

![]()
![]()
![]()
![]()
Information about the goals and organization of the AI Incident Database can be found on the production website. This page concentrates on onboarding for the following types of contributions to the database,
- Contribute changes to the current AI Incident Database.
- Contribute a new summary to the AI Incident Database. A "summary" is a programmatically generated summary of the database contents. Examples are available here.
- Contribute a new taxonomy to the AI Incident Database. Details on taxonomies are available in the arXiv paper.
- Contribute a new application facilitating a new use case for the database.
In most cases unless you are contributing quick fixes, we recommend opening an issue before contributing to the project. You can also Contact us for an invitation to the project's Slack installation. Lurking is encouraged. Finally, for major announcements you can join the announcements-only mailing list.
The AI Incident Database is an open source project inviting contributions from the global community. Anyone with code changes that advance the change thesis of making the world better in the future by remembering the negative outcomes of the past are welcome to submit pull requests. To ensure that submitted changes are likely to be accepted, we recommend becoming familiar with the manner in which we organize our work items and open an issue on GitHub.
The process of completing work through GitHub issues at the highest level is:
Create Issue -> Assign Issue -> Review and Publish
Labels help streamline the process and ensure issues do not get lost or neglected. Label descriptions are on GitHub. The following describes when/how to use a label.
- Consider if the issue is an Initiative, Epic, or Story. All engineering issues aside from Bugs should fall in one of these categories and be assigned a label. Other types of issues (ex: Data Editor-related) may not have this label.
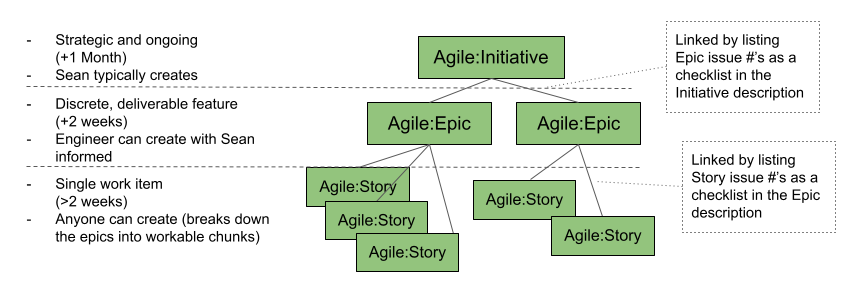
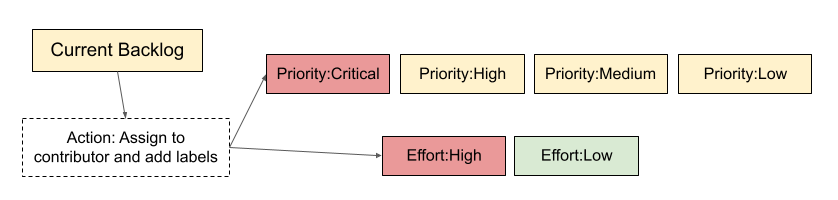
- Apply a descriptor label (when applicable):

Add the label Current Backlog to trigger assigning a contributor. Either the assigner or the contributor adds the issue’s priority and effort labels.
Once the issue has a deliverable output(s), use the Pull Request process to have the contribution reviewed and accepted.
The person opening the PR should create it in a draft status until the work is finished, then they should click on "Ready for review" button and assign it to someone as a reviewer as soon the PR is ready to be reviewed.
In general, PR reviews can be assigned to any member of the @responsible-ai-collaboraite/aiid-dev team, or to the team alias itself. Don't be shy! Above all, contributors and reviewers should assume good intentions. As such, reviewers are also encouraged to re-assign PR reviews based on familiarity and time constraints.
When something is mergeable, then someone else with maintainer permissions (not the implementer or reviewer) can merge it to staging. They can optionally do a final review.
After merging to staging, the code quality is everyone’s responsibility.
For more information on how to create built-in draft pull requests, please refer to the GitHub blog.
Anyone can contribute code to the project. The system is being built as a "do-ocracy", meaning those who "do" have influence over the development of the code.
The steps for contributing changes are the following,
- Create a fork of the repository.
- Clone the fork to your local environment.
- Open a feature branch from whichever branch you would like to change. This is typically the
stagingbranch, so you can dogit checkout stagingthengit checkout -b feature-cool-new-thing. - Make your changes, commit them, then push them remote.
- Open a pull request to the
stagingbranch. - Update the pull request based on the review.
- See the pull request get pulled. :)
Please make sure your code is well organized and commented before opening the pull request.
The site architecture consists of these main components:
-
Deployment Pipeline:
- Hosted in a GitHub repository
- Automated through GitHub Actions workflows that handle building, testing, and deploying the application
- Ensures code quality and successful deployment through automated checks
-
Frontend Hosting: A Gatsby-based static web application hosted on Netlify, along with Netlify Functions for serverless API functionality.
-
Search: Algolia provides the search index functionality, enabling fast and efficient content discovery.
-
Content Management: Prismic CMS allows for dynamic content management including blog posts and other updateable content.
-
Database: A MongoDB database stores the core application data. The database content can be synced periodically to update the Algolia search index, allowing for storage of documents and details that may be either unsupported by or too costly to host in Algolia.
Additional services integrated into the architecture include:
- MailerSend for email communication
- Cloudinary for image hosting and optimization
- Rollbar for error logging and monitoring
- Google Translate API for content translation capabilities
This architecture maintains a serverless approach, with no need for a traditional dynamic backend server, while leveraging specialized services for specific functionalities. The deployment process is fully automated through GitHub Actions, ensuring consistent and reliable deployments with proper testing and validation steps.
More details are available on our documentation.
The site exposes a read-only GraphQL endpoint at /api/graphql.
You can check the endpoint https://incidentdatabase.ai/api/graphql
The endpoint can be queried using any GraphQL client, but for example, if using Apollo:
import { ApolloClient, HttpLink, InMemoryCache, gql } from '@apollo/client';
const client = new ApolloClient({
link: new HttpLink({
uri: `https://incidentdatabase.ai/api/graphql`,
}),
cache: new InMemoryCache()
});
client.query({query: gql`{
reports {
title
report_number
}
}`}).then(result => console.log(result));
For inquiries, you are encouraged to open an issue on this repository or visit the contact page.