Automatically gather jstacks for Spark applications #5
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
b9af486 to
99aaaac
Compare
a5a8e8d to
fcf3b89
Compare
…helper model attribute relations ### What changes were proposed in this pull request? Replace transformer wrappers with helper model attributes ### Why are the changes needed? to simplify the implementations ### Does this PR introduce _any_ user-facing change? no, refactoring-only ### How was this patch tested? existing tests should cover this change ### Was this patch authored or co-authored using generative AI tooling? no Closes apache#49819 from zhengruifeng/ml_connect_wrapper_to_helper. Authored-by: Ruifeng Zheng <[email protected]> Signed-off-by: Ruifeng Zheng <[email protected]>
…ngth, bit_length, and transform ### What changes were proposed in this pull request? Refine docstring `rlike`, `length`, `octet_length`, `bit_length`, and `transform`. ### Why are the changes needed? to improve docs and test coverage ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? doctests ### Was this patch authored or co-authored using generative AI tooling? No Closes apache#49463 from drexler-sky/docstring. Authored-by: Evan Wu <[email protected]> Signed-off-by: Ruifeng Zheng <[email protected]>
…ule later for Spark Classic only ### What changes were proposed in this pull request? This PR is a followup of apache#49704 that Import pyspark.core module later for Spark Classic only. For pure python packaging, `pyspark.core` is not available. ### Why are the changes needed? To recover the build in https://github.com/apache/spark/actions/runs/13164682457/job/36741828881 ### Does this PR introduce _any_ user-facing change? No, test-only. ### How was this patch tested? Will monitor the build. ### Was this patch authored or co-authored using generative AI tooling? No. Closes apache#49820 from HyukjinKwon/SPARK-50922-followup. Authored-by: Hyukjin Kwon <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
…otAllowedError` ### What changes were proposed in this pull request? Clarify error message for `negativeScaleNotAllowedError` with user-facing error class ### Why are the changes needed? Raise a more user-friendly error message when users attempt to use a negative precision for DecimalType when the Spark config `spark.sql.legacy.allowNegativeScaleOfDecimal` is not set. Previously an internal error was raised, which is not correct. ### Does this PR introduce _any_ user-facing change? Yes, it affects the error class when users attempt to use a negative precision for DecimalType when the Spark config `spark.sql.legacy.allowNegativeScaleOfDecimal` is not set. ### How was this patch tested? Added test in `DecimalSuite.scala` ### Was this patch authored or co-authored using generative AI tooling? No Closes apache#49807 from asl3/asl3/negativescalenotallowederror. Authored-by: Amanda Liu <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
…park Connect ### What changes were proposed in this pull request? This PR proposes to add a new configuration called `spark.api.mode` (default `classic`) that allows existing Spark Classic applications to easily use Spark Connect. ### Why are the changes needed? In order users to easily try Spark Connect with their existing Spark Classic applications. ### Does this PR introduce _any_ user-facing change? It adds a new configuration `spark.api.mode` without changing the default behaviour. ### How was this patch tested? For PySpark applications, added unittests for Spark Submissions in Yarn and Kubernates, and manual tests. For Scala applications, it is difficult to add a test because SBT picks up the complied jars into the classpathes automatically (whereas we can easily control it for production environment). For this case, I manually tested as below: ```bash git clone https://github.com/HyukjinKwon/spark-connect-example cd spark-connect-example build/sbt package cd .. git clone https://github.com/apache/spark.git cd spark build/sbt package # sbin/start-connect-server.sh bin/spark-submit --name "testApp" --master "local[*]" --conf spark.api.mode=connect --class com.hyukjinkwon.SparkConnectExample ../spark-connect-example/target/scala-2.13/spark-connect-example_2.13-0.0.1.jar ``` ### Was this patch authored or co-authored using generative AI tooling? No. Closes apache#49107 from HyukjinKwon/api-mode-draft-3. Authored-by: Hyukjin Kwon <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
…feRow and Avro encoding suites ### What changes were proposed in this pull request? Splitting the TransformWithStateSuite into TransformWithStateUnsafeRowEncodingSuite and TransformWithStateAvroEncodingSuite, in order to remove it from the slow test category ### Why are the changes needed? To remove TransformWithState-related suites from the Slow test category ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Just moving tests around, no need to test ### Was this patch authored or co-authored using generative AI tooling? No Closes apache#49815 from ericm-db/split-tws-suite. Authored-by: Eric Marnadi <[email protected]> Signed-off-by: Jungtaek Lim <[email protected]>
