interessadas).
O objetivo de um diagrama da UML é passar uma mensagem de maneira padronizada, onde todos os receptores deste mensagem entendem o padrão usado.
É o famoso: “Entendeu ou quer que eu desenhe?”
Imagine que numa mesma sala, sem internet e telefone, estão três pessoas que só falam seu idioma nativo: um chinês, um francês, e um brasileiro.
Nesta sala tem apenas papel e lápis. O francês quer um café.
Qual será a maneira mais eficiente, considerando os recursos disponíveis na sala, para o francês passar a mensagem “quero um café”?
Talvez fazendo um desenho de uma xícara de café!
Deixar isso claro, de maneira simples, objetiva, transparente e pragmática, é comunicar-se bem.
Levando o raciocínio acima para projetos de software, a UML deve ser utilizada para comunicar o que se quer e/ou como se quer, de maneira eficiente.
- Livro Domain Driven Design - Eric Evans
- http://www.macoratti.net/11/05/ddd_liv1.htm
- http://dddsample.sourceforge.net/architecture.html
- http://www.agileandart.com/2010/07/16/ddd-introducao-a-domain-driven-design/
- https://www.infoq.com/minibooks/domain-driven-design-quickly/
O que é mais importante em um software ?
- O código e a tecnologia usadas, diria o desenvolvedor.
- Os testes, diria o testador.
- O plano de projeto, diria o gerente.
- A arquitetura usada, diria o arquiteto.
Faltou alguma coisa ?
- Faltou o cliente responder, que o mais importante, é o software resolver o problema dele.
- Conclusão: O mais importante é a regra do negócio e o valor que o software agrega ao cliente.
O Domain-Driven Desing (DDD) é uma abordagem de desenvolvimento de software que reúne um conjunto de conceitos, princípios e técnicas cujo foco esta no domínio e na lógica do domínio com o objetivo de criar um Domain Model ou (modelo do domínio).
Usar DDD significa desenvolver software de acordo com o domínio relacionado ao problema que estamos propondo resolver.
Obs: Nesse contexto domínio é o que o programa de software modela e o problema a que ele se propõe a resolver = regras de negócio.
Conhecer o domínio é fundamental e criar um modelo e adotar uma arquitetura para aplicação que melhor reflitam os conceitos do domínio não é uma tarefa fácil nem uma tarefa somente para o analista.
O DDD sugere uma arquitetura padrão de forma que possamos focar o domínio.
A seguir temos uma sugestão para arquitetura em camadas que pode ser usada no modelo do domínio
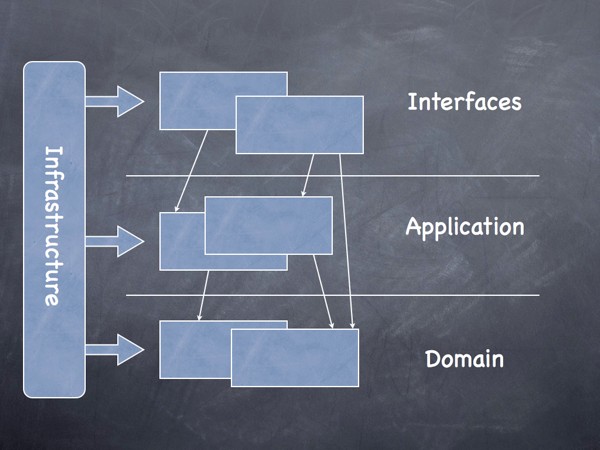
- User Interface - Apresenta a informação ao usuário e interpreta os seus comandos.
- Application - Camada que coordena a atividade da aplicação. Não contém lógica de negócio.
- Domain - Contém informação sobre o domínio. É o coração do negócio.
- Infrastructure - Atua como uma library de suporte para as demais camadas. Realiza a comunicação entre as camadas. Implementa a persistência dos objetos de negócio.
O foco da abordagem é criar um domínio que “fale a língua” do usuário usando o que é conhecido como linguagem Ubíqua (Ubiquitous language ou linguagem Comum, Onipresente).
Por linguagem Ubíqua (linguagem comum) entende-se que ao trabalhar com DDD devemos conversar usando uma mesma língua, em um único modelo, de forma que o mesmo seja compreendido pelo cliente, analista, projetista, desenhista, testador, gerente, etc. nesta linguagem, que seria a linguagem usada no dia a dia.
