Original code: https://github.com/suicao/ai4code-baseline
Early solution for Google AI4Code competition
This solution is based on Amet Erdem's baseline . Instead of predicting the cell position with only the markdown itself, we randomly sample up to 20 code cells to act as the global context. So your input will look something like this:
<s> Markdown content <s> Code content 1 <s> Code content 2 <s> ... <s> Code content 20 <s>
To extract features for training, including the markdown-only dataframes and sampling the code cells needed for each note book, simply run:
$ python preprocess.py --data_dir [your_data_dir]
Outputs will be in the ./data folder:
project
│ train_mark.csv
│ train_fts.json
| train.csv
│ val_mark.csv
│ val_fts.json
│ val.csv
$ python train.py --md_max_len 64 --total_max_len 512 --batch_size 8 --accumulation_steps 4 --epochs 5 --n_workers 8 --train_mark_path ./data/train_mark_clean.csv --val_mark_path ./data/val_mark_clean.csv
Các chiến lược tối ưu trong huấn luyện Transformer và áp dụng trong bài toán Kaggle4Code (Tiếng Việt - Chừng nào rãnh viết Tiếng Anh sau hoặc check link tham khảo)
- Phương pháp Gradient Accumulation
Trong quá trình huấn luyện các mô hình Deep Learning, bằng cách sử dụng batch size lớn giúp tăng khả năng hội tụ của mô hình lên rất nhiều. Tuy nhiên, điều này dẫn đến vấn đề tốn kém chi phí về bộ nhớ. Để mà tối ưu bộ nhớ đối với các hệ thống hạn chế tài nguyên, người ta thường giảm kích thước batch xuống nhưng điều này lại tăng thời gian huấn luyện mô hình lên. Hơn nữa, những thuật toán gradient descent rất nhạy cảm với kích thước batch bởi nó khiến thuật toán mất ổn định và nguy hiểm hơn là giảm hiệu suất (tức làm giảm đi khả năng tìm được cực tiểu toàn cục trong quá