…tions ### What changes were proposed in this pull request? Add parity test for ml functions ### Why are the changes needed? for test coverage ### Does this PR introduce _any_ user-facing change? no, test-only ### How was this patch tested? ci ### Was this patch authored or co-authored using generative AI tooling? no Closes apache#49824 from zhengruifeng/ml_connect_f_ut. Authored-by: Ruifeng Zheng <[email protected]> Signed-off-by: Ruifeng Zheng <[email protected]>
…ias.sql ### What changes were proposed in this pull request? I propose that we extend group-by-alias.sql with some cases where we `group by` aliases. ### Why are the changes needed? Extend the testing coverage. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Added tests. ### Was this patch authored or co-authored using generative AI tooling? No. Closes apache#49750 from mihailoale-db/addgroupbytests. Authored-by: mihailoale-db <[email protected]> Signed-off-by: Max Gekk <[email protected]>
…correctly ### What changes were proposed in this pull request? apache#49559 introduces `AlterColumnSpec`, which has the field `newPosition` that should have been accounted for when calling `resolved`. Because it is currently not accounted for, `AlterColumnSpec` reports `resolved` to be true even when `newPosition` is not resolved. ### Why are the changes needed? While this is currently not a problem with Spark, this might affect extensions or become a surprise in the future. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? New unit test ### Was this patch authored or co-authored using generative AI tooling? No Closes apache#49705 from ctring/SPARK-51010. Authored-by: Cuong Nguyen <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
### What changes were proposed in this pull request? Remove scala option based variant api for value state ### Why are the changes needed? Remove language specific API to ensure consistency across supported languages ### Does this PR introduce _any_ user-facing change? Yes ### How was this patch tested? Existing unit tests ### Was this patch authored or co-authored using generative AI tooling? No Closes apache#49769 from anishshri-db/task/SPARK-51057. Authored-by: Anish Shrigondekar <[email protected]> Signed-off-by: Jungtaek Lim <[email protected]>
…sues ### What changes were proposed in this pull request? This PR fixes a bunch of issues with SQL API docs for Scala and Java: - Removes the now defunct Connect API docs. The current SQL docs provide enough coverage. - Removes the following internal packages from the docs: `org.apache.spark.sql.artifact`, `org.apache.spark.sql.scripting`, and `org.apache.spark.sql.ml`. - Fixes the removal of the `org.apache.spark.error` and `org.apache.spark.sql.error` packages. - Marks a bunch of internal classes in the `org.apache.spark.sql` as `private[sql]` to remove them from the docs. - Moves the `TableValuedFunctionArgument` interface from `org.apache.spark.sql` to `org.apache.spark.sql.internal` because it kept showing up in the docs. ### Why are the changes needed? Readable docs are important! ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manual inspection of the Java and Scala docs. ### Was this patch authored or co-authored using generative AI tooling? No. Closes apache#49800 from hvanhovell/SPARK-49371. Authored-by: Herman van Hovell <[email protected]> Signed-off-by: Herman van Hovell <[email protected]>
…ues` function ### What changes were proposed in this pull request? This PR implements `KVGDS.agg(typedColumn)` function when there is a `mapValues` function defined. This use case was previously unsupported (`mapValues` won't be applied). This PR marks the special handling of `kvds.reduce()` obsolete. However, we keep the server-side code to maintain compatibility with older clients. This implementation is purely done on the client side, oblivious to the Connect server. The mechanism is to first create an intermediate DF that contains only two Struct columns: ``` df |- iv: struct<...schema of the original df...> |- v: struct<...schema of the output of the mapValues func...> ``` Then we re-write all grouping exprs to use `iv` column, and all aggregating exprs to use `v` column as input. The rule is as follows: - Prefix every column reference with `iv` or `v`, e.g., `col1` becomes `iv.col1`. - Rewrite `*` to - `iv.value`, if the original df schema is a primitive type; or - `iv`, if the original df schema is a struct type. Follow-up: - [SPARK-50837](https://issues.apache.org/jira/browse/SPARK-50837): fix wrong output column names. This issue is caused by us manipulating DF schema. - [SPARK-50846](https://issues.apache.org/jira/browse/SPARK-50846): consolidate aggregator-to-proto transformation code path. ### Why are the changes needed? To support a use case that is previously unsupported. ### Does this PR introduce _any_ user-facing change? Yes, see the first section. ### How was this patch tested? New test cases. ### Was this patch authored or co-authored using generative AI tooling? No. Closes apache#49111 from xupefei/kvds-mapvalues. Authored-by: Paddy Xu <[email protected]> Signed-off-by: Herman van Hovell <[email protected]>
