变量代表一个有名字的、具有特定属性的存储单元。它用来存放数据,也就是存放变量的值。在程序运行期间,变量的值时可以改变的。
变量必须先定义,后使用。在定义变量时指定该变量的名字和类型。定义变量的一般格式如下:
存储类别 数据类型 变量名1,变量名2,······,变量名n
存储类别指定变量时存放在静态存储区还是动态存储区,存储类别可以省略,因为局部变量默认的存储类别是auto(自动的),可以省略。
注意:
1.变量只能以下划线或字母开头
2.可以由**数字、字母、下划线_、美元符号$**组成
3.不能以数字开头
4.不能是关键字
5.区分大小写
在程序执行过程中,值不发生改变的量称为常量。C语言的常量可以分为直接常量和符号常量。
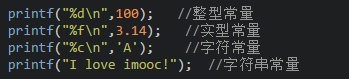
直接常量也称为字面量,是可以直接拿来使用,无需说明的量,比如: 整型常量:13、0、-13; 实型常量:13.33、-24.4; 字符常量:‘a’、‘M’ 字符串常量:”I love imooc!”
1.基本形式:符号整数部分,小数部分和E指数部分。首先写整数部分(可以带符号),接着写小数部分,然后写 e或者 E,最后再写一个有符号整数。 小数形式是由数字和小数点组成的一种实数表示形式,例如0.123、.123、123.、0.0等都是合法的实型常量。注意:小数形式表示的实型常量必须要有小数点。 指数形式就是在数学中,一个可以用幂的形式来表示的形式。在C语言中,则以“e”或“E”后跟一个整数来表示以“10”为底数的幂数。C语言语法规定,字母e或E之前必须要有数字,且e或E后面的指数必须为整数。注意:在字母e或E的前后以及数字之间不得插入空格。
2.常见格式:+1.2E+5,1.5e-9,-5.0e10
3.浮点型常量又包括单精度实型(float),双精度实型(double)和长精度实型(long double)。
4.浮点型常量又叫实型常量,是在C语言中可以用两种形式表示一个实型常量。用于表示小数部分的十进制数。
5.浮点型常量默认是 double 类型的。
6.一个浮点型常量可以赋给一个 float 型、double 型或 long double 变量。根据变量的类型截取浮点型常量中相应的有效位数字。
7.浮点型常量进行声明时,如果没有显示的在常量后面加f,那么系统会按照double类型来储存。
注意:浮点型常量中不能有空格!
1.基本整型(int)
2.字符型(char)
3.浮点型
float型(单精度浮点型)
double型(双精度浮点型)
注:再C语言中进行浮点数的算数运算时,将float型数据都自动转换为double型,然后在两个double型数据之间进行运算



格式化输出语句,也可以说是占位输出,是将各种类型的数据按照格式化后的类型及指定的位置从计算机上显示。
其格式为:printf("输出格式符",输出项);

数据类型存在自动转换的情况.
自动转换发生在不同数据类型运算时,在编译的时候自动完成。char类型数据转换为int类型数据遵循ASCII码中的对应值且为8进制数.
注意:
- 字节小的可以向字节大的自动转换,但字节大的不能向字节小的自动转换
- char可以转换为int,int可以转换为double,char可以转换为double。但是不可以反向。
强制类型转换是通过定义类型转换运算来实现的。其一般形式为:(数据类型) (表达式)。其作用是把表达式的运算结果强制转换成类型说明符所表示的类型。
注意:
- 数据类型和表达式都必须加括号, 如把
(int)(x/2+y)写成(int)x/2+y则成了把x转换成int型之后再除2再与y相加了。 - 转换后不会改变原数据的类型及变量值,只在本次运算中临时性转换。
- 强制转换后的运算结果不遵循四舍五入原则。
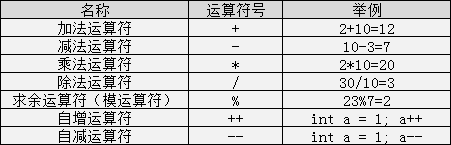
除法运算中注意:
如果相除的两个数都是整数的话,则结果也为整数,小数部分省略,如
8/3 = 2;
而两数中有一个为小数,结果则为小数,如:
9.0/2 = 4.500000。
取余运算中注意:
该运算只适合用两个整数进行取余运算,如:
10%3 = 1;
而10.0%3则是错误的;运算后的符号取决于被模数的符号,如
(-10)%3 = -1;而10%(-3) = 1;
%%表示这里就是一个%符.
- 自增运算符为
++,其功能是使变量的值自增1 - 自减运算符为
--,其功能是使变量值自减1。
它们经常使用在循环中。自增自减运算符有以下几种形式:

C语言中赋值运算符分为简单赋值运算符和复合赋值运算符
简单赋值运算符=号了,下面讲一下复合赋值运算符:
复合赋值运算符就是在简单赋值符=之前加上其它运算符构成.
例如+=、-=、*=、/=、%=
分析:定义整型变量a并赋值为3,a += 5;这个算式就等价于a = a+5; 将变量a和5相加之后再赋值给a
注意:复合运算符中运算符和等号之间是不存在空格的。
C语言中的关系运算符:
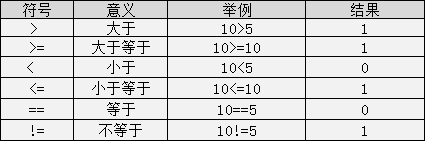
关系表达式的值是真和假,在C程序用整数1和0表示。
注意:>=, <=, ==, !=这种符号之间不能存在空格。
C语言中的逻辑运算符:
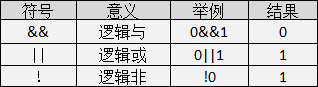
逻辑运算的值也是有两种分别为真和假,C语言中用整型的1和0来表示。其求值规则如下:
- 与运算
&&(逻辑与)
参与运算的两个变量都为真时,结果才为真,否则为假。例如:5>=5 && 7>5 ,运算结果为真;
- 或运算
||(逻辑或)
参与运算的两个变量只要有一个为真,结果就为真。 两个量都为假时,结果为假。例如:5>=5||5>8,运算结果为真;
- 非运算
!(逻辑非)
参与运算的变量为真时,结果为假;参与运算量为假时,结果为真。例如:!(5>8),运算结果为真。
注意:操作数的值为非0时,表示逻辑为真(条件成立);操作数的值为0时,表示逻辑为假(条件不成立),且操作数可以为表达式,也可以为变量或常量
C语言中的三目运算符:?:,其格式为:
表达式1 ? 表达式2 : 表达式3;
执行过程是:先判断表达式1的值是否为真,如果是真的话执行表达式2;如果是假的话执行表达式3。(是返回1,否返回0)
#include <stdio.h>
int main()
{
//定义小编兜里的钱
double money =12.0 ;
//定义打车回家的费用
double cost =11.5 ;
printf("小编能不能打车回家呢:");
//输出y小编就打车回家了,输出n小编就不能打车回家
printf("%c\n",money>=cost?'y':'n');
return 0;
}c语言提供一种特殊的运算符,逗号运算符,优先级别最低,它将两个及其以上的式子联接起来,从左往右逐个计算表达式,整个表达式的值为最后一个表达式的值。如:(3+5,6+8)称为逗号表达式,其求解过程先表达式1,后表达式2,整个表达式值是表达式2的值,如:(3+5,6+8)的值是14;a=(a=3×5,a×4)的值是60,其中(a=3×5,a×4)的值是60, a的值在逗号表达式里一直是15,最后被逗号表达式赋值为60,a的值最终为60。
逗号表达式格式为:
表达式1,表达式2,表达式3,...... ,表达式n
逗号运算符的注意点:
- 逗号表达式的运算过程为:从左往右逐个计算表达式。
- 逗号表达式作为一个整体,它的值为最后一个表达式(也即表达式n)的值。
- 逗号运算符的优先级别在所有运算符中最低。
sizeof是C语言中保留关键字,也可以认为是一种单目运算符。sizeof操作符以字节形式给出了其操作数的存储大小。操作数可以是一个表达式或括在括号内的类型名。操作数的存储大小由操作数的类型决定。
使用方法:
1,用于数据类型 sizeof使用形式:sizeof(type) 数据类型必须用括号括住。如sizeof(int)
2.用于变量
sizeof使用形式:sizeof(var_name)或sizeof var_name
变量名可以不用括号括住。如sizeof (var_name),sizeof var_name等都是正确形式。带括号的用法更普遍,大多数程序员采用这种形式。
注意:sizeof操作符不能用于函数类型,不完全类型或位字段。不完全类型指具有未知存储大小的数据类型,如未知存储大小的数组类型、未知内容的结构或联合类型、void类型等。
如sizeof(max)若此时变量max定义为int max(),sizeof(char_v) 若此时char_v定义为char char_v [MAX]且MAX未知,sizeof(void)都不是正确形式。
优先级关系:sizeof的优先级为2级,比/、%等3级运算符优先级高。它可以与其他操作符一起组成表达式。如i*sizeof(int);其中i为int类型变量。
各种运算符号的顺序:

优先级别为1的优先级最高,优先级别为10的优先级别最低。
注意:优先级 算术运算>关系运算>逻辑运算>赋值运算
注意:逗号运算优先级最低
转义字符 字 符 值 输 出 结 果
\' 一个单撇号(') 输出单撇号字符'
\'' 一个双撇号(") 输出双撇号字符"
\? 一个人问号(?) 输出问号字符?
\\ 一个反斜杠(\) 输出反斜杠字符\
\a 警告(alert) 产生声音或视觉信号
\b 退格(backspace) 将光标当前位置后退一个字符
\f 换页(from feed) 将光标当前位置移到下一页的开头
\n 换行 将光标当前位置移到下一行的开头
\r 回车(carriagereturn) 将光标当前位置移到本行的开头
\t 水平制表符 将光标当前位置移到下一个Tab位置
\v 垂直制表符 将光标当前位置移到下一个垂直表对齐点
\o、\oo、\ooo其中o表示一个八进制数字 与该八进制码对应的ASCII字符 与该八进制码对应的字符
\xh[h...]其中h代表一个十六进制数字 与该十六进制码对应的ASCII字符 与该十六进制码对应的字符简单if语句的基本结构如下:
if(表达式)
{
执行代码块;
}其语义是:如果表达式的值为真,则执行其后的语句,否则不执行该语句。
简单的if-else语句的基本结构:

语义是:依次判断表达式的值,当出现某个值为真时,则执行对应代码块,否则执行代码块n。
关于表达式:
a.用非 0 值表示真,用 0 表示假;
b.if(flag) 相当于 if(flag!=0);
c.浮点数无法与 0 比较,只能用近似的值比较;例: 1e-6 等于1x10的-6次方可以看成0来使用;
C语言中多重if-else语句,其结构如下:

语义是:依次判断表达式的值,当出现某个值为真时,则执行对应代码块,否则执行代码块n。
注意:当某一条件为真的时候,则不会向下执行该分支结构的其他语句。
C语言中嵌套if-else语句。嵌套if-else语句的意思,就是在if-else语句中,再写if-else语句。其一般形式为:

注意:C语言规定:else子句总是与其之前最近且没有配对过的if配对。
switch语句是一个多分支选择语句,并且可以支持嵌套。switch语句通过将表达式的值与常量值进行比对,如果相等则执行后面的语句,如果不相等则跳到下一个case语句,当表达式和常量值相等,switch语句会将当前case语句以及后面所有的case语句全部输出。default的作用就是当表达式的值和常量值全部对比过之后,如果没有匹配的就会输出default后的语句。
switch语句格式:
switch(表达式) {
case 常量1:语句1
case 常量2:语句2
……
case 常量n:语句n
default:语句n+1
}注意:
(1) 括号内的“表达式”,其值的类型应为整数类型(包括字符型)。 (2) 花括号内是一个复合语句,内包含多个以关键字case开头的语句行和最多一个以default开头的行。case后面跟一个常量(或常量表达式),它们和default都是起标号作用,用来标志一个位置。执行switch语句时,先计算switch后面的“表达式”的值,然后将它与各case标号比较,如果与某一个case标号中的常量相同,流程就转到此case标号后面的语句。如果没有与switch表达式相匹配的case常量,流程转去执行default标号后面的语句。 (3) 可以没有default标号,此时如果没有与switch表达式相匹配的case常量,则不执行任何语句。 (4) 各个case标号出现次序不影响执行结果。 (5) 每一个case常量必须互不相同;否则就会出现互相矛盾的现象。 (6) case标号只起标记的作用。在执行switch语句时,根据switch表达式的值找到匹配的入口标号,在执行完一个case标号后面的语句后,就从此标号开始执行下去,不再进行判断。因此,一般情况下,在执行一个case子句后,应当用break语句使流程跳出switch结构。最后一个case子句(今为default子句)中可不加break语句。 (7) 在case子句中虽然包含了一个以上执行语句,但可以不必用花括号括起来,会自动顺序执行本case标号后面所有的语句。当然加上花括号也可以。 (8) 多个case标号可以共用一组执行语句。
例1:要求按照百分制分数段输出考试成绩的等级,85分以上为A等,70~84分为B等,60~69分为C等, 60分以下为D等。成绩的等级由键盘输入。
#include <stdio.h>
int main() {
int x,score;
scanf("%d",&score);
x=score/10;
if(score>=80 && score<=84) x=7;
switch(x) {
case 8:
case 9:
case 10:printf("A\n");break;
case 7:printf("B\n");break;
case 6:printf("C\n");break;
default:printf("D\n");
}
return 0;
}
其中表达式表示循环条件,执行代码块为循环体。
while语句的语义是:计算表达式的值,当值为
真(非0)时, 执行循环体代码块。
- while语句中的表达式一般是关系表达或逻辑表达式,当表达式的值为假时不执行循环体,反之则循环体一直执行。
- 一定要记着在循环体中改变循环变量的值,否则会出现死循环(无休止的执行)。
- 循环体如果包括有一个以上的语句,则必须用
{}括起来,组成复合语句。

do—while语句的语义是:它先执行循环中的执行代码块,然后再判断while中表达式是否为真,如果为真则继续循环;如果为假,则终止循环。因此,do-while循环至少要执行一次循环语句。
注意:使用do-while结构语句时,while括号后必须有分号。
c语言中for循环一般形式:

它的执行过程如下:
1.执行表达式1,对循环变量做初始化; 2.判断表达式2,若其值为真(非0),则执行for循环体中执行代码块,然后向下执行表达式3;若其值为假(0),则结束循环; 3.执行完语句块,然后执行表达式3,(i++)等对于循环变量进行操作的语句; 4.执行for循环中执行代码块后执行第二步;第一步初始化只会执行一次。 5.循环结束,程序继续向下执行。
在for循环中:
- 表达式1是一个或多个赋值语句,它用来控制变量的初始值;
- 表达式2是一个关系表达式,它决定什么时候退出循环;
- 表达式3是循环变量的步进值,定义控制循环变量每循环一次后按什么方式变化。
- 这三部分之间用分号
;分开。
使用for语句的注意点:
1.for循环中的“表达式1、2、3”均可不写为空,但两个分号(;;)不能缺省。 2.省略“表达式1(循环变量赋初值)”,表示不对循环变量赋初始值。 3.省略“表达式2(循环条件)”,不做其它处理,循环一直执行(死循环)。 4.省略“表达式3(循环变量增减量)”,不做其他处理,循环一直执行(死循环)。 5.表达式1可以是设置循环变量的初值的赋值表达式,也可以是其他表达式。 6.表达式1和表达式3可以是一个简单表达式也可以是多个表达式以逗号分割。

7.表达式2一般是关系表达式或逻辑表达式,但也可是数值表达式或字符表达式,只要其值非零,就执行循环体。
8.各表达式中的变量一定要在for循环之前定义。
9.for循环中的两个分号一定要写
多重循环就是在循环结构的循环体中又出现循环结构。
在实际开发中一般最多用到三层重循环。
不同循环之间也是可以嵌套的。
多重循环在执行的过程中,外层循环为父循环,内层循环为子循环,
**父循环一次,子循环需要全部执行完,直到跳出循环。**父循环再进入下一次,子循环继续执行…

例1:打印三角形星星堆
#include <stdio.h>
int main()
{
int i, j, k;
for(i=1; i<5; i++)
{
/* 观察每行的空格数量,补全循环条件 */
for(j=i; j<5; j++)
{
printf(" "); //输出空格
}
/* 观察每行*号的数量,补全循环条件 */
for( k=0;k<2*i-1;k++)
{
printf("*"); //每行输出的*号
}
printf("\n"); //每次循环换行
}
return 0;
}例2:使用for循环打印9×9乘法表
#include <stdio.h>
int main()
{
// 定义相乘数字i,j以及结果result
int i, j, result;
for(i=9;i>=1;i--)
{
for(j=1;j<=i;j++)
{
printf("%d*%d=%d ",i,j,result=i*j);
}
printf("\n");
}
return 0;
}while, do-while和for三种循环在具体的使用场合上是有区别的,如下:
- 在知道循环次数的情况下更适合使用for循环;
- 在不知道循环次数的情况下适合使用while或者do-while循环;
- 如果有可能一次都不循环应考虑使用while循环
- 如果至少循环一次应考虑使用do-while循环。
Tips:从本质上讲,while,do-while和for循环之间是可以相互转换的。
break语句:当switch语句运行时遇到break关键字时会跳出,意思就是当语句运行到break时就不再运行了,接下来剩下的case语句也不会再执行,switch语句结束。
(1)只能在循环体内和switch语句体内使用break。 (2)不管是哪种循环,一旦在循环体中遇到break,系统将完全结束循环,开始执行循环之后的代码。 (3)当break出现在循环体中的switch语句体内时,起作用只是跳出该switch语句体,并不能终止循环体的执行。若想强行终止循环体的执行,可以在循环体中,但并不在switch语句中设置break语句,满足某种条件则跳出本层循环体。
(4) 当break语句出现在嵌套循环中的内层循环时,它只能跳出内层循环,如果想使用break语句跳出外层循环,则需要在外层循环中使用break语句。
注意:
- 在没有循环结构的情况下,break不能用在单独的if-else语句中。
- 在多层循环中,一个break语句只跳出当前循环。
在C语言中,可以使用continue语句进行中断
continue语句的作用是结束本次循环开始执行下一次循环。
(1) continue语句的作用是跳过本次循环体中剩下尚未执行的语句,立即进行下一次的循环条件判定,可以理解为只是中止(跳过)本次循环,接着开始下一次循环。
(2)continue语句并没有使整个循环终止。
(3)continue 只能在循环语句中使用,即只能在 for、while 和 do…while 语句中使用。
辨析:break语句与continue语句的区别
- break是跳出当前整个循环,continue是结束本次循环开始下一次循环。
(1)标准库函数(包含于stdio.h的头文件里):
(2)数学库函数(包含于math.h的头文件里):
32个数学函数中只有abs的数据类型是:”整型“,”int“。
**log10、logE中的10与E是在log的左下角位置。其余求弧度函数需要看清楚是不是指数。 **
排列方式如下:函数名:函数功能参数介绍,返回值,说明。函数原型。
abs: 求整型x的绝对值,返回计算结果。 int abs(int x);
acos: 计算COS-1(x)的值,返回计算结果,x应在-1到1范围内。 double acos(double x);
asin: 计算SIN-1(x)的值,返回计算结果,x应在-1到1范围内。 double asin(double x);
atan: 计算TAN-1(x)的值,返回计算结果。 double atan(double x);
atan2: 计算TAN-1/(x/y)的值,返回计算结果。 double atan2(double x,double y);
cos: 计算COS(x)的值,返回计算结果,x的单位为弧度。 double cos(double x);
cosh: 计算x的双曲余弦COSH(x)的值,返回计算结果。 double cosh(double x);
exp: 求Ex的值,返回计算结果。 double exp(double x);
fabs: 求x的绝对值,返回计算结果。 duoble fabs(fouble x);
floor: 求出不大于x的最大整数,返回该整数的双精度实数。 double floor(double x);
fmod: 求整除x/y的余数,返回该余数的双精度。 double fmod(double x,double y);
frexp: 把双精度数val分解为数字部分(尾数)x和以2为底的指数n,即val=x*2n,n存放在eptr指向的变量中。返回数字部分x0.5<=x<1。 double frexp(double x, double *eptr);
log: 求log e x,In x。返回计算结果。 double log(double x);
log10: 求log10x。返回计算结果。 double log10(double x);
modf: 把双精度数val分解为整数部分和小数部分,把整数部分存到iptr指向的单元。返回val的小数部分。 double modf(double val,double *iptr);
pow: 计算Xy的值,返回计算结果。 double pow(double x,double *iprt);
rand: 产生-90到32767间的随机整数。返回随机整数。 int rand(void);
sin: 计算SINx的值。返回计算结果。x单位为弧度。 double sin(double x);
sinh: 计算x的双曲正弦函数SINH(x)的值,返回计算结果。 double sinh(double x);
sqrt: 计算根号x。返回计算结果。x应>=0。 double sqrt(double x);
tan: 计算TAN(x)的值,返回计算结果。x单位为弧度。 double tan(double x);
tanh: 计算x的双曲正切函数tanh(x)的值。返回计算结果。 double tanh(double x);**
(1)用户自定义函数的一般形式:

[]包含的内容可以省略,数据类型说明省略,默认是int类型函数; 参数省略表示该函数是无参函数,参数不省略表示该函数是有参函数;- 函数名称遵循标识符命名规范;
- 自定义函数尽量放在
main函数之前,如果要放在main函数后面的话, 需要在main函数之前先声明自定义函数,声明格式为:
[数据类型说明] 函数名称([参数]);
(2)用户自定义函数的写法
第一种写法(即上述样例写法),在程序的最前面先声明,在main()函数后定义,这种也是最规范的写法:
#include <stdio.h>
int plus(int x,int y); //此处有分号,表示函数的声明
int main()
{
int a,b,c;
a=1;
b=2;
c=plus(a,b); //函数的调用
printf("%d",c);
return 0;
}
int plus(int x,int y) //此处无分号,表示函数的定义
{
int result;
result=x+y;
return result;
}第二种写法,直接在主函数前定义函数:
#include <stdio.h>
int plus(int x,int y); //此处无分号
{
int result;
result=x+y;
return result;
}
int main()
{
int a,b,c;
a=1;
b=2;
c=plus(a,b); //函数的调用
printf("%d",c);
return 0;
}(3)用户自定义函数的参数
函数名后面的括号为参数表,括号内表示接收的参数,函数可以不接收参数,也可以接收一个或多个参数。 注意:函数后参数表内定义的变量名仅仅是名字。例(因为函数的的本质是传值)
(4)用户自定义函数的返回值
函数的返回值最多有一个,或者无返回值。
除了以void声明的函数以外,所有的函数都需要有返回值。(void中文翻译:无类型)
在自创函数里,如果你不需要返回值,那么可以用void来声明函数。
其他的自创函数中,函数有且仅有一个返回值。
1.使用返回值:
#include <stdio.h>
int plus(int x,int y);
int main()
{
int a,b,c;
a=1;
b=2;
c=plus(a,b); //函数的调用,并且被赋值给了c,在这里使用了返回值
printf("%d",c);
return 0;
}
int plus(int x,int y)
{
int result;
result=x+y;
return result;
}2.丢弃返回值
#include <stdio.h>
int plus(int x,int y);
int main()
{
int a,b,c;
a=1;
b=2;
plus(a,b); //函数的调用,在这里,返回值没有被任何语句接收
printf("%d",c); //由于c没有被赋值,所以输出来的会是一个随机值(原先c这个空间内存的值)
return 0;
}
int plus(int x,int y)
{
int result;
result=x+y;
return result;
}(5)用户自定义函数内变量的生存周期和作用域
函数内所有变量的作用域都在从变量声明时开始到函数结束时结束。 “变量声明”时开始:如果变量a是在函数的中间声明的,那么在函数的前一半部分,无法使用变量a。 “函数结束”时结束:例如在plus函数中创建的变量,无法在主函数中使用。同理,主函数中的变量也无法在自创变量中使用。 但全局变量(声明在最前面,主函数的外面)可以在全局都使用。 一般的变量的生存周期都是会随着函数的结束而销毁,函数开始时为变量分配存储空间,函数结束时函数内的变量销毁,把空间释放。但是static型的变量的生存周期是全局,不会随着函数的结束而销毁。注:static变量的作用域依旧是从变量声明开始,到函数结束。
static变量的举例:
#include <stdio.h>
int plus(void);
int main()
{
int x;
x=plus;
x=plus;
x=plus;
printf("%d",x);
return 0;
}
int plus(int x,int y)
{
static a=1;
a++;
return a;
}(6)用户自定义函数变量的“就近”
#include <stdio.h>
int main()
{
int a=1;
{
int a=2;
printf("%d ",a);
}
printf("%d",a);
return 0;
}在一对{}内声明的变量,作用域和生存周期也不会超出这对{}(一切同上文所述规则)。
在这个例子中,第一条输出语句,输出的是与其最近的2,而不是1。
当{}结束后,内部的a变量被销毁,因此第二条输出语句输出的是1.
注意,在同一个区域内,一个变量不能被重复声明。
SP:
(1)C语言函数不允许嵌套定义。即在函数中可以调用函数,但是不能定义函数。 (2)在函数参数表中的逗号仅仅用于分隔变量,而不是逗号运算符。
我们需要用到自定义的函数的时候,就得调用它,那么在调用的时候就称之为函数调用。
在C语言中,函数调用的一般形式为:
函数名([参数]);
注意:
1.对无参函数调用的时候可以将[]包含的省略。
2.[]中可以是常数,变量或其它构造类型数据及表达式,多个参数之间用逗号分隔。
在函数中不需要函数参数的称之为无参函数,在函数中需要函数参数的称之为有参函数。
有参和无参函数的一般形式如下:

