
In this project, I will create a recommendation engine for users of the IBM Watson Studio blog article platform. This engine will provide new articles for the user, no matter if the user is new or have already interacted with the platform.
Therefore, I will use the following algorithms:
-
Ranked-Based
-
User-Based
-
Matrix Factorization (FunkSVD)
-
Jupyter Notebook:
Recommendation Engine for IBM Watson Studio Blog Articles.ipynb- This Jupyter Notebook includes the following content:
- Exploratory Data Analysis
- Ranked-Based Recommendation
- User-Based Recommendation
- Matrix Factorization Recommendation
- Final Model
- Used Libraries:
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport statisticsfrom collections import Counter
- This Jupyter Notebook includes the following content:
-
CSV-file:
articles_community.csv- File with all blog articles from the platform
- 5 columns (datatypes: 1 integers, 4 objects)
- 1056 rows
- Hardly any duplicates/NaN-Values
-
CSV-file:
user-item-interactions.csv- File with all user-article interactions
- 3 columns (datatypes: 1 float, 2 objects)
- 45993 rows
In the file user-item-interactions.csv, there are the following findings:
- 80% of articles were viewed 80 times:
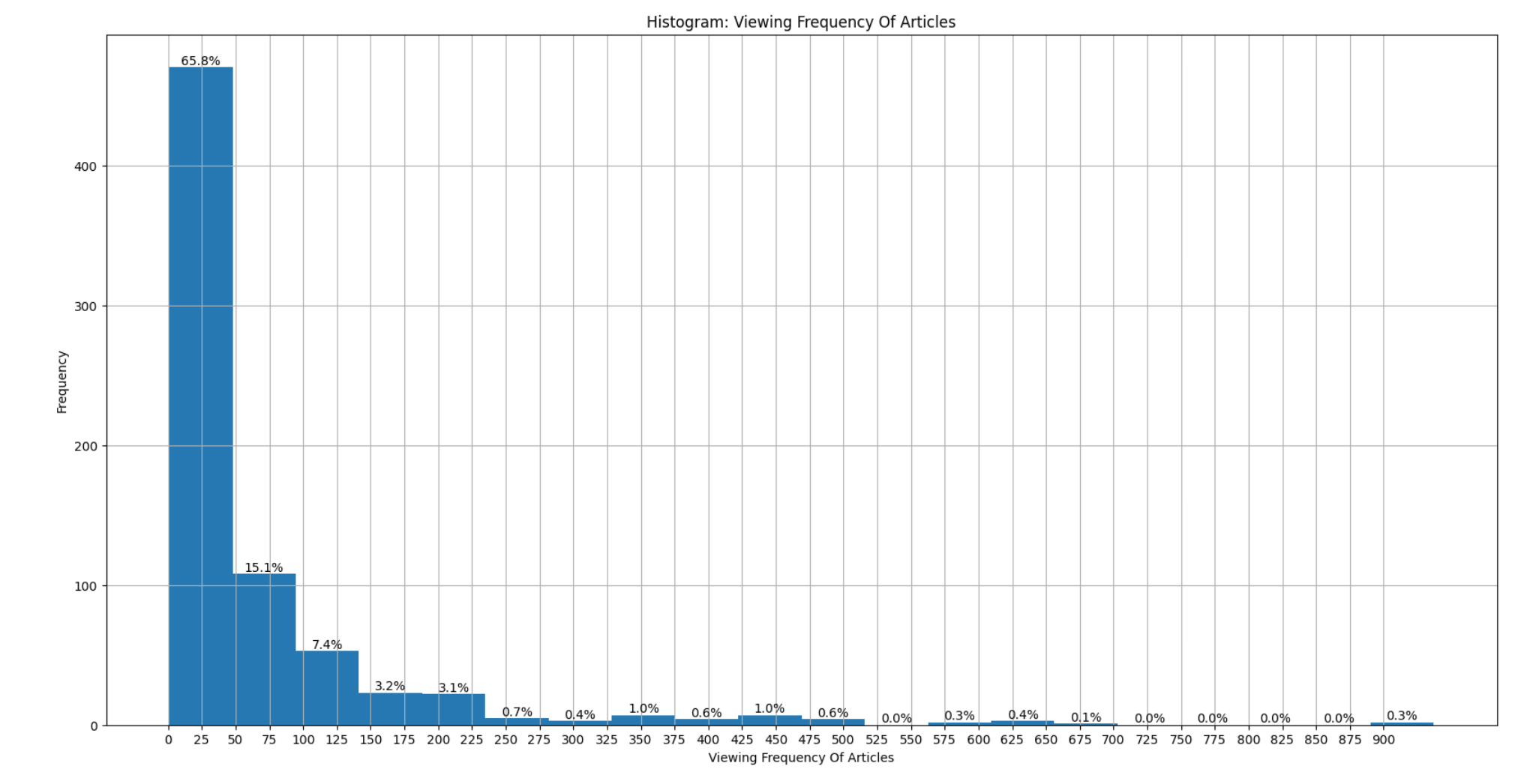
- Most users interacted with 1 to 20 articles:

- Most users viewed 1 to 7 different articles (not including multi viewing):

The algorithm uses a ranking to find the most viewed items and sorts them from most viewed to least viewed.
The algorithm search for user with similar behavior. To find similar behavior, I look at the articles a user has viewed and compare them to all users to find the user with the most matches. The items that the first user didn't see, but the similar user did, will be recommended.
he next recommendation algorithm will be based on the Matrix Factorization. Therefore, I use the famous FUNK-SVD algorithm.
The FUNK-SVD based on the splitting of a matrix in three matrices with latent factors. The problem with the normal SVD is that it can´t work with nan values, so objects which a user didn´t see jet. So, solve this problem, the FUNK-SVD use just the existing rating of a user and updated the nan and all other values of the latent factors with it. This will be done so long until a minimum error is reached.
The smallest MSE in at the number of 3 latent factors.

The define the cut point is at ± 0.000356 (the MSE at the lowest point).
The Ranked-Based Recommendation just recommend the most popular articles. For completely new users (cold-start-problem) this is complete enough. But for older user this is not satisficing. Therefore, the User-Based Recommendation can be used. The problem here is that a minimum number of articles seen is necessary. If this value is by 3, then just 50% of the users can have a recommendation with this algorithm. The last recommendation function can solve the problem. With the FUNK-SVD there is the possibility to predict article for a user. Just on interaction with an article can be enough. But the accuracy depends on the number of previews user interactions. Therefore, a cutoff value is necessary to find just the articles with the best accuracy. Overall, a combination of all 3 algorithm is the best option to find the best recommendation.
An improvement for my final model can be to restart the searching in the User-Based-Recommendation, when articles are sorted out because they have already been seen.
The dataset for this analyzation was thankfully provided from IBM Watson Studio: https://www.ibm.com/blogs/watson/