Design Document
v1.0 - 2023.10.08 Initial version
v1.1 - 2023.10.22 Upload Frontend Class Diagram, Update API Documentation & External Libraries
v1.2 - 2023.11.05 Update Backend Class Diagram & API Documentation
v1.3 - 2023.11.19 Update Testing Plan
v1.4 - 2023.11.28 Update on
- Frontend Class diagram
- Backend Class disagrm
- ML Deploy
- UI Demo


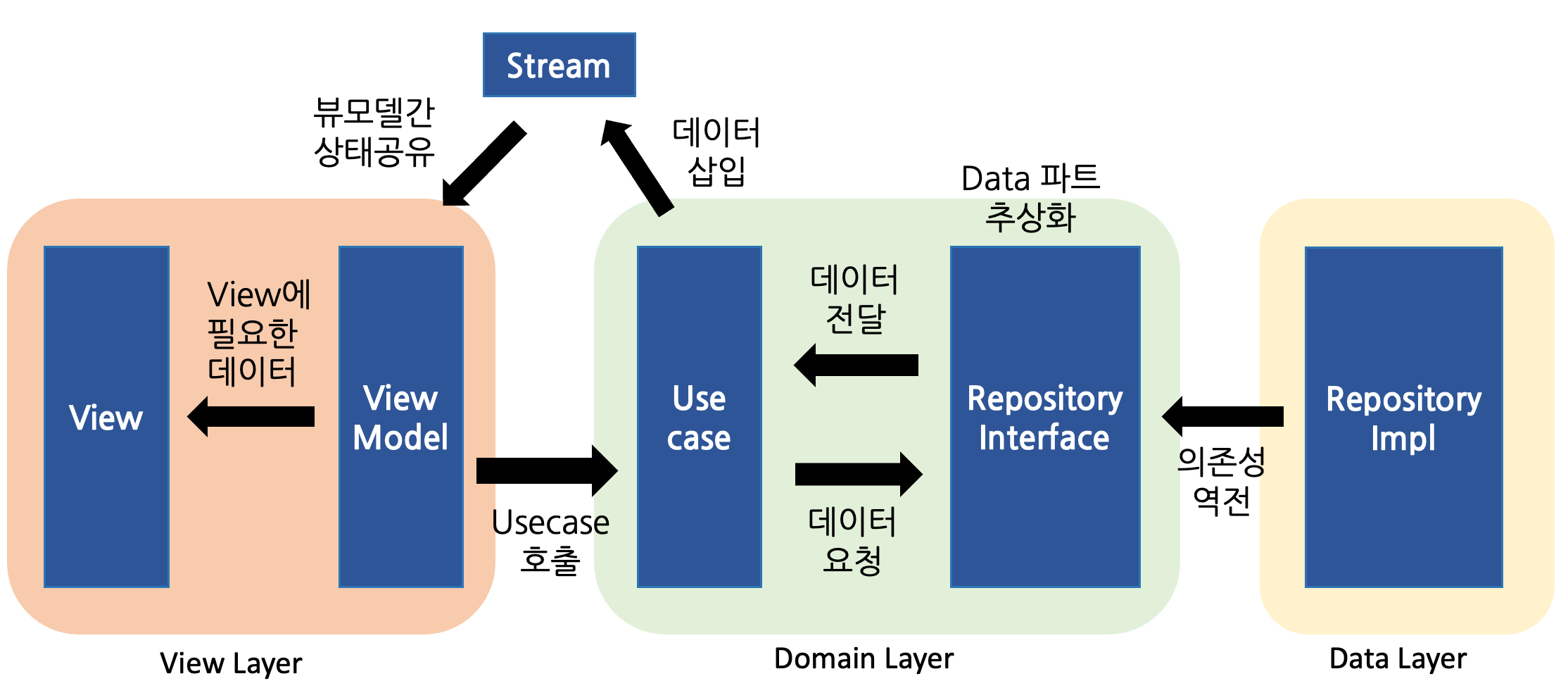

- The code is comprised of implementations of the screens that users see.
- It displays data received from the server to the users and accepts user inputs.
- If any user input is related to business logic, the methods performing those actions are all taken from within the ViewModel.