有参函数和无参函数的唯一区别在于:函数 () 中多了一个参数列表。
注意:
- 有参函数更为灵活,输出的内容可以随着n的改变而随意变动,只要在main函数中传递一个参数就可以了。
- 而在无参函数中输出的相对就比较固定,当需要改动的时候还需要到自定义的方法内改变循环变量的值。
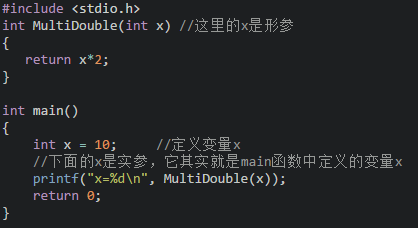
函数的参数分为形参和实参两种。
形参是在定义函数名和函数体的时候使用的参数,目的是用来接收调用该函数时传入的参数。
(就类似小明,说了的话而不实际行动;)
实参是在调用时传递该函数的参数。
(就如小刚能实际行动起来。)
函数的形参和实参具有以下特点:
-
形参只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只有在函数内部有效。
(函数调用结束返回主调函数后则不能再使用该形参变量。)
-
实参可以是常量、变量、表达式、函数等。
(无论实参是何种类型的量,在进行函数调用时,它们都必须具有确定的值,以便把这些值传送给形参。因此应预先用赋值等办法使实参获得确定值。)
-
在参数传递时,实参和形参在数量上,类型上,顺序上应严格一致,否则会发生类型不匹配的错误。
函数的返回值是指函数被调用之后,执行函数体中的程序段所取得的并返回给主调函数的值。
注意:
函数的值只能通过
return语句返回主调函数。(return语句的一般形式为:return 表达式 或者为: return (表达式);)
函数值的类型和函数定义中函数的类型应保持一致。
(如果两者不一致,则以函数返回类型为准,自动进行类型转换。)
没有返回值的函数,返回类型为
void。
void函数中可以有执行代码块,但是不能有返回值.void函数中如果有return语句,该语句**只能起到结束函数运行的功能。**其格式为: return;
递归就是一个函数在它的函数体内调用它自身。
执行递归函数将反复调用其自身,每调用一次就进入新的一层。
注意:递归函数必须有结束条件
例1:5的阶乘
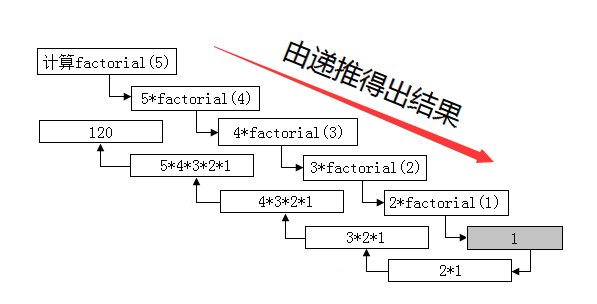
程序在计算5的阶乘的时候,先执行递推,当n=1或者n=0的时候返回1,再回推将计算并返回。由此可以看出递归函数必须有结束条件。
递归函数特点:
- 每一级函数调用时都有自己的变量,但是函数代码并不会得到复制,如计算5的阶乘时每递推一次变量都不同;
- 每次调用都会有一次返回,如计算5的阶乘时每递推一次都返回进行下一次;
- 递归函数中,位于递归调用前的语句和各级被调用函数具有相同的执行顺序;
- 递归函数中,位于递归调用后的语句的执行顺序和各个被调用函数的顺序相反;
- 递归函数中必须有终止语句。
总结:自我调用且有完成状态
例2:猴子第一天摘下N个桃子,当时就吃了一半,还不过瘾,就又多吃了一个。第二天又将剩下的桃子吃掉一半,又多吃了一个。以后每天都吃前一天剩下的一半零一个。到第10天在想吃的时候就剩一个桃子了,问第一天共摘下来多少个桃子?并反向打印每天所剩桃子数。
#include <stdio.h>
int getPeachNumber(int n)
{
int num;
if(n==10)
{
return 1;
}
else
{
num = (getPeachNumber(n+1)+1)*2;
printf("第%d天所剩桃子%d个\n", n, num);
}
return num;
}
int main()
{
int num = getPeachNumber(1);
printf("猴子第一天摘了:%d个桃子。\n", num);
return 0;
}例3:有5个人坐在一起,问第5个人多少岁?他说比第4个人大2岁。问第4个人岁数,他说比第3个人大2岁。问第3个人,又说比第2人大两岁。问第2个人,说比第1个人大两岁。最后 问第1个人,他说是10岁。请问第5个人多大?
#include <stdio.h>
int dfs(int n) {
return n == 1 ? 10 : dfs(n - 1) + 2;
}
int main()
{
printf("第5个人的年龄是%d岁", dfs(5));
return 0;
}
/*程序分析:
利用递归的方法,递归分为回推和递推两个阶段。要想知道第5个人岁数,需知道第4人的岁数,依次类推,推到第1人(10岁),再往回推。*/C语言中的变量,按作用域范围可分为两种,即局部变量和全局变量。
- 局部变量也称为内部变量。局部变量是在函数内作定义说明的。其作用域仅限于函数内, 离开该函数后再使用这种变量是非法的。在复合语句中也可定义变量,其作用域只在复合语句范围内。
- 全局变量也称为外部变量,它是在函数外部定义的变量。它不属于哪一个函数,它属于一个源程序文件。其作用域是整个源程序。
- 在C语言中不能被其他源文件调用的函数称谓内部函数 ,内部函数由static关键字来定义,因此又被称谓静态函数,形式为: static [数据类型] 函数名([参数])
- 这里的static是对函数的作用范围的一个限定,限定该函数只能在其所处的源文件中使用,因此在不同文件中出现相同的函数名称的内部函数是没有问题的。
- 在C语言中能被其他源文件调用的函数称谓外部函数 ,外部函数由extern关键字来定义,形式为: extern [数据类型] 函数名([参数])
- C语言规定,在没有指定函数的作用范围时,系统会默认认为是外部函数,因此当需要定义外部函数时extern也可以省略。
C语言程序编译过程:

语法:#define name stuff (用stuff替换name)
#define MAX 100
#define STR "hehe"
int main()
{
int max = MAX;
printf("%d\n", max); //输出100
printf("%s\n",STR); //输出 hehe
return 0;
}注意:
- #define 机制包括了一个机制,允许把参数替换到文本中,这种实现通常称为宏或者宏定义
- 宏的申明方式:#define name(parament-list) stuff 其中的parament-list是一个由逗号隔开的符号表,他们可能出现在stuff中。
- 参数列表的左括号必须与name紧邻,如果两者之间有任何空白存在,参数列表就会解释为stuff 的一部分。
注意对比以下代码:
#define SQUARE(X) X*X
int main()
{
int ret = SQUARE(5);
printf("%d\n",ret); //输出25
return 0;
}如果我们换一个参数(将5换成5+1)输出的不是36而是11为什呢?
#define SQUARE(X) X*X
int main()
{
int ret = SQUARE(5+1);//替换之后就是(5+1*5+1 = 11)
printf("%d\n",ret);//输出11
return 0;
}注意:造成结果差异是因为没加括号。因此,用于对数值表达式进行求值的宏定义都应该用这种方式加上括号,避免在使用宏时由于参数中的操作符或临近操作符之间不可预料的相互作用。
正确的代码:
#define SQUARE(X) (X)*(X))
int main()
{
int ret = SQUARE(5+1);
printf("%d\n",ret);//输出36
return 0;
}1.#define NAME “lisa”
程序中有"NAME",但”“内的东西不会被宏替换。
2.宏定义前面的那个必须是合法的用户标识符
3.宏定义也不是说后面东西随便写,不能把字符串的两个”“拆开。
4.#define NAME “lisa” 程序中有上面的宏定义,并且,程序里有句: NAMELIST这样,不会被替换成"lisa"LIST
5.宏不能出现递归
C语言根据变量的生存周期来划分,可以分为静态存储方式和动态存储方式。
- 静态存储方式:是指在程序运行期间分配固定的存储空间的方式。静态存储区中存放了在整个程序执行过程中都存在的变量,如全局变量。
- 动态存储方式:是指在程序运行期间根据需要进行动态的分配存储空间的方式。动态存储区中存放的变量是根据程序运行的需要而建立和释放的,通常包括:函数形式参数;自动变量;函数调用时的现场保护和返回地址等。
| 自动类型 | auto |
|---|---|
| 静态类型 | static |
| 寄存器类型 | register |
| 外部类型 | extern |
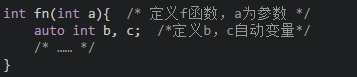
(1)Auto类:用关键字auto定义的变量为自动变量,auto可以省略,auto不写则隐含定为“自动存储类别”,属于动态存储方式。如:
(2)Static类:用static修饰的为静态变量,如果定义在函数内部的,称之为静态局部变量;如果定义在函数外部,称之为静态外部变量。如下为静态局部变量:
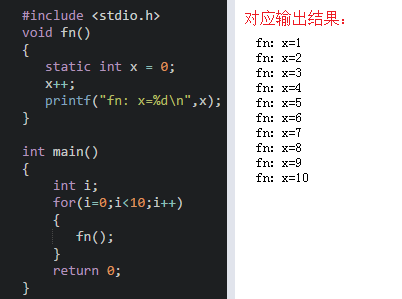
- 注意:静态局部变量属于静态存储类别,在静态存储区内分配存储单元,在程序整个运行期间都不释放;静态局部变量在编译时赋初值,即只赋初值一次;如果在定义局部变量时不赋初值的话,则对静态局部变量来说,编译时自动赋初值0(对数值型变量)或空字符(对字符变量)。
(3)Register类:为了提高效率,C语言允许将局部变量得值放在CPU中的寄存器中,这种变量叫“寄存器变量”,用关键字register作声明。例如:
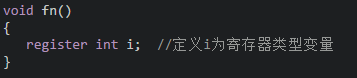
- 注意:只有局部自动变量和形式参数可以作为寄存器变量;一个计算机系统中的寄存器数目有限,不能定义任意多个寄存器变量;局部静态变量不能定义为寄存器变量。
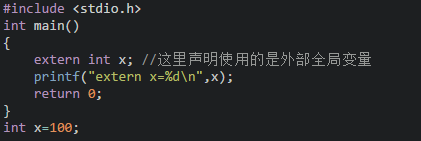
(4)Extern类:用extern声明的的变量是外部变量,外部变量的意义是某函数可以调用在该函数之后定义的变量。如:
C语言注释方法有两种:
多行注释:
/* 注释内容 */
单行注释:
//注释一行
程序中也需要容器,只不过该容器有点特殊,它在程序中是一块连续的,大小固定并且里面的数据类型一致的内存空间,它还有个好听的名字叫数组。可以将数组理解为大小固定,所放物品为同类的一个购物袋,在该购物袋中的物品是按一定顺序放置的。
如何声明一个数组 数据类型 数组名称[长度];
数组初始化是有三种形式:
- 数据类型 数组名称[长度n] = {元素1,元素2…元素n};
- 数据类型 数组名称[] = {元素1,元素2…元素n};
- 数据类型 数组名称[长度n]; 数组名称[0] = 元素1; 数组名称[1] = 元素2; 数组名称[n-1] = 元素n;
如何获取数组中的元素 数组名称[元素所对应下标];
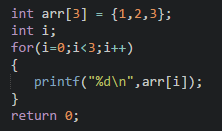
例子:初始化一个数组 int arr[3] = {1,2,3}; 那么arr[0]就是元素1。
注意:
- 数组的下标均以0开始;
- 数组在初始化的时候,数组内元素的个数不能大于声明的数组长度;
- 如果采用第一种初始化方式,元素个数小于数组的长度时,多余的数组元素初始化为0;
- 在声明数组后没有进行初始化的时候,静态(static)和外部(extern)类型的数组元素初始化元素为0,自动(auto)类型的数组的元素初始化值不确定。
数组就可以采用循环的方式将每个元素遍历出来,而不用人为的每次获取指定某个位置上的元素。
例子:用for循环遍历一个数组
注意;
- 最好避免出现数组越界访问,循环变量最好不要超出数组的长度.
- C语言的数组长度一经声明,长度就是固定,无法改变,并且C语言并不提供计算数组长度的方法。
- C语言是没有检查数组长度改变或者数组越界的这个机制,可能会在编辑器中编译并通过,但是结果就不能肯定了,因此还是不要越界或者改变数组的长度
int length = sizeof(arr)/sizeof(arr[0]);//c语言获取数组长度方法数组可以由整个数组当作函数的参数,也可以由数组中的某个元素当作函数的参数:
1.整个数组当作函数参数,即把数组名称传入函数中,例如:
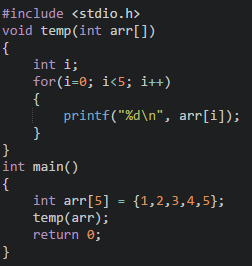
2.数组中的元素当作函数参数,即把数组中的参数传入函数中,例如:
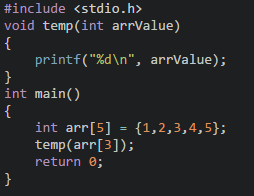
数组作为函数参数时注意以下事项:
- 数组名作为函数实参传递时,函数定义处作为接收参数的数组类型形参既可以指定长度也可以不指定长度。
- 数组元素作为函数实参传递时,数组元素类型必须与形参数据类型一致。
[冒泡排序]以升序排序为例冒泡排序的思想:相邻元素两两比较,将较大的数字放在后面,直到将所有数字全部排序。
就像小学排队时按大小个排一样,将一个同学拉出来和后面的比比,如果高就放后面,一直把队伍排好。
#include <stdio.h>
int main()
{
double arr[]={1.78, 1.77, 1.82, 1.79, 1.85, 1.75, 1.86, 1.77, 1.81, 1.80};
int i,j;
printf("\n************排队前*************\n");
for(i=0;i<10;i++)
{
if(i != 9)
printf("%1.2f, ", arr[i]); //%1.2f表示小数点前一位,小数点后精确到两位
else
printf("%1.2f", arr[i]); //%1.2f表示小数点前一位,小数点后精确到两位
}
for(i=8; i>=0; i--)
{
for(j=0;j<=i;j++)
{
if( arr[j]>arr[j+1]) //当前面的数比后面的数大时
{
double temp; //定义临时变量temp
temp=arr[j];//将前面的数赋值给temp
arr[j]=arr[j+1]; //前后之数颠倒位置
arr[j+1]=temp;//将较大的数放在后面
}
}
}
printf("\n************排队后*************\n");
for(i=0;i<10;i++)
{
if(i != 9)
printf("%1.2f, ", arr[i]); //%1.2f表示小数点前一位,小数点后精确到两位
else
printf("%1.2f", arr[i]); //%1.2f表示小数点前一位,小数点后精确到两位
}
return 0;
}[数组查找功能]当我们购物之后,拎着购物袋回到家,会一一检查购物袋中的物品看是否缺少或者都是想购之物。
那么应用到程序中,可以使用数组查找功能,看看是否存在该数据,如果存在并返回该元素的下标。
#include <stdio.h>
int getIndex(int arr[5],int value)
{
int i;
int index;
for(i=0;i<5;i++)
{
/* 请完善数组查询功能 */
if(arr[i]==value)
{
index=i;
break;
}
index=-1;
}
return index;
}
int main()
{
int arr[5]={3,12,9,8,6};
int value = 8;
int index = getIndex(arr,value); //这里应该传什么参数呢?
if(index!=-1)
{
printf("%d在数组中存在,下标为:%d\n",value,index);
}
else
{
printf("%d在数组中不存在。\n",value);
}
return 0;
}二维数组定义的一般形式是:
dataType arrayName[length1][length2];其中,dataType 为数据类型,arrayName 为数组名,length1 为第一维下标的长度,length2 为第二维下标的长度。
我们可以将二维数组看做一个 Excel 表格,有行有列,length1 表示行数,length2 表示列数,要在二维数组中定位某个元素,必须同时指明行和列。例如:
int a[3][4];定义了一个 3 行 4 列的二维数组,共有 3×4=12 个元素,数组名为 a,即:
a[0][0], a[0][1], a[0][2], a[0][3]
a[1][0], a[1][1], a[1][2], a[1][3]
a[2][0], a[2][1], a[2][2], a[2][3]
如果想表示第 2 行第 1 列的元素,应该写作 a[2][1]。
也可以将二维数组看成一个坐标系,有 x 轴和 y 轴,要想在一个平面中确定一个点,必须同时知道 x 轴和 y 轴。
二维数组在概念上是二维的,但在内存中是连续存放的;换句话说,二维数组的各个元素是相互挨着的,彼此之间没有缝隙。那么,如何在线性内存中存放二维数组呢?有两种方式:
- 一种是按行排列, 即放完一行之后再放入第二行;
- 另一种是按列排列, 即放完一列之后再放入第二列。
在C语言中,二维数组是按行排列的。也就是先存放 a[0] 行,再存放 a[1] 行,最后存放 a[2] 行;每行中的 4 个元素也是依次存放。数组 a 为 int 类型,每个元素占用 4 个字节,整个数组共占用 4×(3×4)=48 个字节。
你可以这样认为,二维数组是由多个长度相同的一维数组构成的。
例子1:一个学习小组有 5 个人,每个人有 3 门课程的考试成绩,求该小组各科的平均分和总平均分。
| 名称 | Math | C | English |
|---|---|---|---|
| 张涛 | 80 | 75 | 92 |
| 王正华 | 61 | 65 | 71 |
| 李丽丽 | 59 | 63 | 70 |
| 赵圈圈 | 85 | 87 | 90 |
| 周梦真 | 76 | 77 | 85 |
对于该题目,可以定义一个二维数组 a[5][3] 存放 5 个人 3 门课的成绩,定义一个一维数组 v[3] 存放各科平均分,再定义一个变量 average 存放总平均分。
代码如下:
#include <stdio.h>
int main(){
int i, j; //二维数组下标
int sum = 0; //当前科目的总成绩
int average; //总平均分
int v[3]; //各科平均分
int a[5][3]; //用来保存每个同学各科成绩的二维数组
printf("Input score:\n");
for(i=0; i<3; i++){
for(j=0; j<5; j++){
scanf("%d", &a[j][i]); //输入每个同学的各科成绩
sum += a[j][i]; //计算当前科目的总成绩
}
v[i]=sum/5; // 当前科目的平均分
sum=0;
}
average = (v[0] + v[1] + v[2]) / 3;
printf("Math: %d\nC Languag: %d\nEnglish: %d\n", v[0], v[1], v[2]);
printf("Total: %d\n", average);
return 0;
}运行结果:
Input score:
80 61 59 85 76 75 65 63 87 77 92 71 70 90 85↙
Math: 72
C Languag: 73
English: 81
Total: 75
二维数组的初始化可以按行分段赋值,也可按行连续赋值。
例如,对于数组 a[5][3],按行分段赋值应该写作:
int a[5][3]={ {80,75,92}, {61,65,71}, {59,63,70}, {85,87,90}, {76,77,85} };按行连续赋值应该写作:
int a[5][3]={80, 75, 92, 61, 65, 71, 59, 63, 70, 85, 87, 90, 76, 77, 85};这两种赋初值的结果是完全相同的。
例子1:求各科的平均分和总平均分,不过本例要求在初始化数组的时候直接给出成绩。
#include <stdio.h>
int main(){
int i, j; //二维数组下标
int sum = 0; //当前科目的总成绩
int average; //总平均分
int v[3]; //各科平均分
int a[5][3] = {{80,75,92}, {61,65,71}, {59,63,70}, {85,87,90}, {76,77,85}};
for(i=0; i<3; i++){
for(j=0; j<5; j++){
sum += a[j][i]; //计算当前科目的总成绩
}
v[i] = sum / 5; // 当前科目的平均分
sum = 0;
}
average = (v[0] + v[1] + v[2]) / 3;
printf("Math: %d\nC Languag: %d\nEnglish: %d\n", v[0], v[1], v[2]);
printf("Total: %d\n", average);
return 0;
}运行结果:
Math: 72
C Languag: 73
English: 81
Total: 75
对于二维数组的初始化还要注意以下几点:
1)可以只对部分元素赋值,未赋值的元素自动取“零”值。例如:
int a[3][3] = {{1}, {2}, {3}};是对每一行的第一列元素赋值,未赋值的元素的值为 0。赋值后各元素的值为: 1 0 0 2 0 0 3 0 0
再如:
int a[3][3] = {{0,1}, {0,0,2}, {3}};赋值后各元素的值为: 0 1 0 0 0 2 3 0 0
2)如果对全部元素赋值,那么第一维的长度可以不给出。例如:
int a[3][3] = {1, 2, 3, 4, 5, 6, 7, 8, 9};可以写为:
int a[][3] = {1, 2, 3, 4, 5, 6, 7, 8, 9};3)二维数组可以看作是由一维数组嵌套而成的;如果一个数组的每个元素又是一个数组,那么它就是二维数组。当然,前提是各个元素的类型必须相同。根据这样的分析,一个二维数组也可以分解为多个一维数组,C语言允许这种分解。
例如,二维数组
a[3][4]可分解为三个一维数组,它们的数组名分别为 a[0]、a[1]、a[2]。这三个一维数组可以直接拿来使用。这三个一维数组都有 4 个元素,比如,一维数组 a[0] 的元素为a[0][0]、a[0][1]、a[0][2]、a[0][3]
多维数组的定义格式是: 数据类型 数组名称[常量表达式1][常量表达式2]…[常量表达式n];

定义了一个名称为num,数据类型为int的二维数组。其中第一个[3]表示第一维下标的长度,就像购物时分类存放的购物;第二个[3]表示第二维下标的长度,就像每个购物袋中的元素。