…ly methods ### What changes were proposed in this pull request? This PR add the `ClassicOnly` annotation for methods in the Scala SQL interface that are only available in the classic implementation. I have annotated all classic only methods accordingly. ### Why are the changes needed? This makes it clearer from the code that a methods is only available in classic. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? No tests needed. ### Was this patch authored or co-authored using generative AI tooling? No. Closes apache#49801 from hvanhovell/SPARK-49698. Authored-by: Herman van Hovell <[email protected]> Signed-off-by: Herman van Hovell <[email protected]>
…als with one call in Unsafe* classes ### What changes were proposed in this pull request? Write the month and days fields of intervals with one call to Platform.put/getLong() instead of two calls to Platform.put/getInt(). In commit ac07cea there was a performance improvement to reading a writing CalendarIntervals in UnsafeRow. This makes writing intervals consistent with UnsafeRow and has better performance compared to the original code. This also fixes big endian platforms where the old (two calls to getput) and new methods of reading and writing CalendarIntervals do not order the bytes in the same way. Currently CalendarInterval related tests in Catalyst and SQL are failing on big endian platforms. There is no effect on little endian platforms (byte order is not affected) except for performance improvement. ### Why are the changes needed? * Improves performance reading and writing CalendarIntervals in Unsafe* classes * Fixes big endian platforms where CalendarIntervals are not read or written correctly in Unsafe* classes ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing unit tests on big and little endian platforms ### Was this patch authored or co-authored using generative AI tooling? No Closes apache#49737 from jonathan-albrecht-ibm/master-endian-interval. Authored-by: Jonathan Albrecht <[email protected]> Signed-off-by: Max Gekk <[email protected]>
### What changes were proposed in this pull request? Currently, the [Spark website](https://spark.apache.org/docs/latest/) fails to load bootstrap.bundle.min.js/jquery.js/etc due to the following errors ``` Refused to load the stylesheet '<URL>' because it violates the following Content Security Policy directive: "style-src 'self' 'unsafe-inline' data:". Note that 'style-src-elem' was not explicitly set, so 'style-src' is used as a fallback. Understand this errorAI latest/:1 Refused to load the script 'https://cdn.jsdelivr.net/npm/bootstrap5.0.2/dist/js/bootstrap.bundle.min.js' because it violates the following Content Security Policy directive: "script-src 'self' 'unsafe-inline' 'unsafe-eval' https://analytics.apache.org/". Note that 'script-src-elem' was not explicitly set, so 'script-src' is used as a fallback. Understand this errorAI latest/:1 Refused to load the script 'https://code.jquery.com/jquery.js' because it violates the following Content Security Policy directive: "script-src 'self' 'unsafe-inline' 'unsafe-eval' https://analytics.apache.org/". Note that 'script-src-elem' was not explicitly set, so 'script-src' is used as a fallback. ... ``` As a result, the website looks like: <img width="1040" alt="image" src="https://github.com/user-attachments/assets/77898702-c0be-4898-88d7-e5f4e368dfad" /> To fix the issue, I suggest using self-host javascript and CSS in Spark website ### Why are the changes needed? Fix the broken styling on the Spark website. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Test locally ### Was this patch authored or co-authored using generative AI tooling? No Closes apache#49823 from gengliangwang/fixWebsite. Authored-by: Gengliang Wang <[email protected]> Signed-off-by: Gengliang Wang <[email protected]>
…site ### What changes were proposed in this pull request? Follow-up of apache#49823, we need to self-host docsearch.min.css in Spark website as well ### Why are the changes needed? Fix the broken styling on the Spark website. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Local build and preview ### Was this patch authored or co-authored using generative AI tooling? No Closes apache#49838 from gengliangwang/fixWebsiteFollowup. Authored-by: Gengliang Wang <[email protected]> Signed-off-by: Gengliang Wang <[email protected]>
### What changes were proposed in this pull request?
Adds logs when the Python worker looks stuck.
