{kind=link}
There are not many reference implementations of deploying deep learning models within the Django REST framework.
The master branch contains a single view which loads a Bidirectional LSTM + MLP model to classify single sentences as positive or negative.The dev branch contains the work-in-progress scaleable API with message queuing and separate model server.
Clone the repo:
git clone [email protected]:NickLeoMartin/sentiment_api.git
cd sentiment_api/
Head into the repo and create and activate a virtual environment:
virtualenv --no-site-packages -p python3 venv
source venv/bin/activate
Install the packages used:
pip install -r requirements.txt
To see the demo run Django lightweight development sever which is available on http://127.0.0.1:8000/ :
./manage.py runserver
The demo was trained on single-sentence book reviews, avaliable here.
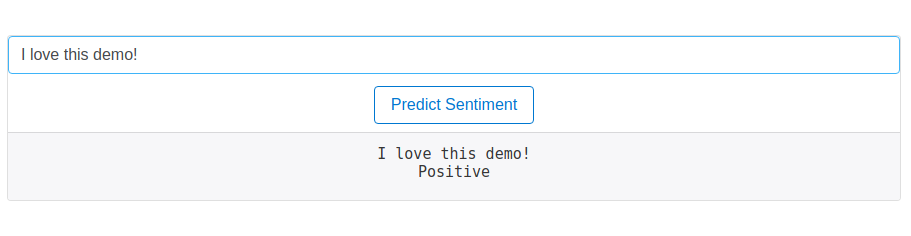
You can access the API directly, via http://127.0.0.1:8000/api/get_sentiment/:
curl --header "Content-Type: application/json" --request POST --data '{"input":"This documentation is terrible"}' http://127.0.0.1:8000/api/get_sentiment/
{"response": "Successful", "status": 200, "text": "This documentation is terrible", "sentiment_score": ["Negative"]}
Pre-trained model weights, parameters and text preprocessor are housed in trained_models/ . To load the pre-trained model:
from models.wrapper import SentimentAnalysisModel
weights_file = "trained_models/2018_06_15_10_weights.h5"
params_file = "trained_models/2018_06_15_10_params.json"
preprocessor_file = "trained_models/2018_06_15_10_preprocessor.pkl"
sentiment_model = SentimentAnalysisModel.load(weights_file,params_file,preprocessor_file)To predict on a new sentence:
sentiment_model.predict(["This documentation is terrible"])
['Negative']Simply specify the path to a tab separated text file (see example here) and the training parameters, Then run:
from models.wrapper import SentimentAnalysisModel
sentiment_model = SentimentAnalysisModel(
dataset_path="data/training.txt", model_name="bilstm", save_model=True, word_embedding_dim=100, word_lstm_size=100,fc_dim=100,
fc_activation='tanh', fc_n_layers=2, dropout=0.5, embeddings=None, loss = 'binary_crossentropy', optimizer="adam",
shuffle=True, batch_size=64, epochs=4)
sentiment_model.fit()The model is not correctly tuned and overfits to the training data. It can't handle out-of-vocabulary words as well as negation i.e. "not good". Hyperparameter tuning, character-level embeddings and a more diverse training set are logical next steps. API will not scale i.e. add message queuing, a model server and containerize.
V1: Model pipeline + REST API
- Simple Boostrap interface
- Basic Class-based API endpoint
- Ajax call to API endpoint
- BaseModel class
- Bidirectional LSTM with word
- Vocabulary builder
- DocIdTransformer
- Model training
- Model storage
- Model wrapper
- Model prediction
- Local loading and prediction through API endpoint
- Downloading of weights from git-lfs
- Run demo from scratch
- YML config file
- Input validation, error handling, documentation etc.
- Dockerize project
- Deploy demo
- Stress test
- Jupyter Notebook to demonstrate model reasoning i.e. negation, OOV terms etc.
V2: Scaleable API
- Message Queuing: Redis
- Apache Server to load model and poll (prevent loading a new model for every view)
- Update DockerFile
- Deploy demo
- Stress test
- Testing Suite
Extensions: Model Improvements + Code Resusability
- Use Glove embeddings
- Hyperparameter tuning, training summary statistic, more comprehensive dataset
- Asynchronous prediction with Celery
- Downloading script for short-text sentiment data
- Character-level embeddings (Raw or FastText)
- Multi-task learning for entities and sentiment
- Separate models and API