最近在做一些强化学习方面的工作,这里对一些传统的强化学习算法做一个总结,不断整理。 本repo提供的代码,参考莫烦和baseline进行实现,实验环境基于openai gym, 不涉及图像处理相关,较为纯净的强化学习部分实现。 实验结果主要以gym的实验结果为主,有一些实验是在自己实现的一套1v1 6DoF飞行器博弈仿真环境做的实验,该环境较为复杂,对各种算法也有更加全面的验证。
已完成:
DQN_IN_PROJECT目录为整理成项目架构形式的算法,可以兼容以上五种算法,将网络结构,agent学习,主程序分开封装。
三类算法对比:(DQN, DoubleDQN, Dueling DQN)
- gym CartPole-v0 环境:
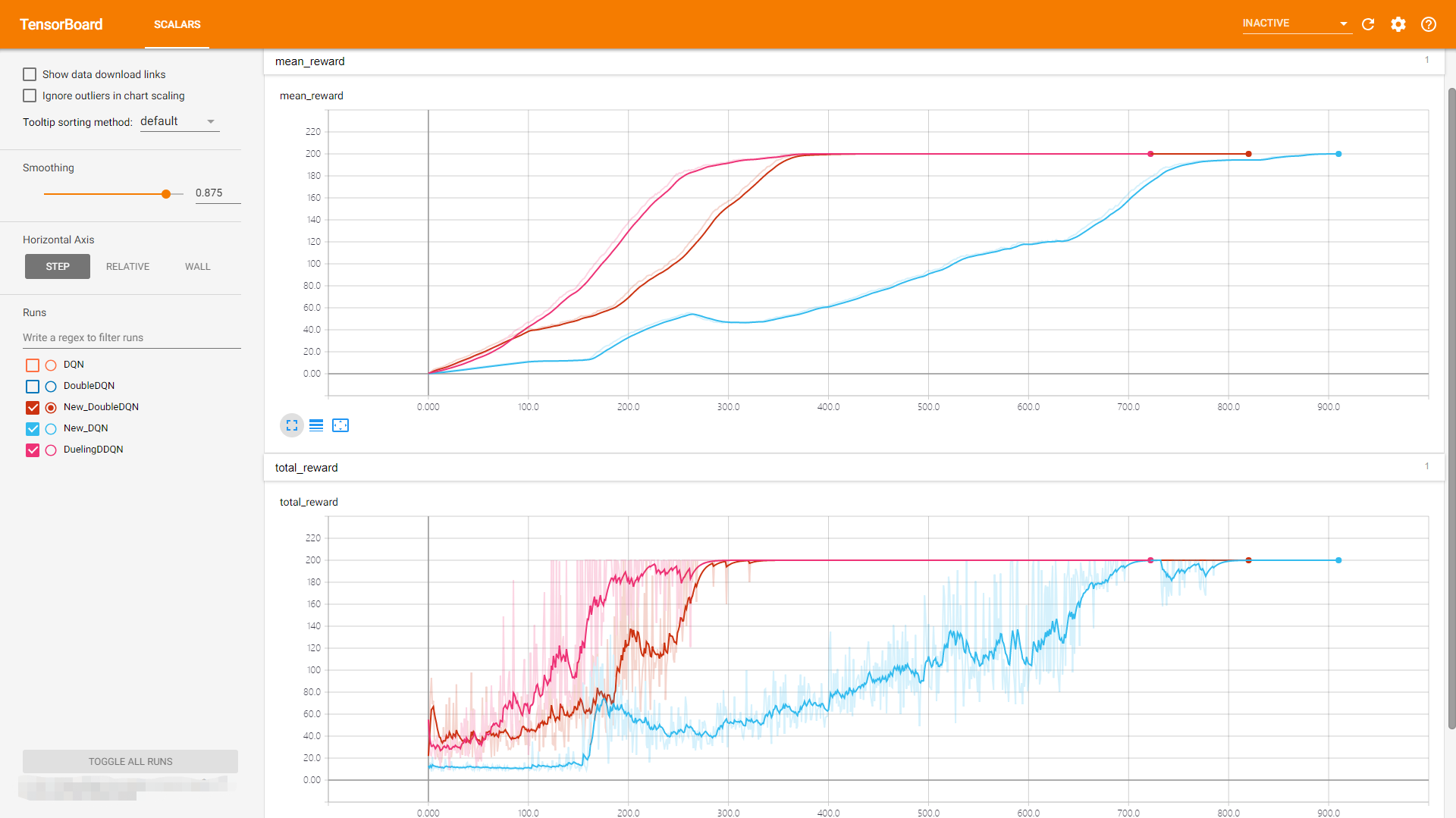
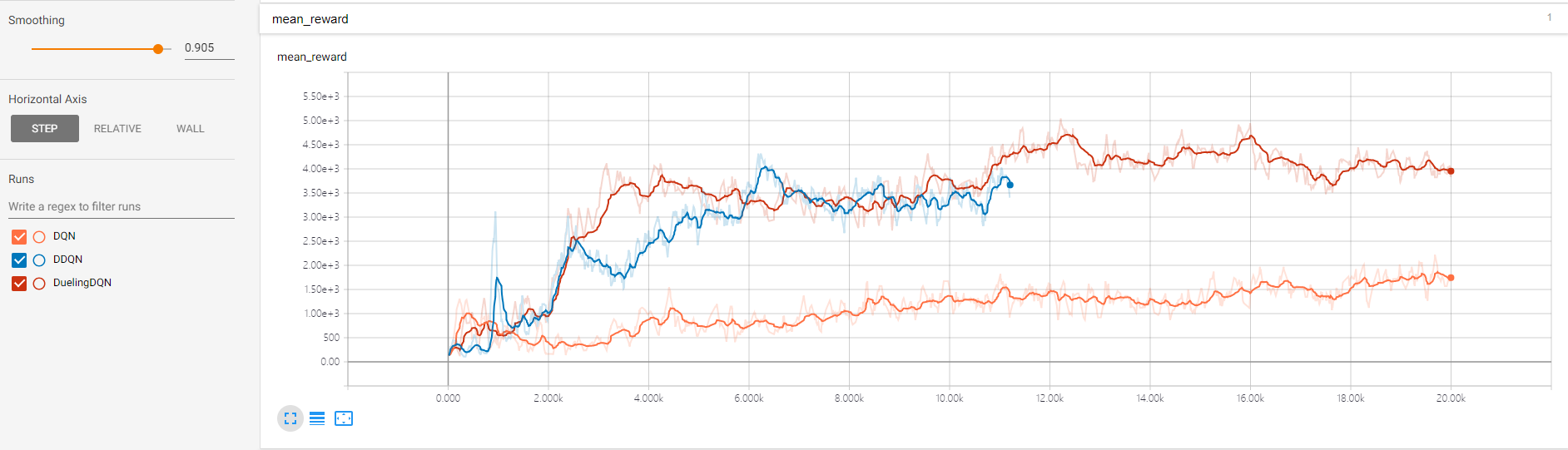