- Spark conf: `spark.python.worker.idleTimeoutSeconds` (default `0` that means no timeout)
The time (in seconds) Spark will wait for activity (e.g., data transfer or communication) from a Python worker before considering it potentially idle or unresponsive. When the timeout is triggered, Spark will log the network-related status for debugging purposes. However, the Python worker will remain active and continue waiting for communication. The default is `0` that means no timeout.
- SQL conf: `spark.sql.execution.pyspark.udf.idleTimeoutSeconds`
The same as `spark.python.worker.idleTimeoutSeconds`, but this is a runtime conf for Python UDFs. Falls back to `spark.python.worker.idleTimeoutSeconds`.
For example:
```py
import time
from pyspark.sql import functions as sf
spark.conf.set('spark.sql.execution.pyspark.udf.idleTimeoutSeconds', '1s')
sf.udf
def f(x):
time.sleep(2)
return str(x)
spark.range(1).select(f("id")).show()
```
will show a warning message:
```
... WARN PythonUDFWithNamedArgumentsRunner: Idle timeout reached for Python worker (timeout: 1 seconds). No data received from the worker process: handle.map(_.isAlive) = Some(true), channel.isConnected = true, channel.isBlocking = false, selector.isOpen = true, selectionKey.isValid = true, selectionKey.interestOps = 1, hasInputs = false
```
### Why are the changes needed?
For the monitoring of the Python worker.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually checked the logs.
### Was this patch authored or co-authored using generative AI tooling?
No.
Closes apache#49818 from ueshin/issues/SPARK-51099/pythonrunner_logging.
Authored-by: Takuya Ueshin <[email protected]>
Signed-off-by: Takuya Ueshin <[email protected]>
…nes about strings join and reduce the redundant lines ### What changes were proposed in this pull request? - Refactor CommandBuilderUtils#join to reuse the lines about strings join and reduce the redundant lines. ### Why are the changes needed? - Refactor CommandBuilderUtils#join to reuse the lines about strings join and reduce the redundant lines. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GitHub Actions ### Was this patch authored or co-authored using generative AI tooling? No Closes apache#49826 from RocMarshal/SPARK-51107. Authored-by: Roc Marshal <[email protected]> Signed-off-by: yangjie01 <[email protected]>
….connect.functions` ### What changes were proposed in this pull request? Add doctest for `pyspark.ml.connect.functions` ### Why are the changes needed? to improve the test coverage ### Does this PR introduce _any_ user-facing change? no, test-only ### How was this patch tested? ci ### Was this patch authored or co-authored using generative AI tooling? no Closes apache#49821 from zhengruifeng/ml_connect_function_doc_tests. Authored-by: Ruifeng Zheng <[email protected]> Signed-off-by: Ruifeng Zheng <[email protected]>
### What changes were proposed in this pull request? Optimize the memory usage in KDE examples, the memory usage for KDE computation should be about 10% X previous value. ### Why are the changes needed? apache@4b7191d computes all metrics for all curves together, so only need one pass on the dataset. however, it increase the memory usage, so fail the dynamic plot generation. ### Does this PR introduce _any_ user-facing change? yes, minor quality loss before:  after: 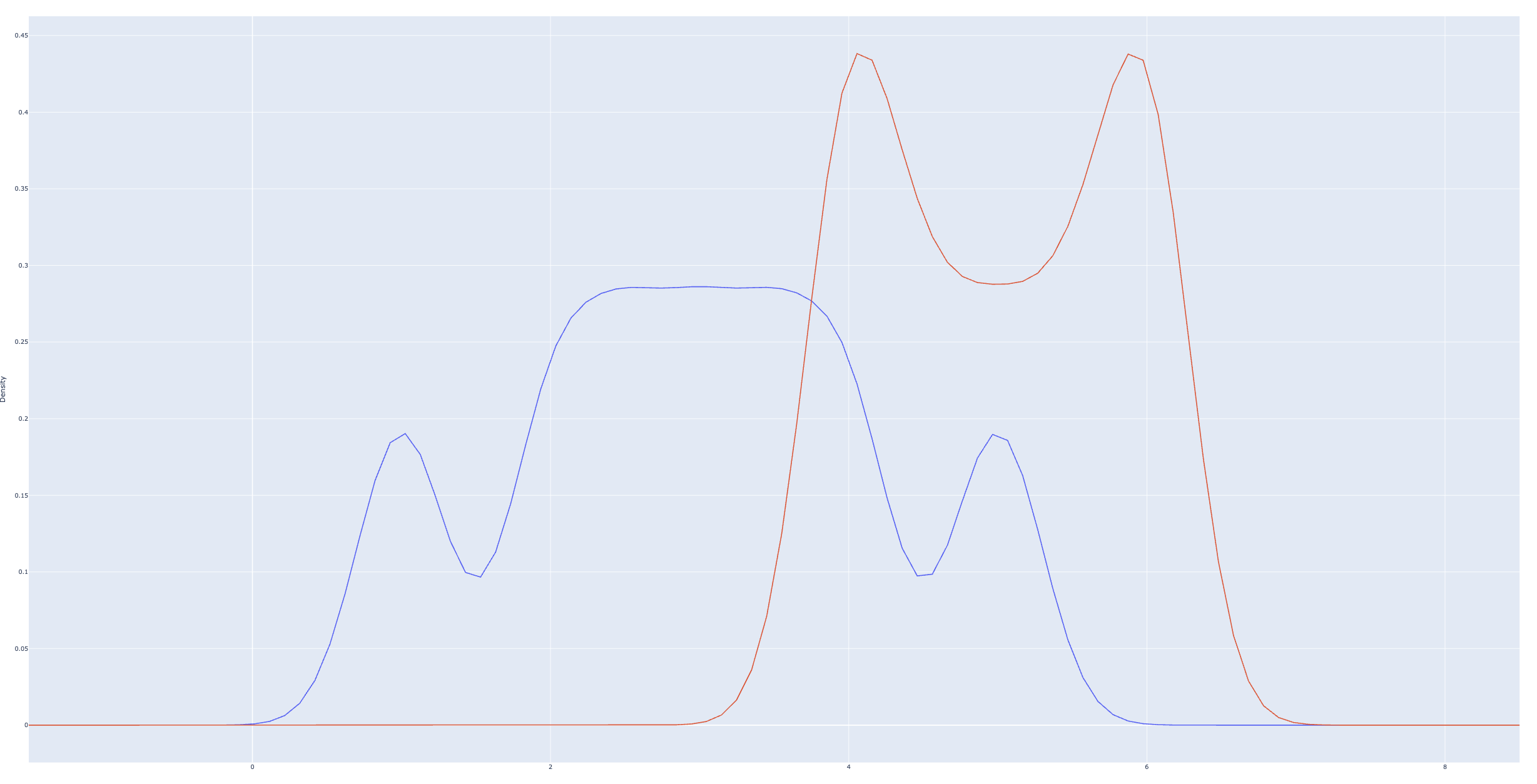 ### How was this patch tested? manually test, with `bin/pyspark`, the example fails with OOM before ### Was this patch authored or co-authored using generative AI tooling? no Closes apache#49842 from zhengruifeng/ps_kde_memory_opt. Authored-by: Ruifeng Zheng <[email protected]> Signed-off-by: Ruifeng Zheng <[email protected]>
…ven_test.yml` ### What changes were proposed in this pull request? This pr aims to add install Python packages process for `yarn` module in `maven_test.yml` ### Why are the changes needed? Synchronize the changes made to `build_and_test.yml` in SPARK-50605. