NeuralCoref is a pipeline extension for spaCy 2.1+ which annotates and resolves coreference clusters using a neural network. NeuralCoref is production-ready, integrated in spaCy's NLP pipeline and extensible to new training datasets.
For a brief introduction to coreference resolution and NeuralCoref, please refer to our blog post. NeuralCoref is written in Python/Cython and comes with a pre-trained statistical model for English only.
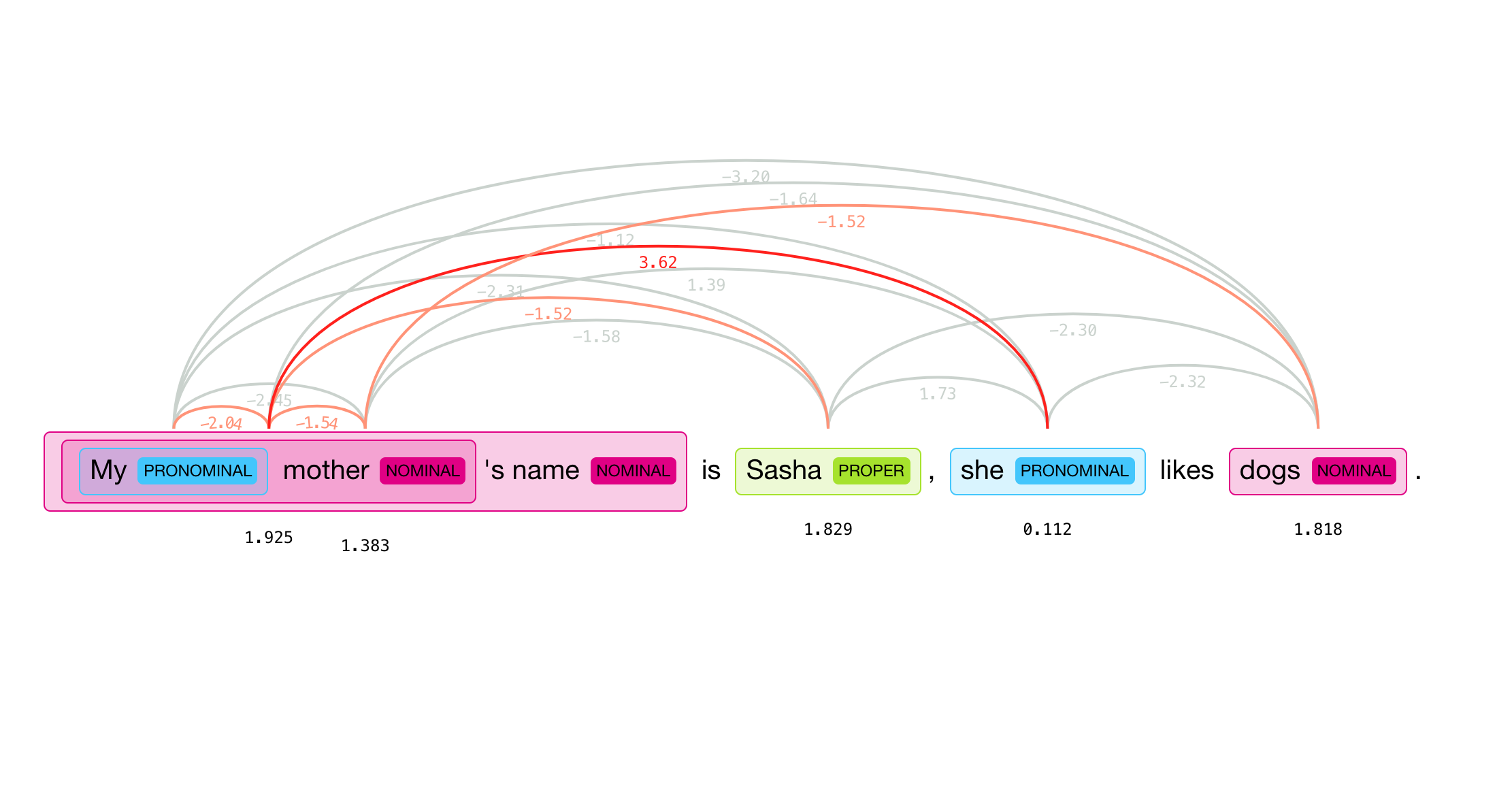
NeuralCoref is accompanied by a visualization client NeuralCoref-Viz, a web interface powered by a REST server that can be tried online. NeuralCoref is released under the MIT license.