多维数组的初始化与一维数组的初始化类似也是分两种:
- 数据类型 数组名称[常量表达式1][常量表达式2]…[常量表达式n] = {{值1,…,值n},{值1,…,值n},…,{值1,…,值n}};
- 数据类型 数组名称[常量表达式1][常量表达式2]…[常量表达式n]; 数组名称[下标1][下标2]…[下标n] = 值;
多维数组初始化要注意以下事项:
- 采用第一种始化时数组声明必须指定列的维数。(因为系统会根据数组中元素的总个数来分配空间,当知道元素总个数以及列的维数后,会直接计算出行的维数;)
- 采用第二种初始化时数组声明必须同时指定行和列的维数。
二维数组定义的时候,可以不指定行的数量,但是必须指定列的数量
多维数组也是存在遍历的,和一维数组遍历一样,也是需要用到循环。不一样的就是多维数组需要采用嵌套循环。
多维数组的每一维下标均不能越界
例子:
#include <stdio.h>
#define N 10
//打印分数
void printScore(int score[])
{
int i;
printf("\n");
for(i=0;i<N;i++)
{
printf("%d ",score[i]);
}
printf("\n");
}
//计算考试总分
int getTotalScore(int score[])
{
int sum = 0;
int i;
for(i=0;i<N;i++)
{
sum+=score[i];
}
return sum;
}
//计算平均分
int getAvgScore(int score[])
{
return getTotalScore(score)/N;
}
//计算最高分
int getMax(int score[])
{
int max = -1;
int i;
for(i=0;i<N;i++)
{
if(score[i]>max)
{
max = score[i];
}
}
return max;
}
//计算最低分
int getMin(int score[])
{
int min =100;
int i;
for(i=0;i<N;i++)
{
if(score[i]< min)
{
min = score[i];
}
}
return min;
}
//分数降序排序
void sort(int score[])
{
int i,j;
for(i=N-2;i>=0;i--)
{
for(j=0;j<=i;j++)
{
if(score[j]<score[j+1])
{
int temp;
temp = score[j];
score[j] = score[j+1];
score[j+1]=temp;
}
}
}
printScore(score);
}
int main()
{
int score[N]={67,98,75,63,82,79,81,91,66,84};
int sum,avg,max,min;
sum = getTotalScore(score);
avg = getAvgScore(score);
max = getMax(score);
min = getMin(score);
printf("总分是:%d\n",sum);
printf("平均分是:%d\n",avg);
printf("最高分是:%d\n",max);
printf("最低分是:%d\n",min);
printf("----------成绩排名---------\n");
sort(score);
return 0;
}用来存放字符的数组称为字符数组
例如:
char a[10]; //一维字符数组
char b[5][10]; //二维字符数组
char c[20]={'c', ' ', 'p', 'r', 'o', 'g', 'r', 'a','m'}; // 给部分数组元素赋值
char d[]={'c', ' ', 'p', 'r', 'o', 'g', 'r', 'a', 'm' }; //对全体元素赋值时可以省去长度字符数组实际上是一系列字符的集合,也就是字符串(String)。在C语言中,没有专门的字符串变量,没有string类型,通常就用一个字符数组来存放一个字符串。
C语言规定,可以将字符串直接赋值给字符数组
例如:
char str[30] = {"c.biancheng.net"};
char str[30] = "c.biancheng.net"; //这种形式更加简洁,实际开发中常用数组第 0 个元素为'c',第 1 个元素为'.',第 2 个元素为'b',后面的元素以此类推。
也可以不指定数组长度,从而写作:
char str[] = {"c.biancheng.net"};
char str[] = "c.biancheng.net"; //这种形式更加简洁,实际开发中常用给字符数组赋值时,我们通常使用这种写法,将字符串一次性地赋值(可以指明数组长度,也可以不指明),而不是一个字符一个字符地赋值。
字符数组只有在定义时才能将整个字符串一次性地赋值给它,一旦定义完了,就只能一个字符一个字符地赋值了。请看下面的例子:
char str[7];
str = "abc123"; //错误
//正确
str[0] = 'a'; str[1] = 'b'; str[2] = 'c';
str[3] = '1'; str[4] = '2'; str[5] = '3';字符串是一系列连续的字符的组合,要想在内存中定位一个字符串,除了要知道它的开头,还要知道它的结尾。找到字符串的开头很容易,知道它的名字(字符数组名或者字符串名)就可以。
在C语言中,字符串总是以
'\0'作为结尾,所以'\0'也被称为字符串结束标志,或者字符串结束符。
'\0'是 ASCII 码表中的第 0 个字符,英文称为 NUL,中文称为“空字符”。该字符既不能显示,也没有控制功能,输出该字符不会有任何效果,它在C语言中唯一的作用就是作为字符串结束标志。
C语言在处理字符串时,会从前往后逐个扫描字符,一旦遇到
'\0'就认为到达了字符串的末尾,就结束处理。'\0'至关重要,没有'\0'就意味着永远也到达不了字符串的结尾。由
" "包围的字符串会自动在末尾添加'\0'。例如,"abc123"从表面看起来只包含了 6 个字符,其实不然,C语言会在最后隐式地添加一个'\0',这个过程是在后台默默地进行的。
下图演示了"C program"在内存中的存储情形:

需要注意的是,逐个字符地给数组赋值并不会自动添加
'\0',例如:char str[] = {'a', 'b', 'c'};数组 str 的长度为 3,而不是 4,因为最后没有
'\0'。
当用字符数组存储字符串时,要特别注意
'\0',要为'\0'留个位置;这意味着,字符数组的长度至少要比字符串的长度大 1。请看下面的例子:char str[7] = "abc123";
"abc123"看起来只包含了 6 个字符,我们却将 str 的长度定义为 7,就是为了能够容纳最后的'\0'。如果将 str 的长度定义为 6,它就无法容纳'\0'了。
有些时候,程序的逻辑要求我们必须逐个字符地为数组赋值,这个时候就很容易遗忘字符串结束标志'\0'。下面的代码中,我们将 26 个大写英文字符存入字符数组,并以字符串的形式输出:
#include <stdio.h>
int main(){
char str[30];
char c;
int i;
for(c=65,i=0; c<=90; c++,i++){
str[i] = c;
}
printf("%s\n", str);
return 0;
}运行结果:
ABCDEFGHIJKLMNOPQRSTUVWXYZ口口口口i口口0 ?
注释:口表示无法显示的特殊字符。
大写字母在 ASCII 码表中是连续排布的,编码值从 65 开始,到 90 结束,使用循环非常方便。
在函数内部定义的变量、数组、结构体、共用体等都称为局部数据。在很多编译器下,局部数据的初始值都是随机的、无意义的,而不是我们通常认为的“零”值。这一点非常重要,大家一定要谨记,否则后面会遇到很多奇葩的错误。
本例中的 str 数组在定义完成以后并没有立即初始化,所以它所包含的元素的值都是随机的,只有很小的概率会是“零”值。循环结束以后,str 的前 26 个元素被赋值了,剩下的 4 个元素的值依然是随机的,不知道是什么。
printf() 输出字符串时,会从第 0 个元素开始往后检索,直到遇见'\0'才停止,然后把'\0'前面的字符全部输出,这就是 printf() 输出字符串的原理。本例中我们使用 printf() 输出 str,按理说到了第 26 个元素就能检索到'\0',就到达了字符串的末尾,然而事实却不是这样,由于我们并未对最后 4 个元素赋值,所以第 26 个元素不是'\0',第 27 个也不是,第 28 个也不是……可能到了第 50 个元素才遇到'\0',printf() 把这 50 个字符全部输出出来,就是上面的样子,多出来的字符毫无意义,甚至不能显示。
数组总共才 30 个元素,到了第 50 个元素不早就超出数组范围了吗?是的,的确超出范围了!然而,数组后面依然有其它的数据,printf() 也会将这些数据作为字符串输出。
你看,不注意'\0'的后果有多严重,不但不能正确处理字符串,甚至还会毁坏其它数据。
要想避免这些问题也很容易,在字符串的最后手动添加'\0'即可。修改上面的代码,在循环结束后添加'\0':
#include <stdio.h>
int main(){
char str[30];
char c;
int i;
for(c=65,i=0; c<=90; c++,i++){
str[i] = c;
}
str[i] = 0; //此处为添加的代码,也可以写作 str[i] = '\0';
printf("%s\n", str);
return 0;
}第 9 行为新添加的代码,它让字符串能够正常结束。根据 ASCII 码表,字符'\0'的编码值就是 0。
但是,这样的写法貌似有点业余,或者说不够简洁,更加专业的做法是将数组的所有元素都初始化为“零”值,这样才能够从根本上避免问题。再次修改上面的代码:
#include <stdio.h>
int main(){
char str[30] = {0}; //将所有元素都初始化为 0,或者说 '\0'
char c;
int i;
for(c=65,i=0; c<=90; c++,i++){
str[i] = c;
}
printf("%s\n", str);
return 0;
}如果只初始化部分数组元素,那么剩余的数组元素也会自动初始化为“零”值,所以我们只需要将 str 的第 0 个元素赋值为 0,剩下的元素就都是 0 了。
所谓字符串长度,就是字符串包含了多少个字符(不包括最后的结束符'\0')。例如"abc"的长度是 3,而不是 4。
在C语言中,我们使用string.h头文件中的 strlen() 函数来求字符串的长度,它的用法为:
length strlen(strname);strname 是字符串的名字,或者字符数组的名字;length 是使用 strlen() 后得到的字符串长度,是一个整数。
下面是一个完整的例子,它输出网址的长度:
#include <stdio.h>
#include <string.h> //记得引入该头文件
int main(){
char str[] = "http://c.biancheng.net/c/";
long len = strlen(str);
printf("The lenth of the string is %ld.\n", len);
return 0;
}运行结果:
The lenth of the string is 25.
在C语言中,有两个函数可以在控制台(显示器)上输出字符串,它们分别是:
- puts():输出字符串并自动换行,该函数只能输出字符串。
- printf():通过格式控制符
%s输出字符串,不能自动换行。除了字符串,printf() 还能输出其他类型的数据。
请看下面的代码:
#include <stdio.h>
int main(){
char str[] = "http://c.biancheng.net";
printf("%s\n", str); //通过字符串名字输出
printf("%s\n", "http://c.biancheng.net"); //直接输出
puts(str); //通过字符串名字输出
puts("http://c.biancheng.net"); //直接输出
return 0;
}运行结果:
http://c.biancheng.net
http://c.biancheng.net
http://c.biancheng.net
http://c.biancheng.net
注意,输出字符串时只需要给出名字,不能带后边的
[ ],例如,下面的两种写法都是错误的:printf("%s\n", str[]); puts(str[10]);
在C语言中,有两个函数可以让用户从键盘上输入字符串,它们分别是:
- scanf():通过格式控制符
%s输入字符串。除了字符串,scanf() 还能输入其他类型的数据。- gets():直接输入字符串,并且只能输入字符串。
scanf() 和 gets() 是有区别的:
- scanf() 读取字符串时以空格为分隔,遇到空格就认为当前字符串结束了,所以无法读取含有空格的字符串。
- gets() 认为空格也是字符串的一部分,只有遇到回车键时才认为字符串输入结束,所以,不管输入了多少个空格,只要不按下回车键,对 gets() 来说就是一个完整的字符串。换句话说,gets() 用来读取一整行字符串。
请看下面的例子:
#include <stdio.h>
int main(){
char str1[30] = {0};
char str2[30] = {0};
char str3[30] = {0};
//gets() 用法
printf("Input a string: ");
gets(str1);
//scanf() 用法
printf("Input a string: ");
scanf("%s", str2);
scanf("%s", str3);
printf("\nstr1: %s\n", str1);
printf("str2: %s\n", str2);
printf("str3: %s\n", str3);
return 0;
}运行结果:
Input a string: C C++ Java Python↙
Input a string: PHP JavaScript↙
str1: C C++ Java Python
str2: PHP
str3: JavaScript
第一次输入的字符串被 gets() 全部读取,并存入 str1 中。第二次输入的字符串,前半部分被第一个 scanf() 读取并存入 str2 中,后半部分被第二个 scanf() 读取并存入 str3 中。
注意,scanf() 在读取数据时需要的是数据的地址,这一点是恒定不变的,所以对于 int、char、float 等类型的变量都要在前边添加&以获取它们的地址。但是在本段代码中,我们只给出了字符串的名字,却没有在前边添加&,这是为什么呢?因为字符串名字或者数组名字在使用的过程中一般都会转换为地址,所以再添加&就是多此一举,甚至会导致错误了。
就目前学到的知识而言,int、char、float 等类型的变量用于 scanf() 时都要在前面添加
&,而数组或者字符串用于 scanf() 时不用添加&,它们本身就会转换为地址。
其实 scanf() 也可以读取带空格的字符串
以上是 scanf() 和 gets() 的一般用法,很多教材也是这样讲解的,所以大部分初学者都认为 scanf() 不能读取包含空格的字符串,不能替代 gets()。其实不然,scanf() 的用法还可以更加复杂和灵活,它不但可以完全替代 gets() 读取一整行字符串,而且比 gets() 的功能更加强大。比如,以下功能都是 gets() 不具备的:
- scanf() 可以控制读取字符的数目;
- scanf() 可以只读取指定的字符;
- scanf() 可以不读取某些字符;
- scanf() 可以把读取到的字符丢弃。
C语言提供了丰富的字符串处理函数,可以对字符串进行输入、输出、合并、修改、比较、转换、复制、搜索等操作,使用这些现成的函数可以大大减轻我们的编程负担。
用于输入输出的字符串函数,例如printf、puts、scanf、gets等,使用时要包含头文件stdio.h,而使用其它字符串函数要包含头文件string.h。
string.h是一个专门用来处理字符串的头文件,它包含了很多字符串处理函数,由于篇幅限制,本节只能讲解几个常用的,有兴趣的读者请猛击这里查阅所有函数。
strcat 是 string catenate 的缩写,意思是把两个字符串拼接在一起,语法格式为:
strcat(arrayName1, arrayName2);注释:arrayName1、arrayName2 为需要拼接的字符串。
strcat() 将把 arrayName2 连接到 arrayName1 后面,并删除原来 arrayName1 最后的结束标志'\0'。这意味着,arrayName1 必须足够长,要能够同时容纳 arrayName1 和 arrayName2,否则会越界(超出范围)。
strcat() 的返回值为 arrayName1 的地址。
例子:
#include <stdio.h>
#include <string.h>
int main(){
char str1[100]="The URL is ";
char str2[60];
printf("Input a URL: ");
gets(str2);
strcat(str1, str2);
puts(str1);
return 0;
}运行结果:
Input a URL: http://c.biancheng.net/cpp/u/jiaocheng/↙
The URL is http://c.biancheng.net/cpp/u/jiaocheng/
strcpy 是 string copy 的缩写,意思是字符串复制,也即将字符串从一个地方复制到另外一个地方,语法格式为:
strcpy(arrayName1, arrayName2);strcpy() 会把 arrayName2 中的字符串拷贝到 arrayName1 中,字符串结束标志'\0'也一同拷贝。
例子:
#include <stdio.h>
#include <string.h>
int main(){
char str1[50] = "《C语言变怪兽》";
char str2[50] = "http://c.biancheng.net/cpp/u/jiaocheng/";
strcpy(str1, str2);
printf("str1: %s\n", str1);
return 0;
}运行结果:
str1: http://c.biancheng.net/cpp/u/jiaocheng/
将 str2 复制到 str1 后,str1 中原来的内容就被覆盖了。
另外,strcpy() 要求 arrayName1 要有足够的长度,否则不能全部装入所拷贝的字符串。
strcmp 是 string compare 的缩写,意思是字符串比较,语法格式为:
strcmp(arrayName1, arrayName2);
arrayName1 和 arrayName2 是需要比较的两个字符串。
字符本身没有大小之分,strcmp() 以各个字符对应的 ASCII 码值进行比较。strcmp() 从两个字符串的第 0 个字符开始比较,如果它们相等,就继续比较下一个字符,直到遇见不同的字符,或者到字符串的末尾。
返回值:若 arrayName1 和 arrayName2 相同,则返回0;若 arrayName1 大于 arrayName2,则返回大于 0 的值;若 arrayName1 小于 arrayName2,则返回小于0 的值。
对4组字符串进行比较:
#include <stdio.h>
#include <string.h>
int main(){
char a[] = "aBcDeF";
char b[] = "AbCdEf";
char c[] = "aacdef";
char d[] = "aBcDeF";
printf("a VS b: %d\n", strcmp(a, b));
printf("a VS c: %d\n", strcmp(a, c));
printf("a VS d: %d\n", strcmp(a, d));
return 0;
}运行结果:
a VS b: 32
a VS c: -31
a VS d: 0
计算机中所有的数据都必须放在内存中,不同类型的数据占用的字节数不一样,例如 int 占用 4 个字节,char 占用 1 个字节。为了正确地访问这些数据,必须为每个字节都编上号码,就像门牌号、身份证号一样,每个字节的编号是唯一的,根据编号可以准确地找到某个字节。
下图是 4G 内存中每个字节的编号(以十六进制表示):

我们将内存中字节的编号称为地址(Address)或指针(Pointer)。地址从 0 开始依次增加,对于 32 位环境,程序能够使用的内存为 4GB,最小的地址为 0,最大的地址为 0XFFFFFFFF。
下面的代码演示了如何输出一个地址:
#include <stdio.h>
int main(){
int a = 100;
char str[20] = "c.biancheng.net";
printf("%#X, %#X\n", &a, str);
return 0;
}运行结果:
0X28FF3C, 0X28FF10
%#X表示以十六进制形式输出,并附带前缀0X。a 是一个变量,用来存放整数,需要在前面加&来获得它的地址;str 本身就表示字符串的首地址,不需要加&。
C语言用变量来存储数据,用函数来定义一段可以重复使用的代码,它们最终都要放到内存中才能供 CPU 使用。
数据和代码都以二进制的形式存储在内存中,计算机无法从格式上区分某块内存到底存储的是数据还是代码。当程序被加载到内存后,操作系统会给不同的内存块指定不同的权限,拥有读取和执行权限的内存块就是代码,而拥有读取和写入权限(也可能只有读取权限)的内存块就是数据。
CPU 只能通过地址来取得内存中的代码和数据,程序在执行过程中会告知 CPU 要执行的代码以及要读写的数据的地址。如果程序不小心出错,或者开发者有意为之,在 CPU 要写入数据时给它一个代码区域的地址,就会发生内存访问错误。这种内存访问错误会被硬件和操作系统拦截,强制程序崩溃,程序员没有挽救的机会。
CPU 访问内存时需要的是地址,而不是变量名和函数名!变量名和函数名只是地址的一种助记符,当源文件被编译和链接成可执行程序后,它们都会被替换成地址。编译和链接过程的一项重要任务就是找到这些名称所对应的地址。
假设变量 a、b、c 在内存中的地址分别是 0X1000、0X2000、0X3000,那么加法运算
c = a + b;将会被转换成类似下面的形式:0X3000 = (0X1000) + (0X2000);
( )表示取值操作,整个表达式的意思是,取出地址 0X1000 和 0X2000 上的值,将它们相加,把相加的结果赋值给地址为 0X3000 的内存变量名和函数名为我们提供了方便,让我们在编写代码的过程中可以使用易于阅读和理解的英文字符串,不用直接面对二进制地址,那场景简直让人崩溃。
需要注意的是,虽然变量名、函数名、字符串名和数组名在本质上是一样的,它们都是地址的助记符,但在编写代码的过程中,我们认为变量名表示的是数据本身,而函数名、字符串名和数组名表示的是代码块或数据块的首地址。
直接访问比如 a=5;
系统在编译时,已经对变量分配了地址,例如,若变量a分配的地址是2000,则该语句的作用就是把常数5保存到地址为2000的单元中
间接访问比如:scanf(“%d”,&a);
调用函数时,把变量a的地址传递给函数scanf,函数首先把该地址保存到一个单元中,然后把从键盘接收的数据通过所存储的地址保存到a变量中
数据在内存中的地址也称为指针,如果一个变量存储了一份数据的指针,我们就称它为指针变量。
在C语言中,允许用一个变量来存放指针,这种变量称为指针变量。指针变量的值就是某份数据的地址,这样的一份数据可以是数组、字符串、函数,也可以是另外的一个普通变量或指针变量。
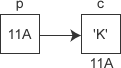
现在假设有一个 char 类型的变量 c,它存储了字符 'K'(ASCII码为十进制数 75),并占用了地址为 0X11A 的内存(地址通常用十六进制表示)。另外有一个指针变量 p,它的值为 0X11A,正好等于变量 c 的地址,这种情况我们就称 p 指向了 c,或者说 p 是指向变量 c 的指针。
定义指针变量与定义普通变量非常类似,不过要在变量名前面加星号*,格式为:
datatype *name;
或者
datatype *name = value;
*表示这是一个指针变量,datatype表示该指针变量所指向的数据的类型 。
例如:
int *p1;
p1 是一个指向 int 类型数据的指针变量,至于 p1 究竟指向哪一份数据,应该由赋予它的值决定。
再如:
int a = 100;
int *p_a = &a;在定义指针变量 p_a 的同时对它进行初始化,并将变量 a 的地址赋予它,此时 p_a 就指向了 a。值得注意的是,p_a 需要的一个地址,a 前面必须要加取地址符&,否则是不对的。
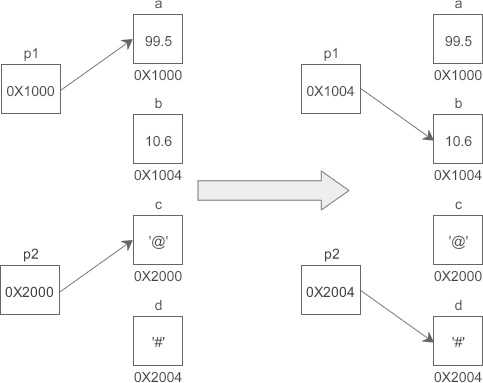
和普通变量一样,指针变量也可以被多次写入,只要你想,随时都能够改变指针变量的值,
请看下面的代码:
//定义普通变量
float a = 99.5, b = 10.6;
char c = '@', d = '#';
//定义指针变量
float *p1 = &a;
char *p2 = &c;
//修改指针变量的值
p1 = &b;
p2 = &d;*是一个特殊符号,表明一个变量是指针变量,定义 p1、p2 时必须带*。而给 p1、p2 赋值时,因为已经知道了它是一个指针变量,就没必要多此一举再带上*,后边可以像使用普通变量一样来使用指针变量。也就是说,定义指针变量时必须带*,给指针变量赋值时不能带*。
假设变量 a、b、c、d 的地址分别为 0X1000、0X1004、0X2000、0X2004,下面的示意图很好地反映了 p1、p2 指向的变化:
需要强调的是,p1、p2 的类型分别是float*和char*,而不是float和char,它们是完全不同的数据类型,读者要引起注意。
指针变量也可以连续定义,例如:
int *a, *b, *c; //a、b、c 的类型都是 int*注意每个变量前面都要带*。如果写成下面的形式,那么只有 a 是指针变量,b、c 都是类型为 int 的普通变量:
int *a, b, c;指针变量存储了数据的地址,通过指针变量能够获得该地址上的数据,格式为:
*pointer;
这里的*称为指针运算符,用来取得某个地址上的数据,请看下面的例子:
#include <stdio.h>
int main(){
int a = 15;
int *p = &a;
printf("%d, %d\n", a, *p); //两种方式都可以输出a的值
return 0;
}运行结果:
15, 15
假设 a 的地址是 0X1000,p 指向 a 后,p 本身的值也会变为 0X1000,*p 表示获取地址 0X1000 上的数据,也即变量 a 的值。从运行结果看,*p 和 a 是等价的。
上节我们说过,CPU 读写数据必须要知道数据在内存中的地址,普通变量和指针变量都是地址的助记符,虽然通过 *p 和 a 获取到的数据一样,但它们的运行过程稍有不同:a 只需要一次运算就能够取得数据,而 *p 要经过两次运算,多了一层“间接”。
假设变量 a、p 的地址分别为 0X1000、0XF0A0,它们的指向关系如下图所示:
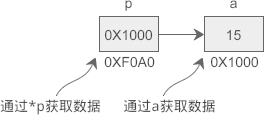
*程序被编译和链接后,a、p 被替换成相应的地址。使用 p 的话,要先通过地址 0XF0A0 取得变量 p 本身的值,这个值是变量 a 的地址,然后再通过这个值取得变量 a 的数据,前后共有两次运算;而使用 a 的话,可以通过地址 0X1000 直接取得它的数据,只需要一步运算。
也就是说,使用指针是间接获取数据,使用变量名是直接获取数据,前者比后者的代价要高。
指针除了可以获取内存上的数据,也可以修改内存上的数据,例如:
#include <stdio.h>
int main(){
int a = 15, b = 99, c = 222;
int *p = &a; //定义指针变量
*p = b; //通过指针变量修改内存上的数据
c = *p; //通过指针变量获取内存上的数据
printf("%d, %d, %d, %d\n", a, b, c, *p);
return 0;
}运行结果:
99, 99, 99, 99
*p 代表的是 a 中的数据,它等价于 a,可以将另外的一份数据赋值给它,也可以将它赋值给另外的一个变量。
*在不同的场景下有不同的作用:*可以用在指针变量的定义中,表明这是一个指针变量,以和普通变量区分开;使用指针变量时在前面加*表示获取指针指向的数据,或者说表示的是指针指向的数据本身。
也就是说,定义指针变量时的
*和使用指针变量时的*意义完全不同。以下面的语句为例:int *p = &a; *p = 100;第1行代码中
*用来指明 p 是一个指针变量,第2行代码中*用来获取指针指向的数据。需要注意的是,给指针变量本身赋值时不能加
*。修改上面的语句:int *p; p = &a; *p = 100;第2行代码中的 p 前面就不能加
*。
指针变量也可以出现在普通变量能出现的任何表达式中,例如:
int x, y, *px = &x, *py = &y;
y = *px + 5; //表示把x的内容加5并赋给y,*px+5相当于(*px)+5
y = ++*px; //px的内容加上1之后赋给y,++*px相当于++(*px)
y = *px++; //相当于y=*(px++)
py = px; //把一个指针的值赋给另一个指针例子1:通过指针交换两个变量的值。
#include <stdio.h>
int main(){
int a = 100, b = 999, temp;
int *pa = &a, *pb = &b;
printf("a=%d, b=%d\n", a, b);
/*****开始交换*****/
temp = *pa; //将a的值先保存起来
*pa = *pb; //将b的值交给a
*pb = temp; //再将保存起来的a的值交给b
/*****结束交换*****/
printf("a=%d, b=%d\n", a, b);
return 0;
}运行结果:
a=100, b=999
a=999, b=100
从运行结果可以看出,a、b 的值已经发生了交换。需要注意的是临时变量 temp,它的作用特别重要,因为执行*pa = *pb;语句后 a 的值会被 b 的值覆盖,如果不先将 a 的值保存起来以后就找不到了。
假设有一个 int 类型的变量 a,pa 是指向它的指针,那么
*&a和&*pa分别是什么意思呢?
*&a可以理解为*(&a),&a表示取变量 a 的地址(等价于 pa),*(&a)表示取这个地址上的数据(等价于 *pa),绕来绕去,又回到了原点,*&a仍然等价于 a。
&*pa可以理解为&(*pa),*pa表示取得 pa 指向的数据(等价于 a),&(*pa)表示数据的地址(等价于 &a),所以&*pa等价于 pa。
在我们目前所学到的语法中,星号
*主要有三种用途:
- 表示乘法,例如
int a = 3, b = 5, c; c = a * b;,这是最容易理解的。- 表示定义一个指针变量,以和普通变量区分开,例如
int a = 100; int *p = &a;。- 表示获取指针指向的数据,是一种间接操作,例如
int a, b, *p = &a; *p = 100; b = *p;。
指针变量保存的是地址,而地址本质上是一个整数,所以指针变量可以进行部分运算,例如加法、减法、比较等,请看下面的代码:
#include <stdio.h>
int main(){
int a = 10, *pa = &a, *paa = &a;
double b = 99.9, *pb = &b;
char c = '@', *pc = &c;
//最初的值
printf("&a=%#X, &b=%#X, &c=%#X\n", &a, &b, &c);
printf("pa=%#X, pb=%#X, pc=%#X\n", pa, pb, pc);
//加法运算
pa++; pb++; pc++;
printf("pa=%#X, pb=%#X, pc=%#X\n", pa, pb, pc);
//减法运算
pa -= 2; pb -= 2; pc -= 2;
printf("pa=%#X, pb=%#X, pc=%#X\n", pa, pb, pc);
//比较运算
if(pa == paa){
printf("%d\n", *paa);
}else{
printf("%d\n", *pa);
}
return 0;
}运行结果:
&a=0X28FF44, &b=0X28FF30, &c=0X28FF2B
pa=0X28FF44, pb=0X28FF30, pc=0X28FF2B
pa=0X28FF48, pb=0X28FF38, pc=0X28FF2C
pa=0X28FF40, pb=0X28FF28, pc=0X28FF2A
2686784
从运算结果可以看出:pa、pb、pc 每次加 1,它们的地址分别增加 4、8、1,正好是 int、double、char 类型的长度;减 2 时,地址分别减少 8、16、2,正好是 int、double、char 类型长度的 2 倍。
指针变量加减运算的结果跟数据类型的长度有关,而不是简单地加 1 或减 1,这是为什么呢?
以 a 和 pa 为例,a 的类型为 int,占用 4 个字节,pa 是指向 a 的指针,如下图所示:
刚开始的时候,pa 指向 a 的开头,通过 *pa 读取数据时,从 pa 指向的位置向后移动 4 个字节,把这 4 个字节的内容作为要获取的数据,这 4 个字节也正好是变量 a 占用的内存。
如果
pa++;使得地址加 1 的话,就会变成如下图所示的指向关系:
这个时候 pa 指向整数 a 的中间,*pa 使用的是红色虚线画出的 4 个字节,其中前 3 个是变量 a 的,后面 1 个是其它数据的,把它们“搅和”在一起显然没有实际的意义,取得的数据也会非常怪异。
如果
pa++;使得地址加 4 的话,正好能够完全跳过整数 a,指向它后面的内存,如下图所示:
我们知道,数组中的所有元素在内存中是连续排列的,如果一个指针指向了数组中的某个元素,那么加 1 就表示指向下一个元素,减 1 就表示指向上一个元素,这样指针的加减运算就具有了现实的意义.