Quais as vantagens em usar DDD ?
- O código fica menos acoplado e mais coeso;
- O negócio é melhor compreendido por todos da equipe o que facilita o desenvolvimento;
- O DDD não é uma ‘bala de prata’ nem uma arquitetura universal, mas uma abordagem que deve ser considerada e aplicada ou não ao seu problema após você pensar e estudar muito sobre a suas aplicações e as suas conseqüências.
Lembre-se, você não tem que sair por ai aplicando (tentando aplicar) DDD a todos os tipos de projetos.
Também chamado de Teorema de Brewer, afirma que é impossível que o armazenamento de dados distribuído forneça simultaneamente mais de duas das três garantias seguintes:
-
Consistência (Consistency): Cada leitura recebe a escrita mais recente ou um erro
-
Disponibilidade (Availability): Cada pedido recebe uma resposta (sem erro) - sem garantia de que contém a escrita mais recente
-
Tolerância a particionamentos (Partition tolerance): O sistema continua a funcionar apesar de um número arbitrário de mensagens serem descartadas (ou atrasadas) pela rede entre nós
Nenhum sistema distribuído está protegido contra falhas de rede, portanto, a partição geralmente deve ser tolerada. Na presença de partições, são dadas duas opções: consistência ou disponibilidade.
Ao escolher consistência em relação à disponibilidade, o sistema retornará um erro ou um tempo limite se informações específicas não puderem ser garantidamente actualizadas devido à sua partilha na rede.
Ao escolher disponibilidade sobre consistência, o sistema sempre processará a consulta e tentará retornar a versão disponível mais recente da informação, mesmo que não possa garantir que ela esteja atualizada devido às partições.
Versão super resumida: bancos de dados só podem escolher 2 dos 3 elementos. É matemáticamente impossível ter os 3.

- IPv4 == Internet Protocol Versão 4
- Formato por 4 bytes (10111011.01101011.11111011.01011011) = 2^32 = 4.294.967.296
- Example: 192.168.0.1

- IPv6 == Internet Protocol Versão 6
- Versão 6, por falta de endereços suficientes atualmente
- 3,4x10^38 endereços

- MacAddress == Media Access Control
- Endereço "único" físico associado à interface de comunicação, que conecta um dispositivo à rede.
- Sua identificação é gravada em hardware, isto é, na memória ROM (Read-Only-Memory).
- Os três primeiros bytes são destinados a identificação do fabricante - eles são fornecidos pela própria IEEE
- Os três últimos bytes são definidos pelo fabricante, sendo este responsável pelo controle da numeração de cada placa que produz. Apesar de ser único e gravado em hardware, o endereço MAC pode ser alterado através de técnicas específicas.
- HTTP == HyperText Transfer Protocol
- Utilizado para sistemas de informação de hipermídia e hypertexto
- HTTP: Port 80
- HTTPS: Port 443
- Camada OSI & Protocolos TCP/IP
- Transmission Control Protocol é um conjunto de protocolos de comunicação entre computadores em rede. O conjunto de protocolos pode ser visto como um modelo de camadas (Modelo OSI), onde cada camada é responsável por um grupo de tarefas, fornecendo um conjunto de serviços bem definidos para o protocolo da camada superior. As camadas mais altas, estão logicamente mais perto do usuário (chamada camada de aplicação) e lidam com dados mais abstratos, confiando em protocolos de camadas mais baixas para tarefas de menor nível de abstração. É orientado a conexão, ou seja, antes de enviar os dados é feito uma comunicação entre o rementente e o destinatário e cria-se um canal de comunicação, então é transmitido os dados. Exemplo de uso: gerenciadores de FTP (File Transfer Protocol), como o FileZilla, pois precisam garantir a integridade do recebimento/envio do arquivo.
- Benefícios
- Padronização: um padrão, um protocolo roteável que é o mais completo e aceito protocolo disponível atualmente. Todos os sistemas operacionais modernos oferecem suporte para o TCP/IP e a maioria das grandes redes se baseia em TCP/IP para a maior parte de seu tráfego.
- Interconectividade: uma tecnologia para conectar sistemas não similares. Muitos utilitários padrões de conectividade estão disponíveis para acessar e transferir dados entre esses sistemas não similares, incluindo FTP (File Transfer Protocol) e Telnet (Terminal Emulation Protocol).