✨ Version 4.0 out now! Available on pip and compatible with SpaCy 2.1+.


- Operating system: macOS / OS X · Linux · Windows (Cygwin, MinGW, Visual Studio)
- Python version: Python 3.5+ (only 64 bit)
- Package managers: [pip]
This is the easiest way to install NeuralCoref.
pip install neuralcorefIf you have an error mentioning spacy.strings.StringStore size changed, may indicate binary incompatibility when loading NeuralCoref with import neuralcoref, it means you'll have to install NeuralCoref from the distribution's sources instead of the wheels to get NeuralCoref to build against the most recent version of SpaCy for your system.
In this case, simply re-install neuralcoref as follows:
pip uninstall neuralcoref
pip install neuralcoref --no-binary neuralcorefTo be able to use NeuralCoref you will also need to have an English model for SpaCy.
You can use whatever english model works fine for your application but note that the performances of NeuralCoref are strongly dependent on the performances of the SpaCy model and in particular on the performances of SpaCy model's tagger, parser and NER components. A larger SpaCy English model will thus improve the quality of the coreference resolution as well (see some details in the Internals and Model section below).
Here is an example of how you can install SpaCy and a (small) English model for SpaCy, more information can be found on spacy's website:
pip install -U spacy
python -m spacy download enYou can also install NeuralCoref from sources. You will need to install the dependencies first which includes Cython and SpaCy.
Here is the process:
venv .env
source .env/bin/activate
git clone https://github.com/huggingface/neuralcoref.git
cd neuralcoref
pip install -r requirements.txt
pip install -e .NeuralCoref is made of two sub-modules:
- a rule-based mentions-detection module which uses SpaCy's tagger, parser and NER annotations to identify a set of potential coreference mentions, and
- a feed-forward neural-network which compute a coreference score for each pair of potential mentions.
The first time you import NeuralCoref in python, it will download the weights of the neural network model in a cache folder.
The cache folder is set by defaults to ~/.neuralcoref_cache (see file_utils.py) but this behavior can be overided by setting the environment variable NEURALCOREF_CACHE to point to another location.
The cache folder can be safely deleted at any time and the module will download again the model the next time it is loaded.
You can have more information on the location, downloading and caching process of the internal model by activating python's logging module before loading NeuralCoref as follows:
import logging;
logging.basicConfig(level=logging.INFO)
import neuralcoref
>>> INFO:neuralcoref:Getting model from https://s3.amazonaws.com/models.huggingface.co/neuralcoref/neuralcoref.tar.gz or cache
>>> INFO:neuralcoref.file_utils:https://s3.amazonaws.com/models.huggingface.co/neuralcoref/neuralcoref.tar.gz not found in cache, downloading to /var/folders/yx/cw8n_njx3js5jksyw_qlp8p00000gn/T/tmp_8y5_52m
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 40155833/40155833 [00:06<00:00, 6679263.76B/s]
>>> INFO:neuralcoref.file_utils:copying /var/folders/yx/cw8n_njx3js5jksyw_qlp8p00000gn/T/tmp_8y5_52m to cache at /Users/thomaswolf/.neuralcoref_cache/f46bc05a4bfba2ae0d11ffd41c4777683fa78ed357dc04a23c67137abf675e14.7d6f9a6fecf5cf09e74b65f85c7d6896b21decadb2554d486474f63b95ec4633
>>> INFO:neuralcoref.file_utils:creating metadata file for /Users/thomaswolf/.neuralcoref_cache/f46bc05a4bfba2ae0d11ffd41c4777683fa78ed357dc04a23c67137abf675e14.7d6f9a6fecf5cf09e74b65f85c7d6896b21decadb2554d486474f63b95ec4633
>>> INFO:neuralcoref.file_utils:removing temp file /var/folders/yx/cw8n_njx3js5jksyw_qlp8p00000gn/T/tmp_8y5_52m
>>> INFO:neuralcoref:extracting archive file /Users/thomaswolf/.neuralcoref_cache/f46bc05a4bfba2ae0d11ffd41c4777683fa78ed357dc04a23c67137abf675e14.7d6f9a6fecf5cf09e74b65f85c7d6896b21decadb2554d486474f63b95ec4633 to dir /Users/thomaswolf/.neuralcoref_cache/neuralcorefHere is the recommended way to instantiate NeuralCoref and add it to SpaCY's pipeline of annotations:
# Load your usual SpaCy model (one of SpaCy English models)
import spacy
nlp = spacy.load('en')
# Add neural coref to SpaCy's pipe
import neuralcoref
neuralcoref.add_to_pipe(nlp)
