{kind=link}
The connected wearables project was created for an Etherios hackathon in order to connect data from wearable devices to the Device Cloud by Etherios. The project was created by 3 engineers from Etherios Wireless Design Servies: Paul Osborne (posborne), Tom Manley (tpmanley), and Stephen Stack (swstack).
The basic architecture for the connected wearables system is pretty simple overall as shown in this architecture diagram.
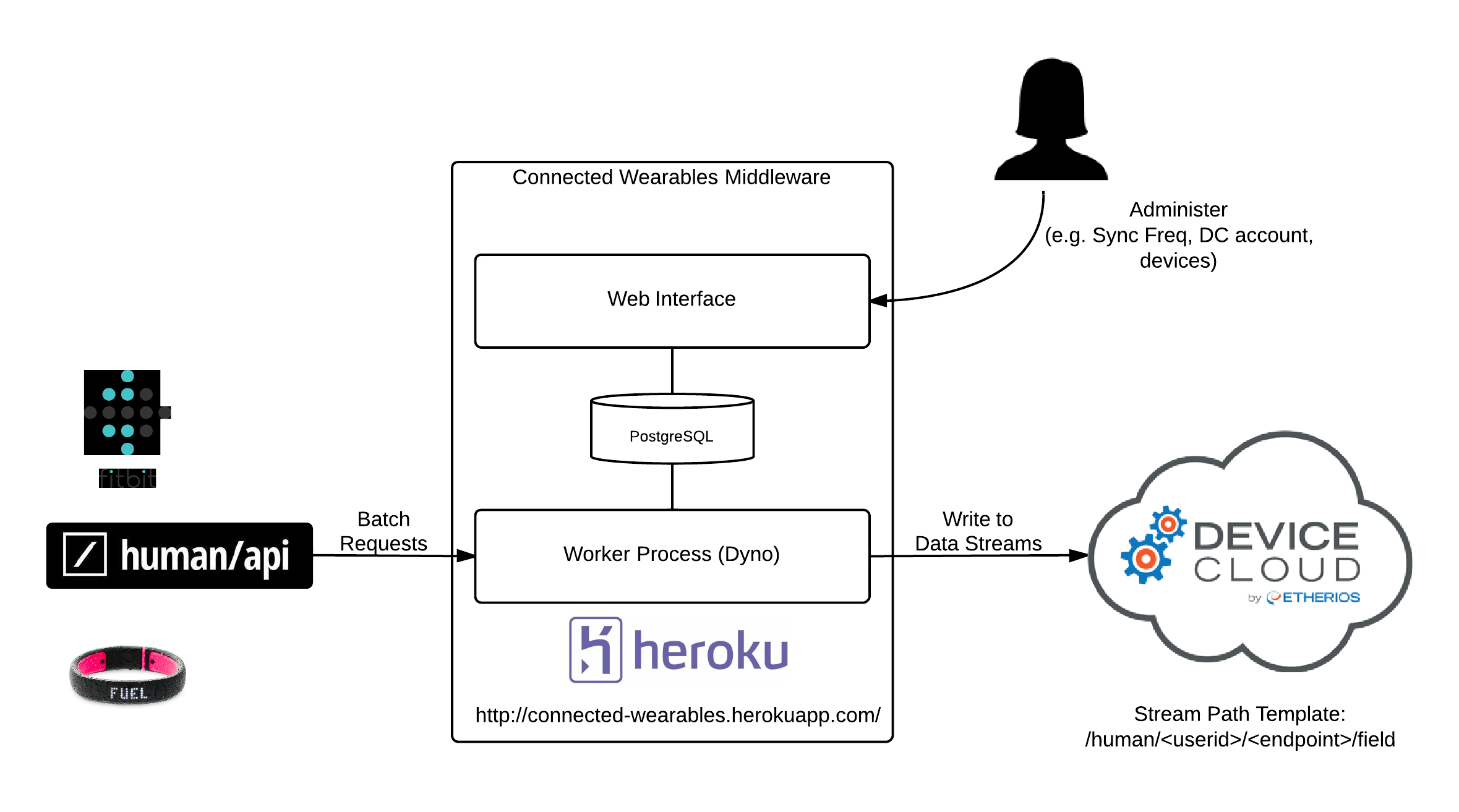
Notable things from the overall architecture:
- System consists of two processes. One is just responsible for doing web interface things and the other runs in the background and synchronizes data between the device cloud and humanapi.
- The two applications share state via a PostgreSQL database with a few simple relations. Data from humanapi is not stored in this database.
- The web interface allows for configuration of multiple "applications" so that synchronization can happen between multiple humanapi and device cloud accounts.
- Great care is taken to perform the humanapi -> device cloud synchronization with great efficiency. During the poll period for each logical application, the human api is polled for changes to data for all associated users since the last time we checked -- in turn, those changes are batched in web service calls of up to 250 datapoints and are written to streams on the device cloud.
Choosing a proper path for data streams based on the data being received from the HumanAPI was a challenge. As there did not seem to be one-size-fits-all solution for all potential consumers of data out of the device cloud, we attempted to provide a few options to that implementor.
For all cases, the following basic stream path format is used:
/human/<userid>/<endpoint>/<field/key>
An example which would include the "steps" for a user over time being:
human/537ac6902f143657390c766e/activities/steps
The actual mapping of data from the humanapi data sources to streams in the device cloud is done in an elegant and streamlined fashion. Rather than having loads of code for each endpoint (e.g. activities, blood_glucose, etc.) a generic way to describe the form of the data from HumanAPI and those parts that we want to map to the Device Cloud is used.
This mapping can be found in humanapi_mapping.yml
An example of how the mapping is done for blood_oxygen information is shown here:
# Property Type Description
# -----------------------------
# id String The id of the blood oxygen measurement
# userId String The global Id of the user
# timestamp Date The original date and time of the measurement
# source String The source service for the measurement, where
it was created
# value Number The value of the measurement in the unit
specified
# unit String The unit of the measurement value
# createdAt Date The time the measurement was created on the
Human API server
# updatedAt Date The time the measurement was updated on the
Human API server
blood_oxygens:
timestamp_field: timestamp
forward_fields:
source: string
value:
type: float
unit_field: unit
createdAt: datetime
updatedAt: datetime
Based on this, we know to do things like take the "value" field from humanapi data received on this endpoint and send it along to the device cloud with the stream unit for that stream set to be the "unit" field from the JSON document received from humanapi. This makes changing what gets sent extremely simple.
The connected wearables is written for Python 2.7 and is designed to run on Heroku.
- Python 2.7
- Pip
- Virtualenv
- PostgreSQL
Install these for your sytem. To setup a virtualenv and install dependencies for development you can do the following:
$ virtualenv env
$ source env/bin/activate
(env) $ pip install -r requirements.txtAlthough it is possible to tell SQLAlchemy to use sqlite during development, we find it preferrable to install postgresql to minimize difference between production and development platforms.
Create a postgresql user and database:
postgres=# create user cwear password 'cwear';
postgres=# create database cwear owner cwear;Run the latest migrations:
$ alembic upgrade headAs mentioned, heroku is used for deployment. Follow the basic instructions online and things should mostly just work.
If a new version includes changes to the database (captured in an alembic migration) then you will need to run the following to ensure that the migraton happens on the production database.
$ heroku run alembic upgrade headThere are a few small issues that are known and probably a bunch that are unknown:
- No Security on login... Login the first time and an account is created
- No ability to add devices directly from web app (need to go to human api site)
- Probably not super robust at this point (but some work done on this)
- Dyno worker costs ~$34/month
We don't have separate functionality for this. You can view it on the Device Cloud directly.