- Roteamento: permite e habilita as tecnologias mais antigas e as novas a se conectarem à Internet. Trabalha com protocolos de linha como P2P (Point to Point Protocol) permitindo conexão remota a partir de linha discada ou dedicada. Trabalha como os mecanismos IPCs e interfaces mais utilizados pelos sistemas operacionais, como sockets do Windows e NetBIOS.
- Protocolo Robusto: escalável, multiplataforma, com estrutura para ser utilizada em sistemas operacionais cliente/servidor, permitindo a utilização de aplicações desse porte entre dois pontos distantes.
- Internet: é através da suíte de protocolos TCP/IP que obtemos acesso a Internet. As redes locais distribuem servidores de acesso a Internet (proxy servers) e os hosts locais se conectam a estes servidores para obter o acesso a Internet. Este acesso só pode ser conseguido se os computadores estiverem configurados para utilizar TCP/IP.
- Total de Portas TCP: 2^16 = 65.536
- UDP = User Datagram Protocol é um protocolo simples da camada de transporte. Ele é descrito na RFC 768 e permite que a aplicação envie um datagrama encapsulado num pacote IPv4 ou IPv6 a um destino, porém sem qualquer tipo de garantia que o pacote chegue corretamente (ou de qualquer modo). Não é orientado a conexão, portanto os dados são enviados sem ter a certeza de que o receptor recebeu os dados. Exemplo de uso: são aqueles que não precisam de garantir a chegada dos dados. Todos os programas de video e voz são do tipo UDP (skype, todos os programas do tipo "Voz sobre IP" e streaming de videos).
- ICMP = Internet Control Message Protocol é um protocolo integrante do Protocolo IP, definido pelo RFC 792, é utilizado para fornecer relatórios de erros à fonte original. Qualquer computador que utilize IP precisa aceitar as mensagens ICMP e alterar o seu comportamento de acordo com o erro relatado.
- TYPE (8 bits): identifica o tipo mensagem, por exemplo, se o valor for 8 é uma requisição (echo request). Se o conteúdo for 0 é uma reposta (echo reply).
- CODE (8 bits): utilizado em conjunto com o campo TYPE para identificar o tipo de mensagem ICMP que está sendo enviada.
- CHECKSUM (16 bits): verifica a integridade do pacote ICMP.
- MESSAGE CONTENTS (Tamanho Variável): contém o conteúdo da mensagem ICMP.
- Open System Interconnection é um modelo de rede de computador com objetivo de ser um padrão, para protocolos de comunicação entre os mais diversos sistemas em uma rede local (Ethernet), garantindo a comunicação entre dois sistemas computacionais (end-to-end) divido em 7 camadas.
- PING ou Latência é um utilitário que usa o protocolo ICMP para testar a conectividade entre equipamentos. É um comando disponível praticamente em todos os sistemas operacionais. Seu funcionamento consiste no envio de pacotes para o equipamento de destino e na "escuta" das respostas. Se o equipamento de destino estiver ativo, uma "resposta" (o "pong", uma analogia ao famoso jogo de ping-pong) é devolvida ao computador solicitante. $ ping -c 5 google.com
- Firewal ou Parede de Fogo é um dispositivo de uma rede de computadores que tem por objetivo aplicar uma política de segurança a um determinado ponto da rede. O firewall pode ser do tipo filtros de pacotes, proxy de aplicações, etc. Os firewalls são geralmente associados a redes TCP/IP.[1]. Este dispositivo de segurança existe na forma de software e de hardware, a combinação de ambos é chamado tecnicamente de "appliance".
- Gateway = Ponte de ligação possui os seguintes significados:
- Em uma rede de comunicações, um nó de rede equipado para interfacear com outra rede que usa protocolos diferentes.
- Um computador ou programa de computador configurado para realizar as tarefas de um gateway.
- Para que serve: Organizar o tráfego de informações entre um equipamento final (computador, notebook, smartphone, tablet, etc) e a internet além de “traduzir” as informações entre redes heterogêneas. Isto é, permitir a comunicação entre diferentes ambientes e arquiteturas. Assim, a ferramenta é capaz de converter os dados entre sistemas diferentes, de modo que cada lado seja capaz de “entender” o outro.
- Exemplos de uso: roteador e firewall.