# You're done. You can now use NeuralCoref as you usually manipulate a SpaCy document annotations.
doc = nlp(u'My sister has a dog. She loves him.')
doc._.has_coref
doc._.coref_clustersAn equivalent way of adding NeuralCoref to a SpaCy model pipe is to instantiate the NeuralCoref class first and then add it manually to the pipe of the SpaCy Language model.
# Load your usual SpaCy model (one of SpaCy English models)
import spacy
nlp = spacy.load('en')
# load NeuralCoref and add it to the pipe of SpaCy's model
import neuralcoref
coref = neuralcoref.NeuralCoref(nlp.vocab)
nlp.add_pipe(coref, name='neuralcoref')
# You're done. You can now use NeuralCoref the same way you usually manipulate a SpaCy document and it's annotations.
doc = nlp(u'My sister has a dog. She loves him.')
doc._.has_coref
doc._.coref_clustersNeuralCoref will resolve the coreferences and annotate them as extension attributes in the spaCy Doc, Span and Token objects under the ._. dictionary.
Here is the list of the annotations:
| Attribute | Type | Description |
|---|---|---|
doc._.has_coref |
boolean | Has any coreference has been resolved in the Doc |
doc._.coref_clusters |
list of Cluster |
All the clusters of corefering mentions in the doc |
doc._.coref_resolved |
unicode | Unicode representation of the doc where each corefering mention is replaced by the main mention in the associated cluster. |
doc._.coref_scores |
Dict of Dict | Scores of the coreference resolution between mentions. |
span._.is_coref |
boolean | Whether the span has at least one corefering mention |
span._.coref_cluster |
Cluster |
Cluster of mentions that corefer with the span |
span._.coref_scores |
Dict | Scores of the coreference resolution of & span with other mentions (if applicable). |
token._.in_coref |
boolean | Whether the token is inside at least one corefering mention |
token._.coref_clusters |
list of Cluster |
All the clusters of corefering mentions that contains the token |
A Cluster is a cluster of coreferring mentions which has 3 attributes and a few methods to simplify the navigation inside a cluster:
| Attribute or method | Type / Return type | Description |
|---|---|---|
i |
int | Index of the cluster in the Doc |
main |
Span |
Span of the most representative mention in the cluster |
mentions |
list of Span |
List of all the mentions in the cluster |
__getitem__ |
return Span |
Access a mention in the cluster |
__iter__ |
yields Span |
Iterate over mentions in the cluster |
__len__ |
return int | Number of mentions in the cluster |
You can also easily navigate the coreference cluster chains and display clusters and mentions.
Here are some examples, try them out to test it for yourself.
import spacy
import neuralcoref
nlp = spacy.load('en')
neuralcoref.add_to_pipe(nlp)
doc = nlp(u'My sister has a dog. She loves him')
doc._.coref_clusters
doc._.coref_clusters[1].mentions
doc._.coref_clusters[1].mentions[-1]
doc._.coref_clusters[1].mentions[-1]._.coref_cluster.main
token = doc[-1]
token._.in_coref
token._.coref_clusters
span = doc[-1:]
span._.is_coref
span._.coref_cluster.main
span._.coref_cluster.main._.coref_clusterImportant: NeuralCoref mentions are spaCy Span objects which means you can access all the usual Span attributes like span.start (index of the first token of the span in the document), span.end (index of the first token after the span in the document), etc...
