This is Implement of Video Embedding based on Tensorflow, Inception-V3 & FCNN(Frames Supported Convolution Neural Network)
Video Embeding can be interpreted as the processing of Video Features Extraction. As figure-1, a video consisits of a lots of images (named frame). Each frame contants image concept, and these concept can be organized to a matrix in time sequence (we call it Video-Matrix) which can be used for representing the content of the video in frame leval details. The extraction of Video-Matrix is as the same as image embedding. We choose Inception-v3 to solve it.
However, we don't need the frame details in some video applications, for example, Video-Retrieval, Recommendation etc. So we prepose a new CNN to compress the 2-D Video-Matrix to a 1-D Video-Vector.

figure-1. The Processing of Video Embedding
The new CNN, which is called FCNN (Frames Supported Convolution Neural Network), contains 6 f_conv layers, 1 densely connect layer and 1 softmax layer. The output of densely connect layer (the last layer before softmax) is the Video-Vector. FCNN is trained by using Weibo-MCN classificated data-set, and it also can be used for video classification.
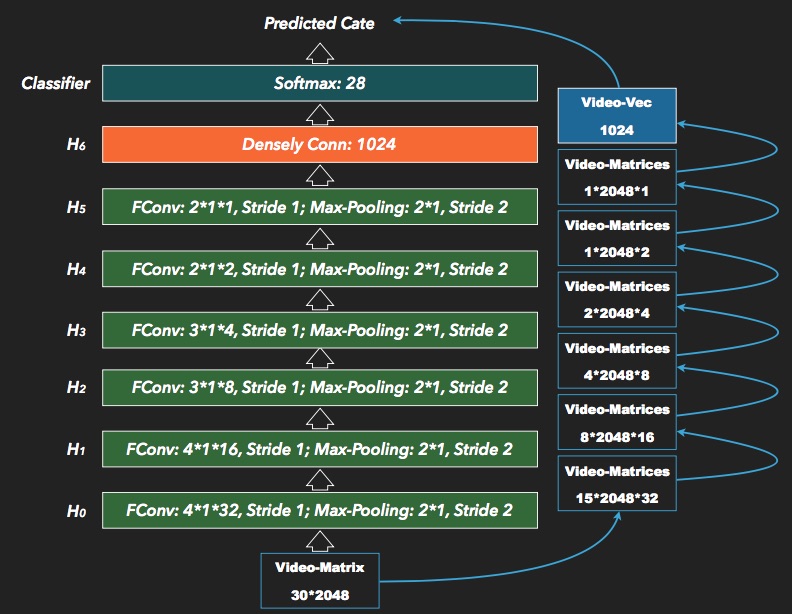
figure-2. The architecture of Weibo-FCNN
- Python 3.x
- Tensorflow >= 1.0
- OpenCV >= 3.2
(1) Install TensorFlow
See Installing TensorFlow for instructions on how to install the release binaries or how to build from source.
(2) Install OpenCV on Python
You can find the introduction and Download link at OpenCV-3.2 or other websites. Choose the right version (over version 3.2) to install on your enverimant.
(2) Clone the source of video_embedding
git clone https://github.com/fengyoung/video_embedding.git <YOUR REPO PATH>
Some resources and testing models are provided, such as:
- Inception-v3: Graph file of inception-v3.
- FCNN model: trained FCNN model based on Weibo-MCN Classification data set.
- 2 short videos: short videos for testing of features extraction or classification.
- Weibo-MCN Video-Mat-Set: 60,000+ video-matrices of Weibo-MCN classification data set in format of tfrecord proto.
There are 2 types of features extraction to get Video-Matrix & Video-Vector respectively:
(1) The Video-Matrix could be extracted from a video file by using video2mat.py like:
cd <THIS REPO>
python video2mat.py --graph_file <inception-v3 graph file> --input <video file> --output <output video-matrix file>
You can get the usage and argumets description using "-h", like:
python video2mat.py -h
(2) The Video-Vector could be extracted from a video file by using video2vec.py like:
python video2vec.py --graph_file <inception-v3 graph file> --fcnn_model <FCNN model file> --input_file <video file> --output_file <output video-vector file>
(3) The Video-Vector also could be extracted from a Video-Matrix by using vmat2vec.py like:
python vmat2vec.py --fcnn_model <FCNN model file> --input_file <input VMP file> --output_file <output video-vector file>
FCNN could be used for video classification. The example is video_classify.py:
python video_classify.py --graph_file <inception-v3 graph file> --fcnn_model <FCNN model file> --input_file <video file>
Then predicted probilities and corresponding classes would be printed on the screen. Each class is encode to a ingeter ID, you can find the mapping between IDs and classes in Weibo CateID mapping
You can construct your own classification video data set, extract Video-Matrices and generate VMP files in tfrecord proto as your own training set. Or you can use Weibo-MCN Video-Mat-Set, which provided before, to train a new FCNN model by using train_fcnn.py. Like:
python train_fcnn.py --vmp_path <VMP_PATH> --naming <NAMING> --model_path <MODEL_PATH> --epoch 100 --batch_size 10
Then copy <MODEL_PATH>/<NAMEING>/video_embedding_fcnn.ckpt-done as the final FCNN model.
Arguments of "train_fcnn.py" are as follow:
--vmp_path VMP_PATH
Training VMP data path. Tfrecord proto supported only
--naming NAMING
The name of this model. Determine the path to save checkpoint and events file.
--model_path MODEL_PATH
Root path to save checkpoint and events file. The final path would be <model_path>/<naming>
--epoch EPOCH
Epoch times. Default is 100
--batch_size BATCH_SIZE
How many samples should be used in one time of model updating. Default is 50
There are two supported types of the Video-Matrix Patterns (VMP): pattern-string & tfrecord.
Specially, Video-Vector can be regarded as a type of Video-Matrix which contains 1 frame only.
mid,labelid0_labelid1_labelid2,height_width,x0_x1_x2_..._xn
mid,labelid2_labelid5,height_width,x0_x1_x2_..._xn
...
features: {
feature: {
key: "mid"
value: {
bytes_list: {
value: [mid string]
}
}
}
feature: {
key: "label"
value: {
bytes_list: {
value: ["0,3,7"] # labelid list string
}
}
}
feature: {
key: "size"
value: {
int64_list: {
value: [v_height, v_width]
}
}
}
feature: {
key: "feature"
value: {
float_list: {
value: [(v_height * width) float features]
}
}
}
}