不过C语言并没有规定变量的存储方式,如果连续定义多个变量,它们有可能是挨着的,也有可能是分散的,这取决于变量的类型、编译器的实现以及具体的编译模式,所以对于指向普通变量的指针,我们往往不进行加减运算,虽然编译器并不会报错,但这样做没有意义,因为不知道它后面指向的是什么数据。
下面的例子是一个反面教材,警告读者不要尝试通过指针获取下一个变量的地址:
#include <stdio.h>
int main(){
int a = 1, b = 2, c = 3;
int *p = &c;
int i;
for(i=0; i<8; i++){
printf("%d, ", *(p+i) );
}
return 0;
}运行结果为:
3, -858993460, -858993460, 2, -858993460, -858993460, 1, -858993460,
可以发现,变量 a、b、c 并不挨着,它们中间还参杂了别的辅助数据。
指针变量除了可以参与加减运算,还可以参与比较运算。当对指针变量进行比较运算时,比较的是指针变量本身的值,也就是数据的地址。如果地址相等,那么两个指针就指向同一份数据,否则就指向不同的数据。
上面的代码(第一个例子)在比较 pa 和 paa 的值时,pa 已经指向了 a 的上一份数据,所以它们不相等。而 a 的上一份数据又不知道是什么,所以会导致 printf() 输出一个没有意义的数,这正好印证了上面的观点,不要对指向普通变量的指针进行加减运算。
另外需要说明的是,不能对指针变量进行乘法、除法、取余等其他运算,除了会发生语法错误,也没有实际的含义。
数组(Array)是一系列具有相同类型的数据的集合,每一份数据叫做一个数组元素(Element)。数组中的所有元素在内存中是连续排列的,整个数组占用的是一块内存。以int arr[] = { 99, 15, 100, 888, 252 };为例,该数组在内存中的分布如下图所示:

定义数组时,要给出数组名和数组长度,数组名可以认为是一个指针,它指向数组的第 0 个元素。在C语言中,我们将第 0 个元素的地址称为数组的首地址。以上面的数组为例,下图是 arr 的指向:

数组名的本意是表示整个数组,也就是表示多份数据的集合,但在使用过程中经常会转换为指向数组第 0 个元素的指针,所以上面使用了“认为”一词,表示数组名和数组首地址并不总是等价。初学者可以暂时忽略这个细节,把数组名当做指向第 0 个元素的指针使用即可.
下面的例子演示了如何以指针的方式遍历数组元素:
#include <stdio.h>
int main(){
int arr[] = { 99, 15, 100, 888, 252 };
int len = sizeof(arr) / sizeof(int); //求数组长度
int i;
for(i=0; i<len; i++){
printf("%d ", *(arr+i) ); //*(arr+i)等价于arr[i]
}
printf("\n");
return 0;
}运行结果:
99 15 100 888 252
第 5 行代码用来求数组的长度,sizeof(arr) 会获得整个数组所占用的字节数,sizeof(int) 会获得一个数组元素所占用的字节数,它们相除的结果就是数组包含的元素个数,也即数组长度。
第 8 行代码中我们使用了*(arr+i)这个表达式,arr 是数组名,指向数组的第 0 个元素,表示数组首地址, arr+i 指向数组的第 i 个元素,*(arr+i) 表示取第 i 个元素的数据,它等价于 arr[i]。
arr 是
int*类型的指针,每次加 1 时它自身的值会增加 sizeof(int),加 i 时自身的值会增加 sizeof(int) * i.
我们也可以定义一个指向数组的指针,例如:
int arr[] = { 99, 15, 100, 888, 252 };
int *p = arr;arr 本身就是一个指针,可以直接赋值给指针变量 p。arr 是数组第 0 个元素的地址,所以int *p = arr;也可以写作int *p = &arr[0];。也就是说,arr、p、&arr[0] 这三种写法都是等价的,它们都指向数组第 0 个元素,或者说指向数组的开头。
“arr 本身就是一个指针”这种表述并不准确,严格来说应该是“arr 被转换成了一个指针”。
如果一个指针指向了数组,我们就称它为数组指针(Array Pointer)。
数组指针指向的是数组中的一个具体元素,而不是整个数组,所以数组指针的类型和数组元素的类型有关,上面的例子中,p 指向的数组元素是 int 类型,所以 p 的类型必须也是int *。
反过来想,p 并不知道它指向的是一个数组,p 只知道它指向的是一个整数,究竟如何使用 p 取决于程序员的编码。
更改上面的代码,使用数组指针来遍历数组元素:
#include <stdio.h>
int main(){
int arr[] = { 99, 15, 100, 888, 252 };
int i, *p = arr, len = sizeof(arr) / sizeof(int);
for(i=0; i<len; i++){
printf("%d ", *(p+i) );
}
printf("\n");
return 0;
}数组在内存中只是数组元素的简单排列,没有开始和结束标志,在求数组的长度时不能使用sizeof(p) / sizeof(int),因为 p 只是一个指向 int 类型的指针,编译器并不知道它指向的到底是一个整数还是一系列整数(数组),所以 sizeof(p) 求得的是 p 这个指针变量本身所占用的字节数,而不是整个数组占用的字节数。
也就是说,根据数组指针不能逆推出整个数组元素的个数,以及数组从哪里开始、到哪里结束等信息。不像字符串,数组本身也没有特定的结束标志,如果不知道数组的长度,那么就无法遍历整个数组。
上节我们讲到,对指针变量进行加法和减法运算时,是根据数据类型的长度来计算的。如果一个指针变量 p 指向了数组的开头,那么 p+i 就指向数组的第 i 个元素;如果 p 指向了数组的第 n 个元素,那么 p+i 就是指向第 n+i 个元素;而不管 p 指向了数组的第几个元素,p+1 总是指向下一个元素,p-1 也总是指向上一个元素。
更改上面的代码,让 p 指向数组中的第二个元素:
#include <stdio.h>
int main(){
int arr[] = { 99, 15, 100, 888, 252 };
int *p = &arr[2]; //也可以写作 int *p = arr + 2;
printf("%d, %d, %d, %d, %d\n", *(p-2), *(p-1), *p, *(p+1), *(p+2) );
return 0;
}运行结果:
99, 15, 100, 888, 252
引入数组指针后,我们就有两种方案来访问数组元素了,一种是使用下标,另外一种是使用指针。
也就是采用 arr[i] 的形式访问数组元素。如果 p 是指向数组 arr 的指针,那么也可以使用 p[i] 来访问数组元素,它等价于 arr[i]。
也就是使用 *(p+i) 的形式访问数组元素。另外数组名本身也是指针,也可以使用 *(arr+i) 来访问数组元素,它等价于 *(p+i)。
不管是数组名还是数组指针,都可以使用上面的两种方式来访问数组元素。不同的是,数组名是常量,它的值不能改变,而数组指针是变量(除非特别指明它是常量),它的值可以任意改变。也就是说,数组名只能指向数组的开头,而数组指针可以先指向数组开头,再指向其他元素。
更改上面的代码,借助自增运算符来遍历数组元素:
#include <stdio.h>
int main(){
int arr[] = { 99, 15, 100, 888, 252 };
int i, *p = arr, len = sizeof(arr) / sizeof(int);
for(i=0; i<len; i++){
printf("%d ", *p++ );
}
printf("\n");
return 0;
}运行结果:
99 15 100 888 252
第 8 行代码中,*p++ 应该理解为 *(p++),每次循环都会改变 p 的值(p++ 使得 p 自身的值增加),以使 p 指向下一个数组元素。该语句不能写为 *arr++,因为 arr 是常量,而 arr++ 会改变它的值,这显然是错误的。
假设 p 是指向数组 arr 中第 n 个元素的指针,那么 p++、++p、(*p)++ 分别是什么意思呢?
**p++ 等价于 (p++),表示先取得第 n 个元素的值,再将 p 指向下一个元素,上面已经进行了详细讲解。
***++p 等价于 (++p),会先进行 ++p 运算,使得 p 的值增加,指向下一个元素,整体上相当于 (p+1),所以会获得第 n+1 个数组元素的值。
*(p)++ 就非常简单了,会先取得第 n 个元素的值,再对该元素的值加 1。假设 p 指向第 0 个元素,并且第 0 个元素的值为 99,执行完该语句后,第 0 个元素的值就会变为 100。
C语言中没有特定的字符串类型,我们通常是将字符串放在一个字符数组中.
#include <stdio.h>
#include <string.h>
int main(){
char str[] = "http://c.biancheng.net";
int len = strlen(str), i;
//直接输出字符串
printf("%s\n", str);
//每次输出一个字符
for(i=0; i<len; i++){
printf("%c", str[i]);
}
printf("\n");
return 0;
}运行结果:
http://c.biancheng.net
http://c.biancheng.net
字符数组归根结底还是一个数组,上节讲到的关于指针和数组的规则同样也适用于字符数组。更改上面的代码,使用指针的方式来输出字符串:
#include <stdio.h>
#include <string.h>
int main(){
char str[] = "http://c.biancheng.net";
char *pstr = str;
int len = strlen(str), i;
//使用*(pstr+i)
for(i=0; i<len; i++){
printf("%c", *(pstr+i));
}
printf("\n");
//使用pstr[i]
for(i=0; i<len; i++){
printf("%c", pstr[i]);
}
printf("\n");
//使用*(str+i)
for(i=0; i<len; i++){
printf("%c", *(str+i));
}
printf("\n");
return 0;
}运行结果:
http://c.biancheng.net
http://c.biancheng.net
http://c.biancheng.net
除了字符数组,C语言还支持另外一种表示字符串的方法,就是直接使用一个指针指向字符串,例如:
char *str = "http://c.biancheng.net";或者:
char *str;
str = "http://c.biancheng.net";字符串中的所有字符在内存中是连续排列的,str 指向的是字符串的第 0 个字符;我们通常将第 0 个字符的地址称为字符串的首地址。字符串中每个字符的类型都是char,所以 str 的类型也必须是char *。
下面的例子演示了如何输出这种字符串:
#include <stdio.h>
#include <string.h>
int main(){
char *str = "http://c.biancheng.net";
int len = strlen(str), i;
//直接输出字符串
printf("%s\n", str);
//使用*(str+i)
for(i=0; i<len; i++){
printf("%c", *(str+i));
}
printf("\n");
//使用str[i]
for(i=0; i<len; i++){
printf("%c", str[i]);
}
printf("\n");
return 0;
}运行结果:
http://c.biancheng.net
http://c.biancheng.net
http://c.biancheng.net
这一切看起来和字符数组是多么地相似,它们都可以使用%s输出整个字符串,都可以使用*或[ ]获取单个字符,这两种表示字符串的方式是不是就没有区别了呢?
有!它们最根本的区别是在内存中的存储区域不一样,字符数组存储在全局数据区或栈区,第二种形式的字符串存储在常量区。全局数据区和栈区的字符串(也包括其他数据)有读取和写入的权限,而常量区的字符串(也包括其他数据)只有读取权限,没有写入权限。
内存权限的不同导致的一个明显结果就是,字符数组在定义后可以读取和修改每个字符,而对于第二种形式的字符串,一旦被定义后就只能读取不能修改,任何对它的赋值都是错误的。
我们将第二种形式的字符串称为字符串常量,意思很明显,常量只能读取不能写入。请看下面的演示:
#include <stdio.h>
int main(){
char *str = "Hello World!";
str = "I love C!"; //正确
str[3] = 'P'; //错误
return 0;
}这段代码能够正常编译和链接,但在运行时会出现段错误(Segment Fault)或者写入位置错误。
第4行代码是正确的,可以更改指针变量本身的指向;第5行代码是错误的,不能修改字符串中的字符。
在编程过程中如果只涉及到对字符串的读取,那么字符数组和字符串常量都能够满足要求;如果有写入(修改)操作,那么只能使用字符数组,不能使用字符串常量。
获取用户输入的字符串就是一个典型的写入操作,只能使用字符数组,不能使用字符串常量,请看下面的代码:
#include <stdio.h>
int main(){
char str[30];
gets(str);
printf("%s\n", str);
return 0;
}运行结果:
C C++ Java Python JavaScript
C C++ Java Python JavaScript
最后我们来总结一下,C语言有两种表示字符串的方法,一种是字符数组,另一种是字符串常量,它们在内存中的存储位置不同,使得字符数组可以读取和修改,而字符串常量只能读取不能修改。
在C语言中,函数的参数不仅可以是整数、小数、字符等具体的数据,还可以是指向它们的指针。用指针变量作函数参数可以将函数外部的地址传递到函数内部,使得在函数内部可以操作函数外部的数据,并且这些数据不会随着函数的结束而被销毁。
像数组、字符串、动态分配的内存等都是一系列数据的集合,没有办法通过一个参数全部传入函数内部,只能传递它们的指针,在函数内部通过指针来影响这些数据集合。
有的时候,对于整数、小数、字符等基本类型数据的操作也必须要借助指针,一个典型的例子就是交换两个变量的值。
有些初学者可能会使用下面的方法来交换两个变量的值:
#include <stdio.h>
void swap(int a, int b){
int temp; //临时变量
temp = a;
a = b;
b = temp;
}
int main(){
int a = 66, b = 99;
swap(a, b);
printf("a = %d, b = %d\n", a, b);
return 0;
}运行结果:
a = 66, b = 99
从结果可以看出,a、b 的值并没有发生改变,交换失败。这是因为 swap() 函数内部的 a、b 和 main() 函数内部的 a、b 是不同的变量,占用不同的内存,它们除了名字一样,没有其他任何关系,swap() 交换的是它内部 a、b 的值,不会影响它外部(main() 内部) a、b 的值。
改用指针变量作参数后就很容易解决上面的问题:
#include <stdio.h>
void swap(int *p1, int *p2){
int temp; //临时变量
temp = *p1;
*p1 = *p2;
*p2 = temp;
}
int main(){
int a = 66, b = 99;
swap(&a, &b);
printf("a = %d, b = %d\n", a, b);
return 0;
}运行结果:
a = 99, b = 66
调用 swap() 函数时,将变量 a、b 的地址分别赋值给 p1、p2,这样 *p1、*p2 代表的就是变量 a、b 本身,交换 *p1、*p2 的值也就是交换 a、b 的值。函数运行结束后虽然会将 p1、p2 销毁,但它对外部 a、b 造成的影响是“持久化”的,不会随着函数的结束而“恢复原样”。
需要注意的是临时变量 temp,它的作用特别重要,因为执行
*p1 = *p2;语句后 a 的值会被 b 的值覆盖,如果不先将 a 的值保存起来以后就找不到了。
数组是一系列数据的集合,无法通过参数将它们一次性传递到函数内部,如果希望在函数内部操作数组,必须传递数组指针。下面的例子定义了一个函数 max(),用来查找数组中值最大的元素:
#include <stdio.h>
int max(int *intArr, int len){
int i, maxValue = intArr[0]; //假设第0个元素是最大值
for(i=1; i<len; i++){
if(maxValue < intArr[i]){
maxValue = intArr[i];
}
}
return maxValue;
}
int main(){
int nums[6], i;
int len = sizeof(nums)/sizeof(int);
//读取用户输入的数据并赋值给数组元素
for(i=0; i<len; i++){
scanf("%d", nums+i);
}
printf("Max value is %d!\n", max(nums, len));
return 0;
}运行结果:
12 55 30 8 93 27↙
Max value is 93!
参数 intArr 仅仅是一个数组指针,在函数内部无法通过这个指针获得数组长度,必须将数组长度作为函数参数传递到函数内部。数组 nums 的每个元素都是整数,scanf() 在读取用户输入的整数时,要求给出存储它的内存的地址,nums+i就是第 i 个数组元素的地址。
用数组做函数参数时,参数也能够以“真正”的数组形式给出。例如对于上面的 max() 函数,它的参数可以写成下面的形式:
int max(int intArr[6], int len){
int i, maxValue = intArr[0]; //假设第0个元素是最大值
for(i=1; i<len; i++){
if(maxValue < intArr[i]){
maxValue = intArr[i];
}
}
return maxValue;
}int intArr[6]好像定义了一个拥有 6 个元素的数组,调用 max() 时可以将数组的所有元素“一股脑”传递进来。
读者也可以省略数组长度,把形参简写为下面的形式:
int max(int intArr[], int len){
int i, maxValue = intArr[0]; //假设第0个元素是最大值
for(i=1; i<len; i++){
if(maxValue < intArr[i]){
maxValue = intArr[i];
}
}
return maxValue;
}int intArr[]虽然定义了一个数组,但没有指定数组长度,好像可以接受任意长度的数组。
实际上这两种形式的数组定义都是假象,不管是int intArr[6]还是int intArr[]都不会创建一个数组出来,编译器也不会为它们分配内存,实际的数组是不存在的,它们最终还是会转换为int *intArr这样的指针。这就意味着,两种形式都不能将数组的所有元素“一股脑”传递进来,大家还得规规矩矩使用数组指针。
int intArr[6]这种形式只能说明函数期望用户传递的数组有 6 个元素,并不意味着数组只能有 6 个元素,真正传递的数组可以有少于或多于 6 个的元素。
需要强调的是,不管使用哪种方式传递数组,都不能在函数内部求得数组长度,因为 intArr 仅仅是一个指针,而不是真正的数组,所以必须要额外增加一个参数来传递数组长度。
C语言为什么不允许直接传递数组的所有元素,而必须传递数组指针呢?
参数的传递本质上是一次赋值的过程,赋值就是对内存进行拷贝。所谓内存拷贝,是指将一块内存上的数据复制到另一块内存上。
对于像 int、float、char 等基本类型的数据,它们占用的内存往往只有几个字节,对它们进行内存拷贝非常快速。而数组是一系列数据的集合,数据的数量没有限制,可能很少,也可能成千上万,对它们进行内存拷贝有可能是一个漫长的过程,会严重拖慢程序的效率,为了防止技艺不佳的程序员写出低效的代码,C语言没有从语法上支持数据集合的直接赋值。
除了C语言,C++、Java、Python 等其它语言也禁止对大块内存进行拷贝,在底层都使用类似指针的方式来实现。
C语言允许函数的返回值是一个指针(地址),我们将这样的函数称为指针函数。下面的例子定义了一个函数 strlong(),用来返回两个字符串中较长的一个:
#include <stdio.h>
#include <string.h>
char *strlong(char *str1, char *str2){
if(strlen(str1) >= strlen(str2)){
return str1;
}else{
return str2;
}
}
int main(){
char str1[30], str2[30], *str;
gets(str1);
gets(str2);
str = strlong(str1, str2);
printf("Longer string: %s\n", str);
return 0;
}运行结果:
C Language↙
c.biancheng.net↙
Longer string: c.biancheng.net
用指针作为函数返回值时需要注意的一点是,函数运行结束后会销毁在它内部定义的所有局部数据,包括局部变量、局部数组和形式参数,函数返回的指针请尽量不要指向这些数据,C语言没有任何机制来保证这些数据会一直有效,它们在后续使用过程中可能会引发运行时错误。请看下面的例子:
#include <stdio.h>
int *func(){
int n = 100;
return &n;
}
int main(){
int *p = func(), n;
n = *p;
printf("value = %d\n", n);
return 0;
}运行结果:
value = 100
n 是 func() 内部的局部变量,func() 返回了指向 n 的指针,根据上面的观点,func() 运行结束后 n 将被销毁,使用 *p 应该获取不到 n 的值。但是从运行结果来看,我们的推理好像是错误的,func() 运行结束后 *p 依然可以获取局部变量 n 的值,这个上面的观点不是相悖吗?
为了进一步看清问题的本质,不妨将上面的代码稍作修改,在第9~10行之间增加一个函数调用,看看会有什么效果:
#include <stdio.h>
int *func(){
int n = 100;
return &n;
}
int main(){
int *p = func(), n;
printf("c.biancheng.net\n");
n = *p;
printf("value = %d\n", n);
return 0;
}运行结果:
c.biancheng.net
value = -2
可以看到,现在 p 指向的数据已经不是原来 n 的值了,它变成了一个毫无意义的甚至有些怪异的值。与前面的代码相比,该段代码仅仅是在 *p 之前增加了一个函数调用,这一细节的不同却导致运行结果有天壤之别,究竟是为什么呢?
前面我们说函数运行结束后会销毁所有的局部数据,这个观点并没错,大部分C语言教材也都强调了这一点。但是,这里所谓的销毁并不是将局部数据所占用的内存全部抹掉,而是程序放弃对它的使用权限,弃之不理,后面的代码可以随意使用这块内存。对于上面的两个例子,func() 运行结束后 n 的内存依然保持原样,值还是 100,如果使用及时也能够得到正确的数据,如果有其它函数被调用就会覆盖这块内存,得到的数据就失去了意义。
第一个例子在调用其他函数之前使用 *p 抢先获得了 n 的值并将它保存起来,第二个例子显然没有抓住机会,有其他函数被调用后才使用 *p 获取数据,这个时候已经晚了,内存已经被后来的函数覆盖了,而覆盖它的究竟是一份什么样的数据我们无从推断(一般是一个没有意义甚至有些怪异的值)。
指针可以指向一份普通类型的数据,例如 int、double、char 等,也可以指向一份指针类型的数据,例如 int *、double *、char * 等。
如果一个指针指向的是另外一个指针,我们就称它为二级指针,或者指向指针的指针。
假设有一个 int 类型的变量 a,p1是指向 a 的指针变量,p2 又是指向 p1 的指针变量,它们的关系如下图所示:

