![]()
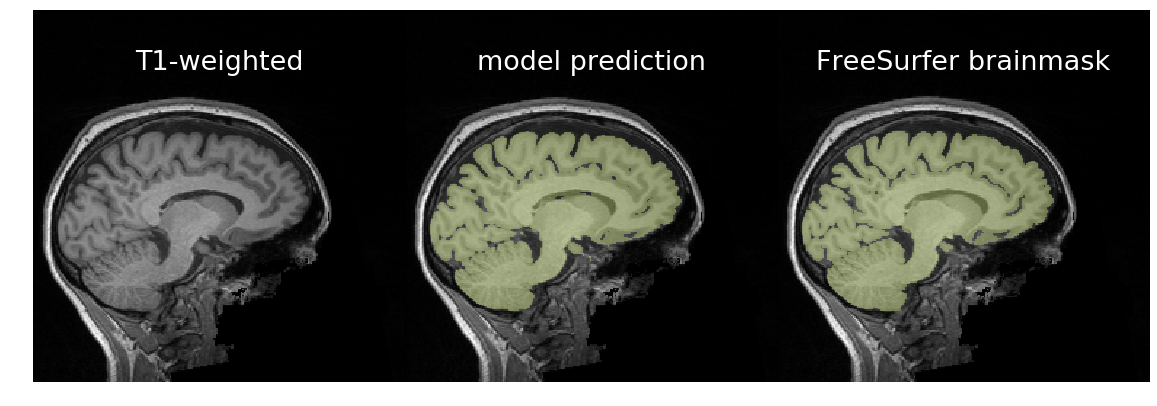
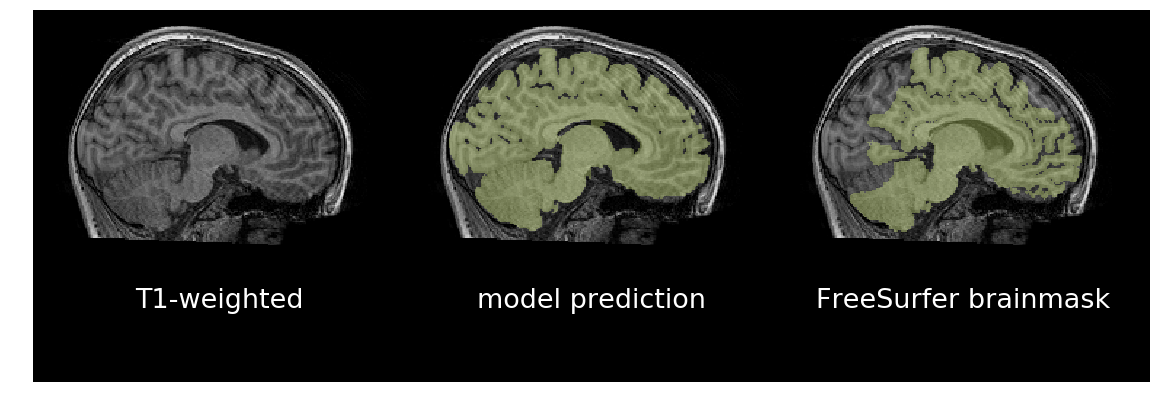 Figure: In the first column are T1-weighted brain scans, in the middle
are a trained model's predictions, and on the right are binarized FreeSurfer
segmentations. Despite being trained on binarized FreeSurfer segmentations,
the model outperforms FreeSurfer in the bottom scan, which exhibits motion
distortion. It took about three seconds for the model to predict each brainmask
using an NVIDIA GTX 1080Ti. It takes about 70 seconds on a recent CPU.
Figure: In the first column are T1-weighted brain scans, in the middle
are a trained model's predictions, and on the right are binarized FreeSurfer
segmentations. Despite being trained on binarized FreeSurfer segmentations,
the model outperforms FreeSurfer in the bottom scan, which exhibits motion
distortion. It took about three seconds for the model to predict each brainmask
using an NVIDIA GTX 1080Ti. It takes about 70 seconds on a recent CPU.