- If a user's input is not particularly related to business logic, the methods performing those actions are declared and used within the View.
- The ViewModel acts as a mediator connecting the View and UseCase (business logic).
- It holds the data to be displayed in the View, and if a user's input from the View is related to business logic, the methods related to those inputs should be declared within the ViewModel.
- The Necessity of sharing ViewModel States
- The main issue with ViewModel is the need for sharing states between ViewModels. A ViewModel shouldn't be too large, and some degree of separation is necessary. For example, the user’s personal information and the list of posts written by the user can both be managed within a single ViewModel since they pertain to user information. However, managing both sets of information within one ViewModel makes it cumbersome and creates problems due to high dependencies. Therefore, it would be appropriate to manage these sets of information in separate ViewModels.
- However, by dividing the ViewModel, there are definitely cases where multiple ViewModels need to be updated simultaneously. Although I can't think of an example off the top of my head to write here, you would agree that such cases exist. However, in Flutter, using Provider for ViewModel requires context, making it difficult to share states between ViewModels. Using navigatorKey to use context universally also feels like not fully utilizing Flutter itself.
- State Sharing Between ViewModels Using Stream
- Therefore, if there is a need for ViewModels to share states, we have decided to use Stream. If specific data needs to be data in multiple ViewModels, the data is placed in a Stream, and each ViewModel subscribes to the Stream to update their states.
- In other words, Stream acts as a mediator that allows multiple ViewModels to share states.
- Separation of Data Calls and Screen Rendering Using Stream
- Additionally, using Stream allows for the separation of data call logic and screen rendering logic. The implementation method is as follows:
-
The View receives user input, and the ViewModel makes a data call through the UseCase.
-
Once the UseCase receives data from the server, it places this data into a Stream.
-
Example
class FetchMembersUseCase { final MemberRepository memberRepository; const FetchMembersUseCase({ required this.memberRepository, }); Future<void> call() async { final memberDTOListStatus = await memberRepository.fetchMembers(); if (memberDTOListStatus.isFail) { return; } final List<MemberDTO> memberDTOList = memberDTOListStatus.data; final List<Member> memberList = memberDTOList.map((e) => Member.fromMemberDTO(e)).toList(); MemberListStream.add(memberList); } }
-
-
The ViewModel subscribes to the Stream and renders the screen when data is received
-
- As stated above, the ViewModel requests data at step 1 and renders the screen at step 3 when data is received, thus separating the two logics.
- Additionally, using Stream allows for the separation of data call logic and screen rendering logic. The implementation method is as follows:
- A UseCase can be thought of as a specification document that defines the functions needed in this app. All planning intentions should be well encapsulated in the UseCase.
- If a planner who knows a bit of coding wants to check the code, they should be able to confirm the plan by looking at the UseCase.
- UseCases should be as clear and concise as possible.
- **UseCases should only be called from the ViewModel. **They should not be called from the View. UseCases call service_interface and repository_interface internally.
- A Repository is defined as the area used when accessing the database from the server.
- It is named "repository interface" because it is declared as an abstract class for the inversion of dependency.
- For example, the current repository interface includes admin_repository, demand_repository, member_repository, and work_history_repository.
- The Repository Interface, a collection of abstract classes, is inherited to implement actual functions. Through this, the Domain Layer can use business logic without knowing the actual internal implementation of the Repository.
![System Architecture]

- Controller (Server-Side Logic):
- Processes requests from the client, executes business logic, interacts with the model, and sends back the response.
- Implement using backend frameworks ‘Django’.
- Model (Data Handling):
- Responsible for data retrieval, storage, and processing.
- Interacts with databases, external APIs, or other data sources.
- Implement using ORM tools, database drivers, or data handling libraries.
- Database
- Stores users’ emotional state records, investment decisions, and other relevant data.
- Consider using SQL databases ‘MySQ’L for structured data, or NoSQL databases MongoDB for flexible data schema.