- 1v1 6DoF飞行器博弈仿真环境做的实验(mean_reward越大越优)
- DRQN 考虑加入部分可观马尔科夫时序处理
- Multistep DQN (重要性采样)
- Priority Replay buffer
已完成:
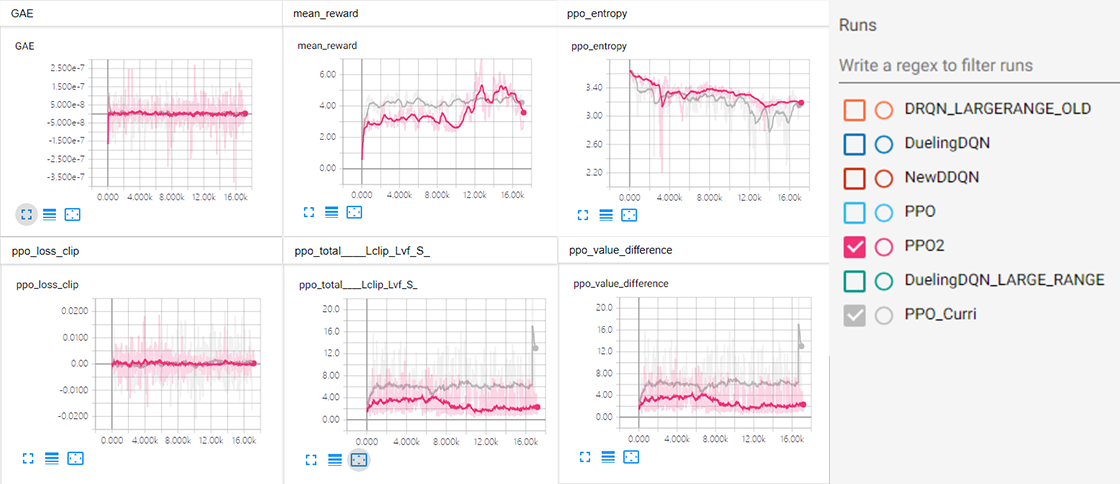
- PPO2 (Clip advantage)
- 加入 exploration curriculum 参考 Emergent Complexity via Multi-agent Competition
代码在PPO2部分
已完成:
- GAIL (WGAN-GP)
- PPO2
- seprate net
代码在GAIL
- VAE VAE
- 参考复现 Robust Imitation of Diverse Behaviors