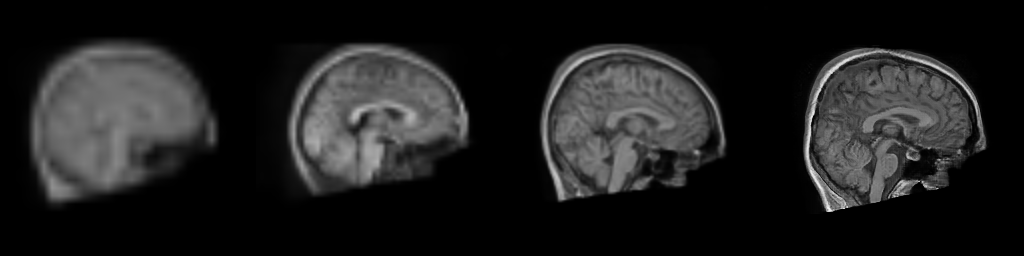
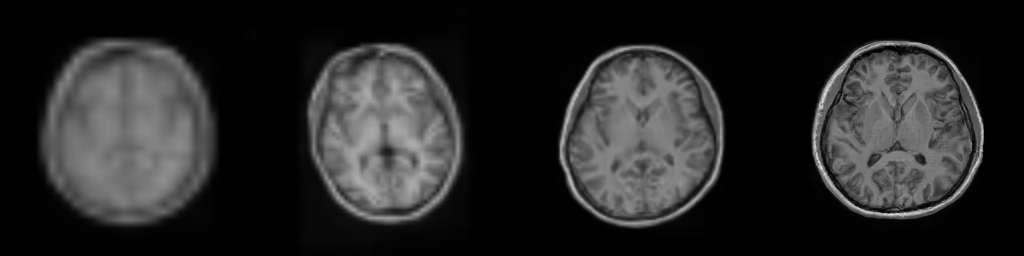
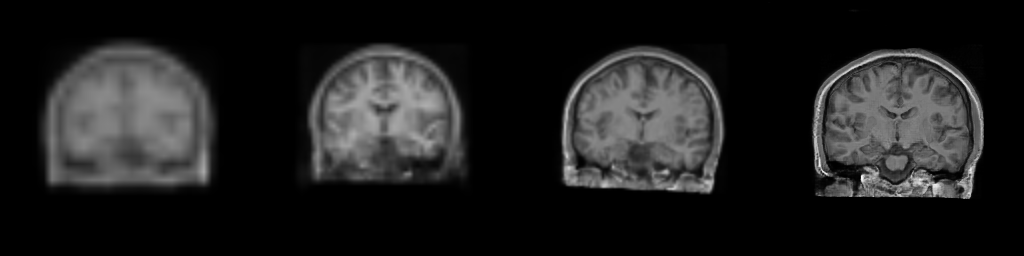 Figure: Progressive generation of T1-weighted brain MR scan starting
from a resolution of 32 to 256 (Left to Right: 323, 643,
1283, 2563). The brain scans are generated using the same
latents in all resolutions. It took about 6 milliseconds for the model to generate
the 2563 brainscan using an NVIDIA TESLA V-100.
Figure: Progressive generation of T1-weighted brain MR scan starting
from a resolution of 32 to 256 (Left to Right: 323, 643,
1283, 2563). The brain scans are generated using the same
latents in all resolutions. It took about 6 milliseconds for the model to generate
the 2563 brainscan using an NVIDIA TESLA V-100.
Nobrainer is a deep learning framework for 3D image processing. It implements several 3D convolutional models from recent literature, methods for loading and augmenting volumetric data that can be used with any TensorFlow or Keras model, losses and metrics for 3D data, and simple utilities for model training, evaluation, prediction, and transfer learning.
Nobrainer also provides pre-trained models for brain extraction, brain segmentation, brain generation and other tasks. Please see the Trained models repository for more information.