trình tối ưu hàm mục tiêu). Để mà giải quyết vấn đề này, người ta đề ra chiến lược Gradient Accumulation. Bằng cách chạy nhiều lần (accumulation steps) và tích trữ (tính toán trung bình) gradient của một số lượng cụ thể accumulation steps, và khi đó ta có đủ gradient để tính toán bước nhảy tối ưu (optimization step).

Áp dụng chiến lược cho KaggleAI4Code như sau:
for e in range(epochs):
...
for idx, data in enumerate(tbar):
...
if idx % args.accumulation_steps == 0 or idx == len(tbar) - 1:
# before gradient clipping the optimizer parameters must be unscaled.
scaler.unscale_(optimizer)
# perform optimization step
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
scheduler.step()- Phương pháp tối ưu huấn luyện với Automatic Mixed Precision Training
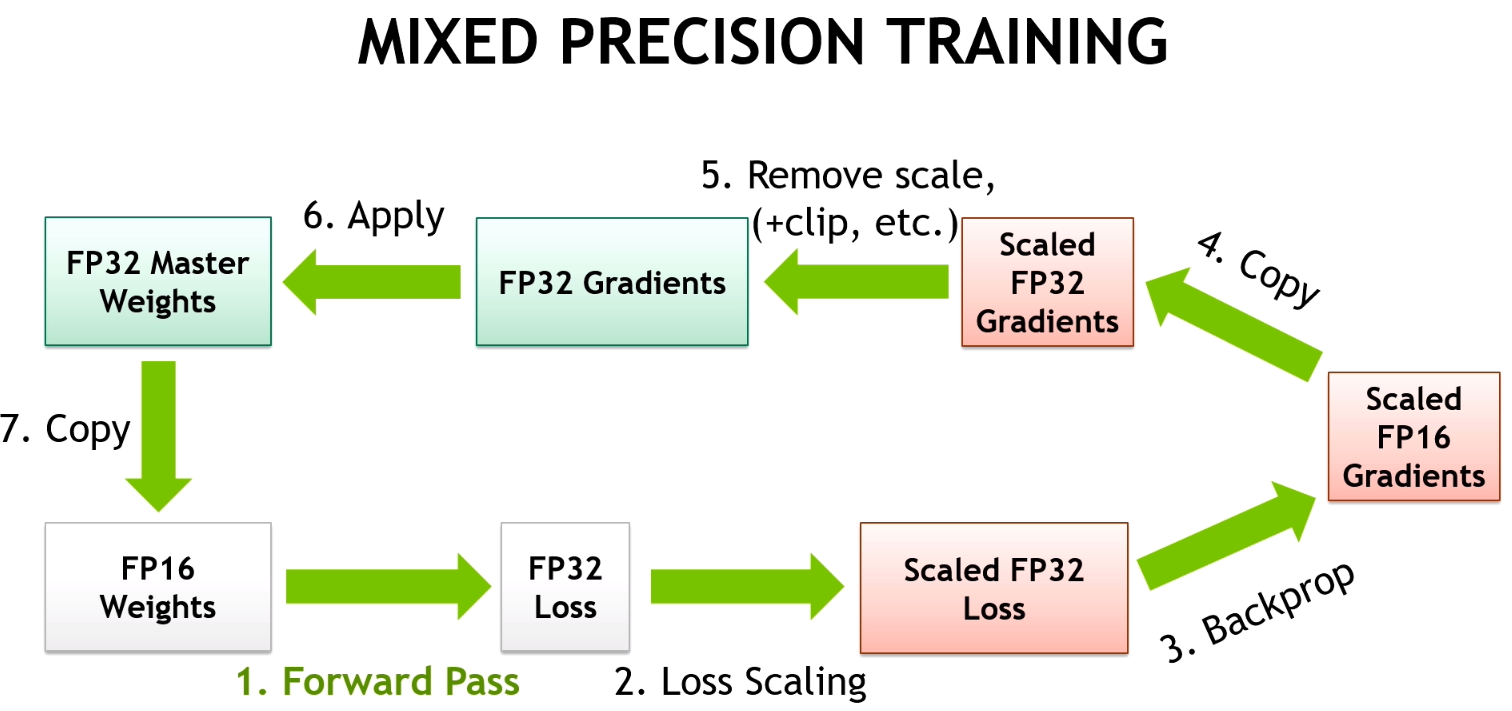
Trong các phương pháp tối ưu (giảm thiểu) bộ nhớ (reducing memory consumption) và giảm thiểu thời gian huấn luyện mô hình Deep Learning nhưng không làm (ít làm) giảm độ chính xác và chất lượng của mô hình, phương pháp Automatic Mixed Precision (AMP) được nhiều người sử dụng thường xuyên. Phương pháp được giới thiệu trong bài báo Mixed Precision Training bởi Paulius Micikevicius cùng các cộng sự đến từ NVIDIA và Baidu vào năm 2017. Ý tưởng cốt lỗi đằng sau phương pháp này là sử dụng lower precision hay half-precision (số chấm động 16bit - float16) để lưu trữ gradient và parameters (ở dạng Tensors) của mô hình trong bộ nhớ, thay vì sử dụng full precision (số chấm động 32bit - float32). Hơn nữa, để tránh hiện tượng "over flow", tức là khi tính toán ở half-precision có một số giá trị bị tiêu biến thành giá trị 0 (zero value), bài báo đề xuất phương pháp gradient scaling. Hình bên dưới minh họa quá trình xử lý của phương pháp.