- Proxy = "Procurador ou Representante" é um servidor (um sistema de computador ou uma aplicação) que age como um intermediário para requisições de clientes solicitando recursos de outros servidores. Um cliente conecta-se ao servidor proxy, solicitando algum serviço, como um arquivo, conexão, página web ou outros recursos disponíveis de um servidor diferente, e o proxy avalia a solicitação como um meio de simplificar e controlar sua complexidade. Um proxy de cache HTTP ou, em inglês, caching proxy, permite por exemplo que o cliente requisite um documento na World Wide Web e o proxy procura pelo documento na sua caixa (cache). Se encontrado, a requisição é atendida e o documento é retornado imediatamente. Caso contrário, o proxy busca o documento no servidor remoto, entrega-o ao cliente e salva uma cópia em seu cache. Isto permite uma diminuição na latência, já que o servidor proxy, e não o servidor original, é requisitado, proporcionando ainda uma redução do uso da largura de banda.
- Traceroute é uma ferramenta de diagnóstico que rastreia a rota de um pacote através de uma rede de computadores que utiliza os protocolos IP e o ICMP. Seu funcionamento está baseado no uso do campo Time to Live (TTL) do pacote IPv4[8] destinado a limitar o tempo de vida dele. Este valor é decrementado a cada vez que o pacote é encaminhado por um roteador. Ao atingir o valor zero o pacote é descartado e o originador é alertado por uma mensagem ICMP TIME_EXCEEDED. $ traceroute google.com
- PAN = Personal Area Network é uma rede doméstica que liga recursos diversos ao longo de uma residência. Através da tecnologia Bluetooth e/ou cabo USB obtém-se uma rede PAN.
- LAN = Local Area Network é um conjunto de hardware e software que permite a computadores individuais estabelecerem comunicação entre si, trocando e compartilhando informações e recursos. Estas redes são denominadas locais por cobrirem uma área bem limitada, porém com o avanço tecnológico a LAN tem ultrapassado os 100 m de cobertura para se estender a uma área maior
- MAN = Metropolitan Area Network são redes maiores que as LANs. Este tipo de rede é caracterizada por ter um alcance maior que as do tipo LAN, abrangendo cidades próximas ou regiões metropolitanas, por exemplo. Em uma definição mais prática, imaginemos por exemplo, que uma empresa possui dois escritórios em uma mesma cidade e deseja que os computadores permaneçam interligados. Para isso existe a rede de área metropolitana, que conecta diversas redes locais dentro de algumas dezenas de quilômetros.
- WAN = Wide Area Network é uma rede de computadores que abrange uma grande área geográfica, com frequência um país ou continente. Um exemplo clássico de uma rede tipicamente WAN é a própria Internet pelo fato de abranger uma área geográfica global, interligando países e continentes.
- Camadas OSI
- Tree Way Handshake





- URL = Uniform Resource Locator (Nome do Domínio)
- Subdomínio
- URN == Uniform Resource Name
- /maps (recurso que será usado na URL)
- URI == Uniform Resource Identifier
- https://google.com/maps (URL + URN)
- TDL == Top Level Domain ou Domínio de Nível Superior
- A IANA (Autoridade para Atribuição de Números na Internet) atualmente distingue os seguintes grupos de domínios de topo
- domínios de topo de código de país (country-code top-level domains ou ccTLD): têm sempre duas letras e derivam do código ISO 3166-1 alpha-2
- domínios de topo genéricos (generic top-level domains ou gTLD): têm sempre mais do que duas letras
- domínios de topo patrocinados (sponsored top-level domains ou sTLD)
- domínios de topo não patrocinados (unsponsored top-level domains)
- domínios de topo de infraestruturas (infrastructure top-level domain)
- domínios de topo internacionalizados (internationalized top-level domains ou IDN)
- domínios de topo de código de país internacionalizado (internationalized country code top-level domains ou IDN ccTLD)
- domínios de topo em teste (testing top-level domains)
- A IANA (Autoridade para Atribuição de Números na Internet) atualmente distingue os seguintes grupos de domínios de topo
- DNS == Domain Name System
- É um sistema hierárquico e distribuído de gerenciamento de nomes para computadores, serviços ou qualquer máquina conectada à Internet ou a uma rede privada.
- Por padrão, o DNS usa o protocolo User Datagram Protocol (UDP) na porta 53 para servir as solicitações e as requisições.