The Nobrainer project is supported by NIH RF1MH121885 and is distributed under the Apache 2.0 license. It was started under the support of NIH R01 EB020470.
- Guide Jupyter Notebooks
- Installation
- Using pre-trained networks
- Data augmentation
- Package layout
- Questions or issues
Please refer to the Jupyter notebooks in the guide directory to get started with Nobrainer. Try them out in Google Colaboratory!
We recommend using the official Nobrainer Docker container, which includes all of the dependencies necessary to use the framework. Please see the available images on DockerHub
The Nobrainer containers with GPU support use CUDA 10, which requires Linux
NVIDIA drivers >=410.48. These drivers are not included in the container.
$ docker pull neuronets/nobrainer:latest-gpu
$ singularity pull docker://neuronets/nobrainer:latest-gpu
This container can be used on all systems that have Docker or Singularity and does not require special hardware. This container, however, should not be used for model training (it will be very slow).
$ docker pull neuronets/nobrainer:latest-cpu
$ singularity pull docker://neuronets/nobrainer:latest-cpu
Nobrainer can also be installed with pip. Use the extra [gpu] to install
TensorFlow with GPU support and the [cpu] extra to install TensorFlow without
GPU support. GPU support requires CUDA 10, which requires Linux NVIDIA drivers
>=410.48.
$ pip install --no-cache-dir nobrainer[gpu]
Pre-trained networks are available in the Trained models
repository. Prediction can be done on the command-line with nobrainer predict
or in Python. Similarly, generation can be done on the command-line with
nobrainer generate or in Python.
In the following examples, we will use a 3D U-Net trained for brain extraction and documented in Trained models.
In the base case, we run the T1w scan through the model for prediction.
# Get sample T1w scan.
wget -nc https://dl.dropbox.com/s/g1vn5p3grifro4d/T1w.nii.gz
docker run --rm -v $PWD:/data neuronets/nobrainer \
predict \
--model=/models/neuronets/brainy/0.1.0/brain-extraction-unet-128iso-model.h5 \
--verbose \
/data/T1w.nii.gz \
/data/brainmask.nii.gzFor binary segmentation where we expect one predicted region, as is the case with brain extraction, we can reduce false positives by removing all predictions not connected to the largest contiguous label.
# Get sample T1w scan.
wget -nc https://dl.dropbox.com/s/g1vn5p3grifro4d/T1w.nii.gz
docker run --rm -v $PWD:/data neuronets/nobrainer \
predict \
--model=/models/neuronets/brainy/0.1.0/brain-extraction-unet-128iso-model.h5 \
--largest-label \
--verbose \
/data/T1w.nii.gz \
/data/brainmask-largestlabel.nii.gzBecause the network was trained on randomly rotated data, it should be agnostic
to orientation. Therefore, we can rotate the volume, predict on it, undo the
rotation in the prediction, and average the prediction with that from the original
volume. This can lead to a better overall prediction but will at least double the
processing time. To enable this, use the flag --rotate-and-predict in
nobrainer predict.
# Get sample T1w scan.
wget -nc https://dl.dropbox.com/s/g1vn5p3grifro4d/T1w.nii.gz
docker run --rm -v $PWD:/data neuronets/nobrainer \
predict \
--model=/models/neuronets/brainy/0.1.0/brain-extraction-unet-128iso-model.h5 \
--rotate-and-predict \
--verbose \
/data/T1w.nii.gz \
/data/brainmask-withrotation.nii.gzCombining the above, we can usually achieve the best brain extraction by using
--rotate-and-predict in conjunction with --largest-label.
# Get sample T1w scan.
wget -nc https://dl.dropbox.com/s/g1vn5p3grifro4d/T1w.nii.gz
docker run --rm -v $PWD:/data neuronets/nobrainer \
predict \
--model=/models/neuronets/brainy/0.1.0/brain-extraction-unet-128iso-model.h5 \
--largest-label \
--rotate-and-predict \
--verbose \
/data/T1w.nii.gz \
/data/brainmask-maybebest.nii.gzIn the following examples, we will use a Progressive Generative Adversarial Network trained for brain image generation and documented in Trained models.