1. User Authentication
-
Register
- Endpoint:
api/user/signup/ - Request
- POST
{ "google_id": "string", "nickname": "string" }
- POST
- Response
- Status: 201 Created
{ "access token": "string", "refresh token": "string" } - Status: 400 Bad Request
{ "<error type>": [ "<error message>" ] }
- Status: 201 Created
- Endpoint:
-
Sign in
- Endpoint:
api/user/signin/ - Request
- POST
{ "google_id": "string" }
- POST
- Response
- Status: 200 OK
{ "access token": "string", "refresh token": "string" } - Status: 401 Unauthorized
{ "message": "User with Google id ‘<google_id>’ doesn’t exist." }
- Status: 200 OK
- Endpoint:
-
Sign out
- Endpoint:
api/user/signout/ - Request
- POST
{}
- POST
- Response
- Status: 200 OK
{ "message": "Signout Success" } - Status: 401 Unauthorized
{ "<error type>": [ "<error message>" ] }
- Status: 200 OK
- Endpoint:
-
Verify
- Endpoint:
api/user/verify/ - Request
- POST
{}
- POST
- Response
- Status: 200 OK
{ "user_id": "int", "google_id": "string", "nickname": "string", } - Status: 401 Unauthorized
{ "<error type>": [ "<error message>" ] }
- Status: 200 OK
- Endpoint:
2. Emotion
-
Get emotion data (for calendar)
- Endpoint:
api/emotions/<int: year>/<int: month>/ - Description: 유저의 감정 기록을 불러옵니다.
- Request
- GET
{}
- GET
- Response
- Status: 200 OK
{ "emotions": [ { "date": "int", "emotion": "int", "text": "string", }, ... ] }
- Status: 200 OK
- Endpoint:
-
Record
- Endpoint:
api/emotions/<int: year>/<int: month>/<int: day>/ - Description: 유저가 메인 화면의 달력을 통해 감정을 등록/수정/삭제합니다.
- Request
- PUT
{ "emotion": "int", "text": "string" } - DELETE
{}
- PUT
- Response (PUT)
- Status: 201 Created / 200 OK
{ "message": "Record Success" } - Status: 405 Method Not Allowed
{ "message": "Not allowed to modify emotions from before this week" }
- Status: 201 Created / 200 OK
- Response (DELETE)
- Status: 200 OK
{ "message": "Delete Success" } - Status: 404 Not Found
{ "message": "No emotion record for that date" } - Status: 405 Method Not Allowed
{ "message": "Not allowed to modify emotions from before this week" }
- Status: 200 OK
- Endpoint:
3. Stock
-
Get stock information by name
- Endpoint:
stock/ - Description: 요청한 문자열이 종목 이름에 포함되어 있는 주식 종목들의 정보를 불러옵니다.
- Request
- GET
Query: name=<string>
- GET
- Response
- Status: 200 OK
{ [ { "ticker": "int", "name": "string", "market_type": "char", "current_price": "int", "closing_price": "int", "fluctuation_rate": "float" }, ... ] } - Status: 404 Not Found
- Status: 200 OK
- Endpoint:
-
Get stock information by ticker
- Endpoint:
stock/<int: ticker>/ - Description: 특정 주식 종목의 세부 정보를 불러옵니다.
- Request
- GET
{}
- GET
- Response
- Status: 200 OK
{ { "ticker": "int", "name": "string", "market_type": "char", "current_price": "int", "closing_price": "int", "fluctuation_rate": "float" } } - Status: 404 Not Found
{ "message": "Stock with ticker ‘<ticker>’ doesn’t exist." }
- Status: 200 OK
- Endpoint:
-
Get my_stock_history information
- Endpoint:
mystock/ - Description: 모든 주식 매매 기록 정보를 불러옵니다.
- Request
- GET
Query: name=<string>
- GET
- Response
- Status: 200 OK
{ [ { "id": "int", "ticker": "int", "stock": "char", "user": "int", "price": "int", "transaction_type": "char", "quantity": "float" }, ... ] } - Status: 404 Not Found
- Status: 200 OK
- Endpoint:
-
Get my_stock_history by ticker
- Endpoint:
mystock/<int: ticker>/ - Description: 특정 주식 종목의 history를 불러옵니다.