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Monitor maven daily test after merged. ### Was this patch authored or co-authored using generative AI tooling? No Closes apache#49827 from LuciferYang/SPARK-51108. Authored-by: yangjie01 <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
### What changes were proposed in this pull request? Self host docsearch.min.css.map in Spark website ### Why are the changes needed? In the console of Spark website, I saw error messages after using the search box: ``` ERROR /docs/latest/css/docsearch.min.css.map' not found ``` Although the website is still functioning, it's nice to self-host the `.map` file as well. It can help debugging and reduce error logs. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Local build and preview ### Was this patch authored or co-authored using generative AI tooling? No Closes apache#49844 from gengliangwang/includeMap. Authored-by: Gengliang Wang <[email protected]> Signed-off-by: Gengliang Wang <[email protected]>
… of Python Connect build with development build ### What changes were proposed in this pull request? This Pr is a followup of apache#48139 that matches pandas version in Python Connect build ### Why are the changes needed? To fix https://github.com/apache/spark/actions/runs/13186023784/job/36808188511 ### Does this PR introduce _any_ user-facing change? No, test-only. ### How was this patch tested? Will monitor the CI ### Was this patch authored or co-authored using generative AI tooling? No. Closes apache#49846 from HyukjinKwon/SPARK-49792-followup. Authored-by: Hyukjin Kwon <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
### What changes were proposed in this pull request? Fix minor endianness issues in the following tests. ArrayBasedMapBuilderSuite: The output of the UnsafeRow.toString() is based on the underlying bytes and is endian dependent. Add an expected value for big endian platforms. Add an expected value for big endian platforms. WriteDistributionAndOrderingSuite: Casting the id of type Int to Long doesn't work on big endian platforms because the BucketFunction calls UnsafeRow.getLong() for that column. That happens to work on little endian since an int field is stored in the first 4 bytes of the 8 byte field so positive ints are layed out the same as positive longs ie. little endian order. On big endian, the layout of UnsafeRow int fields does not happen to match the layout of long fields for the same number. Change the type of the id column to Long so that it matches what BucketFunction expects. Change the type of the id column to Long so that it matches what BucketFunction expects. ### Why are the changes needed? Allow tests to pass on big endian platforms ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Ran existing tests on amd64 (little endian) and s390x (big endian) ### Was this patch authored or co-authored using generative AI tooling? No Closes apache#49812 from jonathan-albrecht-ibm/master-endian-testEndianness. Authored-by: Jonathan Albrecht <[email protected]> Signed-off-by: Max Gekk <[email protected]>
### What changes