将这种关系转换为C语言代码:
int a =100;
int *p1 = &a;
int **p2 = &p1;指针变量也是一种变量,也会占用存储空间,也可以使用&获取它的地址。C语言不限制指针的级数,每增加一级指针,在定义指针变量时就得增加一个星号*。p1 是一级指针,指向普通类型的数据,定义时有一个*;p2 是二级指针,指向一级指针 p1,定义时有两个*。
如果我们希望再定义一个三级指针 p3,让它指向 p2,那么可以这样写:
int ***p3 = &p2;四级指针也是类似的道理:
int ****p4 = &p3;实际开发中会经常使用一级指针和二级指针,几乎用不到高级指针。
想要获取指针指向的数据时,一级指针加一个*,二级指针加两个*,三级指针加三个*,以此类推,请看代码:
#include <stdio.h>
int main(){
int a =100;
int *p1 = &a;
int **p2 = &p1;
int ***p3 = &p2;
printf("%d, %d, %d, %d\n", a, *p1, **p2, ***p3);
printf("&p2 = %#X, p3 = %#X\n", &p2, p3);
printf("&p1 = %#X, p2 = %#X, *p3 = %#X\n", &p1, p2, *p3);
printf(" &a = %#X, p1 = %#X, *p2 = %#X, **p3 = %#X\n", &a, p1, *p2, **p3);
return 0;
}运行结果:
100, 100, 100, 100
&p2 = 0X28FF3C, p3 = 0X28FF3C
&p1 = 0X28FF40, p2 = 0X28FF40, *p3 = 0X28FF40
&a = 0X28FF44, p1 = 0X28FF44, *p2 = 0X28FF44, **p3 = 0X28FF44
以三级指针 p3 为例来分析上面的代码。***p3等价于*(*(*p3))。p3 得到的是 p2 的值,也即 p1 的地址;(p3) 得到的是 p1 的值,也即 a 的地址;经过三次“取值”操作后,(*(*p3)) 得到的才是 a 的值。
假设 a、p1、p2、p3 的地址分别是 0X00A0、0X1000、0X2000、0X3000,它们之间的关系可以用下图来描述:

注释:方框里面是变量本身的值,方框下面是变量的地址。
一个函数总是占用一段连续的内存区域,函数名在表达式中有时也会被转换为该函数所在内存区域的首地址,这和数组名非常类似。我们可以把函数的这个首地址(或称入口地址)赋予一个指针变量,使指针变量指向函数所在的内存区域,然后通过指针变量就可以找到并调用该函数。这种指针就是函数指针。
函数指针的定义形式为:
returnType (*pointerName)(param list);
returnType 为函数返回值类型,pointerName 为指针名称,param list 为函数参数列表。参数列表中可以同时给出参数的类型和名称,也可以只给出参数的类型,省略参数的名称,这一点和函数原型非常类似。
注意( )的优先级高于*,第一个括号不能省略,如果写作returnType *pointerName(param list);就成了函数原型,它表明函数的返回值类型为returnType *。
例子:用指针来实现对函数的调用。
#include <stdio.h>
//返回两个数中较大的一个
int max(int a, int b){
return a>b ? a : b;
}
int main(){
int x, y, maxval;
//定义函数指针
int (*pmax)(int, int) = max; //也可以写作int (*pmax)(int a, int b)
printf("Input two numbers:");
scanf("%d %d", &x, &y);
maxval = (*pmax)(x, y);
printf("Max value: %d\n", maxval);
return 0;
}运行结果:
Input two numbers:10 50↙
Max value: 50
注释:第 14 行代码对函数进行了调用。pmax 是一个函数指针,在前面加 * 就表示对它指向的函数进行调用。注意( )的优先级高于*,第一个括号不能省略。
指针(Pointer)就是内存的地址,C语言允许用一个变量来存放指针,这种变量称为指针变量。指针变量可以存放基本类型数据的地址,也可以存放数组、函数以及其他指针变量的地址。
程序在运行过程中需要的是数据和指令的地址,变量名、函数名、字符串名和数组名在本质上是一样的,它们都是地址的助记符:在编写代码的过程中,我们认为变量名表示的是数据本身,而函数名、字符串名和数组名表示的是代码块或数据块的首地址;程序被编译和链接后,这些名字都会消失,取而代之的是它们对应的地址。
| 常见指针变量的定义 |
|---|
| 定 义 | 含 义 |
|---|---|
| int *p; | p 可以指向 int 类型的数据,也可以指向类似 int arr[n] 的数组。 |
| int **p; | p 为二级指针,指向 int * 类型的数据。 |
| int *p[n]; | p 为指针数组。[ ] 的优先级高于 *,所以应该理解为 int *(p[n]); |
| int (*p)[n]; | p 为二维数组指针。 |
| int *p(); | p 是一个函数,它的返回值类型为 int *。 |
| int (*p)(); | p 是一个函数指针,指向原型为 int func() 的函数。 |
指针变量可以进行加减运算,例如
p++、p+i、p-=i。指针变量的加减运算并不是简单的加上或减去一个整数,而是跟指针指向的数据类型有关。给指针变量赋值时,要将一份数据的地址赋给它,不能直接赋给一个整数,例如
int *p = 1000;是没有意义的,使用过程中一般会导致程序崩溃。使用指针变量之前一定要初始化,否则就不能确定指针指向哪里,如果它指向的内存没有使用权限,程序就崩溃了。对于暂时没有指向的指针,建议赋值
NULL。两个指针变量可以相减。如果两个指针变量指向同一个数组中的某个元素,那么相减的结果就是两个指针之间相差的元素个数。
数组也是有类型的,数组名的本意是表示一组类型相同的数据。在定义数组时,或者和 sizeof、& 运算符一起使用时数组名才表示整个数组,表达式中的数组名会被转换为一个指向数组的指针。
前面的教程中我们讲解了数组(Array),它是一组具有相同类型的数据的集合。但在实际的编程过程中,我们往往还需要一组类型不同的数据,例如对于学生信息登记表,姓名为字符串,学号为整数,年龄为整数,所在的学习小组为字符,成绩为小数,因为数据类型不同,显然不能用一个数组来存放。
在C语言中,可以使用**结构体(Struct)**来存放一组不同类型的数据。结构体的定义形式为:
struct 结构体名{
结构体所包含的变量或数组
};结构体是一种集合,它里面包含了多个变量或数组,它们的类型可以相同,也可以不同,每个这样的变量或数组都称为结构体的成员(Member)。请看下面的一个例子:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在学习小组
float score; //成绩
};stu 为结构体名,它包含了 5 个成员,分别是 name、num、age、group、score。结构体成员的定义方式与变量和数组的定义方式相同,只是不能初始化。
注意大括号后面的分号
;不能少,这是一条完整的语句。
结构体也是一种数据类型,它由程序员自己定义,可以包含多个其他类型的数据。
像 int、float、char 等是由C语言本身提供的数据类型,不能再进行分拆,我们称之为基本数据类型;而结构体可以包含多个基本类型的数据,也可以包含其他的结构体,我们将它称为复杂数据类型或构造数据类型。
既然结构体是一种数据类型,那么就可以用它来定义变量。例如:
struct stu stu1, stu2;
定义了两个变量 stu1 和 stu2,它们都是 stu 类型,都由 5 个成员组成。注意关键字struct不能少。
stu 就像一个“模板”,定义出来的变量都具有相同的性质。也可以将结构体比作“图纸”,将结构体变量比作“零件”,根据同一张图纸生产出来的零件的特性都是一样的。
你也可以在定义结构体的同时定义结构体变量:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在学习小组
float score; //成绩
} stu1, stu2;将变量放在结构体定义的最后即可。
如果只需要 stu1、stu2 两个变量,后面不需要再使用结构体名定义其他变量,那么在定义时也可以不给出结构体名,如下所示:
struct{ //没有写 stu
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在学习小组
float score; //成绩
} stu1, stu2;这样做书写简单,但是因为没有结构体名,后面就没法用该结构体定义新的变量。
理论上讲结构体的各个成员在内存中是连续存储的,和数组非常类似,例如上面的结构体变量 stu1、stu2 的内存分布如下图所示,共占用 4+4+4+1+4 = 17 个字节。

但是在编译器的具体实现中,各个成员之间可能会存在缝隙,对于 stu1、stu2,成员变量 group 和 score 之间就存在 3 个字节的空白填充(见下图)。这样算来,stu1、stu2 其实占用了 17 + 3 = 20 个字节。