Áp dụng chiến lược cho KaggleAI4Code như sau:
...
for idx, data in enumerate(tbar):
inputs, target = read_data(data)
# Cast value
with torch.cuda.amp.autocast():
pred = model(*inputs)
# computing loss
loss = criterion(pred, target)
# scale gradint and perform backward pass
scaler.scale(loss).backward()
if idx % args.accumulation_steps == 0 or idx == len(tbar) - 1:
# before gradient clipping the optimizer parameters must be unscaled.
scaler.unscale_(optimizer)
# perform optimization step
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
# step scaler for optimizer and update scaler
scaler.step(optimizer)
scaler.update()
# zero gradient for optimzer befere new iteration
optimizer.zero_grad()
# step schduler
scheduler.step()- Sử dụng 8-bit Optimizers - 8-bit Adam/AdamW Optimizer
Trong thời gian gần đây, những bộ tối ưu tham số được cải tiến nhiều hơn nhằm tăng tốc tính toán và cải thiện hiệu năng trong dò tìm các nghiệm cho việc tối ưu hiệu quả các hàm mục tiêu cho các mô hình Deep Learning, 8-bit Optimizers là một trong những cải tiến nổi bật. Ý tưởng đằng sau của nó cũng khá tương tự với chiến lược Automatic Mixed Precision Training mà vừa đề cập ở trên. Được đề xuất trong bài báo 8-bit Optimizers via Block-wise Quantization bởi Tim Dettmers và cộng sự đến từ Meta Research, bài báo đã chứng minh được hiệu quả của 8-bit Optimizers trong việc giải quyết vấn đề bộ nhớ và tăng tốc huấn luyện mô hình. Hơn nữa, các tác động bởi siêu tham số đến các bộ tối ưu 8-bit cũng được nghiên cứu và cho thấy rằng learning rate, betas và weight decay parameters không có tác động lớn đến hiệu suất cũng như hiệu quả của mô hình học.

Áp dụng chiến lược cho KaggleAI4Code như sau:
Cài đặt thư viện bitsandbytes-cuda110, chọn version phù hợp
!pip install -q bitsandbytes-cuda110
# Sử dụng optimizer Adam 8bit
optimizer = bnb.optim.Adam8bit(optimizer_grouped_parameters, lr=3e-5)
# Sử dựng optimizer AdamW 8bit
#optimizer = bnb.optim.AdamW8bit(optimizer_grouped_parameters, lr=3e-5)def set_embedding_parameters_bits(embeddings_path, optim_bits=32):
"""
https://github.com/huggingface/transformers/issues/14819#issuecomment-1003427930
"""
embedding_types = ("word", "position", "token_type")
for embedding_type in embedding_types:
attr_name = f"{embedding_type}_embeddings"
if hasattr(embeddings_path, attr_name):
bnb.optim.GlobalOptimManager.get_instance().register_module_override(
getattr(embeddings_path, attr_name), 'weight', {
'optim_bits': optim_bits}
)- Sử dụng Fast Tokenizers
HuggingFace cung cấp Fast Tokenizers được cài đặt bằng Rust với tốc độ cải thiện nhanh đáng kể trong các mô hình ngôn ngữ. Áp dụng chiến lược cho KaggleAI4Code như sau:
class MarkdownDataset(Dataset):
def __init__(self, df, model_name_or_path, total_max_len, md_max_len, fts):
super().__init__()
self.df = df.reset_index(drop=True)
self.md_max_len = md_max_len
self.total_max_len = total_max_len # maxlen allowed by model config
# Sử dụng AutoTokenizer, optimize với fast tokenizer với option use_fast = True
#self.tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
# self.tokenizer AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
# Sử dụng một tokenizer từ một model pretrain trước
self.tokenizer = AutoTokenizer.from_pretrained("tals/roberta_python")
# Nếu tokenizer chưa có pad_token, thêm vào
if self.tokenizer.pad_token is None:
self.tokenizer.add_special_tokens({'pad_token': '[PAD]'})[1] Vadim Irtlach (vad13irt). Optimization approaches for Transformers. https://www.kaggle.com/code/vad13irt/optimization-approaches-for-transformers