In the base case, we generate a T1w scan through the model for a given resolution.
We need to pass the directory containing the models (tf.SavedModel) created
while training the networks.
docker run --rm -v $PWD:/data neuronets/nobrainer \
generate \
--model=/models/neuronets/braingen/0.1.0 \
--output-shape=128 128 128 \
/data/generated.nii.gzWe can also generate multiple resolutions of the brain image using the same latents to visualize the progression
# Get sample T1w scan.
docker run --rm -v $PWD:/data neuronets/nobrainer \
generate \
--model=/models/neuronets/braingen/0.1.0 \
--multi-resolution \
/data/generated.nii.gzIn the above example, the multi resolution images will be saved as
generated_res_{resolution}.nii.gz
The pre-trained models can be used for transfer learning. To avoid forgetting important information in the pre-trained model, you can apply regularization to the kernel weights and also use a low learning rate. For more information, please see the Nobrainer guide notebook on transfer learning.
As an example of transfer learning, @kaczmarj re-trained a brain extraction model to label meningiomas in 3D T1-weighted, contrast-enhanced MR scans. The original model is publicly available and was trained on 10,000 T1-weighted MR brain scans from healthy participants. These were all research scans (i.e., non-clinical) and did not include any contrast agents. The meningioma dataset, on the other hand, was composed of relatively few scans, all of which were clinical and used gadolinium as a contrast agent. You can observe the differences in contrast below.

Despite the differences between the two datasets, transfer learning led to a much better model than training from randomly-initialized weights. As evidence, please see below violin plots of Dice coefficients on a validation set. In the left plot are Dice coefficients of predictions obtained with the model trained from randomly-initialized weights, and on the right are Dice coefficients of predictions obtained with the transfer-learned model. In general, Dice coefficients are higher on the right, and the variance of Dice scores is lower. Overall, the model on the right is more accurate and more robust than the one on the left.


Nobrainer provides methods of augmenting volumetric data. Augmentation is useful
when the amount of data is low, and it can create more generalizable and robust
models. Other packages have implemented methods of augmenting volumetric data,
but Nobrainer is unique in that its augmentation methods are written in pure
TensorFlow. This allows these methods to be part of serializable tf.data.Dataset
pipelines.
In practice, @kaczmarj has found that augmentations improve the generalizability of semantic segmentation models for brain extraction. Augmentation also seems to improve transfer learning models. For example, a meningioma model trained from a brain extraction model that employed augmentation performed better than a meningioma model trained from a brain extraction model that did not use augmentation.
A rigid transformation is one that allows for rotations, translations, and reflections.
Nobrainer implements rigid transformations in pure TensorFlow. Please refer to
nobrainer.transform.warp to apply a transformation matrix to a volume. You can
also apply random rigid transformations to the data input pipeline. When creating
your tf.data.Dataset with nobrainer.volume.get_dataset, simply set augment=True,
and about 50% of volumes will be augmented with random rigid transformations. To
use the function directly, please refer to nobrainer.volume.apply_random_transform.
Features and labels are transformed in the same way. Features are interpolated
linearly, whereas labels are interpolated using nearest neighbor. Below is an
example of a random rigid transformation applied to features and labels. The mask
in the right-hand column is a brain mask. Note that the MRI scan and brain mask
are transformed in the same way.

nobrainer.io: input/output methodsnobrainer.layers: custom layers, which conform to the Keras APInobrainer.losses: loss functions for volumetric segmentationnobrainer.metrics: metrics for volumetric segmentationnobrainer.models: pre-defined Keras modelsnobrainer.training: training utilities (supports training on single and multiple GPUs)nobrainer.transform: random rigid transformations for data augmentationnobrainer.volume:tf.data.Datasetcreation and data augmentation utilities
If you have questions about Nobrainer or encounter any issues using the framework, please submit a GitHub issue.