结构体和数组类似,也是一组数据的集合,整体使用没有太大的意义。数组使用下标[ ]获取单个元素,结构体使用点号.获取单个成员。获取结构体成员的一般格式为:
结构体变量名.成员名;
通过这种方式可以获取成员的值,也可以给成员赋值:
#include <stdio.h>
int main(){
struct{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1;
//给结构体成员赋值
stu1.name = "Tom";
stu1.num = 12;
stu1.age = 18;
stu1.group = 'A';
stu1.score = 136.5;
//读取结构体成员的值
printf("%s的学号是%d,年龄是%d,在%c组,今年的成绩是%.1f!\n", stu1.name, stu1.num, stu1.age, stu1.group, stu1.score);
return 0;
}运行结果:
Tom的学号是12,年龄是18,在A组,今年的成绩是136.5!
除了可以对成员进行逐一赋值,也可以在定义时整体赋值,例如:
struct{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1, stu2 = { "Tom", 12, 18, 'A', 136.5 };不过整体赋值仅限于定义结构体变量的时候,在使用过程中只能对成员逐一赋值,这和数组的赋值非常类似。
需要注意的是,结构体是一种自定义的数据类型,是创建变量的模板,不占用内存空间;结构体变量才包含了实实在在的数据,需要内存空间来存储。
所谓结构体数组,是指数组中的每个元素都是一个结构体。在实际应用中,C语言结构体数组常被用来表示一个拥有相同数据结构的群体,比如一个班的学生、一个车间的职工等。
在C语言中,定义结构体数组和定义结构体变量的方式类似,请看下面的例子:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
}class[5];表示一个班级有5个学生。
结构体数组在定义的同时也可以初始化,例如:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
}class[5] = {
{"Li ping", 5, 18, 'C', 145.0},
{"Zhang ping", 4, 19, 'A', 130.5},
{"He fang", 1, 18, 'A', 148.5},
{"Cheng ling", 2, 17, 'F', 139.0},
{"Wang ming", 3, 17, 'B', 144.5}
};当对数组中全部元素赋值时,也可不给出数组长度,例如:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
}class[] = {
{"Li ping", 5, 18, 'C', 145.0},
{"Zhang ping", 4, 19, 'A', 130.5},
{"He fang", 1, 18, 'A', 148.5},
{"Cheng ling", 2, 17, 'F', 139.0},
{"Wang ming", 3, 17, 'B', 144.5}
};结构体数组的使用也很简单,例如,获取 Wang ming 的成绩:
class[4].score;
修改 Li ping 的学习小组:
class[0].group = 'B';
例子:计算全班学生的总成绩、平均成绩和以及 140 分以下的人数。
#include <stdio.h>
struct{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
}class[] = {
{"Li ping", 5, 18, 'C', 145.0},
{"Zhang ping", 4, 19, 'A', 130.5},
{"He fang", 1, 18, 'A', 148.5},
{"Cheng ling", 2, 17, 'F', 139.0},
{"Wang ming", 3, 17, 'B', 144.5}
};
int main(){
int i, num_140 = 0;
float sum = 0;
for(i=0; i<5; i++){
sum += class[i].score;
if(class[i].score < 140) num_140++;
}
printf("sum=%.2f\naverage=%.2f\nnum_140=%d\n", sum, sum/5, num_140);
return 0;
}运行结果:
sum=707.50
average=141.50
num_140=2
当一个指针变量指向结构体时,我们就称它为**结构体指针**。C语言结构体指针的定义形式一般为:
struct 结构体名 *变量名;
下面是一个定义结构体指针的实例:
//结构体
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1 = { "Tom", 12, 18, 'A', 136.5 };
//结构体指针
struct stu *pstu = &stu1;也可以在定义结构体的同时定义结构体指针:
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1 = { "Tom", 12, 18, 'A', 136.5 }, *pstu = &stu1;注意:结构体变量名和数组名不同,数组名在表达式中会被转换为数组指针,而结构体变量名不会,无论在任何表达式中它表示的都是整个集合本身,要想取得结构体变量的地址,必须在前面加
&,所以给 pstu 赋值只能写作:struct stu *pstu = &stu1;而不能写作:
struct stu *pstu = stu1;
还应该注意,结构体和结构体变量是两个不同的概念:结构体是一种数据类型,是一种创建变量的模板,编译器不会为它分配内存空间,就像 int、float、char 这些关键字本身不占用内存一样;结构体变量才包含实实在在的数据,才需要内存来存储。下面的写法是错误的,不可能去取一个结构体名的地址,也不能将它赋值给其他变量:
struct stu *pstu = &stu; struct stu *pstu = stu;
通过结构体指针可以获取结构体成员,一般形式为:
(*pointer).memberName
或者:
pointer->memberName
第一种写法中,.的优先级高于*,(*pointer)两边的括号不能少。如果去掉括号写作*pointer.memberName,那么就等效于*(pointer.memberName),这样意义就完全不对了。
第二种写法中,->是一个新的运算符,习惯称它为“箭头”,有了它,可以通过结构体指针直接取得结构体成员;这也是->在C语言中的唯一用途。
上面的两种写法是等效的,我们通常采用后面的写法,这样更加直观。
例子:结构体指针的使用。
#include <stdio.h>
int main(){
struct{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1 = { "Tom", 12, 18, 'A', 136.5 }, *pstu = &stu1;
//读取结构体成员的值
printf("%s的学号是%d,年龄是%d,在%c组,今年的成绩是%.1f!\n", (*pstu).name, (*pstu).num, (*pstu).age, (*pstu).group, (*pstu).score);
printf("%s的学号是%d,年龄是%d,在%c组,今年的成绩是%.1f!\n", pstu->name, pstu->num, pstu->age, pstu->group, pstu->score);
return 0;
}运行结果:
Tom的学号是12,年龄是18,在A组,今年的成绩是136.5!
Tom的学号是12,年龄是18,在A组,今年的成绩是136.5!
例子:结构体数组指针的使用。
#include <stdio.h>
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
}stus[] = {
{"Zhou ping", 5, 18, 'C', 145.0},
{"Zhang ping", 4, 19, 'A', 130.5},
{"Liu fang", 1, 18, 'A', 148.5},
{"Cheng ling", 2, 17, 'F', 139.0},
{"Wang ming", 3, 17, 'B', 144.5}
}, *ps;
int main(){
//求数组长度
int len = sizeof(stus) / sizeof(struct stu);
printf("Name\t\tNum\tAge\tGroup\tScore\t\n");
for(ps=stus; ps<stus+len; ps++){
printf("%s\t%d\t%d\t%c\t%.1f\n", ps->name, ps->num, ps->age, ps->group, ps->score);
}
return 0;
}运行结果:
Name Num Age Group Score
Zhou ping 5 18 C 145.0
Zhang ping 4 19 A 130.5
Liu fang 1 18 A 148.5
Cheng ling 2 17 F 139.0
Wang ming 3 17 B 144.5
结构体变量名代表的是整个集合本身,作为函数参数时传递的整个集合,也就是所有成员,而不是像数组一样被编译器转换成一个指针。如果结构体成员较多,尤其是成员为数组时,传送的时间和空间开销会很大,影响程序的运行效率。所以最好的办法就是使用结构体指针,这时由实参传向形参的只是一个地址,非常快速。
例子:计算全班学生的总成绩、平均成绩和以及 140 分以下的人数。
#include <stdio.h>
struct stu{
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
}stus[] = {
{"Li ping", 5, 18, 'C', 145.0},
{"Zhang ping", 4, 19, 'A', 130.5},
{"He fang", 1, 18, 'A', 148.5},
{"Cheng ling", 2, 17, 'F', 139.0},
{"Wang ming", 3, 17, 'B', 144.5}
};
void average(struct stu *ps, int len);
int main(){
int len = sizeof(stus) / sizeof(struct stu);
average(stus, len);
return 0;
}
void average(struct stu *ps, int len){
int i, num_140 = 0;
float average, sum = 0;
for(i=0; i<len; i++){
sum += (ps + i) -> score;
if((ps + i)->score < 140) num_140++;
}
printf("sum=%.2f\naverage=%.2f\nnum_140=%d\n", sum, sum/5, num_140);
}运行结果:
sum=707.50
average=141.50
num_140=2
在实际编程中,有些数据的取值往往是有限的,只能是非常少量的整数,并且最好为每个值都取一个名字,以方便在后续代码中使用,比如一个星期只有七天,一年只有十二个月,一个班每周有六门课程等。
以每周七天为例,我们可以使用#define命令来给每天指定一个名字:
#include <stdio.h>
#define Mon 1
#define Tues 2
#define Wed 3
#define Thurs 4
#define Fri 5
#define Sat 6
#define Sun 7
int main(){
int day;
scanf("%d", &day);
switch(day){
case Mon: puts("Monday"); break;
case Tues: puts("Tuesday"); break;
case Wed: puts("Wednesday"); break;
case Thurs: puts("Thursday"); break;
case Fri: puts("Friday"); break;
case Sat: puts("Saturday"); break;
case Sun: puts("Sunday"); break;
default: puts("Error!");
}
return 0;
}运行结果:
5↙
Friday
#define命令虽然能解决问题,但也带来了不小的副作用,导致宏名过多,代码松散,看起来总有点不舒服。C语言提供了一种枚举(Enum)类型,能够列出所有可能的取值,并给它们取一个名字。
枚举类型的定义形式为:
enum typeName{ valueName1, valueName2, valueName3, ...... };
enum是一个新的关键字,专门用来定义枚举类型,这也是它在C语言中的唯一用途;typeName是枚举类型的名字;valueName1, valueName2, valueName3, ......是每个值对应的名字的列表。注意最后的;不能少。
例如,列出一个星期有几天:
enum week{ Mon, Tues, Wed, Thurs, Fri, Sat, Sun };可以看到,我们仅仅给出了名字,却没有给出名字对应的值,这是因为枚举值默认从 0 开始,往后逐个加 1(递增);也就是说,week 中的 Mon、Tues ...... Sun 对应的值分别为 0、1 ...... 6。
我们也可以给每个名字都指定一个值:
enum week{ Mon = 1, Tues = 2, Wed = 3, Thurs = 4, Fri = 5, Sat = 6, Sun = 7 };更为简单的方法是只给第一个名字指定值:
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun };这样枚举值就从 1 开始递增,跟上面的写法是等效的。
枚举是一种类型,通过它可以定义枚举变量:
enum week a, b, c;也可以在定义枚举类型的同时定义变量:
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun } a, b, c;有了枚举变量,就可以把列表中的值赋给它:
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun };
enum week a = Mon, b = Wed, c = Sat;或者:
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun } a = Mon, b = Wed, c = Sat;例子:判断用户输入的是星期几。
#include <stdio.h>
int main(){
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun } day;
scanf("%d", &day);
switch(day){
case Mon: puts("Monday"); break;
case Tues: puts("Tuesday"); break;
case Wed: puts("Wednesday"); break;
case Thurs: puts("Thursday"); break;
case Fri: puts("Friday"); break;
case Sat: puts("Saturday"); break;
case Sun: puts("Sunday"); break;
default: puts("Error!");
}
return 0;
}运行结果:
4↙
Thursday
需要注意的两点是:
枚举列表中的 Mon、Tues、Wed 这些标识符的作用范围是全局的(严格来说是 main() 函数内部),不能再定义与它们名字相同的变量。
Mon、Tues、Wed 等都是常量,不能对它们赋值,只能将它们的值赋给其他的变量。
枚举和宏其实非常类似:宏在预处理阶段将名字替换成对应的值,枚举在编译阶段将名字替换成对应的值。我们可以将枚举理解为编译阶段的宏。
对于上面的代码,在编译的某个时刻会变成类似下面的样子:
#include <stdio.h>
int main(){
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun } day;
scanf("%d", &day);
switch(day){
case 1: puts("Monday"); break;
case 2: puts("Tuesday"); break;
case 3: puts("Wednesday"); break;
case 4: puts("Thursday"); break;
case 5: puts("Friday"); break;
case 6: puts("Saturday"); break;
case 7: puts("Sunday"); break;
default: puts("Error!");
}
return 0;
}Mon、Tues、Wed 这些名字都被替换成了对应的数字。这意味着,Mon、Tues、Wed 等都不是变量,它们不占用数据区(常量区、全局数据区、栈区和堆区)的内存,而是直接被编译到命令里面,放到代码区,所以不能用&取得它们的地址。这就是枚举的本质。
注释:case 关键字后面必须是一个整数,或者是结果为整数的表达式,但不能包含任何变量,正是由于 Mon、Tues、Wed 这些名字最终会被替换成一个整数,所以它们才能放在 case 后面。
枚举类型变量需要存放的是一个整数,我猜测它的长度和 int 应该相同,下面来验证一下:
#include <stdio.h>
int main(){
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun } day = Mon;
printf("%d, %d, %d, %d, %d\n", sizeof(enum week), sizeof(day), sizeof(Mon), sizeof(Wed), sizeof(int) );
return 0;
}运行结果:
4, 4, 4, 4, 4
通过前面的讲解,我们知道结构体(Struct)是一种构造类型或复杂类型,它可以包含多个类型不同的成员。在C语言中,还有另外一种和结构体非常类似的语法,叫做共用体(Union),它的定义格式为:
union 共用体名{
成员列表
};
共用体有时也被称为联合或者联合体,这也是 Union 这个单词的本意。
结构体和共用体的区别在于:结构体的各个成员会占用不同的内存,互相之间没有影响;而共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。
结构体占用的内存大于等于所有成员占用的内存的总和(成员之间可能会存在缝隙),共用体占用的内存等于最长的成员占用的内存。共用体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉。
共用体也是一种自定义类型,可以通过它来创建变量,例如:
union data{
int n;
char ch;
double f;
};
union data a, b, c;上面是先定义共用体,再创建变量,也可以在定义共用体的同时创建变量:
union data{
int n;
char ch;
double f;
} a, b, c;如果不再定义新的变量,也可以将共用体的名字省略:
union{
int n;
char ch;
double f;
} a, b, c;共用体 data 中,成员 f 占用的内存最多,为 8 个字节,所以 data 类型的变量(也就是 a、b、c)也占用 8 个字节的内存,请看下面的演示:
#include <stdio.h>
union data{
int n;
char ch;
short m;
};
int main(){
union data a;
printf("%d, %d\n", sizeof(a), sizeof(union data) );
a.n = 0x40;
printf("%X, %c, %hX\n", a.n, a.ch, a.m);
a.ch = '9';
printf("%X, %c, %hX\n", a.n, a.ch, a.m);
a.m = 0x2059;
printf("%X, %c, %hX\n", a.n, a.ch, a.m);
a.n = 0x3E25AD54;
printf("%X, %c, %hX\n", a.n, a.ch, a.m);
return 0;
}运行结果:
4, 4
40, @, 40
39, 9, 39
2059, Y, 2059
3E25AD54, T, AD54
这段代码不但验证了共用体的长度,还说明共用体成员之间会相互影响,修改一个成员的值会影响其他成员。
要想理解上面的输出结果,弄清成员之间究竟是如何相互影响的,就得了解各个成员在内存中的分布。以上面的 data 为例,各个成员在内存中的分布如下:
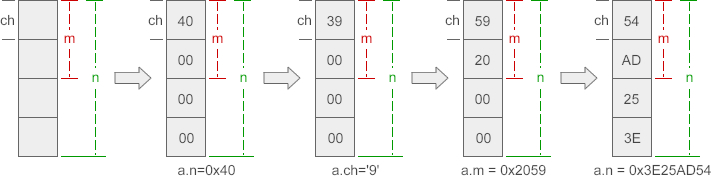
成员 n、ch、m 在内存中“对齐”到一头,对 ch 赋值修改的是前一个字节,对 m 赋值修改的是前两个字节,对 n 赋值修改的是全部字节。也就是说,ch、m 会影响到 n 的一部分数据,而 n 会影响到 ch、m 的全部数据。
共用体在一般的编程中应用较少,在单片机中应用较多。对于 PC 机,经常使用到的一个实例是: 现有一张关于学生信息和教师信息的表格。学生信息包括姓名、编号、性别、职业、分数,教师的信息包括姓名、编号、性别、职业、教学科目。请看下面的表格:
| Name | Num | Sex | Profession | Score / Course |
|---|---|---|---|---|
| HanXiaoXiao | 501 | f | s | 89.5 |
| YanWeiMin | 1011 | m | t | math |
| LiuZhenTao | 109 | f | t | English |
| ZhaoFeiYan | 982 | m | s | 95.0 |
f 和 m 分别表示女性和男性,s 表示学生,t 表示教师。可以看出,学生和教师所包含的数据是不同的。现在要求把这些信息放在同一个表格中,并设计程序输入人员信息然后输出。
如果把每个人的信息都看作一个结构体变量的话,那么教师和学生的前 4 个成员变量是一样的,第 5 个成员变量可能是 score 或者 course。当第 4 个成员变量的值是 s 的时候,第 5 个成员变量就是 score;当第 4 个成员变量的值是 t 的时候,第 5 个成员变量就是 course。
经过上面的分析,我们可以设计一个包含共用体的结构体,请看下面的代码:
#include <stdio.h>
#include <stdlib.h>
#define TOTAL 4 //人员总数
struct{
char name[20];
int num;
char sex;
char profession;
union{
float score;
char course[20];
} sc;
} bodys[TOTAL];
int main(){
int i;
//输入人员信息
for(i=0; i<TOTAL; i++){
printf("Input info: ");
scanf("%s %d %c %c", bodys[i].name, &(bodys[i].num), &(bodys[i].sex), &(bodys[i].profession));
if(bodys[i].profession == 's'){ //如果是学生
scanf("%f", &bodys[i].sc.score);
}else{ //如果是老师
scanf("%s", bodys[i].sc.course);
}
fflush(stdin);
}
//输出人员信息
printf("\nName\t\tNum\tSex\tProfession\tScore / Course\n");
for(i=0; i<TOTAL; i++){
if(bodys[i].profession == 's'){ //如果是学生
printf("%s\t%d\t%c\t%c\t\t%f\n", bodys[i].name, bodys[i].num, bodys[i].sex, bodys[i].profession, bodys[i].sc.score);
}else{ //如果是老师
printf("%s\t%d\t%c\t%c\t\t%s\n", bodys[i].name, bodys[i].num, bodys[i].sex, bodys[i].profession, bodys[i].sc.course);
}
}
return 0;
}运行结果:
Input info: HanXiaoXiao 501 f s 89.5↙
Input info: YanWeiMin 1011 m t math↙
Input info: LiuZhenTao 109 f t English↙
Input info: ZhaoFeiYan 982 m s 95.0↙
Name Num Sex Profession Score / Course
HanXiaoXiao 501 f s 89.500000
YanWeiMin 1011 m t math
LiuZhenTao 109 f t English
ZhaoFeiYan 982 m s 95.000000我们对文件的概念已经非常熟悉了,比如常见的 Word 文档、txt 文件、源文件等。文件是数据源的一种,最主要的作用是保存数据。
在操作系统中,为了统一对各种硬件的操作,简化接口,不同的硬件设备也都被看成一个文件。对这些文件的操作,等同于对磁盘上普通文件的操作。例如:
- 通常把显示器称为标准输出文件,printf 就是向这个文件输出数据;
- 通常把键盘称为标准输入文件,scanf 就是从这个文件读取数据。
| 常见硬件设备所对应的文件 |
|---|
| 文件 | 硬件设备 |
|---|---|
| stdin | 标准输入文件,一般指键盘;scanf()、getchar() 等函数默认从 stdin 获取输入。 |
| stdout | 标准输出文件,一般指显示器;printf()、putchar() 等函数默认向 stdout 输出数据。 |
| stderr | 标准错误文件,一般指显示器;perror() 等函数默认向 stderr 输出数据(后续会讲到)。 |
| stdprn | 标准打印文件,一般指打印机。 |
我们不去探讨硬件设备是如何被映射成文件的,大家只需要记住,在C语言中硬件设备可以看成文件,有些输入输出函数不需要你指明到底读写哪个文件,系统已经为它们设置了默认的文件,当然你也可以更改,例如让 printf 向磁盘上的文件输出数据。
操作文件的正确流程为:打开文件 --> 读写文件 --> 关闭文件。文件在进行读写操作之前要先打开,使用完毕要关闭。
所谓打开文件,就是获取文件的有关信息,例如文件名、文件状态、当前读写位置等,这些信息会被保存到一个 FILE 类型的结构体变量中。关闭文件就是断开与文件之间的联系,释放结构体变量,同时禁止再对该文件进行操作。
在C语言中,文件有多种读写方式,可以一个字符一个字符地读取,也可以读取一整行,还可以读取若干个字节。文件的读写位置也非常灵活,可以从文件开头读取,也可以从中间位置读取。
所有的文件(保存在磁盘)都要载入内存才能处理,所有的数据必须写入文件(磁盘)才不会丢失。数据在文件和内存之间传递的过程叫做文件流,类似水从一个地方流动到另一个地方。数据从文件复制到内存的过程叫做输入流,从内存保存到文件的过程叫做输出流。
文件是数据源的一种,除了文件,还有数据库、网络、键盘等;数据传递到内存也就是保存到C语言的变量(例如整数、字符串、数组、缓冲区等)。我们把数据在数据源和程序(内存)之间传递的过程叫做数据流(Data Stream)。相应的,数据从数据源到程序(内存)的过程叫做输入流(Input Stream),从程序(内存)到数据源的过程叫做输出流(Output Stream)。
输入输出(Input output,IO)是指程序(内存)与外部设备(键盘、显示器、磁盘、其他计算机等)进行交互的操作。几乎所有的程序都有输入与输出操作,如从键盘上读取数据,从本地或网络上的文件读取数据或写入数据等。通过输入和输出操作可以从外界接收信息,或者是把信息传递给外界。
我们可以说,打开文件就是打开了一个流。
在C语言中,操作文件之前必须先打开文件;所谓“打开文件”,就是让程序和文件建立连接的过程。
打开文件之后,程序可以得到文件的相关信息,例如大小、类型、权限、创建者、更新时间等。在后续读写文件的过程中,程序还可以记录当前读写到了哪个位置,下次可以在此基础上继续操作。
标准输入文件 stdin(表示键盘)、标准输出文件 stdout(表示显示器)、标准错误文件 stderr(表示显示器)是由系统打开的,可直接使用。
使用 <stdio.h> 头文件中的 fopen() 函数即可打开文件,它的用法为:
FILE *fopen(char *filename, char *mode);
filename为文件名(包括文件路径),mode为打开方式,它们都是字符串。
fopen() 会获取文件信息,包括文件名、文件状态、当前读写位置等,并将这些信息保存到一个 FILE 类型的结构体变量中,然后将该变量的地址返回。
FILE 是 <stdio.h> 头文件中的一个结构体,它专门用来保存文件信息。我们不用关心 FILE 的具体结构,只需要知道它的用法就行。
如果希望接收 fopen() 的返回值,就需要定义一个 FILE 类型的指针。例如:
FILE *fp = fopen("demo.txt", "r");表示以“只读”方式打开当前目录下的 demo.txt 文件,并使 fp 指向该文件,这样就可以通过 fp 来操作 demo.txt 了。fp 通常被称为文件指针。
再来看一个例子:
FILE *fp = fopen("D:\\demo.txt","rb+");表示以二进制方式打开 D 盘下的 demo.txt 文件,允许读和写。
判断文件是否打开成功
打开文件出错时,fopen() 将返回一个空指针,也就是 NULL,我们可以利用这一点来判断文件是否打开成功,请看下面的代码:
FILE *fp; if( (fp=fopen("D:\\demo.txt","rb")) == NULL ){ printf("Fail to open file!\n"); exit(0); //退出程序(结束程序) }我们通过判断 fopen() 的返回值是否和 NULL 相等来判断是否打开失败:如果 fopen() 的返回值为 NULL,那么 fp 的值也为 NULL,此时 if 的判断条件成立,表示文件打开失败。
以上代码是文件操作的规范写法,读者在打开文件时一定要判断文件是否打开成功,因为一旦打开失败,后续操作就都没法进行了,往往以“结束程序”告终。
不同的操作需要不同的文件权限。例如,只想读取文件中的数据的话,“只读”权限就够了;既想读取又想写入数据的话,“读写”权限就是必须的了。
另外,文件也有不同的类型,按照数据的存储方式可以分为二进制文件和文本文件,它们的操作细节是不同的。
在调用 fopen() 函数时,这些信息都必须提供,称为“文件打开方式”。最基本的文件打开方式有以下几种:
| 控制读写权限的字符串(必须指明) |
|---|
| 打开方式 | 说明 |
|---|---|
| "r" | 以“只读”方式打开文件。只允许读取,不允许写入。文件必须存在,否则打开失败。 |
| "w" | 以“写入”方式打开文件。如果文件不存在,那么创建一个新文件;如果文件存在,那么清空文件内容(相当于删除原文件,再创建一个新文件)。 |
| "a" | 以“追加”方式打开文件。如果文件不存在,那么创建一个新文件;如果文件存在,那么将写入的数据追加到文件的末尾(文件原有的内容保留)。 |
| "r+" | 以“读写”方式打开文件。既可以读取也可以写入,也就是随意更新文件。文件必须存在,否则打开失败。 |
| "w+" | 以“写入/更新”方式打开文件,相当于w和r+叠加的效果。既可以读取也可以写入,也就是随意更新文件。如果文件不存在,那么创建一个新文件;如果文件存在,那么清空文件内容(相当于删除原文件,再创建一个新文件)。 |
| "a+" | 以“追加/更新”方式打开文件,相当于a和r+叠加的效果。既可以读取也可以写入,也就是随意更新文件。如果文件不存在,那么创建一个新文件;如果文件存在,那么将写入的数据追加到文件的末尾(文件原有的内容保留)。 |
| 控制读写方式的字符串(可以不写) |
|---|
| 打开方式 | 说明 |
|---|---|
| "t" | 文本文件。如果不写,默认为"t"。 |
| "b" | 二进制文件。 |
调用 fopen() 函数时必须指明读写权限,但是可以不指明读写方式(此时默认为"t")。
读写权限和读写方式可以组合使用,但是必须将读写方式放在读写权限的中间或者尾部(换句话说,不能将读写方式放在读写权限的开头)。
例如:
- 将读写方式放在读写权限的末尾:"rb"、"wt"、"ab"、"r+b"、"w+t"、"a+t"
- 将读写方式放在读写权限的中间:"rb+"、"wt+"、"ab+"
整体来说,文件打开方式由 r、w、a、t、b、+ 六个字符拼成,各字符的含义是:
- r(read):读
- w(write):写
- a(append):追加
- t(text):文本文件
- b(binary):二进制文件
- +:读和写
文件一旦使用完毕,应该用 fclose() 函数把文件关闭,以释放相关资源,避免数据丢失。fclose() 的用法为:
int fclose(FILE *fp);fp 为文件指针。例如:
fclose(fp);文件正常关闭时,fclose() 的返回值为0,如果返回非零值则表示有错误发生。
例子:fopen 函数的用法,这个例子会一行一行地读取文本文件的所有内容
#include <stdio.h>
#include <stdlib.h>
#define N 100
int main() {
FILE *fp;
char str[N + 1];
//判断文件是否打开失败
if ( (fp = fopen("d:\\demo.txt", "rt")) == NULL ) {
puts("Fail to open file!");
exit(0);
}
//循环读取文件的每一行数据
while( fgets(str, N, fp) != NULL ) {
printf("%s", str);
}
//操作结束后关闭文件
fclose(fp);
return 0;
}
定义: 文本文件是把数据的终端形式的二进制数据输出到磁盘上存放,即存放的是数据的终端形式. 文本文件(也称为ASCII文件):它的每一个字节存放的是可表示为一个字符的ASCII代码的文件。它是以 “行”为基本结构的一种信息组织和存储方式的文件,可用任何文字处理程序阅读的简单文本文件。
读取流程: 文本工具打开一个文件的过程是怎样的呢?拿记事本来说,它首先读取文件物理上所对应的二进制比特流,然后按照你所选择的解码方式来解释这个流,然后将解释结果显示出来。一般来说,你选取的解码方式会是ASCII码形式(ASCII码的一个字符是8个比特),接下来,它8个比特8个比特地来解释这个文件流。例如对于这么一个文件流”01000000_01000001_01000010_01000011”, 第一个8比特”01000000”按ASCII码来解码的话,所对应的字符是字符”A”,同理其它3个8比特可分别解码为”BCD”,即这个文件流可解释成“ABCD”,然后记事本就将这个“ABCD”显示在屏幕上。
选择: 如果是需要频繁的保存和访问数据,那么应该采取二进制文件进行存放,这样可以节省存储空间和转换时间。 如果需要频繁的向终端显示数据或从终端读入数据,那么应该采用文本文件进行存放,这样可以节省转换时间。
区别: window 文本模式中,在存储\n时要转化为\r\n,读取文件时进行逆转换。window二进制模式时,则不进行转换。
如果要求在外存(磁盘)上以ASCII码的形式存储,则需要在存储前转换。以ASCII字符的形式存储的文件就是文本文件。 往文件中写入10000这个数,其文本文件格式如下:

定义: 二进制文件就是把内存中的数据按其在内存中存储的形式原样输出到磁盘中存放,即存放的是数据的原形式。二进制文件是包含在 ASCII 及扩展 ASCII 字符中编写的数据或程序指令的文件。一般是可执行程序、图形、声音等文件,有自己特殊的编解码格式。不同的应用程序对二进制文件中的每个值会有不同的解读,要打开二进制文件需要对应的二进制文件解码器。
读取流程: 用记事本打开二进制文件的流程是怎样的呢?记事本无论打开什么文件都按既定的字符编码工作(如ASCII码),用ASCII码的规则去解读二进制文件时,会出现乱码。所以当他打开二进制文件时,出现乱码也是很必然的一件事情,解码和译码不对应。例如文件流”00000000_00000000_00000000_00000001”可能在二进制文件中对应的是一个四字节的整数int 1,在记事本里解释就变成了”NULL_NULL_NULL_SOH”这四个控制符。文本文件将浮点数80.000000用了38(表示8) 30(表示0) 2E(表示.) 30(表示0) 30(表示0) 30(表示0) 30(表示0) 30(表示0) 30(表示0),二进制文件用了4个字节表示浮点数00 00 A0 42。字符型的内容都是ASCii码的形式,没有区别。
例子: 在计算机中,所有的颜色都可以映射为一个二进制的值。图片存储时,图片上每个点都有自己的颜色值,将每个点的颜色值,以及图片本身的宽高信息储存起来,就是最基本的位图存储(bmp),位图存储是没有压缩的。将位图信息,经过二次编码,压缩就形成了压缩后的图片。算法不同产生的图片格式也有区别。常见的包括jpg,png,gif等。文本文件基本上是定长编码的(也有非定长的编码如UTF-8)。而二进制文件可看成是变长编码的,因为是值编码,多少个比特代表一个值,完全由自定义的编解码规则决定。像BMP文件,其头部是较为固定长度的文件头信息,前2字节用来记录文件为BMP格式,接下来的8个字节用来记录文件长度,再接下来的4字节用来记录bmp文件头的长度。
数据在内存中以二进制的形式存储,如果不加转换的输出到外存(磁盘),就是二进制文件!

二进制文件是按二进制的编码方式来存放文件的。 例如, 数10000的存储形式为:0010 0111 0001 0000只占二个字节。二进制文件虽然也可在屏幕上显示,但其内容无法读懂。具体这个是什么,是根据文本编码显示的符号,其本身还是二进制,不需要深究!
无论是文本文件还是二进制文件,其本质都是二进制存储。
假定:还是将10000这个数以ASCII码的形式存储在文件中
数10000的二进制形式为:0010 0111 0001 0000只占二个字节,则在储存前我们需要将其转换为ASCII码的形式,即‘1’,‘0’,‘0’,‘0’,‘0’一个ASCII码字符的大小是1byte,所以数字10000的文本文件所占的字节大小为5byte。

数据在内存中以二进制的形式存储,不加转换的输出到外存(磁盘)!