- BIND == Berkeley Internet Name Domain é o servidor para o protocolo DNS mais utilizado na Internet, especialmente em sistemas do tipo Unix.
- 13 Root Servers
- https://www.iana.org/domains/root/servers
- The authoritative name servers that serve the DNS root zone, commonly known as the “root servers”, are a network of hundreds of servers in many countries around the world. They are configured in the DNS root zone as 13 named authorities, as follows.
List of Root Servers HOSTNAME IP ADDRESSES MANAGER a.root-servers.net 198.41.0.4, 2001:503:ba3e::2:30 VeriSign, Inc. b.root-servers.net 199.9.14.201, 2001:500:200::b University of Southern California (ISI) c.root-servers.net 192.33.4.12, 2001:500:2::c Cogent Communications d.root-servers.net 199.7.91.13, 2001:500:2d::d University of Maryland e.root-servers.net 192.203.230.10, 2001:500:a8::e NASA (Ames Research Center) f.root-servers.net 192.5.5.241, 2001:500:2f::f Internet Systems Consortium, Inc. g.root-servers.net 192.112.36.4, 2001:500:12::d0d US Department of Defense (NIC) h.root-servers.net 198.97.190.53, 2001:500:1::53 US Army (Research Lab) i.root-servers.net 192.36.148.17, 2001:7fe::53 Netnod j.root-servers.net 192.58.128.30, 2001:503:c27::2:30 VeriSign, Inc. k.root-servers.net 193.0.14.129, 2001:7fd::1 RIPE NCC l.root-servers.net 199.7.83.42, 2001:500:9f::42 ICANN m.root-servers.net 202.12.27.33, 2001:dc3::35 WIDE Project

- SaaS
- O SaaS (Software como Serviço) permite aos usuários se conectar e usar aplicativos baseados em nuvem pela Internet. Exemplos comuns são email, calendário e ferramentas do Office (como Microsoft Office 365).
- O SaaS fornece uma solução de software completa que você pode comprar em um regime pré-pago de um provedor de serviço de nuvem. Você pode alugar o uso de aplicativo para sua organização e seus usuários se conectarem a ele pela Internet, normalmente por um navegador da Web. Toda a infraestrutura subjacente, middleware, software de aplicativo e dados de aplicativo ficam no datacenter do provedor de serviços. O provedor de serviço gerencia hardware e software e, com o contrato de serviço apropriado, garante a disponibilidade e a segurança do aplicativo e de seus dados.
- Exemplo: Apps/aplicativos hospedados (Office 365, Google Docs)
- PaaS
- PaaS (Plataforma como serviço) é um ambiente de desenvolvimento e implantação completo na nuvem, com recursos que permitem a você fornecer tudo, de aplicativos simples baseados em nuvem a sofisticados aplicativos empresariais habilitados para a nuvem. Você adquire os recursos necessários por meio de um provedor de serviços de nuvem em uma base pré-paga e os acessa por uma conexão com a Internet segura.
- Assim como IaaS, PaaS inclui infraestrutura – servidores, armazenamento e rede –, além de middleware, ferramentas de desenvolvimento, serviços de BI (business intelligence), sistemas de gerenciamento de banco de dados e muito mais. PaaS é criado para dar suporte ao ciclo de vida do aplicativo Web completo: compilação, teste, implantação, gerenciamento e atualização.
- Exemplo: Ferramentas de desenvolvimento, gerenciamento de banco de dados, análise de negócios, Sistemas operacionais.
- IaaS
- IaaS (Infraestrutura como serviço) é uma infraestrutura de computação instantânea, provisionada e gerenciada pela Internet. Escale ou reduza verticalmente com demanda e pague somente pelo que usar.
- IaaS ajuda a evitar gastos e complexidade de comprar e gerenciar seus próprios servidores físicos e outras infraestruturas do datacenter. Cada recurso é oferecido como um componente de serviço separado e você só pode alugar um específico pelo tempo que precisar. O provedor de serviços de computação em nuvem gerencia a infraestrutura, enquanto você adquire, instala, configura e gerencia seu próprio software – sistemas operacionais, middleware e aplicativos.
- Exemplo: Servidores e armazenamento Segurança/firewalls de rede Construção/planta física do datacenter





{kind=link}
{kind=link}
{kind=link}