Lore Goetschalckx, Maryam Zolfaghar, Alekh K. Ashok, Lakshmi N. Govindarajan, Drew Linsley, Thomas Serre
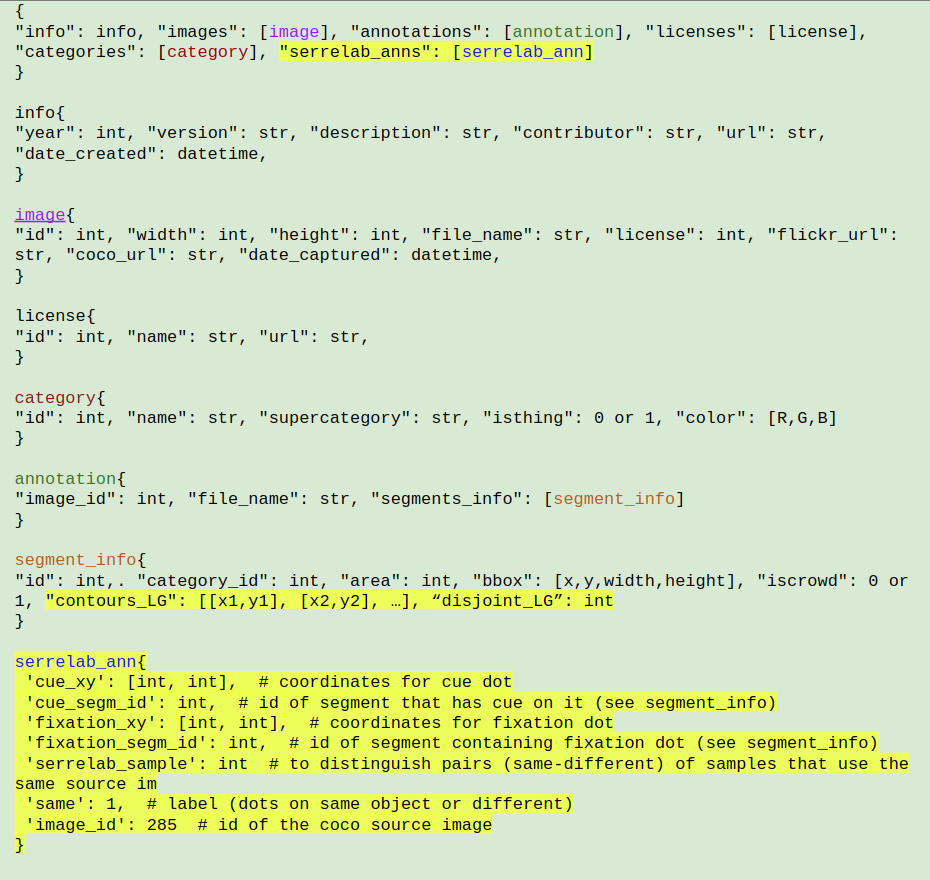
COCO Dots is based on the original COCO panoptic segmentation dataset. It was designed to train models on a grouping task similar to the one used in a human psychophysics study by Jeurissen et al. (2016). The most important addition to the original COCO panoptic json-file is the serrelab_anns key.
The format of the original annotation file can be found here: COCO 2017 Annotations Format
We have modified the annotations file to include the following, highlighted fields:
- Download the COCO 2017 train and validation datasets:
- Download the our modified Annotation files:
- Create the DataLoaders as follows:
from data import CocoDots
train_loader = torch.utils.data.DataLoader(
CocoDots("<PATH_TO_TRAIN_ANNOTATIONS_JSON>", "<PATH_TO_COCO_2017_TRAIN_IMAGES>", conversion='WhiteOutline'),
batch_size=128, num_workers=4, pin_memory=False, drop_last=True)
val_loader = torch.utils.data.DataLoader(
CocoDots("<PATH_TO_VAL_ANNOTATIONS_JSON>", "<PATH_TO_COCO_2017_VAL_IMAGES>", conversion='WhiteOutline'),
batch_size=128, num_workers=4, pin_memory=False, drop_last=True)