二进制文件是按二进制的编码方式来存放文件的。
例如, 数10000的存储形式为:0010 0111 0001 0000只占二个字节
在C语言中,读写文件比较灵活,既可以每次读写一个字符,也可以读写一个字符串,甚至是任意字节的数据(数据块)。本节介绍以字符形式读写文件。
以字符形式读写文件时,每次可以从文件中读取一个字符,或者向文件中写入一个字符。主要使用两个函数,分别是 fgetc() 和 fputc()。
fgetc 是 file get char 的缩写,意思是从指定的文件中读取一个字符。fgetc() 的用法为:
int fgetc (FILE *fp);fp 为文件指针。fgetc() 读取成功时返回读取到的字符,读取到文件末尾或读取失败时返回EOF。
EOF 是 end of file 的缩写,表示文件末尾,是在 stdio.h 中定义的宏,它的值是一个负数,往往是 -1。fgetc() 的返回值类型之所以为 int,就是为了容纳这个负数(char不能是负数)。
EOF 不绝对是 -1,也可以是其他负数,这要看编译器的实现。
fgetc() 的用法举例:
char ch;
FILE *fp = fopen("D:\\demo.txt", "r+");
ch = fgetc(fp);表示从D:\\demo.txt文件中读取一个字符,并保存到变量 ch 中。
在文件内部有一个位置指针,用来指向当前读写到的位置,也就是读写到第几个字节。在文件打开时,该指针总是指向文件的第一个字节。使用 fgetc() 函数后,该指针会向后移动一个字节,所以可以连续多次使用 fgetc() 读取多个字符。
注意:这个文件内部的位置指针与C语言中的指针不是一回事。位置指针仅仅是一个标志,表示文件读写到的位置,也就是读写到第几个字节,它不表示地址。文件每读写一次,位置指针就会移动一次,它不需要你在程序中定义和赋值,而是由系统自动设置,对用户是隐藏的。
例子:在屏幕上显示 D:\demo.txt 文件的内容。
#include<stdio.h>
int main(){
FILE *fp;
char ch;
//如果文件不存在,给出提示并退出
if( (fp=fopen("D:\\demo.txt","rt")) == NULL ){
puts("Fail to open file!");
exit(0);
}
//每次读取一个字节,直到读取完毕
while( (ch=fgetc(fp)) != EOF ){
putchar(ch);
}
putchar('\n'); //输出换行符
fclose(fp);
return 0;
}在D盘下创建 demo.txt 文件,输入任意内容并保存,运行程序,就会看到刚才输入的内容全部都显示在屏幕上。
该程序的功能是从文件中逐个读取字符,在屏幕上显示,直到读取完毕。
程序第 13 行是关键,while 循环的条件为(ch=fgetc(fp)) != EOF。fget() 每次从位置指针所在的位置读取一个字符,并保存到变量 ch,位置指针向后移动一个字节。当文件指针移动到文件末尾时,fget() 就无法读取字符了,于是返回 EOF,表示文件读取结束了。
对 EOF 的说明
EOF 本来表示文件末尾,意味着读取结束,但是很多函数在读取出错时也返回 EOF,那么当返回 EOF 时,到底是文件读取完毕了还是读取出错了?我们可以借助 stdio.h 中的两个函数来判断,分别是 feof() 和 ferror()。
feof() 函数用来判断文件内部指针是否指向了文件末尾,它的原型是:
int feof ( FILE * fp );当指向文件末尾时返回非零值,否则返回零值。
ferror() 函数用来判断文件操作是否出错,它的原型是:
int ferror ( FILE *fp );出错时返回非零值,否则返回零值。
要说明的是,文件出错是非常少见的情况,上面的示例基本能够保证将文件内的数据读取完毕。如果追求完美,也可以加上判断并给出提示:
#include<stdio.h> int main(){ FILE *fp; char ch; //如果文件不存在,给出提示并退出 if( (fp=fopen("D:\\demo.txt","rt")) == NULL ){ puts("Fail to open file!"); exit(0); } //每次读取一个字节,直到读取完毕 while( (ch=fgetc(fp)) != EOF ){ putchar(ch); } putchar('\n'); //输出换行符 if(ferror(fp)){ puts("读取出错"); }else{ puts("读取成功"); } fclose(fp); return 0; }这样,不管是出错还是正常读取,都能够做到心中有数。
fputc 是 file output char 的所以,意思是向指定的文件中写入一个字符。fputc() 的用法为:
int fputc ( int ch, FILE *fp );ch 为要写入的字符,fp 为文件指针。fputc() 写入成功时返回写入的字符,失败时返回 EOF,返回值类型为 int 也是为了容纳这个负数。例如:
fputc('a', fp);或者:
char ch = 'a';
fputc(ch, fp);表示把字符 'a' 写入fp所指向的文件中。
两点说明
\1) 被写入的文件可以用写、读写、追加方式打开,用写或读写方式打开一个已存在的文件时将清除原有的文件内容,并将写入的字符放在文件开头。如需保留原有文件内容,并把写入的字符放在文件末尾,就必须以追加方式打开文件。不管以何种方式打开,被写入的文件若不存在时则创建该文件。
\2) 每写入一个字符,文件内部位置指针向后移动一个字节。
例子:从键盘输入一行字符,写入文件。
#include<stdio.h>
int main(){
FILE *fp;
char ch;
//判断文件是否成功打开
if( (fp=fopen("D:\\demo.txt","wt+")) == NULL ){
puts("Fail to open file!");
exit(0);
}
printf("Input a string:\n");
//每次从键盘读取一个字符并写入文件
while ( (ch=getchar()) != '\n' ){
fputc(ch,fp);
}
fclose(fp);
return 0;
}运行程序,输入一行字符并按回车键结束,打开D盘下的 demo.txt 文件,就可以看到刚才输入的内容。
程序每次从键盘读取一个字符并写入文件,直到按下回车键,while 条件不成立,结束读取。
fgetc() 和 fputc() 函数每次只能读写一个字符,速度较慢;实际开发中往往是每次读写一个字符串或者一个数据块,这样能明显提高效率。
fgets() 函数用来从指定的文件中读取一个字符串,并保存到字符数组中,它的用法为:
char *fgets ( char *str, int n, FILE *fp );str 为字符数组,n 为要读取的字符数目,fp 为文件指针。
返回值:读取成功时返回字符数组首地址,也即 str;读取失败时返回 NULL;如果开始读取时文件内部指针已经指向了文件末尾,那么将读取不到任何字符,也返回 NULL。
注意,读取到的字符串会在末尾自动添加 '\0',n 个字符也包括 '\0'。也就是说,实际只读取到了 n-1 个字符,如果希望读取 100 个字符,n 的值应该为 101。例如:
#define N 101
char str[N];
FILE *fp = fopen("D:\\demo.txt", "r");
fgets(str, N, fp);表示从 D:\demo.txt 中读取 100 个字符,并保存到字符数组 str 中。
需要重点说明的是,在读取到 n-1 个字符之前如果出现了换行,或者读到了文件末尾,则读取结束。这就意味着,不管 n 的值多大,fgets() 最多只能读取一行数据,不能跨行。在C语言中,没有按行读取文件的函数,我们可以借助 fgets(),将 n 的值设置地足够大,每次就可以读取到一行数据。
例子:一行一行地读取文件。
#include <stdio.h>
#include <stdlib.h>
#define N 100
int main(){
FILE *fp;
char str[N+1];
if( (fp=fopen("d:\\demo.txt","rt")) == NULL ){
puts("Fail to open file!");
exit(0);
}
while(fgets(str, N, fp) != NULL){
printf("%s", str);
}
fclose(fp);
return 0;
}将下面的内容复制到 D:\demo.txt:
Vincent Croft
Hello World!
那么运行结果为:
Vincent Croft
Hello World!
fgets() 遇到换行时,会将换行符一并读取到当前字符串。该示例的输出结果之所以和 demo.txt 保持一致,该换行的地方换行,就是因为 fgets() 能够读取到换行符。而 gets() 不一样,它会忽略换行符。
fputs() 函数用来向指定的文件写入一个字符串,它的用法为:
int fputs( char *str, FILE *fp );str 为要写入的字符串,fp 为文件指针。写入成功返回非负数,失败返回 EOF。例如:
char *str = "http://c.biancheng.net";
FILE *fp = fopen("D:\\demo.txt", "at+");
fputs(str, fp);表示把把字符串 str 写入到 D:\demo.txt 文件中。
例子:向上例中建立的 d:\demo.txt 文件中追加一个字符串。
#include<stdio.h>
int main(){
FILE *fp;
char str[102] = {0}, strTemp[100];
if( (fp=fopen("D:\\demo.txt", "at+")) == NULL ){
puts("Fail to open file!");
exit(0);
}
printf("Input a string:");
gets(strTemp);
strcat(str, "\n");
strcat(str, strTemp);
fputs(str, fp);
fclose(fp);
return 0;
}运行程序,输入Welcome,打开 D:\demo.txt,文件内容为:
Vincent Croft
Hello World!
Welcome
fgets() 有局限性,每次最多只能从文件中读取一行内容,因为 fgets() 遇到换行符就结束读取。如果希望读取多行内容,需要使用 fread() 函数;相应地写入函数为 fwrite()。
fread() 函数用来从指定文件中读取块数据。所谓块数据,也就是若干个字节的数据,可以是一个字符,可以是一个字符串,可以是多行数据,并没有什么限制。fread() 的原型为:
size_t fread ( void *ptr, size_t size, size_t count, FILE *fp );fwrite() 函数用来向文件中写入块数据,它的原型为:
size_t fwrite ( void * ptr, size_t size, size_t count, FILE *fp );对参数的说明:
- ptr 为内存区块的指针,它可以是数组、变量、结构体等。fread() 中的 ptr 用来存放读取到的数据,fwrite() 中的 ptr 用来存放要写入的数据。
- size:表示每个数据块的字节数。
- count:表示要读写的数据块的块数。
- fp:表示文件指针。
- 理论上,每次读写 size*count 个字节的数据。
size_t 是在 stdio.h 和 stdlib.h 头文件中使用 typedef 定义的数据类型,表示无符号整数,也即非负数,常用来表示数量。
返回值:返回成功读写的块数,也即 count。
如果返回值小于 count:
- 对于 fwrite() 来说,肯定发生了写入错误,可以用 ferror() 函数检测。
- 对于 fread() 来说,可能读到了文件末尾,可能发生了错误,可以用 ferror() 或 feof() 检测。
例子:从键盘输入一个数组,将数组写入文件再读取出来。
#include<stdio.h>
#define N 5
int main(){
//从键盘输入的数据放入a,从文件读取的数据放入b
int a[N], b[N];
int i, size = sizeof(int);
FILE *fp;
if( (fp=fopen("D:\\demo.txt", "rb+")) == NULL ){ //以二进制方式打开
puts("Fail to open file!");
exit(0);
}
//从键盘输入数据 并保存到数组a
for(i=0; i<N; i++){
scanf("%d", &a[i]);
}
//将数组a的内容写入到文件
fwrite(a, size, N, fp);
//将文件中的位置指针重新定位到文件开头
rewind(fp);
//从文件读取内容并保存到数组b
fread(b, size, N, fp);
//在屏幕上显示数组b的内容
for(i=0; i<N; i++){
printf("%d ", b[i]);
}
printf("\n");
fclose(fp);
return 0;
}运行结果:
Input data:
Tom 2 15 90.5↙
Hua 1 14 99↙
Tom 2 15 90.500000
Hua 1 14 99.000000fscanf() 和 fprintf() 函数与前面使用的 scanf() 和 printf() 功能相似,都是格式化读写函数,两者的区别在于 fscanf() 和 fprintf() 的读写对象不是键盘和显示器,而是磁盘文件。
这两个函数的原型为:
int fscanf ( FILE *fp, char * format, ... );
int fprintf ( FILE *fp, char * format, ... );fp 为文件指针,format 为格式控制字符串,... 表示参数列表。与 scanf() 和 printf() 相比,它们仅仅多了一个 fp 参数。例如:
FILE *fp;
int i, j;
char *str, ch;
fscanf(fp, "%d %s", &i, str);
fprintf(fp,"%d %c", j, ch);fprintf() 返回成功写入的字符的个数,失败则返回负数。fscanf() 返回参数列表中被成功赋值的参数个数。
例子:用 fscanf 和 fprintf 函数来完成对学生信息的读写。
#include<stdio.h>
#define N 2
struct stu{
char name[10];
int num;
int age;
float score;
} boya[N], boyb[N], *pa, *pb;
int main(){
FILE *fp;
int i;
pa=boya;
pb=boyb;
if( (fp=fopen("D:\\demo.txt","wt+")) == NULL ){
puts("Fail to open file!");
exit(0);
}
//从键盘读入数据,保存到boya
printf("Input data:\n");
for(i=0; i<N; i++,pa++){
scanf("%s %d %d %f", pa->name, &pa->num, &pa->age, &pa->score);
}
pa = boya;
//将boya中的数据写入到文件
for(i=0; i<N; i++,pa++){
fprintf(fp,"%s %d %d %f\n", pa->name, pa->num, pa->age, pa->score);
}
//重置文件指针
rewind(fp);
//从文件中读取数据,保存到boyb
for(i=0; i<N; i++,pb++){
fscanf(fp, "%s %d %d %f\n", pb->name, &pb->num, &pb->age, &pb->score);
}
pb=boyb;
//将boyb中的数据输出到显示器
for(i=0; i<N; i++,pb++){
printf("%s %d %d %f\n", pb->name, pb->num, pb->age, pb->score);
}
fclose(fp);
return 0;
}运行结果:
Input data:
Tom 2 15 90.5↙
Hua 1 14 99↙
Tom 2 15 90.500000
Hua 1 14 99.000000
打开 D:\demo.txt,发现文件的内容是可以阅读的,格式非常清晰。用 fprintf() 和 fscanf() 函数读写配置文件、日志文件会非常方便,不但程序能够识别,用户也可以看懂,可以手动修改。
如果将 fp 设置为 stdin,那么 fscanf() 函数将会从键盘读取数据,与 scanf 的作用相同;设置为 stdout,那么 fprintf() 函数将会向显示器输出内容,与 printf 的作用相同。例如:
#include<stdio.h>
int main(){
int a, b, sum;
fprintf(stdout, "Input two numbers: ");
fscanf(stdin, "%d %d", &a, &b);
sum = a + b;
fprintf(stdout, "sum=%d\n", sum);
return 0;
}运行结果:
Input two numbers: 10 20↙
sum=30前面介绍的文件读写函数都是顺序读写,即读写文件只能从头开始,依次读写各个数据。但在实际开发中经常需要读写文件的中间部分,要解决这个问题,就得先移动文件内部的位置指针,再进行读写。这种读写方式称为随机读写,也就是说从文件的任意位置开始读写。
实现随机读写的关键是要按要求移动位置指针,这称为文件的定位。
移动文件内部位置指针的函数主要有两个,即 rewind() 和 fseek()。
rewind() 用来将位置指针移动到文件开头,前面已经多次使用过,它的原型为:
void rewind ( FILE *fp );
fseek() 用来将位置指针移动到任意位置,它的原型为:
int fseek ( FILE *fp, long offset, int origin );
参数说明:
fp 为文件指针,也就是被移动的文件。
offset 为偏移量,也就是要移动的字节数。之所以为 long 类型,是希望移动的范围更大,能处理的文件更大。offset 为正时,向后移动;offset 为负时,向前移动。
origin 为起始位置,也就是从何处开始计算偏移量。C语言规定的起始位置有三种,分别为文件开头、当前位置和文件末尾,每个位置都用对应的常量来表示:
起始点 常量名 常量值 文件开头 SEEK_SET 0 当前位置 SEEK_CUR 1 文件末尾 SEEK_END 2
例如,把位置指针移动到离文件开头100个字节处:
fseek(fp, 100, 0);值得说明的是,fseek() 一般用于二进制文件,在文本文件中由于要进行转换,计算的位置有时会出错。
在移动位置指针之后,就可以用前面介绍的任何一种读写函数进行读写了。由于是二进制文件,因此常用 fread() 和 fwrite() 读写。
例子:从键盘输入三组学生信息,保存到文件中,然后读取第二个学生的信息。
#include<stdio.h>
#define N 3
struct stu{
char name[10]; //姓名
int num; //学号
int age; //年龄
float score; //成绩
}boys[N], boy, *pboys;
int main(){
FILE *fp;
int i;
pboys = boys;
if( (fp=fopen("d:\\demo.txt", "wb+")) == NULL ){
printf("Cannot open file, press any key to exit!\n");
getch();
exit(1);
}
printf("Input data:\n");
for(i=0; i<N; i++,pboys++){
scanf("%s %d %d %f", pboys->name, &pboys->num, &pboys->age, &pboys->score);
}
fwrite(boys, sizeof(struct stu), N, fp); //写入三条学生信息
fseek(fp, sizeof(struct stu), SEEK_SET); //移动位置指针
fread(&boy, sizeof(struct stu), 1, fp); //读取一条学生信息
printf("%s %d %d %f\n", boy.name, boy.num, boy.age, boy.score);
fclose(fp);
return 0;
}运行结果:
Input data:
Tom 2 15 90.5↙
Hua 1 14 99↙
Zhao 10 16 95.5↙
Hua 1 14 99.000000
【单选题】
下列叙述中正确的是( )。
-
A、
main函数中至少必须有一条语句
-
B、
C程序总是在执行完main函数的最后一条语句后结束
-
C、
C程序总是从main函数的第一条语句开始执行
-
D、
main函数必须出现在其他函数之前
正确答案: C 我的答案:C
2
【单选题】以下叙述中正确的是( )。
-
A、
C语言程序可以由一个或多个函数组成
-
B、
main( ){ }必须位于程序的开始
-
C、
C语言程序的每一行只能写一条语句
-
D、
在编译时可以发现注释中的拼写错误
正确答案: A 我的答案:A
3
【单选题】在一个源程序中main函数的位置( )。
-
A、
必须在最开始
-
B、
必须在最后
-
C、
必须放在其它函数里
-
D、
可以在其他函数之前或之后
正确答案: D 我的答案:D
4
【单选题】以下叙述正确的是( )。
-
A、
C程序中的注释只能出现在程序的开始位置和语句的后面
-
B、
C程序书写格式严格,要求一行内只能写一个语句
-
C、
C程序书写格式自由,一个语句可以写在多行上
-
D、
用C语言编写的程序只能放在一个程序文件中
正确答案: C 我的答案:C
5
【单选题】以下叙述中正确的是( )。
-
A、
C语言程序将从源程序中的第一个函数开始执行
-
B、
可以在程序中由用户指定任意一个函数作为主函数,程序将从此开始执行
-
C、
C语言规定必须用main作为主函数名,程序将从此开始执行,在此结束
-
D、
main可作为用户标识符,用以命名任意一个函数作为主函数
正确答案: C 我的答案:C
1
【单选题】下列四个叙述中,错误的是:
-
A、
C 语言中的关键字必须小写
-
B、
C 语言中的标识符必须全部由字母组成
-
C、
C 语言不提供输入输出语句
-
D、
C 语言中的注释行可以出现在程序的任何位置
正确答案: B 我的答案:B
解析:C语言的标识符必须以字母或下划线开头,包含字母、数字和下划线。
2
【单选题】下列符号中能用作C标识符的是:
-
A、
5abc
-
B、
if
-
C、
–abc
-
D、
_abc
正确答案: D 我的答案:D
解析:标识符只能以字母或下划线开头,不允许为关键字
3
【单选题】下列能用作用户自定义的标识符为:
A、doubleB、–varC、3Xyz-D、Float
正确答案: D 我的答案:D
解析:标识符只能以字母或下划线开头,不允许为关键字
4
【单选题】以下选项中,不能作为合法常量的是:
-
A、
0X2A
-
B、
015
-
C、
2.8e9
-
D、
123.6e0.4
正确答案: D 我的答案:D
解析:浮点数的指数形式e后必须为整数
5
【单选题】在 C 语言中,要求运算数必须是整型的运算符是 :
-
A、
%
-
B、
/
-
C、
-
D、
正确答案: A 我的答案:A
6
【单选题】在数学式(6ab)/(7xy)中,变量x和y为float数据类型,而变量a和b为int数据类型。在C程序中该数学式的正确表达式是:
-
A、
6/7ab/x/y
-
B、
6/xab/7/y
-
C、
6ab/7/x/y
-
D、
6ab/7xy
正确答案: B 我的答案:B
7
【单选题】已知有声明“int n; float x,y;”,则执行语句“y = n = x = 3.89;”后,y的值为:
-
A、
3
-
B、
3.0
-
C、
3.89
-
D、
4.0
正确答案: B 我的答案:B
8
【单选题】设有语句:int a=12,b=12;printf(“%d %d\n”,--a,b++);则屏幕上输出的是:
-
A、
12 12
-
B、
11 13
-
C、
11 12
-
D、
12 13
正确答案: C 我的答案:C
9
【单选题】设x为整型变量,则执行以下语句 x=6;x-=x-=x; 后,x的值为:
-
A、
6
-
B、
0
-
C、
12
-
D、
-6
正确答案: B 我的答案:B
10
【单选题】设有定义:int k=0;,以下选项的四个表达式中与其他三个表达式的值不相同的是:
-
A、
k++
-
B、
k+=1
-
C、
++k
-
D、
k+1
正确答案: A 我的答案:A
11
【单选题】已知有声明”int a=3,b=4,c;”,则执行语句”c=1/2*(a+b);”后,c的值为:
-
A、
3
-
B、
3.5
-
C、
4
-
D、
0
正确答案: D 我的答案:D
12
【单选题】已知有声明”int a=3,b=4;”,下列表达式中合法的是:
-
A、
a+b=7
-
B、
a=|b|
-
C、
a=b=0
-
D、
(a++)++
正确答案: C 我的答案:C
13
【单选题】设有说明语句:char a='\72';则变量a:
-
A、
说明不合法
-
B、
包含3个字符
-
C、
包含1个字符
-
D、
包含2个字符
正确答案: C 我的答案:C
14
【单选题】表达式18/4*sqrt(4.0)/8值的数据类型为:
-
A、
float
-
B、
double
-
C、
不确定
-
D、
int
正确答案: B 我的答案:B
15
【单选题】以下不正确的叙述是:
A、若a和b类型相同,在执行了赋值语句a=b;后b中的值将放入a中,b中的值不变B、当输入数值数据时,对于整型变量只能输入整型值;对于实型变量只能输入实型值C、程序中,APH和aph是两个不同的变量D、在C程序中所用的变量必须先定义后使用
正确答案: B 我的答案:B
16
【单选题】C语言中,double类型数据占:
A、4个字节B、8个字节C、1个字节D、2个字节
正确答案: B 我的答案:B
17
【单选题】以下选项中,与k=n++完全等价的表达式是:
A、k=n,n=n+1B、n=n+1,k=nC、k+=n+1D、k=++n
正确答案: A 我的答案:A
18
【单选题】下列变量说明语句中,正确的是:
A、char a;b;c;B、int x,z;C、char:a b c;D、int x;z;
正确答案: B 我的答案:B
19
【单选题】以下字符中不是转义字符的是:
A、'\'B、’\c'C、’\t'D、’\b'
正确答案: B 我的答案:B
20
【单选题】算术运算符、赋值运算符和关系运算符的运算优先级按从高到低的顺序依次为:
A、算术运算、关系运算、赋值运算B、算术运算、赋值运算、关系运算C、关系运算、赋值运算、算术运算D、关系运算、算术运算、赋值运算
正确答案: A 我的答案:A
1
【单选题】以下if语句的表达不正确的是:
-
A、
if(a<b) a=0,else b=0;
-
B、
if(a==b) a=0,b++;
-
C、
if(a<b);
-
D、
if(a!=b) a=b;
正确答案: A 我的答案:A
2
【单选题】以下程序运行后输出的结果是:
#include<stdio.h>
void main()
{
int a=4,b=2,c=3;
if(a>b)a=b;
if(c>b)a=c;
printf(“a=%d\n”,a);
}
-
A、
3
-
B、
2
-
C、
4
-
D、
任意值
正确答案: A 我的答案:A
3
【单选题】下列条件语句中,功能与其他语句不同的是:
-
A、
if(a) printf(“%d\n”,x); else printf(“%d\n”,y);
-
B、
if(a!=0) printf(“%d\n”,x); else printf(“%d\n”,y);
-
C、
if(a==0) printf(“%d\n”,x); else printf(“%d\n”,y);
-
D、
if(a==0) printf(“%d\n”,y); else printf(“%d\n”,x);
正确答案: C 我的答案:C
4
【单选题】以下if结构形式错误的是:
-
A、
if(x<y ||x==y);
-
B、
if(x=y) x+=y;
-
C、
if(x!=y) x++ else y++;
-
D、
if(x>y) {x++;y++;}
正确答案: C 我的答案:C
5
【单选题】设x 为整数,C中能正确地表达数学式0≤x<5的是:
-
A、
0<=x<15
-
B、
x=0 || x=1 || x=2 || x=3 || x=4
-
C、
x>=0 || x<5
-
D、
!(x<0 || x>=5)
正确答案: D 我的答案:D
6
【单选题】关于以下程序的说法中正确的是:
#include <stdio.h>
void main()
{
int x=3,y=0,z=0;
if(x=y+z)
printf(“11\n”);
else
printf(“22\n”);
}
-
A、
输出11
-
B、
有语法错误不能通过编译
-
C、
输出22
-
D、
能通过编译,但不能运行
正确答案: C 我的答案:C
7
【单选题】下列程序运行时,输出到屏幕的结果是:
#include<stdio.h>
void main()
{
int a=0,b=1,d=10;
if(a)
if(b)
d=20;
else
d=30;
printf(“%d\n”,d);
}
-
A、
8
-
B、
9
-
C、
10
-
D、
11
正确答案: C 我的答案:C
8