- Request
- GET
{}
- GET
- Response
- Status: 200 OK
{ { "id": "int", "ticker": "int", "stock": "char", "user": "int", "price": "int", "transaction_type": "char", "quantity": "float" } } - Status: 404 Not Found
{ "message": "Stock with ticker ‘<ticker>’ doesn’t exist." }
- Status: 200 OK
- Endpoint:
-
Create my_stock_history
- Endpoint:
mystock/ - Description: 주식 매매기록을 생성합니다.
- Request
- POST
{ { "stock": "char", "user": "int", "price": "int", "transaction_type": "char", "quantity": "float" } }
- POST
- Response
- Status: 200 OK
{ { "id": "int", "ticker": "int", "stock": "char", "user": "int", "price": "int", "transaction_type": "char", "quantity": "float" } } - Status: 404 Not Found
- Status: 200 OK
- Endpoint:
-
Update my_stock_history
- Endpoint:
mystock/{id:int} - Description: 특정 주식 매매기록을 수정합니다.
- Request
- PUT
{ { "stock": "char", "user": "int", "price": "int", "transaction_type": "char", "quantity": "float" } }
- PUT
- Response
- Status: 200 OK
{ { "id": "int", "ticker": "int", "stock": "char", "user": "int", "price": "int", "transaction_type": "char", "quantity": "float" } } - Status: 404 Not Found
- Status: 200 OK
- Endpoint:
-
Delete my_stock_history
- Endpoint:
mystock/{id:int} - Description: 특정 주식 매매기록을 삭제합니다.
- Request
- Delete
{ }
- Delete
- Response
- Status: 200 OK
- Status: 404 Not Found
- Endpoint:
-
User balance
- Endpoint:
api/user/<string: google_id>/stocks/ - Description: 유저의 주식 잔고를 불러옵니다.
- Request
- GET
{}
- GET
- Response
- Status: 200 OK
{ "stocks": [ { "ticker": "int", "average_price": "int", "quantity": "int" }, ... ] } - Status: 404 Not Found
{ "message": "User with Google id ‘<google_id>’ doesn’t exist." }
- Status: 200 OK
- Endpoint:
-
User balance update
- Endpoint:
api/user/<string: google_id>/stocks/<int: ticker>/ - Description: 유저가 특정 주식 종목을 자신의 잔고에 추가하거나, 매수/매도 거래를 잔고에 반영합니다.
- Request
- PUT
{ "type": "int", "price": "int", "quantity": "int" }
- PUT
- Response
- Status: 200 OK
{ "message": "Update Success" } - Status: 404 Not Found
{ "message": "User with Google id ‘<google_id>’ doesn’t exist." } - Status: 404 Not Found
{ "message": "Stock with ticker ‘<ticker>’ doesn’t exist." }
- Status: 200 OK
- Endpoint:
4. Report
-
Get weekly report
- Endpoint:
api/reports/<int: year>/<int: month>/<int: week>/ - Description: 유저의 주간 리포트를 불러옵니다.
- Request
- GET
{}
- GET
- Response
- Status: 200 OK
{} - Status: 404 Not Found
{ "message": "User with Google id ‘<google_id>’ doesn’t exist." } - Status: 404 Not Found
{ "message": "No report for that week" }
- Status: 200 OK
- Endpoint:
-
Get monthly report
- Endpoint:
api/reports/<int: year>/<int: month>/ - Description: 유저의 월간 리포트를 불러옵니다.
- Request
- GET
{}
- GET
- Response
- Status: 200 OK
{} - Status: 404 Not Found
{ "message": "User with Google id ‘<google_id>’ doesn’t exist." } - Status: 404 Not Found
{ "message": "No report for that month" }
- Status: 200 OK
- Endpoint:
The stock report texts are about the process of extracting essential data (labels) from an unlabeled summary. It involves extracting the top five keywords using keyword extraction algorithms for creating good summaries. Although extracting summaries on a sentence level was considered, keyword-level extractive summary is more suitable for this project since important content in an article is often scattered.
Choosing a keyword extraction algorithm is a complex issue requiring justification. It necessitates creating a dataset for uniform training and defining quantitative metrics to compare algorithm performance. Code optimization to enhance each algorithm's performance is also needed.