Ex: doc._.coref_clusters[1].mentions[-1].start will give you the index of the first token of the last mention of the second coreference cluster in the document.
You can pass several additional parameters to neuralcoref.add_to_pipe or NeuralCoref() to control the behavior of NeuralCoref.
Here is the full list of these parameters and their descriptions:
| Parameter | Type | Description |
|---|---|---|
greedyness |
float | A number between 0 and 1 determining how greedy the model is about making coreference decisions (more greedy means more coreference links). The default value is 0.5. |
max_dist |
int | How many mentions back to look when considering possible antecedents of the current mention. Decreasing the value will cause the system to run faster but less accurately. The default value is 50. |
max_dist_match |
int | The system will consider linking the current mention to a preceding one further than max_dist away if they share a noun or proper noun. In this case, it looks max_dist_match away instead. The default value is 500. |
blacklist |
boolean | Should the system resolve coreferences for pronouns in the following list: ["i", "me", "my", "you", "your"]. The default value is True (coreference resolved). |
store_scores |
boolean | Should the system store the scores for the coreferences in annotations. The default value is True. |
conv_dict |
dict(str, list(str)) | A conversion dictionary that you can use to replace the embeddings of rare words (keys) by an average of the embeddings of a list of common words (values). Ex: conv_dict={"Angela": ["woman", "girl"]} will help resolving coreferences for Angela by using the embeddings for the more common woman and girl instead of the embedding of Angela. This currently only works for single words (not for words groups). |
import spacy
import neuralcoref
# Let's load a SpaCy model
nlp = spacy.load('en')
# First way we can control a parameter
neuralcoref.add_to_pipe(nlp, greedyness=0.75)
# Another way we can control a parameter
nlp.remove_pipe("neuralcoref") # This remove the current neuralcoref instance from SpaCy pipe
coref = neuralcoref.NeuralCoref(nlp.vocab, greedyness=0.75)
nlp.add_pipe(coref, name='neuralcoref')Here is an example on how we can use the parameter conv_dict to help resolving coreferences of a rare word like a name:
import spacy
import neuralcoref
nlp = spacy.load('en')
# Let's try before using the conversion dictionary:
neuralcoref.add_to_pipe(nlp)
doc = nlp(u'Deepika has a dog. She loves him. The movie star has always been fond of animals')
doc._.coref_clusters
doc._.coref_resolved
# >>> [Deepika: [Deepika, She, him, The movie star]]
# >>> 'Deepika has a dog. Deepika loves Deepika. Deepika has always been fond of animals'
# >>> Not very good...
# Here are three ways we can add the conversion dictionary
nlp.remove_pipe("neuralcoref")
neuralcoref.add_to_pipe(nlp, conv_dict={'Deepika': ['woman', 'actress']})
# or
nlp.remove_pipe("neuralcoref")
coref = neuralcoref.NeuralCoref(nlp.vocab, conv_dict={'Deepika': ['woman', 'actress']})
nlp.add_pipe(coref, name='neuralcoref')
# or after NeuralCoref is already in SpaCy's pipe, by modifying NeuralCoref in the pipeline
nlp.get_pipe('neuralcoref').set_conv_dict({'Deepika': ['woman', 'actress']})
# Let's try agin with the conversion dictionary:
doc = nlp(u'Deepika has a dog. She loves him. The movie star has always been fond of animals')
doc._.coref_clusters
# >>> [Deepika: [Deepika, She, The movie star], a dog: [a dog, him]]
# >>> 'Deepika has a dog. Deepika loves a dog. Deepika has always been fond of animals'
# >>> A lot better!A simple example of server script for integrating NeuralCoref in a REST API is provided as an example in examples/server.py.
To use it you need to install falcon first:
pip install falconYou can then start the server as follows:
cd examples
python ./server.pyAnd query the server like this:
curl --data-urlencode "text=My sister has a dog. She loves him." -G localhost:8000There are many other ways you can manage and deploy NeuralCoref. Some examples can be found in spaCy Universe.
If you want to retrain the model or train it on another language, see our training instructions as well as our blog post