were proposed in this pull request? Four new types were added to the Parquet Variant spec (apache/parquet-format@25f05e7): UUID, Time, Timestamp(NANOS) and TimestampNTZ(NANOS). They don't correspond to an existing Spark type, so there is no need to allow them to be constructed in Spark. But when reading from another tool, we should be able to handle them gracefully: specifically, casts to JSON/string should work, and SchemaOfVariant should produce a reasonable result. This PR only adds support for UUID. Support for the other types should be similar, mainly differing in the details of casting to string. ### Why are the changes needed? Support reading Variant values produced by other tools. ### Does this PR introduce _any_ user-facing change? In Spark 4.0, we would fail when trying to read a Variant value containing UUID. With this change, we should be able to handle it. ### How was this patch tested? Added unit tests. ### Was this patch authored or co-authored using generative AI tooling? No. Closes apache#50025 from cashmand/uuid_support. Authored-by: cashmand <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
…xedSeq` from `scalastyle-config.xml` ### What changes were proposed in this pull request? This pr aims to remove `IllegalImportsChecker` for `s.c.Seq/IndexedSeq` from `scalastyle-config.xml` because after Spark 4.0, only Scala 2.13 is supported, eliminating the issue of cross-compilation. ### Why are the changes needed? Cleaning up outdated scala style checking rule. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GitHub Actions ### Was this patch authored or co-authored using generative AI tooling? No Closes apache#50105 from LuciferYang/SPARK-51339. Authored-by: yangjie01 <[email protected]> Signed-off-by: yangjie01 <[email protected]>
…ushing down EXTRACT ### What changes were proposed in this pull request? This is a followup of apache#48210 to fix correctness issues caused by pgsql filter pushdown. These datetime fields were picked wrongly before, see https://neon.tech/postgresql/postgresql-date-functions/postgresql-extract ### Why are the changes needed? bug fix ### Does this PR introduce _any_ user-facing change? Yes, query result is corrected, but this bug is not released yet. ### How was this patch tested? updated test ### Was this patch authored or co-authored using generative AI tooling? no Closes apache#50101 from cloud-fan/pgsql. Authored-by: Wenchen Fan <[email protected]> Signed-off-by: Wenchen Fan <[email protected]>
…pInPandas/mapInArrow batched in byte size ### What changes were proposed in this pull request? This PR is a followup of apache#50096 that reverts unrelated changes and mark mapInPandas/mapInArrow batched in byte size ### Why are the changes needed? To make the original change self-contained, and mark mapInPandas/mapInArrow batched in byte size to be consistent. ### Does this PR introduce _any_ user-facing change? No, the main change has not been released out yet. ### How was this patch tested? Manually. ### Was this patch authored or co-authored using generative AI tooling? No. Closes apache#50111 from HyukjinKwon/SPARK-51316-followup. Authored-by: Hyukjin Kwon <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]>
fcf3b89 to
2bb6398
Compare
|
New PR: #8 |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
What changes were proposed in this pull request?
Why are the changes needed?
Does this PR introduce any user-facing change?
How was this patch tested?
Was this patch authored or co-authored using generative AI tooling?