Our group did some experiment about extracting keyword, and we chose KeyBERT. KEYBERT IS a keyword extraction algorithm using BERT for text embedding, extracts keywords considering the overall content of a document and distinguishes between top and bottom keywords through context understanding. Its high keyword extraction accuracy is a key advantage. However, it requires a large amount of data for model training and takes a long time to train. The method of extracting keywords using KeyBERT is as follows:
- Represent at the document level through document embeddings extracted by BERT.
- Represent at the phrase level using word embeddings for N-gram words/phrases and BERT.
- Find the most similar words/phrases to the document using cosine similarity.
- Here, one can use MMR or Max Sum Similarity methods.
- Extract words/phrases that best describe the entire document.
- MMR adjusts the diversity and relevance of search results in search engines, minimizing redundancy and maximizing diversity in text summarization. It involves repeatedly selecting new candidates that are similar to the document but not to already selected keywords.
The reason for the experiment with MMR: MMR was used because it calculates document similarity using cosine similarity between vectors. It was chosen to adjust the diversity and relevance of search results related to text searches in search engines, avoiding redundancy of keywords with similar meanings in simple distance-based approaches. MMR minimizes redundancy and maximizes diversity in text summarization. The process involves repeatedly selecting new candidates that are similar to the document but different from already chosen keywords.
Experiment method:
- Select the most similar keyword to the document.
- Repeatedly choose new candidates that are similar to the document and not similar to the already selected keywords.
- Generate five diverse keywords with high diversity values.
Experiment result: Extracting keywords using MMR did not always include all five keywords in the summary, resulting in a performance of only 0.622. MMR tended to select frequently occurring words in the article body without understanding the context.
The core content of articles obtained through keyword extraction methods in the previous step is composed of a collection of words, which is not user-friendly and, while containing important contents of the article, does not encompass all the essential information. Therefore, to present it to users, a summary generation model should be used to create natural language sentences that include the important content extracted from the keywords.
Task Challenges: Creating summaries for texts is difficult because defining what constitutes an appropriate summary is challenging, and there is no definitive answer as there are no existing summaries for training. Hence, it's hard to resolve this with supervised learning model training, and even after training a generative model, evaluating its performance is difficult. For performance evaluation and training in this project, although the core content of articles was extracted in the form of keywords, designing and training a model to generate summaries that must include this essential information is also a complex problem.
Emostock_solution: Existing methods involve research on pre-training encoder-decoder structure transformer models to gain summary generation capabilities. However, these methods ultimately show decreased summarization performance without supervised learning using datasets with provided correct summaries. Therefore, in this project, we decided to use the Korean-trained BART model, KoBART, and fine-tune it through supervised learning.
For supervised learning fine-tuning, a dataset of original text-summary pairs is required. However, as there are no correct summaries for articles in the app database, we generated similar summaries for these articles using OPENAI's GPT 3.5 API to use as labels for supervised learning. The reason for considering the summaries generated by GPT as similar summaries, not correct ones, is that the Korean generation capability of GPT 3.5 is not perfect, and there's no way to confirm if the summaries generated by GPT are appropriate. Therefore, it is inappropriate to consider the summaries generated by GPT 3.5 as correct and rely on them for model training.
Experiment Reason: We conducted an experiment to see if economic-related content associations could be derived using Sentence Embedding vectors. Additionally, the experiment aimed to determine if specific company names significantly influence the composition of these vectors when extracted through Sentence Embedding.
Experiment Method:
- Data was structured as a list of [{company name, original article text}, ...].
- Data preprocessing was done to form [{company name, original text embedding vector list, replacement list, deletion list}].
- We checked if there was a divergence in similarity values between original/replacement/deletion vectors for the same company name.
- A matrix was created by calculating the similarity of one article's vector with the vectors of other articles.
- Abstract Factory
- Observer
- TBD
- TBD
- Database: PostgreSQL
1. Unit Testing & Integration Testing:
Framework:
- Backend: Django test framework
- Coverage Goals: Aim for at least 80% code coverage for both frontend and backend components.
- Procedure: Integration Testing, create tests that cover the interaction between multiple units (e.g., function calls, data flow).
2. Acceptance Testing: User stories