【单选题】在C语言中,if语句后的一对原括号中,用以决定分支的流程的表达式:
-
A、
只能用关系表达式
-
B、
只能用逻辑表达式
-
C、
只能用逻辑表达式或关系表达式
-
D、
可用任意表达式
正确答案: D 我的答案:D
9
【单选题】
为了避免在嵌套的条件语句 if-else 中产生二义性,C语言规定:else子句总是与()配对。
-
A、
其之后最近的且没有配过对的if
-
B、
其之前最近的且没有配过对的if
-
C、
缩排位置相同的if
-
D、
同一行上的if
正确答案: B 我的答案:B
10
【单选题】
如果int a=2,b=3,c=0,下列描述正确的是:
-
A、
a||(b=c)执行后b的值为0
-
B、
a>b!=c和a>(b!=c)的执行顺序是一样的
-
C、
a&&b>c的结果为0
-
D、
!a!=(b!=c)表达式的值为1
正确答案: D 我的答案:D
11
【单选题】已有声明”int x,a=3,b=2;”,则执行赋值语句”x=a>b++?a++:b++;”后,变量x、a、b的值分别为:
-
A、
3 4 3
-
B、
3 3 4
-
C、
3 3 3
-
D、
4 3 4
正确答案: A 我的答案:A
12
【单选题】
若有定义int x,y; 并已正确给变量赋值,则以下选项中与表达式(x-y)?(x++):(y++)中的条件表达式(x-y) 等价的是:
-
A、
(x-y<0||x-y>0)
-
B、
(x-y<0)
-
C、
(x-y>0)
-
D、
(x-y==0)
正确答案: A 我的答案:A
13
【单选题】执行下列程序段后,变量i的值为:
#include <stdio.h>
void main()
{
int i=10;
switch(i)
{
case 9: i+=1;
case 10: i+=1;
case 11: i+=1;
default: i+=1;
}
printf(“%d\n”,i);
}
-
A、
13
-
B、
12
-
C、
11
-
D、
14
正确答案: A 我的答案:A
14
【单选题】已知有声明”int x,y;”,若要求编写一段程序实现”当x大于等于0时y取值1,否则y取值-1”,则以下程序段中错误的是:
-
A、
if(x>=0) y=1; else y=-1;
-
B、
y=x>=0?1:-1;
-
C、
switch()
{
case x>=0: y=1; break;
default: y=-1;
}
-
D、
switch(x-abs(x))
{
case 0: y=1; break;
default: y=-1;
}
正确答案: C 我的答案:C
15
【单选题】以下程序的运行后输出的结果是:
#include <stdio.h>
void main()
{
int x=0,a=0,b=0;
switch(x)
{
case 0:b+a;
case 1:++a;
case 2:a--;b--;
}
printf(“a=%d,b=%d\n”,a,b);
}
-
A、
a=0,b=1
-
B、
a=0,b=-1
-
C、
a=-1,b=-1
-
D、
a=-1,b=0
正确答案: B 我的答案:B
1
【单选题】若变量已正确定义,执行语句scanf("%d,%d,%d ",&k1,&k2,&k3);时,正确的输入是:
-
A、
20 30 40
-
B、
20;30;40
-
C、
k1=20,k2=30,k3=40
-
D、
20,30,40
正确答案: D 我的答案:D
2
【单选题】
以下程序的输出结果是:
#include<stdio.h>
int main()
{
char c1 = 'A', c2 = 'Y';
printf("%d,%d\n", c1, c2);
return 0;
}
-
A、
65,90
-
B、
A,Y
-
C、
65,89
-
D、
因输出格式不合法,无正确输出
正确答案: C 我的答案:C
3
【单选题】
以下程序段的输出是:
float a=3.1415;
printf("|%6.0f|\n", a);
-
A、
|3.1415|
-
B、
| 3|
-
C、
| 3.0|
-
D、
| 3.|
正确答案: B 我的答案:B
4
【单选题】
以下程序的输出结果是
int main()
{
int a=2, b=5;
printf("a=%%d,b=%%d\n",a, b);
return 0;
}
-
A、
a=%2,b=%5
-
B、
a=%%d,b=%%d
-
C、
a=%d,b=%d
-
D、
a=2,b=5
正确答案: C 我的答案:C
5
【单选题】
下列程序的输出结果为:
int main()
{
int m=7,n=4;
float a=38.4,b=6.4,x;
x=m/2+n*a/b+1/2;
printf("%f\n",x);
}
-
A、
28.000000
-
B、
27.500000
-
C、
28.500000
-
D、
27.000000
正确答案: D 我的答案:D
6
【单选题】
下列程序的输出结果是:
int main()
{
int a=011;
printf("%d\n",++a);
return 0;
}
-
A、
12
-
B、
10
-
C、
11
-
D、
9
正确答案: B 我的答案:B
7
【单选题】以下程序段的输出结果是:
double x=5.16894;
printf("%f\n",(int)(x*1000+0.5)/(float)1000);
-
A、
5.17000
-
B、
输出格式说明与输出项不匹配,输出无定值
-
C、
5.168000
-
D、
5.169000
正确答案: D 我的答案:D
8
【单选题】
以下程序的输出结果是:
int main()
{
double a = -3.0, b = 2;
printf("%3.0f,%3.1f\n", a, b );
return 0;
}
-
A、
-3,2
-
B、
-3.0,2.1
-
C、
-3,2.0
-
D、
3,2.0
正确答案: C 我的答案:C
9
【单选题】已知i、j、k为int型变量,若从键盘输入:1,2,3<回车>,使i的值为1、j的值为2、k的值为3,以下选项中正确的输入语句是:
-
A、
scanf("%d %d %d",&i,&j,&k);
-
B、
scanf("%d,%d,%d",&i,&j,&k);
-
C、
scanf("%2d%2d%2d",&i,&j,&k);
-
D、
scanf("i=%d,j=%d,k=%d",&i,&j,&k);
正确答案: B 我的答案:B
10
【单选题】
以下程序的输出结果是:
int main()
{
float x=3.6;
int i;
i=(int)x;
printf("x=%f,i=%d\n",x,i);
return 0;
}
-
A、
x=3 i=3.600000
-
B、
x=3.600000,i=4
-
C、
x=3,i=3
-
D、
x=3.600000,i=3
正确答案: D 我的答案:D
1
【单选题】
以下程序的执行结果是_______
int main()
{
int num = 0;
while( num <= 2 )
{ num++; printf( "%d,",num ); }
return 0;
}
-
A、
1,2,3,
-
B、
1,2,3,4,
-
C、
1,2,
-
D、
0,1,2,
正确答案: A 我的答案:A
2
【单选题】
下列程序的输出为_________.
int main()
{ int y=10;
while(y--);
printf("y=%d\n",y);
return 0;
}
-
A、
while构成无限循环
-
B、
y=0
-
C、
y=-1
-
D、
y=1
正确答案: C 我的答案:C
3
【单选题】
语句while(!E);中的表达式!E等价于________.
-
A、
E!=1
-
B、
E==0
-
C、
E==1
-
D、
E!=0
正确答案: B 我的答案:B
4
【单选题】
C语言中 while 和 do-while 循环的主要区别是__________.
A、
B、
C、
D、
-
A、
while的循环控制条件比 do-while的循环控制条件更严格
-
B、
do-while 的循环体至少无条件执行一次
-
C、
do-while 的循环体不能是复合语句
-
D、
do-while 允许从外部转到循环体内
正确答案: B 我的答案:B
5
【单选题】
以下程序段的输出结果是 .
int n=10;
while(n>7)
{ n--;
printf("%d", n );
}
-
A、
1098
-
B、
10987
-
C、
987
-
D、
9876
正确答案: C 我的答案:C
6
【单选题】
以下程序段的输出结果是
int x= 3;
do
{ printf("%3d", x-=2);
} while (!(--x));
-
A、
死循环
-
B、
1 -2
-
C、
3 0
-
D、
1
正确答案: B 我的答案:B
7
【单选题】
以下描述中正确的是________.
-
A、
do-while 循环中,根据情况可以省略 while
-
B、
由于do-while 循环中循环体语句只能是一条可执行语句,所以循环体内不能使用复合语句
-
C、
do-while 循环由do开始,用while结束,在 while(表达式)后面不能写分号
-
D、
在 do-while 循环体中,一般要有能使 while 后面表达式的值变为零("假")的操作
正确答案: D 我的答案:D
8
【单选题】
下面程序的功能是把316表示为两个加数的和,使两个加数分别能被13和11整除,请选择( )填空。
#include <stdio.h>
int main()
{
int i=0,j,k;
do
{i++;k=316-13*i;}
while______;
j=k/11;
printf("316=13*%d+11*%d",i,j);
return 0;
}
A、
B、
C、
D、
-
A、
k%11==0
-
B、
k/11
-
C、
k%11
-
D、
k/11==0
正确答案: C 我的答案:C
9
【单选题】
t为int类型,进入下面的循环之前,t的值为0
while( t=1 )
{ ……}
则以下叙述中正确的是__________.
A、
B、
C、
D、
-
A、
循环控制表达式的值为1
-
B、
循环控制表达式的值为0
-
C、
循环控制表达式不合法
-
D、
以上说法都不对
正确答案: A 我的答案:A
10
【单选题】
以下程序的执行结果是_________.
int main()
{ int x = 0, s = 0;
while( !x != 0 ) s += ++x;
printf( "%d ",s );
return 0;
}
-
A、
无限循环
-
B、
0
-
C、
1
-
D、
语法错误
正确答案: C 我的答案:C
11
【单选题】
对 for(表达式1; ;表达式3) 可理解为_________.
-
A、
for(表达式1;1;表达式3)
-
B、
for(表达式1;0;表达式3)
-
C、
for(表达式1;表达式1;表达式3)
-
D、
for(表达式1;表达式3;表达式3)
正确答案: A 我的答案:A
12
【单选题】
有以下程序
int main()
{ int i;
for(i=0; i<3; i++)
switch(i)
{ case 1: printf("%d", i);
case 2: printf("%d", i);
default : printf("%d", i);
}
return 0;
}
执行后输出结果是________.
-
A、
011122
-
B、
120
-
C、
012020
-
D、
012
正确答案: A 我的答案:A
13
【单选题】
设j和k都是int类型,则下面的for循环语句__________.
for(j=0,k=0;j<=9&&k!=876;j++) scanf("%d",&k);
-
A、
最多执行9次
-
B、
循环体一次也不执行
-
C、
最多执行10次
-
D、
是无限循环
正确答案: C 我的答案:C
14
【单选题】
以下程序的输出结果是_________.
int main()
{ int y = 10;
for(; y > 0; y --)
if(y % 3 == 0)
{ printf("%d", --y);
continue;
}
return 0;
}
-
A、
741
-
B、
963
-
C、
875421
-
D、
852
正确答案: D 我的答案:D
15
【单选题】
以下程序段的输出结果为_________.
for(i=4;i>1;i--)
for(j=1;j<i;j++) putchar('#');
-
A、
######
-
B、
无
-
C、
#
-
D、
###
正确答案: A 我的答案:A
16
【单选题】
下面有关 for 循环的正确描述是_______。
-
A、
for 循环是先执行循环的循环体语句,后判断表达式
-
B、
在 for 循环中,不能用 break 语句跳出循环体
-
C、
for 循环只能用于循环次数已经确定的情况
-
D、
for 循环的循环体语句中,可以包含多条语句,但必须用花括号括起来
正确答案: D 我的答案:D
17
【单选题】
以下程序的输出结果是_______.
int main()
{ int i, sum;
for(i = 1; i < 6; i++)
sum += i;
printf("%d\n",sum);
return 0;
}
-
A、
15
-
B、
不确定
-
C、
16
-
D、
0
正确答案: B 我的答案:B
18
【单选题】
以下程序中,while循环的循环次数是( )。
int main()
{
int i=0;
while(i<10)
{
if(i<1) continue;
if(i==5) break;
i++;
}
return 0;
}
-
A、
死循环,不能确定次数
-
B、
6
-
C、
4
-
D、
1
正确答案: A 我的答案:A
1
【单选题】以下正确的描述是:
-
A、
在C语言程序中,函数的定义可以嵌套,但函数的调用不可以嵌套
-
B、
在C语言程序中,函数的定义不可以嵌套,但函数的调用可以嵌套
-
C、
在C语言程序中,函数的定义和函数的调用均可以嵌套
-
D、
在C语言程序中,函数的定义和函数的调用均不可以嵌套
正确答案: B 我的答案:B
2
【单选题】
以下函数调用语句:
func((e1,e2),(e3,e4,e5));
实参的个数是
-
A、
语法错误
-
B、
5
-
C、
3
-
D、
2
正确答案: D 我的答案:D
3
【单选题】以下正确的函数形式是
-
A、
double fun(int x,y)
{
double z; z=x+y, return z;
}
-
B、
double fun(int x,int y)
{
return (x+y);
}
-
C、
double fun(x,y)
{
int x,y;
double z;
z=x+y;
return z;
}
-
D、
double fun(int x,y)
{
int z;
z=x+y;
return (double)z;
}
正确答案: B 我的答案:B
4
【单选题】
C语言程序中,当调用函数时
-
A、
实参和形参可以共用存储单元
-
B、
实参和形参各占一个独立的存储单元
-
C、
计算机系统自动确定是否共用存储单元
-
D、
可以由用户指定是否共用存储单元
正确答案: B 我的答案:B
5
【单选题】
以下程序的输出结果是
int f(int a, int b)
{
int c;
c = a;
if(a > b)
c = 1;
else if(a == b)
c = 0;
else c = -1;
return c;
}
void main()
{
int i =2, p;
p = f(i, i + 1);
printf(“%d”, p);
}
-
A、
-1
-
B、
1
-
C、
2
-
D、
0
正确答案: A 我的答案:A
6
【单选题】
以下程序的输出结果是
fun1(int a, int b)
{
int c;
a += a; b += b;
c = fun2(a, b);
return c * c;
}
fun2(int a, int b)
{
int c;
c = a * b % 3;
return c;
}
main()
{
int x = 11, y = 19;
printf(“%d\n”, fun1(x, y));
return 0;
}
-
A、
2
-
B、
4
-
C、
0
-
D、
1
正确答案: B 我的答案:B
7
【单选题】
设有函数定义”int f1(void){ return 100 , 200 ; }”,设用函数f1()后
-
A、
函数返回值100
-
B、
函数返回两个值100和200
-
C、
函数返回值200
-
D、
语句”return 100,200; “语法错,不能调用函数
正确答案: C 我的答案:C
8
【单选题】
若有以下函数定义:
void f(int x,float y ){…}
若以下选项中的整形变量a和实型变量b都已正确定义且赋值,则对函数f的正确调用语句是
-
A、
f(int a,float b);
-
B、
void f(a,b);
-
C、
k=f(a,b);
-
D、
f(a,b);
正确答案: D 我的答案:D
1
【单选题】下列数组定义中错误的是___________。
-
A、
int a[2]={1};
-
B、
int n = 5;
int a[n];
-
C、
int a[’n’];
-
D、
int a[1];
正确答案: B 我的答案:B
2
【单选题】下列数组定义中正确的是___________。
-
A、
int a1[2][3]={1,2,3,4,5,6,7};
-
B、
int a2[][2] = {{1},{2,3}};
-
C、
int a3[][3];
-
D、
int a[2][] = {1,2,3};
正确答案: B 我的答案:B
3
【单选题】
下面程序的输出结果是________。
#include<stdio.h>
void main()
{
int a[3][3] = {1,2,3,4,5,6,7,8,9}, i;
for(i=0; i<3; i++)
printf("%d ", a[i][2-i]);
}
-
A、
1 5 9
-
B、
7 5 3
-
C、
3 5 7
-
D、
5 9 1
正确答案: C 我的答案:C
4
【单选题】与下述函数原型声明等价的是_______________。 int fun(int a[10],int b[3][4]);
-
A、
int test(int a[],int b[][]);
-
B、
int test(int a[],int b[3][]);
-
C、
int test(int a[10],int b[][3]);
-
D、
int test(int a[],int b[][4]);
正确答案: D 我的答案:D
5
【单选题】已知fun函数的头部为“int fun(int x[],int n)”,main函数中有声明“int a[10]={1},b=10;”,欲在main函数中调用fun函数,则下列调用语句正确的是_______。
-
A、
fun(a, fun(a,b));
-
B、
fun(a[10],b);
-
C、
fun(a[], a[0]);
-
D、
fun(b, a);
正确答案: A 我的答案:A
6
【单选题】
下面程序的功能是输出数组s中最大元素的下标,横线处应填__________。
#include <stdio.h>
void main()
{
int max = 0, i, a[8] = {1,2,3,4,5,6,7,8};
for(i=0;i<8;i++)
{
if(a[i] > a[max])
_______________;
}
printf("%d\n",max);
}
-
A、
max = a[i];
-
B、
max = i;
-
C、
i = max;
-
D、
a[i] = max;
正确答案: B 我的答案:B
7
【单选题】
以下程序的输出结果是________。
#include<stdio.h>
void reverse(int a[], int n)
{
int i,t;
for(i=0;i<n/2;i++)
{
t = a[i];
a[i] = a[n-1-i];
a[n-1-i] = t;
}
}
int main()
{
int b[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int i, s=0;
reverse(b,9);
for(i=5;i<10;i++)
s += b[i];
printf("%d\n",s);
return 0;
}
-
A、
55
-
B、
15
-
C、
20
-
D、
40
正确答案: C 我的答案:C
8
【单选题】
以下程序的功能是从键盘输入十个学生的成绩,统计最高分,最低分和平均分。max代表最高分,min代表最低分,avg代表平均分。程序A、B、C、D四处语句中错误的是__________。
#include <stdio.h>
void main( )
{
int i;
float a[10], min, max, avg;
printf("input 10 score:");
for(i=0; i<=9; i++)
{
printf("input a score of student:");
scanf("%f", &a); //A处
}
max = min = avg = a[0]; //B处
for(i=1; i<=9; i++)
{
if(min < a[i]) //C处
min = a[i];
if(max < a[i]) //D处
max = a[i];
avg = avg + a[i];
}
avg = avg/10;
printf("max:%f\nmin:%f\navg:%f\n",max,min,avg);
}
-
A、
A处
-
B、
B处
-
C、
C处
-
D、
D处
正确答案: C 我的答案:C
【单选题】已知有声明char str[20]=”Hello!”,在程序运行过程中,若要使数组s中的内容改为“Hi!”,则以下语句中能够实现此功能的是__________。
-
A、
str[20]={”Hi!”};
-
B、
str[20]=”Hi!”;
-
C、
strcat(str,”Hi!”);
-
D、
strcpy(str,”Hi!”);
正确答案: D 我的答案:D
2
【单选题】有声名char str[ ] = {"Welcome!"}; ,在程序中执行语句printf(“%s”,str+3);后输出为__________。
-
A、
Welcome!
-
B、
Wel
-
C、
come
-
D、
come!
正确答案: D 我的答案:D
3
【单选题】
有如下程序段:
char s1[40]=”China”,s2[20]=”Jiangsu”,s3[20]=”Nanjing”;
strcat(s1, strcpy(s2,s3));
printf(“%s”,s1);
执行该程序段后的输出是________。
-
A、
ChinaJiangsuNanjing
-
B、
ChinaJiangsu
-
C、
JiangsuNanjing
-
D、
ChinaNanjing
正确答案: D 我的答案:D
4
【单选题】
若有以下定义,则对字符串的操作错误的是___________。
char s[15]=”computer”,t[]=”games”;
-
A、
strcpy(t,s);
-
B、
printf("%d",strlen(s));
-
C、
strcat(s,t);
-
D、
scanf("%s",t);
正确答案: A 我的答案:A
5
【单选题】
以下程序运行时,输出到屏幕的结果是__________。
#include<stdio.h>
void fun(char s[])
{
int i, j;
for(i=j=0; s[i]!='\0'; i++)
{
if(s[i]>='A' && s[i]<='Z')
s[j++] = s[i]+32;
}
s[j]='\0';
}
int main()
{
char ss[20]="GooD LucK!";
fun(ss);
printf("%s\n",ss);
return 0;
}
-
A、
goodluck
-
B、
gl
-
C、
oouc
-
D、
gdlk
正确答案: D 我的答案:D
1
【单选题】变量的指针,其含义是指该变量的( )。
-
A、
名称
-
B、
地址
-
C、
标志
-
D、
取值
正确答案: B 我的答案:B
2
【单选题】若有说明:int k=8,*p=&k,*q=p;,则以下非法的赋值语句是( )。
-
A、
k=*q
-
B、
*p=*q
-
C、
*q=p
-
D、
p=q
正确答案: C 我的答案:C
3
【单选题】若有int i=6,*p; p=&i;下列语句中输出结果为6的是( )。
-
A、
printf("%d",&p);
-
B、
printf("%d",p);
-
C、
printf("%d",*i);
-
D、
printf("%d",*p);
正确答案: D 我的答案:D
4
【单选题】
若有下列定义,则对a数组元素正确引用的是( )。
int a[5],*p=a;
-
A、
*(p+5)
-
B、
*&a[5]
-
C、
p+2
-
D、
*(a+2)
正确答案: D 我的答案:D
5
【单选题】若有int a[10]={1,2,3,4,5,6,7,8,9,0},*p=a;则输出结果不为8的语句为( )。
-
A、
printf("%d",*p[7]);
-
B、
printf("%d",p[7]);
-
C、
printf("%d",*(p+7));
-
D、
printf("%d",*(a+7));
正确答案: A 我的答案:A
6
【单选题】
以下程序的输出结果是:
int main()
{ int a[] = {2, 4, 6, 8, 10}, y = 1, x, *p;
p = &a[1];
for(x = 0; x < 3; x++)
y += *(p + x);
printf(“%d\n”, y);
}
-
A、
20
-
B、
18
-
C、
17
-
D、
19
正确答案: D 我的答案:D
7
【单选题】
以下程序的输出结果是:
int main()
{ int k = 2, m = 4, n = 6;
int *pk = &k, *pm = &m, *p;
*(p = &n) = *pk * (*pm);
printf(“%d\n”, n);
}
-
A、
8
-
B、
10
-
C、
6
-
D、
4
正确答案: A 我的答案:A
8
【单选题】
以下程序段的输出结果是:
char str[] = “ABCD”, *p = str;
printf(“%d\n”, *(p+4));
-
A、
不确定的值
-
B、
字符D的地址
-
C、
68
-
D、
0
正确答案: D 我的答案:D
1
【单选题】当说明一个结构体变量时系统分配给它的内存是( )。
-
A、
成员中占内存量最大者所需的容量
-
B、
结构中最后一个成员所需内存量
-
C、
结构中第一个成员所需内存量
-
D、
结构体各成员所需内存量的总和
正确答案: D 我的答案:D
2
【单选题】
相同结构体类型的变量之间,可以:
-
A、
比较大小
-
B、
地址相同
-
C、
赋值
-
D、
相加
正确答案: C 我的答案:C
3
【单选题】
static struct
{
int a1;
float a2;
char a3;
}a[10]={1,3.5,'A'};
说明数组a是数组,它有10个结构体型的元素,采用静态存储方式,其中被初始化的元素是:
-
A、
a[10]
-
B、
a[0]
-
C、
a[1]
-
D、
a[-1]
正确答案: B 我的答案:B
4
【单选题】
结构体类型的定义允许嵌套是指:
-
A、
定义多个结构体型
-
B、
成员可以重名
-
C、
成员必须是已经定义的结构体类型
-
D、
成员是已经或正在定义的结构体型
正确答案: D 我的答案:D
5
【单选题】
在下列程序段中,枚举变量c1,c2的值依次是( )。
enum color {red,yellow,blue=5,green,white} c1,c2;
c1=red;c2=green;
printf(“%d,%d\n”,c1,c2);
-
A、
1,6
-
B、
1,4
-
C、
0,6
-
D、
0,4
正确答案: C 我的答案:C
1
【单选题】
C语言中的文件按照数据存放的格式有:
-
A、
ASCII文件和二进制文件两种
-
B、
二进制文件一种
-
C、
文本文件一种
-
D、
索引文件和文本文件两种
正确答案: A 我的答案:A
2
【单选题】
应用缓冲文件系统对文件进行读写操作,打开文件的函数名为:
-
A、
close
-
B、
fopen
-
C、
fclose
-
D、
open
正确答案: B 我的答案:B
3
【单选题】
若要打开A盘上user子目录下名为abc.txt的文本文件进行读、写操作,
下面符合此要求的函数调用是:
-
A、
fopen("A:\user\abc.txt","rb")
-
B、
fopen("A:\user\abc.txt","r")
-
C、
fopen("A:\user\abc.txt","w")
-
D、
fopen("A:\user\abc.txt","r+")
正确答案: D 我的答案:D
4
【单选题】
fgets(str,n,fp)函数从文件中读入一个字符串,以下正确的叙述是:
-
A、
字符串读入后不会自动加入'\0'
-
B、
fgets函数将从文件中最多读入n个字符
-
C、
str是file类型的指针
-
D、
fgets函数将从文件中最多读入n-1个字符
正确答案: D 我的答案:D
5
【单选题】
若以"a+"方式打开一个已存在的文件,则以下叙述正确的是( )。
-
A、
文件打开时,原有文件内容不被删除,位置指针移到文件末尾,可作添加和读操作
-
B、
文件打开时,原有文件内容被删除,只可作写操作
-
C、
文件打开时,原有文件内容不被删除,位置指针移到文件开头,可作重写和读操作
-
D、
以上各种说法皆不正确
正确答案: A 我的答案:A